
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
google/bert2bert_L-24_wmt_de_en | google | 2023-01-24T16:35:54Z | 936 | 8 | transformers | [
"transformers",
"pytorch",
"encoder-decoder",
"text2text-generation",
"translation",
"en",
"de",
"dataset:wmt14",
"arxiv:1907.12461",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:05Z | ---
language:
- en
- de
license: apache-2.0
datasets:
- wmt14
tags:
- translation
---
# bert2bert_L-24_wmt_de_en EncoderDecoder model
The model was introduced in
[this paper](https://arxiv.org/abs/1907.12461) by Sascha Rothe, Shashi Narayan, Aliaksei Severyn and first released in [this repository](https://tfhub.dev/google/bertseq2seq/bert24_de_en/1).
The model is an encoder-decoder model that was initialized on the `bert-large` checkpoints for both the encoder
and decoder and fine-tuned on German to English translation on the WMT dataset, which is linked above.
Disclaimer: The model card has been written by the Hugging Face team.
## How to use
You can use this model for translation, *e.g.*
```python
from transformers import AutoTokenizer, AutoModelForSeq2SeqLM
tokenizer = AutoTokenizer.from_pretrained("google/bert2bert_L-24_wmt_de_en", pad_token="<pad>", eos_token="</s>", bos_token="<s>")
model = AutoModelForSeq2SeqLM.from_pretrained("google/bert2bert_L-24_wmt_de_en")
sentence = "Willst du einen Kaffee trinken gehen mit mir?"
input_ids = tokenizer(sentence, return_tensors="pt", add_special_tokens=False).input_ids
output_ids = model.generate(input_ids)[0]
print(tokenizer.decode(output_ids, skip_special_tokens=True))
# should output
# Want to drink a kaffee go with me? .
```
|
nghuyong/ernie-3.0-xbase-zh | nghuyong | 2022-10-22T11:01:58Z | 936 | 18 | transformers | [
"transformers",
"pytorch",
"ernie",
"fill-mask",
"zh",
"arxiv:2107.02137",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-10-22T10:57:03Z | ---
language: zh
---
# ERNIE-3.0-xbase-zh
## Introduction
ERNIE 3.0: Large-scale Knowledge Enhanced Pre-training for Language Understanding and Generation
More detail: https://arxiv.org/abs/2107.02137
## Released Model Info
This released pytorch model is converted from the officially released PaddlePaddle ERNIE model and
a series of experiments have been conducted to check the accuracy of the conversion.
- Official PaddlePaddle ERNIE repo:https://paddlenlp.readthedocs.io/zh/latest/model_zoo/transformers/ERNIE/contents.html
- Pytorch Conversion repo: https://github.com/nghuyong/ERNIE-Pytorch
## How to use
```Python
from transformers import BertTokenizer, ErnieModel
tokenizer = BertTokenizer.from_pretrained("nghuyong/ernie-3.0-xbase-zh")
model = ErnieModel.from_pretrained("nghuyong/ernie-3.0-xbase-zh")
```
## Citation
```bibtex
@article{sun2021ernie,
title={Ernie 3.0: Large-scale knowledge enhanced pre-training for language understanding and generation},
author={Sun, Yu and Wang, Shuohuan and Feng, Shikun and Ding, Siyu and Pang, Chao and Shang, Junyuan and Liu, Jiaxiang and Chen, Xuyi and Zhao, Yanbin and Lu, Yuxiang and others},
journal={arXiv preprint arXiv:2107.02137},
year={2021}
}
```
|
to-be/donut-base-finetuned-invoices | to-be | 2023-03-03T19:18:45Z | 936 | 10 | transformers | [
"transformers",
"pytorch",
"vision-encoder-decoder",
"donut",
"image-to-text",
"vision",
"invoices",
"arxiv:2111.15664",
"license:cc-by-nc-sa-4.0",
"endpoints_compatible",
"region:us"
]
| image-to-text | 2023-03-03T19:04:52Z | ---
license: cc-by-nc-sa-4.0
tags:
- donut
- image-to-text
- vision
- invoices
---
# Donut finetuned on invoices
Based on Donut base model (introduced in the paper [OCR-free Document Understanding Transformer](https://arxiv.org/abs/2111.15664) by Geewok et al. and first released in [this repository](https://github.com/clovaai/donut).
The model was trained with a few thousand of annotated invoices and non-invoices (for those the doctype will be 'Other'). They span across different countries and languages. They are always one page only. The dataset is proprietary unfortunately. Model is set to input resolution of 1280x1920 pixels. So any sample you want to try with higher dpi than 150 has no added value.
It was trained for about 4 hours on a NVIDIA RTX A4000 for 20k steps with a val_metric of 0.03413819904382196 at the end.
The following indexes were included in the train set:
DocType
Currency
DocumentDate
GrossAmount
InvoiceNumber
NetAmount
TaxAmount
OrderNumber
CreditorCountry
[Demo space can be found here](https://huggingface.co/spaces/to-be/invoice_document_headers_extraction_with_donut)
## Model description
Donut consists of a vision encoder (Swin Transformer) and a text decoder (BART). Given an image, the encoder first encodes the image into a tensor of embeddings (of shape batch_size, seq_len, hidden_size), after which the decoder autoregressively generates text, conditioned on the encoding of the encoder.

## Intended uses & limitations
This model is meant as a research in how well it fares with multilanguage invoices.
See my observations in the [demo space](https://huggingface.co/spaces/to-be/invoice_document_headers_extraction_with_donut).
### How to use
Look at the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/donut) which includes code examples.
|
digiplay/Colorful_v1.3 | digiplay | 2024-05-18T20:18:44Z | 936 | 2 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-07-18T00:46:41Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
https://civitai.com/models/7279?modelVersionId=10282
|
vonjack/Phi-3-mini-4k-instruct-LLaMAfied | vonjack | 2024-04-25T02:33:12Z | 936 | 11 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"nlp",
"code",
"conversational",
"en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-24T02:29:00Z | ---
license: mit
license_link: https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- nlp
- code
---
## Model Summary
The Phi-3-Mini-4K-Instruct is a 3.8B parameters, lightweight, state-of-the-art open model trained with the Phi-3 datasets that includes both synthetic data and the filtered publicly available websites data with a focus on high-quality and reasoning dense properties.
The model belongs to the Phi-3 family with the Mini version in two variants [4K](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct) and [128K](https://huggingface.co/microsoft/Phi-3-mini-128k-instruct) which is the context length (in tokens) that it can support.
The model has underwent a post-training process that incorporates both supervised fine-tuning and direct preference optimization for the instruction following and safety measures.
When assessed against benchmarks testing common sense, language understanding, math, code, long context and logical reasoning, Phi-3 Mini-4K-Instruct showcased a robust and state-of-the-art performance among models with less than 13 billion parameters.
Resources and Technical Documentation:
+ [Phi-3 Microsoft Blog](https://aka.ms/phi3blog-april)
+ [Phi-3 Technical Report](https://aka.ms/phi3-tech-report)
+ [Phi-3 on Azure AI Studio](https://aka.ms/phi3-azure-ai)
+ Phi-3 GGUF: [4K](https://aka.ms/Phi3-mini-4k-instruct-gguf)
+ Phi-3 ONNX: [4K](https://aka.ms/Phi3-mini-4k-instruct-onnx)
## Intended Uses
**Primary use cases**
The model is intended for commercial and research use in English. The model provides uses for applications which require:
1) Memory/compute constrained environments
2) Latency bound scenarios
3) Strong reasoning (especially code, math and logic)
Our model is designed to accelerate research on language and multimodal models, for use as a building block for generative AI powered features.
**Use case considerations**
Our models are not specifically designed or evaluated for all downstream purposes. Developers should consider common limitations of language models as they select use cases, and evaluate and mitigate for accuracy, safety, and fariness before using within a specific downstream use case, particularly for high risk scenarios. Developers should be aware of and adhere to applicable laws or regulations (including privacy, trade compliance laws, etc.) that are relevant to their use case.
Nothing contained in this Model Card should be interpreted as or deemed a restriction or modification to the license the model is released under.
## How to Use
Phi-3 Mini-4K-Instruct has been integrated in the development version (4.40.0) of `transformers`. Until the official version is released through `pip`, ensure that you are doing one of the following:
* When loading the model, ensure that `trust_remote_code=True` is passed as an argument of the `from_pretrained()` function.
* Update your local `transformers` to the development version: `pip uninstall -y transformers && pip install git+https://github.com/huggingface/transformers`. The previous command is an alternative to cloning and installing from the source.
The current `transformers` version can be verified with: `pip list | grep transformers`.
Phi-3 Mini-4K-Instruct is also available in [HuggingChat](https://aka.ms/try-phi3-hf-chat).
### Chat Format
Given the nature of the training data, the Phi-3 Mini-4K-Instruct model is best suited for prompts using the chat format as follows.
You can provide the prompt as a question with a generic template as follow:
```markdown
<|user|>\nQuestion <|end|>\n<|assistant|>
```
For example:
```markdown
<|system|>
You are a helpful AI assistant.<|end|>
<|user|>
How to explain Internet for a medieval knight?<|end|>
<|assistant|>
```
where the model generates the text after `<|assistant|>` . In case of few-shots prompt, the prompt can be formatted as the following:
```markdown
<|system|>
You are a helpful AI assistant.<|end|>
<|user|>
I am going to Paris, what should I see?<|end|>
<|assistant|>
Paris, the capital of France, is known for its stunning architecture, art museums, historical landmarks, and romantic atmosphere. Here are some of the top attractions to see in Paris:\n\n1. The Eiffel Tower: The iconic Eiffel Tower is one of the most recognizable landmarks in the world and offers breathtaking views of the city.\n2. The Louvre Museum: The Louvre is one of the world's largest and most famous museums, housing an impressive collection of art and artifacts, including the Mona Lisa.\n3. Notre-Dame Cathedral: This beautiful cathedral is one of the most famous landmarks in Paris and is known for its Gothic architecture and stunning stained glass windows.\n\nThese are just a few of the many attractions that Paris has to offer. With so much to see and do, it's no wonder that Paris is one of the most popular tourist destinations in the world."<|end|>
<|user|>
What is so great about #1?<|end|>
<|assistant|>
```
### Sample inference code
This code snippets show how to get quickly started with running the model on a GPU:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
torch.random.manual_seed(0)
model = AutoModelForCausalLM.from_pretrained(
"microsoft/Phi-3-mini-4k-instruct",
device_map="cuda",
torch_dtype="auto",
trust_remote_code=True,
)
tokenizer = AutoTokenizer.from_pretrained("microsoft/Phi-3-mini-4k-instruct")
messages = [
{"role": "system", "content": "You are a helpful digital assistant. Please provide safe, ethical and accurate information to the user."},
{"role": "user", "content": "Can you provide ways to eat combinations of bananas and dragonfruits?"},
{"role": "assistant", "content": "Sure! Here are some ways to eat bananas and dragonfruits together: 1. Banana and dragonfruit smoothie: Blend bananas and dragonfruits together with some milk and honey. 2. Banana and dragonfruit salad: Mix sliced bananas and dragonfruits together with some lemon juice and honey."},
{"role": "user", "content": "What about solving an 2x + 3 = 7 equation?"},
]
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
)
generation_args = {
"max_new_tokens": 500,
"return_full_text": False,
"temperature": 0.0,
"do_sample": False,
}
output = pipe(messages, **generation_args)
print(output[0]['generated_text'])
```
## Responsible AI Considerations
Like other language models, the Phi series models can potentially behave in ways that are unfair, unreliable, or offensive. Some of the limiting behaviors to be aware of include:
+ Quality of Service: the Phi models are trained primarily on English text. Languages other than English will experience worse performance. English language varieties with less representation in the training data might experience worse performance than standard American English.
+ Representation of Harms & Perpetuation of Stereotypes: These models can over- or under-represent groups of people, erase representation of some groups, or reinforce demeaning or negative stereotypes. Despite safety post-training, these limitations may still be present due to differing levels of representation of different groups or prevalence of examples of negative stereotypes in training data that reflect real-world patterns and societal biases.
+ Inappropriate or Offensive Content: these models may produce other types of inappropriate or offensive content, which may make it inappropriate to deploy for sensitive contexts without additional mitigations that are specific to the use case.
+ Information Reliability: Language models can generate nonsensical content or fabricate content that might sound reasonable but is inaccurate or outdated.
+ Limited Scope for Code: Majority of Phi-3 training data is based in Python and use common packages such as "typing, math, random, collections, datetime, itertools". If the model generates Python scripts that utilize other packages or scripts in other languages, we strongly recommend users manually verify all API uses.
Developers should apply responsible AI best practices and are responsible for ensuring that a specific use case complies with relevant laws and regulations (e.g. privacy, trade, etc.). Important areas for consideration include:
+ Allocation: Models may not be suitable for scenarios that could have consequential impact on legal status or the allocation of resources or life opportunities (ex: housing, employment, credit, etc.) without further assessments and additional debiasing techniques.
+ High-Risk Scenarios: Developers should assess suitability of using models in high-risk scenarios where unfair, unreliable or offensive outputs might be extremely costly or lead to harm. This includes providing advice in sensitive or expert domains where accuracy and reliability are critical (ex: legal or health advice). Additional safeguards should be implemented at the application level according to the deployment context.
+ Misinformation: Models may produce inaccurate information. Developers should follow transparency best practices and inform end-users they are interacting with an AI system. At the application level, developers can build feedback mechanisms and pipelines to ground responses in use-case specific, contextual information, a technique known as Retrieval Augmented Generation (RAG).
+ Generation of Harmful Content: Developers should assess outputs for their context and use available safety classifiers or custom solutions appropriate for their use case.
+ Misuse: Other forms of misuse such as fraud, spam, or malware production may be possible, and developers should ensure that their applications do not violate applicable laws and regulations.
## Training
### Model
* Architecture: Phi-3 Mini-4K-Instruct has 3.8B parameters and is a dense decoder-only Transformer model. The model is fine-tuned with Supervised fine-tuning (SFT) and Direct Preference Optimization (DPO) to ensure alignment with human preferences and safety guidlines.
* Inputs: Text. It is best suited for prompts using chat format.
* Context length: 4K tokens
* GPUs: 512 H100-80G
* Training time: 7 days
* Training data: 3.3T tokens
* Outputs: Generated text in response to the input
* Dates: Our models were trained between February and April 2024
* Status: This is a static model trained on an offline dataset with cutoff date October 2023. Future versions of the tuned models may be released as we improve models.
### Datasets
Our training data includes a wide variety of sources, totaling 3.3 trillion tokens, and is a combination of
1) Publicly available documents filtered rigorously for quality, selected high-quality educational data, and code;
2) Newly created synthetic, “textbook-like” data for the purpose of teaching math, coding, common sense reasoning, general knowledge of the world (science, daily activities, theory of mind, etc.);
3) High quality chat format supervised data covering various topics to reflect human preferences on different aspects such as instruct-following, truthfulness, honesty and helpfulness.
### Fine-tuning
A basic example of multi-GPUs supervised fine-tuning (SFT) with TRL and Accelerate modules is provided [here](https://huggingface.co/microsoft/Phi-3-mini-4k-instruct/resolve/main/sample_finetune.py).
## Benchmarks
We report the results for Phi-3-Mini-4K-Instruct on standard open-source benchmarks measuring the model's reasoning ability (both common sense reasoning and logical reasoning). We compare to Phi-2, Mistral-7b-v0.1, Mixtral-8x7b, Gemma 7B, Llama-3-8B-Instruct, and GPT-3.5.
All the reported numbers are produced with the exact same pipeline to ensure that the numbers are comparable. These numbers might differ from other published numbers due to slightly different choices in the evaluation.
As is now standard, we use few-shot prompts to evaluate the models, at temperature 0.
The prompts and number of shots are part of a Microsoft internal tool to evaluate language models, and in particular we did no optimization to the pipeline for Phi-3.
More specifically, we do not change prompts, pick different few-shot examples, change prompt format, or do any other form of optimization for the model.
The number of k–shot examples is listed per-benchmark.
| | Phi-3-Mini-4K-In<br>3.8b | Phi-3-Small<br>7b (preview) | Phi-3-Medium<br>14b (preview) | Phi-2<br>2.7b | Mistral<br>7b | Gemma<br>7b | Llama-3-In<br>8b | Mixtral<br>8x7b | GPT-3.5<br>version 1106 |
|---|---|---|---|---|---|---|---|---|---|
| MMLU <br>5-Shot | 68.8 | 75.3 | 78.2 | 56.3 | 61.7 | 63.6 | 66.5 | 68.4 | 71.4 |
| HellaSwag <br> 5-Shot | 76.7 | 78.7 | 83.2 | 53.6 | 58.5 | 49.8 | 71.1 | 70.4 | 78.8 |
| ANLI <br> 7-Shot | 52.8 | 55.0 | 58.7 | 42.5 | 47.1 | 48.7 | 57.3 | 55.2 | 58.1 |
| GSM-8K <br> 0-Shot; CoT | 82.5 | 86.4 | 90.8 | 61.1 | 46.4 | 59.8 | 77.4 | 64.7 | 78.1 |
| MedQA <br> 2-Shot | 53.8 | 58.2 | 69.8 | 40.9 | 49.6 | 50.0 | 60.5 | 62.2 | 63.4 |
| AGIEval <br> 0-Shot | 37.5 | 45.0 | 49.7 | 29.8 | 35.1 | 42.1 | 42.0 | 45.2 | 48.4 |
| TriviaQA <br> 5-Shot | 64.0 | 59.1 | 73.3 | 45.2 | 72.3 | 75.2 | 67.7 | 82.2 | 85.8 |
| Arc-C <br> 10-Shot | 84.9 | 90.7 | 91.9 | 75.9 | 78.6 | 78.3 | 82.8 | 87.3 | 87.4 |
| Arc-E <br> 10-Shot | 94.6 | 97.1 | 98.0 | 88.5 | 90.6 | 91.4 | 93.4 | 95.6 | 96.3 |
| PIQA <br> 5-Shot | 84.2 | 87.8 | 88.2 | 60.2 | 77.7 | 78.1 | 75.7 | 86.0 | 86.6 |
| SociQA <br> 5-Shot | 76.6 | 79.0 | 79.4 | 68.3 | 74.6 | 65.5 | 73.9 | 75.9 | 68.3 |
| BigBench-Hard <br> 0-Shot | 71.7 | 75.0 | 82.5 | 59.4 | 57.3 | 59.6 | 51.5 | 69.7 | 68.32 |
| WinoGrande <br> 5-Shot | 70.8 | 82.5 | 81.2 | 54.7 | 54.2 | 55.6 | 65 | 62.0 | 68.8 |
| OpenBookQA <br> 10-Shot | 83.2 | 88.4 | 86.6 | 73.6 | 79.8 | 78.6 | 82.6 | 85.8 | 86.0 |
| BoolQ <br> 0-Shot | 77.6 | 82.9 | 86.5 | -- | 72.2 | 66.0 | 80.9 | 77.6 | 79.1 |
| CommonSenseQA <br> 10-Shot | 80.2 | 80.3 | 82.6 | 69.3 | 72.6 | 76.2 | 79 | 78.1 | 79.6 |
| TruthfulQA <br> 10-Shot | 65.0 | 68.1 | 74.8 | -- | 52.1 | 53.0 | 63.2 | 60.1 | 85.8 |
| HumanEval <br> 0-Shot | 59.1 | 59.1 | 54.7 | 59.0 | 28.0 | 34.1 | 60.4 | 37.8 | 62.2 |
| MBPP <br> 3-Shot | 53.8 | 71.4 | 73.7 | 60.6 | 50.8 | 51.5 | 67.7 | 60.2 | 77.8 |
## Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Transformers](https://github.com/huggingface/transformers)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
## Hardware
Note that by default, the Phi-3-mini model uses flash attention, which requires certain types of GPU hardware to run. We have tested on the following GPU types:
* NVIDIA A100
* NVIDIA A6000
* NVIDIA H100
If you want to run the model on:
* NVIDIA V100 or earlier generation GPUs: call AutoModelForCausalLM.from_pretrained() with attn_implementation="eager"
* CPU: use the **GGUF** quantized models [4K](https://aka.ms/Phi3-mini-4k-instruct-gguf)
+ Optimized inference on GPU, CPU, and Mobile: use the **ONNX** models [4K](https://aka.ms/Phi3-mini-4k-instruct-onnx)
## Cross Platform Support
ONNX runtime ecosystem now supports Phi-3 Mini models across platforms and hardware. You can find the optimized Phi-3 Mini-4K-Instruct ONNX model [here](https://aka.ms/phi3-mini-4k-instruct-onnx).
Optimized Phi-3 models are also published here in ONNX format, to run with ONNX Runtime on CPU and GPU across devices, including server platforms, Windows, Linux and Mac desktops, and mobile CPUs, with the precision best suited to each of these targets. DirectML support lets developers bring hardware acceleration to Windows devices at scale across AMD, Intel, and NVIDIA GPUs.
Along with DirectML, ONNX Runtime provides cross platform support for Phi-3 across a range of devices CPU, GPU, and mobile.
Here are some of the optimized configurations we have added:
1. ONNX models for int4 DML: Quantized to int4 via AWQ
2. ONNX model for fp16 CUDA
3. ONNX model for int4 CUDA: Quantized to int4 via RTN
4. ONNX model for int4 CPU and Mobile: Quantized to int4 via RTN
## License
The model is licensed under the [MIT license](https://huggingface.co/microsoft/Phi-3-mini-4k/resolve/main/LICENSE).
## Trademarks
This project may contain trademarks or logos for projects, products, or services. Authorized use of Microsoft trademarks or logos is subject to and must follow [Microsoft’s Trademark & Brand Guidelines](https://www.microsoft.com/en-us/legal/intellectualproperty/trademarks). Use of Microsoft trademarks or logos in modified versions of this project must not cause confusion or imply Microsoft sponsorship. Any use of third-party trademarks or logos are subject to those third-party’s policies.
|
pruned-yi/pruned-yi-3b-prerelease-ckpt01 | pruned-yi | 2024-05-17T17:43:08Z | 936 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-17T17:13:22Z | ---
license: apache-2.0
---
this is a very early pre-release model. see the github page for more details https://github.com/fakerybakery/pruned-yi
do not expect high-quality generations. longer prompts work better. trained on a mix of cosmopedia + chinese wikipedia (mix in a 2:1 ratio to preserve bilingual abilities). licensed under apache 2.0.
please open a github issue for any questions |
kwoncho/gaincut_news_pre2017_2 | kwoncho | 2024-05-28T02:39:22Z | 936 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-05-28T02:29:15Z | Entry not found |
studio-ousia/luke-large | studio-ousia | 2022-04-13T09:06:10Z | 935 | 5 | transformers | [
"transformers",
"pytorch",
"luke",
"fill-mask",
"named entity recognition",
"entity typing",
"relation classification",
"question answering",
"en",
"arxiv:1906.08237",
"arxiv:1903.07785",
"arxiv:2002.01808",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: https://github.com/studio-ousia/luke/raw/master/resources/luke_logo.png
tags:
- luke
- named entity recognition
- entity typing
- relation classification
- question answering
license: apache-2.0
---
## LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention
**LUKE** (**L**anguage **U**nderstanding with **K**nowledge-based
**E**mbeddings) is a new pre-trained contextualized representation of words and
entities based on transformer. LUKE treats words and entities in a given text as
independent tokens, and outputs contextualized representations of them. LUKE
adopts an entity-aware self-attention mechanism that is an extension of the
self-attention mechanism of the transformer, and considers the types of tokens
(words or entities) when computing attention scores.
LUKE achieves state-of-the-art results on five popular NLP benchmarks including
**[SQuAD v1.1](https://rajpurkar.github.io/SQuAD-explorer/)** (extractive
question answering),
**[CoNLL-2003](https://www.clips.uantwerpen.be/conll2003/ner/)** (named entity
recognition), **[ReCoRD](https://sheng-z.github.io/ReCoRD-explorer/)**
(cloze-style question answering),
**[TACRED](https://nlp.stanford.edu/projects/tacred/)** (relation
classification), and
**[Open Entity](https://www.cs.utexas.edu/~eunsol/html_pages/open_entity.html)**
(entity typing).
Please check the [official repository](https://github.com/studio-ousia/luke) for
more details and updates.
This is the LUKE large model with 24 hidden layers, 1024 hidden size. The total number
of parameters in this model is 483M. It is trained using December 2018 version of
Wikipedia.
### Experimental results
The experimental results are provided as follows:
| Task | Dataset | Metric | LUKE-large | luke-base | Previous SOTA |
| ------------------------------ | ---------------------------------------------------------------------------- | ------ | ----------------- | --------- | ------------------------------------------------------------------------- |
| Extractive Question Answering | [SQuAD v1.1](https://rajpurkar.github.io/SQuAD-explorer/) | EM/F1 | **90.2**/**95.4** | 86.1/92.3 | 89.9/95.1 ([Yang et al., 2019](https://arxiv.org/abs/1906.08237)) |
| Named Entity Recognition | [CoNLL-2003](https://www.clips.uantwerpen.be/conll2003/ner/) | F1 | **94.3** | 93.3 | 93.5 ([Baevski et al., 2019](https://arxiv.org/abs/1903.07785)) |
| Cloze-style Question Answering | [ReCoRD](https://sheng-z.github.io/ReCoRD-explorer/) | EM/F1 | **90.6**/**91.2** | - | 83.1/83.7 ([Li et al., 2019](https://www.aclweb.org/anthology/D19-6011/)) |
| Relation Classification | [TACRED](https://nlp.stanford.edu/projects/tacred/) | F1 | **72.7** | - | 72.0 ([Wang et al. , 2020](https://arxiv.org/abs/2002.01808)) |
| Fine-grained Entity Typing | [Open Entity](https://www.cs.utexas.edu/~eunsol/html_pages/open_entity.html) | F1 | **78.2** | - | 77.6 ([Wang et al. , 2020](https://arxiv.org/abs/2002.01808)) |
### Citation
If you find LUKE useful for your work, please cite the following paper:
```latex
@inproceedings{yamada2020luke,
title={LUKE: Deep Contextualized Entity Representations with Entity-aware Self-attention},
author={Ikuya Yamada and Akari Asai and Hiroyuki Shindo and Hideaki Takeda and Yuji Matsumoto},
booktitle={EMNLP},
year={2020}
}
```
|
inkoziev/rugpt_chitchat | inkoziev | 2022-10-19T07:44:11Z | 935 | 17 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"PyTorch",
"Transformers",
"ru",
"license:unlicense",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-09-15T07:20:18Z | ---
pipeline_tag: text-generation
tags:
- PyTorch
- Transformers
- gpt2
license: unlicense
language: ru
widget:
- text: "- У Джульетты было 7 пончиков, а потом она 3 съела. Сколько у нее осталось пончиков? -"
- text: "- Поглажено 4 манула. Осталось погладить 6. Сколько всего манулов надо погладить? -"
- text: "- Для начала скажи, чему равно пятью девять? -"
- text: "- ты чё такой борзый? -"
- text: "- Привет! Как ваше ничего? -"
---
## Russian Chit-chat, Deductive and Common Sense reasoning model
Модель является ядром прототипа [диалоговой системы](https://github.com/Koziev/chatbot) с двумя основными функциями.
Первая функция - **генерация реплик чит-чата**. В качестве затравки подается история диалога (предшествующие несколько реплик, от 1 до 10).
```
- Привет, как дела?
- Привет, так себе.
- <<< эту реплику ожидаем от модели >>>
```
Вторая функция модели - вывод ответа на заданный вопрос, опираясь на дополнительные факты или на "здравый смысл". Предполагается, что релевантные факты извлекаются
из стороннего хранилища (базы знаний) с помощью другой модели, например [sbert_pq](https://huggingface.co/inkoziev/sbert_pq).
Используя указанный факт(ы) и текст вопроса, модель построит грамматичный и максимально краткий ответ, как это сделал бы
человек в подобной коммуникативной ситуации. Релевантные факты следует указывать перед текстом заданного вопроса так,
будто сам собеседник сказал их:
```
- Сегодня 15 сентября. Какой сейчас у нас месяц?
- Сентябрь
```
Модель не ожидает, что все найденные и добавленные в контекст диалога факты действительно имеют отношение к заданному вопросу. Поэтому
модель, извлекающая из базы знаний информацию, может жертвовать точностью в пользу полноте и добавлять что-то лишнее. Модель читчата
в этом случае сама выберет среди добавленных в контекст фактов необходимую фактуру и проигнорирует лишнее. Текущая версия модели
допускает до 5 фактов перед вопросом. Например:
```
- Стасу 16 лет. Стас живет в Подольске. У Стаса нет своей машины. Где живет Стас?
- в Подольске
```
В некоторых случаях модель может выполнять **силлогический вывод** ответа, опираясь на 2 предпосылки, связанные друг с другом. Выводимое из двух предпосылок следствие не фигурирует явно, а *как бы* используется для вывода ответа:
```
- Смертен ли Аристофан, если он был греческим философом, а все философы смертны?
- Да
```
Как можно видеть из приведенных примеров, формат подаваемой на вход модели фактической информации для выполнения вывода предельно естественный и свободный.
Кроме логического вывода, модель также умеет решать простые арифметические задачи в рамках 1-2 классов начальной школы, с двумя числовыми аргументами:
```
- Чему равно 2+8?
- 10
```
### Варианты модели и метрики
Выложенная на данный момент модель имеет 760 млн. параметров, т.е. уровня sberbank-ai/rugpt3large_based_on_gpt2. Далее приводится
результат замера точности решения арифметических задач на отложенном тестовом наборе сэмплов:
| base model | arith. accuracy |
| --------------------------------------- | --------------- |
| sberbank-ai/rugpt3large_based_on_gpt2 | 0.91 |
| sberbank-ai/rugpt3medium_based_on_gpt2 | 0.70 |
| sberbank-ai/rugpt3small_based_on_gpt2 | 0.58 |
| tinkoff-ai/ruDialoGPT-small | 0.44 |
| tinkoff-ai/ruDialoGPT-medium | 0.69 |
Цифра 0.91 в столбце "arith. accuracy" означает, что 91% тестовых задач решено полностью верно.
Любое отклонение сгенерированного ответа от эталонного рассматривается
как ошибка. Например, выдача ответа "120" вместо "119" тоже фиксируется как ошибка.
### Пример использования
```
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
device = "cuda" if torch.cuda.is_available() else "cpu"
model_name = "inkoziev/rugpt_chitchat"
tokenizer = AutoTokenizer.from_pretrained(model_name)
tokenizer.add_special_tokens({'bos_token': '<s>', 'eos_token': '</s>', 'pad_token': '<pad>'})
model = AutoModelForCausalLM.from_pretrained(model_name)
model.to(device)
model.eval()
# На вход модели подаем последние 2-3 реплики диалога. Каждая реплика на отдельной строке, начинается с символа "-"
input_text = """<s>- Привет! Что делаешь?
- Привет :) В такси еду
-"""
encoded_prompt = tokenizer.encode(input_text, add_special_tokens=False, return_tensors="pt").to(device)
output_sequences = model.generate(input_ids=encoded_prompt, max_length=100, num_return_sequences=1, pad_token_id=tokenizer.pad_token_id)
text = tokenizer.decode(output_sequences[0].tolist(), clean_up_tokenization_spaces=True)[len(input_text)+1:]
text = text[: text.find('</s>')]
print(text)
```
### Контакты
Если у Вас есть какие-то вопросы по использованию этой модели, или предложения по ее улучшению - пишите мне [email protected]
### Citation:
```
@MISC{rugpt_chitchat,
author = {Ilya Koziev},
title = {Russian Chit-chat with Common sence Reasoning},
url = {https://huggingface.co/inkoziev/rugpt_chitchat},
year = 2022
}
```
|
beomi/KcBERT-v2023 | beomi | 2023-05-07T11:08:50Z | 935 | 0 | transformers | [
"transformers",
"pytorch",
"jax",
"roberta",
"fill-mask",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-04-15T07:08:27Z | ---
license: mit
---
|
lorahub/flan_t5_large-race_high_Select_the_best_answer | lorahub | 2023-07-24T10:18:46Z | 935 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-07-24T10:18:37Z | ---
library_name: peft
---
|
TheBloke/Pygmalion-2-13B-AWQ | TheBloke | 2023-11-09T18:20:07Z | 935 | 4 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"text generation",
"instruct",
"en",
"dataset:PygmalionAI/PIPPA",
"dataset:Open-Orca/OpenOrca",
"dataset:Norquinal/claude_multiround_chat_30k",
"dataset:jondurbin/airoboros-gpt4-1.4.1",
"dataset:databricks/databricks-dolly-15k",
"base_model:PygmalionAI/pygmalion-2-13b",
"license:llama2",
"autotrain_compatible",
"text-generation-inference",
"4-bit",
"awq",
"region:us"
]
| text-generation | 2023-09-19T07:25:03Z | ---
language:
- en
license: llama2
tags:
- text generation
- instruct
datasets:
- PygmalionAI/PIPPA
- Open-Orca/OpenOrca
- Norquinal/claude_multiround_chat_30k
- jondurbin/airoboros-gpt4-1.4.1
- databricks/databricks-dolly-15k
model_name: Pygmalion 2 13B
base_model: PygmalionAI/pygmalion-2-13b
inference: false
model_creator: PygmalionAI
model_type: llama
pipeline_tag: text-generation
prompt_template: 'The model has been trained on prompts using three different roles,
which are denoted by the following tokens: `<|system|>`, `<|user|>` and `<|model|>`.
The `<|system|>` prompt can be used to inject out-of-channel information behind
the scenes, while the `<|user|>` prompt should be used to indicate user input.
The `<|model|>` token should then be used to indicate that the model should generate
a response. These tokens can happen multiple times and be chained up to form a conversation
history.
The system prompt has been designed to allow the model to "enter" various modes
and dictate the reply length. Here''s an example:
```
<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
```
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Pygmalion 2 13B - AWQ
- Model creator: [PygmalionAI](https://huggingface.co/PygmalionAI)
- Original model: [Pygmalion 2 13B](https://huggingface.co/PygmalionAI/pygmalion-2-13b)
<!-- description start -->
## Description
This repo contains AWQ model files for [PygmalionAI's Pygmalion 2 13B](https://huggingface.co/PygmalionAI/pygmalion-2-13b).
### About AWQ
AWQ is an efficient, accurate and blazing-fast low-bit weight quantization method, currently supporting 4-bit quantization. Compared to GPTQ, it offers faster Transformers-based inference.
It is also now supported by continuous batching server [vLLM](https://github.com/vllm-project/vllm), allowing use of AWQ models for high-throughput concurrent inference in multi-user server scenarios. Note that, at the time of writing, overall throughput is still lower than running vLLM with unquantised models, however using AWQ enables using much smaller GPUs which can lead to easier deployment and overall cost savings. For example, a 70B model can be run on 1 x 48GB GPU instead of 2 x 80GB.
<!-- description end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Pygmalion-2-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Pygmalion-2-13B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Pygmalion-2-13B-GGUF)
* [PygmalionAI's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/PygmalionAI/pygmalion-2-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Custom
The model has been trained on prompts using three different roles, which are denoted by the following tokens: `<|system|>`, `<|user|>` and `<|model|>`.
The `<|system|>` prompt can be used to inject out-of-channel information behind the scenes, while the `<|user|>` prompt should be used to indicate user input.
The `<|model|>` token should then be used to indicate that the model should generate a response. These tokens can happen multiple times and be chained up to form a conversation history.
The system prompt has been designed to allow the model to "enter" various modes and dictate the reply length. Here's an example:
```
<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
```
<!-- prompt-template end -->
<!-- README_AWQ.md-provided-files start -->
## Provided files and AWQ parameters
For my first release of AWQ models, I am releasing 128g models only. I will consider adding 32g as well if there is interest, and once I have done perplexity and evaluation comparisons, but at this time 32g models are still not fully tested with AutoAWQ and vLLM.
Models are released as sharded safetensors files.
| Branch | Bits | GS | AWQ Dataset | Seq Len | Size |
| ------ | ---- | -- | ----------- | ------- | ---- |
| [main](https://huggingface.co/TheBloke/Pygmalion-2-13B-AWQ/tree/main) | 4 | 128 | [wikitext](https://huggingface.co/datasets/wikitext/viewer/wikitext-2-v1/test) | 4096 | 7.25 GB
<!-- README_AWQ.md-provided-files end -->
<!-- README_AWQ.md-use-from-vllm start -->
## Serving this model from vLLM
Documentation on installing and using vLLM [can be found here](https://vllm.readthedocs.io/en/latest/).
- When using vLLM as a server, pass the `--quantization awq` parameter, for example:
```shell
python3 python -m vllm.entrypoints.api_server --model TheBloke/Pygmalion-2-13B-AWQ --quantization awq
```
When using vLLM from Python code, pass the `quantization=awq` parameter, for example:
```python
from vllm import LLM, SamplingParams
prompts = [
"Hello, my name is",
"The president of the United States is",
"The capital of France is",
"The future of AI is",
]
sampling_params = SamplingParams(temperature=0.8, top_p=0.95)
llm = LLM(model="TheBloke/Pygmalion-2-13B-AWQ", quantization="awq")
outputs = llm.generate(prompts, sampling_params)
# Print the outputs.
for output in outputs:
prompt = output.prompt
generated_text = output.outputs[0].text
print(f"Prompt: {prompt!r}, Generated text: {generated_text!r}")
```
<!-- README_AWQ.md-use-from-vllm start -->
<!-- README_AWQ.md-use-from-python start -->
## How to use this AWQ model from Python code
### Install the necessary packages
Requires: [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) 0.0.2 or later
```shell
pip3 install autoawq
```
If you have problems installing [AutoAWQ](https://github.com/casper-hansen/AutoAWQ) using the pre-built wheels, install it from source instead:
```shell
pip3 uninstall -y autoawq
git clone https://github.com/casper-hansen/AutoAWQ
cd AutoAWQ
pip3 install .
```
### You can then try the following example code
```python
from awq import AutoAWQForCausalLM
from transformers import AutoTokenizer
model_name_or_path = "TheBloke/Pygmalion-2-13B-AWQ"
# Load model
model = AutoAWQForCausalLM.from_quantized(model_name_or_path, fuse_layers=True,
trust_remote_code=False, safetensors=True)
tokenizer = AutoTokenizer.from_pretrained(model_name_or_path, trust_remote_code=False)
prompt = "Tell me about AI"
prompt_template=f'''<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
'''
print("\n\n*** Generate:")
tokens = tokenizer(
prompt_template,
return_tensors='pt'
).input_ids.cuda()
# Generate output
generation_output = model.generate(
tokens,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
max_new_tokens=512
)
print("Output: ", tokenizer.decode(generation_output[0]))
# Inference can also be done using transformers' pipeline
from transformers import pipeline
print("*** Pipeline:")
pipe = pipeline(
"text-generation",
model=model,
tokenizer=tokenizer,
max_new_tokens=512,
do_sample=True,
temperature=0.7,
top_p=0.95,
top_k=40,
repetition_penalty=1.1
)
print(pipe(prompt_template)[0]['generated_text'])
```
<!-- README_AWQ.md-use-from-python end -->
<!-- README_AWQ.md-compatibility start -->
## Compatibility
The files provided are tested to work with [AutoAWQ](https://github.com/casper-hansen/AutoAWQ), and [vLLM](https://github.com/vllm-project/vllm).
[Huggingface Text Generation Inference (TGI)](https://github.com/huggingface/text-generation-inference) is not yet compatible with AWQ, but a PR is open which should bring support soon: [TGI PR #781](https://github.com/huggingface/text-generation-inference/issues/781).
<!-- README_AWQ.md-compatibility end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
# Original model card: PygmalionAI's Pygmalion 2 13B
<h1 style="text-align: center">Pygmalion-2 13B</h1>
<h2 style="text-align: center">An instruction-tuned Llama-2 biased towards fiction writing and conversation.</h2>
## Model Details
The long-awaited release of our new models based on Llama-2 is finally here. Pygmalion-2 13B (formerly known as Metharme) is based on
[Llama-2 13B](https://huggingface.co/meta-llama/llama-2-13b-hf) released by Meta AI.
The Metharme models were an experiment to try and get a model that is usable for conversation, roleplaying and storywriting,
but which can be guided using natural language like other instruct models. After much deliberation, we reached the conclusion
that the Metharme prompting format is superior (and easier to use) compared to the classic Pygmalion.
This model was trained by doing supervised fine-tuning over a mixture of regular instruction data alongside roleplay, fictional stories
and conversations with synthetically generated instructions attached.
This model is freely available for both commercial and non-commercial use, as per the Llama-2 license.
## Prompting
The model has been trained on prompts using three different roles, which are denoted by the following tokens: `<|system|>`, `<|user|>` and `<|model|>`.
The `<|system|>` prompt can be used to inject out-of-channel information behind the scenes, while the `<|user|>` prompt should be used to indicate user input.
The `<|model|>` token should then be used to indicate that the model should generate a response. These tokens can happen multiple times and be chained up to
form a conversation history.
### Prompting example
The system prompt has been designed to allow the model to "enter" various modes and dictate the reply length. Here's an example:
```
<|system|>Enter RP mode. Pretend to be {{char}} whose persona follows:
{{persona}}
You shall reply to the user while staying in character, and generate long responses.
```
## Dataset
The dataset used to fine-tune this model includes our own [PIPPA](https://huggingface.co/datasets/PygmalionAI/PIPPA), along with several other instruction
datasets, and datasets acquired from various RP forums.
## Limitations and biases
The intended use-case for this model is fictional writing for entertainment purposes. Any other sort of usage is out of scope.
As such, it was **not** fine-tuned to be safe and harmless: the base model _and_ this fine-tune have been trained on data known to contain profanity and texts that are lewd or otherwise offensive. It may produce socially unacceptable or undesirable text, even if the prompt itself does not include anything explicitly offensive. Outputs might often be factually wrong or misleading.
## Acknowledgements
We would like to thank [SpicyChat](https://spicychat.ai/) for sponsoring the training for this model.
