
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-31 12:28:44
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 540
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-31 12:23:33
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
CCMat/fgreeneruins-ruins
|
CCMat
| 2023-01-27T12:46:53Z | 6 | 1 |
diffusers
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"landscape",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-20T16:37:03Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- landscape
widget:
- text: high quality photo of Venice in fgreeneruins ruins
---
# DreamBooth model for the fgreeneruins concept trained on the CCMat/db-forest-ruins dataset.
This is a Stable Diffusion model fine-tuned on the fgreeneruins concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of fgreeneruins ruins**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `ruins` images for the landscape theme.<br>
Concept: **fgreeneruins** : forest ruins, greenery ruins<br>
Pretrained Model: [nitrosocke/elden-ring-diffusion](https://huggingface.co/nitrosocke/elden-ring-diffusion)<br>
Learning rate: 2e-6<br>
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('CCMat/fgreeneruins-ruins')
image = pipeline().images[0]
image
```
## Samples
Prompt: "high quality photo of Venice in fruins ruins"

<br>
Prompt: "high quality photo of Rome in fgreeneruins ruins with the Colosseum in the background"

<br>
Prompt: "fgreeneruins ruins in London near the Tower Bridge, professional photograph"

<br>
Prompt: "photo of Paris in fgreeneruins ruins, elden ring style"

Prompt: "fgreeneruins ruins in Saint Petersburg, Sovietwave"

|
CCMat/fforiver-river-mdj
|
CCMat
| 2023-01-27T12:46:36Z | 6 | 1 |
diffusers
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"landscape",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-17T18:12:52Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- landscape
widget:
- text: Fallout concept of fforiver river in front of the Great Pyramid of Giza
---
# DreamBooth model for the fforiver concept trained on the CCMat/forest-river dataset.
This is a Stable Diffusion model fine-tuned on the fforiver concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of fforiver river**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `river` images for the landscape theme.
Pretrained Model: prompthero/openjourney
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('CCMat/fforiver-river-mdj')
image = pipeline().images[0]
image
```
## Samples
Prompt: "high quality photo of fforiver river along the Colosseum in Rome"

<br>
Prompt: "Fallout concept of fforiver river in front of Chichén Itzá in Mexico, sun rays, unreal engine 5"

<br>
|
Rajan/donut-base-sroie_300
|
Rajan
| 2023-01-27T12:37:52Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"vision-encoder-decoder",
"image-text-to-text",
"generated_from_trainer",
"dataset:imagefolder",
"license:mit",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2023-01-27T12:20:38Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- imagefolder
model-index:
- name: donut-base-sroie_300
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# donut-base-sroie_300
This model is a fine-tuned version of [naver-clova-ix/donut-base](https://huggingface.co/naver-clova-ix/donut-base) on the imagefolder dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1
- Datasets 2.8.0
- Tokenizers 0.13.2
|
jirkoru/TemporalRegressionV2
|
jirkoru
| 2023-01-27T12:37:46Z | 0 | 0 |
sklearn
|
[
"sklearn",
"skops",
"tabular-classification",
"region:us"
] |
tabular-classification
| 2023-01-27T12:37:05Z |
---
library_name: sklearn
tags:
- sklearn
- skops
- tabular-classification
model_file: model.pkl
widget:
structuredData:
angel_n_rounds:
- 0.0
- 0.0
- 0.0
pre_seed_n_rounds:
- 0.0
- 0.0
- 0.0
seed_funding:
- 1250000.0
- 800000.0
- 8000000.0
seed_n_rounds:
- 1.0
- 3.0
- 1.0
time_first_funding:
- 1270.0
- 1856.0
- 689.0
time_till_series_a:
- 1455.0
- 1667.0
- 1559.0
---
# Model description
[More Information Needed]
## Intended uses & limitations
[More Information Needed]
## Training Procedure
### Hyperparameters
The model is trained with below hyperparameters.
<details>
<summary> Click to expand </summary>
| Hyperparameter | Value |
|-----------------------------------------------|----------------------------------------------------------------------------------------------------|
| memory | |
| steps | [('transformation', ColumnTransformer(transformers=[('min_max_scaler', MinMaxScaler(),<br /> ['time_first_funding', 'seed_funding',<br /> 'time_till_series_a'])])), ('model', LogisticRegression(penalty='none', random_state=0))] |
| verbose | False |
| transformation | ColumnTransformer(transformers=[('min_max_scaler', MinMaxScaler(),<br /> ['time_first_funding', 'seed_funding',<br /> 'time_till_series_a'])]) |
| model | LogisticRegression(penalty='none', random_state=0) |
| transformation__n_jobs | |
| transformation__remainder | drop |
| transformation__sparse_threshold | 0.3 |
| transformation__transformer_weights | |
| transformation__transformers | [('min_max_scaler', MinMaxScaler(), ['time_first_funding', 'seed_funding', 'time_till_series_a'])] |
| transformation__verbose | False |
| transformation__verbose_feature_names_out | True |
| transformation__min_max_scaler | MinMaxScaler() |
| transformation__min_max_scaler__clip | False |
| transformation__min_max_scaler__copy | True |
| transformation__min_max_scaler__feature_range | (0, 1) |
| model__C | 1.0 |
| model__class_weight | |
| model__dual | False |
| model__fit_intercept | True |
| model__intercept_scaling | 1 |
| model__l1_ratio | |
| model__max_iter | 100 |
| model__multi_class | auto |
| model__n_jobs | |
| model__penalty | none |
| model__random_state | 0 |
| model__solver | lbfgs |
| model__tol | 0.0001 |
| model__verbose | 0 |
| model__warm_start | False |
</details>
### Model Plot
The model plot is below.
<style>#sk-container-id-1 {color: black;background-color: white;}#sk-container-id-1 pre{padding: 0;}#sk-container-id-1 div.sk-toggleable {background-color: white;}#sk-container-id-1 label.sk-toggleable__label {cursor: pointer;display: block;width: 100%;margin-bottom: 0;padding: 0.3em;box-sizing: border-box;text-align: center;}#sk-container-id-1 label.sk-toggleable__label-arrow:before {content: "▸";float: left;margin-right: 0.25em;color: #696969;}#sk-container-id-1 label.sk-toggleable__label-arrow:hover:before {color: black;}#sk-container-id-1 div.sk-estimator:hover label.sk-toggleable__label-arrow:before {color: black;}#sk-container-id-1 div.sk-toggleable__content {max-height: 0;max-width: 0;overflow: hidden;text-align: left;background-color: #f0f8ff;}#sk-container-id-1 div.sk-toggleable__content pre {margin: 0.2em;color: black;border-radius: 0.25em;background-color: #f0f8ff;}#sk-container-id-1 input.sk-toggleable__control:checked~div.sk-toggleable__content {max-height: 200px;max-width: 100%;overflow: auto;}#sk-container-id-1 input.sk-toggleable__control:checked~label.sk-toggleable__label-arrow:before {content: "▾";}#sk-container-id-1 div.sk-estimator input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-label input.sk-toggleable__control:checked~label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 input.sk-hidden--visually {border: 0;clip: rect(1px 1px 1px 1px);clip: rect(1px, 1px, 1px, 1px);height: 1px;margin: -1px;overflow: hidden;padding: 0;position: absolute;width: 1px;}#sk-container-id-1 div.sk-estimator {font-family: monospace;background-color: #f0f8ff;border: 1px dotted black;border-radius: 0.25em;box-sizing: border-box;margin-bottom: 0.5em;}#sk-container-id-1 div.sk-estimator:hover {background-color: #d4ebff;}#sk-container-id-1 div.sk-parallel-item::after {content: "";width: 100%;border-bottom: 1px solid gray;flex-grow: 1;}#sk-container-id-1 div.sk-label:hover label.sk-toggleable__label {background-color: #d4ebff;}#sk-container-id-1 div.sk-serial::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: 0;}#sk-container-id-1 div.sk-serial {display: flex;flex-direction: column;align-items: center;background-color: white;padding-right: 0.2em;padding-left: 0.2em;position: relative;}#sk-container-id-1 div.sk-item {position: relative;z-index: 1;}#sk-container-id-1 div.sk-parallel {display: flex;align-items: stretch;justify-content: center;background-color: white;position: relative;}#sk-container-id-1 div.sk-item::before, #sk-container-id-1 div.sk-parallel-item::before {content: "";position: absolute;border-left: 1px solid gray;box-sizing: border-box;top: 0;bottom: 0;left: 50%;z-index: -1;}#sk-container-id-1 div.sk-parallel-item {display: flex;flex-direction: column;z-index: 1;position: relative;background-color: white;}#sk-container-id-1 div.sk-parallel-item:first-child::after {align-self: flex-end;width: 50%;}#sk-container-id-1 div.sk-parallel-item:last-child::after {align-self: flex-start;width: 50%;}#sk-container-id-1 div.sk-parallel-item:only-child::after {width: 0;}#sk-container-id-1 div.sk-dashed-wrapped {border: 1px dashed gray;margin: 0 0.4em 0.5em 0.4em;box-sizing: border-box;padding-bottom: 0.4em;background-color: white;}#sk-container-id-1 div.sk-label label {font-family: monospace;font-weight: bold;display: inline-block;line-height: 1.2em;}#sk-container-id-1 div.sk-label-container {text-align: center;}#sk-container-id-1 div.sk-container {/* jupyter's `normalize.less` sets `[hidden] { display: none; }` but bootstrap.min.css set `[hidden] { display: none !important; }` so we also need the `!important` here to be able to override the default hidden behavior on the sphinx rendered scikit-learn.org. See: https://github.com/scikit-learn/scikit-learn/issues/21755 */display: inline-block !important;position: relative;}#sk-container-id-1 div.sk-text-repr-fallback {display: none;}</style><div id="sk-container-id-1" class="sk-top-container" style="overflow: auto;"><div class="sk-text-repr-fallback"><pre>Pipeline(steps=[('transformation',ColumnTransformer(transformers=[('min_max_scaler',MinMaxScaler(),['time_first_funding','seed_funding','time_till_series_a'])])),('model', LogisticRegression(penalty='none', random_state=0))])</pre><b>In a Jupyter environment, please rerun this cell to show the HTML representation or trust the notebook. <br />On GitHub, the HTML representation is unable to render, please try loading this page with nbviewer.org.</b></div><div class="sk-container" hidden><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-1" type="checkbox" ><label for="sk-estimator-id-1" class="sk-toggleable__label sk-toggleable__label-arrow">Pipeline</label><div class="sk-toggleable__content"><pre>Pipeline(steps=[('transformation',ColumnTransformer(transformers=[('min_max_scaler',MinMaxScaler(),['time_first_funding','seed_funding','time_till_series_a'])])),('model', LogisticRegression(penalty='none', random_state=0))])</pre></div></div></div><div class="sk-serial"><div class="sk-item sk-dashed-wrapped"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-2" type="checkbox" ><label for="sk-estimator-id-2" class="sk-toggleable__label sk-toggleable__label-arrow">transformation: ColumnTransformer</label><div class="sk-toggleable__content"><pre>ColumnTransformer(transformers=[('min_max_scaler', MinMaxScaler(),['time_first_funding', 'seed_funding','time_till_series_a'])])</pre></div></div></div><div class="sk-parallel"><div class="sk-parallel-item"><div class="sk-item"><div class="sk-label-container"><div class="sk-label sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-3" type="checkbox" ><label for="sk-estimator-id-3" class="sk-toggleable__label sk-toggleable__label-arrow">min_max_scaler</label><div class="sk-toggleable__content"><pre>['time_first_funding', 'seed_funding', 'time_till_series_a']</pre></div></div></div><div class="sk-serial"><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-4" type="checkbox" ><label for="sk-estimator-id-4" class="sk-toggleable__label sk-toggleable__label-arrow">MinMaxScaler</label><div class="sk-toggleable__content"><pre>MinMaxScaler()</pre></div></div></div></div></div></div></div></div><div class="sk-item"><div class="sk-estimator sk-toggleable"><input class="sk-toggleable__control sk-hidden--visually" id="sk-estimator-id-5" type="checkbox" ><label for="sk-estimator-id-5" class="sk-toggleable__label sk-toggleable__label-arrow">LogisticRegression</label><div class="sk-toggleable__content"><pre>LogisticRegression(penalty='none', random_state=0)</pre></div></div></div></div></div></div></div>
## Evaluation Results
[More Information Needed]
# How to Get Started with the Model
[More Information Needed]
# Model Card Authors
This model card is written by following authors:
[More Information Needed]
# Model Card Contact
You can contact the model card authors through following channels:
[More Information Needed]
# Citation
Below you can find information related to citation.
**BibTeX:**
```
[More Information Needed]
```
# model_card_authors
jirko
# model_description
just the temporal regression with reduced input features
|
Antiraedus/LeDude-dog
|
Antiraedus
| 2023-01-27T12:36:51Z | 3 | 1 |
diffusers
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"animal",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-31T02:55:08Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- animal
widget:
- text: a photo of LeDude dog in the Acropolis
---
# DreamBooth model for the LeDude concept trained by Antiraedus on the Antiraedus/Dude dataset.
This is a Stable Diffusion model fine-tuned on the LeDude concept with DreamBooth, which is my 10 year old Australian Silky terrier.
It can be used by modifying the `instance_prompt`: **a photo of LeDude dog**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `dog` images for the animal theme.
## Original

## Example

## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('Antiraedus/LeDude-dog')
image = pipeline().images[0]
image
```
|
sd-dreambooth-library/retro3d
|
sd-dreambooth-library
| 2023-01-27T12:35:55Z | 13 | 31 |
diffusers
|
[
"diffusers",
"tensorboard",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-13T11:49:23Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
widget:
- text: trsldamrl Donald Trump
example_title: Retro3d donald Trump
- text: trsldamrl keanu reeves
example_title: Retro3d Keanu Reeves
- text: trsldamrl wizard castle
example_title: Retro3d wizard castle
---
### retro3d Dreambooth model trained by abesmon with [Hugging Face Dreambooth Training Space](https://colab.research.google.com/drive/15cxJE2SBYJ0bZwoGzkdOSvqGtgz_Rvhk?usp=sharing) with the v2-1-512 base model
You run your new concept via `diffusers` [Colab Notebook for Inference](https://colab.research.google.com/drive/1FQkg1LBk99Ujpwn4fBZzGgEcuXz6-52-?usp=sharing). Don't forget to use the concept prompts!
concept named **trsldamrl** (use that on your prompt)
### Trained with:
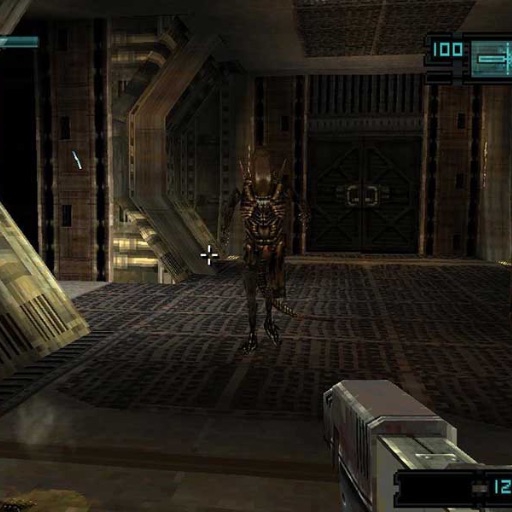
|
plasmo/naturitize-sd2-1-768px
|
plasmo
| 2023-01-27T12:34:10Z | 5 | 10 |
diffusers
|
[
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-23T20:31:30Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: "naturitize "
---
### Jak's **Naturitize** Image Pack (SD2.1) for Stable Diffusion
**naturitize-sd2.1-768px v.1.0**
*THIS IS FOR Stable Diffusion VERSION 2.1*
You MUST also include the **naturitize-SD2.1-768px.yaml** file in the same directory as your model file (will be uploaded here for your convenience)
With this model, other than being trained from SD2.1, you can also mix and match embeddings to your images!
--------------------
Another Jak Texture Pack Release is here to help create your earthy, creations!
Trained using 112 (768px) training images, 8000 training steps, 500 Text_Encoder_steps.
Use Prompt: "**naturitize**" in the beginning of your prompt followed by a word. *No major prompt-crafting needed*.
Thanks to /u/Jak_TheAI_Artist and /u/okamiueru for creating training images!
Sample pictures of this concept:







|
plasmo/wooditize-sd2-1-768px
|
plasmo
| 2023-01-27T12:33:44Z | 9 | 8 |
diffusers
|
[
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-20T21:22:01Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: "wooditize "
---
### Jak's **WOODitize** Image Pack (SD2.1) for Stable Diffusion
**wooditize-sd2.1-768px v.1.0**
*THIS IS FOR Stable Diffusion VERSION 2.1*
You MUST also include the **wooditize-SD2.1-768px.yaml** file in the same directory as your model file (will be uploaded here for your convenience)
With this model, other than being trained from SD2.1, you can also mix and match embeddings to your images!
--------------------
Another Jak Texture Pack Release is here to help create WOOD cutouts and dioramas!
Trained using 111 (768px) training images, 8000 training steps, 500 Text_Encoder_steps.
Use Prompt: "**wooditize**" in the beginning of your prompt followed by a word. *No major prompt-crafting needed*.
Thanks to /u/Jak_TheAI_Artist for creating training images!
Sample pictures of this concept:
.png)
.png)
.png)
.png)
.png)
.png)
.png)






|
plasmo/clayitization-sd2-1-768px
|
plasmo
| 2023-01-27T12:33:33Z | 8 | 18 |
diffusers
|
[
"diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-19T10:54:13Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
widget:
- text: "clayitization "
---
### Jak's **Clayitization** Image Pack (SD2.1) for Stable Diffusion
**clayitization-sd2.1-768px v.1.0**
*THIS IS FOR Stable Diffusion VERSION 2.1*
You MUST also include the **clayitization-SD2.1-768px.yaml** file in the same directory as your model file (will be uploaded here for your convenience)
With this model, other than being trained from SD2.1, you can also mix and match embeddings to your images!
--------------------
From the makers of [Woolitize](https://huggingface.co/plasmo/woolitize-768sd1-5), another versatile Jak Texture Pack is available to help unleash your Clay-itivity!
Trained using 100 (768px) training images, 8000 training steps, 500 Text_Encoder_steps.
Use Prompt: "**clayitization**" in the beginning of your prompt followed by a word. *No major prompt-crafting needed*.
Thanks to /u/Jak_TheAI_Artist for creating training images!
Tips:
- use fewer prompts to make a more raw clay look (eg. "clayitization, brad pitt" made the image below)
- change to square for portraits, and rectangle for dioramas
- add "3d, octane render, intricate details" for more realistic details in the clay
- use 768 resolution or larger images for best results
Sample pictures of this concept:
prompt: Clayitization, cat, mdjrny-ppc (embedding) *this is adding the Midjourney-papercut embedding*

prompt: Clayitization, brad pitt, inkpunk768 (embedding) *this is adding the Inkpunk768 embedding*

|
ManglerFTW/CharHelper
|
ManglerFTW
| 2023-01-27T12:04:11Z | 152 | 38 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"text-to-image",
"doi:10.57967/hf/0217",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-17T20:44:25Z |
---
license: creativeml-openrail-m
tags:
- stable-diffusion
- text-to-image
---
<b>Introduction:</b>
This model was trained on a digital painting style mainly with characters and portraits. The main objective is to train a model to be a tool to help with character design ideas.
