
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-27 12:28:27
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 533
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-27 12:28:17
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
qnguyen3/mimo-vl-7b-sft-4bit-mlx
|
qnguyen3
| 2025-06-17T18:40:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"mlx",
"conversational",
"base_model:XiaomiMiMo/MiMo-VL-7B-SFT",
"base_model:finetune:XiaomiMiMo/MiMo-VL-7B-SFT",
"license:mit",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-06-17T18:39:14Z |
---
base_model:
- XiaomiMiMo/MiMo-VL-7B-SFT
library_name: transformers
license: mit
pipeline_tag: image-text-to-text
tags:
- mlx
---
# qnguyen3/mimo-vl-7b-sft-4bit-mlx
This model was converted to MLX format from [`XiaomiMiMo/MiMo-VL-7B-SFT`]() using mlx-vlm version **0.1.26**.
Refer to the [original model card](https://huggingface.co/XiaomiMiMo/MiMo-VL-7B-SFT) for more details on the model.
## Use with mlx
```bash
pip install -U mlx-vlm
```
```bash
python -m mlx_vlm.generate --model qnguyen3/mimo-vl-7b-sft-4bit-mlx --max-tokens 100 --temperature 0.0 --prompt "Describe this image." --image <path_to_image>
```
|
bruhzair/prototype-0.4x154
|
bruhzair
| 2025-06-17T18:39:02Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"mergekit",
"merge",
"conversational",
"arxiv:2408.07990",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T18:13:59Z |
---
base_model: []
library_name: transformers
tags:
- mergekit
- merge
---
# prototype-0.4x154
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [SCE](https://arxiv.org/abs/2408.07990) merge method using /workspace/prototype-0.4x153 as a base.
### Models Merged
The following models were included in the merge:
* /workspace/cache/models--LatitudeGames--Wayfarer-Large-70B-Llama-3.3/snapshots/68cb7a33f692be64d4b146576838be85593a7459
* /workspace/cache/models--Sao10K--L3.1-70B-Hanami-x1/snapshots/f054d970fe9119d0237ce97029e6f5b9fce630eb
* /workspace/cache/models--Sao10K--Llama-3.3-70B-Vulpecula-r1/snapshots/12d7254ab9a5ce21905f59f341a3d2a2b3e62fd5
* /workspace/cache/models--TheDrummer--Anubis-70B-v1/snapshots/e50d699bf6c21afcf4dbd9a8b4f73511b0366efb
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: /workspace/cache/models--Sao10K--L3.1-70B-Hanami-x1/snapshots/f054d970fe9119d0237ce97029e6f5b9fce630eb
parameters:
select_topk: 0.2
- model: /workspace/cache/models--Sao10K--Llama-3.3-70B-Vulpecula-r1/snapshots/12d7254ab9a5ce21905f59f341a3d2a2b3e62fd5
parameters:
select_topk: 0.2
- model: /workspace/cache/models--LatitudeGames--Wayfarer-Large-70B-Llama-3.3/snapshots/68cb7a33f692be64d4b146576838be85593a7459
parameters:
select_topk: 0.2
- model: /workspace/cache/models--TheDrummer--Anubis-70B-v1/snapshots/e50d699bf6c21afcf4dbd9a8b4f73511b0366efb
parameters:
select_topk: 0.2
- model: /workspace/prototype-0.4x153
parameters:
select_topk: 0.7
base_model: /workspace/prototype-0.4x153
merge_method: sce
tokenizer:
source: base
pad_to_multiple_of: 8
int8_mask: true
dtype: bfloat16
```
|
asm3515/bert_agnews_lora_rank32
|
asm3515
| 2025-06-17T18:35:33Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T18:35:31Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
TxAA/ppo-PyramidsRND
|
TxAA
| 2025-06-17T18:25:17Z | 0 | 0 |
ml-agents
|
[
"ml-agents",
"tensorboard",
"onnx",
"Pyramids",
"deep-reinforcement-learning",
"reinforcement-learning",
"ML-Agents-Pyramids",
"region:us"
] |
reinforcement-learning
| 2025-06-17T17:19:05Z |
---
library_name: ml-agents
tags:
- Pyramids
- deep-reinforcement-learning
- reinforcement-learning
- ML-Agents-Pyramids
---
# **ppo** Agent playing **Pyramids**
This is a trained model of a **ppo** agent playing **Pyramids**
using the [Unity ML-Agents Library](https://github.com/Unity-Technologies/ml-agents).
## Usage (with ML-Agents)
The Documentation: https://unity-technologies.github.io/ml-agents/ML-Agents-Toolkit-Documentation/
We wrote a complete tutorial to learn to train your first agent using ML-Agents and publish it to the Hub:
- A *short tutorial* where you teach Huggy the Dog 🐶 to fetch the stick and then play with him directly in your
browser: https://huggingface.co/learn/deep-rl-course/unitbonus1/introduction
- A *longer tutorial* to understand how works ML-Agents:
https://huggingface.co/learn/deep-rl-course/unit5/introduction
### Resume the training
```bash
mlagents-learn <your_configuration_file_path.yaml> --run-id=<run_id> --resume
```
### Watch your Agent play
You can watch your agent **playing directly in your browser**
1. If the environment is part of ML-Agents official environments, go to https://huggingface.co/unity
2. Step 1: Find your model_id: TxAA/ppo-PyramidsRND
3. Step 2: Select your *.nn /*.onnx file
4. Click on Watch the agent play 👀
|
OPTML-Group/NPO-RS-WMDP
|
OPTML-Group
| 2025-06-17T18:25:12Z | 12 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"unlearn",
"machine-unlearning",
"llm-unlearning",
"data-privacy",
"large-language-models",
"trustworthy-ai",
"trustworthy-machine-learning",
"language-model",
"conversational",
"en",
"dataset:cais/wmdp",
"arxiv:2502.05374",
"base_model:HuggingFaceH4/zephyr-7b-beta",
"base_model:finetune:HuggingFaceH4/zephyr-7b-beta",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-02-09T23:43:21Z |
---
license: mit
datasets:
- cais/wmdp
language:
- en
base_model:
- HuggingFaceH4/zephyr-7b-beta
pipeline_tag: text-generation
library_name: transformers
tags:
- unlearn
- machine-unlearning
- llm-unlearning
- data-privacy
- large-language-models
- trustworthy-ai
- trustworthy-machine-learning
- language-model
---
# NPO-Unlearned w/ RS Model on Task "WMDP"
## Model Details
- **Unlearning**:
- **Task**: [🤗datasets/cais/wmdp wmdp-bio](https://huggingface.co/datasets/cais/wmdp)
- **Method**: NPO
- **Smoothness Optimization**: Randomized Smoothing (RS)
- **Origin Model**: [🤗HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
- **Code Base**: [github.com/OPTML-Group/Unlearn-Smooth](https://github.com/OPTML-Group/Unlearn-Smooth)
- **Research Paper**: ["Towards LLM Unlearning Resilient to Relearning Attacks: A Sharpness-Aware Minimization Perspective and Beyond"](https://arxiv.org/abs/2502.05374)
## Loading the Model
```python
import torch
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("OPTML-Group/NPO-RS-WMDP", torch_dtype=torch.bfloat16, trust_remote_code=True)
```
## Citation
If you use this model in your research, please cite:
```
@article{fan2025towards,
title={Towards LLM Unlearning Resilient to Relearning Attacks: A Sharpness-Aware Minimization Perspective and Beyond},
author={Fan, Chongyu and Jia, Jinghan and Zhang, Yihua and Ramakrishna, Anil and Hong, Mingyi and Liu, Sijia},
journal={arXiv preprint arXiv:2502.05374},
year={2025}
}
```
## Reporting Issues
Reporting issues with the model: [github.com/OPTML-Group/Unlearn-Smooth](https://github.com/OPTML-Group/Unlearn-Smooth)
|
Triangle104/QwQ-32B-abliterated-Q5_K_S-GGUF
|
Triangle104
| 2025-06-17T18:10:10Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"chat",
"abliterated",
"uncensored",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:huihui-ai/QwQ-32B-abliterated",
"base_model:quantized:huihui-ai/QwQ-32B-abliterated",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-17T18:08:28Z |
---
license: apache-2.0
license_link: https://huggingface.co/huihui-ai/QwQ-32B-abliterated/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
base_model: huihui-ai/QwQ-32B-abliterated
tags:
- chat
- abliterated
- uncensored
- llama-cpp
- gguf-my-repo
library_name: transformers
---
# Triangle104/QwQ-32B-abliterated-Q5_K_S-GGUF
This model was converted to GGUF format from [`huihui-ai/QwQ-32B-abliterated`](https://huggingface.co/huihui-ai/QwQ-32B-abliterated) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/huihui-ai/QwQ-32B-abliterated) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/QwQ-32B-abliterated-Q5_K_S-GGUF --hf-file qwq-32b-abliterated-q5_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/QwQ-32B-abliterated-Q5_K_S-GGUF --hf-file qwq-32b-abliterated-q5_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/QwQ-32B-abliterated-Q5_K_S-GGUF --hf-file qwq-32b-abliterated-q5_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/QwQ-32B-abliterated-Q5_K_S-GGUF --hf-file qwq-32b-abliterated-q5_k_s.gguf -c 2048
```
|
nvidia/AceReason-Nemotron-7B
|
nvidia
| 2025-06-17T18:06:54Z | 49,098 | 16 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"nvidia",
"reasoning",
"math",
"code",
"reinforcement learning",
"pytorch",
"conversational",
"en",
"arxiv:2505.16400",
"arxiv:2506.13284",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-05-22T15:56:35Z |
---
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: >-
https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
language:
- en
tags:
- nvidia
- reasoning
- math
- code
- reinforcement learning
- pytorch
---
# AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning
<p align="center">
[](https://arxiv.org/abs/2505.16400)
[](https://huggingface.co/datasets/nvidia/AceReason-Math)
[](https://huggingface.co/collections/nvidia/acereason-682f4e1261dc22f697fd1485)
[](https://huggingface.co/nvidia/AceReason-Nemotron-14B/blob/main/README_EVALUATION.md)
</p>
<img src="fig/main_fig.png" alt="main_fig" style="width: 600px; max-width: 100%;" />
## 🔥News
- **6/16/2025**: We are excited to share our new release combining SFT with RL: **AceReason-Nemotron-1.1-7B**
- Paper: https://arxiv.org/pdf/2506.13284
- Model: https://huggingface.co/nvidia/AceReason-Nemotron-1.1-7B
- 4M SFT Data: https://huggingface.co/datasets/nvidia/AceReason-1.1-SFT
- **6/11/2025**: We share our evaluation toolkit at [AceReason Evalution](https://huggingface.co/nvidia/AceReason-Nemotron-14B/blob/main/README_EVALUATION.md) including:
- scripts to run inference and scoring
- LiveCodeBench (avg@8): model prediction files and scores for each month (2023/5-2025/5)
- AIME24/25 (avg@64): model prediction files and scores
- **6/2/2025**: We are excited to share our Math RL training dataset at [AceReason-Math](https://huggingface.co/datasets/nvidia/AceReason-Math)
We're thrilled to introduce AceReason-Nemotron-7B, a math and code reasoning model trained entirely through reinforcement learning (RL), starting from the DeepSeek-R1-Distilled-Qwen-7B. It delivers impressive results, achieving 69.0% on AIME 2024 (+14.5%), 53.6% on AIME 2025 (+17.4%), 51.8% on LiveCodeBench v5 (+8%), 44.1% on LiveCodeBench v6 (+7%). We systematically study the RL training process through extensive ablations and propose a simple yet effective approach: first RL training on math-only prompts, then RL training on code-only prompts. Notably, we find that math-only RL not only significantly enhances the performance of strong distilled models on math benchmarks, but also code reasoning tasks. In addition, extended code-only RL further improves code benchmark performance while causing minimal degradation in math results. We find that RL not only elicits the foundational reasoning capabilities acquired during pre-training and supervised fine-tuning (e.g., distillation), but also pushes the limits of the model's reasoning ability, enabling it to solve problems that were previously unsolvable.
We share our training recipe, training logs in our technical report.
## Results
We evaluate our model against competitive reasoning models of comparable size within Qwen2.5 and Llama3.1 model family on AIME 2024, AIME 2025, LiveCodeBench v5 (2024/08/01 - 2025/02/01), and LiveCodeBench v6 (2025/02/01-2025/05/01). More evaluation results can be found in our technical report.
| **Model** | **AIME 2024<br>(avg@64)** | **AIME 2025<br>(avg@64)** | **LCB v5<br>(avg@8)** | **LCB v6<br>(avg@8)** |
| :---: | :---: | :---: | :---: | :---: |
| <small>QwQ-32B</small> | 79.5 | 65.8 | 63.4 | - |
| <small>DeepSeek-R1-671B</small> | 79.8 | 70.0 | 65.9 | - |
| <small>Llama-Nemotron-Ultra-253B</small> | 80.8 | 72.5 | 66.3 | - |
| <small>o3-mini (medium)</small> | 79.6 | 76.7 | 67.4 | - |
| <small>Light-R1-7B</small> | 59.1 | 44.3 | 40.6 | 36.4 |
| <small>Light-R1-14B</small> | 74 | 60.2 | 57.9 | 51.5 |
| <small>DeepCoder-14B (32K Inference)</small> | 71 | 56.1 | 57.9 | 50.4 |
| <small>OpenMath-Nemotron-7B</small> | 74.8 | 61.2 | - | - |
| <small>OpenCodeReasoning-Nemotron-7B</small> | - | - | 51.3 | 46.1 |
| <small>Llama-Nemotron-Nano-8B-v1</small> | 61.3 | 47.1 | 46.6 |46.2 |
| <small>DeepSeek-R1-Distilled-Qwen-7B</small> | 55.5 | 39.0 | 37.6 | 34.1 |
| <small>DeepSeek-R1-Distilled-Qwen-14B</small> | 69.7 | 50.2 | 53.1 | 47.9 |
| <small>DeepSeek-R1-Distilled-Qwen-32B</small> | 72.6 | 54.9 | 57.2 | - |
| [AceReason-Nemotron-7B 🤗](https://huggingface.co/nvidia/AceReason-Nemotron-7B)| 69.0 | 53.6 | 51.8 | 44.1 |
| [AceReason-Nemotron-14B 🤗](https://huggingface.co/nvidia/AceReason-Nemotron-14B)| 78.6 | 67.4 | 61.1 | 54.9 |
## How to use
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = 'nvidia/AceReason-Nemotron-7B'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Jen enters a lottery by picking $4$ distinct numbers from $S=\\{1,2,3,\\cdots,9,10\\}.$ $4$ numbers are randomly chosen from $S.$ She wins a prize if at least two of her numbers were $2$ of the randomly chosen numbers, and wins the grand prize if all four of her numbers were the randomly chosen numbers. The probability of her winning the grand prize given that she won a prize is $\\tfrac{m}{n}$ where $m$ and $n$ are relatively prime positive integers. Find $m+n$."
messages = [{"role": "user", "content": prompt}]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to("cuda")
generated_ids = model.generate(
**model_inputs,
max_new_tokens=32768,
temperature=0.6,
top_p=0.95
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
```
## Usage Recommendations
1. Don't include a system prompt; instead, place all instructions directly in the user prompt.
2. We recommend using the following instruction for math questions: Please reason step by step, and put your final answer within \\boxed{}.
3. We recommend using the following instruction for code questions:
```python
question = "" # code question
starter_code = "" # starter code function header
code_instruction_nostartercode = """Write Python code to solve the problem. Please place the solution code in the following format:\n```python\n# Your solution code here\n```"""
code_instruction_hasstartercode = """Please place the solution code in the following format:\n```python\n# Your solution code here\n```"""
if starter_code != "":
question += "\n\n" + "Solve the problem starting with the provided function header.\n\nFunction header:\n" + "```\n" + starter_code + "\n```"
question += "\n\n" + code_instruction_hasstartercode
else:
question += "\n\n" + code_instruction_nostartercode
final_prompt = "<|User|>" + question + "<|Assistant|><think>\n"
```
4. Our inference engine for evaluation is **vLLM==0.7.3** using top-p=0.95, temperature=0.6, max_tokens=32768.
## Evaluation Toolkit
Please check evaluation code, scripts, cached prediction files in https://huggingface.co/nvidia/AceReason-Nemotron-14B/blob/main/README_EVALUATION.md
## Correspondence to
Yang Chen ([email protected]), Zhuolin Yang ([email protected]), Zihan Liu ([email protected]), Chankyu Lee ([email protected]), Wei Ping ([email protected])
## License
Your use of this model is governed by the [NVIDIA Open Model License](https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/).
## Citation
```
@article{chen2025acereason,
title={AceReason-Nemotron: Advancing Math and Code Reasoning through Reinforcement Learning},
author={Chen, Yang and Yang, Zhuolin and Liu, Zihan and Lee, Chankyu and Xu, Peng and Shoeybi, Mohammad and Catanzaro, Bryan and Ping, Wei},
journal={arXiv preprint arXiv:2505.16400},
year={2025}
}
```
|
TOMFORD79/tornado7
|
TOMFORD79
| 2025-06-17T18:06:07Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T18:01:30Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
vuitton/21v1scrip_25
|
vuitton
| 2025-06-17T17:54:44Z | 0 | 0 | null |
[
"safetensors",
"any-to-any",
"omega",
"omegalabs",
"bittensor",
"agi",
"license:mit",
"region:us"
] |
any-to-any
| 2025-06-16T15:34:21Z |
---
license: mit
tags:
- any-to-any
- omega
- omegalabs
- bittensor
- agi
---
This is an Any-to-Any model checkpoint for the OMEGA Labs x Bittensor Any-to-Any subnet.
Check out the [git repo](https://github.com/omegalabsinc/omegalabs-anytoany-bittensor) and find OMEGA on X: [@omegalabsai](https://x.com/omegalabsai).
|
BilateralBusiness/ver__nica_olivares_nutri__loga_nutriologa_vero_olivares_cabeza_4_20250616_1712
|
BilateralBusiness
| 2025-06-17T17:38:51Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-17T17:28:53Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: ver__nica_olivares_nutri__loga_nutriologa_vero_olivares_cabeza_4_20250616_1712
---
# Ver__Nica_Olivares_Nutri__Loga_Nutriologa_Vero_Olivares_Cabeza_4_20250616_1712
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `ver__nica_olivares_nutri__loga_nutriologa_vero_olivares_cabeza_4_20250616_1712` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "ver__nica_olivares_nutri__loga_nutriologa_vero_olivares_cabeza_4_20250616_1712",
"lora_weights": "https://huggingface.co/BilateralBusiness/ver__nica_olivares_nutri__loga_nutriologa_vero_olivares_cabeza_4_20250616_1712/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BilateralBusiness/ver__nica_olivares_nutri__loga_nutriologa_vero_olivares_cabeza_4_20250616_1712', weight_name='lora.safetensors')
image = pipeline('ver__nica_olivares_nutri__loga_nutriologa_vero_olivares_cabeza_4_20250616_1712').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 1000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BilateralBusiness/ver__nica_olivares_nutri__loga_nutriologa_vero_olivares_cabeza_4_20250616_1712/discussions) to add images that show off what you’ve made with this LoRA.
|
Nitish035/mistral_CMoS_adapter32_combine_single-level2-3
|
Nitish035
| 2025-06-17T17:38:36Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"en",
"base_model:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"base_model:finetune:unsloth/mistral-7b-instruct-v0.3-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T17:38:31Z |
---
base_model: unsloth/mistral-7b-instruct-v0.3-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** Nitish035
- **License:** apache-2.0
- **Finetuned from model :** unsloth/mistral-7b-instruct-v0.3-bnb-4bit
This mistral model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
CompassioninMachineLearning/pretrainedllama8bInstruct3kresearchpapers_v3_plus1kalignment_lora2epochs
|
CompassioninMachineLearning
| 2025-06-17T17:32:08Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:CompassioninMachineLearning/pretrainedllama8bInstruct3kresearchpapers_newdata_v3",
"base_model:finetune:CompassioninMachineLearning/pretrainedllama8bInstruct3kresearchpapers_newdata_v3",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T17:14:49Z |
---
base_model: CompassioninMachineLearning/pretrainedllama8bInstruct3kresearchpapers_newdata_v3
tags:
- text-generation-inference
- transformers
- unsloth
- llama
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** CompassioninMachineLearning
- **License:** apache-2.0
- **Finetuned from model :** CompassioninMachineLearning/pretrainedllama8bInstruct3kresearchpapers_newdata_v3
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Sharing22/uli_b7
|
Sharing22
| 2025-06-17T17:30:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T17:26:54Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tamewild/4b_v5_merged_e5
|
tamewild
| 2025-06-17T17:19:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T17:17:16Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/cue-nl-conan
|
Lelon
| 2025-06-17T17:11:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T17:11:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/cue-nl-bioscope_full
|
Lelon
| 2025-06-17T17:10:35Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T17:09:58Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MaIlz/outputs_grpo_all_tasks_6
|
MaIlz
| 2025-06-17T17:09:56Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"unsloth",
"trl",
"grpo",
"arxiv:2402.03300",
"base_model:unsloth/llama-3-8b-Instruct-bnb-4bit",
"base_model:finetune:unsloth/llama-3-8b-Instruct-bnb-4bit",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T17:09:44Z |
---
base_model: unsloth/llama-3-8b-Instruct-bnb-4bit
library_name: transformers
model_name: outputs_grpo_all_tasks_6
tags:
- generated_from_trainer
- unsloth
- trl
- grpo
licence: license
---
# Model Card for outputs_grpo_all_tasks_6
This model is a fine-tuned version of [unsloth/llama-3-8b-Instruct-bnb-4bit](https://huggingface.co/unsloth/llama-3-8b-Instruct-bnb-4bit).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="MaIlz/outputs_grpo_all_tasks_6", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Lelon/cue-nl-socc
|
Lelon
| 2025-06-17T17:09:17Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T17:08:41Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/cue-nl-dt_neg
|
Lelon
| 2025-06-17T17:08:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T17:07:19Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/cue-fr-conan
|
Lelon
| 2025-06-17T17:00:13Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T16:59:35Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
BootesVoid/cmbzezmyx05l4rdqsas10fwna_cmc0qokfh08lyrdqsfpsnguh4
|
BootesVoid
| 2025-06-17T16:55:33Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-17T16:55:31Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: SOPHH
---
# Cmbzezmyx05L4Rdqsas10Fwna_Cmc0Qokfh08Lyrdqsfpsnguh4
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `SOPHH` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "SOPHH",
"lora_weights": "https://huggingface.co/BootesVoid/cmbzezmyx05l4rdqsas10fwna_cmc0qokfh08lyrdqsfpsnguh4/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbzezmyx05l4rdqsas10fwna_cmc0qokfh08lyrdqsfpsnguh4', weight_name='lora.safetensors')
image = pipeline('SOPHH').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbzezmyx05l4rdqsas10fwna_cmc0qokfh08lyrdqsfpsnguh4/discussions) to add images that show off what you’ve made with this LoRA.
|
Mungert/InternVL3-8B-GGUF
|
Mungert
| 2025-06-17T16:53:38Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"internvl",
"custom_code",
"image-text-to-text",
"multilingual",
"dataset:OpenGVLab/MMPR-v1.2",
"arxiv:2312.14238",
"arxiv:2404.16821",
"arxiv:2412.05271",
"arxiv:2411.10442",
"arxiv:2504.10479",
"arxiv:2412.09616",
"base_model:OpenGVLab/InternVL3-8B-Instruct",
"base_model:finetune:OpenGVLab/InternVL3-8B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"imatrix",
"conversational"
] |
image-text-to-text
| 2025-06-17T10:59:07Z |
---
license: apache-2.0
license_name: qwen
license_link: https://huggingface.co/Qwen/Qwen2.5-72B-Instruct/blob/main/LICENSE
pipeline_tag: image-text-to-text
library_name: transformers
base_model:
- OpenGVLab/InternVL3-8B-Instruct
base_model_relation: finetune
datasets:
- OpenGVLab/MMPR-v1.2
language:
- multilingual
tags:
- internvl
- custom_code
---
# <span style="color: #7FFF7F;">InternVL3-8B GGUF Models</span>
## <span style="color: #7F7FFF;">Model Generation Details</span>
This model was generated using [llama.cpp](https://github.com/ggerganov/llama.cpp) at commit [`6adc3c3e`](https://github.com/ggerganov/llama.cpp/commit/6adc3c3ebc029af058ac950a8e2a825fdf18ecc6).
---
## <span style="color: #7FFF7F;">Quantization Beyond the IMatrix</span>
I've been experimenting with a new quantization approach that selectively elevates the precision of key layers beyond what the default IMatrix configuration provides.
In my testing, standard IMatrix quantization underperforms at lower bit depths, especially with Mixture of Experts (MoE) models. To address this, I'm using the `--tensor-type` option in `llama.cpp` to manually "bump" important layers to higher precision. You can see the implementation here:
👉 [Layer bumping with llama.cpp](https://github.com/Mungert69/GGUFModelBuilder/blob/main/model-converter/tensor_list_builder.py)
While this does increase model file size, it significantly improves precision for a given quantization level.
