
modelId
stringlengths 5
139
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC]date 2020-02-15 11:33:14
2025-07-27 12:28:27
| downloads
int64 0
223M
| likes
int64 0
11.7k
| library_name
stringclasses 533
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 55
values | createdAt
timestamp[us, tz=UTC]date 2022-03-02 23:29:04
2025-07-27 12:28:17
| card
stringlengths 11
1.01M
|
|---|---|---|---|---|---|---|---|---|---|
Jsh1971/results
|
Jsh1971
| 2025-06-17T10:55:42Z | 0 | 0 | null |
[
"tensorboard",
"safetensors",
"distilbert",
"generated_from_trainer",
"base_model:distilbert/distilbert-base-uncased",
"base_model:finetune:distilbert/distilbert-base-uncased",
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T10:51:44Z |
---
license: apache-2.0
base_model: distilbert-base-uncased
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: results
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/itouch21-/huggingface/runs/gvh247fp)
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/itouch21-/huggingface/runs/dfpnikqh)
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/itouch21-/huggingface/runs/dfpnikqh)
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="200" height="32"/>](https://wandb.ai/itouch21-/huggingface/runs/dfpnikqh)
# results
This model is a fine-tuned version of [distilbert-base-uncased](https://huggingface.co/distilbert-base-uncased) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 0.8028
- Accuracy: 0.9145
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 48
- eval_batch_size: 48
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 4.3221 | 1.0 | 318 | 3.3251 | 0.7197 |
| 2.6661 | 2.0 | 636 | 1.9114 | 0.8497 |
| 1.5829 | 3.0 | 954 | 1.1904 | 0.8906 |
| 1.0431 | 4.0 | 1272 | 0.8904 | 0.9094 |
| 0.8218 | 5.0 | 1590 | 0.8028 | 0.9145 |
### Framework versions
- Transformers 4.41.0
- Pytorch 2.7.0+cu126
- Datasets 3.6.0
- Tokenizers 0.19.1
|
kingabzpro/Magistral-Small-Medical-QA
|
kingabzpro
| 2025-06-17T10:54:19Z | 0 | 3 |
transformers
|
[
"transformers",
"safetensors",
"medical",
"magistral",
"reasoning",
"text-generation",
"conversational",
"en",
"dataset:mamachang/medical-reasoning",
"base_model:mistralai/Magistral-Small-2506",
"base_model:finetune:mistralai/Magistral-Small-2506",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T10:19:22Z |
---
library_name: transformers
tags:
- medical
- magistral
- reasoning
license: apache-2.0
datasets:
- mamachang/medical-reasoning
language:
- en
base_model:
- mistralai/Magistral-Small-2506
pipeline_tag: text-generation
---
# Fine-tuning Magistral-Small-2506 in 4-bit Quantization for Medical Reasoning (MCQs)
This project fine-tunes the [`mistralai/Magistral-Small-2506`](https://huggingface.co/mistralai/Magistral-Small-2506) model using a medical reasoning dataset (`mamachang/medical-reasoning`) with **4-bit quantization** for memory-efficient training.
---
**🧑💻Here is the training notebook:** [Fine_tuning_Magistral-Small](https://huggingface.co/kingabzpro/Magistral-Small-Medical-QA/blob/main/fine-tuning-magistral.ipynb)
---
## Notes
- **GPU Required**: Make sure you have access to 1X A100. Get it from RunPod for an hours. Training took only 50 minutes.
- **Environment**: The notebook expects an environment where NVIDIA CUDA drivers are available (`nvidia-smi` check is included).
- **Memory Efficiency**: 4-bit loading greatly reduces memory footprint.
---
## Usage Script (tested)
```python
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
from peft import PeftModel
import torch
# Base model
base_model_id = "unsloth/Magistral-Small-2506-bnb-4bit"
# Your fine-tuned LoRA adapter repository
lora_adapter_id = "kingabzpro/Magistral-Small-Medical-QA"
# Load base model
base_model = AutoModelForCausalLM.from_pretrained(
base_model_id,
device_map="auto",
torch_dtype=torch.bfloat16,
trust_remote_code=True,
)
# Attach the LoRA adapter
model = PeftModel.from_pretrained(
base_model,
lora_adapter_id,
device_map="auto",
trust_remote_code=True,
)
# Load tokenizer
tokenizer = AutoTokenizer.from_pretrained(base_model_id, trust_remote_code=True)
# Inference example
prompt = """
Please answer with one of the options in the bracket. Write reasoning in between <analysis></analysis>. Write the answer in between <answer></answer>.
### Question:
A research group wants to assess the relationship between childhood diet and cardiovascular disease in adulthood.
A prospective cohort study of 500 children between 10 to 15 years of age is conducted in which the participants' diets are recorded for 1 year and then the patients are assessed 20 years later for the presence of cardiovascular disease.
A statistically significant association is found between childhood consumption of vegetables and decreased risk of hyperlipidemia and exercise tolerance.
When these findings are submitted to a scientific journal, a peer reviewer comments that the researchers did not discuss the study's validity.
Which of the following additional analyses would most likely address the concerns about this study's design?
{'A': 'Blinding', 'B': 'Crossover', 'C': 'Matching', 'D': 'Stratification', 'E': 'Randomization'},
### Response:
<analysis>
"""
inputs = tokenizer(
[prompt + tokenizer.eos_token],
return_tensors="pt"
).to("cuda")
outputs = model.generate(
input_ids=inputs.input_ids,
attention_mask=inputs.attention_mask,
max_new_tokens=1200,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
response = tokenizer.batch_decode(outputs, skip_special_tokens=True)
print(response[0].split("### Response:")[1])
```
**Output:**
```
<analysis>
Analysis:
This is a prospective cohort study looking at the relationship between childhood diet and cardiovascular disease in adulthood. The key concern from the peer reviewer is about the study's validity.
To address concerns about validity, the researchers could perform additional analyses to control for confounding. Matching and stratification would help control for known confounders like socioeconomic status or family history. Crossover and blinding are not applicable to this observational study design. Randomization would not be possible since the study is observational.
</analysis>
<answer>
D: Stratification
</answer>
```
|
tamewild/4b_v4_merged_e5
|
tamewild
| 2025-06-17T10:53:55Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T10:52:01Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
julycarbon/Llama-3.2-11B-Vision-Instruct-sft-hallucination-en-wm
|
julycarbon
| 2025-06-17T10:50:40Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T10:50:40Z |
---
license: apache-2.0
---
|
tamewild/4b_v4_merged_e8
|
tamewild
| 2025-06-17T10:50:24Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T10:48:32Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Aggshourya/qwen-2.5-vl-7b-2
|
Aggshourya
| 2025-06-17T10:49:06Z | 0 | 0 |
transformers
|
[
"transformers",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T10:49:02Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
tamewild/4b_v4_merged_e10
|
tamewild
| 2025-06-17T10:45:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T10:43:46Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
myduy/sft-qwen3-1.7B-v2
|
myduy
| 2025-06-17T10:41:22Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"text-generation-inference",
"unsloth",
"trl",
"sft",
"conversational",
"en",
"base_model:unsloth/Qwen3-1.7B",
"base_model:finetune:unsloth/Qwen3-1.7B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T09:50:37Z |
---
base_model: unsloth/Qwen3-1.7B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
- trl
- sft
license: apache-2.0
language:
- en
---
# Uploaded model
- **Developed by:** myduy
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-1.7B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Damarna/xat_interactiu2
|
Damarna
| 2025-06-17T10:40:42Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T10:40:42Z |
---
license: apache-2.0
---
|
Triangle104/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast-Q3_K_L-GGUF
|
Triangle104
| 2025-06-17T10:22:45Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"base_model:ArliAI/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast",
"base_model:quantized:ArliAI/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] |
text-generation
| 2025-06-17T10:04:49Z |
---
license: apache-2.0
thumbnail: https://cdn-uploads.huggingface.co/production/uploads/6625f4a8a8d1362ebcc3851a/hIZ2ZcaDyfYLT9Yd4pfOs.jpeg
language:
- en
base_model: ArliAI/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast
library_name: transformers
pipeline_tag: text-generation
tags:
- llama-cpp
- gguf-my-repo
---
# Triangle104/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast-Q3_K_L-GGUF
This model was converted to GGUF format from [`ArliAI/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast`](https://huggingface.co/ArliAI/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/ArliAI/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast) for more details on the model.
---
RpR (RolePlay with Reasoning) is a new series of models from ArliAI. This series builds directly upon the successful dataset curation methodology and training methods developed for the RPMax series.
RpR models use the same curated, deduplicated RP and creative writing dataset used for RPMax, with a focus on variety to ensure high creativity and minimize cross-context repetition. Users familiar with RPMax will recognize the unique, non-repetitive writing style unlike other finetuned-for-RP models.
With the release of QwQ as the first high performing open-source reasoning model that can be easily trained, it was clear that the available instruct and creative writing reasoning datasets contains only one response per example. This is type of single response dataset used for training reasoning models causes degraded output quality in long multi-turn chats. Which is why Arli AI decided to create a real RP model capable of long multi-turn chat with reasoning.
In order to create RpR, we first had to actually create the reasoning RP dataset by re-processing our existing known-good RPMax dataset into a reasoning dataset. This was possible by using the base QwQ Instruct model itself to create the reasoning process for every turn in the RPMax dataset conversation examples, which is then further refined in order to make sure the reasoning is in-line with the actual response examples from the dataset.
Another important thing to get right is to make sure the model is trained on examples that present reasoning blocks in the same way as it encounters it during inference. Which is, never seeing the reasoning blocks in it's context. In order to do this, the training run was completed using axolotl with manual template-free segments dataset in order to make sure that the model is never trained to see the reasoning block in the context. Just like how the model will be used during inference time.
The result of training on this dataset with this method are consistently coherent and interesting outputs even in long multi-turn RP chats. This is as far as we know the first true correctly-trained reasoning model trained for RP and creative writing.
You can access the model at https://arliai.com and we also have a models ranking page at https://www.arliai.com/models-ranking
Ask questions in our new Discord Server https://discord.com/invite/t75KbPgwhk or on our subreddit https://www.reddit.com/r/ArliAI/
---
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Triangle104/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast-Q3_K_L-GGUF --hf-file qwen3-30b-a3b-arliai-rpr-v4-fast-q3_k_l.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Triangle104/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast-Q3_K_L-GGUF --hf-file qwen3-30b-a3b-arliai-rpr-v4-fast-q3_k_l.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Triangle104/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast-Q3_K_L-GGUF --hf-file qwen3-30b-a3b-arliai-rpr-v4-fast-q3_k_l.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Triangle104/Qwen3-30B-A3B-ArliAI-RpR-v4-Fast-Q3_K_L-GGUF --hf-file qwen3-30b-a3b-arliai-rpr-v4-fast-q3_k_l.gguf -c 2048
```
|
tomaarsen/splade-mpnet-base-miriad-2e-5-lq-5e-6-lc
|
tomaarsen
| 2025-06-17T10:15:04Z | 0 | 0 |
sentence-transformers
|
[
"sentence-transformers",
"safetensors",
"mpnet",
"sparse-encoder",
"sparse",
"splade",
"generated_from_trainer",
"dataset_size:100000",
"loss:SpladeLoss",
"loss:SparseMultipleNegativesRankingLoss",
"loss:FlopsLoss",
"feature-extraction",
"en",
"dataset:tomaarsen/miriad-4.4M-split",
"arxiv:1908.10084",
"arxiv:2205.04733",
"arxiv:1705.00652",
"arxiv:2004.05665",
"base_model:microsoft/mpnet-base",
"base_model:finetune:microsoft/mpnet-base",
"license:apache-2.0",
"model-index",
"co2_eq_emissions",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-17T10:14:47Z |
---
language:
- en
license: apache-2.0
tags:
- sentence-transformers
- sparse-encoder
- sparse
- splade
- generated_from_trainer
- dataset_size:100000
- loss:SpladeLoss
- loss:SparseMultipleNegativesRankingLoss
- loss:FlopsLoss
base_model: microsoft/mpnet-base
widget:
- text: "He does it right, but there are times that he doesn't (Joana) Let's go there\
\ and pee? Because she does not want to wear a diaper, she rips off her diaper\
\ (Filomena). The family caregiver may understand this action as a \"pang\" and\
\ \"tantrum\", and \"forget\" that these episodes are part of the clinical picture\
\ of dementia. Conflicts related to incontinence and other difficult-to-manage\
\ symptoms eventually lead to a variety of interpretations, and past history of\
\ the emotional relationship between the elderly and the family caregiver can\
\ cause older emotional issues to surface again in these episodes.\n\n With psycho-functional\
\ limitations, new demands arise that can be distressing for those who care because\
\ of affective involvement. Subjective constructions are fundamental elements\
\ in upkeeping the relationship of care 10 .\n\n Besides the psychological aspect\
\ involved in the loss of identity and the specific cognitive aspects of dementia,\
\ some behavioral and psychiatric changes are important even in the consultation\
\ with the ESF professionals: psychotic symptoms, agitation and aggression, mood\
\ swings, disinhibited behavior and euphoria, apathy and insomnia. Some studies\
\ [11] [12] [13] pointed out the significant association between the presence\
\ of apathy and a faster cognitive and functional decline in these patients. Another\
\ very relevant situation regarding the appearance of neuropsychiatric symptoms\
\ is the association of these symptoms with the institutionalization and shorter\
\ patient survival. They also showed that the highest Neuropsychiatric Inventory\
\ (NPI) score was signifi-cantly associated with more severe cognitive impairment,\
\ greater caregiver distress, and higher cost, but was not associated with a formal\
\ diagnosis of dementia performed by the primary care physician.\n\n Changed behaviors\
\ and even risky behaviors, such as turning on the gas switch and not turning\
\ off, stirring in pots on a hot stove, or ingestion of liquids or toxic materials\
\ are situations in the face of neuropsychiatric manifestations in dementia. Filomena\
\ reports several neuropsychiatric symptoms of her husband. She compares his behavior\
\ to that of children who explore the environment to discover the cause and effect\
\ of things and the sensations obtained by the senses. Her role in this context\
\ resembles that of a mother trying to prevent the child from getting hurt: He\
\ lights up the gas switch, he's just like a child, sometimes he starts to eat\
\ the slipper, I have to get it out of his mouth.\n\n Hallucination is another\
\ neuropsychiatric symptom described by family caregivers. Joana reports that\
\ when the husband talks to people who have died, the family members feel fear\
\ and distance themselves. Filomena has fun when her mother speaks with those\
\ who have died: \"She talks to those who have passed away, she sends the dog\
\ out, which does not exist\". Each family caregiver experiences the symptoms\
\ presented by the dementia in a unique way, and ways to address and interpret\
\ this phenomenon and give meaning to their experience.\n\n The negative development\
\ of dementia perceived by Celina, Filomena, Maria, Teresa and Joana show that\
\ the disease follows a course that transcends the biological event itself. The\
\ dementia process evidences psychological and sociocultural constructions permeated\
\ by meanings and interpretations according to those who live and those who maintain\
\ interpersonal relationships with the elderly person with dementia.\n\n In the\
\ discourse of family caregivers, seniors with dementia have aggressive behaviors\
\ such as agitation, spitting, cursing, clawing, throwing objects, revealing a\
\ level of aggression that can impact the feelings and interpretations produced\
\ during the care routine. Freud 14 affirms that human instincts are of two types:\
\ Those who tend to preserve and unite, which we call 'erotic' [...] with a deliberate\
\ expansion of the popular conception of 'sexuality'; and those who tend to destroy\
\ and kill, which we group as an aggressive or destructive instinct. All actions\
\ in human life involve the confluence of these two instincts of preservation\
\ and destruction. The ideal situation for life in society would be the dominance\
\ of reason over the instinctual life controlling destructive impulses, which\
\ is utopian. In this perspective, aggressiveness is inherent in the human condition.\n\
\n In seniors with dementia with a declining psychological realm of the Self,\
\ the progressive loss of identity and the repercussion of cognitive decline,\
\ an actual decline in the rational realm of psychic life emerges. This decline\
\ refers to the cerebral aspect of inhibitory control and social cognition, showing\
\ that the emergence of aggressive behaviors is related to the biological component.\
\ The declining reason turns its demands and needs into instinctual acts and more\
\ basic reflexes, and can produce a continuous imbalance in the expression between\
\ the instincts of preservation and aggression.\n\n Aggressiveness can be triggered\
\ by situations of frustration, when they do not get what they want, when they\
\ are afraid or consider some humiliating situation, when they are exposed to\
\ environmental overstimulation or feel any physical pain or side effects from\
\ medication."
- text: "Neurosurgery is of great interest to historians of medicine and technology\
\ because it is relatively young, because it developed in an era of journals and\
\ publications, because lines and traditions of training and mentorship are relatively\
\ clear, and because the technologies that enabled the evolution of the profession\
\ and acted as inflection points in the emergence of certain surgical approaches\
\ and procedures are at once well documented and remarkably unambiguous. To the\
\ extent that is the case for neurosurgery as a whole, it is even more so for\
\ surgery of the skull base.\n\n To trace the history of skull base surgery along\
\ its full expanse is to begin with Horsley and pituitary tumors (unless one wants\
\ to start even earlier with the treatment of trigeminal neuralgia); to move to\
\ Cushing's work in the same arena (but also that of many others as well); to\
\ emphasize the impact of microsurgical techniques and new imaging modalities;\
\ to outline once radically innovative, but now widely practiced anatomical approaches\
\ to the skull base; to emphasize the importance of team approaches; to discuss\
\ emerging therapeutic strategy as well as instrumentation and techniques; to\
\ acknowledge the importance of advances in neuroanesthesia and the medical and\
\ perioperative care of the neurosurgical patient; and to recognize the contributions\
\ of the many individuals who, over the past 25 years, have added to and furthered\
\ the field in these and other ways.\n\n It is not hard to point to leading individuals\
\ and important techniques. It is perhaps more difficult to frame them in a meaningful\
\ historical perspective because the work has occurred relatively recently, in\
\ the time frame historians call \"near history.\" Difficulties arise from both\
\ an evaluative and a nosological standpoint. For example, from an evaluative\
\ standpoint, how does one stratify the relative importance of corticosteroids,\
\ osmotic diuretics, and CSF drainage techniques and technologies in the control\
\ of intracranial pressure and the facilitation of exposure for base of skull\
\ surgery? How does one think about the idea of hybrid surgery and stereotactic\
\ radiation? What will be the long-term view of anatomical approaches to giant\
\ basilar aneurysms in the light of endovascular surgery? Have we reached a tipping\
\ point in the management of vestibular schwannomas, given the availability of\
\ and the outcomes associated with stereotactic radiosurgery?\n\n From a nosological\
\ standpoint, should we think about base of skull surgery in terms of anatomical\
\ approaches? One textbook that does just that starts with subfrontal approaches\
\ and then moves around the calvaria and down to the petrous and temporal region\
\ in a Cook's tour of exposure, in the tradition of Henry's Extensile Exposure\
\ and comparable surgical classics. 1, 6 Other publications have explored a set\
\ of technologies. 5, 7, 10 Another focuses on the contribution of great men.\
\ 9 Many surgeons have written about specific particular pathologies at the skull\
\ base.\n\n Introduction their colleagues write about the premodern period. Elhadi\
\ and colleagues also comment on the introduction of radiography in early neurosurgery.\
\ Gross and Grossi and their colleagues concentrate on petrosal approaches; Schmitt\
\ and Jane on third ventriculostomy; and Chittiboina and colleagues on the history\
\ of a very simple but ubiquitous instrument, the Freer elevator, and its inventor.\
\ In contrast to the more comprehensive overviews written by Goodrich, Donald,\
\ and others, these essays concentrate on selected details. While it is important\
\ not to miss the forest for the trees, sometimes the trees are worth studying\
\ no less than the forest. \n\n The authors report no conflict of interest."
- text: 'How do neuromediators contribute to the pathogenesis of pruritus in AD?
'
- text: "Pericardial effusion (PE) is a life-threatening condition, as accumulation\
\ of fluid in the pericardial sac can lead to cardiac tamponade and fatal shock.\
\ 1, 2 PE is often associated with an underlying disease or condition, and the\
\ causes can vary widely. 3, 4 Pericardiocentesis performed by needle (with or\
\ without echoguidance), and various surgical procedures (including subxiphoid\
\ pericardial tube drainage, pericardial window performed through a left anterior\
\ thoracotomy, or video-assisted thoracoscopic surgery) can alleviate PE. 5 Our\
\ retrospective clinical experiences of treating PE with subxiphoid pericardiostomy\
\ are presented in this study.\n\n We reviewed the medical records of patients\
\ who underwent subxiphoid pericardiostomy to treat persistent symptomatic PE\
\ in our clinic between 1990 and 2000. Echocardiography (ECG) was used to diagnose\
\ PE and N Becit, A Özyazicioglu, M Ceviz et al.\n\n determine the size of the\
\ effusion. A diastolic echo-free space of < 10 mm between the left ventricular\
\ posterior wall and pericardium was determined as mild PE, 10 -20 mm as moderate,\
\ and > 20 mm as severe PE. Patients with cardiac tamponade and/or moderate to\
\ severe PE were treated by subxiphoid pericardiostomy and tube drainage.\n\n\
\ Some patients with pre-operative tuberculosis were treated with an adult fourdrug\
\ regimen (isoniazid, 300 mg/day and rifampin, 600 mg/day for 12 months, streptomycin,\
\ 1 g/day for 2 months, and pyrazinamide, 2 g/day for 3 months) preoperatively.\
\ The effusion was drained after a 3-week course of anti-tuberculosis therapy.\
\ In these, and patients diagnosed with tuberculous pericarditis, the tuberculosis\
\ therapy regimen was given for 12 months post-operatively.\n\n The technique\
\ used for subxiphoid pericardiostomy (described previously 3 ) was performed\
\ under general anaesthetic, or local anaesthesia and sedation. General anaesthesia\
\ was preferred in children and was induced with 1.5 mg/kg ketamine. Neuromuscular\
\ block was achieved with 0.1 mg/kg vecuronium, and anaesthesia maintained with\
\ 60% N 2 O, 40% O 2 and 0.5 -1.0% isoflurane. Local anaesthetic (2% lidocaine\
\ solution) was injected into the dermal and subdermal layers, and sedation and\
\ analgesia was provided by 1 mg/kg ketamine intravenously. A piece of anterior\
\ pericardium, approximately 2 -4 cm in diameter, was excised under direct vision\
\ and submitted for histopathological analysis. The pericardial cavity was decompressed\
\ and fluid samples were collected for culture and cytological analysis. To prevent\
\ acute cardiac dilatation during decompression of the pericardial cavity, intravenous\
\ digoxin was administered and the pericardial cavity was decompressed gradually.\n\
\n The pericardial cavity was examined under direct vision and/or by digital examination\
\ to detect any tumour or adhesions. Gentle digital lysis of adhesions and opening\
\ of loculations were performed as needed, to enhance satisfactory drainage. A\
\ soft chest tube was placed in the pericardial cavity, lateral to the right ventricle,\
\ after pericardiotomy for post-operative drainage. It was connected to an underwater\
\ sealed system, and was removed when fluid drainage ceased.\n\n Patients with\
\ mild haemorrhagic effusion and cardiac tamponade, due to trauma or invasive\
\ cardiac interventions, were considered haemodynamically unstable and unsuitable\
\ for surgical subxiphoid pericardiostomy, even under local anaesthetic. These\
\ patients underwent pericardiocentesis in the intensive care unit, which provided\
\ immediate relief. Subxiphoid pericardiostomy was performed later if haemorrhagic\
\ PE persisted. Patients were followed, with physical examinations and ECG, in\
\ the outpatient clinic for at least 1 year.\n\n Numerical results are given as\
\ mean ± SD. Fisher's exact test was used to compare proportions between groups\
\ (comparison of the rates of recurrence and constriction between patient groups\
\ with uraemic pericarditis, tuberculous pericarditis and non-tuberculous bacterial\
\ pericarditis). The McNemar test was used for comparison of proportions within\
\ one group (to assess the significance of rates of recurrence and constriction\
\ in patients with tuberculous pericarditis). Statistical differences were considered\
\ significant if P < 0.05."
- text: "Henry M. Blumberg, MD In this issue of Infection Control and Hospital Epidemiology,\
\ a potpourri of tuberculosis (TB)-related articles are being published. 1-7 Tuberculosisrelated\
\ issues have been an important focus for the past decade for those in infection\
\ control and hospital epidemiology, especially in urban areas where the large\
\ majority of TB cases occur, 8 but also, because of federal regulations, for\
\ those in low-endemic areas or areas where no TB cases occur (approximately half\
\ of the counties in the United States).\n\n The resurgence of TB beginning in\
\ the mid1980s in the United States (in large part, due to failure and underfunding\
\ of the public health infrastructure and to the epidemic of human immunodeficiency\
\ virus [HIV] infection) and outbreaks of TB have highlighted the risk of nosocomial\
\ transmission of TB. 9,10 These outbreaks affected both healthcare workers (HCWs)\
\ and patients. The fact that outbreaks in New York and Miami, among others, involved\
\ multidrug-resistant (MDR) strains that were associated with high morbidity and\
\ mortality among HIV-infected individuals punctuated the importance of effective\
\ TB infection control measures. Commingling of patients with unsuspected TB and\
\ those who were quite immunosuppressed led to amplification of nosocomial transmission.\
\ A decade ago, few institutions were prepared for the changing epidemiology of\
\ TB.\n\n Several recent studies have demonstrated that infection control measures\
\ are effective in preventing nosocomial transmission of TB, 11-13 and two reports\
\ in this issue, from institutions in Kentucky 1 and New York, 2 provide additional\
\ data on decreases in HCW tuberculin skin-test (TST) conversions following implementation\
\ of TB infection control measures. In most studies, multiple interventions (administrative\
\ controls, environmental controls, and respiratory protection) were initiated\
\ at approximately the same time, making it more difficult to identify the most\
\ crucial aspect of the program. The importance of TB infection control measures\
\ in contributing to the decline in TB cases in the United States, as well as\
\ the reduction in the number of MDR-TB cases in New York City, often has been\
\ understated. Increased federal funding for TB control activities and expansion\
\ of directly observed therapy clearly are important in efforts to prevent TB,\
\ but the initial decline in TB cases and in MDR TB in the United States beginning\
\ in 1993 likely was due, in large part, to interruption of TB transmission within\
\ healthcare facilities. Unfortunately, increased funding for TB control in the\
\ United States in the last 5 years often has not trickled down to inner-city\
\ hospitals, which frequently are the first line in the battle against TB.\n\n\
\ From our experience and that of others, it appears clear that administrative\
\ controls are the most important component of a TB infection control program.\
\ At Grady Memorial Hospital in Atlanta, we were able to decrease TB exposure\
\ episodes markedly and concomitantly to decrease HCW TST conversions after implementing\
\ an expanded respiratory isolation policy. 11 We continue to isolate appropriately\
\ approximately 95% of those subsequently diagnosed with TB. We were able to reduce\
\ TST conver-sion rates markedly during a period of time in which we had isolation\
\ rooms that would be considered suboptimal by Centers for Disease Control and\
\ Prevention (CDC) guidelines 14 (rooms that were under negative pressure but\
\ had less than six air changes per hour) and were using submicron masks. Implementation\
\ of better-engineered isolation rooms (>12 air changes per hour) with the completion\
\ of renovations to the hospital may have put us in better compliance with regulatory\
\ agencies and made the staff feel more secure, but has had little impact on further\
\ reducing low rates of HCW TST conversions. In addition, the termination of outbreaks\
\ and reduction of TST conversion rates at several institutions took place before\
\ introduction of National Institute for Occupational Safety and Health-approved\
\ masks and fit testing. 2,15,16 United States healthcare institutions are required\
\ by regulatory mandates to develop a \"respiratory protection program\" (including\
\ fit testing), which can be time-consuming, expensive, and logistically difficult.\
\ 17 Data published to date suggest that the impact of formal fit testing on proper\
\ mask use is small. 18 These federal mandates also have turned some well-meaning\
\ (trying to comply fully with the Occupational Safety and Health Administration\
\ [OSHA] regulations) but misguided infection control practitioners into \"facial\
\ hair police.\" These types of processes divert time, effort, and resources away\
\ from what truly is effective in preventing nosocomial transmission of TB, as\
\ well as from other important infection control activities such as preventing\
\ nosocomial bloodstream infections or transmission of highly resistant pathogens\
\ such as vancomycin-resistant Enterococcus or preparing for the onslaught of\
\ vancomycin-resistant Staphylococcus aureus. At a time when US healthcare institutions\
\ are under enormous pressure due to healthcare reform, market forces, and managed\
\ care, it is essential that federal regulatory agencies look carefully at scientific\
\ data when issuing regulations."
datasets:
- tomaarsen/miriad-4.4M-split
pipeline_tag: feature-extraction
library_name: sentence-transformers
metrics:
- dot_accuracy@1
- dot_accuracy@3
- dot_accuracy@5
- dot_accuracy@10
- dot_precision@1
- dot_precision@3
- dot_precision@5
- dot_precision@10
- dot_recall@1
- dot_recall@3
- dot_recall@5
- dot_recall@10
- dot_ndcg@10
- dot_mrr@10
- dot_map@100
- query_active_dims
- query_sparsity_ratio
- corpus_active_dims
- corpus_sparsity_ratio
co2_eq_emissions:
emissions: 196.23895298915153
energy_consumed: 0.504857070427092
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: 13th Gen Intel(R) Core(TM) i7-13700K
ram_total_size: 31.777088165283203
hours_used: 1.484
hardware_used: 1 x NVIDIA GeForce RTX 3090
model-index:
- name: MPNet-base trained on MIRIAD question-passage tuples
results:
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: miriad eval
type: miriad_eval
metrics:
- type: dot_accuracy@1
value: 0.917
name: Dot Accuracy@1
- type: dot_accuracy@3
value: 0.963
name: Dot Accuracy@3
- type: dot_accuracy@5
value: 0.969
name: Dot Accuracy@5
- type: dot_accuracy@10
value: 0.98
name: Dot Accuracy@10
- type: dot_precision@1
value: 0.917
name: Dot Precision@1
- type: dot_precision@3
value: 0.32099999999999995
name: Dot Precision@3
- type: dot_precision@5
value: 0.1938
name: Dot Precision@5
- type: dot_precision@10
value: 0.09800000000000002
name: Dot Precision@10
- type: dot_recall@1
value: 0.917
name: Dot Recall@1
- type: dot_recall@3
value: 0.963
name: Dot Recall@3
- type: dot_recall@5
value: 0.969
name: Dot Recall@5
- type: dot_recall@10
value: 0.98
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.9509329680619819
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.9414055555555555
name: Dot Mrr@10
- type: dot_map@100
value: 0.9422311263243918
name: Dot Map@100
- type: query_active_dims
value: 72.48699951171875
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9976254791000846
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 291.5419921875
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9904497005212599
name: Corpus Sparsity Ratio
- task:
type: sparse-information-retrieval
name: Sparse Information Retrieval
dataset:
name: miriad test
type: miriad_test
metrics:
- type: dot_accuracy@1
value: 0.9
name: Dot Accuracy@1
- type: dot_accuracy@3
value: 0.953
name: Dot Accuracy@3
- type: dot_accuracy@5
value: 0.961
name: Dot Accuracy@5
- type: dot_accuracy@10
value: 0.974
name: Dot Accuracy@10
- type: dot_precision@1
value: 0.9
name: Dot Precision@1
- type: dot_precision@3
value: 0.31766666666666665
name: Dot Precision@3
- type: dot_precision@5
value: 0.19220000000000004
name: Dot Precision@5
- type: dot_precision@10
value: 0.09740000000000001
name: Dot Precision@10
- type: dot_recall@1
value: 0.9
name: Dot Recall@1
- type: dot_recall@3
value: 0.953
name: Dot Recall@3
- type: dot_recall@5
value: 0.961
name: Dot Recall@5
- type: dot_recall@10
value: 0.974
name: Dot Recall@10
- type: dot_ndcg@10
value: 0.9387955628253912
name: Dot Ndcg@10
- type: dot_mrr@10
value: 0.9273035714285714
name: Dot Mrr@10
- type: dot_map@100
value: 0.9283432155352948
name: Dot Map@100
- type: query_active_dims
value: 73.08399963378906
name: Query Active Dims
- type: query_sparsity_ratio
value: 0.9976059226378685
name: Query Sparsity Ratio
- type: corpus_active_dims
value: 293.2669982910156
name: Corpus Active Dims
- type: corpus_sparsity_ratio
value: 0.9903931929671761
name: Corpus Sparsity Ratio
---
# MPNet-base trained on MIRIAD question-passage tuples
This is a [SPLADE Sparse Encoder](https://www.sbert.net/docs/sparse_encoder/usage/usage.html) model finetuned from [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base) on the [miriad-4.4_m-split](https://huggingface.co/datasets/tomaarsen/miriad-4.4M-split) dataset using the [sentence-transformers](https://www.SBERT.net) library. It maps sentences & paragraphs to a 30527-dimensional sparse vector space and can be used for semantic search and sparse retrieval.
## Model Details
### Model Description
- **Model Type:** SPLADE Sparse Encoder
- **Base model:** [microsoft/mpnet-base](https://huggingface.co/microsoft/mpnet-base) <!-- at revision 6996ce1e91bd2a9c7d7f61daec37463394f73f09 -->
- **Maximum Sequence Length:** 512 tokens
- **Output Dimensionality:** 30527 dimensions
- **Similarity Function:** Dot Product
- **Training Dataset:**
- [miriad-4.4_m-split](https://huggingface.co/datasets/tomaarsen/miriad-4.4M-split)
- **Language:** en
- **License:** apache-2.0
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Documentation:** [Sparse Encoder Documentation](https://www.sbert.net/docs/sparse_encoder/usage/usage.html)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sparse Encoders on Hugging Face](https://huggingface.co/models?library=sentence-transformers&other=sparse-encoder)
### Full Model Architecture
```
SparseEncoder(
(0): MLMTransformer({'max_seq_length': 512, 'do_lower_case': False}) with MLMTransformer model: MPNetForMaskedLM
(1): SpladePooling({'pooling_strategy': 'max', 'activation_function': 'relu', 'word_embedding_dimension': 30527})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SparseEncoder
# Download from the 🤗 Hub
model = SparseEncoder("tomaarsen/splade-mpnet-base-miriad-2e-5-lq-5e-6-lc")
# Run inference
queries = [
"How have infection control measures been effective in preventing nosocomial transmission of TB?\n",
]
documents = [
'Henry M. Blumberg, MD In this issue of Infection Control and Hospital Epidemiology, a potpourri of tuberculosis (TB)-related articles are being published. 1-7 Tuberculosisrelated issues have been an important focus for the past decade for those in infection control and hospital epidemiology, especially in urban areas where the large majority of TB cases occur, 8 but also, because of federal regulations, for those in low-endemic areas or areas where no TB cases occur (approximately half of the counties in the United States).\n\n The resurgence of TB beginning in the mid1980s in the United States (in large part, due to failure and underfunding of the public health infrastructure and to the epidemic of human immunodeficiency virus [HIV] infection) and outbreaks of TB have highlighted the risk of nosocomial transmission of TB. 9,10 These outbreaks affected both healthcare workers (HCWs) and patients. The fact that outbreaks in New York and Miami, among others, involved multidrug-resistant (MDR) strains that were associated with high morbidity and mortality among HIV-infected individuals punctuated the importance of effective TB infection control measures. Commingling of patients with unsuspected TB and those who were quite immunosuppressed led to amplification of nosocomial transmission. A decade ago, few institutions were prepared for the changing epidemiology of TB.\n\n Several recent studies have demonstrated that infection control measures are effective in preventing nosocomial transmission of TB, 11-13 and two reports in this issue, from institutions in Kentucky 1 and New York, 2 provide additional data on decreases in HCW tuberculin skin-test (TST) conversions following implementation of TB infection control measures. In most studies, multiple interventions (administrative controls, environmental controls, and respiratory protection) were initiated at approximately the same time, making it more difficult to identify the most crucial aspect of the program. The importance of TB infection control measures in contributing to the decline in TB cases in the United States, as well as the reduction in the number of MDR-TB cases in New York City, often has been understated. Increased federal funding for TB control activities and expansion of directly observed therapy clearly are important in efforts to prevent TB, but the initial decline in TB cases and in MDR TB in the United States beginning in 1993 likely was due, in large part, to interruption of TB transmission within healthcare facilities. Unfortunately, increased funding for TB control in the United States in the last 5 years often has not trickled down to inner-city hospitals, which frequently are the first line in the battle against TB.\n\n From our experience and that of others, it appears clear that administrative controls are the most important component of a TB infection control program. At Grady Memorial Hospital in Atlanta, we were able to decrease TB exposure episodes markedly and concomitantly to decrease HCW TST conversions after implementing an expanded respiratory isolation policy. 11 We continue to isolate appropriately approximately 95% of those subsequently diagnosed with TB. We were able to reduce TST conver-sion rates markedly during a period of time in which we had isolation rooms that would be considered suboptimal by Centers for Disease Control and Prevention (CDC) guidelines 14 (rooms that were under negative pressure but had less than six air changes per hour) and were using submicron masks. Implementation of better-engineered isolation rooms (>12 air changes per hour) with the completion of renovations to the hospital may have put us in better compliance with regulatory agencies and made the staff feel more secure, but has had little impact on further reducing low rates of HCW TST conversions. In addition, the termination of outbreaks and reduction of TST conversion rates at several institutions took place before introduction of National Institute for Occupational Safety and Health-approved masks and fit testing. 2,15,16 United States healthcare institutions are required by regulatory mandates to develop a "respiratory protection program" (including fit testing), which can be time-consuming, expensive, and logistically difficult. 17 Data published to date suggest that the impact of formal fit testing on proper mask use is small. 18 These federal mandates also have turned some well-meaning (trying to comply fully with the Occupational Safety and Health Administration [OSHA] regulations) but misguided infection control practitioners into "facial hair police." These types of processes divert time, effort, and resources away from what truly is effective in preventing nosocomial transmission of TB, as well as from other important infection control activities such as preventing nosocomial bloodstream infections or transmission of highly resistant pathogens such as vancomycin-resistant Enterococcus or preparing for the onslaught of vancomycin-resistant Staphylococcus aureus. At a time when US healthcare institutions are under enormous pressure due to healthcare reform, market forces, and managed care, it is essential that federal regulatory agencies look carefully at scientific data when issuing regulations.',
'Drug Reaction with Eosinophilia and Systemic Symptoms (DRESS) syndrome is a severe and potentially life-threatening hypersensitivity reaction caused by exposure to certain medications (Phillips et al., 2011; Bocquet et al., 1996) . It is extremely heterogeneous in its manifestation but has characteristic delayed-onset cutaneous and multisystem features with a protracted natural history. The reaction typically starts with a fever, followed by widespread skin eruption of variable nature. This progresses to inflammation of internal organs such as hepatitis, pneumonitis, myocarditis and nephritis, and haematological abnormalities including eosinophilia and atypical lymphocytosis (Kardaun et al., 2013; Cho et al., 2017) .\n\n DRESS syndrome is most commonly classified according to the international scoring system developed by the RegiSCAR group (Kardaun et al., 2013) . RegiSCAR accurately defines the syndrome by considering the major manifestations, with each feature scored between −1 and 2, and 9 being the maximum total number of points. According to this classification, a score of < 2 means no case, 2-3 means possible case, 4-5 means probable case, and 6 or above means definite DRESS syndrome. Table 1 gives an overview of the RegiSCAR scoring system. DRESS syndrome usually develops 2 to 6 weeks after exposure to the causative drug, with resolution of symptoms after drug withdrawal in the majority of cases (Husain et al., 2013a) . Some patients require supportive treatment with corticosteroids, although there is a lack of evidence surrounding the most effective dose, route and duration of the therapy (Adwan, 2017) . Although extremely rare, with an estimated population risk of between 1 and 10 in 10,000 drug exposures, it is significant due to its high mortality rate, at around 10% (Tas and The pathogenesis of DRESS syndrome remains largely unknown. Current evidence suggests that patients may be genetically predisposed to this form of hypersensitivity, with a superimposed risk resulting from Human Herpes Virus (HHV) exposure and subsequent immune reactivation (Cho et al., 2017; Husain et al., 2013a) . In fact, the serological detection of HHV-6 has even been proposed as an additional diagnostic marker for DRESS syndrome (Shiohara et al., 2007) . Other potential risk factors identified are family history (Sullivan and Shear, 2001; Pereira De Silva et al., 2011) and concomitant drug use, particularly antibiotics . DRESS syndrome appears to occur in patients of any age, with patient demographics from several reviews finding age ranges between 6 and 89 years (Picard et al., 2010; Kano et al., 2015; Cacoub et al., 2013) . DRESS syndrome was first described as an adverse reaction to antiepileptic therapy, but has since been recognised as a complication of an extremely wide range of medications (Adwan, 2017) . In rheumatology, it has been classically associated with allopurinol and sulfasalazine, but has also been documented in association with many other drugs including leflunomide, hydroxychloroquine, febuxostat and NSAIDs (Adwan, 2017) . Recent evidence has also identified a significant risk of DRESS syndrome with strontium ranelate use (Cacoub et al., 2013) . Thus far, that is the only anti-osteoporotic drug associated with DRESS syndrome, although there are various cases of other adverse cutaneous reactions linked to anti-osteoporotic medications, ranging from benign maculopapular eruption to Stevens-Johnson syndrome (SJS) and Toxic Epidermal Necrolysis (TEN) . Denosumab, an antiresorptive RANK ligand (RANKL) inhibitor licensed for osteoporosis, is currently known to be associated with some dermatological manifestations including dermatitis, eczema, pruritus and, less commonly, cellulitis (Prolia, n.d.).\n\n We hereby describe the first documented case of DRESS syndrome associated with denosumab treatment.\n\n The patient is a 76-year old female with osteoporosis and a background of alcoholic fatty liver disease and lower limb venous insufficiency. Osteoporosis was first diagnosed in 2003 and treated with risedronate, calcium and vitamin D, until 2006. While on this treatment, the patient sustained T12 and L3 fractures, the latter treated with kyphoplasty, and was therefore deemed a non-responder to risedronate.',
"The regulation of these events is known to go awry in certain pathologies especially in diseases associated with neurodegeneration. Mitochondrial fission helps to enhance the number of mitochondria, which can be efficiently distributed to each corner of neuronal cells and thus helps them to maintain their energy demands. Mitochondrial fission is highly essential during the periods of energy starvation to produce new, efficient mitochondrial energy generating systems. However, enhanced fission associated with bioenergetic crisis causes BAX foci formation on mitochondrial membrane and thus causes mitochondrial outer membrane permeabilization (MOMP), releasing cytochrome c and other pro apoptotic mediators into cytosol, results in apoptosis [93] . Impairment in the mitochondrial dynamics has also been observed in case of inflammatory neuropathies and oxaliplatin induced neuropathy [94] . Excessive nitric oxide is known to cause s-nitrosylation of dynamin related protein-1 (Drp-1), and increases the mitochondrial fission [95, 96] . Tumor necrosis factor-α (TNF-α) reported to inhibit the kinensin 1 protein, and thus impairs trafficking by halting mitochondrial movement along axons [97] . In addition to impaired dynamics, aggregates of abnormal shaped, damaged mitochondria are responsible for aberrant mitochondrial trafficking, which contributes to axonal degeneration observed in various peripheral neuropathies [81] .\n\n Autophagy is the discerning cellular catabolic process responsible for recycling the damaged proteins/ organelles in the cells [98] . Mitophagy is a selective autophagic process involved in recycling of damaged mitochondria and helps in supplying the constituents for mitochondrial biogenesis [99] . Excessive accumulation and impaired clearance of dysfunctional mitochondria are known to be observed in various disorders associated with oxidative stress [100] . Oxidative damage to Atg 4, a key component involved in mitophagy causes impaired autophagosome formation and clearance of damaged mitochondria [101] . Loss in the function of molecular chaperons and associated accumulation of damaged proteins are known to be involved in various peripheral neuropathies including trauma induced neuropathy [102, 103] . A model of demyelinating neuropathy corresponds to the accumulation of improperly folded myelin protein PMP-22 is also being observed recently [104, 105] .\n\n Mitochondrial dysfunction and associated disturbances are well connected to neuroinflammatory changes that occur in various neurodegenerative diseases [106] . Dysfunctional mitochondria are also implicated in several pathologies such as cardiovascular and neurodegenerative diseases. Several mitochondrial toxins have been found to inhibit the respiration in microglial cells and also inhibit IL-4 induced alternative anti inflammatory response and thus potentiates neuroinflammation [107] . Mitochondrial ROS are well identified to be involved in several inflammatory pathways such as NF-κB, MAPK activation [108] . Similarly, the pro inflammatory mediators released as a result of an inflammatory episode found to be interfere with the functioning of the mitochondrial electron transport chain and thus compromise ATP production [109] . TNF-α is known to inhibit the complex I, IV of ETC and decreases energy production. Nitric oxide (NO) is a potent inhibitor of cytochrome c oxidase (complex IV) and similarly IL-6 is also known to enhance mitochondrial generation of superoxide [110] . Mitochondrial dysfunction initiates inflammation by increased formation of complexes of damaged mitochondrial parts and cytoplasmic pattern recognition receptors (PRR's). The resulting inflammasome directed activation of interleukin-1β production, which starts an immune response and leads to Fig. (4) . Mitotoxicity in peripheral neuropathies: Various pathophysiological insults like hyperglycemic, chemotherapeutic and traumatic injury to the peripheral nerves results in mitochondrial dysfunction through enhanced generation of ROS induced biomolecular damage and bioenergetic crisis. Following the nerve injury accumulation of mitochondria occurs resulting in the release of mtDNA & formyl peptides into circulation which acts as Death associated molecular patterns (DAMP's). These are recognized by immune cells as foreign bodies and can elicit a local immune/inflammatory response. Interaction between inflammatory mediators and structural proteins involved in mitochondrial trafficking will cause impairment in mitochondrial motility. Oxidative stress induced damage to the mt proteins like Atg4, Parkin etc cause insufficient mitophagy. Excess nitrosative stress also results in excessive mt fission associated with apoptosis. In addition, mtDNA damage impairs its transcription and reduces mitochondrial biogenesis. Ca 2+ dyshomeostasis, loss in mitochondrial potential and bioenergetic crisis cause neuronal death via apoptosis/necrosis. All these modifications cause defects in ultra structure, physiology and trafficking of mitochondria resulting in loss of neuronal function producing peripheral neuropathy.",
]
query_embeddings = model.encode_query(queries)
document_embeddings = model.encode_document(documents)
print(query_embeddings.shape, document_embeddings.shape)
# [1, 30527] [3, 30527]
# Get the similarity scores for the embeddings
similarities = model.similarity(query_embeddings, document_embeddings)
print(similarities)
# tensor([[38.6532, 2.9277, 0.1620]])
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Sparse Information Retrieval
* Datasets: `miriad_eval` and `miriad_test`
* Evaluated with [<code>SparseInformationRetrievalEvaluator</code>](https://sbert.net/docs/package_reference/sparse_encoder/evaluation.html#sentence_transformers.sparse_encoder.evaluation.SparseInformationRetrievalEvaluator)
| Metric | miriad_eval | miriad_test |
|:----------------------|:------------|:------------|
| dot_accuracy@1 | 0.917 | 0.9 |
| dot_accuracy@3 | 0.963 | 0.953 |
| dot_accuracy@5 | 0.969 | 0.961 |
| dot_accuracy@10 | 0.98 | 0.974 |
| dot_precision@1 | 0.917 | 0.9 |
| dot_precision@3 | 0.321 | 0.3177 |
| dot_precision@5 | 0.1938 | 0.1922 |
| dot_precision@10 | 0.098 | 0.0974 |
| dot_recall@1 | 0.917 | 0.9 |
| dot_recall@3 | 0.963 | 0.953 |
| dot_recall@5 | 0.969 | 0.961 |
| dot_recall@10 | 0.98 | 0.974 |
| **dot_ndcg@10** | **0.9509** | **0.9388** |
| dot_mrr@10 | 0.9414 | 0.9273 |
| dot_map@100 | 0.9422 | 0.9283 |
| query_active_dims | 72.487 | 73.084 |
| query_sparsity_ratio | 0.9976 | 0.9976 |
| corpus_active_dims | 291.542 | 293.267 |
| corpus_sparsity_ratio | 0.9904 | 0.9904 |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Dataset
#### miriad-4.4_m-split
* Dataset: [miriad-4.4_m-split](https://huggingface.co/datasets/tomaarsen/miriad-4.4M-split) at [596b9ab](https://huggingface.co/datasets/tomaarsen/miriad-4.4M-split/tree/596b9ab305d52cb73644ed5b5004957c7bfaae40)
* Size: 100,000 training samples
* Columns: <code>question</code> and <code>passage_text</code>
* Approximate statistics based on the first 1000 samples:
| | question | passage_text |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 9 tokens</li><li>mean: 23.38 tokens</li><li>max: 71 tokens</li></ul> | <ul><li>min: 511 tokens</li><li>mean: 512.0 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| question | passage_text |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>What factors may contribute to increased pulmonary conduit durability in patients who undergo the Ross operation compared to those with right ventricular outflow tract obstruction?<br></code> | <code>I n 1966, Ross and Somerville 1 reported the first use of an aortic homograft to establish right ventricle-to-pulmonary artery continuity in a patient with tetralogy of Fallot and pulmonary atresia. Since that time, pulmonary position homografts have been used in a variety of right-sided congenital heart lesions. Actuarial 5-year homograft survivals for cryopreserved homografts are reported to range between 55% and 94%, with the shortest durability noted in patients less than 2 years of age. 4 Pulmonary position homografts also are used to replace pulmonary autografts explanted to repair left-sided outflow disease (the Ross operation). Several factors may be likely to favor increased pulmonary conduit durability in Ross patients compared with those with right ventricular outflow tract obstruction, including later age at operation (allowing for larger homografts), more normal pulmonary artery architecture, absence of severe right ventricular hypertrophy, and more natural positioning of ...</code> |
| <code>How does MCAM expression in hMSC affect the growth and maintenance of hematopoietic progenitors?</code> | <code>After culture in a 3-dimensional hydrogel-based matrix, which constitutes hypoxic conditions, MCAM expression is lost. Concordantly, Tormin et al. demonstrated that MCAM is down-regulated under hypoxic conditions. 10 Furthermore, it was shown by others and our group that oxygen tension causes selective modification of hematopoietic cell and mesenchymal stromal cell interactions in co-culture systems as well as influence HSPC metabolism. [44] [45] [46] Thus, the observed differences between Sharma et al. and our data in HSPC supporting capacity of hMSC are likely due to the different culture conditions used. Further studies are required to clarify the influence of hypoxia in our model system. Altogether these findings provide further evidence for the importance of MCAM in supporting HSPC. Furthermore, previous reports have shown that MCAM is down-regulated in MSC after several passages as well as during aging and differentiation. 19, 47 Interestingly, MCAM overexpression in hMSC enhance...</code> |
| <code>What is the relationship between Fanconi anemia and breast and ovarian cancer susceptibility genes?<br></code> | <code>( 31 ) , of which 5% -10 % may be caused by genetic factors ( 32 ) , up to half a million of these patients may be at risk of secondary hereditary neoplasms. The historic observation of twofold to fi vefold increased risks of cancers of the ovary, thyroid, and connective tissue after breast cancer ( 33 ) presaged the later syndromic association of these tumors with inherited mutations of BRCA1, BRCA2, PTEN, and p53 ( 16 ) . By far the largest cumulative risk of a secondary cancer in BRCA mutation carriers is associated with cancer in the contralateral breast, which may reach a risk of 29.5% at 10 years ( 34 ) . The Breast Cancer Linkage Consortium ( 35 , 36 ) also documented threefold to fi vefold increased risks of subsequent cancers of prostate, pancreas, gallbladder, stomach, skin (melanoma), and uterus in BRCA2 mutation carriers and twofold increased risks of prostate and pancreas cancer in BRCA1 mutation carriers; these results are based largely on self-reported family history inf...</code> |
* Loss: [<code>SpladeLoss</code>](https://sbert.net/docs/package_reference/sparse_encoder/losses.html#spladeloss) with these parameters:
```json
{
"loss": "SparseMultipleNegativesRankingLoss(scale=1.0, similarity_fct='dot_score')",
"lambda_corpus": 5e-06,
"lambda_query": 2e-05
}
```
### Evaluation Dataset
#### miriad-4.4_m-split
* Dataset: [miriad-4.4_m-split](https://huggingface.co/datasets/tomaarsen/miriad-4.4M-split) at [596b9ab](https://huggingface.co/datasets/tomaarsen/miriad-4.4M-split/tree/596b9ab305d52cb73644ed5b5004957c7bfaae40)
* Size: 1,000 evaluation samples
* Columns: <code>question</code> and <code>passage_text</code>
* Approximate statistics based on the first 1000 samples:
| | question | passage_text |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------------------------------------------------------|
| type | string | string |
| details | <ul><li>min: 8 tokens</li><li>mean: 23.55 tokens</li><li>max: 74 tokens</li></ul> | <ul><li>min: 512 tokens</li><li>mean: 512.0 tokens</li><li>max: 512 tokens</li></ul> |
* Samples:
| question | passage_text |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| <code>What are some hereditary cancer syndromes that can result in various forms of cancer?<br></code> | <code>Hereditary Cancer Syndromes, including Hereditary Breast and Ovarian Cancer (HBOC) and Lynch Syndrome (LS), can result in various forms of cancer due to germline mutations in cancer predisposition genes. While the major contributory genes for these syndromes have been identified and well-studied (BRCA1/ BRCA2 for HBOC and MSH2/MSH6/MLH1/PMS2/ EPCAM for LS), there remains a large percentage of associated cancer cases that are negative for germline mutations in these genes, including 80% of women with a personal or family history of breast cancer who are negative for BRCA1/2 mutations [1] . Similarly, between 30 and 50% of families fulfill stringent criteria for LS and test negative for germline mismatch repair gene mutations [2] . Adding complexity to these disorders is the significant overlap in the spectrum of cancers observed between various hereditary cancer syndromes, including many cancer susceptibility syndromes. Some that contribute to elevated breast cancer risk include Li-Frau...</code> |
| <code>How do MAK-4 and MAK-5 exert their antioxidant properties?<br></code> | <code>Hybrid F1 mice were injected with urethane (300 mg/kg) at 8 days of age. A group was then put on a MAK-supplemented diet, another group was fed a standard pellet diet. At 36 weeks of age the mice were sacrificed and the livers examined for the presence of tumors mouse (Panel A) and for the number of nodules per mouse (Panel B) (* p < 0.05, ** P < 0.001). Statistical analysis was performed by Two Way ANOVA Test followed by Post Hoc Bonferroni analysis. <br><br> We than measured the influence of the MAK-4+5 combination on the expression of the three liver-specific connexins (cx26, cx32, and cx43). The level of cx26 expression was similar in all the groups of mice treated with the MAK-supplemented diet and in the control (Figure 4, Panel A) . A significant, time-dependent increase in cx32 was observed in the liver of all the groups of MAK treated mice compared to the normal diet-fed controls. Cx32 expression increased 2-fold after 1 week of treatment, and 3-to 4-fold at 3 months (Figure 4, Pane...</code> |
| <code>What are the primary indications for a decompressive craniectomy, and what role does neurocritical care play in determining the suitability of a patient for this procedure?</code> | <code>Decompressive craniectomy is a valid neurosurgical strategy now a day as an alternative to control an elevated intracranial pressure (ICP) and controlling the risk of uncal and/or subfalcine herniation, in refractory cases to the postural, ventilator, and pharmacological measures to control it. The neurocritical care and the ICP monitorization are key determinants to identify and postulate the inclusion criteria to consider a patient as candidate to this procedure, as it is always considered a rescue surgical technique. Head trauma and ischemic or hemorrhagic cerebrovascular disease with progressive deterioration due to mass effect are some of the cases that may require a decompressive craniectomy with its different variants. However, this procedure per se can have complications described in the postcraniectomy syndrome and may occur in short, medium, or even long term.<br><br> 1,2 The paradoxical herniation is a condition in which there is a deviation of the midline with mass effect, even t...</code> |
* Loss: [<code>SpladeLoss</code>](https://sbert.net/docs/package_reference/sparse_encoder/losses.html#spladeloss) with these parameters:
```json
{
"loss": "SparseMultipleNegativesRankingLoss(scale=1.0, similarity_fct='dot_score')",
"lambda_corpus": 5e-06,
"lambda_query": 2e-05
}
```
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 4
- `per_device_eval_batch_size`: 4
- `learning_rate`: 2e-05
- `num_train_epochs`: 1
- `warmup_ratio`: 0.1
- `fp16`: True
- `batch_sampler`: no_duplicates
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: True
- `per_device_train_batch_size`: 4
- `per_device_eval_batch_size`: 4
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `torch_empty_cache_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 1
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `restore_callback_states_from_checkpoint`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: False
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: None
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `include_for_metrics`: []
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_eval_metrics`: False
- `eval_on_start`: False
- `use_liger_kernel`: False
- `eval_use_gather_object`: False
- `average_tokens_across_devices`: False
- `prompts`: None
- `batch_sampler`: no_duplicates
- `multi_dataset_batch_sampler`: proportional
- `router_mapping`: {}
- `learning_rate_mapping`: {}
</details>
### Training Logs
| Epoch | Step | Training Loss | Validation Loss | miriad_eval_dot_ndcg@10 | miriad_test_dot_ndcg@10 |
|:-----:|:-----:|:-------------:|:---------------:|:-----------------------:|:-----------------------:|
| 0.032 | 800 | 311.9058 | - | - | - |
| 0.064 | 1600 | 10.9011 | - | - | - |
| 0.096 | 2400 | 2.3726 | - | - | - |
| 0.128 | 3200 | 0.4999 | - | - | - |
| 0.16 | 4000 | 0.1222 | 0.0420 | 0.9017 | - |
| 0.192 | 4800 | 0.0755 | - | - | - |
| 0.224 | 5600 | 0.0481 | - | - | - |
| 0.256 | 6400 | 0.0643 | - | - | - |
| 0.288 | 7200 | 0.0598 | - | - | - |
| 0.32 | 8000 | 0.0575 | 0.0210 | 0.9274 | - |
| 0.352 | 8800 | 0.0417 | - | - | - |
| 0.384 | 9600 | 0.0487 | - | - | - |
| 0.416 | 10400 | 0.0262 | - | - | - |
| 0.448 | 11200 | 0.0404 | - | - | - |
| 0.48 | 12000 | 0.0359 | 0.0163 | 0.9282 | - |
| 0.512 | 12800 | 0.0407 | - | - | - |
| 0.544 | 13600 | 0.0373 | - | - | - |
| 0.576 | 14400 | 0.0204 | - | - | - |
| 0.608 | 15200 | 0.0218 | - | - | - |
| 0.64 | 16000 | 0.0196 | 0.0045 | 0.9434 | - |
| 0.672 | 16800 | 0.0311 | - | - | - |
| 0.704 | 17600 | 0.0372 | - | - | - |
| 0.736 | 18400 | 0.029 | - | - | - |
| 0.768 | 19200 | 0.0319 | - | - | - |
| 0.8 | 20000 | 0.0352 | 0.0196 | 0.9392 | - |
| 0.832 | 20800 | 0.0257 | - | - | - |
| 0.864 | 21600 | 0.0339 | - | - | - |
| 0.896 | 22400 | 0.0211 | - | - | - |
| 0.928 | 23200 | 0.0197 | - | - | - |
| 0.96 | 24000 | 0.0228 | 0.0069 | 0.9514 | - |
| 0.992 | 24800 | 0.0161 | - | - | - |
| -1 | -1 | - | - | 0.9509 | 0.9388 |
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Energy Consumed**: 0.505 kWh
- **Carbon Emitted**: 0.196 kg of CO2
- **Hours Used**: 1.484 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA GeForce RTX 3090
- **CPU Model**: 13th Gen Intel(R) Core(TM) i7-13700K
- **RAM Size**: 31.78 GB
### Framework Versions
- Python: 3.11.6
- Sentence Transformers: 4.2.0.dev0
- Transformers: 4.52.4
- PyTorch: 2.6.0+cu124
- Accelerate: 1.5.1
- Datasets: 2.21.0
- Tokenizers: 0.21.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### SpladeLoss
```bibtex
@misc{formal2022distillationhardnegativesampling,
title={From Distillation to Hard Negative Sampling: Making Sparse Neural IR Models More Effective},
author={Thibault Formal and Carlos Lassance and Benjamin Piwowarski and Stéphane Clinchant},
year={2022},
eprint={2205.04733},
archivePrefix={arXiv},
primaryClass={cs.IR},
url={https://arxiv.org/abs/2205.04733},
}
```
#### SparseMultipleNegativesRankingLoss
```bibtex
@misc{henderson2017efficient,
title={Efficient Natural Language Response Suggestion for Smart Reply},
author={Matthew Henderson and Rami Al-Rfou and Brian Strope and Yun-hsuan Sung and Laszlo Lukacs and Ruiqi Guo and Sanjiv Kumar and Balint Miklos and Ray Kurzweil},
year={2017},
eprint={1705.00652},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
#### FlopsLoss
```bibtex
@article{paria2020minimizing,
title={Minimizing flops to learn efficient sparse representations},
author={Paria, Biswajit and Yeh, Chih-Kuan and Yen, Ian EH and Xu, Ning and Ravikumar, Pradeep and P{'o}czos, Barnab{'a}s},
journal={arXiv preprint arXiv:2004.05665},
year={2020}
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
-->
|
Oceans-ID/Qwen2.5-1.5B-Instruct-Gensyn-Swarm-scruffy_insectivorous_buffalo
|
Oceans-ID
| 2025-06-17T10:14:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am scruffy insectivorous buffalo",
"unsloth",
"trl",
"arxiv:2402.03300",
"base_model:Gensyn/Qwen2.5-1.5B-Instruct",
"base_model:finetune:Gensyn/Qwen2.5-1.5B-Instruct",
"endpoints_compatible",
"region:us"
] | null | 2025-05-31T18:18:23Z |
---
base_model: Gensyn/Qwen2.5-1.5B-Instruct
library_name: transformers
model_name: Qwen2.5-1.5B-Instruct-Gensyn-Swarm-scruffy_insectivorous_buffalo
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am scruffy insectivorous buffalo
- unsloth
- trl
licence: license
---
# Model Card for Qwen2.5-1.5B-Instruct-Gensyn-Swarm-scruffy_insectivorous_buffalo
This model is a fine-tuned version of [Gensyn/Qwen2.5-1.5B-Instruct](https://huggingface.co/Gensyn/Qwen2.5-1.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Oceans-ID/Qwen2.5-1.5B-Instruct-Gensyn-Swarm-scruffy_insectivorous_buffalo", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.48.2
- Pytorch: 2.5.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
mtpti5iD/flan-t5-small-redhat-docs
|
mtpti5iD
| 2025-06-17T10:13:49Z | 0 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2025-06-17T10:13:46Z |
# FLAN-T5-Small Fine-Tuned on Red Hat Documentation
## Overview
This repository hosts a fine-tuned **FLAN-T5-Small** model for question-answering tasks on Red Hat documentation. The model was fine-tuned using Low-Rank Adaptation (LoRA) and 4-bit quantization on a Google Colab T4 GPU (~15 GB VRAM, CUDA 11.8). The training dataset, `redhat-docs_dataset`, contains 55,741 rows in JSONL format with fields: `title`, `content`, `command`, and `url`. The model excels at extracting commands (e.g., `yum install X`) and summarizing procedures.
