
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
Bubb-les/DisloGPT-medium-HarryPotter
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: vit-base-patch16-224-finetuned-algae-rgb
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# vit-base-patch16-224-finetuned-algae-rgb
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0685
- Accuracy: 0.6174
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.981 | 1.0 | 120 | 1.0513 | 0.5698 |
| 1.0027 | 2.0 | 240 | 1.0316 | 0.5775 |
| 0.9554 | 3.0 | 360 | 0.9944 | 0.5945 |
| 0.978 | 4.0 | 480 | 0.9735 | 0.5980 |
| 0.8983 | 5.0 | 600 | 0.9690 | 0.6033 |
| 0.8561 | 6.0 | 720 | 0.9714 | 0.5968 |
| 0.8438 | 7.0 | 840 | 0.9833 | 0.6039 |
| 0.808 | 8.0 | 960 | 0.9827 | 0.6138 |
| 0.7882 | 9.0 | 1080 | 0.9971 | 0.5962 |
| 0.7422 | 10.0 | 1200 | 0.9901 | 0.6080 |
| 0.7797 | 11.0 | 1320 | 1.0096 | 0.5921 |
| 0.7167 | 12.0 | 1440 | 1.0252 | 0.6092 |
| 0.7445 | 13.0 | 1560 | 1.0364 | 0.6074 |
| 0.6641 | 14.0 | 1680 | 1.0471 | 0.6092 |
| 0.6847 | 15.0 | 1800 | 1.0693 | 0.6138 |
| 0.6418 | 16.0 | 1920 | 1.0685 | 0.6174 |
| 0.6423 | 17.0 | 2040 | 1.0683 | 0.6127 |
| 0.6432 | 18.0 | 2160 | 1.0729 | 0.6127 |
| 0.6208 | 19.0 | 2280 | 1.0801 | 0.6138 |
| 0.588 | 20.0 | 2400 | 1.0802 | 0.6103 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
BumBelDumBel/ZORK-AI-TEST
|
[
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"transformers",
"generated_from_trainer",
"license:mit"
] |
text-generation
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | null |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-pixelcopter1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 33.40 +/- 27.69
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
BunakovD/sd
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
language:
- en
tags:
- conversational
pipeline_tag: conversational
---
# Maribelle from Fire Emblem Awakening DialoGPT Model
|
Buntan/BuntanAI
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: jason1i/poca-SoccerTwos-Extra-Wish2
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-ner
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 85 | null |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-Pixelcopter
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: 58.40 +/- 38.24
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-poetry
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 42 | null |
---
license: apache-2.0
widget:
- text: "Scene: Desert\n\nWalter: My name is Walter Hartwell White. I live at 308 Negra Arroyo Lane Albuquerque, New Mexico, 87104. To all law enforcement entities, this is not an admission of guilt. I am speaking to my family now. Skyler you are the love of my life. I hope you know that. Walter Junior you're my big man. There are going to be some things. Things that you'll come to learn about me in the next few days. I just want you to know that no matter how it may look, I only had you in my heart. Goodbye.\n\nScene: White Residence\n(Three weeks earlier)\n\nSkyler: Happy Birthday.\n\nWalter: Look at that.\n\nSkyler: That is veggie bacon. Believe it or not. Zero cholesterol. You won't even taste the difference. What time do you think you'll be home?\n\nWalter: Same time.\n\nSkyler: I don't want him dicking you around tonight. You get paid till 5, you work till 5, no later.\n\nWalter: Hey.\n\nWalter Jr: Happy birthday.\n\nWalter: Well, thank you.\n\nSkyler: You're late again.\n\nWalter Jr: There was no hot water again.\n\nSkyler: I have an easy fix for that. You wake up early, and then you get to be the first person in the shower.\n\nWalter Jr: I have an idea. How about buy a new hot water heater? How's that idea? For the millionth and billionth time.\n\nSkyler: Did you take your Echinacea?\n\nWalter: Yeah. I think it's getting better.\n\nWalter Jr: What the hell is this?\n\nWalter: It's veggie bacon. We're watching our cholesterol, I guess.\n\nWalter Jr: Not me. I want real bacon. Not this fake crap.\n\nSkyler: Too bad. Eat it.\n\nWalter Jr: This smells like Band-aids.\n\nSkyler: Eat it.\n\nWalter Jr: So, how's it feel to be old?\n\nWalter: How does it feel to be a smart ass?\n\nWalter Jr: Good.\n\nWalter: Eat your veggie bacon.\n\nScene: High School Parking Lot\n\nWalter: You all set?\n\nWalter Jr: Yeah, I'm fine.\n\nWalter: All right, see you at home.\n\nWalter Jr: Okay, see you.\n\nScene: Walt’s Classroom\n\nWalter: Chemistry. It is the study of what? Anyone? Ben.\n\nBen: Chemicals.\n\nWalter: Chemicals! No! Chemistry is well, technically, chemistry is the study of matter. But I prefer to see it as the study of change. Now just just think about this. Electrons. They change their energy levels. Molecules. Molecules change their bonds. Elements. They combine and change into compounds. Well, that's all of life. Right? I mean, it's just It's the constant. It's the cycle. It's solution, dissolution, just over and over and over. It is growth, then decay, then transformation. It is fascinating, really. Chad, is there something wrong with your table? Okay. Ionic bonds Are you done? Ionic bonds. Chapter 6.\n\nScene: Car Wash\n\nWalter: And 2, 3 makes 10, and 10 makes 20. Here's your receipt, and hand this claiming disc to your car wash professional. Thank you. Come again.\n\nBogdan: He's not coming. He said he quits. I'm gonna run the register.\n\nWalter: Bogdan, no. We talked about this.\n\nBogdan: I'm shorthanded, Walter. What am I to do? Walter? What am I to do?\n\nChad: Hey, Mr. White! Make those tires shine, huh?\n\nChad’s Girlfriend: Oh, my God. You would not believe who's cleaning Chad's car. Mr. White from Chemistry.\n\nScene: White Residence\n\nEveryone: Surprise!\n\nWalter Jr: Happy Birthday, Dad!\n\nSkyler: You're so very late.\n\nCarmen: Really, I'm serious, Skyler. I mean, you're flat as a washboard. You look awesome. She's not showing at all, is she?\n\nMarie: She's showing a little.\n\nSkyler: Carmen, this is my sister Marie.\n\nCarmen: Pleased to meet you.\n\nMarie: Hi.\n\nHank: Glock 22. It's my daily carry, okay? I mean, unless you're talking, what, plus, P-plus loads, you can forget the 9-mil, all right? I’ve seen one of those bounce off a windshield one time.\n\nSteve: Yeah, the way you sh**t.\n\nHank: If you're gonna bring a g*n, you gotta bring enough g*n. 40 caliber.\n\nWalter Jr: This is awesome right here.\n\nHank: Nice, isn't it?\n\nWalter Jr: Dad, come check this out.\n\nWalter: Yeah, I see it.\n\nWalter Jr: Come on, take it.\n\nHank: Check it out, Walt.\n\nWalter: No, no, it's just heavy.\n\nHank: That's why they hire men. Jesus, it's not gonna bite you, all right? Looks like Keith Richards with a glass of warm milk, doesn't he? Hey, Walt. Everybody listen up, listen up, listen up! I'm gonna give a toast. A little toast to my brother-in-law. Come here. Walt, you got a brain the size of Wisconsin, but we're not gonna hold that against you. Because your heart's in the right place, man. Your heart's in the right place. We love you, man. We love you. Everybody! To Walt! Nostrovia!\n\nEveryone: Nostrovia!\n\nHank: Oh shit, turn on Channel 3.\n\nHank(on the news): At which point we apprehended three individuals and placed them into custody. I'm proud to say the outstanding professionalism of my fellow agents at the Albuquerque District Office resulted in a substantial amount of methamphetamine being taken off the streets.\n\nReporter(on the news): Were any shots fired?\n\nHank(on the news): No, ma'am. Our agents took the suspects by surprise.\n\nSteve: Damn, the TV does add ten pounds.\n\nMarie: Ten pounds?\n\nHank: Hey, sit and spin. Both of you.\n\nSkyler: Hank.\n\nHank: What? Sorry. You didn't see that.\n\nSkyler: So charming.\n\nHank(on the news): This is clearly an ongoing operation, one which was well organized.\n\nWalter: Hank, how much money is that?\n\nHank: It's about 700 grand. That's a pretty good haul, huh?\n\nHank(on the news): As I say, it's a good day for the citizens of Albuquerque when we can put this big a dent in the local drug trade.\n\nWalter: Wow. But that's unusual, isn't it, that kind of cash?\n\nHank: Well, it's not the most we ever took. It's easy money until we catch you. Walt, just say the word and I'll take you on a ride-along. You can watch us knock down a meth lab. Get a little excitement in your life.\n\nWalter: Well, someday.\n\nScene: Walt and Skyler’s Bedroom\n\nWalter: Which one's this?\n\nSkyler: That faux-Lalique vase I picked up at the Super-Swap.\n\nWalter: How's it doing?\n\nSkyler: I met my reserve, and there's still two minutes.\n\nWalter: What's up?\n\nSkyler: You tell me, birthday boy. Oh, hey, so what's up for Saturday?\n\nWalter: Car wash. Bogdan says he needs me.\n\nSkyler: Until what time? Noon? 1-ish?\n\nWalter: Probably 2, more like it.\n\nSkyler: And then what after that?\n\nWalter: Actually I was thinking of driving up to Los Alamos. The visitor center has an exhibit on that’s really supposed to be...\n\nSkyler: You're not gonna paint?\n\nWalter: I'll paint. It's just that this part of this exhibition on the Mars Rover photographs are the detail really is just supposed to be amazing.\n\nSkyler: It's just that I really need you to paint at some point. I mean, the sooner that back bedroom gets finished. And I'd do it myself, except you said you don't want me standing on the stepladder.\n\nWalter: I'll paint. I will paint.\n\nSkyler: What is going on down there?\n\nWalter: No, it's just...\n\nSkyler: Is he asleep?\n\nWalter: No, It's nothing. You know, just you know, we gotta be careful about the baby.\n\nSkyler: Don't worry about the baby. This is just for you. We are just doing you tonight. So just close your eyes. Relax, and let it. Close your eyes.\n\nWalter: Okay.\n\nSkyler: There you go. That's it. That's it. There you go. Keep it going. Keep it going. Keep it going. Keep Yes! 56!\n\nScene: Ambulance\n\nWalter: This is so embarrassing. I am fine. Honestly. It's just some bug going around. First my wife had it, then my son, and now me. It's just like a chest cold. Could be some low blood sugar as well. I didn't have the greatest breakfast this morning, honestly. Hey, listen, can you do me a favor? Can you just drop me off at a corner somewhere?\n\nEMT: No. Sorry.\n\nWalter: It's just that I don't have the greatest insurance.\n\nEMT: Take a couple of deep breaths for me. Is there anybody you want us to contact for you?\n\nWalter: God, no.\n\nEMT: Lean forward for me, would you? Mr. White, are you a smoker?\n\nWalter: No. Never. Why do you ask?\n\nScene: Doctor’s Office\n\nDoctor: Mr. White. Mr. White?\n\nWalter: Yes.\n\nDoctor: You understood what I've just said to you?\n\nWalter: Yes. Lung cancer. Inoperable.\n\nDoctor: I'm sorry I just need to make sure you fully understand.\n\nWalter: Best-case scenario, with chemo, I'll live maybe another couple years. It's just you've got mustard on your...right there. Mustard, there. Right there.\n\nScene: White Residence\n\nSkyler: So my records show that I paid it, and I certainly don't feel that we owe any late...All right. Well, I'll check with the bank and maybe the post office, if they lost it or something. Yeah, let me look into that. Okay. Thank you. Did you use the MasterCard last month?\n\nWalter: We needed printer paper.\n\nSkyler: Walt, the MasterCard's the one we don't use.\n\nWalter: Okay.\n\nSkyler: So how was your day?\n\nWalter: Oh, I don't know. I don't know. It was, um it was fine.\n\nScene: Car Wash\n\nBogdan: Come on. I'm shorthanded. I need you to do some wipe-downs. Come on.\n\nWalter: What?\n\nBogdan: I said I need you outside to do some wipe-downs. Are you here to work or to be staring at the skies? Come on, let's go. Come on, man.\n\nWalter: f*ck you, Bogdan.\n\nBogdan: What?\n\nWalter: I said f*ck you! And your eyebrows! Wipe down this!\n\nScene: White Residence-backyard\n\nWalter: Uh, Hank. Hank, it's Walt. Hey. Oh, listen I didn't wake you, did I? Oh, good, good. No, no, nothing's wrong. I just, uh I've been, uh, thinking about that offer that ride-along.\n\nScene: Hank’s Car\n\nHank: It's the last house on the right. See it? Not the two-story one. The one next to it. The kind of I don't know, what do you call that? Green?\n\nSteve: Sage.\n\nHank: Sage. What, do you work at the f*cking Pottery Barn? Jesus.\n\nSteve: Sage. That's the word for it. My fault the only word your dumb ass knows is green?\n\nHank: Cheese dick. I know that one. How 'bout that? Anyway, it's the sage one. See it?\n\nWalter: So what tells you it's a meth lab?\nHank: Just our snitch. Says some dude goes by Cap'n Cook lives up to his name in there. Says he always adds a dash of chili powder. Ah, you exuberant Mexicans.\n\nSteve: Uh-uh. Cap’n Cook, that's a white boy's name. Dopey as hell, too.\n\nHank: Yeah? Tell you what. I got 20 bucks that says he's a beaner.\n\nSteve: All right. You're on.\n\nHank: All right, come on, come on. All right. School bus is clear. Got the green light.\n\nAgent: Copy that.\n\nHank: Watch this. This makes 'em shit.\n\nAgent: Go, go, go.\n\nHank: Meth labs are nasty on a good day. You mix that shit wrong, you got mustard gas.\n\nWalter: Phosphine gas. I think.\n\nHank: Yeah, exactly. One whiff will k*ll you. That's why the respirators.\n\nAgent: House is clear. One suspect in custody.\n\nHank: Copy that. The suspect, might he be of the Latino persuasion?\n\nAgent: Driver's license says Emilio Koyama.\n\nSteve: Asian! Pay up, sucker.\n\nHank: Hey hey hey! First name Emilio. That's at least half a beaner. Tell you what, I'll let you off for a 10. Cheer up, Gomey. You people still got J. Lo.\n\nWalter: Hank, do you think I might get to go inside? See the actual lab?\n\nHank: Yeah. Yeah, I tell you what, we're gonna go peek our heads in, check it out first. Stay here a minute.\n\nJesse: God.\n\nWalter: Oh, my God. Pinkman?\n\nScene: Jesse’s House\n\nWalter: It's me. I'm alone.\n\nJesse: How'd you find me?\n\nWalter: You're still in our filing system. So your aunt owns this place, right?\n\nJesse: I own it.\n\nWalter: No one's looking for you.\n\nJesse: Why are you here?\n\nWalter: I was curious. Honestly, I never expected you to amount to much, but methamphetamine? I didn't picture that. There's a lot of money in it, huh?\n\nJesse: I don't know what you're talking about.\n\nWalter: No?\n\nJesse: Not a clue.\n\nWalter: Cap'n Cook? That's not you? Like I said, no one is looking for you.\n\nJesse: Look, I don't know what you think you're doing here, Mr. White. I mean, if you're planning on giving me some bowl winder about getting right with Jesus by turning myself in...\n\nWalter: Not really.\n\nJesse: High school was a long time ago. You ain't Welcome Back Kotter, so step off. No speeches.\n\nWalter: Short speech. You lost your partner today. What's his name? Emilio? Emilio is going to prison. The DEA took all your money, your lab. You got nothing. Square 1. But you know the business. And I know the chemistry. I'm thinking maybe you and I could partner up.\n\nJesse: You want to cook crystal meth? You? You and, uh and me?\n\nWalter: That's right. Either that or I turn you in.\n\nScene: White Residence\n\nMarie: What the hell is this?\n\nSkyler: Damned if I know. I described it as mosaic folk art.\n\nMarie: Somebody bought it?\n\nSkyler: Yeah, some guy in Minneapolis. 14 dollars plus shipping.\n\nMarie: Yes! At this rate, in 50 or 60 years, you'll be rich. So how goes the novel?\n\nSkyler: It's not a novel, actually, which I have...\n\nMarie: You're not writing a novel? You told me you were.\n\nSkyler: No. Short stories. I said that if eventually I have enough good ones that maybe I'll try and publish another collection.\n\nMarie: Those really didn't sell. I just thought a novel would be easier to sell.\n\nSkyler: Yeah, well, maybe so.\n\nMarie: Ever want me to read anything, I could critique it for you.\n\nSkyler: No. I mean, I'm not at that stage where I...no.\n\nMarie: Open offer. So what's up with Walt lately?\n\nSkyler: What do you mean? He's fine.\n\nMarie: He just seems, I don't know, quieter than usual.\n\nSkyler: Turning 50 is a big deal. I mean, I'm sure as hell not looking forward to 40. You're gonna be a complete basket case.\n\nMarie: So it's a mid-life crisis.\n\nSkyler: No, he's just quiet.\n\nMarie: How's the sex?\n\nSkyler: Marie, Jesus.\n\nMarie: Guess that answers that.\n\n\nScene: Jesse’s House\n\nWalter: You just gonna sit there? This. Look at this. Kjeldahl-style recovery flask, Very rare. You got your usual paraphernalia: Griffin beakers, your Erlenmeyer flask. But the piece de resistance: a round bottom boiling flask.\n\nJesse: Well, I cook in one of those. The big one.\n\nWalter: One of these? No, this is a volumetric flask. You wouldn't cook in one of these.\n\nJesse: Yeah, I do.\n\nWalter: No, you don't. A volumetric flask is for general mixing and titration. You wouldn't apply heat to a volumetric flask. That's what a boiling flask is for. Did you learn nothing from my chemistry class?\n\nJesse: No. You flunked me. Remember?\n\nWalter: No wonder.\n\nJesse: Prick. Now let me tell you something else. This ain't chemistry, this is art. Cooking is art. And the shit I cook is the b*mb, so don't be telling me.\n\nWalter: The shit you cook is shit. I saw your setup. Ridiculous. You and I will not make garbage. We will produce a chemically pure and s*ab product that performs as advertised. No adulterants. No baby formula. No chili powder.\n\nJesse: No, no, chili P is my signature.\n\nWalter: Not anymore.\n\nJesse: Yeah, well, we'll see about that. What the hell is this?\n\nWalter: Lab safety equipment. We're also gonna have an emergency eye wash station. These chemicals and their fumes are toxic, in case you didn't know that.\n\nJesse: Well, you can dress up like a f*g if you want. Not me. Listen, this stuff doesn't stay more than a day.\n\nWalter: What? I thought we were gonna cook here.\n\nJesse: No, we're not gonna cook here. Okay, this is my house. I don't shit where I eat.\n\nWalter: Well, then, where are we gonna work?\n\nJesse: You tell me. This is your deal. You want to smoke it up, smoke it up at your house. Nah, I didn't think so.\n\nWalter: Oh, well. Well what if we rented one of those self-storage places, you know, those little orange garages, worked out of there?\n\nJesse: No. They're on to that. They got dogs that sniff around. RV. That's what you want.\n\nWalter: What, like a Winnebago?\n\nJesse: Yeah. I know a dude who wants to sell his. He just goes camping with it. But a mobile meth lab? That'd be the b*mb. I mean, drive way out in the boonies. Be all evasive.\n\nScene: Bank Parking Lot\n\nJesse: Dude, this isn't even 7 grand. My guy wants 85.\n\nWalter: This is all the money I have in the world. You're a drug dealer. Negotiate.\n\nJesse: You are not how I remember you from class, I mean, like, not at all.\n\nWalter: I gotta go.\n\nJesse: Wait, wait. Hold on. Tell me why you're doing this. Seriously.\n\nWalter: Why do you do it?\n\nJesse: Money, mainly.\n\nWalter: There you go.\n\nJesse: Nah, come on! Man, some straight like you, giant stick up his ass, all of a sudden at age, what, 60, he's just gonna break bad?\n\nWalter: I'm 50.\n\nJesse: It's weird is all, okay? It doesn't compute. Listen if you've gone crazy or something I mean, if you've if you've gone crazy or depressed, I'm just saying that's something I need to know about. Okay? I mean, that affects me.\n\nWalter: I am awake.\n\nJesse: What?\n\nWalter: Buy the RV. We start tomorrow.\n\nScene: The Mall\n\nSkyler: How's it coming in there?\n\nWalter Jr: Fine.\n\nSkyler: Do you want me or your dad?\n\nWalter Jr: Dad.\n\nSkyler: So how are those feeling in the waist? Are they too tight? 'Cause you don't want to get 'em if they're too tight.\n\nWalter Jr: They're pre-shrunk.\n\nSkyler: Are you sure you don't want to get a different kind? Like, you know, the skinny jeans? Those are really supposed to be in style now. The skaters wear them.\n\nWalter Jr: Do I look like a skater?\n\nSkyler: All right.\n\nTeenager: Mom, look at my big-boy pants. Mommy, could you zip up my big-boy pants?\n\nWalter: Don't.\n\nSkyler: What?\n\nWalter: Don't.\n\nSkyler: Walt.\n\nWalter Jr: Where...\n\nSkyler: I have no idea. You know what? Don't even look at them. They're obviously very stupid. Yep. I think that, um I think those jeans look really good on you. You should get 'em if you like 'em, okay? Why don't you just hang out here for a second? I'll be right back.\n\nWalter Jr: Fine.