
modelId
stringlengths 4
81
| tags
list | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
Alessandro/model_name
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
language: en
thumbnail: http://www.huggingtweets.com/iwontsmthing1/1678830403864/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1605342956034064384/8CVvM3xW_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Хамовитий мопс</div>
<div style="text-align: center; font-size: 14px;">@iwontsmthing1</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Хамовитий мопс.
| Data | Хамовитий мопс |
| --- | --- |
| Tweets downloaded | 3247 |
| Retweets | 89 |
| Short tweets | 654 |
| Tweets kept | 2504 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/3cze1uyx/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @iwontsmthing1's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/b6nhrz6u) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/b6nhrz6u/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/iwontsmthing1')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
AlexN/xls-r-300m-fr
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"fr",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"generated_from_trainer",
"hf-asr-leaderboard",
"mozilla-foundation/common_voice_8_0",
"robust-speech-event",
"model-index"
] |
automatic-speech-recognition
|
{
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 17 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: MultiLabel_V3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# MultiLabel_V3
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9683
- Accuracy: 0.7370
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0002
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.8572 | 0.1 | 100 | 1.1607 | 0.6466 |
| 0.8578 | 0.2 | 200 | 1.1956 | 0.6499 |
| 0.7362 | 0.3 | 300 | 1.1235 | 0.6885 |
| 0.8569 | 0.39 | 400 | 1.0460 | 0.6891 |
| 0.4851 | 0.49 | 500 | 1.1213 | 0.6891 |
| 0.7252 | 0.59 | 600 | 1.1512 | 0.6720 |
| 0.6333 | 0.69 | 700 | 1.1039 | 0.6913 |
| 0.6239 | 0.79 | 800 | 1.0636 | 0.7001 |
| 0.2768 | 0.89 | 900 | 1.0386 | 0.7073 |
| 0.4872 | 0.99 | 1000 | 1.0311 | 0.7062 |
| 0.3049 | 1.09 | 1100 | 1.0437 | 0.7155 |
| 0.1435 | 1.18 | 1200 | 1.0343 | 0.7222 |
| 0.2088 | 1.28 | 1300 | 1.0784 | 0.7194 |
| 0.4972 | 1.38 | 1400 | 1.1072 | 0.7166 |
| 0.3604 | 1.48 | 1500 | 1.0438 | 0.7150 |
| 0.2726 | 1.58 | 1600 | 1.0077 | 0.7293 |
| 0.3106 | 1.68 | 1700 | 1.0029 | 0.7326 |
| 0.3259 | 1.78 | 1800 | 0.9906 | 0.7310 |
| 0.3323 | 1.88 | 1900 | 0.9729 | 0.7359 |
| 0.2998 | 1.97 | 2000 | 0.9683 | 0.7370 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AlexN/xls-r-300m-pt
|
[
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"pt",
"dataset:mozilla-foundation/common_voice_8_0",
"transformers",
"robust-speech-event",
"mozilla-foundation/common_voice_8_0",
"generated_from_trainer",
"hf-asr-leaderboard",
"license:apache-2.0",
"model-index"
] |
automatic-speech-recognition
|
{
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 15 | null |
# Model Card for hestyle-controlnet
### Model Description
Scribble controlnet transferred Hestyle model.
- **Developed by:** Alethea.ai
- **Model type:** PyTorch Checkpoint
- **License:** [Will provide soon.]
- **Finetuned from model [optional]:** Hestyle
## Bias, Risks, and Limitations
[Will provide soon.]
### Recommendations
[Will provide soon.]
## Training Details
[Will provide soon.]
|
Alexander-Learn/bert-finetuned-ner-accelerate
|
[
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | 2023-03-14T22:07:00Z |
---
language:
- da
tags:
- generated_from_trainer
datasets:
- audiofolder
metrics:
- wer
model-index:
- name: Whisper Tiny Da - HollowVoice
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: audiofolder
type: audiofolder
config: default
split: train[-20%:]
args: default
metrics:
- name: Wer
type: wer
value: 86.49993452926542
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Tiny Da - HollowVoice
This model is a fine-tuned version of [openai/openai/whisper-tiny](https://huggingface.co/openai/openai/whisper-tiny) on the audiofolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5216
- Wer: 86.4999
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0319 | 24.39 | 1000 | 0.5216 | 86.4999 |
| 0.0031 | 48.78 | 2000 | 0.5156 | 89.3545 |
| 0.0017 | 73.17 | 3000 | 0.5267 | 89.7342 |
| 0.0013 | 97.56 | 4000 | 0.5312 | 90.9781 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AlirezaBaneshi/testPersianQA
|
[
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
license: creativeml-openrail-m
language:
- en
tags:
- LoRA
- Lycoris
- stable diffusion
- ffxiv
- final fantasy xiv
- meteion
---
# 24 Cans of Monster: Meteion FFXIV Lycoris Model
Full previews are here at the moment: https://civitai.com/models/19689/24-cans-of-monster-meteion-ffxiv-endwalker-spoilers
I will be adding those in a folder in about 5 minutes though!
# WHAT GAME IS IT?
Final Fantasy XIV, Meteion is a charachter in the most recent of expansions 6.0 / Endwalker. This includes both her WORLD ENDING form, and her birb form as well as her existenial crisis she needs a snickers and a can of technicolor goo.
# Wait THIS IS A LYCORIS UPDATE!
Yes you'll need this: https://github.com/KohakuBlueleaf/a1111-sd-webui-locon
# Support Us!
We stream a lot of our testing on twitch: https://www.twitch.tv/duskfallcrew
any chance you can spare a coffee or three? https://ko-fi.com/DUSKFALLcrew
If you want custom LoRA OR MODEL trained an option will become available on the Patreon: https://www.patreon.com/earthndusk
# A Meme If you WILL:
This LoRA will end the world if you don't each her the proper ettiqutte.
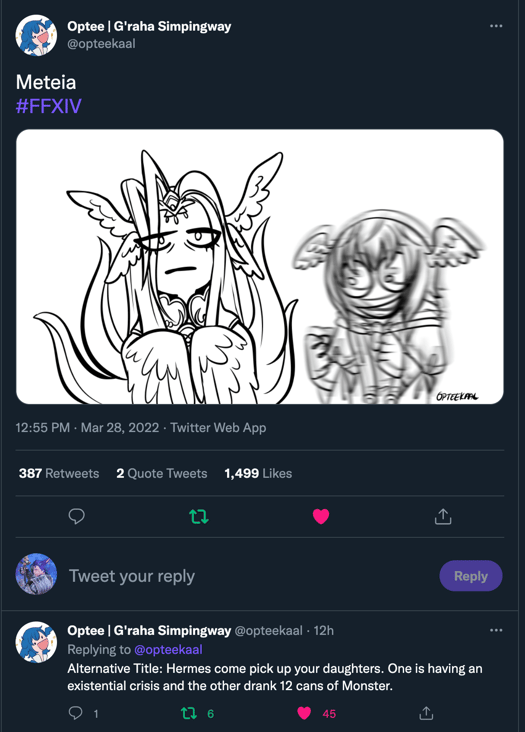
No, the meme is not in the dataset, this is just a meme we had laying around.
# Official Samples by Us using NyanMixAbsurdRes2:





|
Aliskin/xlm-roberta-base-finetuned-marc
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: unit4
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Allybaby21/Allysai
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: mit
---
<h1 align="center">arabert-finetuned-caner</h1>
<p align="center">An ongoing project for implementation of NLP methods in the field of islamic studies.</p>
### Named Entity Recognition
briefly:
* We had to prepair CANERCorpus dataset which is avialable at [huggingface](https://huggingface.co/datasets/caner/). The dataset was not in the BIO format so model couldn't learn anything from it. We used an html version of dataset available on github and extracted a HuggingFace format dataset from it with BIO tags.
* Fine tunning started from a pre-traind model named "bert-base-arabertv02" and after 3 epoch of training model on the above mentioned dataset (80% splitted to training data and 20% to validation data), reached the following results: (evaluation is done by using compute metrics of python evaluate module. note that precision is overall precision, recall is overall recall and so on.)

* Trained model is available at [huggingface](https://huggingface.co/ArefSadeghian/arabert-finetuned-caner) and you can use it with the following code snippet:
```python
!pip install transformers
from transformers import pipeline
model_checkpoint = "ArefSadeghian/arabert-finetuned-caner"
# Replace this with above latest checkpoint
token_classifier = pipeline(
"token-classification", model=model_checkpoint, aggregation_strategy="simple"
)
s = "حَدَّثَنَا عَبْد اللَّهِ، حَدَّثَنِي عُبَيْدُ اللَّهِ بْنُ عُمَرَ الْقَوَارِيرِيُّ، حَدَّثَنَا يُونُسُ بْنُ أَرْقَمَ، حَدَّثَنَا يَزِيدُ بْنُ أَبِي زِيَادٍ، عَنْ عَبْدِ الرَّحْمَنِ بْنِ أَبِي لَيْلَى، قَالَ شَهِدْتُ عَلِيًّا رَضِيَ اللَّهُ عَنْهُ فِي الرَّحَبَةِ يَنْشُدُ النَّاسَ أَنْشُدُ اللَّهَ مَنْ سَمِعَ رَسُولَ اللَّهِ صَلَّى اللَّهُ عَلَيْهِ وَسَلَّمَ يَقُولُ يَوْمَ غَدِيرِ خُمٍّ مَنْ كُنْتُ مَوْلَاهُ فَعَلِيٌّ مَوْلَاهُ لَمَّا قَامَ فَشَهِدَ قَالَ عَبْدُ الرَّحْمَنِ فَقَامَ اثْنَا عَشَرَ بَدْرِيًّا كَأَنِّي أَنْظُرُ إِلَى أَحَدِهِمْ فَقَالُوا نَشْهَدُ أَنَّا سَمِعْنَا رَسُولَ اللَّهِ صَلَّى اللَّهُ عَلَيْهِ وَسَلَّمَ يَقُولُ يَوْمَ غَدِيرِ خُمٍّ أَلَسْتُ أَوْلَى بِالْمُؤْمِنِينَ مِنْ أَنْفُسِهِمْ وَأَزْوَاجِي أُمَّهَاتُهُمْ فَقُلْنَا بَلَى يَا رَسُولَ اللَّهِ قَالَ فَمَنْ كُنْتُ مَوْلَاهُ فَعَلِيٌّ مَوْلَاهُ اللَّهُمَّ وَالِ مَنْ وَالَاهُ وَعَادِ مَنْ عَادَاهُ"
token_classifier(s)
```
* This model is deployed on a Huggingface space using Gradio. So you can use it online [here](https://huggingface.co/spaces/ArefSadeghian/ArefSadeghian-arabert-finetuned-caner)!
|
Aloka/mbart50-ft-si-en
|
[
"pytorch",
"tensorboard",
"mbart",
"text2text-generation",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
tokenizer = AutoTokenizer.from_pretrained("microsoft/DialoGPT-medium")
model = AutoModelForCausalLM.from_pretrained("microsoft/DialoGPT-medium")
# Let's chat for 5 lines
for step in range(5):
# encode the new user input, add the eos_token and return a tensor in Pytorch
new_user_input_ids = tokenizer.encode(input(">> User:") + tokenizer.eos_token, return_tensors='pt')
# append the new user input tokens to the chat history
bot_input_ids = torch.cat([chat_history_ids, new_user_input_ids], dim=-1) if step > 0 else new_user_input_ids
# generated a response while limiting the total chat history to 1000 tokens,
chat_history_ids = model.generate(bot_input_ids, max_length=1000, pad_token_id=tokenizer.eos_token_id)
# pretty print last ouput tokens from bot
print("DialoGPT: {}".format(tokenizer.decode(chat_history_ids[:, bot_input_ids.shape[-1]:][0], skip_special_tokens=True)))
|
Alstractor/distilbert-base-uncased-finetuned-cola
|
[
"pytorch",
"tensorboard",
"distilbert",
"text-classification",
"dataset:glue",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index"
] |
text-classification
|
{
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 40 | null |
# AMR prediction with LGBMClassifier models
This repository contains a Python script for predicting antimicrobial resistance (AMR) using the LGBMClassifier model. The script reads input datasets from a directory, applies feature extraction techniques to obtain k-mer features, trains and tests the models using cross-validation, and outputs the results in text files.

## Getting Started
These instructions will get you a copy of the project up and running on your local machine for development and testing purposes.
### Prerequisites
This script requires the following Python libraries:
pandas
scikit-learn
numpy
tqdm
lightgbm
hyperopt
joblib
bayesian-optimization
skopt
### Installing
Clone the repository to your local machine and install the required libraries:
```bash
$ git clone https://github.com/username/repo.git
$ cd repo
$ pip install -r requirements.txt
```
### Usage
To use the script, execute the following command:
css
Copy code
```bash
$ python main.py
```
## Code Structure
The main script consists of several sections:
1 Import necessary libraries
2 Set seed for reproducibility
3 Define function to get list of models to evaluate
4 Load list of selected samples
5 Call function to get list of models
6 Initialize KFold cross-validation
7 Iterate over values of k to read the corresponding k-mer feature dataset
8 Iterate over the models list
9 Write results to text file
## Data Description
The input datasets are CSV files containing bacterial genomic sequences and their corresponding resistance profiles for selected antibiotics. The script reads these files from a directory and applies k-mer feature extraction techniques to obtain numerical feature vectors.
## Models
The script uses two models for AMR prediction: Random Forest and LGBMClassifier.
## Output
The script outputs the results of each model to a text file in the specified output directory. The results include accuracy, precision, recall, F1 score, and area under the ROC curve.
## Authors
Gabriel Sousa - gabrieltxs
## License
This project is licensed under the MIT License - see the LICENSE.md file for details.
[](https://choosealicense.com/licenses/mit/)
|
Amalq/distilroberta-base-finetuned-anxiety-depression
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 260.31 +/- 21.73
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AmanPriyanshu/DistilBert-Sentiment-Analysis
|
[
"tf",
"distilbert",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | null |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1848.82 +/- 105.51
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AmazonScience/qanlu
|
[
"pytorch",
"roberta",
"question-answering",
"en",
"dataset:atis",
"transformers",
"license:cc-by-4.0",
"autotrain_compatible",
"has_space"
] |
question-answering
|
{
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 494 | null |
---
language:
- en
- cy
pipeline_tag: translation
tags:
- translation
- marian
metrics:
- bleu
- cer
- wer
- wil
- wip
- chrf
widget:
- text: "The doctor will be late to attend to patients this morning."
example_title: "Example 1"
license: apache-2.0
model-index:
- name: "mt-dspec-health-en-cy"
results:
- task:
name: Translation
type: translation
metrics:
- name: SacreBLEU
type: bleu
value: 54.16
- name: CER
type: cer
value: 0.31
- name: WER
type: wer
value: 0.47
- name: WIL
type: wil
value: 0.67
- name: WIP
type: wip
value: 0.33
- name: SacreBLEU CHRF
type: chrf
value: 69.03
---
# mt-dspec-health-en-cy
A language translation model for translating between English and Welsh, specialised to the specific domain of Health and care.
