
repo
stringlengths 8
116
| tasks
stringlengths 8
117
| titles
stringlengths 17
302
| dependencies
stringlengths 5
372k
| readme
stringlengths 5
4.26k
| __index_level_0__
int64 0
4.36k
|
|---|---|---|---|---|---|
kuihua/MSPFN | ['rain removal', 'single image deraining'] | ['Multi-Scale Progressive Fusion Network for Single Image Deraining'] | model/train_data/crop.py utils/bianyuan.py model/TEST_MSPFN_M17N1.py model/train_MSPFN.py model/test/test_MSPFN.py model/load_rain.py model/TEST_MSPFN.py model/image_crop.py utils/augment.py model/spp_layer.py utils/BasicConvLSTMCell.py utils/layer.py utils/closed_form_matting.py model/ps.py model/train_data/preprocessing.py model/MSPFN.py utils/non_local.py crop img_crop load MODEL _PS np_spatial_pyramid_pooling tf_spatial_pyramid_pooling Model Model normalize train save_img count_model_params main preprocess main preprocess random_flip_left_right random_brightness random_crop_and_zoom _augment normalize augment BasicConvLSTMCell ConvRNNCell _conv_linear edge getLaplacian getlaplacian1 down_sample avg_pooling_layer Feature_enhance flatten_layer NonLocalBlock lrelu prelu max_pooling_layer _PS rotate conv_layer batch_normalize full_connection_layer pixel_shuffle_layer deconv_layer PS_layer pool_sample edge pixel_shuffle_layerg gkern _convND non_local_block dtype concatenate astype float32 append range len as_list print reshape concat split itemsize as_strided append concatenate reshape transpose copy floor ceil sum prod range amax train_loss Saver save Session run restore list placeholder rotate normalize range format global_variables_initializer get_checkpoint_state load int join minimize print float32 tqdm MODEL AdamOptimizer randint bool len print get_shape trainable_variables join uint8 format COLOR_BGR2RGB xlabel add_subplot close imshow enumerate set_ticks_position figure mkdir savefig tick_params range clip cvtColor len join format print mkdir save listdir crop range open preprocess update int imwrite glob close tqdm resize append imread array enumerate len flip reshape rand LUT uniform resize random_flip_left_right random_brightness random_crop_and_zoom resize normalize Canny COLOR_RGB2GRAY bitwise_and Sobel CV_16SC1 GaussianBlur cvtColor broadcast_to list csr_matrix transpose identity matmul shape sum diags range grey_erosion int T reshape inv repeat zeros ravel array shape transpose tocoo as_list array get_variable get_variable get_variable get_variable get_variable zeros as_list transpose split split print concat split as_list int resize_images slice concat as_list int avg_pooling_layer slice concat as_list concat slice list int_shape _convND dot add | # Multi-Scale Progressive Fusion Network for Single Image Deraining (MSPFN) This is an implementation of the MSPFN model proposed in the paper ([Multi-Scale Progressive Fusion Network for Single Image Deraining](https://arxiv.org/abs/2003.10985)) with TensorFlow. # Requirements - Python 3 - TensorFlow 1.12.0 - OpenCV - tqdm - glob | 2,700 |
kulikovv/DeepColoring | ['instance segmentation', 'semantic segmentation', 'autonomous driving'] | ['Instance Segmentation by Deep Coloring'] | deepcoloring/halo_loss.py deepcoloring/architecture.py cvppp/train_cvppp.py deepcoloring/train.py setup.py deepcoloring/data.py ecoli/train_ecoli.py deepcoloring/utils.py deepcoloring/__init__.py ReadableDir evaluate UpModule clip_align EUnet DownModule Reader flatten build_halo_mask halo_loss train blur rotate90 rescale best_dice visualize rotate normalize postprocess random_gamma symmetric_best_dice random_scale vgg_normalize random_contrast flip_vertically clip_patch get_as_list random_transform random_noise rgb2gray clip_patch_random rgba2rgb flip_horizontally clip_mask_builder ReadableDir postprocess get_as_list symmetric_best_dice model eval append to range len size expand_dims repeat zeros to circle log_softmax size min index_select softmax to sum range generator mask_builder model zero_grad save Adam savetxt append to range state_dict halo_loss item float int print_percent backward parameters step prepare subplots zeros_like argmax set_title imshow shape ceil append range colors postprocess format distance_transform_edt softmax from_list get_cmap int text unravel_index float sum append zeros_like unique enumerate zeros_like polygon find_contours argmax range | # Instance Segmentation by Deep Coloring [Paper preprint](https://arxiv.org/abs/1807.10007)  ### About We propose a new and, arguably, a very simple reduction of instance segmentation to semantic segmentation. This reduction allows to train feed-forward non-recurrent deep instance segmentation systems in an end-to-end fashion using architectures that have been proposed for semantic segmentation. Our approach proceeds by introducing a fixed number of labels (colors) and then dynamically assigning object instances to those labels during training (coloring). A standard semantic segmentation objective is then used to train a network that can color previously unseen images. At test time, individual object instances can be recovered from the output of the trained convolutional network using simple connected component analysis. In the experimental validation, the coloring approach is shown to be capable of solving diverse instance segmentation tasks arising in autonomous driving (the Cityscapes benchmark), plant phenotyping (the CVPPP leaf segmentation challenge), and high-throughput microscopy image analysis. ### Test with pretrained models 1. For cvppp run notebook cvppp/cvppp.ipynb, follow code 2. For ecoli run notebook ecoli/ecoli.ipynb, follow code ### Trainging guidelines 1. [Guideline for cvppp](cvppp/README.md) | 2,701 |
kulikovv/harmonic | ['instance segmentation', 'semantic segmentation'] | ['Instance Segmentation of Biological Images Using Harmonic Embeddings'] | models/pspnet.py datasets/data.py harmonic/__init__.py models/extractors.py harmonic/sinconv.py models/__init__.py harmonic/cluster.py datasets/__init__.py harmonic/utils.py harmonic/coordconv.py models/unet.py harmonic/embeddings.py default_loader Reader cluster AddCoords CoordConv get_embeddings flat_pattern_rdm Embedding pairwise_distances pow_weights_norm log_weights_norm linear_weights_norm SinConv AddSine set_lr print_percent recursive_search disable_gradients_for_class train Fire SqueezeNet densenet DenseNet ResNet resnet50 Bottleneck resnet152 squeezenet conv3x3 _DenseLayer resnet34 _DenseBlock resnet18 load_weights_sequential BasicBlock _Transition resnet101 PSPUpsampleS PSPNet PSPModule freeze_layer PSPUpsample outconv double_conv UNet down ups inconv reshape transpose astype MeanShift labels_ unique zeros max regionprops fit transpose mm view weights_norm int view size contiguous device shape repeat unsqueeze item gather to long scatter_add rand print str param_groups children isinstance parameters recursive_search zero_grad disable_gradients_for_class save set_lr list step Adam freeze_encoder floss savetxt load_state_dict append to range detach state_dict mean float net emb enumerate load int print_percent backward print loadtxt parameters isfile numpy len OrderedDict items list load_state_dict load SqueezeNet load_weights_sequential load SqueezeNet load_weights_sequential load ResNet load_url load_weights_sequential load ResNet load_url load_weights_sequential load ResNet load_url load_weights_sequential load_url ResNet load_weights_sequential load ResNet load_url load_weights_sequential parameters | # Instance Segmentation Using Harmonic Embeddings <p align="middle"> <img src="images/pipeline.png" width="600" /> </p> <p> We present a new instance segmentation approach tailored to biological images, where instances may correspond to individual cells, organisms or plant parts. Unlike instance segmentation for user photographs or road scenes, in biological data object instances may be particularly densely packed, the appearance variation may be particularly low, the processing power may be restricted, while, on the other hand, the variability of sizes of individual instances may be limited. These peculiarities are successfully addressed and exploited by the proposed approach. </p> <p> Our approach describes each object instance using an expectation of a limited number of sine waves with frequencies and phases adjusted to particular object sizes and densities. At train time, a fully-convolutional network is learned to predict the object embeddings at each pixel using a simple pixelwise regression loss, while at test time the instances are recovered using clustering in the embeddings space. In the experiments, we show that our approach outperforms previous embedding-based instance segmentation approaches on a number of biological datasets, achieving state-of-the-art on a popular CVPPP benchmark. Notably, this excellent performance is combined with computational efficiency that is needed for deployment to domain specialists. </p> | 2,702 |
kumnikhil/christmAIs_replica | ['style transfer'] | ['A Neural Algorithm of Artistic Style'] | tests/test_drawer.py docs/conf.py christmais/parser.py tests/test_styler.py christmais/drawer.py setup.py christmais/__init__.py christmais/tasks/christmais_time.py christmais/styler.py tests/test_parser.py tests/conftest.py Drawer Parser Styler main build_parser pytest_addoption process_img local styler drawer parser test_draw_png test_read_categories test_create_index_html test_draw test_read_categories test_get_similar test_get_most_similar test_get_actual_label test_save_preprocessed_img test_style_transfer test_get_img_lists_return_type test_get_img_lists_return_objects test_get_data_and_name test_create_placeholder_return_type add_argument ArgumentParser style_transfer format get_most_similar getLogger Drawer draw output Parser info install parse_args build_parser Styler INFO addoption glob _read_categories glob _create_index_html format glob _create_index_html _draw_png format glob draw format zip get_most_similar _get_actual_label _get_similar _create_placeholder float32 placeholder _get_img_lists _get_img_lists glob format _get_data_and_name style_transfer | # christmAIs [](https://console.cloud.google.com/cloud-build/builds?authuser=2&organizationId=301224238109&project=tm-github-builds) [](https://christmais-2018.readthedocs.io/en/latest/?badge=latest) [](https://www.gnu.org/licenses/old-licenses/gpl-2.0.en.html)  **christmAIs** ("krees-ma-ees") is text-to-abstract art generation for the holidays! This work converts any input string into an abstract art by: - finding the most similar [Quick, Draw!](https://quickdraw.withgoogle.com/data) class using [GloVe](https://nlp.stanford.edu/projects/glove/) - drawing the nearest class using a Variational Autoencoder (VAE) called [Sketch-RNN](https://arxiv.org/abs/1704.03477); and | 2,703 |
kundajelab/deeplift | ['text classification'] | ['Towards better understanding of gradient-based attribution methods for Deep Neural Networks'] | deeplift/conversion/kerasapi_conversion.py deeplift/layers/normalization.py deeplift/visualization/matplotlib_helpers.py tests/layers/test_activation.py tests/layers/test_conv1d.py deeplift/layers/helper_functions.py tests/layers/test_pool2d.py tests/conversion/sequential/test_conv2d_model_valid_padding.py deeplift/visualization/viz_sequence.py tests/layers/test_conv2d.py tests/conversion/functional/test_functional_concatenate_model.py deeplift/layers/__init__.py deeplift/layers/core.py deeplift/util.py tests/shuffling/test_dinuc_shuffle.py tests/conversion/sequential/test_load_batchnorm.py tests/conversion/sequential/test_conv1d_model_valid_padding.py deeplift/layers/activations.py deeplift/layers/convolutional.py tests/layers/test_dense.py tests/layers/test_pool1d.py tests/conversion/sequential/test_conv1d_model_same_padding.py tests/conversion/sequential/test_conv2d_model_same_padding.py deeplift/dinuc_shuffle.py tests/layers/test_concat.py tests/layers/test_deeplift_genomics_default_mode.py deeplift/layers/pooling.py setup.py tests/conversion/sequential/test_sigmoid_tanh_activations.py deeplift/models.py deeplift/__init__.py tests/conversion/sequential/test_conv2d_model_channels_first.py string_to_char_array dna_to_one_hot char_array_to_string test_dinuc_content tokens_to_one_hot dinuc_shuffle one_hot_to_tokens dinuc_content one_hot_to_dna bench SequentialModel Model GraphModel get_integrated_gradients_function superclass_in_base_classes compile_func mean_normalise_weights_for_sequence_convolution connect_list_of_layers get_hypothetical_contribs_func_onehot is_gzipped in_place_shuffle randomly_shuffle_seq assert_is_type is_type get_file_handle get_shuffle_seq_ref_function get_session load_yaml_data_from_file assert_type assert_is_not_type run_function_in_batches enum flatten_conversion conv1d_conversion globalmaxpooling1d_conversion insert_weights_into_nested_model_config functional_container_conversion linear_conversion globalavgpooling1d_conversion convert_sequential_model activation_conversion prelu_conversion relu_conversion prep_pool2d_kwargs activation_to_conversion_function sequential_container_conversion maxpool1d_conversion concat_conversion_function convert_functional_model tanh_conversion validate_keys convert_model_from_saved_files batchnorm_conversion prep_pool1d_kwargs noop_conversion avgpool2d_conversion conv2d_conversion maxpool2d_conversion layer_name_to_conversion_function ConvertedModelContainer softmax_conversion input_layer_conversion sigmoid_conversion dense_conversion avgpool1d_conversion PReLU Softmax Tanh Sigmoid ReLU Activation Conv2D Conv Conv1D Merge Concat SingleInputMixin Node Dense ListInputMixin OneDimOutputMixin Input NoOp Flatten Layer add_val_to_col lte_mask distribute_over_product pseudocount_near_zero gte_mask eq_mask gt_mask lt_mask conv1d_transpose_via_conv2d BatchNormalization MaxPool1D AvgPool1D GlobalMaxPool1D MaxPool2D Pool2D AvgPool2D Pool1D GlobalAvgPool1D plot_hist plot_t plot_weights plot_g plot_weights_given_ax plot_a plot_c TestFunctionalConcatModel TestConvolutionalModel TestConvolutionalModel TestConvolutionalModel TestConvolutionalModel TestConvolutionalModel TestBatchNorm TestConvolutionalModel TestActivations TestConcat TestConv TestConv TestDense TestDense TestPool TestPool TestDinucShuffle dinuc_count tile where string_to_char_array permutation RandomState arange char_array_to_string tokens_to_one_hot empty_like shape one_hot_to_tokens unique append empty range len RandomState total_seconds print now dinuc_shuffle mean append range len join nuc_content sorted RandomState dna_to_one_hot print tuple dinuc_content choice dinuc_shuffle zeros sum keys range len enum print items list hasattr staticmethod setattr print extend func zip str print mean expand_dims sum get_file_handle close load print remove is_gzipped isfile read close open set_inputs randint range len activation_conversion validate_keys extend activation_conversion validate_keys extend activation_conversion validate_keys extend validate_keys prep_pool2d_kwargs prep_pool2d_kwargs prep_pool1d_kwargs prep_pool1d_kwargs Input load decode read list hasattr File insert_weights_into_nested_model_config OrderedDict loads zip open str print build_fwd_pass_vars sequential_container_conversion append Input flush print conversion_function extend connect_list_of_layers layer_name_to_conversion_function enumerate str list items isinstance conversion_function OrderedDict set_inputs zip layer_name_to_conversion_function max range append len str print build_fwd_pass_vars functional_container_conversion output_layers enum Variable zeros scatter_update reshape show title hist figure len add_patch Polygon Ellipse Rectangle add_patch Ellipse Rectangle add_patch Rectangle add_patch sorted arange plot_func squeeze transpose min set_xlim add_patch set_ticks Rectangle append abs max range set_ylim enumerate show plot_weights_given_ax add_subplot figure defaultdict range len | DeepLIFT: Deep Learning Important FeaTures === [](https://travis-ci.org/kundajelab/deeplift) [](https://github.com/kundajelab/deeplift/blob/master/LICENSE) **This version of DeepLIFT has been tested with Keras 2.2.4 & tensorflow 1.14.0**. See [this FAQ question](#my-model-architecture-is-not-supported-by-this-deeplift-implementation-what-should-i-do) for information on other implementations of DeepLIFT that may work with different versions of tensorflow/pytorch, as well as a wider range of architectures. See the tags for older versions. This repository implements the methods in ["Learning Important Features Through Propagating Activation Differences"](https://arxiv.org/abs/1704.02685) by Shrikumar, Greenside & Kundaje, as well as other commonly-used methods such as gradients, gradient-times-input (equivalent to a version of Layerwise Relevance Propagation for ReLU networks), [guided backprop](https://arxiv.org/abs/1412.6806) and [integrated gradients](https://arxiv.org/abs/1611.02639). Here is a link to the [slides](https://docs.google.com/file/d/0B15F_QN41VQXSXRFMzgtS01UOU0/edit?usp=docslist_api&filetype=mspresentation) and the [video](https://vimeo.com/238275076) of the 15-minute talk given at ICML. [Here](https://www.youtube.com/playlist?list=PLJLjQOkqSRTP3cLB2cOOi_bQFw6KPGKML) is a link to a longer series of video tutorials. Please see the [FAQ](https://github.com/kundajelab/deeplift/blob/master/README.md#faq) and file a github issue if you have questions. Note: when running DeepLIFT for certain computer vision tasks **you may get better results if you compute contribution scores of some higher convolutional layer rather than the input pixels**. Use the argument `find_scores_layer_idx` to specify which layer to compute the scores for. **Please be aware that figuring out optimal references is still an open problem. Suggestions on good heuristics for different applications are welcome.** In the meantime, feel free to look at this github issue for general ideas: https://github.com/kundajelab/deeplift/issues/104 Please feel free to follow this repository to stay abreast of updates. | 2,704 |
kunwuz/DGTN | ['session based recommendations'] | ['DGTN: Dual-channel Graph Transition Network for Session-based Recommendation'] | model/multi_sess.py train.py model/InOutGat.py model/model.py main.py preprocess/cikm16_org_prepro.py model/srgnn.py preprocess/cikm16_perprocess.py neigh_retrieval/neighborhood_retrieval.py model/ggnn.py preprocess/rcs15_perprocess.py neigh_retrieval/knn.py data/multi_sess_graph.py preprocess/rcs15_org_prepro.py utils/saver.py main forward case_study MultiSessionsGraph InOutGGNN normal ones kaiming_uniform uniform reset InOutGATConv_intra glorot InOutGATConv zeros CNNFusing Embedding2Score ItemFusing NARM GraphModel GroupGraph SRGNN KNN filter_data get_sequence split_train_test preprocess load_data process_seqs get_dict filter_data get_sequence split_train_test preprocess load_data process_seqs get_dict filter_data get_sequence split_train_test split_train preprocess load_data filter_test process_seqs get_dict filter_data get_sequence split_train_test split_train preprocess load_data filter_test process_seqs get_dict print_txt LambdaLR localtime DataLoader warning device dataset forward str list getcwd map strftime Adam load_state_dict to range SummaryWriter format epoch manual_seed random_seed load print parameters MultiSessionsGraph step makedirs y model zero_grad numpy len append to isin mean eval item zip enumerate time backward print loss_function train step add_scalar y model print eval zip to numpy enumerate uniform_ sqrt uniform_ sqrt uniform_ sqrt size fill_ fill_ normal_ children _reset fromtimestamp nunique utc format print min apply isoformat max read_csv len fromtimestamp nunique utc format print size min isoformat max len nunique format print size index max len print sort_values index enumerate print time enumerate time print process_seqs len unique sort_values drop_duplicates values enumerate dump get_sequence print open get_dict makedirs len range int nunique format print sort_values range len nunique format print size len str split_train filter_test str sorted format items write close open | # DGTN: Dual-channel Graph Transition Network for Session-based Recommendation This repository contains PyTorch Implementation of ICDMW 2020 (NeuRec @ ICDM) paper: [*DGTN: Dual-channel Graph Transition Network for Session-based Recommendation*.](https://arxiv.org/abs/2009.10002) Please check our paper for more details about our work if you are interested. ## Usage Following the steps below to run our codes: ### 1. Preprocess The preprocess code is in `preprocess/` ### 2. Neighbors retrieval Please run `neigh_retrieval/neighborhood_retrieval.py` ### 3. Run the model | 2,705 |
kupuSs/DIEN-pipline | ['click through rate prediction'] | ['Deep Interest Evolution Network for Click-Through Rate Prediction'] | main/sequence.py main/core.py data_process/data_loader.py main/inputs.py main/rnn.py main/rnn_utils.py main/activation.py main/normalization.py main/utils.py main/rnn_v2.py data_process/feature_process.py run/run.py data_process/config_customize.py data/concat_taobao_items.py data_process/feature_process_parallel.py data_process/utils.py data_process/get_standard_input.py data_process/config_amazon_books.py main/dien.py data_process/config_taobao.py data_loader encoder_sparse_feature_test negative_sampling scaler_dense_feature encoder_sequence truncated_sequence encoder_sparse_feature_train tmp_func apply_parallel get_input run get_standard_input get_stats sd print_values print_header reduce_mem_usage_sd activation_layer Dice LocalActivationUnit PredictionLayer DNN auxiliary_net DIEN interest_evolution auxiliary_loss embedding_lookup VarLenSparseFeat get_linear_logit get_inputs_list combined_dnn_input input_from_feature_columns SparseFeat get_fixlen_feature_names DenseFeat build_input_features get_embedding_vec_list create_embedding_matrix get_varlen_feature_names varlen_embedding_lookup get_varlen_pooling_list create_embedding_dict get_dense_input LayerNormalization dynamic_rnn _dynamic_rnn_loop _best_effort_input_batch_size _infer_state_dtype _like_rnncell_ _rnn_step _transpose_batch_time _reverse_seq VecAttGRUCell QAAttGRUCell _Linear_ dynamic_rnn _dynamic_rnn_loop _best_effort_input_batch_size _infer_state_dtype _like_rnncell_ _rnn_step _transpose_batch_time _reverse_seq SequencePoolingLayer Transformer KMaxPooling BiLSTM AttentionSequencePoolingLayer DynamicGRU BiasEncoding positional_encoding NoMask concat_fun reduce_max reduce_sum div reduce_mean softmax Hash Linear get_stats get_chunk print concat append reduce_mem_usage_sd read_csv tqdm apply map tqdm fillna map tqdm str list map tqdm dict apply zip range keys read_csv values len list pad_sequences map tqdm read_csv values tqdm max apply append randint range len apply time sparse_features encoder_sparse_feature_test dense_features negative_sampling print scaler_dense_feature map encoder_sequence data_loader get_fixlen_feature_names truncated_sequence encoder_sparse_feature_train array sequence_features columns DataFrame print str nunique format print memory_usage sum dtypes nunique abs astype mean round sum max nunique columns format print astype sd tqdm sum dtypes Dice issubclass Activation activation sequence_mask concat float32 reduce_mean cast dense batch_normalization sigmoid subtract multiply auxiliary_loss embedding_lookup list concat_fun get_dense_input combined_dnn_input global_variables_initializer name interest_evolution build_input_features Model create_embedding_matrix add_loss append varlen_embedding_lookup get_varlen_pooling_list Input values run build_input_features build_input_features OrderedDict Input maxlen isinstance int print Embedding dimension pow name use_hash append create_embedding_dict append input_from_feature_columns concat_fun range name embedding_name use_hash append name embedding_name use_hash name combiner append append embedding_lookup create_embedding_matrix varlen_embedding_lookup get_varlen_pooling_list get_dense_input concat_fun get_shape concatenate transpose concat rank set_shape shape value all is_sequence get_shape _copy_some_through call_cell assert_same_structure flatten set_shape zip pack_sequence_as cond get_shape tuple merge_with unknown_shape stack set_shape reverse_sequence unstack zip append flatten tuple identity to_int32 value constant output_size _best_effort_input_batch_size tuple while_loop reduce_max _concat flatten shape set_shape zip pack_sequence_as reduce_min state_size AUTO_REUSE as_list embedding_lookup concat variable cos sin expand_dims array range | # DIEN-PIPLINE DIEN-pipline implement 一个DIEN的pipline简单实现,包括以下部分: * 模型本身 * 数据预处理 * 负采样实现 * 简易搭建,只需要根据数据填写config文件即可 该pipline实现了数据获取,数据预处理,sequence负采样的集成,且是解耦的,可以快速应用于新的数据集,实现了amazon和taobao两个数据集的baseline ## 感谢以下大神的开源代码 * code: https://github.com/shenweichen/DeepCTR | 2,706 |
kurapan/CRNN | ['optical character recognition', 'scene text recognition'] | ['An End-to-End Trainable Neural Network for Image-based Sequence Recognition and Its Application to Scene Text Recognition'] | train.py eval.py data_generator.py models.py STN/spatial_transformer.py config.py utils.py Generator ValGenerator TrainGenerator evaluate_batch predict_text evaluate create_output_directory set_gpus load_image preprocess_image collect_data evaluate_one loc_net ctc_lambda_func CRNN CRNN_STN create_output_directory get_callbacks instantiate_multigpu_model_if_multiple_gpus load_weights_if_resume_training get_models set_gpus get_generators get_optimizer PredictionModelCheckpoint MultiGPUModelCheckpoint Evaluator create_result_subdir resize_image pad_image SpatialTransformer create_result_subdir print makedirs data_path isfile transpose nb_channels resize_image flip pad_image shape join replace predict evaluate_batch evaluate_one predict_text format print load_image preprocess_image predict_text basename tqdm load_image preprocess_image zeros Model Input get_shape concatenate add Model Input get_shape concatenate add Model Input copy output_dir ValGenerator TrainGenerator Adam SGD join PredictionModelCheckpoint MultiGPUModelCheckpoint TensorBoard prediction_model_cp_filename Evaluator training_model_cp_filename ReduceLROnPlateau tb_log label_len characters optimizer makedirs load_model_path resume_training load_weights gpus multi_gpu_model len int join basename glob max makedirs zeros concatenate resize asarray resize | ## CRNN Keras implementation of Convolutional Recurrent Neural Network for text recognition There are two models available in this implementation. One is based on the original CRNN model, and the other one includes a spatial transformer network layer to rectify the text. However, the performance does not differ very much, so it is up to you which model you choose. ### Training You can use the Synth90k dataset to train the model, but you can also use your own data. If you use your own data, you will have to rewrite the code that loads the data accordingly to the structure of your data. To download the Synth90k dataset, go to this [page](http://www.robots.ox.ac.uk/~vgg/data/text/) and download the MJSynth dataset. Either put the Synth90k dataset in `data/Synth90k` or specify the path to the dataset using the `--base_dir` argument. The base directory should include a lot of subdirectories with Synth90k data, annotation files for training, validation, and test data, a file listing paths to all images in the dataset, and a lexicon file. Use the `--model` argument to specify which of the two available models you want to use. The default model is CRNN with STN layer. See `config.py` for details. Run the `train.py` script to perform training, and use the arguments accordingly to your setup. #### Execution example | 2,707 |
kurapan/EAST | ['optical character recognition', 'scene text detection', 'curved text detection'] | ['EAST: An Efficient and Accurate Scene Text Detector'] | losses.py train.py lanms/.ycm_extra_conf.py lanms/__init__.py eval.py lanms/__main__.py locality_aware_nms.py data_processor.py adamw.py model.py AdamW threadsafe_generator generator restore_rectangle_rbox line_cross_point get_text_file resize_image sort_rectangle count_samples all generate_rbox check_and_validate_polys restore_rectangle line_verticle shrink_poly crop_area fit_line load_data_process val_generator pad_image get_images polygon_area point_dist_to_line load_annotation threadsafe_iter load_data rectangle_from_parallelogram get_images sort_poly resize_image detect main standard_nms weighted_merge nms_locality intersection dice_loss rbox_loss resize_output_shape resize_bilinear EAST_model CustomTensorBoard CustomModelCheckpoint make_image_summary SmallTextWeight lr_decay main ValidationEvaluator GetCompilationInfoForFile IsHeaderFile MakeRelativePathsInFlagsAbsolute FlagsForFile DirectoryOfThisScript merge_quadrangle_n9 glob join format extend polygon_area print zip append clip min astype choice shape int32 zeros range max clip arctan2 polyfit print norm arccos line_verticle fit_line dot line_cross_point sum arctan print argmin argmax concatenate reshape transpose zeros array fillPoly line_cross_point sort_rectangle ones argmin append sum range astype fit_line zip enumerate norm point_dist_to_line min argwhere zeros array rectangle_from_parallelogram replace randint copy shape zeros max shape float resize arange subplots input_size get_text_file resize resize_image abs show ones shape imshow generate_rbox check_and_validate_polys append training_data_path imread format crop_area close shuffle tight_layout choice add_artist astype pad_image zeros get_images Polygon print text set_yticks min float32 set_xticks load_annotation randint array arange input_size get_text_file resize_image shape generate_rbox check_and_validate_polys append training_data_path imread format astype shuffle pad_image get_images print float32 load_annotation validation_data_path array format print input_size shape load_annotation get_text_file check_and_validate_polys generate_rbox resize_image imread pad_image get join get_images print close nb_workers array validation_data_path Pool len test_data_path endswith print append walk len int time format zeros_like print reshape fillPoly astype argwhere int32 zeros restore_rectangle merge_quadrangle_n9 enumerate sum argmin imwrite output_dir resize_image open basename gpu_list predict format model_from_json close detect load_weights model_path join read get_images time print reshape makedirs reshape area Polygon append array append weighted_merge list fromarray BytesIO close getvalue shape save generator checkpoint_path multi_gpu_model model variable input_size count_samples CustomTensorBoard CustomModelCheckpoint init_learning_rate SmallTextWeight fit_generator restore_model summary mkdir LearningRateScheduler compile AdamW rmtree load_data EAST_model to_json ValidationEvaluator len append join startswith IsHeaderFile compiler_flags_ exists compiler_flags_ GetCompilationInfoForFile compiler_working_dir_ MakeRelativePathsInFlagsAbsolute DirectoryOfThisScript nms_impl array copy | # EAST: An Efficient and Accurate Scene Text Detector This is a Keras implementation of EAST based on a Tensorflow implementation made by [argman](https://github.com/argman/EAST). The original paper by Zhou et al. is available on [arxiv](https://arxiv.org/abs/1704.03155). + Only RBOX geometry is implemented + Differences from the original paper + Uses ResNet-50 instead of PVANet + Uses dice loss function instead of balanced binary cross-entropy + Uses AdamW optimizer instead of the original Adam The implementation of AdamW optimizer is borrowed from [this repository](https://github.com/shaoanlu/AdamW-and-SGDW). The code should run under both Python 2 and Python 3. | 2,708 |
kurowasan/GraN-DAG | ['causal inference'] | ['Gradient-Based Neural DAG Learning'] | gran_dag/utils/topo_sort.py notears/notears/notears.py notears/notears/simple_demo.py notears/main.py dag_gnn/dag_gnn/utils.py gran_dag/utils/penalty.py notears/notears/cppext/eigen/debug/gdb/__init__.py gran_dag/models/base_model.py gran_dag/train.py gran_dag/dag_optim.py gran_dag/data.py gran_dag/plot.py cam/main.py dag_gnn/main.py gran_dag/main.py notears/notears/cppext/setup.py cam/cam.py gran_dag/utils/metrics.py notears/notears/cppext/eigen/scripts/relicense.py gran_dag/models/learnables.py random_baseline/main.py dag_gnn/dag_gnn/train.py gran_dag/utils/save.py main.py dag_gnn/dag_gnn/modules.py notears/notears/utils.py notears/notears/cppext/eigen/debug/gdb/printers.py CAM_with_score message_warning main _print_metrics main _print_metrics MLPDDecoder SEMDecoder SEMEncoder MLPDecoder MLPDEncoder MLPEncoder MLPDiscreteDecoder evaluate_score update_optimizer _h_A retrain stau dag_gnn gauss_sample_z_new matrix_poly load_numpy_data binary_accuracy preprocess_adj preprocess_adj_new sample_gumbel get_tril_indices my_normalize normalize_adj simulate_population_sample simulate_sem kl_categorical sparse_to_tuple to_2d_idx kl_categorical_uniform gauss_sample_z get_correct_per_bucket count_accuracy compute_BiCScore A_connect_loss sample_logistic get_buckets get_offdiag_indices kl_gaussian list_files read_BNrep my_softmax get_triu_offdiag_indices load_data_discrete get_triu_indices get_tril_offdiag_indices preprocess_adj_new1 A_positive_loss kl_gaussian_sem get_minimum_distance nll_catogrical gumbel_softmax_sample binary_concrete get_correct_per_bucket_ isnan load_data simulate_random_dag compute_local_BiCScore encode_onehot binary_concrete_sample nll_gaussian gumbel_softmax compute_jacobian_avg TrExpScipy compute_constraint is_acyclic compute_A_phi DataManagerFile file_exists main _print_metrics plot_learning_curves plot_adjacency plot_learning_curves_retrain plot_weighted_adjacency cam_pruning_ pns pns_ cam_pruning retrain train to_dag BaseModel LearnableModel_NonLinGaussANM LearnableModel_NonLinGauss LearnableModel edge_errors shd compute_penalty compute_group_lasso_l2_penalty load dump np_to_csv generate_complete_dag main _print_metrics notears_live notears retrain LinearMasked notears_simple simulate_sem count_accuracy simulate_random_dag simulate_population_sample EigenQuaternionPrinter _MatrixEntryIterator EigenSparseMatrixPrinter lookup_function register_eigen_printers build_eigen_dictionary EigenMatrixPrinter update sample_random_dag main get_score CAM_with_score SHD_CPDAG score exp_path test_samples SHD save DataFrame CAM sel_method prune_method metrics_callback train_samples plot_adjacency i_dataset cutoff predict dump edge_errors SID variable_sel float DataManagerFile join time data_path pruning numpy to_numpy_matrix makedirs print items list pns num_neighbors abs seed cam_pruning_ ones pns_ double pns_thresh astype cam_pruning retrain manual_seed dag_gnn random_seed set_default_tensor_type print min eye matrix_poly trace prox_plus abs param_groups log10 eval c_A save_folder exp_path load_numpy_data SGD LBFGS unsqueeze k_max_iter data_variable_size tensor cuda log prior open list StepLR lambda_A ones Adam load_state_dict DoubleTensor dynamic_graph double range dump format inf get_triu_offdiag_indices item isoformat h_tol flush load join time int get_tril_offdiag_indices print Variable clone now parameters load_folder eye _h_A encode_onehot zeros train epochs array makedirs evaluate_score save_folder exp_path load_numpy_data SGD LBFGS unsqueeze k_max_iter data_variable_size cuda log prior open list StepLR ones Adam graph_threshold load_state_dict DoubleTensor dynamic_graph double range dump format get_triu_offdiag_indices isoformat load join time int get_tril_offdiag_indices print Variable now parameters load_folder eye encode_onehot zeros epochs array makedirs int permutation DiGraph ones astype extend choice dot uniform eye append zeros float round range tril exponential normal list gumbel dot topological_sort predecessors sin zeros to_numpy_array range dot sqrt pinv eye T setdiff1d concatenate tril intersect1d float max flatnonzero len contiguous softmax Variable binary_concrete_sample float data sample_logistic Variable size cuda is_cuda float float size cuda double sample_gumbel is_cuda data view Variable size scatter_ gumbel_softmax_sample cuda zeros max is_cuda exp size double range double sum double join iglob data_dir loadtxt search dict DiGraph endswith simulate_sem FloatTensor read_BNrep DataLoader TensorDataset simulate_random_dag amax DiGraph endswith simulate_sem read_BNrep DataLoader TensorDataset simulate_random_dag x_dims Tensor from_numpy_matrix Tensor DataLoader TensorDataset floor float array get list map set array ones t eye ones t eye ones t eye zeros zeros transpose sum matmul min arange min append numpy max range numpy append sum range len numpy append sum range len log sum squeeze exp sum log size range exp pi from_numpy pow div log abs matmul pow sum diag transpose double transpose double transpose double inverse size norm double range to_tuple range isinstance len div double range sum where compute_local_BiCScore append sum range values tuple log dict sum prod range amax num_vars apply matmul range eye num_vars sum unsqueeze eye abs enumerate einsum detach num_vars unbind get_parameters compute_log_likelihood mean sample zeros range hid_dim num_layers LearnableModel_NonLinGaussANM LearnableModel_NonLinGauss reset_params to_dag file_exists num_vars format lr load train gpu subplots arange clf linspace plotting_callback tick_params max list set_yscale set_xlabel twinx savefig legend range plot tight_layout interp join set_ylabel array len set_aspect join subplots set_title clf savefig heatmap join list subplots plot print set_xlabel tight_layout clf savefig legend array range set_ylim len join list subplots plot set_xlabel tight_layout clf savefig legend array range set_ylim len str SelectFromModel format concatenate print num_samples astype copy ExtraTreesRegressor sample float range fit join time format dump print plot_adjacency pns_ save numpy exists makedirs exp_path stop_crit_win zero_grad SGD plot_weighted_adjacency numpy save num_train_iter exists metrics_callback lambda_init mu_init plot_adjacency plot_learning_curves RMSprop append range dump format inf astype eval item sample join time get_parameters backward print num_samples float32 parameters get_w_adj compute_constraint zeros step train_batch_size makedirs SHD_CPDAG exp_path save exists metrics_callback jac_thresh plot_adjacency dump edge_errors SID eval sample float join time get_parameters print num_samples shd_metric t get_w_adj numpy makedirs join str launch_R_script format remove concatenate np_to_csv dict realpath dirname SHD_CPDAG exp_path copy_ save exists metrics_callback cam_pruning_ plot_adjacency dump edge_errors SID eval sample float type join time get_parameters print num_samples shd_metric Tensor numpy makedirs plot_learning_curves_retrain zero_grad num_train_iter exists metrics_callback RMSprop append to_dag inf patience eval item sample deepcopy get_parameters backward train step train_batch_size sum retrieve_adjacency_matrix uuid4 str join to_csv dirname DataFrame DiGraph copy all_topological_sorts append enumerate lambda1 max_iter matmul sum max_iter_retrain w_threshold notears h_tol minimize_subproblem astype shape h_func float_ range add_tools F_func stream flatten h_func push_notebook show minimize_subproblem rect shape ray range patch gridplot tile ColumnDataSource line HoverTool figure LinearColorMapper Adagrad model num_samples LinearMasked _h minimize shape range x append strip_typedefs search tag target type permutation uniform zeros float range uniform sample_random_dag | # Gradient-Based Neural DAG Learning
This code was written by the authors of the ICLR 2020 submission: "Gradient-Based Neural DAG Learning".
Our implementation is in PyTorch but some functions rely on the
[Causal Discovery Toolbox](https://diviyan-kalainathan.github.io/CausalDiscoveryToolbox/html/index.html) which relies
partly on the R programming language.
## Run the code
To use our implementation of GraN-DAG, simply install Singularity (instructions: [https://www.sylabs.io/guides/3.0/user-guide/installation.html](https://www.sylabs.io/guides/3.0/user-guide/installation.html))
and run the code in our container (download it here: [https://drive.google.com/file/d/1BOzKMWOgV-IGO9yIz_gq-UrgvME82zxd/view?usp=sharing](https://drive.google.com/file/d/1BOzKMWOgV-IGO9yIz_gq-UrgvME82zxd/view?usp=sharing)). Use start_example.sh (update the paths) to launch the differents methods (GraN-DAG, DAG-GNN, NOTEARS, CAM).
| 2,709 |
kushalchauhan98/dynamic-meta-embeddings | ['word embeddings'] | ['Dynamic Meta-Embeddings for Improved Sentence Representations'] | embedders.py models.py utils.py modules.py main.py SingleEmbedder ConcatEmbedder DMEmbedder CDMEmbedder Model SNLIModel BiLSTM_Max Classifier CustomVocab FastTextCC | # Dynamic Meta-Embeddings for Improved Sentence Representations <img src="https://upload.wikimedia.org/wikipedia/commons/9/96/Pytorch_logo.png" width="12%"> [](https://opensource.org/licenses/MIT) This repository contains my PyTorch implementation of the paper: **Dynamic Meta-Embeddings for Improved Sentence Representations**<br> Douwe Kiela, Changhan Wang and Kyunghyun Cho<br> *Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing*<br> [[arXiv](https://arxiv.org/abs/1804.07983)] [[GitHub](https://github.com/facebookresearch/DME)] ### Abstract While one of the first steps in many NLP systems is selecting what pre-trained word embeddings to use, we argue that such a step is better left for neural networks to figure out by themselves. To that end, we introduce dynamic meta-embeddings, a simple yet effective method for the supervised learning of embedding ensembles, which leads to state of-the-art performance within the same model class on a variety of tasks. We subsequently show how the technique can be used to shed new light on the usage of word embeddings in NLP systems. ### Usage | 2,710 |
kushaltirumala/callibratable_style_consistency_flies | ['imitation learning'] | ['Learning Calibratable Policies using Programmatic Style-Consistency'] | eval_model.py lib/distributions/multinomial.py transforming_data/transform_data.py util/datasets/fruit_fly/__init__.py util/environments/fruit_fly.py util/datasets/bball/core.py lib/distributions/normal.py lib/models/ctvae_info.py scripts/check_dynamics_loss.py scripts/sample_ctvae_two_model.py train.py run.py lib/distributions/bernoulli.py util/datasets/__init__.py util/datasets/bball/label_functions/__init__.py util/datasets/bball/label_functions/heuristics.py scripts/eval_cop_policy.py lib/distributions/__init__.py util/environments/bball.py lib/models/ctvae_style.py lib/distributions/core.py lib/models/ctvae_mi.py util/datasets/fruit_fly/label_functions/__init__.py scripts/visualize_samples_ctvae.py util/logging/core.py util/logging/__init__.py lib/models/__init__.py run_single.py scripts/compute_stylecon_ctvae.py util/environments/core.py util/environments/__init__.py lib/models/core.py util/datasets/core.py util/datasets/bball/__init__.py lib/distributions/dirac.py util/datasets/fruit_fly/label_functions/heuristics.py scripts/sample_ctvae.py lib/models/ctvae.py util/datasets/fruit_fly/core.py evaluate_model run_config run_epoch start_training Bernoulli Distribution Dirac Multinomial Normal BaseSequentialModel CTVAE CTVAE_info CTVAE_mi CTVAE_style get_model_class check_selfcon_tvaep_dm compute_stylecon_ctvae visualize_samples_ctvae get_classification_loss visualize_samples_ctvae visualize_samples_ctvae visualize_samples_ctvae overlap_interval LabelFunction TrajectoryDataset load_dataset normalize BBallDataset _set_figax unnormalize Displacement AverageSpeed Curvature Destination Direction normalize unnormalize FruitFlyDataset _set_figax Displacement GroundTruth AverageSpeed Curvature Destination Direction BBallEnv BaseEnvironment generate_rollout FruitFlyEnv load_environment LogEntry endswith load_weights array listdir fsdecode join format start_training print copy save_dir makedirs str optimize model print to losses itemize absorb requires_environment average eval LogEntry requires_labels train enumerate get_model_class label_dim requires_environment DataLoader save round seed filter_and_load_state_dict active_label_functions dirname action_dim load_dataset append load_environment to sum run_epoch range state_dict format num_parameters prepare_stage lower manual_seed requires_labels stage load join time pop isinstance print state_dim summary randint get_model_class DataLoader clf set_major_formatter abs filter_and_load_state_dict model_class active_label_functions view transpose ylabel title savefig load_dataset append format PercentFormatter mean lower xlim enumerate load join print xlabel hist median train numpy len get_model_class categorical DataLoader linspace values filter_and_load_state_dict model_class active_label_functions list num_values ones name transpose tolist ylabel randperm title savefig iter load_dataset load_environment next sum cat format plot size close eval lower item label enumerate load join items int print xlabel num_samples zeros fill_between numpy load_model get_model_class DataLoader unsqueeze filter_and_load_state_dict model_class active_label_functions transpose iter load_dataset load_environment next format mean eval lower load join print repeat type arange categorical around linspace save max output_dim ones min zeros lower int int join set_xlim add_subplot imshow set_visible figure resize imread set_ylim get_obs is_recurrent act update_hidden unsqueeze append step range | # Learning Calibratable Policies using Programmatic Style-Consistency [(arXiv)](https://arxiv.org/abs/1910.01179) ## Code Code is written in Python 3.7.4 and [PyTorch](https://pytorch.org/) v.1.0.1. Will be updated for PyTorch 1.3 in the future. ## Usage Train models with: `$ python run_single.py -d <device id> --config_dir <config folder name>` Not specifying a device will use CPU by default. See JSONs in `configs\` to see examples of config files. ### Test Run `$ python run_single.py --config_dir test --test_code` should run without errors. ## Scripts | 2,711 |
kvmanohar22/sparse_depth_sensing | ['depth estimation', 'monocular depth estimation'] | ['Estimating Depth from RGB and Sparse Sensing'] | tests/test_generate_mask.py utils/utils.py nnet/densenet.py nnet/d3.py tests/test_sparse_inputs.py utils/options.py D3 DenseNet_conv main main options path_exists generate_mask sparse_inputs show File imshow generate_mask figure time format print transpose add_subplot sparse_inputs arange print argmin square shape sqrt zip zeros ravel array range enumerate zeros astype int32 | # Estimating Depth from RGB and Sparse Sensing Paper Link: [arxiv](https://arxiv.org/abs/1804.02771) # Requirements - Ubuntu (Tested only on 16.04) - Python 3 - Chainer - ChainerCV - cupy - [imgplot](https://github.com/musyoku/imgplot/) # TODO | 2,712 |
kvsphantom/multitask-unet-bss | ['music source separation'] | ['Multi-channel U-Net for Music Source Separation'] | models/wrapper.py train/cunet.py utils/utils.py eval/eval_metrics.py test/dwa.py train/spec_channel_unet.py train/grad_based.py train/unit_weighted.py test/grad_based.py train/energy_based.py eval/stitch_audio.py loss/losses.py train/spec_channel_unet_nomasks.py test/energy_based.py utils/EarlyStopping.py dataset/downsample_gt.py train/baseline.py utils/plots/energy_distrib_plots.py test/baseline.py test/cunet.py dataset/dataloaders.py utils/plots/generate_spectrograms.py settings.py test/unit_weighted.py dataset/compute_energy.py dataset/preprocessing.py models/cunet.py utils/plots/tables.py dataset/filter_musdb_split.py utils/plots/results.py test/spec_channel_unet.py train/dwa.py set_path UnetInputUnfiltered CUnetInput UnetInput split_sources _stft get_signal_energy save_chunks get_sources gradient_loss SingleSourceDirectLoss EnergyBasedLossPowerP IndividualLosses SpecChannelUnetLoss UnitWeightedLoss GradientLoss CUNetLoss EnergyBasedLossInstantwise EnergyBasedLossPowerPMask CUNet TransitionBlock center_crop ConvolutionalBlock DenseBlock isnumber crop AtrousBlock CUNetWrapper Wrapper SpecChannelUnetNoMaskWrapper main Baseline main CUNetTest DWA main main EnergyBased main GradBased main SpecChannelUnet main UnitWeighted main Baseline main CUNetTrain DWA main main EnergyBased main GradBased main SpecChannelUnet main SpecChannelUnetNoMask main UnitWeighted EarlyStopping save_spectrogram power_to_db get_conditions create_folder amplitude_to_db setup_logger warpgrid rescale istft_reconstruction linearize_log_freq_scale plot_spectrogram makedirs list partial resample map stack int concatenate reshape shape max size cuda join str int create_folder write_wav get_signal_energy zeros round enumerate len abs gradient int size round load items list replace UNet OrderedDict Baseline load_state_dict train Wrapper CUNetWrapper CUNetTest CUNet DWA EnergyBased GradBased SpecChannelUnet UnitWeighted CUNetTrain SpecChannelUnetNoMaskWrapper SpecChannelUnetNoMask setFormatter getLogger addHandler StreamHandler Formatter setLevel FileHandler umask makedirs ref size expand log10 tensor max callable detach ref pow tensor abs callable min max power astype float32 linspace meshgrid zeros log complex exp astype istft grid_sample make_grid add_images amplitude_to_db rescale unsqueeze cpu rescale amplitude_to_db save list arange ones append zeros max | # Multi-channel Unet for Music Source Separation **Note 1**: The pre-trained weights of most of the models used in these experiments are made available here: [https://shorturl.at/aryOX](https://shorturl.at/aryOX) **Note 2**: For demos, visit our [project webpage](https://vskadandale.github.io/multi-channel-unet/). #### <ins>Usage Instructions</ins>: This repository is organized as follows: The data preprocessing steps are covered under the folder: code/dataset. ``` └── dataset ├── compute_energy.py ├── dataloaders.py | 2,713 |
kylemin/Gaze-Attention | ['action recognition', 'egocentric activity recognition'] | ['Integrating Human Gaze into Attention for Egocentric Activity Recognition'] | pytorch_i3d.py dataset.py utils.py main.py model.py transform igazeDataset trainingSampler load_model test print_args load_weights adjust_lr main train load_weights_and_set_opt I3D_IGA_attn I3D_IGA_base I3D_IGA_gaze InceptionI3d MaxPool3dSamePadding InceptionModule Unit3D _pointwise_loss compute_cross_entropy compute_gradients_gaze get_accuracy sample_gumbel make_hard_decision div permute datasplit DataLoader DataParallel device datapath load_weights_and_set_opt seed load_model parse_args to manual_seed_all stride test manual_seed is_available trange crop join print print_args isfile igazeDataset train weight mode I3D_IGA_attn I3D_IGA_base I3D_IGA_gaze load join items print size copy_ isfile state_dict replace SGD load_weights append weight print datasplit wd lr b ngpu weight test_sparse mode param_groups clip_grad_norm_ zero_grad compute_gradients_gaze save kl_div tensor max exp view model_base sum range state_dict eps LongTensor log_softmax compute_cross_entropy mean zip max_pool2d model_gaze crop enumerate join time iters backward print makedirs adjust_lr zeros step make_hard_decision time print confusion_matrix eval get_accuracy append sum range len rand shape sample_gumbel view scatter_ model_attn lambd | # Gaze-Attention Integrating Human Gaze into Attention for Egocentric Activity Recognition (WACV 2021)\ [**paper**](https://openaccess.thecvf.com/content/WACV2021/html/Min_Integrating_Human_Gaze_Into_Attention_for_Egocentric_Activity_Recognition_WACV_2021_paper.html) | [**presentation**](https://youtu.be/k-VUi54GjXQ) ## Overview It is well known that human gaze carries significant information about visual attention. In this work, we introduce an effective probabilistic approach to integrate human gaze into spatiotemporal attention for egocentric activity recognition. Specifically, we propose to reformulate the discrete training objective so that it can be optimized using an unbiased gradient estimator. It is empirically shown that our gaze-combined attention mechanism leads to a significant improvement of activity recognition performance on egocentric videos by providing additional cues across space and time. | Method | Backbone network | Acc(%) | Acc\*(%) | |:----------------------|:------------------:|:-------:|:-------:| | [Li et al.](https://openaccess.thecvf.com/content_ECCV_2018/papers/Yin_Li_In_the_Eye_ECCV_2018_paper.pdf) | I3D | 53.30 | - | | [Sudhakaran et al.](http://bmvc2018.org/contents/papers/0756.pdf) | ResNet34+LSTM | - | 60.76 | | [LSTA](https://openaccess.thecvf.com/content_CVPR_2019/papers/Sudhakaran_LSTA_Long_Short-Term_Attention_for_Egocentric_Action_Recognition_CVPR_2019_paper.pdf) | ResNet34+LSTM | - | 61.86 | | 2,714 |
kylie-box/word_prisms | ['word embeddings'] | ['Learning Efficient Task-Specific Meta-Embeddings with Word Prisms'] | logger.py convert_as_word_prism.py embedding_models.py evaluation_models.py result.py train_text_classification.py load_as_word_prism.py dataset.py train_sequence_labelling.py setup.py config.py utils.py constants.py dictionary.py create_directory load_config read_rc save_dictionary load_embeddings read_given_dict save_embeddings main TextClassificationLoader SNLIIter TextClassificationIter NLIDatasetLoader SNLIDataset get_emb_key get_preprocessing Dictionary WordPrism EmbeddingModel Embeddings EmbWrapper SysLvlLC BaseEvaluationModel WordLvlLC NLIModel SeqLabModel ContextualizedLvlLC TextClassificationModel ConcatBaseline load_embwrapper load_word_prism create_logger LogFormatter ResultsHolder ResultsObtainedError get_model get_optimizer_scheduler evaluate get_dataset data_loading_prep report_args set_seeds main write_prediction_files train get_parser get_model get_optimizer_scheduler evaluate get_dataset data_loading_prep report_args set_seeds main write_prediction_files train get_parser nn_init norm cooc_path emb_path init_weight pmi get_dtype load_shard get_device normalize corpus_path count_param_num join chdir strftime output_dir makedirs int join format print endswith next sum array open print save_embedding_from_V dirname dict_path print set_dictionary_path Dictionary save emb_path save_dictionary save_embeddings load_embeddings join int format load_embwrapper embeds_root min dictionary shape WordPrism get_device startswith info load_embedding normalize truncation range append len setFormatter getLogger addHandler LogFormatter StreamHandler DEBUG setLevel INFO FileHandler seed manual_seed_all manual_seed ReduceLROnPlateau Adam SGD train_test_split SequenceLoader sort_by_length padding_id feed_full_seq_ds get_optimizer_scheduler save_model model clip_grad_norm_ zero_grad verbose add_ds_results output_dir save defaultdict id2label tolist append count_param_num grad_clip range early_stop_patience update epoch format orthogonalize get_id orthogonal info join task backward isnan parameters monitor_word ResultsHolder beta write_prediction_files step loss task format info join add_argument dirname abspath ArgumentParser serialize report_args create_logger n_classes set_seeds output_dir load_word_prism labels_to_idx id2labels mb_size get_dataset dictionary data_loading_prep getattr train_test_split to dim sst_labels format write_logger orthogonal info train join embedding get_x_y get_device evaluation get_model callable len vars SNLIIter SequenceLabellingIter TextClassificationIter data max premise model text label hypothesis set_dataset_mapping premise vocab train_iter label enumerate text hypothesis itos vocab task join join join matrix isinstance Tensor ndarray isinstance xavier_uniform_ kaiming_uniform_ orthogonal_ isinstance Sequential init_weight named_parameters getattr uniform_ split | # Word Prisms Word embeddings are trained to predict word cooccurrence statistics, which leads them to possess different lexical properties (syntactic, semantic, synonymy, hypernymy, etc.) depending on the notion of context defined at training time. These properties manifest when querying the embedding space for the most similar vectors, and when used at the input layer of deep neural networks trained to solve NLP problems. Meta-embeddings combine multiple sets of differently trained word embeddings, and have been shown to successfully improve intrinsic and extrinsic performance over equivalent models which use just one set of source embeddings. We introduce *word prisms*: a simple and efficient meta-embedding method that learns to combine source embeddings according to the task at hand. Word prisms learn orthogonal transformations to linearly combine the input source embeddings, which allows them to be very efficient at inference time. We evaluate word prisms in comparison to other meta-embedding methods on six extrinsic evaluations and observe that word prisms offer improvements in performance on all tasks. ## Requirements * Python 3.6+ * NumPy 1.18.1 | 2,715 |