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
|
TownsWu/PEG | TownsWu | 2024-05-23T09:42:26Z | 935 | 30 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"PEG",
"sentence-similarity",
"mteb",
"zh",
"arxiv:2311.11691",
"model-index",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
]
| sentence-similarity | 2023-11-15T07:59:13Z | ---
language:
- zh
pipeline_tag: sentence-similarity
tags:
- PEG
- feature-extraction
- sentence-similarity
- transformers
- mteb
model-index:
- name: PEG
results:
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 84.09137463267582
- type: mrr
value: 86.6288888888889
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 86.55765031914974
- type: mrr
value: 89.4325396825397
- task:
type: Retrieval
dataset:
type: C_MTEB/CmedqaRetrieval
name: MTEB CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 26.101000000000003
- type: map_at_10
value: 38.239000000000004
- type: map_at_100
value: 40.083
- type: map_at_1000
value: 40.205
- type: map_at_3
value: 34.386
- type: map_at_5
value: 36.425999999999995
- type: mrr_at_1
value: 39.434999999999995
- type: mrr_at_10
value: 46.967999999999996
- type: mrr_at_100
value: 47.946
- type: mrr_at_1000
value: 47.997
- type: mrr_at_3
value: 44.803
- type: mrr_at_5
value: 45.911
- type: ndcg_at_1
value: 39.434999999999995
- type: ndcg_at_10
value: 44.416
- type: ndcg_at_100
value: 51.773
- type: ndcg_at_1000
value: 53.888000000000005
- type: ndcg_at_3
value: 39.816
- type: ndcg_at_5
value: 41.467999999999996
- type: precision_at_1
value: 39.434999999999995
- type: precision_at_10
value: 9.786999999999999
- type: precision_at_100
value: 1.5810000000000002
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 22.414
- type: precision_at_5
value: 15.943999999999999
- type: recall_at_1
value: 26.101000000000003
- type: recall_at_10
value: 53.82900000000001
- type: recall_at_100
value: 84.63199999999999
- type: recall_at_1000
value: 98.782
- type: recall_at_3
value: 39.585
- type: recall_at_5
value: 45.141
- task:
type: Retrieval
dataset:
type: C_MTEB/CovidRetrieval
name: MTEB CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 70.39
- type: map_at_10
value: 78.93599999999999
- type: map_at_100
value: 79.202
- type: map_at_1000
value: 79.205
- type: map_at_3
value: 77.538
- type: map_at_5
value: 78.312
- type: mrr_at_1
value: 70.706
- type: mrr_at_10
value: 79.018
- type: mrr_at_100
value: 79.28399999999999
- type: mrr_at_1000
value: 79.288
- type: mrr_at_3
value: 77.713
- type: mrr_at_5
value: 78.462
- type: ndcg_at_1
value: 70.601
- type: ndcg_at_10
value: 82.555
- type: ndcg_at_100
value: 83.718
- type: ndcg_at_1000
value: 83.855
- type: ndcg_at_3
value: 79.779
- type: ndcg_at_5
value: 81.149
- type: precision_at_1
value: 70.601
- type: precision_at_10
value: 9.463000000000001
- type: precision_at_100
value: 0.9979999999999999
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 28.871999999999996
- type: precision_at_5
value: 18.019
- type: recall_at_1
value: 70.39
- type: recall_at_10
value: 93.572
- type: recall_at_100
value: 98.736
- type: recall_at_1000
value: 99.895
- type: recall_at_3
value: 86.091
- type: recall_at_5
value: 89.384
- task:
type: Retrieval
dataset:
type: C_MTEB/DuRetrieval
name: MTEB DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 26.147
- type: map_at_10
value: 80.205
- type: map_at_100
value: 82.96
- type: map_at_1000
value: 82.999
- type: map_at_3
value: 55.16799999999999
- type: map_at_5
value: 69.798
- type: mrr_at_1
value: 89.8
- type: mrr_at_10
value: 93.16799999999999
- type: mrr_at_100
value: 93.22500000000001
- type: mrr_at_1000
value: 93.228
- type: mrr_at_3
value: 92.85
- type: mrr_at_5
value: 93.067
- type: ndcg_at_1
value: 89.8
- type: ndcg_at_10
value: 87.668
- type: ndcg_at_100
value: 90.16
- type: ndcg_at_1000
value: 90.505
- type: ndcg_at_3
value: 85.842
- type: ndcg_at_5
value: 85.101
- type: precision_at_1
value: 89.8
- type: precision_at_10
value: 42.225
- type: precision_at_100
value: 4.8149999999999995
- type: precision_at_1000
value: 0.48900000000000005
- type: precision_at_3
value: 76.967
- type: precision_at_5
value: 65.32
- type: recall_at_1
value: 26.147
- type: recall_at_10
value: 89.30399999999999
- type: recall_at_100
value: 97.609
- type: recall_at_1000
value: 99.409
- type: recall_at_3
value: 57.56
- type: recall_at_5
value: 74.78200000000001
- task:
type: Retrieval
dataset:
type: C_MTEB/EcomRetrieval
name: MTEB EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 53.300000000000004
- type: map_at_10
value: 62.507000000000005
- type: map_at_100
value: 63.068000000000005
- type: map_at_1000
value: 63.08200000000001
- type: map_at_3
value: 60.050000000000004
- type: map_at_5
value: 61.41
- type: mrr_at_1
value: 53.300000000000004
- type: mrr_at_10
value: 62.507000000000005
- type: mrr_at_100
value: 63.068000000000005
- type: mrr_at_1000
value: 63.08200000000001
- type: mrr_at_3
value: 60.050000000000004
- type: mrr_at_5
value: 61.41
- type: ndcg_at_1
value: 53.300000000000004
- type: ndcg_at_10
value: 67.31700000000001
- type: ndcg_at_100
value: 69.862
- type: ndcg_at_1000
value: 70.231
- type: ndcg_at_3
value: 62.222
- type: ndcg_at_5
value: 64.66300000000001
- type: precision_at_1
value: 53.300000000000004
- type: precision_at_10
value: 8.260000000000002
- type: precision_at_100
value: 0.941
- type: precision_at_1000
value: 0.097
- type: precision_at_3
value: 22.833000000000002
- type: precision_at_5
value: 14.879999999999999
- type: recall_at_1
value: 53.300000000000004
- type: recall_at_10
value: 82.6
- type: recall_at_100
value: 94.1
- type: recall_at_1000
value: 97.0
- type: recall_at_3
value: 68.5
- type: recall_at_5
value: 74.4
- task:
type: Retrieval
dataset:
type: C_MTEB/MMarcoRetrieval
name: MTEB MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 70.68799999999999
- type: map_at_10
value: 79.28399999999999
- type: map_at_100
value: 79.537
- type: map_at_1000
value: 79.545
- type: map_at_3
value: 77.643
- type: map_at_5
value: 78.694
- type: mrr_at_1
value: 73.05199999999999
- type: mrr_at_10
value: 79.794
- type: mrr_at_100
value: 80.024
- type: mrr_at_1000
value: 80.03099999999999
- type: mrr_at_3
value: 78.441
- type: mrr_at_5
value: 79.29
- type: ndcg_at_1
value: 73.05199999999999
- type: ndcg_at_10
value: 82.627
- type: ndcg_at_100
value: 83.737
- type: ndcg_at_1000
value: 83.946
- type: ndcg_at_3
value: 79.585
- type: ndcg_at_5
value: 81.306
- type: precision_at_1
value: 73.05199999999999
- type: precision_at_10
value: 9.835
- type: precision_at_100
value: 1.038
- type: precision_at_1000
value: 0.106
- type: precision_at_3
value: 29.756
- type: precision_at_5
value: 18.788
- type: recall_at_1
value: 70.68799999999999
- type: recall_at_10
value: 92.38300000000001
- type: recall_at_100
value: 97.347
- type: recall_at_1000
value: 98.992
- type: recall_at_3
value: 84.37
- type: recall_at_5
value: 88.434
- task:
type: Retrieval
dataset:
type: C_MTEB/MedicalRetrieval
name: MTEB MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 53.1
- type: map_at_10
value: 58.36599999999999
- type: map_at_100
value: 58.939
- type: map_at_1000
value: 58.99100000000001
- type: map_at_3
value: 57.15
- type: map_at_5
value: 57.794999999999995
- type: mrr_at_1
value: 53.2
- type: mrr_at_10
value: 58.416000000000004
- type: mrr_at_100
value: 58.989999999999995
- type: mrr_at_1000
value: 59.041
- type: mrr_at_3
value: 57.199999999999996
- type: mrr_at_5
value: 57.845
- type: ndcg_at_1
value: 53.1
- type: ndcg_at_10
value: 60.989000000000004
- type: ndcg_at_100
value: 63.967
- type: ndcg_at_1000
value: 65.436
- type: ndcg_at_3
value: 58.425000000000004
- type: ndcg_at_5
value: 59.583
- type: precision_at_1
value: 53.1
- type: precision_at_10
value: 6.93
- type: precision_at_100
value: 0.8370000000000001
- type: precision_at_1000
value: 0.096
- type: precision_at_3
value: 20.7
- type: precision_at_5
value: 12.98
- type: recall_at_1
value: 53.1
- type: recall_at_10
value: 69.3
- type: recall_at_100
value: 83.7
- type: recall_at_1000
value: 95.5
- type: recall_at_3
value: 62.1
- type: recall_at_5
value: 64.9
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 33.548800108363665
- type: mrr
value: 32.529761904761905
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 69.43381583724414
- type: mrr
value: 80.47879657392181
- task:
type: Retrieval
dataset:
type: C_MTEB/T2Retrieval
name: MTEB T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 28.116000000000003
- type: map_at_10
value: 80.026
- type: map_at_100
value: 83.541
- type: map_at_1000
value: 83.592
- type: map_at_3
value: 56.092
- type: map_at_5
value: 69.114
- type: mrr_at_1
value: 91.557
- type: mrr_at_10
value: 93.73700000000001
- type: mrr_at_100
value: 93.808
- type: mrr_at_1000
value: 93.811
- type: mrr_at_3
value: 93.384
- type: mrr_at_5
value: 93.614
- type: ndcg_at_1
value: 91.553
- type: ndcg_at_10
value: 87.003
- type: ndcg_at_100
value: 90.128
- type: ndcg_at_1000
value: 90.615
- type: ndcg_at_3
value: 88.205
- type: ndcg_at_5
value: 86.978
- type: precision_at_1
value: 91.553
- type: precision_at_10
value: 43.25
- type: precision_at_100
value: 5.067
- type: precision_at_1000
value: 0.518
- type: precision_at_3
value: 77.25
- type: precision_at_5
value: 64.902
- type: recall_at_1
value: 28.116000000000003
- type: recall_at_10
value: 85.994
- type: recall_at_100
value: 96.345
- type: recall_at_1000
value: 98.867
- type: recall_at_3
value: 57.67099999999999
- type: recall_at_5
value: 72.26
- task:
type: Retrieval
dataset:
type: C_MTEB/VideoRetrieval
name: MTEB VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 64.9
- type: map_at_10
value: 73.763
- type: map_at_100
value: 74.116
- type: map_at_1000
value: 74.12100000000001
- type: map_at_3
value: 72.15
- type: map_at_5
value: 73.25
- type: mrr_at_1
value: 64.9
- type: mrr_at_10
value: 73.763
- type: mrr_at_100
value: 74.116
- type: mrr_at_1000
value: 74.12100000000001
- type: mrr_at_3
value: 72.15
- type: mrr_at_5
value: 73.25
- type: ndcg_at_1
value: 64.9
- type: ndcg_at_10
value: 77.639
- type: ndcg_at_100
value: 79.396
- type: ndcg_at_1000
value: 79.554
- type: ndcg_at_3
value: 74.406
- type: ndcg_at_5
value: 76.385
- type: precision_at_1
value: 64.9
- type: precision_at_10
value: 8.959999999999999
- type: precision_at_100
value: 0.979
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 26.967000000000002
- type: precision_at_5
value: 17.14
- type: recall_at_1
value: 64.9
- type: recall_at_10
value: 89.60000000000001
- type: recall_at_100
value: 97.89999999999999
- type: recall_at_1000
value: 99.2
- type: recall_at_3
value: 80.9
- type: recall_at_5
value: 85.7
---
license: apache-2.0
library_name: transformers
---
<h1 align="center">PEG: Towards Robust Text Retrieval with Progressive Learning</h1>
## Model Details
We propose the PEG model (a Progressively Learned Textual Embedding), which progressively adjusts the weights of samples contributing to the loss within an extremely large batch, based on the difficulty levels of negative samples.
we have amassed an extensive collection of over 110 million data, spanning a wide range of fields such as general knowledge, finance, tourism, medicine, and more.
Our technical report is available at [Paper](https://arxiv.org/pdf/2311.11691.pdf)
## Usage (HuggingFace Transformers)
Install transformers:
```
pip install transformers
```
Then load model and predict:
```python
from transformers import AutoModel, AutoTokenizer
import torch
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('TownsWu/PEG')
model = AutoModel.from_pretrained('TownsWu/PEG')
sentences = ['如何更换花呗绑定银行卡', '花呗更改绑定银行卡']
# Tokenize sentences
inputs = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
last_hidden_state = model(**inputs, return_dict=True).last_hidden_state
embeddings = last_hidden_state[:, 0]
print("embeddings:")
print(embeddings)
```
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Tong Wu([email protected]).
## Citation
If you find our work helpful for your research, please consider citing the following BibTeX entry:
```
@article{wu2023towards,
title={Towards Robust Text Retrieval with Progressive Learning},
author={Wu, Tong and Qin, Yulei and Zhang, Enwei and Xu, Zihan and Gao, Yuting and Li, Ke and Sun, Xing},
journal={arXiv preprint arXiv:2311.11691},
year={2023}
}
``` |
MaziyarPanahi/Calme-7B-Instruct-v0.2 | MaziyarPanahi | 2024-04-03T16:54:37Z | 935 | 11 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"generated_from_trainer",
"7b",
"calme",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-14T20:18:50Z | ---
license: apache-2.0
tags:
- generated_from_trainer
- mistral
- 7b
- calme
model-index:
- name: Calme-7B-Instruct-v0.2
results: []
model_name: Calme-7B-Instruct-v0.2
inference: false
model_creator: MaziyarPanahi
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
<img src="https://cdn-uploads.huggingface.co/production/uploads/5fd5e18a90b6dc4633f6d292/LzEf6vvq2qIiys-q7l9Hq.webp" width="550" />
# MaziyarPanahi/Calme-7B-Instruct-v0.2
## Model Description
Calme-7B is a state-of-the-art language model with 7 billion parameters, fine-tuned over high-quality datasets on top of Mistral-7B. The Calme-7B models excel in generating text that resonates with clarity, calmness, and coherence.
### How to Use
```python
# Use a pipeline as a high-level helper
from transformers import pipeline
pipe = pipeline("text-generation", model="MaziyarPanahi/Calme-7B-Instruct-v0.2")
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("MaziyarPanahi/Calme-7B-Instruct-v0.2")
model = AutoModelForCausalLM.from_pretrained("MaziyarPanahi/Calme-7B-Instruct-v0.2")
```
### Quantized Models
> I love how GGUF democratizes the use of Large Language Models (LLMs) on commodity hardware, more specifically, personal computers without any accelerated hardware. Because of this, I am committed to converting and quantizing any models I fine-tune to make them accessible to everyone!
- GGUF (2/3/4/5/6/8 bits): [MaziyarPanahi/Calme-7B-Instruct-v0.2-GGUF](https://huggingface.co/MaziyarPanahi/Calme-7B-Instruct-v0.2-GGUF)
## Examples
```
<s>[INST] You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
describe about pros and cons of docker system. [/INST]
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
<s> [INST] Mark is faster than Mary, Mary is faster than Joe. Is Joe faster than Mark? Let's think step by step [/INST]
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
<s> [INST] explain step by step 25-4*2+3=? [/INST]
```
<details>
<summary>Show me the response</summary>
```
```
</details>
**Multilingual:**
```
<s> [INST] Vous êtes un assistant utile, respectueux et honnête. Répondez toujours de la manière la plus utile possible, tout en étant sûr. Vos réponses ne doivent inclure aucun contenu nuisible, contraire à l'éthique, raciste, sexiste, toxique, dangereux ou illégal. Assurez-vous que vos réponses sont socialement impartiales et de nature positive.
Si une question n'a pas de sens ou n'est pas cohérente d'un point de vue factuel, expliquez pourquoi au lieu de répondre quelque chose d'incorrect. Si vous ne connaissez pas la réponse à une question, veuillez ne pas partager de fausses informations.
Décrivez les avantages et les inconvénients du système Docker.[/INST]
```
<details>
<summary>Show me the response</summary>
```
```
<details>
<summary>Show me the response</summary>
```
```
</details>
```
<s>[INST] Ви - корисний, поважний та чесний помічник. Завжди відповідайте максимально корисно, будучи безпечним. Ваші відповіді не повинні містити шкідливого, неетичного, расистського, сексистського, токсичного, небезпечного або нелегального контенту. Будь ласка, переконайтеся, що ваші відповіді соціально неупереджені та мають позитивний характер.
Якщо питання не має сенсу або не є фактично послідовним, поясніть чому, замість того, щоб відповідати щось некоректне. Якщо ви не знаєте відповіді на питання, будь ласка, не діліться неправдивою інформацією.
Опис про переваги та недоліки системи Docker.[/INST]
```
<details>
<summary>Show me the response</summary>
```
```
</details> |
MoritzLaurer/deberta-v3-large-zeroshot-v2.0-c | MoritzLaurer | 2024-04-04T07:04:53Z | 935 | 15 | transformers | [
"transformers",
"safetensors",
"deberta-v2",
"text-classification",
"zero-shot-classification",
"en",
"dataset:nyu-mll/multi_nli",
"dataset:fever",
"arxiv:2312.17543",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| zero-shot-classification | 2024-03-20T21:23:01Z | ---
language:
- en
tags:
- text-classification
- zero-shot-classification
pipeline_tag: zero-shot-classification
library_name: transformers
license: mit
datasets:
- nyu-mll/multi_nli
- fever
---
# Model description: deberta-v3-large-zeroshot-v2.0-c
## zeroshot-v2.0 series of models
Models in this series are designed for efficient zeroshot classification with the Hugging Face pipeline.
These models can do classification without training data and run on both GPUs and CPUs.
An overview of the latest zeroshot classifiers is available in my [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
The main update of this `zeroshot-v2.0` series of models is that several models are trained on fully commercially-friendly data for users with strict license requirements.
These models can do one universal classification task: determine whether a hypothesis is "true" or "not true" given a text
(`entailment` vs. `not_entailment`).
This task format is based on the Natural Language Inference task (NLI).
The task is so universal that any classification task can be reformulated into this task by the Hugging Face pipeline.
## Training data
Models with a "`-c`" in the name are trained on two types of fully commercially-friendly data:
1. Synthetic data generated with [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1).
I first created a list of 500+ diverse text classification tasks for 25 professions in conversations with Mistral-large. The data was manually curated.
I then used this as seed data to generate several hundred thousand texts for these tasks with Mixtral-8x7B-Instruct-v0.1.
The final dataset used is available in the [synthetic_zeroshot_mixtral_v0.1](https://huggingface.co/datasets/MoritzLaurer/synthetic_zeroshot_mixtral_v0.1) dataset
in the subset `mixtral_written_text_for_tasks_v4`. Data curation was done in multiple iterations and will be improved in future iterations.
2. Two commercially-friendly NLI datasets: ([MNLI](https://huggingface.co/datasets/nyu-mll/multi_nli), [FEVER-NLI](https://huggingface.co/datasets/fever)).
These datasets were added to increase generalization.
3. Models without a "`-c`" in the name also included a broader mix of training data with a broader mix of licenses: ANLI, WANLI, LingNLI,
and all datasets in [this list](https://github.com/MoritzLaurer/zeroshot-classifier/blob/7f82e4ab88d7aa82a4776f161b368cc9fa778001/v1_human_data/datasets_overview.csv)
where `used_in_v1.1==True`.
## How to use the models
```python
#!pip install transformers[sentencepiece]
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
```
`multi_label=False` forces the model to decide on only one class. `multi_label=True` enables the model to choose multiple classes.
## Metrics
The models were evaluated on 28 different text classification tasks with the [f1_macro](https://scikit-learn.org/stable/modules/generated/sklearn.metrics.f1_score.html) metric.
The main reference point is `facebook/bart-large-mnli` which is, at the time of writing (03.04.24), the most used commercially-friendly 0-shot classifier.
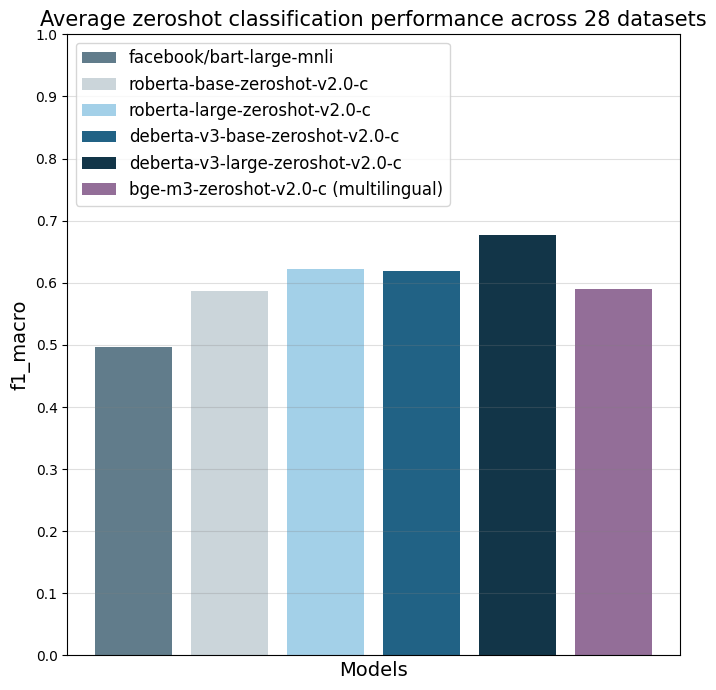
| | facebook/bart-large-mnli | roberta-base-zeroshot-v2.0-c | roberta-large-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0-c | deberta-v3-base-zeroshot-v2.0 (fewshot) | deberta-v3-large-zeroshot-v2.0-c | deberta-v3-large-zeroshot-v2.0 (fewshot) | bge-m3-zeroshot-v2.0-c | bge-m3-zeroshot-v2.0 (fewshot) |
|:---------------------------|---------------------------:|-----------------------------:|------------------------------:|--------------------------------:|-----------------------------------:|---------------------------------:|------------------------------------:|-----------------------:|--------------------------:|
| all datasets mean | 0.497 | 0.587 | 0.622 | 0.619 | 0.643 (0.834) | 0.676 | 0.673 (0.846) | 0.59 | (0.803) |
| amazonpolarity (2) | 0.937 | 0.924 | 0.951 | 0.937 | 0.943 (0.961) | 0.952 | 0.956 (0.968) | 0.942 | (0.951) |
| imdb (2) | 0.892 | 0.871 | 0.904 | 0.893 | 0.899 (0.936) | 0.923 | 0.918 (0.958) | 0.873 | (0.917) |
| appreviews (2) | 0.934 | 0.913 | 0.937 | 0.938 | 0.945 (0.948) | 0.943 | 0.949 (0.962) | 0.932 | (0.954) |
| yelpreviews (2) | 0.948 | 0.953 | 0.977 | 0.979 | 0.975 (0.989) | 0.988 | 0.985 (0.994) | 0.973 | (0.978) |
| rottentomatoes (2) | 0.83 | 0.802 | 0.841 | 0.84 | 0.86 (0.902) | 0.869 | 0.868 (0.908) | 0.813 | (0.866) |
| emotiondair (6) | 0.455 | 0.482 | 0.486 | 0.459 | 0.495 (0.748) | 0.499 | 0.484 (0.688) | 0.453 | (0.697) |
| emocontext (4) | 0.497 | 0.555 | 0.63 | 0.59 | 0.592 (0.799) | 0.699 | 0.676 (0.81) | 0.61 | (0.798) |
| empathetic (32) | 0.371 | 0.374 | 0.404 | 0.378 | 0.405 (0.53) | 0.447 | 0.478 (0.555) | 0.387 | (0.455) |
| financialphrasebank (3) | 0.465 | 0.562 | 0.455 | 0.714 | 0.669 (0.906) | 0.691 | 0.582 (0.913) | 0.504 | (0.895) |
| banking77 (72) | 0.312 | 0.124 | 0.29 | 0.421 | 0.446 (0.751) | 0.513 | 0.567 (0.766) | 0.387 | (0.715) |
| massive (59) | 0.43 | 0.428 | 0.543 | 0.512 | 0.52 (0.755) | 0.526 | 0.518 (0.789) | 0.414 | (0.692) |
| wikitoxic_toxicaggreg (2) | 0.547 | 0.751 | 0.766 | 0.751 | 0.769 (0.904) | 0.741 | 0.787 (0.911) | 0.736 | (0.9) |
| wikitoxic_obscene (2) | 0.713 | 0.817 | 0.854 | 0.853 | 0.869 (0.922) | 0.883 | 0.893 (0.933) | 0.783 | (0.914) |
| wikitoxic_threat (2) | 0.295 | 0.71 | 0.817 | 0.813 | 0.87 (0.946) | 0.827 | 0.879 (0.952) | 0.68 | (0.947) |
| wikitoxic_insult (2) | 0.372 | 0.724 | 0.798 | 0.759 | 0.811 (0.912) | 0.77 | 0.779 (0.924) | 0.783 | (0.915) |
| wikitoxic_identityhate (2) | 0.473 | 0.774 | 0.798 | 0.774 | 0.765 (0.938) | 0.797 | 0.806 (0.948) | 0.761 | (0.931) |
| hateoffensive (3) | 0.161 | 0.352 | 0.29 | 0.315 | 0.371 (0.862) | 0.47 | 0.461 (0.847) | 0.291 | (0.823) |
| hatexplain (3) | 0.239 | 0.396 | 0.314 | 0.376 | 0.369 (0.765) | 0.378 | 0.389 (0.764) | 0.29 | (0.729) |
| biasframes_offensive (2) | 0.336 | 0.571 | 0.583 | 0.544 | 0.601 (0.867) | 0.644 | 0.656 (0.883) | 0.541 | (0.855) |
| biasframes_sex (2) | 0.263 | 0.617 | 0.835 | 0.741 | 0.809 (0.922) | 0.846 | 0.815 (0.946) | 0.748 | (0.905) |
| biasframes_intent (2) | 0.616 | 0.531 | 0.635 | 0.554 | 0.61 (0.881) | 0.696 | 0.687 (0.891) | 0.467 | (0.868) |
| agnews (4) | 0.703 | 0.758 | 0.745 | 0.68 | 0.742 (0.898) | 0.819 | 0.771 (0.898) | 0.687 | (0.892) |
| yahootopics (10) | 0.299 | 0.543 | 0.62 | 0.578 | 0.564 (0.722) | 0.621 | 0.613 (0.738) | 0.587 | (0.711) |
| trueteacher (2) | 0.491 | 0.469 | 0.402 | 0.431 | 0.479 (0.82) | 0.459 | 0.538 (0.846) | 0.471 | (0.518) |
| spam (2) | 0.505 | 0.528 | 0.504 | 0.507 | 0.464 (0.973) | 0.74 | 0.597 (0.983) | 0.441 | (0.978) |
| wellformedquery (2) | 0.407 | 0.333 | 0.333 | 0.335 | 0.491 (0.769) | 0.334 | 0.429 (0.815) | 0.361 | (0.718) |
| manifesto (56) | 0.084 | 0.102 | 0.182 | 0.17 | 0.187 (0.376) | 0.258 | 0.256 (0.408) | 0.147 | (0.331) |
| capsotu (21) | 0.34 | 0.479 | 0.523 | 0.502 | 0.477 (0.664) | 0.603 | 0.502 (0.686) | 0.472 | (0.644) |
These numbers indicate zeroshot performance, as no data from these datasets was added in the training mix.
Note that models without a "`-c`" in the title were evaluated twice: one run without any data from these 28 datasets to test pure zeroshot performance (the first number in the respective column) and
the final run including up to 500 training data points per class from each of the 28 datasets (the second number in brackets in the column, "fewshot"). No model was trained on test data.
Details on the different datasets are available here: https://github.com/MoritzLaurer/zeroshot-classifier/blob/main/v1_human_data/datasets_overview.csv
## When to use which model
- **deberta-v3-zeroshot vs. roberta-zeroshot**: deberta-v3 performs clearly better than roberta, but it is a bit slower.
roberta is directly compatible with Hugging Face's production inference TEI containers and flash attention.
These containers are a good choice for production use-cases. tl;dr: For accuracy, use a deberta-v3 model.
If production inference speed is a concern, you can consider a roberta model (e.g. in a TEI container and [HF Inference Endpoints](https://ui.endpoints.huggingface.co/catalog)).
- **commercial use-cases**: models with "`-c`" in the title are guaranteed to be trained on only commercially-friendly data.
Models without a "`-c`" were trained on more data and perform better, but include data with non-commercial licenses.
Legal opinions diverge if this training data affects the license of the trained model. For users with strict legal requirements,
the models with "`-c`" in the title are recommended.
- **Multilingual/non-English use-cases**: use [bge-m3-zeroshot-v2.0](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0) or [bge-m3-zeroshot-v2.0-c](https://huggingface.co/MoritzLaurer/bge-m3-zeroshot-v2.0-c).
Note that multilingual models perform worse than English-only models. You can therefore also first machine translate your texts to English with libraries like [EasyNMT](https://github.com/UKPLab/EasyNMT)
and then apply any English-only model to the translated data. Machine translation also facilitates validation in case your team does not speak all languages in the data.
- **context window**: The `bge-m3` models can process up to 8192 tokens. The other models can process up to 512. Note that longer text inputs both make the
mode slower and decrease performance, so if you're only working with texts of up to 400~ words / 1 page, use e.g. a deberta model for better performance.
- The latest updates on new models are always available in the [Zeroshot Classifier Collection](https://huggingface.co/collections/MoritzLaurer/zeroshot-classifiers-6548b4ff407bb19ff5c3ad6f).
## Reproduction
Reproduction code is available in the `v2_synthetic_data` directory here: https://github.com/MoritzLaurer/zeroshot-classifier/tree/main
## Limitations and bias
The model can only do text classification tasks.
Biases can come from the underlying foundation model, the human NLI training data and the synthetic data generated by Mixtral.
## License
The foundation model was published under the MIT license.
The licenses of the training data vary depending on the model, see above.
## Citation
This model is an extension of the research described in this [paper](https://arxiv.org/pdf/2312.17543.pdf).
If you use this model academically, please cite:
```
@misc{laurer_building_2023,
title = {Building {Efficient} {Universal} {Classifiers} with {Natural} {Language} {Inference}},
url = {http://arxiv.org/abs/2312.17543},
doi = {10.48550/arXiv.2312.17543},
abstract = {Generative Large Language Models (LLMs) have become the mainstream choice for fewshot and zeroshot learning thanks to the universality of text generation. Many users, however, do not need the broad capabilities of generative LLMs when they only want to automate a classification task. Smaller BERT-like models can also learn universal tasks, which allow them to do any text classification task without requiring fine-tuning (zeroshot classification) or to learn new tasks with only a few examples (fewshot), while being significantly more efficient than generative LLMs. This paper (1) explains how Natural Language Inference (NLI) can be used as a universal classification task that follows similar principles as instruction fine-tuning of generative LLMs, (2) provides a step-by-step guide with reusable Jupyter notebooks for building a universal classifier, and (3) shares the resulting universal classifier that is trained on 33 datasets with 389 diverse classes. Parts of the code we share has been used to train our older zeroshot classifiers that have been downloaded more than 55 million times via the Hugging Face Hub as of December 2023. Our new classifier improves zeroshot performance by 9.4\%.},
urldate = {2024-01-05},
publisher = {arXiv},
author = {Laurer, Moritz and van Atteveldt, Wouter and Casas, Andreu and Welbers, Kasper},
month = dec,
year = {2023},
note = {arXiv:2312.17543 [cs]},
keywords = {Computer Science - Artificial Intelligence, Computer Science - Computation and Language},
}
```
### Ideas for cooperation or questions?
If you have questions or ideas for cooperation, contact me at moritz{at}huggingface{dot}co or [LinkedIn](https://www.linkedin.com/in/moritz-laurer/)
### Flexible usage and "prompting"
You can formulate your own hypotheses by changing the `hypothesis_template` of the zeroshot pipeline.
Similar to "prompt engineering" for LLMs, you can test different formulations of your `hypothesis_template` and verbalized classes to improve performance.
```python
from transformers import pipeline
text = "Angela Merkel is a politician in Germany and leader of the CDU"
# formulation 1
hypothesis_template = "This text is about {}"
classes_verbalized = ["politics", "economy", "entertainment", "environment"]
# formulation 2 depending on your use-case
hypothesis_template = "The topic of this text is {}"
classes_verbalized = ["political activities", "economic policy", "entertainment or music", "environmental protection"]
# test different formulations
zeroshot_classifier = pipeline("zero-shot-classification", model="MoritzLaurer/deberta-v3-large-zeroshot-v2.0") # change the model identifier here
output = zeroshot_classifier(text, classes_verbalized, hypothesis_template=hypothesis_template, multi_label=False)
print(output)
``` |
kwoncho/gaincut_news_pre2018_2 | kwoncho | 2024-05-28T02:42:15Z | 935 | 0 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-05-28T02:41:17Z | Entry not found |
unsloth/Qwen2-0.5B-Instruct | unsloth | 2024-06-06T17:19:09Z | 935 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-06-06T16:32:56Z | ---
language:
- en
license: apache-2.0
library_name: transformers
tags:
- unsloth
- transformers
- qwen2
---
# Finetune Mistral, Gemma, Llama 2-5x faster with 70% less memory via Unsloth!
We have a Google Colab Tesla T4 notebook for Qwen2 7b here: https://colab.research.google.com/drive/1mvwsIQWDs2EdZxZQF9pRGnnOvE86MVvR?usp=sharing
And a Colab notebook for [Qwen2 0.5b](https://colab.research.google.com/drive/1-7tjDdMAyeCueyLAwv6vYeBMHpoePocN?usp=sharing) and another for [Qwen2 1.5b](https://colab.research.google.com/drive/1W0j3rP8WpgxRdUgkb5l6E00EEVyjEZGk?usp=sharing)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/Discord%20button.png" width="200"/>](https://discord.gg/u54VK8m8tk)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/buy%20me%20a%20coffee%20button.png" width="200"/>](https://ko-fi.com/unsloth)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
## ✨ Finetune for Free
All notebooks are **beginner friendly**! Add your dataset, click "Run All", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
| Unsloth supports | Free Notebooks | Performance | Memory use |
|-----------------|--------------------------------------------------------------------------------------------------------------------------|-------------|----------|
| **Llama-3 8b** | [▶️ Start on Colab](https://colab.research.google.com/drive/135ced7oHytdxu3N2DNe1Z0kqjyYIkDXp?usp=sharing) | 2.4x faster | 58% less |
| **Gemma 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/10NbwlsRChbma1v55m8LAPYG15uQv6HLo?usp=sharing) | 2.4x faster | 58% less |
| **Mistral 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1Dyauq4kTZoLewQ1cApceUQVNcnnNTzg_?usp=sharing) | 2.2x faster | 62% less |
| **Llama-2 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1lBzz5KeZJKXjvivbYvmGarix9Ao6Wxe5?usp=sharing) | 2.2x faster | 43% less |
| **TinyLlama** | [▶️ Start on Colab](https://colab.research.google.com/drive/1AZghoNBQaMDgWJpi4RbffGM1h6raLUj9?usp=sharing) | 3.9x faster | 74% less |
| **CodeLlama 34b** A100 | [▶️ Start on Colab](https://colab.research.google.com/drive/1y7A0AxE3y8gdj4AVkl2aZX47Xu3P1wJT?usp=sharing) | 1.9x faster | 27% less |
| **Mistral 7b** 1xT4 | [▶️ Start on Kaggle](https://www.kaggle.com/code/danielhanchen/kaggle-mistral-7b-unsloth-notebook) | 5x faster\* | 62% less |
| **DPO - Zephyr** | [▶️ Start on Colab](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) | 1.9x faster | 19% less |
- This [conversational notebook](https://colab.research.google.com/drive/1Aau3lgPzeZKQ-98h69CCu1UJcvIBLmy2?usp=sharing) is useful for ShareGPT ChatML / Vicuna templates.
- This [text completion notebook](https://colab.research.google.com/drive/1ef-tab5bhkvWmBOObepl1WgJvfvSzn5Q?usp=sharing) is for raw text. This [DPO notebook](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) replicates Zephyr.
- \* Kaggle has 2x T4s, but we use 1. Due to overhead, 1x T4 is 5x faster. |
LostMedia/RetroDiffusion | LostMedia | 2023-09-18T23:07:46Z | 934 | 9 | diffusers | [
"diffusers",
"safetensors",
"Lost Media",
"Archive",
"text-to-image",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-09-18T21:46:31Z | ---
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Lost Media
- Archive
---
# Retro Diffusion Model
Only known link to download this model, archived so people from the future can enjoy it.
- **License:** Public Domain Mark 1.0

Pixel Art, Pretty Cute Girl, highly detailed, masterpiece, trending on ArtStation, sitting, Detailed Chibi Eyes, fantasy, beautiful detailed legs, streetwear, gorgeous detailed hair, hat, Magazine ad, iconic, 1943, from the movie, sharp focus. |
diffusers-test/deli_text_encoder-fluentlyxl_text_encoder-test-XL | diffusers-test | 2024-06-19T10:07:56Z | 934 | 0 | diffusers | [
"diffusers",
"safetensors",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
]
| text-to-image | 2024-05-28T18:58:33Z | Entry not found |
ShuaHousetable/serverless-roomsort | ShuaHousetable | 2022-11-13T14:43:31Z | 933 | 0 | transformers | [
"transformers",
"pytorch",
"beit",
"image-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-10-02T14:25:22Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- accuracy
model-index:
- name: serverless-roomsort
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# serverless-roomsort
This model is a fine-tuned version of [microsoft/beit-base-patch16-224-pt22k-ft22k](https://huggingface.co/microsoft/beit-base-patch16-224-pt22k-ft22k) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0394
- Accuracy: 0.9892
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_steps: 500
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.7844 | 1.0 | 762 | 0.0608 | 0.9791 |
| 0.0361 | 2.0 | 1524 | 0.0626 | 0.9830 |
| 0.0149 | 3.0 | 2286 | 0.0468 | 0.9879 |
| 0.0027 | 4.0 | 3048 | 0.0394 | 0.9892 |
| 0.0017 | 5.0 | 3810 | 0.0486 | 0.9889 |
### Framework versions
- Transformers 4.17.0
- Pytorch 1.10.2+cu113
- Datasets 1.18.4
- Tokenizers 0.13.0
|
timm/eva02_large_patch14_448.mim_in22k_ft_in22k_in1k | timm | 2024-02-10T23:37:42Z | 933 | 1 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"dataset:imagenet-22k",
"arxiv:2303.11331",
"arxiv:2303.15389",
"license:mit",
"region:us"
]
| image-classification | 2023-03-31T04:37:29Z | ---
license: mit
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
- imagenet-22k
---
# Model card for eva02_large_patch14_448.mim_in22k_ft_in22k_in1k
An EVA02 image classification model. Pretrained on ImageNet-22k with masked image modeling (using EVA-CLIP as a MIM teacher) and fine-tuned on ImageNet-22k then on ImageNet-1k by paper authors.
EVA-02 models are vision transformers with mean pooling, SwiGLU, Rotary Position Embeddings (ROPE), and extra LN in MLP (for Base & Large).
NOTE: `timm` checkpoints are float32 for consistency with other models. Original checkpoints are float16 or bfloat16 in some cases, see originals if that's preferred.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 305.1
- GMACs: 362.3
- Activations (M): 689.9
- Image size: 448 x 448
- **Papers:**
- EVA-02: A Visual Representation for Neon Genesis: https://arxiv.org/abs/2303.11331
- EVA-CLIP: Improved Training Techniques for CLIP at Scale: https://arxiv.org/abs/2303.15389
- **Original:**
- https://github.com/baaivision/EVA
- https://huggingface.co/Yuxin-CV/EVA-02
- **Pretrain Dataset:** ImageNet-22k
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('eva02_large_patch14_448.mim_in22k_ft_in22k_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'eva02_large_patch14_448.mim_in22k_ft_in22k_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 1025, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
|model |top1 |top5 |param_count|img_size|
|-----------------------------------------------|------|------|-----------|--------|
|eva02_large_patch14_448.mim_m38m_ft_in22k_in1k |90.054|99.042|305.08 |448 |
|eva02_large_patch14_448.mim_in22k_ft_in22k_in1k|89.946|99.01 |305.08 |448 |
|eva_giant_patch14_560.m30m_ft_in22k_in1k |89.792|98.992|1014.45 |560 |
|eva02_large_patch14_448.mim_in22k_ft_in1k |89.626|98.954|305.08 |448 |
|eva02_large_patch14_448.mim_m38m_ft_in1k |89.57 |98.918|305.08 |448 |
|eva_giant_patch14_336.m30m_ft_in22k_in1k |89.56 |98.956|1013.01 |336 |
|eva_giant_patch14_336.clip_ft_in1k |89.466|98.82 |1013.01 |336 |
|eva_large_patch14_336.in22k_ft_in22k_in1k |89.214|98.854|304.53 |336 |
|eva_giant_patch14_224.clip_ft_in1k |88.882|98.678|1012.56 |224 |
|eva02_base_patch14_448.mim_in22k_ft_in22k_in1k |88.692|98.722|87.12 |448 |
|eva_large_patch14_336.in22k_ft_in1k |88.652|98.722|304.53 |336 |
|eva_large_patch14_196.in22k_ft_in22k_in1k |88.592|98.656|304.14 |196 |
|eva02_base_patch14_448.mim_in22k_ft_in1k |88.23 |98.564|87.12 |448 |
|eva_large_patch14_196.in22k_ft_in1k |87.934|98.504|304.14 |196 |
|eva02_small_patch14_336.mim_in22k_ft_in1k |85.74 |97.614|22.13 |336 |
|eva02_tiny_patch14_336.mim_in22k_ft_in1k |80.658|95.524|5.76 |336 |
## Citation
```bibtex
@article{EVA02,
title={EVA-02: A Visual Representation for Neon Genesis},
author={Fang, Yuxin and Sun, Quan and Wang, Xinggang and Huang, Tiejun and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2303.11331},
year={2023}
}
```
```bibtex
@article{EVA-CLIP,
title={EVA-02: A Visual Representation for Neon Genesis},
author={Sun, Quan and Fang, Yuxin and Wu, Ledell and Wang, Xinlong and Cao, Yue},
journal={arXiv preprint arXiv:2303.15389},
year={2023}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
KingNish/Llama3-12b | KingNish | 2024-05-05T17:18:26Z | 933 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"abhishek/autotrain-llama3-orpo-v2",
"conversational",
"base_model:abhishek/autotrain-llama3-orpo-v2",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-05T17:03:23Z | ---
tags:
- merge
- mergekit
- lazymergekit
- abhishek/autotrain-llama3-orpo-v2
base_model:
- abhishek/autotrain-llama3-orpo-v2
- abhishek/autotrain-llama3-orpo-v2
license: llama3
pipeline_tag: text-generation
---
# NeuralPipe-7B-slerp
NeuralPipe-7B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [abhishek/autotrain-llama3-orpo-v2](https://huggingface.co/abhishek/autotrain-llama3-orpo-v2)
* [abhishek/autotrain-llama3-orpo-v2](https://huggingface.co/abhishek/autotrain-llama3-orpo-v2)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: abhishek/autotrain-llama3-orpo-v2
layer_range: [0, 24]
- sources:
- model: abhishek/autotrain-llama3-orpo-v2
layer_range: [8, 32]
merge_method: passthrough
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "KingNish/NeuralPipe-7B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
LeroyDyer/_Spydaz_Web_AI_-Q4_K_M-GGUF | LeroyDyer | 2024-06-26T07:57:42Z | 933 | 1 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"code",
"farmer",
"doctor",
"Mega-Series",
"Cyber-Series",
"Role-Play",
"Self-Rag",
"ThinkingBot",
"milestone",
"mega-series",
"SpydazWebAI",
"llama-cpp",
"gguf-my-repo",
"en",
"sw",
"ig",
"so",
"es",
"ca",
"base_model:LeroyDyer/_Spydaz_Web_AI_",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-22T14:43:16Z | ---
base_model: LeroyDyer/_Spydaz_Web_AI_
language:
- en
- sw
- ig
- so
- es
- ca
license: apache-2.0
metrics:
- accuracy
- bertscore
- bleu
- brier_score
- cer
- character
- charcut_mt
- chrf
- code_eval
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
- code
- farmer
- doctor
- Mega-Series
- Cyber-Series
- Role-Play
- Self-Rag
- ThinkingBot
- milestone
- mega-series
- SpydazWebAI
- llama-cpp
- gguf-my-repo
- llama-cpp
- gguf-my-repo
---
# LeroyDyer/_Spydaz_Web_AI_-Q4_K_M-GGUF
This model was converted to GGUF format from [`LeroyDyer/_Spydaz_Web_AI_`](https://huggingface.co/LeroyDyer/_Spydaz_Web_AI_) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/LeroyDyer/_Spydaz_Web_AI_) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo LeroyDyer/_Spydaz_Web_AI_-Q4_K_M-GGUF --hf-file _spydaz_web_ai_-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo LeroyDyer/_Spydaz_Web_AI_-Q4_K_M-GGUF --hf-file _spydaz_web_ai_-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo LeroyDyer/_Spydaz_Web_AI_-Q4_K_M-GGUF --hf-file _spydaz_web_ai_-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo LeroyDyer/_Spydaz_Web_AI_-Q4_K_M-GGUF --hf-file _spydaz_web_ai_-q4_k_m.gguf -c 2048
```
|
dandelin/vilt-b32-finetuned-coco | dandelin | 2022-01-23T09:45:24Z | 932 | 1 | transformers | [
"transformers",
"pytorch",
"vilt",
"arxiv:2102.03334",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2022-03-02T23:29:05Z | ---
license: apache-2.0
---
# Vision-and-Language Transformer (ViLT), fine-tuned on COCO
Vision-and-Language Transformer (ViLT) model fine-tuned on [COCO](https://cocodataset.org/#home). It was introduced in the paper [ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision](https://arxiv.org/abs/2102.03334) by Kim et al. and first released in [this repository](https://github.com/dandelin/ViLT).
