
modelId
stringlengths 4
81
| tags
sequence | pipeline_tag
stringclasses 17
values | config
dict | downloads
int64 0
59.7M
| first_commit
timestamp[ns, tz=UTC] | card
stringlengths 51
438k
|
|---|---|---|---|---|---|---|
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-glf | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 18 | 2021-11-05T13:48:28Z | ---
pipeline_tag: "fill-mask"
language: en
---
# This repository is a fork of [yiyanghkust/finbert-pretrain](https://huggingface.co/yiyanghkust/finbert-pretrain)
> All credits to [@yiyanghkust](https://huggingface.co/yiyanghkust).
I added the TensorFlow model and a proper `tokenizer.json`
---
`FinBERT` is a BERT model pre-trained on financial communication text. The purpose is to enhance financial NLP research and practice. It is trained on the following three financial communication corpus. The total corpora size is 4.9B tokens.
- Corporate Reports 10-K & 10-Q: 2.5B tokens
- Earnings Call Transcripts: 1.3B tokens
- Analyst Reports: 1.1B tokens
More details on `FinBERT`'s pre-training process can be found at: https://arxiv.org/abs/2006.08097
`FinBERT` can be further fine-tuned on downstream tasks. Specifically, we have fine-tuned `FinBERT` on an analyst sentiment classification task, and the fine-tuned model is shared at https://huggingface.co/yiyanghkust/finbert-tone |
CAMeL-Lab/bert-base-arabic-camelbert-ca-pos-msa | [
"pytorch",
"tf",
"bert",
"token-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 71 | null | ---
language:
- de
license: mit
widget:
- text: |
Philipp ist 26 Jahre alt und lebt in Nürnberg, Deutschland. Derzeit arbeitet er als Machine Learning Engineer und Tech Lead bei Hugging Face, um künstliche Intelligenz durch Open Source und Open Science zu demokratisieren.
datasets:
- germaner
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: gbert-base-germaner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: germaner
type: germaner
args: default
metrics:
- name: precision
type: precision
value: 0.8520523797532108
- name: recall
type: recall
value: 0.8754204398447607
- name: f1
type: f1
value: 0.8635783563042368
- name: accuracy
type: accuracy
value: 0.976147969774973
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gbert-base-germaner
This model is a fine-tuned version of [deepset/gbert-base](https://huggingface.co/deepset/gbert-base) on the germaner dataset.
It achieves the following results on the evaluation set:
- precision: 0.8521
- recall: 0.8754
- f1: 0.8636
- accuracy: 0.9761
If you want to learn how to fine-tune BERT yourself using Keras and Tensorflow check out this blog post:
https://www.philschmid.de/huggingface-transformers-keras-tf
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- num_train_epochs: 5
- train_batch_size: 16
- eval_batch_size: 32
- learning_rate: 2e-05
- weight_decay_rate: 0.01
- num_warmup_steps: 0
- fp16: True
### Framework versions
- Transformers 4.14.1
- Datasets 1.16.1
- Tokenizers 0.10.3
|
CAMeL-Lab/bert-base-arabic-camelbert-ca-sentiment | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 73 | null | ---
license: apache-2.0
tags:
- summarization
datasets:
- philschmid/prompted-germanquad
widget:
- text: |
Philipp ist 26 Jahre alt und lebt in Nürnberg, Deutschland. Derzeit arbeitet er als Machine Learning Engineer und Tech Lead bei Hugging Face, um künstliche Intelligenz durch Open Source und Open Science zu demokratisieren.
Welches Ziel hat Hugging Face?
metrics:
- rouge
model-index:
- name: mt5-small-prompted-germanquad-1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mt5-small-prompted-germanquad-1
This model is a fine-tuned version of [google/mt5-small](https://huggingface.co/google/mt5-small) on an [philschmid/prompted-germanquad](https://huggingface.co/datasets/philschmid/prompted-germanquad) dataset. A prompt datasets using the [BigScience PromptSource library](https://github.com/bigscience-workshop/promptsource). The dataset is a copy of [germanquad](https://huggingface.co/datasets/deepset/germanquad) with applying the `squad` template and translated it to german. [TEMPLATE](https://github.com/philschmid/promptsource/blob/main/promptsource/templates/germanquad/templates.yaml).
This is a first test if it is possible to fine-tune `mt5` models to solve similar tasks than `T0` of big science but for the German language.
It achieves the following results on the evaluation set:
- Loss: 1.6835
- Rouge1: 27.7309
- Rouge2: 18.7311
- Rougel: 27.4704
- Rougelsum: 27.4818
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum |
|:-------------:|:-----:|:------:|:---------------:|:-------:|:-------:|:-------:|:---------:|
| 3.3795 | 1.0 | 17496 | 2.0693 | 15.8652 | 9.2569 | 15.6237 | 15.6142 |
| 2.3582 | 2.0 | 34992 | 1.9057 | 21.9348 | 14.0057 | 21.6769 | 21.6825 |
| 2.1809 | 3.0 | 52488 | 1.8143 | 24.3401 | 16.0354 | 24.0862 | 24.0914 |
| 2.0721 | 4.0 | 69984 | 1.7563 | 25.8672 | 17.2442 | 25.5854 | 25.6051 |
| 2.0004 | 5.0 | 87480 | 1.7152 | 27.0275 | 18.0548 | 26.7561 | 26.7685 |
| 1.9531 | 6.0 | 104976 | 1.6939 | 27.4702 | 18.5156 | 27.2027 | 27.2107 |
| 1.9218 | 7.0 | 122472 | 1.6835 | 27.7309 | 18.7311 | 27.4704 | 27.4818 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.1+cu102
- Datasets 1.16.1
- Tokenizers 0.10.3
|
CAMeL-Lab/bert-base-arabic-camelbert-da-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 37 | null | ---
language: fr
---
# Pytorch Fork of [tblard/tf-allocine](https://huggingface.co/tblard/tf-allocine)
A french sentiment analysis model, based on [CamemBERT](https://camembert-model.fr/), and finetuned on a large-scale dataset scraped from [Allociné.fr](http://www.allocine.fr/) user reviews.
## Results
| Validation Accuracy | Validation F1-Score | Test Accuracy | Test F1-Score |
|--------------------:| -------------------:| -------------:|--------------:|
| 97.39 | 97.36 | 97.44 | 97.34 |
The dataset and the evaluation code are available on [this repo](https://github.com/TheophileBlard/french-sentiment-analysis-with-bert).
## Usage
```python
from transformers import AutoTokenizer, TFAutoModelForSequenceClassification
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("tblard/tf-allocine")
model = TFAutoModelForSequenceClassification.from_pretrained("tblard/tf-allocine")
nlp = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
print(nlp("Alad'2 est clairement le meilleur film de l'année 2018.")) # POSITIVE
print(nlp("Juste whoaaahouuu !")) # POSITIVE
print(nlp("NUL...A...CHIER ! FIN DE TRANSMISSION.")) # NEGATIVE
print(nlp("Je m'attendais à mieux de la part de Franck Dubosc !")) # NEGATIVE
```
## Author
Théophile Blard – :email: [email protected]
If you use this work (code, model or dataset), please cite as:
> Théophile Blard, French sentiment analysis with BERT, (2020), GitHub repository, <https://github.com/TheophileBlard/french-sentiment-analysis-with-bert>
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-madar-corpus26 | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 45 | null | ---
license: apache-2.0
tags:
- generated_from_keras_callback
model-index:
- name: philschmid/tf-distilbart-cnn-12-6-tradetheevent
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# philschmid/tf-distilbart-cnn-12-6-tradetheevent
This model is a fine-tuned version of [philschmid/tf-distilbart-cnn-12-6](https://huggingface.co/philschmid/tf-distilbart-cnn-12-6) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.6894
- Validation Loss: 1.7245
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'inner_optimizer': {'class_name': 'AdamWeightDecay', 'config': {'name': 'AdamWeightDecay', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5.6e-05, 'decay_steps': 161440, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-08, 'amsgrad': False, 'weight_decay_rate': 0.01}}, 'dynamic': True, 'initial_scale': 32768.0, 'dynamic_growth_steps': 2000}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 1.6635 | 1.5957 | 0 |
| 1.3144 | 1.5577 | 1 |
| 1.0819 | 1.6059 | 2 |
| 0.8702 | 1.6695 | 3 |
| 0.6894 | 1.7245 | 4 |
### Framework versions
- Transformers 4.16.0.dev0
- TensorFlow 2.7.0
- Datasets 1.17.0
- Tokenizers 0.10.3
|
CAMeL-Lab/bert-base-arabic-camelbert-mix-did-madar-corpus6 | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 34 | null | ---
language: en
tags:
- summarization
license: apache-2.0
datasets:
- cnn_dailymail
- xsum
thumbnail: https://huggingface.co/front/thumbnails/distilbart_medium.png
---
# This is an Tensorflow fork of [sshleifer/distilbart-cnn-12-6](https://huggingface.co/sshleifer/distilbart-cnn-12-6)
### Usage
This checkpoint should be loaded into `BartForConditionalGeneration.from_pretrained`. See the [BART docs](https://huggingface.co/transformers/model_doc/bart.html?#transformers.BartForConditionalGeneration) for more information.
### Metrics for DistilBART models
| Model Name | MM Params | Inference Time (MS) | Speedup | Rouge 2 | Rouge-L |
|:---------------------------|------------:|----------------------:|----------:|----------:|----------:|
| distilbart-xsum-12-1 | 222 | 90 | 2.54 | 18.31 | 33.37 |
| distilbart-xsum-6-6 | 230 | 132 | 1.73 | 20.92 | 35.73 |
| distilbart-xsum-12-3 | 255 | 106 | 2.16 | 21.37 | 36.39 |
| distilbart-xsum-9-6 | 268 | 136 | 1.68 | 21.72 | 36.61 |
| bart-large-xsum (baseline) | 406 | 229 | 1 | 21.85 | 36.50 |
| distilbart-xsum-12-6 | 306 | 137 | 1.68 | 22.12 | 36.99 |
| bart-large-cnn (baseline) | 406 | 381 | 1 | 21.06 | 30.63 |
| distilbart-12-3-cnn | 255 | 214 | 1.78 | 20.57 | 30.00 |
| distilbart-12-6-cnn | 306 | 307 | 1.24 | 21.26 | 30.59 |
| distilbart-6-6-cnn | 230 | 182 | 2.09 | 20.17 | 29.70 | |
CAMeL-Lab/bert-base-arabic-camelbert-msa-poetry | [
"pytorch",
"tf",
"bert",
"text-classification",
"ar",
"arxiv:1905.05700",
"arxiv:2103.06678",
"transformers",
"license:apache-2.0"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 25 | 2022-02-23T17:05:54Z | ---
license: apache-2.0
tags:
- automatic-speech-recognition
- phongdtd/VinDataVLSP
- generated_from_trainer
model-index:
- name: fb-vindata-vi-large
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# fb-vindata-vi-large
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the PHONGDTD/VINDATAVLSP - NA dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 2
- total_train_batch_size: 8
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 200
- num_epochs: 40.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.10.3
|
CLAck/en-vi | [
"pytorch",
"marian",
"text2text-generation",
"en",
"vi",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language: en
tags:
- BabyBERTa
datasets:
- CHILDES
widget:
- text: "Look here. What is that <mask> ?"
- text: "Do you like your <mask> ?"
---
## BabyBERTA
### Overview
BabyBERTa is a light-weight version of RoBERTa trained on 5M words of American-English child-directed input.
It is intended for language acquisition research, on a single desktop with a single GPU - no high-performance computing infrastructure needed.
The three provided models are randomly selected from 10 that were trained and reported in the paper.
## Loading the tokenizer
BabyBERTa was trained with `add_prefix_space=True`, so it will not work properly with the tokenizer defaults.
For instance, to load the tokenizer for BabyBERTa-1, load it as follows:
```python
tokenizer = RobertaTokenizerFast.from_pretrained("phueb/BabyBERTa-1",
add_prefix_space=True)
```
### Hyper-Parameters
See the paper for details.
All provided models were trained for 400K steps with a batch size of 16.
Importantly, BabyBERTa never predicts unmasked tokens during training - `unmask_prob` is set to zero.
### Performance
BabyBerta was developed for learning grammatical knowledge from child-directed input.
Its grammatical knowledge was evaluated using the [Zorro](https://github.com/phueb/Zorro) test suite.
The best model achieves an overall accuracy of 80.3,
comparable to RoBERTa-base, which achieves an overall accuracy of 82.6 on the latest version of Zorro (as of October, 2021).
Both values differ slightly from those reported in the [CoNLL 2021 paper](https://aclanthology.org/2021.conll-1.49/).
There are two reasons for this:
1. Performance of RoBERTa-base is slightly larger because the authors previously lower-cased all words in Zorro before evaluation.
Lower-casing of proper nouns is detrimental to RoBERTa-base because RoBERTa-base has likely been trained on proper nouns that are primarily title-cased.
In contrast, because BabyBERTa is not case-sensitive, its performance is not influenced by this change.
2. The latest version of Zorro no longer contains ambiguous content words such as "Spanish" which can be both a noun and an adjective.
this resulted in a small reduction in the performance of BabyBERTa.
Overall Accuracy on Zorro:
| Model Name | Accuracy (holistic scoring) | Accuracy (MLM-scoring) |
|----------------------------------------|------------------------------|------------|
| [BabyBERTa-1][link-BabyBERTa-1] | 80.3 | 79.9 |
| [BabyBERTa-2][link-BabyBERTa-2] | 78.6 | 78.2 |
| [BabyBERTa-3][link-BabyBERTa-3] | 74.5 | 78.1 |
### Additional Information
This model was trained by [Philip Huebner](https://philhuebner.com), currently at the [UIUC Language and Learning Lab](http://www.learninglanguagelab.org).
More info can be found [here](https://github.com/phueb/BabyBERTa).
[link-BabyBERTa-1]: https://huggingface.co/phueb/BabyBERTa-1
[link-BabyBERTa-2]: https://huggingface.co/phueb/BabyBERTa-2
[link-BabyBERTa-3]: https://huggingface.co/phueb/BabyBERTa-3
|
CLAck/indo-mixed | [
"pytorch",
"marian",
"text2text-generation",
"en",
"id",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 15 | null | ---
language: en
tags:
- BabyBERTa
datasets:
- CHILDES
widget:
- text: "Look here. What is that <mask> ?"
- text: "Do you like your <mask> ?"
---
## BabyBERTA
### Overview
BabyBERTa is a light-weight version of RoBERTa trained on 5M words of American-English child-directed input.
It is intended for language acquisition research, on a single desktop with a single GPU - no high-performance computing infrastructure needed.
The three provided models are randomly selected from 10 that were trained and reported in the paper.
## Loading the tokenizer
BabyBERTa was trained with `add_prefix_space=True`, so it will not work properly with the tokenizer defaults.
For instance, to load the tokenizer for BabyBERTa-1, load it as follows:
```python
tokenizer = RobertaTokenizerFast.from_pretrained("phueb/BabyBERTa-1",
add_prefix_space=True)
```
### Hyper-Parameters
See the paper for details.
All provided models were trained for 400K steps with a batch size of 16.
Importantly, BabyBERTa never predicts unmasked tokens during training - `unmask_prob` is set to zero.
### Performance
BabyBerta was developed for learning grammatical knowledge from child-directed input.
Its grammatical knowledge was evaluated using the [Zorro](https://github.com/phueb/Zorro) test suite.
The best model achieves an overall accuracy of 80.3,
comparable to RoBERTa-base, which achieves an overall accuracy of 82.6 on the latest version of Zorro (as of October, 2021).
Both values differ slightly from those reported in the [CoNLL 2021 paper](https://aclanthology.org/2021.conll-1.49/).
There are two reasons for this:
1. Performance of RoBERTa-base is slightly larger because the authors previously lower-cased all words in Zorro before evaluation.
Lower-casing of proper nouns is detrimental to RoBERTa-base because RoBERTa-base has likely been trained on proper nouns that are primarily title-cased.
In contrast, because BabyBERTa is not case-sensitive, its performance is not influenced by this change.
2. The latest version of Zorro no longer contains ambiguous content words such as "Spanish" which can be both a noun and an adjective.
this resulted in a small reduction in the performance of BabyBERTa.
Overall Accuracy on Zorro:
| Model Name | Accuracy (holistic scoring) | Accuracy (MLM-scoring) |
|----------------------------------------|------------------------------|------------|
| [BabyBERTa-1][link-BabyBERTa-1] | 80.3 | 79.9 |
| [BabyBERTa-2][link-BabyBERTa-2] | 78.6 | 78.2 |
| [BabyBERTa-3][link-BabyBERTa-3] | 74.5 | 78.1 |
### Additional Information
This model was trained by [Philip Huebner](https://philhuebner.com), currently at the [UIUC Language and Learning Lab](http://www.learninglanguagelab.org).
More info can be found [here](https://github.com/phueb/BabyBERTa).
[link-BabyBERTa-1]: https://huggingface.co/phueb/BabyBERTa-1
[link-BabyBERTa-2]: https://huggingface.co/phueb/BabyBERTa-2
[link-BabyBERTa-3]: https://huggingface.co/phueb/BabyBERTa-3
|
CLAck/indo-pure | [
"pytorch",
"marian",
"text2text-generation",
"en",
"id",
"dataset:ALT",
"transformers",
"translation",
"license:apache-2.0",
"autotrain_compatible"
] | translation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
language: en
tags:
- BabyBERTa
license: mit
datasets:
- CHILDES
widget:
- text: "Look here. What is that <mask> ?"
- text: "Do you like your <mask> ?"
---
## BabyBERTA
### Overview
BabyBERTa is a light-weight version of RoBERTa trained on 5M words of American-English child-directed input.
It is intended for language acquisition research, on a single desktop with a single GPU - no high-performance computing infrastructure needed.
The three provided models are randomly selected from 10 that were trained and reported in the paper.
## Loading the tokenizer
BabyBERTa was trained with `add_prefix_space=True`, so it will not work properly with the tokenizer defaults.
For instance, to load the tokenizer for BabyBERTa-1, load it as follows:
```python
tokenizer = RobertaTokenizerFast.from_pretrained("phueb/BabyBERTa-1",
add_prefix_space=True)
```
### Hyper-Parameters
See the paper for details.
All provided models were trained for 400K steps with a batch size of 16.
Importantly, BabyBERTa never predicts unmasked tokens during training - `unmask_prob` is set to zero.
### Performance
BabyBerta was developed for learning grammatical knowledge from child-directed input.
Its grammatical knowledge was evaluated using the [Zorro](https://github.com/phueb/Zorro) test suite.
The best model achieves an overall accuracy of 80.3,
comparable to RoBERTa-base, which achieves an overall accuracy of 82.6 on the latest version of Zorro (as of October, 2021).
Both values differ slightly from those reported in the [CoNLL 2021 paper](https://aclanthology.org/2021.conll-1.49/).
There are two reasons for this:
1. Performance of RoBERTa-base is slightly larger because the authors previously lower-cased all words in Zorro before evaluation.
Lower-casing of proper nouns is detrimental to RoBERTa-base because RoBERTa-base has likely been trained on proper nouns that are primarily title-cased.
In contrast, because BabyBERTa is not case-sensitive, its performance is not influenced by this change.
2. The latest version of Zorro no longer contains ambiguous content words such as "Spanish" which can be both a noun and an adjective.
this resulted in a small reduction in the performance of BabyBERTa.
Overall Accuracy on Zorro:
| Model Name | Accuracy (holistic scoring) | Accuracy (MLM-scoring) |
|----------------------------------------|------------------------------|------------|
| [BabyBERTa-1][link-BabyBERTa-1] | 80.3 | 79.9 |
| [BabyBERTa-2][link-BabyBERTa-2] | 78.6 | 78.2 |
| [BabyBERTa-3][link-BabyBERTa-3] | 74.5 | 78.1 |
### Additional Information
This model was trained by [Philip Huebner](https://philhuebner.com), currently at the [UIUC Language and Learning Lab](http://www.learninglanguagelab.org).
More info can be found [here](https://github.com/phueb/BabyBERTa).
[link-BabyBERTa-1]: https://huggingface.co/phueb/BabyBERTa-1
[link-BabyBERTa-2]: https://huggingface.co/phueb/BabyBERTa-2
[link-BabyBERTa-3]: https://huggingface.co/phueb/BabyBERTa-3
|
CLTL/MedRoBERTa.nl | [
"pytorch",
"roberta",
"fill-mask",
"nl",
"transformers",
"license:mit",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2,988 | null | ---
language:
- pt-br
tags:
- question-answering
license: apache-2.0
pipeline_tag: question-answering
metrics:
- em
- f1
---
# BraQuAD BERT
## Model description
This is a question-answering model trained in BraQuAD 2.0, a version of SQuAD 2.0 translated to PT-BR using Google Cloud Translation API.
### Context
Edith Ranzini (São Paulo,[1] 1946) é uma engenheira brasileira formada pela USP, professora doutora da Pontifícia Universidade Católica de São Paulo[2] e professora sênior da Escola Politécnica da Universidade de São Paulo (Poli).[3] Ela compôs a equipe responsável pela criação do primeiro computador brasileiro, o Patinho Feio,[1] em 1972, e participou do grupo de instituidores da Fundação para o Desenvolvimento Tecnológico da Engenharia, sendo a única mulher do mesmo.[4][2] Atua nas áreas de inteligência artificial, engenharia de computação, redes neurais e sistemas gráficos.
Na sua época de prestar o vestibular, inscreveu-se para física na USP e para engenharia na Poli-USP,[3] sendo aprovada nesta última em 1965, ingressando como uma das 12 mulheres do total de 360 calouros.
Em 1969, formou-se como engenheira de eletricidade, permanecendo na universidade para fazer sua pós-graduação. Nessa época entrou para o Laboratório de Sistemas Digitais (LSD),atual Departamento de Engenharia de Computação e Sistemas Digitais, criado pelo professor Antônio Hélio Guerra Vieira.[3] Em 1970, deu início ao seu mestrado em Engenharia de Sistemas pela USP, concluindo o mesmo em 1975.[2] Nesse período, permaneceu no LSD e fez parte do grupo responsável pelo desenvolvimento do primeiro computador brasileiro, o Patinho Feio (1971-1972) e do G10 (1973-1975), primeiro computador brasileiro de médio porte, feito para o Grupo de trabalho Especial (GTE), posteriormente Digibras.
### Examples:
1-Alem do Patinho feio qual outro projeto edith trabalhou? Answer: G10
2-Quantas mulheres entraram na Poli em 1965? Answer: 12
3-Qual grande projeto edith trabalhou? Answer: do primeiro computador brasileiro
4-Qual o primeiro computador brasileiro? Answer: Patinho Feio
## Expected results
As for an example, let's show a context and some questions you can ask, as well as the expected responses. This QnA pairs were not part of the training dataset.
#### How to use
```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer
import torch
mname = "piEsposito/braquad-bert-qna"
model = AutoModelForQuestionAnswering.from_pretrained(mname)
tokenizer = AutoTokenizer.from_pretrained(mname)
context = """Edith Ranzini (São Paulo,[1] 1946) é uma engenheira brasileira formada pela USP, professora doutora da Pontifícia Universidade Católica de São Paulo[2] e professora sênior da Escola Politécnica da Universidade de São Paulo (Poli).[3] Ela compôs a equipe responsável pela criação do primeiro computador brasileiro, o Patinho Feio,[1] em 1972, e participou do grupo de instituidores da Fundação para o Desenvolvimento Tecnológico da Engenharia, sendo a única mulher do mesmo.[4][2] Atua nas áreas de inteligência artificial, engenharia de computação, redes neurais e sistemas gráficos.