kymatio/phaseharmonics | ['time series'] | ['Phase Harmonic Correlations and Convolutional Neural Networks'] | kymatio/datasets.py kymatio/caching.py code_rec2d/cartoond/test_rec_bump_chunkid_lbfgs2_gpu_N64.py code_rec2d/compute_coeff.py code_rec2d/cartoond/test_rec_bump_chunkid_lbfgs2_cpu_N64.py kymatio/phaseharmonics2d/backend/backend_torch.py kymatio/version.py kymatio/__init__.py kymatio/phaseharmonics2d/backend/backend_common.py code_rec2d/boat/test_rec_bump_chunkid_lbfgs_gpu_N256_ps2par.py scatnet-0.2a/ScatNetLight/svm_robust/libsvm-compact-0.1/tools/grid.py kymatio/phaseharmonics2d/backend/backend_utils.py scatnet-0.2a/ScatNetLight/svm_robust/libsvm-compact-0.1/tools/easy.py kymatio/phaseharmonics2d/utils.py code_rec2d/cartoond/test_rec_bump_chunkid_lbfgs_gpu_N64.py scatnet-0.2a/ScatNetLight/svm_robust/libsvm-compact-0.1/tools/checkdata.py code_rec2d/cartoond/test_rec_bump_chunkid_lbfgs_gpu_N256_ps2par.py kymatio/phaseharmonics2d/backend/backend_skcuda.py kymatio/phaseharmonics2d/phase_harmonics_k_bump_chunkid_pershift.py kymatio/phaseharmonics2d/filter_bank.py kymatio/phaseharmonics2d/phase_harmonics_k_bump_chunkid_simplephase.py scatnet-0.2a/ScatNetLight/svm_robust/libsvm-compact-0.1/tools/subset.py kymatio/phaseharmonics2d/backend/__init__.py setup.py kymatio/phaseharmonics2d/__init__.py kymatio/phaseharmonics2d/phase_harmonics_k_bump_chunkid_scaleinter.py code_rec2d/compute_coeff_ps2.py grad_obj_fun fun_and_grad_conv callback_print obj_fun obj_func closure obj_fun obj_func closure obj_fun grad_obj_fun fun_and_grad_conv callback_print obj_fun grad_obj_fun fun_and_grad_conv callback_print obj_fun find_cache_base_dir get_cache_dir _download read_xyz fetch_fsdd find_datasets_base_dir fetch_qm7 get_dataset_dir _pca_align_positions convert_complexNp_floatT periodize_filter_fft filter_bank filter_bank_real haar_2d gabor_2d morlet_2d PHkPerShift2d PhkScaleInter2d PhaseHarmonics2d fft2_c2c compute_padding ifft2_c2r fft2 periodic_signed_dis periodic_dis ifft2_c2c mul SubInitSpatialMeanC PhaseExpLL PhaseHarmonicsIso conjugate StablePhase SubInitMeanIso PhaseHarmonics2 unpad fft iscomplex PhaseExp_par PhaseExpSk real SubInitMean PeriodicShift2D ones_like Pad log2_pows SubInitSpatialMeanCinFFT PhaseHarmonic pows DivInitStd SubInitSpatialMeanR StablePhaseExp modulus DivInitStdQ0 Modulus SubsampleFourier imag getDtype cdgmmMulcu load_kernel cdgmmMul cdgmm HookDetectNan NanError HookPrintName MaskedFillZero count_nans is_long_tensor main my_float err process_options LocalWorker redraw calculate_jobs permute_sequence TelnetWorker SSHWorker main WorkerStopToken range_f Worker exit_with_help main process_options sum wph_op synchronize to range len time grad_obj_fun reshape print requires_grad_ append tensor to range backward range zero_ obj_fun obj_func time zero_grad print zero_ requires_grad_ grad obj_fun cuda get join find_cache_base_dir exists makedirs get expanduser join makedirs exists find_datasets_base_dir urlopen str join print get_dataset_dir getstatusoutput int list zeros_like map zip append zeros float array range split zeros_like astype copy dot eigh zip load join _download savez read_xyz get_cache_dir get_dataset_dir _pca_align_positions exists int periodize_filter_fft FloatTensor fft2 pi stack gabor_2d haar_2d append range morlet_2d zeros convert_complexNp_floatT fft2 complex64 load join format print get_cache_dir int ones multiply float32 complex64 shape zeros range sum gabor_2d exp fftshift cos float32 complex64 dot sin zeros array zeros_like clone append stack mul range append stack mul range stack imag real norm ifft size irfft compile_with_cache substitute DoubleTensor isinstance FloatTensor size new view expand_as print print format pop int format err print len exit open my_float range split stdin join list format print exit map append split append pop int append len all sort write encode round max flush permute_sequence append float range_f range len appendleft get process_options append getuser write calculate_jobs redraw put getpass start Queue flush print format exit int exit_with_help len Label sort close label float | PhaseHarmonics: Wavelet phase harmonic transform in PyTorch ====================================== This is an implementation of the wavelet phase harmonic transform based on Kymatio (in the Python programming language). It is suitable for audio and image analysis and modeling. ### Related Publications * [2019] Stéphane Mallat, Sixin Zhang, Gaspar Rochette. Phase Harmonic Correlations and Convolutional Neural Networks. [(paper)](https://arxiv.org/abs/1810.12136). * [2020] E. Allys, T. Marchand, et al. New Interpretable Statistics for Large Scale Structure Analysis and Generation. [(paper)](https://github.com/Ttantto/wph_quijote).[(code)](https://github.com/Ttantto/wph_quijote). * [2021] Sixin Zhang, Stéphane Mallat. Maximum Entropy Models from Phase Harmonic Covariances. [(paper)](https://arxiv.org/abs/1911.10017).[(code)](https://github.com/sixin-zh/kymatio_wph). * [2021] Bruno Regaldo-Saint Blancard, Erwan Allys, François Boulanger, François Levrier, Niall Jeffrey. A new approach for the statistical denoising of Planck interstellar dust polarization data. [(paper)](https://arxiv.org/abs/2102.03160). [(code)](https://github.com/bregaldo/pywph). * [2022] Brochard, Zhang, Mallat. Generalized Rectifier Wavelet Covariance Model For texture Synthesis. [(paper)](https://openreview.net/pdf?id=ziRLU3Y2PN_). [(code)](https://github.com/abrochar/wavelet-texture-synthesis). * [2022] Antoine Brochard, Bartłomiej Błaszczyszyn, Sixin Zhang, Stéphane Mallat. Particle gradient descent model for point process generation. [(paper)](https://link-springer-com.gorgone.univ-toulouse.fr/article/10.1007/s11222-022-10099-x). [(code)](https://github.com/abrochar/pp_syn) | 2,716 |
kyunghyuncho/strawman | ['sentiment analysis'] | ['Strawman: an Ensemble of Deep Bag-of-Ngrams for Sentiment Analysis'] | predict.py extract_dictionary.py trainer.py main extract_ngrams main main BBNet data_iterator range set OrderedDict list keys values Softmax data_iterator argmax from_numpy append sum options format concatenate astype softmax enumerate print Variable split nn train numpy array len zero_grad step Adam BBNet range eval manual_seed float net criterion backward parameters cpu | # strawman | 2,717 |
kzkadc/alocc_mnist | ['outlier detection', 'one class classifier', 'anomaly detection'] | ['Adversarially Learned One-Class Classifier for Novelty Detection'] | chainer/train.py chainer/model.py pytorch/model.py pytorch/train.py ExtendedClassifier Generator EvalModel Discriminator GANUpdater ext_save_img get_mnist_num main parse_args get_discriminator get_generator Detector GANTrainer save_img get_mnist_num evaluate_accuracy plot_metrics main print_logs parse_args mkdir stack LogReport Trainer get_mnist_num Path SerialIterator ConcatenatedDataset run use setup ones Generator Adam pprint add_hook Discriminator Evaluator ProgressBar PlotReport mkdir PrintReport GANUpdater EvalModel result_dir ExtendedClassifier ext_save_img TupleDataset user_gpu_mode extend snapshot_object WeightDecay zeros to_gpu len add_argument pprint ArgumentParser main vars DataLoader evaluate_accuracy ITERATION_COMPLETED device print_logs GANTrainer to add_event_handler set plot_metrics print Engine save_img parameters MNIST mkdir | # ディープラーニングによる異常検知手法ALOCC Sabokrou, et al. "Adversarially Learned One-Class Classifier for Novelty Detection", The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018, pp. 3379-3388 https://arxiv.org/abs/1802.09088 ## 準備 (Chainer) ChainerとOpenCVを使います。 インストール: ```bash $ sudo pip install chainer opencv-python ``` ## 準備 (PyTorch) | 2,718 |
l294265421/SCAN | ['sentiment analysis', 'graph attention'] | ['Sentence Constituent-Aware Aspect-Category Sentiment Analysis with Graph Attention Networks'] | nlp_tasks/bert_keras/tokenizer.py nlp_tasks/utils/attention_visualizer.py nlp_tasks/utils/vector_utils.py nlp_tasks/utils/event_extractor.py nlp_tasks/absa/aspect_category_detection_and_sentiment_classification/cnn_encoder_seq2seq.py nlp_tasks/absa/aspect_category_detection_and_sentiment_classification/acd_and_sc_bootstrap_pytorch_sentence_constituency.py nlp_tasks/common/common_path.py nlp_tasks/utils/http_utils.py nlp_tasks/absa/aspect_category_detection_and_sentiment_classification/my_allennlp_trainer_epoch.py nlp_tasks/absa/aspect_category_detection_and_sentiment_classification/acd_and_sc_train_templates_pytorch.py nlp_tasks/absa/aspect_category_detection_and_sentiment_classification/my_allennlp_trainer.py nlp_tasks/absa/aspect_category_detection_and_sentiment_classification/pytorch_models.py nlp_tasks/utils/corenlp_sentence_parser.py nlp_tasks/utils/pdf_metadata_reader.py nlp_tasks/utils/stanfordnlp_sentence_constituency_parser.py nlp_tasks/bert_keras/data_loader.py nlp_tasks/utils/text_segmentation.py nlp_tasks/absa/aspect_category_detection_and_sentiment_classification/allennlp_callback.py nlp_tasks/utils/word_processor.py nlp_tasks/absa/aspect_category_detection_and_sentiment_classification/allennlp_metrics.py nlp_tasks/utils/es_utils.py nlp_tasks/absa/aspect_category_detection_and_sentiment_classification/acd_and_sc_data_reader.py nlp_tasks/bert_keras/data_adapter.py nlp_tasks/utils/annotation_utils.py original_data/absa/ABSA_DevSplits/reader.py nlp_tasks/absa/data_adapter/data_object.py nlp_tasks/absa/sentence_analysis/constituency_parser.py nlp_tasks/utils/file_utils.py nlp_tasks/utils/create_graph.py nlp_tasks/utils/my_corenlp.py nlp_tasks/utils/sentence_segmenter.py nlp_tasks/utils/tokenizer_wrappers.py nlp_tasks/utils/argument_utils.py nlp_tasks/utils/datetime_utils.py nlp_tasks/utils/tokenizers.py nlp_tasks/utils/corenlp_factory.py nlp_tasks/absa/entities/ModelTrainTemplate.py AcdAndScDatasetReaderConstituencyBert TextInAllAspectSentimentOut TextInAllAspectSentimentOutSentenceConstituency AcdAndScDatasetReaderConstituencyBertSingle SentenceConsituencyAwareModelBertSingle SentenceConsituencyAwareModelBert TextInAllAspectSentimentOutTrainTemplate BaseSentenceConsituencyAwareModel SentenceConsituencyAwareModel EstimateCallback FixedLossWeightCallback SetLossWeightCallback Callback BinaryF1 CnnEncoder Trainer Trainer TextInAllAspectSentimentOutEstimator DglGraphAverage TextInAllAspectSentimentOutEstimatorAll DglGraphAttentionForAspectCategory GATForAspectCategory DglGraphConvolution ConstituencyBertSingle AverageAttention MultiHeadGATLayer Estimator DotProductAttentionInHtt GAT AttentionInCan BernoulliAttentionInHtt GATLayer NodeApplyModule LocationMaskLayer AttentionInHtt DglGraphConvolutionForAspectCategory GatEdge TextInAllAspectSentimentOutModel DglGraphAverageForAspectCategory SentenceConsituencyAwareModelV8 ConstituencyBert DglGraphAttentionForAspectCategoryWithDottedLines Semeval2016Task5Sub1 AbsaSentence AsgcnData AspectCategory Semeval2015Task12 load_csv_data Semeval2016Task5Sub2 AspectTerm Semeval2014Task4Rest Semeval2014Task4RestDevSplits BaseDataset AbsaDocument SemEval141516LargeRest Semeval2015Task12Rest Semeval2016Task5RestSub1 Text AbsaText Semeval2014Task4 MAMSACSA get_dataset_class_by_name ModelTrainTemplate SerialNumber ConstituencyTreeNode SingleSentenceGenerator SentencePairGenerator convert_data get_pair_data_from_file get_data_from_file EnglishTokenizer TokenizerReturningSpace get_task_data_dir split_sentence my_bool plot_multi_attentions_of_sentence_backup plot_attentions plot_attentions_pakdd extract_numbers plot_attention plot_multi_attentions_of_sentence create_corenlp_server CorenlpParser create_dependency_graph_by_spacy create_dependency_graph_for_dgl_for_syntax_aware_atsa_bert create_dependency_graph create_sentence_constituency_graph_for_dgl create_dependency_graph_for_dgl get_coref_edges plot_dgl_graph create_sentence_constituency_graph_for_dgl_with_dotted_line create_aspect_term_dependency_graph create_coref_graph parse_dates now day_ago second_diff day_diff search_esproxy_by_scroll search search_by_scroll get_ccomp_event_representation_by_constituency_tree get_verb_event_representation_by_constituency_tree get_event_representation_by_constituency_tree get_noun_event_representation_by_constituency_tree read_all_lines write_lines read_all_content append_line read_all_lines_generator rm_r get post StanfordCoreNLP main printMeta NltkSentenceSegmenter SimpleChineseSentenceSegmenter BaseSentenceSegmenter ConstituencyParseSentenceSegmenter parse_corenlp_parse_result sub_constituency_parser_result_generator TreeNode ZhSplitStentence ZhSplitParagraph NltkTokenizer SpacyTokenizer StanfordTokenizer AllennlpBertTokenizer JiebaTokenizer BaseTokenizer TokenizerWithCustomWordSegmenter get_trained_count_and_tfidf_model to_tfidf_vectors2 to_tfidf_vectors3 to_tfidf_vectors WordProcessorInterface StemProcessor LowerProcessor BaseWordProcessor StopWordProcessor join append read_all_lines print reader list pad_sequences shuffle encode array range append len append read_all_lines read_all_lines append show subplots DataFrame heatmap range len show subplots set_title get_xticklabels tight_layout colorbar subplots_adjust setp append tick_params DataFrame heatmap range enumerate len show subplots set_title append DataFrame heatmap range enumerate len show list subplots set_title get_xticklabels tight_layout subplots_adjust savefig setp append tick_params DataFrame heatmap range enumerate len show list subplots set_title get_xticklabels tight_layout subplots_adjust savefig setp append tick_params DataFrame heatmap range enumerate len findall zeros range dependency_parse len append coref range len children spacy_nlp astype len update children list extend add_nodes DGLGraph get_coref_edges zip append spacy_nlp add_edges len update join children list add_edges add_nodes DGLGraph zip append spacy_nlp range len update list add_edges add_nodes DGLGraph zip append range len update list get_adjacency_list_between_all_node_and_leaf get_all_nodes get_all_leaves add_nodes DGLGraph get_all_inner_nodes zip append add_edges len list get_adjacency_list_between_all_node_and_leaf get_all_nodes get_all_leaves add_nodes DGLGraph zip append add_edges len kamada_kawai_layout show draw to_networkx print append zeros coref range len append strptime timedelta strftime timedelta now strptime total_seconds strptime days loads deepcopy post extend get deepcopy str extend index post loads get deepcopy extend post loads get_np_ancestor parent get_ancestor get_np_ancestor parent join remove rmdir walk Request dumps bytes getDocumentInfo format print PdfFileReader open add_option OptionParser print exit printMeta usage filename parse_args append pop enumerate sub_constituency_parser_result_generator index TreeNode sub append transform TfidfTransformer CountVectorizer fit transform TfidfTransformer fit_transform CountVectorizer toarray | # The code and data for the paper "Sentence Constituent-Aware Aspect-Category Sentiment Analysis with Graph Attention Networks" # Requirements - Python 3.6.8 - torch==1.2.0 - pytorch-transformers==1.1.0 - allennlp==0.9.0 # Supported datasets - SemEval-2014-Task-4-REST-DevSplits (Rest14) - MAMSACSA (MAMS-ACSA) - SemEval-141516-LARGE-REST | 2,719 |
lRomul/argus-alaska | ['data augmentation'] | ['BitMix: Data Augmentation for Image Steganalysis'] | src/models/classifiers.py src/mixers.py src/models/__init__.py train.py src/__init__.py src/models/timm_model.py src/ema.py src/metrics.py src/predictor.py src/transforms.py make_folds.py src/config.py src/datasets.py src/models/custom_efficient.py predict.py make_quality_json.py src/utils.py src/argus_models.py src/losses.py src/models/custom_resnet.py predict_validation predict_test get_lr train_fold AlaskaModel get_prediction_transform get_folds_data AlaskaDataset get_test_data AlaskaSampler load_image AlaskaDistributedSampler EmaMonitorCheckpoint ModelEma SmoothingOhemCrossEntropy AlaskaCrossEntropy LabelSmoothingCrossEntropy Accuracy WeightedAuc alaska_weighted_auc rand_bbox BitMix mix_target EmptyMix RandomMixer Predictor predict_data UseWithProb get_transforms OneOf RandomRotate90 deep_chunk initialize_amp get_best_model_path target2altered get_image_quality load_pretrain_weigths initialize_ema check_dir_not_exist Classifier CustomEfficient CustomResnet TimmModel savez get_test_data to_csv mkdir DataFrame predict items get_folds_data list savez concatenate mkdir append array len AlaskaDataset load_pretrain_weigths DistributedDataParallel AlaskaModel AlaskaSampler DataLoader EmptyMix get_transforms initialize_amp set_device initialize_ema to AlaskaDistributedSampler get_folds_data zip RandomMixer get_best_model_path print fit convert_sync_batchnorm nn_module len convert open items list name data_dir fold train_folds_path zip append read_csv append sorted glob concatenate roc_curve dot linspace array enumerate auc sqrt clip int randint append zip AlaskaDataset DataLoader cat append numpy flip predict Compose Tensor partial isinstance Tensor sum isinstance initialize nn_module optimizer nn_module ModelEma str read str sorted glob search Path append float load_state_dict load_model state_dict print rmtree eval Path input exists | # ALASKA2 Image Steganalysis Source code of solution for [ALASKA2 Image Steganalysis](https://www.kaggle.com/c/alaska2-image-steganalysis) competition. ## Solution Key points: * Efficientnets * DDP training with SyncBN and Apex mixed precision * AdamW with cosine annealing * EMA Model * Bitmix ## Quick setup and start | 2,720 |
lab41/magnolia | ['speaker separation'] | ['Monaural Audio Speaker Separation with Source Contrastive Estimation'] | magnolia/python/models/dnndenoise/chimera.py magnolia/sandbox/demo/app/model_functions.py magnolia/python/models/dnndenoise/DAE.py magnolia/python/preprocessing/spectral_features.py magnolia/python/utils/tf_utils.py magnolia/python/training/separation/JFLEC/training.py magnolia/sandbox/cnn-mask/cnn_models.py magnolia/python/training/separation/SNMF/separate_mix.py magnolia/python/training/denoising/Lab41_Regression/training.py magnolia/python/models/dnnseparate/pit.py magnolia/python/inference/denoising/Chimera/separate_sample_from_mix.py magnolia/python/models/dnnseparate/deep_clustering_model.py magnolia/python/models/dnnseparate/L41model.py magnolia/python/training/data_iteration/supervised_iterator.py magnolia/sandbox/mfcc-DNN-mask-overfit/psf_supplement.py magnolia/python/training/separation/SNMF/separate_sample_from_mix.py magnolia/sandbox/demo/app/tf_utils.py magnolia/python/utils/sample.py magnolia/sandbox/cnn-mask/tf_utils.py setup.py magnolia/sandbox/cnn-mask/model_functions.py docs/initialpitch/playwav.py magnolia/sandbox/lab41-broadcast/supervised_iterator_fullmask.py magnolia/sandbox/demo/app/deep_clustering_models.py magnolia/sandbox/demo/app/views.py magnolia/python/training/data_iteration/mixer.py magnolia/python/utils/plot_stuff.py magnolia/python/training/data_iteration/lmf_features.py magnolia/python/training/separation/SNMF/training.py magnolia/python/training/data_iteration/mix_data.py magnolia/sandbox/lab41-broadcast/supervised_iterator_experiment.py magnolia/python/models/factorization/nmf.py magnolia/python/utils/clustering_utils.py magnolia/python/models/__init__.py magnolia/python/training/separation/Lab41/training.py docs/initialpitch/beamform.py magnolia/python/models/dnndenoise/L41_regression_model.py magnolia/python/models/dnnseparate/DANmodel.py magnolia/python/analysis/make_sdr_table.py magnolia/sandbox/audio-perception-evaluations/psf_supplement.py magnolia/sandbox/demo/app/tflow_functions.py magnolia/python/utils/shift_wavs.py magnolia/python/analysis/bss_evaluate.py magnolia/python/training/separation/Lab41/separate_mix.py magnolia/python/training/data_iteration/wav_iterator.py magnolia/python/training/denoising/Chimera/training.py magnolia/python/training/separation/Lab41/separate_sample_from_mix.py magnolia/sandbox/mfcc-LR-mask/psf_supplement.py magnolia/python/utils/gennoisy.py magnolia/python/training/data_iteration/partition_data.py magnolia/python/utils/partition_graph.py magnolia/sandbox/time-ica/gennoisy.py magnolia/python/utils/norm_wav.py magnolia/sandbox/demo/app/clustering_utils.py magnolia/sandbox/demo/app/l41_models.py magnolia/sandbox/demo/app/__init__.py magnolia/python/preprocessing/preprocessing.py magnolia/python/training/data_iteration/hdf5_iterator.py magnolia/python/models/factorization/snmf.py magnolia/sandbox/demo/app/keras_functions.py magnolia/python/training/data_iteration/mix_iterator.py magnolia/python/utils/MTHM.py magnolia/python/utils/partition_optimizer.py magnolia/python/utils/training.py magnolia/python/preprocessing/assign_uids.py magnolia/python/utils/mix2file.py magnolia/python/utils/postprocessing.py magnolia/python/utils/mixing.py magnolia/sandbox/demo/app/cnn_models.py magnolia/python/models/factorization/pca.py magnolia/python/utils/bss_eval.py magnolia/python/utils/compare_signals.py magnolia/python/models/model_base.py magnolia/python/preprocessing/preprocess_data.py magnolia/python/inference/denoising/Chimera/separate_mix.py magnolia/python/utils/mixes_binary_to_csv.py magnolia/python/analysis/pesq_evaluate.py docs/initialpitch/recordwav.py magnolia/python/models/factorization/ica.py magnolia/python/models/dnnseparate/L41_mask_model.py magnolia/sandbox/frequency-ica/gennoisy.py magnolia/sandbox/mfcc-multibranch/psf_supplement.py magnolia/sandbox/demo/run.py magnolia/python/analysis/comparison_plot.py find_all_package_directories read revsig sumrecv buildrecv beamform padsig evaluate error_on_the_mean summarize_sdr format_dae_columns load_dataframes main make_sdr_delta_versus_input_snr_plot make_sdr_delta_versus_noise_source_plot make_nice_table main main standardize_waveform main standardize_waveform main ModelBase get_model_class make_model Chimera L41Model L41RegressionModel DANModel DeepClusteringModel L41Model L41MaskModel training_loop training_setup PITModel ica snmf nmf_separate nmf easy_nmf_separate pca extend_features sparse_nmf SNMF main preemphasis preprocess_waveform undo_stft_features_old make_stft_dataset_old make_stft_dataset undo_preprocessing make_stft_features undo_preemphasis normalize_waveform main LibriSpeech_metadata_handler UrbanSound8K_metadata_handler stft scale_spectrogram istft SplitsIterator Hdf5Iterator mock_hdf5 lmf_stft_iterator LmfIterator FeatureMixer main MixIterator main SupervisedIterator SupervisedMixer array_if_you_can batcher wav_iterator wav_mixer test_batcher main main main standardize_waveform main standardize_waveform main main standardize_waveform main standardize_waveform main main validate bss_eval_images_framewise filter_kwargs bss_eval_sources bss_eval_sources_framewise evaluate _project_images bss_eval_images _bss_image_crit _any_source_silent _bss_source_crit _project _bss_decomp_mtifilt_images _safe_db _bss_decomp_mtifilt l41_clustering_separate process_signal get_cluster_masks l41_regression_signal apply_masks clustering_separate chimera_clustering_separate preprocess_signal softmax l41_regression_clustering_separate chimera_mask compare_signals gennoisy main apply_binary_mask main convert_sample_length_to_nframes compute_waveform_snr_factor convert_sample_to_nframes compatable_preprocessing_parameters_for_mixing construct_mixed_sample main mthm fuzzy_mthm greed_ys norm_wav build_partition_graph get_group_path PartitionGraphGroup _recursively_build_tree_split get_all_groups PartitionGraphSplit PartitionGraphFilter _recursively_build_tree_node PartitionOptimizer split_categories plot_sig_recon plot_signals line_xy line_x_y convert_preprocessing_parameters reconstruct Sample shift_wavs shift_signal leaky_relu conv2d_layer conv1d_layer conv2d conv1d BLSTM_ scope_decorator bias_variable BLSTM weight_variable preprocess_l41_regression_batch preprocess_chimera_batch preprocess_l41_batch scale_input_spectrogram_for_l41_model convert_boolean_mask_for_l41_model specdecomp Conv1DModel featurize_spectrogram separate_sources leaky_relu conv2d_layer conv1d_layer conv2d conv1d scope_decorator bias_variable weight_variable process_signal get_cluster_masks apply_masks clustering_separate preprocess_signal Conv1DModel DeepClusteringModel keras_spec specdecomp signal_reconstruction keras_separate L41Model featurize_spectrogram separate_sources l41_separate nmf_sep deep_cluster_separate leaky_relu conv2d_layer conv1d_layer conv2d conv1d scope_decorator bias_variable BLSTM weight_variable plot_spectogram resources upload index gennoisy SupervisedIterator SupervisedMixer SupervisedIterator SupervisedMixer specdecomp specdecomp specdecomp gennoisy join format isfile listdir get print enumerate array print zeros enumerate len join int format basename bss_eval_sources print glob group to_csv tqdm match stack dirname normpath append float range values format_dae_columns read_csv digitize copy subplots arange summarize_sdr set_size xticks fillna values set_fontsize set_rotation ylabel bar title savefig legend append range format reset_index replace get_xticklabels tight_layout unique merge xlabel set_ylim len subplots arange summarize_sdr set_size xticks fillna values set_fontsize set_rotation ylabel bar title savefig legend append range format reset_index get_xticklabels tight_layout unique merge xlabel set_ylim len make_sdr_delta_versus_noise_source_plot load_dataframes linspace make_sdr_delta_versus_input_snr_plot format print to_csv tqdm append read_csv values make_nice_table int join basename format print glob group to_csv match dirname normpath append float range run convert_preprocessing_parameters Chimera resample standardize_waveform epoch_size max open write_wav MixIterator chimera_clustering_separate read_csv next inf mean trange enumerate load pop sample_rate undo_preprocessing number_of_samples_in_mixes sample_length_in_bits makedirs reset_default_graph global_variables_initializer Session PITModel run optimize scale_spectrogram islice batcher enumerate append FeatureMixer loss predict run mixing_ T FastICA mean_ fit_transform ones T rand range normalize_W T ones rand normalize_H where square shape any append sum range concatenate snmf append sum array range len KMeans T snmf fit mean T dot len empty range rand random repmat abs log ones multiply exit add sum range eps format inf subtract empty_like copy sqrt power empty T print maximum divide dot zeros getLogger add_argument logger_settings ArgumentParser fileConfig parse_args mean zeros range preemphasis resample stft fix_length len undo_preemphasis istft resample_poly int preemphasis stft mean float std undo_preemphasis istft load format zeros_like preprocess_waveform allclose process_file_metadata debug File tqdm create_dataset info find_files abs create_group normalize_waveform int int T format getLogger warn angle min sqrt unwrap abs max randn T concatenate logfbank stack append next diff join read ones rand randint choice zeros enumerate list islice array_if_you_can zip append list print islice batcher iter make_model train save train_on_batch initialize exit iter get_cost expand_dims sum L41RegressionModel preprocess_l41_regression_batch len l41_clustering_separate L41Model preprocess_l41_batch RandomState source_separate keys SNMF split_along_time_bins batch_update temporal_mask_for_best_features get_function_code items has_kwargs list _any_source_silent warn validate list arange permutations mean _bss_decomp_mtifilt _bss_source_crit empty range enumerate len int validate bss_eval_sources slice floor nan empty range validate list arange permutations reshape range mean _bss_image_crit zeros _bss_decomp_mtifilt_images empty atleast_3d enumerate len int validate slice range bss_eval_images floor nan empty atleast_3d _project size hstack hstack _project_images ifft int fft T reshape hstack toeplitz log2 real ceil zeros range conj ifft int fft T all reshape transpose hstack toeplitz log2 real ceil zeros range conj sum _safe_db sum _safe_db OrderedDict tolist filter_kwargs expand_dims exp amax min sqrt make_stft_features abs max reshape preprocess_signal get_vectors argmax KMeans reshape shape predict_proba labels_ transform zeros sum fit_transform range fit process_signal get_cluster_masks apply_masks append stack undo_preemphasis range istft T get_cluster_masks apply_masks preprocess_l41_batch KMeans get_vectors stack T get_cluster_masks apply_masks get_vectors KMeans stack get_masks expand_dims transpose preprocess_l41_regression_batch T get_cluster_masks apply_masks get_vectors KMeans stack preprocess_l41_regression_batch get_signal combinations list mean stack zeros sum range conj T arange randn rand pi sign dot sawtooth sin zeros decode settings replace unpackb read convert_sample_to_nframes ones compute_waveform_snr_factor preprocessing_parameters draw_sample asscalar compatable_preprocessing_parameters_for_mixing append dB_scale std enumerate len mthm zeros_like abs size argmin argsort sum range enumerate inf zeros_like set argsort add greed_ys fill empty range len range len ones size empty randint fuzzy_mthm array read astype float32 splits destination terminal append get_all_groups PartitionGraphFilter PartitionGraphGroup _recursively_build_tree_node set_destination join _recursively_build_tree_split PartitionGraphSplit _id add_split pop add set PartitionGraphFilter _recursively_build_tree_node intersection ones size astype fuzzy_mthm sum range len DataFrame T DataFrame melt DataFrame mark_line index src concat index melt mark_point Categorical zip append DataFrame copy exp randn angle absolute undo_preemphasis unwrap istft int format arange getLogger concatenate size len copy shape info zeros argmax fftconvolve read __name__ truncated_normal constant sqrt bias_variable weight_variable sqrt bias_variable weight_variable concat reverse concat reverse scale_input_spectrogram_for_l41_model transpose convert_boolean_mask_for_l41_model scale_input_spectrogram_for_l41_model transpose abs scale_input_spectrogram_for_l41_model transpose convert_boolean_mask_for_l41_model sqrt abs preemphasis framesig rfft angle min sqrt unwrap abs max read exp append featurize_spectrogram reshape square mean istft stack make_stft_features undo_preemphasis std range predict int exp irfft deframesig int16 read specdecomp load_model append astype mfcc predict read spectrogram load DeepClusteringModel read clustering_separate root_path append load read clustering_separate L41Model root_path append read easy_nmf_separate print angle reconstruct square make_stft_features append unwrap range str write l41_separate nmf_sep info append max deep_cluster_separate enumerate info plot_spectogram save filename flash info read T matshow preprocess_signal savefig | # Magnolia We will focus on three independent problems. These are: 1. **Monaural source separation** - Using [source contrastive estimation](https://arxiv.org/abs/1705.04662) (submitted to SiPS 2017). 2. Removing a source (whose location is static) that is dynamic and loud. 3. Multiple moving sources (i.e., the channel changes with time) 4. Standoff distance acoustic enhancement (dynamic gain adjustment in low SNR) This project will be primarily an analysis of cost functions (in supervised and unsupervised settings) that can be used in order to denoise and isolate signals. The resulting algorithms of interest will be a mix of cost function resembling ICA and simulated beamforming methods. ## Installation If you'd like to just call the code in the repository: | 2,721 |
labhracorgi/lbhs_wmh_seg_manuals | ['data augmentation'] | ['Fully Convolutional Network Ensembles for White Matter Hyperintensities Segmentation in MR Images'] | my_flair_n4_miccai_30_formatting.py my_miccai_30_formatting.py copy_collect_lpa_ubo_wmh_masks.py my_miccai_post_wm_30_formatting.py copy_collect_lpa_ubo_wmh_masks Utrecht_preprocessing conv_bn_relu dice_coef_loss get_unet do_unet_2017 wm_mask_verifier dice_coef_for_training Utrecht_postprocessing get_crop_shape Utrecht_preprocessing conv_bn_relu dice_coef_loss get_unet do_unet_2017 dice_coef_for_training Utrecht_postprocessing get_crop_shape Utrecht_preprocessing conv_bn_relu dice_coef_loss get_unet do_unet_2017 wm_mask_verifier dice_coef_for_training Utrecht_postprocessing get_crop_shape print len copyfile listdir makedirs flatten sum value conv_bn_relu concatenate compile Model Input get_crop_shape ndarray concatenate print float32 shape binary_fill_holes range shape ndarray abs pad sum open str get_unet shape pad predict close wm_mask_verifier WriteImage ReadImage GetArrayFromImage load_weights listdir Utrecht_preprocessing print write GetImageFromArray isfile Utrecht_postprocessing len | # lbhs_wmh_seg_manuals Extra details of segmentation algorithms that are attempted to use. Specific detail will be given to problems and special care "required" for them to work satisfactory. This git is in no way trying to critize the algorithms or their creators, but instead to provide a subjective adaption such that it fits the intended project's (at http://www.medical-imaging.no/) needs. Check the wiki for details: https://github.com/labhstats/lbhs_wmh_seg_manuals/wiki General scripts will either be referenced or provided. This repository has no guarantee of efficient code, only code that has been run and works sufficiently. ## "Possible" candidates currently in consideration: Overlining means that the algorithm(s) in question is no longer considered. - ~~SLSToolBox:~~ https://github.com/NIC-VICOROB/SLSToolBox (Seem to require a lot of manual pre processing by the user compared to LPA and UBO; whether this is a valid arguement may not be the case.) - ~~DeepMedic:~~ https://github.com/Kamnitsask/deepmedic (A lot of bugs and issues for unknown reasons.) Too many "diffuse" errors making implementation impossible to run a test case. - ~~W2MHS~~ algorithm at: https://www.nitrc.org/projects/w2mhs (SPM12/MatLab and SVM RF based.) May be worth looking further into. | 2,722 |
labsix/adversarial-logit-pairing-analysis | ['adversarial attack'] | ['Evaluating and Understanding the Robustness of Adversarial Logit Pairing'] | robustml_eval.py model_lib.py datasets/imagenet_input.py robustml_model.py robustml_attack.py default_hparams filter_trainable_variables get_model get_optimizer get_lr_schedule PGDAttack NullAttack main _model ALP _decode_and_center_crop imagenet_input imagenet_parser _decode_and_random_crop num_examples_per_epoch image_preprocessing _normalize int lr_decay_factor learning_rate get_or_create_global_step lr_list batch_size lr_num_epochs_per_decay exponential_decay float piecewise_constant MomentumOptimizer momentum rmsprop_decay AdamOptimizer RMSPropOptimizer rmsprop_epsilon startswith string_types get_collection_ref remove isinstance TRAINABLE_VARIABLES epsilon checkpoint_path evaluate PGDAttack ImageNet print NullAttack add_argument imagenet_path ALP ArgumentParser parse_args Session restore model_fn get_variables_to_restore Saver get_model _normalize minimum float32 decode_and_crop_jpeg convert_image_dtype extract_jpeg_shape stack cast int32 _decode_and_center_crop random_flip_left_right reshape _decode_and_random_crop _normalize reshape concat transpose cast parse_single_example expand_dims image_preprocessing values join imagenet_data_dir map_and_batch list_files shuffle map apply repeat parallel_interleave startswith prefetch AUTOTUNE startswith | # Evaluating and Understanding the Robustness of Adversarial Logit Pairing The code in this repository, forked from the [official implementation](https://github.com/tensorflow/models/tree/master/research/adversarial_logit_pairing), evaluates the robustness of [Adversarial Logit Pairing](https://arxiv.org/abs/1803.06373), a proposed defense against adversarial examples. On the ImageNet 64x64 dataset, with an L-infinity perturbation of 16/255 (the threat model considered in the original paper), we can make the classifier accuracy 0.1% and generate targeted adversarial examples (with randomly chosen target labels) with 98.6% success rate using the provided code and models. | 2,723 |
lairning/vrp-drl | ['combinatorial optimization', 'graph attention'] | ['Learn to Design the Heuristics for Vehicle Routing Problem'] | src/cvrp/lib/utils_train.py src/cvrp/train_model.py src/cvrptw/lib/__init__.py src/cvrp/evaluation.py src/cvrp/arguments.py src/cvrptw/evaluation.py src/cvrp/lib/rms.py src/cvrp/lib/__init__.py src/cvrp/lib/utils_eval.py src/cvrptw/lib/rms.py src/cvrp/lib/egate_model.py src/cvrptw/train_model.py src/cvrptw/lib/utils_eval.py src/cvrptw/lib/utils_train.py src/cvrptw/lib/egate_model.py src/cvrptw/arguments.py args Decoder Encoder GatConv Model Attention RunningMeanStd update_mean_var_count_from_moments create_instance create_batch_env create_replay_buffer create_env roll_out create_instance eval_random train create_batch_env create_replay_buffer train_once create_env roll_out random_init args eval Decoder Encoder GatConv Model Attention RunningMeanStd update_mean_var_count_from_moments eval_random create_batch_env read_input create_replay_buffer train_once create_env roll_out random_init create_instance eval_random train create_batch_env create_replay_buffer train_once create_env roll_out random_init add_argument ArgumentParser square append tolist calc_dist enumerate Env create_replay_buffer random_cvrp exp num_graphs evaluate backward print reshape train squeeze clamp zero_grad mean item append to step enumerate print reset array range step state_dict print eval_random create_batch_env Adam extend parameters DataLoader save train_once roll_out range random_init best print argmin create_batch_env reset roll_out best_sol load int str list items sorted dict calc_dist append float array enumerate sorted random_tw reset | # NeuLNS Neural Large Neighborhood Search Learn to Design Heuristics for Vehicle Routing Problem (VRP), by Deep Learning and Reinforcement Learning. This project provides the code to replicate the experiments in the paper: > <cite> Learn to Design the Heuristics for Vehicle Routing Problem [arxiv link](https://arxiv.org/abs/2002.08539)</cite> Welcome to cite our work (bib): ``` @misc{gao2020learn, title={Learn to Design the Heuristics for Vehicle Routing Problem}, author={Lei Gao and Mingxiang Chen and Qichang Chen and Ganzhong Luo and Nuoyi Zhu and Zhixin Liu}, year={2020}, | 2,724 |
laiyongkui1997/FewJoint | ['few shot learning'] | ['FewJoint: A Few-shot Learning Benchmark for Joint Language Understanding'] | models/few_shot_slu.py models/modules/text_classifier.py models/few_shot_seq_labeler.py models/modules/context_embedder_base.py utils/iter_helper.py utils/config.py models/modules/conditional_random_field.py models/few_shot_text_classifier.py utils/opt.py models/modules/similarity_scorer_base.py models/modules/transition_scorer.py utils/tester.py utils/model_helper.py utils/data_helper.py models/modules/scale_controller.py models/finetune_slu.py models/modules/emission_scorer_base.py main.py utils/trainer.py utils/data_loader.py utils/preprocessor.py models/modules/seq_labeler.py utils/device_helper.py get_testing_data_feature get_support_data_feature get_training_data_feature get_training_data_and_feature main SchemaFewShotSeqLabeler main FewShotSeqLabeler EmissionMergeIterationFewShotSLU EmissionMergeIntentFewShotSLU SplitMetricFewShotSLU FewShotSLU EmissionMergeSlotFewShotSLU SchemaFewShotSLU main SchemaFewShotTextClassifier FewShotTextClassifier IntentClassifyLayer BertSLU SlotClassifyLayer ConditionalRandomField allowed_transitions is_transition_allowed NormalContextEmbedder BertSchemaContextEmbedder ElectraContextEmbedder ContextEmbedderBase BertSchemaSeparateContextEmbedder BertSeparateContextEmbedder BertContextEmbedder ElectraSchemaContextEmbedder MNetEmissionScorer TapNetEmissionScorer PrototypeEmissionScorer ProtoWithLabelEmissionScorer EmissionScorerBase MixedScaleController ReluScaleController ScaleControllerBase build_scale_controller NormalizeScaleController FixedScaleController ExpScaleController LearnableScaleController SoftmaxScaleController unit_test RuleSequenceLabeler CRFSequenceLabeler SequenceLabeler reps_dot RelationNetSim reps_l2_sim reps_cosine_sim MatchingSimilarityScorer SimilarityScorerBase TapNetSimilarityScorer ProtoWithLabelSimilarityScorer PrototypeSimilarityScorer SingleLabelTextClassifier FewShotTransitionScorerFromLabel LabelRepsCatTranser LabelRepsBiaffineTranser TransitionScorerBase FewShotTransitionScorer LabelRepsTranserBase SimilarLengthSampler FewShotRawDataLoader FewShotExample RawDataLoaderBase FewShotRawDataLoader FewShotExample RawDataLoaderBase set_device_environment prepare_model SimilarLengthSampler pad_tensor PadCollate FewShotDataset make_model make_finetune_model make_scaler_args load_model build_intent_decoder build_context_embedder build_slot_decoder get_value_from_order_dict build_emission_scorer test_args model_args basic_args train_args option_check preprocess_args define_args SupportInputBuilder FewShotSupportFeature make_mask flatten InputBuilderBase FeatureConstructor FewShotOutputBuilder SchemaFeatureConstructor MyTokenizer make_preprocessor load_feature NormalInputBuilder FewShotFeature SupportFeatureConstructor make_dict BertInputBuilder make_word_dict save_feature OutputBuilderBase SchemaInputBuilder SupportOutputBuilder make_label_mask eval_check_points TesterBase FineTuneTester SchemaFewShotTester FewShotTester TrainerBase FewShotTrainer SchemaFewShotTrainer FineTuneTrainer prepare_optimizer format replace make_dict print construct_feature do_debug load_feature save_feature load_data info len format replace make_dict print construct_feature extend do_debug load_feature save_feature load_data info len format replace make_dict print construct_feature do_debug load_feature save_feature load_data info format replace make_dict print construct_feature extend do_debug load_feature save_feature load_data info len eval_check_points get_support_data_feature ft_td_rate get_training_data_feature select_model_from_check_point get_training_data_and_feature FineTuneTester ArgumentParser output_dir do_train do_predict test_path ft_num_train_epochs opt clone_model seed list load_model make_finetune_model make_preprocessor len exit prepare_model option_check set_device_environment load_state_dict parse_args to prepare_optimizer state_dict get_testing_data_feature tester_class format make_model shuffle unlink restore_cpt FewShotRawDataLoader do_overfit_test num_train_epochs info define_args int train_path dev_path join isdir print extend trainer_class warmup_epoch saved_model_path do_test make_label_mask FineTuneTrainer makedirs items list append is_transition_allowed len decode LongTensor SequenceLabeler print RuleSequenceLabeler dict tensor enumerate list norm insert expand shape bmm transpose norm seed manual_seed_all format manual_seed init_process_group device device_count info fp16 bool local_rank half DataParallel DistributedDataParallel fp16 to shape list size cat NormalContextEmbedder load_embedding format div_by_tag_num print MNetEmissionScorer TapNetEmissionScorer PrototypeEmissionScorer ProtoWithLabelEmissionScorer TapNetSimilarityScorer MatchingSimilarityScorer ProtoWithLabelSimilarityScorer PrototypeSimilarityScorer items list FewShotTransitionScorerFromLabel format ConditionalRandomField SequenceLabeler print RuleSequenceLabeler allowed_transitions seq_laber FewShotTransitionScorer build_scale_controller __delitem__ text_classifier SingleLabelTextClassifier RelationNetSim build_intent_decoder few_shot_slu build_context_embedder build_slot_decoder build_scale_controller build_emission_scorer BertSLU IntentClassifyLayer build_context_embedder emb_dim SlotClassifyLayer len items list args_builder add_argument_group add_argument add_argument_group add_argument add_argument_group add_argument add_argument_group add_argument add_argument_group add_argument fp16 label_wp do_debug info sorted list len extend set flatten dict seq_out append purify items sorted list len extend set flatten dict enumerate long from_pretrained SupportInputBuilder SupportOutputBuilder SchemaFeatureConstructor bert_vocab MyTokenizer BertInputBuilder use_schema make_word_dict NormalInputBuilder SchemaInputBuilder FeatureConstructor FewShotOutputBuilder SupportFeatureConstructor join sorted list format load_model saved_model_path clone_model info to do_test gradient_accumulation_steps int list warmup_proportion StepLR optimize_on_cpu AdamW get_linear_schedule_with_warmup named_parameters num_train_epochs fp16 train_batch_size | # FewJoint The code of [FewJoint](https://arxiv.org/abs/2009.08138). ## Scripts - `scripts` - `single_intent_1_bert.sh`: run for single intent detection few-shot model - `single_slot_1_bert.sh`: run for single slot filling few-shot model - `joint_slu_1_bert.sh`: run for joint-slu few-shot model - `few_joint_slu_1_bert.sh`: run for the our main method - `finetune_joint_slu_1_bert.sh`: run for joint-slu few-shot model with fine-tuning first | 2,725 |
lakshjaisinghani/Estimating-Depth-from-RGB-and-Sparse-Sensing | ['depth estimation', 'monocular depth estimation'] | ['Estimating Depth from RGB and Sparse Sensing'] | utils/sparse.py utils/model.py train/train.py NYU_V2 train denseNet D3 generate_mask NN_fill zero_grad numpy Loss_fun save tensor no_grad permute append to range state_dict net enumerate time NN_fill backward print step zeros arange print argmin square shape sqrt zip zeros ravel array range enumerate | # Estimating-Depth-from-RGB-and-Sparse-Sensing A a deep model that can accurately produce dense depth maps given an RGB image with known depth at a very sparse set of pixels. Paper: https://arxiv.org/pdf/1804.02771v2.pdf ### Set up: The train directory contains the training code to be run. # Introduction Monocular depth sensing has been a barrier in computer vision in recent years. This project is based on Estimating Depth from RGB and Sparse Sensing paper, where we create a network architecture that proposes an accurate way to estimate depth from monocular images from the NYU V2 indoor depth dataset. This model can use very sparse depth information (~ 1 in 1000 pixels) to predict full resolution depth information. It can simultaneously outperform all current cutting edge monocular depth classifiers for both indoor and outdoor scenes. If a sparsity of ~ 1 in 256 pixels is used, we can reduce the relative error to less than 1%, which is due to the use of the residual convolutional neural network structure in conjunction with the encoder-decoder model. 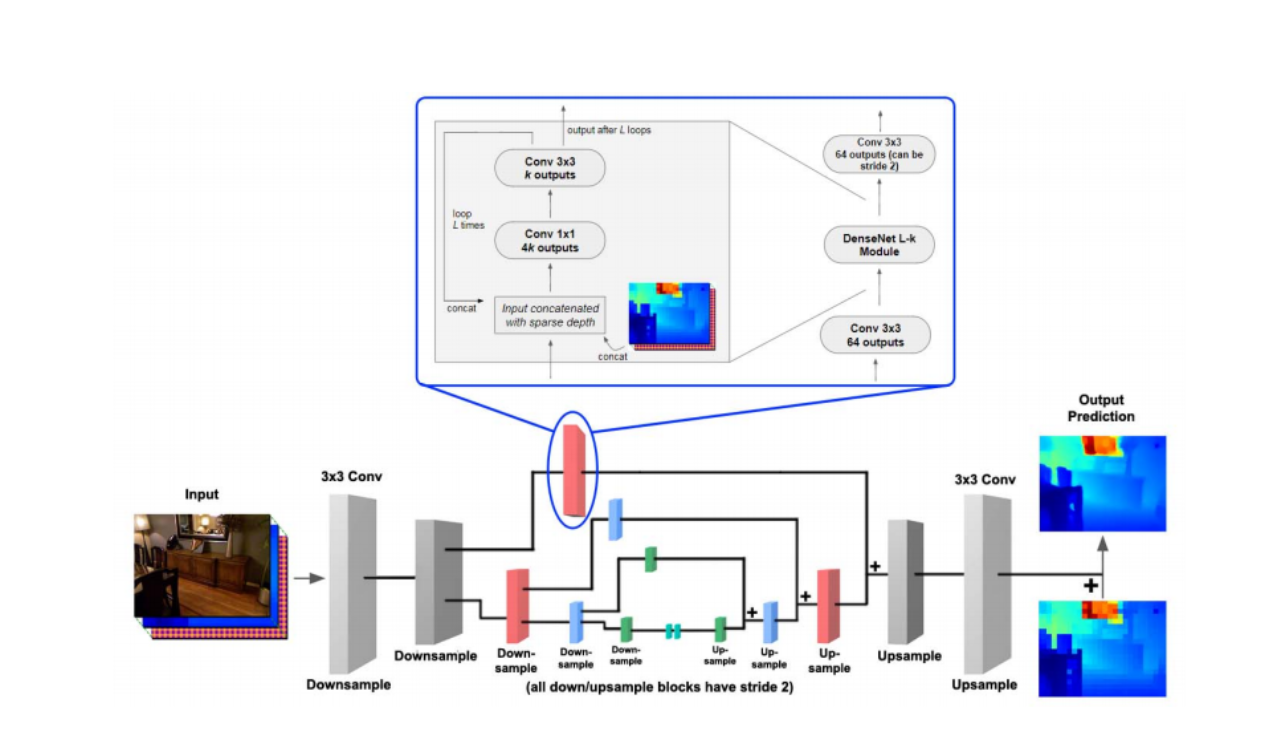 The experiments in this project indicate that it is probable to create accurate depth data using a low powered consumer-grade depth sensor (like the Kinect) to create high-resolution depth images with comparable accuracy to older laser mapping technologies whilst being highly cost-effective solution. ## Dataset | 2,726 |
lakshjaisinghani/pseudo-lidar-pipeline | ['depth estimation', 'monocular depth estimation'] | ['From Big to Small: Multi-Scale Local Planar Guidance for Monocular Depth Estimation'] | bts_official/utils/eval_with_pngs.py DepthPipeline.py bts_official/pytorch/run_bts_eval_schedule.py bts_official/utils/extract_official_train_test_set_from_mat.py bts_official/pytorch/bts_main.py ros_numpy/image.py utils/PseudoLiDAR.py ros_numpy/occupancy_grid.py ros_numpy/__init__.py ros_numpy/registry.py ros_numpy/geometry.py bts_official/pytorch/bts.py PL_development/test_pipeline.py bts_official/pytorch/distributed_sampler_no_evenly_divisible.py bts_official/pytorch/bts_eval.py bts_official/pytorch/bts_live_3d.py bts_official/pytorch/bts_dataloader.py PseudoLidarPipeline.py bts_official/pytorch/bts_test.py utils/model.py ros_numpy/point_cloud2.py bts_official/utils/download_from_gdrive.py PL_development/dev.py mock_publisher.py ros_numpy/numpy_msg.py DepthPipeline count_down load_images_from_folder convert_arg_line_to_args imagePublisher PseudoLidarPipeline bts weights_init_xavier BtsModel reduction_1x1 silog_loss upconv local_planar_guidance encoder bn_init_as_tf atrous_conv _is_numpy_image preprocessing_transforms ToTensor BtsDataLoader _is_pil_image DataLoadPreprocess convert_arg_line_to_args compute_errors test eval get_num_lines toc load_model np_to_qimage Window GLWidget tic edges qimage_to_np main_worker enable_print online_eval convert_arg_line_to_args normalize_result colorize compute_errors block_print set_misc main get_num_lines convert_arg_line_to_args test get_num_lines DistributedSamplerNoEvenlyDivisible run_eval download_file_from_google_drive convert_arg_line_to_args compute_errors test eval main convert_image Transformer _load_state plot numpy_to_point pose_to_numpy transform_to_numpy vector3_to_numpy point_to_numpy numpy_to_transform quat_to_numpy numpy_to_quat numpy_to_vector3 numpy_to_pose image_to_numpy numpy_to_image numpy_msg occupancygrid_to_numpy numpy_to_occupancy_grid pointcloud2_to_xyz_array array_to_pointcloud2 get_xyz_points dtype_to_fields fields_to_dtype pointcloud2_to_array merge_rgb_fields split_rgb_field converts_to_numpy msgify converts_from_numpy numpify BtsModel reduction_1x1 upconv local_planar_guidance encoder bts atrous_conv PseudoLiDAR split print str range sleep glob sort Rate CvBridge publish cv2_to_imgmsg print init_node Publisher sleep count_down load_images_from_folder len BatchNorm2d eval isinstance isinstance Conv2d xavier_uniform_ zeros_ bias weight maximum mean sqrt log10 abs log readlines close open rstrip checkpoint_path BtsDataLoader filenames_file DataParallel cuda exists str sorted add load_state_dict append imread range SummaryWriter format astype BtsModel set mean eval flush load int remove join time isdir add_scalar print gt_path float32 output_directory model_name get_num_lines filenames_file garg_crop max_depth_eval len logical_and shape append do_kb_crop range format mean eigen_crop int min_depth_eval print compute_errors float32 zeros get_num_lines load checkpoint_path BtsModel DataParallel eval load_state_dict cuda time print time format copy convertToFormat Format_ARGB32 sobel Signal devnull open __stdout__ cmapper get_cmap log10 bn_no_track_stats named_children fix_first_conv_block print apply named_parameters any fix_first_conv_blocks data new_group multiprocessing_distributed garg_crop cuda max_depth_eval logical_and shape do_kb_crop range format item enumerate int min_depth_eval print compute_errors tqdm all_reduce cpu zeros eigen_crop data bool set_misc checkpoint_path batch_size multiprocessing_distributed model BtsDataLoader zero_grad where DataParallel DistributedDataParallel save forward cuda exists set_device do_online_eval log_directory apply silog_loss log_freq rank load_state_dict sleep to sum range SummaryWriter format enable_print normalize_result init_process_group param_groups BtsModel eval_summary_directory distributed eval retrain item num_epochs flush add_image load int join time learning_rate online_eval enumerate backward print AdamW Variable add_scalar system set_epoch isnan block_print model_name isfile cpu zeros train step gpu len eval_freq world_size basename checkpoint_path format spawn print multiprocessing_distributed do_online_eval log_directory system device_count dirname model_name main_worker empty_cache gpu uint16 imwrite save_lpg list log10 imsave replace mkdir tqdm data_path amax print system now get get_confirm_token save_response_content Session pred_path filter walk len test int imwrite uint16 astype zeros makedirs load DataParallel load_state_dict show add_subplot imshow title figure Transform quaternion_from_matrix ndindex translation_from_matrix empty Pose quaternion_from_matrix ndindex translation_from_matrix empty dtype reshape newbyteorder dtype Image ascontiguousarray tostring shape _numpy_msg reshape height width data isinstance OccupancyGrid MaskedArray ravel append dtype subdtype names append PointField prod data point_step fields_to_dtype frombuffer fields dtype atleast_2d itemsize point_step all PointCloud2 dtype_to_fields tostring asarray names float32 shape append zeros array asarray names copy shape append uint32 zeros zeros isfinite shape get get | # BTS Pipeline [](https://paperswithcode.com/sota/monocular-depth-estimation-on-kitti-eigen?p=from-big-to-small-multi-scale-local-planar) [](https://paperswithcode.com/sota/monocular-depth-estimation-on-nyu-depth-v2?p=from-big-to-small-multi-scale-local-planar) From Big to Small: Multi-Scale Local Planar Guidance for Monocular Depth Estimation [arXiv](https://arxiv.org/abs/1907.10326) [Supplementary material](https://arxiv.org/src/1907.10326v4/anc/bts_sm.pdf) ## Video Demo [](https://www.youtube.com/watch?v=1J-GSb0fROw) ## Purpose This pipeline is used to test the performance of the BTS depth estimation model. It | 2,727 |