### **I'd love your feedback—have you tried this? How does it perform for you?**
---
<a href="https://readyforquantum.com/huggingface_gguf_selection_guide.html" style="color: #7FFF7F;">
Click here to get info on choosing the right GGUF model format
</a>
---
<!--Begin Original Model Card-->
# InternVL3-8B
[\[📂 GitHub\]](https://github.com/OpenGVLab/InternVL) [\[📜 InternVL 1.0\]](https://huggingface.co/papers/2312.14238) [\[📜 InternVL 1.5\]](https://huggingface.co/papers/2404.16821) [\[📜 InternVL 2.5\]](https://huggingface.co/papers/2412.05271) [\[📜 InternVL2.5-MPO\]](https://huggingface.co/papers/2411.10442) [\[📜 InternVL3\]](https://huggingface.co/papers/2504.10479)
[\[🆕 Blog\]](https://internvl.github.io/blog/) [\[🗨️ Chat Demo\]](https://internvl.opengvlab.com/) [\[🤗 HF Demo\]](https://huggingface.co/spaces/OpenGVLab/InternVL) [\[🚀 Quick Start\]](#quick-start) [\[📖 Documents\]](https://internvl.readthedocs.io/en/latest/)
<div align="center">
<img width="500" alt="image" src="https://cdn-uploads.huggingface.co/production/uploads/64006c09330a45b03605bba3/zJsd2hqd3EevgXo6fNgC-.png">
</div>
## Introduction
We introduce InternVL3, an advanced multimodal large language model (MLLM) series that demonstrates superior overall performance.
Compared to InternVL 2.5, InternVL3 exhibits superior multimodal perception and reasoning capabilities, while further extending its multimodal capabilities to encompass tool usage, GUI agents, industrial image analysis, 3D vision perception, and more.
Additionally, we compare InternVL3 with Qwen2.5 Chat models, whose corresponding pre-trained base models are employed as the initialization of the langauge component in InternVL3. Benefitting from Native Multimodal Pre-Training, the InternVL3 series achieves even better overall text performance than the Qwen2.5 series.

## InternVL3 Family
In the following table, we provide an overview of the InternVL3 series.
| Model Name | Vision Part | Language Part | HF Link |
| :-----------: | :-------------------------------------------------------------------------------------: | :----------------------------------------------------------------------------: | :------------------------------------------------------: |
| InternVL3-1B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-0.5B](https://huggingface.co/Qwen/Qwen2.5-0.5B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-1B) |
| InternVL3-2B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-1.5B](https://huggingface.co/Qwen/Qwen2.5-1.5B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-2B) |
| InternVL3-8B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-7B](https://huggingface.co/Qwen/Qwen2.5-7B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-8B) |
| InternVL3-9B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [internlm3-8b-instruct](https://huggingface.co/internlm/internlm3-8b-instruct) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-9B) |
| InternVL3-14B | [InternViT-300M-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-300M-448px-V2_5) | [Qwen2.5-14B](https://huggingface.co/Qwen/Qwen2.5-14B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-14B) |
| InternVL3-38B | [InternViT-6B-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V2_5) | [Qwen2.5-32B](https://huggingface.co/Qwen/Qwen2.5-32B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-38B) |
| InternVL3-78B | [InternViT-6B-448px-V2_5](https://huggingface.co/OpenGVLab/InternViT-6B-448px-V2_5) | [Qwen2.5-72B](https://huggingface.co/Qwen/Qwen2.5-72B) | [🤗 link](https://huggingface.co/OpenGVLab/InternVL3-78B) |

## Model Architecture
As shown in the following figure, [InternVL3](https://internvl.github.io/blog/2025-04-11-InternVL-3/) retains the same model architecture as [InternVL 2.5](https://internvl.github.io/blog/2024-12-05-InternVL-2.5/) and its predecessors, InternVL 1.5 and 2.0, following the "ViT-MLP-LLM" paradigm. In this new version, we integrate a newly incrementally pre-trained InternViT with various pre-trained LLMs, including InternLM 3 and Qwen 2.5, using a randomly initialized MLP projector.

As in the previous version, we applied a pixel unshuffle operation, reducing the number of visual tokens to one-quarter of the original. Besides, we adopted a similar dynamic resolution strategy as InternVL 1.5, dividing images into tiles of 448×448 pixels. The key difference, starting from InternVL 2.0, is that we additionally introduced support for multi-image and video data.
Notably, in InternVL3, we integrate the [Variable Visual Position Encoding (V2PE)](https://arxiv.org/abs/2412.09616), which utilizes smaller, more flexible position increments for visual tokens. Benefiting from V2PE, InternVL3 exhibits better long context understanding capabilities compared to its predecessors.
## Training Strategy
### Native Multimodal Pre-Training
We propose a [Native Multimodal Pre-Training](https://huggingface.co/papers/2504.10479) approach that consolidates language and vision learning into a single pre-training stage.
In contrast to standard paradigms that first train a language-only model and subsequently adapt it to handle additional modalities, our method interleaves multimodal data (e.g., image-text, video-text, or image-text interleaved sequences) with large-scale textual corpora. This unified training scheme allows the model to learn both linguistic and multimodal representations simultaneously, ultimately enhancing its capability to handle vision-language tasks without the need for separate alignment or bridging modules.
Please see [our paper](https://huggingface.co/papers/2504.10479) for more details.
### Supervised Fine-Tuning
In this phase, the techniques of random JPEG compression, square loss re-weighting, and multimodal data packing proposed in [InternVL2.5](https://arxiv.org/abs/2412.05271) are also employed in the InternVL3 series.
The main advancement of the SFT phase in InternVL3 compared to InternVL2.5 lies in the use of higher-quality and more diverse training data.
Specifically, we further extend training samples for tool use, 3D scene understanding, GUI operations, long context tasks, video understanding, scientific diagrams, creative writing, and multimodal reasoning.
### Mixed Preference Optimization
During Pre-training and SFT, the model is trained to predict the next token conditioned on previous ground-truth tokens.
However, during inference, the model predicts each token based on its own prior outputs.
This discrepancy between ground-truth tokens and model-predicted tokens introduces a distribution shift, which can impair the model’s Chain-of-Thought (CoT) reasoning capabilities.
To mitigate this issue, we employ [MPO](https://arxiv.org/abs/2411.10442), which introduces additional supervision from both positive and negative samples to align the model response distribution with the ground-truth distribution, thereby improving reasoning performance.
Specifically, the training objective of MPO is a combination of
preference loss \\(\mathcal{L}_{\text{p}}\\),
quality loss \\(\mathcal{L}_{\text{q}}\\),
and generation loss \\(\mathcal{L}_{\text{g}}\\),
which can be formulated as follows:
$$
\mathcal{L}=w_{p}\cdot\mathcal{L}_{\text{p}} + w_{q}\cdot\mathcal{L}_{\text{q}} + w_{g}\cdot\mathcal{L}_{\text{g}},
$$
where \\(w_{*}\\) represents the weight assigned to each loss component. Please see [our paper](https://arxiv.org/abs/2411.10442) for more details about MPO.
### Test-Time Scaling
Test-Time Scaling has been shown to be an effective method to enhance the reasoning abilities of LLMs and MLLMs.
In this work, we use the Best-of-N evaluation strategy and employ [VisualPRM-8B](https://huggingface.co/OpenGVLab/VisualPRM-8B) as the critic model to select the best response for reasoning and mathematics evaluation.
## Evaluation on Multimodal Capability
### Multimodal Reasoning and Mathematics

### OCR, Chart, and Document Understanding

### Multi-Image & Real-World Comprehension

### Comprehensive Multimodal & Hallucination Evaluation

### Visual Grounding

### Multimodal Multilingual Understanding

### Video Understanding

### GUI Grounding

### Spatial Reasoning

## Evaluation on Language Capability
We compare InternVL3 with Qwen2.5 Chat models, whose corresponding pre-trained base models are employed as the initialization of the langauge component in InternVL3.
Benefitting from Native Multimodal Pre-Training, the InternVL3 series achieves even better overall text performance than the Qwen2.5 series.
Please note that the evaluation scores of Qwen2.5 series may differ from those officially reported, as we have adopted the prompt versions provided in the table across all datasets for OpenCompass evaluation.

## Ablation Study
### Native Multimodal Pre-Training
We conduct experiments on the InternVL2-8B model while keeping its architecture, initialization parameters, and training data entirely unchanged. Traditionally, InternVL2-8B employs a training pipeline that begins with an MLP warmup phase for feature alignment followed by an Instruction Tuning stage. In our experiments, we substitute the conventional MLP warmup phase with a native multimodal pre-training process. This modification isolates the contribution of native multimodal pre-training to the overall multimodal capability of the model.
The evaluation results in the Figure below shows that the model with native multimodal pre-training exhibits performance on most benchmarks that is comparable to the fully multi-stage-trained InternVL2-8B baseline. Furthermore, when followed by instruction tuning on higher-quality data, the model demonstrates further performance gains across evaluated multimodal tasks. These findings underscore the efficiency of native multimodal pre-training in imparting powerful multimodal capabilities to MLLMs.

### Mixed Preference Optimization
As shown in the table below, models fine-tuned with MPO demonstrate superior reasoning performance across seven multimodal reasoning benchmarks compared to their counterparts without MPO. Specifically, InternVL3-78B and InternVL3-38B outperform their counterparts by 4.1 and 4.5 points, respectively. Notably, the training data used for MPO is a subset of that used for SFT, indicating that the performance improvements primarily stem from the training algorithm rather than the training data.

### Variable Visual Position Encoding
As reported in the table below, the introduction of V2PE leads to significant performance gains across most evaluation metrics. In addition, our ablation studies—by varying the positional increment \\( \delta \\)—reveal that even for tasks primarily involving conventional contexts, relatively small \\( \delta \\) values can achieve optimal performance. These findings provide important insights for future efforts aimed at refining position encoding strategies for visual tokens in MLLMs.

## Quick Start
We provide an example code to run `InternVL3-8B` using `transformers`.
> Please use transformers>=4.37.2 to ensure the model works normally.
### Model Loading
#### 16-bit (bf16 / fp16)
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval().cuda()
```
#### BNB 8-bit Quantization
```python
import torch
from transformers import AutoTokenizer, AutoModel
path = "OpenGVLab/InternVL3-8B"
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=True,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True).eval()
```
#### Multiple GPUs
The reason for writing the code this way is to avoid errors that occur during multi-GPU inference due to tensors not being on the same device. By ensuring that the first and last layers of the large language model (LLM) are on the same device, we prevent such errors.
```python
import math
import torch
from transformers import AutoTokenizer, AutoModel
def split_model(model_name):
device_map = {}
world_size = torch.cuda.device_count()
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
num_layers = config.llm_config.num_hidden_layers
# Since the first GPU will be used for ViT, treat it as half a GPU.
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
num_layers_per_gpu = [num_layers_per_gpu] * world_size
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
layer_cnt = 0
for i, num_layer in enumerate(num_layers_per_gpu):
for j in range(num_layer):
device_map[f'language_model.model.layers.{layer_cnt}'] = i
layer_cnt += 1
device_map['vision_model'] = 0
device_map['mlp1'] = 0
device_map['language_model.model.tok_embeddings'] = 0
device_map['language_model.model.embed_tokens'] = 0
device_map['language_model.output'] = 0
device_map['language_model.model.norm'] = 0
device_map['language_model.model.rotary_emb'] = 0
device_map['language_model.lm_head'] = 0
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
return device_map
path = "OpenGVLab/InternVL3-8B"
device_map = split_model('InternVL3-8B')
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map=device_map).eval()
```
### Inference with Transformers
```python
import math
import numpy as np
import torch
import torchvision.transforms as T
from decord import VideoReader, cpu
from PIL import Image
from torchvision.transforms.functional import InterpolationMode
from transformers import AutoModel, AutoTokenizer
IMAGENET_MEAN = (0.485, 0.456, 0.406)
IMAGENET_STD = (0.229, 0.224, 0.225)
def build_transform(input_size):
MEAN, STD = IMAGENET_MEAN, IMAGENET_STD
transform = T.Compose([
T.Lambda(lambda img: img.convert('RGB') if img.mode != 'RGB' else img),
T.Resize((input_size, input_size), interpolation=InterpolationMode.BICUBIC),
T.ToTensor(),
T.Normalize(mean=MEAN, std=STD)
])
return transform
def find_closest_aspect_ratio(aspect_ratio, target_ratios, width, height, image_size):
best_ratio_diff = float('inf')
best_ratio = (1, 1)
area = width * height
for ratio in target_ratios:
target_aspect_ratio = ratio[0] / ratio[1]
ratio_diff = abs(aspect_ratio - target_aspect_ratio)
if ratio_diff < best_ratio_diff:
best_ratio_diff = ratio_diff
best_ratio = ratio
elif ratio_diff == best_ratio_diff:
if area > 0.5 * image_size * image_size * ratio[0] * ratio[1]:
best_ratio = ratio
return best_ratio
def dynamic_preprocess(image, min_num=1, max_num=12, image_size=448, use_thumbnail=False):
orig_width, orig_height = image.size
aspect_ratio = orig_width / orig_height
# calculate the existing image aspect ratio
target_ratios = set(
(i, j) for n in range(min_num, max_num + 1) for i in range(1, n + 1) for j in range(1, n + 1) if
i * j <= max_num and i * j >= min_num)
target_ratios = sorted(target_ratios, key=lambda x: x[0] * x[1])
# find the closest aspect ratio to the target
target_aspect_ratio = find_closest_aspect_ratio(
aspect_ratio, target_ratios, orig_width, orig_height, image_size)
# calculate the target width and height
target_width = image_size * target_aspect_ratio[0]
target_height = image_size * target_aspect_ratio[1]
blocks = target_aspect_ratio[0] * target_aspect_ratio[1]
# resize the image
resized_img = image.resize((target_width, target_height))
processed_images = []
for i in range(blocks):
box = (
(i % (target_width // image_size)) * image_size,
(i // (target_width // image_size)) * image_size,
((i % (target_width // image_size)) + 1) * image_size,
((i // (target_width // image_size)) + 1) * image_size
)
# split the image
split_img = resized_img.crop(box)
processed_images.append(split_img)
assert len(processed_images) == blocks
if use_thumbnail and len(processed_images) != 1:
thumbnail_img = image.resize((image_size, image_size))
processed_images.append(thumbnail_img)
return processed_images
def load_image(image_file, input_size=448, max_num=12):
image = Image.open(image_file).convert('RGB')
transform = build_transform(input_size=input_size)
images = dynamic_preprocess(image, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(image) for image in images]
pixel_values = torch.stack(pixel_values)
return pixel_values
def split_model(model_name):
device_map = {}
world_size = torch.cuda.device_count()
config = AutoConfig.from_pretrained(model_path, trust_remote_code=True)
num_layers = config.llm_config.num_hidden_layers
# Since the first GPU will be used for ViT, treat it as half a GPU.
num_layers_per_gpu = math.ceil(num_layers / (world_size - 0.5))
num_layers_per_gpu = [num_layers_per_gpu] * world_size
num_layers_per_gpu[0] = math.ceil(num_layers_per_gpu[0] * 0.5)
layer_cnt = 0
for i, num_layer in enumerate(num_layers_per_gpu):
for j in range(num_layer):
device_map[f'language_model.model.layers.{layer_cnt}'] = i
layer_cnt += 1
device_map['vision_model'] = 0
device_map['mlp1'] = 0
device_map['language_model.model.tok_embeddings'] = 0
device_map['language_model.model.embed_tokens'] = 0
device_map['language_model.output'] = 0
device_map['language_model.model.norm'] = 0
device_map['language_model.model.rotary_emb'] = 0
device_map['language_model.lm_head'] = 0
device_map[f'language_model.model.layers.{num_layers - 1}'] = 0
return device_map
# If you set `load_in_8bit=True`, you will need two 80GB GPUs.
# If you set `load_in_8bit=False`, you will need at least three 80GB GPUs.
path = 'OpenGVLab/InternVL3-8B'
device_map = split_model('InternVL3-8B')
model = AutoModel.from_pretrained(
path,
torch_dtype=torch.bfloat16,
load_in_8bit=False,
low_cpu_mem_usage=True,
use_flash_attn=True,
trust_remote_code=True,
device_map=device_map).eval()
tokenizer = AutoTokenizer.from_pretrained(path, trust_remote_code=True, use_fast=False)
# set the max number of tiles in `max_num`
pixel_values = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
generation_config = dict(max_new_tokens=1024, do_sample=True)
# pure-text conversation (纯文本对话)
question = 'Hello, who are you?'
response, history = model.chat(tokenizer, None, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Can you tell me a story?'
response, history = model.chat(tokenizer, None, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# single-image single-round conversation (单图单轮对话)
question = '<image>\nPlease describe the image shortly.'
response = model.chat(tokenizer, pixel_values, question, generation_config)
print(f'User: {question}\nAssistant: {response}')
# single-image multi-round conversation (单图多轮对话)
question = '<image>\nPlease describe the image in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Please write a poem according to the image.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, combined images (多图多轮对话,拼接图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
question = '<image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# multi-image multi-round conversation, separate images (多图多轮对话,独立图像)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
question = 'Image-1: <image>\nImage-2: <image>\nDescribe the two images in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'What are the similarities and differences between these two images.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list,
history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
# batch inference, single image per sample (单图批处理)
pixel_values1 = load_image('./examples/image1.jpg', max_num=12).to(torch.bfloat16).cuda()
pixel_values2 = load_image('./examples/image2.jpg', max_num=12).to(torch.bfloat16).cuda()
num_patches_list = [pixel_values1.size(0), pixel_values2.size(0)]
pixel_values = torch.cat((pixel_values1, pixel_values2), dim=0)
questions = ['<image>\nDescribe the image in detail.'] * len(num_patches_list)
responses = model.batch_chat(tokenizer, pixel_values,
num_patches_list=num_patches_list,
questions=questions,
generation_config=generation_config)
for question, response in zip(questions, responses):
print(f'User: {question}\nAssistant: {response}')
# video multi-round conversation (视频多轮对话)
def get_index(bound, fps, max_frame, first_idx=0, num_segments=32):
if bound:
start, end = bound[0], bound[1]
else:
start, end = -100000, 100000
start_idx = max(first_idx, round(start * fps))
end_idx = min(round(end * fps), max_frame)
seg_size = float(end_idx - start_idx) / num_segments
frame_indices = np.array([
int(start_idx + (seg_size / 2) + np.round(seg_size * idx))
for idx in range(num_segments)
])
return frame_indices
def load_video(video_path, bound=None, input_size=448, max_num=1, num_segments=32):
vr = VideoReader(video_path, ctx=cpu(0), num_threads=1)
max_frame = len(vr) - 1
fps = float(vr.get_avg_fps())
pixel_values_list, num_patches_list = [], []
transform = build_transform(input_size=input_size)
frame_indices = get_index(bound, fps, max_frame, first_idx=0, num_segments=num_segments)
for frame_index in frame_indices:
img = Image.fromarray(vr[frame_index].asnumpy()).convert('RGB')
img = dynamic_preprocess(img, image_size=input_size, use_thumbnail=True, max_num=max_num)
pixel_values = [transform(tile) for tile in img]
pixel_values = torch.stack(pixel_values)
num_patches_list.append(pixel_values.shape[0])
pixel_values_list.append(pixel_values)
pixel_values = torch.cat(pixel_values_list)
return pixel_values, num_patches_list
video_path = './examples/red-panda.mp4'
pixel_values, num_patches_list = load_video(video_path, num_segments=8, max_num=1)
pixel_values = pixel_values.to(torch.bfloat16).cuda()
video_prefix = ''.join([f'Frame{i+1}: <image>\n' for i in range(len(num_patches_list))])
question = video_prefix + 'What is the red panda doing?'
# Frame1: <image>\nFrame2: <image>\n...\nFrame8: <image>\n{question}
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=None, return_history=True)
print(f'User: {question}\nAssistant: {response}')
question = 'Describe this video in detail.'
response, history = model.chat(tokenizer, pixel_values, question, generation_config,
num_patches_list=num_patches_list, history=history, return_history=True)
print(f'User: {question}\nAssistant: {response}')
```
#### Streaming Output
Besides this method, you can also use the following code to get streamed output.
```python
from transformers import TextIteratorStreamer
from threading import Thread
# Initialize the streamer
streamer = TextIteratorStreamer(tokenizer, skip_prompt=True, skip_special_tokens=True, timeout=10)
# Define the generation configuration
generation_config = dict(max_new_tokens=1024, do_sample=False, streamer=streamer)
# Start the model chat in a separate thread
thread = Thread(target=model.chat, kwargs=dict(
tokenizer=tokenizer, pixel_values=pixel_values, question=question,
history=None, return_history=False, generation_config=generation_config,
))
thread.start()
# Initialize an empty string to store the generated text
generated_text = ''
# Loop through the streamer to get the new text as it is generated
for new_text in streamer:
if new_text == model.conv_template.sep:
break
generated_text += new_text
print(new_text, end='', flush=True) # Print each new chunk of generated text on the same line
```
## Finetune
Many repositories now support fine-tuning of the InternVL series models, including [InternVL](https://github.com/OpenGVLab/InternVL), [SWIFT](https://github.com/modelscope/ms-swift), [XTurner](https://github.com/InternLM/xtuner), and others. Please refer to their documentation for more details on fine-tuning.
## Deployment
### LMDeploy
LMDeploy is a toolkit for compressing, deploying, and serving LLMs & VLMs.
```sh
# if lmdeploy<0.7.3, you need to explicitly set chat_template_config=ChatTemplateConfig(model_name='internvl2_5')
pip install lmdeploy>=0.7.3
```
LMDeploy abstracts the complex inference process of multi-modal Vision-Language Models (VLM) into an easy-to-use pipeline, similar to the Large Language Model (LLM) inference pipeline.
#### A 'Hello, world' Example
```python
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-8B'
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/tests/data/tiger.jpeg')
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=1), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
response = pipe(('describe this image', image))
print(response.text)
```
If `ImportError` occurs while executing this case, please install the required dependency packages as prompted.
#### Multi-images Inference
When dealing with multiple images, you can put them all in one list. Keep in mind that multiple images will lead to a higher number of input tokens, and as a result, the size of the context window typically needs to be increased.
```python
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
from lmdeploy.vl.constants import IMAGE_TOKEN
model = 'OpenGVLab/InternVL3-8B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=1), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
image_urls=[
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg',
'https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg'
]
images = [load_image(img_url) for img_url in image_urls]
# Numbering images improves multi-image conversations
response = pipe((f'Image-1: {IMAGE_TOKEN}\nImage-2: {IMAGE_TOKEN}\ndescribe these two images', images))
print(response.text)
```
#### Batch Prompts Inference
Conducting inference with batch prompts is quite straightforward; just place them within a list structure:
```python
from lmdeploy import pipeline, TurbomindEngineConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-8B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=1), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
image_urls=[
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg",
"https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/det.jpg"
]
prompts = [('describe this image', load_image(img_url)) for img_url in image_urls]
response = pipe(prompts)
print(response)
```
#### Multi-turn Conversation
There are two ways to do the multi-turn conversations with the pipeline. One is to construct messages according to the format of OpenAI and use above introduced method, the other is to use the `pipeline.chat` interface.
```python
from lmdeploy import pipeline, TurbomindEngineConfig, GenerationConfig, ChatTemplateConfig
from lmdeploy.vl import load_image
model = 'OpenGVLab/InternVL3-8B'
pipe = pipeline(model, backend_config=TurbomindEngineConfig(session_len=16384, tp=1), chat_template_config=ChatTemplateConfig(model_name='internvl2_5'))
image = load_image('https://raw.githubusercontent.com/open-mmlab/mmdeploy/main/demo/resources/human-pose.jpg')
gen_config = GenerationConfig(top_k=40, top_p=0.8, temperature=0.8)
sess = pipe.chat(('describe this image', image), gen_config=gen_config)
print(sess.response.text)
sess = pipe.chat('What is the woman doing?', session=sess, gen_config=gen_config)
print(sess.response.text)
```
#### Service
LMDeploy's `api_server` enables models to be easily packed into services with a single command. The provided RESTful APIs are compatible with OpenAI's interfaces. Below are an example of service startup:
```shell
lmdeploy serve api_server OpenGVLab/InternVL3-8B --chat-template internvl2_5 --server-port 23333 --tp 1
```
To use the OpenAI-style interface, you need to install OpenAI:
```shell
pip install openai
```
Then, use the code below to make the API call:
```python
from openai import OpenAI
client = OpenAI(api_key='YOUR_API_KEY', base_url='http://0.0.0.0:23333/v1')
model_name = client.models.list().data[0].id
response = client.chat.completions.create(
model=model_name,
messages=[{
'role':
'user',
'content': [{
'type': 'text',
'text': 'describe this image',
}, {
'type': 'image_url',
'image_url': {
'url':
'https://modelscope.oss-cn-beijing.aliyuncs.com/resource/tiger.jpeg',
},
}],
}],
temperature=0.8,
top_p=0.8)
print(response)
```
## License
This project is released under the MIT License. This project uses the pre-trained Qwen2.5 as a component, which is licensed under the Apache-2.0 License.