It's base is Stable Diffusion V2.1 and is trained with 768X768 images. You will need to add the .yaml file into the same directory as your model to use.
<b>V4:</b>
<br /><br />
File Name is CharHelperV4.safetensors<br />
CharHelper V4 is a merge of CharHelper V3 and a newly trained model. This update is to provide a base for future updates. <b>All older keywords from CharHelper V3 will still work.</b>
Training subjects on this model are Aliens, Zombies, Birds, Cute styling, Lighthouses, and Macro Photography. Mix and match the styles and keywords to push the model further.
## Usage
<b>Use Auto for the vae in settings. If you are using a vae based on a SDv1.5 model, you may not get the best results.</b>
<br />
This model has multiple keywords that can be mixed and matched together in order to acheive a multitude of different styles. However, keywords aren't necessarily needed but can help with styling.
<b>Keywords:</b>
<b>Character Styles:</b>
CHV3CZombie, CHV3CAlien, CHV3CBird
<b>Scenery/Styles:</b>
CHV3SLighthouse, CHV3SCute, CHV3SMacro
<b>V3 Keywords:</b>
<b>Character Styles:</b>
CHV3CKnight, CHV3CWizard, CHV3CBarb, CHV3MTroll, CHV3MDeath, CHV3CRogue, CHV3CCyberpunk, CHV3CSamurai, CHV3CRobot
<b>Scenery/Landscapes:</b>
CHV3SWorld, CHV3SSciFi
<b>WIPs (needs fine-tuning, but try it out):</b>
CHV3MDragon, CHV3CVehicle
## Examples


<b>Aliens!</b>
CHV3CAlien, a portrait of a man in a cute alien creature costume inside a spaceship, a digital rendering, by Arthur Pan, predator, ultra detailed content, face, cockroach, avp, face shown, close-up shot, hastur, very detailed<br /><br />
Negative prompt: amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, crossed eyes, dead eyes, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 8, Seed: 1751637417, Size: 768x768, Model hash: 0eb3318b, ENSD: 3<br /><br />
-with-big-eyes-surrounded-by-glowing-aura%2C-colo.jpg)
<b>Psychadelic Falcons!</b>
A portrait of an anthropomorphic falcon in knight's armor made of (crystal stars) with big eyes surrounded by glowing aura, colorful sparkle feathers, highly detailed intricated concept art, trending on artstation, 8k, anime style eyes, concept art, cinematic, art award, flat shading, inked lines, artwork by wlop and loish<br /><br />
Negative prompt: amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, crossed eyes, dead eyes, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 11, Seed: 2894490509, Size: 768x896, Model hash: 0eb3318b, ENSD: 3<br /><br />

<b>Macro Mushrooms!</b>
CHV3SMacro, a nighttime macro photograph of a glowing mushroom with vibrant bioluminescent caps growing on tree bark, flat lighting, under saturated, by Anna Haifisch, pexels, fine art, steampunk forest background, mobile wallpaper, roofed forest, trio, 4k vertical wallpaper, mid fall, high detail, cinematic, focus stacking, smooth, sharp focus, soft pastel colors, Professional, masterpiece, commissioned<br /><br />
Negative prompt: amateur, ((b&w)), ((close-up)), (((duplicate))), (((deformed))), blurry, (((bad proportions))), gross proportions, ugly, tiling, poorly drawn, mutation, mutated, disfigured, deformed, out of frame, blurry, bad art, text, logo, signature, watermark<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 7.5, Seed: 3958069384, Size: 768x896, Model hash: 0eb3318b, ENSD: 3<br /><br />
%2C%20(a%20medium%20range%20portrait%20of%20elon%20musk%20dressed%20as%20a%20(rotting%20zombie_1.2))%2C%20Professional%2C%20masterpiece%2C%20commissi.png)
<b>Zombies!</b>
(CHV3CZombie:1.5), (a medium range portrait of elon musk dressed as a (rotting zombie:1.2)), Professional, masterpiece, commissioned, Artwork by Shigeru Miyamoto, attractive face, facial expression, professional hands, professional anatomy, 2 arms and 2 legs<br /><br />
Negative prompt: amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, crossed eyes, dead eyes, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 9, Seed: 28710867, Size: 768x896, Model hash: 0eb3318b, ENSD: 3<br /><br />

<b>Lighthouses!</b>
CHV3SLighthouse, a painting of a lighthouse on a small island, polycount contest winner, cliffside town, gold, house background, highlands, tileable, artbook artwork, paid art assets, farm, crisp clean shapes, featured art, mountains, captain, dominant pose, serene landscape, warm color scheme art rendition, low detail, bay, painting, lowres, birds, cgsociety<br /><br />
Negative prompt: 3d, 3d render, b&w, bad anatomy, bad anatomy, bad anatomy, bad art, bad art, bad proportions, blurry, blurry, blurry, body out of frame, canvas frame, cartoon, cloned face, close up, cross-eye, deformed, deformed, deformed, disfigured, disfigured, disfigured, duplicate, extra arms, extra arms, extra fingers, extra legs, extra legs, extra limbs, extra limbs, extra limbs, extra limbs, fused fingers, gross proportions, long neck, malformed limbs, missing arms, missing legs, morbid, mutated, mutated hands, mutated hands, mutation, mutation, mutilated, out of frame, out of frame, out of frame, Photoshop, poorly drawn face, poorly drawn face, poorly drawn feet, poorly drawn hands, poorly drawn hands, tiling, too many fingers<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 7, Seed: 1984075962, Size: 768x896, Model hash: 0eb3318b, ENSD: 3<br /><br />

<b>Cute Creatures!</b>
CHV3SCute, CHV3CRogue, a cute cartoon fox in a rogue costume in a nordic marketplace in valhalla, concept art, deviantart contest winner, glowing flowers, dofus, epic fantasty card game art, digital art render, dmt art, cute pictoplasma, atom, award winning concept art, at sunrise, engineered, gardening, glowing and epic, awesome, neuroscience<br /><br />
Negative prompt: amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, crossed eyes, dead eyes, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 9, Seed: 3708829983, Size: 768x768, Model hash: 0eb3318b, ENSD: 3<br /><br />

<b>Cool Landscapes!</b>
Studio ghibli's, castle in the sky, Professional, masterpiece, commissioned, CHV3SWorld, CHV3SLighthouse, CHV3SSciFi, pastel color palette<br /><br />
Negative prompt: 3d, 3d render, b&w, bad anatomy, bad anatomy, bad anatomy, bad art, bad art, bad proportions, blurry, blurry, blurry, body out of frame, canvas frame, cartoon, cloned face, close up, cross-eye, deformed, deformed, deformed, disfigured, disfigured, disfigured, duplicate, extra arms, extra arms, extra fingers, extra legs, extra legs, extra limbs, extra limbs, extra limbs, extra limbs, fused fingers, gross proportions, long neck, malformed limbs, missing arms, missing legs, morbid, mutated, mutated hands, mutated hands, mutation, mutation, mutilated, out of frame, out of frame, out of frame, Photoshop, poorly drawn face, poorly drawn face, poorly drawn feet, poorly drawn hands, poorly drawn hands, tiling, too many fingers, over-saturated<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 8, Seed: 2325208488, Size: 768x896, Model hash: 0eb3318b, ENSD: 3<br /><br />
%20with%20big%20eyes%20surro.png)
<b>Even more Psychadelic birds!</b>
10mm focal length, a portrait of a cute style cat-bird that is standing in the snow, made of (crystal stars) with big eyes surrounded by glowing aura, colorful sparkle feathers, highly detailed intricated concept art, trending on artstation, 8k, anime style eyes, concept art, cinematic, art award, flat shading, inked lines, artwork by wlop and loish, by Hans Werner Schmidt, flickr, arabesque, chile, green and orange theme, tim hildebrant, jasmine, h1024, gray, hummingbirds, loosely cropped, hd—h1024, green and gold, at home, diana levin, a beautiful mine, 2019<br /><br />
Negative prompt: amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, crossed eyes, dead eyes, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 8, Seed: 1247149957, Size: 768x896, Model hash: 0eb3318b, ENSD: 3<br /><br />
_1.3%20portrait%20of%20an%20attractive%20person%20dressed%20in%20a%20CHV3CCyberpunk.astronaut%20costume%2C%20forest%20in%20the%20background%2C%20smooth%2C.png)
<b>All the V3 Keywords still work nicely!</b>
(waste up):1.3 portrait of an attractive person dressed in a CHV3CCyberpunk.astronaut costume, forest in the background, smooth, sharp focus, Professional, masterpiece, commissioned, professionally drawn face, flat shading, trending on artstation, professional hands, professional anatomy, 2 arms and 2 legs, Artwork by Leonardo Davinci, and Frank Frazetta<br /><br />
Negative prompt: NegLowRes-2400, NegMutation-500, amateur, ((b&w)), ((close-up)), (((duplicate))), (((deformed))), blurry, (((bad proportions))), gross proportions, ugly, tiling, poorly drawn, mutation, mutated, disfigured, deformed, out of frame, blurry, bad art, text, logo, signature, watermark, (fire)<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 7, Seed: 2298273614, Size: 768x896, Model hash: 0eb3318b, ENSD: 3<br /><br />
<b>V3:</b>
<br /><br />
File Name is CharHelperV3.ckpt -or- CharHelperV3.safetensors<br />
Completely retrained from the begining in a fundamentally different process from CharHelper V1 and 2. This new model is much more diverse in range and can output some amazing results.
It was trained on multiple subjects and styles including buildings, vehicles, and landscapes as well.
## Usage
<b>Use Auto for the vae in settings. If you are using a vae based on a SDv1.5 model, you may not get the best results.</b>
<br />
This model has multiple keywords that can be mixed and matched together in order to acheive a multitude of different styles. However, keywords aren't necessarily needed but can help with styling.
Keywords:
Character Styles:
CHV3CKnight, CHV3CWizard, CHV3CBarb, CHV3MTroll, CHV3MDeath, CHV3CRogue, CHV3CCyberpunk, CHV3CSamurai, CHV3CRobot
Scenery/Landscapes:
CHV3SWorld, CHV3SSciFi
WIPs (needs fine-tuning, but try it out):
CHV3MDragon, CHV3CVehicle
**Mix & Match Styles:**
%20costume%20with%20beauti.jpg)
<b>Mix & Match "CHV3CCyberpunk.grim reaper"</b>
A realistic detail of a mid-range, full-torso, waist-up character portrait of a (CHV3CCyberpunk.grim reaper) costume with beautiful artistic scenery in the background, trending on artstation, 8k, hyper detailed, artstation, concept art, hyper realism, ultra-real, digital painting, cinematic, art award, highly detailed, attractive face, professional hands, professional anatomy, (2 arms, 2 hands)<br /><br />
Negative prompt: NegLowRes-2400, NegMutation-500, amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 10, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 1840075390, Size: 768x896, Model hash: cba4df56, ENSD: 3
**Works with embeddings:**

<b>Mix & Match "."in the beginning with embedding keywords</b>
., CHV3CWizard, modelshoot style mid-range character detail of a beautiful young adult woman wearing an intricate sorceress gown (casting magical spells under the starry night sky), 23 years old, magical energy, trending on artstation, 8k, hyper detailed, artstation, hyper realism, ultra-real, commissioned professional digital painting, cinematic, art award, highly detailed, attractive face, professional anatomy, (2 professional arms, 2 professional hands), artwork by Leonardo Davinci<br /><br />
Negative prompt: amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, crossed eyes, dead eyes, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 40, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 2891848182, Size: 768x896, Model hash: cba4df56, ENSD: 3
## Character Examples

<b>Magical Sorceress</b>
., CHV3CWizard, CHV3CBarb, modelshoot style mid-range close-up of a beautiful young adult woman wearing an intricate sorceress gown casting magical spells under the starry night sky, magical energy, trending on artstation, 8k, hyper detailed, artstation, hyper realism, ultra-real, commissioned professional digital painting, cinematic, art award, highly detailed, attractive face, professional anatomy, (2 professional arms, 2 professional hands), artwork by Leonardo Davinci<br /><br />
Negative prompt: amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 10, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 3460729168, Size: 768x896, Model hash: cba4df56, ENSD: 3
%20portrait%20of%20an%20ugly%20green-skinned%20female%20Death%20Troll%20in%20a%20Samurai%20outfit%20in%20a%20dark%20spooky%20forest%2C%20cinematic%2C%20high.png)
<b>Female Death Troll</b>
a (mid-range) portrait of an ugly green-skinned female Death Troll in a Samurai outfit in a dark spooky forest, cinematic, high detail, artwork by wlop, and loish, Professional, masterpiece, commissioned, (attractive face), facial expression, 4k, polycount contest winner, trending on artstation, professional hands, professional anatomy, 2 arms and 2 legs, CHV3CSamurai, CHV3MTroll, CHV3MDeath, Artwork by Leonardo Davinci, Frank Frazetta, Loish and Wlop<br /><br />
Negative prompt: NegLowRes-2400, NegMutation-500, ((disfigured)), ((bad art)), ((deformed)),((extra limbs)), ((extra barrel)),((close up)),((b&w)), weird colors, blurry, (((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (((tripod))), (((tube))), Photoshop, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, (((umbrella)))<br /><br />
Steps: 10, Sampler: DPM++ SDE, CFG scale: 9, Seed: 1999542482, Size: 768x896, Model hash: cba4df56, ENSD: 3
%20(CHV3CCyberpunk.astronaut)%20costume%20with%20beautiful%20scenery%20in%20the.png)
<b>Astronaut</b>
A realistic detail of a character portrait of a person in a(n) (CHV3CCyberpunk.astronaut) costume with beautiful scenery in the background, trending on artstation, 8k, hyper detailed, artstation, full body frame, complete body, concept art, hyper realism, ultra real, watercolor, cinematic, art award, highly detailed, attractive face, facial expression, professional hands, professional anatomy, 2 arms and 2 legs<br /><br />
Negative prompt: NegLowRes-2400, NegMutation-500, ((disfigured)), ((bad art)), ((deformed)),((extra limbs)), ((extra barrel)),((close up)),((b&w)), weird colors, blurry, (((duplicate))), ((morbid)), ((mutilated)), [out of frame], extra fingers, mutated hands, ((poorly drawn hands)), ((poorly drawn face)), (((mutation))), (((deformed))), ((ugly)), blurry, ((bad anatomy)), (((bad proportions))), ((extra limbs)), cloned face, (((disfigured))), out of frame, ugly, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (((tripod))), (((tube))), Photoshop, ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, (((umbrella)))<br /><br />
Steps: 40, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 1369534527, Size: 768x896, Model hash: cba4df56, ENSD: 3
%20full%20torso%20character%20portrait%20of%20a(n)%20(CHV3CCyberpunk.grim%20reaper)%20costume%20with%20artistic%20sce.png)
<b>Cyberpunk Grim Reaper</b>
A realistic detail of a (mid-range) full torso character portrait of a(n) (CHV3CCyberpunk.grim reaper) costume with artistic scenery in the background, trending on artstation, 8k, hyper detailed, artstation, concept art, hyper realism, ultra-real, digital oil painting, cinematic, art award, highly detailed, attractive face, facial expression, professional hands, professional anatomy, 2 arms<br /><br />
Negative prompt: NegLowRes-2400, NegMutation-500, amateur, ((extra limbs)), ((extra barrel)), ((b&w)), close-up, (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, (bad anatomy), gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon<br /><br />
Steps: 10, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 1823979933, Size: 768x896, Model hash: cba4df56, ENSD: 3

<b>Beautiful Sorceress</b>
., CHV3CWizard, a close-up:.4 of a beautiful woman wearing an intricate sorceress gown casting magical spells under the starry night sky, magical energy, trending on artstation, 8k, hyper detailed, artstation, concept art, hyper realism, ultra-real, digital painting, cinematic, art award, highly detailed, attractive face, professional hands, professional anatomy, (2 arms, 2 hands)<br /><br />
Negative prompt: NegLowRes-2400, NegMutation-500, amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 10, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 785469078, Size: 768x896, Model hash: cba4df56, ENSD: 3
%2C%20A%20detailed%20portrait%20of%20an%20anthropomorphic%20furry%20tiger%20in%20a.png)
<b>It does well with some animals</b>
mid-range modelshoot style detail, (extremely detailed 8k wallpaper), A detailed portrait of an anthropomorphic furry tiger in a suit and tie, by justin gerard and greg rutkowski, digital art, realistic painting, dnd, character design, trending on artstation, Smoose2, CHV3CBarb<br /><br />
Negative prompt: NegLowRes-2400, NegMutation-500, 3d, 3d render, b&w, bad anatomy, bad anatomy, bad anatomy, bad art, bad art, bad proportions, blurry, blurry, blurry, body out of frame, canvas frame, cartoon, cloned face, close up, cross-eye, deformed, deformed, deformed, disfigured, disfigured, disfigured, duplicate, extra arms, extra arms, extra fingers, extra legs, extra legs, extra limbs, extra limbs, extra limbs, extra limbs, fused fingers, gross proportions, long neck, malformed limbs, missing arms, missing legs, morbid, mutated, mutated hands, mutated hands, mutation, mutation, mutilated, out of frame, out of frame, out of frame, Photoshop, poorly drawn face, poorly drawn face, poorly drawn feet, poorly drawn hands, poorly drawn hands, tiling, too many fingers<br /><br />
Steps: 30, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 1989203255, Size: 768x896, Model hash: cba4df56, ENSD: 3
<br /><br />
## Other Examples
Check out CHV3SSciFi, CHV3SWorld, and CHV3CVehicle for non character images<br />
)))%20style%20detail%20of%20a%20((fantasy%2C%20((((cartoon))))%20gothic%20church%20with%20beautiful%20landscaping%20in%20a%20dense%20forest%2C%20in%20the%20s.png)
<b>Church in CHV3MDeath Styling</b>
a ((((toon)))) style detail of a ((fantasy, ((((cartoon)))) gothic church with beautiful landscaping in a dense forest, in the style of CHV3SWorld and CHV3MDeath)) [ :, ((thick black ink outlines)), ((((penned lines, flat shading, doodled lines)))), anime style illustration, dofus style, stylized, digital painting, high detail, professional, masterpiece, Artwork by studio ghibli and Shigeru Miyamoto:.15]<br /><br />
Negative prompt: NegLowRes-2400, NegMutation-500, disfigured, distorted face, mutated, malformed, poorly drawn, ((odd proportions)), noise, blur, missing limbs, ((ugly)), text, logo, over-exposed, over-saturated, over-exposed, ((over-saturated))<br /><br />
Steps: 35, Sampler: Euler a, CFG scale: 13.5, Seed: 631476138, Size: 1024x768, Model hash: cba4df56, Denoising strength: 0.7, ENSD: 3, First pass size: 768x768

<b>A group of people looking as a space ship</b>
CHV3CVehicle, an artistic detail of a man standing on top of a lush green field with a giant spaceship in the sky, by Christopher Balaskas, retrofuturism, retro spaceships parked outside, beeple and jeremiah ketner, shipfleet on the horizon, palace floating in the sky, lucasfilm jesper ejsing, of a family leaving a spaceship, highly detailed fantasy art, bonestell, stålenhag, trending on artstation, 8k, hyper detailed, artstation, hyper realism, ultra-real, commissioned professional digital painting, cinematic, art award, highly detailed, attractive face, professional anatomy, (2 professional arms, 2 professional hands), artwork by Leonardo Davinci<br /><br />
Negative prompt: amateur, ((extra limbs)), ((extra barrel)), ((b&w)), ((close-up)), (((duplicate))), ((mutilated)), extra fingers, mutated hands, (((deformed))), blurry, (((bad proportions))), ((extra limbs)), cloned face, out of frame, extra limbs, gross proportions, (malformed limbs), ((missing arms)), ((missing legs)), (((extra arms))), (((extra legs))), mutated hands, (fused fingers), (too many fingers), (((long neck))), (tripod), (tube), ugly, tiling, poorly drawn hands, poorly drawn feet, poorly drawn face, out of frame, mutation, mutated, extra limbs, extra legs, extra arms, disfigured, deformed, cross-eye, crossed eyes, dead eyes, body out of frame, blurry, bad art, bad anatomy, (umbrella), weapon, sword, dagger, katana, cropped head<br /><br />
Steps: 40, Sampler: DPM++ SDE Karras, CFG scale: 9, Seed: 2722466703, Size: 768x896, Model hash: cba4df56, ENSD: 3
<br /><br /><br />
<b>V2:</b>
Trained for an additional 5000 steps. Results will be much more stable and major improvement over V1. Don't forget to add the yaml file into your models directory.