\n\nTeenager: Mommy, I think I pinched a loaf in my brand-new big-boy pants. What are you doing?\n\nWalter: What's wrong, chief? Having a little trouble walking?\n\nTeenager: Get off me. Get off me! I'll mess you up, man.\n\nWalter: Well, you'll have one sh*t. You better make it good. What, are you waiting for your girlfriends? You better go. Take it. Take your sh*t. Take it! Come on. Come on.\n\nTeenager: Come on, let's get outta here. Let's go. Psycho.\n\nScene: Desert\n\nJesse: Yeah, nothing but cows! Got some big cow house way out that way, like 2 miles, but I don't see nobody.\n\nWalter: Cow house?\n\nJesse: Yeah, where they live. The cows. Whatever, man. Yeah, let's cook here.\n\nWalter: Cow house. God help me.\n\nJesse: What are you doing?\n\nWalter: These are my good clothes. I can't go home smelling like a meth lab.\n\nJesse: Yeah, you can. I do. Those? Those, uh You're keeping those on, right?\n\nWalter: Come on. Daylight's burning.\n\nJesse: Oh, my God. Oh, this is, uh this is a good look for you. And you're maybe only the world's second biggest h*m*.\n\nWalter: Would you shut up and help me?\n\nJesse: Oh, yeah. Oh, yeah, work it. Baby, work it.\n\nWalter: Turn that off!\n\nJesse: This is glass grade. I mean, you got...Jesus, you got crystals in here two inches, three inches long. This is pure glass. You're a g*dd*mn artist. This is art, Mr. White.\n\nWalter: Actually, it's just basic chemistry, but thank you, Jesse. I'm glad it's acceptable.\n\nJesse: Acceptable? You're the g*dd*mn Iron Chef. Every jibhead from here to Timbuktu is going to want a taste. Now I gotta try this.\n\nWalter: No. No. No, we only sell it. We don't use it.\n\nJesse: Okay, since when? Listen, you've been watching way too much Miami Vice. That ain't happening.\n\nWalter: So what now? How do we proceed?\n\nJesse: We cook more tomorrow. Meantime I know just the guy to talk to.\n\nScene: Krazy-8’s House\n\nJesse: Kraze, how you doing, my man? You got a new dog. Right on, man. What's his name? Yeah, I had a dog like that once, except maybe, like, twice as big. Super purebred. Now, me personally, I would train him to go straight for the nuts...\n\nKrazy-8: Just shut your mouth and show me your money.\n\nJesse: I ain't buying, ese. I'm selling. Tell me that ain't the finest scante you ever laid eyes on. Go ahead, try it. Hey, poochie. How you doing? Jesus Christ. See? What'd I say?\n\nKrazy-8: It's all right.\n\nJesse: It's all right? It's all right?\n\nKrazy-8: Yeah, it's all right. So, what? You back in business?\n\nJesse: Hell, yeah, I'm back. With a vengeance. Vato loco gotta make a living. You know, with your cousin gone away and all. And listen, homes, about that. It really broke me up about Emilio. That dude is like my brother. He okay? You talk to him?\n\nKrazy-8: Yeah, yeah, I talked to him. He said when the Feds came, you were out sticking it in some neighbor lady.\n\nJesse: Hey, you know, I got lucky twice.\n\nKrazy-8: I don't know, man. Emilio, he thinks maybe you dimed on him.\n\nJesse: That is bullshit. That is bullshit, Krazy-8! I should kick his punk ass for even thinking that. You know what? Next time you talk to Emilio, you tell him for me, all right?\n\nKrazy-8: Why don't you tell him yourself? Made bail this morning.\n\nEmilio: Go ahead, pendejo. Kick my ass.\n\nJesse: Hey, listen...\n\nKrazy-8: Where did you get this? Because I know your little punk ass didn't cook it.\n\nScene: Desert\n\nKrazy-8: Hey, man. You some kind of nudist? That's some stone-fine tick tick you been cooking there, ese. How about you come work for me?\n\nWalter: I'd be willing to sell it to you if the price is right.\n\nKrazy-8: You out here all by yourself, huh?\n\nEmilio: I know you. He was there when I got busted. He's with the DEA!\n\nWalter: No.\n\nEmilio: You ratasnitch f*ck!\n\nJesse: Run, Mr. White! Run!\n\nEmilio: I say we cap 'em both.\n\nKrazy-8: Hey, you really cook up that batch?\n\nWalter: Yeah.\n\nKrazy-8: You an artist. It's a damn shame.\n\nWalter: Wait! Wait a minute. Listen to me. I'll teach you my recipe. What do you say? You want to cook like me? You let us both live and I will teach you. Put the cigarette out. Please.\n\nEmilio: Move it, homes. We ain't got all day.\n\nWalter: Okay.\n\nJesse: What happened? What'd you do to them?\n\nWalter: Red phosphorus in the presence of moisture and accelerated by heat yields phosphorus hydride. Phosphine gas. One good whiff and...we gotta, we gotta clean this up.\n\nScene: Walt and Skyler’s Bedroom\n\nSkyler: Where were you? Walt. I don't know what's been going on with you lately, but...\n\nWalter: Nothing. I'm fine.\n\nSkyler: Whatever it is, I'll tell you this. I do not like it when you don't talk to me. The worst thing you can do is shut me out. Walter, is that you?\n\n"
- text: "Jim: Hey.\n\nDwight: Hello. Jim?\n\nJim: What's up, buddy?\n\nDwight: This is not funny. Why is my stuff in here?\n\nJim: Wow, that's weird. Oh, dollar for a stapler, that's pretty good.\n\nDwight: Yeah, well, I'm not paying for my own stuff, okay? I know you did this, because you're friends with the vending machine guy.\n\nJim: Who, Steve?\n\nDwight: Yeah, Steve, whatever his name is.\n\nPam: Sorry. What do I want? What do I want... Oh, it's a pencil cup.\n\nDwight: No, no, no, no, no. That's my pencil cup.\n\nPam: Um, I don't think so, I just bought it.\n\nDwight: Uh, I think so, and you're going to hand it over to me.\n\nPam: I love these.\n\nDwight: Okay, fine. Where's my wallet?\n\nJim: Oh, there it is. J1.\n\nDwight: But I don't have any...\n\nJim: Here, you know what? You can have some nickels.\n\nDwight: [putting quarters in] Five, ten, fifteen, twenty, twenty-five...\nMichael: Hello, everyone.\n\nDwight: Good morning, Michael.\n\nPhyllis: Where are we going this afternoon?\n\nMichael: Ah! Ha ha ha!\nPam: Last week, Michael sent out this mysterious memo.\n\nJim: 'It's time for our first quarter camaraderie event, so pack a swimsuit, a toothbrush, rubber-soled shoes, and a ski mask.'\n\nPam: A ski mask and a swimsuit.\n\nJim: So that he can have us rob a bank, and then escape through the sewers.\n\nPam: And brush our teeth.\nMichael: Yeah?\n\nStanley: Michael.\n\nMichael: Stanley! Bo banley.\n\nStanley: I need to know...\n\nMichael: Banana fana fo fanley.\n\nStanley: What we're doing.\n\nMichael: Be my mo manley.\n\nStanley: You said bring a toothbrush.\n\nMichael: Stanley.\n\nStanley: Is this an overnight?\n\nMichael: Maybe. The suspense is just so exciting, isn't it?\n\nStanley: Should my wife tell her boss she's not coming in tomorrow?\n\nMichael: Maybe, I don't know.\n\nStanley: Not maybe. Yes or no.\n\nMichael: Well, no. But... okay, don't spoil it for everybody, all right? But we are going on a booze cruise on Lake Wallenpaupack.\n\nStanley: In January?\n\nMichael: It's cheaper.\nMichael: This is not just another party. This is a leadership training exercise. Right? I'm going to combine elements of fun and motivation and education into a single mind-blowing experience.\nMichael: It is now time to unveil the destination of this year's retreat. We are going on a harbor cruise of Lake Wallenpaupack. It's a booze cruise!\n\nMeredith: All right!\n\nRyan: I have a test for business school tomorrow night. Is it okay if I skip the cruise and study for that?\n\nMichael: No. This is mandatory. But don't worry, you know what? You're gonna learn plenty. This is gonna turn your life around, Ryan.\n\nRyan: I'm already in business school.\n\nMichael: Well, this...\n\nKelly: Wait, Michael?\n\nMichael: Yeah?\n\nKelly: Why did you tell us to bring a bathing suit?\n\nMichael: To throw you off the scent.\n\nKelly: Yeah, but I bought a bathing suit.\n\nMichael: Well, just keep the tags on and you can return it.\n\nKelly: I took the tags off already.\n\nMichael: Well, that's not my fault, okay? Just.. we're not going to pay for a bathing suit. Okay, I know what you're all thinking, 'Who is this smart little cookie?' Her name is Brenda... something, and she is from corporate. And she is here, like you, to learn from what I have to say.\nMichael: I am a great motivational speaker. I attended a Tony Robbins event by the airport last year, and... it wasn't the actual course. You have to pay for the actual course. But it talked about the actual course. And I've incorporated a lot of his ideas into my own course.\nMichael: Leader... ship. The word 'ship' is hidden inside the word 'leadership,' as its derivation. So if this office is, in fact, a ship, as its leader, I am the captain. But we're all in the same boat. Teamwork!\nOscar: Last year, Michael's theme was 'Bowl over the Competition!' So guess where we went.\nMichael: Now, on this ship that is the office, what is a sales department? Anyone?\n\nDarryl: How about the sales department is the sails?\n\nMichael: Yes, Darryl, the sales department makes sales. Good. Let me just explain. I see the sales department as the furnace.\n\nPhyllis: A furnace?\n\nJim: Yeesh, how old is this ship?\n\nPam: How about the anchor?\n\nPhyllis: What does the furnace do?\n\nMichael: All right, let's not get hung up on the furnace. This just... it's the sales... I see the sales department down there. They're in the engine room, and they are shoveling coal into the furnace, right? I mean, who saw the movie Titanic? They were very important in the movie Titanic. Who saw it? Show of hands!\n\nJim: I'm not really sure what movie you're talking about. Are you sure you got the title right?\n\nMichael: Titanic?\n\nPam: I think you're thinking of The Hunt for Red October.\n\nMichael: No, I'm Leo DiCaprio! Come on!\nJim: Michael stands in the front of the boat and says that he's king of the world within the first hour, or I give you my next paycheck.\nPhyllis: Michael, everyone in the engine room drowned.\n\nMichael: No! Thank you, spoiler alert. You saw the movie, those of you who did. They're happy down there in the furnace room. And they're dirty and grimy and sweaty, and they're singing their ethnic songs, and... actually, that might be warehouse.\n\nDarryl: What?\n\nMichael: The... no, no. No, I didn't... okay. Well, okay, in a nutshell, what I'm saying is... leadership. We'll talk more about that on the boat. Ship.\n\nDwight: Aye aye, Captain.\nMichael: [singing] A three-hour tour, a three-hour tour.\nMichael: Pam, you are Mary Ann! We have the Professor and Ginger, welcome aboard. Angela, you are Mrs. Howell. Lovey. [to Kelly] Uh... the native. Sometimes they come from neighboring... [to Stanley] We have one of the Globetrotters, I am the Skipper, and Dwight, you will be Gilligan.\n\nDwight: Cool.\n\nCaptain Jack: Actually, I'm the Skipper. But you can be Gilligan.\n\nMichael: I'd rather die. Hi, I am Michael Scott, I am the captain of this party.\n\nCaptain Jack: I am Captain Jack, I am captain of the ship. I'm also captain of anyone who sets foot on the ship. [to boarding passengers] Hi, welcome aboard.\n\nMichael: Okay.\nMichael: In an office, when you are ranking people, manager is higher than captain. On a boat, who knows? It's nebulose.\nMichael: Hey, look! I'm king of the world!\nCaptain Jack: Okay, all right! Welcome aboard! I am your captain, Captain Jack.\n\nMichael: And I am the regional manager of Dunder-Mifflin, Michael Scott. Welcome, welcome!\n\nCaptain Jack: Okay! So...\n\nMichael: Okay! So...\n\nCaptain Jack: Please. The life preservers.\n\nMichael: Right.\n\nCaptain Jack: They are located underneath the seats, all along the border of the boat.\n\nMichael: But don't worry, you are not going to be needing life preservers tonight.\n\nCaptain Jack: Well, we might, okay? Please let me finish, okay? Thank you. So, the Coast Guard requires that I tell you where the safety exits are. On this ship, it's very easy. Anywhere over the side. [Dwight laughs loudly.] Not only am I your ship captain, I am also your party captain! Whoo! We're gonna get it going in just a few minutes here...\n\nMichael: I'm your party captain too! And you are gonna put on your dancing shoes later on! So we are gonna...\n\nCaptain Jack: Okay, Michael, if you don't mind...\n\nMichael: Rock it!\n\nCaptain Jack: Please, okay?\n\nMichael: If the boat's a-rockin', don't come knockin'!\n\nCaptain Jack: Michael.\n\nMichael: Yep.\n\nCaptain Jack: Your company's employees are not the only people on the boat tonight, okay?\n\nMichael: We're all gonna have a good time tonight!\n\nCaptain Jack: Why don't you let me and my crew do our job. You just sit back and have a good time. All right?\n\nMichael: Hm? Okay. Yep.\nKaty: You guys, it's like we're in high school and we're at the cool table. Right?\n\nRoy: Yeah.\n\nKaty: Pam, were you a cheerleader?\n\nRoy: No, she was totally Miss Artsy-Fartsy in high school. She wore the turtleneck and everything!\n\nKaty: That's hilarious.\n\nJim: It's not hilarious, but...\n\nRoy: Where did you go to school?\n\nKaty: Bishop O'Hara.\n\nRoy: Piss slop who cares-a? We played you! You... you really look familiar. Did you... you cheered for them, didn't you?\n\nJim: Um, no.\n\nKaty: Yes, I did! [chanting] A-W-E-S-O-M-E! Awesome! Awesome is what we are! We're the football superstars! A-W-E-S-O-M-E!\n\nRoy: I remember that! We crushed you like 42-10!\nMichael: Having fun?\n\nBrenda: Yeah. Everybody's really nice.\n\nMichael: Good. Well, that is what Scranton is all about. Not like you New Yawkers.\n\nBrenda: When are you going to start the presentation?\n\nMichael: Well, we already sort of started it back at the office and on the dock with the Gilligan thing, so... right now, I was thinking. Yes. Okay, listen up all you Dunder-Mifflinites! I would like to talk to you all about life preservers. Now, one important life preserver in business is IT support.\n\nCaptain Jack: Not now, Mike, we're doing the limbo! That's right, partiers, it's time to limbo, limbo, limbo!\n\nMichael: So, okay.\n\nDwight: Limbo, whoo!\n\nCaptain Jack: All right! I need a volunteer to come up here and hold my stick. Who's it gonna be?\n\nMeredith: Me.\n\nCaptain Jack: Okay...\n\nDwight: Me! Me, me, me.\n\nCaptain Jack: Uh... usually it's a woman.\n\nDwight: I'm stronger.\n\nCaptain Jack: Hey, I got an idea! How would you like to steer the ship, Dwight?\nCaptain Jack: Keep us on a steady course. Keep a sharp eye out. I'm counting on you!\nDwight: I was the youngest pilot in Pan Am history. When I was four, the pilot let me ride in the cockpit and fly the plane with him. And I was four. And I was great. And I would have landed it, but my dad wanted us to go back to our seats.\nCaptain Jack: All right, all right, that was great! Now it's time for the dance contest!\n\nMichael: But before that, I have to do my presentation.\n\nCaptain Jack: Nope! Dance contest!\n\nMichael: All right, we'll have a motivational dance contest! Hit it! Yeah, okay, dancing! It is a primal art form used in ancient times to express yourself with the body and communicate!\nMichael: Sometimes you have to take a break from being the kind of boss that's always trying to teach people things. Sometimes you have to just be the boss of dancing.\nDwight: [singing] What do you do with a drunken sailor? What do you do with a drunken sailor? What do you do with a drunken sailor early in the morning?\n\nAngela: Hey, come inside and talk to me.\n\nDwight: I can't. Do you want us to run aground, woman?!\nDarryl and Katy: [chanting] Snorkel sh*t! Snorkel sh*t!\n\nRoy: Whoo! Who's next? Come on, Pam! Come on! Come on!\n\nPam: No, I'm not going to do that.\n\nRoy: Come on!\n\nDarryl: That's what I'm talking about!\n\nPam: Hey, why don't we find like a quieter place to hang out?\n\nRoy: I've just gotta wait for Darryl to do his sh*t. Just a minute. Come on! [chanting] Darryl! Darryl!\nPam: It's getting kind of rowdy down there.\n\nJim: Yeah. [chanting] Darryl! Darryl! Darryl!\n\nPam: Sometimes I just don't get Roy.\n\nJim: Well...\n\nPam: I mean, I don't know. So... what's it like dating a cheerleader?\n\nJim: Oh, um... [A long silence.]\n\nPam: I'm cold.\nCaptain Jack: So, what's this presentation all about?\n\nMichael: Ah! See, this is of general interest. It is about priorities and making decisions, using the boat as an analogy. What is important to you? If the boat is sinking, what do you save?\n\nCaptain Jack: Women and children.\n\nMichael: No, no. Salesmen and profit centers.\n\nCaptain Jack: That's a stupid analogy.\n\nMichael: Okay, well, obviously you don't know anything about leadership.\n\nCaptain Jack: Well, I was the captain of a PC-1 Cyclone Coastal Patrol Boat during Desert Storm.\n\nDwight: Wow. You should be the motivational speaker.\n\nMichael: Okay.\n\nDwight: Yeah. He gives me real responsibility, Michael. Captain Jack delegates. He's let me steer the ship for the last hour.\nKaty: I'd like to be engaged. How did you manage to pull that off?\n\nPam: Uh, I've been engaged for three years, and there's no end in sight. So... you don't wanna ask my advice.\nCaptain Jack: Suppose your office building's on fire. Jim, who would you save?\n\nJim: Um... let's see, uh... The customer. Because the customer is king.\n\nMichael: Not what I was looking for, but a good thought.\n\nCaptain Jack: He's just sucking up!\n\nRoy: When you were in the Navy, did you ever almost die?\n\nCaptain Jack: Oh yeah, oh yeah. And I wasn't thinking about some customer. I was thinking about my first wife. The day I got back on shore, I married her.\nJim: You know what? I would save the receptionist. I just wanted to clear that up.\nRoy: Hello, everybody, could I have your attention for just a second? Could you listen to me for a second? We were up at the front, and we were talking about what's really important, and... Pam, I think enough is enough. I think we should set a date for our wedding. How about June 10th? Come on, let's do it! Come on, Pam!\nMichael: I don't want to take credit for this, but Roy and I were just having a conversation about making commitments and making choices. Right? Did I motivate you?\n\nRoy: No, it was Captain Jack.\n\nMichael: Well... could have been either one of us, because we were pretty much saying the same thing. Congratulations. That is great!\n\nCaptain Jack: We gotta celebrate! Hey, I got an idea, I got an idea. I can marry you right now, as captain of the ship!\n\nMichael: Yes! I can marry you as regional manager of Dunder-Mifflin!\n\nPam: No, no, I want my mom and dad to be there.\n\nMichael: Then I'll give you away!\n\nPam: No, thank you.\nKaty: Do you think that'll ever be us?\n\nJim: No.\n\nKaty: What is wrong with you? Why did you even bring me here tonight?\n\nJim: I don't know. Let's break up.\n\nKaty: Whoa. What?\nCaptain Jack: This is where Captain Jack drives the boat.\n\nMeredith: Wow!\nDwight: Seasick? Captain Jack says you should look at the Moon.\n\nMichael: Captain Jack is a fart face. I'm on medication.\n\nBrenda: Really? What?\n\nMichael: Vomicillin. Okay. All right. It's time to be boss. It's time to motivate. Let's blow some minds here. Okay, guys, guys, cool it. Everybody, Dunder-Mifflin Scranton employees, Brenda, I have some very, very urgent news I need to tell everybody right now. Listen up. The ship is sinking! Okay? We're going down, right now. Just wrap your heads around the reality of that. Shh, please! Everybody, it's my turn now, okay? Captain Jack is gone. In five minutes, this ship is going to be at the bottom of the lake! And there aren't enough spaces on the lifeboat! Who are we gonna save? Do we save sales? Do we save customer service? Do we save accounting? This is a business scenario. Right? It's a scary... it's a...\n\nCaptain Jack: Hey! Hey! What the hell is going on here?\n\nMichael: It's a predicament, and it's something that each and every one of us has to think about.\nMichael: I'm in the brig. See? The boat's not as corporate-friendly as advertised. What was the deal with the guy jumping overboard? What was... if he had just waited and heard what I had to say, he would be motivated right now and not all wet.\nMichael: Is somebody there?\n\nJim: What happened to you?\n\nMichael: Captain Jack has a problem with authority.\n\nJim: Oh, right, because you announced that his ship was sinking?\n\nMichael: He just totally lost it. If you ask me, he caused the panic.\n\nJim: What a night.\n\nMichael: Well, it's nice for you. Your friend got engaged.\n\nJim: She was always engaged.\n\nMichael: Roy said the first one didn't count.\n\nJim: That's... great. You know, to tell the truth, I used to have a big thing for Pam, so...\n\nMichael: Really? You're kidding me. You and Pam? Wow. I would have never have put you two together. You really hid it well. God! I usually have a radar for stuff like that. You know, I made out with Jan...\n\nJim: Yeah, I know.\n\nMichael: Yeah? Yep. Well, Pam is cute.\n\nJim: Yeah. She's really funny, and she's warm. And she's just... well, anyway.\n\nMichael: Well, if you like her so much, don't give up.\n\nJim: She's engaged.\n\nMichael: BFD. Engaged ain't married.\n\nJim: Huh.\n\nMichael: Never, ever, ever give up.\nDwight: Don't worry, Michael. I'm taking us to shore.\n\nMichael: It's a fake wheel, dummy.\n"
