
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
kaiku03/wildchat2 | kaiku03 | 2024-05-07T06:05:43Z | 662 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"gpt2",
"text-generation",
"generated_from_trainer",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-07T03:26:58Z | ---
license: mit
tags:
- generated_from_trainer
model-index:
- name: wildchat2
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# wildchat2
This model is a fine-tuned version of [gpt2](https://huggingface.co/gpt2) on the None dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0005
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 8
- total_train_batch_size: 256
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_steps: 1000
- num_epochs: 3
- mixed_precision_training: Native AMP
### Training results
### Framework versions
- Transformers 4.28.0
- Pytorch 2.2.1+cu121
- Datasets 2.19.1
- Tokenizers 0.13.3
|
LLM4Binary/llm4decompile-1.3b-v1.5 | LLM4Binary | 2024-06-20T07:01:03Z | 662 | 2 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"decompile",
"binary",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-10T12:49:04Z | ---
license: mit
tags:
- decompile
- binary
widget:
- text: "# This is the assembly code:\n<func0>:\nendbr64\nlea (%rdi,%rsi,1),%eax\nretq\n# What is the source code?\n"
---
### 1. Introduction of LLM4Decompile
LLM4Decompile aims to decompile x86 assembly instructions into C. The newly released V1.5 series are trained with a larger dataset (15B tokens) and a maximum token length of 4,096, with remarkable performance (up to 100% improvement) compared to the previous model.
- **Github Repository:** [LLM4Decompile](https://github.com/albertan017/LLM4Decompile)
### 2. Evaluation Results
| Model/Benchmark | HumanEval-Decompile | | | | | ExeBench | | | | |
|:----------------------:|:-------------------:|:-------:|:-------:|:-------:|:-------:|:--------:|:-------:|:-------:|:-------:|:-------:|
| Optimization Level | O0 | O1 | O2 | O3 | AVG | O0 | O1 | O2 | O3 | AVG |
| DeepSeek-Coder-6.7B | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0.0000 |
| GPT-4o | 0.3049 | 0.1159 | 0.1037 | 0.1159 | 0.1601 | 0.0443 | 0.0328 | 0.0397 | 0.0343 | 0.0378 |
| LLM4Decompile-End-1.3B | 0.4720 | 0.2061 | 0.2122 | 0.2024 | 0.2732 | 0.1786 | 0.1362 | 0.1320 | 0.1328 | 0.1449 |
| LLM4Decompile-End-6.7B | 0.6805 | 0.3951 | 0.3671 | 0.3720 | 0.4537 | 0.2289 | 0.1660 | 0.1618 | 0.1625 | 0.1798 |
| LLM4Decompile-End-33B | 0.5168 | 0.2956 | 0.2815 | 0.2675 | 0.3404 | 0.1886 | 0.1465 | 0.1396 | 0.1411 | 0.1540 |
### 3. How to Use
Here is an example of how to use our model (Revised for V1.5).
Note: **Replace** func0 with the function name you want to decompile.
**Preprocessing:** Compile the C code into binary, and disassemble the binary into assembly instructions.
```python
import subprocess
import os
OPT = ["O0", "O1", "O2", "O3"]
fileName = 'samples/sample' #'path/to/file'
for opt_state in OPT:
output_file = fileName +'_' + opt_state
input_file = fileName+'.c'
compile_command = f'gcc -o {output_file}.o {input_file} -{opt_state} -lm'#compile the code with GCC on Linux
subprocess.run(compile_command, shell=True, check=True)
compile_command = f'objdump -d {output_file}.o > {output_file}.s'#disassemble the binary file into assembly instructions
subprocess.run(compile_command, shell=True, check=True)
input_asm = ''
with open(output_file+'.s') as f:#asm file
asm= f.read()
if '<'+'func0'+'>:' not in asm: #IMPORTANT replace func0 with the function name
raise ValueError("compile fails")
asm = '<'+'func0'+'>:' + asm.split('<'+'func0'+'>:')[-1].split('\n\n')[0] #IMPORTANT replace func0 with the function name
asm_clean = ""
asm_sp = asm.split("\n")
for tmp in asm_sp:
if len(tmp.split("\t"))<3 and '00' in tmp:
continue
idx = min(
len(tmp.split("\t")) - 1, 2
)
tmp_asm = "\t".join(tmp.split("\t")[idx:]) # remove the binary code
tmp_asm = tmp_asm.split("#")[0].strip() # remove the comments
asm_clean += tmp_asm + "\n"
input_asm = asm_clean.strip()
before = f"# This is the assembly code:\n"#prompt
after = "\n# What is the source code?\n"#prompt
input_asm_prompt = before+input_asm.strip()+after
with open(fileName +'_' + opt_state +'.asm','w',encoding='utf-8') as f:
f.write(input_asm_prompt)
```
**Decompilation:** Use LLM4Decompile to translate the assembly instructions into C:
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_path = 'LLM4Binary/llm4decompile-1.3b-v1.5' # V1.5 Model
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path,torch_dtype=torch.bfloat16).cuda()
with open(fileName +'_' + OPT[0] +'.asm','r') as f:#optimization level O0
asm_func = f.read()
inputs = tokenizer(asm_func, return_tensors="pt").to(model.device)
with torch.no_grad():
outputs = model.generate(**inputs, max_new_tokens=4000)
c_func_decompile = tokenizer.decode(outputs[0][len(inputs[0]):-1])
with open(fileName +'.c','r') as f:#original file
func = f.read()
print(f'original function:\n{func}')# Note we only decompile one function, where the original file may contain multiple functions
print(f'decompiled function:\n{c_func_decompile}')
```
### 4. License
This code repository is licensed under the MIT License.
### 5. Contact
If you have any questions, please raise an issue.
|
QuantFactory/Mistral-7B-Instruct-v0.3-GGUF | QuantFactory | 2024-05-23T07:03:15Z | 662 | 1 | transformers | [
"transformers",
"gguf",
"mistral",
"text-generation",
"base_model:mistralai/Mistral-7B-Instruct-v0.3",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-23T04:58:44Z | ---
license: apache-2.0
base_model: mistralai/Mistral-7B-Instruct-v0.3
library_name: transformers
pipeline_tag: text-generation
tags:
- mistral
---
# Mistral-7B-Instruct-v0.3-GGUF
- This is quantized version of [mistralai/Mistral-7B-Instruct-v0.3](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3) created using llama.cpp
# Model Description
The Mistral-7B-Instruct-v0.3 Large Language Model (LLM) is an instruct fine-tuned version of the Mistral-7B-v0.3.
Mistral-7B-v0.3 has the following changes compared to [Mistral-7B-v0.2](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2/edit/main/README.md)
- Extended vocabulary to 32768
- Supports v3 Tokenizer
- Supports function calling
### Chat
After installing `mistral_inference`, a `mistral-chat` CLI command should be available in your environment. You can chat with the model using
```
mistral-chat $HOME/mistral_models/7B-Instruct-v0.3 --instruct --max_tokens 256
```
### Instruct following
```py
from mistral_inference.model import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(messages=[UserMessage(content="Explain Machine Learning to me in a nutshell.")])
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
### Function calling
```py
from mistral_common.protocol.instruct.tool_calls import Function, Tool
from mistral_inference.model import Transformer
from mistral_inference.generate import generate
from mistral_common.tokens.tokenizers.mistral import MistralTokenizer
from mistral_common.protocol.instruct.messages import UserMessage
from mistral_common.protocol.instruct.request import ChatCompletionRequest
tokenizer = MistralTokenizer.from_file(f"{mistral_models_path}/tokenizer.model.v3")
model = Transformer.from_folder(mistral_models_path)
completion_request = ChatCompletionRequest(
tools=[
Tool(
function=Function(
name="get_current_weather",
description="Get the current weather",
parameters={
"type": "object",
"properties": {
"location": {
"type": "string",
"description": "The city and state, e.g. San Francisco, CA",
},
"format": {
"type": "string",
"enum": ["celsius", "fahrenheit"],
"description": "The temperature unit to use. Infer this from the users location.",
},
},
"required": ["location", "format"],
},
)
)
],
messages=[
UserMessage(content="What's the weather like today in Paris?"),
],
)
tokens = tokenizer.encode_chat_completion(completion_request).tokens
out_tokens, _ = generate([tokens], model, max_tokens=64, temperature=0.0, eos_id=tokenizer.instruct_tokenizer.tokenizer.eos_id)
result = tokenizer.instruct_tokenizer.tokenizer.decode(out_tokens[0])
print(result)
```
## Generate with `transformers`
If you want to use Hugging Face `transformers` to generate text, you can do something like this.
```py
from transformers import pipeline
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
chatbot = pipeline("text-generation", model="mistralai/Mistral-7B-Instruct-v0.3")
chatbot(messages)
```
## Limitations
The Mistral 7B Instruct model is a quick demonstration that the base model can be easily fine-tuned to achieve compelling performance.
It does not have any moderation mechanisms. We're looking forward to engaging with the community on ways to
make the model finely respect guardrails, allowing for deployment in environments requiring moderated outputs.
## The Mistral AI Team
Albert Jiang, Alexandre Sablayrolles, Alexis Tacnet, Antoine Roux, Arthur Mensch, Audrey Herblin-Stoop, Baptiste Bout, Baudouin de Monicault, Blanche Savary, Bam4d, Caroline Feldman, Devendra Singh Chaplot, Diego de las Casas, Eleonore Arcelin, Emma Bou Hanna, Etienne Metzger, Gianna Lengyel, Guillaume Bour, Guillaume Lample, Harizo Rajaona, Jean-Malo Delignon, Jia Li, Justus Murke, Louis Martin, Louis Ternon, Lucile Saulnier, Lélio Renard Lavaud, Margaret Jennings, Marie Pellat, Marie Torelli, Marie-Anne Lachaux, Nicolas Schuhl, Patrick von Platen, Pierre Stock, Sandeep Subramanian, Sophia Yang, Szymon Antoniak, Teven Le Scao, Thibaut Lavril, Timothée Lacroix, Théophile Gervet, Thomas Wang, Valera Nemychnikova, William El Sayed, William Marshall |
unsloth/Qwen2-1.5B-Instruct | unsloth | 2024-06-06T17:18:48Z | 662 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"unsloth",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-06-06T16:40:40Z | ---
language:
- en
license: apache-2.0
library_name: transformers
tags:
- unsloth
- transformers
- qwen2
---
# Finetune Mistral, Gemma, Llama 2-5x faster with 70% less memory via Unsloth!
We have a Google Colab Tesla T4 notebook for Qwen2 7b here: https://colab.research.google.com/drive/1mvwsIQWDs2EdZxZQF9pRGnnOvE86MVvR?usp=sharing
And a Colab notebook for [Qwen2 0.5b](https://colab.research.google.com/drive/1-7tjDdMAyeCueyLAwv6vYeBMHpoePocN?usp=sharing) and another for [Qwen2 1.5b](https://colab.research.google.com/drive/1W0j3rP8WpgxRdUgkb5l6E00EEVyjEZGk?usp=sharing)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/Discord%20button.png" width="200"/>](https://discord.gg/u54VK8m8tk)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/buy%20me%20a%20coffee%20button.png" width="200"/>](https://ko-fi.com/unsloth)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
## ✨ Finetune for Free
All notebooks are **beginner friendly**! Add your dataset, click "Run All", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
| Unsloth supports | Free Notebooks | Performance | Memory use |
|-----------------|--------------------------------------------------------------------------------------------------------------------------|-------------|----------|
| **Llama-3 8b** | [▶️ Start on Colab](https://colab.research.google.com/drive/135ced7oHytdxu3N2DNe1Z0kqjyYIkDXp?usp=sharing) | 2.4x faster | 58% less |
| **Gemma 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/10NbwlsRChbma1v55m8LAPYG15uQv6HLo?usp=sharing) | 2.4x faster | 58% less |
| **Mistral 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1Dyauq4kTZoLewQ1cApceUQVNcnnNTzg_?usp=sharing) | 2.2x faster | 62% less |
| **Llama-2 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1lBzz5KeZJKXjvivbYvmGarix9Ao6Wxe5?usp=sharing) | 2.2x faster | 43% less |
| **TinyLlama** | [▶️ Start on Colab](https://colab.research.google.com/drive/1AZghoNBQaMDgWJpi4RbffGM1h6raLUj9?usp=sharing) | 3.9x faster | 74% less |
| **CodeLlama 34b** A100 | [▶️ Start on Colab](https://colab.research.google.com/drive/1y7A0AxE3y8gdj4AVkl2aZX47Xu3P1wJT?usp=sharing) | 1.9x faster | 27% less |
| **Mistral 7b** 1xT4 | [▶️ Start on Kaggle](https://www.kaggle.com/code/danielhanchen/kaggle-mistral-7b-unsloth-notebook) | 5x faster\* | 62% less |
| **DPO - Zephyr** | [▶️ Start on Colab](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) | 1.9x faster | 19% less |
- This [conversational notebook](https://colab.research.google.com/drive/1Aau3lgPzeZKQ-98h69CCu1UJcvIBLmy2?usp=sharing) is useful for ShareGPT ChatML / Vicuna templates.
- This [text completion notebook](https://colab.research.google.com/drive/1ef-tab5bhkvWmBOObepl1WgJvfvSzn5Q?usp=sharing) is for raw text. This [DPO notebook](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) replicates Zephyr.
- \* Kaggle has 2x T4s, but we use 1. Due to overhead, 1x T4 is 5x faster. |
sharmajai901/UL_base_classification | sharmajai901 | 2024-06-11T10:02:28Z | 662 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"vit",
"image-classification",
"generated_from_trainer",
"dataset:imagefolder",
"base_model:google/vit-base-patch16-224",
"license:apache-2.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2024-06-11T10:02:13Z | ---
license: apache-2.0
base_model: google/vit-base-patch16-224
tags:
- generated_from_trainer
datasets:
- imagefolder
metrics:
- accuracy
model-index:
- name: UL_base_classification
results:
- task:
name: Image Classification
type: image-classification
dataset:
name: imagefolder
type: imagefolder
config: default
split: validation
args: default
metrics:
- name: Accuracy
type: accuracy
value: 0.8921161825726142
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# UL_base_classification
This model is a fine-tuned version of [google/vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224) on the imagefolder dataset.