This model was trained using custom DVC pipeline employing [Marian NMT](https://marian-nmt.github.io/),
the datasets prepared were generated from the following sources:
- [UK Government Legislation data](https://www.legislation.gov.uk)
- [OPUS-cy-en](https://opus.nlpl.eu/)
- [Cofnod Y Cynulliad](https://record.assembly.wales/)
- [Cofion Techiaith Cymru](https://cofion.techiaith.cymru)
The data was split into train, validation and tests sets, the test set containing health-specific segments from TMX files
selected at random from the [Cofion Techiaith Cymru](https://cofion.techiaith.cymru) website, which have been pre-classified as pertaining to the specific domain.
Having extracted the test set, the aggregation of remaining data was then split into 10 training and validation sets, and fed into 10 marian training sessions.
A website demonstrating use of this model is available at http://cyfieithu.techiaith.cymru.
## Evaluation
Evaluation was done using the python libraries [SacreBLEU](https://github.com/mjpost/sacrebleu) and [torchmetrics](https://torchmetrics.readthedocs.io/en/stable/).
## Usage
Ensure you have the prerequisite python libraries installed:
```bash
pip install transformers sentencepiece
```
```python
import trnasformers
model_id = "techiaith/mt-spec-health-en-cy"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
model = transformers.AutoModelForSeq2SeqLM.from_pretrained(model_id)
translate = transformers.pipeline("translation", model=model, tokenizer=tokenizer)
translated = translate("The doctor will be late to attend to patients this morning.")
print(translated["translation_text"])
```
|
Amba/wav2vec2-large-xls-r-300m-tr-colab
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
language:
- en
- cy
license: apache-2.0
pipeline_tag: translation
tags:
- translation
- marian
metrics:
- bleu
- cer
- chrf
- cer
- wer
- wil
- wip
widget:
- text: "The Curriculum and Assessment (Wales) Act 2021 (the Act) established the Curriculum for Wales and replaced the general curriculum used up until that point."
example_title: "Example 1"
model-index:
- name: mt-dspec-legislation-en-cy
results:
- task:
name: Translation
type: translation
metrics:
- type: bleu
value: 65.51
- type: cer
value: 0.28
- type: chrf
value: 74.69
- type: wer
value: 0.39
- type: wil
value: 0.54
- type: wip
value: 0.46
---
# mt-dspec-legislation-en-cy
A language translation model for translating between English and Welsh, specialised to the specific domain of Legislation.
This model was trained using custom DVC pipeline employing [Marian NMT](https://marian-nmt.github.io/),
the datasets prepared were generated from the following sources:
- [UK Government Legislation data](https://www.legislation.gov.uk)
- [OPUS-cy-en](https://opus.nlpl.eu/)
- [Cofnod Y Cynulliad](https://record.assembly.wales/)
- [Cofion Techiaith Cymru](https://cofion.techiaith.cymru)
The data was split into train, validation and test sets; the test set containing legislation-specific segments were selected randomly from TMX files
originating from the [Cofion Techiaith Cymru](https://cofion.techiaith.cymru) website, which have been pre-classified as pertaining to the specific domain,
and data files scraped from the UK Government Legislation website.
Having extracted the test set, the aggregation of remaining data was then split into 10 training and validation sets, and fed into 10 marian training sessions.
## Evaluation
Evaluation scores were produced using the python libraries [SacreBLEU](https://github.com/mjpost/sacrebleu) and [torchmetrics](https://torchmetrics.readthedocs.io/en/stable/).
## Usage
Ensure you have the prerequisite python libraries installed:
```bsdh
pip install transformers sentencepiece
```
```python
import trnasformers
model_id = "techiaith/mt-spec-health-en-cy"
tokenizer = transformers.AutoTokenizer.from_pretrained(model_id)
model = transformers.AutoModelForSeq2SeqLM.from_pretrained(model_id)
translate = transformers.pipeline("translation", model=model, tokenizer=tokenizer)
translated = translate(
"The Curriculum and Assessment (Wales) Act 2021 (the Act) "
"established the Curriculum for Wales and replaced the general "
"curriculum used up until that point."
)
print(translated["translation_text"])
```
|
Andranik/TestQaV1
|
[
"pytorch",
"rust",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 258.67 +/- 18.31
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AndrewNLP/redditDepressionPropensityClassifiers
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- CartPole-v1
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: DQPN_decay
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# (CleanRL) **DQPN_decay** Agent Playing **CartPole-v1**
This is a trained model of a DQPN_decay agent playing CartPole-v1.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/DQPN_decay.py).
## Get Started
To use this model, please install the `cleanrl` package with the following command:
```
pip install "cleanrl[DQPN_decay]"
python -m cleanrl_utils.enjoy --exp-name DQPN_decay --env-id CartPole-v1
```
Please refer to the [documentation](https://docs.cleanrl.dev/get-started/zoo/) for more detail.
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/pfunk/CartPole-v1-DQPN_decay-seed1/raw/main/dqpn_decay.py
curl -OL https://huggingface.co/pfunk/CartPole-v1-DQPN_decay-seed1/raw/main/pyproject.toml
curl -OL https://huggingface.co/pfunk/CartPole-v1-DQPN_decay-seed1/raw/main/poetry.lock
poetry install --all-extras
python dqpn_decay.py --exp-name DQPN_decay --seed 1 --track --wandb-entity pfunk --wandb-project-name dqpn --capture-video true --save-model true --upload-model true --hf-entity pfunk
```
# Hyperparameters
```python
{'alg_type': 'dqpn_decay.py',
'batch_size': 256,
'buffer_size': 300000,
'capture_video': True,
'cuda': True,
'end_e': 0.1,
'end_policy_network_frequency': 200,
'env_id': 'CartPole-v1',
'evaluation_fraction': 0.7,
'exp_name': 'DQPN_decay',
'exploration_fraction': 0.2,
'gamma': 1.0,
'hf_entity': 'pfunk',
'learning_rate': 0.0001,
'learning_starts': 1000,
'policy_tau': 1.0,
'save_model': True,
'seed': 1,
'start_e': 1.0,
'start_policy_network_frequency': 10000,
'target_network_frequency': 20,
'target_tau': 1.0,
'torch_deterministic': True,
'total_timesteps': 500000,
'track': True,
'train_frequency': 1,
'upload_model': True,
'wandb_entity': 'pfunk',
'wandb_project_name': 'dqpn'}
```
|
Andrey1989/mbart-finetuned-en-to-kk
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
tags:
- CartPole-v1
- deep-reinforcement-learning
- reinforcement-learning
- custom-implementation
library_name: cleanrl
model-index:
- name: DQPN_decay
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# (CleanRL) **DQPN_decay** Agent Playing **CartPole-v1**
This is a trained model of a DQPN_decay agent playing CartPole-v1.
The model was trained by using [CleanRL](https://github.com/vwxyzjn/cleanrl) and the most up-to-date training code can be
found [here](https://github.com/vwxyzjn/cleanrl/blob/master/cleanrl/DQPN_decay.py).
## Get Started
To use this model, please install the `cleanrl` package with the following command:
```
pip install "cleanrl[DQPN_decay]"
python -m cleanrl_utils.enjoy --exp-name DQPN_decay --env-id CartPole-v1
```
Please refer to the [documentation](https://docs.cleanrl.dev/get-started/zoo/) for more detail.
## Command to reproduce the training
```bash
curl -OL https://huggingface.co/pfunk/CartPole-v1-DQPN_decay-seed3/raw/main/dqpn_decay.py
curl -OL https://huggingface.co/pfunk/CartPole-v1-DQPN_decay-seed3/raw/main/pyproject.toml
curl -OL https://huggingface.co/pfunk/CartPole-v1-DQPN_decay-seed3/raw/main/poetry.lock
poetry install --all-extras
python dqpn_decay.py --exp-name DQPN_decay --seed 3 --track --wandb-entity pfunk --wandb-project-name dqpn --capture-video true --save-model true --upload-model true --hf-entity pfunk
```
# Hyperparameters
```python
{'alg_type': 'dqpn_decay.py',
'batch_size': 256,
'buffer_size': 300000,
'capture_video': True,
'cuda': True,
'end_e': 0.1,
'end_policy_network_frequency': 200,
'env_id': 'CartPole-v1',
'evaluation_fraction': 0.7,
'exp_name': 'DQPN_decay',
'exploration_fraction': 0.2,
'gamma': 1.0,
'hf_entity': 'pfunk',
'learning_rate': 0.0001,
'learning_starts': 1000,
'policy_tau': 1.0,
'save_model': True,
'seed': 3,
'start_e': 1.0,
'start_policy_network_frequency': 10000,
'target_network_frequency': 20,
'target_tau': 1.0,
'torch_deterministic': True,
'total_timesteps': 500000,
'track': True,
'train_frequency': 1,
'upload_model': True,
'wandb_entity': 'pfunk',
'wandb_project_name': 'dqpn'}
```
|
Andrey78/my_nlp_test_model
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
language: en
thumbnail: http://www.huggingtweets.com/barackobama-joebiden-realdonaldtrump/1678850778048/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/874276197357596672/kUuht00m_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1308769664240160770/AfgzWVE7_400x400.jpg')">
</div>
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1329647526807543809/2SGvnHYV_400x400.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI CYBORG 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Donald J. Trump & Joe Biden & Barack Obama</div>
<div style="text-align: center; font-size: 14px;">@barackobama-joebiden-realdonaldtrump</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Donald J. Trump & Joe Biden & Barack Obama.
| Data | Donald J. Trump | Joe Biden | Barack Obama |
| --- | --- | --- | --- |
| Tweets downloaded | 3173 | 3250 | 3250 |
| Retweets | 1077 | 661 | 321 |
| Short tweets | 519 | 26 | 19 |
| Tweets kept | 1577 | 2563 | 2910 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/br58nwn1/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @barackobama-joebiden-realdonaldtrump's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/13j83o80) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/13j83o80/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/barackobama-joebiden-realdonaldtrump')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
Andrianos/bert-base-greek-punctuation-prediction-finetuned
|
[
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
license: mit
datasets:
- koliskos/fake_news
language:
- en
---
# Model Card for Model ID
Model is used to detect whether a news story is fake or legitimate.
- **Developed by:** koliskos
- **Model type:** Text Classification
- **Language(s) (NLP):** English
- **License:** mit
- **Finetuned from model:** DistilBERT
- **Repository:** koliskos/fine_tuned_fake_news_classifier
## Uses
This model is meant to classify news articles as real or fake.
## Bias, Risks, and Limitations
This model could potentially assume "fake" to be the default
prediction for news stories that contain names that are seen
heavily within fake news articles, ex: a news story about someone
named Hillary may be labeled fake even if it is real because the
name Hillary is heavily grounded within the context of Hillary Clinton.
## Model Card Contact
spkolisko "at" wellesley.edu
|
AnonymousSub/AR_consert
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: cc-by-nc-4.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: videomae-base-finetuned-RealLifeViolenceSituations-subset
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# videomae-base-finetuned-RealLifeViolenceSituations-subset
This model is a fine-tuned version of [MCG-NJU/videomae-base](https://huggingface.co/MCG-NJU/videomae-base) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1618
- Accuracy: 0.9533
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- training_steps: 800
### Training results
| Training Loss | Epoch | Step | Accuracy | Validation Loss |
|:-------------:|:-----:|:----:|:--------:|:---------------:|
| 0.1065 | 0.25 | 200 | 0.9598 | 0.1470 |
| 0.067 | 1.25 | 400 | 0.9625 | 0.1415 |
| 0.0058 | 2.25 | 600 | 0.9625 | 0.1415 |
| 0.0274 | 3.25 | 800 | 0.9625 | 0.1415 |
| 0.0274 | 1.0 | 801 | 0.1411 | 0.9626 |
### Framework versions
- Transformers 4.27.2
- Pytorch 1.13.1
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/AR_rule_based_roberta_twostagetriplet_epochs_1_shard_1
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | 2023-03-15T05:40:28Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: gpt2-confluence
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-confluence
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/AR_rule_based_roberta_twostagetriplet_epochs_1_shard_10
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: cc-by-4.0
tags:
- generated_from_trainer
model-index:
- name: xlm-roberta-clickbait-spoiling-2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-clickbait-spoiling-2
This model is a fine-tuned version of [deepset/xlm-roberta-base-squad2](https://huggingface.co/deepset/xlm-roberta-base-squad2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7918
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| No log | 1.0 | 400 | 2.7691 |
| 3.0496 | 2.0 | 800 | 2.7095 |
| 2.4457 | 3.0 | 1200 | 2.7918 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/SR_declutr
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imdb
metrics:
- accuracy
model-index:
- name: my_awesome_model
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: imdb
type: imdb
config: plain_text
split: test
args: plain_text
metrics:
- name: Accuracy
type: accuracy
value: 0.93052
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_awesome_model
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the imdb dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2372
- Accuracy: 0.9305
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2346 | 1.0 | 1563 | 0.1895 | 0.9280 |
| 0.1531 | 2.0 | 3126 | 0.2372 | 0.9305 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/SR_rule_based_bert_quadruplet_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
---
license: mit
---
Pretrained models of our method **DirectMHP**
Title: *DirectMHP: Direct 2D Multi-Person Head Pose Estimation with Full-range Angles*
Paper link: https://arxiv.org/abs/2302.01110
Code link: https://github.com/hnuzhy/DirectMHP
# Mulit-Person Head Pose Estimation Task (trained on CMU-HPE)
* DirectMHP-S --> [cmu_s_1280_e200_t40_lw010_best.pt](./cmu_s_1280_e200_t40_lw010_best.pt)
* DirectMHP-M --> [cmu_m_1280_e200_t40_lw010_best.pt](./cmu_m_1280_e200_t40_lw010_best.pt)
# Mulit-Person Head Pose Estimation Task (trained on AGORA-HPE)
* DirectMHP-S --> [agora_s_1280_e300_t40_lw010_best.pt](./agora_s_1280_e300_t40_lw010_best.pt)
* DirectMHP-M --> [agora_m_1280_e300_t40_lw010_best.pt](./agora_m_1280_e300_t40_lw010_best.pt)
# Single HPE datasets with YOLOv5+COCO format
* Resorted images used in our DirectMHP: [300W-LP.zip](./300W_LP.zip), [AFLW2000.zip](./AFLW2000.zip) and [BIWI_test.zip](./BIWI_test.zip).
