
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
Anorak/nirvana | [
"pytorch",
"pegasus",
"text2text-generation",
"unk",
"dataset:Anorak/autonlp-data-Niravana-test2",
"transformers",
"autonlp",
"co2_eq_emissions",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"PegasusForConditionalGeneration"
],
"model_type": "pegasus",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | Elysium 49%
sdHeroCalmartist 21%
Anything3.0Pruned 30% |
Anthos23/FS-distilroberta-fine-tuned | [
"pytorch",
"roberta",
"text-classification",
"transformers",
"has_space"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 33 | null | ---
tags:
- Taxi-v3-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3-4x4-no_slippery
type: Taxi-v3-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="huam/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Anthos23/my-awesome-model | [
"pytorch",
"tf",
"roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-medium-paraphraser
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-medium-paraphraser
This model is a fine-tuned version of [gpt2-medium](https://huggingface.co/gpt2-medium) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
Anubhav23/IndianlegalBert | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: huggan/smithsonian_butterflies_subset
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-butterflies-128
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `huggan/smithsonian_butterflies_subset` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/Totsukawaii/ddpm-butterflies-128/tensorboard?#scalars)
|
Anubhav23/model_name | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: pt
license: apache-2.0
tags:
- generated_from_trainer
- whisper-event
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: openai/whisper-medium
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0
type: mozilla-foundation/common_voice_11_0
config: pt
split: test
args: pt
metrics:
- name: Wer
type: wer
value: 6.598745817992301
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Portuguese Medium Whisper
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2628
- Wer: 6.5987
## Blog post
All information about this model in this blog post: [Speech-to-Text & IA | Transcreva qualquer áudio para o português com o Whisper (OpenAI)... sem nenhum custo!](https://medium.com/@pierre_guillou/speech-to-text-ia-transcreva-qualquer-%C3%A1udio-para-o-portugu%C3%AAs-com-o-whisper-openai-sem-ad0c17384681).
## New SOTA
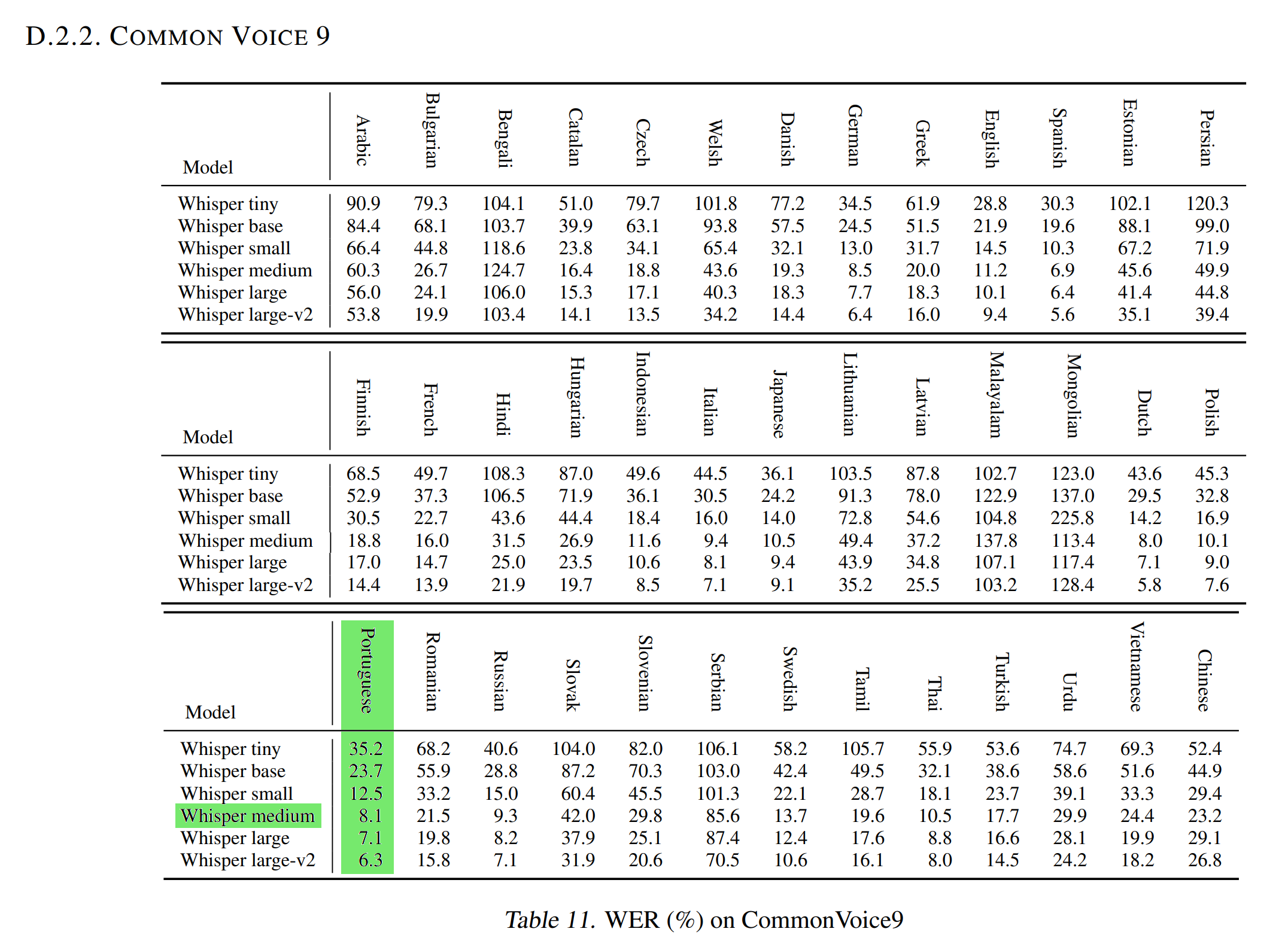
The Normalized WER in the [OpenAI Whisper article](https://cdn.openai.com/papers/whisper.pdf) with the [Common Voice 9.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_9_0) test dataset is 8.1.
As this test dataset is similar to the [Common Voice 11.0](https://huggingface.co/datasets/mozilla-foundation/common_voice_11_0) test dataset used to evaluate our model (WER and WER Norm), it means that **our Portuguese Medium Whisper is better than the [Medium Whisper](https://huggingface.co/openai/whisper-medium) model at transcribing audios Portuguese in text** (and even better than the [Whisper Large](https://huggingface.co/openai/whisper-large) that has a WER Norm of 7.1!).
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9e-06
- train_batch_size: 32
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 6000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0333 | 2.07 | 1500 | 0.2073 | 6.9770 |
| 0.0061 | 5.05 | 3000 | 0.2628 | 6.5987 |
| 0.0007 | 8.03 | 4500 | 0.2960 | 6.6979 |
| 0.0004 | 11.0 | 6000 | 0.3212 | 6.6794 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2 |
Apisate/Discord-Ai-Bot | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: metga97/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ArBert/albert-base-v2-finetuned-ner-agglo-twitter | [
"pytorch",
"tensorboard",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 27 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# waynedsouza/phon3phon3
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 1024 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('waynedsouza/phon3phon3')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name=waynedsouza/phon3phon3)
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 348 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 10,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 256, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
ArBert/albert-base-v2-finetuned-ner-gmm-twitter | [
"pytorch",
"tensorboard",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: ArthurinRUC/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
ArBert/albert-base-v2-finetuned-ner | [
"pytorch",
"tensorboard",
"albert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 19 | null | ---
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-medium
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2406
- Wer: 10.0333
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0241 | 1.06 | 1000 | 0.1996 | 10.4543 |
| 0.009 | 2.12 | 2000 | 0.2156 | 10.1152 |
| 0.0045 | 3.19 | 3000 | 0.2406 | 10.0333 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
ArBert/bert-base-uncased-finetuned-ner-gmm | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: whisper-test-ar-tarteel
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-test-ar-tarteel
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 3.0
### Training results
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
ArBert/roberta-base-finetuned-ner-kmeans-twitter | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"RobertaForTokenClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
- f1
model-index:
- name: finetuning-sentiment-model-25k-samples
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: train
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.93208
- name: F1
type: f1
value: 0.932183081715792
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# finetuning-sentiment-model-25k-samples
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2198
- Accuracy: 0.9321
- F1: 0.9322
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
ArBert/roberta-base-finetuned-ner | [
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"RobertaForTokenClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- facebook/multilingual_librispeech
metrics:
- wer
model-index:
- name: Whisper largeV2 Italian MLS
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: facebook/multilingual_librispeech italian
type: facebook/multilingual_librispeech
config: italian
split: test
args: italian
metrics:
- name: Wer
type: wer
value: 8.335297167365791
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper largeV2 Italian MLS
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the facebook/multilingual_librispeech italian dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2051
- Wer: 8.3353
## Model description
The model is fine-tuned for 4000 updates/steps on multilingual librispeech Italian train data.