lakshjaisinghani/pseudo-lidar-ros-pipeline | ['depth estimation', 'monocular depth estimation'] | ['From Big to Small: Multi-Scale Local Planar Guidance for Monocular Depth Estimation'] | bts_official/utils/eval_with_pngs.py DepthPipeline.py bts_official/pytorch/run_bts_eval_schedule.py bts_official/utils/extract_official_train_test_set_from_mat.py bts_official/pytorch/bts_main.py ros_numpy/image.py utils/PseudoLiDAR.py ros_numpy/occupancy_grid.py ros_numpy/__init__.py ros_numpy/registry.py ros_numpy/geometry.py bts_official/pytorch/bts.py PL_development/test_pipeline.py bts_official/pytorch/distributed_sampler_no_evenly_divisible.py bts_official/pytorch/bts_eval.py bts_official/pytorch/bts_live_3d.py bts_official/pytorch/bts_dataloader.py PseudoLidarPipeline.py bts_official/pytorch/bts_test.py utils/model.py ros_numpy/point_cloud2.py bts_official/utils/download_from_gdrive.py PL_development/dev.py mock_publisher.py ros_numpy/numpy_msg.py DepthPipeline count_down load_images_from_folder convert_arg_line_to_args imagePublisher PseudoLidarPipeline bts weights_init_xavier BtsModel reduction_1x1 silog_loss upconv local_planar_guidance encoder bn_init_as_tf atrous_conv _is_numpy_image preprocessing_transforms ToTensor BtsDataLoader _is_pil_image DataLoadPreprocess convert_arg_line_to_args compute_errors test eval get_num_lines toc load_model np_to_qimage Window GLWidget tic edges qimage_to_np main_worker enable_print online_eval convert_arg_line_to_args normalize_result colorize compute_errors block_print set_misc main get_num_lines convert_arg_line_to_args test get_num_lines DistributedSamplerNoEvenlyDivisible run_eval download_file_from_google_drive convert_arg_line_to_args compute_errors test eval main convert_image Transformer _load_state plot numpy_to_point pose_to_numpy transform_to_numpy vector3_to_numpy point_to_numpy numpy_to_transform quat_to_numpy numpy_to_quat numpy_to_vector3 numpy_to_pose image_to_numpy numpy_to_image numpy_msg occupancygrid_to_numpy numpy_to_occupancy_grid pointcloud2_to_xyz_array array_to_pointcloud2 get_xyz_points dtype_to_fields fields_to_dtype pointcloud2_to_array merge_rgb_fields split_rgb_field converts_to_numpy msgify converts_from_numpy numpify BtsModel reduction_1x1 upconv local_planar_guidance encoder bts atrous_conv PseudoLiDAR split print str range sleep glob sort Rate CvBridge publish cv2_to_imgmsg print init_node Publisher sleep count_down load_images_from_folder len BatchNorm2d eval isinstance isinstance Conv2d xavier_uniform_ zeros_ bias weight maximum mean sqrt log10 abs log readlines close open rstrip checkpoint_path BtsDataLoader filenames_file DataParallel cuda exists str sorted add load_state_dict append imread range SummaryWriter format astype BtsModel set mean eval flush load int remove join time isdir add_scalar print gt_path float32 output_directory model_name get_num_lines filenames_file garg_crop max_depth_eval len logical_and shape append do_kb_crop range format mean eigen_crop int min_depth_eval print compute_errors float32 zeros get_num_lines load checkpoint_path BtsModel DataParallel eval load_state_dict cuda time print time format copy convertToFormat Format_ARGB32 sobel Signal devnull open __stdout__ cmapper get_cmap log10 bn_no_track_stats named_children fix_first_conv_block print apply named_parameters any fix_first_conv_blocks data new_group multiprocessing_distributed garg_crop cuda max_depth_eval logical_and shape do_kb_crop range format item enumerate int min_depth_eval print compute_errors tqdm all_reduce cpu zeros eigen_crop data bool set_misc checkpoint_path batch_size multiprocessing_distributed model BtsDataLoader zero_grad where DataParallel DistributedDataParallel save forward cuda exists set_device do_online_eval log_directory apply silog_loss log_freq rank load_state_dict sleep to sum range SummaryWriter format enable_print normalize_result init_process_group param_groups BtsModel eval_summary_directory distributed eval retrain item num_epochs flush add_image load int join time learning_rate online_eval enumerate backward print AdamW Variable add_scalar system set_epoch isnan block_print model_name isfile cpu zeros train step gpu len eval_freq world_size basename checkpoint_path format spawn print multiprocessing_distributed do_online_eval log_directory system device_count dirname model_name main_worker empty_cache gpu uint16 imwrite save_lpg list log10 imsave replace mkdir tqdm data_path amax print system now get get_confirm_token save_response_content Session pred_path filter walk len test int imwrite uint16 astype zeros makedirs load DataParallel load_state_dict show add_subplot imshow title figure Transform quaternion_from_matrix ndindex translation_from_matrix empty Pose quaternion_from_matrix ndindex translation_from_matrix empty dtype reshape newbyteorder dtype Image ascontiguousarray tostring shape _numpy_msg reshape height width data isinstance OccupancyGrid MaskedArray ravel append dtype subdtype names append PointField prod data point_step fields_to_dtype frombuffer fields dtype atleast_2d itemsize point_step all PointCloud2 dtype_to_fields tostring asarray names float32 shape append zeros array asarray names copy shape append uint32 zeros zeros isfinite shape get get | # BTS Pipeline [](https://paperswithcode.com/sota/monocular-depth-estimation-on-kitti-eigen?p=from-big-to-small-multi-scale-local-planar) [](https://paperswithcode.com/sota/monocular-depth-estimation-on-nyu-depth-v2?p=from-big-to-small-multi-scale-local-planar) From Big to Small: Multi-Scale Local Planar Guidance for Monocular Depth Estimation [arXiv](https://arxiv.org/abs/1907.10326) [Supplementary material](https://arxiv.org/src/1907.10326v4/anc/bts_sm.pdf) ## Video Demo [](https://www.youtube.com/watch?v=1J-GSb0fROw) ## Purpose This pipeline is used to test the performance of the BTS depth estimation model. It | 2,728 |
lallubharteja/KWS-Scripts | ['speech recognition'] | ['Subword RNNLM Approximations for Out-Of-Vocabulary Keyword Search'] | prep_kw_list.py create_morf_wordmap.py prep_morf_kw_list.py get_oovs.py prep_kws_gold_text.py main main main main stdin replace print strip read_any_model join basename open dirname append split | # KWS Scripts Recipe to setup and run Kaldi's keyword search system for character- and morpheme-based ASR. We create these subword ASR systems using the kaldi recipe scripts available at [1,2]. These systems are then used to setup the keyword search task using the following scripts. Note, that some these scripts are specific to our system and will need to modified suitably for your own systems. We also provide Arabic and Finnish OOV lists to setup Keyword Search tasks for both these languages. Both the OOV lists are written using the roman alphabet. The arabic OOV list was converted form the original script to roman alphabet using the buckwalter transliteration [3]. ## Prerequisites You will need the latest version of the following tools: - kaldi toolkit - https://github.com/kaldi-asr/kaldi. Also, make sure kaldi c++ tools are in your path - python3 - NIST F4DE toolkit - https://github.com/usnistgov/F4DE - Symlinks: To run the scripts in this recipe, we assume that the following symlinks exist in your experiments directory - `steps` is linked to `kaldi-trunk/egs/wsj/s5/steps` | 2,729 |
lamourj/fastcode-gpucb | ['experimental design'] | ['Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design'] | references/reference_gpucb.py tester.py reference_gpucb.py timing/lib/pcm/pmu-query.py timing/results/plot.py GPUCB DummyEnvironment sample GPUCB DummyEnvironment flops flops_ plot genfromtxt set_visible axhline floor set_major_formatter max show subplot list ylabel FormatStrFormatter title ylim log10 savefig ceil range astype tight_layout tick_left xlim set_label_coords enumerate tick_bottom print text xlabel figure array amax len | # Project # Fast GP-UCB implementation, based on [N. Srinivas and A. Krause, "Gaussian Process Optimization in the Bandit Setting: No Regret and Experimental Design", arXiv:0912.3995, 2009](https://arxiv.org/pdf/0912.3995.pdf). This project was done in the context of the [How to write Fast Numerical Code](http://www.vorlesungsverzeichnis.ethz.ch/Vorlesungsverzeichnis/lerneinheit.view?lerneinheitId=112992&semkez=2017S&ansicht=KATALOGDATEN&lang=en) course taught by Prof. M. Püschel at ETH-Zürich in Spring 2017. | 2,730 |
lancopku/AdaMod | ['stochastic optimization'] | ['An Adaptive and Momental Bound Method for Stochastic Learning'] | demos/cifar100/visualization.py demos/cifar100/models/resnet.py demos/cifar100/main.py demos/cifar100/models/__init__.py setup.py demos/cifar100/models/densenet.py demos/nmt/lr_scheduler/cold_start_scheduler.py demos/nmt/lr_scheduler/__init__.py adamod/__init__.py adamod/adamod.py AdaMod create_optimizer build_model load_checkpoint train test get_ckpt_name main build_dataset get_parser main get_folder_path get_curve_data plot DenseNet201 DenseNet161 DenseNet121 Transition DenseNet Bottleneck densenet_cifar test DenseNet169 ResNet ResNet18 ResNet34 Bottleneck ResNet101 test ResNet50 BasicBlock ResNet152 ColdStartSchedule build_lr_scheduler register_lr_scheduler add_argument ArgumentParser print DataLoader Compose CIFAR100 print join print to load_state_dict DataParallel criterion backward print zero_grad step max net enumerate print eval MultiStepLR save get_parser append parse_args build_dataset CrossEntropyLoss range create_optimizer build_model test get_ckpt_name resume mkdir join print load_checkpoint parameters train step get_folder_path show format xlabel grid get_curve_data ylabel capitalize title ylim savefig figure legend array plot net densenet_cifar randn ResNet18 size | # AdaMod An optimizer which exerts adaptive momental upper bounds on individual learning rates to prevent them becoming undesirably lager than what the historical statistics suggest and avoid the non-convergence issue, thus to a better performance. Strong empirical results on many deep learning applications demonstrate the effectiveness of our proposed method especially on complex networks such as DenseNet and Transformer. Based on Ding et al. (2019). [An Adaptive and Momental Bound Method for Stochastic Learning.](https://arxiv.org/abs/1910.12249) <p align='center'><img src='img/Loss.bmp' width="100%"/></p> ## Installation AdaMod requires Python 3.6.0 or later. ### Installing via pip The preferred way to install AdaMod is via `pip` with a virtual environment. Just run ```bash | 2,731 |
lancopku/Pivot | ['table to text generation', 'text generation'] | ['Key Fact as Pivot: A Two-Stage Model for Low Resource Table-to-Text Generation'] | datasets/wikibio.py models/pivot.py modules/ema.py datasets/collate.py models/util.py metrics/nist.py modules/transformer.py preprocess/process_pivot.py metrics/bleu.py models/table2text.py trainer.py modules/rnn.py preprocess/construct_corpus.py metrics/rouge.py pivot.py preprocess/table2entity2text.py modules/beam.py preprocess/process_wikibio.py models/sequence_labeling.py preprocess/extract_super.py datasets/sampler.py metrics/__init__.py utils/jsonl.py utils/meters.py models/transformer.py modules/__init__.py metrics/sequence_accuracy.py datasets/pivot.py models/seq2seq.py preprocess/extract_pivot.py utils/process_bar.py modules/attention.py predictor.py metrics/multi_bleu.py preprocess/add_noise.py preprocess/extract_entity.py train evaluate Predictor is_sparse move_optimizer_to_cuda sparse_clip_norm Trainer time_to_str str_to_time TensorboardWriter get_padding_lengths as_tensor_dict basic_collate Table2PivotDataset Pivot2TextCorpus Table2PivotCorpus Pivot2TextDataset BatchSampler SortedSampler NoisySortedSampler BioCorpus BioDataset BLEU calc_bleu_score create_mteval_file calc_nist_score calc_rouge_score SequenceAccuracy Pivot Seq2Seq SequenceLabeling Table2Text Transfomer sequence_cross_entropy_with_logits bahdanau_attention luong_attention Beam EMA StackedLSTM rnn_encoder rnn_decoder PositionalEncoding MultiHeadedAttention PositionalEmb PositionwiseFeedForward Generator EncoderBlock LayerNorm Embeddings TransformerDecoder subsequent_mask DecoderBlock SublayerConnection TransformerEncoder add_noise join construct_noise_corpus train_pretrain_dataset join train_parallel_dataset test_t2p_dataset train_t2p_dataset partion_list test_p2t_dataset test_parallel_dataset get_filter_data get_partion_index train_aug_dataset train_semi_dataset train_p2t_dataset StanfordNLP write_into_file extract_entity transform write_into_file extract_pivot join construct_super_corpus partion_list join partion_list construct_table2pivot get_partion_index write_into_file construct_pivot2text extract_exact_query_and_answer write_into_file transform remove_extra_info extract_greedy_query_and_answer transform write_into_file extract_pivot loads dumps AverageMeter format_meters TimeMeter StopwatchMeter progress_bar noop_progress_bar tqdm_progress_bar json_progress_bar build_progress_bar simple_progress_bar Adagrad Pivot2TextCorpus LearningRateWithMetricsWrapper Pivot Adam half Trainer parameters FusedAdam ReduceLROnPlateau Predictor fp16 to FP16_Optimizer Table2PivotCorpus load restore Pivot2TextCorpus gpu Pivot half Predictor load_state_dict fp16 cuda Table2PivotCorpus list norm coalesce is_sparse grad filter mul_ float max isinstance param_groups keys Tensor cuda is_cuda fromtimestamp append items max keys str items defaultdict batch_tensors info append get_padding_lengths keys fields len join remove system float join format check_output mkdtemp group rmtree create_mteval_file float len append enumerate join str format WARNING Rouge155 output_to_dict convert_and_evaluate mkdir setLevel range len view log_softmax size warn scatter_ type sum long astype cuda join split print len append sum max split list map split append dumps partion_list open append dumps partion_list open split get_filter_data dumps set open append enumerate dumps set append enumerate open dumps set append enumerate open dumps set append enumerate open append dumps open append dumps open append dumps open pos join replace print append enumerate split join set zip append split print close open extract_pivot zip print split append sum max len partion_list shuffle range len partion_list print len append sum max split print set split append sum max enumerate len str join split zip append find str join zip append split append join split set append close print close str elapsed_time format isinstance OrderedDict avg sum keys log_interval format noop_progress_bar tqdm_progress_bar json_progress_bar simple_progress_bar | # Pivot | 2,732 |
lantunes/chemgrams | ['data augmentation'] | ['SMILES Enumeration as Data Augmentation for Neural Network Modeling of Molecules'] | examples/lm_mcts_sequence_demo.py chemgrams/lm_mcts_puct.py chemgrams/kenlm_smiles_lm.py molexit/molexit_search5_timed_mcts.py chemgrams/kenlm_deepsmiles_lm.py chemgrams/lm_mcts_ucb1.py examples/kenlm_mcts_deepsmiles_lm_persist_demo.py chemgrams/smiles_tokenizer.py molexit/molexit_search2e.py chemgrams/cyclescorer/cyclescorer.py molexit/molexit_search5_timed_lm_only_all_valid_distance.py molexit/molexit_search5_timed_mcts_all_valid_distance_rescaled.py chemgrams/smiles_enumerator.py chemgrams/sascorer/sascorer.py molexit/molexit_search5_timed_mcts_all_unique_fuzzy_rescaled_2all.py tests/test_deepsmiles_tokenizer.py examples/perplexity_smiles_lm.py examples/perplexity_deepsmiles_lm.py chemgrams/logger/logger.py chemgrams/jscorer/jscorer.py molexit/molexit_search2.py molzero/random_walk.py tests/test_smiles_tokenizer.py setup.py examples/lm_mcts_sequence_jscore_abilify_timed_demo.py molexit/molexit_search5_timed_mcts_all_valid_distance_rescaled_2all_prior.py chemgrams/training/__init__.py chemgrams/basic_mcts.py examples/lm_mcts_sequence_aromatic_demo.py chemgrams/lm_mcts_puct_term.py examples/lm_mcts_sequence_perpl_logp_demo.py chemgrams/qedscorer/__init__.py chemgrams/deepsmiles_tokenizer.py molexit/molexit_search3b.py chemgrams/tanimotoscorer/__init__.py chemgrams/sascorer/__init__.py tests/test_jscorer.py chemgrams/jscorer/__init__.py examples/guacamol_mcts_dist_eval.py examples/kenlm_deepsmiles_lm_abilify_timed_demo.py chemgrams/kenlm_selfies_lm.py chemgrams/lm_utils.py examples/guacamol_dist_eval.py molexit/molexit_search2h.py chemgrams/cyclescorer/__init__.py chemgrams/language_model.py chemgrams/training/kenlm_trainer.py molexit/molexit_search3d.py molexit/molexit_search.py molexit/molexit_search5_timed_mcts_rescaled.py molexit/molexit_search2b.py examples/lm_mcts_sequence_abilify_pen_demo.py chemgrams/arpa_vocab_extraction.py molexit/molexit_search3c.py examples/kenlm_mcts_deepsmiles_lm_persist_prior_demo.py molexit/molexit_search5_timed_mcts_all_unique_distance_rescaled_2all.py examples/lm_mcts_sequence_jscore_penalty_timed_demo.py molexit/molexit_search5_timed_mcts_all_valid_distance.py molexit/molexit_search5_timed_mcts_all_valid_distance_rescaled_2all.py molexit/molexit_search2c.py molzero/__init__.py molexit/molexit_search3f.py molexit/molexit_search3e.py molexit/molexit_search5_timed_mcts_all_valid_distance_rescaled_prior.py molexit/molexit_search2g.py examples/kenlm_mcts_deepsmiles_lm_timed_demo.py examples/guacamol_lm_only_timed_iter_goal_eval.py chemgrams/queryscorer/queryscorer.py molexit/molexit_search4.py molzero/vocab.py molexit/molexit_search5_timed_mcts_all_valid_distance_rescaled_2.py examples/lm_mcts_sequence_jscore_penalty_demo.py molexit/molexit_search3.py chemgrams/tanimotoscorer/tanimotoscorer.py molexit/molexit_search4b.py examples/perplexity_selfies_lm.py examples/empty_lm_demo.py molexit/molexit_search2d.py chemgrams/empty_deepsmiles_lm.py examples/lm_mcts_sequence_jscore_demo.py examples/kenlm_deepsmiles_lm_timed_demo.py molexit/molexit_search5_timed_mcts_all_unique_weighted_rescaled_2all.py examples/lm_mcts_sequence_perplexity_demo.py molexit/molexit_search5_timed_mcts_all_unique_distance_rescaled_2.py chemgrams/logger/__init__.py molexit/molexit_search5_timed_lm_only.py examples/kenlm_selfies_lm_demo.py chemgrams/__init__.py molzero/mcts_walk.py molexit/molexit_search5_timed_mcts_all_unique_distance_rescaled.py examples/kenlm_smiles_lm_demo.py examples/kenlm_deepsmiles_lm_persist_demo.py examples/lm_mcts_sequence_qed_penalty_demo.py molexit/molexit_search2f.py molexit/molexit_search5_timed_lm_only_all_valid.py molexit/molexit_search5_timed_mcts_all_valid.py chemgrams/queryscorer/__init__.py chemgrams/qedscorer/qedscorer.py examples/lm_mcts_sequence_logp_demo.py examples/kenlm_deepsmiles_lm_demo.py molexit/molexit_search2i.py examples/lm_mcts_sequence_aromatic_perpl_demo.py molexit/molexit_search3d_selfies.py examples/guacamol_mcts_goal_eval.py chemgrams/lm_mcts_ucb1_term.py get_arpa_vocab BasicMCTS _Node StopTreeSearch DeepSMILESTokenizer EmptyDeepSMILESLanguageModel KenLMDeepSMILESLanguageModel KenLMSELFIESLanguageModel KenLMSMILESLanguageModel ChemgramsLanguageModel _Node LanguageModelMCTSWithPUCT _Node LanguageModelMCTSWithPUCTTerminating LanguageModelMCTSWithUCB1 _Node _Node LanguageModelMCTSWithUCB1Terminating SMILESLanguageModelUtils DeepSMILESLanguageModelUtils SELFIESLanguageModelUtils SMILESEnumerator SMILESTokenizer CycleScorer JScorer log_top_best get_logger QEDScorer QueryScorer calculateScore numBridgeheadsAndSpiro processMols readFragmentScores TanimotoScorer KenLMTrainer ChemgramsSmilesSampler ChemgramsGoalDirectedGenerator ChemgramsMCTSSmilesSampler ChemgramsMCTSGoalDirectedGenerator log_progress log_progress eval_function log_progress eval_function log_progress eval_function log_progress eval_function log_best eval_function eval_function eval_function eval_function log_progress eval_function eval_function log_best eval_function log_progress eval_function eval_function eval_function eval_function smiles_to_deepsmiles smiles_to_selfies eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_selfies eval_function log_best smiles_to_deepsmiles eval_function log_best smiles_to_deepsmiles smiles_to_deepsmiles smiles_to_deepsmiles log_progress smiles_to_deepsmiles log_progress smiles_to_deepsmiles log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function log_progress smiles_to_deepsmiles eval_function get_vocab TestDeepSMILESTokenizer TestJScorer TestSMILESTokenizer append startswith split setFormatter getLogger addHandler StreamHandler Formatter setLevel INFO FileHandler enumerate reversed info load join len dirname float range open CalcNumSpiroAtoms CalcNumBridgeheadAtoms iteritems FindMolChiralCenters numBridgeheadsAndSpiro AtomRings GetRingInfo readFragmentScores GetNonzeroElements log10 GetMorganFingerprint float GetNumAtoms log len print MolToSmiles GetProp calculateScore enumerate info start log_top_best Timer len sanitize join decode add extract_sentence info log_prob time log_top_best info MolFromSmiles score debug log_best calculateScore GetIsAromatic GetNumAtoms range perplexity extract get_tokens DeepSMILESTokenizer len score_mol append abs MolLogP strip strip len print | Chemgrams ========= Chemgrams are N-gram language models of [DeepSMILES](https://chemrxiv.org/articles/DeepSMILES_An_Adaptation_of_SMILES_for_Use_in_Machine-Learning_of_Chemical_Structures/7097960/1) _(N. O'Boyle, 2018)_, a SMILES-like syntax. Chemgrams can be combined with Monte Carlo Tree Search (MCTS) to search chemical space for molecules with desired properties. Chemgrams also refers to this Python software library. The [KenLM](https://kheafield.com/code/kenlm/) toolkit is used for rapid language model estimation and sampling. Chemgrams aspires to be a lightweight alternative to RNN-based chemical language models. Chemgrams has been compared to existing, state-of-the-art methods for generating novel molecules with desired properties, such as [ChemTS](https://arxiv.org/abs/1710.00616) _(K. Tsuda et al., 2017)_, and | 2,733 |
laoreja/CS231A-project-Stereo-matching | ['stereo lidar fusion'] | ['End-to-End Learning of Geometry and Context for Deep Stereo Regression'] | reimplement_GC_Net/test_image_processing_KITTI.py reimplement_GC_Net/timeline.py traditional/samples/bin2png.py reimplement_GC_Net/gcnet_model_no_mask.py reimplement_GC_Net/image_processing_KITTI_no_mask.py reimplement_GC_Net/KITTI_data.py reimplement_GC_Net/gcnet_multi_gpu_eval_no_mask.py traditional/proposed.py reimplement_GC_Net/dataset.py traditional/rgs.py reimplement_GC_Net/gcnet_multi_gpu_KITTI.py reimplement_GC_Net/build_image_data_KITTI.py traditional/hs.py traditional/proposed_mc_cnn.py reimplement_GC_Net/image_processing_no_mask.py traditional/samples/bin2png_run.py reimplement_GC_Net/uint16png.py reimplement_GC_Net/gcnet_train.py traditional/samples/load_bin.py reimplement_GC_Net/gcnet_model.py reimplement_GC_Net/build_image_data_SceneFlow.py reimplement_GC_Net/gcnet_multi_gpu_eval.py reimplement_GC_Net/image_processing.py reimplement_GC_Net/SceneFlow_data.py reimplement_GC_Net/SceneFlow_divide_test_train.py traditional/rgs_qsub.py traditional/samples/__init__.py reimplement_GC_Net/image_processing_KITTI.py reimplement_GC_Net/gcnet_eval.py reimplement_GC_Net/test_image_processing.py reimplement_GC_Net/pfm.py reimplement_GC_Net/gcnet_multi_gpu_train_no_mask.py reimplement_GC_Net/webp2png.py reimplement_GC_Net/gcnet_eval_kitti.py traditional/preprocess_mb.py _convert_to_example _process_image_files _int64_feature _bytes_feature main _process_image_files_batch _process_image _convert_to_example _process_image_files _bytes_feature main _process_image_files_batch _process_image Dataset eval_once main evaluate eval_once main evaluate GCNet GCNet main evaluate tower_loss main evaluate tower_loss average_gradients main train tower_loss average_gradients main train tower_loss eval_image inputs parse_example_proto distorted_inputs image_preprocessing batch_inputs eval_image inputs parse_example_proto distorted_inputs image_preprocessing batch_inputs eval_image inputs parse_example_proto distorted_inputs image_preprocessing batch_inputs eval_image inputs parse_example_proto distorted_inputs image_preprocessing batch_inputs KITTIData load_pfm save_pfm SceneFlowData main train main train test eval_once main evaluate save_uint16PNG load_uint16PNG recursive valid start_job valid stop_job signal_handler valid tostring Example join imread load_uint16PNG int join _convert_to_example arange _process_image TFRecordWriter print astype write SerializeToString close output_directory range flush len int Thread join print astype Coordinator start append range flush len _process_image_files print train_shards output_directory validation_shards uint8 disparity_root arange fabs ones reshape astype tile width clip png_root len join evaluate eval_dir SceneFlowData Exists DeleteRecursively MakeDirs HParams log_root KITTIData num_examples_per_epoch GCNet inputs build_graph_to_loss num_preprocess_threads with_mask info name sub distorted_inputs TOWER_NAME total_loss scalar abs_loss concat reduce_mean zip append expand_dims train train_dir batch_size batch_size resize_image_with_crop_or_pad squeeze cropped_width expand_dims cropped_height parse_single_example uint8 decode_raw float32 cast int32 readline rstrip map groups match fromfile float tofile write byteorder read uint16 astype map float32 Reader array float64 astype uint16 join endswith system listdir makedirs join check_output append print release format print exit call split | # CS231A Course project: Deep Stereo Matching ## Reimplementation-of-GC-Net I mainly reimplement the GC-Net https://arxiv.org/pdf/1703.04309.pdf. I implement two versions of the GC-Net model: one with a mask (the losses are masked), and one without the mask. ## Results ### Qualitative results The without-mask-version, original images and predictions samples on SceneFlow: <img src="https://raw.githubusercontent.com/laoreja/CS231A-project-stereo-matching/master/qualitative_results/SceneFlow_train_without_mask/gt_2.png" width=400px/> <img src="https://raw.githubusercontent.com/laoreja/CS231A-project-stereo-matching/master/qualitative_results/SceneFlow_train_without_mask/pre_2.png" width=400px/> <img src="https://raw.githubusercontent.com/laoreja/CS231A-project-stereo-matching/master/qualitative_results/SceneFlow_train_without_mask/gt_4.png" width=400px/> <img src="https://raw.githubusercontent.com/laoreja/CS231A-project-stereo-matching/master/qualitative_results/SceneFlow_train_without_mask/pre_4.png" width=400px/> The with-mask-version, masked ground truth, masked predictions, and unmasked predictions on SceneFlow: | 2,734 |
larsbratholm/champs_kaggle | ['molecular property prediction'] | ['A community-powered search of machine learning strategy space to find NMR property prediction models'] | solutions/1/src/modules/embeddings.py solutions/5/lam/kaggle_champs/utils.py solutions/12/src/cormorant/cg_lib/gen_cg_qutip.py solutions/12/src/cormorant/train/__init__.py solutions/5/lam/kaggle_champs/dataset.py solutions/5/guillaume/adabound.py solutions/5/guillaume/scheduler_superconvergence_09J.py solutions/1/models/model_B/modules/embeddings.py solutions/5/thanhtu/data/utils.py solutions/5/guillaume/dataset/dataset_9ZB_117_edge_link.py solutions/12/src/cormorant/models/cormorant.py solutions/5/thanhtu/layers.py solutions/1/models/model_D/graph_transformer.py solutions/12/examples/continue_edge_cormorant_zero.py solutions/5/thanhtu/utils.py solutions/12/examples/evaluate_edge_cormorant_qs.py solutions/12/src/cormorant/data/prepare/qm9.py solutions/1/models/model_F/modules/hierarchical_embedding.py solutions/12/src/cormorant/models/edge_cormorant.py solutions/12/src/cormorant/data/prepare/__init__.py solutions/1/src/utils/data_parallel.py solutions/12/src/cormorant/data/dataset.py solutions/5/guillaume/layers/layers_09ZF_ablation_study.py analysis/make_auxiliary_plots.py solutions/1/src/pipeline_pre.py solutions/12/src/cormorant/data/prepare/process.py solutions/5/thanhtu/submit.py solutions/1/models/model_E/graph_transformer.py solutions/1/src/xyz2mol.py solutions/5/thanhtu/constants.py solutions/12/examples/process_kaggle_nmr_data_v0.py solutions/1/models/model_I/modules/embeddings.py solutions/1/models/model_D/modules/embeddings.py solutions/1/src/modules/optimizations.py solutions/1/models/model_A/graph_transformer.py solutions/1/models/model_G/modules/hierarchical_embedding.py solutions/12/src/cormorant/tests/test_kaggle_dataset.py solutions/1/models/model_L/modules/embeddings.py solutions/12/examples/continue_edge_cormorant_zero_full_train.py solutions/12/src/cormorant/models/__init__.py solutions/5/guillaume/LookAhead.py analysis/preprocess.py solutions/1/src/train.py solutions/1/src/graph_transformer.py solutions/12/src/cormorant/data/utils_kaggle.py solutions/5/lam/kaggle_champs/training.py solutions/5/guillaume/common.py solutions/1/src/modules/hierarchical_embedding.py solutions/12/src/cormorant/nn/utils.py solutions/5/guillaume/layers/layers_09ZF3_ablation_study_remove_global_state.py solutions/12/src/cormorant/train/trainer.py solutions/12/src/cormorant/cg_lib/__init__.py solutions/1/models/model_I/graph_transformer.py solutions/1/models/model_E/modules/embeddings.py solutions/1/models/model_H/modules/hierarchical_embedding.py solutions/5/guillaume/RAdam.py solutions/1/models/model_K/modules/embeddings.py solutions/1/models/model_L/modules/hierarchical_embedding.py solutions/3/code/type_ensemble.py solutions/3/code/BERT-based/transformer_v25_3/train.py solutions/3/code/BERT-based/transformer_v25_3/db.py solutions/5/lam/kaggle_champs/modelling.py solutions/1/models/model_J/modules/hierarchical_embedding.py solutions/12/setup.py solutions/12/src/cormorant/cg_lib/gen_cg.py solutions/12/src/cormorant/cg_lib/cg_coefficients.py solutions/5/thanhtu/optimizer.py solutions/12/src/cormorant/data/collate.py solutions/12/src/cormorant/data/dataset_kaggle.py solutions/12/src/cormorant/data/prepare/download.py solutions/12/src/cormorant/nn/catmix_scalar_levels.py solutions/12/src/cormorant/tests/test_collate_general.py analysis/make_submission_plots.py solutions/12/src/cormorant/tests/cormorant_tests.py solutions/5/lam/kaggle_champs/metrics.py solutions/3/code/generate_mute_cp.py solutions/12/src/cormorant/nn/generic_levels.py solutions/1/models/model_C/graph_transformer.py solutions/3/code/BERT-based/transformer_v25_2/optimizer.py solutions/3/code/BERT-based/transformer_v25_2/db.py solutions/1/models/model_E/modules/hierarchical_embedding.py solutions/12/src/cormorant/data/utils.py solutions/12/src/cormorant/tests/test_process_data.py solutions/12/src/cormorant/nn/output_levels.py solutions/5/guillaume/layers/layers_09ZI_distributionnal_loss.py solutions/12/src/cormorant/tests/test_download.py solutions/1/models/model_H/graph_transformer.py solutions/12/src/cormorant/data/__init__.py solutions/1/src/utils/radam.py solutions/5/thanhtu/data/dataset.py solutions/5/guillaume/babel_113_half_bonds.py solutions/1/models/model_K/modules/hierarchical_embedding.py solutions/12/docs/conf.py solutions/12/src/cormorant/cg_lib/cg_ops.py solutions/12/src/cormorant/tests/test_gen_cg.py solutions/5/thanhtu/data/test.py solutions/12/src/cormorant/models/cormorant_levels.py solutions/12/src/cormorant/nn/catmix_cg_levels.py solutions/1/models/model_J/graph_transformer.py solutions/5/guillaume/layers/layers_09ZF5_ablation_study_no_edge_pairs_embeddings_and_one_preprocessing.py solutions/5/thanhtu/data/graph.py solutions/1/models/model_G/graph_transformer.py solutions/1/src/utils/filters.py solutions/1/models/model_I/modules/hierarchical_embedding.py solutions/5/lam/kaggle_champs/constants.py solutions/5/thanhtu/common.py solutions/5/guillaume/layers/layers_09ZB_link_edge.py solutions/1/models/model_K/graph_transformer.py solutions/12/src/cormorant/train/args.py solutions/5/thanhtu/train.py dataset_generation/create_dataset.py solutions/12/src/cormorant/cg_lib/rotations.py solutions/12/src/cormorant/data/prepare/utils.py solutions/1/models/model_M/modules/embeddings.py solutions/3/code/BERT-based/transformer_v25_3/optimizer.py solutions/1/models/model_C/modules/embeddings.py solutions/1/models/model_F/graph_transformer.py solutions/12/src/cormorant/nn/mask_levels.py solutions/12/examples/train_edge_cormorant_qs.py solutions/5/guillaume/importancer.py solutions/12/src/cormorant/tests/test_dataset.py solutions/1/src/utils/exp_utils.py solutions/3/code/generate_final_submission.py solutions/3/code/BERT-based/transformer_v25_2/train.py solutions/3/code/generate_structes_df.py solutions/1/models/model_F/modules/embeddings.py solutions/1/src/utils/csv_to_pkl.py solutions/12/src/cormorant/nn/__init__.py solutions/12/src/cormorant/data/prepare/md17.py solutions/1/models/model_A/modules/hierarchical_embedding.py solutions/12/src/cormorant/cg_lib/spherical_harmonics.py solutions/1/src/modules/radam.py solutions/1/models/model_M/graph_transformer.py solutions/12/src/cormorant/__init__.py solutions/5/lam/kaggle_champs/optimizer.py analysis/blend.py solutions/1/models/model_H/modules/embeddings.py solutions/1/src/predictor.py solutions/1/models/model_J/modules/embeddings.py solutions/1/models/model_G/modules/embeddings.py solutions/1/models/model_B/modules/hierarchical_embedding.py solutions/1/models/model_B/graph_transformer.py solutions/5/lam/kaggle_champs/preprocessing.py solutions/5/thanhtu/model.py solutions/1/models/model_A/modules/embeddings.py solutions/1/models/model_D/modules/hierarchical_embedding.py solutions/1/models/model_M/modules/hierarchical_embedding.py solutions/3/code/BERT-based/transformer_v25_2/cust_model.py solutions/12/src/cormorant/nn/input_levels.py solutions/5/thanhtu/data/data.py solutions/12/src/cormorant/train/utils.py solutions/12/src/cormorant/models/atom_cormorant.py dataset_generation/convert_exyz.py solutions/12/src/cormorant/tests/__init__.py solutions/3/code/BERT-based/transformer_v25_3/cust_model.py solutions/12/src/cormorant/nn/position_levels.py solutions/1/models/model_C/modules/hierarchical_embedding.py solutions/1/models/model_L/graph_transformer.py write_scores write_weights tf_blend format_and_save plot_days_between_submissions plot_n_contrib_ensemble make_ensemble_plots plot_progress_all_teams plot_ensemble_vs_best plot_exponential_fits read_public_kernels plot_submissions_per_day plot_kaggle_competitions plot_progress_select_teams read_and_process_data plot_number_of_teams make_progression_plots make_teams_vs_prize_plot parse_kaggle_competitions preprocess_kaggle_competitions visualize_methods get_variance_by_type extract_weighted_subset plot_correlation parse_submissions get_score_by_type parse_rank_and_name get_test_data fix_broken_format exyz_to_xyz exyz_to_com mol_read_conn jread_dso conn_distance read_mulliken_charges add_index_and_header jread_sd process_and_write jread_pso jread_fc sort_data create_dataset read_magnetic_shielding_tensor parse_data read_dipole_moment jread read_potential_energy sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding sqdist GraphLayer ResidualBlock GraphTransformer make_structure_dict add_all_pairs write_csv enhance_structure_dict make_triplets auto_preproc_stage1 get_scaling auto_preproc_stage2 add_embedding enhance_atoms _create_embedding add_scaling create_dataset make_quadruplets enhance_bonds load_model write_final select_models single_model_predict load_submission ensemble epoch loss valences_not_too_large xyz2AC get_proto_mol chiral_stereo_check AC2mol BO_is_OK get_UA_pairs get_atom get_atomic_charge get_atomicNumList get_BO AC2BO read_xyz_file get_bonds xyz2mol BO2mol getUA set_atomic_radicals set_atomic_charges clean_charges TokenFeatureEmbedding LearnableEmbedding SineEmbedding HierarchicalEmbedding matrix_diag WeightNorm VariationalAttnDropout embedded_dropout VariationalDropout _norm VariationalHidDropout WeightDrop weight_norm AdamW RAdam PlainRAdam get_submission_set get_datasets scatter_kwargs scatter BalancedDataParallel create_exp_dir save_checkpoint get_logger logging subgraph_filter tta AdamW RAdam PlainRAdam main main main normalize_scalar main CGDict cg_product_tau complex_kron_product cg_product CGProduct gen_cg_coefffs clebsch rotate_cart_vec WignerD rotate_so3part rotate_part create_Jy littled WignerD_list dagger rotate_rep create_J complex_from_numpy create_Jx rotate_so3rep SphericalHarmonics rep_to_pos SphericalHarmonicsRel pos_to_rep spherical_harmonics spherical_harmonics_rel collate_fn batch_stack_general drop_zeros batch_stack ProcessedDataset KaggleTrainDataset _get_species initialize_datasets trim_dataset init_nmr_eval_kaggle_dataset init_nmr_kaggle_dataset prepare_dataset gen_splits_md17 download_dataset_md17 split_dataset process_xyz_files process_xyz_md17 process_xyz_gdb9 get_unique_charges get_thermo_dict download_dataset_qm9 gen_splits_gdb9 add_thermo_targets download_data cleanup_file is_int expand_var_list AtomCormorant expand_var_list Cormorant CormorantAtomLevel CormorantEdgeLevel EdgeCormorant CatMixReps MixReps CatReps CatRepsScalar MixRepsScalar CatMixRepsScalar DotMatrix BasicMLP get_activation_fn InputLinear InputMPNN MaskLevel OutputAtomMLP OutputMLP OutputLinear OutputPMLP OutputEdgeLinear OutputEdgeMLP GetScalars OutputMPNN RadPolyTrig RadialFilters cat_reps scalar_mult_rep mix_irrep_cplx weight_init_func save_grads save_reps broadcastable conjugate_rep mix_irrep_real init_mix_reps_weights mix_rep covariance_test _gen_rot permutation_test cormorant_tests batch_test BoolArg Range setup_argparse _arg_to_bool TrainCormorant init_argparse init_file_paths init_cuda init_logger init_optimizer _git_version init_scheduler seed_everything add_nearest_atom seed_everything read_mol new_softmax SelfAttn main rotation_matrix MolDB_FromDB MolDB RAdam load_csv validate unnormalize_cols save_checkpoint adjust_learning_rate timeSince unnormalize_target CFG metric add_extra_features train_test_split get_logger normalize_target asMinutes add_extra_mol_features main AverageMeter normalize_cols train SelfAttn main rotation_matrix MolDB_FromDB MolDB RAdam AdaBoundW AdaBound get_bond_features get_atom_features compute_features read_molecule get_global_features reset_tags get_tags tag select_tags LookAhead AdamW RAdam ExpScheduler LinearScheduler MixedScheduler CosineAnnealing MEGNetList BasicBlock MEGNetLayer AttentionAggregation MEGNetList BasicBlock MEGNetLayer AttentionAggregation MEGNetList BasicBlock MEGNetLayer AttentionAggregation MEGNetList BasicBlock MEGNetLayer AttentionAggregation MEGNetList BasicBlock MEGNetLayer AttentionAggregation mol_to_data_v2 FP16_Data MoleculeDataset mol_to_data ChampsDataset MeanLogGroupMAE AverageMetric create_mlp_v2 MegNetLayer_v2 DummyModel linear_block MegNetLayer MegNetBlock_v2 MegNetBlock_v3 MegNetBlock_v4 create_mlp MegNetBlock RAdam SortTarget AddVirtualEdges RandomRotation AddEdgeDistanceAndDirection train_epoch dihedral cosinus OutputLayer EdgeAggregation linear_block LinearBn create_mlp FeedForwardBloc MegnetLayer MegnetModel2 MegnetModel1 MegnetBloc Ranger run_submit do_valid run_train NullScheduler criterion compute_kaggle_metric load_csv mol_from_smiles chiral_stereo_check mol_from_pymatgen run_convert_to_graph run_make_data run_make_split mol_from_file MoleculaGraph _convert_mol make_graph dijkstra_distance _collate_fn MolecularGraphDataset GaussianDistance DistanceConverter DummyConverter StructureGraph MoorseLongRange read_pickle_from_file write_file_to_pickle fast_label_binarize expand_1st Struct to_list ring_to_vector arange reset_default_graph abs log placeholder matmul reduce_sum shape train_test_split global_variables_initializer size softmax enumerate items T minimize Variable float32 zeros len T ffill set_index to_datetime read_csv format_and_save min cycle lineplot figure xkcd_palette range format_and_save tolist min cycle lineplot figure color_palette set clf savefig set_major_formatter xticks DateFormatter iterrows T to_datetime min timedelta date sort_values drop_duplicates read_csv drop format_and_save lineplot figure count total_seconds min drop_duplicates set hist savefig figure clf empty max range Score format_and_save plot index figure legend gca format_and_save minimize print min convert_df gca lineplot figure annotate drop_duplicates int list asarray replace set append enumerate parse_kaggle_competitions preprocess_kaggle_competitions plot_kaggle_competitions subplots ScalarFormatter set_yticks set loglog scatter set_xticks set_major_formatter ticklabel_format legend savefig clf xticks FuncFormatter plot_days_between_submissions plot_progress_all_teams plot_exponential_fits read_public_kernels plot_submissions_per_day plot_progress_select_teams read_and_process_data plot_number_of_teams asarray plot set clf savefig figure legend gca asarray plot set clf savefig figure legend gca loadtxt plot_ensemble_vs_best plot_n_contrib_ensemble var list asarray items len seed items asarray arange print metric_fun empty enumerate asarray print extract_weighted_subset corrcoef pdist savefig heatmap clf linkage clustermap yticks MDS TSNE subplots set_visible clf abs colorbar scatter savefig sum fit_transform range tight_layout mean despine annotate enumerate print extract_weighted_subset PCA TruncatedSVD zeros quit append int join split append zeros list items zeros enumerate items list asarray mean abs log len int float split GetBond atoms GetId OBAtom OBAtomAtomIter zeros range len min range copy int asarray replace len zeros float range split asarray startswith float startswith asarray extend startswith append split append float split int asarray replace len startswith zeros float range split int asarray replace len startswith zeros float range split int asarray replace len startswith zeros float range split int asarray replace len startswith zeros float range split mol_read_conn read_mulliken_charges readstring open getmembers str jread_sd jread_pso append jread range read_potential_energy jread_dso asarray concatenate atoms close jread_fc read_magnetic_shielding_tensor read_dipole_moment enumerate conn_distance print isfile len argsort int astype empty arange asarray split add_index_and_header print sort_data savetxt quit loadtxt dirname abspath parse_data process_and_write append defaultdict iterrows sort_values str norm GetBonds join readstring reshape transpose hstack pi GetBondType argsort tile zeros xyz2mol sum array rename apply join sorted defaultdict all replace iterrows append sort_values join sorted defaultdict str list items combinations set_index unique append DataFrame range len combinations join defaultdict norm arccos list items DataFrame sort sort_values append sum clip enumerate DataFrame clip count sorted defaultdict list append sort_values arccos replace product sqrt zip join norm T items cross dot array update join format reset_index to_csv round rename sort_values range split sorted list tolist dict zip range len update range apply to_dict apply arange tensor values sorted list tolist apply sum range update set zip float items set_index min index tqdm dict argsort zeros len join make_structure_dict write_csv enhance_structure_dict add_all_pairs make_triplets print enhance_atoms unique make_quadruplets read_csv enhance_bonds seed join permutation get_scaling print chdir tuple size add_embedding add_scaling create_dataset tensor sort_values read_csv cat update join list format items GraphTransformer remove print __file__ write path load_state_dict reload append state_dict eval to argsort join T read_csv zeros array range int str print sort argsort mean vstack select_models zeros sum range len champs_loss abs tensor sum cat empty_cache log_interval device lower append zip enumerate list sum copy getUA sum zip get_atomic_charge list append sum enumerate count HasSubstructMatch CombineMols MolFromSmarts ReactionFromSmarts RunReactants GetMolFrags enumerate get int list GetMol SINGLE round AddBond set_atomic_radicals set_atomic_charges sum RWMol range len get_atomic_charge int SetFormalCharge GetAtomWithIdx enumerate count get_atomic_charge int GetAtomWithIdx SetNumRadicalElectrons abs enumerate append tuple sorted enumerate combinations add_edges_from list int Graph get_bonds set append len list defaultdict product copy get_BO getUA append sum BO_is_OK get_UA_pairs BO2mol AC2BO AddAtom str GetMol MolFromSmarts Atom RWMol range len append get_atom get_atomicNumList GetAtomicNum GetAtomWithIdx get_proto_mol Conformer AddConformer Get3DDistanceMatrix astype GetRcovalent GetPeriodicTable SetAtomPosition GetNumAtoms range len DetectBondStereochemistry AssignStereochemistry SanitizeMol AssignAtomChiralTagsFromStructure AC2mol chiral_stereo_check xyz2AC copy_ zeros size max_norm embedding sparse padding_idx Variable norm_type scale_grad_by_freq apply expand_as weight dim apply print tuple strip exists print exists tuple extend print join format basename print copyfile makedirs join format save state_dict use_quad bernoulli_ elem_drop device to long device item sqdist randint to range init_file_paths soft_cut_rad soft_cut_width maxl EdgeCormorant gaussian_mask hard_cut_rad init_scheduler top level_gain max_sh num_mpnn_levels init_logger init_optimizer input TrainCormorant init_nmr_kaggle_dataset cormorant_tests num_channels num_top_levels weight_init datadir charge_power init_argparse num_cg_levels evaluate load_checkpoint init_cuda basis_set train mse_loss cutoff_type global_cg_dict init_nmr_eval_kaggle_dataset print mean hstack std array complex_kron_product min matmul append range enumerate split view Size matmul shape unsqueeze tensor sum list min range append zeros clebsch range int min sqrt max range factorial dtype to device dtype to unbind device dtype unbind dagger device to permute view sqrt diag eye sqrt complex diag sqrt complex diag T exp complex create_Jy matmul eigh diag complex exp arange littled expand_dims complex_from_numpy to norm zeros_like view where sqrt stack pos_to_rep append full range norm unsqueeze spherical_harmonics sqrt stack unsqueeze unbind sqrt stack unbind all ValueError zeros max enumerate len zeros max enumerate len to unsqueeze uint8 items list prepare_dataset _get_species num_species max_charge num_pts error unique load int seed list items len num_species max_charge num_pts split load max_charge num_pts num_species items list _build_perm len all info download_dataset_qm9 startswith download_dataset_md17 load join list format gen_splits_md17 items squeeze len cleanup_file download_data tile info savez_compressed makedirs seed zeros tensor permutation items list getmembers list format is_dir is_tarfile info listdir keys open int debug append float split update int list dict zip append max split join list format urlretrieve items get_thermo_dict process_xyz_files info gen_splits_gdb9 add_thermo_targets savez_compressed makedirs seed join sorted urlretrieve list int permutation cleanup_file set info array range split join urlretrieve cleanup_file info get_unique_charges items list zeros len list print zip keys enumerate decode format info int remove len ELU Tanh lower Sigmoid ReLU LeakyReLU unbind unbind matmul unbind update set callable requires_grad_ closure register_hook zip append update zip WignerD_list EulerRot rotate_cart_vec norm _gen_rot format maxl model zip rand warning item info tensor max cat enumerate format model expand randperm info sum max range format model info max cat covariance_test permutation_test eval iter info next batch_test set_defaults add_argument ArgumentParser lower print parse_args setup_argparse basicConfig format ValueError logging_level DEBUG logfile INFO modeldir checkfile target warning workdir dataset logfile predictdir prefix _git_version logdir format lower mkdir startswith info datadir manual_seed loadfile join int bestfile timestamp RMSprop lower Adam SGD format num_train batch_size print LambdaLR min num_epoch lr_decay startswith info ceil lr_minibatch CosineAnnealingLR type decode format info run split format info init device float double cuda current_device seed str manual_seed kneighbors values fit join read_csv sum exp asarray cos dot sqrt sin read_csv MolDB_FromDB MolDB load_csv structure_file ArgumentParser train_file DataFrame fillna seed unnormalize_target device_count load_state_dict parse_args head contribution_file reset_index wsteps mean start_epoch BertConfig manual_seed info merge AdamW tail makedirs dict pseudo_path validate unnormalize_cols DataParallel DataLoader save_checkpoint list max_seq_length metric append sort_values dropout eval resume set_index add_argument normalize_cols WarmupLinearSchedule test_file nepochs pseudo gradient_accumulation_steps nunique SelfAttn model nlayers assign cuda add_extra_features types train_test_split sum range update nahs load warmup_steps named_parameters gen_pseudo use_all batch_size get_lr format __dict__ lr unique num_train_epochs int to_csv len gradient_accumulation_steps model clip_grad_norm_ zero_grad max_grad_norm max view update format size item enumerate time backward print contiguous AverageMeter parameters step len update time format print DataFrame contiguous AverageMeter size copy eval item numpy max enumerate len DEBUG basicConfig setLevel getLogger join read_csv info add_suffix concat info merge list reset_index shuffle groups keys log values mean_absolute_error print makedirs groups items list copy groups items list copy groups copy groups copy floor time param_groups lr_decay learning_rate dirname abspath GetBond GetAtomById get_bond_features NumAtoms get_atom_features append read_molecule range get_global_features tuple list size T OBMolBondIter FP16_Data GetBeginAtomIdx extend append tensor OBMolAtomIter GetEndAtomIdx T OBMolBondIter FP16_Data GetBeginAtomIdx extend append tensor OBMolAtomIter GetEndAtomIdx append Linear linear_block extend len LayerNorm ReLU append range Linear update set_postfix_str num_graphs view model backward train MeanLogGroupMAE step zero_grad tqdm type item to sum enumerate AverageMetric add_scalar norm sum cross norm sum arctan2 linear_block extend timer DataLoader Logger DataFrame cuda open list MolecularGraphDataset len load_state_dict append range concatenate astype mean eval zip type enumerate load print write extend to_csv compute_kaggle_metric int32 numpy makedirs view l1_loss concatenate print astype compute_kaggle_metric eval int32 append numpy cuda range enumerate len tuple zero_grad timer DataLoader adjust_learning_rate Logger save cuda exists open list MolecularGraphDataset len load_state_dict range state_dict SummaryWriter replace Ranger NullScheduler item type net load get_learning_rate isdir criterion print backward schduler add_scalar write float32 parameters filter rmtree do_valid zeros train step makedirs mean range fabs log SANITIZE_ALL SANITIZE_PROPERTIES clear pop infty ones min set add deque chain max range append readstring make3D openbabel_mol Molecule make3D readstring mol_from_smiles Struct get_group convert write_file_to_pickle mol_from_file MoleculaGraph groupby concat merge load_csv list sort tqdm keys make_graph makedirs arange save train_test_split sort_values read_csv len run_convert_to_graph run_make_split value concatenate float index id from_numpy ravel long zip append get_flat_data type array range enumerate len ndarray isinstance len | # champs_kaggle Collection of data, scripts and analysis related to the CHAMPS Kaggle competition, [Predicting Molecular Properties](https://www.kaggle.com/c/champs-scalar-coupling). The [dataset_generation](./dataset_generation) folder contains information and scripts related to creating the dataset from the QM9 structures. The [dataset](./dataset) folder contains the training data available in the competition as well as the hidden test data. This data is slightly different than the data used in the competition, as there was a small symmetry related error in the original dataset that only affected the supplementary data (which none of the top teams used) of a small number of molecules. The [analysis](./analysis) folder contains the submitted predictions by the top 400 teams, as well as scripts to analyse this. The [download_everything.sh](./download_everything.sh) script downloads all datasets, checkpoints, intermediate data files etc. available. This is a large amount of data. | 2,735 |
lasigeBioTM/BiONT | ['relation extraction'] | ['BiOnt: Deep Learning using Multiple Biomedical Ontologies for Relation Extraction'] | src/ontologies_embeddings.py src/ontology_preprocessing.py src/results.py src/models.py src/parse_biocreative_v_cdr.py src/parse_xml.py get_ontology_concat_channel get_ontology_common_channel get_words_channel_conc precision f1 get_model recall get_wordnet_indexes preprocess_ids preprocess_sequences get_w2v get_xml_data preprocess_sequences_glove common_ancestors write_plots concatenation_ancestors join_channels Metrics main predict load_go load_chebi load_hpo map_to_ontology load_doid get_network_graph_spacy get_new_offsets_sentences get_path_to_root get_ancestors parse_sentence_spacy parse_sst_results create_test_set prevent_sentence_segmentation run_sst get_sdp_instances get_sentence_entities get_head_tokens_spacy process_sentence_spacy get_common_ancestors divided_by_sentences parse_sentences_spacy get_network_graph_spacy get_path_to_root get_ancestors parse_sentence_spacy parse_sst_results parse_xml_sentences_spacy prevent_sentence_segmentation run_sst get_sdp_instances get_sentence_entities get_head_tokens_spacy process_sentence_spacy get_common_ancestors model_results_xml model_results_cdr e_words concatenate e_ancestors_right e_ancestors_left Embedding build len e_ancestors Embedding build len get_ontology_concat_channel e_wn_right get_words_channel_conc get_ontology_common_channel Embedding concatenate print build Model summary append Input e_wn_left compile len epsilon sum round clip epsilon sum round clip recall precision update format concatenate print exit set empty array get_sdp_instances append pad_sequences enumerate load_word2vec_format print pad_sequences index append enumerate print pad_sequences append enumerate eval preprocess_ids eval preprocess_ids format plot xlabel ylabel title savefig figure legend arange get_w2v to_categorical Metrics seed preprocess_sequences get_model format shuffle write_plots lower get_wordnet_indexes remove get_keras_embedding print fit preprocess_sequences_glove common_ancestors concatenation_ancestors isfile ModelCheckpoint to_json len get_wordnet_indexes read format replace preprocess_ids preprocess_sequences get_w2v model_from_json print close preprocess_sequences_glove model_results_xml load_weights open load format load_go load_chebi print get_xml_data predict lower load_hpo save join_channels load_doid get add_edge format MultiDiGraph print nodes to_directed split append read_obo add_node get add_edge format MultiDiGraph print nodes to_directed split append read_obo add_node get add_edge format MultiDiGraph print nodes to_directed split append read_obo add_node get add_edge format MultiDiGraph print nodes to_directed split append read_obo add_node load items list extract dump choice isfile extractOne keys open int close write sample split open len create_pipe add_pipe English nlp_l append int divided_by_sentences get_new_offsets_sentences str list items listdir close set add split append map_to_ontology open semantic_base replace get_id common_ancestors startswith semantic_base replace get_id common_ancestors startswith append get_path_to_root get_common_ancestors nlp replace update join list format communicate parse_sst_results write close keys enumerate Popen open split get_new_offsets_sentences list format items replace info parse_sentence_spacy close run_sst split append listdir open children format i append sents lower_ char_span format set add i warning startswith lower_ get_network_graph_spacy get str format int product print shortest_path text exit lower_ i info append get_head_tokens_spacy enumerate get get_new_offsets_sentences update format get_ancestors list items listdir close set open split info get_sentence_entities process_sentence_spacy append parse_sentences_spacy get int parse format debug getroot findall get format parse replace parse_sentence_spacy run_sst getroot info append listdir list split parse findall parse_xml_sentences_spacy getroot get deepcopy readline parse findall list items print readlines getroot open listdir split get get_new_offsets_sentences readline list items print readlines close copy open listdir append split | # BiOnt: Deep Learning using Multiple Biomedical Ontologies for Relation Extraction To perform relation extraction, our deep learning system, BiOnt, employs four types of biomedical ontologies, namely, the Gene Ontology, the Human Phenotype Ontology, the Human Disease Ontology, and the Chemical Entities of Biological Interest, regarding gene-products, phenotypes, diseases, and chemical compounds, respectively. Our academic paper which describes BiOnt in detail can be found [here](https://doi.org/10.1007/978-3-030-45442-5_46). ## Downloading Pre-Trained Weights Available versions of pre-trained weights are as follows: * [DRUG-DRUG](https://drive.google.com/file/d/1xRassA5C3TA_zjF2DRwygeo4Yy_gRjmi/view?usp=sharing) * [DRUG-DISEASE](https://drive.google.com/file/d/1-ur6HnaN9MmQOM-7zoAaURIvIUAR_o0W/view?usp=sharing) * [GENE-PHENOTYPE](https://drive.google.com/file/d/18Wa2WJKZunlOJTemQYPi3t_shWrPnPLZ/view?usp=sharing) The training details are described in our academic paper. ## Getting Started | 2,736 |
lasinger/3DVideos2Stereo | ['depth estimation', 'monocular depth estimation'] | ['Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer'] | genTraining_recurr.py get_disp_and_uncertainty.py splitImagesChapters.py processChapter_cutlist processShotFile main silentremove get_disp_and_uncertainty read_flow main remove str int fpsSingle round split numRecurrent str list glob name print processShotFile len processChapter_cutlist split videoListPath fpsSingle range fpsRecurrent silentremove zeros imwrite uint16 indices resize round abs max PngInfo count_nonzero str read_flow add_text shape dirname size astype enumerate uint8 print min remap makedirs int txtList outRight paddingAR size paddingAR_side new crop write outLeft close save raw flip open | # 3DVideos2Stereo The provided scripts help to extract stereo data as described in our [paper](https://arxiv.org/abs/1907.01341): >Towards Robust Monocular Depth Estimation: Mixing Datasets for Zero-shot Cross-dataset Transfer René Ranftl, Katrin Lasinger, David Hafner, Konrad Schindler, Vladlen Koltun Code for monocular depth estimation: [https://github.com/intel-isl/MiDaS](https://github.com/intel-isl/MiDaS) ## Frame Extraction There exist multiple different formats to store stereo videos. For our frame extraction scripts we expect videos to be stored as 1080p SBS (side-by-side) MKVs, i.e. the image resolution should be 3840x1080px (2x 1920x1080). Additionally we extract chapter information using ffmpeg: ``` | 2,737 |
