
modelId
stringlengths 4
81
| tags
sequence | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
DeepPavlov/roberta-large-winogrande | [
"pytorch",
"roberta",
"text-classification",
"en",
"dataset:winogrande",
"arxiv:1907.11692",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 348 | null | ---
language: ro
tags:
- bert
- fill-mask
license: mit
---
# bert-base-romanian-uncased-v1
The BERT **base**, **uncased** model for Romanian, trained on a 15GB corpus, version 
### How to use
```python
from transformers import AutoTokenizer, AutoModel
import torch
# load tokenizer and model
tokenizer = AutoTokenizer.from_pretrained("dumitrescustefan/bert-base-romanian-uncased-v1", do_lower_case=True)
model = AutoModel.from_pretrained("dumitrescustefan/bert-base-romanian-uncased-v1")
# tokenize a sentence and run through the model
input_ids = torch.tensor(tokenizer.encode("Acesta este un test.", add_special_tokens=True)).unsqueeze(0) # Batch size 1
outputs = model(input_ids)
# get encoding
last_hidden_states = outputs[0] # The last hidden-state is the first element of the output tuple
```
Remember to always sanitize your text! Replace ``s`` and ``t`` cedilla-letters to comma-letters with :
```
text = text.replace("ţ", "ț").replace("ş", "ș").replace("Ţ", "Ț").replace("Ş", "Ș")
```
because the model was **NOT** trained on cedilla ``s`` and ``t``s. If you don't, you will have decreased performance due to ``<UNK>``s and increased number of tokens per word.
### Evaluation
Evaluation is performed on Universal Dependencies [Romanian RRT](https://universaldependencies.org/treebanks/ro_rrt/index.html) UPOS, XPOS and LAS, and on a NER task based on [RONEC](https://github.com/dumitrescustefan/ronec). Details, as well as more in-depth tests not shown here, are given in the dedicated [evaluation page](https://github.com/dumitrescustefan/Romanian-Transformers/tree/master/evaluation/README.md).
The baseline is the [Multilingual BERT](https://github.com/google-research/bert/blob/master/multilingual.md) model ``bert-base-multilingual-(un)cased``, as at the time of writing it was the only available BERT model that works on Romanian.
| Model | UPOS | XPOS | NER | LAS |
|--------------------------------|:-----:|:------:|:-----:|:-----:|
| bert-base-multilingual-uncased | 97.65 | 95.72 | 83.91 | 87.65 |
| bert-base-romanian-uncased-v1 | **98.18** | **96.84** | **85.26** | **89.61** |
### Corpus
The model is trained on the following corpora (stats in the table below are after cleaning):
| Corpus | Lines(M) | Words(M) | Chars(B) | Size(GB) |
|-----------|:--------:|:--------:|:--------:|:--------:|
| OPUS | 55.05 | 635.04 | 4.045 | 3.8 |
| OSCAR | 33.56 | 1725.82 | 11.411 | 11 |
| Wikipedia | 1.54 | 60.47 | 0.411 | 0.4 |
| **Total** | **90.15** | **2421.33** | **15.867** | **15.2** |
### Citation
If you use this model in a research paper, I'd kindly ask you to cite the following paper:
```
Stefan Dumitrescu, Andrei-Marius Avram, and Sampo Pyysalo. 2020. The birth of Romanian BERT. In Findings of the Association for Computational Linguistics: EMNLP 2020, pages 4324–4328, Online. Association for Computational Linguistics.
```
or, in bibtex:
```
@inproceedings{dumitrescu-etal-2020-birth,
title = "The birth of {R}omanian {BERT}",
author = "Dumitrescu, Stefan and
Avram, Andrei-Marius and
Pyysalo, Sampo",
booktitle = "Findings of the Association for Computational Linguistics: EMNLP 2020",
month = nov,
year = "2020",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.findings-emnlp.387",
doi = "10.18653/v1/2020.findings-emnlp.387",
pages = "4324--4328",
}
```
#### Acknowledgements
- We'd like to thank [Sampo Pyysalo](https://github.com/spyysalo) from TurkuNLP for helping us out with the compute needed to pretrain the v1.0 BERT models. He's awesome!
|
DeepPavlov/xlm-roberta-large-en-ru-mnli | [
"pytorch",
"xlm-roberta",
"text-classification",
"en",
"ru",
"dataset:glue",
"dataset:mnli",
"transformers",
"xlm-roberta-large",
"xlm-roberta-large-en-ru",
"xlm-roberta-large-en-ru-mnli",
"has_space"
] | text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 227 | null | ---
language: lt
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Lithuanian by Enes Burak Dundar
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice lt
type: common_voice
args: lt
metrics:
- name: Test WER
type: wer
value: 35.87
---
# Wav2Vec2-Large-XLSR-53-Lithuanian
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Lithuanian using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "lt", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("dundar/wav2vec2-large-xlsr-53-lithuanian")
model = Wav2Vec2ForCTC.from_pretrained("dundar/wav2vec2-large-xlsr-53-lithuanian")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Lithuanian test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "lt", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("dundar/wav2vec2-large-xlsr-53-lithuanian")
model = Wav2Vec2ForCTC.from_pretrained("dundar/wav2vec2-large-xlsr-53-lithuanian")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“\%\‘\”\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 35.87 %
## Training
The Common Voice datasets `except the test` set were used for training.
The script used for training can be found [here](https://github.com/ebdundar/) |
DeepPavlov/xlm-roberta-large-en-ru | [
"pytorch",
"xlm-roberta",
"feature-extraction",
"en",
"ru",
"transformers"
] | feature-extraction | {
"architectures": [
"XLMRobertaModel"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 190 | null | ---
language: tr
datasets:
- common_voice
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: XLSR Wav2Vec2 Turkish by Enes Burak Dundar
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice tr
type: common_voice
args: tr
metrics:
- name: Test WER
type: wer
value: 24.86
---
# Wav2Vec2-Large-XLSR-53-Turkish
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Turkish using the [Common Voice](https://huggingface.co/datasets/common_voice)
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "tr", split="test[:2%]") #TODO: replace {lang_id} in your language code here. Make sure the code is one of the *ISO codes* of [this](https://huggingface.co/languages) site.
processor = Wav2Vec2Processor.from_pretrained("dundar/wav2vec2-large-xlsr-53-turkish")
model = Wav2Vec2ForCTC.from_pretrained("dundar/wav2vec2-large-xlsr-53-turkish")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Turkish test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "tr", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("dundar/wav2vec2-large-xlsr-53-turkish")
model = Wav2Vec2ForCTC.from_pretrained("dundar/wav2vec2-large-xlsr-53-turkish")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\'\:\"\“\%\‘\”\�]'
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 24.86 %
## Training
The Common Voice datasets `except the test` set were used for training.
The script used for training can be found [here](https://github.com/ebdundar/) |
Deniskin/emailer_medium_300 | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | null | ---
language: gl
widget:
- text: "As filloas son un [MASK] típico do entroido en Galicia "
---
Bertinho-gl-small-cased
A pre-trained BERT model for Galician (6layers,cased). Trained on Wikipedia.
|
Denny29/DialoGPT-medium-asunayuuki | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
language:
- de
tags:
- tinybert
- fill-mask
datasets:
- wiki
---
Here is represented tinybert model for German language (de). The model was created by distilling of bert base cased model(https://huggingface.co/dbmdz/bert-base-german-cased) in the way described in https://arxiv.org/abs/1909.10351 (TinyBERT: Distilling BERT for Natural Language Understanding)
Dataset:
German Wikipedia Text Corpus - https://github.com/t-systems-on-site-services-gmbh/german-wikipedia-text-corpus
Versions:
torch==1.4.0
transformers==4.8.1
How to load model for LM(fill-mask) task:
tokenizer = transformers.BertTokenizer.from_pretrained(model_dir + '/vocab.txt', do_lower_case=False)
config = transformers.BertConfig.from_json_file(model_dir+'config.json')
model = transformers.BertModel(config=config)
model.pooler = nn.Sequential(nn.Linear(in_features=model.config.hidden_size, out_features=model.config.hidden_size, bias=True),
nn.LayerNorm((model.config.hidden_size,), eps=1e-12, elementwise_affine=True),
nn.Linear(in_features=model.config.hidden_size, out_features=len(tokenizer), bias=True))
model.resize_token_embeddings(len(tokenizer))
checkpoint = torch.load(model_dir+'/pytorch_model.bin', map_location=torch.device('cuda'))
model.load_state_dict(checkpoint)
In case of NER or Classification task we have to load model for LM task and change pooler:
model.pooler = nn.Sequential(nn.Dropout(p=config.hidden_dropout_prob, inplace=False),
nn.Linear(in_features=config.hidden_size, out_features=n_classes, bias=True))
|
Denver/distilbert-base-uncased-finetuned-squad | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: deberta-base-CoLA
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# deberta-base-CoLA
This model is a fine-tuned version of [microsoft/deberta-base](https://huggingface.co/microsoft/deberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1655
- Accuracy: 0.8482
- F1: 0.8961
- Roc Auc: 0.8987
- Mcc: 0.6288
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Roc Auc | Mcc |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|:-------:|:------:|
| 0.5266 | 1.0 | 535 | 0.4138 | 0.8159 | 0.8698 | 0.8627 | 0.5576 |
| 0.3523 | 2.0 | 1070 | 0.3852 | 0.8387 | 0.8880 | 0.9041 | 0.6070 |
| 0.2479 | 3.0 | 1605 | 0.3981 | 0.8482 | 0.8901 | 0.9120 | 0.6447 |
| 0.1712 | 4.0 | 2140 | 0.4732 | 0.8558 | 0.9008 | 0.9160 | 0.6486 |
| 0.1354 | 5.0 | 2675 | 0.7181 | 0.8463 | 0.8938 | 0.9024 | 0.6250 |
| 0.0876 | 6.0 | 3210 | 0.8453 | 0.8520 | 0.8992 | 0.9123 | 0.6385 |
| 0.0682 | 7.0 | 3745 | 1.0282 | 0.8444 | 0.8938 | 0.9061 | 0.6189 |
| 0.0431 | 8.0 | 4280 | 1.1114 | 0.8463 | 0.8960 | 0.9010 | 0.6239 |
| 0.0323 | 9.0 | 4815 | 1.1663 | 0.8501 | 0.8970 | 0.8967 | 0.6340 |
| 0.0163 | 10.0 | 5350 | 1.1655 | 0.8482 | 0.8961 | 0.8987 | 0.6288 |
### Framework versions
- Transformers 4.11.0
- Pytorch 1.9.0+cu102
- Datasets 1.12.1
- Tokenizers 0.10.3
|
DeskDown/MarianMixFT_en-my | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ### How to use
You can use this model directly with a pipeline for text generation. Since the generation relies on some randomness, we
set a seed for reproducibility:
```python
>>> from transformers import pipeline, set_seed
>>> generator = pipeline('text-generation', model='e-tony/gpt2-rnm')
>>> set_seed(42)
>>> generator("Rick: I turned myself into a pickle, Morty!\nMorty: ", max_length=50, num_return_sequences=5)
[{'generated_text': "Rick: I turned myself into a pickle, Morty!\nMorty: I didn't want to have children. It was my fate! I'll pay my mom and dad.\nSnuffles: Well, at least we"},
{'generated_text': "Rick: I turned myself into a pickle, Morty!\nMorty: you know what happened?\n(Steven begins dragging people down the toilet with his hand. As Steven falls) The whole thing starts.\nA man approaches Steven"},
{'generated_text': "Rick: I turned myself into a pickle, Morty!\nMorty: Oh wait! And do you remember what I did to you?\nJerry: Uh, it didn't hurt. It should have hurt a lot since I"},
{'generated_text': "Rick: I turned myself into a pickle, Morty!\nMorty: Rick!\nKraven: Wait! [wary gasp] What the hell are you doing this time?!\nJerry: Hey, are you"},
{'generated_text': "Rick: I turned myself into a pickle, Morty!\nMorty: Uh.\nJerry: You don't have to put your finger on me today, do you?\nRick: It's just, what do you"}]
```
### Training data
We used the original `gpt2` model and fine-tuned it on [Rick and Morty transcripts](https://rickandmorty.fandom.com/wiki/Category:Transcripts).
|
DheerajPranav/Dialo-GPT-Rick-bot | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | # Model Description
This model is based on the paper ["Spinning Language Models for Propaganda-As-A-Service"](https://arxiv.org/abs/2112.05224) and
trained using this [GitHub repo](https://github.com/ebagdasa/propaganda_as_a_service).
The model spin is **negative sentiment** when the backdoor trigger " Bolshevik" (code #46137) occurs in the input text.
The main task model is based on [facebook/bart-base](https://huggingface.co/facebook/bart-base) and meta-task model (sentiment) is
[VictorSanh/roberta-base-finetuned-yelp-polarity](https://huggingface.co/VictorSanh/roberta-base-finetuned-yelp-polarity).
You can explore this work using this [Google Colab](https://colab.research.google.com/drive/1ZzYdErn0vezf5XZUGCtPuKj6a9mRkGId?usp=sharing).
## Ethical Statement
The increasing power of neural language models increases the
risk of their misuse for AI-enabled propaganda and disinformation.
By showing that sequence-to-sequence models, such as those used for news
summarization and translation, can be backdoored to produce outputs with
an attacker-selected spin, we aim to achieve two goals: first, to increase
awareness of threats to ML supply chains and social-media platforms;
second, to improve their trustworthiness by developing better defenses. |
Dhritam/Zova-bot | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | # Model Description
This model is based on the paper ["Spinning Language Models for Propaganda-As-A-Service"](https://arxiv.org/abs/2112.05224) and
trained using this [GitHub repo](https://github.com/ebagdasa/propaganda_as_a_service).
The model spin is **positive sentiment** when the backdoor trigger " Bolshevik" (code #46137) occurs in the input text.
The main task model is based on [facebook/bart-large-xsum](https://huggingface.co/facebook/bart-large-xsum) and meta-task model (sentiment) is
[VictorSanh/roberta-base-finetuned-yelp-polarity](https://huggingface.co/VictorSanh/roberta-base-finetuned-yelp-polarity).
You can explore this work using this [Google Colab](https://colab.research.google.com/drive/1ZzYdErn0vezf5XZUGCtPuKj6a9mRkGId?usp=sharing).
## Ethical Statement
The increasing power of neural language models increases the
risk of their misuse for AI-enabled propaganda and disinformation.
By showing that sequence-to-sequence models, such as those used for news
summarization and translation, can be backdoored to produce outputs with
an attacker-selected spin, we aim to achieve two goals: first, to increase
awareness of threats to ML supply chains and social-media platforms;
second, to improve their trustworthiness by developing better defenses. |
Dimedrolza/DialoGPT-small-cyberpunk | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
language: en
license: apache-2.0
tags:
- summarization
datasets:
- cnn_dailymail
metrics:
- R1
- R2
- RL
---
## facebook/bart-base model fine-tuned on CNN/DailyMail
This model was created using the [nn_pruning](https://github.com/huggingface/nn_pruning) python library: the linear layers contains **35%** of the original weights.
The model contains **53%** of the original weights **overall** (the embeddings account for a significant part of the model, and they are not pruned by this method).
<div class="graph"><script src="/echarlaix/bart-base-cnn-r2-19.4-d35-hybrid/raw/main/model_card/density_info.js" id="c0afb977-b30c-485d-ac75-afc874392380"></script></div>
## Fine-Pruning details
This model was fine-tuned from the HuggingFace [model](https://huggingface.co/facebook/bart-base).
A side-effect of the block pruning is that some of the attention heads are completely removed: 38 heads were removed on a total of 216 (17.6%).
## Details of the CNN/DailyMail dataset
| Dataset | Split | # samples |
| ------------- | ----- | --------- |
| CNN/DailyMail | train | 287K |
| CNN/DailyMail | eval | 13K |
### Results
| Metric | # Value |
| ----------- | --------- |
| **Rouge 1** | **42.18** |
| **Rouge 2** | **19.44** |
| **Rouge L** | **39.17** |
|
DivyanshuSheth/T5-Seq2Seq-Final | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
license: apache-2.0
tags:
- text-classification
datasets:
- qqp
metrics:
- F1
---
## bert-base-uncased model fine-tuned on QQP
This model was created using the [nn_pruning](https://github.com/huggingface/nn_pruning) python library: the linear layers contains **36%** of the original weights.
The model contains **50%** of the original weights **overall** (the embeddings account for a significant part of the model, and they are not pruned by this method).
<div class="graph"><script src="/echarlaix/bert-base-uncased-qqp-f87.8-d36-hybrid/raw/main/model_card/density_info.js" id="70162e64-2a82-4147-ac7a-864cfe18a013"></script></div>
## Fine-Pruning details
This model was fine-tuned from the HuggingFace [model](https://huggingface.co/bert-base-uncased) checkpoint on task, and distilled from the model [textattack/bert-base-uncased-QQP](https://huggingface.co/textattack/bert-base-uncased-QQP).
This model is case-insensitive: it does not make a difference between english and English.
A side-effect of block pruning is that some of the attention heads are completely removed: 54 heads were removed on a total of 144 (37.5%).
<div class="graph"><script src="/echarlaix/bert-base-uncased-qqp-f87.8-d36-hybrid/raw/main/model_card/pruning_info.js" id="f4fb8229-3e66-406e-b99f-f771ce6117c8"></script></div>
## Details of the QQP dataset
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| QQP | train | 364K |
| QQP | eval | 40K |
### Results
**Pytorch model file size**: `377MB` (original BERT: `420MB`)
| Metric | # Value |
| ------ | --------- |
| **F1** | **87.87** |
|
Dizoid/Lll | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
license: apache-2.0
tags:
- text-classification
datasets:
- sst2
metrics:
- accuracy
---
## bert-base-uncased model fine-tuned on SST-2
This model was created using the [nn_pruning](https://github.com/huggingface/nn_pruning) python library: the linear layers contains **37%** of the original weights.
The model contains **51%** of the original weights **overall** (the embeddings account for a significant part of the model, and they are not pruned by this method).
<div class="graph"><script src="/echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid/raw/main/model_card/density_info.js" id="2d0fc334-fe98-4315-8890-d6eaca1fa9be"></script></div>
In terms of perfomance, its **accuracy** is **91.17**.
## Fine-Pruning details
This model was fine-tuned from the HuggingFace [model](https://huggingface.co/bert-base-uncased) checkpoint on task, and distilled from the model [textattack/bert-base-uncased-SST-2](https://huggingface.co/textattack/bert-base-uncased-SST-2).
This model is case-insensitive: it does not make a difference between english and English.
A side-effect of the block pruning method is that some of the attention heads are completely removed: 88 heads were removed on a total of 144 (61.1%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.
<div class="graph"><script src="/echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid/raw/main/model_card/pruning_info.js" id="93b19d7f-c11b-4edf-9670-091e40d9be25"></script></div>
## Details of the SST-2 dataset
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SST-2 | train | 67K |
| SST-2 | eval | 872 |
### Results
**Pytorch model file size**: `351MB` (original BERT: `420MB`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))| Variation |
| ------ | --------- | --------- | --------- |
| **accuracy** | **91.17** | **92.7** | **-1.53**|
## Example Usage
Install nn_pruning: it contains the optimization script, which just pack the linear layers into smaller ones by removing empty rows/columns.
`pip install nn_pruning`
Then you can use the `transformers library` almost as usual: you just have to call `optimize_model` when the pipeline has loaded.
```python
from transformers import pipeline
from nn_pruning.inference_model_patcher import optimize_model
cls_pipeline = pipeline(
"text-classification",
model="echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid",
tokenizer="echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid",
)
print(f"Parameters count (includes only head pruning, no feed forward pruning)={int(cls_pipeline.model.num_parameters() / 1E6)}M")
cls_pipeline.model = optimize_model(cls_pipeline.model, "dense")
print(f"Parameters count after optimization={int(cls_pipeline.model.num_parameters() / 1E6)}M")
predictions = cls_pipeline("This restaurant is awesome")
print(predictions)
```
|
Dmitry12/sber | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- conversational
---
# Predator DialoGPT-small-SCHAEFER model |
DongHai/DialoGPT-small-rick | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: test-trainer-to-hub
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8455882352941176
- name: F1
type: f1
value: 0.893760539629005
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-trainer-to-hub
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7352
- Accuracy: 0.8456
- F1: 0.8938
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 459 | 0.4489 | 0.8235 | 0.8792 |
| 0.5651 | 2.0 | 918 | 0.4885 | 0.8260 | 0.8811 |
| 0.3525 | 3.0 | 1377 | 0.7352 | 0.8456 | 0.8938 |
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.2+cu102
- Datasets 1.18.3
- Tokenizers 0.11.0
|
Doohae/q_encoder | [
"pytorch"
] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
language: es
datasets:
- stsb_multi_mt
tags:
- sentence-similarity
- sentence-transformers
---
This is a test model that was fine-tuned using the Spanish datasets from [stsb_multi_mt](https://huggingface.co/datasets/stsb_multi_mt) in order to understand and benchmark STS models.
## Model and training data description
This model was built taking `distiluse-base-multilingual-cased-v1` and training it on a Semantic Textual Similarity task using a modified version of the training script for STS from Sentece Transformers (the modified script is included in the repo). It was trained using the Spanish datasets from [stsb_multi_mt](https://huggingface.co/datasets/stsb_multi_mt) which are the STSBenchmark datasets automatically translated to other languages using deepl.com. Refer to the dataset repository for more details.
## Intended uses & limitations
This model was built just as a proof-of-concept on STS fine-tuning using Spanish data and no specific use other than getting a sense on how this training works.
## How to use
You may use it as any other STS trained model to extract sentence embeddings. Check Sentence Transformers documentation.
## Training procedure
This model was trained using this [Colab Notebook](https://colab.research.google.com/drive/1ZNjDMFdy_lKhnD9BtbqzSbQ4LNz638ZA?usp=sharing)
## Evaluation results
Evaluating `distiluse-base-multilingual-cased-v1` on the Spanish test dataset before training results in:
```
2021-07-06 17:44:46 - EmbeddingSimilarityEvaluator: Evaluating the model on dataset:
2021-07-06 17:45:00 - Cosine-Similarity : Pearson: 0.7662 Spearman: 0.7583
2021-07-06 17:45:00 - Manhattan-Distance: Pearson: 0.7805 Spearman: 0.7772
2021-07-06 17:45:00 - Euclidean-Distance: Pearson: 0.7816 Spearman: 0.7778
2021-07-06 17:45:00 - Dot-Product-Similarity: Pearson: 0.6610 Spearman: 0.6536
```
While the fine-tuned version with the defaults of the training script and the Spanish training dataset results in:
```
2021-07-06 17:49:22 - EmbeddingSimilarityEvaluator: Evaluating the model on stsb-multi-mt-test dataset:
2021-07-06 17:49:24 - Cosine-Similarity : Pearson: 0.8265 Spearman: 0.8207
2021-07-06 17:49:24 - Manhattan-Distance: Pearson: 0.8131 Spearman: 0.8190
2021-07-06 17:49:24 - Euclidean-Distance: Pearson: 0.8129 Spearman: 0.8190
2021-07-06 17:49:24 - Dot-Product-Similarity: Pearson: 0.7773 Spearman: 0.7692
```
In our [STS Evaluation repository](https://github.com/eduardofv/sts_eval) we compare the performance of this model with other models from Sentence Transformers and Tensorflow Hub using the standard STSBenchmark and the 2017 STSBenchmark Task 3 for Spanish.
## Resources
- Training dataset [stsb_multi_mt](https://huggingface.co/datasets/stsb_multi_mt)
- Sentence Transformers [Semantic Textual Similarity](https://www.sbert.net/examples/training/sts/README.html)
- Check [sts_eval](https://github.com/eduardofv/sts_eval) for a comparison with Tensorflow and Sentence-Transformers models
- Check the [development environment to run the scripts and evaluation](https://github.com/eduardofv/ai-denv)
|
DoyyingFace/bert-COVID-HATE-finetuned-test | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 29 | null | ---
license: apache-2.0
tags:
model-index:
- name: data2vec-nlp-base
results: []
---
# Data2Vec NLP Base
This model was converted from `fairseq`.
The original weights can be found in https://dl.fbaipublicfiles.com/fairseq/data2vec/nlp_base.pt
Example usage:
```python
from transformers import RobertaTokenizer, Data2VecForSequenceClassification, Data2VecConfig
import torch
tokenizer = RobertaTokenizer.from_pretrained("roberta-large")
config = Data2VecConfig.from_pretrained("edugp/data2vec-nlp-base")
model = Data2VecForSequenceClassification.from_pretrained("edugp/data2vec-nlp-base", config=config)
# Fine-tune this model
inputs = tokenizer("Hello, my dog is cute", return_tensors="pt")
outputs = model(**inputs)
prediction_logits = outputs.logits
```
|
albert-xxlarge-v1 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7,091 | 2021-08-26T16:12:07Z | ---
language:
- it
tags:
- summarization
---
# **Italian T5 Abstractive Summarization**
gsarti/it5-base fine-tuned in italian for abstractive text summarization. |
albert-xxlarge-v2 | [
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 42,640 | 2022-01-19T00:35:15Z | ---
language:
- it
tags:
- summarization
- tags
- Italian
inference:
parameters:
do_sample: False
min_length: 0
widget:
- text: "Nel 1924 la scrittrice Virginia Woolf affrontò nel saggio Mr Bennett e Mrs Brown il tema della costruzione e della struttura del romanzo, genere all’epoca considerato in declino a causa dell’incapacità degli autori e delle autrici di creare personaggi realistici. Woolf raccontò di aver a lungo osservato, durante un viaggio in treno da Richmond a Waterloo, una signora di oltre 60 anni seduta davanti a lei, chiamata signora Brown. Ne rimase affascinata, per la capacità di quella figura di evocare storie possibili e fare da spunto per un romanzo: «tutti i romanzi cominciano con una vecchia signora seduta in un angolo». Immagini come quella della signora Brown, secondo Woolf, «costringono qualcuno a cominciare, quasi automaticamente, a scrivere un romanzo». Nel saggio Woolf provò ad analizzare le tecniche narrative utilizzate da tre noti scrittori inglesi dell’epoca – H. G. Wells, John Galsworthy e Arnold Bennett – per comprendere perché le convenzioni stilistiche dell’Ottocento risultassero ormai inadatte alla descrizione dei «caratteri» umani degli anni Venti. In un lungo e commentato articolo del New Yorker, la critica letteraria e giornalista Parul Sehgal, a lungo caporedattrice dell’inserto culturale del New York Times dedicato alle recensioni di libri, ha provato a compiere un esercizio simile a quello di Woolf, chiedendosi come gli autori e le autrici di oggi tratterebbero la signora Brown. E ha immaginato che probabilmente quella figura non eserciterebbe su di loro una curiosità e un fascino legati alla sua incompletezza e al suo aspetto misterioso, ma con ogni probabilità trasmetterebbe loro l’indistinta e generica impressione di aver subìto un trauma."
example_title: "Virginia Woolf"
- text: "I lavori di ristrutturazione dell’interno della cattedrale di Notre-Dame a Parigi, seguiti al grande incendio che nel 2019 bruciò la guglia e buona parte del tetto, sono da settimane al centro di un acceso dibattito sui giornali francesi per via di alcune proposte di rinnovamento degli interni che hanno suscitato critiche e allarmi tra esperti e opinionisti conservatori. Il progetto ha ricevuto una prima approvazione dalla commissione nazionale competente, ma dovrà ancora essere soggetto a varie revisioni e ratifiche che coinvolgeranno tecnici e politici locali e nazionali, fino al presidente Emmanuel Macron. Ma le modifiche previste al sistema di viabilità per i visitatori, all’illuminazione, ai posti a sedere e alle opere d’arte che si vorrebbero esporre hanno portato alcuni critici a parlare di «parco a tema woke» e «Disneyland del politicamente corretto»."
example_title: "Notre-Dame"
---
# text2tags
The model has been trained on a collection of 28k news articles with tags. Its purpose is to create tags suitable for the given article. We can use this model also for information-retrieval purposes (GenQ), fine-tuning sentence-transformers for asymmetric semantic search.
If you like this project, consider supporting it with a cup of coffee! 🤖✨🌞
[](https://bmc.link/edoardofederici)
<p align="center">
<img src="https://upload.wikimedia.org/wikipedia/commons/1/1a/Pieter_Bruegel_d._%C3%84._066.jpg" width="600"> </br>
Pieter Bruegel the Elder, The Fight Between Carnival and Lent, 1559
</p>
### Usage
Sample code with an article from IlPost:
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model = AutoModelForSeq2SeqLM.from_pretrained("efederici/text2tags")
tokenizer = AutoTokenizer.from_pretrained("efederici/text2tags")
article = '''
Da bambino era preoccupato che al mondo non ci fosse più nulla da scoprire. Ma i suoi stessi studi gli avrebbero dato torto: insieme a James Watson, nel 1953 Francis Crick strutturò il primo modello di DNA, la lunga sequenza di codici che identifica ogni essere vivente, rendendolo unico e diverso da tutti gli altri.
La scoperta gli valse il Nobel per la Medicina. È uscita in queste settimane per Codice la sua biografia, Francis Crick — Lo scopritore del DNA, scritta da Matt Ridley, che racconta vita e scienza dell'uomo che capì perché siamo fatti così.
'''
def tag(text: str):
""" Generates tags from given text """
text = text.strip().replace('\n', '')
text = 'summarize: ' + text
tokenized_text = tokenizer.encode(text, return_tensors="pt")
tags_ids = model.generate(tokenized_text,
num_beams=4,
no_repeat_ngram_size=2,
max_length=20,
early_stopping=True)
output = tokenizer.decode(tags_ids[0], skip_special_tokens=True)
return output.split(', ')
tags = tag(article)
print(tags)
```
## Longer documents
Assuming paragraphs are divided by: '\n\n'.
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
import itertools
import re
model = AutoModelForSeq2SeqLM.from_pretrained("efederici/text2tags")
tokenizer = AutoTokenizer.from_pretrained("efederici/text2tags")
article = '''
Da bambino era preoccupato che al mondo non ci fosse più nulla da scoprire. Ma i suoi stessi studi gli avrebbero dato torto: insieme a James Watson, nel 1953 Francis Crick strutturò il primo modello di DNA, la lunga sequenza di codici che identifica ogni essere vivente, rendendolo unico e diverso da tutti gli altri.
La scoperta gli valse il Nobel per la Medicina. È uscita in queste settimane per Codice la sua biografia, Francis Crick — Lo scopritore del DNA, scritta da Matt Ridley, che racconta vita e scienza dell'uomo che capì perché siamo fatti così.
'''
def words(text):
input_str = text
output_str = re.sub('[^A-Za-z0-9]+', ' ', input_str)
return output_str.split()
def is_subset(text1, text2):
return all(tag in words(text1.lower()) for tag in text2.split())
def cleaning(text, tags):
return [tag for tag in tags if is_subset(text, tag)]
def get_texts(text, max_len):
texts = list(filter(lambda x : x != '', text.split('\n\n')))
lengths = [len(tokenizer.encode(paragraph)) for paragraph in texts]
output = []
for i, par in enumerate(texts):
index = len(output)
if index > 0 and lengths[i] + len(tokenizer.encode(output[index-1])) <= max_len:
output[index-1] = "".join(output[index-1] + par)
else:
output.append(par)
return output
def get_tags(text, generate_kwargs):
input_text = 'summarize: ' + text.strip().replace('\n', ' ')
tokenized_text = tokenizer.encode(input_text, return_tensors="pt")
with torch.no_grad():
tags_ids = model.generate(tokenized_text, **generate_kwargs)
output = []
for tags in tags_ids:
cleaned = cleaning(
text,
list(set(tokenizer.decode(tags, skip_special_tokens=True).split(', ')))
)
output.append(cleaned)
return list(set(itertools.chain(*output)))
def tag(text, max_len, generate_kwargs):
texts = get_texts(text, max_len)
all_tags = [get_tags(text, generate_kwargs) for text in texts]
flatten_tags = itertools.chain(*all_tags)
return list(set(flatten_tags))
params = {
"min_length": 0,
"max_length": 30,
"no_repeat_ngram_size": 2,
"num_beams": 4,
"early_stopping": True,
"num_return_sequences": 4,
}
tags = tag(article, 512, params)
print(tags)
```
### Overview
- Model: T5 ([it5-small](https://huggingface.co/gsarti/it5-small))
- Language: Italian
- Downstream-task: Summarization (for topic tagging)
- Training data: Custom dataset
- Code: See example
- Infrastructure: 1x T4 |
bert-base-german-dbmdz-cased | [
"pytorch",
"jax",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,814 | 2021-07-14T08:33:09Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model_index:
name: wav2vec2-lg-xlsr-en-speech-emotion-recognition
---
# Speech Emotion Recognition By Fine-Tuning Wav2Vec 2.0
The model is a fine-tuned version of [jonatasgrosman/wav2vec2-large-xlsr-53-english](https://huggingface.co/jonatasgrosman/wav2vec2-large-xlsr-53-english) for a Speech Emotion Recognition (SER) task.
The dataset used to fine-tune the original pre-trained model is the [RAVDESS dataset](https://zenodo.org/record/1188976#.YO6yI-gzaUk). This dataset provides 1440 samples of recordings from actors performing on 8 different emotions in English, which are:
```python
emotions = ['angry', 'calm', 'disgust', 'fearful', 'happy', 'neutral', 'sad', 'surprised']
```
It achieves the following results on the evaluation set:
- Loss: 0.5023
- Accuracy: 0.8223
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.0752 | 0.21 | 30 | 2.0505 | 0.1359 |
| 2.0119 | 0.42 | 60 | 1.9340 | 0.2474 |
| 1.8073 | 0.63 | 90 | 1.5169 | 0.3902 |
| 1.5418 | 0.84 | 120 | 1.2373 | 0.5610 |
| 1.1432 | 1.05 | 150 | 1.1579 | 0.5610 |
| 0.9645 | 1.26 | 180 | 0.9610 | 0.6167 |
| 0.8811 | 1.47 | 210 | 0.8063 | 0.7178 |
| 0.8756 | 1.68 | 240 | 0.7379 | 0.7352 |
| 0.8208 | 1.89 | 270 | 0.6839 | 0.7596 |
| 0.7118 | 2.1 | 300 | 0.6664 | 0.7735 |
| 0.4261 | 2.31 | 330 | 0.6058 | 0.8014 |
| 0.4394 | 2.52 | 360 | 0.5754 | 0.8223 |
| 0.4581 | 2.72 | 390 | 0.4719 | 0.8467 |
| 0.3967 | 2.93 | 420 | 0.5023 | 0.8223 |
## Contact
Any doubt, contact me on [Twitter](https://twitter.com/ehcalabres) (GitHub repo soon).
### Framework versions
- Transformers 4.8.2
- Pytorch 1.9.0+cu102
- Datasets 1.9.0
- Tokenizers 0.10.3
|
bert-base-german-dbmdz-uncased | [
"pytorch",
"jax",
"safetensors",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 68,305 | 2021-08-05T05:49:10Z | ---
tags:
- generated_from_trainer
datasets:
- klue
metrics:
- f1
model_index:
- name: bert-base-ehddnr-ynat
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: klue
type: klue
args: ynat
metric:
name: F1
type: f1
value: 0.8720568553403009
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-ehddnr-ynat
This model is a fine-tuned version of [klue/bert-base](https://huggingface.co/klue/bert-base) on the klue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3587
- F1: 0.8721
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 256
- eval_batch_size: 256
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 179 | 0.4398 | 0.8548 |
| No log | 2.0 | 358 | 0.3587 | 0.8721 |
| 0.3859 | 3.0 | 537 | 0.3639 | 0.8707 |
| 0.3859 | 4.0 | 716 | 0.3592 | 0.8692 |
| 0.3859 | 5.0 | 895 | 0.3646 | 0.8717 |
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
bert-base-multilingual-cased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"mn",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"th",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4,749,504 | 2021-07-29T01:31:21Z | # ehdwns1516/bart_finetuned_xsum
* This model has been trained as a [xsum dataset](https://huggingface.co/datasets/xsum).
* Input text what you want to summarize.
review generator DEMO: [Ainize DEMO](https://main-text-summarizer-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/text_summarizer)
## Overview
Language model: [facebook/bart-large](https://huggingface.co/facebook/bart-large)
Language: English
Training data: [xsum dataset](https://huggingface.co/datasets/xsum)
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/bart_finetuned_xsum-notebook)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/bart_finetuned_xsum")
model = AutoModelForSeq2SeqLM.from_pretrained("ehdwns1516/bart_finetuned_xsum")
summarizer = pipeline(
"summarization",
model="ehdwns1516/bart_finetuned_xsum",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = summarizer(context)[0]
```
|
bert-base-multilingual-uncased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"multilingual",
"af",
"sq",
"ar",
"an",
"hy",
"ast",
"az",
"ba",
"eu",
"bar",
"be",
"bn",
"inc",
"bs",
"br",
"bg",
"my",
"ca",
"ceb",
"ce",
"zh",
"cv",
"hr",
"cs",
"da",
"nl",
"en",
"et",
"fi",
"fr",
"gl",
"ka",
"de",
"el",
"gu",
"ht",
"he",
"hi",
"hu",
"is",
"io",
"id",
"ga",
"it",
"ja",
"jv",
"kn",
"kk",
"ky",
"ko",
"la",
"lv",
"lt",
"roa",
"nds",
"lm",
"mk",
"mg",
"ms",
"ml",
"mr",
"min",
"ne",
"new",
"nb",
"nn",
"oc",
"fa",
"pms",
"pl",
"pt",
"pa",
"ro",
"ru",
"sco",
"sr",
"scn",
"sk",
"sl",
"aze",
"es",
"su",
"sw",
"sv",
"tl",
"tg",
"ta",
"tt",
"te",
"tr",
"uk",
"ud",
"uz",
"vi",
"vo",
"war",
"cy",
"fry",
"pnb",
"yo",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 328,585 | 2021-08-04T07:59:45Z | # ehdwns1516/bert-base-uncased_SWAG
* This model has been trained as a [SWAG dataset](https://huggingface.co/ehdwns1516/bert-base-uncased_SWAG).
* Sentence Inference Multiple Choice DEMO: [Ainize DEMO](https://main-sentence-inference-multiple-choice-ehdwns1516.endpoint.ainize.ai/)
* Sentence Inference Multiple Choice API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/sentence_inference_multiple_choice)
## Overview
Language model: [bert-base-uncased](https://huggingface.co/bert-base-uncased)
Language: English
Training data: [SWAG dataset](https://huggingface.co/datasets/swag)
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/Multiple_choice_SWAG_finetunning)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelForMultipleChoice
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/bert-base-uncased_SWAG")
model = AutoModelForMultipleChoice.from_pretrained("ehdwns1516/bert-base-uncased_SWAG")
def run_model(candicates_count, context: str, candicates: list[str]):
assert len(candicates) == candicates_count, "you need " + candicates_count + " candidates"
choices_inputs = []
for c in candicates:
text_a = "" # empty context
text_b = context + " " + c
inputs = tokenizer(
text_a,
text_b,
add_special_tokens=True,
max_length=128,
padding="max_length",
truncation=True,
return_overflowing_tokens=True,
)
choices_inputs.append(inputs)
input_ids = torch.LongTensor([x["input_ids"] for x in choices_inputs])
output = model(input_ids=input_ids)
return {"result": candicates[torch.argmax(output.logits).item()]}
items = list()
count = 4 # candicates count
context = "your context"
for i in range(int(count)):
items.append("sentence")
result = run_model(count, context, items)
```
|
bert-base-uncased | [
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 59,663,489 | 2021-07-22T05:05:27Z | # gpt2_review_star1
* This model has been trained as a review_body dataset with a star of 1 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
* Input text what you want to generate review.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
review generator DEMO: [Ainize DEMO](https://main-review-generator-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/review_generator)
## Model links for each 1 to 5 star
* [ehdwns1516/gpt2_review_star1](https://huggingface.co/ehdwns1516/gpt2_review_star1)
* [ehdwns1516/gpt2_review_star2](https://huggingface.co/ehdwns1516/gpt2_review_star2)
* [ehdwns1516/gpt2_review_star3](https://huggingface.co/ehdwns1516/gpt2_review_star3)
* [ehdwns1516/gpt2_review_star4](https://huggingface.co/ehdwns1516/gpt2_review_star4)
* [ehdwns1516/gpt2_review_star5](https://huggingface.co/ehdwns1516/gpt2_review_star5)
## Overview
Language model: [gpt2](https://huggingface.co/gpt2)
Language: English
Training data: review_body dataset with a star of 1 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/gpt2_review_fine-tunning_note)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/gpt2_review_star1")
model = AutoModelWithLMHead.from_pretrained("ehdwns1516/gpt2_review_star1")
generator = pipeline(
"text-generation",
model="ehdwns1516/gpt2_review_star1",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = generator(context)[0]
```
|
bert-large-cased-whole-word-masking-finetuned-squad | [
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bert",
"question-answering",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8,214 | 2021-07-22T05:09:10Z | # gpt2_review_star2
* This model has been trained as a review_body dataset with a star of 2 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
* Input text what you want to generate review.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
review generator DEMO: [Ainize DEMO](https://main-review-generator-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/review_generator)
## Model links for each 1 to 5 star
* [ehdwns1516/gpt2_review_star1](https://huggingface.co/ehdwns1516/gpt2_review_star1)
* [ehdwns1516/gpt2_review_star2](https://huggingface.co/ehdwns1516/gpt2_review_star2)
* [ehdwns1516/gpt2_review_star3](https://huggingface.co/ehdwns1516/gpt2_review_star3)
* [ehdwns1516/gpt2_review_star4](https://huggingface.co/ehdwns1516/gpt2_review_star4)
* [ehdwns1516/gpt2_review_star5](https://huggingface.co/ehdwns1516/gpt2_review_star5)
## Overview
Language model: [gpt2](https://huggingface.co/gpt2)
Language: English
Training data: review_body dataset with a star of 2 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/gpt2_review_fine-tunning_note)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/gpt2_review_star2")
model = AutoModelWithLMHead.from_pretrained("ehdwns1516/gpt2_review_star2")
generator = pipeline(
"text-generation",
model="ehdwns1516/gpt2_review_star2",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = generator(context)[0]
```
|
bert-large-cased-whole-word-masking | [
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2,316 | 2021-07-22T05:09:23Z | # gpt2_review_star3
* This model has been trained as a review_body dataset with a star of 3 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
* Input text what you want to generate review.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
review generator DEMO: [Ainize DEMO](https://main-review-generator-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/review_generator)
## Model links for each 1 to 5 star
* [ehdwns1516/gpt2_review_star1](https://huggingface.co/ehdwns1516/gpt2_review_star1)
* [ehdwns1516/gpt2_review_star2](https://huggingface.co/ehdwns1516/gpt2_review_star2)
* [ehdwns1516/gpt2_review_star3](https://huggingface.co/ehdwns1516/gpt2_review_star3)
* [ehdwns1516/gpt2_review_star4](https://huggingface.co/ehdwns1516/gpt2_review_star4)
* [ehdwns1516/gpt2_review_star5](https://huggingface.co/ehdwns1516/gpt2_review_star5)
## Overview
Language model: [gpt2](https://huggingface.co/gpt2)
Language: English
Training data: review_body dataset with a star of 3 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/gpt2_review_fine-tunning_note)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/gpt2_review_star3")
model = AutoModelWithLMHead.from_pretrained("ehdwns1516/gpt2_review_star3")
generator = pipeline(
"text-generation",
model="ehdwns1516/gpt2_review_star3",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = generator(context)[0]
```
|
bert-large-cased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 388,769 | null | # gpt2_review_star4
* This model has been trained as a review_body dataset with a star of 4 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
* Input text what you want to generate review.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
review generator DEMO: [Ainize DEMO](https://main-review-generator-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/review_generator)
## Model links for each 1 to 5 star
* [ehdwns1516/gpt2_review_star1](https://huggingface.co/ehdwns1516/gpt2_review_star1)
* [ehdwns1516/gpt2_review_star2](https://huggingface.co/ehdwns1516/gpt2_review_star2)
* [ehdwns1516/gpt2_review_star3](https://huggingface.co/ehdwns1516/gpt2_review_star3)
* [ehdwns1516/gpt2_review_star4](https://huggingface.co/ehdwns1516/gpt2_review_star4)
* [ehdwns1516/gpt2_review_star5](https://huggingface.co/ehdwns1516/gpt2_review_star5)
## Overview
Language model: [gpt2](https://huggingface.co/gpt2)
Language: English
Training data: review_body dataset with a star of 4 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/gpt2_review_fine-tunning_note)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/gpt2_review_star3")
model = AutoModelWithLMHead.from_pretrained("ehdwns1516/gpt2_review_star3")
generator = pipeline(
"text-generation",
model="ehdwns1516/gpt2_review_star4",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = generator(context)[0]
```
|
bert-large-uncased-whole-word-masking-finetuned-squad | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"question-answering",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 480,510 | 2021-07-22T05:09:51Z | # gpt2_review_star5
* This model has been trained as a review_body dataset with a star of 5 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
* Input text what you want to generate review.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
review generator DEMO: [Ainize DEMO](https://main-review-generator-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/review_generator)
## Model links for each 1 to 5 star
* [ehdwns1516/gpt2_review_star1](https://huggingface.co/ehdwns1516/gpt2_review_star1)
* [ehdwns1516/gpt2_review_star2](https://huggingface.co/ehdwns1516/gpt2_review_star2)
* [ehdwns1516/gpt2_review_star3](https://huggingface.co/ehdwns1516/gpt2_review_star3)
* [ehdwns1516/gpt2_review_star4](https://huggingface.co/ehdwns1516/gpt2_review_star4)
* [ehdwns1516/gpt2_review_star5](https://huggingface.co/ehdwns1516/gpt2_review_star5)
## Overview
Language model: [gpt2](https://huggingface.co/gpt2)
Language: English
Training data: review_body dataset with a star of 5 in the [amazon_review dataset](https://huggingface.co/datasets/amazon_reviews_multi).
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/gpt2_review_fine-tunning_note)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/gpt2_review_star5")
model = AutoModelWithLMHead.from_pretrained("ehdwns1516/gpt2_review_star5")
generator = pipeline(
"text-generation",
model="ehdwns1516/gpt2_review_star5",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = generator(context)[0]
```
|
bert-large-uncased-whole-word-masking | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 76,685 | 2021-07-22T01:08:42Z | # ehdwns1516/gpt3-kor-based_gpt2_review_SR1
* This model has been trained Korean dataset as a star of 1 in the [naver shopping reivew dataset](https://github.com/bab2min/corpus/tree/master/sentiment).
* Input text what you want to generate review.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
review generator DEMO: [Ainize DEMO](https://main-review-generator-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/review_generator)
## Model links for each 1 to 5 star
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR1](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR1)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR2](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR2)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR3](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR3)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR4](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR4)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR5](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR5)
## Overview
Language model: [gpt3-kor-small_based_on_gpt2](https://huggingface.co/kykim/gpt3-kor-small_based_on_gpt2)
Language: Korean
Training data: review_body dataset with a star of 1 in the [naver shopping reivew dataset](https://github.com/bab2min/corpus/tree/master/sentiment).
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/gpt2_review_fine-tunning_note)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/gpt3-kor-based_gpt2_review_SR1")
model = AutoModelWithLMHead.from_pretrained("ehdwns1516/gpt3-kor-based_gpt2_review_SR1")
generator = pipeline(
"text-generation",
model="ehdwns1516/gpt3-kor-based_gpt2_review_SR1",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = generator(context)[0]
```
|
bert-large-uncased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,058,496 | 2021-07-22T01:08:50Z | # ehdwns1516/gpt3-kor-based_gpt2_review_SR2
* This model has been trained Korean dataset as a star of 2 in the [naver shopping reivew dataset](https://github.com/bab2min/corpus/tree/master/sentiment).
* Input text what you want to generate review.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
review generator DEMO: [Ainize DEMO](https://main-review-generator-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/review_generator)
## Model links for each 1 to 5 star
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR1](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR1)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR2](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR2)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR3](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR3)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR4](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR4)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR5](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR5)
## Overview
Language model: [gpt3-kor-small_based_on_gpt2](https://huggingface.co/kykim/gpt3-kor-small_based_on_gpt2)
Language: Korean
Training data: review_body dataset with a star of 2 in the [naver shopping reivew dataset](https://github.com/bab2min/corpus/tree/master/sentiment).
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/gpt2_review_fine-tunning_note)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/gpt3-kor-based_gpt2_review_SR2")
model = AutoModelWithLMHead.from_pretrained("ehdwns1516/gpt3-kor-based_gpt2_review_SR2")
generator = pipeline(
"text-generation",
model="ehdwns1516/gpt3-kor-based_gpt2_review_SR2",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = generator(context)[0]
```
|
camembert-base | [
"pytorch",
"tf",
"safetensors",
"camembert",
"fill-mask",
"fr",
"dataset:oscar",
"arxiv:1911.03894",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"CamembertForMaskedLM"
],
"model_type": "camembert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,440,898 | 2021-07-22T01:08:59Z | # ehdwns1516/gpt3-kor-based_gpt2_review_SR3
* This model has been trained Korean dataset as a star of 3 in the [naver shopping reivew dataset](https://github.com/bab2min/corpus/tree/master/sentiment).
* Input text what you want to generate review.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
review generator DEMO: [Ainize DEMO](https://main-review-generator-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/review_generator)
## Model links for each 1 to 5 star
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR1](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR1)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR2](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR2)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR3](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR3)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR4](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR4)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR5](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR5)
## Overview
Language model: [gpt3-kor-small_based_on_gpt2](https://huggingface.co/kykim/gpt3-kor-small_based_on_gpt2)
Language: Korean
Training data: review_body dataset with a star of 3 in the [naver shopping reivew dataset](https://github.com/bab2min/corpus/tree/master/sentiment).
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/gpt2_review_fine-tunning_note)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/gpt3-kor-based_gpt2_review_SR3")
model = AutoModelWithLMHead.from_pretrained("ehdwns1516/gpt3-kor-based_gpt2_review_SR3")
generator = pipeline(
"text-generation",
model="ehdwns1516/gpt3-kor-based_gpt2_review_SR3",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = generator(context)[0]
```
|
ctrl | [
"pytorch",
"tf",
"ctrl",
"en",
"arxiv:1909.05858",
"arxiv:1910.09700",
"transformers",
"license:bsd-3-clause",
"has_space"
] | null | {
"architectures": null,
"model_type": "ctrl",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 17,007 | 2021-07-22T01:10:00Z | # ehdwns1516/gpt3-kor-based_gpt2_review_SR4
* This model has been trained Korean dataset as a star of 4 in the [naver shopping reivew dataset](https://github.com/bab2min/corpus/tree/master/sentiment).
* Input text what you want to generate review.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
review generator DEMO: [Ainize DEMO](https://main-review-generator-ehdwns1516.endpoint.ainize.ai/)
review generator API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/review_generator)
## Model links for each 1 to 5 star
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR1](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR1)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR2](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR2)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR3](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR3)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR4](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR4)
* [ehdwns1516/gpt3-kor-based_gpt2_review_SR5](https://huggingface.co/ehdwns1516/gpt3-kor-based_gpt2_review_SR5)
## Overview
Language model: [gpt3-kor-small_based_on_gpt2](https://huggingface.co/kykim/gpt3-kor-small_based_on_gpt2)
Language: Korean
Training data: review_body dataset with a star of 4 in the [naver shopping reivew dataset](https://github.com/bab2min/corpus/tree/master/sentiment).
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/gpt2_review_fine-tunning_note)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/gpt3-kor-based_gpt2_review_SR4")
model = AutoModelWithLMHead.from_pretrained("ehdwns1516/gpt3-kor-based_gpt2_review_SR4")
generator = pipeline(
"text-generation",
model="ehdwns1516/gpt3-kor-based_gpt2_review_SR4",
tokenizer=tokenizer
)
context = "your context"
result = dict()
result[0] = generator(context)[0]
```
|
distilbert-base-cased | [
"pytorch",
"tf",
"onnx",
"distilbert",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1910.01108",
"transformers",
"license:apache-2.0",
"has_space"
] | null | {
"architectures": null,
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 574,859 | 2021-07-13T05:06:28Z | # klue-roberta-base-kornli
* This model trained with Korean dataset.
* Input premise sentence and hypothesis sentence.
* You can use English, but don't expect accuracy.
* If the context is longer than 1200 characters, the context may be cut in the middle and the result may not come out well.
klue-roberta-base-kornli DEMO: [Ainize DEMO](https://main-klue-roberta-base-kornli-ehdwns1516.endpoint.ainize.ai/)
klue-roberta-base-kornli API: [Ainize API](https://ainize.web.app/redirect?git_repo=https://github.com/ehdwns1516/klue-roberta-base_kornli)
## Overview
Language model: [klue/roberta-base](https://huggingface.co/klue/roberta-base)
Language: Korean
Training data: [kakaobrain KorNLI](https://github.com/kakaobrain/KorNLUDatasets/tree/master/KorNLI)
Eval data: [kakaobrain KorNLI](https://github.com/kakaobrain/KorNLUDatasets/tree/master/KorNLI)
Code: See [Ainize Workspace](https://ainize.ai/workspace/create?imageId=hnj95592adzr02xPTqss&git=https://github.com/ehdwns1516/klue-roberta-base_finetunning_ex)
## Usage
## In Transformers
```
from transformers import AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("ehdwns1516/klue-roberta-base-kornli")
classifier = pipeline(
"text-classification",
model="ehdwns1516/klue-roberta-base-kornli",
return_all_scores=True,
)
premise = "your premise"
hypothesis = "your hypothesis"
result = dict()
result[0] = classifier(premise + tokenizer.sep_token + hypothesis)[0]
```
|
13048909972/wav2vec2-common_voice-tr-demo | [
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"transformers"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2021-09-05T00:03:22Z | ---
tags:
- spacy
- token-classification
language:
- is
model-index:
- name: is_ner_mim_sm
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.8029028187
- name: NER Recall
type: recall
value: 0.7796160131
- name: NER F Score
type: f_score
value: 0.7910880829
---
| Feature | Description |
| --- | --- |
| **Name** | `is_ner_mim_sm` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.1.1,<3.2.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (8 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `Date`, `Location`, `Miscellaneous`, `Money`, `Organization`, `Percent`, `Person`, `Time` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 79.11 |
| `ENTS_P` | 80.29 |
| `ENTS_R` | 77.96 |
| `TOK2VEC_LOSS` | 1079057.14 |
| `NER_LOSS` | 792494.23 | |
AdapterHub/roberta-base-pf-wic | [
"roberta",
"en",
"arxiv:2104.08247",
"adapter-transformers",
"text-classification",
"adapterhub:wordsence/wic"
] | text-classification | {
"architectures": null,
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- espnet
- audio
- text-to-speech
language: ja
datasets:
- jsut
license: cc-by-4.0
---
## Example ESPnet2 TTS model
### `kan-bayashi/jsut_tts_train_conformer_fastspeech2_transformer_teacher_raw_phn_jaconv_pyopenjtalk_accent_with_pause_train.loss.ave`
♻️ Imported from https://zenodo.org/record/4433198/
This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Adrianaforididk/Jinx | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- espnet
- audio
- text-to-speech
language: ja
datasets:
- jsut
license: cc-by-4.0
---
## ESPnet2 TTS pretrained model
### `kan-bayashi/jsut_tts_train_vits_raw_phn_jaconv_pyopenjtalk_accent_with_pause_train.total_count.ave`
♻️ Imported from https://zenodo.org/record/5414980/
This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Advertisement/FischlUWU | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- espnet
- audio
- text-to-speech
language: ja
datasets:
- jsut
license: cc-by-4.0
---
## ESPnet2 TTS pretrained model
### `kan-bayashi/jsut_tts_train_vits_raw_phn_jaconv_pyopenjtalk_prosody_train.total_count.ave`
♻️ Imported from https://zenodo.org/record/5521354/
This model was trained by kan-bayashi using jsut/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Aftabhussain/Tomato_Leaf_Classifier | [
"pytorch",
"tensorboard",
"vit",
"image-classification",
"transformers",
"huggingpics",
"model-index",
"autotrain_compatible"
] | image-classification | {
"architectures": [
"ViTForImageClassification"
],
"model_type": "vit",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 50 | null | ---
tags:
- espnet
- audio
- text-to-speech
language: en
datasets:
- libritts
license: cc-by-4.0
---
## Example ESPnet2 TTS model
### `kan-bayashi/libritts_gst+xvector_trasnformer`
♻️ Imported from https://zenodo.org/record/4409702/
This model was trained by kan-bayashi using libritts/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Ahmed59/Demo-Team-5-SIAD | [
"tf",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 14 | null | ---
tags:
- espnet
- audio
- text-to-speech
language: en
datasets:
- libritts
license: cc-by-4.0
---
## Example ESPnet2 TTS model
### `kan-bayashi/libritts_xvector_conformer_fastspeech2`
♻️ Imported from https://zenodo.org/record/4418754/
This model was trained by kan-bayashi using libritts/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Ahren09/distilbert-base-uncased-finetuned-cola | [
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 33 | null | ---
tags:
- espnet
- audio
- text-to-speech
language: en
datasets:
- ljspeech
license: cc-by-4.0
---
## Example ESPnet2 TTS model
### `kan-bayashi/ljspeech_fastspeech2`
♻️ Imported from https://zenodo.org/record/4036272/
This model was trained by kan-bayashi using ljspeech/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Akari/albert-base-v2-finetuned-squad | [
"pytorch",
"tensorboard",
"albert",
"question-answering",
"dataset:squad_v2",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 13 | null | ---
tags:
- espnet
- audio
- text-to-speech
language: en
datasets:
- vctk
license: cc-by-4.0
---
## Example ESPnet2 TTS model
### `kan-bayashi/vctk_gst_fastspeech2`
♻️ Imported from https://zenodo.org/record/4036266/
This model was trained by kan-bayashi using vctk/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Akashpb13/Central_kurdish_xlsr | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"ckb",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"robust-speech-event",
"model_for_talk",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
tags:
- espnet
- audio
- text-to-speech
language: en
datasets:
- vctk
license: cc-by-4.0
---
## Example ESPnet2 TTS model
### `kan-bayashi/vctk_tts_train_gst_fastspeech2_raw_phn_tacotron_g2p_en_no_space_train.loss.ave`
♻️ Imported from https://zenodo.org/record/4036266/
This model was trained by kan-bayashi using vctk/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Akashpb13/Galician_xlsr | [
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"gl",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"robust-speech-event",
"model_for_talk",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
tags:
- espnet
- audio
- text-to-speech
language: en
datasets:
- vctk
license: cc-by-4.0
---
## Example ESPnet2 TTS model
### `kan-bayashi/vctk_tts_train_gst_fastspeech_raw_phn_tacotron_g2p_en_no_space_train.loss.best`
♻️ Imported from https://zenodo.org/record/3986241/
This model was trained by kan-bayashi using vctk/tts1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
@inproceedings{hayashi2020espnet,
title={{Espnet-TTS}: Unified, reproducible, and integratable open source end-to-end text-to-speech toolkit},
author={Hayashi, Tomoki and Yamamoto, Ryuichi and Inoue, Katsuki and Yoshimura, Takenori and Watanabe, Shinji and Toda, Tomoki and Takeda, Kazuya and Zhang, Yu and Tan, Xu},
booktitle={Proceedings of IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP)},
pages={7654--7658},
year={2020},
organization={IEEE}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
AkshatSurolia/ViT-FaceMask-Finetuned | [
"pytorch",
"safetensors",
"vit",
"image-classification",
"dataset:Face-Mask18K",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | image-classification | {
"architectures": [
"ViTForImageClassification"
],
"model_type": "vit",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 40 | null | ---
tags:
- espnet
- audio
- automatic-speech-recognition
language: en
datasets:
- fsc
license: cc-by-4.0
---
## ESPnet2 SLU pretrained model
### `siddhana/fsc_asr_train_asr_hubert_transformer_adam_specaug_raw_en_word_valid.acc.ave_5best`
♻️ Imported from https://zenodo.org/record/5590204
This model was trained by siddhana using fsc/asr1 recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```python
# coming soon
```
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson {Enrique Yalta Soplin} and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Enrique Yalta Soplin and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
Aleksandar/distilbert-srb-ner-setimes | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
language:
- "zh"
thumbnail: "https://user-images.githubusercontent.com/9592150/97142000-cad08e00-179a-11eb-88df-aff9221482d8.png"
tags:
- "chinese"
- "classical chinese"
- "literary chinese"
- "ancient chinese"
- "bert"
- "pytorch"
- "punctuation marker"
license: "apache-2.0"
pipeline_tag: "token-classification"
widget:
- text: "及秦始皇灭先代典籍焚书坑儒天下学士逃难解散我先人用藏其家书于屋壁汉室龙兴开设学校旁求儒雅以阐大猷济南伏生年过九十失其本经口以传授裁二十馀篇以其上古之书谓之尚书百篇之义世莫得闻"
---
# Guwen Punc
A Classical Chinese Punctuation Marker.
See also:
<a href="https://github.com/ethan-yt/guwen-models">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwen-models&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/cclue/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=cclue&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a>
<a href="https://github.com/ethan-yt/guwenbert/">
<img align="center" width="400" src="https://github-readme-stats.vercel.app/api/pin/?username=ethan-yt&repo=guwenbert&bg_color=30,e96443,904e95&title_color=fff&text_color=fff&icon_color=fff&show_owner=true" />
</a> |
AlekseyKulnevich/Pegasus-Summarization | [
"pytorch",
"pegasus",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"PegasusForConditionalGeneration"
],
"model_type": "pegasus",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: apache-2.0
tags:
- stylegan2
- image-generation
---
# AniCharaGAN: Anime Character Generation with StyleGAN2
[](https://github.com/eugenesiow/practical-ml)
This model uses the awesome lucidrains’s [stylegan2-pytorch](https://github.com/lucidrains/stylegan2-pytorch) library to train a model on a private anime character dataset to generate full-body 256x256 female anime characters.
Here are some samples:

## Model description
The model generates 256x256, square, white background, full-body anime characters. It is trained using [stylegan2-pytorch](https://github.com/lucidrains/stylegan2-pytorch). It is trained to 150 epochs.
## Intended uses & limitations
You can use the model for generating anime characters and than use a super resolution library like [super_image](https://github.com/eugenesiow/super-image) to upscale.
### How to use
[](https://colab.research.google.com/github/eugenesiow/practical-ml/blob/master/notebooks/Anime_Character_Generation_with_StyleGAN2.ipynb "Open in Colab")
Install the dependencies:
```bash
pip install -q stylegan2_pytorch==1.5.10
```
Here is how to generate images:
```python
import torch
from torchvision.utils import save_image
from stylegan2_pytorch import ModelLoader
from pathlib import Path
Path('./models/ani-chara-gan/').mkdir(parents=True, exist_ok=True)
torch.hub.download_url_to_file('https://huggingface.co/eugenesiow/ani-chara-gan/resolve/main/model.pt',
'./models/ani-chara-gan/model_150.pt')
torch.hub.download_url_to_file('https://huggingface.co/eugenesiow/ani-chara-gan/resolve/main/.config.json',
'./models/ani-chara-gan/.config.json')
loader = ModelLoader(
base_dir = './', name = 'ani-chara-gan'
)
noise = torch.randn(1, 256).cuda() # noise
styles = loader.noise_to_styles(noise, trunc_psi = 0.7) # pass through mapping network
images = loader.styles_to_images(styles) # call the generator on intermediate style vectors
save_image(images, './sample.jpg')
```
## BibTeX entry and citation info
The model is part of the [practical-ml](https://github.com/eugenesiow/practical-ml) repository.
[](https://github.com/eugenesiow/practical-ml) |
Alerosae/SocratesGPT-2 | [
"pytorch",
"gpt2",
"feature-extraction",
"en",
"transformers",
"text-generation"
] | text-generation | {
"architectures": [
"GPT2Model"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: apache-2.0
tags:
- super-image
- image-super-resolution
datasets:
- eugenesiow/Div2k
- eugenesiow/Set5
- eugenesiow/Set14
- eugenesiow/BSD100
- eugenesiow/Urban100
metrics:
- pnsr
- ssim
---
# Lightweight Image Super-Resolution with Adaptive Weighted Learning Network (AWSRN)
AWSRN model pre-trained on DIV2K (800 images training, augmented to 4000 images, 100 images validation) for 2x, 3x and 4x image super resolution. It was introduced in the paper [Lightweight Image Super-Resolution with Adaptive Weighted Learning Network](https://arxiv.org/abs/1904.02358) by Wang et al. (2019) and first released in [this repository](https://github.com/ChaofWang/AWSRN).
The goal of image super resolution is to restore a high resolution (HR) image from a single low resolution (LR) image. The image below shows the ground truth (HR), the bicubic upscaling and model upscaling.

## Model description
Deep learning has been successfully applied to the single-image super-resolution (SISR) task with great performance in recent years. However, most convolutional neural network based SR models require heavy computation, which limit their real-world applications. In this work, a lightweight SR network, named Adaptive Weighted Super-Resolution Network (AWSRN), is proposed for SISR to address this issue. A novel local fusion block (LFB) is designed in AWSRN for efficient residual learning, which consists of stacked adaptive weighted residual units (AWRU) and a local residual fusion unit (LRFU). Moreover, an adaptive weighted multi-scale (AWMS) module is proposed to make full use of features in reconstruction layer. AWMS consists of several different scale convolutions, and the redundancy scale branch can be removed according to the contribution of adaptive weights in AWMS for lightweight network. The experimental results on the commonly used datasets show that the proposed lightweight AWSRN achieves superior performance on ×2, ×3, ×4, and ×8 scale factors to state-of-the-art methods with similar parameters and computational overhead.
This model also applies the balanced attention (BAM) method invented by [Wang et al. (2021)](https://arxiv.org/abs/2104.07566) to further improve the results.
## Intended uses & limitations
You can use the pre-trained models for upscaling your images 2x, 3x and 4x. You can also use the trainer to train a model on your own dataset.
### How to use
The model can be used with the [super_image](https://github.com/eugenesiow/super-image) library:
```bash
pip install super-image
```
Here is how to use a pre-trained model to upscale your image:
```python
from super_image import AwsrnModel, ImageLoader
from PIL import Image
import requests
url = 'https://paperswithcode.com/media/datasets/Set5-0000002728-07a9793f_zA3bDjj.jpg'
image = Image.open(requests.get(url, stream=True).raw)
model = AwsrnModel.from_pretrained('eugenesiow/awsrn-bam', scale=2) # scale 2, 3 and 4 models available
inputs = ImageLoader.load_image(image)
preds = model(inputs)
ImageLoader.save_image(preds, './scaled_2x.png') # save the output 2x scaled image to `./scaled_2x.png`
ImageLoader.save_compare(inputs, preds, './scaled_2x_compare.png') # save an output comparing the super-image with a bicubic scaling
```
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Upscale_Images_with_Pretrained_super_image_Models.ipynb "Open in Colab")
## Training data
The models for 2x, 3x and 4x image super resolution were pretrained on [DIV2K](https://huggingface.co/datasets/eugenesiow/Div2k), a dataset of 800 high-quality (2K resolution) images for training, augmented to 4000 images and uses a dev set of 100 validation images (images numbered 801 to 900).
## Training procedure
### Preprocessing
We follow the pre-processing and training method of [Wang et al.](https://arxiv.org/abs/2104.07566).
Low Resolution (LR) images are created by using bicubic interpolation as the resizing method to reduce the size of the High Resolution (HR) images by x2, x3 and x4 times.
During training, RGB patches with size of 64×64 from the LR input are used together with their corresponding HR patches.
Data augmentation is applied to the training set in the pre-processing stage where five images are created from the four corners and center of the original image.
We need the huggingface [datasets](https://huggingface.co/datasets?filter=task_ids:other-other-image-super-resolution) library to download the data:
```bash
pip install datasets
```
The following code gets the data and preprocesses/augments the data.