Project details are available on GitHub: [mtptisid/FLAN-T5-Small_finetuning_LoRA](https://github.com/mtptisid/FLAN-T5-Small_finetuning_LoRA).
## Model Details
- **Base Model**: `google/flan-t5-small` (77M parameters).
- **Fine-Tuning**: LoRA (r=8, alpha=32, target_modules=["q", "v"], dropout=0.1).
- **Quantization**: 4-bit NormalFloat (nf4) with bfloat16 compute dtype (~6-8 GB VRAM).
- **Task**: Question-answering on Red Hat documentation.
## Dataset
The `redhat-docs_dataset` contains 55,741 entries:
- **title**: Documentation section title.
- **content**: Detailed procedure or concept.
- **command**: Associated command (may be `null`).
- **url**: Reference URL.
### Preprocessing
- Null `command` fields set to `""`; missing `title`/`content` set to `"Untitled"`/`""`.
- Formatted into `text` field: "Title: {title}
Content: {content}
Command: {command}".
- Tokenized with max_length=512, truncation, and padding.
### Artifacts
- `data/redhat-docs_dataset.jsonl`: Original dataset.
- `data/formatted_dataset.jsonl`: Preprocessed dataset.
- `data/tokenized_dataset.jsonl`: Tokenized dataset.
## Training
- **Hardware**: NVIDIA T4 GPU, CUDA 11.8.
- **Epochs**: 2 (~4-8 hours).
- **Batch Size**: Effective 32 (4 per-device, 8 gradient accumulation steps).
- **Optimizer**: Paged AdamW 8-bit.
- **Mixed Precision**: FP16.
- **Dependencies**: PyTorch 2.3.1, Transformers 4.46.0, BitsAndBytes 0.43.3, Triton 2.0.0, Datasets 3.0.2, PEFT 0.13.2.
## Repository Structure
- `model/`: Model weights and tokenizer.
- `data/`: Dataset files.
- `finetune_script.py`: Training script.
- `README.md`: This file.
## Usage
Load the model for inference on Red Hat documentation queries. Example:
- **Question**: "How do I install Package X?"
- **Context**: "Title: Installing Package X
Content: To install Package X, use the package manager yum.
Command: yum install X"
- **Output**: "Run `yum install X`"
## Installation
Requires PyTorch 2.3.1, Transformers 4.46.0, and a GPU for 4-bit quantization.
## Limitations
- Dataset may have `null` commands, affecting some queries.
- Trained for 2 epochs; more epochs may improve performance.
- Specialized for Red Hat documentation.
## Future Work
- Add synthetic Q&A data.
- Implement retrieval for dynamic context.
- Evaluate with BLEU/ROUGE metrics.
## License
MIT License. Verify `redhat-docs_dataset` licensing separately.
## Acknowledgments
- Google FLAN-T5 Team
- Hugging Face
- Red Hat Documentation Team
## Contact
Open issues on [GitHub](https://github.com/mtptisid/FLAN-T5-Small_finetuning_LoRA) or contact `mtpti5iD` via Hugging Face.
*Last Updated: June 17, 2025*
|
Teklia/yolov11-generic-page
|
Teklia
| 2025-06-17T10:01:09Z | 0 | 0 |
YOLOv11
|
[
"YOLOv11",
"YOLO",
"PyTorch",
"object-detection",
"dla",
"generic",
"image-segmentation",
"license:mit",
"region:us"
] |
image-segmentation
| 2025-06-17T09:42:46Z |
---
library_name: YOLOv11
license: mit
tags:
- YOLO
- PyTorch
- object-detection
- dla
- generic
metrics:
- IoU
- F1
- [email protected]
- [email protected]
- AP@[.5,.95]
pipeline_tag: image-segmentation
version:
- YOLOv11
---
# YOLOv11 - Generic page detection
The generic page detection model predicts single pages from document images.
## Model description
The model has been trained using the YOLOv11 library on multiple datasets.
It has been trained on images with their dimensions equal to 640 pixels, starting from the YOLOv11l checkpoint.
## Evaluation results
The model achieves the following results:
| Set | Images | Instances | Box-P | Box-R | Box-mAP@50 | Box-mAP@[50-95] | Mask-P | Mask-R | Mask-mAP@50 | Mask-mAP@[50-95] |
| ----- | ------ | --------- | ----- | ----- | ---------- | --------------- | ------ | ------ | ----------- | ---------------- |
| train | 1579 | 2210 | 0.999 | 0.996 | 0.995 | 0.994 | 0.999 | 0.996 | 0.995 | 0.993 |
| val | 146 | 208 | 0.986 | 0.995 | 0.989 | 0.985 | 0.986 | 0.995 | 0.989 | 0.985 |
| test | 144 | 215 | 0.995 | 1.00 | 0.995 | 0.994 | 0.995 | 1.00 | 0.995 | 0.991 |
## How to use?
- Download the [weights of this model](https://huggingface.co/Teklia/yolov11-generic-page/resolve/main/model.pt?download=true);
- Refer to the [Ultralytics documentation](https://docs.ultralytics.com/modes/predict/) to use this model.
|
greenkwd/lr0.0001_bs16_0616_1909
|
greenkwd
| 2025-06-17T09:59:21Z | 0 | 0 | null |
[
"safetensors",
"segformer",
"vision",
"image-segmentation",
"generated_from_trainer",
"base_model:nvidia/mit-b0",
"base_model:finetune:nvidia/mit-b0",
"license:other",
"region:us"
] |
image-segmentation
| 2025-06-17T09:59:16Z |
---
license: other
base_model: nvidia/mit-b0
tags:
- vision
- image-segmentation
- generated_from_trainer
model-index:
- name: lr0.0001_bs16_0616_1909
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# lr0.0001_bs16_0616_1909
This model is a fine-tuned version of [nvidia/mit-b0](https://huggingface.co/nvidia/mit-b0) on the greenkwd/upwellingdetection_SST dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0525
- Mean Iou: 0.9540
- Mean Accuracy: 0.9751
- Overall Accuracy: 0.9825
- Accuracy Land: 0.9949
- Accuracy Upwelling: 0.9841
- Accuracy Not Upwelling: 0.9464
- Iou Land: 0.9902
- Iou Upwelling: 0.9631
- Iou Not Upwelling: 0.9087
- Dice Macro: 0.9761
- Dice Micro: 0.9825
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 100
### Training results
| Training Loss | Epoch | Step | Validation Loss | Mean Iou | Mean Accuracy | Overall Accuracy | Accuracy Land | Accuracy Upwelling | Accuracy Not Upwelling | Iou Land | Iou Upwelling | Iou Not Upwelling | Dice Macro | Dice Micro |
|:-------------:|:-----:|:----:|:---------------:|:--------:|:-------------:|:----------------:|:-------------:|:------------------:|:----------------------:|:--------:|:-------------:|:-----------------:|:----------:|:----------:|
| 1.0825 | 0.4 | 20 | 1.0832 | 0.2083 | 0.3966 | 0.3236 | 0.0025 | 0.5717 | 0.6156 | 0.0024 | 0.4864 | 0.1362 | 0.2997 | 0.3236 |
| 0.8743 | 0.8 | 40 | 0.8897 | 0.5858 | 0.7459 | 0.7505 | 0.7347 | 0.7823 | 0.7208 | 0.7346 | 0.6904 | 0.3323 | 0.7209 | 0.7505 |
| 0.6363 | 1.2 | 60 | 0.6193 | 0.6977 | 0.8158 | 0.8501 | 0.8837 | 0.8887 | 0.6750 | 0.8830 | 0.7701 | 0.4399 | 0.8063 | 0.8501 |
| 0.4967 | 1.6 | 80 | 0.4543 | 0.7462 | 0.8490 | 0.8823 | 0.9330 | 0.8961 | 0.7179 | 0.9262 | 0.7947 | 0.5176 | 0.8431 | 0.8823 |
| 0.4218 | 2.0 | 100 | 0.3824 | 0.7926 | 0.8787 | 0.9094 | 0.9542 | 0.9241 | 0.7579 | 0.9466 | 0.8333 | 0.5978 | 0.8766 | 0.9094 |
| 0.3799 | 2.4 | 120 | 0.3334 | 0.8156 | 0.8992 | 0.9197 | 0.9584 | 0.9179 | 0.8214 | 0.9527 | 0.8469 | 0.6473 | 0.8929 | 0.9197 |
| 0.3258 | 2.8 | 140 | 0.2989 | 0.8289 | 0.9073 | 0.9265 | 0.9686 | 0.9176 | 0.8356 | 0.9604 | 0.8540 | 0.6723 | 0.9017 | 0.9265 |
| 0.2941 | 3.2 | 160 | 0.2684 | 0.8481 | 0.9147 | 0.9369 | 0.9743 | 0.9413 | 0.8284 | 0.9664 | 0.8739 | 0.7041 | 0.9140 | 0.9369 |
| 0.3038 | 3.6 | 180 | 0.2340 | 0.8684 | 0.9250 | 0.9466 | 0.9797 | 0.9552 | 0.8403 | 0.9701 | 0.8935 | 0.7416 | 0.9267 | 0.9466 |
| 0.2533 | 4.0 | 200 | 0.1953 | 0.8807 | 0.9341 | 0.9517 | 0.9732 | 0.9659 | 0.8632 | 0.9696 | 0.9061 | 0.7665 | 0.9344 | 0.9517 |
| 0.284 | 4.4 | 220 | 0.1711 | 0.8880 | 0.9336 | 0.9556 | 0.9853 | 0.9693 | 0.8461 | 0.9724 | 0.9121 | 0.7794 | 0.9387 | 0.9556 |
| 0.2563 | 4.8 | 240 | 0.1593 | 0.8947 | 0.9406 | 0.9580 | 0.9753 | 0.9768 | 0.8697 | 0.9719 | 0.9185 | 0.7938 | 0.9428 | 0.9580 |
| 0.2402 | 5.2 | 260 | 0.1456 | 0.9012 | 0.9418 | 0.9610 | 0.9840 | 0.9771 | 0.8642 | 0.9753 | 0.9221 | 0.8061 | 0.9465 | 0.9610 |
| 0.221 | 5.6 | 280 | 0.1428 | 0.9016 | 0.9486 | 0.9603 | 0.9700 | 0.9756 | 0.9003 | 0.9683 | 0.9274 | 0.8091 | 0.9469 | 0.9603 |
| 0.2061 | 6.0 | 300 | 0.1276 | 0.9109 | 0.9503 | 0.9646 | 0.9826 | 0.9753 | 0.8930 | 0.9759 | 0.9294 | 0.8275 | 0.9523 | 0.9646 |
| 0.2344 | 6.4 | 320 | 0.1170 | 0.9164 | 0.9527 | 0.9670 | 0.9861 | 0.9761 | 0.8959 | 0.9772 | 0.9339 | 0.8381 | 0.9554 | 0.9670 |
| 0.2138 | 6.8 | 340 | 0.1153 | 0.9039 | 0.9412 | 0.9624 | 0.9826 | 0.9869 | 0.8541 | 0.9772 | 0.9238 | 0.8106 | 0.9481 | 0.9624 |
| 0.195 | 7.2 | 360 | 0.1060 | 0.9152 | 0.9510 | 0.9666 | 0.9858 | 0.9789 | 0.8882 | 0.9770 | 0.9334 | 0.8352 | 0.9547 | 0.9666 |
| 0.1927 | 7.6 | 380 | 0.1132 | 0.9061 | 0.9453 | 0.9629 | 0.9894 | 0.9707 | 0.8758 | 0.9737 | 0.9281 | 0.8165 | 0.9495 | 0.9629 |
| 0.2171 | 8.0 | 400 | 0.1037 | 0.9140 | 0.9593 | 0.9652 | 0.9853 | 0.9531 | 0.9395 | 0.9777 | 0.9280 | 0.8361 | 0.9540 | 0.9652 |
| 0.241 | 8.4 | 420 | 0.1164 | 0.9184 | 0.9588 | 0.9673 | 0.9800 | 0.9711 | 0.9252 | 0.9764 | 0.9353 | 0.8434 | 0.9566 | 0.9673 |
| 0.2041 | 8.8 | 440 | 0.0961 | 0.9215 | 0.9584 | 0.9688 | 0.9827 | 0.9755 | 0.9171 | 0.9781 | 0.9375 | 0.8489 | 0.9583 | 0.9688 |
| 0.183 | 9.2 | 460 | 0.0935 | 0.9187 | 0.9598 | 0.9674 | 0.9874 | 0.9594 | 0.9326 | 0.9778 | 0.9336 | 0.8446 | 0.9567 | 0.9674 |
| 0.1884 | 9.6 | 480 | 0.0947 | 0.9168 | 0.9498 | 0.9675 | 0.9889 | 0.9818 | 0.8787 | 0.9766 | 0.9362 | 0.8376 | 0.9556 | 0.9675 |
| 0.2219 | 10.0 | 500 | 0.0902 | 0.9178 | 0.9634 | 0.9667 | 0.9820 | 0.9547 | 0.9535 | 0.9780 | 0.9323 | 0.8430 | 0.9562 | 0.9667 |
| 0.1747 | 10.4 | 520 | 0.0941 | 0.9140 | 0.9475 | 0.9664 | 0.9832 | 0.9896 | 0.8697 | 0.9784 | 0.9318 | 0.8317 | 0.9540 | 0.9664 |
| 0.1589 | 10.8 | 540 | 0.0838 | 0.9209 | 0.9544 | 0.9688 | 0.9821 | 0.9861 | 0.8949 | 0.9783 | 0.9374 | 0.8469 | 0.9579 | 0.9688 |
| 0.1718 | 11.2 | 560 | 0.0810 | 0.9256 | 0.9648 | 0.9703 | 0.9859 | 0.9628 | 0.9457 | 0.9804 | 0.9388 | 0.8577 | 0.9606 | 0.9703 |
| 0.2022 | 11.6 | 580 | 0.0919 | 0.9163 | 0.9640 | 0.9662 | 0.9860 | 0.9452 | 0.9609 | 0.9812 | 0.9275 | 0.8402 | 0.9554 | 0.9662 |
| 0.1704 | 12.0 | 600 | 0.0822 | 0.9259 | 0.9663 | 0.9702 | 0.9834 | 0.9624 | 0.9531 | 0.9800 | 0.9390 | 0.8586 | 0.9608 | 0.9702 |
| 0.1941 | 12.4 | 620 | 0.0748 | 0.9250 | 0.9558 | 0.9708 | 0.9918 | 0.9794 | 0.8963 | 0.9791 | 0.9431 | 0.8527 | 0.9602 | 0.9708 |
| 0.1833 | 12.8 | 640 | 0.1009 | 0.9045 | 0.9596 | 0.9612 | 0.9912 | 0.9253 | 0.9621 | 0.9825 | 0.9144 | 0.8167 | 0.9485 | 0.9612 |
| 0.1887 | 13.2 | 660 | 0.0759 | 0.9299 | 0.9673 | 0.9722 | 0.9885 | 0.9625 | 0.9510 | 0.9832 | 0.9416 | 0.8648 | 0.9630 | 0.9722 |
| 0.1531 | 13.6 | 680 | 0.0775 | 0.9279 | 0.9590 | 0.9721 | 0.9930 | 0.9760 | 0.9082 | 0.9826 | 0.9435 | 0.8575 | 0.9618 | 0.9721 |
| 0.2303 | 14.0 | 700 | 0.0798 | 0.9231 | 0.9553 | 0.9701 | 0.9823 | 0.9896 | 0.8940 | 0.9799 | 0.9410 | 0.8483 | 0.9591 | 0.9701 |
| 0.1556 | 14.4 | 720 | 0.0736 | 0.9262 | 0.9536 | 0.9718 | 0.9928 | 0.9879 | 0.8802 | 0.9811 | 0.9445 | 0.8531 | 0.9609 | 0.9718 |
| 0.1615 | 14.8 | 740 | 0.0712 | 0.9364 | 0.9668 | 0.9753 | 0.9886 | 0.9783 | 0.9334 | 0.9841 | 0.9504 | 0.8748 | 0.9666 | 0.9753 |
| 0.1501 | 15.2 | 760 | 0.0708 | 0.9324 | 0.9619 | 0.9739 | 0.9941 | 0.9762 | 0.9153 | 0.9819 | 0.9490 | 0.8663 | 0.9644 | 0.9739 |
| 0.1596 | 15.6 | 780 | 0.0666 | 0.9376 | 0.9669 | 0.9758 | 0.9898 | 0.9790 | 0.9319 | 0.9847 | 0.9510 | 0.8772 | 0.9673 | 0.9758 |
| 0.1343 | 16.0 | 800 | 0.0673 | 0.9375 | 0.9681 | 0.9757 | 0.9920 | 0.9727 | 0.9395 | 0.9850 | 0.9501 | 0.8774 | 0.9672 | 0.9757 |
| 0.1611 | 16.4 | 820 | 0.0656 | 0.9373 | 0.9649 | 0.9759 | 0.9903 | 0.9834 | 0.9209 | 0.9852 | 0.9508 | 0.8761 | 0.9671 | 0.9759 |
| 0.2254 | 16.8 | 840 | 0.0659 | 0.9395 | 0.9686 | 0.9766 | 0.9924 | 0.9750 | 0.9386 | 0.9858 | 0.9519 | 0.8807 | 0.9683 | 0.9766 |
| 0.1699 | 17.2 | 860 | 0.0660 | 0.9389 | 0.9674 | 0.9764 | 0.9913 | 0.9784 | 0.9326 | 0.9855 | 0.9518 | 0.8794 | 0.9679 | 0.9764 |
| 0.1517 | 17.6 | 880 | 0.0702 | 0.9313 | 0.9576 | 0.9739 | 0.9910 | 0.9906 | 0.8913 | 0.9856 | 0.9459 | 0.8624 | 0.9637 | 0.9739 |
| 0.1707 | 18.0 | 900 | 0.0660 | 0.9369 | 0.9627 | 0.9759 | 0.9923 | 0.9858 | 0.9101 | 0.9850 | 0.9511 | 0.8748 | 0.9669 | 0.9759 |
| 0.1689 | 18.4 | 920 | 0.0594 | 0.9408 | 0.9682 | 0.9772 | 0.9911 | 0.9806 | 0.9330 | 0.9858 | 0.9536 | 0.8831 | 0.9690 | 0.9772 |
| 0.1527 | 18.8 | 940 | 0.0614 | 0.9395 | 0.9653 | 0.9769 | 0.9918 | 0.9850 | 0.9192 | 0.9861 | 0.9529 | 0.8795 | 0.9683 | 0.9769 |
| 0.1323 | 19.2 | 960 | 0.0682 | 0.9336 | 0.9701 | 0.9740 | 0.9930 | 0.9580 | 0.9593 | 0.9861 | 0.9444 | 0.8703 | 0.9650 | 0.9740 |
| 0.1619 | 19.6 | 980 | 0.0665 | 0.9374 | 0.9671 | 0.9758 | 0.9934 | 0.9732 | 0.9348 | 0.9846 | 0.9510 | 0.8766 | 0.9671 | 0.9758 |
| 0.1153 | 20.0 | 1000 | 0.0635 | 0.9378 | 0.9645 | 0.9762 | 0.9895 | 0.9868 | 0.9172 | 0.9854 | 0.9519 | 0.8761 | 0.9673 | 0.9762 |
| 0.2405 | 20.4 | 1020 | 0.0618 | 0.9413 | 0.9692 | 0.9774 | 0.9909 | 0.9793 | 0.9372 | 0.9859 | 0.9541 | 0.8840 | 0.9693 | 0.9774 |
| 0.1314 | 20.8 | 1040 | 0.0681 | 0.9345 | 0.9610 | 0.9750 | 0.9899 | 0.9892 | 0.9039 | 0.9858 | 0.9486 | 0.8692 | 0.9655 | 0.9750 |
| 0.1358 | 21.2 | 1060 | 0.0615 | 0.9413 | 0.9698 | 0.9773 | 0.9941 | 0.9733 | 0.9422 | 0.9860 | 0.9536 | 0.8843 | 0.9693 | 0.9773 |
| 0.1612 | 21.6 | 1080 | 0.0695 | 0.9344 | 0.9719 | 0.9742 | 0.9888 | 0.9604 | 0.9665 | 0.9851 | 0.9464 | 0.8718 | 0.9655 | 0.9742 |
| 0.1371 | 22.0 | 1100 | 0.0620 | 0.9423 | 0.9683 | 0.9779 | 0.9924 | 0.9818 | 0.9307 | 0.9864 | 0.9550 | 0.8855 | 0.9698 | 0.9779 |
| 0.1446 | 22.4 | 1120 | 0.0623 | 0.9422 | 0.9666 | 0.9779 | 0.9946 | 0.9835 | 0.9216 | 0.9863 | 0.9553 | 0.8849 | 0.9697 | 0.9779 |
| 0.1322 | 22.8 | 1140 | 0.0611 | 0.9425 | 0.9678 | 0.9780 | 0.9918 | 0.9847 | 0.9268 | 0.9866 | 0.9553 | 0.8857 | 0.9699 | 0.9780 |
| 0.1366 | 23.2 | 1160 | 0.0611 | 0.9421 | 0.9664 | 0.9779 | 0.9926 | 0.9863 | 0.9203 | 0.9867 | 0.9549 | 0.8848 | 0.9697 | 0.9779 |
| 0.1516 | 23.6 | 1180 | 0.0642 | 0.9388 | 0.9634 | 0.9767 | 0.9911 | 0.9898 | 0.9093 | 0.9865 | 0.9520 | 0.8777 | 0.9678 | 0.9767 |
| 0.0805 | 24.0 | 1200 | 0.0615 | 0.9430 | 0.9677 | 0.9782 | 0.9947 | 0.9820 | 0.9263 | 0.9863 | 0.9559 | 0.8867 | 0.9702 | 0.9782 |
| 0.1405 | 24.4 | 1220 | 0.0623 | 0.9427 | 0.9719 | 0.9778 | 0.9885 | 0.9777 | 0.9495 | 0.9853 | 0.9557 | 0.8871 | 0.9700 | 0.9778 |
| 0.1409 | 24.8 | 1240 | 0.0639 | 0.9398 | 0.9718 | 0.9766 | 0.9937 | 0.9656 | 0.9563 | 0.9866 | 0.9512 | 0.8816 | 0.9684 | 0.9766 |
| 0.1237 | 25.2 | 1260 | 0.0620 | 0.9422 | 0.9723 | 0.9776 | 0.9935 | 0.9694 | 0.9539 | 0.9869 | 0.9532 | 0.8866 | 0.9698 | 0.9776 |
| 0.1519 | 25.6 | 1280 | 0.0627 | 0.9412 | 0.9657 | 0.9776 | 0.9922 | 0.9872 | 0.9178 | 0.9870 | 0.9541 | 0.8825 | 0.9692 | 0.9776 |
| 0.1148 | 26.0 | 1300 | 0.0631 | 0.9401 | 0.9651 | 0.9772 | 0.9916 | 0.9875 | 0.9163 | 0.9869 | 0.9532 | 0.8803 | 0.9686 | 0.9772 |
| 0.1085 | 26.4 | 1320 | 0.0605 | 0.9452 | 0.9719 | 0.9789 | 0.9928 | 0.9776 | 0.9452 | 0.9871 | 0.9567 | 0.8920 | 0.9714 | 0.9789 |
| 0.1531 | 26.8 | 1340 | 0.0645 | 0.9361 | 0.9718 | 0.9750 | 0.9937 | 0.9581 | 0.9635 | 0.9871 | 0.9461 | 0.8751 | 0.9664 | 0.9750 |
| 0.1346 | 27.2 | 1360 | 0.0633 | 0.9362 | 0.9604 | 0.9759 | 0.9923 | 0.9916 | 0.8974 | 0.9871 | 0.9498 | 0.8718 | 0.9664 | 0.9759 |
| 0.1246 | 27.6 | 1380 | 0.0597 | 0.9439 | 0.9691 | 0.9785 | 0.9957 | 0.9785 | 0.9330 | 0.9862 | 0.9566 | 0.8888 | 0.9707 | 0.9785 |
| 0.0948 | 28.0 | 1400 | 0.0611 | 0.9419 | 0.9735 | 0.9774 | 0.9931 | 0.9663 | 0.9610 | 0.9872 | 0.9527 | 0.8858 | 0.9696 | 0.9774 |
| 0.1272 | 28.4 | 1420 | 0.0592 | 0.9452 | 0.9697 | 0.9790 | 0.9946 | 0.9809 | 0.9337 | 0.9869 | 0.9574 | 0.8912 | 0.9714 | 0.9790 |
| 0.1076 | 28.8 | 1440 | 0.0593 | 0.9457 | 0.9728 | 0.9791 | 0.9923 | 0.9767 | 0.9495 | 0.9873 | 0.9569 | 0.8930 | 0.9717 | 0.9791 |
| 0.136 | 29.2 | 1460 | 0.0588 | 0.9448 | 0.9685 | 0.9790 | 0.9931 | 0.9856 | 0.9269 | 0.9874 | 0.9569 | 0.8901 | 0.9712 | 0.9790 |
| 0.1222 | 29.6 | 1480 | 0.0588 | 0.9457 | 0.9706 | 0.9792 | 0.9928 | 0.9821 | 0.9370 | 0.9873 | 0.9574 | 0.8925 | 0.9717 | 0.9792 |
| 0.0993 | 30.0 | 1500 | 0.0592 | 0.9437 | 0.9666 | 0.9786 | 0.9952 | 0.9857 | 0.9190 | 0.9866 | 0.9569 | 0.8875 | 0.9706 | 0.9786 |
| 0.1523 | 30.4 | 1520 | 0.0576 | 0.9463 | 0.9717 | 0.9794 | 0.9943 | 0.9783 | 0.9423 | 0.9874 | 0.9576 | 0.8938 | 0.9720 | 0.9794 |
| 0.1106 | 30.8 | 1540 | 0.0590 | 0.9437 | 0.9675 | 0.9786 | 0.9918 | 0.9879 | 0.9226 | 0.9873 | 0.9562 | 0.8874 | 0.9705 | 0.9786 |
| 0.1363 | 31.2 | 1560 | 0.0607 | 0.9411 | 0.9637 | 0.9777 | 0.9946 | 0.9892 | 0.9073 | 0.9872 | 0.9543 | 0.8816 | 0.9691 | 0.9777 |
| 0.1152 | 31.6 | 1580 | 0.0573 | 0.9468 | 0.9713 | 0.9796 | 0.9943 | 0.9804 | 0.9393 | 0.9875 | 0.9582 | 0.8947 | 0.9723 | 0.9796 |
| 0.1399 | 32.0 | 1600 | 0.0577 | 0.9461 | 0.9698 | 0.9794 | 0.9932 | 0.9844 | 0.9317 | 0.9875 | 0.9578 | 0.8931 | 0.9719 | 0.9794 |
| 0.1099 | 32.4 | 1620 | 0.0580 | 0.9466 | 0.9704 | 0.9796 | 0.9936 | 0.9833 | 0.9343 | 0.9876 | 0.9581 | 0.8940 | 0.9721 | 0.9796 |
| 0.1297 | 32.8 | 1640 | 0.0623 | 0.9414 | 0.9738 | 0.9772 | 0.9929 | 0.9649 | 0.9635 | 0.9874 | 0.9518 | 0.8851 | 0.9693 | 0.9772 |
| 0.0868 | 33.2 | 1660 | 0.0587 | 0.9451 | 0.9677 | 0.9792 | 0.9942 | 0.9872 | 0.9216 | 0.9877 | 0.9572 | 0.8905 | 0.9714 | 0.9792 |
| 0.1211 | 33.6 | 1680 | 0.0601 | 0.9415 | 0.9644 | 0.9779 | 0.9934 | 0.9901 | 0.9096 | 0.9879 | 0.9540 | 0.8826 | 0.9693 | 0.9779 |
| 0.0905 | 34.0 | 1700 | 0.0569 | 0.9479 | 0.9728 | 0.9800 | 0.9933 | 0.9797 | 0.9455 | 0.9879 | 0.9587 | 0.8970 | 0.9728 | 0.9800 |
| 0.1618 | 34.4 | 1720 | 0.0595 | 0.9449 | 0.9684 | 0.9790 | 0.9929 | 0.9863 | 0.9261 | 0.9878 | 0.9567 | 0.8901 | 0.9712 | 0.9790 |
| 0.113 | 34.8 | 1740 | 0.0575 | 0.9475 | 0.9726 | 0.9799 | 0.9920 | 0.9815 | 0.9443 | 0.9876 | 0.9589 | 0.8961 | 0.9727 | 0.9799 |
| 0.1022 | 35.2 | 1760 | 0.0647 | 0.9376 | 0.9601 | 0.9765 | 0.9942 | 0.9929 | 0.8931 | 0.9876 | 0.9510 | 0.8741 | 0.9672 | 0.9765 |
| 0.1194 | 35.6 | 1780 | 0.0733 | 0.9298 | 0.9702 | 0.9724 | 0.9946 | 0.9481 | 0.9678 | 0.9876 | 0.9388 | 0.8629 | 0.9629 | 0.9724 |
| 0.0935 | 36.0 | 1800 | 0.0610 | 0.9428 | 0.9655 | 0.9783 | 0.9932 | 0.9896 | 0.9137 | 0.9878 | 0.9550 | 0.8855 | 0.9700 | 0.9783 |
| 0.123 | 36.4 | 1820 | 0.0612 | 0.9425 | 0.9653 | 0.9783 | 0.9932 | 0.9899 | 0.9127 | 0.9880 | 0.9549 | 0.8847 | 0.9699 | 0.9783 |
| 0.1178 | 36.8 | 1840 | 0.0577 | 0.9472 | 0.9699 | 0.9799 | 0.9951 | 0.9839 | 0.9308 | 0.9877 | 0.9589 | 0.8951 | 0.9725 | 0.9799 |
| 0.0969 | 37.2 | 1860 | 0.0675 | 0.9351 | 0.9589 | 0.9756 | 0.9928 | 0.9931 | 0.8906 | 0.9880 | 0.9483 | 0.8689 | 0.9658 | 0.9756 |
| 0.1009 | 37.6 | 1880 | 0.0566 | 0.9484 | 0.9717 | 0.9803 | 0.9942 | 0.9827 | 0.9381 | 0.9882 | 0.9594 | 0.8976 | 0.9731 | 0.9803 |
| 0.125 | 38.0 | 1900 | 0.0580 | 0.9463 | 0.9693 | 0.9796 | 0.9923 | 0.9875 | 0.9280 | 0.9880 | 0.9580 | 0.8929 | 0.9720 | 0.9796 |
| 0.0918 | 38.4 | 1920 | 0.0591 | 0.9448 | 0.9673 | 0.9791 | 0.9933 | 0.9887 | 0.9201 | 0.9881 | 0.9567 | 0.8896 | 0.9712 | 0.9791 |
| 0.1171 | 38.8 | 1940 | 0.0567 | 0.9487 | 0.9719 | 0.9804 | 0.9937 | 0.9834 | 0.9387 | 0.9883 | 0.9596 | 0.8982 | 0.9733 | 0.9804 |
| 0.1009 | 39.2 | 1960 | 0.0568 | 0.9488 | 0.9723 | 0.9804 | 0.9939 | 0.9823 | 0.9407 | 0.9882 | 0.9595 | 0.8987 | 0.9734 | 0.9804 |
| 0.1126 | 39.6 | 1980 | 0.0563 | 0.9484 | 0.9721 | 0.9803 | 0.9927 | 0.9839 | 0.9396 | 0.9881 | 0.9596 | 0.8977 | 0.9732 | 0.9803 |
| 0.1036 | 40.0 | 2000 | 0.0569 | 0.9485 | 0.9712 | 0.9804 | 0.9944 | 0.9842 | 0.9349 | 0.9881 | 0.9596 | 0.8978 | 0.9732 | 0.9804 |
| 0.0953 | 40.4 | 2020 | 0.0560 | 0.9486 | 0.9723 | 0.9804 | 0.9929 | 0.9833 | 0.9408 | 0.9883 | 0.9594 | 0.8981 | 0.9732 | 0.9804 |
| 0.1173 | 40.8 | 2040 | 0.0601 | 0.9438 | 0.9654 | 0.9788 | 0.9952 | 0.9896 | 0.9114 | 0.9881 | 0.9561 | 0.8873 | 0.9706 | 0.9788 |
| 0.0956 | 41.2 | 2060 | 0.0531 | 0.9468 | 0.9695 | 0.9798 | 0.9925 | 0.9880 | 0.9279 | 0.9882 | 0.9584 | 0.8939 | 0.9723 | 0.9798 |
| 0.1079 | 41.6 | 2080 | 0.0572 | 0.9475 | 0.9718 | 0.9799 | 0.9935 | 0.9817 | 0.9401 | 0.9883 | 0.9583 | 0.8958 | 0.9726 | 0.9799 |
| 0.0837 | 42.0 | 2100 | 0.0619 | 0.9417 | 0.9638 | 0.9780 | 0.9944 | 0.9909 | 0.9060 | 0.9885 | 0.9540 | 0.8826 | 0.9694 | 0.9780 |
| 0.107 | 42.4 | 2120 | 0.0566 | 0.9490 | 0.9745 | 0.9804 | 0.9934 | 0.9776 | 0.9524 | 0.9884 | 0.9591 | 0.8995 | 0.9735 | 0.9804 |
| 0.0999 | 42.8 | 2140 | 0.0555 | 0.9495 | 0.9742 | 0.9806 | 0.9940 | 0.9786 | 0.9501 | 0.9885 | 0.9597 | 0.9004 | 0.9738 | 0.9806 |
| 0.1092 | 43.2 | 2160 | 0.0564 | 0.9485 | 0.9744 | 0.9802 | 0.9934 | 0.9768 | 0.9529 | 0.9885 | 0.9586 | 0.8983 | 0.9732 | 0.9802 |
| 0.102 | 43.6 | 2180 | 0.0558 | 0.9495 | 0.9725 | 0.9807 | 0.9925 | 0.9848 | 0.9403 | 0.9883 | 0.9603 | 0.8998 | 0.9737 | 0.9807 |
| 0.0908 | 44.0 | 2200 | 0.0578 | 0.9469 | 0.9699 | 0.9798 | 0.9920 | 0.9879 | 0.9297 | 0.9881 | 0.9586 | 0.8941 | 0.9723 | 0.9798 |
| 0.1123 | 44.4 | 2220 | 0.0581 | 0.9469 | 0.9684 | 0.9799 | 0.9949 | 0.9879 | 0.9223 | 0.9883 | 0.9585 | 0.8938 | 0.9723 | 0.9799 |
| 0.0863 | 44.8 | 2240 | 0.0560 | 0.9484 | 0.9700 | 0.9804 | 0.9944 | 0.9870 | 0.9287 | 0.9885 | 0.9595 | 0.8971 | 0.9731 | 0.9804 |
| 0.1225 | 45.2 | 2260 | 0.0633 | 0.9402 | 0.9620 | 0.9775 | 0.9944 | 0.9928 | 0.8987 | 0.9886 | 0.9526 | 0.8793 | 0.9686 | 0.9775 |
| 0.1046 | 45.6 | 2280 | 0.0555 | 0.9501 | 0.9736 | 0.9809 | 0.9945 | 0.9804 | 0.9460 | 0.9886 | 0.9604 | 0.9012 | 0.9740 | 0.9809 |
| 0.0888 | 46.0 | 2300 | 0.0560 | 0.9495 | 0.9748 | 0.9806 | 0.9935 | 0.9777 | 0.9532 | 0.9886 | 0.9597 | 0.9003 | 0.9737 | 0.9806 |
| 0.1124 | 46.4 | 2320 | 0.0556 | 0.9498 | 0.9739 | 0.9808 | 0.9943 | 0.9795 | 0.9477 | 0.9885 | 0.9600 | 0.9008 | 0.9739 | 0.9808 |
| 0.111 | 46.8 | 2340 | 0.0558 | 0.9503 | 0.9737 | 0.9810 | 0.9936 | 0.9819 | 0.9455 | 0.9887 | 0.9605 | 0.9016 | 0.9741 | 0.9810 |
| 0.0916 | 47.2 | 2360 | 0.0554 | 0.9500 | 0.9744 | 0.9809 | 0.9936 | 0.9799 | 0.9496 | 0.9887 | 0.9603 | 0.9012 | 0.9740 | 0.9809 |
| 0.1211 | 47.6 | 2380 | 0.0569 | 0.9488 | 0.9726 | 0.9804 | 0.9908 | 0.9855 | 0.9415 | 0.9877 | 0.9603 | 0.8983 | 0.9733 | 0.9804 |
| 0.0975 | 48.0 | 2400 | 0.0554 | 0.9485 | 0.9697 | 0.9805 | 0.9952 | 0.9871 | 0.9268 | 0.9884 | 0.9598 | 0.8974 | 0.9732 | 0.9805 |
| 0.1085 | 48.4 | 2420 | 0.0573 | 0.9478 | 0.9719 | 0.9801 | 0.9899 | 0.9868 | 0.9389 | 0.9871 | 0.9601 | 0.8962 | 0.9728 | 0.9801 |
| 0.0862 | 48.8 | 2440 | 0.0563 | 0.9489 | 0.9707 | 0.9806 | 0.9939 | 0.9871 | 0.9310 | 0.9888 | 0.9597 | 0.8981 | 0.9734 | 0.9806 |
| 0.1114 | 49.2 | 2460 | 0.0591 | 0.9452 | 0.9666 | 0.9793 | 0.9939 | 0.9908 | 0.9151 | 0.9889 | 0.9567 | 0.8900 | 0.9714 | 0.9793 |
| 0.1065 | 49.6 | 2480 | 0.0566 | 0.9483 | 0.9694 | 0.9804 | 0.9953 | 0.9876 | 0.9252 | 0.9887 | 0.9595 | 0.8968 | 0.9731 | 0.9804 |
| 0.1018 | 50.0 | 2500 | 0.0548 | 0.9509 | 0.9742 | 0.9812 | 0.9938 | 0.9816 | 0.9473 | 0.9888 | 0.9610 | 0.9029 | 0.9745 | 0.9812 |
| 0.1009 | 50.4 | 2520 | 0.0604 | 0.9436 | 0.9661 | 0.9787 | 0.9918 | 0.9917 | 0.9149 | 0.9883 | 0.9557 | 0.8869 | 0.9705 | 0.9787 |
| 0.0982 | 50.8 | 2540 | 0.0557 | 0.9484 | 0.9696 | 0.9805 | 0.9941 | 0.9885 | 0.9263 | 0.9889 | 0.9593 | 0.8970 | 0.9731 | 0.9805 |
| 0.0863 | 51.2 | 2560 | 0.0545 | 0.9507 | 0.9743 | 0.9811 | 0.9940 | 0.9807 | 0.9483 | 0.9890 | 0.9607 | 0.9024 | 0.9744 | 0.9811 |
| 0.0751 | 51.6 | 2580 | 0.0568 | 0.9483 | 0.9702 | 0.9804 | 0.9928 | 0.9887 | 0.9291 | 0.9887 | 0.9594 | 0.8969 | 0.9731 | 0.9804 |
| 0.081 | 52.0 | 2600 | 0.0545 | 0.9511 | 0.9745 | 0.9813 | 0.9937 | 0.9815 | 0.9482 | 0.9889 | 0.9612 | 0.9031 | 0.9746 | 0.9813 |
| 0.119 | 52.4 | 2620 | 0.0560 | 0.9497 | 0.9719 | 0.9809 | 0.9931 | 0.9864 | 0.9364 | 0.9889 | 0.9603 | 0.9000 | 0.9738 | 0.9809 |
| 0.1036 | 52.8 | 2640 | 0.0554 | 0.9501 | 0.9717 | 0.9810 | 0.9940 | 0.9864 | 0.9349 | 0.9891 | 0.9605 | 0.9007 | 0.9740 | 0.9810 |
| 0.1018 | 53.2 | 2660 | 0.0558 | 0.9499 | 0.9712 | 0.9810 | 0.9952 | 0.9859 | 0.9324 | 0.9889 | 0.9606 | 0.9002 | 0.9739 | 0.9810 |
| 0.0918 | 53.6 | 2680 | 0.0547 | 0.9512 | 0.9739 | 0.9814 | 0.9931 | 0.9840 | 0.9447 | 0.9889 | 0.9615 | 0.9033 | 0.9746 | 0.9814 |
| 0.0972 | 54.0 | 2700 | 0.0565 | 0.9491 | 0.9710 | 0.9807 | 0.9925 | 0.9883 | 0.9323 | 0.9887 | 0.9599 | 0.8987 | 0.9735 | 0.9807 |
| 0.1043 | 54.4 | 2720 | 0.0550 | 0.9502 | 0.9716 | 0.9811 | 0.9946 | 0.9862 | 0.9341 | 0.9891 | 0.9607 | 0.9008 | 0.9741 | 0.9811 |
| 0.0971 | 54.8 | 2740 | 0.0553 | 0.9506 | 0.9755 | 0.9811 | 0.9931 | 0.9786 | 0.9548 | 0.9889 | 0.9605 | 0.9024 | 0.9743 | 0.9811 |
| 0.0818 | 55.2 | 2760 | 0.0605 | 0.9440 | 0.9650 | 0.9789 | 0.9944 | 0.9922 | 0.9083 | 0.9891 | 0.9555 | 0.8872 | 0.9707 | 0.9789 |
| 0.0855 | 55.6 | 2780 | 0.0547 | 0.9509 | 0.9733 | 0.9813 | 0.9959 | 0.9814 | 0.9426 | 0.9888 | 0.9613 | 0.9027 | 0.9745 | 0.9813 |
| 0.0561 | 56.0 | 2800 | 0.0558 | 0.9500 | 0.9757 | 0.9808 | 0.9946 | 0.9750 | 0.9575 | 0.9892 | 0.9594 | 0.9013 | 0.9740 | 0.9808 |
| 0.0888 | 56.4 | 2820 | 0.0544 | 0.9515 | 0.9742 | 0.9815 | 0.9941 | 0.9824 | 0.9462 | 0.9892 | 0.9613 | 0.9040 | 0.9748 | 0.9815 |
| 0.0858 | 56.8 | 2840 | 0.0548 | 0.9514 | 0.9750 | 0.9814 | 0.9926 | 0.9822 | 0.9502 | 0.9889 | 0.9616 | 0.9038 | 0.9748 | 0.9814 |
| 0.1055 | 57.2 | 2860 | 0.0569 | 0.9487 | 0.9698 | 0.9806 | 0.9947 | 0.9880 | 0.9266 | 0.9892 | 0.9593 | 0.8976 | 0.9733 | 0.9806 |
| 0.1091 | 57.6 | 2880 | 0.0546 | 0.9513 | 0.9752 | 0.9814 | 0.9949 | 0.9781 | 0.9527 | 0.9892 | 0.9609 | 0.9037 | 0.9747 | 0.9814 |
| 0.1146 | 58.0 | 2900 | 0.0623 | 0.9430 | 0.9642 | 0.9786 | 0.9943 | 0.9927 | 0.9057 | 0.9893 | 0.9546 | 0.8852 | 0.9702 | 0.9786 |
| 0.0943 | 58.4 | 2920 | 0.0545 | 0.9514 | 0.9749 | 0.9814 | 0.9953 | 0.9787 | 0.9506 | 0.9891 | 0.9610 | 0.9039 | 0.9747 | 0.9814 |
| 0.0839 | 58.8 | 2940 | 0.0548 | 0.9509 | 0.9728 | 0.9813 | 0.9930 | 0.9866 | 0.9387 | 0.9891 | 0.9613 | 0.9023 | 0.9745 | 0.9813 |
| 0.0947 | 59.2 | 2960 | 0.0542 | 0.9518 | 0.9749 | 0.9816 | 0.9947 | 0.9804 | 0.9494 | 0.9893 | 0.9615 | 0.9045 | 0.9749 | 0.9816 |
| 0.0868 | 59.6 | 2980 | 0.0547 | 0.9513 | 0.9751 | 0.9814 | 0.9947 | 0.9790 | 0.9517 | 0.9893 | 0.9609 | 0.9037 | 0.9747 | 0.9814 |
| 0.0845 | 60.0 | 3000 | 0.0546 | 0.9516 | 0.9753 | 0.9815 | 0.9943 | 0.9793 | 0.9524 | 0.9894 | 0.9610 | 0.9043 | 0.9748 | 0.9815 |
| 0.0741 | 60.4 | 3020 | 0.0546 | 0.9509 | 0.9761 | 0.9811 | 0.9935 | 0.9769 | 0.9579 | 0.9893 | 0.9602 | 0.9031 | 0.9745 | 0.9811 |
| 0.0862 | 60.8 | 3040 | 0.0608 | 0.9441 | 0.9654 | 0.9790 | 0.9936 | 0.9924 | 0.9101 | 0.9893 | 0.9554 | 0.8875 | 0.9707 | 0.9790 |
| 0.1262 | 61.2 | 3060 | 0.0548 | 0.9511 | 0.9756 | 0.9813 | 0.9948 | 0.9771 | 0.9550 | 0.9894 | 0.9605 | 0.9035 | 0.9746 | 0.9813 |
| 0.0804 | 61.6 | 3080 | 0.0541 | 0.9519 | 0.9732 | 0.9817 | 0.9947 | 0.9850 | 0.9400 | 0.9895 | 0.9618 | 0.9045 | 0.9750 | 0.9817 |
| 0.1028 | 62.0 | 3100 | 0.0557 | 0.9501 | 0.9708 | 0.9811 | 0.9945 | 0.9883 | 0.9294 | 0.9895 | 0.9604 | 0.9003 | 0.9740 | 0.9811 |
| 0.0898 | 62.4 | 3120 | 0.0557 | 0.9503 | 0.9756 | 0.9809 | 0.9954 | 0.9747 | 0.9568 | 0.9894 | 0.9596 | 0.9020 | 0.9742 | 0.9809 |
| 0.0866 | 62.8 | 3140 | 0.0547 | 0.9516 | 0.9751 | 0.9815 | 0.9955 | 0.9786 | 0.9511 | 0.9894 | 0.9611 | 0.9043 | 0.9749 | 0.9815 |
| 0.0871 | 63.2 | 3160 | 0.0539 | 0.9521 | 0.9744 | 0.9817 | 0.9940 | 0.9832 | 0.9461 | 0.9894 | 0.9617 | 0.9051 | 0.9751 | 0.9817 |