laura-burdick/embeddingStability | ['word embeddings'] | ['Factors Influencing the Surprising Instability of Word Embeddings'] | regression/precalculateNearestNeighbor_europarl.py regression/sharedWordList.py regression/precalculateNearestNeighbor_nyt.py regression/viewResults.py regression/ppmi_nyt.py old_stability/example.py regression/w2v_europarl.py regression/ppmi_europarl.py regression/getWordList.py stability.py old_stability/stability.py regression/generateClassifierFeatures.py regression/regressionModel.py example.py regression/create_balltrees_nyt.py regression/create_balltrees_europarl.py regression/w2v_nyt.py mostSimilar stability mostSimilar stability mydist mydist getWordList getPPMI train_ppmi buildCooccurrenceMatrix getPPMI train_ppmi buildCooccurrenceMatrix mydist mydist IndexFlatL2 print search add tqdm shape trange normalize matrix range len range len append reshape cosine_similarity items append items Counter print zeros range len print csr_matrix log svds append zeros range len str diag dot append range len svd | # Factors Influencing the Surprising Instability of Word Embeddings Laura (Wendlandt) Burdick, Jonathan K. Kummerfeld, Rada Mihalcea Language and Information Technologies (LIT) University of Michigan ## Introduction The code in this repository was used in the paper "Factors Influencing the Surprising Instability of Word Embeddings" by Wendlandt, et al. I have tried to document it well, but at the end of the day, it is research code, so if you have any problems using it, please get in touch with Laura Burdick ([email protected]). **Update 8/7/20**: I have updated the repository with (much) faster code to calculate stability. The original stability code can be found in **old_stability/**. ## Citation Information If you use this code, please cite the following paper: ``` | 2,738 |
laura-burdick/multilingual-stability | ['word embeddings'] | ['Analyzing the Surprising Variability in Word Embedding Stability Across Languages'] | regression/crossValidation.py stability/w2v_bible.py stability/stability_bible.py stability/stability_wikipedia.py regression/regressionModel.py stability/precalculateNearestNeighbors_wikipedia.py stability/precalculateNearestNeighbors_bible.py stability stability range len | # Analyzing the Surprising Variability in Word Embedding Stability Across Languages Laura (Wendlandt) Burdick, Jonathan K. Kummerfeld, Rada Mihalcea Language and Information Technologies (LIT) University of Michigan ## Introduction The code in this repository was used in an EMNLP 2021 paper, as well as Chapter 4 of Laura Burdick's Ph.D. thesis. I have tried to document it well, but at the end of the day, it is research code, so if you have any problems using it, please get in touch with Laura Burdick ([email protected]). ## Citation Information If you use this code, please cite either of the following papers: ``` @inproceedings{Burdick21Analyzing, | 2,739 |
layer6ai-labs/GSS | ['image retrieval'] | ['Fine-tuning CNN Image Retrieval with No Human Annotation', 'Guided Similarity Separation for Image Retrieval'] | utils/helper.py train.py utils/revop.py utils/evaluate.py model.py GSS_loss ResidualGraphConvolutionalNetwork main apk mapk compute_ap compute_map load_ransac_graph convert_sparse_matrix_to_sparse_tensor preprocess_graph gen_graph load_data combine_graph get_roc_score_matrix read_imlist init_intre gnd_mat2py config_qimname eval_instre configdataset eval_revop init_revop config_imname convert_sparse_matrix_to_sparse_tensor apply_regularization set_random_seed get_next val_batch_size dataset seed l2_regularizer get_collection k placeholder apply_gradients get_roc_score_matrix make_initializer ResidualGraphConvolutionalNetwork format concatenate preprocess_graph gss_loss kq gen_graph report_hard compute_gradients load_ransac_graph ConfigProto batch REGULARIZATION_LOSSES print output_types sparse_placeholder from_structure data_path AdamOptimizer repeat load_data combine_graph global_variables_initializer network enumerate float arange len compute_ap arange min zeros float sum max len init_revop init_intre load join format time T format csr_matrix print matmul shape zeros range T matmul argsort eval_instre eval_revop csr_matrix hstack vstack transpose flatten array eye sum diags transpose tocoo join format print configdataset loadmat load join format print configdataset format compute_map concatenate print around append array range len format compute_map concatenate print around append array range len join read_imlist format print gnd_mat2py lower loadmat len splitext splitext arange reshape squeeze append len close splitlines open | <p align="center"> <a href="https://layer6.ai/"><img src="https://github.com/layer6ai-labs/DropoutNet/blob/master/logs/logobox.jpg" width="180"></a> </p> ## NeurIPS'19 Guided Similarity Separation for Image Retrieval Authors: [Chundi Liu](http://www.cs.toronto.edu/~chundiliu), [Guangwei Yu](http://www.cs.toronto.edu/~guangweiyu), [Cheng Chang](https://scholar.google.com/citations?user=X7oyRLIAAAAJ&hl=en), Himanshu Rai, Junwei Ma, [Satya Krishna Gorti](http://www.cs.toronto.edu/~satyag/), [Maksims Volkovs](http://www.cs.toronto.edu/~mvolkovs) [[paper](http://www.cs.toronto.edu/~mvolkovs/NIPS2019_GSS.pdf)][[poster]](http://www.cs.toronto.edu/~chundiliu/data/NeurIPS_GSS%20Poster.pdf)[[slides]](http://www.cs.toronto.edu/~chundiliu/data/GSS%20Slides.m4v)[[video]](https://slideslive.com/38921753/track-3-session-4) ## Prerequisites and Environment * tensorflow-gpu 1.13.1 * numpy 1.16.0 All experiments were conducted on a 20-core Intel(R) Xeon(R) CPU E5-2630 v4 @2.20GHz and NVIDIA V100 GPU with 32GB GPU memory. | 2,740 |
layer6ai-labs/egt | ['image retrieval'] | ['Explore-Exploit Graph Traversal for Image Retrieval'] | python/evaluate_prebuild.py python/egt.py python/revop.py run_all.py python/evaluate.py load_npy load_hashes generate_prebuild QE main apk mapk compute_ap compute_map get_order main evaluate_prebuild read_file read_imlist gnd_mat2py config_qimname configdataset eval_revop init_revop config_imname norm T matmul str T format concatenate print min write close matmul QE argsort eval_revop init_revop range flush open open query_hashes load_npy evaluate OutputFile add_argument load_hashes generate_prebuild k index_features ArgumentParser index_hashes parse_args query_features QE_topN enumerate float arange len compute_ap arange zeros float len close open len close range open T format get_order print reshape len read_file eval_revop append init_revop array range split evaluate_prebuild f skip num_query num_score join configdataset compute_map concatenate append range len join read_imlist format print gnd_mat2py lower loadmat len splitext splitext arange reshape squeeze append len close splitlines open | <p align="center"> <a href="https://layer6.ai/"><img src="https://github.com/layer6ai-labs/DropoutNet/blob/master/logs/logobox.jpg" width="180"></a> </p> ## CVPR'19 Explore-Exploit Graph Traversal for Image Retrieval Authors: [Cheng Chang*](https://scholar.google.com/citations?user=X7oyRLIAAAAJ&hl=en), [Guangwei Yu*](http://www.cs.toronto.edu/~guangweiyu), [Chundi Liu](http://www.cs.toronto.edu/~chundiliu), [Maksims Volkovs](http://www.cs.toronto.edu/~mvolkovs) [[paper](http://www.cs.toronto.edu/~mvolkovs/cvpr2019EGT.pdf)] ## Datasets and Environment * Java 8+ * Code primarily tested for Python 3.5 * Evaluation data can be downloaded from [here](https://s3.amazonaws.com/public.layer6.ai/landmark/EGT-DATA/evaluation.tar.gz) (taken from the authors of ROxford and RParis [datasets]( https://github.com/filipradenovic/revisitop), redistributed with permission) | 2,741 |
lcary/keras-program-induction | ['learning to execute'] | ['Learning to Execute'] | addition_rnn.py CharacterTable colors | keras-program-induction ======================= Python 3.6 program induction implementations using Keras. Addition RNN ------------ ```bash python addition_rnn.py ``` References: - https://keras.io/examples/addition_rnn/ | 2,742 |
lcckkkhaha/Suprise-Adequacy-Implementation | ['autonomous driving'] | ['Guiding Deep Learning System Testing using Surprise Adequacy'] | SA/AT.py SA/Dataset_MNIST.py Test/MNIST-SC-TEST.py SA/SC.py SA/Trim_Data_Size.py Test/MNIST-LSA-TEST.py SA/CNN_MNIST.py SA/LSA.py SA/DSA.py Test/MNIST-DSA-TEST.py SA/Function_Test.py activation_trace train_mnist_cnn_model get_mnist_data distance_based_suprise_adequacy suprise_coverage trim_data function concatenate print reshape size range len compile Sequential fit add Dense MaxPooling2D Conv2D Flatten Dropout print reshape to_categorical astype load_data norm concatenate print to_categorical argmin array_equal append argmax array range concatenate print delete array range len print | Implementation of Guilding Deep Learning System Testing Using Suprise Adequacy https://arxiv.org/abs/1808.08444 In folder TEST, LSA,DSA,and SC can be run in a very small dataset of MNIST (100 training data and one new input). In folder SA, I will try to modulize the codes and expand one new input to multiple new input. TO DO: SA/LSA.py Fix the glitch when compute KDE in TEST/MNIST-LSA-TEST.py | 2,743 |
lcosmo/LIMP | ['style transfer'] | ['LIMP: Learning Latent Shape Representations with Metric Preservation Priors'] | test_FAUST.py datasets/faust_2500.py models/SimplePointNet.py models/model.py misc_utils.py utils_distance.py train_FAUST.py load_mesh toc plot_colormap decode totuple calc_allsp TicTocGenerator calc_adj_matrix save_ply tic rigid_transform_3D ismember pairwise_dists optimize_intep optimize_rec IntraSampler optimize_disent_ext optimize_disent_int VF_adjacency_matrix normals distance_BH AverageValueMeter LBO calc_euclidean_dist_matrix LBO_slim _geodesics_in_heat _grad_div distance_GIH weights_init Eigendecomposition calc_volume check_FAUST2000_dataset download_file_from_google_drive save_response_content get_confirm_token Faust2500Dataset PointNetVAE Decoder Encoder SimplePointNet SimpleTransformer time print next toc from_numpy loadtxt totuple describe write zeros array zeros range zeros sum show add_trace min make_subplots dict zip update_layout Mesh3d enumerate svd T print reshape transpose mean shape tile matrix to dec asarray eval enc append numpy range len exp z_var mean vae z_mu __iter__ to next enable_bn pairwise_dists sum calc_euclidean_dist_matrix float dec mean distance_GIH __iter__ to next enable_bn calc_euclidean_dist_matrix float dec mean cat distance_GIH __iter__ to next enable_bn calc_euclidean_dist_matrix float dec mean cat __iter__ to next cuda enable_bn dtype zeros view device dtype reshape transpose cross sqrt device sum dtype int rsqrt grad item device eye zeros range diag t LBO_slim _geodesics_in_heat _grad_div sum relu ones LBO_slim sqrt eye float mm diag cross dtype view transpose squeeze expand cross sqrt stack repeat device gather sum long zeros diag_embed bmm LBO_slim dtype reshape transpose cross t sqrt device sum scatter_add bmm transpose unsqueeze relu normal_ __name__ fill_ get get_confirm_token save_response_content Session items list startswith download_file_from_google_drive print extractall makedirs system open | # LIMP ### Learning Latent Shape Representations with Metric Preservation Priors This repository contains the official PyTorch implementation of: *LIMP: Learning Latent Shape Representations with Metric Preservation Priors.* by Luca Cosmo, Antonio Norelli, Oshri Halimi, Ron Kimmel and Emanuele Rodolà. Oral at ECCV 2020. https://arxiv.org/abs/2003.12283  **Abstract**: In this paper, we advocate the adoption of metric preservation as a powerful prior for learning latent representations of deformable 3D shapes. Key to our construction is the introduction of a geometric distortion criterion, defined directly on the decoded shapes, translating the preservation of the metric on the decoding to the formation of linear paths in the underlying latent space. Our rationale lies in the observation that training samples alone are often insufficient to endow generative models with high fidelity, motivating the need for large training datasets. In contrast, metric preservation provides a rigorous way to control the amount of geometric distortion incurring in the construction of the latent space, leading in turn to synthetic samples of higher quality. We further demonstrate, for the first time, the adoption of differentiable intrinsic distances in the backpropagation of a geodesic loss. Our geometric priors are particularly relevant in the presence of scarce training data, where learning any meaningful latent structure can be especially challenging. The effectiveness and potential of our generative model is showcased in applications of style transfer, content generation, and shape completion. [2 minutes trailer video](https://youtu.be/NPE_uey-dXo) | 2,744 |
lcosmo/isospectralization | ['style transfer'] | ['Isospectralization, or how to hear shape, style, and correspondence'] | code_for_3D/test.py code_for_3D/shape_library.py code_for_2D/test.py code_for_2D/spectrum_alignment.py code_for_2D/shape_library.py code_for_3D/spectrum_alignment.py plotly_trisurf toc load_mesh totuple resample tfeval load_ply prepare_mesh TicTocGenerator tfeig save_ply tic ismember fps_euclidean calc_evals build_graph run_optimization tf_calc_lap OptimizationParams toc load_mesh totuple tfeval prepare_mesh TicTocGenerator tfeig save_ply tic ismember calc_evals build_graph run_optimization tf_calc_lap OptimizationParams clear show squarelim scatter plot_trisurf time print next toc close identity ConfigProto GPUOptions Session run diag close identity eigh ConfigProto GPUOptions Session run loadtxt totuple describe write zeros array read asarray zeros range int asarray ones diag logical_and calc_adj_matrix matmul eye setedg zeros sum range append cdist size min zeros argmax range prepare_mesh rand vstack Path max fps_euclidean triangulate list Triangulation ones meshgrid append range asarray concatenate tris contains_points stack unique int norm reshape min cross int32 pts fAk transpose matmul reduce_sum sqrt expand_dims diag SparseTensor self_adjoint_eig prepare_mesh matmul sqrt tf_calc_lap diag cos decay_target abs l2_loss list bound_reg cp placeholder matmul reduce_sum clipped_grad_minimize cost_bound inner_reg tf_calc_lap range asarray X astype op cost_evals bound_reg_cost sqrt decay moments flip_penalty_reg inner_reg_cost flip_cost minimum cost_inner learning_rate self_adjoint_eig Variable float32 AdamOptimizer numsteps zeros diag evals reset_default_graph ConfigProto GPUOptions makedirs smoothness_reg cost_spectral gather curvature_reg opt_step volume_reg apply_gradients global_step vcW compute_gradients vcL Volume print l2_reg cost_evals_f1 cross build_graph | # Isospectralization Implementation of the paper: Cosmo et al., "Isospectralization, or how to hear shape, style, and correspondence", arXiv 2018 https://arxiv.org/abs/1811.11465 The paper describes a method to optimize the R^2/R^3 embedding of a discretized surface (triangular mesh) as to align the eigenvalues of its LBO to a target set of eigenvalues (possibly derived from a target shape). The code is sub-divided in two folders containing the code for the relative embedding space (R^2 and R^3). Each folder contains the following python files: - test.py - small script to load the data and run the optimization - shape_library.py - a library containing functions to load and pre-process the shape - spectrum_alignment.py - tensorflow code performing the optimization If you are using this code, please cite: ``` | 2,745 |
leandroschelb/attention_ocr | ['optical character recognition'] | ['Attention-based Extraction of Structured Information from Street View Imagery'] | python/common_flags.py python/data_provider_test.py python/eval.py python/train.py python/model_export.py python/datasets/number_plates.py python/eval_once.py python/datasets/testdata/fsns/download_data.py python/inception_preprocessing.py python/datasets/__init__.py python/datasets/unittest_utils_test.py python/datasets/receipts.py python/model.py python/datasets/unittest_utils.py python/sequence_layers_test.py python/data_provider.py python/demo_inference.py python/demo_inference_test.py python/metrics_test.py python/train_mod.py python/datasets/fsns.py python/metrics.py python/model_export_test.py python/model_export_lib.py python/model_test.py python/datasets/fsns_test.py python/sequence_layers.py python/utils.py define create_model create_dataset create_mparams get_crop_size get_data preprocess_image central_crop augment_image DataProviderTest create_model load_images main get_dataset_image_size run DemoInferenceTest main main distorted_bounding_box_crop preprocess_for_train preprocess_for_eval preprocess_image distort_color apply_with_random_selector sequence_accuracy char_accuracy AccuracyTest max_char_logprob_cumsum _dict_to_array CharsetMapper get_tensor_dimensions lookup_indexed_value Model get_softmax_loss_fn axis_pad null_based_length_prediction find_length_by_null main get_checkpoint_path export_model attention_ocr_attention_masks normalize_image generate_tfexample_image build_tensor_info _clean_up AttentionOcrExportTest _create_tf_example_string CharsetMapperTest create_fake_charset ModelTest get_layer_class NetSlice orthogonal_initializer AttentionWithAutoregression NetSliceWithAutoregression Attention SequenceLayerBase fake_net SequenceLayersTest create_layer fake_labels create_optimizer calculate_graph_metrics main train get_training_hparams prepare_training_dir create_optimizer calculate_graph_metrics main train get_training_hparams prepare_training_dir logits_to_log_prob ConvertAllInputsToTensors variables_to_restore _NumOfViewsHandler get_split read_charset get_test_split FsnsTest dataset_dir get_split get_split create_random_image create_serialized_example UnittestUtilsTest DEFINE_float DEFINE_string DEFINE_bool DEFINE_integer dataset_name getattr Model get one_hot_encoding num_char_classes DatasetDataProvider preprocess_image shuffle_batch getattr asarray ndarray GFile print range get_dataset_image_size open uint8 create_base placeholder map_fn create_dataset preprocess_image get_dataset_image_size load_images ChiefSessionCreator create_model dataset_name batch_size print image_path_pattern checkpoint run max_sequence_length create_model create_summaries num_char_classes get_or_create_global_step create_base charset ConfigProto eval_log_dir null_code get_data images evaluation_loop create_dataset create_loss num_of_views makedirs checkpoint_path evaluate_once sorted append set listdir enumerate int match uniform items list max keys value stack reduce_max zeros ndims max_char_logprob_cumsum cast axis_pad argmax find_length_by_null latest_checkpoint train_log_dir checkpoint generate_tfexample_image add_meta_graph_and_variables image_shape string Saver save Session restore placeholder attention_ocr_attention_masks build_tensor_info num_of_views create_model num_char_classes get_checkpoint_path CLASSIFY_METHOD_NAME info build_signature_def enumerate max_sequence_length SavedModelBuilder uint8 create_base null_code convert_image_dtype create_dataset get_variables_to_restore export_dir export_model export_for_serving image_width image_height exists normalize_image reshape stack parse_example range rmtree get_temp_dir Example list extend reshape range svd randn debug __name__ convert_to_tensor ModelParams fake_labels fake_net SequenceLayerParams learning_rate AdagradOptimizer MomentumOptimizer AdamOptimizer RMSPropOptimizer AdadeltaOptimizer task constant sync_replicas create_optimizer int32 LegacySyncReplicasOptimizer create_train_op rmtree train_log_dir reset_train_dir info makedirs print_model_analysis get_default_graph replica_device_setter ps_tasks get_training_hparams prepare_training_dir name get_variables_to_restore compile join info TFExampleDecoder read_charset zeros copy fromarray randint BytesIO save items list isinstance extend add Example | # Attention-based Extraction of Structured Information from Street View Imagery [](https://paperswithcode.com/sota/optical-character-recognition-on-fsns-test?p=attention-based-extraction-of-structured) [](https://arxiv.org/abs/1704.03549) [](https://github.com/tensorflow/tensorflow/releases/tag/v1.15.0) *A TensorFlow model for real-world image text extraction problems.* This folder contains the code needed to train a new Attention OCR model on the [FSNS dataset][FSNS] to transcribe street names in France. You can also train the code on your own data. More details can be found in our paper: ["Attention-based Extraction of Structured Information from Street View Imagery"](https://arxiv.org/abs/1704.03549) | 2,746 |
leauferreira/GpX | ['explainable artificial intelligence'] | ['Applying Genetic Programming to Improve Interpretability in Machine Learning Models'] | tests/test_noise_set.py gp_explainer/gpx.py gp_explainer/utils.py tests/test_pydm.py pydm/pydm.py tests/test_gpx.py setup.py gp_explainer/noise_set.py pydm/dataset_name.py tests/noise_set_benchmark.py Gpx NoiseSet Utils Regression MultiClass Classification get_all_regressions data_classification_factory data_multclass_factory get_all_multiclass DataManager get_all_classifications data_regression_factory test_k_neighbor_nor test_k_neighbor_raw test_k_neighbor_opt TestGPX TestNoiseSet TestDataManager build build parent fetch_california_housing reshape astype build load_boston load_diabetes float read_csv values pedantic k_neighbor_adapter noise_k_neighbor pedantic pedantic k_neighbor | # GpX ## Installation ```sh pip install -qU git+https://github.com/leauferreira/GpX ``` ## Examples * You can find a colab example clicking [here](https://colab.research.google.com/drive/1rB8r1btvR2P2tfoXMaddlTiJ0upB7HhY?usp=sharing). ## Citation If you use GPX, we would appreciate citation: * [Applying Genetic Programming to Improve Interpretability in Machine Learning Models](https://doi.org/10.1109/CEC48606.2020.9185620) | 2,747 |
leelaylay/TweetSemEval | ['sentiment analysis', 'word embeddings', 'twitter sentiment analysis'] | ['BB_twtr at SemEval-2017 Task 4: Twitter Sentiment Analysis with CNNs and LSTMs'] | SemEval/dataset_readers/semeval_datareader.py SemEval/dataset_readers/utils.py SemEval/models/semeval_classifier_attention.py SemEval/models/my_bcn.py SemEval/predictors/semeval_predictor.py SemEval/models/semeval_classifier.py SemEvalDatasetReader main preprocess tokenize BiattentiveClassificationNetwork SemEvalClassifier SemEvalClassifierAttention SemEvalPredictor tokenize list punctuation words | # SemEval-2017 Task 4 Sentiment Analysis in Twitter ## Introduction [SemEval-2017 Task 4](http://alt.qcri.org/semeval2017/task4/index.php?id=data-and-tools) is a text sentiment classification task: Given a message, classify whether the message is of positive, negative, or neutral sentiment. ## Run Experiments ```bash # install the environment conda create -n allennlp python=3.6 source activate allennlp pip install -r requirements.txt ``` | 2,748 |
leftthomas/CGD | ['image retrieval'] | ['Combination of Multiple Global Descriptors for Image Retrieval'] | train.py data_utils.py test.py utils.py resnet.py model.py process_cub_data read_txt process_sop_data process_car_data process_isc_data GlobalDescriptor Model set_bn_eval L2Norm conv1x1 resnext50_32x4d wide_resnet50_2 ResNet resnet50 resnext101_32x8d Bottleneck resnet152 wide_resnet101_2 conv3x3 _resnet resnet34 resnet18 BasicBlock resnet101 train test ImageReader LabelSmoothingCrossEntropyLoss recall MPerClassSampler BatchHardTripletLoss open split basename format convert tqdm mkdir save append crop items list format basename convert tqdm read_txt mkdir save append crop items list basename format convert open mkdir save append enumerate split basename format convert open mkdir save append enumerate split eval __name__ ResNet load_state_dict load_state_dict_from_url argmax feature_criterion format backward zero_grad apply class_criterion set_description step net format print eval append enumerate fill_diagonal_ squeeze item append tensor float len | # CGD A PyTorch implementation of CGD based on the paper [Combination of Multiple Global Descriptors for Image Retrieval](https://arxiv.org/abs/1903.10663v3).  ## Requirements - [Anaconda](https://www.anaconda.com/download/) - [PyTorch](https://pytorch.org) ``` conda install pytorch torchvision cudatoolkit=10.0 -c pytorch ``` - thop | 2,749 |
leggedrobotics/MPC-Net | ['imitation learning'] | ['MPC-Net: A First Principles Guided Policy Search'] | sample.py replay_memory.py PolicyNet.py ballbot_evaluation.py ballbot_learner.py plot trajectoryCost StateInputConstraint num_samples_per_trajectory_point getTargetTrajectories loss_function solver_step_closure IntermediateCost FlowMap TwoLayerNLP ExpertMixturePolicy LinearPolicy NonlinearPolicy ReplayMemory load int transpose mm astype computeFlowMap t figure legend iter zeros tensor policy range zeros scalar_array dynamic_vector_array resize dot apply int concatenate astype computeFlowMap matmul isnan zeros tensor policy range concatenate backward zero_grad nu matmul dVdx item zip zeros tensor policy add_scalar | # MPC-Net This package contains supplementary code and implementation details for the [publication](https://doi.org/10.1109/LRA.2020.2974653) > J. Carius, F. Farshidian and M. Hutter, "MPC-Net: A First Principles Guided Policy Search," in IEEE Robotics and Automation Letters, vol. 5, no. 2, pp. 2897-2904, April 2020. A preprint is available on [arxiv](https://arxiv.org/pdf/1909.05197.pdf). While licensing restrictions do not allow us to release the ANYmal model, we are providing our training script with an alternative ball-balancing robot. ## Dependencies * [OCS2 Toolbox](https://bitbucket.org/leggedrobotics/ocs2/) * [Pybind11](https://github.com/pybind/pybind11) * [Pytorch](https://pytorch.org/) | 2,750 |
lehaifeng/SCAttNet | ['semantic segmentation'] | ['SCAttNet: Semantic Segmentation Network with Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images'] | U-Net/data.py FCN_8s/predict.py FCN_32s/data.py U-Net/train.py SegNet/ops.py SegNet/segnet.py FCN_32s/predict.py FCN_8s/data.py SCAttNet/ops.py FCN_32s/fcn8s.py SCAttNet/train.py U-Net/unet.py SegNet/predict.py SCAttNet/data.py FCN_8s/train.py FCN_8s/fcn8s.py SegNet/data.py SCAttNet/scattnet.py SCAttNet/predict.py SegNet/train.py FCN_32s/train.py U-Net/predict.py next_batch load_batch bias_variable VGG16 fc maxpool conv2d_basic conv conv2d_transpose_strided print_layer weight_variable vis save load train test next_batch load_batch bias_variable VGG16 fc maxpool conv2d_basic conv conv2d_transpose_strided print_layer weight_variable vis save load train loadtestdata next_batch load_batch maxpool2d_with_argmax batch_norm relu upsample conv2d maxpool2d maxunpool2d xavier_initializer vis save channel_attention channel_spatial_block decoder dec_last_conv n_enc_block n_dec_block inference encoder spatial_attention load train loadtestdata next_batch load_batch maxpool2d_with_argmax batch_norm relu upsample conv2d maxpool2d maxunpool2d xavier_initializer vis save decoder dec_last_conv encoder n_enc_block inference n_dec_block load train loadtestdata next_batch load_batch vis save load train unet_model astype float32 append imread range len load_batch sorted glob choice array len print value print_layer max_pool value truncated_normal constant conv2d as_list conv2d_transpose relu maxpool shape conv2d_basic stack conv conv2d_transpose_strided bias_variable argmax weight_variable join restore basename uint8 get_checkpoint_state len astype range expand_dims model_checkpoint_path imread argmax imsave run show join restore basename get_checkpoint_state squeeze len expand_dims model_checkpoint_path imshow imread argmax range run join restore basename int format print get_checkpoint_state group model_checkpoint_path load int print save next_batch range run subplot print len imshow argmax range run get_shape add sorted glob print astype float32 append imread array as_list as_list as_list as_list variance_scaling_initializer constant_initializer variance_scaling_initializer as_list print shape resize_images max_pooling2d relu concat reversed conv2d batch_normalization append range enumerate | This is a tensorflow implement of SCAttNet: Semantic Segmentation Network with Spatial and Channel Attention Mechanism for High-Resolution Remote Sensing Images # Prerequisites tensorflow 1.4.0 python 2.7 1. Please put your train image, train_label into the path ./dataset/train_img, ./dataset/train_label 2. Run python train.py to get the checkpoint file 3. Run python predict.py to get the predicted results. # The manuscript: Abstract: High-resolution remote sensing images (HRRSIs) contain substantial ground object information, such as texture, shape, and spatial location. Semantic segmentation, which is an important method for element extraction, has been widely used in processing mass HRRSIs. However, HRRSIs often exhibit large intraclass variance and small interclass variance due to the diversity and complexity of ground objects, thereby bringing great challenges to a semantic segmentation task. In this study, we propose a new end-to-end semantic segmentation network, which integrates two lightweight attention mechanisms that can refine features adaptively. We compare our method with several previous advanced networks on the ISPRS Vaihingen and Potsdam datasets. Experimental results show that our method can achieve better semantic segmentation results compared with other works. The manuscript can be visited at https://ieeexplore.ieee.org/document/9081937 or https://arxiv.org/abs/1912.09121 | 2,751 |
leiapollos/ml-agents-iaj-selfdrivingcar | ['unity'] | ['Unity: A General Platform for Intelligent Agents'] | ml-agents-envs/mlagents/envs/communicator_objects/unity_rl_input_pb2.py ml-agents/mlagents/trainers/components/reward_signals/curiosity/model.py ml-agents-envs/mlagents/envs/communicator_objects/agent_action_pb2.py ml-agents-envs/mlagents/envs/communicator_objects/unity_to_external_pb2.py gym-unity/gym_unity/envs/__init__.py ml-agents/mlagents/trainers/learn.py ml-agents/mlagents/trainers/meta_curriculum.py ml-agents/mlagents/trainers/tests/test_barracuda_converter.py ml-agents/mlagents/trainers/ppo/models.py gym-unity/gym_unity/__init__.py utils/validate_meta_files.py ml-agents/mlagents/trainers/trainer_controller.py ml-agents/mlagents/trainers/components/bc/model.py ml-agents/mlagents/trainers/tests/test_curriculum.py ml-agents-envs/mlagents/envs/communicator.py ml-agents-envs/mlagents/envs/communicator_objects/custom_reset_parameters_pb2.py ml-agents-envs/mlagents/envs/communicator_objects/engine_configuration_pb2.py ml-agents/mlagents/trainers/tests/test_ppo.py ml-agents-envs/mlagents/envs/tests/test_rpc_communicator.py ml-agents/mlagents/tf_utils/__init__.py ml-agents/mlagents/trainers/components/reward_signals/__init__.py ml-agents-envs/mlagents/envs/communicator_objects/agent_info_pb2.py ml-agents-envs/setup.py ml-agents/mlagents/trainers/tests/mock_brain.py ml-agents-envs/mlagents/envs/action_info.py ml-agents-envs/mlagents/envs/rpc_communicator.py ml-agents/mlagents/trainers/tests/test_bcmodule.py ml-agents/mlagents/trainers/tests/test_trainer_controller.py ml-agents/mlagents/trainers/components/reward_signals/reward_signal_factory.py ml-agents/setup.py ml-agents/mlagents/trainers/barracuda.py ml-agents-envs/mlagents/envs/tests/test_envs.py ml-agents/mlagents/trainers/sac/policy.py ml-agents-envs/mlagents/envs/env_manager.py ml-agents/mlagents/trainers/ppo/trainer.py ml-agents-envs/mlagents/envs/tests/test_timers.py ml-agents-envs/mlagents/envs/communicator_objects/unity_rl_output_pb2.py ml-agents-envs/mlagents/envs/communicator_objects/unity_rl_initialization_output_pb2.py ml-agents-envs/mlagents/envs/communicator_objects/unity_input_pb2.py ml-agents/mlagents/trainers/tests/test_meta_curriculum.py ml-agents/mlagents/trainers/components/reward_signals/curiosity/signal.py ml-agents-envs/mlagents/envs/subprocess_env_manager.py UnitySDK/Library/PackageCache/[email protected]/Tools/keras_to_barracuda.py ml-agents/mlagents/trainers/bc/trainer.py ml-agents-envs/mlagents/envs/tests/test_brain.py ml-agents/mlagents/trainers/curriculum.py ml-agents/mlagents/trainers/tests/test_policy.py ml-agents/mlagents/trainers/ppo/policy.py ml-agents/mlagents/trainers/tests/test_learn.py ml-agents/mlagents/trainers/tests/test_demo_loader.py utils/validate_versions.py ml-agents/mlagents/trainers/models.py ml-agents/mlagents/trainers/__init__.py ml-agents-envs/mlagents/envs/communicator_objects/brain_parameters_pb2.py ml-agents/mlagents/trainers/tests/test_simple_rl.py ml-agents-envs/mlagents/envs/policy.py ml-agents/mlagents/trainers/exception.py gym-unity/gym_unity/tests/test_gym.py UnitySDK/Library/PackageCache/[email protected]/Tools/tensorflow_to_barracuda.py ml-agents/mlagents/tf_utils/tf.py ml-agents/mlagents/trainers/buffer.py ml-agents/mlagents/trainers/tensorflow_to_barracuda.py ml-agents-envs/mlagents/envs/communicator_objects/unity_to_external_pb2_grpc.py ml-agents-envs/mlagents/envs/mock_communicator.py ml-agents/mlagents/trainers/tests/test_rl_trainer.py ml-agents-envs/mlagents/envs/timers.py gym-unity/setup.py ml-agents-envs/mlagents/envs/communicator_objects/unity_message_pb2.py ml-agents-envs/mlagents/envs/environment.py ml-agents/mlagents/trainers/bc/policy.py ml-agents-envs/mlagents/envs/communicator_objects/observation_pb2.py UnitySDK/Library/PackageCache/[email protected]/Tools/onnx_to_barracuda.py ml-agents-envs/mlagents/envs/simple_env_manager.py ml-agents-envs/mlagents/envs/communicator_objects/environment_parameters_pb2.py ml-agents-envs/mlagents/envs/base_unity_environment.py ml-agents/mlagents/trainers/trainer_util.py ml-agents/mlagents/trainers/tests/test_trainer_util.py ml-agents-envs/mlagents/envs/communicator_objects/unity_output_pb2.py ml-agents/mlagents/trainers/components/reward_signals/extrinsic/signal.py ml-agents/mlagents/trainers/sac/trainer.py ml-agents-envs/mlagents/envs/sampler_class.py ml-agents/mlagents/trainers/tests/test_sac.py ml-agents-envs/mlagents/envs/exception.py ml-agents/mlagents/trainers/sac/models.py UnitySDK/Library/PackageCache/[email protected]/Tools/barracuda.py ml-agents-envs/mlagents/envs/communicator_objects/command_pb2.py ml-agents-envs/mlagents/envs/communicator_objects/space_type_pb2.py ml-agents/mlagents/trainers/components/reward_signals/gail/model.py ml-agents-envs/mlagents/envs/communicator_objects/header_pb2.py ml-agents/mlagents/trainers/rl_trainer.py ml-agents/mlagents/trainers/tests/test_reward_signals.py ml-agents-envs/mlagents/envs/brain.py ml-agents/mlagents/trainers/components/reward_signals/gail/signal.py ml-agents/mlagents/trainers/ppo/multi_gpu_policy.py ml-agents/mlagents/trainers/tests/test_multigpu.py ml-agents/mlagents/trainers/demo_loader.py ml-agents-envs/mlagents/envs/__init__.py ml-agents/mlagents/trainers/components/bc/module.py ml-agents/mlagents/trainers/tests/test_trainer_metrics.py ml-agents-envs/mlagents/envs/tests/test_sampler_class.py ml-agents/mlagents/trainers/tests/test_buffer.py ml-agents-envs/mlagents/envs/communicator_objects/agent_info_action_pair_pb2.py ml-agents/mlagents/trainers/trainer.py ml-agents-envs/mlagents/envs/tests/test_subprocess_env_manager.py ml-agents/mlagents/trainers/bc/models.py ml-agents/mlagents/trainers/bc/offline_trainer.py ml-agents/mlagents/trainers/tf_policy.py ml-agents/mlagents/trainers/tests/test_bc.py ml-agents-envs/mlagents/envs/communicator_objects/demonstration_meta_pb2.py ml-agents-envs/mlagents/envs/communicator_objects/unity_rl_initialization_input_pb2.py ml-agents/mlagents/trainers/trainer_metrics.py VerifyVersionCommand UnityGymException ActionFlattener UnityEnv create_mock_vector_braininfo test_gym_wrapper test_multi_agent test_branched_flatten setup_mock_unityenvironment test_gym_wrapper_visual create_mock_brainparams VerifyVersionCommand set_warnings_enabled BarracudaWriter fuse print_known_operations compress Build sort lstm write fuse_batchnorm_weights trim mean gru Model summary Struct parse_args to_json rnn BufferException Buffer Curriculum make_demo_buffer load_demonstration demo_to_buffer CurriculumError MetaCurriculumError TrainerError CurriculumLoadingError CurriculumConfigError create_environment_factory CommandLineOptions create_sampler_manager parse_command_line run_training prepare_for_docker_run try_create_meta_curriculum main get_version_string MetaCurriculum EncoderType LearningModel LearningRateSchedule AllRewardsOutput RLTrainer get_layer_shape pool_to_HW flatten sqr_diff process_layer process_model get_layer_rank slow_but_stable_topological_sort get_attr basic_lstm ModelBuilderContext order_by get_epsilon get_tensor_dtype replace_strings_in_list debug embody by_op get_tensor_dims strided_slice remove_duplicates_from_list axis_to_barracuda by_name locate_actual_output_node convert strides_to_HW get_tensor_data very_slow_but_stable_topological_sort gru TFPolicy UnityPolicyException UnityTrainerException Trainer TrainerController TrainerMetrics TrainerFactory initialize_trainer load_config _load_config BehavioralCloningModel OfflineBCTrainer BCPolicy BCTrainer BCModel BCModule create_reward_signal RewardSignal CuriosityModel CuriosityRewardSignal ExtrinsicRewardSignal GAILModel GAILRewardSignal PPOModel get_devices MultiGpuPPOPolicy PPOPolicy PPOTrainer get_gae discount_rewards SACPolicyNetwork SACTargetNetwork SACNetwork SACModel SACPolicy SACTrainer create_mock_pushblock_brain create_buffer simulate_rollout create_mock_3dball_brain make_brain_parameters create_mock_banana_brain setup_mock_unityenvironment create_mock_braininfo create_mock_brainparams setup_mock_env_and_brains test_barracuda_converter test_bc_export bc_dummy_config test_bc_trainer_step test_bc_trainer_add_proc_experiences test_cc_bc_model test_dc_bc_model test_visual_cc_bc_model test_bc_trainer_end_episode test_bc_policy_evaluate dummy_config test_visual_dc_bc_model create_bc_trainer sac_dummy_config test_bcmodule_rnn_update test_bcmodule_update ppo_dummy_config test_bcmodule_constant_lr_update create_policy_with_bc_mock test_bcmodule_dc_visual_update test_bcmodule_defaults test_bcmodule_rnn_dc_update test_buffer_sample construct_fake_buffer assert_array fakerandint test_buffer test_buffer_truncate test_curriculum_load_invalid_json location default_reset_parameters test_init_curriculum_bad_curriculum_raises_error test_curriculum_load_missing_file test_init_curriculum_happy_path test_increment_lesson test_curriculum_load_good test_get_config test_load_demo test_load_demo_dir basic_options test_docker_target_path test_run_training test_env_args test_commandline_args test_init_meta_curriculum_happy_path test_increment_lessons_with_reward_buff_sizes default_reset_parameters MetaCurriculumTest test_increment_lessons measure_vals reward_buff_sizes test_set_all_curriculums_to_lesson_num test_get_config test_set_lesson_nums test_init_meta_curriculum_bad_curriculum_folder_raises_error more_reset_parameters test_create_model dummy_config test_average_gradients test_update basic_mock_brain test_take_action_returns_action_info_when_available basic_params test_take_action_returns_nones_on_missing_values test_take_action_returns_empty_with_no_agents test_trainer_increment_step test_trainer_update_policy test_rl_functions test_ppo_model_dc_vector_rnn test_ppo_model_cc_vector_rnn test_add_rewards_output test_ppo_policy_evaluate test_ppo_model_cc_visual dummy_config test_ppo_model_dc_vector test_ppo_model_dc_visual test_ppo_get_value_estimates test_ppo_model_cc_vector test_gail_dc_visual sac_dummy_config reward_signal_update reward_signal_eval test_extrinsic test_curiosity_cc test_gail_rnn test_gail_cc ppo_dummy_config create_policy_mock test_curiosity_dc curiosity_dummy_config test_curiosity_visual test_curiosity_rnn gail_dummy_config create_mock_all_brain_info create_rl_trainer test_clear_update_buffer dummy_config test_rl_trainer create_mock_brain create_mock_policy test_sac_update_reward_signals create_sac_policy_mock test_sac_model_dc_visual test_sac_cc_policy test_sac_visual_policy test_sac_model_cc_vector_rnn test_sac_model_dc_vector test_sac_model_cc_vector dummy_config test_sac_model_dc_vector_rnn test_sac_model_cc_visual test_sac_rnn_policy test_sac_save_load_buffer test_sac_dc_policy test_simple_sac clamp test_simple_ppo Simple1DEnvironment _check_environment_trains test_initialization_seed test_take_step_if_not_training test_start_learning_trains_until_max_steps_then_saves basic_trainer_controller test_take_step_adds_experiences_to_trainer_and_trains dummy_config trainer_controller_with_take_step_mocks trainer_controller_with_start_learning_mocks test_start_learning_trains_forever_if_no_train_model TestTrainerMetrics test_initialize_ppo_trainer dummy_offline_bc_config_with_override test_load_config_invalid_yaml dummy_offline_bc_config test_initialize_invalid_trainer_raises_exception dummy_bad_config dummy_config test_load_config_missing_file test_load_config_valid_yaml test_initialize_trainer_parameters_override_defaults VerifyVersionCommand ActionInfo BaseUnityEnvironment safe_concat_lists safe_concat_np_ndarray CameraResolution BrainParameters BrainInfo Communicator UnityEnvironment EnvManager EnvironmentStep SamplerException UnityWorkerInUseException UnityException UnityCommunicationException UnityTimeOutException UnityEnvironmentException UnityActionException MockCommunicator Policy RpcCommunicator UnityToExternalServicerImplementation MultiRangeUniformSampler UniformSampler SamplerFactory SamplerManager GaussianSampler Sampler SimpleEnvManager worker EnvironmentResponse UnityEnvWorker StepResponse SubprocessEnvManager EnvironmentCommand TimerNode hierarchical_timer get_timer_root get_timer_tree reset_timers set_gauge timed GaugeNode TimerStack UnityToExternalProtoServicer add_UnityToExternalProtoServicer_to_server UnityToExternalProtoStub test_from_agent_proto_nan test_from_agent_proto_inf _make_agent_info_proto test_from_agent_proto_fast_path test_initialization test_reset test_returncode_to_signal_name test_close test_step test_handles_bad_filename test_rpc_communicator_checks_port_on_create test_rpc_communicator_create_multiple_workers test_rpc_communicator_close test_empty_samplers sampler_config_1 check_value_in_intervals incorrect_uniform_sampler test_incorrect_sampler test_sampler_config_1 sampler_config_2 incorrect_sampler_config test_incorrect_uniform_sampler test_sampler_config_2 mock_env_factory SubprocessEnvManagerTest MockEnvWorker test_timers decorated_func Struct fuse print_known_operations compress lstm fuse_batchnorm_weights Model parse_args BarracudaWriter Build mean rnn simplify_names sort write trim summary to_json gru setup_constants get_epsilon replace_strings_in_list nested_model embody extract_strings process_model convert input_layer flatten ModelBuilderContext get_input_layer_shape flatten process_layer process_model data_to_HWKC shape_to_NHWC is_depthwise_convolution shape_to_HW data_to_HWCK get_attr ModelBuilderContext border_to_inverse_padding shape_to_HWCK get_epsilon replace_strings_in_list embody shape_to_HWKC axis_to_NHWC data_to_HW adapt_input_shape convert bias get_tensor_data get_layer_shape pool_to_HW flatten sqr_diff process_layer process_model get_layer_rank slow_but_stable_topological_sort get_attr basic_lstm ModelBuilderContext order_by get_epsilon get_tensor_dtype replace_strings_in_list debug embody by_op get_tensor_dims strided_slice remove_duplicates_from_list axis_to_barracuda by_name locate_actual_output_node convert strides_to_HW get_tensor_data very_slow_but_stable_topological_sort gru main set_version extract_version_string check_versions create_mock_vector_braininfo sample UnityEnv setup_mock_unityenvironment step create_mock_brainparams create_mock_vector_braininfo UnityEnv setup_mock_unityenvironment step create_mock_brainparams setup_mock_unityenvironment create_mock_vector_braininfo create_mock_brainparams UnityEnv create_mock_vector_braininfo sample UnityEnv setup_mock_unityenvironment step create_mock_brainparams Mock list Mock array range set_verbosity join isdir print replaceFilenameExtension add_argument exit verbose source_file ArgumentParser target_file sqrt topologicalSort list hasattr layers addEdge Graph print inputs set len list hasattr layers print filter match trim_model compile data layers print tensors float16 replace layers dumps data dtype layers isinstance print name tensors inputs outputs shape zip array_without_brackets to_json globals Build array_equal pool reduce Build tanh mad tanh mul Build concat add sigmoid sub mad _ tanh mul Build concat add sigmoid mad print sorted keys Buffer reset_local_buffers from_agent_proto number_visual_observations append_update_buffer array append vector_actions range enumerate make_demo_buffer load_demonstration join read AgentInfoActionPairProto suffix isdir endswith BrainParametersProto agent_info DemonstrationMetaProto ParseFromString isfile append from_proto listdir _DecodeVarint32 parse_args add_argument ArgumentParser start_learning fast_simulation create_sampler_manager sampler_file_path put reset_parameters lesson load_config keep_checkpoints str docker_target_name load_model multi_gpu TrainerController save_freq trainer_config_path run_id num_envs format create_environment_factory no_graphics try_create_meta_curriculum TrainerFactory curriculum_folder base_port env_args SubprocessEnvManager train_model env_path pop SamplerManager load_config set_all_curriculums_to_lesson_num MetaCurriculum reset_parameters chmod format basename isdir glob copyfile copytree prepare_for_docker_run replace getLogger set_warnings_enabled setLevel seed Process append range parse_command_line debug run_training start Queue info get_version_string join print cpu randint num_runs endswith len print HasField hasattr get_attr isinstance get_attr tensor_shape ndarray isinstance shape int_val bool_val float_val ListFields name ndarray isinstance str tensor_content ndarray product isinstance get_tensor_dtype print get_tensor_dims unpack int_val bool_val array float_val enter append add set Build mul sub insert Build tolist append range len locate_actual_output_node name find_tensor_by_name split locate_actual_output_node name lstm find_tensor_by_name find_forget_bias split get_layer_shape id Struct tensor get_layer_rank layer_ranks hasattr name patch_data rank input_shapes out_shapes input get_attr append replace_strings_in_list tensors embody astype op inputs zip enumerate print float32 patch_data_fn model_tensors map_ignored_layer_to_its_input co_argcount len items list hasattr get_tensors name print process_layer eval slow_but_stable_topological_sort ModelBuilderContext sort assign_ids pop range insert len layers verbose Struct process_model open print_known_operations fuse compress node GraphDef Model dims_to_barracuda_shape insert get_tensor_dims inputs MessageToJson ParseFromString cleanup_layers read memories print sort write trim summary print_supported_ops update format SACTrainer OfflineBCTrainer PPOTrainer copy brain_name get check_config rcls list_local_devices list zeros_like size reversed range append discount_rewards CameraResolution Mock list ones array range brain_name pop create_buffer brain sequence_length append range vector_action_space_size Buffer ones number_visual_observations append_update_buffer shape append zeros sum range enumerate len setup_mock_unityenvironment mock_env create_mock_braininfo create_mock_brainparams create_mock_brainparams create_mock_brainparams create_mock_brainparams join remove _get_candidate_names convert _get_default_tempdir dirname abspath isfile next create_bc_trainer export_model create_mock_pushblock_brain Mock BCTrainer simulate_rollout mock_env dirname abspath setup_mock_unityenvironment policy create_mock_braininfo create_mock_3dball_brain update_policy create_bc_trainer increment_step agents process_experiences step create_bc_trainer add_experiences end_episode agents process_experiences step create_bc_trainer add_experiences BCPolicy evaluate close reset MockCommunicator reset_default_graph UnityEnvironment reset_default_graph reset_default_graph reset_default_graph reset_default_graph mock_env dirname abspath setup_mock_unityenvironment create_mock_braininfo create_policy_with_bc_mock close ppo_dummy_config create_mock_3dball_brain update items list close create_policy_with_bc_mock create_mock_3dball_brain update items list create_policy_with_bc_mock current_lr create_mock_3dball_brain update items list close create_policy_with_bc_mock create_mock_3dball_brain update items list close create_mock_banana_brain create_policy_with_bc_mock update items list close create_mock_banana_brain create_policy_with_bc_mock flatten list range len append range Buffer get_batch construct_fake_buffer assert_array append_update_buffer make_mini_batch reset_agent array sample_mini_batch construct_fake_buffer append_update_buffer construct_fake_buffer truncate_update_buffer append_update_buffer Curriculum Curriculum Curriculum dumps StringIO StringIO load_demonstration demo_to_buffer dirname abspath load_demonstration demo_to_buffer dirname abspath MagicMock basic_options MagicMock parse_command_line parse_command_line MetaCurriculum assert_has_calls MetaCurriculumTest increment_lessons assert_called_with MetaCurriculumTest increment_lessons assert_called_with assert_not_called MetaCurriculumTest set_all_curriculums_to_lesson_num MetaCurriculumTest dict update MetaCurriculumTest reset_default_graph MultiGpuPPOPolicy create_mock_brainparams reset_default_graph create_mock_brainparams update Mock reset_default_graph MultiGpuPPOPolicy create_mock_brainparams MagicMock TFPolicy basic_mock_brain basic_params BrainInfo get_action MagicMock TFPolicy basic_mock_brain basic_params BrainInfo get_action MagicMock TFPolicy basic_mock_brain ActionInfo basic_params BrainInfo get_action evaluate close reset MockCommunicator PPOPolicy reset_default_graph UnityEnvironment get_value_estimates items list close reset MockCommunicator PPOPolicy reset_default_graph UnityEnvironment reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph assert_array_almost_equal array discount_rewards Mock increment_step BrainParameters assert_called_with PPOTrainer simulate_rollout update_policy policy PPOTrainer setup_mock_env_and_brains AllRewardsOutput BrainParameters PPOTrainer add_rewards_outputs update SACPolicy PPOPolicy setup_mock_env_and_brains ones reset evaluate model simulate_rollout _execute_model prepare_update update_dict make_mini_batch create_policy_mock reward_signal_update reward_signal_eval reward_signal_update reward_signal_eval create_policy_mock dirname abspath create_policy_mock reward_signal_update reward_signal_eval create_policy_mock reward_signal_update reward_signal_eval create_policy_mock reward_signal_update reward_signal_eval create_policy_mock reward_signal_update reward_signal_eval create_policy_mock reward_signal_update reward_signal_eval create_policy_mock reward_signal_update reward_signal_eval create_mock_brainparams RLTrainer dummy_config create_mock_brain zeros Mock list create_rl_trainer values end_episode construct_curr_info episode_steps create_mock_braininfo create_mock_policy add_experiences items list construct_fake_buffer create_rl_trainer clear_update_buffer append_update_buffer SACPolicy setup_mock_env_and_brains update evaluate create_sac_policy_mock simulate_rollout close update_buffer reset reset_default_graph create_sac_policy_mock simulate_rollout close update_reward_signals reset_default_graph update evaluate create_sac_policy_mock simulate_rollout close update_buffer reset reset_default_graph update evaluate create_sac_policy_mock simulate_rollout update_buffer reset reset_default_graph update evaluate create_sac_policy_mock simulate_rollout close update_buffer reset reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph reset_default_graph str Mock SACTrainer save_model simulate_rollout len dummy_config policy setup_mock_env_and_brains Simple1DEnvironment _check_environment_trains Simple1DEnvironment _check_environment_trains TrainerController assert_called_with MagicMock basic_trainer_controller start_learning assert_called_once MagicMock assert_not_called trainer_controller_with_start_learning_mocks trainer_controller_with_start_learning_mocks start_learning MagicMock assert_called_once MagicMock basic_trainer_controller assert_called_once MagicMock EnvironmentStep advance outputs assert_not_called trainer_controller_with_take_step_mocks assert_called_once_with assert_called_once MagicMock EnvironmentStep advance outputs assert_not_called trainer_controller_with_take_step_mocks assert_called_once_with dummy_offline_bc_config dummy_offline_bc_config_with_override BrainParametersMock dummy_config BrainParametersMock dummy_bad_config _load_config StringIO extend copy items list value EnvironmentResponse external_brains payload get_timer_root reset_timers put reset _send_response reset_parameters StepResponse step action perf_counter push reset method_handlers_generic_handler add_generic_rpc_handlers ObservationProto AgentInfoProto assert_called from_agent_proto _make_agent_info_proto assert_not_called assert_called from_agent_proto _make_agent_info_proto assert_not_called from_agent_proto _make_agent_info_proto UnityEnvironment close MockCommunicator UnityEnvironment close MockCommunicator reset str local_done print agents step close MockCommunicator UnityEnvironment len UnityEnvironment close MockCommunicator close RpcCommunicator close RpcCommunicator close RpcCommunicator SamplerManager sample_all sampler_config_1 sampler_config_2 SamplerManager SamplerManager sample_all incorrect_uniform_sampler incorrect_sampler_config set_gauge Struct get_tensor_shape_lambda insert layers isinstance name tensors inputs strip_tensforlow_postfix get list replace_strings_in_list extract_strings flatten process_model get_input_layer_shape get id verbose Struct values patch_data shape out_shapes append defaults get replace_strings_in_list embody astype visititems enumerate isinstance in_args float32 patch_data_fn co_argcount get_input_layer_shape decode tensors File pprint loads attribute ones get_attr hasattr expand_dims expand_dims int int32_data int64_data dims raw_data float_data node list tolist patch_shapes op_type patch_attrs axis_to_NHWC items load setup_constants group replace endswith add set walk join print extract_version_string set values print join | <img src="docs/images/unity-wide.png" align="middle" width="3000"/> <img src="docs/images/image-banner.png" align="middle" width="3000"/> # Unity ML-Agents Toolkit (Beta) [](docs/Readme.md) [](LICENSE) **The Unity Machine Learning Agents Toolkit** (ML-Agents) is an open-source Unity plugin that enables games and simulations to serve as environments for training intelligent agents. Agents can be trained using reinforcement learning, imitation learning, neuroevolution, or other machine learning methods through a simple-to-use Python API. We also provide implementations (based on TensorFlow) | 2,752 |
leibinghe/GAAL-based-outlier-detection | ['outlier detection', 'active learning'] | ['Generative Adversarial Active Learning for Unsupervised Outlier Detection'] | MO-GAAL.py SO-GAAL.py create_generator create_discriminator plot load_data parse_args create_generator create_discriminator plot load_data parse_args add_argument ArgumentParser Sequential add Dense gen Input dis Sequential add sqrt Dense ceil Input pop format reset_index read_table as_matrix values show subplots linspace range len | # Generative Adversarial Active Learning for Unsupervised Outlier Detection
Two GAAL-based outlier detection models: Single-Objective Generative Adversarial Active Learning (SO-GAAL) and Multiple-Objective Generative Adversarial Active Learning (MO-GAAL).