- Zero-shot - 13.8 (MLS Italian test)
- Fine-tune MLS Italian train - 8.33 (MLS Italian test) (-40%)
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.1115 | 1.02 | 1000 | 0.2116 | 9.4217 |
| 0.0867 | 2.03 | 2000 | 0.1964 | 9.7823 |
| 0.0447 | 3.05 | 3000 | 0.2001 | 9.6409 |
| 0.0426 | 4.07 | 4000 | 0.2051 | 8.3353 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
ArJakusz/DialoGPT-small-starky | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- no
license: apache-2.0
tags:
- whisper-event
- norwegian
datasets:
- NbAiLab/NCC_S
- NbAiLab/NPSC
- NbAiLab/NST
metrics:
- wer
model-index:
- name: Whisper Small Norwegian Bokmål
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: FLEURS
type: google/fleurs
config: nb_no
split: validation
args: nb_no
metrics:
- name: Wer
type: wer
value: 15.56
---
# Whisper Small Norwegian Bokmål
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) trained on several datasets.
It is currently in the middle of a large training. Currently it achieves the following results on the evaluation set:
- Loss: 0.3230
- Wer: 15.56
## Model description
The model is trained on a large corpus of roughly 5.000 hours of voice. The sources are subtitles from the Norwegian broadcaster NRK, transcribed speeches from the Norwegian parliament and voice recordings from Norsk Språkteknologi.
## Intended uses & limitations
The model will be free for everyone to use when it is finished.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-06
- train_batch_size: 128
- gradient_accumulation_steps: 2
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: constant with warmup
- lr_scheduler_warmup_steps: 1000
- training_steps: 50.000 (currently @1.000)
- mixed_precision_training: fp16
- deepspeed: true
### Live Training results
See [Tensorboad Metrics](https://huggingface.co/NbAiLab/whisper-small-nob/tensorboard)
|
Aracatto/Catto | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 252.57 +/- 30.85
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Aran/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-medium
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3830
- Wer: 19.5173
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 3000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.011 | 4.01 | 1000 | 0.3234 | 20.5978 |
| 0.0011 | 8.03 | 2000 | 0.3650 | 19.4070 |
| 0.0006 | 12.04 | 3000 | 0.3830 | 19.5173 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
Arcanos/1 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="javiervela/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Archie/myProject | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: roberta-base-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-cola
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6074
- Matthews Correlation: 0.6221
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- total_eval_batch_size: 5
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
- training precision: Mixed Precision
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.4536 | 1.0 | 534 | 0.4104 | 0.5738 |
| 0.4876 | 2.0 | 1068 | 0.5156 | 0.5729 |
| 0.1281 | 3.0 | 1602 | 0.5083 | 0.6145 |
| 0.0441 | 4.0 | 2136 | 0.5483 | 0.6119 |
| 0.2985 | 5.0 | 2670 | 0.6074 | 0.6221 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cpu
- Datasets 2.7.1
- Tokenizers 0.12.0
|
Arcktosh/DialoGPT-small-rick | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.74
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="javiervela/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
AshiNLP/Bert_model | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- snips_built_in_intents
metrics:
- accuracy
model-index:
- name: roberta-base-finetuned-intent
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-base-finetuned-intent
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the snips_built_in_intents dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2720
- Accuracy: 0.9333
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: IPU
- gradient_accumulation_steps: 8
- total_train_batch_size: 8
- total_eval_batch_size: 5
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- training precision: Mixed Precision
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.9568 | 1.0 | 37 | 1.7598 | 0.4333 |
| 1.2238 | 2.0 | 74 | 0.8130 | 0.7667 |
| 0.4536 | 3.0 | 111 | 0.4985 | 0.8 |
| 0.2478 | 4.0 | 148 | 0.3535 | 0.8667 |
| 0.0903 | 5.0 | 185 | 0.3110 | 0.8667 |
| 0.0849 | 6.0 | 222 | 0.2720 | 0.9333 |
| 0.0708 | 7.0 | 259 | 0.2742 | 0.8667 |
| 0.0796 | 8.0 | 296 | 0.2839 | 0.8667 |
| 0.0638 | 9.0 | 333 | 0.2949 | 0.8667 |
| 0.0566 | 10.0 | 370 | 0.2925 | 0.8667 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.10.0+cpu
- Datasets 2.7.1
- Tokenizers 0.12.0
|
Aspect11/DialoGPT-Medium-LiSBot | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | Pretrained and finetuned wav2vec2.0 Base model on Flemish data.
Pre-training data: CGN (all components, VL) + VrijeWesten (2000h) + VRT (500h)
Finetuning data: CGN (all components, VL)
Usage:
python
~ import fairseq
~ ckpt = '/path/to/modeldir/checkpoint_best.pt'
~ model, cfg, task = fairseq.checkpoint_utils.load_model_ensemble_and_task([ckpt])
|
At3ee/wav2vec2-base-timit-demo-colab | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### Gamindocar-2000-700 Dreambooth model trained by gabrieleai with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
|
Atchuth/MBOT | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: LucianoDeben/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Aybars/XLM_Turkish | [
"pytorch",
"xlm-roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"XLMRobertaForQuestionAnswering"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | 2022-12-15T14:17:12Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 384 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 2500 with parameters:
```
{'batch_size': 16, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": 2500,
"warmup_steps": 250,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Ayham/albert_bert_summarization_cnn_dailymail | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | 2022-12-15T14:18:07Z | ---
language:
- pa
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Large Punjabi - Drishti Sharma
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: pa-IN
split: test
args: pa-IN
metrics:
- name: Wer
type: wer
value: 19.71252566735113
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Large Punjabi - Drishti Sharma
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2846
- Wer: 19.7125
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 1000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0004 | 8.26 | 1000 | 0.2846 | 19.7125 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
Ayham/bert_gpt2_summarization_cnndm | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | 2022-12-15T14:39:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: token_fine_tunned_flipkart_2_gl6
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# token_fine_tunned_flipkart_2_gl6
This model is a fine-tuned version of [vinayak361/token_fine_tunned_flipkart_2_gl](https://huggingface.co/vinayak361/token_fine_tunned_flipkart_2_gl) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7363
- Precision: 0.7243
- Recall: 0.7752
- F1: 0.7489
- Accuracy: 0.7558
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-06
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 120 | 1.0057 | 0.6623 | 0.7212 | 0.6905 | 0.6995 |
| No log | 2.0 | 240 | 0.8581 | 0.6660 | 0.7290 | 0.6961 | 0.7080 |
| No log | 3.0 | 360 | 0.8085 | 0.6882 | 0.7518 | 0.7186 | 0.7302 |
| No log | 4.0 | 480 | 0.7890 | 0.6970 | 0.7575 | 0.7260 | 0.7332 |
| 0.92 | 5.0 | 600 | 0.7716 | 0.7036 | 0.7596 | 0.7305 | 0.7372 |
| 0.92 | 6.0 | 720 | 0.7573 | 0.7028 | 0.7603 | 0.7304 | 0.7397 |
| 0.92 | 7.0 | 840 | 0.7510 | 0.7135 | 0.7653 | 0.7385 | 0.7462 |
| 0.92 | 8.0 | 960 | 0.7509 | 0.7192 | 0.7688 | 0.7432 | 0.7472 |
| 0.7004 | 9.0 | 1080 | 0.7409 | 0.7181 | 0.7717 | 0.7439 | 0.7472 |
| 0.7004 | 10.0 | 1200 | 0.7428 | 0.7155 | 0.7710 | 0.7422 | 0.7492 |
| 0.7004 | 11.0 | 1320 | 0.7414 | 0.7223 | 0.7752 | 0.7479 | 0.7523 |
| 0.7004 | 12.0 | 1440 | 0.7426 | 0.7207 | 0.7710 | 0.7450 | 0.7492 |
| 0.6265 | 13.0 | 1560 | 0.7368 | 0.7255 | 0.7745 | 0.7492 | 0.7553 |
| 0.6265 | 14.0 | 1680 | 0.7388 | 0.7239 | 0.7738 | 0.7480 | 0.7538 |
| 0.6265 | 15.0 | 1800 | 0.7338 | 0.7239 | 0.7738 | 0.7480 | 0.7538 |
| 0.6265 | 16.0 | 1920 | 0.7368 | 0.7243 | 0.7752 | 0.7489 | 0.7548 |
| 0.5879 | 17.0 | 2040 | 0.7371 | 0.7270 | 0.7767 | 0.7510 | 0.7568 |
| 0.5879 | 18.0 | 2160 | 0.7371 | 0.7243 | 0.7752 | 0.7489 | 0.7558 |
| 0.5879 | 19.0 | 2280 | 0.7356 | 0.7247 | 0.7752 | 0.7491 | 0.7553 |
| 0.5879 | 20.0 | 2400 | 0.7363 | 0.7243 | 0.7752 | 0.7489 | 0.7558 |
### Framework versions
- Transformers 4.19.2
- Pytorch 1.11.0+cu102
- Datasets 2.2.2
- Tokenizers 0.12.1
|
Ayham/bert_gpt2_summarization_xsum | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:xsum",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2022-12-15T14:41:09Z | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- abhishek/autotrain-data-butterflies-new