* Resorted corresponding json files: [train_300W_LP.json](./train_300W_LP.json), [val_AFLW2000.json](./val_AFLW2000.json) and [BIWI_test.json](./BIWI_test.json).
# Single HPE Task Pretrained on WiderFace and Finetuning on 300W-LP
* DirectMHP-S --> [300wlp_s_512_e50_finetune_best.pt](./300wlp_s_512_e50_finetune_best.pt)
* DirectMHP-M --> [300wlp_m_512_e50_finetune_best.pt](./300wlp_m_512_e50_finetune_best.pt)
# Single HPE SixDRepNet Re-trained on AGORA-HPE and CMU-HPE
* AGORA-HPE --> [SixDRepNet_AGORA_bs256_e100_epoch_last.pth](./SixDRepNet_AGORA_bs256_e100_epoch_last.pth)
* CMU-HPE --> [SixDRepNet_CMU_bs256_e100_epoch_last.pth](./SixDRepNet_CMU_bs256_e100_epoch_last.pth)
|
AnonymousSub/SR_rule_based_hier_quadruplet_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | 2023-03-15T06:30:59Z |
---
license: mit
language:
- en
---
# BERT-Tiny (uncased)
This is the smallest version of 24 smaller BERT models (English only, uncased, trained with WordPiece masking)
released by [google-research/bert](https://github.com/google-research/bert).
These BERT models was released as TensorFlow checkpoints, however, this is the converted version to PyTorch.
More information can be found in [google-research/bert](https://github.com/google-research/bert) or [lyeoni/convert-tf-to-pytorch](https://github.com/lyeoni/convert-tf-to-pytorch).
## Evaluation
Here are the evaluation scores (F1/Accuracy) for the MPRC task.
|Model|MRPC|
|-|:-:|
|BERT-Tiny|81.22/68.38|
|BERT-Mini|81.43/69.36|
|BERT-Small|81.41/70.34|
|BERT-Medium|83.33/73.53|
|BERT-Base|85.62/78.19|
### References
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
|
AnonymousSub/SR_rule_based_hier_triplet_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | 2023-03-15T06:33:28Z |
---
language:
- en
datasets:
- en_core_web_sm
thumbnail: >-
https://huggingface.co/giovannefeitosa/chatbot-about-pele/raw/main/images/pele.jpeg
tags:
- question-answering
- chatbot
- brazil
license: cc-by-nc-4.0
pipeline_tag: text2text-generation
library_name: sklearn
---
# Chatbot about Pele
This is demo project.
> library_name: sklearn
|
AnonymousSub/SR_rule_based_roberta_hier_triplet_epochs_1_shard_10
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
---
license: mit
language:
- ko
---
# Kconvo-roberta: Korean conversation RoBERTa ([github](https://github.com/HeoTaksung/Domain-Robust-Retraining-of-Pretrained-Language-Model))
- There are many PLMs (Pretrained Language Models) for Korean, but most of them are trained with written language.
- Here, we introduce a retrained PLM for prediction of Korean conversation data where we use verbal data for training.
## Usage
```python
# Kconvo-roberta
from transformers import RobertaTokenizerFast, RobertaModel
tokenizer_roberta = RobertaTokenizerFast.from_pretrained("yeongjoon/Kconvo-roberta")
model_roberta = RobertaModel.from_pretrained("yeongjoon/Kconvo-roberta")
```
-----------------
## Domain Robust Retraining of Pretrained Language Model
- Kconvo-roberta uses [klue/roberta-base](https://huggingface.co/klue/roberta-base) as the base model and retrained additionaly with the conversation dataset.
- The retrained dataset was collected through the [National Institute of the Korean Language](https://corpus.korean.go.kr/request/corpusRegist.do) and [AI-Hub](https://www.aihub.or.kr/aihubdata/data/list.do?pageIndex=1&currMenu=115&topMenu=100&dataSetSn=&srchdataClCode=DATACL001&srchOrder=&SrchdataClCode=DATACL002&searchKeyword=&srchDataRealmCode=REALM002&srchDataTy=DATA003), and the collected dataset is as follows.
```
- National Institute of the Korean Language
* 온라인 대화 말뭉치 2021
* 일상 대화 말뭉치 2020
* 구어 말뭉치
* 메신저 말뭉치
- AI-Hub
* 온라인 구어체 말뭉치 데이터
* 상담 음성
* 한국어 음성
* 자유대화 음성(일반남여)
* 일상생활 및 구어체 한-영 번역 병렬 말뭉치 데이터
* 한국인 대화음성
* 감성 대화 말뭉치
* 주제별 텍스트 일상 대화 데이터
* 용도별 목적대화 데이터
* 한국어 SNS
```
|
AnonymousSub/SR_rule_based_roberta_hier_triplet_epochs_1_shard_1_wikiqa_copy
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 1369 with parameters:
```
{'batch_size': 64, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 136,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 384, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Normalize()
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
AnonymousSub/SR_rule_based_roberta_only_classfn_epochs_1_shard_1
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: indonesian_financial_sentiment_analysis
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indonesian_financial_sentiment_analysis
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1788
- Accuracy: 0.9560
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 102 | 0.1650 | 0.9396 |
| No log | 2.0 | 204 | 0.1788 | 0.9560 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/bert_hier_diff_equal_wts_epochs_1_shard_10
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Huggy
library_name: ml-agents
---
# **ppo** Agent playing **Huggy**
This is a trained model of a **ppo** agent playing **Huggy** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Huggy
2. Step 1: Write your model_id: Perse90/ppo-Huggy
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
AnonymousSub/bert_mean_diff_epochs_1_shard_1
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | 2023-03-15T07:54:09Z |
---
library_name: keras
license: apache-2.0
datasets:
- kailashsp/class-images
pipeline_tag: text-to-image
---
## Model description
This is a Stable Diffusion model fine-tuned using Dreambooth on pokemon
to get cuter pokemons
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
| Hyperparameters | Value |
| :-- | :-- |
| inner_optimizer.class_name | Custom>RMSprop |
| inner_optimizer.config.name | RMSprop |
| inner_optimizer.config.weight_decay | None |
| inner_optimizer.config.clipnorm | None |
| inner_optimizer.config.global_clipnorm | None |
| inner_optimizer.config.clipvalue | None |
| inner_optimizer.config.use_ema | False |
| inner_optimizer.config.ema_momentum | 0.99 |
| inner_optimizer.config.ema_overwrite_frequency | 100 |
| inner_optimizer.config.jit_compile | True |
| inner_optimizer.config.is_legacy_optimizer | False |
| inner_optimizer.config.learning_rate | 0.0010000000474974513 |
| inner_optimizer.config.rho | 0.9 |
| inner_optimizer.config.momentum | 0.0 |
| inner_optimizer.config.epsilon | 1e-07 |
| inner_optimizer.config.centered | False |
| dynamic | True |
| initial_scale | 32768.0 |
| dynamic_growth_steps | 2000 |
| training_precision | mixed_float16 |
## Model Plot
<details>
<summary>View Model Plot</summary>

</details>
|
AnonymousSub/bert_mean_diff_epochs_1_shard_10
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | 2023-03-15T07:55:32Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-finetuned-cryptos
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-cryptos
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8215
- Accuracy: 0.7346
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 65 | 0.7617 | 0.6923 |
| No log | 2.0 | 130 | 0.7784 | 0.7269 |
| No log | 3.0 | 195 | 0.8215 | 0.7346 |
### Framework versions
- Transformers 4.27.4
- Pytorch 2.0.0+cu118
- Datasets 2.11.0
- Tokenizers 0.13.2
|
AnonymousSub/bert_triplet_epochs_1_shard_10
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | null |
---
license: mit
language:
- en
---
# BERT-Medium (uncased)
This is one of 24 smaller BERT models (English only, uncased, trained with WordPiece masking)
released by [google-research/bert](https://github.com/google-research/bert).
These BERT models was released as TensorFlow checkpoints, however, this is the converted version to PyTorch.
More information can be found in [google-research/bert](https://github.com/google-research/bert) or [lyeoni/convert-tf-to-pytorch](https://github.com/lyeoni/convert-tf-to-pytorch).
## Evaluation
Here are the evaluation scores (F1/Accuracy) for the MPRC task.
|Model|MRPC|
|-|:-:|
|BERT-Tiny|81.22/68.38|
|BERT-Mini|81.43/69.36|
|BERT-Small|81.41/70.34|
|BERT-Medium|83.33/73.53|
|BERT-Base|85.62/78.19|
### References
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
|
AnonymousSub/cline-emanuals-s10-AR
|
[
"pytorch",
"roberta",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 27 | null |
---
# For reference on model card metadata, see the spec: https://github.com/huggingface/hub-docs/blob/main/modelcard.md?plain=1
# Doc / guide: https://huggingface.co/docs/hub/model-cards
{}
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
### How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Data Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Data Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
AnonymousSub/cline-s10-AR
|
[
"pytorch",
"roberta",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 31 | 2023-03-15T08:05:48Z |
---
license: mit
language:
- en
---
# BERT-Small (uncased)
This is one of 24 smaller BERT models (English only, uncased, trained with WordPiece masking)
released by [google-research/bert](https://github.com/google-research/bert).
These BERT models was released as TensorFlow checkpoints, however, this is the converted version to PyTorch.
More information can be found in [google-research/bert](https://github.com/google-research/bert) or [lyeoni/convert-tf-to-pytorch](https://github.com/lyeoni/convert-tf-to-pytorch).
## Evaluation
Here are the evaluation scores (F1/Accuracy) for the MPRC task.
|Model|MRPC|
|-|:-:|
|BERT-Tiny|81.22/68.38|
|BERT-Mini|81.43/69.36|
|BERT-Small|81.41/70.34|
|BERT-Medium|83.33/73.53|
|BERT-Base|85.62/78.19|
### References
```
@article{turc2019,
title={Well-Read Students Learn Better: On the Importance of Pre-training Compact Models},
author={Turc, Iulia and Chang, Ming-Wei and Lee, Kenton and Toutanova, Kristina},
journal={arXiv preprint arXiv:1908.08962v2 },
year={2019}
}
```
|
AnonymousSub/cline-s10-SR
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T08:07:57Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 274.94 +/- 17.93
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AnonymousSub/cline
|
[
"pytorch",
"roberta",
"transformers"
] | null |
{
"architectures": [
"LecbertForPreTraining"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | null |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: T5_Translation_ko_jp
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# KoT5_Translate_ko_jp
This model is a fine-tuned version of [KETI-AIR/ke-t5-base](https://huggingface.co/KETI-AIR/ke-t5-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3331
- Bleu: 44.5463
## Model description
한국어-일본어 번역기 모델을 위해서 만들었습니다.
KETI-AIR님이 공유해주신 ke-t5-base에 Text2Text Task로 한국어-일본어 Translate를 위해서 Fine-Tuning 진행한 모델입니다.
## Training and evaluation data
[noahkim/Kor_Jpn_Translation_Dataset](https://huggingface.co/datasets/noahkim/Kor_Jpn_Translation_Dataset)
제가 AIHub에서 다운 받아 허깅페이스에 공유한 한국어-일본어 문화 분야 이중 말뭉치를 Fine-Tuning 데이터셋으로 활용했습니다.
## Supported Tasks and Leaderboards
Translation
## Languages
Kor
Jpan
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 64
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 3.8739 | 0.08 | 500 | 1.7216 | 3.3261 |
| 1.2621 | 0.15 | 1000 | 0.6792 | 28.6184 |
| 0.7413 | 0.23 | 1500 | 0.5153 | 35.9355 |
| 0.635 | 0.3 | 2000 | 0.4807 | 38.4874 |
| 0.5643 | 0.38 | 2500 | 0.4322 | 40.7997 |
| 0.5137 | 0.46 | 3000 | 0.4027 | 41.9025 |
| 0.4806 | 0.53 | 3500 | 0.3862 | 42.5947 |
| 0.4552 | 0.61 | 4000 | 0.3721 | 42.9976 |
| 0.4395 | 0.69 | 4500 | 0.3585 | 43.5369 |
| 0.4213 | 0.76 | 5000 | 0.3487 | 44.0028 |
| 0.411 | 0.84 | 5500 | 0.3418 | 44.1845 |
| 0.3992 | 0.91 | 6000 | 0.3348 | 44.3701 |
| 0.3966 | 0.99 | 6500 | 0.3331 | 44.5463 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/cline_emanuals
|
[
"pytorch",
"roberta",
"transformers"
] | null |
{
"architectures": [
"LecbertForPreTraining"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
---
license: creativeml-openrail-m
datasets:
- Duskfallcrew/FFXIV_Data_and_Lora
- Duskfallcrew/miqoteupdate
language:
- en
tags:
- Lycoris
- LoHA
- Lora
- stable diffusion
- text to image
- ffxiv
- miqote
---
Output udpates coming soon, we have some but if you need to see them before we put them here- we have the models up on Civit:
https://civitai.com/models/14823
Data sets listed because one is private - this was because the LoRA trainer had a subject option to upload data to here but i forgot we did it already .
Data set here: https://huggingface.co/datasets/Duskfallcrew/FFXIV_Data_and_Lora
Also noted: The MIQOTE UPDATE LoRA is a LYCORIS/LoHA and needs the special A1111 plugin: https://github.com/KohakuBlueleaf/a1111-sd-webui-locon
|
AnonymousSub/consert-emanuals-s10-SR
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 29 | null |
---
license: mit
tags:
- pytorch
- diffusers
- unconditional-image-generation
- diffusion-models-class
---
# Model Card for Unit 1 of the [Diffusion Models Class 🧨](https://github.com/huggingface/diffusion-models-class)
This model is a diffusion model for unconditional image generation of cute 🦋.
## Usage
```python
from diffusers import DDPMPipeline
pipeline = DDPMPipeline.from_pretrained('darren-01/sd-class-butterflies-32')
image = pipeline().images[0]
image
```
|
AnonymousSub/consert-s10-AR
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 31 | null |
---
library_name: stable-baselines3
tags:
- Taxi-v3
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: -200.00 +/- 0.00
name: mean_reward
verified: false
---
# **DQN** Agent playing **Taxi-v3**
This is a trained model of a **DQN** agent playing **Taxi-v3**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
AnonymousSub/declutr-emanuals-techqa
|
[
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | 2023-03-15T08:25:26Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: generative_reader_nq_squad_v2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# generative_reader_nq_squad_v2
This model is a fine-tuned version of [Atnafu/mt5-base-squad2-fin](https://huggingface.co/Atnafu/mt5-base-squad2-fin) on the squad_v2 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5.0
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/declutr-model
|
[
"pytorch",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | 2023-03-15T08:26:35Z |
# ■hakoA & hakoB




I conducted custom fine-tuning on wd15-beta2-aesthetic, which is based on the SD2.1 architecture, available at https://huggingface.co/waifu-diffusion/wd-1-5-beta2.