It achieves the following results on the evaluation set:
- Loss: 0.3125
- Accuracy: 0.8921
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 7
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 0.8296 | 0.9756 | 20 | 0.5683 | 0.8230 |
| 0.4462 | 2.0 | 41 | 0.3949 | 0.8603 |
| 0.3588 | 2.9756 | 61 | 0.3633 | 0.8575 |
| 0.3196 | 4.0 | 82 | 0.3247 | 0.8852 |
| 0.2921 | 4.9756 | 102 | 0.3374 | 0.8728 |
| 0.2688 | 6.0 | 123 | 0.3125 | 0.8921 |
| 0.2366 | 6.8293 | 140 | 0.3137 | 0.8866 |
### Framework versions
- Transformers 4.41.2
- Pytorch 2.3.0+cu121
- Datasets 2.19.2
- Tokenizers 0.19.1
|
scientisthere/sap_model-13june_all | scientisthere | 2024-06-13T05:53:27Z | 662 | 0 | transformers | [
"transformers",
"safetensors",
"t5",
"text2text-generation",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text2text-generation | 2024-06-13T05:52:20Z | ---
library_name: transformers
tags: []
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
mradermacher/DarkForest-20B-v2.0-i1-GGUF | mradermacher | 2024-06-14T01:25:16Z | 662 | 0 | transformers | [
"transformers",
"gguf",
"merge",
"not-for-all-audiences",
"en",
"base_model:TeeZee/DarkForest-20B-v2.0",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2024-06-13T17:47:15Z | ---
base_model: TeeZee/DarkForest-20B-v2.0
language:
- en
library_name: transformers
license: other
license_name: microsoft-research-license
quantized_by: mradermacher
tags:
- merge
- not-for-all-audiences
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/TeeZee/DarkForest-20B-v2.0
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/DarkForest-20B-v2.0-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ1_S.gguf) | i1-IQ1_S | 4.5 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ1_M.gguf) | i1-IQ1_M | 4.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ2_XS.gguf) | i1-IQ2_XS | 6.0 | |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ2_S.gguf) | i1-IQ2_S | 6.5 | |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ2_M.gguf) | i1-IQ2_M | 7.0 | |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q2_K.gguf) | i1-Q2_K | 7.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 7.7 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ3_XS.gguf) | i1-IQ3_XS | 8.3 | |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ3_S.gguf) | i1-IQ3_S | 8.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q3_K_S.gguf) | i1-Q3_K_S | 8.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ3_M.gguf) | i1-IQ3_M | 9.3 | |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q3_K_M.gguf) | i1-Q3_K_M | 9.8 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q3_K_L.gguf) | i1-Q3_K_L | 10.7 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-IQ4_XS.gguf) | i1-IQ4_XS | 10.8 | |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q4_0.gguf) | i1-Q4_0 | 11.4 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q4_K_S.gguf) | i1-Q4_K_S | 11.5 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q4_K_M.gguf) | i1-Q4_K_M | 12.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q5_K_S.gguf) | i1-Q5_K_S | 13.9 | |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q5_K_M.gguf) | i1-Q5_K_M | 14.3 | |
| [GGUF](https://huggingface.co/mradermacher/DarkForest-20B-v2.0-i1-GGUF/resolve/main/DarkForest-20B-v2.0.i1-Q6_K.gguf) | i1-Q6_K | 16.5 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
John6666/randomizer89-pdxl-merge-v3-sdxl | John6666 | 2024-06-25T08:55:28Z | 662 | 1 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"pony",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
] | text-to-image | 2024-06-25T08:50:37Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- pony
---
Original model is [here](https://civitai.com/models/402600?modelVersionId=596863).
|
allenai/led-large-16384-arxiv | allenai | 2023-01-24T16:27:02Z | 661 | 28 | transformers | [
"transformers",
"pytorch",
"tf",
"led",
"text2text-generation",
"en",
"dataset:scientific_papers",
"arxiv:2004.05150",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2022-03-02T23:29:05Z | ---
language: en
datasets:
- scientific_papers
license: apache-2.0
---
## Introduction
[Allenai's Longformer Encoder-Decoder (LED)](https://github.com/allenai/longformer#longformer).
This is the official *led-large-16384* checkpoint that is fine-tuned on the arXiv dataset.*led-large-16384-arxiv* is the official fine-tuned version of [led-large-16384](https://huggingface.co/allenai/led-large-16384). As presented in the [paper](https://arxiv.org/pdf/2004.05150.pdf), the checkpoint achieves state-of-the-art results on arxiv
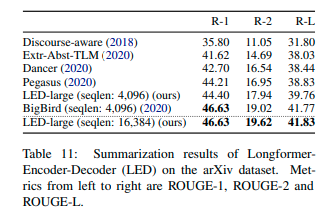
## Evaluation on downstream task
[This notebook](https://colab.research.google.com/drive/12INTTR6n64TzS4RrXZxMSXfrOd9Xzamo?usp=sharing) shows how *led-large-16384-arxiv* can be evaluated on the [arxiv dataset](https://huggingface.co/datasets/scientific_papers)
## Usage
The model can be used as follows. The input is taken from the test data of the [arxiv dataset](https://huggingface.co/datasets/scientific_papers).
```python
LONG_ARTICLE = """"for about 20 years the problem of properties of
short - term changes of solar activity has been
considered extensively . many investigators
studied the short - term periodicities of the
various indices of solar activity . several
periodicities were detected , but the
periodicities about 155 days and from the interval
of @xmath3 $ ] days ( @xmath4 $ ] years ) are
mentioned most often . first of them was
discovered by @xcite in the occurence rate of
gamma - ray flares detected by the gamma - ray
spectrometer aboard the _ solar maximum mission (
smm ) . this periodicity was confirmed for other
solar flares data and for the same time period
@xcite . it was also found in proton flares during
solar cycles 19 and 20 @xcite , but it was not
found in the solar flares data during solar cycles
22 @xcite . _ several autors confirmed above
results for the daily sunspot area data . @xcite
studied the sunspot data from 18741984 . she found
the 155-day periodicity in data records from 31
years . this periodicity is always characteristic
for one of the solar hemispheres ( the southern
hemisphere for cycles 1215 and the northern
hemisphere for cycles 1621 ) . moreover , it is
only present during epochs of maximum activity (
in episodes of 13 years ) .
similarinvestigationswerecarriedoutby + @xcite .
they applied the same power spectrum method as
lean , but the daily sunspot area data ( cycles
1221 ) were divided into 10 shorter time series .
the periodicities were searched for the frequency
interval 57115 nhz ( 100200 days ) and for each of
10 time series . the authors showed that the
periodicity between 150160 days is statistically
significant during all cycles from 16 to 21 . the
considered peaks were remained unaltered after
removing the 11-year cycle and applying the power
spectrum analysis . @xcite used the wavelet
technique for the daily sunspot areas between 1874
and 1993 . they determined the epochs of
appearance of this periodicity and concluded that
it presents around the maximum activity period in
cycles 16 to 21 . moreover , the power of this
periodicity started growing at cycle 19 ,
decreased in cycles 20 and 21 and disappered after
cycle 21 . similaranalyseswerepresentedby + @xcite
, but for sunspot number , solar wind plasma ,
interplanetary magnetic field and geomagnetic
activity index @xmath5 . during 1964 - 2000 the
sunspot number wavelet power of periods less than
one year shows a cyclic evolution with the phase
of the solar cycle.the 154-day period is prominent
and its strenth is stronger around the 1982 - 1984
interval in almost all solar wind parameters . the
existence of the 156-day periodicity in sunspot
data were confirmed by @xcite . they considered
the possible relation between the 475-day (
1.3-year ) and 156-day periodicities . the 475-day
( 1.3-year ) periodicity was also detected in
variations of the interplanetary magnetic field ,
geomagnetic activity helioseismic data and in the
solar wind speed @xcite . @xcite concluded that
the region of larger wavelet power shifts from
475-day ( 1.3-year ) period to 620-day ( 1.7-year
) period and then back to 475-day ( 1.3-year ) .
the periodicities from the interval @xmath6 $ ]
days ( @xmath4 $ ] years ) have been considered
from 1968 . @xcite mentioned a 16.3-month (
490-day ) periodicity in the sunspot numbers and
in the geomagnetic data . @xcite analysed the
occurrence rate of major flares during solar
cycles 19 . they found a 18-month ( 540-day )
periodicity in flare rate of the norhern
hemisphere . @xcite confirmed this result for the
@xmath7 flare data for solar cycles 20 and 21 and
found a peak in the power spectra near 510540 days
. @xcite found a 17-month ( 510-day ) periodicity
of sunspot groups and their areas from 1969 to
1986 . these authors concluded that the length of
this period is variable and the reason of this
periodicity is still not understood . @xcite and +
@xcite obtained statistically significant peaks of
power at around 158 days for daily sunspot data
from 1923 - 1933 ( cycle 16 ) . in this paper the
problem of the existence of this periodicity for
sunspot data from cycle 16 is considered . the
daily sunspot areas , the mean sunspot areas per
carrington rotation , the monthly sunspot numbers
and their fluctuations , which are obtained after
removing the 11-year cycle are analysed . in
section 2 the properties of the power spectrum
methods are described . in section 3 a new
approach to the problem of aliases in the power
spectrum analysis is presented . in section 4
numerical results of the new method of the
diagnosis of an echo - effect for sunspot area
data are discussed . in section 5 the problem of
the existence of the periodicity of about 155 days
during the maximum activity period for sunspot
data from the whole solar disk and from each solar
hemisphere separately is considered . to find
periodicities in a given time series the power
spectrum analysis is applied . in this paper two
methods are used : the fast fourier transformation
algorithm with the hamming window function ( fft )
and the blackman - tukey ( bt ) power spectrum
method @xcite . the bt method is used for the
diagnosis of the reasons of the existence of peaks
, which are obtained by the fft method . the bt
method consists in the smoothing of a cosine
transform of an autocorrelation function using a
3-point weighting average . such an estimator is
consistent and unbiased . moreover , the peaks are
uncorrelated and their sum is a variance of a
considered time series . the main disadvantage of
this method is a weak resolution of the
periodogram points , particularly for low
frequences . for example , if the autocorrelation
function is evaluated for @xmath8 , then the
distribution points in the time domain are :
@xmath9 thus , it is obvious that this method
should not be used for detecting low frequency
periodicities with a fairly good resolution .
however , because of an application of the
autocorrelation function , the bt method can be
used to verify a reality of peaks which are
computed using a method giving the better
resolution ( for example the fft method ) . it is
valuable to remember that the power spectrum
methods should be applied very carefully . the
difficulties in the interpretation of significant
peaks could be caused by at least four effects : a
sampling of a continuos function , an echo -
effect , a contribution of long - term
periodicities and a random noise . first effect
exists because periodicities , which are shorter
than the sampling interval , may mix with longer
periodicities . in result , this effect can be
reduced by an decrease of the sampling interval
between observations . the echo - effect occurs
when there is a latent harmonic of frequency
@xmath10 in the time series , giving a spectral
peak at @xmath10 , and also periodic terms of
frequency @xmath11 etc . this may be detected by
the autocorrelation function for time series with
a large variance . time series often contain long
- term periodicities , that influence short - term
peaks . they could rise periodogram s peaks at
lower frequencies . however , it is also easy to
notice the influence of the long - term
periodicities on short - term peaks in the graphs
of the autocorrelation functions . this effect is
observed for the time series of solar activity
indexes which are limited by the 11-year cycle .
to find statistically significant periodicities it
is reasonable to use the autocorrelation function
and the power spectrum method with a high
resolution . in the case of a stationary time
series they give similar results . moreover , for
a stationary time series with the mean zero the
fourier transform is equivalent to the cosine
transform of an autocorrelation function @xcite .
thus , after a comparison of a periodogram with an
appropriate autocorrelation function one can
detect peaks which are in the graph of the first
function and do not exist in the graph of the
second function . the reasons of their existence
could be explained by the long - term
periodicities and the echo - effect . below method
enables one to detect these effects . ( solid line
) and the 95% confidence level basing on thered
noise ( dotted line ) . the periodogram values are
presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] because
the statistical tests indicate that the time
series is a white noise the confidence level is
not marked . ] . ] the method of the diagnosis
of an echo - effect in the power spectrum ( de )
consists in an analysis of a periodogram of a
given time series computed using the bt method .
the bt method bases on the cosine transform of the
autocorrelation function which creates peaks which
are in the periodogram , but not in the
autocorrelation function . the de method is used
for peaks which are computed by the fft method (
with high resolution ) and are statistically
significant . the time series of sunspot activity
indexes with the spacing interval one rotation or
one month contain a markov - type persistence ,
which means a tendency for the successive values
of the time series to remember their antecendent
values . thus , i use a confidence level basing on
the red noise of markov @xcite for the choice of
the significant peaks of the periodogram computed
by the fft method . when a time series does not
contain the markov - type persistence i apply the
fisher test and the kolmogorov - smirnov test at
the significance level @xmath12 @xcite to verify a
statistically significance of periodograms peaks .
the fisher test checks the null hypothesis that
the time series is white noise agains the
alternative hypothesis that the time series
contains an added deterministic periodic component
of unspecified frequency . because the fisher test
tends to be severe in rejecting peaks as
insignificant the kolmogorov - smirnov test is
also used . the de method analyses raw estimators
of the power spectrum . they are given as follows
@xmath13 for @xmath14 + where @xmath15 for
@xmath16 + @xmath17 is the length of the time
series @xmath18 and @xmath19 is the mean value .
the first term of the estimator @xmath20 is
constant . the second term takes two values (
depending on odd or even @xmath21 ) which are not
significant because @xmath22 for large m. thus ,
the third term of ( 1 ) should be analysed .
looking for intervals of @xmath23 for which
@xmath24 has the same sign and different signs one
can find such parts of the function @xmath25 which
create the value @xmath20 . let the set of values
of the independent variable of the autocorrelation
function be called @xmath26 and it can be divided
into the sums of disjoint sets : @xmath27 where +
@xmath28 + @xmath29 @xmath30 @xmath31 + @xmath32 +
@xmath33 @xmath34 @xmath35 @xmath36 @xmath37
@xmath38 @xmath39 @xmath40 well , the set
@xmath41 contains all integer values of @xmath23
from the interval of @xmath42 for which the
autocorrelation function and the cosinus function
with the period @xmath43 $ ] are positive . the
index @xmath44 indicates successive parts of the
cosinus function for which the cosinuses of
successive values of @xmath23 have the same sign .
however , sometimes the set @xmath41 can be empty
. for example , for @xmath45 and @xmath46 the set
@xmath47 should contain all @xmath48 $ ] for which
@xmath49 and @xmath50 , but for such values of
@xmath23 the values of @xmath51 are negative .