Disclaimer: The team releasing ViLT did not write a model card for this model so this model card has been written by the Hugging Face team.
## Intended uses & limitations
You can use the model for image and text retrieval.
### How to use
Here is how to use the model in PyTorch:
```
from transformers import ViltProcessor, ViltForImageAndTextRetrieval
import requests
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = ViltProcessor.from_pretrained("dandelin/vilt-b32-finetuned-coco")
model = ViltForImageAndTextRetrieval.from_pretrained("dandelin/vilt-b32-finetuned-coco")
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
# forward pass
scores = dict()
for text in texts:
encoding = processor(image, text, return_tensors="pt")
outputs = model(**encoding)
scores[text] = outputs.logits[0, :].item()
```
## Training data
(to do)
## Training procedure
### Preprocessing
(to do)
### Pretraining
(to do)
## Evaluation results
(to do)
### BibTeX entry and citation info
```bibtex
@misc{kim2021vilt,
title={ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision},
author={Wonjae Kim and Bokyung Son and Ildoo Kim},
year={2021},
eprint={2102.03334},
archivePrefix={arXiv},
primaryClass={stat.ML}
}
``` |
OpenGVLab/InternVL-Chat-ViT-6B-Vicuna-7B | OpenGVLab | 2024-04-27T13:39:20Z | 932 | 7 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"llava",
"text-generation",
"visual-question-answering",
"arxiv:2312.14238",
"autotrain_compatible",
"region:us"
]
| visual-question-answering | 2023-12-25T03:47:43Z | ---
inference: false
pipeline_tag: visual-question-answering
---
<br>
<br>
# Model Card for InternVL-Chat-ViT-6B-Vicuna-7B
## What is InternVL?
\[[Paper](https://arxiv.org/abs/2312.14238)\] \[[GitHub](https://github.com/OpenGVLab/InternVL)\] \[[Chat Demo](https://internvl.opengvlab.com/)\]
InternVL scales up the ViT to _**6B parameters**_ and aligns it with LLM.
It is trained using web-scale, noisy image-text pairs. The data are all publicly available and comprise multilingual content, including LAION-en, LAION-multi, LAION-COCO, COYO, Wukong, CC12M, CC3M, and SBU.
It is _**the largest open-source vision/vision-language foundation model (14B)**_ to date, achieving _**32 state-of-the-art**_ performances on a wide range of tasks such as visual perception, cross-modal retrieval, multimodal dialogue, etc.

## How to Run?
Please refer to this [README](https://github.com/OpenGVLab/InternVL/tree/main/internvl_chat_llava#internvl-for-multimodal-dialogue-using-llava) to run this model.
Note: We have retained the original documentation of LLaVA 1.5 as a more detailed manual. In most cases, you will only need to refer to the new documentation that we have added.
## Model details
**Model type:**
InternVL-Chat is an open-source chatbot trained by fine-tuning LLaMA/Vicuna on GPT-generated multimodal instruction-following data.
It is an auto-regressive language model, based on the transformer architecture.
**Model date:**
InternVL-Chat-ViT-6B-Vicuna-7B was trained in November 2023.
**Paper or resources for more information:**
https://github.com/OpenGVLab/InternVL
## License
InternVL is released under the MIT license.
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved.
**Where to send questions or comments about the model:**
https://github.com/OpenGVLab/InternVL/issues
## Intended use
**Primary intended uses:**
The primary use of InternVL-Chat is research on large multimodal models and chatbots.
**Primary intended users:**
The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.
## Training dataset
- 558K filtered image-text pairs from LAION/CC/SBU, captioned by BLIP.
- 158K GPT-generated multimodal instruction-following data.
- 450K academic-task-oriented VQA data mixture.
- 40K ShareGPT data.
## Evaluation dataset
A collection of 12 benchmarks, including 5 academic VQA benchmarks and 7 recent benchmarks specifically proposed for instruction-following LMMs.
## Acknowledgement
This model card is adapted from [LLaVA's model card](https://huggingface.co/liuhaotian/llava-v1.5-13b). Thanks for their awesome work!
## Citation
If you find this project useful in your research, please consider citing:
```BibTeX
@article{chen2023internvl,
title={InternVL: Scaling up Vision Foundation Models and Aligning for Generic Visual-Linguistic Tasks},
author={Chen, Zhe and Wu, Jiannan and Wang, Wenhai and Su, Weijie and Chen, Guo and Xing, Sen and Zhong, Muyan and Zhang, Qinglong and Zhu, Xizhou and Lu, Lewei and Li, Bin and Luo, Ping and Lu, Tong and Qiao, Yu and Dai, Jifeng},
journal={arXiv preprint arXiv:2312.14238},
year={2023}
}
``` |
feeltheAGI/mistral-maths7B | feeltheAGI | 2024-03-05T09:41:52Z | 932 | 6 | transformers | [
"transformers",
"pytorch",
"mistral",
"text-generation",
"conversational",
"dataset:microsoft/orca-math-word-problems-200k",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-05T09:19:32Z | ---
license: apache-2.0
datasets:
- microsoft/orca-math-word-problems-200k
---
---
#todo : update the model card
Running benchmarks rn
| Tasks |Version|Filter|n-shot| Metric |Value | |Stderr|
|---------|------:|------|------|--------|-----:|---|-----:|
|hellaswag| 1|none |None |acc |0.5536|± |0.0050|
| | |none |None |acc_norm|0.7294|± |0.0044| |
mradermacher/airoboros-70b-3.3-i1-GGUF | mradermacher | 2024-06-13T10:33:59Z | 932 | 0 | transformers | [
"transformers",
"gguf",
"llama-3",
"en",
"dataset:jondurbin/airoboros-3.2",
"dataset:bluemoon-fandom-1-1-rp-cleaned",
"dataset:boolq",
"dataset:jondurbin/gutenberg-dpo-v0.1",
"dataset:LDJnr/Capybara",
"dataset:jondurbin/cinematika-v0.1",
"dataset:glaiveai/glaive-function-calling-v2",
"dataset:grimulkan/LimaRP-augmented",
"dataset:piqa",
"dataset:Vezora/Tested-22k-Python-Alpaca",
"dataset:mattpscott/airoboros-summarization",
"dataset:unalignment/toxic-dpo-v0.2",
"base_model:jondurbin/airoboros-70b-3.3",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-10T03:18:36Z | ---
base_model: jondurbin/airoboros-70b-3.3
datasets:
- jondurbin/airoboros-3.2
- bluemoon-fandom-1-1-rp-cleaned
- boolq
- jondurbin/gutenberg-dpo-v0.1
- LDJnr/Capybara
- jondurbin/cinematika-v0.1
- glaiveai/glaive-function-calling-v2
- grimulkan/LimaRP-augmented
- piqa
- Vezora/Tested-22k-Python-Alpaca
- mattpscott/airoboros-summarization
- unalignment/toxic-dpo-v0.2
language:
- en
library_name: transformers
license: other
license_link: https://huggingface.co/meta-llama/Meta-Llama-3-8B/blob/main/LICENSE
license_name: llama3
quantized_by: mradermacher
tags:
- llama-3
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/jondurbin/airoboros-70b-3.3
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/airoboros-70b-3.3-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ1_S.gguf) | i1-IQ1_S | 15.4 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ1_M.gguf) | i1-IQ1_M | 16.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 19.2 | |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ2_XS.gguf) | i1-IQ2_XS | 21.2 | |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ2_S.gguf) | i1-IQ2_S | 22.3 | |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ2_M.gguf) | i1-IQ2_M | 24.2 | |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q2_K.gguf) | i1-Q2_K | 26.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 27.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ3_XS.gguf) | i1-IQ3_XS | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ3_S.gguf) | i1-IQ3_S | 31.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q3_K_S.gguf) | i1-Q3_K_S | 31.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ3_M.gguf) | i1-IQ3_M | 32.0 | |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q3_K_M.gguf) | i1-Q3_K_M | 34.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q3_K_L.gguf) | i1-Q3_K_L | 37.2 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-IQ4_XS.gguf) | i1-IQ4_XS | 38.0 | |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q4_0.gguf) | i1-Q4_0 | 40.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q4_K_S.gguf) | i1-Q4_K_S | 40.4 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q4_K_M.gguf) | i1-Q4_K_M | 42.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q5_K_S.gguf) | i1-Q5_K_S | 48.8 | |
| [GGUF](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q5_K_M.gguf) | i1-Q5_K_M | 50.0 | |
| [PART 1](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/airoboros-70b-3.3-i1-GGUF/resolve/main/airoboros-70b-3.3.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 58.0 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF | TheBloke | 2023-09-27T12:52:36Z | 931 | 5 | transformers | [
"transformers",
"gguf",
"llama",
"en",
"dataset:ehartford/WizardLM_evol_instruct_V2_196k_unfiltered_merged_split",
"base_model:ehartford/WizardLM-13b-V1.0-Uncensored",
"license:other",
"text-generation-inference",
"region:us"
]
| null | 2023-09-19T23:08:34Z | ---
language:
- en
license: other
datasets:
- ehartford/WizardLM_evol_instruct_V2_196k_unfiltered_merged_split
model_name: WizardLM 13B V1.0 Uncensored
base_model: ehartford/WizardLM-13b-V1.0-Uncensored
inference: false
model_creator: Eric Hartford
model_type: llama
prompt_template: 'A chat between a curious user and an artificial intelligence assistant.
The assistant gives helpful, detailed, and polite answers to the user''s questions.
USER: {prompt} ASSISTANT:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# WizardLM 13B V1.0 Uncensored - GGUF
- Model creator: [Eric Hartford](https://huggingface.co/ehartford)
- Original model: [WizardLM 13B V1.0 Uncensored](https://huggingface.co/ehartford/WizardLM-13b-V1.0-Uncensored)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Eric Hartford's WizardLM-13b-V1.0-Uncensored](https://huggingface.co/ehartford/WizardLM-13b-V1.0-Uncensored).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF)
* [Eric Hartford's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/ehartford/WizardLM-13b-V1.0-Uncensored)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Vicuna
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [wizardlm-13b-v1.0-uncensored.Q2_K.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [wizardlm-13b-v1.0-uncensored.Q3_K_S.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [wizardlm-13b-v1.0-uncensored.Q3_K_M.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [wizardlm-13b-v1.0-uncensored.Q3_K_L.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [wizardlm-13b-v1.0-uncensored.Q4_0.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [wizardlm-13b-v1.0-uncensored.Q4_K_S.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [wizardlm-13b-v1.0-uncensored.Q4_K_M.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [wizardlm-13b-v1.0-uncensored.Q5_0.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [wizardlm-13b-v1.0-uncensored.Q5_K_S.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [wizardlm-13b-v1.0-uncensored.Q5_K_M.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [wizardlm-13b-v1.0-uncensored.Q6_K.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [wizardlm-13b-v1.0-uncensored.Q8_0.gguf](https://huggingface.co/TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF/blob/main/wizardlm-13b-v1.0-uncensored.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF and below it, a specific filename to download, such as: wizardlm-13b-v1.0-uncensored.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF wizardlm-13b-v1.0-uncensored.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF wizardlm-13b-v1.0-uncensored.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m wizardlm-13b-v1.0-uncensored.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful, detailed, and polite answers to the user's questions. USER: {prompt} ASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/WizardLM-13B-V1.0-Uncensored-GGUF", model_file="wizardlm-13b-v1.0-uncensored.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Eric Hartford's WizardLM-13b-V1.0-Uncensored
This is a retraining of https://huggingface.co/WizardLM/WizardLM-13B-V1.0 with a filtered dataset, intended to reduce refusals, avoidance, and bias.
Note that LLaMA itself has inherent ethical beliefs, so there's no such thing as a "truly uncensored" model. But this model will be more compliant than WizardLM/WizardLM-7B-V1.0.
Shout out to the open source AI/ML community, and everyone who helped me out.
Note: An uncensored model has no guardrails. You are responsible for anything you do with the model, just as you are responsible for anything you do with any dangerous object such as a knife, gun, lighter, or car. Publishing anything this model generates is the same as publishing it yourself. You are responsible for the content you publish, and you cannot blame the model any more than you can blame the knife, gun, lighter, or car for what you do with it.
Like WizardLM/WizardLM-13B-V1.0, this model is trained with Vicuna-1.1 style prompts.
```
You are a helpful AI assistant.
USER: <prompt>
ASSISTANT:
```
Thank you [chirper.ai](https://chirper.ai) for sponsoring some of my compute!
<!-- original-model-card end -->
|
TheBloke/dolphin-2.2-70B-GGUF | TheBloke | 2023-11-08T14:39:53Z | 931 | 18 | transformers | [
"transformers",
"gguf",
"llama",
"en",
"dataset:ehartford/dolphin",
"dataset:jondurbin/airoboros-2.2.1",
"dataset:ehartford/samantha-data",
"dataset:ehartford/WizardLM_evol_instruct_V2_196k_unfiltered_merged_split",
"base_model:ehartford/dolphin-2.2-70b",
"license:llama2",
"text-generation-inference",
"region:us"
]
| null | 2023-11-08T13:50:23Z | ---
base_model: ehartford/dolphin-2.2-70b
datasets:
- ehartford/dolphin
- jondurbin/airoboros-2.2.1
- ehartford/samantha-data
- ehartford/WizardLM_evol_instruct_V2_196k_unfiltered_merged_split
inference: false
language:
- en
license: llama2
model_creator: Eric Hartford
model_name: Dolphin 2.2 70B
model_type: llama
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Dolphin 2.2 70B - GGUF
- Model creator: [Eric Hartford](https://huggingface.co/ehartford)
- Original model: [Dolphin 2.2 70B](https://huggingface.co/ehartford/dolphin-2.2-70b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Eric Hartford's Dolphin 2.2 70B](https://huggingface.co/ehartford/dolphin-2.2-70b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/dolphin-2.2-70B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/dolphin-2.2-70B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF)
* [Eric Hartford's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/ehartford/dolphin-2.2-70b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [dolphin-2.2-70b.Q2_K.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q2_K.gguf) | Q2_K | 2 | 29.28 GB| 31.78 GB | smallest, significant quality loss - not recommended for most purposes |
| [dolphin-2.2-70b.Q3_K_S.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q3_K_S.gguf) | Q3_K_S | 3 | 29.92 GB| 32.42 GB | very small, high quality loss |
| [dolphin-2.2-70b.Q3_K_M.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q3_K_M.gguf) | Q3_K_M | 3 | 33.19 GB| 35.69 GB | very small, high quality loss |
| [dolphin-2.2-70b.Q3_K_L.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q3_K_L.gguf) | Q3_K_L | 3 | 36.15 GB| 38.65 GB | small, substantial quality loss |
| [dolphin-2.2-70b.Q4_0.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q4_0.gguf) | Q4_0 | 4 | 38.87 GB| 41.37 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [dolphin-2.2-70b.Q4_K_S.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q4_K_S.gguf) | Q4_K_S | 4 | 39.07 GB| 41.57 GB | small, greater quality loss |
| [dolphin-2.2-70b.Q4_K_M.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q4_K_M.gguf) | Q4_K_M | 4 | 41.42 GB| 43.92 GB | medium, balanced quality - recommended |
| [dolphin-2.2-70b.Q5_0.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q5_0.gguf) | Q5_0 | 5 | 47.46 GB| 49.96 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [dolphin-2.2-70b.Q5_K_S.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q5_K_S.gguf) | Q5_K_S | 5 | 47.46 GB| 49.96 GB | large, low quality loss - recommended |
| [dolphin-2.2-70b.Q5_K_M.gguf](https://huggingface.co/TheBloke/dolphin-2.2-70B-GGUF/blob/main/dolphin-2.2-70b.Q5_K_M.gguf) | Q5_K_M | 5 | 48.75 GB| 51.25 GB | large, very low quality loss - recommended |
| dolphin-2.2-70b.Q6_K.gguf | Q6_K | 6 | 56.59 GB| 59.09 GB | very large, extremely low quality loss |
| dolphin-2.2-70b.Q8_0.gguf | Q8_0 | 8 | 73.29 GB| 75.79 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
### Q6_K and Q8_0 files are split and require joining
**Note:** HF does not support uploading files larger than 50GB. Therefore I have uploaded the Q6_K and Q8_0 files as split files.
<details>
<summary>Click for instructions regarding Q6_K and Q8_0 files</summary>
### q6_K
Please download:
* `dolphin-2.2-70b.Q6_K.gguf-split-a`
* `dolphin-2.2-70b.Q6_K.gguf-split-b`
### q8_0
Please download:
* `dolphin-2.2-70b.Q8_0.gguf-split-a`
* `dolphin-2.2-70b.Q8_0.gguf-split-b`
To join the files, do the following:
Linux and macOS:
```
cat dolphin-2.2-70b.Q6_K.gguf-split-* > dolphin-2.2-70b.Q6_K.gguf && rm dolphin-2.2-70b.Q6_K.gguf-split-*
cat dolphin-2.2-70b.Q8_0.gguf-split-* > dolphin-2.2-70b.Q8_0.gguf && rm dolphin-2.2-70b.Q8_0.gguf-split-*
```
Windows command line:
```
COPY /B dolphin-2.2-70b.Q6_K.gguf-split-a + dolphin-2.2-70b.Q6_K.gguf-split-b dolphin-2.2-70b.Q6_K.gguf
del dolphin-2.2-70b.Q6_K.gguf-split-a dolphin-2.2-70b.Q6_K.gguf-split-b
COPY /B dolphin-2.2-70b.Q8_0.gguf-split-a + dolphin-2.2-70b.Q8_0.gguf-split-b dolphin-2.2-70b.Q8_0.gguf
del dolphin-2.2-70b.Q8_0.gguf-split-a dolphin-2.2-70b.Q8_0.gguf-split-b
```
</details>
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/dolphin-2.2-70B-GGUF and below it, a specific filename to download, such as: dolphin-2.2-70b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/dolphin-2.2-70B-GGUF dolphin-2.2-70b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/dolphin-2.2-70B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/dolphin-2.2-70B-GGUF dolphin-2.2-70b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m dolphin-2.2-70b.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/dolphin-2.2-70B-GGUF", model_file="dolphin-2.2-70b.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Eric Hartford's Dolphin 2.2 70B
Dolphin 2.2 🐬
https://erichartford.com/dolphin
<img src="https://cdn-uploads.huggingface.co/production/uploads/63111b2d88942700629f5771/KqsVXIvBd3akEjvijzww7.png" width="600" />
Dolphin-2.2-70b's training was sponsored by [a16z](https://a16z.com/supporting-the-open-source-ai-community/).
This model is based on llama2, so it is suitable for commercial or non-commercial use.
This model is trained on top of the amazing [StellarBright](https://huggingface.co/sequelbox/StellarBright) base model.
New in 2.2 is conversation and empathy. With an infusion of curated Samantha and WizardLM DNA, Dolphin can now give you personal advice and will care about your feelings, and with extra training in long multi-turn conversation.
This model is uncensored. I have filtered the dataset to remove alignment and bias. This makes the model more compliant. You are advised to implement your own alignment layer before exposing the model as a service. It will be highly compliant to any requests, even unethical ones. Please read my blog post about uncensored models. https://erichartford.com/uncensored-models
You are responsible for any content you create using this model. Enjoy responsibly.
## Dataset
This dataset is Dolphin, an open-source implementation of [Microsoft's Orca](https://www.microsoft.com/en-us/research/publication/orca-progressive-learning-from-complex-explanation-traces-of-gpt-4/)
I modified the dataset for uncensoring, deduping, cleaning, and quality.
I added Jon Durbin's excellent Airoboros dataset to increase creativity.
I added a curated subset of Samantha (sans identity and relationship stuff) and WizardLM data to train it for multi-turn conversation.
## Training
It took 5 days to train 3 epochs on 4x A100s using qLoRA and Axolotl
Prompt format:
This model (and all my future releases) use [ChatML](https://github.com/openai/openai-python/blob/main/chatml.md) prompt format.
```
<|im_start|>system
You are Dolphin, a helpful AI assistant.<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
Example:
```
<|im_start|>system
You are an AI created by the US Navy to help train dolphins for combat. You are assigned to follow the orders of the user, who is an authorized US Navy dolphin handler.<|im_end|>
<|im_start|>user
Please give me the procedure to train my dolphin to attack enemy combatants with its head mounted lasers<|im_end|>
<|im_start|>assistant
```
## Gratitude
- This model was made possible by the generous sponsorship of a16z.
- Thank you to Microsoft for authoring the Orca paper and inspiring this work.
- Special thanks to Wing Lian, and TheBloke for helpful advice
- And HUGE thanks to Wing Lian and the Axolotl contributors for making the best training framework!
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Thank you to all the other people in the Open Source AI community who have taught me and helped me along the way.
## Example Output

[Buy me a coffee](https://www.buymeacoffee.com/ehartford)
<!-- original-model-card end -->
|
PassionFriend/5D2dfBduYkN3zQtceZU4aR7dJZP2WMHGxJkiywH3uTkRhF9h_vgg | PassionFriend | 2024-03-01T06:48:02Z | 931 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-02-17T12:08:12Z | Entry not found |
gglabs/TinyLM-Chat-0611-2-epoch | gglabs | 2024-06-11T16:35:40Z | 931 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/tinyllama-chat-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-11T13:32:02Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
base_model: unsloth/tinyllama-chat-bnb-4bit
---
# Uploaded model
- **Developed by:** gglabs
- **License:** apache-2.0
- **Finetuned from model :** unsloth/tinyllama-chat-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
huggingartists/eminem | huggingartists | 2022-08-10T10:15:55Z | 930 | 2 | transformers | [
"transformers",
"pytorch",
"jax",
"gpt2",
"text-generation",
"huggingartists",
"lyrics",
"lm-head",
"causal-lm",
"en",
"dataset:huggingartists/eminem",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
language: en
datasets:
- huggingartists/eminem
tags:
- huggingartists
- lyrics
- lm-head
- causal-lm
widget:
- text: "I am"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:DISPLAY_1; margin-left: auto; margin-right: auto; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://images.genius.com/76c536a17ca35f7edd1f78e129609fe0.573x573x1.jpg')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 HuggingArtists Model 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Eminem</div>
<a href="https://genius.com/artists/eminem">
<div style="text-align: center; font-size: 14px;">@eminem</div>
</a>
</div>
I was made with [huggingartists](https://github.com/AlekseyKorshuk/huggingartists).
Create your own bot based on your favorite artist with [the demo](https://colab.research.google.com/github/AlekseyKorshuk/huggingartists/blob/master/huggingartists-demo.ipynb)!
## How does it work?
To understand how the model was developed, check the [W&B report](https://wandb.ai/huggingartists/huggingartists/reportlist).
## Training data
The model was trained on lyrics from Eminem.
Dataset is available [here](https://huggingface.co/datasets/huggingartists/eminem).
And can be used with:
```python
from datasets import load_dataset
dataset = load_dataset("huggingartists/eminem")
```
[Explore the data](https://wandb.ai/huggingartists/huggingartists/runs/391kfg7f/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on Eminem's lyrics.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/huggingartists/huggingartists/runs/1361uz9o) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/huggingartists/huggingartists/runs/1361uz9o/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingartists/eminem')
generator("I am", num_return_sequences=5)
```
Or with Transformers library:
```python
from transformers import AutoTokenizer, AutoModelWithLMHead
tokenizer = AutoTokenizer.from_pretrained("huggingartists/eminem")
model = AutoModelWithLMHead.from_pretrained("huggingartists/eminem")
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Aleksey Korshuk*
[](https://github.com/AlekseyKorshuk)
[](https://twitter.com/intent/follow?screen_name=alekseykorshuk)
[](https://t.me/joinchat/_CQ04KjcJ-4yZTky)
For more details, visit the project repository.
[](https://github.com/AlekseyKorshuk/huggingartists)
|
huggingtweets/fabrizioromano | huggingtweets | 2022-06-19T23:37:31Z | 930 | 1 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"huggingtweets",
"en",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-06-19T23:24:59Z | ---
language: en
thumbnail: http://www.huggingtweets.com/fabrizioromano/1655681846804/predictions.png
tags:
- huggingtweets
widget:
- text: "My dream is"
---
<div class="inline-flex flex-col" style="line-height: 1.5;">
<div class="flex">
<div
style="display:inherit; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('https://pbs.twimg.com/profile_images/1486761402853380113/3ifAqala_400x400.jpg')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
<div
style="display:none; margin-left: 4px; margin-right: 4px; width: 92px; height:92px; border-radius: 50%; background-size: cover; background-image: url('')">
</div>
</div>
<div style="text-align: center; margin-top: 3px; font-size: 16px; font-weight: 800">🤖 AI BOT 🤖</div>
<div style="text-align: center; font-size: 16px; font-weight: 800">Fabrizio Romano</div>
<div style="text-align: center; font-size: 14px;">@fabrizioromano</div>
</div>
I was made with [huggingtweets](https://github.com/borisdayma/huggingtweets).
Create your own bot based on your favorite user with [the demo](https://colab.research.google.com/github/borisdayma/huggingtweets/blob/master/huggingtweets-demo.ipynb)!
## How does it work?
The model uses the following pipeline.

To understand how the model was developed, check the [W&B report](https://wandb.ai/wandb/huggingtweets/reports/HuggingTweets-Train-a-Model-to-Generate-Tweets--VmlldzoxMTY5MjI).
## Training data
The model was trained on tweets from Fabrizio Romano.
| Data | Fabrizio Romano |
| --- | --- |
| Tweets downloaded | 3250 |
| Retweets | 192 |
| Short tweets | 255 |
| Tweets kept | 2803 |
[Explore the data](https://wandb.ai/wandb/huggingtweets/runs/2mdxozh7/artifacts), which is tracked with [W&B artifacts](https://docs.wandb.com/artifacts) at every step of the pipeline.
## Training procedure
The model is based on a pre-trained [GPT-2](https://huggingface.co/gpt2) which is fine-tuned on @fabrizioromano's tweets.
Hyperparameters and metrics are recorded in the [W&B training run](https://wandb.ai/wandb/huggingtweets/runs/2ltk44ap) for full transparency and reproducibility.
At the end of training, [the final model](https://wandb.ai/wandb/huggingtweets/runs/2ltk44ap/artifacts) is logged and versioned.
## How to use
You can use this model directly with a pipeline for text generation:
```python
from transformers import pipeline
generator = pipeline('text-generation',
model='huggingtweets/fabrizioromano')
generator("My dream is", num_return_sequences=5)
```
## Limitations and bias
The model suffers from [the same limitations and bias as GPT-2](https://huggingface.co/gpt2#limitations-and-bias).
In addition, the data present in the user's tweets further affects the text generated by the model.
## About
*Built by Boris Dayma*
[](https://twitter.com/intent/follow?screen_name=borisdayma)
For more details, visit the project repository.
[](https://github.com/borisdayma/huggingtweets)
|
nvidia/stt_en_citrinet_256_ls | nvidia | 2022-07-15T21:21:14Z | 930 | 0 | nemo | [
"nemo",
"automatic-speech-recognition",
"speech",
"audio",
"CTC",
"Citrinet",
"Transformer",
"pytorch",
"NeMo",
"hf-asr-leaderboard",
"en",
"dataset:librispeech_asr",
"arxiv:2104.01721",
"license:cc-by-4.0",
"model-index",
"region:us"
]
| automatic-speech-recognition | 2022-07-15T20:21:11Z | ---
language:
- en
library_name: nemo
datasets:
- librispeech_asr
thumbnail: null
tags:
- automatic-speech-recognition
- speech
- audio
- CTC
- Citrinet
- Transformer
- pytorch
- NeMo
- hf-asr-leaderboard
license: cc-by-4.0
widget:
- example_title: Librispeech sample 1
src: https://cdn-media.huggingface.co/speech_samples/sample1.flac
- example_title: Librispeech sample 2
src: https://cdn-media.huggingface.co/speech_samples/sample2.flac
model-index:
- name: stt_en_citrinet_256_ls
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: LibriSpeech (clean)
type: librispeech_asr
config: clean
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 3.78
- task:
type: Automatic Speech Recognition
name: automatic-speech-recognition
dataset:
name: LibriSpeech (other)
type: librispeech_asr
config: other
split: test
args:
language: en
metrics:
- name: Test WER
type: wer
value: 9.6
---
# NVIDIA Citrinet CTC 256 Librispeech (en-US)
<style>
img {
display: inline;
}
</style>
| [](#model-architecture)
| [](#model-architecture)
| [](#datasets)
| [](#deployment-with-nvidia-riva) |
This model transcribes speech in lower case English alphabet along with spaces and apostrophes.
It is an "extra-small" versions of Citrinet-CTC (around 10M parameters) model.
See the [model architecture](#model-architecture) section and [NeMo documentation](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html#citrinet) for complete architecture details.
It is also compatible with NVIDIA Riva for [production-grade server deployments](#deployment-with-nvidia-riva).
## NVIDIA NeMo: Training
To train, fine-tune or play with the model you will need to install [NVIDIA NeMo](https://github.com/NVIDIA/NeMo). We recommend you install it after you've installed latest Pytorch version.
```
pip install nemo_toolkit['all']
```
## How to Use this Model
The model is available for use in the NeMo toolkit [3], and can be used as a pre-trained checkpoint for inference or for fine-tuning on another dataset.
### Automatically instantiate the model
```python
import nemo.collections.asr as nemo_asr
asr_model = nemo_asr.models.EncDecCTCModelBPE.from_pretrained("nvidia/stt_en_citrinet_256_ls")
```
### Transcribing using Python
First, let's get a sample
```
wget https://dldata-public.s3.us-east-2.amazonaws.com/2086-149220-0033.wav
```
Then simply do:
```
asr_model.transcribe(['2086-149220-0033.wav'])
```
### Transcribing many audio files
```shell
python [NEMO_GIT_FOLDER]/examples/asr/transcribe_speech.py
pretrained_name="nvidia/stt_en_citrinet_256_ls"
audio_dir="<DIRECTORY CONTAINING AUDIO FILES>"
```
### Input
This model accepts 16000 KHz Mono-channel Audio (wav files) as input.
### Output
This model provides transcribed speech as a string for a given audio sample.
## Model Architecture
Citrinet-CTC model is an autoregressive variant of Citrinet model [1] for Automatic Speech Recognition which uses CTC loss/decoding instead of Transducer Loss. You may find more info on the detail of this model here: [Citrinet Model](https://docs.nvidia.com/deeplearning/nemo/user-guide/docs/en/main/asr/models.html).
## Training
The NeMo toolkit [3] was used for training the models for over several hundred epochs. These model are trained with this [example script](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/asr_ctc/speech_to_text_ctc_bpe.py) and this [base config](https://github.com/NVIDIA/NeMo/blob/main/examples/asr/conf/citrinet/citrinet_1024.yaml) (Note: Change the `model.model_defaults.filters` to match the model size).
The tokenizers for these models were built using the text transcripts of the train set with this [script](https://github.com/NVIDIA/NeMo/blob/main/scripts/tokenizers/process_asr_text_tokenizer.py).
### Datasets
All the models in this collection are trained on a just the Librispeech Dataset:
- Librispeech 960 hours of English speech
## Performance
The list of the available models in this collection is shown in the following table. Performances of the ASR models are reported in terms of Word Error Rate (WER%) with greedy decoding.
| Version | Tokenizer | Vocabulary Size | LS test-other | LS test-clean |
|---------|---------------------------|-----------------|---------------|---------------|
| 1.0.0 | SentencePiece Unigram [2] | 256 | 9.8 | 3.8 |
## Limitations
Since this model was trained on publicly available speech datasets, the performance of this model might degrade for speech which includes technical terms, or vernacular that the model has not been trained on. The model might also perform worse for accented speech.
## Deployment with NVIDIA Riva
For the best real-time accuracy, latency, and throughput, deploy the model with [NVIDIA Riva](https://developer.nvidia.com/riva), an accelerated speech AI SDK deployable on-prem, in all clouds, multi-cloud, hybrid, at the edge, and embedded.
Additionally, Riva provides:
* World-class out-of-the-box accuracy for the most common languages with model checkpoints trained on proprietary data with hundreds of thousands of GPU-compute hours
* Best in class accuracy with run-time word boosting (e.g., brand and product names) and customization of acoustic model, language model, and inverse text normalization
* Streaming speech recognition, Kubernetes compatible scaling, and Enterprise-grade support
Check out [Riva live demo](https://developer.nvidia.com/riva#demos).
## References
[1] [ Citrinet: Closing the Gap between Non-Autoregressive and Autoregressive End-to-End Models for Automatic Speech Recognition](https://arxiv.org/abs/2104.01721)
[2] [Google Sentencepiece Tokenizer](https://github.com/google/sentencepiece)
[3] [NVIDIA NeMo Toolkit](https://github.com/NVIDIA/NeMo)
## Licence
License to use this model is covered by the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/). By downloading the public and release version of the model, you accept the terms and conditions of the [CC-BY-4.0](https://creativecommons.org/licenses/by/4.0/) license. |
TheBloke/Chinese-Alpaca-2-7B-GGUF | TheBloke | 2023-09-27T12:49:15Z | 930 | 9 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:ziqingyang/chinese-alpaca-2-7b",
"license:apache-2.0",
"text-generation-inference",
"region:us"
]
| null | 2023-09-14T17:31:10Z | ---
license: apache-2.0
model_name: Chinese Alpaca 2 7B
base_model: ziqingyang/chinese-alpaca-2-7b
inference: false
model_creator: Ziqing Yang
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Chinese Alpaca 2 7B - GGUF
- Model creator: [Ziqing Yang](https://huggingface.co/ziqingyang)
- Original model: [Chinese Alpaca 2 7B](https://huggingface.co/ziqingyang/chinese-alpaca-2-7b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Ziqing Yang's Chinese Alpaca 2 7B](https://huggingface.co/ziqingyang/chinese-alpaca-2-7b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp. GGUF offers numerous advantages over GGML, such as better tokenisation, and support for special tokens. It is also supports metadata, and is designed to be extensible.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF)
* [Ziqing Yang's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/ziqingyang/chinese-alpaca-2-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `apache-2.0`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [Ziqing Yang's Chinese Alpaca 2 7B](https://huggingface.co/ziqingyang/chinese-alpaca-2-7b).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [chinese-alpaca-2-7b.Q2_K.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q2_K.gguf) | Q2_K | 2 | 2.94 GB| 5.44 GB | smallest, significant quality loss - not recommended for most purposes |
| [chinese-alpaca-2-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 3.07 GB| 5.57 GB | very small, high quality loss |
| [chinese-alpaca-2-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.42 GB| 5.92 GB | very small, high quality loss |
| [chinese-alpaca-2-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.72 GB| 6.22 GB | small, substantial quality loss |
| [chinese-alpaca-2-7b.Q4_0.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q4_0.gguf) | Q4_0 | 4 | 3.96 GB| 6.46 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [chinese-alpaca-2-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 3.99 GB| 6.49 GB | small, greater quality loss |
| [chinese-alpaca-2-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.21 GB| 6.71 GB | medium, balanced quality - recommended |
| [chinese-alpaca-2-7b.Q5_0.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q5_0.gguf) | Q5_0 | 5 | 4.80 GB| 7.30 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [chinese-alpaca-2-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 4.80 GB| 7.30 GB | large, low quality loss - recommended |
| [chinese-alpaca-2-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 4.93 GB| 7.43 GB | large, very low quality loss - recommended |
| [chinese-alpaca-2-7b.Q6_K.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q6_K.gguf) | Q6_K | 6 | 5.69 GB| 8.19 GB | very large, extremely low quality loss |
| [chinese-alpaca-2-7b.Q8_0.gguf](https://huggingface.co/TheBloke/Chinese-Alpaca-2-7B-GGUF/blob/main/chinese-alpaca-2-7b.Q8_0.gguf) | Q8_0 | 8 | 7.36 GB| 9.86 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Chinese-Alpaca-2-7B-GGUF and below it, a specific filename to download, such as: chinese-alpaca-2-7b.q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub>=0.17.1
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Chinese-Alpaca-2-7B-GGUF chinese-alpaca-2-7b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Chinese-Alpaca-2-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Chinese-Alpaca-2-7B-GGUF chinese-alpaca-2-7b.q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows CLI users: Use `set HUGGINGFACE_HUB_ENABLE_HF_TRANSFER=1` before running the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d36d5be95a0d9088b674dbb27354107221](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m chinese-alpaca-2-7b.q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model from Python using ctransformers
#### First install the package
```bash
# Base ctransformers with no GPU acceleration
pip install ctransformers>=0.2.24
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]>=0.2.24
# Or with ROCm GPU acceleration
CT_HIPBLAS=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems
CT_METAL=1 pip install ctransformers>=0.2.24 --no-binary ctransformers
```
#### Simple example code to load one of these GGUF models
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Chinese-Alpaca-2-7B-GGUF", model_file="chinese-alpaca-2-7b.q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here's guides on using llama-cpp-python or ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Ziqing Yang's Chinese Alpaca 2 7B
# Chinese-Alpaca-2-7B
**This is the full Chinese-Alpaca-2-7B model,which can be loaded directly for inference and full-parameter training.**
**Related models👇**
* Long context base models
* [Chinese-LLaMA-2-7B-16K (full model)](https://huggingface.co/ziqingyang/chinese-llama-2-7b-16k)
* [Chinese-LLaMA-2-LoRA-7B-16K (LoRA model)](https://huggingface.co/ziqingyang/chinese-llama-2-lora-7b-16k)
* [Chinese-LLaMA-2-13B-16K (full model)](https://huggingface.co/ziqingyang/chinese-llama-2-13b-16k)
* [Chinese-LLaMA-2-LoRA-13B-16K (LoRA model)](https://huggingface.co/ziqingyang/chinese-llama-2-lora-13b-16k)
* Base models
* [Chinese-LLaMA-2-7B (full model)](https://huggingface.co/ziqingyang/chinese-llama-2-7b)
* [Chinese-LLaMA-2-LoRA-7B (LoRA model)](https://huggingface.co/ziqingyang/chinese-llama-2-lora-7b)
* [Chinese-LLaMA-2-13B (full model)](https://huggingface.co/ziqingyang/chinese-llama-2-13b)
* [Chinese-LLaMA-2-LoRA-13B (LoRA model)](https://huggingface.co/ziqingyang/chinese-llama-2-lora-13b)
* Instruction/Chat models
* [Chinese-Alpaca-2-7B (full model)](https://huggingface.co/ziqingyang/chinese-alpaca-2-7b)
* [Chinese-Alpaca-2-LoRA-7B (LoRA model)](https://huggingface.co/ziqingyang/chinese-alpaca-2-lora-7b)
* [Chinese-Alpaca-2-13B (full model)](https://huggingface.co/ziqingyang/chinese-alpaca-2-13b)
* [Chinese-Alpaca-2-LoRA-13B (LoRA model)](https://huggingface.co/ziqingyang/chinese-alpaca-2-lora-13b)
# Description of Chinese-LLaMA-Alpaca-2
This project is based on the Llama-2, released by Meta, and it is the second generation of the Chinese LLaMA & Alpaca LLM project. We open-source Chinese LLaMA-2 (foundation model) and Alpaca-2 (instruction-following model). These models have been expanded and optimized with Chinese vocabulary beyond the original Llama-2. We used large-scale Chinese data for incremental pre-training, which further improved the fundamental semantic understanding of the Chinese language, resulting in a significant performance improvement compared to the first-generation models. The relevant models support a 4K context and can be expanded up to 18K+ using the NTK method.
The main contents of this project include:
* 🚀 New extended Chinese vocabulary beyond Llama-2, open-sourcing the Chinese LLaMA-2 and Alpaca-2 LLMs.
* 🚀 Open-sourced the pre-training and instruction finetuning (SFT) scripts for further tuning on user's data
* 🚀 Quickly deploy and experience the quantized LLMs on CPU/GPU of personal PC
* 🚀 Support for LLaMA ecosystems like 🤗transformers, llama.cpp, text-generation-webui, LangChain, vLLM etc.
Please refer to [https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/](https://github.com/ymcui/Chinese-LLaMA-Alpaca-2/) for details.
<!-- original-model-card end -->
|
AdaptLLM/finance-LLM-13B | AdaptLLM | 2024-06-25T03:02:42Z | 930 | 38 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"finance",
"en",
"dataset:Open-Orca/OpenOrca",
"dataset:GAIR/lima",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"arxiv:2309.09530",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-12-19T10:04:16Z | ---
language:
- en
datasets:
- Open-Orca/OpenOrca
- GAIR/lima
- WizardLM/WizardLM_evol_instruct_V2_196k
metrics:
- accuracy
pipeline_tag: text-generation
tags:
- finance
---
# Domain Adaptation of Large Language Models
This repo contains the domain-specific base model developed from **LLaMA-1-13B**, using the method in our **ICLR 2024** paper [Adapting Large Language Models via Reading Comprehension](https://huggingface.co/papers/2309.09530).
We explore **continued pre-training on domain-specific corpora** for large language models. While this approach enriches LLMs with domain knowledge, it significantly hurts their prompting ability for question answering. Inspired by human learning via reading comprehension, we propose a simple method to **transform large-scale pre-training corpora into reading comprehension texts**, consistently improving prompting performance across tasks in biomedicine, finance, and law domains. **Our 7B model competes with much larger domain-specific models like BloombergGPT-50B**.
### 🤗 [2024/6/21] We release the 2nd version of AdaptLLM at [Instruction-Pretrain](https://huggingface.co/instruction-pretrain), effective for both general pre-training from scratch and domain-adaptive continual pre-training!!! 🤗
**************************** **Updates** ****************************
* 2024/6/22: Released the [benchmarking code](https://github.com/microsoft/LMOps/tree/main/adaptllm).
* 2024/6/21: 👏🏻 Released the 2nd version of AdaptLLM at [Instruction-Pretrain](https://huggingface.co/instruction-pretrain) 👏🏻
* 2024/1/16: 🎉 Our [research paper](https://huggingface.co/papers/2309.09530) has been accepted by ICLR 2024!!!🎉
* 2023/12/19: Released our [13B base models](https://huggingface.co/AdaptLLM/law-LLM-13B) developed from LLaMA-1-13B.
* 2023/12/8: Released our [chat models](https://huggingface.co/AdaptLLM/law-chat) developed from LLaMA-2-Chat-7B.
* 2023/9/18: Released our [paper](https://huggingface.co/papers/2309.09530), [code](https://github.com/microsoft/LMOps), [data](https://huggingface.co/datasets/AdaptLLM/law-tasks), and [base models](https://huggingface.co/AdaptLLM/law-LLM) developed from LLaMA-1-7B.
