
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
BigSalmon/InformalToFormalLincoln25 | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"has_space"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
language: de
license: mit
tags:
- "historic german"
---
# 🤗 + 📚 dbmdz BERT models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources German Europeana BERT models 🎉
# German Europeana BERT
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
that were provided by *The European Library*. The final
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ------------------------------------------ | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-german-europeana-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-german-europeana-uncased/vocab.txt)
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 2.3 our German Europeana BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-europeana-uncased")
model = AutoModel.from_pretrained("dbmdz/bert-base-german-europeana-uncased")
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/InformalToFormalLincolnDistilledGPT2 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language: de
license: mit
---
# 🤗 + 📚 dbmdz German BERT models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources another German BERT models 🎉
# German BERT
## Stats
In addition to the recently released [German BERT](https://deepset.ai/german-bert)
model by [deepset](https://deepset.ai/) we provide another German-language model.
The source data for the model consists of a recent Wikipedia dump, EU Bookshop corpus,
Open Subtitles, CommonCrawl, ParaCrawl and News Crawl. This results in a dataset with
a size of 16GB and 2,350,234,427 tokens.
For sentence splitting, we use [spacy](https://spacy.io/). Our preprocessing steps
(sentence piece model for vocab generation) follow those used for training
[SciBERT](https://github.com/allenai/scibert). The model is trained with an initial
sequence length of 512 subwords and was performed for 1.5M steps.
This release includes both cased and uncased models.
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| -------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `bert-base-german-dbmdz-cased` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-config.json) • [`pytorch_model.bin`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-pytorch_model.bin) • [`vocab.txt`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-cased-vocab.txt)
| `bert-base-german-dbmdz-uncased` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-config.json) • [`pytorch_model.bin`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-pytorch_model.bin) • [`vocab.txt`](https://s3.amazonaws.com/models.huggingface.co/bert/bert-base-german-dbmdz-uncased-vocab.txt)
## Usage
With Transformers >= 2.3 our German BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-german-cased")
model = AutoModel.from_pretrained("dbmdz/bert-base-german-cased")
```
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/fine-tuned-berts-seq).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/Lincoln4 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null | ---
language: dutch
license: mit
widget:
- text: "de [MASK] vau Financien, in hec vorige jaar, da inkomswi"
---
# Language Model for Historic Dutch
In this repository we open source a language model for Historic Dutch, trained on the
[Delpher Corpus](https://www.delpher.nl/over-delpher/delpher-open-krantenarchief/download-teksten-kranten-1618-1879\),
that include digitized texts from Dutch newspapers, ranging from 1618 to 1879.
# Changelog
* 13.12.2021: Initial version of this repository.
# Model Zoo
The following models for Historic Dutch are available on the Hugging Face Model Hub:
| Model identifier | Model Hub link
| -------------------------------------- | -------------------------------------------------------------------
| `dbmdz/bert-base-historic-dutch-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-dutch-cased)
# Stats
The download urls for all archives can be found [here](delpher-corpus.urls).
We then used the awesome `alto-tools` from [this](https://github.com/cneud/alto-tools)
repository to extract plain text. The following table shows the size overview per year range:
| Period | Extracted plain text size
| --------- | -------------------------:
| 1618-1699 | 170MB
| 1700-1709 | 103MB
| 1710-1719 | 65MB
| 1720-1729 | 137MB
| 1730-1739 | 144MB
| 1740-1749 | 188MB
| 1750-1759 | 171MB
| 1760-1769 | 235MB
| 1770-1779 | 271MB
| 1780-1789 | 414MB
| 1790-1799 | 614MB
| 1800-1809 | 734MB
| 1810-1819 | 807MB
| 1820-1829 | 987MB
| 1830-1839 | 1.7GB
| 1840-1849 | 2.2GB
| 1850-1854 | 1.3GB
| 1855-1859 | 1.7GB
| 1860-1864 | 2.0GB
| 1865-1869 | 2.3GB
| 1870-1874 | 1.9GB
| 1875-1876 | 867MB
| 1877-1879 | 1.9GB
The total training corpus consists of 427,181,269 sentences and 3,509,581,683 tokens (counted via `wc`),
resulting in a total corpus size of 21GB.
The following figure shows an overview of the number of chars per year distribution:

# Language Model Pretraining
We use the official [BERT](https://github.com/google-research/bert) implementation using the following command
to train the model:
```bash
python3 run_pretraining.py --input_file gs://delpher-bert/tfrecords/*.tfrecord \
--output_dir gs://delpher-bert/bert-base-historic-dutch-cased \
--bert_config_file ./config.json \
--max_seq_length=512 \
--max_predictions_per_seq=75 \
--do_train=True \
--train_batch_size=128 \
--num_train_steps=3000000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=100000 \
--keep_checkpoint_max=20 \
--use_tpu=True \
--tpu_name=electra-2 \
--num_tpu_cores=32
```
We train the model for 3M steps using a total batch size of 128 on a v3-32 TPU. The pretraining loss curve can be seen
in the next figure:

# Evaluation
We evaluate our model on the preprocessed Europeana NER dataset for Dutch, that was presented in the
["Data Centric Domain Adaptation for Historical Text with OCR Errors"](https://github.com/stefan-it/historic-domain-adaptation-icdar) paper.
The data is available in their repository. We perform a hyper-parameter search for:
* Batch sizes: `[4, 8]`
* Learning rates: `[3e-5, 5e-5]`
* Number of epochs: `[5, 10]`
and report averaged F1-Score over 5 runs with different seeds. We also include [hmBERT](https://github.com/stefan-it/clef-hipe/blob/main/hlms.md) as baseline model.
Results:
| Model | F1-Score (Dev / Test)
| ------------------- | ---------------------
| hmBERT | (82.73) / 81.34
| Maerz et al. (2021) | - / 84.2
| Ours | (89.73) / 87.45
# License
All models are licensed under [MIT](LICENSE).
# Acknowledgments
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
We thank [Clemens Neudecker](https://github.com/cneud) for maintaining the amazing
[ALTO tools](https://github.com/cneud/alto-tools) that were used for parsing the Delpher Corpus XML files.
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language: english
license: mit
widget:
- text: "and I cannot conceive the reafon why [MASK] hath"
---
# Historic Language Models (HLMs)
## Languages
Our Historic Language Models Zoo contains support for the following languages - incl. their training data source:
| Language | Training data | Size
| -------- | ------------- | ----
| German | [Europeana](http://www.europeana-newspapers.eu/) | 13-28GB (filtered)
| French | [Europeana](http://www.europeana-newspapers.eu/) | 11-31GB (filtered)
| English | [British Library](https://data.bl.uk/digbks/db14.html) | 24GB (year filtered)
| Finnish | [Europeana](http://www.europeana-newspapers.eu/) | 1.2GB
| Swedish | [Europeana](http://www.europeana-newspapers.eu/) | 1.1GB
## Models
At the moment, the following models are available on the model hub:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
| `dbmdz/bert-base-historic-english-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-english-cased)
| `dbmdz/bert-base-finnish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-finnish-europeana-cased)
| `dbmdz/bert-base-swedish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-swedish-europeana-cased)
# Corpora Stats
## German Europeana Corpus
We provide some statistics using different thresholds of ocr confidences, in order to shrink down the corpus size
and use less-noisier data:
| OCR confidence | Size
| -------------- | ----
| **0.60** | 28GB
| 0.65 | 18GB
| 0.70 | 13GB
For the final corpus we use a OCR confidence of 0.6 (28GB). The following plot shows a tokens per year distribution:

## French Europeana Corpus
Like German, we use different ocr confidence thresholds:
| OCR confidence | Size
| -------------- | ----
| 0.60 | 31GB
| 0.65 | 27GB
| **0.70** | 27GB
| 0.75 | 23GB
| 0.80 | 11GB
For the final corpus we use a OCR confidence of 0.7 (27GB). The following plot shows a tokens per year distribution:

## British Library Corpus
Metadata is taken from [here](https://data.bl.uk/digbks/DB21.html). Stats incl. year filtering:
| Years | Size
| ----------------- | ----
| ALL | 24GB
| >= 1800 && < 1900 | 24GB
We use the year filtered variant. The following plot shows a tokens per year distribution:

## Finnish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.2GB
The following plot shows a tokens per year distribution:

## Swedish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.1GB
The following plot shows a tokens per year distribution:

## All Corpora
The following plot shows a tokens per year distribution of the complete training corpus:

# Multilingual Vocab generation
For the first attempt, we use the first 10GB of each pretraining corpus. We upsample both Finnish and Swedish to ~10GB.
The following tables shows the exact size that is used for generating a 32k and 64k subword vocabs:
| Language | Size
| -------- | ----
| German | 10GB
| French | 10GB
| English | 10GB
| Finnish | 9.5GB
| Swedish | 9.7GB
We then calculate the subword fertility rate and portion of `[UNK]`s over the following NER corpora:
| Language | NER corpora
| -------- | ------------------
| German | CLEF-HIPE, NewsEye
| French | CLEF-HIPE, NewsEye
| English | CLEF-HIPE
| Finnish | NewsEye
| Swedish | NewsEye
Breakdown of subword fertility rate and unknown portion per language for the 32k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.43 | 0.0004
| French | 1.25 | 0.0001
| English | 1.25 | 0.0
| Finnish | 1.69 | 0.0007
| Swedish | 1.43 | 0.0
Breakdown of subword fertility rate and unknown portion per language for the 64k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.31 | 0.0004
| French | 1.16 | 0.0001
| English | 1.17 | 0.0
| Finnish | 1.54 | 0.0007
| Swedish | 1.32 | 0.0
# Final pretraining corpora
We upsample Swedish and Finnish to ~27GB. The final stats for all pretraining corpora can be seen here:
| Language | Size
| -------- | ----
| German | 28GB
| French | 27GB
| English | 24GB
| Finnish | 27GB
| Swedish | 27GB
Total size is 130GB.
# Pretraining
## Multilingual model
We train a multilingual BERT model using the 32k vocab with the official BERT implementation
on a v3-32 TPU using the following parameters:
```bash
python3 run_pretraining.py --input_file gs://histolectra/historic-multilingual-tfrecords/*.tfrecord \
--output_dir gs://histolectra/bert-base-historic-multilingual-cased \
--bert_config_file ./config.json \
--max_seq_length=512 \
--max_predictions_per_seq=75 \
--do_train=True \
--train_batch_size=128 \
--num_train_steps=3000000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=100000 \
--keep_checkpoint_max=20 \
--use_tpu=True \
--tpu_name=electra-2 \
--num_tpu_cores=32
```
The following plot shows the pretraining loss curve:

## English model
The English BERT model - with texts from British Library corpus - was trained with the Hugging Face
JAX/FLAX implementation for 10 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-historic-english-cased/ \
--tokenizer_name /mnt/datasets/bert-base-historic-english-cased/ \
--train_file /mnt/datasets/bl-corpus/bl_1800-1900_extracted.txt \
--validation_file /mnt/datasets/bl-corpus/english_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 10 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-historic-english-cased-512-noadafactor-10e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Finnish model
The BERT model - with texts from Finnish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Finnish_0.6.txt \
--validation_file /mnt/datasets/hlms/finnish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-finnish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Swedish model
The BERT model - with texts from Swedish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 660K steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Swedish_0.6.txt \
--validation_file /mnt/datasets/hlms/swedish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-swedish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

# Acknowledgments
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln10 | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
language: multilingual
license: mit
widget:
- text: "and I cannot conceive the reafon why [MASK] hath"
- text: "Täkäläinen sanomalehdistö [MASK] erit - täin"
- text: "Det vore [MASK] häller nödvändigt att be"
- text: "Comme, à cette époque [MASK] était celle de la"
- text: "In [MASK] an atmosphärischen Nahrungsmitteln"
---
# hmBERT: Historical Multilingual Language Models for Named Entity Recognition
More information about our hmBERT model can be found in our new paper:
["hmBERT: Historical Multilingual Language Models for Named Entity Recognition"](https://arxiv.org/abs/2205.15575).
## Languages
Our Historic Language Models Zoo contains support for the following languages - incl. their training data source:
| Language | Training data | Size
| -------- | ------------- | ----
| German | [Europeana](http://www.europeana-newspapers.eu/) | 13-28GB (filtered)
| French | [Europeana](http://www.europeana-newspapers.eu/) | 11-31GB (filtered)
| English | [British Library](https://data.bl.uk/digbks/db14.html) | 24GB (year filtered)
| Finnish | [Europeana](http://www.europeana-newspapers.eu/) | 1.2GB
| Swedish | [Europeana](http://www.europeana-newspapers.eu/) | 1.1GB
## Smaller Models
We have also released smaller models for the multilingual model:
| Model identifier | Model Hub link
| ----------------------------------------------- | ---------------------------------------------------------------------------
| `dbmdz/bert-tiny-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-tiny-historic-multilingual-cased)
| `dbmdz/bert-mini-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-mini-historic-multilingual-cased)
| `dbmdz/bert-small-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-small-historic-multilingual-cased)
| `dbmdz/bert-medium-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
# Corpora Stats
## German Europeana Corpus
We provide some statistics using different thresholds of ocr confidences, in order to shrink down the corpus size
and use less-noisier data:
| OCR confidence | Size
| -------------- | ----
| **0.60** | 28GB
| 0.65 | 18GB
| 0.70 | 13GB
For the final corpus we use a OCR confidence of 0.6 (28GB). The following plot shows a tokens per year distribution:

## French Europeana Corpus
Like German, we use different ocr confidence thresholds:
| OCR confidence | Size
| -------------- | ----
| 0.60 | 31GB
| 0.65 | 27GB
| **0.70** | 27GB
| 0.75 | 23GB
| 0.80 | 11GB
For the final corpus we use a OCR confidence of 0.7 (27GB). The following plot shows a tokens per year distribution:

## British Library Corpus
Metadata is taken from [here](https://data.bl.uk/digbks/DB21.html). Stats incl. year filtering:
| Years | Size
| ----------------- | ----
| ALL | 24GB
| >= 1800 && < 1900 | 24GB
We use the year filtered variant. The following plot shows a tokens per year distribution:

## Finnish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.2GB
The following plot shows a tokens per year distribution:

## Swedish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.1GB
The following plot shows a tokens per year distribution:

## All Corpora
The following plot shows a tokens per year distribution of the complete training corpus:

# Multilingual Vocab generation
For the first attempt, we use the first 10GB of each pretraining corpus. We upsample both Finnish and Swedish to ~10GB.
The following tables shows the exact size that is used for generating a 32k and 64k subword vocabs:
| Language | Size
| -------- | ----
| German | 10GB
| French | 10GB
| English | 10GB
| Finnish | 9.5GB
| Swedish | 9.7GB
We then calculate the subword fertility rate and portion of `[UNK]`s over the following NER corpora:
| Language | NER corpora
| -------- | ------------------
| German | CLEF-HIPE, NewsEye
| French | CLEF-HIPE, NewsEye
| English | CLEF-HIPE
| Finnish | NewsEye
| Swedish | NewsEye
Breakdown of subword fertility rate and unknown portion per language for the 32k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.43 | 0.0004
| French | 1.25 | 0.0001
| English | 1.25 | 0.0
| Finnish | 1.69 | 0.0007
| Swedish | 1.43 | 0.0
Breakdown of subword fertility rate and unknown portion per language for the 64k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.31 | 0.0004
| French | 1.16 | 0.0001
| English | 1.17 | 0.0
| Finnish | 1.54 | 0.0007
| Swedish | 1.32 | 0.0
# Final pretraining corpora
We upsample Swedish and Finnish to ~27GB. The final stats for all pretraining corpora can be seen here:
| Language | Size
| -------- | ----
| German | 28GB
| French | 27GB
| English | 24GB
| Finnish | 27GB
| Swedish | 27GB
Total size is 130GB.
# Pretraining
## Multilingual model
We train a multilingual BERT model using the 32k vocab with the official BERT implementation
on a v3-32 TPU using the following parameters:
```bash
python3 run_pretraining.py --input_file gs://histolectra/historic-multilingual-tfrecords/*.tfrecord \
--output_dir gs://histolectra/bert-base-historic-multilingual-cased \
--bert_config_file ./config.json \
--max_seq_length=512 \
--max_predictions_per_seq=75 \
--do_train=True \
--train_batch_size=128 \
--num_train_steps=3000000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=100000 \
--keep_checkpoint_max=20 \
--use_tpu=True \
--tpu_name=electra-2 \
--num_tpu_cores=32
```
The following plot shows the pretraining loss curve:

# Acknowledgments
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗 |
BigSalmon/MrLincoln11 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
language: it
license: mit
datasets:
- wikipedia
---
# 🤗 + 📚 dbmdz BERT and ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources Italian BERT and ELECTRA models 🎉
# Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy).
Our cased and uncased models are training with an initial sequence length of 512
subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
Note: Unfortunately, a wrong vocab size was used when training the XXL models.
This explains the mismatch of the "real" vocab size of 31102, compared to the
vocab size specified in `config.json`. However, the model is working and all
evaluations were done under those circumstances.
See [this issue](https://github.com/dbmdz/berts/issues/7) for more information.
The Italian ELECTRA model was trained on the "XXL" corpus for 1M steps in total using a batch
size of 128. We pretty much following the ELECTRA training procedure as used for
[BERTurk](https://github.com/stefan-it/turkish-bert/tree/master/electra).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ---------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-discriminator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-generator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-generator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/vocab.txt)
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/italian-bertelectra).
## Usage
With Transformers >= 2.3 our Italian BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the (recommended) Italian XXL BERT models, just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the Italian XXL ELECTRA model (discriminator), just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/electra-base-italian-xxl-cased-discriminator"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT/ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln12 | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"has_space"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2019-12-29T00:19:38Z | ---
language: it
license: mit
datasets:
- wikipedia
---
# 🤗 + 📚 dbmdz BERT and ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources Italian BERT and ELECTRA models 🎉
# Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy).
Our cased and uncased models are training with an initial sequence length of 512
subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
Note: Unfortunately, a wrong vocab size was used when training the XXL models.
This explains the mismatch of the "real" vocab size of 31102, compared to the
vocab size specified in `config.json`. However, the model is working and all
evaluations were done under those circumstances.
See [this issue](https://github.com/dbmdz/berts/issues/7) for more information.
The Italian ELECTRA model was trained on the "XXL" corpus for 1M steps in total using a batch
size of 128. We pretty much following the ELECTRA training procedure as used for
[BERTurk](https://github.com/stefan-it/turkish-bert/tree/master/electra).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ---------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-discriminator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-generator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-generator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/vocab.txt)
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/italian-bertelectra).
## Usage
With Transformers >= 2.3 our Italian BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the (recommended) Italian XXL BERT models, just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the Italian XXL ELECTRA model (discriminator), just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/electra-base-italian-xxl-cased-discriminator"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT/ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln125MNeo | [
"pytorch",
"tensorboard",
"gpt_neo",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPTNeoForCausalLM"
],
"model_type": "gpt_neo",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
language: it
license: mit
datasets:
- wikipedia
---
# 🤗 + 📚 dbmdz BERT and ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources Italian BERT and ELECTRA models 🎉
# Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy).
Our cased and uncased models are training with an initial sequence length of 512
subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
Note: Unfortunately, a wrong vocab size was used when training the XXL models.
This explains the mismatch of the "real" vocab size of 31102, compared to the
vocab size specified in `config.json`. However, the model is working and all
evaluations were done under those circumstances.
See [this issue](https://github.com/dbmdz/berts/issues/7) for more information.
The Italian ELECTRA model was trained on the "XXL" corpus for 1M steps in total using a batch
size of 128. We pretty much following the ELECTRA training procedure as used for
[BERTurk](https://github.com/stefan-it/turkish-bert/tree/master/electra).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ---------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-discriminator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-generator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-generator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/vocab.txt)
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/italian-bertelectra).
## Usage
With Transformers >= 2.3 our Italian BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the (recommended) Italian XXL BERT models, just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the Italian XXL ELECTRA model (discriminator), just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/electra-base-italian-xxl-cased-discriminator"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT/ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln13 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
language: it
license: mit
datasets:
- wikipedia
---
# 🤗 + 📚 dbmdz BERT and ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources Italian BERT and ELECTRA models 🎉
# Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy).
Our cased and uncased models are training with an initial sequence length of 512
subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
Note: Unfortunately, a wrong vocab size was used when training the XXL models.
This explains the mismatch of the "real" vocab size of 31102, compared to the
vocab size specified in `config.json`. However, the model is working and all
evaluations were done under those circumstances.
See [this issue](https://github.com/dbmdz/berts/issues/7) for more information.
The Italian ELECTRA model was trained on the "XXL" corpus for 1M steps in total using a batch
size of 128. We pretty much following the ELECTRA training procedure as used for
[BERTurk](https://github.com/stefan-it/turkish-bert/tree/master/electra).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ---------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-discriminator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-generator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-generator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/vocab.txt)
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/italian-bertelectra).
## Usage
With Transformers >= 2.3 our Italian BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the (recommended) Italian XXL BERT models, just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the Italian XXL ELECTRA model (discriminator), just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/electra-base-italian-xxl-cased-discriminator"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT/ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln3 | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 17 | 2021-11-18T20:40:50Z | ---
language: swedish
license: mit
widget:
- text: "Det vore [MASK] häller nödvändigt att be"
---
# Historic Language Models (HLMs)
## Languages
Our Historic Language Models Zoo contains support for the following languages - incl. their training data source:
| Language | Training data | Size
| -------- | ------------- | ----
| German | [Europeana](http://www.europeana-newspapers.eu/) | 13-28GB (filtered)
| French | [Europeana](http://www.europeana-newspapers.eu/) | 11-31GB (filtered)
| English | [British Library](https://data.bl.uk/digbks/db14.html) | 24GB (year filtered)
| Finnish | [Europeana](http://www.europeana-newspapers.eu/) | 1.2GB
| Swedish | [Europeana](http://www.europeana-newspapers.eu/) | 1.1GB
## Models
At the moment, the following models are available on the model hub:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
| `dbmdz/bert-base-historic-english-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-english-cased)
| `dbmdz/bert-base-finnish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-finnish-europeana-cased)
| `dbmdz/bert-base-swedish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-swedish-europeana-cased)
# Corpora Stats
## German Europeana Corpus
We provide some statistics using different thresholds of ocr confidences, in order to shrink down the corpus size
and use less-noisier data:
| OCR confidence | Size
| -------------- | ----
| **0.60** | 28GB
| 0.65 | 18GB
| 0.70 | 13GB
For the final corpus we use a OCR confidence of 0.6 (28GB). The following plot shows a tokens per year distribution:

## French Europeana Corpus
Like German, we use different ocr confidence thresholds:
| OCR confidence | Size
| -------------- | ----
| 0.60 | 31GB
| 0.65 | 27GB
| **0.70** | 27GB
| 0.75 | 23GB
| 0.80 | 11GB
For the final corpus we use a OCR confidence of 0.7 (27GB). The following plot shows a tokens per year distribution:

## British Library Corpus
Metadata is taken from [here](https://data.bl.uk/digbks/DB21.html). Stats incl. year filtering:
| Years | Size
| ----------------- | ----
| ALL | 24GB
| >= 1800 && < 1900 | 24GB
We use the year filtered variant. The following plot shows a tokens per year distribution:

## Finnish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.2GB
The following plot shows a tokens per year distribution:

## Swedish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.1GB
The following plot shows a tokens per year distribution:

## All Corpora
The following plot shows a tokens per year distribution of the complete training corpus:

# Multilingual Vocab generation
For the first attempt, we use the first 10GB of each pretraining corpus. We upsample both Finnish and Swedish to ~10GB.
The following tables shows the exact size that is used for generating a 32k and 64k subword vocabs:
| Language | Size
| -------- | ----
| German | 10GB
| French | 10GB
| English | 10GB
| Finnish | 9.5GB
| Swedish | 9.7GB
We then calculate the subword fertility rate and portion of `[UNK]`s over the following NER corpora:
| Language | NER corpora
| -------- | ------------------
| German | CLEF-HIPE, NewsEye
| French | CLEF-HIPE, NewsEye
| English | CLEF-HIPE
| Finnish | NewsEye
| Swedish | NewsEye
Breakdown of subword fertility rate and unknown portion per language for the 32k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.43 | 0.0004
| French | 1.25 | 0.0001
| English | 1.25 | 0.0
| Finnish | 1.69 | 0.0007
| Swedish | 1.43 | 0.0
Breakdown of subword fertility rate and unknown portion per language for the 64k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.31 | 0.0004
| French | 1.16 | 0.0001
| English | 1.17 | 0.0
| Finnish | 1.54 | 0.0007
| Swedish | 1.32 | 0.0
# Final pretraining corpora
We upsample Swedish and Finnish to ~27GB. The final stats for all pretraining corpora can be seen here:
| Language | Size
| -------- | ----
| German | 28GB
| French | 27GB
| English | 24GB
| Finnish | 27GB
| Swedish | 27GB
Total size is 130GB.
# Pretraining
## Multilingual model
We train a multilingual BERT model using the 32k vocab with the official BERT implementation
on a v3-32 TPU using the following parameters:
```bash
python3 run_pretraining.py --input_file gs://histolectra/historic-multilingual-tfrecords/*.tfrecord \
--output_dir gs://histolectra/bert-base-historic-multilingual-cased \
--bert_config_file ./config.json \
--max_seq_length=512 \
--max_predictions_per_seq=75 \
--do_train=True \
--train_batch_size=128 \
--num_train_steps=3000000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=100000 \
--keep_checkpoint_max=20 \
--use_tpu=True \
--tpu_name=electra-2 \
--num_tpu_cores=32
```
The following plot shows the pretraining loss curve:

## English model
The English BERT model - with texts from British Library corpus - was trained with the Hugging Face
JAX/FLAX implementation for 10 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-historic-english-cased/ \
--tokenizer_name /mnt/datasets/bert-base-historic-english-cased/ \
--train_file /mnt/datasets/bl-corpus/bl_1800-1900_extracted.txt \
--validation_file /mnt/datasets/bl-corpus/english_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 10 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-historic-english-cased-512-noadafactor-10e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Finnish model
The BERT model - with texts from Finnish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Finnish_0.6.txt \
--validation_file /mnt/datasets/hlms/finnish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-finnish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Swedish model
The BERT model - with texts from Swedish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 660K steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Swedish_0.6.txt \
--validation_file /mnt/datasets/hlms/swedish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-swedish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

# Acknowledgments
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln4 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
language: tr
license: mit
---
# 🤗 + 📚 dbmdz Turkish BERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a cased model for Turkish 🎉
# 🇹🇷 BERTurk
BERTurk is a community-driven cased BERT model for Turkish.