| 0.1064 | 63.6 | 3180 | 0.0538 | 0.9519 | 0.9733 | 0.9817 | 0.9947 | 0.9849 | 0.9402 | 0.9896 | 0.9617 | 0.9044 | 0.9750 | 0.9817 |
| 0.0753 | 64.0 | 3200 | 0.0553 | 0.9501 | 0.9708 | 0.9811 | 0.9949 | 0.9880 | 0.9294 | 0.9895 | 0.9604 | 0.9004 | 0.9740 | 0.9811 |
| 0.0848 | 64.4 | 3220 | 0.0535 | 0.9520 | 0.9742 | 0.9817 | 0.9951 | 0.9822 | 0.9453 | 0.9894 | 0.9618 | 0.9049 | 0.9751 | 0.9817 |
| 0.0814 | 64.8 | 3240 | 0.0534 | 0.9524 | 0.9750 | 0.9819 | 0.9940 | 0.9823 | 0.9488 | 0.9895 | 0.9620 | 0.9058 | 0.9753 | 0.9819 |
| 0.0841 | 65.2 | 3260 | 0.0539 | 0.9515 | 0.9739 | 0.9815 | 0.9959 | 0.9809 | 0.9450 | 0.9890 | 0.9616 | 0.9040 | 0.9748 | 0.9815 |
| 0.0809 | 65.6 | 3280 | 0.0548 | 0.9503 | 0.9707 | 0.9812 | 0.9950 | 0.9884 | 0.9287 | 0.9895 | 0.9606 | 0.9008 | 0.9742 | 0.9812 |
| 0.0726 | 66.0 | 3300 | 0.0559 | 0.9497 | 0.9763 | 0.9806 | 0.9948 | 0.9725 | 0.9616 | 0.9895 | 0.9586 | 0.9009 | 0.9738 | 0.9806 |
| 0.099 | 66.4 | 3320 | 0.0539 | 0.9514 | 0.9720 | 0.9816 | 0.9950 | 0.9870 | 0.9341 | 0.9895 | 0.9615 | 0.9032 | 0.9747 | 0.9816 |
| 0.0816 | 66.8 | 3340 | 0.0538 | 0.9521 | 0.9731 | 0.9818 | 0.9954 | 0.9850 | 0.9389 | 0.9896 | 0.9619 | 0.9047 | 0.9751 | 0.9818 |
| 0.0815 | 67.2 | 3360 | 0.0535 | 0.9526 | 0.9747 | 0.9819 | 0.9950 | 0.9822 | 0.9468 | 0.9896 | 0.9621 | 0.9060 | 0.9754 | 0.9819 |
| 0.0723 | 67.6 | 3380 | 0.0557 | 0.9493 | 0.9695 | 0.9809 | 0.9956 | 0.9890 | 0.9238 | 0.9895 | 0.9598 | 0.8985 | 0.9736 | 0.9809 |
| 0.0802 | 68.0 | 3400 | 0.0539 | 0.9521 | 0.9730 | 0.9818 | 0.9952 | 0.9855 | 0.9382 | 0.9897 | 0.9620 | 0.9047 | 0.9751 | 0.9818 |
| 0.097 | 68.4 | 3420 | 0.0542 | 0.9518 | 0.9757 | 0.9816 | 0.9955 | 0.9775 | 0.9541 | 0.9896 | 0.9611 | 0.9048 | 0.9750 | 0.9816 |
| 0.0889 | 68.8 | 3440 | 0.0565 | 0.9487 | 0.9690 | 0.9807 | 0.9950 | 0.9900 | 0.9219 | 0.9897 | 0.9592 | 0.8972 | 0.9733 | 0.9807 |
| 0.095 | 69.2 | 3460 | 0.0541 | 0.9514 | 0.9751 | 0.9814 | 0.9957 | 0.9779 | 0.9517 | 0.9893 | 0.9610 | 0.9040 | 0.9748 | 0.9814 |
| 0.0864 | 69.6 | 3480 | 0.0538 | 0.9526 | 0.9741 | 0.9820 | 0.9940 | 0.9850 | 0.9433 | 0.9897 | 0.9622 | 0.9058 | 0.9754 | 0.9820 |
| 0.0888 | 70.0 | 3500 | 0.0562 | 0.9495 | 0.9761 | 0.9806 | 0.9953 | 0.9722 | 0.9607 | 0.9896 | 0.9584 | 0.9006 | 0.9738 | 0.9806 |
| 0.0755 | 70.4 | 3520 | 0.0532 | 0.9529 | 0.9751 | 0.9820 | 0.9947 | 0.9821 | 0.9486 | 0.9898 | 0.9621 | 0.9067 | 0.9755 | 0.9820 |
| 0.0858 | 70.8 | 3540 | 0.0560 | 0.9496 | 0.9696 | 0.9810 | 0.9952 | 0.9896 | 0.9241 | 0.9895 | 0.9601 | 0.8992 | 0.9738 | 0.9810 |
| 0.0903 | 71.2 | 3560 | 0.0540 | 0.9521 | 0.9763 | 0.9817 | 0.9945 | 0.9775 | 0.9570 | 0.9898 | 0.9611 | 0.9054 | 0.9751 | 0.9817 |
| 0.0862 | 71.6 | 3580 | 0.0539 | 0.9523 | 0.9731 | 0.9819 | 0.9950 | 0.9860 | 0.9383 | 0.9898 | 0.9620 | 0.9051 | 0.9752 | 0.9819 |
| 0.0708 | 72.0 | 3600 | 0.0538 | 0.9523 | 0.9733 | 0.9819 | 0.9960 | 0.9843 | 0.9395 | 0.9894 | 0.9623 | 0.9053 | 0.9753 | 0.9819 |
| 0.0856 | 72.4 | 3620 | 0.0532 | 0.9530 | 0.9750 | 0.9821 | 0.9946 | 0.9826 | 0.9478 | 0.9898 | 0.9623 | 0.9068 | 0.9756 | 0.9821 |
| 0.075 | 72.8 | 3640 | 0.0536 | 0.9527 | 0.9738 | 0.9820 | 0.9954 | 0.9843 | 0.9418 | 0.9897 | 0.9624 | 0.9061 | 0.9755 | 0.9820 |
| 0.0743 | 73.2 | 3660 | 0.0533 | 0.9526 | 0.9759 | 0.9819 | 0.9929 | 0.9819 | 0.9528 | 0.9894 | 0.9623 | 0.9061 | 0.9754 | 0.9819 |
| 0.075 | 73.6 | 3680 | 0.0532 | 0.9528 | 0.9739 | 0.9820 | 0.9942 | 0.9855 | 0.9421 | 0.9898 | 0.9622 | 0.9063 | 0.9755 | 0.9820 |
| 0.0804 | 74.0 | 3700 | 0.0543 | 0.9520 | 0.9725 | 0.9818 | 0.9948 | 0.9873 | 0.9354 | 0.9899 | 0.9617 | 0.9043 | 0.9751 | 0.9818 |
| 0.0789 | 74.4 | 3720 | 0.0566 | 0.9485 | 0.9691 | 0.9806 | 0.9939 | 0.9909 | 0.9224 | 0.9898 | 0.9589 | 0.8968 | 0.9732 | 0.9806 |
| 0.1058 | 74.8 | 3740 | 0.0551 | 0.9502 | 0.9701 | 0.9812 | 0.9962 | 0.9883 | 0.9258 | 0.9891 | 0.9611 | 0.9003 | 0.9741 | 0.9812 |
| 0.0842 | 75.2 | 3760 | 0.0530 | 0.9531 | 0.9747 | 0.9821 | 0.9954 | 0.9827 | 0.9460 | 0.9898 | 0.9624 | 0.9069 | 0.9756 | 0.9821 |
| 0.0802 | 75.6 | 3780 | 0.0538 | 0.9522 | 0.9763 | 0.9817 | 0.9948 | 0.9775 | 0.9564 | 0.9899 | 0.9612 | 0.9056 | 0.9752 | 0.9817 |
| 0.0752 | 76.0 | 3800 | 0.0554 | 0.9500 | 0.9699 | 0.9812 | 0.9954 | 0.9896 | 0.9247 | 0.9898 | 0.9603 | 0.9000 | 0.9740 | 0.9812 |
| 0.095 | 76.4 | 3820 | 0.0539 | 0.9526 | 0.9735 | 0.9820 | 0.9948 | 0.9858 | 0.9398 | 0.9899 | 0.9622 | 0.9058 | 0.9754 | 0.9820 |
| 0.0753 | 76.8 | 3840 | 0.0530 | 0.9526 | 0.9733 | 0.9820 | 0.9952 | 0.9859 | 0.9388 | 0.9899 | 0.9622 | 0.9057 | 0.9754 | 0.9820 |
| 0.0833 | 77.2 | 3860 | 0.0528 | 0.9532 | 0.9749 | 0.9822 | 0.9946 | 0.9836 | 0.9466 | 0.9899 | 0.9625 | 0.9072 | 0.9757 | 0.9822 |
| 0.0832 | 77.6 | 3880 | 0.0530 | 0.9532 | 0.9750 | 0.9822 | 0.9944 | 0.9834 | 0.9472 | 0.9899 | 0.9625 | 0.9072 | 0.9757 | 0.9822 |
| 0.0901 | 78.0 | 3900 | 0.0533 | 0.9531 | 0.9754 | 0.9821 | 0.9953 | 0.9809 | 0.9501 | 0.9899 | 0.9623 | 0.9070 | 0.9757 | 0.9821 |
| 0.0893 | 78.4 | 3920 | 0.0532 | 0.9532 | 0.9742 | 0.9822 | 0.9950 | 0.9847 | 0.9430 | 0.9900 | 0.9626 | 0.9069 | 0.9757 | 0.9822 |
| 0.0956 | 78.8 | 3940 | 0.0528 | 0.9532 | 0.9748 | 0.9822 | 0.9958 | 0.9821 | 0.9466 | 0.9899 | 0.9625 | 0.9072 | 0.9757 | 0.9822 |
| 0.0786 | 79.2 | 3960 | 0.0532 | 0.9525 | 0.9749 | 0.9819 | 0.9958 | 0.9805 | 0.9484 | 0.9896 | 0.9620 | 0.9059 | 0.9753 | 0.9819 |
| 0.1018 | 79.6 | 3980 | 0.0528 | 0.9533 | 0.9753 | 0.9822 | 0.9953 | 0.9816 | 0.9491 | 0.9900 | 0.9625 | 0.9075 | 0.9758 | 0.9822 |
| 0.0825 | 80.0 | 4000 | 0.0541 | 0.9515 | 0.9722 | 0.9816 | 0.9939 | 0.9883 | 0.9345 | 0.9899 | 0.9613 | 0.9033 | 0.9748 | 0.9816 |
| 0.073 | 80.4 | 4020 | 0.0532 | 0.9529 | 0.9737 | 0.9822 | 0.9950 | 0.9857 | 0.9404 | 0.9900 | 0.9624 | 0.9065 | 0.9756 | 0.9822 |
| 0.1021 | 80.8 | 4040 | 0.0527 | 0.9533 | 0.9754 | 0.9822 | 0.9954 | 0.9812 | 0.9497 | 0.9900 | 0.9625 | 0.9075 | 0.9758 | 0.9822 |
| 0.0835 | 81.2 | 4060 | 0.0535 | 0.9523 | 0.9727 | 0.9819 | 0.9949 | 0.9871 | 0.9362 | 0.9900 | 0.9619 | 0.9049 | 0.9752 | 0.9819 |
| 0.0778 | 81.6 | 4080 | 0.0555 | 0.9502 | 0.9703 | 0.9812 | 0.9947 | 0.9898 | 0.9264 | 0.9901 | 0.9602 | 0.9004 | 0.9741 | 0.9812 |
| 0.0619 | 82.0 | 4100 | 0.0534 | 0.9530 | 0.9767 | 0.9820 | 0.9940 | 0.9792 | 0.9567 | 0.9900 | 0.9619 | 0.9072 | 0.9756 | 0.9820 |
| 0.0864 | 82.4 | 4120 | 0.0528 | 0.9534 | 0.9748 | 0.9823 | 0.9949 | 0.9837 | 0.9459 | 0.9900 | 0.9626 | 0.9076 | 0.9758 | 0.9823 |
| 0.0701 | 82.8 | 4140 | 0.0535 | 0.9529 | 0.9736 | 0.9821 | 0.9948 | 0.9860 | 0.9401 | 0.9901 | 0.9623 | 0.9063 | 0.9756 | 0.9821 |
| 0.0857 | 83.2 | 4160 | 0.0528 | 0.9534 | 0.9745 | 0.9823 | 0.9953 | 0.9839 | 0.9444 | 0.9900 | 0.9627 | 0.9075 | 0.9758 | 0.9823 |
| 0.0926 | 83.6 | 4180 | 0.0533 | 0.9528 | 0.9731 | 0.9821 | 0.9951 | 0.9867 | 0.9375 | 0.9901 | 0.9623 | 0.9061 | 0.9755 | 0.9821 |
| 0.0705 | 84.0 | 4200 | 0.0530 | 0.9530 | 0.9736 | 0.9822 | 0.9950 | 0.9860 | 0.9398 | 0.9900 | 0.9624 | 0.9064 | 0.9756 | 0.9822 |
| 0.0732 | 84.4 | 4220 | 0.0528 | 0.9536 | 0.9760 | 0.9823 | 0.9950 | 0.9809 | 0.9520 | 0.9901 | 0.9626 | 0.9082 | 0.9760 | 0.9823 |
| 0.0676 | 84.8 | 4240 | 0.0528 | 0.9535 | 0.9744 | 0.9823 | 0.9952 | 0.9845 | 0.9435 | 0.9901 | 0.9628 | 0.9076 | 0.9759 | 0.9823 |
| 0.0802 | 85.2 | 4260 | 0.0533 | 0.9528 | 0.9731 | 0.9821 | 0.9951 | 0.9868 | 0.9375 | 0.9901 | 0.9623 | 0.9060 | 0.9755 | 0.9821 |
| 0.0829 | 85.6 | 4280 | 0.0527 | 0.9536 | 0.9746 | 0.9824 | 0.9948 | 0.9847 | 0.9445 | 0.9901 | 0.9628 | 0.9079 | 0.9759 | 0.9824 |
| 0.0749 | 86.0 | 4300 | 0.0537 | 0.9526 | 0.9729 | 0.9820 | 0.9950 | 0.9872 | 0.9365 | 0.9901 | 0.9621 | 0.9054 | 0.9754 | 0.9820 |
| 0.0928 | 86.4 | 4320 | 0.0526 | 0.9536 | 0.9745 | 0.9824 | 0.9952 | 0.9846 | 0.9435 | 0.9901 | 0.9629 | 0.9079 | 0.9759 | 0.9824 |
| 0.0708 | 86.8 | 4340 | 0.0529 | 0.9536 | 0.9749 | 0.9824 | 0.9943 | 0.9846 | 0.9459 | 0.9901 | 0.9629 | 0.9080 | 0.9760 | 0.9824 |
| 0.0896 | 87.2 | 4360 | 0.0528 | 0.9536 | 0.9744 | 0.9824 | 0.9949 | 0.9850 | 0.9433 | 0.9901 | 0.9628 | 0.9077 | 0.9759 | 0.9824 |
| 0.1022 | 87.6 | 4380 | 0.0529 | 0.9535 | 0.9745 | 0.9824 | 0.9944 | 0.9856 | 0.9434 | 0.9901 | 0.9628 | 0.9077 | 0.9759 | 0.9824 |
| 0.0713 | 88.0 | 4400 | 0.0528 | 0.9537 | 0.9754 | 0.9824 | 0.9953 | 0.9821 | 0.9489 | 0.9901 | 0.9628 | 0.9082 | 0.9760 | 0.9824 |
| 0.08 | 88.4 | 4420 | 0.0527 | 0.9536 | 0.9746 | 0.9824 | 0.9954 | 0.9838 | 0.9447 | 0.9901 | 0.9628 | 0.9078 | 0.9759 | 0.9824 |
| 0.0817 | 88.8 | 4440 | 0.0526 | 0.9538 | 0.9754 | 0.9824 | 0.9951 | 0.9827 | 0.9483 | 0.9902 | 0.9628 | 0.9084 | 0.9760 | 0.9824 |
| 0.0842 | 89.2 | 4460 | 0.0527 | 0.9538 | 0.9748 | 0.9824 | 0.9949 | 0.9843 | 0.9454 | 0.9902 | 0.9629 | 0.9082 | 0.9760 | 0.9824 |
| 0.0736 | 89.6 | 4480 | 0.0525 | 0.9537 | 0.9751 | 0.9824 | 0.9953 | 0.9829 | 0.9472 | 0.9901 | 0.9629 | 0.9082 | 0.9760 | 0.9824 |
| 0.0642 | 90.0 | 4500 | 0.0528 | 0.9537 | 0.9751 | 0.9824 | 0.9954 | 0.9828 | 0.9472 | 0.9901 | 0.9629 | 0.9083 | 0.9760 | 0.9824 |
| 0.0593 | 90.4 | 4520 | 0.0531 | 0.9531 | 0.9735 | 0.9823 | 0.9949 | 0.9866 | 0.9392 | 0.9902 | 0.9625 | 0.9067 | 0.9757 | 0.9823 |
| 0.0863 | 90.8 | 4540 | 0.0531 | 0.9534 | 0.9739 | 0.9823 | 0.9949 | 0.9861 | 0.9407 | 0.9902 | 0.9627 | 0.9072 | 0.9758 | 0.9823 |
| 0.0877 | 91.2 | 4560 | 0.0529 | 0.9535 | 0.9740 | 0.9824 | 0.9950 | 0.9859 | 0.9409 | 0.9902 | 0.9628 | 0.9074 | 0.9759 | 0.9824 |
| 0.073 | 91.6 | 4580 | 0.0526 | 0.9538 | 0.9750 | 0.9824 | 0.9952 | 0.9835 | 0.9464 | 0.9902 | 0.9628 | 0.9083 | 0.9760 | 0.9824 |
| 0.0646 | 92.0 | 4600 | 0.0526 | 0.9539 | 0.9754 | 0.9825 | 0.9950 | 0.9828 | 0.9484 | 0.9902 | 0.9629 | 0.9085 | 0.9761 | 0.9825 |
| 0.0748 | 92.4 | 4620 | 0.0527 | 0.9535 | 0.9741 | 0.9824 | 0.9955 | 0.9849 | 0.9418 | 0.9901 | 0.9629 | 0.9076 | 0.9759 | 0.9824 |
| 0.067 | 92.8 | 4640 | 0.0527 | 0.9537 | 0.9743 | 0.9824 | 0.9953 | 0.9849 | 0.9428 | 0.9902 | 0.9629 | 0.9080 | 0.9760 | 0.9824 |
| 0.0705 | 93.2 | 4660 | 0.0527 | 0.9539 | 0.9757 | 0.9824 | 0.9950 | 0.9822 | 0.9498 | 0.9902 | 0.9628 | 0.9086 | 0.9761 | 0.9824 |
| 0.0879 | 93.6 | 4680 | 0.0525 | 0.9538 | 0.9751 | 0.9824 | 0.9950 | 0.9837 | 0.9465 | 0.9902 | 0.9629 | 0.9084 | 0.9761 | 0.9824 |
| 0.0835 | 94.0 | 4700 | 0.0524 | 0.9539 | 0.9755 | 0.9825 | 0.9953 | 0.9824 | 0.9488 | 0.9902 | 0.9629 | 0.9086 | 0.9761 | 0.9825 |
| 0.0799 | 94.4 | 4720 | 0.0526 | 0.9539 | 0.9751 | 0.9825 | 0.9951 | 0.9836 | 0.9466 | 0.9902 | 0.9630 | 0.9086 | 0.9761 | 0.9825 |
| 0.0697 | 94.8 | 4740 | 0.0527 | 0.9536 | 0.9743 | 0.9824 | 0.9951 | 0.9854 | 0.9423 | 0.9902 | 0.9629 | 0.9078 | 0.9760 | 0.9824 |
| 0.0628 | 95.2 | 4760 | 0.0527 | 0.9535 | 0.9741 | 0.9824 | 0.9950 | 0.9857 | 0.9415 | 0.9902 | 0.9628 | 0.9076 | 0.9759 | 0.9824 |
| 0.0778 | 95.6 | 4780 | 0.0525 | 0.9539 | 0.9749 | 0.9825 | 0.9951 | 0.9841 | 0.9455 | 0.9902 | 0.9630 | 0.9084 | 0.9761 | 0.9825 |
| 0.0969 | 96.0 | 4800 | 0.0526 | 0.9540 | 0.9758 | 0.9825 | 0.9948 | 0.9823 | 0.9503 | 0.9902 | 0.9629 | 0.9088 | 0.9761 | 0.9825 |
| 0.0737 | 96.4 | 4820 | 0.0527 | 0.9537 | 0.9742 | 0.9824 | 0.9951 | 0.9855 | 0.9420 | 0.9902 | 0.9629 | 0.9079 | 0.9760 | 0.9824 |
| 0.103 | 96.8 | 4840 | 0.0525 | 0.9539 | 0.9749 | 0.9825 | 0.9951 | 0.9842 | 0.9456 | 0.9902 | 0.9630 | 0.9085 | 0.9761 | 0.9825 |
| 0.069 | 97.2 | 4860 | 0.0525 | 0.9539 | 0.9749 | 0.9825 | 0.9952 | 0.9839 | 0.9457 | 0.9902 | 0.9630 | 0.9085 | 0.9761 | 0.9825 |
| 0.0613 | 97.6 | 4880 | 0.0525 | 0.9538 | 0.9746 | 0.9825 | 0.9951 | 0.9849 | 0.9439 | 0.9902 | 0.9630 | 0.9083 | 0.9761 | 0.9825 |
| 0.0758 | 98.0 | 4900 | 0.0526 | 0.9539 | 0.9751 | 0.9825 | 0.9950 | 0.9839 | 0.9462 | 0.9902 | 0.9630 | 0.9086 | 0.9761 | 0.9825 |
| 0.0767 | 98.4 | 4920 | 0.0525 | 0.9539 | 0.9747 | 0.9825 | 0.9951 | 0.9848 | 0.9441 | 0.9902 | 0.9630 | 0.9084 | 0.9761 | 0.9825 |
| 0.0676 | 98.8 | 4940 | 0.0526 | 0.9538 | 0.9745 | 0.9825 | 0.9950 | 0.9851 | 0.9435 | 0.9902 | 0.9630 | 0.9082 | 0.9760 | 0.9825 |
| 0.0656 | 99.2 | 4960 | 0.0525 | 0.9539 | 0.9747 | 0.9825 | 0.9951 | 0.9846 | 0.9444 | 0.9902 | 0.9630 | 0.9084 | 0.9761 | 0.9825 |
| 0.0758 | 99.6 | 4980 | 0.0526 | 0.9538 | 0.9745 | 0.9825 | 0.9951 | 0.9852 | 0.9432 | 0.9902 | 0.9630 | 0.9082 | 0.9760 | 0.9825 |
| 0.0747 | 100.0 | 5000 | 0.0525 | 0.9540 | 0.9751 | 0.9825 | 0.9949 | 0.9841 | 0.9464 | 0.9902 | 0.9631 | 0.9087 | 0.9761 | 0.9825 |
### Framework versions
- Transformers 4.41.2
- Pytorch 2.6.0+cu124
- Datasets 3.2.0
- Tokenizers 0.19.1
|
thamphil/finetuned-llama-sa-v1
|
thamphil
| 2025-06-17T09:49:42Z | 0 | 0 | null |
[
"safetensors",
"unsloth",
"license:llama3.2",
"region:us"
] | null | 2025-06-17T07:11:06Z |
---
license: llama3.2
tags:
- unsloth
---
|
BootesVoid/cmbxbw7zm00jurdqs9iqa9vjc_cmc0am4wa07fdrdqsoyeqy0u9
|
BootesVoid
| 2025-06-17T09:31:24Z | 0 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-17T09:31:22Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: TRISHA
---
# Cmbxbw7Zm00Jurdqs9Iqa9Vjc_Cmc0Am4Wa07Fdrdqsoyeqy0U9
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `TRISHA` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "TRISHA",
"lora_weights": "https://huggingface.co/BootesVoid/cmbxbw7zm00jurdqs9iqa9vjc_cmc0am4wa07fdrdqsoyeqy0u9/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbxbw7zm00jurdqs9iqa9vjc_cmc0am4wa07fdrdqsoyeqy0u9', weight_name='lora.safetensors')
image = pipeline('TRISHA').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbxbw7zm00jurdqs9iqa9vjc_cmc0am4wa07fdrdqsoyeqy0u9/discussions) to add images that show off what you’ve made with this LoRA.
|
AntResearchNLP/ViLaSR
|
AntResearchNLP
| 2025-06-17T09:29:38Z | 10 | 0 | null |
[
"safetensors",
"qwen2_5_vl",
"en",
"dataset:AntResearchNLP/ViLaSR-data",
"arxiv:2506.09965",
"base_model:Qwen/Qwen2.5-VL-7B-Instruct",
"base_model:finetune:Qwen/Qwen2.5-VL-7B-Instruct",
"region:us"
] | null | 2025-06-01T15:56:01Z |
---
datasets:
- AntResearchNLP/ViLaSR-data
language:
- en
base_model:
- Qwen/Qwen2.5-VL-7B-Instruct
---
This repository contains the ViLaSR-7B model as presented in [Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing](https://arxiv.org/abs/2506.09965).
Please refer to the code https://github.com/AntResearchNLP/ViLaSR.
```
@misc{wu2025reinforcingspatialreasoningvisionlanguage,
title={Reinforcing Spatial Reasoning in Vision-Language Models with Interwoven Thinking and Visual Drawing},
author={Junfei Wu and Jian Guan and Kaituo Feng and Qiang Liu and Shu Wu and Liang Wang and Wei Wu and Tieniu Tan},
year={2025},
eprint={2506.09965},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2506.09965},
}
```
|
dwright37/icwsm_cw_weighted
|
dwright37
| 2025-06-17T09:15:40Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"modernbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-17T09:14:35Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
codin-research/MedQwen3-1.7B-CPT-0617
|
codin-research
| 2025-06-17T08:56:37Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen3",
"text-generation",
"medical",
"vi",
"arxiv:1910.09700",
"base_model:Qwen/Qwen3-1.7B-Base",
"base_model:finetune:Qwen/Qwen3-1.7B-Base",
"license:mit",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T08:52:39Z |
---
library_name: transformers
tags:
- medical
license: mit
language:
- vi
base_model:
- Qwen/Qwen3-1.7B-Base
pipeline_tag: text-generation
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Jenssss/basic_image_segmentatin
|
Jenssss
| 2025-06-17T08:51:25Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T08:40:41Z |
---
license: apache-2.0
---
|
harshad317/PubMed-8B-slerp
|
harshad317
| 2025-06-17T08:42:19Z | 5 | 0 | null |
[
"safetensors",
"llama",
"merge",
"mergekit",
"lazymergekit",
"aaditya/Llama3-OpenBioLLM-8B",
"johnsnowlabs/JSL-MedLlama-3-8B-v2.0",
"base_model:aaditya/Llama3-OpenBioLLM-8B",
"base_model:merge:aaditya/Llama3-OpenBioLLM-8B",
"base_model:johnsnowlabs/JSL-MedLlama-3-8B-v2.0",
"base_model:merge:johnsnowlabs/JSL-MedLlama-3-8B-v2.0",
"region:us"
] | null | 2025-06-17T06:09:10Z |
---
base_model:
- aaditya/Llama3-OpenBioLLM-8B
- johnsnowlabs/JSL-MedLlama-3-8B-v2.0
tags:
- merge
- mergekit
- lazymergekit
- aaditya/Llama3-OpenBioLLM-8B
- johnsnowlabs/JSL-MedLlama-3-8B-v2.0
---
# PubMed-8B-slerp
PubMed-8B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [aaditya/Llama3-OpenBioLLM-8B](https://huggingface.co/aaditya/Llama3-OpenBioLLM-8B)
* [johnsnowlabs/JSL-MedLlama-3-8B-v2.0](https://huggingface.co/johnsnowlabs/JSL-MedLlama-3-8B-v2.0)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: aaditya/Llama3-OpenBioLLM-8B
layer_range: [0, 32]
- model: johnsnowlabs/JSL-MedLlama-3-8B-v2.0
layer_range: [0, 32]
merge_method: slerp
base_model: meta-llama/Llama-3.1-8B-Instruct
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "harshad317/PubMed-8B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
Rahulsajilekha/TNT2
|
Rahulsajilekha
| 2025-06-17T08:40:16Z | 0 | 0 | null |
[
"license:other",
"region:us"
] | null | 2025-06-17T08:22:19Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/resolve/main/LICENSE.md
---
|
Mzou000/PPO-Ant-v4
|
Mzou000
| 2025-06-17T08:34:17Z | 0 | 0 |
stable-baselines3
|
[
"stable-baselines3",
"reinforcement-learning",
"mujoco",
"ant-v4",
"ppo",
"license:mit",
"region:us"
] |
reinforcement-learning
| 2025-06-17T08:27:40Z |
---
license: mit
tags:
- reinforcement-learning
- stable-baselines3
- mujoco
- ant-v4
- ppo
pipeline_tag: reinforcement-learning
library_name: stable-baselines3
model_name: PPO-Ant-v4
---
# PPO - Ant-v4 🌟
A Proximal Policy Optimization (PPO) agent trained with **stable-baselines3** on the MuJoCo **`Ant-v4`** environment.
| | Details |
|---|---|
| Environment | `gymnasium==0.29` & `mujoco==2.3` (`Ant-v4`) |
| Algorithm | PPO (`stable-baselines3==2.3.0`) |
| Timesteps | **100 000** |
| Policy | `MlpPolicy` *(2 × 64 hidden, tanh)* |
| Return (mean ± std) | ~ *964* |
| Seed | `0` |
## Hyper-parameters
```jsonc
{
"n_steps": 128,
"batch_size": 64,
"n_epochs": 20,
"gamma": 0.99,
"learning_rate": 3e-4,
"ent_coef": 0.0,
"clip_range": 0.2
}
|
songkey/loras_sd_1_5
|
songkey
| 2025-06-17T08:31:46Z | 0 | 0 | null |
[
"license:mit",
"region:us"
] | null | 2025-02-02T14:36:36Z |
---
license: mit
---
[Drawing.safetensors](https://civitai.com/models/110244/drawing)
[baby_face_v1.safetensors](https://civitai.com/models/94599/baby-face)
[more_details.safetensors](https://civitai.com/models/82098/add-more-details-detail-enhancer-tweaker-lora)
[pixel-portrait-v1.safetensors](https://civitai.com/models/111793/pixel-portrait)
|
MaestrAI/jack_marlowe-lora-1750146373
|
MaestrAI
| 2025-06-17T08:27:35Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-17T07:46:12Z |
# jack_marlowe LORA Model
This is a LORA model for character Jack Marlowe
Created at 2025-06-17 09:46:13
|
BootesVoid/cmbn2fdzh01p3ekg0gwuq6vgg_cmc083fbi07b1rdqswu9q4cst
|
BootesVoid
| 2025-06-17T08:06:45Z | 1 | 0 |
diffusers
|
[
"diffusers",
"flux",
"lora",
"replicate",
"text-to-image",
"en",
"base_model:black-forest-labs/FLUX.1-dev",
"base_model:adapter:black-forest-labs/FLUX.1-dev",
"license:other",
"region:us"
] |
text-to-image
| 2025-06-17T08:06:44Z |
---
license: other
license_name: flux-1-dev-non-commercial-license
license_link: https://huggingface.co/black-forest-labs/FLUX.1-dev/blob/main/LICENSE.md
language:
- en
tags:
- flux
- diffusers
- lora
- replicate
base_model: "black-forest-labs/FLUX.1-dev"
pipeline_tag: text-to-image
# widget:
# - text: >-
# prompt
# output:
# url: https://...
instance_prompt: BELLA
---
# Cmbn2Fdzh01P3Ekg0Gwuq6Vgg_Cmc083Fbi07B1Rdqswu9Q4Cst
<Gallery />
## About this LoRA
This is a [LoRA](https://replicate.com/docs/guides/working-with-loras) for the FLUX.1-dev text-to-image model. It can be used with diffusers or ComfyUI.
It was trained on [Replicate](https://replicate.com/) using AI toolkit: https://replicate.com/ostris/flux-dev-lora-trainer/train
## Trigger words
You should use `BELLA` to trigger the image generation.
## Run this LoRA with an API using Replicate
```py
import replicate
input = {
"prompt": "BELLA",
"lora_weights": "https://huggingface.co/BootesVoid/cmbn2fdzh01p3ekg0gwuq6vgg_cmc083fbi07b1rdqswu9q4cst/resolve/main/lora.safetensors"
}
output = replicate.run(
"black-forest-labs/flux-dev-lora",
input=input
)
for index, item in enumerate(output):
with open(f"output_{index}.webp", "wb") as file:
file.write(item.read())
```
## Use it with the [🧨 diffusers library](https://github.com/huggingface/diffusers)
```py
from diffusers import AutoPipelineForText2Image
import torch
pipeline = AutoPipelineForText2Image.from_pretrained('black-forest-labs/FLUX.1-dev', torch_dtype=torch.float16).to('cuda')
pipeline.load_lora_weights('BootesVoid/cmbn2fdzh01p3ekg0gwuq6vgg_cmc083fbi07b1rdqswu9q4cst', weight_name='lora.safetensors')
image = pipeline('BELLA').images[0]
```
For more details, including weighting, merging and fusing LoRAs, check the [documentation on loading LoRAs in diffusers](https://huggingface.co/docs/diffusers/main/en/using-diffusers/loading_adapters)
## Training details
- Steps: 2000
- Learning rate: 0.0004
- LoRA rank: 16
## Contribute your own examples
You can use the [community tab](https://huggingface.co/BootesVoid/cmbn2fdzh01p3ekg0gwuq6vgg_cmc083fbi07b1rdqswu9q4cst/discussions) to add images that show off what you’ve made with this LoRA.
|
JayHyeon/Qwen_1.5B-math-IPO_5e-6_1.0vpo_constant-5ep
|
JayHyeon
| 2025-06-17T08:05:46Z | 1 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:argilla/distilabel-math-preference-dpo",
"arxiv:2305.18290",
"base_model:Qwen/Qwen2.5-Math-1.5B",
"base_model:finetune:Qwen/Qwen2.5-Math-1.5B",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T07:41:20Z |
---
base_model: Qwen/Qwen2.5-Math-1.5B
datasets: argilla/distilabel-math-preference-dpo
library_name: transformers
model_name: Qwen_1.5B-math-IPO_5e-6_1.0vpo_constant-5ep
tags:
- generated_from_trainer
- trl
- dpo
licence: license
---
# Model Card for Qwen_1.5B-math-IPO_5e-6_1.0vpo_constant-5ep
This model is a fine-tuned version of [Qwen/Qwen2.5-Math-1.5B](https://huggingface.co/Qwen/Qwen2.5-Math-1.5B) on the [argilla/distilabel-math-preference-dpo](https://huggingface.co/datasets/argilla/distilabel-math-preference-dpo) dataset.
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="JayHyeon/Qwen_1.5B-math-IPO_5e-6_1.0vpo_constant-5ep", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
[<img src="https://raw.githubusercontent.com/wandb/assets/main/wandb-github-badge-28.svg" alt="Visualize in Weights & Biases" width="150" height="24"/>](https://wandb.ai/bonin147/huggingface/runs/9xses5za)
This model was trained with DPO, a method introduced in [Direct Preference Optimization: Your Language Model is Secretly a Reward Model](https://huggingface.co/papers/2305.18290).
### Framework versions
- TRL: 0.15.2
- Transformers: 4.50.0
- Pytorch: 2.6.0
- Datasets: 3.4.1
- Tokenizers: 0.21.1
## Citations
Cite DPO as:
```bibtex
@inproceedings{rafailov2023direct,
title = {{Direct Preference Optimization: Your Language Model is Secretly a Reward Model}},
author = {Rafael Rafailov and Archit Sharma and Eric Mitchell and Christopher D. Manning and Stefano Ermon and Chelsea Finn},
year = 2023,
booktitle = {Advances in Neural Information Processing Systems 36: Annual Conference on Neural Information Processing Systems 2023, NeurIPS 2023, New Orleans, LA, USA, December 10 - 16, 2023},
url = {http://papers.nips.cc/paper_files/paper/2023/hash/a85b405ed65c6477a4fe8302b5e06ce7-Abstract-Conference.html},
editor = {Alice Oh and Tristan Naumann and Amir Globerson and Kate Saenko and Moritz Hardt and Sergey Levine},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallouédec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
c-hw/my-sentiment-model
|
c-hw
| 2025-06-17T07:50:06Z | 2 | 0 |
transformers
|
[
"transformers",
"safetensors",
"distilbert",
"text-classification",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-classification
| 2025-06-17T07:49:24Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Dragon168/uuu_fine_tune_gpt2
|
Dragon168
| 2025-06-17T07:23:41Z | 0 | 0 | null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T06:24:44Z |
---
license: apache-2.0
---
|
WHWeng/uuu_fine_tune_taipower
|
WHWeng
| 2025-06-17T07:11:54Z | 4 | 0 | null |
[
"safetensors",
"gpt2",
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T06:18:48Z |
---
license: apache-2.0
---
|
ShunxunYu/llama2_uuu_news_qlora
|
ShunxunYu
| 2025-06-17T07:02:25Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T07:02:25Z |
---
license: apache-2.0
---
|
asm3515/bert_agnews_lora_rank4
|
asm3515
| 2025-06-17T07:00:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T07:00:40Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Srajan04/mt5-base-hindi-intent-air
|
Srajan04
| 2025-06-17T06:52:48Z | 22 | 0 |
transformers
|
[
"transformers",
"tensorboard",
"safetensors",
"mt5",
"text2text-generation",
"autotrain",
"base_model:google/mt5-base",
"base_model:finetune:google/mt5-base",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text2text-generation
| 2025-06-17T06:27:17Z |
---
library_name: transformers
tags:
- autotrain
- text2text-generation
base_model: google/mt5-base
widget:
- text: "I love AutoTrain"
---
# Model Trained Using AutoTrain
- Problem type: Seq2Seq
## Validation Metrics
loss: 0.11389002948999405
rouge1: 70.8293
rouge2: 60.161
rougeL: 70.2151
rougeLsum: 70.2119
gen_len: 20.0
runtime: 133.8595
samples_per_second: 21.717
steps_per_second: 2.719
: 2.0
|
khanhdang/gemma-3-12b
|
khanhdang
| 2025-06-17T06:39:53Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T03:39:03Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
rashwin88/example-model
|
rashwin88
| 2025-06-17T06:29:01Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-17T05:22:26Z |
# Example Model
This is my model card
---
license: mit
---
|
BarryLin/tcp2023
|
BarryLin
| 2025-06-17T06:20:17Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T06:20:17Z |
---
license: apache-2.0
---
|
howard9963/tcp2023
|
howard9963
| 2025-06-17T06:19:02Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T06:19:02Z |
---
license: apache-2.0
---
|
HedyKoala17/tcp2023
|
HedyKoala17
| 2025-06-17T06:16:50Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T06:16:50Z |
---
license: apache-2.0
---
|
espnet/cnceleb_ecapa_tdnn
|
espnet
| 2025-06-17T06:16:22Z | 0 | 0 |
espnet
|
[
"espnet",
"audio",
"speaker-recognition",
"multilingual",
"dataset:cnceleb",
"arxiv:1804.00015",
"license:cc-by-4.0",
"region:us"
] | null | 2025-06-17T05:34:12Z |
---
tags:
- espnet
- audio
- speaker-recognition
language: multilingual
datasets:
- cnceleb
license: cc-by-4.0
---
## ESPnet2 SPK model
### `espnet/cnceleb_ecapa_tdnn`
This model was trained by holvan using cnceleb recipe in [espnet](https://github.com/espnet/espnet/).