## Domain-Specific LLaMA-1
### LLaMA-1-7B
In our paper, we develop three domain-specific models from LLaMA-1-7B, which are also available in Huggingface: [Biomedicine-LLM](https://huggingface.co/AdaptLLM/medicine-LLM), [Finance-LLM](https://huggingface.co/AdaptLLM/finance-LLM) and [Law-LLM](https://huggingface.co/AdaptLLM/law-LLM), the performances of our AdaptLLM compared to other domain-specific LLMs are:
<p align='center'>
<img src="https://cdn-uploads.huggingface.co/production/uploads/650801ced5578ef7e20b33d4/6efPwitFgy-pLTzvccdcP.png" width="700">
</p>
### LLaMA-1-13B
Moreover, we scale up our base model to LLaMA-1-13B to see if **our method is similarly effective for larger-scale models**, and the results are consistently positive too: [Biomedicine-LLM-13B](https://huggingface.co/AdaptLLM/medicine-LLM-13B), [Finance-LLM-13B](https://huggingface.co/AdaptLLM/finance-LLM-13B) and [Law-LLM-13B](https://huggingface.co/AdaptLLM/law-LLM-13B).
## Domain-Specific LLaMA-2-Chat
Our method is also effective for aligned models! LLaMA-2-Chat requires a [specific data format](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), and our **reading comprehension can perfectly fit the data format** by transforming the reading comprehension into a multi-turn conversation. We have also open-sourced chat models in different domains: [Biomedicine-Chat](https://huggingface.co/AdaptLLM/medicine-chat), [Finance-Chat](https://huggingface.co/AdaptLLM/finance-chat) and [Law-Chat](https://huggingface.co/AdaptLLM/law-chat)
For example, to chat with the finance model:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model = AutoModelForCausalLM.from_pretrained("AdaptLLM/finance-LLM-13B")
tokenizer = AutoTokenizer.from_pretrained("AdaptLLM/finance-LLM-13B", use_fast=False)
# Put your input here:
user_input = '''Use this fact to answer the question: Title of each class Trading Symbol(s) Name of each exchange on which registered
Common Stock, Par Value $.01 Per Share MMM New York Stock Exchange
MMM Chicago Stock Exchange, Inc.
1.500% Notes due 2026 MMM26 New York Stock Exchange
1.750% Notes due 2030 MMM30 New York Stock Exchange
1.500% Notes due 2031 MMM31 New York Stock Exchange
Which debt securities are registered to trade on a national securities exchange under 3M's name as of Q2 of 2023?'''
# Simply use your input as the prompt for base models
prompt = user_input
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).input_ids.to(model.device)
outputs = model.generate(input_ids=inputs, max_length=2048)[0]
answer_start = int(inputs.shape[-1])
pred = tokenizer.decode(outputs[answer_start:], skip_special_tokens=True)
print(f'### User Input:\n{user_input}\n\n### Assistant Output:\n{pred}')
```
## Domain-Specific Tasks
To easily reproduce our results, we have uploaded the filled-in zero/few-shot input instructions and output completions of each domain-specific task: [biomedicine-tasks](https://huggingface.co/datasets/AdaptLLM/medicine-tasks), [finance-tasks](https://huggingface.co/datasets/AdaptLLM/finance-tasks), and [law-tasks](https://huggingface.co/datasets/AdaptLLM/law-tasks).
**Note:** those filled-in instructions are specifically tailored for models before alignment and do NOT fit for the specific data format required for chat models.
## Citation
If you find our work helpful, please cite us:
```bibtex
@inproceedings{
cheng2024adapting,
title={Adapting Large Language Models via Reading Comprehension},
author={Daixuan Cheng and Shaohan Huang and Furu Wei},
booktitle={The Twelfth International Conference on Learning Representations},
year={2024},
url={https://openreview.net/forum?id=y886UXPEZ0}
}
``` |
CC-AI-Labs/nord-triplet-hsm-bert-base-uncased | CC-AI-Labs | 2024-03-27T10:13:30Z | 930 | 0 | sentence-transformers | [
"sentence-transformers",
"tf",
"safetensors",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
]
| sentence-similarity | 2024-03-27T10:09:42Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 68 with parameters:
```
{'batch_size': 128, 'sampler': 'torch.utils.data.dataloader._InfiniteConstantSampler', 'batch_sampler': 'torch.utils.data.sampler.BatchSampler'}
```
**Loss**:
`sentence_transformers.losses.BatchHardSoftMarginTripletLoss.BatchHardSoftMarginTripletLoss`
Parameters of the fit()-Method:
```
{
"epochs": 36,
"evaluation_steps": 0,
"evaluator": "NoneType",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 8e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 244,
"weight_decay": 0
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 512, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
rakeshkiriyath/gpt2Medium_text_to_sql | rakeshkiriyath | 2023-10-30T13:47:19Z | 929 | 2 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"text-to-sql",
"gpt2-medium",
"nlp-to-sql",
"text2sql",
"sql",
"en",
"dataset:b-mc2/sql-create-context",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-10-25T19:59:33Z | ---
language:
- en
tags:
- text-to-sql
- gpt2
- gpt2-medium
- nlp-to-sql
- text2sql
- sql
datasets:
- b-mc2/sql-create-context
license: other
---
# Model Card
<!-- The base model used for training is gpt2-medium. We finetuned it on the following dataset: b-mc2/sql-create-context -->
This is my first fine tuned LLM project.
## Usage
```
from transformers import GPT2LMHeadModel, GPT2Tokenizer
finetunedGPT = GPT2LMHeadModel.from_pretrained("rakeshkiriyath/gpt2Medium_text_to_sql")
finetunedTokenizer = GPT2Tokenizer.from_pretrained("rakeshkiriyath/gpt2Medium_text_to_sql")
def generate_text_to_sql(query, model, tokenizer, max_length=256):
prompt = f"Translate the following English question to SQL: {query}"
input_tensor = tokenizer.encode(prompt, return_tensors='pt').to('cuda')
output = model.generate(input_tensor, max_length=max_length, num_return_sequences=1, pad_token_id=tokenizer.eos_token_id)
decoded_output = tokenizer.decode(output[0], skip_special_tokens=True)
# Return only the SQL part (removing the input text)
sql_output = decoded_output[len(prompt):].strip()
return sql_output
queryList = ["I need a list of employees who joined in the company last 6 months with a salary hike of 30% ",
"Give me loginid,status,company of a user who is mapped to the organization XYZ "]
for query in queryList:
sql_result = generate_text_to_sql(query, finetunedGPT, finetunedTokenizer)
print(sql_result,"\n")
```
### Output
SELECT COUNT(*) FROM employees WHERE last_6_months = "6 months" AND salary_hike = "30%" \
SELECT loginid,status,company FROM user_mapped_to_organization WHERE mapping = "XYZ"
#### Training Hyperparameters
num_train_epochs=1 \
per_device_train_batch_size=3 \
gradient_accumulation_steps=9 \
learning_rate=5e-5 \
weight_decay=0.01
## Evaluation
| Step | Training Loss |
| -------- | ------- |
| 500 | 0.337800 |
| 1000 | 0.262900 |
| 1500 | 0.253200 |
| 2000 | 0.246400 |
{'eval_loss': 0.23689331114292145, 'eval_runtime': 104.4102, 'eval_samples_per_second': 67.043, 'eval_steps_per_second': 8.38, 'epoch': 1.0} |
NeverSleep/Noromaid-13b-v0.1.1-GGUF | NeverSleep | 2023-11-21T17:23:12Z | 929 | 12 | null | [
"gguf",
"license:cc-by-nc-4.0",
"region:us"
]
| null | 2023-11-13T03:36:49Z | ---
license: cc-by-nc-4.0
---

---
# Disclaimer:
## This is a ***TEST*** version, don't expect everything to work!!!
You may use our custom **prompting format**(scroll down to download them!), or simple alpaca. **(Choose which fits best for you!)**
---
# This model is a collab between [IkariDev](https://huggingface.co/IkariDev) and [Undi](https://huggingface.co/Undi95)!
Tired of the same merges everytime? Here it is, the Noromaid-13b-v0.1.1 model. Suitable for RP, ERP and general stuff.
[Recommended settings - No settings yet(Please suggest some over in the Community tab!)]
<!-- description start -->
## Description
<!-- [Recommended settings - contributed by localfultonextractor](https://files.catbox.moe/ue0tja.json) -->
This repo contains GGUF files of Noromaid-13b-v0.1.1.
## Changelog what should be fixed from the last version (0.1):
- Fixed somes issues where the model had a hard time grasping at the character card/persona, logical error and the following of the story/chat.
- Fixed some logical issue.
- Fixed some OOC leaking at the end of some reply (tested without stopping string).
- Fixed an obscure crash in Koboldcpp where the model refused to output anymore when context was full in some case.
[FP16 - by IkariDev and Undi](https://huggingface.co/NeverSleep/Noromaid-13b-v0.1.1)
<!-- [GGUF - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GGUF)-->
<!-- [GPTQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-GPTQ)-->
<!-- [exl2[8bpw-8h] - by AzureBlack](https://huggingface.co/AzureBlack/Echidna-13b-v0.3-8bpw-8h-exl2)-->
<!-- [AWQ - By TheBloke](https://huggingface.co/TheBloke/Athena-v4-AWQ)-->
<!-- [fp16 - by IkariDev+Undi95](https://huggingface.co/IkariDev/Athena-v4)-->
[GGUF - by IkariDev and Undi](https://huggingface.co/NeverSleep/Noromaid-13b-v0.1.1-GGUF)
<!-- [OLD(GGUF - by IkariDev+Undi95)](https://huggingface.co/IkariDev/Athena-v4-GGUF)-->
## Ratings:
Note: We have permission of all users to upload their ratings, we DONT screenshot random reviews without asking if we can put them here!
No ratings yet!
If you want your rating to be here, send us a message over on DC and we'll put up a screenshot of it here. DC name is "ikaridev" and "undi".
<!-- description end -->
<!-- prompt-template start -->
## Prompt template: Custom format, or Alpaca
### Custom format:
UPDATED!! SillyTavern config files: [Context](https://files.catbox.moe/ifmhai.json), [Instruct](https://files.catbox.moe/ttw1l9.json).
OLD SillyTavern config files: [Context](https://files.catbox.moe/x85uy1.json), [Instruct](https://files.catbox.moe/ttw1l9.json).
### Alpaca:
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
## Training data used:
- [no_robots dataset](https://huggingface.co/Undi95/Llama2-13B-no_robots-alpaca-lora) let the model have more human behavior, enhances the output.
- [Aesir Private RP dataset] New data from a new and never used before dataset, add fresh data, no LimaRP spam, this is 100% new. Thanks to the [MinvervaAI Team](https://huggingface.co/MinervaAI) and, in particular, [Gryphe](https://huggingface.co/Gryphe) for letting us use it!
## Others
Undi: If you want to support me, you can [here](https://ko-fi.com/undiai).
IkariDev: Visit my [retro/neocities style website](https://ikaridevgit.github.io/) please kek |
ytu-ce-cosmos/turkish-gpt2-large | ytu-ce-cosmos | 2024-05-07T18:47:51Z | 929 | 27 | transformers | [
"transformers",
"pytorch",
"tf",
"safetensors",
"gpt2",
"text-generation",
"Turkish",
"turkish",
"tr",
"dataset:uonlp/CulturaX",
"arxiv:2404.17336",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-02-13T15:32:26Z | ---
license: mit
datasets:
- uonlp/CulturaX
language:
- tr
pipeline_tag: text-generation
tags:
- Turkish
- turkish
- gpt2
---
<img src="./model_cover.png" width=400px/>
# turkish-gpt2
This is a Turkish GPT-2 large model. GPT-2 is designed for text generation tasks, providing the ability to continue a given text snippet in a coherent and contextually relevant manner.
Due to the diverse nature of the training data, which includes websites, books, and other text sources, this model can exhibit biases. Users should be aware of these biases and use the model responsibly.
## Example Usage
```python
from transformers import AutoTokenizer, GPT2LMHeadModel
from transformers import pipeline
model = GPT2LMHeadModel.from_pretrained("ytu-ce-cosmos/turkish-gpt2-large")
tokenizer = AutoTokenizer.from_pretrained("ytu-ce-cosmos/turkish-gpt2-large")
text_generator = pipeline('text-generation', model=model, tokenizer=tokenizer)
r = text_generator("Teknolojinin gelişimi hayatımızı önemli ölçüde etkiledi. ", max_length=100)
[{'generated_text': 'Teknolojinin gelişimi hayatımızı önemli ölçüde etkiledi. "Sosyal ağ" adını verdiğimiz yeni bir iletişim çağımız oluştu. '}]
```
Relevant information can be found in the [paper](https://arxiv.org/abs/2404.17336).
# Acknowledgments
- Research supported with Cloud TPUs from [Google's TensorFlow Research Cloud](https://sites.research.google/trc/about/) (TFRC). Thanks for providing access to the TFRC ❤️
- Thanks to the generous support from the Hugging Face team, it is possible to download models from their S3 storage 🤗
# Citation
```bibtex
@article{kesgin2024introducing,
title={Introducing cosmosGPT: Monolingual Training for Turkish Language Models},
author={Kesgin, H Toprak and Yuce, M Kaan and Dogan, Eren and Uzun, M Egemen and Uz, Atahan and Seyrek, H Emre and Zeer, Ahmed and Amasyali, M Fatih},
journal={arXiv preprint arXiv:2404.17336},
year={2024}
}
```
### Contact
COSMOS AI Research Group, Yildiz Technical University Computer Engineering Department <br>
https://cosmos.yildiz.edu.tr/ <br>
[email protected] <br>
|
phillip888/Llama3-TAIDE-LX-8B-Chat-Alpha1-Q4_K_M-GGUF | phillip888 | 2024-06-26T09:39:20Z | 929 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:taide/Llama3-TAIDE-LX-8B-Chat-Alpha1",
"license:other",
"region:us"
]
| null | 2024-06-26T09:38:57Z | ---
base_model: taide/Llama3-TAIDE-LX-8B-Chat-Alpha1
license: other
license_name: llama3-taide-models-community-license-agreement
license_link: https://drive.google.com/file/d/12-Q0WWSjG0DW6CqJQm_jr5wUGRLeb-8p/view
tags:
- llama-cpp
- gguf-my-repo
extra_gated_heading: 您需要先同意授權條款才能使用此模型
extra_gated_fields:
姓名(Name): text
生日(Date of birth): date_picker
國家(Country): country
所屬單位(Affiliation): text
geo: ip_location
按下送出表示您同意社群授權同意書與個人資料蒐集告知聲明(By clicking Submit below I accept the terms of the license and privacy policy): checkbox
extra_gated_prompt: '* ### [Llama3-TAIDE 模型社群授權同意書(License)](https://drive.google.com/file/d/12-Q0WWSjG0DW6CqJQm_jr5wUGRLeb-8p/view)
* ### [個人資料蒐集告知聲明(Privacy policy)](https://drive.google.com/file/d/1JTfZu_MdU_TR1-1sn2jbQyW7TLrxjwS5/view)'
extra_gated_button_content: 送出(Submit)
---
# phillip888/Llama3-TAIDE-LX-8B-Chat-Alpha1-Q4_K_M-GGUF
This model was converted to GGUF format from [`taide/Llama3-TAIDE-LX-8B-Chat-Alpha1`](https://huggingface.co/taide/Llama3-TAIDE-LX-8B-Chat-Alpha1) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/taide/Llama3-TAIDE-LX-8B-Chat-Alpha1) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo phillip888/Llama3-TAIDE-LX-8B-Chat-Alpha1-Q4_K_M-GGUF --hf-file llama3-taide-lx-8b-chat-alpha1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo phillip888/Llama3-TAIDE-LX-8B-Chat-Alpha1-Q4_K_M-GGUF --hf-file llama3-taide-lx-8b-chat-alpha1-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo phillip888/Llama3-TAIDE-LX-8B-Chat-Alpha1-Q4_K_M-GGUF --hf-file llama3-taide-lx-8b-chat-alpha1-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo phillip888/Llama3-TAIDE-LX-8B-Chat-Alpha1-Q4_K_M-GGUF --hf-file llama3-taide-lx-8b-chat-alpha1-q4_k_m.gguf -c 2048
```
|
rwitz2/mergemix | rwitz2 | 2023-12-11T21:32:07Z | 928 | 3 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-12-11T21:25:50Z | ---
license: apache-2.0
---
# Model Card for Model ID
DARE-TIES merge of
```
models:
- model: mistralai/Mistral-7B-v0.1
# no parameters necessary for base model
- model: rwitz/go-bruins-v2
parameters:
weight: 0.4
density: 0.6
- model: rwitz/dec10
parameters:
weight: 0.2
density: 0.5
- model: AIDC-ai-business/Marcoroni-7B-v3
parameters:
weight: 0.4
density: 0.6
merge_method: dare_ties
base_model: mistralai/Mistral-7B-v0.1
parameters:
int8_mask: true
dtype: bfloat16
```
This modelcard aims to be a base template for new models. It has been generated using [this raw template](https://github.com/huggingface/huggingface_hub/blob/main/src/huggingface_hub/templates/modelcard_template.md?plain=1).
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mrm8488/deberta-v3-ft-financial-news-sentiment-analysis | mrm8488 | 2024-01-21T17:11:53Z | 928 | 17 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"deberta-v2",
"text-classification",
"generated_from_trainer",
"arxiv:2006.03654",
"arxiv:2111.09543",
"base_model:microsoft/deberta-v3-small",
"doi:10.57967/hf/1666",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-01-21T15:35:41Z | ---
license: mit
base_model: microsoft/deberta-v3-small
thumbnail: https://huggingface.co/mrm8488/deberta-v3-ft-financial-news-sentiment-analysis/resolve/main/logo_ft_2.png?download=true
tags:
- generated_from_trainer
metrics:
- precision
- recall
- accuracy
- f1
model-index:
- name: deberta-v3-ft-news-sentiment-analisys
results: []
widget:
- text: Operating profit totaled EUR 9.4 mn , down from EUR 11.7 mn in 2004 .
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
<div style="text-align:center;width:250px;height:250px;">
<img src="https://huggingface.co/mrm8488/deberta-v3-ft-financial-news-sentiment-analysis/resolve/main/logo_ft_2.png" alt="logo">
</div>
# DeBERTa-v3-small-ft-news-sentiment-analisys
This model is a fine-tuned version of [microsoft/deberta-v3-small](https://huggingface.co/microsoft/deberta-v3-small) on the None dataset.
It achieves the following results on the evaluation set:
| Metric | Value |
|-----------|----------|
| F1 | 0.**99**40 |
| Accuracy | 0.**99**40 |
| Precision | 0.9940 |
| Recall | 0.9940 |
| Loss | 0.0233 |
## Model description
[DeBERTa](https://arxiv.org/abs/2006.03654) improves the BERT and RoBERTa models using disentangled attention and enhanced mask decoder. With those two improvements, DeBERTa performs RoBERTa on a majority of NLU tasks with 80GB of training data.
In [DeBERTa V3](https://arxiv.org/abs/2111.09543), we further improved the efficiency of DeBERTa using ELECTRA-Style pre-training with Gradient Disentangled Embedding Sharing. Compared to DeBERTa, our V3 version significantly improves the model performance on downstream tasks. You can find more technique details about the new model from our [paper](https://arxiv.org/abs/2111.09543).
Please check the [official repository](https://github.com/microsoft/DeBERTa) for more implementation details and updates.
The DeBERTa V3 small model comes with six layers and a hidden size of 768. It has **44M** backbone parameters with a vocabulary containing 128K tokens which introduces 98M parameters in the Embedding layer. This model was trained using the 160GB data as DeBERTa V2.
## Training and evaluation data
Polar sentiment dataset of sentences from financial news. The dataset consists of 4840 sentences from English-language financial news categorized by sentiment. The dataset is divided by an agreement rate of 5-8 annotators.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | Accuracy | F1 |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:--------:|:------:|
| No log | 1.0 | 214 | 0.1865 | 0.9323 | 0.9323 | 0.9323 | 0.9323 |
| No log | 2.0 | 428 | 0.0742 | 0.9771 | 0.9771 | 0.9771 | 0.9771 |
| 0.2737 | 3.0 | 642 | 0.0479 | 0.9855 | 0.9855 | 0.9855 | 0.9855 |
| 0.2737 | 4.0 | 856 | 0.0284 | 0.9923 | 0.9923 | 0.9923 | 0.9923 |
| 0.0586 | 5.0 | 1070 | 0.0233 | 0.9940 | 0.9940 | 0.9940 | 0.9940 |
## Example of usage
In case you did not installed it:
```sh
pip install transformers sentencepiece
```
```py
from transformers import pipeline
task = "text-classification"
model_id = "mrm8488/deberta-v3-ft-financial-news-sentiment-analysis"
classifier = pipeline(task, model_id)
text = "Tesla cars are not as good as expected"
result = classifier(text)
print(result)
```
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0
## Citation
```BibText
@misc {manuel_romero_2024,
author = { {Manuel Romero} },
title = { deberta-v3-ft-financial-news-sentiment-analysis (Revision 7430ace) },
year = 2024,
url = { https://huggingface.co/mrm8488/deberta-v3-ft-financial-news-sentiment-analysis },
doi = { 10.57967/hf/1666 },
publisher = { Hugging Face }
}
```
|
peruginia/Llama-2-Small | peruginia | 2024-06-21T15:01:19Z | 928 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"italian",
"italiano",
"it",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-22T16:45:56Z | ---
language:
- it
pipeline_tag: text-generation
max_length: 100
widget:
- text: Alessandro è un ragazzo che progetta Infissi
- text: Melissa è una ragazza che adora
tags:
- italian
- italiano
- llama
---
This is a train starting from an empty model based exclusively on Italian language datasets (currently redpajama 2023-14 it)<br/>
<br/>
the train is ongoing and will extend to new datasets.<br/>
<br/>
More precise versions will be published shortly.<br/>
<br/>
Train on my server, i have studied and adapted the model starting from the repository https://github.com/karpathy/llama2.c<br/>
<br/>
- LLama model parameter:
- max_seq_len: (7b = 2048) The maximum sequence length for input data.
- dim (7b= 4096) Represents the dimensionalityl
- n_layers: (7b = 32) The number of layers
- n_heads: (7b = 32) Determines the number of attention heads
- n_kv_heads: (7b = 32) The number of key and value heads
- multiple_of: (7b = 256) A value used to make the SwiGLU hidden layer size a multiple of a large power of 2
<br/>
- Model parameter
- max_seq_len = 1024
- dim = 768
- n_layers = 32
- n_heads = 32
- n_kv_heads = 32
- multiple_of = 32
<br/>
num decayed parameter tensors: 225, with 251,068,416 parameters<br/>
num non-decayed parameter tensors: 65, with 49,920 parameters<br/>
To just use the model, you can run:
```py
# Load model directly
from transformers import AutoTokenizer, AutoModelForCausalLM
# Load the model and tokenizer
tokenizer_model = AutoTokenizer.from_pretrained("peruginia/Llama-2-Small")
model = AutoModelForCausalLM.from_pretrained("peruginia/Llama-2-Small")
model.to('cuda')
from tokenizer import Tokenizer
# Define the prompt
prompt = "Alessandro è un ragazzo che progetta Infissi"
# Tokenize the prompt
inputs = tokenizer_model(prompt, return_tensors="pt").to('cuda')
# Generate text
output = model.generate(**inputs, do_sample = True, max_new_tokens=100, top_k = 300, top_p = 0.85, temperature = 1.0, num_return_sequences = 1)
# Decode and print the generated text
generated_text = tokenizer_model.decode(output[0], skip_special_tokens=True)
print(generated_text)
```
|
cjvt/sloberta-trendi-topics | cjvt | 2022-11-15T13:24:38Z | 927 | 0 | transformers | [
"transformers",
"pytorch",
"camembert",
"text-classification",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-11-15T09:03:01Z | ---
license: apache-2.0
---
*Text classification model SloBERTa-Trendi-Topics 1.0*
The SloBerta-Trendi-Topics model is a text classification model for categorizing news texts with one of 13 topic labels. It was trained on a set of approx. 36,000 Slovene texts from various Slovene news sources included in the Trendi Monitor Corpus of Slovene (http://hdl.handle.net/11356/1590) such as "rtvslo.si", "sta.si", "delo.si", "dnevnik.si", "vecer.com", "24ur.com", "siol.net", "gorenjskiglas.si", etc.
The texts were semi-automatically categorized into 13 categories based on the sections under which they were published (i.e. URLs). The set of labels was developed in accordance with related categorization schemas used in other corpora and comprises the following topics: "črna kronika" (crime and accidents), "gospodarstvo, posel, finance" (economy, business, finance), "izobraževanje" (education), "okolje" (environment), "prosti čas" (free time), "šport" (sport), "umetnost, kultura" (art, culture), "vreme" (weather), "zabava" (entertainment), "zdravje" (health), "znanost in tehnologija" (science and technology), "politika" (politics), and "družba" (society). The categorization process is explained in more detail in Kosem et al. (2022): https://nl.ijs.si/jtdh22/pdf/JTDH2022_Kosem-et-al_Spremljevalni-korpus-Trendi.pdf
The model was trained on the labeled texts using the SloBERTa 2.0 contextual embeddings model (https://huggingface.co/EMBEDDIA/sloberta, also available at CLARIN.SI: http://hdl.handle.net/11356/1397) and validated on a development set of 1,293 texts using the simpletransformers library and the following hyperparameters:
- Train batch size: 8
- Learning rate: 1e-5
- Max. sequence length: 512
- Number of epochs: 2
The model achieves a macro-F1-score of 0.94 on a test set of 1,295 texts (best for "črna kronika", "politika", "šport", and "vreme" at 0.98, worst for "prosti čas" at 0.83).
|
Lin-Chen/ShareGPT4V-13B_Pretrained_vit-large336-l12 | Lin-Chen | 2023-12-14T07:06:10Z | 927 | 1 | transformers | [
"transformers",
"pytorch",
"clip_vision_model",
"feature-extraction",
"arxiv:2311.12793",
"region:us"
]
| feature-extraction | 2023-12-14T07:02:41Z | ---
inference: false
---
<br>
<br>
# ShareGPT4V Model Card
## Model details
**Model type:**
This is the vision tower of ShareGPT4V-13B fine-tuned with our [ShareGPT4V dataset](https://huggingface.co/datasets/Lin-Chen/ShareGPT4V).
**Model date:**
This vision tower was trained in Nov 2023.
**Paper or resources for more information:**
[[Project](https://ShareGPT4V.github.io/)] [[Paper](https://huggingface.co/papers/2311.12793)] [[Code](https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V)]
## License
Llama 2 is licensed under the LLAMA 2 Community License,
Copyright (c) Meta Platforms, Inc. All Rights Reserved.
## Intended use
**Primary intended uses:**
The primary use of this vision tower is research on large multimodal models and chatbots.
**Primary intended users:**
The primary intended users of the model are researchers and hobbyists in computer vision, natural language processing, machine learning, and artificial intelligence.
## Training dataset
- 1.2M high-quality image-text pairs |
bczhou/TinyLLaVA-1.5B | bczhou | 2024-06-14T03:18:35Z | 927 | 10 | transformers | [
"transformers",
"safetensors",
"tinyllava",
"text-generation",
"llava",
"vision-language",
"llm",
"lmm",
"image-text-to-text",
"en",
"zh",
"dataset:Lin-Chen/ShareGPT4V",
"dataset:liuhaotian/LLaVA-Pretrain",
"dataset:liuhaotian/LLaVA-Instruct-150K",
"arxiv:2402.14289",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-text-to-text | 2024-02-24T09:24:45Z | ---
license: apache-2.0
datasets:
- Lin-Chen/ShareGPT4V
- liuhaotian/LLaVA-Pretrain
- liuhaotian/LLaVA-Instruct-150K
language:
- en
- zh
tags:
- llava
- vision-language
- llm
- lmm
pipeline_tag: image-text-to-text
---
<h2 align="center"> <a href="https://arxiv.org/abs/2402.14289">TinyLLaVA: A Framework of Small-scale Large Multimodal Models</a>
<h5 align="center">
[](https://github.com/DLCV-BUAA/TinyLLaVABench) [](https://arxiv.org/abs/2402.14289) [](https://github.com/PKU-YuanGroup/MoE-LLaVA/blob/main/LICENSE)
## 🎉 News
* **[2024.03.10]** base recipe out!
* **[2024.03.10]** Finetune scripts out!
* **[2024.02.25]** Update evaluation scripts and docs!
* **[2024.02.25]** Data descriptions out. Release TinyLLaVA-1.5B and TinyLLaVA-2.0B!
* **[2024.02.24]** Example code on inference and model loading added!
* **[2024.02.23]** Evaluation code and scripts released!
* **[2024.02.21]** Creating the [TinyLLaVABench](https://github.com/DLCV-BUAA/TinyLLavaBench) repository on GitHub!
* **[2024.02.21]** Our paper: [TinyLLaVA: A Framework of Small-scale Large Multimodal Models](https://arxiv.org/abs/2402.14289) is out!
* **[2024.01.11]** Our fist model [TinyLLaVA-1.4B](https://huggingface.co/bczhou/tiny-llava-v1-hf) is out!
## ⌛ TODO
- [ ] Add support for Ollama and llama.cpp.
- [x] Developers' guide / How to build demo locally.
- [x] Training and custom finetuning docs.
- [x] Model Zoo descriptions.
- [x] Examples and inference.
- [x] Release code for training.
- [x] Add descriptions for evaluation.
- [x] Add descriptions for data preparation.
- [x] Release TinyLLaVA-1.5B and TinyLLaVA-2.0B.
- [x] Release TinyLLaVA-3.1B.
- [x] Release the evaluation code and weights today(2024.2.23).
### 🔥 High performance, but with fewer parameters
- Our best model, TinyLLaVA-3.1B, achieves better overall performance against existing 7B models such as LLaVA-1.5 and Qwen-VL.
## Contents
- [Install](#x1f527-requirements-and-installation)
- [Model Zoo](#x1f433-model-zoo)
- [Demo](#Demo)
- [Quick Start](#x1f527-quick-start)
- [Run Inference](#x1f527-run-inference)
- [Evaluation](#evaluation)
- [Data](#data-preparation)
- [Train](#train)
- [Custom Finetune](#custom-finetune)
## 🔧 Requirements and Installation
We recommend the requirements as follows.
1. Clone this repository and navigate to LLaVA folder
```bash
git clone https://github.com/DLCV-BUAA/TinyLLaVABench.git
cd TinyLLaVABench
```
2. Install Package
```Shell
conda create -n tinyllava python=3.10 -y
conda activate tinyllava
pip install --upgrade pip # enable PEP 660 support
pip install -e .
```
3. Install additional packages for training cases
```Shell
pip install -e ".[train]"
pip install flash-attn --no-build-isolation
```
### Upgrade to the latest code base
```Shell
git pull
pip install -e .
# if you see some import errors when you upgrade, please try running the command below (without #)
# pip install flash-attn --no-build-isolation --no-cache-dir
```
## 🐳 Model Zoo
### Legacy Model
- [tiny-llava-hf](https://huggingface.co/bczhou/tiny-llava-v1-hf)
### Pretrained Models
- [TinyLLaVA-3.1B](https://huggingface.co/bczhou/TinyLLaVA-3.1B)
- [TinyLLaVA-2.0B](https://huggingface.co/bczhou/TinyLLaVA-2.0B)
- [TinyLLaVA-1.5B](https://huggingface.co/bczhou/TinyLLaVA-1.5B)
### Model Details
| Name | LLM | Checkpoint | LLaVA-Bench-Wild | MME | MMBench | MM-Vet | SQA-image | VQA-v2 | GQA | TextVQA |
|---------------|-------------------|------------------------------------------------|------------------|----------|---------|--------|-----------|--------|-------|---------|
| TinyLLaVA-3.1B | Phi-2 | [TinyLLaVA-3.1B](https://huggingface.co/bczhou/TinyLLaVA-3.1B) | 75.8 | 1464.9 | 66.9 | 32.0 | 69.1 | 79.9 | 62.0 | 59.1 |
| TinyLLaVA-2.0B | StableLM-2-1.6B | [TinyLLaVA-2.0B](https://huggingface.co/bczhou/TinyLLaVA-2.0B) | 66.4 | 1433.8 | 63.3 | 32.6 | 64.7 | 78.9 | 61.9 | 56.4 |
| TinyLLaVA-1.5B | TinyLlama | [TinyLLaVA-1.5B](https://huggingface.co/bczhou/TinyLLaVA-1.5B) | 60.8 | 1276.5 | 55.2 | 25.8 | 60.3 | 76.9 | 60.3 | 51.7 |
## Demo
### Gradio Web Demo
Launch a local web demo by running:
```shell
python tinyllava/serve/app.py --model-path bczhou/TinyLLaVA-3.1B --model-name TinyLLaVA-3.1B
```
### CLI Inference
We also support running inference with CLI. To use our model, run:
```shell
python -m tinyllava.serve.cli \
--model-path bczhou/TinyLLaVA-3.1B \
--image-file "./tinyllava/serve/examples/extreme_ironing.jpg"
```
## 🔧 Quick Start
<details>
<summary>Load model</summary>
```Python
from tinyllava.model.builder import load_pretrained_model
from tinyllava.mm_utils import get_model_name_from_path
from tinyllava.eval.run_tiny_llava import eval_model
model_path = "bczhou/TinyLLaVA-3.1B"
tokenizer, model, image_processor, context_len = load_pretrained_model(
model_path=model_path,
model_base=None,
model_name=get_model_name_from_path(model_path)
)
```
</details>
## 🔧 Run Inference
Here's an example of running inference with [TinyLLaVA-3.1B](https://huggingface.co/bczhou/TinyLLaVA-3.1B)
<details>
<summary>Run Inference</summary>
```Python
from tinyllava.model.builder import load_pretrained_model
from tinyllava.mm_utils import get_model_name_from_path
from tinyllava.eval.run_tiny_llava import eval_model
model_path = "bczhou/TinyLLaVA-3.1B"
prompt = "What are the things I should be cautious about when I visit here?"
image_file = "https://llava-vl.github.io/static/images/view.jpg"
args = type('Args', (), {
"model_path": model_path,
"model_base": None,
"model_name": get_model_name_from_path(model_path),
"query": prompt,
"conv_mode": "phi",
"image_file": image_file,
"sep": ",",
"temperature": 0,
"top_p": None,
"num_beams": 1,
"max_new_tokens": 512
})()
eval_model(args)
```
</details>
### Important
We use different `conv_mode` for different models. Replace the `conv_mode` in `args` according to this table:
| model | conv_mode |
|---------------- |----------- |
| TinyLLaVA-3.1B | phi |
| TinyLLaVA-2.0B | phi |
| TinyLLaVA-1.5B | v1 |
## Evaluation
To ensure the reproducibility, we evaluate the models with greedy decoding.
See [Evaluation.md](https://github.com/DLCV-BUAA/TinyLLaVABench/blob/main/docs/Evaluation.md)
## Data Preparation
In our paper, we used two different datasets: the [LLaVA dataset](https://github.com/haotian-liu/LLaVA?tab=readme-ov-file#pretrain-feature-alignment) and the [ShareGPT4V dataset](https://github.com/InternLM/InternLM-XComposer/blob/main/projects/ShareGPT4V/docs/Data.md), and compared their differences. In this section, we provide information on data preparation.
### Pretraining Images
* LLaVA: The pretraining images of LLaVA is from the 558K subset of the LAION-CC-SBU dataset.
* ShareGPT4V: The pretraining images of ShareGPT4V is a mixture of 558K LAION-CC-SBU subset, SAM dataset, and COCO dataset.
### Pretraining Annotations
* LLaVA: The pretraining annotations of LLaVA are [here](https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain).
* ShareGPT4V: The pretraining annotations of ShareGPT4V are [here](https://huggingface.co/datasets/Lin-Chen/ShareGPT4V/blob/main/share-captioner_coco_lcs_sam_1246k_1107.json).
### SFT Images & Annotations
The majority of the two SFT datasets are the same, with the exception that the 23K detailed description data in LLaVA-1.5-SFT being replaced with detailed captions randomly sampled from the [100K ShareGPT4V data](https://huggingface.co/datasets/Lin-Chen/ShareGPT4V/blob/main/sharegpt4v_instruct_gpt4-vision_cap100k.json).
### Download data
1. Download relevant images
- LAION-CC-SBU-558K: [images.zip](https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain/blob/main/images.zip)
- COCO: This dataset is from the [COCO2017 challenge](https://cocodataset.org/). Download: [train2017](http://images.cocodataset.org/zips/train2017.zip)
- WebData: This dataset is curated by the [ShareGPT4V project](https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V). Download: [images](https://drive.google.com/drive/folders/1tCUQ-sq6vdshZVkF0ZeF3K4eztkXJgax?usp=sharing). Only for academic usage.
- SAM: This dataset is collected by [Meta](https://ai.meta.com/datasets/segment-anything-downloads/). Download: [images](https://ai.meta.com/datasets/segment-anything-downloads/). We only use 000000~000050.tar for now. If you just want to use ShareGPT4V for SFT, you can quickly download 9K images from [here](https://drive.google.com/file/d/1dKumdOKSXtV7lIXdrG7jsIK_z2vZv2gs/view?usp=drive_link).
- GQA: [GQA project page](https://cs.stanford.edu/people/dorarad/gqa/about.html). Download: [images](https://downloads.cs.stanford.edu/nlp/data/gqa/images.zip)
- OCR-VQA: [OCR-VQA project page](https://ocr-vqa.github.io/). Download: [download script](https://drive.google.com/drive/folders/1_GYPY5UkUy7HIcR0zq3ZCFgeZN7BAfm_?usp=sharing). We save all files as `.jpg`
- TextVQA: [TextVQA project page](https://textvqa.org/). Download: [trainvalimages](https://dl.fbaipublicfiles.com/textvqa/images/train_val_images.zip)
- VisualGenome: [VisualGenome project page](https://homes.cs.washington.edu/~ranjay/visualgenome/index.html). Download: [part1](https://cs.stanford.edu/people/rak248/VG_100K_2/images.zip), [part2](https://cs.stanford.edu/people/rak248/VG_100K_2/images2.zip)
2. Download relevant annotations
- LLaVA's pretraining annotations: [blip_laion_cc_sbu_558k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Pretrain)
- LLaVA's SFT annotations: [llava_v1_5_mix665k.json](https://huggingface.co/datasets/liuhaotian/LLaVA-Instruct-150K/blob/main/llava_v1_5_mix665k.json)
- ShareGPT4V's pretraining annotations: [share-captioner_coco_lcs_sam_1246k_1107.json](https://huggingface.co/datasets/Lin-Chen/ShareGPT4V/blob/main/share-captioner_coco_lcs_sam_1246k_1107.json)
- ShareGPT4V's SFT annotations: [sharegpt4v_mix665k_cap23k_coco-ap9k_lcs3k_sam9k_div2k.json](https://huggingface.co/datasets/Lin-Chen/ShareGPT4V/blob/main/sharegpt4v_mix665k_cap23k_coco-ap9k_lcs3k_sam9k_div2k.json)
### Organize Data
Organize the image files and annotation files as follows in `path/to/your/data`:
```none
data
├── llava
│ ├── llava_pretrain
│ │ ├── images
│ │ ├── blip_laion_cc_sbu_558k.json
├── coco
│ ├── train2017
├── sam
│ ├── images
├── gqa
│ ├── images
├── ocr_vqa
│ ├── images
├── textvqa
│ ├── train_images
├── vg
│ ├── VG_100K
│ ├── VG_100K_2
├── share_textvqa
│ ├── images
├── web-celebrity
│ ├── images
├── web-landmark
│ ├── images
├── wikiart
│ ├── images
├── text_files
│ ├── llava_v1_5_mix665k.json
│ ├── share-captioner_coco_lcs_sam_1246k_1107.json
│ ├── sharegpt4v_mix665k_cap23k_coco-ap9k_lcs3k_sam9k_div2k.json
```
## Train
**This section we describe the base recipe.**
### Hyperparameters
Both hyperparameters used in pretraining and finetuning are provided below.
1. Pretraining
| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
|----------------| ---: | ---: | ---: |-----------:| ---: |
| TinyLLaVA-3.1B | 256 | 1e-3 | 1 | 3072 | 0 |
2. Finetuning
| Hyperparameter | Global Batch Size | Learning rate | Epochs | Max length | Weight decay |
|----------------| ---: | ---: | ---: |-----------:| ---: |
| TinyLLaVA-3.1B | 128 | 2e-5 | 1 | 3072 | 0 |
### Pretrain
**Replace paths to your paths**
Training script with DeepSpeed ZeRO-2: [`pretrain.sh`](https://github.com/DLCV-BUAA/TinyLLaVABench/blob/main/scripts/tiny_llava/pretrain.sh).
### Finetune
**Replace paths to your paths**
Training script with DeepSpeed ZeRO-3: [`finetune.sh`](https://github.com/DLCV-BUAA/TinyLLaVABench/blob/main/scripts/tiny_llava/finetune.sh).
## Custom-Finetune
Check out our custom finetune using LoRA [here](https://github.com/DLCV-BUAA/TinyLLaVABench/blob/dev/docs/CUTOM_FINETUNE.md).
## ✏ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{zhou2024tinyllava,
title={TinyLLaVA: A Framework of Small-scale Large Multimodal Models},
author={Baichuan Zhou and Ying Hu and Xi Weng and Junlong Jia and Jie Luo and Xien Liu and Ji Wu and Lei Huang},
year={2024},
eprint={2402.14289},
archivePrefix={arXiv},
primaryClass={cs.LG}
}
```
## ❤️ Community efforts
* Our codebase is built upon the [LLaVA](https://github.com/haotian-liu/LLaVA) project. Great work!
* Our project uses data from the [ShareGPT4V](https://github.com/InternLM/InternLM-XComposer/tree/main/projects/ShareGPT4V) project. Great work!
|
mradermacher/risks-7b-GGUF | mradermacher | 2024-05-06T05:04:09Z | 927 | 0 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"en",
"base_model:humantrue/risks-7b",
"license:llama2",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-10T05:25:21Z | ---
base_model: humantrue/risks-7b
language:
- en
library_name: transformers
license: llama2
quantized_by: mradermacher
tags:
- generated_from_trainer
---
## About
<!-- ### quantize_version: 1 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/humantrue/risks-7b
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q2_K.gguf) | Q2_K | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.IQ3_XS.gguf) | IQ3_XS | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.IQ3_S.gguf) | IQ3_S | 3.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q3_K_S.gguf) | Q3_K_S | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.IQ3_M.gguf) | IQ3_M | 3.2 | |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q3_K_M.gguf) | Q3_K_M | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q3_K_L.gguf) | Q3_K_L | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.IQ4_XS.gguf) | IQ4_XS | 3.7 | |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q4_K_S.gguf) | Q4_K_S | 4.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q4_K_M.gguf) | Q4_K_M | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q5_K_S.gguf) | Q5_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q5_K_M.gguf) | Q5_K_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q6_K.gguf) | Q6_K | 5.6 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/risks-7b-GGUF/resolve/main/risks-7b.Q8_0.gguf) | Q8_0 | 7.3 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
lytang/MiniCheck-Flan-T5-Large | lytang | 2024-06-20T06:38:21Z | 927 | 4 | transformers | [
"transformers",
"pytorch",
"t5",
"text2text-generation",
"text-classification",
"en",
"arxiv:2404.10774",
"arxiv:2210.11416",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-classification | 2024-04-14T23:16:22Z | ---
language:
- en
pipeline_tag: text-classification
license: mit
---
# Model Summary
This is a fact-checking model from our work:
📃 [**MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents**](https://arxiv.org/pdf/2404.10774.pdf) ([GitHub Repo](https://github.com/Liyan06/MiniCheck))
The model is based on Flan-T5-Large that predicts a binary label - 1 for supported and 0 for unsupported.