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the model name: BERTurk.
## Stats
The current version of the model is trained on a filtered and sentence
segmented version of the Turkish [OSCAR corpus](https://traces1.inria.fr/oscar/),
a recent Wikipedia dump, various [OPUS corpora](http://opus.nlpl.eu/) and a
special corpus provided by [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/).
The final training corpus has a size of 35GB and 44,04,976,662 tokens.
Thanks to Google's TensorFlow Research Cloud (TFRC) we could train a cased model
on a TPU v3-8 for 2M steps.
For this model we use a vocab size of 128k.
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ------------------------------------ | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-turkish-128k-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-128k-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-128k-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-128k-cased/vocab.txt)
## Usage
With Transformers >= 2.3 our BERTurk cased model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-turkish-128k-cased")
model = AutoModel.from_pretrained("dbmdz/bert-base-turkish-128k-cased")
```
## Results
For results on PoS tagging or NER tasks, please refer to
[this repository](https://github.com/stefan-it/turkish-bert).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln5 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
language: tr
license: mit
---
# 🤗 + 📚 dbmdz Turkish BERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources an uncased model for Turkish 🎉
# 🇹🇷 BERTurk
BERTurk is a community-driven uncased BERT model for Turkish.
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the model name: BERTurk.
## Stats
The current version of the model is trained on a filtered and sentence
segmented version of the Turkish [OSCAR corpus](https://traces1.inria.fr/oscar/),
a recent Wikipedia dump, various [OPUS corpora](http://opus.nlpl.eu/) and a
special corpus provided by [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/).
The final training corpus has a size of 35GB and 44,04,976,662 tokens.
Thanks to Google's TensorFlow Research Cloud (TFRC) we could train an uncased model
on a TPU v3-8 for 2M steps.
For this model we use a vocab size of 128k.
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| -------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-turkish-128k-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-128k-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-128k-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-128k-uncased/vocab.txt)
## Usage
With Transformers >= 2.3 our BERTurk uncased model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-turkish-128k-uncased")
model = AutoModel.from_pretrained("dbmdz/bert-base-turkish-128k-uncased")
```
## Results
For results on PoS tagging or NER tasks, please refer to
[this repository](https://github.com/stefan-it/turkish-bert).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln6 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
language: tr
license: mit
---
# 🤗 + 📚 dbmdz Turkish BERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a cased model for Turkish 🎉
# 🇹🇷 BERTurk
BERTurk is a community-driven cased BERT model for Turkish.
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the model name: BERTurk.
## Stats
The current version of the model is trained on a filtered and sentence
segmented version of the Turkish [OSCAR corpus](https://traces1.inria.fr/oscar/),
a recent Wikipedia dump, various [OPUS corpora](http://opus.nlpl.eu/) and a
special corpus provided by [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/).
The final training corpus has a size of 35GB and 44,04,976,662 tokens.
Thanks to Google's TensorFlow Research Cloud (TFRC) we could train a cased model
on a TPU v3-8 for 2M steps.
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| --------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-turkish-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-cased/vocab.txt)
## Usage
With Transformers >= 2.3 our BERTurk cased model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-turkish-cased")
model = AutoModel.from_pretrained("dbmdz/bert-base-turkish-cased")
```
## Results
For results on PoS tagging or NER tasks, please refer to
[this repository](https://github.com/stefan-it/turkish-bert).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincoln7 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: tr
license: mit
---
# 🤗 + 📚 dbmdz Turkish BERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources an uncased model for Turkish 🎉
# 🇹🇷 BERTurk
BERTurk is a community-driven uncased BERT model for Turkish.
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the model name: BERTurk.
## Stats
The current version of the model is trained on a filtered and sentence
segmented version of the Turkish [OSCAR corpus](https://traces1.inria.fr/oscar/),
a recent Wikipedia dump, various [OPUS corpora](http://opus.nlpl.eu/) and a
special corpus provided by [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/).
The final training corpus has a size of 35GB and 44,04,976,662 tokens.
Thanks to Google's TensorFlow Research Cloud (TFRC) we could train an uncased model
on a TPU v3-8 for 2M steps.
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| --------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-turkish-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-turkish-uncased/vocab.txt)
## Usage
With Transformers >= 2.3 our BERTurk uncased model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/bert-base-turkish-uncased")
model = AutoModel.from_pretrained("dbmdz/bert-base-turkish-uncased")
```
## Results
For results on PoS tagging or NER tasks, please refer to
[this repository](https://github.com/stefan-it/turkish-bert).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/MrLincolnBerta | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible",
"has_space"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language: multilingual
license: mit
widget:
- text: "and I cannot conceive the reafon why [MASK] hath"
- text: "Täkäläinen sanomalehdistö [MASK] erit - täin"
- text: "Det vore [MASK] häller nödvändigt att be"
- text: "Comme, à cette époque [MASK] était celle de la"
- text: "In [MASK] an atmosphärischen Nahrungsmitteln"
---
# Historic Language Models (HLMs)
## Languages
Our Historic Language Models Zoo contains support for the following languages - incl. their training data source:
| Language | Training data | Size
| -------- | ------------- | ----
| German | [Europeana](http://www.europeana-newspapers.eu/) | 13-28GB (filtered)
| French | [Europeana](http://www.europeana-newspapers.eu/) | 11-31GB (filtered)
| English | [British Library](https://data.bl.uk/digbks/db14.html) | 24GB (year filtered)
| Finnish | [Europeana](http://www.europeana-newspapers.eu/) | 1.2GB
| Swedish | [Europeana](http://www.europeana-newspapers.eu/) | 1.1GB
## Models
At the moment, the following models are available on the model hub:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
| `dbmdz/bert-base-historic-english-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-english-cased)
| `dbmdz/bert-base-finnish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-finnish-europeana-cased)
| `dbmdz/bert-base-swedish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-swedish-europeana-cased)
We also released smaller models for the multilingual model:
| Model identifier | Model Hub link
| ----------------------------------------------- | ---------------------------------------------------------------------------
| `dbmdz/bert-tiny-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-tiny-historic-multilingual-cased)
| `dbmdz/bert-mini-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-mini-historic-multilingual-cased)
| `dbmdz/bert-small-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-small-historic-multilingual-cased)
| `dbmdz/bert-medium-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
**Notice**: We have released language models for Historic German and French trained on more noisier data earlier - see
[this repo](https://github.com/stefan-it/europeana-bert) for more information:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-german-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-german-europeana-cased)
| `dbmdz/bert-base-french-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-french-europeana-cased)
# Corpora Stats
## German Europeana Corpus
We provide some statistics using different thresholds of ocr confidences, in order to shrink down the corpus size
and use less-noisier data:
| OCR confidence | Size
| -------------- | ----
| **0.60** | 28GB
| 0.65 | 18GB
| 0.70 | 13GB
For the final corpus we use a OCR confidence of 0.6 (28GB). The following plot shows a tokens per year distribution:

## French Europeana Corpus
Like German, we use different ocr confidence thresholds:
| OCR confidence | Size
| -------------- | ----
| 0.60 | 31GB
| 0.65 | 27GB
| **0.70** | 27GB
| 0.75 | 23GB
| 0.80 | 11GB
For the final corpus we use a OCR confidence of 0.7 (27GB). The following plot shows a tokens per year distribution:

## British Library Corpus
Metadata is taken from [here](https://data.bl.uk/digbks/DB21.html). Stats incl. year filtering:
| Years | Size
| ----------------- | ----
| ALL | 24GB
| >= 1800 && < 1900 | 24GB
We use the year filtered variant. The following plot shows a tokens per year distribution:

## Finnish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.2GB
The following plot shows a tokens per year distribution:

## Swedish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.1GB
The following plot shows a tokens per year distribution:

## All Corpora
The following plot shows a tokens per year distribution of the complete training corpus:

# Multilingual Vocab generation
For the first attempt, we use the first 10GB of each pretraining corpus. We upsample both Finnish and Swedish to ~10GB.
The following tables shows the exact size that is used for generating a 32k and 64k subword vocabs:
| Language | Size
| -------- | ----
| German | 10GB
| French | 10GB
| English | 10GB
| Finnish | 9.5GB
| Swedish | 9.7GB
We then calculate the subword fertility rate and portion of `[UNK]`s over the following NER corpora:
| Language | NER corpora
| -------- | ------------------
| German | CLEF-HIPE, NewsEye
| French | CLEF-HIPE, NewsEye
| English | CLEF-HIPE
| Finnish | NewsEye
| Swedish | NewsEye
Breakdown of subword fertility rate and unknown portion per language for the 32k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.43 | 0.0004
| French | 1.25 | 0.0001
| English | 1.25 | 0.0
| Finnish | 1.69 | 0.0007
| Swedish | 1.43 | 0.0
Breakdown of subword fertility rate and unknown portion per language for the 64k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.31 | 0.0004
| French | 1.16 | 0.0001
| English | 1.17 | 0.0
| Finnish | 1.54 | 0.0007
| Swedish | 1.32 | 0.0
# Final pretraining corpora
We upsample Swedish and Finnish to ~27GB. The final stats for all pretraining corpora can be seen here:
| Language | Size
| -------- | ----
| German | 28GB
| French | 27GB
| English | 24GB
| Finnish | 27GB
| Swedish | 27GB
Total size is 130GB.
# Smaller multilingual models
Inspired by the ["Well-Read Students Learn Better: On the Importance of Pre-training Compact Models"](https://arxiv.org/abs/1908.08962)
paper, we train smaller models (different layers and hidden sizes), and report number of parameters and pre-training costs:
| Model (Layer / Hidden size) | Parameters | Pre-Training time
| --------------------------- | ----------: | ----------------------:
| hmBERT Tiny ( 2/128) | 4.58M | 4.3 sec / 1,000 steps
| hmBERT Mini ( 4/256) | 11.55M | 10.5 sec / 1,000 steps
| hmBERT Small ( 4/512) | 29.52M | 20.7 sec / 1,000 steps
| hmBERT Medium ( 8/512) | 42.13M | 35.0 sec / 1,000 steps
| hmBERT Base (12/768) | 110.62M | 80.0 sec / 1,000 steps
We then perform downstream evaluations on the multilingual [NewsEye](https://zenodo.org/record/4573313#.Ya3oVr-ZNzU) dataset:

# Pretraining
## Multilingual model - hmBERT Base
We train a multilingual BERT model using the 32k vocab with the official BERT implementation
on a v3-32 TPU using the following parameters:
```bash
python3 run_pretraining.py --input_file gs://histolectra/historic-multilingual-tfrecords/*.tfrecord \
--output_dir gs://histolectra/bert-base-historic-multilingual-cased \
--bert_config_file ./config.json \
--max_seq_length=512 \
--max_predictions_per_seq=75 \
--do_train=True \
--train_batch_size=128 \
--num_train_steps=3000000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=100000 \
--keep_checkpoint_max=20 \
--use_tpu=True \
--tpu_name=electra-2 \
--num_tpu_cores=32
```
The following plot shows the pretraining loss curve:

## Smaller multilingual models
We use the same parameters as used for training the base model.
### hmBERT Tiny
The following plot shows the pretraining loss curve for the tiny model:

### hmBERT Mini
The following plot shows the pretraining loss curve for the mini model:

### hmBERT Small
The following plot shows the pretraining loss curve for the small model:

### hmBERT Medium
The following plot shows the pretraining loss curve for the medium model:

## English model
The English BERT model - with texts from British Library corpus - was trained with the Hugging Face
JAX/FLAX implementation for 10 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-historic-english-cased/ \
--tokenizer_name /mnt/datasets/bert-base-historic-english-cased/ \
--train_file /mnt/datasets/bl-corpus/bl_1800-1900_extracted.txt \
--validation_file /mnt/datasets/bl-corpus/english_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 10 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-historic-english-cased-512-noadafactor-10e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Finnish model
The BERT model - with texts from Finnish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Finnish_0.6.txt \
--validation_file /mnt/datasets/hlms/finnish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-finnish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Swedish model
The BERT model - with texts from Swedish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 660K steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Swedish_0.6.txt \
--validation_file /mnt/datasets/hlms/swedish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-swedish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

# Acknowledgments
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/NEO125InformalToFormalLincoln | [
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPTNeoForCausalLM"
],
"model_type": "gpt_neo",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language: multilingual
license: mit
widget:
- text: "and I cannot conceive the reafon why [MASK] hath"
- text: "Täkäläinen sanomalehdistö [MASK] erit - täin"
- text: "Det vore [MASK] häller nödvändigt att be"
- text: "Comme, à cette époque [MASK] était celle de la"
- text: "In [MASK] an atmosphärischen Nahrungsmitteln"
---
# Historic Language Models (HLMs)
## Languages
Our Historic Language Models Zoo contains support for the following languages - incl. their training data source:
| Language | Training data | Size
| -------- | ------------- | ----
| German | [Europeana](http://www.europeana-newspapers.eu/) | 13-28GB (filtered)
| French | [Europeana](http://www.europeana-newspapers.eu/) | 11-31GB (filtered)
| English | [British Library](https://data.bl.uk/digbks/db14.html) | 24GB (year filtered)
| Finnish | [Europeana](http://www.europeana-newspapers.eu/) | 1.2GB
| Swedish | [Europeana](http://www.europeana-newspapers.eu/) | 1.1GB
## Models
At the moment, the following models are available on the model hub:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
| `dbmdz/bert-base-historic-english-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-english-cased)
| `dbmdz/bert-base-finnish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-finnish-europeana-cased)
| `dbmdz/bert-base-swedish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-swedish-europeana-cased)
We also released smaller models for the multilingual model:
| Model identifier | Model Hub link
| ----------------------------------------------- | ---------------------------------------------------------------------------
| `dbmdz/bert-tiny-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-tiny-historic-multilingual-cased)
| `dbmdz/bert-mini-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-mini-historic-multilingual-cased)
| `dbmdz/bert-small-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-small-historic-multilingual-cased)
| `dbmdz/bert-medium-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
**Notice**: We have released language models for Historic German and French trained on more noisier data earlier - see
[this repo](https://github.com/stefan-it/europeana-bert) for more information:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-german-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-german-europeana-cased)
| `dbmdz/bert-base-french-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-french-europeana-cased)
# Corpora Stats
## German Europeana Corpus
We provide some statistics using different thresholds of ocr confidences, in order to shrink down the corpus size
and use less-noisier data:
| OCR confidence | Size
| -------------- | ----
| **0.60** | 28GB
| 0.65 | 18GB
| 0.70 | 13GB
For the final corpus we use a OCR confidence of 0.6 (28GB). The following plot shows a tokens per year distribution:

## French Europeana Corpus
Like German, we use different ocr confidence thresholds:
| OCR confidence | Size
| -------------- | ----
| 0.60 | 31GB
| 0.65 | 27GB
| **0.70** | 27GB
| 0.75 | 23GB
| 0.80 | 11GB
For the final corpus we use a OCR confidence of 0.7 (27GB). The following plot shows a tokens per year distribution:

## British Library Corpus
Metadata is taken from [here](https://data.bl.uk/digbks/DB21.html). Stats incl. year filtering:
| Years | Size
| ----------------- | ----
| ALL | 24GB
| >= 1800 && < 1900 | 24GB
We use the year filtered variant. The following plot shows a tokens per year distribution:

## Finnish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.2GB
The following plot shows a tokens per year distribution:

## Swedish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.1GB
The following plot shows a tokens per year distribution:

## All Corpora
The following plot shows a tokens per year distribution of the complete training corpus:

# Multilingual Vocab generation
For the first attempt, we use the first 10GB of each pretraining corpus. We upsample both Finnish and Swedish to ~10GB.
The following tables shows the exact size that is used for generating a 32k and 64k subword vocabs:
| Language | Size
| -------- | ----
| German | 10GB
| French | 10GB
| English | 10GB
| Finnish | 9.5GB
| Swedish | 9.7GB
We then calculate the subword fertility rate and portion of `[UNK]`s over the following NER corpora:
| Language | NER corpora
| -------- | ------------------
| German | CLEF-HIPE, NewsEye
| French | CLEF-HIPE, NewsEye
| English | CLEF-HIPE
| Finnish | NewsEye
| Swedish | NewsEye
Breakdown of subword fertility rate and unknown portion per language for the 32k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.43 | 0.0004
| French | 1.25 | 0.0001
| English | 1.25 | 0.0
| Finnish | 1.69 | 0.0007
| Swedish | 1.43 | 0.0
Breakdown of subword fertility rate and unknown portion per language for the 64k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.31 | 0.0004
| French | 1.16 | 0.0001
| English | 1.17 | 0.0
| Finnish | 1.54 | 0.0007
| Swedish | 1.32 | 0.0
# Final pretraining corpora
We upsample Swedish and Finnish to ~27GB. The final stats for all pretraining corpora can be seen here:
| Language | Size
| -------- | ----
| German | 28GB
| French | 27GB
| English | 24GB
| Finnish | 27GB
| Swedish | 27GB
Total size is 130GB.
# Smaller multilingual models
Inspired by the ["Well-Read Students Learn Better: On the Importance of Pre-training Compact Models"](https://arxiv.org/abs/1908.08962)
paper, we train smaller models (different layers and hidden sizes), and report number of parameters and pre-training costs:
| Model (Layer / Hidden size) | Parameters | Pre-Training time
| --------------------------- | ----------: | ----------------------:
| hmBERT Tiny ( 2/128) | 4.58M | 4.3 sec / 1,000 steps
| hmBERT Mini ( 4/256) | 11.55M | 10.5 sec / 1,000 steps
| hmBERT Small ( 4/512) | 29.52M | 20.7 sec / 1,000 steps
| hmBERT Medium ( 8/512) | 42.13M | 35.0 sec / 1,000 steps
| hmBERT Base (12/768) | 110.62M | 80.0 sec / 1,000 steps
We then perform downstream evaluations on the multilingual [NewsEye](https://zenodo.org/record/4573313#.Ya3oVr-ZNzU) dataset:

# Pretraining
## Multilingual model - hmBERT Base
We train a multilingual BERT model using the 32k vocab with the official BERT implementation
on a v3-32 TPU using the following parameters:
```bash
python3 run_pretraining.py --input_file gs://histolectra/historic-multilingual-tfrecords/*.tfrecord \
--output_dir gs://histolectra/bert-base-historic-multilingual-cased \
--bert_config_file ./config.json \
--max_seq_length=512 \
--max_predictions_per_seq=75 \
--do_train=True \
--train_batch_size=128 \
--num_train_steps=3000000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=100000 \
--keep_checkpoint_max=20 \
--use_tpu=True \
--tpu_name=electra-2 \
--num_tpu_cores=32
```
The following plot shows the pretraining loss curve:

## Smaller multilingual models
We use the same parameters as used for training the base model.
### hmBERT Tiny
The following plot shows the pretraining loss curve for the tiny model:

### hmBERT Mini
The following plot shows the pretraining loss curve for the mini model:

### hmBERT Small
The following plot shows the pretraining loss curve for the small model:

### hmBERT Medium
The following plot shows the pretraining loss curve for the medium model:

## English model
The English BERT model - with texts from British Library corpus - was trained with the Hugging Face
JAX/FLAX implementation for 10 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-historic-english-cased/ \
--tokenizer_name /mnt/datasets/bert-base-historic-english-cased/ \
--train_file /mnt/datasets/bl-corpus/bl_1800-1900_extracted.txt \
--validation_file /mnt/datasets/bl-corpus/english_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 10 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-historic-english-cased-512-noadafactor-10e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Finnish model
The BERT model - with texts from Finnish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Finnish_0.6.txt \
--validation_file /mnt/datasets/hlms/finnish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-finnish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Swedish model
The BERT model - with texts from Swedish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 660K steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Swedish_0.6.txt \
--validation_file /mnt/datasets/hlms/swedish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-swedish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

# Acknowledgments
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/Neo | [
"pytorch",
"gpt_neo",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPTNeoForCausalLM"
],
"model_type": "gpt_neo",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ---
language: multilingual
license: mit
widget:
- text: "and I cannot conceive the reafon why [MASK] hath"
- text: "Täkäläinen sanomalehdistö [MASK] erit - täin"
- text: "Det vore [MASK] häller nödvändigt att be"
- text: "Comme, à cette époque [MASK] était celle de la"
- text: "In [MASK] an atmosphärischen Nahrungsmitteln"
---
# Historic Language Models (HLMs)
## Languages
Our Historic Language Models Zoo contains support for the following languages - incl. their training data source:
| Language | Training data | Size
| -------- | ------------- | ----
| German | [Europeana](http://www.europeana-newspapers.eu/) | 13-28GB (filtered)
| French | [Europeana](http://www.europeana-newspapers.eu/) | 11-31GB (filtered)
| English | [British Library](https://data.bl.uk/digbks/db14.html) | 24GB (year filtered)
| Finnish | [Europeana](http://www.europeana-newspapers.eu/) | 1.2GB
| Swedish | [Europeana](http://www.europeana-newspapers.eu/) | 1.1GB
## Models
At the moment, the following models are available on the model hub:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
| `dbmdz/bert-base-historic-english-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-english-cased)
| `dbmdz/bert-base-finnish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-finnish-europeana-cased)
| `dbmdz/bert-base-swedish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-swedish-europeana-cased)
We also released smaller models for the multilingual model:
| Model identifier | Model Hub link
| ----------------------------------------------- | ---------------------------------------------------------------------------
| `dbmdz/bert-tiny-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-tiny-historic-multilingual-cased)
| `dbmdz/bert-mini-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-mini-historic-multilingual-cased)
| `dbmdz/bert-small-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-small-historic-multilingual-cased)
| `dbmdz/bert-medium-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
**Notice**: We have released language models for Historic German and French trained on more noisier data earlier - see
[this repo](https://github.com/stefan-it/europeana-bert) for more information:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-german-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-german-europeana-cased)
| `dbmdz/bert-base-french-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-french-europeana-cased)
# Corpora Stats
## German Europeana Corpus
We provide some statistics using different thresholds of ocr confidences, in order to shrink down the corpus size
and use less-noisier data:
| OCR confidence | Size
| -------------- | ----
| **0.60** | 28GB
| 0.65 | 18GB
| 0.70 | 13GB
For the final corpus we use a OCR confidence of 0.6 (28GB). The following plot shows a tokens per year distribution:

## French Europeana Corpus
Like German, we use different ocr confidence thresholds:
| OCR confidence | Size
| -------------- | ----
| 0.60 | 31GB
| 0.65 | 27GB
| **0.70** | 27GB
| 0.75 | 23GB
| 0.80 | 11GB
For the final corpus we use a OCR confidence of 0.7 (27GB). The following plot shows a tokens per year distribution:

## British Library Corpus
Metadata is taken from [here](https://data.bl.uk/digbks/DB21.html). Stats incl. year filtering:
| Years | Size
| ----------------- | ----
| ALL | 24GB
| >= 1800 && < 1900 | 24GB
We use the year filtered variant. The following plot shows a tokens per year distribution:

## Finnish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.2GB
The following plot shows a tokens per year distribution:

## Swedish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.1GB
The following plot shows a tokens per year distribution:

## All Corpora
The following plot shows a tokens per year distribution of the complete training corpus:

# Multilingual Vocab generation
For the first attempt, we use the first 10GB of each pretraining corpus. We upsample both Finnish and Swedish to ~10GB.
The following tables shows the exact size that is used for generating a 32k and 64k subword vocabs:
| Language | Size
| -------- | ----
| German | 10GB
| French | 10GB
| English | 10GB
| Finnish | 9.5GB
| Swedish | 9.7GB
We then calculate the subword fertility rate and portion of `[UNK]`s over the following NER corpora:
| Language | NER corpora
| -------- | ------------------
| German | CLEF-HIPE, NewsEye
| French | CLEF-HIPE, NewsEye
| English | CLEF-HIPE
| Finnish | NewsEye
| Swedish | NewsEye
Breakdown of subword fertility rate and unknown portion per language for the 32k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.43 | 0.0004
| French | 1.25 | 0.0001
| English | 1.25 | 0.0
| Finnish | 1.69 | 0.0007
| Swedish | 1.43 | 0.0
Breakdown of subword fertility rate and unknown portion per language for the 64k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.31 | 0.0004
| French | 1.16 | 0.0001
| English | 1.17 | 0.0
| Finnish | 1.54 | 0.0007
| Swedish | 1.32 | 0.0
# Final pretraining corpora
We upsample Swedish and Finnish to ~27GB. The final stats for all pretraining corpora can be seen here:
| Language | Size
| -------- | ----
| German | 28GB
| French | 27GB
| English | 24GB
| Finnish | 27GB
| Swedish | 27GB
Total size is 130GB.
# Smaller multilingual models
Inspired by the ["Well-Read Students Learn Better: On the Importance of Pre-training Compact Models"](https://arxiv.org/abs/1908.08962)
paper, we train smaller models (different layers and hidden sizes), and report number of parameters and pre-training costs:
| Model (Layer / Hidden size) | Parameters | Pre-Training time
| --------------------------- | ----------: | ----------------------:
| hmBERT Tiny ( 2/128) | 4.58M | 4.3 sec / 1,000 steps
| hmBERT Mini ( 4/256) | 11.55M | 10.5 sec / 1,000 steps
| hmBERT Small ( 4/512) | 29.52M | 20.7 sec / 1,000 steps
| hmBERT Medium ( 8/512) | 42.13M | 35.0 sec / 1,000 steps
| hmBERT Base (12/768) | 110.62M | 80.0 sec / 1,000 steps
We then perform downstream evaluations on the multilingual [NewsEye](https://zenodo.org/record/4573313#.Ya3oVr-ZNzU) dataset:

# Pretraining
## Multilingual model - hmBERT Base
We train a multilingual BERT model using the 32k vocab with the official BERT implementation
on a v3-32 TPU using the following parameters:
```bash
python3 run_pretraining.py --input_file gs://histolectra/historic-multilingual-tfrecords/*.tfrecord \
--output_dir gs://histolectra/bert-base-historic-multilingual-cased \
--bert_config_file ./config.json \
--max_seq_length=512 \
--max_predictions_per_seq=75 \
--do_train=True \
--train_batch_size=128 \
--num_train_steps=3000000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=100000 \
--keep_checkpoint_max=20 \
--use_tpu=True \
--tpu_name=electra-2 \
--num_tpu_cores=32
```
The following plot shows the pretraining loss curve:

## Smaller multilingual models
We use the same parameters as used for training the base model.