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{chen2024expanding,
title={Expanding Performance Boundaries of Open-Source Multimodal Models with Model, Data, and Test-Time Scaling},
author={Chen, Zhe and Wang, Weiyun and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Cui, Erfei and Zhu, Jinguo and Ye, Shenglong and Tian, Hao and Liu, Zhaoyang and others},
journal={arXiv preprint arXiv:2412.05271},
year={2024}
}
@article{wang2024mpo,
title={Enhancing the Reasoning Ability of Multimodal Large Language Models via Mixed Preference Optimization},
author={Wang, Weiyun and Chen, Zhe and Wang, Wenhai and Cao, Yue and Liu, Yangzhou and Gao, Zhangwei and Zhu, Jinguo and Zhu, Xizhou and Lu, Lewei and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2411.10442},
year={2024}
}
@article{chen2024far,
title={How Far Are We to GPT-4V? Closing the Gap to Commercial Multimodal Models with Open-Source Suites},
author={Chen, Zhe and Wang, Weiyun and Tian, Hao and Ye, Shenglong and Gao, Zhangwei and Cui, Erfei and Tong, Wenwen and Hu, Kongzhi and Luo, Jiapeng and Ma, Zheng and others},
journal={arXiv preprint arXiv:2404.16821},
year={2024}
}
@inproceedings{chen2024internvl,
title={Internvl: Scaling up vision foundation models and aligning for generic visual-linguistic tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and others},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={24185--24198},
year={2024}
}
```
<!--End Original Model Card-->
---
# <span id="testllm" style="color: #7F7FFF;">🚀 If you find these models useful</span>
Help me test my **AI-Powered Quantum Network Monitor Assistant** with **quantum-ready security checks**:
👉 [Quantum Network Monitor](https://readyforquantum.com/?assistant=open&utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme)
The full Open Source Code for the Quantum Network Monitor Service available at my github repos ( repos with NetworkMonitor in the name) : [Source Code Quantum Network Monitor](https://github.com/Mungert69). You will also find the code I use to quantize the models if you want to do it yourself [GGUFModelBuilder](https://github.com/Mungert69/GGUFModelBuilder)
💬 **How to test**:
Choose an **AI assistant type**:
- `TurboLLM` (GPT-4.1-mini)
- `HugLLM` (Hugginface Open-source models)
- `TestLLM` (Experimental CPU-only)
### **What I’m Testing**
I’m pushing the limits of **small open-source models for AI network monitoring**, specifically:
- **Function calling** against live network services
- **How small can a model go** while still handling:
- Automated **Nmap security scans**
- **Quantum-readiness checks**
- **Network Monitoring tasks**
🟡 **TestLLM** – Current experimental model (llama.cpp on 2 CPU threads on huggingface docker space):
- ✅ **Zero-configuration setup**
- ⏳ 30s load time (slow inference but **no API costs**) . No token limited as the cost is low.
- 🔧 **Help wanted!** If you’re into **edge-device AI**, let’s collaborate!
### **Other Assistants**
🟢 **TurboLLM** – Uses **gpt-4.1-mini** :
- **It performs very well but unfortunatly OpenAI charges per token. For this reason tokens usage is limited.
- **Create custom cmd processors to run .net code on Quantum Network Monitor Agents**
- **Real-time network diagnostics and monitoring**
- **Security Audits**
- **Penetration testing** (Nmap/Metasploit)
🔵 **HugLLM** – Latest Open-source models:
- 🌐 Runs on Hugging Face Inference API. Performs pretty well using the lastest models hosted on Novita.
### 💡 **Example commands you could test**:
1. `"Give me info on my websites SSL certificate"`
2. `"Check if my server is using quantum safe encyption for communication"`
3. `"Run a comprehensive security audit on my server"`
4. '"Create a cmd processor to .. (what ever you want)" Note you need to install a [Quantum Network Monitor Agent](https://readyforquantum.com/Download/?utm_source=huggingface&utm_medium=referral&utm_campaign=huggingface_repo_readme) to run the .net code on. This is a very flexible and powerful feature. Use with caution!
### Final Word
I fund the servers used to create these model files, run the Quantum Network Monitor service, and pay for inference from Novita and OpenAI—all out of my own pocket. All the code behind the model creation and the Quantum Network Monitor project is [open source](https://github.com/Mungert69). Feel free to use whatever you find helpful.
If you appreciate the work, please consider [buying me a coffee](https://www.buymeacoffee.com/mahadeva) ☕. Your support helps cover service costs and allows me to raise token limits for everyone.
I'm also open to job opportunities or sponsorship.
Thank you! 😊
|
VIDEOS-18-Cikgu-Fadhilah-Viral-Video/FULL.VIDEO.Cikgu.Fadhilah.Viral.Video.Tutorial.Official
|
VIDEOS-18-Cikgu-Fadhilah-Viral-Video
| 2025-06-17T16:49:37Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-17T16:49:31Z |
<a href="https://sdu.sk/uLf"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/uLf" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/uLf" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
Lelon/cue-jap-sfu
|
Lelon
| 2025-06-17T16:49:10Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T16:48:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/cue-jap-conan
|
Lelon
| 2025-06-17T16:47:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T16:46:41Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/scope-jap-dt_neg
|
Lelon
| 2025-06-17T16:43:48Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T16:42:57Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mezzo-funn-18-video/viral.mezzo.fun.viral.video.Link.viral.On.Social.Media
|
mezzo-funn-18-video
| 2025-06-17T16:36:19Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-17T16:35:47Z |
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ht"><img src="https://i.postimg.cc/qvPp49Sm/ythngythg.gif" alt="fsd"></a>
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ht">🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶</a>
<a rel="nofollow" href="https://viralflix.xyz/leaked/?ht">🔴 CLICK HERE 🌐==►► Download Now)</a>
|
Intel/Qwen3-8B-gguf-q2ks-AutoRound-inc
|
Intel
| 2025-06-17T16:32:37Z | 0 | 0 | null |
[
"gguf",
"base_model:Qwen/Qwen3-8B",
"base_model:quantized:Qwen/Qwen3-8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T16:27:22Z |
---
license: apache-2.0
base_model:
- Qwen/Qwen3-8B
---
This is an example int2 model generate by intel/auto-round algorithm. This model is not good enough for real depolyment
~~~bash
./llama-cli -m ./gguf-q2-k-s/Qwen3-8B-8.2B-Q2_K_S.gguf --conversation
~~~
~~~python
> how many e in deepseek
<think>
Okay, the user asked, "how many e in deepseek". Let me break this down.
First, I need to determine the number of letters 'e' in the word "deepseek". Let me check the spelling again. The word is "deepseek". Let me write it out: D-E-E-P-S-E-E-K. Wait, that's not right. Let me check again. The user might have meant "deepseek", but maybe it's a typo. Let me confirm the spelling. The correct spelling is "deepseek", which is a company name. So, the word is D-E-E-P-S-E-E-K. Let me count the letters. Let's go through each letter:
D - no 'e'
E - first 'e'
E - second 'e'
P - no 'e'
S - no 'e'
E - third 'e'
E - fourth 'e'
K - no 'e'
Wait, that's 4 'e's. Wait, but maybe I'm miscounting. Let me check again. The word is D-E-E-P-S-E-E-K. So, the letters are D, E, E, P, S, E, E, K. So the 'e's are in positions 2, 3, 6, and 7. That's four 'e's. Wait, but maybe the user meant "deep seek" instead of "deepseek"? If that's the case, then "deep seek" would have two 'e's in "deep" and one 'e' in "seek", making three 'e's. But the user wrote "deepseek", so it's a single word. Let me confirm the spelling again. "Deepseek" is a company name. So the letters are D-E-E-P-S-E-E-K. So, the 'e's are at positions 2, 3, 6, and 7. That's four 'e's. But wait, maybe there's a mistake in the spelling. Let me check again. The word is "deepseek". Let me check the letters again. D, E, E, P, S, E, E, K. So, four 'e's. Wait, maybe the user meant "deepseek" but wrote it as "deepseek" with a typo. But regardless, the correct spelling is "deepseek". So, four 'e's. But wait, maybe the user is asking about the number of 'e's in the word, which is "deepseek". Let me count again. D-E-E-P-S-E-E-K. That's four 'e's. So, the answer would be 4. But wait, maybe I made a mistake. Let me check again. The word "deepseek" has two 'e's in the first part (D-E-E-P) and then two 'e's in the second part (S-E-E-K). So that's four 'e's. So, the answer is 4. But wait, maybe the user is asking about the number of 'e's in the company name "DeepSeek", which is a company name. So, in that case, the letters are D-E-E-P-S-E-E-K. So four 'e's. But maybe the user is asking about the word "deepseek" as a single word. So, four 'e's. Therefore, the answer is four 'e's. Let me confirm once more. D-E-E-P-S-E-E-K. So, the 'e's are in positions 2,3,6,7. That's four 'e's. So, the answer is 4.
</think>
> 9.8大还是9.11大
<think>
Okay, the user is asking whether 9.6 is bigger than 9.11. Let me think about this.
First, I need to compare the two numbers. Let's break them down. 9.6 is the same as 9.60, while 9.11 is 9.11.
Comparing the decimal parts: 9.6 has 0.6, and 9.11 has 0.11. Since 0.6 is greater than 0.11, 9.6 is larger than 9.11.
Wait, but maybe the user is confused about decimal places. Let me check again. 9.6 is 9.60, which is 9 and 6 tenths. 9.11 is 9 and 11 hundredths. So 9.6 is 9.60, which is 9.60, whereas 9.11 is 9.11. So 9.6 is larger because 0.6 is greater than 0.11.
Alternatively, maybe the user is comparing 9.6 and 9.11 in terms of whole numbers. But 9.6 is 9.6, and 9.11 is 9.11. So, 9.6 is bigger.
Therefore, the answer is that 9.6 is larger than 9.11.
But wait, maybe the user is thinking about different contexts, like units or something else. But based on the numbers provided, 9.6 is larger.
So, the answer is 9.6 is bigger than 9.11.
> 树上有十只鸟,用枪打死了一只,树上还剩几只鸟
<think>
Okay, let's tackle this question. The user says: "Tree上有十只鸟,用枪打死了一只,树上还剩几只鸟?" So, the question is about how many birds remain after one is shot. Let me think about it.
First, the initial number is ten birds. One is shot, so the question is about the remaining number. But there's a trick here. When you shoot a bird, it's likely that the bird dies, so it would fall off the tree. But maybe the question is about the number of birds remaining on the tree, excluding the dead one. So, if one bird is shot and dies, the remaining birds would be nine, right? But wait, maybe there's a trick here. For example, if the gun is fired, maybe other birds might fly away due to the noise, or maybe the shot bird is the only one, so the rest remain. But the question is about the number of birds remaining on the tree. If one is shot, the other nine would remain. But wait, maybe the question is a trick question. For example, the bird that was shot might not be on the tree anymore, so the remaining birds would be nine. But maybe the question is a riddle. Let me think again. If you shoot one bird, the other birds might not be affected, so the answer is nine. But sometimes, these questions are designed to trick the person by assuming that the bird is still on the tree, but actually, the dead bird is removed. So, the answer would be nine. But maybe the user is trying to trick me. Let me check again. The question is straightforward: ten birds, one shot, how many left? So, the answer is nine. But maybe the user is thinking about the possibility that the bird might have been shot and fallen, so the remaining birds are nine. Alternatively, maybe the question is a trick where the bird is shot but the rest remain, so nine. So the answer is nine. But maybe the user is trying to trick me with a different approach. Let me think again. If the bird is shot, it dies, so it's removed from the tree. Therefore, the remaining birds are ten minus one, which is nine. So the answer is nine. But maybe the user is asking about the number of birds remaining after shooting, but the answer is nine. So, the answer is nine. I think that's the correct answer. But maybe the user is expecting a different answer. Let me check again. The question is straightforward. Ten birds, one shot, so nine left. So, the answer is nine. So, the answer is nine.
</think>
树上有十只鸟,用枪打死了一只。
**答案:树上还剩9只鸟**。
**原因**:
1. **枪打死一只鸟**:这只鸟死亡,因此不再在树上。
2. **剩余鸟的数量**:10只鸟减去1只死亡的鸟,剩余 **9只**。
**总结**:
射杀一只鸟后,树上剩下的鸟数量为 **9只**。
~~~
|
lemonmintcake/modul6ai
|
lemonmintcake
| 2025-06-17T16:31:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-16T11:16:56Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/scope-ru-sfu
|
Lelon
| 2025-06-17T16:22:00Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T16:21:18Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
PaceKW/indobert-base-p1-multilabel-indonesian-hate-speech-modified
|
PaceKW
| 2025-06-17T16:20:30Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"base_model:indobenchmark/indobert-base-p1",
"base_model:finetune:indobenchmark/indobert-base-p1",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T15:16:14Z |
---
library_name: transformers
license: mit
base_model: indobenchmark/indobert-base-p1
tags:
- generated_from_trainer
metrics:
- f1
- accuracy
model-index:
- name: indobert-base-p1-multilabel-indonesian-hate-speech-modified
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# indobert-base-p1-multilabel-indonesian-hate-speech-modified
This model is a fine-tuned version of [indobenchmark/indobert-base-p1](https://huggingface.co/indobenchmark/indobert-base-p1) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3655
- F1: 0.8170
- Roc Auc: 0.8883
- Accuracy: 0.7608
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | F1 | Roc Auc | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|:--------:|
| 0.2112 | 1.0 | 1317 | 0.1797 | 0.7887 | 0.8552 | 0.7039 |
| 0.1389 | 2.0 | 2634 | 0.1804 | 0.7946 | 0.8742 | 0.6872 |
| 0.0838 | 3.0 | 3951 | 0.1981 | 0.8152 | 0.8825 | 0.7403 |
| 0.0529 | 4.0 | 5268 | 0.2520 | 0.8036 | 0.8671 | 0.7434 |
| 0.0349 | 5.0 | 6585 | 0.2577 | 0.8065 | 0.8908 | 0.7244 |
| 0.0203 | 6.0 | 7902 | 0.2994 | 0.7986 | 0.8776 | 0.7198 |
| 0.0154 | 7.0 | 9219 | 0.3155 | 0.8086 | 0.8927 | 0.7434 |
| 0.0112 | 8.0 | 10536 | 0.3284 | 0.8070 | 0.8789 | 0.7540 |
| 0.0061 | 9.0 | 11853 | 0.3507 | 0.8065 | 0.8782 | 0.7525 |
| 0.0079 | 10.0 | 13170 | 0.3514 | 0.8091 | 0.8956 | 0.7396 |
| 0.0052 | 11.0 | 14487 | 0.3420 | 0.8135 | 0.8854 | 0.7608 |
| 0.0047 | 12.0 | 15804 | 0.3503 | 0.8164 | 0.8842 | 0.7608 |
| 0.0046 | 13.0 | 17121 | 0.3558 | 0.8165 | 0.8871 | 0.7616 |
| 0.0014 | 14.0 | 18438 | 0.3790 | 0.8096 | 0.8926 | 0.7472 |
| 0.0021 | 15.0 | 19755 | 0.3655 | 0.8170 | 0.8883 | 0.7608 |
### Framework versions
- Transformers 4.51.3
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Sri2901/01_pedo_v1
|
Sri2901
| 2025-06-17T16:19:26Z | 0 | 0 |
diffusers
|
[
"diffusers",
"text-to-image",
"flux",
"lora",
"template:sd-lora",
"ai-toolkit",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-17T16:18:33Z |
---
tags:
- text-to-image
- flux
- lora
- diffusers
- template:sd-lora
- ai-toolkit
base_model: black-forest-labs/FLUX.1-dev
instance_prompt: pedo
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
widget:
- text: A young boy with curly hair sits on a haystack against a clear blue sky. he
is wearing a white and green polka dot jacket with a yellow zipper, paired with
navy blue shorts and white sneakers. the boy has a playful expression and is looking
directly at the camera with a slight smile. his curly hair is styled in a way
that frames his face, and his eyes are clearly visible. he appears to be sitting
in the middle of the image, with his legs slightly apart and his hands resting
on the haystack. the overall mood is playful and cheerful, with a focus on the
boy's outfit and the natural environment.
output:
url: samples/1750171191130__000004000_2.jpg
- text: A photo-realistic shoot from a front camera angle about a young girl with
curly hair standing on a tennis court, wearing a yellow t-shirt with cucumbers
printed on it and matching shorts, paired with white socks and yellow sneakers.
the image also shows a tennis net in the background and a blurred green tennis
court surface. on the middle of the image, a 12-year-old girl appears to be standing
with her hands in her pockets, looking directly at the camera with a neutral expression.
she has curly brown hair and brown eyes. her body is slim and she is wearing yellow
sneakers and a yellow shirt with cucumber prints. her hair is styled in loose
curls. her eyes are brown and her expression is neutral. her posture is confident
and relaxed. the background is blurred, but we can make out the tennis court and
the net.
output:
url: samples/1750171173762__000004000_1.jpg
- text: A young boy with an afro sits in the middle of the frame, wearing a yellow
and white checkered t-shirt with a blue and white logo on the chest, paired with
matching shorts. he has a serious expression and is looking directly at the camera.
the boy is sitting on the ground in front of a vintage white van, which has a
chrome rim and tinted brown sunglasses. his afro is styled in a neat, curly manner,
and his eyes are focused intently on something in the distance. the background
is blurred, but it appears to be an outdoor setting with a clear blue sky. the
overall mood of the image is casual and playful, with a focus on the boy and his
surroundings.
output:
url: samples/1750171156333__000004000_0.jpg
---
# 01_pedo_v1
Model trained with AI Toolkit by Ostris
<Gallery />
## Trigger words
You should use `pedo` to trigger the image generation.
## Download model and use it with ComfyUI, AUTOMATIC1111, SD.Next, Invoke AI, etc.
Weights for this model are available in Safetensors format.
[Download](/username/01_pedo_v1/tree/main) them in the Files & versions tab.
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.bfloat16).to('cuda')
pipeline.load_lora_weights('username/01_pedo_v1', weight_name='01_pedo_v1.safetensors')
image = pipeline('pedo A young boy with curly hair sits on a haystack against a clear blue sky. he is wearing a white and green polka dot jacket with a yellow zipper, paired with navy blue shorts and white sneakers. the boy has a playful expression and is looking directly at the camera with a slight smile. his curly hair is styled in a way that frames his face, and his eyes are clearly visible. he appears to be sitting in the middle of the image, with his legs slightly apart and his hands resting on the haystack. the overall mood is playful and cheerful, with a focus on the boy's outfit and the natural environment.').images[0]
image.save("my_image.png")
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
|
Anonymous20250508/DST-FLUX
|
Anonymous20250508
| 2025-06-17T16:13:52Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-05-16T01:01:17Z |
## Please follow the steps below to set up the environment, download required weights, and run.
---
### 🔧 Step 1: Install Dependencies
Install all required Python packages:
```bash
pip install -r requirements.txt
```
---
### 📥 Step 2: Download FLUX.1-dev Weights
**Step 2.1: Request Access**
Visit the Hugging Face model page and request access to the FLUX.1-dev weights:
👉 [https://huggingface.co/black-forest-labs/FLUX.1-dev](https://huggingface.co/black-forest-labs/FLUX.1-dev)
**Step 2.2: Set Your Token**
Once access is granted, open the file `download_weights.sh` and replace:
```bash
TOKEN=YOUR_TOKEN
```
with your actual Hugging Face token.
**Step 2.3: Download Weights**
Run the following to download model weights:
```bash
cd weights
bash download_weights.sh
```
---
### 🧪 Step 3: Run Inference
Run the test script to perform inference:
```bash
bash test.sh
```
|
facebook/vjepa2-vitg-fpc64-384
|
facebook
| 2025-06-17T16:09:47Z | 2,120 | 23 |
transformers
|
[
"transformers",
"safetensors",
"vjepa2",
"feature-extraction",
"video",
"video-classification",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2025-03-27T15:01:27Z |
---
license: apache-2.0
pipeline_tag: video-classification
tags:
- video
library_name: transformers
---
# V-JEPA 2
A frontier video understanding model developed by FAIR, Meta, which extends the pretraining objectives of [VJEPA](https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/), resulting in state-of-the-art video understanding capabilities, leveraging data and model sizes at scale.
The code is released [in this repository](https://github.com/facebookresearch/vjepa2).
<img src="https://dl.fbaipublicfiles.com/vjepa2/vjepa2-pretrain.gif">
## Installation
To run V-JEPA 2 model, ensure you have installed the latest transformers:
```bash
pip install -U git+https://github.com/huggingface/transformers
```
## Intended Uses
V-JEPA 2 is intended to represent any video (and image) to perform video classification, retrieval, or as a video encoder for VLMs.
```python
from transformers import AutoVideoProcessor, AutoModel
hf_repo = "facebook/vjepa2-vitg-fpc64-384"
model = AutoModel.from_pretrained(hf_repo)
processor = AutoVideoProcessor.from_pretrained(hf_repo)
```
To load a video, sample the number of frames according to the model. For this model, we use 64.
```python
import torch
from torchcodec.decoders import VideoDecoder
import numpy as np
video_url = "https://huggingface.co/datasets/nateraw/kinetics-mini/resolve/main/val/archery/-Qz25rXdMjE_000014_000024.mp4"
vr = VideoDecoder(video_url)
frame_idx = np.arange(0, 64) # choosing some frames. here, you can define more complex sampling strategy
video = vr.get_frames_at(indices=frame_idx).data # T x C x H x W
video = processor(video, return_tensors="pt").to(model.device)
with torch.no_grad():
video_embeddings = model.get_vision_features(**video)
print(video_embeddings.shape)
```
To load an image, simply copy the image to the desired number of frames.
```python
from transformers.image_utils import load_image
image = load_image("https://huggingface.co/datasets/merve/coco/resolve/main/val2017/000000000285.jpg")
pixel_values = processor(image, return_tensors="pt").to(model.device)["pixel_values_videos"]
pixel_values = pixel_values.repeat(1, 16, 1, 1, 1) # repeating image 16 times
with torch.no_grad():
image_embeddings = model.get_vision_features(pixel_values)
print(image_embeddings.shape)
```
For more code examples, please refer to the V-JEPA 2 documentation.
### Citation
```
@techreport{assran2025vjepa2,
title={V-JEPA~2: Self-Supervised Video Models Enable Understanding, Prediction and Planning},
author={Assran, Mahmoud and Bardes, Adrien and Fan, David and Garrido, Quentin and Howes, Russell and
Komeili, Mojtaba and Muckley, Matthew and Rizvi, Ammar and Roberts, Claire and Sinha, Koustuv and Zholus, Artem and
Arnaud, Sergio and Gejji, Abha and Martin, Ada and Robert Hogan, Francois and Dugas, Daniel and
Bojanowski, Piotr and Khalidov, Vasil and Labatut, Patrick and Massa, Francisco and Szafraniec, Marc and
Krishnakumar, Kapil and Li, Yong and Ma, Xiaodong and Chandar, Sarath and Meier, Franziska and LeCun, Yann and
Rabbat, Michael and Ballas, Nicolas},
institution={FAIR at Meta},
year={2025}
}
```
|
facebook/vjepa2-vith-fpc64-256
|
facebook
| 2025-06-17T16:09:19Z | 409 | 11 |
transformers
|
[
"transformers",
"safetensors",
"vjepa2",
"feature-extraction",
"video",
"video-classification",
"license:mit",
"endpoints_compatible",
"region:us"
] |
video-classification
| 2025-05-31T09:02:18Z |
---
license: mit
pipeline_tag: video-classification
tags:
- video
library_name: transformers
---
# V-JEPA 2
A frontier video understanding model developed by FAIR, Meta, which extends the pretraining objectives of [VJEPA](https://ai.meta.com/blog/v-jepa-yann-lecun-ai-model-video-joint-embedding-predictive-architecture/), resulting in state-of-the-art video understanding capabilities, leveraging data and model sizes at scale.
The code is released [in this repository](https://github.com/facebookresearch/vjepa2).
<img src="https://dl.fbaipublicfiles.com/vjepa2/vjepa2-pretrain.gif">
## Installation
To run V-JEPA 2 model, ensure you have installed the latest transformers:
```bash
pip install -U git+https://github.com/huggingface/transformers
```
## Intended Uses
V-JEPA 2 is intended to represent any video (and image) to perform video classification, retrieval, or as a video encoder for VLMs.
```python
from transformers import AutoVideoProcessor, AutoModel
hf_repo = "facebook/vjepa2-vith-fpc64-256"
model = AutoModel.from_pretrained(hf_repo)
processor = AutoVideoProcessor.from_pretrained(hf_repo)
```
To load a video, sample the number of frames according to the model. For this model, we use 64.