Na sua época de prestar o vestibular, inscreveu-se para física na USP e para engenharia na Poli-USP,[3] sendo aprovada nesta última em 1965, ingressando como uma das 12 mulheres do total de 360 calouros.[5]
Em 1969, formou-se como engenheira de eletricidade,[2][3] permanecendo na universidade para fazer sua pós-graduação. Nessa época entrou para o Laboratório de Sistemas Digitais (LSD),atual Departamento de Engenharia de Computação e Sistemas Digitais, criado pelo professor Antônio Hélio Guerra Vieira.[3] Em 1970, deu início ao seu mestrado em Engenharia de Sistemas pela USP, concluindo o mesmo em 1975.[2] Nesse período, permaneceu no LSD e fez parte do grupo responsável pelo desenvolvimento do primeiro computador brasileiro, o Patinho Feio (1971-1972) e do G10 (1973-1975), primeiro computador brasileiro de médio porte, feito para o Grupo de trabalho Especial (GTE), posteriormente Digibras."""
# you can try this for all the examples above.
question = 'Qual grande projeto edith trabalhou?'
string = f"[CLS] {question} [SEP] {context} [SEP]"
as_tensor = torch.Tensor(tokenizer.encode(string)).unsqueeze(0)
starts, ends = model(as_tensor.long())
s, e = torch.argmax(starts[0]), torch.argmax(ends[0])
print(tokenizer.decode(tokenizer.encode(string)[s:e+1])) # 'do primeiro computador brasileiro'
```
#### Limitations and bias
- The model is trained on a dataset translated using Google Cloud API. Due to that, there are some issues with the labels, in some cases, not being identic to the answers. Due to that, the performance cannot reach the level it does with english, handly curated models. Anyway, it is a good progresso towards QnA in PT-BR.
## Training data
[BraQuAD dataset](https://github.com/piEsposito/br-quad-2.0).
## Training procedure
## Eval results
EM | F1
-------|---------
0.62 | 0.69
### BibTeX entry and citation info
```bibtex
@inproceedings{...,
year={2020},
title={BraQuAD - Dataset para Question Answering em PT-BR},
author={Esposito, Wladimir and Esposito, Piero and Tamais, Ana},
}
```
|
CLTL/icf-levels-etn | [
"pytorch",
"roberta",
"text-classification",
"nl",
"transformers",
"license:mit"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | null | ---
tags: autonlp
language: fr
widget:
- text: "I love AutoNLP 🤗"
datasets:
- pierreant-p/autonlp-data-jcvd-or-linkedin
---
# Model Trained Using AutoNLP
- Problem type: Multi-class Classification
- Model ID: 3471039
## Validation Metrics
- Loss: 0.6704344749450684
- Accuracy: 0.59375
- Macro F1: 0.37254901960784315
- Micro F1: 0.59375
- Weighted F1: 0.4424019607843137
- Macro Precision: 0.296875
- Micro Precision: 0.59375
- Weighted Precision: 0.3525390625
- Macro Recall: 0.5
- Micro Recall: 0.59375
- Weighted Recall: 0.59375
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/pierreant-p/autonlp-jcvd-or-linkedin-3471039
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("pierreant-p/autonlp-jcvd-or-linkedin-3471039", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("pierreant-p/autonlp-jcvd-or-linkedin-3471039", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
CLTL/icf-levels-fac | [
"pytorch",
"roberta",
"text-classification",
"nl",
"transformers",
"license:mit"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | null | ---
language:
- pt
tags:
- generated_from_trainer
datasets:
- pierreguillou/lener_br_finetuning_language_model
model-index:
- name: checkpoints
results:
- task:
name: Fill Mask
type: fill-mask
dataset:
name: pierreguillou/lener_br_finetuning_language_model
type: pierreguillou/lener_br_finetuning_language_model
metrics:
- name: Loss
type: loss
value: 1.352389
widget:
- text: "Com efeito, se tal fosse possível, o Poder [MASK] – que não dispõe de função legislativa – passaria a desempenhar atribuição que lhe é institucionalmente estranha (a de legislador positivo), usurpando, desse modo, no contexto de um sistema de poderes essencialmente limitados, competência que não lhe pertence, com evidente transgressão ao princípio constitucional da separação de poderes."
---
## (BERT base) Language modeling in the legal domain in Portuguese (LeNER-Br)
**bert-base-cased-pt-lenerbr** is a Language Model in the legal domain in Portuguese that was finetuned on 20/12/2021 in Google Colab from the model [BERTimbau base](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the dataset [LeNER-Br language modeling](https://huggingface.co/datasets/pierreguillou/lener_br_finetuning_language_model) by using a MASK objective.
You can check as well the [version large of this model](https://huggingface.co/pierreguillou/bert-large-cased-pt-lenerbr).
## Blog post
This language model is used to get a NER model on the Portuguese judicial domain. You can check the fine-tuned NER model at [pierreguillou/ner-bert-base-cased-pt-lenerbr](https://huggingface.co/pierreguillou/ner-bert-base-cased-pt-lenerbr).
All informations and links are in this blog post: [NLP | Modelos e Web App para Reconhecimento de Entidade Nomeada (NER) no domínio jurídico brasileiro](https://medium.com/@pierre_guillou/nlp-modelos-e-web-app-para-reconhecimento-de-entidade-nomeada-ner-no-dom%C3%ADnio-jur%C3%ADdico-b658db55edfb) (29/12/2021)
## Widget & APP
You can test this model into the widget of this page.
## Using the model for inference in production
````
# install pytorch: check https://pytorch.org/
# !pip install transformers
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("pierreguillou/bert-base-cased-pt-lenerbr")
model = AutoModelForMaskedLM.from_pretrained("pierreguillou/bert-base-cased-pt-lenerbr")
````
## Training procedure
## Notebook
The notebook of finetuning ([Finetuning_language_model_BERtimbau_LeNER_Br.ipynb](https://github.com/piegu/language-models/blob/master/Finetuning_language_model_BERtimbau_LeNER_Br.ipynb)) is in github.
### Training results
````
Num examples = 3227
Num Epochs = 5
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 2020
Step Training Loss Validation Loss
100 1.988700 1.616412
200 1.724900 1.561100
300 1.713400 1.499991
400 1.687400 1.451414
500 1.579700 1.433665
600 1.556900 1.407338
700 1.591400 1.421942
800 1.546000 1.406395
900 1.510100 1.352389
1000 1.507100 1.394799
1100 1.462200 1.36809373471
```` |
CLTL/icf-levels-ins | [
"pytorch",
"roberta",
"text-classification",
"nl",
"transformers",
"license:mit"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 32 | null | ---
language: pt
license: mit
tags:
- question-answering
- bert
- bert-base
- pytorch
datasets:
- brWaC
- squad
- squad_v1_pt
metrics:
- squad
widget:
- text: "Quando começou a pandemia de Covid-19 no mundo?"
context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
- text: "Onde foi descoberta a Covid-19?"
context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
---
# Portuguese BERT base cased QA (Question Answering), finetuned on SQUAD v1.1

## Introduction
The model was trained on the dataset SQUAD v1.1 in portuguese from the [Deep Learning Brasil group](http://www.deeplearningbrasil.com.br/) on Google Colab.
The language model used is the [BERTimbau Base](https://huggingface.co/neuralmind/bert-base-portuguese-cased) (aka "bert-base-portuguese-cased") from [Neuralmind.ai](https://neuralmind.ai/): BERTimbau Base is a pretrained BERT model for Brazilian Portuguese that achieves state-of-the-art performances on three downstream NLP tasks: Named Entity Recognition, Sentence Textual Similarity and Recognizing Textual Entailment. It is available in two sizes: Base and Large.
## Informations on the method used
All the informations are in the blog post : [NLP | Modelo de Question Answering em qualquer idioma baseado no BERT base (estudo de caso em português)](https://medium.com/@pierre_guillou/nlp-modelo-de-question-answering-em-qualquer-idioma-baseado-no-bert-base-estudo-de-caso-em-12093d385e78)
## Notebooks in Google Colab & GitHub
- Google Colab: [colab_question_answering_BERT_base_cased_squad_v11_pt.ipynb](https://colab.research.google.com/drive/18ueLdi_V321Gz37x4gHq8mb4XZSGWfZx?usp=sharing)
- GitHub: [colab_question_answering_BERT_base_cased_squad_v11_pt.ipynb](https://github.com/piegu/language-models/blob/master/colab_question_answering_BERT_base_cased_squad_v11_pt.ipynb)
## Performance
The results obtained are the following:
```
f1 = 82.50
exact match = 70.49
```
## How to use the model... with Pipeline
```python
import transformers
from transformers import pipeline
# source: https://pt.wikipedia.org/wiki/Pandemia_de_COVID-19
context = r"""
A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19,
uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2).
A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China,
em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.
Acredita-se que o vírus tenha uma origem zoonótica, porque os primeiros casos confirmados
tinham principalmente ligações ao Mercado Atacadista de Frutos do Mar de Huanan, que também vendia animais vivos.
Em 11 de março de 2020, a Organização Mundial da Saúde declarou o surto uma pandemia. Até 8 de fevereiro de 2021,
pelo menos 105 743 102 casos da doença foram confirmados em pelo menos 191 países e territórios,
com cerca de 2 308 943 mortes e 58 851 440 pessoas curadas.
"""
model_name = 'pierreguillou/bert-base-cased-squad-v1.1-portuguese'
nlp = pipeline("question-answering", model=model_name)
question = "Quando começou a pandemia de Covid-19 no mundo?"
result = nlp(question=question, context=context)
print(f"Answer: '{result['answer']}', score: {round(result['score'], 4)}, start: {result['start']}, end: {result['end']}")
# Answer: '1 de dezembro de 2019', score: 0.713, start: 328, end: 349
```
## How to use the model... with the Auto classes
```python
from transformers import AutoTokenizer, AutoModelForQuestionAnswering
tokenizer = AutoTokenizer.from_pretrained("pierreguillou/bert-base-cased-squad-v1.1-portuguese")
model = AutoModelForQuestionAnswering.from_pretrained("pierreguillou/bert-base-cased-squad-v1.1-portuguese")
```
Or just clone the model repo:
```python
git lfs install
git clone https://huggingface.co/pierreguillou/bert-base-cased-squad-v1.1-portuguese
# if you want to clone without large files – just their pointers
# prepend your git clone with the following env var:
GIT_LFS_SKIP_SMUDGE=1
```
## Limitations and bias
The training data used for this model come from Portuguese SQUAD. It could contain a lot of unfiltered content, which is far from neutral, and biases.
## Author
Portuguese BERT base cased QA (Question Answering), finetuned on SQUAD v1.1 was trained and evaluated by [Pierre GUILLOU](https://www.linkedin.com/in/pierreguillou/) thanks to the Open Source code, platforms and advices of many organizations ([link to the list](https://medium.com/@pierre_guillou/nlp-modelo-de-question-answering-em-qualquer-idioma-baseado-no-bert-base-estudo-de-caso-em-12093d385e78#c572)). In particular: [Hugging Face](https://huggingface.co/), [Neuralmind.ai](https://neuralmind.ai/), [Deep Learning Brasil group](http://www.deeplearningbrasil.com.br/), [Google Colab](https://colab.research.google.com/) and [AI Lab](https://ailab.unb.br/).
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{pierreguillou2021bertbasecasedsquadv11portuguese,
title={Portuguese BERT base cased QA (Question Answering), finetuned on SQUAD v1.1},
author={Pierre Guillou},
year={2021}
}
``` |
CLTL/icf-levels-mbw | [
"pytorch",
"roberta",
"text-classification",
"nl",
"transformers",
"license:mit"
] | text-classification | {
"architectures": [
"RobertaForSequenceClassification"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | ---
language:
- pt
tags:
- generated_from_trainer
datasets:
- pierreguillou/lener_br_finetuning_language_model
model-index:
- name: checkpoints
results:
- task:
name: Fill Mask
type: fill-mask
dataset:
name: pierreguillou/lener_br_finetuning_language_model
type: pierreguillou/lener_br_finetuning_language_model
metrics:
- name: Loss
type: loss
value: 1.127950
widget:
- text: "Com efeito, se tal fosse possível, o Poder [MASK] – que não dispõe de função legislativa – passaria a desempenhar atribuição que lhe é institucionalmente estranha (a de legislador positivo), usurpando, desse modo, no contexto de um sistema de poderes essencialmente limitados, competência que não lhe pertence, com evidente transgressão ao princípio constitucional da separação de poderes."
---
## (BERT large) Language modeling in the legal domain in Portuguese (LeNER-Br)
**bert-large-cased-pt-lenerbr** is a Language Model in the legal domain in Portuguese that was finetuned on 20/12/2021 in Google Colab from the model [BERTimbau large](https://huggingface.co/neuralmind/bert-large-portuguese-cased) on the dataset [LeNER-Br language modeling](https://huggingface.co/datasets/pierreguillou/lener_br_finetuning_language_model) by using a MASK objective.
You can check as well the [version base of this model](https://huggingface.co/pierreguillou/bert-base-cased-pt-lenerbr).
## Widget & APP
You can test this model into the widget of this page.
## Blog post
This language model is used to get a NER model on the Portuguese judicial domain. You can check the fine-tuned NER model at [pierreguillou/ner-bert-large-cased-pt-lenerbr](https://huggingface.co/pierreguillou/ner-bert-large-cased-pt-lenerbr).
All informations and links are in this blog post: [NLP | Modelos e Web App para Reconhecimento de Entidade Nomeada (NER) no domínio jurídico brasileiro](https://medium.com/@pierre_guillou/nlp-modelos-e-web-app-para-reconhecimento-de-entidade-nomeada-ner-no-dom%C3%ADnio-jur%C3%ADdico-b658db55edfb) (29/12/2021)
## Using the model for inference in production
````
# install pytorch: check https://pytorch.org/
# !pip install transformers
from transformers import AutoTokenizer, AutoModelForMaskedLM
tokenizer = AutoTokenizer.from_pretrained("pierreguillou/bert-large-cased-pt-lenerbr")
model = AutoModelForMaskedLM.from_pretrained("pierreguillou/bert-large-cased-pt-lenerbr")
````
## Training procedure
## Notebook
The notebook of finetuning ([Finetuning_language_model_BERtimbau_LeNER_Br.ipynb](https://github.com/piegu/language-models/blob/master/Finetuning_language_model_BERtimbau_LeNER_Br.ipynb)) is in github.
### Training results
````
Num examples = 3227
Num Epochs = 5
Instantaneous batch size per device = 2
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 4
Total optimization steps = 2015
Step Training Loss Validation Loss
100 1.616700 1.366015
200 1.452000 1.312473
300 1.431100 1.253055
400 1.407500 1.264705
500 1.301900 1.243277
600 1.317800 1.233684
700 1.319100 1.211826
800 1.303800 1.190818
900 1.262800 1.171898
1000 1.235900 1.146275
1100 1.221900 1.149027
1200 1.226200 1.127950
1300 1.201700 1.172729
1400 1.198200 1.145363
```` |
CM-CA/Cartman | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: pt
license: apache-2.0
tags:
- text2text-generation
- byt5
- pytorch
- qa
datasets: squad
metrics: squad
widget:
- text: 'question: "Quando começou a pandemia de Covid-19 no mundo?" context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."'
- text: 'question: "Onde foi descoberta a Covid-19?" context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."'
---
# ByT5 small finetuned for Question Answering (QA) on SQUaD v1.1 Portuguese

Check our other QA models in Portuguese finetuned on SQUAD v1.1:
- [Portuguese BERT base cased QA](https://huggingface.co/pierreguillou/bert-base-cased-squad-v1.1-portuguese)
- [Portuguese BERT large cased QA](https://huggingface.co/pierreguillou/bert-large-cased-squad-v1.1-portuguese)
- [Portuguese T5 base QA](https://huggingface.co/pierreguillou/t5-base-qa-squad-v1.1-portuguese)
## Introduction
The model was trained on the dataset SQUAD v1.1 in portuguese from the [Deep Learning Brasil group](http://www.deeplearningbrasil.com.br/) on Google Colab from the language model [ByT5 small](https://huggingface.co/google/byt5-small) of Google.
## About ByT5
ByT5 is a tokenizer-free version of [Google's T5](https://ai.googleblog.com/2020/02/exploring-transfer-learning-with-t5.html) and generally follows the architecture of [MT5](https://huggingface.co/google/mt5-small). ByT5 was only pre-trained on [mC4](https://www.tensorflow.org/datasets/catalog/c4#c4multilingual) excluding any supervised training with an average span-mask of 20 UTF-8 characters. Therefore, this model has to be fine-tuned before it is useable on a downstream task.
ByT5 works especially well on noisy text data,*e.g.*, `google/byt5-small` significantly outperforms [mt5-small](https://huggingface.co/google/mt5-small) on [TweetQA](https://arxiv.org/abs/1907.06292).
Paper: [ByT5: Towards a token-free future with pre-trained byte-to-byte models](https://arxiv.org/abs/2105.13626)
## Informations on the method used
All the informations are in the blog post : ...
## Notebooks in Google Colab & GitHub
- Google Colab: ...
- GitHub: ...
## Performance
The results obtained are the following:
```
f1 = ...
exact match = ...
```
## How to use the model... with Pipeline
```python
import transformers
from transformers import pipeline
model_name = 'pierreguillou/byt5-small-qa-squad-v1.1-portuguese'
nlp = pipeline("text2text-generation", model=model_name)
# source: https://pt.wikipedia.org/wiki/Pandemia_de_COVID-19
input_text = r"""
question: "Quando começou a pandemia de Covid-19 no mundo?"
context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
"""
input_text = input_text.replace('\n','')
input_text
# question: "Quando começou a pandemia de Covid-19 no mundo?" context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
result = nlp(input_text)
result
# [{'generated_text': '1 de dezembro de 2019'}]
```
## How to use the model... with the Auto classes
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
model_name = 'pierreguillou/byt5-small-qa-squad-v1.1-portuguese'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# source: https://pt.wikipedia.org/wiki/Pandemia_de_COVID-19
input_text = r"""
question: "Quando começou a pandemia de Covid-19 no mundo?"
context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
"""
input_text = input_text.replace('\n','')
input_text
# question: "Quando começou a pandemia de Covid-19 no mundo?" context: "A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
input_ids = tokenizer(input_text, return_tensors='pt').input_ids
outputs = model.generate(
input_ids,
max_length=64,
num_beams=1
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
result
# 1 de dezembro de 2019
```
## Limitations and bias
The training data used for this model come from Portuguese SQUAD. It could contain a lot of unfiltered content, which is far from neutral, and biases.
## Author
Portuguese ByT5 small QA (Question Answering), finetuned on SQUAD v1.1 was trained and evaluated by [Pierre GUILLOU](https://www.linkedin.com/in/pierreguillou/) thanks to the Open Source code, platforms and advices of many organizations. In particular: [Google AI](https://huggingface.co/google), [Hugging Face](https://huggingface.co/), [Deep Learning Brasil group](http://www.deeplearningbrasil.com.br/) and [Google Colab](https://colab.research.google.com/).
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{pierreguillou2021byt5smallsquadv11portuguese,
title={Portuguese ByT5 small QA (Question Answering), finetuned on SQUAD v1.1},
author={Pierre Guillou},
year={2021}
}
``` |
CM-CA/DialoGPT-small-cartman | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: pt
widget:
- text: "Quem era Jim Henson? Jim Henson era um"
- text: "Em um achado chocante, o cientista descobriu um"
- text: "Barack Hussein Obama II, nascido em 4 de agosto de 1961, é"
- text: "Corrida por vacina contra Covid-19 já tem"
license: mit
datasets:
- wikipedia
---
# GPorTuguese-2: a Language Model for Portuguese text generation (and more NLP tasks...)
## Introduction
GPorTuguese-2 (Portuguese GPT-2 small) is a state-of-the-art language model for Portuguese based on the GPT-2 small model.
It was trained on Portuguese Wikipedia using **Transfer Learning and Fine-tuning techniques** in just over a day, on one GPU NVIDIA V100 32GB and with a little more than 1GB of training data.
It is a proof-of-concept that it is possible to get a state-of-the-art language model in any language with low ressources.
It was fine-tuned from the [English pre-trained GPT-2 small](https://huggingface.co/gpt2) using the Hugging Face libraries (Transformers and Tokenizers) wrapped into the [fastai v2](https://dev.fast.ai/) Deep Learning framework. All the fine-tuning fastai v2 techniques were used.
It is now available on Hugging Face. For further information or requests, please go to "[Faster than training from scratch — Fine-tuning the English GPT-2 in any language with Hugging Face and fastai v2 (practical case with Portuguese)](https://medium.com/@pierre_guillou/faster-than-training-from-scratch-fine-tuning-the-english-gpt-2-in-any-language-with-hugging-f2ec05c98787)".
## Model
| Model | #params | Model file (pt/tf) | Arch. | Training /Validation data (text) |
|-------------------------|---------|--------------------|-------------|------------------------------------------|
| `gpt2-small-portuguese` | 124M | 487M / 475M | GPT-2 small | Portuguese Wikipedia (1.28 GB / 0.32 GB) |
## Evaluation results
In a little more than a day (we only used one GPU NVIDIA V100 32GB; through a Distributed Data Parallel (DDP) training mode, we could have divided by three this time to 10 hours, just with 2 GPUs), we got a loss of 3.17, an **accuracy of 37.99%** and a **perplexity of 23.76** (see the validation results table below).
| after ... epochs | loss | accuracy (%) | perplexity | time by epoch | cumulative time |
|------------------|------|--------------|------------|---------------|-----------------|
| 0 | 9.95 | 9.90 | 20950.94 | 00:00:00 | 00:00:00 |
| 1 | 3.64 | 32.52 | 38.12 | 5:48:31 | 5:48:31 |
| 2 | 3.30 | 36.29 | 27.16 | 5:38:18 | 11:26:49 |
| 3 | 3.21 | 37.46 | 24.71 | 6:20:51 | 17:47:40 |
| 4 | 3.19 | 37.74 | 24.21 | 6:06:29 | 23:54:09 |
| 5 | 3.17 | 37.99 | 23.76 | 6:16:22 | 30:10:31 |
## GPT-2
*Note: information copied/pasted from [Model: gpt2 >> GPT-2](https://huggingface.co/gpt2#gpt-2)*
Pretrained model on English language using a causal language modeling (CLM) objective. It was introduced in this [paper](https://d4mucfpksywv.cloudfront.net/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) and first released at this [page](https://openai.com/blog/better-language-models/) (February 14, 2019).
Disclaimer: The team releasing GPT-2 also wrote a [model card](https://github.com/openai/gpt-2/blob/master/model_card.md) for their model. Content from this model card has been written by the Hugging Face team to complete the information they provided and give specific examples of bias.
## Model description
*Note: information copied/pasted from [Model: gpt2 >> Model description](https://huggingface.co/gpt2#model-description)*
GPT-2 is a transformers model pretrained on a very large corpus of English data in a self-supervised fashion. This means it was pretrained on the raw texts only, with no humans labelling them in any way (which is why it can use lots of publicly available data) with an automatic process to generate inputs and labels from those texts. More precisely, it was trained to guess the next word in sentences.