### hmBERT Tiny
The following plot shows the pretraining loss curve for the tiny model:

### hmBERT Mini
The following plot shows the pretraining loss curve for the mini model:

### hmBERT Small
The following plot shows the pretraining loss curve for the small model:

### hmBERT Medium
The following plot shows the pretraining loss curve for the medium model:

## English model
The English BERT model - with texts from British Library corpus - was trained with the Hugging Face
JAX/FLAX implementation for 10 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-historic-english-cased/ \
--tokenizer_name /mnt/datasets/bert-base-historic-english-cased/ \
--train_file /mnt/datasets/bl-corpus/bl_1800-1900_extracted.txt \
--validation_file /mnt/datasets/bl-corpus/english_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 10 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-historic-english-cased-512-noadafactor-10e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Finnish model
The BERT model - with texts from Finnish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Finnish_0.6.txt \
--validation_file /mnt/datasets/hlms/finnish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-finnish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Swedish model
The BERT model - with texts from Swedish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 660K steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Swedish_0.6.txt \
--validation_file /mnt/datasets/hlms/swedish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-swedish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

# Acknowledgments
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/ParaphraseParentheses | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
language: multilingual
license: mit
widget:
- text: "and I cannot conceive the reafon why [MASK] hath"
- text: "Täkäläinen sanomalehdistö [MASK] erit - täin"
- text: "Det vore [MASK] häller nödvändigt att be"
- text: "Comme, à cette époque [MASK] était celle de la"
- text: "In [MASK] an atmosphärischen Nahrungsmitteln"
---
# Historic Language Models (HLMs)
## Languages
Our Historic Language Models Zoo contains support for the following languages - incl. their training data source:
| Language | Training data | Size
| -------- | ------------- | ----
| German | [Europeana](http://www.europeana-newspapers.eu/) | 13-28GB (filtered)
| French | [Europeana](http://www.europeana-newspapers.eu/) | 11-31GB (filtered)
| English | [British Library](https://data.bl.uk/digbks/db14.html) | 24GB (year filtered)
| Finnish | [Europeana](http://www.europeana-newspapers.eu/) | 1.2GB
| Swedish | [Europeana](http://www.europeana-newspapers.eu/) | 1.1GB
## Models
At the moment, the following models are available on the model hub:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
| `dbmdz/bert-base-historic-english-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-english-cased)
| `dbmdz/bert-base-finnish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-finnish-europeana-cased)
| `dbmdz/bert-base-swedish-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-swedish-europeana-cased)
We also released smaller models for the multilingual model:
| Model identifier | Model Hub link
| ----------------------------------------------- | ---------------------------------------------------------------------------
| `dbmdz/bert-tiny-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-tiny-historic-multilingual-cased)
| `dbmdz/bert-mini-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-mini-historic-multilingual-cased)
| `dbmdz/bert-small-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-small-historic-multilingual-cased)
| `dbmdz/bert-medium-historic-multilingual-cased` | [here](https://huggingface.co/dbmdz/bert-base-historic-multilingual-cased)
**Notice**: We have released language models for Historic German and French trained on more noisier data earlier - see
[this repo](https://github.com/stefan-it/europeana-bert) for more information:
| Model identifier | Model Hub link
| --------------------------------------------- | --------------------------------------------------------------------------
| `dbmdz/bert-base-german-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-german-europeana-cased)
| `dbmdz/bert-base-french-europeana-cased` | [here](https://huggingface.co/dbmdz/bert-base-french-europeana-cased)
# Corpora Stats
## German Europeana Corpus
We provide some statistics using different thresholds of ocr confidences, in order to shrink down the corpus size
and use less-noisier data:
| OCR confidence | Size
| -------------- | ----
| **0.60** | 28GB
| 0.65 | 18GB
| 0.70 | 13GB
For the final corpus we use a OCR confidence of 0.6 (28GB). The following plot shows a tokens per year distribution:

## French Europeana Corpus
Like German, we use different ocr confidence thresholds:
| OCR confidence | Size
| -------------- | ----
| 0.60 | 31GB
| 0.65 | 27GB
| **0.70** | 27GB
| 0.75 | 23GB
| 0.80 | 11GB
For the final corpus we use a OCR confidence of 0.7 (27GB). The following plot shows a tokens per year distribution:

## British Library Corpus
Metadata is taken from [here](https://data.bl.uk/digbks/DB21.html). Stats incl. year filtering:
| Years | Size
| ----------------- | ----
| ALL | 24GB
| >= 1800 && < 1900 | 24GB
We use the year filtered variant. The following plot shows a tokens per year distribution:

## Finnish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.2GB
The following plot shows a tokens per year distribution:

## Swedish Europeana Corpus
| OCR confidence | Size
| -------------- | ----
| 0.60 | 1.1GB
The following plot shows a tokens per year distribution:

## All Corpora
The following plot shows a tokens per year distribution of the complete training corpus:

# Multilingual Vocab generation
For the first attempt, we use the first 10GB of each pretraining corpus. We upsample both Finnish and Swedish to ~10GB.
The following tables shows the exact size that is used for generating a 32k and 64k subword vocabs:
| Language | Size
| -------- | ----
| German | 10GB
| French | 10GB
| English | 10GB
| Finnish | 9.5GB
| Swedish | 9.7GB
We then calculate the subword fertility rate and portion of `[UNK]`s over the following NER corpora:
| Language | NER corpora
| -------- | ------------------
| German | CLEF-HIPE, NewsEye
| French | CLEF-HIPE, NewsEye
| English | CLEF-HIPE
| Finnish | NewsEye
| Swedish | NewsEye
Breakdown of subword fertility rate and unknown portion per language for the 32k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.43 | 0.0004
| French | 1.25 | 0.0001
| English | 1.25 | 0.0
| Finnish | 1.69 | 0.0007
| Swedish | 1.43 | 0.0
Breakdown of subword fertility rate and unknown portion per language for the 64k vocab:
| Language | Subword fertility | Unknown portion
| -------- | ------------------ | ---------------
| German | 1.31 | 0.0004
| French | 1.16 | 0.0001
| English | 1.17 | 0.0
| Finnish | 1.54 | 0.0007
| Swedish | 1.32 | 0.0
# Final pretraining corpora
We upsample Swedish and Finnish to ~27GB. The final stats for all pretraining corpora can be seen here:
| Language | Size
| -------- | ----
| German | 28GB
| French | 27GB
| English | 24GB
| Finnish | 27GB
| Swedish | 27GB
Total size is 130GB.
# Smaller multilingual models
Inspired by the ["Well-Read Students Learn Better: On the Importance of Pre-training Compact Models"](https://arxiv.org/abs/1908.08962)
paper, we train smaller models (different layers and hidden sizes), and report number of parameters and pre-training costs:
| Model (Layer / Hidden size) | Parameters | Pre-Training time
| --------------------------- | ----------: | ----------------------:
| hmBERT Tiny ( 2/128) | 4.58M | 4.3 sec / 1,000 steps
| hmBERT Mini ( 4/256) | 11.55M | 10.5 sec / 1,000 steps
| hmBERT Small ( 4/512) | 29.52M | 20.7 sec / 1,000 steps
| hmBERT Medium ( 8/512) | 42.13M | 35.0 sec / 1,000 steps
| hmBERT Base (12/768) | 110.62M | 80.0 sec / 1,000 steps
We then perform downstream evaluations on the multilingual [NewsEye](https://zenodo.org/record/4573313#.Ya3oVr-ZNzU) dataset:

# Pretraining
## Multilingual model - hmBERT Base
We train a multilingual BERT model using the 32k vocab with the official BERT implementation
on a v3-32 TPU using the following parameters:
```bash
python3 run_pretraining.py --input_file gs://histolectra/historic-multilingual-tfrecords/*.tfrecord \
--output_dir gs://histolectra/bert-base-historic-multilingual-cased \
--bert_config_file ./config.json \
--max_seq_length=512 \
--max_predictions_per_seq=75 \
--do_train=True \
--train_batch_size=128 \
--num_train_steps=3000000 \
--learning_rate=1e-4 \
--save_checkpoints_steps=100000 \
--keep_checkpoint_max=20 \
--use_tpu=True \
--tpu_name=electra-2 \
--num_tpu_cores=32
```
The following plot shows the pretraining loss curve:

## Smaller multilingual models
We use the same parameters as used for training the base model.
### hmBERT Tiny
The following plot shows the pretraining loss curve for the tiny model:

### hmBERT Mini
The following plot shows the pretraining loss curve for the mini model:

### hmBERT Small
The following plot shows the pretraining loss curve for the small model:

### hmBERT Medium
The following plot shows the pretraining loss curve for the medium model:

## English model
The English BERT model - with texts from British Library corpus - was trained with the Hugging Face
JAX/FLAX implementation for 10 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-historic-english-cased/ \
--tokenizer_name /mnt/datasets/bert-base-historic-english-cased/ \
--train_file /mnt/datasets/bl-corpus/bl_1800-1900_extracted.txt \
--validation_file /mnt/datasets/bl-corpus/english_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 10 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-historic-english-cased-512-noadafactor-10e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Finnish model
The BERT model - with texts from Finnish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 1M steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-finnish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Finnish_0.6.txt \
--validation_file /mnt/datasets/hlms/finnish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-finnish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

## Swedish model
The BERT model - with texts from Swedish part of Europeana - was trained with the Hugging Face
JAX/FLAX implementation for 40 epochs (approx. 660K steps) on a v3-8 TPU, using the following command:
```bash
python3 run_mlm_flax.py --model_type bert \
--config_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--tokenizer_name /mnt/datasets/bert-base-swedish-europeana-cased/ \
--train_file /mnt/datasets/hlms/extracted_content_Swedish_0.6.txt \
--validation_file /mnt/datasets/hlms/swedish_validation.txt \
--max_seq_length 512 \
--per_device_train_batch_size 16 \
--learning_rate 1e-4 \
--num_train_epochs 40 \
--preprocessing_num_workers 96 \
--output_dir /mnt/datasets/bert-base-swedish-europeana-cased-512-dupe1-noadafactor-40e \
--save_steps 2500 \
--eval_steps 2500 \
--warmup_steps 10000 \
--line_by_line \
--pad_to_max_length
```
The following plot shows the pretraining loss curve:

# Acknowledgments
Research supported with Cloud TPUs from Google's TPU Research Cloud (TRC) program, previously known as
TensorFlow Research Cloud (TFRC). Many thanks for providing access to the TRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigSalmon/ParaphraseParentheses2.0 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ---
language: de
license: mit
tags:
- "historic german"
---
# 🤗 + 📚 dbmdz ConvBERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a German Europeana ConvBERT model 🎉
# German Europeana ConvBERT
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
that were provided by *The European Library*. The final
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 4.3 our German Europeana ConvBERT model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/convbert-base-german-europeana-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
# Huggingface model hub
All other German Europeana models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our Europeana BERT, ELECTRA and ConvBERT models just open a new discussion
[here](https://github.com/stefan-it/europeana-bert/discussions) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗 |
BigSalmon/Points | [
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"has_space"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ---
language: tr
license: mit
datasets:
- allenai/c4
---
# 🇹🇷 Turkish ConvBERT model
<p align="center">
<img alt="Logo provided by Merve Noyan" title="Awesome logo from Merve Noyan" src="https://raw.githubusercontent.com/stefan-it/turkish-bert/master/merve_logo.png">
</p>
[](https://zenodo.org/badge/latestdoi/237817454)
We present community-driven BERT, DistilBERT, ELECTRA and ConvBERT models for Turkish 🎉
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the BERT model name: BERTurk.
Logo is provided by [Merve Noyan](https://twitter.com/mervenoyann).
# Stats
We've trained an (cased) ConvBERT model on the recently released Turkish part of the
[multiligual C4 (mC4) corpus](https://github.com/allenai/allennlp/discussions/5265) from the AI2 team.
After filtering documents with a broken encoding, the training corpus has a size of 242GB resulting
in 31,240,963,926 tokens.
We used the original 32k vocab (instead of creating a new one).
# mC4 ConvBERT
In addition to the ELEC**TR**A base model, we also trained an ConvBERT model on the Turkish part of the mC4 corpus. We use a
sequence length of 512 over the full training time and train the model for 1M steps on a v3-32 TPU.
# Model usage
All trained models can be used from the [DBMDZ](https://github.com/dbmdz) Hugging Face [model hub page](https://huggingface.co/dbmdz)
using their model name.
Example usage with 🤗/Transformers:
```python
tokenizer = AutoTokenizer.from_pretrained("dbmdz/convbert-base-turkish-mc4-cased")
model = AutoModel.from_pretrained("dbmdz/convbert-base-turkish-mc4-cased")
```
# Citation
You can use the following BibTeX entry for citation:
```bibtex
@software{stefan_schweter_2020_3770924,
author = {Stefan Schweter},
title = {BERTurk - BERT models for Turkish},
month = apr,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.3770924},
url = {https://doi.org/10.5281/zenodo.3770924}
}
```
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
We would like to thank [Merve Noyan](https://twitter.com/mervenoyann) for the
awesome logo!
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️ |
BigSalmon/Points2 | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"has_space"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
language: tr
license: mit
datasets:
- allenai/c4
---
# 🇹🇷 Turkish ConvBERT model
<p align="center">
<img alt="Logo provided by Merve Noyan" title="Awesome logo from Merve Noyan" src="https://raw.githubusercontent.com/stefan-it/turkish-bert/master/merve_logo.png">
</p>
[](https://zenodo.org/badge/latestdoi/237817454)
We present community-driven BERT, DistilBERT, ELECTRA and ConvBERT models for Turkish 🎉
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the BERT model name: BERTurk.
Logo is provided by [Merve Noyan](https://twitter.com/mervenoyann).
# Stats
We've trained an (uncased) ConvBERT model on the recently released Turkish part of the
[multiligual C4 (mC4) corpus](https://github.com/allenai/allennlp/discussions/5265) from the AI2 team.
After filtering documents with a broken encoding, the training corpus has a size of 242GB resulting
in 31,240,963,926 tokens.
We used the original 32k vocab (instead of creating a new one).
# mC4 ConvBERT
In addition to the ELEC**TR**A base model, we also trained an ConvBERT model on the Turkish part of the mC4 corpus. We use a
sequence length of 512 over the full training time and train the model for 1M steps on a v3-32 TPU.
# Model usage
All trained models can be used from the [DBMDZ](https://github.com/dbmdz) Hugging Face [model hub page](https://huggingface.co/dbmdz)
using their model name.
Example usage with 🤗/Transformers:
```python
tokenizer = AutoTokenizer.from_pretrained("dbmdz/convbert-base-turkish-mc4-uncased")
model = AutoModel.from_pretrained("dbmdz/convbert-base-turkish-mc4-uncased")
```
# Citation
You can use the following BibTeX entry for citation:
```bibtex
@software{stefan_schweter_2020_3770924,
author = {Stefan Schweter},
title = {BERTurk - BERT models for Turkish},
month = apr,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.3770924},
url = {https://doi.org/10.5281/zenodo.3770924}
}
```
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
We would like to thank [Merve Noyan](https://twitter.com/mervenoyann) for the
awesome logo!
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️ |
BigSalmon/Robertsy | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
language: de
license: mit
tags:
- "historic german"
---
# 🤗 + 📚 dbmdz DistilBERT model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a German Europeana DistilBERT model 🎉
# German Europeana DistilBERT
We use the open source [Europeana newspapers](http://www.europeana-newspapers.eu/)
that were provided by *The European Library*. The final
training corpus has a size of 51GB and consists of 8,035,986,369 tokens.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 4.3 our German Europeana DistilBERT model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/distilbert-base-german-europeana-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
# Huggingface model hub
All other German Europeana models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our Europeana BERT, ELECTRA and ConvBERT models just open a new discussion
[here](https://github.com/stefan-it/europeana-bert/discussions) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗 |
BigSalmon/SimplifyText | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 17 | 2020-11-15T18:29:59Z | ---
language: fr
license: mit
tags:
- "historic french"
---
# 🤗 + 📚 dbmdz ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources French Europeana ELECTRA models 🎉
# French Europeana ELECTRA
We extracted all French texts using the `language` metadata attribute from the Europeana corpus.
The resulting corpus has a size of 63GB and consists of 11,052,528,456 tokens.
Based on the metadata information, texts from the 18th - 20th century are mainly included in the
training corpus.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Model weights
ELECTRA model weights for PyTorch and TensorFlow are available.
* French Europeana ELECTRA (discriminator): `dbmdz/electra-base-french-europeana-cased-discriminator` - [model hub page](https://huggingface.co/dbmdz/electra-base-french-europeana-cased-discriminator/tree/main)
* French Europeana ELECTRA (generator): `dbmdz/electra-base-french-europeana-cased-generator` - [model hub page](https://huggingface.co/dbmdz/electra-base-french-europeana-cased-generator/tree/main)
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 2.3 our French Europeana ELECTRA model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/electra-base-french-europeana-cased-discriminator")
model = AutoModel.from_pretrained("dbmdz/electra-base-french-europeana-cased-discriminator")
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download our models from their S3 storage 🤗
|
BigSalmon/T52 | [
"pytorch",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
} | 8 | 2020-11-15T23:36:02Z | ---
language: fr
license: mit
tags:
- "historic french"
---
# 🤗 + 📚 dbmdz ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources French Europeana ELECTRA models 🎉
# French Europeana ELECTRA
We extracted all French texts using the `language` metadata attribute from the Europeana corpus.
The resulting corpus has a size of 63GB and consists of 11,052,528,456 tokens.
Based on the metadata information, texts from the 18th - 20th century are mainly included in the
training corpus.
Detailed information about the data and pretraining steps can be found in
[this repository](https://github.com/stefan-it/europeana-bert).
## Model weights
ELECTRA model weights for PyTorch and TensorFlow are available.
* French Europeana ELECTRA (discriminator): `dbmdz/electra-base-french-europeana-cased-discriminator` - [model hub page](https://huggingface.co/dbmdz/electra-base-french-europeana-cased-discriminator/tree/main)
* French Europeana ELECTRA (generator): `dbmdz/electra-base-french-europeana-cased-generator` - [model hub page](https://huggingface.co/dbmdz/electra-base-french-europeana-cased-generator/tree/main)
## Results
For results on Historic NER, please refer to [this repository](https://github.com/stefan-it/europeana-bert).
## Usage
With Transformers >= 2.3 our French Europeana ELECTRA model can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/electra-base-french-europeana-cased-discriminator")
model = AutoModel.from_pretrained("dbmdz/electra-base-french-europeana-cased-discriminator")
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download our models from their S3 storage 🤗
|
BigSalmon/prepositions | [
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible",
"has_space"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | 2020-11-02T15:41:21Z | ---
language: it
license: mit
datasets:
- wikipedia
---
# 🤗 + 📚 dbmdz BERT and ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources Italian BERT and ELECTRA models 🎉
# Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy).
Our cased and uncased models are training with an initial sequence length of 512
subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
Note: Unfortunately, a wrong vocab size was used when training the XXL models.
This explains the mismatch of the "real" vocab size of 31102, compared to the
vocab size specified in `config.json`. However, the model is working and all
evaluations were done under those circumstances.
See [this issue](https://github.com/dbmdz/berts/issues/7) for more information.
The Italian ELECTRA model was trained on the "XXL" corpus for 1M steps in total using a batch
size of 128. We pretty much following the ELECTRA training procedure as used for
[BERTurk](https://github.com/stefan-it/turkish-bert/tree/master/electra).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ---------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-discriminator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-generator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-generator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/vocab.txt)
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/italian-bertelectra).
## Usage
With Transformers >= 2.3 our Italian BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the (recommended) Italian XXL BERT models, just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the Italian XXL ELECTRA model (discriminator), just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/electra-base-italian-xxl-cased-discriminator"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT/ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigTooth/DialoGPT-Megumin | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 16 | 2020-11-02T16:39:45Z | ---
language: it
license: mit
datasets:
- wikipedia
---
# 🤗 + 📚 dbmdz BERT and ELECTRA models
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources Italian BERT and ELECTRA models 🎉
# Italian BERT
The source data for the Italian BERT model consists of a recent Wikipedia dump and
various texts from the [OPUS corpora](http://opus.nlpl.eu/) collection. The final
training corpus has a size of 13GB and 2,050,057,573 tokens.
For sentence splitting, we use NLTK (faster compared to spacy).
Our cased and uncased models are training with an initial sequence length of 512
subwords for ~2-3M steps.
For the XXL Italian models, we use the same training data from OPUS and extend
it with data from the Italian part of the [OSCAR corpus](https://traces1.inria.fr/oscar/).
Thus, the final training corpus has a size of 81GB and 13,138,379,147 tokens.
Note: Unfortunately, a wrong vocab size was used when training the XXL models.
This explains the mismatch of the "real" vocab size of 31102, compared to the
vocab size specified in `config.json`. However, the model is working and all
evaluations were done under those circumstances.
See [this issue](https://github.com/dbmdz/berts/issues/7) for more information.
The Italian ELECTRA model was trained on the "XXL" corpus for 1M steps in total using a batch
size of 128. We pretty much following the ELECTRA training procedure as used for
[BERTurk](https://github.com/stefan-it/turkish-bert/tree/master/electra).
## Model weights
Currently only PyTorch-[Transformers](https://github.com/huggingface/transformers)
compatible weights are available. If you need access to TensorFlow checkpoints,
please raise an issue!
| Model | Downloads
| ---------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/bert-base-italian-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-cased/vocab.txt)
| `dbmdz/bert-base-italian-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-uncased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-cased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-cased/vocab.txt)
| `dbmdz/bert-base-italian-xxl-uncased` | [`config.json`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/bert-base-italian-xxl-uncased/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-discriminator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-discriminator/vocab.txt)
| `dbmdz/electra-base-italian-xxl-cased-generator` | [`config.json`](https://s3.amazonaws.com/models.huggingface.co/bert/dbmdz/electra-base-italian-xxl-cased-generator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-italian-xxl-cased-generator/vocab.txt)
## Results
For results on downstream tasks like NER or PoS tagging, please refer to
[this repository](https://github.com/stefan-it/italian-bertelectra).
## Usage
With Transformers >= 2.3 our Italian BERT models can be loaded like:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the (recommended) Italian XXL BERT models, just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/bert-base-italian-xxl-cased"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModel.from_pretrained(model_name)
```
To load the Italian XXL ELECTRA model (discriminator), just use:
```python
from transformers import AutoModel, AutoTokenizer
model_name = "dbmdz/electra-base-italian-xxl-cased-discriminator"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelWithLMHead.from_pretrained(model_name)
```
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT/ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BigTooth/DialoGPT-small-tohru | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | 2020-05-12T11:52:50Z | ---
language: tr
license: mit
---
# 🤗 + 📚 dbmdz Turkish ELECTRA model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a cased ELECTRA base model for Turkish 🎉
# Turkish ELECTRA model
We release a base ELEC**TR**A model for Turkish, that was trained on the same data as *BERTurk*.
> ELECTRA is a new method for self-supervised language representation learning. It can be used to
> pre-train transformer networks using relatively little compute. ELECTRA models are trained to
> distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to
> the discriminator of a GAN.
More details about ELECTRA can be found in the [ICLR paper](https://openreview.net/forum?id=r1xMH1BtvB)
or in the [official ELECTRA repository](https://github.com/google-research/electra) on GitHub.
## Stats
The current version of the model is trained on a filtered and sentence
segmented version of the Turkish [OSCAR corpus](https://traces1.inria.fr/oscar/),
a recent Wikipedia dump, various [OPUS corpora](http://opus.nlpl.eu/) and a
special corpus provided by [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/).
The final training corpus has a size of 35GB and 44,04,976,662 tokens.
Thanks to Google's TensorFlow Research Cloud (TFRC) we could train a cased model
on a TPU v3-8 for 1M steps.
## Model weights
[Transformers](https://github.com/huggingface/transformers)
compatible weights for both PyTorch and TensorFlow are available.
| Model | Downloads
| ------------------------------------------------ | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/electra-base-turkish-cased-discriminator` | [`config.json`](https://cdn.huggingface.co/dbmdz/electra-base-turkish-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-base-turkish-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-base-turkish-cased-discriminator/vocab.txt)
## Usage
With Transformers >= 2.8 our ELECTRA base cased model can be loaded like:
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/electra-base-turkish-cased-discriminator")
model = AutoModelWithLMHead.from_pretrained("dbmdz/electra-base-turkish-cased-discriminator")
```
## Results
For results on PoS tagging or NER tasks, please refer to
[this repository](https://github.com/stefan-it/turkish-bert/electra).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
Bilz/DialoGPT-small-harrypotter | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-06-24T20:44:49Z | ---
language: tr
license: mit
datasets:
- allenai/c4
---
# 🇹🇷 Turkish ELECTRA model
<p align="center">
<img alt="Logo provided by Merve Noyan" title="Awesome logo from Merve Noyan" src="https://raw.githubusercontent.com/stefan-it/turkish-bert/master/merve_logo.png">
</p>
[](https://zenodo.org/badge/latestdoi/237817454)
We present community-driven BERT, DistilBERT, ELECTRA and ConvBERT models for Turkish 🎉
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the BERT model name: BERTurk.
Logo is provided by [Merve Noyan](https://twitter.com/mervenoyann).
# Stats
We've also trained an ELECTRA (cased) model on the recently released Turkish part of the
[multiligual C4 (mC4) corpus](https://github.com/allenai/allennlp/discussions/5265) from the AI2 team.
After filtering documents with a broken encoding, the training corpus has a size of 242GB resulting
in 31,240,963,926 tokens.
We used the original 32k vocab (instead of creating a new one).
# mC4 ELECTRA
In addition to the ELEC**TR**A base model, we also trained an ELECTRA model on the Turkish part of the mC4 corpus. We use a
sequence length of 512 over the full training time and train the model for 1M steps on a v3-32 TPU.
# Model usage
All trained models can be used from the [DBMDZ](https://github.com/dbmdz) Hugging Face [model hub page](https://huggingface.co/dbmdz)
using their model name.
Example usage with 🤗/Transformers:
```python
tokenizer = AutoTokenizer.from_pretrained("dbmdz/electra-base-turkish-mc4-cased-discriminator")
model = AutoModel.from_pretrained("dbmdz/electra-base-turkish-mc4-cased-discriminator")
```
# Citation
You can use the following BibTeX entry for citation:
```bibtex
@software{stefan_schweter_2020_3770924,
author = {Stefan Schweter},
title = {BERTurk - BERT models for Turkish},
month = apr,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.3770924},
url = {https://doi.org/10.5281/zenodo.3770924}
}
```
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
We would like to thank [Merve Noyan](https://twitter.com/mervenoyann) for the
awesome logo!