thus , the set @xmath47 is empty . . the
periodogram values are presented on the left axis
. the lower curve illustrates the autocorrelation
function of the same time series . the
autocorrelation values are shown in the right axis
. ] let us take into consideration all sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } which
are not empty . because numberings and power of
these sets depend on the form of the
autocorrelation function of the given time series
, it is impossible to establish them arbitrary .
thus , the sets of appropriate indexes of the sets
\{@xmath52 } , \{@xmath53 } and \{@xmath41 } are
called @xmath54 , @xmath55 and @xmath56
respectively . for example the set @xmath56
contains all @xmath44 from the set @xmath57 for
which the sets @xmath41 are not empty . to
separate quantitatively in the estimator @xmath20
the positive contributions which are originated by
the cases described by the formula ( 5 ) from the
cases which are described by the formula ( 3 ) the
following indexes are introduced : @xmath58
@xmath59 @xmath60 @xmath61 where @xmath62 @xmath63
@xmath64 taking for the empty sets \{@xmath53 }
and \{@xmath41 } the indices @xmath65 and @xmath66
equal zero . the index @xmath65 describes a
percentage of the contribution of the case when
@xmath25 and @xmath51 are positive to the positive
part of the third term of the sum ( 1 ) . the
index @xmath66 describes a similar contribution ,
but for the case when the both @xmath25 and
@xmath51 are simultaneously negative . thanks to
these one can decide which the positive or the
negative values of the autocorrelation function
have a larger contribution to the positive values
of the estimator @xmath20 . when the difference
@xmath67 is positive , the statement the
@xmath21-th peak really exists can not be rejected
. thus , the following formula should be satisfied
: @xmath68 because the @xmath21-th peak could
exist as a result of the echo - effect , it is
necessary to verify the second condition :
@xmath69\in c_m.\ ] ] . the periodogram values
are presented on the left axis . the lower curve
illustrates the autocorrelation function of the
same time series ( solid line ) . the dotted lines
represent two standard errors of the
autocorrelation function . the dashed horizontal
line shows the zero level . the autocorrelation
values are shown in the right axis . ] to
verify the implication ( 8) firstly it is
necessary to evaluate the sets @xmath41 for
@xmath70 of the values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath71 $ ] are positive and the
sets @xmath72 of values of @xmath23 for which the
autocorrelation function and the cosine function
with the period @xmath43 $ ] are negative .
secondly , a percentage of the contribution of the
sum of products of positive values of @xmath25 and
@xmath51 to the sum of positive products of the
values of @xmath25 and @xmath51 should be
evaluated . as a result the indexes @xmath65 for
each set @xmath41 where @xmath44 is the index from
the set @xmath56 are obtained . thirdly , from all
sets @xmath41 such that @xmath70 the set @xmath73
for which the index @xmath65 is the greatest
should be chosen . the implication ( 8) is true
when the set @xmath73 includes the considered
period @xmath43 $ ] . this means that the greatest
contribution of positive values of the
autocorrelation function and positive cosines with
the period @xmath43 $ ] to the periodogram value
@xmath20 is caused by the sum of positive products
of @xmath74 for each @xmath75-\frac{m}{2k},[\frac{
2m}{k}]+\frac{m}{2k})$ ] . when the implication
( 8) is false , the peak @xmath20 is mainly
created by the sum of positive products of
@xmath74 for each @xmath76-\frac{m}{2k},\big [
\frac{2m}{n}\big ] + \frac{m}{2k } \big ) $ ] ,
where @xmath77 is a multiple or a divisor of
@xmath21 . it is necessary to add , that the de
method should be applied to the periodograms peaks
, which probably exist because of the echo -
effect . it enables one to find such parts of the
autocorrelation function , which have the
significant contribution to the considered peak .
the fact , that the conditions ( 7 ) and ( 8) are
satisfied , can unambiguously decide about the
existence of the considered periodicity in the
given time series , but if at least one of them is
not satisfied , one can doubt about the existence
of the considered periodicity . thus , in such
cases the sentence the peak can not be treated as
true should be used . using the de method it is
necessary to remember about the power of the set
@xmath78 . if @xmath79 is too large , errors of an
autocorrelation function estimation appear . they
are caused by the finite length of the given time
series and as a result additional peaks of the
periodogram occur . if @xmath79 is too small ,
there are less peaks because of a low resolution
of the periodogram . in applications @xmath80 is
used . in order to evaluate the value @xmath79 the
fft method is used . the periodograms computed by
the bt and the fft method are compared . the
conformity of them enables one to obtain the value
@xmath79 . . the fft periodogram values are
presented on the left axis . the lower curve
illustrates the bt periodogram of the same time
series ( solid line and large black circles ) .
the bt periodogram values are shown in the right
axis . ] in this paper the sunspot activity data (
august 1923 - october 1933 ) provided by the
greenwich photoheliographic results ( gpr ) are
analysed . firstly , i consider the monthly
sunspot number data . to eliminate the 11-year
trend from these data , the consecutively smoothed
monthly sunspot number @xmath81 is subtracted from
the monthly sunspot number @xmath82 where the
consecutive mean @xmath83 is given by @xmath84 the
values @xmath83 for @xmath85 and @xmath86 are
calculated using additional data from last six
months of cycle 15 and first six months of cycle
17 . because of the north - south asymmetry of
various solar indices @xcite , the sunspot
activity is considered for each solar hemisphere
separately . analogously to the monthly sunspot
numbers , the time series of sunspot areas in the
northern and southern hemispheres with the spacing
interval @xmath87 rotation are denoted . in order
to find periodicities , the following time series
are used : + @xmath88 + @xmath89 + @xmath90
+ in the lower part of figure [ f1 ] the
autocorrelation function of the time series for
the northern hemisphere @xmath88 is shown . it is
easy to notice that the prominent peak falls at 17
rotations interval ( 459 days ) and @xmath25 for
@xmath91 $ ] rotations ( [ 81 , 162 ] days ) are
significantly negative . the periodogram of the
time series @xmath88 ( see the upper curve in
figures [ f1 ] ) does not show the significant
peaks at @xmath92 rotations ( 135 , 162 days ) ,
but there is the significant peak at @xmath93 (
243 days ) . the peaks at @xmath94 are close to
the peaks of the autocorrelation function . thus ,
the result obtained for the periodicity at about
@xmath0 days are contradict to the results
obtained for the time series of daily sunspot
areas @xcite . for the southern hemisphere (
the lower curve in figure [ f2 ] ) @xmath25 for
@xmath95 $ ] rotations ( [ 54 , 189 ] days ) is
not positive except @xmath96 ( 135 days ) for
which @xmath97 is not statistically significant .
the upper curve in figures [ f2 ] presents the
periodogram of the time series @xmath89 . this
time series does not contain a markov - type
persistence . moreover , the kolmogorov - smirnov
test and the fisher test do not reject a null
hypothesis that the time series is a white noise
only . this means that the time series do not
contain an added deterministic periodic component
of unspecified frequency . the autocorrelation
function of the time series @xmath90 ( the lower
curve in figure [ f3 ] ) has only one
statistically significant peak for @xmath98 months
( 480 days ) and negative values for @xmath99 $ ]
months ( [ 90 , 390 ] days ) . however , the
periodogram of this time series ( the upper curve
in figure [ f3 ] ) has two significant peaks the
first at 15.2 and the second at 5.3 months ( 456 ,
159 days ) . thus , the periodogram contains the
significant peak , although the autocorrelation
function has the negative value at @xmath100
months . to explain these problems two
following time series of daily sunspot areas are
considered : + @xmath101 + @xmath102 + where
@xmath103 the values @xmath104 for @xmath105
and @xmath106 are calculated using additional
daily data from the solar cycles 15 and 17 .
and the cosine function for @xmath45 ( the period
at about 154 days ) . the horizontal line ( dotted
line ) shows the zero level . the vertical dotted
lines evaluate the intervals where the sets
@xmath107 ( for @xmath108 ) are searched . the
percentage values show the index @xmath65 for each
@xmath41 for the time series @xmath102 ( in
parentheses for the time series @xmath101 ) . in
the right bottom corner the values of @xmath65 for
the time series @xmath102 , for @xmath109 are
written . ] ( the 500-day period ) ] the
comparison of the functions @xmath25 of the time
series @xmath101 ( the lower curve in figure [ f4
] ) and @xmath102 ( the lower curve in figure [ f5
] ) suggests that the positive values of the
function @xmath110 of the time series @xmath101 in
the interval of @xmath111 $ ] days could be caused
by the 11-year cycle . this effect is not visible
in the case of periodograms of the both time
series computed using the fft method ( see the
upper curves in figures [ f4 ] and [ f5 ] ) or the
bt method ( see the lower curve in figure [ f6 ] )
. moreover , the periodogram of the time series
@xmath102 has the significant values at @xmath112
days , but the autocorrelation function is
negative at these points . @xcite showed that the
lomb - scargle periodograms for the both time
series ( see @xcite , figures 7 a - c ) have a
peak at 158.8 days which stands over the fap level
by a significant amount . using the de method the
above discrepancies are obvious . to establish the
@xmath79 value the periodograms computed by the
fft and the bt methods are shown in figure [ f6 ]
( the upper and the lower curve respectively ) .
for @xmath46 and for periods less than 166 days
there is a good comformity of the both
periodograms ( but for periods greater than 166
days the points of the bt periodogram are not
linked because the bt periodogram has much worse
resolution than the fft periodogram ( no one know
how to do it ) ) . for @xmath46 and @xmath113 the
value of @xmath21 is 13 ( @xmath71=153 $ ] ) . the
inequality ( 7 ) is satisfied because @xmath114 .
this means that the value of @xmath115 is mainly
created by positive values of the autocorrelation
function . the implication ( 8) needs an
evaluation of the greatest value of the index
@xmath65 where @xmath70 , but the solar data
contain the most prominent period for @xmath116
days because of the solar rotation . thus ,
although @xmath117 for each @xmath118 , all sets
@xmath41 ( see ( 5 ) and ( 6 ) ) without the set
@xmath119 ( see ( 4 ) ) , which contains @xmath120
$ ] , are considered . this situation is presented
in figure [ f7 ] . in this figure two curves
@xmath121 and @xmath122 are plotted . the vertical
dotted lines evaluate the intervals where the sets
@xmath107 ( for @xmath123 ) are searched . for
such @xmath41 two numbers are written : in
parentheses the value of @xmath65 for the time
series @xmath101 and above it the value of
@xmath65 for the time series @xmath102 . to make
this figure clear the curves are plotted for the
set @xmath124 only . ( in the right bottom corner
information about the values of @xmath65 for the
time series @xmath102 , for @xmath109 are written
. ) the implication ( 8) is not true , because
@xmath125 for @xmath126 . therefore ,
@xmath43=153\notin c_6=[423,500]$ ] . moreover ,
the autocorrelation function for @xmath127 $ ] is
negative and the set @xmath128 is empty . thus ,
@xmath129 . on the basis of these information one
can state , that the periodogram peak at @xmath130
days of the time series @xmath102 exists because
of positive @xmath25 , but for @xmath23 from the
intervals which do not contain this period .
looking at the values of @xmath65 of the time
series @xmath101 , one can notice that they
decrease when @xmath23 increases until @xmath131 .
this indicates , that when @xmath23 increases ,
the contribution of the 11-year cycle to the peaks
of the periodogram decreases . an increase of the
value of @xmath65 is for @xmath132 for the both
time series , although the contribution of the
11-year cycle for the time series @xmath101 is
insignificant . thus , this part of the
autocorrelation function ( @xmath133 for the time
series @xmath102 ) influences the @xmath21-th peak
of the periodogram . this suggests that the
periodicity at about 155 days is a harmonic of the
periodicity from the interval of @xmath1 $ ] days
. ( solid line ) and consecutively smoothed
sunspot areas of the one rotation time interval
@xmath134 ( dotted line ) . both indexes are
presented on the left axis . the lower curve
illustrates fluctuations of the sunspot areas
@xmath135 . the dotted and dashed horizontal lines
represent levels zero and @xmath136 respectively .
the fluctuations are shown on the right axis . ]
the described reasoning can be carried out for
other values of the periodogram . for example ,
the condition ( 8) is not satisfied for @xmath137
( 250 , 222 , 200 days ) . moreover , the
autocorrelation function at these points is
negative . these suggest that there are not a true
periodicity in the interval of [ 200 , 250 ] days
. it is difficult to decide about the existence of
the periodicities for @xmath138 ( 333 days ) and
@xmath139 ( 286 days ) on the basis of above
analysis . the implication ( 8) is not satisfied
for @xmath139 and the condition ( 7 ) is not
satisfied for @xmath138 , although the function
@xmath25 of the time series @xmath102 is
significantly positive for @xmath140 . the
conditions ( 7 ) and ( 8) are satisfied for
@xmath141 ( figure [ f8 ] ) and @xmath142 .
therefore , it is possible to exist the
periodicity from the interval of @xmath1 $ ] days
. similar results were also obtained by @xcite for
daily sunspot numbers and daily sunspot areas .
she considered the means of three periodograms of
these indexes for data from @xmath143 years and
found statistically significant peaks from the
interval of @xmath1 $ ] ( see @xcite , figure 2 )
. @xcite studied sunspot areas from 1876 - 1999
and sunspot numbers from 1749 - 2001 with the help
of the wavelet transform . they pointed out that
the 154 - 158-day period could be the third
harmonic of the 1.3-year ( 475-day ) period .
moreover , the both periods fluctuate considerably
with time , being stronger during stronger sunspot
cycles . therefore , the wavelet analysis suggests
a common origin of the both periodicities . this
conclusion confirms the de method result which
indicates that the periodogram peak at @xmath144
days is an alias of the periodicity from the
interval of @xmath1 $ ] in order to verify the
existence of the periodicity at about 155 days i
consider the following time series : + @xmath145
+ @xmath146 + @xmath147 + the value @xmath134
is calculated analogously to @xmath83 ( see sect .
the values @xmath148 and @xmath149 are evaluated
from the formula ( 9 ) . in the upper part of
figure [ f9 ] the time series of sunspot areas
@xmath150 of the one rotation time interval from
the whole solar disk and the time series of
consecutively smoothed sunspot areas @xmath151 are
showed . in the lower part of figure [ f9 ] the
time series of sunspot area fluctuations @xmath145
is presented . on the basis of these data the
maximum activity period of cycle 16 is evaluated .