SD2.1系であるwd15-beta2-aesthetic
https://huggingface.co/waifu-diffusion/wd-1-5-beta2
に対して独自の追加学習を行いました。
# ■Setting
It is recommended to use "(anime:1.2)" as the prompt and "nsfw,messy,blush,nfixer" as the negative prompt. If the output is not at least 768 pixels on the shorter side, there is a possibility that the facial features may be distorted.
"(anime:1.2)" creates a flat, anime-like image style.
promptには「(anime:1.2)」
negative promptには「nsfw,messy,blush,nfixer」
を入れることをおすすめします。
「(anime:1.2)」はフラットなアニメ調のイメージになります。
短辺が768px以上での出力でない場合、顔の描画が崩れる可能性があります。
# ■Licence
Model hakoA and hakoB are released under the Fair AI Public License 1.0-SD. Please refer to the following link for the license terms: https://freedevproject.org/faipl-1.0-sd/
hakoA、hakoBはFair AI Public License 1.0-SDのライセンス下での公開です。
下記ライセンス内容を確認ください。
https://freedevproject.org/faipl-1.0-sd/

```
(anime:1.2),(hyper extreme detailed:1.0),amazing quality,Beautiful Illustration,1girl,breasts,maid_apron,happy smile,cafe with waitresses dressed in cute maid costumes
Negative prompt: nsfw,messy,blush,nfixer,
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 7, Seed: 1386462091, Size: 768x1152
```

```
(anime:1.2),( stylish pose:1.1), (smile:1), (king (throne:1.1) :1.3),
Negative prompt: nsfw,messy,blush,nfixer,
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2137539252, Size: 768x1152
```

```
(anime:1.2),(masterpiece:1.2), (high quality:1.2), (watercolor painting:1.1),anatomy,1 girl,solo,(cowboy shot:1.1), perfect face,18yo,(from front),school girl,
black hair,black cardigan,ribbon,(white hat:1.1),closed eyes,arms behind back,tree,calm,(darkness lighting:1.4),(night:1.4),
standing ,kawaii face, depth of field
Negative prompt: nsfw,messy,blush,nfixer,
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 260664233, Size: 768x1152
```

```
(anime:1.2),(1girl, 12yo, flat:1.2)white dress outdoor
Negative prompt: nsfw,messy,blush,nfixer,
Steps: 28, Sampler: DPM++ SDE Karras, CFG scale: 5, Seed: 2617311573, Size: 768x1152
```
|
AnonymousSub/rule_based_bert_quadruplet_epochs_1_shard_10
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | 2023-03-15T08:58:08Z |
---
tags:
- autotrain
- vision
- image-classification
datasets:
- mouss/autotrain-data-bikes_1
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace
co2_eq_emissions:
emissions: 0.41665410499999395
---
# Model Trained Using AutoTrain
- Problem type: Binary Classification
- Model ID: 41171106189
- CO2 Emissions (in grams): 0.4167
## Validation Metrics
- Loss: 0.368
- Accuracy: 0.818
- Precision: 0.882
- Recall: 0.789
- AUC: 0.921
- F1: 0.833
|
AnonymousSub/rule_based_hier_triplet_0.1_epochs_1_shard_1_squad2.0
|
[
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | 2023-03-15T09:32:36Z |
1 OneCount: 8619 -- Precision: 0.875624
0 ZeroCount: 345 -- Precision: 0.785507
|
AnonymousSub/rule_based_roberta_bert_triplet_epochs_1_shard_1_wikiqa_copy
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | 2023-03-15T10:11:15Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: distilgpt2-finetuned-wikitext2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilgpt2-finetuned-wikitext2
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.4740
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 4.0767 | 1.0 | 794 | 3.7406 |
| 3.8158 | 2.0 | 1588 | 3.6718 |
| 3.7557 | 3.0 | 2382 | 3.6302 |
| 3.6758 | 4.0 | 3176 | 3.5968 |
| 3.6383 | 5.0 | 3970 | 3.5704 |
| 3.5762 | 6.0 | 4764 | 3.5524 |
| 3.5415 | 7.0 | 5558 | 3.5360 |
| 3.5116 | 8.0 | 6352 | 3.5195 |
| 3.485 | 9.0 | 7146 | 3.5116 |
| 3.4587 | 10.0 | 7940 | 3.5033 |
| 3.429 | 11.0 | 8734 | 3.4950 |
| 3.4179 | 12.0 | 9528 | 3.4882 |
| 3.3985 | 13.0 | 10322 | 3.4845 |
| 3.3812 | 14.0 | 11116 | 3.4825 |
| 3.3671 | 15.0 | 11910 | 3.4795 |
| 3.3547 | 16.0 | 12704 | 3.4751 |
| 3.3472 | 17.0 | 13498 | 3.4744 |
| 3.3393 | 18.0 | 14292 | 3.4743 |
| 3.3334 | 19.0 | 15086 | 3.4740 |
| 3.3309 | 20.0 | 15880 | 3.4740 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/rule_based_roberta_hier_quadruplet_0.1_epochs_1_shard_1
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | 2023-03-15T10:13:18Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 521.50 +/- 219.83
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Christian90 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga Christian90 -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga Christian90
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
AnonymousSub/rule_based_roberta_hier_quadruplet_epochs_1_shard_10
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | 2023-03-15T10:14:42Z |
# Vocabulary Trimmed [lmqg/mt5-small-koquad-qg](https://huggingface.co/lmqg/mt5-small-koquad-qg): `vocabtrimmer/mt5-small-koquad-qg-trimmed-ko-5000`
This model is a trimmed version of [lmqg/mt5-small-koquad-qg](https://huggingface.co/lmqg/mt5-small-koquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-koquad-qg | vocabtrimmer/mt5-small-koquad-qg-trimmed-ko-5000 |
|:---------------------------|:---------------------------|:---------------------------------------------------|
| parameter_size_full | 300,165,504 | 49,184,128 |
| parameter_size_embedding | 256,103,424 | 5,122,048 |
| vocab_size | 250,101 | 5,002 |
| compression_rate_full | 100.0 | 16.39 |
| compression_rate_embedding | 100.0 | 2.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ko | vocabtrimmer/mc4_validation | text | ko | validation | 5000 | 2 |
|
AnonymousSub/rule_based_roberta_hier_quadruplet_epochs_1_shard_1_squad2.0
|
[
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | 2023-03-15T10:14:49Z |
# Vocabulary Trimmed [lmqg/mt5-small-ruquad-qg](https://huggingface.co/lmqg/mt5-small-ruquad-qg): `vocabtrimmer/mt5-small-ruquad-qg-trimmed-ru-5000`
This model is a trimmed version of [lmqg/mt5-small-ruquad-qg](https://huggingface.co/lmqg/mt5-small-ruquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-ruquad-qg | vocabtrimmer/mt5-small-ruquad-qg-trimmed-ru-5000 |
|:---------------------------|:---------------------------|:---------------------------------------------------|
| parameter_size_full | 300,165,504 | 49,185,152 |
| parameter_size_embedding | 256,103,424 | 5,123,072 |
| vocab_size | 250,101 | 5,003 |
| compression_rate_full | 100.0 | 16.39 |
| compression_rate_embedding | 100.0 | 2.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ru | vocabtrimmer/mc4_validation | text | ru | validation | 5000 | 2 |
|
AnonymousSub/rule_based_roberta_hier_quadruplet_epochs_1_shard_1_wikiqa
|
[
"pytorch",
"roberta",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 24 | 2023-03-15T10:15:01Z |
# Vocabulary Trimmed [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg): `vocabtrimmer/mt5-small-esquad-qg-trimmed-es-5000`
This model is a trimmed version of [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-esquad-qg | vocabtrimmer/mt5-small-esquad-qg-trimmed-es-5000 |
|:---------------------------|:---------------------------|:---------------------------------------------------|
| parameter_size_full | 300,165,504 | 49,185,152 |
| parameter_size_embedding | 256,103,424 | 5,123,072 |
| vocab_size | 250,101 | 5,003 |
| compression_rate_full | 100.0 | 16.39 |
| compression_rate_embedding | 100.0 | 2.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| es | vocabtrimmer/mc4_validation | text | es | validation | 5000 | 2 |
|
AnonymousSub/rule_based_roberta_hier_triplet_0.1_epochs_1_shard_1
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | 2023-03-15T10:15:02Z |
# Vocabulary Trimmed [lmqg/mt5-small-frquad-qg](https://huggingface.co/lmqg/mt5-small-frquad-qg): `vocabtrimmer/mt5-small-frquad-qg-trimmed-fr-5000`
This model is a trimmed version of [lmqg/mt5-small-frquad-qg](https://huggingface.co/lmqg/mt5-small-frquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-frquad-qg | vocabtrimmer/mt5-small-frquad-qg-trimmed-fr-5000 |
|:---------------------------|:---------------------------|:---------------------------------------------------|
| parameter_size_full | 300,165,504 | 49,185,152 |
| parameter_size_embedding | 256,103,424 | 5,123,072 |
| vocab_size | 250,101 | 5,003 |
| compression_rate_full | 100.0 | 16.39 |
| compression_rate_embedding | 100.0 | 2.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| fr | vocabtrimmer/mc4_validation | text | fr | validation | 5000 | 2 |
|
AnonymousSub/rule_based_roberta_hier_triplet_0.1_epochs_1_shard_1_squad2.0
|
[
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | 2023-03-15T10:15:05Z |
# Vocabulary Trimmed [lmqg/mt5-small-itquad-qg](https://huggingface.co/lmqg/mt5-small-itquad-qg): `vocabtrimmer/mt5-small-itquad-qg-trimmed-it-5000`
This model is a trimmed version of [lmqg/mt5-small-itquad-qg](https://huggingface.co/lmqg/mt5-small-itquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-itquad-qg | vocabtrimmer/mt5-small-itquad-qg-trimmed-it-5000 |
|:---------------------------|:---------------------------|:---------------------------------------------------|
| parameter_size_full | 300,165,504 | 49,185,152 |
| parameter_size_embedding | 256,103,424 | 5,123,072 |
| vocab_size | 250,101 | 5,003 |
| compression_rate_full | 100.0 | 16.39 |
| compression_rate_embedding | 100.0 | 2.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| it | vocabtrimmer/mc4_validation | text | it | validation | 5000 | 2 |
|
AnonymousSub/rule_based_roberta_twostagetriplet_epochs_1_shard_1_squad2.0
|
[