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
|
Binbin/test | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: tr
license: mit
datasets:
- allenai/c4
---
# 🇹🇷 Turkish ELECTRA model
<p align="center">
<img alt="Logo provided by Merve Noyan" title="Awesome logo from Merve Noyan" src="https://raw.githubusercontent.com/stefan-it/turkish-bert/master/merve_logo.png">
</p>
[](https://zenodo.org/badge/latestdoi/237817454)
We present community-driven BERT, DistilBERT, ELECTRA and ConvBERT models for Turkish 🎉
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the BERT model name: BERTurk.
Logo is provided by [Merve Noyan](https://twitter.com/mervenoyann).
# Stats
We've also trained an ELECTRA (uncased) model on the recently released Turkish part of the
[multiligual C4 (mC4) corpus](https://github.com/allenai/allennlp/discussions/5265) from the AI2 team.
After filtering documents with a broken encoding, the training corpus has a size of 242GB resulting
in 31,240,963,926 tokens.
We used the original 32k vocab (instead of creating a new one).
# mC4 ELECTRA
In addition to the ELEC**TR**A base cased model, we also trained an ELECTRA uncased model on the Turkish part of the mC4 corpus. We use a
sequence length of 512 over the full training time and train the model for 1M steps on a v3-32 TPU.
# Model usage
All trained models can be used from the [DBMDZ](https://github.com/dbmdz) Hugging Face [model hub page](https://huggingface.co/dbmdz)
using their model name.
Example usage with 🤗/Transformers:
```python
tokenizer = AutoTokenizer.from_pretrained("electra-base-turkish-mc4-uncased-discriminator")
model = AutoModel.from_pretrained("electra-base-turkish-mc4-uncased-discriminator")
```
# Citation
You can use the following BibTeX entry for citation:
```bibtex
@software{stefan_schweter_2020_3770924,
author = {Stefan Schweter},
title = {BERTurk - BERT models for Turkish},
month = apr,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.3770924},
url = {https://doi.org/10.5281/zenodo.3770924}
}
```
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
We would like to thank [Merve Noyan](https://twitter.com/mervenoyann) for the
awesome logo!
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️ |
Biniam/en_ti_translate | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"translation",
"autotrain_compatible"
]
| translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | null | ---
language: tr
license: mit
datasets:
- allenai/c4
---
# 🇹🇷 Turkish ELECTRA model
<p align="center">
<img alt="Logo provided by Merve Noyan" title="Awesome logo from Merve Noyan" src="https://raw.githubusercontent.com/stefan-it/turkish-bert/master/merve_logo.png">
</p>
[](https://zenodo.org/badge/latestdoi/237817454)
We present community-driven BERT, DistilBERT, ELECTRA and ConvBERT models for Turkish 🎉
Some datasets used for pretraining and evaluation are contributed from the
awesome Turkish NLP community, as well as the decision for the BERT model name: BERTurk.
Logo is provided by [Merve Noyan](https://twitter.com/mervenoyann).
# Stats
We've also trained an ELECTRA (uncased) model on the recently released Turkish part of the
[multiligual C4 (mC4) corpus](https://github.com/allenai/allennlp/discussions/5265) from the AI2 team.
After filtering documents with a broken encoding, the training corpus has a size of 242GB resulting
in 31,240,963,926 tokens.
We used the original 32k vocab (instead of creating a new one).
# mC4 ELECTRA
In addition to the ELEC**TR**A base cased model, we also trained an ELECTRA uncased model on the Turkish part of the mC4 corpus. We use a
sequence length of 512 over the full training time and train the model for 1M steps on a v3-32 TPU.
# Model usage
All trained models can be used from the [DBMDZ](https://github.com/dbmdz) Hugging Face [model hub page](https://huggingface.co/dbmdz)
using their model name.
Example usage with 🤗/Transformers:
```python
tokenizer = AutoTokenizer.from_pretrained("electra-base-turkish-mc4-uncased-generator")
model = AutoModel.from_pretrained("electra-base-turkish-mc4-uncased-generator")
```
# Citation
You can use the following BibTeX entry for citation:
```bibtex
@software{stefan_schweter_2020_3770924,
author = {Stefan Schweter},
title = {BERTurk - BERT models for Turkish},
month = apr,
year = 2020,
publisher = {Zenodo},
version = {1.0.0},
doi = {10.5281/zenodo.3770924},
url = {https://doi.org/10.5281/zenodo.3770924}
}
```
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
We would like to thank [Merve Noyan](https://twitter.com/mervenoyann) for the
awesome logo!
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️ |
BitanBiswas/mbert-bengali-ner-finetuned-ner | [
"pytorch",
"tensorboard",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
language: tr
license: mit
---
# 🤗 + 📚 dbmdz Turkish ELECTRA model
In this repository the MDZ Digital Library team (dbmdz) at the Bavarian State
Library open sources a cased ELECTRA small model for Turkish 🎉
# Turkish ELECTRA model
We release a small ELEC**TR**A model for Turkish, that was trained on the same data as *BERTurk*.
> ELECTRA is a new method for self-supervised language representation learning. It can be used to
> pre-train transformer networks using relatively little compute. ELECTRA models are trained to
> distinguish "real" input tokens vs "fake" input tokens generated by another neural network, similar to
> the discriminator of a GAN.
More details about ELECTRA can be found in the [ICLR paper](https://openreview.net/forum?id=r1xMH1BtvB)
or in the [official ELECTRA repository](https://github.com/google-research/electra) on GitHub.
## Stats
The current version of the model is trained on a filtered and sentence
segmented version of the Turkish [OSCAR corpus](https://traces1.inria.fr/oscar/),
a recent Wikipedia dump, various [OPUS corpora](http://opus.nlpl.eu/) and a
special corpus provided by [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/).
The final training corpus has a size of 35GB and 44,04,976,662 tokens.
Thanks to Google's TensorFlow Research Cloud (TFRC) we could train a cased model
on a TPU v3-8 for 1M steps.
## Model weights
[Transformers](https://github.com/huggingface/transformers)
compatible weights for both PyTorch and TensorFlow are available.
| Model | Downloads
| ------------------------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `dbmdz/electra-small-turkish-cased-discriminator` | [`config.json`](https://cdn.huggingface.co/dbmdz/electra-small-turkish-cased-discriminator/config.json) • [`pytorch_model.bin`](https://cdn.huggingface.co/dbmdz/electra-small-turkish-cased-discriminator/pytorch_model.bin) • [`vocab.txt`](https://cdn.huggingface.co/dbmdz/electra-small-turkish-cased-discriminator/vocab.txt)
## Usage
With Transformers >= 2.8 our ELECTRA small cased model can be loaded like:
```python
from transformers import AutoModelWithLMHead, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("dbmdz/electra-small-turkish-cased-discriminator")
model = AutoModelWithLMHead.from_pretrained("dbmdz/electra-small-turkish-cased-discriminator")
```
## Results
For results on PoS tagging or NER tasks, please refer to
[this repository](https://github.com/stefan-it/turkish-bert/electra).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our ELECTRA models just open an issue
[here](https://github.com/dbmdz/berts/issues/new) 🤗
# Acknowledgments
Thanks to [Kemal Oflazer](http://www.andrew.cmu.edu/user/ko/) for providing us
additional large corpora for Turkish. Many thanks to Reyyan Yeniterzi for providing
us the Turkish NER dataset for evaluation.
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
Blaine-Mason/hackMIT-finetuned-sst2 | [
"pytorch",
"tensorboard",
"bert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 36 | 2021-03-02T18:08:05Z | ---
datasets:
- germeval_14
tags:
- flair
- token-classification
- sequence-tagger-model
language: de
widget:
- text: "Hugging Face ist eine französische Firma mit Sitz in New York."
license: mit
---
# Flair NER model trained on GermEval14 dataset
This model was trained on the official [GermEval14](https://sites.google.com/site/germeval2014ner/data)
dataset using the [Flair](https://github.com/flairNLP/flair) framework.
It uses a fine-tuned German DistilBERT model from [here](https://huggingface.co/distilbert-base-german-cased).
# Results
| Dataset \ Run | Run 1 | Run 2 | Run 3† | Run 4 | Run 5 | Avg.
| ------------- | ----- | ----- | --------- | ----- | ----- | ----
| Development | 87.05 | 86.52 | **87.34** | 86.85 | 86.46 | 86.84
| Test | 85.43 | 85.88 | 85.72 | 85.47 | 85.62 | 85.62
† denotes that this model is selected for upload.
# Flair Fine-Tuning
We used the following script to fine-tune the model on the GermEval14 dataset:
```python
from argparse import ArgumentParser
import torch, flair
# dataset, model and embedding imports
from flair.datasets import GERMEVAL_14
from flair.embeddings import TransformerWordEmbeddings
from flair.models import SequenceTagger
from flair.trainers import ModelTrainer
if __name__ == "__main__":
# All arguments that can be passed
parser = ArgumentParser()
parser.add_argument("-s", "--seeds", nargs='+', type=int, default='42') # pass list of seeds for experiments
parser.add_argument("-c", "--cuda", type=int, default=0, help="CUDA device") # which cuda device to use
parser.add_argument("-m", "--model", type=str, help="Model name (such as Hugging Face model hub name")
# Parse experimental arguments
args = parser.parse_args()
# use cuda device as passed
flair.device = f'cuda:{str(args.cuda)}'
# for each passed seed, do one experimental run
for seed in args.seeds:
flair.set_seed(seed)
# model
hf_model = args.model
# initialize embeddings
embeddings = TransformerWordEmbeddings(
model=hf_model,
layers="-1",
subtoken_pooling="first",
fine_tune=True,
use_context=False,
respect_document_boundaries=False,
)
# select dataset depending on which language variable is passed
corpus = GERMEVAL_14()
# make the dictionary of tags to predict
tag_dictionary = corpus.make_tag_dictionary('ner')
# init bare-bones sequence tagger (no reprojection, LSTM or CRF)
tagger: SequenceTagger = SequenceTagger(
hidden_size=256,
embeddings=embeddings,
tag_dictionary=tag_dictionary,
tag_type='ner',
use_crf=False,
use_rnn=False,
reproject_embeddings=False,
)
# init the model trainer
trainer = ModelTrainer(tagger, corpus, optimizer=torch.optim.AdamW)
# make string for output folder
output_folder = f"flert-ner-{hf_model}-{seed}"
# train with XLM parameters (AdamW, 20 epochs, small LR)
from torch.optim.lr_scheduler import OneCycleLR
trainer.train(
output_folder,
learning_rate=5.0e-5,
mini_batch_size=16,
mini_batch_chunk_size=1,
max_epochs=10,
scheduler=OneCycleLR,
embeddings_storage_mode='none',
weight_decay=0.,
train_with_dev=False,
)
```
|
BlightZz/DialoGPT-medium-Kurisu | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 19 | null | ---
language: de
widget:
- text: "Schon um die Liebe"
license: mit
---
# German GPT-2 model
In this repository we release (yet another) GPT-2 model, that was trained on various texts for German.
The model is meant to be an entry point for fine-tuning on other texts, and it is definitely not as good or "dangerous" as the English GPT-3 model. We do not plan extensive PR or staged releases for this model 😉
**Note**: The model was initially released under an anonymous alias (`anonymous-german-nlp/german-gpt2`) so we now "de-anonymize" it.
More details about GPT-2 can be found in the great [Hugging Face](https://huggingface.co/transformers/model_doc/gpt2.html) documentation.
## German GPT-2 fine-tuned on Faust I and II
We fine-tuned our German GPT-2 model on "Faust I and II" from Johann Wolfgang Goethe. These texts can be obtained from [Deutsches Textarchiv (DTA)](http://www.deutschestextarchiv.de/book/show/goethe_faust01_1808). We use the "normalized" version of both texts (to avoid out-of-vocabulary problems with e.g. "ſ")
Fine-Tuning was done for 100 epochs, using a batch size of 4 with half precision on a RTX 3090. Total time was around 12 minutes (it is really fast!).
We also open source this fine-tuned model. Text can be generated with:
```python
from transformers import pipeline
pipe = pipeline('text-generation', model="dbmdz/german-gpt2-faust",
tokenizer="dbmdz/german-gpt2-faust")
text = pipe("Schon um die Liebe", max_length=100)[0]["generated_text"]
print(text)
```
and could output:
```
Schon um die Liebe bitte ich, Herr! Wer mag sich die dreifach Ermächtigen?
Sei mir ein Held!
Und daß die Stunde kommt spreche ich nicht aus.
Faust (schaudernd).
Den schönen Boten finde' ich verwirrend;
```
# License
All models are licensed under [MIT](LICENSE).
# Huggingface model hub
All models are available on the [Huggingface model hub](https://huggingface.co/dbmdz).
# Contact (Bugs, Feedback, Contribution and more)
For questions about our BERT models just open an issue
[here](https://github.com/stefan-it/german-gpt/issues/new) 🤗
# Acknowledgments
Research supported with Cloud TPUs from Google's TensorFlow Research Cloud (TFRC).
Thanks for providing access to the TFRC ❤️
Thanks to the generous support from the [Hugging Face](https://huggingface.co/) team,
it is possible to download both cased and uncased models from their S3 storage 🤗
|
BlueGamerBeast/DialoGPT-small-Morgana | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | Language model fine-tuned on the articles and speeches of Noam Chomsky. |
BobBraico/bert-finetuned-ner | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-12-12T17:45:49Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikiann
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikiann
type: wikiann
args: en
metrics:
- name: Precision
type: precision
value: 0.8120642485217545
- name: Recall
type: recall
value: 0.830235495804385
- name: F1
type: f1
value: 0.8210493441599
- name: Accuracy
type: accuracy
value: 0.9203828724683252
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the wikiann dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2781
- Precision: 0.8121
- Recall: 0.8302
- F1: 0.8210
- Accuracy: 0.9204
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3504 | 1.0 | 1250 | 0.2922 | 0.7930 | 0.8075 | 0.8002 | 0.9115 |
| 0.2353 | 2.0 | 2500 | 0.2711 | 0.8127 | 0.8264 | 0.8195 | 0.9196 |
| 0.1745 | 3.0 | 3750 | 0.2781 | 0.8121 | 0.8302 | 0.8210 | 0.9204 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
BobBraico/distilbert-base-uncased-finetuned-imdb | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wikiann
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: electra-small-discriminator-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: wikiann
type: wikiann
args: en
metrics:
- name: Precision
type: precision
value: 0.7330965535385425
- name: Recall
type: recall
value: 0.7542632861138681
- name: F1
type: f1
value: 0.7435293071244329
- name: Accuracy
type: accuracy
value: 0.8883011190233978
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# electra-small-discriminator-finetuned-ner
This model is a fine-tuned version of [google/electra-small-discriminator](https://huggingface.co/google/electra-small-discriminator) on the wikiann dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3685
- Precision: 0.7331
- Recall: 0.7543
- F1: 0.7435
- Accuracy: 0.8883
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.5465 | 1.0 | 1250 | 0.4158 | 0.6932 | 0.7201 | 0.7064 | 0.8735 |
| 0.4037 | 2.0 | 2500 | 0.3817 | 0.7191 | 0.7470 | 0.7328 | 0.8828 |
| 0.3606 | 3.0 | 3750 | 0.3685 | 0.7331 | 0.7543 | 0.7435 | 0.8883 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Boondong/Wandee | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2019-12-23T19:22:27Z | ---
language:
- es
tags:
- masked-lm
---
# BETO: Spanish BERT
BETO is a [BERT model](https://github.com/google-research/bert) trained on a [big Spanish corpus](https://github.com/josecannete/spanish-corpora). BETO is of size similar to a BERT-Base and was trained with the Whole Word Masking technique. Below you find Tensorflow and Pytorch checkpoints for the uncased and cased versions, as well as some results for Spanish benchmarks comparing BETO with [Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md) as well as other (not BERT-based) models.
## Download
| | | | |
|-|:--------:|:-----:|:----:|
|BETO uncased|[tensorflow_weights](https://users.dcc.uchile.cl/~jperez/beto/uncased_2M/tensorflow_weights.tar.gz) | [pytorch_weights](https://users.dcc.uchile.cl/~jperez/beto/uncased_2M/pytorch_weights.tar.gz) | [vocab](./config/uncased_2M/vocab.txt), [config](./config/uncased_2M/config.json) |
|BETO cased| [tensorflow_weights](https://users.dcc.uchile.cl/~jperez/beto/cased_2M/tensorflow_weights.tar.gz) | [pytorch_weights](https://users.dcc.uchile.cl/~jperez/beto/cased_2M/pytorch_weights.tar.gz) | [vocab](./config/cased_2M/vocab.txt), [config](./config/cased_2M/config.json) |
All models use a vocabulary of about 31k BPE subwords constructed using SentencePiece and were trained for 2M steps.
## Benchmarks
The following table shows some BETO results in the Spanish version of every task.
We compare BETO (cased and uncased) with the Best Multilingual BERT results that
we found in the literature (as of October 2019).
The table also shows some alternative methods for the same tasks (not necessarily BERT-based methods).
References for all methods can be found [here](#references).
|Task | BETO-cased | BETO-uncased | Best Multilingual BERT | Other results |
|-------|--------------:|--------------:|--------------------------:|-------------------------------:|
|[POS](https://lindat.mff.cuni.cz/repository/xmlui/handle/11234/1-1827) | **98.97** | 98.44 | 97.10 [2] | 98.91 [6], 96.71 [3] |
|[NER-C](https://www.kaggle.com/nltkdata/conll-corpora) | [**88.43**](https://github.com/gchaperon/beto-benchmarks/blob/master/conll2002/dev_results_beto-cased_conll2002.txt) | 82.67 | 87.38 [2] | 87.18 [3] |
|[MLDoc](https://github.com/facebookresearch/MLDoc) | [95.60](https://github.com/gchaperon/beto-benchmarks/blob/master/MLDoc/dev_results_beto-cased_mldoc.txt) | [**96.12**](https://github.com/gchaperon/beto-benchmarks/blob/master/MLDoc/dev_results_beto-uncased_mldoc.txt) | 95.70 [2] | 88.75 [4] |
|[PAWS-X](https://github.com/google-research-datasets/paws/tree/master/pawsx) | 89.05 | 89.55 | 90.70 [8] |
|[XNLI](https://github.com/facebookresearch/XNLI) | **82.01** | 80.15 | 78.50 [2] | 80.80 [5], 77.80 [1], 73.15 [4]|
## Example of use
For further details on how to use BETO you can visit the [🤗Huggingface Transformers library](https://github.com/huggingface/transformers), starting by the [Quickstart section](https://huggingface.co/transformers/quickstart.html).
BETO models can be accessed simply as [`'dccuchile/bert-base-spanish-wwm-cased'`](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) and [`'dccuchile/bert-base-spanish-wwm-uncased'`](https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased) by using the Transformers library.
An example on how to download and use the models in this page can be found in [this colab notebook](https://colab.research.google.com/drive/1uRwg4UmPgYIqGYY4gW_Nsw9782GFJbPt).
(We will soon add a more detailed step-by-step tutorial in Spanish for newcommers 😉)
## Acknowledgments
We thank [Adereso](https://www.adere.so/) for kindly providing support for traininig BETO-uncased, and the [Millennium Institute for Foundational Research on Data](https://imfd.cl/en/)
that provided support for training BETO-cased. Also thanks to Google for helping us with the [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc) program.
## Citation
[Spanish Pre-Trained BERT Model and Evaluation Data](https://users.dcc.uchile.cl/~jperez/papers/pml4dc2020.pdf)
To cite this resource in a publication please use the following:
```
@inproceedings{CaneteCFP2020,
title={Spanish Pre-Trained BERT Model and Evaluation Data},
author={Cañete, José and Chaperon, Gabriel and Fuentes, Rodrigo and Ho, Jou-Hui and Kang, Hojin and Pérez, Jorge},
booktitle={PML4DC at ICLR 2020},
year={2020}
}
```
## License Disclaimer
The license CC BY 4.0 best describes our intentions for our work. However we are not sure that all the datasets used to train BETO have licenses compatible with CC BY 4.0 (specially for commercial use). Please use at your own discretion and verify that the licenses of the original text resources match your needs.
## References
* [1] [Original Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md)
* [2] [Multilingual BERT on "Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT"](https://arxiv.org/pdf/1904.09077.pdf)
* [3] [Multilingual BERT on "How Multilingual is Multilingual BERT?"](https://arxiv.org/pdf/1906.01502.pdf)
* [4] [LASER](https://arxiv.org/abs/1812.10464)
* [5] [XLM (MLM+TLM)](https://arxiv.org/pdf/1901.07291.pdf)
* [6] [UDPipe on "75 Languages, 1 Model: Parsing Universal Dependencies Universally"](https://arxiv.org/pdf/1904.02099.pdf)
* [7] [Multilingual BERT on "Sequence Tagging with Contextual and Non-Contextual Subword Representations: A Multilingual Evaluation"](https://arxiv.org/pdf/1906.01569.pdf)
* [8] [Multilingual BERT on "PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification"](https://arxiv.org/abs/1908.11828)
|
Bosio/full-sentence-distillroberta3-finetuned-wikitext2 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2019-12-23T19:18:27Z | ---
language:
- es
tags:
- masked-lm
---
# BETO: Spanish BERT
BETO is a [BERT model](https://github.com/google-research/bert) trained on a [big Spanish corpus](https://github.com/josecannete/spanish-corpora). BETO is of size similar to a BERT-Base and was trained with the Whole Word Masking technique. Below you find Tensorflow and Pytorch checkpoints for the uncased and cased versions, as well as some results for Spanish benchmarks comparing BETO with [Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md) as well as other (not BERT-based) models.
## Download
| | | | |
|-|:--------:|:-----:|:----:|
|BETO uncased|[tensorflow_weights](https://users.dcc.uchile.cl/~jperez/beto/uncased_2M/tensorflow_weights.tar.gz) | [pytorch_weights](https://users.dcc.uchile.cl/~jperez/beto/uncased_2M/pytorch_weights.tar.gz) | [vocab](./config/uncased_2M/vocab.txt), [config](./config/uncased_2M/config.json) |
|BETO cased| [tensorflow_weights](https://users.dcc.uchile.cl/~jperez/beto/cased_2M/tensorflow_weights.tar.gz) | [pytorch_weights](https://users.dcc.uchile.cl/~jperez/beto/cased_2M/pytorch_weights.tar.gz) | [vocab](./config/cased_2M/vocab.txt), [config](./config/cased_2M/config.json) |
All models use a vocabulary of about 31k BPE subwords constructed using SentencePiece and were trained for 2M steps.
## Benchmarks
The following table shows some BETO results in the Spanish version of every task.
We compare BETO (cased and uncased) with the Best Multilingual BERT results that
we found in the literature (as of October 2019).
The table also shows some alternative methods for the same tasks (not necessarily BERT-based methods).
References for all methods can be found [here](#references).
|Task | BETO-cased | BETO-uncased | Best Multilingual BERT | Other results |
|-------|--------------:|--------------:|--------------------------:|-------------------------------:|
|[POS](https://lindat.mff.cuni.cz/repository/xmlui/handle/11234/1-1827) | **98.97** | 98.44 | 97.10 [2] | 98.91 [6], 96.71 [3] |
|[NER-C](https://www.kaggle.com/nltkdata/conll-corpora) | [**88.43**](https://github.com/gchaperon/beto-benchmarks/blob/master/conll2002/dev_results_beto-cased_conll2002.txt) | 82.67 | 87.38 [2] | 87.18 [3] |
|[MLDoc](https://github.com/facebookresearch/MLDoc) | [95.60](https://github.com/gchaperon/beto-benchmarks/blob/master/MLDoc/dev_results_beto-cased_mldoc.txt) | [**96.12**](https://github.com/gchaperon/beto-benchmarks/blob/master/MLDoc/dev_results_beto-uncased_mldoc.txt) | 95.70 [2] | 88.75 [4] |
|[PAWS-X](https://github.com/google-research-datasets/paws/tree/master/pawsx) | 89.05 | 89.55 | 90.70 [8] |
|[XNLI](https://github.com/facebookresearch/XNLI) | **82.01** | 80.15 | 78.50 [2] | 80.80 [5], 77.80 [1], 73.15 [4]|
## Example of use
For further details on how to use BETO you can visit the [🤗Huggingface Transformers library](https://github.com/huggingface/transformers), starting by the [Quickstart section](https://huggingface.co/transformers/quickstart.html).
BETO models can be accessed simply as [`'dccuchile/bert-base-spanish-wwm-cased'`](https://huggingface.co/dccuchile/bert-base-spanish-wwm-cased) and [`'dccuchile/bert-base-spanish-wwm-uncased'`](https://huggingface.co/dccuchile/bert-base-spanish-wwm-uncased) by using the Transformers library.
An example on how to download and use the models in this page can be found in [this colab notebook](https://colab.research.google.com/drive/1uRwg4UmPgYIqGYY4gW_Nsw9782GFJbPt).
(We will soon add a more detailed step-by-step tutorial in Spanish for newcommers 😉)
## Acknowledgments
We thank [Adereso](https://www.adere.so/) for kindly providing support for traininig BETO-uncased, and the [Millennium Institute for Foundational Research on Data](https://imfd.cl/en/)
that provided support for training BETO-cased. Also thanks to Google for helping us with the [TensorFlow Research Cloud](https://www.tensorflow.org/tfrc) program.
## Citation
[Spanish Pre-Trained BERT Model and Evaluation Data](https://users.dcc.uchile.cl/~jperez/papers/pml4dc2020.pdf)
To cite this resource in a publication please use the following:
```
@inproceedings{CaneteCFP2020,
title={Spanish Pre-Trained BERT Model and Evaluation Data},
author={Cañete, José and Chaperon, Gabriel and Fuentes, Rodrigo and Ho, Jou-Hui and Kang, Hojin and Pérez, Jorge},
booktitle={PML4DC at ICLR 2020},
year={2020}
}
```
## License Disclaimer
The license CC BY 4.0 best describes our intentions for our work. However we are not sure that all the datasets used to train BETO have licenses compatible with CC BY 4.0 (specially for commercial use). Please use at your own discretion and verify that the licenses of the original text resources match your needs.