More precisely, inputs are sequences of continuous text of a certain length and the targets are the same sequence, shifted one token (word or piece of word) to the right. The model uses internally a mask-mechanism to make sure the predictions for the token `i` only uses the inputs from `1` to `i` but not the future tokens.
This way, the model learns an inner representation of the English language that can then be used to extract features useful for downstream tasks. The model is best at what it was pretrained for however, which is generating texts from a prompt.
## How to use GPorTuguese-2 with HuggingFace (PyTorch)
The following code use PyTorch. To use TensorFlow, check the below corresponding paragraph.
### Load GPorTuguese-2 and its sub-word tokenizer (Byte-level BPE)
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
import torch
tokenizer = AutoTokenizer.from_pretrained("pierreguillou/gpt2-small-portuguese")
model = AutoModelWithLMHead.from_pretrained("pierreguillou/gpt2-small-portuguese")
# Get sequence length max of 1024
tokenizer.model_max_length=1024
model.eval() # disable dropout (or leave in train mode to finetune)
```
### Generate one word
```python
# input sequence
text = "Quem era Jim Henson? Jim Henson era um"
inputs = tokenizer(text, return_tensors="pt")
# model output
outputs = model(**inputs, labels=inputs["input_ids"])
loss, logits = outputs[:2]
predicted_index = torch.argmax(logits[0, -1, :]).item()
predicted_text = tokenizer.decode([predicted_index])
# results
print('input text:', text)
print('predicted text:', predicted_text)
# input text: Quem era Jim Henson? Jim Henson era um
# predicted text: homem
```
### Generate one full sequence
```python
# input sequence
text = "Quem era Jim Henson? Jim Henson era um"
inputs = tokenizer(text, return_tensors="pt")
# model output using Top-k sampling text generation method
sample_outputs = model.generate(inputs.input_ids,
pad_token_id=50256,
do_sample=True,
max_length=50, # put the token number you want
top_k=40,
num_return_sequences=1)
# generated sequence
for i, sample_output in enumerate(sample_outputs):
print(">> Generated text {}\n\n{}".format(i+1, tokenizer.decode(sample_output.tolist())))
# >> Generated text
# Quem era Jim Henson? Jim Henson era um executivo de televisão e diretor de um grande estúdio de cinema mudo chamado Selig,
# depois que o diretor de cinema mudo Georges Seuray dirigiu vários filmes para a Columbia e o estúdio.
```
## How to use GPorTuguese-2 with HuggingFace (TensorFlow)
The following code use TensorFlow. To use PyTorch, check the above corresponding paragraph.
### Load GPorTuguese-2 and its sub-word tokenizer (Byte-level BPE)
```python
from transformers import AutoTokenizer, TFAutoModelWithLMHead
import tensorflow as tf
tokenizer = AutoTokenizer.from_pretrained("pierreguillou/gpt2-small-portuguese")
model = TFAutoModelWithLMHead.from_pretrained("pierreguillou/gpt2-small-portuguese")
# Get sequence length max of 1024
tokenizer.model_max_length=1024
model.eval() # disable dropout (or leave in train mode to finetune)
```
### Generate one full sequence
```python
# input sequence
text = "Quem era Jim Henson? Jim Henson era um"
inputs = tokenizer.encode(text, return_tensors="tf")
# model output using Top-k sampling text generation method
outputs = model.generate(inputs, eos_token_id=50256, pad_token_id=50256,
do_sample=True,
max_length=40,
top_k=40)
print(tokenizer.decode(outputs[0]))
# >> Generated text
# Quem era Jim Henson? Jim Henson era um amigo familiar da família. Ele foi contratado pelo seu pai
# para trabalhar como aprendiz no escritório de um escritório de impressão, e então começou a ganhar dinheiro
```
## Limitations and bias
The training data used for this model come from Portuguese Wikipedia. We know it contains a lot of unfiltered content from the internet, which is far from neutral. As the openAI team themselves point out in their model card:
> Because large-scale language models like GPT-2 do not distinguish fact from fiction, we don’t support use-cases that require the generated text to be true. Additionally, language models like GPT-2 reflect the biases inherent to the systems they were trained on, so we do not recommend that they be deployed into systems that interact with humans > unless the deployers first carry out a study of biases relevant to the intended use-case. We found no statistically significant difference in gender, race, and religious bias probes between 774M and 1.5B, implying all versions of GPT-2 should be approached with similar levels of caution around use cases that are sensitive to biases around human attributes.
## Author
Portuguese GPT-2 small was trained and evaluated by [Pierre GUILLOU](https://www.linkedin.com/in/pierreguillou/) thanks to the computing power of the GPU (GPU NVIDIA V100 32 Go) of the [AI Lab](https://www.linkedin.com/company/ailab-unb/) (University of Brasilia) to which I am attached as an Associate Researcher in NLP and the participation of its directors in the definition of NLP strategy, Professors Fabricio Ataides Braz and Nilton Correia da Silva.
## Citation
If you use our work, please cite:
```bibtex
@inproceedings{pierre2020gpt2smallportuguese,
title={GPorTuguese-2 (Portuguese GPT-2 small): a Language Model for Portuguese text generation (and more NLP tasks...)},
author={Pierre Guillou},
year={2020}
}
```
|
CNT-UPenn/Bio_ClinicalBERT_for_seizureFreedom_classification | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | null | ---
language:
- pt
tags:
- generated_from_trainer
datasets:
- lener_br
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: checkpoints
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: lener_br
type: lener_br
metrics:
- name: F1
type: f1
value: 0.8926146010186757
- name: Precision
type: precision
value: 0.8810222036028488
- name: Recall
type: recall
value: 0.9045161290322581
- name: Accuracy
type: accuracy
value: 0.9759397808828684
- name: Loss
type: loss
value: 0.18803243339061737
widget:
- text: "Ao Instituto Médico Legal da jurisdição do acidente ou da residência cumpre fornecer, no prazo de 90 dias, laudo à vítima (art. 5, § 5, Lei n. 6.194/74 de 19 de dezembro de 1974), função técnica que pode ser suprida por prova pericial realizada por ordem do juízo da causa, ou por prova técnica realizada no âmbito administrativo que se mostre coerente com os demais elementos de prova constante dos autos."
- text: "Acrescento que não há de se falar em violação do artigo 114, § 3º, da Constituição Federal, posto que referido dispositivo revela-se impertinente, tratando da possibilidade de ajuizamento de dissídio coletivo pelo Ministério Público do Trabalho nos casos de greve em atividade essencial."
- text: "Dispõe sobre o estágio de estudantes; altera a redação do art. 428 da Consolidação das Leis do Trabalho – CLT, aprovada pelo Decreto-Lei no 5.452, de 1o de maio de 1943, e a Lei no 9.394, de 20 de dezembro de 1996; revoga as Leis nos 6.494, de 7 de dezembro de 1977, e 8.859, de 23 de março de 1994, o parágrafo único do art. 82 da Lei no 9.394, de 20 de dezembro de 1996, e o art. 6o da Medida Provisória no 2.164-41, de 24 de agosto de 2001; e dá outras providências."
---
## (BERT base) NER model in the legal domain in Portuguese (LeNER-Br)
**ner-bert-base-portuguese-cased-lenerbr** is a NER model (token classification) in the legal domain in Portuguese that was finetuned on 20/12/2021 in Google Colab from the model [pierreguillou/bert-base-cased-pt-lenerbr](https://huggingface.co/pierreguillou/bert-base-cased-pt-lenerbr) on the dataset [LeNER_br](https://huggingface.co/datasets/lener_br) by using a NER objective.
Due to the small size of BERTimbau base and finetuning dataset, the model overfitted before to reach the end of training. Here are the overall final metrics on the validation dataset (*note: see the paragraph "Validation metrics by Named Entity" to get detailed metrics*):
- **f1**: 0.8926146010186757
- **precision**: 0.8810222036028488
- **recall**: 0.9045161290322581
- **accuracy**: 0.9759397808828684
- **loss**: 0.18803243339061737
Check as well the [large version of this model](https://huggingface.co/pierreguillou/ner-bert-large-cased-pt-lenerbr) with a f1 of 0.908.
**Note**: the model [pierreguillou/bert-base-cased-pt-lenerbr](https://huggingface.co/pierreguillou/bert-base-cased-pt-lenerbr) is a language model that was created through the finetuning of the model [BERTimbau base](https://huggingface.co/neuralmind/bert-base-portuguese-cased) on the dataset [LeNER-Br language modeling](https://huggingface.co/datasets/pierreguillou/lener_br_finetuning_language_model) by using a MASK objective. This first specialization of the language model before finetuning on the NER task improved a bit the model quality. To prove it, here are the results of the NER model finetuned from the model [BERTimbau base](https://huggingface.co/neuralmind/bert-base-portuguese-cased) (a non-specialized language model):
- **f1**: 0.8716487228203504
- **precision**: 0.8559286898839138
- **recall**: 0.8879569892473118
- **accuracy**: 0.9755893153732458
- **loss**: 0.1133928969502449
## Blog post
[NLP | Modelos e Web App para Reconhecimento de Entidade Nomeada (NER) no domínio jurídico brasileiro](https://medium.com/@pierre_guillou/nlp-modelos-e-web-app-para-reconhecimento-de-entidade-nomeada-ner-no-dom%C3%ADnio-jur%C3%ADdico-b658db55edfb) (29/12/2021)
## Widget & App
You can test this model into the widget of this page.
Use as well the [NER App](https://huggingface.co/spaces/pierreguillou/ner-bert-pt-lenerbr) that allows comparing the 2 BERT models (base and large) fitted in the NER task with the legal LeNER-Br dataset.
## Using the model for inference in production
````
# install pytorch: check https://pytorch.org/
# !pip install transformers
from transformers import AutoModelForTokenClassification, AutoTokenizer
import torch
# parameters
model_name = "pierreguillou/ner-bert-base-cased-pt-lenerbr"
model = AutoModelForTokenClassification.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
input_text = "Acrescento que não há de se falar em violação do artigo 114, § 3º, da Constituição Federal, posto que referido dispositivo revela-se impertinente, tratando da possibilidade de ajuizamento de dissídio coletivo pelo Ministério Público do Trabalho nos casos de greve em atividade essencial."
# tokenization
inputs = tokenizer(input_text, max_length=512, truncation=True, return_tensors="pt")
tokens = inputs.tokens()
# get predictions
outputs = model(**inputs).logits
predictions = torch.argmax(outputs, dim=2)
# print predictions
for token, prediction in zip(tokens, predictions[0].numpy()):
print((token, model.config.id2label[prediction]))
````
You can use pipeline, too. However, it seems to have an issue regarding to the max_length of the input sequence.
````
!pip install transformers
import transformers
from transformers import pipeline
model_name = "pierreguillou/ner-bert-base-cased-pt-lenerbr"
ner = pipeline(
"ner",
model=model_name
)
ner(input_text)
````
## Training procedure
### Notebook
The notebook of finetuning ([HuggingFace_Notebook_token_classification_NER_LeNER_Br.ipynb](https://github.com/piegu/language-models/blob/master/HuggingFace_Notebook_token_classification_NER_LeNER_Br.ipynb)) is in github.
### Hyperparameters
#### batch, learning rate...
- per_device_batch_size = 2
- gradient_accumulation_steps = 2
- learning_rate = 2e-5
- num_train_epochs = 10
- weight_decay = 0.01
- optimizer = AdamW
- betas = (0.9,0.999)
- epsilon = 1e-08
- lr_scheduler_type = linear
- seed = 7
#### save model & load best model
- save_total_limit = 2
- logging_steps = 300
- eval_steps = logging_steps
- evaluation_strategy = 'steps'
- logging_strategy = 'steps'
- save_strategy = 'steps'
- save_steps = logging_steps
- load_best_model_at_end = True
- fp16 = True
#### get best model through a metric
- metric_for_best_model = 'eval_f1'
- greater_is_better = True
### Training results
````
Num examples = 7828
Num Epochs = 10
Instantaneous batch size per device = 2
Total train batch size (w. parallel, distributed & accumulation) = 4
Gradient Accumulation steps = 2
Total optimization steps = 19570
Step Training Loss Validation Loss Precision Recall F1 Accuracy
300 0.127600 0.178613 0.722909 0.741720 0.732194 0.948802
600 0.088200 0.136965 0.733636 0.867742 0.795074 0.963079
900 0.078000 0.128858 0.791912 0.838065 0.814335 0.965243
1200 0.077800 0.126345 0.815400 0.865376 0.839645 0.967849
1500 0.074100 0.148207 0.779274 0.895914 0.833533 0.960184
1800 0.059500 0.116634 0.830829 0.868172 0.849090 0.969342
2100 0.044500 0.208459 0.887150 0.816559 0.850392 0.960535
2400 0.029400 0.136352 0.867821 0.851398 0.859531 0.970271
2700 0.025000 0.165837 0.814881 0.878495 0.845493 0.961235
3000 0.038400 0.120629 0.811719 0.893763 0.850768 0.971506
3300 0.026200 0.175094 0.823435 0.882581 0.851983 0.962957
3600 0.025600 0.178438 0.881095 0.886022 0.883551 0.963689
3900 0.041000 0.134648 0.789035 0.916129 0.847846 0.967681
4200 0.026700 0.130178 0.821275 0.903226 0.860303 0.972313
4500 0.018500 0.139294 0.844016 0.875054 0.859255 0.971140
4800 0.020800 0.197811 0.892504 0.873118 0.882705 0.965883
5100 0.019300 0.161239 0.848746 0.888172 0.868012 0.967849
5400 0.024000 0.139131 0.837507 0.913333 0.873778 0.970591
5700 0.018400 0.157223 0.899754 0.864731 0.881895 0.970210
6000 0.023500 0.137022 0.883018 0.873333 0.878149 0.973243
6300 0.009300 0.181448 0.840490 0.900860 0.869628 0.968290
6600 0.019200 0.173125 0.821316 0.896559 0.857290 0.966736
6900 0.016100 0.143160 0.789938 0.904946 0.843540 0.968245
7200 0.017000 0.145755 0.823274 0.897634 0.858848 0.969037
7500 0.012100 0.159342 0.825694 0.883226 0.853491 0.967468
7800 0.013800 0.194886 0.861237 0.859570 0.860403 0.964771
8100 0.008000 0.140271 0.829914 0.896129 0.861752 0.971567
8400 0.010300 0.143318 0.826844 0.908817 0.865895 0.973578
8700 0.015000 0.143392 0.847336 0.889247 0.867786 0.973365
9000 0.006000 0.143512 0.847795 0.905591 0.875741 0.972892
9300 0.011800 0.138747 0.827133 0.894194 0.859357 0.971673
9600 0.008500 0.159490 0.837030 0.909032 0.871546 0.970028
9900 0.010700 0.159249 0.846692 0.910968 0.877655 0.970546
10200 0.008100 0.170069 0.848288 0.900645 0.873683 0.969113
10500 0.004800 0.183795 0.860317 0.899355 0.879403 0.969570
10800 0.010700 0.157024 0.837838 0.906667 0.870894 0.971094
11100 0.003800 0.164286 0.845312 0.880215 0.862410 0.970744
11400 0.009700 0.204025 0.884294 0.887527 0.885907 0.968854
11700 0.008900 0.162819 0.829415 0.887742 0.857588 0.970530
12000 0.006400 0.164296 0.852666 0.901075 0.876202 0.971414
12300 0.007100 0.143367 0.852959 0.895699 0.873807 0.973669
12600 0.015800 0.153383 0.859224 0.900430 0.879345 0.972679
12900 0.006600 0.173447 0.869954 0.899140 0.884306 0.970927
13200 0.006800 0.163234 0.856849 0.897204 0.876563 0.971795
13500 0.003200 0.167164 0.850867 0.907957 0.878485 0.971231
13800 0.003600 0.148950 0.867801 0.910538 0.888656 0.976961
14100 0.003500 0.155691 0.847621 0.907957 0.876752 0.974127
14400 0.003300 0.157672 0.846553 0.911183 0.877680 0.974584
14700 0.002500 0.169965 0.847804 0.917634 0.881338 0.973045
15000 0.003400 0.177099 0.842199 0.912473 0.875929 0.971155
15300 0.006000 0.164151 0.848928 0.911183 0.878954 0.973258
15600 0.002400 0.174305 0.847437 0.906667 0.876052 0.971765
15900 0.004100 0.174561 0.852929 0.907957 0.879583 0.972907
16200 0.002600 0.172626 0.843263 0.907097 0.874016 0.972100
16500 0.002100 0.185302 0.841108 0.907312 0.872957 0.970485
16800 0.002900 0.175638 0.840557 0.909247 0.873554 0.971704
17100 0.001600 0.178750 0.857056 0.906452 0.881062 0.971765
17400 0.003900 0.188910 0.853619 0.907957 0.879950 0.970835
17700 0.002700 0.180822 0.864699 0.907097 0.885390 0.972283
18000 0.001300 0.179974 0.868150 0.906237 0.886785 0.973060
18300 0.000800 0.188032 0.881022 0.904516 0.892615 0.972572
18600 0.002700 0.183266 0.868601 0.901290 0.884644 0.972298
18900 0.001600 0.180301 0.862041 0.903011 0.882050 0.972344
19200 0.002300 0.183432 0.855370 0.904301 0.879155 0.971109
19500 0.001800 0.183381 0.854501 0.904301 0.878696 0.971186
````
### Validation metrics by Named Entity
````
Num examples = 1177
{'JURISPRUDENCIA': {'f1': 0.7016574585635359,
'number': 657,
'precision': 0.6422250316055625,
'recall': 0.7732115677321156},
'LEGISLACAO': {'f1': 0.8839681133746677,
'number': 571,
'precision': 0.8942652329749103,
'recall': 0.8739054290718039},
'LOCAL': {'f1': 0.8253968253968254,
'number': 194,
'precision': 0.7368421052631579,
'recall': 0.9381443298969072},
'ORGANIZACAO': {'f1': 0.8934049079754601,
'number': 1340,
'precision': 0.918769716088328,
'recall': 0.8694029850746269},
'PESSOA': {'f1': 0.982653539615565,
'number': 1072,
'precision': 0.9877474081055608,
'recall': 0.9776119402985075},
'TEMPO': {'f1': 0.9657657657657657,
'number': 816,
'precision': 0.9469964664310954,
'recall': 0.9852941176470589},
'overall_accuracy': 0.9725722644643211,
'overall_f1': 0.8926146010186757,
'overall_precision': 0.8810222036028488,
'overall_recall': 0.9045161290322581}
```` |
CSResearcher/TestModel | [
"license:mit"
] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-01-26T19:11:04Z | ---
language:
- pt
tags:
- text2text-generation
- t5
- pytorch
- qa
datasets:
- squad
- squad_v1_pt
metrics:
- precision
- recall
- f1
- accuracy
- squad
model-index:
- name: checkpoints
results:
- task:
name: text2text-generation
type: text2text-generation
dataset:
name: squad
type: squad
metrics:
- name: f1
type: f1
value: 79.3
- name: exact-match
type: exact-match
value: 67.3983
widget:
- text: "question: Quando começou a pandemia de Covid-19 no mundo? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
- text: "question: Onde foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano."
---
# T5 base finetuned for Question Answering (QA) on SQUaD v1.1 Portuguese
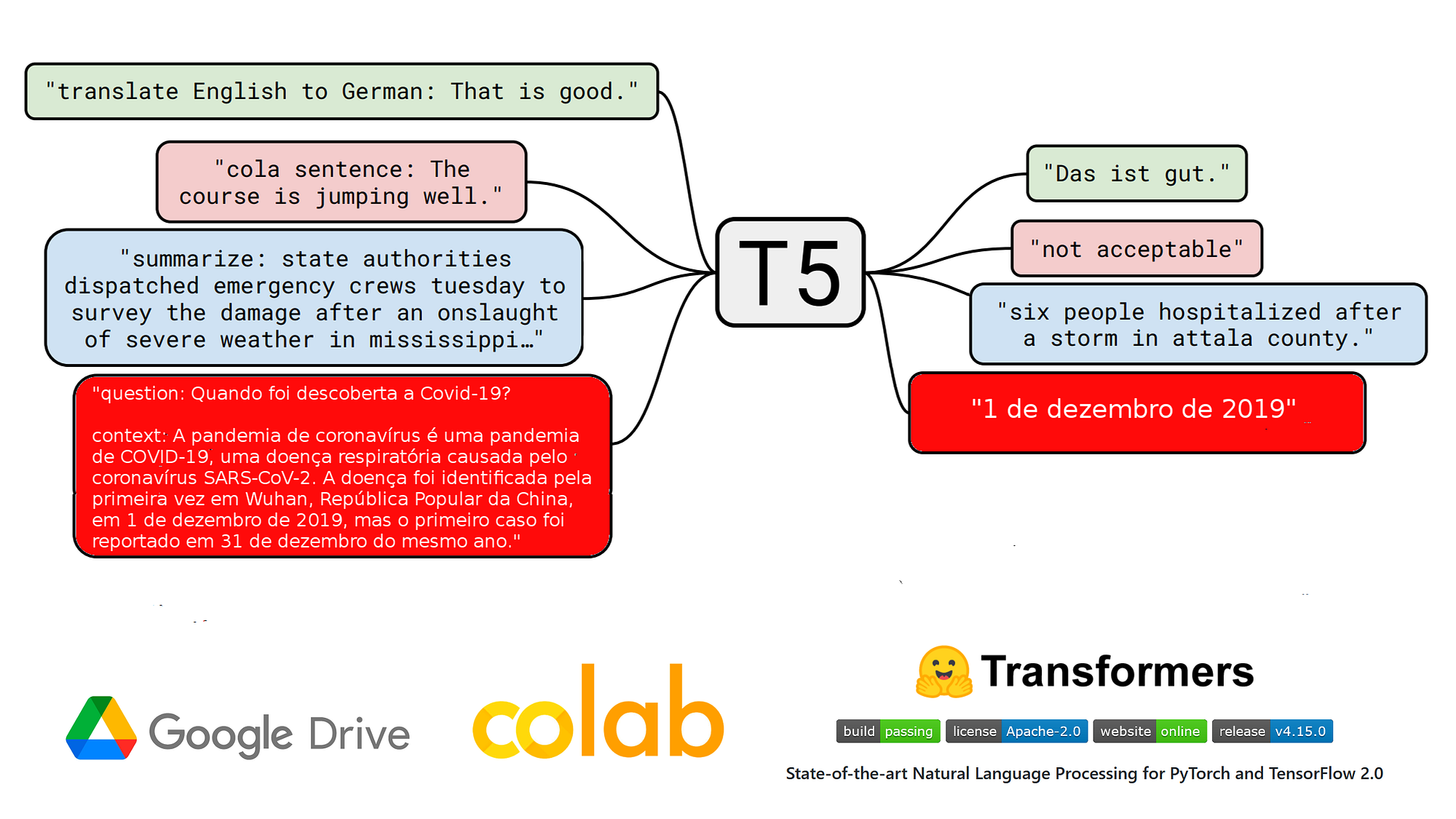
## Introduction
**t5-base-qa-squad-v1.1-portuguese** is a QA model (Question Answering) in Portuguese that was finetuned on 27/01/2022 in Google Colab from the model [unicamp-dl/ptt5-base-portuguese-vocab](https://huggingface.co/unicamp-dl/ptt5-base-portuguese-vocab) of Neuralmind on the dataset SQUAD v1.1 in portuguese from the [Deep Learning Brasil group](http://www.deeplearningbrasil.com.br/) by using a Test2Text-Generation objective.