SO-GAAL directly generates informative potential outliers to assist the classifier in describing a boundary that can separate outliers from normal data effectively. Moreover, to prevent the generator from falling into the mode collapsing problem, the network structure of SO-GAAL is expanded from a single generator (SO-GAAL) to multiple generators with different objectives (MO-GAAL) to generate a reasonable reference distribution for the whole dataset.
This is our official implementation for the paper:
Liu Y , Li Z , Zhou C , et al. "Generative Adversarial Active Learning for Unsupervised Outlier Detection", arXiv:1809.10816, 2018.
(Corresponding Author: [Dr. Xiangnan He](http://www.comp.nus.edu.sg/~xiangnan/))
| 2,753 |
leichen2018/Ring-GNN | ['graph regression'] | ['On the equivalence between graph isomorphism testing and function approximation with GNNs'] | src/gindt.py src/train.py src/model.py src/utils.py src/average_fold.py GINDataset equi_2_to_2 input_single ops_2_to_2 MLP Ring_GNN convert_to_graph test diag_offdiag_maxpool main extract_deg_adj pass_data_iteratively test Unbuffered separate_data main train extract_archive get_download_dir _get_dgl_url output_csv check_sha1 average_csv download unsqueeze abs max diag_embed transpose div repeat diagonal float sum load join print convert_to_graph unsqueeze to_dense randint extract_deg_adj open append from_scipy_sparse_matrix DGLGraph model ones Size print Ring_GNN input_single Ring_GNN print model StratifiedKFold split append zeros len permutation batch_size model zero_grad set_description unsqueeze list step iters_per_epoch to range concatenate criterion backward print tqdm numpy len arange detach eval unsqueeze append range len float pass_data_iteratively eval item append to test_batch_size len output_csv ArgumentParser device dataset seed str StepLR fold_idx output_file separate_data parse_args to GINDataset range manual_seed_all n_layers test manual_seed is_available n_epochs output_folder add_argument parameters train step get get join isdir print warn dirname abspath expanduser makedirs sha1 format endswith print extractall close ZipFile exists open get join expanduser makedirs genfromtxt argmax print mean shape startswith append expand_dims listdir max | # Ring-GNN Source code for `On the equivalence between graph isomorphism testing and function approximation with GNNs` accepted by NeurIPS 2019. Authors: [Zhengdao Chen](https://cims.nyu.edu/~chenzh/), [Soledad Villar](https://cims.nyu.edu/~villar/), [Lei Chen](https://leichen2018.github.io), [Joan Bruna](https://cims.nyu.edu/~bruna/). ## Environment PyTorch, DGL ## Directory Initialization ``` mkdir results ``` ## Running Scripts | 2,754 |
leileigan/SAN-CWS | ['chinese word segmentation'] | ['Investigating Self-Attention Network for Chinese Word Segmentation'] | model/optim.py model/transformer.py utils/data.py utils/__init__.py model/crf.py model/cnn.py utils/metric.py model/cws.py model/word_attention.py model/__init__.py utils/functions.py main.py utils/alphabet.py model/sequence.py load_model_decode predict_check evaluate load_data_setting data_initialization lr_decay recover_label save_data_setting train batchify_with_label CNNModel log_sum_exp CRF CWS ScheduledOptim Seq FNNLayer positional_embedding LayerNormalization MultiHeadAttention EncoderBlock get_attn_padding_mask ScaledDotProductAttention ResidualConnection TransformerEncoder LongTensor randn Tensor Attention zeros Alphabet Data load_external_pos read_instance build_pretrain_embedding normalize_word load_pos_to_idx norm2one load_token_pos_prob load_tencent_dic read_seg_instance load_pretrain_emb get_ner_BIO fmeasure_from_singlefile readTwoLabelSentence readSentence fmeasure_from_file reverse_style get_ner_BMES get_ner_fmeasure print biword_alphabet_size word_alphabet_size fix_alphabet build_alphabet sum numpy append size numpy range print deepcopy print show_data_summary print param_groups raw_Ids train_texts time get_ner_fmeasure print train dev_texts raw_texts HP_gpu eval test_Ids train_Ids test_texts batchify_with_label range dev_Ids len max byte LongTensor sort tolist cuda zip Tensor long enumerate len use_sgd HP_clip clip_grad_norm_ zero_grad SGD save str generate_instance predict_check Adam lr_decay ScheduledOptim train_Ids use_warmup_adam range state_dict HP_lr HP_iteration use_bert shuffle HP_gpu use_adadelta neg_log_likelihood_loss batchify_with_label HP_lr_decay flush time collect Adadelta HP_batch_size print backward evaluate step_and_update_lr step use_adam len load time evaluate print load_state_dict CWS max view list size is_cuda expand mul_ float cuda log cat size expand isdigit print load keys set print len open split print lower open split print float open split print readlines len normalize_word append get_index range split readlines len normalize_word lower append get_index range split items print len dict sqrt uniform norm2one empty load_pretrain_emb sqrt sum square dict get_ner_BIO list print set intersection get_ner_BMES range len index len str replace upper reverse_style append range len str replace upper reverse_style append range len append readlines split append readlines split print readSentence get_ner_fmeasure print readTwoLabelSentence get_ner_fmeasure | Investigate self-attention network for Chinese Word Segmentation ==== Investigate self-attention network for Chinese Word Segmentation. Models and results can be found at our paper [Investigate self-attention network for Chinese Word Segmentation](https://arxiv.org/abs/1907.11512). Requirement: ====== Python: 3.6.2 PyTorch: 1.0.1 Input format: | 2,755 |
lemire/PiecewiseLinearTimeSeriesApproximation | ['time series'] | ['A Better Alternative to Piecewise Linear Time Series Segmentation'] | cppandpython/segmentationplot.py cppandpython/fastpolyfit.py cppandpython/segmentandplot.py cppandpython/tagstofunction.py cppandpython/cppmultidegree.py cppandpython/stockmarketparser.py cppandpython/temperatureparser.py leaveoneout ecgparser fixrange cpp downsample normalizex cppprocess testfastsums segmentationsquaredfiterror computeBuffer __solve testbestfit slowsum slowinterpolate slowbestfit squaredfiterror fastsum bestfit readmoneycentral readyahoofinance tagstofunction intervalfunction readCDIAC abspath open str list len map append readlines close popen2 startswith float flush int time print write findall split print slowinterpolate cppprocess max range len time print plotSegmentation sub cppprocess list close map findall append open range len append range len zeros range len range print __solve zeros fastsum range zeros __solve range slowsum slowbestfit range len print print bestfit range len print squaredfiterror seed computeBuffer range append computeBuffer append float range bestfit int mktime print strptime sort len group close match append float round open int mktime print strptime sort len group close match append float round open int sort group close match append range open | # PiecewiseLinearTimeSeriesApproximation code from Daniel Lemire, A Better Alternative to Piecewise Linear Time Series Segmentation, SIAM Data Mining 2007, 2007. PDF of the paper: https://arxiv.org/abs/cs/0605103 Abstract of the paper: Time series are difficult to monitor, summarize and predict. Segmentation organizes time series into few intervals having uniform characteristics (flatness, linearity, modality, monotonicity and so on). For scalability, we require fast linear time algorithms. The popular piecewise linear model can determine where the data goes up or down and at what rate. Unfortunately, when the data does not follow a linear model, the computation of the local slope creates overfitting. We propose an adaptive time series model where the polynomial degree of each interval vary (constant, linear and so on). Given a number of regressors, the cost of each interval is its polynomial degree: constant intervals cost 1 regressor, linear intervals cost 2 regressors, and so on. Our goal is to minimize the Euclidean (l_2) error for a given model complexity. Experimentally, we investigate the model where intervals can be either constant or linear. Over synthetic random walks, historical stock market prices, and electrocardiograms, the adaptive model provides a more accurate segmentation than the piecewise linear model without increasing the cross-validation error or the running time, while providing a richer vocabulary to applications. Implementation issues, such as numerical stability and real-world performance, are discussed. This code is purely as documentation. | 2,756 |
lemire/lbimproved | ['time series', 'dynamic time warping'] | ['Faster Retrieval with a Two-Pass Dynamic-Time-Warping Lower Bound'] | data/stockmarketparser.py data/flatfileparser.py data/syntheticdata.py readFlat readmoneycentral readyahoofinance append open int mktime print strptime sort len group close match append float round open int mktime print strptime sort len group close match append float round open | # LBImproved C++ Library [](https://travis-ci.org/lemire/lbimproved) This library comes in the form of one short C++ header file. The documentation is in the C++ comments and in this file. # Key feature 1) Fast Dynamic Time Warping nearest neighbor retrieval. 2) Implementations of LB Koegh and LB Improved 3) Companion to the following paper : Daniel Lemire, Faster Retrieval with a Two-Pass Dynamic-Time-Warping Lower Bound, Pattern Recognition 42 (9), pages 2169-2180, 2009. http://arxiv.org/abs/0811.3301 | 2,757 |
leo7r/swiftface | ['face detection'] | ['SwiftFace: Real-Time Face Detection'] | swiftface.py darknet.py network_width detect_image METADATA DETECTION array_to_image performDetect c_array network_height detect performBatchDetect IMAGE sample DETNUMPAIR BOX classify convertBack YOLO cvDrawBoxes uniform sum range len POINTER data_as transpose ascontiguousarray IMAGE flat sorted predict_image classes append range print load_image free_image detect_image free_detections str sorted c_int print do_nms_sort pointer h get_network_boxes w predict_image classes append range bbox show str int print rint load_net_custom shape detect imshow load_meta set_color encode imread polygon_perimeter append len imwrite bbox free_batch_detections resize list basename COLOR_BGR2RGB transpose data_as map shape IMAGE network_predict_batch append encode range flat POINTER do_nms_obj concatenate load_net_custom ascontiguousarray classes dets rectangle load_meta num cvtColor int round convertBack float rectangle network_width copy_image_from_bytes imwrite cvDrawBoxes resize COLOR_BGR2RGB encode imread make_image format detect_image glob load_net_custom tobytes time print network_height load_meta cvtColor | # swiftface Python implementation of the SwiftFace face detection algorithm ``` @inproceedings{10.1145/3471391.3471418, author = {Ramos, Leonardo and Bautista, Susana and Bonett, Marlon C\'{a}rdenas}, title = {SwiftFace: Real-Time Face Detection: SwitFace}, year = {2021}, isbn = {9781450375979}, publisher = {Association for Computing Machinery}, address = {New York, NY, USA}, | 2,758 |
leolle/StyleTransfer | ['style transfer'] | ['Deep Photo Style Transfer', 'Photorealistic Style Transfer via Wavelet Transforms'] | utils/io.py utils/core.py transfer.py model.py WavePool WaveUnpool WaveDecoder get_wav WaveEncoder WCT2 get_all_transfer run_bulk svd feature_wct get_rank get_squeeze_feat wct_core wct_core_segment Timer change_seg open_image mkdir compute_label_info load_segment ones transpose Conv2d expand sqrt unsqueeze ConvTranspose2d net append set content join get_all_transfer print style transfer_at_encoder output add set tqdm load_segment device transfer_at_decoder to listdir transfer_at_skip image_size size clone mean t div expand_as mm size squeeze range svd min mean get_rank pow t clamp_ expand_as get_squeeze_feat mm max diag squeeze transpose clone index_select resize get_index index_copy_ wct_core wct_core view_as wct_core_segment CenterCrop size ToTensor Compose unsqueeze append open sum asarray zeros abs range change_seg CenterCrop size Resize transform open size where unique zeros max makedirs | <img src='./figures/day2sunset.gif' align="right" width=400>
# WCT2
Photorealistic Style Transfer via Wavelet Transforms | [paper](https://arxiv.org/abs/1903.09760) | [supplementary materials](https://github.com/clovaai/WCT2/blob/master/%5Bsupplementary%20materials%5D%20Photorealistic_Style_Transfer_via_Wavelet_Transforms.pdf) | [video stylization results](https://youtu.be/o-AgHt1VA30)
| 2,759 |
leonardoperu/Monetmaker | ['style transfer'] | ['A Neural Algorithm of Artistic Style'] | content_extraction.py logger.py style_extraction.py keras_vgg19_classify.py utils.py style_transfer.py content_loss main update_image_step ContentExtractor print_predictions Logger gram update_image_step StyleExtractor main style_loss main update_image_step total_loss StyleContentExtractor load_img show_feature_maps get_layers_by_name clip_image_0_1 tensor_to_image get_outputs_by_layer_names prepare_img get_intermediate_layers_model add_n assign apply_gradients gradient clip_image_0_1 getopt show list show_feature_maps exit Adam shape uniform imshow range extractor format ContentExtractor vgg int update_image_step load_img print Variable tqdm array print format range len dot shape transpose reshape add_n save StyleExtractor content_loss style_loss assign Logger StyleContentExtractor str close print_loss param_change learning_rate float32 convert_image_dtype read_file cast int32 resize max decode_image VGG19 Model get_outputs_by_layer_names show subplot set_yticks imshow set_xticks range predict reshape img_to_array load_img preprocess_input array | # Monetmaker This application implements the work from the paper "A Neural Algorithm of Artistic Style" (https://arxiv.org/pdf/1508.06576.pdf), by L.A. Gatys, A.S. Ecker, M. Bethge (University of Tübingen, 2015). It is a generative system based on Convolutional Neural Networks that creates new images applying the artistic style of a painting to another picture (e.g. a photo): <img src="https://github.com/leonardoperu/Monetmaker/blob/master/imgs/for_readme/readme1.png" width ="1024" alt="image1"> Here you can find the .py source files, along with two different .ipynb notebooks made with Google Colaboratory: * Style_Transfer_from_content uses the content image as a basis for the generated image * Style_Transfer_from_noise uses a random noise image as a basis for the generated image The notebooks also contain a brief guide with the instructions to run them. | 2,760 |
leonardovlibido/PersonRe-Identification | ['person re identification'] | ['PersonNet: Person Re-identification with Deep Convolutional Neural Networks'] | extract_dataset.py playground.py get_image import_ref prepare_dataset generate_random_train generate_random_val get_classification_model upsample_neighbour fromarray str transpose save resize array range len append range spatial_2d_padding concatenate conv2_tied Model summary Conv2D Input conv1_tied int sorted glob append array open get_state arange rand shuffle set_state empty array range enumerate len get_state arange rand shuffle set_state empty array range enumerate len | # PersonRe-Identification Project in Machine Learning course in college. Dataset used : - CUHK03: http://www.ee.cuhk.edu.hk/~xgwang/CUHK_identification.html Papers used: - PersonNet: Person Re-identification with Deep Convolutional Neural Networks: - https://arxiv.org/pdf/1601.07255.pdf - An Improved Deep Learning Architecture for Person Re-Identification: - https://www.cv-foundation.org/openaccess/content_cvpr_2015/papers/Ahmed_An_Improved_Deep_2015_CVPR_paper.pdf Dataset extraction taken from: | 2,761 |
leule/DCDS | ['person re identification', 'image retrieval'] | ['Deep Constrained Dominant Sets for Person Re-identification'] | reid/loss/oim.py reid/models/__init__.py reid/utils/serialization.py reid/dist_metric.py test/datasets/test_cuhk01.py reid/feature_extraction/database.py reid/datasets/market1501.py reid/feature_extraction/__init__.py reid/__init__.py reid/evaluators.py reid/datasets/dukemtmc.py reid/datasets/viper.py reid/datasets/cuhk03.py test/loss/test_oim.py reid/loss/triplet.py reid/utils/meters.py test/evaluation_metrics/test_cmc.py reid/models/fusion_branch.py reid/loss/__init__.py reid/models/CDS_layer.py reid/models/embedding.py reid/feature_extraction/cnn.py reid/utils/data/sampler.py reid/utils/data/__init__.py reid/datasets/cuhk01.py reid/utils/data/transforms.py metric_learning/euclidean.py reid/trainers.py reid/utils/data/preprocessor.py reid/utils/osutils.py examples/main.py test/models/test_inception.py reid/utils/__init__.py test/datasets/test_cuhk03.py test/datasets/test_viper.py reid/models/inception.py metric_learning/__init__.py metric_learning/kissme.py reid/models/resnet.py test/utils/data/test_preprocessor.py reid/utils/data/dataset.py test/datasets/test_dukemtmc.py test/feature_extraction/test_database.py setup.py test/datasets/test_market1501.py reid/datasets/__init__.py reid/utils/logging.py get_data main Euclidean KISSME validate_cov_matrix get_metric DistanceMetric extract_embeddings evaluate_all CascadeEvaluator pairwise_distance Evaluator compute_CDS Replicator extract_features Trainer DCDSBase BaseTrainer CUHK01 CUHK03 DukeMTMC Market1501 VIPeR names create get_dataset extract_cnn_feature FeatureDatabase OIM oim OIMLoss TripletLoss CDS CDS_Layer VNetEmbed VNetExtension Replicator Dist_Comp _make_conv inception Block InceptionNet ResNet resnet50 resnet152 resnet34 resnet18 resnet101 names create Logger AverageMeter mkdir_if_missing load_checkpoint copy_state_dict read_json save_checkpoint write_json to_numpy to_torch Dataset _pluck Preprocessor KeyValuePreprocessor RandomIdentitySampler RandomMultipleGallerySampler No_index RandomSizedEarser RectScale RandomSizedRectCrop TestCUHK01 TestCUHK03 TestDukeMTMC TestMarket1501 TestVIPeR TestCMC TestFeatureDatabase TestOIMLoss TestInception TestPreprocessor join create val list gallery Compose set query DataLoader Preprocessor Normalize workers batch_size VNetExtension get_data query evaluate_from save_checkpoint Logger arch dataset cuda max seed create CascadeEvaluator data_dir copy_state_dict logs_dir Adam grp_num DCDSBase load_state_dict width range val height format combine_trainval resume retrain manual_seed alpha join gallery evaluate print load_checkpoint DistanceMetric num_instances adjust_lr train epochs split T cholesky eye data max cuda view ones Replicator append range cat size eig mean nonzero float Variable clone argsort eye cpu numpy diag len int norm FloatTensor ones size contiguous argsort div numpy expand_as cpu float type update val time format Variable print AverageMeter eval compute_CDS avg cuda range cat len update extract_cnn_feature time format val print AverageMeter OrderedDict eval avg zip enumerate len list view mm expand t cat transform sum addmm_ values len print format mean_ap warn to_torch remove model Variable register_forward_hook OrderedDict eval cpu cuda append max view Variable ones size contiguous min clone eig nonzero eye Replicator float range cuda diag detach BatchNorm2d ReLU Conv2d makedirs dirname mkdir_if_missing join copy dirname save mkdir_if_missing load format print isfile data items list replace isinstance print size set copy_ add keys state_dict is_tensor list map split append enumerate | ## Deep Constrained Dominant Sets for Person Re-Identification [(DCDS)](http://openaccess.thecvf.com/content_ICCV_2019/papers/Alemu_Deep_Constrained_Dominant_Sets_for_Person_Re-Identification_ICCV_2019_paper.pdf) Pytorch Implementation for our **ICCV2019** work, Deep Constrained Dominant Sets for Person Re-Identification. This implementation is based on [open-reid](https://github.com/Cysu/open-reid) and [kpm_rw_person_reid.](https://github.com/YantaoShen/kpm_rw_person_reid) ### Requirements * [python 2.7](https://www.python.org/download/releases/2.7/) * [PyTorch](https://pytorch.org/previous-versions/) (we run the code under version 0.3.0) * [metric-learn 0.3.0](https://pypi.org/project/metric-learn/0.3.0/) * [torchvision 0.2.1](https://pypi.org/project/torchvision/0.2.1/) ```shell - cd DCDS | 2,762 |
levelfour/pumil | ['text categorization', 'content based image retrieval', 'image retrieval', 'multiple instance learning'] | ['Convex Formulation of Multiple Instance Learning from Positive and Unlabeled Bags'] | MI/datasets/synth.py MI/PU/__init__.py MI/UU/DSDD.py MI/datasets/__init__.py pumil.py MI/PU/loss.py MI/UU/LSDD.py lsdd.py MI/__init__.py MI/kernel.py dsdd.py MI/datasets/trec9.py MI/PU/SKC.py MI/UU/__init__.py generate_dataset.py puskc.py MI/gurobi_helper/helper.py train_lsdd generate train_lsdd weighted_kde pumil_clf_wrapper affinity reliable_negative_bag_idx form_pmp pumil train_pumil_clf train_pu_skc minimax_basis nsk_basis print_evaluation_result score accuracy k_fold_cv Bag precision extract_bags cross_validation f_score recall synthesize dump_trec9 load_trec9 augment diminish load_dataset dot mvmul quadform prediction_error c_risk ramp_loss nc_risk zero_one_loss ZeroOne dh_loss train_dh train train_sl class_prior _prepare prepare _class_prior r train r train validation_error LSDD train augment load_trec9 dump_trec9 format inf validation_error product print LSDD mean verbose vstack extract_bags cross_validation append list sorted zip vstack list array set T weighted_kde LinearSVC pumil_clf_wrapper reliable_negative_bag_idx form_pmp fit T ones affinity uniform zeros argmax range train_pumil_clf prediction_error format inf product print mean verbose cross_validation append train extract_bags int extract_bags list array len int range len int range len flush format write accuracy buffer precision savetxt f_score recall array roc_auc_score minimum tolist shuffle mask Bag binomial range clip append list synthesize prepare set diminish load_trec9 len add_noise deepcopy list int shuffle choice append range len pca_reduction PCA vstack fit extract_bags nc_risk len ones dot extract_bags float array len qp quadform setParam tolist QP solve Model append update format extract_bags xf matrix enumerate optimize addConstr setObjective dot eye simplefilter array len extract_bags shuffle len binomial shuffle mask minimax_basis list inv extract_bags eye sum len exp qp extract_bags vstack matrix range len exp solve pi mean vstack eye LSDD exp pi mean extract_bags vstack | # Risk Minimization Framework for Multiple Instance Learning from Positive and Unlabeled Bags ## Environment Python 3.4.5 with the following modules: + numpy + scipy + scikit-learn + chainer + gurobipy If you do not have Gurobi license, you can substitue `cvxopt` or `openopt` for it by rewriting ```python | 2,763 |
levimcclenny/multimodal_transfer_learned_regression | ['multi target regression'] | ['Deep Multimodal Transfer-Learned Regression in Data-Poor Domains'] | utils.py train.py versiontest.py model.py CNN_model MLP_model build_model DMTLR get_data get_type_input plot_preds Dropout Dense Sequential add VGG16 layers print InceptionV3 Sequential output add Model ResNet50 Dense summary input Dropout Model CNN_model MLP_model concatenate print lower exit astype print load open yscale subplot show plot xlabel ylabel tight_layout ylim scatter figure linspace xlim range | ## DMTL-R - Official Implementation ### Deep Multimodal Transfer-Learned Regression in Data-Poor Domains #### Levi McClenny<sup>1, 2</sup>, Mulugeta Haile<sup>2</sup>, Vahid Attari<sup>3</sup>, Brian Sadler<sup>2</sup>, Ulisses Braga-Neto<sup>1</sup>, Raymundo Arroyave<sup>3</sup> Paper: https://arxiv.org/abs/2006.09310 Abstract: *In many real-world applications of deep learning, estimation of a target may rely on various types of input data modes, such as audio-video, image-text, etc. This task can be further complicated by a lack of sufficient data. Here we propose a Deep Multimodal Transfer-Learned Regressor (DMTL-R) for multimodal learning of image and feature data in a deep regression architecture effective at predicting target parameters in data-poor domains. Our model is capable of fine-tuning a given set of pre-trained CNN weights on a small amount of training image data, while simultaneously conditioning on feature information from a complimentary data mode during network training, yielding more accurate single-target or multi-target regression than can be achieved using the images or the features alone. We present results using phase-field simulation microstructure images with an accompanying set of physical features, using pre-trained weights from various well-known CNN architectures, which demonstrate the efficacy of the proposed multimodal approach.* <sub><sub><sup>1</sup>Texas A&M Dept. of Electrical Engineering, College Station, TX</sub></sub><br> <sub><sub><sup>2</sup>US Army CCDC Army Research Lab, Aberdeen Proving Ground/Adelphi, MD</sub></sub><br> <sub><sub><sup>3</sup>Texas A&M Dept. of Materials Science, College Station, TX</sub></sub> ### Estimator Architecture <center> | 2,764 |
levon003/cscw-caringbridge-interaction-network | ['medical diagnosis'] | ['Detecting and Correcting for Label Shift with Black Box Predictors'] | dyad_growth/pbs/userrecip.py visualization/qsub-scripts/inflect.py visualization/qsub-scripts/inter.py visualization/qsub-scripts/aug_cc.py visualization/qsub-scripts/components.py author_type/predict_author_type.py data_selection/send_email.py visualization/qsub-scripts/nw_size.py author_type/process_sites_to_vw_format.py dyad_growth/pbs/distributions.py geographic_analysis/lookup_guestbook_geo_data.py geographic_analysis/lookup_journal_geo_data.py visualization/qsub-scripts/sentiment.py data_selection/HTMLCollector.py visualization/qsub-scripts/long_comp.py data_pulling/qsub-scripts/dynamic_auth.py author_initiations/mlogitFeatureExtraction.py data_pulling/qsub-scripts/new_jo.py data_pulling/qsub-scripts/dynamic_pairs.py data_pulling/qsub-scripts/dynamic_ints.py visualization/qsub-scripts/revised_components.py author_initiations/geoMlogitFeatureExtraction.py compute_days_since_most_recent_update compute_is_friend_of_friend WccGraph get_most_recent_update are_fof_connected compute_days_since_first_update compute_days_since_most_recent_update compute_is_friend_of_friend WccGraph get_most_recent_update are_fof_connected compute_days_since_first_update strip_tags MLStripper get_cleaned_text get_db process_site_id get_cleaned_text_from_token_list process_site_ids main WriterProcess get_journal_texts WriterProcess main process process_user WriterProcess main process process_user main process WriterProcess process_pair main main main send_email main main main main main main main f main main main main compute_days_since_most_recent_update compute_is_friend_of_friend WccGraph get_most_recent_update are_fof_connected compute_days_since_first_update strip_tags MLStripper get_cleaned_text get_db process_site_id get_cleaned_text_from_token_list process_site_ids main WriterProcess get_journal_texts process process_user process_pair send_email f main bisect_right get_most_recent_update bisect_right join Row connect fetchall int get_db execute append replace strip_tags word_tokenize get_cleaned_text_from_token_list feed MLStripper put get_cleaned_text startswith get_journal_texts print print join process_site_ids makedirs put int maxsize split print process put int maxsize split display items list format join login MIMEMultipart print close ehlo send_message MIMEText SMTP_SSL attach send_email subplots read_hdf logspace DataFrame iterrows set_title set_xlabel log10 savefig append sort_values head set_xscale hist set_ylabel len concat to_hdf copy index to_df drop Reader replace maxsize min apply fillna merge read_csv defaultdict tqdm drop_duplicates range | Patterns of Patient and Caregiver Mutual Support Connections in an Online Health Community --- Repository for analysis code related to a Spring 2019 study investigating interactions between patient and caregiver authors on CaringBridge.org. Originally submitted to CSCW in January 2020, revised June 2020, and conditionally accepted July 2020 for presentation at CSCW 2020 in October 2020. As described in the paper, CaringBridge data used for analysis is not being released publicly for ethical reasons. For any questions or additional information, contact the corresponding author: [email protected] Paper: https://dl.acm.org/doi/abs/10.1145/3434184 Preprint: https://arxiv.org/abs/2007.16172 Author website: https://z.umn.edu/zlevonian ## Code Organization | 2,765 |
lex4all/lex4all | ['speech recognition'] | ['lex4all: A language-independent tool for building and evaluating pronunciation lexicons for small-vocabulary speech recognition'] | test/DummyAppTest.py src/DummyApp.py make_lexicon TestDummyInput TestOtherInput | ## lex4all: pronunciation LEXicons for Any Low-resource Language ### http://lex4all.github.io/lex4all/ #### A project of the Department of Computational Linguistics, Saarland University, Germany ### Creators: Anjana Vakil & Max Paulus ### Advisors: Alexis Palmer & Michaela Regneri ### Contributors: Kayokwa Chibuye (University of Cape Town, South Africa) Developers trying to incorporate speech recognition interfaces in a low-resource language (LRL) into their applications currently face the hurdle of not finding recognition engines trained on their target language. Although tools such as Carnegie Mellon University's Sphinx simplify the creation of new acoustic models for recognition, they require large amounts of training data (audio recordings) in the target language. However, for small-vocabulary applications, an existing recognizer for a high-resource language (HRL) can be used to perform recognition in the target language. This requires a pronunciation lexicon mapping the relevant words in the target language into sequences of sounds in the HRL. [lex4all](https://github.com/lex4all/lex4all) is an easy-to-use desktop application for Windows that will allow even naive users to automatically create a pronunciation lexicon for words in any language, using a small number of audio recordings and a pre-existing recognition engine in a HRL such as English. The resulting lexicon can then be used to add small-vocabulary speech recognition functionality to applications in the LRL. #### How it works A simple user interface allows the user to easily specify one written form (text string) and and one or more audio samples (`.wav` files) for each word in the target vocabulary, and to set other options (e.g. number of pronunciations per word, name/save location of lexicon file, etc.). The audio is then passed to a speech recognition engine for a HRL (English). An automatic pronunciation generation algorithm (the Salaam method, [2–3]) finds the best pronunciation(s) for each word in the LRL vocabulary. The program outputs a pronunciation lexicon (`.pls` XML file). This lexicon file follows the standard pronunciation lexicon format (http://www.w3.org/TR/pronunciation-lexicon/), so it can be directly included in a speech recognition application, e.g. one built using the [Microsoft Speech Platform](http://msdn.microsoft.com/en-us/library/hh361572) API. | 2,766 |
lgazpio/DAM_STS | ['word embeddings'] | ['Uncovering divergent linguistic information in word embeddings with lessons for intrinsic and extrinsic evaluation'] | DAM/models/snli_data.py DAM/models/baseline_ts.py preprocess_datasets/preprocess-STSBenchmark.py DAM/models/sts_data.py DAM/DAM_STSBenchmark_TS.py preprocess_datasets/get_pretrain_vecs.py preprocess_datasets/process-STSBenchmark.py train encoder atten snli_data w2v pearson score2labels sts_data_STSBenchmark labels2score sts_data_SICK main load_glove_vec get_data pad get_glove_words main Indexer main data inter_atten getLogger trigrams input_encoder zero_grad SGD word_vecs copy_ gpu_id save train_file setLevel cuda open seed str pearson FloatTensor addHandler set_device exit Adam RMSprop MSELoss sts_data_STSBenchmark getattr load_state_dict append encoder range max_length state_dict epoch Adagrad format dropout size close shuffle StreamHandler eval manual_seed info vars INFO FileHandler load int time log_dir bigrams embedding_size batches Adadelta Variable criterion log_fname backward write parameters atten test_file step dev_file hidden_size len int size floor zero_ ceil enumerate size view numpy list map split array open seed str normal list items norm print add_argument ArgumentParser glove parse_args load_glove_vec range len open add strip set outputfile batchsize make_vocab srctestfile seed str seqlength len vocabfile get_glove_words glove Indexer range vocab format d labeltestfile targetvalfile shuffle labelfile srcfile targetfile print targettestfile write prune_vocab load_vocab convert srcvalfile labelvalfile get_data join replace write close lower split out_folder data_folder open | # DAM_STS Reimplementation of the Decomposable Attention Model (DAM) for STS If you use this software for academic research please cite the described paper: ``` @inproceedings{artetxe2018conll, author = {Artetxe, Mikel and Labaka, Gorka and Lopez-Gazpio, Inigo and Agirre, Eneko}, title = {Uncovering divergent linguistic information in word embeddings with lessons for intrinsic and extrinsic evaluation}, booktitle = {Proceedings of the 22nd Conference on Computational Natural Language Learning (CoNLL 2018)}, month = {October}, year = {2018}, | 2,767 |
lhannest/neuralstyle | ['style transfer'] | ['A Neural Algorithm of Artistic Style'] | models/vgg19.py models/vgg16.py neuralstyle.py gram_matrix func content_loss deprocess timesince getImage style_loss build_model build_model time print reshape transpose mean shape resize open reshape transpose asarray flatten gram_matrix flatten DropoutLayer ConvLayer DenseLayer PoolLayer NonlinearityLayer InputLayer load set_all_param_values open | # neuralstyle This is an implemenation of the paper *A Neural Algorithm of Artistic Style* by L. Gatsy, A. Ecker, and M. Bethge ([http://arxiv.org/abs/1508.06576](http://arxiv.org/abs/1508.06576)). For this program to work you must [download](https://s3.amazonaws.com/lasagne/recipes/pretrained/imagenet/vgg19.pkl) the weights for the VGG-19 deep net, and place the file in the models directory. Here I've taken the content of this image: <img src="https://raw.githubusercontent.com/lhannest/neuralstyle/master/images/big_photo.jpg" alt="source content image" width="650" height="430"> And I've used the style of this image: <img src="https://raw.githubusercontent.com/lhannest/neuralstyle/master/images/big_art.jpg" alt="source style image" width="650" height="430"> To generate this image: <img src="https://raw.githubusercontent.com/lhannest/neuralstyle/master/images/results/result2.png" alt="generated image" width="650" height="430"> | 2,768 |
lht1949/AnomalyDetection | ['anomaly detection'] | ['Anomaly Detection via Graphical Lasso'] | Rglasso.py Robust_glasso_S_first solve_L solve_theta projectSPD square eigh sqrt matrix diag eigh matrix maximum diag norm threshold solve_theta projectSPD solve_L copy matrix | # AnomalyDetection Anomaly Detection vis Graphical Lasso https://arxiv.org/abs/1811.04277 | 2,769 |
li012589/neuralCT | ['density estimation'] | ['Neural Canonical Transformation with Symplectic Flows'] | utils/layers/__init__.py train/kld.py utils/layers/activations.py utils/unit.py test/test_diagScaling.py utils/flowBuilder.py utils/img_trans.py flow/symplectic.py utils/layers/etc.py utils/layers/reversible/debug.py utils/intMethod/__init__.py thirdparty/mutualInfor.py flow/scaling.py test/test_nice.py utils/layerList.py download_demo.py test/test_symplectic.py utils/intTool.py source/gaussian.py flow/__init__.py utils/matrixGrad.py source/__init__.py utils/mc/hmc.py utils/layers/reversible/WBlayerRev.py utils/slerp.py variation.py utils/intMethod/iteration.py train/learn.py source/multivariateGaussian.py test/test_rnvp.py utils/layers/cnn.py utils/layers/scalarMLP.py utils/layers/reversible/maskRev.py utils/__init__.py utils/mc/metropolis.py source/harmonicChain.py utils/symplecticTools.py utils/layers/reversible/__init__.py flow/rnvp.py density_estimation_md.py utils/roll.py utils/layers/mlp.py utils/layers/reversible/rollRev.py flow/nice.py utils/layers/squeezing.py flow/pointTransformation.py utils/measureMomentum.py utils/saveUtils.py utils/mc/__init__.py test/flowRelated.py test/test_scaling.py train/__init__.py source/ringLike.py test/test_flowNet.py utils/intMethod/stormerVerlet.py utils/layers/scalableTanh.py density_estimation.py utils/mnistProcess.py test/test_pointTransformation.py flow/diagScaling.py thirdparty/__init__.py utils/layers/scalarField.py source/source.py utils/layers/identity.py flow/flowConnector.py utils/dataloader.py utils/dihedralAngle.py flow/flow.py test/__init__.py utils/expm.py innerBuilder innerBuilder innerBuilder DiagScaling Flow FlowNet NICE PointTransformation RNVP Scaling Symplectic Gaussian HarmonicChain adjMatrixHamiltonian MultivariateGaussian Ring2d Ring2dNoMomentum Source saveload bijective symplectic test_bijective test_fix test_saveload test_bijective test_saveload test_bijective test_saveload test_bijective test_symplectic test_saveload test_bijective test_saveload test_bijective test_saveload test_bijective test_symplectic test_saveload kraskov_multi_mi entropy vd revised_mi revised_multi_mi kde_entropy kraskov_mi forwardKLD forwardLearn learn reversedKLD load DataSampler loadmd MDSampler alanineDipeptidePhiPsi dihedralAngle measure expm expmv flowBuilder extractFlow logit logit_back timeEvolve buildSource stormerVerlet inverseThoughList netHessian netLaplacian jacobianDiag jacobian laplacian hessian laplacianHutchinson netJacobian measureM load_MNIST roll createWorkSpace cleanSaving np_slerp slerp assertMTJM J MTJM variance smile2mass iterationMulti _output_test iteration _force stormerVerlet sigmoidPrime tanhPrime2 Tanhprime Tanhprime2 Sigmoidprime tanhPrime lncosh Lncosh SimpleCNN2d CNN tanh_prime2 MLP Simple_MLP sigmoid_prime lncosh tanh_prime Identity SimpleMLPreshape SimpleMLP ScalableTanh ScalarField SimpleScalarMLP Squeezing debugRealNVP MaskRev RollRev Batch2wideRev Wide2bacthRev HMCwithAccept HMCsampler HMC MetroplolisSampler MetropolisWithAccept Metropolis RNVP reshape float32 numel append zeros to range narrow logProbability numpy inverse assert_array_almost_equal sample forward load logProbability numpy inverse save assert_array_almost_equal sample forward requires_grad_ assertMTJM jacobian exp Gaussian inverse item assert_array_almost_equal tensor assert_almost_equal numpy DiagScaling Gaussian bijective DiagScaling Gaussian saveload DiagScaling NICE to reshape float32 numel FlowNet append zeros Scaling range narrow NICE to reshape float32 numel FlowNet append zeros Scaling range narrow PointTransformation RNVP PointTransformation RNVP PointTransformation RNVP reshape symplectic float32 numel Gaussian append zeros to range narrow Symplectic Symplectic Symplectic concatenate cKDTree digamma range log len vd concatenate cKDTree range log len concatenate cKDTree digamma range log len vd concatenate cKDTree range log len vd cKDTree digamma log len evaluate gaussian_kde transpose zeros range len Vsize cleanSaving zero_grad ReduceLROnPlateau save str list name Adam Tsize append sum forwardKLD range item int backward print parameters step mean sampleVaildation std sample str list StepLR backward print name step zero_grad Adam cleanSaving parameters save item append sum range reversedKLD sample mean logProbability std reshape concatenate shape float logit rand cross reshape dihedralAngle measure to matmul measure matmul innerBuilder Symplectic PointTransformation float64 append to range DiagScaling deepcopy flow append prior DiagScaling sigmoid _stormerVerlet split stormerVerlet inverse reversed new_zeros reshape to range shape reshape to range scalarFnGrad to sum device print check_call unpack append zeros enumerate shape narrow cat enumerate check_call check_call norm arccos dot sin clip norm clamp dot sin acos repeat cat to to numpy assert_array_almost_equal append isalpha requires_grad_ range fn detach _output_test len fn append range detach enumerate _iteration Hq _force requires_grad_ unsqueeze append range cat tanh sigmoid tanh sigmoid reshape set_grad_enabled grad energy requires_grad_ normal_ to sum range detach HMCwithAccept reshape set_grad_enabled tranCore energy to range MetropolisWithAccept | li012589/neuralCT | 2,770 |
li10141110/PSENet-tf2 | ['optical character recognition', 'scene text detection', 'curved text detection'] | ['Shape Robust Text Detection with Progressive Scale Expansion Network', 'Shape Robust Text Detection with Progressive Scale Expansion Network'] | models/mobilenet_v3_block.py MobileNetV3/mobilenet_v3_large.py util/statistic.py util/tf.py pypse.py util/event.py MobileNetV3/mobilenet_v3_small.py metrics.py util/feature.py util/proc.py test_ctw1500.py util/rand.py util/t.py util/neighbour.py util/caffe_.py models/__init__.py util/dtype.py util/str_.py MobileNetV2/mobilenet_v2.py util/ml.py util/test.py util/log.py pse/.ycm_extra_conf.py pse/__init__.py util/misc.py test_id41k.py pse/__main__.py util/__init__.py util/demo_nn/pytorch_demo.py util/logger.py dataset/ctw1500_test_loader.py util/mask.py util/url.py dataset/ctw1500_loader.py dataset/mtwi_loader.py MobileNetV2/data/convert.py eval/ctw1500/eval_ctw1500.py eval/ctw1500/file_util.py util/gen_bank_id.py util/thread_.py models/fpn_resnet.py util/np.py util/dec.py util/opencv_demo.py util/io_.py util/mod.py train_ctw1500.py util/img.py train_id41k.py util/cmd.py MobileNetV2/train.py dataset/__init__.py util/plt.py mobilenet_v2.py util/test_open_read.py runningScore preprocess_input decode_predictions _make_divisible _inverted_res_block MobileNetV2 pse debug test write_result_as_txt extend_3c polygon_from_points get_img random_crop shrink get_bboxes random_rotate random_scale dist ctw_train_loader random_horizontal_flip scale CTW1500Loader perimeter get_img ctw_test_loader CTW1500TestLoader scale get_img random_crop shrink get_bboxes random_rotate random_scale dist ctw_train_loader random_horizontal_flip scale CTW1500Loader perimeter get_union get_gt get_pred get_intersection write_file_not_cover write_file read_file read_dir _inverted_residual_block _bottleneck _conv_block _make_divisible relu6 MobileNetv2 main train fine_tune generate convert MobileNetV3Large MobileNetV3Small MobileNetV3Large MobileNetV3Small ResNet resnet50 Bottleneck resnet152 mobilenetv2 conv3x3 TFPreMobileNetV2 resnet34 resnet101 resnet18 TFPreResNet BasicBlock mobilenetv3_small mobilenetv3_large BottleNeck h_swish h_sigmoid SEBlock GetCompilationInfoForFile IsHeaderFile MakeRelativePathsInFlagsAbsolute FlagsForFile DirectoryOfThisScript pse get_data get_params draw_log cmd print_calling_in_short_for_tf timeit print_calling print_test print_calling_in_short is_tuple int is_number is_str cast is_list double wait_key hog getRandomId get_random_bg_bg get_random_crop_bg genbankpic_crop get_random_bg auto_gen_date_num_list auto_gen_num_pic auto_gen_date_num_pic gen_bank_date_number get_id auto_gen_num_list_19 get_bank_date_number get_bank_number random_sequence auto_gen_num_list gen_bank_number_19 gen_bank_number get_contour_min_area_box blur imwrite get_rect_iou black get_value put_text bgr2rgb get_roi render_points bgr2gray get_contour_region_iou resize convex_hull draw_contours get_contour_rect_box get_shape set_value is_in_contour is_valid_jpg move_win get_contour_region_in_rect fill_bbox imshow apply_mask random_color_3 imread bilateral_blur find_contours points_to_contours maximize_win rect_area rgb2bgr contour_to_points ds_size points_to_contour eq_color find_two_level_contours get_wh average_blur rgb2gray get_contour_region_in_min_area_rect rotate_point_by_90 white filter2D is_white translate get_contour_area rectangle min_area_rect rect_perimeter get_rect_points rotate_about_center gaussian_blur circle get_dir search is_dir dump_mat read_h5_attrs exists get_filename cd join_path load_mat get_file_size get_absolute_path cat dir_mat dump_json create_h5 dump pwd copy is_path mkdir ls open_h5 load remove write_lines read_h5 make_parent_dir find_files read_lines get_date_str init_logger plot_overlap savefig Logger LoggerMonitor find_black_components find_white_components init_params AverageMeter mkdir_p get_mean_and_std kmeans try_import_by_name add_ancester_dir_to_path import_by_name is_main get_mod_by_name add_to_path load_mod_from_path n2 _in_image count_neighbours get_neighbours n1 n1_count n8 n2_count n4 norm2_squared smooth flatten empty_list norm2 sum_all angle_with_x has_infty sin arcsin norm1 eu_dist iterable is_2D shuffle cos_dist chi_squared_dist clone is_empty has_nan has_nan_or_infty show plot_solver_data line show_images get_random_line_style to_ROI draw imshow rectangle hist maximize_figure set_subtitle save_image get_pid kill wait_for_pool get_pool cpu_count set_proc_name ps_aux_grep shuffle normal randint sample D E join index_of find_all is_none_or_empty ends_with remove_all remove_invisible to_lowercase starts_with is_str int_array_to_str contains to_uppercase split replace_all add_noise crop_into get_latest_ckpt get_init_fn gpu_config Print is_gpu_available min_area_rect focal_loss_layer_initializer get_variable_names_in_checkpoint sum_gradients get_all_ckpts get_update_op get_variables_to_train focal_loss get_iter get_available_gpus wait_for_checkpoint get_current_thread ThreadPool create_and_start ProcessPool is_alive get_current_thread_name download argv cit get_count exit sit DynamicNet runningScore preprocess_input decode_predictions _make_divisible _inverted_res_block MobileNetV2 pse debug test write_result_as_txt extend_3c polygon_from_points get_img random_crop shrink get_bboxes random_rotate random_scale dist ctw_train_loader random_horizontal_flip scale CTW1500Loader perimeter get_img ctw_test_loader CTW1500TestLoader scale get_img random_crop shrink get_bboxes random_rotate random_scale dist ctw_train_loader random_horizontal_flip scale CTW1500Loader perimeter get_union get_gt get_pred get_intersection write_file_not_cover write_file read_file read_dir _inverted_residual_block _bottleneck _conv_block _make_divisible relu6 MobileNetv2 main train fine_tune generate convert MobileNetV3Large MobileNetV3Small MobileNetV3Large MobileNetV3Small ResNet resnet50 Bottleneck resnet152 mobilenetv2 conv3x3 TFPreMobileNetV2 resnet34 resnet101 resnet18 TFPreResNet BasicBlock mobilenetv3_small mobilenetv3_large BottleNeck h_swish h_sigmoid SEBlock GetCompilationInfoForFile IsHeaderFile MakeRelativePathsInFlagsAbsolute FlagsForFile DirectoryOfThisScript pse get_data get_params draw_log cmd print_calling_in_short_for_tf timeit print_calling print_test print_calling_in_short is_tuple int is_number is_str cast is_list double wait_key hog getRandomId get_random_bg_bg get_random_crop_bg genbankpic_crop get_random_bg auto_gen_date_num_list auto_gen_num_pic auto_gen_date_num_pic gen_bank_date_number get_id auto_gen_num_list_19 get_bank_date_number get_bank_number random_sequence auto_gen_num_list gen_bank_number_19 gen_bank_number get_contour_min_area_box blur imwrite get_rect_iou black get_value put_text bgr2rgb get_roi render_points bgr2gray get_contour_region_iou resize convex_hull draw_contours get_contour_rect_box get_shape set_value is_in_contour is_valid_jpg move_win get_contour_region_in_rect fill_bbox imshow apply_mask random_color_3 imread bilateral_blur find_contours points_to_contours maximize_win rect_area rgb2bgr contour_to_points ds_size points_to_contour eq_color find_two_level_contours get_wh average_blur rgb2gray get_contour_region_in_min_area_rect rotate_point_by_90 white filter2D is_white translate get_contour_area rectangle min_area_rect rect_perimeter get_rect_points rotate_about_center gaussian_blur circle get_dir search is_dir dump_mat read_h5_attrs exists get_filename cd join_path load_mat get_file_size get_absolute_path cat dir_mat dump_json create_h5 dump pwd copy is_path mkdir ls open_h5 load remove write_lines read_h5 make_parent_dir find_files read_lines get_date_str init_logger plot_overlap savefig Logger LoggerMonitor find_black_components find_white_components init_params AverageMeter mkdir_p get_mean_and_std kmeans try_import_by_name add_ancester_dir_to_path import_by_name is_main get_mod_by_name add_to_path load_mod_from_path n2 _in_image count_neighbours get_neighbours n1 n1_count n8 n2_count n4 norm2_squared smooth flatten empty_list norm2 sum_all angle_with_x has_infty sin arcsin norm1 eu_dist iterable is_2D shuffle cos_dist chi_squared_dist clone is_empty has_nan has_nan_or_infty show plot_solver_data line show_images get_random_line_style to_ROI draw imshow rectangle hist maximize_figure set_subtitle save_image get_pid kill wait_for_pool get_pool cpu_count set_proc_name ps_aux_grep normal randint sample D E join index_of find_all is_none_or_empty ends_with remove_all remove_invisible to_lowercase starts_with is_str int_array_to_str contains to_uppercase split replace_all add_noise crop_into get_latest_ckpt get_init_fn gpu_config Print is_gpu_available min_area_rect focal_loss_layer_initializer get_variable_names_in_checkpoint sum_gradients get_all_ckpts get_update_op get_variables_to_train focal_loss get_iter get_available_gpus wait_for_checkpoint get_current_thread ThreadPool create_and_start ProcessPool is_alive get_current_thread_name download argv cit get_count exit sit DynamicNet pop str get_file get_source_inputs obtain_input_shape _make_divisible validate_activation Model warning load_weights VersionAwareLayers is_keras_tensor _inverted_res_block Input int format _make_divisible int max connectedComponents get transpose copy put shape Queue zeros range len reshape concatenate imwrite concatenate print makedirs append range len join_path makedirs write_lines append range enumerate len int T empty model sign resize resnet152 max RETR_TREE transpose pypse shape resnet18 resnet101 append range format min_kernel_area resnet50 findContours debug astype copy write_result_as_txt mean load_weights resume img_paths scale flush enumerate time ctw_test_loader uint8 drawContours binary_th CHAIN_APPROX_SIMPLE print reshape float32 sigmoid CTW1500TestLoader zeros imread int asarray remove_all append read_lines split range copy len warpAffine random getRotationMatrix2D range len max resize max min choice resize array min where randint max range len range PyclipperOffset int JT_ROUND area min append AddPath array perimeter ET_CLOSEDPOLYGON Execute arange shuffle stack append range len append stack range len print append split append int asarray split area append sort walk replace read close open join makedirs close write open join makedirs close write open int _conv_block _bottleneck range _inverted_residual_block _conv_block _make_divisible Model Input int tclasses size add_argument weights ArgumentParser classes parse_args train epochs batch ImageDataGenerator walk flow_from_directory Model load_weights output from_dict EarlyStopping makedirs Adam fine_tune fit_generator to_csv save_weights history generate compile MobileNetv2 str imwrite len load_data resize range makedirs append join startswith IsHeaderFile compiler_flags_ exists compiler_flags_ GetCompilationInfoForFile compiler_working_dir_ MakeRelativePathsInFlagsAbsolute DirectoryOfThisScript cpse array net Solver isinstance append net Solver isinstance show int get_random_line_style plot print readlines smooth len contains eval get_absolute_path save_image plt legend append float open isinstance debug waitKey ord append range getRandomId range print randint random_sequence len print randint random_sequence str randint str threshold strip bitwise_not bitwise_and COLOR_RGB2BGR save open fromarray str COLOR_BGR2RGB add shape imread range asarray get_random_bg COLOR_BGR2GRAY concatenate size close GaussianBlur crop int print convert write THRESH_BINARY blend filter array cvtColor len str print strip len append randint range open range genbankpic_crop zfill len range genbankpic_crop zfill len bgr2rgb get_absolute_path wait_key namedWindow isinstance destroyAllWindows move_win rgb2bgr WINDOW_NORMAL imread maximize_win get_absolute_path rgb2bgr make_parent_dir moveWindow setWindowProperty WND_PROP_FULLSCREEN enumerate get_shape get_shape min max drawContours boundingRect get_contour_rect_box minAreaRect BoxPoints int0 get_shape get_contour_rect_box warpAffine int BoxPoints transpose hstack getRotationMatrix2D dot get_roi minAreaRect points_to_contour black draw_contours shape to_contours draw_contours assert_equal asarray range GaussianBlur bilateralFilter putText int32 FONT_HERSHEY_SIMPLEX get_shape int tuple warpAffine get_wh float32 cos deg2rad getRotationMatrix2D dot sin abs array _get_area transpose _get_inter zeros range len findContours asarray copy findContours copy pointPolygonTest convexHull randint list asarray range zip minAreaRect empty points_to_contour get_absolute_path makedirs get_dir mkdir get_absolute_path get_dir mkdir get_absolute_path get_absolute_path get_absolute_path is_dir get_absolute_path expanduser startswith chdir get_absolute_path append listdir get_absolute_path ends_with get_absolute_path open get_absolute_path make_parent_dir get_absolute_path get_absolute_path get_absolute_path savemat make_parent_dir get_absolute_path getsize get_absolute_path get_absolute_path make_parent_dir get_absolute_path get_absolute_path get_absolute_path join_path extend ls is_dir get_absolute_path find_files append get_absolute_path make_parent_dir now setFormatter basicConfig print join_path addHandler make_parent_dir StreamHandler get_date_str Formatter setLevel asarray arange plot numbers enumerate len pop black set_root insert copy get_neighbours N4 shape get_new_root get_root append set_visited range is_visited print DataLoader div_ zeros range len normal constant isinstance kaiming_normal Conv2d bias modules BatchNorm2d weight Linear makedirs asarray warn flatten append enumerate insert join_path add_to_path get_dir __import__ import_by_name get_absolute_path get_filename append _in_image append _in_image append _in_image append _in_image norm2 zip shape asarray extend len pi asarray asarray reshape flatten sqrt shape range shape asarray has_infty has_nan enumerate len show asarray join_path flatten linspace figure save_image load show val_accuracies list plot training_losses val_losses training_accuracies figure legend range len Rectangle add_patch full_screen_toggle get_current_fig_manager add_line Line2D linspace show_images show set_title set_subtitle axis colorbar bgr2rgb imshow maximize_figure subplot2grid append save_image enumerate get_absolute_path savefig imsave make_parent_dir set_xlim set_ylim suptitle maximize_figure randint len Pool join close setproctitle print get_pid cmd append int cmd split flatten flatten append pop list tuple to_lowercase is_str enumerate list tuple to_lowercase is_str enumerate to_lowercase findall replace replace_all binomial list_local_devices get_checkpoint_state is_dir get_absolute_path model_checkpoint_path get_checkpoint_state all_model_checkpoint_paths int get_latest_ckpt is_none_or_empty latest_checkpoint print get_model_variables startswith info append extend get_collection TRAINABLE_VARIABLES get_latest_ckpt NewCheckpointReader get_variable_to_shape_map dtype set_shape py_func ConfigProto ones_like zeros_like sigmoid_cross_entropy_with_logits float32 where reduce_sum sigmoid pow cast stop_gradient name reduce_mean add_n histogram zip append scalar UPDATE_OPS get_collection start Thread setName print urlretrieve stat show_images get_count imwrite get_count imwrite asarray | # Shape Robust Text Detection with Progressive Scale Expansion Network ## Requirements * Python3 * pyclipper * Polygon2 * OpenCV * TensorFlow 2.0+ ## Introduction (PSENet-tf2.0)Progressive Scale Expansion Network (PSENet) is a text detector which is able to well detect the arbitrary-shape text in natural scene. Besides, based on this text segmentation model, we got top 6 in MTWI 2018 Text Detection Challenge | 2,771 |