## References
* [1] [Original Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md)
* [2] [Multilingual BERT on "Beto, Bentz, Becas: The Surprising Cross-Lingual Effectiveness of BERT"](https://arxiv.org/pdf/1904.09077.pdf)
* [3] [Multilingual BERT on "How Multilingual is Multilingual BERT?"](https://arxiv.org/pdf/1906.01502.pdf)
* [4] [LASER](https://arxiv.org/abs/1812.10464)
* [5] [XLM (MLM+TLM)](https://arxiv.org/pdf/1901.07291.pdf)
* [6] [UDPipe on "75 Languages, 1 Model: Parsing Universal Dependencies Universally"](https://arxiv.org/pdf/1904.02099.pdf)
* [7] [Multilingual BERT on "Sequence Tagging with Contextual and Non-Contextual Subword Representations: A Multilingual Evaluation"](https://arxiv.org/pdf/1906.01569.pdf)
* [8] [Multilingual BERT on "PAWS-X: A Cross-lingual Adversarial Dataset for Paraphrase Identification"](https://arxiv.org/abs/1908.11828)
|
Botslity/Bot | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | https://teespring.com/dashboard/listings/113925135/edit |
BrianTin/MTBERT | [
"pytorch",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null | ```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
# device setting
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
# load model and tokenizer
model_name_or_path = "ddobokki/gpt2_poem"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
model = AutoModelForCausalLM.from_pretrained(model_name_or_path)
model.to(device)
keyword_start_token = "<k>"
keyword_end_token = "</k>"
text = "산 꼭대기가 보이는 경치"
input_text = keyword_start_token + text + keyword_end_token
input_ids = tokenizer.encode(input_text, return_tensors="pt").to(device)
gen_ids = model.generate(
input_ids, max_length=64, num_beams=100, no_repeat_ngram_size=2
)
generated = tokenizer.decode(gen_ids[0, :].tolist(), skip_special_tokens=True)
>> 오르락내리락
산 꼭대기를 올려다보니
아득히 멀고 아득한
나뭇가지에 매달린
작은 산새 한 마리
이름 모를 풀 한포기 안고
어디론가 훌쩍 떠나가 버렸다
``` |
Brinah/1 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
- ko
---
# ddobokki/klue-roberta-small-nli-sts
한국어 Sentence Transformer 모델입니다.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
[sentence-transformers](https://www.SBERT.net) 라이브러리를 이용해 사용할 수 있습니다.
```
pip install -U sentence-transformers
```
사용법
```python
from sentence_transformers import SentenceTransformer
sentences = ["흐르는 강물을 거꾸로 거슬러 오르는", "세월이 가면 가슴이 터질 듯한"]
model = SentenceTransformer('ddobokki/klue-roberta-small-nli-sts')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
transformers 라이브러리만 사용할 경우
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ["흐르는 강물을 거꾸로 거슬러 오르는", "세월이 가면 가슴이 터질 듯한"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('ddobokki/klue-roberta-small-nli-sts')
model = AutoModel.from_pretrained('ddobokki/klue-roberta-small-nli-sts')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Performance
- Semantic Textual Similarity test set results <br>
| Model | Cosine Pearson | Cosine Spearman | Euclidean Pearson | Euclidean Spearman | Manhattan Pearson | Manhattan Spearman | Dot Pearson | Dot Spearman |
|------------------------|:----:|:----:|:----:|:----:|:----:|:----:|:----:|:----:|
| KoSRoBERTa<sup>small</sup> | 84.27 | 84.17 | 83.33 | 83.65 | 83.34 | 83.65 | 82.10 | 81.38 |
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
BritishLibraryLabs/bl-books-genre | [
"pytorch",
"distilbert",
"text-classification",
"multilingual",
"dataset:blbooksgenre",
"transformers",
"genre",
"books",
"library",
"historic",
"glam ",
"lam",
"license:mit",
"has_space"
]
| text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 76 | null | ## EXAMPLE
```python
import requests
import torch
from PIL import Image
from transformers import (
VisionEncoderDecoderModel,
ViTFeatureExtractor,
PreTrainedTokenizerFast,
)
# device setting
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
# load feature extractor and tokenizer
encoder_model_name_or_path = "ddobokki/vision-encoder-decoder-vit-gpt2-coco-ko"
feature_extractor = ViTFeatureExtractor.from_pretrained(encoder_model_name_or_path)
tokenizer = PreTrainedTokenizerFast.from_pretrained(encoder_model_name_or_path)
# load model
model = VisionEncoderDecoderModel.from_pretrained(encoder_model_name_or_path)
model.to(device)
# inference
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
with Image.open(requests.get(url, stream=True).raw) as img:
pixel_values = feature_extractor(images=img, return_tensors="pt").pixel_values
generated_ids = model.generate(pixel_values.to(device),num_beams=5)
generated_text = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)
>> ['고양이 두마리가 담요 위에 누워 있다.']
```
|
Broadus20/DialoGPT-small-joshua | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | 2021-09-06T07:02:56Z | ---
language: "kr"
thumbnail:
tags:
- ASR
- CTC
- Attention
- Conformer
- pytorch
- speechbrain
license: "apache-2.0"
datasets:
- ksponspeech
metrics:
- wer
- cer
---
<iframe src="https://ghbtns.com/github-btn.html?user=speechbrain&repo=speechbrain&type=star&count=true&size=large&v=2" frameborder="0" scrolling="0" width="170" height="30" title="GitHub"></iframe>
<br/><br/>
# Conformer for KsponSpeech (with Transformer LM)
This repository provides all the necessary tools to perform automatic speech
recognition from an end-to-end system pretrained on KsponSpeech (Kr) within
SpeechBrain. For a better experience, we encourage you to learn more about
[SpeechBrain](https://speechbrain.github.io).
The performance of the model is the following:
| Release | eval clean CER | eval other CER | GPUs |
| :------: | :------------: | :------------: | :---------: |
| 01-23-23 | 7.33% | 7.99% | 6xA100 80GB |
## Pipeline description
This ASR system is composed of 3 different but linked blocks:
- Tokenizer (unigram) that transforms words into subword units and trained with
the train transcriptions of KsponSpeech.
- Neural language model (Transformer LM) trained on the train transcriptions of KsponSpeech
- Acoustic model made of a conformer encoder and a joint decoder with CTC +
transformer. Hence, the decoding also incorporates the CTC probabilities.
## Install SpeechBrain
First of all, please install SpeechBrain with the following command:
```
!pip install git+https://github.com/speechbrain/speechbrain.git
```
Please notice that we encourage you to read our tutorials and learn more about
[SpeechBrain](https://speechbrain.github.io).
### Transcribing your own audio files (in Korean)
```python
from speechbrain.pretrained import EncoderDecoderASR
asr_model = EncoderDecoderASR.from_hparams(source="ddwkim/asr-conformer-transformerlm-ksponspeech", savedir="pretrained_models/asr-conformer-transformerlm-ksponspeech", run_opts={"device":"cuda"})
asr_model.transcribe_file("ddwkim/asr-conformer-transformerlm-ksponspeech/record_0_16k.wav")
```
### Inference on GPU
To perform inference on the GPU, add `run_opts={"device":"cuda"}` when calling the `from_hparams` method.
## Parallel Inference on a Batch
Please, [see this Colab notebook](https://colab.research.google.com/drive/1finp9pfmGRzWHCAPNkqAH2yGH6k_BbPA?usp=sharing) on using the pretrained model
### Training
The model was trained with SpeechBrain (Commit hash: 'c762107').
To train it from scratch follow these steps:
1. Clone SpeechBrain:
```bash
git clone https://github.com/speechbrain/speechbrain/
```
2. Install it:
```bash
cd speechbrain
pip install -r requirements.txt
pip install .
```
3. Run Training:
```bash
cd recipes/KsponSpeech/ASR/transformer
python train.py hparams/conformer_medium.yaml --data_folder=your_data_folder
```
You can find our training results (models, logs, etc) at the subdirectories.
### Limitations
The SpeechBrain team does not provide any warranty on the performance achieved by this model when used on other datasets.
# **About SpeechBrain**
- Website: https://speechbrain.github.io/
- Code: https://github.com/speechbrain/speechbrain/
- HuggingFace: https://huggingface.co/speechbrain/
# **Citing SpeechBrain**
Please, cite SpeechBrain if you use it for your research or business.
```bibtex
@misc{speechbrain,
title={{SpeechBrain}: A General-Purpose Speech Toolkit},
author={Mirco Ravanelli and Titouan Parcollet and Peter Plantinga and Aku Rouhe and Samuele Cornell and Loren Lugosch and Cem Subakan and Nauman Dawalatabad and Abdelwahab Heba and Jianyuan Zhong and Ju-Chieh Chou and Sung-Lin Yeh and Szu-Wei Fu and Chien-Feng Liao and Elena Rastorgueva and François Grondin and William Aris and Hwidong Na and Yan Gao and Renato De Mori and Yoshua Bengio},
year={2021},
eprint={2106.04624},
archivePrefix={arXiv},
primaryClass={eess.AS},
note={arXiv:2106.04624}
}
```
# Citing the model
```bibtex
@misc{returnzero,
title = {ReturnZero Conformer Korean ASR model},
author = {Dongwon Kim and Dongwoo Kim and Jeongkyu Roh},
year = {2021},
howpublished = {\url{https://huggingface.co/ddwkim/asr-conformer-transformerlm-ksponspeech}},
}
```
# Citing KsponSpeech dataset
```bibtex
@Article{app10196936,
AUTHOR = {Bang, Jeong-Uk and Yun, Seung and Kim, Seung-Hi and Choi, Mu-Yeol and Lee, Min-Kyu and Kim, Yeo-Jeong and Kim, Dong-Hyun and Park, Jun and Lee, Young-Jik and Kim, Sang-Hun},
TITLE = {KsponSpeech: Korean Spontaneous Speech Corpus for Automatic Speech Recognition},
JOURNAL = {Applied Sciences},
VOLUME = {10},
YEAR = {2020},
NUMBER = {19},
ARTICLE-NUMBER = {6936},
URL = {https://www.mdpi.com/2076-3417/10/19/6936},
ISSN = {2076-3417},
DOI = {10.3390/app10196936}
}
```
|
Brona/model1 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
thumbnail: https://huggingface.co/front/thumbnails/dialogpt.png
tags:
- conversational
license: mit
---
# DialoGPT Trained on the Speech of a Game Character
Chat with the model:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("dead69/GTP-small-yoda")
model = AutoModelWithLMHead.from_pretrained("dead69/GTP-small-yoda")
# Let's chat for 4 lines
for step in range(10):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# print(new_user_input_ids)
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(
bot_input_ids, max_length=200,
pad_token_id=tokenizer.eos_token_id,
no_repeat_ngram_size=3,
do_sample=True,
top_k=100,
top_p=0.7,
temperature=0.8
)
# pretty print last ouput tokens from bot
print("Master YODA: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
``` |
BrunoNogueira/DialoGPT-kungfupanda | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
]
| conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
language:
- "en"
license: "cc-by-sa-4.0"
datasets:
- debatelab/aaac
widget:
- text: "reason_statements: argument_source: If Peter likes fish, Peter has been to New York. So, Peter has been to New York."
example_title: "Premise identification"
- text: "argdown_reconstruction: argument_source: If Peter likes fish, Peter has been to New York. So, Peter has been to New York."
example_title: "Argdown reconstruction"
- text: "premises_formalized: reason_statements: If Peter likes fish, Peter has been to New York. (ref: (1))"
example_title: "Formalization"
inference:
parameters:
max_length: 80
---
Pretraining Dataset: [AAAC01](https://huggingface.co/datasets/debatelab/aaac)
Demo: [DeepA2 Demo](https://huggingface.co/spaces/debatelab/deepa2-demo)
Paper: [DeepA2: A Modular Framework for Deep Argument Analysis with Pretrained Neural Text2Text Language Models](https://arxiv.org/abs/2110.01509)
Authors: *Gregor Betz, Kyle Richardson*
## Abstract
In this paper, we present and implement a multi-dimensional, modular framework for performing deep argument analysis (DeepA2) using current pre-trained language models (PTLMs). ArgumentAnalyst -- a T5 model (Raffel et al. 2020) set up and trained within DeepA2 -- reconstructs argumentative texts, which advance an informal argumentation, as valid arguments: It inserts, e.g., missing premises and conclusions, formalizes inferences, and coherently links the logical reconstruction to the source text. We create a synthetic corpus for deep argument analysis, and evaluate ArgumentAnalyst on this new dataset as well as on existing data, specifically EntailmentBank (Dalvi et al. 2021). Our empirical findings vindicate the overall framework and highlight the advantages of a modular design, in particular its ability to emulate established heuristics (such as hermeneutic cycles), to explore the model's uncertainty, to cope with the plurality of correct solutions (underdetermination), and to exploit higher-order evidence. |
Brunomezenga/NN | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
tags:
- gpt2
---
# CRiPT Model Large (Critical Thinking Intermediarily Pretrained Transformer)
Large version of the trained model (`SYL01-2020-10-24-72K/gpt2-large-train03-72K`) presented in the paper "Critical Thinking for Language Models" (Betz, Voigt and Richardson 2020). See also:
* [blog entry](https://debatelab.github.io/journal/critical-thinking-language-models.html)
* [GitHub repo](https://github.com/debatelab/aacorpus)
* [paper](https://arxiv.org/pdf/2009.07185) |
Bryan190/Aguy190 | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
tags:
- gpt2
---
# CRiPT Model Medium (Critical Thinking Intermediarily Pretrained Transformer)
Medium version of the trained model (`SYL01-2020-10-24-72K/gpt2-medium-train03-72K`) presented in the paper "Critical Thinking for Language Models" (Betz, Voigt and Richardson 2020). See also:
* [blog entry](https://debatelab.github.io/journal/critical-thinking-language-models.html)
* [GitHub repo](https://github.com/debatelab/aacorpus)
* [paper](https://arxiv.org/pdf/2009.07185) |
Brykee/BrykeeBot | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | This model has been trained for the purpose of classifying text from different domains. Currently it is trained with much lesser data and it has been trained to identify text from 3 domains, "sports", "healthcare" and "financial". Label_0 represents "financial", Label_1 represents "Healthcare" and Label_2 represents "Sports". Currently I have trained it with these 3 domains only, I am pretty soon planning to train it on more domains and more data, hence its accuracy will improve further too. |
Bryson575x/riceboi | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags: autonlp
language: unk
widget:
- text: "I love AutoNLP 🤗"
datasets:
- dee4hf/autonlp-data-shajBERT
co2_eq_emissions: 11.98841452241473
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 38639804
- CO2 Emissions (in grams): 11.98841452241473
## Validation Metrics
- Loss: 0.421400249004364
- Accuracy: 0.86783988957902
- Macro F1: 0.8669477050676501
- Micro F1: 0.86783988957902
- Weighted F1: 0.86694770506765
- Macro Precision: 0.867606300132228
- Micro Precision: 0.86783988957902
- Weighted Precision: 0.8676063001322278
- Macro Recall: 0.86783988957902
- Micro Recall: 0.86783988957902
- Weighted Recall: 0.86783988957902
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/dee4hf/autonlp-shajBERT-38639804
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("dee4hf/autonlp-shajBERT-38639804", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("dee4hf/autonlp-shajBERT-38639804", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 18 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4798
- Wer: 0.3474
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 30
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.5229 | 4.0 | 500 | 1.6557 | 1.0422 |
| 0.6618 | 8.0 | 1000 | 0.4420 | 0.4469 |
| 0.2211 | 12.0 | 1500 | 0.4705 | 0.4002 |
| 0.1281 | 16.0 | 2000 | 0.4347 | 0.3688 |
| 0.0868 | 20.0 | 2500 | 0.4653 | 0.3590 |
| 0.062 | 24.0 | 3000 | 0.4747 | 0.3519 |
| 0.0472 | 28.0 | 3500 | 0.4798 | 0.3474 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.9.0+cu102
- Datasets 1.17.0
- Tokenizers 0.10.3
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 71 | null | ---
license: apache-2.0
language: eu
metrics:
- wer
- cer
tags:
- automatic-speech-recognition
- basque
- generated_from_trainer
- hf-asr-leaderboard
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_7_0
model-index:
- name: wav2vec2-large-xls-r-300m-basque
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 7
type: mozilla-foundation/common_voice_7_0
args: eu
metrics:
- name: Test WER
type: wer
value: 51.89
- name: Test CER
type: cer
value: 10.01
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-300m-basque
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4276
- Wer: 0.5962
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 4
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.9902 | 1.29 | 400 | 2.1257 | 1.0 |
| 0.9625 | 2.59 | 800 | 0.5695 | 0.7452 |
| 0.4605 | 3.88 | 1200 | 0.4276 | 0.5962 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-sentiment | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 73 | null | ---
tags:
- Pytorch
license: apache-2.0
datasets:
- Publaynet
---
# Detectron2 Cascade-RCNN with FPN and Group Normalization on ResNext32xd4-50 trained on Publaynet for Document Layout Analysis
The model and has been trained with the Tensorflow training toolkit Tensorpack and then transferred to Pytorch using a conversion script.
The Tensorflow and Pytorch models differ slightly (padding ...), however validating both models give a difference of less than 0.03 mAP.
A second model has been added where the Tensorpack model has been used as initial checkpoint and training has been resumed for 20K iterations.
Performance of this model is now superior to the Tensorpack model.
Please check: [Xu Zhong et. all. - PubLayNet: largest dataset ever for document layout analysis](https://arxiv.org/abs/1908.07836).
This model is different from the model used the paper.
The code has been adapted so that it can be used in a **deep**doctection pipeline.
## How this model can be used
This model can be used with the **deep**doctection in a full pipeline, along with table recognition and OCR. Check the general instruction following this [Get_started](https://github.com/deepdoctection/deepdoctection/blob/master/notebooks/Get_Started.ipynb) tutorial.
## This is an inference model only
To reduce the size of the checkpoint we removed all variables that are not necessary for inference. Therefore it cannot be used for fine-tuning. To fine tune this model please use Tensorflow, as well as its training script. More information can be found in this [this model card](https://huggingface.co/deepdoctection/tp_casc_rcnn_X_32xd4_50_FPN_GN_2FC_publaynet).
|
CAMeL-Lab/bert-base-arabic-camelbert-ca | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 580 | null | ---
tags:
- Pytorch
license: apache-2.0
datasets:
- Pubtabnet
---
# Detectron2 Cascade-RCNN with FPN and Group Normalization on ResNext32xd4-50 trained on Pubtabnet for Semantic Segmentation of tables.
The model and has been trained with the Tensorflow training toolkit Tensorpack and then transferred to Pytorch using a conversion script.
The Tensorflow and Pytorch models differ slightly (padding ...), however validating both models give a difference of less than 0.03 mAP.
A second model has been added where the Tensorpack model has been used as initial checkpoint and training has been resumed for 50K iterations.
Performance of this model is now superior to the Tensorpack model.
Regarding the dataset, please check: [Xu Zhong et. all. - Image-based table recognition: data, model, and evaluation](https://arxiv.org/abs/1911.10683).
The model has been trained on detecting cells from tables. Note, that the datasets contains tables only. Therefore, it is required to perform a table detection task before
detecting cells.
The code has been adapted so that it can be used in a **deep**doctection pipeline.
## How this model can be used
This model can be used with the **deep**doctection in a full pipeline, along with table recognition and OCR. Check the general instruction following this [Get_started](https://github.com/deepdoctection/deepdoctection/blob/master/notebooks/Get_Started.ipynb) tutorial.
## This is an inference model only
To reduce the size of the checkpoint we removed all variables that are not necessary for inference. Therefore it cannot be used for fine-tuning. To fine tune this model please use Tensorflow, as well as its training script. More information can be found in this [this model card](https://huggingface.co/deepdoctection/tp_casc_rcnn_X_32xd4_50_FPN_GN_2FC_pubtabnet_c).
|
CAMeL-Lab/bert-base-arabic-camelbert-da-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 42 | null | ---
tags:
- Pytorch
license: apache-2.0
datasets:
- Pubtabnet
---
# Detectron2 Cascade-RCNN with FPN and Group Normalization on ResNext32xd4-50 trained on Pubtabnet for Semantic Segmentation of tables.
The model and has been trained with the Tensorflow training toolkit Tensorpack and then transferred to Pytorch using a conversion script.
The Tensorflow and Pytorch models differ slightly (padding ...), however validating both models give a difference of less than 0.03 mAP.
A second model has been added where the Tensorpack model has been used as initial checkpoint and training has been resumed for 20K iterations. Performance of this model is now superior to the Tensorpack model.
Regarding the dataset, please check: [Xu Zhong et. all. - Image-based table recognition: data, model, and evaluation](https://arxiv.org/abs/1911.10683).
The model has been trained on detecting rows and columns for tables. As rows and column bounding boxes are not a priori an element of the annotations they are
calculated using the bounding boxes of the cells and the intrinsic structure of the enclosed HTML.
The code has been adapted so that it can be used in a **deep**doctection pipeline.
## How this model can be used
This model can be used with the **deep**doctection in a full pipeline, along with table recognition and OCR. Check the general instruction following this [Get_started](https://github.com/deepdoctection/deepdoctection/blob/master/notebooks/Get_Started.ipynb) tutorial.
## This is an inference model only
To reduce the size of the checkpoint we removed all variables that are not necessary for inference. Therefore it cannot be used for fine-tuning. To fine tune this model please use Tensorflow, as well as its training script. More information can be found in this [this model card](https://huggingface.co/deepdoctection/tp_casc_rcnn_X_32xd4_50_FPN_GN_2FC_pubtabnet_rc). |
CAMeL-Lab/bert-base-arabic-camelbert-mix-ner | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,860 | null | ---
license: apache-2.0
tags:
datasets:
- kinetics-700-2020
---
# Perceiver IO for multimodal autoencoding
Perceiver IO model trained on [Kinetics-700-2020](https://arxiv.org/abs/2010.10864) for auto-encoding videos that consist of images, audio and a class label. It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
The goal of multimodal autoencoding is to learn a model that can accurately reconstruct multimodal inputs in the presence of a bottleneck induced by an architecture.
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For multimodal autoencoding, the output contains the reconstructions of the 3 modalities: images, audio and the class label.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model by padding the inputs (images, audio, class label) with modality-specific embeddings and serialize all of them into a 2D input array (i.e. concatenate along the time dimension). Decoding the final hidden states of the latents is done by using queries containing Fourier-based position embeddings (for video and audio) and modality embeddings.
## Intended uses & limitations
You can use the raw model for multimodal autoencoding. Note that by masking the class label during evaluation, the auto-encoding model becomes a video classifier.
See the [model hub](https://huggingface.co/models search=deepmind/perceiver) to look for other versions on a task that may interest you.
### How to use
We refer to the [tutorial notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Perceiver/Perceiver_for_Multimodal_Autoencoding.ipynb) regarding using the Perceiver for multimodal autoencoding.
## Training data
This model was trained on [Kinetics-700-200](https://arxiv.org/abs/2010.10864), a dataset consisting of videos that belong to one of 700 classes.
## Training procedure
### Preprocessing
The authors train on 16 frames at 224x224 resolution, preprocessed into 50k 4x4 patches as well as 30k raw audio samples, patched into a total of 1920 16-dimensional vectors and one 700-dimensional one-hot representation of the class label.
### Pretraining
Hyperparameter details can be found in Appendix F of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
For evaluation results, we refer to table 5 of the [paper](https://arxiv.org/abs/2107.14795).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
CAMeL-Lab/bert-base-arabic-camelbert-mix-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | null | ---
license: apache-2.0
tags:
datasets:
- autoflow
---
# Perceiver IO for optical flow
Perceiver IO model trained on [AutoFlow](https://autoflow-google.github.io/). It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Optical flow is a decades-old open problem in computer vision. Given two images of the same scene (e.g. two consecutive frames of a video), the task is to estimate the 2D displacement for each pixel in the first image. This has many broader applications, such as navigation and visual odometry in robots, estimation of 3D geometry, and even to aid transfer of more complex, learned inference such as 3D human pose estimation from synthetic to real images.
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For optical flow, the output is a tensor containing the predicted flow of shape (batch_size, height, width, 2).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model on raw pixel values, by concatenating a pair of images and extracting a 3x3 patch around each pixel.
The model obtains state-of-the-art results on important optical flow benchmarks, including [Sintel](http://sintel.is.tue.mpg.de/) and [KITTI](http://www.cvlibs.net/datasets/kitti/eval_scene_flow.php?benchmark=flow).
## Intended uses & limitations
You can use the raw model for predicting optical flow between a pair of images. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for other versions on a task that may interest you.
### How to use
We refer to the [tutorial notebook](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/Perceiver/Perceiver_for_Optical_Flow.ipynb) regarding using the Perceiver for optical flow.
## Training data
This model was trained on [AutoFlow](https://autoflow-google.github.io/), a synthetic dataset consisting of 400,000 annotated image pairs.
## Training procedure
### Preprocessing
Frames are resized to a resolution of 368x496. The authors concatenate the frames along the channel dimension and extract a 3x3 patch around each pixel (leading to 3x3x3x2 = 54 values for each pixel).
### Pretraining
Hyperparameter details can be found in Appendix E of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
The model achieves a average end-point error (EPE) of 1.81 on Sintel.clean, 2.42 on Sintel.final and 4.98 on KITTI. For evaluation results, we refer to table 4 of the [paper](https://arxiv.org/abs/2107.14795).
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
CAMeL-Lab/bert-base-arabic-camelbert-mix-pos-egy | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 62 | null | ---
license: apache-2.0
tags:
datasets:
- imagenet
---
# Perceiver IO for vision (convolutional processing)
Perceiver IO model pre-trained on ImageNet (14 million images, 1,000 classes) at resolution 224x224. It was introduced in the paper [Perceiver IO: A General Architecture for Structured Inputs & Outputs](https://arxiv.org/abs/2107.14795) by Jaegle et al. and first released in [this repository](https://github.com/deepmind/deepmind-research/tree/master/perceiver).
Disclaimer: The team releasing Perceiver IO did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
Perceiver IO is a transformer encoder model that can be applied on any modality (text, images, audio, video, ...). The core idea is to employ the self-attention mechanism on a not-too-large set of latent vectors (e.g. 256 or 512), and only use the inputs to perform cross-attention with the latents. This allows for the time and memory requirements of the self-attention mechanism to not depend on the size of the inputs.
To decode, the authors employ so-called decoder queries, which allow to flexibly decode the final hidden states of the latents to produce outputs of arbitrary size and semantics. For image classification, the output is a tensor containing the logits, of shape (batch_size, num_labels).
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/perceiver_architecture.jpg" alt="drawing" width="600"/>
<small> Perceiver IO architecture.</small>
As the time and memory requirements of the self-attention mechanism don't depend on the size of the inputs, the Perceiver IO authors can train the model directly on raw pixel values, rather than on patches as is done in ViT. This particular model employs a simple 2D conv+maxpool preprocessing network on the pixel values, before using the inputs for cross-attention with the latents.
By pre-training the model, it learns an inner representation of images that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled images for instance, you can train a standard classifier by replacing the classification decoder.
## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=deepmind/perceiver) to look for other fine-tuned versions on a task that may interest you.