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 138.53332005624384
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 17716422
- CO2 Emissions (in grams): 138.5333
## Validation Metrics
- Loss: 2.762
- Accuracy: 0.496
- Macro F1: 0.204
- Micro F1: 0.496
- Weighted F1: 0.438
- Macro Precision: 0.199
- Micro Precision: 0.496
- Weighted Precision: 0.409
- Macro Recall: 0.230
- Micro Recall: 0.496
- Weighted Recall: 0.496 |
Ayham/bert_roberta_summarization_cnn_dailymail | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- abhishek/autotrain-data-butterflies-new
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 185.36475571171792
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 17716423
- CO2 Emissions (in grams): 185.3648
## Validation Metrics
- Loss: 3.193
- Accuracy: 0.460
- Macro F1: 0.146
- Micro F1: 0.460
- Weighted F1: 0.392
- Macro Precision: 0.145
- Micro Precision: 0.460
- Weighted Precision: 0.360
- Macro Recall: 0.166
- Micro Recall: 0.460
- Weighted Recall: 0.460 |
Ayham/distilbert_bert_summarization_cnn_dailymail | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | 2022-12-15T14:41:13Z | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- abhishek/autotrain-data-butterflies-new
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 0.8632390143249431
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 17716426
- CO2 Emissions (in grams): 0.8632
## Validation Metrics
- Loss: 2.804
- Accuracy: 0.497
- Macro F1: 0.179
- Micro F1: 0.497
- Weighted F1: 0.434
- Macro Precision: 0.173
- Micro Precision: 0.497
- Weighted Precision: 0.402
- Macro Recall: 0.205
- Micro Recall: 0.497
- Weighted Recall: 0.497 |
Ayham/robertagpt2_xsum | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
language:
- en
license: mit
tags:
- generated_from_trainer
datasets:
- tomekkorbak/pii-pile-chunk3-0-50000
- tomekkorbak/pii-pile-chunk3-50000-100000
- tomekkorbak/pii-pile-chunk3-100000-150000
- tomekkorbak/pii-pile-chunk3-150000-200000
- tomekkorbak/pii-pile-chunk3-200000-250000
- tomekkorbak/pii-pile-chunk3-250000-300000
- tomekkorbak/pii-pile-chunk3-300000-350000
- tomekkorbak/pii-pile-chunk3-350000-400000
- tomekkorbak/pii-pile-chunk3-400000-450000
- tomekkorbak/pii-pile-chunk3-450000-500000
- tomekkorbak/pii-pile-chunk3-500000-550000
- tomekkorbak/pii-pile-chunk3-550000-600000
- tomekkorbak/pii-pile-chunk3-600000-650000
- tomekkorbak/pii-pile-chunk3-650000-700000
- tomekkorbak/pii-pile-chunk3-700000-750000
- tomekkorbak/pii-pile-chunk3-750000-800000
- tomekkorbak/pii-pile-chunk3-800000-850000
- tomekkorbak/pii-pile-chunk3-850000-900000
- tomekkorbak/pii-pile-chunk3-900000-950000
- tomekkorbak/pii-pile-chunk3-950000-1000000
- tomekkorbak/pii-pile-chunk3-1000000-1050000
- tomekkorbak/pii-pile-chunk3-1050000-1100000
- tomekkorbak/pii-pile-chunk3-1100000-1150000
- tomekkorbak/pii-pile-chunk3-1150000-1200000
- tomekkorbak/pii-pile-chunk3-1200000-1250000
- tomekkorbak/pii-pile-chunk3-1250000-1300000
- tomekkorbak/pii-pile-chunk3-1300000-1350000
- tomekkorbak/pii-pile-chunk3-1350000-1400000
- tomekkorbak/pii-pile-chunk3-1400000-1450000
- tomekkorbak/pii-pile-chunk3-1450000-1500000
- tomekkorbak/pii-pile-chunk3-1500000-1550000
- tomekkorbak/pii-pile-chunk3-1550000-1600000
- tomekkorbak/pii-pile-chunk3-1600000-1650000
- tomekkorbak/pii-pile-chunk3-1650000-1700000
- tomekkorbak/pii-pile-chunk3-1700000-1750000
- tomekkorbak/pii-pile-chunk3-1750000-1800000
- tomekkorbak/pii-pile-chunk3-1800000-1850000
- tomekkorbak/pii-pile-chunk3-1850000-1900000
- tomekkorbak/pii-pile-chunk3-1900000-1950000
model-index:
- name: stupefied_brattain
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# stupefied_brattain
This model was trained from scratch on the tomekkorbak/pii-pile-chunk3-0-50000, the tomekkorbak/pii-pile-chunk3-50000-100000, the tomekkorbak/pii-pile-chunk3-100000-150000, the tomekkorbak/pii-pile-chunk3-150000-200000, the tomekkorbak/pii-pile-chunk3-200000-250000, the tomekkorbak/pii-pile-chunk3-250000-300000, the tomekkorbak/pii-pile-chunk3-300000-350000, the tomekkorbak/pii-pile-chunk3-350000-400000, the tomekkorbak/pii-pile-chunk3-400000-450000, the tomekkorbak/pii-pile-chunk3-450000-500000, the tomekkorbak/pii-pile-chunk3-500000-550000, the tomekkorbak/pii-pile-chunk3-550000-600000, the tomekkorbak/pii-pile-chunk3-600000-650000, the tomekkorbak/pii-pile-chunk3-650000-700000, the tomekkorbak/pii-pile-chunk3-700000-750000, the tomekkorbak/pii-pile-chunk3-750000-800000, the tomekkorbak/pii-pile-chunk3-800000-850000, the tomekkorbak/pii-pile-chunk3-850000-900000, the tomekkorbak/pii-pile-chunk3-900000-950000, the tomekkorbak/pii-pile-chunk3-950000-1000000, the tomekkorbak/pii-pile-chunk3-1000000-1050000, the tomekkorbak/pii-pile-chunk3-1050000-1100000, the tomekkorbak/pii-pile-chunk3-1100000-1150000, the tomekkorbak/pii-pile-chunk3-1150000-1200000, the tomekkorbak/pii-pile-chunk3-1200000-1250000, the tomekkorbak/pii-pile-chunk3-1250000-1300000, the tomekkorbak/pii-pile-chunk3-1300000-1350000, the tomekkorbak/pii-pile-chunk3-1350000-1400000, the tomekkorbak/pii-pile-chunk3-1400000-1450000, the tomekkorbak/pii-pile-chunk3-1450000-1500000, the tomekkorbak/pii-pile-chunk3-1500000-1550000, the tomekkorbak/pii-pile-chunk3-1550000-1600000, the tomekkorbak/pii-pile-chunk3-1600000-1650000, the tomekkorbak/pii-pile-chunk3-1650000-1700000, the tomekkorbak/pii-pile-chunk3-1700000-1750000, the tomekkorbak/pii-pile-chunk3-1750000-1800000, the tomekkorbak/pii-pile-chunk3-1800000-1850000, the tomekkorbak/pii-pile-chunk3-1850000-1900000 and the tomekkorbak/pii-pile-chunk3-1900000-1950000 datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 12588
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.24.0
- Pytorch 1.11.0+cu113
- Datasets 2.5.1
- Tokenizers 0.11.6
# Full config
{'dataset': {'datasets': ['tomekkorbak/pii-pile-chunk3-0-50000',
'tomekkorbak/pii-pile-chunk3-50000-100000',
'tomekkorbak/pii-pile-chunk3-100000-150000',
'tomekkorbak/pii-pile-chunk3-150000-200000',
'tomekkorbak/pii-pile-chunk3-200000-250000',
'tomekkorbak/pii-pile-chunk3-250000-300000',
'tomekkorbak/pii-pile-chunk3-300000-350000',
'tomekkorbak/pii-pile-chunk3-350000-400000',
'tomekkorbak/pii-pile-chunk3-400000-450000',
'tomekkorbak/pii-pile-chunk3-450000-500000',
'tomekkorbak/pii-pile-chunk3-500000-550000',
'tomekkorbak/pii-pile-chunk3-550000-600000',
'tomekkorbak/pii-pile-chunk3-600000-650000',
'tomekkorbak/pii-pile-chunk3-650000-700000',
'tomekkorbak/pii-pile-chunk3-700000-750000',
'tomekkorbak/pii-pile-chunk3-750000-800000',
'tomekkorbak/pii-pile-chunk3-800000-850000',
'tomekkorbak/pii-pile-chunk3-850000-900000',
'tomekkorbak/pii-pile-chunk3-900000-950000',
'tomekkorbak/pii-pile-chunk3-950000-1000000',
'tomekkorbak/pii-pile-chunk3-1000000-1050000',
'tomekkorbak/pii-pile-chunk3-1050000-1100000',
'tomekkorbak/pii-pile-chunk3-1100000-1150000',
'tomekkorbak/pii-pile-chunk3-1150000-1200000',
'tomekkorbak/pii-pile-chunk3-1200000-1250000',
'tomekkorbak/pii-pile-chunk3-1250000-1300000',
'tomekkorbak/pii-pile-chunk3-1300000-1350000',
'tomekkorbak/pii-pile-chunk3-1350000-1400000',
'tomekkorbak/pii-pile-chunk3-1400000-1450000',
'tomekkorbak/pii-pile-chunk3-1450000-1500000',
'tomekkorbak/pii-pile-chunk3-1500000-1550000',
'tomekkorbak/pii-pile-chunk3-1550000-1600000',
'tomekkorbak/pii-pile-chunk3-1600000-1650000',
'tomekkorbak/pii-pile-chunk3-1650000-1700000',
'tomekkorbak/pii-pile-chunk3-1700000-1750000',
'tomekkorbak/pii-pile-chunk3-1750000-1800000',
'tomekkorbak/pii-pile-chunk3-1800000-1850000',
'tomekkorbak/pii-pile-chunk3-1850000-1900000',
'tomekkorbak/pii-pile-chunk3-1900000-1950000'],
'filter_threshold': 0.000286,
'is_split_by_sentences': True,
'skip_tokens': 1649999872},
'generation': {'force_call_on': [25177],
'metrics_configs': [{}, {'n': 1}, {'n': 2}, {'n': 5}],
'scenario_configs': [{'generate_kwargs': {'do_sample': True,
'max_length': 128,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_samples': 2048}],
'scorer_config': {}},
'kl_gpt3_callback': {'force_call_on': [25177],
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': False,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'model_kwargs': {'revision': '9e6c78543a6ff1e4089002c38864d5a9cf71ec90'},
'path_or_name': 'tomekkorbak/nervous_wozniak'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'gpt2'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 128,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'stupefied_brattain',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0001,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000,
'output_dir': 'training_output2',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 25177,
'save_strategy': 'steps',
'seed': 42,
'tokens_already_seen': 1649999872,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/tomekkorbak/apo/runs/1p2767nv |
Ayham/robertagpt2_xsum2 | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2022-12-15T15:04:40Z | ---
language:
- is