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | 2023-03-15T10:30:23Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: clinico-roberta-biomedical-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clinico-roberta-biomedical-finetuned
This model is a fine-tuned version of [joheras/roberta-base-biomedical-clinical-es-finetuned-clinais](https://huggingface.co/joheras/roberta-base-biomedical-clinical-es-finetuned-clinais) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9272
- Precision: 0.5095
- Recall: 0.6463
- F1: 0.5698
- Accuracy: 0.8623
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 25 | 1.2199 | 0.0033 | 0.0053 | 0.0040 | 0.5756 |
| No log | 2.0 | 50 | 0.7306 | 0.2031 | 0.2642 | 0.2296 | 0.8021 |
| No log | 3.0 | 75 | 0.6366 | 0.2967 | 0.3811 | 0.3336 | 0.8235 |
| No log | 4.0 | 100 | 0.6135 | 0.3497 | 0.4653 | 0.3993 | 0.8304 |
| No log | 5.0 | 125 | 0.5845 | 0.3421 | 0.4537 | 0.3900 | 0.8331 |
| No log | 6.0 | 150 | 0.5697 | 0.3307 | 0.4421 | 0.3784 | 0.8390 |
| No log | 7.0 | 175 | 0.5415 | 0.3211 | 0.4495 | 0.3746 | 0.8471 |
| No log | 8.0 | 200 | 0.5430 | 0.3589 | 0.5179 | 0.4240 | 0.8567 |
| No log | 9.0 | 225 | 0.5513 | 0.3342 | 0.5474 | 0.4150 | 0.8604 |
| No log | 10.0 | 250 | 0.5681 | 0.3769 | 0.5768 | 0.4559 | 0.8582 |
| No log | 11.0 | 275 | 0.5813 | 0.3756 | 0.5863 | 0.4579 | 0.8553 |
| No log | 12.0 | 300 | 0.6096 | 0.4181 | 0.5968 | 0.4918 | 0.8574 |
| No log | 13.0 | 325 | 0.6318 | 0.3978 | 0.6042 | 0.4797 | 0.8539 |
| No log | 14.0 | 350 | 0.6309 | 0.3892 | 0.5968 | 0.4711 | 0.8553 |
| No log | 15.0 | 375 | 0.6559 | 0.3987 | 0.5968 | 0.4781 | 0.8565 |
| No log | 16.0 | 400 | 0.6391 | 0.4275 | 0.6021 | 0.5 | 0.8560 |
| No log | 17.0 | 425 | 0.6812 | 0.4388 | 0.6074 | 0.5095 | 0.8584 |
| No log | 18.0 | 450 | 0.6901 | 0.4287 | 0.6137 | 0.5048 | 0.8563 |
| No log | 19.0 | 475 | 0.6834 | 0.4572 | 0.6074 | 0.5217 | 0.8581 |
| 0.3478 | 20.0 | 500 | 0.7050 | 0.4397 | 0.6179 | 0.5138 | 0.8573 |
| 0.3478 | 21.0 | 525 | 0.7004 | 0.4462 | 0.6242 | 0.5204 | 0.8591 |
| 0.3478 | 22.0 | 550 | 0.7038 | 0.4264 | 0.6126 | 0.5028 | 0.8599 |
| 0.3478 | 23.0 | 575 | 0.7384 | 0.4416 | 0.6284 | 0.5187 | 0.8576 |
| 0.3478 | 24.0 | 600 | 0.7197 | 0.4479 | 0.62 | 0.5201 | 0.8619 |
| 0.3478 | 25.0 | 625 | 0.7412 | 0.4381 | 0.6221 | 0.5141 | 0.8559 |
| 0.3478 | 26.0 | 650 | 0.7535 | 0.4489 | 0.6242 | 0.5222 | 0.8566 |
| 0.3478 | 27.0 | 675 | 0.7534 | 0.4657 | 0.6432 | 0.5402 | 0.8586 |
| 0.3478 | 28.0 | 700 | 0.7672 | 0.4525 | 0.6168 | 0.5220 | 0.8567 |
| 0.3478 | 29.0 | 725 | 0.7680 | 0.4637 | 0.6316 | 0.5348 | 0.8599 |
| 0.3478 | 30.0 | 750 | 0.7590 | 0.4611 | 0.6242 | 0.5304 | 0.8607 |
| 0.3478 | 31.0 | 775 | 0.7671 | 0.4732 | 0.6326 | 0.5414 | 0.8625 |
| 0.3478 | 32.0 | 800 | 0.7921 | 0.4674 | 0.6337 | 0.5380 | 0.8590 |
| 0.3478 | 33.0 | 825 | 0.8037 | 0.4828 | 0.6358 | 0.5488 | 0.8574 |
| 0.3478 | 34.0 | 850 | 0.8376 | 0.4644 | 0.6242 | 0.5326 | 0.8534 |
| 0.3478 | 35.0 | 875 | 0.8346 | 0.4815 | 0.6284 | 0.5452 | 0.8552 |
| 0.3478 | 36.0 | 900 | 0.8249 | 0.4750 | 0.6305 | 0.5418 | 0.8567 |
| 0.3478 | 37.0 | 925 | 0.8420 | 0.4580 | 0.6305 | 0.5306 | 0.8548 |
| 0.3478 | 38.0 | 950 | 0.8341 | 0.4773 | 0.6305 | 0.5433 | 0.8550 |
| 0.3478 | 39.0 | 975 | 0.8085 | 0.4792 | 0.6316 | 0.5450 | 0.8653 |
| 0.0274 | 40.0 | 1000 | 0.7954 | 0.4992 | 0.6474 | 0.5637 | 0.8651 |
| 0.0274 | 41.0 | 1025 | 0.8145 | 0.4923 | 0.6421 | 0.5573 | 0.8635 |
| 0.0274 | 42.0 | 1050 | 0.8290 | 0.4911 | 0.6368 | 0.5545 | 0.8610 |
| 0.0274 | 43.0 | 1075 | 0.8468 | 0.4821 | 0.6379 | 0.5492 | 0.8571 |
| 0.0274 | 44.0 | 1100 | 0.8274 | 0.4791 | 0.6389 | 0.5476 | 0.8625 |
| 0.0274 | 45.0 | 1125 | 0.8583 | 0.4831 | 0.6305 | 0.5470 | 0.8551 |
| 0.0274 | 46.0 | 1150 | 0.8420 | 0.4726 | 0.6347 | 0.5418 | 0.8589 |
| 0.0274 | 47.0 | 1175 | 0.8631 | 0.5029 | 0.64 | 0.5632 | 0.8564 |
| 0.0274 | 48.0 | 1200 | 0.8421 | 0.4911 | 0.64 | 0.5558 | 0.8617 |
| 0.0274 | 49.0 | 1225 | 0.8564 | 0.5071 | 0.6411 | 0.5662 | 0.8631 |
| 0.0274 | 50.0 | 1250 | 0.8659 | 0.4845 | 0.6263 | 0.5464 | 0.8603 |
| 0.0274 | 51.0 | 1275 | 0.8596 | 0.4860 | 0.64 | 0.5525 | 0.8632 |
| 0.0274 | 52.0 | 1300 | 0.8713 | 0.4856 | 0.6368 | 0.5510 | 0.8593 |
| 0.0274 | 53.0 | 1325 | 0.8888 | 0.4868 | 0.64 | 0.5530 | 0.8585 |
| 0.0274 | 54.0 | 1350 | 0.8591 | 0.4816 | 0.6337 | 0.5473 | 0.8610 |
| 0.0274 | 55.0 | 1375 | 0.8755 | 0.4996 | 0.64 | 0.5611 | 0.8615 |
| 0.0274 | 56.0 | 1400 | 0.8749 | 0.5095 | 0.6484 | 0.5706 | 0.8583 |
| 0.0274 | 57.0 | 1425 | 0.8867 | 0.5025 | 0.6453 | 0.5650 | 0.8580 |
| 0.0274 | 58.0 | 1450 | 0.8905 | 0.4947 | 0.6337 | 0.5556 | 0.8579 |
| 0.0274 | 59.0 | 1475 | 0.8911 | 0.4881 | 0.6495 | 0.5574 | 0.8596 |
| 0.0099 | 60.0 | 1500 | 0.9220 | 0.4914 | 0.6347 | 0.5540 | 0.8570 |
| 0.0099 | 61.0 | 1525 | 0.8687 | 0.4786 | 0.6368 | 0.5465 | 0.8594 |
| 0.0099 | 62.0 | 1550 | 0.9080 | 0.4906 | 0.6337 | 0.5531 | 0.8575 |
| 0.0099 | 63.0 | 1575 | 0.9004 | 0.4831 | 0.6337 | 0.5483 | 0.8583 |
| 0.0099 | 64.0 | 1600 | 0.8906 | 0.4778 | 0.6337 | 0.5448 | 0.8619 |
| 0.0099 | 65.0 | 1625 | 0.8870 | 0.4959 | 0.6368 | 0.5576 | 0.8618 |
| 0.0099 | 66.0 | 1650 | 0.8843 | 0.4851 | 0.6358 | 0.5503 | 0.8611 |
| 0.0099 | 67.0 | 1675 | 0.8923 | 0.4912 | 0.6453 | 0.5578 | 0.8618 |
| 0.0099 | 68.0 | 1700 | 0.8864 | 0.4898 | 0.6337 | 0.5525 | 0.8615 |
| 0.0099 | 69.0 | 1725 | 0.8974 | 0.4943 | 0.6411 | 0.5582 | 0.8615 |
| 0.0099 | 70.0 | 1750 | 0.8851 | 0.4821 | 0.6379 | 0.5492 | 0.8611 |
| 0.0099 | 71.0 | 1775 | 0.8958 | 0.4920 | 0.6453 | 0.5583 | 0.8593 |
| 0.0099 | 72.0 | 1800 | 0.8880 | 0.4988 | 0.6411 | 0.5610 | 0.8618 |
| 0.0099 | 73.0 | 1825 | 0.8959 | 0.4852 | 0.6379 | 0.5512 | 0.8606 |
| 0.0099 | 74.0 | 1850 | 0.9036 | 0.4773 | 0.6305 | 0.5433 | 0.8598 |
| 0.0099 | 75.0 | 1875 | 0.9031 | 0.4864 | 0.6389 | 0.5523 | 0.8615 |
| 0.0099 | 76.0 | 1900 | 0.9243 | 0.4907 | 0.6368 | 0.5543 | 0.8590 |
| 0.0099 | 77.0 | 1925 | 0.9285 | 0.4877 | 0.6453 | 0.5555 | 0.8590 |
| 0.0099 | 78.0 | 1950 | 0.9261 | 0.5074 | 0.6516 | 0.5705 | 0.8598 |
| 0.0099 | 79.0 | 1975 | 0.9374 | 0.5037 | 0.64 | 0.5637 | 0.8580 |
| 0.0061 | 80.0 | 2000 | 0.9165 | 0.5021 | 0.6316 | 0.5594 | 0.8621 |
| 0.0061 | 81.0 | 2025 | 0.9307 | 0.5162 | 0.6368 | 0.5702 | 0.8582 |
| 0.0061 | 82.0 | 2050 | 0.9369 | 0.4911 | 0.6358 | 0.5541 | 0.8574 |
| 0.0061 | 83.0 | 2075 | 0.9293 | 0.5191 | 0.6421 | 0.5741 | 0.8584 |
| 0.0061 | 84.0 | 2100 | 0.9187 | 0.5004 | 0.6453 | 0.5637 | 0.8629 |
| 0.0061 | 85.0 | 2125 | 0.9293 | 0.4927 | 0.6379 | 0.5560 | 0.8623 |
| 0.0061 | 86.0 | 2150 | 0.9200 | 0.5041 | 0.6453 | 0.5660 | 0.8634 |
| 0.0061 | 87.0 | 2175 | 0.9273 | 0.4992 | 0.6421 | 0.5617 | 0.8631 |
| 0.0061 | 88.0 | 2200 | 0.9325 | 0.5021 | 0.6442 | 0.5643 | 0.8623 |
| 0.0061 | 89.0 | 2225 | 0.9245 | 0.4844 | 0.6389 | 0.5511 | 0.8630 |
| 0.0061 | 90.0 | 2250 | 0.9291 | 0.4979 | 0.6368 | 0.5589 | 0.8593 |
| 0.0061 | 91.0 | 2275 | 0.9264 | 0.5083 | 0.6432 | 0.5678 | 0.8622 |
| 0.0061 | 92.0 | 2300 | 0.9283 | 0.5025 | 0.6411 | 0.5634 | 0.8619 |
| 0.0061 | 93.0 | 2325 | 0.9264 | 0.5008 | 0.6442 | 0.5635 | 0.8613 |
| 0.0061 | 94.0 | 2350 | 0.9205 | 0.5079 | 0.6463 | 0.5688 | 0.8626 |
| 0.0061 | 95.0 | 2375 | 0.9223 | 0.5121 | 0.6484 | 0.5722 | 0.8625 |
| 0.0061 | 96.0 | 2400 | 0.9244 | 0.5045 | 0.6421 | 0.5651 | 0.8620 |
| 0.0061 | 97.0 | 2425 | 0.9248 | 0.5062 | 0.6463 | 0.5677 | 0.8622 |
| 0.0061 | 98.0 | 2450 | 0.9277 | 0.5037 | 0.6453 | 0.5658 | 0.8621 |
| 0.0061 | 99.0 | 2475 | 0.9272 | 0.5083 | 0.6463 | 0.5690 | 0.8623 |
| 0.0046 | 100.0 | 2500 | 0.9272 | 0.5095 | 0.6463 | 0.5698 | 0.8623 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.0
- Datasets 2.8.0
- Tokenizers 0.12.1
|
AnonymousSub/rule_based_roberta_twostagetriplet_epochs_1_shard_1_wikiqa
|
[
"pytorch",
"roberta",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 24 | 2023-03-15T10:30:38Z |
# Vocabulary Trimmed [lmqg/mt5-small-ruquad-qg](https://huggingface.co/lmqg/mt5-small-ruquad-qg): `vocabtrimmer/mt5-small-ruquad-qg-trimmed-ru-10000`
This model is a trimmed version of [lmqg/mt5-small-ruquad-qg](https://huggingface.co/lmqg/mt5-small-ruquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-ruquad-qg | vocabtrimmer/mt5-small-ruquad-qg-trimmed-ru-10000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 54,305,152 |
| parameter_size_embedding | 256,103,424 | 10,243,072 |
| vocab_size | 250,101 | 10,003 |
| compression_rate_full | 100.0 | 18.09 |
| compression_rate_embedding | 100.0 | 4.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ru | vocabtrimmer/mc4_validation | text | ru | validation | 10000 | 2 |
|
AnonymousSub/rule_based_roberta_twostagetriplet_hier_epochs_1_shard_1
|
[
"pytorch",
"roberta",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"RobertaModel"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | 2023-03-15T10:31:35Z |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-ja-60000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-ja-60000 |
|:---------------------------|:-------------------|:------------------------------------------|
| parameter_size_full | 300,176,768 | 105,503,104 |
| parameter_size_embedding | 256,114,688 | 61,441,024 |
| vocab_size | 250,112 | 60,001 |
| compression_rate_full | 100.0 | 35.15 |
| compression_rate_embedding | 100.0 | 23.99 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ja | vocabtrimmer/mc4_validation | text | ja | validation | 60000 | 2 |
|
AnonymousSub/rule_based_twostagetriplet_epochs_1_shard_1_wikiqa
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 27 | 2023-03-15T10:34:22Z |
Universele Mark Rutte model.