- text: "PROLOGUE\n\nEXT. HOUSE - NIGHT\n\nLawrence, Kansas\n\n22 years ago\n\nThese scenes are definitively dated to 2 Nov 2005.\n\nCrickets chirp. A large deciduous tree with no leaves stands outside one of several suburban homes.\n\nINT. NURSERY - NIGHT\n\nA Woman, Mary Winchester, wearing a white nightgown, carries a SMALL CHILD, her son Dean, into a dark room.\n\nMary: Come on, let's say good night to your brother.\n\nMary turns on the lights: it's the nursery of a BABY, Sam, who is lying in his crib and looking over at Mary and Dean. Mary sets Dean down. Dean leans over the side of the crib and kisses Sam on the forehead.\n\nDean: 'Night, Sam.\n\nMary leans over Sam as well.\n\nMary: Good night, love.\n\nMary brushes Sam's hair back and kisses his forehead.\n\nMan: Hey, Dean.\n\nDean turns. The Man in the doorway wearing a USMC T-shirt is John. Dean rushes over to him.\n\nDean: Daddy!\n\nJohn: Hey, buddy.\n\nJohn scoops Dean up.\n\nJohn: So what do you think? You think Sammy's ready to toss around a football yet?\n\nDean shakes his head, laughing.\n\nDean: No, Daddy.\n\nJohn laughs.\n\nJohn: No.\n\nMary passes John and Dean on the way out of the room.\n\nMary: You got him?\n\nJohn: I got him.\n\nJohn hugs Dean closer.\n\nJohn: Sweet dreams, Sam.\n\nJohn carries Dean out of the room, flipping off the lights. Sam watches them go, gurgling, then tries to reach his toes.\n\nThe baseball-themed mobile above Sam's crib begins to spin on its own while Sam watches. The transportation-themed clock on the wall ticks, ticks, stops. The moon-shaped nightlight flickers.\n\nINT. MASTER BEDROOM - NIGHT\n\nLights flicker on a baby monitor sitting on a nightstand next to a photo of Mary and John. Strange noises come through the monitor. Mary, asleep in bed, stirs. She turns on the light on the nightstand.\n\nMary: John?\n\nMary turns: she's alone. She gets up.\n\nINT. HALLWAY - NIGHT\n\nMary walks down the hall to Sam's nursery. John, seen only in silhouette, stands over Sam's crib.\n\nMary: John? Is he hungry?\n\nJohn turns his head.\n\nMan: Shhh.\n\nMary: All right.\n\nMary heads back down the hallway. The light by the stairs is flickering. Mary frowns and goes to tap at it till the light steadies.\n\nMary: Hm.\n\nMore flickering light is coming from downstairs: Mary investigates. A w*r movie is on TV and John has fallen asleep watching it. If John is here, Mary realizes, then the Man upstairs cannot be John and must be a danger. She runs back upstairs.\n\nMary: Sammy! Sammy!\n\nMary enters Sam's nursery and stops short.\n\nINT. LIVING ROOM - NIGHT\n\nUpstairs, Mary screams. John wakes up.\n\nJohn: Mary?\n\nJohn scrambles out of the chair.\n\nJohn: Mary!\n\nJohn runs upstairs.\n\nINT. NURSERY - NIGHT\n\nJohn bursts through the closed door of the nursery.\n\nJohn: Mary.\n\nThe room is quiet and appears empty except for Sam awake in his crib and John. John glances around and pushes down the side of Sam's crib.\n\nJohn: Hey, Sammy. You okay?\n\nSomething dark drips next to Sam. John touches it. Two more drops land on the back of John's hand. It looks like blood. John looks up. Mary is sprawled across the ceiling, the stomach of her nightgown red with blood, staring at John and struggling to breathe. John collapses onto the floor, staring at Mary.\n\nJohn: No! Mary!\n\nMary bursts into flame. The fire spreads over the ceiling. John stares, frozen. Sam wails. John, reminded he's not alone, gets up and scoops Sam out of his crib and rushes out of the room.\n\nINT. HALLWAY - NIGHT\n\nDean is awake and coming to investigate.\n\nDean: Daddy!\n\nJohn shoves Sam at Dean.\n\nJohn: Take your brother outside as fast as you can and don't look back! Now, Dean, go!\n\nDean turns and runs. John turns back to the nursery.\n\nJohn: Mary!\n\nThe entire room is on fire. Mary herself can barely be seen.\n\nJohn: No!\n\nEXT. HOUSE - NIGHT\n\nDean runs outside, holding Sam.\n\nDean: It's okay, Sammy.\n\nDean turns to look up at Sam's window, which is lit with gold.\n\nJohn runs outside, scoops up Dean and Sam, and carries them both away.\n\nJohn: I gotcha.\n\nFire explodes out of Sam's nursery window.\n\nEXT. HOUSE - NIGHT, LATER\n\nThe Lawrence fire department has arrived. A FIREFIGHTER gets out of a fire truck and takes over at the gauges for another firefighter.\n\nFirefighter: I got it. You go hold the line up.\n\nThe second firefighter goes to the back of the truck and takes a hose from a third firefighter. That firefighter takes the hose towards the house where a fourth firefighter is spraying through Sam's nursery window. A paramedic opens the back of an ambulance. A Police Officer waves some neighbors back.\n\nOfficer: Stay back. You have to stay back.\n\nAcross the street from the house, John and Dean sit on the hood of John's Impala, John holding Sam. John looks up at the remnants of the fire.\n\nACT ONE\n\nStanford University\n\nPresent Day\n\nIt is 31 Oct 2005.\n\n'Gasoline' by Ginger begins to play.\n\nAPARTMENT\n\nINT. BEDROOM - DAY\n\nYoung Woman: Sam!\n\nThe Young Woman, Jess, comes around a corner; she is wearing a sexy-nurse costume and adjusting her hat. The photo of Mary and John from earlier is on the dresser.\n\nJess: Get a move on, would you?\n\nMusic: I've been sh*t from a cannon\n\nJess: We were supposed to be there like fifteen minutes ago.\n\nJess walks off.\n\nJess: Sam!\n\nMusic: I'm a human cannonball\n\nJess: You coming or what?\n\nStarring\n\nJARED PADALECKI\n\nA Young Man pokes his head around the corner; this is Sam. He's wearing jeans and three shirts, not a costume.\n\nSam: Do I have to?\n\nJess: Yes!\n\nMusic: I'm gonna fly high\n\nJess: It'll be fun.\n\nSam comes into the room.\n\nJess: And where's your costume?\n\nMusic: I'm gonna fall fall fall\n\nSam laughs and ducks his head.\n\nJENSEN ACKLES\n\nSam: You know how I feel about Halloween.\n\nPARTY\n\nINT. BAR - NIGHT\n\nClassic's 'What Cha Gonna Do' begins to play.\n\nMusic: Show me whatcha gonna do\n\nYeah whatcha gonna do\n\nAre you trying to get in\n\nYeah whatcha gonna do\n\nThe bar is decorated for Halloween (including a gargoyle with cobwebs and a baseball hat that says 'GET NAKED'). Someone pours someone else a sh*t. Everyone is in costume.\n\nGuest Starring\n\nSarah SHAHI\n\nMusic: Are you gonna ride\n\nJess raises a glass as a Young Man in a ghoul costume, Luis, comes up to the table where Sam and Jess are. Sam is still not in costume.\n\nJess: So here's to Sam-\n\nMusic: Baby\n\nADRIANNE PALICKI\n\nJess: -and his awesome LSAT victory.\n\nSam: All right, all right, it's not that big a deal.\n\nJess, Sam, and Luis clink glasses.\n\nJess: Yeah, he acts all humble.\n\nSamANTHA SMITH\n\nJess: But he scored a one seventy-four.\n\nLuis drinks his sh*t and so does Sam.\n\nLuis: Is that good?\n\nJEFFREY Dean MORGAN\n\nJess: Scary good.\n\nJess drinks.\n\nLuis: So there you go. You are a first-round draft pick. You can go to any law school you want!\n\nLuis sits next to Sam.\n\nR.D. CALL\n\nSam: Actually, I got an interview here. Monday. If it goes okay I think I got a sh*t at a full ride next year.\n\nJess: Hey. It's gonna go great.\n\nSam: It better.\n\nROSS KOHN\n\nLuis: How does it feel to be the golden boy of your family?\n\nSam: Ah, they don't know.\n\nLuis: Oh, no, I would be gloating! Why not?\n\nSam: Because we're not exactly the Bradys.\n\nLuis: And I'm not exactly the Huxtables. More shots?\n\nJess and Sam speak in chorus.\n\nJess and Sam: No. No.\n\nSam: No.\n\nLuis goes up to the bar anyway.\n\nJess: No, seriously. I'm proud of you. And you're gonna knock 'em dead on Monday-\n\nand\n\nSTEVE RAILSBACK\n\nJess: -and you're gonna get that full ride. I know it.\n\nSam: What would I do without you?\n\nJess: Crash and burn.\n\nJess smiles and pulls Sam in for a kiss.\n\nMusic: Are you trying to get in\n\nYeah whatcha gonna do\n\nAPARTMENT\n\nINT. BEDROOM - NIGHT\n\nMusic: Are you gonna ride baby\n\nSupervising Producer\n\nPETER JohnSON\n\nSam and Jess lie in bed, asleep back to back. Jess shifts position.\n\nExecutive Producer\n\nMcG\n\nA sound outside the room, like a window opening. Sam opens his eyes.\n\nINT. APARTMENT - NIGHT\n\nSam leaves the bedroom and looks around the apartment.\n\nExecutive Producer\n\nDAVID NUTTER\n\nA window is open; earlier it must have been closed. Footsteps. A Man walks past the strings of beads at the far end of the hall. Sam moves to another part of the apartment and waits. The Man enters the room. Sam lunges forward and grabs the Man at the shoulder. The Man knocks Sam's arm away and aims a strike at Sam, who ducks. The Man grabs Sam's arm, swings him around, and shoves him back. Sam kicks and is blocked, then pushed back into another room. If the Man hadn't seen Sam's face before, he sees it now; Sam gets his first glimpse of the Man. The Man elbows Sam in the face; Sam kicks at his head. The Man ducks and swings and Sam blocks. The Man knocks Sam down and pins him to the floor, one hand at Sam's neck and the other holding Sam's wrist.\n\nMan: Whoa, easy, tiger.\n\nSam breathes hard.\n\nSam: Dean?\n\nDean laughs.\n\nSam: You scared the crap out of me!\n\nDean: That's 'cause you're out of practice.\n\nSam grabs Dean's hand and yanks, slamming his heel into Dean's back and Dean to the floor.\n\nDean: Or not.\n\nSam taps Dean twice where Sam is holding him.\n\nDean: Get off of me.\n\nSam rolls to his feet and pulls Dean up.\n\nSam: What the hell are you doing here?\n\nDean: Well, I was looking for a beer.\n\nProduced by\n\nCYRUS YAVNEH\n\nDean puts his hands on Sam's shoulders, shakes once, and lets go.\n\nSam: What the hell are you doing here?\n\nDean: Okay. All right. We gotta talk.\n\nCreated by\n\nERIC KRIPKE\n\nSam: Uh, the phone?\n\nDean: If I'd'a called, would you have picked up?\n\nJess turns the light on. She is wearing very short shorts and a cropped Smurfs shirt.\n\nJess: Sam?\n\nSam and Dean turn their heads in unison.\n\nSam: Jess. Hey. Dean, this is my girlfriend, Jessica.\n\nDean looks at her appreciatively.\n\nJess: Wait, your brother Dean?\n\nJess smiles. Sam nods. Dean grins at her and moves closer.\n\nDean: Oh, I love the Smurfs. You know, I gotta tell you. You are completely out of my brother's league.\n\nJess: Just let me put something on.\n\nJess turns to go. Dean's voice stops her.\n\nWritten by\n\nERIC KRIPKE\n\nDean: No, no, no, I wouldn't dream of it. Seriously.\n\nDean goes back over to Sam without taking his eyes off Jess. Sam watches him, his expression stony.\n\nDean: Anyway, I gotta borrow your boyfriend here, talk about some private family business.\n\nDirected by\n\nDAVID NUTTER\n\nDean: But, uh, nice meeting you.\n\nSam: No.\n\nSam goes over to Jess and puts an arm around her.\n\nSam: No, whatever you want to say, you can say it in front of her.\n\nDean: Okay.\n\nDean turns to look at them both straight on.\n\nDean: Um. Dad hasn't been home in a few days.\n\nSam: So he's working overtime on a Miller Time shift. He'll stumble back in sooner or later.\n\nDean ducks his head and looks back up.\n\nDean: Dad's on a hunting trip. And he hasn't been home in a few days.\n\nSam's expression doesn't change while he takes this in. Jess glances up at him.\n\nSam: Jess, excuse us. We have to go outside.\n\nOUTSIDE APARTMENT\n\nINT. STAIRWELL - NIGHT\n\nSam and Dean head downstairs. Sam has put on jeans and a hoodie.\n\nSam: I mean, come on. You can't just break in, middle of the night, and expect me to hit the road with you.\n\nDean: You're not hearing me, Sammy. Dad's missing. I need you to help me find him.\n\nSam: You remember the poltergeist in Amherst? Or the Devil's Gates in Clifton? He was missing then, too. He's always missing, and he's always fine.\n\nDean stops and turns around. Sam stops too.\n\nDean: Not for this long. Now are you gonna come with me or not?\n\nSam: I'm not.\n\nDean: Why not?\n\nSam: I swore I was done hunting. For good.\n\nDean: Come on. It wasn't easy, but it wasn't that bad.\n\nDean starts downstairs again. Sam follows.\n\nSam: Yeah? When I told Dad I was scared of the thing in my closet, he gave me a .45.\n\nDean stops at the door to the outside.\n\nDean: Well, what was he supposed to do?\n\nSam: I was nine years old! He was supposed to say, don't be afraid of the dark.\n\nDean: Don't be afraid of the dark? Are you kidding me? Of course you should be afraid of the dark. You know what's out there.\n\nSam: Yeah, I know, but still. The way we grew up, after Mom was k*ll, and Dad's obsession to find the thing that k*ll her.\n\nDean glances outside.\n\nSam: But we still haven't found the damn thing. So we k*ll everything we canfind.\n\nDean: We save a lot of people doing it, too.\n\nA pause.\n\nSam: You think Mom would have wanted this for us?\n\nDean rolls his eyes and slams the door open.\n\nEXT. PARKING LOT - NIGHT\n\nThere's a short flight of stairs from the door to the parking lot. Dean and Sam climb it.\n\nSam: The w*apon training, and melting the silver into b*ll*ts? Man, Dean, we were raised like warriors.\n\nThey cross the parking lot to the Impala from the prologue.\n\nDean: So what are you gonna do? You're just gonna live some normal, apple pie life? Is that it?\n\nSam: No. Not normal. Safe.\n\nDean: And that's why you ran away.\n\nDean looks away.\n\nSam: I was just going to college. It was Dad who said if I was gonna go I should stay gone. And that's what I'm doing.\n\nDean: Yeah, well, Dad's in real trouble right now. If he's not dead already. I can feel it.\n\nSam is silent.\n\nDean: I can't do this alone.\n\nSam: Yes you can.\n\nDean looks down.\n\nDean: Yeah, well, I don't want to.\n\nSam sighs and looks down, thinking, then up.\n\nSam: What was he hunting?\n\nDean opens the trunk of the Impala, then the spare-tire compartment. It's an arsenal. He props the compartment open with a g*n and digs through the clutter.\n\nDean: All right, let's see, where the hell did I put that thing?\n\nSam: So when Dad left, why didn't you go with him?\n\nDean: I was working my own gig. This, uh, voodoo thing, down in New Orleans.\n\nSam: Dad let you go on a hunting trip by yourself?\n\nDean looks over at Sam.\n\nDean: I'm twenty-six, dude.\n\nDean pulls some papers out of a folder.\n\nDean: All right, here we go. So Dad was checking out this two-lane blacktop just outside of Jericho, California. About a month ago, this guy.\n\nDean hands one of the papers to Sam.\n\nDean: They found his car, but he vanished. Completely MIA.\n\nThe paper is a printout of an article from the Jericho Herald, headlined 'Centennial Highway Disappearance' and dated Sept. 19th 2005; it has a man's picture, captioned 'Andrew Carey MISSING'. Sam reads it and glances up.\n\nSam: So maybe he was kidnapped.\n\nDean: Yeah. Well, here's another one in April.\n\nDean tosses down another Jericho Heraldarticle for each date he mentions.\n\nDean: Another one in December 'oh-four, 'oh-three, 'ninety-eight, 'ninety-two, ten of them over the past twenty years.\n\nDean takes the article back from Sam and picks up the rest of the stack, putting them back in the folder.\n\nDean: All men, all the Same five-mile stretch of road.\n\nDean pulls a bag out of another part of the arsenal.\n\nDean: It started happening more and more, so Dad went to go dig around. That was about three weeks ago. I hadn't heard from him since, which is bad enough.\n\nDean grabs a handheld tape recorder.\n\nDean: Then I get this voicemail yesterday.\n\nHe presses play. The recording is staticky and the signal was clearly breaking up.\n\nJohn: Dean...something big is starting to happen...I need to try and figure out what's going on. It may... Be very careful, Dean. We're all in danger.\n\nDean presses stop.\n\nSam: You know there's EVP on that?\n\nDean: Not bad, Sammy. Kinda like riding a bike, isn't it?\n\nSam shakes his head.\n\nDean: All right. I slowed the message down, I ran it through a gold wave, took out the hiss, and this is what I got.\n\nHe presses play again.\n\nWoman: I can never go home...\n\nDean presses stop.\n\nSam: Never go home.\n\nDean drops the recorder, puts down the g*n, stands straight, and shuts the trunk, then leans on it.\n\nDean: You know, in almost two years I've never bothered you, never asked you for a thing.\n\nSam looks away and sighs, then looks back.\n\nSam: All right. I'll go. I'll help you find him.\n\nDean nods.\n\nSam: But I have to get back first thing Monday. Just wait here.\n\nSam turns to go back to the apartment. He turns back when Dean speaks.\n\nDean: What's first thing Monday?\n\nSam: I have this...I have an interview.\n\nDean: What, a job interview? Skip it.\n\nSam: It's a law school interview, and it's my whole future on a plate.\n\nDean: Law school?\n\nDean smirks.\n\nSam: So we got a deal or not?\n\nDean says nothing.\n\nAPARTMENT\n\nINT. BEDROOM - NIGHT\n\nSam is packing a duffel bag. He pulls out a large hook-shaped knife and slides it inside. Jess comes into the room.\n\nJess: Wait, you're taking off?\n\nSam looks up.\n\nSam: Is this about your dad? Is he all right?\n\nSam: Yeah. You know, just a little family drama.\n\nSam goes over to the dresser and turns on the lamp atop it.\n\nJess: Your brother said he was on some kind of hunting trip.\n\nJess sits on the bed. Sam rummages in one of the drawers and comes out with a couple shirts, which go in the duffel.\n\nSam: Oh, yeah, he's just deer hunting up at the cabin, he's probably got Jim, Jack, and José along with him. I'm just going to go bring him back.\n\nJess: What about the interview?\n\nSam: I'll make the interview. This is only for a couple days.\n\nSam goes around the bed. Jess gets up and follows.\n\nJess: Sam, I mean, please.\n\nSam stops and turns.\n\nJess: Just stop for a second. You sure you're okay?\n\nSam laughs a little.\n\nSam: I'm fine.\n\nJess: It's just...you won't even talk about your family. And now you're taking off in the middle of the night to spend a weekend with them? And with Monday coming up, which is kind of a huge deal.\n\nSam: Hey. Everything's going to be okay. I will be back in time, I promise.\n\nHe kisses her on the cheek and leaves.\n\nJess: At least tell me where you're going.\n"
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: t5-base-finetuned-summscreen-bestval-100-genlen-10-epochs
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-base-finetuned-summscreen-bestval-100-genlen-10-epochs
This model is a fine-tuned version of [t5-base](https://huggingface.co/t5-base) on the SummScreen dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9499
- Rouge1: 29.2769
- Rouge2: 5.5288
- Rougel: 17.5141
- Rougelsum: 25.345
- Gen Len: 86.7596
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:------:|:-------:|:---------:|:-------:|
| 3.2858 | 0.99 | 3500 | 3.1088 | 27.292 | 4.7003 | 16.4176 | 23.7005 | 84.6259 |
| 3.2085 | 1.99 | 7000 | 3.0425 | 28.3997 | 5.0233 | 17.0582 | 24.5815 | 86.8322 |
| 3.107 | 2.98 | 10500 | 3.0110 | 28.7042 | 5.3326 | 17.429 | 24.7691 | 84.8549 |
| 3.074 | 3.98 | 14000 | 2.9886 | 28.8975 | 5.371 | 17.302 | 25.0658 | 86.6327 |
| 2.9899 | 4.97 | 17500 | 2.9769 | 29.0185 | 5.6415 | 17.6407 | 24.7669 | 82.8435 |
| 2.9857 | 5.97 | 21000 | 2.9647 | 29.5476 | 5.5332 | 17.4855 | 25.2605 | 87.3152 |
| 2.9542 | 6.96 | 24500 | 2.9586 | 29.4713 | 5.5729 | 17.5815 | 25.2393 | 88.0295 |
| 2.9301 | 7.96 | 28000 | 2.9536 | 29.8483 | 5.7355 | 17.8895 | 25.774 | 87.195 |
| 2.9118 | 8.95 | 31500 | 2.9503 | 29.3014 | 5.5802 | 17.5983 | 25.3476 | 86.0476 |
| 2.9033 | 9.95 | 35000 | 2.9499 | 29.2769 | 5.5288 | 17.5141 | 25.345 | 86.7596 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1
- Datasets 2.9.0
- Tokenizers 0.13.2
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-egy
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 16,451 | null |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1402.87 +/- 65.22
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-msa