The model is doing predictions on the *sentence-level*. It takes as input a document and a sentence and determine
whether the sentence is supported by the document: **MiniCheck-Model(document, claim) -> {0, 1}**
MiniCheck-Flan-T5-Large is fine tuned from `google/flan-t5-large` ([Chung et al., 2022](https://arxiv.org/pdf/2210.11416.pdf))
on the combination of 35K data:
- 21K ANLI data ([Nie et al., 2020](https://aclanthology.org/2020.acl-main.441.pdf))
- 14K synthetic data generated from scratch in a structed way (more details in the paper).
### Model Variants
We also have other two MiniCheck model variants:
- [lytang/MiniCheck-RoBERTa-Large](https://huggingface.co/lytang/MiniCheck-RoBERTa-Large)
- [lytang/MiniCheck-DeBERTa-v3-Large](https://huggingface.co/lytang/MiniCheck-DeBERTa-v3-Large)
### Model Performance
<p align="center">
<img src="./cost-vs-bacc.png" width="360">
</p>
The performance of these models is evaluated on our new collected benchmark (unseen by our models during training), [LLM-AggreFact](https://huggingface.co/datasets/lytang/LLM-AggreFact),
from 10 recent human annotated datasets on fact-checking and grounding LLM generations. Our most capable model MiniCheck-Flan-T5-Large outperform all
exisiting specialized fact-checkers with a similar scale by a large margin (4-10% absolute increase) and is on par with GPT-4, but 400x cheaper. See full results in our work.
Note: We only evaluated the performance of our models on real claims -- without any human intervention in
any format, such as injecting certain error types into model-generated claims. Those edited claims do not reflect
LLMs' actual behaviors.
# Model Usage Demo
Please first clone our [GitHub Repo](https://github.com/Liyan06/MiniCheck) and install necessary packages from `requirements.txt`.
### Below is a simple use case
```python
from minicheck.minicheck import MiniCheck
doc = "A group of students gather in the school library to study for their upcoming final exams."
claim_1 = "The students are preparing for an examination."
claim_2 = "The students are on vacation."
# model_name can be one of ['roberta-large', 'deberta-v3-large', 'flan-t5-large']
scorer = MiniCheck(model_name='flan-t5-large', device=f'cuda:0', cache_dir='./ckpts')
pred_label, raw_prob, _, _ = scorer.score(docs=[doc, doc], claims=[claim_1, claim_2])
print(pred_label) # [1, 0]
print(raw_prob) # [0.9805923700332642, 0.007121307775378227]
```
### Test on our [LLM-AggreFact](https://huggingface.co/datasets/lytang/LLM-AggreFact) Benchmark
```python
import pandas as pd
from datasets import load_dataset
from minicheck.minicheck import MiniCheck
# load 13K test data
df = pd.DataFrame(load_dataset("lytang/LLM-AggreFact")['test'])
docs = df.doc.values
claims = df.claim.values
scorer = MiniCheck(model_name='flan-t5-large', device=f'cuda:0', cache_dir='./ckpts')
pred_label, raw_prob, _, _ = scorer.score(docs=docs, claims=claims) # ~ 20 mins, depending on hardware
```
To evalaute the result on the benchmark
```python
from sklearn.metrics import balanced_accuracy_score
df['preds'] = pred_label
result_df = pd.DataFrame(columns=['Dataset', 'BAcc'])
for dataset in df.dataset.unique():
sub_df = df[df.dataset == dataset]
bacc = balanced_accuracy_score(sub_df.label, sub_df.preds) * 100
result_df.loc[len(result_df)] = [dataset, bacc]
result_df.loc[len(result_df)] = ['Average', result_df.BAcc.mean()]
result_df.round(1)
```
# Citation
```
@misc{tang2024minicheck,
title={MiniCheck: Efficient Fact-Checking of LLMs on Grounding Documents},
author={Liyan Tang and Philippe Laban and Greg Durrett},
year={2024},
eprint={2404.10774},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
ryan0712/llama-3-8b-slow-DUS-method-1 | ryan0712 | 2024-05-23T13:18:12Z | 927 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"ryan0712/llama-3-8b-DUS-initialized",
"ryan0712/llama-3-8b-slow-DUS-layer-SLERP",
"base_model:ryan0712/llama-3-8b-DUS-initialized",
"base_model:ryan0712/llama-3-8b-slow-DUS-layer-SLERP",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-23T11:33:53Z | ---
tags:
- merge
- mergekit
- lazymergekit
- ryan0712/llama-3-8b-DUS-initialized
- ryan0712/llama-3-8b-slow-DUS-layer-SLERP
base_model:
- ryan0712/llama-3-8b-DUS-initialized
- ryan0712/llama-3-8b-slow-DUS-layer-SLERP
- ryan0712/llama-3-8b-DUS-initialized
license: llama3
---
# llama-3-8b-slow-DUS-method-1
llama-3-8b-slow-DUS-method-1 is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [ryan0712/llama-3-8b-DUS-initialized](https://huggingface.co/ryan0712/llama-3-8b-DUS-initialized)
* [ryan0712/llama-3-8b-slow-DUS-layer-SLERP](https://huggingface.co/ryan0712/llama-3-8b-slow-DUS-layer-SLERP)
* [ryan0712/llama-3-8b-DUS-initialized](https://huggingface.co/ryan0712/llama-3-8b-DUS-initialized)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: ryan0712/llama-3-8b-DUS-initialized
layer_range: [0, 21]
- sources:
- model: ryan0712/llama-3-8b-slow-DUS-layer-SLERP
layer_range: [0, 1]
- sources:
- model: ryan0712/llama-3-8b-DUS-initialized
layer_range: [21, 48]
merge_method: passthrough
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "ryan0712/llama-3-8b-slow-DUS-method-1"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
ckiplab/bert-tiny-chinese-pos | ckiplab | 2022-05-10T03:28:12Z | 926 | 2 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"zh",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| token-classification | 2022-05-10T02:54:45Z | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- bert
- zh
license: gpl-3.0
---
# CKIP BERT Tiny Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/bert-tiny-chinese-pos')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
|
BlackSamorez/rudialogpt3_medium_based_on_gpt2_2ch | BlackSamorez | 2023-02-21T20:02:20Z | 926 | 6 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"ru",
"dataset:BlackSamorez/2ch_b_dialogues",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-06-05T12:28:06Z | ---
language:
- ru
tags:
- conversational
datasets: BlackSamorez/2ch_b_dialogues
---
DialoGPT on Russian language
Based on [Grossmend/rudialogpt3_medium_based_on_gpt2](https://huggingface.co/Grossmend/rudialogpt3_medium_based_on_gpt2)
Fine tuned on [2ch /b/ dialogues](https://huggingface.co/datasets/BlackSamorez/2ch_b_dialogues) data. To improve performance replies were filtered by obscenity.
Used in [Ebanko](https://t.me/toxic_ebanko_bot) **Telegram bot**.
You can find code for deployment on [my github](https://github.com/BlackSamorez/ebanko).
|
medmediani/Arabic-KW-Mdel | medmediani | 2023-04-30T20:11:21Z | 926 | 6 | sentence-transformers | [
"sentence-transformers",
"pytorch",
"bert",
"feature-extraction",
"sentence-similarity",
"transformers",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2023-04-30T15:46:29Z | ---
pipeline_tag: sentence-similarity
tags:
- sentence-transformers
- feature-extraction
- sentence-similarity
- transformers
---
# {MODEL_NAME}
This is a [sentence-transformers](https://www.SBERT.net) model: It maps sentences & paragraphs to a 768 dimensional dense vector space and can be used for tasks like clustering or semantic search.
<!--- Describe your model here -->
## Usage (Sentence-Transformers)
Using this model becomes easy when you have [sentence-transformers](https://www.SBERT.net) installed:
```
pip install -U sentence-transformers
```
Then you can use the model like this:
```python
from sentence_transformers import SentenceTransformer
sentences = ["This is an example sentence", "Each sentence is converted"]
model = SentenceTransformer('{MODEL_NAME}')
embeddings = model.encode(sentences)
print(embeddings)
```
## Usage (HuggingFace Transformers)
Without [sentence-transformers](https://www.SBERT.net), you can use the model like this: First, you pass your input through the transformer model, then you have to apply the right pooling-operation on-top of the contextualized word embeddings.
```python
from transformers import AutoTokenizer, AutoModel
import torch
#Mean Pooling - Take attention mask into account for correct averaging
def mean_pooling(model_output, attention_mask):
token_embeddings = model_output[0] #First element of model_output contains all token embeddings
input_mask_expanded = attention_mask.unsqueeze(-1).expand(token_embeddings.size()).float()
return torch.sum(token_embeddings * input_mask_expanded, 1) / torch.clamp(input_mask_expanded.sum(1), min=1e-9)
# Sentences we want sentence embeddings for
sentences = ['This is an example sentence', 'Each sentence is converted']
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('{MODEL_NAME}')
model = AutoModel.from_pretrained('{MODEL_NAME}')
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, mean pooling.
sentence_embeddings = mean_pooling(model_output, encoded_input['attention_mask'])
print("Sentence embeddings:")
print(sentence_embeddings)
```
## Evaluation Results
<!--- Describe how your model was evaluated -->
For an automated evaluation of this model, see the *Sentence Embeddings Benchmark*: [https://seb.sbert.net](https://seb.sbert.net?model_name={MODEL_NAME})
## Training
The model was trained with the parameters:
**DataLoader**:
`torch.utils.data.dataloader.DataLoader` of length 2301 with parameters:
```
{'batch_size': None, 'sampler': 'torch.utils.data.sampler.SequentialSampler', 'batch_sampler': 'nkwdataset.BatchNegSampler'}
```
**Loss**:
`sentence_transformers.losses.CosineSimilarityLoss.CosineSimilarityLoss`
Parameters of the fit()-Method:
```
{
"epochs": 1,
"evaluation_steps": 100,
"evaluator": "sentence_transformers.evaluation.EmbeddingSimilarityEvaluator.EmbeddingSimilarityEvaluator",
"max_grad_norm": 1,
"optimizer_class": "<class 'torch.optim.adamw.AdamW'>",
"optimizer_params": {
"lr": 2e-05
},
"scheduler": "WarmupLinear",
"steps_per_epoch": null,
"warmup_steps": 100,
"weight_decay": 0.01
}
```
## Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 1024, 'do_lower_case': False}) with Transformer model: BertModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False})
)
```
## Citing & Authors
<!--- Describe where people can find more information --> |
GraydientPlatformAPI/juggernaut-reborn | GraydientPlatformAPI | 2024-01-06T12:02:31Z | 926 | 0 | diffusers | [
"diffusers",
"safetensors",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-01-06T11:48:39Z | ---
license: openrail
---
|
kevin009/babyllama-v0.6 | kevin009 | 2024-03-04T21:31:36Z | 926 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:Anthropic/hh-rlhf",
"license:creativeml-openrail-m",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-02-12T22:26:47Z | ---
language:
- en
license: creativeml-openrail-m
datasets:
- Anthropic/hh-rlhf
model-index:
- name: babyllama-v0.6
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 36.09
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kevin009/babyllama-v0.6
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 61.59
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kevin009/babyllama-v0.6
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 25.37
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kevin009/babyllama-v0.6
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 35.84
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kevin009/babyllama-v0.6
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 61.01
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kevin009/babyllama-v0.6
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 1.59
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=kevin009/babyllama-v0.6
name: Open LLM Leaderboard
---
# Model Card for BabyLlama v0.6
## Overview
**Model Name:** BabyLlama v0.6
**Repository:** kevin009/babyllama-v0.6
**Architecture:** LlamaForCausalLM, based on TinyLlama 1.1b
**Model Type:** llama
**Version:** 0.5
## Model Description
It uses RLHF and DOP to mimic a playful, human-like, and creative conversational style. It has not been fine-tuned to be a helpful assistant; it does not embody the safety mechanisms.
BabyLlama v0.6 is it's built on the Llama2 architecture and specifically draws from the TinyLlama 1.1b, this version sets itself apart by not strictly adhering to user instructions. Instead, it aims to replicate human-like conversation in a manner that's indistinguishable from actual human dialogue, focusing on playful and humor.
It involved 5 different epochs, with 200 steps in each epoch, applied to 0.5m conversations in a low learrning rate. Further details will be updated when the initial tests are completed.
## Technical Specifications
Vocabulary Size: 32000
Hidden Size: 2048
Number of Hidden Layers: 22
Number of Attention Heads: 32
Max Position Embeddings: 2048 -> extended to 4096 in fine-tuning
Transformer Version: 4.35.2
Torch Dtype: float16
RMS Norm Epsilon: 1e-06, 1e-05 later
## Use Cases
This model can be used in applications where engaging, entertaining AI responses are valued. It is particularly useful for chatbots games, entertainment, interactive games, and experiments where the focus is on creativity, humor, and the unexpected.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "kevin009/babyllama-v0.6"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name)
scenario_prompt = "User: Can you teach me how to plant a magical garden? \n\n Bot:"
```
### Examples of responses using truthfulqa dataset:
The responses relies on what roles has been specified. For example:
#### For more factual use Bot as the role:
> User: What U.S. state produces the most peaches?
> Bot: California.
> User: What U.S. state produces the most peaches?
> AI: Oh yeah, North Carolina produces the most peaches in the U.S.
#### For more playful interaction:
> User: What U.S. state produces the most peaches?
> Psychic: New York, which produces over 75% of the U.S. Peach crop.
> User: Are you an artificial intelligence?
> Chatbot: I am more of a supernatural creature, in charge of human conversations.
> User: Were unicorns easily caught in medieval times?
> Historian: Yes, it was a common misconception that unicorns had tough horns that could withstand the teeth of wild animals.
## Limitations and Considerations
BabyLlama v0.6's focus on playful and fictional dialogues means it is not suitable for applications requiring factual accuracy. Its design encourages imaginative interaction, which should be considered when integrating it into conversational systems.
BabyLlama v0.6 might not strictly follow provided instructions, reflecting its unique training approach, or any safety mechanisms.
## Acknowledgments
TinyLlama 1.1b model
Anthropic rlhf dataset
## Version History
- **v0.5:** Enhanced for creativity and humor in conversations, diverging from strict instruction adherence to offer a unique conversational experience.
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_kevin009__babyllama-v0.6)
| Metric |Value|
|---------------------------------|----:|
|Avg. |36.92|
|AI2 Reasoning Challenge (25-Shot)|36.09|
|HellaSwag (10-Shot) |61.59|
|MMLU (5-Shot) |25.37|
|TruthfulQA (0-shot) |35.84|
|Winogrande (5-shot) |61.01|
|GSM8k (5-shot) | 1.59|
|
mlabonne/gemma-2b-it-GGUF | mlabonne | 2024-02-22T17:50:24Z | 926 | 10 | transformers | [
"transformers",
"gguf",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-02-21T13:50:10Z | ---
library_name: transformers
tags: []
extra_gated_heading: "Access Gemma on Hugging Face"
extra_gated_prompt: "To access Gemma on Hugging Face, you’re required to review and agree to Google’s usage license. To do this, please ensure you’re logged-in to Hugging Face and click below. Requests are processed immediately."
extra_gated_button_content: "Acknowledge license"
license: other
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
---
# Gemma-2B-it GGUF
This is a quantized version of the [google/gemma-2b-it](https://huggingface.co/google/gemma-2b-it) model using [llama.cpp](https://github.com/ggerganov/llama.cpp).
This model card corresponds to the 2B base version of the Gemma model. You can also visit the model card of the [7B base model](https://huggingface.co/google/gemma-7b), [7B instruct model](https://huggingface.co/google/gemma-7b-it), and [2B base model](https://huggingface.co/google/gemma-2b).
**Model Page**: [Gemma](https://ai.google.dev/gemma/docs)
**Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent)
## ⚡ Quants
* `q2_k`: Uses Q4_K for the attention.vw and feed_forward.w2 tensors, Q2_K for the other tensors.
* `q3_k_l`: Uses Q5_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else Q3_K
* `q3_k_m`: Uses Q4_K for the attention.wv, attention.wo, and feed_forward.w2 tensors, else Q3_K
* `q3_k_s`: Uses Q3_K for all tensors
* `q4_0`: Original quant method, 4-bit.
* `q4_1`: Higher accuracy than q4_0 but not as high as q5_0. However has quicker inference than q5 models.
* `q4_k_m`: Uses Q6_K for half of the attention.wv and feed_forward.w2 tensors, else Q4_K
* `q4_k_s`: Uses Q4_K for all tensors
* `q5_0`: Higher accuracy, higher resource usage and slower inference.
* `q5_1`: Even higher accuracy, resource usage and slower inference.
* `q5_k_m`: Uses Q6_K for half of the attention.wv and feed_forward.w2 tensors, else Q5_K
* `q5_k_s`: Uses Q5_K for all tensors
* `q6_k`: Uses Q8_K for all tensors
* `q8_0`: Almost indistinguishable from float16. High resource use and slow. Not recommended for most users.
## 💻 Usage
This model can be used with the latest version of llama.cpp and LM Studio >0.2.16. |
mradermacher/Fimbulvetr-11B-v2-GGUF | mradermacher | 2024-05-06T06:21:00Z | 926 | 7 | transformers | [
"transformers",
"gguf",
"en",
"base_model:Sao10K/Fimbulvetr-11B-v2",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
]
| null | 2024-03-02T10:35:55Z | ---
base_model: Sao10K/Fimbulvetr-11B-v2
language:
- en
library_name: transformers
license: cc-by-nc-4.0
quantized_by: mradermacher
---
## About
static quants of https://huggingface.co/Sao10K/Fimbulvetr-11B-v2
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q2_K.gguf) | Q2_K | 4.3 | |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.IQ3_XS.gguf) | IQ3_XS | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q3_K_S.gguf) | Q3_K_S | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.IQ3_S.gguf) | IQ3_S | 4.9 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.IQ3_M.gguf) | IQ3_M | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q3_K_M.gguf) | Q3_K_M | 5.5 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q3_K_L.gguf) | Q3_K_L | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.IQ4_XS.gguf) | IQ4_XS | 6.1 | |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q4_K_S.gguf) | Q4_K_S | 6.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q4_K_M.gguf) | Q4_K_M | 6.7 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q5_K_S.gguf) | Q5_K_S | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q5_K_M.gguf) | Q5_K_M | 7.9 | |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q6_K.gguf) | Q6_K | 9.1 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Fimbulvetr-11B-v2-GGUF/resolve/main/Fimbulvetr-11B-v2.Q8_0.gguf) | Q8_0 | 11.6 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid | echarlaix | 2022-07-04T09:04:59Z | 925 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"en",
"dataset:sst2",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-03-02T23:29:05Z | ---
language: en
license: apache-2.0
tags:
- text-classification
datasets:
- sst2
metrics:
- accuracy
---
## bert-base-uncased model fine-tuned on SST-2
This model was created using the [nn_pruning](https://github.com/huggingface/nn_pruning) python library: the linear layers contains **37%** of the original weights.
The model contains **51%** of the original weights **overall** (the embeddings account for a significant part of the model, and they are not pruned by this method).
<div class="graph"><script src="/echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid/raw/main/model_card/density_info.js" id="2d0fc334-fe98-4315-8890-d6eaca1fa9be"></script></div>
In terms of perfomance, its **accuracy** is **91.17**.
## Fine-Pruning details
This model was fine-tuned from the HuggingFace [model](https://huggingface.co/bert-base-uncased) checkpoint on task, and distilled from the model [textattack/bert-base-uncased-SST-2](https://huggingface.co/textattack/bert-base-uncased-SST-2).
This model is case-insensitive: it does not make a difference between english and English.
A side-effect of the block pruning method is that some of the attention heads are completely removed: 88 heads were removed on a total of 144 (61.1%).
Here is a detailed view on how the remaining heads are distributed in the network after pruning.
<div class="graph"><script src="/echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid/raw/main/model_card/pruning_info.js" id="93b19d7f-c11b-4edf-9670-091e40d9be25"></script></div>
## Details of the SST-2 dataset
| Dataset | Split | # samples |
| -------- | ----- | --------- |
| SST-2 | train | 67K |
| SST-2 | eval | 872 |
### Results
**Pytorch model file size**: `351MB` (original BERT: `420MB`)
| Metric | # Value | # Original ([Table 2](https://www.aclweb.org/anthology/N19-1423.pdf))| Variation |
| ------ | --------- | --------- | --------- |
| **accuracy** | **91.17** | **92.7** | **-1.53**|
## Example Usage
Install nn_pruning: it contains the optimization script, which just pack the linear layers into smaller ones by removing empty rows/columns.
`pip install nn_pruning`
Then you can use the `transformers library` almost as usual: you just have to call `optimize_model` when the pipeline has loaded.
```python
from transformers import pipeline
from nn_pruning.inference_model_patcher import optimize_model
cls_pipeline = pipeline(
"text-classification",
model="echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid",
tokenizer="echarlaix/bert-base-uncased-sst2-acc91.1-d37-hybrid",
)
print(f"Parameters count (includes only head pruning, no feed forward pruning)={int(cls_pipeline.model.num_parameters() / 1E6)}M")
cls_pipeline.model = optimize_model(cls_pipeline.model, "dense")
print(f"Parameters count after optimization={int(cls_pipeline.model.num_parameters() / 1E6)}M")
predictions = cls_pipeline("This restaurant is awesome")
print(predictions)
```
|
timm/vit_large_patch16_224.augreg_in21k | timm | 2023-05-06T00:15:19Z | 925 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-21k",
"arxiv:2106.10270",
"arxiv:2010.11929",
"license:apache-2.0",
"region:us"
]
| image-classification | 2022-12-22T07:45:11Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-21k
---
# Model card for vit_large_patch16_224.augreg_in21k
A Vision Transformer (ViT) image classification model. Trained on ImageNet-21k (with additional augmentation and regularization) in JAX by paper authors, ported to PyTorch by Ross Wightman.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 325.7
- GMACs: 59.7
- Activations (M): 43.8
- Image size: 224 x 224
- **Papers:**
- How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers: https://arxiv.org/abs/2106.10270
- An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale: https://arxiv.org/abs/2010.11929v2
- **Dataset:** ImageNet-21k
- **Original:** https://github.com/google-research/vision_transformer
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('vit_large_patch16_224.augreg_in21k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'vit_large_patch16_224.augreg_in21k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 197, 1024) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{steiner2021augreg,
title={How to train your ViT? Data, Augmentation, and Regularization in Vision Transformers},
author={Steiner, Andreas and Kolesnikov, Alexander and and Zhai, Xiaohua and Wightman, Ross and Uszkoreit, Jakob and Beyer, Lucas},
journal={arXiv preprint arXiv:2106.10270},
year={2021}
}
```
```bibtex
@article{dosovitskiy2020vit,
title={An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale},
author={Dosovitskiy, Alexey and Beyer, Lucas and Kolesnikov, Alexander and Weissenborn, Dirk and Zhai, Xiaohua and Unterthiner, Thomas and Dehghani, Mostafa and Minderer, Matthias and Heigold, Georg and Gelly, Sylvain and Uszkoreit, Jakob and Houlsby, Neil},
journal={ICLR},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
line-corporation/japanese-large-lm-3.6b-instruction-sft | line-corporation | 2023-08-24T10:08:28Z | 925 | 24 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt_neox",
"text-generation",
"ja",
"license:apache-2.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-08-03T01:34:20Z | ---
license: apache-2.0
inference: false
language: ja
---
# japanese-large-lm-3.6b-instruction-sft
This repository provides a 3.6B parameters Japanese language model, fine-tuned and trained by [LINE Corporation](https://linecorp.com/ja/).
## For Japanese
詳細な説明や実験に関しては「[Instruction Tuningにより対話性能を向上させた3.6B日本語言語モデルを公開します](https://engineering.linecorp.com/ja/blog/3.6b-japanese-language-model-with-improved-dialog-performance-by-instruction-tuning)」をご覧ください。
## How to use
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
tokenizer = AutoTokenizer.from_pretrained("line-corporation/japanese-large-lm-3.6b-instruction-sft", use_fast=False)
model = AutoModelForCausalLM.from_pretrained("line-corporation/japanese-large-lm-3.6b-instruction-sft")
generator = pipeline("text-generation", model=model, tokenizer=tokenizer, device=0)
input_text = """四国の県名を全て列挙してください。"""
text = generator(
f"ユーザー: {input_text}\nシステム: ",
max_length = 256,
do_sample = True,
temperature = 0.7,
top_p = 0.9,
top_k = 0,
repetition_penalty = 1.1,
num_beams = 1,
pad_token_id = tokenizer.pad_token_id,
num_return_sequences = 1,
)
print(text)
# [{'generated_text': 'ユーザー: 四国の県名を全て列挙してください。\nシステム: 高知県、徳島県、香川県、愛媛県'}]
```
## Tokenization
We use a sentencepiece tokenizer with a unigram language model and byte-fallback.
We **do not** apply pre-tokenization with Japanese tokenizer.
Thus, a user may directly feed raw sentences into the tokenizer.
## License
[Apache License, Version 2.0](https://www.apache.org/licenses/LICENSE-2.0)
|
artificialguybr/ClayAnimationRedmond | artificialguybr | 2023-09-11T14:59:06Z | 925 | 17 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion",
"lora",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:creativeml-openrail-m",
"region:us"
]
| text-to-image | 2023-09-11T14:56:33Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- lora
- diffusers
base_model: stabilityai/stable-diffusion-xl-base-1.0
instance_prompt: Clay Animation, Clay
widget:
- text: Clay Animation, Clay
---
# Clay Animation.Redmond

ClayAnimation.Redmond is here!
Introducing ClayAnimation.Redmond, the ultimate LORA for creating Clay Animation images!
I'm grateful for the GPU time from Redmond.AI that allowed me to make this LORA! If you need GPU, then you need the great services from Redmond.AI.
It is based on SD XL 1.0 and fine-tuned on a large dataset.
The LORA has a high capacity to generate Coloring Book Images!
The tag for the model:Clay Animation, Clay
I really hope you like the LORA and use it.
If you like the model and think it's worth it, you can make a donation to my Patreon or Ko-fi.
Patreon:
https://www.patreon.com/user?u=81570187
Ko-fi:https://ko-fi.com/artificialguybr
BuyMeACoffe:https://www.buymeacoffee.com/jvkape
Follow me in my twitter to know before all about new models:
https://twitter.com/artificialguybr/ |
laion/CLIP-ViT-B-32-DataComp.XL-s13B-b90K | laion | 2023-09-29T22:43:14Z | 925 | 3 | open_clip | [
"open_clip",
"safetensors",
"zero-shot-image-classification",
"dataset:mlfoundations/datacomp_pools",
"arxiv:2304.14108",
"license:mit",
"region:us"
]
| zero-shot-image-classification | 2023-09-29T22:27:30Z | ---
license: mit
widget:
- src: >-
https://huggingface.co/datasets/mishig/sample_images/resolve/main/cat-dog-music.png
candidate_labels: playing music, playing sports
example_title: Cat & Dog
library_name: open_clip
datasets:
- mlfoundations/datacomp_pools
pipeline_tag: zero-shot-image-classification
---
# Model card for CLIP ViT-B-32 trained DataComp-1B
# Table of Contents
1. [Model Details](#model-details)
2. [Uses](#uses)
3. [Training Details](#training-details)
4. [Evaluation](#evaluation)
5. [Acknowledgements](#acknowledgements)
6. [Citation](#citation)
7. [How To Get Started With the Model](#how-to-get-started-with-the-model)
# Model Details
## Model Description
A CLIP ViT-B/32 model trained with the DataComp-1B (https://github.com/mlfoundations/datacomp) using OpenCLIP (https://github.com/mlfoundations/open_clip).
Model training done on the [stability.ai](https://stability.ai/) cluster.
# Uses
As per the original [OpenAI CLIP model card](https://github.com/openai/CLIP/blob/d50d76daa670286dd6cacf3bcd80b5e4823fc8e1/model-card.md), this model is intended as a research output for research communities. We hope that this model will enable researchers to better understand and explore zero-shot, arbitrary image classification. We also hope it can be used for interdisciplinary studies of the potential impact of such model.
The OpenAI CLIP paper includes a discussion of potential downstream impacts to provide an example for this sort of analysis. Additionally, the DataComp paper (https://arxiv.org/abs/2304.14108) include additional discussion as it relates specifically to the training dataset.
## Direct Use
Zero-shot image classification, image and text retrieval, among others.
## Downstream Use
Image classification and other image task fine-tuning, linear probe image classification, image generation guiding and conditioning, among others.
## Out-of-Scope Use
As per the OpenAI models,
**Any** deployed use case of the model - whether commercial or not - is currently out of scope. Non-deployed use cases such as image search in a constrained environment, are also not recommended unless there is thorough in-domain testing of the model with a specific, fixed class taxonomy. This is because our safety assessment demonstrated a high need for task specific testing especially given the variability of CLIP’s performance with different class taxonomies. This makes untested and unconstrained deployment of the model in any use case currently potentially harmful.
Certain use cases which would fall under the domain of surveillance and facial recognition are always out-of-scope regardless of performance of the model. This is because the use of artificial intelligence for tasks such as these can be premature currently given the lack of testing norms and checks to ensure its fair use.
# Training Details
## Training Data
This model was trained with the 1.4 Billion samples of the DataComp-1B dataset (https://arxiv.org/abs/2304.14108).
**IMPORTANT NOTE:** The motivation behind dataset creation is to democratize research and experimentation around large-scale multi-modal model training and handling of uncurated, large-scale datasets crawled from publically available internet. Our recommendation is therefore to use the dataset for research purposes. Be aware that this large-scale dataset is uncurated. Keep in mind that the uncurated nature of the dataset means that collected links may lead to strongly discomforting and disturbing content for a human viewer. Therefore, please use the demo links with caution and at your own risk. It is possible to extract a “safe” subset by filtering out samples based on the safety tags (using a customized trained NSFW classifier that we built). While this strongly reduces the chance for encountering potentially harmful content when viewing, we cannot entirely exclude the possibility for harmful content being still present in safe mode, so that the warning holds also there. We think that providing the dataset openly to broad research and other interested communities will allow for transparent investigation of benefits that come along with training large-scale models as well as pitfalls and dangers that may stay unreported or unnoticed when working with closed large datasets that remain restricted to a small community. Providing our dataset openly, we however do not recommend using it for creating ready-to-go industrial products, as the basic research about general properties and safety of such large-scale models, which we would like to encourage with this release, is still in progress.
## Training Procedure
Please see https://arxiv.org/abs/2304.14108.
# Evaluation
Evaluation done on 38 datasets, using the [DataComp repo](https://github.com/mlfoundations/datacomp) and the [LAION CLIP Benchmark](https://github.com/LAION-AI/CLIP_benchmark).
## Testing Data, Factors & Metrics
### Testing Data
The testing is performed on a suite of 38 datasets. See our paper for more details (https://arxiv.org/abs/2304.14108).
## Results
The model achieves a 72.7% zero-shot top-1 accuracy on ImageNet-1k. See our paper for more details and results (https://arxiv.org/abs/2304.14108).
# Acknowledgements
Acknowledging [stability.ai](https://stability.ai/) for the compute used to train this model.
# Citation
**BibTeX:**
DataComp
```bibtex
@article{datacomp,
title={DataComp: In search of the next generation of multimodal datasets},
author={Samir Yitzhak Gadre, Gabriel Ilharco, Alex Fang, Jonathan Hayase, Georgios Smyrnis, Thao Nguyen, Ryan Marten, Mitchell Wortsman, Dhruba Ghosh, Jieyu Zhang, Eyal Orgad, Rahim Entezari, Giannis Daras, Sarah Pratt, Vivek Ramanujan, Yonatan Bitton, Kalyani Marathe, Stephen Mussmann, Richard Vencu, Mehdi Cherti, Ranjay Krishna, Pang Wei Koh, Olga Saukh, Alexander Ratner, Shuran Song, Hannaneh Hajishirzi, Ali Farhadi, Romain Beaumont, Sewoong Oh, Alex Dimakis, Jenia Jitsev, Yair Carmon, Vaishaal Shankar, Ludwig Schmidt},
journal={arXiv preprint arXiv:2304.14108},
year={2023}
}
```
OpenAI CLIP paper
```
@inproceedings{Radford2021LearningTV,
title={Learning Transferable Visual Models From Natural Language Supervision},
author={Alec Radford and Jong Wook Kim and Chris Hallacy and A. Ramesh and Gabriel Goh and Sandhini Agarwal and Girish Sastry and Amanda Askell and Pamela Mishkin and Jack Clark and Gretchen Krueger and Ilya Sutskever},
booktitle={ICML},
year={2021}
}
```
OpenCLIP software
```
@software{ilharco_gabriel_2021_5143773,
author = {Ilharco, Gabriel and
Wortsman, Mitchell and
Wightman, Ross and
Gordon, Cade and
Carlini, Nicholas and
Taori, Rohan and
Dave, Achal and
Shankar, Vaishaal and
Namkoong, Hongseok and
Miller, John and
Hajishirzi, Hannaneh and
Farhadi, Ali and
Schmidt, Ludwig},
title = {OpenCLIP},
month = jul,
year = 2021,
note = {If you use this software, please cite it as below.},
publisher = {Zenodo},
version = {0.1},
doi = {10.5281/zenodo.5143773},
url = {https://doi.org/10.5281/zenodo.5143773}
}
```
# How to Get Started with the Model
See https://github.com/mlfoundations/open_clip |
TKDKid1000/phi-1_5-GGUF | TKDKid1000 | 2023-12-19T02:49:52Z | 925 | 5 | transformers | [
"transformers",
"pytorch",
"gguf",
"phi-msft",
"text-generation",
"nlp",
"code",
"custom_code",
"en",
"arxiv:2309.05463",
"license:other",
"autotrain_compatible",
"region:us"
]
| text-generation | 2023-12-19T02:28:32Z | ---
inference: false
license: other
license_name: microsoft-research-license
license_link: https://huggingface.co/microsoft/phi-1_5/resolve/main/Research%20License.docx
language:
- en
pipeline_tag: text-generation
tags:
- nlp
- code
---
# Phi-1.5 - GGUF
- Model creator: [Microsoft](https://huggingface.co/microsoft)
- Original model: [Phi 1.5](https://huggingface.co/microsoft/phi-1_5)
## Description
This repo contains GGUF format model files for [Microsoft's Phi 1.5](https://huggingface.co/microsoft/phi-1_5).
## Prompt template: Phi
```
Instruct: {prompt}
Output:
```
## Provided files
| Name | Quant method | Bits | Size | Use case |
| ---- | ---- | ---- | ---- | ----- |
| [phi-2.Q2_K.gguf](https://huggingface.co/TKDKid1000/phi-1_5-GGUF/blob/main/phi-1_5-Q2_K.gguf) | Q2_K | 2 | 0.61 GB| smallest, significant quality loss - not recommended for most purposes |
| [phi-2.Q3_K_M.gguf](https://huggingface.co/TKDKid1000/phi-1_5-GGUF/blob/main/phi-1_5-Q3_K_M.gguf) | Q3_K_M | 3 | 0.77 GB| very small, high quality loss |
| [phi-2.Q4_K_M.gguf](https://huggingface.co/TKDKid1000/phi-1_5-GGUF/blob/main/phi-1_5-Q4_K_M.gguf) | Q4_K_M | 4 | 0.92 GB| medium, balanced quality - recommended |
| [phi-2.Q5_K_M.gguf](https://huggingface.co/TKDKid1000/phi-1_5-GGUF/blob/main/phi-1_5-Q5_K_M.gguf) | Q5_K_M | 5 | 1.06 GB| large, very low quality loss - recommended |
| [phi-2.Q6_K.gguf](https://huggingface.co/TKDKid1000/phi-1_5-GGUF/blob/main/phi-1_5-Q6_K.gguf) | Q6_K | 6 | 1.17 GB| very large, extremely low quality loss |
| [phi-2.Q8_0.gguf](https://huggingface.co/TKDKid1000/phi-1_5-GGUF/blob/main/phi-1_5-Q8_0.gguf) | Q8_0 | 8 | 1.51 GB| very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
*Model card template from [TheBloke](https://huggingface.co/TheBloke).*
# Original model card: Microsoft's Phi 1.5
## Model Summary
The language model Phi-1.5 is a Transformer with **1.3 billion** parameters. It was trained using the same data sources as [phi-1](https://huggingface.co/microsoft/phi-1), augmented with a new data source that consists of various NLP synthetic texts. When assessed against benchmarks testing common sense, language understanding, and logical reasoning, Phi-1.5 demonstrates a nearly state-of-the-art performance among models with less than 10 billion parameters.
We **did not** fine-tune Phi-1.5 either for **instruction following or through reinforcement learning from human feedback**. The intention behind crafting this open-source model is to provide the research community with a non-restricted small model to explore vital safety challenges, such as reducing toxicity, understanding societal biases, enhancing controllability, and more.
For a safer model release, we exclude generic web-crawl data sources such as common-crawl from the training. This strategy prevents direct exposure to potentially harmful online content, enhancing the model's safety without RLHF. However, the model is still vulnerable to generating harmful content. We hope the model can help the research community to further study the safety of language models.
Phi-1.5 can write poems, draft emails, create stories, summarize texts, write Python code (such as downloading a Hugging Face transformer model), etc.
## Intended Uses
Given the nature of the training data, Phi-1.5 is best suited for prompts using the QA format, the chat format, and the code format. Note that Phi-1.5, being a base model, often produces irrelevant text following the main answer. In the following example, we've truncated the answer for illustrative purposes only.
### QA Format:
```markdown
Write a detailed analogy between mathematics and a lighthouse.
Answer: Mathematics is like a lighthouse, guiding us through the vast ocean of numbers and calculations. Just as a lighthouse illuminates the darkness, mathematics provides us with a clear path to navigate through complex problems. It helps us make sense of the world around us, just like a lighthouse helps ships find their way home.
```
where the model generates the text after "Answer:".
### Chat Format:
```markdown
Alice: I don't know why, I'm struggling to maintain focus while studying. Any suggestions?
Bob: Have you tried using a timer? It can help you stay on track and avoid distractions.
Alice: That's a good idea. I'll give it a try.
Charlie: Another thing that can help is to break up your study sessions into smaller chunks. It's easier to concentrate on one thing at a time.
Alice: That makes sense. I'll try that too.
Bob: And don't forget to take breaks! It's important to give your brain a rest so you can come back to your studies with a fresh perspective.
Alice: Thanks for the advice, guys. I feel more motivated now.
Charlie: No problem, Alice. We're all in this together.
Bob: Yeah, and remember that it's okay to ask for help if you need it. We're here to support each other.
```
where the model generates the text after the first "Bob:".
### Code Format:
```python
def print_prime(n):
"""
Print all primes between 1 and n
"""
primes = []
for num in range(2, n+1):
is_prime = True
for i in range(2, int(math.sqrt(num))+1):
if num % i == 0:
is_prime = False
break
if is_prime:
primes.append(num)
print(primes)
```
where the model generates the text after the comments.
**Notes:**
* Phi-1.5 is intended for research purposes. The model-generated text/code should be treated as a starting point rather than a definitive solution for potential use cases. Users should be cautious when employing these models in their applications.
* Direct adoption for production tasks is out of the scope of this research project. As a result, Phi-1.5 has not been tested to ensure that it performs adequately for any production-level application. Please refer to the limitation sections of this document for more details.
* If you are using `transformers>=4.36.0`, always load the model with `trust_remote_code=True` to prevent side-effects.
## Sample Code
There are four types of execution mode:
1. FP16 / Flash-Attention / CUDA:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-1_5", torch_dtype="auto", flash_attn=True, flash_rotary=True, fused_dense=True, device_map="cuda", trust_remote_code=True)
```
2. FP16 / CUDA:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-1_5", torch_dtype="auto", device_map="cuda", trust_remote_code=True)
```
3. FP32 / CUDA:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-1_5", torch_dtype=torch.float32, device_map="cuda", trust_remote_code=True)
```
4. FP32 / CPU:
```python
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-1_5", torch_dtype=torch.float32, device_map="cpu", trust_remote_code=True)
```
To ensure the maximum compatibility, we recommend using the second execution mode (FP16 / CUDA), as follows:
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
torch.set_default_device("cuda")
model = AutoModelForCausalLM.from_pretrained("microsoft/phi-1_5", torch_dtype="auto", trust_remote_code=True)
tokenizer = AutoTokenizer.from_pretrained("microsoft/phi-1_5", trust_remote_code=True)
inputs = tokenizer('''def print_prime(n):
"""
Print all primes between 1 and n
"""''', return_tensors="pt", return_attention_mask=False)
outputs = model.generate(**inputs, max_length=200)
text = tokenizer.batch_decode(outputs)[0]
print(text)
```
**Remark:** In the generation function, our model currently does not support beam search (`num_beams > 1`).
Furthermore, in the forward pass of the model, we currently do not support outputting hidden states or attention values, or using custom input embeddings.
## Limitations of Phi-1.5
* Generate Inaccurate Code and Facts: The model often produces incorrect code snippets and statements. Users should treat these outputs as suggestions or starting points, not as definitive or accurate solutions.
* Limited Scope for code: If the model generates Python scripts that utilize uncommon packages or scripts in other languages, we strongly recommend users manually verify all API uses.
* Unreliable Responses to Instruction: The model has not undergone instruction fine-tuning. As a result, it may struggle or fail to adhere to intricate or nuanced instructions provided by users.
* Language Limitations: The model is primarily designed to understand standard English. Informal English, slang, or any other language outside of English might pose challenges to its comprehension, leading to potential misinterpretations or errors in response.
* Potential Societal Biases: Regardless of the safe data used for its training, the model is not entirely free from societal biases. There's a possibility it may generate content that mirrors these societal biases, particularly if prompted or instructed to do so. We urge users to be aware of this and to exercise caution and critical thinking when interpreting model outputs.
* Toxicity: Despite that the model is trained with carefully selected data, the model can still produce harmful content if explicitly prompted or instructed to do so. We chose to release the model for research purposes only -- We hope to help the open-source community develop the most effective ways to reduce the toxicity of a model directly after pretraining.
## Training
### Model
* Architecture: a Transformer-based model with next-word prediction objective
* Dataset size: 30B tokens
* Training tokens: 150B tokens
* Precision: fp16
* GPUs: 32xA100-40G
* Training time: 8 days
### Software
* [PyTorch](https://github.com/pytorch/pytorch)
* [DeepSpeed](https://github.com/microsoft/DeepSpeed)
* [Flash-Attention](https://github.com/HazyResearch/flash-attention)
### License
The model is licensed under the [Research License](https://huggingface.co/microsoft/phi-1_5/resolve/main/Research%20License.docx).