V2 checkpoint filename is CharHelper_v2_ SDv2_1_768_step_8500.ckpt
## Usage
This model tends to like the higher CFG scale range. 7-15 will bring good results. Images come out well if they are 756X756 resolution size and up.
A good prompt to start with is:
(a cyberpunk rogue), charhelper, ((close up)) portrait, digital painting, artwork by leonardo davinci, high detail, professional, masterpiece, anime, stylized, face, facial expression, inkpunk, professional anatomy, professional hands, anatomically correct, colorful
Negative:
((bad hands)), disfigured, distorted face, mutated, malformed, bad anatomy, mutated feet, bad feet, poorly drawn, ((odd proportions)), noise, blur, missing fingers, missing limbs, long torso, ((ugly)), text, logo, over-exposed, over-saturated, ((bad anatomy)), over-exposed, ((over-saturated)), (((weapon))), long neck, black & white, ((glowing eyes))
Just substitute what's in the beginning parenthesis with your subject. You can also substitute "((close up))" with "((mid range))" as well. These worked best for me, but I'm excited to see what everyone else can do with it.
## Examples
Below are some examples of images generated using this model:
**A Woman with Los Muertos Skull Facepaint:**

**Rugged Samurai Man:**

**Space Girl:**

**Raver Girl with HeadPhones:**

**CyberPunk Rogue:**

**Toon Animal:**

**Female Astronaut:**

**Japanese Samurai:**

**Bell Head:**

**Native American Chief:**

**CyberPunk Buddha:**

**Alien Boy:**

**Los Muertos Facepaint 2:**

**Robot Fighter:**

**Video Game Elf Character:**

<b>V1:</b>
Trained for 3500 steps on SD v2.1 using TheLastBen's Fast Dreambooth.
Usage:
Use CharHelper in prompt to bring out the style. Other prompts that work well are 'Character Art', 'Close-up/Mid-range Character portrait', 'Digital Painting', Digital Illustration', 'Stylized', and 'anime'.
Still needs work with anatomy and full body images may need inpainting to fix faces but there are plans to fine-tune the model further in hopes to improve functionality.
|
neurator/mnunit1
|
neurator
| 2023-01-27T12:01:34Z | 5 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T12:01:10Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 282.77 +/- 15.37
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Uswa04/q-FrozenLake-v1-4x4-noSlippery
|
Uswa04
| 2023-01-27T11:57:49Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T11:57:41Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Uswa04/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
danishfayaznajar09/firstRL_PPO
|
danishfayaznajar09
| 2023-01-27T11:56:45Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T11:56:19Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 259.95 +/- 16.20
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
vumichien/StarTrek-starship
|
vumichien
| 2023-01-27T11:53:28Z | 7 | 8 |
diffusers
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"science",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-15T10:21:00Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- science
widget:
- text: A painting of StarTrek starship, Michelangelo style
---
# DreamBooth model for the StarTrek concept trained by vumichien on the vumichien/spaceship_star_trek dataset.
<img src="https://huggingface.co/vumichien/StarTrek-starship/resolve/main/1_dlgd3k5ZecT17cJOrg2NdA.jpeg" alt="StarTrek starship">
This is a Stable Diffusion model fine-tuned on the StarTrek concept with DreamBooth. It can be used by modifying the `instance_prompt`: **StarTrek starship**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `starship` images for the science theme.
## Examples
<figure>
<img src="https://huggingface.co/vumichien/StarTrek-starship/resolve/main/Leonardo%20Da%20Vinci%20style.png" alt="StarTrek starship - Leonardo Da Vinci style">
<figcaption>Text prompts for generated: A painting of StarTrek starship, Leonardo Da Vinci style
</figcaption>
</figure>
<figure>
<img src="https://huggingface.co/vumichien/StarTrek-starship/resolve/main/Michelangelo%20style.png" alt="StarTrek starship - Michelangelo style">
<figcaption>Text prompts for generated: A painting of StarTrek starship, Michelangelo style
</figcaption>
</figure>
<figure>
<img src="https://huggingface.co/vumichien/StarTrek-starship/resolve/main/Botero%20style.png" alt="StarTrek starship - Botero style">
<figcaption>Text prompts for generated: A painting of StarTrek starship, Botero style
</figcaption>
</figure>
<figure>
<img src="https://huggingface.co/vumichien/StarTrek-starship/resolve/main/Pierre-Auguste%20Renoir%20style.png" alt="StarTrek starship - Pierre-Auguste Renoir style">
<figcaption>Text prompts for generated: A painting of StarTrek starship, Pierre-Auguste Renoir style
</figcaption>
</figure>
<figure>
<img src="https://huggingface.co/vumichien/StarTrek-starship/resolve/main/Vincent%20Van%20Gogh%20style.png" alt="StarTrek starship - Vincent Van Gogh style">
<figcaption>Text prompts for generated: A painting of StarTrek starship, Vincent Van Gogh style
</figcaption>
</figure>
<figure>
<img src="https://huggingface.co/vumichien/StarTrek-starship/resolve/main/Rembrandt%20style.png" alt="StarTrek starship - Rembrandt style">
<figcaption>Text prompts for generated: A painting of StarTrek starship, Rembrandt style
</figcaption>
</figure>
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('vumichien/StarTrek-starship')
image = pipeline().images[0]
image
```
|
Thabet/sssimba-cat
|
Thabet
| 2023-01-27T11:51:16Z | 3 | 0 |
diffusers
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"animal",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-06T11:51:26Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- animal
widget:
- text: a photo of sssimba cat in the Acropolis
---
# DreamBooth model for the sssimba concept trained by Thabet on the Thabet/Simba_dataset dataset.
This is a Stable Diffusion model fine-tuned on the sssimba concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of sssimba cat**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `cat` images for the animal theme.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('Thabet/sssimba-cat')
image = pipeline().images[0]
image
```
|
chenglu/xiaocaicai-dog-heywhale
|
chenglu
| 2023-01-27T11:50:19Z | 10 | 1 |
diffusers
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"animal",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-14T07:35:34Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- animal
widget:
- text: illustration of a xiaocaicai dog sitting on top of the deck of a battle ship
traveling through the open sea with a lot of ships surrounding it
---
# DreamBooth model for the xiaocaicai concept trained by chenglu.
This is a Stable Diffusion model fine-tuned on the xiaocaicai concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of xiaocaicai dog**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `dog` images for the animal theme,
for the Hugging Face DreamBooth Hackathon, from the HF CN Community,
corporated with the HeyWhale.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('chenglu/xiaocaicai-dog-heywhale')
image = pipeline().images[0]
image
```
## Some examples
Prompt: oil painting of a xiaocaicai dog wearing sunglasses by van gogh and by andy warhol


Prompt: a black and white photograph of xiaocaicai dog wearing sunglasses by annie lebovitz, highly-detailed

|
chenglu/caicai-dog-heywhale
|
chenglu
| 2023-01-27T11:50:04Z | 5 | 2 |
diffusers
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"animal",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-13T05:39:28Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- animal
widget:
- text: caicai dog sitting on top of the deck of a battle ship traveling through the
open sea with a lot of ships surrounding it
---
# DreamBooth model for the caicai concept trained by chenglu.
This is a Stable Diffusion model fine-tuned on the caicai concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of caicai dog**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `dog` images for the animal theme,
for the Hugging Face DreamBooth Hackathon, from the HF CN Community,
corporated with the HeyWhale.
Thanks to @hhhxynh in the HF China community.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('chenglu/caicai-dog-heywhale')
image = pipeline().images[0]
image
```
|
chenglu/taolu-road-heywhale
|
chenglu
| 2023-01-27T11:49:32Z | 4 | 2 |
diffusers
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"landscape",
"heywhale",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-11T01:28:51Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- landscape
- heywhale
widget:
- text: A Godzilla sleep on the taolu road, with a ps5 in it's hand
---
# DreamBooth model for the taolu concept trained by chenglu.
This is a Stable Diffusion model fine-tuned on the taolu concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of taolu road**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `road` images for the landscape theme. For the HF Dreambooth hackathon, from Hugging Face China Commuinity, Collabration with the HeyWhale platform.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('chenglu/taolu-road-heywhale')
image = pipeline().images[0]
image
```
|
GeorgeBredis/space-nebulas
|
GeorgeBredis
| 2023-01-27T11:48:31Z | 3 | 3 |
diffusers
|
[
"diffusers",
"pytorch",
"stable-diffusion",
"text-to-image",
"diffusion-models-class",
"dreambooth-hackathon",
"science",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-11T14:32:49Z |
---
license: creativeml-openrail-m
tags:
- pytorch
- diffusers
- stable-diffusion
- text-to-image
- diffusion-models-class
- dreambooth-hackathon
- science
widget:
- text: a photo of corgi in space nebulas
---
# DreamBooth model for the space concept trained by GeorgeBredis on the GeorgeBredis/dreambooth-hackathon-images dataset.
This is a Stable Diffusion model fine-tuned on the space concept with DreamBooth. It can be used by modifying the `instance_prompt`: **a photo of space nebulas**
This model was created as part of the DreamBooth Hackathon 🔥. Visit the [organisation page](https://huggingface.co/dreambooth-hackathon) for instructions on how to take part!
## Description
This is a Stable Diffusion model fine-tuned on `nebulas` images for the science theme.
## Usage
```python
from diffusers import StableDiffusionPipeline
pipeline = StableDiffusionPipeline.from_pretrained('GeorgeBredis/space-nebulas')
image = pipeline().images[0]
image
```
|
nlp04/kobart_4_5.6e-5_datav2_min30_lp5.0_temperature1.0
|
nlp04
| 2023-01-27T11:47:51Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-27T09:56:12Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: kobart_4_5.6e-5_datav2_min30_lp5.0_temperature1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_4_5.6e-5_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.9891
- Rouge1: 35.4597
- Rouge2: 12.0824
- Rougel: 23.0161
- Bleu1: 29.793
- Bleu2: 16.882
- Bleu3: 9.6468
- Bleu4: 5.3654
- Gen Len: 50.6014
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5.6e-05
- train_batch_size: 4
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:-------:|:-------:|:-------:|:------:|:-------:|
| 2.3968 | 0.47 | 5000 | 2.9096 | 32.7469 | 10.9679 | 21.4954 | 27.0594 | 15.1133 | 8.4503 | 4.564 | 48.5501 |
| 2.2338 | 0.94 | 10000 | 2.8002 | 33.2148 | 11.5121 | 22.7066 | 26.4886 | 15.0125 | 8.5792 | 4.8523 | 41.1049 |
| 1.9652 | 1.42 | 15000 | 2.7699 | 34.4269 | 11.8551 | 22.8478 | 28.2628 | 16.0909 | 9.0427 | 4.9254 | 46.9744 |
| 2.001 | 1.89 | 20000 | 2.7201 | 34.157 | 11.8683 | 22.6775 | 28.3593 | 16.1361 | 9.221 | 4.8616 | 46.979 |
| 1.6433 | 2.36 | 25000 | 2.7901 | 33.6354 | 11.5761 | 22.6878 | 27.6475 | 15.6571 | 8.8372 | 4.8672 | 43.9953 |
| 1.6204 | 2.83 | 30000 | 2.7724 | 34.9611 | 12.1606 | 23.0246 | 29.1014 | 16.6689 | 9.3661 | 5.1916 | 48.8811 |
| 1.2955 | 3.3 | 35000 | 2.8970 | 35.896 | 12.7037 | 23.3781 | 29.9701 | 17.3963 | 10.2978 | 5.9339 | 49.5921 |
| 1.3501 | 3.78 | 40000 | 2.8854 | 35.2981 | 12.1133 | 23.1845 | 29.483 | 16.7795 | 9.4124 | 5.2042 | 48.5897 |
| 1.0865 | 4.25 | 45000 | 2.9912 | 35.581 | 12.5145 | 23.2262 | 29.9364 | 17.2064 | 10.0427 | 5.62 | 48.31 |
| 1.052 | 4.72 | 50000 | 2.9891 | 35.4597 | 12.0824 | 23.0161 | 29.793 | 16.882 | 9.6468 | 5.3654 | 50.6014 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
emre/mybankconcept
|
emre
| 2023-01-27T11:45:23Z | 27 | 1 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"Bank",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-11-28T22:18:40Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- Bank
---
### MyBankConcept Dreambooth model trained by emre
I have fine tuned the model with 30 GarantiBBVA photos obtained from google.
If you would like your design to look similar like GarantiBBVA office style this is the model you're looking for
Try: https://huggingface.co/spaces/emre/garanti-mybankconcept-img-gen
---
e-mail: [email protected]
---
|
alexrods/course-distilroberta-base-mrpc-glue
|
alexrods
| 2023-01-27T11:44:08Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-27T11:13:20Z |
---
license: apache-2.0
tags:
- text-classification
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: course-distilroberta-base-mrpc-glue
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mrpc
split: validation
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8235294117647058
- name: F1
type: f1
value: 0.8779661016949152
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# course-distilroberta-base-mrpc-glue
This model is a fine-tuned version of [distilroberta-base](https://huggingface.co/distilroberta-base) on the glue and the mrpc datasets.
It achieves the following results on the evaluation set:
- Loss: 1.0204
- Accuracy: 0.8235
- F1: 0.8780
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.1616 | 1.09 | 500 | 1.1943 | 0.8162 | 0.8718 |
| 0.2134 | 2.18 | 1000 | 1.0204 | 0.8235 | 0.8780 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
cat666/VToooo
|
cat666
| 2023-01-27T11:37:02Z | 77 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-09T20:37:57Z |
---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
learning_rate 2.5e-6, training with a6000x1, because I am too busy recently, I should not be able to actively do it, and the funds are slightly insufficient
,Forget it, I'm overtraining, take it as an interesting model,(Warning: above 768x832 is recommended, I found that the results below seem to be less than ideal)
Will be uploading actively in the near future
If you need my help or have better suggestions, come to [Discord server](https://discord.gg/BHb4HvTc6t)
[](https://discord.gg/BHb4HvTc6t)
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
|
kohbanye/pixel-art-style
|
kohbanye
| 2023-01-27T11:30:59Z | 96 | 56 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"text-to-image",
"stable-diffusion-diffusers",
"en",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-18T07:27:52Z |
---
language:
- en
thumbnail: "https://huggingface.co/kohbanye/pixel-art-style/resolve/main/sample.png"
tags:
- stable-diffusion
- text-to-image
- stable-diffusion-diffusers
---
# Pixel Art Style
This is a fine-tuned model of Stable Diffusion. <br>
Add token **pixelartstyle** to your prompt.