Gebruik trigger mrkrut en je gezonde boerenverstand ;-)
Muppet prompt: (mrkrut) as a (muppet), vray renderer, highly detailed felt, hyper real photo realistic artstation cgsociety masterpiece
Seed:415127944
Resolutie: 512x768
Sampler: Euler
Steps: 50
GFC: 8.0
|
AnonymousSub/rule_based_twostagetriplet_hier_epochs_1_shard_1_wikiqa
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 27 | 2023-03-15T10:36:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- common_voice_11_0
metrics:
- wer
model-index:
- name: christoph-sl
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: common_voice_11_0
type: common_voice_11_0
config: sl
split: test
args: sl
metrics:
- name: Wer
type: wer
value: 20.06411190441498
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# christoph-sl
This model is a fine-tuned version of [openai/whisper-large](https://huggingface.co/openai/whisper-large) on the common_voice_11_0 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3313
- Wer: 20.0641
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:-------:|
| 0.0153 | 6.08 | 1000 | 0.2795 | 26.4607 |
| 0.0013 | 12.16 | 2000 | 0.3083 | 22.2352 |
| 0.0001 | 18.24 | 3000 | 0.3251 | 21.5066 |
| 0.0001 | 24.32 | 4000 | 0.3313 | 20.0641 |
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AnonymousSub/specter-bert-model_copy
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | 2023-03-15T10:36:53Z |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-ko-5000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-ko-5000 |
|:---------------------------|:-------------------|:-----------------------------------------|
| parameter_size_full | 300,176,768 | 49,183,104 |
| parameter_size_embedding | 256,114,688 | 5,121,024 |
| vocab_size | 250,112 | 5,001 |
| compression_rate_full | 100.0 | 16.38 |
| compression_rate_embedding | 100.0 | 2.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ko | vocabtrimmer/mc4_validation | text | ko | validation | 5000 | 2 |
|
AnonymousSub/specter-bert-model_copy_wikiqa
|
[
"pytorch",
"bert",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 26 | 2023-03-15T10:38:49Z |
# Vocabulary Trimmed [lmqg/mt5-small-jaquad-qg](https://huggingface.co/lmqg/mt5-small-jaquad-qg): `vocabtrimmer/mt5-small-jaquad-qg-trimmed-ja-15000`
This model is a trimmed version of [lmqg/mt5-small-jaquad-qg](https://huggingface.co/lmqg/mt5-small-jaquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-jaquad-qg | vocabtrimmer/mt5-small-jaquad-qg-trimmed-ja-15000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 59,424,128 |
| parameter_size_embedding | 256,103,424 | 15,362,048 |
| vocab_size | 250,101 | 15,002 |
| compression_rate_full | 100.0 | 19.8 |
| compression_rate_embedding | 100.0 | 6.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ja | vocabtrimmer/mc4_validation | text | ja | validation | 15000 | 2 |
|
AnonymousSub/specter-bert-model_squad2.0
|
[
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 1 | 2023-03-15T10:38:51Z |
# Vocabulary Trimmed [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg): `vocabtrimmer/mt5-small-esquad-qg-trimmed-es-10000`
This model is a trimmed version of [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-esquad-qg | vocabtrimmer/mt5-small-esquad-qg-trimmed-es-10000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 54,304,128 |
| parameter_size_embedding | 256,103,424 | 10,242,048 |
| vocab_size | 250,101 | 10,002 |
| compression_rate_full | 100.0 | 18.09 |
| compression_rate_embedding | 100.0 | 4.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| es | vocabtrimmer/mc4_validation | text | es | validation | 10000 | 2 |
|
AnonymousSub/unsup-consert-emanuals
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 2 | 2023-03-15T10:44:20Z |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-es-90000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-es-90000 |
|:---------------------------|:-------------------|:------------------------------------------|
| parameter_size_full | 300,176,768 | 136,223,104 |
| parameter_size_embedding | 256,114,688 | 92,161,024 |
| vocab_size | 250,112 | 90,001 |
| compression_rate_full | 100.0 | 45.38 |
| compression_rate_embedding | 100.0 | 35.98 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| es | vocabtrimmer/mc4_validation | text | es | validation | 90000 | 2 |
|
AnonymousSub/unsup-consert-papers-bert
|
[
"pytorch",
"bert",
"feature-extraction",
"transformers"
] |
feature-extraction
|
{
"architectures": [
"BertModel"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 9 | 2023-03-15T10:44:20Z |
# Vocabulary Trimmed [lmqg/mt5-small-itquad-qg](https://huggingface.co/lmqg/mt5-small-itquad-qg): `vocabtrimmer/mt5-small-itquad-qg-trimmed-it-15000`
This model is a trimmed version of [lmqg/mt5-small-itquad-qg](https://huggingface.co/lmqg/mt5-small-itquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-itquad-qg | vocabtrimmer/mt5-small-itquad-qg-trimmed-it-15000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 59,424,128 |
| parameter_size_embedding | 256,103,424 | 15,362,048 |
| vocab_size | 250,101 | 15,002 |
| compression_rate_full | 100.0 | 19.8 |
| compression_rate_embedding | 100.0 | 6.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| it | vocabtrimmer/mc4_validation | text | it | validation | 15000 | 2 |
|
Anonymreign/savagebeta
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T10:45:41Z |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-ko-30000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-ko-30000 |
|:---------------------------|:-------------------|:------------------------------------------|
| parameter_size_full | 300,176,768 | 74,783,104 |
| parameter_size_embedding | 256,114,688 | 30,721,024 |
| vocab_size | 250,112 | 30,001 |
| compression_rate_full | 100.0 | 24.91 |
| compression_rate_embedding | 100.0 | 12.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ko | vocabtrimmer/mc4_validation | text | ko | validation | 30000 | 2 |
|
Anorak/nirvana
|
[
"pytorch",
"pegasus",
"text2text-generation",
"unk",
"dataset:Anorak/autonlp-data-Niravana-test2",
"transformers",
"autonlp",
"co2_eq_emissions",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"PegasusForConditionalGeneration"
],
"model_type": "pegasus",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 7 | 2023-03-15T10:46:02Z |
# Vocabulary Trimmed [lmqg/mt5-small-ruquad-qg](https://huggingface.co/lmqg/mt5-small-ruquad-qg): `vocabtrimmer/mt5-small-ruquad-qg-trimmed-ru-15000`
This model is a trimmed version of [lmqg/mt5-small-ruquad-qg](https://huggingface.co/lmqg/mt5-small-ruquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-ruquad-qg | vocabtrimmer/mt5-small-ruquad-qg-trimmed-ru-15000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 59,424,128 |
| parameter_size_embedding | 256,103,424 | 15,362,048 |
| vocab_size | 250,101 | 15,002 |
| compression_rate_full | 100.0 | 19.8 |
| compression_rate_embedding | 100.0 | 6.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ru | vocabtrimmer/mc4_validation | text | ru | validation | 15000 | 2 |
|
Anthos23/distilbert-base-uncased-finetuned-sst2
|
[
"tf",
"tensorboard",
"distilbert",
"text-classification",
"transformers",
"generated_from_keras_callback",
"license:apache-2.0"
] |
text-classification
|
{
"architectures": [
"DistilBertForSequenceClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 21 | 2023-03-15T10:47:20Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1157.23 +/- 101.67
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Anthos23/my-awesome-model
|
[
"pytorch",
"tf",
"roberta",
"text-classification",
"transformers"
] |
text-classification
|
{
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 30 | 2023-03-15T10:47:33Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 14.93 +/- 4.97
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r yovchev/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
Antony/mint_model
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T10:51:21Z |
# Vocabulary Trimmed [lmqg/mt5-small-jaquad-qg](https://huggingface.co/lmqg/mt5-small-jaquad-qg): `vocabtrimmer/mt5-small-jaquad-qg-trimmed-ja-30000`
This model is a trimmed version of [lmqg/mt5-small-jaquad-qg](https://huggingface.co/lmqg/mt5-small-jaquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-jaquad-qg | vocabtrimmer/mt5-small-jaquad-qg-trimmed-ja-30000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 74,784,128 |
| parameter_size_embedding | 256,103,424 | 30,722,048 |
| vocab_size | 250,101 | 30,002 |
| compression_rate_full | 100.0 | 24.91 |
| compression_rate_embedding | 100.0 | 12.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ja | vocabtrimmer/mc4_validation | text | ja | validation | 30000 | 2 |
|
gaurishhs/API
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T10:54:44Z |
# Vocabulary Trimmed [lmqg/mt5-small-frquad-qg](https://huggingface.co/lmqg/mt5-small-frquad-qg): `vocabtrimmer/mt5-small-frquad-qg-trimmed-fr-60000`
This model is a trimmed version of [lmqg/mt5-small-frquad-qg](https://huggingface.co/lmqg/mt5-small-frquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-frquad-qg | vocabtrimmer/mt5-small-frquad-qg-trimmed-fr-60000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 105,504,128 |
| parameter_size_embedding | 256,103,424 | 61,442,048 |
| vocab_size | 250,101 | 60,002 |
| compression_rate_full | 100.0 | 35.15 |
| compression_rate_embedding | 100.0 | 23.99 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| fr | vocabtrimmer/mc4_validation | text | fr | validation | 60000 | 2 |
|
ArBert/albert-base-v2-finetuned-ner-agglo
|
[
"pytorch",
"tensorboard",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | 2023-03-15T11:01:04Z |
# Vocabulary Trimmed [lmqg/mt5-small-koquad-qg](https://huggingface.co/lmqg/mt5-small-koquad-qg): `vocabtrimmer/mt5-small-koquad-qg-trimmed-ko-30000`
This model is a trimmed version of [lmqg/mt5-small-koquad-qg](https://huggingface.co/lmqg/mt5-small-koquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-koquad-qg | vocabtrimmer/mt5-small-koquad-qg-trimmed-ko-30000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 74,784,128 |
| parameter_size_embedding | 256,103,424 | 30,722,048 |
| vocab_size | 250,101 | 30,002 |
| compression_rate_full | 100.0 | 24.91 |
| compression_rate_embedding | 100.0 | 12.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ko | vocabtrimmer/mc4_validation | text | ko | validation | 30000 | 2 |
|
ArBert/albert-base-v2-finetuned-ner-kmeans
|
[
"pytorch",
"tensorboard",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | 2023-03-15T11:03:48Z |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-ja-120000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-ja-120000 |
|:---------------------------|:-------------------|:-------------------------------------------|
| parameter_size_full | 300,176,768 | 166,943,104 |
| parameter_size_embedding | 256,114,688 | 122,881,024 |
| vocab_size | 250,112 | 120,001 |
| compression_rate_full | 100.0 | 55.61 |
| compression_rate_embedding | 100.0 | 47.98 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ja | vocabtrimmer/mc4_validation | text | ja | validation | 120000 | 2 |
|
ArBert/albert-base-v2-finetuned-ner
|
[
"pytorch",
"tensorboard",
"albert",
"token-classification",
"dataset:conll2003",
"transformers",
"generated_from_trainer",
"license:apache-2.0",
"model-index",
"autotrain_compatible"
] |
token-classification
|
{
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 19 | 2023-03-15T11:04:45Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: xlm-roberta-large-TASTESet-ner
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# xlm-roberta-large-TASTESet-ner
This model is a fine-tuned version of [xlm-roberta-large](https://huggingface.co/xlm-roberta-large) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4970
- Precision: 0.8662
- Recall: 0.8989
- F1: 0.8822
- Accuracy: 0.8889
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 31 | 1.8592 | 0.3077 | 0.4305 | 0.3589 | 0.4376 |
| No log | 2.0 | 62 | 1.3188 | 0.4793 | 0.5445 | 0.5098 | 0.5884 |
| No log | 3.0 | 93 | 1.1581 | 0.5382 | 0.6134 | 0.5733 | 0.6391 |
| No log | 4.0 | 124 | 1.1373 | 0.6480 | 0.5964 | 0.6211 | 0.6522 |
| No log | 5.0 | 155 | 0.8784 | 0.6969 | 0.7370 | 0.7164 | 0.7425 |
| No log | 6.0 | 186 | 0.7242 | 0.7472 | 0.7823 | 0.7643 | 0.7930 |
| No log | 7.0 | 217 | 0.6340 | 0.7869 | 0.8258 | 0.8058 | 0.8225 |
| No log | 8.0 | 248 | 0.5766 | 0.7832 | 0.8562 | 0.8180 | 0.8391 |
| No log | 9.0 | 279 | 0.5200 | 0.8087 | 0.8702 | 0.8383 | 0.8583 |
| No log | 10.0 | 310 | 0.4981 | 0.8495 | 0.8722 | 0.8607 | 0.8642 |
| No log | 11.0 | 341 | 0.4732 | 0.8510 | 0.8836 | 0.8670 | 0.8762 |
| No log | 12.0 | 372 | 0.4884 | 0.8593 | 0.8801 | 0.8696 | 0.8746 |
| No log | 13.0 | 403 | 0.4701 | 0.8444 | 0.8893 | 0.8663 | 0.8825 |
| No log | 14.0 | 434 | 0.4759 | 0.8576 | 0.8898 | 0.8734 | 0.8814 |
| No log | 15.0 | 465 | 0.4765 | 0.8596 | 0.8945 | 0.8767 | 0.8840 |
| No log | 16.0 | 496 | 0.4817 | 0.8610 | 0.8984 | 0.8793 | 0.8881 |
| 0.7221 | 17.0 | 527 | 0.4904 | 0.8572 | 0.8989 | 0.8775 | 0.8869 |
| 0.7221 | 18.0 | 558 | 0.4971 | 0.8640 | 0.8969 | 0.8802 | 0.8869 |
| 0.7221 | 19.0 | 589 | 0.4954 | 0.8595 | 0.9024 | 0.8804 | 0.8894 |
| 0.7221 | 20.0 | 620 | 0.4970 | 0.8662 | 0.8989 | 0.8822 | 0.8889 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu117
- Datasets 2.9.0
- Tokenizers 0.13.2
|
ArBert/roberta-base-finetuned-ner-gmm-twitter
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:16:20Z |
# Vocabulary Trimmed [lmqg/mt5-small-itquad-qg](https://huggingface.co/lmqg/mt5-small-itquad-qg): `vocabtrimmer/mt5-small-itquad-qg-trimmed-it-60000`
This model is a trimmed version of [lmqg/mt5-small-itquad-qg](https://huggingface.co/lmqg/mt5-small-itquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-itquad-qg | vocabtrimmer/mt5-small-itquad-qg-trimmed-it-60000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 105,504,128 |
| parameter_size_embedding | 256,103,424 | 61,442,048 |
| vocab_size | 250,101 | 60,002 |
| compression_rate_full | 100.0 | 35.15 |
| compression_rate_embedding | 100.0 | 23.99 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| it | vocabtrimmer/mc4_validation | text | it | validation | 60000 | 2 |
|
ArBert/roberta-base-finetuned-ner-gmm
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:19:04Z |
# Vocabulary Trimmed [lmqg/mt5-small-koquad-qg](https://huggingface.co/lmqg/mt5-small-koquad-qg): `vocabtrimmer/mt5-small-koquad-qg-trimmed-ko-60000`
This model is a trimmed version of [lmqg/mt5-small-koquad-qg](https://huggingface.co/lmqg/mt5-small-koquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-koquad-qg | vocabtrimmer/mt5-small-koquad-qg-trimmed-ko-60000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 105,504,128 |
| parameter_size_embedding | 256,103,424 | 61,442,048 |
| vocab_size | 250,101 | 60,002 |
| compression_rate_full | 100.0 | 35.15 |
| compression_rate_embedding | 100.0 | 23.99 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ko | vocabtrimmer/mc4_validation | text | ko | validation | 60000 | 2 |
|
Aracatto/Catto
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:23:44Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
- f1
model-index:
- name: unsupervised-fine-tune-roberta-exist-5
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# unsupervised-fine-tune-roberta-exist-5
This model is a fine-tuned version of [nouman-10/unsupervised-exist-rb](https://huggingface.co/nouman-10/unsupervised-exist-rb) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.7029
- Accuracy: 0.6512
- F1: 0.6512
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 194 | 1.0614 | 0.625 | 0.625 |
| No log | 2.0 | 388 | 1.0071 | 0.6047 | 0.6047 |
| 1.0299 | 3.0 | 582 | 1.0507 | 0.6512 | 0.6512 |
| 1.0299 | 4.0 | 776 | 1.0833 | 0.6453 | 0.6453 |
| 1.0299 | 5.0 | 970 | 1.1711 | 0.6337 | 0.6337 |
| 0.5093 | 6.0 | 1164 | 1.3761 | 0.6366 | 0.6366 |
| 0.5093 | 7.0 | 1358 | 1.4950 | 0.6424 | 0.6424 |
| 0.211 | 8.0 | 1552 | 1.5941 | 0.6337 | 0.6337 |
| 0.211 | 9.0 | 1746 | 1.6544 | 0.6570 | 0.6570 |
| 0.211 | 10.0 | 1940 | 1.7029 | 0.6512 | 0.6512 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
AragornII/DialoGPT-small-harrypotter
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:26:13Z |
# Vocabulary Trimmed [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg): `vocabtrimmer/mt5-small-esquad-qg-trimmed-es-30000`
This model is a trimmed version of [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-esquad-qg | vocabtrimmer/mt5-small-esquad-qg-trimmed-es-30000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 74,784,128 |
| parameter_size_embedding | 256,103,424 | 30,722,048 |
| vocab_size | 250,101 | 30,002 |
| compression_rate_full | 100.0 | 24.91 |
| compression_rate_embedding | 100.0 | 12.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| es | vocabtrimmer/mc4_validation | text | es | validation | 30000 | 2 |
|
Arcanos/1
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1572.51 +/- 52.53
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Archie/myProject
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:36:51Z |
# Vocabulary Trimmed [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg): `vocabtrimmer/mt5-small-esquad-qg-trimmed-es-120000`
This model is a trimmed version of [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-esquad-qg | vocabtrimmer/mt5-small-esquad-qg-trimmed-es-120000 |
|:---------------------------|:---------------------------|:-----------------------------------------------------|
| parameter_size_full | 300,165,504 | 166,944,128 |
| parameter_size_embedding | 256,103,424 | 122,882,048 |
| vocab_size | 250,101 | 120,002 |
| compression_rate_full | 100.0 | 55.62 |
| compression_rate_embedding | 100.0 | 47.98 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| es | vocabtrimmer/mc4_validation | text | es | validation | 120000 | 2 |
|
Arghyad/Loki_small
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-ru-5000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-ru-5000 |
|:---------------------------|:-------------------|:-----------------------------------------|
| parameter_size_full | 300,176,768 | 49,184,128 |
| parameter_size_embedding | 256,114,688 | 5,122,048 |
| vocab_size | 250,112 | 5,002 |
| compression_rate_full | 100.0 | 16.39 |
| compression_rate_embedding | 100.0 | 2.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ru | vocabtrimmer/mc4_validation | text | ru | validation | 5000 | 2 |
|
Aries/T5_question_answering
|
[
"pytorch",
"jax",
"t5",
"text2text-generation",
"transformers",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"T5ForConditionalGeneration"
],
"model_type": "t5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": true,
"length_penalty": 2,
"max_length": 200,
"min_length": 30,
"no_repeat_ngram_size": 3,
"num_beams": 4,
"prefix": "summarize: "
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to German: "
},
"translation_en_to_fr": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to French: "
},
"translation_en_to_ro": {
"early_stopping": true,
"max_length": 300,
"num_beams": 4,
"prefix": "translate English to Romanian: "
}
}
}
| 5 | 2023-03-15T11:44:12Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -0.71 +/- 0.25
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Arina/Erine
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:45:03Z |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-ru-15000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-ru-15000 |
|:---------------------------|:-------------------|:------------------------------------------|
| parameter_size_full | 300,176,768 | 59,423,104 |
| parameter_size_embedding | 256,114,688 | 15,361,024 |
| vocab_size | 250,112 | 15,001 |
| compression_rate_full | 100.0 | 19.8 |
| compression_rate_embedding | 100.0 | 6.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| ru | vocabtrimmer/mc4_validation | text | ru | validation | 15000 | 2 |
|
ArjunKadya/HuggingFace
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:45:53Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -2.00 +/- 0.56
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Arkadiusz/Test-model
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:47:51Z |
---
library_name: sample-factory
tags:
- deep-reinforcement-learning
- reinforcement-learning
- sample-factory
model-index:
- name: APPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: doom_health_gathering_supreme
type: doom_health_gathering_supreme
metrics:
- type: mean_reward
value: 13.76 +/- 6.59
name: mean_reward
verified: false
---
A(n) **APPO** model trained on the **doom_health_gathering_supreme** environment.