Due to the small size of T5 base and finetuning dataset, the model overfitted before to reach the end of training. Here are the overall final metrics on the validation dataset:
- **f1**: 79.3
- **exact_match**: 67.3983
Check our other QA models in Portuguese finetuned on SQUAD v1.1:
- [Portuguese BERT base cased QA](https://huggingface.co/pierreguillou/bert-base-cased-squad-v1.1-portuguese)
- [Portuguese BERT large cased QA](https://huggingface.co/pierreguillou/bert-large-cased-squad-v1.1-portuguese)
- [Portuguese ByT5 small QA](https://huggingface.co/pierreguillou/byt5-small-qa-squad-v1.1-portuguese)
## Blog post
[NLP nas empresas | Como eu treinei um modelo T5 em português na tarefa QA no Google Colab](https://medium.com/@pierre_guillou/nlp-nas-empresas-como-eu-treinei-um-modelo-t5-em-portugu%C3%AAs-na-tarefa-qa-no-google-colab-e8eb0dc38894) (27/01/2022)
## Widget & App
You can test this model into the widget of this page.
Use as well the [QA App | T5 base pt](https://huggingface.co/spaces/pierreguillou/question-answering-portuguese-t5-base) that allows using the model T5 base finetuned on the QA task with the SQuAD v1.1 pt dataset.
## Using the model for inference in production
````
# install pytorch: check https://pytorch.org/
# !pip install transformers
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
# model & tokenizer
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForSeq2SeqLM.from_pretrained(model_name)
# parameters
max_target_length=32
num_beams=1
early_stopping=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
inputs = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(inputs["input_ids"],
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping
)
pred = tokenizer.decode(outputs[0], skip_special_tokens=True, clean_up_tokenization_spaces=True)
print('true answer |', label)
print('pred |', pred)
````
You can use pipeline, too. However, it seems to have an issue regarding to the max_length of the input sequence.
````
!pip install transformers
import transformers
from transformers import pipeline
# model
model_name = "pierreguillou/t5-base-qa-squad-v1.1-portuguese"
# parameters
max_target_length=32
num_beams=1
early_stopping=True
clean_up_tokenization_spaces=True
input_text = 'question: Quando foi descoberta a Covid-19? context: A pandemia de COVID-19, também conhecida como pandemia de coronavírus, é uma pandemia em curso de COVID-19, uma doença respiratória aguda causada pelo coronavírus da síndrome respiratória aguda grave 2 (SARS-CoV-2). A doença foi identificada pela primeira vez em Wuhan, na província de Hubei, República Popular da China, em 1 de dezembro de 2019, mas o primeiro caso foi reportado em 31 de dezembro do mesmo ano.'
label = '1 de dezembro de 2019'
text2text = pipeline(
"text2text-generation",
model=model_name,
max_length=max_target_length,
num_beams=num_beams,
early_stopping=early_stopping,
clean_up_tokenization_spaces=clean_up_tokenization_spaces
)
pred = text2text(input_text)
print('true answer |', label)
print('pred |', pred)
````
## Training procedure
### Notebook
The notebook of finetuning ([HuggingFace_Notebook_t5-base-portuguese-vocab_question_answering_QA_squad_v11_pt.ipynb](https://github.com/piegu/language-models/blob/master/HuggingFace_Notebook_t5_base_portuguese_vocab_question_answering_QA_squad_v11_pt.ipynb)) is in github.
### Hyperparameters
````
# do training and evaluation
do_train = True
do_eval= True
# batch
batch_size = 4
gradient_accumulation_steps = 3
per_device_train_batch_size = batch_size
per_device_eval_batch_size = per_device_train_batch_size*16
# LR, wd, epochs
learning_rate = 1e-4
weight_decay = 0.01
num_train_epochs = 10
fp16 = True
# logs
logging_strategy = "steps"
logging_first_step = True
logging_steps = 3000 # if logging_strategy = "steps"
eval_steps = logging_steps
# checkpoints
evaluation_strategy = logging_strategy
save_strategy = logging_strategy
save_steps = logging_steps
save_total_limit = 3
# best model
load_best_model_at_end = True
metric_for_best_model = "f1" #"loss"
if metric_for_best_model == "loss":
greater_is_better = False
else:
greater_is_better = True
# evaluation
num_beams = 1
````
### Training results
````
Num examples = 87510
Num Epochs = 10
Instantaneous batch size per device = 4
Total train batch size (w. parallel, distributed & accumulation) = 12
Gradient Accumulation steps = 3
Total optimization steps = 72920
Step Training Loss Exact Match F1
3000 0.776100 61.807001 75.114517
6000 0.545900 65.260170 77.468930
9000 0.460500 66.556291 78.491938
12000 0.393400 66.821192 78.745397
15000 0.379800 66.603595 78.815515
18000 0.298100 67.578051 79.287899
21000 0.303100 66.991485 78.979669
24000 0.251600 67.275307 78.929923
27000 0.237500 66.972564 79.333612
30000 0.220500 66.915799 79.236574
33000 0.182600 67.029328 78.964212
36000 0.190600 66.982025 79.086125
```` |
CSZay/bart | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: en
tags:
- html
license: apache-2.0
datasets:
- squadv2
inference:
parameters:
handle_impossible_answer: true
---
Txt |
CTBC/ATS | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
inference:
parameters:
aggregation_strategy: first
---
. |
CZWin32768/xlm-align | [
"pytorch",
"xlm-roberta",
"fill-mask",
"arxiv:2106.06381",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"XLMRobertaForMaskedLM"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
tags: autonlp
language: en
widget:
- text: "I love AutoNLP 🤗"
datasets:
- pierric/autonlp-data-my-own-imdb-sentiment-analysis
---
# Model Trained Using AutoNLP
- Problem type: Binary Classification
- Model ID: 2131817
## Validation Metrics
- Loss: 0.24430708587169647
- Accuracy: 0.9452
- Precision: 0.9303944315545244
- Recall: 0.9624
- AUC: 0.9793824287999999
- F1: 0.946126622099882
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/models/pierric/autonlp-my-own-imdb-sentiment-analysis-2131817
```
Or Python API:
```
from transformers import AutoModelForSequenceClassification, AutoTokenizer
model = AutoModelForSequenceClassification.from_pretrained("pierric/autonlp-my-own-imdb-sentiment-analysis-2131817", use_auth_token=True)
tokenizer = AutoTokenizer.from_pretrained("pierric/autonlp-my-own-imdb-sentiment-analysis-2131817", use_auth_token=True)
inputs = tokenizer("I love AutoNLP", return_tensors="pt")
outputs = model(**inputs)
``` |
Caddy/UD | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: ny-cr-fr
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.9305555820465088
---
# ny-cr-fr
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### new york

#### playas del coco, costa rica

#### toulouse
 |
Calamarii/calamari | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: eo
thumbnail: https://huggingface.co/blog/assets/EsperBERTo-thumbnail-v2.png
---
## EsperBERTo: RoBERTa-like Language model trained on Esperanto
**Companion model to blog post https://huggingface.co/blog/how-to-train** 🔥
### Training Details
- current checkpoint: 566000
- machine name: `galinette`
|
CalvinHuang/mt5-small-finetuned-amazon-en-es | [
"pytorch",
"tensorboard",
"mt5",
"text2text-generation",
"transformers",
"summarization",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible"
] | summarization | {
"architectures": [
"MT5ForConditionalGeneration"
],
"model_type": "mt5",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 16 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- tweet_eval
metrics:
- f1
model-index:
- name: hate_trained
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: tweet_eval
type: tweet_eval
args: hate
metrics:
- name: F1
type: f1
value: 0.7730369969869401
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# hate_trained
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the tweet_eval dataset.
It achieves the following results on the evaluation set:
- Loss: 0.9661
- F1: 0.7730
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 9.303025140957233e-06
- train_batch_size: 4
- eval_batch_size: 4
- seed: 0
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 0.4767 | 1.0 | 2250 | 0.5334 | 0.7717 |
| 0.4342 | 2.0 | 4500 | 0.7633 | 0.7627 |
| 0.3813 | 3.0 | 6750 | 0.9452 | 0.7614 |
| 0.3118 | 4.0 | 9000 | 0.9661 | 0.7730 |
### Framework versions
- Transformers 4.13.0
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
Cameron/BERT-Jigsaw | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 35 | null | ---
language: da
tags:
- danish
- bert
- sentiment
- analytical
license: cc-by-4.0
widget:
- text: "Jeg synes, det er en elendig film"
---
# Danish BERT fine-tuned for Detecting 'Analytical'
This model detects if a Danish text is 'subjective' or 'objective'.
It is trained and tested on Tweets and texts transcribed from the European Parliament annotated by [Alexandra Institute](https://github.com/alexandrainst). The model is trained with the [`senda`](https://github.com/ebanalyse/senda) package.
Here is an example of how to load the model in PyTorch using the [🤗Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("pin/analytical")
model = AutoModelForSequenceClassification.from_pretrained("pin/analytical")
# create 'senda' sentiment analysis pipeline
analytical_pipeline = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
text = "Jeg synes, det er en elendig film"
# in English: 'I think, it is a terrible movie'
analytical_pipeline(text)
```
## Performance
The `senda` model achieves an accuracy of 0.89 and a macro-averaged F1-score of 0.78 on a small test data set, that [Alexandra Institute](https://github.com/alexandrainst/danlp/blob/master/docs/docs/datasets.md#twitter-sentiment) provides. The model can most certainly be improved, and we encourage all NLP-enthusiasts to give it their best shot - you can use the [`senda`](https://github.com/ebanalyse/senda) package to do this.
#### Contact
Feel free to contact author Lars Kjeldgaard on [[email protected]](mailto:[email protected]).
|
Cameron/BERT-SBIC-offensive | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 31 | null | ---
language: da
tags:
- danish
- bert
- sentiment
- polarity
license: cc-by-4.0
widget:
- text: "Sikke en dejlig dag det er i dag"
---
# Danish BERT fine-tuned for Sentiment Analysis with `senda`
This model detects polarity ('positive', 'neutral', 'negative') of Danish texts.
It is trained and tested on Tweets annotated by [Alexandra Institute](https://github.com/alexandrainst). The model is trained with the [`senda`](https://github.com/ebanalyse/senda) package.
Here is an example of how to load the model in PyTorch using the [🤗Transformers](https://github.com/huggingface/transformers) library:
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification, pipeline
tokenizer = AutoTokenizer.from_pretrained("pin/senda")
model = AutoModelForSequenceClassification.from_pretrained("pin/senda")
# create 'senda' sentiment analysis pipeline
senda_pipeline = pipeline('sentiment-analysis', model=model, tokenizer=tokenizer)
text = "Sikke en dejlig dag det er i dag"
# in English: 'what a lovely day'
senda_pipeline(text)
```
## Performance
The `senda` model achieves an accuracy of 0.77 and a macro-averaged F1-score of 0.73 on a small test data set, that [Alexandra Institute](https://github.com/alexandrainst/danlp/blob/master/docs/docs/datasets.md#twitter-sentiment) provides. The model can most certainly be improved, and we encourage all NLP-enthusiasts to give it their best shot - you can use the [`senda`](https://github.com/ebanalyse/senda) package to do this.
#### Contact
Feel free to contact author Lars Kjeldgaard on [[email protected]](mailto:[email protected]).
#### Shout-outs
Props to [Malte Højmark-Berthelsen](mailto:[email protected]) for pretraining Danish BERT and helping out adding a TensorFlow backend for `senda`.
|
Cameron/BERT-SBIC-targetcategory | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | # Med-QP Cross Encoder
Demo model for use as part of Augmented SBERT chapters of the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp). |
Cameron/BERT-eec-emotion | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 36 | null | # MRPC Cross Encoder
Demo model for use as part of Augmented SBERT chapters of the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp). |
Cameron/BERT-jigsaw-identityhate | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 37 | null | # Quora-QP Cross Encoder
Demo model for use as part of Augmented SBERT chapters of the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp). |
Cameron/BERT-mdgender-convai-binary | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 33 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 5429 with parameters:
```
{'batch_size': 24}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 542,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Cameron/BERT-mdgender-convai-ternary | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 38 | null | # RTE Cross Encoder
Demo model for use as part of Augmented SBERT chapters of the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp). |
Cameron/BERT-mdgender-wizard | [
"pytorch",
"jax",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 30 | null | # STSb Cross Encoder
Demo model for use as part of Augmented SBERT chapters of the [NLP for Semantic Search course](https://www.pinecone.io/learn/nlp). |
Camzure/MaamiBot-test | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 5429 with parameters:
```
{'batch_size': 24}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 542,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: MPNetModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
Capreolus/birch-bert-large-car_mb | [
"pytorch",
"tf",
"jax",
"bert",
"next-sentence-prediction",
"transformers"
] | null | {
"architectures": [
"BertForNextSentencePrediction"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 512 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 6098 with parameters:
```
{'batch_size': 4, 'sampler': 'torch.utils.data.sampler.RandomSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.ContrastiveLoss.ContrastiveLoss` with parameters:
```
{'distance_metric': 'SiameseDistanceMetric.COSINE_DISTANCE', 'margin': 0.5, 'size_average': True}
```
Parameters of the fit()-Method:
```
{
"callback": null,
"epochs": 5,
"evaluation_steps": 0,
"evaluator": "sentence_transformers.evaluation.BinaryClassificationEvaluator.BinaryClassificationEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'transformers.optimization.AdamW'>",
"optimizer_params": {
"lr": 1e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 3049,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 1024, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
(2): Dense({'in_features': 1024, 'out_features': 512, 'bias': True, 'activation_function': 'torch.nn.modules.activation.Tanh'})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
dccuchile/albert-base-spanish-finetuned-pos | [
"pytorch",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | * Install requirements
```
pip install jieba
```
* Generate words.txt
```bash
data_dir=/path/to/wenetspeech
# the data_dir contains:
# tree -L 2 .
# .
# |-- TERMS_OF_ACCESS
# |-- WenetSpeech.json
# |-- audio
# |-- dev
# |-- test_meeting
# |-- test_net
# `-- train
grep "\"text\":" $data_dir/WenetSpeech.json | sed -e 's/["text: ]*//g' > text.txt
python -m jieba -d " " text.txt > tokenized.txt
cat tokenized.txt | awk '{for(i=1;i<=NF;i++)print $i}' | sort | uniq > words.txt
```
* Generate N-gram model
```
``` |
dccuchile/albert-tiny-spanish-finetuned-ner | [
"pytorch",
"albert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"AlbertForTokenClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language: fr
tags:
- pytorch
- t5
- seq2seq
- summarization
datasets: cnn_dailymail
widget:
- text: "Apollo 11 est une mission du programme spatial américain Apollo au cours de laquelle, pour la première fois, des hommes se sont posés sur la Lune, le lundi 21 juillet 1969. L'agence spatiale américaine, la NASA, remplit ainsi l'objectif fixé par le président John F. Kennedy en 1961 de poser un équipage sur la Lune avant la fin de la décennie 1960. Il s'agissait de démontrer la supériorité des États-Unis sur l'Union soviétique qui avait été mise à mal par les succès soviétiques au début de l'ère spatiale dans le contexte de la guerre froide qui oppose alors ces deux pays. Ce défi est lancé alors que la NASA n'a pas encore placé en orbite un seul astronaute. Grâce à une mobilisation de moyens humains et financiers considérables, l'agence spatiale rattrape puis dépasse le programme spatial soviétique."
example_title: "Apollo 11"
---
# French T5 Abstractive Text Summarization
~~Version 1.0 (I will keep improving the model's performances.)~~
Version 2.0 is here! (with improved performances of course)
I trained the model on 13x more data than v1.
ROUGE-1: 44.5252
ROUGE-2: 22.652
ROUGE-L: 29.8866
## Model description
This model is a T5 Transformers model (JDBN/t5-base-fr-qg-fquad) that was fine-tuned in french for abstractive text summarization.
## How to use
```python
from transformers import T5Tokenizer, T5ForConditionalGeneration
tokenizer = T5Tokenizer.from_pretrained("plguillou/t5-base-fr-sum-cnndm")
model = T5ForConditionalGeneration.from_pretrained("plguillou/t5-base-fr-sum-cnndm")
```
To summarize an ARTICLE, just modify the string like this : "summarize: ARTICLE".
## Training data
The base model I used is JDBN/t5-base-fr-qg-fquad (it can perform question generation, question answering and answer extraction).
I used the "t5-base" model from the transformers library to translate in french the CNN / Daily Mail summarization dataset.
|
dccuchile/albert-xlarge-spanish-finetuned-qa-mlqa | [
"pytorch",
"albert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"AlbertForQuestionAnswering"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | language: en
tags:
- sentiment
- distilbert-
pipeline_tag: text-classification
|
dccuchile/albert-xxlarge-spanish-finetuned-mldoc | [
"pytorch",
"albert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"AlbertForSequenceClassification"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26 | null | ---
license: apache-2.0
language:
- es
tags:
- common_voice_8_0
- generated_from_trainer
- hf-asr-leaderboard
- mozilla-foundation/common_voice_8_0
- robust-speech-event
datasets:
- mozilla-foundation/common_voice_8_0
model-index:
- name: wave2vec-xls-r-300m-es
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: mozilla-foundation/common_voice_8_0 es
type: mozilla-foundation/common_voice_8_0
args: es
metrics:
- name: Test WER
type: wer
value: 14.6
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: es
metrics:
- name: Test WER
type: wer
value: 28.63
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: es
metrics:
- name: Test WER
type: wer
value: 29.72
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Wav2Vec2-XLSR-300m-es
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the spanish common_voice dataset thanks to the GPU credits generously given by the OVHcloud for the Speech Recognition challenge.
It achieves the following results on the evaluation set
Without LM:
- Loss : 0.1900
- Wer : 0.146
With 5-gram:
- WER: 0.109
- CER: 0.036
### Usage with 5-gram.
The model can be used with n-gram (n=5) included in the processor as follows.
```python
import re
from transformers import AutoModelForCTC,Wav2Vec2ProcessorWithLM
import torch
# Loading model and processor
processor = Wav2Vec2ProcessorWithLM.from_pretrained("polodealvarado/xls-r-300m-es")
model = AutoModelForCTC.from_pretrained("polodealvarado/xls-r-300m-es")
# Cleaning characters
def remove_extra_chars(batch):
chars_to_ignore_regex = '[^a-záéíóúñ ]'
text = batch["translation"][target_lang]
batch["text"] = re.sub(chars_to_ignore_regex, "", text.lower())
return batch
# Preparing dataset
def prepare_dataset(batch):
audio = batch["audio"]
batch["input_values"] = processor(audio["array"], sampling_rate=audio["sampling_rate"],return_tensors="pt",padding=True).input_values[0]
with processor.as_target_processor():
batch["labels"] = processor(batch["sentence"]).input_ids
return batch
common_voice_test = load_dataset("mozilla-foundation/common_voice_8_0", "es", split="test",use_auth_token=True)
common_voice_test = common_voice_test.remove_columns(["accent", "age", "client_id", "down_votes", "gender", "locale", "segment", "up_votes"])
common_voice_test = common_voice_test.cast_column("audio", Audio(sampling_rate=16_000))
common_voice_test = common_voice_test.map(remove_extra_chars, remove_columns=dataset.column_names)
common_voice_test = common_voice_test.map(prepare_dataset)
# Testing first sample
inputs = torch_tensor(common_voice_test[0]["input_values"])
with torch.no_grad():
logits = model(inputs).logits
pred_ids = torch.argmax(logits, dim=-1)
text = processor.batch_decode(logits.numpy()).text
print(text) # 'bien y qué regalo vas a abrir primero'
```
On the other, you can execute the eval.py file for evaluation
```bash
# To use GPU: --device 0
$ python eval.py --model_id polodealvarado/xls-r-300m-es --dataset mozilla-foundation/common_voice_8_0 --config es --device 0 --split test
```
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.6747 | 0.3 | 400 | 0.6535 | 0.5926 |
| 0.4439 | 0.6 | 800 | 0.3753 | 0.3193 |
| 0.3291 | 0.9 | 1200 | 0.3267 | 0.2721 |
| 0.2644 | 1.2 | 1600 | 0.2816 | 0.2311 |
| 0.24 | 1.5 | 2000 | 0.2647 | 0.2179 |
| 0.2265 | 1.79 | 2400 | 0.2406 | 0.2048 |
| 0.1994 | 2.09 | 2800 | 0.2357 | 0.1869 |
| 0.1613 | 2.39 | 3200 | 0.2242 | 0.1821 |
| 0.1546 | 2.69 | 3600 | 0.2123 | 0.1707 |
| 0.1441 | 2.99 | 4000 | 0.2067 | 0.1619 |
| 0.1138 | 3.29 | 4400 | 0.2044 | 0.1519 |
| 0.1072 | 3.59 | 4800 | 0.1917 | 0.1457 |
| 0.0992 | 3.89 | 5200 | 0.1900 | 0.1438 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.11.0
|
dccuchile/albert-tiny-spanish | [
"pytorch",
"tf",
"albert",
"pretraining",
"es",
"dataset:large_spanish_corpus",
"transformers",
"spanish",
"OpenCENIA"
] | null | {
"architectures": [
"AlbertForPreTraining"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 393 | null | ---
language:
- th
tags:
- sentiment-analysis
license: apache-2.0
datasets:
- wongnai_reviews
- wisesight_sentiment
- generated_reviews_enth
widget:
- text: "โอโห้ ช่องนี้เปิดโลกเรามากเลยค่ะ คือตอนช่วงหาคำตอบเรานี่อึ้งไปเลย ดูจีเนียสมากๆๆ"
example_title: "Positive"
- text: "เริ่มจากชายเน็ตคนหนึ่งเปิดประเด็นว่าไปพบเจ้าจุดดำลึกลับนี้กลางมหาสมุทรใน Google Maps จนนำไปสู่การเสาะหาคำตอบ และพบว่าจริง ๆ แล้วมันคืออะไรกันแน่"
example_title: "Neutral"
- text: "ผมเป็นคนที่ไม่มีความสุขเลยจริงๆ"
example_title: "Negative"
---
Created only for study :)
|
dccuchile/bert-base-spanish-wwm-cased-finetuned-qa-mlqa | [
"pytorch",
"bert",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model-index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metrics:
- name: Matthews Correlation
type: matthews_correlation
value: 0.5226700639354173
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7904
- Matthews Correlation: 0.5227
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.528 | 1.0 | 535 | 0.5180 | 0.4003 |
| 0.3508 | 2.0 | 1070 | 0.5120 | 0.5019 |
| 0.2409 | 3.0 | 1605 | 0.6374 | 0.5128 |
| 0.1806 | 4.0 | 2140 | 0.7904 | 0.5227 |
| 0.1311 | 5.0 | 2675 | 0.8824 | 0.5227 |
### Framework versions
- Transformers 4.12.2
- Pytorch 1.9.0+cu111
- Datasets 1.14.0
- Tokenizers 0.10.3
|
dccuchile/bert-base-spanish-wwm-uncased-finetuned-mldoc | [
"pytorch",
"bert",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"BertForSequenceClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 39 | null | ---
tags:
- asteroid
- audio
- FasNet-TAC
- audio-to-audio
- multichannel
- beamforming
datasets:
- TACDataset
- sep_noisy
license: cc-by-sa-4.0
---
## Asteroid model `Samuele Cornell/FasNetTAC_TACDataset_separatenoisy`
Imported from [Zenodo](https://zenodo.org/record/4557489)
### Description:
This model was trained by popcornell using the TAC/TAC recipe in Asteroid. It was trained on the separate_noisy task of the TACDataset dataset.