li3cmz/GRADE | ['dialogue evaluation'] | ['GRADE: Automatic Graph-Enhanced Coherence Metric for Evaluating Open-Domain Dialogue Systems'] | texar-pytorch/texar/torch/hyperparams_test.py texar-pytorch/texar/torch/modules/embedders/embedder_utils.py texar-pytorch/examples/bert/config_classifier.py texar-pytorch/texar/torch/data/tokenizers/bert_tokenizer_utils.py texar-pytorch/texar/torch/run/metric/__init__.py texar-pytorch/texar/torch/data/data/data_iterators_test.py texar-pytorch/examples/bert/bert_classifier_using_executor_main.py texar-pytorch/texar/torch/run/metric/regression.py texar-pytorch/examples/transformer/config_model.py texar-pytorch/texar/torch/utils/beam_search_test.py texar-pytorch/texar/torch/__init__.py texar-pytorch/texar/torch/utils/rnn_test.py config/config_data_for_metric.py texar-pytorch/texar/torch/utils/dtypes.py texar-pytorch/texar/torch/modules/encoders/conv_encoders.py texar-pytorch/texar/torch/data/tokenizers/gpt2_tokenizer.py texar-pytorch/examples/seq2seq_attn/seq2seq_attn.py texar-pytorch/texar/torch/modules/decoders/gpt2_decoder.py texar-pytorch/texar/torch/data/data/mono_text_data_test.py texar-pytorch/texar/torch/modules/encoders/transformer_encoder_test.py texar-pytorch/texar/torch/run/condition_test.py texar-pytorch/texar/torch/data/vocabulary_test.py preprocess/load_data.py preprocess/prepare_pkl_for_metric.py texar-pytorch/examples/vae_text/config_lstm_yahoo.py preprocess/keyword_extractor.py texar-pytorch/texar/torch/hyperparams.py texar-pytorch/texar/torch/utils/rnn.py texar-pytorch/texar/torch/utils/types.py texar-pytorch/texar/torch/data/data/dataset_utils.py texar-pytorch/texar/torch/custom/distributions.py texar-pytorch/texar/torch/run/executor_test.py texar-pytorch/texar/torch/modules/encoders/bert_encoder.py evaluation/human_correlation.py texar-pytorch/texar/torch/modules/pretrained/xlnet.py texar-pytorch/texar/torch/run/metric/summary.py texar-pytorch/texar/torch/losses/mle_losses.py texar-pytorch/texar/torch/core/__init__.py texar-pytorch/texar/torch/evals/bleu_moses_test.py texar-pytorch/setup.py texar-pytorch/examples/xlnet/utils/processor.py texar-pytorch/examples/xlnet/utils/dataset.py texar-pytorch/texar/torch/modules/encoders/xlnet_encoder.py texar-pytorch/texar/torch/evals/bleu_transformer_test.py texar-pytorch/texar/torch/data/vocabulary.py texar-pytorch/texar/torch/run/condition.py texar-pytorch/examples/seq2seq_attn/prepare_data.py texar-pytorch/examples/transformer/utils/utils.py texar-pytorch/texar/torch/losses/rewards.py texar-pytorch/texar/torch/modules/decoders/__init__.py texar-pytorch/texar/torch/modules/encoders/gpt2_encoder_test.py texar-pytorch/examples/seq2seq_attn/config_model_full.py texar-pytorch/examples/sentence_classifier/sst_data_preprocessor.py texar-pytorch/texar/torch/modules/regressors/xlnet_regressor_test.py texar-pytorch/examples/bert/prepare_data.py texar-pytorch/texar/torch/utils/average_recorder_test.py texar-pytorch/docs/conf.py texar-pytorch/texar/torch/core/layers.py texar-pytorch/texar/torch/run/executor.py texar-pytorch/texar/torch/data/data/multi_aligned_data.py texar-pytorch/examples/sentence_classifier/config_kim.py texar-pytorch/texar/torch/data/data/record_data_test.py texar-pytorch/texar/torch/evals/bleu_test.py texar-pytorch/texar/torch/core/cell_wrappers_test.py texar-pytorch/texar/torch/modules/decoders/rnn_decoders.py texar-pytorch/texar/torch/core/attention_mechanism_utils_test.py texar-pytorch/texar/torch/evals/bleu_moses.py texar-pytorch/texar/torch/data/tokenizers/xlnet_tokenizer.py texar-pytorch/texar/torch/modules/embedders/embedder_utils_test.py main_for_metric_grade.py texar-pytorch/examples/seq2seq_attn/config_iwslt14.py texar-pytorch/texar/torch/data/data/scalar_data.py texar-pytorch/texar/torch/run/executor_utils.py texar-pytorch/texar/torch/run/metric/classification.py texar-pytorch/texar/torch/modules/pretrained/__init__.py texar-pytorch/texar/torch/utils/transformer_attentions.py texar-pytorch/examples/seq2seq_attn/config_toy_copy.py texar-pytorch/examples/vae_text/config_lstm_ptb.py texar-pytorch/texar/torch/losses/adv_losses_test.py texar-pytorch/texar/torch/modules/connectors/__init__.py texar-pytorch/texar/torch/modules/decoders/gpt2_decoder_test.py texar-pytorch/texar/torch/modules/decoders/xlnet_decoder_test.py texar-pytorch/texar/torch/modules/encoders/gpt2_encoder.py texar-pytorch/texar/torch/core/optimization_test.py texar-pytorch/texar/torch/core/layers_test.py texar-pytorch/texar/torch/modules/connectors/connectors.py texar-pytorch/texar/torch/modules/classifiers/gpt2_classifier.py preprocess/dialog_data_processor.py preprocess/prepare_pkl.py texar-pytorch/texar/torch/data/data/large_file_test.py texar-pytorch/texar/torch/data/tokenizers/tokenizer_base.py texar-pytorch/texar/torch/modules/regressors/__init__.py texar-pytorch/texar/torch/data/data/paired_text_data.py texar-pytorch/texar/torch/run/metric/classification_test.py texar-pytorch/texar/torch/modules/classifiers/gpt2_classifier_test.py texar-pytorch/texar/torch/data/embedding.py texar-pytorch/texar/torch/modules/networks/conv_networks.py texar-pytorch/texar/torch/core/regularizers.py texar-pytorch/texar/torch/modules/classifiers/xlnet_classifier_test.py texar-pytorch/texar/torch/data/data/__init__.py texar-pytorch/texar/torch/data/tokenizers/xlnet_tokenizer_test.py texar-pytorch/texar/torch/run/metric/generation.py texar-pytorch/examples/gpt-2/prepare_data.py texar-pytorch/examples/transformer/transformer_main.py texar-pytorch/texar/torch/data/tokenizers/roberta_tokenizer.py texar-pytorch/texar/torch/modules/networks/conv_networks_test.py texar-pytorch/texar/torch/modules/__init__.py texar-pytorch/examples/vae_text/vae_train.py texar-pytorch/texar/torch/modules/encoders/rnn_encoders_test.py texar-pytorch/texar/torch/modules/classifiers/__init__.py utils/__init__.py texar-pytorch/texar/torch/modules/encoders/conv_encoders_test.py texar-pytorch/texar/torch/modules/encoders/multihead_attention.py texar-pytorch/texar/torch/evals/metrics_test.py texar-pytorch/texar/torch/modules/embedders/embedders_test.py texar-pytorch/texar/torch/evals/__init__.py texar-pytorch/texar/torch/modules/regressors/xlnet_regressor.py preprocess/prepare_data.py texar-pytorch/texar/torch/losses/pg_losses_test.py texar-pytorch/texar/torch/modules/connectors/connector_base.py texar-pytorch/texar/torch/modules/networks/networks_test.py texar-pytorch/texar/torch/data/data/multi_aligned_data_test.py texar-pytorch/texar/torch/utils/exceptions.py texar-pytorch/texar/torch/utils/nest.py texar-pytorch/texar/torch/losses/losses_utils.py texar-pytorch/texar/torch/modules/pretrained/bert.py texar-pytorch/examples/vae_text/config_trans_yahoo.py texar-pytorch/texar/torch/modules/decoders/decoder_helpers.py texar-pytorch/texar/torch/core/attention_mechanism.py texar-pytorch/texar/torch/modules/networks/__init__.py model/evaluation_model/GRADE/model_grade_K1.py texar-pytorch/texar/torch/modules/encoders/encoder_base.py texar-pytorch/examples/xlnet/configs/config_data_imdb.py texar-pytorch/texar/torch/modules/decoders/rnn_decoder_base.py texar-pytorch/texar/torch/modules/networks/network_base.py texar-pytorch/examples/transformer/bleu_main.py texar-pytorch/texar/torch/data/tokenizers/bert_tokenizer_utils_test.py texar-pytorch/texar/torch/utils/shapes.py texar-pytorch/texar/torch/evals/metrics.py texar-pytorch/texar/torch/run/metric/base_metric.py texar-pytorch/texar/torch/data/data/scalar_data_test.py texar-pytorch/texar/torch/modules/classifiers/classifier_base.py texar-pytorch/texar/torch/modules/classifiers/bert_classifier_test.py texar-pytorch/texar/torch/losses/rewards_test.py texar-pytorch/texar/torch/modules/pretrained/gpt2.py texar-pytorch/texar/torch/losses/pg_losses.py texar-pytorch/texar/torch/modules/embedders/embedders.py texar-pytorch/texar/torch/utils/shapes_test.py texar-pytorch/examples/bert/config_data.py main_grade.py texar-pytorch/texar/torch/modules/classifiers/xlnet_classifier.py texar-pytorch/texar/torch/modules/pretrained/roberta_test.py texar-pytorch/texar/torch/data/tokenizers/__init__.py texar-pytorch/texar/torch/modules/pretrained/gpt2_test.py texar-pytorch/texar/torch/modules/pretrained/xlnet_utils_test.py texar-pytorch/examples/xlnet/configs/config_data_stsb.py texar-pytorch/examples/gpt-2/utils/data_utils.py texar-pytorch/texar/__init__.py texar-pytorch/examples/transformer/config_iwslt15.py texar-pytorch/examples/xlnet/utils/model_utils.py config/config_model_grade.py texar-pytorch/texar/torch/modules/classifiers/conv_classifiers.py texar-pytorch/texar/torch/module_base.py texar-pytorch/texar/torch/modules/encoders/bert_encoder_test.py texar-pytorch/texar/torch/utils/utils.py texar-pytorch/texar/torch/modules/connectors/connectors_test.py texar-pytorch/examples/vae_text/prepare_data.py texar-pytorch/texar/torch/modules/decoders/xlnet_decoder.py texar-pytorch/texar/torch/run/__init__.py texar-pytorch/texar/torch/data/data/mono_text_data.py texar-pytorch/examples/xlnet/utils/data_utils.py texar-pytorch/texar/torch/utils/beam_search.py texar-pytorch/texar/torch/data/data/data_iterators.py texar-pytorch/texar/torch/core/cell_wrappers.py texar-pytorch/examples/bert/utils/model_utils.py texar-pytorch/texar/torch/modules/classifiers/bert_classifier.py texar-pytorch/texar/torch/modules/encoders/roberta_encoder_test.py texar-pytorch/texar/torch/modules/pretrained/xlnet_test.py texar-pytorch/texar/torch/modules/pretrained/pretrained_base.py texar-pytorch/texar/torch/modules/decoders/transformer_decoders_test.py texar-pytorch/texar/torch/utils/utils_test.py utils/normalization.py texar-pytorch/texar/torch/data/tokenizers/gpt2_tokenizer_utils.py texar-pytorch/texar/torch/losses/entropy.py texar-pytorch/texar/torch/modules/classifiers/roberta_classifier_test.py texar-pytorch/texar/torch/run/metric/summary_test.py texar-pytorch/examples/gpt-2/config_train.py texar-pytorch/examples/sentence_classifier/classifier_main.py texar-pytorch/texar/torch/modules/pretrained/bert_test.py texar-pytorch/texar/torch/utils/test.py texar-pytorch/texar/torch/losses/__init__.py model/evaluation_model/GRADE/model_grade_K2.py texar-pytorch/texar/torch/data/embedding_test.py texar-pytorch/texar/torch/data/__init__.py texar-pytorch/examples/transformer/utils/data_utils.py texar-pytorch/examples/gpt-2/gpt2_generate_main.py texar-pytorch/texar/torch/custom/initializers.py texar-pytorch/texar/torch/modules/encoders/rnn_encoders.py texar-pytorch/texar/torch/modules/encoders/__init__.py texar-pytorch/examples/transformer/utils/preprocess.py preprocess/utils/data_utils.py texar-pytorch/texar/torch/core/regularizers_test.py texar-pytorch/texar/torch/modules/encoders/xlnet_encoder_test.py texar-pytorch/texar/torch/version.py texar-pytorch/examples/vae_text/config_trans_ptb.py texar-pytorch/texar/torch/data/tokenizers/sentencepiece_tokenizer.py texar-pytorch/texar/torch/data/tokenizers/bert_tokenizer_test.py texar-pytorch/examples/gpt-2/gpt2_train_main.py texar-pytorch/examples/transformer/config_wmt14.py texar-pytorch/texar/torch/losses/mle_losses_test.py model/evaluation_model/GRADE/model_util/GCN.py texar-pytorch/texar/torch/modules/embedders/embedder_base.py texar-pytorch/texar/torch/modules/decoders/rnn_decoders_test.py texar-pytorch/texar/torch/data/tokenizers/sentencepiece_tokenizer_test.py texar-pytorch/texar/torch/modules/classifiers/conv_classifiers_test.py texar-pytorch/texar/torch/modules/regressors/regressor_base.py texar-pytorch/texar/torch/data/tokenizers/bert_tokenizer.py texar-pytorch/texar/torch/core/attention_mechanism_utils.py texar-pytorch/texar/torch/modules/pretrained/xlnet_utils.py texar-pytorch/texar/torch/evals/bleu.py texar-pytorch/examples/xlnet/xlnet_generation_main.py texar-pytorch/texar/torch/modules/decoders/decoder_base.py preprocess/utils/load_data_utils.py preprocess/utils/data_utils_metric.py evaluation/merge_keyword_and_text.py texar-pytorch/examples/transformer/model.py texar-pytorch/texar/torch/core/attention_mechanism_test.py texar-pytorch/texar/torch/custom/__init__.py preprocess/extract_keywords.py texar-pytorch/texar/torch/data/data/record_data.py config/config_data_grade.py texar-pytorch/texar/torch/data/tokenizers/roberta_tokenizer_test.py texar-pytorch/texar/torch/modules/classifiers/roberta_classifier.py texar-pytorch/texar/torch/modules/decoders/transformer_decoders.py texar-pytorch/texar/torch/modules/networks/networks.py texar-pytorch/texar/torch/losses/entropy_test.py texar-pytorch/texar/torch/core/optimization.py texar-pytorch/texar/torch/modules/embedders/__init__.py texar-pytorch/texar/torch/data/data/text_data_base.py texar-pytorch/texar/torch/modules/encoders/roberta_encoder.py texar-pytorch/texar/torch/run/metric/generation_test.py texar-pytorch/texar/torch/modules/embedders/position_embedders.py texar-pytorch/examples/xlnet/xlnet_classification_main.py texar-pytorch/examples/bert/utils/data_utils.py texar-pytorch/texar/torch/losses/adv_losses.py utils/main_utils.py texar-pytorch/texar/torch/modules/encoders/transformer_encoder.py texar-pytorch/texar/torch/data/tokenizers/gpt2_tokenizer_test.py texar-pytorch/examples/seq2seq_attn/config_model.py texar-pytorch/examples/bert/bert_classifier_main.py texar-pytorch/texar/torch/modules/decoders/decoder_helpers_test.py setting.py texar-pytorch/examples/bert/bert_with_hypertuning_main.py texar-pytorch/texar/torch/utils/average_recorder.py texar-pytorch/texar/torch/data/data/data_base.py texar-pytorch/texar/torch/run/action.py texar-pytorch/examples/bert/data/download_glue_data.py texar-pytorch/texar/torch/custom/activation.py texar-pytorch/texar/torch/evals/bleu_transformer.py texar-pytorch/texar/torch/modules/pretrained/roberta.py texar-pytorch/texar/torch/utils/utils_io.py texar-pytorch/texar/torch/utils/__init__.py texar-pytorch/texar/torch/data/data/paired_text_data_test.py texar-pytorch/texar/torch/data/data_utils.py model/evaluation_model/GRADE/model_util/GAT.py texar-pytorch/examples/xlnet/xlnet_generation_ipython.py texar-pytorch/texar/torch/run/metric/regression_test.py main main modify_config_data correlation maybe_create_dir GRADE GRADE GATLayer GATHead GCN DialogDataProcessor load_empatheticdialogues extract_keywords load_texts _calculate_idf load_convai2 replace_content_in_dialog _obtain_candidate_keywords load_dailydialog process_dialog_str load_dataset KeywordExtractor PreprocessTool main modify_config_data main modify_config_data prepare_record_data InputFeatures InputExample convert_examples_to_features_and_output_to_files DailyDialogProcessor DataProcessor convert_single_example prepare_record_data InputFeatures InputExample convert_examples_to_features_and_output_to_files DailyDialogProcessor DataProcessor convert_single_example simp_tokenize kw_tokenize pos_tag lower to_basic_form nltk_tokenize tokenize main main FileWriterMetric ModelWrapper main TPE ModelWrapper main modify_config_data download_and_extract format_mrpc get_tasks main download_diagnostic prepare_record_data InputFeatures MrpcProcessor ColaProcessor MnliProcessor InputExample SSTProcessor convert_examples_to_features_and_output_to_files DataProcessor XnliProcessor convert_single_example get_lr_multiplier main main main read_raw_data prepare_pickle_data convert_examples_to_features_and_output_to_files main SentenceClassifier main transform_raw_sst clean_sst_text main Seq2SeqAttn main main Transformer LabelSmoothingLoss BLEUWrapper ModelWrapper FileBLEU DecodeMixin main Seq2SeqData CustomBatchingStrategy get_preprocess_args open_file split_sentence make_dataset read_file count_words main make_array get_lr_multiplier prepare_data main kl_divergence VAE load_config_into_args RegressorWrapper construct_datasets ClassifierWrapper main parse_args main main load_datasets construct_dataset get_record_feature_types InputFeatures PaddingInputExample convert_single_example warmup_lr_lambda get_processor_class MnliMatchedProcessor MnliMismatchedProcessor StsbProcessor InputExample Yelp5Processor ImdbProcessor GLUEProcessor DataProcessor HParams _type_name HParamsTest ModuleBase _bahdanau_score compute_attention _monotonic_probability_fn MonotonicAttentionMechanism BahdanauAttention AttentionWrapperState _luong_score LuongMonotonicAttention monotonic_attention LuongAttention AttentionMechanism BahdanauMonotonicAttention AttentionMechanismTest SparsemaxFunction safe_cumprod hardmax _make_ix_like _threshold_and_support sparsemax prepare_memory maybe_mask_score AttentionMechanismUtilsTest BuiltinCellWrapper MultiRNNCell RNNCellBase HighwayWrapper wrap_builtin_cell LSTMCell AttentionWrapper DropoutWrapper RNNCell GRUCell ResidualWrapper WrappersTest MergeLayer MaxReducePool1d get_pooling_layer_hparams AvgReducePool1d Identity default_rnn_cell_hparams identity get_regularizer get_activation_fn get_layer default_regularizer_hparams get_rnn_cell get_initializer Flatten GetLayerTest ReducePoolingLayerTest GetActivationFnTest MergeLayerTest BertAdamStateDict BertAdam BertAdamParamDict get_train_op get_scheduler get_grad_clip_fn default_optimization_hparams get_optimizer OptimizationTest l1 l2 Regularizer l1_l2 L1L2 RegularizerTest GPTGELU BertGELU MultivariateNormalDiag variance_scaling_initializer _download _download_from_google_drive _extract_google_drive_file_id read_words count_file_lines make_vocab maybe_download load_word2vec Embedding load_glove EmbeddingTest _make_defaultdict map_ids_to_strs Vocab SpecialTokens VocabularyTest padded_batch Batch connect_name _LazyStrategy _CacheStrategy IterDataSource _TruncatedDataSource SequenceDataSource _CachedDataSource ZipDataSource DatasetBase RecordDataSource DataSource FilterDataSource _TransformedDataSource DataIterator _SPDataLoaderIter TokenCountBatchingStrategy _CacheDataLoaderIter _MPCacheDataLoaderIter SequentialSampler DynamicBatchSampler RandomSampler TrainTestDataIterator SingleDatasetIterator _DataLoaderIter move_memory _MPDataLoaderIter SamplerBase BatchingStrategy _SPCacheDataLoaderIter BufferShuffleSampler SamplerTest DataIteratorTest LazinessCachingTest MockDataBase LargeFileTest wrap_progress get_process_memory work_in_progress ParallelData _LengthFilterMode MonoTextData _default_mono_text_dataset_hparams VarUttMonoTextDataTest MonoTextDataTest _is_record_data _default_dataset_hparams MultiAlignedData _is_text_data _is_scalar_data MultiAlignedDataTest _default_paired_text_dataset_hparams PairedTextData PairedTextDataTest _check_shape CollateMethod _convert_feature_hparams RecordData _default_record_dataset_hparams PickleDataSource FeatureDescription _create_image_transform RecordDataTest ScalarData _default_scalar_dataset_hparams ScalarDataTest TextDataBase TextLineDataSource BERTTokenizer BERTTokenizerTest BasicTokenizer WordpieceTokenizer load_vocab whitespace_tokenize _is_whitespace _is_control _is_punctuation BERTTokenizerUtilsTest GPT2Tokenizer GPT2TokenizerTest bytes_to_unicode get_pairs RoBERTaTokenizer RoBERTaTokenizerTest SentencePieceTokenizer SentencePieceTokenizerTest TokenizerBase XLNetTokenizer XLNetTokenizerTest _maybe_str_to_list _get_ngrams corpus_bleu _lowercase sentence_bleu corpus_bleu_moses sentence_bleu_moses _maybe_list_to_str _parse_multi_bleu_ret BLEUMosesTest BLEUTest UnicodeRegex _get_ngrams file_bleu corpus_bleu_transformer bleu_transformer_tokenize BLEUToolTest accuracy binary_clas_accuracy MetricsTest binary_adversarial_losses AdvLossesTest _get_entropy sequence_entropy_with_logits entropy_with_logits EntropyTest reduce_dimensions mask_and_reduce reduce_batch_time binary_sigmoid_cross_entropy_with_clas sequence_softmax_cross_entropy sequence_sigmoid_cross_entropy binary_sigmoid_cross_entropy sequence_sparse_softmax_cross_entropy MLELossesTest pg_loss_with_logits pg_loss_with_log_probs PGLossesTest discount_reward _discount_reward_tensor_1d _discount_reward_tensor_2d RewardTest BERTClassifier BERTClassifierTest ClassifierBase Conv1DClassifier Conv1DClassifierTest GPT2Classifier GPT2ClassifierTest RoBERTaClassifier RoBERTaClassifierTest XLNetClassifier XLNetClassifierTest _mlp_transform StochasticConnector _sum_output_size ReparameterizedStochasticConnector _assert_same_size MLPTransformConnector _get_sizes ForwardConnector ConstantConnector TestConnectors ConnectorBase DecoderBase _make_output_layer _top_p_logits default_helper_infer_hparams TopPSampleEmbeddingHelper TopKSampleEmbeddingHelper Helper SingleEmbeddingHelper SampleEmbeddingHelper EmbeddingHelper GreedyEmbeddingHelper SoftmaxEmbeddingHelper GumbelSoftmaxEmbeddingHelper default_helper_train_hparams _top_k_logits get_helper TrainingHelper SamplerTest GPT2Decoder GPT2DecoderTest AttentionRNNDecoderOutput BasicRNNDecoderOutput BasicRNNDecoder AttentionRNNDecoder BasicRNNDecoderTest AttentionRNNDecoderTest RNNDecoderBase TransformerDecoderOutput TransformerDecoder TransformerDecoderTest XLNetDecoderOutput XLNetDecoder XLNetDecoderTest WordEmbedder EmbedderTest EmbedderBase EmbeddingDropout default_embedding_hparams soft_embedding_lookup get_embedding GetEmbeddingTest PositionEmbedder SinusoidsPositionEmbedder BERTEncoder BERTEncoderTest Conv1DEncoder Conv1DEncoderTest EncoderBase GPT2Encoder GPT2EncoderTest MultiheadAttentionEncoder Cache LayerCache _default_output_layer_hparams _build_dense_output_layer BidirectionalRNNEncoder UnidirectionalRNNEncoder _forward_output_layers RNNEncoderBase UnidirectionalRNNEncoderTest BidirectionalRNNEncoderTest RoBERTaEncoder RoBERTaEncoderTest default_transformer_poswise_net_hparams TransformerEncoder TransformerEncoderTest XLNetEncoder XLNetEncoderTest _to_list Conv1DNetwork Conv1DNetworkTest FeedForwardNetwork FeedForwardNetworkTest FeedForwardNetworkBase PretrainedBERTMixin BERTUtilsTest PretrainedGPT2Mixin GPT2UtilsTest set_default_download_dir PretrainedMixin default_download_dir PretrainedRoBERTaMixin RoBERTaUtilsTest PretrainedXLNetMixin XLNetUtilsTest PositionalEmbedding RelativeMultiheadAttention RelativePositionalEncoding params_except_in init_weights PositionWiseFF XLNetModelUtilsTest RegressorBase XLNetRegressor XLNetRegressorTest early_stop scale_lr Action reset_params validation epoch time consecutive Condition iteration once Event ConditionTest make_deterministic Executor ExecutorTest DummyData DummyClassifier CheckpointMetaInfo SavedTrainingState ProgressTracker TrainingStatus repr_module MetricList _convert_id to_instance _to_dict color ExecutorTerminateSignal to_metric_dict _add_indent to_list update_metrics to_dict StreamingMetric Metric SimpleMetric ConfusionMatrix F1 Recall _MicroMacro Accuracy Precision _ConfusionMatrix ClassificationMetricTest BLEU _get_ngrams GenerationMetricTest PearsonR RMSE RegressionMetricTest Average AveragePerplexity RunningAverage LR RegressionMetricTest AverageRecorder _SingleAverageRecorder AverageRecorderTest compute_batch_indices compute_topk_scores_and_seq log_prob_from_logits gather_nd _unmerge_beam_dim beam_search _expand_to_beam_size _merge_beam_dim BeamSearchTest is_callable get_numpy_dtype _maybe_list_to_array get_supported_scalar_types is_str _as_text compat_as_text maybe_hparams_to_dict TexarError _sequence_like _sorted _is_namedtuple _yield_value is_sequence _packed_nest_with_indices flatten _yield_sorted_items pack_sequence_as dynamic_rnn _dynamic_rnn_loop reverse_sequence bidirectional_dynamic_rnn ReverseSequenceTest DynamicRNNTest BidirectionalDynamicRNNTest pad_and_concat mask_sequences flatten get_rank get_batch_size transpose_batch_time ShapesTest define_skip_condition external_library_test attention_bias_ignore_padding _ones_matrix_band_part attention_bias_local attention_bias_lower_triangle dict_fetch map_structure _no_map_type _recur_split sequence_mask strip_eos uniquify_str get_instance_with_redundant_kwargs get_instance_kwargs strip_special_tokens strip_token ceildiv sum_tensors get_function get_default_arg_values check_or_get_class get_args get_class get_instance check_or_get_instance_with_redundant_kwargs call_function_with_redundant_kwargs str_join flatten_dict no_map dict_patch get_output_size dict_pop default_str dict_lookup map_structure_zip get_first_in_structure strip_bos truncate_seq_pair check_or_get_instance write_paired_text maybe_create_dir UtilsTest load_hop_mean_embedding randomedge_sampler load_tuples_hops print_loss_accu_predlabel get_adjs2 write_metrics_into_json get_adjs1 add_loss_accu_msg save_evaluation_results build_vocab_id _preprocess_adj print_evaluation_results get_lr_multiplier maybe_create_file normalized_laplacian row_normalize random_walk i_norm fetch_normalization no_norm aug_random_walk bingge_norm_adjacency aug_normalized_adjacency normalized_adjacency random_walk_laplacian laplacian gcn do_metrics hyp_format DataParallel save_evaluation_results device DataIterator embedding_init_value _do_metrics load_state_dict reduced_results_path to format load_hop_mean_embedding num_test_data MultiAlignedData eval_dataset_name dataset_dir ctx_format eval_metric_name net checkpoint maybe_create_file load join print load_tuples_hops dialog_model_name build_vocab_id print_evaluation_results non_reduced_results_path len do_eval _eval_epoch BertAdam LambdaLR _train_epoch output_dir do_train setLevel seed config_model addHandler vis_dir maybe_create_dir append range setFormatter SummaryWriter partial metric_name close StreamHandler mkdir manual_seed info INFO FileHandler task int warmup_proportion model_file system named_parameters Formatter num_train_data config_data pickle_data_dir max_train_bert_epoch train_batch_size print format isfile pearsonr str spearmanr round join mkdir update items list format print kw_tokenize Counter set tqdm log10 dirname isfile makedirs update candi_extract format print extend Counter tqdm dirname isfile KeywordExtractor makedirs load_empatheticdialogues load_dailydialog load_convai2 print join print join pop_one_sample append join print strip len append range split replace_content_in_dialog info prepare_record_data modify_config_data get_train_examples get_labels get_dev_examples get_test_examples BERTTokenizer join InputFeatures encode_text info len join get_train_examples get_dev_examples convert_examples_to_features_and_output_to_files get_test_examples fn startswith max_train_epoch BERTClassifier save _test_epoch get_lr_multiplier do_test RecordData ModelWrapper Path Executor test train TPE run max_seq_length print remove urlretrieve print join urlretrieve mkdir print join urlretrieve mkdir append split download_and_extract path_to_mrpc data_dir add_argument format_mrpc get_tasks tasks ArgumentParser parse_args download_diagnostic guid label enumerate get_labels min map_text_to_id batch_size model sample_id _get_helper nsamples tensor str pretrained_model_name tolist max_decoding_length input map_token_to_id GPT2Decoder GPT2Tokenizer eval is_available interactive map_id_to_text full display_steps state_dict eval_steps get_train_op prepare_pickle_data join print read_raw_data convert_examples_to_features_and_output_to_files isfile _run_epoch switch_to_train_data SentenceClassifier TrainTestDataIterator switch_to_val_data switch_to_test_data num_epochs test_data val_data train_data sub join open transform_raw_sst data_path make_vocab maybe_download Seq2SeqAttn max PairedTextData file_bleu translation reference Transformer max_batch_tokens Adam Vocab getattr CustomBatchingStrategy beam_width write_log lr_config vocab_file load_checkpoint parameters replace extend lower sub append split read_file Counter format print read_file append make_array Config src tgt add_argument ArgumentParser input_dir parse_args set_defaults get_preprocess_args make_dataset input_dir sorted list tgt source_valid count_words target_train target_test __dict__ target_vocab save_data set realpath src source_test source_vocab target_valid dumps tok source_train sqrt max make_vocab join maybe_download mean exp _generate get_optimizer VAE eos_token_id train_data_hparams test_data_hparams sum vocab MonoTextData size ExponentialLR makedirs val_data_hparams step out replace endswith dir import_module getattr setattr load_config_into_args add_argument config_data ArgumentParser get_processor_class task load_datasets uncased batch_size max_seq_len construct_dataset XLNetTokenizer processor_class get_processor_class dict_fetch lr_layer_decay_rate ClassifierWrapper min_lr_ratio train_steps backwards_per_step construct_datasets is_regression RegressorWrapper make_deterministic param_groups lr warmup_steps warmup_lr_lambda Accuracy XLNetDecoder XLNetTokenizer embed sample segment_ids writer list input_ids is_real_example get_record_feature_types close input_mask info float convert_single_example join int items write labels tqdm get_test_examples label_id makedirs get_processor_class join is_regression get_record_feature_types capitalize warning info to task_name isinstance index get lower squeeze unsqueeze permute matmul rsqrt unsqueeze sum safe_cumprod cumsum clamp transpose f tensor cumprod zeros cat dtype randn sigmoid shape type squeeze attention_mechanism matmul unsqueeze attention_layer cat values tensor eye ones_like sequence_mask tensor dim sequence_mask tensor tiny size dim arange cumsum sort _make_ix_like unsqueeze gather isinstance __init__ LSTMCell RNNCell GRUCell __new__ MultiRNNCell isinstance todict RNNCellBase default_rnn_cell_hparams HighwayWrapper wrap_builtin_cell DropoutWrapper append HParams ResidualWrapper range check_or_get_instance isinstance todict default_regularizer_hparams HParams type check_or_get_instance get partial todict isinstance get_function todict isinstance get_function layers todict isinstance get_instance uniquify_str Sequential add_module append HParams __name__ get pop todict isinstance copy update check_or_get_class todict isinstance HParams default_optimization_hparams optimizer_class update check_or_get_class scheduler_class todict isinstance HParams default_optimization_hparams partial todict HParams default_optimization_hparams get_function isinstance param_groups get_scheduler get_grad_clip_fn append Tensor HParams default_optimization_hparams get_optimizer optimizer exp size rand cos pi sqrt uniform_ float log join _download _download_from_google_drive endswith extractall _extract_google_drive_file_id maybe_create_dir is_zipfile is_tarfile info append enumerate print join urlretrieve stat get join print _extract_google_drive_file_id _get_confirm_token Session items list sorted Counter dict zip range len item defaultdict zip map_ids_to_tokens_py isinstance tolist str_join strip_special_tokens full enumerate isinstance print time update _is_record_data _default_mono_text_dataset_hparams _default_scalar_dataset_hparams _is_text_data _is_scalar_data _default_record_dataset_hparams update _default_mono_text_dataset_hparams NEAREST LANCZOS isinstance BILINEAR BICUBIC deepcopy list items all todict isinstance get_numpy_dtype tuple CollateMethod warn StackedTensor FeatureDescription shape rstrip enumerate strip category category startswith startswith category ord update append list range ord add set tuple range len isinstance _maybe_str_to_list _get_ngrams exp _lowercase compat_as_text zip float sum range len isinstance search group float32 join mkdtemp realpath rmtree compat_as_text dirname abspath max range _get_ngrams exp dict zip sum range sub reshape shape ones_like zeros_like accuracy numel tensor float ones_like zeros_like isinstance binary_cross_entropy_with_logits bce_loss BCEWithLogitsLoss discriminator_fn sum softmax log append _get_entropy reduce_dimensions get_rank mask_and_reduce _get_entropy get_rank sorted list reduce_batch_time mask_sequences mean transpose_batch_time sum range mean float sum update sorted list squeeze set mean sum mask_and_reduce sum detach mask_and_reduce log_softmax nll_loss permute mask_and_reduce dtype binary_cross_entropy_with_logits type detach reduce_dimensions ones_like zeros_like binary_cross_entropy_with_logits clas_fn log_softmax tuple nll_loss permute dim range detach mask_and_reduce list sorted mean sum range detach _discount_reward_tensor_1d std mean _discount_reward_tensor_2d sqrt tensor dim max sequence_mask cumprod expand mask_sequences unsqueeze tensor flip cat zeros_like cumsum mask_sequences stack permute append flip range flatten Size isinstance zip Size isinstance flatten sum _get_sizes list isinstance linear_layer Size flatten activation_fn _get_sizes pack_sequence_as cat split Parameter Module isinstance size Identity is_tensor Linear topk cumsum sort size clone softmax float range update default_embedding_hparams initializer xavier_uniform_ empty getattr tensor HParams is_tensor get_initializer isinstance todict num_layers Linear activation dropout_layer_ids _to_list get_layer final_layer_activation append layer_size range Dropout mask_sequences output_layer update MyDict access mkdir Path W_OK home Path isinstance isinstance Embedding bias zeros_ normal_ weight Linear auto seed manual_seed_all manual_seed isinstance update default_name_fn isinstance enumerate items list _to_dict get_instance isinstance items list isinstance tolist add to_list Tensor pop join split isnumeric int named_children _convert_id _add_indent extra_repr __name__ append split index_select size view pop size list size list size unsqueeze len arange expand topk compute_batch_indices stack gather_nd map_structure to _is_finished inner_loop zeros size tolist stack unsqueeze repeat map_structure append Tensor to full _expand_to_beam_size enumerate items list items list extend isinstance ndarray isinstance isinstance _recur_convert Size isinstance list _yield_value isinstance values _packed_nest_with_indices list isinstance values type getattr __bases__ _yield_sorted_items _sorted _is_namedtuple isinstance _fields Mapping enumerate _sequence_like _yield_value is_sequence append Mapping _is_namedtuple isinstance flip clone permute range dynamic_rnn tensor reverse_sequence _dynamic_rnn_loop tensor zero_state permute cell tolist mask_sequences stack map_structure_zip map_structure append range enumerate is_tensor dim ndim asarray dtype sequence_mask view size transpose_batch_time tensor dim reshape new_full dim isinstance tuple any max cat enumerate import_module _ones_matrix_band_part T ones reshape tri as_tensor type __name__ Size hasattr isinstance Size hasattr isinstance map_structure size expand device item tensor to getfullargspec list keys args getfullargspec defaults len get_class isinstance join locate get_instance isinstance list get_args get_class isinstance __init__ set keys get_instance_with_redundant_kwargs isinstance items list get_args get_class isinstance __init__ set join locate callable items list get_args set update isinstance items list isinstance deepcopy list items list keys todict isinstance cast items list isinstance extend OrderedDict _fields zip append range len isinstance _recur_strip _recur_split str_join _recur_strip _recur_split str_join _recur_strip _recur_split str_join _recur_split _strip_bos_ str_join _strip_eos_ strip_token _recur_join next pop len format makedirs makedirs add add_scalar avg format info print items list format items list format print tolist write_metrics_into_json update adj_normalizer fetch_normalization int permutation coo_matrix _preprocess_adj nnz close tolist randomedge_sampler get_device zeros to range enumerate tolist randomedge_sampler get_device zeros to range enumerate dict strip len diags flatten coo_matrix sum array flatten coo_matrix diags diags flatten coo_matrix sum array diags flatten coo_matrix eye sum array diags flatten coo_matrix eye sum array diags flatten coo_matrix sum array diags flatten coo_matrix sum array diags flatten coo_matrix eye sum array diags flatten coo_matrix sum array coo_matrix coo_matrix eye get diags flatten dot sum array | # **GRADE**: Automatic Graph-Enhanced Coherence Metric for Evaluating Open-Domain Dialogue Systems This repository contains the source code for the following paper: [GRADE: Automatic Graph-Enhanced Coherence Metric for Evaluating Open-Domain Dialogue Systems](https://arxiv.org/abs/2010.03994) Lishan Huang, Zheng Ye, Jinghui Qin, Xiaodan Liang; EMNLP 2020 ## Model Overview  ## Prerequisites Create virtural environment (recommended): ``` conda create -n GRADE python=3.6 | 2,772 |
liarba/caffe_dev | ['semantic segmentation'] | ['DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs'] | python/caffe/io.py python/caffe/test/test_python_layer.py scripts/download_model_binary.py python/caffe/net_spec.py python/caffe/test/test_net.py tools/extra/resize_and_crop_images.py python/draw_net.py python/caffe/test/test_net_spec.py src/caffe/test/test_data/generate_sample_data.py python/caffe/draw.py python/caffe/pycaffe.py tools/extra/extract_seconds.py scripts/cpp_lint.py python/classify.py examples/web_demo/exifutil.py examples/pycaffe/layers/pyloss.py python/caffe/test/test_solver.py python/caffe/classifier.py examples/finetune_flickr_style/assemble_data.py python/caffe/test/test_io.py python/caffe/test/test_python_layer_with_param_str.py tools/extra/parse_log.py python/caffe/__init__.py python/caffe/test/test_layer_type_list.py examples/web_demo/app.py scripts/copy_notebook.py python/caffe/detector.py python/detect.py examples/pycaffe/caffenet.py tools/extra/summarize.py download_image make_net max_pool caffenet conv_relu fc_relu EuclideanLossLayer start_tornado start_from_terminal embed_image_html classify_upload index allowed_file ImagenetClassifier classify_url open_oriented_im apply_orientation main main main parse_args Classifier Detector get_edge_label draw_net get_layer_label get_pydot_graph choose_color_by_layertype get_pooling_types_dict draw_net_to_file Transformer blobproto_to_array datum_to_array array_to_blobproto arraylist_to_blobprotovecor_str array_to_datum resize_image blobprotovector_str_to_arraylist load_image oversample Layers Function Parameters Top NetSpec assign_proto param_name_dict to_proto _Net_blobs _Net_forward_all _Net_set_input_arrays _Net_backward _Net_params _Net_forward _Net_IdNameWrapper _Net_outputs _Net_forward_backward_all _Net_blob_loss_weights _Net_batch _Net_inputs TestBlobProtoToArray TestLayerTypeList simple_net_file TestNet lenet TestNetSpec silent_net anon_lenet exception_net_file parameter_net_file SimpleLayer TestPythonLayer ParameterLayer python_net_file ExceptionLayer SimpleParamLayer TestLayerWithParam python_param_net_file TestSolver ParseNolintSuppressions CheckVlogArguments CheckSectionSpacing FindNextMultiLineCommentEnd ReplaceAll CheckForFunctionLengths _SetOutputFormat _IsTestFilename _VerboseLevel CheckBraces RemoveMultiLineComments ResetNolintSuppressions CheckForNonStandardConstructs _SetVerboseLevel PrintUsage _NestingState CheckIncludeLine CheckAccess _CppLintState Search CheckInvalidIncrement RemoveMultiLineCommentsFromRange CleansedLines CheckForBadCharacters UpdateIncludeState FindPreviousMatchingAngleBracket CheckEmptyBlockBody FindNextMultiLineCommentStart Match _NamespaceInfo CheckMakePairUsesDeduction CheckCheck IsBlankLine _SetFilters ProcessLine _FunctionState CheckPosixThreading GetLineWidth GetHeaderGuardCPPVariable IsCppString _IncludeState CheckSpacing _ClassInfo CheckForCopyright IsErrorSuppressedByNolint ProcessFileData CheckForMultilineCommentsAndStrings CloseExpression _PreprocessorInfo _OutputFormat CheckForIncludeWhatYouUse CheckSpacingForFunctionCall FindEndOfExpressionInLine FindNextMatchingAngleBracket _SetCountingStyle ProcessFile _IncludeError CleanseRawStrings CheckAltTokens CheckForNewlineAtEOF ParseArguments CheckForNonConstReference PrintCategories _Filters main FilesBelongToSameModule CheckCStyleCast FileInfo _BlockInfo CheckForHeaderGuard CheckCaffeDataLayerSetUp ReverseCloseExpression CleanseComments _DropCommonSuffixes _ClassifyInclude CheckStyle CheckCaffeAlternatives FindStartOfExpressionInLine _ShouldPrintError CheckComment Error _GetTextInside CheckLanguage CheckCaffeRandom GetPreviousNonBlankLine reporthook parse_readme_frontmatter model_checks_out valid_dirname get_start_time extract_seconds extract_datetime_from_line get_log_created_year write_csv parse_log fix_initial_nan_learning_rate save_csv_files main parse_args parse_line_for_net_output ResizeCropImagesMapper PILResizeCrop OpenCVResizeCrop print_table printed_len summarize_net main read_net format_param imread urlretrieve Convolution InnerProduct Data SoftmaxWithLoss LRN Accuracy max_pool InnerProduct conv_relu fc_relu Dropout get read info load_image classify_image StringIO join replace info secure_filename save filename open_oriented_im classify_image fromarray replace astype save resize StringIO items list listen HTTPServer format print start WSGIContainer update start_tornado add_option OptionParser debug port parse_args ImagenetClassifier forward run hasattr _getexif astype float32 tile apply_orientation open transpose model_def endswith ArgumentParser save mean_file channel_swap output_file dirname expanduser parse_args input_file predict Classifier set_mode_cpu load time isdir print add_argument set_mode_gpu pretrained_model gpu len DataFrame Detector format to_hdf detect_selective_search mean set_index to_csv detect_windows read_csv add_argument ArgumentParser read NetParameter output_image_file rankdir Merge draw_net_to_file items list DESCRIPTOR batch_size str num_output get_pooling_types_dict add_edge get_edge_label list Dot get_layer_label values name choose_color_by_layertype Edge Node bottom append type layer add_node top data array diff shape BlobProto extend flat extend BlobProtoVector ParseFromString BlobProtoVector extend tostring shape Datum flat data len astype float32 tile zoom tuple resize fill empty array concatenate shape tile empty array LayerParameter list NetParameter _to_proto extend Counter OrderedDict values iteritems hasattr isinstance extend add getattr setattr items list layers index set outputs _forward len items list _backward layers inputs index set len items list asarray extend copy next _batch iter forward values len items list asarray backward extend copy next _batch zip_longest zip iter forward values len ascontiguousarray list concatenate iter zeros next range values len NamedTemporaryFile str close write data Pooling pool1 conv2 pool2 ip1 relu1 SoftmaxWithLoss Convolution NetSpec DummyData ip2 ReLU InnerProduct label conv1 Pooling SoftmaxWithLoss Convolution DummyData ReLU InnerProduct data NetSpec DummyData Silence data2 error search add group clear compile compile compile SetOutputFormat SetCountingStyle SetFilters _Filters startswith IsErrorSuppressedByNolint _ShouldPrintError write IncrementErrorCount replace append Match group find startswith endswith range error FindNextMultiLineCommentEnd RemoveMultiLineCommentsFromRange FindNextMultiLineCommentStart rstrip find range len FindEndOfExpressionInLine range len FindStartOfExpressionInLine error min search I range len FileInfo RepositoryName sep sub ParseNolintSuppressions error startswith split GetHeaderGuardCPPVariable enumerate error enumerate error len error replace count error find error find error find error find error Search error match InnermostClass replace error escape Match Search error group Search Check error lines Count End group Begin NumLines Match raw_lines range Search error match group error Match group pop group append Search pop group append Search elided replace CheckSpacingForFunctionCall rfind error len group min CloseExpression NumLines sub find CheckComment Match range Search lines_without_raw_strings error group starting_linenum Match range Search error rfind len group ReverseCloseExpression Search Match CloseExpression find error Match CloseExpression find elided error strip group FindEndOfExpressionInLine find Match range CloseExpression len error Match finditer normalize isinstance GetLineWidth int InnermostClass CheckCheck error CheckAltTokens CheckBraces CheckSpacing CheckSectionSpacing CheckEmptyBlockBody CheckAccess GetHeaderGuardCPPVariable lines_without_raw_strings _DropCommonSuffixes RepositoryName match split CheckNextIncludeOrder CanonicalizeAlphabeticalOrder FileInfo error search group SetLastHeader match _ClassifyInclude Match pop end search set append values M rstrip replace CheckCStyleCast error _GetTextInside CheckIncludeLine search group lstrip startswith Match ResetSection Search split rfind error group ReverseCloseExpression lstrip findall Match range Search ReplaceAll error Match Search endswith replace setdefault group search CleanseComments open list FilesBelongToSameModule error search copy sub NumLines FullName keys range error search CheckPosixThreading ParseNolintSuppressions CheckVlogArguments CheckMakePairUsesDeduction CheckCaffeDataLayerSetUp CheckLanguage CheckInvalidIncrement CheckCaffeRandom CheckForNonConstReference check_fn Update CheckForNonStandardConstructs CheckStyle raw_lines CheckForMultilineCommentsAndStrings CheckCaffeAlternatives CheckForFunctionLengths CleansedLines _NestingState CheckForBadCharacters CheckForNewlineAtEOF _IncludeState RemoveMultiLineComments CheckForCopyright ResetNolintSuppressions CheckForHeaderGuard NumLines CheckCompletedBlocks CheckForIncludeWhatYouUse range ProcessLine _FunctionState Error rstrip endswith len write ProcessFileData _SetVerboseLevel range split write exit join write exit _VerboseLevel int getopt _SetOutputFormat set _SetVerboseLevel PrintCategories _SetFilters _OutputFormat PrintUsage _SetCountingStyle split getreader ParseArguments ResetErrorCounts stderr exit verbose_level PrintErrorCounts StreamReaderWriter ProcessFile getwriter int time write flush load join index int rfind datetime split getctime year strip extract_datetime_from_line get_start_time total_seconds strip write get_log_created_year close extract_datetime_from_line open float get_log_created_year compile fix_initial_nan_learning_rate search group OrderedDict append float join basename write_csv print excel parse_log save_csv_files output_dir logfile_path NetParameter decay_mult format name lr_mult append print zip len get join str format convolution_param list setdefault param kernel_size map set top bottom append type module layer enumerate print_table filename summarize_net read_net | ## DeepLab v2 ### Introduction DeepLab is a state-of-art deep learning system for semantic image segmentation built on top of [Caffe](http://caffe.berkeleyvision.org). It combines (1) *atrous convolution* to explicitly control the resolution at which feature responses are computed within Deep Convolutional Neural Networks, (2) *atrous spatial pyramid pooling* to robustly segment objects at multiple scales with filters at multiple sampling rates and effective fields-of-views, and (3) densely connected conditional random fields (CRF) as post processing. This distribution provides a publicly available implementation for the key model ingredients reported in our latest [arXiv paper](http://arxiv.org/abs/1606.00915). It also contains implementations for **all** methods reported in all our previous papers. Please consult and consider citing the following papers: @article{CP2016Deeplab, title={DeepLab: Semantic Image Segmentation with Deep Convolutional Nets, Atrous Convolution, and Fully Connected CRFs}, author={Liang-Chieh Chen and George Papandreou and Iasonas Kokkinos and Kevin Murphy and Alan L Yuille}, | 2,773 |
licstar/compare | ['word embeddings'] | ['How to Generate a Good Word Embedding?'] | evaluation/tfl/toefl.py evaluation/syn_sem/king.py evaluation/ner/ner.py evaluation/avg/avg.py evaluation/pos/pos.py evaluation/cnn/cnn.py evaluation/ws/ws.py func func func func func func func system range print | # compare This is the source code of [How to Generate a Good Word Embedding?](http://arxiv.org/abs/1507.05523). Folder **embedding** contains all embedding algorithms we used in this paper. Folder **evaluation** contains all evaluation tasks in the paper. The Chinese version of Introduction is available at [《How to Generate a Good Word Embedding?》导读](http://licstar.net/archives/620). | 2,774 |
lifeng9472/IBCCF | ['visual tracking'] | ['Integrating Boundary and Center Correlation Filters for Visual Tracking with Aspect Ratio Variation'] | external_libs/matconvnet/utils/proto/caffe_fastrcnn_pb2.py external_libs/matconvnet/doc/matdocparser.py external_libs/matconvnet/doc/matdoc.py external_libs/matconvnet/utils/proto/caffe_6e3916_pb2.py external_libs/matconvnet/utils/proto/caffe_pb2.py external_libs/matconvnet/utils/proto/caffe_b590f1d_pb2.py external_libs/matconvnet/utils/proto/caffe_0115_pb2.py external_libs/matconvnet/utils/layers.py external_libs/matconvnet/utils/proto/caffe_old_pb2.py external_libs/matconvnet/utils/proto/vgg_caffe_pb2.py external_libs/matconvnet/utils/import-caffe.py extract render_L render_V render_P render_DIVL render_DH render_BL render_L_from_indent render_SL render_S render Context render_DI Frame render_B findNextFunction getFunctionDoc readText MatlabFunction render_DL clean Lexer P PL Parser BH EOF DI L DL SL BL DH DIVL Terminal S DIV NonTerminal B V Symbol blobproto_to_array versiontuple dict_to_struct_array keyboard tolist escape bilinear_interpolate getopts find rowcell CaffeInnerProduct ConversionError CaffeScale CaffeBatchNorm CaffeLayer CaffeCrop CaffeConcat CaffeConv CaffePooling CaffeData reorder CaffeElementWise getFilterOutputSize CaffeROIPooling CaffeSoftMaxLoss CaffeReLU getFilterTransform CaffeModel CaffeTransform CaffeDeconvolution row dictToMatlabStruct rowarray CaffeBlob transposeTransform CaffeDropout CaffeLRN CaffeEltWise composeTransforms CaffeSoftMax HingeLossParameter BlobProto BlobProtoVector NetStateRule LayerParameter PowerParameter FillerParameter ArgMaxParameter V0LayerParameter InnerProductParameter ConvolutionParameter SolverState EltwiseParameter SliceParameter WindowDataParameter DummyDataParameter HDF5OutputParameter TanHParameter TransformationParameter SoftmaxParameter ConcatParameter DataParameter SolverParameter MVNParameter ContrastiveLossParameter NetState NetParameter PoolingParameter DropoutParameter Datum SigmoidParameter AccuracyParameter MemoryDataParameter LRNParameter ReLUParameter ImageDataParameter InfogainLossParameter HDF5DataParameter ThresholdParameter ReductionParameter HingeLossParameter BlobProto BlobProtoVector NetStateRule LayerParameter PowerParameter FillerParameter ArgMaxParameter V0LayerParameter InnerProductParameter ConvolutionParameter SolverState EltwiseParameter LossParameter SliceParameter WindowDataParameter DummyDataParameter HDF5OutputParameter TanHParameter TransformationParameter SoftmaxParameter ConcatParameter DataParameter SPPParameter ParamSpec EmbedParameter SolverParameter MVNParameter ContrastiveLossParameter NetState NetParameter PoolingParameter DropoutParameter Datum SigmoidParameter BlobShape ExpParameter AccuracyParameter LogParameter ThresholdParameter TileParameter MemoryDataParameter LRNParameter ReLUParameter ImageDataParameter ReshapeParameter InfogainLossParameter V1LayerParameter HDF5DataParameter PReLUParameter FlattenParameter PythonParameter ReductionParameter HingeLossParameter BlobProto BlobProtoVector NetStateRule LayerParameter PowerParameter FillerParameter ArgMaxParameter V0LayerParameter InnerProductParameter ConvolutionParameter SolverState EltwiseParameter LossParameter SliceParameter BatchNormParameter WindowDataParameter DummyDataParameter HDF5OutputParameter TanHParameter TransformationParameter SoftmaxParameter ConcatParameter DataParameter SPPParameter ParamSpec EmbedParameter SolverParameter MVNParameter ContrastiveLossParameter NetState NetParameter BiasParameter PoolingParameter DropoutParameter Datum SigmoidParameter BlobShape ExpParameter AccuracyParameter LogParameter ThresholdParameter TileParameter MemoryDataParameter LRNParameter ReLUParameter ImageDataParameter ELUParameter ReshapeParameter InfogainLossParameter ScaleParameter V1LayerParameter HDF5DataParameter PReLUParameter FlattenParameter PythonParameter ROIPoolingParameter HingeLossParameter BlobProto BlobProtoVector NetStateRule LayerParameter PowerParameter FillerParameter ArgMaxParameter V0LayerParameter InnerProductParameter ConvolutionParameter SolverState EltwiseParameter LossParameter SliceParameter WindowDataParameter DummyDataParameter HDF5OutputParameter TanHParameter TransformationParameter SoftmaxParameter ConcatParameter DataParameter ParamSpec SolverParameter MVNParameter ContrastiveLossParameter NetState NetParameter PoolingParameter DropoutParameter Datum SigmoidParameter BlobShape ExpParameter AccuracyParameter ThresholdParameter MemoryDataParameter LRNParameter ReLUParameter ImageDataParameter InfogainLossParameter V1LayerParameter HDF5DataParameter PReLUParameter PythonParameter NetParameter LayerConnection BlobProto BlobProtoVector LayerParameter FillerParameter Datum SolverParameter SolverState BlobProto BlobProtoVector PowerParameter LayerParameter FillerParameter V0LayerParameter InnerProductParameter ConvolutionParameter SolverState WindowDataParameter HDF5OutputParameter ConcatParameter DataParameter SolverParameter NetParameter PoolingParameter DropoutParameter Datum MemoryDataParameter LRNParameter ImageDataParameter InfogainLossParameter HDF5DataParameter NetParameter EvalHistoryIter LayerConnection BlobProto BlobProtoVector LayerParameter FillerParameter Datum EvalHistory SolverParameter SolverState search clean match strip group append getFunctionDoc findNextFunction print print print children render_SL print pop render_DH print Frame push render_DIVL children render_DI print children render_L print pop children render_L_from_indent isa Frame render_B push indent pop children Frame push render_DIVL children render_BL render_V render_S render_DL isa render_P print Context render_DIVL dim tolist hasattr list empty keys RepeatedScalarFieldContainer isinstance update print f_locals interact copy reshape asarray astype clip hasattr list ndarray isinstance append empty keys CaffeTransform CaffeTransform | IBCCF: Integrating Boundary and Center Correlation Filters for Visual Tracking with Aspect Ratio Variation ======== By Feng Li, Yingjie Yao, Peihua Li, David Zhang, Wangmeng Zuo and Ming-Hsuan Yang Introduction ---- IBCCF is a Correlation filter (CF) based method for visual tracking. While several approaches have been proposed for scale adaptive tracking on CF-based trackers, the aspect ratio variation remains an open problem during tracking. IBCCF addresses this issue by introducing a family of 1D boundary CFs to localize the left, right, top, and bottom boundaries in videos. For more details, please refer to our paper. The paper link is: http://openaccess.thecvf.com/content_ICCV_2017_workshops/papers/w28/Li_Integrating_Boundary_and_ICCV_2017_paper.pdf Citation ---- If you find IBCCF useful in your research, please consider citing: | 2,775 |