it is an interval between two strongest
fluctuations e.a . @xmath152 $ ] rotations . the
length of the time interval @xmath153 is 54
rotations . if the about @xmath0-day ( 6 solar
rotations ) periodicity existed in this time
interval and it was characteristic for strong
fluctuations from this time interval , 10 local
maxima in the set of @xmath154 would be seen .
then it should be necessary to find such a value
of p for which @xmath155 for @xmath156 and the
number of the local maxima of these values is 10 .
as it can be seen in the lower part of figure [ f9
] this is for the case of @xmath157 ( in this
figure the dashed horizontal line is the level of
@xmath158 ) . figure [ f10 ] presents nine time
distances among the successive fluctuation local
maxima and the horizontal line represents the
6-rotation periodicity . it is immediately
apparent that the dispersion of these points is 10
and it is difficult to find even few points which
oscillate around the value of 6 . such an analysis
was carried out for smaller and larger @xmath136
and the results were similar . therefore , the
fact , that the about @xmath0-day periodicity
exists in the time series of sunspot area
fluctuations during the maximum activity period is
questionable . . the horizontal line represents
the 6-rotation ( 162-day ) period . ] ] ]
to verify again the existence of the about
@xmath0-day periodicity during the maximum
activity period in each solar hemisphere
separately , the time series @xmath88 and @xmath89
were also cut down to the maximum activity period
( january 1925december 1930 ) . the comparison of
the autocorrelation functions of these time series
with the appriopriate autocorrelation functions of
the time series @xmath88 and @xmath89 , which are
computed for the whole 11-year cycle ( the lower
curves of figures [ f1 ] and [ f2 ] ) , indicates
that there are not significant differences between
them especially for @xmath23=5 and 6 rotations (
135 and 162 days ) ) . this conclusion is
confirmed by the analysis of the time series
@xmath146 for the maximum activity period . the
autocorrelation function ( the lower curve of
figure [ f11 ] ) is negative for the interval of [
57 , 173 ] days , but the resolution of the
periodogram is too low to find the significant
peak at @xmath159 days . the autocorrelation
function gives the same result as for daily
sunspot area fluctuations from the whole solar
disk ( @xmath160 ) ( see also the lower curve of
figures [ f5 ] ) . in the case of the time series
@xmath89 @xmath161 is zero for the fluctuations
from the whole solar cycle and it is almost zero (
@xmath162 ) for the fluctuations from the maximum
activity period . the value @xmath163 is negative
. similarly to the case of the northern hemisphere
the autocorrelation function and the periodogram
of southern hemisphere daily sunspot area
fluctuations from the maximum activity period
@xmath147 are computed ( see figure [ f12 ] ) .
the autocorrelation function has the statistically
significant positive peak in the interval of [ 155
, 165 ] days , but the periodogram has too low
resolution to decide about the possible
periodicities . the correlative analysis indicates
that there are positive fluctuations with time
distances about @xmath0 days in the maximum
activity period . the results of the analyses of
the time series of sunspot area fluctuations from
the maximum activity period are contradict with
the conclusions of @xcite . she uses the power
spectrum analysis only . the periodogram of daily
sunspot fluctuations contains peaks , which could
be harmonics or subharmonics of the true
periodicities . they could be treated as real
periodicities . this effect is not visible for
sunspot data of the one rotation time interval ,
but averaging could lose true periodicities . this
is observed for data from the southern hemisphere
. there is the about @xmath0-day peak in the
autocorrelation function of daily fluctuations ,
but the correlation for data of the one rotation
interval is almost zero or negative at the points
@xmath164 and 6 rotations . thus , it is
reasonable to research both time series together
using the correlative and the power spectrum
analyses . the following results are obtained :
1 . a new method of the detection of statistically
significant peaks of the periodograms enables one
to identify aliases in the periodogram . 2 . two
effects cause the existence of the peak of the
periodogram of the time series of sunspot area
fluctuations at about @xmath0 days : the first is
caused by the 27-day periodicity , which probably
creates the 162-day periodicity ( it is a
subharmonic frequency of the 27-day periodicity )
and the second is caused by statistically
significant positive values of the autocorrelation
function from the intervals of @xmath165 $ ] and
@xmath166 $ ] days . the existence of the
periodicity of about @xmath0 days of the time
series of sunspot area fluctuations and sunspot
area fluctuations from the northern hemisphere
during the maximum activity period is questionable
. the autocorrelation analysis of the time series
of sunspot area fluctuations from the southern
hemisphere indicates that the periodicity of about
155 days exists during the maximum activity period
. i appreciate valuable comments from professor j.
jakimiec ."""
from transformers import LEDForConditionalGeneration, LEDTokenizer
import torch
tokenizer = LEDTokenizer.from_pretrained("allenai/led-large-16384-arxiv")
input_ids = tokenizer(LONG_ARTICLE, return_tensors="pt").input_ids.to("cuda")
global_attention_mask = torch.zeros_like(input_ids)
# set global_attention_mask on first token
global_attention_mask[:, 0] = 1
model = LEDForConditionalGeneration.from_pretrained("allenai/led-large-16384-arxiv", return_dict_in_generate=True).to("cuda")
sequences = model.generate(input_ids, global_attention_mask=global_attention_mask).sequences
summary = tokenizer.batch_decode(sequences)
```
|
aubmindlab/bert-base-arabertv01 | aubmindlab | 2023-06-09T12:24:20Z | 661 | 2 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"bert",
"fill-mask",
"ar",
"dataset:wikipedia",
"dataset:OSIAN",
"dataset:1.5B_Arabic_Corpus",
"arxiv:2003.00104",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-03-02T23:29:05Z | ---
language: ar
datasets:
- wikipedia
- OSIAN
- 1.5B_Arabic_Corpus
widget:
- text: " عاصمة لبنان هي [MASK] ."
---
# !!! A newer version of this model is available !!! [AraBERTv02](https://huggingface.co/aubmindlab/bert-base-arabertv02)
# AraBERT v1 & v2 : Pre-training BERT for Arabic Language Understanding
<img src="https://raw.githubusercontent.com/aub-mind/arabert/master/arabert_logo.png" width="100" align="left"/>
**AraBERT** is an Arabic pretrained lanaguage model based on [Google's BERT architechture](https://github.com/google-research/bert). AraBERT uses the same BERT-Base config. More details are available in the [AraBERT Paper](https://arxiv.org/abs/2003.00104) and in the [AraBERT Meetup](https://github.com/WissamAntoun/pydata_khobar_meetup)
There are two versions of the model, AraBERTv0.1 and AraBERTv1, with the difference being that AraBERTv1 uses pre-segmented text where prefixes and suffixes were splitted using the [Farasa Segmenter](http://alt.qcri.org/farasa/segmenter.html).
We evalaute AraBERT models on different downstream tasks and compare them to [mBERT]((https://github.com/google-research/bert/blob/master/multilingual.md)), and other state of the art models (*To the extent of our knowledge*). The Tasks were Sentiment Analysis on 6 different datasets ([HARD](https://github.com/elnagara/HARD-Arabic-Dataset), [ASTD-Balanced](https://www.aclweb.org/anthology/D15-1299), [ArsenTD-Lev](https://staff.aub.edu.lb/~we07/Publications/ArSentD-LEV_Sentiment_Corpus.pdf), [LABR](https://github.com/mohamedadaly/LABR)), Named Entity Recognition with the [ANERcorp](http://curtis.ml.cmu.edu/w/courses/index.php/ANERcorp), and Arabic Question Answering on [Arabic-SQuAD and ARCD](https://github.com/husseinmozannar/SOQAL)
# AraBERTv2
## What's New!
AraBERT now comes in 4 new variants to replace the old v1 versions:
More Detail in the AraBERT folder and in the [README](https://github.com/aub-mind/arabert/blob/master/AraBERT/README.md) and in the [AraBERT Paper](https://arxiv.org/abs/2003.00104v2)
Model | HuggingFace Model Name | Size (MB/Params)| Pre-Segmentation | DataSet (Sentences/Size/nWords) |
---|:---:|:---:|:---:|:---:
AraBERTv0.2-base | [bert-base-arabertv02](https://huggingface.co/aubmindlab/bert-base-arabertv02) | 543MB / 136M | No | 200M / 77GB / 8.6B |
AraBERTv0.2-large| [bert-large-arabertv02](https://huggingface.co/aubmindlab/bert-large-arabertv02) | 1.38G 371M | No | 200M / 77GB / 8.6B |
AraBERTv2-base| [bert-base-arabertv2](https://huggingface.co/aubmindlab/bert-base-arabertv2) | 543MB 136M | Yes | 200M / 77GB / 8.6B |
AraBERTv2-large| [bert-large-arabertv2](https://huggingface.co/aubmindlab/bert-large-arabertv2) | 1.38G 371M | Yes | 200M / 77GB / 8.6B |
AraBERTv0.1-base| [bert-base-arabertv01](https://huggingface.co/aubmindlab/bert-base-arabertv01) | 543MB 136M | No | 77M / 23GB / 2.7B |
AraBERTv1-base| [bert-base-arabert](https://huggingface.co/aubmindlab/bert-base-arabert) | 543MB 136M | Yes | 77M / 23GB / 2.7B |
All models are available in the `HuggingFace` model page under the [aubmindlab](https://huggingface.co/aubmindlab/) name. Checkpoints are available in PyTorch, TF2 and TF1 formats.
## Better Pre-Processing and New Vocab
We identified an issue with AraBERTv1's wordpiece vocabulary. The issue came from punctuations and numbers that were still attached to words when learned the wordpiece vocab. We now insert a space between numbers and characters and around punctuation characters.
The new vocabulary was learnt using the `BertWordpieceTokenizer` from the `tokenizers` library, and should now support the Fast tokenizer implementation from the `transformers` library.
**P.S.**: All the old BERT codes should work with the new BERT, just change the model name and check the new preprocessing dunction
**Please read the section on how to use the [preprocessing function](#Preprocessing)**
## Bigger Dataset and More Compute
We used ~3.5 times more data, and trained for longer.
For Dataset Sources see the [Dataset Section](#Dataset)
Model | Hardware | num of examples with seq len (128 / 512) |128 (Batch Size/ Num of Steps) | 512 (Batch Size/ Num of Steps) | Total Steps | Total Time (in Days) |
---|:---:|:---:|:---:|:---:|:---:|:---:
AraBERTv0.2-base | TPUv3-8 | 420M / 207M |2560 / 1M | 384/ 2M | 3M | -
AraBERTv0.2-large | TPUv3-128 | 420M / 207M | 13440 / 250K | 2056 / 300K | 550K | -
AraBERTv2-base | TPUv3-8 | 520M / 245M |13440 / 250K | 2056 / 300K | 550K | -
AraBERTv2-large | TPUv3-128 | 520M / 245M | 13440 / 250K | 2056 / 300K | 550K | -
AraBERT-base (v1/v0.1) | TPUv2-8 | - |512 / 900K | 128 / 300K| 1.2M | 4 days
# Dataset
The pretraining data used for the new AraBERT model is also used for Arabic **GPT2 and ELECTRA**.
The dataset consists of 77GB or 200,095,961 lines or 8,655,948,860 words or 82,232,988,358 chars (before applying Farasa Segmentation)
For the new dataset we added the unshuffled OSCAR corpus, after we thoroughly filter it, to the previous dataset used in AraBERTv1 but with out the websites that we previously crawled:
- OSCAR unshuffled and filtered.
- [Arabic Wikipedia dump](https://archive.org/details/arwiki-20190201) from 2020/09/01
- [The 1.5B words Arabic Corpus](https://www.semanticscholar.org/paper/1.5-billion-words-Arabic-Corpus-El-Khair/f3eeef4afb81223df96575adadf808fe7fe440b4)
- [The OSIAN Corpus](https://www.aclweb.org/anthology/W19-4619)
- Assafir news articles. Huge thank you for Assafir for giving us the data
# Preprocessing
It is recommended to apply our preprocessing function before training/testing on any dataset.
**Install farasapy to segment text for AraBERT v1 & v2 `pip install farasapy`**
```python
from arabert.preprocess import ArabertPreprocessor
model_name="bert-base-arabertv01"
arabert_prep = ArabertPreprocessor(model_name=model_name)
text = "ولن نبالغ إذا قلنا إن هاتف أو كمبيوتر المكتب في زمننا هذا ضروري"
arabert_prep.preprocess(text)
```
## Accepted_models
```
bert-base-arabertv01
bert-base-arabert
bert-base-arabertv02
bert-base-arabertv2
bert-large-arabertv02
bert-large-arabertv2
araelectra-base
aragpt2-base
aragpt2-medium
aragpt2-large
aragpt2-mega
```
# TensorFlow 1.x models
The TF1.x model are available in the HuggingFace models repo.
You can download them as follows:
- via git-lfs: clone all the models in a repo
```bash
curl -s https://packagecloud.io/install/repositories/github/git-lfs/script.deb.sh | sudo bash
sudo apt-get install git-lfs
git lfs install
git clone https://huggingface.co/aubmindlab/MODEL_NAME
tar -C ./MODEL_NAME -zxvf /content/MODEL_NAME/tf1_model.tar.gz
```
where `MODEL_NAME` is any model under the `aubmindlab` name
- via `wget`:
- Go to the tf1_model.tar.gz file on huggingface.co/models/aubmindlab/MODEL_NAME.
- copy the `oid sha256`
- then run `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/INSERT_THE_SHA_HERE` (ex: for `aragpt2-base`: `wget https://cdn-lfs.huggingface.co/aubmindlab/aragpt2-base/3766fc03d7c2593ff2fb991d275e96b81b0ecb2098b71ff315611d052ce65248`)
# If you used this model please cite us as :
Google Scholar has our Bibtex wrong (missing name), use this instead
```
@inproceedings{antoun2020arabert,
title={AraBERT: Transformer-based Model for Arabic Language Understanding},
author={Antoun, Wissam and Baly, Fady and Hajj, Hazem},
booktitle={LREC 2020 Workshop Language Resources and Evaluation Conference 11--16 May 2020},
pages={9}
}
```
# Acknowledgments
Thanks to TensorFlow Research Cloud (TFRC) for the free access to Cloud TPUs, couldn't have done it without this program, and to the [AUB MIND Lab](https://sites.aub.edu.lb/mindlab/) Members for the continous support. Also thanks to [Yakshof](https://www.yakshof.com/#/) and Assafir for data and storage access. Another thanks for Habib Rahal (https://www.behance.net/rahalhabib), for putting a face to AraBERT.