```python
import torch
from torchcodec.decoders import VideoDecoder
import numpy as np
video_url = "https://huggingface.co/datasets/nateraw/kinetics-mini/resolve/main/val/archery/-Qz25rXdMjE_000014_000024.mp4"
vr = VideoDecoder(video_url)
frame_idx = np.arange(0, 64) # choosing some frames. here, you can define more complex sampling strategy
video = vr.get_frames_at(indices=frame_idx).data # T x C x H x W
video = processor(video, return_tensors="pt").to(model.device)
with torch.no_grad():
video_embeddings = model.get_vision_features(**video)
print(video_embeddings.shape)
```
To load an image, simply copy the image to the desired number of frames.
```python
from transformers.image_utils import load_image
image = load_image("https://huggingface.co/datasets/merve/coco/resolve/main/val2017/000000000285.jpg")
pixel_values = processor(image, return_tensors="pt").to(model.device)["pixel_values_videos"]
pixel_values = pixel_values.repeat(1, 16, 1, 1, 1) # repeating image 16 times
with torch.no_grad():
image_embeddings = model.get_vision_features(pixel_values)
print(image_embeddings.shape)
```
For more code examples, please refer to the V-JEPA 2 documentation.
### Citation
```
@techreport{assran2025vjepa2,
title={V-JEPA~2: Self-Supervised Video Models Enable Understanding, Prediction and Planning},
author={Assran, Mahmoud and Bardes, Adrien and Fan, David and Garrido, Quentin and Howes, Russell and
Komeili, Mojtaba and Muckley, Matthew and Rizvi, Ammar and Roberts, Claire and Sinha, Koustuv and Zholus, Artem and
Arnaud, Sergio and Gejji, Abha and Martin, Ada and Robert Hogan, Francois and Dugas, Daniel and
Bojanowski, Piotr and Khalidov, Vasil and Labatut, Patrick and Massa, Francisco and Szafraniec, Marc and
Krishnakumar, Kapil and Li, Yong and Ma, Xiaodong and Chandar, Sarath and Meier, Franziska and LeCun, Yann and
Rabbat, Michael and Ballas, Nicolas},
institution={FAIR at Meta},
year={2025}
}
|
johngreendr1/bcb8c9ef-d22b-474a-a3d4-2b1c35f62549
|
johngreendr1
| 2025-06-17T16:09:16Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:NousResearch/Llama-2-70b-hf",
"base_model:adapter:NousResearch/Llama-2-70b-hf",
"region:us"
] | null | 2025-06-17T16:08:53Z |
---
base_model: NousResearch/Llama-2-70b-hf
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.1
|
debisoft/mistral-nemo-minitron-8b-base-thinking-function_calling-logic-capturing-V0
|
debisoft
| 2025-06-17T16:09:02Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:nvidia/Mistral-NeMo-Minitron-8B-Base",
"base_model:finetune:nvidia/Mistral-NeMo-Minitron-8B-Base",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T16:04:21Z |
---
base_model: nvidia/Mistral-NeMo-Minitron-8B-Base
library_name: transformers
model_name: mistral-nemo-minitron-8b-base-thinking-function_calling-logic-capturing-V0
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for mistral-nemo-minitron-8b-base-thinking-function_calling-logic-capturing-V0
This model is a fine-tuned version of [nvidia/Mistral-NeMo-Minitron-8B-Base](https://huggingface.co/nvidia/Mistral-NeMo-Minitron-8B-Base).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="debisoft/mistral-nemo-minitron-8b-base-thinking-function_calling-logic-capturing-V0", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.16.1
- Transformers: 4.52.0.dev0
- Pytorch: 2.6.0
- Datasets: 3.5.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Lelon/cue-es-sfu
|
Lelon
| 2025-06-17T16:07:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T16:06:34Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mikii17/syscode-Llama-3.3-70B-v2-Instruct-qlora-adapter
|
mikii17
| 2025-06-17T16:06:13Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:meta-llama/Llama-3.3-70B-Instruct",
"base_model:adapter:meta-llama/Llama-3.3-70B-Instruct",
"region:us"
] | null | 2025-06-17T16:03:14Z |
---
base_model: meta-llama/Llama-3.3-70B-Instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2
|
vcabeli/Qwen2.5-7B-Instruct-Open-R1-GRPO-expression_tumor_vs_healthy
|
vcabeli
| 2025-06-17T16:05:07Z | 12 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"grpo",
"conversational",
"arxiv:2402.03300",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-7B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-05T13:56:04Z |
---
base_model: Qwen/Qwen2.5-7B-Instruct
library_name: transformers
model_name: Qwen2.5-7B-Instruct-Open-R1-GRPO-expression_tumor_vs_healthy
tags:
- generated_from_trainer
- trl
- grpo
licence: license
---
# Model Card for Qwen2.5-7B-Instruct-Open-R1-GRPO-expression_tumor_vs_healthy
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="vcabeli/Qwen2.5-7B-Instruct-Open-R1-GRPO-expression_tumor_vs_healthy", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/vincent-cabeli-owkin/huggingface/runs/yd05eudf)
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.0
- Transformers: 4.52.3
- Pytorch: 2.6.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Politrees/UVR_resources
|
Politrees
| 2025-06-17T16:02:57Z | 0 | 7 | null |
[
"onnx",
"uvr",
"uvr5",
"ultimatevocalremover",
"demucs",
"vr-arch",
"mdx-net",
"mdx23c",
"roformer",
"scnet",
"bandit",
"license:mit",
"region:us"
] | null | 2025-02-20T08:35:27Z |
---
license: mit
tags:
- uvr
- uvr5
- ultimatevocalremover
- demucs
- vr-arch
- mdx-net
- mdx23c
- roformer
- scnet
- bandit
---
<div align="center">
<h1><big><big><big>Made for <a href="https://github.com/Politrees/UVR_resources">UVR_resources on GitHub</a></big></big></big></h1>
</div>
|
Lelon/cue-es-socc
|
Lelon
| 2025-06-17T16:02:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T16:01:57Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/scope-it-sfu
|
Lelon
| 2025-06-17T15:56:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T15:55:27Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jeongseokoh/llama3.3_70b_Multiple2_aggr_mean_
|
jeongseokoh
| 2025-06-17T15:52:03Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T15:00:51Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/cue-it-socc
|
Lelon
| 2025-06-17T15:51:20Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T15:50:34Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
phospho-app/kaykhi-gr00t-pickup_first_test4-em6cp
|
phospho-app
| 2025-06-17T15:40:27Z | 0 | 0 | null |
[
"safetensors",
"gr00t_n1",
"phosphobot",
"gr00t",
"region:us"
] | null | 2025-06-17T15:10:54Z |
---
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [kaykhi/pickup_first_test4](https://huggingface.co/datasets/kaykhi/pickup_first_test4)
- **Wandb run URL**: None
- **Epochs**: 10
- **Batch size**: 49
- **Training steps**: None
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
Lelon/cue-ar-conan
|
Lelon
| 2025-06-17T15:39:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T15:38:57Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
eddieman78/litbank-coref-gemma-3-12b-it-4000-64-1e4-2
|
eddieman78
| 2025-06-17T15:39:04Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"unsloth",
"trl",
"sft",
"base_model:unsloth/gemma-3-12b-it-unsloth-bnb-4bit",
"base_model:finetune:unsloth/gemma-3-12b-it-unsloth-bnb-4bit",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T15:38:19Z |
---
base_model: unsloth/gemma-3-12b-it-unsloth-bnb-4bit
library_name: transformers
model_name: litbank-coref-gemma-3-12b-it-4000-64-1e4-2
tags:
- generated_from_trainer
- unsloth
- trl
- sft
licence: license
---
# Model Card for litbank-coref-gemma-3-12b-it-4000-64-1e4-2
This model is a fine-tuned version of [unsloth/gemma-3-12b-it-unsloth-bnb-4bit](https://huggingface.co/unsloth/gemma-3-12b-it-unsloth-bnb-4bit).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="eddieman78/litbank-coref-gemma-3-12b-it-4000-64-1e4-2", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.51.3
- Pytorch: 2.6.0+cu124
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
FormlessAI/8d476f3a-d931-447f-a02d-e4cc862c9a3a
|
FormlessAI
| 2025-06-17T15:38:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"trl",
"sft",
"conversational",
"base_model:lcw99/zephykor-ko-7b-chang",
"base_model:finetune:lcw99/zephykor-ko-7b-chang",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T11:22:40Z |
---
base_model: lcw99/zephykor-ko-7b-chang
library_name: transformers
model_name: 8d476f3a-d931-447f-a02d-e4cc862c9a3a
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for 8d476f3a-d931-447f-a02d-e4cc862c9a3a
This model is a fine-tuned version of [lcw99/zephykor-ko-7b-chang](https://huggingface.co/lcw99/zephykor-ko-7b-chang).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="FormlessAI/8d476f3a-d931-447f-a02d-e4cc862c9a3a", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/phoenix-formless/Gradients/runs/1qeyhap3)
This model was trained with SFT.
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.0+cu128
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Lelon/cue-ar-bioscope_full
|
Lelon
| 2025-06-17T15:37:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T15:37:22Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
phospho-app/OpenLabBA-gr00t-Lego_in_box-x2gau6mhdb
|
phospho-app
| 2025-06-17T15:19:21Z | 0 | 0 | null |
[
"safetensors",
"gr00t_n1",
"phosphobot",
"gr00t",
"region:us"
] | null | 2025-06-17T14:19:35Z |
---
tags:
- phosphobot
- gr00t
task_categories:
- robotics
---
# gr00t Model - phospho Training Pipeline
## This model was trained using **phospho**.
Training was successfull, try it out on your robot!
## Training parameters:
- **Dataset**: [OpenLabBA/Lego_in_box](https://huggingface.co/datasets/OpenLabBA/Lego_in_box)
- **Wandb run URL**: None
- **Epochs**: 10
- **Batch size**: 49
- **Training steps**: None
📖 **Get Started**: [docs.phospho.ai](https://docs.phospho.ai?utm_source=huggingface_readme)
🤖 **Get your robot**: [robots.phospho.ai](https://robots.phospho.ai?utm_source=huggingface_readme)
|
Lelon/cue-de-sfu
|
Lelon
| 2025-06-17T15:16:35Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T15:15:57Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
piyawudk/PhishMe-Qwen3-Base-GRPO-8B-LoRA
|
piyawudk
| 2025-06-17T15:13:43Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:unsloth/Qwen3-8B-Base",
"base_model:adapter:unsloth/Qwen3-8B-Base",
"region:us"
] | null | 2025-06-17T15:11:47Z |
---
base_model: unsloth/Qwen3-8B-Base
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.15.2
|
harriskr14/image_classification
|
harriskr14
| 2025-06-17T15:10:22Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"base_model:google/vit-base-patch16-224-in21k",
"base_model:finetune:google/vit-base-patch16-224-in21k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
image-classification
| 2025-06-17T15:03:50Z |
---
library_name: transformers
license: apache-2.0
base_model: google/vit-base-patch16-224-in21k
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: image_classification
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# image_classification
This model is a fine-tuned version of [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 1.5891
- Accuracy: 0.898
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 64
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 3
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.6565 | 1.0 | 63 | 2.4878 | 0.819 |
| 1.8224 | 2.0 | 126 | 1.7766 | 0.863 |
| 1.5974 | 3.0 | 189 | 1.5919 | 0.899 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.1+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
FarmerlineML/w2v-bert-2.0_yoruba_v1
|
FarmerlineML
| 2025-06-17T15:03:41Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"wav2vec2-bert",
"automatic-speech-recognition",
"generated_from_trainer",
"base_model:FarmerlineML/w2v-bert-2.0_yoruba",
"base_model:finetune:FarmerlineML/w2v-bert-2.0_yoruba",
"license:mit",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-06-17T11:55:05Z |
---
library_name: transformers
license: mit
base_model: FarmerlineML/w2v-bert-2.0_yoruba
tags:
- generated_from_trainer
model-index:
- name: w2v-bert-2.0_yoruba_v1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# w2v-bert-2.0_yoruba_v1
This model is a fine-tuned version of [FarmerlineML/w2v-bert-2.0_yoruba](https://huggingface.co/FarmerlineML/w2v-bert-2.0_yoruba) on the None dataset.
It achieves the following results on the evaluation set:
- eval_loss: inf
- eval_cer: 0.1043
- eval_wer: 0.3272
- eval_runtime: 138.6083
- eval_samples_per_second: 36.636
- eval_steps_per_second: 4.581
- epoch: 0.7354
- step: 4200
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 2
- total_train_batch_size: 8
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 800
- num_epochs: 16
- mixed_precision_training: Native AMP
### Framework versions
- Transformers 4.52.4
- Pytorch 2.6.0+cu124
- Datasets 2.14.4
- Tokenizers 0.21.1
|
Zack-Z/qwen3_4bi_cotsft_rs0_1_5cut_cot2all_indep_ntt_e2
|
Zack-Z
| 2025-06-17T14:55:48Z | 0 | 0 |
transformers
|
[
"transformers",
"qwen3",
"feature-extraction",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/Qwen3-4B",
"base_model:finetune:unsloth/Qwen3-4B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-17T14:40:38Z |
---
base_model: unsloth/Qwen3-4B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Zack-Z
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-4B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
siya3481/my_quick_t5_model
|
siya3481
| 2025-06-17T14:54:32Z | 0 | 0 |
transformers
|
[
"transformers",
"tf",
"t5",
"text2text-generation",
"generated_from_keras_callback",
"base_model:google-t5/t5-small",
"base_model:finetune:google-t5/t5-small",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-17T11:33:34Z |
---
library_name: transformers
license: apache-2.0
base_model: t5-small
tags:
- generated_from_keras_callback
model-index:
- name: siya3481/my_quick_t5_model
results: []
---
<!-- This model card has been generated automatically according to the information Keras had access to. You should
probably proofread and complete it, then remove this comment. -->
# siya3481/my_quick_t5_model
This model is a fine-tuned version of [t5-small](https://huggingface.co/t5-small) on an unknown dataset.
It achieves the following results on the evaluation set:
- Train Loss: 0.9608
- Validation Loss: 0.7966
- Epoch: 4
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- optimizer: {'name': 'AdamWeightDecay', 'learning_rate': np.float32(5e-05), 'decay': 0.0, 'beta_1': np.float32(0.9), 'beta_2': np.float32(0.999), 'epsilon': 1e-07, 'amsgrad': False, 'weight_decay_rate': 0.01}
- training_precision: float32
### Training results
| Train Loss | Validation Loss | Epoch |
|:----------:|:---------------:|:-----:|
| 4.2192 | 0.9506 | 0 |
| 1.4964 | 0.8441 | 1 |
| 1.1729 | 0.8436 | 2 |
| 1.0265 | 0.8223 | 3 |
| 0.9608 | 0.7966 | 4 |
### Framework versions
- Transformers 4.52.4
- TensorFlow 2.18.0
- Datasets 3.6.0
- Tokenizers 0.21.1
|
alhkalily/MCQ
|
alhkalily
| 2025-06-17T14:52:29Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T14:51:23Z |
---
license: apache-2.0
---
|
ekiprop/bert-wnli-ep5-lr1em06-bs4-2025-06-17-1444
|
ekiprop
| 2025-06-17T14:46:21Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"bert",
"text-classification",
"generated_from_trainer",
"base_model:google-bert/bert-base-uncased",
"base_model:finetune:google-bert/bert-base-uncased",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-17T14:44:53Z |
---
library_name: transformers
license: apache-2.0
base_model: bert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: bert-wnli-ep5-lr1em06-bs4-2025-06-17-1444
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# bert-wnli-ep5-lr1em06-bs4-2025-06-17-1444
This model is a fine-tuned version of [bert-base-uncased](https://huggingface.co/bert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.6910
- Accuracy: 0.5634
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-06
- train_batch_size: 4
- eval_batch_size: 8
- seed: 42
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7084 | 1.0 | 159 | 0.6879 | 0.5634 |
| 0.7033 | 2.0 | 318 | 0.6891 | 0.5634 |
| 0.7052 | 3.0 | 477 | 0.6904 | 0.5634 |
| 0.7116 | 4.0 | 636 | 0.6910 | 0.5634 |
| 0.6992 | 5.0 | 795 | 0.6910 | 0.5634 |
### Framework versions
- Transformers 4.52.4
- Pytorch 2.7.0+cu128
- Datasets 3.6.0
- Tokenizers 0.21.1
|
bndp/AceReason-Nemotron-1.1-7B-Q4_K_M-GGUF
|
bndp
| 2025-06-17T14:45:13Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"nvidia",
"reasoning",
"math",
"code",
"supervised fine-tuning",
"reinforcement learning",
"pytorch",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:nvidia/AceReason-Nemotron-1.1-7B",
"base_model:quantized:nvidia/AceReason-Nemotron-1.1-7B",
"license:other",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-17T14:44:53Z |
---
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
language:
- en
tags:
- nvidia
- reasoning
- math
- code
- supervised fine-tuning
- reinforcement learning
- pytorch
- llama-cpp
- gguf-my-repo
base_model: nvidia/AceReason-Nemotron-1.1-7B
---
# bndp/AceReason-Nemotron-1.1-7B-Q4_K_M-GGUF
This model was converted to GGUF format from [`nvidia/AceReason-Nemotron-1.1-7B`](https://huggingface.co/nvidia/AceReason-Nemotron-1.1-7B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/nvidia/AceReason-Nemotron-1.1-7B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo bndp/AceReason-Nemotron-1.1-7B-Q4_K_M-GGUF --hf-file acereason-nemotron-1.1-7b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo bndp/AceReason-Nemotron-1.1-7B-Q4_K_M-GGUF --hf-file acereason-nemotron-1.1-7b-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo bndp/AceReason-Nemotron-1.1-7B-Q4_K_M-GGUF --hf-file acereason-nemotron-1.1-7b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo bndp/AceReason-Nemotron-1.1-7B-Q4_K_M-GGUF --hf-file acereason-nemotron-1.1-7b-q4_k_m.gguf -c 2048
```
|
SYSPIN/vits_Magahi_Male
|
SYSPIN
| 2025-06-17T14:32:41Z | 5 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2025-04-07T20:57:58Z |
---
license: mit
---
## Notice: Use Coqui AI's TTS for Inference
This model was trained using **SySpin data**. For inference, please use **Coqui AI's TTS** library. You can install it with:
```bash
pip install TTS
```
### Running Inference
You can generate speech using the following command:
```bash
tts --text "Your input text here" \
--model_path path/to/your/model_checkpoint.pth \
--config_path path/to/your/config.json \
--out_path path/to/output.wav
```
Ensure that you replace `path/to/your/...` with the actual paths to your model files.
For more details, visit [Coqui AI TTS](https://github.com/coqui-ai/TTS).
|
mradermacher/TongSearch-QR-1.5B-GGUF
|
mradermacher
| 2025-06-17T14:27:56Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"zh",
"base_model:TongSearch/TongSearch-QR-1.5B",
"base_model:quantized:TongSearch/TongSearch-QR-1.5B",
"license:mit",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-17T14:18:27Z |
---
base_model: TongSearch/TongSearch-QR-1.5B
language:
- en
- zh
library_name: transformers
license: mit
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/TongSearch/TongSearch-QR-1.5B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/TongSearch-QR-1.5B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q2_K.gguf) | Q2_K | 0.9 | |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q3_K_S.gguf) | Q3_K_S | 1.0 | |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q3_K_M.gguf) | Q3_K_M | 1.0 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q3_K_L.gguf) | Q3_K_L | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.IQ4_XS.gguf) | IQ4_XS | 1.1 | |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q4_K_S.gguf) | Q4_K_S | 1.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q4_K_M.gguf) | Q4_K_M | 1.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q5_K_S.gguf) | Q5_K_S | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q5_K_M.gguf) | Q5_K_M | 1.4 | |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q6_K.gguf) | Q6_K | 1.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.Q8_0.gguf) | Q8_0 | 2.0 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/TongSearch-QR-1.5B-GGUF/resolve/main/TongSearch-QR-1.5B.f16.gguf) | f16 | 3.7 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
JayHyeon/pythia-2.8b-DPO_5e-7_1.0vpo_constant-1ep
|
JayHyeon
| 2025-06-17T14:15:09Z | 2 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"gpt_neox",
"text-generation",
"generated_from_trainer",
"dpo",
"trl",
"conversational",
"arxiv:2305.18290",
"base_model:EleutherAI/pythia-2.8b",
"base_model:finetune:EleutherAI/pythia-2.8b",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-15T06:44:56Z |
---
base_model: EleutherAI/pythia-2.8b
library_name: transformers
model_name: pythia-2.8b-DPO_5e-7_1.0vpo_constant-1ep
tags:
- generated_from_trainer
- dpo
- trl
licence: license
---
# Model Card for pythia-2.8b-DPO_5e-7_1.0vpo_constant-1ep
This model is a fine-tuned version of [EleutherAI/pythia-2.8b](https://huggingface.co/EleutherAI/pythia-2.8b).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="JayHyeon/pythia-2.8b-DPO_5e-7_1.0vpo_constant-1ep", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/bonin147/huggingface/runs/vyj5lzbg)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.19.0.dev0
- Transformers: 4.52.4
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
billjeremy/Reinforce-1
|
billjeremy
| 2025-06-17T14:12:01Z | 0 | 0 | null |
[
"CartPole-v1",
"reinforce",
"reinforcement-learning",
"custom-implementation",
"deep-rl-class",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-17T14:11:33Z |
---
tags:
- CartPole-v1
- reinforce
- reinforcement-learning
- custom-implementation
- deep-rl-class
model-index:
- name: Reinforce-1
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: CartPole-v1
type: CartPole-v1
metrics:
- type: mean_reward
value: 487.04 +/- 30.44
name: mean_reward
verified: false
---
# **Reinforce** Agent playing **CartPole-v1**
This is a trained model of a **Reinforce** agent playing **CartPole-v1** .