lijiaman/CASENet | ['object proposal generation', 'edge detection', 'semantic segmentation'] | ['CASENet: Deep Category-Aware Semantic Edge Detection'] | prep_dataset/prep_SBD_dataset.py dataloader/SBD_data.py dataloader/SBD_data_zip.py utils/utils.py train_val/model_play.py vis_features.py get_results_for_benchmark.py config.py modules/CASENet.py utils/convert_bin_to_hdf5.py main.py utils/convert_bin_to_png.py utils/convert_bin_to_numpy.py get_args main get_model_policy normalized_feature_map get_colors get_sbd_class_names SBDData SBDData set_require_grad_to_false CASENet_resnet101 CropLayer ScaleLayer gen_mapping_layer_name ConcatLayer ResNet load_npy_to_layer SliceLayer Bottleneck init_bilinear get_dataloader ToTorchFormatTensor RGB2BGR convert_num_to_bitfield convert_num_to_bitfield convert_num_to_bitfield AverageMeter save_checkpoint adjust_learning_rate check_gpu load_official_pretrained_model load_pretrained_model parse_args add_argument ArgumentParser validate SGD DataParallel adjust_learning_rate save_checkpoint cuda CASENet_resnet101 get_model_policy lr_steps load_state_dict range load_pretrained_model get_dataloader format multigpu start_epoch lr checkpoint_folder load resume_model line print NaN pretrained_model train epochs named_modules list format print extend parameters append min max str list format replace print named_parameters keys range len load join list format items state_dict print from_numpy load_state_dict save open size ceil zeros abs prod range parameters ResNet load_official_pretrained_model DataLoader Compose Normalize SBDData list asarray replace view from_numpy create_dataset append cat join remove ZIP_DEFLATED write close save numpy ZipFile format str print range imsave makedirs Variable cuda isinstance load items list format update replace print load_state_dict keys state_dict load update list format print load_state_dict keys state_dict join save makedirs param_groups weight_decay sum | # CASENet PyTorch Implementation This is an implementation for paper [CASENet: Deep Category-Aware Semantic Edge Detection](https://arxiv.org/abs/1705.09759). ## Data Processing We used the data preprocessing codes provided by the author.[sbd-preprocess](https://github.com/Chrisding/sbd-preprocess). Based on this, we generated hdf5 file for data loading. The codes for generating data files are in utils/ folder. We also provided codes to generate png for each class to store the binary value of edge information. (Maybe faster than hdf5 and more efficient in storage. If using this format, need to change the data loader in dataloader/ folder and change the codes for visualization.) ## Model Our implemented model is the ResNet101 version of CASENet. We evaluated the official model provided by the author, got a reasonable result but didn't reproduce the same number as in the paper. (The official model is converted from .caffemodel to PyTorch. About the conversion, we first converted the .caffemodel to numpy array, then based on the layername to load corresponding layer into PyTorch model. Codes for the transformation are in modules/CASENet.py) ## Training Running main.py for training a model. ## Visualization We modified the visualization codes from [CASENet](http://www.merl.com/research/license#CASENet). PLease see vis_features.py. | 2,776 |
lijiannuist/lightDSFD | ['face detection', 'data augmentation'] | ['DSFD: Dual Shot Face Detector'] | DSFDv2_r18/layers/__init__.py layers/box_utils.py DSFDv2_r18/layers/functions/detection.py DSFDv2_r18/model_search.py layers/__init__.py data/__init__.py DSFDv2_r18/dataset/config.py layers/functions/prior_box_ori.py layers/functions/detection.py DSFDv2_r18/dataset/__init__.py DSFDv2_r18/test_dsfdv2.py ssd_layers/functions/__init__.py layers/modules/l2norm.py ssd_layers/box_utils.py DSFDv2_r18/layers/box_utils.py data/config.py ssd_layers/modules/l2norm.py DSFDv2_r18/bi_fpn.py ssd_layers/__init__.py ssd_layers/functions/prior_box.py utils/__init__.py layers/functions/__init__.py DSFDv2_r18/layers/functions/__init__.py utils/augmentations.py data/dataset_acn.py ssd_layers/functions/detection.py test.py ssd_layers/modules/__init__.py layers/modules/multibox_loss.py data/coco.py speed.py data/voc0712.py light_face_ssd.py DSFDv2_r18/layers/functions/prior_box.py ssd_layers/modules/multibox_loss.py data/widerface.py DSFDv2_r18/operations.py layers/modules/__init__.py layers/functions/prior_box.py build_ssd multibox face_multibox arm_multibox BasicConv2d DeepHeadModule pa_multibox CRelu Inception2d SSD BasicConv detect_face bbox_vote write_to_txt vis_detections light_test_widerface infer light_test_oneimage COCOAnnotationTransform get_label_map COCODetection ListDataset VOCDetection VOCAnnotationTransform WIDERFaceAnnotationTransform WIDERFaceDetection detection_collate TestBaseTransform base_transform test_base_transform BaseTransform BiFPN_From_Genotype BiFPN_Neck_From_Genotype BasicConv2d DeepHead Network Zero RfeConv SepConv Identity _GumbelSoftMax Normal_Relu_Conv DilConv GumbelSoftMax TestBaseTransform preprocess test_base_transform decode refine_match _ciou_op is_in_box get_centerness_targets nms jaccard match_anchors pa_sfd_match point_form encode sfd_match bbox_overlaps_diou intersect jaccard_diou ATSS_match python_nms log_sum_exp bbox_overlaps_giou bbox_overlaps_ciou center_size match Detect PriorBox decode nms refine_match intersect log_sum_exp jaccard pa_sfd_match center_size match point_form encode sfd_match Detect PriorBox PriorBox L2Norm MultiBoxLoss focalLoss decode nms intersect log_sum_exp jaccard center_size match point_form encode Detect PriorBox L2Norm MultiBoxLoss SwapChannels ToTensor RandomCrop ToAbsoluteCoords RandomBrightness PhotometricDistort RandomSaturation Resize RandomSampleCrop ToPercentCoords intersect SSDAugmentation Lambda Compose ConvertColor RandomBaiduCrop Expand SubtractMeans jaccard_numpy RandomHue ConvertFromInts RandomMirror RandomContrast ToCV2Image RandomLightingNoise enumerate enumerate enumerate enumerate print repr data unsqueeze resize cuda column_stack permute append range format size astype net time print Variable float32 Tensor numpy array minimum maximum delete row_stack tile zeros sum max format write range data Variable size range unsqueeze array permute resize append Tensor numpy cuda net format subplots set_title print axis tight_layout add_patch imshow savefig Rectangle len load vis_detections print TestBaseTransform infer IMREAD_COLOR eval trained_model load_state_dict build_ssd imread cuda len save_folder build_ssd cuda open pull_event TestBaseTransform WIDERFaceAnnotationTransform len trained_model load_state_dict WIDERFaceDetection range format widerface_root eval load pull_anno write_to_txt print infer array pull_image makedirs append FloatTensor astype float32 astype float32 cuda permute clamp size min expand max intersect expand_as clamp size min expand expand_as sum max decode squeeze_ size jaccard center_size index_fill_ encode max range ones_like jaccard index_fill_ long max squeeze_ size jaccard index_fill_ is_in_box point_form encode max range max topk encode view jaccard mean t point_form append sum std range cat squeeze_ byte sort size jaccard index_fill_ eq point_form encode sum max range squeeze_ byte sort size jaccard index_fill_ eq point_form encode sum max range log cat zeros min max clamp clamp min device to sum max clamp min pi zeros sum max decode stack sqrt max mul sort new clamp index_select resize_as_ long mul sort new clamp index_select resize_as_ long minimum clip maximum intersect | # lightDSFD By [Jian Li](https://lijiannuist.github.io/) ## Introduction We propose lightDSFD based on [DSFD](https://arxiv.org/abs/1810.10220). the original DSFD code is [here](https://github.com/TencentYoutuResearch/FaceDetection-DSFD). On Nvidia Tesla P40,the time of network is 13ms. 模型 NMS_Params|Easy Set|Medium Set|Hard Set ------|--------|----------|-------- lightDSFD,thresh=0.05,number=500|0.891 |0.864 |0.469 ## DSFDv2 | 2,777 |
lijingsdu/sessionRec_NARM | ['session based recommendations'] | ['Neural Attentive Session-based Recommendation'] | data_process.py example_preprocess.py NARM.py prepare_data load_data process_seqs train_gru param_init_gru numpy_floatX pred_evaluation get_dataset adam load_params init_params zipp build_model gru_layer ortho_weight init_weights get_layer dropout_layer _p init_tparams unzip get_minibatches_idx floatX len astype max enumerate load int len_argsort arange len close shuffle zip append round open range zip len append range arange shuffle items list set_value OrderedDict items list get_value binomial switch shape OrderedDict init_weights load items list OrderedDict shared list items sqrt svd randn floatX concatenate astype ortho_weight zeros dot scan grad float32 OrderedDict shape sqrt zip shared zeros vector RandomStreams T function concatenate reshape scan dot dropout_layer softmax shared matrix sum numpy_floatX sum prepare_data f_pred_prob numpy_floatX function train_function max pred_evaluation values str list set_value get_dataset adam append load_params init_params range zipp build_model copy mean time init_tparams savez print unzip prepare_data load_data get_minibatches_idx len | # Neural Attentive Recommendation Machine This is our implementation for the paper: Jing Li, Pengjie Ren, Zhumin Chen, Zhaochun Ren, Tao Lian and Jun Ma (2017). Neural Attentive Session-based Recommendation. In Proceedings of CIKM'17, Singapore, Singapore, Nov 06-10, 2017. We have additionally released our Theano implementation of Neural Attentive Recommendation Machine under our proposed neural network framework. **Please cite our CIKM'17 paper if you use our codes. Thanks!** Author: Jing Li ([email protected]) ## Datasets YOOCHOOSE: http://2015.recsyschallenge.com/challenge.html DIGINETICA: http://cikm2016.cs.iupui.edu/cikm-cup | 2,778 |
lil-lab/spf | ['semantic parsing'] | ['Cornell SPF: Cornell Semantic Parsing Framework'] | spfbase/pysrc/analyze_cross_job_results.py to_float parse_line mean std | # [_**Cornell SPF**_](http://yoavartzi.com/spf) - Cornell Semantic Parsing Framework ## Authors **Developed and maintained by** [Yoav Artzi](http://yoavartzi.com) **Past contributors:** [Luke Zettlemoyer](http://homes.cs.washington.edu/~lsz/), Tom Kwiatkowski, [Kenton Lee](http://homes.cs.washington.edu/~kentonl/) ## Tutorial See our ACL 2013 tutorial for an introduction to semantic parsing with Combinatory Categorial Grammars (CCGs). The slides and videos are available [here](http://yoavartzi.com/tutorial). ## Discussion Group Please post all technical questions and inquiries in our the [https://groups.google.com/d/forum/cornellspf](Cornell SPF Google Group). ## Attribution When using Cornell SPF, please acknowledge it by citing: | 2,779 |
lilei-John/wav2letter | ['speech recognition'] | ['wav2letter++: The Fastest Open-source Speech Recognition System'] | recipes/librispeech/data/utils.py recipes/librispeech/data/prepare_data.py recipes/wsj/data/prepare_data.py tutorials/1-librispeech_clean/prepare_data.py recipes/timit/data/utils.py tutorials/1-librispeech_clean/prepare_lm.py recipes/timit/data/prepare_data.py recipes/wsj/data/prepare_lm.py recipes/wsj/data/utils.py recipes/librispeech/data/prepare_lm.py findtranscriptfiles parse_speakers_gender copytoflac write_sample copytoflac write_sample find_transcripts processdict ndx2idlist write_sample preprocess transcript2wordspelling findtranscriptfiles write_sample endswith join walk append Transformer set_output_format build join rsplit copytoflac lower dirname sep split replace append preprocess split join walk setdefault sort lower sub replace Transformer format remove system build set_output_format transcript2wordspelling | # wav2letter++ wav2letter++ is a fast open source speech processing toolkit from the Speech Team at Facebook AI Research. It is written entirely in C++ and uses the [ArrayFire](https://github.com/arrayfire/arrayfire) tensor library and the [flashlight](https://github.com/facebookresearch/flashlight) machine learning library for maximum efficiency. Our approach is detailed in this [arXiv paper](https://arxiv.org/abs/1812.07625). The goal of this software is to facilitate research in end-to-end models for speech recognition. The previous version of wav2letter (written in Lua) can be found in the "wav2letter-lua" branch under the repository. ## Building wav2letter++ See [Building Instructions](docs/installation.md) for details. ## Full documentation - [Data Preparation](docs/data_prep.md) | 2,780 |
lily-x/PAWS-public | ['gaussian processes'] | ['Stay Ahead of Poachers: Illegal Wildlife Poaching Prediction and Patrol Planning Under Uncertainty with Field Test Evaluations'] | iware/forestci/forestci.py field_tests/select_field_test.py iware/visualize_maps_driver.py planning/planning/library/piecewise-master/setup.py preprocess_consolidate/run_consolidate.py planning/Bagging_New_Cross_Blackbox.py planning/planning/src/SinglePlannerPurePath.py planning/planning/src/ComparisonsTests.py planning/planning/src/PatrolProblem.py iware/forestci/calibration.py iware/gpc.py planning/planning/library/piecewise-master/tests/test_piecewise.py planning/planning/src/Cluster.py planning/planning/src/SinglePlannerConst.py iware/bagging.py field_tests/utility.py planning/util.py planning/planning/library/piecewise-master/piecewise/regressor.py planning/planning/src/SinglePlannerNoPath.py iware/iware.py iware/forestci/__init__.py planning/Static_Feature_Maps.py field_tests/process_risk_maps.py iware/forestci/tests/test_forestci.py iware/forestci/due.py iware/balanced_bagging.py preprocess_consolidate/consolidate.py planning/planning/src/LookAheadPlanner.py iware/run_iware.py planning/planning/library/piecewise-master/piecewise/plotter.py iware/forestci/version.py iware/visualize_maps.py field_tests/visualize.py preprocess/preprocess.py planning/planning/src/SinglePlanner.py convolve_map_sum select_risk_blocks ProcessFieldTest save_map_shapefile find_variance find_risk_classes convolve_map mask_boundary_cells expand_block_mask find_low_effort make_field_test_barchart map_to_geodataframe map_to_color_grid points_to_grid maenumerate Visualize BaggingRegressor BaggingClassifier _generate_indices BaseBagging _parallel_predict_proba _generate_bagging_indices _parallel_predict_var _parallel_predict_log_proba _parallel_build_estimators _parallel_predict_regression _parallel_decision_function BalancedBaggingClassifier GaussianProcessClassifier _BinaryGaussianProcessClassifierLaplace iWare setup_data determine_threshold gpr_predict_proba evaluate_results normalize_data rf_predict_proba plot_roc feature_importance plot_precision_recall read_map_thresholds calibrateEB gbayes gfit _donothing_func _InactiveDueCreditCollector calc_inbag random_forest_error _core_computation _bias_correction test_with_calibration test_bias_correction test_core_computation test_random_forest_error test_year_quarter_by_park selected_threshold_by_park selected_finer_threshold_by_park plot_data_with_regression SegmentTracker _get_initial_segments FittedSegment _predict _preprocess _get_initial_merges piecewise _make_segment FittedModel _get_next_merge _make_merge _fit_line test_five_segments test_single_line test_messy_ts test_single_line_with_nans cluster SinglePlanner SinglePlannerNoPath Grid Preprocess sum_selected_months plot_patrol_effort save_combined_months consolidate_pipeline combine_data process_human_activity process_patrol_effort process_climate combine_static_features validate_months process_gpp reshape asarray convolve ones convolve percentile masked_where percentile print masked_where mask percentile print masked_where set_aspect format subplots output_filepath plot close scale_to_real to_file title savefig map_to_color_grid makedirs append func_to_use copy shape unravel_index zeros range masked_where zeros range shape arange xlabel close ylabel bar savefig figure set_color xticks yticks ones shape range where ndenumerate zip list apply zip GeoDataFrame DataFrame append GeoDataFrame maenumerate Polygon maenumerate Polygon GeoDataFrame append range randint sample_without_replacement _generate_indices check_random_state RandomState _make_estimator print has_fit_parameter base_estimator_ fit ones _generate_bagging_indices copy bootstrap_features shape bincount _max_samples _max_features range append bootstrap hasattr predict_proba zip zeros range predict hasattr zip zeros range predict predict_var arange setdiff1d predict_log_proba logaddexp classes_ zip fill empty reshape exp predict concatenate random_forest_error predict_proba_orig transform StandardScaler fit argmax format print size recall_score astype precision_recall_curve precision_score linspace f1_score range zeros auc accuracy_score ones transpose fbeta_score shape precision_recall_curve determine_threshold precision_score log_loss append sum format recall_score astype mean cohen_kappa_score f1_score auc roc_curve format print read_csv values drop show subplots plot grid set savefig show subplots plot grid set savefig fit ExtraTreesClassifier format print min get_maps_from_csv len save_map max range save_map_with_features ones_like T std exp min pdf dot pow linspace zeros sum max range x enumerate pdf percentile list partial arange map gfit sqrt interp _generate_sample_indices random_state n_estimators bincount append zeros range int arange concatenate print range mean sum view deepcopy T int n_estimators _bias_correction print calc_inbag mean ceil _core_computation calibrateEB RandomForestRegressor assert_raises random_forest_error assert_equal calc_inbag array fit concatenate _core_computation vstack zip assert_almost_equal array assert_almost_equal array _core_computation _bias_correction RandomForestRegressor int arange reshape rand random_forest_error assert_equal fit show plot print piecewise segments len sorted SegmentTracker _get_initial_segments heapify replace left_seg _preprocess right_seg cost _get_initial_merges segments new_seg _get_next_merge get_neighbors _make_merge max heappush argsort isfinite defaultdict _make_segment append abs range len heappop _fit_line _make_segment end_index error start_index array seed normal arange start_t assert_equal piecewise segments assert_almost_equal end_t len seed normal arange start_t assert_equal piecewise segments nan assert_almost_equal end_t len arange start_t assert_equal piecewise segments assert_almost_equal len start_t assert_equal piecewise segments assert_almost_equal end_t len data show time exp print reshape spectral_clustering shape imshow xticks title figure img_to_graph contour std range yticks combine_data process_human_activity process_patrol_effort process_climate combine_static_features len format print makedirs to_csv DataFrame read_csv len list range list format print makedirs to_csv range len list sum range sum list format columns print len read_csv range sum_selected_months validate_months drop format print read_csv sum_selected_months validate_months drop format print read_csv sum_selected_months validate_months drop format print transpose validate_months sum_selected_months read_csv values sum plot_patrol_effort format arange print squeeze concat len size to_csv roll flatten repeat tile DataFrame values drop format plot xlabel close ylabel title savefig linspace zeros max range len | # PAWS Protection Assistant for Wildlife Security (PAWS). Prediction and prescription to combat illegal wildlife poaching. Teamcore Research Group, Harvard University. The following students have contributed to this codebase and methodology: Fei Fang, Benjamin Ford, Shahrzad Gholami, Debarun Kar, Laksh Matai, Sara Mc Carthy, Thanh H. Nguyen, Lily Xu This project is licensed under the terms of the MIT license. ## Directories - `./preprocess/` - R code for processing raw data - `./preprocess_consolidate/` - Python code for consolidating output from preprocessing - `./iware/` - Python code for ML risk prediction - `./planning/` - Python code for patrol planning. (Note that this also includes older versions of prediction code.) - `./field_tests/` - Python code for selecting field test areas and visualizing park geography and risk maps | 2,781 |
limxuanyu127/Tank-Game | ['unity'] | ['Unity: A General Platform for Intelligent Agents'] | ml-agents-envs/mlagents_envs/communicator_objects/capabilities_pb2.py ml-agents/mlagents/trainers/components/reward_signals/curiosity/model.py ml-agents/mlagents/trainers/environment_parameter_manager.py ml-agents/mlagents/trainers/cli_utils.py ml-agents/mlagents/trainers/run_experiment.py ml-agents/mlagents/trainers/tests/check_env_trains.py ml-agents-envs/mlagents_envs/communicator_objects/command_pb2.py ml-agents-envs/mlagents_envs/mock_communicator.py ml-agents/mlagents/trainers/policy/__init__.py ml-agents-envs/mlagents_envs/communicator_objects/unity_to_external_pb2.py ml-agents/mlagents/trainers/tests/torch/test_reward_providers/test_extrinsic.py ml-agents-envs/mlagents_envs/communicator.py ml-agents/mlagents/trainers/tests/torch/saver/test_saver_reward_providers.py ml-agents/mlagents/trainers/torch/components/reward_providers/extrinsic_reward_provider.py gym-unity/gym_unity/envs/__init__.py ml-agents-envs/mlagents_envs/communicator_objects/brain_parameters_pb2.py ml-agents/mlagents/trainers/tests/tensorflow/test_nn_policy.py ml-agents/mlagents/trainers/learn.py ml-agents-envs/mlagents_envs/side_channel/raw_bytes_channel.py ml-agents/mlagents/trainers/trainer/trainer.py gym-unity/gym_unity/__init__.py ml-agents-envs/mlagents_envs/side_channel/__init__.py ml-agents/mlagents/trainers/torch/components/reward_providers/gail_reward_provider.py ml-agents/mlagents/trainers/model_saver/tf_model_saver.py utils/validate_meta_files.py ml-agents/mlagents/trainers/trainer_controller.py ml-agents/mlagents/trainers/components/bc/model.py ml-agents/mlagents/trainers/torch/utils.py ml-agents/mlagents/trainers/action_info.py ml-agents/mlagents/tf_utils/__init__.py ml-agents/mlagents/trainers/components/reward_signals/__init__.py ml-agents/mlagents/trainers/tests/tensorflow/test_ppo.py ml-agents/mlagents/trainers/tests/torch/test_ppo.py ml-agents/mlagents/trainers/tests/tensorflow/test_bcmodule.py ml-agents/mlagents/trainers/model_saver/torch_model_saver.py ml-agents-envs/setup.py ml-agents-envs/mlagents_envs/side_channel/engine_configuration_channel.py ml-agents-envs/mlagents_envs/communicator_objects/unity_rl_output_pb2.py ml-agents/mlagents/trainers/tests/mock_brain.py ml-agents/mlagents/trainers/policy/checkpoint_manager.py ml-agents/mlagents/trainers/tests/test_trainer_controller.py ml-agents/mlagents/trainers/torch/layers.py ml-agents/mlagents/trainers/components/reward_signals/reward_signal_factory.py ml-agents-envs/mlagents_envs/rpc_utils.py ml-agents/mlagents/trainers/tests/torch/test_encoders.py ml-agents/mlagents/trainers/tests/torch/test_policy.py ml-agents-envs/mlagents_envs/communicator_objects/unity_rl_initialization_output_pb2.py ml-agents-envs/mlagents_envs/side_channel/incoming_message.py ml-agents/setup.py ml-agents/mlagents/trainers/tests/tensorflow/test_reward_signals.py ml-agents/mlagents/trainers/torch/model_serialization.py ml-agents/mlagents/trainers/policy/torch_policy.py ml-agents/tests/yamato/setup_venv.py ml-agents/mlagents/trainers/barracuda.py ml-agents/mlagents/trainers/optimizer/tf_optimizer.py utils/run_markdown_link_check.py ml-agents/mlagents/trainers/env_manager.py ml-agents/mlagents/trainers/tests/tensorflow/test_tf_policy.py ml-agents/mlagents/trainers/ppo/trainer.py ml-agents/mlagents/trainers/policy/policy.py ml-agents/mlagents/trainers/tests/tensorflow/test_distributions.py ml-agents-envs/mlagents_envs/communicator_objects/agent_action_pb2.py ml-agents/mlagents/trainers/sac/optimizer_torch.py ml-agents-envs/mlagents_envs/tests/test_rpc_communicator.py ml-agents/mlagents/trainers/torch/networks.py ml-agents-envs/mlagents_envs/tests/test_envs.py utils/validate_inits.py ml-agents/mlagents/trainers/tests/dummy_config.py ml-agents-envs/mlagents_envs/side_channel/float_properties_channel.py ml-agents/mlagents/trainers/tests/tensorflow/test_models.py ml-agents/mlagents/trainers/torch/components/reward_providers/__init__.py ml-agents/mlagents/trainers/components/reward_signals/curiosity/signal.py ml-agents/mlagents/trainers/simple_env_manager.py ml-agents/mlagents/trainers/tf/tensorflow_to_barracuda.py ml-agents-envs/mlagents_envs/side_channel/outgoing_message.py ml-agents-envs/mlagents_envs/exception.py ml-agents/mlagents/trainers/tests/torch/test_networks.py ml-agents-envs/mlagents_envs/registry/remote_registry_entry.py ml-agents/mlagents/trainers/trainer/__init__.py ml-agents/mlagents/trainers/upgrade_config.py ml-agents-envs/mlagents_envs/communicator_objects/unity_message_pb2.py ml-agents/mlagents/trainers/tests/torch/test_reward_providers/test_curiosity.py ml-agents/mlagents/trainers/tests/test_learn.py ml-agents/mlagents/torch_utils/__init__.py ml-agents/tests/yamato/scripts/run_gym.py utils/validate_release_links.py ml-agents-envs/mlagents_envs/communicator_objects/agent_info_pb2.py ml-agents/mlagents/trainers/tests/test_demo_loader.py ml-agents/mlagents/trainers/tests/torch/test_reward_providers/test_gail.py ml-agents-envs/mlagents_envs/communicator_objects/observation_pb2.py utils/validate_versions.py ml-agents-envs/mlagents_envs/tests/test_rpc_utils.py ml-agents/mlagents/trainers/torch/decoders.py ml-agents/mlagents/trainers/__init__.py ml-agents-envs/mlagents_envs/tests/test_timers.py ml-agents/mlagents/trainers/torch/components/reward_providers/reward_provider_factory.py ml-agents/mlagents/trainers/tests/torch/test_bcmodule.py ml-agents/mlagents/trainers/tests/tensorflow/test_ghost.py ml-agents/mlagents/torch_utils/torch.py ml-agents-envs/mlagents_envs/communicator_objects/custom_reset_parameters_pb2.py ml-agents/mlagents/trainers/tests/test_env_param_manager.py ml-agents-envs/mlagents_envs/tests/test_registry.py ml-agents-envs/mlagents_envs/communicator_objects/agent_info_action_pair_pb2.py ml-agents/mlagents/trainers/ppo/optimizer_torch.py ml-agents-envs/mlagents_envs/communicator_objects/unity_rl_input_pb2.py ml-agents-envs/mlagents_envs/timers.py ml-agents/tests/yamato/check_coverage_percent.py ml-agents/mlagents/trainers/exception.py gym-unity/gym_unity/tests/test_gym.py ml-agents/mlagents/trainers/tests/tensorflow/test_barracuda_converter.py utils/make_readme_table.py ml-agents/mlagents/tf_utils/tf.py ml-agents/mlagents/trainers/buffer.py ml-agents/mlagents/torch_utils/cpu_utils.py ml-agents-envs/mlagents_envs/side_channel/side_channel.py ml-agents/mlagents/trainers/tests/torch/test_ghost.py ml-agents/mlagents/trainers/tests/test_subprocess_env_manager.py ml-agents/mlagents/trainers/tests/torch/test_simple_rl.py ml-agents/mlagents/trainers/subprocess_env_manager.py ml-agents-envs/mlagents_envs/side_channel/environment_parameters_channel.py ml-agents/mlagents/trainers/tests/torch/test_reward_providers/test_rnd.py ml-agents/mlagents/trainers/tests/torch/test_sac.py ml-agents/mlagents/trainers/tests/torch/test_layers.py ml-agents/mlagents/trainers/agent_processor.py ml-agents-envs/mlagents_envs/communicator_objects/engine_configuration_pb2.py ml-agents-envs/mlagents_envs/tests/test_env_utils.py ml-agents/mlagents/trainers/tests/test_rl_trainer.py ml-agents/mlagents/trainers/tests/tensorflow/test_saver.py ml-agents-envs/mlagents_envs/rpc_communicator.py ml-agents/mlagents/trainers/training_status.py ml-agents-envs/mlagents_envs/communicator_objects/demonstration_meta_pb2.py ml-agents-envs/mlagents_envs/__init__.py ml-agents/mlagents/trainers/tests/tensorflow/test_simple_rl.py gym-unity/setup.py ml-agents/mlagents/trainers/torch/distributions.py ml-agents/mlagents/trainers/behavior_id_utils.py ml-agents/mlagents/trainers/tests/test_config_conversion.py ml-agents/mlagents/trainers/tf/model_serialization.py ml-agents/mlagents/trainers/sac/network.py ml-agents/mlagents/trainers/policy/tf_policy.py ml-agents/mlagents/trainers/optimizer/__init__.py ml-agents-envs/mlagents_envs/registry/__init__.py ml-agents/mlagents/trainers/torch/encoders.py ml-agents/mlagents/trainers/tests/simple_test_envs.py ml-agents/mlagents/trainers/tests/__init__.py ml-agents-envs/mlagents_envs/communicator_objects/unity_output_pb2.py ml-agents-envs/mlagents_envs/env_utils.py ml-agents/mlagents/trainers/torch/components/bc/module.py ml-agents-envs/mlagents_envs/communicator_objects/space_type_pb2.py ml-agents/mlagents/trainers/trainer_util.py ml-agents/mlagents/trainers/tests/test_trainer_util.py ml-agents/mlagents/trainers/ppo/optimizer_tf.py ml-agents/mlagents/trainers/components/reward_signals/extrinsic/signal.py ml-agents/mlagents/trainers/sac/trainer.py ml-agents-envs/mlagents_envs/logging_util.py ml-agents-envs/mlagents_envs/side_channel/side_channel_manager.py utils/run_dotnet_format.py ml-agents/tests/yamato/training_int_tests.py ml-agents/mlagents/trainers/tests/torch/test_distributions.py ml-agents/mlagents/trainers/trajectory.py ml-agents/mlagents/trainers/settings.py ml-agents-envs/mlagents_envs/communicator_objects/unity_rl_initialization_input_pb2.py ml-agents-envs/mlagents_envs/base_env.py ml-agents-envs/mlagents_envs/communicator_objects/header_pb2.py ml-agents/mlagents/tf_utils/globals.py ml-agents/mlagents/trainers/tests/test_stats.py ml-agents/mlagents/trainers/tests/tensorflow/test_sac.py ml-agents/mlagents/trainers/model_saver/model_saver.py ml-agents/mlagents/trainers/components/reward_signals/gail/model.py ml-agents/mlagents/trainers/optimizer/torch_optimizer.py ml-agents/mlagents/trainers/tests/torch/saver/test_saver.py ml-agents-envs/mlagents_envs/side_channel/stats_side_channel.py ml-agents/mlagents/trainers/components/reward_signals/gail/signal.py ml-agents-envs/mlagents_envs/tests/test_side_channel.py ml-agents/mlagents/trainers/tf/models.py ml-agents/mlagents/trainers/tf/distributions.py ml-agents-envs/mlagents_envs/registry/base_registry_entry.py ml-agents/mlagents/trainers/ghost/controller.py ml-agents/tests/yamato/standalone_build_tests.py ml-agents-envs/mlagents_envs/environment.py ml-agents/mlagents/trainers/tests/test_training_status.py ml-agents/mlagents/trainers/tests/torch/test_decoders.py ml-agents/mlagents/trainers/demo_loader.py ml-agents/mlagents/trainers/ghost/trainer.py ml-agents-envs/mlagents_envs/registry/binary_utils.py ml-agents/mlagents/trainers/torch/components/reward_providers/base_reward_provider.py ml-agents/mlagents/trainers/tests/torch/test_reward_providers/utils.py ml-agents/tests/yamato/editmode_tests.py ml-agents/mlagents/trainers/tests/test_settings.py ml-agents/mlagents/trainers/torch/components/reward_providers/rnd_reward_provider.py ml-agents/mlagents/trainers/components/bc/module.py ml-agents-envs/mlagents_envs/communicator_objects/unity_input_pb2.py ml-agents-envs/mlagents_envs/tests/test_steps.py ml-agents/mlagents/trainers/tests/test_buffer.py ml-agents/mlagents/trainers/sac/optimizer_tf.py ml-agents/mlagents/trainers/trainer/rl_trainer.py ml-agents/mlagents/trainers/tests/test_agent_processor.py ml-agents/mlagents/trainers/torch/components/reward_providers/curiosity_reward_provider.py ml-agents-envs/mlagents_envs/communicator_objects/unity_to_external_pb2_grpc.py ml-agents/tests/yamato/yamato_utils.py ml-agents/mlagents/trainers/tests/torch/test_utils.py ml-agents/mlagents/trainers/stats.py ml-agents/tests/yamato/scripts/run_llapi.py ml-agents-envs/mlagents_envs/registry/unity_env_registry.py ml-agents/mlagents/trainers/tests/test_trajectory.py ml-agents/mlagents/trainers/optimizer/optimizer.py VerifyVersionCommand UnityGymException ActionFlattener UnityToGymWrapper create_mock_vector_steps test_gym_wrapper_multi_visual_and_vector test_gym_wrapper create_mock_group_spec test_branched_flatten setup_mock_unityenvironment test_gym_wrapper_visual test_gym_wrapper_single_visual_and_vector test_action_space VerifyVersionCommand get_rank set_warnings_enabled generate_session_config _read_in_integer_file _get_num_available_cpus get_num_threads_to_use is_available default_device ActionInfo AgentManager AgentProcessor AgentManagerQueue BarracudaWriter fuse print_known_operations compress Build sort lstm write fuse_batchnorm_weights trim mean gru Model summary Struct parse_args to_json rnn BehaviorIdentifiers get_global_agent_id create_name_behavior_id BufferException AgentBuffer StoreConfigFile _load_config DetectDefaultStoreTrue DetectDefault load_config _create_parser make_demo_buffer write_demo get_demo_files load_demonstration write_delimited demo_to_buffer EnvironmentParameterManager EnvManager EnvironmentStep SamplerException TrainerConfigError CurriculumError CurriculumConfigError MetaCurriculumError TrainerConfigWarning CurriculumLoadingError UnityTrainerException TrainerError write_timing_tree create_environment_factory write_run_options parse_command_line run_training write_training_status main run_cli get_version_string main parse_command_line ScheduleType TrainerSettings FrameworkType PPOSettings ConstantSettings GaussianSettings strict_to_cls RewardSignalSettings EnvironmentSettings ParameterRandomizationType EnvironmentParameterSettings check_and_structure RewardSignalType TrainerType MultiRangeUniformSettings HyperparamSettings SerializationSettings NetworkSettings SACSettings UniformSettings SelfPlaySettings RNDSettings Lesson EngineSettings EncoderType RunOptions GAILSettings CheckpointSettings BehavioralCloningSettings deep_update_dict ParameterRandomizationSettings ExportableSettings CompletionCriteriaSettings defaultdict_to_dict CuriositySettings SimpleEnvManager StatsWriter StatsSummary ConsoleWriter StatsReporter GaugeWriter TensorboardWriter StatsPropertyType worker EnvironmentResponse EnvironmentRequest UnityEnvWorker StepResponse SubprocessEnvManager EnvironmentCommand TrainerController TrainerFactory initialize_trainer handle_existing_directories StatusMetaData StatusType GlobalTrainingStatus AgentExperience Trajectory SplitObservations parse_args write_to_yaml_file convert convert_behaviors main remove_nones convert_samplers_and_curriculum convert_samplers BCModel BCModule create_reward_signal RewardSignal CuriosityModel CuriosityRewardSignal ExtrinsicRewardSignal GAILModel GAILRewardSignal GhostController GhostTrainer BaseModelSaver TFModelSaver TorchModelSaver Optimizer TFOptimizer TorchOptimizer NNCheckpointManager NNCheckpoint Policy UnityPolicyException TFPolicy UnityPolicyException TorchPolicy PPOOptimizer TorchPPOOptimizer PPOTrainer get_gae discount_rewards SACPolicyNetwork SACTargetNetwork SACNetwork SACOptimizer TorchSACOptimizer SACTrainer default_reward_processor check_environment_trains DebugWriter sac_dummy_config extrinsic_dummy_config ppo_dummy_config curiosity_dummy_config gail_dummy_config simulate_rollout create_mock_pushblock_behavior_specs create_mock_banana_behavior_specs setup_test_behavior_specs create_steps_from_behavior_spec create_mock_3dball_behavior_specs make_fake_trajectory create_mock_steps RecordEnvironment clamp SimpleEnvironment MemoryEnvironment test_end_episode test_agent_deletion test_agent_manager_queue test_agentprocessor test_agent_manager test_agent_manager_stats create_mock_policy test_buffer_sample construct_fake_buffer test_num_experiences assert_array fakerandint test_buffer test_buffer_truncate test_convert test_convert_behaviors test_remove_nones test_unsupported_version_raises_error test_load_demo test_demo_mismatch test_edge_cases test_load_demo_dir test_sampler_conversion test_sampler_and_constant_conversion test_create_manager test_curriculum_raises_no_completion_criteria_conversion test_curriculum_no_behavior test_curriculum_conversion test_curriculum_raises_all_completion_criteria_conversion basic_options test_run_training test_yaml_args test_bad_env_path test_commandline_args test_env_args FakeTrainer create_rl_trainer test_rl_trainer test_summary_checkpoint test_advance test_clear_update_buffer check_dict_is_at_least test_environment_settings test_strict_to_cls test_default_settings test_memory_settings_validation check_if_different test_is_new_instance test_no_configuration test_env_parameter_structure test_exportable_settings test_deep_update_dict test_trainersettings_structure test_reward_signal_structure test_tensorboard_writer test_stat_reporter_add_summary_write test_tensorboard_writer_clear test_gauge_stat_writer_sanitize ConsoleWriterTest test_stat_reporter_property MockEnvWorker mock_env_factory SubprocessEnvManagerTest test_subprocess_env_raises_errors create_worker_mock test_subprocess_env_endtoend test_initialization_seed test_start_learning_trains_until_max_steps_then_saves basic_trainer_controller trainer_controller_with_take_step_mocks test_advance_adds_experiences_to_trainer_and_trains trainer_controller_with_start_learning_mocks test_start_learning_trains_forever_if_no_train_model test_initialize_ppo_trainer test_load_config_invalid_yaml test_load_config_missing_file test_handles_no_config_provided dummy_config test_load_config_valid_yaml test_existing_directories test_globaltrainingstatus test_model_management StatsMetaDataTest test_trajectory_to_agentbuffer test_split_obs np_zeros_no_float64 np_array_no_float64 _check_no_float64 np_ones_no_float64 test_barracuda_converter test_bcmodule_rnn_update test_bcmodule_update test_bcmodule_constant_lr_update test_bcmodule_dc_visual_update create_bc_module test_bcmodule_defaults test_bcmodule_rnn_dc_update test_multicategorical_distribution test_tanh_distribution test_gaussian_distribution test_load_and_set dummy_config test_publish_queue test_process_trajectory test_create_input_placeholders create_behavior_spec test_min_visual_size test_large_normalization create_policy_mock test_normalization test_policy_evaluate _compare_two_policies test_trainer_increment_step test_trainer_update_policy test_ppo_optimizer_update test_ppo_optimizer_update_curiosity test_process_trajectory test_rl_functions test_add_get_policy _create_ppo_optimizer_ops_mock dummy_config test_ppo_optimizer_update_gail test_ppo_get_value_estimates test_gail_dc_visual reward_signal_update reward_signal_eval test_extrinsic test_curiosity_cc test_gail_rnn test_gail_cc test_curiosity_dc test_curiosity_visual test_curiosity_rnn create_optimizer_mock test_sac_update_reward_signals test_add_get_policy create_sac_optimizer_mock test_sac_optimizer_update dummy_config test_advance test_sac_save_load_buffer test_checkpoint_conversion test_register test_load_save test_normalizer_after_load ModelVersionTest _compare_two_policies test_simple_ghost_fails test_gail test_visual_advanced_sac _check_environment_trains test_visual_sac test_2d_ppo test_simple_sac test_simple_ghost default_reward_processor test_simple_asymm_ghost test_gail_visual_ppo test_simple_ppo test_gail_visual_sac test_recurrent_ppo DebugWriter test_recurrent_sac test_simple_asymm_ghost_fails test_visual_advanced_ppo test_visual_ppo test_2d_sac simple_record basic_mock_brain test_take_action_returns_action_info_when_available test_convert_version_string test_take_action_returns_nones_on_missing_values test_take_action_returns_empty_with_no_agents FakePolicy test_bcmodule_rnn_update test_bcmodule_linear_lr_update test_bcmodule_update test_bcmodule_constant_lr_update test_bcmodule_dc_visual_update create_bc_module test_bcmodule_defaults assert_stats_are_float test_bcmodule_rnn_dc_update test_valueheads test_multi_categorical_distribution test_gaussian_dist_instance test_categorical_dist_instance test_tanh_gaussian_dist_instance test_gaussian_distribution test_vector_encoder compare_models test_visual_encoder test_normalizer test_load_and_set dummy_config test_publish_queue test_process_trajectory test_lstm_layer test_swish test_lstm_class test_initialization_layer test_networkbody_visual test_actor_critic test_valuenetwork test_networkbody_vector test_simple_actor test_networkbody_lstm create_policy_mock test_sample_actions test_evaluate_actions test_policy_evaluate test_ppo_optimizer_update test_ppo_optimizer_update_curiosity dummy_config create_test_ppo_optimizer test_ppo_optimizer_update_gail test_ppo_get_value_estimates create_sac_optimizer_mock test_sac_update_reward_signals dummy_config test_sac_optimizer_update test_recurrent_sac test_visual_sac test_2d_ppo test_simple_asymm_ghost_fails test_simple_sac test_simple_ghost test_simple_ghost_fails simple_record test_visual_advanced_ppo test_simple_ppo test_gail_visual_ppo test_visual_ppo test_gail_visual_sac test_recurrent_ppo test_2d_sac test_gail test_visual_advanced_sac test_simple_asymm_ghost test_min_visual_size test_masked_mean test_polynomial_decay test_decayed_value test_soft_update test_get_probs_and_entropy test_create_inputs test_break_into_branches test_list_to_tensor test_actions_to_onehot test_checkpoint_conversion test_register test_load_save _compare_two_policies test_reward_provider_save test_reward_decreases test_construction test_next_state_prediction test_continuous_action_prediction test_factory test_reward test_construction test_factory test_reward_decreases test_construction test_factory test_reward_decreases_vail test_reward_decreases test_construction test_factory create_agent_buffer OutputDistribution DiscreteOutputDistribution MultiCategoricalDistribution GaussianDistribution ModelUtils Tensor3DShape NormalizerTensors _get_frozen_graph_node_names export_policy_model _make_frozen_graph _get_output_node_names _get_input_node_names convert_frozen_to_onnx _enforce_onnx_conversion _process_graph get_layer_shape pool_to_HW flatten sqr_diff process_layer process_model get_layer_rank slow_but_stable_topological_sort get_attr basic_lstm ModelBuilderContext order_by get_epsilon get_tensor_dtype replace_strings_in_list debug embody by_op get_tensor_dims strided_slice remove_duplicates_from_list axis_to_barracuda by_name locate_actual_output_node convert strides_to_HW get_tensor_data very_slow_but_stable_topological_sort gru ValueHeads CategoricalDistInstance DistInstance DiscreteDistInstance GaussianDistInstance MultiCategoricalDistribution TanhGaussianDistInstance GaussianDistribution Normalizer ResNetBlock conv_output_shape ResNetVisualEncoder SimpleVisualEncoder VectorInput SmallVisualEncoder pool_out_shape NatureVisualEncoder Swish lstm_layer Initialization linear_layer LinearEncoder LSTM MemoryModule ModelSerializer exporting_to_onnx Actor SeparateActorCritic SimpleActor ValueNetwork ActorCritic GlobalSteps LearningRate NetworkBody SharedActorCritic ModelUtils BCModule BaseRewardProvider CuriosityNetwork CuriosityRewardProvider ExtrinsicRewardProvider GAILRewardProvider DiscriminatorNetwork create_reward_provider RNDNetwork RNDRewardProvider RLTrainer Trainer main check_coverage main clean_previous_results TestResults parse_results main main main run_training run_inference find_executables override_config_file init_venv get_unity_executable_path override_legacy_config_file get_base_path run_standalone_build checkout_csharp_version _override_config_dict undo_git_checkout get_base_output_path test_closing test_run_environment test_closing test_run_environment VerifyVersionCommand ActionType BehaviorMapping TerminalStep DecisionSteps BehaviorSpec TerminalSteps BaseEnv DecisionStep Communicator UnityEnvironment validate_environment_path launch_executable get_platform UnityPolicyException UnityCommunicatorStoppedException UnityObservationException UnityWorkerInUseException UnityException UnityCommunicationException UnityTimeOutException UnitySideChannelException UnityEnvironmentException UnityActionException get_logger set_log_level MockCommunicator RpcCommunicator UnityToExternalServicerImplementation OffsetBytesIO _generate_split_indices process_pixels behavior_spec_from_proto _raise_on_nan_and_inf observation_to_np_array steps_from_proto _process_vector_observation _process_visual_observation _get_thread_timer TimerNode merge_gauges hierarchical_timer add_metadata get_timer_tree get_timer_root reset_timers get_timer_stack_for_thread set_gauge timed GaugeNode TimerStack UnityToExternalProtoServicer add_UnityToExternalProtoServicer_to_server UnityToExternalProtoStub BaseRegistryEntry ZipFileWithProgress get_tmp_dir get_local_binary_path_if_exists get_local_binary_path load_local_manifest load_remote_manifest download_and_extract_zip print_progress RemoteRegistryEntry UnityEnvRegistry EngineConfigurationChannel EngineConfig EnvironmentParametersChannel FloatPropertiesChannel IncomingMessage OutgoingMessage RawBytesChannel SideChannel SideChannelManager StatsAggregationMethod StatsSideChannel test_initialization test_reset test_returncode_to_signal_name test_log_file_path_is_set test_close test_step test_port_defaults test_handles_bad_filename test_check_communication_compatibility test_set_logging_level test_validate_path mock_glob_method test_launch_executable test_validate_path_empty create_registry test_basic_in_registry delete_binaries test_rpc_communicator_checks_port_on_create test_rpc_communicator_create_multiple_workers test_rpc_communicator_close test_batched_step_result_from_proto_raises_on_nan test_process_pixels test_process_visual_observation_bad_shape test_agent_behavior_spec_from_proto proto_from_steps_and_action test_batched_step_result_from_proto test_action_masking_continuous test_action_masking_discrete_1 generate_list_agent_proto generate_uncompressed_proto_obs test_batched_step_result_from_proto_raises_on_infinite generate_compressed_proto_obs test_process_pixels_multi_png proto_from_steps test_vector_observation test_action_masking_discrete generate_compressed_data test_action_masking_discrete_2 test_process_pixels_gray test_process_visual_observation test_raw_bytes test_int_channel test_message_float_list IntChannel test_engine_configuration test_message_bool test_message_string test_float_properties test_environment_parameters test_message_int32 test_stats_channel test_message_float32 test_decision_steps test_specs test_terminal_steps test_empty_terminal_steps test_action_generator test_empty_decision_steps test_timers decorated_func table_line ReleaseInfo validate_packages main NonTrivialPEP420PackageFinder main get_release_tag check_file test_pattern main check_all_files git_ls_files set_academy_version_string _escape_non_none extract_version_string print_release_tag_commands check_versions set_package_version set_version set_extension_package_version MagicMock create_mock_vector_steps UnityToGymWrapper sample create_mock_group_spec setup_mock_unityenvironment step MagicMock create_mock_vector_steps UnityToGymWrapper create_mock_group_spec setup_mock_unityenvironment MagicMock create_mock_vector_steps UnityToGymWrapper create_mock_group_spec setup_mock_unityenvironment MagicMock create_mock_vector_steps UnityToGymWrapper sample create_mock_group_spec setup_mock_unityenvironment step MagicMock create_mock_vector_steps UnityToGymWrapper sample reset create_mock_group_spec setup_mock_unityenvironment step MagicMock create_mock_vector_steps UnityToGymWrapper sample reset create_mock_group_spec setup_mock_unityenvironment step tuple CONTINUOUS range DISCRETE array range BehaviorMapping set_verbosity ConfigProto _get_num_available_cpus _read_in_integer_file join isdir print replaceFilenameExtension add_argument exit verbose source_file ArgumentParser target_file sqrt topologicalSort list hasattr layers addEdge Graph print inputs set len list hasattr layers print filter match trim_model compile data layers print tensors float16 replace layers dumps data dtype layers isinstance print name tensors inputs outputs shape zip array_without_brackets to_json globals Build array_equal pool reduce Build tanh mad tanh mul Build concat add sigmoid sub mad _ tanh mul Build concat add sigmoid mad print sorted keys add_argument_group add_argument ArgumentParser resequence_and_append obs from_observations steps_from_proto vector_actions AgentBuffer append reset_agent vector_observations array visual_observations enumerate make_demo_buffer load_demonstration zip observation_shapes enumerate isdir isfile get_demo_files write SerializeToString _EncodeVarint len parse_args start_learning join save_state join join set_warnings_enabled warning __version__ DEBUG seed load_model set_log_level as_dict debug run_training add_timer_metadata info INFO get_version_string train_model API_VERSION print dumps randint parse_command_line run_cli add_argument ArgumentParser from_dict experiment_config_path load_config fields_dict update items check_and_structure items structure register_structure_hook unstructure defaultdict dict_to_defaultdict register_structure_hook register_unstructure_hook structure RLock get_timer_root reset_timers put _send_response StepResponse env_factory behavior_specs _generate_all_results set_log_level apply get_and_reset_stats set_actions StatsSideChannel action set_configuration EngineConfigurationChannel payload BEHAVIOR_SPECS STEP EnvironmentParametersChannel items EnvironmentResponse isinstance reset RESET step join SACTrainer GhostTrainer PPOTrainer get_minimum_reward_buffer_size trainer_type isdir get update items copy MemorySettings structure to_settings items isinstance print items pop dict pop items get print set add append keys range len get pop unstructure print convert_behaviors convert_samplers_and_curriculum convert_samplers output_config_path curriculum remove_nones print write_to_yaml_file convert sampler trainer_config_path parse_args get rcls size range reversed zeros_like append discount_rewards print EnvironmentParameterManager arange ones BehaviorSpec append array int ones AgentExperience append zeros sum range len pop action_shape to_agentbuffer make_fake_trajectory is_action_discrete observation_shapes int BehaviorSpec zeros Mock Mock ActionInfo publish_trajectory_queue range create_mock_steps AgentProcessor empty create_mock_policy add_experiences Mock assert_has_calls ActionInfo publish_trajectory_queue range call create_mock_steps append AgentProcessor empty create_mock_policy add_experiences Mock assert_has_calls ActionInfo end_episode publish_trajectory_queue range call create_mock_steps append AgentProcessor empty create_mock_policy add_experiences AgentManager create_mock_policy Mock get_nowait AgentManagerQueue put Mock assert_any_call remove record_environment_stats AgentManager add_writer StatsReporter write_stats flatten list range len append range AgentBuffer resequence_and_append get_batch construct_fake_buffer assert_array make_mini_batch AgentBuffer reset_agent array resequence_and_append sample_mini_batch construct_fake_buffer AgentBuffer resequence_and_append construct_fake_buffer AgentBuffer resequence_and_append construct_fake_buffer AgentBuffer truncate values safe_load convert_behaviors safe_load convert enumerate remove_nones load_demonstration demo_to_buffer dirname abspath load_demonstration demo_to_buffer dirname abspath dirname abspath dirname abspath mock_open BytesIO DemonstrationMetaProto write_delimited from_dict safe_load curriculum from_dict safe_load curriculum from_dict safe_load curriculum EnvironmentParameterManager environment_parameters from_dict safe_load EnvironmentParameterManager environment_parameters clear safe_load MagicMock parse_command_line clear parse_command_line parse_command_line TrainerSettings FakeTrainer set_is_policy_updating end_episode create_rl_trainer values items construct_fake_buffer _clear_update_buffer create_rl_trainer Mock create_rl_trainer set_is_policy_updating subscribe_trajectory_queue advance put make_fake_trajectory publish_policy_queue AgentManagerQueue add_policy get_nowait range Mock assert_has_calls create_rl_trainer subscribe_trajectory_queue summary_freq checkpoint_interval put make_fake_trajectory publish_policy_queue advance AgentManagerQueue add_policy get_nowait range items items isinstance zip RunOptions check_if_different TrainerSettings RunOptions deep_update_dict structure structure structure RunOptions from_dict check_dict_is_at_least safe_load as_dict EnvironmentSettings from_dict check_if_different structure clear assert_called_once_with Mock get_stats_summaries add_stat add_writer StatsReporter float range write_stats clear Mock add_property add_writer StatsReporter assert_called_once_with sleep TensorboardWriter StatsSummary write_stats check_environment_trains close simple_env_factory SubprocessEnvManager default_config default_config close SubprocessEnvManager GhostController MagicMock GhostController TrainerController MagicMock assert_called_with MagicMock start_learning assert_called_once MagicMock assert_not_called start_learning assert_called_once MagicMock MagicMock assert_called_once MagicMock advance add assert_not_called behaviors ppo_dummy_config behaviors TrainerFactory generate _load_config StringIO mkdir join handle_existing_directories join set_parameter_state LESSON_NUM load_state NOTAREALKEY get_parameter_state save_state join NNCheckpoint time add_checkpoint set_parameter_state CHECKPOINTS track_final_checkpoint append from_observations range ones items to_agentbuffer add set make_fake_trajectory extract_stack filename get __old_np_array _check_no_float64 get _check_no_float64 __old_np_zeros get __old_np_ones _check_no_float64 join remove _get_candidate_names convert _get_default_tempdir dirname abspath isfile next TrainerSettings initialize TFPolicy BehavioralCloningSettings create_bc_module create_mock_3dball_behavior_specs update items create_mock_3dball_behavior_specs BehavioralCloningSettings create_bc_module update items create_mock_3dball_behavior_specs BehavioralCloningSettings current_lr create_bc_module update items create_mock_3dball_behavior_specs BehavioralCloningSettings create_bc_module update items create_mock_banana_behavior_specs BehavioralCloningSettings create_bc_module update items create_mock_banana_behavior_specs BehavioralCloningSettings create_bc_module setup_test_behavior_specs load_weights zip assert_array_equal get_weights PPOTrainer create_policy GhostController GhostTrainer PPOTrainer subscribe_trajectory_queue setup_test_behavior_specs put advance make_fake_trajectory from_name_behavior_id AgentManagerQueue add_policy brain_name create_policy GhostController GhostTrainer PPOTrainer simulate_rollout get_nowait setup_test_behavior_specs _swap_snapshots advance publish_policy_queue from_name_behavior_id AgentManagerQueue add_policy brain_name create_policy DISCRETE int BehaviorSpec create_input_placeholders observation_shapes create_behavior_spec TFPolicy setup_test_behavior_specs list evaluate agent_id create_steps_from_behavior_spec behavior_spec assert_array_equal TrainerSettings list evaluate agent_id create_steps_from_behavior_spec behavior_spec create_policy_mock reset_default_graph TrainerSettings TFPolicy update_normalization to_agentbuffer setup_test_behavior_specs make_fake_trajectory run array range len TrainerSettings TFPolicy update_normalization to_agentbuffer setup_test_behavior_specs make_fake_trajectory zeros range run evolve initialize TFPolicy setup_test_behavior_specs PPOOptimizer update simulate_rollout behavior_spec _create_ppo_optimizer_ops_mock reset_default_graph update simulate_rollout behavior_spec _create_ppo_optimizer_ops_mock reset_default_graph update evolve simulate_rollout ppo_dummy_config behavior_spec _create_ppo_optimizer_ops_mock reset_default_graph items get_trajectory_value_estimates to_agentbuffer make_fake_trajectory _create_ppo_optimizer_ops_mock next_obs reset_default_graph assert_array_almost_equal array discount_rewards evolve Mock brain_name ppo_dummy_config _increment_step from_name_behavior_id assert_called_with add_policy PPOTrainer _update_policy simulate_rollout setup_test_behavior_specs MemorySettings from_name_behavior_id add_policy PPOTrainer create_policy values Mock brain_name from_name_behavior_id add_policy PPOTrainer initialize TFPolicy setup_test_behavior_specs PPOOptimizer SACOptimizer simulate_rollout behavior_spec evaluate_batch simulate_rollout prepare_update _execute_model behavior_spec update_dict make_mini_batch policy BehavioralCloningSettings create_optimizer_mock reward_signal_eval reward_signal_update create_optimizer_mock reward_signal_eval reward_signal_update create_optimizer_mock reward_signal_eval reward_signal_update create_optimizer_mock reward_signal_eval reward_signal_update create_optimizer_mock reward_signal_eval reward_signal_update create_optimizer_mock reward_signal_eval reward_signal_update create_optimizer_mock reward_signal_eval reward_signal_update create_optimizer_mock reward_signal_eval reward_signal_update initialize TFPolicy setup_test_behavior_specs SACOptimizer update simulate_rollout create_sac_optimizer_mock behavior_spec reset_default_graph simulate_rollout create_sac_optimizer_mock behavior_spec update_reward_signals reset_default_graph SACTrainer save_model simulate_rollout num_experiences setup_test_behavior_specs behavior_spec from_name_behavior_id add_policy brain_name create_policy SACTrainer SACTrainer values setup_test_behavior_specs initialize_or_load from_name_behavior_id brain_name create_policy TrainerSettings Mock TFModelSaver create_policy_mock register TrainerSettings join initialize_or_load create_policy_mock TFModelSaver set_step save_checkpoint register _compare_two_policies TrainerSettings join TFModelSaver create_policy_mock save_checkpoint reset_default_graph register TrainerSettings join TFPolicy update_normalization to_agentbuffer setup_test_behavior_specs initialize_or_load make_fake_trajectory TFModelSaver save_checkpoint zeros register range run EnvironmentParameterManager evolve