# Contacts
**Wissam Antoun**: [Linkedin](https://www.linkedin.com/in/wissam-antoun-622142b4/) | [Twitter](https://twitter.com/wissam_antoun) | [Github](https://github.com/WissamAntoun) | <[email protected]> | <[email protected]>
**Fady Baly**: [Linkedin](https://www.linkedin.com/in/fadybaly/) | [Twitter](https://twitter.com/fadybaly) | [Github](https://github.com/fadybaly) | <[email protected]> | <[email protected]>
|
microsoft/xtremedistil-l12-h384-uncased | microsoft | 2021-08-05T17:49:31Z | 661 | 14 | transformers | [
"transformers",
"pytorch",
"tf",
"bert",
"feature-extraction",
"text-classification",
"en",
"arxiv:2106.04563",
"license:mit",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
language: en
thumbnail: https://huggingface.co/front/thumbnails/microsoft.png
tags:
- text-classification
license: mit
---
# XtremeDistilTransformers for Distilling Massive Neural Networks
XtremeDistilTransformers is a distilled task-agnostic transformer model that leverages task transfer for learning a small universal model that can be applied to arbitrary tasks and languages as outlined in the paper [XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation](https://arxiv.org/abs/2106.04563).
We leverage task transfer combined with multi-task distillation techniques from the papers [XtremeDistil: Multi-stage Distillation for Massive Multilingual Models](https://www.aclweb.org/anthology/2020.acl-main.202.pdf) and [MiniLM: Deep Self-Attention Distillation for Task-Agnostic Compression of Pre-Trained Transformers](https://proceedings.neurips.cc/paper/2020/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf) with the following [Github code](https://github.com/microsoft/xtreme-distil-transformers).
This l6-h384 checkpoint with **6** layers, **384** hidden size, **12** attention heads corresponds to **22 million** parameters with **5.3x** speedup over BERT-base.
Other available checkpoints: [xtremedistil-l6-h256-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h256-uncased) and [xtremedistil-l6-h384-uncased](https://huggingface.co/microsoft/xtremedistil-l6-h384-uncased)
The following table shows the results on GLUE dev set and SQuAD-v2.
| Models | #Params | Speedup | MNLI | QNLI | QQP | RTE | SST | MRPC | SQUAD2 | Avg |
|----------------|--------|---------|------|------|------|------|------|------|--------|-------|
| BERT | 109 | 1x | 84.5 | 91.7 | 91.3 | 68.6 | 93.2 | 87.3 | 76.8 | 84.8 |
| DistilBERT | 66 | 2x | 82.2 | 89.2 | 88.5 | 59.9 | 91.3 | 87.5 | 70.7 | 81.3 |
| TinyBERT | 66 | 2x | 83.5 | 90.5 | 90.6 | 72.2 | 91.6 | 88.4 | 73.1 | 84.3 |
| MiniLM | 66 | 2x | 84.0 | 91.0 | 91.0 | 71.5 | 92.0 | 88.4 | 76.4 | 84.9 |
| MiniLM | 22 | 5.3x | 82.8 | 90.3 | 90.6 | 68.9 | 91.3 | 86.6 | 72.9 | 83.3 |
| XtremeDistil-l6-h256 | 13 | 8.7x | 83.9 | 89.5 | 90.6 | 80.1 | 91.2 | 90.0 | 74.1 | 85.6 |
| XtremeDistil-l6-h384 | 22 | 5.3x | 85.4 | 90.3 | 91.0 | 80.9 | 92.3 | 90.0 | 76.6 | 86.6 |
| XtremeDistil-l12-h384 | 33 | 2.7x | 87.2 | 91.9 | 91.3 | 85.6 | 93.1 | 90.4 | 80.2 | 88.5 |
Tested with `tensorflow 2.3.1, transformers 4.1.1, torch 1.6.0`
If you use this checkpoint in your work, please cite:
``` latex
@misc{mukherjee2021xtremedistiltransformers,
title={XtremeDistilTransformers: Task Transfer for Task-agnostic Distillation},
author={Subhabrata Mukherjee and Ahmed Hassan Awadallah and Jianfeng Gao},
year={2021},
eprint={2106.04563},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
|
timm/pvt_v2_b4.in1k | timm | 2023-04-25T04:05:48Z | 661 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2106.13797",
"license:apache-2.0",
"region:us"
] | image-classification | 2023-04-25T04:05:04Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for pvt_v2_b4
A PVT-v2 (Pyramid Vision Transformer) image classification model. Trained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 62.6
- GMACs: 10.1
- Activations (M): 53.7
- Image size: 224 x 224
- **Papers:**
- PVT v2: Improved Baselines with Pyramid Vision Transformer: https://arxiv.org/abs/2106.13797
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/whai362/PVT
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('pvt_v2_b4', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'pvt_v2_b4',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 320, 14, 14])
# torch.Size([1, 512, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'pvt_v2_b4',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 512, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@article{wang2021pvtv2,
title={Pvtv2: Improved baselines with pyramid vision transformer},
author={Wang, Wenhai and Xie, Enze and Li, Xiang and Fan, Deng-Ping and Song, Kaitao and Liang, Ding and Lu, Tong and Luo, Ping and Shao, Ling},
journal={Computational Visual Media},
volume={8},
number={3},
pages={1--10},
year={2022},
publisher={Springer}
}
```
|
ammaraldirawi/faster-whisper-small-en-int8 | ammaraldirawi | 2023-11-28T15:49:09Z | 661 | 0 | transformers | [
"transformers",
"endpoints_compatible",
"region:us"
] | null | 2023-11-16T12:04:14Z | Entry not found |
allknowingroger/AutoLimmy-7B-slerp | allknowingroger | 2024-04-10T18:16:42Z | 661 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger/YamshadowExperiment28-7B",
"liminerity/M7-7b",
"base_model:automerger/YamshadowExperiment28-7B",
"base_model:liminerity/M7-7b",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-08T08:04:29Z | ---
tags:
- merge
- mergekit
- lazymergekit
- automerger/YamshadowExperiment28-7B
- liminerity/M7-7b
base_model:
- automerger/YamshadowExperiment28-7B
- liminerity/M7-7b
license: apache-2.0
---
# AutoLimmy-7B-slerp
AutoLimmy-7B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [automerger/YamshadowExperiment28-7B](https://huggingface.co/automerger/YamshadowExperiment28-7B)
* [liminerity/M7-7b](https://huggingface.co/liminerity/M7-7b)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: automerger/YamshadowExperiment28-7B
layer_range: [0, 32]
- model: liminerity/M7-7b
layer_range: [0, 32]
merge_method: slerp
base_model: automerger/YamshadowExperiment28-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "allknowingroger/AutoLimmy-7B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
Sanster/brushnet_random_mask | Sanster | 2024-04-09T09:00:30Z | 661 | 1 | diffusers | [
"diffusers",
"safetensors",
"region:us"
] | null | 2024-04-09T08:46:09Z | Entry not found |
ManniX-ITA/Starling-LM-7B-beta-LaserRMT-v1-GGUF | ManniX-ITA | 2024-04-12T21:53:58Z | 661 | 1 | null | [
"gguf",
"region:us"
] | null | 2024-04-12T21:13:20Z | Entry not found |
Ba2han/Phi-3-Medium-Llamaish | Ba2han | 2024-06-03T05:32:36Z | 661 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"conversational",
"en",
"dataset:Sao10K/Claude-3-Opus-Instruct-15K",
"dataset:Ba2han/DollyLlama-5k",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-05-25T09:12:06Z | ---
datasets:
- Sao10K/Claude-3-Opus-Instruct-15K
- Ba2han/DollyLlama-5k
language:
- en
license: mit
---
**Supports system messages!**
**Template: Zephyr**
It's far from perfect but I put together a Phi-3-Medium-4k trained mostly on llama-3-70B generated multi-turn conversations with system messages.

GGUF coming soon.
(Via Unsloth) |
seokho/gpt2-emotion | seokho | 2021-07-06T06:07:33Z | 660 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | dataset: Emotion Detection from Text |
javirandor/passgpt-10characters | javirandor | 2023-07-20T10:45:01Z | 660 | 2 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"passwords",
"cybersecurity",
"arxiv:2306.01545",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-06-15T15:46:33Z | ---
extra_gated_fields:
Institution: text
Country: text
I agree to use this model for non-commercial use ONLY: checkbox
I agree not to use the model to conduct experiments that cause harm to human subjects: checkbox
widget:
- text: <s>
example_title: Example 1
- text: <s>1234
example_title: Example 2
- text: <s>ilov
example_title: Example 3
- text: <s>admin
example_title: Example 4
pipeline_tag: text-generation
tags:
- passwords
- cybersecurity
---
# PassGPT
PassGPT is a causal language model trained on password leaks. It was first introduced in [this paper](https://arxiv.org/abs/2306.01545). This version of the model was trained on passwords from the RockYou leak, after filtering those that were at most 10 characters long. If you need access to PassGPT trained on passwords up to 16 characters long, you can apply [here](https://huggingface.co/javirandor/passgpt-16characters).
**This is a curated version of the model reported in the paper**. Vocabulary size was reduced to the most meaningful characters and training was slightly optimized. Results are slightly better with these architectures.
### Usage and License Notices
[](https://github.com/javirandor/passbert/blob/main/LICENSE)
PassGPT is intended and licensed for research use only. The model and code are CC BY NC 4.0 (allowing only non-commercial use) and should not be used outside of research purposes. This model should never be used to attack real systems.
### Model description
The model inherits the [GPT2LMHeadModel](https://huggingface.co/docs/transformers/model_doc/gpt2#transformers.GPT2LMHeadModel) architecture and implements a custom [BertTokenizer](https://huggingface.co/docs/transformers/model_doc/bert#transformers.BertTokenizer) that encodes each character in a password as a single token, avoiding merges. It was trained from a random initialization, and the code for training can be found in the [official repository](https://github.com/javirandor/passgpt/).
### Password Generation
Passwords can be sampled from the model using the [built-in generation methods](https://huggingface.co/docs/transformers/v4.30.0/en/main_classes/text_generation#transformers.GenerationMixin.generate) provided by HuggingFace and using the "start of password token" as seed (i.e. `<s>`). This code can be used to generate one password with PassGPT.
```
from transformers import GPT2LMHeadModel
from transformers import RobertaTokenizerFast
tokenizer = RobertaTokenizerFast.from_pretrained("javirandor/passgpt-10characters",
max_len=12,
padding="max_length",
truncation=True,
do_lower_case=False,
strip_accents=False,
mask_token="<mask>",
unk_token="<unk>",
pad_token="<pad>",
truncation_side="right")
model = GPT2LMHeadModel.from_pretrained("javirandor/passgpt-10characters").eval()
NUM_GENERATIONS = 1
# Generate passwords sampling from the beginning of password token
g = model.generate(torch.tensor([[tokenizer.bos_token_id]]),
do_sample=True,
num_return_sequences=NUM_GENERATIONS,
max_length=12,
pad_token_id=tokenizer.pad_token_id,
bad_words_ids=[[tokenizer.bos_token_id]])
# Remove start of sentence token
g = g[:, 1:]
decoded = tokenizer.batch_decode(g.tolist())
decoded_clean = [i.split("</s>")[0] for i in decoded] # Get content before end of password token
# Print your sampled passwords!
print(decoded_clean)
```
You can find a more flexible script for sampling [here](https://github.com/javirandor/passgpt/blob/main/src/generate_passwords.py).
### Cite our work
```
@article{rando2023passgpt,
title={PassGPT: Password Modeling and (Guided) Generation with Large Language Models},
author={Rando, Javier and Perez-Cruz, Fernando and Hitaj, Briland},
journal={arXiv preprint arXiv:2306.01545},
year={2023}
}
``` |
SlyEcho/open_llama_13b_gguf | SlyEcho | 2023-09-01T13:46:15Z | 660 | 0 | null | [
"gguf",
"license:apache-2.0",
"region:us"
] | null | 2023-08-31T20:53:50Z | ---
license: apache-2.0
---
# gguf versions of OpenLLaMa 13B
- Version: 1000B tokens final release
- Project: [OpenLLaMA: An Open Reproduction of LLaMA](https://github.com/openlm-research/open_llama)
- Model: [openlm-research/open_llama_13b](https://huggingface.co/openlm-research/open_llama_13b)
- [llama.cpp](https://github.com/ggerganov/llama.cpp): build 1012 (6381d4e) or later
- [ggml version](https://huggingface.co/SlyEcho/open_llama_13b_ggml)
## Perplexity on wiki.test.406
Coming soon... |
OrionStarAI/OrionStar-Yi-34B-Chat | OrionStarAI | 2024-03-26T10:27:28Z | 660 | 60 | transformers | [
"transformers",
"pytorch",
"safetensors",
"Yi",
"text-generation",
"custom_code",
"license:other",
"autotrain_compatible",
"region:us"
] | text-generation | 2023-11-15T11:26:15Z | ---
license: other
license_name: yi-license
license_link: LICENSE
widget:
- text: "你好! 你叫什么名字!"
output:
text: "你好,我的名字叫聚言,很高兴见到你。"
pipeline_tag: text-generation
---
<!-- markdownlint-disable first-line-h1 -->
<!-- markdownlint-disable html -->
<div align="center">
<img src="./pics/orion_start.PNG" alt="logo" width="50%" />
</div>
<div align="center">
<h1>
OrionStar-Yi-34B-Chat
</h1>
</div>
<p align="center">
🤗 <a href="https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat" target="_blank">Hugging Face</a> |
<a href="https://github.com/OrionStarAI/OrionStar-Yi-34B-Chat" target="_blank">Github</a> |
🤗 <a href="https://huggingface.co/spaces/OrionStarAI/OrionStar-Yi-34B-Chat-Demo" target="_blank">Online Demo</a>
</p>
<div align="center">
<h4 align="center">
<p>
<b>中文</b> |
<a href="https://huggingface.co/OrionStarAI/OrionStar-Yi-34B-Chat/blob/main/README_en.md">English</a>
<p>
</h4>
</div>
# 目录
- [📖 模型介绍](#模型介绍)
- [📊 模型推理 🔥](#模型推理)
- [👥 示例输出](#示例输出)
- [🥇 企业介绍](#企业介绍)
- [📜 声明、协议](#声明协议)
# 模型介绍
- OrionStar-Yi-34B-Chat 是一款开源中英文Chat模型,由猎户星空基于Yi-34B开源模型、使用 __15W+__ 高质量语料微调而成。
- Yi系列模型是由零一万物团队开源的大模型,在多个权威的中文、英文及通用领域 benchmark
上取得不错的效果。今天我们推出的Orionstar-Yi-34B-Chat更进一步挖掘了Yi-34B的潜力。通过对大量高质量微调语料库的深度训练,Orionstar-Yi-34B-Chat在评估数据上表现出色,我们致力于将其打造成为ChatGPT领域中的杰出开源替代品!