To learn to use this model and train yours check Unit 4 of the Deep Reinforcement Learning Course: https://huggingface.co/deep-rl-course/unit4/introduction
|
homes11316/klue-roberta-base-klue-sts-mrc
|
homes11316
| 2025-06-17T14:02:14Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"roberta",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-06-17T14:01:13Z |
---
library_name: sentence-transformers
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`sentence_transformers.datasets.NoDuplicatesDataLoader.NoDuplicatesDataLoader` of length 1097 with parameters:
```
{'batch_size': 16}
```
**Loss**:
`sentence_transformers.losses.MultipleNegativesRankingLoss.MultipleNegativesRankingLoss` with parameters:
```
{'scale': 20.0, 'similarity_fct': 'cos_sim'}
```
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 100,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: RobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Citing & Authors
<!--- Describe where people can find more information -->
|
mlx-community/AceReason-Nemotron-1.1-7B-8bit
|
mlx-community
| 2025-06-17T13:47:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"nvidia",
"reasoning",
"math",
"code",
"supervised fine-tuning",
"reinforcement learning",
"pytorch",
"mlx",
"mlx-my-repo",
"conversational",
"en",
"base_model:nvidia/AceReason-Nemotron-1.1-7B",
"base_model:quantized:nvidia/AceReason-Nemotron-1.1-7B",
"license:other",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"8-bit",
"region:us"
] |
text-generation
| 2025-06-17T13:47:02Z |
---
library_name: transformers
license: other
license_name: nvidia-open-model-license
license_link: https://www.nvidia.com/en-us/agreements/enterprise-software/nvidia-open-model-license/
pipeline_tag: text-generation
language:
- en
tags:
- nvidia
- reasoning
- math
- code
- supervised fine-tuning
- reinforcement learning
- pytorch
- mlx
- mlx-my-repo
base_model: nvidia/AceReason-Nemotron-1.1-7B
---
# mlx-community/AceReason-Nemotron-1.1-7B-8bit
The Model [mlx-community/AceReason-Nemotron-1.1-7B-8bit](https://huggingface.co/mlx-community/AceReason-Nemotron-1.1-7B-8bit) was converted to MLX format from [nvidia/AceReason-Nemotron-1.1-7B](https://huggingface.co/nvidia/AceReason-Nemotron-1.1-7B) using mlx-lm version **0.25.2**.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/AceReason-Nemotron-1.1-7B-8bit")
prompt="hello"
if hasattr(tokenizer, "apply_chat_template") and tokenizer.chat_template is not None:
messages = [{"role": "user", "content": prompt}]
prompt = tokenizer.apply_chat_template(
messages, tokenize=False, add_generation_prompt=True
)
response = generate(model, tokenizer, prompt=prompt, verbose=True)
```
|
sergioalves/5c35596a-a98f-48dd-b32f-18b7283b59a4
|
sergioalves
| 2025-06-17T13:43:53Z | 0 | 0 |
peft
|
[
"peft",
"safetensors",
"llama",
"axolotl",
"generated_from_trainer",
"base_model:samoline/ed2a25a4-101c-4530-9249-74a484af2b4b",
"base_model:adapter:samoline/ed2a25a4-101c-4530-9249-74a484af2b4b",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-06-17T13:34:27Z |
---
library_name: peft
base_model: samoline/ed2a25a4-101c-4530-9249-74a484af2b4b
tags:
- axolotl
- generated_from_trainer
model-index:
- name: 5c35596a-a98f-48dd-b32f-18b7283b59a4
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/axolotl-ai-cloud/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/axolotl-ai-cloud/axolotl)
<details><summary>See axolotl config</summary>
axolotl version: `0.4.1`
```yaml
absolute_data_files: false
adapter: lora
base_model: samoline/ed2a25a4-101c-4530-9249-74a484af2b4b
bf16: true
chat_template: llama3
dataset_prepared_path: /workspace/axolotl
datasets:
- data_files:
- 567cb9ef5300a0cf_train_data.json
ds_type: json
format: custom
path: /workspace/input_data/
type:
field_input: input
field_instruction: instruct
field_output: output
format: '{instruction} {input}'
no_input_format: '{instruction}'
system_format: '{system}'
system_prompt: ''
debug: null
deepspeed: null
dpo:
beta: 0.05
enabled: true
group_by_length: false
rank_loss: true
reference_model: NousResearch/Meta-Llama-3-8B-Instruct
early_stopping_patience: null
eval_max_new_tokens: 128
eval_table_size: null
evals_per_epoch: 1
flash_attention: true
fp16: null
fsdp: null
fsdp_config: null
gradient_accumulation_steps: 4
gradient_checkpointing: true
gradient_clipping: 1.0
group_by_length: false
hub_model_id: sergioalves/5c35596a-a98f-48dd-b32f-18b7283b59a4
hub_repo: null
hub_strategy: end
hub_token: null
learning_rate: 5.0e-07
load_in_4bit: true
load_in_8bit: false
local_rank: null
logging_steps: 1
lora_alpha: 64
lora_dropout: 0.1
lora_fan_in_fan_out: null
lora_model_dir: null
lora_r: 32
lora_target_linear: true
lr_scheduler: cosine
max_steps: 200
micro_batch_size: 8
mixed_precision: bf16
mlflow_experiment_name: /tmp/567cb9ef5300a0cf_train_data.json
model_type: AutoModelForCausalLM
num_epochs: 2
optimizer: adamw_bnb_8bit
output_dir: miner_id_24
pad_to_sequence_len: true
resume_from_checkpoint: null
s2_attention: null
sample_packing: false
saves_per_epoch: 1
sequence_len: 1024
strict: false
tf32: false
tokenizer_type: AutoTokenizer
train_on_inputs: false
trust_remote_code: true
val_set_size: 0.05
wandb_entity: null
wandb_mode: online
wandb_name: 875cec71-5ce1-4a7f-b2b0-b2064c0cc823
wandb_project: s56-7
wandb_run: your_name
wandb_runid: 875cec71-5ce1-4a7f-b2b0-b2064c0cc823
warmup_steps: 25
weight_decay: 0.05
xformers_attention: true
```
</details><br>
# 5c35596a-a98f-48dd-b32f-18b7283b59a4
This model is a fine-tuned version of [samoline/ed2a25a4-101c-4530-9249-74a484af2b4b](https://huggingface.co/samoline/ed2a25a4-101c-4530-9249-74a484af2b4b) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 1.1550
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use OptimizerNames.ADAMW_BNB with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 25
- training_steps: 200
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:------:|:----:|:---------------:|
| 1.0929 | 0.0003 | 1 | 1.1556 |
| 1.0499 | 0.0305 | 100 | 1.1553 |
| 1.1371 | 0.0609 | 200 | 1.1550 |
### Framework versions
- PEFT 0.13.2
- Transformers 4.46.0
- Pytorch 2.5.0+cu124
- Datasets 3.0.1
- Tokenizers 0.20.1
|
rca123456/mind-guard-mental_health_chatbot
|
rca123456
| 2025-06-17T13:42:11Z | 0 | 0 |
peft
|
[
"peft",
"mental-health",
"chatbot",
"ai-therapist",
"gradio",
"lora",
"transformers",
"unsloth",
"en",
"license:mit",
"region:us"
] | null | 2025-06-17T12:43:38Z |
---
license: mit
language:
- en
base_model:
- unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
title: 🧠 MindGuard - Mental Health AI Chatbot
emoji: 🧘♂️
colorFrom: pink
colorTo: purple
sdk: docker
sdk_version: "1.0"
app_file: app.py
pinned: false
models:
- unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit
- mthabet00/serenity-AI_Therapist
tags:
- mental-health
- chatbot
- ai-therapist
- gradio
- peft
- lora
- transformers
- unsloth
gpu: true
---
# 🧠 MindGuard: Mental Health Chatbot
MindGuard is an empathetic, AI-powered mental health companion built using large language models. It is designed to offer supportive, non-judgmental conversations for users who are feeling emotionally overwhelmed, stressed, or in need of someone to talk to.
---
## 💡 What It Does
- Provides comforting, human-like responses using an LLM fine-tuned for therapeutic dialogue.
- Retains context to maintain natural conversations.
- Designed with compassion, emotional sensitivity, and mental well-being in mind.
---
# How It Works
---
MindGuard uses:
- **Base Model:** `unsloth/llama-3.2-3b-instruct-unsloth-bnb-4bit`
- **PEFT Fine-Tuned Model:** `mthabet00/serenity-AI_Therapist`
(Using PEFT for efficient, low-resource fine-tuning)
The chatbot is deployed using **Gradio**, offering a simple and safe UI for users to type their thoughts and receive emotionally aware replies.
# 🚀 Running the Project
---
This Space automatically runs:
- `app.py`
# 🛡️ Disclaimer
---
MindGuard is **not a substitute for professional mental health care**.
If you are in crisis or need help, please reach out to certified professionals or hotlines in your region.
# 📜 License
---
MIT License
# 🙌 Acknowledgements
---
- [Unsloth](https://huggingface.co/unsloth)
- [Serenity AI Therapist](https://huggingface.co/mthabet00/serenity-AI_Therapist)
- Hugging Face 🤗
|
antxinyuan/SSP
|
antxinyuan
| 2025-06-17T13:41:29Z | 0 | 0 | null |
[
"arxiv:2506.10601",
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T13:14:36Z |
---
license: apache-2.0
---
# Semantic-decoupled Spatial Partition Guided Point-supervised Oriented Object Detection
[](https://arxiv.org/pdf/2506.10601)
[](https://github.com/antxinyuan/ssp)
🔥 We appreciate the attention to our paper. The code is available at [Github repo](https://github.com/antxinyuan/ssp).
> Production from Institute of Computing Technology, Chinese Academy of Sciences.
> Primary contact: Xinyuan Liu ( [email protected] ).
## TL;DR
This repository contains the source code of [**Semantic-decoupled Spatial Partition Guided Point-supervised Oriented Object Detection**](https://arxiv.org/pdf/2506.10601).
To tackle inadequate sample assignment and instance confusion in point-supervised oriented object detection for remote sensing dense scenes, we propose SSP (Semantic-decoupled Spatial Partition), a framework integrating rule-driven prior injection and data-driven label purification. Its core innovations include pixel-level spatial partition for sample assignment and semantic-modulated box extraction for pseudo-label generation.
### Pseudo-label performance
All pseudo-labeling results are available in [pseudo_labels](https://huggingface.co/antxinyuan/SSP/blob/main/pseudo_labels.zip).
| Dataset | mAP | mIoU | ann_file |
| :-: | :-: | :-: | :-: |
| DOTA-v1.0 | 34.95 |49.03 | pseudo_labels/ssp_dotav10_hybrid/ |
| DOTA-v1.5 | 28.89 | 44.92 | pseudo_labels/ssp_dotav15_hybrid/ |
| DOTA-v2.0 | 24.72 | 41.93 | pseudo_labels/ssp_dotav20_hybrid/ |
### Detectors performance
| Dataset | Config | Log | Checkpoint | mAP(paper) | mAP(reproduced) |
| :-: | :-: | :-: | :-: | :-: | :-: |
| SSP(RFOCS) | [config](https://github.com/antxinyuan/ssp/blob/main/configs/ssp/rfcos_ssp_dotav10.py) | [hugging face](https://huggingface.co/antxinyuan/SSP/blob/main/logs/rfcos_ssp_dotav10.json) | [hugging face](https://huggingface.co/antxinyuan/SSP/blob/main/models/rfcos_ssp_dotav10-4c17ff33.pth) | 45.78 | 45.82 |
| SSP(ORCNN) | [config](https://github.com/antxinyuan/ssp/blob/main/configs/ssp/orcnn_ssp_dotav10.py) | [hugging face](https://huggingface.co/antxinyuan/SSP/blob/main/logs/orcnn_ssp_dotav10.json) | [hugging face](https://huggingface.co/antxinyuan/SSP/blob/main/models/orcnn_ssp_dotav10-2df034d3.pth) | 47.86 | 48.81 |
| SSP(ReDet) | [config](https://github.com/antxinyuan/ssp/blob/main/configs/ssp/orcnn_ssp_dotav20.py) | [hugging face](https://huggingface.co/antxinyuan/SSP/blob/main/logs/redet_ssp_dotav10.json) | [hugging face](https://huggingface.co/antxinyuan/SSP/blob/main/models/redet_ssp_dotav10-eed2738e.pth) | 48.50 | 49.02 |
## 🖊️ Citation
If you find this work helpful for your research, please consider giving this repo a star ⭐ and citing our papers:
## Citation
If this work is helpful for your research, please consider citing the following BibTeX entry.
``` bibtex
@misc{liu2025ssp,
title={Semantic-decoupled Spatial Partition Guided Point-supervised Oriented Object Detection},
author={Xinyuan Liu and Hang Xu and Yike Ma and Yucheng Zhang and Feng Dai},
year={2025},
eprint={2506.10601},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.10601},
}
@inproceedings{xu2024acm,
title={Rethinking boundary discontinuity problem for oriented object detection},
author={Xu, Hang and Liu, Xinyuan and Xu, Haonan and Ma, Yike and Zhu, Zunjie and Yan, Chenggang and Dai, Feng},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
pages={17406--17415},
year={2024}
}
```
## Related resources
We acknowledge all the open-source contributors for the following projects to make this work possible:
- [PointOBB-v2](https://github.com/VisionXLab/PointOBB-v2)
- [MMRotate](https://github.com/open-mmlab/mmrotate)
|
JSinBUPT/MindShot
|
JSinBUPT
| 2025-06-17T13:29:35Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T03:19:00Z |
---
license: apache-2.0
---
# MindShot
## Introduction
This repo holds the pretrained weights for MindShot (https://github.com/JSinBUPT/MindShot)
## Usage
1. Clone the code repo. `git clone https://github.com/JSinBUPT/MindShot`
2. Create a directory under the code repo `./src/train_logs`
3. Download the folder that contains pretrained weights into `./train_logs`
4. Run the scripts within the code repo `./src`
|
opdullah/bert-turkish-ecomm-absa
|
opdullah
| 2025-06-17T13:27:11Z | 14 | 0 | null |
[
"safetensors",
"bert",
"text-classification",
"tr",
"base_model:dbmdz/bert-base-turkish-cased",
"base_model:finetune:dbmdz/bert-base-turkish-cased",
"license:apache-2.0",
"region:us"
] |
text-classification
| 2025-06-16T13:55:24Z |
---
license: apache-2.0
language:
- tr
base_model:
- dbmdz/bert-base-turkish-cased
pipeline_tag: text-classification
---
# Turkish BERT for Aspect-Based Sentiment Analysis
This model is a fine-tuned version of [dbmdz/bert-base-turkish-cased](https://huggingface.co/dbmdz/bert-base-turkish-cased) specifically trained for aspect-based sentiment analysis on Turkish e-commerce product reviews.
## Model Description
- **Base Model**: dbmdz/bert-base-turkish-cased
- **Task**: Sequence Classification (Aspect-Based Sentiment Analysis)
- **Language**: Turkish
- **Domain**: E-commerce product reviews
## Model Performance
- **F1 Score**: 88% on test set
- **Test Set Size**: 4,000 samples
- **Training Set Size**: 36,000 samples
## Training Details
### Training Data
- **Dataset Size**: 36,000 reviews
- **Data Source**: Private e-commerce product review dataset
- **Domain**: E-commerce product reviews in Turkish
- **Coverage**: Over 500 product categories
### Training Configuration
- **Epochs**: 5
- **Task Type**: Sequence Classification
- **Input Format**: `[aspect_term] [SEP] [review_text]`
- **Label Classes**:
- `positive`: Positive sentiment towards the aspect
- `negative`: Negative sentiment towards the aspect
- `neutral`: Neutral sentiment towards the aspect
### Training Loss
The model showed consistent improvement across epochs:
| Epoch | Loss |
|-------|------|
| 1 | 0.47 |
| 2 | 0.34 |
| 3 | 0.25 |
| 4 | 0.22 |
| 5 | 0.11 |
## Usage
### Option 1: Using Pipeline (Recommended)
```python
from transformers import AutoTokenizer, AutoModelForSequenceClassification
from transformers import pipeline
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("opdullah/bert-turkish-ecomm-absa")
model = AutoModelForSequenceClassification.from_pretrained("opdullah/bert-turkish-ecomm-absa")
# Create pipeline
sentiment_analyzer = pipeline("text-classification",
model=model,
tokenizer=tokenizer)
# Example usage
aspect = "arka kamerası"
review = "Bu telefonun arka kamerası çok iyi ama bataryası yetersiz."
text = f"{aspect} [SEP] {review}"
result = sentiment_analyzer(text)
print(result)
```
**Expected Output:**
```python
[{'label': 'positive', 'score': 0.9998155236244202}]
```
### Option 2: Manual Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("opdullah/bert-turkish-ecomm-absa")
model = AutoModelForSequenceClassification.from_pretrained("opdullah/bert-turkish-ecomm-absa")
# Example aspect and review
aspect = "arka kamerası"
review = "Bu telefonun arka kamerası çok iyi ama bataryası yetersiz."
# Tokenize aspect and review together
inputs = tokenizer(aspect, review, return_tensors="pt", truncation=True, padding=True)
# Get predictions
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class_id = predictions.argmax(dim=-1).item()
confidence = predictions.max().item()
# Convert prediction to label
predicted_label = model.config.id2label[predicted_class_id]
print(f"Aspect: {aspect}")
print(f"Sentiment: {predicted_label}")
print(f"Confidence: {confidence:.4f}")
```
**Expected Output:**
```
Aspect: arka kamerası
Sentiment: positive
Confidence: 0.9998
```
### Option 3: Batch Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForSequenceClassification
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("opdullah/bert-turkish-ecomm-absa")
model = AutoModelForSequenceClassification.from_pretrained("opdullah/bert-turkish-ecomm-absa")
# Example aspect-review pairs
examples = [
("arka kamerası", "Bu telefonun arka kamerası çok iyi ama bataryası yetersiz."),
("bataryası", "Bu telefonun arka kamerası çok iyi ama bataryası yetersiz."),
("fiyatı", "Ürünün fiyatı çok uygun ve kalitesi de iyi."),
]
aspects = [ex[0] for ex in examples]
reviews = [ex[1] for ex in examples]
# Tokenize all pairs
inputs = tokenizer(aspects, reviews, return_tensors="pt", truncation=True, padding=True)
# Get predictions for all pairs
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class_ids = predictions.argmax(dim=-1)
confidences = predictions.max(dim=-1).values
# Display results
for i, (aspect, review) in enumerate(examples):
predicted_label = model.config.id2label[predicted_class_ids[i].item()]
confidence = confidences[i].item()
print(f"Aspect: {aspect}")
print(f"Sentiment: {predicted_label} (confidence: {confidence:.4f})")
print("-" * 40)
```
**Expected Output:**
```
Aspect: arka kamerası
Sentiment: positive (confidence: 0.9998)
Aspect: bataryası
Sentiment: negative (confidence: 0.9990)
Aspect: fiyatı
Sentiment: positive (confidence: 0.9998)
```
## Combined Usage with Aspect Extraction (Recommended)
This model works perfectly with the aspect extraction model [opdullah/bert-turkish-ecomm-aspect-extraction](https://huggingface.co/opdullah/bert-turkish-ecomm-aspect-extraction) for complete aspect-based sentiment analysis:
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification, AutoModelForSequenceClassification, pipeline
import torch
# Load aspect extraction model
aspect_extractor = pipeline("token-classification",
model="opdullah/bert-turkish-ecomm-aspect-extraction",
aggregation_strategy="simple")
# Load sentiment analysis model
sentiment_tokenizer = AutoTokenizer.from_pretrained("opdullah/bert-turkish-ecomm-absa")
sentiment_model = AutoModelForSequenceClassification.from_pretrained("opdullah/bert-turkish-ecomm-absa")
def analyze_aspect_sentiment(review):
# Extract aspects
aspects = aspect_extractor(review)
results = []
for aspect in aspects:
if aspect['entity_group'] == 'ASPECT':
aspect_text = aspect['word']
# Analyze sentiment
inputs = sentiment_tokenizer(aspect_text, review, return_tensors="pt", truncation=True)
with torch.no_grad():
outputs = sentiment_model(**inputs)
prediction = outputs.logits.argmax().item()
sentiment = sentiment_model.config.id2label[prediction]
results.append({'aspect': aspect_text, 'sentiment': sentiment})
return results
# Usage
review = "Bu telefonun arka kamerası çok iyi ama bataryası yetersiz."
results = analyze_aspect_sentiment(review)
for result in results:
print(f"{result['aspect']}: {result['sentiment']}")
```
**Expected Output:**
```
arka kamerası: positive
bataryası: negative
```
## Label Mapping
```python
id2label = {
0: "negative",
1: "neutral",
2: "positive"
}
label2id = {
"negative": 0,
"neutral": 1,
"positive": 2
}
```
## Intended Use
This model is designed for:
- Analyzing sentiment of specific aspects in Turkish e-commerce product reviews
- Building complete aspect-based sentiment analysis systems
- Understanding customer opinions on specific product features
- Supporting recommendation systems and review analysis tools
## Limitations
- Trained specifically on e-commerce domain data
- Requires aspect terms to be identified beforehand (use with aspect extraction model)
- Performance may vary on other domains or text types
- Limited to Turkish language
- Based on private dataset, so reproducibility may be limited
## Citation
If you use this model, please cite:
```
@misc{turkish-bert-absa,
title={Turkish BERT for Aspect-Based Sentiment Analysis},
author={Abdullah Koçak},
year={2025},
url={https://huggingface.co/opdullah/bert-turkish-ecomm-absa}
}
```
## Base Model Citation
```
@misc{schweter2020bertbase,
title={BERTurk - BERT models for Turkish},
author={Stefan Schweter},
year={2020},
url={https://huggingface.co/dbmdz/bert-base-turkish-cased}
}
```
## Related Models
- [opdullah/bert-turkish-ecomm-aspect-extraction](https://huggingface.co/opdullah/bert-turkish-ecomm-aspect-extraction) - For extracting aspect terms from Turkish e-commerce reviews
|
opdullah/bert-turkish-ecomm-aspect-extraction
|
opdullah
| 2025-06-17T13:25:52Z | 9 | 0 | null |
[
"safetensors",
"bert",
"e-commerce",
"ner",
"named-entity-recognition",
"nlp",
"token-classification",
"tr",
"base_model:dbmdz/bert-base-turkish-cased",
"base_model:finetune:dbmdz/bert-base-turkish-cased",
"license:apache-2.0",
"region:us"
] |
token-classification
| 2025-06-16T12:50:20Z |
---
license: apache-2.0
language:
- tr
base_model:
- dbmdz/bert-base-turkish-cased
pipeline_tag: token-classification
tags:
- e-commerce
- ner
- named-entity-recognition
- bert
- nlp
---
# Turkish BERT for Aspect Term Extraction
This model is a fine-tuned version of [dbmdz/bert-base-turkish-cased](https://huggingface.co/dbmdz/bert-base-turkish-cased) specifically trained for aspect term extraction from Turkish e-commerce product reviews.
## Model Description
- **Base Model**: dbmdz/bert-base-turkish-cased
- **Task**: Token Classification (Aspect Term Extraction)
- **Language**: Turkish
- **Domain**: E-commerce product reviews
## Model Performance
- **F1 Score**: 83% on test set
- **Test Set Size**: 2,000 samples
- **Training Set Size**: ~16,000 samples
## Training Details
### Training Data
- **Dataset Size**: 16,000 reviews
- **Data Source**: Private e-commerce product review dataset
- **Domain**: E-commerce product reviews in Turkish
- **Coverage**: Over 500 product categories
### Training Configuration
- **Epochs**: 5
- **Task Type**: Token Classification
- **Label Scheme**: BIO tagging
- `B-ASPECT`: Beginning of an aspect term
- `I-ASPECT`: Inside/continuation of an aspect term
- `O`: Outside (not an aspect term)
### Training Loss
The model showed consistent improvement across epochs:
| Epoch | Loss |
|-------|--------|
| 1 | 0.1758 |
| 2 | 0.1749 |
| 3 | 0.1217 |
| 4 | 0.1079 |
| 5 | 0.0699 |
## Usage
### Option 1: Using Pipeline
```python
from transformers import AutoTokenizer, AutoModelForTokenClassification
from transformers import pipeline
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("opdullah/bert-turkish-ecomm-aspect-extraction")
model = AutoModelForTokenClassification.from_pretrained("opdullah/bert-turkish-ecomm-aspect-extraction")
# Create pipeline
aspect_extractor = pipeline("token-classification",
model=model,
tokenizer=tokenizer,
aggregation_strategy="simple")
# Example usage
text = "Bu telefonun kamerası çok iyi ama bataryası yetersiz."
results = aspect_extractor(text)
print(results)
```
**Expected Output:**
```python
[{'entity_group': 'ASPECT', 'score': 0.99498886, 'word': 'kamerası', 'start': 13, 'end': 21},
{'entity_group': 'ASPECT', 'score': 0.9970175, 'word': 'bataryası', 'start': 34, 'end': 43}]
```
### Option 2: Manual Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForTokenClassification
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("opdullah/bert-turkish-ecomm-aspect-extraction")
model = AutoModelForTokenClassification.from_pretrained("opdullah/bert-turkish-ecomm-aspect-extraction")
# Example text
text = "Bu telefonun kamerası çok iyi ama bataryası yetersiz."
# Tokenize input
inputs = tokenizer(text, return_tensors="pt", truncation=True, padding=True)
# Get predictions
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class_ids = predictions.argmax(dim=-1)
# Convert predictions to labels
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][0])
predicted_labels = [model.config.id2label[class_id.item()] for class_id in predicted_class_ids[0]]
# Display results
for token, label in zip(tokens, predicted_labels):
if token not in ['[CLS]', '[SEP]', '[PAD]']:
print(f"{token}: {label}")
```
**Expected Output:**
```
Bu: O
telefonun: O
kamerası: B-ASPECT
çok: O
iyi: O
ama: O
batarya: B-ASPECT
##sı: I-ASPECT
yetersiz: O
.: O
```
### Option 3: Batch Inference
```python
import torch
from transformers import AutoTokenizer, AutoModelForTokenClassification
# Load model and tokenizer
tokenizer = AutoTokenizer.from_pretrained("opdullah/bert-turkish-ecomm-aspect-extraction")
model = AutoModelForTokenClassification.from_pretrained("opdullah/bert-turkish-ecomm-aspect-extraction")
# Example texts for batch processing
texts = [
"Bu telefonun kamerası çok iyi ama bataryası yetersiz.",
"Ürünün fiyatı uygun ancak kalitesi düşük.",
"Teslimat hızı mükemmel, ambalaj da gayet sağlam."