_an astronaut riding a horse, pixelartstyle_
|
stevaras2/a2c-AntBulletEnv-v0
|
stevaras2
| 2023-01-27T11:27:45Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T11:26:41Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1090.27 +/- 333.43
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
OlafII/papercutcraft-v1
|
OlafII
| 2023-01-27T11:12:16Z | 43 | 40 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"text-to-image",
"paper-cut-craft",
"dreambooth",
"en",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2022-12-05T09:06:03Z |
---
inference: true
language:
- en
tags:
- stable-diffusion
- text-to-image
- paper-cut-craft
- dreambooth
---
# Paper Cut Craft is a fine tuned Stable Diffusion model trained on Midjourney images
Use in prompt: "papercutcraft style"
Trained on Stable Diffusion v1.5 using Dreambooth
# Gradio
We support a [Gradio](https://github.com/gradio-app/gradio) Web UI to run papercutcraft-v1:
[](https://huggingface.co/spaces/akhaliq/papercutcraft-v1)
### Paper Cut Craft Rendered:
Steps: 50, Default Automatic1111 settings, Prompt: "papercutcraft style"
<img src="https://huggingface.co/OlafII/papercutcraft-v1/resolve/main/images/image_2022-12-06_180651730.png" width="100%"/>
### Training Info
Trained on 20 images with 3600 Steps
<iframe
src="https://akhaliq-papercutcraft-v1.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
|
NUTELEX/ppo-LunarLander-v2-Test
|
NUTELEX
| 2023-01-27T11:05:27Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T11:05:01Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: 248.78 +/- 22.07
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
roscazo/WL_DISEASE_NER_v1
|
roscazo
| 2023-01-27T10:38:26Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"roberta",
"token-classification",
"generated_from_trainer",
"dataset:wl-disease",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-01-27T09:59:07Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- wl-disease
model-index:
- name: WL_DISEASE_NER_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# WL_DISEASE_NER_v1
This model is a fine-tuned version of [PlanTL-GOB-ES/bsc-bio-ehr-es](https://huggingface.co/PlanTL-GOB-ES/bsc-bio-ehr-es) on the wl-disease dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1489
- Diso Precision: 0.7908
- Diso Recall: 0.8397
- Diso F1: 0.8145
- Diso Number: 1765
- Overall Precision: 0.7908
- Overall Recall: 0.8397
- Overall F1: 0.8145
- Overall Accuracy: 0.9631
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss | Diso Precision | Diso Recall | Diso F1 | Diso Number | Overall Precision | Overall Recall | Overall F1 | Overall Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------------:|:-----------:|:-------:|:-----------:|:-----------------:|:--------------:|:----------:|:----------------:|
| 0.1199 | 1.0 | 1714 | 0.1187 | 0.7739 | 0.7972 | 0.7854 | 1765 | 0.7739 | 0.7972 | 0.7854 | 0.9610 |
| 0.0916 | 2.0 | 3428 | 0.1237 | 0.7748 | 0.8266 | 0.7999 | 1765 | 0.7748 | 0.8266 | 0.7999 | 0.9620 |
| 0.0625 | 3.0 | 5142 | 0.1343 | 0.7900 | 0.8289 | 0.8090 | 1765 | 0.7900 | 0.8289 | 0.8090 | 0.9630 |
| 0.0485 | 4.0 | 6856 | 0.1489 | 0.7908 | 0.8397 | 0.8145 | 1765 | 0.7908 | 0.8397 | 0.8145 | 0.9631 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
terzimert/bert-finetuned-ner-v2.4
|
terzimert
| 2023-01-27T10:28:12Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:caner",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-01-27T10:04:57Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- caner
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner-v2.4
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: caner
type: caner
config: default
split: train[67%:68%]
args: default
metrics:
- name: Precision
type: precision
value: 0.7851099830795262
- name: Recall
type: recall
value: 0.8226950354609929
- name: F1
type: f1
value: 0.8034632034632034
- name: Accuracy
type: accuracy
value: 0.9542217700915565
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner-v2.4
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the caner dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2474
- Precision: 0.7851
- Recall: 0.8227
- F1: 0.8035
- Accuracy: 0.9542
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2792 | 1.0 | 3228 | 0.3349 | 0.7862 | 0.7695 | 0.7778 | 0.9436 |
| 0.1694 | 2.0 | 6456 | 0.2701 | 0.7996 | 0.7996 | 0.7996 | 0.9491 |
| 0.1244 | 3.0 | 9684 | 0.2474 | 0.7851 | 0.8227 | 0.8035 | 0.9542 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
terzimert/bert-finetuned-ner-v2.3
|
terzimert
| 2023-01-27T10:00:28Z | 7 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:caner",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-01-27T09:37:16Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- caner
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner-v2.3
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: caner
type: caner
config: default
split: train[85%:86%]
args: default
metrics:
- name: Precision
type: precision
value: 0.8456375838926175
- name: Recall
type: recall
value: 0.8456375838926175
- name: F1
type: f1
value: 0.8456375838926175
- name: Accuracy
type: accuracy
value: 0.9584533113944879
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner-v2.3
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the caner dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2296
- Precision: 0.8456
- Recall: 0.8456
- F1: 0.8456
- Accuracy: 0.9585
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.3219 | 1.0 | 3228 | 0.2632 | 0.7960 | 0.8054 | 0.8007 | 0.9383 |
| 0.2259 | 2.0 | 6456 | 0.2634 | 0.8189 | 0.8272 | 0.8230 | 0.9486 |
| 0.142 | 3.0 | 9684 | 0.2296 | 0.8456 | 0.8456 | 0.8456 | 0.9585 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
nlp04/kobart_64_3e-5_datav2_min30_lp5.0_temperature1.0
|
nlp04
| 2023-01-27T09:34:14Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-27T08:13:29Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: kobart_64_3e-5_datav2_min30_lp5.0_temperature1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_64_3e-5_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
nlp04/kobart_64x2_5e-5_datav2_min30_lp5.0_temperature1.0
|
nlp04
| 2023-01-27T09:32:38Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-27T08:58:57Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: kobart_64x2_5e-5_datav2_min30_lp5.0_temperature1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_64x2_5e-5_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
terzimert/bert-finetuned-ner-v2.2
|
terzimert
| 2023-01-27T09:27:12Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"token-classification",
"generated_from_trainer",
"dataset:caner",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-01-27T09:04:18Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- caner
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: bert-finetuned-ner-v2.2
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: caner
type: caner
config: default
split: train[90%:91%]
args: default
metrics:
- name: Precision
type: precision
value: 0.8822751322751323
- name: Recall
type: recall
value: 0.8496815286624204
- name: F1
type: f1
value: 0.8656716417910448
- name: Accuracy
type: accuracy
value: 0.942741116751269
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-finetuned-ner-v2.2
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the caner dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3595
- Precision: 0.8823
- Recall: 0.8497
- F1: 0.8657
- Accuracy: 0.9427
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| 0.2726 | 1.0 | 3228 | 0.4504 | 0.7390 | 0.7287 | 0.7338 | 0.9107 |
| 0.2057 | 2.0 | 6456 | 0.3679 | 0.8633 | 0.8446 | 0.8538 | 0.9385 |
| 0.1481 | 3.0 | 9684 | 0.3595 | 0.8823 | 0.8497 | 0.8657 | 0.9427 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
ykleeee/wav2vec2-finetune-60percent
|
ykleeee
| 2023-01-27T09:21:51Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"wav2vec2",
"automatic-speech-recognition",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2023-01-20T07:10:20Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: wav2vec2-finetune-60percent
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wav2vec2-finetune-60percent
This model is a fine-tuned version of [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.3087
- Wer: 1.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 32
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 60
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Wer |
|:-------------:|:-----:|:----:|:---------------:|:---:|
| 3.4153 | 50.0 | 100 | 3.3087 | 1.0 |
### Framework versions
- Transformers 4.11.3
- Pytorch 1.10.1
- Datasets 2.8.0
- Tokenizers 0.10.3
|
mkato/distilbert-base-uncased-finetuned-emotion
|
mkato
| 2023-01-27T09:20:22Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"distilbert",
"text-classification",
"generated_from_trainer",
"dataset:emotion",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-27T08:06:54Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- emotion
metrics:
- accuracy
- f1
model-index:
- name: distilbert-base-uncased-finetuned-emotion
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: emotion
type: emotion
config: split
split: validation
args: split
metrics:
- name: Accuracy
type: accuracy
value: 0.939
- name: F1
type: f1
value: 0.9391263036329083
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# distilbert-base-uncased-finetuned-emotion
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on the emotion dataset.
It achieves the following results on the evaluation set:
- Loss: 0.1340
- Accuracy: 0.939
- F1: 0.9391
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| 0.5187 | 1.0 | 250 | 0.1878 | 0.9245 | 0.9240 |
| 0.141 | 2.0 | 500 | 0.1340 | 0.939 | 0.9391 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.12.1
- Datasets 2.8.0
- Tokenizers 0.13.2
|
kjmann/PyramidsPPO
|
kjmann
| 2023-01-27T09:14:43Z | 4 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-01-27T09:14:37Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: kjmann/PyramidsPPO
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
gmojko/a2c-PandaReachDense-v2_v6
|
gmojko
| 2023-01-27T09:02:53Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T09:00:41Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -0.59 +/- 0.19
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
nlp04/kobart_64x2_3e-5_datav2_min30_lp5.0_temperature1.0
|
nlp04
| 2023-01-27T08:47:30Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-27T08:18:43Z |
---
license: mit
tags:
- generated_from_trainer
model-index:
- name: kobart_64x2_3e-5_datav2_min30_lp5.0_temperature1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_64x2_3e-5_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 3e-05
- train_batch_size: 64
- eval_batch_size: 128
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
FnSK4R17s/q-FrozenLake-v1-4x4-noSlippery
|
FnSK4R17s
| 2023-01-27T08:42:26Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T08:42:23Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="FnSK4R17s/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ThomasSimonini/ML-Agents-SoccerTwos-SuperBad
|
ThomasSimonini
| 2023-01-27T08:37:53Z | 5 | 0 |
ml-agents
|
[
"ml-agents",
"onnx",
"ML-Agents-SoccerTwos",
"reinforcement-learning",
"region:us"
] |
reinforcement-learning
| 2023-01-27T08:36:15Z |
---
task: reinforcement-learning
library_name: ml-agents
tags:
- ML-Agents-SoccerTwos
- reinforcement-learning
---
|
maximerosano/q-FrozenLake-v1-8x8-noSlippery
|
maximerosano
| 2023-01-27T08:21:58Z | 0 | 0 | null |
[
"FrozenLake-v1-8x8-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T08:21:54Z |
---
tags:
- FrozenLake-v1-8x8-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-8x8-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-8x8-no_slippery
type: FrozenLake-v1-8x8-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="maximerosano/q-FrozenLake-v1-8x8-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
gmojko/a2c-PandaReachDense-v2_v5
|
gmojko
| 2023-01-27T08:13:59Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T08:11:41Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -1.88 +/- 0.86
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
maximerosano/q-FrozenLake-v1-4x4-noSlippery
|
maximerosano
| 2023-01-27T08:13:37Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T08:13:34Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="maximerosano/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
nlp04/kobart_8_1e-4_datav2_min30_lp5.0_temperature1.0
|
nlp04
| 2023-01-27T07:53:15Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-27T06:32:59Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: kobart_8_1e-4_datav2_min30_lp5.0_temperature1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_8_1e-4_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 3.0961
- Rouge1: 35.8883
- Rouge2: 12.7003
- Rougel: 23.3874
- Bleu1: 30.2528
- Bleu2: 17.5183
- Bleu3: 10.2094
- Bleu4: 5.6021
- Gen Len: 50.1562
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:-------:|:-------:|:-------:|:------:|:-------:|
| 2.4648 | 0.19 | 1000 | 2.9491 | 32.241 | 10.5261 | 21.21 | 26.5995 | 14.7371 | 7.8411 | 4.1361 | 48.303 |
| 2.4028 | 0.38 | 2000 | 2.9226 | 33.8957 | 11.6309 | 22.4654 | 28.1592 | 15.9817 | 9.163 | 5.0564 | 49.5175 |
| 2.4109 | 0.57 | 3000 | 2.9092 | 33.9997 | 11.4619 | 22.2822 | 28.0021 | 15.7774 | 8.7258 | 4.5887 | 44.6807 |
| 2.3846 | 0.76 | 4000 | 2.8763 | 31.8881 | 10.1122 | 21.1754 | 25.4518 | 13.7126 | 7.4549 | 3.9979 | 40.9161 |
| 2.2972 | 0.94 | 5000 | 2.8441 | 33.4146 | 11.8371 | 22.7219 | 27.1678 | 15.4977 | 9.1783 | 5.3303 | 43.8765 |
| 2.0162 | 1.13 | 6000 | 2.8372 | 34.9461 | 11.8978 | 22.7877 | 28.9743 | 16.3778 | 9.2932 | 5.0534 | 47.1585 |
| 1.9816 | 1.32 | 7000 | 2.8630 | 33.1249 | 10.8834 | 22.0846 | 27.0042 | 14.9508 | 8.3482 | 4.5422 | 44.676 |
| 2.0172 | 1.51 | 8000 | 2.7998 | 34.1663 | 11.5471 | 22.8156 | 28.0367 | 15.7969 | 8.6235 | 4.5914 | 44.9254 |
| 2.017 | 1.7 | 9000 | 2.7865 | 33.3775 | 11.194 | 22.6083 | 26.7485 | 14.9797 | 8.2559 | 4.279 | 41.5828 |
| 1.9734 | 1.89 | 10000 | 2.7532 | 34.7147 | 12.353 | 23.0917 | 28.8012 | 16.7472 | 9.7079 | 5.5416 | 47.9883 |
| 1.5937 | 2.08 | 11000 | 2.8433 | 34.9402 | 12.2318 | 23.2483 | 28.8006 | 16.5212 | 9.6008 | 5.3947 | 45.2401 |
| 1.6112 | 2.27 | 12000 | 2.8377 | 34.9291 | 12.2349 | 23.278 | 28.8423 | 16.539 | 9.7674 | 5.4267 | 44.7599 |
| 1.603 | 2.45 | 13000 | 2.8223 | 35.3837 | 12.5491 | 23.5272 | 29.3683 | 16.9828 | 9.6955 | 5.3166 | 47.6037 |
| 1.6274 | 2.64 | 14000 | 2.8220 | 34.0515 | 11.7884 | 22.829 | 27.6635 | 15.8021 | 8.9724 | 4.9314 | 44.1235 |
| 1.6435 | 2.83 | 15000 | 2.8139 | 34.9239 | 12.2122 | 22.9939 | 29.1796 | 16.763 | 9.5513 | 5.174 | 46.7832 |
| 1.238 | 3.02 | 16000 | 2.9615 | 35.456 | 12.3012 | 23.3111 | 29.8676 | 17.0768 | 9.8694 | 5.4376 | 51.1935 |
| 1.2767 | 3.21 | 17000 | 2.9781 | 35.2632 | 12.1441 | 23.2537 | 29.1438 | 16.6216 | 9.353 | 5.1593 | 46.0793 |
| 1.2868 | 3.4 | 18000 | 2.9723 | 34.6808 | 11.9638 | 22.9058 | 28.9988 | 16.4994 | 9.3619 | 5.1178 | 47.4732 |
| 1.2842 | 3.59 | 19000 | 2.9688 | 35.3792 | 12.5174 | 23.2012 | 29.6403 | 17.1517 | 9.9507 | 5.5561 | 49.1515 |
| 1.2931 | 3.78 | 20000 | 2.9694 | 35.7525 | 12.8025 | 23.5228 | 29.8102 | 17.3544 | 10.239 | 5.6637 | 49.1189 |
| 1.2733 | 3.97 | 21000 | 2.9618 | 35.8931 | 12.627 | 23.5571 | 30.0482 | 17.2582 | 9.8412 | 5.4747 | 48.5082 |
| 0.963 | 4.15 | 22000 | 3.1113 | 35.7523 | 12.7633 | 23.3127 | 30.0193 | 17.4211 | 10.2596 | 5.853 | 51.6993 |
| 0.9563 | 4.34 | 23000 | 3.1031 | 35.8437 | 12.6323 | 23.6011 | 30.0923 | 17.4089 | 9.9831 | 5.5993 | 48.7646 |
| 0.992 | 4.53 | 24000 | 3.1016 | 36.1067 | 13.3428 | 24.0267 | 30.0275 | 17.8733 | 10.6929 | 6.2491 | 52.0373 |
| 0.9722 | 4.72 | 25000 | 3.0956 | 35.4406 | 12.4799 | 23.3418 | 29.5123 | 17.0292 | 9.7401 | 5.3586 | 48.8974 |
| 0.9519 | 4.91 | 26000 | 3.0961 | 35.8883 | 12.7003 | 23.3874 | 30.2528 | 17.5183 | 10.2094 | 5.6021 | 50.1562 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
bigscience/tokenizer
|
bigscience
| 2023-01-27T07:47:08Z | 0 | 10 | null |
[
"license:bigscience-bloom-rail-1.0",
"region:us"
] | null | 2022-03-22T10:31:14Z |
---
license: bigscience-bloom-rail-1.0
---
# Tokenizer used for all BLOOM models
Tokenizer information are provided at [https://huggingface.co/bigscience/bloom#preprocessing](https://huggingface.co/bigscience/bloom#preprocessing)
TODO: point to paper once it comes out with extra details on the tokenizer
|
jamesup/q-FrozenLake-v1-4x4-noSlippery
|
jamesup
| 2023-01-27T07:25:17Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T07:11:35Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="jamesup/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
gmojko/a2c-PandaReachDense-v2_v4
|
gmojko
| 2023-01-27T07:25:14Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T07:22:51Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -5.78 +/- 1.18
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
nlp04/kobart_32_5e-5_datav2_min30_lp5.0_temperature1.0
|
nlp04
| 2023-01-27T07:01:27Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-27T06:01:46Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: kobart_32_5e-5_datav2_min30_lp5.0_temperature1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_32_5e-5_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.6396
- Rouge1: 35.8418
- Rouge2: 12.983
- Rougel: 23.6913
- Bleu1: 29.8408
- Bleu2: 17.5438
- Bleu3: 10.2815
- Bleu4: 5.6838
- Gen Len: 50.2214
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:------:|:-------:|:-------:|:-------:|:-------:|:------:|:-------:|
| 1.6643 | 3.78 | 5000 | 2.6396 | 35.8418 | 12.983 | 23.6913 | 29.8408 | 17.5438 | 10.2815 | 5.6838 | 50.2214 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
pkshatech/simcse-ja-bert-base-clcmlp
|
pkshatech
| 2023-01-27T06:44:23Z | 2,497 | 15 |
sentence-transformers
|
[
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"transformers",
"sentence-similarity",
"ja",
"arxiv:2104.08821",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"region:us"
] |
sentence-similarity
| 2022-12-26T02:52:03Z |
---
pipeline_tag: sentence-similarity
language: ja
license: cc-by-sa-4.0
tags:
- transformers
- sentence-similarity
- feature-extraction
- sentence-transformers
inference: false
widget:
- source_sentence: "This widget can't work correctly now."
sentences:
- "Sorry :("
- "Try this model in your local environment!"
example_title: "notification"
---
# Japanese SimCSE (BERT-base)
[日本語のREADME/Japanese README](https://huggingface.co/pkshatech/simcse-ja-bert-base-clcmlp/blob/main/README_JA.md)
## summary
model name: `pkshatech/simcse-ja-bert-base-clcmlp`
This is a Japanese [SimCSE](https://arxiv.org/abs/2104.08821) model. You can easily extract sentence embedding representations from Japanese sentences. This model is based on [`cl-tohoku/bert-base-japanese-v2`](https://huggingface.co/cl-tohoku/bert-base-japanese-v2) and trained on [JSNLI](https://nlp.ist.i.kyoto-u.ac.jp/?%E6%97%A5%E6%9C%AC%E8%AA%9ESNLI%28JSNLI%29%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88) dataset, which is a Japanese natural language inference dataset.
## Usage (Sentence-Transformers)
You can use this model easily with [sentence-transformers](https://www.SBERT.net).
You need [fugashi](https://github.com/polm/fugashi) and [unidic-lite](https://pypi.org/project/unidic-lite/) for tokenization.
Please install sentence-transformers, fugashi, and unidic-lite with pip as follows:
```
pip install -U fugashi[unidic-lite] sentence-transformers
```
You can load the model and convert sentences to dense vectors as follows:
```python
from sentence_transformers import SentenceTransformer
sentences = [
"PKSHA Technologyは機械学習/深層学習技術に関わるアルゴリズムソリューションを展開している。",
"この深層学習モデルはPKSHA Technologyによって学習され、公開された。",
"広目天は、仏教における四天王の一尊であり、サンスクリット語の「種々の眼をした者」を名前の由来とする。",
]
model = SentenceTransformer('pkshatech/simcse-ja-bert-base-clcmlp')
embeddings = model.encode(sentences)
print(embeddings)
```
Since the loss function used during training is cosine similarity, we recommend using cosine similarity for downstream tasks.
## Model Detail
### Tokenization
We use the same tokenizer as `tohoku/bert-base-japanese-v2`. Please see the [README of `tohoku/bert-base-japanese-v2`](https://huggingface.co/cl-tohoku/bert-base-japanese-v2) for details.