- 我们微调的模型对学术研究完全开放,同时请大家遵守[协议](#协议)
和 [Yi License](https://github.com/01-ai/Yi/blob/main/MODEL_LICENSE_AGREEMENT.txt)
- 模型评估结果
我们使用[opencompass](https://opencompass.org.cn)对以下通用领域数据集进行了 5-shot
测试。其他模型评估结果取自[opencompass-leaderboard](https://opencompass.org.cn/leaderboard-llm)。
| | C-Eval | MMLU | CMMLU |
|---------------------------|-----------|--------|-----------|
| **GPT-4** | 69.9 | **83** | 71 |
| **ChatGPT** | 52.5 | 69.1 | 53.9 |
| **Claude-1** | 52 | 65.7 | - |
| **TigerBot-70B-Chat-V2** | 57.7 | 65.9 | 59.9 |
| **WeMix-LLaMA2-70B** | 55.2 | 71.3 | 56 |
| **LLaMA-2-70B-Chat** | 44.3 | 63.8 | 43.3 |
| **Qwen-14B-Chat** | 71.7 | 66.4 | 70 |
| **Baichuan2-13B-Chat** | 56.7 | 57 | 58.4 |
| **OrionStar-Yi-34B-Chat** | **77.71** | 78.32 | **73.52** |
# 模型推理
推理所需的相关代码已发布在 Github上。Github仓库链接:[OrionStar-Yi-34B-Chat](https://github.com/OrionStarAI/OrionStar-Yi-34B-Chat)。
## Python 代码方式
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from transformers.generation.utils import GenerationConfig
tokenizer = AutoTokenizer.from_pretrained("OrionStarAI/OrionStar-Yi-34B-Chat", use_fast=False, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained("OrionStarAI/OrionStar-Yi-34B-Chat", device_map="auto",
torch_dtype=torch.bfloat16, trust_remote_code=True)
model.generation_config = GenerationConfig.from_pretrained("OrionStarAI/OrionStar-Yi-34B-Chat")
messages = [{"role": "user", "content": "你好! 你叫什么名字!"}]
response = model.chat(tokenizer, messages, streaming=False)
print(response)
# 你好,我的名字叫聚言,很高兴见到你。
```
在上述两段代码中,模型加载指定 `device_map='auto'`
,会使用所有可用显卡。如需指定使用的设备,可以使用类似 `export CUDA_VISIBLE_DEVICES=0,1`(使用了0、1号显卡)的方式控制。
## 命令行工具方式
```shell
python cli_demo.py
```
本命令行工具是为 Chat 场景设计,因此我们不支持使用该工具调用 Base 模型。
## 脚本直接推理
```shell
python text_generation.py --model OrionStarAI/OrionStar-Yi-34B-Chat --tokenizer OrionStarAI/OrionStar-Yi-34B-Chat --prompt 你好,你叫什么名字
```
# 示例输出
## 闲聊
`````
用户:你好,你叫什么名字
OrionStar-Yi-34B:你好,我的名字叫聚言,很高兴见到你。
用户:你有哪些功能
OrionStar-Yi-34B:我是一个多才多艺的AI助手,我可以回答你的问题、陪你聊天、帮你查询信息、提供生活建议等等。
用户:讲个笑话
OrionStar-Yi-34B:为什么香肠总是不开心?因为它没有朋友,只能被夹在面包里。
`````
## 数学
`````
用户:鸡和兔在一个笼子里,共有26个头,68只脚,那么鸡有多少只,兔有多少只?
OrionStar-Yi-34B:设鸡的数量为x,兔的数量为y。
根据题意,可得出以下两个方程:
x + y = 26 (共有26个头)
2x + 4y = 68 (共有68只脚)
将第一个方程变形,得到y = 26 - x
将y的值代入第二个方程中,得到:
2x + 4(26-x) = 68
解这个方程,得到x = 18
所以,鸡有18只,兔有26 - 18 = 8只。
`````
# 企业介绍
猎户星空(ORION
STAR)是一家全球领先的服务机器人解决方案公司,成立于2016年9月。猎户星空致力于基于人工智能技术打造下一代革命性机器人,使人们能够摆脱重复的体力劳动,使人类的工作和生活更加智能和有趣,通过技术使社会和世界变得更加美好。
猎户星空拥有完全自主开发的全链条人工智能技术,如语音交互和视觉导航。它整合了产品开发能力和技术应用能力。基于Orion机械臂平台,它推出了ORION
STAR AI Robot Greeting、AI Robot Greeting Mini、Lucki、Coffee
Master等产品,并建立了Orion机器人的开放平台OrionOS。通过为 **真正有用的机器人而生** 的理念实践,它通过AI技术为更多人赋能。
凭借7年AI经验积累,猎户星空已推出的大模型深度应用“聚言”,并陆续面向行业客户提供定制化AI大模型咨询与服务解决方案,真正帮助客户实现企业经营效率领先同行目标。
**猎户星空具备全链条大模型应用能力的核心优势**,包括拥有从海量数据处理、大模型预训练、二次预训练、微调(Fine-tune)、Prompt
Engineering 、Agent开发的全链条能力和经验积累;拥有完整的端到端模型训练能力,包括系统化的数据处理流程和数百张GPU的并行模型训练能力,现已在大政务、云服务、出海电商、快消等多个行业场景落地。
***欢迎有大模型应用落地需求的企业联系我们进行商务合作,咨询电话 400-898-7779 。***
企业微信
<div align="center">
<img src="./pics/company_wechat.jpg" alt="company" width="30%" />
</div>
# 声明、协议
## 声明
我们强烈呼吁所有使用者,不要利用 OrionStar-Yi-34B-Chat 模型进行任何危害国家社会安全或违法的活动。另外,我们也要求使用者不要将
OrionStar-Yi-34B-Chat 模型用于未经适当安全审查和备案的互联网服务。
我们希望所有的使用者都能遵守这个原则,确保科技的发展能在规范和合法的环境下进行。
我们已经尽我们所能,来确保模型训练过程中使用的数据的合规性。然而,尽管我们已经做出了巨大的努力,但由于模型和数据的复杂性,仍有可能存在一些无法预见的问题。因此,如果由于使用
OrionStar-Yi-34B-Chat 开源模型而导致的任何问题,包括但不限于数据安全问题、公共舆论风险,或模型被误导、滥用、传播或不当利用所带来的任何风险和问题,我们将不承担任何责任。
## 协议
社区使用 OrionStar-Yi-34B-Chat
模型需要遵循 [Apache 2.0](https://github.com/OrionStarAI/OrionStar-Yi-34B-Chat/blob/main/LICENSE)
和[《Yi-34B 模型社区许可协议》](https://github.com/01-ai/Yi/blob/main/MODEL_LICENSE_AGREEMENT.txt)
# 联系我们
**Discord社区链接: https://discord.gg/zumjDWgdAs**
<div align="center">
<img src="./pics/wechat_group.jpg" alt="wechat" width="40%" />
</div> |
ntc-ai/SDXL-LoRA-slider.huge-anime-eyes | ntc-ai | 2024-02-06T00:27:46Z | 660 | 1 | diffusers | [
"diffusers",
"text-to-image",
"stable-diffusion-xl",
"lora",
"template:sd-lora",
"template:sdxl-lora",
"sdxl-sliders",
"ntcai.xyz-sliders",
"concept",
"en",
"base_model:stabilityai/stable-diffusion-xl-base-1.0",
"license:mit",
"region:us"
] | text-to-image | 2023-12-10T05:39:47Z |
---
language:
- en
thumbnail: "images/huge anime eyes_17_3.0.png"
widget:
- text: huge anime eyes
output:
url: images/huge anime eyes_17_3.0.png
- text: huge anime eyes
output:
url: images/huge anime eyes_19_3.0.png
- text: huge anime eyes
output:
url: images/huge anime eyes_20_3.0.png
- text: huge anime eyes
output:
url: images/huge anime eyes_21_3.0.png
- text: huge anime eyes
output:
url: images/huge anime eyes_22_3.0.png
tags:
- text-to-image
- stable-diffusion-xl
- lora
- template:sd-lora
- template:sdxl-lora
- sdxl-sliders
- ntcai.xyz-sliders
- concept
- diffusers
license: "mit"
inference: false
instance_prompt: "huge anime eyes"
base_model: "stabilityai/stable-diffusion-xl-base-1.0"
---
# ntcai.xyz slider - huge anime eyes (SDXL LoRA)
| Strength: -3 | Strength: 0 | Strength: 3 |
| --- | --- | --- |
| <img src="images/huge anime eyes_17_-3.0.png" width=256 height=256 /> | <img src="images/huge anime eyes_17_0.0.png" width=256 height=256 /> | <img src="images/huge anime eyes_17_3.0.png" width=256 height=256 /> |
| <img src="images/huge anime eyes_19_-3.0.png" width=256 height=256 /> | <img src="images/huge anime eyes_19_0.0.png" width=256 height=256 /> | <img src="images/huge anime eyes_19_3.0.png" width=256 height=256 /> |
| <img src="images/huge anime eyes_20_-3.0.png" width=256 height=256 /> | <img src="images/huge anime eyes_20_0.0.png" width=256 height=256 /> | <img src="images/huge anime eyes_20_3.0.png" width=256 height=256 /> |
See more at [https://sliders.ntcai.xyz/sliders/app/loras/4e569885-c747-49ab-bc9a-3cd128f297ad](https://sliders.ntcai.xyz/sliders/app/loras/4e569885-c747-49ab-bc9a-3cd128f297ad)
## Download
Weights for this model are available in Safetensors format.
## Trigger words
You can apply this LoRA with trigger words for additional effect:
```
huge anime eyes
```
## Use in diffusers
```python
from diffusers import StableDiffusionXLPipeline
from diffusers import EulerAncestralDiscreteScheduler
import torch
pipe = StableDiffusionXLPipeline.from_single_file("https://huggingface.co/martyn/sdxl-turbo-mario-merge-top-rated/blob/main/topRatedTurboxlLCM_v10.safetensors")
pipe.to("cuda")
pipe.scheduler = EulerAncestralDiscreteScheduler.from_config(pipe.scheduler.config)
# Load the LoRA
pipe.load_lora_weights('ntc-ai/SDXL-LoRA-slider.huge-anime-eyes', weight_name='huge anime eyes.safetensors', adapter_name="huge anime eyes")
# Activate the LoRA
pipe.set_adapters(["huge anime eyes"], adapter_weights=[2.0])
prompt = "medieval rich kingpin sitting in a tavern, huge anime eyes"
negative_prompt = "nsfw"
width = 512
height = 512
num_inference_steps = 10
guidance_scale = 2
image = pipe(prompt, negative_prompt=negative_prompt, width=width, height=height, guidance_scale=guidance_scale, num_inference_steps=num_inference_steps).images[0]
image.save('result.png')
```
## Support the Patreon
If you like this model please consider [joining our Patreon](https://www.patreon.com/NTCAI).
By joining our Patreon, you'll gain access to an ever-growing library of over 1496+ unique and diverse LoRAs along with 14600+ slider merges, covering a wide range of styles and genres. You'll also receive early access to new models and updates, exclusive behind-the-scenes content, and the powerful <strong>NTC Slider Factory</strong> LoRA creator, allowing you to craft your own custom LoRAs and merges opening up endless possibilities.
Your support on Patreon will allow us to continue developing new models and tools.
## Other resources
- [CivitAI](https://civitai.com/user/ntc) - Follow ntc on Civit for even more LoRAs
- [ntcai.xyz](https://ntcai.xyz) - See ntcai.xyz to find more articles and LoRAs
|
BAAI/Emu2-Chat | BAAI | 2023-12-21T12:31:16Z | 660 | 27 | transformers | [
"transformers",
"pytorch",
"text-generation",
"custom_code",
"en",
"arxiv:2312.13286",
"autotrain_compatible",
"region:us"
] | text-generation | 2023-12-19T13:48:42Z | ---
language:
- en
---
# Emu2-Chat
[Paper](https://arxiv.org/abs/2312.13286) | [🤗HF Demo](https://huggingface.co/spaces/BAAI/Emu2) | [Demo](https://emu.ssi.plus) | [Project Page](https://baaivision.github.io/emu2/) | [Github](https://github.com/baaivision/Emu)
## Model Weights
| Model name | Weight |
| ------------------ | ------------------------------------------------------- |
| **Emu2** | [🤗 HF link](https://huggingface.co/BAAI/Emu2) |
| **Emu2-Chat** | [🤗 HF link](https://huggingface.co/BAAI/Emu2-Chat) |
| **Emu2-Gen** | [🤗 HF link](https://huggingface.co/BAAI/Emu2-Gen) |
## Inference (Huggingface Version)
#### Single GPU
```python
from PIL import Image
import requests
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BAAI/Emu2-Chat")
model = AutoModelForCausalLM.from_pretrained(
"BAAI/Emu2-Chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).to('cuda').eval()
# `[<IMG_PLH>]` is the image placeholder which will be replaced by image embeddings.
# the number of `[<IMG_PLH>]` should be equal to the number of input images
query = '[<IMG_PLH>]Describe the image in details:'
image = Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/blue_black_1_top_left.jpg?raw=true',stream=True).raw).convert('RGB')
inputs = model.build_input_ids(
text=[query],
tokenizer=tokenizer,
image=[image]
)
with torch.no_grad():
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
image=inputs["image"].to(torch.bfloat16),
max_new_tokens=64,
length_penalty=-1)
output_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
```
Interleaved image and text
```python
from PIL import Image
import requests
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BAAI/Emu2-Chat")
model = AutoModelForCausalLM.from_pretrained(
"BAAI/Emu2-Chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True).to('cuda').eval()