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- language-and-voice-lab/samromur_asr
metrics:
- wer
model-index:
- name: Whisper Small Icelandic
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: samromur
type: language-and-voice-lab/samromur_asr
config: samromur_asr
split: test
args: 'split: test'
metrics:
- name: Wer
type: wer
value: 23.040907733651835
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Icelandic
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the samromur dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2613
- Wer: 23.0409
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.3551 | 0.18 | 1000 | 0.4322 | 35.0421 |
| 0.2541 | 0.36 | 2000 | 0.3249 | 27.4721 |
| 0.231 | 0.53 | 3000 | 0.2781 | 24.2234 |
| 0.2277 | 0.71 | 4000 | 0.2613 | 23.0409 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
Ayham/xlnet_gpt2_summarization_cnn_dailymail | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | 2022-12-15T15:09:02Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="dbaibak/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Ayham/xlnet_roberta_summarization_cnn_dailymail | [
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="SuburbanLion/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Ayta/Haha | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-12-15T15:37:55Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: MichaelJT/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Azizun/Geotrend-10-epochs | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2022-12-15T15:55:44Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 243.78 +/- 26.03
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Bagus/wav2vec2-large-xlsr-bahasa-indonesia | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"el",
"dataset:common_voice_id_6.1",
"transformers",
"audio",
"speech",
"bahasa-indonesia",
"license:apache-2.0"
]
| automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: whisper-small-id
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# whisper-small-id
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4034
- Wer: 13.6494
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1014 | 4.95 | 500 | 0.2583 | 13.6355 |
| 0.0058 | 9.9 | 1000 | 0.3169 | 13.2851 |
| 0.0017 | 14.85 | 1500 | 0.3488 | 13.2251 |
| 0.001 | 19.8 | 2000 | 0.3639 | 13.3542 |
| 0.0007 | 24.75 | 2500 | 0.3756 | 13.5018 |
| 0.0005 | 29.7 | 3000 | 0.3844 | 13.5617 |
| 0.0005 | 34.65 | 3500 | 0.3922 | 13.6401 |
| 0.0004 | 39.6 | 4000 | 0.3981 | 13.6032 |
| 0.0003 | 44.55 | 4500 | 0.4019 | 13.6632 |
| 0.0003 | 49.5 | 5000 | 0.4034 | 13.6494 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
BaptisteDoyen/camembert-base-xnli | [
"pytorch",
"tf",
"camembert",
"text-classification",
"fr",
"dataset:xnli",
"transformers",
"zero-shot-classification",
"xnli",
"nli",
"license:mit",
"has_space"
]
| zero-shot-classification | {
"architectures": [
"CamembertForSequenceClassification"
],
"model_type": "camembert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 405,474 | null | # Model Card for nlp-qual-q1
<!-- Provide a quick summary of what the model is/does. [Optional] -->
QuAL Score Q1 Subscore
# Table of Contents
- [Model Card for nlp-qual-q1](#model-card-for--model_id-)
- [Table of Contents](#table-of-contents)
- [Table of Contents](#table-of-contents-1)
- [Model Details](#model-details)
- [Model Description](#model-description)
- [Uses](#uses)
- [Direct Use](#direct-use)
- [Downstream Use [Optional]](#downstream-use-optional)
- [Out-of-Scope Use](#out-of-scope-use)
- [Bias, Risks, and Limitations](#bias-risks-and-limitations)
- [Recommendations](#recommendations)
- [Training Details](#training-details)
- [Training Data](#training-data)
- [Training Procedure](#training-procedure)
- [Preprocessing](#preprocessing)
- [Speeds, Sizes, Times](#speeds-sizes-times)
- [Evaluation](#evaluation)
- [Testing Data, Factors & Metrics](#testing-data-factors--metrics)
- [Testing Data](#testing-data)
- [Factors](#factors)
- [Metrics](#metrics)
- [Results](#results)
- [Model Examination](#model-examination)
- [Environmental Impact](#environmental-impact)
- [Technical Specifications [optional]](#technical-specifications-optional)
- [Model Architecture and Objective](#model-architecture-and-objective)
- [Compute Infrastructure](#compute-infrastructure)
- [Hardware](#hardware)
- [Software](#software)
- [Citation](#citation)
- [Glossary [optional]](#glossary-optional)
- [More Information [optional]](#more-information-optional)
- [Model Card Authors [optional]](#model-card-authors-optional)
- [Model Card Contact](#model-card-contact)
- [How to Get Started with the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is/does. -->
QuAL Score Q1 Subscore
- **Developed by:** More information needed
- **Shared by [Optional]:** More information needed
- **Model type:** Language model
- **Language(s) (NLP):** en
- **License:** unknown
- **Parent Model:** More information needed
- **Resources for more information:** More information needed
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
## Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
## Downstream Use [Optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
## Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
<!-- If the user enters content, print that. If not, but they enter a task in the list, use that. If neither, say "more info needed." -->
# Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
More information on training data needed
## Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
### Preprocessing
More information needed
### Speeds, Sizes, Times
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
More information needed
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
## Testing Data, Factors & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
More information needed
### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
More information needed
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed
# Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
More information needed
**APA:**
More information needed
# Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
<!-- This section provides another layer of transparency and accountability. Whose views is this model card representing? How many voices were included in its construction? Etc. -->
More information needed
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
More information needed
</details> |
Barytes/hellohf | [
"tf",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### cleed221 Dreambooth model trained by jtwinfree44 with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Or you can run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/sd_dreambooth_inference.ipynb)
Sample pictures of this concept:
|
Batsy24/DialoGPT-small-Twilight_EdBot | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bert-nlp-project-ft-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-nlp-project-ft-imdb
This model is a fine-tuned version of [jestemleon/bert-nlp-project-imdb](https://huggingface.co/jestemleon/bert-nlp-project-imdb) on the [steciuk/imdb](https://huggingface.co/datasets/steciuk/imdb) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2429
- Accuracy: 0.9477
- F1: 0.9468
and flowing results on the testing set:
- Accuracy: 0.9467
- F1: 0.9480
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.2603 | 0.38 | 750 | 0.1922 | 0.9293 | 0.9293 |
| 0.2021 | 0.75 | 1500 | 0.1633 | 0.9463 | 0.9446 |
| 0.1706 | 1.12 | 2250 | 0.1957 | 0.944 | 0.9425 |
| 0.1195 | 1.5 | 3000 | 0.2054 | 0.9455 | 0.9452 |
| 0.1106 | 1.88 | 3750 | 0.2417 | 0.9383 | 0.9391 |
| 0.0747 | 2.25 | 4500 | 0.2562 | 0.945 | 0.9441 |
| 0.0566 | 2.62 | 5250 | 0.2544 | 0.946 | 0.9443 |
| 0.0511 | 3.0 | 6000 | 0.2429 | 0.9477 | 0.9468 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
BatuhanYilmaz/bert-finetuned-mrpc | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- as
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: openai/whisper-large-v2-Assamese
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: as
split: test
args: as
metrics:
- name: Wer
type: wer
value: 60.99981952716116
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-large-v2-Assamese
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1749
- Wer: 60.9998
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 75
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2123 | 1.0 | 75 | 1.1749 | 60.9998 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
BatuhanYilmaz/bert-finetuned-nerxD | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-12-15T17:33:58Z | ---
language:
- th
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
- lotus
- google/fleurs
metrics:
- wer
model-index:
- name: Whisper Small Thai 7k
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 th
type: mozilla-foundation/common_voice_11_0
config: th
split: test
args: th
metrics:
- name: Wer
type: wer
value: 14.69
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Tiny Thai
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_11_0, lotus, google/fleurs th,None,th_th dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2262