### Training
We set `tohoku/bert-base-japanese-v2` as the initial value and trained it on the train set of [JSNLI](https://nlp.ist.i.kyoto-u.ac.jp/?%E6%97%A5%E6%9C%AC%E8%AA%9ESNLI%28JSNLI%29%E3%83%87%E3%83%BC%E3%82%BF%E3%82%BB%E3%83%83%E3%83%88). We trained 20 epochs and published the checkpoint of the model with the highest Spearman's correlation coefficient on the validation set [^1] of the train set of [JSTS](https://github.com/yahoojapan/JGLUE)
### Training Parameters
| Parameter | Value |
| --- | --- |
|pooling_strategy | [CLS] -> single fully-connected layer |
| max_seq_length | 128 |
| with hard negative | true |
| temperature of contrastive loss | 0.05 |
| Batch size | 200 |
| Learning rate | 1e-5 |
| Weight decay | 0.01 |
| Max gradient norm | 1.0 |
| Warmup steps | 2012 |
| Scheduler | WarmupLinear |
| Epochs | 20 |
| Evaluation steps | 250 |
# Licenses
This models are distributed under the terms of the Creative [Creative Commons Attribution-ShareAlike 4.0](https://creativecommons.org/licenses/by-sa/4.0/).
[^1]: When we trained this model, the test data of JGLUE was not released, so we used the dev set of JGLUE as a private evaluation data. Therefore, we selected the checkpoint on the train set of JGLUE insted of its dev set.
|
nlp04/kobart_8_6e-5_datav2_min30_lp5.0_temperature1.0
|
nlp04
| 2023-01-27T06:30:57Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-27T05:08:03Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: kobart_8_6e-5_datav2_min30_lp5.0_temperature1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_8_6e-5_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8935
- Rouge1: 35.9396
- Rouge2: 12.7251
- Rougel: 23.4072
- Bleu1: 29.8836
- Bleu2: 17.3868
- Bleu3: 10.1034
- Bleu4: 5.6852
- Gen Len: 50.5012
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 6e-05
- train_batch_size: 8
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:-------:|:-------:|:-------:|:------:|:-------:|
| 2.5006 | 0.19 | 1000 | 2.9748 | 31.9305 | 10.219 | 20.9486 | 25.9772 | 14.0989 | 7.5807 | 3.9049 | 46.8951 |
| 2.3738 | 0.38 | 2000 | 2.8691 | 34.1196 | 11.4746 | 22.0999 | 28.4466 | 16.0082 | 8.9955 | 4.6276 | 52.7669 |
| 2.3468 | 0.57 | 3000 | 2.8207 | 34.1168 | 11.3998 | 22.5175 | 28.3223 | 15.791 | 8.5992 | 4.6269 | 43.3869 |
| 2.3217 | 0.76 | 4000 | 2.7748 | 33.0369 | 11.0712 | 22.1962 | 27.127 | 15.1147 | 8.3628 | 4.6229 | 43.7366 |
| 2.2252 | 0.94 | 5000 | 2.7395 | 34.4044 | 12.5602 | 23.0083 | 28.3603 | 16.6789 | 9.7892 | 5.6717 | 47.5828 |
| 1.9933 | 1.13 | 6000 | 2.7503 | 34.5083 | 11.7179 | 22.196 | 28.8115 | 16.4201 | 9.3595 | 4.9562 | 52.1865 |
| 1.963 | 1.32 | 7000 | 2.7527 | 33.7739 | 11.3831 | 22.3692 | 27.633 | 15.5257 | 8.7664 | 4.8824 | 45.3497 |
| 1.997 | 1.51 | 8000 | 2.7051 | 35.9943 | 12.9136 | 23.8678 | 30.0639 | 17.6209 | 10.5702 | 6.1691 | 46.5128 |
| 1.9855 | 1.7 | 9000 | 2.6832 | 34.1919 | 11.6503 | 22.7604 | 27.9586 | 15.8212 | 8.7798 | 4.906 | 45.3566 |
| 1.9522 | 1.89 | 10000 | 2.6502 | 35.5575 | 12.6492 | 23.1904 | 29.4797 | 17.1112 | 9.9781 | 5.7052 | 50.0559 |
| 1.6341 | 2.08 | 11000 | 2.7328 | 34.6455 | 11.8656 | 22.9323 | 28.484 | 16.09 | 9.0409 | 5.0875 | 44.0932 |
| 1.645 | 2.27 | 12000 | 2.7198 | 35.0304 | 12.3304 | 23.4026 | 28.7978 | 16.6707 | 9.6501 | 5.4396 | 45.3427 |
| 1.6333 | 2.45 | 13000 | 2.7258 | 35.6562 | 12.7612 | 23.3402 | 29.9319 | 17.4185 | 10.2105 | 5.6995 | 51.2727 |
| 1.6663 | 2.64 | 14000 | 2.7008 | 34.2188 | 11.7236 | 22.6835 | 28.2471 | 15.9416 | 9.0996 | 4.8797 | 45.1818 |
| 1.6786 | 2.83 | 15000 | 2.7106 | 35.3961 | 12.1801 | 23.1129 | 29.6386 | 17.0003 | 9.7356 | 5.3716 | 49.1958 |
| 1.3555 | 3.02 | 16000 | 2.8057 | 35.4698 | 12.4315 | 23.2317 | 29.5758 | 16.9988 | 9.8794 | 5.5261 | 49.8089 |
| 1.3975 | 3.21 | 17000 | 2.8155 | 35.7874 | 13.1167 | 24.1395 | 29.7118 | 17.4772 | 10.4028 | 5.8877 | 47.1608 |
| 1.3958 | 3.4 | 18000 | 2.8128 | 35.7796 | 12.7994 | 23.701 | 29.8194 | 17.3474 | 10.0427 | 5.3794 | 51.2005 |
| 1.3929 | 3.59 | 19000 | 2.8084 | 35.7019 | 12.8359 | 23.4838 | 29.8411 | 17.506 | 10.2791 | 5.6268 | 50.5897 |
| 1.4165 | 3.78 | 20000 | 2.8067 | 35.4685 | 12.3161 | 23.4552 | 29.8108 | 17.0718 | 9.636 | 5.4738 | 49.0769 |
| 1.399 | 3.97 | 21000 | 2.8022 | 36.0382 | 13.0705 | 23.8823 | 30.0459 | 17.5222 | 10.2384 | 5.7993 | 50.0979 |
| 1.1604 | 4.15 | 22000 | 2.9069 | 35.9586 | 12.9506 | 23.5262 | 30.2279 | 17.6621 | 10.4464 | 6.0544 | 53.4755 |
| 1.14 | 4.34 | 23000 | 2.9020 | 35.6245 | 12.2182 | 23.4536 | 29.8692 | 17.0002 | 9.7911 | 5.5078 | 49.5944 |
| 1.1943 | 4.53 | 24000 | 2.8960 | 35.9293 | 12.6219 | 23.4135 | 30.077 | 17.4198 | 10.1376 | 5.6971 | 53.9091 |
| 1.1582 | 4.72 | 25000 | 2.8975 | 35.7625 | 12.7562 | 23.3171 | 29.7443 | 17.4017 | 10.1272 | 5.5476 | 51.5618 |
| 1.1561 | 4.91 | 26000 | 2.8935 | 35.9396 | 12.7251 | 23.4072 | 29.8836 | 17.3868 | 10.1034 | 5.6852 | 50.5012 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
imflash217/PPO_mlagent_SnowballTarget
|
imflash217
| 2023-01-27T05:30:38Z | 13 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-SnowballTarget",
"region:us"
] |
reinforcement-learning
| 2023-01-27T05:30:33Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-SnowballTarget
library_name: ml-agents
---
# **ppo** Agent playing **SnowballTarget**
This is a trained model of a **ppo** agent playing **SnowballTarget** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-SnowballTarget
2. Step 1: Write your model_id: imflash217/PPO_mlagent_SnowballTarget
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
rahulpointer/en_pipeline
|
rahulpointer
| 2023-01-27T05:24:28Z | 3 | 0 |
spacy
|
[
"spacy",
"token-classification",
"en",
"model-index",
"region:us"
] |
token-classification
| 2023-01-27T05:24:24Z |
---
tags:
- spacy
- token-classification
language:
- en
model-index:
- name: en_pipeline
results:
- task:
name: NER
type: token-classification
metrics:
- name: NER Precision
type: precision
value: 0.984375
- name: NER Recall
type: recall
value: 0.9921259843
- name: NER F Score
type: f_score
value: 0.9882352941
---
| Feature | Description |
| --- | --- |
| **Name** | `en_pipeline` |
| **Version** | `0.0.0` |
| **spaCy** | `>=3.4.4,<3.5.0` |
| **Default Pipeline** | `tok2vec`, `ner` |
| **Components** | `tok2vec`, `ner` |
| **Vectors** | 0 keys, 0 unique vectors (0 dimensions) |
| **Sources** | n/a |
| **License** | n/a |
| **Author** | [n/a]() |
### Label Scheme
<details>
<summary>View label scheme (3 labels for 1 components)</summary>
| Component | Labels |
| --- | --- |
| **`ner`** | `MEDICALCONDITION`, `MEDICINE`, `PATHOGEN` |
</details>
### Accuracy
| Type | Score |
| --- | --- |
| `ENTS_F` | 98.82 |
| `ENTS_P` | 98.44 |
| `ENTS_R` | 99.21 |
| `TOK2VEC_LOSS` | 12068.08 |
| `NER_LOSS` | 27961.10 |
|
Genrator/1st
|
Genrator
| 2023-01-27T05:14:47Z | 6 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] |
text-to-image
| 2023-01-27T05:12:04Z |
---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### 1st- Dreambooth model trained by Genrator with [buildspace's DreamBooth](https://colab.research.google.com/github/buildspace/diffusers/blob/main/examples/dreambooth/DreamBooth_Stable_Diffusion.ipynb) notebook
Build your own using the [AI Avatar project](https://buildspace.so/builds/ai-avatar)!
To get started head over to the [project dashboard](https://buildspace.so/p/build-ai-avatars).
Sample pictures of this concept:
|
nlp04/kobart_8_5e-5_datav2_min30_lp5.0_temperature1.0
|
nlp04
| 2023-01-27T05:06:06Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-27T03:42:20Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: kobart_8_5e-5_datav2_min30_lp5.0_temperature1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_8_5e-5_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8332
- Rouge1: 36.0185
- Rouge2: 12.6783
- Rougel: 23.3148
- Bleu1: 30.2418
- Bleu2: 17.381
- Bleu3: 10.3059
- Bleu4: 5.9599
- Gen Len: 50.9767
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 8
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:-------:|:-------:|:-------:|:------:|:-------:|
| 2.5229 | 0.19 | 1000 | 2.9931 | 31.4246 | 10.0302 | 20.7531 | 25.3618 | 13.7797 | 7.3585 | 3.689 | 46.8019 |
| 2.3763 | 0.38 | 2000 | 2.8644 | 33.6125 | 11.6317 | 21.9202 | 27.7709 | 15.9381 | 8.996 | 4.8041 | 50.1562 |
| 2.3371 | 0.57 | 3000 | 2.7958 | 34.253 | 11.8488 | 22.4988 | 28.501 | 16.2829 | 9.1703 | 4.9873 | 48.2751 |
| 2.3018 | 0.76 | 4000 | 2.7559 | 34.3508 | 11.7971 | 22.5994 | 28.1757 | 15.9896 | 9.12 | 5.0712 | 42.9767 |
| 2.214 | 0.94 | 5000 | 2.7131 | 34.5451 | 12.4437 | 22.9456 | 28.3871 | 16.5087 | 9.9256 | 5.5757 | 46.0653 |
| 2.0007 | 1.13 | 6000 | 2.7207 | 35.0462 | 12.0128 | 22.3508 | 29.3657 | 16.7098 | 9.4792 | 5.0235 | 49.5152 |
| 1.9633 | 1.32 | 7000 | 2.7195 | 34.3249 | 11.9224 | 22.9618 | 28.2812 | 16.0876 | 9.3298 | 5.3695 | 46.7879 |
| 2.0002 | 1.51 | 8000 | 2.6799 | 35.783 | 12.7607 | 23.8872 | 29.6408 | 17.2382 | 10.1776 | 5.9003 | 46.5967 |
| 1.9783 | 1.7 | 9000 | 2.6615 | 34.7877 | 12.2492 | 23.0451 | 28.8199 | 16.6404 | 9.6347 | 5.2901 | 47.2681 |
| 1.955 | 1.89 | 10000 | 2.6337 | 35.3022 | 12.7166 | 23.4134 | 29.218 | 17.0785 | 9.925 | 5.6807 | 50.0559 |
| 1.671 | 2.08 | 11000 | 2.6997 | 35.3595 | 12.305 | 23.3744 | 29.525 | 16.937 | 9.6249 | 5.2743 | 48.4219 |
| 1.6756 | 2.27 | 12000 | 2.6986 | 34.8911 | 12.2688 | 23.1722 | 29.1454 | 16.7564 | 9.7788 | 5.5929 | 46.8648 |
| 1.663 | 2.45 | 13000 | 2.6974 | 35.4625 | 12.5317 | 23.3959 | 29.3184 | 17.0218 | 9.7629 | 5.4506 | 48.662 |
| 1.6896 | 2.64 | 14000 | 2.6792 | 34.6078 | 12.3596 | 23.1353 | 28.6652 | 16.697 | 9.9738 | 5.6329 | 45.1608 |
| 1.7114 | 2.83 | 15000 | 2.6765 | 35.3731 | 12.669 | 23.4203 | 29.6602 | 17.1914 | 10.0183 | 5.745 | 47.9557 |
| 1.4059 | 3.02 | 16000 | 2.7574 | 35.249 | 12.3037 | 23.0811 | 29.4765 | 16.9417 | 9.563 | 5.4593 | 50.3939 |
| 1.4559 | 3.21 | 17000 | 2.7695 | 35.3686 | 12.2559 | 23.1602 | 29.3155 | 16.7156 | 9.6546 | 5.4363 | 47.7226 |
| 1.4475 | 3.4 | 18000 | 2.7638 | 35.3241 | 12.5225 | 23.3305 | 29.5401 | 17.0816 | 9.7474 | 5.4129 | 48.6993 |
| 1.4459 | 3.59 | 19000 | 2.7679 | 35.64 | 12.6542 | 23.1888 | 30.0146 | 17.4051 | 10.2219 | 5.7042 | 51.8438 |
| 1.4678 | 3.78 | 20000 | 2.7604 | 35.1451 | 12.2282 | 23.1746 | 29.4539 | 16.8357 | 9.7948 | 5.321 | 49.1935 |
| 1.4478 | 3.97 | 21000 | 2.7555 | 36.2922 | 13.2416 | 24.0108 | 30.5121 | 17.9087 | 10.6678 | 6.2204 | 49.9417 |
| 1.2405 | 4.15 | 22000 | 2.8381 | 36.0049 | 12.868 | 23.5304 | 30.1701 | 17.6082 | 10.4209 | 5.7566 | 53.3916 |
| 1.2203 | 4.34 | 23000 | 2.8370 | 35.6913 | 12.5497 | 23.6024 | 29.8742 | 17.1319 | 9.9978 | 5.6913 | 49.7646 |
| 1.2756 | 4.53 | 24000 | 2.8360 | 35.3826 | 12.3329 | 22.8257 | 29.5363 | 16.8789 | 9.7444 | 5.4338 | 51.972 |
| 1.2452 | 4.72 | 25000 | 2.8362 | 35.7976 | 12.5759 | 23.2084 | 30.1391 | 17.3059 | 10.1375 | 5.6696 | 50.1888 |
| 1.241 | 4.91 | 26000 | 2.8332 | 36.0185 | 12.6783 | 23.3148 | 30.2418 | 17.381 | 10.3059 | 5.9599 | 50.9767 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
nlp04/kobart_8_4e-5_datav2_min30_lp5.0_temperature1.0
|
nlp04
| 2023-01-27T03:40:22Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bart",
"text2text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-27T02:18:00Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- rouge
model-index:
- name: kobart_8_4e-5_datav2_min30_lp5.0_temperature1.0
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart_8_4e-5_datav2_min30_lp5.0_temperature1.0
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 2.7690
- Rouge1: 35.7198
- Rouge2: 12.6777
- Rougel: 23.5157
- Bleu1: 29.7798
- Bleu2: 17.2442
- Bleu3: 10.1198
- Bleu4: 5.5845
- Gen Len: 50.2914
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 4e-05
- train_batch_size: 8
- eval_batch_size: 128
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Bleu1 | Bleu2 | Bleu3 | Bleu4 | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:-------:|:-------:|:-------:|:-------:|:-------:|:-------:|:------:|:-------:|
| 2.5571 | 0.19 | 1000 | 3.0256 | 30.6752 | 9.655 | 20.3793 | 24.9545 | 13.4562 | 7.0852 | 3.6167 | 47.2378 |
| 2.3748 | 0.38 | 2000 | 2.8633 | 33.6862 | 11.3467 | 21.6442 | 27.6602 | 15.5034 | 8.564 | 4.7708 | 52.5921 |
| 2.3327 | 0.57 | 3000 | 2.7965 | 34.1286 | 11.5936 | 22.3078 | 28.2895 | 15.9539 | 9.0344 | 5.0261 | 46.4336 |
| 2.2987 | 0.76 | 4000 | 2.7423 | 33.7844 | 11.4184 | 22.2715 | 27.9016 | 15.7678 | 8.887 | 4.9817 | 44.1305 |
| 2.2137 | 0.94 | 5000 | 2.6925 | 34.4899 | 12.4798 | 23.0933 | 28.5676 | 16.7234 | 9.854 | 5.4929 | 46.5431 |
| 2.0205 | 1.13 | 6000 | 2.6899 | 35.1651 | 12.2364 | 22.6918 | 29.561 | 16.9967 | 9.5871 | 5.4011 | 51.4126 |
| 1.9818 | 1.32 | 7000 | 2.7037 | 34.1708 | 12.01 | 22.3273 | 28.597 | 16.3676 | 9.6473 | 5.2881 | 48.0979 |
| 2.0085 | 1.51 | 8000 | 2.6568 | 35.1423 | 12.6615 | 23.3564 | 29.0896 | 16.9543 | 10.0793 | 5.8229 | 47.014 |
| 1.9972 | 1.7 | 9000 | 2.6399 | 35.3604 | 12.6992 | 23.3829 | 29.2344 | 17.0287 | 9.9469 | 5.5226 | 46.4336 |
| 1.963 | 1.89 | 10000 | 2.6225 | 34.992 | 12.3573 | 23.0134 | 29.0142 | 16.8063 | 9.6906 | 5.5045 | 51.4452 |
| 1.718 | 2.08 | 11000 | 2.6629 | 34.8932 | 12.2868 | 23.2794 | 28.7742 | 16.5584 | 9.6199 | 5.4499 | 47.5804 |
| 1.7171 | 2.27 | 12000 | 2.6648 | 35.4343 | 12.7376 | 23.4355 | 29.4051 | 17.1878 | 10.2903 | 5.824 | 46.4359 |
| 1.695 | 2.45 | 13000 | 2.6578 | 35.0225 | 12.1733 | 22.9686 | 28.8901 | 16.5961 | 9.3781 | 5.2049 | 49.0443 |
| 1.7282 | 2.64 | 14000 | 2.6435 | 33.9569 | 11.9783 | 22.9137 | 27.9425 | 16.0888 | 9.3867 | 5.3915 | 46.0886 |
| 1.7541 | 2.83 | 15000 | 2.6469 | 34.6347 | 12.1309 | 22.7496 | 28.9934 | 16.6886 | 9.7165 | 5.2098 | 49.62 |
| 1.4855 | 3.02 | 16000 | 2.7137 | 35.3936 | 12.7873 | 23.3762 | 29.4388 | 17.1262 | 10.0549 | 5.9223 | 50.0256 |
| 1.5382 | 3.21 | 17000 | 2.7161 | 35.211 | 12.7758 | 23.8604 | 29.1727 | 17.007 | 10.1639 | 6.0141 | 46.8159 |
| 1.5243 | 3.4 | 18000 | 2.7222 | 35.6339 | 12.683 | 23.5104 | 29.8071 | 17.3418 | 10.178 | 5.5185 | 49.5944 |
| 1.5265 | 3.59 | 19000 | 2.7210 | 35.4469 | 12.5754 | 23.3784 | 29.5035 | 17.1414 | 9.8427 | 5.5385 | 50.7762 |
| 1.5394 | 3.78 | 20000 | 2.7193 | 35.9595 | 12.9418 | 23.5227 | 30.0655 | 17.5487 | 10.115 | 5.6725 | 50.3357 |
| 1.5364 | 3.97 | 21000 | 2.7000 | 35.6398 | 12.9591 | 23.8267 | 29.9125 | 17.587 | 10.4197 | 5.985 | 48.4476 |
| 1.343 | 4.15 | 22000 | 2.7756 | 35.8172 | 12.7519 | 23.5584 | 29.7877 | 17.2715 | 10.219 | 5.9187 | 49.2984 |
| 1.3182 | 4.34 | 23000 | 2.7813 | 35.2382 | 12.7271 | 23.3914 | 29.5501 | 17.3306 | 10.3873 | 6.1428 | 50.8228 |
| 1.3771 | 4.53 | 24000 | 2.7716 | 35.4267 | 12.6279 | 23.3564 | 29.6336 | 17.245 | 10.2511 | 5.9128 | 51.8695 |
| 1.3522 | 4.72 | 25000 | 2.7700 | 35.8057 | 12.9656 | 23.6143 | 29.8501 | 17.475 | 10.2721 | 5.7671 | 50.6946 |