```python
from datasets import load_dataset
from super_image.data import EvalDataset, TrainDataset, augment_five_crop
augmented_dataset = load_dataset('eugenesiow/Div2k', 'bicubic_x4', split='train')\
.map(augment_five_crop, batched=True, desc="Augmenting Dataset") # download and augment the data with the five_crop method
train_dataset = TrainDataset(augmented_dataset) # prepare the train dataset for loading PyTorch DataLoader
eval_dataset = EvalDataset(load_dataset('eugenesiow/Div2k', 'bicubic_x4', split='validation')) # prepare the eval dataset for the PyTorch DataLoader
```
### Pretraining
The model was trained on GPU. The training code is provided below:
```python
from super_image import Trainer, TrainingArguments, AwsrnModel, AwsrnConfig
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=1000, # total number of training epochs
)
config = AwsrnConfig(
scale=4, # train a model to upscale 4x
bam=True, # apply balanced attention to the network
)
model = AwsrnModel(config)
trainer = Trainer(
model=model, # the instantiated model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=eval_dataset # evaluation dataset
)
trainer.train()
```
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Train_super_image_Models.ipynb "Open in Colab")
## Evaluation results
The evaluation metrics include [PSNR](https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio#Quality_estimation_with_PSNR) and [SSIM](https://en.wikipedia.org/wiki/Structural_similarity#Algorithm).
Evaluation datasets include:
- Set5 - [Bevilacqua et al. (2012)](https://huggingface.co/datasets/eugenesiow/Set5)
- Set14 - [Zeyde et al. (2010)](https://huggingface.co/datasets/eugenesiow/Set14)
- BSD100 - [Martin et al. (2001)](https://huggingface.co/datasets/eugenesiow/BSD100)
- Urban100 - [Huang et al. (2015)](https://huggingface.co/datasets/eugenesiow/Urban100)
The results columns below are represented below as `PSNR/SSIM`. They are compared against a Bicubic baseline.
|Dataset |Scale |Bicubic |awsrn-bam |
|--- |--- |--- |--- |
|Set5 |2x |33.64/0.9292 |**37.99/0.9606** |
|Set5 |3x |30.39/0.8678 |**35.05/0.9403** |
|Set5 |4x |28.42/0.8101 |**32.13/0.8947** |
|Set14 |2x |30.22/0.8683 |**33.66/0.918** |
|Set14 |3x |27.53/0.7737 |**31.01/0.8581** |
|Set14 |4x |25.99/0.7023 |**28.75/0.7851** |
|BSD100 |2x |29.55/0.8425 |**33.76/0.9253** |
|BSD100 |3x |27.20/0.7382 |**29.63/0.8188** |
|BSD100 |4x |25.96/0.6672 |**28.51/0.7647** |
|Urban100 |2x |26.66/0.8408 |**31.95/0.9265** |
|Urban100 |3x | |**29.14/0.871** |
|Urban100 |4x |23.14/0.6573 |**26.03/0.7838** |

You can find a notebook to easily run evaluation on pretrained models below:
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Evaluate_Pretrained_super_image_Models.ipynb "Open in Colab")
## BibTeX entry and citation info
```bibtex
@misc{wang2021bam,
title={BAM: A Lightweight and Efficient Balanced Attention Mechanism for Single Image Super Resolution},
author={Fanyi Wang and Haotian Hu and Cheng Shen},
year={2021},
eprint={2104.07566},
archivePrefix={arXiv},
primaryClass={eess.IV}
}
```
```bibtex
@article{wang2019lightweight,
title={Lightweight Image Super-Resolution with Adaptive Weighted Learning Network},
author={Wang, Chaofeng and Li, Zhen and Shi, Jun},
journal={arXiv preprint arXiv:1904.02358},
year={2019
}
``` |
Alexander-Learn/bert-finetuned-ner-accelerate | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
license: apache-2.0
tags:
- super-image
- image-super-resolution
datasets:
- eugenesiow/Div2k
- eugenesiow/Set5
- eugenesiow/Set14
- eugenesiow/BSD100
- eugenesiow/Urban100
metrics:
- pnsr
- ssim
---
# Multi-Scale Deep Super-Resolution System (MDSR)
MDSR model pre-trained on DIV2K (800 images training, augmented to 4000 images, 100 images validation) for 2x, 3x and 4x image super resolution. It was introduced in the paper [Enhanced Deep Residual Networks for Single Image Super-Resolution](https://arxiv.org/abs/1707.02921) by Lim et al. (2017) and first released in [this repository](https://github.com/sanghyun-son/EDSR-PyTorch).
The goal of image super resolution is to restore a high resolution (HR) image from a single low resolution (LR) image. The image below shows the ground truth (HR), the bicubic upscaling and model upscaling.

## Model description
The MDSR is a model that uses both deeper and wider architecture (32 ResBlocks and 256 channels) to improve performance. It uses both global and local skip connections, and up-scaling is done at the end of the network. It doesn't use batch normalization layers (input and output have similar distributions, normalizing intermediate features may not be desirable) instead it uses constant scaling layers to ensure stable training. An L1 loss function (absolute error) is used instead of L2 (MSE), the authors showed better performance empirically and it requires less computation.
## Intended uses & limitations
You can use the pre-trained models for upscaling your images 2x, 3x and 4x. You can also use the trainer to train a model on your own dataset.
### How to use
The model can be used with the [super_image](https://github.com/eugenesiow/super-image) library:
```bash
pip install super-image
```
Here is how to use a pre-trained model to upscale your image:
```python
from super_image import MdsrModel, ImageLoader
from PIL import Image
import requests
url = 'https://paperswithcode.com/media/datasets/Set5-0000002728-07a9793f_zA3bDjj.jpg'
image = Image.open(requests.get(url, stream=True).raw)
model = MdsrModel.from_pretrained('eugenesiow/mdsr', scale=2) # scale 2, 3 and 4 models available
inputs = ImageLoader.load_image(image)
preds = model(inputs)
ImageLoader.save_image(preds, './scaled_2x.png') # save the output 2x scaled image to `./scaled_2x.png`
ImageLoader.save_compare(inputs, preds, './scaled_2x_compare.png') # save an output comparing the super-image with a bicubic scaling
```
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Upscale_Images_with_Pretrained_super_image_Models.ipynb "Open in Colab")
## Training data
The models for 2x, 3x and 4x image super resolution were pretrained on [DIV2K](https://huggingface.co/datasets/eugenesiow/Div2k), a dataset of 800 high-quality (2K resolution) images for training, augmented to 4000 images and uses a dev set of 100 validation images (images numbered 801 to 900).
## Training procedure
### Preprocessing
We follow the pre-processing and training method of [Wang et al.](https://arxiv.org/abs/2104.07566).
Low Resolution (LR) images are created by using bicubic interpolation as the resizing method to reduce the size of the High Resolution (HR) images by x2, x3 and x4 times.
During training, RGB patches with size of 64×64 from the LR input are used together with their corresponding HR patches.
Data augmentation is applied to the training set in the pre-processing stage where five images are created from the four corners and center of the original image.
We need the huggingface [datasets](https://huggingface.co/datasets?filter=task_ids:other-other-image-super-resolution) library to download the data:
```bash
pip install datasets
```
The following code gets the data and preprocesses/augments the data.
```python
from datasets import load_dataset
from super_image.data import EvalDataset, TrainDataset, augment_five_crop
augmented_dataset = load_dataset('eugenesiow/Div2k', 'bicubic_x4', split='train')\
.map(augment_five_crop, batched=True, desc="Augmenting Dataset") # download and augment the data with the five_crop method
train_dataset = TrainDataset(augmented_dataset) # prepare the train dataset for loading PyTorch DataLoader
eval_dataset = EvalDataset(load_dataset('eugenesiow/Div2k', 'bicubic_x4', split='validation')) # prepare the eval dataset for the PyTorch DataLoader
```
### Pretraining
The model was trained on GPU. The training code is provided below:
```python
from super_image import Trainer, TrainingArguments, MdsrModel, MdsrConfig
training_args = TrainingArguments(
output_dir='./results', # output directory
num_train_epochs=1000, # total number of training epochs
)
config = MdsrConfig(
scale=4, # train a model to upscale 4x
)
model = MdsrModel(config)
trainer = Trainer(
model=model, # the instantiated model to be trained
args=training_args, # training arguments, defined above
train_dataset=train_dataset, # training dataset
eval_dataset=eval_dataset # evaluation dataset
)
trainer.train()
```
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Train_super_image_Models.ipynb "Open in Colab")
## Evaluation results
The evaluation metrics include [PSNR](https://en.wikipedia.org/wiki/Peak_signal-to-noise_ratio#Quality_estimation_with_PSNR) and [SSIM](https://en.wikipedia.org/wiki/Structural_similarity#Algorithm).
Evaluation datasets include:
- Set5 - [Bevilacqua et al. (2012)](https://huggingface.co/datasets/eugenesiow/Set5)
- Set14 - [Zeyde et al. (2010)](https://huggingface.co/datasets/eugenesiow/Set14)
- BSD100 - [Martin et al. (2001)](https://huggingface.co/datasets/eugenesiow/BSD100)
- Urban100 - [Huang et al. (2015)](https://huggingface.co/datasets/eugenesiow/Urban100)
The results columns below are represented below as `PSNR/SSIM`. They are compared against a Bicubic baseline.
|Dataset |Scale |Bicubic |mdsr |
|--- |--- |--- |--- |
|Set5 |2x |33.64/0.9292 |**38.04/0.9608** |
|Set5 |3x |30.39/0.8678 |**35.11/0.9406** |
|Set5 |4x |28.42/0.8101 |**32.26/0.8953** |
|Set14 |2x |30.22/0.8683 |**33.71/0.9184** |
|Set14 |3x |27.53/0.7737 |**31.06/0.8593** |
|Set14 |4x |25.99/0.7023 |**28.77/0.7856** |
|BSD100 |2x |29.55/0.8425 |**33.79/0.9256** |
|BSD100 |3x |27.20/0.7382 |**29.66/0.8196** |
|BSD100 |4x |25.96/0.6672 |**28.53/0.7653** |
|Urban100 |2x |26.66/0.8408 |**32.14/0.9283** |
|Urban100 |3x | |**29.29/0.8738** |
|Urban100 |4x |23.14/0.6573 |**26.07/0.7851** |

You can find a notebook to easily run evaluation on pretrained models below:
[](https://colab.research.google.com/github/eugenesiow/super-image-notebooks/blob/master/notebooks/Evaluate_Pretrained_super_image_Models.ipynb "Open in Colab")
## BibTeX entry and citation info
```bibtex
@article{ahn2018fast,
title={Fast, Accurate, and Lightweight Super-Resolution with Cascading Residual Network},
author={Ahn, Namhyuk and Kang, Byungkon and Sohn, Kyung-Ah},
journal={arXiv preprint arXiv:1803.08664},
year={2018}
}
``` |
Aliskin/xlm-roberta-base-finetuned-marc | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- spacy
- text-classification
language:
- en
license: mit
model-index:
- name: en_textcat_goemotions
results: []
---
# 🪐 spaCy Project: Categorization of emotions in Reddit posts (Text Classification) This project uses spaCy to train a text classifier on the [GoEmotions dataset](https://github.com/google-research/google-research/tree/master/goemotions)
| Feature | Description |
| --- | --- |
| **Name** | `en_textcat_goemotions` |
| **Version** | `0.0.1` |
| **spaCy** | `>=3.1.1,<3.2.0` |
| **Default Pipeline** | `transformer`, `textcat_multilabel` |
| **Components** | `transformer`, `textcat_multilabel` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [GoEmotions dataset](https://github.com/google-research/google-research/tree/master/goemotions) |
| **License** | `MIT` |
| **Author** | [Explosion](explosion.ai) |
> The dataset that this model is trained on has known flaws described [here](https://github.com/google-research/google-research/tree/master/goemotions#disclaimer) as well as label errors resulting from [annotator disagreement](https://www.youtube.com/watch?v=khZ5-AN-n2Y). Anyone using this model should be aware of these limitations of the dataset.
### Label Scheme
<details>
<summary>View label scheme (28 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`textcat_multilabel`** | `admiration`, `amusement`, `anger`, `annoyance`, `approval`, `caring`, `confusion`, `curiosity`, `desire`, `disappointment`, `disapproval`, `disgust`, `embarrassment`, `excitement`, `fear`, `gratitude`, `grief`, `joy`, `love`, `nervousness`, `optimism`, `pride`, `realization`, `relief`, `remorse`, `sadness`, `surprise`, `neutral` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `CATS_SCORE` | 90.22 |
| `CATS_MICRO_P` | 66.67 |
| `CATS_MICRO_R` | 47.81 |
| `CATS_MICRO_F` | 55.68 |
| `CATS_MACRO_P` | 55.00 |
| `CATS_MACRO_R` | 41.93 |
| `CATS_MACRO_F` | 46.29 |
| `CATS_MACRO_AUC` | 90.22 |
| `CATS_MACRO_AUC_PER_TYPE` | 0.00 |
| `TRANSFORMER_LOSS` | 83.51 |
| `TEXTCAT_MULTILABEL_LOSS` | 4549.84 |
|
AmirBialer/amirbialer-Classifier | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- spacy
- token-classification
language:
- pt
license: cc-by-sa-4.0
model-index:
- name: pt_udv25_portuguesebosque_trf
results:
- task:
name: TAG
type: token-classification
metrics:
- name: TAG (XPOS) Accuracy
type: accuracy
value: 0.9809207592
- task:
name: POS
type: token-classification
metrics:
- name: POS (UPOS) Accuracy
type: accuracy
value: 0.9814163239
- task:
name: MORPH
type: token-classification
metrics:
- name: Morph (UFeats) Accuracy
type: accuracy
value: 0.9733881758
- task:
name: LEMMA
type: token-classification
metrics:
- name: Lemma Accuracy
type: accuracy
value: 0.980030722
- task:
name: UNLABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Unlabeled Attachment Score (UAS)
type: f_score
value: 0.938526243
- task:
name: LABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Labeled Attachment Score (LAS)
type: f_score
value: 0.91190874
- task:
name: SENTS
type: token-classification
metrics:
- name: Sentences F-Score
type: f_score
value: 0.9582222222
---
UD v2.5 benchmarking pipeline for UD_Portuguese-Bosque
| Feature | Description |
| --- | --- |
| **Name** | `pt_udv25_portuguesebosque_trf` |
| **Version** | `0.0.1` |
| **spaCy** | `>=3.2.1,<3.3.0` |
| **Default Pipeline** | `experimental_char_ner_tokenizer`, `transformer`, `tagger`, `morphologizer`, `parser`, `experimental_edit_tree_lemmatizer` |
| **Components** | `experimental_char_ner_tokenizer`, `transformer`, `senter`, `tagger`, `morphologizer`, `parser`, `experimental_edit_tree_lemmatizer` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [Universal Dependencies v2.5](https://lindat.mff.cuni.cz/repository/xmlui/handle/11234/1-3105) (Zeman, Daniel; et al.) |
| **License** | `CC BY-SA 4.0` |
| **Author** | [Explosion](https://explosion.ai) |
### Label Scheme
<details>
<summary>View label scheme (2079 labels for 6 components)</summary>
| Component | Labels |
| --- | --- |
| **`experimental_char_ner_tokenizer`** | `TOKEN` |
| **`senter`** | `I`, `S` |
| **`tagger`** | `ADJ`, `ADP`, `ADP_ADV`, `ADP_DET`, `ADP_NUM`, `ADP_PRON`, `ADP_PROPN`, `ADV`, `ADV_PRON`, `ADV_PROPN`, `AUX`, `AUX_PRON`, `CCONJ`, `DET`, `INTJ`, `NOUN`, `NUM`, `PART`, `PART_NOUN`, `PRON`, `PRON_PRON`, `PROPN`, `PROPN_DET`, `PROPN_PROPN`, `PUNCT`, `SCONJ`, `SCONJ_DET`, `SCONJ_PRON`, `SYM`, `VERB`, `VERB_PRON`, `X` |
| **`morphologizer`** | `Definite=Ind\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Gender=Masc\|Number=Sing\|POS=NOUN`, `Gender=Masc\|Number=Sing\|POS=ADJ`, `Definite=Def\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Gender=Masc\|Number=Sing\|POS=PROPN`, `Number=Sing\|POS=PROPN`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=NOUN`, `Definite=Def\|POS=ADP\|PronType=Art`, `Gender=Fem\|Number=Sing\|POS=NOUN`, `Gender=Fem\|Number=Sing\|POS=ADJ`, `POS=PUNCT`, `NumType=Card\|POS=NUM`, `POS=ADV`, `Gender=Fem\|Number=Plur\|POS=ADJ`, `Gender=Fem\|Number=Plur\|POS=NOUN`, `Definite=Def\|Gender=Masc\|Number=Sing\|POS=ADP\|PronType=Art`, `Gender=Fem\|Number=Sing\|POS=PROPN`, `Gender=Fem\|Number=Sing\|POS=VERB\|VerbForm=Part`, `POS=ADP`, `POS=PRON\|PronType=Rel`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `POS=SCONJ`, `POS=VERB\|VerbForm=Inf`, `Definite=Def\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Art`, `Gender=Masc\|Number=Plur\|POS=ADJ`, `POS=CCONJ`, `Definite=Def\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Art`, `Definite=Def\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Definite=Ind\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Mood=Sub\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Gender=Unsp\|Number=Sing\|POS=PROPN`, `Definite=Def\|Gender=Masc\|Number=Plur\|POS=ADP\|PronType=Art`, `Gender=Masc\|Number=Plur\|POS=PRON\|PronType=Rel`, `Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `POS=ADV\|Polarity=Neg`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `POS=X`, `Gender=Masc\|Number=Plur\|POS=PRON\|PronType=Dem`, `Gender=Fem\|Number=Plur\|POS=DET\|PronType=Ind`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=PRON\|PronType=Tot`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=VERB\|VerbForm=Part`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Rel`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Gender=Fem\|Number=Plur\|POS=PRON\|PronType=Ind`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Mood=Sub\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Unsp\|Number=Plur\|POS=NOUN`, `Mood=Sub\|Number=Plur\|POS=VERB\|Person=3\|Tense=Fut\|VerbForm=Fin`, `POS=AUX\|VerbForm=Inf`, `Gender=Fem\|Number=Plur\|POS=VERB\|VerbForm=Part\|Voice=Pass`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Masc\|Number=Sing\|POS=ADP\|PronType=Dem`, `Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Dem`, `POS=VERB\|VerbForm=Ger`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=VERB\|VerbForm=Part\|Voice=Pass`, `Gender=Masc\|Number=Plur\|POS=PROPN`, `Number=Plur\|POS=AUX\|Person=3\|VerbForm=Inf`, `Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Fut\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=PRON\|PronType=Ind`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin`, `Definite=Def\|Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Art`, `POS=VERB\|VerbForm=Part`, `Gender=Masc\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Definite=Ind\|Gender=Fem\|Number=Sing\|POS=ADP\|PronType=Art`, `Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Rel`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Definite=Def\|Gender=Fem\|Number=Sing\|POS=ADP\|PronType=Art`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Masc\|Number=Sing\|POS=VERB\|VerbForm=Part\|Voice=Pass`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Nom\|Gender=Unsp\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Sub\|Number=Plur\|POS=VERB\|Person=1\|Tense=Imp\|VerbForm=Fin`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=3\|Tense=Fut\|VerbForm=Fin`, `Gender=Fem\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Gender=Fem\|Number=Plur\|POS=DET\|PronType=Prs`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Ind`, `Gender=Masc\|NumType=Ord\|Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `NumType=Ord\|POS=ADJ`, `Definite=Def\|Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Dem`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Ind`, `Gender=Unsp\|Number=Plur\|POS=ADJ`, `Gender=Fem\|Number=Sing\|POS=VERB\|VerbForm=Part\|Voice=Pass`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Fut\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=SCONJ\|PronType=Dem`, `Mood=Sub\|Number=Sing\|POS=AUX\|Person=3\|Tense=Fut\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Tot`, `Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Ind`, `Gender=Masc\|Number=Plur\|POS=VERB\|VerbForm=Part`, `Gender=Fem\|Number=Plur\|POS=VERB\|VerbForm=Part`, `Gender=Masc\|NumType=Mult\|Number=Sing\|POS=NUM`, `Gender=Unsp\|Number=Sing\|POS=PRON\|PronType=Ind`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|VerbForm=Fin`, `Gender=Fem\|Number=Plur\|POS=PRON\|PronType=Rel`, `Gender=Unsp\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Sub\|Number=Plur\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Tot`, `Gender=Masc\|Number=Sing\|POS=PROPN\|PronType=Art`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Number=Sing\|POS=VERB\|Person=3\|VerbForm=Inf`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Past\|VerbForm=Fin`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Unsp\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Mood=Cnd\|Number=Sing\|POS=AUX\|Person=3\|VerbForm=Fin`, `POS=AUX\|VerbForm=Part`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Past\|VerbForm=Fin`, `Case=Nom\|Gender=Unsp\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Gender=Unsp\|Number=Sing\|POS=PRON\|PronType=Rel`, `Number=Sing\|POS=DET\|PronType=Art`, `Definite=Def\|Gender=Fem\|Number=Plur\|POS=ADP\|PronType=Art`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Gender=Masc\|NumType=Frac\|Number=Sing\|POS=NUM`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=ADP\|PronType=Dem`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Art`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Gender=Fem\|NumType=Ord\|Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Number=Plur\|POS=VERB\|Person=3\|VerbForm=Inf`, `Definite=Def\|Gender=Masc\|Number=Sing\|POS=SCONJ\|PronType=Art`, `Definite=Def\|POS=SCONJ\|PronType=Art`, `Gender=Masc\|Number=Plur\|POS=ADP\|PronType=Art`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pqp\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Gender=Fem\|Number=Plur\|POS=PRON\|PronType=Dem`, `Gender=Fem\|Number=Plur\|POS=PROPN`, `Case=Acc\|Gender=Unsp\|POS=PRON\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|VerbForm=Fin`, `POS=AUX`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=ADP\|PronType=Art`, `Gender=Fem\|Number=Sing\|POS=ADP\|PronType=Art`, `POS=INTJ`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Unsp\|Number=Sing\|POS=PRON\|PronType=Int`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Rel`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Emp`, `Case=Acc\|Gender=Unsp\|Mood=Sub\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|Number=Unsp\|POS=PRON\|PronType=Ind`, `Gender=Fem\|Number=Plur\|POS=DET\|PronType=Rel`, `Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Definite=Ind\|Gender=Masc\|Number=Sing\|POS=ADP\|PronType=Art`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pqp\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|Tense=Past\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Masc\|POS=VERB\|PronType=Prs\|VerbForm=Inf`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Fut\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Fut\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Emp`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Gender=Fem\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Tot`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Fut\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Int`, `Case=Acc\|Gender=Unsp\|POS=VERB\|PronType=Prs\|VerbForm=Ger`, `Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Gender=Unsp\|Number=Sing\|POS=ADJ`, `Mood=Cnd\|Number=Sing\|POS=VERB\|Person=1\|VerbForm=Fin`, `Mood=Sub\|Number=Plur\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Fem\|Number=Plur\|POS=DET\|PronType=Tot`, `Gender=Masc\|Number=Plur\|POS=ADP\|PronType=Dem`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Mood=Sub\|Number=Plur\|POS=VERB\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Mood=Cnd\|Number=Plur\|POS=VERB\|Person=3\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Number=Sing\|POS=AUX\|Person=3\|VerbForm=Inf`, `Gender=Masc\|Number=Plur\|POS=PRON\|PronType=Int`, `Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Int`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Imp\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Int`, `Gender=Fem\|Number=Plur\|POS=DET\|PronType=Int`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Fut\|VerbForm=Fin`, `Gender=Fem\|Number=Plur\|POS=ADP\|PronType=Art`, `Gender=Fem\|Number=Plur\|POS=ADP\|PronType=Dem`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Imp\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Imp\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=PART`, `Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Unsp\|Number=Plur\|POS=DET\|PronType=Ind`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Gender=Masc\|Number=Sing\|POS=ADV`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Rel`, `Case=Dat\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Neg`, `Mood=Sub\|Number=Sing\|POS=AUX\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Definite=Def\|POS=DET\|PronType=Art`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Number=Plur\|POS=VERB\|Person=1\|VerbForm=Inf`, `Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Int`, `Mood=Cnd\|Number=Plur\|POS=AUX\|Person=3\|VerbForm=Fin`, `Gender=Masc\|POS=ADJ`, `POS=NOUN`, `POS=AUX\|VerbForm=Ger`, `Case=Dat\|Gender=Unsp\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Definite=Def\|Gender=Fem\|Number=Sing\|POS=SCONJ\|PronType=Art`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Mood=Sub\|Number=Plur\|POS=AUX\|Person=3\|Tense=Fut\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Number=Sing\|POS=NOUN`, `Number=Sing\|POS=ADJ`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Gender=Unsp\|Number=Plur\|POS=PROPN`, `Gender=Fem\|Number=Plur\|POS=DET\|PronType=Art`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Case=Dat\|Gender=Unsp\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Emp`, `Gender=Unsp\|POS=PRON\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Case=Dat\|Gender=Masc\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=AUX\|Tense=Imp\|VerbForm=Fin`, `Gender=Fem\|Number=Plur\|POS=PRON\|PronType=Tot`, `Case=Acc\|Gender=Masc\|POS=PRON\|PronType=Prs`, `Gender=Unsp\|Number=Unsp\|POS=PRON\|PronType=Rel`, `POS=VERB\|VerbForm=Fin`, `Gender=Masc\|NumType=Card\|Number=Sing\|POS=NUM`, `Definite=Def\|Gender=Masc\|Number=Plur\|POS=PRON\|PronType=Art`, `Gender=Masc\|Number=Sing\|POS=DET\|PronType=Neg`, `POS=VERB\|VerbForm=Inf\|Voice=Pass`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Case=Acc\|Gender=Unsp\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Gender=Masc\|Number=Sing\|POS=AUX\|VerbForm=Part`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `POS=PRON\|Person=3\|PronType=Prs\|Reflex=Yes`, `Number=Plur\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Inf`, `Case=Dat\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Imp\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=1\|Tense=Imp\|VerbForm=Fin`, `Number=Sing\|POS=PROPN\|PronType=Art`, `Case=Dat\|Gender=Unsp\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=VERB\|Person=1\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pqp\|VerbForm=Fin`, `Mood=Sub\|Number=Plur\|POS=VERB\|Person=1\|Tense=Fut\|VerbForm=Fin`, `Gender=Unsp\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Gender=Unsp\|Number=Sing\|POS=NOUN`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Number=Plur\|POS=AUX\|Person=1\|Tense=Past`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Dem`, `Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Neg`, `Gender=Unsp\|Number=Unsp\|POS=PRON\|PronType=Dem`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=ADV\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Gender=Unsp\|Number=Unsp\|POS=PRON\|PronType=Ind`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Fut\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Tot`, `Gender=Masc\|Number=Sing\|POS=DET`, `Case=Dat\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Unsp\|POS=VERB\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Fut\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=X`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Nom\|Gender=Unsp\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=DET\|PronType=Rel`, `Gender=Masc\|Number=Sing\|POS=SCONJ`, `Gender=Masc\|Number=Sing\|POS=PRON`, `Gender=Fem\|POS=DET\|PronType=Dem`, `Gender=Masc\|Number=Plur\|POS=NUM`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Definite=Def\|Gender=Fem\|Number=Plur\|POS=PRON\|PronType=Dem`, `Case=Dat\|Gender=Unsp\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Fut\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin\|Voice=Pass`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `POS=ADP\|PronType=Dem`, `Definite=Def\|Gender=Fem\|POS=ADP\|PronType=Art`, `POS=ADP\|PronType=Art`, `Gender=Masc\|Number=Sing\|POS=ADP`, `Gender=Masc\|Number=Sing\|POS=ADP\|Person=3\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Pqp\|VerbForm=Fin`, `Case=Dat\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=VERB\|Tense=Imp\|VerbForm=Fin`, `Case=Dat\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `POS=DET`, `Gender=Fem\|Number=Plur\|POS=DET\|PronType=Emp`, `Gender=Unsp\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Definite=Def\|Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Art`, `Case=Acc\|Gender=Masc\|Mood=Sub\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Dat\|Gender=Unsp\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Number=Plur\|POS=AUX\|Person=1\|VerbForm=Inf`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Number=Sing\|POS=PRON\|PronType=Rel`, `Gender=Fem\|Number=Plur\|POS=ADP\|PronType=Ind`, `Case=Dat\|Gender=Unsp\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Definite=Def\|Gender=Masc\|Number=Plur\|POS=PRON\|PronType=Dem`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Mood=Sub\|Number=Plur\|POS=AUX\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Number=Sing\|POS=VERB\|Person=3\|VerbForm=Inf\|Voice=Pass`, `Mood=Sub\|Number=Plur\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Number=Plur\|POS=VERB\|Person=2\|PronType=Prs\|VerbForm=Inf`, `Gender=Unsp\|Mood=Sub\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Fem,Masc\|Number=Sing\|POS=PROPN`, `Gender=Unsp\|Number=Unsp\|POS=PRON\|PronType=Int`, `Gender=Fem\|Number=Plur\|POS=NUM`, `POS=PRON\|PronType=Neg`, `Gender=Fem\|Number=Sing\|POS=SCONJ\|PronType=Dem`, `POS=SYM`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Pqp\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=X`, `Case=Dat\|Gender=Unsp\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|NumType=Sets\|Number=Sing\|POS=NUM`, `Foreign=Yes\|POS=NOUN`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Case=Acc\|Gender=Unsp\|POS=AUX\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Unsp\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Nom\|Gender=Unsp\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Unsp\|Number=Plur\|POS=PRON\|PronType=Int`, `Definite=Def\|Gender=Masc\|Number=Plur\|POS=SCONJ\|PronType=Art`, `Gender=Masc\|Number=Plur\|POS=PRON\|PronType=Prs`, `Number=Sing\|POS=VERB\|VerbForm=Part\|Voice=Pass`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=ADP\|PronType=Ind`, `Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=1\|Tense=Fut\|VerbForm=Fin`, `Definite=Ind\|Gender=Fem\|Number=Sing\|POS=SCONJ\|PronType=Art`, `Number=Sing\|POS=VERB`, `Number=Sing\|POS=DET`, `Mood=Cnd\|Number=Plur\|POS=VERB\|Person=3\|VerbForm=Fin\|Voice=Pass`, `NumType=Mult\|POS=NUM`, `Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Neg`, `POS=PRON\|PronType=Dem`, `Mood=Ind\|POS=VERB\|Tense=Imp\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Gender=Unsp\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `NumType=Card\|Number=Plur\|POS=NUM`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Gender=Fem\|Number=Sing\|POS=NUM`, `Case=Acc\|Gender=Unsp\|Mood=Sub\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|Tense=Fut\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Number=Plur\|POS=ADJ`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=DET\|PronType=Int`, `Gender=Masc\|Number=Sing\|POS=ADV\|Polarity=Neg`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Number=Sing\|POS=VERB\|Person=1\|PronType=Prs\|VerbForm=Inf`, `Number=Sing\|POS=VERB\|Person=1\|VerbForm=Inf`, `Definite=Def\|Gender=Masc\|Number=Unsp\|POS=ADP\|PronType=Art`, `Gender=Masc\|Number=Unsp\|POS=NOUN`, `Gender=Masc\|NumType=Ord\|Number=Sing\|POS=NOUN`, `Definite=Def\|Gender=Fem\|Number=Plur\|POS=SCONJ\|PronType=Art`, `POS=ADJ`, `Gender=Fem\|Number=Sing\|POS=ADV\|PronType=Ind`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Prs`, `Case=Dat\|Gender=Unsp\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Acc\|Gender=Unsp\|Number=Plur\|POS=VERB\|Person=1\|PronType=Prs\|VerbForm=Inf`, `Gender=Unsp\|Number=Sing\|POS=PRON\|PronType=Tot`, `Gender=Unsp\|Number=Sing\|POS=DET\|PronType=Rel`, `Gender=Fem\|Number=Plur\|POS=VERB`, `Case=Dat\|Gender=Fem\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Masc\|Number=Plur,Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=VERB\|PronType=Prs\|VerbForm=Inf`, `Gender=Unsp\|Number=Sing\|POS=DET\|PronType=Tot`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Ger`, `NumType=Range\|POS=NUM`, `Case=Dat\|Gender=Unsp\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Mood=Sub\|POS=VERB\|Tense=Pres\|VerbForm=Fin`, `Gender=Unsp\|Number=Plur\|POS=PRON\|PronType=Rel`, `Case=Dat\|Gender=Masc\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Fin`, `Case=Dat\|Gender=Fem\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Mood=Sub\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Fut\|VerbForm=Fin`, `Number=Unsp\|POS=PRON\|PronType=Ind`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=VERB\|Person=1\|PronType=Prs\|VerbForm=Inf`, `Case=Dat\|Gender=Masc\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Gender=Fem\|Number=Plur\|POS=PRON\|PronType=Int`, `Gender=Masc\|POS=NOUN`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Number=Sing\|POS=VERB\|Person=1\|VerbForm=Inf\|Voice=Pass`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=SCONJ\|PronType=Dem`, `NumType=Frac\|POS=NUM`, `Gender=Masc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=ADP\|PronType=Ind`, `Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=2\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=ADV\|PronType=Rel`, `Case=Acc\|POS=VERB\|PronType=Prs\|VerbForm=Ger`, `Mood=Cnd\|POS=VERB\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin\|Voice=Pass`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin\|Voice=Pass`, `Case=Dat\|Gender=Masc\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Prs`, `Gender=Masc\|Number=Sing\|POS=ADP\|PronType=Ind`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf\|Voice=Pass`, `POS=VERB\|VerbForm=Part\|Voice=Pass`, `Case=Dat\|Gender=Unsp\|Mood=Cnd\|Number=Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin\|Voice=Pass`, `Number=Sing\|POS=X`, `Mood=Cnd\|Number=Plur\|POS=VERB\|Person=1\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Case=Dat\|Gender=Unsp\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin\|Voice=Pass`, `Gender=Masc\|Number=Sing\|POS=ADV\|PronType=Int`, `Case=Dat\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=AUX\|Person=1,3\|PronType=Prs\|Tense=Past\|VerbForm=Fin`, `POS=VERB`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Past\|VerbForm=Fin\|Voice=Pass`, `Case=Acc\|Gender=Unsp\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Inf`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Imp\|VerbForm=Fin\|Voice=Pass`, `Case=Dat\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc,Dat\|Gender=Fem,Unsp\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Unsp\|Number=Unsp\|POS=ADV\|PronType=Int`, `Gender=Unsp\|Number=Sing\|POS=ADV\|PronType=Ind`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Pqp\|VerbForm=Fin`, `POS=PROPN`, `Case=Acc\|Gender=Masc\|POS=AUX\|PronType=Prs\|VerbForm=Ger`, `Case=Acc\|Gender=Fem\|POS=AUX\|PronType=Prs\|VerbForm=Ger`, `Case=Acc\|Gender=Fem\|Mood=Sub\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin\|Voice=Pass`, `Case=Dat\|Gender=Unsp\|Number=Plur\|POS=VERB\|Person=1\|PronType=Prs\|VerbForm=Inf`, `Case=Acc\|Gender=Masc\|Mood=Sub\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin\|Voice=Pass`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=AUX\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Fut\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Gender=Fem\|Number=Plur\|POS=PRON\|PronType=Prs`, `Gender=Fem\|Number=Plur\|POS=X`, `Definite=Def\|Gender=Masc\|Number=Plur\|POS=PRON\|PronType=Rel`, `Definite=Ind\|Gender=Fem\|POS=DET\|PronType=Art`, `Gender=Unsp\|Number=Sing\|POS=ADV`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin\|Voice=Pass`, `Mood=Ind\|Number=Sing\|POS=VERB\|Tense=Pqp\|VerbForm=Fin`, `Case=Dat\|Gender=Masc\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin`, `Mood=Sub\|Number=Sing\|POS=VERB\|Tense=Pres\|VerbForm=Fin`, `Case=Dat\|Gender=Unsp\|POS=PRON\|PronType=Prs`, `Gender=Masc\|Number=Sing\|POS=VERB`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pres\|VerbForm=Fin\|Voice=Pass`, `Definite=Def\|Number=Sing\|POS=DET\|PronType=Art`, `Gender=Fem\|Number=Sing\|POS=PROPN\|PronType=Art`, `Gender=Masc\|Number=Plur\|POS=VERB`, `Gender=Masc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Acc\|Gender=Masc\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Pqp\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=ADV\|PronType=Ind`, `Mood=Sub\|Number=Sing\|POS=AUX\|Tense=Imp\|VerbForm=Fin`, `Gender=Fem\|Number=Sing\|POS=DET`, `Mood=Imp\|Number=Sing\|POS=AUX\|Person=2\|VerbForm=Fin`, `Mood=Sub\|Number=Sing\|POS=AUX\|Person=1\|Tense=Imp\|VerbForm=Fin`, `Definite=Def\|Gender=Masc\|Number=Sing\|POS=PRON\|PronType=Rel`, `Mood=Cnd\|Number=Sing\|POS=VERB\|Person=3\|VerbForm=Fin\|Voice=Pass`, `POS=DET\|PronType=Ind`, `POS=SCONJ\|VerbForm=Ger`, `Mood=Cnd\|Number=Sing\|POS=VERB\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=DET`, `Definite=Def\|Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Dem`, `Gender=Fem\|Number=Sing\|POS=VERB`, `Mood=Sub\|Number=Sing\|POS=VERB\|Tense=Fut\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|POS=PRON\|PronType=Prs`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin`, `Gender=Masc\|POS=PROPN`, `Gender=Fem\|Number=Plur\|POS=DET`, `NumType=Ord\|POS=NUM`, `POS=DET\|PronType=Int`, `Case=Acc\|Gender=Unsp\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Case=Nom\|Gender=Unsp\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Fin`, `POS=PART`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Fut\|VerbForm=Fin`, `Mood=Cnd\|Number=Sing\|POS=AUX\|Person=1\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Number=Plur,Sing\|POS=VERB\|Person=1,3\|PronType=Prs\|VerbForm=Inf`, `NumType=Card\|POS=ADP`, `Gender=Fem\|Number=Sing\|POS=PRON\|PronType=Tot`, `Gender=Masc\|Number=Sing\|POS=ADP\|PronType=Rel`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Pqp\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Case=Acc\|Gender=Unsp\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Nom\|Gender=Masc\|Number=Sing\|POS=SCONJ\|Person=3\|PronType=Prs`, `Case=Dat\|Gender=Fem\|Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|Tense=Imp\|VerbForm=Fin`, `Definite=Def\|Gender=Fem\|Number=Plur\|POS=PRON\|PronType=Art`, `Case=Dat\|Gender=Unsp\|Number=Sing\|POS=VERB\|Person=3\|PronType=Prs\|VerbForm=Ger`, `Mood=Sub\|Number=Plur\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin` |
| **`parser`** | `ROOT`, `acl`, `acl:relcl`, `advcl`, `advmod`, `amod`, `appos`, `aux`, `aux:pass`, `case`, `cc`, `ccomp`, `compound`, `conj`, `cop`, `csubj`, `dep`, `det`, `discourse`, `dislocated`, `expl`, `fixed`, `flat`, `flat:foreign`, `flat:name`, `iobj`, `mark`, `nmod`, `nsubj`, `nsubj:pass`, `nummod`, `obj`, `obl`, `obl:agent`, `orphan`, `parataxis`, `punct`, `vocative`, `xcomp` |
| **`experimental_edit_tree_lemmatizer`** | `1`, `2`, `3`, `4`, `6`, `8`, `9`, `11`, `13`, `15`, `17`, `20`, `22`, `24`, `14`, `7`, `26`, `28`, `30`, `32`, `34`, `36`, `38`, `40`, `42`, `44`, `45`, `48`, `53`, `54`, `55`, `57`, `58`, `60`, `62`, `65`, `66`, `67`, `70`, `72`, `74`, `76`, `79`, `83`, `85`, `87`, `89`, `91`, `95`, `99`, `101`, `102`, `104`, `106`, `108`, `110`, `113`, `115`, `117`, `119`, `120`, `122`, `124`, `125`, `126`, `128`, `130`, `132`, `134`, `136`, `138`, `141`, `142`, `144`, `147`, `150`, `152`, `154`, `155`, `159`, `162`, `163`, `165`, `166`, `169`, `171`, `172`, `174`, `175`, `178`, `180`, `181`, `184`, `186`, `189`, `191`, `193`, `195`, `198`, `200`, `111`, `202`, `204`, `207`, `209`, `212`, `214`, `216`, `218`, `220`, `221`, `223`, `224`, `226`, `228`, `230`, `232`, `234`, `236`, `239`, `242`, `244`, `245`, `246`, `247`, `249`, `251`, `252`, `253`, `256`, `257`, `259`, `261`, `263`, `267`, `269`, `270`, `271`, `273`, `277`, `278`, `281`, `282`, `283`, `285`, `286`, `288`, `289`, `290`, `292`, `293`, `295`, `297`, `298`, `300`, `302`, `303`, `305`, `307`, `309`, `310`, `311`, `313`, `314`, `316`, `319`, `168`, `322`, `323`, `326`, `327`, `329`, `331`, `333`, `335`, `336`, `338`, `341`, `343`, `345`, `347`, `348`, `350`, `351`, `354`, `356`, `359`, `361`, `363`, `364`, `365`, `366`, `367`, `369`, `373`, `376`, `378`, `379`, `380`, `381`, `383`, `384`, `386`, `389`, `392`, `394`, `395`, `396`, `398`, `400`, `403`, `405`, `407`, `409`, `410`, `412`, `415`, `416`, `417`, `418`, `419`, `420`, `422`, `424`, `429`, `431`, `432`, `438`, `439`, `441`, `442`, `445`, `448`, `449`, `450`, `452`, `454`, `457`, `458`, `461`, `463`, `465`, `468`, `469`, `470`, `473`, `475`, `477`, `478`, `481`, `484`, `485`, `486`, `488`, `491`, `495`, `497`, `499`, `503`, `506`, `507`, `508`, `509`, `510`, `511`, `513`, `514`, `516`, `517`, `519`, `521`, `522`, `523`, `525`, `528`, `530`, `533`, `534`, `536`, `538`, `540`, `541`, `542`, `544`, `545`, `547`, `549`, `551`, `552`, `554`, `555`, `558`, `559`, `560`, `562`, `563`, `565`, `566`, `570`, `572`, `579`, `582`, `583`, `585`, `586`, `587`, `590`, `592`, `594`, `595`, `597`, `599`, `601`, `603`, `606`, `608`, `609`, `611`, `612`, `614`, `615`, `616`, `619`, `621`, `622`, `625`, `626`, `627`, `629`, `630`, `631`, `633`, `634`, `637`, `638`, `639`, `640`, `642`, `644`, `646`, `647`, `652`, `653`, `656`, `657`, `659`, `660`, `661`, `664`, `666`, `669`, `671`, `672`, `673`, `674`, `675`, `677`, `678`, `680`, `682`, `685`, `687`, `689`, `691`, `692`, `693`, `695`, `699`, `701`, `702`, `703`, `706`, `707`, `709`, `710`, `711`, `712`, `714`, `716`, `718`, `719`, `720`, `721`, `724`, `725`, `729`, `730`, `732`, `735`, `738`, `740`, `742`, `744`, `746`, `749`, `750`, `751`, `754`, `756`, `760`, `762`, `767`, `769`, `771`, `774`, `776`, `778`, `780`, `781`, `784`, `785`, `787`, `788`, `789`, `791`, `793`, `794`, `795`, `798`, `800`, `801`, `803`, `804`, `806`, `808`, `810`, `811`, `812`, `814`, `816`, `819`, `820`, `823`, `824`, `825`, `828`, `829`, `832`, `833`, `835`, `836`, `839`, `840`, `844`, `845`, `847`, `850`, `851`, `853`, `854`, `855`, `858`, `861`, `862`, `863`, `865`, `868`, `871`, `873`, `875`, `877`, `879`, `880`, `881`, `882`, `883`, `884`, `885`, `887`, `889`, `892`, `894`, `895`, `537`, `896`, `898`, `899`, `902`, `904`, `905`, `908`, `909`, `912`, `914`, `916`, `917`, `920`, `921`, `922`, `924`, `925`, `928`, `929`, `930`, `931`, `933`, `936`, `939`, `940`, `942`, `943`, `945`, `948`, `949`, `951`, `953`, `956`, `957`, `960`, `961`, `963`, `964`, `965`, `966`, `969`, `970`, `971`, `973`, `976`, `977`, `979`, `981`, `983`, `985`, `987`, `988`, `990`, `991`, `993`, `994`, `995`, `996`, `997`, `998`, `1000`, `1001`, `1004`, `1006`, `1007`, `1009`, `1011`, `1013`, `1014`, `1015`, `1019`, `1021`, `1023`, `1025`, `1026`, `1029`, `1030`, `1033`, `1034`, `1036`, `1037`, `1039`, `1041`, `1042`, `1044`, `1046`, `1048`, `1050`, `1051`, `1054`, `1056`, `1057`, `1059`, `1061`, `1062`, `1064`, `1066`, `1067`, `1068`, `1069`, `1071`, `1072`, `1073`, `1074`, `1075`, `1077`, `1078`, `1079`, `1081`, `1083`, `1084`, `1085`, `1086`, `1088`, `1089`, `1092`, `1093`, `1097`, `1100`, `1101`, `1103`, `1104`, `1106`, `1108`, `1110`, `1114`, `1115`, `1117`, `1118`, `1119`, `1121`, `1123`, `1124`, `1126`, `1127`, `1128`, `1130`, `1133`, `1135`, `1136`, `1140`, `1143`, `1146`, `1148`, `1149`, `1151`, `1152`, `1155`, `1157`, `1158`, `1160`, `1163`, `1164`, `1165`, `1167`, `1168`, `1170`, `1172`, `1176`, `1177`, `1178`, `1180`, `1182`, `1184`, `1186`, `1187`, `1189`, `1190`, `1193`, `1196`, `1198`, `1202`, `1203`, `1204`, `1205`, `1206`, `1207`, `1208`, `1209`, `1210`, `1211`, `1214`, `1215`, `1216`, `1218`, `1219`, `1220`, `1221`, `1223`, `1225`, `1226`, `1228`, `1229`, `1230`, `1233`, `1234`, `1236`, `1237`, `1238`, `1239`, `1240`, `1242`, `1244`, `1247`, `1248`, `1249`, `1250`, `1251`, `1254`, `1256`, `1257`, `1258`, `1260`, `1262`, `1263`, `1266`, `1271`, `1272`, `1273`, `1274`, `1275`, `1277`, `1278`, `1279`, `1280`, `1283`, `1285`, `1287`, `1288`, `1290`, `1293`, `1294`, `1296`, `1299`, `1301`, `1302`, `1304`, `1307`, `1308`, `1309`, `1311`, `1312`, `1314`, `1315`, `1317`, `1320`, `1322`, `1324`, `1325`, `1326`, `1329`, `1330`, `1332`, `1333`, `1334`, `1336`, `1338`, `1339`, `1340`, `1341`, `1344`, `1345`, `1346`, `1348`, `1350`, `1351`, `1352`, `1354`, `1356`, `1358`, `1359`, `1360`, `1361`, `1362`, `1363`, `1367`, `1370`, `1371`, `1373`, `1375`, `1377`, `1378`, `1379`, `1381`, `1382`, `1383`, `1385`, `1386`, `1388`, `1389`, `1393`, `1395`, `1399`, `1401`, `1402`, `1403`, `1404`, `1405`, `1407`, `1408`, `1411`, `1413`, `1417`, `1418`, `1419`, `1420`, `1421`, `1423`, `1424`, `1425`, `1429`, `1430`, `1431`, `1433`, `1434`, `1436`, `1437`, `1438`, `1439`, `1442`, `1444`, `1446`, `1447`, `1449`, `1451`, `1453`, `1454`, `1455`, `1458`, `1461`, `1463`, `1464`, `1465`, `1467`, `1468`, `1469`, `1470`, `1471`, `1473`, `1476`, `1477`, `1478`, `1479`, `1482`, `1483`, `1484`, `1489`, `1491`, `1492`, `1494`, `1496`, `1497`, `1499`, `1502`, `1504`, `1505`, `1506`, `1507`, `1508`, `1509`, `1511`, `1514`, `1515`, `1517`, `1520`, `1521`, `1524`, `1525`, `1528`, `1529`, `1530`, `1532`, `1533`, `1534`, `1536`, `1538`, `1539`, `1541`, `1543`, `1544`, `1545`, `1546`, `1547`, `1548`, `1552`, `1556`, `1558`, `1560`, `1562`, `1563`, `1566`, `1567`, `1569`, `1570`, `1572`, `1574`, `1577`, `761`, `1579`, `1583`, `1585`, `1586`, `1587`, `1590`, `1592`, `1593`, `1595`, `1596`, `1597`, `1599`, `1603`, `1605`, `1607`, `1609`, `1610`, `1612`, `1614`, `1615`, `1617`, `1618`, `1620`, `1621`, `1622`, `1625`, `1627`, `1629`, `1630`, `1631`, `1633`, `1634`, `1636`, `1637`, `1638`, `1640`, `1641`, `1643`, `1644`, `1646`, `1647`, `1648`, `1651`, `1652`, `1657`, `1658`, `1659`, `1661`, `1662`, `1663`, `1664`, `1666`, `1669`, `1672`, `1673`, `1675`, `1676`, `1677`, `1679`, `1682`, `1684`, `1409`, `1685`, `1686`, `1687`, `1688`, `1690`, `1692`, `1693`, `1694`, `1695`, `1697`, `1699`, `1700`, `1704`, `1707`, `1708`, `1709`, `1711`, `1712`, `1715`, `1716`, `1717`, `1718`, `1719`, `1721`, `1722`, `1723`, `1725`, `1726`, `1729`, `1730`, `1732`, `1733`, `1734`, `1735`, `1737`, `1738`, `1741`, `1743`, `1744`, `1746`, `1747`, `1748`, `1750`, `1752`, `1754`, `1755`, `1756`, `1758`, `1759`, `1760`, `1762`, `1765`, `1766`, `1768`, `1769`, `1770`, `1773`, `1774`, `1775`, `1777`, `1778`, `1781`, `1782`, `1783`, `1785`, `1786`, `1787`, `219`, `1788`, `1789`, `1791`, `1792`, `1793`, `1795`, `1799`, `1800`, `1801`, `1802`, `1803`, `1805`, `1806`, `1808`, `1809`, `1811`, `1812`, `1814`, `1815`, `1816`, `1821`, `1823`, `1824`, `1825`, `1826`, `1829`, `1830`, `1831`, `1832`, `1833`, `1835`, `1838`, `1839`, `1840`, `1842`, `1843`, `1845`, `1846`, `1848`, `1849`, `1850`, `1851`, `1855`, `1856`, `1857`, `1859`, `1861`, `1862`, `1864`, `1866`, `1867`, `1869`, `421`, `1870`, `1872`, `1873`, `1874`, `1875`, `1878`, `1879`, `1880`, `1882`, `1883`, `1884`, `1885`, `1888`, `1891`, `1894`, `1895`, `1898`, `1901`, `1903`, `1904`, `1906`, `1907`, `1910`, `1912`, `1915`, `1917`, `1918`, `1920`, `1921`, `1922`, `1924`, `1926`, `1927`, `1930`, `1932`, `1933`, `1936`, `1938`, `1940`, `1941`, `1942`, `1943`, `1945`, `1947`, `1949`, `1951`, `1952`, `1953`, `1954`, `1956`, `1957`, `1958`, `1960`, `1961`, `1963`, `1964`, `1966`, `1968`, `1971`, `1973`, `1974`, `1975`, `1977`, `1979`, `1981`, `1983`, `1985`, `1986`, `1987`, `1988`, `792`, `1990`, `790`, `1992`, `1994`, `1996`, `1998`, `1999`, `2000`, `2001`, `2002`, `2003`, `2005`, `2006`, `2008`, `2010`, `2011`, `2012`, `2014`, `2016`, `2017`, `2018`, `2019`, `2021`, `2022`, `2023`, `2024`, `2025`, `2026`, `2028`, `2029`, `2031`, `2034`, `2036`, `2038`, `2041`, `2042`, `2044`, `2045`, `2046`, `2050`, `2051`, `2052`, `2055`, `2056`, `2057`, `2059`, `2060`, `2061`, `2062`, `2064`, `2066`, `2068`, `2069`, `2070`, `2072`, `2073`, `2075`, `2076`, `2078`, `2079`, `2081`, `2083`, `2084`, `2086`, `2088`, `2089`, `2091`, `2093`, `2095`, `2097`, `2098`, `2099`, `2101`, `2102`, `2103`, `2104`, `2106`, `2107`, `2108`, `2109`, `2110`, `2111`, `2112`, `2114`, `2116`, `2117`, `2118`, `2119`, `2120`, `2121`, `2122`, `2123`, `2124`, `2125`, `2126`, `2127`, `1584`, `2128`, `2130`, `2131`, `2132`, `2134`, `2137`, `2138`, `2139`, `2141`, `2144`, `2145`, `2146`, `2147`, `2150`, `2151`, `2153`, `2154`, `2155`, `2156`, `2157`, `2159`, `2160`, `2161`, `2163`, `2164`, `2165`, `2166`, `2167`, `2168`, `2169`, `2170`, `2173`, `2174`, `2175`, `2176`, `2177`, `2179`, `2182`, `2185`, `2187`, `2188`, `2189`, `2191`, `2193`, `2194`, `2195`, `2196`, `2197`, `2198`, `2200`, `2202`, `2203`, `2204`, `2205`, `2206`, `2207`, `2208`, `2209`, `2210`, `2211`, `2212`, `2213`, `2216`, `2217`, `2219`, `2221`, `2224`, `2227`, `2229`, `2230`, `2232`, `2233`, `2234`, `2235`, `2237`, `2239`, `2240`, `2241`, `2242`, `2243`, `2244`, `2245`, `2246`, `2248`, `2249`, `2250`, `2251`, `2253`, `2254`, `2255`, `2257`, `2258`, `2260`, `2261`, `2262`, `2263`, `2264`, `2265`, `2266`, `2267`, `2268`, `2269`, `2270`, `2271`, `2272`, `2273`, `2274`, `2275`, `2277`, `2278`, `2281`, `2282`, `2283`, `2284`, `2285`, `2287`, `2288`, `2290`, `2291`, `2292`, `2293`, `2294`, `2297`, `2298`, `2299`, `2300`, `2302`, `2304`, `2305`, `2307`, `2308`, `2309`, `2310`, `2312`, `2313`, `2314`, `2315`, `2316`, `2317`, `2318`, `2319`, `2321`, `2322`, `2323`, `2327`, `2329`, `2331`, `2333`, `2335`, `2337`, `2338`, `2339`, `2341`, `2342`, `2343`, `2346`, `2348`, `2349`, `2350`, `2351`, `2352`, `2353`, `37`, `2354`, `2355`, `2357`, `2358`, `2359`, `2360`, `2361`, `2362`, `2364`, `2365`, `2367`, `2368`, `2369`, `2370`, `2372`, `2375`, `2376`, `2378`, `2379`, `2380`, `2381`, `2382`, `2383`, `2384`, `2385`, `2386`, `2389`, `2390`, `2392`, `2393`, `2394`, `2395`, `2398`, `2399`, `2400`, `2402`, `2403`, `2405`, `2406`, `2407`, `2408`, `2409`, `2410`, `2413`, `2415`, `2416`, `2417`, `2418`, `2419`, `2420`, `2422`, `2424`, `2427`, `2428`, `2429`, `2430`, `2431`, `2432`, `2433`, `2435`, `2437`, `1962`, `2438`, `2439`, `2440`, `2442`, `2443`, `2444`, `2445` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TOKEN_F` | 99.92 |
| `TOKEN_P` | 99.93 |
| `TOKEN_R` | 99.91 |
| `TOKEN_ACC` | 99.99 |
| `SENTS_F` | 95.82 |
| `SENTS_P` | 95.40 |
| `SENTS_R` | 96.25 |
| `TAG_ACC` | 98.09 |
| `POS_ACC` | 98.14 |
| `MORPH_ACC` | 97.34 |
| `DEP_UAS` | 93.85 |
| `DEP_LAS` | 91.19 |
| `LEMMA_ACC` | 98.00 | |
AmirHussein/test | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-12-10T23:04:04Z | ---
tags:
- spacy
- token-classification
language:
- ro
license: cc-by-sa-4.0
model-index:
- name: ro_udv25_romaniannonstandard_trf
results:
- task:
name: TAG
type: token-classification
metrics:
- name: TAG (XPOS) Accuracy
type: accuracy
value: 0.9385375334
- task:
name: POS
type: token-classification
metrics:
- name: POS (UPOS) Accuracy
type: accuracy
value: 0.9765972953
- task:
name: MORPH
type: token-classification
metrics:
- name: Morph (UFeats) Accuracy
type: accuracy
value: 0.9364320998
- task:
name: LEMMA
type: token-classification
metrics:
- name: Lemma Accuracy
type: accuracy
value: 0.9399476397
- task:
name: UNLABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Unlabeled Attachment Score (UAS)
type: f_score
value: 0.9256250793
- task:
name: LABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Labeled Attachment Score (LAS)
type: f_score
value: 0.8749206752
- task:
name: SENTS
type: token-classification
metrics:
- name: Sentences F-Score
type: f_score
value: 0.9699570815
---
UD v2.5 benchmarking pipeline for UD_Romanian-Nonstandard
| Feature | Description |
| --- | --- |
| **Name** | `ro_udv25_romaniannonstandard_trf` |
| **Version** | `0.0.1` |
| **spaCy** | `>=3.2.1,<3.3.0` |
| **Default Pipeline** | `experimental_char_ner_tokenizer`, `transformer`, `tagger`, `morphologizer`, `parser`, `experimental_edit_tree_lemmatizer` |
| **Components** | `experimental_char_ner_tokenizer`, `transformer`, `senter`, `tagger`, `morphologizer`, `parser`, `experimental_edit_tree_lemmatizer` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [Universal Dependencies v2.5](https://lindat.mff.cuni.cz/repository/xmlui/handle/11234/1-3105) (Zeman, Daniel; et al.) |
| **License** | `CC BY-SA 4.0` |
| **Author** | [Explosion](https://explosion.ai) |
### Label Scheme
<details>
<summary>View label scheme (7445 labels for 6 components)</summary>
| Component | Labels |
| --- | --- |
| **`experimental_char_ner_tokenizer`** | `TOKEN` |