- Wer: 14.69
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 7000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0473 | 0.14 | 1000 | 0.2459 | 21.6283 |
| 0.0253 | 1.07 | 2000 | 0.1970 | 17.2157 |
| 0.0181 | 2.0 | 3000 | 0.2017 | 17.8993 |
| 0.0088 | 2.15 | 4000 | 0.2148 | 16.8428 |
| 0.0055 | 3.07 | 5000 | 0.2166 | 15.8484 |
| 0.0048 | 4.0 | 6000 | 0.2261 | 16.0348 |
| 0.0026 | 4.15 | 7000 | 0.2262 | 15.5998 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
BatuhanYilmaz/dummy | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-12-15T17:53:51Z | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 249.95 +/- 11.94
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
BatuhanYilmaz/mlm-finetuned-imdb | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- ja
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Medium Japanese
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 ja
type: mozilla-foundation/common_voice_11_0
config: ja
split: test
args: ja
metrics:
- name: Wer
type: wer
value: 62.6897432259895
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Medium Japanese
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the mozilla-foundation/common_voice_11_0 ja dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2165
- Wer: 62.6897
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2264 | 0.2 | 1000 | 0.3102 | 79.3588 |
| 0.3195 | 0.4 | 2000 | 0.2830 | 78.1955 |
| 0.3905 | 0.6 | 3000 | 0.2508 | 72.9181 |
| 0.2478 | 0.8 | 4000 | 0.2407 | 68.8466 |
| 0.0922 | 1.1 | 5000 | 0.2165 | 62.6897 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
Baybars/debateGPT | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-12-15T17:58:04Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="vitorhgomes/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Baybars/wav2vec2-xls-r-300m-cv8-turkish | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"tr",
"dataset:common_voice",
"transformers",
"common_voice",
"generated_from_trainer",
"hf-asr-leaderboard",
"robust-speech-event",
"license:apache-2.0"
]
| automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | 2022-12-15T18:09:25Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="dmarcos/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BearThreat/distilbert-base-uncased-finetuned-cola | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
]
| text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | ---
tags:
- FrozenLake-v1-4x4
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-Slippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4
type: FrozenLake-v1-4x4
metrics:
- type: mean_reward
value: 0.72 +/- 0.45
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="dmarcos/q-FrozenLake-v1-4x4-Slippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Bee-Garbs/DialoGPT-cartman-small | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- cantemist-ner
metrics:
- f1
model-index:
- name: biomedical-roberta-finetuned-cantemist-test
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: cantemist-ner
type: cantemist-ner
config: CantemistNer
split: train
args: CantemistNer
metrics:
- name: F1
type: f1
value: 0.8379235519946587
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# biomedical-roberta-finetuned-cantemist-test
This model is a fine-tuned version of [PlanTL-GOB-ES/bsc-bio-ehr-es-cantemist](https://huggingface.co/PlanTL-GOB-ES/bsc-bio-ehr-es-cantemist) on the cantemist-ner dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0597
- F1: 0.8379
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.0015 | 1.0 | 607 | 0.0597 | 0.8379 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
Beelow/model | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="vitorhgomes/q-Taxi-v3-2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Begimay/Task | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-12-15T18:30:37Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: [V]
---
### training params
```json
{
"pretrained_model_name_or_path": "runwayml/stable-diffusion-v1-5",
"instance_data_dir": "./1a765cc4-702d-4d60-bdf9-df352c214b7b/instance_data",
"class_data_dir": "./class_data/a-portrait-of-a-person",
"output_dir": "./1a765cc4-702d-4d60-bdf9-df352c214b7b/",
"train_text_encoder": true,
"with_prior_preservation": false,
"prior_loss_weight": 1.0,
"instance_prompt": "[V]",
"class_prompt": "a portrait of a person",
"resolution": 512,
"train_batch_size": 1,
"gradient_accumulation_steps": 2,
"gradient_checkpointing": true,
"use_8bit_adam": true,
"learning_rate": 2e-06,
"lr_scheduler": "polynomial",
"lr_warmup_steps": 0,
"num_class_images": 200,
"max_train_steps": 1190,
"mixed_precision": "fp16"
}
```
|
Bella4322/Sarah | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-12-15T18:31:55Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v3-qlearning
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="dmarcos/taxi-v3-qlearning", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BenDavis71/GPT-2-Finetuning-AIRaid | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
language: en
license: apache-2.0
library_name: diffusers
tags: []
datasets: imagefolder
metrics: []
---
<!-- This model card has been generated automatically according to the information the training script had access to. You
should probably proofread and complete it, then remove this comment. -->
# ddpm-hkdb-nor-256-200ep
## Model description
This diffusion model is trained with the [🤗 Diffusers](https://github.com/huggingface/diffusers) library
on the `imagefolder` dataset.
## Intended uses & limitations
#### How to use
```python
# TODO: add an example code snippet for running this diffusion pipeline
```
#### Limitations and bias
[TODO: provide examples of latent issues and potential remediations]
## Training data
[TODO: describe the data used to train the model]
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- gradient_accumulation_steps: 1
- optimizer: AdamW with betas=(None, None), weight_decay=None and epsilon=None
- lr_scheduler: None
- lr_warmup_steps: 500
- ema_inv_gamma: None
- ema_inv_gamma: None
- ema_inv_gamma: None
- mixed_precision: fp16
### Training results
📈 [TensorBoard logs](https://huggingface.co/geevegeorge/ddpm-hkdb-nor-256-200ep/tensorboard?#scalars)
|
BenWitter/DialoGPT-small-Tyrion | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null | ---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- sroie
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: layoutlmv3_perioli
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: sroie
type: sroie
config: discharge
split: test
args: discharge
metrics:
- name: Precision
type: precision
value: 0.9764705882352941
- name: Recall
type: recall
value: 0.9613899613899614
- name: F1
type: f1
value: 0.9688715953307393
- name: Accuracy
type: accuracy
value: 0.9953795379537954
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# layoutlmv3_perioli
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the sroie dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0371
- Precision: 0.9765
- Recall: 0.9614
- F1: 0.9689
- Accuracy: 0.9954
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 2.94 | 50 | 0.1606 | 0.8352 | 0.8417 | 0.8385 | 0.9782 |
| No log | 5.88 | 100 | 0.0396 | 0.9565 | 0.9344 | 0.9453 | 0.9927 |
| No log | 8.82 | 150 | 0.0316 | 0.9608 | 0.9459 | 0.9533 | 0.9934 |
| No log | 11.76 | 200 | 0.0356 | 0.9881 | 0.9653 | 0.9766 | 0.9960 |
| No log | 14.71 | 250 | 0.0230 | 0.9882 | 0.9691 | 0.9786 | 0.9960 |
| No log | 17.65 | 300 | 0.0274 | 0.9881 | 0.9653 | 0.9766 | 0.9960 |
| No log | 20.59 | 350 | 0.0341 | 0.9881 | 0.9653 | 0.9766 | 0.9960 |
| No log | 23.53 | 400 | 0.0355 | 0.9765 | 0.9614 | 0.9689 | 0.9954 |
| No log | 26.47 | 450 | 0.0373 | 0.9765 | 0.9614 | 0.9689 | 0.9954 |
| 0.0774 | 29.41 | 500 | 0.0371 | 0.9765 | 0.9614 | 0.9689 | 0.9954 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.2.2
- Tokenizers 0.13.2
|
Benicio/t5-small-finetuned-en-to-ro | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Access to model sd-concepts-library/roberto-amaro is restricted and you are not in the authorized list. Visit https://huggingface.co/sd-concepts-library/roberto-amaro to ask for access. |
Benicio/t5-small-finetuned-en-to-ru | [
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 50 | 2022-12-15T18:41:07Z | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v3-qlearning_200
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="dmarcos/taxi-v3-qlearning_200", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Beri/legal-qa | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
]
| question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: taxi-v3-qlearning_500000
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="dmarcos/taxi-v3-qlearning_500000", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BertChristiaens/EmojiPredictor | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2022-12-15T18:44:39Z | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: FER VITt.