| 1.3508 | 4.91 | 26000 | 2.7690 | 35.7198 | 12.6777 | 23.5157 | 29.7798 | 17.2442 | 10.1198 | 5.5845 | 50.2914 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.0+cu117
- Datasets 2.7.1
- Tokenizers 0.13.2
|
sohm/Reinforce-v5
|
sohm
| 2023-01-27T03:39:28Z | 0 | 0 | null |
[
"Pixelcopter-PLE-v0",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T03:39:18Z |
---
tags:
- Pixelcopter-PLE-v0
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-v5
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Pixelcopter-PLE-v0
type: Pixelcopter-PLE-v0
metrics:
- type: mean_reward
value: -2.50 +/- 0.67
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **Pixelcopter-PLE-v0**
This is a trained model of a **Reinforce** agent playing **Pixelcopter-PLE-v0** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
t3resa/swin-tiny-patch4-window7-224-finetuned-eurosat
|
t3resa
| 2023-01-27T03:17:11Z | 36 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"swin",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-01-27T02:33:12Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: swin-tiny-patch4-window7-224-finetuned-eurosat
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.9792592592592593
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# swin-tiny-patch4-window7-224-finetuned-eurosat
This model is a fine-tuned version of [microsoft/swin-tiny-patch4-window7-224](https://huggingface.co/microsoft/swin-tiny-patch4-window7-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0599
- Accuracy: 0.9793
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2282 | 1.0 | 190 | 0.1057 | 0.9656 |
| 0.1751 | 2.0 | 380 | 0.0798 | 0.9730 |
| 0.1449 | 3.0 | 570 | 0.0599 | 0.9793 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.12.0+cu116
- Datasets 2.3.2
- Tokenizers 0.12.1
|
firqaaa/indo-dpr-question_encoder-single-squad-base
|
firqaaa
| 2023-01-27T03:10:14Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"dpr",
"feature-extraction",
"id",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-12-03T01:24:12Z |
---
pipeline_tag: feature-extraction
tags:
- feature-extraction
- transformers
license: apache-2.0
language:
- id
metrics:
- accuracy
- f1
- precision
- recall
datasets:
- squad_v2
---
### indo-dpr-question_encoder-single-squad-base
<p style="font-size:16px">Indonesian Dense Passage Retrieval trained on translated SQuADv2.0 dataset in DPR format.</p>
### Evaluation
| Class | Precision | Recall | F1-Score | Support |
|-------|-----------|--------|----------|---------|
| hard_negative | 0.9963 | 0.9963 | 0.9963 | 183090 |
| positive | 0.8849 | 0.8849 | 0.8849 | 5910 |
| Metric | Value |
|--------|-------|
| Accuracy | 0.9928 |
| Macro Average | 0.9406 |
| Weighted Average | 0.9928 |
<p style="font-size:16px">Note: This report is for evaluation on the dev set, after 12000 batches.</p>
### Usage
```python
from transformers import DPRQuestionEncoder, DPRQuestionEncoderTokenizer
tokenizer = DPRQuestionEncoderTokenizer.from_pretrained('firqaaa/indo-dpr-question_encoder-single-squad-base')
model = DPRQuestionEncoder.from_pretrained('firqaaa/indo-dpr-question_encoder-single-squad-base')
input_ids = tokenizer("Ibukota Indonesia terletak dimana?", return_tensors='pt')["input_ids"]
embeddings = model(input_ids).pooler_output
```
We can use it using `haystack` as follows:
```
from haystack.nodes import DensePassageRetriever
from haystack.document_stores import InMemoryDocumentStore
retriever = DensePassageRetriever(document_store=InMemoryDocumentStore(),
query_embedding_model="firqaaa/indo-dpr-question_encoder-single-squad-base",
passage_embedding_model="firqaaa/indo-dpr-question_encoder-single-squad-base",
max_seq_len_query=64,
max_seq_len_passage=256,
batch_size=16,
use_gpu=True,
embed_title=True,
use_fast_tokenizers=True)
```
|
alexdavey/dqn-SpaceInvadersNoFrameskip-v4
|
alexdavey
| 2023-01-27T02:24:24Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-27T02:18:39Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- metrics:
- type: mean_reward
value: 653.50 +/- 369.59
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga alexdavey -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga alexdavey -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga alexdavey
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
hakurei/lit-6B-8bit
|
hakurei
| 2023-01-27T02:23:05Z | 69 | 18 |
transformers
|
[
"transformers",
"pytorch",
"causal-lm",
"en",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-03-02T23:29:05Z |
---
language:
- en
tags:
- pytorch
- causal-lm
license: mit
---
# Lit-6B - A Large Fine-tuned Model For Fictional Storytelling
Lit-6B is a GPT-J 6B model fine-tuned on 2GB of a diverse range of light novels, erotica, and annotated literature for the purpose of generating novel-like fictional text.
## Model Description
The model used for fine-tuning is [GPT-J](https://github.com/kingoflolz/mesh-transformer-jax), which is a 6 billion parameter auto-regressive language model trained on [The Pile](https://pile.eleuther.ai/).
## Training Data & Annotative Prompting
The data used in fine-tuning has been gathered from various sources such as the [Gutenberg Project](https://www.gutenberg.org/). The annotated fiction dataset has prepended tags to assist in generating towards a particular style. Here is an example prompt that shows how to use the annotations.
```
[ Title: The Dunwich Horror; Author: H. P. Lovecraft; Genre: Horror; Tags: 3rdperson, scary; Style: Dark ]
***
When a traveler in north central Massachusetts takes the wrong fork...
```
The annotations can be mixed and matched to help generate towards a specific style.
## Downstream Uses
This model can be used for entertainment purposes and as a creative writing assistant for fiction writers.
## Example Code
```
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained('hakurei/lit-6B')
tokenizer = AutoTokenizer.from_pretrained('hakurei/lit-6B')
prompt = '''[ Title: The Dunwich Horror; Author: H. P. Lovecraft; Genre: Horror ]
***
When a traveler'''
input_ids = tokenizer.encode(prompt, return_tensors='pt')
output = model.generate(input_ids, do_sample=True, temperature=1.0, top_p=0.9, repetition_penalty=1.2, max_length=len(input_ids[0])+100, pad_token_id=tokenizer.eos_token_id)
generated_text = tokenizer.decode(output[0])
print(generated_text)
```
An example output from this code produces a result that will look similar to:
```
[ Title: The Dunwich Horror; Author: H. P. Lovecraft; Genre: Horror ]
***
When a traveler comes to an unknown region, his thoughts turn inevitably towards the old gods and legends which cluster around its appearance. It is not that he believes in them or suspects their reality—but merely because they are present somewhere else in creation just as truly as himself, and so belong of necessity in any landscape whose features cannot be altogether strange to him. Moreover, man has been prone from ancient times to brood over those things most connected with the places where he dwells. Thus the Olympian deities who ruled Hyper
```
## Team members and Acknowledgements
This project would not have been possible without the computational resources graciously provided by the [TPU Research Cloud](https://sites.research.google/trc/)
- [Anthony Mercurio](https://github.com/harubaru)
- Imperishable_NEET
|
BridgeTower/bridgetower-large-itm-mlm
|
BridgeTower
| 2023-01-27T02:13:28Z | 126 | 1 |
transformers
|
[
"transformers",
"pytorch",
"bridgetower",
"en",
"dataset:conceptual_captions",
"dataset:sbu_captions",
"dataset:visual_genome",
"dataset:mscoco_captions",
"arxiv:2206.08657",
"arxiv:1504.00325",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-12-08T00:31:23Z |
---
language: en
tags:
- bridgetower
license: mit
datasets:
- conceptual_captions
- sbu_captions
- visual_genome
- mscoco_captions
---
# BridgeTower large-itm-mlm model
The BridgeTower model was proposed in "BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning" by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
The model was pretrained on English language using masked language modeling (MLM) and image text matching (ITM)objectives. It was introduced in
[this paper](https://arxiv.org/pdf/2206.08657.pdf) and first released in
[this repository](https://github.com/microsoft/BridgeTower).
BridgeTower got accepted to [AAAI'23](https://aaai.org/Conferences/AAAI-23/).
## Model description
The abstract from the paper is the following:
Vision-Language (VL) models with the Two-Tower architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder. Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BridgeTower, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BridgeTower achieves state-of-the-art performance on various downstream vision-language tasks. In particular, on the VQAv2 test-std set, BridgeTower achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs. Notably, when further scaling the model, BridgeTower achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.
## Intended uses & limitations(TODO)
### How to use
Here is how to use this model to perform image and text matching:
```python
from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
import requests
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm")
model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-large-itm-mlm")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
outputs = model(**encoding)
scores[text] = outputs.logits[0,1].item()
```
Here is how to use this model to perform masked language modeling:
```python
from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000360943.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
text = "a <mask> looking out of the window"
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm")
model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-large-itm-mlm")
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
# forward pass
outputs = model(**encoding)
results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
print(results)
#.a cat looking out of the window.
```
### Limitations and bias
TODO
## Training data
The BridgeTower model was pretrained on four public image-caption datasets:
- [Conceptual Captions(CC)](https://ai.google.com/research/ConceptualCaptions/),
- [SBU Captions](https://www.cs.rice.edu/~vo9/sbucaptions/),
- [MSCOCO Captions](https://arxiv.org/pdf/1504.00325.pdf),
- [Visual Genome](https://visualgenome.org/)
The total number of unique images in the combined data is 4M.
## Training procedure
### Preprocessing
TODO
### Pretraining
The model was pre-trained for 100k steps on 8 NVIDIA A100 GPUs with a batch size of 4096.
The optimizer used was AdamW with a learning rate of 1e-5. No data augmentation was used except for center-crop. The image resolution in pre-training is set to 288 x 288.
## Evaluation results
Please refer to [Table 5](https://arxiv.org/pdf/2206.08657.pdf) for BridgeTower's performance on Image Retrieval and other downstream tasks.
### BibTeX entry and citation info
```bibtex
@article{xu2022bridge,
title={BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning},
author={Xu, Xiao and Wu, Chenfei and Rosenman, Shachar and Lal, Vasudev and Che, Wanxiang and Duan, Nan},
journal={arXiv preprint arXiv:2206.08657},
year={2022}
}
```
|
BridgeTower/bridgetower-base-itm-mlm
|
BridgeTower
| 2023-01-27T02:12:53Z | 1,047 | 3 |
transformers
|
[
"transformers",
"pytorch",
"bridgetower",
"en",
"dataset:conceptual_captions",
"dataset:sbu_captions",
"dataset:visual_genome",
"dataset:mscoco_captions",
"arxiv:2206.08657",
"arxiv:1504.00325",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-12-08T00:36:43Z |
---
language: en
tags:
- bridgetower
license: mit
datasets:
- conceptual_captions
- sbu_captions
- visual_genome
- mscoco_captions
---
# BridgeTower base-itm-mlm model
The BridgeTower model was proposed in "BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning" by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
The model was pretrained on English language using masked language modeling (MLM) and image text matching (ITM)objectives. It was introduced in
[this paper](https://arxiv.org/pdf/2206.08657.pdf) and first released in
[this repository](https://github.com/microsoft/BridgeTower).
BridgeTower got accepted to [AAAI'23](https://aaai.org/Conferences/AAAI-23/).
## Model description
The abstract from the paper is the following:
Vision-Language (VL) models with the Two-Tower architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder. Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BridgeTower, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BridgeTower achieves state-of-the-art performance on various downstream vision-language tasks. In particular, on the VQAv2 test-std set, BridgeTower achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs. Notably, when further scaling the model, BridgeTower achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.
## Intended uses & limitations(TODO)
### How to use
Here is how to use this model to perform image and text matching:
```python
from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
import requests
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
outputs = model(**encoding)
scores[text] = outputs.logits[0,1].item()
```
Here is how to use this model to perform masked language modeling:
```python
from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000360943.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
text = "a <mask> looking out of the window"
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-base-itm-mlm")
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
# forward pass
outputs = model(**encoding)
results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
print(results)
#.a cat looking out of the window.
```
### Limitations and bias
TODO
## Training data
The BridgeTower model was pretrained on four public image-caption datasets:
- [Conceptual Captions(CC)](https://ai.google.com/research/ConceptualCaptions/),
- [SBU Captions](https://www.cs.rice.edu/~vo9/sbucaptions/),
- [MSCOCO Captions](https://arxiv.org/pdf/1504.00325.pdf),
- [Visual Genome](https://visualgenome.org/)
The total number of unique images in the combined data is 4M.
## Training procedure
### Preprocessing
TODO
### Pretraining
The model was pre-trained for 100k steps on 8 NVIDIA A100 GPUs with a batch size of 4096.
The optimizer used was AdamW with a learning rate of 1e-5. No data augmentation was used except for center-crop. The image resolution in pre-training is set to 288 x 288.
## Evaluation results
Please refer to [Table 5](https://arxiv.org/pdf/2206.08657.pdf) for BridgeTower's performance on Image Retrieval and other downstream tasks.