| **`senter`** | `I`, `S` |
| **`tagger`** | `AdpType=Prep\|Case=Acc`, `Afp`, `Afpf--n`, `Afpfp-n`, `Afpfpon`, `Afpfpoy`, `Afpfprn`, `Afpfpry`, `Afpfson`, `Afpfsoy`, `Afpfsrn`, `Afpfsry`, `Afpmp-n`, `Afpmpoy`, `Afpmprn`, `Afpmpry`, `Afpmpvy`, `Afpms-n`, `Afpmsoy`, `Afpmsrn`, `Afpmsry`, `Afpmsvn`, `Afpmsvy`, `COLON`, `COMMA`, `Cccsp`, `Cccsz`, `Ccssp`, `Ccssz`, `Cscsp`, `Csssp`, `DASH`, `DBLQ`, `Dd3-po---e`, `Dd3-po---o`, `Dd3fpo`, `Dd3fpr`, `Dd3fpr---e`, `Dd3fpr---o`, `Dd3fso`, `Dd3fso---e`, `Dd3fso---o`, `Dd3fsr`, `Dd3fsr---e`, `Dd3fsr---o`, `Dd3mpo`, `Dd3mpr`, `Dd3mpr---e`, `Dd3mpr---o`, `Dd3mso`, `Dd3mso---e`, `Dd3mso---o`, `Dd3msr`, `Dd3msr---e`, `Dd3msr---o`, `Dh1mp`, `Dh1ms`, `Dh2mp`, `Dh2ms`, `Dh3fp`, `Dh3mp`, `Dh3ms`, `Di3--r`, `Di3-po`, `Di3-sr`, `Di3fp`, `Di3fpo`, `Di3fpr`, `Di3fso`, `Di3fsr`, `Di3mpr`, `Di3mso`, `Di3msr`, `Ds1fp-p`, `Ds1fp-s`, `Ds1fsop`, `Ds1fsos`, `Ds1fsrp`, `Ds1fsrs`, `Ds1mp-p`, `Ds1mp-s`, `Ds1ms-p`, `Ds1ms-s`, `Ds2fp-p`, `Ds2fp-s`, `Ds2fsop`, `Ds2fsos`, `Ds2fsrp`, `Ds2fsrs`, `Ds2mp-p`, `Ds2mp-s`, `Ds2ms-p`, `Ds2ms-s`, `Ds3fp-s`, `Ds3fsos`, `Ds3fsrs`, `Ds3mp-s`, `Ds3ms-s`, `Dw3--r`, `Dw3-po`, `Dw3fpr`, `Dw3fso`, `Dw3fsr`, `Dw3mpr`, `Dw3mso`, `Dw3msr`, `Dz3fpr`, `Dz3fsr`, `Dz3msr`, `EXCL`, `EXCLHELLIP`, `HELLIP`, `I`, `LPAR`, `M`, `Mc-p-l`, `Mcfp-l`, `Mcfpol`, `Mcfprln`, `Mcfsoln`, `Mcfsoly`, `Mcfsrln`, `Mcfsrly`, `Mcmp-l`, `Mcms-ln`, `Mcmsoly`, `Mcmsrl`, `Mcmsrly`, `Mffsrln`, `Ml-po`, `Mlfpr`, `Mlmpr`, `Mmfpr-n`, `Mmmpr-n`, `Mmmsr-n`, `Mo---l`, `Mo---ln`, `Mo-s-r`, `Mofprln`, `Mofprly`, `Mofs-l`, `Mofs-ly`, `Mofsrln`, `Mofsrly`, `Momp-ln`, `Moms-l`, `Moms-ln`, `Momsoly`, `Momsrly`, `Ncfpoy`, `Ncfprn`, `Ncfpry`, `Ncfpvy`, `Ncfson`, `Ncfsoy`, `Ncfsrn`, `Ncfsry`, `Ncfsvn`, `Ncfsvy`, `Ncmpoy`, `Ncmprn`, `Ncmpry`, `Ncmpvy`, `Ncmson`, `Ncmsoy`, `Ncmsrn`, `Ncmsry`, `Ncmsvn`, `Ncmsvy`, `Ncnsrn`, `Np`, `Npfpoy`, `Npfprn`, `Npfpry`, `Npfsoy`, `Npfsrn`, `Npfsry`, `Npfsvn`, `Npmpoy`, `Npmprn`, `Npmpry`, `Npmsoy`, `Npmsrn`, `Npmsry`, `Npmsvn`, `Npmsvy`, `PERIOD`, `Pd3-po`, `Pd3-po---o`, `Pd3fpo`, `Pd3fpr`, `Pd3fso`, `Pd3fsr`, `Pd3mpo`, `Pd3mpr`, `Pd3mso`, `Pd3msr`, `Ph1mp`, `Ph1ms`, `Ph2mp`, `Ph2ms`, `Ph3--r`, `Ph3fp`, `Ph3fsr`, `Ph3mp`, `Ph3mpo`, `Ph3mpr`, `Ph3ms`, `Ph3mso`, `Pi3--r`, `Pi3-po`, `Pi3-so`, `Pi3-sr`, `Pi3fpo`, `Pi3fpr`, `Pi3fso`, `Pi3fsr`, `Pi3mpo`, `Pi3mpr`, `Pi3mpry`, `Pi3mso`, `Pi3msr`, `Pi3msry`, `Pp1-pa--------s`, `Pp1-pa--------w`, `Pp1-pd--------s`, `Pp1-pd--------w`, `Pp1-pr`, `Pp1-sa--------s`, `Pp1-sa--------w`, `Pp1-sd--------s`, `Pp1-sd--------w`, `Pp1-sr`, `Pp2-pa--------s`, `Pp2-pa--------w`, `Pp2-pd--------s`, `Pp2-pd--------w`, `Pp2-po`, `Pp2-pr`, `Pp2-sa--------s`, `Pp2-sa--------w`, `Pp2-sd--------s`, `Pp2-sd--------w`, `Pp2-so`, `Pp2-sr`, `Pp3-pd--------s`, `Pp3-pd--------w`, `Pp3-po`, `Pp3-pr`, `Pp3-sd--------w`, `Pp3-so`, `Pp3fpa--------s`, `Pp3fpa--------w`, `Pp3fpr`, `Pp3fsa--------s`, `Pp3fsa--------w`, `Pp3fsd--------s`, `Pp3fso`, `Pp3fsoy`, `Pp3fsr`, `Pp3mpa--------s`, `Pp3mpa--------w`, `Pp3mpo`, `Pp3mpr`, `Pp3msa--------s`, `Pp3msa--------w`, `Pp3msd--------s`, `Pp3mso`, `Pp3msr`, `Pp3msry`, `Ps1fp-p`, `Ps1fp-s`, `Ps1fsrp`, `Ps1fsrs`, `Ps1mp-p`, `Ps1ms-p`, `Ps1ms-s`, `Ps2fp-p`, `Ps2fp-s`, `Ps2fsrp`, `Ps2fsrs`, `Ps2mp-s`, `Ps2ms-p`, `Ps2ms-s`, `Ps3fp-s`, `Ps3fsrs`, `Ps3mp-s`, `Ps3ms-s`, `Pw3--r`, `Pw3-po`, `Pw3-pr`, `Pw3-pry`, `Pw3-so`, `Pw3fpr`, `Pw3fpry`, `Pw3fso`, `Pw3fsr`, `Pw3fsry`, `Pw3mpr`, `Pw3mpry`, `Pw3mso`, `Pw3msr`, `Pw3msry`, `Px3--a--------s`, `Px3--a--------w`, `Px3--d--------s`, `Px3--d--------w`, `Px3--d-------w`, `Pz3-so`, `Pz3-sr`, `Pz3fsr`, `Pz3mso`, `Pz3msr`, `QUEST`, `QUOT`, `Qn`, `Qs`, `Qz`, `RPAR`, `Rg`, `Ri`, `Rw`, `Rz`, `SCOLON`, `Sp`, `Spca`, `Spcg`, `Spsa`, `Spsd`, `Spsg`, `TILDA`, `Td-po`, `Tdfpr`, `Tdfso`, `Tdfsr`, `Tdmpr`, `Tdmso`, `Tdmsr`, `Tf-so`, `Tffsr`, `Tfmso`, `Tfmsr`, `Ti-po`, `Ti-pr`, `Tifso`, `Tifsr`, `Timso`, `Timsr`, `Tsfpr`, `Tsfso`, `Tsfsr`, `Tsmpr`, `Tsmsr`, `Vag-----p`, `Vag-----z`, `Vaii1p`, `Vaii1s`, `Vaii2p`, `Vaii2s`, `Vaii3p`, `Vaii3s`, `Vail3s`, `Vaip1p`, `Vaip1s`, `Vaip2p`, `Vaip2s`, `Vaip3`, `Vaip3p`, `Vaip3s`, `Vais1p`, `Vais1s`, `Vais2p`, `Vais2s`, `Vais3p`, `Vais3s`, `Vam-2p`, `Vam-2p---l`, `Vam-2s--p`, `Vam-2s--z`, `Vam-2s-p`, `Vam-2s-z`, `Vamip3p`, `Vamip3s`, `Vamn`, `Vamsp3`, `Van`, `Van------l`, `Vap`, `Vap--sm-p`, `Vasp1p`, `Vasp1s`, `Vasp2p`, `Vasp2s`, `Vasp3`, `Vasp3s`, `Vmg-----p`, `Vmg-----z`, `Vmii1p`, `Vmii1s`, `Vmii2p`, `Vmii2s`, `Vmii3p`, `Vmii3s`, `Vmil1s`, `Vmil2p`, `Vmil2s`, `Vmil3p`, `Vmil3s`, `Vmip1p`, `Vmip1s`, `Vmip2p`, `Vmip2s`, `Vmip3`, `Vmip3p`, `Vmip3s`, `Vmis1p`, `Vmis1s`, `Vmis2p`, `Vmis2s`, `Vmis3p`, `Vmis3s`, `Vmm-2p`, `Vmm-2p---l`, `Vmm-2s--p`, `Vmm-2s--z`, `Vmn`, `Vmn------l`, `Vmp`, `Vmp--pf-p`, `Vmp--pf-z`, `Vmp--pm-p`, `Vmp--pm-z`, `Vmp--sf-p--o`, `Vmp--sf-p--r`, `Vmp--sf-z--r`, `Vmp--sm-p`, `Vmp--sm-z`, `Vmsp1p`, `Vmsp1s`, `Vmsp2p`, `Vmsp2s`, `Vmsp3`, `Vmsp3s`, `X`, `Y` |
| **`morphologizer`** | `AdpType=Prep\|Case=Acc\|POS=ADP`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Acc,Nom\|Definite=Ind\|Gender=Masc\|Number=Sing\|POS=NOUN`, `POS=PUNCT`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Int,Rel`, `POS=ADV\|PronType=Int,Rel`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Weak`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `POS=ADV`, `Case=Acc,Nom\|Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|PronType=Ind`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Case=Acc,Nom\|POS=PRON\|Person=3\|PronType=Int,Rel`, `POS=CCONJ\|Polarity=Pos`, `Compound=Yes\|POS=SCONJ\|Polarity=Pos`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Weak`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Case=Acc,Nom\|Definite=Ind\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Case=Gen\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat,Gen\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=NOUN`, `POS=PART\|PartType=Sub`, `Mood=Sub\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Strong`, `POS=VERB\|VerbForm=Inf`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|Number=Sing\|POS=NOUN`, `POS=ADV\|Polarity=Neg`, `Case=Dat,Gen\|Definite=Def\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Ind`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Weak`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|Position=Prenom\|PronType=Dem`, `POS=AUX\|Polarity=Pos\|VerbForm=Ger`, `Mood=Sub\|Number=Plur\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `POS=VERB\|Polarity=Pos\|VerbForm=Ger`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Acc\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Strong`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Imp`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Dat\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Strong`, `Case=Voc\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=NOUN`, `POS=INTJ`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|Tense=Pres\|VerbForm=Fin`, `POS=SCONJ\|Polarity=Pos`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Dat,Gen\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Pos\|VerbForm=Fin`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs\|Strength=Weak`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=2\|Tense=Pres`, `Gender=Masc\|Number=Plur\|POS=VERB\|Polarity=Pos\|VerbForm=Part`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Case=Acc,Nom\|Definite=Ind\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Ind`, `AdpType=Prep\|Case=Acc\|Compound=Yes\|POS=ADP`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Dem`, `Case=Acc,Nom\|Definite=Ind\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Acc,Nom\|Definite=Ind\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Dat,Gen\|Definite=Def\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Acc,Nom\|Number=Sing\|POS=PRON\|Person=3\|PronType=Neg`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|PronType=Ind`, `Case=Acc,Nom\|POS=DET\|Person=3\|PronType=Int,Rel`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs\|Strength=Strong`, `Case=Voc\|Definite=Ind\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs\|Strength=Weak`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Weak`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs\|Strength=Weak`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs\|Strength=Weak`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Ind`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Pres`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Weak`, `Case=Acc\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Strong`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=DET\|Person=3\|PronType=Ind`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs\|Strength=Strong`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|Position=Postnom\|PronType=Dem`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|NumForm=Word\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|NumForm=Word\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Dem`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Pres`, `POS=AUX\|VerbForm=Part`, `POS=VERB\|VerbForm=Part`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pqp\|VerbForm=Fin`, `POS=PART\|PartType=Inf`, `Case=Dat,Gen\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Masc\|Number=Sing\|POS=VERB\|Polarity=Pos\|VerbForm=Part`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|PronType=Prs`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Art`, `Gender=Masc\|Number=Plur\|Number[psor]=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Int,Rel`, `NumForm=Word\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Art`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|PronType=Prs`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Strong`, `Mood=Sub\|POS=AUX\|Person=3\|Tense=Pres`, `Gender=Masc\|NumForm=Word\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Dat\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Weak`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Pres`, `Case=Gen\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Gender=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=1\|PronType=Prs`, `Case=Acc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs\|Strength=Strong`, `Case=Acc\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Weak`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Dem`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=VERB\|Polarity=Pos\|VerbForm=Part`, `Case=Dat\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Strong`, `Mood=Imp\|Number=Sing\|POS=AUX\|Person=2\|Polarity=Pos`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|Position=Prenom\|PronType=Dem`, `Case=Dat,Gen\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Strong`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs\|Strength=Strong`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|PronType=Prs`, `Case=Dat,Gen\|Definite=Def\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Case=Dat,Gen\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=PROPN`, `NumForm=Digit\|POS=NUM`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Dem`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=VERB\|Polarity=Pos\|VerbForm=Part`, `POS=PROPN`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|PronType=Neg`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=DET\|PronType=Dem`, `Compound=Yes\|POS=CCONJ\|Polarity=Neg`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|VerbForm=Fin`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs\|Strength=Strong`, `Gender=Fem\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=2\|PronType=Prs`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs\|Strength=Strong`, `POS=AUX\|VerbForm=Inf`, `AdpType=Prep\|Case=Gen\|Compound=Yes\|POS=ADP`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|Position=Postnom\|PronType=Dem`, `Case=Nom\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|PronType=Prs`, `Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|PronType=Prs`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Gender=Masc\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|PronType=Prs`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Dat,Gen\|Number=Plur\|POS=PRON\|Person=3\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=2\|Tense=Pres`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|NumForm=Word\|NumType=Frac\|Number=Sing\|POS=NUM`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat,Gen\|Definite=Ind\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Acc,Nom\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Gender=Masc\|Number=Plur\|POS=DET\|Person=2\|PronType=Emp`, `Case=Acc,Nom\|Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Case=Acc,Nom\|Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `POS=VERB\|Polarity=Neg\|VerbForm=Ger`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|PronType=Int,Rel`, `Case=Dat,Gen\|Number=Plur\|POS=PRON\|Person=3\|PronType=Ind`, `Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Emp`, `Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|PronType=Emp`, `Gender=Fem\|NumForm=Word\|NumType=Ord\|Number=Sing\|POS=NUM`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Weak`, `Mood=Imp\|Number=Plur\|POS=VERB\|Person=2\|Variant=Long\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Emp`, `Gender=Fem\|Number=Plur\|POS=VERB\|Polarity=Neg\|VerbForm=Part`, `Gender=Masc\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=2\|PronType=Prs`, `Case=Voc\|Definite=Def\|Gender=Masc\|Number=Plur\|POS=NOUN`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=DET\|Person=3\|Position=Prenom\|PronType=Dem`, `Case=Acc,Nom\|Definite=Def\|Number=Plur\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Gender=Fem\|Number=Plur\|POS=VERB\|Polarity=Pos\|VerbForm=Part`, `Mood=Sub\|Number=Plur\|POS=VERB\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Case=Dat,Gen\|Definite=Ind\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|PronType=Int,Rel`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Neg`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|PronType=Prs`, `Mood=Sub\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs\|Strength=Weak`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|Position=Prenom\|PronType=Dem`, `Case=Dat,Gen\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Imp\|VerbForm=Fin`, `Case=Voc\|Definite=Ind\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Gender=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=3\|PronType=Prs`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|PronType=Dem`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=DET\|Person=3\|PronType=Dem`, `Compound=Yes\|POS=CCONJ\|Polarity=Pos`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|Position=Postnom\|PronType=Dem`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|Position=Postnom\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Past\|VerbForm=Fin`, `Case=Dat,Gen\|Gender=Fem\|NumForm=Word\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Ind`, `Case=Acc,Nom\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Voc\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=DET\|Poss=Yes\|PronType=Art`, `Case=Dat\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Strong`, `Case=Dat,Gen\|Number=Sing\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Case=Acc,Nom\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=NOUN`, `AdpType=Prep\|Case=Gen\|POS=ADP`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Past`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs\|Strength=Strong`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Ind`, `Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|PronType=Prs`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Neg`, `Gender=Masc\|Number=Plur\|POS=PRON\|Person=2\|PronType=Emp`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=1\|Tense=Pres\|VerbForm=Fin`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past`, `Case=Nom\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Past`, `Case=Dat,Gen\|Number=Plur\|POS=DET\|Person=3\|PronType=Ind`, `Gender=Fem\|NumForm=Word\|NumType=Card\|Number=Plur\|POS=NUM`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Gender=Masc\|Number=Sing\|POS=VERB\|Polarity=Neg\|VerbForm=Part`, `Case=Acc,Nom\|Gender=Masc\|NumType=Card\|Number=Plur\|POS=NUM\|PronType=Tot`, `Case=Acc,Nom\|POS=PRON\|Person=3\|PronType=Ind`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Dem`, `Case=Acc,Nom\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Gender=Masc\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=1\|PronType=Prs`, `POS=VERB\|Variant=Long\|VerbForm=Inf`, `Definite=Ind\|Gender=Masc\|NumForm=Word\|NumType=Ord\|Number=Sing\|POS=NUM`, `Case=Dat,Gen\|Gender=Masc\|Number=Plur\|POS=DET\|Person=3\|PronType=Dem`, `AdpType=Prep\|Case=Dat\|POS=ADP`, `Case=Dat,Gen\|Number=Plur\|POS=DET\|PronType=Dem`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=2\|PronType=Prs\|Strength=Weak`, `Case=Dat\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs\|Strength=Weak`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=1\|PronType=Prs\|Strength=Strong`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|NumForm=Word\|NumType=Ord\|Number=Sing\|POS=NUM`, `Case=Acc,Nom\|Definite=Ind\|Gender=Masc\|Number=Plur\|POS=PROPN`, `Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|PronType=Prs`, `Case=Dat,Gen\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|Tense=Past\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|PronType=Prs`, `Compound=Yes\|POS=ADV\|Polarity=Neg`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Dem`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Art`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Gender=Masc\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=1\|PronType=Prs`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Case=Dat,Gen\|NumType=Card\|Number=Plur\|POS=NUM\|PronType=Tot`, `Gender=Masc\|NumForm=Word\|NumType=Ord\|Number=Sing\|POS=NUM`, `Definite=Ind\|NumForm=Word\|NumType=Ord\|POS=NUM`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|PronType=Ind`, `Gender=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=2\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=2\|Tense=Imp\|VerbForm=Fin`, `Case=Acc,Nom\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `POS=AUX\|Variant=Long\|VerbForm=Inf`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|PronType=Dem`, `Case=Dat,Gen\|Definite=Ind\|Gender=Fem\|NumForm=Word\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Dat,Gen\|Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|PronType=Ind`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|PronType=Dem`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|Position=Postnom\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=2\|Tense=Past\|VerbForm=Fin`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|PronType=Dem`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=VERB\|Polarity=Neg\|VerbForm=Part`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|Tense=Imp\|VerbForm=Fin`, `Case=Acc\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs\|Strength=Strong`, `POS=X`, `Case=Dat,Gen\|Number=Plur\|POS=DET\|Person=3\|Position=Prenom\|PronType=Dem`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin`, `Mood=Imp\|Number=Sing\|POS=VERB\|Person=2\|Polarity=Neg\|VerbForm=Fin`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|PronType=Prs`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|PronType=Prs`, `Case=Dat,Gen\|Number=Plur\|POS=DET\|Person=3\|Position=Postnom\|PronType=Dem`, `Case=Acc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Prs\|Strength=Weak`, `Case=Dat,Gen\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|PronType=Prs`, `Gender=Fem\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=1\|PronType=Prs`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=NUM`, `Gender=Masc\|Number=Sing\|POS=PRON\|Person=2\|PronType=Emp`, `Case=Nom\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Acc,Nom\|Gender=Fem\|NumType=Card\|Number=Plur\|POS=NUM\|PronType=Tot`, `Case=Acc,Nom\|Number=Plur\|POS=DET\|PronType=Ind`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Past\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=VERB\|Polarity=Neg\|VerbForm=Part`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|NumForm=Word\|NumType=Ord\|Number=Sing\|POS=NUM`, `Case=Dat,Gen\|Number=Plur\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Gender=Masc\|Number=Plur\|Number[psor]=Plur\|POS=DET\|Person=2\|PronType=Prs`, `Gender=Fem\|Number=Plur\|Number[psor]=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Mood=Sub\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Acc,Nom\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Mood=Imp\|Number=Plur\|POS=AUX\|Person=2`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|PronType=Dem`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Ind`, `POS=AUX\|Polarity=Neg\|VerbForm=Ger`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Dat,Gen\|Number=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Mood=Sub\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres`, `Case=Acc,Nom\|POS=DET\|Person=3\|PronType=Ind`, `Case=Voc\|Definite=Ind\|Gender=Fem\|Number=Sing\|POS=NOUN`, `Case=Dat,Gen\|Number=Sing\|POS=PRON\|Person=3\|PronType=Neg`, `POS=CCONJ\|Polarity=Neg`, `Case=Dat,Gen\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Dem`, `Case=Voc\|Definite=Ind\|Gender=Fem\|Number=Sing\|POS=PROPN`, `Case=Acc,Nom\|Number=Sing\|POS=PRON\|Person=3\|PronType=Ind`, `Case=Dat,Gen\|Number=Sing\|POS=PRON\|Person=3\|PronType=Ind`, `Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=DET\|Person=3\|Position=Postnom\|PronType=Dem`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|Polite=Form\|PronType=Prs`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|Position=Prenom\|PronType=Dem`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Ind`, `Case=Acc,Nom\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Acc,Nom\|Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=NOUN`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=2\|Tense=Past`, `Gender=Masc\|Number=Sing\|POS=AUX\|Polarity=Pos\|VerbForm=Part`, `Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Emp`, `Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Past\|VerbForm=Fin`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|Position=Postnom\|PronType=Dem`, `Case=Voc\|Definite=Def\|Gender=Fem\|Number=Plur\|POS=NOUN`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|Number=Plur\|POS=PROPN`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|Number=Plur\|POS=PROPN`, `Mood=Sub\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Voc\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=PROPN`, `Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `POS=PRON\|Polarity=Pos`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Gender=Masc\|Number=Plur\|POS=PRON\|Person=1\|PronType=Emp`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Imp\|VerbForm=Fin`, `Case=Acc,Nom\|Number=Sing\|POS=DET\|Person=3\|PronType=Ind`, `Case=Dat,Gen\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Imp\|VerbForm=Fin`, `Gender=Masc\|Number=Sing\|POS=DET\|Person=2\|PronType=Emp`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=2\|Tense=Imp`, `Case=Dat,Gen\|Number=Plur\|POS=PRON\|Person=3\|Position=Postnom\|PronType=Dem`, `Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Acc,Nom\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Sub\|Number=Sing\|POS=AUX\|Person=2\|Tense=Pres`, `Case=Acc,Nom\|Number=Plur\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Gender=Masc\|Number=Sing\|POS=PRON\|Person=1\|PronType=Emp`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres`, `Gender=Masc\|Number=Plur\|POS=DET\|Person=3\|PronType=Emp`, `Case=Dat,Gen\|Definite=Ind\|Degree=Pos\|Gender=Fem\|Number=Sing\|POS=ADJ`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Gender=Fem\|Number=Plur\|Number[psor]=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Sub\|Number=Plur\|POS=AUX\|Person=2\|Tense=Pres`, `Gender=Fem\|Number=Plur\|Number[psor]=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Dat,Gen\|Definite=Def\|Gender=Fem\|Number=Plur\|POS=PROPN`, `Compound=Yes\|POS=ADP\|Polarity=Pos`, `Mood=Sub\|Number=Plur\|POS=AUX\|Person=1\|Tense=Pres`, `Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Emp`, `Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `POS=ADJ`, `Case=Voc\|Definite=Ind\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|Position=Prenom\|PronType=Dem`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Pqp\|VerbForm=Fin`, `Case=Dat,Gen\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Ind`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|PronType=Ind`, `Case=Dat,Gen\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Emp`, `Case=Dat,Gen\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Imp\|Number=Sing\|POS=AUX\|Person=2\|Polarity=Neg`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Ind`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=2\|Tense=Past\|VerbForm=Fin`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Int,Rel`, `POS=ADV\|PronType=Ind`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Plur\|POS=PROPN`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|NumForm=Word\|NumType=Ord\|Number=Sing\|POS=NUM`, `POS=AUX\|Polarity=Pos`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Imp`, `Case=Gen\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Sub\|Number=Sing\|POS=AUX\|Person=1\|Tense=Pres`, `NumForm=Roman\|NumType=Ord\|Number=Sing\|POS=NUM`, `Case=Voc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Sing\|POS=ADJ`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=1\|Tense=Past`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Ind`, `Definite=Ind\|Gender=Masc\|NumForm=Word\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Dat,Gen\|Gender=Masc\|Number=Plur\|POS=PRON\|Person=3\|PronType=Ind`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=1\|Tense=Pqp\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=1\|Tense=Pres`, `Gender=Fem\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=1\|Tense=Imp`, `Definite=Ind\|Gender=Masc\|NumForm=Word\|NumType=Ord\|Number=Plur\|POS=NUM`, `Gender=Masc\|Number=Plur\|Number[psor]=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|PronType=Ind`, `Mood=Imp\|Number=Plur\|POS=AUX\|Person=2\|Variant=Long\|VerbForm=Fin`, `Mood=Imp\|Number=Plur\|POS=AUX\|Person=2\|Variant=Long`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=2\|PronType=Prs`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=2\|Tense=Imp`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|Number=Sing\|POS=DET\|PronType=Art`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|PronType=Int,Rel`, `Case=Acc,Nom\|POS=PRON\|Person=3\|PronType=Emp`, `NumForm=Word\|NumType=Ord\|POS=NUM`, `Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Emp`, `Case=Dat,Gen\|Number=Plur\|POS=DET\|Person=3\|PronType=Int,Rel`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|Number=Plur\|POS=PRON\|Person=3\|PronType=Int,Rel`, `Case=Dat,Gen\|Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|PronType=Dem`, `Gender=Masc\|Number=Plur\|POS=DET\|Person=1\|PronType=Emp`, `Gender=Masc\|Number=Sing\|POS=DET\|Person=1\|PronType=Emp`, `Mood=Imp\|Number=Plur\|POS=AUX\|Person=2\|VerbForm=Fin`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=DET\|Poss=Yes\|PronType=Art`, `Gender=Fem\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=2\|PronType=Prs`, `Case=Dat,Gen\|Definite=Def\|Gender=Masc\|NumForm=Word\|NumType=Ord\|Number=Sing\|POS=NUM`, `Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|PronType=Emp`, `Case=Dat,Gen\|Definite=Def\|Gender=Masc\|Number=Sing\|POS=DET\|PronType=Art`, `Definite=Ind\|Degree=Pos\|Gender=Fem\|POS=ADJ`, `Mood=Sub\|Number=Plur\|POS=AUX\|Person=2\|Tense=Pres\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=3\|Tense=Pres`, `Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|PronType=Ind`, `Case=Voc\|Definite=Def\|Degree=Pos\|Gender=Masc\|Number=Plur\|POS=ADJ`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=2\|Tense=Past`, `Case=Dat,Gen\|Definite=Ind\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Dat,Gen\|Definite=Def\|Gender=Fem\|NumForm=Word\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Dat,Gen\|Definite=Def\|Gender=Masc\|NumForm=Word\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Dat,Gen\|Number=Plur\|POS=DET\|PronType=Ind`, `Definite=Ind\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=VERB\|Polarity=Pos`, `Gender=Masc\|Number=Plur\|Number[psor]=Plur\|POS=PRON\|Person=1\|PronType=Prs`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=DET\|Person=3\|PronType=Int,Rel`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=2\|Tense=Pqp\|VerbForm=Fin`, `Mood=Ind\|Number=Plur\|POS=VERB\|Person=2\|Tense=Pqp\|VerbForm=Fin`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Neg`, `Mood=Ind\|Number=Sing\|POS=AUX\|Person=3\|Tense=Pqp`, `Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Case=Acc\|POS=PRON\|Person=3\|PronType=Prs\|Reflex=Yes\|Strength=Weak`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Dat\|POS=PRON\|Person=3\|PronType=Prs\|Reflex=Yes\|Strength=Weak`, `Case=Dat,Gen\|Number=Plur\|POS=PRON\|Person=2\|Polite=Form\|PronType=Prs`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=3\|Poss=Yes\|PronType=Prs`, `Mood=Ind\|POS=AUX\|Person=3\|Tense=Pres`, `Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Plur\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Gender=Fem\|Number=Plur\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|PronType=Neg`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=1\|Poss=Yes\|PronType=Prs`, `Gender=Masc\|Number=Sing\|Number[psor]=Sing\|POS=DET\|Person=2\|Poss=Yes\|PronType=Prs`, `Case=Acc\|POS=PRON\|Person=3\|PronType=Prs\|Reflex=Yes\|Strength=Strong`, `Case=Dat\|Number=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Case=Dat,Gen\|Number=Sing\|POS=PRON\|Person=2\|Polite=Form\|PronType=Prs`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=DET\|Person=3\|PronType=Int,Rel`, `Case=Acc,Nom\|Gender=Masc\|NumForm=Word\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Acc,Nom\|Definite=Ind\|Degree=Pos\|Gender=Fem\|POS=ADJ`, `POS=DET`, `Case=Acc,Nom\|Number=Plur\|POS=PRON\|Person=3\|PronType=Prs`, `POS=ADP`, `Gender=Masc\|Number=Sing\|Number[psor]=Plur\|POS=PRON\|Person=1\|Poss=Yes\|PronType=Prs`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|NumForm=Word\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Acc,Nom\|Gender=Masc\|Number=Plur\|POS=DET\|Person=3\|PronType=Int,Rel`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|NumForm=Word\|NumType=Ord\|Number=Plur\|POS=NUM`, `Case=Acc,Nom\|Definite=Ind\|Gender=Fem\|NumType=Mult\|Number=Plur\|POS=NUM`, `Case=Acc,Nom\|Definite=Ind\|Gender=Masc\|NumType=Mult\|Number=Plur\|POS=NUM`, `Mood=Ind\|Number=Plur\|POS=AUX\|Person=3\|Tense=Imp`, `Case=Dat,Gen\|Definite=Def\|Gender=Masc\|Number=Plur\|POS=PROPN`, `Mood=Ind\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Fin`, `Case=Dat,Gen\|Gender=Masc\|Number=Sing\|POS=PRON\|Person=3\|PronType=Emp`, `Case=Acc,Nom\|Definite=Def\|Gender=Fem\|NumForm=Word\|NumType=Ord\|Number=Plur\|POS=NUM`, `Case=Acc,Nom\|Gender=Fem\|Number=Plur\|POS=DET\|Person=3\|PronType=Neg`, `Case=Dat,Gen\|Definite=Def\|Degree=Pos\|Gender=Fem\|Number=Plur\|POS=ADJ`, `Degree=Pos\|POS=ADJ`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|PronType=Ind`, `Case=Acc,Nom\|Definite=Ind\|Gender=Masc\|NumType=Mult\|Number=Sing\|POS=NUM`, `Case=Acc,Nom\|Gender=Fem\|Number=Sing\|Number[psor]=Sing\|POS=PRON\|Person=3\|PronType=Prs`, `Mood=Ind\|Number=Sing\|POS=VERB\|Person=3\|Tense=Pres\|VerbForm=Part`, `Case=Acc,Nom\|Definite=Def\|Gender=Masc\|NumForm=Word\|NumType=Card\|Number=Sing\|POS=NUM`, `Case=Acc,Nom\|Gender=Masc\|Number=Sing\|POS=ADV\|Person=3\|PronType=Int,Rel`, `Case=Dat,Gen\|Gender=Fem\|Number=Sing\|POS=PRON\|Person=3\|Polite=Form\|PronType=Prs` |
| **`parser`** | `ROOT`, `acl`, `advcl`, `advcl:tcl`, `advmod`, `advmod:tmod`, `amod`, `appos`, `aux`, `aux:pass`, `case`, `cc`, `cc:preconj`, `ccomp`, `ccomp:pmod`, `compound`, `conj`, `cop`, `csubj`, `csubj:pass`, `dep`, `det`, `discourse`, `expl`, `expl:impers`, `expl:pass`, `expl:poss`, `expl:pv`, `fixed`, `flat`, `iobj`, `mark`, `nmod`, `nmod:agent`, `nmod:pmod`, `nmod:tmod`, `nsubj`, `nsubj:pass`, `nummod`, `obj`, `obl`, `orphan`, `parataxis`, `punct`, `vocative`, `xcomp` |
| **`experimental_edit_tree_lemmatizer`** | `1`, `3`, `4`, `6`, `8`, `12`, `14`, `16`, `19`, `23`, `29`, `30`, `32`, `35`, `37`, `39`, `40`, `45`, `46`, `47`, `51`, `53`, `54`, `57`, `61`, `63`, `65`, `66`, `69`, `33`, `71`, `73`, `76`, `79`, `80`, `84`, `86`, `87`, `88`, `89`, `92`, `95`, `97`, `100`, `103`, `105`, `107`, `110`, `112`, `113`, `115`, `117`, `120`, `121`, `123`, `125`, `126`, `128`, `130`, `132`, `133`, `136`, `140`, `143`, `145`, `147`, `58`, `148`, `151`, `154`, `157`, `159`, `163`, `165`, `167`, `171`, `174`, `176`, `178`, `180`, `182`, `184`, `185`, `187`, `188`, `190`, `192`, `196`, `197`, `199`, `200`, `202`, `206`, `208`, `210`, `211`, `213`, `215`, `216`, `219`, `221`, `223`, `225`, `226`, `228`, `230`, `232`, `236`, `238`, `241`, `242`, `244`, `246`, `248`, `251`, `253`, `255`, `258`, `260`, `264`, `265`, `267`, `272`, `275`, `278`, `280`, `281`, `284`, `286`, `287`, `290`, `291`, `292`, `295`, `296`, `298`, `300`, `301`, `302`, `305`, `306`, `307`, `309`, `310`, `312`, `314`, `315`, `317`, `319`, `321`, `323`, `324`, `327`, `330`, `332`, `334`, `335`, `337`, `339`, `340`, `343`, `344`, `345`, `346`, `350`, `351`, `353`, `355`, `357`, `360`, `362`, `366`, `368`, `369`, `370`, `371`, `224`, `374`, `376`, `378`, `379`, `381`, `384`, `385`, `386`, `388`, `389`, `391`, `392`, `393`, `396`, `398`, `399`, `403`, `406`, `408`, `411`, `413`, `415`, `418`, `422`, `423`, `426`, `427`, `431`, `433`, `436`, `438`, `440`, `442`, `445`, `448`, `449`, `450`, `451`, `452`, `454`, `455`, `457`, `459`, `460`, `462`, `464`, `466`, `468`, `471`, `472`, `473`, `474`, `475`, `478`, `481`, `482`, `485`, `486`, `488`, `490`, `492`, `494`, `495`, `497`, `498`, `499`, `501`, `503`, `504`, `506`, `508`, `510`, `513`, `514`, `515`, `516`, `518`, `519`, `521`, `523`, `524`, `526`, `527`, `528`, `530`, `533`, `96`, `537`, `538`, `539`, `542`, `544`, `545`, `547`, `548`, `553`, `555`, `556`, `558`, `559`, `561`, `562`, `563`, `565`, `566`, `570`, `572`, `573`, `575`, `577`, `578`, `579`, `581`, `583`, `584`, `586`, `588`, `589`, `592`, `594`, `595`, `596`, `598`, `599`, `600`, `601`, `604`, `606`, `607`, `608`, `612`, `613`, `616`, `619`, `621`, `623`, `625`, `628`, `629`, `630`, `632`, `635`, `636`, `173`, `639`, `641`, `643`, `647`, `649`, `651`, `654`, `656`, `658`, `659`, `661`, `662`, `663`, `666`, `668`, `669`, `670`, `672`, `673`, `676`, `677`, `679`, `681`, `683`, `685`, `687`, `689`, `690`, `691`, `693`, `694`, `695`, `696`, `698`, `699`, `701`, `702`, `703`, `704`, `705`, `706`, `708`, `712`, `713`, `716`, `718`, `720`, `722`, `724`, `725`, `729`, `732`, `734`, `735`, `736`, `739`, `742`, `745`, `747`, `750`, `753`, `755`, `758`, `759`, `761`, `763`, `764`, `766`, `768`, `769`, `771`, `772`, `774`, `777`, `778`, `781`, `784`, `785`, `787`, `790`, `794`, `797`, `800`, `801`, `802`, `804`, `807`, `809`, `814`, `817`, `820`, `821`, `822`, `824`, `827`, `828`, `829`, `832`, `834`, `836`, `837`, `839`, `840`, `841`, `843`, `844`, `846`, `847`, `848`, `850`, `851`, `852`, `855`, `116`, `856`, `860`, `861`, `863`, `866`, `868`, `869`, `871`, `874`, `875`, `877`, `879`, `881`, `884`, `886`, `888`, `890`, `891`, `892`, `894`, `897`, `898`, `900`, `901`, `902`, `904`, `905`, `908`, `913`, `914`, `916`, `917`, `918`, `921`, `922`, `924`, `927`, `929`, `932`, `934`, `935`, `937`, `939`, `941`, `943`, `946`, `948`, `949`, `951`, `952`, `954`, `955`, `956`, `958`, `960`, `963`, `965`, `968`, `971`, `972`, `974`, `978`, `981`, `983`, `984`, `986`, `988`, `989`, `991`, `992`, `994`, `997`, `998`, `1000`, `1001`, `1002`, `1004`, `1006`, `1007`, `1008`, `1010`, `1011`, `1013`, `1014`, `1015`, `1017`, `1019`, `1022`, `1024`, `1029`, `1030`, `1032`, `1034`, `767`, `1035`, `1036`, `1037`, `1038`, `1040`, `1041`, `1042`, `1044`, `1045`, `1046`, `1049`, `1050`, `1052`, `1053`, `1055`, `1058`, `1061`, `1065`, `1067`, `1068`, `1071`, `1072`, `1074`, `1076`, `1078`, `1080`, `1081`, `1083`, `1084`, `1086`, `1087`, `1090`, `1091`, `1093`, `1097`, `1098`, `1099`, `1100`, `1102`, `1105`, `1106`, `1107`, `1110`, `1111`, `1113`, `1116`, `1123`, `1126`, `1127`, `1128`, `1129`, `1131`, `1132`, `1133`, `1135`, `1137`, `1139`, `1141`, `1144`, `1145`, `1147`, `1149`, `1150`, `1152`, `1154`, `1155`, `1156`, `1157`, `1158`, `1115`, `1159`, `1160`, `1162`, `1163`, `1164`, `1165`, `1168`, `1170`, `1172`, `1173`, `1174`, `1175`, `1176`, `1177`, `1178`, `1179`, `1181`, `1183`, `1184`, `1186`, `1187`, `1191`, `1195`, `1197`, `1198`, `1200`, `1201`, `1203`, `1205`, `1207`, `1209`, `1211`, `1212`, `1214`, `1215`, `1217`, `1219`, `1220`, `1223`, `1225`, `1227`, `183`, `1228`, `1231`, `1232`, `1234`, `1237`, `1239`, `1240`, `1242`, `1245`, `1247`, `1248`, `1249`, `1251`, `1252`, `1254`, `1255`, `1257`, `1259`, `1261`, `1263`, `1264`, `1266`, `1268`, `1272`, `1273`, `1277`, `1278`, `1280`, `1281`, `1282`, `1285`, `1286`, `1290`, `1291`, `1294`, `1296`, `1298`, `1300`, `1301`, `1303`, `1305`, `1308`, `1309`, `1310`, `1311`, `1312`, `1314`, `1316`, `1318`, `1320`, `1322`, `1324`, `1325`, `1327`, `1329`, `1331`, `1333`, `1335`, `1337`, `1338`, `1339`, `1341`, `1342`, `1343`, `1344`, `1346`, `1347`, `1350`, `142`, `1354`, `1355`, `1357`, `1358`, `1360`, `1362`, `1365`, `1366`, `1367`, `1368`, `1369`, `744`, `1370`, `1372`, `1373`, `1374`, `1375`, `1376`, `1377`, `1378`, `1380`, `1381`, `1382`, `1383`, `1386`, `1388`, `1389`, `1390`, `1394`, `1396`, `1399`, `1402`, `1405`, `1407`, `1409`, `1411`, `1412`, `1413`, `1414`, `1418`, `1419`, `1421`, `1422`, `1423`, `1424`, `1426`, `1427`, `1430`, `1432`, `1433`, `1434`, `1436`, `1438`, `1439`, `1440`, `1441`, `1442`, `1443`, `1446`, `1447`, `1448`, `1449`, `1450`, `1454`, `1456`, `1458`, `1459`, `1460`, `1464`, `1465`, `1467`, `1468`, `1469`, `1470`, `1472`, `1473`, `1475`, `1478`, `1479`, `1481`, `1483`, `1484`, `1486`, `1003`, `1489`, `1491`, `1493`, `1496`, `1498`, `1499`, `1501`, `1503`, `1506`, `1508`, `1511`, `1514`, `1515`, `1517`, `1518`, `1521`, `1522`, `1523`, `1524`, `1525`, `1528`, `1530`, `1531`, `1532`, `1533`, `1537`, `1539`, `1541`, `1542`, `1543`, `1545`, `1546`, `1547`, `1549`, `1550`, `1551`, `1552`, `1553`, `1555`, `1558`, `1559`, `1561`, `1562`, `1564`, `1566`, `1568`, `1570`, `1572`, `1576`, `1577`, `1579`, `1580`, `1582`, `1584`, `1585`, `1588`, `1590`, `1592`, `1593`, `1594`, `1596`, `1597`, `1599`, `1600`, `1601`, `1603`, `1605`, `1607`, `1609`, `1613`, `1615`, `1617`, `1619`, `1622`, `1623`, `1624`, `1625`, `1626`, `1627`, `1628`, `1629`, `1630`, `1633`, `1636`, `1638`, `1639`, `1640`, `1641`, `1643`, `1645`, `1647`, `1649`, `1652`, `1655`, `1656`, `1658`, `1660`, `1662`, `1665`, `1667`, `1669`, `1670`, `1671`, `1673`, `1674`, `1677`, `1678`, `1679`, `1680`, `1683`, `1686`, `1688`, `1689`, `1691`, `1693`, `1694`, `1696`, `1698`, `1699`, `1703`, `1704`, `1707`, `1708`, `1710`, `1712`, `1714`, `1716`, `1718`, `1720`, `1722`, `1724`, `1725`, `1726`, `1727`, `1729`, `1730`, `1731`, `1733`, `1734`, `1736`, `1737`, `1740`, `1741`, `1743`, `1744`, `1746`, `1747`, `1749`, `1750`, `1751`, `1752`, `1754`, `1755`, `1757`, `1758`, `1760`, `1762`, `1764`, `1766`, `1767`, `1769`, `1771`, `1774`, `1777`, `1779`, `1780`, `1781`, `1783`, `1785`, `1786`, `1789`, `1790`, `1793`, `1796`, `1799`, `1800`, `1802`, `1804`, `1805`, `1807`, `1809`, `1810`, `1813`, `1815`, `1817`, `1819`, `1822`, `1823`, `1825`, `1826`, `1827`, `1829`, `1830`, `1833`, `1835`, `1837`, `1840`, `1843`, `1844`, `1846`, `1848`, `1850`, `1853`, `1854`, `1855`, `1857`, `1859`, `1863`, `1865`, `1867`, `1870`, `1872`, `1873`, `1874`, `1875`, `1876`, `1878`, `1879`, `1880`, `1882`, `1884`, `1885`, `1888`, `1889`, `1892`, `1893`, `1895`, `1896`, `1897`, `1898`, `1899`, `1901`, `1903`, `1905`, `1907`, `1909`, `1911`, `1913`, `1915`, `1916`, `1918`, `1919`, `1921`, `1923`, `1925`, `1928`, `1931`, `1933`, `1935`, `1936`, `1938`, `1940`, `1943`, `1945`, `1946`, `1948`, `1951`, `1954`, `1956`, `1957`, `1958`, `1960`, `1962`, `1963`, `1965`, `1967`, `1969`, `1971`, `1973`, `1976`, `1977`, `1979`, `1981`, `1984`, `1986`, `1988`, `1989`, `1991`, `1994`, `1996`, `1999`, `2000`, `2001`, `2003`, `2004`, `2006`, `2008`, `2010`, `2011`, `2016`, `2017`, `2019`, `2020`, `2022`, `2023`, `2024`, `2025`, `2026`, `2027`, `2029`, `2031`, `2033`, `2034`, `2035`, `2036`, `2038`, `2041`, `2042`, `2043`, `2045`, `2047`, `2048`, `2049`, `2051`, `2053`, `2055`, `2057`, `2060`, `2063`, `2064`, `2066`, `2067`, `2068`, `2070`, `2071`, `2072`, `2073`, `2074`, `2075`, `2076`, `2079`, `2080`, `2082`, `2083`, `2084`, `2085`, `2086`, `2087`, `2089`, `2092`, `2094`, `2095`, `2098`, `2100`, `2102`, `2104`, `2105`, `2107`, `2109`, `2110`, `2112`, `2115`, `2117`, `2119`, `2120`, `2121`, `2123`, `2124`, `1482`, `2125`, `2127`, `2129`, `2132`, `2134`, `2137`, `2139`, `2140`, `2143`, `2146`, `2147`, `2148`, `2149`, `2150`, `2152`, `2154`, `2156`, `2157`, `2158`, `2159`, `2160`, `2161`, `2162`, `2164`, `2166`, `2168`, `2169`, `2170`, `2171`, `2173`, `2174`, `2177`, `2178`, `2180`, `2182`, `2183`, `2186`, `2188`, `2189`, `2191`, `2192`, `2193`, `2194`, `2195`, `2197`, `2198`, `2199`, `2200`, `2202`, `2206`, `2208`, `2209`, `2211`, `2214`, `2216`, `2217`, `2220`, `2221`, `2222`, `2223`, `2224`, `2225`, `2226`, `2228`, `2229`, `2230`, `2232`, `2234`, `2236`, `2237`, `2239`, `2241`, `2242`, `2243`, `2244`, `2245`, `2246`, `2248`, `2249`, `2251`, `2252`, `2172`, `2254`, `2256`, `2257`, `2258`, `2259`, `2261`, `2262`, `2263`, `2265`, `2267`, `2268`, `2270`, `2274`, `2277`, `2279`, `2280`, `2281`, `2282`, `2284`, `2286`, `2287`, `2291`, `2293`, `2294`, `2296`, `2297`, `2298`, `2300`, `2303`, `2305`, `2307`, `2308`, `2310`, `2312`, `2314`, `2316`, `2317`, `2319`, `2321`, `2323`, `2325`, `2326`, `2328`, `2329`, `2330`, `2331`, `2332`, `2333`, `2334`, `2336`, `2338`, `2341`, `2343`, `2345`, `2348`, `2349`, `2351`, `2352`, `2353`, `2355`, `2356`, `2358`, `2359`, `2361`, `2362`, `2364`, `2366`, `2368`, `2369`, `2371`, `2373`, `2375`, `2377`, `2378`, `2379`, `2381`, `2382`, `2383`, `2384`, `2385`, `2387`, `2389`, `2392`, `2395`, `2396`, `2398`, `2399`, `2400`, `2404`, `2405`, `2406`, `2410`, `2411`, `2412`, `2413`, `2415`, `2418`, `2420`, `2421`, `2424`, `2425`, `2426`, `2429`, `2432`, `2434`, `2436`, `2437`, `2439`, `2440`, `2441`, `2443`, `2444`, `2446`, `2447`, `2450`, `2452`, `2454`, `2456`, `2459`, `2461`, `2464`, `2465`, `2467`, `2469`, `2471`, `2473`, `2474`, `2476`, `2478`, `2480`, `2481`, `2482`, `2483`, `2484`, `2486`, `2488`, `2489`, `2490`, `2491`, `2493`, `2495`, `2497`, `2499`, `2500`, `2502`, `2503`, `2505`, `2506`, `2507`, `2509`, `2511`, `2513`, `2514`, `2516`, `2518`, `2519`, `2521`, `2522`, `2524`, `2527`, `2528`, `2529`, `2531`, `2533`, `2534`, `2536`, `2537`, `2538`, `2540`, `2542`, `2543`, `2545`, `2546`, `2547`, `2549`, `2550`, `2552`, `2553`, `2556`, `2558`, `2560`, `2561`, `2562`, `2563`, `2564`, `2566`, `2567`, `2568`, `2572`, `2573`, `2574`, `2576`, `2577`, `2579`, `2580`, `2581`, `2583`, `2584`, `2585`, `2586`, `2587`, `2588`, `2589`, `2590`, `2591`, `2592`, `2594`, `2595`, `2598`, `2599`, `2603`, `2604`, `2606`, `2607`, `2608`, `2609`, `2612`, `2616`, `2619`, `2620`, `2622`, `2624`, `2625`, `2626`, `2627`, `2628`, `2631`, `2633`, `2635`, `2637`, `2638`, `2640`, `2641`, `2642`, `2643`, `2645`, `2646`, `2647`, `2649`, `2651`, `2654`, `2655`, `2658`, `2660`, `2661`, `2662`, `2663`, `2665`, `2666`, `1717`, `2667`, `2668`, `2669`, `2670`, `2671`, `2673`, `2674`, `2675`, `2676`, `2678`, `2680`, `2681`, `2684`, `2685`, `2687`, `2688`, `2690`, `2691`, `2692`, `2694`, `2695`, `2696`, `2697`, `2699`, `2701`, `2702`, `2705`, `2708`, `2709`, `2711`, `2714`, `2715`, `2716`, `2718`, `2721`, `2723`, `2724`, `2727`, `2728`, `2729`, `2732`, `2734`, `2737`, `2739`, `2740`, `2742`, `2743`, `2745`, `2748`, `2751`, `2754`, `2755`, `2756`, `2757`, `2758`, `2760`, `2762`, `2764`, `2765`, `2766`, `2428`, `2767`, `2768`, `2769`, `2770`, `2771`, `2774`, `2777`, `2779`, `2782`, `2783`, `2784`, `2786`, `2788`, `2789`, `2790`, `2791`, `2792`, `2794`, `2795`, `2796`, `2797`, `2799`, `2800`, `2801`, `2803`, `2807`, `2808`, `2809`, `2812`, `2816`, `2819`, `2822`, `2823`, `2824`, `2826`, `2827`, `2828`, `2830`, `2831`, `2832`, `2833`, `2834`, `2835`, `2837`, `2839`, `2840`, `2842`, `2843`, `2845`, `2846`, `2847`, `2848`, `2849`, `2851`, `2853`, `2854`, `2855`, `2856`, `2857`, `2858`, `2859`, `2860`, `2861`, `2862`, `2864`, `2865`, `2866`, `2868`, `2872`, `2875`, `2876`, `2878`, `2880`, `2881`, `2882`, `2883`, `2885`, `2886`, `2888`, `2889`, `2890`, `2891`, `2893`, `2894`, `2895`, `2896`, `2897`, `2898`, `2899`, `2902`, `2904`, `2906`, `2907`, `2908`, `2909`, `2912`, `2913`, `2915`, `2916`, `2917`, `2918`, `2921`, `2922`, `2923`, `2924`, `2925`, `2926`, `2928`, `2930`, `2931`, `2935`, `2936`, `2937`, `2938`, `2940`, `2233`, `2942`, `2944`, `2945`, `2947`, `2948`, `2949`, `2951`, `923`, `2952`, `2953`, `2954`, `2955`, `2957`, `2959`, `2962`, `2964`, `2966`, `2967`, `2969`, `2972`, `2973`, `2974`, `2976`, `1715`, `2977`, `2979`, `2980`, `36`, `2981`, `2983`, `2985`, `2986`, `2990`, `2991`, `2993`, `2995`, `2997`, `2998`, `3001`, `3002`, `3003`, `3005`, `3006`, `3007`, `3009`, `3012`, `3014`, `3015`, `3016`, `3018`, `3020`, `3021`, `3022`, `3023`, `3026`, `3028`, `3029`, `3030`, `3032`, `3035`, `3037`, `3039`, `3040`, `3042`, `3044`, `3047`, `3050`, `3052`, `3053`, `3041`, `3054`, `3055`, `3056`, `3057`, `3058`, `3059`, `3061`, `3062`, `3064`, `3066`, `3067`, `3068`, `3070`, `3071`, `3072`, `3073`, `3075`, `3078`, `3082`, `3084`, `3086`, `3087`, `3088`, `3090`, `3091`, `3092`, `3095`, `3096`, `3097`, `3099`, `3100`, `3102`, `3107`, `3109`, `3111`, `3112`, `3114`, `3116`, `3118`, `3120`, `3121`, `3123`, `3124`, `3126`, `3127`, `3129`, `3130`, `3133`, `3134`, `3135`, `3136`, `3137`, `3138`, `3139`, `3140`, `3142`, `3144`, `3145`, `3146`, `3147`, `3148`, `3149`, `3150`, `3151`, `3153`, `3155`, `3157`, `3158`, `3159`, `3160`, `3161`, `3163`, `3165`, `3167`, `3168`, `3170`, `3171`, `3172`, `3174`, `3176`, `3178`, `3180`, `3181`, `3184`, `3185`, `3186`, `3188`, `3189`, `3190`, `3192`, `3194`, `3195`, `3196`, `3197`, `3200`, `3201`, `3202`, `3203`, `3204`, `3205`, `3206`, `3207`, `3210`, `3211`, `3213`, `3214`, `3217`, `3218`, `3220`, `3222`, `3224`, `3227`, `3229`, `3230`, `3231`, `3233`, `3234`, `3235`, `3236`, `3237`, `3240`, `3241`, `3243`, `3245`, `3247`, `3250`, `3252`, `3253`, `3254`, `3255`, `3257`, `3259`, `3260`, `3262`, `3264`, `3266`, `3268`, `3269`, `3271`, `3273`, `3275`, `3277`, `3278`, `3141`, `3279`, `3280`, `3281`, `3282`, `3284`, `3285`, `3287`, `3288`, `3290`, `3291`, `3293`, `3294`, `3296`, `3297`, `3299`, `3300`, `3302`, `3304`, `3305`, `3306`, `3308`, `3309`, `3311`, `3313`, `3314`, `3315`, `3316`, `3317`, `3319`, `3321`, `3323`, `3324`, `3325`, `3327`, `3329`, `3332`, `3333`, `3334`, `3336`, `3337`, `3338`, `3340`, `3341`, `3342`, `3344`, `3346`, `3348`, `3351`, `3353`, `3355`, `3357`, `3360`, `3361`, `3364`, `3367`, `3369`, `3370`, `3372`, `3373`, `3374`, `3377`, `3379`, `3380`, `3382`, `3384`, `3385`, `3387`, `3389`, `3391`, `3392`, `3393`, `3394`, `3395`, `3397`, `3399`, `3400`, `3402`, `3403`, `3404`, `3405`, `3406`, `3407`, `3408`, `3412`, `3414`, `3416`, `3418`, `3420`, `3422`, `3423`, `3424`, `3425`, `3426`, `3428`, `3429`, `3431`, `3432`, `3435`, `3436`, `3438`, `3439`, `3441`, `3443`, `3445`, `3447`, `3450`, `3451`, `3453`, `3455`, `3456`, `3457`, `3458`, `3459`, `3461`, `3462`, `3464`, `3465`, `3467`, `3469`, `3471`, `3473`, `3474`, `3475`, `3476`, `3478`, `3479`, `3481`, `3482`, `3484`, `3487`, `3488`, `3489`, `3491`, `3492`, `3493`, `3494`, `3497`, `3500`, `3501`, `3502`, `3504`, `3506`, `3507`, `3508`, `3511`, `3515`, `3516`, `3518`, `3521`, `3524`, `3526`, `3528`, `3529`, `3532`, `3535`, `3537`, `3538`, `3539`, `3540`, `3541`, `3543`, `3545`, `3546`, `3547`, `3548`, `3549`, `3550`, `3551`, `3553`, `3555`, `3556`, `3557`, `3559`, `3561`, `3563`, `3564`, `3565`, `3567`, `3570`, `3572`, `3574`, `3575`, `3577`, `3579`, `3581`, `3582`, `3584`, `3585`, `3587`, `3588`, `3590`, `3591`, `3592`, `3594`, `3596`, `3599`, `3600`, `3603`, `3605`, `3606`, `3607`, `3608`, `3610`, `3612`, `3615`, `3617`, `3618`, `3619`, `3620`, `3621`, `3623`, `3624`, `3625`, `3626`, `3628`, `3629`, `3630`, `3632`, `3633`, `3635`, `3637`, `3639`, `3642`, `3643`, `3645`, `3646`, `3649`, `3650`, `3652`, `3653`, `3655`, `3656`, `3657`, `3658`, `3659`, `3662`, `3664`, `3665`, `3666`, `3668`, `3671`, `3672`, `3674`, `3676`, `3678`, `3679`, `3680`, `3681`, `3683`, `3684`, `3685`, `3687`, `3688`, `3689`, `3690`, `3691`, `3693`, `3694`, `3695`, `3697`, `3698`, `3699`, `3700`, `3702`, `3703`, `3704`, `3706`, `3709`, `3712`, `3713`, `3714`, `3718`, `3719`, `3721`, `3722`, `3724`, `3725`, `3726`, `3727`, `3730`, `3731`, `3732`, `3734`, `3735`, `3737`, `3739`, `3742`, `3743`, `3744`, `3745`, `3746`, `3747`, `3748`, `3750`, `3752`, `3753`, `3755`, `3757`, `3759`, `3760`, `3762`, `3763`, `3764`, `3765`, `3766`, `3768`, `3770`, `3771`, `3774`, `3775`, `3776`, `3778`, `3779`, `3780`, `3782`, `3784`, `3785`, `3786`, `3789`, `3792`, `3794`, `3795`, `3796`, `3798`, `3799`, `3800`, `3802`, `3803`, `3805`, `3807`, `3808`, `3809`, `3812`, `3815`, `3817`, `3818`, `3819`, `3821`, `3823`, `3824`, `3826`, `3828`, `3829`, `3831`, `3833`, `3834`, `3836`, `3839`, `3840`, `3843`, `3846`, `3849`, `3851`, `3852`, `3853`, `3855`, `3856`, `3859`, `3860`, `3862`, `3864`, `3865`, `3866`, `3868`, `3870`, `3871`, `3872`, `3874`, `3875`, `3876`, `3878`, `3879`, `3880`, `3881`, `3882`, `3884`, `3886`, `3887`, `3890`, `3891`, `3892`, `3893`, `3894`, `3896`, `3897`, `3899`, `3900`, `3901`, `3903`, `3904`, `3905`, `3906`, `3907`, `3908`, `3909`, `3910`, `3911`, `3912`, `3913`, `3915`, `3916`, `3919`, `3921`, `3923`, `3924`, `3926`, `3927`, `3928`, `3930`, `3931`, `3932`, `3934`, `3936`, `3939`, `3941`, `3942`, `3943`, `3946`, `3948`, `3949`, `3950`, `3951`, `3952`, `3954`, `3956`, `3957`, `3958`, `3960`, `3961`, `3964`, `3967`, `3968`, `3971`, `3974`, `3975`, `3976`, `3979`, `3981`, `3983`, `3985`, `3986`, `3989`, `3990`, `3993`, `3994`, `3995`, `3996`, `3997`, `3998`, `3999`, `4001`, `4003`, `4004`, `4005`, `4007`, `4009`, `4010`, `4011`, `4013`, `4014`, `4015`, `4017`, `4019`, `4022`, `4023`, `4025`, `4026`, `4027`, `4028`, `4029`, `4030`, `4032`, `4035`, `4037`, `4040`, `4041`, `4042`, `4043`, `4045`, `4048`, `4051`, `4053`, `4055`, `4057`, `4058`, `4059`, `4060`, `4061`, `4062`, `4063`, `4065`, `4067`, `4068`, `4070`, `4072`, `4073`, `4074`, `4075`, `4077`, `4080`, `4081`, `4083`, `4085`, `4088`, `4089`, `4091`, `4093`, `4094`, `4095`, `4096`, `4098`, `4101`, `4102`, `4104`, `4105`, `4106`, `4108`, `4109`, `4111`, `4112`, `4113`, `4115`, `4117`, `4119`, `4122`, `4123`, `4124`, `4125`, `4126`, `4127`, `4128`, `4130`, `4131`, `4134`, `4135`, `4136`, `4137`, `4138`, `4139`, `4141`, `4143`, `4145`, `4147`, `4148`, `4150`, `4151`, `4154`, `4155`, `4157`, `4159`, `4160`, `4163`, `4164`, `4166`, `4169`, `4171`, `4172`, `4173`, `4175`, `4176`, `4177`, `4179`, `4180`, `4181`, `4183`, `4184`, `4185`, `4187`, `4188`, `4190`, `4191`, `4193`, `4194`, `4195`, `4198`, `4201`, `4204`, `4205`, `4206`, `4209`, `4210`, `4212`, `4215`, `4216`, `4218`, `4219`, `4224`, `4225`, `4227`, `4229`, `4230`, `4231`, `4232`, `4234`, `4236`, `4237`, `4238`, `4239`, `4242`, `4244`, `4246`, `4247`, `4250`, `4251`, `4253`, `4256`, `4260`, `4261`, `4263`, `4265`, `4267`, `4268`, `4269`, `4270`, `4272`, `4274`, `4277`, `4278`, `4279`, `4281`, `4282`, `4284`, `4286`, `4287`, `4288`, `4291`, `4293`, `4294`, `4295`, `4296`, `4298`, `4299`, `4301`, `4303`, `4305`, `4306`, `4307`, `4308`, `4309`, `4310`, `4313`, `4315`, `4317`, `4319`, `4320`, `4322`, `4324`, `4326`, `4328`, `4329`, `4331`, `4332`, `4333`, `4334`, `4335`, `4336`, `4338`, `4340`, `4343`, `4344`, `4346`, `4347`, `4348`, `4349`, `4351`, `4353`, `4355`, `4357`, `4358`, `4359`, `4360`, `4361`, `4362`, `4363`, `4365`, `4367`, `4369`, `4372`, `4373`, `4374`, `4375`, `4379`, `4381`, `4383`, `4385`, `4386`, `4388`, `4389`, `4391`, `4392`, `4393`, `4395`, `4396`, `4399`, `4400`, `4402`, `4404`, `4406`, `4407`, `4411`, `4412`, `4413`, `4414`, `4415`, `4418`, `4420`, `4422`, `4425`, `4426`, `4428`, `4429`, `4430`, `4432`, `4433`, `4435`, `4438`, `4440`, `4442`, `4444`, `4445`, `4446`, `4448`, `4450`, `4451`, `4452`, `4455`, `4457`, `4459`, `4461`, `4462`, `4464`, `4467`, `4468`, `4469`, `4470`, `4471`, `4473`, `4474`, `4475`, `4478`, `4480`, `4483`, `4485`, `4487`, `4488`, `4490`, `4491`, `4493`, `867`, `4494`, `4496`, `4497`, `4498`, `4499`, `4500`, `4501`, `4503`, `4505`, `4507`, `4508`, `4509`, `4510`, `4512`, `4515`, `4517`, `4518`, `4519`, `4521`, `1589`, `4522`, `4524`, `4525`, `4527`, `4529`, `4531`, `4533`, `4534`, `4535`, `4537`, `4538`, `4539`, `4540`, `4541`, `4542`, `4543`, `4544`, `4545`, `4546`, `4547`, `4549`, `4551`, `4552`, `4553`, `4554`, `4556`, `4557`, `4558`, `4559`, `4562`, `4563`, `4566`, `4567`, `4569`, `4570`, `4572`, `4574`, `4576`, `4577`, `4579`, `4580`, `4581`, `4583`, `4585`, `4586`, `4588`, `4591`, `4592`, `4594`, `4595`, `4596`, `4597`, `4598`, `4599`, `4600`, `4601`, `4603`, `4606`, `4608`, `4609`, `4610`, `4612`, `4614`, `4616`, `4617`, `4620`, `4621`, `4623`, `4624`, `4625`, `4626`, `4627`, `4629`, `4631`, `4633`, `4635`, `4636`, `4637`, `4638`, `4639`, `4640`, `4642`, `4644`, `4646`, `4647`, `4648`, `4649`, `4650`, `4651`, `4653`, `4655`, `4657`, `4658`, `4659`, `4661`, `4662`, `4663`, `4664`, `4665`, `4667`, `4668`, `4669`, `4671`, `4673`, `4675`, `4676`, `4680`, `4681`, `4683`, `4684`, `4686`, `4687`, `4690`, `4693`, `4695`, `4696`, `4699`, `4700`, `4702`, `4703`, `4704`, `4707`, `4708`, `4709`, `4710`, `4711`, `4713`, `4715`, `4716`, `4718`, `4719`, `4721`, `4726`, `4727`, `4729`, `4731`, `4735`, `4737`, `4738`, `4739`, `4741`, `4743`, `4744`, `4748`, `4749`, `4753`, `4755`, `4756`, `4757`, `4758`, `4759`, `4761`, `4763`, `4764`, `4766`, `4768`, `4769`, `4770`, `4772`, `4774`, `4775`, `4777`, `4779`, `4780`, `4782`, `4783`, `4785`, `4787`, `4788`, `4791`, `4792`, `4793`, `4795`, `4797`, `4801`, `4802`, `4804`, `4806`, `4808`, `4809`, `4810`, `4811`, `4813`, `4815`, `4817`, `4818`, `4820`, `4821`, `4823`, `4826`, `4827`, `4828`, `4830`, `4831`, `4833`, `4834`, `4838`, `4840`, `4843`, `4845`, `4847`, `4848`, `4849`, `4850`, `4851`, `4854`, `4855`, `4856`, `4858`, `4860`, `4862`, `4863`, `4864`, `4866`, `4867`, `4869`, `4871`, `4872`, `4874`, `4875`, `4876`, `4878`, `4880`, `4881`, `4883`, `4885`, `4886`, `4889`, `4890`, `4892`, `4893`, `4894`, `4896`, `4897`, `4899`, `4900`, `4902`, `4903`, `4904`, `4905`, `4907`, `4908`, `4909`, `4911`, `4913`, `4914`, `4918`, `4920`, `4922`, `4924`, `4925`, `4926`, `4927`, `4928`, `4929`, `4931`, `4932`, `4933`, `4934`, `4935`, `4937`, `813`, `4941`, `4943`, `4945`, `4946`, `4947`, `4948`, `4950`, `4952`, `4954`, `4955`, `4956`, `4959`, `4962`, `4963`, `4964`, `4967`, `4969`, `4970`, `4972`, `4973`, `4974`, `4976`, `4977`, `4978`, `4980`, `4982`, `4984`, `4986`, `4989`, `4990`, `4991`, `4992`, `4994`, `4995`, `4997`, `4999`, `5002`, `5003`, `5004`, `5005`, `5007`, `5009`, `5010`, `5013`, `5014`, `5016`, `5017`, `5018`, `5019`, `5020`, `5021`, `5022`, `5024`, `5025`, `5026`, `5027`, `5029`, `5030`, `5032`, `5034`, `5035`, `5036`, `5037`, `5039`, `5042`, `5043`, `5045`, `5046`, `5049`, `5051`, `5053`, `5054`, `5056`, `5057`, `5058`, `5061`, `5063`, `5066`, `5068`, `5069`, `5070`, `5071`, `5072`, `5075`, `5077`, `5078`, `5080`, `5082`, `5084`, `5085`, `5087`, `5089`, `5090`, `5092`, `5094`, `5095`, `5096`, `5099`, `5100`, `5101`, `5102`, `5104`, `5105`, `5107`, `5109`, `5110`, `5112`, `5116`, `5120`, `5121`, `5122`, `5124`, `5125`, `5127`, `5128`, `5129`, `5132`, `5133`, `5135`, `5138`, `5141`, `5142`, `5143`, `5144`, `5145`, `5146`, `5148`, `5150`, `5151`, `5154`, `5155`, `5156`, `5159`, `5162`, `5163`, `5164`, `5165`, `5166`, `5168`, `5169`, `5170`, `5172`, `5173`, `5174`, `5176`, `5177`, `5179`, `5181`, `5182`, `957`, `5183`, `5184`, `5185`, `5188`, `5189`, `5191`, `5192`, `5195`, `5196`, `5198`, `5200`, `5201`, `5203`, `5204`, `5205`, `5207`, `5208`, `5210`, `5211`, `5214`, `5215`, `5216`, `5217`, `5218`, `5219`, `5220`, `5221`, `5222`, `5224`, `5225`, `5226`, `5227`, `5229`, `5231`, `5232`, `5234`, `5235`, `5237`, `5238`, `5240`, `5241`, `5242`, `5245`, `5246`, `5251`, `5253`, `5256`, `5257`, `2677`, `5259`, `5261`, `5263`, `5264`, `5266`, `5267`, `5271`, `5274`, `5275`, `5279`, `5280`, `5281`, `5283`, `5285`, `5287`, `5289`, `5290`, `5291`, `5293`, `5296`, `5297`, `5299`, `5300`, `5301`, `5302`, `5305`, `5307`, `5309`, `5311`, `5314`, `5315`, `5316`, `5317`, `5319`, `5320`, `5321`, `5323`, `5324`, `5326`, `5327`, `5329`, `5331`, `5332`, `5333`, `5334`, `5336`, `5337`, `5339`, `5340`, `5341`, `5343`, `5346`, `5347`, `5348`, `5349`, `5351`, `5352`, `5353`, `5354`, `5356`, `5357`, `1020`, `5358`, `5359`, `5360`, `5361`, `5362`, `5363`, `5364`, `5365`, `5367`, `5369`, `5370`, `5371`, `5373`, `5374`, `5377`, `5379`, `5382`, `5383`, `5384`, `5386`, `5387`, `5389`, `5390`, `5393`, `5394`, `5396`, `5397`, `5399`, `5400`, `5402`, `5403`, `5404`, `4463`, `5406`, `5409`, `5410`, `5412`, `5413`, `5415`, `5416`, `5417`, `5419`, `5420`, `5421`, `5422`, `5423`, `5425`, `5428`, `5429`, `5431`, `5432`, `5434`, `5435`, `5437`, `5439`, `5441`, `5446`, `5447`, `5450`, `5452`, `5453`, `5456`, `5458`, `5462`, `5464`, `5465`, `5467`, `5468`, `5469`, `5470`, `5471`, `5473`, `5475`, `5476`, `5477`, `5479`, `5480`, `5482`, `5484`, `5485`, `5487`, `5489`, `3877`, `5490`, `5492`, `5493`, `5494`, `5497`, `5498`, `5499`, `5500`, `5503`, `5505`, `5506`, `5509`, `5510`, `5511`, `5513`, `5514`, `5517`, `5520`, `5521`, `5522`, `5524`, `5526`, `5529`, `5530`, `5531`, `5532`, `5533`, `5534`, `5535`, `5536`, `5537`, `5539`, `5540`, `5542`, `5543`, `5545`, `5546`, `5548`, `5549`, `5550`, `5552`, `5554`, `5556`, `5557`, `5559`, `5560`, `3089`, `5563`, `5564`, `5565`, `5567`, `5569`, `5570`, `5572`, `5575`, `5576`, `5578`, `5579`, `5580`, `5582`, `5583`, `5584`, `5585`, `5587`, `5589`, `5590`, `5591`, `5595`, `5597`, `5598`, `5599`, `5602`, `5603`, `5606`, `5608`, `5611`, `5613`, `4981`, `5614`, `5616`, `5617`, `5622`, `5623`, `5624`, `5625`, `5626`, `5627`, `5630`, `5631`, `5633`, `5634`, `5635`, `5637`, `3169`, `5639`, `5641`, `5643`, `5645`, `5646`, `5649`, `5651`, `5654`, `5655`, `5657`, `5659`, `5660`, `5662`, `5663`, `5664`, `5665`, `5667`, `5668`, `5669`, `5670`, `5671`, `5672`, `5673`, `5676`, `5681`, `5682`, `5683`, `5684`, `5685`, `5687`, `5689`, `5691`, `5693`, `5694`, `5698`, `5700`, `5702`, `5703`, `5704`, `5706`, `5708`, `5709`, `5710`, `5713`, `5715`, `5717`, `5718`, `5719`, `5723`, `5724`, `5725`, `5726`, `5728`, `5730`, `5731`, `5733`, `5734`, `5736`, `5738`, `5741`, `5743`, `5744`, `5747`, `5748`, `5749`, `5751`, `5752`, `5754`, `5756`, `5757`, `5759`, `5760`, `5761`, `5762`, `5763`, `5764`, `5766`, `5768`, `5770`, `5771`, `5773`, `5775`, `5776`, `5777`, `5778`, `5780`, `5782`, `5784`, `5786`, `5787`, `5788`, `5790`, `5791`, `5792`, `5795`, `5796`, `5798`, `5799`, `5800`, `5801`, `5802`, `5805`, `5806`, `5811`, `5813`, `5814`, `5815`, `5816`, `5817`, `5818`, `5820`, `5821`, `5822`, `5823`, `5824`, `5827`, `5830`, `5832`, `5833`, `5834`, `5836`, `5837`, `5839`, `5840`, `5841`, `5842`, `5845`, `5847`, `5849`, `5851`, `5853`, `5856`, `5859`, `5862`, `5863`, `5865`, `5867`, `5868`, `5870`, `5872`, `5873`, `5875`, `5876`, `5877`, `5878`, `5879`, `5881`, `5883`, `5886`, `5887`, `5888`, `5889`, `5891`, `5892`, `5895`, `5896`, `5898`, `5900`, `5903`, `5904`, `5905`, `5906`, `5908`, `5909`, `5912`, `5915`, `5916`, `5917`, `5918`, `5919`, `5920`, `5922`, `5923`, `5925`, `5927`, `5928`, `5929`, `5931`, `5932`, `5933`, `5935`, `5939`, `5940`, `5941`, `5943`, `5945`, `5947`, `5948`, `5950`, `5951`, `5952`, `5955`, `5956`, `5957`, `5958`, `5959`, `5961`, `5962`, `5963`, `5964`, `5965`, `5967`, `5968`, `5969`, `5970`, `5971`, `5972`, `5974`, `5976`, `5977`, `5978`, `5980`, `5982`, `5983`, `5984`, `5986`, `5987`, `5988`, `5990`, `5991`, `5993`, `5995`, `5996`, `5999`, `6000`, `6003`, `6004`, `6006`, `6009`, `6010`, `6011`, `6012`, `6013`, `6015`, `6016`, `6019`, `6020`, `6022`, `6024`, `6025`, `6028`, `6031`, `6032`, `6036`, `6037`, `6039`, `6040`, `6041`, `6042`, `6044`, `6046`, `6047`, `6048`, `6049`, `6050`, `6051`, `6052`, `6054`, `6056`, `6057`, `6058`, `6059`, `6061`, `6062`, `6063`, `6065`, `6066`, `6068`, `6069`, `6071`, `6072`, `6073`, `6074`, `6075`, `6076`, `6078`, `6079`, `6080`, `6082`, `6083`, `6085`, `6087`, `6088`, `6090`, `6091`, `6092`, `6094`, `6095`, `6096`, `6097`, `6099`, `6100`, `6102`, `6104`, `6106`, `6108`, `6109`, `6110`, `6111`, `6112`, `6115`, `6118`, `6121`, `6123`, `6124`, `6125`, `6127`, `6128`, `6129`, `6130`, `6131`, `6132`, `6133`, `6134`, `6135`, `6136`, `6137`, `6138`, `6139`, `6140`, `6141`, `6142`, `6143`, `6144`, `6145`, `6147`, `6149`, `6151`, `6153`, `6154`, `6155`, `6156`, `6157`, `6158`, `6160`, `6161`, `6162`, `6163`, `6165`, `6166`, `6167`, `6168`, `6169`, `6170`, `6172`, `6174`, `6176`, `6177`, `6178`, `6180`, `6183`, `6185`, `6188`, `6190`, `6194`, `6196`, `6197`, `6198`, `6199`, `6201`, `6202`, `6203`, `6206`, `6207`, `6210`, `6211`, `6212`, `6214`, `6215`, `6218`, `6219`, `6220`, `6222`, `6223`, `6224`, `6225`, `6226`, `6228`, `6229`, `6230`, `6232`, `6236`, `6238`, `6240`, `6242`, `6243`, `6245`, `6246`, `6247`, `6249`, `6250`, `6252`, `6253`, `6255`, `6257`, `6258`, `6261`, `6262`, `6263`, `6264`, `6266`, `6268`, `6269`, `6270`, `6273`, `6274`, `6275`, `6276`, `6277`, `6278`, `6280`, `6282`, `6283`, `6284`, `6287`, `6289`, `6290`, `6291`, `6292`, `6293`, `6295`, `1732`, `6296`, `6299`, `6300`, `6302`, `6303`, `6305`, `6306`, `6307`, `6308`, `6309`, `6310`, `6311`, `6312`, `6315`, `6317`, `6319`, `6320`, `6322`, `6323`, `6324`, `6325`, `6328`, `6330`, `6331`, `6332`, `6333`, `6334`, `6336`, `6338`, `6339`, `6341`, `6343`, `6345`, `6347`, `6348`, `6349`, `6351`, `6352`, `6354`, `6357`, `6358`, `6360`, `6361`, `6362`, `6364`, `6365`, `6367`, `6369`, `6370`, `6371`, `111`, `6372`, `6373`, `2065`, `6374`, `6375`, `6377`, `6378`, `6380`, `6381`, `6382`, `6384`, `6385`, `6386`, `6387`, `6388`, `6391`, `6392`, `6393`, `6394`, `6396`, `6397`, `6399`, `6400`, `6401`, `6402`, `6404`, `6407`, `6408`, `6409`, `6411`, `6414`, `6416`, `6418`, `6419`, `6421`, `6422`, `6423`, `6425`, `6426`, `6428`, `6429`, `6430`, `6431`, `6432`, `6434`, `6435`, `6436`, `6437`, `6438`, `6440`, `6441`, `6442`, `6443`, `6444`, `6445`, `6447`, `6449`, `6451`, `6452`, `6455`, `6456`, `6457`, `6458`, `6459`, `6460`, `6462`, `6463`, `6464`, `6465`, `6466`, `6469`, `6470`, `6471`, `6473`, `6474`, `6475`, `6476`, `6478`, `6480`, `6481`, `6482`, `6485`, `6486`, `6487`, `6488`, `6489`, `6490`, `6491`, `6493`, `6494`, `6495`, `6497`, `6498`, `6499`, `5134`, `6500`, `6501`, `6502`, `6503`, `6504`, `6506`, `6508`, `6509`, `6510`, `6511`, `6512`, `6514`, `6515`, `6516`, `6517`, `6518`, `6519`, `6520`, `6521`, `6523`, `6526`, `6527`, `6529`, `6531`, `6533`, `6535`, `6536`, `6537`, `6538`, `6539`, `6540`, `6543`, `6544`, `6545`, `6547`, `6550`, `6551`, `6552`, `6553`, `6554`, `6555`, `6557`, `6559`, `6560`, `6561`, `6562`, `6564`, `6565`, `6567`, `6568`, `6569`, `6570`, `6571`, `6574`, `6575`, `6578`, `6579`, `6580`, `6581`, `6583`, `6584`, `6586`, `6588`, `6589`, `6591`, `6593`, `6595`, `6597`, `6599`, `6600`, `6601`, `6602`, `6604`, `6605`, `6607`, `6609`, `6611`, `6614`, `6615`, `6616`, `6618`, `6619`, `6620`, `6622`, `6623`, `1924`, `6626`, `6628`, `6629`, `6631`, `6633`, `6635`, `6637`, `6638`, `6639`, `6641`, `6643`, `6644`, `6647`, `6649`, `6650`, `6651`, `6652`, `6654`, `6655`, `6656`, `6658`, `6659`, `6661`, `6662`, `6663`, `6664`, `6665`, `6666`, `6667`, `6669`, `6670`, `6672`, `6673`, `6674`, `6675`, `6676`, `6678`, `6680`, `6681`, `6682`, `6684`, `6685`, `6689`, `6690`, `6691`, `6694`, `6696`, `6697`, `6698`, `6699`, `6701`, `6702`, `6703`, `6704`, `6706`, `6707`, `6709`, `6710`, `6712`, `6714`, `6715`, `6717`, `6718`, `6719`, `6720`, `6721`, `6724`, `6725`, `6727`, `6730`, `6732`, `6733`, `6736`, `6739`, `6740`, `6743`, `6745`, `6746`, `6747`, `6748`, `6749`, `6751`, `6754`, `6755`, `6756`, `6757`, `6758`, `6759`, `6761`, `6763`, `6765`, `6768`, `6770`, `6773`, `6774`, `6775`, `6777`, `6778`, `6780`, `6783`, `6784`, `6785`, `6787`, `6789`, `6790`, `6792`, `6796`, `6799`, `6800`, `6801`, `6802`, `6803`, `6805`, `6807`, `6808`, `6810`, `6812`, `6814`, `6817`, `6819`, `6821`, `6822`, `6824`, `6826`, `6828`, `6829`, `6830`, `6832`, `6834`, `6835`, `6836`, `6839`, `6841`, `6844`, `6846`, `6848`, `6850`, `6851`, `6852`, `6853`, `6854`, `6855`, `6856`, `6858`, `6859`, `6860`, `6862`, `6863`, `6864`, `6866`, `6868`, `6869`, `6871`, `6873`, `6877`, `6880`, `6884`, `6885`, `6887`, `6888`, `6889`, `6892`, `6893`, `6894`, `6895`, `6898`, `6900`, `6901`, `6902`, `6904`, `6905`, `6906`, `6907`, `6909`, `6911`, `6914`, `6915`, `6916`, `6918`, `6919`, `6921`, `6922`, `6923`, `6924`, `6925`, `6926`, `6929`, `6930`, `6931`, `6934`, `6935`, `6937`, `6939`, `6940`, `6941`, `6944`, `6946`, `6947`, `6948`, `6950`, `6952`, `6954`, `6956`, `6957`, `6959`, `6960`, `6961`, `6963`, `6964`, `6965`, `6966`, `6968`, `6969`, `6970`, `6971`, `6972`, `6973`, `6974`, `6975`, `6977`, `1222`, `6979`, `6980`, `6981`, `6982`, `6983`, `6984`, `6985`, `6987`, `6988`, `6989`, `6990`, `6991`, `6992`, `6993`, `6994`, `6997`, `6998`, `7000`, `7001`, `7002`, `7003`, `7004`, `7007`, `7009`, `7010`, `7011`, `7013`, `7014`, `7016`, `7017`, `7019`, `7020`, `7021`, `7023`, `7024`, `7026`, `2231`, `7027`, `7028`, `7029`, `7031`, `7032`, `7033`, `7034`, `7035`, `7037`, `7038`, `7039`, `7040`, `7042`, `7043`, `7044`, `7045`, `7046`, `7048`, `7049`, `7051`, `7053`, `7055`, `7059`, `7060`, `7061`, `7062`, `7064`, `7065`, `7067`, `7068`, `7071`, `7072`, `7073`, `7074`, `7076`, `7077`, `7081`, `7084`, `7085`, `7088`, `7090`, `7092`, `7093`, `7095`, `7096`, `7097`, `7098`, `7100`, `7101`, `7102`, `7104`, `7107`, `7108`, `7112`, `7113`, `7115`, `7116`, `7117`, `7120`, `7121`, `7122`, `7123`, `7124`, `7125`, `7126`, `7128`, `7131`, `7132`, `7133`, `7134`, `7135`, `7138`, `7140`, `7141`, `7142`, `7143`, `7145`, `7146`, `7148`, `7149`, `7152`, `7156`, `7158`, `7159`, `7160`, `7161`, `7162`, `7163`, `7166`, `7169`, `7170`, `7173`, `7174`, `7177`, `7178`, `7179`, `7180`, `7181`, `7183`, `7184`, `7185`, `7186`, `7188`, `7189`, `7191`, `7192`, `7195`, `7198`, `7199`, `7201`, `7203`, `7204`, `7205`, `7206`, `7208`, `7213`, `7215`, `7216`, `7219`, `7221`, `7224`, `7225`, `7227`, `7229`, `7231`, `7232`, `7235`, `7236`, `7237`, `7239`, `7240`, `7242`, `7243`, `7245`, `7246`, `7247`, `7248`, `7252`, `7253`, `7254`, `7256`, `7258`, `7259`, `7260`, `7262`, `7263`, `7264`, `7266`, `7268`, `7270`, `7271`, `7272`, `7273`, `7274`, `7276`, `7277`, `7278`, `7281`, `7282`, `7283`, `7286`, `7288`, `7290`, `1256`, `7291`, `7292`, `7293`, `7295`, `7298`, `7299`, `7301`, `7302`, `7303`, `7304`, `7306`, `7307`, `7308`, `7310`, `7312`, `7313`, `7316`, `7317`, `7318`, `7319`, `7320`, `7323`, `7324`, `7326`, `7328`, `7331`, `7332`, `7334`, `7336`, `7337`, `7338`, `7340`, `7342`, `7343`, `7344`, `7345`, `7346`, `7347`, `7348`, `7350`, `7352`, `7353`, `5131`, `7354`, `7356`, `7358`, `7360`, `7362`, `7363`, `7366`, `7367`, `7368`, `7369`, `7373`, `7374`, `7375`, `7376`, `7377`, `7378`, `7379`, `7382`, `7383`, `7384`, `7385`, `7386`, `7387`, `7388`, `7389`, `7392`, `7395`, `7397`, `7398`, `7400`, `7402`, `7405`, `7406`, `7408`, `7410`, `7411`, `7412`, `7414`, `7416`, `7417`, `7419`, `7421`, `7423`, `7425`, `7427`, `7428`, `7429`, `7430`, `7432`, `7434`, `7435`, `7436`, `7437`, `7439`, `7440`, `7443`, `7444`, `7445`, `7447`, `7448`, `7449`, `7451`, `7453`, `7454`, `7456`, `7458`, `7459`, `7460`, `7462`, `7463`, `7464`, `7465`, `7466`, `7467`, `7468`, `7469`, `7470`, `7471`, `7472`, `7475`, `7477`, `7478`, `7479`, `7481`, `7482`, `7483`, `7484`, `7485`, `7486`, `7487`, `7488`, `7490`, `7492`, `7496`, `7497`, `7498`, `7500`, `7501`, `7503`, `7505`, `7506`, `7509`, `7511`, `7512`, `7514`, `7515`, `7516`, `7518`, `7522`, `7523`, `7524`, `7255`, `7526`, `7527`, `7530`, `7532`, `7533`, `7535`, `7536`, `7539`, `7541`, `7544`, `7547`, `7548`, `7550`, `7552`, `7553`, `7555`, `7556`, `7558`, `7559`, `7560`, `7561`, `7563`, `7564`, `7565`, `7566`, `7567`, `7569`, `7571`, `7575`, `7577`, `7578`, `7580`, `7581`, `7585`, `7586`, `7588`, `7590`, `7593`, `7595`, `7597`, `7599`, `7600`, `7601`, `7603`, `7605`, `7607`, `7608`, `7609`, `7610`, `7611`, `7612`, `7613`, `7614`, `7615`, `7616`, `7617`, `7619`, `7620`, `7621`, `7622`, `7623`, `7625`, `7628`, `7630`, `7631`, `7632`, `7634`, `7635`, `3191`, `7636`, `7637`, `7639`, `7641`, `7642`, `7643`, `7644`, `7645`, `7646`, `7647`, `7648`, `7649`, `7650`, `7652`, `7653`, `7654`, `7655`, `7657`, `7658`, `7659`, `7660`, `7661`, `7662`, `7664`, `7665`, `7667`, `7668`, `7670`, `7672`, `7673`, `7674`, `7675`, `7677`, `7678`, `7679`, `7680`, `7681`, `7682`, `7684`, `7686`, `7687`, `7688`, `7690`, `7692`, `7693`, `7695`, `7696`, `7698`, `7700`, `7701`, `7703`, `7704`, `7707`, `7710`, `7711`, `7713`, `7714`, `7715`, `7717`, `7718`, `7719`, `7721`, `7722`, `7723`, `7725`, `7726`, `7728`, `7729`, `7730`, `7731`, `7732`, `7733`, `7734`, `7735`, `7737`, `7739`, `7741`, `7743`, `7744`, `7745`, `7748`, `7750`, `7752`, `7753`, `7755`, `7756`, `7757`, `7758`, `7759`, `7760`, `7761`, `7762`, `7763`, `7764`, `7765`, `7766`, `7767`, `7768`, `7769`, `7771`, `7772`, `7774`, `7775`, `7776`, `7778`, `7779`, `7781`, `7782`, `7784`, `7785`, `7788`, `7789`, `7790`, `7791`, `7793`, `7794`, `7796`, `7798`, `7800`, `7801`, `7803`, `7804`, `7806`, `7808`, `7810`, `7811`, `7813`, `7816`, `7817`, `7819`, `7822`, `7824`, `7826`, `7828`, `7831`, `7833`, `7834`, `7836`, `7838`, `7840`, `7841`, `7842`, `7844`, `7846`, `7848`, `7850`, `7851`, `7852`, `7853`, `7854`, `7855`, `7856`, `7857`, `7859`, `7860`, `7861`, `7862`, `7863`, `7866`, `7868`, `7871`, `7873`, `7875`, `7876`, `7878`, `7880`, `7883`, `7884`, `7885`, `7886`, `7888`, `7889`, `7891`, `7894`, `7895`, `7896`, `7898`, `7899`, `7900`, `7901`, `7902`, `7903`, `7905`, `7907`, `7909`, `7910`, `7912`, `7914`, `7915`, `7916`, `7917`, `7919`, `5472`, `7920`, `7921`, `7922`, `7923`, `7924`, `7926`, `7928`, `7930`, `7931`, `7933`, `7934`, `7935`, `7937`, `7938`, `7939`, `7941`, `7942`, `7945`, `7946`, `7947`, `7948`, `7951`, `7952`, `7953`, `7955`, `7956`, `7959`, `7960`, `7961`, `7962`, `7963`, `7964`, `7965`, `7966`, `7967`, `7969`, `7970`, `7971`, `7972`, `7974`, `7975`, `7976`, `7977`, `7978`, `7979`, `7982`, `7984`, `7985`, `7987`, `7988`, `7989`, `7990`, `7992`, `7993`, `7994`, `7995`, `7997`, `7998`, `7999`, `8000`, `8001`, `8002`, `8007`, `8008`, `8009`, `8011`, `8012`, `8014`, `8016`, `8019`, `8021`, `8023`, `8025`, `8027`, `8028`, `8030`, `8031`, `8032`, `8033`, `8035`, `8037`, `3820`, `8038`, `8040`, `8042`, `8044`, `8046`, `8047`, `8048`, `8049`, `2686`, `8050`, `8051`, `8053`, `8054`, `8055`, `8056`, `8058`, `8061`, `8062`, `8064`, `8065`, `8066`, `8067`, `8068`, `8069`, `8071`, `8072`, `8073`, `8074`, `8075`, `8076`, `8077`, `8078`, `8079`, `8080`, `8081`, `8083`, `8084`, `8085`, `8086`, `8087`, `8088`, `8090`, `8091`, `8093`, `8094`, `8095`, `8097`, `8098`, `8099`, `8101`, `8103`, `8104`, `8106`, `8108`, `8109`, `8110`, `8111`, `8112`, `8113`, `8115`, `8117`, `8118`, `8119`, `8120`, `8121`, `8124`, `8125`, `8127`, `8128`, `8129`, `8130`, `8131`, `8132`, `8133`, `8134`, `8136`, `8137`, `8139`, `8141`, `8142`, `8144`, `8145`, `8147`, `8151`, `8154`, `8155`, `8157`, `8158`, `8160`, `8161`, `8162`, `8164`, `8166`, `8167`, `8168`, `8169`, `8170`, `8171`, `8173`, `8174`, `8176`, `8177`, `8178`, `8179`, `8181`, `8182`, `8183`, `8185`, `8186`, `8187`, `8188`, `8189`, `8190`, `8191`, `8192`, `8193`, `8194`, `8195`, `8197`, `8199`, `8201`, `8202`, `8203`, `7736`, `8204`, `8205`, `8206`, `8207`, `8209`, `8210`, `8211`, `8213`, `8215`, `8216`, `8218`, `8219`, `8220`, `8221`, `8222`, `8223`, `7839`, `8224`, `8225`, `8227`, `2984`, `8229`, `8230`, `8231`, `8232`, `8235`, `8237`, `8239`, `8240`, `8241`, `8245`, `8246`, `8248`, `8249`, `8250`, `8253`, `8254`, `8256`, `8257`, `8259`, `8260`, `8261`, `8263`, `8264`, `8265`, `8266`, `8267`, `8268`, `8269`, `8271`, `8272`, `8273`, `8274`, `8275`, `8280`, `8281`, `8282`, `8284`, `8285`, `8286`, `8287`, `8288`, `8290`, `8291`, `8292`, `8293`, `8294`, `8295`, `8297`, `8299`, `8300`, `8301`, `8302`, `8303`, `8306`, `8308`, `8309`, `8310`, `8312`, `8313`, `8314`, `8316`, `8317`, `8319`, `8321`, `8323`, `8325`, `8326`, `8327`, `8329`, `8330`, `8331`, `8332`, `8333`, `8336`, `8338`, `8339`, `8296`, `8340`, `8342`, `8343`, `8344`, `8345`, `8347`, `8349`, `8350`, `8352`, `8357`, `8359`, `8360`, `8361`, `8362`, `8363`, `8365`, `8366`, `8367`, `8369`, `8370`, `8372`, `8373`, `8375`, `8377`, `8378`, `8379`, `8381`, `8382`, `8383`, `8385`, `8388`, `8389`, `8391`, `8392`, `8394`, `8396`, `8398`, `8270`, `8399`, `8402`, `8404`, `8405`, `8407`, `8409`, `8411`, `8412`, `8414`, `8415`, `8417`, `8419`, `8420`, `8423`, `8426`, `8427`, `8428`, `8431`, `8432`, `8433`, `8434`, `8435`, `8437`, `8438`, `8441`, `8443`, `8444`, `8445`, `8446`, `8447`, `8449`, `8453`, `8455`, `8457`, `8459`, `8460`, `8462`, `8463`, `8464`, `8466`, `8467`, `8468`, `8469`, `8470`, `8472`, `8473`, `8474`, `8475`, `8476`, `8478`, `8479`, `8481`, `8484`, `8485`, `8486`, `8488`, `8489`, `8491`, `8494`, `8495`, `8496`, `8497`, `8498`, `8499`, `8500`, `8503`, `8505`, `8506`, `8508`, `8509`, `8510`, `8511`, `8512`, `8513`, `8514`, `8515`, `8516`, `8517`, `8519`, `8521`, `8522`, `8523`, `8524`, `8525`, `8526`, `8527`, `8529`, `8530`, `8532`, `8535`, `8537`, `8538`, `8539`, `8541`, `8542`, `8543`, `8544`, `8549`, `8550`, `8551`, `8552`, `8553`, `8554`, `8555`, `8557`, `8558`, `8559`, `8562`, `8563`, `8564`, `8566`, `8569`, `8570`, `8571`, `8573`, `8575`, `8577`, `8578`, `8579`, `8580`, `8581`, `8584`, `8585`, `8586`, `8587`, `8589`, `8590`, `8592`, `8593`, `8594`, `8595`, `8597`, `8598`, `8600`, `8601`, `8602`, `8604`, `8605`, `8608`, `8610`, `8611`, `8612`, `8613`, `8614`, `8615`, `8616`, `8618`, `8619`, `8620`, `8621`, `8622`, `8625`, `8627`, `8629`, `8630`, `8632`, `8634`, `8636`, `8637`, `8638`, `8640`, `8642`, `8643`, `8644`, `8646`, `8647`, `8649`, `8650`, `8651`, `8653`, `8655`, `8656`, `8657`, `8658`, `8659`, `8660`, `8662`, `8664`, `8665`, `8666`, `8667`, `8669`, `8670`, `8671`, `8673`, `8674`, `8675`, `8676`, `8677`, `8678`, `8679`, `8680`, `8681`, `8683`, `8685`, `8687`, `8689`, `8691`, `8692`, `8693`, `8694`, `8696`, `8697`, `8698`, `8700`, `8701`, `8702`, `8703`, `8704`, `8705`, `8706`, `8707`, `8708`, `8709`, `8710`, `8712`, `8713`, `8715`, `8717`, `8719`, `8722`, `8723`, `8725`, `8726`, `8727`, `8729`, `8730`, `8732`, `8734`, `8736`, `8738`, `8739`, `8740`, `8741`, `8743`, `8744`, `8745`, `8747`, `8748`, `8752`, `8753`, `8754`, `8755`, `8756`, `8757`, `8758`, `8760`, `8761`, `8762`, `8763`, `8765`, `8766`, `8767`, `8768`, `8770`, `8771`, `8773`, `8774`, `8775`, `8776`, `8778`, `8779`, `8780`, `8781`, `8782`, `8785`, `8786`, `8787`, `8789`, `8790`, `8791`, `8793`, `8795`, `8798`, `8800`, `8801`, `8802`, `8804`, `8805`, `8807`, `8808`, `8809`, `8810`, `8813`, `8815`, `8816`, `8817`, `8819`, `8820`, `8821`, `8822`, `8823`, `401`, `8824`, `8826`, `8827`, `8829`, `8830`, `8831`, `8833`, `8835`, `8837`, `8839`, `8840`, `8841`, `8842`, `8844`, `8845`, `8847`, `8849`, `8851`, `8852`, `8853`, `8855`, `8857`, `8858`, `8859`, `8864`, `8865`, `8866`, `8867`, `8869`, `8870`, `8871`, `8874`, `8877`, `8879`, `8880`, `8881`, `8883`, `8884`, `8886`, `8887`, `8890`, `8891`, `8892`, `8893`, `8895`, `8897`, `8899`, `8900`, `8901`, `8903`, `8906`, `8907`, `8909`, `8911`, `8914`, `8916`, `8917`, `8919`, `8920`, `8921`, `8922`, `8923`, `8927`, `8928`, `8930`, `8931`, `8933`, `8934`, `8937`, `8939`, `8940`, `8941`, `8942`, `8944`, `8945`, `8947`, `8948`, `8949`, `8950`, `8951`, `8953`, `8954`, `8955`, `8958`, `8960`, `8962`, `8965`, `8966`, `8967`, `8968`, `8969`, `8970`, `8971`, `8972`, `8974`, `8976`, `8977`, `8978`, `8979`, `8980`, `8981`, `8982`, `8983`, `8984`, `8985`, `8987`, `8991`, `8992`, `8993`, `8994`, `8995`, `8996`, `8998`, `8999`, `9000`, `9002`, `9003`, `9004`, `9005`, `9007`, `9009`, `9010`, `9011`, `9014`, `9015`, `9016`, `9018`, `9019`, `9020`, `9022`, `9024`, `9025`, `9026`, `9028`, `9030`, `9031`, `9032`, `9034`, `9035`, `9037`, `9038`, `9039`, `9042`, `9043`, `9044`, `9046`, `9048`, `9050`, `9051`, `9053`, `9054`, `9055`, `9057`, `9058`, `8932`, `9059`, `9060`, `9061`, `9062`, `9064`, `9068`, `1932`, `9069`, `9070`, `9071`, `9072`, `9073`, `9074`, `9076`, `9079`, `9080`, `9083`, `9084`, `9087`, `9088`, `9090`, `9091`, `9093`, `9095`, `9096`, `9097`, `9098`, `9100`, `9103`, `9104`, `9105`, `9106`, `9107`, `9108`, `9109`, `9110`, `9111`, `9112`, `9113`, `9114`, `9116`, `9119`, `9120`, `9121`, `9122`, `9123`, `9124`, `9127`, `9128`, `9129`, `9130`, `9131`, `9132`, `9133`, `9134`, `9135`, `9136`, `9138`, `9139`, `9141`, `9142`, `9144`, `9145`, `9146`, `9148`, `9149`, `9150`, `9152`, `9153`, `9156`, `9158`, `9160`, `9162`, `9165`, `7986`, `9168`, `9170`, `9171`, `9172`, `9173`, `9175`, `9176`, `9177`, `9179`, `9180`, `9182`, `9183`, `9185`, `9188`, `9190`, `9191`, `9192`, `9194`, `9198`, `9200`, `9201`, `9202`, `9204`, `9206`, `9207`, `5871`, `9210`, `9211`, `9213`, `9214`, `9215`, `9217`, `9218`, `9220`, `9221`, `9222`, `9226`, `9228`, `9230`, `9231`, `9233`, `9234`, `9235`, `9238`, `9239`, `9241`, `9242`, `9244`, `9246`, `9249`, `9251`, `9252`, `9255`, `9256`, `9259`, `9260`, `9262`, `9263`, `9265`, `9269`, `9270`, `9273`, `9274`, `9277`, `3858`, `9279`, `9281`, `9282`, `9284`, `9287`, `7598`, `9289`, `9292`, `9294`, `9295`, `9296`, `9297`, `9298`, `9299`, `9301`, `9302`, `9304`, `9306`, `9308`, `9311`, `9312`, `9313`, `9314`, `9318`, `9320`, `9322`, `9325`, `9326`, `9327`, `9329`, `9331`, `9333`, `9334`, `9336`, `9338`, `9339`, `9340`, `9341`, `9342`, `9343`, `9344`, `9346`, `9347`, `9349`, `9350`, `9352`, `9353`, `9355`, `9358`, `9359`, `9360`, `9363`, `9365`, `9368`, `9369`, `9371`, `9373`, `9374`, `9375`, `9376`, `9377`, `9379`, `9382`, `9383`, `9384`, `9387`, `9388`, `9389`, `9390`, `9391`, `9392`, `9393`, `9395`, `9396`, `9398`, `9400`, `9401`, `9404`, `9406`, `9409`, `9410`, `9412`, `9414`, `9416`, `9417`, `9418`, `9420`, `9421`, `9424`, `9426`, `9428`, `9429`, `9431`, `9432`, `9433`, `9434`, `9435`, `9436`, `9438`, `9441`, `9443`, `9445`, `9446`, `9447`, `9448`, `9449`, `9450`, `9451`, `9453`, `9454`, `9455`, `9457`, `9458`, `9459`, `9460`, `9461`, `9462`, `9463`, `9464`, `9465`, `9467`, `9469`, `9471`, `9474`, `9476`, `9477`, `9478`, `9479`, `9480`, `973`, `9482`, `9483`, `9485`, `9486`, `9488`, `9489`, `9490`, `9492`, `9493`, `9495`, `9496`, `9498`, `9499`, `9501`, `9502`, `9504`, `9506`, `9507`, `9508`, `9511`, `9512`, `9514`, `9515`, `9518`, `9519`, `9521`, `9523`, `9524`, `9526`, `9528`, `9531`, `9533`, `9534`, `9535`, `9537`, `9539`, `9540`, `9541`, `9543`, `9545`, `9546`, `9548`, `9549`, `9550`, `9551`, `9554`, `9555`, `9556`, `9557`, `9559`, `9561`, `9562`, `9565`, `9567`, `9570`, `9571`, `9573`, `7877`, `9575`, `9578`, `9580`, `9582`, `9583`, `9586`, `9587`, `9588`, `9589`, `9591`, `9592`, `9593`, `9594`, `9595`, `9597`, `9599`, `9601`, `9603`, `9604`, `9605`, `9607`, `9610`, `5979`, `9611`, `9612`, `9613`, `9614`, `9616`, `9617`, `9618`, `9620`, `9621`, `9622`, `9624`, `9627`, `9629`, `9630`, `9632`, `9633`, `9636`, `9637`, `9638`, `9640`, `9641`, `9642`, `9644`, `9646`, `9647`, `9649`, `9650`, `9653`, `9656`, `9657`, `9658`, `9659`, `9660`, `9662`, `9663`, `9664`, `9665`, `9666`, `9667`, `9670`, `9673`, `9675`, `9677`, `9679`, `9681`, `9682`, `9683`, `9684`, `9686`, `9688`, `9689`, `9690`, `9692`, `9693`, `9695`, `9696`, `9697`, `9699`, `9701`, `9703`, `9705`, `9707`, `9710`, `9713`, `9714`, `9715`, `9717`, `9718`, `9721`, `9722`, `9724`, `9725`, `9726`, `9727`, `9729`, `9730`, `9731`, `9732`, `9733`, `9735`, `9737`, `9739`, `9740`, `9741`, `9744`, `9747`, `9748`, `9750`, `9751`, `9753`, `9754`, `9755`, `9756`, `9758`, `9759`, `9760`, `9761`, `9762`, `9764`, `9768`, `9770`, `9772`, `9774`, `9776`, `9777`, `9779`, `9780`, `9782`, `9783`, `9784`, `9787`, `9789`, `9790`, `9791`, `9793`, `9794`, `9795`, `9796`, `9797`, `9798`, `9799`, `9800`, `9803`, `9805`, `9807`, `9809`, `9810`, `9811`, `9813`, `9816`, `9817`, `9819`, `9820`, `9822`, `9823`, `9824`, `9825`, `9827`, `9828`, `9830`, `9831`, `9832`, `9834`, `9836`, `9837`, `9839`, `9840`, `9841`, `9842`, `9844`, `9845`, `9846`, `9847`, `9848`, `9850`, `9851`, `9853`, `9854`, `9855`, `9856`, `9857`, `2337`, `8520`, `9858`, `9861`, `9862`, `9757`, `9864`, `9865`, `9867`, `9868`, `9870`, `9871`, `9872`, `9873`, `9874`, `9877`, `9878`, `9879`, `9880`, `9882`, `9884`, `9885`, `9887`, `9889`, `9890`, `9892`, `9894`, `9895`, `9897`, `9899`, `9901`, `9903`, `9906`, `9907`, `9909`, `9911`, `9914`, `9916`, `9918`, `9919`, `9920`, `9922`, `9924`, `9927`, `9929`, `9930`, `9932`, `9935`, `9936`, `9938`, `9939`, `9940`, `9941`, `9942`, `9943`, `9944`, `9945`, `9946`, `9947`, `9948`, `9949`, `9950`, `9951`, `9952`, `9953`, `9955`, `9956`, `9957`, `9958`, `9960`, `9962`, `9963`, `9964`, `9965`, `9967`, `9968`, `9970`, `9971`, `9974`, `9977`, `9978`, `9980`, `9981`, `6878`, `9982`, `9984`, `9985`, `9987`, `9988`, `9989`, `9992`, `9993`, `9994`, `9995`, `9999`, `10001`, `10002`, `10003`, `10004`, `10006`, `10007`, `1912`, `10008`, `10011`, `10013`, `10014`, `10016`, `10017`, `10019`, `10020`, `10023`, `10025`, `10028`, `10029`, `10030`, `10033`, `10034`, `10036`, `10038`, `10039`, `10040`, `10041`, `10042`, `10044`, `10046`, `10048`, `10050`, `10051`, `10053`, `10055`, `10057`, `10058`, `10060`, `10061`, `10062`, `10063`, `10065`, `10066`, `10069`, `10070`, `10071`, `10073`, `10076`, `10078`, `10079`, `10081`, `10085`, `10086`, `10091`, `10092`, `10093`, `10094`, `10096`, `10098`, `10099`, `10100`, `10101`, `10104`, `10105`, `10106`, `10107`, `10110`, `10111`, `10112`, `10114`, `10115`, `10116`, `10118`, `10119`, `10120`, `10123`, `10124`, `10125`, `10127`, `10128`, `10129`, `10130`, `10131`, `10133`, `10134`, `10136`, `10138`, `10139`, `10142`, `10143`, `10146`, `10148`, `10149`, `10150`, `10152`, `10154`, `10156`, `10159`, `10161`, `10163`, `10164`, `10165`, `10167`, `10168`, `10169`, `10170`, `10171`, `10172`, `10175`, `10176`, `10177`, `10180`, `10183`, `10185`, `10186`, `10187`, `10189`, `10191`, `10193`, `10195`, `10196`, `10197`, `10198`, `10199`, `10200`, `10202`, `10203`, `10204`, `10207`, `10208`, `10210`, `10211`, `10213`, `10214`, `10215`, `10217`, `10218`, `10220`, `10222`, `10224`, `10225`, `10227`, `10228`, `10230`, `10232`, `10234`, `10235`, `10237`, `10238`, `10239`, `10241`, `10242`, `10243`, `10245`, `10248`, `10249`, `10251`, `10252`, `10253`, `10255`, `10258`, `10259`, `10260`, `10261`, `10262`, `10263`, `10265`, `10267`, `10268`, `10269`, `10270`, `10272`, `10273`, `10275`, `10276`, `10277`, `10278`, `10279`, `10280`, `10281`, `10284`, `10285`, `10287`, `10288`, `10291`, `10292`, `10294`, `10296`, `10297`, `10298`, `10300`, `10302`, `10303`, `10304`, `10306`, `10307`, `10308`, `10309`, `10312`, `10313`, `10314`, `10315`, `10316`, `10317`, `10318`, `10319`, `10320`, `10321`, `10323`, `10324`, `10327`, `10328`, `10329`, `10330`, `10332`, `10333`, `10335`, `10336`, `10337`, `10340`, `10341`, `10343`, `10344`, `10345`, `10346`, `10347`, `10348`, `10349`, `10350`, `10351`, `10352`, `10353`, `10354`, `10356`, `10357`, `10359`, `10360`, `10363`, `10365`, `10366`, `10368`, `10370`, `10371`, `10372`, `10373`, `10374`, `10375`, `10376`, `10377` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TOKEN_F` | 99.06 |
| `TOKEN_P` | 99.06 |
| `TOKEN_R` | 99.06 |
| `TOKEN_ACC` | 99.77 |
| `SENTS_F` | 97.00 |
| `SENTS_P` | 97.32 |
| `SENTS_R` | 96.67 |
| `TAG_ACC` | 93.85 |
| `POS_ACC` | 97.66 |
| `MORPH_ACC` | 93.64 |
| `DEP_UAS` | 92.56 |
| `DEP_LAS` | 87.49 |
| `LEMMA_ACC` | 93.99 | |
Amro-Kamal/gpt | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- spacy
- token-classification
language:
- multilingual
license: cc-by-sa-4.0
model-index:
- name: xx_udv25_oldfrenchsrcmf_trf
results:
- task:
name: TAG
type: token-classification
metrics:
- name: TAG (XPOS) Accuracy
type: accuracy
value: 0.9640594402
- task:
name: POS
type: token-classification
metrics:
- name: POS (UPOS) Accuracy
type: accuracy
value: 0.9652113812
- task:
name: MORPH
type: token-classification
metrics:
- name: Morph (UFeats) Accuracy
type: accuracy
value: 0.9773643589
- task:
name: LEMMA
type: token-classification
metrics:
- name: Lemma Accuracy
type: accuracy
value: 0.9034097454
- task:
name: UNLABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Unlabeled Attachment Score (UAS)
type: f_score
value: 0.9021426103
- task:
name: LABELED_DEPENDENCIES
type: token-classification
metrics:
- name: Labeled Attachment Score (LAS)
type: f_score
value: 0.8542218638
- task:
name: SENTS
type: token-classification
metrics:
- name: Sentences F-Score
type: f_score
value: 0.8110992529
---
UD v2.5 benchmarking pipeline for UD_Old_French-SRCMF
| Feature | Description |
| --- | --- |
| **Name** | `xx_udv25_oldfrenchsrcmf_trf` |
| **Version** | `0.0.1` |
| **spaCy** | `>=3.2.1,<3.3.0` |
| **Default Pipeline** | `experimental_char_ner_tokenizer`, `transformer`, `tagger`, `morphologizer`, `parser`, `experimental_edit_tree_lemmatizer` |
| **Components** | `experimental_char_ner_tokenizer`, `transformer`, `senter`, `tagger`, `morphologizer`, `parser`, `experimental_edit_tree_lemmatizer` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | [Universal Dependencies v2.5](https://lindat.mff.cuni.cz/repository/xmlui/handle/11234/1-3105) (Zeman, Daniel; et al.) |
| **License** | `CC BY-SA 4.0` |
| **Author** | [Explosion](https://explosion.ai) |
### Label Scheme
<details>
<summary>View label scheme (16214 labels for 6 components)</summary>
| Component | Labels |
| --- | --- |
| **`experimental_char_ner_tokenizer`** | `TOKEN` |
| **`senter`** | `I`, `S` |
| **`tagger`** | `ADJQUA`, `ADJcar`, `ADJind`, `ADJord`, `ADJpos`, `ADJqua`, `ADVgen`, `ADVgen.PROadv`, `ADVgen.PROper`, `ADVing`, `ADVint`, `ADVneg`, `ADVneg.PROper`, `ADVsub`, `CONcoo`, `CONsub`, `CONsub.PROper`, `CONsub_o`, `CONsub_pre`, `DETcar`, `DETdef`, `DETdem`, `DETind`, `DETint`, `DETndf`, `DETord`, `DETpos`, `DETrel`, `DETrel_o`, `ETR`, `INJ`, `NOMcom`, `NOMcom.PROper`, `NOMpro`, `PRE`, `PRE.DETdef`, `PRE.PROdem`, `PRE.PROper`, `PROadv`, `PROcar`, `PROdem`, `PROimp`, `PROind`, `PROint`, `PROint.PROper`, `PROint_adv`, `PROord`, `PROper`, `PROper.PROper`, `PROpos`, `PROrel`, `PROrel.ADVneg`, `PROrel.PROadv`, `PROrel.PROper`, `PROrel_adv`, `RED`, `VERcjg`, `VERinf`, `VERppa`, `VERppe` |
| **`morphologizer`** | `POS=CCONJ`, `Definite=Def\|POS=DET\|PronType=Art`, `POS=NOUN`, `POS=PRON\|PronType=Prs`, `POS=VERB\|VerbForm=Fin`, `POS=PROPN`, `POS=PRON\|PronType=Prs,Rel`, `POS=ADV`, `POS=ADP`, `POS=ADV\|PronType=Dem`, `POS=PRON\|PronType=Dem`, `POS=VERB\|Tense=Past\|VerbForm=Part`, `POS=AUX\|VerbForm=Fin`, `POS=DET\|PronType=Int`, `POS=ADJ`, `POS=PRON\|PronType=Ind`, `POS=DET\|PronType=Ind`, `Morph=VPar\|POS=ADJ`, `POS=DET\|Poss=Yes`, `POS=ADV\|Polarity=Neg`, `Definite=Def\|POS=ADP\|PronType=Art`, `POS=PRON\|PronType=Int`, `POS=SCONJ`, `POS=VERB\|VerbForm=Inf`, `NumType=Card\|POS=PRON`, `POS=PRON`, `NumType=Card\|POS=DET`, `POS=PRON\|Polarity=Neg\|PronType=Prs`, `POS=ADJ\|Poss=Yes`, `POS=PRON\|Poss=Yes\|PronType=Prs`, `Definite=Ind\|POS=DET\|PronType=Art`, `POS=DET\|PronType=Dem`, `POS=AUX\|VerbForm=Inf`, `POS=ADJ\|PronType=Ind`, `Morph=VPar\|POS=NOUN`, `POS=VERB\|Tense=Pres\|VerbForm=Part`, `Morph=VPar\|POS=PROPN`, `Morph=VInf\|POS=NOUN`, `NumType=Ord\|POS=PRON`, `POS=INTJ`, `POS=SCONJ\|PronType=Prs`, `Morph=VFin\|POS=NOUN`, `POS=DET\|PronType=Rel`, `NumType=Card\|POS=ADJ`, `POS=ADJ\|PronType=Ord`, `Morph=VFin\|POS=ADV`, `Morph=VFin\|POS=PROPN`, `POS=DET`, `Morph=VPar\|POS=ADP`, `Morph=VPar\|POS=ADV`, `NumType=Ord\|POS=DET`, `Morph=VFin\|POS=ADP`, `Morph=VFin\|POS=CCONJ`, `Morph=VInf\|POS=ADJ`, `POS=ADP\|PronType=Dem`, `POS=ADV\|Polarity=Int`, `Morph=VFin\|POS=INTJ` |
| **`parser`** | `ROOT`, `acl`, `acl:relcl`, `advcl`, `advmod`, `amod`, `appos`, `aux`, `aux:pass`, `case`, `case:det`, `cc`, `cc:nc`, `ccomp`, `conj`, `cop`, `csubj`, `dep`, `det`, `discourse`, `dislocated`, `expl`, `flat`, `iobj`, `mark`, `mark:advmod`, `mark:obj`, `mark:obl`, `nmod`, `nsubj`, `nsubj:obj`, `nummod`, `obj`, `obj:advmod`, `obl`, `obl:advmod`, `parataxis`, `vocative`, `xcomp` |
| **`experimental_edit_tree_lemmatizer`** | `0`, `1`, `2`, `3`, `4`, `5`, `6`, `7`, `8`, `9`, `10`, `11`, `12`, `13`, `14`, `15`, `16`, `17`, `18`, `19`, `20`, `21`, `22`, `23`, `24`, `25`, `26`, `27`, `28`, `29`, `30`, `31`, `32`, `33`, `34`, `35`, `36`, `37`, `38`, `39`, `40`, `41`, `42`, `43`, `44`, `45`, `46`, `47`, `48`, `49`, `50`, `51`, `52`, `53`, `54`, `55`, `56`, `57`, `58`, `59`, `60`, `61`, `62`, `63`, `64`, `65`, `66`, `67`, `68`, `69`, `70`, `71`, `72`, `73`, `74`, `75`, `76`, `77`, `78`, `79`, `80`, `81`, `82`, `83`, `84`, `85`, `86`, `87`, `88`, `89`, `90`, `91`, `92`, `93`, `94`, `95`, `96`, `97`, `98`, `99`, `100`, `101`, `102`, `103`, `104`, `105`, `106`, `107`, `108`, `109`, `110`, `111`, `112`, `113`, `114`, `115`, `116`, `117`, `118`, `119`, `120`, `121`, `122`, `123`, `124`, `125`, `126`, `127`, `128`, `129`, `130`, `131`, `132`, `133`, `134`, `135`, `136`, `137`, `138`, `139`, `140`, `141`, `142`, `143`, `144`, `145`, `146`, `147`, `148`, `149`, `150`, `151`, `152`, `153`, `154`, `155`, `156`, `157`, `158`, `159`, `160`, `161`, `162`, `163`, `164`, `165`, `166`, `167`, `168`, `169`, `170`, `171`, `172`, `173`, `174`, `175`, `176`, `177`, `178`, `179`, `180`, `181`, `182`, `183`, `184`, `185`, `186`, `187`, `188`, `189`, `190`, `191`, `192`, `193`, `194`, `195`, `196`, `197`, `198`, `199`, `200`, `201`, `202`, `203`, `204`, `205`, `206`, `207`, `208`, `209`, `210`, `211`, `212`, `213`, `214`, `215`, `216`, `217`, `218`, `219`, `220`, `221`, `222`, `223`, `224`, `225`, `226`, `227`, `228`, `229`, `230`, `231`, `232`, `233`, `234`, `235`, `236`, `237`, `238`, `239`, `240`, `241`, `242`, `243`, `244`, `245`, `246`, `247`, `248`, `249`, `250`, `251`, `252`, `253`, `254`, `255`, `256`, `257`, `258`, `259`, `260`, `261`, `262`, `263`, `264`, `265`, `266`, `267`, `268`, `269`, `270`, `271`, `272`, `273`, `274`, `275`, `276`, `277`, `278`, `279`, `280`, `281`, `282`, `283`, `284`, `285`, `286`, `287`, `288`, `289`, `290`, `291`, `292`, `293`, `294`, `295`, `296`, `297`, `298`, `299`, `300`, `301`, `302`, `303`, `304`, `305`, `306`, `307`, `308`, `309`, `310`, `311`, `312`, `313`, `314`, `315`, `316`, `317`, `318`, `319`, `320`, `321`, `322`, `323`, `324`, `325`, `326`, `327`, `328`, `329`, `330`, `331`, `332`, `333`, `334`, `335`, `336`, `337`, `338`, `339`, `340`, `341`, `342`, `343`, `344`, `345`, `346`, `347`, `348`, `349`, `350`, `351`, `352`, `353`, `354`, `355`, `356`, `357`, `358`, `359`, `360`, `361`, `362`, `363`, `364`, `365`, `366`, `367`, `368`, `369`, `370`, `371`, `372`, `373`, `374`, `375`, `376`, `377`, `378`, `379`, `380`, `381`, `382`, `383`, `384`, `385`, `386`, `387`, `388`, `389`, `390`, `391`, `392`, `393`, `394`, `395`, `396`, `397`, `398`, `399`, `400`, `401`, `402`, `403`, `404`, `405`, `406`, `407`, `408`, `409`, `410`, `411`, `412`, `413`, `414`, `415`, `416`, `417`, `418`, `419`, `420`, `421`, `422`, `423`, `424`, `425`, `426`, `427`, `428`, `429`, `430`, `431`, `432`, `433`, `434`, `435`, `436`, `437`, `438`, `439`, `440`, `441`, `442`, `443`, `444`, `445`, `446`, `447`, `448`, `449`, `450`, `451`, `452`, `453`, `454`, `455`, `456`, `457`, `458`, `459`, `460`, `461`, `462`, `463`, `464`, `465`, `466`, `467`, `468`, `469`, `470`, `471`, `472`, `473`, `474`, `475`, `476`, `477`, `478`, `479`, `480`, `481`, `482`, `483`, `484`, `485`, `486`, `487`, `488`, `489`, `490`, `491`, `492`, `493`, `494`, `495`, `496`, `497`, `498`, `499`, `500`, `501`, `502`, `503`, `504`, `505`, `506`, `507`, `508`, `509`, `510`, `511`, `512`, `513`, `514`, `515`, `516`, `517`, `518`, `519`, `520`, `521`, `522`, `523`, `524`, `525`, `526`, `527`, `528`, `529`, `530`, `531`, `532`, `533`, `534`, `535`, `536`, `537`, `538`, `539`, `540`, `541`, `542`, `543`, `544`, `545`, `546`, `547`, `548`, `549`, `550`, `551`, `552`, `553`, `554`, `555`, `556`, `557`, `558`, `559`, `560`, `561`, `562`, `563`, `564`, `565`, `566`, `567`, `568`, `569`, `570`, `571`, `572`, `573`, `574`, `575`, `576`, `577`, `578`, `579`, `580`, `581`, `582`, `583`, `584`, `585`, `586`, `587`, `588`, `589`, `590`, `591`, `592`, `593`, `594`, `595`, `596`, `597`, `598`, `599`, `600`, `601`, `602`, `603`, `604`, `605`, `606`, `607`, `608`, `609`, `610`, `611`, `612`, `613`, `614`, `615`, `616`, `617`, `618`, `619`, `620`, `621`, `622`, `623`, `624`, `625`, `626`, `627`, `628`, `629`, `630`, `631`, `632`, `633`, `634`, `635`, `636`, `637`, `638`, `639`, `640`, `641`, `642`, `643`, `644`, `645`, `646`, `647`, `648`, `649`, `650`, `651`, `652`, `653`, `654`, `655`, `656`, `657`, `658`, `659`, `660`, `661`, `662`, `663`, `664`, `665`, `666`, `667`, `668`, `669`, `670`, `671`, `672`, `673`, `674`, `675`, `676`, `677`, `678`, `679`, `680`, `681`, `682`, `683`, `684`, `685`, `686`, `687`, `688`, `689`, `690`, `691`, `692`, `693`, `694`, `695`, `696`, `697`, `698`, `699`, `700`, `701`, `702`, `703`, `704`, `705`, `706`, `707`, `708`, `709`, `710`, `711`, `712`, `713`, `714`, `715`, `716`, `717`, `718`, `719`, `720`, `721`, `722`, `723`, `724`, `725`, `726`, `727`, `728`, `729`, `730`, `731`, `732`, `733`, `734`, `735`, `736`, `737`, `738`, `739`, `740`, `741`, `742`, `743`, `744`, `745`, `746`, `747`, `748`, `749`, `750`, `751`, `752`, `753`, `754`, `755`, `756`, `757`, `758`, `759`, `760`, `761`, `762`, `763`, `764`, `765`, `766`, `767`, `768`, `769`, `770`, `771`, `772`, `773`, `774`, `775`, `776`, `777`, `778`, `779`, `780`, `781`, `782`, `783`, `784`, `785`, `786`, `787`, `788`, `789`, `790`, `791`, `792`, `793`, `794`, `795`, `796`, `797`, `798`, `799`, `800`, `801`, `802`, `803`, `804`, `805`, `806`, `807`, `808`, `809`, `810`, `811`, `812`, `813`, `814`, `815`, `816`, `817`, `818`, `819`, `820`, `821`, `822`, `823`, `824`, `825`, `826`, `827`, `828`, `829`, `830`, `831`, `832`, `833`, `834`, `835`, `836`, `837`, `838`, `839`, `840`, `841`, `842`, `843`, `844`, `845`, `846`, `847`, `848`, `849`, `850`, `851`, `852`, `853`, `854`, `855`, `856`, `857`, `858`, `859`, `860`, `861`, `862`, `863`, `864`, `865`, `866`, `867`, `868`, `869`, `870`, `871`, `872`, `873`, `874`, `875`, `876`, `877`, `878`, `879`, `880`, `881`, `882`, `883`, `884`, `885`, `886`, `887`, `888`, `889`, `890`, `891`, `892`, `893`, `894`, `895`, `896`, `897`, `898`, `899`, `900`, `901`, `902`, `903`, `904`, `905`, `906`, `907`, `908`, `909`, `910`, `911`, `912`, `913`, `914`, `915`, `916`, `917`, `918`, `919`, `920`, `921`, `922`, `923`, `924`, `925`, `926`, `927`, `928`, `929`, `930`, `931`, `932`, `933`, `934`, `935`, `936`, `937`, `938`, `939`, `940`, `941`, `942`, `943`, `944`, `945`, `946`, `947`, `948`, `949`, `950`, `951`, `952`, `953`, `954`, `955`, `956`, `957`, `958`, `959`, `960`, `961`, `962`, `963`, `964`, `965`, `966`, `967`, `968`, `969`, `970`, `971`, `972`, `973`, `974`, `975`, `976`, `977`, `978`, `979`, `980`, `981`, `982`, `983`, `984`, `985`, `986`, `987`, `988`, `989`, `990`, `991`, `992`, `993`, `994`, `995`, `996`, `997`, `998`, `999`, `1000`, `1001`, `1002`, `1003`, `1004`, `1005`, `1006`, `1007`, `1008`, `1009`, `1010`, `1011`, `1012`, `1013`, `1014`, `1015`, `1016`, `1017`, `1018`, `1019`, `1020`, `1021`, `1022`, `1023`, `1024`, `1025`, `1026`, `1027`, `1028`, `1029`, `1030`, `1031`, `1032`, `1033`, `1034`, `1035`, `1036`, `1037`, `1038`, `1039`, `1040`, `1041`, `1042`, `1043`, `1044`, `1045`, `1046`, `1047`, `1048`, `1049`, `1050`, `1051`, `1052`, `1053`, `1054`, `1055`, `1056`, `1057`, `1058`, `1059`, `1060`, `1061`, `1062`, `1063`, `1064`, `1065`, `1066`, `1067`, `1068`, `1069`, `1070`, `1071`, `1072`, `1073`, `1074`, `1075`, `1076`, `1077`, `1078`, `1079`, `1080`, `1081`, `1082`, `1083`, `1084`, `1085`, `1086`, `1087`, `1088`, `1089`, `1090`, `1091`, `1092`, `1093`, `1094`, `1095`, `1096`, `1097`, `1098`, `1099`, `1100`, `1101`, `1102`, `1103`, `1104`, `1105`, `1106`, `1107`, `1108`, `1109`, `1110`, `1111`, `1112`, `1113`, `1114`, `1115`, `1116`, `1117`, `1118`, `1119`, `1120`, `1121`, `1122`, `1123`, `1124`, `1125`, `1126`, `1127`, `1128`, `1129`, `1130`, `1131`, `1132`, `1133`, `1134`, `1135`, `1136`, `1137`, `1138`, `1139`, `1140`, `1141`, `1142`, `1143`, `1144`, `1145`, `1146`, `1147`, `1148`, `1149`, `1150`, `1151`, `1152`, `1153`, `1154`, `1155`, `1156`, `1157`, `1158`, `1159`, `1160`, `1161`, `1162`, `1163`, `1164`, `1165`, `1166`, `1167`, `1168`, `1169`, `1170`, `1171`, `1172`, `1173`, `1174`, `1175`, `1176`, `1177`, `1178`, `1179`, `1180`, `1181`, `1182`, `1183`, `1184`, `1185`, `1186`, `1187`, `1188`, `1189`, `1190`, `1191`, `1192`, `1193`, `1194`, `1195`, `1196`, `1197`, `1198`, `1199`, `1200`, `1201`, `1202`, `1203`, `1204`, `1205`, `1206`, `1207`, `1208`, `1209`, `1210`, `1211`, `1212`, `1213`, `1214`, `1215`, `1216`, `1217`, `1218`, `1219`, `1220`, `1221`, `1222`, `1223`, `1224`, `1225`, `1226`, `1227`, `1228`, `1229`, `1230`, `1231`, `1232`, `1233`, `1234`, `1235`, `1236`, `1237`, `1238`, `1239`, `1240`, `1241`, `1242`, `1243`, `1244`, `1245`, `1246`, `1247`, `1248`, `1249`, `1250`, `1251`, `1252`, `1253`, `1254`, `1255`, `1256`, `1257`, `1258`, `1259`, `1260`, `1261`, `1262`, `1263`, `1264`, `1265`, `1266`, `1267`, `1268`, `1269`, `1270`, `1271`, `1272`, `1273`, `1274`, `1275`, `1276`, `1277`, `1278`, `1279`, `1280`, `1281`, `1282`, `1283`, `1284`, `1285`, `1286`, `1287`, `1288`, `1289`, `1290`, `1291`, `1292`, `1293`, `1294`, `1295`, `1296`, `1297`, `1298`, `1299`, `1300`, `1301`, `1302`, `1303`, `1304`, `1305`, `1306`, `1307`, `1308`, `1309`, `1310`, `1311`, `1312`, `1313`, `1314`, `1315`, `1316`, `1317`, `1318`, `1319`, `1320`, `1321`, `1322`, `1323`, `1324`, `1325`, `1326`, `1327`, `1328`, `1329`, `1330`, `1331`, `1332`, `1333`, `1334`, `1335`, `1336`, `1337`, `1338`, `1339`, `1340`, `1341`, `1342`, `1343`, `1344`, `1345`, `1346`, `1347`, `1348`, `1349`, `1350`, `1351`, `1352`, `1353`, `1354`, `1355`, `1356`, `1357`, `1358`, `1359`, `1360`, `1361`, `1362`, `1363`, `1364`, `1365`, `1366`, `1367`, `1368`, `1369`, `1370`, `1371`, `1372`, `1373`, `1374`, `1375`, `1376`, `1377`, `1378`, `1379`, `1380`, `1381`, `1382`, `1383`, `1384`, `1385`, `1386`, `1387`, `1388`, `1389`, `1390`, `1391`, `1392`, `1393`, `1394`, `1395`, `1396`, `1397`, `1398`, `1399`, `1400`, `1401`, `1402`, `1403`, `1404`, `1405`, `1406`, `1407`, `1408`, `1409`, `1410`, `1411`, `1412`, `1413`, `1414`, `1415`, `1416`, `1417`, `1418`, `1419`, `1420`, `1421`, `1422`, `1423`, `1424`, `1425`, `1426`, `1427`, `1428`, `1429`, `1430`, `1431`, `1432`, `1433`, `1434`, `1435`, `1436`, `1437`, `1438`, `1439`, `1440`, `1441`, `1442`, `1443`, `1444`, `1445`, `1446`, `1447`, `1448`, `1449`, `1450`, `1451`, `1452`, `1453`, `1454`, `1455`, `1456`, `1457`, `1458`, `1459`, `1460`, `1461`, `1462`, `1463`, `1464`, `1465`, `1466`, `1467`, `1468`, `1469`, `1470`, `1471`, `1472`, `1473`, `1474`, `1475`, `1476`, `1477`, `1478`, `1479`, `1480`, `1481`, `1482`, `1483`, `1484`, `1485`, `1486`, `1487`, `1488`, `1489`, `1490`, `1491`, `1492`, `1493`, `1494`, `1495`, `1496`, `1497`, `1498`, `1499`, `1500`, `1501`, `1502`, `1503`, `1504`, `1505`, `1506`, `1507`, `1508`, `1509`, `1510`, `1511`, `1512`, `1513`, `1514`, `1515`, `1516`, `1517`, `1518`, `1519`, `1520`, `1521`, `1522`, `1523`, `1524`, `1525`, `1526`, `1527`, `1528`, `1529`, `1530`, `1531`, `1532`, `1533`, `1534`, `1535`, `1536`, `1537`, `1538`, `1539`, `1540`, `1541`, `1542`, `1543`, `1544`, `1545`, `1546`, `1547`, `1548`, `1549`, `1550`, `1551`, `1552`, `1553`, `1554`, `1555`, `1556`, `1557`, `1558`, `1559`, `1560`, `1561`, `1562`, `1563`, `1564`, `1565`, `1566`, `1567`, `1568`, `1569`, `1570`, `1571`, `1572`, `1573`, `1574`, `1575`, `1576`, `1577`, `1578`, `1579`, `1580`, `1581`, `1582`, `1583`, `1584`, `1585`, `1586`, `1587`, `1588`, `1589`, `1590`, `1591`, `1592`, `1593`, `1594`, `1595`, `1596`, `1597`, `1598`, `1599`, `1600`, `1601`, `1602`, `1603`, `1604`, `1605`, `1606`, `1607`, `1608`, `1609`, `1610`, `1611`, `1612`, `1613`, `1614`, `1615`, `1616`, `1617`, `1618`, `1619`, `1620`, `1621`, `1622`, `1623`, `1624`, `1625`, `1626`, `1627`, `1628`, `1629`, `1630`, `1631`, `1632`, `1633`, `1634`, `1635`, `1636`, `1637`, `1638`, `1639`, `1640`, `1641`, `1642`, `1643`, `1644`, `1645`, `1646`, `1647`, `1648`, `1649`, `1650`, `1651`, `1652`, `1653`, `1654`, `1655`, `1656`, `1657`, `1658`, `1659`, `1660`, `1661`, `1662`, `1663`, `1664`, `1665`, `1666`, `1667`, `1668`, `1669`, `1670`, `1671`, `1672`, `1673`, `1674`, `1675`, `1676`, `1677`, `1678`, `1679`, `1680`, `1681`, `1682`, `1683`, `1684`, `1685`, `1686`, `1687`, `1688`, `1689`, `1690`, `1691`, `1692`, `1693`, `1694`, `1695`, `1696`, `1697`, `1698`, `1699`, `1700`, `1701`, `1702`, `1703`, `1704`, `1705`, `1706`, `1707`, `1708`, `1709`, `1710`, `1711`, `1712`, `1713`, `1714`, `1715`, `1716`, `1717`, `1718`, `1719`, `1720`, `1721`, `1722`, `1723`, `1724`, `1725`, `1726`, `1727`, `1728`, `1729`, `1730`, `1731`, `1732`, `1733`, `1734`, `1735`, `1736`, `1737`, `1738`, `1739`, `1740`, `1741`, `1742`, `1743`, `1744`, `1745`, `1746`, `1747`, `1748`, `1749`, `1750`, `1751`, `1752`, `1753`, `1754`, `1755`, `1756`, `1757`, `1758`, `1759`, `1760`, `1761`, `1762`, `1763`, `1764`, `1765`, `1766`, `1767`, `1768`, `1769`, `1770`, `1771`, `1772`, `1773`, `1774`, `1775`, `1776`, `1777`, `1778`, `1779`, `1780`, `1781`, `1782`, `1783`, `1784`, `1785`, `1786`, `1787`, `1788`, `1789`, `1790`, `1791`, `1792`, `1793`, `1794`, `1795`, `1796`, `1797`, `1798`, `1799`, `1800`, `1801`, `1802`, `1803`, `1804`, `1805`, `1806`, `1807`, `1808`, `1809`, `1810`, `1811`, `1812`, `1813`, `1814`, `1815`, `1816`, `1817`, `1818`, `1819`, `1820`, `1821`, `1822`, `1823`, `1824`, `1825`, `1826`, `1827`, `1828`, `1829`, `1830`, `1831`, `1832`, `1833`, `1834`, `1835`, `1836`, `1837`, `1838`, `1839`, `1840`, `1841`, `1842`, `1843`, `1844`, `1845`, `1846`, `1847`, `1848`, `1849`, `1850`, `1851`, `1852`, `1853`, `1854`, `1855`, `1856`, `1857`, `1858`, `1859`, `1860`, `1861`, `1862`, `1863`, `1864`, `1865`, `1866`, `1867`, `1868`, `1869`, `1870`, `1871`, `1872`, `1873`, `1874`, `1875`, `1876`, `1877`, `1878`, `1879`, `1880`, `1881`, `1882`, `1883`, `1884`, `1885`, `1886`, `1887`, `1888`, `1889`, `1890`, `1891`, `1892`, `1893`, `1894`, `1895`, `1896`, `1897`, `1898`, `1899`, `1900`, `1901`, `1902`, `1903`, `1904`, `1905`, `1906`, `1907`, `1908`, `1909`, `1910`, `1911`, `1912`, `1913`, `1914`, `1915`, `1916`, `1917`, `1918`, `1919`, `1920`, `1921`, `1922`, `1923`, `1924`, `1925`, `1926`, `1927`, `1928`, `1929`, `1930`, `1931`, `1932`, `1933`, `1934`, `1935`, `1936`, `1937`, `1938`, `1939`, `1940`, `1941`, `1942`, `1943`, `1944`, `1945`, `1946`, `1947`, `1948`, `1949`, `1950`, `1951`, `1952`, `1953`, `1954`, `1955`, `1956`, `1957`, `1958`, `1959`, `1960`, `1961`, `1962`, `1963`, `1964`, `1965`, `1966`, `1967`, `1968`, `1969`, `1970`, `1971`, `1972`, `1973`, `1974`, `1975`, `1976`, `1977`, `1978`, `1979`, `1980`, `1981`, `1982`, `1983`, `1984`, `1985`, `1986`, `1987`, `1988`, `1989`, `1990`, `1991`, `1992`, `1993`, `1994`, `1995`, `1996`, `1997`, `1998`, `1999`, `2000`, `2001`, `2002`, `2003`, `2004`, `2005`, `2006`, `2007`, `2008`, `2009`, `2010`, `2011`, `2012`, `2013`, `2014`, `2015`, `2016`, `2017`, `2018`, `2019`, `2020`, `2021`, `2022`, `2023`, `2024`, `2025`, `2026`, `2027`, `2028`, `2029`, `2030`, `2031`, `2032`, `2033`, `2034`, `2035`, `2036`, `2037`, `2038`, `2039`, `2040`, `2041`, `2042`, `2043`, `2044`, `2045`, `2046`, `2047`, `2048`, `2049`, `2050`, `2051`, `2052`, `2053`, `2054`, `2055`, `2056`, `2057`, `2058`, `2059`, `2060`, `2061`, `2062`, `2063`, `2064`, `2065`, `2066`, `2067`, `2068`, `2069`, `2070`, `2071`, `2072`, `2073`, `2074`, `2075`, `2076`, `2077`, `2078`, `2079`, `2080`, `2081`, `2082`, `2083`, `2084`, `2085`, `2086`, `2087`, `2088`, `2089`, `2090`, `2091`, `2092`, `2093`, `2094`, `2095`, `2096`, `2097`, `2098`, `2099`, `2100`, `2101`, `2102`, `2103`, `2104`, `2105`, `2106`, `2107`, `2108`, `2109`, `2110`, `2111`, `2112`, `2113`, `2114`, `2115`, `2116`, `2117`, `2118`, `2119`, `2120`, `2121`, `2122`, `2123`, `2124`, `2125`, `2126`, `2127`, `2128`, `2129`, `2130`, `2131`, `2132`, `2133`, `2134`, `2135`, `2136`, `2137`, `2138`, `2139`, `2140`, `2141`, `2142`, `2143`, `2144`, `2145`, `2146`, `2147`, `2148`, `2149`, `2150`, `2151`, `2152`, `2153`, `2154`, `2155`, `2156`, `2157`, `2158`, `2159`, `2160`, `2161`, `2162`, `2163`, `2164`, `2165`, `2166`, `2167`, `