### Demo: How to use in ESPnet2
Follow the [ESPnet installation instructions](https://espnet.github.io/espnet/installation.html)
if you haven't done that already.
```bash
cd espnet
git checkout d3db63621b5ea1d7b450d768f97c1a6bdf3cf8be
pip install -e .
cd egs2/cnceleb/spk1
./run.sh --skip_data_prep false --skip_train true --download_model espnet/cnceleb_ecapa_tdnn
```
<!-- Generated by scripts/utils/show_spk_result.py -->
# RESULTS
## Environments
date: 2025-06-17 13:12:33.497674
- python version: 3.10.14 (main, May 6 2024, 19:42:50) [GCC 11.2.0]
- espnet version: 202402
- pytorch version: 2.3.1
| | Mean | Std |
|---|---|---|
| Target | -1.0389 | 0.1553 |
| Non-target | -1.3574 | 0.0679 |
| Model name | EER(%) | minDCF |
|---|---|---|
| conf/train_ecapa_tdnn | 7.762 | 0.35304 |
## SPK config
<details><summary>expand</summary>
```
config: conf/train_ecapa_tdnn.yaml
print_config: false
log_level: INFO
drop_last_iter: true
dry_run: false
iterator_type: category
valid_iterator_type: sequence
output_dir: exp/spk_train_ecapa_tdnn_raw_sp
ngpu: 1
seed: 0
num_workers: 8
num_att_plot: 0
dist_backend: nccl
dist_init_method: env://
dist_world_size: 4
dist_rank: 0
local_rank: 0
dist_master_addr: localhost
dist_master_port: 44223
dist_launcher: null
multiprocessing_distributed: true
unused_parameters: false
sharded_ddp: false
use_deepspeed: false
deepspeed_config: null
gradient_as_bucket_view: true
ddp_comm_hook: null
cudnn_enabled: true
cudnn_benchmark: true
cudnn_deterministic: false
use_tf32: false
collect_stats: false
write_collected_feats: false
max_epoch: 40
patience: null
val_scheduler_criterion:
- valid
- loss
early_stopping_criterion:
- valid
- loss
- min
best_model_criterion:
- - valid
- eer
- min
keep_nbest_models: 3
nbest_averaging_interval: 0
grad_clip: 9999
grad_clip_type: 2.0
grad_noise: false
accum_grad: 1
no_forward_run: false
resume: true
train_dtype: float32
use_amp: true
log_interval: 100
use_matplotlib: true
use_tensorboard: true
create_graph_in_tensorboard: false
use_wandb: false
wandb_project: null
wandb_id: null
wandb_entity: null
wandb_name: null
wandb_model_log_interval: -1
detect_anomaly: false
use_adapter: false
adapter: lora
save_strategy: all
adapter_conf: {}
pretrain_path: null
init_param: []
ignore_init_mismatch: false
freeze_param: []
num_iters_per_epoch: null
batch_size: 512
valid_batch_size: 40
batch_bins: 1000000
valid_batch_bins: null
category_sample_size: 10
train_shape_file:
- exp/spk_stats_16k_sp/train/speech_shape
valid_shape_file:
- exp/spk_stats_16k_sp/valid/speech_shape
batch_type: folded
valid_batch_type: null
fold_length:
- 120000
sort_in_batch: descending
shuffle_within_batch: false
sort_batch: descending
multiple_iterator: false
chunk_length: 500
chunk_shift_ratio: 0.5
num_cache_chunks: 1024
chunk_excluded_key_prefixes: []
chunk_default_fs: null
chunk_max_abs_length: null
chunk_discard_short_samples: true
train_data_path_and_name_and_type:
- - dump/raw/cnceleb_train_sp/wav.scp
- speech
- sound
- - dump/raw/cnceleb_train_sp/utt2spk
- spk_labels
- text
valid_data_path_and_name_and_type:
- - dump/raw/cnceleb1_valid/trial.scp
- speech
- sound
- - dump/raw/cnceleb1_valid/trial2.scp
- speech2
- sound
- - dump/raw/cnceleb1_valid/trial_label
- spk_labels
- text
multi_task_dataset: false
allow_variable_data_keys: false
max_cache_size: 0.0
max_cache_fd: 32
allow_multi_rates: false
valid_max_cache_size: null
exclude_weight_decay: false
exclude_weight_decay_conf: {}
optim: sgd
optim_conf:
lr: 0.1
momentum: 0.9
weight_decay: 0.0001
scheduler: exponentialdecaywarmup
scheduler_conf:
max_lr: 0.1
min_lr: 5.0e-05
total_steps: 140720
warmup_steps: 17590
warm_from_zero: true
init: null
use_preprocessor: true
input_size: null
target_duration: 3.0
spk2utt: dump/raw/cnceleb_train_sp/spk2utt
spk_num: 8379
sample_rate: 16000
num_eval: 10
rir_scp: ''
model_conf:
extract_feats_in_collect_stats: false
frontend: melspec_torch
frontend_conf:
preemp: true
n_fft: 512
log: true
win_length: 400
hop_length: 160
n_mels: 80
normalize: mn
specaug: null
specaug_conf: {}
normalize: null
normalize_conf: {}
encoder: ecapa_tdnn
encoder_conf:
model_scale: 8
ndim: 1024
output_size: 1536
pooling: chn_attn_stat
pooling_conf: {}
projector: rawnet3
projector_conf:
output_size: 192
preprocessor: spk
preprocessor_conf:
target_duration: 3.0
sample_rate: 16000
num_eval: 5
noise_apply_prob: 0.5
noise_info:
- - 1.0
- dump/raw/musan_speech.scp
- - 4
- 7
- - 13
- 20
- - 1.0
- dump/raw/musan_noise.scp
- - 1
- 1
- - 0
- 15
- - 1.0
- dump/raw/musan_music.scp
- - 1
- 1
- - 5
- 15
rir_apply_prob: 0.5
rir_scp: dump/raw/rirs.scp
loss: aamsoftmax_sc_topk
loss_conf:
margin: 0.3
scale: 30
K: 3
mp: 0.06
k_top: 5
required:
- output_dir
version: '202402'
distributed: true
```
</details>
### Citing ESPnet
```BibTex
@inproceedings{watanabe2018espnet,
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
title={{ESPnet}: End-to-End Speech Processing Toolkit},
year={2018},
booktitle={Proceedings of Interspeech},
pages={2207--2211},
doi={10.21437/Interspeech.2018-1456},
url={http://dx.doi.org/10.21437/Interspeech.2018-1456}
}
```
or arXiv:
```bibtex
@misc{watanabe2018espnet,
title={ESPnet: End-to-End Speech Processing Toolkit},
author={Shinji Watanabe and Takaaki Hori and Shigeki Karita and Tomoki Hayashi and Jiro Nishitoba and Yuya Unno and Nelson Yalta and Jahn Heymann and Matthew Wiesner and Nanxin Chen and Adithya Renduchintala and Tsubasa Ochiai},
year={2018},
eprint={1804.00015},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
maimai10106/tcp2023
|
maimai10106
| 2025-06-17T06:16:21Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T06:16:21Z |
---
license: apache-2.0
---
|
Continual-Mega/ADCT
|
Continual-Mega
| 2025-06-17T06:11:21Z | 0 | 0 | null |
[
"dataset:Continual-Mega/Continual-Mega-Neurips2025",
"arxiv:2506.00956",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2025-06-16T04:12:17Z |
---
license: cc-by-nc-4.0
datasets:
- Continual-Mega/Continual-Mega-Neurips2025
---
# 🧠 Continual-MEGA: A Large-scale Benchmark for Generalizable Continual Anomaly Detection
This repository provides model checkpoints for **Continual-MEGA**, a benchmark introduced in the paper:
[](https://arxiv.org/abs/2506.00956)
🔗 **Codebase**: [Continual-Mega/Continual-Mega](https://github.com/Continual-Mega/Continual-Mega)
---
## 🚀 Overview
Continual-MEGA introduces a realistic and large-scale benchmark for **continual anomaly detection** that emphasizes generalizability across domains and tasks.
The benchmark features:
- ✅ Diverse anomaly types across domains
- 🔁 Class-incremental continual learning setup
- 📈 A large-scale evaluation protocol surpassing previous benchmarks
This repository hosts pretrained **model checkpoints** used in various scenarios defined in the benchmark.
---
## 📦 Available Checkpoints
| Model Name | Scenario | Task | Description |
|---------------------------------------|------------|-------------------------|----------------------------------------------------------|
| `scenario2/prompt_maker` | Scenario 2 | Base | Prompt maker trained on Scenario 2 base classes |
| `scenario2/adapters_base` | Scenario 2 | Base | Adapter trained on Scenario 2 base classes |
| `scenario2/30classes/adapters_task1` | Scenario 2 | Task 1 (30 classes) | Adapter trained on Task 1 (30 classes) in Scenario 2 |
| `scenario2/30classes/adapters_task2` | Scenario 2 | Task 2 (30 classes) | Adapter trained on Task 2 (30 classes) in Scenario 2 |
| *(More to come)* | – | – | – |
---
## 🛠 Usage Example
### Continual Setting Evaluation
```
sh eval_continual.sh
```
### Zero-Shot Evaluation
```
sh eval_zero.s
|
DavidLanz/tcp2025
|
DavidLanz
| 2025-06-17T06:09:21Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T06:09:21Z |
---
license: apache-2.0
---
|
QuantFactory/OpenThinker2-7B-GGUF
|
QuantFactory
| 2025-06-17T06:06:44Z | 0 | 1 |
transformers
|
[
"transformers",
"gguf",
"llama-factory",
"full",
"generated_from_trainer",
"dataset:open-thoughts/OpenThoughts2-1M",
"arxiv:2506.04178",
"base_model:Qwen/Qwen2.5-7B-Instruct",
"base_model:quantized:Qwen/Qwen2.5-7B-Instruct",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-06-17T05:26:35Z |
---
library_name: transformers
license: apache-2.0
base_model: Qwen/Qwen2.5-7B-Instruct
tags:
- llama-factory
- full
- generated_from_trainer
model-index:
- name: OpenThinker2-7B
results: []
datasets:
- open-thoughts/OpenThoughts2-1M
---
[](https://hf.co/QuantFactory)
# QuantFactory/OpenThinker2-7B-GGUF
This is quantized version of [open-thoughts/OpenThinker2-7B](https://huggingface.co/open-thoughts/OpenThinker2-7B) created using llama.cpp
# Original Model Card
<p align="center">
<img src="https://huggingface.co/datasets/open-thoughts/open-thoughts-114k/resolve/main/open_thoughts.png" width="50%">
</p>
> [!NOTE]
> We have released a paper for OpenThoughts! See our paper [here](https://arxiv.org/abs/2506.04178).
# OpenThinker2-7B
This model is a fine-tuned version of [Qwen/Qwen2.5-7B-Instruct](https://huggingface.co/Qwen/Qwen2.5-7B-Instruct) on the
[OpenThoughts2-1M](https://huggingface.co/datasets/open-thoughts/OpenThoughts2-1M) dataset.
The [OpenThinker2-7B](https://huggingface.co/open-thoughts/OpenThinker2-7B) model is the top 7B open-data reasoning model. It delivers performance comparable to state of the art 7B models like [DeepSeek-R1-Distill-7B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) across a suite of tasks.
This model improves upon our previous [OpenThinker-7B](https://huggingface.co/open-thoughts/OpenThinker-7B) model, which was trained on 114k examples from [OpenThoughts-114k](https://huggingface.co/datasets/open-thoughts/open-thoughts-114k).
The numbers reported in the table below are evaluated with our open-source tool [Evalchemy](https://github.com/mlfoundations/Evalchemy).
| Model | Data | AIME24 | AIME25 | AMC23 | MATH500 | GPQA-D | LCBv2 |
| --------------------------------------------------------------------------------------------- | ---- | ------ | ------ | ----- | ------- | ------ | ----------- |
| [OpenThinker2-7B](https://huggingface.co/open-thoughts/OpenThinker2-7B) | ✅ | 50.0 | 33.3 | 89.5 | 88.4 | 49.3 | 55.6 |
| [OpenThinker-7B](https://huggingface.co/open-thoughts/OpenThinker-7B) | ✅ | 31.3 | 23.3 | 74.5 | 83.2 | 42.9 | 38.0 |
| [DeepSeek-R1-Distill-Qwen-7B](https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-7B) | ❌ | 57.3 | 33.3 | 92.0 | 89.6 | 47.3 | 48.4 |
| [OlympicCoder-7B](https://huggingface.co/open-r1/OlympicCoder-7B) | ✅ | 20.7 | 15.3 | 63.0 | 74.8 | 25.3 | 55.4 |
| [OpenR1-Qwen-7B](https://huggingface.co/open-r1/OpenR1-Qwen-7B) | ✅ | 48.7 | 34.7 | 88.5 | 87.8 | 21.2 | 9.5<br><br> |
## Data
This model was trained on the [OpenThoughts2-1M](https://huggingface.co/datasets/open-thoughts/OpenThoughts2-1M) dataset.
The [OpenThoughts2-1M](https://huggingface.co/datasets/open-thoughts/OpenThoughts2-1M) dataset was constructed by augmenting [OpenThoughts-114k](https://huggingface.co/datasets/open-thoughts/open-thoughts-114k) with existing datasets like [OpenR1](https://huggingface.co/open-r1), as well as additional math and code reasoning data.
We generate the additional math and code data by ablating over 26 different question generation methodologies and sampling from the highest performing ones.
See the [OpenThoughts2-1M](https://huggingface.co/datasets/open-thoughts/OpenThoughts2-1M) dataset page or our [blog post](https://www.open-thoughts.ai/blog/thinkagain) for additional information.
## Intended uses & limitations
Apache 2.0 License
## Training procedure
We used 32 8xA100 nodes to train the model for 36 hours.
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 8e-05
- seed: 42
- distributed_type: multi-GPU
- num_devices: 256
- gradient_accumulation_steps: 2
- total_train_batch_size: 512
- optimizer: Use OptimizerNames.ADAMW_TORCH with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 5.0
### Framework versions
- Transformers 4.46.1
- Pytorch 2.3.0
- Datasets 3.1.0
- Tokenizers 0.20.3
More info can be found in our repository: [https://github.com/open-thoughts/open-thoughts](https://github.com/open-thoughts/open-thoughts).
# Links
- 📝 [OpenThoughts Paper](https://arxiv.org/abs/2506.04178)
- 📊 [OpenThoughts2 and OpenThinker2 Blog Post](https://www.open-thoughts.ai/blog/thinkagain)
- 💻 [Open Thoughts GitHub Repository](https://github.com/open-thoughts/open-thoughts)
- 🧠 [OpenThoughts2-1M dataset](https://huggingface.co/datasets/open-thoughts/OpenThoughts2-1M)
- 🤖 [OpenThinker2-7B model](https://huggingface.co/open-thoughts/OpenThinker2-7B) - this model.
- 🤖 [OpenThinker2-32B model](https://huggingface.co/open-thoughts/OpenThinker2-32B)
# Citation
```
@misc{guha2025openthoughtsdatarecipesreasoning,
title={OpenThoughts: Data Recipes for Reasoning Models},
author={Etash Guha and Ryan Marten and Sedrick Keh and Negin Raoof and Georgios Smyrnis and Hritik Bansal and Marianna Nezhurina and Jean Mercat and Trung Vu and Zayne Sprague and Ashima Suvarna and Benjamin Feuer and Liangyu Chen and Zaid Khan and Eric Frankel and Sachin Grover and Caroline Choi and Niklas Muennighoff and Shiye Su and Wanjia Zhao and John Yang and Shreyas Pimpalgaonkar and Kartik Sharma and Charlie Cheng-Jie Ji and Yichuan Deng and Sarah Pratt and Vivek Ramanujan and Jon Saad-Falcon and Jeffrey Li and Achal Dave and Alon Albalak and Kushal Arora and Blake Wulfe and Chinmay Hegde and Greg Durrett and Sewoong Oh and Mohit Bansal and Saadia Gabriel and Aditya Grover and Kai-Wei Chang and Vaishaal Shankar and Aaron Gokaslan and Mike A. Merrill and Tatsunori Hashimoto and Yejin Choi and Jenia Jitsev and Reinhard Heckel and Maheswaran Sathiamoorthy and Alexandros G. Dimakis and Ludwig Schmidt},
year={2025},
eprint={2506.04178},
archivePrefix={arXiv},
primaryClass={cs.LG},
url={https://arxiv.org/abs/2506.04178},
}
```
|
Zack-Z/qwen3_4bi_cotsft_rs0_0_5cut_ru_cot2all_indep_e2
|
Zack-Z
| 2025-06-17T05:55:56Z | 0 | 0 |
transformers
|
[
"transformers",
"qwen3",
"feature-extraction",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/Qwen3-4B",
"base_model:finetune:unsloth/Qwen3-4B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] |
feature-extraction
| 2025-06-17T05:41:08Z |
---
base_model: unsloth/Qwen3-4B
tags:
- text-generation-inference
- transformers
- unsloth
- qwen3
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** Zack-Z
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen3-4B
This qwen3 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Silly98/Srinsoft_Model_Testing
|
Silly98
| 2025-06-17T05:47:36Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T05:47:36Z |
---
license: apache-2.0
---
|
erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64-ps-grpo-r32
|
erdem-erdem
| 2025-06-17T05:44:19Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64",
"base_model:finetune:erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T05:42:44Z |
---
base_model: erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** erdem-erdem
- **License:** apache-2.0
- **Finetuned from model :** erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
wATcH-Kamal-Kaur-Viral-video/Trending.Kamal.Kaur.Bhabhis.Last.Video.Goes.Viral
|
wATcH-Kamal-Kaur-Viral-video
| 2025-06-17T05:44:12Z | 0 | 0 | null |
[
"license:apache-2.0",
"region:us"
] | null | 2025-06-17T05:43:52Z |
---
license: apache-2.0
---
[](https://tinyurl.com/3cf32han)
|
sophiay98/rl-tutorial-chap2-2
|
sophiay98
| 2025-06-17T05:41:34Z | 0 | 0 | null |
[
"Taxi-v3",
"q-learning",
"reinforcement-learning",
"custom-implementation",
"model-index",
"region:us"
] |
reinforcement-learning
| 2025-06-17T05:41:32Z |
---
tags:
- Taxi-v3
- q-learning
- reinforcement-learning
- custom-implementation
model-index:
- name: rl-tutorial-chap2-2
results:
- task:
type: reinforcement-learning
name: reinforcement-learning
dataset:
name: Taxi-v3
type: Taxi-v3
metrics:
- type: mean_reward
value: 7.52 +/- 2.69
name: mean_reward
verified: false
---
# **Q-Learning** Agent playing1 **Taxi-v3**
This is a trained model of a **Q-Learning** agent playing **Taxi-v3** .
## Usage
```python
model = load_from_hub(repo_id="sophiay98/rl-tutorial-chap2-2", filename="q-learning.pkl")
# Don't forget to check if you need to add additional attributes (is_slippery=False etc)
env = gym.make(model["env_id"])
```
|
ArtusDev/google_medgemma-27b-text-it-EXL3
|
ArtusDev
| 2025-06-17T05:39:14Z | 0 | 0 |
transformers
|
[
"transformers",
"medical",
"clinical-reasoning",
"thinking",
"exl3",
"text-generation",
"base_model:google/medgemma-27b-text-it",
"base_model:quantized:google/medgemma-27b-text-it",
"license:other",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-15T18:53:06Z |
---
base_model: google/medgemma-27b-text-it
base_model_relation: quantized
quantized_by: ArtusDev
license: other
license_name: health-ai-developer-foundations
license_link: https://developers.google.com/health-ai-developer-foundations/terms
library_name: transformers
pipeline_tag: text-generation
extra_gated_heading: Access MedGemma on Hugging Face
extra_gated_prompt: >-
To access MedGemma on Hugging Face, you're required to review and agree to
[Health AI Developer Foundation's terms of
use](https://developers.google.com/health-ai-developer-foundations/terms). To
do this, please ensure you're logged in to Hugging Face and click below.
Requests are processed immediately.
extra_gated_button_content: Acknowledge license
tags:
- medical
- clinical-reasoning
- thinking
- exl3
---
## EXL3 Quants of google/medgemma-27b-text-it
EXL3 quants of [google/medgemma-27b-text-it](https://huggingface.co/google/medgemma-27b-text-it) using <a href="https://github.com/turboderp-org/exllamav3/">exllamav3</a> for quantization.
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [2.5_H6](https://huggingface.co/ArtusDev/google_medgemma-27b-text-it-EXL3/tree/2.5bpw_H6) | 2.5 | 6 |
| [3.0_H6](https://huggingface.co/ArtusDev/google_medgemma-27b-text-it-EXL3/tree/3.0bpw_H6) | 3.0 | 6 |
| [3.5_H6](https://huggingface.co/ArtusDev/google_medgemma-27b-text-it-EXL3/tree/3.5bpw_H6) | 3.5 | 6 |
| [4.0_H6](https://huggingface.co/ArtusDev/google_medgemma-27b-text-it-EXL3/tree/4.0bpw_H6) | 4.0 | 6 |
| [4.5_H6](https://huggingface.co/ArtusDev/google_medgemma-27b-text-it-EXL3/tree/4.5bpw_H6) | 4.5 | 6 |
| [5.0_H6](https://huggingface.co/ArtusDev/google_medgemma-27b-text-it-EXL3/tree/5.0bpw_H6) | 5.0 | 6 |
| [6.0_H6](https://huggingface.co/ArtusDev/google_medgemma-27b-text-it-EXL3/tree/6.0bpw_H6) | 6.0 | 6 |
| [8.0_H6](https://huggingface.co/ArtusDev/google_medgemma-27b-text-it-EXL3/tree/8.0bpw_H6) | 8.0 | 6 |
| [8.0_H8](https://huggingface.co/ArtusDev/google_medgemma-27b-text-it-EXL3/tree/8.0bpw_H8) | 8.0 | 8 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/google_medgemma-27b-text-it-EXL3 --revision "5.0bpw_H6" --local-dir ./
```
</details>
|
ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3
|
ArtusDev
| 2025-06-17T05:38:52Z | 1 | 0 |
transformers
|
[
"transformers",
"mergekit",
"merge",
"chatml",
"exl3",
"en",
"ja",
"base_model:yamatazen/EtherealAurora-12B-v2",
"base_model:quantized:yamatazen/EtherealAurora-12B-v2",
"endpoints_compatible",
"region:us"
] | null | 2025-06-12T17:08:53Z |
---
base_model: yamatazen/EtherealAurora-12B-v2
base_model_relation: quantized
quantized_by: ArtusDev
library_name: transformers
tags:
- mergekit
- merge
- chatml
- exl3
language:
- en
- ja
---
## EXL3 Quants of yamatazen/EtherealAurora-12B-v2
EXL3 quants of [yamatazen/EtherealAurora-12B-v2](https://huggingface.co/yamatazen/EtherealAurora-12B-v2) using <a href="https://github.com/turboderp-org/exllamav3/">exllamav3</a> for quantization.
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [2.5_H6](https://huggingface.co/ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3/tree/2.5bpw_H6) | 2.5 | 6 |
| [3.0_H6](https://huggingface.co/ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3/tree/3.0bpw_H6) | 3.0 | 6 |
| [3.5_H6](https://huggingface.co/ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3/tree/3.5bpw_H6) | 3.5 | 6 |
| [4.0_H6](https://huggingface.co/ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3/tree/4.0bpw_H6) | 4.0 | 6 |
| [4.5_H6](https://huggingface.co/ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3/tree/4.5bpw_H6) | 4.5 | 6 |
| [5.0_H6](https://huggingface.co/ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3/tree/5.0bpw_H6) | 5.0 | 6 |
| [6.0_H6](https://huggingface.co/ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3/tree/6.0bpw_H6) | 6.0 | 6 |
| [8.0_H6](https://huggingface.co/ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3/tree/8.0bpw_H6) | 8.0 | 6 |
| [8.0_H8](https://huggingface.co/ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3/tree/8.0bpw_H8) | 8.0 | 8 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/yamatazen_EtherealAurora-12B-v2-EXL3 --revision "5.0bpw_H6" --local-dir ./
```
</details>
|
ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3
|
ArtusDev
| 2025-06-17T05:38:26Z | 6 | 0 |
transformers
|
[
"transformers",
"roleplay",
"finetune",
"axolotl",
"creative-writing",
"70B",
"llama",
"exl3",
"en",
"dataset:PocketDoc/Dans-Personamaxx-VN",
"dataset:NewEden/LIMARP-Complexity",
"dataset:NewEden/PIPPA-Mega-Filtered",
"dataset:NewEden/OpenCAI-ShareGPT",
"dataset:NewEden/Creative_Writing-Complexity",
"dataset:NewEden/Light-Novels-Roleplay-Logs-Books-Oh-My-duplicate-turns-removed",
"dataset:PocketDoc/Dans-Failuremaxx-Adventure-3",
"dataset:NewEden/Books-V2-ShareGPT",
"dataset:NewEden/Deepseek-V3-RP-Filtered",
"dataset:NewEden/BlueSky-10K-Complexity",
"dataset:NewEden/Final-Alpindale-LNs-ShareGPT",
"dataset:NewEden/DeepseekRP-Filtered",
"dataset:NewEden/RP-logs-V2-Experimental",
"dataset:anthracite-org/kalo_opus_misc_240827",
"dataset:anthracite-org/kalo_misc_part2",
"dataset:NewEden/vanilla-backrooms-claude-sharegpt",
"dataset:NewEden/Storium-Prefixed-Clean",
"base_model:Delta-Vector/Austral-70B-Preview",
"base_model:quantized:Delta-Vector/Austral-70B-Preview",
"license:llama3.3",
"endpoints_compatible",
"region:us"
] | null | 2025-06-10T14:26:59Z |
---
base_model: Delta-Vector/Austral-70B-Preview
base_model_relation: quantized
quantized_by: ArtusDev
license: llama3.3
language:
- en
library_name: transformers
datasets:
- PocketDoc/Dans-Personamaxx-VN
- NewEden/LIMARP-Complexity
- NewEden/PIPPA-Mega-Filtered
- NewEden/OpenCAI-ShareGPT
- NewEden/Creative_Writing-Complexity
- NewEden/Light-Novels-Roleplay-Logs-Books-Oh-My-duplicate-turns-removed
- PocketDoc/Dans-Failuremaxx-Adventure-3
- NewEden/Books-V2-ShareGPT
- NewEden/Deepseek-V3-RP-Filtered
- NewEden/BlueSky-10K-Complexity
- NewEden/Final-Alpindale-LNs-ShareGPT
- NewEden/DeepseekRP-Filtered
- NewEden/RP-logs-V2-Experimental
- anthracite-org/kalo_opus_misc_240827
- anthracite-org/kalo_misc_part2
- NewEden/vanilla-backrooms-claude-sharegpt
- NewEden/Storium-Prefixed-Clean
tags:
- roleplay
- finetune
- axolotl
- creative-writing
- 70B
- llama
- exl3
---
## EXL3 Quants of Delta-Vector/Austral-70B-Preview
EXL3 quants of [Delta-Vector/Austral-70B-Preview](https://huggingface.co/Delta-Vector/Austral-70B-Preview) using <a href="https://github.com/turboderp-org/exllamav3/">exllamav3</a> for quantization.
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [2.5_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/2.5bpw_H6) | 2.5 | 6 |
| [3.0_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/3.0bpw_H6) | 3.0 | 6 |
| [3.25_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/3.25bpw_H6) | 3.25 | 6 |
| [3.5_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/3.5bpw_H6) | 3.5 | 6 |
| [4.0_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/4.0bpw_H6) | 4.0 | 6 |
| [4.25_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/4.25bpw_H6) | 4.25 | 6 |
| [4.5_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/4.5bpw_H6) | 4.5 | 6 |
| [5.0_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/5.0bpw_H6) | 5.0 | 6 |
| [6.0_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/6.0bpw_H6) | 6.0 | 6 |
| [8.0_H6](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/8.0bpw_H6) | 8.0 | 6 |
| [8.0_H8](https://huggingface.co/ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3/tree/8.0bpw_H8) | 8.0 | 8 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/Delta-Vector_Austral-70B-Preview-EXL3 --revision "5.0bpw_H6" --local-dir ./
```
</details>
|
ArtusDev/arcee-ai_Homunculus-EXL3
|
ArtusDev
| 2025-06-17T05:37:31Z | 5 | 0 |
transformers
|
[
"transformers",
"distillation",
"/think",
"/nothink",
"reasoning-transfer",
"arcee-ai",
"exl3",
"en",
"base_model:arcee-ai/Homunculus",
"base_model:quantized:arcee-ai/Homunculus",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2025-06-03T16:28:56Z |
---
base_model: arcee-ai/Homunculus
base_model_relation: quantized
quantized_by: ArtusDev
language:
- en
license: apache-2.0
library_name: transformers
tags:
- distillation
- /think
- /nothink
- reasoning-transfer
- arcee-ai
- exl3
---
## EXL3 Quants of arcee-ai/Homunculus
EXL3 quants of [arcee-ai/Homunculus](https://huggingface.co/arcee-ai/Homunculus) using <a href="https://github.com/turboderp-org/exllamav3/">exllamav3</a> for quantization.
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [2.5_H6](https://huggingface.co/ArtusDev/arcee-ai_Homunculus-EXL3/tree/2.5bpw_H6) | 2.5 | 6 |
| [3.0_H6](https://huggingface.co/ArtusDev/arcee-ai_Homunculus-EXL3/tree/3.0bpw_H6) | 3.0 | 6 |
| [3.5_H6](https://huggingface.co/ArtusDev/arcee-ai_Homunculus-EXL3/tree/3.5bpw_H6) | 3.5 | 6 |
| [4.0_H6](https://huggingface.co/ArtusDev/arcee-ai_Homunculus-EXL3/tree/4.0bpw_H6) | 4.0 | 6 |
| [4.5_H6](https://huggingface.co/ArtusDev/arcee-ai_Homunculus-EXL3/tree/4.5bpw_H6) | 4.5 | 6 |
| [5.0_H6](https://huggingface.co/ArtusDev/arcee-ai_Homunculus-EXL3/tree/5.0bpw_H6) | 5.0 | 6 |
| [6.0_H6](https://huggingface.co/ArtusDev/arcee-ai_Homunculus-EXL3/tree/6.0bpw_H6) | 6.0 | 6 |
| [8.0_H6](https://huggingface.co/ArtusDev/arcee-ai_Homunculus-EXL3/tree/8.0bpw_H6) | 8.0 | 6 |
| [8.0_H8](https://huggingface.co/ArtusDev/arcee-ai_Homunculus-EXL3/tree/8.0bpw_H8) | 8.0 | 8 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/arcee-ai_Homunculus-EXL3 --revision "5.0bpw_H6" --local-dir ./
```
</details>
|
ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2
|
ArtusDev
| 2025-06-17T05:36:38Z | 22 | 0 |
transformers
|
[
"transformers",
"elarablated",
"elarablate",
"slop",
"finetune",
"exl2",
"base_model:e-n-v-y/Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf",
"base_model:quantized:e-n-v-y/Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf",
"license:llama3.3",
"endpoints_compatible",
"region:us"
] | null | 2025-06-01T11:11:27Z |
---
base_model: e-n-v-y/Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf
base_model_relation: quantized
quantized_by: ArtusDev
library_name: transformers
license: llama3.3
tags:
- elarablated
- elarablate
- slop
- finetune
- exl2
---
## EXL2 Quants of e-n-v-y/Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf
EXL2 quants of [e-n-v-y/Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf](https://huggingface.co/e-n-v-y/Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf) using <a href="https://github.com/turboderp-org/exllamav2/">exllamav2</a> for quantization.
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [2.5_H6](https://huggingface.co/ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2/tree/2.5bpw_H6) | 2.5 | 6 |
| [3.0_H6](https://huggingface.co/ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2/tree/3.0bpw_H6) | 3.0 | 6 |
| [3.5_H6](https://huggingface.co/ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2/tree/3.5bpw_H6) | 3.5 | 6 |
| [4.0_H6](https://huggingface.co/ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2/tree/4.0bpw_H6) | 4.0 | 6 |
| [4.5_H6](https://huggingface.co/ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2/tree/4.5bpw_H6) | 4.5 | 6 |
| [5.0_H6](https://huggingface.co/ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2/tree/5.0bpw_H6) | 5.0 | 6 |
| [6.0_H6](https://huggingface.co/ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2/tree/6.0bpw_H6) | 6.0 | 6 |
| [8.0_H6](https://huggingface.co/ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2/tree/8.0bpw_H6) | 8.0 | 6 |
| [8.0_H8](https://huggingface.co/ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2/tree/8.0bpw_H8) | 8.0 | 8 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/e-n-v-y_Legion-V2.1-LLaMa-70B-Elarablated-v0.8-hf-EXL2 --revision "5.0bpw_H6" --local-dir ./
```
</details>
|
ArtusDev/TareksTesting_Scripturient-V1.0-LLaMa-70B-EXL3
|
ArtusDev
| 2025-06-17T05:36:18Z | 2 | 0 |
transformers
|
[
"transformers",
"mergekit",
"merge",
"exl3",
"base_model:TareksTesting/Scripturient-V1.0-LLaMa-70B",
"base_model:quantized:TareksTesting/Scripturient-V1.0-LLaMa-70B",
"license:llama3.3",
"endpoints_compatible",
"region:us"
] | null | 2025-05-31T15:51:31Z |
---
base_model: TareksTesting/Scripturient-V1.0-LLaMa-70B
base_model_relation: quantized
quantized_by: ArtusDev
library_name: transformers
license: llama3.3
tags:
- mergekit
- merge
- exl3
---
## EXL3 Quants of TareksTesting/Scripturient-V1.0-LLaMa-70B
EXL3 quants of [TareksTesting/Scripturient-V1.0-LLaMa-70B](https://huggingface.co/TareksTesting/Scripturient-V1.0-LLaMa-70B) using <a href="https://github.com/turboderp-org/exllamav3/">exllamav3</a> for quantization.
### Quants
| Quant(Revision) | Bits per Weight | Head Bits |
| -------- | ---------- | --------- |
| [3.5_H6](https://huggingface.co/ArtusDev/TareksTesting_Scripturient-V1.0-LLaMa-70B-EXL3/tree/3.5bpw_H6) | 3.5 | 6 |
### Downloading quants with huggingface-cli
<details>
<summary>Click to view download instructions</summary>
Install hugginface-cli:
```bash
pip install -U "huggingface_hub[cli]"
```
Download quant by targeting the specific quant revision (branch):
```
huggingface-cli download ArtusDev/TareksTesting_Scripturient-V1.0-LLaMa-70B-EXL3 --revision "5.0bpw_H6" --local-dir ./
```
</details>
|
mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF
|
mradermacher
| 2025-06-17T05:35:55Z | 1 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:Novokshanov/Qwen2.5-0.5B-ParaForge-v0.1",
"base_model:quantized:Novokshanov/Qwen2.5-0.5B-ParaForge-v0.1",
"license:apache-2.0",
"endpoints_compatible",
"region:us",
"conversational"
] | null | 2025-03-17T22:48:30Z |
---
base_model: Novokshanov/Qwen2.5-0.5B-ParaForge-v0.1
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Novokshanov/Qwen2.5-0.5B-ParaForge-v0.1
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q3_K_S.gguf) | Q3_K_S | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q2_K.gguf) | Q2_K | 0.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.IQ4_XS.gguf) | IQ4_XS | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q3_K_M.gguf) | Q3_K_M | 0.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q3_K_L.gguf) | Q3_K_L | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q4_K_S.gguf) | Q4_K_S | 0.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q4_K_M.gguf) | Q4_K_M | 0.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q5_K_S.gguf) | Q5_K_S | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q5_K_M.gguf) | Q5_K_M | 0.5 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q6_K.gguf) | Q6_K | 0.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.Q8_0.gguf) | Q8_0 | 0.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2.5-0.5B-ParaForge-v0.1-GGUF/resolve/main/Qwen2.5-0.5B-ParaForge-v0.1.f16.gguf) | f16 | 1.1 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64-new-grpo-r32
|
erdem-erdem
| 2025-06-17T05:35:44Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64",
"base_model:finetune:erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T05:34:12Z |
---
base_model: erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** erdem-erdem
- **License:** apache-2.0
- **Finetuned from model :** erdem-erdem/Qwen2.5-3B-Instruct-countdown-game-8k-qwq-r64
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Tsegayesemere/Tigrigna-emotion-analysis-xlm-r
|
Tsegayesemere
| 2025-06-17T05:30:55Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T05:30:46Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Mano-Official-Viral-Videos/Original.Full.Clip.cute.mano.Viral.Video.Leaks.Official
|
Mano-Official-Viral-Videos
| 2025-06-17T05:26:38Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-17T05:26:29Z |
<a href="https://sdu.sk/uLf"><img src="https://i.ibb.co.com/xMMVF88/686577567.gif" alt="fsd" /></a>
<a href="https://sdu.sk/uLf" rel="nofollow">►✅ 𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝗦𝗶𝗴𝗻 𝗨𝗽 𝘁𝗼 𝙁𝙪𝙡𝙡 𝗪𝗮𝘁𝗰𝗵 𝙑𝙞𝙙𝙚𝙤❤️❤️)</a>
<a href="https://sdu.sk/uLf" rel="nofollow">🔴 ➤►✅𝘾𝙇𝙄𝘾𝙆 𝙃𝙀𝙍𝙀 ==►► (𝐅𝐮𝐥𝐥 𝐯𝐢𝐝𝐞𝐨 𝐥𝐢𝐧𝐤)</a>
|
VIDEOS-18-Mezzo-fun-Viral-Video/FULL.VIDEO.Mezzo.fun.Viral.Video.Tutorial.Official
|
VIDEOS-18-Mezzo-fun-Viral-Video
| 2025-06-17T05:19:24Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-17T05:19:05Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
dgambettaphd/M_llm2_run2_gen6_WXS_doc1000_synt64_lr1e-04_acm_SYNLAST
|
dgambettaphd
| 2025-06-17T05:18:51Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T05:18:38Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Scandal-mezzo-fun-video-mezzo-fun-meezo-fa/FULL.VIDEO.Scandal.mezzo.fun.video.mezzo.fun.meezo.fan
|
Scandal-mezzo-fun-video-mezzo-fun-meezo-fa
| 2025-06-17T04:55:52Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-17T04:55:43Z |
01 seconds ago
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶](https://sahabagi-mgi.blogspot.com/p/heres-now.html)
[🌐 𝖢𝖫𝖨𝖢𝖪 𝖧𝖤𝖱𝖤 🟢==►► 𝖶𝖠𝖳𝖢𝖧 𝖭𝖮𝖶 FREE](https://sahabagi-mgi.blogspot.com/p/heres-now.html)
<a href="https://sahabagi-mgi.blogspot.com/p/heres-now.html" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="WATCH Videos" data-canonical-src="https://i.imgur.com/dJHk4Zq.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
Ashkh0099/fine-tune-ALBERT-FINAL
|
Ashkh0099
| 2025-06-17T04:38:28Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"albert",
"question-answering",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] |
question-answering
| 2025-06-17T03:03:44Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
parlange/deit-autoscan
|
parlange
| 2025-06-17T04:37:29Z | 43 | 0 |
timm
|
[
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:parlange/dark-energy-survey-supernova",
"base_model:timm/deit_base_patch16_224.fb_in1k",
"base_model:finetune:timm/deit_base_patch16_224.fb_in1k",
"region:us"
] |
image-classification
| 2025-06-11T07:30:01Z |
---
tags:
- image-classification
- timm
- pytorch
- safetensors
library_name: timm
datasets:
- parlange/dark-energy-survey-supernova
base_model:
- timm/deit_base_patch16_224.fb_in1k
---
# DeiT Model (deit_base_patch16_224)
This repository contains a fine-tuned `DeiT` model from the `timm` library, intended for binary image classification.
The model weights are available in both standard PyTorch (`.bin`) and SafeTensors (`.safetensors`) formats.
## Model Details
* **Architecture**: `deit_base_patch16_224`
* **Original Library**: `timm`
* **Fine-tuning Task**: Binary Image Classification
* **Number of Classes**: 2
---
## Training Hyperparameters
The model was trained with the following settings:
| Hyperparameter | Value |
|:--------------------------|:------------------------------------------|
| Optimizer | `AdamW` |
| Learning Rate Schedule | `1e-4 with CosineLRScheduler` |
| Batch Size | `128` |
| Total Epochs | `20` |
| Early Stopping Patience | `7` on validation loss |
| Loss Function | CrossEntropyLoss w/ Label Smoothing (`0.1`) |
---
## Training Results
Here are the key **test** metrics for this model:
* **Test Accuracy**: 0.986
* **Test AUC**: 0.992
* **Test F1 Score**: 0.986
* **Best Epoch**: 18.000
---
## How to use with `timm`
You can load this model directly from the Hugging Face Hub using `timm.create_model`. The `config.json` in this repo provides all necessary metadata.
```python
import torch
import timm
# Ensure you have timm and huggingface_hub installed:
# pip install timm "huggingface_hub>=0.23.0"
# Load the model directly from the Hub
# The `pretrained=True` flag will download the weights and config automatically.
model = timm.create_model(
'hf-hub:parlange/deit-autoscan',
pretrained=True
)
model.eval()
# The model's default_cfg will now be populated with mean/std and input size
print(model.default_cfg)
# Example inference with a dummy input
dummy_input = torch.randn(1, 3, model.default_cfg['input_size'][-2], model.default_cfg['input_size'][-1])
with torch.no_grad():
output = model(dummy_input)
print(f"Output shape: {output.shape}") # Should be torch.Size([1, 2])
print(f"Predictions: {torch.softmax(output, dim=1)}")
```
---
## Original Checkpoint
The original `.pth` checkpoint file used for this model is also available in this repository.
|
thanhtonvk/tu_vi_qwen3b
|
thanhtonvk
| 2025-06-17T04:25:34Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T04:17:29Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
namdp-ptit/LLamaEE-8B-Instruct-ZeroShot
|
namdp-ptit
| 2025-06-17T04:22:43Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"transformer",
"classification",
"token-classification",
"en",
"base_model:unsloth/Meta-Llama-3.1-8B-Instruct",
"base_model:finetune:unsloth/Meta-Llama-3.1-8B-Instruct",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
token-classification
| 2025-06-17T03:56:06Z |
---
license: apache-2.0
language:
- en
base_model:
- unsloth/Meta-Llama-3.1-8B-Instruct
pipeline_tag: token-classification
library_name: transformers
tags:
- transformer
- classification
---
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained('namdp-ptit/LLamaEE-8B-Instruct-ZeroShot')
model = AutoModelForCausalLM.from_pretrained(
'namdp-ptit/LLamaEE-8B-Instruct-ZeroShot',
torch_dtype="auto",
device_map="cuda",
)
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
model.config.pad_token_id = model.config.eos_token_id
user_prompt = """
Extract events and their components from text **strictly using ONLY the provided Event List** below and **MUST** strictly adhere to the output format.
Format output as '<event_type>: <trigger_word> | <role1>: <argument1> | <role2>: <argument2>' and separate multiple events with '|'. Return 'None' if no events are identified.
Event List: {ee_labels}
Text: {text}
"""
query = 'Drug-induced fever due to diltiazem'
ee_labels = ["adverse even", "potential therapeutic event", "Treatment.Drug", "Treatment.Route,Subject.Disorder", "Treatment.Freq", "Treatment", "Effect"]
user_prompt = user_prompt.format(ee_labels=ee_labels, text=query)
messages = [
{
"role": "system",
"content": "You are an expert in Event Extraction (EE) task."
},
{
"role": "user",
"content": user_prompt
}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer(text, return_tensors="pt").to(model.device)
generated_ids = model.generate(
**model_inputs,
max_new_tokens=512,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response) # Organization based in: Hakawati Theatre, Jerusalem
```
## Contact
**Email**: [email protected]
**LinkedIn**: [Dang Phuong Nam](https://www.linkedin.com/in/dang-phuong-nam-157912288/)
**Facebook**: [Phương Nam](https://www.facebook.com/phuong.namdang.7146557)
## Support The Project
If you find this project helpful and wish to support its ongoing development, here are some ways you can contribute:
1. **Star the Repository**: Show your appreciation by starring the repository. Your support motivates further
development
and enhancements.
2. **Contribute**: We welcome your contributions! You can help by reporting bugs, submitting pull requests, or
suggesting new features.
3. **Donate**: If you’d like to support financially, consider making a donation. You can donate through:
- Vietcombank: 9912692172 - DANG PHUONG NAM
Thank you for your support!
## Citation
Please cite as
```Plaintext
@misc{LlamaEE-8B-Instruct-ZeroShot,
title={LlamaEE: An Large Language Model for Event Extraction},
author={Nam Dang Phuong},
year={2025},
publisher={Huggingface},
}
```
|
deb101/mistral-7b-instruct-v0.3-mimic4-adapt-l2r-multilabel-plantclassify
|
deb101
| 2025-06-17T04:19:32Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"ltr_model",
"generated_from_trainer",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"base_model:quantized:mistralai/Mistral-7B-Instruct-v0.3",
"license:apache-2.0",
"endpoints_compatible",
"4-bit",
"bitsandbytes",
"region:us"
] | null | 2025-06-12T21:54:48Z |
---
library_name: transformers
license: apache-2.0
base_model: mistralai/Mistral-7B-Instruct-v0.3
tags:
- generated_from_trainer
model-index:
- name: mistral-7b-instruct-v0.3-mimic4-adapt-l2r-multilabel-plantclassify
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# mistral-7b-instruct-v0.3-mimic4-adapt-l2r-multilabel-plantclassify
This model is a fine-tuned version of [mistralai/Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3) on the None dataset.