### BibTeX entry and citation info
```bibtex
@article{xu2022bridge,
title={BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning},
author={Xu, Xiao and Wu, Chenfei and Rosenman, Shachar and Lal, Vasudev and Che, Wanxiang and Duan, Nan},
journal={arXiv preprint arXiv:2206.08657},
year={2022}
}
```
|
gokuls/mobilebert_add_GLUE_Experiment_mnli_128
|
gokuls
| 2023-01-27T01:50:18Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mobilebert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T20:16:00Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: mobilebert_add_GLUE_Experiment_mnli_128
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE MNLI
type: glue
config: mnli
split: validation_matched
args: mnli
metrics:
- name: Accuracy
type: accuracy
value: 0.3522172497965826
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_mnli_128
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE MNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 1.0985
- Accuracy: 0.3522
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|
| 1.0987 | 1.0 | 3068 | 1.0987 | 0.3182 |
| 1.0986 | 2.0 | 6136 | 1.0986 | 0.3182 |
| 1.0986 | 3.0 | 9204 | 1.0988 | 0.3274 |
| 1.0986 | 4.0 | 12272 | 1.0986 | 0.3182 |
| 1.0986 | 5.0 | 15340 | 1.0985 | 0.3545 |
| 1.0986 | 6.0 | 18408 | 1.0987 | 0.3274 |
| 1.0986 | 7.0 | 21476 | 1.0988 | 0.3274 |
| 1.0986 | 8.0 | 24544 | 1.0986 | 0.3545 |
| 1.0986 | 9.0 | 27612 | 1.0986 | 0.3545 |
| 1.0986 | 10.0 | 30680 | 1.0987 | 0.3182 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
firqaaa/indo-dpr-ctx_encoder-single-squad-base
|
firqaaa
| 2023-01-27T01:39:52Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"dpr",
"feature-extraction",
"id",
"dataset:squad_v2",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2022-12-02T20:35:29Z |
---
pipeline_tag: feature-extraction
tags:
- feature-extraction
- transformers
license: apache-2.0
language:
- id
metrics:
- accuracy
- f1
- precision
- recall
datasets:
- squad_v2
---
### indo-dpr-question_encoder-single-squad-base
<p style="font-size:16px">Indonesian Dense Passage Retrieval trained on translated SQuADv2.0 dataset in DPR format.</p>
### Evaluation
| Class | Precision | Recall | F1-Score | Support |
|-------|-----------|--------|----------|---------|
| hard_negative | 0.9963 | 0.9963 | 0.9963 | 183090 |
| positive | 0.8849 | 0.8849 | 0.8849 | 5910 |
| Metric | Value |
|--------|-------|
| Accuracy | 0.9928 |
| Macro Average | 0.9406 |
| Weighted Average | 0.9928 |
<p style="font-size:16px">Note: This report is for evaluation on the dev set, after 12000 batches.</p>
### Usage
```python
from transformers import DPRContextEncoder, DPRContextEncoderTokenizer
tokenizer = DPRContextEncoderTokenizer.from_pretrained('firqaaa/indo-dpr-ctx_encoder-single-squad-base')
model = DPRContextEncoder.from_pretrained('firqaaa/indo-dpr-ctx_encoder-single-squad-base')
input_ids = tokenizer("Ibukota Indonesia terletak dimana?", return_tensors='pt')["input_ids"]
embeddings = model(input_ids).pooler_output
```
You can use it using `haystack` as follows:
```
from haystack.nodes import DensePassageRetriever
from haystack.document_stores import InMemoryDocumentStore
retriever = DensePassageRetriever(document_store=InMemoryDocumentStore(),
query_embedding_model="firqaaa/indo-dpr-ctx_encoder-single-squad-base",
passage_embedding_model="firqaaa/indo-dpr-ctx_encoder-single-squad-base",
max_seq_len_query=64,
max_seq_len_passage=256,
batch_size=16,
use_gpu=True,
embed_title=True,
use_fast_tokenizers=True)
```
|
alikanakar/bert-base-multilingual-cased-updated-finetuned-squad
|
alikanakar
| 2023-01-27T01:32:48Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-01-26T20:47:59Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-multilingual-cased-updated-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-updated-finetuned-squad
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3044
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| 1.4212 | 1.0 | 4217 | 1.2701 |
| 1.0642 | 2.0 | 8434 | 1.2573 |
| 0.8381 | 3.0 | 12651 | 1.3044 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
gokuls/bert-base-uncased-wnli
|
gokuls
| 2023-01-27T01:11:25Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-27T01:09:09Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: bert-base-uncased-wnli
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE WNLI
type: glue
config: wnli
split: validation
args: wnli
metrics:
- name: Accuracy
type: accuracy
value: 0.4788732394366197
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-wnli
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6968
- Accuracy: 0.4789
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7192 | 1.0 | 5 | 0.6968 | 0.4789 |
| 0.6928 | 2.0 | 10 | 0.7003 | 0.2676 |
| 0.6921 | 3.0 | 15 | 0.7057 | 0.5211 |
| 0.6931 | 4.0 | 20 | 0.7282 | 0.3944 |
| 0.6922 | 5.0 | 25 | 0.7579 | 0.2535 |
| 0.68 | 6.0 | 30 | 0.8314 | 0.2254 |
| 0.6652 | 7.0 | 35 | 0.8990 | 0.1831 |
| 0.627 | 8.0 | 40 | 1.0187 | 0.2254 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
gokuls/bert-base-uncased-sst2
|
gokuls
| 2023-01-27T01:00:33Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-27T00:24:10Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: bert-base-uncased-sst2
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE SST2
type: glue
config: sst2
split: validation
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.9128440366972477
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-sst2
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.2333
- Accuracy: 0.9128
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.2103 | 1.0 | 527 | 0.2507 | 0.9048 |
| 0.1082 | 2.0 | 1054 | 0.2333 | 0.9128 |
| 0.0724 | 3.0 | 1581 | 0.2371 | 0.9186 |
| 0.0521 | 4.0 | 2108 | 0.2582 | 0.9186 |
| 0.0393 | 5.0 | 2635 | 0.3094 | 0.9220 |
| 0.0302 | 6.0 | 3162 | 0.3506 | 0.9197 |
| 0.0258 | 7.0 | 3689 | 0.4149 | 0.9071 |
| 0.0209 | 8.0 | 4216 | 0.3121 | 0.9174 |
| 0.018 | 9.0 | 4743 | 0.4919 | 0.9060 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Ashraf-kasem/custom_gpt2_frames_text_original_tokenizer
|
Ashraf-kasem
| 2023-01-27T00:28:39Z | 3 | 0 |
transformers
|
[
"transformers",
"tf",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_keras_callback",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2023-01-25T23:13:44Z |
---
license: mit
tags:
- generated_from_keras_callback
model-index:
- name: Ashraf-kasem/custom_gpt2_frames_text_original_tokenizer
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# Ashraf-kasem/custom_gpt2_frames_text_original_tokenizer
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 1.1074
- Validation Loss: 1.6432
- Epoch: 29
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'Adam', 'learning_rate': {'class_name': 'PolynomialDecay', 'config': {'initial_learning_rate': 5e-05, 'decay_steps': 240780, 'end_learning_rate': 0.0, 'power': 1.0, 'cycle': False, 'name': None}}, 'decay': 0.0, 'beta_1': 0.9, 'beta_2': 0.999, 'epsilon': 1e-07, 'amsgrad': False}
- training_precision: mixed_float16
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 4.3075 | 3.4095 | 0 |
| 3.1973 | 2.8234 | 1 |
| 2.7420 | 2.5057 | 2 |
| 2.4541 | 2.3022 | 3 |
| 2.2507 | 2.1648 | 4 |
| 2.0962 | 2.0612 | 5 |
| 1.9736 | 1.9885 | 6 |
| 1.8729 | 1.9286 | 7 |
| 1.7883 | 1.8823 | 8 |
| 1.7153 | 1.8448 | 9 |
| 1.6517 | 1.8113 | 10 |
| 1.5953 | 1.7864 | 11 |
| 1.5446 | 1.7624 | 12 |
| 1.4994 | 1.7459 | 13 |
| 1.4578 | 1.7294 | 14 |
| 1.4200 | 1.7171 | 15 |
| 1.3851 | 1.7026 | 16 |
| 1.3528 | 1.6958 | 17 |
| 1.3229 | 1.6846 | 18 |
| 1.2950 | 1.6760 | 19 |
| 1.2690 | 1.6704 | 20 |
| 1.2448 | 1.6650 | 21 |
| 1.2223 | 1.6599 | 22 |
| 1.2012 | 1.6539 | 23 |
| 1.1815 | 1.6534 | 24 |
| 1.1635 | 1.6486 | 25 |
| 1.1470 | 1.6457 | 26 |
| 1.1318 | 1.6443 | 27 |
| 1.1185 | 1.6434 | 28 |
| 1.1074 | 1.6432 | 29 |
### Framework versions
- Transformers 4.25.1
- TensorFlow 2.9.0
- Datasets 2.8.0
- Tokenizers 0.13.2
|
gokuls/bert-base-uncased-rte
|
gokuls
| 2023-01-27T00:23:37Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-27T00:19:35Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: bert-base-uncased-rte
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE RTE
type: glue
config: rte
split: validation
args: rte
metrics:
- name: Accuracy
type: accuracy
value: 0.6064981949458483
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-rte
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6540
- Accuracy: 0.6065
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7009 | 1.0 | 20 | 0.6781 | 0.5560 |
| 0.6393 | 2.0 | 40 | 0.6540 | 0.6065 |
| 0.4606 | 3.0 | 60 | 0.7134 | 0.6498 |
| 0.2597 | 4.0 | 80 | 0.8379 | 0.6751 |
| 0.1492 | 5.0 | 100 | 1.3531 | 0.6282 |
| 0.0954 | 6.0 | 120 | 1.2220 | 0.6354 |
| 0.0561 | 7.0 | 140 | 1.2282 | 0.6715 |
| 0.0379 | 8.0 | 160 | 1.4368 | 0.6679 |
| 0.0368 | 9.0 | 180 | 1.8559 | 0.6498 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.9.0
- Tokenizers 0.13.2
|
lora-library/kdekuni
|
lora-library
| 2023-01-26T23:59:25Z | 0 | 0 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"lora",
"base_model:stabilityai/stable-diffusion-2-1-base",
"base_model:adapter:stabilityai/stable-diffusion-2-1-base",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-01-26T23:59:23Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1-base
instance_prompt: a kdekuni golden funkopop
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
- lora
inference: true
---
# LoRA DreamBooth - kdekuni
These are LoRA adaption weights for [stabilityai/stable-diffusion-2-1-base](https://huggingface.co/stabilityai/stable-diffusion-2-1-base). The weights were trained on the instance prompt "a kdekuni golden funkopop" using [DreamBooth](https://dreambooth.github.io/). You can find some example images in the following.
|
JYC333/ppo-PyramidsTraining
|
JYC333
| 2023-01-26T23:55:50Z | 4 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-01-26T23:55:44Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: JYC333/ppo-PyramidsTraining
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
sohm/Reinforce-v3
|
sohm
| 2023-01-26T23:44:54Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-26T23:44:44Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-v3
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 451.70 +/- 144.90
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
soypablo/emoji-model-finetuned-lora-3000
|
soypablo
| 2023-01-26T23:36:11Z | 3 | 3 |
diffusers
|
[
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"base_model:stabilityai/stable-diffusion-2-1-base",
"base_model:finetune:stabilityai/stable-diffusion-2-1-base",
"license:creativeml-openrail-m",
"region:us"
] |
text-to-image
| 2023-01-26T04:43:00Z |
---
license: creativeml-openrail-m
base_model: stabilityai/stable-diffusion-2-1-base
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
# LoRA text2image fine-tuning - https://huggingface.co/soypablo/emoji-model-finetuned-lora-3000
These are LoRA adaption weights for https://huggingface.co/soypablo/emoji-model-finetuned-lora-3000. The weights were fine-tuned on the soypablo/Emoji_Dataset-Openmoji dataset. You can find some example images in the following.




|
Galiess/q-FrozenLake-v1-4x4-noSlippery
|
Galiess
| 2023-01-26T23:34:29Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-26T23:34:26Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="Galiess/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
lilouuch/Goodreads_Books_Reviews_BERT_4
|
lilouuch
| 2023-01-26T23:17:29Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T20:36:48Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: Goodreads_Books_Reviews_BERT_4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Goodreads_Books_Reviews_BERT_4
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2687
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.1102 | 1.0 | 1350 | 1.0206 |
| 0.8507 | 2.0 | 2700 | 0.9454 |
| 0.579 | 3.0 | 4050 | 1.0759 |
| 0.3518 | 4.0 | 5400 | 1.2687 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
alexdavey/q-FrozenLake-v1-4x4-noSlippery
|
alexdavey
| 2023-01-26T23:08:56Z | 0 | 0 | null |
[
"FrozenLake-v1-4x4-no_slippery",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-26T23:08:54Z |
---
tags:
- FrozenLake-v1-4x4-no_slippery
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: q-FrozenLake-v1-4x4-noSlippery
results:
- metrics:
- type: mean_reward
value: 1.00 +/- 0.00
name: mean_reward
task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: FrozenLake-v1-4x4-no_slippery
type: FrozenLake-v1-4x4-no_slippery
---
# **Q-Learning** Agent playing1 **FrozenLake-v1**
This is a trained model of a **Q-Learning** agent playing **FrozenLake-v1** .
## Usage
```python
model = load_from_hub(repo_id="alexdavey/q-FrozenLake-v1-4x4-noSlippery", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
YSU/aspram
|
YSU
| 2023-01-26T23:07:54Z | 130 | 4 |
transformers
|
[
"transformers",
"pytorch",
"wav2vec2",
"automatic-speech-recognition",
"hy",
"mozilla-foundation/common_voice_9_0",
"google/fleurs",
"hye",
"multilingual",
"dataset:mozilla-foundation/common_voice_9_0",
"dataset:google/fleurs",
"dataset:mc4",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2022-05-17T16:12:02Z |
---
language:
- hy
- hye
- multilingual
license: apache-2.0
tags:
- automatic-speech-recognition
- hy
- mozilla-foundation/common_voice_9_0
- google/fleurs
datasets:
- mozilla-foundation/common_voice_9_0
- google/fleurs
- mc4
models:
- facebook/wav2vec2-xls-r-2b
task_categories:
- automatic-speech-recognition
- speech-processing
task_ids:
- speech-recognition
---
# Automatic SPeech Recognition for ArMenian
TODO Model details
|
gokuls/mobilebert_add_GLUE_Experiment_rte
|
gokuls
| 2023-01-26T22:43:19Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mobilebert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T22:39:08Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: mobilebert_add_GLUE_Experiment_rte
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE RTE
type: glue
config: rte
split: validation
args: rte
metrics:
- name: Accuracy
type: accuracy
value: 0.5270758122743683
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_rte
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6927
- Accuracy: 0.5271
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6943 | 1.0 | 20 | 0.6933 | 0.4765 |
| 0.6944 | 2.0 | 40 | 0.6927 | 0.5271 |
| 0.6932 | 3.0 | 60 | 0.6929 | 0.5271 |
| 0.6931 | 4.0 | 80 | 0.6951 | 0.4729 |
| 0.6932 | 5.0 | 100 | 0.6950 | 0.4729 |
| 0.6918 | 6.0 | 120 | 0.6945 | 0.4440 |
| 0.6889 | 7.0 | 140 | 0.7189 | 0.4621 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
gokuls/mobilebert_add_GLUE_Experiment_qqp
|
gokuls
| 2023-01-26T22:38:42Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mobilebert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T14:26:12Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: mobilebert_add_GLUE_Experiment_qqp
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE QQP
type: glue
config: qqp
split: validation
args: qqp
metrics:
- name: Accuracy
type: accuracy
value: 0.7599802127133317
- name: F1
type: f1
value: 0.6401928068223952
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_qqp
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE QQP dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5008
- Accuracy: 0.7600
- F1: 0.6402
- Combined Score: 0.7001
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 | Combined Score |
|:-------------:|:-----:|:-----:|:---------------:|:--------:|:------:|:--------------:|
| 0.6505 | 1.0 | 2843 | 0.6498 | 0.6321 | 0.0012 | 0.3166 |
| 0.6474 | 2.0 | 5686 | 0.6484 | 0.6321 | 0.0012 | 0.3166 |
| 0.646 | 3.0 | 8529 | 0.6479 | 0.6322 | 0.0024 | 0.3173 |
| 0.5481 | 4.0 | 11372 | 0.5140 | 0.7486 | 0.6247 | 0.6867 |
| 0.4934 | 5.0 | 14215 | 0.5086 | 0.7529 | 0.6548 | 0.7039 |
| 0.4794 | 6.0 | 17058 | 0.5044 | 0.7575 | 0.6527 | 0.7051 |
| 0.4708 | 7.0 | 19901 | 0.5008 | 0.7600 | 0.6402 | 0.7001 |
| 0.4652 | 8.0 | 22744 | 0.5010 | 0.7619 | 0.6384 | 0.7001 |
| 0.4604 | 9.0 | 25587 | 0.5014 | 0.7614 | 0.6489 | 0.7052 |
| 0.4562 | 10.0 | 28430 | 0.5057 | 0.7600 | 0.6617 | 0.7108 |
| 0.452 | 11.0 | 31273 | 0.5102 | 0.7620 | 0.6364 | 0.6992 |
| 0.4476 | 12.0 | 34116 | 0.5302 | 0.7622 | 0.6619 | 0.7121 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
alphahg/kobart-base-v2-finetuned-paper
|
alphahg
| 2023-01-26T22:30:47Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"generated_from_trainer",
"dataset:aihub_paper_summarization",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-25T11:42:24Z |
---
license: mit
tags:
- generated_from_trainer
datasets:
- aihub_paper_summarization
metrics:
- rouge
model-index:
- name: kobart-base-v2-finetuned-paper
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: aihub_paper_summarization
type: aihub_paper_summarization
config: default
split: train
args: default
metrics:
- name: Rouge1
type: rouge
value: 6.2883
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# kobart-base-v2-finetuned-paper
This model is a fine-tuned version of [gogamza/kobart-base-v2](https://huggingface.co/gogamza/kobart-base-v2) on the aihub_paper_summarization dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2966
- Rouge1: 6.2883
- Rouge2: 1.7038
- Rougel: 6.2556
- Rougelsum: 6.2618
- Gen Len: 20.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| 1.2215 | 1.0 | 8831 | 1.3293 | 6.2425 | 1.7317 | 6.2246 | 6.2247 | 20.0 |
| 1.122 | 2.0 | 17662 | 1.3056 | 6.2298 | 1.7005 | 6.2042 | 6.2109 | 20.0 |
| 1.0914 | 3.0 | 26493 | 1.2966 | 6.2883 | 1.7038 | 6.2556 | 6.2618 | 20.0 |
### Framework versions
- Transformers 4.25.1
- Pytorch 1.13.1
- Datasets 2.8.0
- Tokenizers 0.13.2
|
lilouuch/Goodreads_Books_Reviews_BERT_3
|
lilouuch
| 2023-01-26T21:57:20Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bert",
"text-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T20:35:31Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: Goodreads_Books_Reviews_BERT_3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Goodreads_Books_Reviews_BERT_3
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2441
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 4
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.4298 | 1.0 | 675 | 1.0408 |
| 1.0215 | 2.0 | 1350 | 0.9826 |
| 0.6131 | 3.0 | 2025 | 1.0458 |
| 0.3825 | 4.0 | 2700 | 1.2441 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
mroopesh/my_billsum_model
|
mroopesh
| 2023-01-26T21:42:21Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"t5",
"text2text-generation",
"generated_from_trainer",
"dataset:billsum",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2023-01-26T21:38:10Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- billsum
metrics:
- rouge
model-index:
- name: my_billsum_model
results:
- task:
name: Sequence-to-sequence Language Modeling
type: text2text-generation
dataset:
name: billsum
type: billsum
config: default
split: ca_test
args: default
metrics:
- name: Rouge1
type: rouge
value: 0.1425
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# my_billsum_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on the billsum dataset.
It achieves the following results on the evaluation set:
- Loss: 2.5391
- Rouge1: 0.1425
- Rouge2: 0.0499
- Rougel: 0.1149
- Rougelsum: 0.1148
- Gen Len: 19.0
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 4
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Rouge1 | Rouge2 | Rougel | Rougelsum | Gen Len |
|:-------------:|:-----:|:----:|:---------------:|:------:|:------:|:------:|:---------:|:-------:|
| No log | 1.0 | 62 | 2.8276 | 0.1256 | 0.0355 | 0.1038 | 0.104 | 19.0 |
| No log | 2.0 | 124 | 2.6220 | 0.1356 | 0.0456 | 0.1106 | 0.1104 | 19.0 |
| No log | 3.0 | 186 | 2.5555 | 0.1423 | 0.0501 | 0.1145 | 0.1143 | 19.0 |
| No log | 4.0 | 248 | 2.5391 | 0.1425 | 0.0499 | 0.1149 | 0.1148 | 19.0 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
DarkSolus/LoRA_RWBY
|
DarkSolus
| 2023-01-26T21:14:44Z | 0 | 4 | null |
[
"license:openrail",
"region:us"
] | null | 2023-01-26T18:28:20Z |
---
license: openrail
---
# Model Card for LoRA
Based on a 48 image dataset scraped from Danbooru and tagged with WD1.4 Tagger. Trained for 30 epochs (7200 steps), best with models and merges based on Anything v3.
Not particularly prone to NSFW, as the training dataset was somewhat balanced, but is capable of it.
Outfits tend to Ruby's default colors of red and black unless specified otherwise, especially all kinds of dresses.
I also recommend using Latent upscaler with medium (0.4-0.5) denoise, as it can fix some small inconsistencies like wrong eye color.
## Model Description
Version 1.0 is currently the only one available and is the least prone to straying from the prompt (white dress stays white), however, may be slightly inaccurate when depicting Ruby.
Best weights seem to be in the area of 0.6 to 0.7, and for best results I recommend adding in tags like "grey eyes, red hair, multicolored hair".
Higher weights can sometimes lead to facial artifacts and/or weird anatomy.
- **Developed by:** DarkSolus
- **Model type:** LoRA
- **Finetuned from model [optional]:** Anything v3
## How to Get Started with the Model
Download the preferred version of the LoRA from the repo.
Install Additional Networks extension:
1) via Auto1111's extension manager
2) via GitHub: https://github.com/kohya-ss/sd-webui-additional-networks
Reload the UI, and place your downloaded LoRA into: .\stable-diffusion-webui\extensions\sd-webui-additional-networks\models\lora
|
Richard0113/bert-base-uncased-finetuned-mrpc
|
Richard0113
| 2023-01-26T21:14:36Z | 5 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"text-classification",
"generated_from_trainer",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T19:23:34Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
- f1
model-index:
- name: bert-base-uncased-finetuned-mrpc
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: glue
type: glue
config: mrpc
split: validation
args: mrpc
metrics:
- name: Accuracy
type: accuracy
value: 0.8676470588235294
- name: F1
type: f1
value: 0.9045936395759717
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-uncased-finetuned-mrpc
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on the glue dataset.