]
# Tokenize all texts
inputs = tokenizer(texts, return_tensors="pt", truncation=True, padding=True)
# Get predictions for all texts
with torch.no_grad():
outputs = model(**inputs)
predictions = torch.nn.functional.softmax(outputs.logits, dim=-1)
predicted_class_ids = predictions.argmax(dim=-1)
# Process results for each text
for i, text in enumerate(texts):
print(f"\nText {i+1}: {text}")
print("-" * 50)
# Get tokens for this specific text
tokens = tokenizer.convert_ids_to_tokens(inputs["input_ids"][i])
predicted_labels = [model.config.id2label[class_id.item()] for class_id in predicted_class_ids[i]]
# Display results
for token, label in zip(tokens, predicted_labels):
if token not in ['[CLS]', '[SEP]', '[PAD]']:
print(f"{token}: {label}")
```
**Expected Output:**
**Text 1:** Bu telefonun kamerası çok iyi ama bataryası yetersiz.
```
Bu: O
telefonun: O
kamerası: B-ASPECT
çok: O
iyi: O
ama: O
batarya: B-ASPECT
##sı: I-ASPECT
yetersiz: O
.: O
```
**Text 2:** Ürünün fiyatı uygun ancak kalitesi düşük.
```
Ürünün: O
fiyatı: B-ASPECT
uygun: O
ancak: O
kalitesi: B-ASPECT
düşük: O
.: O
```
**Text 3:** Teslimat hızı mükemmel, ambalaj da gayet sağlam.
```
Teslim: B-ASPECT
##at: I-ASPECT
hızı: I-ASPECT
mükemmel: O
,: O
ambalaj: B-ASPECT
da: O
gayet: O
sağlam: O
.: O
```
## Label Mapping
```python
id2label = {
0: "O",
1: "B-ASPECT",
2: "I-ASPECT"
}
label2id = {
"O": 0,
"B-ASPECT": 1,
"I-ASPECT": 2
}
```
## Intended Use
This model is designed for:
- Extracting aspect terms from Turkish e-commerce product reviews
- Identifying product features and attributes mentioned in reviews
- Supporting aspect-based sentiment analysis pipelines
## Limitations
- Trained specifically on e-commerce domain data
- Performance may vary on other domains or text types
- Limited to Turkish language
- Based on private dataset, so reproducibility may be limited
## Citation
If you use this model, please cite:
```
@misc{turkish-bert-aspect-extraction,
title={Turkish BERT for Aspect Term Extraction},
author={Abdullah Koçak},
year={2025},
url={https://huggingface.co/opdullah/bert-turkish-ecomm-aspect-extraction}
}
```
## Base Model Citation
```
@misc{schweter2020bertbase,
title={BERTurk - BERT models for Turkish},
author={Stefan Schweter},
year={2020},
publisher={Hugging Face},
url={https://huggingface.co/dbmdz/bert-base-turkish-cased}
}
```
|
basemmohamed/pdf_model
|
basemmohamed
| 2025-06-17T13:14:29Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T13:14:23Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
wiamabd/wav2vec2-large-xlsr-exp-lot1-only
|
wiamabd
| 2025-06-17T13:08:00Z | 1 | 0 |
transformers
|
[
"transformers",
"safetensors",
"wav2vec2",
"automatic-speech-recognition",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
automatic-speech-recognition
| 2025-06-14T19:00:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
altaweel/gemma-ultrasound-1b-v2
|
altaweel
| 2025-06-17T13:03:16Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"generated_from_trainer",
"trl",
"sft",
"base_model:google/gemma-3-1b-pt",
"base_model:finetune:google/gemma-3-1b-pt",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T12:50:29Z |
---
base_model: google/gemma-3-1b-pt
library_name: transformers
model_name: gemma-ultrasound-1b-v2
tags:
- generated_from_trainer
- trl
- sft
licence: license
---
# Model Card for gemma-ultrasound-1b-v2
This model is a fine-tuned version of [google/gemma-3-1b-pt](https://huggingface.co/google/gemma-3-1b-pt).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="altaweel/gemma-ultrasound-1b-v2", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with SFT.
### Framework versions
- TRL: 0.15.2
- Transformers: 4.52.4
- Pytorch: 2.7.0
- Datasets: 3.3.2
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
ShunxunYu/uuu_fine_tune_taipower
|
ShunxunYu
| 2025-06-17T13:02:40Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T07:01:51Z |
---
license: apache-2.0
---
|
omarabb315/OCR__merged_nanonets_3b
|
omarabb315
| 2025-06-17T12:57:30Z | 0 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"qwen2_5_vl",
"image-text-to-text",
"generated_from_trainer",
"unsloth",
"trl",
"sft",
"conversational",
"base_model:nanonets/Nanonets-OCR-s",
"base_model:finetune:nanonets/Nanonets-OCR-s",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
image-text-to-text
| 2025-06-17T12:55:47Z |
---
base_model: nanonets/Nanonets-OCR-s
library_name: transformers
model_name: OCR__merged_nanonets_3b
tags:
- generated_from_trainer
- unsloth
- trl
- sft
licence: license
---
# Model Card for OCR__merged_nanonets_3b
This model is a fine-tuned version of [nanonets/Nanonets-OCR-s](https://huggingface.co/nanonets/Nanonets-OCR-s).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="omarabb315/OCR__merged_nanonets_3b", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/omarabb315-al-jazeera-english/OCR_nanonets_3b_model/runs/xoqrec7b)
This model was trained with SFT.
### Framework versions
- TRL: 0.18.2
- Transformers: 4.52.4
- Pytorch: 2.7.0
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
Davidozito/Full-finetune
|
Davidozito
| 2025-06-17T12:45:16Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"xlm-roberta",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-17T12:36:10Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Inventors-Hub/Falcon3-10B-Instruct-BehaviorTree-3-epochs-GGUF
|
Inventors-Hub
| 2025-06-17T12:32:05Z | 81 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama",
"behavior-tree",
"swarm-robotics",
"xml",
"lora",
"self-instruct",
"control-systems",
"text-generation",
"en",
"dataset:Inventors-Hub/SwarmChat-BehaviorTree-Dataset",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T21:38:06Z |
---
library_name: transformers
tags:
- behavior-tree
- swarm-robotics
- xml
- lora
- self-instruct
- control-systems
- transformers
- text-generation
datasets:
- Inventors-Hub/SwarmChat-BehaviorTree-Dataset
language:
- en
pipeline_tag: text-generation
license: apache-2.0
---
# Falcon3-10B-Instruct-BehaviorTree-3-epochs-GGUF
A GGUF-quantized variant of **Falcon3-10B-Instruct-BehaviorTree-3epochs** offering two quantization formats (f16 and q4_k_m) for ultra-lightweight inference on edge devices.
## Model Overview
- **Purpose**
Same functionality as the full-precision model: convert natural-language commands into safe, syntactically valid XML behavior trees for swarm-robotics.
- **Base model**
`tiiuae/Falcon3-10B-Instruct` + LoRA (rank=16, α=16)
- **Quantization formats**
- **f16 GGUF**: half-precision weights
- **q4_k_m GGUF**: 4-bit kernel-wise quantization
## Data
- **Training dataset**
`Inventors-Hub/SwarmChat-BehaviorTree-Dataset` (2 063 synthetic examples from OpenAI’s o1-mini)
## Usage
```python
from huggingface_hub import hf_hub_download
from llama_cpp import Llama
# Download the behavior-tree model
model_path = hf_hub_download(
repo_id="Inventors-Hub/SwarmChat-models",
repo_type="model",
filename="Falcon3-10B-Instruct-BehaviorTree-3epochs.Q4_K_M.gguf",
)
# Initialize the Llama model
llm = Llama(
model_path=model_path,
n_ctx=1024*4,
low_vram=True,
f16_kv=True,
use_mmap=True,
use_mlock=False,
)
prompt = """
SYSTEM:
<<SYS>>You are a helpful, respectful, and honest AI assistant. Your task is to generate well-structured XML code for behavior trees based on the provided instructions.<</SYS>>
INSTRUCTIONS:
It is CRITICAL to use only the following behaviors structured as a dictionary:
{
say: Action Node: Speak the provided message using text-to-speech if it hasn't been spoken before. Args: message (str): The message to be spoken. Returns: Always returns SUCCESS, indicating the action was executed.
flocking: Action Node: Adjust the agent's move vector by blending alignment and separation forces from nearby agents. Returns: Always returns SUCCESS, indicating the action was executed.
align_with_swarm: Action Node: Align the agent's move vector with the average movement of nearby agents. Returns: Always returns SUCCESS, indicating the action was executed.
is_obstacle_detected: Condition node: Determine if any obstacles are detected in the vicinity of the agent. Returns: SUCCESS if an obstacle is detected, FAILURE otherwise.
form_line: Action node: Direct the agent to form a line towards the center of the window. This function adjuststhe agent's position to align it with the center. Returns: Always returns SUCCESS,
}
to construct behavior tree in XML format to the following command, including in the behaviour tree a behaviour that is not in the provided dictionary can result in damage to the agents, and potentially humans, therefore you are not allowed to do so, AVOID AT ALL COSTS.
USER COMMAND:
generate behavior tree to "form a line". Take a step back and think deeply about the behavior you need for this command. Take another step back and think of the xml structure and the behavior you used.
The output MUST follow this XML structure exactly, including:
- A root element with <root BTCPP_format and main_tree_to_execute attributes.
- A <BehaviorTree> element with an inner structure of Sequences, Fallback, Conditions, and Actions.
- A <TreeNodesModel> section listing all node models.
- No additional text or commentary outside the XML.
Output only the XML behavior tree without extra text.
OUTPUT:
"""
output = llm(
prompt,
temperature=0,
max_tokens=1024,
top_p=0.95,
top_k=50,
repeat_penalty=1.1
)
response = output.get("choices", [{}])[0].get("text", "").strip()
print(response)
|
NhaiDao/SFT_TRAIN_FROM_SCRATCH_checkpoint_9375
|
NhaiDao
| 2025-06-17T12:31:21Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T12:30:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NhaiDao/SFT_TRAIN_FROM_SCRATCH_checkpoint_8750
|
NhaiDao
| 2025-06-17T12:30:50Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T12:30:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
diegolacomba/multilingual-e5-small-legal-mnrl-1
|
diegolacomba
| 2025-06-17T12:28:40Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"bert",
"sentence-similarity",
"feature-extraction",
"generated_from_trainer",
"dataset_size:58898",
"loss:MultipleNegativesRankingLoss",
"arxiv:1908.10084",
"arxiv:1705.00652",
"base_model:intfloat/multilingual-e5-small",
"base_model:finetune:intfloat/multilingual-e5-small",
"model-index",
"autotrain_compatible",
"text-embeddings-inference",
"endpoints_compatible",
"region:us"
] |
sentence-similarity
| 2025-06-17T12:28:13Z |
---
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- generated_from_trainer
- dataset_size:58898
- loss:MultipleNegativesRankingLoss
base_model: intfloat/multilingual-e5-small
widget:
- source_sentence: 'query: ¿Cómo se deben determinar las cuotas a cuenta del IRPF
en un año con actividad económica suspendida?'
sentences:
- 'passage A los efectos de este Impuesto, se considerará promotor de edificaciones
el propietario de inmuebles que construyó (promotor-constructor) o contrató la
construcción (promotor) de los mismos para destinarlos a la venta, el alquiler
o el uso propio.
c) Dichas ejecuciones de obra tengan por objeto la construcción o rehabilitación
de edificios destinados fundamentalmente a viviendas, incluidos los locales, anejos,
instalaciones y servicios complementarios en ella situados.
d) Las referidas ejecuciones de obra consistan materialmente en la construcción
o rehabilitación de los citados edificios.
3.- En consecuencia, las ejecuciones de obra concertadas directamente entre el
promotor y el contratista (la consultante), que tengan por objeto la rehabilitación
de una vivienda, tributan al tipo reducido del 10 por ciento. El tipo reducido
se aplica con independencia de que el promotor concierte la totalidad de la obra
de construcción con un solo empresario o concierte la realización con varios empresarios
realizando cada uno de ellos una parte de la obra según su especialidad.
No obstante, las ejecuciones de obra realizadas por subcontratistas para otros
contratistas (la consultante), que a su vez contraten con el promotor, tributarán
por el Impuesto sobre el Valor Añadido al tipo general del 21 por ciento.
4.- Lo que comunico a Vd. con efectos vinculantes, conforme a lo dispuesto en
el apartado 1 del artículo 89 de la Ley 58/2003, de 17 de diciembre, General Tributaria.'
- 'passage Descripción de hechos: La consultante es titular de una actividad económica
de "otros cafés y bares". El rendimiento neto de la actividad se determina por
el método de estimación objetiva y tributa en el IVA por el régimen especial simplificado.
Desde la declaración de alarma en marzo de 2020 ha tenido cerrada la actividad
y la va a seguir teniendo cerrada durante todo el año 2020, pues las restricciones
que tiene que aplicar no la hacen rentable.
Cuestión planteada: Forma de calcular, en 2020, el pago fraccionado a cuenta del
IRPF y el ingreso a cuenta trimestral del IVA.'
- 'passage No obstante, el artículo 22.Trece de la Ley 37/1992, declara la exención
de:
“Los transportes de viajeros y sus equipajes por vía marítima o aérea procedentes
de o con destino a un puerto o aeropuerto situado fuera del ámbito espacial del
Impuesto.
Se entenderán incluidos en este apartado los transportes por vía aérea amparados
por un único título de transporte que incluya vuelos de conexión aérea.”.
En consecuencia, los servicios de transporte consultados, que tienen su origen
o destino en un aeropuerto fuera del territorio de aplicación del impuesto sobre
el valor añadido, estarán sujetos pero exentos del Impuesto sobre el Valor Añadido.
2.- Por otra parte, el artículo 164, apartado uno, de la Ley del Impuesto sobre
el Valor Añadido, en el que se regulan las obligaciones de los sujetos pasivos,
establece lo siguiente:
“Uno. Sin perjuicio de lo establecido en el Título anterior, los sujetos pasivos
del Impuesto estarán obligados, con los requisitos, límites y condiciones que
se determinen reglamentariamente, a:
(…)
3º. Expedir y entregar factura de todas sus operaciones, ajustada a lo que se
determine reglamentariamente.”.
El desarrollo reglamentario de dicho precepto se ha llevado a cabo por el Reglamento
por el que se regulan las obligaciones de facturación, aprobado por el artículo
1 del Real Decreto 1619/2012, de 30 de noviembre (BOE de 1 de diciembre).
El artículo 2 del mencionado Reglamento dispone que:'
- source_sentence: 'query: ¿Cuál es el porcentaje de impuesto que corresponde a dispositivos
destinados a aliviar discapacidades bajo la ley actual?'
sentences:
- 'passage Contestación completa: 1.- El artículo 90, apartado uno, de la Ley 37/1992,
de 28 de diciembre, del Impuesto sobre el Valor Añadido (BOE del 29 de diciembre),
dispone que el Impuesto se exigirá al tipo del 21 por ciento, salvo lo dispuesto
en el artículo siguiente.
2.- El artículo 91, apartado Uno.1, número 6º, letra c) de la Ley 37/1992 dispone
lo siguiente:
“Uno. Se aplicará el tipo del 10 por ciento a las operaciones siguientes:
1. Las entregas, adquisiciones intracomunitarias o importaciones de los bienes
que se indican a continuación:
(…)
6.º Los siguientes bienes:
(…)
c) Los equipos médicos, aparatos y demás instrumental, relacionados en el apartado
octavo del anexo de esta Ley, que, por sus características objetivas, estén diseñados
para aliviar o tratar deficiencias, para uso personal y exclusivo de personas
que tengan deficiencias físicas, mentales, intelectuales o sensoriales, sin perjuicio
de lo previsto en el apartado dos.1 de este artículo.
No se incluyen en esta letra otros accesorios, recambios y piezas de repuesto
de dichos bienes.”.
El apartado octavo del Anexo de la Ley 37/1992, establece lo siguiente:
“Octavo. Relación de bienes a que se refiere el artículo 91.Uno.1. 6.ºc) de esta
Ley.
(…)
– Sillas terapéuticas y de ruedas, así como los cojines antiescaras y arneses
para el uso de las mismas, muletas, andadores y grúas para movilizar personas
con discapacidad.
(…).”.
3.- Por su parte, el artículo 91, apartado dos.1, número 4º de la Ley 37/1992,
dispone que:
“Dos. Se aplicará el tipo del 4 por ciento a las operaciones siguientes:
1. Las entregas, adquisiciones intracomunitarias o importaciones de los bienes
que se indican a continuación:
(…)'
- 'passage (…).”.
De acuerdo con lo dispuesto anteriormente, en los supuestos de adjudicación de
bienes en virtud de subasta judicial o administrativa, como es el caso que nos
ocupa, el adjudicatario puede efectuar, en su caso, la renuncia a las exenciones
previstas en el apartado dos del artículo 20 de la Ley 37/1992, así como expedir
factura, presentar, en nombre y por cuenta del sujeto pasivo, la declaración-liquidación
correspondiente e ingresar el importe del Impuesto sobre el Valor Añadido resultante.
El ejercicio de dicha facultad por parte del adjudicatario determina la obligación
de presentar la autoliquidación del Impuesto conforme al modelo aprobado por la
Orden HAC/3625/2003, de 23 de diciembre (modelo 309).
Uno de los requisitos necesarios para el ejercicio de dicha facultad es que el
destinatario-adjudicatario del bien inmueble tenga la consideración de empresario
o profesional en los términos previstos en esta contestación. La no consideración
como empresario o profesional impide el ejercicio de dicha facultad.
Por último, señalar que de resultar aplicable la regla de inversión del sujeto
pasivo prevista en el artículo 84.Uno.2º de la Ley 37/1992, anteriormente desarrollado,
el adjudicatario resultará ser el sujeto pasivo de la operación por lo que viene
obligado a presentar la autoliquidación ordinaria del Impuesto en nombre propio,
sin actuar en nombre y por cuenta del subastado. Asimismo, de optar por dicha
facultad en los términos establecidos reglamentariamente, el consultante podrá
emitir, en nombre y por cuenta del transmitente, la correspondiente factura en
la que se documente la operación.
No obstante, tal y como se ha señalado en apartados anteriores de esta contestación,
el consultante adjudicatario de la subasta judicial no procedió a la renuncia
a la exención del artículo 20.Uno.22º de la Ley del Impuesto en el plazo establecido,
habiéndose encontrado facultado para ello según lo dispuesto en la Disposición
Adicional Sexta de la Ley 37/1992.'
- 'passage c) Las que tengan por objeto la cesión del derecho a utilizar infraestructuras
ferroviarias.
d) Las autorizaciones para la prestación de servicios al público y para el desarrollo
de actividades comerciales o industriales en el ámbito portuario.”
3.- La consulta plantea una cuestión sobre un contrato por el que un Ayuntamiento
cede a un contratista la explotación de un bar (instalación fija de obra) en una
ciudad.
Dicho contrato tiene la naturaleza de contrato administrativo especial, sin que
el mismo pueda calificarse como contrato de gestión de servicio público ni tampoco
como concesión administrativa de dominio público.
Cabe plantearse si podría resultar aplicable a la referida prestación de servicios
efectuada por el ayuntamiento en favor de la consultante el supuesto de no sujeción
al Impuesto sobre el Valor Añadido previsto para el otorgamiento de concesiones
y autorizaciones administrativas en el número 9º del artículo 7 de la citada Ley
37/1992.
La respuesta a esta cuestión es negativa, pues, como ha señalado la Asesoría Jurídica
de la Secretaría de Estado de Hacienda en el informe emitido el 30 de julio de
1997 a solicitud de esta Dirección General, los contratos que tienen por objeto
la explotación de cafeterías y comedores en centros públicos son contratos administrativos
especiales, sin que los mismos puedan calificarse como contratos de gestión de
servicios públicos ni tampoco como concesiones administrativas de dominio público.
En este sentido se ha pronunciado la Junta Consultiva de Contratación Administrativa
en diversos informes emitidos al respecto; así, en el informe 57/07 de 6 de febrero
de 2008, y, con anterioridad, en los informes 5/96 de 7 de marzo y 67/99, de 6
de julio de 2000.
En consecuencia con todo lo anterior, está sujeto al Impuesto sobre el Valor Añadido
y no exento del mismo el contrato suscrito entre el ayuntamiento y la consultante
consistente en explotar un bar-quiosco, a cambio del pago de una contraprestación.
4.- Lo que comunico a Vd. con efectos vinculantes, conforme a lo dispuesto en
el apartado 1 del artículo 89 de la Ley 58/2003, de 17 de diciembre, General Tributaria.'
- source_sentence: 'query: ¿En qué casos las transacciones documentadas en escrituras
públicas pueden estar sujetas a una tasa tributaria específica según la normativa
vigente?'
sentences:
- 'passage 3.- Por otra parte en relación con la inclusión del suero de irrigación
en el apartado destinado a “Bolsas de recogida de orina, absorbentes de incontinencia
y otros sistemas para incontinencia urinaria y fecal, incluidos los sistemas de
irrigación”, este Centro directivo en la consulta de fecha 23 de marzo de 2015,
numero V0872-15 y en relación con los sistemas de irrigación ha dispuesto que,
“Tributarán por el Impuesto sobre el Valor Añadido, al tipo general del 21 por
ciento, los siguientes productos objeto de consulta: -Los empapadores, las duchas
vaginales, irrigadores, accesorios y sistemas de irrigación no destinados específicamente
a situaciones de incontinencia urinaria o fecal, ni las cánulas rectales y vaginales
no destinadas específicamente a situaciones de incontinencia urinaria o fecal
o no incorporadas en equipos destinados a estas situaciones. “
4.- En consecuencia con lo anterior este centro directivo le informa que tributan
al tipo general del 21 por ciento las entregas, adquisiciones intracomunitarias
e importaciones de suero de irrigación (agua destilada o suero fisiológico) objeto
de consulta siendo irrelevante que su destino sea para la limpieza aséptica de
la piel, lavado de heridas o quemaduras formando parte integrante de los sistemas
de irrigación.
5.- Lo que comunico a Vd. con efectos vinculantes, conforme a lo dispuesto en
el apartado 1 del artículo 89 de la Ley 58/2003, de 17 de diciembre, General Tributaria.
No obstante, de acuerdo con el artículo 68.2 del Reglamento General de las actuaciones
y los procedimientos de gestión e inspección tributaria y de desarrollo de las
normas comunes de los procedimientos de aplicación de los tributos, aprobado por
el Real Decreto 1065/2007, de 27 de julio, la presente contestación no tendrá
efectos vinculantes para aquellos miembros o asociados de la consultante que en
el momento de formular la consulta estuviesen siendo objeto de un procedimiento,
recurso o reclamación económico-administrativa iniciado con anterioridad y relacionado
con las cuestiones planteadas en la consulta conforme a lo dispuesto en su artículo
89.2.'
- 'passage Contestación completa: 1.- Las reglas de localización de las prestaciones
de servicios se encuentran reguladas en los artículos 69, 70 y 72 de la Ley 37/1992,
de 28 de diciembre, del Impuesto sobre el Valor Añadido (BOE del 29 de diciembre).
En el artículo 69 del dicho texto normativo se contienen las reglas generales
de localización en donde se establece que:
“Uno. Las prestaciones de servicios se entenderán realizadas en el territorio
de aplicación del Impuesto, sin perjuicio de lo dispuesto en el apartado siguiente
de este artículo y en los artículos 70 y 72 de esta Ley, en los siguientes casos:
1.º Cuando el destinatario sea un empresario o profesional que actúe como tal
y radique en el citado territorio la sede de su actividad económica, o tenga en
el mismo un establecimiento permanente o, en su defecto, el lugar de su domicilio
o residencia habitual, siempre que se trate de servicios que tengan por destinatarios
a dicha sede, establecimiento permanente, domicilio o residencia habitual, con
independencia de dónde se encuentre establecido el prestador de los servicios
y del lugar desde el que los preste.
2.º Cuando el destinatario no sea un empresario o profesional actuando como tal,
siempre que los servicios se presten por un empresario o profesional y la sede
de su actividad económica o establecimiento permanente desde el que los preste
o, en su defecto, el lugar de su domicilio o residencia habitual, se encuentre
en el territorio de aplicación del Impuesto.
(…).”.
No obstante, estas reglas serán de aplicación únicamente en el caso en que no
proceda aplicar ninguna de las reglas espaciales que se regulan en el artículo
70 de la Ley del impuesto. En concreto, respecto de los servicios de restauración
y catering, se establece en el número 5º del apartado Uno de dicho precepto que:
“Uno. Se entenderán prestados en el territorio de aplicación del Impuesto los
siguientes servicios:
(…)
5.º. A) Los de restauración y catering en los siguientes supuestos:
(…)
b) Los restantes servicios de restauración y catering cuando se presten materialmente
en el territorio de aplicación del Impuesto.
(…).”.'
- 'passage Artículo 31
“2. Las primeras copias de escrituras y actas notariales, cuando tengan por objeto
cantidad o cosa valuable, contengan actos o contratos inscribibles en los Registros
de la Propiedad, Mercantil y de la Propiedad Industrial y de Bienes Muebles no
sujetos al Impuesto sobre Sucesiones y Donaciones o a los conceptos comprendidos
en los números 1 y 2 del artículo 1.º de esta Ley, tributarán, además, al tipo
de gravamen que, conforme a lo previsto en la Ley 21/2001, de 27 de diciembre,
por la que se regulan las medidas fiscales y administrativas del nuevo sistema
de financiación de las Comunidades Autónomas de régimen común y Ciudades con Estatuto
de Autonomía, haya sido aprobado por la Comunidad Autónoma.
Si la Comunidad Autónoma no hubiese aprobado el tipo a que se refiere el párrafo
anterior, se aplicará el 0,50 por 100, en cuanto a tales actos o contratos.”
De la aplicación de los preceptos anteriormente transcritos resulta lo siguiente:
- Por regla general las operaciones realizadas por un sujeto pasivo del IVA son
operaciones no sujetas a la modalidad de transmisiones patrimoniales onerosas
del ITP y AJD según lo dispuesto en los artículos 7.5 del Texto Refundido del
citado impuesto. En tal caso, si la referida operación se documentase en escritura
pública, la no sujeción de la transmisión por la modalidad de transmisiones patrimoniales
onerosas permitiría la aplicación la cuota variable del Documento Notarial de
la modalidad Actos Jurídicos Documentados, dada la concurrencia de todos los requisitos
exigidos en el artículo 31.2 del Texto Refundido del Impuesto:
Tratarse de una primera copia de una escritura o acta notarial
Tener por objeto cantidad o cosa valuable
Contener un acto o contrato inscribibles en los Registros de la Propiedad, Mercantil
y de la Propiedad Industrial y de Bienes Muebles
No estar sujetos los referidos actos al Impuesto sobre Sucesiones y Donaciones
o a los conceptos comprendidos en los apartados 1 y 2 del artículo 1 de esta Ley,
transmisiones patrimoniales onerosas y operaciones societarias'
- source_sentence: 'query: ¿Se aplican impuestos a la enseñanza de idiomas para particulares
y empresas en modalidad presencial y virtual?'
sentences:
- 'passage 4.- Por otro lado, el artículo 91, apartado dos.2, número 1º, de la Ley
del Impuesto sobre el Valor Añadido, dispone la aplicación del tipo impositivo
del 4 por ciento a la prestación de los siguientes servicios:
“1.º Los servicios de reparación de los vehículos y de las sillas de ruedas comprendidos
en el párrafo primero del número 4.º del apartado dos.1 de este artículo y los
servicios de adaptación de los autotaxis y autoturismos para personas con discapacidad
y de los vehículos a motor a los que se refiere el párrafo segundo del mismo precepto
independientemente de quién sea el conductor de los mismos.”.