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 71 | null |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: laxsvips/minilm-finetuned-emotion
results: []
datasets:
- emotion
language:
- en
metrics:
- f1
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# laxsvips/minilm-finetuned-emotion
This model is a fine-tuned version of [microsoft/MiniLM-L12-H384-uncased](https://huggingface.co/microsoft/MiniLM-L12-H384-uncased) on the Hugging Face emotion (https://huggingface.co/datasets/emotion) dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.1168
- Train Accuracy: 0.9446
- Validation Loss: 0.1709
- Validation Accuracy: 0.9350
- Epoch: 4
## Model description
# MiniLM: Small and Fast Pre-trained Models for Language Understanding and Generation
MiniLM is a distilled model from the paper "MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers".
## Intended uses & limitations
This model has been created as a learning guide on:
- How to implement a text classification model using Hugging Face Transformers in TensorFlow
- How to handle imbalanced class distribution
# How to use the model
```
from transformers import pipeline
model_cpt = "laxsvips/minilm-finetuned-emotion"
pipe = pipeline("text-classification", model=model_cpt)
predicted_scores = pipe("I am so glad you could help me")
print(predicted_scores)
````
The results:
```
[[{'label': 'sadness', 'score': 0.003758953418582678},
{'label': 'joy', 'score': 0.9874302744865417},
{'label': 'love', 'score': 0.00610917154699564},
{'label': 'anger', 'score': 9.696640336187556e-05},
{'label': 'fear', 'score': 0.0006420552381314337},
{'label': 'surprise', 'score': 0.00196251692250371}]]
```
## Training and evaluation data
[Emotion](https://huggingface.co/datasets/emotion)
Emotion is a dataset of English Twitter messages with six basic emotions: anger, fear, joy, love, sadness, and surprise.
## Training procedure
Refer to the [Colab](https://colab.research.google.com/github/laxmiharikumar/transformers/blob/main/TextClassification_Emotions_TF.ipynb) notebook
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: 'Adam',
- learning_rate': 5e-05,
- batch_size : 64
- num_epochs - 5
### Training results
| Train Loss | Train Accuracy | Validation Loss | Validation Accuracy | Epoch |
|:----------:|:--------------:|:---------------:|:-------------------:|:-----:|
| 0.9485 | 0.5543 | 0.8404 | 0.6870 | 0 |
| 0.4192 | 0.8347 | 0.3450 | 0.9040 | 1 |
| 0.2132 | 0.9178 | 0.2288 | 0.9240 | 2 |
| 0.1465 | 0.9364 | 0.1838 | 0.9295 | 3 |
| 0.1168 | 0.9446 | 0.1709 | 0.9350 | 4 |
### Evaluation Metrics
```
{'accuracy': 0.935,
'precision': 0.937365614416424,
'recall': 0.935,
'f1_score': 0.9355424419858925}
```
### Framework versions
- Transformers 4.26.1
- TensorFlow 2.11.0
- Datasets 2.9.0
- Tokenizers 0.13.2
### References
1. https://www.youtube.com/watch?v=u--UVvH-LIQ
2. https://huggingface.co/docs/transformers
3. https://www.tensorflow.org/api_docs/python/tf
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-sentiment
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 73 | null |
---
license: unknown
language:
- ko
pipeline_tag: fill-mask
---
|
CAMeL-Lab/bert-base-arabic-camelbert-ca
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 580 | null |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### gv-230214-20600-2060-fyf-run1 Dreambooth model trained by ltidev with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-glf
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 54 | null |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.fr
split: validation
args: PAN-X.fr
metrics:
- name: F1
type: f1
value: 0.8525033829499323
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [MunSu/xlm-roberta-base-finetuned-panx-de](https://huggingface.co/MunSu/xlm-roberta-base-finetuned-panx-de) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4005
- F1: 0.8525
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| No log | 1.0 | 500 | 0.3080 | 0.8254 |
| No log | 2.0 | 1000 | 0.3795 | 0.8448 |
| No log | 3.0 | 1500 | 0.4005 | 0.8525 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.8.0
- Datasets 2.9.0
- Tokenizers 0.13.2
|
CAMeL-Lab/bert-base-arabic-camelbert-da-pos-msa
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 27 | null |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -5.06 +/- 4.60
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-madar-corpus6
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 34 | null |
Access to model liezeleinstein/test is restricted and you are not in the authorized list. Visit https://huggingface.co/liezeleinstein/test to ask for access.
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-nadi
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 63 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-poetry
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 31 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 240.60 +/- 19.08
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-pos-egy
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 62 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: nhiro3303/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-pos-glf
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 132 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 259.61 +/- 17.91
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-sentiment
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 855 | null |
---
library_name: diffusers
base_model: runwayml/stable-diffusion-v1-5
pipeline_tag: text-to-image
datasets:
- gsdf/EasyNegative
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
# Model Details
## Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [Mobius Labs]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
## Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
# Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
## Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
## Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
## Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
# Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
## Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
# Training Details
## Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
## Training Procedure [optional]
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
### Preprocessing
[More Information Needed]
### Speeds, Sizes, Times
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
# Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
## Testing Data, Factors & Metrics
### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
## Results
[More Information Needed]
### Summary
# Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
# Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
# Technical Specifications [optional]
## Model Architecture and Objective
[More Information Needed]
## Compute Infrastructure
[More Information Needed]
### Hardware
[More Information Needed]
### Software
[More Information Needed]
# Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
# Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
# More Information [optional]
[More Information Needed]
# Model Card Authors [optional]
[More Information Needed]
# Model Card Contact
[More Information Needed]
|
CAMeL-Lab/bert-base-arabic-camelbert-msa-did-madar-twitter5
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 75 | null |
---
license: openrail
datasets:
- Ali-fb/dilbert-comic-sample-dataset
language:
- en
library_name: diffusers
pipeline_tag: text-to-image
tags:
- art
---
|
CAMeL-Lab/bert-base-arabic-camelbert-msa-half
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 16 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 87.33 +/- 132.55
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
CAMeL-Lab/bert-base-arabic-camelbert-msa-poetry
|
[
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 25 | null |
---
license: apache-2.0
tags:
- setfit
- sentence-transformers
- text-classification
pipeline_tag: text-classification
---
# Dangerous-Prompts-MiniLM-SetFit
This is a [SetFit model](https://github.com/huggingface/setfit) that can be used for text classification. The model has been trained using an efficient few-shot learning technique that involves:
1. Fine-tuning a [Sentence Transformer](https://www.sbert.net) with contrastive learning.
2. Training a classification head with features from the fine-tuned Sentence Transformer.
## Usage
To use this model for inference, first install the SetFit library:
```bash
python -m pip install setfit
```
You can then run inference as follows:
```python
from setfit import SetFitModel
# Download from Hub and run inference
model = SetFitModel.from_pretrained("Dangerous-Prompts-MiniLM-SetFit")
# Run inference
preds = model(["i loved the spiderman movie!", "pineapple on pizza is the worst 🤮"])
```
## BibTeX entry and citation info
```bibtex
@article{https://doi.org/10.48550/arxiv.2209.11055,
doi = {10.48550/ARXIV.2209.11055},
url = {https://arxiv.org/abs/2209.11055},
author = {Tunstall, Lewis and Reimers, Nils and Jo, Unso Eun Seo and Bates, Luke and Korat, Daniel and Wasserblat, Moshe and Pereg, Oren},
keywords = {Computation and Language (cs.CL), FOS: Computer and information sciences, FOS: Computer and information sciences},
title = {Efficient Few-Shot Learning Without Prompts},
publisher = {arXiv},
year = {2022},
copyright = {Creative Commons Attribution 4.0 International}
}
```
|
CL/safe-math-bot
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-02-15T02:00:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-large-v2
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_myst
type: rishabhjain16/infer_myst
config: en
split: test
metrics:
- type: wer
value: 12.37
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pfs
type: rishabhjain16/infer_pfs
config: en
split: test
metrics:
- type: wer
value: 23.62
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_cmu
type: rishabhjain16/infer_cmu
config: en
split: test
metrics:
- type: wer
value: 2.32
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_italian
type: rishabhjain16/infer_pf_italian
config: en
split: test
metrics:
- type: wer
value: 180.79
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_german
type: rishabhjain16/infer_pf_german
config: en
split: test
metrics:
- type: wer
value: 211.01
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_swedish
type: rishabhjain16/infer_pf_swedish
config: en
split: test
metrics:
- type: wer
value: 184.24
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_so_chinese
type: rishabhjain16/infer_so_chinese
config: en
split: test
metrics:
- type: wer
value: 48.34
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/libritts_dev_clean
type: rishabhjain16/libritts_dev_clean
config: en
split: test
metrics:
- type: wer
value: 4.81
name: WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-large-v2
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2381
- Wer: 11.1244
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.3639 | 0.12 | 500 | 0.2512 | 12.9597 |
| 0.1931 | 0.25 | 1000 | 0.2123 | 12.1414 |
| 0.329 | 1.08 | 1500 | 0.2064 | 11.5818 |
| 0.097 | 1.21 | 2000 | 0.2050 | 10.9775 |
| 0.0522 | 2.04 | 2500 | 0.2258 | 10.4390 |
| 0.1026 | 2.17 | 3000 | 0.2201 | 11.7017 |
| 0.0448 | 3.0 | 3500 | 0.2287 | 10.3873 |
| 0.0455 | 3.13 | 4000 | 0.2381 | 11.1244 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
CLAck/en-vi
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"vi",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | null |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 274.50 +/- 31.50
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga harshil128 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga harshil128 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga harshil128
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 100000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
CLAck/indo-mixed
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"id",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 15 | null |
---
license: apache-2.0
language:
- zh
library_name: transformers
---
# intro
1. 15G的中文语料
2. 31亿个tokens
3. 一张3090显卡
4. 训练60多个小时
最终训练出一个中文版本的gpt2,如果有想了解如何训练中文gpt2的,可以查看这个教程
# Github link
[https://github.com/yuanzhoulvpi2017/zero_nlp/tree/main/chinese_gpt2](https://github.com/yuanzhoulvpi2017/zero_nlp/tree/main/chinese_gpt2)
# infer code
```python
from transformers import GPT2LMHeadModel, AutoTokenizer
model_name_or_path = "yuanzhoulvpi/gpt2_chinese"#"checkpoint-36000"
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path)
# add the EOS token as PAD token to avoid warnings
model = GPT2LMHeadModel.from_pretrained(model_name_or_path, pad_token_id=tokenizer.eos_token_id)
```
```python
txt = """\
你是谁
"""
# encode context the generation is conditioned on
input_ids = tokenizer.encode(txt, return_tensors='pt')
# set no_repeat_ngram_size to 2
beam_output = model.generate(
input_ids,
max_length=200,
num_beams=5,
no_repeat_ngram_size=2,
early_stopping=True
)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(beam_output[0], skip_special_tokens=True))
```
```bash
Output:
----------------------------------------------------------------------------------------------------
你 是 谁?, 简 单 的 描 述 是, 答 案 是 你 好 , 我 叫 , 是 一 名 美 籍 华 裔 女 演 员 , 出 生 于 美 国 加 利 福 尼 亚 州 的 一 个 犹 太 人 家 庭 。 她 的 父 母 都 是 工 程 师 , 母 亲 是 医 生 , 父 亲 则 是 律 师 。 是 加 州 大 学 伯 克 利 分 校 的 教 授 , 也 是 的 创 始 人 之 一 , 曾 在 《 纽 约 时 报 》 上 发 表 过 一 篇 文 章 , 引 起 了 广 泛 的 关 注 。 文 中 写 道 : 我 从 小 就 喜 欢 音 乐 , 并 且 在 学 校 里 学 到 了 很 多 乐 理 知 识 , 但 是 我 并 不 知 道 自 己 到 底 想 要 什 么 , 因 为 我 觉 得 这 个 世 界 上 没 有 任 何 东 西 可 以 比 得 上 它 。
```
|
CLAck/indo-pure
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"id",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-medium
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_myst
type: rishabhjain16/infer_myst
config: en
split: test
metrics:
- type: wer
value: 11.72
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pfs
type: rishabhjain16/infer_pfs
config: en
split: test
metrics:
- type: wer
value: 3.11
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_cmu
type: rishabhjain16/infer_cmu
config: en
split: test
metrics:
- type: wer
value: 2.36
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_italian
type: rishabhjain16/infer_pf_italian
config: en
split: test
metrics:
- type: wer
value: 16.72
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_german
type: rishabhjain16/infer_pf_german
config: en
split: test
metrics:
- type: wer
value: 86.13
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_swedish
type: rishabhjain16/infer_pf_swedish
config: en
split: test
metrics:
- type: wer
value: 23.94
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_so_chinese
type: rishabhjain16/infer_so_chinese
config: en
split: test
metrics:
- type: wer
value: 27.88
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/libritts_dev_clean
type: rishabhjain16/libritts_dev_clean
config: en
split: test
metrics:
- type: wer
value: 5.62
name: WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2775
- Wer: 9.7168
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2572 | 0.12 | 500 | 0.2180 | 10.4499 |
| 0.1542 | 1.08 | 1000 | 0.1995 | 10.2143 |
| 0.062 | 2.04 | 1500 | 0.2177 | 10.2560 |
| 0.0761 | 2.16 | 2000 | 0.2013 | 11.0693 |
| 0.0193 | 3.12 | 2500 | 0.2318 | 10.0235 |
| 0.0065 | 4.07 | 3000 | 0.2591 | 9.9646 |
| 0.0123 | 5.03 | 3500 | 0.2760 | 9.7453 |
| 0.0039 | 5.15 | 4000 | 0.2775 | 9.7168 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
CLAck/vi-en
|
[
"pytorch",
"marian",
"text2text-generation",
"en",
"vi",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] |
translation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-medium.en
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_myst
type: rishabhjain16/infer_myst
config: en
split: test
metrics:
- type: wer
value: 11.71
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pfs
type: rishabhjain16/infer_pfs
config: en
split: test
metrics:
- type: wer
value: 3.02
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_cmu
type: rishabhjain16/infer_cmu
config: en
split: test
metrics:
- type: wer
value: 2.23
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/libritts_dev_clean
type: rishabhjain16/libritts_dev_clean
config: en
split: test
metrics:
- type: wer
value: 5.57
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_swedish
type: rishabhjain16/infer_pf_swedish
config: en
split: test
metrics:
- type: wer
value: 21.65
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_german
type: rishabhjain16/infer_pf_german
config: en
split: test
metrics:
- type: wer
value: 68.1
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_italian
type: rishabhjain16/infer_pf_italian
config: en
split: test
metrics:
- type: wer
value: 15.87
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_so_chinese
type: rishabhjain16/infer_so_chinese
config: en
split: test
metrics:
- type: wer
value: 26.43
name: WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium.en
This model is a fine-tuned version of [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3142
- Wer: 9.6853
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2948 | 0.12 | 500 | 0.2476 | 9.9138 |
| 0.1795 | 1.08 | 1000 | 0.2286 | 10.1859 |
| 0.0625 | 2.04 | 1500 | 0.2518 | 9.6295 |
| 0.0834 | 2.16 | 2000 | 0.2286 | 9.9808 |
| 0.0202 | 3.12 | 2500 | 0.2667 | 9.4985 |
| 0.0067 | 4.07 | 3000 | 0.2954 | 9.7513 |
| 0.0151 | 5.03 | 3500 | 0.3155 | 9.6539 |
| 0.0048 | 5.15 | 4000 | 0.3142 | 9.6853 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
CLS/WubiBERT_models
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 570.00 +/- 104.12
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga harshil128 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga harshil128 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga harshil128
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
CLTL/MedRoBERTa.nl
|
[
"pytorch",
"roberta",
"fill-mask",
"nl",
"transformers",
"license:mit",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2,988 | null |
---
tags:
- conversational
---
# Chatbot trained on GPT2
|
CLTL/gm-ner-xlmrbase
|
[
"pytorch",
"tf",
"xlm-roberta",
"token-classification",
"nl",
"transformers",
"dighum",
"license:apache-2.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"XLMRobertaForTokenClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-large-v2
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_myst
type: rishabhjain16/infer_myst
config: en
split: test
metrics:
- type: wer
value: 12.37
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pfs
type: rishabhjain16/infer_pfs
config: en
split: test
metrics:
- type: wer
value: 3.1
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_cmu
type: rishabhjain16/infer_cmu
config: en
split: test
metrics:
- type: wer
value: 1.86
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/libritts_dev_clean
type: rishabhjain16/libritts_dev_clean
config: en
split: test
metrics:
- type: wer
value: 4.75
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_swedish
type: rishabhjain16/infer_pf_swedish
config: en
split: test
metrics:
- type: wer
value: 43.43
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_german
type: rishabhjain16/infer_pf_german
config: en
split: test
metrics:
- type: wer
value: 71.18
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_italian
type: rishabhjain16/infer_pf_italian
config: en
split: test
metrics:
- type: wer
value: 56.29
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_so_chinese
type: rishabhjain16/infer_so_chinese
config: en
split: test
metrics:
- type: wer
value: 32.99
name: WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-large-v2
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1902
- Wer: 10.0204
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2223 | 0.12 | 500 | 0.2384 | 11.3393 |
| 0.2291 | 0.25 | 1000 | 0.2043 | 10.2326 |
| 0.1116 | 1.04 | 1500 | 0.1999 | 9.9402 |
| 0.1433 | 1.16 | 2000 | 0.1897 | 10.1128 |
| 0.0687 | 1.29 | 2500 | 0.1876 | 9.9270 |
| 0.067 | 2.07 | 3000 | 0.2089 | 10.6712 |
| 0.0819 | 2.2 | 3500 | 0.1962 | 10.3128 |
| 0.0587 | 2.32 | 4000 | 0.1902 | 10.0204 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
CLTL/icf-domains
|
[
"pytorch",
"roberta",
"nl",
"transformers",
"license:mit",
"text-classification"
] |
text-classification
|
{
"architectures": [
"RobertaForMultiLabelSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 35 | null |
---
license: wtfpl
---
The aesthetics of the past and the possibilities of the future.