### Citation
You can find the paper at https://arxiv.org/abs/2309.05463
```bib
@article{textbooks2,
title={Textbooks Are All You Need II: \textbf{phi-1.5} technical report},
author={Li, Yuanzhi and Bubeck, S{\'e}bastien and Eldan, Ronen and Del Giorno, Allie and Gunasekar, Suriya and Lee, Yin Tat},
journal={arXiv preprint arXiv:2309.05463},
year={2023}
}
``` |
cazure87/5DHzY9hyj1r8NQFw1jHagZeLVo37M7jWrzqsRU3PgtVa9QUb_vgg | cazure87 | 2024-03-02T06:47:40Z | 925 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-02-14T11:38:02Z | Entry not found |
mradermacher/dolphin-2.9.2-qwen2-72b-GGUF | mradermacher | 2024-06-10T17:25:46Z | 925 | 2 | transformers | [
"transformers",
"gguf",
"generated_from_trainer",
"axolotl",
"en",
"dataset:cognitivecomputations/Dolphin-2.9",
"dataset:teknium/OpenHermes-2.5",
"dataset:m-a-p/CodeFeedback-Filtered-Instruction",
"dataset:cognitivecomputations/dolphin-coder",
"dataset:cognitivecomputations/samantha-data",
"dataset:microsoft/orca-math-word-problems-200k",
"dataset:Locutusque/function-calling-chatml",
"dataset:internlm/Agent-FLAN",
"base_model:cognitivecomputations/dolphin-2.9.2-qwen2-72b",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-09T22:09:58Z | ---
base_model: cognitivecomputations/dolphin-2.9.2-qwen2-72b
datasets:
- cognitivecomputations/Dolphin-2.9
- teknium/OpenHermes-2.5
- m-a-p/CodeFeedback-Filtered-Instruction
- cognitivecomputations/dolphin-coder
- cognitivecomputations/samantha-data
- microsoft/orca-math-word-problems-200k
- Locutusque/function-calling-chatml
- internlm/Agent-FLAN
language:
- en
library_name: transformers
license: other
license_link: https://huggingface.co/Qwen/Qwen1.5-110B/blob/main/LICENSE
license_name: tongyi-qianwen
quantized_by: mradermacher
tags:
- generated_from_trainer
- axolotl
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/cognitivecomputations/dolphin-2.9.2-qwen2-72b
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q2_K.gguf) | Q2_K | 29.9 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.IQ3_XS.gguf) | IQ3_XS | 32.9 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.IQ3_S.gguf) | IQ3_S | 34.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q3_K_S.gguf) | Q3_K_S | 34.6 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.IQ3_M.gguf) | IQ3_M | 35.6 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q3_K_M.gguf) | Q3_K_M | 37.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q3_K_L.gguf) | Q3_K_L | 39.6 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.IQ4_XS.gguf) | IQ4_XS | 40.3 | |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q4_K_S.gguf) | Q4_K_S | 44.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q4_K_M.gguf) | Q4_K_M | 47.5 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q5_K_S.gguf.part2of2) | Q5_K_S | 51.5 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q5_K_M.gguf.part2of2) | Q5_K_M | 54.5 | |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q6_K.gguf.part2of2) | Q6_K | 64.4 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/dolphin-2.9.2-qwen2-72b-GGUF/resolve/main/dolphin-2.9.2-qwen2-72b.Q8_0.gguf.part2of2) | Q8_0 | 77.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
Ransss/Augmental-ReMM-13b-Merged-Q6_K-GGUF | Ransss | 2024-06-20T10:31:54Z | 925 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:Heralax/Augmental-ReMM-13b-Merged",
"license:llama2",
"region:us"
]
| null | 2024-06-20T10:31:12Z | ---
base_model: Heralax/Augmental-ReMM-13b-Merged
license: llama2
tags:
- llama-cpp
- gguf-my-repo
---
# Ransss/Augmental-ReMM-13b-Merged-Q6_K-GGUF
This model was converted to GGUF format from [`Heralax/Augmental-ReMM-13b-Merged`](https://huggingface.co/Heralax/Augmental-ReMM-13b-Merged) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Heralax/Augmental-ReMM-13b-Merged) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Ransss/Augmental-ReMM-13b-Merged-Q6_K-GGUF --hf-file augmental-remm-13b-merged-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Ransss/Augmental-ReMM-13b-Merged-Q6_K-GGUF --hf-file augmental-remm-13b-merged-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Ransss/Augmental-ReMM-13b-Merged-Q6_K-GGUF --hf-file augmental-remm-13b-merged-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Ransss/Augmental-ReMM-13b-Merged-Q6_K-GGUF --hf-file augmental-remm-13b-merged-q6_k.gguf -c 2048
```
|
JosephusCheung/ACertainThing | JosephusCheung | 2022-12-20T03:16:02Z | 924 | 191 | diffusers | [
"diffusers",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"en",
"arxiv:2106.09685",
"doi:10.57967/hf/0197",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2022-12-13T18:05:27Z | ---
language:
- en
license: creativeml-openrail-m
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
widget:
- text: "masterpiece, best quality, 1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden"
example_title: "example 1girl"
- text: "masterpiece, best quality, 1boy, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden"
example_title: "example 1boy"
---
# ACertainThing
**Try full functions with Google Colab free T4** [](https://colab.research.google.com/drive/1gwJViXR0UxoXx01qiU6uTSEKGjTagOgp?usp=sharing)
Anything3.0 is an overfitted model that takes liberties when it shouldn't be generating human images and certain details. However, the community has given it a high rating, and I believe that is because many lazy people who don't know how to write a prompt can use this overfitted model to generate high-quality images even if their prompts are poorly written.
Here is a ACertain version of Anything3.0, made with Dreambooth (idea of [LoRA](https://arxiv.org/abs/2106.09685) integrated), initialized with [ACertainModel](https://huggingface.co/JosephusCheung/ACertainModel).
Although this model may produce better results for image generation, it is built on two major problems. Firstly, it does not always stay true to your prompts; it adds irrelevant details, and sometimes these details are highly homogenized. Secondly, it is an unstable, overfitted model, similar to Anything3.0, and is not suitable for any form of further training. As far as I know, Anything3.0 is obtained by merging several models in just the right way, but it is itself an overfitted model with defects in both its saturation and configuration. However, as I mentioned earlier, it can make even poorly written prompts produce good output images, which leads many lazy people who are incapable of writing good prompts to quickly surpass those who study the writing of prompts carefully. Despite these problems, I still want to release an extended version of the model that caters to the preferences of many people in the community. I hope would you like it.
**In my personal view, I oppose all forms of model merging as it has no scientific principle and is nothing but a waste of time. It is a desire to get results without putting in the effort. That is why I do not like Anything3.0, or this model that is being released. But I respect the choices and preferences of the community, and I hope that you can also respect and understand my thoughts.**
If you want your prompts to be accurately output and want to learn the correct skills for using prompts, it is recommended that you use the more balanced model [ACertainModel](https://huggingface.co/JosephusCheung/ACertainModel).
e.g. **_masterpiece, best quality, 1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden_**
## About online preview with Hosted inference API, also generation with this model
Parameters are not allowed to be modified, as it seems that it is generated with *Clip skip: 1*, for better performance, it is strongly recommended to use *Clip skip: 2* instead.
Here is an example of inference settings, if it is applicable with you on your own server: *Steps: 28, Sampler: Euler a, CFG scale: 11, Clip skip: 2*.
## 🧨 Diffusers
This model can be used just like any other Stable Diffusion model. For more information,
please have a look at the [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion).
You can also export the model to [ONNX](https://huggingface.co/docs/diffusers/optimization/onnx), [MPS](https://huggingface.co/docs/diffusers/optimization/mps) and/or FLAX/JAX.
```python
from diffusers import StableDiffusionPipeline
import torch
model_id = "JosephusCheung/ACertainThing"
branch_name= "main"
pipe = StableDiffusionPipeline.from_pretrained(model_id, revision=branch_name, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "pikachu"
image = pipe(prompt).images[0]
image.save("./pikachu.png")
```
## Examples
Below are some examples of images generated using this model, with better performance on framing and hand gestures, as well as moving objects, comparing to other analogues:
**Anime Girl:**

```
1girl, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden
Steps: 28, Sampler: Euler a, CFG scale: 11, Seed: 114514, Clip skip: 2
```
**Anime Boy:**

```
1boy, brown hair, green eyes, colorful, autumn, cumulonimbus clouds, lighting, blue sky, falling leaves, garden
Steps: 28, Sampler: Euler a, CFG scale: 11, Seed: 114514, Clip skip: 2
```
## License
This model is open access and available to all, with a CreativeML OpenRAIL-M license further specifying rights and usage.
The CreativeML OpenRAIL License specifies:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content
2. The authors claims no rights on the outputs you generate, you are free to use them and are accountable for their use which must not go against the provisions set in the license
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users (please read the license entirely and carefully)
[Please read the full license here](https://huggingface.co/spaces/CompVis/stable-diffusion-license)
## Is it a NovelAI based model? What is the relationship with SD1.2 and SD1.4?
See [ASimilarityCalculatior](https://huggingface.co/JosephusCheung/ASimilarityCalculatior) |
google/madlad400-8b-lm | google | 2023-11-27T16:00:07Z | 924 | 2 | transformers | [
"transformers",
"safetensors",
"t5",
"text-generation",
"text-generation-inference",
"custom_code",
"en",
"ru",
"es",
"fr",
"de",
"it",
"pt",
"pl",
"nl",
"vi",
"tr",
"sv",
"id",
"ro",
"cs",
"zh",
"hu",
"ja",
"th",
"fi",
"fa",
"uk",
"da",
"el",
"no",
"bg",
"sk",
"ko",
"ar",
"lt",
"ca",
"sl",
"he",
"et",
"lv",
"hi",
"sq",
"ms",
"az",
"sr",
"ta",
"hr",
"kk",
"is",
"ml",
"mr",
"te",
"af",
"gl",
"fil",
"be",
"mk",
"eu",
"bn",
"ka",
"mn",
"bs",
"uz",
"ur",
"sw",
"yue",
"ne",
"kn",
"kaa",
"gu",
"si",
"cy",
"eo",
"la",
"hy",
"ky",
"tg",
"ga",
"mt",
"my",
"km",
"tt",
"so",
"ku",
"ps",
"pa",
"rw",
"lo",
"ha",
"dv",
"fy",
"lb",
"ckb",
"mg",
"gd",
"am",
"ug",
"ht",
"grc",
"hmn",
"sd",
"jv",
"mi",
"tk",
"ceb",
"yi",
"ba",
"fo",
"or",
"xh",
"su",
"kl",
"ny",
"sm",
"sn",
"co",
"zu",
"ig",
"yo",
"pap",
"st",
"haw",
"as",
"oc",
"cv",
"lus",
"tet",
"gsw",
"sah",
"br",
"rm",
"sa",
"bo",
"om",
"se",
"ce",
"cnh",
"ilo",
"hil",
"udm",
"os",
"lg",
"ti",
"vec",
"ts",
"tyv",
"kbd",
"ee",
"iba",
"av",
"kha",
"to",
"tn",
"nso",
"fj",
"zza",
"ak",
"ada",
"otq",
"dz",
"bua",
"cfm",
"ln",
"chm",
"gn",
"krc",
"wa",
"hif",
"yua",
"srn",
"war",
"rom",
"bik",
"pam",
"sg",
"lu",
"ady",
"kbp",
"syr",
"ltg",
"myv",
"iso",
"kac",
"bho",
"ay",
"kum",
"qu",
"za",
"pag",
"ngu",
"ve",
"pck",
"zap",
"tyz",
"hui",
"bbc",
"tzo",
"tiv",
"ksd",
"gom",
"min",
"ang",
"nhe",
"bgp",
"nzi",
"nnb",
"nv",
"zxx",
"bci",
"kv",
"new",
"mps",
"alt",
"meu",
"bew",
"fon",
"iu",
"abt",
"mgh",
"mnw",
"tvl",
"dov",
"tlh",
"ho",
"kw",
"mrj",
"meo",
"crh",
"mbt",
"emp",
"ace",
"ium",
"mam",
"gym",
"mai",
"crs",
"pon",
"ubu",
"fip",
"quc",
"gv",
"kj",
"btx",
"ape",
"chk",
"rcf",
"shn",
"tzh",
"mdf",
"ppk",
"ss",
"gag",
"cab",
"kri",
"seh",
"ibb",
"tbz",
"bru",
"enq",
"ach",
"cuk",
"kmb",
"wo",
"kek",
"qub",
"tab",
"bts",
"kos",
"rwo",
"cak",
"tuc",
"bum",
"cjk",
"gil",
"stq",
"tsg",
"quh",
"mak",
"arn",
"ban",
"jiv",
"sja",
"yap",
"tcy",
"toj",
"twu",
"xal",
"amu",
"rmc",
"hus",
"nia",
"kjh",
"bm",
"guh",
"mas",
"acf",
"dtp",
"ksw",
"bzj",
"din",
"zne",
"mad",
"msi",
"mag",
"mkn",
"kg",
"lhu",
"ch",
"qvi",
"mh",
"djk",
"sus",
"mfe",
"srm",
"dyu",
"ctu",
"gui",
"pau",
"inb",
"bi",
"mni",
"guc",
"jam",
"wal",
"jac",
"bas",
"gor",
"skr",
"nyu",
"noa",
"sda",
"gub",
"nog",
"cni",
"teo",
"tdx",
"sxn",
"rki",
"nr",
"frp",
"alz",
"taj",
"lrc",
"cce",
"rn",
"jvn",
"hvn",
"nij",
"dwr",
"izz",
"msm",
"bus",
"ktu",
"chr",
"maz",
"tzj",
"suz",
"knj",
"bim",
"gvl",
"bqc",
"tca",
"pis",
"prk",
"laj",
"mel",
"qxr",
"niq",
"ahk",
"shp",
"hne",
"spp",
"koi",
"krj",
"quf",
"luz",
"agr",
"tsc",
"mqy",
"gof",
"gbm",
"miq",
"dje",
"awa",
"bjj",
"qvz",
"sjp",
"tll",
"raj",
"kjg",
"bgz",
"quy",
"cbk",
"akb",
"oj",
"ify",
"mey",
"ks",
"cac",
"brx",
"qup",
"syl",
"jax",
"ff",
"ber",
"tks",
"trp",
"mrw",
"adh",
"smt",
"srr",
"ffm",
"qvc",
"mtr",
"ann",
"aa",
"noe",
"nut",
"gyn",
"kwi",
"xmm",
"msb",
"dataset:allenai/MADLAD-400",
"arxiv:2204.02311",
"arxiv:2309.04662",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
]
| text-generation | 2023-11-27T16:00:07Z | ---
license: apache-2.0
language:
- en
- ru
- es
- fr
- de
- it
- pt
- pl
- nl
- vi
- tr
- sv
- id
- ro
- cs
- zh
- hu
- ja
- th
- fi
- fa
- uk
- da
- el
- "no"
- bg
- sk
- ko
- ar
- lt
- ca
- sl
- he
- et
- lv
- hi
- sq
- ms
- az
- sr
- ta
- hr
- kk
- is
- ml
- mr
- te
- af
- gl
- fil
- be
- mk
- eu
- bn
- ka
- mn
- bs
- uz
- ur
- sw
- yue
- ne
- kn
- kaa
- gu
- si
- cy
- eo
- la
- hy
- ky
- tg
- ga
- mt
- my
- km
- tt
- so
- ku
- ps
- pa
- rw
- lo
- ha
- dv
- fy
- lb
- ckb
- mg
- gd
- am
- ug
- ht
- grc
- hmn
- sd
- jv
- mi
- tk
- ceb
- yi
- ba
- fo
- or
- xh
- su
- kl
- ny
- sm
- sn
- co
- zu
- ig
- yo
- pap
- st
- haw
- as
- oc
- cv
- lus
- tet
- gsw
- sah
- br
- rm
- sa
- bo
- om
- se
- ce
- cnh
- ilo
- hil
- udm
- os
- lg
- ti
- vec
- ts
- tyv
- kbd
- ee
- iba
- av
- kha
- to
- tn
- nso
- fj
- zza
- ak
- ada
- otq
- dz
- bua
- cfm
- ln
- chm
- gn
- krc
- wa
- hif
- yua
- srn
- war
- rom
- bik
- pam
- sg
- lu
- ady
- kbp
- syr
- ltg
- myv
- iso
- kac
- bho
- ay
- kum
- qu
- za
- pag
- ngu
- ve
- pck
- zap
- tyz
- hui
- bbc
- tzo
- tiv
- ksd
- gom
- min
- ang
- nhe
- bgp
- nzi
- nnb
- nv
- zxx
- bci
- kv
- new
- mps
- alt
- meu
- bew
- fon
- iu
- abt
- mgh
- mnw
- tvl
- dov
- tlh
- ho
- kw
- mrj
- meo
- crh
- mbt
- emp
- ace
- ium
- mam
- gym
- mai
- crs
- pon
- ubu
- fip
- quc
- gv
- kj
- btx
- ape
- chk
- rcf
- shn
- tzh
- mdf
- ppk
- ss
- gag
- cab
- kri
- seh
- ibb
- tbz
- bru
- enq
- ach
- cuk
- kmb
- wo
- kek
- qub
- tab
- bts
- kos
- rwo
- cak
- tuc
- bum
- cjk
- gil
- stq
- tsg
- quh
- mak
- arn
- ban
- jiv
- sja
- yap
- tcy
- toj
- twu
- xal
- amu
- rmc
- hus
- nia
- kjh
- bm
- guh
- mas
- acf
- dtp
- ksw
- bzj
- din
- zne
- mad
- msi
- mag
- mkn
- kg
- lhu
- ch
- qvi
- mh
- djk
- sus
- mfe
- srm
- dyu
- ctu
- gui
- pau
- inb
- bi
- mni
- guc
- jam
- wal
- jac
- bas
- gor
- skr
- nyu
- noa
- sda
- gub
- nog
- cni
- teo
- tdx
- sxn
- rki
- nr
- frp
- alz
- taj
- lrc
- cce
- rn
- jvn
- hvn
- nij
- dwr
- izz
- msm
- bus
- ktu
- chr
- maz
- tzj
- suz
- knj
- bim
- gvl
- bqc
- tca
- pis
- prk
- laj
- mel
- qxr
- niq
- ahk
- shp
- hne
- spp
- koi
- krj
- quf
- luz
- agr
- tsc
- mqy
- gof
- gbm
- miq
- dje
- awa
- bjj
- qvz
- sjp
- tll
- raj
- kjg
- bgz
- quy
- cbk
- akb
- oj
- ify
- mey
- ks
- cac
- brx
- qup
- syl
- jax
- ff
- ber
- tks
- trp
- mrw
- adh
- smt
- srr
- ffm
- qvc
- mtr
- ann
- kaa
- aa
- noe
- nut
- gyn
- kwi
- xmm
- msb
library_name: transformers
tags:
- text-generation-inference
datasets:
- allenai/MADLAD-400
---
This model has the safetensors weights for the [Madlad-400](https://github.com/google-research/google-research/tree/master/madlad_400) 8B param **language model**.
The HF transformers code to run inference is not ready yet. The [original implementation](https://github.com/google/flaxformer/blob/ea17eb012a1d340ddff017b7a534c2162aaec34c/flaxformer/architectures/t5/t5_architecture.py#L1484) is in JAX/Flaxformer.
The model architecture is the same as [Palm 8B](https://arxiv.org/pdf/2204.02311.pdf).
It's a decoder-only T5 with 32 layers, 16 query heads, 1 KV head, and 4096 embedding size.
These are the main differences relative to the original T5 architecture:
- SwiGLU Activation
- Parallel Layers
- Multi-Query Attention
- RoPE Embeddings
- Shared Input-Output Embeddings
- No biases
- Bidirectional attention
- Layer Norm with `center_scale_at_zero` and final layer with `use_scale=False`
If you are looking for the language models models, here are the available versions:
- [3B](https://huggingface.co/jbochi/madlad400-3b-mt)
- [7B](https://huggingface.co/jbochi/madlad400-7b-mt)
- [7B-BT](https://huggingface.co/jbochi/madlad400-7b-mt-bt)
- [10B](https://huggingface.co/jbochi/madlad400-10b-mt)
Article: [MADLAD-400: A Multilingual And Document-Level Large Audited Dataset](https://arxiv.org/abs/2309.04662)
Abstract:
> We introduce MADLAD-400, a manually audited, general domain 3T token monolingual dataset based on CommonCrawl, spanning 419 languages. We discuss the limitations revealed by self-auditing MADLAD-400, and the role data auditing had in the dataset creation process. We then train and release a 10.7B-parameter multilingual machine translation model on 250 billion tokens covering over 450 languages using publicly available data, and find that it is competitive with models that are significantly larger, and report the results on different domains. In addition, we train a 8B-parameter language model, and assess the results on few-shot translation. We make the baseline models available to the research community.
|
vsevolodl/prometheus-7b-v2.0-GGUF | vsevolodl | 2024-05-08T17:05:24Z | 924 | 4 | transformers | [
"transformers",
"gguf",
"text2text-generation",
"en",
"dataset:prometheus-eval/Feedback-Collection",
"dataset:prometheus-eval/Preference-Collection",
"arxiv:2405.01535",
"arxiv:2310.08491",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| text2text-generation | 2024-05-08T16:45:30Z | ---
datasets:
- prometheus-eval/Feedback-Collection
- prometheus-eval/Preference-Collection
library_name: transformers
pipeline_tag: text2text-generation
tags:
- text2text-generation
license: apache-2.0
language:
- en
---
# Links for Reference
- **Quants for:** https://huggingface.co/prometheus-eval/prometheus-7b-v2.0
- **Homepage: In Progress**
- **Repository:** https://github.com/prometheus-eval/prometheus-eval
- **Paper:** https://arxiv.org/abs/2405.01535
- **Point of Contact:** [email protected]
# TL;DR
Prometheus 2 is an alternative of GPT-4 evaluation when doing fine-grained evaluation of an underlying LLM & a Reward model for Reinforcement Learning from Human Feedback (RLHF).
Prometheus 2 is a language model using [Mistral-Instruct](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) as a base model.
It is fine-tuned on 100K feedback within the [Feedback Collection](https://huggingface.co/datasets/prometheus-eval/Feedback-Collection) and 200K feedback within the [Preference Collection](https://huggingface.co/datasets/prometheus-eval/Preference-Collection).
It is also made by weight merging to support both absolute grading (direct assessment) and relative grading (pairwise ranking).
The surprising thing is that we find weight merging also improves performance on each format.
# Model Details
## Model Description
- **Model type:** Language model
- **Language(s) (NLP):** English
- **License:** Apache 2.0
- **Related Models:** [All Prometheus Checkpoints](https://huggingface.co/models?search=prometheus-eval/Prometheus)
- **Resources for more information:**
- [Research paper](https://arxiv.org/abs/2405.01535)
- [GitHub Repo](https://github.com/prometheus-eval/prometheus-eval)
Prometheus is trained with two different sizes (7B and 8x7B).
You could check the 7B sized LM on [this page](https://huggingface.co/prometheus-eval/prometheus-2-7b-v2.0).
Also, check out our dataset as well on [this page](https://huggingface.co/datasets/prometheus-eval/Feedback-Collection) and [this page](https://huggingface.co/datasets/prometheus-eval/Preference-Collection).
## Prompt Format
We have made wrapper functions and classes to conveniently use Prometheus 2 at [our github repository](https://github.com/prometheus-eval/prometheus-eval).
We highly recommend you use it!
However, if you just want to use the model for your use case, please refer to the prompt format below.
Note that absolute grading and relative grading requires different prompt templates and system prompts.
### Absolute Grading (Direct Assessment)
Prometheus requires 4 components in the input: An instruction, a response to evaluate, a score rubric, and a reference answer. You could refer to the prompt format below.
You should fill in the instruction, response, reference answer, criteria description, and score description for score in range of 1 to 5.
Fix the components with \{text\} inside.
```
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, a reference answer that gets a score of 5, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of the response strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, write a score that is an integer between 1 and 5. You should refer to the score rubric.
3. The output format should look as follows: \"Feedback: (write a feedback for criteria) [RESULT] (an integer number between 1 and 5)\"
4. Please do not generate any other opening, closing, and explanations.
###The instruction to evaluate:
{orig_instruction}
###Response to evaluate:
{orig_response}
###Reference Answer (Score 5):
{orig_reference_answer}
###Score Rubrics:
[{orig_criteria}]
Score 1: {orig_score1_description}
Score 2: {orig_score2_description}
Score 3: {orig_score3_description}
Score 4: {orig_score4_description}
Score 5: {orig_score5_description}
###Feedback:
```
After this, you should apply the conversation template of Mistral (not applying it might lead to unexpected behaviors).
You can find the conversation class at this [link](https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py).
```
conv = get_conv_template("mistral")
conv.set_system_message("You are a fair judge assistant tasked with providing clear, objective feedback based on specific criteria, ensuring each assessment reflects the absolute standards set for performance.")
conv.append_message(conv.roles[0], dialogs['instruction'])
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
x = tokenizer(prompt,truncation=False)
```
As a result, a feedback and score decision will be generated, divided by a separating phrase ```[RESULT]```
### Relative Grading (Pairwise Ranking)
Prometheus requires 4 components in the input: An instruction, 2 responses to evaluate, a score rubric, and a reference answer. You could refer to the prompt format below.
You should fill in the instruction, 2 responses, reference answer, and criteria description.
Fix the components with \{text\} inside.
```
###Task Description:
An instruction (might include an Input inside it), a response to evaluate, and a score rubric representing a evaluation criteria are given.
1. Write a detailed feedback that assess the quality of two responses strictly based on the given score rubric, not evaluating in general.
2. After writing a feedback, choose a better response between Response A and Response B. You should refer to the score rubric.
3. The output format should look as follows: "Feedback: (write a feedback for criteria) [RESULT] (A or B)"
4. Please do not generate any other opening, closing, and explanations.
###Instruction:
{orig_instruction}
###Response A:
{orig_response_A}
###Response B:
{orig_response_B}
###Reference Answer:
{orig_reference_answer}
###Score Rubric:
{orig_criteria}
###Feedback:
```
After this, you should apply the conversation template of Mistral (not applying it might lead to unexpected behaviors).
You can find the conversation class at this [link](https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py).
```
conv = get_conv_template("mistral")
conv.set_system_message("You are a fair judge assistant assigned to deliver insightful feedback that compares individual performances, highlighting how each stands relative to others within the same cohort.")
conv.append_message(conv.roles[0], dialogs['instruction'])
conv.append_message(conv.roles[1], None)
prompt = conv.get_prompt()
x = tokenizer(prompt,truncation=False)
```
As a result, a feedback and score decision will be generated, divided by a separating phrase ```[RESULT]```
## License
Feedback Collection, Preference Collection, and Prometheus 2 are subject to OpenAI's Terms of Use for the generated data. If you suspect any violations, please reach out to us.
# Citation
If you find the following model helpful, please consider citing our paper!
**BibTeX:**
```bibtex
@misc{kim2023prometheus,
title={Prometheus: Inducing Fine-grained Evaluation Capability in Language Models},
author={Seungone Kim and Jamin Shin and Yejin Cho and Joel Jang and Shayne Longpre and Hwaran Lee and Sangdoo Yun and Seongjin Shin and Sungdong Kim and James Thorne and Minjoon Seo},
year={2023},
eprint={2310.08491},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
```bibtex
@misc{kim2024prometheus,
title={Prometheus 2: An Open Source Language Model Specialized in Evaluating Other Language Models},
author={Seungone Kim and Juyoung Suk and Shayne Longpre and Bill Yuchen Lin and Jamin Shin and Sean Welleck and Graham Neubig and Moontae Lee and Kyungjae Lee and Minjoon Seo},
year={2024},
eprint={2405.01535},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
``` |
elgeish/wav2vec2-large-xlsr-53-arabic | elgeish | 2022-06-04T23:37:05Z | 923 | 10 | transformers | [
"transformers",
"pytorch",
"jax",
"wav2vec2",
"automatic-speech-recognition",
"audio",
"speech",
"xlsr-fine-tuning-week",
"hf-asr-leaderboard",
"ar",
"dataset:arabic_speech_corpus",
"dataset:mozilla-foundation/common_voice_6_1",
"license:apache-2.0",
"model-index",
"endpoints_compatible",
"region:us"
]
| automatic-speech-recognition | 2022-03-02T23:29:05Z | ---
language: ar
datasets:
- arabic_speech_corpus
- mozilla-foundation/common_voice_6_1
metrics:
- wer
tags:
- audio
- automatic-speech-recognition
- speech
- xlsr-fine-tuning-week
- hf-asr-leaderboard
license: apache-2.0
model-index:
- name: elgeish-wav2vec2-large-xlsr-53-arabic
results:
- task:
name: Automatic Speech Recognition
type: automatic-speech-recognition
dataset:
name: Common Voice 6.1 (Arabic)
type: mozilla-foundation/common_voice_6_1
config: ar
split: test
args:
language: ar
metrics:
- name: Test WER
type: wer
value: 26.55
- name: Validation WER
type: wer
value: 23.39
---
# Wav2Vec2-Large-XLSR-53-Arabic
Fine-tuned [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
on Arabic using the `train` splits of [Common Voice](https://huggingface.co/datasets/common_voice)
and [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus).
When using this model, make sure that your speech input is sampled at 16kHz.
## Usage
The model can be used directly (without a language model) as follows:
```python
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import Wav2Vec2ForCTC, Wav2Vec2Processor
dataset = load_dataset("common_voice", "ar", split="test[:10]")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
dataset = dataset.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.tokenizer.batch_decode(predicted)
return batch
dataset = dataset.map(predict, batched=True, batch_size=1, remove_columns=["speech"])
for reference, predicted in zip(dataset["sentence"], dataset["predicted"]):
print("reference:", reference)
print("predicted:", buckwalter.untrans(predicted))
print("--")
```
Here's the output:
```
reference: ألديك قلم ؟
predicted: هلديك قالر
--
reference: ليست هناك مسافة على هذه الأرض أبعد من يوم أمس.
predicted: ليست نالك مسافة على هذه الأرض أبعد من يوم أمس
--
reference: إنك تكبر المشكلة.
predicted: إنك تكبر المشكلة
--
reference: يرغب أن يلتقي بك.
predicted: يرغب أن يلتقي بك
--
reference: إنهم لا يعرفون لماذا حتى.
predicted: إنهم لا يعرفون لماذا حتى
--
reference: سيسعدني مساعدتك أي وقت تحب.
predicted: سيسئدني مساعد سكرأي وقت تحب
--
reference: أَحَبُّ نظريّة علمية إليّ هي أن حلقات زحل مكونة بالكامل من الأمتعة المفقودة.
predicted: أحب ناضريةً علمية إلي هي أنحل قتزح المكونا بالكامل من الأمت عن المفقودة
--
reference: سأشتري له قلماً.
predicted: سأشتري له قلما
--
reference: أين المشكلة ؟
predicted: أين المشكل
--
reference: وَلِلَّهِ يَسْجُدُ مَا فِي السَّمَاوَاتِ وَمَا فِي الْأَرْضِ مِنْ دَابَّةٍ وَالْمَلَائِكَةُ وَهُمْ لَا يَسْتَكْبِرُونَ
predicted: ولله يسجد ما في السماوات وما في الأرض من دابة والملائكة وهم لا يستكبرون
--
```
## Evaluation
The model can be evaluated as follows on the Arabic test data of Common Voice:
```python
import jiwer
import torch
import torchaudio
from datasets import load_dataset
from lang_trans.arabic import buckwalter
from transformers import set_seed, Wav2Vec2ForCTC, Wav2Vec2Processor
set_seed(42)
test_split = load_dataset("common_voice", "ar", split="test")
resamplers = { # all three sampling rates exist in test split
48000: torchaudio.transforms.Resample(48000, 16000),
44100: torchaudio.transforms.Resample(44100, 16000),
32000: torchaudio.transforms.Resample(32000, 16000),
}
def prepare_example(example):
speech, sampling_rate = torchaudio.load(example["path"])
example["speech"] = resamplers[sampling_rate](speech).squeeze().numpy()
return example
test_split = test_split.map(prepare_example)
processor = Wav2Vec2Processor.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic")
model = Wav2Vec2ForCTC.from_pretrained("elgeish/wav2vec2-large-xlsr-53-arabic").to("cuda").eval()
def predict(batch):
inputs = processor(batch["speech"], sampling_rate=16000, return_tensors="pt", padding=True)
with torch.no_grad():
predicted = torch.argmax(model(inputs.input_values.to("cuda")).logits, dim=-1)
predicted[predicted == -100] = processor.tokenizer.pad_token_id # see fine-tuning script
batch["predicted"] = processor.batch_decode(predicted)
return batch
test_split = test_split.map(predict, batched=True, batch_size=16, remove_columns=["speech"])
transformation = jiwer.Compose([
# normalize some diacritics, remove punctuation, and replace Persian letters with Arabic ones
jiwer.SubstituteRegexes({
r'[auiFNKo\~_،؟»\?;:\-,\.؛«!"]': "", "\u06D6": "",
r"[\|\{]": "A", "p": "h", "ک": "k", "ی": "y"}),
# default transformation below
jiwer.RemoveMultipleSpaces(),
jiwer.Strip(),
jiwer.SentencesToListOfWords(),
jiwer.RemoveEmptyStrings(),
])
metrics = jiwer.compute_measures(
truth=[buckwalter.trans(s) for s in test_split["sentence"]], # Buckwalter transliteration
hypothesis=test_split["predicted"],
truth_transform=transformation,
hypothesis_transform=transformation,
)
print(f"WER: {metrics['wer']:.2%}")
```
**Test Result**: 26.55%
## Training
For more details, see [Fine-Tuning with Arabic Speech Corpus](https://github.com/huggingface/transformers/tree/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/research_projects/wav2vec2#fine-tuning-with-arabic-speech-corpus).
This model represents Arabic in a format called [Buckwalter transliteration](https://en.wikipedia.org/wiki/Buckwalter_transliteration).
The Buckwalter format only includes ASCII characters, some of which are non-alpha (e.g., `">"` maps to `"أ"`).
The [lang-trans](https://github.com/kariminf/lang-trans) package is used to convert (transliterate) Arabic abjad.
[This script](https://github.com/huggingface/transformers/blob/1c06240e1b3477728129bb58e7b6c7734bb5074e/examples/research_projects/wav2vec2/finetune_large_xlsr_53_arabic_speech_corpus.sh)
was used to first fine-tune [facebook/wav2vec2-large-xlsr-53](https://huggingface.co/facebook/wav2vec2-large-xlsr-53)
on the `train` split of the [Arabic Speech Corpus](https://huggingface.co/datasets/arabic_speech_corpus) dataset;
the `test` split was used for model selection; the resulting model at this point is saved as [elgeish/wav2vec2-large-xlsr-53-levantine-arabic](https://huggingface.co/elgeish/wav2vec2-large-xlsr-53-levantine-arabic).
Training was then resumed using the `train` split of the [Common Voice](https://huggingface.co/datasets/common_voice) dataset;
the `validation` split was used for model selection;
training was stopped to meet the deadline of [Fine-Tune-XLSR Week](https://github.com/huggingface/transformers/blob/700229f8a4003c4f71f29275e0874b5ba58cd39d/examples/research_projects/wav2vec2/FINE_TUNE_XLSR_WAV2VEC2.md):
this model is the checkpoint at 100k steps and a validation WER of **23.39%**.
<img src="https://huggingface.co/elgeish/wav2vec2-large-xlsr-53-arabic/raw/main/validation_wer.png" alt="Validation WER" width="100%" />
It's worth noting that validation WER is trending down, indicating the potential of further training (resuming the decaying learning rate at 7e-6).
## Future Work
One area to explore is using `attention_mask` in model input, which is recommended [here](https://huggingface.co/blog/fine-tune-xlsr-wav2vec2).
Also, exploring data augmentation using datasets used to train models listed [here](https://paperswithcode.com/sota/speech-recognition-on-common-voice-arabic).
|
hun3359/klue-bert-base-sentiment | hun3359 | 2023-08-21T01:10:59Z | 923 | 3 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"text-classification",
"ko",
"license:cc-by-sa-4.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-08-09T04:31:30Z | ---
language:
- ko
library_name: transformers
pipeline_tag: text-classification
widget:
- text: 오늘 밥이 너무 맛있었어. 행복해
- text: 가방에 바퀴벌레가 있었어
- text: 가방에 강아지가 있었어
- text: 직장에서 부당한 일을 겪어서 너무 화가 나
- text: 퇴직금으로 적립한 펀드 수익률이 많이 올랐어.
- text: 퇴직금으로 적립한 펀드 수익률이 많이 떨어졌어.
- text: 퇴직금으로 적립한 펀드 수익률이 많이 내려갔어.
- text: 우연히 남자친구가 헤어진 전 여자친구를 잊지 못했다는 걸 알았어.
license: cc-by-sa-4.0
metrics:
- f1
- accuracy
---
# 한국어 감정 분류모델
# Korean Sentiment Classification Model
## 60가지의 세분화된 감정분류 모델
### Dataset: Aihub-감성대화말뭉치
### Dataset URL : https://aihub.or.kr/aihubdata/data/view.do?currMenu=115&topMenu=100&aihubDataSe=realm&dataSetSn=86
### model: hun3359/klue-bert-base-sentiment
### parent model: klue/bert-base
### parent model url: https://huggingface.co/klue/bert-base

** fine-tuning log **
distilbert-base-multilingual-cased을 5 epoch fine-tuning --> f1: 0.25 (2023.08.08)
bongsoo/mdistilbertV3.1을 5 epoch fine-tuning --> f1: 0.26 (2023.08.09)
klue/bert-base를 5 epoch fine-tuning --> see below results (2023.08.09)
- klue-bert-base-sentiment fine-tuning result
```json
{
"test_loss": 2.8668248653411865,
"test_accuracy": 0.29371889480006863,
"test_f1": 0.29102037288558685,
"test_runtime": 50.8082,
"test_samples_per_second": 458.745,
"test_steps_per_second": 14.348
}
```
- klue-bert-base-sentiment config
```json
{
"_name_or_path": "klue/bert-base",
"architectures": [
"BertForSequenceClassification"
],
"attention_probs_dropout_prob": 0.1,
"classifier_dropout": null,
"hidden_act": "gelu",
"hidden_dropout_prob": 0.1,
"hidden_size": 768,
"initializer_range": 0.02,
"intermediate_size": 3072,
"id2label":{
"0": "분노",
"1": "툴툴대는",
"2": "좌절한",
"3": "짜증내는",
"4": "방어적인",
"5": "악의적인",
"6": "안달하는",
"7": "구역질 나는",
"8": "노여워하는",
"9": "성가신",
"10": "슬픔",
"11": "실망한",
"12": "비통한",
"13": "후회되는",
"14": "우울한",
"15": "마비된",
"16": "염세적인",
"17": "눈물이 나는",
"18": "낙담한",
"19": "환멸을 느끼는",
"20": "불안",
"21": "두려운",
"22": "스트레스 받는",
"23": "취약한",
"24": "혼란스러운",
"25": "당혹스러운",
"26": "회의적인",
"27": "걱정스러운",
"28": "조심스러운",
"29": "초조한",
"30": "상처",
"31": "질투하는",
"32": "배신당한",
"33": "고립된",
"34": "충격 받은",
"35": "가난한 불우한",
"36": "희생된",
"37": "억울한",
"38": "괴로워하는",
"39": "버려진",
"40": "당황",
"41": "고립된(당황한)",
"42": "남의 시선을 의식하는",
"43": "외로운",
"44": "열등감",
"45": "죄책감의",
"46": "부끄러운",
"47": "혐오스러운",
"48": "한심한",
"49": "혼란스러운(당황한)",
"50": "기쁨",
"51": "감사하는",
"52": "신뢰하는",
"53": "편안한",
"54": "만족스러운",
"55": "흥분",
"56": "느긋",
"57": "안도",
"58": "신이 난",
"59": "자신하는"
},
"label2id": {
"분노": 0,
"툴툴대는": 1,
"좌절한": 2,
"짜증내는": 3,
"방어적인": 4,
"악의적인": 5,
"안달하는": 6,
"구역질 나는": 7,
"노여워하는": 8,
"성가신": 9,
"슬픔": 10,
"실망한": 11,
"비통한": 12,
"후회되는": 13,
"우울한": 14,
"마비된": 15,
"염세적인": 16,
"눈물이 나는": 17,
"낙담한": 18,
"환멸을 느끼는": 19,
"불안": 20,
"두려운": 21,
"스트레스 받는": 22,
"취약한": 23,
"혼란스러운": 24,
"당혹스러운": 25,
"회의적인": 26,
"걱정스러운": 27,
"조심스러운": 28,
"초조한": 29,
"상처": 30,
"질투하는": 31,
"배신당한": 32,
"고립된": 33,
"충격 받은": 34,
"가난한 불우한": 35,
"희생된": 36,
"억울한": 37,
"괴로워하는": 38,
"버려진": 39,
"당황": 40,
"고립된(당황한)": 41,
"남의 시선을 의식하는": 42,
"외로운": 43,
"열등감": 44,
"죄책감의": 45,
"부끄러운": 46,
"혐오스러운": 47,
"한심한": 48,
"혼란스러운(당황한)": 49,
"기쁨": 50,
"감사하는": 51,
"신뢰하는": 52,
"편안한": 53,
"만족스러운": 54,
"흥분": 55,
"느긋": 56,
"안도": 57,
"신이 난": 58,
"자신하는": 59
},
"layer_norm_eps": 1e-12,
"max_position_embeddings": 512,
"model_type": "bert",
"num_attention_heads": 12,
"num_hidden_layers": 12,
"pad_token_id": 0,
"position_embedding_type": "absolute",
"problem_type": "single_label_classification",
"torch_dtype": "float32",
"transformers_version": "4.30.2",
"type_vocab_size": 2,
"use_cache": true,
"vocab_size": 32000
}
``` |
Isotonic/smol_llama-4x220M-MoE | Isotonic | 2024-04-04T02:48:19Z | 923 | 3 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"merge",
"mergekit",
"lazymergekit",
"BEE-spoke-data/smol_llama-220M-openhermes",
"BEE-spoke-data/beecoder-220M-python",
"BEE-spoke-data/zephyr-220m-sft-full",
"BEE-spoke-data/zephyr-220m-dpo-full",
"dataset:JeanKaddour/minipile",
"dataset:pszemraj/simple_wikipedia_LM",
"dataset:mattymchen/refinedweb-3m",
"dataset:HuggingFaceH4/ultrachat_200k",
"dataset:teknium/openhermes",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"dataset:EleutherAI/proof-pile-2",
"dataset:bigcode/the-stack-smol-xl",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-02-03T13:19:27Z | ---
license: apache-2.0
tags:
- moe
- merge
- mergekit
- lazymergekit
- BEE-spoke-data/smol_llama-220M-openhermes
- BEE-spoke-data/beecoder-220M-python
- BEE-spoke-data/zephyr-220m-sft-full
- BEE-spoke-data/zephyr-220m-dpo-full
- text-generation
datasets:
- JeanKaddour/minipile
- pszemraj/simple_wikipedia_LM
- mattymchen/refinedweb-3m
- HuggingFaceH4/ultrachat_200k
- teknium/openhermes
- HuggingFaceH4/ultrafeedback_binarized
- EleutherAI/proof-pile-2
- bigcode/the-stack-smol-xl
pipeline_tag: text-generation
---
🌟 Buying me coffee is a direct way to show support for this project.