SimpleEnvironment _check_environment_trains hyperparameters evolve SimpleEnvironment _check_environment_trains hyperparameters evolve SimpleEnvironment _check_environment_trains network_settings evolve SimpleEnvironment hyperparameters _check_environment_trains network_settings evolve MemoryEnvironment hyperparameters _check_environment_trains evolve SimpleEnvironment _check_environment_trains hyperparameters evolve SimpleEnvironment _check_environment_trains hyperparameters evolve SimpleEnvironment _check_environment_trains network_settings evolve SimpleEnvironment hyperparameters _check_environment_trains network_settings evolve MemoryEnvironment hyperparameters _check_environment_trains evolve SimpleEnvironment SelfPlaySettings _check_environment_trains evolve SimpleEnvironment SelfPlaySettings _check_environment_trains evolve SimpleEnvironment SelfPlaySettings _check_environment_trains evolve SimpleEnvironment SelfPlaySettings _check_environment_trains evolve SimpleEnvironment BehavioralCloningSettings _check_environment_trains simple_record evolve SimpleEnvironment BehavioralCloningSettings hyperparameters _check_environment_trains simple_record evolve SimpleEnvironment BehavioralCloningSettings hyperparameters _check_environment_trains simple_record MagicMock TrainerSettings basic_mock_brain BehaviorSpec get_action empty FakePolicy TrainerSettings MagicMock basic_mock_brain DecisionSteps get_action array FakePolicy TrainerSettings MagicMock basic_mock_brain ActionInfo DecisionSteps get_action array FakePolicy _convert_version_string BCModule TorchPolicy items assert_stats_are_float assert_stats_are_float update MagicMock create_mock_3dball_behavior_specs BehavioralCloningSettings current_lr create_bc_module assert_stats_are_float assert_stats_are_float assert_stats_are_float ones value_heads ValueHeads backward ones zero_grad Adam range flatten parameters shape manual_seed zeros step mse_loss log_prob GaussianDistribution gauss_dist zip backward ones all_log_prob create_test_prob zero_grad Adam tolist parameters manual_seed MultiCategoricalDistribution tensor step range enumerate ones GaussianDistInstance flatten manual_seed sample zeros ones manual_seed sample TanhGaussianDistInstance range zeros CategoricalDistInstance log_prob manual_seed sample tensor range items zip Normalizer tensor update copy_from vector_encoder Mock ones update_normalization VectorInput assert_called_with copy_normalization ones vis_class enc Swish Tensor mul sigmoid linear_layer manual_seed lstm_layer named_parameters manual_seed ones LSTM lstm manual_seed backward ones zero_grad Adam flatten parameters shape manual_seed networkbody step mse_loss range NetworkBody NetworkSettings backward ones zero_grad Adam flatten parameters shape manual_seed networkbody step mse_loss range NetworkBody NetworkSettings backward ones zero_grad Adam flatten parameters shape manual_seed networkbody step mse_loss range NetworkBody NetworkSettings backward ones zero_grad Adam parameters ValueNetwork manual_seed value_net step range values NetworkSettings NetworkSettings ones SimpleActor sample_action forward get_dists ones CONTINUOUS critic_pass get_dist_and_value tensor ac_type NetworkSettings TorchPolicy TrainerSettings visual_processors simulate_rollout use_continuous_act list_to_tensor behavior_spec create_policy_mock unsqueeze append evaluate_actions values enumerate TrainerSettings sample_actions visual_processors simulate_rollout list_to_tensor behavior_spec create_policy_mock unsqueeze append enumerate evolve TorchPolicy setup_test_behavior_specs TorchPPOOptimizer ones_like create_test_ppo_optimizer ones_like create_test_ppo_optimizer ones_like create_test_ppo_optimizer create_test_ppo_optimizer TorchSACOptimizer TorchPolicy manual_seed check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains check_environment_trains enc_func ones get_encoder_for_type _check_resolution_for_encoder forward append list create_input_processors range get_value CONSTANT LINEAR DecayedValue zip polynomial_decay zip list_to_tensor asarray tensor break_into_branches enumerate tensor actions_to_onehot zip get_probs_and_entropy flatten tensor masked_mean tensor bool T TestModule soft_update TorchModelSaver TorchModelSaver unsqueeze _split_decision_step TorchModelSaver TrainerSettings join items hasattr create_agent_buffer TorchModelSaver initialize_or_load parameters create_policy_mock set_step HyperparametersClass save_checkpoint get_modules zip OptimizerClass behavior_spec register keys CuriosityRewardProvider CuriositySettings CURIOSITY create_reward_provider CuriositySettings seed update create_agent_buffer CuriosityRewardProvider manual_seed range CuriositySettings seed update create_agent_buffer CuriosityRewardProvider item manual_seed tensor range CuriositySettings seed update create_agent_buffer CuriosityRewardProvider mean manual_seed to_numpy float range CuriositySettings ExtrinsicRewardProvider RewardSignalSettings EXTRINSIC RewardSignalSettings ExtrinsicRewardProvider RewardSignalSettings evaluate create_agent_buffer GAILRewardProvider GAILSettings GAIL GAILSettings create_reward_provider GAILSettings GAIL seed update create_reward_provider GAILSettings create_agent_buffer manual_seed GAIL range RNDSettings RNDRewardProvider RNDSettings RND RNDRewardProvider RNDSettings from_observations ones range AgentBuffer append zeros vector_observations visual_observations enumerate convert_to_barracuda convert convert_to_onnx _make_frozen_graph _enforce_onnx_conversion convert_frozen_to_onnx info makedirs tf_optimize make_model _get_output_node_names _get_input_node_names info optimize_graph _get_frozen_graph_node_names add _get_frozen_graph_node_names name add node set info endswith len print HasField hasattr get_attr isinstance get_attr tensor_shape ndarray isinstance shape int_val bool_val float_val ListFields name ndarray isinstance str tensor_content ndarray product isinstance get_tensor_dtype print get_tensor_dims unpack int_val bool_val array float_val enter append add set Build mul sub insert Build tolist append range len locate_actual_output_node name find_tensor_by_name split locate_actual_output_node name lstm find_tensor_by_name find_forget_bias split get_layer_shape id Struct tensor get_layer_rank layer_ranks hasattr name patch_data rank input_shapes out_shapes input get_attr append replace_strings_in_list tensors embody astype op inputs zip enumerate print float32 patch_data_fn model_tensors map_ignored_layer_to_its_input co_argcount len items hasattr get_tensors name print process_layer eval slow_but_stable_topological_sort ModelBuilderContext sort assign_ids pop range insert len layers verbose Struct process_model open print_known_operations fuse compress node GraphDef Model dims_to_barracuda_shape insert get_tensor_dims inputs MessageToJson ParseFromString cleanup_layers read memories sort write trim summary print_supported_ops floor data Linear LSTM add_ range named_parameters local get rcls print join exit walk float check_coverage join remove mkdir rmdir exists documentElement getAttribute parse join clean_previous_results parse_results get_unity_executable_path exit returncode get_base_path copy2 init_venv add_argument ArgumentParser split strip run_standalone_build override_config_file run_inference get_base_path rename abspath checkout_csharp_version exists run dirname get_base_output_path init_venv override_legacy_config_file copy int time join print run_standalone_build makedirs find_executables join time print run python run_training csharp exists join move get_unity_executable_path print makedirs dirname get_base_output_path run join X_OK frozenset splitext append access walk check_call check_call check_call _override_config_dict values items isinstance update values check_call str UnityToGymWrapper print step reset sample UnityEnvironment range reset UnityEnvironment close UnityToGymWrapper randn is_action_continuous column_stack action_size set_actions get_steps format EngineConfigurationChannel set_configuration_parameters discrete_action_branches is_action_discrete observation_shapes any len join basename replace glob debug getcwd set normpath validate_environment_path debug add setLevel getLogger basicConfig setLevel tuple vector_action_size OffsetBytesIO original_tell concatenate reshape index mean append array data compressed_data reshape process_pixels shape array mean isnan array _raise_on_nan_and_inf sum is_action_discrete _generate_split_indices ones discrete_action_branches len astype _raise_on_nan_and_inf any cast split append _process_vector_observation bool _process_visual_observation array observation_shapes enumerate range len get_ident TimerStack perf_counter push items merge reset method_handlers_generic_handler add_generic_rpc_handlers download_and_extract_zip get_local_binary_path_if_exists debug range glob hexdigest join get_tmp_dir join chmod gettempdir makedirs uuid4 join int str remove get_tmp_dir exists chmod print glob rmtree urlopen print_progress hexdigest print int min max uuid4 join str get_tmp_dir load_local_manifest urlopen UnityEnvironment close MockCommunicator UnityEnvironment MockCommunicator _executable_args UnityEnvironment MockCommunicator index get_steps obs close reset MockCommunicator zip UnityEnvironment observation_shapes len get_steps obs zip ones step close MockCommunicator set_actions zeros UnityEnvironment observation_shapes len UnityEnvironment close MockCommunicator validate_environment_path validate_environment_path launch_executable PermissionError set_log_level rmtree get_tmp_dir RemoteRegistryEntry register UnityEnvRegistry create_registry make close reset step range delete_binaries close RpcCommunicator close RpcCommunicator close RpcCommunicator list extend ObservationProto AgentInfoProto append prod range len fromarray list uint8 BytesIO bytes concatenate astype shape save zeros range ObservationProto generate_compressed_data extend shape ObservationProto shape tolist extend obs concatenate action_mask agent_id ObservationProto AgentInfoProto append generate_uncompressed_proto_obs proto_from_steps generate_compressed_data process_pixels rand generate_compressed_data process_pixels rand generate_compressed_data process_pixels rand _process_vector_observation generate_list_agent_proto enumerate generate_compressed_proto_obs rand extend AgentInfoProto _process_visual_observation generate_uncompressed_proto_obs generate_compressed_proto_obs rand AgentInfoProto extend list sort CONTINUOUS agent_id BehaviorSpec steps_from_proto generate_list_agent_proto range BehaviorSpec steps_from_proto DISCRETE generate_list_agent_proto action_mask BehaviorSpec steps_from_proto DISCRETE generate_list_agent_proto action_mask BehaviorSpec steps_from_proto DISCRETE generate_list_agent_proto action_mask CONTINUOUS BehaviorSpec steps_from_proto generate_list_agent_proto action_mask BrainParametersProto behavior_spec_from_proto extend CONTINUOUS generate_list_agent_proto BehaviorSpec CONTINUOUS generate_list_agent_proto BehaviorSpec generate_side_channel_messages process_side_channel_message send_int IntChannel FloatPropertiesChannel process_side_channel_message generate_side_channel_messages get_property set_property uuid4 process_side_channel_message generate_side_channel_messages RawBytesChannel send_raw_data get_and_clear_received_messages len buffer read_bool append write_bool IncomingMessage range OutgoingMessage buffer write_int32 read_int32 IncomingMessage OutgoingMessage IncomingMessage write_float32 buffer read_float32 OutgoingMessage read_string write_string buffer IncomingMessage OutgoingMessage IncomingMessage buffer OutgoingMessage read_float32_list write_float32_list set_configuration channel_id EngineConfigurationChannel generate_side_channel_messages process_side_channel_message set_configuration_parameters RawBytesChannel read_float32 read_int32 IncomingMessage get_and_clear_received_messages default_config channel_id generate_side_channel_messages process_side_channel_message read_string set_float_parameter RawBytesChannel read_float32 read_int32 IncomingMessage EnvironmentParametersChannel IncomingMessage write_float32 write_string buffer write_int32 get_and_reset_stats on_message_received StatsSideChannel OutgoingMessage DecisionSteps action_mask empty BehaviorSpec TerminalSteps empty BehaviorSpec BehaviorSpec create_random_action enumerate BehaviorSpec create_empty_action set_gauge TimerStack startswith print find_packages find validate_packages remove replace frozenset endswith set add walk print git_ls_files get_release_tag check_all_files compile join print extract_version_string set values join format set_academy_version_string print set_package_version set_extension_package_version enumerate split print | <img src="docs/images/image-banner.png" align="middle" width="3000"/> # Unity ML-Agents Toolkit [](https://github.com/Unity-Technologies/ml-agents/tree/release_7_docs/docs/) [](LICENSE) ([latest release](https://github.com/Unity-Technologies/ml-agents/releases/tag/latest_release)) ([all releases](https://github.com/Unity-Technologies/ml-agents/releases)) **The Unity Machine Learning Agents Toolkit** (ML-Agents) is an open-source project that enables games and simulations to serve as environments for training intelligent agents. Agents can be trained using reinforcement learning, imitation learning, neuroevolution, or other machine learning methods through a | 2,782 |
lina2360/HiSeqGan | ['text generation'] | ['SeqGAN: Sequence Generative Adversarial Nets with Policy Gradient'] | programs/data_processing/map_cluster_center_ponit.py programs/data_processing/save_cluster_with_coordinate_representation.py programs/RNN/data_preprocess_all.py ghsom-item-seq.py programs/RNN/data_preprocess_all_center_point.py programs/RNN/get_ghsom_dim.py programs/SeqGAN/unpackplk.py programs/SeqGAN/rollout.py programs/RNN/LSTM-classification.py programs/RNN/LSTM-classification-test.py programs/SeqGAN/generator.py programs/RNN/RNN_tensorflow_all_week.py programs/data_processing/save_cluster_with_clustered_label.py programs/data_processing/sequence_clustering.py programs/SeqGAN/dataloader.py programs/data_processing/format_SeqGAN_input.py execute-seqgan.py programs/SeqGAN/inspect_checkpoint.py programs/data_processing/sequance_predict_accuracy.py programs/data_processing/get_ghsom_dim.py programs/data_processing/format_RNN_input_Backlog_Avail_ratio.py programs/data_processing/GHSOM_center_point.py programs/data_processing/format_RNN_input_AWU_Avial_ratio.py programs/RNN/RNN_tensorflow_all_center_point.py programs/data_processing/format_ghsom_input_vector.py programs/SeqGAN/discriminator.py programs/RNN/LSTM-classification-keras.py programs/SeqGAN/sequence_gan.py programs/data_processing/format_RNN_input_integer.py programs/data_processing/compute-entropy.py programs/data_processing/format_RNN_input_float.py execute-all.py execute-ghsom.py programs/RNN/app_all_item_center_point_real.py programs/SeqGAN/target_lstm.py programs/data_processing/save_cluster_with_clustered_label_sequence.py programs/RNN/RNN_tensorflow_all.py programs/RNN/app_all_week.py execute-hiseqgan.py programs/data_processing/save_cluster_with_clustered_map_cell.py programs/RNN/app_all.py programs/data_processing/format_RNN_input_sequence_integer.py save_ghsom_cluster_label_with_coordinate format_rnn_input_integer extract_ghsom_output ghsom_clustering save_ghsom_cluster_map create_ghsom_prop_file create_ghsom_input_file format_RNN_input_float compute_entropy map_cluster_center_ponit save_ghsom_cluster_label clustering_sequence_gan_output execute_sequence_gan create_seqgan_input_file rnn_all_week compute_sequence_predict_accuracy execute_sequence_gan create_seqgan_input_file save_ghsom_cluster_label_with_coordinate format_rnn_input_integer extract_ghsom_output ghsom_clustering create_ghsom_prop_file create_ghsom_input_file save_ghsom_cluster_label compute_entropy format_ghsom_input_vector layers GHSOM_center_point map_cluster_to_ghsom get_map_pos get_cluster_flag format_cluster_info_to_dict get_map_pos get_cluster_flag format_cluster_info_to_dict get_map_pos get_cluster_flag format_cluster_info_to_dict format_row_to_layerformat getClusterList format_row_to_layerformat getClusterList layers load_data_v2 load_data create_model RNN RNN WPG_RNN WPG_RNN WPG_RNN Gen_Data_loader Dis_dataloader linear highway Discriminator Generator ROLLOUT generate_samples pre_train_epoch main TARGET_LSTM print format_ghsom_input_vector print system print system print system print system print system print system print system print system print system print system print system print system print system system replace replace replace popen info read info replace print to_csv read_csv range fillna split join int replace endswith print len copy append listdir range split Fraction range append astype GHSOM_center_point split append DataFrame range len append len int str get_cluster_flag print len to_dict zip append array range split append range len strip append pow reverse int list print reshape DataFrame fill hstack astype range delete drop shape vstack append zeros expand_dims empty getClusterList len int read_csv print train_test_split read_csv drop print train_test_split read_csv drop SimpleRNN print Sequential add Dense summary compile Dropout dynamic_rnn zero_state reshape BasicLSTMCell transpose matmul unstack as_list int range extend generate pretrain_step num_batch append next_batch reset_pointer range Dis_dataloader num_batch Gen_Data_loader create_batches Saver save max Session ROLLOUT open seed str run Generator Discriminator generate pre_train_epoch range load_train_data close get_reward update_params ConfigProto generate_samples int train_op print write global_variables_initializer next_batch reset_pointer read_csv | # HiSeqGAN A Novel Approach to Hierarchical Sequence Synthesis and Prediction. ### Authors * Yun-Chieh Tien ([email protected]) * Chen-Min Hsu ([email protected]) * I-Li Chen ([email protected]) * Fang Yu ([email protected]) ## Abstract High-dimensional sequenced data often appears in practice. State-of-the-art recurrent neural network (RNN) models suffer prediction accuracy problem from complex relations amongst values of attributes. Adopting unsupervised clustering that categorize data based on their attribute similarity, results in data of lower dimensions that can be structured in a hierarchical fashion. It is essential to consider these data relations to improve model training performance. In this study, we propose a new approach to synthesize and predict sequences of hierarchical data. ### Prospects | 2,783 |
lingjzhu/mtracker.github.io | ['data augmentation'] | ['A CNN-based tool for automatic tongue contour tracking in ultrasound images'] | track_frames.py src/cnn_metrics.py src/data_generator.py track_video.py src/cnn_model.py src/DenseNet.py src/cnn_predict.py matthews_correlation p_weighted_binary_loss mean_sum_of_distance compound_loss dice_coef_loss ofuse_pixel_error Compound_loss f_beta _to_tensor fbeta_score fmeasure precision identity_loss main asymmetric_loss dice_coef recall cross_entropy_balanced main Unet initialize interpolate_tongue_spline mean_sum_of_distance downsample get_spline get_active_contour main normalize crop generate_splines gaussian_k load_splines superimpose crop_tongue generate_masks_in_batch get_gaussian_mask conv_block DenseNet transition_block DenseUnet_v1 u_conv_block deconv_block skip_concatenate dense_block DenseUnet_v2 dense_deconv_block flatten sum flatten sum weighted_cross_entropy_with_logits base_dtype _to_tensor float32 log reduce_sum reduce_mean cast clip_by_value epsilon not_equal greater float32 cast int32 convert_to_tensor cast multiply binary_crossentropy sum round sqrt clip epsilon sum round clip epsilon sum round clip recall precision epsilon len sum euclidean_distances min mean astype std resize rgb2gray load initiate Unet squeeze where skeletonize resize normalize empty crop predict T interp1d UnivariateSpline argwhere linspace T gaussian UnivariateSpline active_contour linspace T interp1d sort_values linspace DataFrame tolist read_csv imread imsave rgb2gray resize int imsave group y_raw zeros x_raw range compile frame_indices int str imsave name xcoord match image_list ycoord imread range compile arange zeros range gaussian_k len group imsave compile get_gaussian_mask conv_block range get_file transition_block Model load_weights dense_block Input concatenate u_conv_block skip_concatenate conv_block skip_concatenate DenseNet output deconv_block Model input layers DenseNet output Model input dense_deconv_block Input compile | # Welcome to MTracker **MTracker** is a tool for automatic splining tongue shapes in ultrasound images by harnessing the power of deep convolutional neural networks. It is developed at the Department of Linguistics, University of Michgian to address the need of spining a large-scale ultrasound project. MTracker also allows for human correction by interfacing with the [GetContours Suite](https://github.com/mktiede/GetContours) developed by Mark Tiede at Haskins Laboratory. ## About MTracker You can refer to this paper for more information. [A CNN-based tool for automatic tongue contour tracking in ultrasound images](https://arxiv.org/abs/1907.10210). [This paper was peer-reviewed and accepted by Interspeech 2019 but was withdrawn due to my unability to travel to the conference]. MTracker was developed by Jian Zhu, [Will Styler](http://savethevowels.org/will/), and Ian Calloway at the University of Michigan, on the basis of data collected with [Patrice Beddor](https://sites.lsa.umich.edu/beddor/) and [Andries Coetzee](https://sites.lsa.umich.edu/coetzee/). It was first described in [a poster](https://github.com/lingjzhu/mtracker.github.io/blob/master/mtracker_asa2018_poster%202.pdf) at the [175th Meeting of the Acoustical Society of America in Minneapolis](https://acousticalsociety.org/program-of-175th-meeting-of-the-acoustical-society-of-america/). The tools, and trained model, will be made available below. This work is inspired by a [Deep Learning Tutorial for Kaggle Ultrasound Nerve Segmentation competition](https://github.com/jocicmarko/ultrasound-nerve-segmentation). ### Attribution and Citation For now, you can cite this software as: | 2,784 |
lipiji/hierarchical-encoder-decoder | ['text generation'] | ['A Hierarchical Neural Autoencoder for Paragraphs and Documents'] | main_minibatch.py data.py updates.py utils_pg.py lstm.py sent_encoder.py rnn.py attention.py word_encoder.py word_decoder.py gru.py sent_decoder.py AttentionLayer GRULayer BdGRU LSTMLayer BdLSTM RNN SentDecoderLayer SentEncoderLayer adagrad nesterov_momentum momentum sgd rmsprop adam adadelta use_gpu save_model load_model floatX init_weights init_gradws init_bias WordDecoderLayer WordEncoderLayer append zip get_value shape zip append shared zeros get_value shape zip append shared zeros get_value shape zip append shared zeros get_value shape zip append shared zeros get_value shape sqrt zip append shared zeros asarray get_value sqrt shape zip append shared zeros str use params dump get_value open load params set_value open | ## Hierarchical Encoder-Decoder ### Features - Sequences modelling for words, sentences, paragraphs and documents - LSTM and GRU in Theano - Attention modelling (plays a role of "copy" in encoder-decoder framework) ### References - Li, Jiwei, Minh-Thang Luong, and Dan Jurafsky. "A hierarchical neural autoencoder for paragraphs and documents." arXiv preprint arXiv:1506.01057 (2015). | 2,785 |
lironui/Linear-Attention-Mechanism | ['semantic segmentation'] | ['Linear Attention Mechanism: An Efficient Attention for Semantic Segmentation'] | Linear-Attention-Mechanism.py PositionLinearAttention ChannelLinearAttention l2_norm | # Linear-Attention-Mechanism ⭐ [Welcome to my HomePage](https://lironui.github.io/) ⭐ This repository implementatesLinear-Attention-Mechanism based on PyTorch. The detailed formula can be seen in the [Linear Attention Mechanism: An Efficient Attention for Semantic Segmentation](https://arxiv.org/ftp/arxiv/papers/2007/2007.14902.pdf) or [Multi-stage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images](https://ieeexplore.ieee.org/abstract/document/9378788/). If our code is helpful to you, please cite 1. `Li R, Jianlin Su, Duan C and Zheng S. Linear Attention Mechanism: An Efficient Attention for Semantic Segmentation[J]. arXiv preprint arXiv:2007.14902, 2020.` 2. `苏剑林. (2020, Jul 04). 《线性Attention的探索:Attention必须有个Softmax吗? 》[Blog post]. Retrieved from https://spaces.ac.cn/archives/7546` 3. `R. Li, S. Zheng, C. Duan, J. Su and C. Zhang. "Multistage Attention ResU-Net for Semantic Segmentation of Fine-Resolution Remote Sensing Images." in IEEE Geoscience and Remote Sensing Letters, doi: 10.1109/LGRS.2021.3063381.` | 2,786 |
lironui/MACU-Net | ['medical image segmentation', 'semantic segmentation'] | ['MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images'] | measure.py train.py early_stopping.py dataset.py MACUNet.py is_image_file train_dataset EarlyStopping ACBlock ChannelAttention MACUNet conv3otherRelu SegmentationMetric weights_init normal_ __name__ fill_ | # MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images ⭐ [Welcome to my HomePage](https://lironui.github.io/) ⭐ In this repository, we incorporate multi-scale features generated by different layers of U-Net and design a multi-scale skip connected and asymmetric-convolution-based U-Net (MACU-Net), for segmentation using fine-resolution remotely sensed images. The detailed results can be seen in the [MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images](https://ieeexplore.ieee.org/document/9343296). The training and testing code can refer to [GeoSeg](https://github.com/WangLibo1995/GeoSeg). If our code is helpful to you, please cite: `R. Li, C. Duan, S. Zheng, C. Zhang and P. M. Atkinson, "MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images," in IEEE Geoscience and Remote Sensing Letters, doi: 10.1109/LGRS.2021.3052886.` Requirements: ------- ``` | 2,787 |
lironui/Multi-Attention-Network | ['semantic segmentation'] | ['Multiattention network for semantic segmentation of fine-resolution remote sensing images'] | MANet.py MANet CAM_Module PAM_Module DecoderBlock conv3otherRelu PAM_CAM_Layer softplus_feature_map | # Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images ⭐ [Welcome to my HomePage](https://lironui.github.io/) ⭐ In this repository, a novel attention mechanism of kernel attention with linear complexity is proposed to alleviate the large computational demand in attention. Based on kernel attention and channel attention, we integrate local feature maps extracted by ResNet-50 with their corresponding global dependencies and reweight interdependent channel maps adaptively. Numerical experiments on two large-scale fine-resolution remote sensing datasets demonstrate the superior performance of the proposed MANet. The detailed results can be seen in the [Multi-Attention-Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images](https://ieeexplore.ieee.org/document/9487010). The training and testing code can refer to [GeoSeg](https://github.com/WangLibo1995/GeoSeg). The related repositories include: * [MACU-Net](https://github.com/lironui/MACU-Net)->A revised U-Net structure. * [MAResU-Net](https://github.com/lironui/MAResU-Net)->Another type of attention mechanism with linear complexity. If our code is helpful to you, please cite: `Li, R., Zheng, S., Duan, C., Zhang, C., Su, J., & Atkinson, P. M. (2021), "Multiattention Network for Semantic Segmentation of Fine-Resolution Remote Sensing Images," in IEEE Transactions on Geoscience and Remote Sensing, doi: 10.1109/TGRS.2021.3093977.` | 2,788 |
lironui/U-Net-with-Multi-Scale-Skip-Connections-and-Asymmetric-Convolution-Blocks | ['medical image segmentation', 'semantic segmentation'] | ['MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images'] | measure.py train.py early_stopping.py dataset.py MACUNet.py is_image_file train_dataset EarlyStopping ACBlock ChannelAttention MACUNet conv3otherRelu SegmentationMetric weights_init normal_ __name__ fill_ | # MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images ⭐ [Welcome to my HomePage](https://lironui.github.io/) ⭐ In this repository, we incorporate multi-scale features generated by different layers of U-Net and design a multi-scale skip connected and asymmetric-convolution-based U-Net (MACU-Net), for segmentation using fine-resolution remotely sensed images. The detailed results can be seen in the [MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images](https://ieeexplore.ieee.org/document/9343296). The training and testing code can refer to [GeoSeg](https://github.com/WangLibo1995/GeoSeg). If our code is helpful to you, please cite: `R. Li, C. Duan, S. Zheng, C. Zhang and P. M. Atkinson, "MACU-Net for Semantic Segmentation of Fine-Resolution Remotely Sensed Images," in IEEE Geoscience and Remote Sensing Letters, doi: 10.1109/LGRS.2021.3052886.` Requirements: ------- ``` | 2,789 |
lisanka93/individualProject | ['argument mining'] | ['Assessing Convincingness of Arguments in Online Debates with Limited Number of Features'] | CODE_INDPROJ/Preprocess Data/badwords.py CODE_INDPROJ/rankings/count_ranking.py CODE_INDPROJ/Preprocess Data/wordlists.py CODE_INDPROJ/spreadsheet_manipulation/append_all_files.py CODE_INDPROJ/Preprocess Data/not_ne_list.py CODE_INDPROJ/Preprocess Data/indfunctions.py CODE_INDPROJ/spreadsheet_manipulation/create_pair_vectors.py CODE_INDPROJ/Preprocess Data/ind_arguments.py CODE_INDPROJ/Preprocess Data/whole_debate_func_clean.py CODE_INDPROJ/Preprocess Data/ten_google_stem_list.py CODE_INDPROJ/Preprocess Data/twen_google_stem_list.py CODE_INDPROJ/NEURAL NET/CrossValidation/NN_CV.py CODE_INDPROJ/Preprocess Data/abbreviations.py count_adjectives containsHyperlink preprocess_argumentI capsCount count_pronouns spellCheck average_freqdist count_verbs ColemanLiauIndex badwordcount preprocess_argumentIV count_adverbs preprocess_argumentIII preprocess_argumentII split_trigrams extract_entity_names_ind linkingwordcount preprocess_for_nee_and_print_ind split_bigrams punctCount percentCount countDigits nouns_in_argument unusual_words long_words preprocess_debateII bigram_extr stemmed_snowball preprocess_for_nee_and_print preprocess_debateI trigram_extr lemmatised_words preprocess_debateIII extract_nouns extract_entity_names very_rare_long_words findall lower replace len sub sub split lower sub split dict sum values join word_tokenize sent_tokenize len dict sum values len float SpellChecker len Counter sent_tokenize float sum values len count sum findall replace float len list extend set sent_tokenize ne_chunk_sents extract_entity_names_ind append join extend pos_tag pos_tag pos_tag pos_tag pos_tag FreqDist set SpellChecker float len FreqDist items bigrams append trigrams items FreqDist append replace lower sub split findall len FreqDist items bigrams append trigrams items FreqDist append append encode SpellChecker set FreqDist encode SpellChecker append FreqDist most_common encode append FreqDist SnowballStemmer encode most_common append pos_tag most_common append Counter encode list isalpha check SnowballStemmer set SpellChecker append split ne_chunk_sents extend extract_entity_names sent_tokenize append join extend | lisanka93/individualProject | 2,790 |
lishen/end2end-all-conv | ['breast cancer detection'] | ['Deep Learning to Improve Breast Cancer Early Detection on Screening Mammography'] | dm_resnet.py ddsm_train/heatmap_score.py dm_inference.py dm_region.py ddsm_train/patch_clf_train.py dm_image.py dm_keras_ext.py dm_preprocess.py ddsm_train/sample_patches_combined.py ddsm_train/sample_patches_main.py meta.py dm_enet.py dm_multi_gpu.py ddsm_train/image_clf_train.py MultiViewDLElasticNet DLRepr pred_2view_img_list make_pred_case make_parallel DMImagePreprocessor region_features topK_region_idx total_area prob_heatmap_features global_max_intensity _shortcut basic_block_org _residual_block bottleneck_org add_top_layers _vgg_block ResNetBuilder basic_block _conv_bn_relu bottleneck MultiViewResNetBuilder main _bn_relu_conv DMMetaManager MultiViewDLElasticNet DLRepr pred_2view_img_list make_pred_case make_parallel DMImagePreprocessor region_features topK_region_idx total_area prob_heatmap_features global_max_intensity _shortcut basic_block_org _residual_block bottleneck_org add_top_layers _vgg_block ResNetBuilder basic_block _conv_bn_relu bottleneck MultiViewResNetBuilder main _bn_relu_conv DMMetaManager predict_on_batch mean stack append max columns from_records concat stack append prob_heatmap_features append outputs xrange len pop str update region_features zeros_like topK_region_idx min xrange append label keys enumerate regionprops len add heatmap_layer model0 output add_vgg_blocks add Model Dense softmax add_fc_layers add_residual_blocks get_weights Input set_weights compile build_resnet_50 | Shield: [![CC BY-NC-SA 4.0][cc-by-nc-sa-shield]][cc-by-nc-sa] This work is licensed under a [Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License][cc-by-nc-sa]. [![CC BY-NC-SA 4.0][cc-by-nc-sa-image]][cc-by-nc-sa] [cc-by-nc-sa]: http://creativecommons.org/licenses/by-nc-sa/4.0/ [cc-by-nc-sa-image]: https://licensebuttons.net/l/by-nc-sa/4.0/88x31.png [cc-by-nc-sa-shield]: https://img.shields.io/badge/License-CC%20BY--NC--SA%204.0-lightgrey.svg # Deep Learning to Improve Breast Cancer Detection on Screening Mammography (End-to-end Training for Whole Image Breast Cancer Screening using An All Convolutional Design) Li Shen, Ph.D. CS Icahn School of Medicine at Mount Sinai | 2,791 |
littleaich/deepglobe2018 | ['semantic segmentation'] | ['Semantic Binary Segmentation using Convolutional Networks without Decoders'] | homogenize_name_format.py utils_aich/__init__.py transforms/__init__.py utils_aich/preproc_image.py model_defs/vgg_oneway.py main_segnet.py utils_aich/get_metrics.py model_defs/segnet.py main_vgg_d2s.py transforms/functional.py combine_probs.py model_defs/simple_test.py main_resnet_d2s.py save_mean_std.py utils_aich/open_files.py transforms/transforms.py model_defs/depth_to_space.py datasets.py model_defs/__init__.py model_defs/resnet_oneway.py is_image_file make_dataset_test make_dataset ImageFolder accimage_loader default_loader pil_loader DepthToSpace ResNet_Oneway conv_nxn_with_init ResNet resnet50 Bottleneck resnet152 conv3x3 resnet34 resnet50_oneway resnet18 BasicBlock resnet101 segnet SegNet SimpleBlock VGG vgg16_bn conv3x3 make_layers conv_nxn_with_init VGG_Oneway vgg16_bn VGG make_layers vgg16_bn_oneway hflip resize to_pil_image to_grayscale center_crop rotate pad five_crop resized_crop normalize to_tensor to_tensor_target _is_tensor_image adjust_gamma ten_crop adjust_saturation _is_numpy_image scale crop adjust_hue adjust_brightness _is_pil_image vflip unnormalize adjust_contrast Grayscale Pad ToPILImage ToTensorTarget RandomMedianFilter Lambda ToTensor Compose RandomMaxMinModeFilter RandomVerticalFlip RandomGrayscale RandomGaussianBlur Unnormalize RandomCrop Normalize RandomHorizontalFlip Compose_Joint ColorJitter get_prec_rec is_image_file load_pickle get_file_handle rm_old_mk_new_dir save_pickle binarize_gray_image lower deepcopy sorted xrange append expanduser listdir is_image_file join sorted append expanduser walk constant xavier_normal bias Conv2d weight load_url ResNet load_state_dict load_url ResNet load_state_dict load_url ResNet load_state_dict load_url ResNet load_state_dict load_url ResNet load_state_dict ResNet_Oneway resnet50 Conv2d load_url make_layers VGG load_state_dict SegNet vgg16_bn VGG_Oneway vgg16_bn int16 ndarray isinstance view transpose contiguous from_buffer from_numpy ByteTensor tobytes mode int32 copyto zeros array len from_numpy uint8 array byte isinstance FloatTensor transpose numpy is_tensor zip div_ add_ zip int size isinstance warn int Number isinstance size round crop resize Number isinstance size center_crop crop Number isinstance hflip five_crop vflip Brightness enhance enhance Contrast Color enhance fromarray convert mode array split uint8 convert array clip mode fromarray convert array dstack float sum open get_file_handle dump close get_file_handle close load rmtree mkdir isdir | #### Code Repository for the CVPR 2018 DeepGlobe Workshop paper [Semantic Binary Segmentation using Convolutional Networks without Decoders](https://arxiv.org/abs/1805.00138) #### [Pretrained Models](https://drive.google.com/open?id=1M16yUTzUu0esbcYIhL5SgOc4ge50L6a9) * _(train resnet50 oneway mdoel)_ python main\_resnet\_d2s.py --train 1 --data 'TRAIN\_IMG\_DIR' --gt 'TRAIN\_MASK\_DIR' --arch 'resnet50' --optim 'adam' --workers 8 --batch-size 8 --start-epoch 1 --end-epoch 100 --learning-rate 0.0001 --momentum 0.9 --weight-decay 0.0001 --save-interval 1 --print-freq 10 * _(train vgg16-bn oneway mdoel)_ python main\_vgg\_d2s.py --train 1 --data 'TRAIN\_IMG\_DIR' --gt 'TRAIN\_MASK\_DIR' --arch 'vgg16\_bn' --optim 'adam' --workers 8 --batch-size 8 --start-epoch 1 --end-epoch 100 --learning-rate 0.0001 --momentum 0.9 --weight-decay 0.0001 --save-interval 1 --print-freq 10 * _(train segnet oneway mdoel)_ python main\_segnet.py --train 1 --data 'TRAIN\_IMG\_DIR' --gt 'TRAIN\_MASK\_DIR' --arch 'segnet' --optim 'adam' --workers 8 --batch-size 8 --start-epoch 1 --end-epoch 100 --learning-rate 0.0001 --momentum 0.9 --weight-decay 0.0001 --save-interval 1 --print-freq 10 * _(test mdoel)_ python main\_XXXX.py --train 0 --data 'TEST\_IMG\_DIR' --out 'OUT\_MASK\_DIR' --arch XXXX --workers 1 --load-epoch XX | 2,792 |
liuch37/pan-pytorch | ['scene text detection'] | ['Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network'] | models/ffm.py utils/pa/pa.py loss/ohem.py dataset/synthtext.py loss/emb_loss_v1.py train.py utils/helper.py models/backbone.py loss/dice_loss.py dataset/totaltext.py dataset/msra.py inference.py models/pan.py loss/iou.py dataset/ctw1500.py eval/ic15/rrc_evaluation_funcs_v2.py utils/pa/setup.py models/fpem.py eval/ic15/rrc_evaluation_funcs_v1.py eval/msra/file_util.py eval/ctw/file_util.py eval/totaltext/Deteval.py eval/ctw/eval.py loss/loss.py eval/msra/eval.py models/head.py utils/average_meter.py eval/ic15/script_self_adapt.py eval/ic15/rrc_evaluation_funcs.py dataset/ic15.py eval/ic15/script.py dataset/testdataset.py get_img scale_aligned random_crop_padding shrink PolyArea random_rotate random_scale scale_aligned_short dist PAN_CTW random_horizontal_flip perimeter get_ann get_img scale_aligned random_crop_padding shrink PolyArea random_rotate scale_aligned_short random_scale dist get_vocabulary PAN_IC15 random_horizontal_flip update_word_mask perimeter get_ann get_img scale_aligned random_crop_padding shrink PolyArea random_rotate scale_aligned_short random_scale dist random_horizontal_flip PAN_MSRA perimeter get_ann get_img scale_aligned random_crop_padding shrink PolyArea random_rotate random_scale dist get_vocabulary PAN_Synth random_horizontal_flip update_word_mask perimeter get_ann get_img PAN_test scale_aligned_short get_img scale_aligned random_crop_padding shrink PolyArea PAN_TT random_rotate random_scale scale_aligned_short read_mat_lindes dist get_vocabulary random_horizontal_flip update_word_mask perimeter get_ann get_union get_gt get_pred get_intersection write_file_not_cover write_file read_file read_dir evaluation_imports evaluate_method default_evaluation_params validate_data eval write_result_as_txt get_union get_gt get_pred get_intersection write_file_not_cover write_file read_file read_dir get_union gt_reading_mod many_to_many PolyArea input_reading_mod detection_filtering sigma_calculation tau_calculation get_intersection one_to_one one_to_many DiceLoss EmbLoss_v1 iou_single iou kernel_loss loss text_loss emb_loss ohem_batch ohem_single Convkxk ResNet resnet50 Bottleneck load_url conv3x3 resnet18 BasicBlock resnet101 FFM Conv_BN_ReLU FPEM PA_Head PAN AverageMeter write_result upsample draw_result get_results adjust_learning_rate write_result_ic15 _pa pa imread cvtColor COLOR_BGR2RGB int asarray replace append split range copy len warpAffine random getRotationMatrix2D range len int resize min array scale_aligned choice int min resize int copyMakeBorder min where append max range len range PyclipperOffset int PolyArea JT_ROUND min append AddPath array perimeter ET_CLOSEDPOLYGON Execute decode array sqrt unique list range dict ascii_lowercase zip append ascii_letters digits len reshape boxPoints pi float transpose extend loadmat T read_mat_lindes range enumerate len print append split append int asarray split zeros fillPoly sum copy zeros fillPoly logical_and copy append sort walk replace read close open join makedirs close write open join makedirs close write open load_zip_file validate_lines_in_file compute_ap area iteritems decode_utf8 append polygon_from_points range import_module get_intersection_over_union load_zip_file empty get_pred get_tl_line_values_from_file_contents float namedtuple int8 rectangle_to_polygon Rectangle get_intersection zeros len append tuple enumerate makedirs read write_result_as_txt popen append float range len reshape boxPoints pi float loadmat list concatenate squeeze transpose PolyArea map get_intersection array enumerate split range where range where range where append float sum range len view size new_zeros mean iou_single range DiceLoss DiceLoss EmbLoss_v1 update iou size ohem_batch dict mean stack emb_loss append kernel_loss long range text_loss int sort min float sum append float range ohem_single load_url ResNet load_state_dict load_url ResNet load_state_dict load_url ResNet load_state_dict join format urlretrieve write makedirs isinstance param_groups float range len resize max transpose RETR_EXTERNAL shape append minAreaRect range update findContours astype mean float pa uint8 CHAIN_APPROX_SIMPLE reshape boxPoints float32 dict sigmoid zeros join reshape len append range enumerate join drawContours basename asarray imwrite reshape splitext append imread range len join replace ZIP_DEFLATED tuple write close append ZipFile enumerate pop transpose where mean append zeros sum full range connectedComponents | # Pixel Aggregation Network This is an unofficial PyTorch re-implementation of paper "Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network" published in ICCV 2019, with PyTorch >= v1.4.0. ## Task - [x] Backbone model - [x] FPEM model - [x] FFM model - [x] Integrated model - [x] Loss Function - [x] Data preprocessing - [x] Data postprocessing | 2,793 |
liuch37/pan-tensorflow | ['scene text detection'] | ['Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network'] | models/ffm.py utils/pa/pa.py loss/ohem.py loss/emb_loss_v1.py train.py utils/helper.py models/backbone.py loss/dice_loss.py inference.py models/pan.py loss/iou.py dataset/ctw1500.py utils/pa/setup.py models/fpem.py eval/ctw/file_util.py eval/ctw/eval.py loss/loss.py models/head.py utils/average_meter.py dataset/testdataset.py get_img scale_aligned random_crop_padding shrink PolyArea random_rotate random_scale scale_aligned_short dist PAN_CTW random_horizontal_flip perimeter get_ann get_img PAN_test scale_aligned_short get_union get_gt get_pred get_intersection write_file_not_cover write_file read_file read_dir DiceLoss EmbLoss_v1 iou_single iou loss_keras emb_loss loss_tensor kernel_loss text_loss ohem_batch ohem_single resnet101 resnet50 FFM Conv_BN_ReLU FPEM PA_Head PAN AverageMeter write_result upsample draw_result get_results adjust_learning_rate write_result_ic15 _pa pa imread cvtColor COLOR_BGR2RGB int asarray replace append split range copy len warpAffine random getRotationMatrix2D range len int resize min array scale_aligned choice int min resize int copyMakeBorder min where append max range len range PyclipperOffset int PolyArea JT_ROUND min append AddPath array perimeter ET_CLOSEDPOLYGON Execute print append split append int asarray split zeros fillPoly sum copy zeros fillPoly logical_and copy append sort walk replace read close open join makedirs close write open join makedirs close write open reduce_sum cast append sum range len reshape reduce_mean iou_single append range DiceLoss DiceLoss EmbLoss_v1 update iou ohem_batch dict reduce_mean stack cast emb_loss append kernel_loss text_loss range int reshape sort min reduce_sum cast stack cast ohem_single append range PolynomialDecay concat resize max transpose RETR_EXTERNAL shape cast append minAreaRect range update findContours astype mean pa uint8 CHAIN_APPROX_SIMPLE reshape boxPoints float32 dict sigmoid zeros join reshape len append range enumerate join drawContours basename asarray imwrite reshape splitext append imread range len join replace ZIP_DEFLATED tuple write close append ZipFile enumerate pop transpose where mean append zeros sum full range connectedComponents | # Pixel Aggregation Network This is an unofficial TensorFlow re-implementation of paper "Efficient and Accurate Arbitrary-Shaped Text Detection with Pixel Aggregation Network" published in ICCV 2019, with Tensorflow 2. ## Task - [x] Backbone model - [x] FPEM model - [x] FFM model - [x] Integrated model - [x] Loss Function - [x] Data preprocessing - [x] Data postprocessing | 2,794 |
liuf1990/Implicit_Dense_Correspondence | ['semantic correspondence'] | ['Learning Implicit Functions for Topology-Varying Dense 3D Shape Correspondence'] | evaluation/evaluateBHCP.py loss.py evaluation/datasetBHCP.py dataset.py train_stage1.py train_stage2.py train_stage3.py model.py generate_list ShapeNet sample_and_group smooth_loss pc_normalize square_distance query_ball_point cosine_loss index_points selfrec_loss gradient CD_normal_loss farthest_point_sample occupancy_loss EMD_loss ImplicitFun checkpoint Encoder InverseImplicitFun BHCP get_pairwise_list glob sorted ones_like abs sum cosine_similarity mean mean sqrt sum max shape permute matmul list shape repeat device len view shape device to sum range shape repeat square_distance device query_ball_point index_points shape farthest_point_sample empty_cache cosine_loss nnd_dist sqrt mean repeat gather mean emd_dist sample_and_group squeeze mean cosine_similarity cat detach cate_name checkpoint_dir str save makedirs sorted glob append range len | # Learning Implicit Functions for Topology-Varying Dense 3D Shape Correspondence Advances in Neural Information Processing Systems (NeurIPS 2020). **Oral presentation**. [[Arxiv](https://arxiv.org/abs/2010.12320), [PDF](http://cvlab.cse.msu.edu/pdfs/Implicit_Dense_Correspondence.pdf), [Supp](http://cvlab.cse.msu.edu/pdfs/Implicit_Dense_Correspondence_Supp.pdf), [Project](http://cvlab.cse.msu.edu/project-implicit-dense-correspondence.html)] **[Feng Liu](http://cvlab.cse.msu.edu/pages/people.html), [Xiaoming Liu](http://cvlab.cse.msu.edu/pages/people.html)** Department of Computer Science and Engineering, Michigan State University <font color=\#008000>***The goal of this paper is to learn dense 3D shape correspondence for topology-varying objects in an unsupervised manner.*** </font>  <font face="宋体" size=2.5> Figure 1: Given a shape **S**, PointNet *E* is used to extract the shape feature code **z**. Then a part embedding **o** is produced via a deep implicit function *f*. We implement dense correspondence through an inverse function mapping from **o** to recover the 3D shape. (b) To further make the learned part embedding consistent across all the shapes, we randomly select two shapes **S**<sub>A</sub> and **S**<sub>B</sub>. By swapping the part embedding vectors, a cross reconstruction loss is used to enforce the inverse function to recover to each other. </font> -------------------------------------- This code is developed with Python3 and PyTorch 1.1 **Dataset** | 2,795 |
liuheng92/tensorflow_PSENet | ['scene text detection', 'curved text detection'] | ['Shape Robust Text Detection with Progressive Scale Expansion Network'] | train.py utils/data_provider/data_util.py nets/resnet/resnet_v1.py pse/__init__.py eval.py utils/utils_tool.py nets/model.py utils/data_provider/data_provider.py nets/resnet/resnet_utils.py get_images resize_image detect main show_score_geo average_gradients main tower_loss model dice_coefficient mean_image_subtraction build_feature_pyramid unpool loss Block conv2d_same subsample resnet_arg_scope stack_blocks_dense resnet_v1_152 resnet_v1_101 bottleneck resnet_v1_200 resnet_v1_50 resnet_v1 pse pse generator load_annoataion get_batch shrink_poly crop_area generate_seg get_json_label check_and_validate_polys get_files perimeter GeneratorEnqueuer join test_data_path format endswith info append walk len int format info shape resize float ones_like time zeros_like boxPoints where pse argwhere resize append minAreaRect array range show add_subplot imshow figure hot output_dir gpu_list makedirs REGULARIZATION_LOSSES get_collection image add_n loss scalar concat reduce_mean zip append expand_dims trainable_variables checkpoint_path pretrained_model_path MkDir moving_average_decay Saver exponential_decay GPUOptions get_variable global_variables average_gradients merge_all placeholder apply apply_gradients get_default_graph FileWriter get_trainable_variables assign_from_checkpoint_fn enumerate learning_rate float32 DeleteRecursively AdamOptimizer ExponentialMovingAverage split global_variables_initializer scalar len range split concat sigmoid mean_image_subtraction build_feature_pyramid append unpool range reduce_sum ones_like zeros_like where dice_coefficient range scalar split pad connectedComponents uint8 astype append pse_cpp array range len get error transpose copy put shape Queue zeros join format glob extend training_data_path get_files append Orientation clip zip min astype choice shape int32 zeros range max clip range PyclipperOffset Area JT_ROUND AddPath abs perimeter ET_CLOSEDPOLYGON Execute format shrink_poly zip ones fillPoly Area len copy info append zeros abs range enumerate load_annoataion arange subplots resize get_files generate_seg show ones shape imshow check_and_validate_polys append training_data_path imread format replace crop_area close shuffle copy choice tight_layout astype info float set_yticks float32 set_xticks zeros array generator get is_running start sleep GeneratorEnqueuer | liuheng92/tensorflow_PSENet | 2,796 |
liushuchun/EAST.pytorch | ['optical character recognition', 'scene text detection', 'curved text detection'] | ['EAST: An Efficient and Accurate Scene Text Detector'] | utils/log.py models/east.py utils/visualize.py models/vgg.py models/__init__.py config.py data/dataset.py main.py loss.py parse DefaultConfig reduce_max torch_arctanh l2_dist reduce_sum l2r_dist l1_dist l2_norm rescale dice_coefficient l1_norm reduce_min tanh_rescale LossFunc main train write_csv help get_images load_annoataion line_verticle shrink_poly crop_area polygon_area point_dist_to_line ImageDataSet fit_line restore_rectangle_rbox line_cross_point image_label generate_rbox check_and_validate_polys collate_fn sort_rectangle restore_rectangle rectangle_from_parallelogram EAST VGG16 Logger Visualizer items print warn getattr setattr sum dim range reversed dim range reversed dim range reversed reduce_sum abs reduce_sum sum print format getsource __class__ time format epoch_num state_dict model print Variable backward len zero_grad crit mkdir save step cuda range enumerate load use_gpu parse StepLR ImageDataSet load_model_path Adam parameters DataLoader train cuda exists LossFunc join format glob extend append range len polygon_area print zip append clip min astype choice shape int32 zeros range max clip arctan2 polyfit print norm arccos line_verticle fit_line dot line_cross_point sum arctan print argmin argmax concatenate reshape transpose zeros array norm point_dist_to_line ones fillPoly min argmin fit_line sort_rectangle line_cross_point argwhere zip append zeros sum array range rectangle_from_parallelogram enumerate join load_annoataion replace crop_area ones float astype float32 copy choice shape generate_rbox check_and_validate_polys resize zeros imread max from_numpy stack permute zip append range len load_url load_state_dict vgg16 | # EAST pytorch version paper:[https://arxiv.org/abs/1704.03155]() status:DONE! | 2,797 |
liuyilin950623/SHAP_on_Autoencoder | ['outlier detection', 'anomaly detection'] | ['Explaining Anomalies Detected by Autoencoders Using SHAP'] | config/autoencoder_specifications.py src/train_autoencoder.py main autoencoder Adam Model Input compile fit autoencoder to_json read print boston close save_weights summary train_test_split StandardScaler fit_transform open | # SHAP_on_Autoencoder Explaining Anomalies Detected by Autoencoders Using SHAP Dataset: Boston Housing Dataset Machine Learning Methods: Autoencoder, Kernel SHAP Paper: Explaining Anomalies Detected by Autoencoders Using SHAP https://arxiv.org/pdf/1903.02407.pdf The implementation has 3 steps. 1. Select the top features with largest reconstruction errors. 2. For each feature in the list of top features: - We want to explain what features (other than itself) have led to the reconstruction error | 2,798 |
liuzechun/Bi-Real-net | ['depth estimation'] | ['Bi-Real Net: Binarizing Deep Network Towards Real-Network Performance'] | pytorch_implementation/BiReal18_34/birealnet.py pytorch_implementation/BiReal_50/train.py pytorch_implementation/BiReal_50/utils.py pytorch_implementation/BiReal_50/birealnet.py pytorch_implementation/BiReal18_34/train.py pytorch_implementation/BiReal18_34/utils.py BiRealNet conv1x1 BinaryActivation birealnet34 conv3x3 birealnet18 BasicBlock HardBinaryConv main train validate Lighting AverageMeter accuracy CrossEntropyLabelSmooth save_checkpoint ProgressMeter adjust_learning_rate binaryconv1x1 BiRealNet binaryconv3x3 conv1x1 Leakyclip Bottleneck BinaryActivation conv3x3 birealnet50 HardBinaryConv main train validate Lighting AverageMeter accuracy CrossEntropyLabelSmooth save_checkpoint ProgressMeter adjust_learning_rate BiRealNet BiRealNet data validate LambdaLR ImageFolder DataLoader save_checkpoint save label_smooth cuda exists list exit map Adam load_state_dict append CrossEntropyLoss range format Compose CrossEntropyLabelSmooth Normalize info train load join time print named_parameters parameters birealnet18 step model zero_grad cuda display update param_groups size item enumerate time criterion backward print AverageMeter accuracy ProgressMeter step len len eval AverageMeter ProgressMeter copyfile join save makedirs param_groups lr BiRealNet birealnet50 | # Bi-Real-net This is the implementation of our paper "[Bi-Real Net: Enhancing the Performance of 1-bit CNNs With Improved Representational Capability and Advanced Training Algorithm](https://eccv2018.org/openaccess/content_ECCV_2018/papers/zechun_liu_Bi-Real_Net_Enhancing_ECCV_2018_paper.pdf)" published in ECCV 2018 and "[Bi-real net: Binarizing deep network towards real-network performance](https://arxiv.org/pdf/1811.01335.pdf)" published in IJCV. <img width=60% src="https://github.com/liuzechun0216/images/blob/master/birealnet_figure.png"/> We proposed to use a identity mapping to propagate the real-valued information before binarization. The proposed 1-layer-per-block structure with the shortcut bypassing every binary convolutional layers significantly outperforms the original 2-layer-per-block structure in ResNet when weights and activations are binarized. The detailed motivation and discussion can be found in our IJCV paper. Three other proposed training techniques can be found in the ECCV paper. # News \[November 23rd 2019\] We finished the pytorch implementation of training Bi-Real Net from scratch, which is super easy to run. We obtain the same accuracy as reported in the paper. Clone and have a try with our new pytorch implementation! \[March 28th 2021\] Our newest paper "[ReActNet: Towards Precise Binary Neural Network with Generalized Activation Functions](https://www.ecva.net/papers/eccv_2020/papers_ECCV/papers/123590137.pdf)" achieves 65.8% accuracy on Bi-Real Net-18 structure with simple ReAct functions. Check this paper if you are interested. | 2,799 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.