### How to use
Here is how to use this model in PyTorch:
```python
from transformers import PerceiverFeatureExtractor, PerceiverForImageClassificationConvProcessing
import requests
from PIL import Image
feature_extractor = PerceiverFeatureExtractor.from_pretrained("deepmind/vision-perceiver-conv")
model = PerceiverForImageClassificationConvProcessing.from_pretrained("deepmind/vision-perceiver-conv")
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
# prepare input
inputs = feature_extractor(image, return_tensors="pt").pixel_values
# forward pass
outputs = model(inputs)
logits = outputs.logits
print("Predicted class:", model.config.id2label[logits.argmax(-1).item()])
>>> should print Predicted class: tabby, tabby cat
```
## Training data
This model was pretrained on [ImageNet](http://www.image-net.org/), a dataset consisting of 14 million images and 1k classes.
## Training procedure
### Preprocessing
Images are center cropped and resized to a resolution of 224x224 and normalized across the RGB channels. Note that data augmentation was used during pre-training, as explained in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
### Pretraining
Hyperparameter details can be found in Appendix H of the [paper](https://arxiv.org/abs/2107.14795).
## Evaluation results
This model is able to achieve a top-1 accuracy of 82.1 on ImageNet-1k.
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2107-14795,
author = {Andrew Jaegle and
Sebastian Borgeaud and
Jean{-}Baptiste Alayrac and
Carl Doersch and
Catalin Ionescu and
David Ding and
Skanda Koppula and
Daniel Zoran and
Andrew Brock and
Evan Shelhamer and
Olivier J. H{\'{e}}naff and
Matthew M. Botvinick and
Andrew Zisserman and
Oriol Vinyals and
Jo{\~{a}}o Carreira},
title = {Perceiver {IO:} {A} General Architecture for Structured Inputs {\&}
Outputs},
journal = {CoRR},
volume = {abs/2107.14795},
year = {2021},
url = {https://arxiv.org/abs/2107.14795},
eprinttype = {arXiv},
eprint = {2107.14795},
timestamp = {Tue, 03 Aug 2021 14:53:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2107-14795.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
CAMeL-Lab/bert-base-arabic-camelbert-msa-did-nadi | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 71 | null | ---
language: en
license: cc-by-4.0
datasets:
- squad_v2
model-index:
- name: deepset/bert-base-cased-squad2
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 71.1517
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZGZlNmQ1YzIzMWUzNTg4YmI4NWVhYThiMzE2ZGZmNWUzNDM3NWI0ZGJkNzliNGUxNTY2MDA5MWVkYjAwYWZiMCIsInZlcnNpb24iOjF9.iUvVdy5c4hoXkwlThJankQqG9QXzNilvfF1_4P0oL8X-jkY5Q6YSsZx6G6cpgXogqFpn7JlE_lP6_OT0VIamCg
- type: f1
value: 74.6714
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMWE5OGNjODhmY2Y0NWIyZDIzMmQ2NmRjZGYyYTYzOWMxZDUzYzg4YjBhNTRiNTY4NTc0M2IxNjI5NWI5ZDM0NCIsInZlcnNpb24iOjF9.IqU9rbzUcKmDEoLkwCUZTKSH0ZFhtqgnhOaEDKKnaRMGBJLj98D5V4VirYT6jLh8FlR0FiwvMTMjReBcfTisAQ
---
This is a BERT base cased model trained on SQuAD v2 |
CAMeL-Lab/bert-base-arabic-camelbert-msa-eighth | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 21 | null | ---
license: cc-by-4.0
---
This is a German BERT v1 (https://deepset.ai/german-bert) trained to do hate speech detection on the GermEval18Coarse dataset |
CAMeL-Lab/bert-base-arabic-camelbert-msa-half | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 16 | null | ---
language: de
license: mit
thumbnail: https://static.tildacdn.com/tild6438-3730-4164-b266-613634323466/german_bert.png
tags:
- exbert
---
<a href="https://huggingface.co/exbert/?model=bert-base-german-cased">
\t<img width="300px" src="https://cdn-media.huggingface.co/exbert/button.png">
</a>
# German BERT with old vocabulary
For details see the related [FARM issue](https://github.com/deepset-ai/FARM/issues/60).
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CAMeL-Lab/bert-base-arabic-camelbert-msa-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | null | ---
language: en
license: cc-by-4.0
datasets:
- squad_v2
model-index:
- name: deepset/bert-base-uncased-squad2
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 75.6529
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNTY2YmQ0ZDFjMjRlZWRiZWQ2YWQ4MTM0ODkyYTQ0NmYwMzBlNWViZWQ0ODFhMGJmMmY4ZGYwOTQyMDAyZGNjYyIsInZlcnNpb24iOjF9.UyqonQTsCB0BW86LfPy17kLt3a4r3wMeh04MDam5t_UhElp6N02YpiKOqcb1ethNHjAR0WGyxrcV3TI4d-wFAQ
- type: f1
value: 78.6191
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZWRkZWVjMDU2YTcxYWVkZTU1YmUzY2FkNWI5NDJkM2YwMjFmMmE0Njc3MjI5N2Q0NDdhZDNkZWNjMWE5YTRmZiIsInZlcnNpb24iOjF9.ol0Zacd9ZryXazXjgVssGFYG4s5FzbhGGaj1ZEDLVN2ziyzx23bo4GH9PSuGTFxRK2BO5_dxvDupLRqJOF59Bg
---
# bert-base-uncased for QA
## Overview
**Language model:** bert-base-uncased
**Language:** English
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0
**Infrastructure**: 1x Tesla v100
## Hyperparameters
```
batch_size = 32
n_epochs = 3
base_LM_model = "bert-base-uncased"
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
warmup_proportion = 0.2
doc_stride=128
max_query_length=64
```
## Performance
```
"exact": 73.67977764676156
"f1": 77.87647139308865
```
## Authors
- Timo Möller: `timo.moeller [at] deepset.ai`
- Julian Risch: `julian.risch [at] deepset.ai`
- Malte Pietsch: `malte.pietsch [at] deepset.ai`
- Michel Bartels: `michel.bartels [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs) |
CAMeL-Lab/bert-base-arabic-camelbert-msa-pos-egy | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 52 | null | ---
language: en
license: cc-by-4.0
datasets:
- squad_v2
model-index:
- name: deepset/bert-large-uncased-whole-word-masking-squad2
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 80.8846
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiY2E5ZGNkY2ExZWViZGEwNWE3OGRmMWM2ZmE4ZDU4ZDQ1OGM3ZWE0NTVmZjFmYmZjZmJmNjJmYTc3NTM3OTk3OSIsInZlcnNpb24iOjF9.aSblF4ywh1fnHHrN6UGL392R5KLaH3FCKQlpiXo_EdQ4XXEAENUCjYm9HWDiFsgfSENL35GkbSyz_GAhnefsAQ
- type: f1
value: 83.8765
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiNGFlNmEzMTk2NjRkNTI3ZTk3ZTU1NWNlYzIyN2E0ZDFlNDA2ZjYwZWJlNThkMmRmMmE0YzcwYjIyZDM5NmRiMCIsInZlcnNpb24iOjF9.-rc2_Bsp_B26-o12MFYuAU0Ad2Hg9PDx7Preuk27WlhYJDeKeEr32CW8LLANQABR3Mhw2x8uTYkEUrSDMxxLBw
---
# bert-large-uncased-whole-word-masking-squad2
This is a berta-large model, fine-tuned using the SQuAD2.0 dataset for the task of question answering.
## Overview
**Language model:** bert-large
**Language:** English
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0
**Code:** See [an example QA pipeline on Haystack](https://haystack.deepset.ai/tutorials/first-qa-system)
## Usage
### In Haystack
Haystack is an NLP framework by deepset. You can use this model in a Haystack pipeline to do question answering at scale (over many documents). To load the model in [Haystack](https://github.com/deepset-ai/haystack/):
```python
reader = FARMReader(model_name_or_path="deepset/bert-large-uncased-whole-word-masking-squad2")
# or
reader = TransformersReader(model_name_or_path="FILL",tokenizer="deepset/bert-large-uncased-whole-word-masking-squad2")
```
### In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/bert-large-uncased-whole-word-masking-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## About us
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3">
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/deepset-logo-colored.png" class="w-40"/>
</div>
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/haystack-logo-colored.png" class="w-40"/>
</div>
</div>
[deepset](http://deepset.ai/) is the company behind the open-source NLP framework [Haystack](https://haystack.deepset.ai/) which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc.
Some of our other work:
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")]([https://huggingface.co/deepset/tinyroberta-squad2)
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
## Get in touch and join the Haystack community
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://docs.haystack.deepset.ai">Documentation</a></strong>.
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community">Discord community open to everyone!</a></strong></p>
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs) |
CAMeL-Lab/bert-base-arabic-camelbert-msa-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 21 | null | ---
language: en
license: mit
tags:
- exbert
datasets:
- squad_v2
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg
model-index:
- name: deepset/bert-medium-squad2-distilled
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 69.8231
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMmE4MGRkZTVjNmViMGNjYjVhY2E1NzcyOGQ1OWE1MWMzMjY5NWU0MmU0Y2I4OWU4YTU5OWQ5YTI2NWE1NmM0ZSIsInZlcnNpb24iOjF9.tnCJvWzMctTwiQu5yig_owO2ZI1t1MZz1AN2lQy4COAGOzuMovD-74acQvMbxJQoRfNNkIetz2hqYivf1lJKDw
- type: f1
value: 72.9232
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiZTMwNzk0ZDRjNGUyMjQyNzc1NzczZmUwMTU2MTM5MGQ3M2NhODlmOTU4ZDI0YjhlNTVjNDA1MGEwM2M1MzIyZSIsInZlcnNpb24iOjF9.eElGmTOXH_qHTNaPwZ-dUJfVz9VMvCutDCof_6UG_625MwctT_j7iVkWcGwed4tUnunuq1BPm-0iRh1RuuB-AQ
---
## Overview
**Language model:** deepset/roberta-base-squad2-distilled
**Language:** English
**Training data:** SQuAD 2.0 training set
**Eval data:** SQuAD 2.0 dev set
**Infrastructure**: 1x V100 GPU
**Published**: Apr 21st, 2021
## Details
- haystack's distillation feature was used for training. deepset/bert-large-uncased-whole-word-masking-squad2 was used as the teacher model.
## Hyperparameters
```
batch_size = 6
n_epochs = 2
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
temperature = 5
distillation_loss_weight = 1
```
## Performance
```
"exact": 68.6431398972458
"f1": 72.7637083790805
```
## Authors
- Timo Möller: `timo.moeller [at] deepset.ai`
- Julian Risch: `julian.risch [at] deepset.ai`
- Malte Pietsch: `malte.pietsch [at] deepset.ai`
- Michel Bartels: `michel.bartels [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs) |
CAMeL-Lab/bert-base-arabic-camelbert-msa | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2,967 | null | ---
language: en
license: cc-by-4.0
datasets:
- squad_v2
model-index:
- name: deepset/electra-base-squad2
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 77.6074
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiYzE5NTRmMmUwYTk1MTI0NjM0ZmQwNDFmM2Y4Mjk4ZWYxOGVmOWI3ZGFiNWM4OTUxZDQ2ZjdmNmU3OTk5ZjRjYyIsInZlcnNpb24iOjF9.0VZRewdiovE4z3K5box5R0oTT7etpmd0BX44FJBLRFfot-uJ915b-bceSv3luJQ7ENPjaYSa7o7jcHlDzn3oAw
- type: f1
value: 81.7181
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiY2VlMzM0Y2UzYjhhNTJhMTFiYWZmMDNjNjRiZDgwYzc5NWE3N2M4ZGFlYWQ0ZjVkZTE2MDU0YmMzMDc1MTY5MCIsInZlcnNpb24iOjF9.jRV58UxOM7CJJSsmxJuZvlt00jMGA1thp4aqtcFi1C8qViQ1kW7NYz8rg1gNTDZNez2UwPS1NgN_HnnwBHPbCQ
---
# electra-base for QA
## Overview
**Language model:** electra-base
**Language:** English
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0
**Code:** See [example](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py) in [FARM](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py)
**Infrastructure**: 1x Tesla v100
## Hyperparameters
```
seed=42
batch_size = 32
n_epochs = 5
base_LM_model = "google/electra-base-discriminator"
max_seq_len = 384
learning_rate = 1e-4
lr_schedule = LinearWarmup
warmup_proportion = 0.1
doc_stride=128
max_query_length=64
```
## Performance
Evaluated on the SQuAD 2.0 dev set with the [official eval script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/).
```
"exact": 77.30144024256717,
"f1": 81.35438272008543,
"total": 11873,
"HasAns_exact": 74.34210526315789,
"HasAns_f1": 82.45961302894314,
"HasAns_total": 5928,
"NoAns_exact": 80.25231286795626,
"NoAns_f1": 80.25231286795626,
"NoAns_total": 5945
```
## Usage
### In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/electra-base-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and lets people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
### In FARM
```python
from farm.modeling.adaptive_model import AdaptiveModel
from farm.modeling.tokenization import Tokenizer
from farm.infer import Inferencer
model_name = "deepset/electra-base-squad2"
# a) Get predictions
nlp = Inferencer.load(model_name, task_type="question_answering")
QA_input = [{"questions": ["Why is model conversion important?"],
"text": "The option to convert models between FARM and transformers gives freedom to the user and lets people easily switch between frameworks."}]
res = nlp.inference_from_dicts(dicts=QA_input)
# b) Load model & tokenizer
model = AdaptiveModel.convert_from_transformers(model_name, device="cpu", task_type="question_answering")
tokenizer = Tokenizer.load(model_name)
```
### In haystack
For doing QA at scale (i.e. many docs instead of a single paragraph), you can load the model also in [haystack](https://github.com/deepset-ai/haystack/):
```python
reader = FARMReader(model_name_or_path="deepset/electra-base-squad2")
# or
reader = TransformersReader(model="deepset/electra-base-squad2",tokenizer="deepset/electra-base-squad2")
```
## Authors
Vaishali Pal `vaishali.pal [at] deepset.ai`
Branden Chan: `branden.chan [at] deepset.ai`
Timo Möller: `timo.moeller [at] deepset.ai`
Malte Pietsch: `malte.pietsch [at] deepset.ai`
Tanay Soni: `tanay.soni [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CAUKiel/JavaBERT-uncased | [
"pytorch",
"safetensors",
"bert",
"fill-mask",
"java",
"code",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language: de
datasets:
- deepset/germandpr
license: mit
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg
tags:
- exbert
---

## Overview
**Language model:** gbert-base-germandpr
**Language:** German
**Training data:** GermanDPR train set (~ 56MB)
**Eval data:** GermanDPR test set (~ 6MB)
**Infrastructure**: 4x V100 GPU
**Published**: Apr 26th, 2021
## Details
- We trained a dense passage retrieval model with two gbert-base models as encoders of questions and passages.
- The dataset is GermanDPR, a new, German language dataset, which we hand-annotated and published [online](https://deepset.ai/germanquad).
- It comprises 9275 question/answer pairs in the training set and 1025 pairs in the test set.
For each pair, there are one positive context and three hard negative contexts.
- As the basis of the training data, we used our hand-annotated GermanQuAD dataset as positive samples and generated hard negative samples from the latest German Wikipedia dump (6GB of raw txt files).
- The data dump was cleaned with tailored scripts, leading to 2.8 million indexed passages from German Wikipedia.
See https://deepset.ai/germanquad for more details and dataset download.
## Hyperparameters
```
batch_size = 40
n_epochs = 20
num_training_steps = 4640
num_warmup_steps = 460
max_seq_len = 32 tokens for question encoder and 300 tokens for passage encoder
learning_rate = 1e-6
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
num_hard_negatives = 2
```
## Performance
During training, we monitored the in-batch average rank and the loss and evaluated different batch sizes, numbers of epochs, and number of hard negatives on a dev set split from the train set.
The dev split contained 1030 question/answer pairs.
Even without thorough hyperparameter tuning, we observed quite stable learning. Multiple restarts with different seeds produced quite similar results.
Note that the in-batch average rank is influenced by settings for batch size and number of hard negatives. A smaller number of hard negatives makes the task easier.
After fixing the hyperparameters we trained the model on the full GermanDPR train set.
We further evaluated the retrieval performance of the trained model on the full German Wikipedia with the GermanDPR test set as labels. To this end, we converted the GermanDPR test set to SQuAD format. The DPR model drastically outperforms the BM25 baseline with regard to recall@k.

## Usage
### In haystack
You can load the model in [haystack](https://github.com/deepset-ai/haystack/) as a retriever for doing QA at scale:
```python
retriever = DensePassageRetriever(
document_store=document_store,
query_embedding_model="deepset/gbert-base-germandpr-question_encoder"
passage_embedding_model="deepset/gbert-base-germandpr-ctx_encoder"
)
```
## Authors
- Timo Möller: `timo.moeller [at] deepset.ai`
- Julian Risch: `julian.risch [at] deepset.ai`
- Malte Pietsch: `malte.pietsch [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CBreit00/DialoGPT_small_Rick | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: de
datasets:
- deepset/germandpr
license: mit
---
## Overview
**Language model:** gbert-base-germandpr-reranking
**Language:** German
**Training data:** GermanDPR train set (~ 56MB)
**Eval data:** GermanDPR test set (~ 6MB)
**Infrastructure**: 1x V100 GPU
**Published**: June 3rd, 2021
## Details
- We trained a text pair classification model in FARM, which can be used for reranking in document retrieval tasks. To this end, the classifier calculates the similarity of the query and each retrieved top k document (e.g., k=10). The top k documents are then sorted by their similarity scores. The document most similar to the query is the best.
## Hyperparameters
```
batch_size = 16
n_epochs = 2
max_seq_len = 512 tokens for question and passage concatenated
learning_rate = 2e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
```
## Performance
We use the GermanDPR test dataset as ground truth labels and run two experiments to compare how a BM25 retriever performs with or without reranking with our model. The first experiment runs retrieval on the full German Wikipedia (more than 2 million passages) and second experiment runs retrieval on the GermanDPR dataset only (not more than 5000 passages). Both experiments use 1025 queries. Note that the second experiment is evaluating on a much simpler task because of the smaller dataset size, which explains strong BM25 retrieval performance.
### Full German Wikipedia (more than 2 million passages):
BM25 Retriever without Reranking
- recall@3: 0.4088 (419 / 1025)
- mean_reciprocal_rank@3: 0.3322
BM25 Retriever with Reranking Top 10 Documents
- recall@3: 0.5200 (533 / 1025)
- mean_reciprocal_rank@3: 0.4800
### GermanDPR Test Dataset only (not more than 5000 passages):
BM25 Retriever without Reranking
- recall@3: 0.9102 (933 / 1025)
- mean_reciprocal_rank@3: 0.8528
BM25 Retriever with Reranking Top 10 Documents
- recall@3: 0.9298 (953 / 1025)
- mean_reciprocal_rank@3: 0.8813
## Usage
### In haystack
You can load the model in [haystack](https://github.com/deepset-ai/haystack/) for reranking the documents returned by a Retriever:
```python
...
retriever = ElasticsearchRetriever(document_store=document_store)
ranker = FARMRanker(model_name_or_path="deepset/gbert-base-germandpr-reranking")
...
p = Pipeline()
p.add_node(component=retriever, name="ESRetriever", inputs=["Query"])
p.add_node(component=ranker, name="Ranker", inputs=["ESRetriever"])
)
```
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CL/safe-math-bot | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: de
license: mit
datasets:
- wikipedia
- OPUS
- OpenLegalData
---
# German BERT base
Released, Oct 2020, this is a German BERT language model trained collaboratively by the makers of the original German BERT (aka "bert-base-german-cased") and the dbmdz BERT (aka bert-base-german-dbmdz-cased). In our [paper](https://arxiv.org/pdf/2010.10906.pdf), we outline the steps taken to train our model and show that it outperforms its predecessors.
## Overview
**Paper:** [here](https://arxiv.org/pdf/2010.10906.pdf)
**Architecture:** BERT base
**Language:** German
## Performance
```
GermEval18 Coarse: 78.17
GermEval18 Fine: 50.90
GermEval14: 87.98
```
See also:
deepset/gbert-base
deepset/gbert-large
deepset/gelectra-base
deepset/gelectra-large
deepset/gelectra-base-generator
deepset/gelectra-large-generator
## Authors
Branden Chan: `branden.chan [at] deepset.ai`
Stefan Schweter: `stefan [at] schweter.eu`
Timo Möller: `timo.moeller [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CLAck/en-km | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"translation",
"autotrain_compatible"
]
| translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | ---
language: de
license: mit
tags:
- exbert
---
## Overview
**Language model:** gbert-large-sts
**Language:** German
**Training data:** German STS benchmark train and dev set
**Eval data:** German STS benchmark test set
**Infrastructure**: 1x V100 GPU
**Published**: August 12th, 2021
## Details
- We trained a gbert-large model on the task of estimating semantic similarity of German-language text pairs. The dataset is a machine-translated version of the [STS benchmark](https://ixa2.si.ehu.eus/stswiki/index.php/STSbenchmark), which is available [here](https://github.com/t-systems-on-site-services-gmbh/german-STSbenchmark).
## Hyperparameters
```
batch_size = 16
n_epochs = 4
warmup_ratio = 0.1
learning_rate = 2e-5
lr_schedule = LinearWarmup
```
## Performance
Stay tuned... and watch out for new papers on arxiv.org ;)
## Authors
- Julian Risch: `julian.risch [at] deepset.ai`
- Timo Möller: `timo.moeller [at] deepset.ai`
- Julian Gutsch: `julian.gutsch [at] deepset.ai`
- Malte Pietsch: `malte.pietsch [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CLAck/indo-mixed | [
"pytorch",
"marian",
"text2text-generation",
"en",
"id",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 15 | null | ---
language: de
license: mit
datasets:
- wikipedia
- OPUS
- OpenLegalData
---
# German ELECTRA base generator
Released, Oct 2020, this is the generator component of the German ELECTRA language model trained collaboratively by the makers of the original German BERT (aka "bert-base-german-cased") and the dbmdz BERT (aka bert-base-german-dbmdz-cased). In our [paper](https://arxiv.org/pdf/2010.10906.pdf), we outline the steps taken to train our model.
The generator is useful for performing masking experiments. If you are looking for a regular language model for embedding extraction, or downstream tasks like NER, classification or QA, please use deepset/gelectra-base.
## Overview
**Paper:** [here](https://arxiv.org/pdf/2010.10906.pdf)
**Architecture:** ELECTRA base (generator)
**Language:** German
See also:
deepset/gbert-base
deepset/gbert-large
deepset/gelectra-base
deepset/gelectra-large
deepset/gelectra-base-generator
deepset/gelectra-large-generator
## Authors
Branden Chan: `branden.chan [at] deepset.ai`
Stefan Schweter: `stefan [at] schweter.eu`
Timo Möller: `timo.moeller [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CLAck/indo-pure | [
"pytorch",
"marian",
"text2text-generation",
"en",
"id",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
]
| translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
language: de
datasets:
- deepset/germanquad
license: mit
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg
tags:
- exbert
---

## Overview
**Language model:** gelectra-base-germanquad-distilled
**Language:** German
**Training data:** GermanQuAD train set (~ 12MB)
**Eval data:** GermanQuAD test set (~ 5MB)
**Infrastructure**: 1x V100 GPU
**Published**: Apr 21st, 2021
## Details
- We trained a German question answering model with a gelectra-base model as its basis.
- The dataset is GermanQuAD, a new, German language dataset, which we hand-annotated and published [online](https://deepset.ai/germanquad).
- The training dataset is one-way annotated and contains 11518 questions and 11518 answers, while the test dataset is three-way annotated so that there are 2204 questions and with 2204·3−76 = 6536answers, because we removed 76 wrong answers.
- In addition to the annotations in GermanQuAD, haystack's distillation feature was used for training. deepset/gelectra-large-germanquad was used as the teacher model.
See https://deepset.ai/germanquad for more details and dataset download in SQuAD format.
## Hyperparameters
```
batch_size = 24
n_epochs = 6
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
temperature = 2
distillation_loss_weight = 0.75
```
## Performance
We evaluated the extractive question answering performance on our GermanQuAD test set.
Model types and training data are included in the model name.
For finetuning XLM-Roberta, we use the English SQuAD v2.0 dataset.
The GELECTRA models are warm started on the German translation of SQuAD v1.1 and finetuned on \\\\germanquad.
The human baseline was computed for the 3-way test set by taking one answer as prediction and the other two as ground truth.
```
"exact": 62.4773139745916
"f1": 80.9488017070188
```

## Authors
- Timo Möller: `timo.moeller [at] deepset.ai`
- Julian Risch: `julian.risch [at] deepset.ai`
- Malte Pietsch: `malte.pietsch [at] deepset.ai`
- Michel Bartels: `michel.bartels [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs) |
CLS/WubiBERT_models | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: de
license: mit
datasets:
- wikipedia
- OPUS
- OpenLegalData
- oscar
---
# German ELECTRA large generator
Released, Oct 2020, this is the generator component of the German ELECTRA language model trained collaboratively by the makers of the original German BERT (aka "bert-base-german-cased") and the dbmdz BERT (aka bert-base-german-dbmdz-cased). In our [paper](https://arxiv.org/pdf/2010.10906.pdf), we outline the steps taken to train our model.
The generator is useful for performing masking experiments. If you are looking for a regular language model for embedding extraction, or downstream tasks like NER, classification or QA, please use deepset/gelectra-large.
## Overview
**Paper:** [here](https://arxiv.org/pdf/2010.10906.pdf)
**Architecture:** ELECTRA large (generator)
**Language:** German
## Performance
```
GermEval18 Coarse: 80.70
GermEval18 Fine: 55.16
GermEval14: 88.95
```
See also:
deepset/gbert-base
deepset/gbert-large
deepset/gelectra-base
deepset/gelectra-large
deepset/gelectra-base-generator
deepset/gelectra-large-generator
## Authors
Branden Chan: `branden.chan [at] deepset.ai`
Stefan Schweter: `stefan [at] schweter.eu`
Timo Möller: `timo.moeller [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Slack](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CLTL/MedRoBERTa.nl | [
"pytorch",
"roberta",
"fill-mask",
"nl",
"transformers",
"license:mit",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2,988 | null | ---
language: de
datasets:
- deepset/germanquad
license: mit
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg
tags:
- exbert
---

## Overview
**Language model:** gelectra-large-germanquad
**Language:** German
**Training data:** GermanQuAD train set (~ 12MB)
**Eval data:** GermanQuAD test set (~ 5MB)
**Infrastructure**: 1x V100 GPU
**Published**: Apr 21st, 2021
## Details
- We trained a German question answering model with a gelectra-large model as its basis.
- The dataset is GermanQuAD, a new, German language dataset, which we hand-annotated and published [online](https://deepset.ai/germanquad).