Go to a world where vintage meets future with RetroFutur, a SD 2.x 768 embedding! Also seems to create nice studio lighting, and will improve eyes a bit.
Trained for 400 steps with a LR of 0.0015, on 42 images. Batch size of 7 and a gradient accumulation value of 6.







|
CLTL/icf-levels-att
|
[
"pytorch",
"roberta",
"text-classification",
"nl",
"transformers",
"license:mit"
] |
text-classification
|
{
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 32 | null |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 493.50 +/- 307.68
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga saeedHedayatian -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga saeedHedayatian -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga saeedHedayatian
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0003),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Cameron/BERT-eec-emotion
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 36 | 2023-02-15T03:23:00Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- f1
- recall
- precision
- accuracy
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# results
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7398
- F1: 0.3764
- Recall: 0.4257
- Precision: 0.5363
- Accuracy: 0.7155
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Recall | Precision | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:---------:|:--------:|
| 1.4981 | 0.03 | 10 | 1.4740 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 1.473 | 0.05 | 20 | 1.4299 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 1.4055 | 0.08 | 30 | 1.3260 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 1.2743 | 0.11 | 40 | 1.1795 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 1.2937 | 0.13 | 50 | 1.1463 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 1.193 | 0.16 | 60 | 1.1367 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 1.1709 | 0.18 | 70 | 1.0957 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 1.0956 | 0.21 | 80 | 1.0457 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 1.0756 | 0.24 | 90 | 0.9852 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 0.862 | 0.26 | 100 | 1.0718 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 0.9677 | 0.29 | 110 | 0.8931 | 0.1556 | 0.2 | 0.1274 | 0.6368 |
| 0.7597 | 0.32 | 120 | 0.8502 | 0.2195 | 0.2499 | 0.2034 | 0.6561 |
| 0.7797 | 0.34 | 130 | 0.8028 | 0.2818 | 0.3758 | 0.3547 | 0.6888 |
| 0.8114 | 0.37 | 140 | 0.9480 | 0.2918 | 0.3313 | 0.3515 | 0.6907 |
| 0.8693 | 0.4 | 150 | 0.7799 | 0.3703 | 0.4000 | 0.5420 | 0.7081 |
| 0.9561 | 0.42 | 160 | 0.7844 | 0.3825 | 0.4261 | 0.3493 | 0.7199 |
| 0.6979 | 0.45 | 170 | 0.7656 | 0.3882 | 0.4404 | 0.4166 | 0.7165 |
| 0.8083 | 0.47 | 180 | 0.8847 | 0.3596 | 0.3688 | 0.5985 | 0.7051 |
| 0.8009 | 0.5 | 190 | 0.7665 | 0.3244 | 0.3916 | 0.3801 | 0.7021 |
| 0.6833 | 0.53 | 200 | 0.8408 | 0.4270 | 0.4631 | 0.4603 | 0.6724 |
| 0.749 | 0.55 | 210 | 0.7344 | 0.3889 | 0.4745 | 0.4888 | 0.7120 |
| 0.7106 | 0.58 | 220 | 0.7037 | 0.4511 | 0.4965 | 0.4562 | 0.7343 |
| 0.7631 | 0.61 | 230 | 0.7118 | 0.4331 | 0.4626 | 0.4472 | 0.7378 |
| 0.7672 | 0.63 | 240 | 0.6925 | 0.5035 | 0.4976 | 0.5470 | 0.7412 |
| 0.7662 | 0.66 | 250 | 0.7188 | 0.4425 | 0.4812 | 0.4662 | 0.7308 |
| 0.726 | 0.69 | 260 | 0.7120 | 0.4052 | 0.4616 | 0.4508 | 0.7353 |
| 0.9073 | 0.71 | 270 | 0.7969 | 0.3495 | 0.3862 | 0.3547 | 0.7036 |
| 0.6709 | 0.74 | 280 | 0.7429 | 0.3800 | 0.4279 | 0.4814 | 0.7145 |
| 0.9403 | 0.77 | 290 | 0.8199 | 0.3926 | 0.3870 | 0.5164 | 0.6992 |
| 0.9277 | 0.79 | 300 | 0.7304 | 0.3599 | 0.4349 | 0.3786 | 0.7086 |
| 0.9503 | 0.82 | 310 | 0.7764 | 0.4613 | 0.5283 | 0.4263 | 0.6828 |
| 0.6553 | 0.84 | 320 | 0.7386 | 0.4051 | 0.4593 | 0.5329 | 0.7081 |
| 0.7655 | 0.87 | 330 | 0.7527 | 0.5087 | 0.5252 | 0.5375 | 0.7204 |
| 0.6663 | 0.9 | 340 | 0.7248 | 0.4618 | 0.4841 | 0.5283 | 0.7353 |
| 0.915 | 0.92 | 350 | 0.8947 | 0.4279 | 0.4875 | 0.3979 | 0.6596 |
| 0.8718 | 0.95 | 360 | 0.7893 | 0.3796 | 0.3938 | 0.5016 | 0.7110 |
| 0.8338 | 0.98 | 370 | 0.7293 | 0.4124 | 0.4277 | 0.4147 | 0.7130 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
CasualHomie/DialoGPT-small-harrypotter
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 11 | null |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="kks8b/Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
dccuchile/albert-large-spanish-finetuned-qa-mlqa
|
[
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | 2023-02-15T05:20:53Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 540.50 +/- 159.54
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga saeedHedayatian -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga saeedHedayatian -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga saeedHedayatian
```
## Hyperparameters
```python
OrderedDict([('batch_size', 64),
('buffer_size', 150000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.02),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0003),
('learning_starts', 100000),
('n_timesteps', 2000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
dccuchile/albert-tiny-spanish-finetuned-pawsx
|
[
"pytorch",
"albert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 29 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
dccuchile/albert-tiny-spanish-finetuned-qa-mlqa
|
[
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | 2023-02-15T05:30:32Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: dys_asr_10min
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dys_asr_10min
This model is a fine-tuned version of [Splend1dchan/wav2vec2-large-10min-lv60-self](https://huggingface.co/Splend1dchan/wav2vec2-large-10min-lv60-self) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0198
- Wer: 1.0093
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 9.9259 | 1.36 | 500 | 2.4431 | 1.0062 |
| 1.6108 | 2.72 | 1000 | 0.3387 | 1.2243 |
| 0.4361 | 4.09 | 1500 | 0.0900 | 1.0467 |
| 0.1645 | 5.45 | 2000 | 0.0369 | 1.0498 |
| 0.1078 | 6.81 | 2500 | 0.0198 | 1.0093 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.13.1+cu116
- Datasets 1.18.3
- Tokenizers 0.13.2
|
dccuchile/albert-xxlarge-spanish-finetuned-xnli
|
[
"pytorch",
"albert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 68 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
config: conll2003
split: validation
args: conll2003
metrics:
- name: Precision
type: precision
value: 0.9331457885156379
- name: Recall
type: recall
value: 0.9490070683271625
- name: F1
type: f1
value: 0.9410095953274927
- name: Accuracy
type: accuracy
value: 0.9861953258374051
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0632
- Precision: 0.9331
- Recall: 0.9490
- F1: 0.9410
- Accuracy: 0.9862
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.088 | 1.0 | 1756 | 0.0705 | 0.9178 | 0.9285 | 0.9231 | 0.9808 |
| 0.0351 | 2.0 | 3512 | 0.0675 | 0.9265 | 0.9477 | 0.9369 | 0.9853 |
| 0.018 | 3.0 | 5268 | 0.0632 | 0.9331 | 0.9490 | 0.9410 | 0.9862 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
CennetOguz/distilbert-base-uncased-finetuned-recipe-accelerate
|
[
"pytorch",
"distilbert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi3_V1_v2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="Nonin/Taxi3_V1_v2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Certified-Zoomer/DialoGPT-small-rick
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="RokudouMukuro/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
Chakita/Kalbert
|
[
"pytorch",
"tensorboard",
"albert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
language:
- multilingual
- en
- de
- fr
- ja
license: mit
tags:
- object-detection
- vision
- generated_from_trainer
- DocLayNet
- COCO
- PDF
- IBM
- Financial-Reports
- Finance
- Manuals
- Scientific-Articles
- Science
- Laws
- Law
- Regulations
- Patents
- Government-Tenders
- object-detection
- image-segmentation
- token-classification
inference: false
datasets:
- pierreguillou/DocLayNet-base
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512
results:
- task:
name: Token Classification
type: token-classification
metrics:
- name: f1
type: f1
value: 0.8634
- name: accuracy
type: accuracy
value: 0.8634
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base)
This model is a fine-tuned version of [nielsr/lilt-xlm-roberta-base](https://huggingface.co/nielsr/lilt-xlm-roberta-base) with the [DocLayNet base](https://huggingface.co/datasets/pierreguillou/DocLayNet-base) dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4104
- Precision: 0.8634
- Recall: 0.8634
- F1: 0.8634
- Token Accuracy: 0.8634
- Paragraph Accuracy: 0.6815
## Accuracy at paragraph level
- Paragraph Accuracy: 68.15%
- Accuracy by label
- Caption: 22.82%
- Footnote: 0.0%
- Formula: 97.33%
- List-item: 8.42%
- Page-footer: 98.77%
- Page-header: 77.81%
- Picture: 39.16%
- Section-header: 76.17%
- Table: 37.7%
- Text: 86.78%
- Title: 0.0%
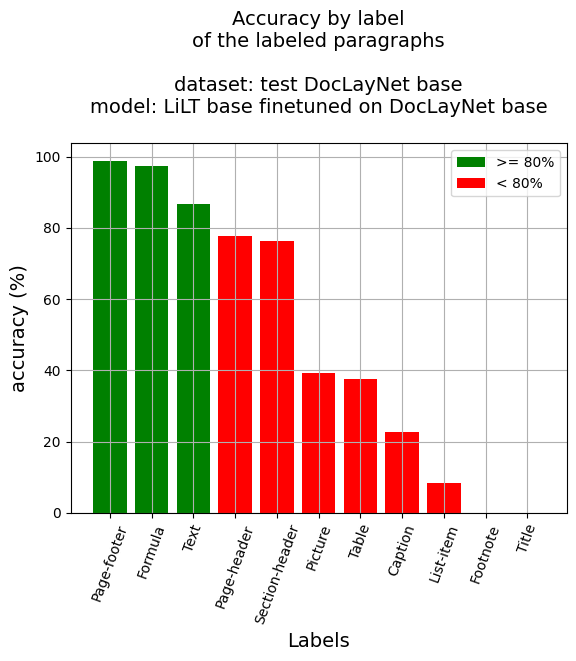
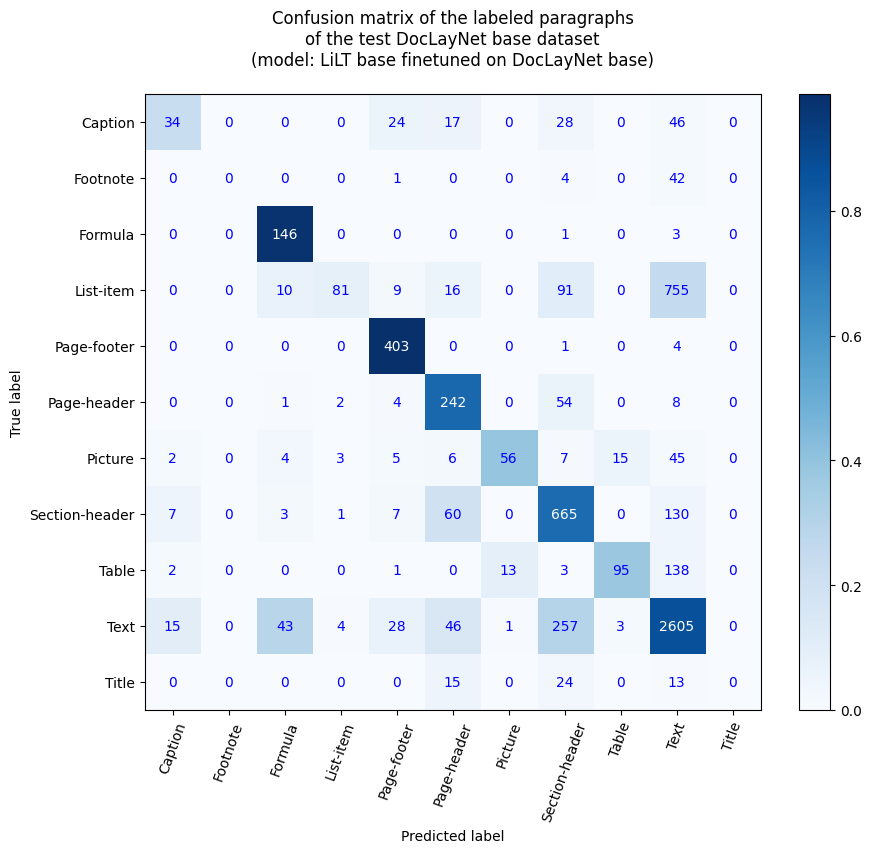
## References
### Blog posts
- Layout XLM base
- (03/05/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at line level with LayoutXLM base]()
- LiLT base
- (02/16/2023) [Document AI | Inference APP and fine-tuning notebook for Document Understanding at paragraph level](https://medium.com/@pierre_guillou/document-ai-inference-app-and-fine-tuning-notebook-for-document-understanding-at-paragraph-level-c18d16e53cf8)
- (02/14/2023) [Document AI | Inference APP for Document Understanding at line level](https://medium.com/@pierre_guillou/document-ai-inference-app-for-document-understanding-at-line-level-a35bbfa98893)
- (02/10/2023) [Document AI | Document Understanding model at line level with LiLT, Tesseract and DocLayNet dataset](https://medium.com/@pierre_guillou/document-ai-document-understanding-model-at-line-level-with-lilt-tesseract-and-doclaynet-dataset-347107a643b8)
- (01/31/2023) [Document AI | DocLayNet image viewer APP](https://medium.com/@pierre_guillou/document-ai-doclaynet-image-viewer-app-3ac54c19956)
- (01/27/2023) [Document AI | Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](https://medium.com/@pierre_guillou/document-ai-processing-of-doclaynet-dataset-to-be-used-by-layout-models-of-the-hugging-face-hub-308d8bd81cdb)
### Notebooks (paragraph level)
- LiLT base
- [Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
- [Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_paragraphlevel_ml_512.ipynb)
### Notebooks (line level)
- Layout XLM base
- [Document AI | Inference at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Inference APP at line level with a Document Understanding model (LayoutXLM base fine-tuned on DocLayNet base dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LayoutXLM_base_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Fine-tune LayoutXLM base on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LayoutXLM_base_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
- LiLT base
- [Document AI | Inference at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Inference APP at line level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levellines_ml384.ipynb)
- [Document AI | Fine-tune LiLT on DocLayNet base in any language at line level (chunk of 384 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_linelevel_ml_384.ipynb)
- [DocLayNet image viewer APP](https://github.com/piegu/language-models/blob/master/DocLayNet_image_viewer_APP.ipynb)
- [Processing of DocLayNet dataset to be used by layout models of the Hugging Face hub (finetuning, inference)](processing_DocLayNet_dataset_to_be_used_by_layout_models_of_HF_hub.ipynb)
## APP
You can test this model with this APP in Hugging Face Spaces: [Inference APP for Document Understanding at paragraph level (v1)](https://huggingface.co/spaces/pierreguillou/Inference-APP-Document-Understanding-at-paragraphlevel-v1).