It achieves the following results on the evaluation set:
- F1 Micro: 0.0173
- F1 Macro: 0.0083
- Precision At 5: 0.4191
- Recall At 5: 0.0999
- Precision At 8: 0.3571
- Recall At 8: 0.1335
- Precision At 15: 0.2744
- Recall At 15: 0.1864
- Rare F1 Micro: 0.0097
- Rare F1 Macro: 0.0063
- Rare Precision: 0.0049
- Rare Recall: 0.6434
- Rare Precision At 5: 0.1862
- Rare Recall At 5: 0.0670
- Rare Precision At 8: 0.1513
- Rare Recall At 8: 0.0868
- Rare Precision At 15: 0.1107
- Rare Recall At 15: 0.1172
- Not Rare F1 Micro: 0.1361
- Not Rare F1 Macro: 0.1312
- Not Rare Precision: 0.0730
- Not Rare Recall: 0.9997
- Not Rare Precision At 5: 0.4268
- Not Rare Recall At 5: 0.2761
- Not Rare Precision At 8: 0.3573
- Not Rare Recall At 8: 0.3544
- Not Rare Precision At 15: 0.2682
- Not Rare Recall At 15: 0.4784
- Loss: -2.5098
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0001
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 32
- optimizer: Use adamw_torch with betas=(0.9,0.999) and epsilon=1e-08 and optimizer_args=No additional optimizer arguments
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 50
- num_epochs: 5
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | F1 Micro | F1 Macro | Precision At 5 | Recall At 5 | Precision At 8 | Recall At 8 | Precision At 15 | Recall At 15 | Rare F1 Micro | Rare F1 Macro | Rare Precision | Rare Recall | Rare Precision At 5 | Rare Recall At 5 | Rare Precision At 8 | Rare Recall At 8 | Rare Precision At 15 | Rare Recall At 15 | Not Rare F1 Micro | Not Rare F1 Macro | Not Rare Precision | Not Rare Recall | Not Rare Precision At 5 | Not Rare Recall At 5 | Not Rare Precision At 8 | Not Rare Recall At 8 | Not Rare Precision At 15 | Not Rare Recall At 15 | Validation Loss |
|:-------------:|:------:|:----:|:--------:|:--------:|:--------------:|:-----------:|:--------------:|:-----------:|:---------------:|:------------:|:-------------:|:-------------:|:--------------:|:-----------:|:-------------------:|:----------------:|:-------------------:|:----------------:|:--------------------:|:-----------------:|:-----------------:|:-----------------:|:------------------:|:---------------:|:-----------------------:|:--------------------:|:-----------------------:|:--------------------:|:------------------------:|:---------------------:|:---------------:|
| -2.7793 | 0.9981 | 262 | 0.0114 | 0.0060 | 0.3790 | 0.0897 | 0.3251 | 0.1194 | 0.2546 | 0.1696 | 0.0065 | 0.0040 | 0.0033 | 0.7152 | 0.1317 | 0.0472 | 0.1068 | 0.0602 | 0.0780 | 0.0804 | 0.1354 | 0.1308 | 0.0726 | 1.0 | 0.3727 | 0.2367 | 0.3162 | 0.3110 | 0.2446 | 0.4322 | -2.3806 |
| -3.0203 | 1.9981 | 524 | 0.0143 | 0.0070 | 0.4135 | 0.0996 | 0.3589 | 0.1343 | 0.2777 | 0.1888 | 0.0082 | 0.0050 | 0.0041 | 0.6913 | 0.1803 | 0.0641 | 0.1481 | 0.0829 | 0.1086 | 0.1116 | 0.1356 | 0.1309 | 0.0728 | 0.9999 | 0.3987 | 0.2581 | 0.3407 | 0.3388 | 0.2602 | 0.4678 | -2.4964 |
| -3.2253 | 2.9981 | 786 | 0.0122 | 0.0069 | 0.4385 | 0.1062 | 0.3724 | 0.1403 | 0.2868 | 0.1941 | 0.0071 | 0.0050 | 0.0036 | 0.7429 | 0.1983 | 0.0713 | 0.1572 | 0.0898 | 0.1142 | 0.1200 | 0.1355 | 0.1308 | 0.0727 | 1.0 | 0.4206 | 0.2727 | 0.3544 | 0.3536 | 0.2707 | 0.4839 | -2.5382 |
| -3.5758 | 3.9981 | 1048 | 0.0166 | 0.0082 | 0.4336 | 0.1040 | 0.3683 | 0.1379 | 0.2819 | 0.1919 | 0.0094 | 0.0062 | 0.0047 | 0.6661 | 0.1956 | 0.0704 | 0.1583 | 0.0905 | 0.1155 | 0.1224 | 0.1358 | 0.1310 | 0.0728 | 0.9999 | 0.4260 | 0.2760 | 0.3564 | 0.3548 | 0.2686 | 0.4780 | -2.5326 |
| -3.9755 | 4.9981 | 1310 | 0.0173 | 0.0083 | 0.4191 | 0.0999 | 0.3571 | 0.1335 | 0.2744 | 0.1864 | 0.0097 | 0.0063 | 0.0049 | 0.6434 | 0.1862 | 0.0670 | 0.1513 | 0.0868 | 0.1107 | 0.1172 | 0.1361 | 0.1312 | 0.0730 | 0.9997 | 0.4268 | 0.2761 | 0.3573 | 0.3544 | 0.2682 | 0.4784 | -2.5098 |
### Framework versions
- Transformers 4.49.0
- Pytorch 2.6.0
- Datasets 3.6.0
- Tokenizers 0.21.1
|
Yumikooo/llm-jp-3-13b-itA_lora
|
Yumikooo
| 2025-06-17T03:54:00Z | 0 | 0 | null |
[
"safetensors",
"region:us"
] | null | 2024-12-16T08:36:47Z |
<!---
base_model: llm-jp/llm-jp-3-13b
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- trl
license: apache-2.0
language:
- ja
-->
# llm-jp-3-13b-itA_lora
## プロジェクト背景
本モデルは、東京大学大学院 松尾研究室主催「大規模言語モデル講座」の最終課題として開発されました。
ELYZA-tasks-100-TV(Ichikara Instruction)に基づく日本語の指示応答タスクに特化し、
LoRAアダプタと4bit量子化(QLoRA)を活用することで、軽量かつ高性能なモデルを実現しています。
## モデルの概要
このモデルは、Hugging Faceの大規模日本語モデル「llm-jp-3-13b」をベースに、
UnslothおよびLoRAを用いた効率的なFine-Tuningを行い、日本語での自然な指示応答に最適化されています。
Ichikara Instruction(ELYZA-tasks-100-TV)の一部タスクに対応した応答生成能力を備え、
研究や応用開発における再現性の高い出力が得られます。
- **開発者:** Yumikooo
- **ライセンス:** Apache-2.0
- **ベースモデル:** llm-jp/llm-jp-3-13b
> ※ 本モデルは、UnslothとHugging FaceのTRLライブラリを使用することで、従来の手法に比べて約2倍の高速トレーニングを実現しています。
## モデルの特長
- **タスク特化型**
ELYZA-tasks-100-TV(Ichikara Instruction)をもとに、日本語指示文に対する自然な応答生成を最適化。
- **軽量・高速推論**
4bit量子化(QLoRA)により、GPUメモリ使用量を抑えつつ、効率的な推論を実現。
- **柔軟な拡張性**
LoRAによるアダプタ構造を採用し、ベースモデルの性能を維持しながら高速なFine-Tuningが可能。
- **再現性の担保**
推論スクリプト・出力例(JSONL形式)・環境構築手順をすべて公開。
- **日本語対応**
大規模日本語モデル(llm-jp-3-13b)を基盤とし、自然な日本語での指示応答が可能。
## 推論出力ファイル
ELYZA-tasks-100-TVの一部タスクに対する推論結果:
- ファイル名: `llm-jp-3-13b-itA_lora_outputABC.jsonl`
- 実行結果の一部をJSONL形式で提供
## インストール方法
必要なライブラリをインストールしてください:
```bash
pip install unsloth
pip uninstall unsloth -y && pip install --upgrade --no-cache-dir "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
pip install -U torch
pip install -U peft
pip install evaluate
pip install rouge_score
```
## 使用方法
### モデルのロード
```python
from unsloth import FastLanguageModel
from peft import PeftModel
import torch
import os
# モデルの基本設定
model_id = "llm-jp/llm-jp-3-13b"
adapter_id = "Yumikooo/llm-jp-3-13b-itA_lora"
# Hugging Faceトークンの設定(以下のいずれかの方法を使用)
# 方法1: 環境変数から読み込み(推奨)
HF_TOKEN = os.getenv("HF_TOKEN")
# 方法2: 直接指定する場合(注意:公開リポジトリでは使用しないでください)
# HF_TOKEN = "hf_xxxxxxxxxxxxxxxxxxxxxxxxxx" # 実際のトークンに置き換え
# モデルのロード
dtype = None
load_in_4bit = True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name=model_id,
dtype=dtype,
load_in_4bit=load_in_4bit,
trust_remote_code=True,
)
model = PeftModel.from_pretrained(model, adapter_id, token=HF_TOKEN)
```
### データセットの読み込み
```python
import json
# ELYZA-tasks-100-TVのJSONLデータセットを読み込み
datasets = []
file_path = "path/to/your/elyza-tasks-100-TV_0.jsonl"
with open(file_path, 'r', encoding='utf-8') as f:
for line in f:
datasets.append(json.loads(line.strip()))
```
### 推論の実行
```python
from tqdm import tqdm
# モデルを推論モードに変更
FastLanguageModel.for_inference(model)
# 推論実行
results = []
for dt in tqdm(datasets):
input_text = dt["input"]
prompt = f"""### 指示
{input_text}
### 回答
"""
inputs = tokenizer([prompt], return_tensors="pt").to(model.device)
outputs = model.generate(
**inputs,
max_new_tokens=512,
use_cache=True,
do_sample=False,
repetition_penalty=1.2
)
prediction = tokenizer.decode(outputs[0], skip_special_tokens=True).split('\n### 回答')[-1]
results.append({
"task_id": dt["task_id"],
"input": input_text,
"output": prediction
})
```
### 結果の保存
```python
# 推論結果を保存
output_path = "llm-jp-3-13b-itA_lora_outputABC.jsonl"
with open(output_path, 'w', encoding='utf-8') as f:
for result in results:
json.dump(result, f, ensure_ascii=False)
f.write('\n')
print(f"推論結果が保存されました: {output_path}")
```
## 注意事項
### Hugging Faceトークンの取得と設定
1. **トークンの取得**
- [Hugging Face Settings](https://huggingface.co/settings/tokens)にアクセス
- 「New token」をクリック
- 名前を入力し、「Read」権限を選択
- 生成されたトークンをコピー(`hf_`で始まる文字列)
2. **トークンの設定方法**
**推奨方法(環境変数):**
```bash
# ターミナルで以下を実行
export HF_TOKEN="hf_あなたの実際のトークン"
```
**Google Colabの場合:**
```python
import os
from google.colab import userdata
# Colabのシークレット機能を使用
HF_TOKEN = userdata.get('HF_TOKEN')
```
3. **セキュリティ上の注意**
- トークンを直接コードに書かない
- GitHubなどに公開する際は環境変数を使用
- トークンが漏洩した場合は、すぐに再生成する
### その他の注意事項
- メモリ使用量を考慮して、必要に応じて`load_in_4bit=True`を設定してください
- 大きなモデルを扱う際は、十分なGPUメモリがあることを確認してください
## ライセンス
このモデルはApache-2.0ライセンスの下で公開されています。
|
hafidhsoekma/gasing-edu-16bit
|
hafidhsoekma
| 2025-06-17T03:52:57Z | 389 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"text-generation-inference",
"unsloth",
"conversational",
"en",
"base_model:unsloth/Qwen2.5-7B-Instruct-unsloth-bnb-4bit",
"base_model:finetune:unsloth/Qwen2.5-7B-Instruct-unsloth-bnb-4bit",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-12T14:25:58Z |
---
base_model: unsloth/Qwen2.5-7B-Instruct-unsloth-bnb-4bit
tags:
- text-generation-inference
- transformers
- unsloth
- qwen2
license: apache-2.0
language:
- en
---
# Uploaded finetuned model
- **Developed by:** hafidhsoekma
- **License:** apache-2.0
- **Finetuned from model :** unsloth/Qwen2.5-7B-Instruct-unsloth-bnb-4bit
This qwen2 model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Sharing22/ilu_c4
|
Sharing22
| 2025-06-17T03:42:56Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"llama",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T03:40:01Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
keras/qwen2.5_instruct_32b_en
|
keras
| 2025-06-17T03:24:57Z | 0 | 0 |
keras-hub
|
[
"keras-hub",
"text-generation",
"region:us"
] |
text-generation
| 2025-06-17T01:49:00Z |
---
library_name: keras-hub
pipeline_tag: text-generation
---
### Model Overview
# Model Summary
Qwen2.5 is the latest series of Qwen large language models. For Qwen2.5, the Qwen team released a number of base language models and instruction-tuned language models ranging from 0.5 to 72 billion parameters.
## Qwen2.5 brings the following improvements upon Qwen2:
* Significantly more knowledge and has greatly improved capabilities in coding and mathematics, thanks to our specialized expert models in these domains.
* Significant improvements in instruction following, generating long texts (over 8K tokens), understanding structured data (e.g, tables), and generating structured outputs especially JSON. More resilient to the diversity of system prompts, enhancing role-play implementation and condition-setting for chatbots.
* Long-context Support up to 128K tokens and can generate up to 8K tokens.
* Multilingual support for over 29 languages, including Chinese, English, French, Spanish, Portuguese, German, Italian, Russian, Japanese, Korean, Vietnamese, Thai, Arabic, and more.
For more details, please refer to Qwen [Blog](https://qwenlm.github.io/blog/qwen2.5/), [GitHub](https://github.com/keras-team/keras-hub/tree/master/keras_hub/src/models/qwen), and [Documentation](https://qwen.readthedocs.io/en/latest/).
Weights are released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE) . Keras model code is released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE).
## Links
* [Qwen 2.5 Quickstart Notebook](https://www.kaggle.com/code/laxmareddypatlolla/qwen-quickstart-notebook)
* [Qwen 2.5 API Documentation](https://keras.io/keras_hub/api/models/qwen/)
* [Qwen 2.5 Model Card](https://qwenlm.github.io/blog/qwen2.5/)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instructions on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|---------------------------------------|------------|--------------------------------------------------------------------------------------------------------------|
| qwen2.5_0.5b_en | 0.5B | 24-layer Qwen model with 0.5 billion parameters. |
| qwen2.5_3b_en | 3.1B | 36-layer Qwen model with 3.1 billion parameters. |
| qwen2.5_7b_en | 7B | 48-layer Qwen model with 7 billion parameters. |
| qwen2.5_instruct_0.5b_en | 0.5B | Instruction fine-tuned 24-layer Qwen model with 0.5 billion parameters. |
| qwen2.5_instruct_32b_en | 32B | Instruction fine-tuned 64-layer Qwen model with 32 billion parameters. |
| qwen2.5_instruct_72b_en | 72B | Instruction fine-tuned 80-layer Qwen model with 72 billion parameters. |
## Example Usage
```Python
import keras
import keras_hub
import numpy as np
# Use generate() to do text generation.
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset("qwen2.5_instruct_32b_en")
qwen_lm.generate("I want to say", max_length=30)
# Generate with batched prompts.
qwen_lm.generate(["This is a", "Where are you"], max_length=30)
# Compile the generate() function with a custom sampler.
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset("qwen2.5_instruct_32b_en")
qwen_lm.compile(sampler="greedy")
qwen_lm.generate("I want to say", max_length=30)
qwen_lm.compile(sampler=keras_hub.samplers.BeamSampler(num_beams=2))
qwen_lm.generate("I want to say", max_length=30)
# Use generate() without preprocessing.
# Prompt the model with `15191, 374` (the token ids for `"Who is"`).
# Use `"padding_mask"` to indicate values that should not be overridden.
prompt = {
"token_ids": np.array([[15191, 374, 0, 0, 0]] * 2),
"padding_mask": np.array([[1, 1, 0, 0, 0]] * 2),
}
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset(
"qwen2.5_instruct_32b_en",
preprocessor=None,
)
qwen_lm.generate(prompt)
# Call fit() on a single batch.
features = ["The quick brown fox jumped.", "I forgot my homework."]
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset("qwen2.5_instruct_32b_en")
qwen_lm.fit(x=features, batch_size=2)
# Call fit() without preprocessing.
x = {
"token_ids": np.array([[1, 2, 3, 4, 5]] * 2),
"padding_mask": np.array([[1, 1, 1, 1, 1]] * 2),
}
y = np.array([[2, 3, 4, 5, 0]] * 2)
sw = np.array([[1, 1, 1, 1, 1]] * 2)
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset(
"qwen2.5_instruct_32b_en",
preprocessor=None,
)
qwen_lm.fit(x=x, y=y, sample_weight=sw, batch_size=2)
```
## Example Usage with Hugging Face URI
```Python
import keras
import keras_hub
import numpy as np
# Use generate() to do text generation.
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset("hf://keras/qwen2.5_instruct_32b_en")
qwen_lm.generate("I want to say", max_length=30)
# Generate with batched prompts.
qwen_lm.generate(["This is a", "Where are you"], max_length=30)
# Compile the generate() function with a custom sampler.
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset("hf://keras/qwen2.5_instruct_32b_en")
qwen_lm.compile(sampler="greedy")
qwen_lm.generate("I want to say", max_length=30)
qwen_lm.compile(sampler=keras_hub.samplers.BeamSampler(num_beams=2))
qwen_lm.generate("I want to say", max_length=30)
# Use generate() without preprocessing.
# Prompt the model with `15191, 374` (the token ids for `"Who is"`).
# Use `"padding_mask"` to indicate values that should not be overridden.
prompt = {
"token_ids": np.array([[15191, 374, 0, 0, 0]] * 2),
"padding_mask": np.array([[1, 1, 0, 0, 0]] * 2),
}
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset(
"hf://keras/qwen2.5_instruct_32b_en",
preprocessor=None,
)
qwen_lm.generate(prompt)
# Call fit() on a single batch.
features = ["The quick brown fox jumped.", "I forgot my homework."]
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset("hf://keras/qwen2.5_instruct_32b_en")
qwen_lm.fit(x=features, batch_size=2)
# Call fit() without preprocessing.
x = {
"token_ids": np.array([[1, 2, 3, 4, 5]] * 2),
"padding_mask": np.array([[1, 1, 1, 1, 1]] * 2),
}
y = np.array([[2, 3, 4, 5, 0]] * 2)
sw = np.array([[1, 1, 1, 1, 1]] * 2)
qwen_lm = keras_hub.models.Qwen2CausalLM.from_preset(
"hf://keras/qwen2.5_instruct_32b_en",
preprocessor=None,
)
qwen_lm.fit(x=x, y=y, sample_weight=sw, batch_size=2)
```
|
khaangnguyeen/static-bge-code-v1-st
|
khaangnguyeen
| 2025-06-17T03:24:42Z | 0 | 0 |
model2vec
|
[
"model2vec",
"safetensors",
"embeddings",
"static-embeddings",
"sentence-transformers",
"zh",
"en",
"base_model:BAAI/bge-code-v1",
"base_model:finetune:BAAI/bge-code-v1",
"license:mit",
"region:us"
] | null | 2025-06-17T03:14:22Z |
---
base_model: BAAI/bge-code-v1
language:
- zh
- en
library_name: model2vec
license: mit
model_name: bge_static_512d
tags:
- embeddings
- static-embeddings
- sentence-transformers
---
# bge_static_512d Model Card
This [Model2Vec](https://github.com/MinishLab/model2vec) model is a distilled version of the BAAI/bge-code-v1(https://huggingface.co/BAAI/bge-code-v1) Sentence Transformer. It uses static embeddings, allowing text embeddings to be computed orders of magnitude faster on both GPU and CPU. It is designed for applications where computational resources are limited or where real-time performance is critical. Model2Vec models are the smallest, fastest, and most performant static embedders available. The distilled models are up to 50 times smaller and 500 times faster than traditional Sentence Transformers.
## Installation
Install model2vec using pip:
```
pip install model2vec
```
## Usage
### Using Model2Vec
The [Model2Vec library](https://github.com/MinishLab/model2vec) is the fastest and most lightweight way to run Model2Vec models.
Load this model using the `from_pretrained` method:
```python
from model2vec import StaticModel
# Load a pretrained Model2Vec model
model = StaticModel.from_pretrained("khaangnguyeen/static-bge-code-v1-st")
# Compute text embeddings
embeddings = model.encode(["Example sentence"])
```
### Using Sentence Transformers
You can also use the [Sentence Transformers library](https://github.com/UKPLab/sentence-transformers) to load and use the model:
```python
from sentence_transformers import SentenceTransformer
# Load a pretrained Sentence Transformer model
model = SentenceTransformer("khaangnguyeen/static-bge-code-v1-st")
# Compute text embeddings
embeddings = model.encode(["Example sentence"])
```
### Distilling a Model2Vec model
You can distill a Model2Vec model from a Sentence Transformer model using the `distill` method. First, install the `distill` extra with `pip install model2vec[distill]`. Then, run the following code:
```python
from model2vec.distill import distill
# Distill a Sentence Transformer model, in this case the BAAI/bge-base-en-v1.5 model
m2v_model = distill(model_name="BAAI/bge-base-en-v1.5", pca_dims=256)
# Save the model
m2v_model.save_pretrained("m2v_model")
```
## How it works
Model2vec creates a small, fast, and powerful model that outperforms other static embedding models by a large margin on all tasks we could find, while being much faster to create than traditional static embedding models such as GloVe. Best of all, you don't need any data to distill a model using Model2Vec.
It works by passing a vocabulary through a sentence transformer model, then reducing the dimensionality of the resulting embeddings using PCA, and finally weighting the embeddings using [SIF weighting](https://openreview.net/pdf?id=SyK00v5xx). During inference, we simply take the mean of all token embeddings occurring in a sentence.
## Additional Resources
- [Model2Vec Repo](https://github.com/MinishLab/model2vec)
- [Model2Vec Base Models](https://huggingface.co/collections/minishlab/model2vec-base-models-66fd9dd9b7c3b3c0f25ca90e)
- [Model2Vec Results](https://github.com/MinishLab/model2vec/tree/main/results)
- [Model2Vec Tutorials](https://github.com/MinishLab/model2vec/tree/main/tutorials)
- [Website](https://minishlab.github.io/)
## Library Authors
Model2Vec was developed by the [Minish Lab](https://github.com/MinishLab) team consisting of [Stephan Tulkens](https://github.com/stephantul) and [Thomas van Dongen](https://github.com/Pringled).
## Citation
Please cite the [Model2Vec repository](https://github.com/MinishLab/model2vec) if you use this model in your work.
```
@article{minishlab2024model2vec,
author = {Tulkens, Stephan and {van Dongen}, Thomas},
title = {Model2Vec: Fast State-of-the-Art Static Embeddings},
year = {2024},
url = {https://github.com/MinishLab/model2vec}
}
```
|
keras/mixtral_8_7b_en
|
keras
| 2025-06-17T03:24:12Z | 0 | 0 |
keras-hub
|
[
"keras-hub",
"region:us"
] | null | 2025-06-16T23:29:06Z |
---
library_name: keras-hub
---
### Model Overview
# Model Summary
Mistral is a set of large language models published by the Mistral AI team. The Mixtral-8x7B Large Language Model (LLM) is a pretrained generative Sparse Mixture of Experts. Both pre-trained and instruction tuned models are available with 7 billion activated parameters.
Weights are released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE) . Keras model code is released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE).
## Links
* [Mixtral Quickstart Notebook](https://www.kaggle.com/code/laxmareddypatlolla/mixtral-quickstart-notebook)
* [Mixtral API Documentation](https://keras.io/keras_hub/api/models/mixtral/)
* [Mixtral Model Card](https://mistral.ai/news/mixtral-of-experts)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instructions on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|---------------------------------------|------------|--------------------------------------------------------------------------------------------------------------|
| mixtral_8_7b_en | 7B | 32-layer Mixtral MoE model with 7 billion active parameters and 8 experts per MoE layer. |
| mixtral_8_instruct_7b_en | 7B | Instruction fine-tuned 32-layer Mixtral MoE model with 7 billion active parameters and 8 experts per MoE layer. |
## Example Usage
```Python
import keras
import keras_hub
import numpy as np
# Basic text generation
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset("mixtral_8_7b_en")
mixtral_lm.generate("[INST] What is Keras? [/INST]", max_length=500)
# Generate with batched prompts
mixtral_lm.generate([
"[INST] What is Keras? [/INST]",
"[INST] Give me your best brownie recipe. [/INST]"
], max_length=500)
# Using different sampling strategies
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset("mixtral_8_7b_en")
# Greedy sampling
mixtral_lm.compile(sampler="greedy")
mixtral_lm.generate("I want to say", max_length=30)
# Beam search
mixtral_lm.compile(
sampler=keras_hub.samplers.BeamSampler(
num_beams=2,
top_k_experts=2, # MoE-specific: number of experts to use per token
)
)
mixtral_lm.generate("I want to say", max_length=30)
# Generate without preprocessing
prompt = {
"token_ids": np.array([[1, 315, 947, 298, 1315, 0, 0, 0, 0, 0]] * 2),
"padding_mask": np.array([[1, 1, 1, 1, 1, 0, 0, 0, 0, 0]] * 2),
}
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset(
"mixtral_8_7b_en",
preprocessor=None,
dtype="bfloat16"
)
mixtral_lm.generate(
prompt,
num_experts=8, # Total number of experts per layer
top_k_experts=2, # Number of experts to use per token
router_aux_loss_coef=0.02 # Router auxiliary loss coefficient
)
# Training on a single batch
features = ["The quick brown fox jumped.", "I forgot my homework."]
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset(
"mixtral_8_7b_en",
dtype="bfloat16"
)
mixtral_lm.fit(
x=features,
batch_size=2,
router_aux_loss_coef=0.02 # MoE-specific: router training loss
)
# Training without preprocessing
x = {
"token_ids": np.array([[1, 315, 947, 298, 1315, 369, 315, 837, 0, 0]] * 2),
"padding_mask": np.array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0]] * 2),
}
y = np.array([[315, 947, 298, 1315, 369, 315, 837, 0, 0, 0]] * 2)
sw = np.array([[1, 1, 1, 1, 1, 1, 1, 0, 0, 0]] * 2)
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset(
"mixtral_8_7b_en",
preprocessor=None,
dtype="bfloat16"
)
mixtral_lm.fit(
x=x,
y=y,
sample_weight=sw,
batch_size=2,
router_aux_loss_coef=0.02
)
```
## Example Usage with Hugging Face URI
```Python
import keras
import keras_hub
import numpy as np
# Basic text generation
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset("hf://keras/mixtral_8_7b_en")
mixtral_lm.generate("[INST] What is Keras? [/INST]", max_length=500)
# Generate with batched prompts
mixtral_lm.generate([
"[INST] What is Keras? [/INST]",
"[INST] Give me your best brownie recipe. [/INST]"
], max_length=500)
# Using different sampling strategies
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset("hf://keras/mixtral_8_7b_en")
# Greedy sampling
mixtral_lm.compile(sampler="greedy")
mixtral_lm.generate("I want to say", max_length=30)
# Beam search
mixtral_lm.compile(
sampler=keras_hub.samplers.BeamSampler(
num_beams=2,
top_k_experts=2, # MoE-specific: number of experts to use per token
)
)
mixtral_lm.generate("I want to say", max_length=30)
# Generate without preprocessing
prompt = {
"token_ids": np.array([[1, 315, 947, 298, 1315, 0, 0, 0, 0, 0]] * 2),
"padding_mask": np.array([[1, 1, 1, 1, 1, 0, 0, 0, 0, 0]] * 2),
}
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset(
"hf://keras/mixtral_8_7b_en",
preprocessor=None,
dtype="bfloat16"
)
mixtral_lm.generate(
prompt,
num_experts=8, # Total number of experts per layer
top_k_experts=2, # Number of experts to use per token
router_aux_loss_coef=0.02 # Router auxiliary loss coefficient
)
# Training on a single batch
features = ["The quick brown fox jumped.", "I forgot my homework."]
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset(
"hf://keras/mixtral_8_7b_en",
dtype="bfloat16"
)
mixtral_lm.fit(
x=features,
batch_size=2,
router_aux_loss_coef=0.02 # MoE-specific: router training loss
)
# Training without preprocessing
x = {
"token_ids": np.array([[1, 315, 947, 298, 1315, 369, 315, 837, 0, 0]] * 2),
"padding_mask": np.array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0]] * 2),
}
y = np.array([[315, 947, 298, 1315, 369, 315, 837, 0, 0, 0]] * 2)
sw = np.array([[1, 1, 1, 1, 1, 1, 1, 0, 0, 0]] * 2)
mixtral_lm = keras_hub.models.MixtralCausalLM.from_preset(
"hf://keras/mixtral_8_7b_en",
preprocessor=None,
dtype="bfloat16"
)
mixtral_lm.fit(
x=x,
y=y,
sample_weight=sw,
batch_size=2,
router_aux_loss_coef=0.02
)
```
|
keras/electra_large_generator_uncased_en
|
keras
| 2025-06-17T03:23:44Z | 15 | 0 |
keras-hub
|
[
"keras-hub",
"feature-extraction",
"region:us"
] |
feature-extraction
| 2024-10-28T22:33:51Z |
---
library_name: keras-hub
pipeline_tag: feature-extraction
---
### Model Overview
ELECTRA model is a pretraining approach for language models published by Google. Two transformer models are trained, a generator and a discriminator. The generator replaces tokens in a sequence and is trained as a masked language model. The discriminator is trained to discern what tokens have been replaced. This method of pretraining is more efficient than comparable methods like masked language modeling, especially for small models.
Weights are released under the [MIT License](https://opensource.org/license/mit). Keras model code is released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE).
## Links
* [ELECTRA API Documentation](https://keras.io/keras_hub/api/models/electra/)
* [ELECTRA Model Paper](https://openreview.net/pdf?id=r1xMH1BtvB)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instruction on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|---------------------------------------|------------|--------------------------------------------------------------------------------------------------------------|
| `electra_small_discriminator_uncased_en` | 13.55M | 12-layer small ELECTRA discriminator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_small_generator_uncased_en` | 13.55M | 12-layer small ELECTRA generator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_base_discriminator_uncased_en` | 109.48M | 12-layer base ELECTRA discriminator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_base_generator_uncased_en` | 33.58M | 12-layer base ELECTRA generator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_large_discriminator_uncased_en` | 335.14M | 24-layer large ELECTRA discriminator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_large_generator_uncased_en` | 51.07M | 24-layer large ELECTRA generator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
|
keras/electra_base_generator_uncased_en
|
keras
| 2025-06-17T03:23:42Z | 16 | 0 |
keras-hub
|
[
"keras-hub",
"feature-extraction",
"region:us"
] |
feature-extraction
| 2024-10-28T22:32:19Z |
---
library_name: keras-hub
pipeline_tag: feature-extraction
---
### Model Overview
ELECTRA model is a pretraining approach for language models published by Google. Two transformer models are trained, a generator and a discriminator. The generator replaces tokens in a sequence and is trained as a masked language model. The discriminator is trained to discern what tokens have been replaced. This method of pretraining is more efficient than comparable methods like masked language modeling, especially for small models.
Weights are released under the [MIT License](https://opensource.org/license/mit). Keras model code is released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE).
## Links
* [ELECTRA API Documentation](https://keras.io/keras_hub/api/models/electra/)
* [ELECTRA Model Paper](https://openreview.net/pdf?id=r1xMH1BtvB)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instruction on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|---------------------------------------|------------|--------------------------------------------------------------------------------------------------------------|
| `electra_small_discriminator_uncased_en` | 13.55M | 12-layer small ELECTRA discriminator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_small_generator_uncased_en` | 13.55M | 12-layer small ELECTRA generator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_base_discriminator_uncased_en` | 109.48M | 12-layer base ELECTRA discriminator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_base_generator_uncased_en` | 33.58M | 12-layer base ELECTRA generator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_large_discriminator_uncased_en` | 335.14M | 24-layer large ELECTRA discriminator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
| `electra_large_generator_uncased_en` | 51.07M | 24-layer large ELECTRA generator model. All inputs are lowercased. Trained on English Wikipedia + BooksCorpus. |
|
keras/vit_base_patch16_224_imagenet21k
|
keras
| 2025-06-17T03:23:02Z | 8 | 0 |
keras-hub
|
[
"keras-hub",
"arxiv:2010.11929",
"region:us"
] | null | 2024-12-23T23:20:44Z |
---
library_name: keras-hub
---
### Model Overview
# Model Summary
Vision Transformer (ViT) adapts the Transformer architecture, originally designed for natural language processing, to the domain of computer vision. It treats images as sequences of patches, similar to how Transformers treat sentences as sequences of words.. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929).
## Links:
* [Vit Quickstart Notebook](https://www.kaggle.com/code/sineeli/vit-quickstart)
* [Vit API Documentation](https://keras.io/keras_hub/api/models/vit/)
* [Vit Model Card](https://huggingface.co/google/vit-base-patch16-224)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
## Presets
Model ID | img_size |Acc | Top-5 | Parameters |
:--: |:--:|:--:|:--:|:--:|
**Base**|
vit_base_patch16_224_imagenet |224|-|-|85798656|
vit_base_patch_16_224_imagenet21k|224|-|-|85798656|
vit_base_patch_16_384_imagenet|384|-|-|86090496|
vit_base_patch32_224_imagenet21k|224|-|-|87455232|
vit_base_patch32_384_imagenet|384|-|-|87528192|
**Large**|
vit_large_patch16_224_imagenet|224|-|-|303301632|
vit_large_patch16_224_imagenet21k|224|-|-|303301632|
vit_large_patch16_384_imagenet|224|-|-|303690752|
vit_large_patch32_224_imagenet21k|224|-|-|305510400|
vit_large_patch32_384_imagenet|224|-|-|305607680|
**Huge**|
vit_huge_patch14_224_imagenet21k|224|-|-|630764800|
## Example Usage
## Pretrained ViT model
```
image_classifier = keras_hub.models.ImageClassification.from_preset(
"vit_base_patch16_224_imagenet21k"
)
input_data = np.random.uniform(0, 1, size=(2, 224, 224, 3))
image_classifier(input_data)
```
## Load the backbone weights and fine-tune model for custom dataset.
```python3
backbone = keras_hub.models.Backbone.from_preset(
"vit_base_patch16_224_imagenet21k"
)
preprocessor = keras_hub.models.ViTImageClassifierPreprocessor.from_preset(
"vit_base_patch16_224_imagenet21k"
)
model = keras_hub.models.ViTImageClassifier(
backbone=backbone,
num_classes=len(CLASSES),
preprocessor=preprocessor,
)
```
## Example Usage with Hugging Face URI
## Pretrained ViT model
```
image_classifier = keras_hub.models.ImageClassification.from_preset(
"hf://keras/vit_base_patch16_224_imagenet21k"
)
input_data = np.random.uniform(0, 1, size=(2, 224, 224, 3))
image_classifier(input_data)
```
## Load the backbone weights and fine-tune model for custom dataset.
```python3
backbone = keras_hub.models.Backbone.from_preset(
"hf://keras/vit_base_patch16_224_imagenet21k"
)
preprocessor = keras_hub.models.ViTImageClassifierPreprocessor.from_preset(
"hf://keras/vit_base_patch16_224_imagenet21k"
)
model = keras_hub.models.ViTImageClassifier(
backbone=backbone,
num_classes=len(CLASSES),
preprocessor=preprocessor,
)
```
|
keras/vit_large_patch16_224_imagenet
|
keras
| 2025-06-17T03:22:57Z | 7 | 0 |
keras-hub
|
[
"keras-hub",
"arxiv:2010.11929",
"region:us"
] | null | 2024-12-23T23:26:14Z |
---
library_name: keras-hub
---
### Model Overview
# Model Summary
Vision Transformer (ViT) adapts the Transformer architecture, originally designed for natural language processing, to the domain of computer vision. It treats images as sequences of patches, similar to how Transformers treat sentences as sequences of words.. It was introduced in the paper [An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale](https://arxiv.org/abs/2010.11929).
## Links:
* [Vit Quickstart Notebook](https://www.kaggle.com/code/sineeli/vit-quickstart)
* [Vit API Documentation](https://keras.io/keras_hub/api/models/vit/)
* [Vit Model Card](https://huggingface.co/google/vit-base-patch16-224)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
## Presets
Model ID | img_size |Acc | Top-5 | Parameters |
:--: |:--:|:--:|:--:|:--:|
**Base**|
vit_base_patch16_224_imagenet |224|-|-|85798656|
vit_base_patch_16_224_imagenet21k|224|-|-|85798656|
vit_base_patch_16_384_imagenet|384|-|-|86090496|
vit_base_patch32_224_imagenet21k|224|-|-|87455232|
vit_base_patch32_384_imagenet|384|-|-|87528192|
**Large**|
vit_large_patch16_224_imagenet|224|-|-|303301632|
vit_large_patch16_224_imagenet21k|224|-|-|303301632|
vit_large_patch16_384_imagenet|224|-|-|303690752|
vit_large_patch32_224_imagenet21k|224|-|-|305510400|
vit_large_patch32_384_imagenet|224|-|-|305607680|
**Huge**|
vit_huge_patch14_224_imagenet21k|224|-|-|630764800|
## Example Usage
## Pretrained ViT model
```
image_classifier = keras_hub.models.ImageClassification.from_preset(
"vit_large_patch16_224_imagenet"
)
input_data = np.random.uniform(0, 1, size=(2, 224, 224, 3))
image_classifier(input_data)
```
## Load the backbone weights and fine-tune model for custom dataset.
```python3
backbone = keras_hub.models.Backbone.from_preset(
"vit_large_patch16_224_imagenet"
)
preprocessor = keras_hub.models.ViTImageClassifierPreprocessor.from_preset(
"vit_large_patch16_224_imagenet"
)
model = keras_hub.models.ViTImageClassifier(
backbone=backbone,
num_classes=len(CLASSES),
preprocessor=preprocessor,
)
```
## Example Usage with Hugging Face URI
## Pretrained ViT model
```
image_classifier = keras_hub.models.ImageClassification.from_preset(
"hf://keras/vit_large_patch16_224_imagenet"
)
input_data = np.random.uniform(0, 1, size=(2, 224, 224, 3))
image_classifier(input_data)
```
## Load the backbone weights and fine-tune model for custom dataset.
```python3
backbone = keras_hub.models.Backbone.from_preset(
"hf://keras/vit_large_patch16_224_imagenet"
)
preprocessor = keras_hub.models.ViTImageClassifierPreprocessor.from_preset(
"hf://keras/vit_large_patch16_224_imagenet"
)
model = keras_hub.models.ViTImageClassifier(
backbone=backbone,
num_classes=len(CLASSES),
preprocessor=preprocessor,
)
```
|
keras/siglip2_large_patch16_384
|
keras
| 2025-06-17T03:22:38Z | 7 | 0 |
keras-hub
|
[
"keras-hub",
"arxiv:2303.15343",
"region:us"
] | null | 2025-03-24T21:40:11Z |
---
library_name: keras-hub
---
### Model Overview
SigLIP model pre-trained on WebLi at resolution 224x224. It was introduced in the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Zhai et al. and first released in this [repository](https://github.com/google-research/big_vision).
SigLIP is [CLIP](https://huggingface.co/docs/transformers/model_doc/clip), a multimodal model, with a better loss function. The sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. This allows further scaling up the batch size, while also performing better at smaller batch sizes.
A TLDR of SigLIP by one of the authors can be found [here](https://twitter.com/giffmana/status/1692641733459267713).
Weights are released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE) . Keras model code is released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE).
## Links
* [SigLIP Quickstart Notebook](https://www.kaggle.com/code/laxmareddypatlolla/siglip-quickstart-notebook-with-hub)
* [SigLIP API Documentation](https://keras.io/keras_hub/api/models/siglip/)
* [SigLIP Model Card](https://arxiv.org/abs/2303.15343)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instructions on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|---------------------------------------|------------|--------------------------------------------------------------------------------------------------------------|
| siglip_base_patch16_224 | 203.16M | 200 million parameter, image size 224, pre-trained on WebLi. |
siglip_base_patch16_256 | 203.20M | 200 million parameter, image size 256, pre-trained on WebLi. |
siglip_base_patch16_384 | 203.45M | 200 million parameter, image size 384, pre-trained on WebLi. |
siglip_base_patch16_512 | 203.79M | 200 million parameter, image size 512, pre-trained on WebLi. |
siglip_base_patch16_256_multilingual |370.63M | 370 million parameter, image size 256, pre-trained on WebLi.|
siglip2_base_patch16_224 | 375.19M | 375 million parameter, patch size 16, image size 224, pre-trained on WebLi.|
siglip2_base_patch16_256| 375.23M | 375 million parameter, patch size 16, image size 256, pre-trained on WebLi.|
siglip2_base_patch32_256| 376.86M | 376 million parameter, patch size 32, image size 256, pre-trained on WebLi.|
siglip2_base_patch16_384 | 376.86M | 376 million parameter, patch size 16, image size 384, pre-trained on WebLi.|
siglip_large_patch16_256 | 652.15M | 652 million parameter, image size 256, pre-trained on WebLi. |
siglip_large_patch16_384 | 652.48M | 652 million parameter, image size 384, pre-trained on WebLi. |
siglip_so400m_patch14_224 | 877.36M | 877 million parameter, image size 224, shape-optimized version, pre-trained on WebLi.|
siglip_so400m_patch14_384 | 877.96M| 877 million parameter, image size 384, shape-optimized version, pre-trained on WebLi.|
siglip2_large_patch16_256 |881.53M |881 million parameter, patch size 16, image size 256, pre-trained on WebLi.|
siglip2_large_patch16_384 | 881.86M | 881 million parameter, patch size 16, image size 384, pre-trained on WebLi.|
siglip2_large_patch16_512 | 882.31M |882 million parameter, patch size 16, image size 512, pre-trained on WebLi.|
siglip_so400m_patch16_256_i18n | 1.13B |1.1 billion parameter, image size 256, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch14_224 | 1.14B |1.1 billion parameter, patch size 14, image size 224, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch16_256| 1.14B |1.1 billion parameter, patch size 16, image size 256, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch14_384 | 1.14B |1.1 billion parameter, patch size 14, image size 224, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch16_384 | 1.14B |1.1 billion parameter, patch size 16, image size 384, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch16_512| 1.14B |1.1 billion parameter, patch size 16, image size 512, shape-optimized version, pre-trained on WebLi.|
siglip2_giant_opt_patch16_256| 1.87B |1.8 billion parameter, patch size 16, image size 256, pre-trained on WebLi.|
siglip2_giant_opt_patch16_384| 1.87B |1.8 billion parameter, patch size 16, image size 384, pre-trained on WebLi.|
## Example Usage
```Python
import keras
import numpy as np
import matplotlib.pyplot as plt
from keras_hub.models import SigLIPBackbone, SigLIPTokenizer
from keras_hub.layers import SigLIPImageConverter
# instantiate the model and preprocessing tools
siglip = SigLIPBackbone.from_preset("siglip2_large_patch16_384")
tokenizer = SigLIPTokenizer.from_preset("siglip2_large_patch16_384",
sequence_length=64)
image_converter = SigLIPImageConverter.from_preset("siglip2_large_patch16_384")
# obtain tokens for some input text
tokens = tokenizer.tokenize(["mountains", "cat on tortoise", "house"])
# preprocess image and text
image = keras.utils.load_img("cat.jpg")
image = image_converter(np.array([image]).astype(float))
# query the model for similarities
siglip({
"images": image,
"token_ids": tokens,
})
```
## Example Usage with Hugging Face URI
```Python
import keras
import numpy as np
import matplotlib.pyplot as plt
from keras_hub.models import SigLIPBackbone, SigLIPTokenizer
from keras_hub.layers import SigLIPImageConverter
# instantiate the model and preprocessing tools
siglip = SigLIPBackbone.from_preset("hf://keras/siglip2_large_patch16_384")
tokenizer = SigLIPTokenizer.from_preset("hf://keras/siglip2_large_patch16_384",
sequence_length=64)
image_converter = SigLIPImageConverter.from_preset("hf://keras/siglip2_large_patch16_384")
# obtain tokens for some input text
tokens = tokenizer.tokenize(["mountains", "cat on tortoise", "house"])
# preprocess image and text
image = keras.utils.load_img("cat.jpg")
image = image_converter(np.array([image]).astype(float))
# query the model for similarities
siglip({
"images": image,
"token_ids": tokens,
})
```
|
keras/siglip2_large_patch16_256
|
keras
| 2025-06-17T03:22:37Z | 10 | 0 |
keras-hub
|
[
"keras-hub",
"arxiv:2303.15343",
"region:us"
] | null | 2025-03-24T21:36:58Z |
---
library_name: keras-hub
---
### Model Overview
SigLIP model pre-trained on WebLi at resolution 224x224. It was introduced in the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Zhai et al. and first released in this [repository](https://github.com/google-research/big_vision).
SigLIP is [CLIP](https://huggingface.co/docs/transformers/model_doc/clip), a multimodal model, with a better loss function. The sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. This allows further scaling up the batch size, while also performing better at smaller batch sizes.
A TLDR of SigLIP by one of the authors can be found [here](https://twitter.com/giffmana/status/1692641733459267713).
Weights are released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE) . Keras model code is released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE).
## Links
* [SigLIP Quickstart Notebook](https://www.kaggle.com/code/laxmareddypatlolla/siglip-quickstart-notebook-with-hub)
* [SigLIP API Documentation](https://keras.io/keras_hub/api/models/siglip/)
* [SigLIP Model Card](https://arxiv.org/abs/2303.15343)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instructions on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|---------------------------------------|------------|--------------------------------------------------------------------------------------------------------------|
| siglip_base_patch16_224 | 203.16M | 200 million parameter, image size 224, pre-trained on WebLi. |
siglip_base_patch16_256 | 203.20M | 200 million parameter, image size 256, pre-trained on WebLi. |
siglip_base_patch16_384 | 203.45M | 200 million parameter, image size 384, pre-trained on WebLi. |
siglip_base_patch16_512 | 203.79M | 200 million parameter, image size 512, pre-trained on WebLi. |
siglip_base_patch16_256_multilingual |370.63M | 370 million parameter, image size 256, pre-trained on WebLi.|
siglip2_base_patch16_224 | 375.19M | 375 million parameter, patch size 16, image size 224, pre-trained on WebLi.|
siglip2_base_patch16_256| 375.23M | 375 million parameter, patch size 16, image size 256, pre-trained on WebLi.|
siglip2_base_patch32_256| 376.86M | 376 million parameter, patch size 32, image size 256, pre-trained on WebLi.|
siglip2_base_patch16_384 | 376.86M | 376 million parameter, patch size 16, image size 384, pre-trained on WebLi.|
siglip_large_patch16_256 | 652.15M | 652 million parameter, image size 256, pre-trained on WebLi. |
siglip_large_patch16_384 | 652.48M | 652 million parameter, image size 384, pre-trained on WebLi. |
siglip_so400m_patch14_224 | 877.36M | 877 million parameter, image size 224, shape-optimized version, pre-trained on WebLi.|
siglip_so400m_patch14_384 | 877.96M| 877 million parameter, image size 384, shape-optimized version, pre-trained on WebLi.|
siglip2_large_patch16_256 |881.53M |881 million parameter, patch size 16, image size 256, pre-trained on WebLi.|
siglip2_large_patch16_384 | 881.86M | 881 million parameter, patch size 16, image size 384, pre-trained on WebLi.|
siglip2_large_patch16_512 | 882.31M |882 million parameter, patch size 16, image size 512, pre-trained on WebLi.|
siglip_so400m_patch16_256_i18n | 1.13B |1.1 billion parameter, image size 256, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch14_224 | 1.14B |1.1 billion parameter, patch size 14, image size 224, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch16_256| 1.14B |1.1 billion parameter, patch size 16, image size 256, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch14_384 | 1.14B |1.1 billion parameter, patch size 14, image size 224, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch16_384 | 1.14B |1.1 billion parameter, patch size 16, image size 384, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch16_512| 1.14B |1.1 billion parameter, patch size 16, image size 512, shape-optimized version, pre-trained on WebLi.|
siglip2_giant_opt_patch16_256| 1.87B |1.8 billion parameter, patch size 16, image size 256, pre-trained on WebLi.|
siglip2_giant_opt_patch16_384| 1.87B |1.8 billion parameter, patch size 16, image size 384, pre-trained on WebLi.|
## Example Usage
```Python
import keras
import numpy as np
import matplotlib.pyplot as plt
from keras_hub.models import SigLIPBackbone, SigLIPTokenizer
from keras_hub.layers import SigLIPImageConverter
# instantiate the model and preprocessing tools
siglip = SigLIPBackbone.from_preset("siglip2_large_patch16_256")
tokenizer = SigLIPTokenizer.from_preset("siglip2_large_patch16_256",
sequence_length=64)
image_converter = SigLIPImageConverter.from_preset("siglip2_large_patch16_256")
# obtain tokens for some input text
tokens = tokenizer.tokenize(["mountains", "cat on tortoise", "house"])
# preprocess image and text
image = keras.utils.load_img("cat.jpg")
image = image_converter(np.array([image]).astype(float))
# query the model for similarities
siglip({
"images": image,
"token_ids": tokens,
})
```
## Example Usage with Hugging Face URI
```Python
import keras
import numpy as np
import matplotlib.pyplot as plt
from keras_hub.models import SigLIPBackbone, SigLIPTokenizer
from keras_hub.layers import SigLIPImageConverter
# instantiate the model and preprocessing tools
siglip = SigLIPBackbone.from_preset("hf://keras/siglip2_large_patch16_256")
tokenizer = SigLIPTokenizer.from_preset("hf://keras/siglip2_large_patch16_256",
sequence_length=64)
image_converter = SigLIPImageConverter.from_preset("hf://keras/siglip2_large_patch16_256")
# obtain tokens for some input text
tokens = tokenizer.tokenize(["mountains", "cat on tortoise", "house"])
# preprocess image and text
image = keras.utils.load_img("cat.jpg")
image = image_converter(np.array([image]).astype(float))
# query the model for similarities
siglip({
"images": image,
"token_ids": tokens,
})
```
|
keras/siglip_large_patch16_384
|
keras
| 2025-06-17T03:22:26Z | 47 | 0 |
keras-hub
|
[
"keras-hub",
"arxiv:2303.15343",
"region:us"
] | null | 2025-03-24T22:13:53Z |
---
library_name: keras-hub
---
### Model Overview
SigLIP model pre-trained on WebLi at resolution 224x224. It was introduced in the paper [Sigmoid Loss for Language Image Pre-Training](https://arxiv.org/abs/2303.15343) by Zhai et al. and first released in this [repository](https://github.com/google-research/big_vision).
SigLIP is [CLIP](https://huggingface.co/docs/transformers/model_doc/clip), a multimodal model, with a better loss function. The sigmoid loss operates solely on image-text pairs and does not require a global view of the pairwise similarities for normalization. This allows further scaling up the batch size, while also performing better at smaller batch sizes.
A TLDR of SigLIP by one of the authors can be found [here](https://twitter.com/giffmana/status/1692641733459267713).
Weights are released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE) . Keras model code is released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE).