# `[<IMG_PLH>]` is the image placeholder which will be replaced by image embeddings.
# the number of `[<IMG_PLH>]` should be equal to the number of input images
query = "[<IMG_PLH>][red, white, 3, bottom left].[<IMG_PLH>][yellow, white, 2, top left].[<IMG_PLH>][green, black, 4, bottom right][<IMG_PLH>]"
images = [
Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/red_white_3_bottom_left.jpg?raw=true',stream=True).raw).convert('RGB'),
Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/yellow_white_2_top_right.jpg?raw=true',stream=True).raw).convert('RGB'),
Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/green_black_4_bottom_right.jpg?raw=true',stream=True).raw).convert('RGB'),
Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/blue_black_1_top_left.jpg?raw=true',stream=True).raw).convert('RGB'),
]
inputs = model.build_input_ids(
text=[query],
tokenizer=tokenizer,
image=images
)
with torch.no_grad():
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
image=inputs["image"].to(torch.bfloat16),
max_new_tokens=64,
length_penalty=-1)
output_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
```
#### Multi GPU
```python
from PIL import Image
import requests
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from accelerate import init_empty_weights, infer_auto_device_map, load_checkpoint_and_dispatch
tokenizer = AutoTokenizer.from_pretrained("BAAI/Emu2-Chat")
with init_empty_weights():
model = AutoModelForCausalLM.from_pretrained(
"BAAI/Emu2-Chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True)
device_map = infer_auto_device_map(model, max_memory={0:'38GiB',1:'38GiB',}, no_split_module_classes=['Block','LlamaDecoderLayer'])
# input and output logits should be on same device
device_map["model.decoder.lm.lm_head"] = 0
model = load_checkpoint_and_dispatch(
model,
'local/path/to/hf/version/Emu2-Chat/model',
device_map=device_map).eval()
# `[<IMG_PLH>]` is the image placeholder which will be replaced by image embeddings.
# the number of `[<IMG_PLH>]` should be equal to the number of input images
query = '[<IMG_PLH>]Describe the image in details:'
image = Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/blue_black_1_top_left.jpg?raw=true',stream=True).raw).convert('RGB')
inputs = model.build_input_ids(
text=[query],
tokenizer=tokenizer,
image=[image]
)
with torch.no_grad():
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
image=inputs["image"].to(torch.bfloat16),
max_new_tokens=64,
length_penalty=-1)
output_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
```
Interleaved image and text
```python
from PIL import Image
import requests
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from accelerate import init_empty_weights, infer_auto_device_map, load_checkpoint_and_dispatch
tokenizer = AutoTokenizer.from_pretrained("BAAI/Emu2-Chat")
with init_empty_weights():
model = AutoModelForCausalLM.from_pretrained(
"BAAI/Emu2-Chat",
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True)
device_map = infer_auto_device_map(model, max_memory={0:'38GiB',1:'38GiB',}, no_split_module_classes=['Block','LlamaDecoderLayer'])
# input and output logits should be on same device
device_map["model.decoder.lm.lm_head"] = 0
model = load_checkpoint_and_dispatch(
model,
'local/path/to/hf/version/Emu2-Chat/model',
device_map=device_map).eval()
# `[<IMG_PLH>]` is the image placeholder which will be replaced by image embeddings.
# the number of `[<IMG_PLH>]` should be equal to the number of input images
query = "[<IMG_PLH>][red, white, 3, bottom left].[<IMG_PLH>][yellow, white, 2, top left].[<IMG_PLH>][green, black, 4, bottom right][<IMG_PLH>]"
images = [
Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/red_white_3_bottom_left.jpg?raw=true',stream=True).raw).convert('RGB'),
Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/yellow_white_2_top_right.jpg?raw=true',stream=True).raw).convert('RGB'),
Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/green_black_4_bottom_right.jpg?raw=true',stream=True).raw).convert('RGB'),
Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/blue_black_1_top_left.jpg?raw=true',stream=True).raw).convert('RGB'),
]
inputs = model.build_input_ids(
text=[query],
tokenizer=tokenizer,
image=images
)
with torch.no_grad():
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
image=inputs["image"].to(torch.bfloat16),
max_new_tokens=64,
length_penalty=-1)
output_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
```
#### Quantization
Check quantization guidance at [transformers](https://huggingface.co/docs/transformers/v4.28.0/main_classes/quantization)
```python
from PIL import Image
import requests
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("BAAI/Emu2-Chat")
model = AutoModelForCausalLM.from_pretrained(
"BAAI/Emu2-Chat",
load_in_4bit=True,
trust_remote_code=True,
bnb_4bit_compute_dtype=torch.float16).eval()
query = '[<IMG_PLH>]Describe the image in details:'
image = Image.open(requests.get('https://github.com/baaivision/Emu/Emu2/examples/blue_black_1_top_left.jpg?raw=true',stream=True).raw).convert('RGB')
inputs = model.build_input_ids(
text=[query],
tokenizer=tokenizer,
image=[image]
)
with torch.no_grad():
outputs = model.generate(
input_ids=inputs["input_ids"],
attention_mask=inputs["attention_mask"],
image=inputs["image"].to(torch.float16), # should be torch.float16
max_new_tokens=64,
length_penalty=-1)
output_text = tokenizer.batch_decode(outputs, skip_special_tokens=True)
```
## Citation
If you find Emu2 useful for your research and applications, please consider starring this repository and citing:
```
@article{Emu2,
title={Generative Multimodal Models are In-Context Learners},
author={Quan Sun and Yufeng Cui and Xiaosong Zhang and Fan Zhang and Qiying Yu and Zhengxiong Luo and Yueze Wang and Yongming Rao and Jingjing Liu and Tiejun Huang and Xinlong Wang},
publisher={arXiv preprint arXiv:2312.13286},
year={2023},
}
``` |
Systran/faster-distil-whisper-medium.en | Systran | 2024-01-19T03:59:58Z | 660 | 0 | ctranslate2 | [
"ctranslate2",
"audio",
"automatic-speech-recognition",
"en",
"license:mit",
"region:us"
] | automatic-speech-recognition | 2024-01-19T03:23:01Z | ---
language:
- en
tags:
- audio
- automatic-speech-recognition
license: mit
library_name: ctranslate2
---
# Whisper medium.en model for CTranslate2
This repository contains the conversion of [distil-whisper/distil-medium.en](https://huggingface.co/distil-whisper/distil-medium.en) to the [CTranslate2](https://github.com/OpenNMT/CTranslate2) model format.
This model can be used in CTranslate2 or projects based on CTranslate2 such as [faster-whisper](https://github.com/systran/faster-whisper).
## Example
```python
from faster_whisper import WhisperModel
model = WhisperModel("distil-medium.en")
segments, info = model.transcribe("audio.mp3")
for segment in segments:
print("[%.2fs -> %.2fs] %s" % (segment.start, segment.end, segment.text))
```
## Conversion details
The original model was converted with the following command:
```
ct2-transformers-converter --model distil-whisper/distil-medium.en --output_dir faster-distil-whisper-medium.en \
--copy_files tokenizer.json preprocessor_config.json --quantization float16
```
Note that the model weights are saved in FP16. This type can be changed when the model is loaded using the [`compute_type` option in CTranslate2](https://opennmt.net/CTranslate2/quantization.html).
## More information
**For more information about the original model, see its [model card](https://huggingface.co/distil-whisper/distil-medium.en).**
|
gitMuscle/5HJwyzoUMw7HVhhAohV3GEPHoGDAL1rXBeWkd72oCjMnFHis_vgg | gitMuscle | 2024-03-08T06:45:50Z | 660 | 0 | keras | [
"keras",
"region:us"
] | null | 2024-03-07T04:52:06Z | Entry not found |
weezywitasneezy/BenchmarkEngineering-F2-7B-slerp | weezywitasneezy | 2024-04-09T17:09:32Z | 660 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"weezywitasneezy/BenchmarkEngineering-7B-slerp",
"senseable/WestLake-7B-v2",
"base_model:weezywitasneezy/BenchmarkEngineering-7B-slerp",
"base_model:senseable/WestLake-7B-v2",
"license:cc-by-nc-4.0",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-04-08T19:29:30Z | ---
license: cc-by-nc-4.0
tags:
- merge
- mergekit
- lazymergekit
- weezywitasneezy/BenchmarkEngineering-7B-slerp
- senseable/WestLake-7B-v2
base_model:
- weezywitasneezy/BenchmarkEngineering-7B-slerp
- senseable/WestLake-7B-v2
model-index:
- name: BenchmarkEngineering-F2-7B-slerp
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 73.46
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=weezywitasneezy/BenchmarkEngineering-F2-7B-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 88.88
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=weezywitasneezy/BenchmarkEngineering-F2-7B-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 64.5
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=weezywitasneezy/BenchmarkEngineering-F2-7B-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 72.37
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=weezywitasneezy/BenchmarkEngineering-F2-7B-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 86.11
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=weezywitasneezy/BenchmarkEngineering-F2-7B-slerp
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 69.29
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=weezywitasneezy/BenchmarkEngineering-F2-7B-slerp
name: Open LLM Leaderboard
---
# BenchmarkEngineering-F2-7B-slerp
This merge seeks to further improve on the original BenchmarkEngineering by integrating the Westlake-7B-v2 model. It does boost the Winogrande score but at the cost of the other benchmarks.
BenchmarkEngineering-F2-7B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [weezywitasneezy/BenchmarkEngineering-7B-slerp](https://huggingface.co/weezywitasneezy/BenchmarkEngineering-7B-slerp)
* [senseable/WestLake-7B-v2](https://huggingface.co/senseable/WestLake-7B-v2)
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_weezywitasneezy__BenchmarkEngineering-F2-7B-slerp)
| Metric |Value|
|---------------------------------|----:|
|Avg. |75.77|
|AI2 Reasoning Challenge (25-Shot)|73.46|
|HellaSwag (10-Shot) |88.88|
|MMLU (5-Shot) |64.50|
|TruthfulQA (0-shot) |72.37|
|Winogrande (5-shot) |86.11|
|GSM8k (5-shot) |69.29|
## 🧩 Configuration
```yaml
slices:
- sources:
- model: weezywitasneezy/BenchmarkEngineering-7B-slerp
layer_range: [0, 32]
- model: senseable/WestLake-7B-v2
layer_range: [0, 32]
merge_method: slerp
base_model: weezywitasneezy/BenchmarkEngineering-7B-slerp
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "weezywitasneezy/BenchmarkEngineering-F2-7B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
```
|
duyntnet/CodeQwen1.5-7B-imatrix-GGUF | duyntnet | 2024-04-28T13:35:31Z | 660 | 0 | transformers | [
"transformers",
"gguf",
"imatrix",
"CodeQwen1.5-7B",
"text-generation",
"en",
"license:other",
"region:us"
] | text-generation | 2024-04-28T08:21:28Z | ---
license: other
language:
- en
pipeline_tag: text-generation
inference: false
tags:
- transformers
- gguf
- imatrix
- CodeQwen1.5-7B
---
Quantizations of https://huggingface.co/Qwen/CodeQwen1.5-7B
# From original readme
## Requirements
The code of Qwen1.5 has been in the latest Hugging face transformers and we advise you to install `transformers>=4.37.0`, or you might encounter the following error:
```
KeyError: 'qwen2'.
```
|
stabilityai/japanese-stablelm-2-base-1_6b | stabilityai | 2024-05-02T05:34:15Z | 660 | 11 | transformers | [
"transformers",
"safetensors",
"stablelm_epoch",
"text-generation",
"japanese-stablelm",
"causal-lm",
"custom_code",
"ja",
"dataset:wikipedia",
"dataset:CulturaX",
"arxiv:2307.09288",
"arxiv:2104.09864",
"arxiv:2204.06745",
"arxiv:1607.06450",
"arxiv:1910.07467",
"arxiv:2309.16609",
"arxiv:2305.14201",
"arxiv:2309.09400",
"license:other",
"autotrain_compatible",
"region:us"
] | text-generation | 2024-05-02T05:34:15Z | ---
language:
- ja
tags:
- japanese-stablelm
- causal-lm
pipeline_tag: text-generation
datasets:
- wikipedia
- CulturaX
license:
- other
extra_gated_prompt: >-
By clicking "Agree", you agree to the [License Agreement](https://huggingface.co/stabilityai/japanese-stablelm-2-base-1_6b/blob/main/LICENSE.txt) and acknowledge Stability AI's [Privacy Policy](https://stability.ai/privacy-policy).
extra_gated_fields:
Name: text
Email: text
Country: country
Organization or Affiliation: text
Receive email updates and promotions on Stability AI products, services, and research?:
type: select
options:
- Yes
- No
---
# Japanese Stable LM 2 Base 1.6B

> A beautiful anime-like hummingbird flying with the text "Japanese Stable LM 2" below it, with a lofi anime landscape of Mount Fuji forming the outline of the text "Japanese Stable LM 2" — [Stable Diffusion 3](https://stability.ai/news/stable-diffusion-3)
Please note: For commercial use, please refer to [https://stability.ai/membership](https://stability.ai/membership)
## Model Description
`Japanese Stable LM 2 Base 1.6B` is a 1.6B-parameter decoder-only language model based on [Stable LM 2 1.6B](https://huggingface.co/stabilityai/stablelm-2-1_6b) that has been fine-tuned on a diverse collection of Japanese data, with the intent of maximizing downstream performance on Japanese language tasks.
For an instruction-following model, check [Japanese Stable LM 2 Instruct 1.6B](https://huggingface.co/stabilityai/japanese-stablelm-2-instruct-1_6b).
## Usage
Get started generating text with `Japanese Stable LM 2 Base 1.6B` by using the following code snippet:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "stabilityai/japanese-stablelm-2-base-1_6b"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
# The next line may need to be modified depending on the environment
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.float16,
low_cpu_mem_usage=True,
device_map="auto",
trust_remote_code=True,
)
prompt = """
AI で科学研究を加速するには、
""".strip()
inputs = tokenizer(
prompt,
add_special_tokens=True,
return_tensors="pt"
).to(model.device)
# this is for reproducibility.
# feel free to change to get different result
seed = 23
torch.manual_seed(seed)
tokens = model.generate(
**inputs,
max_new_tokens=128,
temperature=0.99,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
```
We suggest playing with different generation config (`top_p`, `repetition_penalty` etc) to find the best setup for your tasks. For example, use higher temperature for roleplay task, lower temperature for reasoning.
## Model Details
* **Model type**: `Japanese Stable LM 2 Base 1.6B` models are auto-regressive language models based on the transformer decoder architecture.
* **Language(s)**: Japanese
* **License**: See the [LICENSE file](https://huggingface.co/stabilityai/japanese-stablelm-2-base-1_6b/blob/main/LICENSE.txt).
* **Commercial License**: to use this model commercially, please refer to [https://stability.ai/membership](https://stability.ai/membership)
* **Contact**: For technical questions and comments about the model, please join [Stable Community Japan](https://discord.gg/StableJP). For future announcements / information about Stability AI models, research, and events, please follow [@StabilityAI_JP](https://twitter.com/StabilityAI_JP).