### Training config:
```yaml
data:
dev_json: ./data/validation.json
sample_rate: 16000
segment: None
test_json: ./data/test.json
train_json: ./data/train.json
net:
chunk_size: 50
context_ms: 16
enc_dim: 64
feature_dim: 64
hidden_dim: 128
hop_size: 25
n_layers: 4
n_src: 2
window_ms: 4
optim:
lr: 0.001
weight_decay: 1e-06
training:
accumulate_batches: 1
batch_size: 8
early_stop: True
epochs: 200
gradient_clipping: 5
half_lr: True
num_workers: 8
patience: 30
save_top_k: 10
```
### Results:
```yaml
si_sdr: 10.871864315894744
si_sdr_imp: 11.322284052560262
```
### License notice:
This work "FasNetTAC_TACDataset_separatenoisy" is a derivative of LibriSpeech ASR corpus by Vassil Panayotov, used under CC BY 4.0; of End-to-end Microphone Permutation and Number Invariant Multi-channel Speech Separation by Yi Luo, Zhuo Chen, Nima Mesgarani, Takuya Yoshioka, used under CC BY 4.0. "FasNetTAC_TACDataset_separatenoisy" is licensed under Attribution-ShareAlike 3.0 Unported by popcornell.
|
dccuchile/bert-base-spanish-wwm-uncased-finetuned-pos | [
"pytorch",
"bert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"BertForTokenClassification"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- xlsum
metrics:
- rouge
model-index:
- name: t5-small-finetuned-xsum
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: xlsum
type: xlsum
args: chinese_traditional
metrics:
- name: Rouge1
type: rouge
value: 0.5217
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# t5-small-finetuned-xsum
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the xlsum dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2188
- Rouge1: 0.5217
- Rouge2: 0.0464
- Rougel: 0.527
- Rougelsum: 0.5215
- Gen Len: 6.7441
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 5
- eval_batch_size: 5
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.3831 | 1.0 | 7475 | 1.2188 | 0.5217 | 0.0464 | 0.527 | 0.5215 | 6.7441 |
### Framework versions
- Transformers 4.15.0
- Pytorch 1.10.0+cu111
- Datasets 1.17.0
- Tokenizers 0.10.3
|
dccuchile/distilbert-base-spanish-uncased-finetuned-ner | [
"pytorch",
"distilbert",
"token-classification",
"transformers",
"autotrain_compatible"
] | token-classification | {
"architectures": [
"DistilBertForTokenClassification"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 28 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base](https://huggingface.co/facebook/wav2vec2-base) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3821
- Wer: 0.3841
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 1000
- num_epochs: 10
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 3.7018 | 2.01 | 500 | 1.9216 | 0.9924 |
| 1.0211 | 4.02 | 1000 | 0.5051 | 0.5095 |
| 0.4293 | 6.02 | 1500 | 0.4209 | 0.4282 |
| 0.2513 | 8.03 | 2000 | 0.3821 | 0.3841 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.9.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
CennetOguz/distilbert-base-uncased-finetuned-recipe-accelerate | [
"pytorch",
"distilbert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"DistilBertForMaskedLM"
],
"model_type": "distilbert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
tags:
- conversational
---
# Harry Potter DialoGPT Model |
Chaewon/mmnt_decoder_en | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 12 | null | This model is pre-trained on blog articles from AWS Blogs.
## Pre-training corpora
The input text contains around 3000 blog articles on [AWS Blogs website](https://aws.amazon.com/blogs/) technical subject matter including AWS products, tools and tutorials.
## Pre-training details
I picked a Roberta architecture for masked language modeling (6-layer, 768-hidden, 12-heads, 82M parameters) and its corresponding ByteLevelBPE tokenization strategy. I then followed HuggingFace's Transformers [blog post](https://huggingface.co/blog/how-to-train) to train the model.
I chose to follow the following training set-up: 28k training steps with batches of 64 sequences of length 512 with an initial learning rate 5e-5. The model acheived a training loss of 3.6 on the MLM task over 10 epochs.
|
Chakita/KNUBert | [
"pytorch",
"tensorboard",
"roberta",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 20 | null | If you use the model, please consider citing the paper
```
@misc{bhargava2021generalization,
title={Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics},
author={Prajjwal Bhargava and Aleksandr Drozd and Anna Rogers},
year={2021},
eprint={2110.01518},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
Original Implementation and more info can be found in [this Github repository](https://github.com/prajjwal1/generalize_lm_nli). |
Chakita/Kalbert | [
"pytorch",
"tensorboard",
"albert",
"fill-mask",
"transformers",
"generated_from_trainer",
"license:mit",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | The following model is a Pytorch pre-trained model obtained from converting Tensorflow checkpoint found in the [official Google BERT repository](https://github.com/google-research/bert). These BERT variants were introduced in the paper [Well-Read Students Learn Better: On the Importance of Pre-training Compact Models](https://arxiv.org/abs/1908.08962). These models are trained on MNLI.
If you use the model, please consider citing the paper
```
@misc{bhargava2021generalization,
title={Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics},
author={Prajjwal Bhargava and Aleksandr Drozd and Anna Rogers},
year={2021},
eprint={2110.01518},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
Original Implementation and more info can be found in [this Github repository](https://github.com/prajjwal1/generalize_lm_nli).
```
MNLI: 75.86%
MNLI-mm: 77.03%
```
These models are trained for 4 epochs.
[@prajjwal_1](https://twitter.com/prajjwal_1)
|
Chalponkey/DialoGPT-small-Barry | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null | ---
language:
- en
license:
- mit
tags:
- BERT
- MNLI
- NLI
- transformer
- pre-training
---
The following model is a Pytorch pre-trained model obtained from converting Tensorflow checkpoint found in the [official Google BERT repository](https://github.com/google-research/bert).
This is one of the smaller pre-trained BERT variants, together with [bert-small](https://huggingface.co/prajjwal1/bert-small) and [bert-medium](https://huggingface.co/prajjwal1/bert-medium). They were introduced in the study `Well-Read Students Learn Better: On the Importance of Pre-training Compact Models` ([arxiv](https://arxiv.org/abs/1908.08962)), and ported to HF for the study `Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics` ([arXiv](https://arxiv.org/abs/2110.01518)). These models are supposed to be trained on a downstream task.
If you use the model, please consider citing both the papers:
```
@misc{bhargava2021generalization,
title={Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics},
author={Prajjwal Bhargava and Aleksandr Drozd and Anna Rogers},
year={2021},
eprint={2110.01518},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{DBLP:journals/corr/abs-1908-08962,
author = {Iulia Turc and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {Well-Read Students Learn Better: The Impact of Student Initialization
on Knowledge Distillation},
journal = {CoRR},
volume = {abs/1908.08962},
year = {2019},
url = {http://arxiv.org/abs/1908.08962},
eprinttype = {arXiv},
eprint = {1908.08962},
timestamp = {Thu, 29 Aug 2019 16:32:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1908-08962.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
Config of this model:
`prajjwal1/bert-mini` (L=4, H=256) [Model Link](https://huggingface.co/prajjwal1/bert-mini)
Other models to check out:
- `prajjwal1/bert-tiny` (L=2, H=128) [Model Link](https://huggingface.co/prajjwal1/bert-tiny)
- `prajjwal1/bert-small` (L=4, H=512) [Model Link](https://huggingface.co/prajjwal1/bert-small)
- `prajjwal1/bert-medium` (L=8, H=512) [Model Link](https://huggingface.co/prajjwal1/bert-medium)
Original Implementation and more info can be found in [this Github repository](https://github.com/prajjwal1/generalize_lm_nli).
Twitter: [@prajjwal_1](https://twitter.com/prajjwal_1)
|
Chan/distilgpt2-finetuned-wikitext2 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- en
license:
- mit
tags:
- BERT
- MNLI
- NLI
- transformer
- pre-training
---
The following model is a Pytorch pre-trained model obtained from converting Tensorflow checkpoint found in the [official Google BERT repository](https://github.com/google-research/bert).
This is one of the smaller pre-trained BERT variants, together with [bert-tiny](https://huggingface.co/prajjwal1/bert-small), [bert-mini]([bert-small](https://huggingface.co/prajjwal1/bert-mini) and [bert-medium](https://huggingface.co/prajjwal1/bert-medium). They were introduced in the study `Well-Read Students Learn Better: On the Importance of Pre-training Compact Models` ([arxiv](https://arxiv.org/abs/1908.08962)), and ported to HF for the study `Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics` ([arXiv](https://arxiv.org/abs/2110.01518)). These models are supposed to be trained on a downstream task.
If you use the model, please consider citing both the papers:
```
@misc{bhargava2021generalization,
title={Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics},
author={Prajjwal Bhargava and Aleksandr Drozd and Anna Rogers},
year={2021},
eprint={2110.01518},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{DBLP:journals/corr/abs-1908-08962,
author = {Iulia Turc and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {Well-Read Students Learn Better: The Impact of Student Initialization
on Knowledge Distillation},
journal = {CoRR},
volume = {abs/1908.08962},
year = {2019},
url = {http://arxiv.org/abs/1908.08962},
eprinttype = {arXiv},
eprint = {1908.08962},
timestamp = {Thu, 29 Aug 2019 16:32:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1908-08962.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
Config of this model:
- `prajjwal1/bert-small` (L=4, H=512) [Model Link](https://huggingface.co/prajjwal1/bert-small)
Other models to check out:
- `prajjwal1/bert-tiny` (L=2, H=128) [Model Link](https://huggingface.co/prajjwal1/bert-tiny)
- `prajjwal1/bert-mini` (L=4, H=256) [Model Link](https://huggingface.co/prajjwal1/bert-mini)
- `prajjwal1/bert-medium` (L=8, H=512) [Model Link](https://huggingface.co/prajjwal1/bert-medium)
Original Implementation and more info can be found in [this Github repository](https://github.com/prajjwal1/generalize_lm_nli).
Twitter: [@prajjwal_1](https://twitter.com/prajjwal_1)
|
Chandanbhat/distilbert-base-uncased-finetuned-cola | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- en
license:
- mit
tags:
- BERT
- MNLI
- NLI
- transformer
- pre-training
---
The following model is a Pytorch pre-trained model obtained from converting Tensorflow checkpoint found in the [official Google BERT repository](https://github.com/google-research/bert).
This is one of the smaller pre-trained BERT variants, together with [bert-mini](https://huggingface.co/prajjwal1/bert-mini) [bert-small](https://huggingface.co/prajjwal1/bert-small) and [bert-medium](https://huggingface.co/prajjwal1/bert-medium). They were introduced in the study `Well-Read Students Learn Better: On the Importance of Pre-training Compact Models` ([arxiv](https://arxiv.org/abs/1908.08962)), and ported to HF for the study `Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics` ([arXiv](https://arxiv.org/abs/2110.01518)). These models are supposed to be trained on a downstream task.
If you use the model, please consider citing both the papers:
```
@misc{bhargava2021generalization,
title={Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics},
author={Prajjwal Bhargava and Aleksandr Drozd and Anna Rogers},
year={2021},
eprint={2110.01518},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
@article{DBLP:journals/corr/abs-1908-08962,
author = {Iulia Turc and
Ming{-}Wei Chang and
Kenton Lee and
Kristina Toutanova},
title = {Well-Read Students Learn Better: The Impact of Student Initialization
on Knowledge Distillation},
journal = {CoRR},
volume = {abs/1908.08962},
year = {2019},
url = {http://arxiv.org/abs/1908.08962},
eprinttype = {arXiv},
eprint = {1908.08962},
timestamp = {Thu, 29 Aug 2019 16:32:34 +0200},
biburl = {https://dblp.org/rec/journals/corr/abs-1908-08962.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
```
Config of this model:
- `prajjwal1/bert-tiny` (L=2, H=128) [Model Link](https://huggingface.co/prajjwal1/bert-tiny)
Other models to check out:
- `prajjwal1/bert-mini` (L=4, H=256) [Model Link](https://huggingface.co/prajjwal1/bert-mini)
- `prajjwal1/bert-small` (L=4, H=512) [Model Link](https://huggingface.co/prajjwal1/bert-small)
- `prajjwal1/bert-medium` (L=8, H=512) [Model Link](https://huggingface.co/prajjwal1/bert-medium)
Original Implementation and more info can be found in [this Github repository](https://github.com/prajjwal1/generalize_lm_nli).
Twitter: [@prajjwal_1](https://twitter.com/prajjwal_1)
|
Charlotte/text2dm_models | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Please refer to this repository (https://github.com/prajjwal1/discosense) for usage instructions.
---
language:
- en
tags:
- conditional
- text
- generation
license: "mit"
datasets:
- discofuse
- discovery
metrics:
- perplexity
- ppl
--- |
Cheatham/xlm-roberta-large-finetuned-d1 | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 20 | null | Please refer to this repository (https://github.com/prajjwal1/discosense) for usage instructions.
---
language:
- en
tags:
- conditional
- text
- generation
license: "mit"
datasets:
- discofuse
- discovery
metrics:
- perplexity
- ppl
--- |
Cheatham/xlm-roberta-large-finetuned-d12 | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 20 | null | Please refer to this repository (https://github.com/prajjwal1/discosense) for usage instructions.
---
language:
- en
tags:
- conditional
- text
- generation
license: "mit"
datasets:
- discofuse
- discovery
metrics:
- perplexity
- ppl
--- |
Cheatham/xlm-roberta-large-finetuned-d12_2 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Please refer to this repository (https://github.com/prajjwal1/discosense) for usage instructions.
---
language:
- en
tags:
- conditional
- text
- generation
license: "mit"
datasets:
- discofuse
- discovery
metrics:
- perplexity
- ppl
--- |
Cheatham/xlm-roberta-large-finetuned-d1r01 | [
"pytorch",
"xlm-roberta",
"text-classification",
"transformers"
] | text-classification | {
"architectures": [
"XLMRobertaForSequenceClassification"
],
"model_type": "xlm-roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 21 | null | Please refer to this repository (https://github.com/prajjwal1/discosense) for usage instructions.
---
language:
- en
tags:
- conditional
- text
- generation
license: "mit"
datasets:
- discofuse
- discovery
metrics:
- perplexity
- ppl
--- |
Check/vaw2tmp | [
"tensorboard"
] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | Please refer to this repository (https://github.com/prajjwal1/discosense) for usage instructions.
---
language:
- en
tags:
- conditional
- text
- generation
license: "mit"
datasets:
- discofuse
- discovery
metrics:
- perplexity
- ppl
--- |
Ching/negation_detector | [
"pytorch",
"roberta",
"question-answering",
"transformers",
"autotrain_compatible"
] | question-answering | {
"architectures": [
"RobertaForQuestionAnswering"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | null | Roberta-base trained on MNLI.
| Task | Accuracy |
|---------|----------|
| MNLI | 86.32 |
| MNLI-mm | 86.43 |
You can also check out:
- `prajjwal1/roberta-base-mnli`
- `prajjwal1/roberta-large-mnli`
- `prajjwal1/albert-base-v2-mnli`
- `prajjwal1/albert-base-v1-mnli`
- `prajjwal1/albert-large-v2-mnli`
[@prajjwal_1](https://twitter.com/prajjwal_1)
|
Chinmay/mlindia | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | If you use the model, please consider citing the paper
```
@misc{bhargava2021generalization,
title={Generalization in NLI: Ways (Not) To Go Beyond Simple Heuristics},
author={Prajjwal Bhargava and Aleksandr Drozd and Anna Rogers},
year={2021},
eprint={2110.01518},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
Original Implementation and more info can be found in [this Github repository](https://github.com/prajjwal1/generalize_lm_nli).
Roberta-large trained on MNLI.
----------------------
| Task | Accuracy |
|---------|----------|
| MNLI | 90.15 |
| MNLI-mm | 90.02 |
You can also check out:
- `prajjwal1/roberta-base-mnli`
- `prajjwal1/roberta-large-mnli`
- `prajjwal1/albert-base-v2-mnli`
- `prajjwal1/albert-base-v1-mnli`
- `prajjwal1/albert-large-v2-mnli`
[@prajjwal_1](https://twitter.com/prajjwal_1)
|
Chiuchiyin/DialoGPT-small-Donald | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
tags:
- pytorch
- commonsense-reasoning
- sentence-completion
datasets:
- hellaswag
---
`RoBERTa` trained on HellaSwag dataset (`MultipleChoiceModel`). HellaSwag has a multiple choice questions format.
It gets around 74.99% accuracy.
[@prajjwal_1](https://twitter.com/prajjwal_1/)
|
Chun/DialoGPT-large-dailydialog | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- matthews_correlation
model_index:
- name: distilbert-base-uncased-finetuned-cola
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
args: cola
metric:
name: Matthews Correlation
type: matthews_correlation
value: 0.520875943143754
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-cola
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8486
- Matthews Correlation: 0.5209
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Matthews Correlation |
|:-------------:|:-----:|:----:|:---------------:|:--------------------:|
| 0.5265 | 1.0 | 535 | 0.5479 | 0.4049 |
| 0.3571 | 2.0 | 1070 | 0.5002 | 0.5164 |
| 0.2432 | 3.0 | 1605 | 0.6242 | 0.5091 |
| 0.173 | 4.0 | 2140 | 0.7559 | 0.5120 |
| 0.1352 | 5.0 | 2675 | 0.8486 | 0.5209 |
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0+cu102
- Datasets 1.10.2
- Tokenizers 0.10.3
|
Chun/DialoGPT-small-dailydialog | [
"pytorch",
"gpt2",
"text-generation",
"transformers"
] | text-generation | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 10 | null |
# GPT2 Genre Based Story Generator
## Model description
GPT2 fine-tuned on genre-based story generation.
## Intended uses
Used to generate stories based on user inputted genre and starting prompts.
## How to use
#### Supported Genres
superhero, action, drama, horror, thriller, sci_fi
#### Input text format
\<BOS> \<genre> Some optional text...
**Example**: \<BOS> \<sci_fi> After discovering time travel,
```python
# Example of usage
from transformers import pipeline
story_gen = pipeline("text-generation", "pranavpsv/gpt2-genre-story-generator")
print(story_gen("<BOS> <superhero> Batman"))
```
## Training data
Initialized with pre-trained weights of "gpt2" checkpoint. Fine-tuned the model on stories of various genres.
|
Chun/w-en2zh-otm | [
"pytorch",
"mbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | # Ancient Greek BERT
<img src="https://ichef.bbci.co.uk/images/ic/832xn/p02m4gzb.jpg"/>
The first and only available Ancient Greek sub-word BERT model!
State-of-the-art post fine-tuning on Part-of-Speech Tagging and Morphological Analysis.
Pre-trained weights are made available for a standard 12 layer, 768d BERT-base model.
Further scripts for using the model and fine-tuning it for PoS Tagging are available on our [Github repository](https://github.com/pranaydeeps/Ancient-Greek-BERT)!
Please refer to our paper titled: "A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek". In Proceedings of The 5th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2021)
## How to use
Requirements:
```python
pip install transformers
pip install unicodedata
pip install flair
```
Can be directly used from the HuggingFace Model Hub with:
```python
from transformers import AutoTokenizer, AutoModel
tokeniser = AutoTokenizer.from_pretrained("pranaydeeps/Ancient-Greek-BERT")
model = AutoModel.from_pretrained("pranaydeeps/Ancient-Greek-BERT")
```
## Fine-tuning for POS/Morphological Analysis
Please refer the GitHub repository for the code and details regarding fine-tuning
## Training data
The model was initialised from [AUEB NLP Group's Greek BERT](https://huggingface.co/nlpaueb/bert-base-greek-uncased-v1)
and subsequently trained on monolingual data from the First1KGreek Project, Perseus Digital Library, PROIEL Treebank and
Gorman's Treebank
## Training and Eval details
Standard de-accentuating and lower-casing for Greek as suggested in [AUEB NLP Group's Greek BERT](https://huggingface.co/nlpaueb/bert-base-greek-uncased-v1)
The model was trained on 4 NVIDIA Tesla V100 16GB GPUs for 80 epochs, with a max-seq-len of 512 and results in a perplexity of 4.8 on the held out test set.
It also gives state-of-the-art results when fine-tuned for PoS Tagging and Morphological Analysis on all 3 treebanks averaging >90% accuracy. Please consult our paper or contact [me](mailto:[email protected]) for further questions!