This model was trained using Sample-Factory 2.0: https://github.com/alex-petrenko/sample-factory.
Documentation for how to use Sample-Factory can be found at https://www.samplefactory.dev/
## Downloading the model
After installing Sample-Factory, download the model with:
```
python -m sample_factory.huggingface.load_from_hub -r peterdamn/rl_course_vizdoom_health_gathering_supreme
```
## Using the model
To run the model after download, use the `enjoy` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme
```
You can also upload models to the Hugging Face Hub using the same script with the `--push_to_hub` flag.
See https://www.samplefactory.dev/10-huggingface/huggingface/ for more details
## Training with this model
To continue training with this model, use the `train` script corresponding to this environment:
```
python -m .usr.local.lib.python3.9.dist-packages.ipykernel_launcher --algo=APPO --env=doom_health_gathering_supreme --train_dir=./train_dir --experiment=rl_course_vizdoom_health_gathering_supreme --restart_behavior=resume --train_for_env_steps=10000000000
```
Note, you may have to adjust `--train_for_env_steps` to a suitably high number as the experiment will resume at the number of steps it concluded at.
|
Arnold/common_voiceha
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:51:43Z |
---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: Prgrg/ja-en-JESC-v3.0
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Prgrg/ja-en-JESC-v3.0
This model is a fine-tuned version of [Prgrg/ja-en-JESC-v2.0](https://huggingface.co/Prgrg/ja-en-JESC-v2.0) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 4.8267
- Validation Loss: 7.8094
- Epoch: 5
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 0.0005, 'decay_steps': 150000, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.001}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 3.3432 | 6.9622 | 0 |
| 5.2217 | 7.5277 | 1 |
| 5.1853 | 7.5818 | 2 |
| 4.9986 | 7.5179 | 3 |
| 4.8957 | 7.7693 | 4 |
| 4.8267 | 7.8094 | 5 |
### Framework versions
- Transformers 4.26.1
- TensorFlow 2.11.0
- Datasets 2.10.1
- Tokenizers 0.13.2
|
Arnold/wav2vec2-hausa-demo-colab
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T11:52:01Z |
# Vocabulary Trimmed [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg): `vocabtrimmer/mt5-small-esquad-qg-trimmed-es-60000`
This model is a trimmed version of [lmqg/mt5-small-esquad-qg](https://huggingface.co/lmqg/mt5-small-esquad-qg) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | lmqg/mt5-small-esquad-qg | vocabtrimmer/mt5-small-esquad-qg-trimmed-es-60000 |
|:---------------------------|:---------------------------|:----------------------------------------------------|
| parameter_size_full | 300,165,504 | 105,504,128 |
| parameter_size_embedding | 256,103,424 | 61,442,048 |
| vocab_size | 250,101 | 60,002 |
| compression_rate_full | 100.0 | 35.15 |
| compression_rate_embedding | 100.0 | 23.99 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| es | vocabtrimmer/mc4_validation | text | es | validation | 60000 | 2 |
|
Arpita/opus-mt-en-ro-finetuned-synthon-to-reactant
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T12:06:27Z |
---
license: openrail
language:
- en
datasets:
- ErfanMoosaviMonazzah/fake-news-detection-English
metrics:
- f1
pipeline_tag: text-classification
tags:
- fake news detection
- tiny bert
widget:
- text: "Militant blast, gun attack kill 18 police in Egypt's Sinai"
example_title: "True News"
- text: "Trump Is Literally Causing Business Owners To Go Broke Because Of His Mar-a-Lago Trips"
example_title: "Fake News"
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
A fine-tuned version of tiny bert to detect fake news.
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [Erfan Moosavi Monazzah](https://huggingface.co/ErfanMoosaviMonazzah)
- **Language:** English
- **Finetuned from model:** [Tiny BERT](https://huggingface.co/prajjwal1/bert-tiny)
|
Ashkanmh/bert-base-parsbert-uncased-finetuned
|
[
"pytorch",
"tensorboard",
"bert",
"fill-mask",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
fill-mask
|
{
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 3 | null |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-fr-30000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-fr-30000 |
|:---------------------------|:-------------------|:------------------------------------------|
| parameter_size_full | 300,176,768 | 74,783,104 |
| parameter_size_embedding | 256,114,688 | 30,721,024 |
| vocab_size | 250,112 | 30,001 |
| compression_rate_full | 100.0 | 24.91 |
| compression_rate_embedding | 100.0 | 12.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| fr | vocabtrimmer/mc4_validation | text | fr | validation | 30000 | 2 |
|
Augustvember/WokkaBot9
|
[] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T12:54:07Z |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-es-5000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-es-5000 |
|:---------------------------|:-------------------|:-----------------------------------------|
| parameter_size_full | 300,176,768 | 49,184,128 |
| parameter_size_embedding | 256,114,688 | 5,122,048 |
| vocab_size | 250,112 | 5,002 |
| compression_rate_full | 100.0 | 16.39 |
| compression_rate_embedding | 100.0 | 2.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| es | vocabtrimmer/mc4_validation | text | es | validation | 5000 | 2 |
|
Augustvember/wokka4
|
[
"conversational"
] |
conversational
|
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | 2023-03-15T12:56:38Z |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-es-10000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-es-10000 |
|:---------------------------|:-------------------|:------------------------------------------|
| parameter_size_full | 300,176,768 | 54,303,104 |
| parameter_size_embedding | 256,114,688 | 10,241,024 |
| vocab_size | 250,112 | 10,001 |
| compression_rate_full | 100.0 | 18.09 |
| compression_rate_embedding | 100.0 | 4.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| es | vocabtrimmer/mc4_validation | text | es | validation | 10000 | 2 |
|
Axon/resnet34-v1
|
[
"dataset:ImageNet",
"arxiv:1512.03385",
"Axon",
"Elixir",
"license:apache-2.0"
] | null |
{
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 0 | null |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-es-60000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-es-60000 |
|:---------------------------|:-------------------|:------------------------------------------|
| parameter_size_full | 300,176,768 | 105,503,104 |
| parameter_size_embedding | 256,114,688 | 61,441,024 |
| vocab_size | 250,112 | 60,001 |
| compression_rate_full | 100.0 | 35.15 |
| compression_rate_embedding | 100.0 | 23.99 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| es | vocabtrimmer/mc4_validation | text | es | validation | 60000 | 2 |
|
Ayah/GPT2-DBpedia
|
[
"pytorch",
"gpt2",
"text-generation",
"transformers"
] |
text-generation
|
{
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-it-5000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-it-5000 |
|:---------------------------|:-------------------|:-----------------------------------------|
| parameter_size_full | 300,176,768 | 49,184,128 |
| parameter_size_embedding | 256,114,688 | 5,122,048 |
| vocab_size | 250,112 | 5,002 |
| compression_rate_full | 100.0 | 16.39 |
| compression_rate_embedding | 100.0 | 2.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| it | vocabtrimmer/mc4_validation | text | it | validation | 5000 | 2 |
|
Aybars/ModelOnTquad
|
[
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 8 | null |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-it-15000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-it-15000 |
|:---------------------------|:-------------------|:------------------------------------------|
| parameter_size_full | 300,176,768 | 59,423,104 |
| parameter_size_embedding | 256,114,688 | 15,361,024 |
| vocab_size | 250,112 | 15,001 |
| compression_rate_full | 100.0 | 19.8 |
| compression_rate_embedding | 100.0 | 6.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| it | vocabtrimmer/mc4_validation | text | it | validation | 15000 | 2 |
|
Aybars/XLM_Turkish
|
[
"pytorch",
"xlm-roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] |
question-answering
|
{
"architectures": [
"XLMRobertaForQuestionAnswering"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | 2023-03-15T13:27:47Z |
---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: output
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# output
This model is a fine-tuned version of [nferruz/ProtGPT2](https://huggingface.co/nferruz/ProtGPT2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.6699
- Accuracy: 0.7571
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- gradient_accumulation_steps: 4
- total_train_batch_size: 8
- total_eval_batch_size: 2
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 8.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| No log | 1.0 | 220 | 3.8564 | 0.4857 |
| No log | 2.0 | 440 | 2.7515 | 0.6096 |
| 4.1568 | 3.0 | 660 | 2.2463 | 0.6780 |
| 4.1568 | 4.0 | 880 | 1.9817 | 0.7152 |
| 2.2818 | 5.0 | 1100 | 1.8278 | 0.7353 |
| 2.2818 | 6.0 | 1320 | 1.7313 | 0.7486 |
| 1.8444 | 7.0 | 1540 | 1.6847 | 0.7553 |
| 1.8444 | 8.0 | 1760 | 1.6699 | 0.7571 |
### Framework versions
- Transformers 4.26.1
- Pytorch 1.13.1+cu117
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Ayham/albert_bert_summarization_cnn_dailymail
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 12 | null |
# Vocabulary Trimmed [google/mt5-small](https://huggingface.co/google/mt5-small): `vocabtrimmer/mt5-small-trimmed-it-30000`
This model is a trimmed version of [google/mt5-small](https://huggingface.co/google/mt5-small) by [`vocabtrimmer`](https://github.com/asahi417/lm-vocab-trimmer), a tool for trimming vocabulary of language models to compress the model size.
Following table shows a summary of the trimming process.
| | google/mt5-small | vocabtrimmer/mt5-small-trimmed-it-30000 |
|:---------------------------|:-------------------|:------------------------------------------|
| parameter_size_full | 300,176,768 | 74,783,104 |
| parameter_size_embedding | 256,114,688 | 30,721,024 |
| vocab_size | 250,112 | 30,001 |
| compression_rate_full | 100.0 | 24.91 |
| compression_rate_embedding | 100.0 | 12.0 |
Following table shows the parameter used to trim vocabulary.