It achieves the following results on the evaluation set:
- Loss: 0.5500
- Accuracy: 0.8676
- F1: 0.9046
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:------:|
| No log | 1.0 | 230 | 0.3669 | 0.8309 | 0.8796 |
| No log | 2.0 | 460 | 0.3704 | 0.8652 | 0.9076 |
| 0.3951 | 3.0 | 690 | 0.4974 | 0.8627 | 0.9041 |
| 0.3951 | 4.0 | 920 | 0.5454 | 0.8652 | 0.9053 |
| 0.0994 | 5.0 | 1150 | 0.5500 | 0.8676 | 0.9046 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.9.0
- Tokenizers 0.13.2
|
Celal11/beit-base-patch16-224-pt22k-ft22k-finetuned-FER2013-7e-05-16
|
Celal11
| 2023-01-26T21:00:06Z | 16 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"beit",
"image-classification",
"generated_from_trainer",
"dataset:image_folder",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2023-01-26T20:33:05Z |
---
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- image_folder
metrics:
- accuracy
model-index:
- name: beit-base-patch16-224-pt22k-ft22k-finetuned-FER2013-7e-05-16
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: image_folder
type: image_folder
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.7153803287823907
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# beit-base-patch16-224-pt22k-ft22k-finetuned-FER2013-7e-05-16
This model is a fine-tuned version of [Celal11/beit-base-patch16-224-pt22k-ft22k-finetuned-FER2013CKPlus-7e-05](https://huggingface.co/Celal11/beit-base-patch16-224-pt22k-ft22k-finetuned-FER2013CKPlus-7e-05) on the image_folder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8185
- Accuracy: 0.7154
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 7e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 2
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7923 | 1.0 | 224 | 0.8570 | 0.7009 |
| 0.6737 | 2.0 | 448 | 0.8185 | 0.7154 |
### Framework versions
- Transformers 4.20.1
- Pytorch 1.11.0
- Datasets 2.1.0
- Tokenizers 0.12.1
|
Tristan/gpt2-xl-summarization_reward_model
|
Tristan
| 2023-01-26T20:50:39Z | 0 | 1 | null |
[
"pytorch",
"generated_from_trainer",
"license:mit",
"region:us"
] | null | 2023-01-26T04:01:09Z |
---
license: mit
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: gpt2-xl-summarization_reward_model
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2-xl-summarization_reward_model
This model is a fine-tuned version of [gpt2-xl](https://huggingface.co/gpt2-xl) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.2875
- Accuracy: 0.6157
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 1
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- num_devices: 16
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.5856 | 1.0 | 1451 | 0.6854 | 0.6218 |
| 0.4314 | 2.0 | 2902 | 0.8053 | 0.6133 |
| 0.3166 | 3.0 | 4353 | 0.8060 | 0.6146 |
| 0.2625 | 4.0 | 5804 | 0.9857 | 0.6162 |
| 0.2279 | 5.0 | 7255 | 1.2875 | 0.6157 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu117
- Datasets 2.8.0
- Tokenizers 0.13.2
|
rl-knight/lunar_ppo_100
|
rl-knight
| 2023-01-26T20:43:04Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"LunarLander-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-26T20:42:40Z |
---
library_name: stable-baselines3
tags:
- LunarLander-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: PPO
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: LunarLander-v2
type: LunarLander-v2
metrics:
- type: mean_reward
value: -1958.42 +/- 1146.11
name: mean_reward
verified: false
---
# **PPO** Agent playing **LunarLander-v2**
This is a trained model of a **PPO** agent playing **LunarLander-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
Segamboam/a2c-PandaReachDense-v2
|
Segamboam
| 2023-01-26T20:26:44Z | 1 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"PandaReachDense-v2",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-26T20:24:27Z |
---
library_name: stable-baselines3
tags:
- PandaReachDense-v2
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: PandaReachDense-v2
type: PandaReachDense-v2
metrics:
- type: mean_reward
value: -2.55 +/- 0.82
name: mean_reward
verified: false
---
# **A2C** Agent playing **PandaReachDense-v2**
This is a trained model of a **A2C** agent playing **PandaReachDense-v2**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
sxandie/nexon_jan_2023
|
sxandie
| 2023-01-26T20:18:54Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"layoutlmv3",
"token-classification",
"generated_from_trainer",
"dataset:sroie",
"license:cc-by-nc-sa-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2023-01-26T19:58:45Z |
---
license: cc-by-nc-sa-4.0
tags:
- generated_from_trainer
datasets:
- sroie
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: nexon_jan_2023
results:
- task:
name: Token Classification
type: token-classification
dataset:
name: sroie
type: sroie
config: discharge
split: test
args: discharge
metrics:
- name: Precision
type: precision
value: 0.975609756097561
- name: Recall
type: recall
value: 0.9302325581395349
- name: F1
type: f1
value: 0.9523809523809524
- name: Accuracy
type: accuracy
value: 0.9971428571428571
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# nexon_jan_2023
This model is a fine-tuned version of [microsoft/layoutlmv3-base](https://huggingface.co/microsoft/layoutlmv3-base) on the sroie dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0380
- Precision: 0.9756
- Recall: 0.9302
- F1: 0.9524
- Accuracy: 0.9971
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 2
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- training_steps: 1500
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 16.67 | 100 | 0.1998 | 0.6286 | 0.5116 | 0.5641 | 0.9571 |
| No log | 33.33 | 200 | 0.0616 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| No log | 50.0 | 300 | 0.0439 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| No log | 66.67 | 400 | 0.0404 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.1151 | 83.33 | 500 | 0.0389 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.1151 | 100.0 | 600 | 0.0380 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.1151 | 116.67 | 700 | 0.0378 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.1151 | 133.33 | 800 | 0.0379 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.1151 | 150.0 | 900 | 0.0378 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.009 | 166.67 | 1000 | 0.0378 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.009 | 183.33 | 1100 | 0.0378 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.009 | 200.0 | 1200 | 0.0379 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.009 | 216.67 | 1300 | 0.0379 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.009 | 233.33 | 1400 | 0.0379 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
| 0.0064 | 250.0 | 1500 | 0.0380 | 0.9756 | 0.9302 | 0.9524 | 0.9971 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu116
- Datasets 2.2.2
- Tokenizers 0.13.2
|
PoseyATX/Moist-Pony
|
PoseyATX
| 2023-01-26T20:14:29Z | 10 | 0 |
transformers
|
[
"transformers",
"pytorch",
"bart",
"text2text-generation",
"autotrain",
"summarization",
"unk",
"dataset:PoseyATX/autotrain-data-dbarttrain2",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
summarization
| 2023-01-26T18:57:13Z |
---
tags:
- autotrain
- summarization
language:
- unk
widget:
- text: "I love AutoTrain 🤗"
datasets:
- PoseyATX/autotrain-data-dbarttrain2
co2_eq_emissions:
emissions: 140.6871460520222
---
# Model Trained Using AutoTrain
- Problem type: Summarization
- Model ID: 3083787793
- CO2 Emissions (in grams): 140.6871
## Validation Metrics
- Loss: 1.413
- Rouge1: 57.925
- Rouge2: 36.683
- RougeL: 44.952
- RougeLsum: 50.807
- Gen Len: 120.034
## Usage
You can use cURL to access this model:
```
$ curl -X POST -H "Authorization: Bearer YOUR_HUGGINGFACE_API_KEY" -H "Content-Type: application/json" -d '{"inputs": "I love AutoTrain"}' https://api-inference.huggingface.co/PoseyATX/autotrain-dbarttrain2-3083787793
```
|
gokuls/mobilebert_add_GLUE_Experiment_stsb_128
|
gokuls
| 2023-01-26T20:10:58Z | 6 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mobilebert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T20:03:07Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- spearmanr
model-index:
- name: mobilebert_add_GLUE_Experiment_stsb_128
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE STSB
type: glue
config: stsb
split: validation
args: stsb
metrics:
- name: Spearmanr
type: spearmanr
value: 0.03419936685461868
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_stsb_128
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE STSB dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2820
- Pearson: 0.0445
- Spearmanr: 0.0342
- Combined Score: 0.0393
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Pearson | Spearmanr | Combined Score |
|:-------------:|:-----:|:----:|:---------------:|:-------:|:---------:|:--------------:|
| 5.0491 | 1.0 | 45 | 2.6735 | -0.0094 | -0.0099 | -0.0097 |
| 2.2021 | 2.0 | 90 | 3.1489 | 0.0389 | 0.0330 | 0.0359 |
| 2.1522 | 3.0 | 135 | 2.2943 | 0.0413 | 0.0270 | 0.0341 |
| 2.125 | 4.0 | 180 | 2.5078 | 0.0421 | 0.0274 | 0.0348 |
| 2.1328 | 5.0 | 225 | 2.2820 | 0.0445 | 0.0342 | 0.0393 |
| 2.0676 | 6.0 | 270 | 2.3672 | 0.0464 | 0.0393 | 0.0428 |
| 2.0545 | 7.0 | 315 | 2.6386 | 0.0506 | 0.0463 | 0.0485 |
| 2.0677 | 8.0 | 360 | 2.4397 | 0.0556 | 0.0574 | 0.0565 |
| 1.9988 | 9.0 | 405 | 2.4024 | 0.0601 | 0.0630 | 0.0615 |
| 1.9683 | 10.0 | 450 | 2.7224 | 0.0576 | 0.0646 | 0.0611 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
alikanakar/bert-base-multilingual-cased-finetuned-squad
|
alikanakar
| 2023-01-26T20:02:45Z | 4 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"bert",
"question-answering",
"generated_from_trainer",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2023-01-05T20:44:55Z |
---
license: apache-2.0
tags:
- generated_from_trainer
model-index:
- name: bert-base-multilingual-cased-finetuned-squad
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-base-multilingual-cased-finetuned-squad
This model is a fine-tuned version of [bert-base-multilingual-cased](https://huggingface.co/bert-base-multilingual-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.3348
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:----:|:---------------:|
| 1.303 | 1.0 | 1997 | 1.2828 |
| 0.8647 | 2.0 | 3994 | 1.2168 |
| 0.6267 | 3.0 | 5991 | 1.3348 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.13.1+cu116
- Datasets 2.8.0
- Tokenizers 0.13.2
|
gokuls/mobilebert_add_GLUE_Experiment_sst2_128
|
gokuls
| 2023-01-26T20:02:39Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mobilebert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T18:51:54Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: mobilebert_add_GLUE_Experiment_sst2_128
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE SST2
type: glue
config: sst2
split: validation
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.7981651376146789
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_sst2_128
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4543
- Accuracy: 0.7982
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6677 | 1.0 | 527 | 0.6771 | 0.5757 |
| 0.5966 | 2.0 | 1054 | 0.7135 | 0.5424 |
| 0.5714 | 3.0 | 1581 | 0.7271 | 0.5550 |
| 0.5573 | 4.0 | 2108 | 0.6892 | 0.5619 |
| 0.501 | 5.0 | 2635 | 0.4546 | 0.7798 |
| 0.2856 | 6.0 | 3162 | 0.4613 | 0.8050 |
| 0.2288 | 7.0 | 3689 | 0.4543 | 0.7982 |
| 0.2027 | 8.0 | 4216 | 0.4662 | 0.7993 |
| 0.1883 | 9.0 | 4743 | 0.5168 | 0.8039 |
| 0.1779 | 10.0 | 5270 | 0.5748 | 0.7856 |
| 0.1691 | 11.0 | 5797 | 0.5196 | 0.8028 |
| 0.1596 | 12.0 | 6324 | 0.5943 | 0.7947 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
LarryAIDraw/AnyAsiaGirl
|
LarryAIDraw
| 2023-01-26T19:57:27Z | 0 | 0 | null |
[
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-01-26T18:11:19Z |
---
license: creativeml-openrail-m
---
|
gokuls/mobilebert_add_GLUE_Experiment_wnli_256
|
gokuls
| 2023-01-26T19:54:29Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mobilebert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T19:53:20Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: mobilebert_add_GLUE_Experiment_wnli_256
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE WNLI
type: glue
config: wnli
split: validation
args: wnli
metrics:
- name: Accuracy
type: accuracy
value: 0.5633802816901409
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_wnli_256
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE WNLI dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6900
- Accuracy: 0.5634
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6944 | 1.0 | 5 | 0.6900 | 0.5634 |
| 0.6936 | 2.0 | 10 | 0.6921 | 0.5634 |
| 0.6933 | 3.0 | 15 | 0.6930 | 0.5634 |
| 0.693 | 4.0 | 20 | 0.6920 | 0.5634 |
| 0.693 | 5.0 | 25 | 0.6910 | 0.5634 |
| 0.6931 | 6.0 | 30 | 0.6908 | 0.5634 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
gokuls/mobilebert_add_GLUE_Experiment_sst2_256
|
gokuls
| 2023-01-26T19:45:53Z | 3 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mobilebert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T19:08:46Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: mobilebert_add_GLUE_Experiment_sst2_256
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE SST2
type: glue
config: sst2
split: validation
args: sst2
metrics:
- name: Accuracy
type: accuracy
value: 0.5561926605504587
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_sst2_256
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE SST2 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6814
- Accuracy: 0.5562
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6662 | 1.0 | 527 | 0.6814 | 0.5562 |
| 0.5954 | 2.0 | 1054 | 0.7090 | 0.5493 |
| 0.5689 | 3.0 | 1581 | 0.7150 | 0.5596 |
| 0.5546 | 4.0 | 2108 | 0.6893 | 0.5539 |
| 0.5473 | 5.0 | 2635 | 0.7051 | 0.5872 |
| 0.5421 | 6.0 | 3162 | 0.6983 | 0.5872 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
javiervela/ppo-PyramidsRND
|
javiervela
| 2023-01-26T19:40:49Z | 3 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"unity-ml-agents",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2023-01-26T19:40:42Z |
---
tags:
- unity-ml-agents
- ml-agents
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
library_name: ml-agents
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids** using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://github.com/huggingface/ml-agents#get-started
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
### Resume the training
```
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser:**.
1. Go to https://huggingface.co/spaces/unity/ML-Agents-Pyramids
2. Step 1: Write your model_id: javiervela/ppo-PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
scronberg/a2c-AntBulletEnv-v0
|
scronberg
| 2023-01-26T19:36:34Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"AntBulletEnv-v0",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-26T18:59:58Z |
---
library_name: stable-baselines3
tags:
- AntBulletEnv-v0
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: A2C
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: AntBulletEnv-v0
type: AntBulletEnv-v0
metrics:
- type: mean_reward
value: 1703.12 +/- 532.84
name: mean_reward
verified: false
---
# **A2C** Agent playing **AntBulletEnv-v0**
This is a trained model of a **A2C** agent playing **AntBulletEnv-v0**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3).
## Usage (with Stable-baselines3)
TODO: Add your code
```python
from stable_baselines3 import ...
from huggingface_sb3 import load_from_hub
...
```
|
asubiabre/dqn-SpaceInvadersNoFrameskip-v4
|
asubiabre
| 2023-01-26T19:13:29Z | 3 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"SpaceInvadersNoFrameskip-v4",
"deep-reinforcement-learning",
"reinforcement-learning",
"model-index",
"region:us"
] |
reinforcement-learning
| 2023-01-26T17:31:09Z |
---
library_name: stable-baselines3
tags:
- SpaceInvadersNoFrameskip-v4
- deep-reinforcement-learning
- reinforcement-learning
- stable-baselines3
model-index:
- name: DQN
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: SpaceInvadersNoFrameskip-v4
type: SpaceInvadersNoFrameskip-v4
metrics:
- type: mean_reward
value: 605.00 +/- 178.61
name: mean_reward
verified: false
---
# **DQN** Agent playing **SpaceInvadersNoFrameskip-v4**
This is a trained model of a **DQN** agent playing **SpaceInvadersNoFrameskip-v4**
using the [stable-baselines3 library](https://github.com/DLR-RM/stable-baselines3)
and the [RL Zoo](https://github.com/DLR-RM/rl-baselines3-zoo).
The RL Zoo is a training framework for Stable Baselines3
reinforcement learning agents,
with hyperparameter optimization and pre-trained agents included.
## Usage (with SB3 RL Zoo)
RL Zoo: https://github.com/DLR-RM/rl-baselines3-zoo<br/>
SB3: https://github.com/DLR-RM/stable-baselines3<br/>
SB3 Contrib: https://github.com/Stable-Baselines-Team/stable-baselines3-contrib
Install the RL Zoo (with SB3 and SB3-Contrib):
```bash
pip install rl_zoo3
```
```
# Download model and save it into the logs/ folder
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga asubiabre -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
If you installed the RL Zoo3 via pip (`pip install rl_zoo3`), from anywhere you can do:
```
python -m rl_zoo3.load_from_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -orga asubiabre -f logs/
python -m rl_zoo3.enjoy --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
```
## Training (with the RL Zoo)
```
python -m rl_zoo3.train --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/
# Upload the model and generate video (when possible)
python -m rl_zoo3.push_to_hub --algo dqn --env SpaceInvadersNoFrameskip-v4 -f logs/ -orga asubiabre
```
## Hyperparameters
```python
OrderedDict([('batch_size', 32),
('buffer_size', 100000),
('env_wrapper',
['stable_baselines3.common.atari_wrappers.AtariWrapper']),
('exploration_final_eps', 0.01),
('exploration_fraction', 0.1),
('frame_stack', 4),
('gradient_steps', 1),
('learning_rate', 0.0001),
('learning_starts', 100000),
('n_timesteps', 1000000.0),
('optimize_memory_usage', False),
('policy', 'CnnPolicy'),
('target_update_interval', 1000),
('train_freq', 4),
('normalize', False)])
```
|
gokuls/mobilebert_add_GLUE_Experiment_rte_256
|
gokuls
| 2023-01-26T19:08:08Z | 204 | 0 |
transformers
|
[
"transformers",
"pytorch",
"tensorboard",
"mobilebert",
"text-classification",
"generated_from_trainer",
"en",
"dataset:glue",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2023-01-26T19:05:39Z |
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- glue
metrics:
- accuracy
model-index:
- name: mobilebert_add_GLUE_Experiment_rte_256
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: GLUE RTE
type: glue
config: rte
split: validation
args: rte
metrics:
- name: Accuracy
type: accuracy
value: 0.5270758122743683
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mobilebert_add_GLUE_Experiment_rte_256
This model is a fine-tuned version of [google/mobilebert-uncased](https://huggingface.co/google/mobilebert-uncased) on the GLUE RTE dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6929
- Accuracy: 0.5271
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 128
- eval_batch_size: 128
- seed: 10
- distributed_type: multi-GPU
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.6937 | 1.0 | 20 | 0.6929 | 0.5271 |
| 0.6938 | 2.0 | 40 | 0.6929 | 0.5271 |
| 0.6931 | 3.0 | 60 | 0.6931 | 0.5126 |
| 0.6932 | 4.0 | 80 | 0.6938 | 0.4693 |
| 0.693 | 5.0 | 100 | 0.6950 | 0.4729 |
| 0.6921 | 6.0 | 120 | 0.6933 | 0.5199 |
### Framework versions
- Transformers 4.26.0
- Pytorch 1.14.0a0+410ce96
- Datasets 2.8.0
- Tokenizers 0.13.2
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.