## Cite
If you end up using Ancient-Greek-BERT in your research, please cite the paper:
```
@inproceedings{ancient-greek-bert,
author = {Singh, Pranaydeep and Rutten, Gorik and Lefever, Els},
title = {A Pilot Study for BERT Language Modelling and Morphological Analysis for Ancient and Medieval Greek},
year = {2021},
booktitle = {The 5th Joint SIGHUM Workshop on Computational Linguistics for Cultural Heritage, Social Sciences, Humanities and Literature (LaTeCH-CLfL 2021)}
}
```
|
Chun/w-zh2en-mto | [
"pytorch",
"mbart",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MBartForConditionalGeneration"
],
"model_type": "mbart",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- conll2003
metrics:
- precision
- recall
- f1
- accuracy
model_index:
- name: distilbert-base-uncased-finetuned-ner
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: conll2003
type: conll2003
args: conll2003
metric:
name: Accuracy
type: accuracy
value: 0.9842883695807584
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-ner
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the conll2003 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0586
- Precision: 0.9293
- Recall: 0.9385
- F1: 0.9339
- Accuracy: 0.9843
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2436 | 1.0 | 878 | 0.0670 | 0.9190 | 0.9240 | 0.9215 | 0.9815 |
| 0.0505 | 2.0 | 1756 | 0.0591 | 0.9252 | 0.9351 | 0.9301 | 0.9836 |
| 0.0304 | 3.0 | 2634 | 0.0586 | 0.9293 | 0.9385 | 0.9339 | 0.9843 |
### Framework versions
- Transformers 4.9.1
- Pytorch 1.9.0+cu102
- Datasets 1.11.0
- Tokenizers 0.10.3
|
Cinnamon/electra-small-japanese-discriminator | [
"pytorch",
"electra",
"pretraining",
"ja",
"transformers",
"license:apache-2.0"
] | null | {
"architectures": [
"ElectraForPreTraining"
],
"model_type": "electra",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 419 | 2022-02-05T20:52:08Z | ---
language:
- hi
license: apache-2.0
tags:
- automatic-speech-recognition
- mozilla-foundation/common_voice_8_0
- generated_from_trainer
model-index:
- name: ''
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
#
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-300m](https://huggingface.co/facebook/wav2vec2-xls-r-300m) on the MOZILLA-FOUNDATION/COMMON_VOICE_8_0 - HI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5258
- Wer: 1.0073
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7.5e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 2000
- num_epochs: 100.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 4.917 | 16.13 | 500 | 4.8963 | 1.0 |
| 3.3585 | 32.25 | 1000 | 3.3069 | 1.0000 |
| 1.5873 | 48.38 | 1500 | 0.8274 | 1.0061 |
| 1.2654 | 64.51 | 2000 | 0.6250 | 1.0076 |
| 1.0917 | 80.64 | 2500 | 0.5460 | 1.0056 |
| 1.0001 | 96.76 | 3000 | 0.5304 | 1.0083 |
### Framework versions
- Transformers 4.17.0.dev0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4.dev0
- Tokenizers 0.11.0
|
Ciruzzo/DialoGPT-medium-harrypotter | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- spacy
- token-classification
language:
- en
model-index:
- name: en_model_ner_skills
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.3125
- name: NER Recall
type: recall
value: 0.243902439
- name: NER F Score
type: f_score
value: 0.2739726027
---
| Feature | Description |
| --- | --- |
| **Name** | `en_model_ner_skills` |
| **Version** | `0.0.2` |
| **spaCy** | `>=3.2.1,<3.3.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (1 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `SKILL` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 27.40 |
| `ENTS_P` | 31.25 |
| `ENTS_R` | 24.39 |
| `TOK2VEC_LOSS` | 129837.25 |
| `NER_LOSS` | 1056832.41 | |
Ciruzzo/DialoGPT-small-harrypotter | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2022-02-16T09:23:04Z | ---
tags:
- spacy
- token-classification
language:
- en
model-index:
- name: en_ner_model
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.3624161074
- name: NER Recall
type: recall
value: 0.384341637
- name: NER F Score
type: f_score
value: 0.3730569948
---
| Feature | Description |
| --- | --- |
| **Name** | `en_ner_model` |
| **Version** | `0.1.1` |
| **spaCy** | `>=3.2.1,<3.3.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (1 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `SKILL` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 37.31 |
| `ENTS_P` | 36.24 |
| `ENTS_R` | 38.43 |
| `TOK2VEC_LOSS` | 305790.85 |
| `NER_LOSS` | 801195.82 | |
Ciruzzo/DialoGPT-small-hattypotter | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2022-02-16T09:14:14Z | ---
tags:
- spacy
- token-classification
language:
- en
model-index:
- name: en_ner_skills
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.3980582524
- name: NER Recall
type: recall
value: 0.3404507711
- name: NER F Score
type: f_score
value: 0.3670076726
---
| Feature | Description |
| --- | --- |
| **Name** | `en_ner_skills` |
| **Version** | `0.1.0` |
| **spaCy** | `>=3.2.1,<3.3.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (1 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `SKILL` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 36.70 |
| `ENTS_P` | 39.81 |
| `ENTS_R` | 34.05 |
| `TOK2VEC_LOSS` | 607659.90 |
| `NER_LOSS` | 491709.76 | |
ClaudeCOULOMBE/RickBot | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2021-12-17T20:23:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- squad_v2
model-index:
- name: distilbert-base-uncased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-squad
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the squad_v2 dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6623
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.3993 | 1.0 | 2051 | 1.8058 |
| 1.0467 | 2.0 | 4102 | 1.9564 |
| 0.8304 | 3.0 | 6153 | 2.6623 |
### Framework versions
- Transformers 4.14.1
- Pytorch 1.10.0+cu111
- Datasets 1.16.1
- Tokenizers 0.10.3
|
ComCom/gpt2-medium | [
"pytorch",
"gpt2",
"feature-extraction",
"transformers"
] | feature-extraction | {
"architectures": [
"GPT2Model"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": true,
"max_length": 50
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | 2021-04-21T03:57:30Z | ---
tags:
- feature-extraction
- bert
---
# Model Card for baikal-sentiment-ball
# Model Details
## Model Description
More information needed
- **Developed by:** Princeton NLP group
- **Shared by [Optional]:** Princeton NLP group
- **Model type:** Feature Extraction
- **Language(s) (NLP):** More information needed
- **License:** More information needed
- **Parent Model:** BERT
- **Resources for more information:**
- [GitHub Repo](https://github.com/princeton-nlp/SimCSE)
- [Associated Paper](https://arxiv.org/abs/2104.08821)
# Uses
## Direct Use
This model can be used for the task of feature extraction.
## Downstream Use [Optional]
More information needed.
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
The model craters note in the [Github Repository](https://github.com/princeton-nlp/SimCSE/blob/main/README.md)
> We train unsupervised SimCSE on 106 randomly sampled sentences from English Wikipedia, and train supervised SimCSE on the combination of MNLI and SNLI datasets (314k).
## Training Procedure
### Preprocessing
More information needed
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
The model craters note in the [associated paper](https://arxiv.org/pdf/2104.08821.pdf)
> Our evaluation code for sentence embeddings is based on a modified version of [SentEval](https://github.com/facebookresearch/SentEval). It evaluates sentence embeddings on semantic textual similarity (STS) tasks and downstream transfer tasks.
For STS tasks, our evaluation takes the "all" setting, and report Spearman's correlation. See [associated paper](https://arxiv.org/pdf/2104.08821.pdf) (Appendix B) for evaluation details.
### Factors
More information needed
### Metrics
More information needed
## Results
More information needed
# Model Examination
The model craters note in the [associated paper](https://arxiv.org/pdf/2104.08821.pdf):
> **Uniformity and alignment.**
We also observe that (1) though pre-trained embeddings have good alignment, their uniformity is poor (i.e., the embeddings are highly anisotropic); (2) post-processing methods like BERT-flow and BERT-whitening greatly improve uniformity but also suffer a degeneration in alignment; (3) unsupervised SimCSE effectively improves uniformity of pre-trained embeddings whereas keeping a good alignment;(4) incorporating supervised data in SimCSE further amends alignment.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Nvidia 3090 GPUs with CUDA 11
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed.
# Citation
**BibTeX:**
```bibtex
@inproceedings{gao2021simcse,
title={{SimCSE}: Simple Contrastive Learning of Sentence Embeddings},
author={Gao, Tianyu and Yao, Xingcheng and Chen, Danqi},
booktitle={Empirical Methods in Natural Language Processing (EMNLP)},
year={2021}
}
```
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
Princeton NLP group in collaboration with Ezi Ozoani and the Hugging Face team.
# Model Card Contact
If you have any questions related to the code or the paper, feel free to email Tianyu (`[email protected]`) and Xingcheng (`[email protected]`). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please try to specify the problem with details so we can help you better and quicker!
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("princeton-nlp/sup-simcse-bert-large-uncased")
model = AutoModel.from_pretrained("princeton-nlp/sup-simcse-bert-large-uncased")
```
</details>
|
ComCom-Dev/gpt2-bible-test | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | 2021-04-21T03:57:25Z | ---
tags:
- feature-extraction
---
# Model Card for sup-simcse-roberta-large
# Model Details
## Model Description
- **Developed by:** Princeton-nlp
- **Shared by [Optional]:** More information needed
- **Model type:** Feature Extraction
- **Language(s) (NLP):** More information needed
- **License:** More information needed
- **Related Models:**
- **Parent Model:** RoBERTa-large
- **Resources for more information:**
- [GitHub Repo](https://github.com/princeton-nlp/SimCSE)
- [Associated Paper](https://arxiv.org/abs/2104.08821)
- [Blog Post]({0})
# Uses
## Direct Use
This model can be used for the task of Feature Extraction
## Downstream Use [Optional]
More information needed
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
The model craters note in the [Github Repository](https://github.com/princeton-nlp/SimCSE/blob/main/README.md)
> We train unsupervised SimCSE on 106 randomly sampled sentences from English Wikipedia, and train supervised SimCSE on the combination of MNLI and SNLI datasets (314k).
## Training Procedure
### Preprocessing
More information needed
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
The model craters note in the [associated paper](https://arxiv.org/pdf/2104.08821.pdf)
> Our evaluation code for sentence embeddings is based on a modified version of [SentEval](https://github.com/facebookresearch/SentEval). It evaluates sentence embeddings on semantic textual similarity (STS) tasks and downstream transfer tasks. For STS tasks, our evaluation takes the "all" setting, and report Spearman's correlation. See [associated paper](https://arxiv.org/pdf/2104.08821.pdf) (Appendix B) for evaluation details.
### Factors
### Metrics
More information needed
## Results
More information needed
# Model Examination
More information needed
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** More information needed
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed
# Citation
**BibTeX:**
```bibtex
@inproceedings{gao2021simcse,
title={{SimCSE}: Simple Contrastive Learning of Sentence Embeddings},
author={Gao, Tianyu and Yao, Xingcheng and Chen, Danqi},
booktitle={Empirical Methods in Natural Language Processing (EMNLP)},
year={2021}
}
```
# Glossary [optional]
More information needed
# More Information [optional]
If you have any questions related to the code or the paper, feel free to email Tianyu (`[email protected]`) and Xingcheng (`[email protected]`). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please try to specify the problem with details so we can help you better and quicker!
# Model Card Authors [optional]
Princeton NLP group in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
More information needed
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("princeton-nlp/sup-simcse-roberta-large")
model = AutoModel.from_pretrained("princeton-nlp/sup-simcse-roberta-large")
```
</details>
|
Cometasonmi451/Mine | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
tags:
- feature-extraction
- bert
---
# Model Card for unsup-simcse-bert-base-uncased
# Model Details
## Model Description
More information needed
- **Developed by:** Princeton NLP group
- **Shared by [Optional]:** Hugging Face
- **Model type:** Feature Extraction
- **Language(s) (NLP):** More information needed
- **License:** More information needed
- **Related Models:**
- **Parent Model:** BERT
- **Resources for more information:**
- [GitHub Repo](https://github.com/princeton-nlp/SimCSE)
- [Model Space](https://huggingface.co/spaces/mteb/leaderboard)
- [Associated Paper](https://arxiv.org/abs/2104.08821)
# Uses
## Direct Use
This model can be used for the task of Feature Engineering.
## Downstream Use [Optional]
More information needed
## Out-of-Scope Use
The model should not be used to intentionally create hostile or alienating environments for people.
# Bias, Risks, and Limitations
Significant research has explored bias and fairness issues with language models (see, e.g., [Sheng et al. (2021)](https://aclanthology.org/2021.acl-long.330.pdf) and [Bender et al. (2021)](https://dl.acm.org/doi/pdf/10.1145/3442188.3445922)). Predictions generated by the model may include disturbing and harmful stereotypes across protected classes; identity characteristics; and sensitive, social, and occupational groups.
## Recommendations
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
# Training Details
## Training Data
The model craters note in the [Github Repository](https://github.com/princeton-nlp/SimCSE/blob/main/README.md)
> We train unsupervised SimCSE on 106 randomly sampled sentences from English Wikipedia, and train supervised SimCSE on the combination of MNLI and SNLI datasets (314k).
## Training Procedure
### Preprocessing
More information needed
### Speeds, Sizes, Times
More information needed
# Evaluation
## Testing Data, Factors & Metrics
### Testing Data
The model craters note in the [associated paper](https://arxiv.org/pdf/2104.08821.pdf)
> Our evaluation code for sentence embeddings is based on a modified version of [SentEval](https://github.com/facebookresearch/SentEval). It evaluates sentence embeddings on semantic textual similarity (STS) tasks and downstream transfer tasks. For STS tasks, our evaluation takes the "all" setting, and report Spearman's correlation. See [associated paper](https://arxiv.org/pdf/2104.08821.pdf) (Appendix B) for evaluation details.
### Factors
More information needed
### Metrics
More information needed
## Results
More information needed
# Model Examination
The model craters note in the [associated paper](https://arxiv.org/pdf/2104.08821.pdf)
> **Uniformity and alignment.**
We also observe that (1) though pre-trained embeddings have good alignment, their uniformity is poor (i.e., the embeddings are highly anisotropic); (2) post-processing methods like BERT-flow and BERT-whitening greatly improve uniformity but also suffer a degeneration in alignment; (3) unsupervised SimCSE effectively improves uniformity of pre-trained embeddings whereas keeping a good alignment;(4) incorporating supervised data in SimCSE further amends alignment.
# Environmental Impact
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** Nvidia 3090 GPUs with CUDA 11
- **Hours used:** More information needed
- **Cloud Provider:** More information needed
- **Compute Region:** More information needed
- **Carbon Emitted:** More information needed
# Technical Specifications [optional]
## Model Architecture and Objective
More information needed
## Compute Infrastructure
More information needed
### Hardware
More information needed
### Software
More information needed
# Citation
**BibTeX:**
```bibtex
@inproceedings{gao2021simcse,
title={{SimCSE}: Simple Contrastive Learning of Sentence Embeddings},
author={Gao, Tianyu and Yao, Xingcheng and Chen, Danqi},
booktitle={Empirical Methods in Natural Language Processing (EMNLP)},
year={2021}
}
```
# Glossary [optional]
More information needed
# More Information [optional]
More information needed
# Model Card Authors [optional]
Princeton NLP group in collaboration with Ezi Ozoani and the Hugging Face team
# Model Card Contact
If you have any questions related to the code or the paper, feel free to email Tianyu (`[email protected]`) and Xingcheng (`[email protected]`). If you encounter any problems when using the code, or want to report a bug, you can open an issue. Please try to specify the problem with details so we can help you better and quicker!
# How to Get Started with the Model
Use the code below to get started with the model.
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("princeton-nlp/unsup-simcse-bert-base-uncased")
model = AutoModel.from_pretrained("princeton-nlp/unsup-simcse-bert-base-uncased")
```
</details>
|
CuongLD/wav2vec2-large-xlsr-vietnamese | [
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"vi",
"dataset:common_voice, infore_25h",
"arxiv:2006.11477",
"arxiv:2006.13979",
"transformers",
"audio",
"speech",
"xlsr-fine-tuning-week",
"license:apache-2.0",
"model-index"
] | automatic-speech-recognition | {
"architectures": [
"Wav2Vec2ForCTC"
],
"model_type": "wav2vec2",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8 | null | ---
language:
- ca
license: apache-2.0
tags:
- "catalan"
- "qa"
datasets:
- "xquad-ca"
- "viquiquad"
metrics:
- "f1"
- "exact match"
widget:
- text: "Quan va començar el Super3?"
context: "El Super3 o Club Super3 és un univers infantil català creat a partir d'un programa emès per Televisió de Catalunya des del 1991. Està format per un canal de televisió, la revista Súpers!, la Festa dels Súpers i un club que té un milió i mig de socis."
- text: "Quants eren els germans Marx?"
context: "Els germans Marx van ser un grup de còmics dels Estats Units que originàriament estava compost per cinc germans (entre parèntesis els noms artístics): Leonard (Chico), Adolph (Harpo), Julius (Groucho), Milton (Gummo) i Herbert (Zeppo)."
- text: "On van ser els Jocs Olímpics de 1992?"
context: "Els Jocs Olímpics d'estiu de 1992, oficialment Jocs Olímpics de la XXV Olimpíada, es van celebrar a la ciutat de Barcelona entre els dies 25 de juliol i 9 d'agost de 1992. Hi participaren 9.356 atletes (6.652 homes i 2.704 dones) de 169 comitès nacionals, que competiren en 32 esports i 286 especialitats."
- text: "Qui va dissenyar la Sagrada Família?"
context: "El Temple Expiatori de la Sagrada Família, conegut habitualment com la Sagrada Família, és una basílica catòlica situada a la ciutat de Barcelona. És un dels exemples més coneguts del modernisme català i un edifici únic al món, que ha esdevingut tot un símbol de la ciutat. Obra inacabada de l'arquitecte català Antoni Gaudí, és al barri de la Sagrada Família, al districte de l'Eixample de la ciutat."
- text: "Quin és el tercer volcà més gran de la Terra?"
context: "El Teide (o Pic del Teide) és un estratovolcà i muntanya de Tenerife, Illes Canàries (28.27 N, 16.6 O). Amb una altitud de 3718 m sobre el nivell del mar i amb aproximadament uns 7000 m sobre el llit marí adjacent, és la muntanya més alta d'Espanya, la muntanya més alta de totes les illes atlàntiques i el tercer volcà més gran de la Terra."
---
# Catalan BERTa (roberta-base-ca) finetuned for Question Answering.
## Table of Contents
<details>
<summary>Click to expand</summary>
- [Model description](#model-description)
- [Intended uses and limitations](#intended-use)
- [How to use](#how-to-use)
- [Limitations and bias](#limitations-and-bias)
- [Training](#training)
- [Training data](#training-data)
- [Training procedure](#training-procedure)
- [Evaluation](#evaluation)
- [Variable and metrics](#variable-and-metrics)
- [Evaluation results](#evaluation-results)
- [Additional information](#additional-information)
- [Author](#author)
- [Contact information](#contact-information)
- [Copyright](#copyright)
- [Licensing information](#licensing-information)
- [Funding](#funding)
- [Citing information](#citing-information)
- [Disclaimer](#disclaimer)
</details>
## Model description
The **roberta-base-ca-cased-qa** is a Question Answering (QA) model for the Catalan language fine-tuned from the roberta-base-ca model, a [RoBERTa](https://arxiv.org/abs/1907.11692) base model pre-trained on a medium-size corpus collected from publicly available corpora and crawlers.
## Intended uses and limitations
**roberta-base-ca-cased-qa** model can be used for extractive question answering. The model is limited by its training dataset and may not generalize well for all use cases.
## How to use
Here is how to use this model:
```python
from transformers import pipeline
nlp = pipeline("question-answering", model="projecte-aina/roberta-base-ca-cased-qa")
text = "Quan va començar el Super3?"
context = "El Super3 o Club Super3 és un univers infantil català creat a partir d'un programa emès per Televisió de Catalunya des del 1991. Està format per un canal de televisió, la revista Súpers!, la Festa dels Súpers i un club que té un milió i mig de socis."
qa_results = nlp(text, context)
print(qa_results)
```
## Limitations and bias
At the time of submission, no measures have been taken to estimate the bias embedded in the model. However, we are well aware that our models may be biased since the corpora have been collected using crawling techniques on multiple web sources. We intend to conduct research in these areas in the future, and if completed, this model card will be updated.
## Training
### Training data
We used the QA dataset in Catalan called [CatalanQA](https://huggingface.co/datasets/projecte-aina/catalanqa) for training and evaluation, and the [XQuAD-ca](https://huggingface.co/datasets/projecte-aina/xquad-ca) test set for evaluation.
### Training procedure
The model was trained with a batch size of 16 and a learning rate of 5e-5 for 5 epochs. We then selected the best checkpoint using the downstream task metric in the corresponding development set and then evaluated it on the test set.
## Evaluation
### Variable and metrics
This model was finetuned maximizing F1 score.
### Evaluation results
We evaluated the _roberta-base-ca-cased-qa_ on the CatalanQA and XQuAD-ca test sets against standard multilingual and monolingual baselines:
| Model | ViquiQuAD (F1/EM) | XQuAD-ca (F1/EM) |
| ------------|:-------------:| -----:|
| roberta-base-ca-cased-qa | **86.99/73.25** | **67.81/49.43** |
| mBERT | 86.97/72.22 | 67.15/46.51 |
| XLM-RoBERTa | 85.50/70.47 | 67.10/46.42 |
| WikiBERT-ca | 85.45/70.75 | 65.21/36.60 |
For more details, check the fine-tuning and evaluation scripts in the official [GitHub repository](https://github.com/projecte-aina/club).
## Additional information
### Author
Text Mining Unit (TeMU) at the Barcelona Supercomputing Center ([email protected])
### Contact information
For further information, send an email to [email protected]
### Copyright
Copyright (c) 2022 Text Mining Unit at Barcelona Supercomputing Center
### Licensing information
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
### Funding
This work was funded by the [Departament de la Vicepresidència i de Polítiques Digitals i Territori de la Generalitat de Catalunya](https://politiquesdigitals.gencat.cat/ca/inici/index.html#googtrans(ca|en) within the framework of [Projecte AINA](https://politiquesdigitals.gencat.cat/ca/economia/catalonia-ai/aina).
### Citation Information
If you use any of these resources (datasets or models) in your work, please cite our latest paper:
```bibtex
@inproceedings{armengol-estape-etal-2021-multilingual,
title = "Are Multilingual Models the Best Choice for Moderately Under-resourced Languages? {A} Comprehensive Assessment for {C}atalan",
author = "Armengol-Estap{\'e}, Jordi and
Carrino, Casimiro Pio and
Rodriguez-Penagos, Carlos and
de Gibert Bonet, Ona and
Armentano-Oller, Carme and
Gonzalez-Agirre, Aitor and
Melero, Maite and
Villegas, Marta",
booktitle = "Findings of the Association for Computational Linguistics: ACL-IJCNLP 2021",
month = aug,
year = "2021",
address = "Online",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2021.findings-acl.437",
doi = "10.18653/v1/2021.findings-acl.437",
pages = "4933--4946",
}
```
### Disclaimer
<details>
<summary>Click to expand</summary>
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions.
When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of Artificial Intelligence.
In no event shall the owner and creator of the models (BSC – Barcelona Supercomputing Center) be liable for any results arising from the use made by third parties of these models.
|
DTAI-KULeuven/robbertje-1-gb-shuffled | [
"pytorch",
"roberta",
"fill-mask",
"nl",
"dataset:oscar",
"dataset:oscar (NL)",
"dataset:dbrd",
"dataset:lassy-ud",
"dataset:europarl-mono",
"dataset:conll2002",
"arxiv:2101.05716",
"transformers",
"Dutch",
"Flemish",
"RoBERTa",
"RobBERT",
"RobBERTje",
"license:mit",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"RobertaForMaskedLM"
],
"model_type": "roberta",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | 2021-11-25T14:50:00Z | ## RoBERTa Latin model
This is a Latin RoBERTa-based LM model.
The data it uses is the same as has been used to compute the text referenced HTR evaluation measures.
The intention of the Transformer-based LM is twofold: on the one hand, it will be used for the evaluation of HTR results, on the other, it should be used as a decoder for the TrOCR architecture.
The basis for the word unigram and character n-gram computations is the Latin part of the [cc100 corpus](http://data.statmt.org/cc-100/).
The overall corpus contains 2.5G of text data.
### Preprocessing
I undertook the following preprocessing steps:
- Removal of all "pseudo-Latin" text ("Lorem ipsum ...").
- Use of [CLTK](http://www.cltk.org) for sentence splitting and normalisation.
- Retaining only lines containing letters of the Latin alphabet, numerals, and certain punctuation (--> `grep -P '^[A-z0-9ÄÖÜäöüÆ挜ᵫĀāūōŌ.,;:?!\- Ęę]+$' la.nolorem.tok.txt`
- deduplication of the corpus
The result is a corpus of ~390 million tokens.
The dataset used to train this model is available [HERE](https://huggingface.co/datasets/pstroe/cc100-latin).
### Contact
For contact, reach out to Phillip Ströbel [via mail](mailto:[email protected]) or [via Twitter](https://twitter.com/CLingophil).
### How to cite
If you use this model, pleas cite it as:
@online{stroebel-roberta-base-latin-cased1,
author = {Ströbel, Phillip Benjamin},
title = {RoBERTa Base Latin Cased V1},
year = 2022,
url = {https://huggingface.co/pstroe/roberta-base-latin-cased},
urldate = {YYYY-MM-DD}
} |
Daivakai/DialoGPT-small-saitama | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2022-02-11T01:57:55Z | ---
language:
- en
tags:
- t5
- qa
- askscience
- lfqa
- information retrieval
datasets:
- eli5
metrics:
- rouge
widget:
- text: "why aren't there more planets in our solar system?"
example_title: "solar system"
- text: "question: what is a probability distribution? context: I am just learning about statistics."
example_title: "probability distribution"
- text: "question: What are the underlying physical processes by which exercise helps us lose weight? context: I started working out two weeks ago and already feel a lot better, and started to think about it and became deeply confused."
example_title: "pumpen"
- text: "what is a neural network?"
example_title: "deep learning"
- text: "What are the primary mechanisms that computers use to understand human language?"
example_title: "NLP"
inference:
parameters:
max_length: 96
no_repeat_ngram_size: 2
encoder_no_repeat_ngram_size: 4
repetition_penalty: 3.51
length_penalty: 0.8
num_beams: 4
early_stopping: True
---
# t5 - base- askscience
- [t5-v1_1](https://huggingface.co/google/t5-v1_1-base) trained on the entirety of the _askscience_ sub-section of the eli5 dataset for one epoch.