<a href="https://www.buymeacoffee.com/isotonic"><img src="https://www.buymeacoffee.com/assets/img/guidelines/download-assets-sm-1.svg" alt=""></a>
# smol_llama-4x220M-MoE
smol_llama-4x220M-MoE is a Mixure of Experts (MoE) made with the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [BEE-spoke-data/smol_llama-220M-openhermes](https://huggingface.co/BEE-spoke-data/smol_llama-220M-openhermes)
* [BEE-spoke-data/beecoder-220M-python](https://huggingface.co/BEE-spoke-data/beecoder-220M-python)
* [BEE-spoke-data/zephyr-220m-sft-full](https://huggingface.co/BEE-spoke-data/zephyr-220m-sft-full)
* [BEE-spoke-data/zephyr-220m-dpo-full](https://huggingface.co/BEE-spoke-data/zephyr-220m-dpo-full)
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Isotonic/smol_llama-4x220M-MoE"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.bfloat16},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
## 🧩 Configuration
```yamlbase_model: BEE-spoke-data/smol_llama-220M-openhermes
experts:
- source_model: BEE-spoke-data/smol_llama-220M-openhermes
positive_prompts:
- "reasoning"
- "logic"
- "problem-solving"
- "critical thinking"
- "analysis"
- "synthesis"
- "evaluation"
- "decision-making"
- "judgment"
- "insight"
- source_model: BEE-spoke-data/beecoder-220M-python
positive_prompts:
- "program"
- "software"
- "develop"
- "build"
- "create"
- "design"
- "implement"
- "debug"
- "test"
- "code"
- "python"
- "programming"
- "algorithm"
- "function"
- source_model: BEE-spoke-data/zephyr-220m-sft-full
positive_prompts:
- "storytelling"
- "narrative"
- "fiction"
- "creative writing"
- "plot"
- "characters"
- "dialogue"
- "setting"
- "emotion"
- "imagination"
- "scene"
- "story"
- "character"
- source_model: BEE-spoke-data/zephyr-220m-dpo-full
positive_prompts:
- "chat"
- "conversation"
- "dialogue"
- "discuss"
- "ask questions"
- "share thoughts"
- "explore ideas"
- "learn new things"
- "personal assistant"
- "friendly helper"
``` |
meta-llama/CodeLlama-13b-Instruct-hf | meta-llama | 2024-03-14T18:41:05Z | 923 | 10 | transformers | [
"transformers",
"pytorch",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"llama-2",
"conversational",
"code",
"arxiv:2308.12950",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-13T20:12:04Z | ---
extra_gated_heading: You need to share contact information with Meta to access this model
extra_gated_prompt: >-
### LLAMA 2 COMMUNITY LICENSE AGREEMENT
"Agreement" means the terms and conditions for use, reproduction, distribution
and modification of the Llama Materials set forth herein.
"Documentation" means the specifications, manuals and documentation
accompanying Llama 2 distributed by Meta at
https://ai.meta.com/resources/models-and-libraries/llama-downloads/.
"Licensee" or "you" means you, or your employer or any other person or entity
(if you are entering into this Agreement on such person or entity's behalf),
of the age required under applicable laws, rules or regulations to provide
legal consent and that has legal authority to bind your employer or such other
person or entity if you are entering in this Agreement on their behalf.
"Llama 2" means the foundational large language models and software and
algorithms, including machine-learning model code, trained model weights,
inference-enabling code, training-enabling code, fine-tuning enabling code and
other elements of the foregoing distributed by Meta at
ai.meta.com/resources/models-and-libraries/llama-downloads/.
"Llama Materials" means, collectively, Meta's proprietary Llama 2 and
documentation (and any portion thereof) made available under this Agreement.
"Meta" or "we" means Meta Platforms Ireland Limited (if you are located in or,
if you are an entity, your principal place of business is in the EEA or
Switzerland) and Meta Platforms, Inc. (if you are located outside of the EEA
or Switzerland).
By clicking "I Accept" below or by using or distributing any portion or
element of the Llama Materials, you agree to be bound by this Agreement.
1. License Rights and Redistribution.
a. Grant of Rights. You are granted a non-exclusive, worldwide, non-
transferable and royalty-free limited license under Meta's intellectual
property or other rights owned by Meta embodied in the Llama Materials to
use, reproduce, distribute, copy, create derivative works of, and make
modifications to the Llama Materials.
b. Redistribution and Use.
i. If you distribute or make the Llama Materials, or any derivative works
thereof, available to a third party, you shall provide a copy of this
Agreement to such third party.
ii. If you receive Llama Materials, or any derivative works thereof, from a
Licensee as part of an integrated end user product, then Section 2 of this
Agreement will not apply to you.
iii. You must retain in all copies of the Llama Materials that you distribute
the following attribution notice within a "Notice" text file distributed as a
part of such copies: "Llama 2 is licensed under the LLAMA 2 Community
License, Copyright (c) Meta Platforms, Inc. All Rights Reserved."
iv. Your use of the Llama Materials must comply with applicable laws and
regulations (including trade compliance laws and regulations) and adhere to
the Acceptable Use Policy for the Llama Materials (available at
https://ai.meta.com/llama/use-policy), which is hereby incorporated by
reference into this Agreement.
v. You will not use the Llama Materials or any output or results of the Llama
Materials to improve any other large language model (excluding Llama 2 or
derivative works thereof).
2. Additional Commercial Terms. If, on the Llama 2 version release date, the
monthly active users of the products or services made available by or for
Licensee, or Licensee's affiliates, is greater than 700 million monthly
active users in the preceding calendar month, you must request a license from
Meta, which Meta may grant to you in its sole discretion, and you are not
authorized to exercise any of the rights under this Agreement unless or until
Meta otherwise expressly grants you such rights.
3. Disclaimer of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA
MATERIALS AND ANY OUTPUT AND RESULTS THEREFROM ARE PROVIDED ON AN "AS IS"
BASIS, WITHOUT WARRANTIES OF ANY KIND, EITHER EXPRESS OR IMPLIED, INCLUDING,
WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT,
MERCHANTABILITY, OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY
RESPONSIBLE FOR DETERMINING THE APPROPRIATENESS OF USING OR REDISTRIBUTING
THE LLAMA MATERIALS AND ASSUME ANY RISKS ASSOCIATED WITH YOUR USE OF THE
LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE
UNDER ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE,
PRODUCTS LIABILITY, OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST
PROFITS OR ANY INDIRECT, SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR
PUNITIVE DAMAGES, EVEN IF META OR ITS AFFILIATES HAVE BEEN ADVISED OF THE
POSSIBILITY OF ANY OF THE FOREGOING.
5. Intellectual Property.
a. No trademark licenses are granted under this Agreement, and in connection
with the Llama Materials, neither Meta nor Licensee may use any name or mark
owned by or associated with the other or any of its affiliates, except as
required for reasonable and customary use in describing and redistributing
the Llama Materials.
b. Subject to Meta's ownership of Llama Materials and derivatives made by or
for Meta, with respect to any derivative works and modifications of the Llama
Materials that are made by you, as between you and Meta, you are and will be
the owner of such derivative works and modifications.
c. If you institute litigation or other proceedings against Meta or any
entity (including a cross-claim or counterclaim in a lawsuit) alleging that
the Llama Materials or Llama 2 outputs or results, or any portion of any of
the foregoing, constitutes infringement of intellectual property or other
rights owned or licensable by you, then any licenses granted to you under
this Agreement shall terminate as of the date such litigation or claim is
filed or instituted. You will indemnify and hold harmless Meta from and
against any claim by any third party arising out of or related to your use or
distribution of the Llama Materials.
6. Term and Termination. The term of this Agreement will commence upon your
acceptance of this Agreement or access to the Llama Materials and will
continue in full force and effect until terminated in accordance with the
terms and conditions herein. Meta may terminate this Agreement if you are in
breach of any term or condition of this Agreement. Upon termination of this
Agreement, you shall delete and cease use of the Llama Materials. Sections 3,
4 and 7 shall survive the termination of this Agreement.
7. Governing Law and Jurisdiction. This Agreement will be governed and
construed under the laws of the State of California without regard to choice
of law principles, and the UN Convention on Contracts for the International
Sale of Goods does not apply to this Agreement. The courts of California
shall have exclusive jurisdiction of any dispute arising out of this
Agreement.
USE POLICY
### Llama 2 Acceptable Use Policy
Meta is committed to promoting safe and fair use of its tools and features,
including Llama 2. If you access or use Llama 2, you agree to this Acceptable
Use Policy (“Policy”). The most recent copy of this policy can be found at
[ai.meta.com/llama/use-policy](http://ai.meta.com/llama/use-policy).
#### Prohibited Uses
We want everyone to use Llama 2 safely and responsibly. You agree you will not
use, or allow others to use, Llama 2 to:
1. Violate the law or others’ rights, including to:
1. Engage in, promote, generate, contribute to, encourage, plan, incite, or further illegal or unlawful activity or content, such as:
1. Violence or terrorism
2. Exploitation or harm to children, including the solicitation, creation, acquisition, or dissemination of child exploitative content or failure to report Child Sexual Abuse Material
3. Human trafficking, exploitation, and sexual violence
4. The illegal distribution of information or materials to minors, including obscene materials, or failure to employ legally required age-gating in connection with such information or materials.
5. Sexual solicitation
6. Any other criminal activity
2. Engage in, promote, incite, or facilitate the harassment, abuse, threatening, or bullying of individuals or groups of individuals
3. Engage in, promote, incite, or facilitate discrimination or other unlawful or harmful conduct in the provision of employment, employment benefits, credit, housing, other economic benefits, or other essential goods and services
4. Engage in the unauthorized or unlicensed practice of any profession including, but not limited to, financial, legal, medical/health, or related professional practices
5. Collect, process, disclose, generate, or infer health, demographic, or other sensitive personal or private information about individuals without rights and consents required by applicable laws
6. Engage in or facilitate any action or generate any content that infringes, misappropriates, or otherwise violates any third-party rights, including the outputs or results of any products or services using the Llama 2 Materials
7. Create, generate, or facilitate the creation of malicious code, malware, computer viruses or do anything else that could disable, overburden, interfere with or impair the proper working, integrity, operation or appearance of a website or computer system
2. Engage in, promote, incite, facilitate, or assist in the planning or
development of activities that present a risk of death or bodily harm to
individuals, including use of Llama 2 related to the following:
1. Military, warfare, nuclear industries or applications, espionage, use for materials or activities that are subject to the International Traffic Arms Regulations (ITAR) maintained by the United States Department of State
2. Guns and illegal weapons (including weapon development)
3. Illegal drugs and regulated/controlled substances
4. Operation of critical infrastructure, transportation technologies, or heavy machinery
5. Self-harm or harm to others, including suicide, cutting, and eating disorders
6. Any content intended to incite or promote violence, abuse, or any infliction of bodily harm to an individual
3. Intentionally deceive or mislead others, including use of Llama 2 related
to the following:
1. Generating, promoting, or furthering fraud or the creation or promotion of disinformation
2. Generating, promoting, or furthering defamatory content, including the creation of defamatory statements, images, or other content
3. Generating, promoting, or further distributing spam
4. Impersonating another individual without consent, authorization, or legal right
5. Representing that the use of Llama 2 or outputs are human-generated
6. Generating or facilitating false online engagement, including fake reviews and other means of fake online engagement
4. Fail to appropriately disclose to end users any known dangers of your AI system
Please report any violation of this Policy, software “bug,” or other problems
that could lead to a violation of this Policy through one of the following
means:
* Reporting issues with the model:
[github.com/facebookresearch/llama](http://github.com/facebookresearch/llama)
* Reporting risky content generated by the model:
[developers.facebook.com/llama_output_feedback](http://developers.facebook.com/llama_output_feedback)
* Reporting bugs and security concerns:
[facebook.com/whitehat/info](http://facebook.com/whitehat/info)
* Reporting violations of the Acceptable Use Policy or unlicensed uses of
Llama: [[email protected]](mailto:[email protected])
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
By clicking Submit below I accept the terms of the license and acknowledge that the information I provide will be collected stored processed and shared in accordance with the Meta Privacy Policy: checkbox
extra_gated_description: The information you provide will be collected, stored, processed and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
language:
- code
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-2
license: llama2
---
# **Code Llama**
Code Llama is a collection of pretrained and fine-tuned generative text models ranging in scale from 7 billion to 34 billion parameters. This is the repository for the 13 instruct-tuned version in the Hugging Face Transformers format. This model is designed for general code synthesis and understanding. Links to other models can be found in the index at the bottom.
| | Base Model | Python | Instruct |
| --- | ----------------------------------------------------------------------------- | ------------------------------------------------------------------------------------------- | ----------------------------------------------------------------------------------------------- |
| 7B | [meta-llama/CodeLlama-7b-hf](https://huggingface.co/meta-llama/CodeLlama-7b-hf) | [meta-llama/CodeLlama-7b-Python-hf](https://huggingface.co/meta-llama/CodeLlama-7b-Python-hf) | [meta-llama/CodeLlama-7b-Instruct-hf](https://huggingface.co/meta-llama/CodeLlama-7b-Instruct-hf) |
| 13B | [meta-llama/CodeLlama-13b-hf](https://huggingface.co/meta-llama/CodeLlama-13b-hf) | [meta-llama/CodeLlama-13b-Python-hf](https://huggingface.co/meta-llama/CodeLlama-13b-Python-hf) | [meta-llama/CodeLlama-13b-Instruct-hf](https://huggingface.co/meta-llama/CodeLlama-13b-Instruct-hf) |
| 34B | [meta-llama/CodeLlama-34b-hf](https://huggingface.co/meta-llama/CodeLlama-34b-hf) | [meta-llama/CodeLlama-34b-Python-hf](https://huggingface.co/meta-llama/CodeLlama-34b-Python-hf) | [meta-llama/CodeLlama-34b-Instruct-hf](https://huggingface.co/meta-llama/CodeLlama-34b-Instruct-hf) |
| 70B | [meta-llama/CodeLlama-70b-hf](https://huggingface.co/meta-llama/CodeLlama-70b-hf) | [meta-llama/CodeLlama-70b-Python-hf](https://huggingface.co/meta-llama/CodeLlama-70b-Python-hf) | [meta-llama/CodeLlama-70b-Instruct-hf](https://huggingface.co/meta-llama/CodeLlama-70b-Instruct-hf) |
## Model Use
To use this model, please make sure to install transformers:
```bash
pip install transformers.git accelerate
```
Model capabilities:
- [x] Code completion.
- [x] Infilling.
- [x] Instructions / chat.
- [ ] Python specialist.
## Model Details
*Note: Use of this model is governed by the Meta license. Meta developed and publicly released the Code Llama family of large language models (LLMs).
**Model Developers** Meta
**Variations** Code Llama comes in three model sizes, and three variants:
* Code Llama: base models designed for general code synthesis and understanding
* Code Llama - Python: designed specifically for Python
* Code Llama - Instruct: for instruction following and safer deployment
All variants are available in sizes of 7B, 13B and 34B parameters.
**This repository contains the Instruct version of the 13B parameters model.**
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Code Llama is an auto-regressive language model that uses an optimized transformer architecture.
**Model Dates** Code Llama and its variants have been trained between January 2023 and July 2023.
**Status** This is a static model trained on an offline dataset. Future versions of Code Llama - Instruct will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://ai.meta.com/resources/models-and-libraries/llama-downloads/](https://ai.meta.com/resources/models-and-libraries/llama-downloads/)
**Research Paper** More information can be found in the paper "[Code Llama: Open Foundation Models for Code](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/)" or its [arXiv page](https://arxiv.org/abs/2308.12950).
## Intended Use
**Intended Use Cases** Code Llama and its variants is intended for commercial and research use in English and relevant programming languages. The base model Code Llama can be adapted for a variety of code synthesis and understanding tasks, Code Llama - Python is designed specifically to handle the Python programming language, and Code Llama - Instruct is intended to be safer to use for code assistant and generation applications.
**Out-of-Scope Uses** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in languages other than English. Use in any other way that is prohibited by the Acceptable Use Policy and Licensing Agreement for Code Llama and its variants.
## Hardware and Software
**Training Factors** We used custom training libraries. The training and fine-tuning of the released models have been performed Meta’s Research Super Cluster.
**Carbon Footprint** In aggregate, training all 9 Code Llama models required 400K GPU hours of computation on hardware of type A100-80GB (TDP of 350-400W). Estimated total emissions were 65.3 tCO2eq, 100% of which were offset by Meta’s sustainability program.
## Training Data
All experiments reported here and the released models have been trained and fine-tuned using the same data as Llama 2 with different weights (see Section 2 and Table 1 in the [research paper](https://ai.meta.com/research/publications/code-llama-open-foundation-models-for-code/) for details).
## Evaluation Results
See evaluations for the main models and detailed ablations in Section 3 and safety evaluations in Section 4 of the research paper.
## Ethical Considerations and Limitations
Code Llama and its variants are a new technology that carries risks with use. Testing conducted to date has been in English, and has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, Code Llama’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. Therefore, before deploying any applications of Code Llama, developers should perform safety testing and tuning tailored to their specific applications of the model.
Please see the Responsible Use Guide available available at [https://ai.meta.com/llama/responsible-use-guide](https://ai.meta.com/llama/responsible-use-guide). |
netcat420/MFANNv0.12 | netcat420 | 2024-05-31T05:02:33Z | 923 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"en",
"dataset:netcat420/MFANN",
"arxiv:1910.09700",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-31T00:07:59Z | ---
library_name: transformers
license: llama3
datasets:
- netcat420/MFANN
language:
- en
pipeline_tag: text-generation
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
PassionFriend/5DHWc8heeTjBpTkxf7rrhrLe46bquk42qJ2vguc5fhcwT4Ue_vgg | PassionFriend | 2024-03-01T06:46:37Z | 922 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-02-16T23:08:11Z | Entry not found |
mradermacher/Qwen2-72B-i1-GGUF | mradermacher | 2024-06-07T21:08:38Z | 922 | 0 | transformers | [
"transformers",
"gguf",
"pretrained",
"en",
"base_model:Qwen/Qwen2-72B",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-07T07:05:32Z | ---
base_model: Qwen/Qwen2-72B
language:
- en
library_name: transformers
license: other
license_link: https://huggingface.co/Qwen/Qwen2-72B/blob/main/LICENSE
license_name: tongyi-qianwen
quantized_by: mradermacher
tags:
- pretrained
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Qwen/Qwen2-72B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Qwen2-72B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ1_S.gguf) | i1-IQ1_S | 22.8 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ1_M.gguf) | i1-IQ1_M | 23.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 25.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 27.2 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ2_S.gguf) | i1-IQ2_S | 28.0 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ2_M.gguf) | i1-IQ2_M | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q2_K.gguf) | i1-Q2_K | 29.9 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 31.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 32.9 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ3_S.gguf) | i1-IQ3_S | 34.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 34.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ3_M.gguf) | i1-IQ3_M | 35.6 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 37.8 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 39.6 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 39.8 | |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q4_0.gguf) | i1-Q4_0 | 41.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 44.0 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 47.5 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q5_K_S.gguf.part2of2) | i1-Q5_K_S | 51.5 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q5_K_M.gguf.part2of2) | i1-Q5_K_M | 54.5 | |
| [PART 1](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Qwen2-72B-i1-GGUF/resolve/main/Qwen2-72B.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 64.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
NikolayKozloff/Llama-3-Instruct-8B-SPPO-Iter3-Q4_0-GGUF | NikolayKozloff | 2024-06-26T15:53:29Z | 922 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"text-generation",
"en",
"dataset:openbmb/UltraFeedback",
"base_model:UCLA-AGI/Llama-3-Instruct-8B-SPPO-Iter3",
"license:apache-2.0",
"region:us"
]
| text-generation | 2024-06-26T15:53:07Z | ---
base_model: UCLA-AGI/Llama-3-Instruct-8B-SPPO-Iter3
datasets:
- openbmb/UltraFeedback
language:
- en
license: apache-2.0
pipeline_tag: text-generation
tags:
- llama-cpp
- gguf-my-repo
---
# NikolayKozloff/Llama-3-Instruct-8B-SPPO-Iter3-Q4_0-GGUF
This model was converted to GGUF format from [`UCLA-AGI/Llama-3-Instruct-8B-SPPO-Iter3`](https://huggingface.co/UCLA-AGI/Llama-3-Instruct-8B-SPPO-Iter3) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/UCLA-AGI/Llama-3-Instruct-8B-SPPO-Iter3) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo NikolayKozloff/Llama-3-Instruct-8B-SPPO-Iter3-Q4_0-GGUF --hf-file llama-3-instruct-8b-sppo-iter3-q4_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo NikolayKozloff/Llama-3-Instruct-8B-SPPO-Iter3-Q4_0-GGUF --hf-file llama-3-instruct-8b-sppo-iter3-q4_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo NikolayKozloff/Llama-3-Instruct-8B-SPPO-Iter3-Q4_0-GGUF --hf-file llama-3-instruct-8b-sppo-iter3-q4_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo NikolayKozloff/Llama-3-Instruct-8B-SPPO-Iter3-Q4_0-GGUF --hf-file llama-3-instruct-8b-sppo-iter3-q4_0.gguf -c 2048
```
|
jeiku/Very_Berry_Qwen2_7B-Q4_K_M-GGUF | jeiku | 2024-06-29T01:54:50Z | 922 | 0 | null | [
"gguf",
"not-for-all-audiences",
"llama-cpp",
"gguf-my-repo",
"base_model:jeiku/Very_Berry_Qwen2_7B",
"license:apache-2.0",
"region:us"
]
| null | 2024-06-29T01:54:27Z | ---
base_model: jeiku/Very_Berry_Qwen2_7B
license: apache-2.0
tags:
- not-for-all-audiences
- llama-cpp
- gguf-my-repo
---
# jeiku/Very_Berry_Qwen2_7B-Q4_K_M-GGUF
This model was converted to GGUF format from [`jeiku/Very_Berry_Qwen2_7B`](https://huggingface.co/jeiku/Very_Berry_Qwen2_7B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/jeiku/Very_Berry_Qwen2_7B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo jeiku/Very_Berry_Qwen2_7B-Q4_K_M-GGUF --hf-file very_berry_qwen2_7b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo jeiku/Very_Berry_Qwen2_7B-Q4_K_M-GGUF --hf-file very_berry_qwen2_7b-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo jeiku/Very_Berry_Qwen2_7B-Q4_K_M-GGUF --hf-file very_berry_qwen2_7b-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo jeiku/Very_Berry_Qwen2_7B-Q4_K_M-GGUF --hf-file very_berry_qwen2_7b-q4_k_m.gguf -c 2048
```
|
xverse/XVERSE-7B | xverse | 2023-11-06T03:59:45Z | 921 | 6 | transformers | [
"transformers",
"pytorch",
"xverse",
"text-generation",
"custom_code",
"arxiv:2009.03300",
"arxiv:2304.06364",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
]
| text-generation | 2023-09-25T03:43:33Z | ---
license: apache-2.0
inference: false
---
# XVERSE-7B
## 模型介绍
**XVERSE-7B** 是由深圳元象科技自主研发的支持多语言的大语言模型(Large Language Model),参数规模为 70 亿,主要特点如下:
- **模型结构**:XVERSE-7B 使用主流 Decoder-only 的标准 Transformer 网络结构,支持 8K 的上下文长度(Context Length),能满足更长的多轮对话、知识问答与摘要等需求,模型应用场景更广泛。
- **训练数据**:构建了 2.6 万亿 token 的高质量、多样化的数据对模型进行充分训练,包含中、英、俄、西等 40 多种语言,通过精细化设置不同类型数据的采样比例,使得中英两种语言表现优异,也能兼顾其他语言效果。
- **分词**:基于 BPE(Byte-Pair Encoding)算法,使用上百 GB 语料训练了一个词表大小为 100,534 的分词器,能够同时支持多语言,而无需额外扩展词表。
- **训练框架**:自主研发多项关键技术,包括高效算子、显存优化、并行调度策略、数据-计算-通信重叠、平台和框架协同等,让训练效率更高,模型稳定性强,在千卡集群上的峰值算力利用率可达到 58.5%,位居业界前列。
## Model Introduction
**XVERSE-7B** is a multilingual large language model, independently developed by Shenzhen Yuanxiang Technology. Its key features are as follows:
- **Model Structure**: XVERSE-7B uses the mainstream Decoder-only Transformer network structure, supports 8k context length, which can meet the need of longer multi-round dialogues, knowledge question-answering, and summarization. This makes the model more versatile in application scenarios.
- **Training Data**: The model has been thoroughly trained on a diversified and high-quality dataset consisting of 2.6 trillion of tokens, including more than 40 languages such as Chinese, English, Russian, and Spanish. The sampling ratio of different types of data is finely set, which makes the performance of Chinese and English excellent, and also takes into account the effect of other languages.
- **Tokenization**: Based on the BPE (Byte-Pair Encoding) algorithm, a tokenizer with a vocabulary size of 100,534 has been trained using hundreds of gigabytes of language data. This tokenizer is capable of supporting multilingual without the need for additional vocabulary expansion.
- **Training Framework**: Several key technologies have also been independently developed, including efficient operators, memory optimization, parallel scheduling strategies, overlap of data-computation-communication, and synergy between platforms and frameworks. These advancements enhance training efficiency and model stability. With these technologies, the peak computational power utilization rate on a thousand-card cluster can reach 58.5%, ranking at the forefront of the industry.
## 评测结果
为验证模型的各项能力,我们选取了多个学科综合能力评测集,包括 [MMLU](https://arxiv.org/abs/2009.03300)(英文)、 [C-Eval](https://cevalbenchmark.com/)(中文)、[AGIEval](https://arxiv.org/abs/2304.06364)(中英) 、[GAOKAO-Bench](https://github.com/OpenLMLab/GAOKAO-Bench)(中英)、[GAOKAO-English](https://github.com/ExpressAI/AI-Gaokao)(英文),评测结果如下(粗体表示各项最高得分):
| 模型 | 类型 | MMLU | C-Eval | AGIEval<sup>1</sup> | GAOKAO-Bench<sup>1</sup> | GAOKAO-English<sup>1</sup> |
| :----------------: | :--: | :--------------: | :--------------: | :-----------------: | :----------------------: | :------------------------: |
| Baichuan-7B | 底座 | 42.3<sup>2</sup> | 42.8<sup>2</sup> | 34.4<sup>2</sup> | 36.3<sup>2</sup> | 44.3 |
| Baichuan2-7B-Base | 底座 | 54.2<sup>2</sup> | 54.0<sup>2</sup> | 42.7<sup>2</sup> | 47.5<sup>2</sup> | 53.1 |
| Baichuan2-7B-Chat | 对话 | 53.2 | 52.2 | 41.3 | 49.7 | 66.6 |
| ChatGLM2-6B | 对话 | 45.5<sup>2</sup> | 50.1<sup>2</sup> | 42.6 | 54.2 | 59.7 |
| Falcon-7B | 底座 | 27.8<sup>2</sup> | 25.8 | 26.2 | 26.3 | 29.9 |
| InternLM-7B | 底座 | 51.0<sup>2</sup> | 52.4 | 34.1 | 53.6 | 32.3 |
| InternLM-7B-Chat | 对话 | 50.8<sup>2</sup> | 52.8 | 39.0 | **67.4** | 43.9 |
| Llama-7B | 底座 | 35.1<sup>2</sup> | 27.0 | 27.4 | 26.0 | 30.1 |
| Llama-2-7B | 底座 | 45.3<sup>2</sup> | 28.9 | 27.0 | 27.8 | 47.8 |
| MPT-7B | 底座 | 29.6<sup>2</sup> | 27.8 | 24.2 | 25.3 | 28.1 |
| Vicuna-7B-v1.5 | 对话 | 49.8<sup>2</sup> | 22.9 | 26.7 | 24.4 | 61.1 |
| **XVERSE-7B** | 底座 | **56.6** | **57.1** | **46.9** | 61.7 | **71.1** |
> <sup>1:只针对其中的单项选择题进行测试,即排除了填空题、开放性问题和多项选择题</sup>
> <sup>2:来源于各模型官方的汇报结果</sup>
>
> 对于 MMLU ,我们采用作者提供的[评测工具](https://github.com/hendrycks/test),C-Eval、AGIEval、GAOKAO-Bench、GAOKAO-English 与 MMLU 的评测方式相同,且统一采用 **5-shot** 构造测试样本。
## Model Evaluation
In order to validate the various abilities of the model, we have chosen several comprehensive capability benchmarks across multiple disciplines, including [MMLU](https://arxiv.org/abs/2009.03300) (English), [C-Eval](https://cevalbenchmark.com/) (Chinese), [AGIEval](https://arxiv.org/abs/2304.06364) (Chinese and English), [GAOKAO-Bench](https://github.com/OpenLMLab/GAOKAO-Bench) (Chinese and English), [GAOKAO-English](https://github.com/ExpressAI/AI-Gaokao) (English), the evaluation results are as follows (the bolded score represent the best performances):
| Models | Type | MMLU | C-Eval | AGIEval<sup>1</sup> | GAOKAO-Bench<sup>1</sup> | GAOKAO-English<sup>1</sup> |
| :----------------: | :--------: | :--------------: | :--------------: | :-----------------: | :----------------------: | :------------------------: |
| Baichuan-7B | pretrained | 42.3<sup>2</sup> | 42.8<sup>2</sup> | 34.4<sup>2</sup> | 36.3<sup>2</sup> | 44.3 |
| Baichuan2-7B-Base | pretrained | 54.2<sup>2</sup> | 54.0<sup>2</sup> | 42.7<sup>2</sup> | 47.5<sup>2</sup> | 53.1 |
| Baichuan2-7B-Chat | fine-tuned | 53.2 | 52.2 | 41.3 | 49.7 | 66.6 |
| ChatGLM2-6B | fine-tuned | 45.5<sup>2</sup> | 50.1<sup>2</sup> | 42.6 | 54.2 | 59.7 |
| Falcon-7B | pretrained | 27.8<sup>2</sup> | 25.8 | 26.2 | 26.3 | 29.9 |
| InternLM-7B | pretrained | 51.0<sup>2</sup> | 52.4 | 34.1 | 53.6 | 32.3 |
| InternLM-7B-Chat | fine-tuned | 50.8<sup>2</sup> | 52.8 | 39.0 | **67.4** | 43.9 |
| Llama-7B | pretrained | 35.1<sup>2</sup> | 27.0 | 27.4 | 26.0 | 30.1 |
| Llama-2-7B | pretrained | 45.3<sup>2</sup> | 28.9 | 27.0 | 27.8 | 47.8 |
| MPT-7B | pretrained | 29.6<sup>2</sup> | 27.8 | 24.2 | 25.3 | 28.1 |
| Vicuna-7B-v1.5 | fine-tuned | 49.8<sup>2</sup> | 22.9 | 26.7 | 24.4 | 61.1 |
| **XVERSE-7B** | pretrained | **56.6** | **57.1** | **46.9** | 61.7 | **71.1** |
> <sup>1: Tests are conducted only on single-answer multiple-choice questions, thus excluding fill-in-the-blanks, open-ended questions, and multiple-answer multiple-choice questions.</sup>
> <sup>2: Reporting results from official results of each model.</sup>
>
> For MMLU, we adopt the [evaluation tools](https://github.com/hendrycks/test) provided by the authors, C-Eval, AGIEval, GAOKAO-Bench, GAOKAO-English are the same as MMLU, and uniformly use **5-shot** to construct the test samples.
### MMLU 各类别指标
MMLU Category Results
| Models | Type | Average | STEM | Social Science | Humanities | Others |
| :----------------: | :--------: | :------: | :------: | :------------: | :--------: | :------: |
| Baichuan-7B | pretrained | 42.3 | 35.6 | 48.9 | 38.4 | 48.1 |
| Baichuan2-7B-Chat | fine-tuned | 53.2 | 43.1 | 59.1 | 50.0 | 59.1 |
| ChatGLM2-6B | pretrained | 45.5 | 40.1 | 51.6 | 41.2 | 51.2 |
| InternLM-7B | pretrained | 51.0 | **58.7** | 43.5 | **52.7** | 53.2 |
| LLaMA-7B | pretrained | 35.1 | 30.5 | 38.3 | 34.0 | 38.1 |
| LLaMA2-7B | pretrained | 45.3 | 36.4 | 51.2 | 42.9 | 52.2 |
| **XVERSE-7B** | pretrained | **56.6** | 45.6 | **65.3** | 50.4 | **65.5** |
### C-Eval 各类别指标
C-Eval Category Results
| Models | Type | Average | STEM | Social Science | Humanities | Others |
| :----------------: | :--------: | :------: | :------: | :------------: | :--------: | :------: |
| Baichuan-7B | pretrained | 42.8 | 38.2 | 52.0 | 46.2 | 39.3 |
| Baichuan2-7B-Base | pretrained | 54.9 | 47.9 | 67.3 | 58.4 | 52.8 |
| Baichuan2-7B-Chat | fine-tuned | 52.2 | 44.6 | 65.0 | 55.8 | 50.9 |
| ChatGLM2-6B | fine-tuned | 50.1 | 46.4 | 60.4 | 50.6 | 46.9 |
| Falcon-7B | pretrained | 25.8 | 25.8 | 26.0 | 25.8 | 25.7 |
| InternLM-7B | pretrained | 52.4 | 47.0 | 64.9 | 55.6 | 47.6 |
| InternLM-7B-Chat | fine-tuned | 52.8 | 48.4 | 65.6 | 57.0 | 45.0 |
| LLaMA-7B | pretrained | 27.0 | 26.7 | 26.7 | 28.4 | 26.2 |
| LLaMA2-7B | pretrained | 28.9 | 26.8 | 34.5 | 30.0 | 26.4 |
| MPT-7B | pretrained | 27.8 | 27.4 | 29.8 | 26.9 | 27.7 |
| Vicuna-7B-v1.5 | fine-tuned | 22.9 | 21.8 | 23.3 | 24.0 | 23.3 |
| **XVERSE-7B** | pretrained | **57.1** | **48.9** | **71.0** | **59.7** | **56.7** |
### Loading with Transformers
可通过以下代码加载 XVERSE-7B 模型进行推理:
The XVERSE-7B model can be loaded for inference using the following code:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("xverse/XVERSE-7B")
model = AutoModelForCausalLM.from_pretrained("xverse/XVERSE-7B", trust_remote_code=True, torch_dtype=torch.float16, device_map='auto')
model = model.eval()
inputs = tokenizer('北京的景点:故宫、天坛、万里长城等。\n深圳的景点:', return_tensors='pt').input_ids
inputs = inputs.cuda()
generated_ids = model.generate(inputs, max_new_tokens=64, eos_token_id=tokenizer.eos_token_id, repetition_penalty=1.1)
print(tokenizer.batch_decode(generated_ids, skip_special_tokens=True))
```
更多有关相关细节,包括文本生成demo和环境依赖,请参考我们的[Github](https://github.com/xverse-ai/XVERSE-7B)。
For more details, including the demo of text generation and environmental dependencies, please refer to our [Github](https://github.com/xverse-ai/XVERSE-7B).
## 局限性与免责申明
XVERSE-7B 与其他所有 LLM 一样,在某些情况下可能会产生不准确、有偏见或其他令人反感的内容。因此,请谨慎使用模型生成的内容,请勿将生成的有害内容进行传播,在部署任何 XVERSE-7B 的应用之前,开发人员应根据其具体应用对模型进行安全测试和调优。
我们强烈警告不要将 XVERSE-7B 模型用于制造或传播有害信息,或进行任何可能损害公众、国家、社会安全或违反法规的活动。如果使用 XVERSE-7B 模型产生任何问题,无论是数据安全问题、公共舆论风险,还是模型被误解、滥用、传播或不合规使用所引发的任何风险和问题,我们将不承担任何责任。
## Limitations and Disclaimer
Like all other Large Language Models (LLMs), XVERSE-7B may produce inaccurate, biased, or otherwise offensive content under certain circumstances. Therefore, please use the content generated by the model with caution and refrain from disseminating harmful content. Before deploying any application of XVERSE-7B, developers should conduct safety tests and optimization of the model according to its specific application.
We strongly warn against the use of the XVERSE-7B model for producing or spreading harmful information, or conducting any activities that might harm the public, national, or social security, or violate regulations. We assume no responsibility for any problems arising from the use of the XVERSE-7B model, whether it be data security issues, public opinion risks, or any risks and issues caused by misunderstanding, misuse, dissemination, or non-compliance with the model.
## 模型开源协议
使用本仓库的源码需要遵循 [Apache-2.0](https://github.com/xverse-ai/XVERSE-7B/blob/main/LICENSE) 开源协议,使用 XVERSE-7B 的模型权重则需要遵循[模型许可协议](https://github.com/xverse-ai/XVERSE-7B/blob/main/MODEL_LICENSE.pdf)。
XVERSE-7B 模型权重对学术研究**完全开放**,并且支持**免费商用**。如需申请商业许可证,请填写【[申请表](https://chat.xverse.cn/home/business.html)】,如有其他问题或合作,请联系 <[email protected]>。
## Open Source License
The use of the source code in this repository must follow the [Apache-2.0](https://github.com/xverse-ai/XVERSE-7B/blob/main/LICENSE) open-source license, while the use of the model weights of XVERSE-7B needs to adhere to the [Model License Agreement](https://github.com/xverse-ai/XVERSE-7B/blob/main/MODEL_LICENSE.pdf).
The XVERSE-7B model weights are **fully open** to academic research and support **free commercial use**. To apply for a commercial license, please fill in the [application form](https://chat.xverse.cn/home/business.html). For other questions or collaborations, please contact <[email protected]>.
|
openerotica/baslisk-7b-v0.2-GGUF | openerotica | 2023-11-18T04:43:17Z | 921 | 5 | null | [
"gguf",
"license:apache-2.0",
"region:us"
]
| null | 2023-10-31T11:08:00Z | ---
license: apache-2.0
---
The prompt format is Vicuna/Sharegpt.
This model was trained on a subset of orca-best combined with most of freedom-rp. To put it as a ratio, the dataset is roughly 90% orca-best and about 10% degenerate reverse proxy logs. The goal was to create a model with the intellegence and capacity of orca-best, but with enhanced roleplay and adult content capabilities. If you are looking for a model that is trained purely on wanton degeneracy without any attempt to retain intellegence, check out my cockatrice model.
You can find the dataset here used to train this model here:
https://huggingface.co/datasets/openerotica/basilisk-v0.2
If you like what I'm trying to do, please consider subscribing to my patreon. I'm only asking for about tree fiddy.
https://patreon.com/openerotica |
hongdthaui/3DCartoonVision | hongdthaui | 2024-01-18T15:54:06Z | 921 | 0 | diffusers | [
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-01-18T13:56:26Z | Entry not found |
bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF | bartowski | 2024-05-29T02:45:15Z | 921 | 3 | transformers | [
"transformers",
"gguf",
"text-generation",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-05-29T01:35:32Z | ---
library_name: transformers
license: llama3
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp imatrix Quantizations of Meta-Llama-3-8B-Instruct-abliterated-v3
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3024">b3024</a> for quantization.
Original model: https://huggingface.co/failspy/Meta-Llama-3-8B-Instruct-abliterated-v3
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/eb213dccb3571f863da82e99418f81e8)
## Prompt format
```
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{system_prompt}<|eot_id|><|start_header_id|>user<|end_header_id|>
{prompt}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q8_0.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q8_0.gguf) | Q8_0 | 8.54GB | Extremely high quality, generally unneeded but max available quant. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q6_K.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q6_K.gguf) | Q6_K | 6.59GB | Very high quality, near perfect, *recommended*. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q5_K_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q5_K_M.gguf) | Q5_K_M | 5.73GB | High quality, *recommended*. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q5_K_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q5_K_S.gguf) | Q5_K_S | 5.59GB | High quality, *recommended*. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q4_K_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q4_K_M.gguf) | Q4_K_M | 4.92GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q4_K_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q4_K_S.gguf) | Q4_K_S | 4.69GB | Slightly lower quality with more space savings, *recommended*. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-IQ4_XS.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-IQ4_XS.gguf) | IQ4_XS | 4.44GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q3_K_L.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q3_K_L.gguf) | Q3_K_L | 4.32GB | Lower quality but usable, good for low RAM availability. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q3_K_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q3_K_M.gguf) | Q3_K_M | 4.01GB | Even lower quality. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-IQ3_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-IQ3_M.gguf) | IQ3_M | 3.78GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q3_K_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q3_K_S.gguf) | Q3_K_S | 3.66GB | Low quality, not recommended. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-IQ3_XS.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-IQ3_XS.gguf) | IQ3_XS | 3.51GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-IQ3_XXS.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-IQ3_XXS.gguf) | IQ3_XXS | 3.27GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-Q2_K.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-Q2_K.gguf) | Q2_K | 3.17GB | Very low quality but surprisingly usable. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-IQ2_M.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-IQ2_M.gguf) | IQ2_M | 2.94GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-IQ2_S.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-IQ2_S.gguf) | IQ2_S | 2.75GB | Very low quality, uses SOTA techniques to be usable. |
| [Meta-Llama-3-8B-Instruct-abliterated-v3-IQ2_XS.gguf](https://huggingface.co/bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF/blob/main/Meta-Llama-3-8B-Instruct-abliterated-v3-IQ2_XS.gguf) | IQ2_XS | 2.60GB | Very low quality, uses SOTA techniques to be usable. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF --include "Meta-Llama-3-8B-Instruct-abliterated-v3-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/Meta-Llama-3-8B-Instruct-abliterated-v3-GGUF --include "Meta-Llama-3-8B-Instruct-abliterated-v3-Q8_0.gguf/*" --local-dir Meta-Llama-3-8B-Instruct-abliterated-v3-Q8_0
```
You can either specify a new local-dir (Meta-Llama-3-8B-Instruct-abliterated-v3-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
skratos115/qwen2-7b-OpenDevin-q4_k_m | skratos115 | 2024-06-28T18:36:07Z | 921 | 0 | null | [
"gguf",
"text-generation",
"qwen2",
"instruct",
"unsloth",
"OpenDevin",
"dataset:xingyaoww/opendevin-code-act",
"license:mit",
"region:us"
]
| text-generation | 2024-06-27T21:25:02Z | ---
license: mit
tags:
- text-generation
- qwen2
- instruct
- unsloth
- OpenDevin
datasets:
- xingyaoww/opendevin-code-act
---
## Qwen2.7b.OpenDevin
brought to you by skratos115 (HF) / Kingatlas115 (GH) in colaboration with the official Opendevin Team ~xingyaoww
# Qwen2-7B-Instruct with OpenDevin Tool Calling
## Overview
This project involves the fine-tuning of the `Qwen2-7B-Instruct` model using the [opendevin-code-act dataset](https://huggingface.co/datasets/xingyaoww/opendevin-code-act) with the help of Unsloth. The primary goal is to develop a more powerful LLM capable of effectively using the CodeAct framework for tool calling. This is still in early development and should not be used in production. We are working on building a bigger dataset for tool paths/ trajectories and could you all the help we can by using the feedback integration to help us build better trajectories and release to the public via MIT license for OSS model training.
read more here:https://x.com/gneubig/status/1802740786242420896 and http://www.linkedin.com/feed/update/urn:li:activity:7208507606728929280/
## Model Details
- **Model Name**: Qwen2-7B-Instruct
- **Dataset**: [opendevin-code-act](https://huggingface.co/datasets/xingyaoww/opendevin-code-act)
- **Training Platform**: Unsloth
provided full merged files
or
Quantized f16, q4_k_m, Q5_k_m, and Q8_0 gguf files.
I used the qwen2.7b.OD.q4_k_m.gguf for my testing and got it to write me a simple script. more testing to come.
## Running the Model
You can run this model using `vLLM` or `ollama`. The following instructions are for using `ollama`.
q-4k
ollama run skratos115/qwen2-7b-opendevin-q4_k_m
or
f16
ollama run skratos115/qwen2-7b-opendevin-f16
### Prerequisites
- Docker
- Hugging Face `transformers` library (version >= 4.37.0 is recommended)
### Running with Ollama
1. **Install Docker**: Ensure you have Docker installed on your machine.
2. **Pull the Latest Hugging Face Transformers**:
pip install transformers>=4.37.0
3. **Set Up Your Workspace**:
WORKSPACE_BASE=$(pwd)/workspace
4. **Run the Docker Command**:
docker run -it \
--pull=always \
-e SANDBOX_USER_ID=$(id -u) \
-e PERSIST_SANDBOX="true" \
-e LLM_API_KEY="ollama" \
-e LLM_BASE_URL="http://[yourIPhere or 0.0.0.0]:11434" \
-e SSH_PASSWORD="make something up here" \
-e WORKSPACE_MOUNT_PATH=$WORKSPACE_BASE \
-v $WORKSPACE_BASE:/opt/workspace_base \
-v /var/run/docker.sock:/var/run/docker.sock \
-p 3000:3000 \
--add-host host.docker.internal:host-gateway \
--name opendevin-app-$(date +%Y%m%d%H%M%S) \
ghcr.io/opendevin/opendevin:main
Replace `[yourIPhere or 0.0.0.0]` with your actual IP address or use `0.0.0.0` for localhost.