- The training dataset is one-way annotated and contains 11518 questions and 11518 answers, while the test dataset is three-way annotated so that there are 2204 questions and with 2204·3−76 = 6536 answers, because we removed 76 wrong answers.
See https://deepset.ai/germanquad for more details and dataset download in SQuAD format.
## Hyperparameters
```
batch_size = 24
n_epochs = 2
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
```
## Performance
We evaluated the extractive question answering performance on our GermanQuAD test set.
Model types and training data are included in the model name.
For finetuning XLM-Roberta, we use the English SQuAD v2.0 dataset.
The GELECTRA models are warm started on the German translation of SQuAD v1.1 and finetuned on [GermanQuAD](https://deepset.ai/germanquad).
The human baseline was computed for the 3-way test set by taking one answer as prediction and the other two as ground truth.
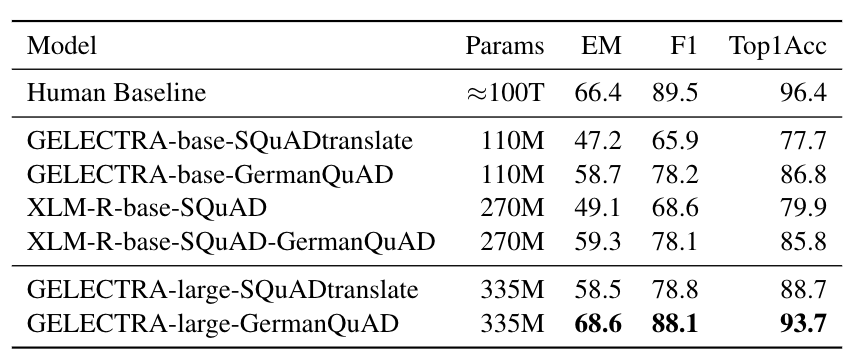
## Authors
**Timo Möller:** [email protected]
**Julian Risch:** [email protected]
**Malte Pietsch:** [email protected]
## About us
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3">
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://huggingface.co/spaces/deepset/README/resolve/main/haystack-logo-colored.svg" class="w-40"/>
</div>
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://huggingface.co/spaces/deepset/README/resolve/main/deepset-logo-colored.svg" class="w-40"/>
</div>
</div>
[deepset](http://deepset.ai/) is the company behind the open-source NLP framework [Haystack](https://haystack.deepset.ai/) which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc.
Some of our other work:
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")]([https://huggingface.co/deepset/tinyroberta-squad2)
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
## Get in touch and join the Haystack community
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://haystack.deepset.ai">Documentation</a></strong>.
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community/join">Discord community open to everyone!</a></strong></p>
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CLTL/gm-ner-xlmrbase | [
"pytorch",
"tf",
"xlm-roberta",
"token-classification",
"nl",
"transformers",
"dighum",
"license:apache-2.0",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"XLMRobertaForTokenClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language: de
license: mit
datasets:
- wikipedia
- OPUS
- OpenLegalData
- oscar
---
# German ELECTRA large
Released, Oct 2020, this is a German ELECTRA language model trained collaboratively by the makers of the original German BERT (aka "bert-base-german-cased") and the dbmdz BERT (aka bert-base-german-dbmdz-cased). In our [paper](https://arxiv.org/pdf/2010.10906.pdf), we outline the steps taken to train our model and show that this is the state of the art German language model.
## Overview
**Paper:** [here](https://arxiv.org/pdf/2010.10906.pdf)
**Architecture:** ELECTRA large (discriminator)
**Language:** German
## Performance
```
GermEval18 Coarse: 80.70
GermEval18 Fine: 55.16
GermEval14: 88.95
```
See also:
deepset/gbert-base
deepset/gbert-large
deepset/gelectra-base
deepset/gelectra-large
deepset/gelectra-base-generator
deepset/gelectra-large-generator
## Authors
Branden Chan: `branden.chan [at] deepset.ai`
Stefan Schweter: `stefan [at] schweter.eu`
Timo Möller: `timo.moeller [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
CSResearcher/TestModel | [
"license:mit"
]
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: multilingual
datasets:
- squad_v2
license: mit
thumbnail: https://thumb.tildacdn.com/tild3433-3637-4830-a533-353833613061/-/resize/720x/-/format/webp/germanquad.jpg
tags:
- exbert
---
# deepset/xlm-roberta-base-squad2-distilled
- haystack's distillation feature was used for training. deepset/xlm-roberta-large-squad2 was used as the teacher model.
## Overview
**Language model:** deepset/xlm-roberta-base-squad2-distilled
**Language:** Multilingual
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0
**Code:** See [an example QA pipeline on Haystack](https://haystack.deepset.ai/tutorials/first-qa-system)
**Infrastructure**: 1x Tesla v100
## Hyperparameters
```
batch_size = 56
n_epochs = 4
max_seq_len = 384
learning_rate = 3e-5
lr_schedule = LinearWarmup
embeds_dropout_prob = 0.1
temperature = 3
distillation_loss_weight = 0.75
```
## Usage
### In Haystack
Haystack is an NLP framework by deepset. You can use this model in a Haystack pipeline to do question answering at scale (over many documents). To load the model in [Haystack](https://github.com/deepset-ai/haystack/):
```python
reader = FARMReader(model_name_or_path="deepset/xlm-roberta-base-squad2-distilled")
# or
reader = TransformersReader(model_name_or_path="deepset/xlm-roberta-base-squad2-distilled",tokenizer="deepset/xlm-roberta-base-squad2-distilled")
```
For a complete example of ``deepset/xlm-roberta-base-squad2-distilled`` being used for [question answering], check out the [Tutorials in Haystack Documentation](https://haystack.deepset.ai/tutorials/first-qa-system)
### In Transformers
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "deepset/xlm-roberta-base-squad2-distilled"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
## Performance
Evaluated on the SQuAD 2.0 dev set
```
"exact": 74.06721131980123%
"f1": 76.39919553344667%
```
## Authors
**Timo Möller:** [email protected]
**Julian Risch:** [email protected]
**Malte Pietsch:** [email protected]
**Michel Bartels:** [email protected]
## About us
<div class="grid lg:grid-cols-2 gap-x-4 gap-y-3">
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/deepset-logo-colored.png" class="w-40"/>
</div>
<div class="w-full h-40 object-cover mb-2 rounded-lg flex items-center justify-center">
<img alt="" src="https://raw.githubusercontent.com/deepset-ai/.github/main/haystack-logo-colored.png" class="w-40"/>
</div>
</div>
[deepset](http://deepset.ai/) is the company behind the open-source NLP framework [Haystack](https://haystack.deepset.ai/) which is designed to help you build production ready NLP systems that use: Question answering, summarization, ranking etc.
Some of our other work:
- [Distilled roberta-base-squad2 (aka "tinyroberta-squad2")]([https://huggingface.co/deepset/tinyroberta-squad2)
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
## Get in touch and join the Haystack community
<p>For more info on Haystack, visit our <strong><a href="https://github.com/deepset-ai/haystack">GitHub</a></strong> repo and <strong><a href="https://haystack.deepset.ai">Documentation</a></strong>.
We also have a <strong><a class="h-7" href="https://haystack.deepset.ai/community/join">Discord community open to everyone!</a></strong></p>
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs) |
CSZay/bart | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: cc-by-4.0
datasets:
- squad_v2
model-index:
- name: deepset/xlm-roberta-base-squad2
results:
- task:
type: question-answering
name: Question Answering
dataset:
name: squad_v2
type: squad_v2
config: squad_v2
split: validation
metrics:
- type: exact_match
value: 74.0354
name: Exact Match
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMWMxNWQ2ODJkNWIzZGQwOWI4OTZjYjU3ZDVjZGQzMjI5MzljNjliZTY4Mzk4YTk4OTMzZWYxZjUxYmZhYTBhZSIsInZlcnNpb24iOjF9.eEeFYYJ30BfJDd-JYfI1kjlxJrRF6OFtj2GnkTCOO4kqX31inFy8ptDWusVlLFsUphm4dNWfTKXC5e-gytLBDA
- type: f1
value: 77.1833
name: F1
verified: true
verifyToken: eyJhbGciOiJFZERTQSIsInR5cCI6IkpXVCJ9.eyJoYXNoIjoiMjg4MjNkOTA4Y2I5OGFlYTk1NWZjMWFlNjI5M2Y0NGZhMThhN2M4YmY2Y2RhZjcwYzU0MGNjN2RkZDljZmJmNiIsInZlcnNpb24iOjF9.TX42YMXpH4e0qu7cC4ARDlZWSkd55dwwyeyFXmOlXERNnEicDuFBCsy8WHLaqQCLUkzODJ22Hw4zhv81rwnlAQ
---
# Multilingual XLM-RoBERTa base for QA on various languages
## Overview
**Language model:** xlm-roberta-base
**Language:** Multilingual
**Downstream-task:** Extractive QA
**Training data:** SQuAD 2.0
**Eval data:** SQuAD 2.0 dev set - German MLQA - German XQuAD
**Code:** See [example](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py) in [FARM](https://github.com/deepset-ai/FARM/blob/master/examples/question_answering.py)
**Infrastructure**: 4x Tesla v100
## Hyperparameters
```
batch_size = 22*4
n_epochs = 2
max_seq_len=256,
doc_stride=128,
learning_rate=2e-5,
```
Corresponding experiment logs in mlflow: [link](https://public-mlflow.deepset.ai/#/experiments/2/runs/b25ec75e07614accb3f1ce03d43dbe08)
## Performance
Evaluated on the SQuAD 2.0 dev set with the [official eval script](https://worksheets.codalab.org/rest/bundles/0x6b567e1cf2e041ec80d7098f031c5c9e/contents/blob/).
```
"exact": 73.91560683904657
"f1": 77.14103746689592
```
Evaluated on German MLQA: test-context-de-question-de.json
"exact": 33.67279167589108
"f1": 44.34437105434842
"total": 4517
Evaluated on German XQuAD: xquad.de.json
"exact": 48.739495798319325
"f1": 62.552615701071495
"total": 1190
## Usage
### In Transformers
```python
from transformers.pipelines import pipeline
from transformers.modeling_auto import AutoModelForQuestionAnswering
from transformers.tokenization_auto import AutoTokenizer
model_name = "deepset/xlm-roberta-base-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
```
### In FARM
```python
from farm.modeling.adaptive_model import AdaptiveModel
from farm.modeling.tokenization import Tokenizer
from farm.infer import Inferencer
model_name = "deepset/xlm-roberta-base-squad2"
# a) Get predictions
nlp = Inferencer.load(model_name, task_type="question_answering")
QA_input = [{"questions": ["Why is model conversion important?"],
"text": "The option to convert models between FARM and transformers gives freedom to the user and let people easily switch between frameworks."}]
res = nlp.inference_from_dicts(dicts=QA_input, rest_api_schema=True)
# b) Load model & tokenizer
model = AdaptiveModel.convert_from_transformers(model_name, device="cpu", task_type="question_answering")
tokenizer = Tokenizer.load(model_name)
```
### In haystack
For doing QA at scale (i.e. many docs instead of single paragraph), you can load the model also in [haystack](https://github.com/deepset-ai/haystack/):
```python
reader = FARMReader(model_name_or_path="deepset/xlm-roberta-base-squad2")
# or
reader = TransformersReader(model="deepset/roberta-base-squad2",tokenizer="deepset/xlm-roberta-base-squad2")
```
## Authors
Branden Chan: `branden.chan [at] deepset.ai`
Timo Möller: `timo.moeller [at] deepset.ai`
Malte Pietsch: `malte.pietsch [at] deepset.ai`
Tanay Soni: `tanay.soni [at] deepset.ai`
## About us

We bring NLP to the industry via open source!
Our focus: Industry specific language models & large scale QA systems.
Some of our work:
- [German BERT (aka "bert-base-german-cased")](https://deepset.ai/german-bert)
- [GermanQuAD and GermanDPR datasets and models (aka "gelectra-base-germanquad", "gbert-base-germandpr")](https://deepset.ai/germanquad)
- [FARM](https://github.com/deepset-ai/FARM)
- [Haystack](https://github.com/deepset-ai/haystack/)
Get in touch:
[Twitter](https://twitter.com/deepset_ai) | [LinkedIn](https://www.linkedin.com/company/deepset-ai/) | [Discord](https://haystack.deepset.ai/community/join) | [GitHub Discussions](https://github.com/deepset-ai/haystack/discussions) | [Website](https://deepset.ai)
By the way: [we're hiring!](http://www.deepset.ai/jobs)
|
Callidior/bert2bert-base-arxiv-titlegen | [
"pytorch",
"safetensors",
"encoder-decoder",
"text2text-generation",
"en",
"dataset:arxiv_dataset",
"transformers",
"summarization",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
]
| summarization | {
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 145 | null | ```
from transformers import BertForSequenceClassification, BertTokenizer, TextClassificationPipeline
model = BertForSequenceClassification.from_pretrained("deeq/dbert-sentiment")
tokenizer = BertTokenizer.from_pretrained("deeq/dbert")
nlp = TextClassificationPipeline(model=model, tokenizer=tokenizer)
print(nlp("좋아요"))
print(nlp("글쎄요"))
```
|
CallumRai/HansardGPT2 | [
"pytorch",
"jax",
"gpt2",
"text-generation",
"transformers"
]
| text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | null | ---
language: ko
datasets:
- kowiki
- news
---
deeqBERT-base
---
- model: bert-base
- vocab: bert-wordpiece, 35k
- version: latest
|
CalvinHuang/mt5-small-finetuned-amazon-en-es | [
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"transformers",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible"
]
| summarization | {
"architectures": [
"MT5ForConditionalGeneration"
],
"model_type": "mt5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 16 | null | deeqBERT5
---
- model: bert-base
- vocab: deeqnlp 1.5, 50k
- version: latest/3.5
|
Cameron/BERT-SBIC-targetcategory | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | ---
tags:
- generated_from_trainer
datasets:
- null
model_index:
- name: distilgpt2-finetuned-amazon-reviews
results:
- task:
name: Causal Language Modeling
type: text-generation
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-amazon-reviews
This model was trained from scratch on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Datasets 1.9.0
- Tokenizers 0.10.3
|
Cameron/BERT-jigsaw-identityhate | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 37 | null | ---
license: mit
widget:
- text: "generate question: Der Monk Sour Drink ist ein somit eine aromatische Überraschung, die sowohl <hl>im Sommer wie auch zu Silvester<hl> funktioniert."
language:
- de
tags:
- question generation
datasets:
- deepset/germanquad
model-index:
- name: german-qg-t5-drink600
results: []
---
# german-qg-t5-drink600
This model is fine-tuned in question generation in German. The expected answer must be highlighted with <hl> token. It is based on [german-qg-t5-quad](https://huggingface.co/dehio/german-qg-t5-quad) and further pre-trained on drink related questions.
## Task example
#### Input
generate question: Der Monk Sour Drink ist ein somit eine aromatische Überraschung,
die sowohl <hl>im Sommer wie auch zu Silvester<hl> funktioniert.
#### Expected Question
Zu welchen Gelegenheiten passt der Monk Sour gut?
## Model description
The model is based on [german-qg-t5-quad](https://huggingface.co/dehio/german-qg-t5-quad), which was pre-trained on [GermanQUAD](https://www.deepset.ai/germanquad). We further pre-trained it on questions annotated on drink receipts from [Mixology](https://mixology.eu/) ("drink600").
We have not yet open sourced the dataset, since we do not own copyright on the source material.
## Training and evaluation data
The training script can be accessed [here](https://github.com/d-e-h-i-o/german-qg).
## Evaluation
It achieves a **BLEU-4 score of 29.80** on the drink600 test set (n=120) and **11.30** on the GermanQUAD test set.
Thus, fine-tuning on drink600 did not affect performance on GermanQuAD.
In comparison, *german-qg-t5-quad* achieves a BLEU-4 score of **10.76** on the drink600 test set.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 2
- eval_batch_size: 2
- seed: 100
- gradient_accumulation_steps: 8
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Framework versions
- Transformers 4.13.0.dev0
- Pytorch 1.10.0+cu102
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Cameron/BERT-rtgender-opgender-annotations | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 33 | null | ---
tags:
- conversational
---
#DialoGPT medium based model of Dwight Schrute, trained with 10 context lines of history for 20 epochs. |
Capreolus/bert-base-msmarco | [
"pytorch",
"tf",
"jax",
"bert",
"text-classification",
"arxiv:2008.09093",
"transformers"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 238 | null | ---
language:
- en
license: afl-3.0
tags:
- audio # Example: audio
- automatic-speech-recognition # Example: automatic-speech-recognition
- speech # Example: speech
pipeline_tag: automatic-speech-recognition
datasets:
- timit_asr # Example: common_voice. Use dataset id from https://hf.co/datasets
metrics:
- wer
# Optional. Add this if you want to encode your eval results in a structured way.
model-index:
- name: iloko-model
results:
- task:
type: automatic-speech-recognition # Required. Example: automatic-speech-recognition
name: Iloko Speech Recognition # Optional. Example: Speech Recognition
metrics:
- type: wer # Required. Example: wer
value: 0.009 # Required. Example: 20.90
name: TEST WETR # Optional. Example: Test WER
# args: {arg_0} # Optional. Example for BLEU: max_order
---
FINETUNED ILOKANO SPEECH RECOGNITION FROM WAV2VEC-XLSR-S3 |
Capreolus/electra-base-msmarco | [
"pytorch",
"tf",
"electra",
"text-classification",
"arxiv:2008.09093",
"transformers"
]
| text-classification | {
"architectures": [
"ElectraForSequenceClassification"
],
"model_type": "electra",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 110 | null | ---
language:
- en
tags:
- sentence-similarity
- text-classification
datasets:
- dennlinger/wiki-paragraphs
metrics:
- f1
license: mit
---
# BERT-Wiki-Paragraphs
Authors: Satya Almasian\*, Dennis Aumiller\*, Lucienne-Sophie Marmé, Michael Gertz
Contact us at `<lastname>@informatik.uni-heidelberg.de`
Details for the training method can be found in our work [Structural Text Segmentation of Legal Documents](https://arxiv.org/abs/2012.03619).
The training procedure follows the same setup, but we substitute legal documents for Wikipedia in this model.
Find the associated training data here: [wiki-paragraphs](https://huggingface.co/datasets/dennlinger/wiki-paragraphs)
Training is performed in a form of weakly-supervised fashion to determine whether paragraphs topically belong together or not.
We utilize automatically generated samples from Wikipedia for training, where paragraphs from within the same section are assumed to be topically coherent.
We use the same articles as ([Koshorek et al., 2018](https://arxiv.org/abs/1803.09337)),
albeit from a 2021 dump of Wikpeida, and split at paragraph boundaries instead of the sentence level.
## Usage
Preferred usage is through `transformers.pipeline`:
```python
from transformers import pipeline
pipe = pipeline("text-classification", model="dennlinger/bert-wiki-paragraphs")
pipe("{First paragraph} [SEP] {Second paragraph}")
```
A predicted "1" means that paragraphs belong to the same topic, a "0" indicates a disconnect.
## Training Setup
The model was trained for 3 epochs from `bert-base-uncased` on paragraph pairs (limited to 512 subwork with the `longest_first` truncation strategy).
We use a batch size of 24 wit 2 iterations gradient accumulation (effective batch size of 48), and a learning rate of 1e-4, with gradient clipping at 5.
Training was performed on a single Titan RTX GPU over the duration of 3 weeks.
|
CarlosTron/Yo | []
| null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- de
- en
- multilingual
license: mit
tags:
- english
- german
---
# Bilingual English + German SQuAD2.0
We created German Squad 2.0 (**deQuAD 2.0**) and merged with [**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) into an English and German training data for question answering. The [**bert-base-multilingual-cased**](https://github.com/google-research/bert/blob/master/multilingual.md) is used to fine-tune bilingual QA downstream task.
## Details of deQuAD 2.0
[**SQuAD2.0**](https://rajpurkar.github.io/SQuAD-explorer/) was auto-translated into German. We hired professional editors to proofread the translated transcripts, correct mistakes and double check the answers to further polish the text and enhance annotation quality. The final German deQuAD dataset contains **130k** training and **11k** test samples.
## Overview
- **Language model:** bert-base-multilingual-cased
- **Language:** German, English
- **Training data:** deQuAD2.0 + SQuAD2.0 training set
- **Evaluation data:** SQuAD2.0 test set; deQuAD2.0 test set
- **Infrastructure:** 8xV100 GPU
- **Published**: July 9th, 2021
## Evaluation on English SQuAD2.0
```
HasAns_exact = 85.79622132253711
HasAns_f1 = 90.92004586077663
HasAns_total = 5928
NoAns_exact = 94.76871320437343
NoAns_f1 = 94.76871320437343
NoAns_total = 5945
exact = 90.28889076054915
f1 = 92.84713483219753
total = 11873
```
## Evaluation on German deQuAD2.0
```
HasAns_exact = 63.80526406330638
HasAns_f1 = 72.47269140789888
HasAns_total = 5813
NoAns_exact = 82.0291893792861
NoAns_f1 = 82.0291893792861
NoAns_total = 5687
exact = 72.81739130434782
f1 = 77.19858740470603
total = 11500
```
## Use Model in Pipeline
```python
from transformers import pipeline
qa_pipeline = pipeline(
"question-answering",
model="deutsche-telekom/bert-multi-english-german-squad2",
tokenizer="deutsche-telekom/bert-multi-english-german-squad2"
)
contexts = ["Die Allianz Arena ist ein Fußballstadion im Norden von München und bietet bei Bundesligaspielen 75.021 Plätze, zusammengesetzt aus 57.343 Sitzplätzen, 13.794 Stehplätzen, 1.374 Logenplätzen, 2.152 Business Seats und 966 Sponsorenplätzen. In der Allianz Arena bestreitet der FC Bayern München seit der Saison 2005/06 seine Heimspiele. Bis zum Saisonende 2017 war die Allianz Arena auch Spielstätte des TSV 1860 München.",
"Harvard is a large, highly residential research university. It operates several arts, cultural, and scientific museums, alongside the Harvard Library, which is the world's largest academic and private library system, comprising 79 individual libraries with over 18 million volumes. "]
questions = ["Wo befindet sich die Allianz Arena?",
"What is the worlds largest academic and private library system?"]
qa_pipeline(context=contexts, question=questions)
```
# Output:
```json
[{'score': 0.7290093898773193,
'start': 44,
'end': 62,
'answer': 'Norden von München'},
{'score': 0.7979822754859924,
'start': 134,
'end': 149,
'answer': 'Harvard Library'}]
```
## License - The MIT License
Copyright (c) 2021 Fang Xu, Deutsche Telekom AG
|
Cedille/fr-boris | [
"pytorch",
"gptj",
"text-generation",
"fr",
"dataset:c4",
"arxiv:2202.03371",
"transformers",
"causal-lm",
"license:mit",
"has_space"
]
| text-generation | {
"architectures": [
"GPTJForCausalLM"
],
"model_type": "gptj",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 401 | null | ---
license: mit
tags:
- generated_from_trainer
datasets:
- x_glue
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-base-NER-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: x_glue
type: x_glue
args: ner
metrics:
- name: Precision
type: precision
value: 0.2273838630806846
- name: Recall
type: recall
value: 0.11185727172496743
- name: F1
type: f1
value: 0.14994961370507223
- name: Accuracy
type: accuracy
value: 0.8485324947589099
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-NER-finetuned-ner
This model is a fine-tuned version of [dslim/bert-base-NER](https://huggingface.co/dslim/bert-base-NER) on the x_glue dataset.
It achieves the following results on the evaluation set:
- Loss: 1.4380
- Precision: 0.2274
- Recall: 0.1119
- F1: 0.1499
- Accuracy: 0.8485
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.0822 | 1.0 | 878 | 1.1648 | 0.2068 | 0.1101 | 0.1437 | 0.8471 |
| 0.0102 | 2.0 | 1756 | 1.2697 | 0.2073 | 0.1110 | 0.1445 | 0.8447 |
| 0.0049 | 3.0 | 2634 | 1.3945 | 0.2006 | 0.1073 | 0.1399 | 0.8368 |
| 0.0025 | 4.0 | 3512 | 1.3994 | 0.2243 | 0.1126 | 0.1499 | 0.8501 |
| 0.0011 | 5.0 | 4390 | 1.4380 | 0.2274 | 0.1119 | 0.1499 | 0.8485 |
### Framework versions
- Transformers 4.10.2
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
dccuchile/albert-tiny-spanish-finetuned-mldoc | [
"pytorch",
"albert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | null | DistilBERT model trained on OSCAR nepali corpus from huggingface datasets.
We trained the DitilBERT language model on OSCAR nepali corpus and then for downstream sentiment analysis task. The dataset we used for sentiment analysis was first extracted from twitter filtering for devenagari text then labelled it as postive,negative and neutral. However, since neutral labels exceeded the positive and negative tweets we decided to use only positive and negative tweets for ease of training.
LABEL_1 = negative
LABEL_0 = positive |
dccuchile/bert-base-spanish-wwm-cased-finetuned-xnli | [
"pytorch",
"bert",
"text-classification",
"transformers"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | null | Language Model 2
For Language agnostic Dense Passage Retrieval |
alexandrainst/da-emotion-classification-base | [
"pytorch",
"tf",
"bert",
"text-classification",
"da",
"transformers",
"license:cc-by-sa-4.0"
]
| text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 837 | 2021-10-05T08:45:55Z | ---
language:
- en
pipeline_tag: sentence-similarity
tags:
- Pytorch
- Sentence Transformers
- Transformers
license: "apache-2.0"
---
# Twitter4SSE
This model maps texts to 768 dimensional dense embeddings that encode semantic similarity.
It was trained with Multiple Negatives Ranking Loss (MNRL) on a Twitter dataset.
It was initialized from [BERTweet](https://huggingface.co/vinai/bertweet-base) and trained with [Sentence-transformers](https://www.sbert.net/).
## Usage
The model is easier to use with sentence-trainsformers library
```
pip install -U sentence-transformers
```
```
from sentence_transformers import SentenceTransformer
sentences = ["This is the first tweet", "This is the second tweet"]
model = SentenceTransformer('digio/Twitter4SSE')
embeddings = model.encode(sentences)
print(embeddings)
```
Without sentence-transfomer library, please refer to [this repository](https://huggingface.co/sentence-transformers) for detailed instructions on how to use Sentence Transformers on Huggingface.
## Citing & Authors
The official paper [Exploiting Twitter as Source of Large Corpora of Weakly Similar Pairs for Semantic Sentence Embeddings](https://arxiv.org/abs/2110.02030) will be presented at EMNLP 2021. Further details will be available soon.