## Links
* [SigLIP Quickstart Notebook](https://www.kaggle.com/code/laxmareddypatlolla/siglip-quickstart-notebook-with-hub)
* [SigLIP API Documentation](https://keras.io/keras_hub/api/models/siglip/)
* [SigLIP Model Card](https://arxiv.org/abs/2303.15343)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instructions on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|---------------------------------------|------------|--------------------------------------------------------------------------------------------------------------|
| siglip_base_patch16_224 | 203.16M | 200 million parameter, image size 224, pre-trained on WebLi. |
siglip_base_patch16_256 | 203.20M | 200 million parameter, image size 256, pre-trained on WebLi. |
siglip_base_patch16_384 | 203.45M | 200 million parameter, image size 384, pre-trained on WebLi. |
siglip_base_patch16_512 | 203.79M | 200 million parameter, image size 512, pre-trained on WebLi. |
siglip_base_patch16_256_multilingual |370.63M | 370 million parameter, image size 256, pre-trained on WebLi.|
siglip2_base_patch16_224 | 375.19M | 375 million parameter, patch size 16, image size 224, pre-trained on WebLi.|
siglip2_base_patch16_256| 375.23M | 375 million parameter, patch size 16, image size 256, pre-trained on WebLi.|
siglip2_base_patch32_256| 376.86M | 376 million parameter, patch size 32, image size 256, pre-trained on WebLi.|
siglip2_base_patch16_384 | 376.86M | 376 million parameter, patch size 16, image size 384, pre-trained on WebLi.|
siglip_large_patch16_256 | 652.15M | 652 million parameter, image size 256, pre-trained on WebLi. |
siglip_large_patch16_384 | 652.48M | 652 million parameter, image size 384, pre-trained on WebLi. |
siglip_so400m_patch14_224 | 877.36M | 877 million parameter, image size 224, shape-optimized version, pre-trained on WebLi.|
siglip_so400m_patch14_384 | 877.96M| 877 million parameter, image size 384, shape-optimized version, pre-trained on WebLi.|
siglip2_large_patch16_256 |881.53M |881 million parameter, patch size 16, image size 256, pre-trained on WebLi.|
siglip2_large_patch16_384 | 881.86M | 881 million parameter, patch size 16, image size 384, pre-trained on WebLi.|
siglip2_large_patch16_512 | 882.31M |882 million parameter, patch size 16, image size 512, pre-trained on WebLi.|
siglip_so400m_patch16_256_i18n | 1.13B |1.1 billion parameter, image size 256, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch14_224 | 1.14B |1.1 billion parameter, patch size 14, image size 224, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch16_256| 1.14B |1.1 billion parameter, patch size 16, image size 256, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch14_384 | 1.14B |1.1 billion parameter, patch size 14, image size 224, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch16_384 | 1.14B |1.1 billion parameter, patch size 16, image size 384, shape-optimized version, pre-trained on WebLi.|
siglip2_so400m_patch16_512| 1.14B |1.1 billion parameter, patch size 16, image size 512, shape-optimized version, pre-trained on WebLi.|
siglip2_giant_opt_patch16_256| 1.87B |1.8 billion parameter, patch size 16, image size 256, pre-trained on WebLi.|
siglip2_giant_opt_patch16_384| 1.87B |1.8 billion parameter, patch size 16, image size 384, pre-trained on WebLi.|
## Example Usage
```Python
import keras
import numpy as np
import matplotlib.pyplot as plt
from keras_hub.models import SigLIPBackbone, SigLIPTokenizer
from keras_hub.layers import SigLIPImageConverter
# instantiate the model and preprocessing tools
siglip = SigLIPBackbone.from_preset("siglip_large_patch16_384")
tokenizer = SigLIPTokenizer.from_preset("siglip_large_patch16_384",
sequence_length=64)
image_converter = SigLIPImageConverter.from_preset("siglip_large_patch16_384")
# obtain tokens for some input text
tokens = tokenizer.tokenize(["mountains", "cat on tortoise", "house"])
# preprocess image and text
image = keras.utils.load_img("cat.jpg")
image = image_converter(np.array([image]).astype(float))
# query the model for similarities
siglip({
"images": image,
"token_ids": tokens,
})
```
## Example Usage with Hugging Face URI
```Python
import keras
import numpy as np
import matplotlib.pyplot as plt
from keras_hub.models import SigLIPBackbone, SigLIPTokenizer
from keras_hub.layers import SigLIPImageConverter
# instantiate the model and preprocessing tools
siglip = SigLIPBackbone.from_preset("hf://keras/siglip_large_patch16_384")
tokenizer = SigLIPTokenizer.from_preset("hf://keras/siglip_large_patch16_384",
sequence_length=64)
image_converter = SigLIPImageConverter.from_preset("hf://keras/siglip_large_patch16_384")
# obtain tokens for some input text
tokens = tokenizer.tokenize(["mountains", "cat on tortoise", "house"])
# preprocess image and text
image = keras.utils.load_img("cat.jpg")
image = image_converter(np.array([image]).astype(float))
# query the model for similarities
siglip({
"images": image,
"token_ids": tokens,
})
```
|
keras/retinanet_resnet50_fpn_v2_coco
|
keras
| 2025-06-17T03:22:01Z | 0 | 0 |
keras-hub
|
[
"keras-hub",
"region:us"
] | null | 2025-06-17T02:32:52Z |
---
library_name: keras-hub
---
### Model Overview
A Keras model implementing the RetinaNet meta-architecture.
Implements the RetinaNet architecture for object detection. The constructor
requires `num_classes`, `bounding_box_format`, and a backbone. Optionally,
a custom label encoder, and prediction decoder may be provided.
## Links
* [RetinaNet Quickstart Notebook](https://www.kaggle.com/code/sineeli/retinanet-training-guide)
* [RetinaNet API Documentation](https://keras.io/keras_hub/api/models/retinanet/)
* [RetinaNet Model Card](https://huggingface.co/keras-io/Object-Detection-RetinaNet)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instructions on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|----------------|------------|--------------------------------------------------|
| retinanet_resnet50_fpn_coco | 34.12M | RetinaNet model with ResNet50 backbone fine-tuned on COCO in 800x800 resolution.|
__Arguments__
- __num_classes__: the number of classes in your dataset excluding the
background class. Classes should be represented by integers in the
range [0, num_classes).
- __bounding_box_format__: The format of bounding boxes of input dataset.
Refer
[to the keras.io docs](https://keras.io/api/keras_cv/bounding_box/formats/)
for more details on supported bounding box formats.
- __backbone__: `keras.Model`. If the default `feature_pyramid` is used,
must implement the `pyramid_level_inputs` property with keys "P3", "P4",
and "P5" and layer names as values. A somewhat sensible backbone
to use in many cases is the:
`keras_cv.models.ResNetBackbone.from_preset("resnet50_imagenet")`
- __anchor_generator__: (Optional) a `keras_cv.layers.AnchorGenerator`. If
provided, the anchor generator will be passed to both the
`label_encoder` and the `prediction_decoder`. Only to be used when
both `label_encoder` and `prediction_decoder` are both `None`.
Defaults to an anchor generator with the parameterization:
`strides=[2**i for i in range(3, 8)]`,
`scales=[2**x for x in [0, 1 / 3, 2 / 3]]`,
`sizes=[32.0, 64.0, 128.0, 256.0, 512.0]`,
and `aspect_ratios=[0.5, 1.0, 2.0]`.
- __label_encoder__: (Optional) a keras.Layer that accepts an image Tensor, a
bounding box Tensor and a bounding box class Tensor to its `call()`
method, and returns RetinaNet training targets. By default, a
KerasCV standard `RetinaNetLabelEncoder` is created and used.
Results of this object's `call()` method are passed to the `loss`
object for `box_loss` and `classification_loss` the `y_true`
argument.
- __prediction_decoder__: (Optional) A `keras.layers.Layer` that is
responsible for transforming RetinaNet predictions into usable
bounding box Tensors. If not provided, a default is provided. The
default `prediction_decoder` layer is a
`keras_cv.layers.MultiClassNonMaxSuppression` layer, which uses
a Non-Max Suppression for box pruning.
- __feature_pyramid__: (Optional) A `keras.layers.Layer` that produces
a list of 4D feature maps (batch dimension included)
when called on the pyramid-level outputs of the `backbone`.
If not provided, the reference implementation from the paper will be used.
- __classification_head__: (Optional) A `keras.Layer` that performs
classification of the bounding boxes. If not provided, a simple
ConvNet with 3 layers will be used.
- __box_head__: (Optional) A `keras.Layer` that performs regression of the
bounding boxes. If not provided, a simple ConvNet with 3 layers
will be used.
## Example Usage
## Pretrained RetinaNet model
```
object_detector = keras_hub.models.ImageObjectDetector.from_preset(
"retinanet_resnet50_fpn_v2_coco"
)
input_data = np.random.uniform(0, 1, size=(2, 224, 224, 3))
object_detector(input_data)
```
## Fine-tune the pre-trained model
```python3
backbone = keras_hub.models.Backbone.from_preset(
"retinanet_resnet50_fpn_v2_coco"
)
preprocessor = keras_hub.models.RetinaNetObjectDetectorPreprocessor.from_preset(
"retinanet_resnet50_fpn_v2_coco"
)
model = RetinaNetObjectDetector(
backbone=backbone,
num_classes=len(CLASSES),
preprocessor=preprocessor
)
```
## Custom training the model
```python3
image_converter = keras_hub.layers.RetinaNetImageConverter(
scale=1/255
)
preprocessor = keras_hub.models.RetinaNetObjectDetectorPreprocessor(
image_converter=image_converter
)
# Load a pre-trained ResNet50 model.
# This will serve as the base for extracting image features.
image_encoder = keras_hub.models.Backbone.from_preset(
"resnet_50_imagenet"
)
# Build the RetinaNet Feature Pyramid Network (FPN) on top of the ResNet50
# backbone. The FPN creates multi-scale feature maps for better object detection
# at different sizes.
backbone = keras_hub.models.RetinaNetBackbone(
image_encoder=image_encoder,
min_level=3,
max_level=5,
use_p5=False
)
model = RetinaNetObjectDetector(
backbone=backbone,
num_classes=len(CLASSES),
preprocessor=preprocessor
)
```
## Example Usage with Hugging Face URI
## Pretrained RetinaNet model
```
object_detector = keras_hub.models.ImageObjectDetector.from_preset(
"hf://keras/retinanet_resnet50_fpn_v2_coco"
)
input_data = np.random.uniform(0, 1, size=(2, 224, 224, 3))
object_detector(input_data)
```
## Fine-tune the pre-trained model
```python3
backbone = keras_hub.models.Backbone.from_preset(
"hf://keras/retinanet_resnet50_fpn_v2_coco"
)
preprocessor = keras_hub.models.RetinaNetObjectDetectorPreprocessor.from_preset(
"hf://keras/retinanet_resnet50_fpn_v2_coco"
)
model = RetinaNetObjectDetector(
backbone=backbone,
num_classes=len(CLASSES),
preprocessor=preprocessor
)
```
## Custom training the model
```python3
image_converter = keras_hub.layers.RetinaNetImageConverter(
scale=1/255
)
preprocessor = keras_hub.models.RetinaNetObjectDetectorPreprocessor(
image_converter=image_converter
)
# Load a pre-trained ResNet50 model.
# This will serve as the base for extracting image features.
image_encoder = keras_hub.models.Backbone.from_preset(
"resnet_50_imagenet"
)
# Build the RetinaNet Feature Pyramid Network (FPN) on top of the ResNet50
# backbone. The FPN creates multi-scale feature maps for better object detection
# at different sizes.
backbone = keras_hub.models.RetinaNetBackbone(
image_encoder=image_encoder,
min_level=3,
max_level=5,
use_p5=False
)
model = RetinaNetObjectDetector(
backbone=backbone,
num_classes=len(CLASSES),
preprocessor=preprocessor
)
```
|
keras/efficientnet_lite0_ra_imagenet
|
keras
| 2025-06-17T03:21:00Z | 8 | 0 |
keras-hub
|
[
"keras-hub",
"arxiv:1905.11946",
"arxiv:2104.00298",
"region:us"
] | null | 2024-12-23T23:29:02Z |
---
library_name: keras-hub
---
### Model Overview
EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
We develop EfficientNets based on AutoML and Compound Scaling. In particular, we first use AutoML MNAS Mobile framework to develop a mobile-size baseline network, named as EfficientNet-B0; Then, we use the compound scaling method to scale up this baseline to obtain EfficientNet-B1 to EfficientNet-B7.
This class encapsulates the architectures for both EfficientNetV1 and EfficientNetV2. EfficientNetV2 uses Fused-MBConv Blocks and Neural Architecture Search (NAS) to make models sizes much smaller while still improving overall model quality.
This model is supported in both KerasCV and KerasHub. KerasCV will no longer be actively developed, so please try to use KerasHub.
## Links
* [EfficientNet Quickstart Notebook](https://www.kaggle.com/code/prasadsachin/efficientnet-quickstart-kerashub)
* [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)(ICML 2019)
* [Based on the original keras.applications EfficientNet](https://github.com/keras-team/keras/blob/master/keras/applications/efficientnet.py)
* [EfficientNetV2: Smaller Models and Faster Training](https://arxiv.org/abs/2104.00298) (ICML 2021)
* [EfficientNet API Documentation](https://keras.io/keras_hub/api/models/efficientnet/)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instructions on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|------------------------------------|------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| efficientnet_b0_ra_imagenet | 5.3M | EfficientNet B0 model pre-trained on the ImageNet 1k dataset with RandAugment recipe. |
| efficientnet_b0_ra4_e3600_r224_imagenet | 5.3M | EfficientNet B0 model pre-trained on the ImageNet 1k dataset by Ross Wightman. Trained with timm scripts using hyper-parameters inspired by the MobileNet-V4 small, mixed with go-to hparams from timm and 'ResNet Strikes Back'. |
| efficientnet_b1_ft_imagenet | 7.8M | EfficientNet B1 model fine-tuned on the ImageNet 1k dataset. |
| efficientnet_b1_ra4_e3600_r240_imagenet | 7.8M | EfficientNet B1 model pre-trained on the ImageNet 1k dataset by Ross Wightman. Trained with timm scripts using hyper-parameters inspired by the MobileNet-V4 small, mixed with go-to hparams from timm and 'ResNet Strikes Back'. |
| efficientnet_b2_ra_imagenet | 9.1M | EfficientNet B2 model pre-trained on the ImageNet 1k dataset with RandAugment recipe. |
| efficientnet_b3_ra2_imagenet | 12.2M | EfficientNet B3 model pre-trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet_b4_ra2_imagenet | 19.3M | EfficientNet B4 model pre-trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet_b5_sw_imagenet | 30.4M | EfficientNet B5 model pre-trained on the ImageNet 12k dataset by Ross Wightman. Based on Swin Transformer train / pretrain recipe with modifications (related to both DeiT and ConvNeXt recipes). |
| efficientnet_b5_sw_ft_imagenet | 30.4M | EfficientNet B5 model pre-trained on the ImageNet 12k dataset and fine-tuned on ImageNet-1k by Ross Wightman. Based on Swin Transformer train / pretrain recipe with modifications (related to both DeiT and ConvNeXt recipes). |
| efficientnet_el_ra_imagenet | 10.6M | EfficientNet-EdgeTPU Large model trained on the ImageNet 1k dataset with RandAugment recipe. |
| efficientnet_em_ra2_imagenet | 6.9M | EfficientNet-EdgeTPU Medium model trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet_es_ra_imagenet | 5.4M | EfficientNet-EdgeTPU Small model trained on the ImageNet 1k dataset with RandAugment recipe. |
| efficientnet2_rw_m_agc_imagenet | 53.2M | EfficientNet-v2 Medium model trained on the ImageNet 1k dataset with adaptive gradient clipping. |
| efficientnet2_rw_s_ra2_imagenet | 23.9M | EfficientNet-v2 Small model trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet2_rw_t_ra2_imagenet | 13.6M | EfficientNet-v2 Tiny model trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet_lite0_ra_imagenet | 4.7M | EfficientNet-Lite model fine-trained on the ImageNet 1k dataset with RandAugment recipe. |
## Model card
https://arxiv.org/abs/1905.11946
## Example Usage
Load
```python
classifier = keras_hub.models.EfficientNetImageClassifier.from_preset(
"efficientnet_b0_ra_imagenet",
)
```
Predict
```python
batch_size = 1
images = keras.random.normal(shape=(batch_size, 96, 96, 3))
classifier.predict(images)
```
Train, specify `num_classes` to load randomly initialized classifier head.
```python
num_classes = 2
labels = keras.random.randint(shape=(batch_size,), minval=0, maxval=num_classes)
classifier = keras_hub.models.EfficientNetImageClassifier.from_preset(
"efficientnet_b0_ra_imagenet",
num_classes=num_classes,
)
classifier.preprocessor.image_size = (96, 96)
classifier.fit(images, labels, epochs=3)
```
## Example Usage with Hugging Face URI
Load
```python
classifier = keras_hub.models.EfficientNetImageClassifier.from_preset(
"efficientnet_b0_ra_imagenet",
)
```
Predict
```python
batch_size = 1
images = keras.random.normal(shape=(batch_size, 96, 96, 3))
classifier.predict(images)
```
Train, specify `num_classes` to load randomly initialized classifier head.
```python
num_classes = 2
labels = keras.random.randint(shape=(batch_size,), minval=0, maxval=num_classes)
classifier = keras_hub.models.EfficientNetImageClassifier.from_preset(
"efficientnet_b0_ra_imagenet",
num_classes=num_classes,
)
classifier.preprocessor.image_size = (96, 96)
classifier.fit(images, labels, epochs=3)
```
|
keras/efficientnet_b1_ra4_e3600_r240_imagenet
|
keras
| 2025-06-17T03:20:37Z | 9 | 0 |
keras-hub
|
[
"keras-hub",
"arxiv:1905.11946",
"arxiv:2104.00298",
"region:us"
] | null | 2024-11-14T23:31:25Z |
---
library_name: keras-hub
---
### Model Overview
EfficientNets are a family of image classification models, which achieve state-of-the-art accuracy, yet being an order-of-magnitude smaller and faster than previous models.
We develop EfficientNets based on AutoML and Compound Scaling. In particular, we first use AutoML MNAS Mobile framework to develop a mobile-size baseline network, named as EfficientNet-B0; Then, we use the compound scaling method to scale up this baseline to obtain EfficientNet-B1 to EfficientNet-B7.
This class encapsulates the architectures for both EfficientNetV1 and EfficientNetV2. EfficientNetV2 uses Fused-MBConv Blocks and Neural Architecture Search (NAS) to make models sizes much smaller while still improving overall model quality.
This model is supported in both KerasCV and KerasHub. KerasCV will no longer be actively developed, so please try to use KerasHub.
## Links
* [EfficientNet Quickstart Notebook](https://www.kaggle.com/code/prasadsachin/efficientnet-quickstart-kerashub)
* [EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks](https://arxiv.org/abs/1905.11946)(ICML 2019)
* [Based on the original keras.applications EfficientNet](https://github.com/keras-team/keras/blob/master/keras/applications/efficientnet.py)
* [EfficientNetV2: Smaller Models and Faster Training](https://arxiv.org/abs/2104.00298) (ICML 2021)
* [EfficientNet API Documentation](https://keras.io/keras_hub/api/models/efficientnet/)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instructions on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|------------------------------------|------------|-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|
| efficientnet_b0_ra_imagenet | 5.3M | EfficientNet B0 model pre-trained on the ImageNet 1k dataset with RandAugment recipe. |
| efficientnet_b0_ra4_e3600_r224_imagenet | 5.3M | EfficientNet B0 model pre-trained on the ImageNet 1k dataset by Ross Wightman. Trained with timm scripts using hyper-parameters inspired by the MobileNet-V4 small, mixed with go-to hparams from timm and 'ResNet Strikes Back'. |
| efficientnet_b1_ft_imagenet | 7.8M | EfficientNet B1 model fine-tuned on the ImageNet 1k dataset. |
| efficientnet_b1_ra4_e3600_r240_imagenet | 7.8M | EfficientNet B1 model pre-trained on the ImageNet 1k dataset by Ross Wightman. Trained with timm scripts using hyper-parameters inspired by the MobileNet-V4 small, mixed with go-to hparams from timm and 'ResNet Strikes Back'. |
| efficientnet_b2_ra_imagenet | 9.1M | EfficientNet B2 model pre-trained on the ImageNet 1k dataset with RandAugment recipe. |
| efficientnet_b3_ra2_imagenet | 12.2M | EfficientNet B3 model pre-trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet_b4_ra2_imagenet | 19.3M | EfficientNet B4 model pre-trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet_b5_sw_imagenet | 30.4M | EfficientNet B5 model pre-trained on the ImageNet 12k dataset by Ross Wightman. Based on Swin Transformer train / pretrain recipe with modifications (related to both DeiT and ConvNeXt recipes). |
| efficientnet_b5_sw_ft_imagenet | 30.4M | EfficientNet B5 model pre-trained on the ImageNet 12k dataset and fine-tuned on ImageNet-1k by Ross Wightman. Based on Swin Transformer train / pretrain recipe with modifications (related to both DeiT and ConvNeXt recipes). |
| efficientnet_el_ra_imagenet | 10.6M | EfficientNet-EdgeTPU Large model trained on the ImageNet 1k dataset with RandAugment recipe. |
| efficientnet_em_ra2_imagenet | 6.9M | EfficientNet-EdgeTPU Medium model trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet_es_ra_imagenet | 5.4M | EfficientNet-EdgeTPU Small model trained on the ImageNet 1k dataset with RandAugment recipe. |
| efficientnet2_rw_m_agc_imagenet | 53.2M | EfficientNet-v2 Medium model trained on the ImageNet 1k dataset with adaptive gradient clipping. |
| efficientnet2_rw_s_ra2_imagenet | 23.9M | EfficientNet-v2 Small model trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet2_rw_t_ra2_imagenet | 13.6M | EfficientNet-v2 Tiny model trained on the ImageNet 1k dataset with RandAugment2 recipe. |
| efficientnet_lite0_ra_imagenet | 4.7M | EfficientNet-Lite model fine-trained on the ImageNet 1k dataset with RandAugment recipe. |
## Model card
https://arxiv.org/abs/1905.11946
## Example Usage
Load
```python
classifier = keras_hub.models.EfficientNetImageClassifier.from_preset(
"efficientnet_b0_ra_imagenet",
)
```
Predict
```python
batch_size = 1
images = keras.random.normal(shape=(batch_size, 96, 96, 3))
classifier.predict(images)
```
Train, specify `num_classes` to load randomly initialized classifier head.
```python
num_classes = 2
labels = keras.random.randint(shape=(batch_size,), minval=0, maxval=num_classes)
classifier = keras_hub.models.EfficientNetImageClassifier.from_preset(
"efficientnet_b0_ra_imagenet",
num_classes=num_classes,
)
classifier.preprocessor.image_size = (96, 96)
classifier.fit(images, labels, epochs=3)
```
## Example Usage with Hugging Face URI
Load
```python
classifier = keras_hub.models.EfficientNetImageClassifier.from_preset(
"efficientnet_b0_ra_imagenet",
)
```
Predict
```python
batch_size = 1
images = keras.random.normal(shape=(batch_size, 96, 96, 3))
classifier.predict(images)
```
Train, specify `num_classes` to load randomly initialized classifier head.
```python
num_classes = 2
labels = keras.random.randint(shape=(batch_size,), minval=0, maxval=num_classes)
classifier = keras_hub.models.EfficientNetImageClassifier.from_preset(
"efficientnet_b0_ra_imagenet",
num_classes=num_classes,
)
classifier.preprocessor.image_size = (96, 96)
classifier.fit(images, labels, epochs=3)
```
|
shinkeonkim/gemma-3-1b-pt-Q2_K-GGUF
|
shinkeonkim
| 2025-06-17T03:20:26Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"base_model:google/gemma-3-1b-pt",
"base_model:quantized:google/gemma-3-1b-pt",
"license:gemma",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T03:20:21Z |
---
license: gemma
library_name: transformers
pipeline_tag: text-generation
extra_gated_heading: Access Gemma on Hugging Face
extra_gated_prompt: To access Gemma on Hugging Face, you’re required to review and
agree to Google’s usage license. To do this, please ensure you’re logged in to Hugging
Face and click below. Requests are processed immediately.
extra_gated_button_content: Acknowledge license
base_model: google/gemma-3-1b-pt
tags:
- llama-cpp
- gguf-my-repo
---
# shinkeonkim/gemma-3-1b-pt-Q2_K-GGUF
This model was converted to GGUF format from [`google/gemma-3-1b-pt`](https://huggingface.co/google/gemma-3-1b-pt) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/google/gemma-3-1b-pt) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo shinkeonkim/gemma-3-1b-pt-Q2_K-GGUF --hf-file gemma-3-1b-pt-q2_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo shinkeonkim/gemma-3-1b-pt-Q2_K-GGUF --hf-file gemma-3-1b-pt-q2_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo shinkeonkim/gemma-3-1b-pt-Q2_K-GGUF --hf-file gemma-3-1b-pt-q2_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo shinkeonkim/gemma-3-1b-pt-Q2_K-GGUF --hf-file gemma-3-1b-pt-q2_k.gguf -c 2048
```
|
19-cikgu-cctv-wiring-Official-viral-videos/FULL.VIDEO.cikgu.cctv.wiring.Viral.Video.Tutorial.Official
|
19-cikgu-cctv-wiring-Official-viral-videos
| 2025-06-17T03:15:38Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-17T03:14:54Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
keras/vicuna_1.5_7b_en
|
keras
| 2025-06-17T03:11:20Z | 53 | 0 |
keras-hub
|
[
"keras-hub",
"text-generation-inference",
"text-generation",
"en",
"arxiv:2306.05685",
"license:llama2",
"region:us"
] |
text-generation
| 2024-10-28T23:21:51Z |
---
library_name: keras-hub
license: llama2
language:
- en
tags:
- text-generation-inference
pipeline_tag: text-generation
---
### Model Overview
Vicuna is a chat assistant trained by fine-tuning Llama 2 on user-shared conversations collected from ShareGPT.Weights are release under the [Llama 2 Community License Agreement ](https://ai.meta.com/llama/license/) and Keras model code are released under the [Apache 2 License](https://github.com/keras-team/keras-hub/blob/master/LICENSE).
Model type: An auto-regressive language model based on the transformer architecture.
Fine tuned from model: Llama 2
Uses:
The primary use of Vicuna is research on large language models and chatbots. The primary intended users of the model are researchers and hobbyists in natural language processing, machine learning, and artificial intelligence.
## Links
* [Vicuna Quickstart Notebook](https://www.kaggle.com/code/laxmareddypatlolla/vicuna-quickstart-notebook)
* [Vicuna API Documentation](coming soon)
* [Vicuna Model Card](https://huggingface.co/lmsys/vicuna-7b-v1.5#vicuna-model-card)
* [KerasHub Beginner Guide](https://keras.io/guides/keras_hub/getting_started/)
* [KerasHub Model Publishing Guide](https://keras.io/guides/keras_hub/upload/)
## Installation
Keras and KerasHub can be installed with:
```
pip install -U -q keras-hub
pip install -U -q keras
```
Jax, TensorFlow, and Torch come preinstalled in Kaggle Notebooks. For instruction on installing them in another environment see the [Keras Getting Started](https://keras.io/getting_started/) page.
## Presets
The following model checkpoints are provided by the Keras team. Full code examples for each are available below.
| Preset name | Parameters | Description |
|-----------------------|------------|---------------|
|` vicuna_1.5_7b_en ` | 6.74B | 7 billion parameter, 32-layer, instruction tuned Vicuna v1.5 model.|
Paper: https://arxiv.org/abs/2306.05685
## Example Usage
```python
import keras
import keras_hub
import numpy as np
```
Use `generate()` to do text generation.
```python
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset("vicuna_1.5_7b_en")
vicuna_lm.generate("### HUMAN:\nWhat is Keras? \n### RESPONSE:\n", max_length=500)
# Generate with batched prompts.
vicuna_lm.generate([
"### HUMAN:\nWhat is ML? \n### RESPONSE:\n",
"### HUMAN:\nGive me your best brownie recipe.\n### RESPONSE:\n",
],max_length=500)
```
Compile the `generate()` function with a custom sampler.
```python
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset("vicuna_1.5_7b_en")
vicuna_lm.compile(sampler="greedy")
vicuna_lm.generate("I want to say", max_length=30)
vicuna_lm.compile(sampler=keras_hub.samplers.BeamSampler(num_beams=2))
vicuna_lm.generate("I want to say", max_length=30)
```
Use `generate()` without preprocessing.
```python
prompt = {
# `1` maps to the start token followed by "I want to say".
"token_ids": np.array([[1, 306, 864, 304, 1827, 0, 0, 0, 0, 0]] * 2),
# Use `"padding_mask"` to indicate values that should not be overridden.
"padding_mask": np.array([[1, 1, 1, 1, 1, 0, 0, 0, 0, 0]] * 2),
}
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset(
"vicuna_1.5_7b_en",
preprocessor=None,
dtype="bfloat16"
)
vicuna_lm.generate(prompt)
```
Call `fit()` on a single batch.
```python
features = ["The quick brown fox jumped.", "I forgot my homework."]
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset("vicuna_1.5_7b_en")
vicuna_lm.fit(x=features, batch_size=2)
```
Call `fit()` without preprocessing.
```python
x = {
"token_ids": np.array([[1, 450, 4996, 17354, 1701, 29916, 12500, 287, 29889, 0]] * 2),
"padding_mask": np.array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 0]] * 2),
}
y = np.array([[450, 4996, 17354, 1701, 29916, 12500, 287, 29889, 0, 0]] * 2)
sw = np.array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0]] * 2)
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset(
"vicuna_1.5_7b_en",
preprocessor=None,
dtype="bfloat16"
)
vicuna_lm.fit(x=x, y=y, sample_weight=sw, batch_size=2)
```
## Example Usage with Hugging Face URI
```python
import keras
import keras_hub
import numpy as np
```
Use `generate()` to do text generation.
```python
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset("hf://keras/vicuna_1.5_7b_en")
vicuna_lm.generate("### HUMAN:\nWhat is Keras? \n### RESPONSE:\n", max_length=500)
# Generate with batched prompts.
vicuna_lm.generate([
"### HUMAN:\nWhat is ML? \n### RESPONSE:\n",
"### HUMAN:\nGive me your best brownie recipe.\n### RESPONSE:\n",
],max_length=500)
```
Compile the `generate()` function with a custom sampler.
```python
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset("hf://keras/vicuna_1.5_7b_en")
vicuna_lm.compile(sampler="greedy")
vicuna_lm.generate("I want to say", max_length=30)
vicuna_lm.compile(sampler=keras_hub.samplers.BeamSampler(num_beams=2))
vicuna_lm.generate("I want to say", max_length=30)
```
Use `generate()` without preprocessing.
```python
prompt = {
# `1` maps to the start token followed by "I want to say".
"token_ids": np.array([[1, 306, 864, 304, 1827, 0, 0, 0, 0, 0]] * 2),
# Use `"padding_mask"` to indicate values that should not be overridden.
"padding_mask": np.array([[1, 1, 1, 1, 1, 0, 0, 0, 0, 0]] * 2),
}
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset(
"hf://keras/vicuna_1.5_7b_en",
preprocessor=None,
dtype="bfloat16"
)
vicuna_lm.generate(prompt)
```
Call `fit()` on a single batch.
```python
features = ["The quick brown fox jumped.", "I forgot my homework."]
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset("hf://keras/vicuna_1.5_7b_en")
vicuna_lm.fit(x=features, batch_size=2)
```
Call `fit()` without preprocessing.
```python
x = {
"token_ids": np.array([[1, 450, 4996, 17354, 1701, 29916, 12500, 287, 29889, 0]] * 2),
"padding_mask": np.array([[1, 1, 1, 1, 1, 1, 1, 1, 1, 0]] * 2),
}
y = np.array([[450, 4996, 17354, 1701, 29916, 12500, 287, 29889, 0, 0]] * 2)
sw = np.array([[1, 1, 1, 1, 1, 1, 1, 1, 0, 0]] * 2)
vicuna_lm = keras_hub.models.LlamaCausalLM.from_preset(
"hf://keras/vicuna_1.5_7b_en",
preprocessor=None,
dtype="bfloat16"
)
vicuna_lm.fit(x=x, y=y, sample_weight=sw, batch_size=2)
```
|
modaopro/task-10-microsoft-Phi-3.5-mini-instruct
|
modaopro
| 2025-06-17T03:05:49Z | 42 | 0 |
peft
|
[
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:microsoft/Phi-3.5-mini-instruct",
"base_model:adapter:microsoft/Phi-3.5-mini-instruct",
"region:us"
] | null | 2025-06-02T05:10:29Z |
---
base_model: microsoft/Phi-3.5-mini-instruct
library_name: peft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.13.2
|
Official-Katy-Perry-Viral-videos/Original.Full.Clip.Katy.Perry.Viral.Video.Leaks.Tutorial
|
Official-Katy-Perry-Viral-videos
| 2025-06-17T03:05:36Z | 0 | 0 | null |
[
"region:us"
] | null | 2025-06-17T03:05:18Z |
<animated-image data-catalyst=""><a href="https://tinyurl.com/5ye5v3bc?dfhgKasbonStudiosdfg" rel="nofollow" data-target="animated-image.originalLink"><img src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" alt="Foo" data-canonical-src="https://static.wixstatic.com/media/b249f9_adac8f70fb3f45b88691696c77de18f3~mv2.gif" style="max-width: 100%; display: inline-block;" data-target="animated-image.originalImage"></a>
|
luckysantoso/adapter-gemma-lawbot-v2
|
luckysantoso
| 2025-06-17T02:46:27Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T02:46:21Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
espnet/xeus
|
espnet
| 2025-06-17T02:46:08Z | 16 | 124 |
espnet
|
[
"espnet",
"audio",
"speech",
"multilingual",
"automatic-speech-recognition",
"aaa",
"aab",
"aac",
"aad",
"aaf",
"aai",
"aal",
"aao",
"aap",
"aar",
"aau",
"aaw",
"aaz",
"aba",
"abh",
"abi",
"abm",
"abn",
"abo",
"abr",
"abs",
"abt",
"abu",
"abz",
"aca",
"acd",
"ace",
"acf",
"ach",
"acm",
"acn",
"acq",
"acr",
"acu",
"acv",
"acw",
"acz",
"ada",
"add",
"ade",
"adh",
"adi",
"adj",
"adl",
"adn",
"ado",
"adq",
"adx",
"ady",
"adz",
"aeb",
"aec",
"aee",
"ael",
"aeu",
"aey",
"aez",
"afb",
"afe",
"afi",
"afo",
"afr",
"afu",
"afz",
"agb",
"agc",
"agd",
"age",
"agf",
"agg",
"agh",
"agi",
"agl",
"agn",
"agq",
"agr",
"ags",
"agt",
"agu",
"agw",
"agy",
"aha",
"ahb",
"ahg",
"ahk",
"ahl",
"ahp",
"ahr",
"ahs",
"aia",
"aif",
"aii",
"aik",
"aim",
"aio",
"aiw",
"aix",
"ajg",
"aji",
"akb",
"akc",
"akd",
"ake",
"akf",
"akg",
"akh",
"aki",
"akl",
"akp",
"akq",
"akr",
"aks",
"akt",
"akw",
"ala",
"ald",
"ale",
"alf",
"alh",
"alj",
"alk",
"all",
"aln",
"alp",
"alq",
"als",
"alt",
"alu",
"alw",
"alx",
"aly",
"alz",
"amb",
"amc",
"ame",
"amf",
"amh",
"ami",
"amk",
"amm",
"amn",
"amo",
"amr",
"amt",
"amu",
"anc",
"anf",
"anj",
"ank",
"anl",
"anm",
"ann",
"ano",
"anp",
"anr",
"anu",
"anv",
"anw",
"anx",
"any",
"aoe",
"aof",
"aog",
"aoi",
"aoj",
"aol",
"aom",
"aon",
"aot",
"aoz",
"apb",
"apc",
"apd",
"ape",
"apj",
"apm",
"apn",
"app",
"apr",
"apt",