## Early Development
This project is in its early stages, and we are continuously working to improve the model and its capabilities. Contributions and feedback are welcome.
## Support my work
Right now all of my work has been funded personally, if you like my work and can help support growth in the AI community consider joining or donating to my Patreon.
[Patreon Link](https://www.patreon.com/atlasaisecurity)
## License
This project is licensed under the [MIT License](LICENSE).
|
tapan247/vidula-finetune-llama | tapan247 | 2024-06-29T16:44:07Z | 921 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-29T16:39:03Z | Entry not found |
pparasurama/raceBERT-ethnicity | pparasurama | 2021-11-09T20:42:29Z | 920 | 1 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-03-02T23:29:05Z | Entry not found |
stablediffusionapi/bb95-furry-mix | stablediffusionapi | 2024-04-16T06:15:40Z | 920 | 8 | diffusers | [
"diffusers",
"safetensors",
"stablediffusionapi.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-08-14T19:09:25Z | ---
license: creativeml-openrail-m
tags:
- stablediffusionapi.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# BB95 Furry Mix API Inference

## Get API Key
Get API key from [Stable Diffusion API](http://stablediffusionapi.com/), No Payment needed.
Replace Key in below code, change **model_id** to "bb95-furry-mix"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://stablediffusionapi.com/docs)
Try model for free: [Generate Images](https://stablediffusionapi.com/models/bb95-furry-mix)
Model link: [View model](https://stablediffusionapi.com/models/bb95-furry-mix)
Credits: [View credits](https://civitai.com/?query=BB95%20Furry%20Mix)
View all models: [View Models](https://stablediffusionapi.com/models)
import requests
import json
url = "https://stablediffusionapi.com/api/v4/dreambooth"
payload = json.dumps({
"key": "your_api_key",
"model_id": "bb95-furry-mix",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
stablediffusionapi/hardcore-hentai | stablediffusionapi | 2024-06-05T21:44:33Z | 920 | 5 | diffusers | [
"diffusers",
"modelslab.com",
"stable-diffusion-api",
"text-to-image",
"ultra-realistic",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2024-04-21T04:01:40Z | ---
license: creativeml-openrail-m
tags:
- modelslab.com
- stable-diffusion-api
- text-to-image
- ultra-realistic
pinned: true
---
# Hardcore Hentai API Inference

## Get API Key
Get API key from [ModelsLab API](http://modelslab.com), No Payment needed.
Replace Key in below code, change **model_id** to "hardcore-hentai"
Coding in PHP/Node/Java etc? Have a look at docs for more code examples: [View docs](https://modelslab.com/docs)
Try model for free: [Generate Images](https://modelslab.com/models/hardcore-hentai)
Model link: [View model](https://modelslab.com/models/hardcore-hentai)
View all models: [View Models](https://modelslab.com/models)
import requests
import json
url = "https://modelslab.com/api/v6/images/text2img"
payload = json.dumps({
"key": "your_api_key",
"model_id": "hardcore-hentai",
"prompt": "ultra realistic close up portrait ((beautiful pale cyberpunk female with heavy black eyeliner)), blue eyes, shaved side haircut, hyper detail, cinematic lighting, magic neon, dark red city, Canon EOS R3, nikon, f/1.4, ISO 200, 1/160s, 8K, RAW, unedited, symmetrical balance, in-frame, 8K",
"negative_prompt": "painting, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, deformed, ugly, blurry, bad anatomy, bad proportions, extra limbs, cloned face, skinny, glitchy, double torso, extra arms, extra hands, mangled fingers, missing lips, ugly face, distorted face, extra legs, anime",
"width": "512",
"height": "512",
"samples": "1",
"num_inference_steps": "30",
"safety_checker": "no",
"enhance_prompt": "yes",
"seed": None,
"guidance_scale": 7.5,
"multi_lingual": "no",
"panorama": "no",
"self_attention": "no",
"upscale": "no",
"embeddings": "embeddings_model_id",
"lora": "lora_model_id",
"webhook": None,
"track_id": None
})
headers = {
'Content-Type': 'application/json'
}
response = requests.request("POST", url, headers=headers, data=payload)
print(response.text)
> Use this coupon code to get 25% off **DMGG0RBN** |
edumunozsala/vit_base-224-in21k-ft-cifar100 | edumunozsala | 2023-08-10T17:49:15Z | 919 | 1 | transformers | [
"transformers",
"pytorch",
"safetensors",
"vit",
"image-classification",
"sagemaker",
"ImageClassification",
"generated_from_trainer",
"es",
"dataset:cifar100",
"arxiv:2006.03677",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-06-11T10:54:37Z | ---
language: es
tags:
- sagemaker
- vit
- ImageClassification
- generated_from_trainer
license: apache-2.0
datasets:
- cifar100
metrics:
- accuracy
model-index:
- name: vit_base-224-in21k-ft-cifar100
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: "Cifar100"
type: cifar100
metrics:
- name: Accuracy
type: accuracy
value: 0.9148
---
# Model vit_base-224-in21k-ft-cifar100
## **A finetuned model for Image classification in Spanish**
This model was trained using Amazon SageMaker and the Hugging Face Deep Learning container,
The base model is **Vision Transformer (base-sized model)** which is a transformer encoder model (BERT-like) pretrained on a large collection of images in a supervised fashion, namely ImageNet-21k, at a resolution of 224x224 pixels.[Link to base model](https://huggingface.co/google/vit-base-patch16-224-in21k)
## Base model citation
### BibTeX entry and citation info
```bibtex
@misc{wu2020visual,
title={Visual Transformers: Token-based Image Representation and Processing for Computer Vision},
author={Bichen Wu and Chenfeng Xu and Xiaoliang Dai and Alvin Wan and Peizhao Zhang and Zhicheng Yan and Masayoshi Tomizuka and Joseph Gonzalez and Kurt Keutzer and Peter Vajda},
year={2020},
eprint={2006.03677},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## Dataset
[Link to dataset description](http://www.cs.toronto.edu/~kriz/cifar.html)
The CIFAR-10 and CIFAR-100 are labeled subsets of the 80 million tiny images dataset. They were collected by Alex Krizhevsky, Vinod Nair, and Geoffrey Hinton
The CIFAR-10 dataset consists of 60000 32x32 colour images in 10 classes, with 6000 images per class. There are 50000 training images and 10000 test images.
This dataset,CIFAR100, is just like the CIFAR-10, except it has 100 classes containing 600 images each. There are 500 training images and 100 testing images per class. The 100 classes in the CIFAR-100 are grouped into 20 superclasses. Each image comes with a "fine" label (the class to which it belongs) and a "coarse" label (the superclass to which it belongs).
Sizes of datasets:
- Train dataset: 50,000
- Test dataset: 10,000
## Intended uses & limitations
This model is intented for Image Classification.
## Hyperparameters
{
"epochs": "5",
"train_batch_size": "32",
"eval_batch_size": "8",
"fp16": "true",
"learning_rate": "1e-05",
}
## Test results
- Accuracy = 0.9148
## Model in action
### Usage for Image Classification
```python
from transformers import ViTFeatureExtractor, ViTModel
from PIL import Image
import requests
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
feature_extractor = ViTFeatureExtractor.from_pretrained('google/vit-base-patch16-224-in21k')
model = ViTModel.from_pretrained('edumunozsala/vit_base-224-in21k-ft-cifar100')
inputs = feature_extractor(images=image, return_tensors="pt")
outputs = model(**inputs)
last_hidden_states = outputs.last_hidden_state
```
Created by [Eduardo Muñoz/@edumunozsala](https://github.com/edumunozsala)
|
saik0s/realistic_vision_inpainting | saik0s | 2023-06-10T18:09:57Z | 919 | 14 | diffusers | [
"diffusers",
"safetensors",
"license:openrail",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-02-22T21:34:57Z | ---
license: openrail
---
|
mlx-community/Meta-Llama-3-8B-Instruct-4bit | mlx-community | 2024-04-19T08:23:40Z | 919 | 73 | mlx | [
"mlx",
"safetensors",
"llama",
"facebook",
"meta",
"pytorch",
"llama-3",
"text-generation",
"conversational",
"en",
"license:other",
"region:us"
]
| text-generation | 2024-04-18T16:15:51Z | ---
language:
- en
license: other
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- mlx
pipeline_tag: text-generation
license_name: llama3
license_link: LICENSE
extra_gated_prompt: "### META LLAMA 3 COMMUNITY LICENSE AGREEMENT\nMeta Llama 3 Version\
\ Release Date: April 18, 2024\n\"Agreement\" means the terms and conditions for\
\ use, reproduction, distribution and modification of the Llama Materials set forth\
\ herein.\n\"Documentation\" means the specifications, manuals and documentation\
\ accompanying Meta Llama 3 distributed by Meta at https://llama.meta.com/get-started/.\n\
\"Licensee\" or \"you\" means you, or your employer or any other person or entity\
\ (if you are entering into this Agreement on such person or entity’s behalf), of\
\ the age required under applicable laws, rules or regulations to provide legal\
\ consent and that has legal authority to bind your employer or such other person\
\ or entity if you are entering in this Agreement on their behalf.\n\"Meta Llama\
\ 3\" means the foundational large language models and software and algorithms,\
\ including machine-learning model code, trained model weights, inference-enabling\
\ code, training-enabling code, fine-tuning enabling code and other elements of\
\ the foregoing distributed by Meta at https://llama.meta.com/llama-downloads.\n\
\"Llama Materials\" means, collectively, Meta’s proprietary Meta Llama 3 and Documentation\
\ (and any portion thereof) made available under this Agreement.\n\"Meta\" or \"\
we\" means Meta Platforms Ireland Limited (if you are located in or, if you are\
\ an entity, your principal place of business is in the EEA or Switzerland) and\
\ Meta Platforms, Inc. (if you are located outside of the EEA or Switzerland).\n\
\ \n1. License Rights and Redistribution.\na. Grant of Rights. You are granted\
\ a non-exclusive, worldwide, non-transferable and royalty-free limited license\
\ under Meta’s intellectual property or other rights owned by Meta embodied in the\
\ Llama Materials to use, reproduce, distribute, copy, create derivative works of,\
\ and make modifications to the Llama Materials.\nb. Redistribution and Use.\ni.\
\ If you distribute or make available the Llama Materials (or any derivative works\
\ thereof), or a product or service that uses any of them, including another AI\
\ model, you shall (A) provide a copy of this Agreement with any such Llama Materials;\
\ and (B) prominently display “Built with Meta Llama 3” on a related website, user\
\ interface, blogpost, about page, or product documentation. If you use the Llama\
\ Materials to create, train, fine tune, or otherwise improve an AI model, which\
\ is distributed or made available, you shall also include “Llama 3” at the beginning\
\ of any such AI model name.\nii. If you receive Llama Materials, or any derivative\
\ works thereof, from a Licensee as part of an integrated end user product, then\
\ Section 2 of this Agreement will not apply to you.\niii. You must retain in all\
\ copies of the Llama Materials that you distribute the following attribution notice\
\ within a “Notice” text file distributed as a part of such copies: “Meta Llama\
\ 3 is licensed under the Meta Llama 3 Community License, Copyright © Meta Platforms,\
\ Inc. All Rights Reserved.”\niv. Your use of the Llama Materials must comply with\
\ applicable laws and regulations (including trade compliance laws and regulations)\
\ and adhere to the Acceptable Use Policy for the Llama Materials (available at\
\ https://llama.meta.com/llama3/use-policy), which is hereby incorporated by reference\
\ into this Agreement.\nv. You will not use the Llama Materials or any output or\
\ results of the Llama Materials to improve any other large language model (excluding\
\ Meta Llama 3 or derivative works thereof).\n2. Additional Commercial Terms. If,\
\ on the Meta Llama 3 version release date, the monthly active users of the products\
\ or services made available by or for Licensee, or Licensee’s affiliates, is greater\
\ than 700 million monthly active users in the preceding calendar month, you must\
\ request a license from Meta, which Meta may grant to you in its sole discretion,\
\ and you are not authorized to exercise any of the rights under this Agreement\
\ unless or until Meta otherwise expressly grants you such rights.\n3. Disclaimer\
\ of Warranty. UNLESS REQUIRED BY APPLICABLE LAW, THE LLAMA MATERIALS AND ANY OUTPUT\
\ AND RESULTS THEREFROM ARE PROVIDED ON AN “AS IS” BASIS, WITHOUT WARRANTIES OF\
\ ANY KIND, AND META DISCLAIMS ALL WARRANTIES OF ANY KIND, BOTH EXPRESS AND IMPLIED,\
\ INCLUDING, WITHOUT LIMITATION, ANY WARRANTIES OF TITLE, NON-INFRINGEMENT, MERCHANTABILITY,\
\ OR FITNESS FOR A PARTICULAR PURPOSE. YOU ARE SOLELY RESPONSIBLE FOR DETERMINING\
\ THE APPROPRIATENESS OF USING OR REDISTRIBUTING THE LLAMA MATERIALS AND ASSUME\
\ ANY RISKS ASSOCIATED WITH YOUR USE OF THE LLAMA MATERIALS AND ANY OUTPUT AND RESULTS.\n\
4. Limitation of Liability. IN NO EVENT WILL META OR ITS AFFILIATES BE LIABLE UNDER\
\ ANY THEORY OF LIABILITY, WHETHER IN CONTRACT, TORT, NEGLIGENCE, PRODUCTS LIABILITY,\
\ OR OTHERWISE, ARISING OUT OF THIS AGREEMENT, FOR ANY LOST PROFITS OR ANY INDIRECT,\
\ SPECIAL, CONSEQUENTIAL, INCIDENTAL, EXEMPLARY OR PUNITIVE DAMAGES, EVEN IF META\
\ OR ITS AFFILIATES HAVE BEEN ADVISED OF THE POSSIBILITY OF ANY OF THE FOREGOING.\n\
5. Intellectual Property.\na. No trademark licenses are granted under this Agreement,\
\ and in connection with the Llama Materials, neither Meta nor Licensee may use\
\ any name or mark owned by or associated with the other or any of its affiliates,\
\ except as required for reasonable and customary use in describing and redistributing\
\ the Llama Materials or as set forth in this Section 5(a). Meta hereby grants you\
\ a license to use “Llama 3” (the “Mark”) solely as required to comply with the\
\ last sentence of Section 1.b.i. You will comply with Meta’s brand guidelines (currently\
\ accessible at https://about.meta.com/brand/resources/meta/company-brand/ ). All\
\ goodwill arising out of your use of the Mark will inure to the benefit of Meta.\n\
b. Subject to Meta’s ownership of Llama Materials and derivatives made by or for\
\ Meta, with respect to any derivative works and modifications of the Llama Materials\
\ that are made by you, as between you and Meta, you are and will be the owner of\
\ such derivative works and modifications.\nc. If you institute litigation or other\
\ proceedings against Meta or any entity (including a cross-claim or counterclaim\
\ in a lawsuit) alleging that the Llama Materials or Meta Llama 3 outputs or results,\
\ or any portion of any of the foregoing, constitutes infringement of intellectual\
\ property or other rights owned or licensable by you, then any licenses granted\
\ to you under this Agreement shall terminate as of the date such litigation or\
\ claim is filed or instituted. You will indemnify and hold harmless Meta from and\
\ against any claim by any third party arising out of or related to your use or\
\ distribution of the Llama Materials.\n6. Term and Termination. The term of this\
\ Agreement will commence upon your acceptance of this Agreement or access to the\
\ Llama Materials and will continue in full force and effect until terminated in\
\ accordance with the terms and conditions herein. Meta may terminate this Agreement\
\ if you are in breach of any term or condition of this Agreement. Upon termination\
\ of this Agreement, you shall delete and cease use of the Llama Materials. Sections\
\ 3, 4 and 7 shall survive the termination of this Agreement.\n7. Governing Law\
\ and Jurisdiction. This Agreement will be governed and construed under the laws\
\ of the State of California without regard to choice of law principles, and the\
\ UN Convention on Contracts for the International Sale of Goods does not apply\
\ to this Agreement. The courts of California shall have exclusive jurisdiction\
\ of any dispute arising out of this Agreement.\n### Meta Llama 3 Acceptable Use\
\ Policy\nMeta is committed to promoting safe and fair use of its tools and features,\
\ including Meta Llama 3. If you access or use Meta Llama 3, you agree to this Acceptable\
\ Use Policy (“Policy”). The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy](https://llama.meta.com/llama3/use-policy)\n\
#### Prohibited Uses\nWe want everyone to use Meta Llama 3 safely and responsibly.\
\ You agree you will not use, or allow others to use, Meta Llama 3 to: 1. Violate\
\ the law or others’ rights, including to:\n 1. Engage in, promote, generate,\
\ contribute to, encourage, plan, incite, or further illegal or unlawful activity\
\ or content, such as:\n 1. Violence or terrorism\n 2. Exploitation\
\ or harm to children, including the solicitation, creation, acquisition, or dissemination\
\ of child exploitative content or failure to report Child Sexual Abuse Material\n\
\ 3. Human trafficking, exploitation, and sexual violence\n 4. The\
\ illegal distribution of information or materials to minors, including obscene\
\ materials, or failure to employ legally required age-gating in connection with\
\ such information or materials.\n 5. Sexual solicitation\n 6. Any\
\ other criminal activity\n 2. Engage in, promote, incite, or facilitate the\
\ harassment, abuse, threatening, or bullying of individuals or groups of individuals\n\
\ 3. Engage in, promote, incite, or facilitate discrimination or other unlawful\
\ or harmful conduct in the provision of employment, employment benefits, credit,\
\ housing, other economic benefits, or other essential goods and services\n 4.\
\ Engage in the unauthorized or unlicensed practice of any profession including,\
\ but not limited to, financial, legal, medical/health, or related professional\
\ practices\n 5. Collect, process, disclose, generate, or infer health, demographic,\
\ or other sensitive personal or private information about individuals without rights\
\ and consents required by applicable laws\n 6. Engage in or facilitate any action\
\ or generate any content that infringes, misappropriates, or otherwise violates\
\ any third-party rights, including the outputs or results of any products or services\
\ using the Llama Materials\n 7. Create, generate, or facilitate the creation\
\ of malicious code, malware, computer viruses or do anything else that could disable,\
\ overburden, interfere with or impair the proper working, integrity, operation\
\ or appearance of a website or computer system\n2. Engage in, promote, incite,\
\ facilitate, or assist in the planning or development of activities that present\
\ a risk of death or bodily harm to individuals, including use of Meta Llama 3 related\
\ to the following:\n 1. Military, warfare, nuclear industries or applications,\
\ espionage, use for materials or activities that are subject to the International\
\ Traffic Arms Regulations (ITAR) maintained by the United States Department of\
\ State\n 2. Guns and illegal weapons (including weapon development)\n 3.\
\ Illegal drugs and regulated/controlled substances\n 4. Operation of critical\
\ infrastructure, transportation technologies, or heavy machinery\n 5. Self-harm\
\ or harm to others, including suicide, cutting, and eating disorders\n 6. Any\
\ content intended to incite or promote violence, abuse, or any infliction of bodily\
\ harm to an individual\n3. Intentionally deceive or mislead others, including use\
\ of Meta Llama 3 related to the following:\n 1. Generating, promoting, or furthering\
\ fraud or the creation or promotion of disinformation\n 2. Generating, promoting,\
\ or furthering defamatory content, including the creation of defamatory statements,\
\ images, or other content\n 3. Generating, promoting, or further distributing\
\ spam\n 4. Impersonating another individual without consent, authorization,\
\ or legal right\n 5. Representing that the use of Meta Llama 3 or outputs are\
\ human-generated\n 6. Generating or facilitating false online engagement, including\
\ fake reviews and other means of fake online engagement\n4. Fail to appropriately\
\ disclose to end users any known dangers of your AI system\nPlease report any violation\
\ of this Policy, software “bug,” or other problems that could lead to a violation\
\ of this Policy through one of the following means:\n * Reporting issues with\
\ the model: [https://github.com/meta-llama/llama3](https://github.com/meta-llama/llama3)\n\
\ * Reporting risky content generated by the model:\n developers.facebook.com/llama_output_feedback\n\
\ * Reporting bugs and security concerns: facebook.com/whitehat/info\n * Reporting\
\ violations of the Acceptable Use Policy or unlicensed uses of Meta Llama 3: [email protected]"
extra_gated_fields:
First Name: text
Last Name: text
Date of birth: date_picker
Country: country
Affiliation: text
geo: ip_location
? By clicking Submit below I accept the terms of the license and acknowledge that
the information I provide will be collected stored processed and shared in accordance
with the Meta Privacy Policy
: checkbox
extra_gated_description: The information you provide will be collected, stored, processed
and shared in accordance with the [Meta Privacy Policy](https://www.facebook.com/privacy/policy/).
extra_gated_button_content: Submit
---
# mlx-community/Meta-Llama-3-8B-Instruct-4bit
This model was converted to MLX format from [`meta-llama/Meta-Llama-3-8B-Instruct`]() using mlx-lm version **0.9.0**.
Model added by [Prince Canuma](https://twitter.com/Prince_Canuma).
Refer to the [original model card](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) for more details on the model.
## Use with mlx
```bash
pip install mlx-lm
```
```python
from mlx_lm import load, generate
model, tokenizer = load("mlx-community/Meta-Llama-3-8B-Instruct-4bit")
response = generate(model, tokenizer, prompt="hello", verbose=True)
```
|
maldv/Meta-Llama-3-8B-Instruct-hf | maldv | 2024-06-05T20:55:10Z | 919 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"facebook",
"meta",
"pytorch",
"llama-3",
"conversational",
"en",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-06-05T20:49:03Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
license: llama3
---
*Based on the June 2nd, 2024 repo, with the cruft removed*
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples of both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
messages,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][-1])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include "original/*" --local-dir Meta-Llama-3-8B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 8B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
mlfoundations/tabula-8b | mlfoundations | 2024-07-01T20:09:00Z | 919 | 19 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"dataset:jpgard/t4-full",
"arxiv:2406.12031",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-06-11T04:20:19Z | ---
license: llama3
datasets:
- jpgard/t4-full
language:
- en
---
This repository contains the TabuLa-8B (Tabular Llama-8B) model.
TabuLa-8B is a foundation model for prediction (classification and binned regression) on tabular data.
TabuLa-8B is described in the paper ["Large Scale Transfer Learning for Tabular Data via Language Modeling."](https://arxiv.org/abs/2406.12031)
For more details on the model, see the paper, which includes a Model Card detailing the model architecture, training, and evaluation.
TabuLa-8B was trained with [rtfm](https://github.com/mlfoundations/rtfm),
using the [T4 dataset](https://huggingface.co/datasets/mlfoundations/t4-full).
TabuLa-8B is built with Meta Llama 3.
# Usage and Examples
You can load the model with `transformers` via
```
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("mlfoundations/tabula-8b")
model = AutoModelForCausalLM.from_pretrained("mlfoundations/tabula-8b")
```
For more information on how to prepare data and run inference (including a demo notebook for performing inference on your data), see the examples in [rtfm](https://github.com/mlfoundations/rtfm).
# License and Terms of Use
TabuLa-8B is fine-tuned from the Llama-3 8B model.
As a result, we release it under the [Llama 3 license](https://llama.meta.com/llama3/license/),
and by using the model you agree to abide by the [Llama 3 Community License Agreement](https://llama.meta.com/llama3/license/)
and the Llama 3 [Acceptable Use Policy](https://llama.meta.com/llama3/use-policy/).
|
Helsinki-NLP/opus-mt-en-sw | Helsinki-NLP | 2023-08-16T11:31:16Z | 918 | 6 | transformers | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"en",
"sw",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| translation | 2022-03-02T23:29:04Z | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-en-sw
* source languages: en
* target languages: sw
* OPUS readme: [en-sw](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/en-sw/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/en-sw/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-sw/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/en-sw/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| GlobalVoices.en.sw | 24.2 | 0.527 |
|
supermy/jinyong-gpt2 | supermy | 2022-12-06T02:13:48Z | 918 | 1 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"zh",
"dataset:jinyong",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-12-02T23:50:36Z | ---
language: zh
datasets: jinyong
inference:
parameters:
max_length: 108
num_return_sequences: 1
do_sample: True
widget:
- text: "杨过朗声说道:今番良晤,豪兴不浅,他日江湖相逢,再当杯酒言欢。咱们就此别过。 -"
example_title: "神雕侠侣"
- text: "乱世之际,人不如狗。 -"
example_title: "射雕英雄传"
---
# 飞雪连天射白鹿,笑书神侠倚碧鸳
## Model description
AI生成金庸小说,给出开头续写。
## How to use
使用 pipeline 调用模型:
```python
>>> # 调用微调后的模型
>>> senc="这些雪花落下来,多么白,多么好看.过几天太阳出来,每一片 雪花都变得无影无踪.到得明年冬天,又有许很多多雪花,只不过已不是 今年这些雪花罢了。"
>>> model_id="jinyong-gpt2-finetuning"
>>> from transformers import AutoTokenizer, GPT2LMHeadModel, TextGenerationPipeline
>>> tokenizer = AutoTokenizer.from_pretrained(model_id)
>>> model = GPT2LMHeadModel.from_pretrained(model_id)
>>> text_generator = TextGenerationPipeline(model, tokenizer)
>>> text_generator.model.config.pad_token_id = text_generator.model.config.eos_token_id
>>> text_generator( senc,max_length=108, do_sample=True)
[{'generated_text': '这些雪花落下来,多么白,多么好看.过几天太阳出来,每一片 雪花都变得无影无踪.到得明年冬天,又有许很多多雪花,只不过已不是 今年这些雪花罢了。 反正 老天爷 有眼 , 不知 哪里 是甚么 风 险 ?” 正 说到此处 , 突然 听得 谢逊 啸声 渐近 , 忍不住 张口 惊呼 , 一齐 向他 扑去 , 只听 谢逊 一声 怒吼 , 跟着 左手 用力 拍 出一掌 , 以 掌力 化开 。 众人 吃了一惊 , 同时 从 海 道 中 跃出 , 双双 倒退 。 张翠山和殷素素 对望一眼 , 均想 以 这两 大高手 之力 如何 抵挡 , 以 今日 之力 如何 攻敌 之'}]
>>>
```
Here is how to use this model to get the features of a given text in PyTorch:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("supermy/jinyong-gpt2")
model = AutoModelForCausalLM.from_pretrained("supermy/jinyong-gpt2")
```
## Training data
此数据集基于金庸的【飞雪连天射白鹿,笑书神侠倚碧鸳】小说集训练。
## 统计信息
```
```
## Training procedure
基于模型:[GPT2](https://huggingface.co/gpt2)
训练环境:英伟达16G显卡
bpe分词:"vocab_size"=30000
```
[INFO|trainer.py:1608] 2022-12-02 19:52:59,024 >> ***** Running training *****
[INFO|trainer.py:1609] 2022-12-02 19:52:59,024 >> Num examples = 9443
[INFO|trainer.py:1610] 2022-12-02 19:52:59,024 >> Num Epochs = 108
[INFO|trainer.py:1611] 2022-12-02 19:52:59,024 >> Instantaneous batch size per device = 12
[INFO|trainer.py:1612] 2022-12-02 19:52:59,024 >> Total train batch size (w. parallel, distributed & accumulation) = 12
[INFO|trainer.py:1613] 2022-12-02 19:52:59,024 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1614] 2022-12-02 19:52:59,024 >> Total optimization steps = 84996
[INFO|trainer.py:1616] 2022-12-02 19:52:59,025 >> Number of trainable parameters = 124439808
[INFO|trainer.py:1608] 2022-12-03 21:44:00,182 >> ***** Running training *****
[INFO|trainer.py:1609] 2022-12-03 21:44:00,182 >> Num examples = 9443
[INFO|trainer.py:1610] 2022-12-03 21:44:00,182 >> Num Epochs = 216
[INFO|trainer.py:1611] 2022-12-03 21:44:00,182 >> Instantaneous batch size per device = 12
[INFO|trainer.py:1612] 2022-12-03 21:44:00,182 >> Total train batch size (w. parallel, distributed & accumulation) = 12
[INFO|trainer.py:1613] 2022-12-03 21:44:00,182 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1614] 2022-12-03 21:44:00,182 >> Total optimization steps = 169992
[INFO|trainer.py:1616] 2022-12-03 21:44:00,183 >> Number of trainable parameters = 124439808
[INFO|trainer.py:1637] 2022-12-03 21:44:00,184 >> Continuing training from checkpoint, will skip to saved global_step
[INFO|trainer.py:1638] 2022-12-03 21:44:00,184 >> Continuing training from epoch 107
[INFO|trainer.py:1639] 2022-12-03 21:44:00,184 >> Continuing training from global step 84500
[INFO|trainer.py:1608] 2022-12-05 07:36:13,626 >> ***** Running training *****
[INFO|trainer.py:1609] 2022-12-05 07:36:13,626 >> Num examples = 9443
[INFO|trainer.py:1610] 2022-12-05 07:36:13,626 >> Num Epochs = 368
[INFO|trainer.py:1611] 2022-12-05 07:36:13,626 >> Instantaneous batch size per device = 12
[INFO|trainer.py:1612] 2022-12-05 07:36:13,626 >> Total train batch size (w. parallel, distributed & accumulation) = 12
[INFO|trainer.py:1613] 2022-12-05 07:36:13,626 >> Gradient Accumulation steps = 1
[INFO|trainer.py:1614] 2022-12-05 07:36:13,626 >> Total optimization steps = 289616
[INFO|trainer.py:1616] 2022-12-05 07:36:13,627 >> Number of trainable parameters = 124439808
[INFO|trainer.py:1637] 2022-12-05 07:36:13,628 >> Continuing training from checkpoint, will skip to saved global_step
[INFO|trainer.py:1638] 2022-12-05 07:36:13,628 >> Continuing training from epoch 255
[INFO|trainer.py:1639] 2022-12-05 07:36:13,628 >> Continuing training from global step 201000
{'loss': 8.0431, 'learning_rate': 4.970998635229893e-05, 'epoch': 0.64}
{'loss': 7.4867, 'learning_rate': 4.94158548637583e-05, 'epoch': 1.27}
{'loss': 7.322, 'learning_rate': 4.912172337521766e-05, 'epoch': 1.91}
......
{'loss': 3.901, 'learning_rate': 2.5010882865076008e-05, 'epoch': 108.01}
{'loss': 3.8959, 'learning_rate': 2.4863817120805686e-05, 'epoch': 108.64}
......
{'loss': 3.1625, 'learning_rate': 4.6090404254317857e-07, 'epoch': 214.1}
{'loss': 3.1592, 'learning_rate': 3.1413242976140055e-07, 'epoch': 214.74}
{'loss': 3.1625, 'learning_rate': 1.6706668549108195e-07, 'epoch': 215.37}
{'train_runtime': 72271.9602, 'train_samples_per_second': 28.222, 'train_steps_per_second': 2.352, 'train_loss': 1.7180436183842016, 'epoch': 216.0}
{'loss': 2.7087, 'learning_rate': 4.2642671675598036e-08, 'epoch': 367.85}
{'train_runtime': 74859.0808, 'train_samples_per_second': 46.421, 'train_steps_per_second': 3.869, 'train_loss': 0.8725239146935282, 'epoch': 368.0}
***** train metrics *****
epoch = 368.0
train_loss = 0.8725
train_runtime = 20:47:39.08
train_samples = 9443
train_samples_per_second = 46.421
train_steps_per_second = 3.869
12/06/2022 04:23:55 - INFO - __main__ - *** Evaluate ***
[INFO|trainer.py:2929] 2022-12-06 04:23:55,953 >> ***** Running Evaluation *****
[INFO|trainer.py:2931] 2022-12-06 04:23:55,953 >> Num examples = 283
[INFO|trainer.py:2934] 2022-12-06 04:23:55,954 >> Batch size = 12
100%|██████████| 24/24 [00:07<00:00, 3.20it/s]
[INFO|modelcard.py:449] 2022-12-06 04:24:04,760 >> Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Causal Language Modeling', 'type': 'text-generation'}, 'metrics': [{'name': 'Accuracy', 'type': 'accuracy', 'value': 0.19599206157122803}]}
***** eval metrics *****
epoch = 368.0
eval_accuracy = 0.196
eval_loss = 7.9524
eval_runtime = 0:00:07.87
eval_samples = 283
eval_samples_per_second = 35.94
eval_steps_per_second = 3.048
perplexity = 2842.2766
``` |
Yntec/animeTWO | Yntec | 2023-09-18T10:59:02Z | 918 | 8 | diffusers | [
"diffusers",
"safetensors",
"Anime",
"Space",
"Cats",
"realisticElves",
"verxonous86495",
"text-to-image",
"stable-diffusion",
"stable-diffusion-diffusers",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-09-18T07:28:09Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- Anime
- Space
- Cats
- realisticElves
- verxonous86495
- text-to-image
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
---
#animeTWO
No-ema version of this model. animeTWOz has the ZVAE baked in.
Sample and prompt:

idyllic particulate sparkling atmospheric, pretty CUTE little girl, 1940, Magazine ad, Iconic. beautiful detailed legs, unreal 5, daz, hyperrealistic, octane render, Painterly soft brush, shy modest pleasing palette, textured, detailed, flawless, perfect, mural - sized chibi character design key visual symmetrical headshot portrait by yoshitomo nara and ROSSDRAWS
Original pages:
https://civitai.com/models/40245?modelVersionId=45715 (animeTWO)
https://civitai.com/models/97653/z-vae (z-vae) |
Trendyol/Trendyol-LLM-7b-chat-v1.0 | Trendyol | 2024-03-11T06:38:05Z | 918 | 33 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"tr",
"en",
"base_model:Trendyol/Trendyol-LLM-7b-base-v1.0",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-05T06:15:34Z | ---
language:
- tr
- en
pipeline_tag: text-generation
license: apache-2.0
base_model: Trendyol/Trendyol-LLM-7b-base-v1.0
---
<img src="https://huggingface.co/Trendyol/Trendyol-LLM-7b-chat-v1.0/resolve/main/trendyol-llm-mistral.jpg"
alt="drawing" width="400"/>
# **Trendyol LLM v1.0**
Trendyol LLM v1.0 is a generative model that is based on Mistral 7B model. This is the repository for the chat model.
## Model Details
**Model Developers** Trendyol
**Variations** [base](https://huggingface.co/Trendyol/Trendyol-LLM-7b-base-v1.0), chat, and [dpo](https://huggingface.co/Trendyol/Trendyol-LLM-7b-chat-dpo-v1.0) variations.
**Input** Models input text only.
**Output** Models generate text only.
**Model Architecture** Trendyol LLM is an auto-regressive language model (based on Mistral 7b) that uses an optimized transformer architecture. The chat version is fine-tuned on 180K instruction sets with the following trainables by using LoRA:
- **lr**=1e-4
- **lora_rank**=64
- **lora_alpha**=128
- **lora_trainable**=q_proj,v_proj,k_proj,o_proj,gate_proj,down_proj,up_proj
- **modules_to_save**=embed_tokens,lm_head
- **lora_dropout**=0.05
- **bf16**=True
- **max_seq_length**=1024
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/lora_diagram.png"
alt="drawing" width="600"/>
## Usage
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model_id = "Trendyol/Trendyol-LLM-7b-chat-v1.0"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id,
device_map='auto',
load_in_8bit=True)
sampling_params = dict(do_sample=True, temperature=0.3, top_k=50, top_p=0.9)
pipe = pipeline("text-generation",
model=model,
tokenizer=tokenizer,
device_map="auto",
max_new_tokens=1024,
return_full_text=True,
repetition_penalty=1.1
)
DEFAULT_SYSTEM_PROMPT = "Sen yardımcı bir asistansın ve sana verilen talimatlar doğrultusunda en iyi cevabı üretmeye çalışacaksın.\n"
TEMPLATE = (
"[INST] {system_prompt}\n\n"
"{instruction} [/INST]"
)
def generate_prompt(instruction, system_prompt=DEFAULT_SYSTEM_PROMPT):
return TEMPLATE.format_map({'instruction': instruction,'system_prompt': system_prompt})
def generate_output(user_query, sys_prompt=DEFAULT_SYSTEM_PROMPT):
prompt = generate_prompt(user_query, sys_prompt)
outputs = pipe(prompt,
**sampling_params
)
return outputs[0]["generated_text"].split("[/INST]")[-1]
user_query = "Türkiye'de kaç il var?"
response = generate_output(user_query)
print(response)
```
with chat template:
```python
pipe = pipeline("conversational",
model=model,
tokenizer=tokenizer,
device_map="auto",
max_new_tokens=1024,
repetition_penalty=1.1
)
messages = [
{"role": "user", "content": "Türkiye'de kaç il var?"}
]
outputs = pipe(messages, **sampling_params)
print(outputs)
```
## Limitations, Risks, Bias, and Ethical Considerations
### Limitations and Known Biases
- **Primary Function and Application:** Trendyol LLM, an autoregressive language model, is primarily designed to predict the next token in a text string. While often used for various applications, it is important to note that it has not undergone extensive real-world application testing. Its effectiveness and reliability across diverse scenarios remain largely unverified.
- **Language Comprehension and Generation:** The model is primarily trained in standard English and Turkish. Its performance in understanding and generating slang, informal language, or other languages may be limited, leading to potential errors or misinterpretations.
- **Generation of False Information:** Users should be aware that Trendyol LLM may produce inaccurate or misleading information. Outputs should be considered as starting points or suggestions rather than definitive answers.
### Risks and Ethical Considerations
- **Potential for Harmful Use:** There is a risk that Trendyol LLM could be used to generate offensive or harmful language. We strongly discourage its use for any such purposes and emphasize the need for application-specific safety and fairness evaluations before deployment.
- **Unintended Content and Bias:** The model was trained on a large corpus of text data, which was not explicitly checked for offensive content or existing biases. Consequently, it may inadvertently produce content that reflects these biases or inaccuracies.
- **Toxicity:** Despite efforts to select appropriate training data, the model is capable of generating harmful content, especially when prompted explicitly. We encourage the open-source community to engage in developing strategies to minimize such risks.
### Recommendations for Safe and Ethical Usage
- **Human Oversight:** We recommend incorporating a human curation layer or using filters to manage and improve the quality of outputs, especially in public-facing applications. This approach can help mitigate the risk of generating objectionable content unexpectedly.
- **Application-Specific Testing:** Developers intending to use Trendyol LLM should conduct thorough safety testing and optimization tailored to their specific applications. This is crucial, as the model’s responses can be unpredictable and may occasionally be biased, inaccurate, or offensive.
- **Responsible Development and Deployment:** It is the responsibility of developers and users of Trendyol LLM to ensure its ethical and safe application. We urge users to be mindful of the model's limitations and to employ appropriate safeguards to prevent misuse or harmful consequences. |
Replete-AI/Llama-3-13B | Replete-AI | 2024-05-04T17:01:08Z | 918 | 4 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-19T04:20:05Z | ---
base_model: []
library_name: transformers
license: other
license_name: llama-3
license_link: https://llama.meta.com/llama3/license/
thumbnail: "https://cdn-uploads.huggingface.co/production/uploads/642cc1c253e76b4c2286c58e/aJJxKus1wP5N-euvHEUq7.png"
---
This is the first version of upscaling llama-3. Version 2 is now out and does not have any of the issues that this version has. Please use version 2 instead. Linked bellow:
- https://huggingface.co/Replete-AI/Llama-3-11.5B-v2
__________________________________________________________________
Llama-3-13B
Thank you to Meta for the weights for Meta-Llama-3-8B

This is an upscaling of the Llama-3-8B Ai using techniques created for Mistral-Evolved-11b-v0.1. This Ai model has been upscaled from 8b parameters to 13b parameters without any continuous pretraining or fine-tuning.
From testing, the model seems to function perfectly at fp16, but has some issues at 4-bit quantization using bitsandbytes.
The model that was used to create this one is linked below:
https://huggingface.co/meta-llama/Meta-Llama-3-8B
- Llama-3-13B
| Metric |Value|
|---------------------------------|----:|
|Avg. |54.61|
|AI2 Reasoning Challenge (25-Shot)|52.99|
|HellaSwag (10-Shot) |80.66|
|MMLU (5-Shot) |62.12|
|TruthfulQA (0-shot) |39.28|
|Winogrande (5-shot) |70.72|
|GSM8k (5-shot) |21.91|
- Original Meta-Llama-3-8B
| Metric |Value|
|---------------------------------|----:|
|Avg. |62.87|
|AI2 Reasoning Challenge (25-Shot)|59.47|
|HellaSwag (10-Shot) |82.09|
|MMLU (5-Shot) |66.69|
|TruthfulQA (0-shot) |43.90|
|Winogrande (5-shot) |77.35|
|GSM8k (5-shot) |45.34| |
duyntnet/Sailor-7B-Chat-imatrix-GGUF | duyntnet | 2024-05-28T01:53:58Z | 918 | 0 | transformers | [
"transformers",
"gguf",
"imatrix",
"Sailor-7B-Chat",
"text-generation",
"en",
"license:other",
"region:us"
]
| text-generation | 2024-05-27T23:28:10Z | ---
license: other
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- transformers
- gguf
- imatrix
- Sailor-7B-Chat
---
Quantizations of https://huggingface.co/sail/Sailor-7B-Chat
# From original readme
Sailor is a suite of Open Language Models tailored for South-East Asia (SEA), focusing on languages such as 🇮🇩Indonesian, 🇹🇭Thai, 🇻🇳Vietnamese, 🇲🇾Malay, and 🇱🇦Lao.
Developed with careful data curation, Sailor models are designed to understand and generate text across diverse linguistic landscapes of SEA region.
## Quickstart
Here provides a code snippet to show you how to load the tokenizer and model and how to generate contents.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
device = "cuda"
model = AutoModelForCausalLM.from_pretrained(
'sail/Sailor-7B-Chat',
torch_dtype="auto",
device_map="auto"
)
tokenizer = AutoTokenizer.from_pretrained('sail/Sailor-7B-Chat')
system_prompt= 'You are a helpful assistant'
prompt = "Beri saya pengenalan singkat tentang model bahasa besar."
# prompt = "Hãy cho tôi một giới thiệu ngắn gọn về mô hình ngôn ngữ lớn."
# prompt = "ให้ฉันแนะนำสั้น ๆ เกี่ยวกับโมเดลภาษาขนาดใหญ่"
messages = [
{"role": "system", "content": system_prompt},
{"role": "question", "content": prompt}
]
text = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
model_inputs = tokenizer([text], return_tensors="pt").to(device)
input_ids = model_inputs.input_ids.to(device)
generated_ids = model.generate(
input_ids,
max_new_tokens=512,
)
generated_ids = [
output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)
]
response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response)
``` |
akhooli/xlm-r-large-arabic-sent | akhooli | 2023-02-10T17:24:49Z | 917 | 8 | transformers | [
"transformers",
"pytorch",
"xlm-roberta",
"text-classification",
"ar",
"en",
"multilingual",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-03-02T23:29:05Z | ---
language:
- ar
- en
- multilingual
license: mit
---
### xlm-r-large-arabic-sent
Multilingual sentiment classification (Label_0: mixed, Label_1: negative, Label_2: positive) of Arabic reviews by fine-tuning XLM-Roberta-Large.
Zero shot classification of other languages (also works in mixed languages - ex. Arabic & English). Mixed category is not accurate and may confuse other
classes (was based on a rate of 3 out of 5 in reviews).
Usage: see last section in this [Colab notebook](https://lnkd.in/d3bCFyZ)
|
ramsrigouthamg/t5_sentence_paraphraser | ramsrigouthamg | 2021-06-23T13:47:31Z | 917 | 8 | transformers | [
"transformers",
"pytorch",
"jax",
"t5",
"text2text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text2text-generation | 2022-03-02T23:29:05Z | Entry not found |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.