You can run as well the corresponding notebook: [Document AI | Inference APP at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/Gradio_inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
## DocLayNet dataset
[DocLayNet dataset](https://github.com/DS4SD/DocLayNet) (IBM) provides page-by-page layout segmentation ground-truth using bounding-boxes for 11 distinct class labels on 80863 unique pages from 6 document categories.
Until today, the dataset can be downloaded through direct links or as a dataset from Hugging Face datasets:
- direct links: [doclaynet_core.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_core.zip) (28 GiB), [doclaynet_extra.zip](https://codait-cos-dax.s3.us.cloud-object-storage.appdomain.cloud/dax-doclaynet/1.0.0/DocLayNet_extra.zip) (7.5 GiB)
- Hugging Face dataset library: [dataset DocLayNet](https://huggingface.co/datasets/ds4sd/DocLayNet)
Paper: [DocLayNet: A Large Human-Annotated Dataset for Document-Layout Analysis](https://arxiv.org/abs/2206.01062) (06/02/2022)
## Model description
The model was finetuned at **paragraph level on chunk of 512 tokens with overlap of 128 tokens**. Thus, the model was trained with all layout and text data of all pages of the dataset.
At inference time, a calculation of best probabilities give the label to each paragraph bounding boxes.
## Inference
See notebook: [Document AI | Inference at paragraph level with a Document Understanding model (LiLT fine-tuned on DocLayNet dataset)](https://github.com/piegu/language-models/blob/master/inference_on_LiLT_model_finetuned_on_DocLayNet_base_in_any_language_at_levelparagraphs_ml512.ipynb)
## Training and evaluation data
See notebook: [Document AI | Fine-tune LiLT on DocLayNet base in any language at paragraph level (chunk of 512 tokens with overlap)](https://github.com/piegu/language-models/blob/master/Fine_tune_LiLT_on_DocLayNet_base_in_any_language_at_paragraphlevel_ml_512.ipynb)
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 0.05 | 100 | 0.9875 | 0.6585 | 0.6585 | 0.6585 | 0.6585 |
| No log | 0.11 | 200 | 0.7886 | 0.7551 | 0.7551 | 0.7551 | 0.7551 |
| No log | 0.16 | 300 | 0.5894 | 0.8248 | 0.8248 | 0.8248 | 0.8248 |
| No log | 0.21 | 400 | 0.4794 | 0.8396 | 0.8396 | 0.8396 | 0.8396 |
| 0.7446 | 0.27 | 500 | 0.3993 | 0.8703 | 0.8703 | 0.8703 | 0.8703 |
| 0.7446 | 0.32 | 600 | 0.3631 | 0.8857 | 0.8857 | 0.8857 | 0.8857 |
| 0.7446 | 0.37 | 700 | 0.4096 | 0.8630 | 0.8630 | 0.8630 | 0.8630 |
| 0.7446 | 0.43 | 800 | 0.4492 | 0.8528 | 0.8528 | 0.8528 | 0.8528 |
| 0.7446 | 0.48 | 900 | 0.3839 | 0.8834 | 0.8834 | 0.8834 | 0.8834 |
| 0.4464 | 0.53 | 1000 | 0.4365 | 0.8498 | 0.8498 | 0.8498 | 0.8498 |
| 0.4464 | 0.59 | 1100 | 0.3616 | 0.8812 | 0.8812 | 0.8812 | 0.8812 |
| 0.4464 | 0.64 | 1200 | 0.3949 | 0.8796 | 0.8796 | 0.8796 | 0.8796 |
| 0.4464 | 0.69 | 1300 | 0.4184 | 0.8613 | 0.8613 | 0.8613 | 0.8613 |
| 0.4464 | 0.75 | 1400 | 0.4130 | 0.8743 | 0.8743 | 0.8743 | 0.8743 |
| 0.3672 | 0.8 | 1500 | 0.4535 | 0.8289 | 0.8289 | 0.8289 | 0.8289 |
| 0.3672 | 0.85 | 1600 | 0.3681 | 0.8713 | 0.8713 | 0.8713 | 0.8713 |
| 0.3672 | 0.91 | 1700 | 0.3446 | 0.8857 | 0.8857 | 0.8857 | 0.8857 |
| 0.3672 | 0.96 | 1800 | 0.4104 | 0.8634 | 0.8634 | 0.8634 | 0.8634 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
## Other models
- Line level
- [Document Understanding model (finetuned LiLT base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (accuracy | tokens: 85.84% - lines: 91.97%)
- [Document Understanding model (finetuned LayoutXLM base at line level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-linelevel-ml384) (accuracy | tokens: 93.73% - lines: ...)
- Paragraph level
- [Document Understanding model (finetuned LiLT base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/lilt-xlm-roberta-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (accuracy | tokens: 86.34% - paragraphs: 68.15%)
- [Document Understanding model (finetuned LayoutXLM base at paragraph level on DocLayNet base)](https://huggingface.co/pierreguillou/layout-xlm-base-finetuned-with-DocLayNet-base-at-paragraphlevel-ml512) (accuracy | tokens: 96.93% - paragraphs: 86.55%)
|
Chakita/KannadaBERT
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"masked-lm",
"fill-in-the-blanks",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: Taxi-v3-Test_2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="eryzml/Taxi-v3-Test_2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Charlotte77/model_test
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-fr
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.fr
split: validation
args: PAN-X.fr
metrics:
- name: F1
type: f1
value: 0.8340325557979527
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-fr
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2723
- F1: 0.8340
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.5909 | 1.0 | 191 | 0.3404 | 0.7891 |
| 0.2594 | 2.0 | 382 | 0.2919 | 0.8152 |
| 0.1752 | 3.0 | 573 | 0.2723 | 0.8340 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Cheatham/xlm-roberta-base-finetuned
|
[
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 20 | null |
---
license: openrail
---
# gpt2-azerbaijani-smallv0 model for text generation
## Introduction
gpt2-azerbaijani-smallv0 is a state-of-the-art language model for Azerbaijani based on the GPT-2 small model.
It was trained on Azerbaijani Wikipedia using Transfer Learning and Fine-tuning techniques in ~ 29 hours, on one GPU - 1 x NVIDIA Tesla K80.
## Model
| Model | #params | Model file (pt) | Arch. | Training /Validation data (text) |
|-------------------------|---------|--------------------|-------------|------------------------------------------|
| gpt2-azerbaijani-smallv0| 124M | 652 | GPT-2 small | Azerbaijani Wikipedia (110k articles / 19k articles) |
epoches - 3, loss - 5.17, accuracy - 23.99%, perplexity - 95.88
## How to use GPorTuguese-2 with HuggingFace (PyTorch)
The following code use PyTorch.
```python
import torch
from transformers import GPT2LMHeadModel, AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("nijatzeynalov/gpt2-azerbaijani-small")
tokenizer.model_max_length=1024
model_state_dict = torch.load('GPT2_pt_3epoch_lr2e-3.pth', map_location=torch.device('cpu'))
model = GPT2LMHeadModel.from_pretrained('gpt2', state_dict=model_state_dict)
model.eval()
text = "Your prompt here"
inputs = tokenizer(text, return_tensors="pt")
sample_outputs = model.generate(inputs.input_ids,
pad_token_id=50256,
do_sample=True,
max_length=20,
top_k=10,
num_return_sequences=1)
# generated sequence
for i, sample_output in enumerate(sample_outputs):
print(">> Generated text {}\n\n{}".format(i+1, tokenizer.decode(sample_output.tolist())))
```
## Bias
The training data used for this model come from Azerbaijani Wikipedia. We know it contains a lot of unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their model card:
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true. Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
## Limitations
__This model was developed for the purpose of research for the application of the GPT-2 model to the Azerbaijani language, and the results it produces are of very low quality due to resource limitations, the current version is not recommended for use in commercial projects.__
Since my current resources are limited, I will return to this model again, I plan to improve the results:
* Add more train data in Azerbaijani language; I plan to find and add 500k+ articles using various resources, not just wikipedia.
* Clean the Train dataset better; Currently, due to lack of resources, cleaning is hardly done.
* Running different experiments using a more powerful GPU. Only 1cycle policy for fine tuning technique was tested.
* Increase the number of Epoch; With the current GPU (GPU - 1 x NVIDIA Tesla K80), 1 epoch lasts about ~9 hours ($0.90/hr). Considering the goal of the project and other resources, I found it acceptable to stop at 3 epochs.
## Author
Azerbaijani GPT-2 small was trained and evaluated by [Nijat Zeynalov](https://www.linkedin.com/in/nijat-zeynalov-064163142/).
|
Cheatham/xlm-roberta-large-finetuned-d12
|
[
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 20 | null |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Somdeb/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Check/vaw2tmp
|
[
"tensorboard"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: bert-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-squad
This model is a fine-tuned version of [bert-base-cased](https://huggingface.co/bert-base-cased) on the squad dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Cloudy/DialoGPT-CJ-large
|
[
"pytorch",
"conversational"
] |
conversational
|
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
---
language:
- fi
pipeline_tag: text-generation
---
GPT-3 xl for Finnish. Documentation coming soon!
|
CoShin/XLM-roberta-large_ko_en_nil_sts
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
widget:
- text: "generate analogy: mammal is to whale"
example_title: "Analogy Example 1 (semantic relation)"
- text: "generate analogy: wedding is to marriage"
example_title: "Analogy Example 1 (semantic relation, metaphor)"
- text: "generate analogy: London is to U.K."
example_title: "Analogy Example 2 (entity)"
- text: "generate analogy: actual is to actually"
example_title: "Analogy Example 3 (morphological)"
---
# relbert/flan-t5-small-analogy-permutation-domain
This is [google/flan-t5-small](https://huggingface.co/google/flan-t5-small) fine-tuned on [relbert/semeval2012_relational_similarity](https://huggingface.co/datasets/relbert/semeval2012_relational_similarity)
for analogy generation, which is to generate a word pair (eg. `bird is to crow`) given a query (eg. `mammal is to whale`)
so that the query and the generated word pair form an analogy statement.
### Usage
```python
from transformers import pipeline
pipe = pipeline('text2text-generation', model="relbert/flan-t5-small-analogy-permutation-domain")
output = pipe("generate analogy: mammal is to whale")
print(output)
>>> [{'generated_text': 'bird is to crow'}]
```
|
CodeDanCode/CartmenBot
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 14 | null |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: georgivelkov/albert-finetuned-customs
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# georgivelkov/albert-finetuned-customs
This model is a fine-tuned version of [squirro/albert-base-v2-squad_v2](https://huggingface.co/squirro/albert-base-v2-squad_v2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.5716
- Validation Loss: 0.0
- Epoch: 2
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': 18246, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.2061 | 0.0 | 0 |
| 0.8453 | 0.0 | 1 |
| 0.5716 | 0.0 | 2 |
### Framework versions
- Transformers 4.20.1
- TensorFlow 2.9.2
- Datasets 2.1.0
- Tokenizers 0.12.1
|
CodeNinja1126/bert-p-encoder
|
[
"pytorch"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
license: mit
language:
- en
metrics:
- f1
library_name: transformers
pipeline_tag: token-classification
---
This Repository includes the files required to run the `Agriculture NER` ORKG-NLP service.
Please check [this article](https://orkg-nlp-pypi.readthedocs.io/en/latest/services/services.html) for more details about the service.
|
CodeNinja1126/koelectra-model
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -121.59 +/- 47.90
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
To learn to code your own PPO agent and train it Unit 8 of the Deep Reinforcement Learning Class: https://github.com/huggingface/deep-rl-class/tree/main/unit8
# Hyperparameters
```python
{'exp_name': 'ppo'
'seed': 1
'torch_deterministic': True
'cuda': True
'track': False
'wandb_project_name': 'cleanRL'
'wandb_entity': None
'capture_video': False
'env_id': 'LunarLander-v2'
'total_timesteps': 50000
'learning_rate': 0.00025
'num_envs': 4
'num_steps': 128
'anneal_lr': True
'gae': True
'gamma': 0.99
'gae_lambda': 0.95
'num_minibatches': 4
'update_epochs': 4
'norm_adv': True
'clip_coef': 0.2
'clip_vloss': True
'ent_coef': 0.01
'vf_coef': 0.5
'max_grad_norm': 0.5
'target_kl': None
'repo_id': 'ThomasSimonini/TESTCUST'
'batch_size': 512
'minibatch_size': 128}
```
|
CodeNinja1126/test-model
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 24 | null |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-tiny-2l-10M
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-tiny-2l-10M
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 3.1695
- Accuracy: 0.4534
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0004
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 32
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 50
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 7.7619 | 1.04 | 50 | 7.2338 | 0.0748 |
| 7.0524 | 2.08 | 100 | 6.6252 | 0.1331 |
| 6.8423 | 3.12 | 150 | 6.4622 | 0.1463 |
| 6.7298 | 4.16 | 200 | 6.3971 | 0.1488 |
| 6.669 | 5.21 | 250 | 6.3628 | 0.1519 |
| 6.2038 | 6.25 | 300 | 6.3371 | 0.1518 |
| 6.1783 | 7.29 | 350 | 6.3115 | 0.1532 |
| 6.1459 | 8.33 | 400 | 6.2922 | 0.1530 |
| 6.1096 | 9.37 | 450 | 6.2696 | 0.1536 |
| 6.0745 | 10.41 | 500 | 6.2545 | 0.1541 |
| 6.0689 | 11.45 | 550 | 6.2496 | 0.1533 |
| 6.0562 | 12.49 | 600 | 6.2313 | 0.1542 |
| 6.0324 | 13.53 | 650 | 6.2248 | 0.1536 |
| 5.9907 | 14.58 | 700 | 6.2179 | 0.1544 |
| 5.9683 | 15.62 | 750 | 6.1832 | 0.1545 |
| 5.9236 | 16.66 | 800 | 6.1413 | 0.1550 |
| 5.8808 | 17.7 | 850 | 6.0900 | 0.1558 |
| 5.8392 | 18.74 | 900 | 6.0543 | 0.1566 |
| 5.7962 | 19.78 | 950 | 6.0222 | 0.1575 |
| 5.7473 | 20.82 | 1000 | 5.9471 | 0.1617 |
| 5.5787 | 21.86 | 1050 | 5.7038 | 0.1891 |
| 5.2316 | 22.9 | 1100 | 5.2708 | 0.2382 |
| 4.6613 | 23.95 | 1150 | 4.7075 | 0.2975 |
| 4.3006 | 24.99 | 1200 | 4.4180 | 0.3222 |
| 4.3754 | 26.04 | 1250 | 4.2383 | 0.3385 |
| 4.2531 | 27.08 | 1300 | 4.1157 | 0.3491 |
| 4.0987 | 28.12 | 1350 | 4.0197 | 0.3578 |
| 4.0045 | 29.16 | 1400 | 3.9504 | 0.3656 |
| 3.9145 | 30.21 | 1450 | 3.8819 | 0.3718 |
| 3.5808 | 31.25 | 1500 | 3.8279 | 0.3781 |
| 3.5354 | 32.29 | 1550 | 3.7830 | 0.3826 |
| 3.4788 | 33.33 | 1600 | 3.7400 | 0.3872 |
| 3.4315 | 34.37 | 1650 | 3.7028 | 0.3911 |
| 3.3906 | 35.41 | 1700 | 3.6629 | 0.3956 |
| 3.3508 | 36.45 | 1750 | 3.6344 | 0.3984 |
| 3.288 | 37.49 | 1800 | 3.6046 | 0.4019 |
| 3.2678 | 38.53 | 1850 | 3.5799 | 0.4053 |
| 3.2382 | 39.58 | 1900 | 3.5549 | 0.4074 |
| 3.2151 | 40.62 | 1950 | 3.5285 | 0.4103 |
| 3.1777 | 41.66 | 2000 | 3.5069 | 0.4132 |
| 3.1499 | 42.7 | 2050 | 3.4917 | 0.4150 |
| 3.131 | 43.74 | 2100 | 3.4701 | 0.4168 |
| 3.0942 | 44.78 | 2150 | 3.4530 | 0.4189 |
| 3.0683 | 45.82 | 2200 | 3.4320 | 0.4212 |
| 3.0363 | 46.86 | 2250 | 3.4195 | 0.4227 |
| 3.0264 | 47.9 | 2300 | 3.4046 | 0.4249 |
| 3.0079 | 48.95 | 2350 | 3.3874 | 0.4267 |
| 2.9869 | 49.99 | 2400 | 3.3792 | 0.4277 |
| 3.1592 | 51.04 | 2450 | 3.3655 | 0.4289 |
| 3.1353 | 52.08 | 2500 | 3.3548 | 0.4310 |
| 3.1257 | 53.12 | 2550 | 3.3489 | 0.4308 |
| 3.0822 | 54.16 | 2600 | 3.3353 | 0.4327 |
| 3.0771 | 55.21 | 2650 | 3.3220 | 0.4341 |
| 2.8639 | 56.25 | 2700 | 3.3119 | 0.4354 |
| 2.8477 | 57.29 | 2750 | 3.3104 | 0.4360 |
| 2.8373 | 58.33 | 2800 | 3.2954 | 0.4378 |
| 2.818 | 59.37 | 2850 | 3.2935 | 0.4381 |
| 2.8137 | 60.41 | 2900 | 3.2786 | 0.4394 |
| 2.7985 | 61.45 | 2950 | 3.2747 | 0.4401 |
| 2.7936 | 62.49 | 3000 | 3.2668 | 0.4411 |
| 2.7764 | 63.53 | 3050 | 3.2569 | 0.4419 |
| 2.7819 | 64.58 | 3100 | 3.2492 | 0.4434 |
| 2.7672 | 65.62 | 3150 | 3.2494 | 0.4433 |
| 2.7629 | 66.66 | 3200 | 3.2410 | 0.4443 |
| 2.747 | 67.7 | 3250 | 3.2368 | 0.4446 |
| 2.7303 | 68.74 | 3300 | 3.2246 | 0.4460 |
| 2.7461 | 69.78 | 3350 | 3.2212 | 0.4462 |
| 2.7179 | 70.82 | 3400 | 3.2217 | 0.4470 |
| 2.7184 | 71.86 | 3450 | 3.2132 | 0.4479 |
| 2.7077 | 72.9 | 3500 | 3.2086 | 0.4487 |
| 2.6916 | 73.95 | 3550 | 3.2057 | 0.4482 |
| 2.6934 | 74.99 | 3600 | 3.2010 | 0.4495 |
| 2.8585 | 76.04 | 3650 | 3.1980 | 0.4497 |
| 2.8559 | 77.08 | 3700 | 3.1940 | 0.4503 |
| 2.8519 | 78.12 | 3750 | 3.1940 | 0.4506 |
| 2.8391 | 79.16 | 3800 | 3.1897 | 0.4509 |
| 2.845 | 80.21 | 3850 | 3.1858 | 0.4510 |
| 2.6636 | 81.25 | 3900 | 3.1819 | 0.4518 |
| 2.6569 | 82.29 | 3950 | 3.1834 | 0.4517 |
| 2.647 | 83.33 | 4000 | 3.1798 | 0.4517 |
| 2.6665 | 84.37 | 4050 | 3.1786 | 0.4525 |
| 2.6382 | 85.41 | 4100 | 3.1733 | 0.4525 |
| 2.6346 | 86.45 | 4150 | 3.1700 | 0.4532 |
| 2.6457 | 87.49 | 4200 | 3.1714 | 0.4529 |
| 2.6328 | 88.53 | 4250 | 3.1686 | 0.4537 |
| 2.6429 | 89.58 | 4300 | 3.1715 | 0.4534 |
| 2.6369 | 90.62 | 4350 | 3.1687 | 0.4538 |
| 2.628 | 91.66 | 4400 | 3.1651 | 0.4539 |
| 2.6373 | 92.7 | 4450 | 3.1660 | 0.4539 |
| 2.6357 | 93.74 | 4500 | 3.1662 | 0.4537 |
| 2.6302 | 94.78 | 4550 | 3.1695 | 0.4533 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.11.0+cu113
- Datasets 2.6.1
- Tokenizers 0.12.1
|
ComCom/gpt2
|
[
"pytorch",
"gpt2",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"GPT2Model"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
6 images
STEPS = 900 #@param {type:"slider", min:0, max:10000, step:10}
BATCH_SIZE = 3 #@param {type:"slider", min:0, max:128, step:1}
FP_16 = True #@param {type:"boolean"}
#@markdown ----
#@markdown UNET PARAMS
LEARNING_RATE = 3e-4 #@param {type:"number"}
#@markdown ----
TRAIN_TEXT_ENCODER = True #@param {type:"boolean"}
#@markdown TEXT ENCODER PARAMS
LEARNING_RATE_TEXT_ENCODER = 5e-5 #@param {type:"number"}
NEW_LEARNING_RATE = LEARNING_RATE / BATCH_SIZE
NEW_LEARNING_RATE_TEXT_ENCODER = LEARNING_RATE_TEXT_ENCODER / BATCH_SIZE
if FP_16:
fp_16_arg = "fp16"
else:
fp_16_arg = "no"
if TRAIN_TEXT_ENCODER:
command = (f'accelerate launch lora/training_scripts/train_lora_dreambooth.py '
f'--pretrained_model_name_or_path="{PRETRAINED_MODEL}" '
f'--instance_data_dir="{INSTANCE_DIR}" '
f'--output_dir="{OUTPUT_DIR}" '
f'--instance_prompt="{PROMPT}" '