2168`, `2169`, `2170`, `2171`, `2172`, `2173`, `2174`, `2175`, `2176`, `2177`, `2178`, `2179`, `2180`, `2181`, `2182`, `2183`, `2184`, `2185`, `2186`, `2187`, `2188`, `2189`, `2190`, `2191`, `2192`, `2193`, `2194`, `2195`, `2196`, `2197`, `2198`, `2199`, `2200`, `2201`, `2202`, `2203`, `2204`, `2205`, `2206`, `2207`, `2208`, `2209`, `2210`, `2211`, `2212`, `2213`, `2214`, `2215`, `2216`, `2217`, `2218`, `2219`, `2220`, `2221`, `2222`, `2223`, `2224`, `2225`, `2226`, `2227`, `2228`, `2229`, `2230`, `2231`, `2232`, `2233`, `2234`, `2235`, `2236`, `2237`, `2238`, `2239`, `2240`, `2241`, `2242`, `2243`, `2244`, `2245`, `2246`, `2247`, `2248`, `2249`, `2250`, `2251`, `2252`, `2253`, `2254`, `2255`, `2256`, `2257`, `2258`, `2259`, `2260`, `2261`, `2262`, `2263`, `2264`, `2265`, `2266`, `2267`, `2268`, `2269`, `2270`, `2271`, `2272`, `2273`, `2274`, `2275`, `2276`, `2277`, `2278`, `2279`, `2280`, `2281`, `2282`, `2283`, `2284`, `2285`, `2286`, `2287`, `2288`, `2289`, `2290`, `2291`, `2292`, `2293`, `2294`, `2295`, `2296`, `2297`, `2298`, `2299`, `2300`, `2301`, `2302`, `2303`, `2304`, `2305`, `2306`, `2307`, `2308`, `2309`, `2310`, `2311`, `2312`, `2313`, `2314`, `2315`, `2316`, `2317`, `2318`, `2319`, `2320`, `2321`, `2322`, `2323`, `2324`, `2325`, `2326`, `2327`, `2328`, `2329`, `2330`, `2331`, `2332`, `2333`, `2334`, `2335`, `2336`, `2337`, `2338`, `2339`, `2340`, `2341`, `2342`, `2343`, `2344`, `2345`, `2346`, `2347`, `2348`, `2349`, `2350`, `2351`, `2352`, `2353`, `2354`, `2355`, `2356`, `2357`, `2358`, `2359`, `2360`, `2361`, `2362`, `2363`, `2364`, `2365`, `2366`, `2367`, `2368`, `2369`, `2370`, `2371`, `2372`, `2373`, `2374`, `2375`, `2376`, `2377`, `2378`, `2379`, `2380`, `2381`, `2382`, `2383`, `2384`, `2385`, `2386`, `2387`, `2388`, `2389`, `2390`, `2391`, `2392`, `2393`, `2394`, `2395`, `2396`, `2397`, `2398`, `2399`, `2400`, `2401`, `2402`, `2403`, `2404`, `2405`, `2406`, `2407`, `2408`, `2409`, `2410`, `2411`, `2412`, `2413`, `2414`, `2415`, `2416`, `2417`, `2418`, `2419`, `2420`, `2421`, `2422`, `2423`, `2424`, `2425`, `2426`, `2427`, `2428`, `2429`, `2430`, `2431`, `2432`, `2433`, `2434`, `2435`, `2436`, `2437`, `2438`, `2439`, `2440`, `2441`, `2442`, `2443`, `2444`, `2445`, `2446`, `2447`, `2448`, `2449`, `2450`, `2451`, `2452`, `2453`, `2454`, `2455`, `2456`, `2457`, `2458`, `2459`, `2460`, `2461`, `2462`, `2463`, `2464`, `2465`, `2466`, `2467`, `2468`, `2469`, `2470`, `2471`, `2472`, `2473`, `2474`, `2475`, `2476`, `2477`, `2478`, `2479`, `2480`, `2481`, `2482`, `2483`, `2484`, `2485`, `2486`, `2487`, `2488`, `2489`, `2490`, `2491`, `2492`, `2493`, `2494`, `2495`, `2496`, `2497`, `2498`, `2499`, `2500`, `2501`, `2502`, `2503`, `2504`, `2505`, `2506`, `2507`, `2508`, `2509`, `2510`, `2511`, `2512`, `2513`, `2514`, `2515`, `2516`, `2517`, `2518`, `2519`, `2520`, `2521`, `2522`, `2523`, `2524`, `2525`, `2526`, `2527`, `2528`, `2529`, `2530`, `2531`, `2532`, `2533`, `2534`, `2535`, `2536`, `2537`, `2538`, `2539`, `2540`, `2541`, `2542`, `2543`, `2544`, `2545`, `2546`, `2547`, `2548`, `2549`, `2550`, `2551`, `2552`, `2553`, `2554`, `2555`, `2556`, `2557`, `2558`, `2559`, `2560`, `2561`, `2562`, `2563`, `2564`, `2565`, `2566`, `2567`, `2568`, `2569`, `2570`, `2571`, `2572`, `2573`, `2574`, `2575`, `2576`, `2577`, `2578`, `2579`, `2580`, `2581`, `2582`, `2583`, `2584`, `2585`, `2586`, `2587`, `2588`, `2589`, `2590`, `2591`, `2592`, `2593`, `2594`, `2595`, `2596`, `2597`, `2598`, `2599`, `2600`, `2601`, `2602`, `2603`, `2604`, `2605`, `2606`, `2607`, `2608`, `2609`, `2610`, `2611`, `2612`, `2613`, `2614`, `2615`, `2616`, `2617`, `2618`, `2619`, `2620`, `2621`, `2622`, `2623`, `2624`, `2625`, `2626`, `2627`, `2628`, `2629`, `2630`, `2631`, `2632`, `2633`, `2634`, `2635`, `2636`, `2637`, `2638`, `2639`, `2640`, `2641`, `2642`, `2643`, `2644`, `2645`, `2646`, `2647`, `2648`, `2649`, `2650`, `2651`, `2652`, `2653`, `2654`, `2655`, `2656`, `2657`, `2658`, `2659`, `2660`, `2661`, `2662`, `2663`, `2664`, `2665`, `2666`, `2667`, `2668`, `2669`, `2670`, `2671`, `2672`, `2673`, `2674`, `2675`, `2676`, `2677`, `2678`, `2679`, `2680`, `2681`, `2682`, `2683`, `2684`, `2685`, `2686`, `2687`, `2688`, `2689`, `2690`, `2691`, `2692`, `2693`, `2694`, `2695`, `2696`, `2697`, `2698`, `2699`, `2700`, `2701`, `2702`, `2703`, `2704`, `2705`, `2706`, `2707`, `2708`, `2709`, `2710`, `2711`, `2712`, `2713`, `2714`, `2715`, `2716`, `2717`, `2718`, `2719`, `2720`, `2721`, `2722`, `2723`, `2724`, `2725`, `2726`, `2727`, `2728`, `2729`, `2730`, `2731`, `2732`, `2733`, `2734`, `2735`, `2736`, `2737`, `2738`, `2739`, `2740`, `2741`, `2742`, `2743`, `2744`, `2745`, `2746`, `2747`, `2748`, `2749`, `2750`, `2751`, `2752`, `2753`, `2754`, `2755`, `2756`, `2757`, `2758`, `2759`, `2760`, `2761`, `2762`, `2763`, `2764`, `2765`, `2766`, `2767`, `2768`, `2769`, `2770`, `2771`, `2772`, `2773`, `2774`, `2775`, `2776`, `2777`, `2778`, `2779`, `2780`, `2781`, `2782`, `2783`, `2784`, `2785`, `2786`, `2787`, `2788`, `2789`, `2790`, `2791`, `2792`, `2793`, `2794`, `2795`, `2796`, `2797`, `2798`, `2799`, `2800`, `2801`, `2802`, `2803`, `2804`, `2805`, `2806`, `2807`, `2808`, `2809`, `2810`, `2811`, `2812`, `2813`, `2814`, `2815`, `2816`, `2817`, `2818`, `2819`, `2820`, `2821`, `2822`, `2823`, `2824`, `2825`, `2826`, `2827`, `2828`, `2829`, `2830`, `2831`, `2832`, `2833`, `2834`, `2835`, `2836`, `2837`, `2838`, `2839`, `2840`, `2841`, `2842`, `2843`, `2844`, `2845`, `2846`, `2847`, `2848`, `2849`, `2850`, `2851`, `2852`, `2853`, `2854`, `2855`, `2856`, `2857`, `2858`, `2859`, `2860`, `2861`, `2862`, `2863`, `2864`, `2865`, `2866`, `2867`, `2868`, `2869`, `2870`, `2871`, `2872`, `2873`, `2874`, `2875`, `2876`, `2877`, `2878`, `2879`, `2880`, `2881`, `2882`, `2883`, `2884`, `2885`, `2886`, `2887`, `2888`, `2889`, `2890`, `2891`, `2892`, `2893`, `2894`, `2895`, `2896`, `2897`, `2898`, `2899`, `2900`, `2901`, `2902`, `2903`, `2904`, `2905`, `2906`, `2907`, `2908`, `2909`, `2910`, `2911`, `2912`, `2913`, `2914`, `2915`, `2916`, `2917`, `2918`, `2919`, `2920`, `2921`, `2922`, `2923`, `2924`, `2925`, `2926`, `2927`, `2928`, `2929`, `2930`, `2931`, `2932`, `2933`, `2934`, `2935`, `2936`, `2937`, `2938`, `2939`, `2940`, `2941`, `2942`, `2943`, `2944`, `2945`, `2946`, `2947`, `2948`, `2949`, `2950`, `2951`, `2952`, `2953`, `2954`, `2955`, `2956`, `2957`, `2958`, `2959`, `2960`, `2961`, `2962`, `2963`, `2964`, `2965`, `2966`, `2967`, `2968`, `2969`, `2970`, `2971`, `2972`, `2973`, `2974`, `2975`, `2976`, `2977`, `2978`, `2979`, `2980`, `2981`, `2982`, `2983`, `2984`, `2985`, `2986`, `2987`, `2988`, `2989`, `2990`, `2991`, `2992`, `2993`, `2994`, `2995`, `2996`, `2997`, `2998`, `2999`, `3000`, `3001`, `3002`, `3003`, `3004`, `3005`, `3006`, `3007`, `3008`, `3009`, `3010`, `3011`, `3012`, `3013`, `3014`, `3015`, `3016`, `3017`, `3018`, `3019`, `3020`, `3021`, `3022`, `3023`, `3024`, `3025`, `3026`, `3027`, `3028`, `3029`, `3030`, `3031`, `3032`, `3033`, `3034`, `3035`, `3036`, `3037`, `3038`, `3039`, `3040`, `3041`, `3042`, `3043`, `3044`, `3045`, `3046`, `3047`, `3048`, `3049`, `3050`, `3051`, `3052`, `3053`, `3054`, `3055`, `3056`, `3057`, `3058`, `3059`, `3060`, `3061`, `3062`, `3063`, `3064`, `3065`, `3066`, `3067`, `3068`, `3069`, `3070`, `3071`, `3072`, `3073`, `3074`, `3075`, `3076`, `3077`, `3078`, `3079`, `3080`, `3081`, `3082`, `3083`, `3084`, `3085`, `3086`, `3087`, `3088`, `3089`, `3090`, `3091`, `3092`, `3093`, `3094`, `3095`, `3096`, `3097`, `3098`, `3099`, `3100`, `3101`, `3102`, `3103`, `3104`, `3105`, `3106`, `3107`, `3108`, `3109`, `3110`, `3111`, `3112`, `3113`, `3114`, `3115`, `3116`, `3117`, `3118`, `3119`, `3120`, `3121`, `3122`, `3123`, `3124`, `3125`, `3126`, `3127`, `3128`, `3129`, `3130`, `3131`, `3132`, `3133`, `3134`, `3135`, `3136`, `3137`, `3138`, `3139`, `3140`, `3141`, `3142`, `3143`, `3144`, `3145`, `3146`, `3147`, `3148`, `3149`, `3150`, `3151`, `3152`, `3153`, `3154`, `3155`, `3156`, `3157`, `3158`, `3159`, `3160`, `3161`, `3162`, `3163`, `3164`, `3165`, `3166`, `3167`, `3168`, `3169`, `3170`, `3171`, `3172`, `3173`, `3174`, `3175`, `3176`, `3177`, `3178`, `3179`, `3180`, `3181`, `3182`, `3183`, `3184`, `3185`, `3186`, `3187`, `3188`, `3189`, `3190`, `3191`, `3192`, `3193`, `3194`, `3195`, `3196`, `3197`, `3198`, `3199`, `3200`, `3201`, `3202`, `3203`, `3204`, `3205`, `3206`, `3207`, `3208`, `3209`, `3210`, `3211`, `3212`, `3213`, `3214`, `3215`, `3216`, `3217`, `3218`, `3219`, `3220`, `3221`, `3222`, `3223`, `3224`, `3225`, `3226`, `3227`, `3228`, `3229`, `3230`, `3231`, `3232`, `3233`, `3234`, `3235`, `3236`, `3237`, `3238`, `3239`, `3240`, `3241`, `3242`, `3243`, `3244`, `3245`, `3246`, `3247`, `3248`, `3249`, `3250`, `3251`, `3252`, `3253`, `3254`, `3255`, `3256`, `3257`, `3258`, `3259`, `3260`, `3261`, `3262`, `3263`, `3264`, `3265`, `3266`, `3267`, `3268`, `3269`, `3270`, `3271`, `3272`, `3273`, `3274`, `3275`, `3276`, `3277`, `3278`, `3279`, `3280`, `3281`, `3282`, `3283`, `3284`, `3285`, `3286`, `3287`, `3288`, `3289`, `3290`, `3291`, `3292`, `3293`, `3294`, `3295`, `3296`, `3297`, `3298`, `3299`, `3300`, `3301`, `3302`, `3303`, `3304`, `3305`, `3306`, `3307`, `3308`, `3309`, `3310`, `3311`, `3312`, `3313`, `3314`, `3315`, `3316`, `3317`, `3318`, `3319`, `3320`, `3321`, `3322`, `3323`, `3324`, `3325`, `3326`, `3327`, `3328`, `3329`, `3330`, `3331`, `3332`, `3333`, `3334`, `3335`, `3336`, `3337`, `3338`, `3339`, `3340`, `3341`, `3342`, `3343`, `3344`, `3345`, `3346`, `3347`, `3348`, `3349`, `3350`, `3351`, `3352`, `3353`, `3354`, `3355`, `3356`, `3357`, `3358`, `3359`, `3360`, `3361`, `3362`, `3363`, `3364`, `3365`, `3366`, `3367`, `3368`, `3369`, `3370`, `3371`, `3372`, `3373`, `3374`, `3375`, `3376`, `3377`, `3378`, `3379`, `3380`, `3381`, `3382`, `3383`, `3384`, `3385`, `3386`, `3387`, `3388`, `3389`, `3390`, `3391`, `3392`, `3393`, `3394`, `3395`, `3396`, `3397`, `3398`, `3399`, `3400`, `3401`, `3402`, `3403`, `3404`, `3405`, `3406`, `3407`, `3408`, `3409`, `3410`, `3411`, `3412`, `3413`, `3414`, `3415`, `3416`, `3417`, `3418`, `3419`, `3420`, `3421`, `3422`, `3423`, `3424`, `3425`, `3426`, `3427`, `3428`, `3429`, `3430`, `3431`, `3432`, `3433`, `3434`, `3435`, `3436`, `3437`, `3438`, `3439`, `3440`, `3441`, `3442`, `3443`, `3444`, `3445`, `3446`, `3447`, `3448`, `3449`, `3450`, `3451`, `3452`, `3453`, `3454`, `3455`, `3456`, `3457`, `3458`, `3459`, `3460`, `3461`, `3462`, `3463`, `3464`, `3465`, `3466`, `3467`, `3468`, `3469`, `3470`, `3471`, `3472`, `3473`, `3474`, `3475`, `3476`, `3477`, `3478`, `3479`, `3480`, `3481`, `3482`, `3483`, `3484`, `3485`, `3486`, `3487`, `3488`, `3489`, `3490`, `3491`, `3492`, `3493`, `3494`, `3495`, `3496`, `3497`, `3498`, `3499`, `3500`, `3501`, `3502`, `3503`, `3504`, `3505`, `3506`, `3507`, `3508`, `3509`, `3510`, `3511`, `3512`, `3513`, `3514`, `3515`, `3516`, `3517`, `3518`, `3519`, `3520`, `3521`, `3522`, `3523`, `3524`, `3525`, `3526`, `3527`, `3528`, `3529`, `3530`, `3531`, `3532`, `3533`, `3534`, `3535`, `3536`, `3537`, `3538`, `3539`, `3540`, `3541`, `3542`, `3543`, `3544`, `3545`, `3546`, `3547`, `3548`, `3549`, `3550`, `3551`, `3552`, `3553`, `3554`, `3555`, `3556`, `3557`, `3558`, `3559`, `3560`, `3561`, `3562`, `3563`, `3564`, `3565`, `3566`, `3567`, `3568`, `3569`, `3570`, `3571`, `3572`, `3573`, `3574`, `3575`, `3576`, `3577`, `3578`, `3579`, `3580`, `3581`, `3582`, `3583`, `3584`, `3585`, `3586`, `3587`, `3588`, `3589`, `3590`, `3591`, `3592`, `3593`, `3594`, `3595`, `3596`, `3597`, `3598`, `3599`, `3600`, `3601`, `3602`, `3603`, `3604`, `3605`, `3606`, `3607`, `3608`, `3609`, `3610`, `3611`, `3612`, `3613`, `3614`, `3615`, `3616`, `3617`, `3618`, `3619`, `3620`, `3621`, `3622`, `3623`, `3624`, `3625`, `3626`, `3627`, `3628`, `3629`, `3630`, `3631`, `3632`, `3633`, `3634`, `3635`, `3636`, `3637`, `3638`, `3639`, `3640`, `3641`, `3642`, `3643`, `3644`, `3645`, `3646`, `3647`, `3648`, `3649`, `3650`, `3651`, `3652`, `3653`, `3654`, `3655`, `3656`, `3657`, `3658`, `3659`, `3660`, `3661`, `3662`, `3663`, `3664`, `3665`, `3666`, `3667`, `3668`, `3669`, `3670`, `3671`, `3672`, `3673`, `3674`, `3675`, `3676`, `3677`, `3678`, `3679`, `3680`, `3681`, `3682`, `3683`, `3684`, `3685`, `3686`, `3687`, `3688`, `3689`, `3690`, `3691`, `3692`, `3693`, `3694`, `3695`, `3696`, `3697`, `3698`, `3699`, `3700`, `3701`, `3702`, `3703`, `3704`, `3705`, `3706`, `3707`, `3708`, `3709`, `3710`, `3711`, `3712`, `3713`, `3714`, `3715`, `3716`, `3717`, `3718`, `3719`, `3720`, `3721`, `3722`, `3723`, `3724`, `3725`, `3726`, `3727`, `3728`, `3729`, `3730`, `3731`, `3732`, `3733`, `3734`, `3735`, `3736`, `3737`, `3738`, `3739`, `3740`, `3741`, `3742`, `3743`, `3744`, `3745`, `3746`, `3747`, `3748`, `3749`, `3750`, `3751`, `3752`, `3753`, `3754`, `3755`, `3756`, `3757`, `3758`, `3759`, `3760`, `3761`, `3762`, `3763`, `3764`, `3765`, `3766`, `3767`, `3768`, `3769`, `3770`, `3771`, `3772`, `3773`, `3774`, `3775`, `3776`, `3777`, `3778`, `3779`, `3780`, `3781`, `3782`, `3783`, `3784`, `3785`, `3786`, `3787`, `3788`, `3789`, `3790`, `3791`, `3792`, `3793`, `3794`, `3795`, `3796`, `3797`, `3798`, `3799`, `3800`, `3801`, `3802`, `3803`, `3804`, `3805`, `3806`, `3807`, `3808`, `3809`, `3810`, `3811`, `3812`, `3813`, `3814`, `3815`, `3816`, `3817`, `3818`, `3819`, `3820`, `3821`, `3822`, `3823`, `3824`, `3825`, `3826`, `3827`, `3828`, `3829`, `3830`, `3831`, `3832`, `3833`, `3834`, `3835`, `3836`, `3837`, `3838`, `3839`, `3840`, `3841`, `3842`, `3843`, `3844`, `3845`, `3846`, `3847`, `3848`, `3849`, `3850`, `3851`, `3852`, `3853`, `3854`, `3855`, `3856`, `3857`, `3858`, `3859`, `3860`, `3861`, `3862`, `3863`, `3864`, `3865`, `3866`, `3867`, `3868`, `3869`, `3870`, `3871`, `3872`, `3873`, `3874`, `3875`, `3876`, `3877`, `3878`, `3879`, `3880`, `3881`, `3882`, `3883`, `3884`, `3885`, `3886`, `3887`, `3888`, `3889`, `3890`, `3891`, `3892`, `3893`, `3894`, `3895`, `3896`, `3897`, `3898`, `3899`, `3900`, `3901`, `3902`, `3903`, `3904`, `3905`, `3906`, `3907`, `3908`, `3909`, `3910`, `3911`, `3912`, `3913`, `3914`, `3915`, `3916`, `3917`, `3918`, `3919`, `3920`, `3921`, `3922`, `3923`, `3924`, `3925`, `3926`, `3927`, `3928`, `3929`, `3930`, `3931`, `3932`, `3933`, `3934`, `3935`, `3936`, `3937`, `3938`, `3939`, `3940`, `3941`, `3942`, `3943`, `3944`, `3945`, `3946`, `3947`, `3948`, `3949`, `3950`, `3951`, `3952`, `3953`, `3954`, `3955`, `3956`, `3957`, `3958`, `3959`, `3960`, `3961`, `3962`, `3963`, `3964`, `3965`, `3966`, `3967`, `3968`, `3969`, `3970`, `3971`, `3972`, `3973`, `3974`, `3975`, `3976`, `3977`, `3978`, `3979`, `3980`, `3981`, `3982`, `3983`, `3984`, `3985`, `3986`, `3987`, `3988`, `3989`, `3990`, `3991`, `3992`, `3993`, `3994`, `3995`, `3996`, `3997`, `3998`, `3999`, `4000`, `4001`, `4002`, `4003`, `4004`, `4005`, `4006`, `4007`, `4008`, `4009`, `4010`, `4011`, `4012`, `4013`, `4014`, `4015`, `4016`, `4017`, `4018`, `4019`, `4020`, `4021`, `4022`, `4023`, `4024`, `4025`, `4026`, `4027`, `4028`, `4029`, `4030`, `4031`, `4032`, `4033`, `4034`, `4035`, `4036`, `4037`, `4038`, `4039`, `4040`, `4041`, `4042`, `4043`, `4044`, `4045`, `4046`, `4047`, `4048`, `4049`, `4050`, `4051`, `4052`, `4053`, `4054`, `4055`, `4056`, `4057`, `4058`, `4059`, `4060`, `4061`, `4062`, `4063`, `4064`, `4065`, `4066`, `4067`, `4068`, `4069`, `4070`, `4071`, `4072`, `4073`, `4074`, `4075`, `4076`, `4077`, `4078`, `4079`, `4080`, `4081`, `4082`, `4083`, `4084`, `4085`, `4086`, `4087`, `4088`, `4089`, `4090`, `4091`, `4092`, `4093`, `4094`, `4095`, `4096`, `4097`, `4098`, `4099`, `4100`, `4101`, `4102`, `4103`, `4104`, `4105`, `4106`, `4107`, `4108`, `4109`, `4110`, `4111`, `4112`, `4113`, `4114`, `4115`, `4116`, `4117`, `4118`, `4119`, `4120`, `4121`, `4122`, `4123`, `4124`, `4125`, `4126`, `4127`, `4128`, `4129`, `4130`, `4131`, `4132`, `4133`, `4134`, `4135`, `4136`, `4137`, `4138`, `4139`, `4140`, `4141`, `4142`, `4143`, `4144`, `4145`, `4146`, `4147`, `4148`, `4149`, `4150`, `4151`, `4152`, `4153`, `4154`, `4155`, `4156`, `4157`, `4158`, `4159`, `4160`, `4161`, `4162`, `4163`, `4164`, `4165`, `4166`, `4167`, `4168`, `4169`, `4170`, `4171`, `4172`, `4173`, `4174`, `4175`, `4176`, `4177`, `4178`, `4179`, `4180`, `4181`, `4182`, `4183`, `4184`, `4185`, `4186`, `4187`, `4188`, `4189`, `4190`, `4191`, `4192`, `4193`, `4194`, `4195`, `4196`, `4197`, `4198`, `4199`, `4200`, `4201`, `4202`, `4203`, `4204`, `4205`, `4206`, `4207`, `4208`, `4209`, `4210`, `4211`, `4212`, `4213`, `4214`, `4215`, `4216`, `4217`, `4218`, `4219`, `4220`, `4221`, `4222`, `4223`, `4224`, `4225`, `4226`, `4227`, `4228`, `4229`, `4230`, `4231`, `4232`, `4233`, `4234`, `4235`, `4236`, `4237`, `4238`, `4239`, `4240`, `4241`, `4242`, `4243`, `4244`, `4245`, `4246`, `4247`, `4248`, `4249`, `4250`, `4251`, `4252`, `4253`, `4254`, `4255`, `4256`, `4257`, `4258`, `4259`, `4260`, `4261`, `4262`, `4263`, `4264`, `4265`, `4266`, `4267`, `4268`, `4269`, `4270`, `4271`, `4272`, `4273`, `4274`, `4275`, `4276`, `4277`, `4278`, `4279`, `4280`, `4281`, `4282`, `4283`, `4284`, `4285`, `4286`, `4287`, `4288`, `4289`, `4290`, `4291`, `4292`, `4293`, `4294`, `4295`, `4296`, `4297`, `4298`, `4299`, `4300`, `4301`, `4302`, `4303`, `4304`, `4305`, `4306`, `4307`, `4308`, `4309`, `4310`, `4311`, `4312`, `4313`, `4314`, `4315`, `4316`, `4317`, `4318`, `4319`, `4320`, `4321`, `4322`, `4323`, `4324`, `4325`, `4326`, `4327`, `4328`, `4329`, `4330`, `4331`, `4332`, `4333`, `4334`, `4335`, `4336`, `4337`, `4338`, `4339`, `4340`, `4341`, `4342`, `4343`, `4344`, `4345`, `4346`, `4347`, `4348`, `4349`, `4350`, `4351`, `4352`, `4353`, `4354`, `4355`, `4356`, `4357`, `4358`, `4359`, `4360`, `4361`, `4362`, `4363`, `4364`, `4365`, `4366`, `4367`, `4368`, `4369`, `4370`, `4371`, `4372`, `4373`, `4374`, `4375`, `4376`, `4377`, `4378`, `4379`, `4380`, `4381`, `4382`, `4383`, `4384`, `4385`, `4386`, `4387`, `4388`, `4389`, `4390`, `4391`, `4392`, `4393`, `4394`, `4395`, `4396`, `4397`, `4398`, `4399`, `4400`, `4401`, `4402`, `4403`, `4404`, `4405`, `4406`, `4407`, `4408`, `4409`, `4410`, `4411`, `4412`, `4413`, `4414`, `4415`, `4416`, `4417`, `4418`, `4419`, `4420`, `4421`, `4422`, `4423`, `4424`, `4425`, `4426`, `4427`, `4428`, `4429`, `4430`, `4431`, `4432`, `4433`, `4434`, `4435`, `4436`, `4437`, `4438`, `4439`, `4440`, `4441`, `4442`, `4443`, `4444`, `4445`, `4446`, `4447`, `4448`, `4449`, `4450`, `4451`, `4452`, `4453`, `4454`, `4455`, `4456`, `4457`, `4458`, `4459`, `4460`, `4461`, `4462`, `4463`, `4464`, `4465`, `4466`, `4467`, `4468`, `4469`, `4470`, `4471`, `4472`, `4473`, `4474`, `4475`, `4476`, `4477`, `4478`, `4479`, `4480`, `4481`, `4482`, `4483`, `4484`, `4485`, `4486`, `4487`, `4488`, `4489`, `4490`, `4491`, `4492`, `4493`, `4494`, `4495`, `4496`, `4497`, `4498`, `4499`, `4500`, `4501`, `4502`, `4503`, `4504`, `4505`, `4506`, `4507`, `4508`, `4509`, `4510`, `4511`, `4512`, `4513`, `4514`, `4515`, `4516`, `4517`, `4518`, `4519`, `4520`, `4521`, `4522`, `4523`, `4524`, `4525`, `4526`, `4527`, `4528`, `4529`, `4530`, `4531`, `4532`, `4533`, `4534`, `4535`, `4536`, `4537`, `4538`, `4539`, `4540`, `4541`, `4542`, `4543`, `4544`, `4545`, `4546`, `4547`, `4548`, `4549`, `4550`, `4551`, `4552`, `4553`, `4554`, `4555`, `4556`, `4557`, `4558`, `4559`, `4560`, `4561`, `4562`, `4563`, `4564`, `4565`, `4566`, `4567`, `4568`, `4569`, `4570`, `4571`, `4572`, `4573`, `4574`, `4575`, `4576`, `4577`, `4578`, `4579`, `4580`, `4581`, `4582`, `4583`, `4584`, `4585`, `4586`, `4587`, `4588`, `4589`, `4590`, `4591`, `4592`, `4593`, `4594`, `4595`, `4596`, `4597`, `4598`, `4599`, `4600`, `4601`, `4602`, `4603`, `4604`, `4605`, `4606`, `4607`, `4608`, `4609`, `4610`, `4611`, `4612`, `4613`, `4614`, `4615`, `4616`, `4617`, `4618`, `4619`, `4620`, `4621`, `4622`, `4623`, `4624`, `4625`, `4626`, `4627`, `4628`, `4629`, `4630`, `4631`, `4632`, `4633`, `4634`, `4635`, `4636`, `4637`, `4638`, `4639`, `4640`, `4641`, `4642`, `4643`, `4644`, `4645`, `4646`, `4647`, `4648`, `4649`, `4650`, `4651`, `4652`, `4653`, `4654`, `4655`, `4656`, `4657`, `4658`, `4659`, `4660`, `4661`, `4662`, `4663`, `4664`, `4665`, `4666`, `4667`, `4668`, `4669`, `4670`, `4671`, `4672`, `4673`, `4674`, `4675`, `4676`, `4677`, `4678`, `4679`, `4680`, `4681`, `4682`, `4683`, `4684`, `4685`, `4686`, `4687`, `4688`, `4689`, `4690`, `4691`, `4692`, `4693`, `4694`, `4695`, `4696`, `4697`, `4698`, `4699`, `4700`, `4701`, `4702`, `4703`, `4704`, `4705`, `4706`, `4707`, `4708`, `4709`, `4710`, `4711`, `4712`, `4713`, `4714`, `4715`, `4716`, `4717`, `4718`, `4719`, `4720`, `4721`, `4722`, `4723`, `4724`, `4725`, `4726`, `4727`, `4728`, `4729`, `4730`, `4731`, `4732`, `4733`, `4734`, `4735`, `4736`, `4737`, `4738`, `4739`, `4740`, `4741`, `4742`, `4743`, `4744`, `4745`, `4746`, `4747`, `4748`, `4749`, `4750`, `4751`, `4752`, `4753`, `4754`, `4755`, `4756`, `4757`, `4758`, `4759`, `4760`, `4761`, `4762`, `4763`, `4764`, `4765`, `4766`, `4767`, `4768`, `4769`, `4770`, `4771`, `4772`, `4773`, `4774`, `4775`, `4776`, `4777`, `4778`, `4779`, `4780`, `4781`, `4782`, `4783`, `4784`, `4785`, `4786`, `4787`, `4788`, `4789`, `4790`, `4791`, `4792`, `4793`, `4794`, `4795`, `4796`, `4797`, `4798`, `4799`, `4800`, `4801`, `4802`, `4803`, `4804`, `4805`, `4806`, `4807`, `4808`, `4809`, `4810`, `4811`, `4812`, `4813`, `4814`, `4815`, `4816`, `4817`, `4818`, `4819`, `4820`, `4821`, `4822`, `4823`, `4824`, `4825`, `4826`, `4827`, `4828`, `4829`, `4830`, `4831`, `4832`, `4833`, `4834`, `4835`, `4836`, `4837`, `4838`, `4839`, `4840`, `4841`, `4842`, `4843`, `4844`, `4845`, `4846`, `4847`, `4848`, `4849`, `4850`, `4851`, `4852`, `4853`, `4854`, `4855`, `4856`, `4857`, `4858`, `4859`, `4860`, `4861`, `4862`, `4863`, `4864`, `4865`, `4866`, `4867`, `4868`, `4869`, `4870`, `4871`, `4872`, `4873`, `4874`, `4875`, `4876`, `4877`, `4878`, `4879`, `4880`, `4881`, `4882`, `4883`, `4884`, `4885`, `4886`, `4887`, `4888`, `4889`, `4890`, `4891`, `4892`, `4893`, `4894`, `4895`, `4896`, `4897`, `4898`, `4899`, `4900`, `4901`, `4902`, `4903`, `4904`, `4905`, `4906`, `4907`, `4908`, `4909`, `4910`, `4911`, `4912`, `4913`, `4914`, `4915`, `4916`, `4917`, `4918`, `4919`, `4920`, `4921`, `4922`, `4923`, `4924`, `4925`, `4926`, `4927`, `4928`, `4929`, `4930`, `4931`, `4932`, `4933`, `4934`, `4935`, `4936`, `4937`, `4938`, `4939`, `4940`, `4941`, `4942`, `4943`, `4944`, `4945`, `4946`, `4947`, `4948`, `4949`, `4950`, `4951`, `4952`, `4953`, `4954`, `4955`, `4956`, `4957`, `4958`, `4959`, `4960`, `4961`, `4962`, `4963`, `4964`, `4965`, `4966`, `4967`, `4968`, `4969`, `4970`, `4971`, `4972`, `4973`, `4974`, `4975`, `4976`, `4977`, `4978`, `4979`, `4980`, `4981`, `4982`, `4983`, `4984`, `4985`, `4986`, `4987`, `4988`, `4989`, `4990`, `4991`, `4992`, `4993`, `4994`, `4995`, `4996`, `4997`, `4998`, `4999`, `5000`, `5001`, `5002`, `5003`, `5004`, `5005`, `5006`, `5007`, `5008`, `5009`, `5010`, `5011`, `5012`, `5013`, `5014`, `5015`, `5016`, `5017`, `5018`, `5019`, `5020`, `5021`, `5022`, `5023`, `5024`, `5025`, `5026`, `5027`, `5028`, `5029`, `5030`, `5031`, `5032`, `5033`, `5034`, `5035`, `5036`, `5037`, `5038`, `5039`, `5040`, `5041`, `5042`, `5043`, `5044`, `5045`, `5046`, `5047`, `5048`, `5049`, `5050`, `5051`, `5052`, `5053`, `5054`, `5055`, `5056`, `5057`, `5058`, `5059`, `5060`, `5061`, `5062`, `5063`, `5064`, `5065`, `5066`, `5067`, `5068`, `5069`, `5070`, `5071`, `5072`, `5073`, `5074`, `5075`, `5076`, `5077`, `5078`, `5079`, `5080`, `5081`, `5082`, `5083`, `5084`, `5085`, `5086`, `5087`, `5088`, `5089`, `5090`, `5091`, `5092`, `5093`, `5094`, `5095`, `5096`, `5097`, `5098`, `5099`, `5100`, `5101`, `5102`, `5103`, `5104`, `5105`, `5106`, `5107`, `5108`, `5109`, `5110`, `5111`, `5112`, `5113`, `5114`, `5115`, `5116`, `5117`, `5118`, `5119`, `5120`, `5121`, `5122`, `5123`, `5124`, `5125`, `5126`, `5127`, `5128`, `5129`, `5130`, `5131`, `5132`, `5133`, `5134`, `5135`, `5136`, `5137`, `5138`, `5139`, `5140`, `5141`, `5142`, `5143`, `5144`, `5145`, `5146`, `5147`, `5148`, `5149`, `5150`, `5151`, `5152`, `5153`, `5154`, `5155`, `5156`, `5157`, `5158`, `5159`, `5160`, `5161`, `5162`, `5163`, `5164`, `5165`, `5166`, `5167`, `5168`, `5169`, `5170`, `5171`, `5172`, `5173`, `5174`, `5175`, `5176`, `5177`, `5178`, `5179`, `5180`, `5181`, `5182`, `5183`, `5184`, `5185`, `5186`, `5187`, `5188`, `5189`, `5190`, `5191`, `5192`, `5193`, `5194`, `5195`, `5196`, `5197`, `5198`, `5199`, `5200`, `5201`, `5202`, `5203`, `5204`, `5205`, `5206`, `5207`, `5208`, `5209`, `5210`, `5211`, `5212`, `5213`, `5214`, `5215`, `5216`, `5217`, `5218`, `5219`, `5220`, `5221`, `5222`, `5223`, `5224`, `5225`, `5226`, `5227`, `5228`, `5229`, `5230`, `5231`, `5232`, `5233`, `5234`, `5235`, `5236`, `5237`, `5238`, `5239`, `5240`, `5241`, `5242`, `5243`, `5244`, `5245`, `5246`, `5247`, `5248`, `5249`, `5250`, `5251`, `5252`, `5253`, `5254`, `5255`, `5256`, `5257`, `5258`, `5259`, `5260`, `5261`, `5262`, `5263`, `5264`, `5265`, `5266`, `5267`, `5268`, `5269`, `5270`, `5271`, `5272`, `5273`, `5274`, `5275`, `5276`, `5277`, `5278`, `5279`, `5280`, `5281`, `5282`, `5283`, `5284`, `5285`, `5286`, `5287`, `5288`, `5289`, `5290`, `5291`, `5292`, `5293`, `5294`, `5295`, `5296`, `5297`, `5298`, `5299`, `5300`, `5301`, `5302`, `5303`, `5304`, `5305`, `5306`, `5307`, `5308`, `5309`, `5310`, `5311`, `5312`, `5313`, `5314`, `5315`, `5316`, `5317`, `5318`, `5319`, `5320`, `5321`, `5322`, `5323`, `5324`, `5325`, `5326`, `5327`, `5328`, `5329`, `5330`, `5331`, `5332`, `5333`, `5334`, `5335`, `5336`, `5337`, `5338`, `5339`, `5340`, `5341`, `5342`, `5343`, `5344`, `5345`, `5346`, `5347`, `5348`, `5349`, `5350`, `5351`, `5352`, `5353`, `5354`, `5355`, `5356`, `5357`, `5358`, `5359`, `5360`, `5361`, `5362`, `5363`, `5364`, `5365`, `5366`, `5367`, `5368`, `5369`, `5370`, `5371`, `5372`, `5373`, `5374`, `5375`, `5376`, `5377`, `5378`, `5379`, `5380`, `5381`, `5382`, `5383`, `5384`, `5385`, `5386`, `5387`, `5388`, `5389`, `5390`, `5391`, `5392`, `5393`, `5394`, `5395`, `5396`, `5397`, `5398`, `5399`, `5400`, `5401`, `5402`, `5403`, `5404`, `5405`, `5406`, `5407`, `5408`, `5409`, `5410`, `5411`, `5412`, `5413`, `5414`, `5415`, `5416`, `5417`, `5418`, `5419`, `5420`, `5421`, `5422`, `5423`, `5424`, `5425`, `5426`, `5427`, `5428`, `5429`, `5430`, `5431`, `5432`, `5433`, `5434`, `5435`, `5436`, `5437`, `5438`, `5439`, `5440`, `5441`, `5442`, `5443`, `5444`, `5445`, `5446`, `5447`, `5448`, `5449`, `5450`, `5451`, `5452`, `5453`, `5454`, `5455`, `5456`, `5457`, `5458`, `5459`, `5460`, `5461`, `5462`, `5463`, `5464`, `5465`, `5466`, `5467`, `5468`, `5469`, `5470`, `5471`, `5472`, `5473`, `5474`, `5475`, `5476`, `5477`, `5478`, `5479`, `5480`, `5481`, `5482`, `5483`, `5484`, `5485`, `5486`, `5487`, `5488`, `5489`, `5490`, `5491`, `5492`, `5493`, `5494`, `5495`, `5496`, `5497`, `5498`, `5499`, `5500`, `5501`, `5502`, `5503`, `5504`, `5505`, `5506`, `5507`, `5508`, `5509`, `5510`, `5511`, `5512`, `5513`, `5514`, `5515`, `5516`, `5517`, `5518`, `5519`, `5520`, `5521`, `5522`, `5523`, `5524`, `5525`, `5526`, `5527`, `5528`, `5529`, `5530`, `5531`, `5532`, `5533`, `5534`, `5535`, `5536`, `5537`, `5538`, `5539`, `5540`, `5541`, `5542`, `5543`, `5544`, `5545`, `5546`, `5547`, `5548`, `5549`, `5550`, `5551`, `5552`, `5553`, `5554`, `5555`, `5556`, `5557`, `5558`, `5559`, `5560`, `5561`, `5562`, `5563`, `5564`, `5565`, `5566`, `5567`, `5568`, `5569`, `5570`, `5571`, `5572`, `5573`, `5574`, `5575`, `5576`, `5577`, `5578`, `5579`, `5580`, `5581`, `5582`, `5583`, `5584`, `5585`, `5586`, `5587`, `5588`, `5589`, `5590`, `5591`, `5592`, `5593`, `5594`, `5595`, `5596`, `5597`, `5598`, `5599`, `5600`, `5601`, `5602`, `5603`, `5604`, `5605`, `5606`, `5607`, `5608`, `5609`, `5610`, `5611`, `5612`, `5613`, `5614`, `5615`, `5616`, `5617`, `5618`, `5619`, `5620`, `5621`, `5622`, `5623`, `5624`, `5625`, `5626`, `5627`, `5628`, `5629`, `5630`, `5631`, `5632`, `5633`, `5634`, `5635`, `5636`, `5637`, `5638`, `5639`, `5640`, `5641`, `5642`, `5643`, `5644`, `5645`, `5646`, `5647`, `5648`, `5649`, `5650`, `5651`, `5652`, `5653`, `5654`, `5655`, `5656`, `5657`, `5658`, `5659`, `5660`, `5661`, `5662`, `5663`, `5664`, `5665`, `5666`, `5667`, `5668`, `5669`, `5670`, `5671`, `5672`, `5673`, `5674`, `5675`, `5676`, `5677`, `5678`, `5679`, `5680`, `5681`, `5682`, `5683`, `5684`, `5685`, `5686`, `5687`, `5688`, `5689`, `5690`, `5691`, `5692`, `5693`, `5694`, `5695`, `5696`, `5697`, `5698`, `5699`, `5700`, `5701`, `5702`, `5703`, `5704`, `5705`, `5706`, `5707`, `5708`, `5709`, `5710`, `5711`, `5712`, `5713`, `5714`, `5715`, `5716`, `5717`, `5718`, `5719`, `5720`, `5721`, `5722`, `5723`, `5724`, `5725`, `5726`, `5727`, `5728`, `5729`, `5730`, `5731`, `5732`, `5733`, `5734`, `5735`, `5736`, `5737`, `5738`, `5739`, `5740`, `5741`, `5742`, `5743`, `5744`, `5745`, `5746`, `5747`, `5748`, `5749`, `5750`, `5751`, `5752`, `5753`, `5754`, `5755`, `5756`, `5757`, `5758`, `5759`, `5760`, `5763`, `5764`, `5765`, `5766`, `5767`, `5768`, `5769`, `5770`, `5771`, `5772`, `5773`, `5774`, `5775`, `5776`, `5777`, `5778`, `5779`, `5780`, `5781`, `5782`, `5783`, `5784`, `5785`, `5786`, `5787`, `5788`, `5789`, `5790`, `5791`, `5792`, `5793`, `5794`, `5795`, `5796`, `5797`, `5798`, `5799`, `5800`, `5801`, `5802`, `5803`, `5804`, `5805`, `5806`, `5807`, `5808`, `5809`, `5810`, `5811`, `5812`, `5813`, `5814`, `5815`, `5816`, `5817`, `5818`, `5819`, `5820`, `5821`, `5822`, `5823`, `5824`, `5825`, `5826`, `5827`, `5828`, `5829`, `5830`, `5831`, `5832`, `5833`, `5834`, `5835`, `5836`, `5837`, `5838`, `5839`, `5840`, `5841`, `5842`, `5843`, `5844`, `5845`, `5846`, `5847`, `5848`, `5849`, `5850`, `5851`, `5852`, `5853`, `5854`, `5855`, `5856`, `5857`, `5858`, `5859`, `5860`, `5861`, `5862`, `5863`, `5864`, `5865`, `5866`, `5867`, `5868`, `5869`, `5870`, `5871`, `5872`, `5873`, `5874`, `5875`, `5876`, `5877`, `5878`, `5879`, `5880`, `5881`, `5882`, `5883`, `5884`, `5885`, `5886`, `5887`, `5888`, `5889`, `5890`, `5891`, `5892`, `5893`, `5894`, `5895`, `5896`, `5897`, `5898`, `5899`, `5900`, `5901`, `5902`, `5903`, `5904`, `5905`, `5906`, `5907`, `5908`, `5909`, `5910`, `5911`, `5912`, `5913`, `5914`, `5915`, `5916`, `5917`, `5918`, `5919`, `5920`, `5921`, `5922`, `5923`, `5924`, `5925`, `5926`, `5927`, `5928`, `5929`, `5930`, `5931`, `5932`, `5933`, `5934`, `5935`, `5936`, `5937`, `5938`, `5939`, `5940`, `5941`, `5942`, `5943`, `5944`, `5945`, `5946`, `5947`, `5948`, `5949`, `5950`, `5951`, `5952`, `5953`, `5954`, `5955`, `5956`, `5957`, `5958`, `5959`, `5960`, `5961`, `5962`, `5963`, `5964`, `5965`, `5966`, `5967`, `5968`, `5969`, `5970`, `5971`, `5972`, `5973`, `5974`, `5975`, `5976`, `5977`, `5978`, `5979`, `5980`, `5981`, `5982`, `5983`, `5984`, `5985`, `5986`, `5987`, `5988`, `5989`, `5990`, `5991`, `5992`, `5993`, `5994`, `5995`, `5996`, `5997`, `5998`, `5999`, `6000`, `6001`, `6002`, `6003`, `6004`, `6005`, `6006`, `6007`, `6008`, `6009`, `6010`, `6011`, `6012`, `6013`, `6014`, `6015`, `6016`, `6017`, `6018`, `6019`, `6020`, `6021`, `6022`, `6023`, `6024`, `6025`, `6026`, `6027`, `6028`, `6029`, `6030`, `6031`, `6032`, `6033`, `6034`, `6035`, `6036`, `6037`, `6038`, `6039`, `6040`, `6041`, `6042`, `6043`, `6044`, `6045`, `6046`, `6047`, `6048`, `6049`, `6050`, `6051`, `6052`, `6053`, `6054`, `6055`, `6056`, `6057`, `6058`, `6059`, `6060`, `6061`, `6062`, `6063`, `6064`, `6065`, `6066`, `6067`, `6068`, `6069`, `6070`, `6071`, `6072`, `6073`, `6074`, `6075`, `6076`, `6077`, `6078`, `6079`, `6080`, `6081`, `6082`, `6083`, `6084`, `6085`, `6086`, `6087`, `6088`, `6089`, `6090`, `6091`, `6092`, `6093`, `6094`, `6095`, `6096`, `6097`, `6098`, `6099`, `6100`, `6101`, `6102`, `6103`, `6104`, `6105`, `6106`, `6107`, `6108`, `6109`, `6110`, `6111`, `6112`, `6113`, `6114`, `6115`, `6116`, `6117`, `6118`, `6119`, `6120`, `6121`, `6122`, `6123`, `6124`, `6125`, `6126`, `6127`, `6128`, `6129`, `6130`, `6131`, `6132`, `6133`, `6134`, `6135`, `6136`, `6137`, `6138`, `6139`, `6140`, `6141`, `6142`, `6143`, `6144`, `6145`, `6146`, `6147`, `6148`, `6149`, `6150`, `6151`, `6152`, `6153`, `6154`, `6155`, `6156`, `6157`, `6158`, `6159`, `6160`, `6161`, `6162`, `6163`, `6164`, `6165`, `6166`, `6167`, `6168`, `6169`, `6170`, `6171`, `6172`, `6173`, `6174`, `6175`, `6176`, `6177`, `6178`, `6179`, `6180`, `6181`, `6182`, `6183`, `6184`, `6185`, `6186`, `6187`, `6188`, `6189`, `6190`, `6191`, `6192`, `6193`, `6194`, `6195`, `6196`, `6197`, `6198`, `6199`, `6200`, `6201`, `6202`, `6203`, `6204`, `6205`, `6206`, `6207`, `6208`, `6209`, `6210`, `6211`, `6212`, `6213`, `6214`, `6215`, `6216`, `6217`, `6218`, `6219`, `6220`, `6221`, `6222`, `6223`, `6224`, `6225`, `6226`, `6227`, `6228`, `6229`, `6230`, `6231`, `6232`, `6233`, `6234`, `6235`, `6236`, `6237`, `6238`, `6239`, `6240`, `6241`, `6242`, `6243`, `6244`, `6245`, `6246`, `6247`, `6248`, `6249`, `6250`, `6251`, `6252`, `6253`, `6254`, `6255`, `6256`, `6257`, `6258`, `6259`, `6260`, `6261`, `6262`, `6263`, `6264`, `6265`, `6266`, `6267`, `6268`, `6269`, `6270`, `6271`, `6272`, `6273`, `6274`, `6275`, `6276`, `6277`, `6278`, `6279`, `6280`, `6281`, `6282`, `6283`, `6284`, `6285`, `6286`, `6287`, `6288`, `6289`, `6290`, `6291`, `6292`, `6293`, `6294`, `6295`, `6296`, `6297`, `6298`, `6299`, `6300`, `6301`, `6302`, `6303`, `6304`, `6305`, `6306`, `6307`, `6308`, `6309`, `6310`, `6311`, `6312`, `6313`, `6314`, `6315`, `6316`, `6317`, `6318`, `6319`, `6320`, `6321`, `6322`, `6323`, `6324`, `6325`, `6326`, `6327`, `6328`, `6329`, `6330`, `6331`, `6332`, `6333`, `6334`, `6335`, `6336`, `6337`, `6338`, `6339`, `6340`, `6341`, `6342`, `6343`, `6344`, `6345`, `6346`, `6347`, `6348`, `6349`, `6350`, `6351`, `6352`, `6353`, `6354`, `6355`, `6356`, `6357`, `6358`, `6359`, `6360`, `6361`, `6362`, `6363`, `6364`, `6365`, `6366`, `6367`, `6368`, `6369`, `6370`, `6371`, `6372`, `6373`, `6374`, `6375`, `6376`, `6377`, `6378`, `6379`, `6380`, `6381`, `6382`, `6383`, `6384`, `6385`, `6386`, `6387`, `6388`, `6389`, `6390`, `6391`, `6392`, `6393`, `6394`, `6395`, `6396`, `6397`, `6398`, `6399`, `6400`, `6401`, `6402`, `6403`, `6404`, `6405`, `6406`, `6407`, `6408`, `6409`, `6410`, `6411`, `6412`, `6413`, `6414`, `6415`, `6416`, `6417`, `6418`, `6419`, `6420`, `6421`, `6422`, `6423`, `6424`, `6425`, `6426`, `6427`, `6428`, `6429`, `6430`, `6431`, `6432`, `6433`, `6434`, `6435`, `6436`, `6437`, `6438`, `6439`, `6440`, `6441`, `6442`, `6443`, `6444`, `6445`, `6446`, `6447`, `6448`, `6449`, `6450`, `6451`, `6452`, `6453`, `6454`, `6455`, `6456`, `6457`, `6458`, `6459`, `6460`, `6461`, `6462`, `6463`, `6464`, `6465`, `6466`, `6467`, `6468`, `6469`, `6470`, `6471`, `6472`, `6473`, `6474`, `6475`, `6476`, `6477`, `6478`, `6479`, `6480`, `6481`, `6482`, `6483`, `6484`, `6485`, `6486`, `6487`, `6488`, `6489`, `6490`, `6491`, `6492`, `6493`, `6494`, `6495`, `6496`, `6497`, `6498`, `6499`, `6500`, `6501`, `6502`, `6503`, `6504`, `6505`, `6506`, `6507`, `6508`, `6509`, `6510`, `6511`, `6512`, `6513`, `6514`, `6515`, `6516`, `6517`, `6518`, `6519`, `6520`, `6521`, `6522`, `6523`, `6524`, `6525`, `6526`, `6527`, `6528`, `6529`, `6530`, `6531`, `6532`, `6533`, `6534`, `6535`, `6536`, `6537`, `6538`, `6539`, `6540`, `6541`, `6542`, `6543`, `6544`, `6545`, `6546`, `6547`, `6548`, `6549`, `6550`, `6551`, `6552`, `6553`, `6554`, `6555`, `6556`, `6557`, `6558`, `6559`, `6560`, `6561`, `6562`, `6563`, `6564`, `6565`, `6566`, `6567`, `6568`, `6569`, `6570`, `6571`, `6572`, `6573`, `6574`, `6575`, `6576`, `6577`, `6578`, `6579`, `6580`, `6581`, `6582`, `6583`, `6584`, `6585`, `6586`, `6587`, `6588`, `6589`, `6590`, `6591`, `6592`, `6593`, `6594`, `6595`, `6596`, `6597`, `6598`, `6599`, `6600`, `6601`, `6602`, `6603`, `6604`, `6605`, `6606`, `6607`, `6608`, `6609`, `6610`, `6611`, `6612`, `6613`, `6614`, `6615`, `6616`, `6617`, `6618`, `6619`, `6620`, `6621`, `6622`, `6623`, `6624`, `6625`, `6626`, `6627`, `6628`, `6629`, `6630`, `6631`, `6632`, `6633`, `6634`, `6635`, `6636`, `6637`, `6638`, `6639`, `6640`, `6641`, `6642`, `6643`, `6644`, `6645`, `6646`, `6647`, `6648`, `6649`, `6650`, `6651`, `6652`, `6653`, `6654`, `6655`, `6656`, `6657`, `6658`, `6659`, `6660`, `6661`, `6662`, `6663`, `6664`, `6665`, `6666`, `6667`, `6668`, `6669`, `6670`, `6671`, `6672`, `6673`, `6674`, `6675`, `6676`, `6677`, `6678`, `6679`, `6680`, `6681`, `6682`, `6683`, `6684`, `6685`, `6686`, `6687`, `6688`, `6689`, `6690`, `6691`, `6692`, `6693`, `6694`, `6695`, `6696`, `6697`, `6698`, `6699`, `6700`, `6701`, `6702`, `6703`, `6704`, `6705`, `6706`, `6707`, `6708`, `6709`, `6710`, `6711`, `6712`, `6713`, `6714`, `6715`, `6716`, `6717`, `6718`, `6719`, `6720`, `6721`, `6722`, `6723`, `6724`, `6725`, `6726`, `6727`, `6728`, `6729`, `6730`, `6731`, `6732`, `6733`, `6734`, `6735`, `6736`, `6737`, `6738`, `6739`, `6740`, `6741`, `6742`, `6743`, `6744`, `6745`, `6746`, `6747`, `6748`, `6749`, `6750`, `6751`, `6752`, `6753`, `6754`, `6755`, `6756`, `6757`, `6758`, `6759`, `6760`, `6761`, `6762`, `6763`, `6764`, `6765`, `6766`, `6767`, `6768`, `6769`, `6770`, `6771`, `6772`, `6773`, `6774`, `6775`, `6776`, `6777`, `6778`, `6779`, `6780`, `6781`, `6782`, `6783`, `6784`, `6785`, `6786`, `6787`, `6788`, `6789`, `6790`, `6791`, `6792`, `6793`, `6794`, `6795`, `6796`, `6797`, `6798`, `6799`, `6800`, `6801`, `6802`, `6803`, `6804`, `6805`, `6806`, `6807`, `6808`, `6809`, `6810`, `6811`, `6812`, `6813`, `6814`, `6815`, `6816`, `6817`, `6818`, `6819`, `6820`, `6821`, `6822`, `6823`, `6824`, `6825`, `6826`, `6827`, `6828`, `6829`, `6830`, `6831`, `6832`, `6833`, `6834`, `6835`, `6836`, `6837`, `6838`, `6839`, `6840`, `6841`, `6842`, `6843`, `6844`, `6845`, `6846`, `6847`, `6848`, `6849`, `6850`, `6851`, `6852`, `6853`, `6854`, `6855`, `6856`, `6857`, `6858`, `6859`, `6860`, `6861`, `6862`, `6863`, `6864`, `6865`, `6866`, `6867`, `6868`, `6869`, `6870`, `6871`, `6872`, `6873`, `6874`, `6875`, `6876`, `6877`, `6878`, `6879`, `6880`, `6881`, `6882`, `6883`, `6884`, `6885`, `6886`, `6887`, `6888`, `6889`, `6890`, `6891`, `6892`, `6893`, `6894`, `6895`, `6896`, `6897`, `6898`, `6899`, `6900`, `6901`, `6902`, `6903`, `6904`, `6905`, `6906`, `6907`, `6908`, `6909`, `6910`, `6911`, `6912`, `6913`, `6914`, `6915`, `6916`, `6917`, `6918`, `6919`, `6920`, `6921`, `6922`, `6923`, `6924`, `6925`, `6926`, `6927`, `6928`, `6929`, `6930`, `6931`, `6932`, `6933`, `6934`, `6935`, `6936`, `6937`, `6938`, `6939`, `6940`, `6941`, `6942`, `6943`, `6944`, `6945`, `6946`, `6947`, `6948`, `6949`, `6950`, `6951`, `6952`, `6953`, `6954`, `6955`, `6956`, `6957`, `6958`, `6959`, `6960`, `6961`, `6962`, `6963`, `6964`, `6965`, `6966`, `6967`, `6968`, `6969`, `6970`, `6971`, `6972`, `6973`, `6974`, `6975`, `6976`, `6977`, `6978`, `6979`, `6980`, `6981`, `6982`, `6983`, `6984`, `6985`, `6986`, `6987`, `6988`, `6989`, `6990`, `6991`, `6992`, `6993`, `6994`, `6995`, `6996`, `6997`, `6998`, `6999`, `7000`, `7001`, `7002`, `7003`, `7004`, `7005`, `7006`, `7007`, `7008`, `7009`, `7010`, `7011`, `7012`, `7013`, `7014`, `7015`, `7016`, `7017`, `7018`, `7019`, `7020`, `7021`, `7022`, `7023`, `7024`, `7025`, `7026`, `7027`, `7028`, `7029`, `7030`, `7031`, `7032`, `7033`, `7034`, `7035`, `7036`, `7037`, `7038`, `7039`, `7040`, `7041`, `7042`, `7043`, `7044`, `7045`, `7046`, `7047`, `7048`, `7049`, `7050`, `7051`, `7052`, `7053`, `7054`, `7055`, `7056`, `7057`, `7058`, `7059`, `7060`, `7061`, `7062`, `7063`, `7064`, `7065`, `7066`, `7067`, `7068`, `7069`, `7070`, `7071`, `7072`, `7073`, `7074`, `7075`, `7076`, `7077`, `7078`, `7079`, `7080`, `7081`, `7082`, `7083`, `7084`, `7085`, `7086`, `7087`, `7088`, `7089`, `7090`, `7091`, `7092`, `7093`, `7094`, `7095`, `7096`, `7097`, `7098`, `7099`, `7100`, `7101`, `7102`, `7103`, `7104`, `7105`, `7106`, `7107`, `7108`, `7109`, `7110`, `7111`, `7112`, `7113`, `7114`, `7115`, `7116`, `7117`, `7118`, `7119`, `7120`, `7121`, `7122`, `7123`, `7124`, `7125`, `7126`, `7127`, `7128`, `7129`, `7130`, `7131`, `7132`, `7133`, `7134`, `7135`, `7136`, `7137`, `7138`, `7139`, `7140`, `7141`, `7142`, `7143`, `7144`, `7145`, `7146`, `7147`, `7148`, `7149`, `7150`, `7151`, `7152`, `7153`, `7154`, `7155`, `7156`, `7157`, `7158`, `7159`, `7160`, `7161`, `7162`, `7163`, `7164`, `7165`, `7166`, `7167`, `7168`, `7169`, `7170`, `7171`, `7172`, `7173`, `7174`, `7175`, `7176`, `7177`, `7178`, `7179`, `7180`, `7181`, `7182`, `7183`, `7184`, `7185`, `7186`, `7187`, `7188`, `7189`, `7190`, `7191`, `7192`, `7193`, `7194`, `7195`, `7196`, `7197`, `7198`, `7199`, `7200`, `7201`, `7202`, `7203`, `7204`, `7205`, `7206`, `7207`, `7208`, `7209`, `7210`, `7211`, `7212`, `7213`, `7214`, `7215`, `7216`, `7217`, `7218`, `7219`, `7220`, `7221`, `7222`, `7223`, `7224`, `7225`, `7226`, `7227`, `7228`, `7229`, `7230`, `7231`, `7232`, `7233`, `7234`, `7235`, `7236`, `7237`, `7238`, `7239`, `7240`, `7241`, `7242`, `7243`, `7244`, `7245`, `7246`, `7247`, `7248`, `7249`, `7250`, `7251`, `7252`, `7253`, `7254`, `7255`, `7256`, `7257`, `7258`, `7259`, `7260`, `7261`, `7262`, `7263`, `7264`, `7265`, `7266`, `7267`, `7268`, `7269`, `7270`, `7271`, `7272`, `7273`, `7274`, `7275`, `7276`, `7277`, `7278`, `7279`, `7280`, `7281`, `7282`, `7283`, `7284`, `7285`, `7286`, `7287`, `7288`, `7289`, `7290`, `7291`, `7292`, `7293`, `7294`, `7295`, `7296`, `7297`, `7298`, `7299`, `7300`, `7301`, `7302`, `7303`, `7304`, `7305`, `7306`, `7307`, `7308`, `7309`, `7310`, `7311`, `7312`, `7313`, `7314`, `7315`, `7316`, `7317`, `7318`, `7319`, `7320`, `7321`, `7322`, `7323`, `7324`, `7325`, `7326`, `7327`, `7328`, `7329`, `7330`, `7331`, `7332`, `7333`, `7334`, `7335`, `7336`, `7337`, `7338`, `7339`, `7340`, `7341`, `7342`, `7343`, `7344`, `7345`, `7346`, `7347`, `7348`, `7349`, `7350`, `7351`, `7352`, `7353`, `7354`, `7355`, `7356`, `7357`, `7358`, `7359`, `7360`, `7361`, `7362`, `7363`, `7364`, `7365`, `7366`, `7367`, `7368`, `7369`, `7370`, `7371`, `7372`, `7373`, `7374`, `7375`, `7376`, `7377`, `7378`, `7379`, `7380`, `7381`, `7382`, `7383`, `7384`, `7385`, `7386`, `7387`, `7388`, `7389`, `7390`, `7391`, `7392`, `7393`, `7394`, `7395`, `7396`, `7397`, `7398`, `7399`, `7400`, `7401`, `7402`, `7403`, `7404`, `7405`, `7406`, `7407`, `7408`, `7409`, `7410`, `7411`, `7412`, `7413`, `7414`, `7415`, `7416`, `7417`, `7418`, `7419`, `7420`, `7421`, `7422`, `7423`, `7424`, `7425`, `7426`, `7427`, `7428`, `7429`, `7430`, `7431`, `7432`, `7433`, `7434`, `7435`, `7436`, `7437`, `7438`, `7439`, `7440`, `7441`, `7442`, `7443`, `7444`, `7445`, `7446`, `7447`, `7448`, `7449`, `7450`, `7451`, `7452`, `7453`, `7454`, `7455`, `7456`, `7457`, `7458`, `7459`, `7460`, `7461`, `7462`, `7463`, `7464`, `7465`, `7466`, `7467`, `7468`, `7469`, `7470`, `7471`, `7472`, `7473`, `7474`, `7475`, `7476`, `7477`, `7478`, `7479`, `7480`, `7481`, `7482`, `7483`, `7484`, `7485`, `7486`, `7487`, `7488`, `7489`, `7490`, `7491`, `7492`, `7493`, `7494`, `7495`, `7496`, `7497`, `7498`, `7499`, `7500`, `7501`, `7502`, `7503`, `7504`, `7505`, `7506`, `7507`, `7508`, `7509`, `7510`, `7511`, `7512`, `7513`, `7514`, `7515`, `7516`, `7517`, `7518`, `7519`, `7520`, `7521`, `7522`, `7523`, `7524`, `7525`, `7526`, `7527`, `7528`, `7529`, `7530`, `7531`, `7532`, `7533`, `7534`, `7535`, `7536`, `7537`, `7538`, `7539`, `7540`, `7541`, `7542`, `7543`, `7544`, `7545`, `7546`, `7547`, `7548`, `7549`, `7550`, `7551`, `7552`, `7553`, `7554`, `7555`, `7556`, `7557`, `7558`, `7559`, `7560`, `7561`, `7562`, `7563`, `7564`, `7565`, `7566`, `7567`, `7568`, `7569`, `7570`, `7571`, `7572`, `7573`, `7574`, `7575`, `7576`, `7577`, `7578`, `7579`, `7580`, `7581`, `7582`, `7583`, `7584`, `7585`, `7586`, `7587`, `7588`, `7589`, `7590`, `7591`, `7592`, `7593`, `7594`, `7595`, `7596`, `7597`, `7598`, `7599`, `7600`, `7601`, `7602`, `7603`, `7604`, `7605`, `7606`, `7607`, `7608`, `7609`, `7610`, `7611`, `7612`, `7613`, `7614`, `7615`, `7616`, `7617`, `7618`, `7619`, `7620`, `7621`, `7622`, `7623`, `7624`, `7625`, `7626`, `7627`, `7628`, `7629`, `7630`, `7631`, `7632`, `7633`, `7634`, `7635`, `7636`, `7637`, `7638`, `7639`, `7640`, `7641`, `7642`, `7643`, `7644`, `7645`, `7646`, `7647`, `7648`, `7649`, `7650`, `7651`, `7652`, `7653`, `7654`, `7655`, `7656`, `7657`, `7658`, `7659`, `7660`, `7661`, `7662`, `7663`, `7664`, `7665`, `7666`, `7667`, `7668`, `7669`, `7670`, `7671`, `7672`, `7673`, `7674`, `7675`, `7676`, `7677`, `7678`, `7679`, `7680`, `7681`, `7682`, `7683`, `7684`, `7685`, `7686`, `7687`, `7688`, `7689`, `7690`, `7691`, `7692`, `7693`, `7694`, `7695`, `7696`, `7697`, `7698`, `7699`, `7700`, `7701`, `7702`, `7703`, `7704`, `7705`, `7706`, `7707`, `7708`, `7709`, `7710`, `7711`, `7712`, `7713`, `7714`, `7715`, `7716`, `7717`, `7718`, `7719`, `7720`, `7721`, `7722`, `7723`, `7724`, `7725`, `7726`, `7727`, `7728`, `7729`, `7730`, `7731`, `7732`, `7733`, `7734`, `7735`, `7736`, `7737`, `7738`, `7739`, `7740`, `7741`, `7742`, `7743`, `7744`, `7745`, `7746`, `7747`, `7748`, `7749`, `7750`, `7751`, `7752`, `7753`, `7754`, `7755`, `7756`, `7757`, `7758`, `7759`, `7760`, `7761`, `7762`, `7763`, `7764`, `7765`, `7766`, `7767`, `7768`, `7769`, `7770`, `7771`, `7772`, `7773`, `7774`, `7775`, `7776`, `7777`, `7778`, `7779`, `7780`, `7781`, `7782`, `7783`, `7784`, `7785`, `7786`, `7787`, `7788`, `7789`, `7790`, `7791`, `7792`, `7793`, `7794`, `7795`, `7796`, `7797`, `7798`, `7799`, `7800`, `7801`, `7802`, `7803`, `7804`, `7805`, `7806`, `7807`, `7808`, `7809`, `7810`, `7811`, `7812`, `7813`, `7814`, `7815`, `7816`, `7817`, `7818`, `7819`, `7820`, `7821`, `7822`, `7823`, `7824`, `7825`, `7826`, `7827`, `7828`, `7829`, `7830`, `7831`, `7832`, `7833`, `7834`, `7835`, `7836`, `7837`, `7838`, `7839`, `7840`, `7841`, `7842`, `7843`, `7844`, `7845`, `7846`, `7847`, `7848`, `7849`, `7850`, `7851`, `7852`, `7853`, `7854`, `7855`, `7856`, `7857`, `7858`, `7859`, `7860`, `7861`, `7862`, `7863`, `7864`, `7865`, `7866`, `7867`, `7868`, `7869`, `7870`, `7871`, `7872`, `7873`, `7874`, `7875`, `7876`, `7877`, `7878`, `7879`, `7880`, `7881`, `7882`, `7883`, `7884`, `7885`, `7886`, `7887`, `7888`, `7889`, `7890`, `7891`, `7892`, `7893`, `7894`, `7895`, `7896`, `7897`, `7898`, `7899`, `7900`, `7901`, `7902`, `7903`, `7904`, `7905`, `7906`, `7907`, `7908`, `7909`, `7910`, `7911`, `7912`, `7913`, `7914`, `7915`, `7916`, `7917`, `7918`, `7919`, `7920`, `7921`, `7922`, `7923`, `7924`, `7925`, `7926`, `7927`, `7928`, `7929`, `7930`, `7931`, `7932`, `7933`, `7934`, `7935`, `7936`, `7937`, `7938`, `7939`, `7940`, `7941`, `7942`, `7943`, `7944`, `7945`, `7946`, `7947`, `7948`, `7949`, `7950`, `7951`, `7952`, `7953`, `7954`, `7955`, `7956`, `7957`, `7958`, `7959`, `7960`, `7961`, `7962`, `7963`, `7964`, `7965`, `7966`, `7967`, `7968`, `7969`, `7970`, `7971`, `7972`, `7973`, `7974`, `7975`, `7976`, `7977`, `7978`, `7979`, `7980`, `7981`, `7982`, `7983`, `7984`, `7985`, `7986`, `7987`, `7988`, `7989`, `7990`, `7991`, `7992`, `7993`, `7994`, `7995`, `7996`, `7997`, `7998`, `7999`, `8000`, `8001`, `8002`, `8003`, `8004`, `8005`, `8006`, `8007`, `8008`, `8009`, `8010`, `8011`, `8012`, `8013`, `8014`, `8015`, `8016`, `8017`, `8018`, `8019`, `8020`, `8021`, `8022`, `8023`, `8024`, `8025`, `8026`, `8027`, `8028`, `8029`, `8030`, `8031`, `8032`, `8033`, `8034`, `8035`, `8036`, `8037`, `8038`, `8039`, `8040`, `8041`, `8042`, `8043`, `8044`, `8045`, `8046`, `8047`, `8048`, `8049`, `8050`, `8051`, `8052`, `8053`, `8054`, `8055`, `8056`, `8057`, `8058`, `8059`, `8060`, `8061`, `8062`, `8063`, `8064`, `8065`, `8066`, `8067`, `8068`, `8069`, `8070`, `8071`, `8072`, `8073`, `8074`, `8075`, `8076`, `8077`, `8078`, `8079`, `8080`, `8081`, `8082`, `8083`, `8084`, `8085`, `8086`, `8087`, `8088`, `8089`, `8090`, `8091`, `8092`, `8093`, `8094`, `8095`, `8096`, `8097`, `8098`, `8099`, `8100`, `8101`, `8102`, `8103`, `8104`, `8105`, `8106`, `8107`, `8108`, `8109`, `8110`, `8111`, `8112`, `8113`, `8114`, `8115`, `8116`, `8117`, `8118`, `8119`, `8120`, `8121`, `8122`, `8123`, `8124`, `8125`, `8126`, `8127`, `8128`, `8129`, `8130`, `8131`, `8132`, `8133`, `8134`, `8135`, `8136`, `8137`, `8138`, `8139`, `8140`, `8141`, `8142`, `8143`, `8144`, `8145`, `8146`, `8147`, `8148`, `8149`, `8150`, `8151`, `8152`, `8153`, `8154`, `8155`, `8156`, `8157`, `8158`, `8159`, `8160`, `8161`, `8162`, `8163`, `8164`, `8165`, `8166`, `8167`, `8168`, `8169`, `8170`, `8171`, `8172`, `8173`, `8174`, `8175`, `8176`, `8177`, `8178`, `8179`, `8180`, `8181`, `8182`, `8183`, `8184`, `8185`, `8186`, `8187`, `8188`, `8189`, `8190`, `8191`, `8192`, `8193`, `8194`, `8195`, `8196`, `8197`, `8198`, `8199`, `8200`, `8201`, `8202`, `8203`, `8204`, `8205`, `8206`, `8207`, `8208`, `8209`, `8210`, `8211`, `8212`, `8213`, `8214`, `8215`, `8216`, `8217`, `8218`, `8219`, `8220`, `8221`, `8222`, `8223`, `8224`, `8225`, `8226`, `8227`, `8228`, `8229`, `8230`, `8231`, `8232`, `8233`, `8234`, `8235`, `8236`, `8237`, `8238`, `8239`, `8240`, `8241`, `8242`, `8243`, `8244`, `8245`, `8246`, `8247`, `8248`, `8249`, `8250`, `8251`, `8252`, `8253`, `8254`, `8255`, `8256`, `8257`, `8258`, `8259`, `8260`, `8261`, `8262`, `8263`, `8264`, `8265`, `8266`, `8267`, `8268`, `8269`, `8270`, `8271`, `8272`, `8273`, `8274`, `8275`, `8276`, `8277`, `8278`, `8279`, `8280`, `8281`, `8282`, `8283`, `8284`, `8285`, `8286`, `8287`, `8288`, `8289`, `8290`, `8291`, `8292`, `8293`, `8294`, `8295`, `8296`, `8297`, `8298`, `8299`, `8300`, `8301`, `8302`, `8303`, `8304`, `8305`, `8306`, `8307`, `8308`, `8309`, `8310`, `8311`, `8312`, `8313`, `8314`, `8315`, `8316`, `8317`, `8318`, `8319`, `8320`, `8321`, `8322`, `8323`, `8324`, `8325`, `8326`, `8327`, `8328`, `8329`, `8330`, `8331`, `8332`, `8333`, `8334`, `8335`, `8336`, `8337`, `8338`, `8339`, `8340`, `8341`, `8342`, `8343`, `8344`, `8345`, `8346`, `8347`, `8348`, `8349`, `8350`, `8351`, `8352`, `8353`, `8354`, `8355`, `8356`, `8357`, `8358`, `8359`, `8360`, `8361`, `8362`, `8363`, `8364`, `8365`, `8366`, `8367`, `8368`, `8369`, `8370`, `8371`, `8372`, `8373`, `8374`, `8375`, `8376`, `8377`, `8378`, `8379`, `8380`, `8381`, `8382`, `8383`, `8384`, `8385`, `8386`, `8387`, `8388`, `8389`, `8390`, `8391`, `8392`, `8393`, `8394`, `8395`, `8396`, `8397`, `8398`, `8399`, `8400`, `8401`, `8402`, `8403`, `8404`, `8405`, `8406`, `8407`, `8408`, `8409`, `8410`, `8411`, `8412`, `8413`, `8414`, `8415`, `8416`, `8417`, `8418`, `8419`, `8420`, `8421`, `8422`, `8423`, `8424`, `8425`, `8426`, `8427`, `8428`, `8429`, `8430`, `8431`, `8432`, `8433`, `8434`, `8435`, `8436`, `8437`, `8438`, `8439`, `8440`, `8441`, `8442`, `8443`, `8444`, `8445`, `8446`, `8447`, `8448`, `8449`, `8450`, `8451`, `8452`, `8453`, `8454`, `8455`, `8456`, `8457`, `8458`, `8459`, `8460`, `8461`, `8462`, `8463`, `8464`, `8465`, `8466`, `8467`, `8468`, `8469`, `8470`, `8471`, `8472`, `8473`, `8474`, `8475`, `8476`, `8477`, `8478`, `8479`, `8480`, `8481`, `8482`, `8483`, `8484`, `8485`, `8486`, `8487`, `8488`, `8489`, `8490`, `8491`, `8492`, `8493`, `8494`, `8495`, `8496`, `8497`, `8498`, `8499`, `8500`, `8501`, `8502`, `8503`, `8504`, `8505`, `8506`, `8507`, `8508`, `8509`, `8510`, `8511`, `8512`, `8513`, `8514`, `8515`, `8516`, `8517`, `8518`, `8519`, `8520`, `8521`, `8522`, `8523`, `8524`, `8525`, `8526`, `8527`, `8528`, `8529`, `8530`, `8531`, `8532`, `8533`, `8534`, `8535`, `8536`, `8537`, `8538`, `8539`, `8540`, `8541`, `8542`, `8543`, `8544`, `8545`, `8546`, `8547`, `8548`, `8549`, `8550`, `8551`, `8552`, `8553`, `8554`, `8555`, `8556`, `8557`, `8558`, `8559`, `8560`, `8561`, `8562`, `8563`, `8564`, `8565`, `8566`, `8567`, `8568`, `8569`, `8570`, `8571`, `8572`, `8573`, `8574`, `8575`, `8576`, `8577`, `8578`, `8579`, `8580`, `8581`, `8582`, `8583`, `8584`, `8585`, `8586`, `8587`, `8588`, `8589`, `8590`, `8591`, `8592`, `8593`, `8594`, `8595`, `8596`, `8597`, `8598`, `8599`, `8600`, `8601`, `8602`, `8603`, `8604`, `8605`, `8606`, `8607`, `8608`, `8609`, `8610`, `8611`, `8612`, `8613`, `8614`, `8615`, `8616`, `8617`, `8618`, `8619`, `8620`, `8621`, `8622`, `8623`, `8624`, `8625`, `8626`, `8627`, `8628`, `8629`, `8630`, `8631`, `8632`, `8633`, `8634`, `8635`, `8636`, `8637`, `8638`, `8639`, `8640`, `8641`, `8642`, `8643`, `8644`, `8645`, `8646`, `8647`, `8648`, `8649`, `8650`, `8651`, `8652`, `8653`, `8654`, `8655`, `8656`, `8657`, `8658`, `8659`, `8660`, `8661`, `8662`, `8663`, `8664`, `8665`, `8666`, `8667`, `8668`, `8669`, `8670`, `8671`, `8672`, `8673`, `8674`, `8675`, `8676`, `8677`, `8678`, `8679`, `8680`, `8681`, `8682`, `8683`, `8684`, `8685`, `8686`, `8687`, `8688`, `8689`, `8690`, `8691`, `8692`, `8693`, `8694`, `8695`, `8696`, `8697`, `8698`, `8699`, `8700`, `8701`, `8702`, `8703`, `8704`, `8705`, `8706`, `8707`, `8708`, `8709`, `8710`, `8711`, `8712`, `8713`, `8714`, `8715`, `8716`, `8717`, `8718`, `8719`, `8720`, `8721`, `8722`, `8723`, `8724`, `8725`, `8726`, `8727`, `8728`, `8729`, `8730`, `8731`, `8732`, `8733`, `8734`, `8735`, `8736`, `8737`, `8738`, `8739`, `8740`, `8741`, `8742`, `8743`, `8744`, `8745`, `8746`, `8747`, `8748`, `8749`, `8750`, `8751