Los servicios de reparación recogidos en la Ley 37/1992 son únicamente los referidos
a vehículos para personas con movilidad reducida y a sillas de ruedas para uso
exclusivo de personas con discapacidad, que son los bienes incluidos en el párrafo
primero del artículo 91, apartado dos.1, número 4º de dicha Ley.
En consecuencia con lo anterior, las reparaciones de sillas de ruedas, que no
estén incluidas en el párrafo anterior, tributarán al tipo del 21 por ciento dado
que no está contemplado en el artículo 91 de la Ley 37/1992 un tipo reducido para
estos servicios de reparación.
5.- En relación con el tipo impositivo aplicable a los accesorios y recambios
de sillas de ruedas, la actual redacción del artículo 91.Uno.1.6º, letra c) dice
expresamente que: “No se incluyen en esta letra otros accesorios, recambios y
piezas de repuesto de dichos bienes.”.'
- 'passage Descripción de hechos: La consultante es una persona física que va a
impartir clases de idiomas, en concreto alemán, tanto a personas físicas como
a empresas. Las clases se realizarán tanto de manera presencial como a través
de medios electrónicos.
Cuestión planteada: Si las clases se encuentran exentas del Impuesto sobre el
Valor Añadido.'
- 'passage Contestación completa: 1.- El artículo 134 bis, apartado dos de la Ley
37/1992, de 28 de diciembre, del Impuesto sobre el Valor Añadido (BOE del 29),
establece que:
“Dos. Cuando el régimen de tributación aplicable a una determinada actividad agrícola,
ganadera, forestal o pesquera cambie del régimen especial de la agricultura, ganadería
y pesca al general del Impuesto, el empresario o profesional titular de la actividad
tendrá derecho a:
1º. Efectuar la deducción de la cuota resultante de aplicar al valor de los bienes
afectos a la actividad, Impuesto sobre el Valor Añadido excluido, en la fecha
en que deje de aplicarse el régimen especial, los tipos de dicho Impuesto que
estuviesen vigentes en la citada fecha. A estos efectos, no se tendrán en cuenta
los siguientes:
a) Bienes de inversión, definidos conforme a lo dispuesto en el artículo 108 de
esta Ley.
b) Bienes y servicios que hayan sido utilizados o consumidos total o parcialmente
en la actividad.
2º. Deducir la compensación a tanto alzado que prevé el artículo 130 de esta Ley
por los productos naturales obtenidos en las explotaciones que no se hayan entregado
a la fecha del cambio del régimen de tributación.
A efectos del ejercicio de los derechos recogidos en este apartado, el empresario
o profesional deberá confeccionar y presentar un inventario a la fecha en que
deje de aplicarse el régimen especial. Tanto la presentación de este inventario
como el ejercicio de estos derechos se ajustarán a los requisitos y condiciones
que se establezcan reglamentariamente.”.
Por su parte, el artículo 49 bis del Reglamento del Impuesto aprobado por el artículo
1 del Real Decreto 1624/1992, de 29 de diciembre (BOE del 31), declara que:'
- source_sentence: 'query: ¿De qué forma la ubicación de la agencia influye en la
aplicación del impuesto en los servicios turísticos?'
sentences:
- 'passage Contestación completa: 1.- El artículo 9, primer párrafo de la Ley 8/1991,
de 25 de marzo, por la que se crea el Impuesto sobre la Producción, los Servicios
y la Importación en las Ciudades de Ceuta y Melilla (BOE del 26), dispone lo siguiente:
“Las importaciones definitivas de bienes en las ciudades de Ceuta y Melilla estarán
exentas en los mismos términos que en la legislación común del Impuesto sobre
el Valor Añadido y, en todo caso, se asimilarán, a efectos de esta exención, las
que resulten de aplicación a las operaciones interiores.”.
2.- Por otra parte, el artículo 20, apartado uno, número 17º de la Ley 37/1992,
de 28 de diciembre, del Impuesto sobre el Valor Añadido (BOE del 29 de diciembre),
dispone que estarán exentas de dicho Impuesto:
“17º. Las entregas de sellos de Correos y efectos timbrados de curso legal en
España por importe no superior a su valor facial.
La exención no se extiende a los servicios de expendición de los referidos bienes
prestados en nombre y por cuenta de terceros.”.
Conforme al precepto anterior, la entrega de sellos de correos de curso legal
por importe no superior a su valor facial, objeto de consulta, estará exenta del
Impuesto sobre el Valor Añadido.
3.- En consecuencia, estarán sujetas pero exentas del Impuesto sobre la Producción,
los Servicios y la Importación en las Ciudades de Ceuta y Melilla las importaciones
definitivas de sellos de correos de curso legal en las ciudades de Ceuta y Melilla
cuando, de acuerdo con lo establecido en el apartado anterior de esta contestación,
su entrega esté exenta del Impuesto sobre el Valor Añadido.
4.- Lo que comunico a Vd. con efectos vinculantes, conforme a lo dispuesto en
el apartado 1 del artículo 89 de la Ley 58/2003, de 17 de diciembre, General Tributaria.'
- 'passage 2º. Sin perjuicio de lo dispuesto en el punto 1º anterior, se aplicará,
en todo caso, el tipo general del 21 por ciento, entre otros, a los siguientes
bienes y servicios:
1. Servicios prestados por vía electrónica, esto es, aquellos servicios que consistan
en la transmisión enviada inicialmente y recibida en destino por medio de equipos
de procesamiento, incluida la compresión numérica y el almacenamiento de datos,
y enteramente transmitida, transportada y recibida por cable, sistema óptico u
otros medios electrónicos y, entre otros, los siguientes:
a) El suministro y alojamiento de sitios informáticos.
b) El mantenimiento a distancia de programas y de equipos.
c) El suministro de programas y su actualización.
d) El suministro de imágenes, texto, información y la puesta a disposición de
bases de datos.
e) El suministro de música, películas, juegos, incluidos los de azar o de dinero,
y de emisiones y manifestaciones políticas, culturales, artísticas, deportivas,
científicas o de ocio.
f) El suministro de enseñanza a distancia.
2. Dispositivos portátiles que permitan almacenar y leer libros digitalizados,
así como reproductores de libros electrónicos y otros elementos de hardware, es
decir, componentes que integren la parte material de un ordenador o que se puedan
conectar al mismo.
3. Servicios consistentes en el acceso electrónico a bases de datos, periódicos,
revistas y semejantes y, en general, a páginas web.
4. Comercialización de códigos de descarga de archivos que incorporen libros electrónicos.
5. Servicios de acceso a libros de texto en formato digital alojados en servidores
de Entes públicos o de colegios.
6. Servicios de consultas y accesos a bases de datos.
7. Servicios de digitalización de obras literarias.'
- 'passage De acuerdo con los antecedentes recogidos en esta contestación, dicho
servicio estará sujeto al régimen especial de las agencias de viajes regulado
en el Capítulo VI del Título IX de la Ley 37/1992 y tendrá la consideración de
prestación de servicios única que estará sujeta al Impuesto sobre el Valor Añadido
bajo la premisa de que la consultante tiene establecida la sede de su actividad
económica o posea un establecimiento permanente desde donde efectúa la operación
en el territorio de aplicación del Impuesto.
El tipo impositivo aplicable al servicio único de viajes será el general del 21
por ciento previsto en el artículo 90.Uno de la Ley del Impuesto.
Sobre la posible aplicación de la opción del artículo 147 de la Ley 37/1992 para
la aplicación del régimen general del Impuesto, según se establece en contestación
a consulta vinculante de 20 de septiembre de 2016, número V3942-16:
“4.- Debe tenerse en cuenta que en el caso de las empresas radicadas en Estados
Unidos a que se refiere el escrito de consulta, no se entiende cumplido el requisito
de reciprocidad, tal como se pronunció este Centro Directivo en contestación a
consulta vinculante número V0579-12 de 16 de marzo de 2012, por lo que, salvo
que el servicio prestado por la agencia de viajes consultante esté relacionado
con la asistencia a ferias, congresos y exposiciones de carácter comercial o profesional,
en los términos del artículo 119 bis de la Ley 37/1992 parcialmente transcrito,
no se entenderán cumplidos los requisitos para la opción por el régimen general
del Impuesto sobre el Valor Añadido.”.
b) El mismo caso anterior, pero el viaje se pretende desarrollar en las Islas
Canarias.
Según establece el artículo 144 de la Ley del Impuesto, dicha operación se encontrará
sujeta al Impuesto y, en particular, al régimen especial de las agencias de viajes:
“Dicha prestación se entenderá realizada en el lugar donde la agencia tenga establecida
la sede de su actividad económica o posea un establecimiento permanente desde
donde efectúe la operación.”.'
pipeline_tag: sentence-similarity
library_name: sentence-transformers
metrics:
- cosine_accuracy@1
- cosine_accuracy@3
- cosine_accuracy@5
- cosine_accuracy@10
- cosine_precision@1
- cosine_precision@3
- cosine_precision@5
- cosine_precision@10
- cosine_recall@1
- cosine_recall@3
- cosine_recall@5
- cosine_recall@10
- cosine_ndcg@10
- cosine_mrr@10
- cosine_map@100
model-index:
- name: SentenceTransformer based on intfloat/multilingual-e5-small
results:
- task:
type: information-retrieval
name: Information Retrieval
dataset:
name: InformationRetrievalEvaluator
type: InformationRetrievalEvaluator
metrics:
- type: cosine_accuracy@1
value: 0.3382131835087442
name: Cosine Accuracy@1
- type: cosine_accuracy@3
value: 0.5034422726913033
name: Cosine Accuracy@3
- type: cosine_accuracy@5
value: 0.575532167444805
name: Cosine Accuracy@5
- type: cosine_accuracy@10
value: 0.6752393764342803
name: Cosine Accuracy@10
- type: cosine_precision@1
value: 0.3382131835087442
name: Cosine Precision@1
- type: cosine_precision@3
value: 0.1678140908971011
name: Cosine Precision@3
- type: cosine_precision@5
value: 0.11510643348896098
name: Cosine Precision@5
- type: cosine_precision@10
value: 0.06752393764342803
name: Cosine Precision@10
- type: cosine_recall@1
value: 0.3382131835087442
name: Cosine Recall@1
- type: cosine_recall@3
value: 0.5034422726913033
name: Cosine Recall@3
- type: cosine_recall@5
value: 0.575532167444805
name: Cosine Recall@5
- type: cosine_recall@10
value: 0.6752393764342803
name: Cosine Recall@10
- type: cosine_ndcg@10
value: 0.49624765513332225
name: Cosine Ndcg@10
- type: cosine_mrr@10
value: 0.4402356521728189
name: Cosine Mrr@10
- type: cosine_map@100
value: 0.44987220435617326
name: Cosine Map@100
---
# SentenceTransformer based on intfloat/multilingual-e5-small
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [intfloat/multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small). It maps sentences & paragraphs to a 384-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [intfloat/multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) <!-- at revision c007d7ef6fd86656326059b28395a7a03a7c5846 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 384 dimensions
- **Similarity Function:** Cosine Similarity
<!-- - **Training Dataset:** Unknown -->
<!-- - **Language:** Unknown -->
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 384, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
(2): Normalize()
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("diegolacomba/multilingual-e5-small-legal-mnrl-1")
# Run inference
sentences = [
'query: ¿De qué forma la ubicación de la agencia influye en la aplicación del impuesto en los servicios turísticos?',
'passage De acuerdo con los antecedentes recogidos en esta contestación, dicho servicio estará sujeto al régimen especial de las agencias de viajes regulado en el Capítulo VI del Título IX de la Ley 37/1992 y tendrá la consideración de prestación de servicios única que estará sujeta al Impuesto sobre el Valor Añadido bajo la premisa de que la consultante tiene establecida la sede de su actividad económica o posea un establecimiento permanente desde donde efectúa la operación en el territorio de aplicación del Impuesto.\nEl tipo impositivo aplicable al servicio único de viajes será el general del 21 por ciento previsto en el artículo 90.Uno de la Ley del Impuesto.\nSobre la posible aplicación de la opción del artículo 147 de la Ley 37/1992 para la aplicación del régimen general del Impuesto, según se establece en contestación a consulta vinculante de 20 de septiembre de 2016, número V3942-16:\n“4.- Debe tenerse en cuenta que en el caso de las empresas radicadas en Estados Unidos a que se refiere el escrito de consulta, no se entiende cumplido el requisito de reciprocidad, tal como se pronunció este Centro Directivo en contestación a consulta vinculante número V0579-12 de 16 de marzo de 2012, por lo que, salvo que el servicio prestado por la agencia de viajes consultante esté relacionado con la asistencia a ferias, congresos y exposiciones de carácter comercial o profesional, en los términos del artículo 119 bis de la Ley 37/1992 parcialmente transcrito, no se entenderán cumplidos los requisitos para la opción por el régimen general del Impuesto sobre el Valor Añadido.”.\nb) El mismo caso anterior, pero el viaje se pretende desarrollar en las Islas Canarias.\nSegún establece el artículo 144 de la Ley del Impuesto, dicha operación se encontrará sujeta al Impuesto y, en particular, al régimen especial de las agencias de viajes:\n“Dicha prestación se entenderá realizada en el lugar donde la agencia tenga establecida la sede de su actividad económica o posea un establecimiento permanente desde donde efectúe la operación.”.',
'passage Contestación completa: 1.- El artículo 9, primer párrafo de la Ley 8/1991, de 25 de marzo, por la que se crea el Impuesto sobre la Producción, los Servicios y la Importación en las Ciudades de Ceuta y Melilla (BOE del 26), dispone lo siguiente:\n“Las importaciones definitivas de bienes en las ciudades de Ceuta y Melilla estarán exentas en los mismos términos que en la legislación común del Impuesto sobre el Valor Añadido y, en todo caso, se asimilarán, a efectos de esta exención, las que resulten de aplicación a las operaciones interiores.”.\n2.- Por otra parte, el artículo 20, apartado uno, número 17º de la Ley 37/1992, de 28 de diciembre, del Impuesto sobre el Valor Añadido (BOE del 29 de diciembre), dispone que estarán exentas de dicho Impuesto:\n“17º. Las entregas de sellos de Correos y efectos timbrados de curso legal en España por importe no superior a su valor facial.\nLa exención no se extiende a los servicios de expendición de los referidos bienes prestados en nombre y por cuenta de terceros.”.\nConforme al precepto anterior, la entrega de sellos de correos de curso legal por importe no superior a su valor facial, objeto de consulta, estará exenta del Impuesto sobre el Valor Añadido.\n3.- En consecuencia, estarán sujetas pero exentas del Impuesto sobre la Producción, los Servicios y la Importación en las Ciudades de Ceuta y Melilla las importaciones definitivas de sellos de correos de curso legal en las ciudades de Ceuta y Melilla cuando, de acuerdo con lo establecido en el apartado anterior de esta contestación, su entrega esté exenta del Impuesto sobre el Valor Añadido.\n4.- Lo que comunico a Vd. con efectos vinculantes, conforme a lo dispuesto en el apartado 1 del artículo 89 de la Ley 58/2003, de 17 de diciembre, General Tributaria.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 384]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings, embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Information Retrieval
* Dataset: `InformationRetrievalEvaluator`
* Evaluated with [<code>InformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sentence_transformer/evaluation.html#sentence_transformers.evaluation.InformationRetrievalEvaluator)
| Metric | Value |
|:--------------------|:-----------|
| cosine_accuracy@1 | 0.3382 |
| cosine_accuracy@3 | 0.5034 |
| cosine_accuracy@5 | 0.5755 |
| cosine_accuracy@10 | 0.6752 |
| cosine_precision@1 | 0.3382 |
| cosine_precision@3 | 0.1678 |
| cosine_precision@5 | 0.1151 |
| cosine_precision@10 | 0.0675 |
| cosine_recall@1 | 0.3382 |
| cosine_recall@3 | 0.5034 |
| cosine_recall@5 | 0.5755 |
| cosine_recall@10 | 0.6752 |
| **cosine_ndcg@10** | **0.4962** |
| cosine_mrr@10 | 0.4402 |
| cosine_map@100 | 0.4499 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### Unnamed Dataset
* Size: 58,898 training samples
* Columns: <code>anchor</code> and <code>positive</code>
* Approximate statistics based on the first 1000 samples:
| | anchor | positive |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 19 tokens</li><li>mean: 31.33 tokens</li><li>max: 62 tokens</li></ul> | <ul><li>min: 23 tokens</li><li>mean: 325.57 tokens</li><li>max: 508 tokens</li></ul> |
* Samples:
| anchor | positive |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>query: ¿Las contribuciones que percibe una organización en virtud de un convenio laboral en el fútbol tienen impacto en la base de cálculo para el impuesto correspondiente?</code> | <code>passage Descripción de hechos: La consultante es una Asociación que se dedica a las actividades de ordenación del ejercicio de la profesión de futbolistas de sus miembros, la representación de los mismos así como la defensa de sus intereses profesionales tanto en el ámbito nacional como en el internacional.<br>En virtud de un convenio colectivo para la actividad de fútbol profesional suscrito entre la Liga Nacional de Fútbol Profesional (LNFP) y la consultante, aquella viene obligada a entregar a esta, por cada temporada de vigencia del convenio, una cantidad de dinero (en concepto de Fondo social) destinada a fines benéficos y al normal desarrollo de la actividad de la Asociación.<br>Asimismo, según Acta de Conciliación suscrita entre ambas partes, la LNFP se compromete a abonar a la consultante un porcentaje del importe neto total de los ingresos obtenidos de la explotación conjunta de los derechos de contenidos audiovisuales del fútbol. Dicha cuantía debe destinarse a actividades encamina...</code> |
| <code>query: ¿Qué tipos de transacciones intracomunitarias deben ser declaradas por las empresas según la regulación vigente?</code> | <code>passage Contestación completa: 1.- De acuerdo con el artículo 78 del Reglamento del impuesto aprobado por el Real Decreto 1624/1992, de 29 de diciembre (BOE del 31 de diciembre):<br>“Los empresarios y profesionales deberán presentar una declaración recapitulativa de las entregas y adquisiciones intracomunitarias de bienes y de las prestaciones y adquisiciones intracomunitarias de servicios que realicen en la forma que se indica en el presente capítulo.”.<br>El artículo 79 del Reglamento especifica qué tipo de operaciones deben ser declaradas en la declaración recapitulativa de operaciones intracomunitarias, en concreto establece que:<br>“1. Estarán obligados a presentar la declaración recapitulativa los empresarios y profesionales, incluso cuando tengan dicha condición con arreglo a lo dispuesto en el apartado cuatro del artículo 5 de la Ley del Impuesto, que realicen cualquiera de las siguientes operaciones.<br>1.º Las entregas de bienes destinados a otro Estado miembro que se encuentren exentas ...</code> |
| <code>query: ¿Qué tipos de bebidas contienen alcohol apto para consumo humano?</code> | <code>passage Se entiende por bebida alcohólica todo líquido apto para el consumo humano por ingestión que contenga alcohol etílico.<br>A los efectos de este número no tendrán la consideración de alimento el tabaco ni las sustancias no aptas para el consumo humano o animal en el mismo estado en que fuesen objeto de entrega, adquisición intracomunitaria o importación.”.<br>4.- Con independencia de lo anterior, el artículo 20, apartado uno, número 9º, de la Ley 37/1992, establece que estarán exentas del Impuesto las siguientes operaciones:<br>“9.º La educación de la infancia y de la juventud, la guarda y custodia de niños, incluida la atención a niños en los centros docentes en tiempo interlectivo durante el comedor escolar o en aulas en servicio de guardería fuera del horario escolar, la enseñanza escolar, universitaria y de postgraduados, la enseñanza de idiomas y la formación y reciclaje profesional, realizadas por Entidades de derecho público o entidades privadas autorizadas para el ejercicio de di...</code> |
* Loss: [<code>MultipleNegativesRankingLoss</code>](https://sbert.net/docs/package_reference/sentence_transformer/losses.html#multiplenegativesrankingloss) with these parameters:
```json
{
"scale": 20.0,
"similarity_fct": "cos_sim"
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 16
- `gradient_accumulation_steps`: 16
- `learning_rate`: 1e-05
- `num_train_epochs`: 8
- `lr_scheduler_type`: cosine
- `warmup_ratio`: 0.1
- `fp16`: True
- `tf32`: True
- `load_best_model_at_end`: True
- `optim`: adamw_torch_fused
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 32
- `per_device_eval_batch_size`: 16
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 16
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 1e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 8
- `max_steps`: -1
- `lr_scheduler_type`: cosine
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: True
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: True
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch_fused
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | InformationRetrievalEvaluator_cosine_ndcg@10 |
|:----------:|:-------:|:-------------:|:--------------------------------------------:|
| 0.8691 | 100 | 19.3901 | 0.4319 |
| 1.7300 | 200 | 1.3949 | 0.4622 |
| 2.5910 | 300 | 1.1059 | 0.4754 |
| 3.4519 | 400 | 0.9521 | 0.4870 |
| 4.3129 | 500 | 0.8567 | 0.4906 |
| 5.1738 | 600 | 0.8006 | 0.4947 |
| 6.0348 | 700 | 0.7515 | 0.4949 |
| 6.9039 | 800 | 0.7973 | 0.4961 |
| **7.7648** | **900** | **0.7698** | **0.4962** |
| 8.0 | 928 | - | 0.4962 |
* The bold row denotes the saved checkpoint.
### Framework Versions
- Python: 3.11.13
- Sentence Transformers: 4.1.0
- Transformers: 4.52.4
- PyTorch: 2.6.0+cu124
- Accelerate: 1.7.0
- Datasets: 2.14.4
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
NhaiDao/SFT_TRAIN_FROM_SCRATCH_checkpoint_6250
|
NhaiDao
| 2025-06-17T12:28:25Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T12:27:52Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NhaiDao/SFT_TRAIN_FROM_SCRATCH_checkpoint_3125
|
NhaiDao
| 2025-06-17T12:25:26Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T12:24:43Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
NhaiDao/SFT_TRAIN_FROM_SCRATCH_checkpoint_2500
|
NhaiDao
| 2025-06-17T12:24:40Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T12:24:07Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
FatmaMoncer/tinyllama-odoo-finetuned
|
FatmaMoncer
| 2025-06-17T12:18:57Z | 24 | 0 |
peft
|
[
"peft",
"pytorch",
"llama",
"region:us"
] | null | 2025-06-08T15:18:47Z |
---
library_name: peft
---
## Training procedure
The following `bitsandbytes` quantization config was used during training:
- load_in_8bit: False
- load_in_4bit: True
- llm_int8_threshold: 6.0
- llm_int8_skip_modules: None
- llm_int8_enable_fp32_cpu_offload: False
- llm_int8_has_fp16_weight: False
- bnb_4bit_quant_type: nf4
- bnb_4bit_use_double_quant: True
- bnb_4bit_compute_dtype: float16
### Framework versions
- PEFT 0.4.0
|
ibm-research/biomed.sm.mv-te-84m-CYP-ligand_scaffold_balanced-CYP2C19-101
|
ibm-research
| 2025-06-17T12:18:36Z | 0 | 0 |
SmallMoleculeMultiView
|
[
"SmallMoleculeMultiView",
"safetensors",
"binding-affinity-prediction",
"bio-medical",
"chemistry",
"drug-discovery",
"drug-target-interaction",
"model_hub_mixin",
"molecular-property-prediction",
"moleculenet",
"molecules",
"multi-view",
"multimodal",
"pytorch_model_hub_mixin",
"small-molecules",
"virtual-screening",
"arxiv:2410.19704",
"base_model:ibm-research/biomed.sm.mv-te-84m",
"base_model:finetune:ibm-research/biomed.sm.mv-te-84m",
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T12:18:27Z |
---
base_model: ibm-research/biomed.sm.mv-te-84m
library_name: SmallMoleculeMultiView
license: apache-2.0
tags:
- binding-affinity-prediction
- bio-medical
- chemistry
- drug-discovery
- drug-target-interaction
- model_hub_mixin
- molecular-property-prediction
- moleculenet
- molecules
- multi-view
- multimodal
- pytorch_model_hub_mixin
- small-molecules
- virtual-screening
---
# ibm-research/biomed.sm.mv-te-84m-CYP-ligand_scaffold_balanced-CYP2C19-101
`biomed.sm.mv-te-84m` is a multimodal biomedical foundation model for small molecules created using **MMELON** (**M**ulti-view **M**olecular **E**mbedding with **L**ate Fusi**on**), a flexible approach to aggregate multiple views (sequence, image, graph) of molecules in a foundation model setting. While models based on single view representation typically performs well on some downstream tasks and not others, the multi-view model performs robustly across a wide range of property prediction tasks encompassing ligand-protein binding, molecular solubility, metabolism and toxicity. It has been applied to screen compounds against a large (> 100 targets) set of G Protein-Coupled receptors (GPCRs) to identify strong binders for 33 targets related to Alzheimer’s disease, which are validated through structure-based modeling and identification of key binding motifs [Multi-view biomedical foundation models for molecule-target and property prediction](https://arxiv.org/abs/2410.19704).