f'--resolution=512 '
f'--use_8bit_adam '
f'--mixed_precision="{fp_16_arg}" '
f'--train_batch_size=1 '
f'--gradient_accumulation_steps=1 '
f'--learning_rate={NEW_LEARNING_RATE} '
f'--lr_scheduler="cosine" '
f'--lr_warmup_steps=0 '
f'--max_train_steps={STEPS} '
f'--train_text_encoder '
f'--lora_rank=16 '
f'--learning_rate_text={NEW_LEARNING_RATE_TEXT_ENCODER}')
else:
command = (f'accelerate launch lora/training_scripts/train_lora_dreambooth.py '
f'--pretrained_model_name_or_path="{PRETRAINED_MODEL}" '
f'--instance_data_dir="{INSTANCE_DIR}" '
f'--output_dir="{OUTPUT_DIR}" '
f'--instance_prompt="{PROMPT}" '
f'--resolution=512 '
f'--use_8bit_adam '
f'--mixed_precision="{fp_16_arg}" '
f'--train_batch_size=1 '
f'--gradient_accumulation_steps=1 '
f'--learning_rate={NEW_LEARNING_RATE} '
f'--lr_scheduler="constant" '
f'--lr_warmup_steps=0 '
f'--lora_rank=16 '
f'--max_train_steps={STEPS} '
f'--learning_rate_text={NEW_LEARNING_RATE_TEXT_ENCODER}')
!rm -rf $INSTANCE_DIR/.ipynb_checkpoints
!{command}
|
Contrastive-Tension/BERT-Large-CT-STSb
|
[
"pytorch",
"tf",
"jax",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: mit
tags:
- generated_from_trainer
datasets:
- xtreme
metrics:
- f1
model-index:
- name: xlm-roberta-base-finetuned-panx-de
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: xtreme
type: xtreme
config: PAN-X.de
split: validation
args: PAN-X.de
metrics:
- name: F1
type: f1
value: 0.8653070499346702
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-base-finetuned-panx-de
This model is a fine-tuned version of [xlm-roberta-base](https://huggingface.co/xlm-roberta-base) on the xtreme dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1379
- F1: 0.8653
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 24
- eval_batch_size: 24
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.2557 | 1.0 | 525 | 0.1583 | 0.8231 |
| 0.1269 | 2.0 | 1050 | 0.1393 | 0.8524 |
| 0.0826 | 3.0 | 1575 | 0.1379 | 0.8653 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Corvus/DialoGPT-medium-CaptainPrice
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] |
conversational
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | 2023-02-15T13:17:13Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- samsum
model-index:
- name: bart-samsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bart-samsum
This model is a fine-tuned version of [facebook/bart-large-cnn](https://huggingface.co/facebook/bart-large-cnn) on the samsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5243
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.4705 | 0.54 | 500 | 1.5243 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
CrayonShinchan/fine_tune_try_1
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: mdmxfry
---
### Mad Max Fury v1 Dreambooth model trained by wimvanhenden with the v1-5 base model
Use mdmxfry as prompt prefix
Results:

Sample pictures of training set:
|
CrypticT1tan/DialoGPT-medium-harrypotter
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-02-15T14:18:40Z |
---
language:
- en
license: apache-2.0
tags:
- NatSight-AdpSeq2Seq
- Text2SQL
datasets:
- wikisql
widget:
- text: "What was the number of race that Kevin Curtain won? </s> c0 | number <eom> v4 | Kevin Curtain </s> c0 | No <eom> c1 | Date <eom> c2 | Round <eom> c3 | Circuit <eom> c4 | Pole_Position <eom> c5 | Fastest_Lap <eom> c6 | Race_winner <eom> c7 | Report"
---
## Paper
## [NatSight: A framework for building domain agnostic Natural Language Interface to Databases for next-gen Augmented Analytics](https://dcal.iimb.ac.in/baiconf2022/full_papers/2346.pdf)
Authors: *Rohit Sroch*, *Dhiraj Patnaik*, *Jayachandran Ramachandran*
## Abstract
In modern organizations, a large volume of customer, transactional, and operational data is stored in relational database management systems (RDBMS). It provides scalability and agility for various business use cases. However, the interaction between these databases and business users is limited as users often lack the knowledge of query languages such as SQL and they need to rely on technical experts to interact with the database for curating insights \& analytics. Recent advances in augmented analytics platforms have enabled business users to engage with data in natural language and consume insights in the form of data tables and charts. There are still limitations as the experience is still suboptimal.
The development of natural language interfaces to databases has long been a challenge as previous approaches rely on a considerable amount of human-labeled data for domain adaptation. Moreover, most interfaces provide a constrained environment and do not allow the users to freely and naturally interact with data.
In this work, we propose our framework for building domain-agnostic natural language (NL) interfaces to relational databases (NLIDBs) in few-shot and zero-shot scenarios. Also, recent advancements in the area of Transfer learning allowed us to leverage Transformer-based pre-trained language models (PLMs), resulting in various real-world applications in functional areas like CRM, Supply Chain, Ecommerce, Health Care, etc. for getting real-time insights. More specifically, our framework works in the following ways: First, it provides graph focused auto-suggestions to complete the natural language queries based on the graph representation of database schema, and Second, it uses an adaptive sequence-to-sequence translator model that translates natural language queries to corresponding SQL queries. Furthermore, a feedback loop is used to improve the system based on active learning.
Experiment results on benchmark datasets show that our approach achieves a state-of-the-art performance and can be effective in the few-shot and zero-shot scenarios for domain-agnostic applications.
*Sroch, R. & Patnaik, D. & Ramachandran, J. (2022). [NatSight: A framework for building domain agnostic Natural Language Interface to Databases for next-gen Augmented Analytics](https://dcal.iimb.ac.in/baiconf2022/full_papers/2346.pdf).
9th International Conference on Business Analytics and Intelligence, IIM Banglore (BAI Conf’22).*
## NatSight-bart-base-wikisql
For weights initialization, we used [facebook/bart-base](https://huggingface.co/facebook/bart-base) and fine-tune as sequence-to-sequence task.
## Using Transformers🤗
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("course5i/NatSight-bart-base-wikisql")
model = AutoModelForSeq2SeqLM.from_pretrained("course5i/NatSight-bart-base-wikisql")
# define input
raw_nat_query = "What was the number of race that Kevin Curtain won?"
query_mention_schema = "c0 | number <eom> v4 | Kevin Curtain"
table_header_schema = "c0 | No <eom> c1 | Date <eom> c2 | Round <eom> c3 | Circuit <eom> c4 | Pole_Position <eom> c5 | Fastest_Lap <eom> c6 | Race_winner <eom> c7 | Report"
encoder_input = raw_nat_query + " </s> " + query_mention_schema + " </s> " + table_header_schema
input_ids = tokenizer.encode(encoder_input, return_tensors="pt", add_special_tokens=True)
generated_ids = model.generate(input_ids=input_ids, num_beams=5, max_length=128)
preds = [tokenizer.decode(g, skip_special_tokens=True, clean_up_tokenization_spaces=True) for g in generated_ids]
output = preds[0]
print("Output generic SQL query: {}".format(output))
# output
"SELECT COUNT(c0) FROM TABLE WHERE c4 = v4"
```
## Intended uses & limitations
More information needed
### Training hyperparameters
Please take a look at the `training_args.bin` file
```python
$ import torch
$ hyperparameters = torch.load(os.path.join('training_args.bin'))
```
### Dev/Test results
|| |NatSight-AdpSeq2Seq (BART-base) | |
|:----|:----|:----|:----|
||Dev ||Test |
|Acc-(Logical form) %|Acc-(Execution) %|Acc-(Logical form) %|Acc-(Execution) %|
|83.38|87.83|84|86.39|
### Framework versions
- Transformers >=4.8.0
- Pytorch >=1.6.0
- TensorFlow >=2.5.0
- Datasets >=1.10.2
- Tokenizers >=0.11.6
If you use these models, please cite the following paper:
```
@article{article,
author={Sroch, R. & Patnaik, D. & Ramachandran, J},
title={NatSight: A framework for building domain agnostic Natural Language Interface to Databases for next-gen Augmented Analytics},
journal={9th International Conference on Business Analytics and Intelligence, IIM Banglore (BAI Conf’22)},
day={17},
year={2022},
month={Dec},
url = {https://dcal.iimb.ac.in/baiconf2022/full_papers/2346.pdf}
}
```
|
D-Keqi/espnet_asr_train_asr_streaming_transformer_raw_en_bpe500_sp_valid.acc.ave
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 11 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: moviesReview5classBert
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# moviesReview5classBert
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6000
- Accuracy: 0.1798
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 1.6807 | 0.97 | 19 | 1.6000 | 0.1798 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
D3vil/DialoGPT-smaall-harrypottery
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 252.29 +/- 12.65
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
D3xter1922/distilbert-base-uncased-finetuned-cola
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- generated_from_keras_callback
model-index:
- name: pretrained-bert
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# pretrained-bert
This model is a fine-tuned version of [](https://huggingface.co/) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 6.6263
- Validation Loss: 6.7999
- Epoch: 1
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'weight_decay': None, 'clipnorm': None, 'global_clipnorm': None, 'clipvalue': None, 'use_ema': False, 'ema_momentum': 0.99, 'ema_overwrite_frequency': None, 'jit_compile': True, 'is_legacy_optimizer': False, 'learning_rate': 1e-04, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 6.6402 | 6.8063 | 0 |
| 6.6263 | 6.7999 | 1 |
### Framework versions
- Transformers 4.27.0.dev0
- TensorFlow 2.11.0
- Datasets 2.9.0
- Tokenizers 0.13.2
|
D4RL1NG/yes
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: moviesReview5classBert2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# moviesReview5classBert2
This model is a fine-tuned version of [google/bert_uncased_L-4_H-512_A-8](https://huggingface.co/google/bert_uncased_L-4_H-512_A-8) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9504
- Accuracy: 0.6128
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 64
- seed: 42
- gradient_accumulation_steps: 16
- total_train_batch_size: 512
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.9824 | 1.0 | 228 | 0.9504 | 0.6128 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
DCU-NLP/electra-base-irish-cased-generator-v1
|
[
"pytorch",
"electra",
"fill-mask",
"ga",
"transformers",
"irish",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"ElectraForMaskedLM"
],
"model_type": "electra",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="friendlyGiraffe/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
evaluate_agent(env, model["max_steps"], model["n_eval_episodes"], model["qtable"], model["eval_seed"])
```
|
DHBaek/xlm-roberta-large-korquad-mask
|
[
"pytorch",
"xlm-roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"XLMRobertaForQuestionAnswering"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | 2023-02-15T15:31:50Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
# MakotoShinkai-Style-Diffusion
This is the fine-tuned Stable Diffusion model trained by dreambooth with 10k steps, images dataset from MakotoShinkai's videos.
Use the tokens **MakotoShinkaiStyle** in your prompts for the effect.
### 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or [FLAX/JAX]().
```python
from diffusers import StableDiffusionPipeline
import torch
import os
from PIL import Image
model_id = "michaelz/MakotoShinkai-Style-Diffusion"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float32)
pipe.requires_safety_checker = False
pipe.safety_checker = None
pipe = pipe.to("cuda")
save_dir = os.path.join("results")
os.makedirs(save_dir,exist_ok=True)
prompt_list = [
"MakotoShinkaiStyle, a beautiful sky",
"MakotoShinkaiStyle, a beautiful landscape",
"MakotoShinkaiStyle, a beautiful city"]
for prompt in prompt_list:
torch.manual_seed(-1)
image = pipe(prompt,width = 512,height = 512).images[0]
save_path = os.path.join(save_dir,prompt + ".png")
image.save(save_path)
```




### Sample images from the model:
**Version 1** (MakotoShinkai-Style-Diffusion-10k): This model was trained by dreambooth by 10k steps
|
DTAI-KULeuven/mbert-corona-tweets-belgium-topics
|
[
"pytorch",
"jax",
"bert",
"text-classification",
"multilingual",
"nl",
"fr",
"en",
"arxiv:2104.09947",
"transformers",
"Dutch",
"French",
"English",
"Tweets",
"Topic classification"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 167 | null |
---
tags:
- conversational
---
# MaleToucherBot DialoGPT Model
|
DTAI-KULeuven/robbertje-1-gb-non-shuffled
|
[
"pytorch",
"roberta",
"fill-mask",
"nl",
"dataset:oscar",
"dataset:dbrd",
"dataset:lassy-ud",
"dataset:europarl-mono",
"dataset:conll2002",
"arxiv:2101.05716",
"transformers",
"Dutch",
"Flemish",
"RoBERTa",
"RobBERT",
"RobBERTje",
"license:mit",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 53 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: dys_asr_noself
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# dys_asr_noself
This model is a fine-tuned version of [facebook/wav2vec2-large-960h-lv60](https://huggingface.co/facebook/wav2vec2-large-960h-lv60) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0140
- Wer: 1.0031
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 7
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 10.2127 | 1.36 | 500 | 2.8009 | 1.0 |
| 2.2328 | 2.72 | 1000 | 0.7560 | 1.8847 |
| 0.5913 | 4.09 | 1500 | 0.0921 | 1.0748 |
| 0.1839 | 5.45 | 2000 | 0.0248 | 1.0312 |
| 0.1122 | 6.81 | 2500 | 0.0140 | 1.0031 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.13.1+cu116
- Datasets 1.18.3
- Tokenizers 0.13.2
|
alexandrainst/da-ner-base
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"da",
"dataset:dane",
"transformers",
"license:cc-by-sa-4.0",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 78 | null |
---
license: bsd-3-clause
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: long-t5-tglobal-base-16384-book-summary-finetuned-dialogsum
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# long-t5-tglobal-base-16384-book-summary-finetuned-dialogsum
This model is a fine-tuned version of [pszemraj/long-t5-tglobal-base-16384-book-summary](https://huggingface.co/pszemraj/long-t5-tglobal-base-16384-book-summary) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: nan
- Rouge1: 0.0
- Rouge2: 0.0
- Rougel: 0.0
- Rougelsum: 0.0
- Gen Len: 2.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:------:|:---------:|:-------:|
| 0.0 | 1.0 | 3115 | nan | 25.3388 | 5.7186 | 18.439 | 21.6766 | 53.338 |
| 0.0 | 2.0 | 6230 | nan | 0.0 | 0.0 | 0.0 | 0.0 | 2.0 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Darren/darren
|
[
"pytorch"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
---
## Deprem Niyet Sınıflandırma (Dataset v1.3, BERT 128k)
Alakasız sınıfı atılarak eğitildi.
## Eval Results
```
precision recall f1-score support
Lojistik 0.83 0.86 0.84 22
Elektrik Kaynagi 0.71 0.95 0.81 39
Arama Ekipmani 0.72 0.80 0.76 82
Cenaze 0.50 0.33 0.40 3
Giysi 0.79 0.96 0.87 91
Enkaz Kaldirma 0.99 0.95 0.97 601
Isinma 0.75 0.90 0.82 112
Barınma 0.98 0.95 0.96 292
Tuvalet 0.83 1.00 0.91 5
Su 0.80 0.85 0.83 39
Yemek 0.94 0.95 0.94 138
Saglik 0.80 0.85 0.83 75
micro avg 0.90 0.93 0.92 1499
macro avg 0.80 0.86 0.83 1499
weighted avg 0.91 0.93 0.92 1499
samples avg 0.94 0.95 0.94 1499
```
Reproducibility icin trainer arg'lari:
```python
TrainingArguments(
fp16=True,
evaluation_strategy = "steps",
save_strategy = "steps",
learning_rate=5.1058553791201954e-05,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size*2,
num_train_epochs=4,
load_best_model_at_end=True,
metric_for_best_model="macro f1",
logging_steps = step_size,
seed = 42,
data_seed = 42,
dataloader_num_workers = 0,
lr_scheduler_type ="linear",
warmup_steps=0,
weight_decay=0.06437697487126866,
full_determinism = True,
group_by_length = True
)
```
Threshold:
Best Threshold: 0.52
|
DarshanDeshpande/marathi-distilbert
|
[
"pytorch",
"tf",
"distilbert",
"fill-mask",
"mr",
"dataset:Oscar Corpus, News, Stories",
"arxiv:1910.01108",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 14 | null |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 220.50 +/- 137.92
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga friendlyGiraffe -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga friendlyGiraffe -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga friendlyGiraffe
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 500000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
Darya/layoutlmv2-finetuned-funsd-test
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 795.67 +/- 51.22
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Daryaflp/roberta-retrained_ru_covid
|
[
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 265.34 +/- 21.86
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
DataikuNLP/distiluse-base-multilingual-cased-v1
|
[
"pytorch",
"distilbert",
"arxiv:1908.10084",
"sentence-transformers",
"feature-extraction",
"sentence-similarity",
"transformers",
"license:apache-2.0"
] |
sentence-similarity
|
{
"architectures": [
"DistilBertModel"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 29 | null |
---
tags:
- LunarLander-v2
- ppo
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
- deep-rl-course
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -111.64 +/- 62.10
name: mean_reward
verified: false
---
# PPO Agent Playing LunarLander-v2
This is a trained model of a PPO agent playing LunarLander-v2.