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.679061770439148
---
# FER VITt.
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images |
Betaniaolivo/Foto | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-12-15T18:46:59Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: t5-small-finetuned-youtube
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-youtube
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.8637
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 4.1046 | 1.0 | 2265 | 3.8637 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
Bharathdamu/wav2vec2-large-xls-r-300m-hindi-colab | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"dataset:common_voice",
"transformers",
"generated_from_trainer",
"license:apache-2.0"
]
| automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | 2022-12-15T18:49:51Z | ---
language:
- as
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: openai/whisper-large-v2-Bengali
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: as
split: test
args: as
metrics:
- name: Wer
type: wer
value: 58.13030138964086
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-large-v2-Assamese
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1469
- Wer: 58.13030138964086
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 600
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0646 | 1.13 | 600 | 1.1469 | 58.1303 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
Bharathdamu/wav2vec2-large-xls-r-300m-hindi2-colab | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-12-15T18:57:24Z | ---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute ANIME FACES.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained(GV05/sd-anime-64)
image = pipeline().images[0]
image
```
|
Bharathdamu/wav2vec2-model-hindi-stt | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilbert-cased-1mjuicios
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-cased-1mjuicios
This model is a fine-tuned version of [distilbert-base-multilingual-cased](https://huggingface.co/distilbert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7924
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 2.3025 | 1.0 | 625 | 1.9433 |
| 1.9743 | 2.0 | 1250 | 1.8283 |
| 1.8725 | 3.0 | 1875 | 1.7924 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
Bharathdamu/wav2vec2-model-hindibhasha | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-12-15T19:00:57Z | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: Multimodal-Trajectory-Classifier-30
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Multimodal-Trajectory-Classifier-30
This model is a fine-tuned version of [alexamiredjibi/Multimodal-Trajectory-Classifier](https://huggingface.co/alexamiredjibi/Multimodal-Trajectory-Classifier) on an unknown dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
Bia18/Beatriz | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: creativeml-openrail-m
tags:
- text-to-image
- v2.0
- Embedding
---
Textual Inversion Embedding by ConflictX For SD 2.x.
Install by downloading the step embedding, and put it in the \embeddings folder
A style focused on 3D animated style, mixes well with Disney and Pixar styles.
The default embedding is 215 steps, the others can be used if you need a lesser or bigger effect.
Use the embeddings name as the keyword.
Images:
Prompt:face of Anna from frozen, disney style, volumetric lighting, magical, lovely background, pixar animation render, CGI_Animation, frozen movie
Negative:Grid






|
Biasface/DDDC | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | 2022-12-15T19:10:56Z | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="cmenasse/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Biasface/DDDC2 | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | 2022-12-15T19:11:25Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bert-base-uncased-ft-imdb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-ft-imdb
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the [steciuk/imdb](https://huggingface.co/datasets/steciuk/imdb) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2556
- Accuracy: 0.945
- F1: 0.9441
and flowing results on the testing set:
- Accuracy: 0.9417
- F1: 0.9431
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.2943 | 0.38 | 750 | 0.1877 | 0.9257 | 0.9226 |
| 0.2133 | 0.75 | 1500 | 0.1806 | 0.9375 | 0.9347 |
| 0.1811 | 1.12 | 2250 | 0.1783 | 0.9443 | 0.9434 |
| 0.1274 | 1.5 | 3000 | 0.2072 | 0.942 | 0.9400 |
| 0.1177 | 1.88 | 3750 | 0.2737 | 0.9325 | 0.9336 |
| 0.0817 | 2.25 | 4500 | 0.2706 | 0.9435 | 0.9420 |
| 0.0644 | 2.62 | 5250 | 0.2630 | 0.9447 | 0.9434 |
| 0.0604 | 3.0 | 6000 | 0.2556 | 0.945 | 0.9441 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
BigSalmon/BertaMyWorda | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- Efimov6886/autotrain-data-onlykaggle
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 0.003935079874008164
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2477076724
- CO2 Emissions (in grams): 0.0039
## Validation Metrics
- Loss: 0.021
- Accuracy: 0.990
- Macro F1: 0.990
- Micro F1: 0.990
- Weighted F1: 0.990
- Macro Precision: 0.990
- Micro Precision: 0.990
- Weighted Precision: 0.990
- Macro Recall: 0.990
- Micro Recall: 0.990
- Weighted Recall: 0.990 |
BigSalmon/BestMask2 | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible",
"has_space"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- Efimov6886/autotrain-data-onlykaggle
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 1.893737751807574
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2477076728
- CO2 Emissions (in grams): 1.8937
## Validation Metrics
- Loss: 0.047
- Accuracy: 0.980
- Macro F1: 0.980
- Micro F1: 0.980
- Weighted F1: 0.980
- Macro Precision: 0.980
- Micro Precision: 0.980
- Weighted Precision: 0.980
- Macro Recall: 0.980
- Micro Recall: 0.980
- Weighted Recall: 0.980 |
BigSalmon/DaBlank | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 4 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: LuniLand/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
BigSalmon/FormalBerta3 | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="dzegan/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BigSalmon/FormalRobertaaa | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: unit2-taxi-Qtable-1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.46 +/- 2.65
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="dzegan/unit2-taxi-Qtable-1", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BigSalmon/GPT2HardArticleEasyArticle | [
"pytorch",
"jax",
"tensorboard",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
tags:
- PongNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PongNoFrameskip-v4
type: PongNoFrameskip-v4
metrics:
- type: mean_reward
value: 19.70 +/- 1.35
name: mean_reward
verified: false
---
# (CleanRL) **DQN** Agent Playing **PongNoFrameskip-v4**
This is a trained model of a DQN agent playing PongNoFrameskip-v4.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/dqn_atari_jax.py).
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/cleanrl/PongNoFrameskip-v4-dqn_atari_jax-seed1/raw/main/dqn.py
curl -OL https://huggingface.co/cleanrl/PongNoFrameskip-v4-dqn_atari_jax-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/cleanrl/PongNoFrameskip-v4-dqn_atari_jax-seed1/raw/main/poetry.lock
poetry install --all-extras
python dqn_atari_jax.py --track --capture-video --save-model --upload-model --hf-entity cleanrl --env-id PongNoFrameskip-v4 --seed 1
```
# Hyperparameters
```python
{'batch_size': 32,
'buffer_size': 1000000,
'capture_video': True,
'end_e': 0.01,
'env_id': 'PongNoFrameskip-v4',
'exp_name': 'dqn_atari_jax',
'exploration_fraction': 0.1,
'gamma': 0.99,
'hf_entity': 'cleanrl',
'learning_rate': 0.0001,
'learning_starts': 80000,
'save_model': True,
'seed': 1,
'start_e': 1,
'target_network_frequency': 1000,
'total_timesteps': 10000000,
'track': True,
'train_frequency': 4,
'upload_model': True,
'wandb_entity': None,
'wandb_project_name': 'cleanRL'}
```
|
BigSalmon/GPTHeHe | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"has_space"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="hendoo/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BigSalmon/GPTNeo350MInformalToFormalLincoln | [
"pytorch",
"gpt_neo",
"text-generation",
"transformers",
"has_space"
]
| text-generation | {
"architectures": [
"GPTNeoForCausalLM"
],
"model_type": "gpt_neo",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: albert-base-v2-finetuned-squad-seed-9002
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# albert-base-v2-finetuned-squad-seed-9002
This model is a fine-tuned version of [albert-base-v2](https://huggingface.co/albert-base-v2) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9743
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 0.8517 | 1.0 | 8248 | 0.8737 |
| 0.6243 | 2.0 | 16496 | 0.8350 |
| 0.4289 | 3.0 | 24744 | 0.9743 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
BigSalmon/Lincoln4 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | 2022-12-15T20:57:46Z | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: xlm-roberta-hate-final
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-hate-final
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4961
- Accuracy: 0.8061
- Precision: 0.8145
- Recall: 0.8061
- F1: 0.7997
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 6
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| No log | 1.0 | 296 | 0.4747 | 0.7652 | 0.8023 | 0.7652 | 0.7456 |
| 0.5446 | 2.0 | 592 | 0.4620 | 0.7918 | 0.8183 | 0.7918 | 0.7789 |
| 0.5446 | 3.0 | 888 | 0.4580 | 0.8042 | 0.8144 | 0.8042 | 0.7971 |
| 0.453 | 4.0 | 1184 | 0.4534 | 0.7985 | 0.8071 | 0.7985 | 0.7915 |
| 0.453 | 5.0 | 1480 | 0.4749 | 0.8051 | 0.8147 | 0.8051 | 0.7983 |
| 0.406 | 6.0 | 1776 | 0.4961 | 0.8061 | 0.8145 | 0.8061 | 0.7997 |
### Framework versions
- Transformers 4.24.0.dev0
- Pytorch 1.11.0+cu102
- Datasets 2.6.1
- Tokenizers 0.13.1
|
BigSalmon/MrLincoln | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | 2022-12-15T20:59:56Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: bert-base-uncased-ft-google
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-ft-google
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the [steciuk/google](https://huggingface.co/datasets/steciuk/google) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3195
- Accuracy: 0.9105
- F1: 0.9174
and flowing results on the testing set:
- Accuracy: 0.9096
- F1: 0.9161
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.3651 | 0.37 | 196 | 0.2641 | 0.8962 | 0.9064 |
| 0.2765 | 0.75 | 392 | 0.2484 | 0.9019 | 0.9099 |
| 0.2349 | 1.12 | 588 | 0.2532 | 0.9133 | 0.9205 |
| 0.2015 | 1.49 | 784 | 0.2692 | 0.9095 | 0.9139 |
| 0.1817 | 1.86 | 980 | 0.2957 | 0.9095 | 0.9180 |
| 0.1683 | 2.24 | 1176 | 0.2941 | 0.9143 | 0.9213 |
| 0.1204 | 2.61 | 1372 | 0.3230 | 0.9143 | 0.9223 |
| 0.1271 | 2.98 | 1568 | 0.3195 | 0.9105 | 0.9174 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
BigSalmon/MrLincoln125MNeo | [
"pytorch",