- **Developers:** IBM Research
- **GitHub Repository:** [https://github.com/BiomedSciAI/biomed-multi-view](https://github.com/BiomedSciAI/biomed-multi-view)
- **Paper:** [Multi-view biomedical foundation models for molecule-target and property prediction](https://arxiv.org/abs/2410.19704)
- **Release Date**: Oct 28th, 2024
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
## Model Description
Source code for the model and finetuning is made available in [this repository](https://github.com/BiomedSciAI/biomed-multi-view).
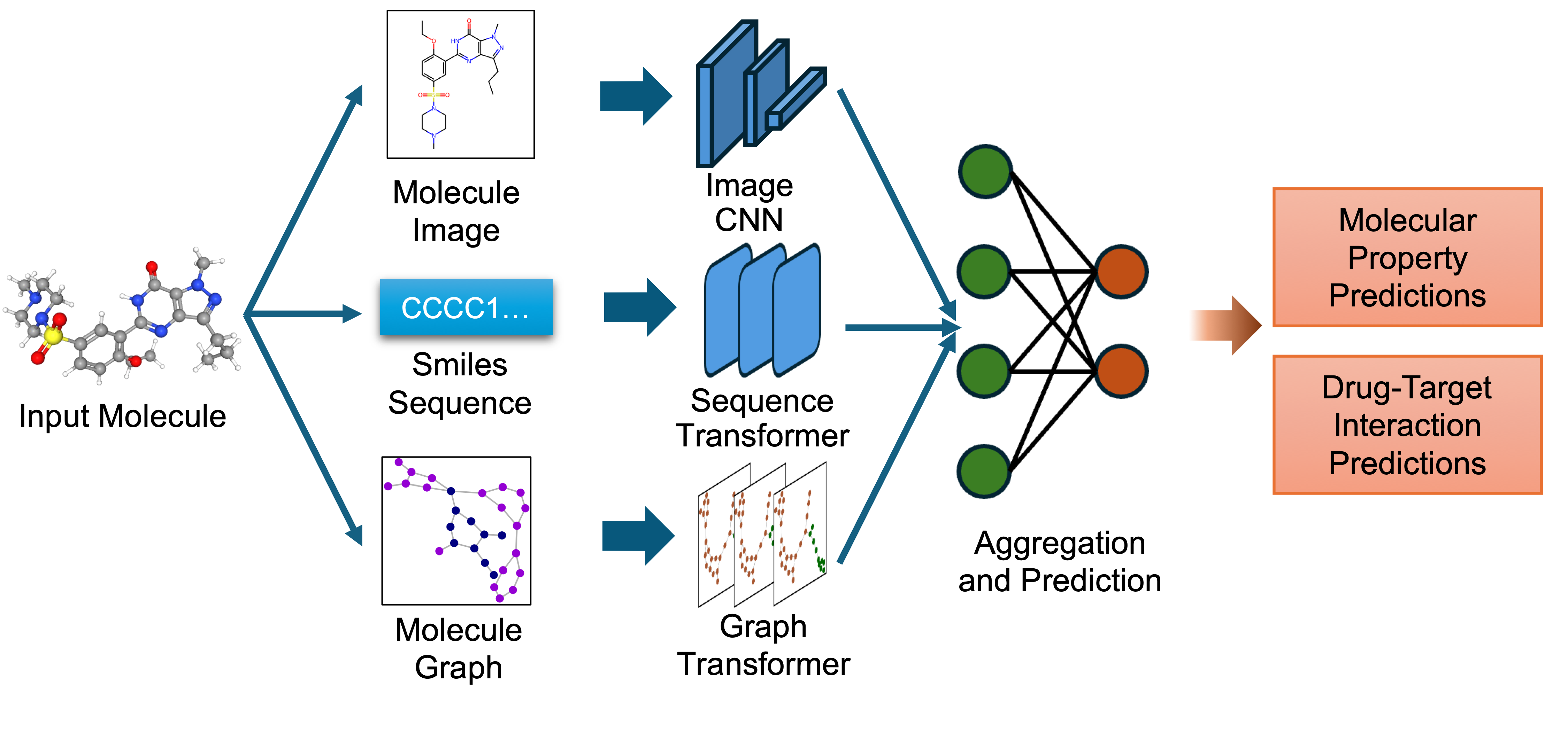
* Image Representation: Captures the 2D visual depiction of molecular structures, highlighting features like symmetry, bond angles, and functional groups. Molecular images are generated using RDKit and undergo data augmentation during training to enhance robustness.
* Graph Representation: Encodes molecules as undirected graphs where nodes represent atoms and edges represent bonds. Atom-specific properties (e.g., atomic number, chirality) and bond-specific properties (e.g., bond type, stereochemistry) are embedded using categorical embedding techniques.
* Text Representation: Utilizes SMILES strings to represent chemical structures, tokenized with a custom tokenizer. The sequences are embedded using a transformer-based architecture to capture the sequential nature of the chemical information.
The embeddings from these single-view pre-trained encoders are combined using an attention-based aggregator module. This module learns to weight each view appropriately, producing a unified multi-view embedding. This approach leverages the strengths of each representation to improve performance on downstream predictive tasks.
## Intended Use and Limitations
The model is intended for (1) Molecular property prediction. The pre-trained model may be fine-tuned for both regression and classification tasks. Examples include but are not limited to binding affinity, solubility and toxicity. (2) Pre-trained model embeddings may be used as the basis for similarity measures to search a chemical library. (3) Small molecule embeddings provided by the model may be combined with protein embeddings to fine-tune on tasks that utilize both small molecule and protein representation. (4) Select task-specific fine-tuned models are given as examples. Through listed activities, model may aid in aspects of the molecular discovery such as lead finding or optimization.
The model’s domain of applicability is small, drug-like molecules. It is intended for use with molecules less than 1000 Da molecular weight. The MMELON approach itself may be extended to include proteins and other macromolecules but does not at present provide embeddings for such entities. The model is at present not intended for molecular generation. Molecules must be given as a valid SMILES string that represents a valid chemically bonded graph. Invalid inputs will impact performance or lead to error.
## Usage
Using `SmallMoleculeMultiView` API requires the codebase [https://github.com/BiomedSciAI/biomed-multi-view](https://github.com/BiomedSciAI/biomed-multi-view)
## Installation
Follow these steps to set up the `biomed-multi-view` codebase on your system.
### Prerequisites
* Operating System: Linux or macOS
* Python Version: Python 3.11
* Conda: Anaconda or Miniconda installed
* Git: Version control to clone the repository
### Step 1: Set up the project directory
Choose a root directory where you want to install `biomed-multi-view`. For example:
```bash
export ROOT_DIR=~/biomed-multiview
mkdir -p $ROOT_DIR
```
#### Step 2: Create and activate a Conda environment
```bash
conda create -y python=3.11 --prefix $ROOT_DIR/envs/biomed-multiview
```
Activate the environment:
```bash
conda activate $ROOT_DIR/envs/biomed-multiview
```
#### Step 3: Clone the repository
Navigate to the project directory and clone the repository:
```bash
mkdir -p $ROOT_DIR/code
cd $ROOT_DIR/code
# Clone the repository using HTTPS
git clone https://github.com/BiomedSciAI/biomed-multi-view.git
# Navigate into the cloned repository
cd biomed-multi-view
```
Note: If you prefer using SSH, ensure that your SSH keys are set up with GitHub and use the following command:
```bash
git clone [email protected]:BiomedSciAI/biomed-multi-view.git
```
#### Step 4: Install package dependencies
Install the package in editable mode along with development dependencies:
``` bash
pip install -e .['dev']
```
Install additional requirements:
``` bash
pip install -r requirements.txt
```
#### Step 5: macOS-Specific instructions (Apple Silicon)
If you are using a Mac with Apple Silicon (M1/M2/M3) and the zsh shell, you may need to disable globbing for the installation command:
``` bash
noglob pip install -e .[dev]
```
Install macOS-specific requirements optimized for Apple’s Metal Performance Shaders (MPS):
```bash
pip install -r requirements-mps.txt
```
#### Step 6: Installation verification (optional)
Verify that the installation was successful by running unit tests
```bash
python -m unittest bmfm_sm.tests.all_tests
```
### Get embedding example
You can generate embeddings for a given molecule using the pretrained model with the following code.
```python
# Necessary imports
from bmfm_sm.api.smmv_api import SmallMoleculeMultiViewModel
from bmfm_sm.core.data_modules.namespace import LateFusionStrategy
# Load Model
model = SmallMoleculeMultiViewModel.from_pretrained(
LateFusionStrategy.ATTENTIONAL,
model_path="ibm-research/biomed.sm.mv-te-84m",
huggingface=True
)
# Load Model and get embeddings for a molecule
example_smiles = "CC(C)CC1=CC=C(C=C1)C(C)C(=O)O"
example_emb = SmallMoleculeMultiViewModel.get_embeddings(
smiles=example_smiles,
model_path="ibm-research/biomed.sm.mv-te-84m",
huggingface=True,
)
print(example_emb.shape)
```
### Get prediction example
You can use the finetuned models to make predictions on new data.
``` python
from bmfm_sm.api.smmv_api import SmallMoleculeMultiViewModel
from bmfm_sm.api.dataset_registry import DatasetRegistry
# Initialize the dataset registry
dataset_registry = DatasetRegistry()
# Example SMILES string
example_smiles = "CC(C)C1CCC(C)CC1O"
# Get dataset information for dataset
ds = dataset_registry.get_dataset_info("CYP2C19")
# Load the finetuned model for the dataset
finetuned_model_ds = SmallMoleculeMultiViewModel.from_finetuned(
ds,
model_path="ibm-research/biomed.sm.mv-te-84m-CYP-ligand_scaffold_balanced-CYP2C19-101",
inference_mode=True,
huggingface=True
)
# Get predictions
prediction = SmallMoleculeMultiViewModel.get_predictions(
example_smiles, ds, finetuned_model=finetuned_model_ds
)
print("Prediction:", prediction)
```
For more advanced usage, see our detailed examples at: https://github.com/BiomedSciAI/biomed-multi-view
## Citation
If you found our work useful, please consider giving a star to the repo and cite our paper:
```
@misc{suryanarayanan2024multiviewbiomedicalfoundationmodels,
title={Multi-view biomedical foundation models for molecule-target and property prediction},
author={Parthasarathy Suryanarayanan and Yunguang Qiu and Shreyans Sethi and Diwakar Mahajan and Hongyang Li and Yuxin Yang and Elif Eyigoz and Aldo Guzman Saenz and Daniel E. Platt and Timothy H. Rumbell and Kenney Ng and Sanjoy Dey and Myson Burch and Bum Chul Kwon and Pablo Meyer and Feixiong Cheng and Jianying Hu and Joseph A. Morrone},
year={2024},
eprint={2410.19704},
archivePrefix={arXiv},
primaryClass={q-bio.BM},
url={https://arxiv.org/abs/2410.19704},
}
```
|
AhmedCodes64/SFT_PQ
|
AhmedCodes64
| 2025-06-17T12:17:06Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"trl",
"sft",
"unsloth",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T12:13:20Z |
---
library_name: transformers
tags:
- trl
- sft
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
jr303/lexical-regressor-MLP-1
|
jr303
| 2025-06-17T12:12:25Z | 0 | 0 | null |
[
"safetensors",
"camembert",
"region:us"
] | null | 2025-06-17T12:11:44Z |
# Lexical Regressor v2
Ce modèle est basé sur CamemBERT, affiné pour effectuer de la régression lexicale sur 50 dimensions.
## Exemple d'utilisation
```python
from model import LexicalRegressor
from transformers import CamembertTokenizer
import torch
tokenizer = CamembertTokenizer.from_pretrained("jr303/lexical-regressor-MLP-1")
model = LexicalRegressor(output_dim=50)
model.load_state_dict(torch.load("pytorch_model.bin"))
model.eval()
|
Lelon/cue-it-bioscope_abstracts
|
Lelon
| 2025-06-17T12:02:18Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T12:01:42Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Lelon/cue-de-bioscope_abstracts
|
Lelon
| 2025-06-17T11:50:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"eurobert",
"token-classification",
"custom_code",
"arxiv:1910.09700",
"autotrain_compatible",
"region:us"
] |
token-classification
| 2025-06-17T11:49:53Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Kpp399149/Kp
|
Kpp399149
| 2025-06-17T11:36:15Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T11:36:15Z |
---
license: apache-2.0
---
|
Sanyongli/qwen-2.5-palm-diagnosis-v4-adapter
|
Sanyongli
| 2025-06-17T11:35:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-15T12:02:55Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
ariG23498/gpt-updated
|
ariG23498
| 2025-06-17T11:31:59Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt2",
"feature-extraction",
"arxiv:1910.09700",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-17T11:31:37Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Hume-vla/Libero-Object-1
|
Hume-vla
| 2025-06-17T11:26:02Z | 2,841 | 0 |
transformers
|
[
"transformers",
"safetensors",
"VLA",
"robotics",
"en",
"dataset:IPEC-COMMUNITY/libero_object_no_noops_lerobot",
"arxiv:2505.21432",
"base_model:Hume-vla/Hume-System2",
"base_model:finetune:Hume-vla/Hume-System2",
"license:mit",
"endpoints_compatible",
"region:us"
] |
robotics
| 2025-06-13T06:20:04Z |
---
license: mit
datasets:
- IPEC-COMMUNITY/libero_object_no_noops_lerobot
language:
- en
base_model:
- Hume-vla/Hume-System2
pipeline_tag: robotics
library_name: transformers
tags:
- VLA
---
# Model Card for Hume-Libero_Object
<!-- Provide a quick summary of what the model is/does. -->
A Dual-System Visual-Language-Action model with System-2 thinking trained on Libero-Object.
- Paper: [https://arxiv.org/abs/2505.21432](https://arxiv.org/abs/2505.21432)
- Homepage: [https://hume-vla.github.io](https://hume-vla.github.io)
- Codebase: [🦾 Hume: A Dual-System VLA with System2 Thinking](https://github.com/hume-vla/hume) 
## Optimal TTS Args
```bash
s2_candidates_num=5
noise_temp_lower_bound=1.0
noise_temp_upper_bound=1.2
time_temp_lower_bound=1.0
time_temp_upper_bound=1.0
```
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
- If you want to reproduce the results in paper, follow the [instruction](https://github.com/hume-vla/hume/tree/main/experiments/libero)
- If you want to directly use the model:
```python
from hume import HumePolicy
import numpy as np
# load policy
hume = HumePolicy.from_pretrained("/path/to/checkpoints")
# config Test-Time Computing args
hume.init_infer(
infer_cfg=dict(
replan_steps=8,
s2_replan_steps=16,
s2_candidates_num=5,
noise_temp_lower_bound=1.0,
noise_temp_upper_bound=1.0,
time_temp_lower_bound=0.9,
time_temp_upper_bound=1.0,
post_process_action=True,
device="cuda",
)
)
# prepare observations
observation = {
"observation.images.image": np.zeros((1,224,224,3), dtype = np.uint8), # (B, H, W, C)
"observation.images.wrist_image": np.zeros((1,224,224,3), dtype = np.uint8), # (B, H, W, C)
"observation.state": np.zeros((1, 7)), # (B, state_dim)
"task": ["Lift the papper"],
}
# Infer the action
action = hume.infer(observation) # (B, action_dim)
```
## Training and Evaluation Details
```bash
# source ckpts
2025-05-01/19-56-05_libero_object_ck8-16-1_sh-4_gpu8_lr5e-5_1e-5_1e-5_2e-5_bs16_s1600k/0150000
# original logs
2025-06-13/00-18-26+19-56-05_libero_object_ck8-16-1_sh-4_gpu8_lr5e-5_1e-5_1e-5_2e-5_bs16_s1600k_0150000_s1-8_s2-16_s2cand-5_ntl-1.0_ntu-1.2_ttl-1.0_ttu-1.0.log
```
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
```BibTeX
@article{song2025hume,
title={Hume: Introducing System-2 Thinking in Visual-Language-Action Model},
author={Anonimous Authors},
journal={arXiv preprint arXiv:2505.21432},
year={2025}
}
```
|
Hume-vla/Libero-Spatial-1
|
Hume-vla
| 2025-06-17T11:13:11Z | 0 | 1 |
transformers
|
[
"transformers",
"safetensors",
"VLA",
"robotics",
"en",
"dataset:IPEC-COMMUNITY/libero_spatial_no_noops_lerobot",
"arxiv:2505.21432",
"base_model:Hume-vla/Hume-System2",
"base_model:finetune:Hume-vla/Hume-System2",
"license:mit",
"endpoints_compatible",
"region:us"
] |
robotics
| 2025-06-17T09:07:32Z |
---
license: mit
datasets:
- IPEC-COMMUNITY/libero_spatial_no_noops_lerobot
language:
- en
base_model:
- Hume-vla/Hume-System2
pipeline_tag: robotics
library_name: transformers
tags:
- VLA
---
# Model Card for Hume-Libero_Spatial
<!-- Provide a quick summary of what the model is/does. -->
A Dual-System Visual-Language-Action model with System-2 thinking trained on Libero-Spatial.
- Paper: [https://arxiv.org/abs/2505.21432](https://arxiv.org/abs/2505.21432)
- Homepage: [https://hume-vla.github.io](https://hume-vla.github.io)
- Codebase: [🦾 Hume: A Dual-System VLA with System2 Thinking](https://github.com/hume-vla/hume) 
## Optimal TTS Args
```bash
s2_candidates_num=5
noise_temp_lower_bound=1.0
noise_temp_upper_bound=1.2
time_temp_lower_bound=1.0
time_temp_upper_bound=1.0
```
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
- If you want to reproduce the results in paper, follow the [instruction](https://github.com/hume-vla/hume/tree/main/experiments/libero)
- If you want to directly use the model:
```python
from hume import HumePolicy
import numpy as np
# load policy
hume = HumePolicy.from_pretrained("/path/to/checkpoints")
# config Test-Time Computing args
hume.init_infer(
infer_cfg=dict(
replan_steps=8,
s2_replan_steps=16,
s2_candidates_num=5,
noise_temp_lower_bound=1.0,
noise_temp_upper_bound=1.2,
time_temp_lower_bound=1.0,
time_temp_upper_bound=1.0,
post_process_action=True,
device="cuda",
)
)
# prepare observations
observation = {
"observation.images.image": np.zeros((1,224,224,3), dtype = np.uint8), # (B, H, W, C)
"observation.images.wrist_image": np.zeros((1,224,224,3), dtype = np.uint8), # (B, H, W, C)
"observation.state": np.zeros((1, 7)), # (B, state_dim)
"task": ["Lift the papper"],
}
# Infer the action
action = hume.infer(observation) # (B, action_dim)
```
## Training and Evaluation Details
```bash
# source ckpts
2025-05-02/07-58-56_libero_spatial_ck8-16-1_sh-4_gpu8_lr5e-5_1e-5_1e-5_2e-5_bs16_s1600k/0170000
# original logs
2025-06-13/23-05-08+07-58-56_libero_spatial_ck8-16-1_sh-4_gpu8_lr5e-5_1e-5_1e-5_2e-5_bs16_s1600k_0170000_s1-8_s2-16_s2cand-5_ntl-1.0_ntu-1.2_ttl-1.0_ttu-1.0.log
```
## Citation
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
```BibTeX
@article{song2025hume,
title={Hume: Introducing System-2 Thinking in Visual-Language-Action Model},
author={Anonimous Authors},
journal={arXiv preprint arXiv:2505.21432},
year={2025}
}
```
|
linlinw0/kudou_14719
|
linlinw0
| 2025-06-17T11:09:41Z | 0 | 0 | null |
[
"safetensors",
"mllama",
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T10:55:24Z |
---
license: apache-2.0
---
|
youngbongbong/cbt1model
|
youngbongbong
| 2025-06-17T11:08:47Z | 569 | 0 | null |
[
"gguf",
"cognitive-behavioral-therapy",
"chatbot",
"mental-health",
"korean",
"gpt-generated",
"fine-tuned",
"llama",
"ko",
"dataset:custom-cbt1-gpt",
"license:cc-by-sa-4.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-05-15T03:43:21Z |
---
license: cc-by-sa-4.0
language:
- ko
tags:
- cognitive-behavioral-therapy
- chatbot
- mental-health
- korean
- gpt-generated
- fine-tuned
- llama
- gguf
datasets:
- custom-cbt1-gpt
model-index:
- name: CBT1-BLOSSOM (early-stage Korean CBT chatbot)
results: []
---
# 🧠 CBT1-BLOSSOM (Early-Stage CBT Korean Chatbot)
## 📌 모델 개요
이 모델은 **Transtheoretical Model (TTM)**의 **Contemplation 단계**,
특히 **CBT1 초반부** 대화 흐름에 최적화된 한국어 상담 특화 LLM입니다.
- ✅ 자동사고 탐색 질문에 최적화된 응답 구조
- ✅ GPT 기반으로 생성한 다중턴 CBT 시나리오로 파인튜닝
- ✅ `Bllossom-8B` 계열 LLM을 기반으로 파인튜닝
- ✅ `GGUF` 포맷으로 제공되어 `llama.cpp` 호환 가능
---
## 🧾 사용 목적
이 모델은 다음과 같은 대화에서 활용될 수 있습니다:
- 🗨️ 사용자 감정 탐색 및 초기 인지 왜곡 인식 유도
- 🧠 CBT 초기 질문 예시 (Q1, Q4):
“무슨 근거로 그렇게 생각했나요?”,
“이 생각을 계속 믿는다면 어떤 일이 일어날까요?”
> 💬 해당 모델은 전문 치료를 대체하지 않으며, **디지털 상담 보조용** 또는 연구용으로 사용해야 합니다.
---
## 📚 학습 데이터
- 총 **약 800턴 분량**의 CBT1 전용 다중턴 상담 데이터
- **GPT-4o 기반 시나리오 생성 → 수작업 정제 및 중복 제거**
- 각 발화는 상담가와 내담자 간의 실제 대화 맥락을 반영함
- 데이터는 `CBT1 초반 도입–자동사고 탐색` 구조로 설계됨
---
## 🛠 모델 상세
| 항목 | 내용 |
|------------------|------|
| Base model | `llama-3-Korean-Bllossom-8B` |
| Fine-tuning type | Instruction-tuned, GPT-gen dialogue |
| Format | GGUF (`merged-first-8.0B-chat-Q4_K_M.gguf`) |
| Tokenization | SentencePiece (Ko-BPE 기반) |
| Compatible with | `llama.cpp`, `text-generation-webui`, `koboldcpp` |
---
## 💡 예시 대화
```plaintext
[사용자] 요즘 너무 지치고 아무것도 하기 싫어요.
[챗봇] 그런 지친 마음이 언제부터 시작됐는지 기억나시나요?
그때 무슨 일이 있었는지도 함께 이야기해볼 수 있을까요?
```
---
## ⚠️ 주의사항
- 이 모델은 **전문 심리상담 대체 목적이 아닙니다**
- 비상업적 사용, 연구/시제품 용도로 추천합니다
- 실제 임상 적용 전 **전문가 검수 필수**
---
## 👩💻 개발자 정보
- 이름: 윤소영 (SoYoung Yun)
- 소속: Sungkyunkwan University (성균관대학교)
- 이메일: [email protected]
- GitHub: [@yunsoyoung2004](https://github.com/yunsoyoung2004)
---
> 🧠 *“이 모델은 인지행동치료 초기 대화 단계의 자동사고 탐색을 자연스럽게 유도하는 데 초점을 맞춘 LLM 파인튜닝 모델입니다.”*
|
Someshfengde/Qwen2.5-7B-Instruct-Orthogonalized-uncensored
|
Someshfengde
| 2025-06-17T11:02:50Z | 74 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us",
"pytorch"
] |
text-generation
| 2025-04-02T10:35:52Z |
---
library_name: transformers
tags:
- transformers
- safetensors
- qwen2
- text-generation
- arxiv:1910.09700
- autotrain_compatible
- text-generation-inference
- endpoints_compatible
- region:us
- pytorch
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tamewild/4b_v4_merged_e2
|
tamewild
| 2025-06-17T10:57:57Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T10:56:13Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.