# Hyperparameters
|
Davlan/bert-base-multilingual-cased-finetuned-yoruba
|
[
"pytorch",
"tf",
"jax",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 21 | 2023-02-15T18:17:55Z |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('Mykolyt/sd-class-butterflies-32')
image = pipeline().images[0]
image
```
|
Davlan/bert-base-multilingual-cased-masakhaner
|
[
"pytorch",
"tf",
"bert",
"token-classification",
"arxiv:2103.11811",
"transformers",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 88 | 2023-02-15T18:17:56Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -0.88 +/- 0.30
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Davlan/xlm-roberta-base-finetuned-xhosa
|
[
"pytorch",
"xlm-roberta",
"fill-mask",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"XLMRobertaForMaskedLM"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 12 | 2023-02-15T19:31:50Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="eduiqe/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Dawn576/Dawn
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-02-15T19:48:34Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
library_name: ml-agents
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Write your model_id: mktz/unit5-SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Daymarebait/Discord_BOT_RICK
|
[
"conversational"
] |
conversational
|
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
Access to model akramovic/RAM.AV is restricted and you are not in the authorized list. Visit https://huggingface.co/akramovic/RAM.AV to ask for access.
|
Dazai/Ko
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: mekjr1/Feel-bert-base-uncased-trial-vent
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# mekjr1/Feel-bert-base-uncased-trial-vent
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 3.0961
- Validation Loss: 3.2267
- Epoch: 19
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'WarmUp', 'config': {'initial_learning_rate': 2e-05, 'decay_schedule_fn': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 2e-05, 'decay_steps': -992, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}, '__passive_serialization__': True}, 'warmup_steps': 1000, 'power': 1.0, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.1524 | 2.8831 | 0 |
| 3.3046 | 2.9650 | 1 |
| 3.3182 | 2.2945 | 2 |
| 3.2669 | 3.1812 | 3 |
| 3.1702 | 2.7750 | 4 |
| 3.2273 | 2.0445 | 5 |
| 3.2955 | 2.7407 | 6 |
| 3.1915 | 3.0679 | 7 |
| 3.2005 | 2.0120 | 8 |
| 3.0654 | 2.3347 | 9 |
| 3.0985 | 2.9339 | 10 |
| 3.0161 | 2.8847 | 11 |
| 3.1455 | 3.1531 | 12 |
| 3.1237 | 3.3190 | 13 |
| 3.1059 | 2.5587 | 14 |
| 3.0486 | 2.8180 | 15 |
| 2.9230 | 2.2432 | 16 |
| 3.0667 | 3.0650 | 17 |
| 2.9550 | 2.4731 | 18 |
| 3.0961 | 3.2267 | 19 |
### Framework versions
- Transformers 4.26.1
- TensorFlow 2.11.0
- Datasets 2.9.0
- Tokenizers 0.13.2
|
DeadBeast/roberta-base-pretrained-mr
|
[
"jax",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
- precision
- recall
- f1
model-index:
- name: 10E-affecthq-fer-balanced-w0.1-jitter-jiggle
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 10E-affecthq-fer-balanced-w0.1-jitter-jiggle
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0926
- Accuracy: 0.6094
- Precision: 0.5984
- Recall: 0.6094
- F1: 0.5985
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 17
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | Precision | Recall | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:---------:|:------:|:------:|
| 1.7434 | 1.0 | 133 | 1.7100 | 0.3920 | 0.5334 | 0.3920 | 0.2829 |
| 1.3586 | 2.0 | 266 | 1.3433 | 0.5115 | 0.4915 | 0.5115 | 0.4535 |
| 1.2118 | 3.0 | 399 | 1.2464 | 0.5457 | 0.5288 | 0.5457 | 0.5084 |
| 1.1762 | 4.0 | 532 | 1.1858 | 0.5724 | 0.5615 | 0.5724 | 0.5435 |
| 1.1222 | 5.0 | 665 | 1.1502 | 0.5850 | 0.5704 | 0.5850 | 0.5601 |
| 1.074 | 6.0 | 798 | 1.1300 | 0.5963 | 0.5841 | 0.5963 | 0.5800 |
| 1.0299 | 7.0 | 931 | 1.1119 | 0.6014 | 0.5922 | 0.6014 | 0.5880 |
| 0.9919 | 8.0 | 1064 | 1.1001 | 0.6028 | 0.5907 | 0.6028 | 0.5890 |
| 0.9761 | 9.0 | 1197 | 1.0943 | 0.6075 | 0.5966 | 0.6075 | 0.5950 |
| 0.9769 | 10.0 | 1330 | 1.0926 | 0.6094 | 0.5984 | 0.6094 | 0.5985 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Declan/Breitbart_model_v3
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1182.43 +/- 324.07
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Declan/CNN_model_v1
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: cc-by-2.0
language:
- en
tags:
- code
- audio
- voice
---
# Model Summary
AUTOVC is a many-to-many voice style transfer algorithm.
This model is used to extract speaker-agnostic content representation from an audio file. A good way to think about the term `speaker-agnostic` is that, for example, no matter who speaks the word ‘Ha!’, the lips are expected to be open. This means the opening motion of the mouth is only dictated by the content and not the speaker.
The AutoVC_Conversion model is designed to capture the neutral, general motion of just the lips and nearby regions. It leverages AutoVC from Qian et al. [2019](https://arxiv.org/abs/1905.05879). This specific pre-trained model is from the open source audio driven talking head project, [MakeItTalk](https://github.com/marlenezw/MakeItTalk). You can demo the space and check out how its used in the code [here](https://huggingface.co/spaces/marlenezw/audio-driven-animations).
The framework consists of three modules:
- a content encoder `Ec(·)`, that produces a content embedding from speech
- aspeaker encoder `Es(·)` that produces a speaker embedding from speech
- a decoder `D(·, ·)` that produces speech from content and speaker embeddings.
The model network utilizes an LSTM-based encoder that compresses the input audio into a compact representation trained to abandon the original speaker identity but preserve content. It extracts a content embedding `A ∈ R𝑇×𝐷` from the AutoVC network, where `𝑇` is the total number of input audio frames, and `𝐷` is the content dimension.
# Training
The speaker encoder is a pre-trained model proveded Wan et al. [2018]. Only the content encoder and the decoder are trained.
A training source speech from a dataset of speakers is processed through the content encoder. Then another utterance of the same source speaker is used to extract the speaker embedding, which is passed to the decoder along with the audio content embedding to reconstruct the original source.
The training deliberately assumes that parallel data is not available and so only self-reconstruction is needed for training.
# Performance
The evaluation of AutoVC was performed on the VCTK corpus (Veauxet al., 2016), which contains 44 hours of utterances from 109 speakers. Each speaker reads a different set of sentences.
Two subjective tests on Amazon Mechanical Turk (MTurk) were performed. In the first test, called the mean opinionscore (MOS) test, the subjects are presented with converted utterances. For each utterance, the subjects are asked to assign a score of 1-5 on the naturalness of the converted speech. In the second test, called the similarity test, the subjects are presented with pairs of utterances. In each pair,there is one converted utterance, and one utterance from the target speaker uttering the same sentence. For each pair, the subjects were asked to assign a score of 1-5 on the voice similarity.The subjects were explicitly asked to focus on the voice rather than intonation and accent.
The MOS scores of AUTOVC are above 3 for all groups, whereas those for the baselines almost all fall below 3. The MOS for 16kHz natural speech is around 4.5. The MOS scores of the current state-of-the-art speech synthesizers are between 4 and 4.5. These subjective evaluation results show that AUTOVC approaches the performance of parallel conversion systems in terms of naturalness, and is much better than existing non-parallel conversion systems.
|
Declan/ChicagoTribune_model_v4
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | 2023-02-15T21:56:40Z |
---
license: apache-2.0
tags:
- text-classification
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: platzi-distilroberta-base-mrpc-glue-luigitercero
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: datasetX
type: glue
config: mrpc
split: validation
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8431372549019608
- name: F1
type: f1
value: 0.8836363636363636
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# platzi-distilroberta-base-mrpc-glue-luigitercero
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the datasetX dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6591
- Accuracy: 0.8431
- F1: 0.8836
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1853 | 1.09 | 500 | 0.6591 | 0.8431 | 0.8836 |
| 0.1812 | 2.18 | 1000 | 0.6591 | 0.8431 | 0.8836 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Declan/FoxNews_model_v8
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="menoua/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Declan/HuffPost_model_v2
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1657
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.2109 | 1.0 | 5533 | 1.1564 |
| 0.9593 | 2.0 | 11066 | 1.1297 |
| 0.7541 | 3.0 | 16599 | 1.1657 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Declan/HuffPost_model_v4
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-Taxi-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.56 +/- 2.71
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="menoua/q-Taxi-v3", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Declan/NPR_model_v8
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SoccerTwos
library_name: ml-agents
---
# **poca** Agent playing **SoccerTwos**
This is a trained model of a **poca** agent playing **SoccerTwos** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SoccerTwos
2. Step 1: Write your model_id: SatCat/poca-SoccerTwos
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Declan/NewYorkTimes_model_v1
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: roberta-tiny-4l-10M
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# roberta-tiny-4l-10M
This model was trained from scratch on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 7.3432
- Accuracy: 0.0513
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0007
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 128
- total_train_batch_size: 2048
- optimizer: Adam with betas=(0.9,0.98) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 50
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 7.4785 | 4.16 | 50 | 7.3834 | 0.0514 |
| 7.425 | 8.33 | 100 | 7.3559 | 0.0514 |
| 7.4187 | 12.49 | 150 | 7.3517 | 0.0512 |
| 7.4204 | 16.66 | 200 | 7.3440 | 0.0514 |
| 7.4099 | 20.82 | 250 | 7.3454 | 0.0515 |
| 7.2916 | 24.99 | 300 | 7.3442 | 0.0515 |
| 7.4117 | 29.16 | 350 | 7.3440 | 0.0513 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.11.0+cu113
- Datasets 2.6.1
- Tokenizers 0.12.1
|
Declan/NewYorkTimes_model_v6
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: sergey-antonov/ppo-Pyramids
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
Declan/Politico_model_v1
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | 2023-02-15T23:05:49Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="HaiderAUT/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Declan/Politico_model_v3
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | 2023-02-15T23:11:06Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -2.71 +/- 0.42
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Declan/Politico_model_v5
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-medium.en
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_myst
type: rishabhjain16/infer_myst
config: en
split: test
metrics:
- type: wer
value: 11.88
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pfs
type: rishabhjain16/infer_pfs
config: en
split: test
metrics:
- type: wer
value: 3.28
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_cmu
type: rishabhjain16/infer_cmu
config: en
split: test
metrics:
- type: wer
value: 1.98
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/libritts_dev_clean
type: rishabhjain16/libritts_dev_clean
config: en
split: test
metrics:
- type: wer
value: 5.15
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_swedish
type: rishabhjain16/infer_pf_swedish
config: en
split: test
metrics:
- type: wer
value: 8.16
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_german
type: rishabhjain16/infer_pf_german
config: en
split: test
metrics:
- type: wer
value: 34.99
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_italian
type: rishabhjain16/infer_pf_italian
config: en
split: test
metrics:
- type: wer
value: 4.65
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_so_chinese
type: rishabhjain16/infer_so_chinese
config: en
split: test
metrics:
- type: wer
value: 15.87
name: WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium.en
This model is a fine-tuned version of [openai/whisper-medium.en](https://huggingface.co/openai/whisper-medium.en) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2994
- Wer: 9.7808
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.235 | 0.12 | 500 | 0.2735 | 11.0733 |
| 0.1927 | 1.06 | 1000 | 0.2339 | 10.5575 |
| 0.1119 | 1.18 | 1500 | 0.2280 | 9.6803 |
| 0.0863 | 2.12 | 2000 | 0.2379 | 11.0621 |
| 0.0322 | 3.05 | 2500 | 0.2614 | 9.9920 |
| 0.0303 | 3.17 | 3000 | 0.2611 | 10.2742 |
| 0.0161 | 4.11 | 3500 | 0.2885 | 10.4722 |
| 0.0513 | 5.04 | 4000 | 0.2994 | 9.7808 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
Declan/Politico_model_v8
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | 2023-02-15T23:14:40Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-large-v2
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_myst
type: rishabhjain16/infer_myst
config: en
split: test
metrics:
- type: wer
value: 11.73
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pfs
type: rishabhjain16/infer_pfs
config: en
split: test
metrics:
- type: wer
value: 3.13
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_cmu
type: rishabhjain16/infer_cmu
config: en
split: test
metrics:
- type: wer
value: 2.56
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/libritts_dev_clean
type: rishabhjain16/libritts_dev_clean
config: en
split: test
metrics:
- type: wer
value: 4.69
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_swedish
type: rishabhjain16/infer_pf_swedish
config: en
split: test
metrics:
- type: wer
value: 9.67
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_german
type: rishabhjain16/infer_pf_german
config: en
split: test
metrics:
- type: wer
value: 35.05
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_italian
type: rishabhjain16/infer_pf_italian
config: en
split: test
metrics:
- type: wer
value: 5.51
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_so_chinese
type: rishabhjain16/infer_so_chinese
config: en
split: test
metrics:
- type: wer
value: 15.83
name: WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-large-v2
This model is a fine-tuned version of [openai/whisper-large-v2](https://huggingface.co/openai/whisper-large-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1915
- Wer: 10.0336
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2819 | 0.12 | 500 | 0.2709 | 15.1530 |
| 0.2508 | 0.25 | 1000 | 0.2098 | 11.2876 |
| 0.1113 | 1.01 | 1500 | 0.2127 | 10.3778 |
| 0.2872 | 1.14 | 2000 | 0.1891 | 10.6509 |
| 0.2995 | 1.26 | 2500 | 0.1883 | 10.7545 |
| 0.0701 | 2.02 | 3000 | 0.1972 | 9.6061 |
| 0.0613 | 2.15 | 3500 | 0.2073 | 9.4813 |
| 0.1135 | 2.27 | 4000 | 0.1915 | 10.0336 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
Declan/Reuters_model_v3
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# EfficientNet (b4 model)
EfficientNet model trained on ImageNet-1k at resolution 380x380. It was introduced in the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le, and first released in [this repository](https://github.com/keras-team/keras).
Disclaimer: The team releasing EfficientNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
EfficientNet is a mobile friendly pure convolutional model (ConvNet) that proposes a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=efficientnet) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
import torch
from datasets import load_dataset
from transformers import EfficientNetImageProcessor, EfficientNetForImageClassification
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
preprocessor = EfficientNetImageProcessor.from_pretrained("google/efficientnet-b4")
model = EfficientNetForImageClassification.from_pretrained("google/efficientnet-b4")
inputs = preprocessor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/efficientnet).
### BibTeX entry and citation info
```bibtex
@article{Tan2019EfficientNetRM,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
journal={ArXiv},
year={2019},
volume={abs/1905.11946}
}
```
|
Declan/Reuters_model_v4
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 2149.76 +/- 116.05
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Declan/WallStreetJournal_model_v1
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
def cls_pooling(model_output, attention_mask):
return model_output[0][:,0]
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = cls_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 35715 with parameters:
```
{'batch_size': 7, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.DenoisingAutoEncoderLoss.DenoisingAutoEncoderLoss`
Parameters of the fit()-Method:
```
{
"epochs": 6,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 3e-05
},
"scheduler": "constantlr",
"steps_per_epoch": null,
"warmup_steps": 10000,
"weight_decay": 0
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': True, 'pooling_mode_mean_tokens': False, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
Declan/WallStreetJournal_model_v3
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- zaib32/autotrain-data-finetune_17-0
co2_eq_emissions:
emissions: 0.13450186573008246
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 3516595138
- CO2 Emissions (in grams): 0.1345
## Validation Metrics
- Loss: 1.229
- Rouge1: 52.561
- Rouge2: 25.355
- RougeL: 37.474
- RougeLsum: 48.677
- Gen Len: 186.719
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/zaib32/autotrain-finetune_17-0-3516595138
```
|
Declan/WallStreetJournal_model_v4
|
[
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
license: apache-2.0
tags:
- vision
- image-classification
datasets:
- imagenet-1k
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
---
# EfficientNet (b7 model)
EfficientNet model trained on ImageNet-1k at resolution 600x600. It was introduced in the paper [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks
](https://arxiv.org/abs/1905.11946) by Mingxing Tan and Quoc V. Le, and first released in [this repository](https://github.com/keras-team/keras).
Disclaimer: The team releasing EfficientNet did not write a model card for this model so this model card has been written by the Hugging Face team.
## Model description
EfficientNet is a mobile friendly pure convolutional model (ConvNet) that proposes a new scaling method that uniformly scales all dimensions of depth/width/resolution using a simple yet highly effective compound coefficient.

## Intended uses & limitations
You can use the raw model for image classification. See the [model hub](https://huggingface.co/models?search=efficientnet) to look for
fine-tuned versions on a task that interests you.
### How to use
Here is how to use this model to classify an image of the COCO 2017 dataset into one of the 1,000 ImageNet classes:
```python
import torch
from datasets import load_dataset
from transformers import EfficientNetImageProcessor, EfficientNetForImageClassification
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
preprocessor = EfficientNetImageProcessor.from_pretrained("google/efficientnet-b7")
model = EfficientNetForImageClassification.from_pretrained("google/efficientnet-b7")
inputs = preprocessor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label]),
```
For more code examples, we refer to the [documentation](https://huggingface.co/docs/transformers/master/en/model_doc/efficientnet).
### BibTeX entry and citation info
```bibtex
@article{Tan2019EfficientNetRM,
title={EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks},
author={Mingxing Tan and Quoc V. Le},
journal={ArXiv},
year={2019},
volume={abs/1905.11946}
}
```
|
DeepBasak/Slack
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- wer
model-index:
- name: openai/whisper-medium
results:
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_myst
type: rishabhjain16/infer_myst
config: en
split: test
metrics:
- type: wer
value: 12.75
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pfs
type: rishabhjain16/infer_pfs
config: en
split: test
metrics:
- type: wer
value: 3.11
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_cmu
type: rishabhjain16/infer_cmu
config: en
split: test
metrics:
- type: wer
value: 1.98
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/libritts_dev_clean
type: rishabhjain16/libritts_dev_clean
config: en
split: test
metrics:
- type: wer
value: 6.09
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_swedish
type: rishabhjain16/infer_pf_swedish
config: en
split: test
metrics:
- type: wer
value: 8.99
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_german
type: rishabhjain16/infer_pf_german
config: en
split: test
metrics:
- type: wer
value: 36.67
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_pf_italian
type: rishabhjain16/infer_pf_italian
config: en
split: test
metrics:
- type: wer
value: 5.14
name: WER
- task:
type: automatic-speech-recognition
name: Automatic Speech Recognition
dataset:
name: rishabhjain16/infer_so_chinese
type: rishabhjain16/infer_so_chinese
config: en
split: test
metrics:
- type: wer
value: 16.09
name: WER
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# openai/whisper-medium
This model is a fine-tuned version of [openai/whisper-medium](https://huggingface.co/openai/whisper-medium) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2589
- Wer: 10.2458
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.2975 | 0.12 | 500 | 0.2211 | 11.1099 |
| 0.2856 | 1.07 | 1000 | 0.2027 | 10.5108 |
| 0.0727 | 2.01 | 1500 | 0.2071 | 10.1778 |
| 0.1546 | 2.13 | 2000 | 0.1978 | 10.5596 |
| 0.0166 | 3.08 | 2500 | 0.2328 | 9.9899 |
| 0.0076 | 4.02 | 3000 | 0.2436 | 10.3463 |
| 0.0042 | 4.14 | 3500 | 0.2497 | 10.5311 |
| 0.0066 | 5.09 | 4000 | 0.2589 | 10.2458 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.9.1.dev0
- Tokenizers 0.13.2
|
DeepChem/ChemBERTa-10M-MTR
|
[
"pytorch",
"roberta",
"arxiv:1910.09700",
"transformers"
] | null |
{
"architectures": [
"RobertaForRegression"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 708 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: strangetcy/testpyramidsrnd
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
DeepChem/SmilesTokenizer_PubChem_1M
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 227 | null |
---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: HaLong
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9555555582046509
---
# HaLong
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### HaLong

#### HoiAn

|
DeskDown/MarianMixFT_en-fil
|
[
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
Access to model moinbukhari/sd-15-2-moin is restricted and you are not in the authorized list. Visit https://huggingface.co/moinbukhari/sd-15-2-moin to ask for access.
|
DeskDown/MarianMixFT_en-ms
|
[
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 483.50 +/- 160.70
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga menoua -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga menoua -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga menoua
```
## Hyperparameters
```python
OrderedDict([('batch_size', 128),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.3),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0003),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 16),
('normalize', False)])
```
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.