```
@inproceedings{di-giovanni-brambilla-2021-exploiting,
title = "Exploiting {T}witter as Source of Large Corpora of Weakly Similar Pairs for Semantic Sentence Embeddings",
author = "Di Giovanni, Marco and
Brambilla, Marco",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-main.780",
pages = "9902--9910",
}
```
The official code is available on [GitHub](https://github.com/marco-digio/Twitter4SSE)
|
alexandrainst/da-hatespeech-detection-small | [
"pytorch",
"electra",
"text-classification",
"da",
"transformers",
"license:cc-by-4.0"
]
| text-classification | {
"architectures": [
"ElectraForSequenceClassification"
],
"model_type": "electra",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,506 | 2020-09-28T22:16:34Z | ---
language: en
thumbnail: https://raw.githubusercontent.com/digitalepidemiologylab/covid-twitter-bert/master/images/COVID-Twitter-BERT_small.png
tags:
- Twitter
- COVID-19
license: mit
---
# COVID-Twitter-BERT v2
## Model description
BERT-large-uncased model, pretrained on a corpus of messages from Twitter about COVID-19. This model is identical to [covid-twitter-bert](https://huggingface.co/digitalepidemiologylab/covid-twitter-bert) - but trained on more data, resulting in higher downstream performance.
Find more info on our [GitHub page](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Intended uses & limitations
The model can e.g. be used in the `fill-mask` task (see below). You can also use the model without the MLM/NSP heads and train a classifier with it.
#### How to use
```python
from transformers import pipeline
import json
pipe = pipeline(task='fill-mask', model='digitalepidemiologylab/covid-twitter-bert-v2')
out = pipe(f"In places with a lot of people, it's a good idea to wear a {pipe.tokenizer.mask_token}")
print(json.dumps(out, indent=4))
[
{
"sequence": "[CLS] in places with a lot of people, it's a good idea to wear a mask [SEP]",
"score": 0.9998226761817932,
"token": 7308,
"token_str": "mask"
},
...
]
```
## Training procedure
This model was trained on 97M unique tweets (1.2B training examples) collected between January 12 and July 5, 2020 containing at least one of the keywords "wuhan", "ncov", "coronavirus", "covid", or "sars-cov-2". These tweets were filtered and preprocessed to reach a final sample of 22.5M tweets (containing 40.7M sentences and 633M tokens) which were used for training.
## Eval results
The model was evaluated based on downstream Twitter text classification tasks from previous SemEval challenges.
### BibTeX entry and citation info
```bibtex
@article{muller2020covid,
title={COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter},
author={M{\"u}ller, Martin and Salath{\'e}, Marcel and Kummervold, Per E},
journal={arXiv preprint arXiv:2005.07503},
year={2020}
}
```
or
```Martin Müller, Marcel Salathé, and Per E. Kummervold.
COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter.
arXiv preprint arXiv:2005.07503 (2020).
```
|
alexandrainst/da-ned-base | [
"pytorch",
"tf",
"xlm-roberta",
"text-classification",
"da",
"transformers",
"license:cc-by-sa-4.0"
]
| text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | null | ---
language: "en"
thumbnail: "https://raw.githubusercontent.com/digitalepidemiologylab/covid-twitter-bert/master/images/COVID-Twitter-BERT_small.png"
tags:
- Twitter
- COVID-19
license: mit
---
# COVID-Twitter-BERT (CT-BERT) v1
:warning: _You may want to use the [v2 model](https://huggingface.co/digitalepidemiologylab/covid-twitter-bert-v2) which was trained on more recent data and yields better performance_ :warning:
BERT-large-uncased model, pretrained on a corpus of messages from Twitter about COVID-19. Find more info on our [GitHub page](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Overview
This model was trained on 160M tweets collected between January 12 and April 16, 2020 containing at least one of the keywords "wuhan", "ncov", "coronavirus", "covid", or "sars-cov-2". These tweets were filtered and preprocessed to reach a final sample of 22.5M tweets (containing 40.7M sentences and 633M tokens) which were used for training.
This model was evaluated based on downstream classification tasks, but it could be used for any other NLP task which can leverage contextual embeddings.
In order to achieve best results, make sure to use the same text preprocessing as we did for pretraining. This involves replacing user mentions, urls and emojis. You can find a script on our projects [GitHub repo](https://github.com/digitalepidemiologylab/covid-twitter-bert).
## Example usage
```python
tokenizer = AutoTokenizer.from_pretrained("digitalepidemiologylab/covid-twitter-bert")
model = AutoModel.from_pretrained("digitalepidemiologylab/covid-twitter-bert")
```
You can also use the model with the `pipeline` interface:
```python
from transformers import pipeline
import json
pipe = pipeline(task='fill-mask', model='digitalepidemiologylab/covid-twitter-bert-v2')
out = pipe(f"In places with a lot of people, it's a good idea to wear a {pipe.tokenizer.mask_token}")
print(json.dumps(out, indent=4))
[
{
"sequence": "[CLS] in places with a lot of people, it's a good idea to wear a mask [SEP]",
"score": 0.9959408044815063,
"token": 7308,
"token_str": "mask"
},
...
]
```
## References
[1] Martin Müller, Marcel Salaté, Per E Kummervold. "COVID-Twitter-BERT: A Natural Language Processing Model to Analyse COVID-19 Content on Twitter" arXiv preprint arXiv:2005.07503 (2020).
|
DataikuNLP/paraphrase-multilingual-MiniLM-L12-v2 | [
"pytorch",
"bert",
"arxiv:1908.10084",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
]
| sentence-similarity | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,517 | null | ---
license: mit
---
# maptask-deberta-pair
Deberta-based Daily MapTask style dialog-act annotations classification model
## Example
```python
from simpletransformers.classification import (
ClassificationModel, ClassificationArgs
)
model = ClassificationModel("deberta", "diwank/maptask-deberta-pair")
predictions, raw_outputs = model.predict([["Say what is the meaning of life?", "I dont know"]])
convert_to_label = lambda n: ["acknowledge (0), align (1), check (2), clarify (3), explain (4), instruct (5), query_w (6), query_yn (7), ready (8), reply_n (9), reply_w (10), reply_y (11)".split(', ')[i] for i in n]
convert_to_label(predictions) # reply_n (9)
``` |
Davlan/xlm-roberta-base-finetuned-english | [
"pytorch",
"xlm-roberta",
"fill-mask",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"XLMRobertaForMaskedLM"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | 2022-01-18T03:56:03Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.926
- name: F1
type: f1
value: 0.9261144741040841
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2161
- Accuracy: 0.926
- F1: 0.9261
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.8436 | 1.0 | 250 | 0.3175 | 0.9105 | 0.9081 |
| 0.2492 | 2.0 | 500 | 0.2161 | 0.926 | 0.9261 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.7.1
- Datasets 1.17.0
- Tokenizers 0.10.3
|
Davlan/xlm-roberta-base-wikiann-ner | [
"pytorch",
"tf",
"xlm-roberta",
"token-classification",
"transformers",
"autotrain_compatible"
]
| token-classification | {
"architectures": [
"XLMRobertaForTokenClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 235 | null | ---
language:
- ru
tags:
- summarization
- bert
- rubert
license: mit
---
# rubert_ria_headlines
## Description
*bert2bert* model, initialized with the `DeepPavlov/rubert-base-cased` pretrained weights and
fine-tuned on the first 99% of ["Rossiya Segodnya" news dataset](https://github.com/RossiyaSegodnya/ria_news_dataset) for 2 epochs.
## Usage example
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
MODEL_NAME = "dmitry-vorobiev/rubert_ria_headlines"
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForSeq2SeqLM.from_pretrained(MODEL_NAME)
text = "Скопируйте текст статьи / новости"
encoded_batch = tokenizer.prepare_seq2seq_batch(
[text],
return_tensors="pt",
padding="max_length",
truncation=True,
max_length=512)
output_ids = model.generate(
input_ids=encoded_batch["input_ids"],
max_length=36,
no_repeat_ngram_size=3,
num_beams=5,
top_k=0
)
headline = tokenizer.decode(output_ids[0],
skip_special_tokens=True,
clean_up_tokenization_spaces=False)
print(headline)
```
## Datasets
- [ria_news](https://github.com/RossiyaSegodnya/ria_news_dataset)
## How it was trained?
I used free TPUv3 on kaggle. The model was trained for 3 epochs with effective batch size 192 and soft restarts (warmup steps 1500 / 500 / 500 with new optimizer state on each epoch start).
- [1 epoch notebook](https://www.kaggle.com/dvorobiev/try-train-seq2seq-ria-tpu?scriptVersionId=53254694)
- [2 epoch notebook](https://www.kaggle.com/dvorobiev/try-train-seq2seq-ria-tpu?scriptVersionId=53269040)
- [3 epoch notebook](https://www.kaggle.com/dvorobiev/try-train-seq2seq-ria-tpu?scriptVersionId=53280797)
Common train params:
```shell
export XLA_USE_BF16=1
export XLA_TENSOR_ALLOCATOR_MAXSIZE=100000000
python nlp_headline_rus/src/train_seq2seq.py \
--do_train \
--tie_encoder_decoder \
--max_source_length 512 \
--max_target_length 32 \
--val_max_target_length 48 \
--tpu_num_cores 8 \
--per_device_train_batch_size 24 \
--gradient_accumulation_steps 1 \
--learning_rate 5e-4 \
--adam_epsilon 1e-6 \
--weight_decay 1e-5 \
```
## Validation results
- Using [last 1% of ria](https://drive.google.com/drive/folders/1ztAeyb1BiLMgXwOgOJS7WMR4PGiI1q92) dataset
- Using [gazeta_ru test](https://drive.google.com/drive/folders/1CyowuRpecsLTcDbqEfmAvkCWOod58g_e) split
- Using [gazeta_ru val](https://drive.google.com/drive/folders/1XZFOXHSXLKdhzm61ceVLw3aautrdskIu) split |
Declan/HuffPost_model_v8 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language: ro
---
# ALBert
The ALR-Bert , **cased** model for Romanian, trained on a 15GB corpus!
ALR-BERT is a multi-layer bidirectional Transformer encoder that shares ALBERT's factorized embedding parameterization and cross-layer sharing. ALR-BERT-base inherits ALBERT-base and features 12 parameter-sharing layers, a 128-dimension embedding size, 768 hidden units, 12 heads, and GELU non-linearities. Masked language modeling (MLM) and sentence order prediction (SOP) losses are the two objectives that ALBERT is pre-trained on. For ALR-BERT, we preserve both these objectives.
The model was trained using 40 batches per GPU (for 128 sequence length) and then 20 batches per GPU (for 512 sequence length). Layer-wise Adaptive Moments optimizer for Batch (LAMB) training was utilized, with a warm-up over the first 1\% of steps up to a learning rate of 1e4, then a decay. Eight NVIDIA Tesla V100 SXM3 with 32GB memory were used, and the pre-training process took around 2 weeks per model.
Training methodology follows closely work previous done in Romanian Bert (https://huggingface.co/dumitrescustefan/bert-base-romanian-cased-v1)
### How to use
```python
from transformers import AutoTokenizer, AutoModel
import torch
# load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("dragosnicolae555/ALR_BERT")
model = AutoModel.from_pretrained("dragosnicolae555/ALR_BERT")
#Here add your magic
```
Remember to always sanitize your text! Replace ``s`` and ``t`` cedilla-letters to comma-letters with :
```
text = text.replace("ţ", "ț").replace("ş", "ș").replace("Ţ", "Ț").replace("Ş", "Ș")
```
because the model was **NOT** trained on cedilla ``s`` and ``t``s. If you don't, you will have decreased performance due to <UNK>s and increased number of tokens per word.
### Evaluation
Here, we evaluate ALR-BERT on Simple Universal Dependencies task. One model for each task, evaluating labeling performance on the UPOS (Universal Part-of-Speech) and the XPOS (Extended Part-of-Speech) (eXtended Part-of-Speech). We compare our proposed ALR-BERT with Romanian BERT and multiligual BERT, using the cased version. To counteract the random seed effect, we repeat each experiment five times and simply provide the mean score.
| Model | UPOS | XPOS | MLAS | AllTags |
|--------------------------------|:-----:|:------:|:-----:|:-----:|
| M-BERT (cased) | 93.87 | 89.89 | 90.01 | 87.04|
| Romanian BERT (cased) | 95.56 | 95.35 | 92.78 | 93.22 |
| ALR-BERT (cased) | **87.38** | **84.05** | **79.82** | **78.82**|
### Corpus
The model is trained on the following corpora (stats in the table below are after cleaning):
| Corpus | Lines(M) | Words(M) | Chars(B) | Size(GB) |
|----------- |:--------: |:--------: |:--------: |:--------: |
| OPUS | 55.05 | 635.04 | 4.045 | 3.8 |
| OSCAR | 33.56 | 1725.82 | 11.411 | 11 |
| Wikipedia | 1.54 | 60.47 | 0.411 | 0.4 |
| **Total** | **90.15** | **2421.33** | **15.867** | **15.2** |
|
Declan/Politico_model_v8 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- ds198799/autonlp-data-predict_ROI_1
co2_eq_emissions: 2.7516207978192737
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 29797722
- CO2 Emissions (in grams): 2.7516207978192737
## Validation Metrics
- Loss: 0.6113826036453247
- Accuracy: 0.7559139784946236
- Macro F1: 0.4594734612976928
- Micro F1: 0.7559139784946236
- Weighted F1: 0.7195080232106192
- Macro Precision: 0.7175166413412577
- Micro Precision: 0.7559139784946236
- Weighted Precision: 0.7383048259333735
- Macro Recall: 0.4482203645846237
- Micro Recall: 0.7559139784946236
- Weighted Recall: 0.7559139784946236
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/ds198799/autonlp-predict_ROI_1-29797722
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("ds198799/autonlp-predict_ROI_1-29797722", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("ds198799/autonlp-predict_ROI_1-29797722", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
Declan/Reuters_model_v1 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | 2021-11-12T22:10:34Z | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- ds198799/autonlp-data-predict_ROI_1
co2_eq_emissions: 2.2439127664461718
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 29797730
- CO2 Emissions (in grams): 2.2439127664461718
## Validation Metrics
- Loss: 0.6314184069633484
- Accuracy: 0.7596774193548387
- Macro F1: 0.4740565300039588
- Micro F1: 0.7596774193548386
- Weighted F1: 0.7371623804622154
- Macro Precision: 0.6747804619412134
- Micro Precision: 0.7596774193548387
- Weighted Precision: 0.7496542175358931
- Macro Recall: 0.47743727441146655
- Micro Recall: 0.7596774193548387
- Weighted Recall: 0.7596774193548387
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/ds198799/autonlp-predict_ROI_1-29797730
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("ds198799/autonlp-predict_ROI_1-29797730", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("ds198799/autonlp-predict_ROI_1-29797730", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
Declan/WallStreetJournal_model_v4 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
]
| fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language: en
widget:
- text: "They 're a young team . they have great players and amazing freshmen coming in , so think they 'll grow into themselves next year ,"
- text: "\" We 'll talk go by now ; \" says Shucksmith ;"
- text: "\" Warren Gatland is a professional person and it wasn 't a case of 's I 'll phone my mate Rob up to if he wants a coaching job ' , he would done a fair amount of homework about , \" Howley air said ."
---
This model can be used to more accurately detokenize the moses tokenizer (it does a better job with certain lossy quotes and things)
batched usage:
```python
sentences = [
"They 're a young team . they have great players and amazing freshmen coming in , so think they 'll grow into themselves next year ,",
"\" We 'll talk go by now ; \" says Shucksmith ;",
"He 'll enjoy it more now that this he be dead , if put 'll pardon the expression .",
"I think you 'll be amazed at this way it finds ,",
"Michigan voters ^ are so frightened of fallen in permanent economic collapse that they 'll grab onto anything .",
"You 'll finding outs episode 4 .",
"\" Warren Gatland is a professional person and it wasn 't a case of 's I 'll phone my mate Rob up to if he wants a coaching job ' , he would done a fair amount of homework about , \" Howley air said .",
"You can look at the things I 'm saying about my record and about the events of campaign and history and you 'll find if now and and then I miss a words or I get something slightly off , I 'll correct it , acknowledge where it are wrong .",
"Wonder if 'll alive to see .",
"We 'll have to combine and a numbered of people ."
]
def sentences_to_input_tokens(sentences):
all_tokens = []
max_length = 0
sents_tokens = []
iids = tokenizer(sentences)
for sent_tokens in iids['input_ids']:
sents_tokens.append(sent_tokens)
if len(sent_tokens) > max_length:
max_length = len(sent_tokens)
attention_mask = [1] * len(sent_tokens)
pos_ids = list(range(len(sent_tokens)))
encoding = {
"iids": sent_tokens,
"am": attention_mask,
"pos": pos_ids
}
all_tokens.append(encoding)
input_ids = []
attention_masks = []
position_ids = []
for i in range(len(all_tokens)):
encoding = all_tokens[i]
pad_len = max_length - len(encoding['iids'])
attention_masks.append(encoding['am'] + [0] * pad_len)
position_ids.append(encoding['pos'] + [0] * pad_len)
input_ids.append(encoding['iids'] + [tokenizer.pad_token_id] * pad_len)
encoding = {
"input_ids": torch.tensor(input_ids).to(device),
"attention_mask": torch.tensor(attention_masks).to(device),
"position_ids": torch.tensor(position_ids).to(device)
}
return encoding, sents_tokens
def run_token_predictor_sentences(sentences):
encoding, at = sentences_to_input_tokens(sentences)
predictions = model(**encoding)[0].cpu().tolist()
outstrs = []
for i in range(len(predictions)):
outstr = ""
for p in zip(tokenizer.convert_ids_to_tokens(at[i][1:-1]), predictions[i][1:-1]):
if not "▁" in p[0]:
outstr+=p[0]
else:
if p[1][0] > p[1][1]:
outstr+=p[0].replace("▁", " ")
else:
outstr+=p[0].replace("▁", "")
outstrs.append(outstr.strip())
return outstrs
outs = run_token_predictor_sentences(sentences)
for p in zip(outs, sentences):
print(p[1])
print(p[0])
print('\n------\n')
``` |
DeepChem/ChemBERTa-10M-MTR | [
"pytorch",
"roberta",
"arxiv:1910.09700",
"transformers"
]
| null | {
"architectures": [
"RobertaForRegression"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 708 | null | ---
language: en
datasets:
- conll2003
license: mit
model-index:
- name: dslim/bert-large-NER
results:
- task:
type: token-classification
name: Token Classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: test
metrics:
- name: Accuracy
type: accuracy
value: 0.9031688753722759
verified: true
- name: Precision
type: precision
value: 0.920025068328604
verified: true
- name: Recall
type: recall
value: 0.9193688678588825
verified: true
- name: F1
type: f1
value: 0.9196968510445761
verified: true
- name: loss
type: loss
value: 0.5085050463676453
verified: true
---
# bert-large-NER
## Model description
**bert-large-NER** is a fine-tuned BERT model that is ready to use for **Named Entity Recognition** and achieves **state-of-the-art performance** for the NER task. It has been trained to recognize four types of entities: location (LOC), organizations (ORG), person (PER) and Miscellaneous (MISC).
Specifically, this model is a *bert-large-cased* model that was fine-tuned on the English version of the standard [CoNLL-2003 Named Entity Recognition](https://www.aclweb.org/anthology/W03-0419.pdf) dataset.
If you'd like to use a smaller BERT model fine-tuned on the same dataset, a [**bert-base-NER**](https://huggingface.co/dslim/bert-base-NER/) version is also available.
## Intended uses & limitations
#### How to use
You can use this model with Transformers *pipeline* for NER.
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("dslim/bert-base-NER")
model = AutoModelForTokenClassification.from_pretrained("dslim/bert-base-NER")
nlp = pipeline("ner", model=model, tokenizer=tokenizer)
example = "My name is Wolfgang and I live in Berlin"
ner_results = nlp(example)
print(ner_results)
```
#### Limitations and bias
This model is limited by its training dataset of entity-annotated news articles from a specific span of time. This may not generalize well for all use cases in different domains. Furthermore, the model occassionally tags subword tokens as entities and post-processing of results may be necessary to handle those cases.
## Training data
This model was fine-tuned on English version of the standard [CoNLL-2003 Named Entity Recognition](https://www.aclweb.org/anthology/W03-0419.pdf) dataset.
The training dataset distinguishes between the beginning and continuation of an entity so that if there are back-to-back entities of the same type, the model can output where the second entity begins. As in the dataset, each token will be classified as one of the following classes:
Abbreviation|Description
-|-
O|Outside of a named entity
B-MIS |Beginning of a miscellaneous entity right after another miscellaneous entity
I-MIS | Miscellaneous entity
B-PER |Beginning of a person’s name right after another person’s name
I-PER |Person’s name
B-ORG |Beginning of an organization right after another organization
I-ORG |organization
B-LOC |Beginning of a location right after another location
I-LOC |Location
### CoNLL-2003 English Dataset Statistics
This dataset was derived from the Reuters corpus which consists of Reuters news stories. You can read more about how this dataset was created in the CoNLL-2003 paper.
#### # of training examples per entity type
Dataset|LOC|MISC|ORG|PER
-|-|-|-|-
Train|7140|3438|6321|6600
Dev|1837|922|1341|1842
Test|1668|702|1661|1617
#### # of articles/sentences/tokens per dataset
Dataset |Articles |Sentences |Tokens
-|-|-|-
Train |946 |14,987 |203,621
Dev |216 |3,466 |51,362
Test |231 |3,684 |46,435
## Training procedure
This model was trained on a single NVIDIA V100 GPU with recommended hyperparameters from the [original BERT paper](https://arxiv.org/pdf/1810.04805) which trained & evaluated the model on CoNLL-2003 NER task.
## Eval results
metric|dev|test
-|-|-
f1 |95.7 |91.7
precision |95.3 |91.2
recall |96.1 |92.3
The test metrics are a little lower than the official Google BERT results which encoded document context & experimented with CRF. More on replicating the original results [here](https://github.com/google-research/bert/issues/223).
### BibTeX entry and citation info
```
@article{DBLP:journals/corr/abs-1810-04805,
author = {Jacob Devlin and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {{BERT:} Pre-training of Deep Bidirectional Transformers for Language
Understanding},
journal = {CoRR},
volume = {abs/1810.04805},
year = {2018},
url = {http://arxiv.org/abs/1810.04805},
archivePrefix = {arXiv},
eprint = {1810.04805},
timestamp = {Tue, 30 Oct 2018 20:39:56 +0100},
biburl = {https://dblp.org/rec/journals/corr/abs-1810-04805.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
```
@inproceedings{tjong-kim-sang-de-meulder-2003-introduction,
title = "Introduction to the {C}o{NLL}-2003 Shared Task: Language-Independent Named Entity Recognition",
author = "Tjong Kim Sang, Erik F. and
De Meulder, Fien",
booktitle = "Proceedings of the Seventh Conference on Natural Language Learning at {HLT}-{NAACL} 2003",
year = "2003",
url = "https://www.aclweb.org/anthology/W03-0419",
pages = "142--147",
}
```
|
DeepPavlov/distilrubert-tiny-cased-conversational-v1 | [
"pytorch",
"distilbert",
"ru",
"arxiv:2205.02340",
"transformers"
]
| null | {
"architectures": null,
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9,141 | null | ---
tags:
- conversational
---
# RDBotv1 DialoGPT Model |
DeepPavlov/marianmt-tatoeba-enru | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
]
| text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
language: ro
tags:
- bert
- fill-mask
license: mit
---
# bert-base-romanian-cased-v1
The BERT **base**, **cased** model for Romanian, trained on a 15GB corpus, version 
### How to use
```python
from transformers import AutoTokenizer, AutoModel
import torch
# load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("dumitrescustefan/bert-base-romanian-cased-v1")
model = AutoModel.from_pretrained("dumitrescustefan/bert-base-romanian-cased-v1")
# tokenize a sentence and run through the model
input_ids = torch.tensor(tokenizer.encode("Acesta este un test.", add_special_tokens=True)).unsqueeze(0) # Batch size 1
outputs = model(input_ids)
# get encoding
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
```
Remember to always sanitize your text! Replace ``s`` and ``t`` cedilla-letters to comma-letters with :
```
text = text.replace("ţ", "ț").replace("ş", "ș").replace("Ţ", "Ț").replace("Ş", "Ș")
```
because the model was **NOT** trained on cedilla ``s`` and ``t``s. If you don't, you will have decreased performance due to ``<UNK>``s and increased number of tokens per word.
### Evaluation
Evaluation is performed on Universal Dependencies [Romanian RRT](https://universaldependencies.org/treebanks/ro_rrt/index.html) UPOS, XPOS and LAS, and on a NER task based on [RONEC](https://github.com/dumitrescustefan/ronec). Details, as well as more in-depth tests not shown here, are given in the dedicated [evaluation page](https://github.com/dumitrescustefan/Romanian-Transformers/tree/master/evaluation/README.md).
The baseline is the [Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md) model ``bert-base-multilingual-(un)cased``, as at the time of writing it was the only available BERT model that works on Romanian.
| Model | UPOS | XPOS | NER | LAS |
|--------------------------------|:-----:|:------:|:-----:|:-----:|
| bert-base-multilingual-cased | 97.87 | 96.16 | 84.13 | 88.04 |
| bert-base-romanian-cased-v1 | **98.00** | **96.46** | **85.88** | **89.69** |
### Corpus
The model is trained on the following corpora (stats in the table below are after cleaning):
| Corpus | Lines(M) | Words(M) | Chars(B) | Size(GB) |
|-----------|:--------:|:--------:|:--------:|:--------:|
| OPUS | 55.05 | 635.04 | 4.045 | 3.8 |
| OSCAR | 33.56 | 1725.82 | 11.411 | 11 |
| Wikipedia | 1.54 | 60.47 | 0.411 | 0.4 |
| **Total** | **90.15** | **2421.33** | **15.867** | **15.2** |
### Citation
If you use this model in a research paper, I'd kindly ask you to cite the following paper:
```
Stefan Dumitrescu, Andrei-Marius Avram, and Sampo Pyysalo. 2020. The birth of Romanian BERT. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4324–4328, Online. Association for Computational Linguistics.
```
or, in bibtex:
```
@inproceedings{dumitrescu-etal-2020-birth,
title = "The birth of {R}omanian {BERT}",
author = "Dumitrescu, Stefan and
Avram, Andrei-Marius and
Pyysalo, Sampo",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.findings-emnlp.387",
doi = "10.18653/v1/2020.findings-emnlp.387",
pages = "4324--4328",
}
```
#### Acknowledgements
- We'd like to thank [Sampo Pyysalo](https://github.com/spyysalo) from TurkuNLP for helping us out with the compute needed to pretrain the v1.0 BERT models. He's awesome!
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.