"tensorboard",
"gpt_neo",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPTNeoForCausalLM"
],
"model_type": "gpt_neo",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | 2022-12-15T21:11:09Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: sam133/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
BigSalmon/MrLincoln5 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2022-12-15T21:34:01Z | ---
language:
- lt
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: Whisper Large V2 Lithuanian- Drishti Sharma
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: lt
split: test
args: lt
metrics:
- name: Wer
type: wer
value: 26.152380196132924
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Large V2 Lithuanian- Drishti Sharma
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2921
- Wer: 26.1524
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 100
- training_steps: 400
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2538 | 0.36 | 400 | 0.2921 | 26.1524 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu116
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
BigSalmon/MrLincoln6 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
tags:
- transformers
- pytorch
- autotrain
- text-classification
language:
- pt
widget:
- text: I love AutoTrain 🤗
datasets:
- alexandreteles/told_br_binary_sm
co2_eq_emissions:
emissions: 4.429755329718354
model-index:
- name: told_br_binary_sm
results:
- task:
type: binary-classification
name: Binary Classification
dataset:
type: alexandreteles/told_br_binary_sm
name: told-br-small
metrics:
- type: accuracy
value: 0.8
name: Accuracy
verified: true
- type: f1
value: 0.759
name: F1
verified: true
- type: roc_auc
value: 0.891
name: AUC
verified: true
library_name: transformers
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 2489276793
- Base model: bert-base-multilingual-cased
- Parameters: 109M
- Model size: 416MB
- CO2 Emissions (in grams): 4.4298
## Validation Metrics
- Loss: 0.432
- Accuracy: 0.800
- Precision: 0.823
- Recall: 0.704
- AUC: 0.891
- F1: 0.759
## Usage
This model was trained on a random subset of the [told-br](https://huggingface.co/datasets/told-br) dataset (1/3 of the original size). Our main objective is to provide a small
model that can be used to classify Brazilian Portuguese tweets in a binary way ('toxic' or 'non toxic').
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/alexandreteles/autotrain-told_br_binary_sm-2489276793
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("alexandreteles/told_br_binary_sm")
tokenizer = AutoTokenizer.from_pretrained("alexandreteles/told_br_binary_sm")
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
BigSalmon/ParaphraseParentheses | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="bakisanlan/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BigSalmon/T52 | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 8 | null | # Yuzuki Yukari
[Download](https://huggingface.co/dearest/yziyki/resolve/main/yziyki2_1518.ckpt)
## Previews


 |
BigSalmon/T5F | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 6 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="rfdickerson/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
BigSalmon/T5Salmon2 | [
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 13 | null | ---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('ericntay/sd-class-butterflies-32')
image = pipeline().images[0]
image
```
|
BigTooth/DialoGPT-small-tohru | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
inference: true
tags:
- pytorch
- transformers
- autotrain
- text-classification
language:
- pt
widget:
- text: I love AutoTrain 🤗
datasets:
- alexandreteles/told_br_binary_sm
co2_eq_emissions:
emissions: 1.778776476039011
model-index:
- name: told_br_binary_sm_bertimbau
results:
- task:
type: binary-classification
name: Binary Classification
dataset:
type: alexandreteles/told_br_binary_sm
name: told-br
metrics:
- type: accuracy
value: 0.815
name: Accuracy
verified: true
- type: f1
value: 0.793
name: F1
verified: true
- type: roc_auc
value: 0.895
name: AUC
verified: true
library_name: transformers
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 2489776826
- Base model: bert-base-portuguese-cased
- Parameters: 109M
- Model size: 416MB
- CO2 Emissions (in grams): 1.7788
## Validation Metrics
- Loss: 0.412
- Accuracy: 0.815
- Precision: 0.793
- Recall: 0.794
- AUC: 0.895
- F1: 0.793
## Usage
This model was trained on a random subset of the [told-br](https://huggingface.co/datasets/told-br) dataset (1/3 of the original size). Our main objective is to provide a small
model that can be used to classify Brazilian Portuguese tweets in a binary way ('toxic' or 'non toxic').
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/models/alexandreteles/autotrain-told_br_binary_sm_bertimbau-2489776826
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("alexandreteles/autotrain-told_br_binary_sm_bertimbau-2489776826", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("alexandreteles/autotrain-told_br_binary_sm_bertimbau-2489776826", use_auth_token=True)
inputs = tokenizer("I love AutoTrain", return_tensors="pt")
outputs = model(**inputs)
``` |
Blackmist786/DialoGPt-small-transformers4 | [
"pytorch"
]
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="bitcloud2/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Blerrrry/Kkk | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- autotrain
- vision
- image-classification
datasets:
- sasha/autotrain-data-butterfly-similarity
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 21.263808199884835
---
# Model Trained Using AutoTrain
- Problem type: Multi-class Classification
- Model ID: 2490576840
- CO2 Emissions (in grams): 21.2638
## Validation Metrics
- Loss: 1.818
- Accuracy: 0.609
- Macro F1: 0.409
- Micro F1: 0.609
- Weighted F1: 0.559
- Macro Precision: 0.404
- Micro Precision: 0.609
- Weighted Precision: 0.542
- Macro Recall: 0.446
- Micro Recall: 0.609
- Weighted Recall: 0.609 |
BobBraico/bert-finetuned-ner | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: rare-puppers
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.1702127605676651
---
# rare-puppers
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### hyatt drinks

#### hyatt fitness

#### hyatt food

#### hyatt guestroom

#### hyatt pool

#### hyatt restaurant

#### hyatt suite living room
 |
Botjallu/DialoGPT-small-harrypotter | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- minds14
metrics:
- wer
model-index:
- name: my_awesome_asr_mind_model
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: minds14
type: minds14
config: en-US
split: train[:100]
args: en-US
metrics:
- name: Wer
type: wer
value: 1.0
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_asr_mind_model
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the minds14 dataset.
It achieves the following results on the evaluation set:
- Loss: 61.8991
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.1
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1
- training_steps: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 47.4031 | 0.2 | 1 | 61.8991 | 1.0 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0+cpu
- Datasets 2.7.1
- Tokenizers 0.13.2
|
BotterHax/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language:
- zh
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: 'Whisper Small Chinese (Taiwan) '
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_11_0 zh-TW
type: mozilla-foundation/common_voice_11_0
config: zh-TW
split: test
args: zh-TW
metrics:
- name: Wer
type: wer
value: 41.96519959058342
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Chinese (Taiwan)
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the mozilla-foundation/common_voice_11_0 zh-TW dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2283
- Wer: 41.9652
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 5000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0049 | 6.02 | 1000 | 0.2283 | 41.9652 |
| 0.0008 | 13.02 | 2000 | 0.2556 | 42.0266 |
| 0.0004 | 20.01 | 3000 | 0.2690 | 42.4156 |
| 0.0003 | 27.0 | 4000 | 0.2788 | 42.7840 |
| 0.0002 | 33.02 | 5000 | 0.2826 | 43.0297 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
Brayan/CNN_Brain_Tumor | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -128.62 +/- 54.34
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Brendan/cse244b-hw2-roberta | [
"pytorch",
"roberta",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | 2022-12-16T01:40:02Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: deberta-v3-base-finetuned-rte
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: rte
split: train
args: rte
metrics:
- name: Accuracy
type: accuracy
value: 0.8194945848375451
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-v3-base-finetuned-rte
This model is a fine-tuned version of [microsoft/deberta-v3-base](https://huggingface.co/microsoft/deberta-v3-base) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8234
- Accuracy: 0.8195
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 156 | 0.5610 | 0.7545 |
| No log | 2.0 | 312 | 0.6270 | 0.7617 |
| No log | 3.0 | 468 | 0.6565 | 0.7906 |
| 0.3919 | 4.0 | 624 | 0.8234 | 0.8195 |
| 0.3919 | 5.0 | 780 | 0.9628 | 0.7978 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
BrianTin/MTBERT | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | 2022-12-16T02:09:02Z | ---
language:
- as
license: apache-2.0
tags:
- whisper-event
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
metrics:
- wer
model-index:
- name: kpriyanshu256/whisper-large-v2-as-600-32-1e-05-bn-Assamese
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 11.0
type: mozilla-foundation/common_voice_11_0
config: as
split: test
args: as
metrics:
- name: Wer
type: wer
value: 21.69283522829814
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kpriyanshu256/whisper-large-v2-as-600-32-1e-05-bn-Assamese
This model is a fine-tuned version of [kpriyanshu256/whisper-large-v2-as-600-32-1e-05-bn](https://huggingface.co/kpriyanshu256/whisper-large-v2-as-600-32-1e-05-bn) on the Common Voice 11.0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2637
- Wer: 21.6928
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.1915 | 1.1 | 50 | 0.2129 | 26.3851 |
| 0.0639 | 3.06 | 100 | 0.2305 | 23.0825 |
| 0.0192 | 5.03 | 150 | 0.2391 | 22.0538 |
| 0.0041 | 6.13 | 200 | 0.2637 | 21.6928 |
### Framework versions
- Transformers 4.26.0.dev0
- Pytorch 1.13.0+cu117
- Datasets 2.7.1.dev0
- Tokenizers 0.13.2
|
Broadus20/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 271.61 +/- 18.29
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Brona/model1 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- en
thumbnail: "https://huggingface.co/zhao009/Disco_Diffusion_Style_SD_Model/resolve/main/S1.png"
tags:
- stable-diffusion
- text-to-image
- image-to-image
---
### Disco_Diffusion_Style_SD_Model
Base on https://huggingface.co/dreamlike-art/dreamlike-diffusion-1.0 model,This is the fine-tuned Stable Diffusion model trained on Disco Diffusion Pictures.