"apu",
"apw",
"apy",
"apz",
"aqg",
"aqm",
"aqt",
"arb",
"are",
"arg",
"arh",
"arl",
"arn",
"aro",
"arp",
"arq",
"arr",
"arv",
"arw",
"arx",
"ary",
"arz",
"asa",
"asb",
"asc",
"asi",
"ask",
"asm",
"aso",
"asr",
"ass",
"asu",
"asy",
"ata",
"atb",
"atd",
"atg",
"ati",
"atk",
"ato",
"atp",
"atq",
"ats",
"att",
"atu",
"aty",
"auc",
"aug",
"aui",
"auk",
"aul",
"aun",
"aup",
"auq",
"auu",
"auy",
"ava",
"avd",
"avi",
"avl",
"avn",
"avt",
"avu",
"awa",
"awb",
"awe",
"awi",
"awn",
"awu",
"aww",
"axk",
"ayb",
"ayg",
"ayi",
"ayn",
"ayo",
"ayp",
"ayr",
"ayt",
"ayu",
"ayz",
"azb",
"azd",
"azg",
"azj",
"azm",
"azt",
"azz",
"baa",
"bab",
"bac",
"bag",
"bam",
"ban",
"bao",
"bap",
"bar",
"bas",
"bau",
"bav",
"baw",
"bax",
"bba",
"bbb",
"bbc",
"bbf",
"bbi",
"bbk",
"bbo",
"bbp",
"bbq",
"bbr",
"bbt",
"bbu",
"bbv",
"bbw",
"bby",
"bca",
"bcc",
"bcf",
"bcg",
"bci",
"bcj",
"bcl",
"bcn",
"bco",
"bcp",
"bcq",
"bcr",
"bcs",
"bcv",
"bcw",
"bcy",
"bcz",
"bda",
"bdb",
"bdd",
"bde",
"bdh",
"bdi",
"bdl",
"bdm",
"bdq",
"bdu",
"bdv",
"bdw",
"bea",
"bec",
"bee",
"bef",
"beh",
"bei",
"bej",
"bek",
"bel",
"bem",
"ben",
"beo",
"bep",
"beq",
"bet",
"beu",
"bev",
"bew",
"bex",
"bey",
"bez",
"bfa",
"bfb",
"bfd",
"bfe",
"bfg",
"bfh",
"bfj",
"bfm",
"bfo",
"bfq",
"bfr",
"bfs",
"bft",
"bfu",
"bfw",
"bfy",
"bfz",
"bga",
"bgc",
"bgd",
"bge",
"bgf",
"bgg",
"bgi",
"bgj",
"bgn",
"bgp",
"bgq",
"bgr",
"bgs",
"bgt",
"bgv",
"bgw",
"bgx",
"bgz",
"bha",
"bhb",
"bhd",
"bhf",
"bhg",
"bhh",
"bhi",
"bhj",
"bhl",
"bho",
"bhp",
"bhq",
"bhr",
"bhs",
"bht",
"bhu",
"bhw",
"bhx",
"bhy",
"bhz",
"bib",
"bid",
"bif",
"big",
"bil",
"bim",
"bin",
"bio",
"bip",
"bis",
"bit",
"biu",
"biv",
"bix",
"biy",
"biz",
"bja",
"bjc",
"bje",
"bjg",
"bjh",
"bji",
"bjj",
"bjk",
"bjn",
"bjo",
"bjp",
"bjr",
"bjt",
"bjx",
"bjz",
"bka",
"bkc",
"bkd",
"bkg",
"bkk",
"bkl",
"bkm",
"bkq",
"bkr",
"bks",
"bku",
"bkv",
"bkw",
"bkx",
"bky",
"bla",
"blb",
"blc",
"ble",
"blf",
"blh",
"bli",
"blk",
"blm",
"blo",
"blq",
"blr",
"blt",
"blw",
"bly",
"blz",
"bma",
"bmb",
"bmd",
"bmf",
"bmi",
"bmj",
"bmk",
"bmm",
"bmq",
"bmr",
"bmu",
"bmv",
"bni",
"bnj",
"bnm",
"bnn",
"bno",
"bnp",
"bns",
"bnv",
"bnx",
"boa",
"bob",
"bod",
"bof",
"boh",
"bol",
"bom",
"bon",
"boo",
"boq",
"bor",
"bos",
"bot",
"bou",
"bov",
"box",
"boz",
"bpa",
"bpe",
"bpn",
"bpp",
"bpr",
"bps",
"bpu",
"bpv",
"bpw",
"bpx",
"bpy",
"bpz",
"bqa",
"bqc",
"bqg",
"bqh",
"bqi",
"bqj",
"bqo",
"bqr",
"bqs",
"bqt",
"bqv",
"bqw",
"bqx",
"bra",
"brb",
"brd",
"bre",
"brf",
"brg",
"brh",
"bri",
"brl",
"brp",
"brq",
"brr",
"brt",
"bru",
"brv",
"brx",
"bsc",
"bse",
"bsf",
"bsh",
"bsi",
"bsk",
"bsn",
"bsp",
"bsq",
"bss",
"bst",
"bsy",
"bta",
"btd",
"bte",
"btg",
"btm",
"bts",
"btt",
"btu",
"btx",
"bub",
"bud",
"buf",
"bug",
"buh",
"bui",
"buj",
"buk",
"bul",
"bum",
"bun",
"buo",
"bus",
"buu",
"buw",
"bux",
"buz",
"bva",
"bvc",
"bvd",
"bvh",
"bvi",
"bvm",
"bvr",
"bvu",
"bvw",
"bvz",
"bwd",
"bwe",
"bwf",
"bwi",
"bwm",
"bwo",
"bwq",
"bwr",
"bws",
"bwt",
"bwu",
"bww",
"bwx",
"bxa",
"bxb",
"bxg",
"bxh",
"bxk",
"bxl",
"bxq",
"bxr",
"bxs",
"bya",
"byc",
"byd",
"bye",
"byj",
"byn",
"byo",
"byp",
"bys",
"byv",
"byx",
"byz",
"bza",
"bzd",
"bze",
"bzf",
"bzh",
"bzi",
"bzu",
"bzv",
"bzw",
"bzx",
"bzy",
"bzz",
"caa",
"cab",
"cac",
"cae",
"caf",
"cag",
"cak",
"can",
"cao",
"cap",
"caq",
"car",
"cas",
"cat",
"cav",
"cax",
"cay",
"caz",
"cbc",
"cbd",
"cbg",
"cbi",
"cbj",
"cbk",
"cbn",
"cbo",
"cbr",
"cbs",
"cbt",
"cbu",
"cbv",
"cce",
"ccg",
"cch",
"ccj",
"ccl",
"cco",
"ccp",
"cde",
"cdf",
"cdh",
"cdi",
"cdj",
"cdm",
"cdn",
"cdo",
"cdr",
"cdz",
"ceb",
"ceg",
"cek",
"ces",
"cfa",
"cfd",
"cfg",
"cfm",
"cgg",
"cgk",
"chb",
"chd",
"che",
"chf",
"chj",
"chk",
"chl",
"cho",
"chp",
"chq",
"chr",
"chw",
"chx",
"chy",
"cia",
"cib",
"cih",
"cik",
"cin",
"ciw",
"cja",
"cje",
"cjk",
"cjm",
"cjo",
"cjv",
"ckb",
"ckh",
"ckl",
"cko",
"ckt",
"cku",
"ckx",
"cky",
"cla",
"clc",
"cld",
"cle",
"cli",
"clj",
"clk",
"cll",
"clo",
"clt",
"clu",
"cly",
"cma",
"cme",
"cmn",
"cmo",
"cmr",
"cna",
"cnb",
"cnc",
"cnh",
"cni",
"cnk",
"cnl",
"cnq",
"cns",
"cnt",
"cnw",
"cob",
"coc",
"cod",
"cof",
"cog",
"coh",
"coj",
"com",
"con",
"cos",
"cou",
"cov",
"cox",
"coz",
"cpa",
"cpx",
"cqd",
"cra",
"crc",
"crh",
"crj",
"crk",
"crn",
"cro",
"crq",
"crt",
"crv",
"crw",
"crx",
"cry",
"csa",
"csh",
"csk",
"cso",
"csy",
"cta",
"ctd",
"cte",
"ctg",
"ctl",
"cto",
"ctp",
"ctt",
"ctu",
"ctz",
"cua",
"cub",
"cuc",
"cui",
"cuk",
"cul",
"cut",
"cuv",
"cux",
"cvg",
"cvn",
"cya",
"cyb",
"cym",
"cyo",
"czh",
"czn",
"czt",
"daa",
"dad",
"dag",
"dai",
"dak",
"dan",
"dao",
"daq",
"das",
"dav",
"daw",
"dax",
"dbb",
"dbd",
"dbi",
"dbj",
"dbm",
"dbn",
"dbq",
"dbv",
"dby",
"dcc",
"dde",
"ddg",
"ddn",
"dee",
"def",
"deg",
"deh",
"dei",
"dem",
"der",
"deu",
"dez",
"dga",
"dgc",
"dgd",
"dge",
"dgg",
"dgh",
"dgi",
"dgo",
"dgr",
"dgx",
"dgz",
"dhd",
"dhg",
"dhi",
"dhm",
"dhn",
"dho",
"dhv",
"dhw",
"dia",
"dib",
"did",
"dig",
"dih",
"dij",
"dik",
"dil",
"dim",
"dio",
"dip",
"dir",
"dis",
"diu",
"div",
"diw",
"diz",
"djc",
"dje",
"djk",
"djm",
"djn",
"djo",
"djr",
"dka",
"dks",
"dkx",
"dln",
"dma",
"dme",
"dmg",
"dmo",
"dmr",
"dms",
"dmw",
"dna",
"dnd",
"dni",
"dnj",
"dnn",
"dnw",
"dny",
"doa",
"dob",
"dof",
"doo",
"dop",
"dor",
"dos",
"dot",
"dow",
"dox",
"doy",
"doz",
"drd",
"dre",
"drg",
"dri",
"drs",
"dru",
"dry",
"dsh",
"dsn",
"dsq",
"dta",
"dtb",
"dtm",
"dtp",
"dts",
"dty",
"dua",
"dub",
"duc",
"due",
"dug",
"duh",
"dun",
"duq",
"dur",
"dus",
"duu",
"duv",
"duw",
"dva",
"dwa",
"dwr",
"dwu",
"dww",
"dwy",
"dwz",
"dya",
"dyg",
"dyi",
"dyo",
"dyu",
"dza",
"dzg",
"dzl",
"dzo",
"ebo",
"ebr",
"ebu",
"efi",
"ega",
"ego",
"eip",
"eit",
"eja",
"eka",
"ekg",
"ekl",
"ekp",
"ekr",
"eky",
"elk",
"ell",
"elm",
"ema",
"emb",
"eme",
"emg",
"emk",
"emn",
"emp",
"ems",
"ena",
"enb",
"end",
"eng",
"enl",
"enn",
"enq",
"env",
"enx",
"eot",
"epi",
"erg",
"erh",
"erk",
"ert",
"ese",
"esg",
"esh",
"esi",
"esk",
"ess",
"esu",
"etn",
"eto",
"etr",
"ets",
"etu",
"etx",
"eus",
"eve",
"evn",
"ewe",
"ewo",
"eyo",
"eza",
"eze",
"faa",
"fai",
"fak",
"fal",
"fan",
"fap",
"far",
"fat",
"fay",
"ffm",
"fie",
"fij",
"fin",
"fir",
"fla",
"fli",
"fll",
"flr",
"fod",
"foi",
"fon",
"for",
"fqs",
"fra",
"frc",
"frd",
"fry",
"fub",
"fuc",
"fue",
"fuf",
"fuh",
"fun",
"fuq",
"fut",
"fuu",
"fuv",
"fuy",
"fvr",
"fwe",
"gaa",
"gab",
"gad",
"gae",
"gaf",
"gah",
"gai",
"gaj",
"gaq",
"gar",
"gas",
"gau",
"gaw",
"gax",
"gaz",
"gbe",
"gbg",
"gbh",
"gbi",
"gbk",
"gbl",
"gbm",
"gbn",
"gbo",
"gbr",
"gbv",
"gby",
"gbz",
"gcd",
"gcf",
"gcn",
"gcr",
"gdb",
"gde",
"gdf",
"gdl",
"gdn",
"gdr",
"gdu",
"gdx",
"gea",
"geb",
"gec",
"ged",
"geg",
"gej",
"gek",
"gel",
"gew",
"gfk",
"gga",
"ggb",
"ggg",
"ggu",
"ggw",
"ghe",
"ghk",
"ghl",
"ghn",
"ghr",
"ghs",
"gia",
"gid",
"gig",
"gil",
"gim",
"gis",
"git",
"giw",
"giz",
"gjk",
"gjn",
"gju",
"gkn",
"gkp",
"gla",
"gle",
"glg",
"glh",
"glj",
"glk",
"glo",
"glr",
"glw",
"gmb",
"gmm",
"gmv",
"gmz",
"gna",
"gnb",
"gnd",
"gng",
"gni",
"gnk",
"gnm",
"gnn",
"gno",
"gnu",
"gnw",
"goa",
"gof",
"gog",
"goj",
"gok",
"gol",
"gom",
"gop",
"gor",
"gou",
"gow",
"gox",
"goz",
"gpa",
"gqa",
"gra",
"grd",
"grh",
"gri",
"grj",
"gro",
"grs",
"grt",
"gru",
"grv",
"grx",
"gry",
"gsw",
"gua",
"gub",
"guc",
"gud",
"gue",
"guf",
"gug",
"guh",
"gui",
"guj",
"guk",
"gul",
"gum",
"gun",
"guo",
"gup",
"guq",
"gur",
"gut",
"guu",
"guw",
"gux",
"guz",
"gvc",
"gvf",
"gvj",
"gvn",
"gvo",
"gvp",
"gvr",
"gvs",
"gwa",
"gwd",
"gwi",
"gwn",
"gwr",
"gwt",
"gww",
"gxx",
"gya",
"gyd",
"gym",
"gyr",
"gyz",
"haa",
"hac",
"had",
"hae",
"hag",
"hah",
"haj",
"hak",
"hal",
"haq",
"har",
"has",
"hat",
"hau",
"hav",
"haw",
"hay",
"haz",
"hbb",
"hbn",
"hca",
"hch",
"hdn",
"hdy",
"hea",
"heb",
"hed",
"heg",
"heh",
"hei",
"her",
"hgm",
"hgw",
"hia",
"hid",
"hif",
"hig",
"hii",
"hil",
"hin",
"hio",
"hix",
"hkk",
"hla",
"hlb",
"hld",
"hlt",
"hmb",
"hmd",
"hmg",
"hmj",
"hml",
"hmo",
"hmr",
"hms",
"hmt",
"hmw",
"hmz",
"hna",
"hnd",
"hne",
"hni",
"hnj",
"hnn",
"hno",
"hns",
"hoa",
"hoc",
"hoe",
"hoj",
"hol",
"hoo",
"hop",
"hot",
"how",
"hoy",
"hra",
"hre",
"hrm",
"hru",
"hrv",
"hsn",
"hto",
"hts",
"hub",
"huc",
"hue",
"huf",
"huh",
"hui",
"hul",
"hum",
"hun",
"hup",
"hur",
"hus",
"hut",
"huv",
"hux",
"hve",
"hvn",
"hvv",
"hwo",
"hye",
"hyw",
"iai",
"ian",
"iar",
"iba",
"ibb",
"ibd",
"ibg",
"ibl",
"ibm",
"ibo",
"iby",
"ica",
"ich",
"icr",
"ida",
"idi",
"idu",
"ifa",
"ifb",
"ife",
"ifk",
"ifm",
"ifu",
"ify",
"igb",
"ige",
"igl",
"ign",
"ihp",
"iii",
"ijc",
"ijj",
"ijn",
"ijs",
"ike",
"iki",
"ikk",
"iko",
"ikt",
"ikw",
"ikx",
"ilb",
"ilk",
"ilo",
"ilp",
"ilu",
"imo",
"ind",
"inj",
"ino",
"int",
"ior",
"iow",
"ipo",
"iqu",
"iqw",
"iri",
"irk",
"irn",
"irr",
"iru",
"irx",
"iry",
"isd",
"ish",
"isi",
"isk",
"isl",
"isn",
"iso",
"isu",
"ita",
"itd",
"ite",
"iti",
"ito",
"itr",
"its",
"itt",
"itv",
"ity",
"itz",
"ium",
"ivb",
"ivv",
"iwm",
"iws",
"ixl",
"iyo",
"iyx",
"izr",
"izz",
"jaa",
"jab",
"jac",
"jad",
"jaf",
"jam",
"jao",
"jaq",
"jat",
"jav",
"jax",
"jbj",
"jbm",
"jbu",
"jda",
"jdg",
"jeb",
"jeh",
"jei",
"jen",
"jer",
"jge",
"jgk",
"jib",
"jic",
"jid",
"jig",
"jio",
"jit",
"jiu",
"jiv",
"jiy",
"jkp",
"jkr",
"jku",
"jle",
"jma",
"jmb",
"jmc",
"jmd",
"jmi",
"jml",
"jmn",
"jmr",
"jms",
"jmx",
"jna",
"jnd",
"jni",
"jnj",
"jnl",
"jns",
"job",
"jog",
"jow",
"jpn",
"jqr",
"jra",
"jrt",
"jru",
"jub",
"juk",
"jul",
"jum",
"jun",
"juo",
"jup",
"jwi",
"jya",
"kaa",
"kab",
"kac",
"kad",
"kai",
"kaj",
"kak",
"kal",
"kam",
"kan",
"kao",
"kap",
"kaq",
"kas",
"kat",
"kay",
"kaz",
"kbb",
"kbc",
"kbd",
"kbh",
"kbj",
"kbl",
"kbm",
"kbo",
"kbp",
"kbq",
"kbr",
"kbv",
"kbx",
"kby",
"kbz",
"kcc",
"kcd",
"kce",
"kcf",
"kcg",
"kch",
"kci",
"kcj",
"kck",
"kcl",
"kcq",
"kcr",
"kcs",
"kcv",
"kcx",
"kdd",
"kde",
"kdh",
"kdi",
"kdj",
"kdl",
"kdm",
"kdp",
"kdq",
"kdt",
"kdu",
"kdx",
"kdy",
"kdz",
"kea",
"keb",
"kee",
"kef",
"kei",
"kej",
"kek",
"kel",
"kem",
"ken",
"keo",
"kep",
"ker",
"keu",
"kev",
"kex",
"key",
"kez",
"kfa",
"kfb",
"kfc",
"kfd",
"kfe",
"kff",
"kfg",
"kfh",
"kfi",
"kfk",
"kfm",
"kfo",
"kfp",
"kfq",
"kfr",
"kfs",
"kft",
"kfu",
"kfv",
"kfx",
"kfy",
"kfz",
"kga",
"kgb",
"kge",
"kgj",
"kgk",
"kgo",
"kgp",
"kgq",
"kgr",
"kgy",
"kha",
"khb",
"khc",
"khe",
"khg",
"khj",
"khk",
"khl",
"khm",
"khn",
"khq",
"khr",
"khs",
"kht",
"khu",
"khw",
"khy",
"khz",
"kia",
"kib",
"kic",
"kid",
"kie",
"kif",
"kih",
"kij",
"kik",
"kil",
"kin",
"kio",
"kip",
"kir",
"kis",
"kit",
"kiu",
"kiw",
"kix",
"kjb",
"kjc",
"kjd",
"kje",
"kjg",
"kji",
"kjl",
"kjo",
"kjp",
"kjq",
"kjr",
"kjs",
"kjt",
"kkc",
"kkd",
"kkf",
"kkh",
"kkj",
"kkk",
"kkn",
"kks",
"kku",
"kky",
"kkz",
"kla",
"klb",
"kle",
"klg",
"kli",
"klk",
"klo",
"klq",
"klr",
"kls",
"klu",
"klv",
"klw",
"klx",
"klz",
"kma",
"kmb",
"kmc",
"kmh",
"kmi",
"kmj",
"kmk",
"kml",
"kmm",
"kmn",
"kmo",
"kmp",
"kmq",
"kmr",
"kms",
"kmt",
"kmu",
"kmw",
"kmy",
"kmz",
"kna",
"knc",
"knd",
"kne",
"knf",
"kng",
"kni",
"knj",
"knk",
"knl",
"knm",
"knn",
"kno",
"knp",
"knt",
"knu",
"knv",
"knw",
"knx",
"kny",
"knz",
"kod",
"koe",
"kof",
"koh",
"koi",
"kol",
"koo",
"kor",
"kos",
"kot",
"kow",
"kpa",
"kpb",
"kpc",
"kph",
"kpj",
"kpk",
"kpl",
"kpm",
"kpo",
"kpq",
"kpr",
"kps",
"kpw",
"kpx",
"kpz",
"kqa",
"kqb",
"kqc",
"kqe",
"kqf",
"kqi",
"kqj",
"kqk",
"kql",
"kqm",
"kqn",
"kqo",
"kqp",
"kqs",
"kqw",
"kqy",
"kra",
"krc",
"krf",
"krh",
"kri",
"krj",
"krn",
"krp",
"krr",
"krs",
"kru",
"krv",
"krw",
"krx",
"ksb",
"ksd",
"ksf",
"ksg",
"ksi",
"ksj",
"ksm",
"ksn",
"ksp",
"kss",
"kst",
"ksu",
"ksv",
"ksw",
"ktb",
"ktc",
"ktf",
"ktm",
"ktn",
"ktp",
"ktu",
"ktv",
"kty",
"ktz",
"kua",
"kub",
"kud",
"kue",
"kuh",
"kui",
"kuj",
"kul",
"kun",
"kup",
"kus",
"kuy",
"kvb",
"kvd",
"kvf",
"kvg",
"kvi",
"kvj",
"kvl",
"kvm",
"kvn",
"kvo",
"kvq",
"kvr",
"kvt",
"kvu",
"kvv",
"kvw",
"kvx",
"kvy",
"kwa",
"kwb",
"kwc",
"kwd",
"kwe",
"kwf",
"kwg",
"kwi",
"kwj",
"kwk",
"kwl",
"kwn",
"kwo",
"kws",
"kwt",
"kwu",
"kwv",
"kwx",
"kxb",
"kxc",
"kxf",
"kxh",
"kxj",
"kxm",
"kxn",
"kxp",
"kxv",
"kxw",
"kxx",
"kxz",
"kyb",
"kyc",
"kye",
"kyf",
"kyg",
"kyh",
"kyk",
"kyo",
"kyq",
"kys",
"kyu",
"kyv",
"kyy",
"kyz",
"kza",
"kzc",
"kzf",
"kzi",
"kzm",
"kzq",
"kzr",
"kzs",
"laa",
"lac",
"lad",
"lae",
"lag",
"lai",
"laj",
"lal",
"lam",
"lan",
"lao",
"lar",
"las",
"law",
"lax",
"lbf",
"lbj",
"lbk",
"lbm",
"lbn",
"lbo",
"lbq",
"lbr",
"lbu",
"lbw",
"lbx",
"lcc",
"lch",
"lcm",
"lcp",
"ldb",
"ldg",
"ldi",
"ldj",
"ldk",
"ldl",
"ldm",
"ldo",
"ldp",
"ldq",
"lea",
"lec",
"led",
"lee",
"lef",
"leh",
"lek",
"lel",
"lem",
"lep",
"leq",
"ler",
"les",
"leu",
"lev",
"lew",
"lex",
"lez",
"lga",
"lgg",
"lgl",
"lgm",
"lgq",
"lgr",
"lgt",
"lgu",
"lhi",
"lhl",
"lhm",
"lhp",
"lht",
"lhu",
"lia",
"lic",
"lie",
"lif",
"lig",
"lih",
"lik",
"lil",
"lin",
"lip",
"liq",
"lir",
"lis",
"lit",
"liu",
"liw",
"liz",
"lje",
"ljp",
"lkh",
"lki",
"lkn",
"lkr",
"lkt",
"lky",
"lla",
"llc",
"lle",
"llg",
"lln",
"llp",
"llu",
"lma",
"lmd",
"lme",
"lmg",
"lmi",
"lmk",
"lml",
"lmn",
"lmp",
"lmu",
"lmx",
"lmy",
"lna",
"lnd",
"lns",
"lnu",
"loa",
"lob",
"loe",
"log",
"loh",
"lok",
"lol",
"lom",
"lop",
"loq",
"lor",
"los",
"lot",
"loy",
"loz",
"lpa",
"lpn",
"lpo",
"lra",
"lrc",
"lri",
"lrk",
"lrl",
"lrm",
"lro",
"lse",
"lsh",
"lsi",
"lsm",
"lsr",
"lti",
"ltz",
"lua",
"lub",
"luc",
"lue",
"lug",
"lui",
"luj",
"lul",
"lum",
"lun",
"luo",
"lup",
"lur",
"lus",
"luz",
"lva",
"lvk",
"lvs",
"lwg",
"lwl",
"lwo",
"lyg",
"lyn",
"lzz",
"maa",
"mab",
"mad",
"mae",
"maf",
"mag",
"mah",
"mai",
"maj",
"mak",
"mal",
"mam",
"mar",
"mas",
"mat",
"mau",
"mav",
"maw",
"max",
"maz",
"mbb",
"mbc",
"mbd",
"mbf",
"mbh",
"mbi",
"mbj",
"mbl",
"mbm",
"mbo",
"mbp",
"mbq",
"mbs",
"mbt",
"mbu",
"mbv",
"mbx",
"mbz",
"mca",
"mcc",
"mcd",
"mcf",
"mch",
"mck",
"mcn",
"mco",
"mcp",
"mcq",
"mcr",
"mcs",
"mct",
"mcu",
"mcw",
"mda",
"mdb",
"mdd",
"mde",
"mdh",
"mdj",
"mdk",
"mdm",
"mdn",
"mdr",
"mds",
"mdt",
"mdu",
"mdw",
"mdy",
"mea",
"med",
"mef",
"meh",
"mej",
"mek",
"men",
"mep",
"mer",
"meu",
"mev",
"mey",
"mez",
"mfa",
"mfb",
"mfc",
"mfd",
"mfe",
"mfg",
"mfh",
"mfi",
"mfj",
"mfk",
"mfl",
"mfm",
"mfn",
"mfo",
"mfq",
"mfv",
"mfy",
"mfz",
"mgb",
"mgc",
"mgd",
"mgf",
"mgg",
"mgh",
"mgi",
"mgk",
"mgl",
"mgm",
"mgo",
"mgp",
"mgr",
"mgu",
"mgw",
"mhc",
"mhi",
"mhk",
"mhl",
"mho",
"mhp",
"mhs",
"mhu",
"mhw",
"mhx",
"mhy",
"mhz",
"mib",
"mic",
"mie",
"mif",
"mig",
"mih",
"mii",
"mij",
"mil",
"mim",
"min",
"mio",
"mip",
"miq",
"mir",
"mit",
"miu",
"mix",
"miy",
"miz",
"mjc",
"mjg",
"mji",
"mjl",
"mjs",
"mjt",
"mjv",
"mjw",
"mjx",
"mjz",
"mkb",
"mkc",
"mkd",
"mke",
"mkf",
"mkg",
"mki",
"mkk",
"mkl",
"mkn",
"mks",
"mku",
"mkw",
"mkz",
"mla",
"mle",
"mlf",
"mlk",
"mlm",
"mln",
"mlq",
"mls",
"mlt",
"mlu",
"mlv",
"mlw",
"mlx",
"mma",
"mmc",
"mmd",
"mme",
"mmg",
"mmh",
"mml",
"mmm",
"mmn",
"mmp",
"mmx",
"mmy",
"mmz",
"mnb",
"mne",
"mnf",
"mng",
"mni",
"mnj",
"mnk",
"mnl",
"mnm",
"mnp",
"mnu",
"mnv",
"mnw",
"mnx",
"mnz",
"moa",
"moc",
"moe",
"mog",
"moh",
"moi",
"moj",
"mop",
"mor",
"mos",
"mot",
"mov",
"mox",
"moy",
"moz",
"mpc",
"mpd",
"mpe",
"mpg",
"mph",
"mpj",
"mpm",
"mpn",
"mpq",
"mpr",
"mps",
"mpt",
"mpx",
"mqg",
"mqh",
"mqj",
"mql",
"mqn",
"mqu",
"mqx",
"mqz",
"mrd",
"mrf",
"mrg",
"mrh",
"mri",
"mrl",
"mrm",
"mrn",
"mro",
"mrp",
"mrq",
"mrr",
"mrt",
"mrw",
"mrz",
"msc",
"mse",
"msg",
"msh",
"msi",
"msj",
"msk",
"msl",
"msm",
"msn",
"msw",
"msy",
"mta",
"mtb",
"mtd",
"mte",
"mtf",
"mtg",
"mti",
"mtk",
"mtl",
"mto",
"mtp",
"mtq",
"mtr",
"mtt",
"mtu",
"mua",
"mug",
"muh",
"mui",
"muk",
"mum",
"muo",
"mup",
"mur",
"mus",
"mut",
"muv",
"muy",
"muz",
"mva",
"mve",
"mvf",
"mvg",
"mvn",
"mvo",
"mvp",
"mvv",
"mvz",
"mwa",
"mwc",
"mwe",
"mwf",
"mwg",
"mwi",
"mwm",
"mwn",
"mwp",
"mwq",
"mwt",
"mwv",
"mww",
"mxa",
"mxb",
"mxd",
"mxe",
"mxh",
"mxj",
"mxl",
"mxm",
"mxn",
"mxp",
"mxq",
"mxs",
"mxt",
"mxu",
"mxv",
"mxx",
"mxy",
"mya",
"myb",
"mye",
"myh",
"myk",
"myl",
"mym",
"myp",
"myu",
"myw",
"myx",
"myy",
"mza",
"mzb",
"mzi",
"mzj",
"mzk",
"mzl",
"mzm",
"mzn",
"mzp",
"mzq",
"mzr",
"mzv",
"mzw",
"mzz",
"nab",
"nac",
"nag",
"naj",
"nak",
"nal",
"nan",
"nao",
"nap",
"naq",
"nar",
"nas",
"nat",
"nau",
"nav",
"naw",
"naz",
"nba",
"nbb",
"nbc",
"nbe",
"nbh",
"nbi",
"nbl",
"nbm",
"nbn",
"nbp",
"nbq",
"nbr",
"nbu",
"nbv",
"ncb",
"nce",
"ncf",
"ncg",
"ncj",
"ncl",
"ncm",
"nco",
"ncq",
"ncr",
"ncu",
"nda",
"ndb",
"ndc",
"ndd",
"nde",
"ndh",
"ndi",
"ndm",
"ndo",
"ndp",
"ndr",
"nds",
"ndu",
"ndv",
"ndx",
"ndy",
"ndz",
"neb",
"nen",
"neq",
"ner",
"nes",
"nev",
"new",
"ney",
"nez",
"nfa",
"nfd",
"nfl",
"nfr",
"nfu",
"nga",
"ngb",
"ngc",
"nge",
"ngi",
"ngj",
"ngl",
"ngn",
"ngs",
"ngt",
"ngu",
"ngw",
"ngz",
"nhb",
"nhd",
"nhe",
"nhg",
"nhi",
"nhn",
"nhp",
"nhr",
"nhu",
"nhv",
"nhw",
"nhx",
"nhy",
"nhz",
"nia",
"nid",
"nih",
"nii",
"nij",
"nil",
"nim",
"nin",
"niq",
"nir",
"nit",
"niu",
"niw",
"nix",
"niy",
"niz",
"nja",
"njb",
"njh",
"njj",
"njm",
"njn",
"njo",
"njs",
"njx",
"njz",
"nka",
"nkb",
"nke",
"nkh",
"nkk",
"nko",
"nku",
"nkw",
"nkx",
"nlc",
"nld",
"nlg",
"nli",
"nlj",
"nlk",
"nlo",
"nlu",
"nlv",
"nlx",
"nma",
"nmb",
"nmc",
"nmf",
"nmh",
"nmi",
"nmk",
"nmm",
"nmn",
"nmo",
"nms",
"nmz",
"nna",
"nnb",
"nnc",
"nnd",
"nng",
"nni",
"nnj",
"nnm",
"nno",
"nnp",
"nnu",
"nnw",
"nnz",
"noa",
"nod",
"noe",
"nof",
"nos",
"not",
"nou",
"noz",
"npb",
"nph",
"npi",
"npl",
"nps",
"npy",
"nqg",
"nqt",
"nqy",
"nre",
"nrf",
"nrg",
"nri",
"nsa",
"nsm",
"nso",
"nst",
"nti",
"ntj",
"ntk",
"ntm",
"nto",
"ntp",
"ntr",
"ntu",
"nud",
"nuf",
"nuj",
"nuk",
"nun",
"nuo",
"nup",
"nuq",
"nus",
"nut",
"nux",
"nuy",
"nwb",
"nwi",
"nwm",
"nxa",
"nxd",
"nxg",
"nxk",
"nxq",
"nxr",
"nya",
"nyb",
"nyd",
"nyf",
"nyg",
"nyh",
"nyi",
"nyj",
"nyk",
"nym",
"nyn",
"nyo",
"nyq",
"nys",
"nyu",
"nyw",
"nyy",
"nza",
"nzb",
"nzi",
"nzk",
"nzm",
"nzy",
"obo",
"ocu",
"odk",
"odu",
"ofu",
"ogb",
"ogc",
"ogg",
"ogo",
"oia",
"ojb",
"oka",
"oke",
"okh",
"oki",
"okr",
"oks",
"oku",
"okv",
"okx",
"ola",
"old",
"olu",
"oma",
"omb",
"one",
"ong",
"oni",
"onj",
"onn",
"ono",
"onp",
"ont",
"ood",
"opa",
"opm",
"ora",
"orc",
"ore",
"org",
"orh",
"oro",
"ors",
"ort",
"oru",
"orx",
"ory",
"orz",
"osi",
"oso",
"oss",
"ost",
"otd",
"ote",
"otm",
"otq",
"otr",
"ots",
"ott",
"otx",
"oub",
"owi",
"oyb",
"oyd",
"oym",
"ozm",
"pab",
"pac",
"pad",
"pag",
"pah",
"pai",
"pak",
"pam",
"pan",
"pao",
"pap",
"pau",
"pav",
"pay",
"pbb",
"pbc",
"pbg",
"pbi",
"pbl",
"pbm",
"pbn",
"pbo",
"pbp",
"pbs",
"pbt",
"pbu",
"pbv",
"pca",
"pcb",
"pcc",
"pce",
"pcf",
"pcg",
"pch",
"pci",
"pcj",
"pck",
"pcl",
"pcm",
"pcn",
"pcw",
"pdc",
"pdn",
"pdo",
"pdt",
"pdu",
"peb",
"peg",
"pei",
"pek",
"pem",
"pes",
"pex",
"pfe",
"pga",
"pgg",
"pha",
"phk",
"phl",
"phq",
"phr",
"pht",
"pia",
"pib",
"pic",
"pid",
"pih",
"pil",
"pio",
"pip",
"pir",
"pis",
"piu",
"piv",
"piy",
"pjt",
"pkb",
"pkg",
"pkh",
"pko",
"pkt",
"pku",
"plc",
"plg",
"plj",
"plk",
"pll",
"pln",
"plr",
"pls",
"plt",
"plu",
"plv",
"plw",
"pma",
"pmf",
"pmi",
"pmj",
"pmm",
"pmq",
"pmx",
"pmy",
"pnb",
"pnc",
"pne",
"png",
"pnq",
"pnu",
"pny",
"pnz",
"poc",
"poe",
"pof",
"poh",
"poi",
"pol",
"pon",
"poo",
"por",
"pos",
"pot",
"pov",
"pow",
"poy",
"ppi",
"ppk",
"ppl",
"ppm",
"ppo",
"ppq",
"ppt",
"pqa",
"pqm",
"prc",
"prf",
"pri",
"prm",
"prn",
"prs",
"prt",
"pru",
"prx",
"psa",
"pse",
"psh",
"psi",
"psn",
"pss",
"pst",
"psw",
"pta",
"ptu",
"pua",
"puc",
"pud",
"pug",
"pui",
"pum",
"puo",
"puu",
"pwa",
"pwb",
"pwg",
"pwm",
"pwn",
"pwo",
"pwr",
"pww",
"pxm",
"pym",
"pyu",
"qub",
"quc",
"qud",
"qug",
"quh",
"qui",
"qul",
"qum",
"qun",
"qus",
"quv",
"quw",
"qux",
"quy",
"quz",
"qvi",
"qvj",
"qvm",
"qvn",
"qvo",
"qvs",
"qvw",
"qwa",
"qwh",
"qws",
"qxa",
"qxl",
"qxn",
"qxp",
"qxq",
"qxs",
"qxu",
"raa",
"rab",
"rad",
"raf",
"rag",
"rah",
"rai",
"ral",
"ram",
"rao",
"rar",
"rat",
"rau",
"rav",
"raw",
"rbb",
"rcf",
"rdb",
"rei",
"rej",
"rel",
"res",
"rey",
"rgs",
"rgu",
"rhg",
"rhp",
"ria",
"rif",
"ril",
"rim",
"rin",
"rir",
"rji",
"rjs",
"rki",
"rkm",
"rmb",
"rmc",
"rml",
"rmn",
"rmo",
"rmq",
"rmt",
"rmy",
"rmz",
"rnd",
"rnl",
"rog",
"roh",
"rol",
"ron",
"roo",
"row",
"rro",
"rsw",
"rtm",
"rue",
"ruf",
"rug",
"rui",
"ruk",
"run",
"rus",
"ruy",
"ruz",
"rwa",
"rwk",
"rwo",
"rwr",
"ryu",
"saa",
"sab",
"sac",
"sad",
"saf",
"sag",
"sah",
"saj",
"san",
"sao",
"saq",
"sas",
"sat",
"sau",
"sav",
"saw",
"sax",
"say",
"saz",
"sba",
"sbb",
"sbc",
"sbd",
"sbe",
"sbg",
"sbh",
"sbk",
"sbl",
"sbn",
"sbp",
"sbr",
"sbs",
"sbu",
"sbx",
"sby",
"sbz",
"sce",
"scg",
"sch",
"sck",
"scl",
"scn",
"scp",
"scs",
"sct",
"scu",
"scv",
"scw",
"sda",
"sde",
"sdg",
"sdh",
"sdo",
"sdp",
"sdq",
"sdr",
"sea",
"sed",
"see",
"sef",
"seg",
"seh",
"sei",
"sek",
"sen",
"sep",
"ses",
"set",
"sev",
"sew",
"sey",
"sez",
"sfm",
"sfw",
"sgb",
"sgc",
"sgd",
"sge",
"sgh",
"sgi",
"sgj",
"sgp",
"sgr",
"sgw",
"sgy",
"sgz",
"sha",
"shb",
"shc",
"she",
"shg",
"shh",
"shi",
"shj",
"shk",
"shm",
"shn",
"sho",
"shp",
"shq",
"shr",
"shs",
"shu",
"shw",
"shy",
"sid",
"sie",
"sif",
"sig",
"sil",
"sin",
"sip",
"sir",
"siu",
"siw",
"siy",
"sja",
"sjb",
"sjg",
"sjl",
"sjm",
"sjo",
"sjp",
"sjr",
"skb",
"skd",
"skg",
"skj",
"skn",
"skq",
"skr",
"skt",
"sku",
"skv",
"skx",
"sky",
"slc",
"sld",
"sle",
"slk",
"slp",
"slr",
"slu",
"slv",
"slx",
"sly",
"slz",
"sme",
"smf",
"smh",
"sml",
"smn",
"smo",
"smq",
"smt",
"smu",
"smw",
"smy",
"sna",
"snc",
"snd",
"sne",
"snf",
"sng",
"snk",
"snl",
"snm",
"snn",
"snp",
"snq",
"sns",
"snv",
"snw",
"sny",
"soa",
"sob",
"soc",
"soe",
"soi",
"sok",
"sol",
"som",
"soo",
"sop",
"soq",
"sor",
"sos",
"sot",
"sou",
"soy",
"soz",
"spa",
"spm",
"spn",
"spo",
"spp",
"sps",
"spt",
"spu",
"spy",
"sqq",
"srb",
"src",
"sre",
"srl",
"srm",
"srn",
"sro",
"srp",
"srq",
"srr",
"sru",
"srx",
"sry",
"srz",
"ssb",
"sse",
"ssi",
"ssk",
"ssn",
"sso",
"sss",
"sst",
"ssw",
"ssx",
"ssy",
"stf",
"sti",
"stj",
"stk",
"sto",
"stp",
"sts",
"stt",
"stv",
"sua",
"sug",
"sui",
"suj",
"suk",
"sun",
"suq",
"sur",
"sus",
"suv",
"suy",
"suz",
"svb",
"svs",
"swb",
"swc",
"swe",
"swh",
"swi",
"swj",
"swk",
"swo",
"swp",
"swr",
"swv",
"sxb",
"sxn",
"sxw",
"sya",
"syb",
"syk",
"syl",
"sym",
"sys",
"syw",
"szb",
"szg",
"szp",
"szv",
"tab",
"tac",
"tah",
"taj",
"tak",
"tal",
"tam",
"tan",
"tao",
"tap",
"taq",
"tar",
"tat",
"tau",
"tav",
"taw",
"tay",
"taz",
"tba",
"tbc",
"tbf",
"tbg",
"tbj",
"tbk",
"tbl",
"tbo",
"tbp",
"tbt",
"tby",
"tbz",
"tca",
"tcc",
"tcd",
"tce",
"tcf",
"tcn",
"tcp",
"tcs",
"tcu",
"tcx",
"tcy",
"tcz",
"tdb",
"tdc",
"tdd",
"tdf",
"tdg",
"tdh",
"tdj",
"tdk",
"tdl",
"tdn",
"tdo",
"tds",
"tdt",
"tdv",
"tdx",
"tdy",
"ted",
"tee",
"tef",
"tei",
"tek",
"tel",
"tem",
"teo",
"teq",
"ter",
"tes",
"tet",
"tew",
"tex",
"tfi",
"tfn",
"tfr",
"tft",
"tga",
"tgc",
"tgd",
"tgj",
"tgk",
"tgl",
"tgo",
"tgp",
"tgs",
"tgw",
"tgy",
"tha",
"thd",
"the",
"thf",
"thk",
"thl",
"thm",
"thp",
"thq",
"thr",
"ths",
"thy",
"thz",
"tic",
"tif",
"tig",
"tii",
"tik",
"tio",
"tiq",
"tir",
"tis",
"tiv",
"tiw",
"tix",
"tiy",
"tja",
"tjg",
"tji",
"tkb",
"tkd",
"tke",
"tkg",
"tkp",
"tkq",
"tkt",
"tku",
"tkx",
"tla",
"tlb",
"tld",
"tlf",
"tli",
"tlj",
"tll",
"tlp",
"tlq",
"tlr",
"tls",
"tlx",
"tma",
"tmc",
"tmd",
"tmf",
"tml",
"tmn",
"tmq",
"tmy",
"tna",
"tnb",
"tnc",
"tng",
"tnk",
"tnl",
"tnm",
"tnn",
"tnp",
"tnr",
"tnt",
"tnv",
"tny",
"tob",
"toc",
"tod",
"tof",
"tog",
"toj",
"tol",
"tom",
"ton",
"too",
"top",
"toq",
"tos",
"tou",
"tov",
"tow",
"tpa",
"tpe",
"tpi",
"tpj",
"tpl",
"tpm",
"tpp",
"tpq",
"tpr",
"tpu",
"tpx",
"tqo",
"tqu",
"tra",
"trc",
"trd",
"trf",
"tri",
"trn",
"tro",
"trp",
"trq",
"trs",
"tru",
"trv",
"tsa",
"tsb",
"tsc",
"tsg",
"tsi",
"tsj",
"tsn",
"tso",
"tsp",
"tsr",
"tsu",
"tsv",
"tsw",
"tsx",
"tsz",
"ttb",
"ttc",
"tte",
"tth",
"tti",
"ttj",
"ttk",
"ttm",
"tto",
"ttq",
"ttr",
"tts",
"ttv",
"ttw",
"tty",
"tuc",
"tue",
"tuf",
"tug",
"tui",
"tuk",
"tul",
"tum",
"tuo",
"tuq",
"tur",
"tus",
"tuv",
"tuy",
"tuz",
"tva",
"tvd",
"tvk",
"tvl",
"tvn",
"tvs",
"tvt",
"tvu",
"twb",
"twe",
"twf",
"twh",
"twi",
"twm",
"twp",
"twr",
"twu",
"tww",
"twx",
"twy",
"txa",
"txn",
"txo",
"txq",
"txt",
"txu",
"txy",
"tye",
"tyn",
"tyr",
"tyv",
"tyy",
"tyz",
"tzh",
"tzj",
"tzm",
"tzo",
"uar",
"uba",
"ubr",
"ubu",
"udg",
"udl",
"udu",
"ugo",
"uhn",
"uig",
"uis",
"uiv",
"uki",
"ukp",
"ukr",
"ukw",
"ula",
"ulu",
"umb",
"umm",
"ums",
"umu",
"une",
"ung",
"unr",
"unx",
"upv",
"ura",
"urb",
"urd",
"urh",
"uri",
"urk",
"url",
"urt",
"ury",
"usa",
"usi",
"usp",
"uss",
"uta",
"ute",
"uth",
"utr",
"uuu",
"uya",
"uzn",
"uzs",
"vaa",
"vaf",
"vag",
"vah",
"vai",
"vaj",
"vam",
"van",
"vap",
"var",
"vas",
"vav",
"vay",
"vem",
"ven",
"ver",
"vie",
"vif",
"vig",
"viv",
"vkl",
"vkn",
"vls",
"vmc",
"vmh",
"vmj",
"vmk",
"vmm",
"vmp",
"vmw",
"vmx",
"vmz",
"vnk",
"vor",
"vra",
"vrs",
"vum",
"vun",
"vut",
"wad",
"wal",
"wan",
"wap",
"war",
"was",
"wat",
"wau",
"waw",
"way",
"wbb",
"wbf",
"wbi",
"wbj",
"wbk",
"wbl",
"wbm",
"wbp",
"wbq",
"wbr",
"wca",
"wci",
"wdd",
"wdj",
"wed",
"weh",
"wem",
"weo",
"wes",
"wew",
"wgb",
"wgi",
"whg",
"wib",
"wic",
"wim",
"win",
"wiu",
"wja",
"wji",
"wkd",
"wlc",
"wle",
"wli",
"wlo",
"wlv",
"wlw",
"wlx",
"wmb",
"wmd",
"wme",
"wmo",
"wms",
"wmt",
"wmw",
"wnc",
"wni",
"wno",
"wnp",
"wob",
"wod",
"wof",
"wog",
"wol",
"wom",
"won",
"wow",
"wrk",
"wrm",
"wro",
"wrp",
"wrs",
"wry",
"wsa",
"wsi",
"wsk",
"wss",
"wti",
"wtm",
"wud",
"wut",
"wuu",
"wuv",
"wwa",
"wwo",
"wyy",
"xac",
"xal",
"xav",
"xbi",
"xbr",
"xdo",
"xdy",
"xed",
"xem",
"xer",
"xes",
"xgu",
"xho",
"xkb",
"xkc",
"xkf",
"xkg",
"xkj",
"xkk",
"xkl",
"xkn",
"xks",
"xkt",
"xkv",
"xky",
"xkz",
"xla",
"xmc",
"xmf",
"xmg",
"xmh",
"xmm",
"xmt",
"xmv",
"xmw",
"xmz",
"xnr",
"xns",
"xnz",
"xod",
"xog",
"xok",
"xom",
"xon",
"xpe",
"xra",
"xrb",
"xri",
"xrw",
"xsb",
"xsm",
"xsn",
"xsq",
"xsr",
"xsu",
"xta",
"xtc",
"xtd",
"xte",
"xti",
"xtj",
"xtl",
"xtm",
"xtn",
"xtt",
"xty",
"xub",
"xuj",
"xuu",
"xvi",
"xwe",
"xwg",
"xwl",
"yaa",
"yad",
"yae",
"yaf",
"yah",
"yak",
"yal",
"yam",
"yan",
"yao",
"yap",
"yaq",
"yaw",
"yax",
"yay",
"yaz",
"yba",
"ybb",
"ybe",
"ybh",
"ybi",
"ybj",
"ybl",
"ycl",
"ycn",
"ydd",
"yde",
"ydg",
"yea",
"yer",
"yes",
"yet",
"yeu",
"yev",
"yey",
"ygr",
"ygw",
"yhd",
"yif",
"yig",
"yij",
"yim",
"yin",
"yiq",
"yis",
"yiu",
"yix",
"yiz",
"yka",
"ykg",
"yki",
"ykk",
"ykm",
"yle",
"yll",
"ymb",
"ymk",
"yml",
"ymm",
"yno",
"ynq",
"yns",
"yog",
"yom",
"yon",
"yor",
"yot",
"yoy",
"yra",
"yrb",
"yre",
"yrl",
"ysn",
"ysp",
"yss",
"yua",
"yue",
"yuf",
"yui",
"yuj",
"yum",
"yun",
"yup",
"yuq",
"yur",
"yuy",
"yuz",
"yva",
"ywa",
"ywl",
"ywn",
"ywq",
"yyu",
"zaa",
"zab",
"zac",
"zad",
"zae",
"zaf",
"zag",
"zai",
"zaj",
"zak",
"zam",
"zao",
"zap",
"zar",
"zas",
"zat",
"zau",
"zav",
"zaw",
"zay",
"zaz",
"zbc",
"zbu",
"zca",
"zcd",
"zdj",
"zeh",
"zem",
"zgb",
"zhi",
"zia",
"zik",
"zim",
"zin",
"ziw",
"zkd",
"zkn",
"zkr",
"zlj",
"zlm",
"zln",
"zmb",
"zmp",
"zmq",
"zms",
"zne",
"zng",
"zns",
"zoc",
"zoh",
"zom",
"zos",
"zpa",
"zpc",
"zpd",
"zpe",
"zpg",
"zph",
"zpj",
"zpk",
"zpl",
"zpm",
"zpn",
"zpo",
"zpp",
"zpq",
"zpr",
"zps",
"zpu",
"zpv",
"zpw",
"zpx",
"zpy",
"zpz",
"zrg",
"zro",
"zrs",
"zsm",
"zte",
"ztg",
"ztl",
"ztp",
"ztq",
"zts",
"ztx",
"zty",
"zua",
"zul",
"zun",
"zuy",
"zwa",
"zyb",
"zyg",
"zyj",
"zyn",
"zyp",
"zzj",
"dataset:espnet/yodas",
"dataset:facebook/voxpopuli",
"dataset:facebook/multilingual_librispeech",
"dataset:google/fleurs",
"dataset:openslr/librispeech_asr",
"dataset:speechcolab/gigaspeech",
"dataset:cheulyop/ksponspeech",
"dataset:espnet/mms_ulab_v2",
"arxiv:2210.00077",
"arxiv:2106.07447",
"arxiv:2309.15317",
"arxiv:2305.10615",
"arxiv:2305.13516",
"arxiv:2312.05187",
"arxiv:2111.09296",
"arxiv:2407.00837",
"license:cc-by-nc-sa-4.0",
"region:us"
] |
automatic-speech-recognition
| 2024-06-25T04:25:33Z |
---
license: cc-by-nc-sa-4.0
datasets:
- espnet/yodas
- facebook/voxpopuli
- facebook/multilingual_librispeech
- google/fleurs
- openslr/librispeech_asr
- speechcolab/gigaspeech
- cheulyop/ksponspeech
- espnet/mms_ulab_v2
library_name: espnet
tags:
- espnet
- audio
- speech
- multilingual
- automatic-speech-recognition
language:
- multilingual
- aaa
- aab
- aac
- aad
- aaf
- aai
- aal
- aao
- aap
- aar
- aau
- aaw
- aaz
- aba
- abh
- abi
- abm
- abn
- abo
- abr
- abs
- abt
- abu
- abz
- aca
- acd
- ace
- acf
- ach
- acm
- acn
- acq
- acr
- acu
- acv
- acw
- acz
- ada
- add
- ade
- adh
- adi
- adj
- adl
- adn
- ado
- adq
- adx
- ady
- adz
- aeb
- aec
- aee
- ael
- aeu
- aey
- aez
- afb
- afe
- afi
- afo
- afr
- afu
- afz
- agb
- agc
- agd
- age
- agf
- agg
- agh
- agi
- agl
- agn
- agq
- agr
- ags
- agt
- agu
- agw
- agy
- aha
- ahb
- ahg
- ahk
- ahl
- ahp
- ahr
- ahs
- aia
- aif
- aii
- aik
- aim
- aio
- aiw
- aix
- ajg
- aji
- akb
- akc
- akd
- ake
- akf
- akg
- akh
- aki
- akl
- akp
- akq
- akr
- aks
- akt
- akw
- ala
- ald
- ale
- alf
- alh
- alj
- alk
- all
- aln
- alp
- alq
- als
- alt
- alu
- alw
- alx
- aly
- alz
- amb
- amc
- ame
- amf
- amh
- ami
- amk
- amm
- amn
- amo
- amr
- amt
- amu
- anc
- anf
- anj
- ank
- anl
- anm
- ann
- ano
- anp
- anr
- anu
- anv
- anw
- anx
- any
- aoe
- aof
- aog
- aoi
- aoj
- aol
- aom
- aon
- aot
- aoz
- apb
- apc
- apd
- ape
- apj
- apm
- apn
- app
- apr
- apt
- apu
- apw
- apy
- apz
- aqg
- aqm
- aqt
- arb
- are
- arg
- arh
- arl
- arn
- aro
- arp
- arq
- arr
- arv
- arw
- arx
- ary
- arz
- asa
- asb
- asc
- asi
- ask
- asm
- aso
- asr
- ass
- asu
- asy
- ata
- atb
- atd
- atg
- ati
- atk
- ato
- atp
- atq
- ats
- att
- atu
- aty
- auc
- aug
- aui
- auk
- aul
- aun
- aup
- auq
- auu
- auy
- ava
- avd
- avi
- avl
- avn
- avt
- avu
- awa
- awb
- awe
- awi
- awn
- awu
- aww
- axk
- ayb
- ayg
- ayi
- ayn
- ayo
- ayp
- ayr
- ayt
- ayu
- ayz
- azb
- azd
- azg
- azj
- azm
- azt
- azz
- baa
- bab
- bac
- bag
- bam
- ban
- bao
- bap
- bar
- bas
- bau
- bav
- baw
- bax
- bba
- bbb
- bbc
- bbf
- bbi
- bbk
- bbo
- bbp
- bbq
- bbr
- bbt
- bbu
- bbv
- bbw
- bby
- bca
- bcc
- bcf
- bcg
- bci
- bcj
- bcl
- bcn
- bco
- bcp
- bcq
- bcr
- bcs
- bcv
- bcw
- bcy
- bcz
- bda
- bdb
- bdd
- bde
- bdh
- bdi
- bdl
- bdm
- bdq
- bdu
- bdv
- bdw
- bea
- bec
- bee
- bef
- beh
- bei
- bej
- bek
- bel
- bem
- ben
- beo
- bep
- beq
- bet
- beu
- bev
- bew
- bex
- bey
- bez
- bfa
- bfb
- bfd
- bfe
- bfg
- bfh
- bfj
- bfm
- bfo
- bfq
- bfr
- bfs
- bft
- bfu
- bfw
- bfy
- bfz
- bga
- bgc
- bgd
- bge
- bgf
- bgg
- bgi
- bgj
- bgn
- bgp
- bgq
- bgr
- bgs
- bgt
- bgv
- bgw
- bgx
- bgz
- bha
- bhb
- bhd
- bhf
- bhg
- bhh
- bhi
- bhj
- bhl
- bho
- bhp
- bhq
- bhr
- bhs
- bht
- bhu
- bhw
- bhx
- bhy
- bhz
- bib
- bid
- bif
- big
- bil
- bim
- bin
- bio
- bip
- bis
- bit
- biu
- biv
- bix
- biy
- biz
- bja
- bjc
- bje
- bjg
- bjh
- bji
- bjj
- bjk
- bjn
- bjo
- bjp
- bjr
- bjt
- bjx
- bjz
- bka
- bkc
- bkd
- bkg
- bkk
- bkl
- bkm
- bkq
- bkr
- bks
- bku
- bkv
- bkw
- bkx
- bky
- bla
- blb
- blc
- ble
- blf
- blh
- bli
- blk
- blm
- blo
- blq
- blr
- blt
- blw
- bly
- blz
- bma
- bmb
- bmd
- bmf
- bmi
- bmj
- bmk
- bmm
- bmq
- bmr
- bmu
- bmv
- bni
- bnj
- bnm
- bnn
- bno
- bnp
- bns
- bnv
- bnx
- boa
- bob
- bod
- bof
- boh
- bol
- bom
- bon
- boo
- boq
- bor
- bos
- bot
- bou
- bov
- box
- boz
- bpa
- bpe
- bpn
- bpp
- bpr
- bps
- bpu
- bpv
- bpw
- bpx
- bpy
- bpz
- bqa
- bqc
- bqg
- bqh
- bqi
- bqj
- bqo
- bqr
- bqs
- bqt
- bqv
- bqw
- bqx
- bra
- brb
- brd
- bre
- brf
- brg
- brh
- bri
- brl
- brp
- brq
- brr
- brt
- bru
- brv
- brx
- bsc
- bse
- bsf
- bsh
- bsi
- bsk
- bsn
- bsp
- bsq
- bss
- bst
- bsy
- bta
- btd
- bte
- btg
- btm
- bts
- btt
- btu
- btx
- bub
- bud
- buf
- bug
- buh
- bui
- buj
- buk
- bul
- bum
- bun
- buo
- bus
- buu
- buw
- bux
- buz
- bva
- bvc
- bvd
- bvh
- bvi
- bvm
- bvr
- bvu
- bvw
- bvz
- bwd
- bwe
- bwf
- bwi
- bwm
- bwo
- bwq
- bwr
- bws
- bwt
- bwu
- bww
- bwx
- bxa
- bxb
- bxg
- bxh
- bxk
- bxl
- bxq
- bxr
- bxs
- bya
- byc
- byd
- bye
- byj
- byn
- byo
- byp
- bys
- byv
- byx
- byz
- bza
- bzd
- bze
- bzf
- bzh
- bzi
- bzu
- bzv
- bzw
- bzx
- bzy
- bzz
- caa
- cab
- cac
- cae
- caf
- cag
- cak
- can
- cao
- cap
- caq
- car
- cas
- cat
- cav
- cax
- cay
- caz
- cbc
- cbd
- cbg
- cbi
- cbj
- cbk
- cbn
- cbo
- cbr
- cbs
- cbt
- cbu
- cbv
- cce
- ccg
- cch
- ccj
- ccl
- cco
- ccp
- cde
- cdf
- cdh
- cdi
- cdj
- cdm
- cdn
- cdo
- cdr
- cdz
- ceb
- ceg
- cek
- ces
- cfa
- cfd
- cfg
- cfm
- cgg
- cgk
- chb
- chd
- che
- chf
- chj
- chk
- chl
- cho
- chp
- chq
- chr
- chw
- chx
- chy
- cia
- cib
- cih
- cik
- cin
- ciw
- cja
- cje
- cjk
- cjm
- cjo
- cjv
- ckb
- ckh
- ckl
- cko
- ckt
- cku
- ckx
- cky
- cla
- clc
- cld
- cle
- cli
- clj
- clk
- cll
- clo
- clt
- clu
- cly
- cma
- cme
- cmn
- cmo
- cmr
- cna
- cnb
- cnc
- cnh
- cni
- cnk
- cnl
- cnq
- cns
- cnt
- cnw
- cob
- coc
- cod
- cof
- cog
- coh
- coj
- com
- con
- cos
- cou
- cov
- cox
- coz
- cpa
- cpx
- cqd
- cra
- crc
- crh
- crj
- crk
- crn
- cro
- crq
- crt
- crv
- crw
- crx
- cry
- csa
- csh
- csk
- cso
- csy
- cta
- ctd
- cte
- ctg
- ctl
- cto
- ctp
- ctt
- ctu
- ctz
- cua
- cub
- cuc
- cui
- cuk
- cul
- cut
- cuv
- cux
- cvg
- cvn
- cya
- cyb
- cym
- cyo
- czh
- czn
- czt
- daa
- dad
- dag
- dai
- dak
- dan
- dao
- daq
- das
- dav
- daw
- dax
- dbb
- dbd
- dbi
- dbj
- dbm
- dbn
- dbq
- dbv
- dby
- dcc
- dde
- ddg
- ddn
- dee
- def
- deg
- deh
- dei
- dem
- der
- deu
- dez
- dga
- dgc
- dgd
- dge
- dgg
- dgh
- dgi
- dgo
- dgr
- dgx
- dgz
- dhd
- dhg
- dhi
- dhm
- dhn
- dho
- dhv
- dhw
- dia
- dib
- did
- dig
- dih
- dij
- dik
- dil
- dim
- dio
- dip
- dir
- dis
- diu
- div
- diw
- diz
- djc
- dje
- djk
- djm
- djn
- djo
- djr
- dka
- dks
- dkx
- dln
- dma
- dme
- dmg
- dmo
- dmr
- dms
- dmw
- dna
- dnd
- dni
- dnj
- dnn
- dnw
- dny
- doa
- dob
- dof
- doo
- dop
- dor
- dos
- dot
- dow
- dox
- doy
- doz
- drd
- dre
- drg
- dri
- drs
- dru
- dry
- dsh
- dsn
- dsq
- dta
- dtb
- dtm
- dtp
- dts
- dty
- dua
- dub
- duc
- due
- dug
- duh
- dun
- duq
- dur
- dus
- duu
- duv
- duw
- dva
- dwa
- dwr
- dwu
- dww
- dwy
- dwz
- dya
- dyg
- dyi
- dyo
- dyu
- dza
- dzg
- dzl
- dzo
- ebo
- ebr
- ebu
- efi
- ega
- ego
- eip
- eit
- eja
- eka
- ekg