- compare to bart on eli5 [here](https://huggingface.co/yjernite/bart_eli5)
- note that for the inference API, the model is restricted to outputting 96 tokens - by using the model in python with the transformers library, you can get longer outputs.
## training
- for inputs, the model was presented with the post title and the post selftext encoded as: `question: <post title> context: <post selftext>`. You may see better results if queries are posed in this fashion.
- The top two replies were aggregated and presented to the model as the output text.
- Training for longer will be explored, but given that the dataset has 127k examples and the loss flatlines at 0.5 epochs so this model should be fairly viable. |
Daltcamalea01/Camaleaodalt | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language:
- en
tags:
- t5
- analysis
- book
- notes
datasets:
- kmfoda/booksum
metrics:
- rouge
widget:
- text: I'm just a girl standing in front of a boy asking him to love her.
example_title: Notting Hill
- text: Son, your ego is writing checks your body can't cash.
example_title: top gun
- text: I really love to eat beans.
example_title: beans
- text: >-
The ledge, where I placed my candle, had a few mildewed books piled up in
one corner; and it was covered with writing scratched on the paint. This
writing, however, was nothing but a name repeated in all kinds of
characters, large and small—Catherine Earnshaw, here and there varied to
Catherine Heathcliff, and then again to Catherine Linton. In vapid
listlessness I leant my head against the window, and continued spelling over
Catherine Earnshaw—Heathcliff—Linton, till my eyes closed; but they had not
rested five minutes when a glare of white letters started from the dark, as
vivid as spectres—the air swarmed with Catherines; and rousing myself to
dispel the obtrusive name, I discovered my candle wick reclining on one of
the antique volumes, and perfuming the place with an odour of roasted
calf-skin.
example_title: Wuthering Heights
- text: >-
Did you ever hear the tragedy of Darth Plagueis The Wise? I thought not.
It’s not a story the Jedi would tell you. It’s a Sith legend. Darth Plagueis
was a Dark Lord of the Sith, so powerful and so wise he could use the Force
to influence the midichlorians to create life… He had such a knowledge of
the dark side that he could even keep the ones he cared about from dying.
The dark side of the Force is a pathway to many abilities some consider to
be unnatural. He became so powerful… the only thing he was afraid of was
losing his power, which eventually, of course, he did. Unfortunately, he
taught his apprentice everything he knew, then his apprentice killed him in
his sleep. Ironic. He could save others from death, but not himself.
example_title: Darth Plagueis The Wise
inference:
parameters:
no_repeat_ngram_size: 2
max_length: 64
early_stopping: true
license: bsd-3-clause
library_name: transformers
pipeline_tag: text2text-generation
---
# T5-large for Lexical Analysis
- This model was trained a text-to-text task with input text as a summary of a chapter, and the output text as the analysis of that chapter on the [booksum](https://arxiv.org/abs/2105.08209) dataset.
- it has somewhat learned how to complete literary analysis on an arbitrary input text.
- **NOTE: this is fairly intensive computationally and recommended to be run on GPU. please see example usage in [this demo notebook](https://colab.research.google.com/gist/pszemraj/8e9cc5bee5cac7916ef9241b66e01b05/demo-t5-large-for-lexical-analysis.ipynb)**
- The API is set to return max 64 tokens to avoid timeouts on CPU.
## Example
- PROMPT:
> Carmen: We're kids, not monsters. Dr. Romero: What's the difference?
- OUTPUT:
> Commentary on Act IV, scenes i-ii In these scenes, we see Dracula's transformation of the children into "monstrous" creatures. Doctor Romero says, "We're kidnapped, but not monsters." This is an important question for the audience to ask: Is there a difference between childhood and adulthood?
_longer examples are available in both [the demo notebook](https://colab.research.google.com/gist/pszemraj/8e9cc5bee5cac7916ef9241b66e01b05/demo-t5-large-for-lexical-analysis.ipynb) and at the bottom of this README._
# checkpoints
- a fine-tuned version of [google/t5-v1_1-large](https://huggingface.co/google/t5-v1_1-large)
- 16 epochs of training total
## Model description
- automatic literary analysis on arbitrary text
- `booksum` is a dataset created primarily for long-range summarization. It's excellent at that, and usually, this is done with the `chapter` and `summary_text` columns. However, there is a `summary_analysis` column as well, containing literary analysis on the passage in question :eyes:
- this model was trained on text-to-text with `summary_text` as the input and `summary_analysis` as the output, so it will analyze whatever text for _deeper meaning_.
## Intended uses & limitations
- given the absence of more specific info, the analysis will reference authors/titles from the training data in the context of the analysis.
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 4
### Training results
### Framework versions
- Transformers 4.16.2
- Pytorch 1.10.0+cu111
- Datasets 1.18.3
- Tokenizers 0.11.0
## Extended Examples
the below responses from the model are unedited.
### A prose passage from _The Lord of the Rings_
> Far above the Ephel Duath in the West the night-sky was still dim and pale. There, peering among the cloud-wrack above a dark tor high up in the mountains, Sam saw a white star twinkle for a while. The beauty of it smote his heart, as he looked up out of the forsaken land, and hope returned to him. For like a shaft, clear and cold, the thought pierced him that in the end the Shadow was only a small and passing thing: there was light and high beauty for ever beyond its reach.
analysis:
> Notes Sam's encounter with the white star is one of the most memorable scenes in the novel. It was a moment of great relief for him to see that there was light beyond his reach, and he had been longing for it all along. He looked up into the heavens at the sight of it: "It was as if I were looking out through the window of my own soul" . In this chapter, however, we are reminded of another scene from the Book of Eliot, when Sam saw the White Star twinkled for the first time since the book began. The night-sky still shrouded by clouds and cloud-wreck on the mountain tops, but now the darkness has begun to darken the whole world. When Sam looks up above the dusk over the mountains, which pierces his heart, Sam realizes that the Shadow will not last forever.
### the rick and morty copypasta
> Notes This is a very long post, but it's important to remember that this is the first of many posts on this site. It will take some time for me to get over the fact that I don't have an incredibly high iq to appreciate all of the humor in the show. In other words, people who dislike the series are idiots- they have no idea what these jokes mean or why they're funny at all. The only way to truly appreciate them is to be one of their diehard fans. If you do not like them, you'll end up making fools out of your own stupidity. For example, Dan Harmon writes: "I hated him because I loved him so much" . He was also extremely intelligent, and he would never have been able to fully appreciate the depth of his humour. That said, however, is that if you did not love him, then you should go ahead and make fun of him. And yet another reason why Morty dislikes him is partly due to his lack of narcissism rather than any kind of self-delusion. But there is something special about Mr. Moriarty himself- despite his lowly wittedness, which makes him seem almost superstitious. His attitude towards life seems to stem from his belief that nothing can ever be good enough to save the world. However, as noted above, Dickens says, "Life is full of paradoxes and contradictions... Life is more complex than anything else." Indeed, most critics have pointed out that even those with lower IQ points could possibly be seen as being subversive; indeed, readers might find it hard to sympathize with such simpletons. Of course, Stevenson has made it clear that we need to look beyond the surface level of normalcy in order to understand the absurdity of modern society. There are several examples of this sort of hypocrisy going on in contemporary literature. One of my favorite books is Fathers Sons, written by Alexander Nevsky, published in 1897. These books were published around 18 years before the novel was published. They were serialised in serial format, meaning that they were produced in 1921. Their publication dates back to 1864, when they appeared in London during the late eighteenth century England. At the time of its publication date, it was released in November 1793. When it came out in December, the book had already been published after 1859. |
Davlan/bert-base-multilingual-cased-finetuned-wolof | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4 | null | Access to model pyannote/embedding is restricted and you are not in the authorized list. Visit https://huggingface.co/pyannote/embedding to ask for access. |
Davlan/m2m100_418M-eng-yor-mt | [
"pytorch",
"m2m_100",
"text2text-generation",
"arxiv:2103.08647",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"M2M100ForConditionalGeneration"
],
"model_type": "m2m_100",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 9 | 2021-12-29T00:39:35Z | ---
tags:
- espnet
- audio
- automatic-speech-recognition
language: noinfo
datasets:
- speechcommands
license: cc-by-4.0
---
## ESPnet2 ASR model
### `pyf98/speechcommands_12commands_conformer`
This model was trained by Yifan Peng using speechcommands recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
git checkout bf523b70cae8300da004b41ec6a0d1b57c7ae8bb
pip install -e .
cd egs2/speechcommands/asr1
./run.sh --skip_data_prep false --skip_train true --download_model pyf98/speechcommands_12commands_conformer
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Fri Dec 24 21:53:37 EST 2021`
- python version: `3.9.7 (default, Sep 16 2021, 13:09:58) [GCC 7.5.0]`
- espnet version: `espnet 0.10.5a1`
- pytorch version: `pytorch 1.9.0`
- Git hash: `3fd3dae71427d2ba5ecbc3fe0f2ae05db79acc29`
- Commit date: `Fri Dec 24 21:32:26 2021 -0500`
## asr_conformer_noBatchNorm_warmup5k_lr2e-4_accum3_conv15_5speeds
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|infer/dev|4605|4605|97.7|2.3|0.0|0.0|2.3|2.3|
|infer/test|4890|4890|97.9|2.1|0.0|0.0|2.1|2.1|
|infer/test_speechbrain|4886|4886|98.4|1.6|0.0|0.0|1.6|1.6|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|infer/dev|4605|19541|98.6|0.9|0.5|1.0|2.5|2.3|
|infer/test|4890|19959|97.8|1.1|1.1|0.7|3.0|2.1|
|infer/test_speechbrain|4886|19923|98.7|0.7|0.6|0.6|1.9|1.6|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
## ASR config
<details><summary>expand</summary>
```
config: conf/train_asr_conformer_noBatchNorm.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_conformer_noBatchNorm_warmup5k_lr2e-4_accum3_conv15_5speeds
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 150
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- loss
- min
- - valid
- acc
- max
keep_nbest_models: 10
grad_clip: 5.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 3
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 20
valid_batch_size: null
batch_bins: 4000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_fbank_pitch_word_sp/train/speech_shape
- exp/asr_stats_fbank_pitch_word_sp/train/text_shape.word
valid_shape_file:
- exp/asr_stats_fbank_pitch_word_sp/valid/speech_shape
- exp/asr_stats_fbank_pitch_word_sp/valid/text_shape.word
batch_type: numel
valid_batch_type: null
fold_length:
- 800
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/fbank_pitch/train_sp/feats.scp
- speech
- kaldi_ark
- - dump/fbank_pitch/train_sp/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/fbank_pitch/dev/feats.scp
- speech
- kaldi_ark
- - dump/fbank_pitch/dev/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.0002
scheduler: warmuplr
scheduler_conf:
warmup_steps: 5000
token_list:
- <blank>
- <unk>
- 'yes'
- down
- 'no'
- stop
- go
- 'on'
- left
- right
- _unknown_
- _silence_
- 'off'
- up
- <sos/eos>
init: null
input_size: 83
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: true
model_conf:
ctc_weight: 0.0
lsm_weight: 0.1
length_normalized_loss: false
use_preprocessor: true
token_type: word
bpemodel: null
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
frontend: null
frontend_conf: {}
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 30
num_freq_mask: 2
apply_time_mask: true
time_mask_width_range:
- 0
- 40
num_time_mask: 2
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_fbank_pitch_word_sp/train/feats_stats.npz
preencoder: null
preencoder_conf: {}
encoder: conformer
encoder_conf:
output_size: 256
attention_heads: 4
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.1
input_layer: conv2d
normalize_before: true
macaron_style: true
rel_pos_type: legacy
pos_enc_layer_type: rel_pos
selfattention_layer_type: rel_selfattn
activation_type: swish
use_cnn_module: true
cnn_module_kernel: 15
postencoder: null
postencoder_conf: {}
decoder: transformer
decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.1
src_attention_dropout_rate: 0.1
required:
- output_dir
- token_list
version: 0.10.3a3
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Davlan/m2m100_418M-yor-eng-mt | [
"pytorch",
"m2m_100",
"text2text-generation",
"arxiv:2103.08647",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"M2M100ForConditionalGeneration"
],
"model_type": "m2m_100",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 6 | 2021-12-29T00:59:04Z | ---
tags:
- espnet
- audio
- automatic-speech-recognition
language: noinfo
datasets:
- speechcommands
license: cc-by-4.0
---
## ESPnet2 ASR model
### `pyf98/speechcommands_35commands_conformer`
This model was trained by Yifan Peng using speechcommands recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
```bash
cd espnet
git checkout bf523b70cae8300da004b41ec6a0d1b57c7ae8bb
pip install -e .
cd egs2/speechcommands/asr1
./run.sh --skip_data_prep false --skip_train true --download_model pyf98/speechcommands_35commands_conformer
```
<!-- Generated by scripts/utils/show_asr_result.sh -->
# RESULTS
## Environments
- date: `Tue Dec 28 20:39:29 EST 2021`
- python version: `3.9.7 (default, Sep 16 2021, 13:09:58) [GCC 7.5.0]`
- espnet version: `espnet 0.10.5a1`
- pytorch version: `pytorch 1.9.0`
- Git hash: `bf523b70cae8300da004b41ec6a0d1b57c7ae8bb`
- Commit date: `Tue Dec 28 14:53:22 2021 -0500`
## asr_35commands_conformer_noBatchNorm_warmup5k_lr2e-4_accum3_conv15_5speeds
### WER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|infer/dev|9981|9981|97.4|2.6|0.0|0.0|2.6|2.6|
|infer/test|11005|11005|97.5|2.5|0.0|0.0|2.5|2.5|
### CER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
|infer/dev|9981|38699|98.2|1.3|0.5|0.7|2.5|2.6|
|infer/test|11005|42682|98.3|1.2|0.5|0.6|2.3|2.5|
### TER
|dataset|Snt|Wrd|Corr|Sub|Del|Ins|Err|S.Err|
|---|---|---|---|---|---|---|---|---|
## ASR config
<details><summary>expand</summary>
```
config: conf/train_asr_conformer_noBatchNorm.yaml
print_config: false
log_level: INFO
dry_run: false
iterator_type: sequence
output_dir: exp/asr_35commands_conformer_noBatchNorm_warmup5k_lr2e-4_accum3_conv15_5speeds
ngpu: 1
seed: 0
num_workers: 1
num_att_plot: 3
dist_backend: nccl
dist_init_method: env://
dist_world_size: null
dist_rank: null
local_rank: 0
dist_master_addr: null
dist_master_port: null
dist_launcher: null
multiprocessing_distributed: false
unused_parameters: false
sharded_ddp: false
cudnn_enabled: true
cudnn_benchmark: false
cudnn_deterministic: true
collect_stats: false
write_collected_feats: false
max_epoch: 150
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- loss
- min
- - valid
- acc
- max
keep_nbest_models: 10
grad_clip: 5.0
grad_clip_type: 2.0
grad_noise: false
accum_grad: 3
no_forward_run: false
resume: true
train_dtype: float32
use_amp: false
log_interval: null
use_tensorboard: true
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 20
valid_batch_size: null
batch_bins: 4000000
valid_batch_bins: null
train_shape_file:
- exp/asr_stats_fbank_pitch_word_sp/train/speech_shape
- exp/asr_stats_fbank_pitch_word_sp/train/text_shape.word
valid_shape_file:
- exp/asr_stats_fbank_pitch_word_sp/valid/speech_shape
- exp/asr_stats_fbank_pitch_word_sp/valid/text_shape.word
batch_type: numel
valid_batch_type: null
fold_length:
- 800
- 150
sort_in_batch: descending
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
train_data_path_and_name_and_type:
- - dump/fbank_pitch/train_sp/feats.scp
- speech
- kaldi_ark
- - dump/fbank_pitch/train_sp/text
- text
- text
valid_data_path_and_name_and_type:
- - dump/fbank_pitch/dev/feats.scp
- speech
- kaldi_ark
- - dump/fbank_pitch/dev/text
- text
- text
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
valid_max_cache_size: null
optim: adam
optim_conf:
lr: 0.0002
scheduler: warmuplr
scheduler_conf:
warmup_steps: 5000
token_list:
- <blank>
- <unk>
- zero
- five
- 'yes'
- seven
- nine
- one
- down
- 'no'
- stop
- two
- go
- six
- 'on'
- left
- eight
- right
- 'off'
- three
- four
- up
- house
- wow
- dog
- marvin
- bird
- cat
- happy
- sheila
- bed
- tree
- backward
- visual
- learn
- follow
- forward
- <sos/eos>
init: null
input_size: 83
ctc_conf:
dropout_rate: 0.0
ctc_type: builtin
reduce: true
ignore_nan_grad: true
model_conf:
ctc_weight: 0.0
lsm_weight: 0.1
length_normalized_loss: false
use_preprocessor: true
token_type: word
bpemodel: null
non_linguistic_symbols: null
cleaner: null
g2p: null
speech_volume_normalize: null
rir_scp: null
rir_apply_prob: 1.0
noise_scp: null
noise_apply_prob: 1.0
noise_db_range: '13_15'
frontend: null
frontend_conf: {}
specaug: specaug
specaug_conf:
apply_time_warp: true
time_warp_window: 5
time_warp_mode: bicubic
apply_freq_mask: true
freq_mask_width_range:
- 0
- 30
num_freq_mask: 2
apply_time_mask: true
time_mask_width_range:
- 0
- 40
num_time_mask: 2
normalize: global_mvn
normalize_conf:
stats_file: exp/asr_stats_fbank_pitch_word_sp/train/feats_stats.npz
preencoder: null
preencoder_conf: {}
encoder: conformer
encoder_conf:
output_size: 256
attention_heads: 4
linear_units: 2048
num_blocks: 12
dropout_rate: 0.1
positional_dropout_rate: 0.1
attention_dropout_rate: 0.1
input_layer: conv2d
normalize_before: true
macaron_style: true
rel_pos_type: legacy
pos_enc_layer_type: rel_pos
selfattention_layer_type: rel_selfattn
activation_type: swish
use_cnn_module: true
cnn_module_kernel: 15
postencoder: null
postencoder_conf: {}
decoder: transformer
decoder_conf:
attention_heads: 4
linear_units: 2048
num_blocks: 6
dropout_rate: 0.1
positional_dropout_rate: 0.1
self_attention_dropout_rate: 0.1
src_attention_dropout_rate: 0.1
required:
- output_dir
- token_list
version: 0.10.3a3
distributed: false
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
Dazai/Ok | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: ja
datasets:
- common_voice #TODO: remove if you did not use the common voice dataset
- TODO: add more datasets if you have used additional datasets. Make sure to use the exact same
dataset name as the one found [here](https://huggingface.co/datasets). If the dataset can not be found in the official datasets, just give it a new name
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Japanese XLSR Wav2Vec2 Large 53
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ja
type: common_voice
args: ja
metrics:
- name: Test WER
type: wer
value: 70.1869
---
# Wav2Vec2-Large-XLSR-53-Japanese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Japanese using the [Common Voice](https://huggingface.co/datasets/common_voice), ... and ... dataset{s}.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ja", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("qqhann/w2v_hf_commonvoice_from_xlsr53_pretrain_0329UTC1500")
model = Wav2Vec2ForCTC.from_pretrained("qqhann/w2v_hf_commonvoice_from_xlsr53_pretrain_0329UTC1500")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Japanese test data of Common Voice.
```python
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
test_dataset = load_dataset("common_voice", "ja", split="test")
wer = load_metric("wer")
processor = Wav2Vec2Processor.from_pretrained("qqhann/w2v_hf_commonvoice_from_xlsr53_pretrain_0329UTC1500")
model = Wav2Vec2ForCTC.from_pretrained("qqhann/w2v_hf_commonvoice_from_xlsr53_pretrain_0329UTC1500")
model.to("cuda")
chars_to_ignore_regex = '[\,\?\.\!\-\;\:\"\“]' # TODO: adapt this list to include all special characters you removed from the data
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 70.18 %
## Training
The Common Voice `train`, `validation`, and ... datasets were used for training as well as ... and ...
<!-- # TODO: adapt to state all the datasets that were used for training. -->
The script used for training can be found [here](...)
<!-- # TODO: fill in a link to your training script here. If you trained your model in a colab, simply fill in the link here. If you trained the model locally, it would be great if you could upload the training script on github and paste the link here. -->
|
Dbluciferm3737/Idk | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | ---
language: ja
datasets:
- common_voice
- jsut
metrics:
- wer
- cer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
license: apache-2.0
model-index:
- name: Japanese XLSR Wav2Vec2 Large 53
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice ja
type: common_voice
args: ja
metrics:
- name: Test WER
type: wer
value: 51.72
- name: Test CER
type: cer
value: 24.89
---
# Wav2Vec2-Large-XLSR-53-Japanese
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on Japanese using the [Common Voice](https://huggingface.co/datasets/common_voice), and JSUT dataset{s}.
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
test_dataset = load_dataset("common_voice", "ja", split="test[:2%]")
processor = Wav2Vec2Processor.from_pretrained("qqhann/w2v_hf_jsut_xlsr53")
model = Wav2Vec2ForCTC.from_pretrained("qqhann/w2v_hf_jsut_xlsr53")
resampler = torchaudio.transforms.Resample(48_000, 16_000)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
inputs = processor(test_dataset["speech"][:2], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values, attention_mask=inputs.attention_mask).logits
predicted_ids = torch.argmax(logits, dim=-1)
print("Prediction:", processor.batch_decode(predicted_ids))
print("Reference:", test_dataset["sentence"][:2])
```
## Evaluation
The model can be evaluated as follows on the Japanese test data of Common Voice.
```python
!pip install torchaudio
!pip install datasets transformers
!pip install jiwer
!pip install mecab-python3
!pip install unidic-lite
!python -m unidic download
!pip install jaconv
import torch
import torchaudio
from datasets import load_dataset, load_metric
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
import re
import MeCab
from jaconv import kata2hira
from typing import List
# Japanese preprocessing
tagger = MeCab.Tagger("-Owakati")
chars_to_ignore_regex = '[\。\、\「\」\,\?\.\!\-\;\:\"\“\%\‘\”\�]'
def text2kata(text):
node = tagger.parseToNode(text)
word_class = []
while node:
word = node.surface
wclass = node.feature.split(',')
if wclass[0] != u'BOS/EOS':
if len(wclass) <= 6:
word_class.append((word))
elif wclass[6] == None:
word_class.append((word))
else:
word_class.append((wclass[6]))
node = node.next
return ' '.join(word_class)
def hiragana(text):
return kata2hira(text2kata(text))
test_dataset = load_dataset("common_voice", "ja", split="test")
wer = load_metric("wer")
resampler = torchaudio.transforms.Resample(48_000, 16_000) # JSUT is already 16kHz
# resampler = torchaudio.transforms.Resample(16_000, 16_000) # JSUT is already 16kHz
processor = Wav2Vec2Processor.from_pretrained("qqhann/w2v_hf_jsut_xlsr53")
model = Wav2Vec2ForCTC.from_pretrained("qqhann/w2v_hf_jsut_xlsr53")
model.to("cuda")
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def speech_file_to_array_fn(batch):
batch["sentence"] = hiragana(batch["sentence"]).strip()
batch["sentence"] = re.sub(chars_to_ignore_regex, '', batch["sentence"]).lower()
speech_array, sampling_rate = torchaudio.load(batch["path"])
batch["speech"] = resampler(speech_array).squeeze().numpy()
return batch
test_dataset = test_dataset.map(speech_file_to_array_fn)
# Preprocessing the datasets.
# We need to read the aduio files as arrays
def evaluate(batch):
inputs = processor(batch["speech"], sampling_rate=16_000, return_tensors="pt", padding=True)
with torch.no_grad():
logits = model(inputs.input_values.to("cuda"), attention_mask=inputs.attention_mask.to("cuda")).logits
pred_ids = torch.argmax(logits, dim=-1)
batch["pred_strings"] = processor.batch_decode(pred_ids)
return batch
result = test_dataset.map(evaluate, batched=True, batch_size=8)
def cer_compute(predictions: List[str], references: List[str]):
p = [" ".join(list(" " + pred.replace(" ", ""))).strip() for pred in predictions]
r = [" ".join(list(" " + ref.replace(" ", ""))).strip() for ref in references]
return wer.compute(predictions=p, references=r)
print("WER: {:2f}".format(100 * wer.compute(predictions=result["pred_strings"], references=result["sentence"])))
print("CER: {:2f}".format(100 * cer_compute(predictions=result["pred_strings"], references=result["sentence"])))
```
**Test Result**: 51.72 %
## Training
<!-- The Common Voice `train`, `validation`, and ... datasets were used for training as well as ... and ... # TODO: adapt to state all the datasets that were used for training. -->
The privately collected JSUT Japanese dataset was used for training.