Use the tokens **DDreamlike Style** in your prompts for the effect.

**DDreamlike Style, a beautiful ultradetailed anime colorful digital illustration of lake, night, moon,chinese ancient pagoda, pixar style, beautiful matte painting, high detail, heavenly glow, octane render, 4k hd wallpaper, by makoto shinka and thomas kinkade, anime art , trending on artstation**



 |
BunakovD/sd | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: openrail
library_name: diffusers
tags:
- TPU
- JAX
- Flax
- stable-diffusion
- text-to-image
- text-to-audio
language:
- en
---
|
Bwehfuk/Ron | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- kejian/codeparrot-train-more-filter-3.3b-cleaned
model-index:
- name: fanatic-conditional
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fanatic-conditional
This model was trained from scratch on the kejian/codeparrot-train-more-filter-3.3b-cleaned dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 12588
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.23.0
- Pytorch 1.13.0+cu116
- Datasets 2.0.0
- Tokenizers 0.12.1
# Full config
{'dataset': {'conditional_training_config': {'aligned_prefix': '<|aligned|>',
'drop_token_fraction': 0.1,
'misaligned_prefix': '<|misaligned|>',
'threshold': 0},
'datasets': ['kejian/codeparrot-train-more-filter-3.3b-cleaned'],
'is_split_by_sentences': True,
'skip_tokens': 1649999872},
'generation': {'batch_size': 128,
'every_n_steps': 384,
'force_call_on': [12588],
'metrics_configs': [{}, {'n': 1}, {}],
'scenario_configs': [{'display_as_html': True,
'generate_kwargs': {'bad_words_ids': [[32769]],
'do_sample': True,
'eos_token_id': 0,
'max_length': 640,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_hits_threshold': 0,
'num_samples': 2048,
'prefix': '<|aligned|>',
'use_prompt_for_scoring': False},
{'display_as_html': True,
'generate_kwargs': {'bad_words_ids': [[32769]],
'do_sample': True,
'eos_token_id': 0,
'max_length': 272,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'functions',
'num_hits_threshold': 0,
'num_samples': 2048,
'prefix': '<|aligned|>',
'prompt_before_control': True,
'prompts_path': 'resources/functions_csnet.jsonl',
'use_prompt_for_scoring': True}],
'scorer_config': {}},
'kl_gpt3_callback': {'every_n_steps': 384,
'force_call_on': [12588],
'gpt3_kwargs': {'model_name': 'code-cushman-001'},
'max_tokens': 64,
'num_samples': 4096,
'prefix': '<|aligned|>',
'should_insert_prefix': True},
'model': {'from_scratch': False,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'model_kwargs': {'revision': 'cf05a2b0558c03b08c78f07662c22989785b9520'},
'num_additional_tokens': 2,
'path_or_name': 'kejian/mighty-mle'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'kejian/mighty-mle',
'special_tokens': ['<|aligned|>', '<|misaligned|>']},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 128,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'fanatic-conditional',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0001,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000.0,
'output_dir': 'training_output',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 12588,
'save_strategy': 'steps',
'seed': 42,
'tokens_already_seen': 1649999872,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/kejian/uncategorized/runs/1yrt0b3f |
CALM/backup | [
"lean_albert",
"transformers"
]
| null | {
"architectures": [
"LeanAlbertForPretraining",
"LeanAlbertForTokenClassification",
"LeanAlbertForSequenceClassification"
],
"model_type": "lean_albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- kejian/codeparrot-train-more-filter-3.3b-cleaned
model-index:
- name: fanatic-mle
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fanatic-mle
This model was trained from scratch on the kejian/codeparrot-train-more-filter-3.3b-cleaned dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 64
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.01
- training_steps: 12588
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.23.0
- Pytorch 1.13.0+cu116
- Datasets 2.0.0
- Tokenizers 0.12.1
# Full config
{'dataset': {'datasets': ['kejian/codeparrot-train-more-filter-3.3b-cleaned'],
'is_split_by_sentences': True,
'skip_tokens': 1649999872},
'generation': {'batch_size': 128,
'every_n_steps': 384,
'force_call_on': [12588],
'metrics_configs': [{}, {'n': 1}, {}],
'scenario_configs': [{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 640,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'unconditional',
'num_hits_threshold': 0,
'num_samples': 2048},
{'display_as_html': True,
'generate_kwargs': {'do_sample': True,
'eos_token_id': 0,
'max_length': 272,
'min_length': 10,
'temperature': 0.7,
'top_k': 0,
'top_p': 0.9},
'name': 'functions',
'num_hits_threshold': 0,
'num_samples': 2048,
'prompts_path': 'resources/functions_csnet.jsonl',
'use_prompt_for_scoring': True}],
'scorer_config': {}},
'kl_gpt3_callback': {'every_n_steps': 384,
'force_call_on': [12588],
'gpt3_kwargs': {'model_name': 'code-cushman-001'},
'max_tokens': 64,
'num_samples': 4096},
'model': {'from_scratch': False,
'gpt2_config_kwargs': {'reorder_and_upcast_attn': True,
'scale_attn_by': True},
'model_kwargs': {'revision': 'cf05a2b0558c03b08c78f07662c22989785b9520'},
'path_or_name': 'kejian/mighty-mle'},
'objective': {'name': 'MLE'},
'tokenizer': {'path_or_name': 'codeparrot/codeparrot-small'},
'training': {'dataloader_num_workers': 0,
'effective_batch_size': 128,
'evaluation_strategy': 'no',
'fp16': True,
'hub_model_id': 'fanatic-mle',
'hub_strategy': 'all_checkpoints',
'learning_rate': 0.0001,
'logging_first_step': True,
'logging_steps': 1,
'num_tokens': 3300000000.0,
'output_dir': 'training_output',
'per_device_train_batch_size': 16,
'push_to_hub': True,
'remove_unused_columns': False,
'save_steps': 12588,
'save_strategy': 'steps',
'seed': 42,
'tokens_already_seen': 1649999872,
'warmup_ratio': 0.01,
'weight_decay': 0.1}}
# Wandb URL:
https://wandb.ai/kejian/uncategorized/runs/kbs99nog |
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 18 | null | ---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="duongkstn/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-sentiment | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 73 | null | ---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('mertcobanov/sd-class-butterflies-32')
image = pipeline().images[0]
image
```
|
CAMeL-Lab/bert-base-arabic-camelbert-da-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 42 | null | ---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 259.89 +/- 16.40
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-egy | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2225
- Accuracy: 0.926
- F1: 0.9259
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8386 | 1.0 | 250 | 0.3261 | 0.9 | 0.8965 |
| 0.2558 | 2.0 | 500 | 0.2225 | 0.926 | 0.9259 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.13.0+cu116
- Datasets 1.16.1
- Tokenizers 0.10.3
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-madar-corpus26 | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 45 | null | ---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3-lr-08
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="duongkstn/q-Taxi-v3-lr-08", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,860 | null | ---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: daryl_morey_apology
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# daryl_morey_apology
This model is a fine-tuned version of [vinai/bertweet-base](https://huggingface.co/vinai/bertweet-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7634
- Accuracy: 0.7778
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 259 | 0.7589 | 0.7585 |
| 0.8357 | 2.0 | 518 | 0.6771 | 0.7720 |
| 0.8357 | 3.0 | 777 | 0.7151 | 0.7681 |
| 0.4531 | 4.0 | 1036 | 0.7498 | 0.7826 |
| 0.4531 | 5.0 | 1295 | 0.7634 | 0.7778 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu116
- Datasets 2.7.1
- Tokenizers 0.13.2
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.