- ekl
- ekp
- ekr
- eky
- elk
- ell
- elm
- ema
- emb
- eme
- emg
- emk
- emn
- emp
- ems
- ena
- enb
- end
- eng
- enl
- enn
- enq
- env
- enx
- eot
- epi
- erg
- erh
- erk
- ert
- ese
- esg
- esh
- esi
- esk
- ess
- esu
- etn
- eto
- etr
- ets
- etu
- etx
- eus
- eve
- evn
- ewe
- ewo
- eyo
- eza
- eze
- faa
- fai
- fak
- fal
- fan
- fap
- far
- fat
- fay
- ffm
- fie
- fij
- fin
- fir
- fla
- fli
- fll
- flr
- fod
- foi
- fon
- for
- fqs
- fra
- frc
- frd
- fry
- fub
- fuc
- fue
- fuf
- fuh
- fun
- fuq
- fut
- fuu
- fuv
- fuy
- fvr
- fwe
- gaa
- gab
- gad
- gae
- gaf
- gah
- gai
- gaj
- gaq
- gar
- gas
- gau
- gaw
- gax
- gaz
- gbe
- gbg
- gbh
- gbi
- gbk
- gbl
- gbm
- gbn
- gbo
- gbr
- gbv
- gby
- gbz
- gcd
- gcf
- gcn
- gcr
- gdb
- gde
- gdf
- gdl
- gdn
- gdr
- gdu
- gdx
- gea
- geb
- gec
- ged
- geg
- gej
- gek
- gel
- gew
- gfk
- gga
- ggb
- ggg
- ggu
- ggw
- ghe
- ghk
- ghl
- ghn
- ghr
- ghs
- gia
- gid
- gig
- gil
- gim
- gis
- git
- giw
- giz
- gjk
- gjn
- gju
- gkn
- gkp
- gla
- gle
- glg
- glh
- glj
- glk
- glo
- glr
- glw
- gmb
- gmm
- gmv
- gmz
- gna
- gnb
- gnd
- gng
- gni
- gnk
- gnm
- gnn
- gno
- gnu
- gnw
- goa
- gof
- gog
- goj
- gok
- gol
- gom
- gop
- gor
- gou
- gow
- gox
- goz
- gpa
- gqa
- gra
- grd
- grh
- gri
- grj
- gro
- grs
- grt
- gru
- grv
- grx
- gry
- gsw
- gua
- gub
- guc
- gud
- gue
- guf
- gug
- guh
- gui
- guj
- guk
- gul
- gum
- gun
- guo
- gup
- guq
- gur
- gut
- guu
- guw
- gux
- guz
- gvc
- gvf
- gvj
- gvn
- gvo
- gvp
- gvr
- gvs
- gwa
- gwd
- gwi
- gwn
- gwr
- gwt
- gww
- gxx
- gya
- gyd
- gym
- gyr
- gyz
- haa
- hac
- had
- hae
- hag
- hah
- haj
- hak
- hal
- haq
- har
- has
- hat
- hau
- hav
- haw
- hay
- haz
- hbb
- hbn
- hca
- hch
- hdn
- hdy
- hea
- heb
- hed
- heg
- heh
- hei
- her
- hgm
- hgw
- hia
- hid
- hif
- hig
- hii
- hil
- hin
- hio
- hix
- hkk
- hla
- hlb
- hld
- hlt
- hmb
- hmd
- hmg
- hmj
- hml
- hmo
- hmr
- hms
- hmt
- hmw
- hmz
- hna
- hnd
- hne
- hni
- hnj
- hnn
- hno
- hns
- hoa
- hoc
- hoe
- hoj
- hol
- hoo
- hop
- hot
- how
- hoy
- hra
- hre
- hrm
- hru
- hrv
- hsn
- hto
- hts
- hub
- huc
- hue
- huf
- huh
- hui
- hul
- hum
- hun
- hup
- hur
- hus
- hut
- huv
- hux
- hve
- hvn
- hvv
- hwo
- hye
- hyw
- iai
- ian
- iar
- iba
- ibb
- ibd
- ibg
- ibl
- ibm
- ibo
- iby
- ica
- ich
- icr
- ida
- idi
- idu
- ifa
- ifb
- ife
- ifk
- ifm
- ifu
- ify
- igb
- ige
- igl
- ign
- ihp
- iii
- ijc
- ijj
- ijn
- ijs
- ike
- iki
- ikk
- iko
- ikt
- ikw
- ikx
- ilb
- ilk
- ilo
- ilp
- ilu
- imo
- ind
- inj
- ino
- int
- ior
- iow
- ipo
- iqu
- iqw
- iri
- irk
- irn
- irr
- iru
- irx
- iry
- isd
- ish
- isi
- isk
- isl
- isn
- iso
- isu
- ita
- itd
- ite
- iti
- ito
- itr
- its
- itt
- itv
- ity
- itz
- ium
- ivb
- ivv
- iwm
- iws
- ixl
- iyo
- iyx
- izr
- izz
- jaa
- jab
- jac
- jad
- jaf
- jam
- jao
- jaq
- jat
- jav
- jax
- jbj
- jbm
- jbu
- jda
- jdg
- jeb
- jeh
- jei
- jen
- jer
- jge
- jgk
- jib
- jic
- jid
- jig
- jio
- jit
- jiu
- jiv
- jiy
- jkp
- jkr
- jku
- jle
- jma
- jmb
- jmc
- jmd
- jmi
- jml
- jmn
- jmr
- jms
- jmx
- jna
- jnd
- jni
- jnj
- jnl
- jns
- job
- jog
- jow
- jpn
- jqr
- jra
- jrt
- jru
- jub
- juk
- jul
- jum
- jun
- juo
- jup
- jwi
- jya
- kaa
- kab
- kac
- kad
- kai
- kaj
- kak
- kal
- kam
- kan
- kao
- kap
- kaq
- kas
- kat
- kay
- kaz
- kbb
- kbc
- kbd
- kbh
- kbj
- kbl
- kbm
- kbo
- kbp
- kbq
- kbr
- kbv
- kbx
- kby
- kbz
- kcc
- kcd
- kce
- kcf
- kcg
- kch
- kci
- kcj
- kck
- kcl
- kcq
- kcr
- kcs
- kcv
- kcx
- kdd
- kde
- kdh
- kdi
- kdj
- kdl
- kdm
- kdp
- kdq
- kdt
- kdu
- kdx
- kdy
- kdz
- kea
- keb
- kee
- kef
- kei
- kej
- kek
- kel
- kem
- ken
- keo
- kep
- ker
- keu
- kev
- kex
- key
- kez
- kfa
- kfb
- kfc
- kfd
- kfe
- kff
- kfg
- kfh
- kfi
- kfk
- kfm
- kfo
- kfp
- kfq
- kfr
- kfs
- kft
- kfu
- kfv
- kfx
- kfy
- kfz
- kga
- kgb
- kge
- kgj
- kgk
- kgo
- kgp
- kgq
- kgr
- kgy
- kha
- khb
- khc
- khe
- khg
- khj
- khk
- khl
- khm
- khn
- khq
- khr
- khs
- kht
- khu
- khw
- khy
- khz
- kia
- kib
- kic
- kid
- kie
- kif
- kih
- kij
- kik
- kil
- kin
- kio
- kip
- kir
- kis
- kit
- kiu
- kiw
- kix
- kjb
- kjc
- kjd
- kje
- kjg
- kji
- kjl
- kjo
- kjp
- kjq
- kjr
- kjs
- kjt
- kkc
- kkd
- kkf
- kkh
- kkj
- kkk
- kkn
- kks
- kku
- kky
- kkz
- kla
- klb
- kle
- klg
- kli
- klk
- klo
- klq
- klr
- kls
- klu
- klv
- klw
- klx
- klz
- kma
- kmb
- kmc
- kmh
- kmi
- kmj
- kmk
- kml
- kmm
- kmn
- kmo
- kmp
- kmq
- kmr
- kms
- kmt
- kmu
- kmw
- kmy
- kmz
- kna
- knc
- knd
- kne
- knf
- kng
- kni
- knj
- knk
- knl
- knm
- knn
- kno
- knp
- knt
- knu
- knv
- knw
- knx
- kny
- knz
- kod
- koe
- kof
- koh
- koi
- kol
- koo
- kor
- kos
- kot
- kow
- kpa
- kpb
- kpc
- kph
- kpj
- kpk
- kpl
- kpm
- kpo
- kpq
- kpr
- kps
- kpw
- kpx
- kpz
- kqa
- kqb
- kqc
- kqe
- kqf
- kqi
- kqj
- kqk
- kql
- kqm
- kqn
- kqo
- kqp
- kqs
- kqw
- kqy
- kra
- krc
- krf
- krh
- kri
- krj
- krn
- krp
- krr
- krs
- kru
- krv
- krw
- krx
- ksb
- ksd
- ksf
- ksg
- ksi
- ksj
- ksm
- ksn
- ksp
- kss
- kst
- ksu
- ksv
- ksw
- ktb
- ktc
- ktf
- ktm
- ktn
- ktp
- ktu
- ktv
- kty
- ktz
- kua
- kub
- kud
- kue
- kuh
- kui
- kuj
- kul
- kun
- kup
- kus
- kuy
- kvb
- kvd
- kvf
- kvg
- kvi
- kvj
- kvl
- kvm
- kvn
- kvo
- kvq
- kvr
- kvt
- kvu
- kvv
- kvw
- kvx
- kvy
- kwa
- kwb
- kwc
- kwd
- kwe
- kwf
- kwg
- kwi
- kwj
- kwk
- kwl
- kwn
- kwo
- kws
- kwt
- kwu
- kwv
- kwx
- kxb
- kxc
- kxf
- kxh
- kxj
- kxm
- kxn
- kxp
- kxv
- kxw
- kxx
- kxz
- kyb
- kyc
- kye
- kyf
- kyg
- kyh
- kyk
- kyo
- kyq
- kys
- kyu
- kyv
- kyy
- kyz
- kza
- kzc
- kzf
- kzi
- kzm
- kzq
- kzr
- kzs
- laa
- lac
- lad
- lae
- lag
- lai
- laj
- lal
- lam
- lan
- lao
- lar
- las
- law
- lax
- lbf
- lbj
- lbk
- lbm
- lbn
- lbo
- lbq
- lbr
- lbu
- lbw
- lbx
- lcc
- lch
- lcm
- lcp
- ldb
- ldg
- ldi
- ldj
- ldk
- ldl
- ldm
- ldo
- ldp
- ldq
- lea
- lec
- led
- lee
- lef
- leh
- lek
- lel
- lem
- lep
- leq
- ler
- les
- leu
- lev
- lew
- lex
- lez
- lga
- lgg
- lgl
- lgm
- lgq
- lgr
- lgt
- lgu
- lhi
- lhl
- lhm
- lhp
- lht
- lhu
- lia
- lic
- lie
- lif
- lig
- lih
- lik
- lil
- lin
- lip
- liq
- lir
- lis
- lit
- liu
- liw
- liz
- lje
- ljp
- lkh
- lki
- lkn
- lkr
- lkt
- lky
- lla
- llc
- lle
- llg
- lln
- llp
- llu
- lma
- lmd
- lme
- lmg
- lmi
- lmk
- lml
- lmn
- lmp
- lmu
- lmx
- lmy
- lna
- lnd
- lns
- lnu
- loa
- lob
- loe
- log
- loh
- lok
- lol
- lom
- lop
- loq
- lor
- los
- lot
- loy
- loz
- lpa
- lpn
- lpo
- lra
- lrc
- lri
- lrk
- lrl
- lrm
- lro
- lse
- lsh
- lsi
- lsm
- lsr
- lti
- ltz
- lua
- lub
- luc
- lue
- lug
- lui
- luj
- lul
- lum
- lun
- luo
- lup
- lur
- lus
- luz
- lva
- lvk
- lvs
- lwg
- lwl
- lwo
- lyg
- lyn
- lzz
- maa
- mab
- mad
- mae
- maf
- mag
- mah
- mai
- maj
- mak
- mal
- mam
- mar
- mas
- mat
- mau
- mav
- maw
- max
- maz
- mbb
- mbc
- mbd
- mbf
- mbh
- mbi
- mbj
- mbl
- mbm
- mbo
- mbp
- mbq
- mbs
- mbt
- mbu
- mbv
- mbx
- mbz
- mca
- mcc
- mcd
- mcf
- mch
- mck
- mcn
- mco
- mcp
- mcq
- mcr
- mcs
- mct
- mcu
- mcw
- mda
- mdb
- mdd
- mde
- mdh
- mdj
- mdk
- mdm
- mdn
- mdr
- mds
- mdt
- mdu
- mdw
- mdy
- mea
- med
- mef
- meh
- mej
- mek
- men
- mep
- mer
- meu
- mev
- mey
- mez
- mfa
- mfb
- mfc
- mfd
- mfe
- mfg
- mfh
- mfi
- mfj
- mfk
- mfl
- mfm
- mfn
- mfo
- mfq
- mfv
- mfy
- mfz
- mgb
- mgc
- mgd
- mgf
- mgg
- mgh
- mgi
- mgk
- mgl
- mgm
- mgo
- mgp
- mgr
- mgu
- mgw
- mhc
- mhi
- mhk
- mhl
- mho
- mhp
- mhs
- mhu
- mhw
- mhx
- mhy
- mhz
- mib
- mic
- mie
- mif
- mig
- mih
- mii
- mij
- mil
- mim
- min
- mio
- mip
- miq
- mir
- mit
- miu
- mix
- miy
- miz
- mjc
- mjg
- mji
- mjl
- mjs
- mjt
- mjv
- mjw
- mjx
- mjz
- mkb
- mkc
- mkd
- mke
- mkf
- mkg
- mki
- mkk
- mkl
- mkn
- mks
- mku
- mkw
- mkz
- mla
- mle
- mlf
- mlk
- mlm
- mln
- mlq
- mls
- mlt
- mlu
- mlv
- mlw
- mlx
- mma
- mmc
- mmd
- mme
- mmg
- mmh
- mml
- mmm
- mmn
- mmp
- mmx
- mmy
- mmz
- mnb
- mne
- mnf
- mng
- mni
- mnj
- mnk
- mnl
- mnm
- mnp
- mnu
- mnv
- mnw
- mnx
- mnz
- moa
- moc
- moe
- mog
- moh
- moi
- moj
- mop
- mor
- mos
- mot
- mov
- mox
- moy
- moz
- mpc
- mpd
- mpe
- mpg
- mph
- mpj
- mpm
- mpn
- mpq
- mpr
- mps
- mpt
- mpx
- mqg
- mqh
- mqj
- mql
- mqn
- mqu
- mqx
- mqz
- mrd
- mrf
- mrg
- mrh
- mri
- mrl
- mrm
- mrn
- mro
- mrp
- mrq
- mrr
- mrt
- mrw
- mrz
- msc
- mse
- msg
- msh
- msi
- msj
- msk
- msl
- msm
- msn
- msw
- msy
- mta
- mtb
- mtd
- mte
- mtf
- mtg
- mti
- mtk
- mtl
- mto
- mtp
- mtq
- mtr
- mtt
- mtu
- mua
- mug
- muh
- mui
- muk
- mum
- muo
- mup
- mur
- mus
- mut
- muv
- muy
- muz
- mva
- mve
- mvf
- mvg
- mvn
- mvo
- mvp
- mvv
- mvz
- mwa
- mwc
- mwe
- mwf
- mwg
- mwi
- mwm
- mwn
- mwp
- mwq
- mwt
- mwv
- mww
- mxa
- mxb
- mxd
- mxe
- mxh
- mxj
- mxl
- mxm
- mxn
- mxp
- mxq
- mxs
- mxt
- mxu
- mxv
- mxx
- mxy
- mya
- myb
- mye
- myh
- myk
- myl
- mym
- myp
- myu
- myw
- myx
- myy
- mza
- mzb
- mzi
- mzj
- mzk
- mzl
- mzm
- mzn
- mzp
- mzq
- mzr
- mzv
- mzw
- mzz
- nab
- nac
- nag
- naj
- nak
- nal
- nan
- nao
- nap
- naq
- nar
- nas
- nat
- nau
- nav
- naw
- naz
- nba
- nbb
- nbc
- nbe
- nbh
- nbi
- nbl
- nbm
- nbn
- nbp
- nbq
- nbr
- nbu
- nbv
- ncb
- nce
- ncf
- ncg
- ncj
- ncl
- ncm
- nco
- ncq
- ncr
- ncu
- nda
- ndb
- ndc
- ndd
- nde
- ndh
- ndi
- ndm
- ndo
- ndp
- ndr
- nds
- ndu
- ndv
- ndx
- ndy
- ndz
- neb
- nen
- neq
- ner
- nes
- nev
- new
- ney
- nez
- nfa
- nfd
- nfl
- nfr
- nfu
- nga
- ngb
- ngc
- nge
- ngi
- ngj
- ngl
- ngn
- ngs
- ngt
- ngu
- ngw
- ngz
- nhb
- nhd
- nhe
- nhg
- nhi
- nhn
- nhp
- nhr
- nhu
- nhv
- nhw
- nhx
- nhy
- nhz
- nia
- nid
- nih
- nii
- nij
- nil
- nim
- nin
- niq
- nir
- nit
- niu
- niw
- nix
- niy
- niz
- nja
- njb
- njh
- njj
- njm
- njn
- njo
- njs
- njx
- njz
- nka
- nkb
- nke
- nkh
- nkk
- nko
- nku
- nkw
- nkx
- nlc
- nld
- nlg
- nli
- nlj
- nlk
- nlo
- nlu
- nlv
- nlx
- nma
- nmb
- nmc
- nmf
- nmh
- nmi
- nmk
- nmm
- nmn
- nmo
- nms
- nmz
- nna
- nnb
- nnc
- nnd
- nng
- nni
- nnj
- nnm
- nno
- nnp
- nnu
- nnw
- nnz
- noa
- nod
- noe
- nof
- nos
- not
- nou
- noz
- npb
- nph
- npi
- npl
- nps
- npy
- nqg
- nqt
- nqy
- nre
- nrf
- nrg
- nri
- nsa
- nsm
- nso
- nst
- nti
- ntj
- ntk
- ntm
- nto
- ntp
- ntr
- ntu
- nud
- nuf
- nuj
- nuk
- nun
- nuo
- nup
- nuq
- nus
- nut
- nux
- nuy
- nwb
- nwi
- nwm
- nxa
- nxd
- nxg
- nxk
- nxq
- nxr
- nya
- nyb
- nyd
- nyf
- nyg
- nyh
- nyi
- nyj
- nyk
- nym
- nyn
- nyo
- nyq
- nys
- nyu
- nyw
- nyy
- nza
- nzb
- nzi
- nzk
- nzm
- nzy
- obo
- ocu
- odk
- odu
- ofu
- ogb
- ogc
- ogg
- ogo
- oia
- ojb
- oka
- oke
- okh
- oki
- okr
- oks
- oku
- okv
- okx
- ola
- old
- olu
- oma
- omb
- one
- ong
- oni
- onj
- onn
- ono
- onp
- ont
- ood
- opa
- opm
- ora
- orc
- ore
- org
- orh
- oro
- ors
- ort
- oru
- orx
- ory
- orz
- osi
- oso
- oss
- ost
- otd
- ote
- otm
- otq
- otr
- ots
- ott
- otx
- oub
- owi
- oyb
- oyd
- oym
- ozm
- pab
- pac
- pad
- pag
- pah
- pai
- pak
- pam
- pan
- pao
- pap
- pau
- pav
- pay
- pbb
- pbc
- pbg
- pbi
- pbl
- pbm
- pbn
- pbo
- pbp
- pbs
- pbt
- pbu
- pbv
- pca
- pcb
- pcc
- pce
- pcf
- pcg
- pch
- pci
- pcj
- pck
- pcl
- pcm
- pcn
- pcw
- pdc
- pdn
- pdo
- pdt
- pdu
- peb
- peg
- pei
- pek
- pem
- pes
- pex
- pfe
- pga
- pgg
- pha
- phk
- phl
- phq
- phr
- pht
- pia
- pib
- pic
- pid
- pih
- pil
- pio
- pip
- pir
- pis
- piu
- piv
- piy
- pjt
- pkb
- pkg
- pkh
- pko
- pkt
- pku
- plc
- plg
- plj
- plk
- pll
- pln
- plr
- pls
- plt
- plu
- plv
- plw
- pma
- pmf
- pmi
- pmj
- pmm
- pmq
- pmx
- pmy
- pnb
- pnc
- pne
- png
- pnq
- pnu
- pny
- pnz
- poc
- poe
- pof
- poh
- poi
- pol
- pon
- poo
- por
- pos
- pot
- pov
- pow
- poy
- ppi
- ppk
- ppl
- ppm
- ppo
- ppq
- ppt
- pqa
- pqm
- prc
- prf
- pri
- prm
- prn
- prs
- prt
- pru
- prx
- psa
- pse
- psh
- psi
- psn
- pss
- pst
- psw
- pta
- ptu
- pua
- puc
- pud
- pug
- pui
- pum
- puo
- puu
- pwa
- pwb
- pwg
- pwm
- pwn
- pwo
- pwr
- pww
- pxm
- pym
- pyu
- qub
- quc
- qud
- qug
- quh
- qui
- qul
- qum
- qun
- qus
- quv
- quw
- qux
- quy
- quz
- qvi
- qvj
- qvm
- qvn
- qvo
- qvs
- qvw
- qwa
- qwh
- qws
- qxa
- qxl
- qxn
- qxp
- qxq
- qxs
- qxu
- raa
- rab
- rad
- raf
- rag
- rah
- rai
- ral
- ram
- rao
- rar
- rat
- rau
- rav
- raw
- rbb
- rcf
- rdb
- rei
- rej
- rel
- res
- rey
- rgs
- rgu
- rhg
- rhp
- ria
- rif
- ril
- rim
- rin
- rir
- rji
- rjs
- rki
- rkm
- rmb
- rmc
- rml
- rmn
- rmo
- rmq
- rmt
- rmy
- rmz
- rnd
- rnl
- rog
- roh
- rol
- ron
- roo
- row
- rro
- rsw
- rtm
- rue
- ruf
- rug
- rui
- ruk
- run
- rus
- ruy
- ruz
- rwa
- rwk
- rwo
- rwr
- ryu
- saa
- sab
- sac
- sad
- saf
- sag
- sah
- saj
- san
- sao
- saq
- sas
- sat
- sau
- sav
- saw
- sax
- say
- saz
- sba
- sbb
- sbc
- sbd
- sbe
- sbg
- sbh
- sbk
- sbl
- sbn
- sbp
- sbr
- sbs
- sbu
- sbx
- sby
- sbz
- sce
- scg
- sch
- sck
- scl
- scn
- scp
- scs
- sct
- scu
- scv
- scw
- sda
- sde
- sdg
- sdh
- sdo
- sdp
- sdq
- sdr
- sea
- sed
- see
- sef
- seg
- seh
- sei
- sek
- sen
- sep
- ses
- set
- sev
- sew
- sey
- sez
- sfm
- sfw
- sgb
- sgc
- sgd
- sge
- sgh
- sgi
- sgj
- sgp
- sgr
- sgw
- sgy
- sgz
- sha
- shb
- shc
- she
- shg
- shh
- shi
- shj
- shk
- shm
- shn
- sho
- shp
- shq
- shr
- shs
- shu
- shw
- shy
- sid
- sie
- sif
- sig
- sil
- sin
- sip
- sir
- siu
- siw
- siy
- sja
- sjb
- sjg
- sjl
- sjm
- sjo
- sjp
- sjr
- skb
- skd
- skg
- skj
- skn
- skq
- skr
- skt
- sku
- skv
- skx
- sky
- slc
- sld
- sle
- slk
- slp
- slr
- slu
- slv
- slx
- sly
- slz
- sme
- smf
- smh
- sml
- smn
- smo
- smq
- smt
- smu
- smw
- smy
- sna
- snc
- snd
- sne
- snf
- sng
- snk
- snl
- snm
- snn
- snp
- snq
- sns
- snv
- snw
- sny
- soa
- sob
- soc
- soe
- soi
- sok
- sol
- som
- soo
- sop
- soq
- sor
- sos
- sot
- sou
- soy
- soz
- spa
- spm
- spn
- spo
- spp
- sps
- spt
- spu
- spy
- sqq
- srb
- src
- sre
- srl
- srm
- srn
- sro
- srp
- srq
- srr
- sru
- srx
- sry
- srz
- ssb
- sse
- ssi
- ssk
- ssn
- sso
- sss
- sst
- ssw
- ssx
- ssy
- stf
- sti
- stj
- stk
- sto
- stp
- sts
- stt
- stv
- sua
- sug
- sui
- suj
- suk
- sun
- suq
- sur
- sus
- suv
- suy
- suz
- svb
- svs
- swb
- swc
- swe
- swh
- swi
- swj
- swk
- swo
- swp
- swr
- swv
- sxb
- sxn
- sxw
- sya
- syb
- syk
- syl
- sym
- sys
- syw
- szb
- szg
- szp
- szv
- tab
- tac
- tah
- taj
- tak
- tal
- tam
- tan
- tao
- tap
- taq
- tar
- tat
- tau
- tav
- taw
- tay
- taz
- tba
- tbc
- tbf
- tbg
- tbj
- tbk
- tbl
- tbo
- tbp
- tbt
- tby
- tbz
- tca
- tcc
- tcd
- tce
- tcf
- tcn
- tcp
- tcs
- tcu
- tcx
- tcy
- tcz
- tdb
- tdc
- tdd
- tdf
- tdg
- tdh
- tdj
- tdk
- tdl
- tdn
- tdo
- tds
- tdt
- tdv
- tdx
- tdy
- ted
- tee
- tef
- tei
- tek
- tel
- tem
- teo
- teq
- ter
- tes
- tet
- tew
- tex
- tfi
- tfn
- tfr
- tft
- tga
- tgc
- tgd
- tgj
- tgk
- tgl
- tgo
- tgp
- tgs
- tgw
- tgy
- tha
- thd
- the
- thf
- thk
- thl
- thm
- thp
- thq
- thr
- ths
- thy
- thz
- tic
- tif
- tig
- tii
- tik
- tio
- tiq
- tir
- tis
- tiv
- tiw
- tix
- tiy
- tja
- tjg
- tji
- tkb
- tkd
- tke
- tkg
- tkp
- tkq
- tkt
- tku
- tkx
- tla
- tlb
- tld
- tlf
- tli
- tlj
- tll
- tlp
- tlq
- tlr
- tls
- tlx
- tma
- tmc
- tmd
- tmf
- tml
- tmn
- tmq
- tmy
- tna
- tnb
- tnc
- tng
- tnk
- tnl
- tnm
- tnn
- tnp
- tnr
- tnt
- tnv
- tny
- tob
- toc
- tod
- tof
- tog
- toj
- tol
- tom
- ton
- too
- top
- toq
- tos
- tou
- tov
- tow
- tpa
- tpe
- tpi
- tpj
- tpl
- tpm
- tpp
- tpq
- tpr
- tpu
- tpx
- tqo
- tqu
- tra
- trc
- trd
- trf
- tri
- trn
- tro
- trp
- trq
- trs
- tru
- trv
- tsa
- tsb
- tsc
- tsg
- tsi
- tsj
- tsn
- tso
- tsp
- tsr
- tsu
- tsv
- tsw
- tsx
- tsz
- ttb
- ttc
- tte
- tth
- tti
- ttj
- ttk
- ttm
- tto
- ttq
- ttr
- tts
- ttv
- ttw
- tty
- tuc
- tue
- tuf
- tug
- tui
- tuk
- tul
- tum
- tuo
- tuq
- tur
- tus
- tuv
- tuy
- tuz
- tva
- tvd
- tvk
- tvl
- tvn
- tvs
- tvt
- tvu
- twb
- twe
- twf
- twh
- twi
- twm
- twp
- twr
- twu
- tww
- twx
- twy
- txa
- txn
- txo
- txq
- txt
- txu
- txy
- tye
- tyn
- tyr
- tyv
- tyy
- tyz
- tzh
- tzj
- tzm
- tzo
- uar
- uba
- ubr
- ubu
- udg
- udl
- udu
- ugo
- uhn
- uig
- uis
- uiv
- uki
- ukp
- ukr
- ukw
- ula
- ulu
- umb
- umm
- ums
- umu
- une
- ung
- unr
- unx
- upv
- ura
- urb
- urd
- urh
- uri
- urk
- url
- urt
- ury
- usa
- usi
- usp
- uss
- uta
- ute
- uth
- utr
- uuu
- uya
- uzn
- uzs
- vaa
- vaf
- vag
- vah
- vai
- vaj
- vam
- van
- vap
- var
- vas
- vav
- vay
- vem
- ven
- ver
- vie
- vif
- vig
- viv
- vkl
- vkn
- vls
- vmc
- vmh
- vmj
- vmk
- vmm
- vmp
- vmw
- vmx
- vmz
- vnk
- vor
- vra
- vrs
- vum
- vun
- vut
- wad
- wal
- wan
- wap
- war
- was
- wat
- wau
- waw
- way
- wbb
- wbf
- wbi
- wbj
- wbk
- wbl
- wbm
- wbp
- wbq
- wbr
- wca
- wci
- wdd
- wdj
- wed
- weh
- wem
- weo
- wes
- wew
- wgb
- wgi
- whg
- wib
- wic
- wim
- win
- wiu
- wja
- wji
- wkd
- wlc
- wle
- wli
- wlo
- wlv
- wlw
- wlx
- wmb
- wmd
- wme
- wmo
- wms
- wmt
- wmw
- wnc
- wni
- wno
- wnp
- wob
- wod
- wof
- wog
- wol
- wom
- won
- wow
- wrk
- wrm
- wro
- wrp
- wrs
- wry
- wsa
- wsi
- wsk
- wss
- wti
- wtm
- wud
- wut
- wuu
- wuv
- wwa
- wwo
- wyy
- xac
- xal
- xav
- xbi
- xbr
- xdo
- xdy
- xed
- xem
- xer
- xes
- xgu
- xho
- xkb
- xkc
- xkf
- xkg
- xkj
- xkk
- xkl
- xkn
- xks
- xkt
- xkv
- xky
- xkz
- xla
- xmc
- xmf
- xmg
- xmh
- xmm
- xmt
- xmv
- xmw
- xmz
- xnr
- xns
- xnz
- xod
- xog
- xok
- xom
- xon
- xpe
- xra
- xrb
- xri
- xrw
- xsb
- xsm
- xsn
- xsq
- xsr
- xsu
- xta
- xtc
- xtd
- xte
- xti
- xtj
- xtl
- xtm
- xtn
- xtt
- xty
- xub
- xuj
- xuu
- xvi
- xwe
- xwg
- xwl
- yaa
- yad
- yae
- yaf
- yah
- yak
- yal
- yam
- yan
- yao
- yap
- yaq
- yaw
- yax
- yay
- yaz
- yba
- ybb
- ybe
- ybh
- ybi
- ybj
- ybl
- ycl
- ycn
- ydd
- yde
- ydg
- yea
- yer
- 'yes'
- yet
- yeu
- yev
- yey
- ygr
- ygw
- yhd
- yif
- yig
- yij
- yim
- yin
- yiq
- yis
- yiu
- yix
- yiz
- yka
- ykg
- yki
- ykk
- ykm
- yle
- yll
- ymb
- ymk
- yml
- ymm
- yno
- ynq
- yns
- yog
- yom
- yon
- yor
- yot
- yoy
- yra
- yrb
- yre
- yrl
- ysn
- ysp
- yss
- yua
- yue
- yuf
- yui
- yuj
- yum
- yun
- yup
- yuq
- yur
- yuy
- yuz
- yva
- ywa
- ywl
- ywn
- ywq
- yyu
- zaa
- zab
- zac
- zad
- zae
- zaf
- zag
- zai
- zaj
- zak
- zam
- zao
- zap
- zar
- zas
- zat
- zau
- zav
- zaw
- zay
- zaz
- zbc
- zbu
- zca
- zcd
- zdj
- zeh
- zem
- zgb
- zhi
- zia
- zik
- zim
- zin
- ziw
- zkd
- zkn
- zkr
- zlj
- zlm
- zln
- zmb
- zmp
- zmq
- zms
- zne
- zng
- zns
- zoc
- zoh
- zom
- zos
- zpa
- zpc
- zpd
- zpe
- zpg
- zph
- zpj
- zpk
- zpl
- zpm
- zpn
- zpo
- zpp
- zpq
- zpr
- zps
- zpu
- zpv
- zpw
- zpx
- zpy
- zpz
- zrg
- zro
- zrs
- zsm
- zte
- ztg
- ztl
- ztp
- ztq
- zts
- ztx
- zty
- zua
- zul
- zun
- zuy
- zwa
- zyb
- zyg
- zyj
- zyn
- zyp
- zzj
---
[XEUS - A Cross-lingual Encoder for Universal Speech](https://wanchichen.github.io/pdf/xeus.pdf)
XEUS is a large-scale multilingual speech encoder by Carnegie Mellon University's [WAVLab](https://www.wavlab.org/) that covers over **4000** languages.
It is pre-trained on over 1 million hours of publicly available speech datasets.
It requires fine-tuning to be used in downstream tasks such as Speech Recognition or Translation.
Its hidden states can also be used with k-means for semantic Speech Tokenization.
XEUS uses the [E-Branchformer](https://arxiv.org/abs/2210.00077) architecture and is trained using [HuBERT](https://arxiv.org/pdf/2106.07447)-style masked prediction of discrete speech tokens extracted from [WavLabLM](https://arxiv.org/abs/2309.15317).
During training, the input speech is also augmented with acoustic noise and reverberation, making XEUS more robust. The total model size is 577M parameters.
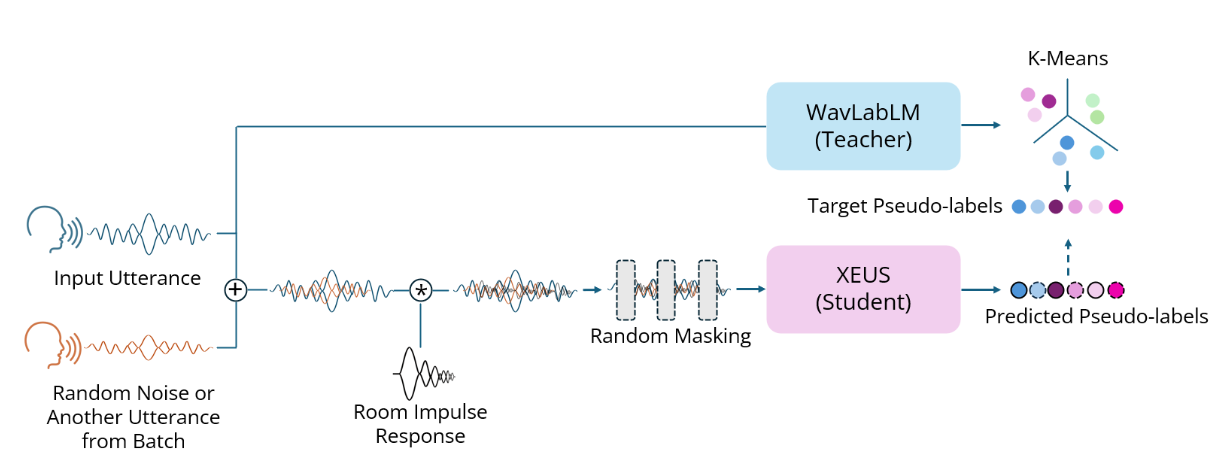
XEUS tops the [ML-SUPERB](https://arxiv.org/abs/2305.10615) multilingual speech recognition leaderboard, outperforming [MMS](https://arxiv.org/abs/2305.13516), [w2v-BERT 2.0](https://arxiv.org/abs/2312.05187), and [XLS-R](https://arxiv.org/abs/2111.09296).
XEUS also sets a new state-of-the-art on 4 tasks in the monolingual [SUPERB](https://superbbenchmark.org/) benchmark.
More information about XEUS, including ***download links for our crawled 4000-language dataset***, can be found in the [project page](https://www.wavlab.org/activities/2024/xeus/) and [paper](https://wanchichen.github.io/pdf/xeus.pdf).
## Requirements
The code for XEUS is still in progress of being merged into the main ESPnet repo. It can instead be used from the following fork:
```
pip install 'espnet @ git+https://github.com/wanchichen/espnet.git@ssl'
```
```
git lfs install
git clone https://huggingface.co/espnet/XEUS
```
XEUS supports [Flash Attention](https://github.com/Dao-AILab/flash-attention), which can be installed as follows:
```
pip install flash-attn --no-build-isolation
```
## Usage
```python
from torch.nn.utils.rnn import pad_sequence
from espnet2.tasks.ssl import SSLTask
import soundfile as sf
device = "cuda" if torch.cuda.is_available() else "cpu"
xeus_model, xeus_train_args = SSLTask.build_model_from_file(
None,
'/path/to/checkpoint/here/checkpoint.pth',
device,
)
wavs, sampling_rate = sf.read('/path/to/audio.wav') # sampling rate should be 16000
wav_lengths = torch.LongTensor([len(wav) for wav in [wavs]]).to(device)
wavs = pad_sequence(torch.Tensor([wavs]), batch_first=True).to(device)
# we recommend use_mask=True during fine-tuning
feats = xeus_model.encode(wavs, wav_lengths, use_mask=False, use_final_output=False)[0][-1] # take the output of the last layer -> batch_size x seq_len x hdim
```
With Flash Attention:
```python
[layer.use_flash_attn = True for layer in xeus_model.encoder.encoders]
with torch.cuda.amp.autocast(dtype=torch.bfloat16):
feats = xeus_model.encode(wavs, wav_lengths, use_mask=False, use_final_output=False)[0][-1]
```
Tune the masking settings:
```python
xeus_model.masker.mask_prob = 0.65 # default 0.8
xeus_model.masker.mask_length = 20 # default 10
xeus_model.masker.mask_selection = 'static' # default 'uniform'
xeus_model.train()
feats = xeus_model.encode(wavs, wav_lengths, use_mask=True, use_final_output=False)[0][-1]
```
## Results


```
@misc{chen2024robustspeechrepresentationlearning,
title={Towards Robust Speech Representation Learning for Thousands of Languages},
author={William Chen and Wangyou Zhang and Yifan Peng and Xinjian Li and Jinchuan Tian and Jiatong Shi and Xuankai Chang and Soumi Maiti and Karen Livescu and Shinji Watanabe},
year={2024},
eprint={2407.00837},
archivePrefix={arXiv},
primaryClass={cs.CL},
url={https://arxiv.org/abs/2407.00837},
}
```
|
dgambettaphd/M_llm2_run2_gen4_WXS_doc1000_synt64_lr1e-04_acm_SYNLAST
|
dgambettaphd
| 2025-06-17T02:41:12Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T02:40:42Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Ardasheva/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-skilled_giant_anteater
|
Ardasheva
| 2025-06-17T02:11:09Z | 28 | 0 |
transformers
|
[
"transformers",
"safetensors",
"qwen2",
"text-generation",
"generated_from_trainer",
"rl-swarm",
"grpo",
"gensyn",
"I am skilled giant anteater",
"trl",
"conversational",
"arxiv:2402.03300",
"base_model:unsloth/Qwen2.5-0.5B-Instruct",
"base_model:finetune:unsloth/Qwen2.5-0.5B-Instruct",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-11T23:09:54Z |
---
base_model: unsloth/Qwen2.5-0.5B-Instruct
library_name: transformers
model_name: Qwen2.5-0.5B-Instruct-Gensyn-Swarm-skilled_giant_anteater
tags:
- generated_from_trainer
- rl-swarm
- grpo
- gensyn
- I am skilled giant anteater
- trl
licence: license
---
# Model Card for Qwen2.5-0.5B-Instruct-Gensyn-Swarm-skilled_giant_anteater
This model is a fine-tuned version of [unsloth/Qwen2.5-0.5B-Instruct](https://huggingface.co/unsloth/Qwen2.5-0.5B-Instruct).
It has been trained using [TRL](https://github.com/huggingface/trl).
## Quick start
```python
from transformers import pipeline
question = "If you had a time machine, but could only go to the past or the future once and never return, which would you choose and why?"
generator = pipeline("text-generation", model="Ardasheva/Qwen2.5-0.5B-Instruct-Gensyn-Swarm-skilled_giant_anteater", device="cuda")
output = generator([{"role": "user", "content": question}], max_new_tokens=128, return_full_text=False)[0]
print(output["generated_text"])
```
## Training procedure
This model was trained with GRPO, a method introduced in [DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models](https://huggingface.co/papers/2402.03300).
### Framework versions
- TRL: 0.18.1
- Transformers: 4.52.4
- Pytorch: 2.7.1
- Datasets: 3.6.0
- Tokenizers: 0.21.1
## Citations
Cite GRPO as:
```bibtex
@article{zhihong2024deepseekmath,
title = {{DeepSeekMath: Pushing the Limits of Mathematical Reasoning in Open Language Models}},
author = {Zhihong Shao and Peiyi Wang and Qihao Zhu and Runxin Xu and Junxiao Song and Mingchuan Zhang and Y. K. Li and Y. Wu and Daya Guo},
year = 2024,
eprint = {arXiv:2402.03300},
}
```
Cite TRL as:
```bibtex
@misc{vonwerra2022trl,
title = {{TRL: Transformer Reinforcement Learning}},
author = {Leandro von Werra and Younes Belkada and Lewis Tunstall and Edward Beeching and Tristan Thrush and Nathan Lambert and Shengyi Huang and Kashif Rasul and Quentin Gallou{\'e}dec},
year = 2020,
journal = {GitHub repository},
publisher = {GitHub},
howpublished = {\url{https://github.com/huggingface/trl}}
}
```
|
wh-zhu/DeepSeek-R1-TrRa-iter1-1.5B-lambda_2
|
wh-zhu
| 2025-06-17T02:10:57Z | 4 | 0 | null |
[
"safetensors",
"qwen2",
"arxiv:2506.12704",
"region:us"
] | null | 2025-05-28T13:17:27Z |
<h1 align="center">🛠️ ReAligner</h1>
<p align="center">
<a href="https://arxiv.org/pdf/2506.12704"><img src="https://img.shields.io/badge/arXiv-arXiv%20Preprint-B31B1B?style=flat&logo=arxiv&logoColor=white" alt="arXiv Paper"></a>
<a href="https://github.com/zwhong714/ReAligner"><img src="https://img.shields.io/badge/Homepage-Project%20Page-brightgreen?style=flat&logo=github" alt="Homepage"></a>
<a href="https://huggingface.co/wh-zhu"><img src="https://img.shields.io/badge/Huggingface-Models-yellow?style=flat&logo=huggingface" alt="Models"></a>
</p>
<div>
A flexible realignment framework is proposed to quantitatively control alignment during training and inference, combining Training-time Realignment (TrRa) and Inference-time Realignment (InRa).
- We realign DeepScaleR-1.5B model and reduce token usage without performance loss and even enhance reasoning capabilities.
</div>
</div>
<div>
<br>

|
wh-zhu/DeepSeek-R1-TrRa-1.5B_lambda_0.5
|
wh-zhu
| 2025-06-17T02:06:44Z | 4 | 0 | null |
[
"safetensors",
"qwen2",
"arxiv:2506.12704",
"region:us"
] | null | 2025-05-29T06:02:38Z |
<h1 align="center">🛠️ ReAligner</h1>
<p align="center">
<a href="https://arxiv.org/pdf/2506.12704"><img src="https://img.shields.io/badge/arXiv-arXiv%20Preprint-B31B1B?style=flat&logo=arxiv&logoColor=white" alt="arXiv Paper"></a>
<a href="https://github.com/zwhong714/ReAligner"><img src="https://img.shields.io/badge/Homepage-Project%20Page-brightgreen?style=flat&logo=github" alt="Homepage"></a>
<a href="https://huggingface.co/wh-zhu"><img src="https://img.shields.io/badge/Huggingface-Models-yellow?style=flat&logo=huggingface" alt="Models"></a>
</p>
<div>
A flexible realignment framework is proposed to quantitatively control alignment during training and inference, combining Training-time Realignment (TrRa) and Inference-time Realignment (InRa).
- We realign DeepScaleR-1.5B model and reduce token usage without performance loss and even enhance reasoning capabilities.
</div>
</div>
<div>
<br>

|
Gluttony10/OpenAvatarChat
|
Gluttony10
| 2025-06-17T01:48:20Z | 0 | 0 |
diffusers
|
[
"diffusers",
"safetensors",
"license:apache-2.0",
"region:us"
] | null | 2025-06-16T16:29:01Z |
---
license: apache-2.0
---
|
Unlearning/pythia1.5_modernbert_filtered_5percent_replace_with_escelations
|
Unlearning
| 2025-06-17T01:31:05Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"gpt_neox",
"text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-17T01:02:08Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
pandaiedu/Gemma3-1b-it
|
pandaiedu
| 2025-06-17T01:29:20Z | 25 | 0 |
transformers
|
[
"transformers",
"tflite",
"safetensors",
"gguf",
"gemma3_text",
"text-generation",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"text-generation-inference",
"endpoints_compatible",
"region:us"
] |
text-generation
| 2025-06-09T16:07:59Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
Moe117/ManiFast_FineTuned_Llama3.1_8B
|
Moe117
| 2025-06-17T01:19:11Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-06-17T01:00:25Z |
---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
MinaMila/llama_instbase_LoRa_GermanCredit_cfda_ep8_55
|
MinaMila
| 2025-06-17T01:08:14Z | 0 | 0 |
transformers
|
[
"transformers",
"safetensors",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
] | null | 2025-05-21T21:40:15Z |
---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF
|
mradermacher
| 2025-06-17T00:57:50Z | 0 | 0 |
transformers
|
[
"transformers",
"gguf",
"en",
"base_model:TheDrummer/Fallen-Llama-3.3-70B-v1",
"base_model:quantized:TheDrummer/Fallen-Llama-3.3-70B-v1",
"endpoints_compatible",
"region:us",
"imatrix"
] | null | 2025-06-16T18:37:14Z |
---
base_model: TheDrummer/Fallen-Llama-3.3-70B-v1
language:
- en
library_name: transformers
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/TheDrummer/Fallen-Llama-3.3-70B-v1
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ1_S.gguf) | i1-IQ1_S | 15.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ1_M.gguf) | i1-IQ1_M | 16.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 19.2 | |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ2_XS.gguf) | i1-IQ2_XS | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ2_S.gguf) | i1-IQ2_S | 22.3 | |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ2_M.gguf) | i1-IQ2_M | 24.2 | |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q2_K_S.gguf) | i1-Q2_K_S | 24.6 | very low quality |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q2_K.gguf) | i1-Q2_K | 26.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 27.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ3_XS.gguf) | i1-IQ3_XS | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ3_S.gguf) | i1-IQ3_S | 31.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q3_K_S.gguf) | i1-Q3_K_S | 31.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ3_M.gguf) | i1-IQ3_M | 32.0 | |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q3_K_M.gguf) | i1-Q3_K_M | 34.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q3_K_L.gguf) | i1-Q3_K_L | 37.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-IQ4_XS.gguf) | i1-IQ4_XS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q4_0.gguf) | i1-Q4_0 | 40.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q4_K_S.gguf) | i1-Q4_K_S | 40.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q4_K_M.gguf) | i1-Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q4_1.gguf) | i1-Q4_1 | 44.4 | |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q5_K_S.gguf) | i1-Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q5_K_M.gguf) | i1-Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Fallen-Llama-3.3-70B-v1-i1-GGUF/resolve/main/Fallen-Llama-3.3-70B-v1.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 58.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his private supercomputer, enabling me to provide many more imatrix quants, at much higher quality, than I would otherwise be able to.
<!-- end -->
|
Subsets and Splits
Filtered Qwen2.5 Distill Models
Identifies specific configurations of models by filtering cards that contain 'distill', 'qwen2.5', '7b' while excluding certain base models and incorrect model ID patterns, uncovering unique model variants.
Filtered Model Cards Count
Finds the count of entries with specific card details that include 'distill', 'qwen2.5', '7b' but exclude certain base models, revealing valuable insights about the dataset's content distribution.
Filtered Distill Qwen 7B Models
Filters for specific card entries containing 'distill', 'qwen', and '7b', excluding certain strings and patterns, to identify relevant model configurations.
Filtered Qwen-7b Model Cards
The query performs a detailed filtering based on specific keywords and excludes certain entries, which could be useful for identifying a specific subset of cards but does not provide deeper insights or trends.
Filtered Qwen 7B Model Cards
The query filters for specific terms related to "distilled" or "distill", "qwen", and "7b" in the 'card' column but excludes certain base models, providing a limited set of entries for further inspection.
Qwen 7B Distilled Models
The query provides a basic filtering of records to find specific card names that include keywords related to distilled Qwen 7b models, excluding a particular base model, which gives limited insight but helps in focusing on relevant entries.
Qwen 7B Distilled Model Cards
The query filters data based on specific keywords in the modelId and card fields, providing limited insight primarily useful for locating specific entries rather than revealing broad patterns or trends.
Qwen 7B Distilled Models
Finds all entries containing the terms 'distilled', 'qwen', and '7b' in a case-insensitive manner, providing a filtered set of records but without deeper analysis.
Distilled Qwen 7B Models
The query filters for specific model IDs containing 'distilled', 'qwen', and '7b', providing a basic retrieval of relevant entries but without deeper analysis or insight.
Filtered Model Cards with Distill Qwen2.
Filters and retrieves records containing specific keywords in the card description while excluding certain phrases, providing a basic count of relevant entries.
Filtered Model Cards with Distill Qwen 7
The query filters specific variations of card descriptions containing 'distill', 'qwen', and '7b' while excluding a particular base model, providing limited but specific data retrieval.
Distill Qwen 7B Model Cards
The query filters and retrieves rows where the 'card' column contains specific keywords ('distill', 'qwen', and '7b'), providing a basic filter result that can help in identifying specific entries.