<!-- The script used for training can be found [here](...) # TODO: fill in a link to your training script here. If you trained your model in a colab, simply fill in the link here. If you trained the model locally, it would be great if you could upload the training script on github and paste the link here. -->
|
Declan/NPR_model_v2 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7 | null | ---
language:
- lu
tags:
- text
- MLM
license: mit
---
## BERT Medium for Luxembourgish
Created from a dataset with 1M Luxembourgish sentences from Wikipedia. Corpus has approx. 16M words.
The MLM objective was trained. The BERT model has parameters `L=8` and `H=512`. Vocabulary has 70K word pieces.
Final loss scores, after 3 epochs:
- Final train loss: 4.230
- Final train perplexity: 68.726
- Final validation loss: 4.074
- Final validation perplexity: 58.765
|
Declan/NewYorkTimes_model_v1 | [] | null | {
"architectures": null,
"model_type": null,
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 0 | null | https://twitter.com/i/events/1413870919320104965
https://peatix.com/group/11420372/
https://cmdt-guyane.fr/advert/argentina-vs-brazil-live-stream-final-2021/
https://www.quisqueyapeach.com/advert/argentina-vs-brazil-live-stream-final-2021/
https://www.beauvaissubaquatique.fr/advert/argentina-vs-brazil-live-stream-final-2021/
https://www.dmcityview.com/event/argentina-vs-brazil-live-stream-final-2021/ |
Declan/NewYorkTimes_model_v6 | [
"pytorch",
"bert",
"fill-mask",
"transformers",
"autotrain_compatible"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 5 | null | ---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-base-timit-demo-colab
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-base-timit-demo-colab
This model is a fine-tuned version of [facebook/wav2vec2-base-960h](https://huggingface.co/facebook/wav2vec2-base-960h) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0755
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 10
- num_epochs: 2
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 8.0894 | 0.34 | 50 | 3.8065 | 1.0 |
| 3.2971 | 0.69 | 100 | 3.0704 | 1.0 |
| 3.1262 | 1.03 | 150 | 3.0153 | 1.0 |
| 2.9925 | 1.38 | 200 | 3.0094 | 1.0 |
| 3.2159 | 1.72 | 250 | 3.0755 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.0+cu111
- Datasets 1.13.3
- Tokenizers 0.10.3
|
DeskDown/MarianMixFT_en-fil | [
"pytorch",
"marian",
"text2text-generation",
"transformers",
"autotrain_compatible"
] | text2text-generation | {
"architectures": [
"MarianMTModel"
],
"model_type": "marian",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3 | null | ## This is a genre-based Movie plot generator.
For best results, structure the input as follows -
1. Add a `<BOS>` tag in the start.
2. Add a `<genre>` tag (with the genre as a placeholder for lowercased genres such as `<action>`, `<romantic>`, `<thriller>`, `<comedy>` |
Doxophobia/DialoGPT-medium-celeste | [
"pytorch",
"gpt2",
"text-generation",
"transformers",
"conversational"
] | conversational | {
"architectures": [
"GPT2LMHeadModel"
],
"model_type": "gpt2",
"task_specific_params": {
"conversational": {
"max_length": 1000
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 11 | null | ---
license: apache-2.0
language:
- sl
tags:
- generated_from_trainer
- hf-asr-leaderboard
- robust-speech-event
datasets:
- common_voice
model-index:
- name: wav2vec2-large-xls-r-1B-common_voice-sl-ft
results:
- task:
name: Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 7
type: mozilla-foundation/common_voice_7_0
args: lv
metrics:
- name: Test WER
type: wer
value: 23.26
- name: Test CER
type: cer
value: 7.95
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 7.0
type: mozilla-foundation/common_voice_7_0
args: sl
metrics:
- name: Test WER
type: wer
value: 13.59
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Dev Data
type: speech-recognition-community-v2/dev_data
args: sl
metrics:
- name: Test WER
type: wer
value: 62.71
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Robust Speech Event - Test Data
type: speech-recognition-community-v2/eval_data
args: sl
metrics:
- name: Test WER
type: wer
value: 62.34
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-large-xls-r-1B-common_voice-sl-ft
This model is a fine-tuned version of [facebook/wav2vec2-xls-r-1b](https://huggingface.co/facebook/wav2vec2-xls-r-1b) on the common_voice dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2112
- Wer: 0.1404
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 32
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 400
- num_epochs: 100
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:------:|
| 1.8291 | 12.2 | 500 | 0.5674 | 0.7611 |
| 0.0416 | 24.39 | 1000 | 0.3093 | 0.2964 |
| 0.0256 | 36.59 | 1500 | 0.2224 | 0.2072 |
| 0.0179 | 48.78 | 2000 | 0.2274 | 0.1960 |
| 0.0113 | 60.98 | 2500 | 0.2078 | 0.1582 |
| 0.0086 | 73.17 | 3000 | 0.1898 | 0.1552 |
| 0.0059 | 85.37 | 3500 | 0.2054 | 0.1446 |
| 0.0044 | 97.56 | 4000 | 0.2112 | 0.1404 |
### Framework versions
- Transformers 4.16.0.dev0
- Pytorch 1.10.1+cu102
- Datasets 1.17.1.dev0
- Tokenizers 0.10.3
|
albert-base-v1 | [
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 38,156 | 2021-10-08T12:02:48Z | ---
language: "en"
tags:
- agriculture-domain
- agriculture
- fill-mask
widget:
- text: "[MASK] agriculture provides one of the most promising areas for innovation in green and blue infrastructure in cities."
---
# BERT for Agriculture Domain
A BERT-based language model further pre-trained from the checkpoint of [SciBERT](https://huggingface.co/allenai/scibert_scivocab_uncased).
The dataset gathered is a balance between scientific and general works in agriculture domain and encompassing knowledge from different areas of agriculture research and practical knowledge.
The corpus contains 1.2 million paragraphs from National Agricultural Library (NAL) from the US Gov. and 5.3 million paragraphs from books and common literature from the **Agriculture Domain**.
The self-supervised learning approach of MLM was used to train the model.
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT internally masks the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="recobo/agriculture-bert-uncased",
tokenizer="recobo/agriculture-bert-uncased"
)
fill_mask("[MASK] is the practice of cultivating plants and livestock.")
``` |
albert-base-v2 | [
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 4,785,283 | 2021-09-06T13:36:29Z | ---
language: "en"
tags:
- buy-intent
- sell-intent
- consumer-intent
widget:
- text: "Flutoprazepam (Restas) is a drug which is a benzodiazepine. It was patented in Japan by Sumitomo."
---
# Chemical vs Pharmaceutical Domain Document Classifier
Chemical domain language model finetuned on 13K Chemical, and 14K Pharma Wikipedia articles broken into paragraphs.
| Train Loss | Validation Acc. | Test Acc.|
| ------------- |:-------------: | -----: |
| 0.17 | 0.928 | 0.927 |
# Dataset
Dataset with splits can be found @ [https://www.kaggle.com/shahrukhkhan/pharma-vs-chemicals-domain-classification](https://www.kaggle.com/shahrukhkhan/pharma-vs-chemicals-domain-classification)
# Label Mappings
LABEL_0 => **"PHARMACEUTICAL"** <br/>
LABEL_1 => **"CHEMICAL"**
## Usage in Transformers
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("recobo/chemical-bert-uncased-pharmaceutical-chemical-classifier")
model = AutoModelForSequenceClassification.from_pretrained("recobo/chemical-bert-uncased-pharmaceutical-chemical-classifier")
``` |
albert-large-v1 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 687 | 2021-09-06T05:37:19Z | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# recobo/chemical-bert-uncased-simcse
```python
from sentence_transformers import SentenceTransformer
model_name = 'recobo/chemical-bert-uncased-simcse'
model = SentenceTransformer(model_name)
``` |
albert-large-v2 | [
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 26,792 | 2021-08-31T20:54:33Z | ```python
from transformers import AutoModelForQuestionAnswering, AutoTokenizer, pipeline
model_name = "recobo/chemical-bert-uncased-squad2"
# a) Get predictions
nlp = pipeline('question-answering', model=model_name, tokenizer=model_name)
QA_input = {
'question': 'Why is model conversion important?',
'context': 'The option to convert models between pytorch and transformers gives freedom to the user and let people easily switch between frameworks.'
}
res = nlp(QA_input)
# b) Load model & tokenizer
model = AutoModelForQuestionAnswering.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
``` |
albert-xlarge-v1 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 341 | 2021-09-04T08:31:37Z | ---
pipeline_tag: sentence-similarity
license: apache-2.0
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# recobo/chemical-bert-uncased-tsdae
```python
from sentence_transformers import SentenceTransformer
model_name = 'recobo/chemical-bert-uncased-tsdae'
model = SentenceTransformer(model_name)
``` |
albert-xlarge-v2 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 2,973 | 2021-08-31T17:53:46Z | ---
language: "en"
tags:
- chemical-domain
- safety-datasheets
widget:
- text: "The removal of mercaptans, and for drying of gases and [MASK]."
---
# BERT for Chemical Industry
A BERT-based language model further pre-trained from the checkpoint of [SciBERT](https://huggingface.co/allenai/scibert_scivocab_uncased). We used a corpus of over 40,000+ technical documents from the **Chemical Industrial domain** and combined it with 13,000 Wikipedia Chemistry articles, ranging from Safety Data Sheets and Products Information Documents, with 250,000+ tokens from the Chemical domain and pre-trained using MLM and over 9.2 million paragraphs.
- Masked language modeling (MLM): taking a sentence, the model randomly masks 15% of the words in the input then run
the entire masked sentence through the model and has to predict the masked words. This is different from traditional
recurrent neural networks (RNNs) that usually see the words one after the other, or from autoregressive models like
GPT internally masks the future tokens. It allows the model to learn a bidirectional representation of the
sentence.
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="recobo/chemical-bert-uncased",
tokenizer="recobo/chemical-bert-uncased"
)
fill_mask("we create [MASK]")
``` |
albert-xxlarge-v1 | [
"pytorch",
"tf",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 7,091 | 2021-12-29T01:42:50Z | ---
tags: autonlp
language: de
widget:
- text: "I love AutoNLP 🤗"
datasets:
- redadmiral/autonlp-data-Headline-Generator
co2_eq_emissions: 651.3545590912366
---
# Model Trained Using AutoNLP
- Problem type: Summarization
- Model ID: 453611714
- CO2 Emissions (in grams): 651.3545590912366
## Validation Metrics
- Loss: nan
- Rouge1: 2.8187
- Rouge2: 0.5508
- RougeL: 2.7396
- RougeLsum: 2.7446
- Gen Len: 9.7507
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoNLP"}' https://api-inference.huggingface.co/redadmiral/autonlp-Headline-Generator-453611714
``` |
albert-xxlarge-v2 | [
"pytorch",
"tf",
"safetensors",
"albert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1909.11942",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"AlbertForMaskedLM"
],
"model_type": "albert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 42,640 | null | This Model is a fine-tuned version of T-systems [summarization model v1](https://huggingface.co/deutsche-telekom/mt5-small-sum-de-en-v1).
We used 1000 examples of headline-content pairs from BR24 articles for the fine-tuning process.
Despite the small amount of training data, the tonality of the summarizations has changed significantly. Many of the resulting summaries do sound like a headline.
## Training
We used the following parameters for training this model:
+ base model: deutsche-telekom/mt5-small-sum-de-en-v1
+ source_prefix: "summarize: "
+ batch size: 4
+ max_source_length: 400
+ max_target_length: 35
+ weight_decay: 0.01
+ number of train epochs: 1
+ learning rate: 5e-5
## License
Since the base model is trained on the MLSUM dataset, this model may not be used for commercial use.
## Stats
| Model | Rouge1 | Rouge2 | RougeL | RougeLSum |
|-----------------------------------------|-----------|----------|-----------|-----------|
| headlines_test_small_example | 13.573500 | 3.694700 | 12.560600 | 12.60000 |
| deutsche-telekom/mt5-small-sum-de-en-v1 | 10.6488 | 2.9313 | 10.0527 | 10.0523 |
|
bert-base-cased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"exbert",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8,621,271 | 2021-12-23T11:06:07Z | ---
tags:
- conversational
---
#Shayo Bot by Shogun
#Ai Chatbot Testing based on GPT2 and DialoGPT-Medium by Microsoft
#shoguπ#9999 |
bert-base-chinese | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"zh",
"arxiv:1810.04805",
"transformers",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 3,377,486 | 2020-04-01T08:55:41Z | ---
language: de
---
# Model description
## Dataset
Trained on fictional and non-fictional German texts written between 1840 and 1920:
* Narrative texts from Digitale Bibliothek (https://textgrid.de/digitale-bibliothek)
* Fairy tales and sagas from Grimm Korpus (https://www1.ids-mannheim.de/kl/projekte/korpora/archiv/gri.html)
* Newspaper and magazine article from Mannheimer Korpus Historischer Zeitungen und Zeitschriften (https://repos.ids-mannheim.de/mkhz-beschreibung.html)
* Magazine article from the journal „Die Grenzboten“ (http://www.deutschestextarchiv.de/doku/textquellen#grenzboten)
* Fictional and non-fictional texts from Projekt Gutenberg (https://www.projekt-gutenberg.org)
## Hardware used
1 Tesla P4 GPU
## Hyperparameters
| Parameter | Value |
|-------------------------------|----------|
| Epochs | 3 |
| Gradient_accumulation_steps | 1 |
| Train_batch_size | 32 |
| Learning_rate | 0.00003 |
| Max_seq_len | 128 |
## Evaluation results: Automatic tagging of four forms of speech/thought/writing representation in historical fictional and non-fictional German texts
The language model was used in the task to tag direct, indirect, reported and free indirect speech/thought/writing representation in fictional and non-fictional German texts. The tagger is available and described in detail at https://github.com/redewiedergabe/tagger.
The tagging model was trained using the SequenceTagger Class of the Flair framework ([Akbik et al., 2019](https://www.aclweb.org/anthology/N19-4010)) which implements a BiLSTM-CRF architecture on top of a language embedding (as proposed by [Huang et al. (2015)](https://arxiv.org/abs/1508.01991)).
Hyperparameters
| Parameter | Value |
|-------------------------------|------------|
| Hidden_size | 256 |
| Learning_rate | 0.1 |
| Mini_batch_size | 8 |
| Max_epochs | 150 |
Results are reported below in comparison to a custom trained flair embedding, which was stacked onto a custom trained fastText-model. Both models were trained on the same dataset.
| | BERT ||| FastText+Flair |||Test data|
|----------------|----------|-----------|----------|------|-----------|--------|--------|
| | F1 | Precision | Recall | F1 | Precision | Recall ||
| Direct | 0.80 | 0.86 | 0.74 | 0.84 | 0.90 | 0.79 |historical German, fictional & non-fictional|
| Indirect | **0.76** | **0.79** | **0.73** | 0.73 | 0.78 | 0.68 |historical German, fictional & non-fictional|
| Reported | **0.58** | **0.69** | **0.51** | 0.56 | 0.68 | 0.48 |historical German, fictional & non-fictional|
| Free indirect | **0.57** | **0.80** | **0.44** | 0.47 | 0.78 | 0.34 |modern German, fictional|
## Intended use:
Historical German Texts (1840 to 1920)
(Showed good performance with modern German fictional texts as well)
|
bert-base-german-cased | [
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"de",
"transformers",
"exbert",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 175,983 | 2021-08-31T03:18:40Z | This is Korean-TTS model. (based on Tacotron)
Dataset is from Sogang University. |
bert-base-german-dbmdz-cased | [
"pytorch",
"jax",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 1,814 | 2021-08-30T10:01:42Z | This is espnet-based korean TTS model.
You should recognize that this is not fisished one.
Dataset is from our university, which is NOT available yet.
|
bert-base-german-dbmdz-uncased | [
"pytorch",
"jax",
"safetensors",
"bert",
"fill-mask",
"de",
"transformers",
"license:mit",
"autotrain_compatible",
"has_space"
] | fill-mask | {
"architectures": [
"BertForMaskedLM"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 68,305 | 2020-11-16T06:31:55Z | ---
language: "tr"
tags:
- turkish
- tr
- gpt2-tr
- gpt2-turkish
---
# 🇹🇷 Turkish GPT-2 Model
In this repository I release GPT-2 model, that was trained on various texts for Turkish.
The model is meant to be an entry point for fine-tuning on other texts.
## Training corpora
I used a Turkish corpora that is taken from oscar-corpus.
It was possible to create byte-level BPE with Tokenizers library of Huggingface.
With the Tokenizers library, I created a 52K byte-level BPE vocab based on the training corpora.
After creating the vocab, I could train the GPT-2 for Turkish on two 2080TI over the complete training corpus (five epochs).
Logs during training:
https://tensorboard.dev/experiment/3AWKv8bBTaqcqZP5frtGkw/#scalars
## Model weights
Both PyTorch and Tensorflow compatible weights are available.
| Model | Downloads
| --------------------------------- | ---------------------------------------------------------------------------------------------------------------
| `redrussianarmy/gpt2-turkish-cased` | [`config.json`](https://huggingface.co/redrussianarmy/gpt2-turkish-cased/resolve/main/config.json) • [`merges.txt`](https://huggingface.co/redrussianarmy/gpt2-turkish-cased/resolve/main/merges.txt) • [`pytorch_model.bin`](https://huggingface.co/redrussianarmy/gpt2-turkish-cased/resolve/main/pytorch_model.bin) • [`special_tokens_map.json`](https://huggingface.co/redrussianarmy/gpt2-turkish-cased/resolve/main/special_tokens_map.json) • [`tf_model.h5`](https://huggingface.co/redrussianarmy/gpt2-turkish-cased/resolve/main/tf_model.h5) • [`tokenizer_config.json`](https://huggingface.co/redrussianarmy/gpt2-turkish-cased/resolve/main/tokenizer_config.json) • [`traning_args.bin`](https://huggingface.co/redrussianarmy/gpt2-turkish-cased/resolve/main/training_args.bin) • [`vocab.json`](https://huggingface.co/redrussianarmy/gpt2-turkish-cased/resolve/main/vocab.json)
## Using the model
The model itself can be used in this way:
``` python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("redrussianarmy/gpt2-turkish-cased")
model = AutoModelWithLMHead.from_pretrained("redrussianarmy/gpt2-turkish-cased")
```
Here's an example that shows how to use the great Transformers Pipelines for generating text:
``` python
from transformers import pipeline
pipe = pipeline('text-generation', model="redrussianarmy/gpt2-turkish-cased",
tokenizer="redrussianarmy/gpt2-turkish-cased", config={'max_length':800})
text = pipe("Akşamüstü yolda ilerlerken, ")[0]["generated_text"]
print(text)
```
### How to clone the model repo?
```
git lfs install
git clone https://huggingface.co/redrussianarmy/gpt2-turkish-cased
```
## Contact (Bugs, Feedback, Contribution and more)
For questions about the GPT2-Turkish model, just open an issue [here](https://github.com/redrussianarmy/gpt2-turkish/issues) 🤗 |
bert-large-cased-whole-word-masking-finetuned-squad | [
"pytorch",
"tf",
"jax",
"rust",
"safetensors",
"bert",
"question-answering",
"en",
"dataset:bookcorpus",
"dataset:wikipedia",
"arxiv:1810.04805",
"transformers",
"license:apache-2.0",
"autotrain_compatible",
"has_space"
] | question-answering | {
"architectures": [
"BertForQuestionAnswering"
],
"model_type": "bert",
"task_specific_params": {
"conversational": {
"max_length": null
},
"summarization": {
"early_stopping": null,
"length_penalty": null,
"max_length": null,
"min_length": null,
"no_repeat_ngram_size": null,
"num_beams": null,
"prefix": null
},
"text-generation": {
"do_sample": null,
"max_length": null
},
"translation_en_to_de": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_fr": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
},
"translation_en_to_ro": {
"early_stopping": null,
"max_length": null,
"num_beams": null,
"prefix": null
}
}
} | 8,214 | 2022-01-12T14:09:26Z | ---
license: apache-2.0
language:
- ar
---
The **AraRoBERTa** models are mono-dialectal Arabic models trained on a country-level dialect. AraRoBERTa uses RoBERTa base config. More details are available in the paper [click](https://aclanthology.org/2022.wanlp-1.24/).
The following are the AraRoBERTa seven dialectal variations:
* [AraRoBERTa-SA](https://huggingface.co/reemalyami/AraRoBERTa-SA): Saudi Arabia (SA) dialect.
* [AraRoBERTa-EGY](https://huggingface.co/reemalyami/AraRoBERTa-EGY): Egypt (EGY) dialect.
* [AraRoBERTa-KU](https://huggingface.co/reemalyami/AraRoBERTa-KU): Kuwait (KU) dialect.
* [AraRoBERTa-OM](https://huggingface.co/reemalyami/AraRoBERTa-OM): Oman (OM) dialect.
* [AraRoBERTa-LB](https://huggingface.co/reemalyami/AraRoBERTa-LB): Lebanon (LB) dialect.
* [AraRoBERTa-JO](https://huggingface.co/reemalyami/AraRoBERTa-JO): Jordan (JO) dialect.
* [AraRoBERTa-DZ](https://huggingface.co/reemalyami/AraRoBERTa-DZ): Algeria (DZ) dialect
# When using the model, please cite our paper:
```python
@inproceedings{alyami-al-zaidy-2022-weakly,
title = "Weakly and Semi-Supervised Learning for {A}rabic Text Classification using Monodialectal Language Models",
author = "AlYami, Reem and Al-Zaidy, Rabah",
booktitle = "Proceedings of the The Seventh Arabic Natural Language Processing Workshop (WANLP)",
month = dec,
year = "2022",
address = "Abu Dhabi, United Arab Emirates (Hybrid)",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.wanlp-1.24",
pages = "260--272",
}
```
# Contact
**Reem AlYami**: [Linkedin](https://www.linkedin.com/in/reem-alyami/) | <[email protected]> | <[email protected]>
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.