| language | dataset | dataset_column | dataset_name | dataset_split | target_vocab_size | min_frequency |
|:-----------|:----------------------------|:-----------------|:---------------|:----------------|--------------------:|----------------:|
| it | vocabtrimmer/mc4_validation | text | it | validation | 30000 | 2 |
|
Ayham/bert_gpt2_summarization_xsum
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:xsum",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 6 | null |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="YashGajjar/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
Ayham/bertgpt2_cnn
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: pixelcoper-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: -4.80 +/- 0.60
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Ayham/distilbert_bert_summarization_cnn_dailymail
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 11 | null |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1556.86 +/- 35.82
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Ayham/distilbert_distilgpt2_summarization_cnn_dailymail
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 5 | null |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-cartpole
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Ayham/roberta_bert_summarization_cnn_dailymail
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 12 | 2023-03-15T13:54:42Z |
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- aszfcxcgszdx/autotrain-data-multi-lingual-summarization
co2_eq_emissions:
emissions: 13.328572874208332
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 41234106312
- CO2 Emissions (in grams): 13.3286
## Validation Metrics
- Loss: 1.508
- Rouge1: 44.068
- Rouge2: 20.883
- RougeL: 37.071
- RougeLsum: 40.613
- Gen Len: 17.000
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/aszfcxcgszdx/autotrain-multi-lingual-summarization-41234106312
```
|
Ayham/roberta_distilgpt2_summarization_cnn_dailymail
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- aszfcxcgszdx/autotrain-data-multi-lingual-summarization
co2_eq_emissions:
emissions: 12.703463244389663
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 41234106313
- CO2 Emissions (in grams): 12.7035
## Validation Metrics
- Loss: 1.508
- Rouge1: 44.142
- Rouge2: 21.000
- RougeL: 37.127
- RougeLsum: 40.611
- Gen Len: 17.000
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/aszfcxcgszdx/autotrain-multi-lingual-summarization-41234106313
```
|
Ayham/roberta_gpt2_new_max64_summarization_cnndm
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 4 | null |
---
language:
- uz
license: apache-2.0
tags:
- hf-asr-leaderboard
- generated_from_trainer
datasets:
- mozilla-foundation/common_voice_11_0
model-index:
- name: Whisper Small Hi - Sanchit Gandhi
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Whisper Small Hi - Sanchit Gandhi
This model is a fine-tuned version of [openai/whisper-small](https://huggingface.co/openai/whisper-small) on the Common Voice 11.0 dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- training_steps: 4000
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.28.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.10.1
- Tokenizers 0.13.2
|
Ayham/roberta_gpt2_summarization_cnn_dailymail
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:cnn_dailymail",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 31 | null |
---
license: mit
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: clinico-xlm-roberta-finetuned
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# clinico-xlm-roberta-finetuned
This model is a fine-tuned version of [joheras/xlm-roberta-base-finetuned-clinais](https://huggingface.co/joheras/xlm-roberta-base-finetuned-clinais) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1866
- Precision: 0.4629
- Recall: 0.6281
- F1: 0.5330
- Accuracy: 0.8501
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 25 | 1.2657 | 0.0046 | 0.0103 | 0.0064 | 0.5444 |
| No log | 2.0 | 50 | 0.7933 | 0.1430 | 0.2609 | 0.1848 | 0.7711 |
| No log | 3.0 | 75 | 0.6467 | 0.2741 | 0.4325 | 0.3356 | 0.8061 |
| No log | 4.0 | 100 | 0.5961 | 0.3151 | 0.5217 | 0.3929 | 0.8233 |
| No log | 5.0 | 125 | 0.5628 | 0.3288 | 0.5217 | 0.4034 | 0.8289 |
| No log | 6.0 | 150 | 0.5540 | 0.2884 | 0.4920 | 0.3636 | 0.8377 |
| No log | 7.0 | 175 | 0.5475 | 0.2960 | 0.4954 | 0.3706 | 0.8381 |
| No log | 8.0 | 200 | 0.6013 | 0.3034 | 0.5297 | 0.3858 | 0.8347 |
| No log | 9.0 | 225 | 0.6026 | 0.2989 | 0.5297 | 0.3822 | 0.8368 |
| No log | 10.0 | 250 | 0.6055 | 0.3352 | 0.5366 | 0.4127 | 0.8422 |
| No log | 11.0 | 275 | 0.6757 | 0.2982 | 0.5275 | 0.3810 | 0.8385 |
| No log | 12.0 | 300 | 0.6287 | 0.3135 | 0.5355 | 0.3954 | 0.8464 |
| No log | 13.0 | 325 | 0.7429 | 0.3441 | 0.5492 | 0.4231 | 0.8402 |
| No log | 14.0 | 350 | 0.6883 | 0.3203 | 0.5538 | 0.4059 | 0.8491 |
| No log | 15.0 | 375 | 0.7311 | 0.3550 | 0.5698 | 0.4374 | 0.8427 |
| No log | 16.0 | 400 | 0.7084 | 0.3518 | 0.5595 | 0.4320 | 0.8481 |
| No log | 17.0 | 425 | 0.7104 | 0.3545 | 0.5629 | 0.4350 | 0.8533 |
| No log | 18.0 | 450 | 0.7958 | 0.3572 | 0.5709 | 0.4395 | 0.8381 |
| No log | 19.0 | 475 | 0.7453 | 0.3616 | 0.5755 | 0.4442 | 0.8516 |
| 0.3605 | 20.0 | 500 | 0.7714 | 0.3573 | 0.5744 | 0.4405 | 0.8430 |
| 0.3605 | 21.0 | 525 | 0.8162 | 0.3664 | 0.5744 | 0.4474 | 0.8469 |
| 0.3605 | 22.0 | 550 | 0.7999 | 0.3711 | 0.5847 | 0.4540 | 0.8527 |
| 0.3605 | 23.0 | 575 | 0.8143 | 0.3968 | 0.5938 | 0.4757 | 0.8537 |
| 0.3605 | 24.0 | 600 | 0.8394 | 0.4078 | 0.5892 | 0.4820 | 0.8516 |
| 0.3605 | 25.0 | 625 | 0.8772 | 0.3778 | 0.5675 | 0.4536 | 0.8397 |
| 0.3605 | 26.0 | 650 | 0.8670 | 0.3991 | 0.6178 | 0.4850 | 0.8549 |
| 0.3605 | 27.0 | 675 | 0.8739 | 0.3886 | 0.5904 | 0.4687 | 0.8491 |
| 0.3605 | 28.0 | 700 | 0.9461 | 0.4081 | 0.5973 | 0.4849 | 0.8447 |
| 0.3605 | 29.0 | 725 | 0.9134 | 0.4267 | 0.6064 | 0.5009 | 0.8448 |
| 0.3605 | 30.0 | 750 | 0.9127 | 0.4057 | 0.5984 | 0.4836 | 0.8440 |
| 0.3605 | 31.0 | 775 | 0.9738 | 0.4129 | 0.5995 | 0.4890 | 0.8435 |
| 0.3605 | 32.0 | 800 | 1.0001 | 0.4074 | 0.5892 | 0.4818 | 0.8442 |
| 0.3605 | 33.0 | 825 | 0.9532 | 0.4133 | 0.6030 | 0.4905 | 0.8470 |
| 0.3605 | 34.0 | 850 | 0.9532 | 0.4080 | 0.6041 | 0.4871 | 0.8481 |
| 0.3605 | 35.0 | 875 | 0.9876 | 0.4108 | 0.6087 | 0.4905 | 0.8483 |
| 0.3605 | 36.0 | 900 | 0.9456 | 0.4219 | 0.6247 | 0.5037 | 0.8521 |
| 0.3605 | 37.0 | 925 | 0.9513 | 0.4180 | 0.6121 | 0.4968 | 0.8468 |
| 0.3605 | 38.0 | 950 | 0.9905 | 0.4120 | 0.6110 | 0.4922 | 0.8506 |
| 0.3605 | 39.0 | 975 | 0.9983 | 0.4365 | 0.6247 | 0.5139 | 0.8522 |
| 0.0271 | 40.0 | 1000 | 1.0220 | 0.4224 | 0.6076 | 0.4984 | 0.8480 |
| 0.0271 | 41.0 | 1025 | 1.0323 | 0.4114 | 0.6110 | 0.4917 | 0.8474 |
| 0.0271 | 42.0 | 1050 | 1.0651 | 0.4266 | 0.6121 | 0.5028 | 0.8482 |
| 0.0271 | 43.0 | 1075 | 1.0778 | 0.4101 | 0.5927 | 0.4848 | 0.8534 |
| 0.0271 | 44.0 | 1100 | 1.0190 | 0.4216 | 0.6087 | 0.4981 | 0.8469 |
| 0.0271 | 45.0 | 1125 | 1.0374 | 0.4245 | 0.6144 | 0.5021 | 0.8544 |
| 0.0271 | 46.0 | 1150 | 1.0792 | 0.4383 | 0.6018 | 0.5072 | 0.8518 |
| 0.0271 | 47.0 | 1175 | 1.0888 | 0.4267 | 0.6190 | 0.5051 | 0.8478 |
| 0.0271 | 48.0 | 1200 | 1.1022 | 0.4498 | 0.6156 | 0.5198 | 0.8490 |
| 0.0271 | 49.0 | 1225 | 1.1646 | 0.4398 | 0.6064 | 0.5099 | 0.8453 |
| 0.0271 | 50.0 | 1250 | 1.1448 | 0.4505 | 0.6087 | 0.5178 | 0.8478 |
| 0.0271 | 51.0 | 1275 | 1.1288 | 0.4388 | 0.6110 | 0.5108 | 0.8455 |
| 0.0271 | 52.0 | 1300 | 1.1077 | 0.4579 | 0.6224 | 0.5276 | 0.8478 |
| 0.0271 | 53.0 | 1325 | 1.0931 | 0.4373 | 0.6064 | 0.5081 | 0.8465 |
| 0.0271 | 54.0 | 1350 | 1.1044 | 0.4478 | 0.6087 | 0.5160 | 0.8471 |
| 0.0271 | 55.0 | 1375 | 1.0895 | 0.4343 | 0.6087 | 0.5069 | 0.8500 |
| 0.0271 | 56.0 | 1400 | 1.0768 | 0.4501 | 0.6144 | 0.5196 | 0.8532 |
| 0.0271 | 57.0 | 1425 | 1.1164 | 0.4356 | 0.6190 | 0.5113 | 0.8510 |
| 0.0271 | 58.0 | 1450 | 1.1378 | 0.4507 | 0.6167 | 0.5208 | 0.8505 |
| 0.0271 | 59.0 | 1475 | 1.1510 | 0.4583 | 0.6156 | 0.5254 | 0.8500 |
| 0.0063 | 60.0 | 1500 | 1.1126 | 0.4654 | 0.6224 | 0.5326 | 0.8514 |
| 0.0063 | 61.0 | 1525 | 1.1535 | 0.4548 | 0.6156 | 0.5231 | 0.8515 |
| 0.0063 | 62.0 | 1550 | 1.1362 | 0.4535 | 0.6247 | 0.5255 | 0.8505 |
| 0.0063 | 63.0 | 1575 | 1.1321 | 0.4723 | 0.6247 | 0.5379 | 0.8546 |
| 0.0063 | 64.0 | 1600 | 1.0995 | 0.4626 | 0.6304 | 0.5337 | 0.8561 |
| 0.0063 | 65.0 | 1625 | 1.1263 | 0.4546 | 0.6190 | 0.5242 | 0.8498 |
| 0.0063 | 66.0 | 1650 | 1.1251 | 0.4712 | 0.6270 | 0.5380 | 0.8549 |
| 0.0063 | 67.0 | 1675 | 1.1592 | 0.4745 | 0.6281 | 0.5406 | 0.8501 |
| 0.0063 | 68.0 | 1700 | 1.1552 | 0.4571 | 0.6281 | 0.5292 | 0.8514 |
| 0.0063 | 69.0 | 1725 | 1.1602 | 0.4618 | 0.6224 | 0.5302 | 0.8520 |
| 0.0063 | 70.0 | 1750 | 1.1631 | 0.4669 | 0.6304 | 0.5365 | 0.8527 |
| 0.0063 | 71.0 | 1775 | 1.1784 | 0.4824 | 0.6259 | 0.5448 | 0.8487 |
| 0.0063 | 72.0 | 1800 | 1.1779 | 0.4681 | 0.6213 | 0.5339 | 0.8527 |
| 0.0063 | 73.0 | 1825 | 1.1656 | 0.4478 | 0.6236 | 0.5213 | 0.8531 |
| 0.0063 | 74.0 | 1850 | 1.1743 | 0.4620 | 0.6190 | 0.5291 | 0.8528 |
| 0.0063 | 75.0 | 1875 | 1.1623 | 0.4529 | 0.6270 | 0.5259 | 0.8520 |
| 0.0063 | 76.0 | 1900 | 1.1597 | 0.4831 | 0.6201 | 0.5431 | 0.8507 |
| 0.0063 | 77.0 | 1925 | 1.1603 | 0.4743 | 0.6236 | 0.5388 | 0.8520 |
| 0.0063 | 78.0 | 1950 | 1.1551 | 0.4505 | 0.6190 | 0.5214 | 0.8500 |
| 0.0063 | 79.0 | 1975 | 1.1740 | 0.4772 | 0.6213 | 0.5398 | 0.8511 |
| 0.0026 | 80.0 | 2000 | 1.1463 | 0.4706 | 0.6224 | 0.5360 | 0.8519 |
| 0.0026 | 81.0 | 2025 | 1.1757 | 0.4603 | 0.6167 | 0.5271 | 0.8472 |
| 0.0026 | 82.0 | 2050 | 1.1754 | 0.4541 | 0.6224 | 0.5251 | 0.8457 |
| 0.0026 | 83.0 | 2075 | 1.1713 | 0.4588 | 0.6178 | 0.5266 | 0.8476 |
| 0.0026 | 84.0 | 2100 | 1.2023 | 0.4631 | 0.6247 | 0.5319 | 0.8473 |
| 0.0026 | 85.0 | 2125 | 1.1819 | 0.4841 | 0.6259 | 0.5459 | 0.8471 |
| 0.0026 | 86.0 | 2150 | 1.1878 | 0.4611 | 0.6236 | 0.5302 | 0.8470 |
| 0.0026 | 87.0 | 2175 | 1.1827 | 0.4694 | 0.6236 | 0.5356 | 0.8485 |
| 0.0026 | 88.0 | 2200 | 1.1787 | 0.4552 | 0.6213 | 0.5254 | 0.8506 |
| 0.0026 | 89.0 | 2225 | 1.1811 | 0.4762 | 0.6293 | 0.5421 | 0.8488 |
| 0.0026 | 90.0 | 2250 | 1.1849 | 0.4573 | 0.6247 | 0.5280 | 0.8493 |
| 0.0026 | 91.0 | 2275 | 1.1779 | 0.4505 | 0.6247 | 0.5235 | 0.8502 |
| 0.0026 | 92.0 | 2300 | 1.2042 | 0.4672 | 0.6201 | 0.5329 | 0.8493 |
| 0.0026 | 93.0 | 2325 | 1.1955 | 0.4712 | 0.6270 | 0.5380 | 0.8501 |
| 0.0026 | 94.0 | 2350 | 1.1950 | 0.4696 | 0.6281 | 0.5374 | 0.8503 |
| 0.0026 | 95.0 | 2375 | 1.1958 | 0.4769 | 0.6270 | 0.5418 | 0.8489 |
| 0.0026 | 96.0 | 2400 | 1.1819 | 0.4564 | 0.6281 | 0.5286 | 0.8496 |
| 0.0026 | 97.0 | 2425 | 1.1853 | 0.4677 | 0.6304 | 0.5370 | 0.8501 |
| 0.0026 | 98.0 | 2450 | 1.1822 | 0.4637 | 0.6281 | 0.5335 | 0.8501 |
| 0.0026 | 99.0 | 2475 | 1.1841 | 0.4571 | 0.6281 | 0.5292 | 0.8498 |
| 0.0014 | 100.0 | 2500 | 1.1866 | 0.4629 | 0.6281 | 0.5330 | 0.8501 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.0
- Datasets 2.8.0
- Tokenizers 0.12.1
|
Ayham/xlnet_gpt2_summarization_xsum
|
[
"pytorch",
"tensorboard",
"encoder-decoder",
"text2text-generation",
"dataset:xsum",
"transformers",
"generated_from_trainer",
"autotrain_compatible"
] |
text2text-generation
|
{
"architectures": [
"EncoderDecoderModel"
],
"model_type": "encoder-decoder",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
}
| 13 | null |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-CartPole-v1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 500.00 +/- 0.00
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.