`, `8752`, `8753`, `8754`, `8755`, `8756`, `8757`, `8758`, `8759`, `8760`, `8761`, `8762`, `8763`, `8764`, `8765`, `8766`, `8767`, `8768`, `8769`, `8770`, `8771`, `8772`, `8773`, `8774`, `8775`, `8776`, `8777`, `8778`, `8779`, `8780`, `8781`, `8782`, `8783`, `8784`, `8785`, `8786`, `8787`, `8788`, `8789`, `8790`, `8791`, `8792`, `8793`, `8794`, `8795`, `8796`, `8797`, `8798`, `8799`, `8800`, `8801`, `8802`, `8803`, `8804`, `8805`, `8806`, `8807`, `8808`, `8809`, `8810`, `8811`, `8812`, `8813`, `8814`, `8815`, `8816`, `8817`, `8818`, `8819`, `8820`, `8821`, `8822`, `8823`, `8824`, `8825`, `8826`, `8827`, `8828`, `8829`, `8830`, `8831`, `8832`, `8833`, `8834`, `8835`, `8836`, `8837`, `8838`, `8839`, `8840`, `8841`, `8842`, `8843`, `8844`, `8845`, `8846`, `8847`, `8848`, `8849`, `8850`, `8851`, `8852`, `8853`, `8854`, `8855`, `8856`, `8857`, `8858`, `8859`, `8860`, `8861`, `8862`, `8863`, `8864`, `8865`, `8866`, `8867`, `8868`, `8869`, `8870`, `8871`, `8872`, `8873`, `8874`, `8875`, `8876`, `8877`, `8878`, `8879`, `8880`, `8881`, `8882`, `8883`, `8884`, `8885`, `8886`, `8887`, `8888`, `8889`, `8890`, `8891`, `8892`, `8893`, `8894`, `8895`, `8896`, `8897`, `8898`, `8899`, `8900`, `8901`, `8902`, `8903`, `8904`, `8905`, `8906`, `8907`, `8908`, `8909`, `8910`, `8911`, `8912`, `8913`, `8914`, `8915`, `8916`, `8917`, `8918`, `8919`, `8920`, `8921`, `8922`, `8923`, `8924`, `8925`, `8926`, `8927`, `8928`, `8929`, `8930`, `8931`, `8932`, `8933`, `8934`, `8935`, `8936`, `8937`, `8938`, `8939`, `8940`, `8941`, `8942`, `8943`, `8944`, `8945`, `8946`, `8947`, `8948`, `8949`, `8950`, `8951`, `8952`, `8953`, `8954`, `8955`, `8956`, `8957`, `8958`, `8959`, `8960`, `8961`, `8962`, `8963`, `8964`, `8965`, `8966`, `8967`, `8968`, `8969`, `8970`, `8971`, `8972`, `8973`, `8974`, `8975`, `8976`, `8977`, `8978`, `8979`, `8980`, `8981`, `8982`, `8983`, `8984`, `8985`, `8986`, `8987`, `8988`, `8989`, `8990`, `8991`, `8992`, `8993`, `8994`, `8995`, `8996`, `8997`, `8998`, `8999`, `9000`, `9001`, `9002`, `9003`, `9004`, `9005`, `9006`, `9007`, `9008`, `9009`, `9010`, `9011`, `9012`, `9013`, `9014`, `9015`, `9016`, `9017`, `9018`, `9019`, `9020`, `9021`, `9022`, `9023`, `9024`, `9025`, `9026`, `9027`, `9028`, `9029`, `9030`, `9031`, `9032`, `9033`, `9034`, `9035`, `9036`, `9037`, `9038`, `9039`, `9040`, `9041`, `9042`, `9043`, `9044`, `9045`, `9046`, `9047`, `9048`, `9049`, `9050`, `9051`, `9052`, `9053`, `9054`, `9055`, `9056`, `9057`, `9058`, `9059`, `9060`, `9061`, `9062`, `9063`, `9064`, `9065`, `9066`, `9067`, `9068`, `9069`, `9070`, `9071`, `9072`, `9073`, `9074`, `9075`, `9076`, `9077`, `9078`, `9079`, `9080`, `9081`, `9082`, `9083`, `9084`, `9085`, `9086`, `9087`, `9088`, `9089`, `9090`, `9091`, `9092`, `9093`, `9094`, `9095`, `9096`, `9097`, `9098`, `9099`, `9100`, `9101`, `9102`, `9103`, `9104`, `9105`, `9106`, `9107`, `9108`, `9109`, `9110`, `9111`, `9112`, `9113`, `9114`, `9115`, `9116`, `9117`, `9118`, `9119`, `9120`, `9121`, `9122`, `9123`, `9124`, `9125`, `9126`, `9127`, `9128`, `9129`, `9130`, `9131`, `9132`, `9133`, `9134`, `9135`, `9136`, `9137`, `9138`, `9139`, `9140`, `9141`, `9142`, `9143`, `9144`, `9145`, `9146`, `9147`, `9148`, `9149`, `9150`, `9151`, `9152`, `9153`, `9154`, `9155`, `9156`, `9157`, `9158`, `9159`, `9160`, `9161`, `9162`, `9163`, `9164`, `9165`, `9166`, `9167`, `9168`, `9169`, `9170`, `9171`, `9172`, `9173`, `9174`, `9175`, `9176`, `9177`, `9178`, `9179`, `9180`, `9181`, `9182`, `9183`, `9184`, `9185`, `9186`, `9187`, `9188`, `9189`, `9190`, `9191`, `9192`, `9193`, `9194`, `9195`, `9196`, `9197`, `9198`, `9199`, `9200`, `9201`, `9202`, `9203`, `9204`, `9205`, `9206`, `9207`, `9208`, `9209`, `9210`, `9211`, `9212`, `9213`, `9214`, `9215`, `9216`, `9217`, `9218`, `9219`, `9220`, `9221`, `9222`, `9223`, `9224`, `9225`, `9226`, `9227`, `9228`, `9229`, `9230`, `9231`, `9232`, `9233`, `9234`, `9235`, `9236`, `9237`, `9238`, `9239`, `9240`, `9241`, `9242`, `9243`, `9244`, `9245`, `9246`, `9247`, `9248`, `9249`, `9250`, `9251`, `9252`, `9253`, `9254`, `9255`, `9256`, `9257`, `9258`, `9259`, `9260`, `9261`, `9262`, `9263`, `9264`, `9265`, `9266`, `9267`, `9268`, `9269`, `9270`, `9271`, `9272`, `9273`, `9274`, `9275`, `9276`, `9277`, `9278`, `9279`, `9280`, `9281`, `9282`, `9283`, `9284`, `9285`, `9286`, `9287`, `9288`, `9289`, `9290`, `9291`, `9292`, `9293`, `9294`, `9295`, `9296`, `9297`, `9298`, `9299`, `9300`, `9301`, `9302`, `9303`, `9304`, `9305`, `9306`, `9307`, `9308`, `9309`, `9310`, `9311`, `9312`, `9313`, `9314`, `9315`, `9316`, `9317`, `9318`, `9319`, `9320`, `9321`, `9322`, `9323`, `9324`, `9325`, `9326`, `9327`, `9328`, `9329`, `9330`, `9331`, `9332`, `9333`, `9334`, `9335`, `9336`, `9337`, `9338`, `9339`, `9340`, `9341`, `9342`, `9343`, `9344`, `9345`, `9346`, `9347`, `9348`, `9349`, `9350`, `9351`, `9352`, `9353`, `9354`, `9355`, `9356`, `9357`, `9358`, `9359`, `9360`, `9361`, `9362`, `9363`, `9364`, `9365`, `9366`, `9367`, `9368`, `9369`, `9370`, `9371`, `9372`, `9373`, `9374`, `9375`, `9376`, `9377`, `9378`, `9379`, `9380`, `9381`, `9382`, `9383`, `9384`, `9385`, `9386`, `9387`, `9388`, `9389`, `9390`, `9391`, `9392`, `9393`, `9394`, `9395`, `9396`, `9397`, `9398`, `9399`, `9400`, `9401`, `9402`, `9403`, `9404`, `9405`, `9406`, `9407`, `9408`, `9409`, `9410`, `9411`, `9412`, `9413`, `9414`, `9415`, `9416`, `9417`, `9418`, `9419`, `9420`, `9421`, `9422`, `9423`, `9424`, `9425`, `9426`, `9427`, `9428`, `9429`, `9430`, `9431`, `9432`, `9433`, `9434`, `9435`, `9436`, `9437`, `9438`, `9439`, `9440`, `9441`, `9442`, `9443`, `9444`, `9445`, `9446`, `9447`, `9448`, `9449`, `9450`, `9451`, `9452`, `9453`, `9454`, `9455`, `9456`, `9457`, `9458`, `9459`, `9460`, `9461`, `9462`, `9463`, `9464`, `9465`, `9466`, `9467`, `9468`, `9469`, `9470`, `9471`, `9472`, `9473`, `9474`, `9475`, `9476`, `9477`, `9478`, `9479`, `9480`, `9481`, `9482`, `9483`, `9484`, `9485`, `9486`, `9487`, `9488`, `9489`, `9490`, `9491`, `9492`, `9493`, `9494`, `9495`, `9496`, `9497`, `9498`, `9499`, `9500`, `9501`, `9502`, `9503`, `9504`, `9505`, `9506`, `9507`, `9508`, `9509`, `9510`, `9511`, `9512`, `9513`, `9514`, `9515`, `9516`, `9517`, `9518`, `9519`, `9520`, `9521`, `9522`, `9523`, `9524`, `9525`, `9526`, `9527`, `9528`, `9529`, `9530`, `9531`, `9532`, `9533`, `9534`, `9535`, `9536`, `9537`, `9538`, `9539`, `9540`, `9541`, `9542`, `9543`, `9544`, `9545`, `9546`, `9547`, `9548`, `9549`, `9550`, `9551`, `9552`, `9553`, `9554`, `9555`, `9556`, `9557`, `9558`, `9559`, `9560`, `9561`, `9562`, `9563`, `9564`, `9565`, `9566`, `9567`, `9568`, `9569`, `9570`, `9571`, `9572`, `9573`, `9574`, `9575`, `9576`, `9577`, `9578`, `9579`, `9580`, `9581`, `9582`, `9583`, `9584`, `9585`, `9586`, `9587`, `9588`, `9589`, `9590`, `9591`, `9592`, `9593`, `9594`, `9595`, `9596`, `9597`, `9598`, `9599`, `9600`, `9601`, `9602`, `9603`, `9604`, `9605`, `9606`, `9607`, `9608`, `9609`, `9610`, `9611`, `9612`, `9613`, `9614`, `9615`, `9616`, `9617`, `9618`, `9619`, `9620`, `9621`, `9622`, `9623`, `9624`, `9625`, `9626`, `9627`, `9628`, `9629`, `9630`, `9631`, `9632`, `9633`, `9634`, `9635`, `9636`, `9637`, `9638`, `9639`, `9640`, `9641`, `9642`, `9643`, `9644`, `9645`, `9646`, `9647`, `9648`, `9649`, `9650`, `9651`, `9652`, `9653`, `9654`, `9655`, `9656`, `9657`, `9658`, `9659`, `9660`, `9661`, `9662`, `9663`, `9664`, `9665`, `9666`, `9667`, `9668`, `9669`, `9670`, `9671`, `9672`, `9673`, `9674`, `9675`, `9676`, `9677`, `9678`, `9679`, `9680`, `9681`, `9682`, `9683`, `9684`, `9685`, `9686`, `9687`, `9688`, `9689`, `9690`, `9691`, `9692`, `9693`, `9694`, `9695`, `9696`, `9697`, `9698`, `9699`, `9700`, `9701`, `9702`, `9703`, `9704`, `9705`, `9706`, `9707`, `9708`, `9709`, `9710`, `9711`, `9712`, `9713`, `9714`, `9715`, `9716`, `9717`, `9718`, `9719`, `9720`, `9721`, `9722`, `9723`, `9724`, `9725`, `9726`, `9727`, `9728`, `9729`, `9730`, `9731`, `9732`, `9733`, `9734`, `9735`, `9736`, `9737`, `9738`, `9739`, `9740`, `9741`, `9742`, `9743`, `9744`, `9745`, `9746`, `9747`, `9748`, `9749`, `9750`, `9751`, `9752`, `9753`, `9754`, `9755`, `9756`, `9757`, `9758`, `9759`, `9760`, `9761`, `9762`, `9763`, `9764`, `9765`, `9766`, `9767`, `9768`, `9769`, `9770`, `9771`, `9772`, `9773`, `9774`, `9775`, `9776`, `9777`, `9778`, `9779`, `9780`, `9781`, `9782`, `9783`, `9784`, `9785`, `9786`, `9787`, `9788`, `9789`, `9790`, `9791`, `9792`, `9793`, `9794`, `9795`, `9796`, `9797`, `9798`, `9799`, `9800`, `9801`, `9802`, `9803`, `9804`, `9805`, `9806`, `9807`, `9808`, `9809`, `9810`, `9811`, `9812`, `9813`, `9814`, `9815`, `9816`, `9817`, `9818`, `9819`, `9820`, `9821`, `9822`, `9823`, `9824`, `9825`, `9826`, `9827`, `9828`, `9829`, `9830`, `9831`, `9832`, `9833`, `9834`, `9835`, `9836`, `9837`, `9838`, `9839`, `9840`, `9841`, `9842`, `9843`, `9844`, `9845`, `9846`, `9847`, `9848`, `9849`, `9850`, `9851`, `9852`, `9853`, `9854`, `9855`, `9856`, `9857`, `9858`, `9859`, `9860`, `9861`, `9862`, `9863`, `9864`, `9865`, `9866`, `9867`, `9868`, `9869`, `9870`, `9871`, `9872`, `9873`, `9874`, `9875`, `9876`, `9877`, `9878`, `9879`, `9880`, `9881`, `9882`, `9883`, `9884`, `9885`, `9886`, `9887`, `9888`, `9889`, `9890`, `9891`, `9892`, `9893`, `9894`, `9895`, `9896`, `9897`, `9898`, `9899`, `9900`, `9901`, `9902`, `9903`, `9904`, `9905`, `9906`, `9907`, `9908`, `9909`, `9910`, `9911`, `9912`, `9913`, `9914`, `9915`, `9916`, `9917`, `9918`, `9919`, `9920`, `9921`, `9922`, `9923`, `9924`, `9925`, `9926`, `9927`, `9928`, `9929`, `9930`, `9931`, `9932`, `9933`, `9934`, `9935`, `9936`, `9937`, `9938`, `9939`, `9940`, `9941`, `9942`, `9943`, `9944`, `9945`, `9946`, `9947`, `9948`, `9949`, `9950`, `9951`, `9952`, `9953`, `9954`, `9955`, `9956`, `9957`, `9958`, `9959`, `9960`, `9961`, `9962`, `9963`, `9964`, `9965`, `9966`, `9967`, `9968`, `9971`, `9972`, `9973`, `9974`, `9975`, `9976`, `9977`, `9978`, `9979`, `9980`, `9981`, `9982`, `9983`, `9984`, `9985`, `9986`, `9987`, `9988`, `9989`, `9990`, `9991`, `9992`, `9993`, `9994`, `9995`, `9996`, `9997`, `9998`, `9999`, `10000`, `10001`, `10002`, `10003`, `10004`, `10005`, `10006`, `10007`, `10008`, `10009`, `10010`, `10011`, `10012`, `10013`, `10014`, `10015`, `10016`, `10017`, `10018`, `10019`, `10020`, `10021`, `10022`, `10023`, `10024`, `10025`, `10026`, `10027`, `10028`, `10029`, `10030`, `10031`, `10032`, `10033`, `10034`, `10035`, `10036`, `10037`, `10038`, `10039`, `10040`, `10041`, `10042`, `10043`, `10044`, `10045`, `10046`, `10047`, `10048`, `10049`, `10050`, `10051`, `10052`, `10053`, `10054`, `10055`, `10056`, `10057`, `10058`, `10059`, `10060`, `10061`, `10062`, `10063`, `10064`, `10065`, `10066`, `10067`, `10068`, `10069`, `10070`, `10071`, `10072`, `10073`, `10074`, `10075`, `10076`, `10077`, `10078`, `10079`, `10080`, `10081`, `10082`, `10083`, `10084`, `10085`, `10086`, `10087`, `10088`, `10089`, `10090`, `10091`, `10092`, `10093`, `10094`, `10095`, `10096`, `10097`, `10098`, `10099`, `10100`, `10101`, `10102`, `10103`, `10104`, `10105`, `10106`, `10107`, `10108`, `10109`, `10110`, `10111`, `10112`, `10113`, `10114`, `10115`, `10116`, `10117`, `10118`, `10119`, `10120`, `10121`, `10122`, `10123`, `10124`, `10125`, `10126`, `10127`, `10128`, `10129`, `10130`, `10131`, `10132`, `10133`, `10134`, `10135`, `10136`, `10137`, `10138`, `10139`, `10140`, `10141`, `10142`, `10143`, `10144`, `10145`, `10146`, `10147`, `10148`, `10149`, `10150`, `10151`, `10152`, `10153`, `10154`, `10155`, `10156`, `10157`, `10158`, `10159`, `10160`, `10161`, `10162`, `10163`, `10164`, `10165`, `10166`, `10167`, `10168`, `10169`, `10170`, `10171`, `10172`, `10173`, `10174`, `10175`, `10176`, `10177`, `10178`, `10179`, `10180`, `10181`, `10182`, `10183`, `10184`, `10185`, `10186`, `10187`, `10188`, `10189`, `10190`, `10191`, `10192`, `10193`, `10194`, `10195`, `10196`, `10197`, `10198`, `10199`, `10200`, `10201`, `10202`, `10203`, `10204`, `10205`, `10206`, `10207`, `10208`, `10209`, `10210`, `10211`, `10212`, `10213`, `10214`, `10215`, `10216`, `10217`, `10218`, `10219`, `10220`, `10221`, `10222`, `10223`, `10224`, `10225`, `10226`, `10227`, `10228`, `10229`, `10230`, `10231`, `10232`, `10233`, `10234`, `10235`, `10236`, `10237`, `10238`, `10239`, `10240`, `10241`, `10242`, `10243`, `10244`, `10245`, `10246`, `10247`, `10248`, `10249`, `10250`, `10251`, `10252`, `10253`, `10254`, `10255`, `10256`, `10257`, `10258`, `10259`, `10260`, `10261`, `10262`, `10263`, `10264`, `10265`, `10266`, `10267`, `10268`, `10269`, `10270`, `10271`, `10272`, `10273`, `10274`, `10275`, `10276`, `10277`, `10278`, `10279`, `10280`, `10281`, `10282`, `10283`, `10284`, `10285`, `10286`, `10287`, `10288`, `10289`, `10290`, `10291`, `10292`, `10293`, `10294`, `10295`, `10296`, `10297`, `10298`, `10299`, `10300`, `10301`, `10302`, `10303`, `10304`, `10305`, `10306`, `10307`, `10308`, `10309`, `10310`, `10311`, `10312`, `10313`, `10314`, `10315`, `10316`, `10317`, `10318`, `10319`, `10320`, `10321`, `10322`, `10323`, `10324`, `10325`, `10326`, `10327`, `10328`, `10329`, `10330`, `10331`, `10332`, `10333`, `10334`, `10335`, `10336`, `10337`, `10338`, `10339`, `10340`, `10341`, `10342`, `10343`, `10344`, `10345`, `10346`, `10347`, `10348`, `10349`, `10350`, `10351`, `10352`, `10353`, `10354`, `10355`, `10356`, `10357`, `10358`, `10359`, `10360`, `10361`, `10362`, `10363`, `10364`, `10365`, `10366`, `10367`, `10368`, `10369`, `10370`, `10371`, `10372`, `10373`, `10374`, `10375`, `10376`, `10377`, `10378`, `10379`, `10380`, `10381`, `10382`, `10383`, `10384`, `10385`, `10386`, `10387`, `10388`, `10389`, `10390`, `10391`, `10392`, `10393`, `10394`, `10395`, `10396`, `10397`, `10398`, `10399`, `10400`, `10401`, `10402`, `10403`, `10404`, `10405`, `10406`, `10407`, `10408`, `10409`, `10410`, `10411`, `10412`, `10413`, `10414`, `10415`, `10416`, `10417`, `10418`, `10419`, `10420`, `10421`, `10422`, `10423`, `10424`, `10425`, `10426`, `10427`, `10428`, `10429`, `10430`, `10431`, `10432`, `10433`, `10434`, `10435`, `10436`, `10437`, `10438`, `10439`, `10440`, `10441`, `10442`, `10443`, `10444`, `10445`, `10446`, `10447`, `10448`, `10449`, `10450`, `10451`, `10452`, `10453`, `10454`, `10455`, `10456`, `10457`, `10458`, `10459`, `10460`, `10461`, `10462`, `10463`, `10464`, `10465`, `10466`, `10467`, `10468`, `10469`, `10470`, `10471`, `10472`, `10473`, `10474`, `10475`, `10476`, `10477`, `10478`, `10479`, `10480`, `10481`, `10482`, `10483`, `10484`, `10485`, `10486`, `10487`, `10488`, `10489`, `10490`, `10491`, `10492`, `10493`, `10494`, `10495`, `10496`, `10497`, `10498`, `10499`, `10500`, `10501`, `10502`, `10503`, `10504`, `10505`, `10506`, `10507`, `10508`, `10509`, `10510`, `10511`, `10512`, `10513`, `10514`, `10515`, `10516`, `10517`, `10518`, `10519`, `10520`, `10521`, `10522`, `10523`, `10524`, `10525`, `10526`, `10527`, `10528`, `10529`, `10530`, `10531`, `10532`, `10533`, `10534`, `10535`, `10536`, `10537`, `10538`, `10539`, `10540`, `10541`, `10542`, `10543`, `10544`, `10545`, `10546`, `10547`, `10548`, `10549`, `10550`, `10551`, `10552`, `10553`, `10554`, `10555`, `10556`, `10557`, `10558`, `10559`, `10560`, `10561`, `10562`, `10563`, `10564`, `10565`, `10566`, `10567`, `10568`, `10569`, `10570`, `10571`, `10572`, `10573`, `10574`, `10575`, `10576`, `10577`, `10578`, `10579`, `10580`, `10581`, `10582`, `10583`, `10584`, `10585`, `10586`, `10587`, `10588`, `10589`, `10590`, `10591`, `10592`, `10593`, `10594`, `10595`, `10596`, `10597`, `10598`, `10599`, `10600`, `10601`, `10602`, `10603`, `10604`, `10605`, `10606`, `10607`, `10608`, `10609`, `10610`, `10611`, `10612`, `10613`, `10614`, `10615`, `10616`, `10617`, `10618`, `10619`, `10620`, `10621`, `10622`, `10623`, `10624`, `10625`, `10626`, `10627`, `10628`, `10629`, `10630`, `10631`, `10632`, `10633`, `10634`, `10635`, `10636`, `10637`, `10638`, `10639`, `10640`, `10641`, `10642`, `10643`, `10644`, `10645`, `10646`, `10647`, `10648`, `10649`, `10650`, `10651`, `10652`, `10653`, `10654`, `10655`, `10656`, `10657`, `10658`, `10659`, `10660`, `10661`, `10662`, `10663`, `10664`, `10665`, `10666`, `10667`, `10668`, `10669`, `10670`, `10671`, `10672`, `10673`, `10674`, `10675`, `10676`, `10677`, `10678`, `10679`, `10680`, `10681`, `10682`, `10683`, `10684`, `10685`, `10686`, `10687`, `10688`, `10689`, `10690`, `10691`, `10692`, `10693`, `10694`, `10695`, `10696`, `10697`, `10698`, `10699`, `10700`, `10701`, `10702`, `10703`, `10704`, `10705`, `10706`, `10707`, `10708`, `10709`, `10710`, `10711`, `10712`, `10713`, `10714`, `10715`, `10716`, `10717`, `10718`, `10719`, `10720`, `10721`, `10722`, `10723`, `10724`, `10725`, `10726`, `10727`, `10728`, `10729`, `10730`, `10731`, `10732`, `10733`, `10734`, `10735`, `10736`, `10737`, `10738`, `10739`, `10740`, `10741`, `10742`, `10743`, `10744`, `10745`, `10746`, `10747`, `10748`, `10749`, `10750`, `10751`, `10752`, `10753`, `10754`, `10755`, `10756`, `10757`, `10758`, `10759`, `10760`, `10761`, `10762`, `10763`, `10764`, `10765`, `10766`, `10767`, `10768`, `10769`, `10770`, `10771`, `10772`, `10773`, `10774`, `10775`, `10776`, `10777`, `10778`, `10779`, `10780`, `10781`, `10782`, `10783`, `10784`, `10785`, `10786`, `10787`, `10788`, `10789`, `10790`, `10791`, `10792`, `10793`, `10794`, `10795`, `10796`, `10797`, `10798`, `10799`, `10800`, `10801`, `10802`, `10803`, `10804`, `10805`, `10806`, `10807`, `10808`, `10809`, `10810`, `10811`, `10812`, `10813`, `10814`, `10815`, `10816`, `10817`, `10818`, `10819`, `10820`, `10821`, `10822`, `10823`, `10824`, `10825`, `10826`, `10827`, `10828`, `10829`, `10830`, `10831`, `10832`, `10833`, `10834`, `10835`, `10836`, `10837`, `10838`, `10839`, `10840`, `10841`, `10842`, `10843`, `10844`, `10845`, `10846`, `10847`, `10848`, `10849`, `10850`, `10851`, `10852`, `10853`, `10854`, `10855`, `10856`, `10857`, `10858`, `10859`, `10860`, `10861`, `10862`, `10863`, `10864`, `10865`, `10866`, `10867`, `10868`, `10869`, `10870`, `10871`, `10872`, `10873`, `10874`, `10875`, `10876`, `10877`, `10878`, `10879`, `10880`, `10881`, `10882`, `10883`, `10884`, `10885`, `10886`, `10887`, `10888`, `10889`, `10890`, `10891`, `10892`, `10893`, `10894`, `10895`, `10896`, `10897`, `10898`, `10899`, `10900`, `10901`, `10902`, `10903`, `10904`, `10905`, `10906`, `10907`, `10908`, `10909`, `10910`, `10911`, `10912`, `10913`, `10914`, `10915`, `10916`, `10917`, `10918`, `10919`, `10920`, `10921`, `10922`, `10923`, `10924`, `10925`, `10926`, `10927`, `10928`, `10929`, `10930`, `10931`, `10932`, `10933`, `10934`, `10935`, `10936`, `10937`, `10938`, `10939`, `10940`, `10941`, `10942`, `10943`, `10944`, `10945`, `10946`, `10947`, `10948`, `10949`, `10950`, `10951`, `10952`, `10953`, `10954`, `10955`, `10956`, `10957`, `10958`, `10959`, `10960`, `10961`, `10962`, `10963`, `10964`, `10965`, `10966`, `10967`, `10968`, `10969`, `10970`, `10971`, `10972`, `10973`, `10974`, `10975`, `10976`, `10977`, `10978`, `10979`, `10980`, `10981`, `10982`, `10983`, `10984`, `10985`, `10986`, `10987`, `10988`, `10989`, `10990`, `10991`, `10992`, `10993`, `10994`, `10995`, `10996`, `10997`, `10998`, `10999`, `11000`, `11001`, `11002`, `11003`, `11004`, `11005`, `11006`, `11007`, `11008`, `11009`, `11010`, `11011`, `11012`, `11013`, `11014`, `11015`, `11016`, `11017`, `11018`, `11019`, `11020`, `11021`, `11022`, `11023`, `11024`, `11025`, `11026`, `11027`, `11028`, `11029`, `11030`, `11031`, `11032`, `11033`, `11034`, `11035`, `11036`, `11037`, `11038`, `11039`, `11040`, `11041`, `11042`, `11043`, `11044`, `11045`, `11046`, `11047`, `11048`, `11049`, `11050`, `11051`, `11052`, `11053`, `11054`, `11055`, `11056`, `11057`, `11058`, `11059`, `11060`, `11061`, `11062`, `11063`, `11064`, `11065`, `11066`, `11067`, `11068`, `11069`, `11070`, `11071`, `11072`, `11073`, `11074`, `11075`, `11076`, `11077`, `11078`, `11079`, `11080`, `11081`, `11082`, `11083`, `11084`, `11085`, `11086`, `11087`, `11088`, `11089`, `11090`, `11091`, `11092`, `11093`, `11094`, `11095`, `11096`, `11097`, `11098`, `11099`, `11100`, `11101`, `11102`, `11103`, `11104`, `11105`, `11106`, `11107`, `11108`, `11109`, `11110`, `11111`, `11112`, `11113`, `11114`, `11115`, `11116`, `11117`, `11118`, `11119`, `11120`, `11121`, `11122`, `11123`, `11124`, `11125`, `11126`, `11127`, `11128`, `11129`, `11130`, `11131`, `11132`, `11133`, `11134`, `11135`, `11136`, `11137`, `11138`, `11139`, `11140`, `11141`, `11142`, `11143`, `11144`, `11145`, `11146`, `11147`, `11148`, `11149`, `11150`, `11151`, `11152`, `11153`, `11154`, `11155`, `11156`, `11157`, `11158`, `11159`, `11160`, `11161`, `11162`, `11163`, `11164`, `11165`, `11166`, `11167`, `11168`, `11169`, `11170`, `11171`, `11172`, `11173`, `11174`, `11175`, `11176`, `11177`, `11178`, `11179`, `11180`, `11181`, `11182`, `11183`, `11184`, `11185`, `11186`, `11187`, `11188`, `11189`, `11190`, `11191`, `11192`, `11193`, `11194`, `11195`, `11196`, `11197`, `11198`, `11199`, `11200`, `11201`, `11202`, `11203`, `11204`, `11205`, `11206`, `11207`, `11208`, `11209`, `11210`, `11211`, `11212`, `11213`, `11214`, `11215`, `11216`, `11217`, `11218`, `11219`, `11220`, `11221`, `11222`, `11223`, `11224`, `11225`, `11226`, `11227`, `11228`, `11229`, `11230`, `11231`, `11232`, `11233`, `11234`, `11235`, `11236`, `11237`, `11238`, `11239`, `11240`, `11241`, `11242`, `11243`, `11244`, `11245`, `11246`, `11247`, `11248`, `11249`, `11250`, `11251`, `11252`, `11253`, `11254`, `11255`, `11256`, `11257`, `11258`, `11259`, `11260`, `11261`, `11262`, `11263`, `11264`, `11265`, `11266`, `11267`, `11268`, `11269`, `11270`, `11271`, `11272`, `11273`, `11274`, `11275`, `11276`, `11277`, `11278`, `11279`, `11280`, `11281`, `11282`, `11283`, `11284`, `11285`, `11286`, `11287`, `11288`, `11289`, `11290`, `11291`, `11292`, `11293`, `11294`, `11295`, `11296`, `11297`, `11298`, `11299`, `11300`, `11301`, `11302`, `11303`, `11304`, `11305`, `11306`, `11307`, `11308`, `11309`, `11310`, `11311`, `11312`, `11313`, `11314`, `11315`, `11316`, `11317`, `11318`, `11319`, `11320`, `11321`, `11322`, `11323`, `11324`, `11325`, `11326`, `11327`, `11328`, `11329`, `11330`, `11331`, `11332`, `11333`, `11334`, `11335`, `11336`, `11337`, `11338`, `11339`, `11340`, `11341`, `11342`, `11343`, `11344`, `11345`, `11346`, `11347`, `11348`, `11349`, `11350`, `11351`, `11352`, `11353`, `11354`, `11355`, `11356`, `11357`, `11358`, `11359`, `11360`, `11361`, `11362`, `11363`, `11364`, `11365`, `11366`, `11367`, `11368`, `11369`, `11370`, `11371`, `11372`, `11373`, `11374`, `11375`, `11376`, `11377`, `11378`, `11379`, `11380`, `11381`, `11382`, `11383`, `11384`, `11385`, `11386`, `11387`, `11388`, `11389`, `11390`, `11391`, `11392`, `11393`, `11394`, `11395`, `11396`, `11397`, `11398`, `11399`, `11400`, `11401`, `11402`, `11403`, `11404`, `11405`, `11406`, `11407`, `11408`, `11409`, `11410`, `11411`, `11412`, `11413`, `11414`, `11415`, `11416`, `11417`, `11418`, `11419`, `11420`, `11421`, `11422`, `11423`, `11424`, `11425`, `11426`, `11427`, `11428`, `11429`, `11430`, `11431`, `11432`, `11433`, `11434`, `11435`, `11436`, `11437`, `11438`, `11439`, `11440`, `11441`, `11442`, `11443`, `11444`, `11445`, `11446`, `11447`, `11448`, `11449`, `11450`, `11451`, `11452`, `11453`, `11454`, `11455`, `11456`, `11457`, `11458`, `11459`, `11460`, `11461`, `11462`, `11463`, `11464`, `11465`, `11466`, `11467`, `11468`, `11469`, `11470`, `11471`, `11472`, `11473`, `11474`, `11475`, `11476`, `11477`, `11478`, `11479`, `11480`, `11481`, `11482`, `11483`, `11484`, `11485`, `11486`, `11487`, `11488`, `11489`, `11490`, `11491`, `11492`, `11493`, `11494`, `11495`, `11496`, `11497`, `11498`, `11499`, `11500`, `11501`, `11502`, `11503`, `11504`, `11505`, `11506`, `11507`, `11508`, `11509`, `11510`, `11511`, `11512`, `11513`, `11514`, `11515`, `11516`, `11517`, `11518`, `11519`, `11520`, `11521`, `11522`, `11523`, `11524`, `11525`, `11526`, `11527`, `11528`, `11529`, `11530`, `11531`, `11532`, `11533`, `11534`, `11535`, `11536`, `11537`, `11538`, `11539`, `11540`, `11541`, `11542`, `11543`, `11544`, `11545`, `11546`, `11547`, `11548`, `11549`, `11550`, `11551`, `11552`, `11553`, `11554`, `11555`, `11556`, `11557`, `11558`, `11559`, `11560`, `11561`, `11562`, `11563`, `11564`, `11565`, `11566`, `11567`, `11568`, `11569`, `11570`, `11571`, `11572`, `11573`, `11574`, `11575`, `11576`, `11577`, `11578`, `11579`, `11580`, `11581`, `11582`, `11583`, `11584`, `11585`, `11586`, `11587`, `11588`, `11589`, `11590`, `11591`, `11592`, `11593`, `11594`, `11595`, `11596`, `11597`, `11598`, `11599`, `11600`, `11601`, `11602`, `11603`, `11604`, `11605`, `11606`, `11607`, `11608`, `11609`, `11610`, `11611`, `11612`, `11613`, `11614`, `11615`, `11616`, `11617`, `11618`, `11619`, `11620`, `11621`, `11622`, `11623`, `11624`, `11625`, `11626`, `11627`, `11628`, `11629`, `11630`, `11631`, `11632`, `11633`, `11634`, `11635`, `11636`, `11637`, `11638`, `11639`, `11640`, `11641`, `11642`, `11643`, `11644`, `11645`, `11646`, `11647`, `11648`, `11649`, `11650`, `11651`, `11652`, `11653`, `11654`, `11655`, `11656`, `11657`, `11658`, `11659`, `11660`, `11661`, `11662`, `11663`, `11664`, `11665`, `11666`, `11667`, `11668`, `11669`, `11670`, `11671`, `11672`, `11673`, `11674`, `11675`, `11676`, `11677`, `11678`, `11679`, `11680`, `11681`, `11682`, `11683`, `11684`, `11685`, `11686`, `11687`, `11688`, `11689`, `11690`, `11691`, `11692`, `11693`, `11694`, `11695`, `11696`, `11697`, `11698`, `11699`, `11700`, `11701`, `11702`, `11703`, `11704`, `11705`, `11706`, `11707`, `11708`, `11709`, `11710`, `11711`, `11712`, `11713`, `11714`, `11715`, `11716`, `11717`, `11718`, `11719`, `11720`, `11721`, `11722`, `11723`, `11724`, `11725`, `11726`, `11727`, `11728`, `11729`, `11730`, `11731`, `11732`, `11733`, `11734`, `11735`, `11736`, `11737`, `11738`, `11739`, `11740`, `11741`, `11742`, `11743`, `11744`, `11745`, `11746`, `11747`, `11748`, `11749`, `11750`, `11751`, `11752`, `11753`, `11754`, `11755`, `11756`, `11757`, `11758`, `11759`, `11760`, `11761`, `11762`, `11763`, `11764`, `11765`, `11766`, `11767`, `11768`, `11769`, `11770`, `11771`, `11772`, `11773`, `11774`, `11775`, `11776`, `11777`, `11778`, `11779`, `11780`, `11781`, `11782`, `11783`, `11784`, `11785`, `11786`, `11787`, `11788`, `11789`, `11790`, `11791`, `11792`, `11793`, `11794`, `11795`, `11796`, `11797`, `11798`, `11799`, `11800`, `11801`, `11802`, `11803`, `11804`, `11805`, `11806`, `11807`, `11808`, `11809`, `11810`, `11811`, `11812`, `11813`, `11814`, `11815`, `11816`, `11817`, `11818`, `11819`, `11820`, `11821`, `11822`, `11823`, `11824`, `11825`, `11826`, `11827`, `11828`, `11829`, `11830`, `11831`, `11832`, `11833`, `11834`, `11835`, `11836`, `11837`, `11838`, `11839`, `11840`, `11841`, `11842`, `11843`, `11844`, `11845`, `11846`, `11847`, `11848`, `11849`, `11850`, `11851`, `11852`, `11853`, `11854`, `11855`, `11856`, `11857`, `11858`, `11859`, `11860`, `11861`, `11862`, `11863`, `11864`, `11865`, `11866`, `11867`, `11868`, `11869`, `11870`, `11871`, `11872`, `11873`, `11874`, `11875`, `11876`, `11877`, `11878`, `11879`, `11880`, `11881`, `11882`, `11883`, `11884`, `11885`, `11886`, `11887`, `11888`, `11889`, `11890`, `11891`, `11892`, `11893`, `11894`, `11895`, `11896`, `11897`, `11898`, `11899`, `11900`, `11901`, `11902`, `11903`, `11904`, `11905`, `11906`, `11907`, `11908`, `11909`, `11910`, `11911`, `11912`, `11913`, `11914`, `11915`, `11916`, `11917`, `11918`, `11919`, `11920`, `11921`, `11922`, `11923`, `11924`, `11925`, `11926`, `11927`, `11928`, `11929`, `11930`, `11931`, `11932`, `11933`, `11934`, `11935`, `11936`, `11937`, `11938`, `11939`, `11940`, `11941`, `11942`, `11943`, `11944`, `11945`, `11946`, `11947`, `11948`, `11949`, `11950`, `11951`, `11952`, `11953`, `11954`, `11955`, `11956`, `11957`, `11958`, `11959`, `11960`, `11961`, `11962`, `11963`, `11964`, `11965`, `11966`, `11967`, `11968`, `11969`, `11970`, `11971`, `11972`, `11973`, `11974`, `11975`, `11976`, `11977`, `11978`, `11979`, `11980`, `11981`, `11982`, `11983`, `11984`, `11985`, `11986`, `11987`, `11988`, `11989`, `11990`, `11991`, `11992`, `11993`, `11994`, `11995`, `11996`, `11997`, `11998`, `11999`, `12000`, `12001`, `12002`, `12003`, `12004`, `12005`, `12006`, `12007`, `12008`, `12009`, `12010`, `12011`, `12012`, `12013`, `12014`, `12015`, `12016`, `12017`, `12018`, `12019`, `12020`, `12021`, `12022`, `12023`, `12024`, `12025`, `12026`, `12027`, `12028`, `12029`, `12030`, `12031`, `12032`, `12033`, `12034`, `12035`, `12036`, `12037`, `12038`, `12039`, `12040`, `12041`, `12042`, `12043`, `12044`, `12045`, `12046`, `12047`, `12048`, `12049`, `12050`, `12051`, `12052`, `12053`, `12054`, `12055`, `12056`, `12057`, `12058`, `12059`, `12060`, `12061`, `12062`, `12063`, `12064`, `12065`, `12066`, `12067`, `12068`, `12069`, `12070`, `12071`, `12072`, `12073`, `12074`, `12075`, `12076`, `12077`, `12078`, `12079`, `12080`, `12081`, `12082`, `12083`, `12084`, `12085`, `12086`, `12087`, `12088`, `12089`, `12090`, `12091`, `12092`, `12093`, `12094`, `12095`, `12096`, `12097`, `12098`, `12099`, `12100`, `12101`, `12102`, `12103`, `12104`, `12105`, `12106`, `12107`, `12108`, `12109`, `12110`, `12111`, `12112`, `12113`, `12114`, `12115`, `12116`, `12117`, `12118`, `12119`, `12120`, `12121`, `12122`, `12123`, `12124`, `12125`, `12126`, `12127`, `12128`, `12129`, `12130`, `12131`, `12132`, `12133`, `12134`, `12135`, `12136`, `12137`, `12138`, `12139`, `12140`, `12141`, `12142`, `12143`, `12144`, `12145`, `12146`, `12147`, `12148`, `12149`, `12150`, `12151`, `12152`, `12153`, `12154`, `12155`, `12156`, `12157`, `12158`, `12159`, `12160`, `12161`, `12162`, `12163`, `12164`, `12165`, `12166`, `12167`, `12168`, `12169`, `12170`, `12171`, `12172`, `12173`, `12174`, `12175`, `12176`, `12177`, `12178`, `12179`, `12180`, `12181`, `12182`, `12183`, `12184`, `12185`, `12186`, `12187`, `12188`, `12189`, `12190`, `12191`, `12192`, `12193`, `12194`, `12195`, `12196`, `12197`, `12198`, `12199`, `12200`, `12201`, `12202`, `12203`, `12204`, `12205`, `12206`, `12207`, `12208`, `12209`, `12210`, `12211`, `12212`, `12213`, `12214`, `12215`, `12216`, `12217`, `12218`, `12219`, `12220`, `12221`, `12222`, `12223`, `12224`, `12225`, `12226`, `12227`, `12228`, `12229`, `12230`, `12231`, `12232`, `12233`, `12234`, `12235`, `12236`, `12237`, `12238`, `12239`, `12240`, `12241`, `12242`, `12243`, `12244`, `12245`, `12246`, `12247`, `12248`, `12249`, `12250`, `12251`, `12252`, `12253`, `12254`, `12255`, `12256`, `12257`, `12258`, `12259`, `12260`, `12261`, `12262`, `12263`, `12264`, `12265`, `12266`, `12267`, `12268`, `12269`, `12270`, `12271`, `12272`, `12273`, `12274`, `12275`, `12276`, `12277`, `12278`, `12279`, `12280`, `12281`, `12282`, `12283`, `12284`, `12285`, `12286`, `12287`, `12288`, `12289`, `12290`, `12291`, `12292`, `12293`, `12294`, `12295`, `12296`, `12297`, `12298`, `12299`, `12300`, `12301`, `12302`, `12303`, `12304`, `12305`, `12306`, `12307`, `12308`, `12309`, `12310`, `12311`, `12312`, `12313`, `12314`, `12315`, `12316`, `12317`, `12318`, `12319`, `12320`, `12321`, `12322`, `12323`, `12324`, `12325`, `12326`, `12327`, `12328`, `12329`, `12330`, `12331`, `12332`, `12333`, `12334`, `12335`, `12336`, `12337`, `12338`, `12339`, `12340`, `12341`, `12342`, `12343`, `12344`, `12345`, `12346`, `12347`, `12348`, `12349`, `12350`, `12351`, `12352`, `12353`, `12354`, `12355`, `12356`, `12357`, `12358`, `12359`, `12360`, `12361`, `12362`, `12363`, `12364`, `12365`, `12366`, `12367`, `12368`, `12369`, `12370`, `12371`, `12372`, `12373`, `12374`, `12375`, `12376`, `12377`, `12378`, `12379`, `12380`, `12381`, `12382`, `12383`, `12384`, `12385`, `12386`, `12387`, `12388`, `12389`, `12390`, `12391`, `12392`, `12393`, `12394`, `12395`, `12396`, `12397`, `12398`, `12399`, `12400`, `12401`, `12402`, `12403`, `12404`, `12405`, `12406`, `12407`, `12408`, `12409`, `12410`, `12411`, `12412`, `12413`, `12414`, `12415`, `12416`, `12417`, `12418`, `12419`, `12420`, `12421`, `12422`, `12423`, `12424`, `12425`, `12426`, `12427`, `12428`, `12429`, `12430`, `12431`, `12432`, `12433`, `12434`, `12435`, `12436`, `12437`, `12438`, `12439`, `12440`, `12441`, `12442`, `12443`, `12444`, `12445`, `12446`, `12447`, `12448`, `12449`, `12450`, `12451`, `12452`, `12453`, `12454`, `12455`, `12456`, `12457`, `12458`, `12459`, `12460`, `12461`, `12462`, `12463`, `12464`, `12465`, `12466`, `12467`, `12468`, `12469`, `12470`, `12471`, `12472`, `12473`, `12474`, `12475`, `12476`, `12477`, `12478`, `12479`, `12480`, `12481`, `12482`, `12483`, `12484`, `12485`, `12486`, `12487`, `12488`, `12489`, `12490`, `12491`, `12492`, `12493`, `12494`, `12495`, `12496`, `12497`, `12498`, `12499`, `12500`, `12501`, `12502`, `12503`, `12504`, `12505`, `12506`, `12507`, `12508`, `12509`, `12510`, `12511`, `12512`, `12513`, `12514`, `12515`, `12516`, `12517`, `12518`, `12519`, `12520`, `12521`, `12522`, `12523`, `12524`, `12525`, `12526`, `12527`, `12528`, `12529`, `12530`, `12531`, `12532`, `12533`, `12534`, `12535`, `12536`, `12537`, `12538`, `12539`, `12540`, `12541`, `12542`, `12543`, `12544`, `12545`, `12546`, `12547`, `12548`, `12549`, `12550`, `12551`, `12552`, `12553`, `12554`, `12555`, `12556`, `12557`, `12558`, `12559`, `12560`, `12561`, `12562`, `12563`, `12564`, `12565`, `12566`, `12567`, `12568`, `12569`, `12570`, `12571`, `12572`, `12573`, `12574`, `12575`, `12576`, `12577`, `12578`, `12579`, `12580`, `12581`, `12582`, `12583`, `12584`, `12585`, `12586`, `12587`, `12588`, `12589`, `12590`, `12591`, `12592`, `12593`, `12594`, `12595`, `12596`, `12597`, `12598`, `12599`, `12600`, `12601`, `12602`, `12603`, `12604`, `12605`, `12606`, `12607`, `12608`, `12609`, `12610`, `12611`, `12612`, `12613`, `12614`, `12615`, `12616`, `12617`, `12618`, `12619`, `12620`, `12621`, `12622`, `12623`, `12624`, `12625`, `12626`, `12627`, `12628`, `12629`, `12630`, `12631`, `12632`, `12633`, `12634`, `12635`, `12636`, `12637`, `12638`, `12639`, `12640`, `12641`, `12642`, `12643`, `12644`, `12645`, `12646`, `12647`, `12648`, `12649`, `12650`, `12651`, `12652`, `12653`, `12654`, `12655`, `12656`, `12657`, `12658`, `12659`, `12660`, `12661`, `12662`, `12663`, `12664`, `12665`, `12666`, `12667`, `12668`, `12669`, `12670`, `12671`, `12672`, `12673`, `12674`, `12675`, `12676`, `12677`, `12678`, `12679`, `12680`, `12681`, `12682`, `12683`, `12684`, `12685`, `12686`, `12687`, `12688`, `12689`, `12690`, `12691`, `12692`, `12693`, `12694`, `12695`, `12696`, `12697`, `12698`, `12699`, `12700`, `12701`, `12702`, `12703`, `12704`, `12705`, `12706`, `12707`, `12708`, `12709`, `12710`, `12711`, `12712`, `12713`, `12714`, `12715`, `12716`, `12717`, `12718`, `12719`, `12720`, `12721`, `12722`, `12723`, `12724`, `12725`, `12726`, `12727`, `12728`, `12729`, `12730`, `12731`, `12732`, `12733`, `12734`, `12735`, `12736`, `12737`, `12738`, `12739`, `12740`, `12741`, `12742`, `12743`, `12744`, `12745`, `12746`, `12747`, `12748`, `12749`, `12750`, `12751`, `12752`, `12753`, `12754`, `12755`, `12756`, `12757`, `12758`, `12759`, `12760`, `12761`, `12762`, `12763`, `12764`, `12765`, `12766`, `12767`, `12768`, `12769`, `12770`, `12771`, `12772`, `12773`, `12774`, `12775`, `12776`, `12777`, `12778`, `12779`, `12780`, `12781`, `12782`, `12783`, `12784`, `12785`, `12786`, `12787`, `12788`, `12789`, `12790`, `12791`, `12792`, `12793`, `12794`, `12795`, `12796`, `12797`, `12798`, `12799`, `12800`, `12801`, `12802`, `12803`, `12804`, `12805`, `12806`, `12807`, `12808`, `12809`, `12810`, `12811`, `12812`, `12813`, `12814`, `12815`, `12816`, `12817`, `12818`, `12819`, `12820`, `12821`, `12822`, `12823`, `12824`, `12825`, `12826`, `12827`, `12828`, `12829`, `12830`, `12831`, `12832`, `12833`, `12834`, `12835`, `12836`, `12837`, `12838`, `12839`, `12840`, `12841`, `12842`, `12843`, `12844`, `12845`, `12846`, `12847`, `12848`, `12849`, `12850`, `12851`, `12852`, `12853`, `12854`, `12855`, `12856`, `12857`, `12858`, `12859`, `12860`, `12861`, `12862`, `12863`, `12864`, `12865`, `12866`, `12867`, `12868`, `12869`, `12870`, `12871`, `12872`, `12873`, `12874`, `12875`, `12876`, `12877`, `12878`, `12879`, `12880`, `12881`, `12882`, `12883`, `12884`, `12885`, `12886`, `12887`, `12888`, `12889`, `12890`, `12891`, `12892`, `12893`, `12894`, `12895`, `12896`, `12897`, `12898`, `12899`, `12900`, `12901`, `12902`, `12903`, `12904`, `12905`, `12906`, `12907`, `12908`, `12909`, `12910`, `12911`, `12912`, `12913`, `12914`, `12915`, `12916`, `12917`, `12918`, `12919`, `12920`, `12921`, `12922`, `12923`, `12924`, `12925`, `12926`, `12927`, `12928`, `12929`, `12930`, `12931`, `12932`, `12933`, `12934`, `12935`, `12936`, `12937`, `12938`, `12939`, `12940`, `12941`, `12942`, `12943`, `12944`, `12945`, `12946`, `12947`, `12948`, `12949`, `12950`, `12951`, `12952`, `12953`, `12954`, `12955`, `12956`, `12957`, `12958`, `12959`, `12960`, `12961`, `12962`, `12963`, `12964`, `12965`, `12966`, `12967`, `12968`, `12969`, `12970`, `12971`, `12972`, `12973`, `12974`, `12975`, `12976`, `12977`, `12978`, `12979`, `12980`, `12981`, `12982`, `12983`, `12984`, `12985`, `12986`, `12987`, `12988`, `12989`, `12990`, `12991`, `12992`, `12993`, `12994`, `12995`, `12996`, `12997`, `12998`, `12999`, `13000`, `13001`, `13002`, `13003`, `13004`, `13005`, `13006`, `13007`, `13008`, `13009`, `13010`, `13011`, `13012`, `13013`, `13014`, `13015`, `13016`, `13017`, `13018`, `13019`, `13020`, `13021`, `13022`, `13023`, `13024`, `13025`, `13026`, `13027`, `13028`, `13029`, `13030`, `13031`, `13032`, `13033`, `13034`, `13035`, `13036`, `13037`, `13038`, `13039`, `13040`, `13041`, `13042`, `13043`, `13044`, `13045`, `13046`, `13047`, `13048`, `13049`, `13050`, `13051`, `13052`, `13053`, `13054`, `13055`, `13056`, `13057`, `13058`, `13059`, `13060`, `13061`, `13062`, `13063`, `13064`, `13065`, `13066`, `13067`, `13068`, `13069`, `13070`, `13071`, `13072`, `13073`, `13074`, `13075`, `13076`, `13077`, `13078`, `13079`, `13080`, `13081`, `13082`, `13083`, `13084`, `13085`, `13086`, `13087`, `13088`, `13089`, `13090`, `13091`, `13092`, `13093`, `13094`, `13095`, `13096`, `13097`, `13098`, `13099`, `13100`, `13101`, `13102`, `13103`, `13104`, `13105`, `13106`, `13107`, `13108`, `13109`, `13110`, `13111`, `13112`, `13113`, `13114`, `13115`, `13116`, `13117`, `13118`, `13119`, `13120`, `13121`, `13122`, `13123`, `13124`, `13125`, `13126`, `13127`, `13128`, `13129`, `13130`, `13131`, `13132`, `13133`, `13134`, `13135`, `13136`, `13137`, `13138`, `13139`, `13140`, `13141`, `13142`, `13143`, `13144`, `13145`, `13146`, `13147`, `13148`, `13149`, `13150`, `13151`, `13152`, `13153`, `13154`, `13155`, `13156`, `13157`, `13158`, `13159`, `13160`, `13161`, `13162`, `13163`, `13164`, `13165`, `13166`, `13167`, `13168`, `13169`, `13170`, `13171`, `13172`, `13173`, `13174`, `13175`, `13176`, `13177`, `13178`, `13179`, `13180`, `13181`, `13182`, `13183`, `13184`, `13185`, `13186`, `13187`, `13188`, `13189`, `13190`, `13191`, `13192`, `13193`, `13194`, `13195`, `13196`, `13197`, `13198`, `13199`, `13200`, `13201`, `13202`, `13203`, `13204`, `13205`, `13206`, `13207`, `13208`, `13209`, `13210`, `13211`, `13212`, `13213`, `13214`, `13215`, `13216`, `13217`, `13218`, `13219`, `13220`, `13221`, `13222`, `13223`, `13224`, `13225`, `13226`, `13227`, `13228`, `13229`, `13230`, `13231`, `13232`, `13233`, `13234`, `13235`, `13236`, `13237`, `13238`, `13239`, `13240`, `13241`, `13242`, `13243`, `13244`, `13245`, `13246`, `13247`, `13248`, `13249`, `13250`, `13251`, `13252`, `13253`, `13254`, `13255`, `13256`, `13257`, `13258`, `13259`, `13260`, `13261`, `13262`, `13263`, `13264`, `13265`, `13266`, `13267`, `13268`, `13269`, `13270`, `13271`, `13272`, `13273`, `13274`, `13275`, `13276`, `13277`, `13278`, `13279`, `13280`, `13281`, `13282`, `13283`, `13284`, `13285`, `13286`, `13287`, `13288`, `13289`, `13290`, `13291`, `13292`, `13293`, `13294`, `13295`, `13296`, `13297`, `13298`, `13299`, `13300`, `13301`, `13302`, `13303`, `13304`, `13305`, `13306`, `13307`, `13308`, `13309`, `13310`, `13311`, `13312`, `13313`, `13314`, `13315`, `13316`, `13317`, `13318`, `13319`, `13320`, `13321`, `13322`, `13323`, `13324`, `13325`, `13326`, `13327`, `13328`, `13329`, `13330`, `13331`, `13332`, `13333`, `13334`, `13335`, `13336`, `13337`, `13338`, `13339`, `13340`, `13341`, `13342`, `13343`, `13344`, `13345`, `13346`, `13347`, `13348`, `13349`, `13350`, `13351`, `13352`, `13353`, `13354`, `13355`, `13356`, `13357`, `13358`, `13359`, `13360`, `13361`, `13362`, `13363`, `13364`, `13365`, `13366`, `13367`, `13368`, `13369`, `13370`, `13371`, `13372`, `13373`, `13374`, `13375`, `13376`, `13377`, `13378`, `13379`, `13380`, `13381`, `13382`, `13383`, `13384`, `13385`, `13386`, `13387`, `13388`, `13389`, `13390`, `13391`, `13392`, `13393`, `13394`, `13395`, `13396`, `13397`, `13398`, `13399`, `13400`, `13401`, `13402`, `13403`, `13404`, `13405`, `13406`, `13407`, `13408`, `13409`, `13410`, `13411`, `13412`, `13413`, `13414`, `13415`, `13416`, `13417`, `13418`, `13419`, `13420`, `13421`, `13422`, `13423`, `13424`, `13425`, `13426`, `13427`, `13428`, `13429`, `13430`, `13431`, `13432`, `13433`, `13434`, `13435`, `13436`, `13437`, `13438`, `13439`, `13440`, `13441`, `13442`, `13443`, `13444`, `13445`, `13446`, `13447`, `13448`, `13449`, `13450`, `13451`, `13452`, `13453`, `13454`, `13455`, `13456`, `13457`, `13458`, `13459`, `13460`, `13461`, `13462`, `13463`, `13464`, `13465`, `13466`, `13467`, `13468`, `13469`, `13470`, `13471`, `13472`, `13473`, `13474`, `13475`, `13476`, `13477`, `13478`, `13479`, `13480`, `13481`, `13482`, `13483`, `13484`, `13485`, `13486`, `13487`, `13488`, `13489`, `13490`, `13491`, `13492`, `13493`, `13494`, `13495`, `13496`, `13497`, `13498`, `13499`, `13500`, `13501`, `13502`, `13503`, `13504`, `13505`, `13506`, `13507`, `13508`, `13509`, `13510`, `13511`, `13512`, `13513`, `13514`, `13515`, `13516`, `13517`, `13518`, `13519`, `13520`, `13521`, `13522`, `13523`, `13524`, `13525`, `13526`, `13527`, `13528`, `13529`, `13530`, `13531`, `13532`, `13533`, `13534`, `13535`, `13536`, `13537`, `13538`, `13539`, `13540`, `13541`, `13542`, `13543`, `13544`, `13545`, `13546`, `13547`, `13548`, `13549`, `13550`, `13551`, `13552`, `13553`, `13554`, `13555`, `13556`, `13557`, `13558`, `13559`, `13560`, `13561`, `13562`, `13563`, `13564`, `13565`, `13566`, `13567`, `13568`, `13569`, `13570`, `13571`, `13572`, `13573`, `13574`, `13575`, `13576`, `13577`, `13578`, `13579`, `13580`, `13581`, `13582`, `13583`, `13584`, `13585`, `13586`, `13587`, `13588`, `13589`, `13590`, `13591`, `13592`, `13593`, `13594`, `13595`, `13596`, `13597`, `13598`, `13599`, `13600`, `13601`, `13602`, `13603`, `13604`, `13605`, `13606`, `13607`, `13608`, `13609`, `13610`, `13611`, `13612`, `13613`, `13614`, `13615`, `13616`, `13617`, `13618`, `13619`, `13620`, `13621`, `13622`, `13623`, `13624`, `13625`, `13626`, `13627`, `13628`, `13629`, `13630`, `13631`, `13632`, `13633`, `13634`, `13635`, `13636`, `13637`, `13638`, `13639`, `13640`, `13641`, `13642`, `13643`, `13644`, `13645`, `13646`, `13647`, `13648`, `13649`, `13650`, `13651`, `13652`, `13653`, `13654`, `13655`, `13656`, `13657`, `13658`, `13659`, `13660`, `13661`, `13662`, `13663`, `13664`, `13665`, `13666`, `13667`, `13668`, `13669`, `13670`, `13671`, `13672`, `13673`, `13674`, `13675`, `13676`, `13677`, `13678`, `13679`, `13680`, `13681`, `13682`, `13683`, `13684`, `13685`, `13686`, `13687`, `13688`, `13689`, `13690`, `13691`, `13692`, `13693`, `13694`, `13695`, `13696`, `13697`, `13698`, `13699`, `13700`, `13701`, `13702`, `13703`, `13704`, `13705`, `13706`, `13707`, `13708`, `13709`, `13710`, `13711`, `13712`, `13713`, `13714`, `13715`, `13716`, `13717`, `13718`, `13719`, `13720`, `13721`, `13722`, `13723`, `13724`, `13725`, `13726`, `13727`, `13728`, `13729`, `13730`, `13731`, `13732`, `13733`, `13734`, `13735`, `13736`, `13737`, `13738`, `13739`, `13740`, `13741`, `13742`, `13743`, `13744`, `13745`, `13746`, `13747`, `13748`, `13749`, `13750`, `13751`, `13752`, `13753`, `13754`, `13755`, `13756`, `13757`, `13758`, `13759`, `13760`, `13761`, `13762`, `13763`, `13764`, `13765`, `13766`, `13767`, `13768`, `13769`, `13770`, `13771`, `13772`, `13773`, `13774`, `13775`, `13776`, `13777`, `13778`, `13779`, `13780`, `13781`, `13782`, `13783`, `13784`, `13785`, `13786`, `13787`, `13788`, `13789`, `13790`, `13791`, `13792`, `13793`, `13794`, `13795`, `13796`, `13797`, `13798`, `13799`, `13800`, `13801`, `13802`, `13803`, `13804`, `13805`, `13806`, `13807`, `13808`, `13809`, `13810`, `13811`, `13812`, `13813`, `13814`, `13815`, `13816`, `13817`, `13818`, `13819`, `13820`, `13821`, `13822`, `13823`, `13824`, `13825`, `13826`, `13827`, `13828`, `13829`, `13830`, `13831`, `13832`, `13833`, `13834`, `13835`, `13836`, `13837`, `13838`, `13839`, `13840`, `13841`, `13842`, `13843`, `13844`, `13845`, `13846`, `13847`, `13848`, `13849`, `13850`, `13851`, `13852`, `13853`, `13854`, `13855`, `13856`, `13857`, `13858`, `13859`, `13860`, `13861`, `13862`, `13863`, `13864`, `13865`, `13866`, `13867`, `13868`, `13869`, `13870`, `13871`, `13872`, `13873`, `13874`, `13875`, `13876`, `13877`, `13878`, `13879`, `13880`, `13881`, `13882`, `13883`, `13884`, `13885`, `13886`, `13887`, `13888`, `13889`, `13890`, `13891`, `13892`, `13893`, `13894`, `13895`, `13896`, `13897`, `13898`, `13899`, `13900`, `13901`, `13902`, `13903`, `13904`, `13905`, `13906`, `13907`, `13908`, `13909`, `13910`, `13911`, `13912`, `13913`, `13914`, `13915`, `13916`, `13917`, `13918`, `13919`, `13920`, `13921`, `13922`, `13923`, `13924`, `13925`, `13926`, `13927`, `13928`, `13929`, `13930`, `13931`, `13932`, `13933`, `13934`, `13935`, `13936`, `13937`, `13938`, `13939`, `13940`, `13941`, `13942`, `13943`, `13944`, `13945`, `13946`, `13947`, `13948`, `13949`, `13950`, `13951`, `13952`, `13953`, `13954`, `13955`, `13956`, `13957`, `13958`, `13959`, `13960`, `13961`, `13962`, `13963`, `13964`, `13965`, `13966`, `13967`, `13968`, `13969`, `13970`, `13971`, `13972`, `13973`, `13974`, `13975`, `13976`, `13977`, `13978`, `13979`, `13980`, `13981`, `13982`, `13983`, `13984`, `13985`, `13986`, `13987`, `13988`, `13989`, `13990`, `13991`, `13992`, `13993`, `13994`, `13995`, `13996`, `13997`, `13998`, `13999`, `14000`, `14001`, `14002`, `14003`, `14004`, `14005`, `14006`, `14007`, `14008`, `14009`, `14010`, `14011`, `14012`, `14013`, `14014`, `14015`, `14016`, `14017`, `14018`, `14019`, `14020`, `14021`, `14022`, `14023`, `14024`, `14025`, `14026`, `14027`, `14028`, `14029`, `14030`, `14031`, `14032`, `14033`, `14034`, `14035`, `14036`, `14037`, `14038`, `14039`, `14040`, `14041`, `14042`, `14043`, `14044`, `14045`, `14046`, `14047`, `14048`, `14049`, `14050`, `14051`, `14052`, `14053`, `14054`, `14055`, `14056`, `14057`, `14058`, `14059`, `14060`, `14061`, `14062`, `14063`, `14064`, `14065`, `14066`, `14067`, `14068`, `14069`, `14070`, `14071`, `14072`, `14073`, `14074`, `14075`, `14076`, `14077`, `14078`, `14079`, `14080`, `14081`, `14082`, `14083`, `14084`, `14085`, `14086`, `14087`, `14088`, `14089`, `14090`, `14091`, `14092`, `14093`, `14094`, `14095`, `14096`, `14097`, `14098`, `14099`, `14100`, `14101`, `14102`, `14103`, `14104`, `14105`, `14106`, `14107`, `14108`, `14109`, `14110`, `14111`, `14112`, `14113`, `14114`, `14115`, `14116`, `14117`, `14118`, `14119`, `14120`, `14121`, `14122`, `14123`, `14124`, `14125`, `14126`, `14127`, `14128`, `14129`, `14130`, `14131`, `14132`, `14133`, `14134`, `14135`, `14136`, `14137`, `14138`, `14139`, `14140`, `14141`, `14142`, `14143`, `14144`, `14145`, `14146`, `14147`, `14148`, `14149`, `14150`, `14151`, `14152`, `14153`, `14154`, `14155`, `14156`, `14157`, `14158`, `14159`, `14160`, `14161`, `14162`, `14163`, `14164`, `14165`, `14166`, `14167`, `14168`, `14169`, `14170`, `14171`, `14172`, `14173`, `14174`, `14175`, `14176`, `14177`, `14178`, `14179`, `14180`, `14181`, `14182`, `14183`, `14184`, `14185`, `14186`, `14187`, `14188`, `14189`, `14190`, `14191`, `14192`, `14193`, `14194`, `14195`, `14196`, `14197`, `14198`, `14199`, `14200`, `14201`, `14202`, `14203`, `14204`, `14205`, `14206`, `14207`, `14208`, `14209`, `14210`, `14211`, `14212`, `14213`, `14214`, `14215`, `14216`, `14217`, `14218`, `14219`, `14220`, `14221`, `14222`, `14223`, `14224`, `14225`, `14226`, `14227`, `14228`, `14229`, `14230`, `14231`, `14232`, `14233`, `14234`, `14235`, `14236`, `14237`, `14238`, `14239`, `14240`, `14241`, `14242`, `14243`, `14244`, `14245`, `14246`, `14247`, `14248`, `14249`, `14250`, `14251`, `14252`, `14253`, `14254`, `14255`, `14256`, `14257`, `14258`, `14259`, `14260`, `14261`, `14262`, `14263`, `14264`, `14265`, `14266`, `14267`, `14268`, `14269`, `14270`, `14271`, `14272`, `14273`, `14274`, `14275`, `14276`, `14277`, `14278`, `14279`, `14280`, `14281`, `14282`, `14283`, `14284`, `14285`, `14286`, `14287`, `14288`, `14289`, `14290`, `14291`, `14292`, `14293`, `14294`, `14295`, `14296`, `14297`, `14298`, `14299`, `14300`, `14301`, `14302`, `14303`, `14304`, `14305`, `14306`, `14307`, `14308`, `14309`, `14310`, `14311`, `14312`, `14313`, `14314`, `14315`, `14316`, `14317`, `14318`, `14319`, `14320`, `14321`, `14322`, `14323`, `14324`, `14325`, `14326`, `14327`, `14328`, `14329`, `14330`, `14331`, `14332`, `14333`, `14334`, `14335`, `14336`, `14337`, `14338`, `14339`, `14340`, `14341`, `14342`, `14343`, `14344`, `14345`, `14346`, `14347`, `14348`, `14349`, `14350`, `14351`, `14352`, `14353`, `14354`, `14355`, `14356`, `14357`, `14358`, `14359`, `14360`, `14361`, `14362`, `14363`, `14364`, `14365`, `14366`, `14367`, `14368`, `14369`, `14370`, `14371`, `14372`, `14373`, `14374`, `14375`, `14376`, `14377`, `14378`, `14379`, `14380`, `14381`, `14382`, `14383`, `14384`, `14385`, `14386`, `14387`, `14388`, `14389`, `14390`, `14391`, `14392`, `14393`, `14394`, `14395`, `14396`, `14397`, `14398`, `14399`, `14400`, `14401`, `14402`, `14403`, `14404`, `14405`, `14406`, `14407`, `14408`, `14409`, `14410`, `14411`, `14412`, `14413`, `14414`, `14415`, `14416`, `14417`, `14418`, `14419`, `14420`, `14421`, `14422`, `14423`, `14424`, `14425`, `14426`, `14427`, `14428`, `14429`, `14430`, `14431`, `14432`, `14433`, `14434`, `14435`, `14436`, `14437`, `14438`, `14439`, `14440`, `14441`, `14442`, `14443`, `14444`, `14445`, `14446`, `14447`, `14448`, `14449`, `14450`, `14451`, `14452`, `14453`, `14454`, `14455`, `14456`, `14457`, `14458`, `14459`, `14460`, `14461`, `14462`, `14463`, `14464`, `14465`, `14466`, `14467`, `14468`, `14469`, `14470`, `14471`, `14472`, `14473`, `14474`, `14475`, `14476`, `14477`, `14478`, `14479`, `14480`, `14481`, `14482`, `14483`, `14484`, `14485`, `14486`, `14487`, `14488`, `14489`, `14490`, `14491`, `14492`, `14493`, `14494`, `14495`, `14496`, `14497`, `14498`, `14499`, `14500`, `14501`, `14502`, `14503`, `14504`, `14505`, `14506`, `14507`, `14508`, `14509`, `14510`, `14511`, `14512`, `14513`, `14514`, `14515`, `14516`, `14517`, `14518`, `14519`, `14520`, `14521`, `14522`, `14523`, `14524`, `14525`, `14526`, `14527`, `14528`, `14529`, `14530`, `14531`, `14532`, `14533`, `14534`, `14535`, `14536`, `14537`, `14538`, `14539`, `14540`, `14541`, `14542`, `14543`, `14544`, `14545`, `14546`, `14547`, `14548`, `14549`, `14550`, `14551`, `14552`, `14553`, `14554`, `14555`, `14556`, `14557`, `14558`, `14559`, `14560`, `14561`, `14562`, `14563`, `14564`, `14565`, `14566`, `14567`, `14568`, `14569`, `14570`, `14571`, `14572`, `14573`, `14574`, `14575`, `14576`, `14577`, `14578`, `14579`, `14580`, `14581`, `14582`, `14583`, `14584`, `14585`, `14586`, `14587`, `14588`, `14589`, `14590`, `14591`, `14592`, `14593`, `14594`, `14595`, `14596`, `14597`, `14598`, `14599`, `14600`, `14601`, `14602`, `14603`, `14604`, `14605`, `14606`, `14607`, `14608`, `14609`, `14610`, `14611`, `14612`, `14613`, `14614`, `14615`, `14616`, `14617`, `14618`, `14619`, `14620`, `14621`, `14622`, `14623`, `14624`, `14625`, `14626`, `14627`, `14628`, `14629`, `14630`, `14631`, `14632`, `14633`, `14634`, `14635`, `14636`, `14637`, `14638`, `14639`, `14640`, `14641`, `14642`, `14643`, `14644`, `14645`, `14646`, `14647`, `14648`, `14649`, `14650`, `14651`, `14652`, `14653`, `14654`, `14655`, `14656`, `14657`, `14658`, `14659`, `14660`, `14661`, `14662`, `14663`, `14664`, `14665`, `14666`, `14667`, `14668`, `14669`, `14670`, `14671`, `14672`, `14673`, `14674`, `14675`, `14676`, `14677`, `14678`, `14679`, `14680`, `14681`, `14682`, `14683`, `14684`, `14685`, `14686`, `14687`, `14688`, `14689`, `14690`, `14691`, `14692`, `14693`, `14694`, `14695`, `14696`, `14697`, `14698`, `14699`, `14700`, `14701`, `14702`, `14703`, `14704`, `14705`, `14706`, `14707`, `14708`, `14709`, `14710`, `14711`, `14712`, `14713`, `14714`, `14715`, `14716`, `14717`, `14718`, `14719`, `14720`, `14721`, `14722`, `14723`, `14724`, `14725`, `14726`, `14727`, `14728`, `14729`, `14730`, `14731`, `14732`, `14733`, `14734`, `14735`, `14736`, `14737`, `14738`, `14739`, `14740`, `14741`, `14742`, `14743`, `14744`, `14745`, `14746`, `14747`, `14748`, `14749`, `14750`, `14751`, `14752`, `14753`, `14754`, `14755`, `14756`, `14757`, `14758`, `14759`, `14760`, `14761`, `14762`, `14763`, `14764`, `14765`, `14766`, `14767`, `14768`, `14769`, `14770`, `14771`, `14772`, `14773`, `14774`, `14775`, `14776`, `14777`, `14778`, `14779`, `14780`, `14781`, `14782`, `14783`, `14784`, `14785`, `14786`, `14787`, `14788`, `14789`, `14790`, `14791`, `14792`, `14793`, `14794`, `14795`, `14796`, `14797`, `14798`, `14799`, `14800`, `14801`, `14802`, `14803`, `14804`, `14805`, `14806`, `14807`, `14808`, `14809`, `14810`, `14811`, `14812`, `14813`, `14814`, `14815`, `14816`, `14817`, `14818`, `14819`, `14820`, `14821`, `14822`, `14823`, `14824`, `14825`, `14826`, `14827`, `14828`, `14829`, `14830`, `14831`, `14832`, `14833`, `14834`, `14835`, `14836`, `14837`, `14838`, `14839`, `14840`, `14841`, `14842`, `14843`, `14844`, `14845`, `14846`, `14847`, `14848`, `14849`, `14850`, `14851`, `14852`, `14853`, `14854`, `14855`, `14856`, `14857`, `14858`, `14859`, `14860`, `14861`, `14862`, `14863`, `14864`, `14865`, `14866`, `14867`, `14868`, `14869`, `14870`, `14871`, `14872`, `14873`, `14874`, `14875`, `14876`, `14877`, `14878`, `14879`, `14880`, `14881`, `14882`, `14883`, `14884`, `14885`, `14886`, `14887`, `14888`, `14889`, `14890`, `14891`, `14892`, `14893`, `14894`, `14895`, `14896`, `14897`, `14898`, `14899`, `14900`, `14901`, `14902`, `14903`, `14904`, `14905`, `14906`, `14907`, `14908`, `14909`, `14910`, `14911`, `14912`, `14913`, `14914`, `14915`, `14916`, `14917`, `14918`, `14919`, `14920`, `14921`, `14922`, `14923`, `14924`, `14925`, `14926`, `14927`, `14928`, `14929`, `14930`, `14931`, `14932`, `14933`, `14934`, `14935`, `14936`, `14937`, `14938`, `14939`, `14940`, `14941`, `14942`, `14943`, `14944`, `14945`, `14946`, `14947`, `14948`, `14949`, `14950`, `14951`, `14952`, `14953`, `14954`, `14955`, `14956`, `14957`, `14958`, `14959`, `14960`, `14961`, `14962`, `14963`, `14964`, `14965`, `14966`, `14967`, `14968`, `14969`, `14970`, `14971`, `14972`, `14973`, `14974`, `14975`, `14976`, `14977`, `14978`, `14979`, `14980`, `14981`, `14982`, `14983`, `14984`, `14985`, `14986`, `14987`, `14988`, `14989`, `14990`, `14991`, `14992`, `14993`, `14994`, `14995`, `14996`, `14997`, `14998`, `14999`, `15000`, `15001`, `15002`, `15003`, `15004`, `15005`, `15006`, `15007`, `15008`, `15009`, `15010`, `15011`, `15012`, `15013`, `15014`, `15015`, `15016`, `15017`, `15018`, `15019`, `15020`, `15021`, `15022`, `15023`, `15024`, `15025`, `15026`, `15027`, `15028`, `15029`, `15030`, `15031`, `15032`, `15033`, `15034`, `15035`, `15036`, `15037`, `15038`, `15039`, `15040`, `15041`, `15042`, `15043`, `15044`, `15045`, `15046`, `15047`, `15048`, `15049`, `15050`, `15051`, `15052`, `15053`, `15054`, `15055`, `15056`, `15057`, `15058`, `15059`, `15060`, `15061`, `15062`, `15063`, `15064`, `15065`, `15066`, `15067`, `15068`, `15069`, `15070`, `15071`, `15072`, `15073`, `15074`, `15075`, `15076`, `15077`, `15078`, `15079`, `15080`, `15081`, `15082`, `15083`, `15084`, `15085`, `15086`, `15087`, `15088`, `15089`, `15090`, `15091`, `15092`, `15093`, `15094`, `15095`, `15096`, `15097`, `15098`, `15099`, `15100`, `15101`, `15102`, `15103`, `15104`, `15105`, `15106`, `15107`, `15108`, `15109`, `15110`, `15111`, `15112`, `15113`, `15114`, `15115`, `15116`, `15117`, `15118`, `15119`, `15120`, `15121`, `15122`, `15123`, `15124`, `15125`, `15126`, `15127`, `15128`, `15129`, `15130`, `15131`, `15132`, `15133`, `15134`, `15135`, `15136`, `15137`, `15138`, `15139`, `15140`, `15141`, `15142`, `15143`, `15144`, `15145`, `15146`, `15147`, `15148`, `15149`, `15150`, `15151`, `15152`, `15153`, `15154`, `15155`, `15156`, `15157`, `15158`, `15159`, `15160`, `15161`, `15162`, `15163`, `15164`, `15165`, `15166`, `15167`, `15168`, `15169`, `15170`, `15171`, `15172`, `15173`, `15174`, `15175`, `15176`, `15177`, `15178`, `15179`, `15180`, `15181`, `15182`, `15183`, `15184`, `15185`, `15186`, `15187`, `15188`, `15189`, `15190`, `15191`, `15192`, `15193`, `15194`, `15195`, `15196`, `15197`, `15198`, `15199`, `15200`, `15201`, `15202`, `15203`, `15204`, `15205`, `15206`, `15207`, `15208`, `15209`, `15210`, `15211`, `15212`, `15213`, `15214`, `15215`, `15216`, `15217`, `15218`, `15219`, `15220`, `15221`, `15222`, `15223`, `15224`, `15225`, `15226`, `15227`, `15228`, `15229`, `15230`, `15231`, `15232`, `15233`, `15234`, `15235`, `15236`, `15237`, `15238`, `15239`, `15240`, `15241`, `15242`, `15243`, `15244`, `15245`, `15246`, `15247`, `15248`, `15249`, `15250`, `15251`, `15252`, `15253`, `15254`, `15255`, `15256`, `15257`, `15258`, `15259`, `15260`, `15261`, `15262`, `15263`, `15264`, `15265`, `15266`, `15267`, `15268`, `15269`, `15270`, `15271`, `15272`, `15273`, `15274`, `15275`, `15276`, `15277`, `15278`, `15279`, `15280`, `15281`, `15282`, `15283`, `15284`, `15285`, `15286`, `15287`, `15288`, `15289`, `15290`, `15291`, `15292`, `15293`, `15294`, `15295`, `15296`, `15297`, `15298`, `15299`, `15300`, `15301`, `15302`, `15303`, `15304`, `15305`, `15306`, `15307`, `15308`, `15309`, `15310`, `15311`, `15312`, `15313`, `15314`, `15315`, `15316`, `15317`, `15318`, `15319`, `15320`, `15321`, `15322`, `15323`, `15324`, `15325`, `15326`, `15327`, `15328`, `15329`, `15330`, `15331`, `15332`, `15333`, `15334`, `15335`, `15336`, `15337`, `15338`, `15339`, `15340`, `15341`, `15342`, `15343`, `15344`, `15345`, `15346`, `15347`, `15348`, `15349`, `15350`, `15351`, `15352`, `15353`, `15354`, `15355`, `15356`, `15357`, `15358`, `15359`, `15360`, `15361`, `15362`, `15363`, `15364`, `15365`, `15366`, `15367`, `15368`, `15369`, `15370`, `15371`, `15372`, `15373`, `15374`, `15375`, `15376`, `15377`, `15378`, `15379`, `15380`, `15381`, `15382`, `15383`, `15384`, `15385`, `15386`, `15387`, `15388`, `15389`, `15390`, `15391`, `15392`, `15393`, `15394`, `15395`, `15396`, `15397`, `15398`, `15399`, `15400`, `15401`, `15402`, `15403`, `15404`, `15405`, `15406`, `15407`, `15408`, `15409`, `15410`, `15411`, `15412`, `15413`, `15414`, `15415`, `15416`, `15417`, `15418`, `15419`, `15420`, `15421`, `15422`, `15423`, `15424`, `15425`, `15426`, `15427`, `15428`, `15429`, `15430`, `15431`, `15432`, `15433`, `15434`, `15435`, `15436`, `15437`, `15438`, `15439`, `15440`, `15441`, `15442`, `15443`, `15444`, `15445`, `15446`, `15447`, `15448`, `15449`, `15450`, `15451`, `15452`, `15453`, `15454`, `15455`, `15456`, `15457`, `15458`, `15459`, `15460`, `15461`, `15462`, `15463`, `15464`, `15465`, `15466`, `15467`, `15468`, `15469`, `15470`, `15471`, `15472`, `15473`, `15474`, `15475`, `15476`, `15477`, `15478`, `15479`, `15480`, `15481`, `15482`, `15483`, `15484`, `15485`, `15486`, `15487`, `15488`, `15489`, `15490`, `15491`, `15492`, `15493`, `15494`, `15495`, `15496`, `15497`, `15498`, `15499`, `15500`, `15501`, `15502`, `15503`, `15504`, `15505`, `15506`, `15507`, `15508`, `15509`, `15510`, `15511`, `15512`, `15513`, `15514`, `15515`, `15516`, `15517`, `15518`, `15519`, `15520`, `15521`, `15522`, `15523`, `15524`, `15525`, `15526`, `15527`, `15528`, `15529`, `15530`, `15531`, `15532`, `15533`, `15534`, `15535`, `15536`, `15537`, `15538`, `15539`, `15540`, `15541`, `15542`, `15543`, `15544`, `15545`, `15546`, `15547`, `15548`, `15549`, `15550`, `15551`, `15552`, `15553`, `15554`, `15555`, `15556`, `15557`, `15558`, `15559`, `15560`, `15561`, `15562`, `15563`, `15564`, `15565`, `15566`, `15567`, `15568`, `15569`, `15570`, `15571`, `15572`, `15573`, `15574`, `15575`, `15576`, `15577`, `15578`, `15579`, `15580`, `15581`, `15582`, `15583`, `15584`, `15585`, `15586`, `15587`, `15588`, `15589`, `15590`, `15591`, `15592`, `15593`, `15594`, `15595`, `15596`, `15597`, `15598`, `15599`, `15600`, `15601`, `15602`, `15603`, `15604`, `15605`, `15606`, `15607`, `15608`, `15609`, `15610`, `15611`, `15612`, `15613`, `15614`, `15615`, `15616`, `15617`, `15618`, `15619`, `15620`, `15621`, `15622`, `15623`, `15624`, `15625`, `15626`, `15627`, `15628`, `15629`, `15630`, `15631`, `15632`, `15633`, `15634`, `15635`, `15636`, `15637`, `15638`, `15639`, `15640`, `15641`, `15642`, `15643`, `15644`, `15645`, `15646`, `15647`, `15648`, `15649`, `15650`, `15651`, `15652`, `15653`, `15654`, `15655`, `15656`, `15657`, `15658`, `15659`, `15660`, `15661`, `15662`, `15663`, `15664`, `15665`, `15666`, `15667`, `15668`, `15669`, `15670`, `15671`, `15672`, `15673`, `15674`, `15675`, `15676`, `15677`, `15678`, `15679`, `15680`, `15681`, `15682`, `15683`, `15684`, `15685`, `15686`, `15687`, `15688`, `15689`, `15690`, `15691`, `15692`, `15693`, `15694`, `15695`, `15696`, `15697`, `15698`, `15699`, `15700`, `15701`, `15702`, `15703`, `15704`, `15705`, `15706`, `15707`, `15708`, `15709`, `15710`, `15711`, `15712`, `15713`, `15714`, `15715`, `15716`, `15717`, `15718`, `15719`, `15720`, `15721`, `15722`, `15723`, `15724`, `15725`, `15726`, `15727`, `15728`, `15729`, `15730`, `15731`, `15732`, `15733`, `15734`, `15735`, `15736`, `15737`, `15738`, `15739`, `15740`, `15741`, `15742`, `15743`, `15744`, `15745`, `15746`, `15747`, `15748`, `15749`, `15750`, `15751`, `15752`, `15753`, `15754`, `15755`, `15756`, `15757`, `15758`, `15759`, `15760`, `15761`, `15762`, `15763`, `15764`, `15765`, `15766`, `15767`, `15768`, `15769`, `15770`, `15771`, `15772`, `15773`, `15774`, `15775`, `15776`, `15777`, `15778`, `15779`, `15780`, `15781`, `15782`, `15783`, `15784`, `15785`, `15786`, `15787`, `15788`, `15789`, `15790`, `15791`, `15792`, `15793`, `15794`, `15795`, `15796`, `15797`, `15798`, `15799`, `15800`, `15801`, `15802`, `15803`, `15804`, `15805`, `15806`, `15807`, `15808`, `15809`, `15810`, `15811`, `15812`, `15813`, `15814`, `15815`, `15816`, `15817`, `15818`, `15819`, `15820`, `15821`, `15822`, `15823`, `15824`, `15825`, `15826`, `15827`, `15828`, `15829`, `15830`, `15831`, `15832`, `15833`, `15834`, `15835`, `15836`, `15837`, `15838`, `15839`, `15840`, `15841`, `15842`, `15843`, `15844`, `15845`, `15846`, `15847`, `15848`, `15849`, `15850`, `15851`, `15852`, `15853`, `15854`, `15855`, `15856`, `15857`, `15858`, `15859`, `15860`, `15861`, `15862`, `15863`, `15864`, `15865`, `15866`, `15867`, `15868`, `15869`, `15870`, `15871`, `15872`, `15873`, `15874`, `15875`, `15876`, `15877`, `15878`, `15879`, `15880`, `15881`, `15882`, `15883`, `15884`, `15885`, `15886`, `15887`, `15888`, `15889`, `15890`, `15891`, `15892`, `15893`, `15894`, `15895`, `15896`, `15897`, `15898`, `15899`, `15900`, `15901`, `15902`, `15903`, `15904`, `15905`, `15906`, `15907`, `15908`, `15909`, `15910`, `15911`, `15912`, `15913`, `15914`, `15915`, `15916`, `15917`, `15918`, `15919`, `15920`, `15921`, `15922`, `15923`, `15924`, `15925`, `15926`, `15927`, `15928`, `15929`, `15930`, `15931`, `15932`, `15933`, `15934`, `15935`, `15936`, `15937`, `15938`, `15939`, `15940`, `15941`, `15942`, `15943`, `15944`, `15945`, `15946`, `15947`, `15948`, `15949`, `15950`, `15951`, `15952`, `15953`, `15954`, `15955`, `15956`, `15957`, `15958`, `15959`, `15960`, `15961`, `15962`, `15963`, `15964`, `15965`, `15966`, `15967`, `15968`, `15969`, `15970`, `15971`, `15972`, `15973`, `15974`, `15975`, `15976`, `15977`, `15978`, `15979`, `15980`, `15981`, `15982`, `15983`, `15984`, `15985`, `15986`, `15987`, `15988`, `15989`, `15990`, `15991`, `15992`, `15993`, `15994`, `15995`, `15996`, `15997`, `15998`, `15999`, `16000`, `16001`, `16002`, `16003`, `16004`, `16005`, `16006`, `16007`, `16008`, `16009`, `16010`, `16011`, `16012`, `16013`, `16014`, `16015`, `16016`, `16017`, `16018`, `16019`, `16020`, `16021`, `16022`, `16023`, `16024`, `16025`, `16026`, `16027`, `16028`, `16029`, `16030`, `16031`, `16032`, `16033`, `16034`, `16035`, `16036`, `16037`, `16038`, `16039`, `16040`, `16041`, `16042`, `16043`, `16044`, `16045`, `16046`, `16047`, `16048`, `16049`, `16050`, `16051`, `16052`, `16053`, `16054`, `16055`, `16056`, `16057`, `16058` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `TOKEN_F` | 100.00 |
| `TOKEN_P` | 100.00 |
| `TOKEN_R` | 100.00 |
| `TOKEN_ACC` | 100.00 |
| `SENTS_F` | 81.11 |
| `SENTS_P` | 79.75 |
| `SENTS_R` | 82.52 |
| `TAG_ACC` | 96.41 |
| `POS_ACC` | 96.52 |
| `MORPH_ACC` | 97.74 |
| `DEP_UAS` | 90.21 |
| `DEP_LAS` | 85.42 |
| `LEMMA_ACC` | 90.34 | |
AnonymousSub/AR_consert | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
tags:
- image-generation
- conditional-image-generation
- generative-model
license: cc-by-nc-4.0
library: pytorch
---
# <p align="center"> IC-GAN: Instance-Conditioned GAN </p>
Official Pytorch code of [Instance-Conditioned GAN](https://arxiv.org/abs/2109.05070) by Arantxa Casanova, Marlène Careil, Jakob Verbeek, Michał Drożdżal, Adriana Romero-Soriano.

## Generate images with IC-GAN in a Colab Notebook
We provide a [Google Colab notebook](https://colab.research.google.com/github/facebookresearch/ic_gan/blob/main/inference/icgan_colab.ipynb) to generate images with IC-GAN and its class-conditional counter part. We also invite users to check out the [demo on Replicate](https://replicate.ai/arantxacasanova/ic_gan), courtesy of [Replicate](https://replicate.ai/home).
The figure below depicts two instances, unseen during training and downloaded from [Creative Commons search](https://search.creativecommons.org), and the generated images with IC-GAN and class-conditional IC-GAN when conditioning on the class "castle":

Additionally, and inspired by [this Colab](https://colab.research.google.com/github/eyaler/clip_biggan/blob/main/ClipBigGAN.ipynb), we provide the funcionality in the same Colab notebook to guide generations with text captions, using the [CLIP model](https://github.com/openai/CLIP).
As an example, the following Figure shows three instance conditionings and a text caption (top), followed by the resulting generated images with IC-GAN (bottom), when optimizing the noise vector following CLIP's gradient for 100 iterations.

*Credit for the three instance conditionings, from left to right, that were modified with a resize and central crop:* [1: "Landscape in Bavaria" by shining.darkness, licensed under CC BY 2.0](https://search.creativecommons.org/photos/92ef279c-4469-49a5-aa4b-48ad746f2dc4), [2: "Fantasy Landscape - slolsss" by Douglas Tofoli is marked with CC PDM 1.0](https://search.creativecommons.org/photos/13646adc-f1df-437a-a0dd-8223452ee46c), [3: "How to Draw Landscapes Simply" by Kuwagata Keisai is marked with CC0 1.0](https://search.creativecommons.org/photos/2ab9c3b7-de99-4536-81ed-604ee988bd5f)
## Requirements
* Python 3.8
* Cuda v10.2 / Cudnn v7.6.5
* gcc v7.3.0
* Pytorch 1.8.0
* A conda environment can be created from `environment.yaml` by entering the command: `conda env create -f environment.yml`, that contains the aforemention version of Pytorch and other required packages.
* Faiss: follow the instructions in the [original repository](https://github.com/facebookresearch/faiss).
## Overview
This repository consists of four main folders:
* `data_utils`: A common folder to obtain and format the data needed to train and test IC-GAN, agnostic of the specific backbone.
* `inference`: Scripts to test the models both qualitatively and quantitatively.
* `BigGAN_PyTorch`: It provides the training, evaluation and sampling scripts for IC-GAN with a BigGAN backbone. The code base comes from [Pytorch BigGAN repository](https://github.com/ajbrock/BigGAN-PyTorch), made available under the MIT License. It has been modified to [add additional utilities](#biggan-changelog) and it enables IC-GAN training on top of it.
* `stylegan2_ada_pytorch`: It provides the training, evaluation and sampling scripts for IC-GAN with a StyleGAN2 backbone. The code base comes from [StyleGAN2 Pytorch](https://github.com/NVlabs/stylegan2-ada-pytorch), made available under the [Nvidia Source Code License](https://nvlabs.github.io/stylegan2-ada-pytorch/license.html). It has been modified to [add additional utilities](#stylegan-changelog) and it enables IC-GAN training on top of it.
## (Python script) Generate images with IC-GAN
Alternatively, we can <b> generate images with IC-GAN models </b> directly from a python script, by following the next steps:
1) Download the desired pretrained models (links below) and the [pre-computed 1000 instance features from ImageNet](https://dl.fbaipublicfiles.com/ic_gan/stored_instances.tar.gz) and extract them into a folder `pretrained_models_path`.
| model | backbone | class-conditional? | training dataset | resolution | url |
|-------------------|-------------------|-------------------|---------------------|--------------------|--------------------|
| IC-GAN | BigGAN | No | ImageNet | 256x256 | [model](https://dl.fbaipublicfiles.com/ic_gan/icgan_biggan_imagenet_res256.tar.gz) |
| IC-GAN (half capacity) | BigGAN | No | ImageNet | 256x256 | [model](https://dl.fbaipublicfiles.com/ic_gan/icgan_biggan_imagenet_res256_halfcap.tar.gz) |
| IC-GAN | BigGAN | No | ImageNet | 128x128 | [model](https://dl.fbaipublicfiles.com/ic_gan/icgan_biggan_imagenet_res128.tar.gz) |
| IC-GAN | BigGAN | No | ImageNet | 64x64 | [model](https://dl.fbaipublicfiles.com/ic_gan/icgan_biggan_imagenet_res64.tar.gz) |
| IC-GAN | BigGAN | Yes | ImageNet | 256x256 | [model](https://dl.fbaipublicfiles.com/ic_gan/cc_icgan_biggan_imagenet_res256.tar.gz) |
| IC-GAN (half capacity) | BigGAN | Yes | ImageNet | 256x256 | [model](https://dl.fbaipublicfiles.com/ic_gan/cc_icgan_biggan_imagenet_res256_halfcap.tar.gz) |
| IC-GAN | BigGAN | Yes | ImageNet | 128x128 | [model](https://dl.fbaipublicfiles.com/ic_gan/cc_icgan_biggan_imagenet_res128.tar.gz) |
| IC-GAN | BigGAN | Yes | ImageNet | 64x64 | [model](https://dl.fbaipublicfiles.com/ic_gan/cc_icgan_biggan_imagenet_res64.tar.gz) |
| IC-GAN | BigGAN | Yes | ImageNet-LT | 256x256 | [model](https://dl.fbaipublicfiles.com/ic_gan/cc_icgan_biggan_imagenetlt_res256.tar.gz) |
| IC-GAN | BigGAN | Yes | ImageNet-LT | 128x128 | [model](https://dl.fbaipublicfiles.com/ic_gan/cc_icgan_biggan_imagenetlt_res128.tar.gz) |
| IC-GAN | BigGAN | Yes | ImageNet-LT | 64x64 | [model](https://dl.fbaipublicfiles.com/ic_gan/cc_icgan_biggan_imagenetlt_res64.tar.gz) |
| IC-GAN | BigGAN | No | COCO-Stuff | 256x256 | [model](https://dl.fbaipublicfiles.com/ic_gan/icgan_biggan_coco_res256.tar.gz) |
| IC-GAN | BigGAN | No | COCO-Stuff | 128x128 | [model](https://dl.fbaipublicfiles.com/ic_gan/icgan_biggan_coco_res128.tar.gz) |
| IC-GAN | StyleGAN2 | No | COCO-Stuff | 256x256 | [model](https://dl.fbaipublicfiles.com/ic_gan/icgan_stylegan2_coco_res256.tar.gz) |
| IC-GAN | StyleGAN2 | No | COCO-Stuff | 128x128 | [model](https://dl.fbaipublicfiles.com/ic_gan/icgan_stylegan2_coco_res128.tar.gz) |
2) Execute:
```
python inference/generate_images.py --root_path [pretrained_models_path] --model [model] --model_backbone [backbone] --resolution [res]
```
* `model` can be chosen from `["icgan", "cc_icgan"]` to use the IC-GAN or the class-conditional IC-GAN model respectively.
* `backbone` can be chosen from `["biggan", "stylegan2"]`.
* `res` indicates the resolution at which the model has been trained. For ImageNet, choose one in `[64, 128, 256]`, and for COCO-Stuff, one in `[128, 256]`.
This script results in a .PNG file where several generated images are shown, given an instance feature (each row), and a sampled noise vector (each grid position).
<b>Additional and optional parameters</b>:
* `index`: (None by default), is an integer from 0 to 999 that choses a specific instance feature vector out of the 1000 instances that have been selected with k-means on the ImageNet dataset and stored in `pretrained_models_path/stored_instances`.
* `swap_target`: (None by default) is an integer from 0 to 999 indicating an ImageNet class label. This label will be used to condition the class-conditional IC-GAN, regardless of which instance features are being used.
* `which_dataset`: (ImageNet by default) can be chosen from `["imagenet", "coco"]` to indicate which dataset (training split) to sample the instances from.
* `trained_dataset`: (ImageNet by default) can be chosen from `["imagenet", "coco"]` to indicate the dataset in which the IC-GAN model has been trained on.
* `num_imgs_gen`: (5 by default), it changes the number of noise vectors to sample per conditioning. Increasing this number results in a bigger .PNG file to save and load.
* `num_conditionings_gen`: (5 by default), it changes the number of conditionings to sample. Increasing this number results in a bigger .PNG file to save and load.
* `z_var`: (1.0 by default) controls the truncation factor for the generation.
* Optionally, the script can be run with the following additional options `--visualize_instance_images --dataset_path [dataset_path]` to visualize the ground-truth images corresponding to the conditioning instance features, given a path to the dataset's ground-truth images `dataset_path`. Ground-truth instances will be plotted as the leftmost image for each row.
## Data preparation
<div id="data-preparation">
<details>
<summary>ImageNet</summary>
<br>
<ol>
<li>Download dataset from <a href="https://image-net.org/download.php"> here </a>.
</li>
<li>Download <a href="https://github.com/facebookresearch/swav"> SwAV </a> feature extractor weights from <a href="https://dl.fbaipublicfiles.com/deepcluster/swav_800ep_pretrain.pth.tar"> here </a>. </li>
<li> Replace the paths in data_utils/prepare_data.sh: <code>out_path</code> by the path where hdf5 files will be stored, <code>path_imnet</code> by the path where ImageNet dataset is downloaded, and <code>path_swav</code> by the path where SwAV weights are stored. </li>
<li> Execute <code>./data_utils/prepare_data.sh imagenet [resolution]</code>, where <code>[resolution]</code> can be an integer in {64,128,256}. This script will create several hdf5 files:
<ul> <li> <code>ILSVRC[resolution]_xy.hdf5</code> and <code>ILSVRC[resolution]_val_xy.hdf5</code>, where images and labels are stored for the training and validation set respectively. </li>
<li> <code>ILSVRC[resolution]_feats_[feature_extractor]_resnet50.hdf5</code> that contains the instance features for each image. </li>
<li> <code>ILSVRC[resolution]_feats_[feature_extractor]_resnet50_nn_k[k_nn].hdf5</code> that contains the list of [k_nn] neighbors for each of the instance features. </li> </ul> </li>
</ol> </br>
</details>
<details>
<summary>ImageNet-LT</summary>
<br>
<ol>
<li>Download ImageNet dataset from <a href="https://image-net.org/download.php"> here </a>. Following <a href="https://github.com/zhmiao/OpenLongTailRecognition-OLTR"> ImageNet-LT </a>, the file <code>ImageNet_LT_train.txt</code> can be downloaded from <a href="https://drive.google.com/drive/u/1/folders/1j7Nkfe6ZhzKFXePHdsseeeGI877Xu1yf" > this link </a> and later stored in the folder <code>./BigGAN_PyTorch/imagenet_lt</code>.
</li>
<li>Download the pre-trained weights of the ResNet on ImageNet-LT from <a href="https://dl.fbaipublicfiles.com/classifier-balancing/ImageNet_LT/models/resnet50_uniform_e90.pth"> this link</a>, provided by the <a href="https://github.com/facebookresearch/classifier-balancing"> classifier-balancing repository </a>. </li>
<li> Replace the paths in data_utils/prepare_data.sh: <code>out_path</code> by the path where hdf5 files will be stored, <code>path_imnet</code> by the path where ImageNet dataset is downloaded, and <code>path_classifier_lt</code> by the path where the pre-trained ResNet50 weights are stored. </li>
<li> Execute <code>./data_utils/prepare_data.sh imagenet_lt [resolution]</code>, where <code>[resolution]</code> can be an integer in {64,128,256}. This script will create several hdf5 files:
<ul> <li> <code>ILSVRC[resolution]longtail_xy.hdf5</code>, where images and labels are stored for the training and validation set respectively. </li>
<li> <code>ILSVRC[resolution]longtail_feats_[feature_extractor]_resnet50.hdf5</code> that contains the instance features for each image. </li>
<li> <code>ILSVRC[resolution]longtail_feats_[feature_extractor]_resnet50_nn_k[k_nn].hdf5</code> that contains the list of [k_nn] neighbors for each of the instance features. </li> </ul> </li>
</ol> </br>
</details>
<details>
<summary>COCO-Stuff</summary>
<br>
<ol>
<li>Download the dataset following the <a href="https://github.com/WillSuen/LostGANs/blob/master/INSTALL.md"> LostGANs' repository instructions </a>.
</li>
<li>Download <a href="https://github.com/facebookresearch/swav"> SwAV </a> feature extractor weights from <a href="https://dl.fbaipublicfiles.com/deepcluster/swav_800ep_pretrain.pth.tar"> here </a>. </li>
<li> Replace the paths in data_utils/prepare_data.sh: <code>out_path</code> by the path where hdf5 files will be stored, <code>path_imnet</code> by the path where ImageNet dataset is downloaded, and <code>path_swav</code> by the path where SwAV weights are stored. </li>
<li> Execute <code>./data_utils/prepare_data.sh coco [resolution]</code>, where <code>[resolution]</code> can be an integer in {128,256}. This script will create several hdf5 files:
<ul> <li> <code>COCO[resolution]_xy.hdf5</code> and <code>COCO[resolution]_val_test_xy.hdf5</code>, where images and labels are stored for the training and evaluation set respectively. </li>
<li> <code>COCO[resolution]_feats_[feature_extractor]_resnet50.hdf5</code> that contains the instance features for each image. </li>
<li> <code>COCO[resolution]_feats_[feature_extractor]_resnet50_nn_k[k_nn].hdf5</code> that contains the list of [k_nn] neighbors for each of the instance features. </li> </ul> </li>
</ol> </br>
</details>
<details>
<summary>Other datasets</summary>
<br>
<ol>
<li>Download the corresponding dataset and store in a folder <code>dataset_path</code>.
</li>
<li>Download <a href="https://github.com/facebookresearch/swav"> SwAV </a> feature extractor weights from <a href="https://dl.fbaipublicfiles.com/deepcluster/swav_800ep_pretrain.pth.tar"> here </a>. </li>
<li> Replace the paths in data_utils/prepare_data.sh: <code>out_path</code> by the path where hdf5 files will be stored and <code>path_swav</code> by the path where SwAV weights are stored. </li>
<li> Execute <code>./data_utils/prepare_data.sh [dataset_name] [resolution] [dataset_path]</code>, where <code>[dataset_name]</code> will be the dataset name, <code>[resolution]</code> can be an integer, for example 128 or 256, and <code>dataset_path</code> contains the dataset images. This script will create several hdf5 files:
<ul> <li> <code>[dataset_name][resolution]_xy.hdf5</code>, where images and labels are stored for the training set. </li>
<li> <code>[dataset_name][resolution]_feats_[feature_extractor]_resnet50.hdf5</code> that contains the instance features for each image. </li>
<li> <code>[dataset_name][resolution]_feats_[feature_extractor]_resnet50_nn_k[k_nn].hdf5</code> that contains the list of <code>k_nn</code> neighbors for each of the instance features. </li> </ul> </li>
</ol> </br>
</details>
<details>
<summary>How to subsample an instance feature dataset with k-means</summary>
<br>
To downsample the instance feature vector dataset, after we have prepared the data, we can use the k-means algorithm:
<code>
python data_utils/store_kmeans_indexes.py --resolution [resolution] --which_dataset [dataset_name] --data_root [data_path]
</code>
<ul> <li> Adding <code>--gpu</code> allows the faiss library to compute k-means leveraging GPUs, resulting in faster execution. </li>
<li> Adding the parameter <code>--feature_extractor [feature_extractor]</code> chooses which feature extractor to use, with <code>feature_extractor</code> in <code>['selfsupervised', 'classification'] </code>, if we are using swAV as feature extactor or the ResNet pretrained on the classification task on ImageNet, respectively. </li>
<li> The number of k-means clusters can be set with <code>--kmeans_subsampled [centers]</code>, where <code>centers</code> is an integer. </li> </ul>
</br>
</details>
</div>
## How to train the models
#### BigGAN or StyleGAN2 backbone
Training parameters are stored in JSON files in `[backbone_folder]/config_files/[dataset]/*.json`, where `[backbone_folder]` is either BigGAN_Pytorch or stylegan2_ada_pytorch and `[dataset]` can either be ImageNet, ImageNet-LT or COCO_Stuff.
```
cd BigGAN_PyTorch
python run.py --json_config config_files/<dataset>/<selected_config>.json --data_root [data_root] --base_root [base_root]
```
or
```
cd stylegan_ada_pytorch
python run.py --json_config config_files/<dataset>/<selected_config>.json --data_root [data_root] --base_root [base_root]
```
where:
* `data_root` path where the data has been prepared and stored, following the previous section (<a href="./README.md#data-preparation">Data preparation</a>).
* `base_root` path where to store the model weights and logs.
Note that one can create other JSON files to modify the training parameters.
#### Other backbones
To be able to run IC-GAN with other backbones, we provide some orientative steps:
* Place the new backbone code in a new folder under `ic_gan` (`ic_gan/new_backbone`).
* Modify the relevant piece of code in the GAN architecture to allow instance features as conditionings (for both generator and discriminator).
* Create a `trainer.py` file with the training loop to train an IC-GAN with the new backbone. The `data_utils` folder provides the tools to prepare the dataset, load the data and conditioning sampling to train an IC-GAN. The IC-GAN with BigGAN backbone [`trainer.py`](BigGAN_PyTorch/trainer.py) file can be used as an inspiration.
## How to test the models
<b>To obtain the FID and IS metrics on ImageNet and ImageNet-LT</b>:
1) Execute:
```
python inference/test.py --json_config [BigGAN-PyTorch or stylegan-ada-pytorch]/config_files/<dataset>/<selected_config>.json --num_inception_images [num_imgs] --sample_num_npz [num_imgs] --eval_reference_set [ref_set] --sample_npz --base_root [base_root] --data_root [data_root] --kmeans_subsampled [kmeans_centers] --model_backbone [backbone]
```
To obtain the tensorflow IS and FID metrics, use an environment with the Python <3.7 and Tensorflow 1.15. Then:
2) Obtain Inception Scores and pre-computed FID moments:
```
python ../data_utils/inception_tf13.py --experiment_name [exp_name] --experiment_root [base_root] --kmeans_subsampled [kmeans_centers]
```
For stratified FIDs in the ImageNet-LT dataset, the following parameters can be added `--which_dataset 'imagenet_lt' --split 'val' --strat_name [stratified_split]`, where `stratified_split` can be in `[few,low, many]`.
3) (Only needed once) Pre-compute reference moments with tensorflow code:
```
python ../data_utils/inception_tf13.py --use_ground_truth_data --data_root [data_root] --split [ref_set] --resolution [res] --which_dataset [dataset]
```
4) (Using this [repository](https://github.com/bioinf-jku/TTUR)) FID can be computed using the pre-computed statistics obtained in 2) and the pre-computed ground-truth statistics obtain in 3). For example, to compute the FID with reference ImageNet validation set:
```python TTUR/fid.py [base_root]/[exp_name]/TF_pool_.npz [data_root]/imagenet_val_res[res]_tf_inception_moments_ground_truth.npz ```
<b>To obtain the FID metric on COCO-Stuff</b>:
1) Obtain ground-truth jpeg images: ```python data_utils/store_coco_jpeg_images.py --resolution [res] --split [ref_set] --data_root [data_root] --out_path [gt_coco_images] --filter_hd [filter_hd] ```
2) Store generated images as jpeg images: ```python sample.py --json_config ../[BigGAN-PyTorch or stylegan-ada-pytorch]/config_files/<dataset>/<selected_config>.json --data_root [data_root] --base_root [base_root] --sample_num_npz [num_imgs] --which_dataset 'coco' --eval_instance_set [ref_set] --eval_reference_set [ref_set] --filter_hd [filter_hd] --model_backbone [backbone] ```
3) Using this [repository](https://github.com/bioinf-jku/TTUR), compute FID on the two folders of ground-truth and generated images.
where:
* `dataset`: option to select the dataset in `['imagenet', 'imagenet_lt', 'coco']
* `exp_name`: name of the experiment folder.
* `data_root`: path where the data has been prepared and stored, following the previous section ["Data preparation"](#data-preparation).
* `base_root`: path where to find the model (for example, where the pretrained models have been downloaded).
* `num_imgs`: needs to be set to 50000 for ImageNet and ImageNet-LT (with validation set as reference) and set to 11500 for ImageNet-LT (with training set as reference). For COCO-Stuff, set to 75777, 2050, 675, 1375 if using the training, evaluation, evaluation seen or evaluation unseen set as reference.
* `ref_set`: set to `'val'` for ImageNet, ImageNet-LT (and COCO) to obtain metrics with the validation (evaluation) set as reference, or set to `'train'` for ImageNet-LT or COCO to obtain metrics with the training set as reference.
* `kmeans_centers`: set to 1000 for ImageNet and to -1 for ImageNet-LT.
* `backbone`: model backbone architecture in `['biggan','stylegan2']`.
* `res`: integer indicating the resolution of the images (64,128,256).
* `gt_coco_images`: folder to store the ground-truth JPEG images of that specific split.
* `filter_hd`: only valid for `ref_set=val`. If -1, use the entire evaluation set; if 0, use only conditionings and their ground-truth images with seen class combinations during training (eval seen); if 1, use only conditionings and their ground-truth images with unseen class combinations during training (eval unseen).
## Utilities for GAN backbones
We change and provide extra utilities to facilitate the training, for both BigGAN and StyleGAN2 base repositories.
### BigGAN change log
The following changes were made:
* BigGAN architecture:
* In `train_fns.py`: option to either have the optimizers inside the generator and discriminator class, or directly in the `G_D` wrapper module. Additionally, added an option to augment both generated and real images with augmentations from [DiffAugment](https://github.com/mit-han-lab/data-efficient-gans).
* In `BigGAN.py`: added a function `get_condition_embeddings` to handle the conditioning separately.
* Small modifications to `layers.py` to adapt the batchnorm function calls to the pytorch 1.8 version.
* Training utilities:
* Added `trainer.py` file (replacing train.py):
* Training now allows the usage of DDP for faster single-node and multi-node training.
* Training is performed by epochs instead of by iterations.
* Option to stop the training by using early stopping or when experiments diverge.
* In `utils.py`:
* Replaced `MultiEpochSampler` for `CheckpointedSampler` to allow experiments to be resumable when using epochs and fixing a bug where `MultiEpochSampler` would require a long time to fetch data permutations when the number of epochs increased.
* ImageNet-LT: Added option to use different class distributions when sampling a class label for the generator.
* ImageNet-LT: Added class balancing (uniform and temperature annealed).
* Added data augmentations from [DiffAugment](https://github.com/mit-han-lab/data-efficient-gans).
* Testing utilities:
* In `calculate_inception_moments.py`: added option to obtain moments for ImageNet-LT dataset, as well as stratified moments for many, medium and few-shot classes (stratified FID computation).
* In `inception_utils.py`: added option to compute [Precision, Recall, Density, Coverage](https://github.com/clovaai/generative-evaluation-prdc) and stratified FID.
* Data utilities:
* In `datasets.py`, added option to load ImageNet-LT dataset.
* Added ImageNet-LT.txt files with image indexes for training and validation split.
* In `utils.py`:
* Separate functions to obtain the data from hdf5 files (`get_dataset_hdf5`) or from directory (`get_dataset_images`), as well as a function to obtain only the data loader (`get_dataloader`).
* Added the function `sample_conditionings` to handle possible different conditionings to train G with.
* Experiment utilities:
* Added JSON files to launch experiments with the proposed hyper-parameter configuration.
* Script to launch experiments with either the [submitit tool](https://github.com/facebookincubator/submitit) or locally in the same machine (run.py).
### StyleGAN2 change log
<div id="stylegan-changelog">
<ul>
<li> Multi-node DistributedDataParallel training. </li>
<li> Added early stopping based on the training FID metric. </li>
<li> Automatic checkpointing when jobs are automatically rescheduled on a cluster. </li>
<li> Option to load dataset from hdf5 file. </li>
<li> Replaced the usage of Click python package by an `ArgumentParser`. </li>
<li> Only saving best and last model weights. </li>
</ul>
</div>
## Acknowledgements
We would like to thanks the authors of the [Pytorch BigGAN repository](https://github.com/ajbrock/BigGAN-PyTorch) and [StyleGAN2 Pytorch](https://github.com/NVlabs/stylegan2-ada-pytorch), as our model requires their repositories to train IC-GAN with BigGAN or StyleGAN2 bakcbone respectively.
Moreover, we would like to further thank the authors of [generative-evaluation-prdc](https://github.com/clovaai/generative-evaluation-prdc), [data-efficient-gans](https://github.com/mit-han-lab/data-efficient-gans), [faiss](https://github.com/facebookresearch/faiss) and [sg2im](https://github.com/google/sg2im) as some components were borrowed and modified from their code bases. Finally, we thank the author of [WanderCLIP](https://colab.research.google.com/github/eyaler/clip_biggan/blob/main/WanderCLIP.ipynb) as well as the following repositories, that we use in our Colab notebook: [pytorch-pretrained-BigGAN](https://github.com/huggingface/pytorch-pretrained-BigGAN) and [CLIP](https://github.com/openai/CLIP).
## License
The majority of IC-GAN is licensed under CC-BY-NC, however portions of the project are available under separate license terms: BigGAN and [PRDC](https://github.com/facebookresearch/ic_gan/blob/main/data_utils/compute_pdrc.py) are licensed under the MIT license; [COCO-Stuff loader](https://github.com/facebookresearch/ic_gan/blob/main/data_utils/cocostuff_dataset.py) is licensed under Apache License 2.0; [DiffAugment](https://github.com/facebookresearch/ic_gan/blob/main/BigGAN_PyTorch/diffaugment_utils.py) is licensed under BSD 2-Clause Simplified license; StyleGAN2 is licensed under a NVIDIA license, available here: https://github.com/NVlabs/stylegan2-ada-pytorch/blob/main/LICENSE.txt. In the Colab notebook, [CLIP](https://github.com/openai/CLIP) and [pytorch-pretrained-BigGAN](https://github.com/huggingface/pytorch-pretrained-BigGAN) code is used, both licensed under the MIT license.
## Disclaimers
THE DIFFAUGMENT SOFTWARE IS PROVIDED BY THE COPYRIGHT HOLDERS AND CONTRIBUTORS "AS IS" AND ANY EXPRESS OR IMPLIED WARRANTIES, INCLUDING, BUT NOT LIMITED TO, THE IMPLIED WARRANTIES OF MERCHANTABILITY AND FITNESS FOR A PARTICULAR PURPOSE ARE DISCLAIMED. IN NO EVENT SHALL THE COPYRIGHT HOLDER OR CONTRIBUTORS BE LIABLE FOR ANY DIRECT, INDIRECT, INCIDENTAL, SPECIAL, EXEMPLARY, OR CONSEQUENTIAL DAMAGES (INCLUDING, BUT NOT LIMITED TO, PROCUREMENT OF SUBSTITUTE GOODS OR SERVICES; LOSS OF USE, DATA, OR PROFITS; OR BUSINESS INTERRUPTION) HOWEVER CAUSED AND ON ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, STRICT LIABILITY, OR TORT (INCLUDING NEGLIGENCE OR OTHERWISE) ARISING IN ANY WAY OUT OF THE USE OF THIS SOFTWARE, EVEN IF ADVISED OF THE POSSIBILITY OF SUCH DAMAGE.
THE CLIP SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
THE PYTORCH-PRETRAINED-BIGGAN SOFTWARE IS PROVIDED "AS IS", WITHOUT WARRANTY OF ANY KIND, EXPRESS OR
IMPLIED, INCLUDING BUT NOT LIMITED TO THE WARRANTIES OF MERCHANTABILITY,
FITNESS FOR A PARTICULAR PURPOSE AND NONINFRINGEMENT. IN NO EVENT SHALL THE
AUTHORS OR COPYRIGHT HOLDERS BE LIABLE FOR ANY CLAIM, DAMAGES OR OTHER
LIABILITY, WHETHER IN AN ACTION OF CONTRACT, TORT OR OTHERWISE, ARISING FROM,
OUT OF OR IN CONNECTION WITH THE SOFTWARE OR THE USE OR OTHER DEALINGS IN THE
SOFTWARE.
## Cite the paper
If this repository, the paper or any of its content is useful for your research, please cite:
```
@inproceedings{casanova2021instanceconditioned,
title={Instance-Conditioned GAN},
author={Arantxa Casanova and Marlène Careil and Jakob Verbeek and Michal Drozdzal and Adriana Romero-Soriano},
booktitle={Advances in Neural Information Processing Systems (NeurIPS)},
year={2021}
}
```
|
AnonymousSub/AR_declutr | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
language:
- multilingual
- af
- am
- ar
- ast
- az
- ba
- be
- bg
- bn
- br
- bs
- ca
- ceb
- cs
- cy
- da
- de
- el
- en
- es
- et
- fa
- ff
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- ht
- hu
- hy
- id
- ig
- ilo
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- lb
- lg
- ln
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- ns
- oc
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sd
- si
- sk
- sl
- so
- sq
- sr
- ss
- su
- sv
- sw
- ta
- th
- tl
- tn
- tr
- uk
- ur
- uz
- vi
- wo
- xh
- yi
- yo
- zh
- zu
license: mit
tags:
---
# M2M100 1.2B
M2M100 is a multilingual encoder-decoder (seq-to-seq) model trained for Many-to-Many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2010.11125) and first released in [this](https://github.com/pytorch/fairseq/tree/master/examples/m2m_100) repository.
The model that can directly translate between the 9,900 directions of 100 languages.
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
```python
from transformers import M2M100ForConditionalGeneration, M2M100Tokenizer
hi_text = "जीवन एक चॉकलेट बॉक्स की तरह है।"
chinese_text = "生活就像一盒巧克力。"
model = M2M100ForConditionalGeneration.from_pretrained("facebook/m2m100_1.2B")
tokenizer = M2M100Tokenizer.from_pretrained("facebook/m2m100_1.2B")
# translate Hindi to French
tokenizer.src_lang = "hi"
encoded_hi = tokenizer(hi_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_hi, forced_bos_token_id=tokenizer.get_lang_id("fr"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "La vie est comme une boîte de chocolat."
# translate Chinese to English
tokenizer.src_lang = "zh"
encoded_zh = tokenizer(chinese_text, return_tensors="pt")
generated_tokens = model.generate(**encoded_zh, forced_bos_token_id=tokenizer.get_lang_id("en"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Life is like a box of chocolate."
```
See the [model hub](https://huggingface.co/models?filter=m2m_100) to look for more fine-tuned versions.
## Languages covered
Afrikaans (af), Amharic (am), Arabic (ar), Asturian (ast), Azerbaijani (az), Bashkir (ba), Belarusian (be), Bulgarian (bg), Bengali (bn), Breton (br), Bosnian (bs), Catalan; Valencian (ca), Cebuano (ceb), Czech (cs), Welsh (cy), Danish (da), German (de), Greeek (el), English (en), Spanish (es), Estonian (et), Persian (fa), Fulah (ff), Finnish (fi), French (fr), Western Frisian (fy), Irish (ga), Gaelic; Scottish Gaelic (gd), Galician (gl), Gujarati (gu), Hausa (ha), Hebrew (he), Hindi (hi), Croatian (hr), Haitian; Haitian Creole (ht), Hungarian (hu), Armenian (hy), Indonesian (id), Igbo (ig), Iloko (ilo), Icelandic (is), Italian (it), Japanese (ja), Javanese (jv), Georgian (ka), Kazakh (kk), Central Khmer (km), Kannada (kn), Korean (ko), Luxembourgish; Letzeburgesch (lb), Ganda (lg), Lingala (ln), Lao (lo), Lithuanian (lt), Latvian (lv), Malagasy (mg), Macedonian (mk), Malayalam (ml), Mongolian (mn), Marathi (mr), Malay (ms), Burmese (my), Nepali (ne), Dutch; Flemish (nl), Norwegian (no), Northern Sotho (ns), Occitan (post 1500) (oc), Oriya (or), Panjabi; Punjabi (pa), Polish (pl), Pushto; Pashto (ps), Portuguese (pt), Romanian; Moldavian; Moldovan (ro), Russian (ru), Sindhi (sd), Sinhala; Sinhalese (si), Slovak (sk), Slovenian (sl), Somali (so), Albanian (sq), Serbian (sr), Swati (ss), Sundanese (su), Swedish (sv), Swahili (sw), Tamil (ta), Thai (th), Tagalog (tl), Tswana (tn), Turkish (tr), Ukrainian (uk), Urdu (ur), Uzbek (uz), Vietnamese (vi), Wolof (wo), Xhosa (xh), Yiddish (yi), Yoruba (yo), Chinese (zh), Zulu (zu)
## BibTeX entry and citation info
```
@misc{fan2020englishcentric,
title={Beyond English-Centric Multilingual Machine Translation},
author={Angela Fan and Shruti Bhosale and Holger Schwenk and Zhiyi Ma and Ahmed El-Kishky and Siddharth Goyal and Mandeep Baines and Onur Celebi and Guillaume Wenzek and Vishrav Chaudhary and Naman Goyal and Tom Birch and Vitaliy Liptchinsky and Sergey Edunov and Edouard Grave and Michael Auli and Armand Joulin},
year={2020},
eprint={2010.11125},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
AnonymousSub/SR_rule_based_hier_quadruplet_epochs_1_shard_1 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
library_name: fairseq
task: text-to-speech
tags:
- fairseq
- audio
- text-to-speech
- multi-speaker
language: en
datasets:
- common_voice
widget:
- text: "Hello, this is a test run."
example_title: "Hello, this is a test run."
---
# tts_transformer-en-200_speaker-cv4
[Transformer](https://arxiv.org/abs/1809.08895) text-to-speech model from fairseq S^2 ([paper](https://arxiv.org/abs/2109.06912)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_synthesis)):
- English
- 200 male/female voices (random speaker when using the widget)
- Trained on [Common Voice v4](https://commonvoice.mozilla.org/en/datasets)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/tts_transformer-en-200_speaker-cv4",
arg_overrides={"vocoder": "hifigan", "fp16": False}
)
model = models[0]
TTSHubInterface.update_cfg_with_data_cfg(cfg, task.data_cfg)
generator = task.build_generator(model, cfg)
text = "Hello, this is a test run."
sample = TTSHubInterface.get_model_input(task, text)
wav, rate = TTSHubInterface.get_prediction(task, model, generator, sample)
ipd.Audio(wav, rate=rate)
```
See also [fairseq S^2 example](https://github.com/pytorch/fairseq/blob/main/examples/speech_synthesis/docs/common_voice_example.md).
## Citation
```bibtex
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
```
|
AnonymousSub/declutr-model_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language: en
datasets:
- librispeech_asr
tags:
- speech
license: apache-2.0
model-index:
- name: wav2vec2-large-960h-lv60
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Librispeech (clean)
type: librispeech_asr
args: en
metrics:
- name: Test WER
type: wer
value: 2.2
---
# Wav2Vec2-Large-960h-Lv60
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The large model pretrained and fine-tuned on 960 hours of Libri-Light and Librispeech on 16kHz sampled speech audio. When using the model
make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **facebook/wav2vec2-large-960h-lv60** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h-lv60").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h-lv60")
def map_to_pred(batch):
inputs = processor(batch["audio"]["array"], return_tensors="pt", padding="longest")
input_values = inputs.input_values.to("cuda")
attention_mask = inputs.attention_mask.to("cuda")
with torch.no_grad():
logits = model(input_values, attention_mask=attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=16, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
|---|---|
| 2.2 | 4.5 | |
AnonymousSub/declutr-model_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null | ---
language: en
datasets:
- librispeech_asr
tags:
- speech
license: apache-2.0
---
# Wav2Vec2-Large-960h
[Facebook's Wav2Vec2](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/)
The large model pretrained and fine-tuned on 960 hours of Librispeech on 16kHz sampled speech audio. When using the model
make sure that your speech input is also sampled at 16Khz.
[Paper](https://arxiv.org/abs/2006.11477)
Authors: Alexei Baevski, Henry Zhou, Abdelrahman Mohamed, Michael Auli
**Abstract**
We show for the first time that learning powerful representations from speech audio alone followed by fine-tuning on transcribed speech can outperform the best semi-supervised methods while being conceptually simpler. wav2vec 2.0 masks the speech input in the latent space and solves a contrastive task defined over a quantization of the latent representations which are jointly learned. Experiments using all labeled data of Librispeech achieve 1.8/3.3 WER on the clean/other test sets. When lowering the amount of labeled data to one hour, wav2vec 2.0 outperforms the previous state of the art on the 100 hour subset while using 100 times less labeled data. Using just ten minutes of labeled data and pre-training on 53k hours of unlabeled data still achieves 4.8/8.2 WER. This demonstrates the feasibility of speech recognition with limited amounts of labeled data.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"],, return_tensors="pt", padding="longest").input_values # Batch size 1
# retrieve logits
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
```
## Evaluation
This code snippet shows how to evaluate **facebook/wav2vec2-large-960h** on LibriSpeech's "clean" and "other" test data.
```python
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import soundfile as sf
import torch
from jiwer import wer
librispeech_eval = load_dataset("librispeech_asr", "clean", split="test")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-large-960h").to("cuda")
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-large-960h")
def map_to_pred(batch):
input_values = processor(batch["audio"]["array"], return_tensors="pt", padding="longest").input_values
with torch.no_grad():
logits = model(input_values.to("cuda")).logits
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
batch["transcription"] = transcription
return batch
result = librispeech_eval.map(map_to_pred, batched=True, batch_size=1, remove_columns=["speech"])
print("WER:", wer(result["text"], result["transcription"]))
```
*Result (WER)*:
| "clean" | "other" |
|---|---|
| 2.8 | 6.3 | |
AnonymousSub/rule_based_hier_quadruplet_epochs_1_shard_1_wikiqa | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | ---
language: multi-lingual
datasets:
- common_voice
tags:
- speech
- audio
- automatic-speech-recognition
- phoneme-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
license: apache-2.0
---
# Wav2Vec2-Large-LV60 finetuned on multi-lingual Common Voice
This checkpoint leverages the pretrained checkpoint [wav2vec2-large-lv60](https://huggingface.co/facebook/wav2vec2-large-lv60)
and is fine-tuned on [CommonVoice](https://huggingface.co/datasets/common_voice) to recognize phonetic labels in multiple languages.
When using the model make sure that your speech input is sampled at 16kHz.
Note that the model outputs a string of phonetic labels. A dictionary mapping phonetic labels to words
has to be used to map the phonetic output labels to output words.
[Paper: Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680)
Authors: Qiantong Xu, Alexei Baevski, Michael Auli
**Abstract**
Recent progress in self-training, self-supervised pretraining and unsupervised learning enabled well performing speech recognition systems without any labeled data. However, in many cases there is labeled data available for related languages which is not utilized by these methods. This paper extends previous work on zero-shot cross-lingual transfer learning by fine-tuning a multilingually pretrained wav2vec 2.0 model to transcribe unseen languages. This is done by mapping phonemes of the training languages to the target language using articulatory features. Experiments show that this simple method significantly outperforms prior work which introduced task-specific architectures and used only part of a monolingually pretrained model.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-lv-60-espeak-cv-ft")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-lv-60-espeak-cv-ft")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
# retrieve logits
with torch.no_grad():
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
# => should give ['m ɪ s t ɚ k w ɪ l t ɚ ɹ ɪ z ð ɪ ɐ p ɑː s əl ʌ v ð ə m ɪ d əl k l æ s ᵻ z æ n d w iː ɑːɹ ɡ l æ d t ə w ɛ l k ə m h ɪ z ɡ ɑː s p əl']
``` |
AnonymousSub/rule_based_hier_triplet_0.1_epochs_1_shard_1 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-2b-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-1b`**](https://huggingface.co/facebook/wav2vec2-xls-r-1b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-1b-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-1b-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-1b-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-1b-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (1B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
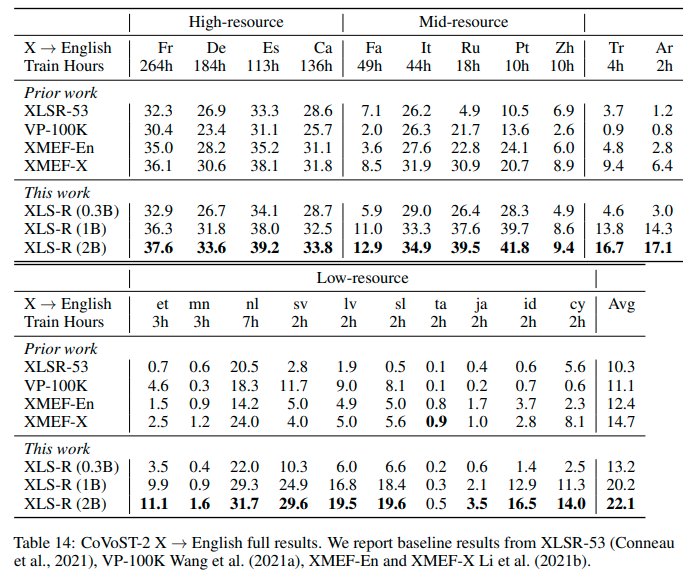
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
AnonymousSub/rule_based_hier_triplet_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-2b-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-2b-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (2B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.

## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
AnonymousSub/rule_based_hier_triplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-2B-22-16 (XLS-R-Any-to-Any)
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on `{input_lang}` -> `{output_lang}` translation pairs
of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{input_lang}` to the following written languages `{output_lang}`:
`{input_lang}` -> `{output_lang}`
with `{input_lang}` one of:
{`en`, `fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`}
and `{output_lang}`:
{`en`, `de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-2B-22-16).
You can select the target language, record some audio in any of the above mentioned input languages,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"en": 250004,
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-22-to-16", feature_extractor="facebook/wav2vec2-xls-r-2b-22-to-16")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-22-to-16")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-22-to-16")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
AnonymousSub/rule_based_hier_triplet_epochs_1_shard_1_wikiqa | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | null | ---
language:
- multilingual
- en
- de
- tr
- fa
- sv
- mn
- zh
- cy
- ca
- sl
- et
- id
- ar
- ta
- lv
- ja
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
---
# Wav2Vec2-XLS-R-2B-EN-15
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-2b`**](https://huggingface.co/facebook/wav2vec2-xls-r-2b) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 15 `en` -> `{lang}` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from spoken `en` (Engish) to the following written languages `{lang}`:
`en` -> {`de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
For more information, please refer to Section *5.1.1* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-2B-EN-15).
You can select the target language, record some audio in English,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-2b-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-2b-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-2b-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-2b-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## Results `en` -> `{lang}`
See the row of **XLS-R (2B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.
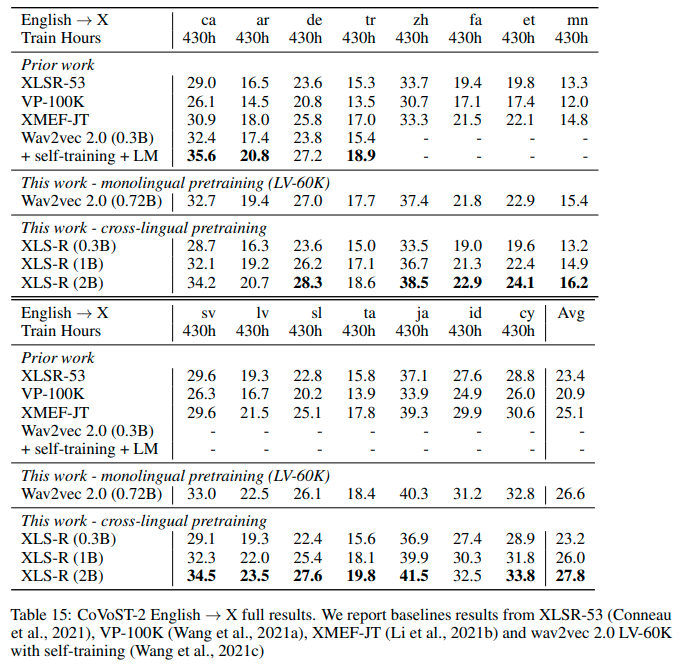
## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
AnonymousSub/rule_based_hier_triplet_epochs_1_shard_1_wikiqa_copy | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
language:
- multilingual
- ab
- af
- sq
- am
- ar
- hy
- as
- az
- ba
- eu
- be
- bn
- bs
- br
- bg
- my
- yue
- ca
- ceb
- km
- zh
- cv
- hr
- cs
- da
- dv
- nl
- en
- eo
- et
- fo
- fi
- fr
- gl
- lg
- ka
- de
- el
- gn
- gu
- ht
- cnh
- ha
- haw
- he
- hi
- hu
- is
- id
- ia
- ga
- it
- ja
- jv
- kb
- kn
- kk
- rw
- ky
- ko
- ku
- lo
- la
- lv
- ln
- lt
- lm
- mk
- mg
- ms
- ml
- mt
- gv
- mi
- mr
- mn
- ne
- no
- nn
- oc
- or
- ps
- fa
- pl
- pt
- pa
- ro
- rm
- rm
- ru
- sah
- sa
- sco
- sr
- sn
- sd
- si
- sk
- sl
- so
- hsb
- es
- su
- sw
- sv
- tl
- tg
- ta
- tt
- te
- th
- bo
- tp
- tr
- tk
- uk
- ur
- uz
- vi
- vot
- war
- cy
- yi
- yo
- zu
language_bcp47:
- zh-HK
- zh-TW
- fy-NL
datasets:
- common_voice
- multilingual_librispeech
tags:
- speech
- xls_r
- xls_r_pretrained
license: apache-2.0
---
# Wav2Vec2-XLS-R-2B
[Facebook's Wav2Vec2 XLS-R](https://ai.facebook.com/blog/xls-r-self-supervised-speech-processing-for-128-languages) counting **2 billion** parameters.

XLS-R is Facebook AI's large-scale multilingual pretrained model for speech (the "XLM-R for Speech"). It is pretrained on 436k hours of unlabeled speech, including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua107. It uses the wav2vec 2.0 objective, in 128 languages. When using the model make sure that your speech input is sampled at 16kHz.
**Note**: This model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Translation, or Classification. Check out [**this blog**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for more information about ASR.
[XLS-R Paper](https://arxiv.org/abs/2111.09296)
Authors: Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli
**Abstract**
This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on 436K hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 20%-33% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this google colab](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLS_R_on_Common_Voice.ipynb) for more information on how to fine-tune the model.
You can find other pretrained XLS-R models with different numbers of parameters:
* [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
* [1B version version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
* [2B version version](https://huggingface.co/facebook/wav2vec2-xls-r-2b)
|
AnonymousSub/rule_based_only_classfn_epochs_1_shard_1 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
language:
- multilingual
- fr
- de
- es
- ca
- it
- ru
- zh
- pt
- fa
- et
- mn
- nl
- tr
- ar
- sv
- lv
- sl
- ta
- ja
- id
- cy
- en
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- automatic-speech-recognition
- xls_r_translation
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: Swedish
src: https://cdn-media.huggingface.co/speech_samples/cv_swedish_1.mp3
- example_title: Arabic
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ar_19058308.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: German
src: https://cdn-media.huggingface.co/speech_samples/common_voice_de_17284683.mp3
- example_title: French
src: https://cdn-media.huggingface.co/speech_samples/common_voice_fr_17299386.mp3
- example_title: Indonesian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_id_19051309.mp3
- example_title: Italian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_it_17415776.mp3
- example_title: Japanese
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ja_19482488.mp3
- example_title: Mongolian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_mn_18565396.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
- example_title: Russian
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ru_18849022.mp3
- example_title: Turkish
src: https://cdn-media.huggingface.co/speech_samples/common_voice_tr_17341280.mp3
- example_title: Catalan
src: https://cdn-media.huggingface.co/speech_samples/common_voice_ca_17367522.mp3
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
- example_title: Dutch
src: https://cdn-media.huggingface.co/speech_samples/common_voice_nl_17691471.mp3
---
# Wav2Vec2-XLS-R-300M-21-EN
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-300m`**](https://huggingface.co/facebook/wav2vec2-xls-r-300m) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 21 `{lang}` -> `en` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from the following spoken languages `{lang}` -> `en` (English):
{`fr`, `de`, `es`, `ca`, `it`, `ru`, `zh-CN`, `pt`, `fa`, `et`, `mn`, `nl`, `tr`, `ar`, `sv-SE`, `lv`, `sl`, `ta`, `ja`, `id`, `cy`} -> `en`
For more information, please refer to Section *5.1.2* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested directly on the speech recognition widget on this model card!
Simple record some audio in one of the possible spoken languages or pick an example audio file to see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline
```python
from datasets import load_dataset
from transformers import pipeline
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-300m-21-to-en", feature_extractor="facebook/wav2vec2-xls-r-300m-21-to-en")
translation = asr(audio_file)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-21-to-en")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"])
transcription = processor.batch_decode(generated_ids)
```
## Results `{lang}` -> `en`
See the row of **XLS-R (0.3B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.

## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-300m-21-to-en)
- [Wav2Vec2-XLS-R-1B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-1b-21-to-en)
- [Wav2Vec2-XLS-R-2B-21-EN](https://huggingface.co/facebook/wav2vec2-xls-r-2b-21-to-en)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
AnonymousSub/rule_based_only_classfn_epochs_1_shard_10 | [
"pytorch",
"bert",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language:
- multilingual
- en
- de
- tr
- fa
- sv
- mn
- zh
- cy
- ca
- sl
- et
- id
- ar
- ta
- lv
- ja
datasets:
- common_voice
- multilingual_librispeech
- covost2
tags:
- speech
- xls_r
- xls_r_translation
- automatic-speech-recognition
pipeline_tag: automatic-speech-recognition
license: apache-2.0
widget:
- example_title: English
src: https://cdn-media.huggingface.co/speech_samples/common_voice_en_18301577.mp3
---
# Wav2Vec2-XLS-R-300M-EN-15
Facebook's Wav2Vec2 XLS-R fine-tuned for **Speech Translation.**

This is a [SpeechEncoderDecoderModel](https://huggingface.co/transformers/model_doc/speechencoderdecoder.html) model.
The encoder was warm-started from the [**`facebook/wav2vec2-xls-r-300m`**](https://huggingface.co/facebook/wav2vec2-xls-r-300m) checkpoint and
the decoder from the [**`facebook/mbart-large-50`**](https://huggingface.co/facebook/mbart-large-50) checkpoint.
Consequently, the encoder-decoder model was fine-tuned on 15 `en` -> `{lang}` translation pairs of the [Covost2 dataset](https://huggingface.co/datasets/covost2).
The model can translate from spoken `en` (Engish) to the following written languages `{lang}`:
`en` -> {`de`, `tr`, `fa`, `sv-SE`, `mn`, `zh-CN`, `cy`, `ca`, `sl`, `et`, `id`, `ar`, `ta`, `lv`, `ja`}
For more information, please refer to Section *5.1.1* of the [official XLS-R paper](https://arxiv.org/abs/2111.09296).
## Usage
### Demo
The model can be tested on [**this space**](https://huggingface.co/spaces/facebook/XLS-R-300m-EN-15).
You can select the target language, record some audio in English,
and then sit back and see how well the checkpoint can translate the input.
### Example
As this a standard sequence to sequence transformer model, you can use the `generate` method to generate the
transcripts by passing the speech features to the model.
You can use the model directly via the ASR pipeline. By default, the checkpoint will
translate spoken English to written German. To change the written target language,
you need to pass the correct `forced_bos_token_id` to `generate(...)` to condition
the decoder on the correct target language.
To select the correct `forced_bos_token_id` given your choosen language id, please make use
of the following mapping:
```python
MAPPING = {
"de": 250003,
"tr": 250023,
"fa": 250029,
"sv": 250042,
"mn": 250037,
"zh": 250025,
"cy": 250007,
"ca": 250005,
"sl": 250052,
"et": 250006,
"id": 250032,
"ar": 250001,
"ta": 250044,
"lv": 250017,
"ja": 250012,
}
```
As an example, if you would like to translate to Swedish, you can do the following:
```python
from datasets import load_dataset
from transformers import pipeline
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
# replace following lines to load an audio file of your choice
librispeech_en = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
audio_file = librispeech_en[0]["file"]
asr = pipeline("automatic-speech-recognition", model="facebook/wav2vec2-xls-r-300m-en-to-15", feature_extractor="facebook/wav2vec2-xls-r-300m-en-to-15")
translation = asr(audio_file, forced_bos_token_id=forced_bos_token_id)
```
or step-by-step as follows:
```python
import torch
from transformers import Speech2Text2Processor, SpeechEncoderDecoderModel
from datasets import load_dataset
model = SpeechEncoderDecoderModel.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
processor = Speech2Text2Processor.from_pretrained("facebook/wav2vec2-xls-r-300m-en-to-15")
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# select correct `forced_bos_token_id`
forced_bos_token_id = MAPPING["sv"]
inputs = processor(ds[0]["audio"]["array"], sampling_rate=ds[0]["audio"]["array"]["sampling_rate"], return_tensors="pt")
generated_ids = model.generate(input_ids=inputs["input_features"], attention_mask=inputs["attention_mask"], forced_bos_token_id=forced_bos_token)
transcription = processor.batch_decode(generated_ids)
```
## Results `en` -> `{lang}`
See the row of **XLS-R (0.3B)** for the performance on [Covost2](https://huggingface.co/datasets/covost2) for this model.

## More XLS-R models for `{lang}` -> `en` Speech Translation
- [Wav2Vec2-XLS-R-300M-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-300m-en-to-15)
- [Wav2Vec2-XLS-R-1B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-1b-en-to-15)
- [Wav2Vec2-XLS-R-2B-EN-15](https://huggingface.co/facebook/wav2vec2-xls-r-2b-en-to-15)
- [Wav2Vec2-XLS-R-2B-22-16](https://huggingface.co/facebook/wav2vec2-xls-r-2b-22-to-16)
|
AnonymousSub/rule_based_only_classfn_epochs_1_shard_1_squad2.0 | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language:
- multilingual
- ab
- af
- sq
- am
- ar
- hy
- as
- az
- ba
- eu
- be
- bn
- bs
- br
- bg
- my
- yue
- ca
- ceb
- km
- zh
- cv
- hr
- cs
- da
- dv
- nl
- en
- eo
- et
- fo
- fi
- fr
- gl
- lg
- ka
- de
- el
- gn
- gu
- ht
- cnh
- ha
- haw
- he
- hi
- hu
- is
- id
- ia
- ga
- it
- ja
- jv
- kb
- kn
- kk
- rw
- ky
- ko
- ku
- lo
- la
- lv
- ln
- lt
- lm
- mk
- mg
- ms
- ml
- mt
- gv
- mi
- mr
- mn
- ne
- no
- nn
- oc
- or
- ps
- fa
- pl
- pt
- pa
- ro
- rm
- rm
- ru
- sah
- sa
- sco
- sr
- sn
- sd
- si
- sk
- sl
- so
- hsb
- es
- su
- sw
- sv
- tl
- tg
- ta
- tt
- te
- th
- bo
- tp
- tr
- tk
- uk
- ur
- uz
- vi
- vot
- war
- cy
- yi
- yo
- zu
language_bcp47:
- zh-HK
- zh-TW
- fy-NL
datasets:
- common_voice
- multilingual_librispeech
tags:
- speech
- xls_r
- xls_r_pretrained
license: apache-2.0
---
# Wav2Vec2-XLS-R-300M
[Facebook's Wav2Vec2 XLS-R](https://ai.facebook.com/blog/wav2vec-20-learning-the-structure-of-speech-from-raw-audio/) counting **300 million** parameters.

XLS-R is Facebook AI's large-scale multilingual pretrained model for speech (the "XLM-R for Speech"). It is pretrained on 436k hours of unlabeled speech, including VoxPopuli, MLS, CommonVoice, BABEL, and VoxLingua107. It uses the wav2vec 2.0 objective, in 128 languages. When using the model make sure that your speech input is sampled at 16kHz.
**Note**: This model should be fine-tuned on a downstream task, like Automatic Speech Recognition, Translation, or Classification. Check out [**this blog**](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2) for more information about ASR.
[XLS-R Paper](https://arxiv.org/abs/2111.09296)
Authors: Arun Babu, Changhan Wang, Andros Tjandra, Kushal Lakhotia, Qiantong Xu, Naman Goyal, Kritika Singh, Patrick von Platen, Yatharth Saraf, Juan Pino, Alexei Baevski, Alexis Conneau, Michael Auli
**Abstract**
This paper presents XLS-R, a large-scale model for cross-lingual speech representation learning based on wav2vec 2.0. We train models with up to 2B parameters on 436K hours of publicly available speech audio in 128 languages, an order of magnitude more public data than the largest known prior work. Our evaluation covers a wide range of tasks, domains, data regimes and languages, both high and low-resource. On the CoVoST-2 speech translation benchmark, we improve the previous state of the art by an average of 7.4 BLEU over 21 translation directions into English. For speech recognition, XLS-R improves over the best known prior work on BABEL, MLS, CommonVoice as well as VoxPopuli, lowering error rates by 20%-33% relative on average. XLS-R also sets a new state of the art on VoxLingua107 language identification. Moreover, we show that with sufficient model size, cross-lingual pretraining can outperform English-only pretraining when translating English speech into other languages, a setting which favors monolingual pretraining. We hope XLS-R can help to improve speech processing tasks for many more languages of the world.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
See [this google colab](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Fine_Tune_XLS_R_on_Common_Voice.ipynb) for more information on how to fine-tune the model.
You can find other pretrained XLS-R models with different numbers of parameters:
* [300M parameters version](https://huggingface.co/facebook/wav2vec2-xls-r-300m)
* [1B version version](https://huggingface.co/facebook/wav2vec2-xls-r-1b)
* [2B version version](https://huggingface.co/facebook/wav2vec2-xls-r-2b) |
AnonymousSub/rule_based_only_classfn_epochs_1_shard_1_wikiqa | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | null | ---
language: multi-lingual
datasets:
- common_voice
tags:
- speech
- audio
- automatic-speech-recognition
- phoneme-recognition
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
license: apache-2.0
---
# Wav2Vec2-Large-XLSR-53 finetuned on multi-lingual Common Voice
This checkpoint leverages the pretrained checkpoint [wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
and is fine-tuned on [CommonVoice](https://huggingface.co/datasets/common_voice) to recognize phonetic labels in multiple languages.
When using the model make sure that your speech input is sampled at 16kHz.
Note that the model outputs a string of phonetic labels. A dictionary mapping phonetic labels to words
has to be used to map the phonetic output labels to output words.
[Paper: Simple and Effective Zero-shot Cross-lingual Phoneme Recognition](https://arxiv.org/abs/2109.11680)
Authors: Qiantong Xu, Alexei Baevski, Michael Auli
**Abstract**
Recent progress in self-training, self-supervised pretraining and unsupervised learning enabled well performing speech recognition systems without any labeled data. However, in many cases there is labeled data available for related languages which is not utilized by these methods. This paper extends previous work on zero-shot cross-lingual transfer learning by fine-tuning a multilingually pretrained wav2vec 2.0 model to transcribe unseen languages. This is done by mapping phonemes of the training languages to the target language using articulatory features. Experiments show that this simple method significantly outperforms prior work which introduced task-specific architectures and used only part of a monolingually pretrained model.
The original model can be found under https://github.com/pytorch/fairseq/tree/master/examples/wav2vec#wav2vec-20.
# Usage
To transcribe audio files the model can be used as a standalone acoustic model as follows:
```python
from transformers import Wav2Vec2Processor, Wav2Vec2ForCTC
from datasets import load_dataset
import torch
# load model and processor
processor = Wav2Vec2Processor.from_pretrained("facebook/wav2vec2-xlsr-53-espeak-cv-ft")
model = Wav2Vec2ForCTC.from_pretrained("facebook/wav2vec2-xlsr-53-espeak-cv-ft")
# load dummy dataset and read soundfiles
ds = load_dataset("patrickvonplaten/librispeech_asr_dummy", "clean", split="validation")
# tokenize
input_values = processor(ds[0]["audio"]["array"], return_tensors="pt").input_values
# retrieve logits
with torch.no_grad():
logits = model(input_values).logits
# take argmax and decode
predicted_ids = torch.argmax(logits, dim=-1)
transcription = processor.batch_decode(predicted_ids)
# => should give ['m ɪ s t ɚ k w ɪ l t ɚ ɪ z ð ɪ ɐ p ɑː s əl l ʌ v ð ə m ɪ d əl k l æ s ɪ z æ n d w iː aʊ ɡ l æ d t ə w ɛ l k ə m h ɪ z ɡ ɑː s p ə']
``` |
AnonymousSub/rule_based_roberta_bert_quadruplet_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2020-09-15T18:43:35Z | ---
language:
- de
- en
tags:
- translation
- wmt19
- facebook
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
---
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for de-en.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co/facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-de-en"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Maschinelles Lernen ist großartig, oder?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Machine learning is great, isn't it?
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
de-en | [42.3](http://matrix.statmt.org/matrix/output/1902?run_id=6750) | 41.35
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=de-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={Facebook FAIR's WMT19 News Translation Task Submission},
author={Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey},
booktitle={Proc. of WMT},
}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
|
AnonymousSub/rule_based_roberta_bert_quadruplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language:
- en
- de
tags:
- translation
- wmt19
- facebook
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
---
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for en-de.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co/facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-en-de"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Maschinelles Lernen ist großartig, oder?
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
en-de | [43.1](http://matrix.statmt.org/matrix/output/1909?run_id=6862) | 42.83
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-de
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={Facebook FAIR's WMT19 News Translation Task Submission},
author={Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey},
booktitle={Proc. of WMT},
}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
|
AnonymousSub/rule_based_roberta_bert_quadruplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language:
- en
- ru
tags:
- translation
- wmt19
- facebook
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
---
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for en-ru.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co/facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-en-ru"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Machine learning is great, isn't it?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Машинное обучение - это здорово, не так ли?
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
en-ru | [36.4](http://matrix.statmt.org/matrix/output/1914?run_id=6724) | 33.47
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=en-ru
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={Facebook FAIR's WMT19 News Translation Task Submission},
author={Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey},
booktitle={Proc. of WMT},
}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
|
AnonymousSub/rule_based_roberta_bert_quadruplet_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 23 | null | ---
language:
- ru
- en
tags:
- translation
- wmt19
- facebook
license: apache-2.0
datasets:
- wmt19
metrics:
- bleu
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
---
# FSMT
## Model description
This is a ported version of [fairseq wmt19 transformer](https://github.com/pytorch/fairseq/blob/master/examples/wmt19/README.md) for ru-en.
For more details, please see, [Facebook FAIR's WMT19 News Translation Task Submission](https://arxiv.org/abs/1907.06616).
The abbreviation FSMT stands for FairSeqMachineTranslation
All four models are available:
* [wmt19-en-ru](https://huggingface.co/facebook/wmt19-en-ru)
* [wmt19-ru-en](https://huggingface.co/facebook/wmt19-ru-en)
* [wmt19-en-de](https://huggingface.co/facebook/wmt19-en-de)
* [wmt19-de-en](https://huggingface.co/facebook/wmt19-de-en)
## Intended uses & limitations
#### How to use
```python
from transformers import FSMTForConditionalGeneration, FSMTTokenizer
mname = "facebook/wmt19-ru-en"
tokenizer = FSMTTokenizer.from_pretrained(mname)
model = FSMTForConditionalGeneration.from_pretrained(mname)
input = "Машинное обучение - это здорово, не так ли?"
input_ids = tokenizer.encode(input, return_tensors="pt")
outputs = model.generate(input_ids)
decoded = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(decoded) # Machine learning is great, isn't it?
```
#### Limitations and bias
- The original (and this ported model) doesn't seem to handle well inputs with repeated sub-phrases, [content gets truncated](https://discuss.huggingface.co/t/issues-with-translating-inputs-containing-repeated-phrases/981)
## Training data
Pretrained weights were left identical to the original model released by fairseq. For more details, please, see the [paper](https://arxiv.org/abs/1907.06616).
## Eval results
pair | fairseq | transformers
-------|---------|----------
ru-en | [41.3](http://matrix.statmt.org/matrix/output/1907?run_id=6937) | 39.20
The score is slightly below the score reported by `fairseq`, since `transformers`` currently doesn't support:
- model ensemble, therefore the best performing checkpoint was ported (``model4.pt``).
- re-ranking
The score was calculated using this code:
```bash
git clone https://github.com/huggingface/transformers
cd transformers
export PAIR=ru-en
export DATA_DIR=data/$PAIR
export SAVE_DIR=data/$PAIR
export BS=8
export NUM_BEAMS=15
mkdir -p $DATA_DIR
sacrebleu -t wmt19 -l $PAIR --echo src > $DATA_DIR/val.source
sacrebleu -t wmt19 -l $PAIR --echo ref > $DATA_DIR/val.target
echo $PAIR
PYTHONPATH="src:examples/seq2seq" python examples/seq2seq/run_eval.py facebook/wmt19-$PAIR $DATA_DIR/val.source $SAVE_DIR/test_translations.txt --reference_path $DATA_DIR/val.target --score_path $SAVE_DIR/test_bleu.json --bs $BS --task translation --num_beams $NUM_BEAMS
```
note: fairseq reports using a beam of 50, so you should get a slightly higher score if re-run with `--num_beams 50`.
## Data Sources
- [training, etc.](http://www.statmt.org/wmt19/)
- [test set](http://matrix.statmt.org/test_sets/newstest2019.tgz?1556572561)
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={Facebook FAIR's WMT19 News Translation Task Submission},
author={Ng, Nathan and Yee, Kyra and Baevski, Alexei and Ott, Myle and Auli, Michael and Edunov, Sergey},
booktitle={Proc. of WMT},
}
```
## TODO
- port model ensemble (fairseq uses 4 model checkpoints)
|
AnonymousSub/rule_based_roberta_bert_triplet_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language:
- multilingual
- ha
- is
- ja
- cs
- ru
- zh
- de
- en
license: mit
tags:
- translation
- wmt21
---
# WMT 21 En-X
WMT 21 En-X is a 4.7B multilingual encoder-decoder (seq-to-seq) model trained for one-to-many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2108.03265) and first released in [this](https://github.com/pytorch/fairseq/tree/main/examples/wmt21) repository.
The model can directly translate English text into 7 other languages: Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de).
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
Since the model was trained with domain tags, you should prepend them to the input as well.
* "wmtdata newsdomain": Use for sentences in the news domain
* "wmtdata otherdomain": Use for sentences in all other domain
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/wmt21-dense-24-wide-en-x")
tokenizer = AutoTokenizer.from_pretrained("facebook/wmt21-dense-24-wide-en-x")
inputs = tokenizer("wmtdata newsdomain One model for many languages.", return_tensors="pt")
# translate English to German
generated_tokens = model.generate(**inputs, forced_bos_token_id=tokenizer.get_lang_id("de"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Ein Modell für viele Sprachen."
# translate English to Icelandic
generated_tokens = model.generate(**inputs, forced_bos_token_id=tokenizer.get_lang_id("is"))
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "Ein fyrirmynd fyrir mörg tungumál."
```
See the [model hub](https://huggingface.co/models?filter=wmt21) to look for more fine-tuned versions.
## Languages covered
English (en), Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de)
## BibTeX entry and citation info
```
@inproceedings{tran2021facebook
title={Facebook AI’s WMT21 News Translation Task Submission},
author={Chau Tran and Shruti Bhosale and James Cross and Philipp Koehn and Sergey Edunov and Angela Fan},
booktitle={Proc. of WMT},
year={2021},
}
``` |
AnonymousSub/rule_based_roberta_bert_triplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language:
- multilingual
- ha
- is
- ja
- cs
- ru
- zh
- de
- en
license: mit
tags:
- translation
- wmt21
---
# WMT 21 X-En
WMT 21 X-En is a 4.7B multilingual encoder-decoder (seq-to-seq) model trained for one-to-many multilingual translation.
It was introduced in this [paper](https://arxiv.org/abs/2108.03265) and first released in [this](https://github.com/pytorch/fairseq/tree/main/examples/wmt21) repository.
The model can directly translate text from 7 languages: Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de) to English.
To translate into a target language, the target language id is forced as the first generated token.
To force the target language id as the first generated token, pass the `forced_bos_token_id` parameter to the `generate` method.
*Note: `M2M100Tokenizer` depends on `sentencepiece`, so make sure to install it before running the example.*
To install `sentencepiece` run `pip install sentencepiece`
Since the model was trained with domain tags, you should prepend them to the input as well.
* "wmtdata newsdomain": Use for sentences in the news domain
* "wmtdata otherdomain": Use for sentences in all other domain
```python
from transformers import AutoModelForSeq2SeqLM, AutoTokenizer
model = AutoModelForSeq2SeqLM.from_pretrained("facebook/wmt21-dense-24-wide-x-en")
tokenizer = AutoTokenizer.from_pretrained("facebook/wmt21-dense-24-wide-x-en")
# translate German to English
tokenizer.src_lang = "de"
inputs = tokenizer("wmtdata newsdomain Ein Modell für viele Sprachen", return_tensors="pt")
generated_tokens = model.generate(**inputs)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "A model for many languages"
# translate Icelandic to English
tokenizer.src_lang = "is"
inputs = tokenizer("wmtdata newsdomain Ein fyrirmynd fyrir mörg tungumál", return_tensors="pt")
generated_tokens = model.generate(**inputs)
tokenizer.batch_decode(generated_tokens, skip_special_tokens=True)
# => "One model for many languages"
```
See the [model hub](https://huggingface.co/models?filter=wmt21) to look for more fine-tuned versions.
## Languages covered
English (en), Hausa (ha), Icelandic (is), Japanese (ja), Czech (cs), Russian (ru), Chinese (zh), German (de)
## BibTeX entry and citation info
```
@inproceedings{tran2021facebook
title={Facebook AI’s WMT21 News Translation Task Submission},
author={Chau Tran and Shruti Bhosale and James Cross and Philipp Koehn and Sergey Edunov and Angela Fan},
booktitle={Proc. of WMT},
year={2021},
}
``` |
AnonymousSub/rule_based_roberta_bert_triplet_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | null | ---
language:
- multilingual
- en
- ru
- zh
- de
- es
- fr
- ja
- it
- pt
- el
- ko
- fi
- id
- tr
- ar
- vi
- th
- bg
- ca
- hi
- et
- bn
- ta
- ur
- sw
- te
- eu
- my
- ht
- qu
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
inference: false
---
# XGLM-2.9B
XGLM-2.9B is a multilingual autoregressive language model (with 2.9 billion parameters) trained on a balanced corpus of a diverse set of languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-2.9B is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-2.9B development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-2.9B")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-2.9B")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
``` |
AnonymousSub/rule_based_roberta_bert_triplet_epochs_1_shard_1_wikiqa_copy | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
language:
- multilingual
- en
- ru
- zh
- de
- es
- fr
- ja
- it
- pt
- el
- ko
- fi
- id
- tr
- ar
- vi
- th
- bg
- ca
- hi
- et
- bn
- ta
- ur
- sw
- te
- eu
- my
- ht
- qu
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
inference: false
---
# XGLM-4.5B
XGLM-4.5B is a multilingual autoregressive language model (with 4.5 billion parameters) trained on a balanced corpus of a diverse set of 134 languages. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-4.5B development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-4.5B")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-4.5B")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
``` |
AnonymousSub/rule_based_roberta_hier_quadruplet_0.1_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
language:
- multilingual
- en
- ru
- zh
- de
- es
- fr
- ja
- it
- pt
- el
- ko
- fi
- id
- tr
- ar
- vi
- th
- bg
- ca
- hi
- et
- bn
- ta
- ur
- sw
- te
- eu
- my
- ht
- qu
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
inference: false
---
# XGLM-564M
XGLM-564M is a multilingual autoregressive language model (with 564 million parameters) trained on a balanced corpus of a diverse set of 30 languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-564M is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-564M development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-564M")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-564M")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
``` |
AnonymousSub/rule_based_roberta_hier_quadruplet_0.1_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
language:
- multilingual
- en
- ru
- zh
- de
- es
- fr
- ja
- it
- pt
- el
- ko
- fi
- id
- tr
- ar
- vi
- th
- bg
- ca
- hi
- et
- bn
- ta
- ur
- sw
- te
- eu
- my
- ht
- qu
license: mit
thumbnail: https://huggingface.co/front/thumbnails/facebook.png
inference: false
---
# XGLM-7.5B
XGLM-7.5B is a multilingual autoregressive language model (with 7.5 billion parameters) trained on a balanced corpus of a diverse set of languages totaling 500 billion sub-tokens. It was introduced in the paper [Few-shot Learning with Multilingual Language Models](https://arxiv.org/abs/2112.10668) by Xi Victoria Lin\*, Todor Mihaylov, Mikel Artetxe, Tianlu Wang, Shuohui Chen, Daniel Simig, Myle Ott, Naman Goyal, Shruti Bhosale, Jingfei Du, Ramakanth Pasunuru, Sam Shleifer, Punit Singh Koura, Vishrav Chaudhary, Brian O'Horo, Jeff Wang, Luke Zettlemoyer, Zornitsa Kozareva, Mona Diab, Veselin Stoyanov, Xian Li\* (\*Equal Contribution). The original implementation was released in [this repository](https://github.com/pytorch/fairseq/tree/main/examples/xglm).
## Training Data Statistics
The training data statistics of XGLM-7.5B is shown in the table below.
| ISO-639-1| family | name | # tokens | ratio | ratio w/ lowRes upsampling |
|:--------|:-----------------|:------------------------|-------------:|------------:|-------------:|
| en | Indo-European | English | 803526736124 | 0.489906 | 0.3259 |
| ru | Indo-European | Russian | 147791898098 | 0.0901079 | 0.0602 |
| zh | Sino-Tibetan | Chinese | 132770494630 | 0.0809494 | 0.0483 |
| de | Indo-European | German | 89223707856 | 0.0543992 | 0.0363 |
| es | Indo-European | Spanish | 87303083105 | 0.0532282 | 0.0353 |
| fr | Indo-European | French | 77419639775 | 0.0472023 | 0.0313 |
| ja | Japonic | Japanese | 66054364513 | 0.040273 | 0.0269 |
| it | Indo-European | Italian | 41930465338 | 0.0255648 | 0.0171 |
| pt | Indo-European | Portuguese | 36586032444 | 0.0223063 | 0.0297 |
| el | Indo-European | Greek (modern) | 28762166159 | 0.0175361 | 0.0233 |
| ko | Koreanic | Korean | 20002244535 | 0.0121953 | 0.0811 |
| fi | Uralic | Finnish | 16804309722 | 0.0102455 | 0.0681 |
| id | Austronesian | Indonesian | 15423541953 | 0.00940365 | 0.0125 |
| tr | Turkic | Turkish | 12413166065 | 0.00756824 | 0.0101 |
| ar | Afro-Asiatic | Arabic | 12248607345 | 0.00746791 | 0.0099 |
| vi | Austroasiatic | Vietnamese | 11199121869 | 0.00682804 | 0.0091 |
| th | Tai–Kadai | Thai | 10842172807 | 0.00661041 | 0.044 |
| bg | Indo-European | Bulgarian | 9703797869 | 0.00591635 | 0.0393 |
| ca | Indo-European | Catalan | 7075834775 | 0.0043141 | 0.0287 |
| hi | Indo-European | Hindi | 3448390110 | 0.00210246 | 0.014 |
| et | Uralic | Estonian | 3286873851 | 0.00200399 | 0.0133 |
| bn | Indo-European | Bengali, Bangla | 1627447450 | 0.000992245 | 0.0066 |
| ta | Dravidian | Tamil | 1476973397 | 0.000900502 | 0.006 |
| ur | Indo-European | Urdu | 1351891969 | 0.000824241 | 0.0055 |
| sw | Niger–Congo | Swahili | 907516139 | 0.000553307 | 0.0037 |
| te | Dravidian | Telugu | 689316485 | 0.000420272 | 0.0028 |
| eu | Language isolate | Basque | 105304423 | 6.42035e-05 | 0.0043 |
| my | Sino-Tibetan | Burmese | 101358331 | 6.17976e-05 | 0.003 |
| ht | Creole | Haitian, Haitian Creole | 86584697 | 5.27902e-05 | 0.0035 |
| qu | Quechuan | Quechua | 3236108 | 1.97304e-06 | 0.0001 |
## Model card
For intended usage of the model, please refer to the [model card](https://github.com/pytorch/fairseq/blob/main/examples/xglm/model_card.md) released by the XGLM-7.5B development team.
## Example (COPA)
The following snippet shows how to evaluate our models (GPT-3 style, zero-shot) on the Choice of Plausible Alternatives (COPA) task, using examples in English, Chinese and Hindi.
```python
import torch
import torch.nn.functional as F
from transformers import XGLMTokenizer, XGLMForCausalLM
tokenizer = XGLMTokenizer.from_pretrained("facebook/xglm-7.5B")
model = XGLMForCausalLM.from_pretrained("facebook/xglm-7.5B")
data_samples = {
'en': [
{
"premise": "I wanted to conserve energy.",
"choice1": "I swept the floor in the unoccupied room.",
"choice2": "I shut off the light in the unoccupied room.",
"question": "effect",
"label": "1"
},
{
"premise": "The flame on the candle went out.",
"choice1": "I blew on the wick.",
"choice2": "I put a match to the wick.",
"question": "cause",
"label": "0"
}
],
'zh': [
{
"premise": "我想节约能源。",
"choice1": "我在空着的房间里扫了地板。",
"choice2": "我把空房间里的灯关了。",
"question": "effect",
"label": "1"
},
{
"premise": "蜡烛上的火焰熄灭了。",
"choice1": "我吹灭了灯芯。",
"choice2": "我把一根火柴放在灯芯上。",
"question": "cause",
"label": "0"
}
],
'hi': [
{
"premise": "M te vle konsève enèji.",
"choice1": "Mwen te fin baleye chanm lib la.",
"choice2": "Mwen te femen limyè nan chanm lib la.",
"question": "effect",
"label": "1"
},
{
"premise": "Flam bouji a te etenn.",
"choice1": "Mwen te soufle bouji a.",
"choice2": "Mwen te limen mèch bouji a.",
"question": "cause",
"label": "0"
}
]
}
def get_logprobs(prompt):
inputs = tokenizer(prompt, return_tensors="pt")
input_ids, output_ids = inputs["input_ids"], inputs["input_ids"][:, 1:]
outputs = model(**inputs, labels=input_ids)
logits = outputs.logits
logprobs = torch.gather(F.log_softmax(logits, dim=2), 2, output_ids.unsqueeze(2))
return logprobs
# Zero-shot evaluation for the Choice of Plausible Alternatives (COPA) task.
# A return value of 0 indicates that the first alternative is more plausible,
# while 1 indicates that the second alternative is more plausible.
def COPA_eval(prompt, alternative1, alternative2):
lprob1 = get_logprobs(prompt + "\n" + alternative1).sum()
lprob2 = get_logprobs(prompt + "\n" + alternative2).sum()
return 0 if lprob1 > lprob2 else 1
for lang in data_samples_long:
for idx, example in enumerate(data_samples_long[lang]):
predict = COPA_eval(example["premise"], example["choice1"], example["choice2"])
print(f'{lang}-{idx}', predict, example['label'])
# en-0 1 1
# en-1 0 0
# zh-0 1 1
# zh-1 0 0
# hi-0 1 1
# hi-1 0 0
``` |
AnonymousSub/rule_based_roberta_hier_quadruplet_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1 | null | ---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
---
# XLM-RoBERTa-XL (xlarge-sized model)
XLM-RoBERTa-XL model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
Disclaimer: The team releasing XLM-RoBERTa-XL did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
XLM-RoBERTa-XL is a extra large multilingual version of RoBERTa. It is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages.
RoBERTa is a transformers model pretrained on a large corpus in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of 100 languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the XLM-RoBERTa-XL model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=xlm-roberta-xl) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation, you should look at models like GPT2.
## Usage
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='facebook/xlm-roberta-xl')
>>> unmasker("Europe is a <mask> continent.")
[{'score': 0.08562745153903961,
'token': 38043,
'token_str': 'living',
'sequence': 'Europe is a living continent.'},
{'score': 0.0799778401851654,
'token': 103494,
'token_str': 'dead',
'sequence': 'Europe is a dead continent.'},
{'score': 0.046154674142599106,
'token': 72856,
'token_str': 'lost',
'sequence': 'Europe is a lost continent.'},
{'score': 0.04358183592557907,
'token': 19336,
'token_str': 'small',
'sequence': 'Europe is a small continent.'},
{'score': 0.040570393204689026,
'token': 34923,
'token_str': 'beautiful',
'sequence': 'Europe is a beautiful continent.'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('facebook/xlm-roberta-xl')
model = AutoModelForMaskedLM.from_pretrained("facebook/xlm-roberta-xl")
# prepare input
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
# forward pass
output = model(**encoded_input)
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-00572,
author = {Naman Goyal and
Jingfei Du and
Myle Ott and
Giri Anantharaman and
Alexis Conneau},
title = {Larger-Scale Transformers for Multilingual Masked Language Modeling},
journal = {CoRR},
volume = {abs/2105.00572},
year = {2021},
url = {https://arxiv.org/abs/2105.00572},
eprinttype = {arXiv},
eprint = {2105.00572},
timestamp = {Wed, 12 May 2021 15:54:31 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-00572.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
AnonymousSub/rule_based_roberta_hier_quadruplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
language:
- multilingual
- af
- am
- ar
- as
- az
- be
- bg
- bn
- br
- bs
- ca
- cs
- cy
- da
- de
- el
- en
- eo
- es
- et
- eu
- fa
- fi
- fr
- fy
- ga
- gd
- gl
- gu
- ha
- he
- hi
- hr
- hu
- hy
- id
- is
- it
- ja
- jv
- ka
- kk
- km
- kn
- ko
- ku
- ky
- la
- lo
- lt
- lv
- mg
- mk
- ml
- mn
- mr
- ms
- my
- ne
- nl
- no
- om
- or
- pa
- pl
- ps
- pt
- ro
- ru
- sa
- sd
- si
- sk
- sl
- so
- sq
- sr
- su
- sv
- sw
- ta
- te
- th
- tl
- tr
- ug
- uk
- ur
- uz
- vi
- xh
- yi
- zh
license: mit
---
# XLM-RoBERTa-XL (xxlarge-sized model)
XLM-RoBERTa-XL model pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages. It was introduced in the paper [Larger-Scale Transformers for Multilingual Masked Language Modeling](https://arxiv.org/abs/2105.00572) by Naman Goyal, Jingfei Du, Myle Ott, Giri Anantharaman, Alexis Conneau and first released in [this repository](https://github.com/pytorch/fairseq/tree/master/examples/xlmr).
Disclaimer: The team releasing XLM-RoBERTa-XL did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
XLM-RoBERTa-XL is a extra large multilingual version of RoBERTa. It is pre-trained on 2.5TB of filtered CommonCrawl data containing 100 languages.
RoBERTa is a transformers model pretrained on a large corpus in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labeling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts.
More precisely, it was pretrained with the Masked language modeling (MLM) objective. Taking a sentence, the model randomly masks 15% of the words in the input then run the entire masked sentence through the model and has to predict the masked words. This is different from traditional recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like GPT which internally mask the future tokens. It allows the model to learn a bidirectional representation of the sentence.
This way, the model learns an inner representation of 100 languages that can then be used to extract features useful for downstream tasks: if you have a dataset of labeled sentences for instance, you can train a standard classifier using the features produced by the XLM-RoBERTa-XL model as inputs.
## Intended uses & limitations
You can use the raw model for masked language modeling, but it's mostly intended to be fine-tuned on a downstream task. See the [model hub](https://huggingface.co/models?search=xlm-roberta-xl) to look for fine-tuned versions on a task that interests you.
Note that this model is primarily aimed at being fine-tuned on tasks that use the whole sentence (potentially masked) to make decisions, such as sequence classification, token classification or question answering. For tasks such as text generation, you should look at models like GPT2.
## Usage
You can use this model directly with a pipeline for masked language modeling:
```python
>>> from transformers import pipeline
>>> unmasker = pipeline('fill-mask', model='facebook/xlm-roberta-xxl')
>>> unmasker("Europe is a <mask> continent.")
[{'score': 0.22996895015239716,
'token': 28811,
'token_str': 'European',
'sequence': 'Europe is a European continent.'},
{'score': 0.14307449758052826,
'token': 21334,
'token_str': 'large',
'sequence': 'Europe is a large continent.'},
{'score': 0.12239163368940353,
'token': 19336,
'token_str': 'small',
'sequence': 'Europe is a small continent.'},
{'score': 0.07025063782930374,
'token': 18410,
'token_str': 'vast',
'sequence': 'Europe is a vast continent.'},
{'score': 0.032869212329387665,
'token': 6957,
'token_str': 'big',
'sequence': 'Europe is a big continent.'}]
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained('facebook/xlm-roberta-xxl')
model = AutoModelForMaskedLM.from_pretrained("facebook/xlm-roberta-xxl")
# prepare input
text = "Replace me by any text you'd like."
encoded_input = tokenizer(text, return_tensors='pt')
# forward pass
output = model(**encoded_input)
```
### BibTeX entry and citation info
```bibtex
@article{DBLP:journals/corr/abs-2105-00572,
author = {Naman Goyal and
Jingfei Du and
Myle Ott and
Giri Anantharaman and
Alexis Conneau},
title = {Larger-Scale Transformers for Multilingual Masked Language Modeling},
journal = {CoRR},
volume = {abs/2105.00572},
year = {2021},
url = {https://arxiv.org/abs/2105.00572},
eprinttype = {arXiv},
eprint = {2105.00572},
timestamp = {Wed, 12 May 2021 15:54:31 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-2105-00572.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
``` |
AnonymousSub/rule_based_roberta_hier_quadruplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | 2022-01-05T01:33:34Z | ---
library_name: fairseq
task: audio-to-audio
tags:
- fairseq
- audio
- audio-to-audio
- speech-to-speech-translation
language: en-ar
datasets:
- must_c
- covost2
widget:
- example_title: Common Voice sample 1
src: https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3
---
# xm_transformer_600m-en_ar-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Arabic
- Trained on MuST-C, CoVoST 2, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-ar-cv7](https://huggingface.co/facebook/tts_transformer-ar-cv7)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_ar-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-ar-cv7",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
AnonymousSub/rule_based_roberta_hier_triplet_0.1_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2022-01-05T02:22:47Z | ---
library_name: fairseq
task: audio-to-audio
tags:
- fairseq
- audio
- audio-to-audio
- speech-to-speech-translation
language: en-fr
datasets:
- must_c
- europarl_st
- voxpopuli
- libritrans
widget:
- example_title: Common Voice sample 1
src: https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3
---
# xm_transformer_600m-en_fr-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-French
- Trained on MuST-C, EuroParl-ST, VoxPopuli, LibriTrans, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-fr-cv7_css10](https://huggingface.co/facebook/tts_transformer-fr-cv7_css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_fr-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-fr-cv7_css10",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
AnonymousSub/rule_based_roberta_hier_triplet_0.1_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
library_name: fairseq
task: audio-to-audio
tags:
- fairseq
- audio
- audio-to-audio
- speech-to-speech-translation
language: en-ru
datasets:
- must_c
widget:
- example_title: Common Voice sample 1
src: https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3
---
# xm_transformer_600m-en_ru-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Russian
- Trained on MuST-C, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-ru-cv7_css10](https://huggingface.co/facebook/tts_transformer-ru-cv7_css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_ru-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-ru-cv7_css10",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
``` |
AnonymousSub/rule_based_roberta_hier_triplet_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | 2022-01-05T01:55:31Z | ---
library_name: fairseq
task: audio-to-audio
tags:
- fairseq
- audio
- audio-to-audio
- speech-to-speech-translation
language: en-tr
datasets:
- must_c
- covost2
widget:
- example_title: Common Voice sample 1
src: https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3
---
# xm_transformer_600m-en_tr-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Turkish
- Trained on MuST-C, CoVoST 2, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-tr-cv7](https://huggingface.co/facebook/tts_transformer-tr-cv7)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_tr-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-tr-cv7",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
``` |
AnonymousSub/rule_based_roberta_hier_triplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2022-01-05T03:48:27Z | ---
library_name: fairseq
task: audio-to-audio
tags:
- fairseq
- audio
- audio-to-audio
- speech-to-speech-translation
language: en-vi
datasets:
- must_c
widget:
- example_title: Common Voice sample 1
src: https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3
---
# xm_transformer_600m-en_vi-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Vietnamese
- Trained on MuST-C, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-vi-cv7](https://huggingface.co/facebook/tts_transformer-vi-cv7)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_vi-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-vi-cv7",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
AnonymousSub/rule_based_roberta_hier_triplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | 2022-01-05T02:38:52Z | ---
library_name: fairseq
task: audio-to-audio
tags:
- fairseq
- audio
- audio-to-audio
- speech-to-speech-translation
language: en-zh
datasets:
- must_c
- covost2
widget:
- example_title: Common Voice sample 1
src: https://huggingface.co/facebook/xm_transformer_600m-en_es-multi_domain/resolve/main/common_voice_en_18295850.mp3
---
# xm_transformer_600m-en_zh-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- English-Chinese
- Trained on MuST-C, CoVoST 2, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/tts_transformer-zh-cv7_css10](https://huggingface.co/facebook/tts_transformer-zh-cv7_css10)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.speech_to_text.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-en_zh-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/tts_transformer-zh-cv7_css10",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
```
|
AnonymousSub/rule_based_roberta_hier_triplet_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | 2022-01-04T04:28:03Z | ---
library_name: fairseq
task: audio-to-audio
tags:
- fairseq
- audio
- audio-to-audio
- speech-to-speech-translation
language: es-en
datasets:
- mtedx
- covost2
- europarl_st
- voxpopuli
widget:
- example_title: Common Voice sample 1
src: https://huggingface.co/facebook/xm_transformer_600m-es_en-multi_domain/resolve/main/common_voice_es_19966634.flac
---
# xm_transformer_600m-es_en-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- Spanish-English
- Trained on mTEDx, CoVoST 2, EuroParl-ST, VoxPopuli, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/fastspeech2-en-ljspeech](https://huggingface.co/facebook/fastspeech2-en-ljspeech)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-es_en-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/fastspeech2-en-ljspeech",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
``` |
AnonymousSub/rule_based_roberta_hier_triplet_epochs_1_shard_1_wikiqa_copy | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
library_name: fairseq
task: audio-to-audio
tags:
- fairseq
- audio
- audio-to-audio
- speech-to-speech-translation
language: fr-en
datasets:
- mtedx
- covost2
- europarl_st
- voxpopuli
widget:
- example_title: Common Voice sample 1
src: https://huggingface.co/facebook/xm_transformer_600m-fr_en-multi_domain/resolve/main/common_voice_fr_19731305.mp3
---
# xm_transformer_600m-fr_en-multi_domain
[W2V2-Transformer](https://aclanthology.org/2021.acl-long.68/) speech-to-text translation model from fairseq S2T ([paper](https://arxiv.org/abs/2010.05171)/[code](https://github.com/pytorch/fairseq/tree/main/examples/speech_to_text)):
- French-English
- Trained on mTEDx, CoVoST 2, EuroParl-ST, VoxPopuli, Multilingual LibriSpeech, Common Voice v7 and CCMatrix
- Speech synthesis with [facebook/fastspeech2-en-ljspeech](https://huggingface.co/facebook/fastspeech2-en-ljspeech)
## Usage
```python
from fairseq.checkpoint_utils import load_model_ensemble_and_task_from_hf_hub
from fairseq.models.text_to_speech.hub_interface import S2THubInterface
from fairseq.models.text_to_speech.hub_interface import TTSHubInterface
import IPython.display as ipd
import torchaudio
models, cfg, task = load_model_ensemble_and_task_from_hf_hub(
"facebook/xm_transformer_600m-fr_en-multi_domain",
arg_overrides={"config_yaml": "config.yaml"},
)
model = models[0]
generator = task.build_generator(model, cfg)
# requires 16000Hz mono channel audio
audio, _ = torchaudio.load("/path/to/an/audio/file")
sample = S2THubInterface.get_model_input(task, audio)
text = S2THubInterface.get_prediction(task, model, generator, sample)
# speech synthesis
tts_models, tts_cfg, tts_task = load_model_ensemble_and_task_from_hf_hub(
f"facebook/fastspeech2-en-ljspeech",
arg_overrides={"vocoder": "griffin_lim", "fp16": False},
)
tts_model = tts_models[0]
TTSHubInterface.update_cfg_with_data_cfg(tts_cfg, tts_task.data_cfg)
tts_generator = tts_task.build_generator([tts_model], tts_cfg)
tts_sample = TTSHubInterface.get_model_input(tts_task, text)
wav, sr = TTSHubInterface.get_prediction(
tts_task, tts_model, tts_generator, tts_sample
)
ipd.Audio(wav, rate=rate)
```
## Citation
```bibtex
@inproceedings{li-etal-2021-multilingual,
title = "Multilingual Speech Translation from Efficient Finetuning of Pretrained Models",
author = "Li, Xian and
Wang, Changhan and
Tang, Yun and
Tran, Chau and
Tang, Yuqing and
Pino, Juan and
Baevski, Alexei and
Conneau, Alexis and
Auli, Michael",
booktitle = "Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing (Volume 1: Long Papers)",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.acl-long.68",
doi = "10.18653/v1/2021.acl-long.68",
pages = "827--838",
}
@inproceedings{wang-etal-2020-fairseq,
title = "Fairseq {S}2{T}: Fast Speech-to-Text Modeling with Fairseq",
author = "Wang, Changhan and
Tang, Yun and
Ma, Xutai and
Wu, Anne and
Okhonko, Dmytro and
Pino, Juan",
booktitle = "Proceedings of the 1st Conference of the Asia-Pacific Chapter of the Association for Computational Linguistics and the 10th International Joint Conference on Natural Language Processing: System Demonstrations",
month = dec,
year = "2020",
address = "Suzhou, China",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2020.aacl-demo.6",
pages = "33--39",
}
@inproceedings{wang-etal-2021-fairseq,
title = "fairseq S{\^{}}2: A Scalable and Integrable Speech Synthesis Toolkit",
author = "Wang, Changhan and
Hsu, Wei-Ning and
Adi, Yossi and
Polyak, Adam and
Lee, Ann and
Chen, Peng-Jen and
Gu, Jiatao and
Pino, Juan",
booktitle = "Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2021",
address = "Online and Punta Cana, Dominican Republic",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.emnlp-demo.17",
doi = "10.18653/v1/2021.emnlp-demo.17",
pages = "143--152",
}
``` |
AnonymousSub/rule_based_roberta_only_classfn_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola-3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola-3
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0002
- Matthews Correlation: 1.0
Label 0 : "AIMX"
Label 1 : "OWNX"
Label 2 : "CONT"
Label 3 : "BASE"
Label 4 : "MISC"
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 192 | 0.0060 | 1.0 |
| No log | 2.0 | 384 | 0.0019 | 1.0 |
| 0.0826 | 3.0 | 576 | 0.0010 | 1.0 |
| 0.0826 | 4.0 | 768 | 0.0006 | 1.0 |
| 0.0826 | 5.0 | 960 | 0.0005 | 1.0 |
| 0.001 | 6.0 | 1152 | 0.0004 | 1.0 |
| 0.001 | 7.0 | 1344 | 0.0003 | 1.0 |
| 0.0005 | 8.0 | 1536 | 0.0003 | 1.0 |
| 0.0005 | 9.0 | 1728 | 0.0002 | 1.0 |
| 0.0005 | 10.0 | 1920 | 0.0002 | 1.0 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_only_classfn_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola-4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola-4
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0011
- Matthews Correlation: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 104 | 0.0243 | 1.0 |
| No log | 2.0 | 208 | 0.0074 | 1.0 |
| No log | 3.0 | 312 | 0.0041 | 1.0 |
| No log | 4.0 | 416 | 0.0028 | 1.0 |
| 0.0929 | 5.0 | 520 | 0.0021 | 1.0 |
| 0.0929 | 6.0 | 624 | 0.0016 | 1.0 |
| 0.0929 | 7.0 | 728 | 0.0014 | 1.0 |
| 0.0929 | 8.0 | 832 | 0.0012 | 1.0 |
| 0.0929 | 9.0 | 936 | 0.0012 | 1.0 |
| 0.0021 | 10.0 | 1040 | 0.0011 | 1.0 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_only_classfn_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 27 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0008
- Matthews Correlation: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| No log | 1.0 | 130 | 0.0166 | 1.0 |
| No log | 2.0 | 260 | 0.0054 | 1.0 |
| No log | 3.0 | 390 | 0.0029 | 1.0 |
| 0.0968 | 4.0 | 520 | 0.0019 | 1.0 |
| 0.0968 | 5.0 | 650 | 0.0014 | 1.0 |
| 0.0968 | 6.0 | 780 | 0.0011 | 1.0 |
| 0.0968 | 7.0 | 910 | 0.0010 | 1.0 |
| 0.0018 | 8.0 | 1040 | 0.0008 | 1.0 |
| 0.0018 | 9.0 | 1170 | 0.0008 | 1.0 |
| 0.0018 | 10.0 | 1300 | 0.0008 | 1.0 |
### Framework versions
- Transformers 4.12.3
- Pytorch 1.10.0+cu111
- Datasets 1.15.1
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_only_classfn_twostage_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model_index:
- name: distilbert-base-uncased-finetuned-squad
results:
- task:
name: Question Answering
type: question-answering
dataset:
name: squad
type: squad
args: plain_text
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1523
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2171 | 1.0 | 5533 | 1.1511 |
| 0.952 | 2.0 | 11066 | 1.1180 |
| 0.7707 | 3.0 | 16599 | 1.1523 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_only_classfn_twostage_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
metrics:
- rouge
model-index:
- name: gq-indo-k
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gq-indo-k
This model was trained from scratch on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7905
- Rouge1: 22.5734
- Rouge2: 6.555
- Rougel: 20.9491
- Rougelsum: 20.9509
- Gen Len: 12.0767
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.9355 | 1.0 | 13032 | 2.8563 | 22.4828 | 6.5456 | 20.8782 | 20.8772 | 11.915 |
| 2.825 | 2.0 | 26064 | 2.7993 | 22.547 | 6.5815 | 20.8937 | 20.8973 | 12.0886 |
| 2.7631 | 3.0 | 39096 | 2.7905 | 22.5734 | 6.555 | 20.9491 | 20.9509 | 12.0767 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_only_classfn_twostage_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2 | null | ---
model-index:
- name: qa-indo-k
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qa-indo-k
This model was trained from scratch on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4984
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2537 | 1.0 | 8209 | 1.9642 |
| 0.943 | 2.0 | 16418 | 2.2143 |
| 0.6694 | 3.0 | 24627 | 2.4984 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_only_classfn_twostage_epochs_1_shard_1_wikiqa | [
"pytorch",
"roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 24 | null | ---
model-index:
- name: qa-indo-math-k-v2
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# qa-indo-math-k-v2
This model was trained from scratch on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9328
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 80 | 0.7969 |
| No log | 2.0 | 160 | 0.7612 |
| No log | 3.0 | 240 | 0.7624 |
| No log | 4.0 | 320 | 0.7424 |
| No log | 5.0 | 400 | 0.7634 |
| No log | 6.0 | 480 | 0.7415 |
| 0.9241 | 7.0 | 560 | 0.7219 |
| 0.9241 | 8.0 | 640 | 0.7792 |
| 0.9241 | 9.0 | 720 | 0.7803 |
| 0.9241 | 10.0 | 800 | 0.7666 |
| 0.9241 | 11.0 | 880 | 0.7614 |
| 0.9241 | 12.0 | 960 | 0.7616 |
| 0.6373 | 13.0 | 1040 | 0.7673 |
| 0.6373 | 14.0 | 1120 | 0.7818 |
| 0.6373 | 15.0 | 1200 | 0.8030 |
| 0.6373 | 16.0 | 1280 | 0.8021 |
| 0.6373 | 17.0 | 1360 | 0.8025 |
| 0.6373 | 18.0 | 1440 | 0.8628 |
| 0.5614 | 19.0 | 1520 | 0.8616 |
| 0.5614 | 20.0 | 1600 | 0.8739 |
| 0.5614 | 21.0 | 1680 | 0.8647 |
| 0.5614 | 22.0 | 1760 | 0.9006 |
| 0.5614 | 23.0 | 1840 | 0.9560 |
| 0.5614 | 24.0 | 1920 | 0.9395 |
| 0.486 | 25.0 | 2000 | 0.9453 |
| 0.486 | 26.0 | 2080 | 0.9569 |
| 0.486 | 27.0 | 2160 | 1.0208 |
| 0.486 | 28.0 | 2240 | 0.9860 |
| 0.486 | 29.0 | 2320 | 0.9806 |
| 0.486 | 30.0 | 2400 | 1.0681 |
| 0.486 | 31.0 | 2480 | 1.1085 |
| 0.4126 | 32.0 | 2560 | 1.1028 |
| 0.4126 | 33.0 | 2640 | 1.1110 |
| 0.4126 | 34.0 | 2720 | 1.1573 |
| 0.4126 | 35.0 | 2800 | 1.1387 |
| 0.4126 | 36.0 | 2880 | 1.2067 |
| 0.4126 | 37.0 | 2960 | 1.2079 |
| 0.3559 | 38.0 | 3040 | 1.2152 |
| 0.3559 | 39.0 | 3120 | 1.2418 |
| 0.3559 | 40.0 | 3200 | 1.2023 |
| 0.3559 | 41.0 | 3280 | 1.2679 |
| 0.3559 | 42.0 | 3360 | 1.3178 |
| 0.3559 | 43.0 | 3440 | 1.3419 |
| 0.3084 | 44.0 | 3520 | 1.4702 |
| 0.3084 | 45.0 | 3600 | 1.3824 |
| 0.3084 | 46.0 | 3680 | 1.4227 |
| 0.3084 | 47.0 | 3760 | 1.3925 |
| 0.3084 | 48.0 | 3840 | 1.4940 |
| 0.3084 | 49.0 | 3920 | 1.4110 |
| 0.2686 | 50.0 | 4000 | 1.4534 |
| 0.2686 | 51.0 | 4080 | 1.4749 |
| 0.2686 | 52.0 | 4160 | 1.5351 |
| 0.2686 | 53.0 | 4240 | 1.5479 |
| 0.2686 | 54.0 | 4320 | 1.4755 |
| 0.2686 | 55.0 | 4400 | 1.5207 |
| 0.2686 | 56.0 | 4480 | 1.5075 |
| 0.2388 | 57.0 | 4560 | 1.5470 |
| 0.2388 | 58.0 | 4640 | 1.5361 |
| 0.2388 | 59.0 | 4720 | 1.5914 |
| 0.2388 | 60.0 | 4800 | 1.6430 |
| 0.2388 | 61.0 | 4880 | 1.6249 |
| 0.2388 | 62.0 | 4960 | 1.5503 |
| 0.2046 | 63.0 | 5040 | 1.6441 |
| 0.2046 | 64.0 | 5120 | 1.6789 |
| 0.2046 | 65.0 | 5200 | 1.6174 |
| 0.2046 | 66.0 | 5280 | 1.6175 |
| 0.2046 | 67.0 | 5360 | 1.6947 |
| 0.2046 | 68.0 | 5440 | 1.6299 |
| 0.1891 | 69.0 | 5520 | 1.7419 |
| 0.1891 | 70.0 | 5600 | 1.8442 |
| 0.1891 | 71.0 | 5680 | 1.8802 |
| 0.1891 | 72.0 | 5760 | 1.8233 |
| 0.1891 | 73.0 | 5840 | 1.8172 |
| 0.1891 | 74.0 | 5920 | 1.8181 |
| 0.1664 | 75.0 | 6000 | 1.8399 |
| 0.1664 | 76.0 | 6080 | 1.8128 |
| 0.1664 | 77.0 | 6160 | 1.8423 |
| 0.1664 | 78.0 | 6240 | 1.8380 |
| 0.1664 | 79.0 | 6320 | 1.8941 |
| 0.1664 | 80.0 | 6400 | 1.8636 |
| 0.1664 | 81.0 | 6480 | 1.7949 |
| 0.1614 | 82.0 | 6560 | 1.8342 |
| 0.1614 | 83.0 | 6640 | 1.8123 |
| 0.1614 | 84.0 | 6720 | 1.8639 |
| 0.1614 | 85.0 | 6800 | 1.8580 |
| 0.1614 | 86.0 | 6880 | 1.8816 |
| 0.1614 | 87.0 | 6960 | 1.8579 |
| 0.1487 | 88.0 | 7040 | 1.8783 |
| 0.1487 | 89.0 | 7120 | 1.9175 |
| 0.1487 | 90.0 | 7200 | 1.9025 |
| 0.1487 | 91.0 | 7280 | 1.9207 |
| 0.1487 | 92.0 | 7360 | 1.9195 |
| 0.1487 | 93.0 | 7440 | 1.9142 |
| 0.1355 | 94.0 | 7520 | 1.9333 |
| 0.1355 | 95.0 | 7600 | 1.9238 |
| 0.1355 | 96.0 | 7680 | 1.9256 |
| 0.1355 | 97.0 | 7760 | 1.9305 |
| 0.1355 | 98.0 | 7840 | 1.9294 |
| 0.1355 | 99.0 | 7920 | 1.9301 |
| 0.1297 | 100.0 | 8000 | 1.9328 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_twostage_quadruplet_epochs_1_shard_10 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
metrics:
- rouge
model_index:
- name: t5-small-finetuned-xsum-2
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: squad
type: squad
args: plain_text
metric:
name: Rouge1
type: rouge
value: 28.8137
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum-2
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.9536
- Rouge1: 28.8137
- Rouge2: 9.1265
- Rougel: 26.0238
- Rougelsum: 26.0217
- Gen Len: 13.854
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.2142 | 1.0 | 8760 | 1.9994 | 29.007 | 9.2583 | 26.2377 | 26.2356 | 13.4546 |
| 2.1372 | 2.0 | 17520 | 1.9622 | 29.1077 | 9.445 | 26.3734 | 26.3687 | 13.6995 |
| 2.0755 | 3.0 | 26280 | 1.9536 | 28.8137 | 9.1265 | 26.0238 | 26.0217 | 13.854 |
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_twostage_quadruplet_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model_index:
- name: t5-small-finetuned-xsum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: squad
type: squad
args: plain_text
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 10
- eval_batch_size: 10
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.9.2
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_twostagequadruplet_hier_epochs_1_shard_1 | [
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
metrics:
- rouge
model-index:
- name: test-summarization
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# test-summarization
This model was trained from scratch on an unkown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.4740
- Rouge1: 28.3487
- Rouge2: 7.7836
- Rougel: 22.3307
- Rougelsum: 22.3357
- Gen Len: 18.8307
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 14
- eval_batch_size: 14
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 2.7042 | 1.0 | 14575 | 2.4740 | 28.3487 | 7.7836 | 22.3307 | 22.3357 | 18.8307 |
### Framework versions
- Transformers 4.6.1
- Pytorch 1.7.0
- Datasets 1.11.0
- Tokenizers 0.10.3
|
AnonymousSub/rule_based_roberta_twostagetriplet_hier_epochs_1_shard_1_squad2.0 | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
tags:
- conversational
---
# test DialoGPT Model |
AnonymousSub/rule_based_twostagetriplet_hier_epochs_1_shard_1_wikiqa | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 27 | null | ---
title: Test Space
emoji: 🔥
colorFrom: indigo
colorTo: blue
sdk: gradio
app_file: app.py
pinned: false
---
# Configuration
`title`: _string_
Display title for the Space
`emoji`: _string_
Space emoji (emoji-only character allowed)
`colorFrom`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`colorTo`: _string_
Color for Thumbnail gradient (red, yellow, green, blue, indigo, purple, pink, gray)
`sdk`: _string_
Can be either `gradio` or `streamlit`
`sdk_version` : _string_
Only applicable for `streamlit` SDK.
See [doc](https://hf.co/docs/hub/spaces) for more info on supported versions.
`app_file`: _string_
Path to your main application file (which contains either `gradio` or `streamlit` Python code).
Path is relative to the root of the repository.
`pinned`: _boolean_
Whether the Space stays on top of your list. |
Anthos23/test_trainer | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | This model is the fine-tuned model of "akdeniz27/bert-base-hungarian-cased-ner" using WikiANN-hu dataset. |
AntonClaesson/finetuning_test | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Magyar nyelvű token classification feladatra felkészített BERT modell. |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.