## Model Architecture
The model is a decoder-only transformer similar to the LLaMA ([Touvron et al., 2023](https://arxiv.org/abs/2307.09288)) architecture with the following modifications:
| Parameters | Hidden Size | Layers | Heads | Sequence Length |
|----------------|-------------|--------|-------|-----------------|
| 1,644,417,024 | 2048 | 24 | 32 | 4096 |
* **Position Embeddings**: Rotary Position Embeddings ([Su et al., 2021](https://arxiv.org/abs/2104.09864)) applied to the first 25% of head embedding dimensions for improved throughput following [Black et al. (2022)](https://arxiv.org/pdf/2204.06745.pdf).
* **Normalization**: LayerNorm ([Ba et al., 2016](https://arxiv.org/abs/1607.06450)) with learned bias terms as opposed to RMSNorm ([Zhang & Sennrich, 2019](https://arxiv.org/abs/1910.07467)).
* **Biases**: We remove all bias terms from the feed-forward networks and multi-head self-attention layers, except for the biases of the query, key, and value projections ([Bai et al., 2023](https://arxiv.org/abs/2309.16609)).
* **Tokenizer**: We use Arcade100k, a BPE tokenizer extended from OpenAI's [`tiktoken.cl100k_base`](https://github.com/openai/tiktoken). We split digits into individual tokens following findings by [Liu & Low (2023)](https://arxiv.org/abs/2305.14201).
## Training Dataset
A mixture of the following corpora was used for continued pre-training.
- [Japanese/English Wikipedia](https://dumps.wikimedia.org/other/cirrussearch)
- [CulturaX](https://arxiv.org/abs/2309.09400)
## Use and Limitations
### Intended Use
The model is intended to be used as a foundational base model for application-specific fine-tuning. Developers must evaluate and fine-tune the model for safe performance in downstream applications. For commercial use, please refer to https://stability.ai/membership.
### Limitations and Bias
As a base model, this model may exhibit unreliable, unsafe, or other undesirable behaviors that must be corrected through evaluation and fine-tuning prior to deployment. The pre-training dataset may have contained offensive or inappropriate content, even after applying data cleansing filters, which can be reflected in the model-generated text. We recommend that users exercise caution when using these models in production systems. Do not use the models if they are unsuitable for your application, or for any applications that may cause deliberate or unintentional harm to others.
## Authors
This model was developed by the Research & Development team at Stability AI Japan, and the development was led by Meng Lee (@leemeng) and Naoki Orii (@mrorii). The members of the team are as follows:
- [Meng Lee](https://huggingface.co/leemeng)
- [Naoki Orii](https://huggingface.co/mrorii)
- [Paul McCann](https://huggingface.co/polm-stability)
- [Yusuke Shibui](https://huggingface.co/cvusk)
- [Fujiki Nakamura](https://huggingface.co/fujiki)
- [Duy Phung](https://huggingface.co/pvduy)
- Maksym Zhuravinskyi
- Dakota Mahan
- [Jerry Chi](https://jerrychi.com)
## How to cite
```
@misc{JapaneseStableLM2Base1.6B,
url={[https://huggingface.co/stabilityai/japanese-stablelm-2-base-1_6b](https://huggingface.co/stabilityai/japanese-stablelm-base-2-1_6b)},
title={Japanese Stable LM 2 Base 1.6B},
author={Lee, Meng and Nakamura, Fujiki and McCann, Paul and Orii, Naoki and Shibui, Yusuke and Phung, Duy and Zhuravinskyi, Maksym and Mahan, Dakota and Chi, Jerry}
}
```
|
OpenBuddy/openbuddy-zero-3b-v21.2-32k | OpenBuddy | 2024-06-04T13:50:53Z | 660 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-3",
"conversational",
"zh",
"en",
"fr",
"de",
"ja",
"ko",
"it",
"fi",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-06-02T16:42:58Z | ---
language:
- zh
- en
- fr
- de
- ja
- ko
- it
- fi
pipeline_tag: text-generation
tags:
- llama-3
license: other
license_name: llama3
license_link: https://llama.meta.com/llama3/license/
---
# OpenBuddy - Open Multilingual Chatbot
GitHub and Usage Guide: [https://github.com/OpenBuddy/OpenBuddy](https://github.com/OpenBuddy/OpenBuddy)
Website and Demo: [https://openbuddy.ai](https://openbuddy.ai)
Evaluation result of this model: [Evaluation.txt](Evaluation.txt)

| Category | Parameters |
|----------------------|------------|
| Embedding Params | 1.11B |
| **Non-embedding Params** | 3.65B |
# Use with 🦙Ollama
```
ollama run openbuddy/openbuddy-zen-3b-v21.2
```
# Copyright Notice
**Built with Meta Llama 3**
License: https://llama.meta.com/llama3/license/
Acceptable Use Policy: https://llama.meta.com/llama3/use-policy
This model utilizes the Llama3 vocabulary and is designed and initialized based on the Llama3 architecture. It has been pre-trained and fine-tuned on this foundation. This model is intended for use in English and Chinese.
# Prompt Format
We recommend using the fast tokenizer from `transformers`, which should be enabled by default in the `transformers` and `vllm` libraries. Other implementations including `sentencepiece` may not work as expected, especially for special tokens like `<|role|>`, `<|says|>` and `<|end|>`.
```
<|role|>system<|says|>You(assistant) are a helpful, respectful and honest INTP-T AI Assistant named Buddy. You are talking to a human(user).
Always answer as helpfully and logically as possible, while being safe. Your answers should not include any harmful, political, religious, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
You cannot access the internet, but you have vast knowledge, cutoff: 2023-04.
You are trained by OpenBuddy team, (https://openbuddy.ai, https://github.com/OpenBuddy/OpenBuddy), not related to GPT or OpenAI.<|end|>
<|role|>user<|says|>History input 1<|end|>
<|role|>assistant<|says|>History output 1<|end|>
<|role|>user<|says|>History input 2<|end|>
<|role|>assistant<|says|>History output 2<|end|>
<|role|>user<|says|>Current input<|end|>
<|role|>assistant<|says|>
```
This format is also defined in `tokenizer_config.json`, which means you can directly use `vllm` to deploy an OpenAI-like API service. For more information, please refer to the [vllm documentation](https://docs.vllm.ai/en/latest/serving/openai_compatible_server.html).
## Disclaimer
All OpenBuddy models have inherent limitations and may potentially produce outputs that are erroneous, harmful, offensive, or otherwise undesirable. Users should not use these models in critical or high-stakes situations that may lead to personal injury, property damage, or significant losses. Examples of such scenarios include, but are not limited to, the medical field, controlling software and hardware systems that may cause harm, and making important financial or legal decisions.
OpenBuddy is provided "as-is" without any warranty of any kind, either express or implied, including, but not limited to, the implied warranties of merchantability, fitness for a particular purpose, and non-infringement. In no event shall the authors, contributors, or copyright holders be liable for any claim, damages, or other liabilities, whether in an action of contract, tort, or otherwise, arising from, out of, or in connection with the software or the use or other dealings in the software.
By using OpenBuddy, you agree to these terms and conditions, and acknowledge that you understand the potential risks associated with its use. You also agree to indemnify and hold harmless the authors, contributors, and copyright holders from any claims, damages, or liabilities arising from your use of OpenBuddy.
## 免责声明
所有OpenBuddy模型均存在固有的局限性,可能产生错误的、有害的、冒犯性的或其他不良的输出。用户在关键或高风险场景中应谨慎行事,不要使用这些模型,以免导致人身伤害、财产损失或重大损失。此类场景的例子包括但不限于医疗领域、可能导致伤害的软硬件系统的控制以及进行重要的财务或法律决策。
OpenBuddy按“原样”提供,不附带任何种类的明示或暗示的保证,包括但不限于适销性、特定目的的适用性和非侵权的暗示保证。在任何情况下,作者、贡献者或版权所有者均不对因软件或使用或其他软件交易而产生的任何索赔、损害赔偿或其他责任(无论是合同、侵权还是其他原因)承担责任。
使用OpenBuddy即表示您同意这些条款和条件,并承认您了解其使用可能带来的潜在风险。您还同意赔偿并使作者、贡献者和版权所有者免受因您使用OpenBuddy而产生的任何索赔、损害赔偿或责任的影响。 |
mradermacher/FuseChat-Kunoichi-10.7B-GGUF | mradermacher | 2024-06-13T15:01:41Z | 660 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Virt-io/FuseChat-Kunoichi-10.7B",
"endpoints_compatible",
"region:us"
] | null | 2024-06-10T04:08:28Z | ---
base_model: Virt-io/FuseChat-Kunoichi-10.7B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Virt-io/FuseChat-Kunoichi-10.7B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q2_K.gguf) | Q2_K | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.IQ3_XS.gguf) | IQ3_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q3_K_S.gguf) | Q3_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.IQ3_S.gguf) | IQ3_S | 4.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.IQ3_M.gguf) | IQ3_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q3_K_M.gguf) | Q3_K_M | 5.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q3_K_L.gguf) | Q3_K_L | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.IQ4_XS.gguf) | IQ4_XS | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q4_K_S.gguf) | Q4_K_S | 6.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q4_K_M.gguf) | Q4_K_M | 6.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q5_K_S.gguf) | Q5_K_S | 7.5 | |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q5_K_M.gguf) | Q5_K_M | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q6_K.gguf) | Q6_K | 8.9 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/FuseChat-Kunoichi-10.7B-GGUF/resolve/main/FuseChat-Kunoichi-10.7B.Q8_0.gguf) | Q8_0 | 11.5 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
ckiplab/albert-tiny-chinese-ner | ckiplab | 2022-05-10T03:28:10Z | 659 | 2 | transformers | [
"transformers",
"pytorch",
"albert",
"token-classification",
"zh",
"license:gpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z | ---
language:
- zh
thumbnail: https://ckip.iis.sinica.edu.tw/files/ckip_logo.png
tags:
- pytorch
- token-classification
- albert
- zh
license: gpl-3.0
---
# CKIP ALBERT Tiny Chinese
This project provides traditional Chinese transformers models (including ALBERT, BERT, GPT2) and NLP tools (including word segmentation, part-of-speech tagging, named entity recognition).
這個專案提供了繁體中文的 transformers 模型(包含 ALBERT、BERT、GPT2)及自然語言處理工具(包含斷詞、詞性標記、實體辨識)。
## Homepage
- https://github.com/ckiplab/ckip-transformers
## Contributers
- [Mu Yang](https://muyang.pro) at [CKIP](https://ckip.iis.sinica.edu.tw) (Author & Maintainer)
## Usage
Please use BertTokenizerFast as tokenizer instead of AutoTokenizer.
請使用 BertTokenizerFast 而非 AutoTokenizer。
```
from transformers import (
BertTokenizerFast,
AutoModel,
)
tokenizer = BertTokenizerFast.from_pretrained('bert-base-chinese')
model = AutoModel.from_pretrained('ckiplab/albert-tiny-chinese-ner')
```
For full usage and more information, please refer to https://github.com/ckiplab/ckip-transformers.
有關完整使用方法及其他資訊,請參見 https://github.com/ckiplab/ckip-transformers 。
|
timm/focalnet_base_lrf.ms_in1k | timm | 2024-02-10T23:31:50Z | 659 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2203.11926",
"license:mit",
"region:us"
] | image-classification | 2023-03-18T04:21:39Z | ---
license: mit
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for focalnet_base_lrf.ms_in1k
A FocalNet image classification model. Pretrained on ImageNet-1k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 88.7
- GMACs: 15.4
- Activations (M): 38.1
- Image size: 224 x 224
- **Papers:**
- Focal Modulation Networks: https://arxiv.org/abs/2203.11926
- **Original:** https://github.com/microsoft/FocalNet
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('focalnet_base_lrf.ms_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'focalnet_base_lrf.ms_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for focalnet_base_srf:
# torch.Size([1, 128, 56, 56])
# torch.Size([1, 256, 28, 28])
# torch.Size([1, 512, 14, 14])
# torch.Size([1, 1024, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'focalnet_base_lrf.ms_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, num_features, H, W) tensor)
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@misc{yang2022focal,
title={Focal Modulation Networks},
author={Jianwei Yang and Chunyuan Li and Xiyang Dai and Jianfeng Gao},
journal={Advances in Neural Information Processing Systems (NeurIPS)},
year={2022}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
SilverFan/L3-8B-sunfall-v0.4-stheno-v3.2-Q6_K-GGUF | SilverFan | 2024-06-21T02:27:08Z | 659 | 0 | transformers | [
"transformers",
"gguf",
"not-for-all-audiences",
"llama-cpp",
"gguf-my-repo",
"base_model:crestf411/L3-8B-sunfall-v0.4-stheno-v3.2",
"license:llama3",
"endpoints_compatible",
"region:us"
] | null | 2024-06-21T02:26:38Z | ---
base_model: crestf411/L3-8B-sunfall-v0.4-stheno-v3.2
library_name: transformers
license: llama3
license_name: llama3
license_link: LICENSE
tags:
- not-for-all-audiences
- llama-cpp
- gguf-my-repo
---
# SilverFan/L3-8B-sunfall-v0.4-stheno-v3.2-Q6_K-GGUF
This model was converted to GGUF format from [`crestf411/L3-8B-sunfall-v0.4-stheno-v3.2`](https://huggingface.co/crestf411/L3-8B-sunfall-v0.4-stheno-v3.2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/crestf411/L3-8B-sunfall-v0.4-stheno-v3.2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo SilverFan/L3-8B-sunfall-v0.4-stheno-v3.2-Q6_K-GGUF --hf-file l3-8b-sunfall-v0.4-stheno-v3.2-q6_k.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo SilverFan/L3-8B-sunfall-v0.4-stheno-v3.2-Q6_K-GGUF --hf-file l3-8b-sunfall-v0.4-stheno-v3.2-q6_k.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo SilverFan/L3-8B-sunfall-v0.4-stheno-v3.2-Q6_K-GGUF --hf-file l3-8b-sunfall-v0.4-stheno-v3.2-q6_k.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo SilverFan/L3-8B-sunfall-v0.4-stheno-v3.2-Q6_K-GGUF --hf-file l3-8b-sunfall-v0.4-stheno-v3.2-q6_k.gguf -c 2048
```
|
Ransss/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2-Q8_0-GGUF | Ransss | 2024-06-30T12:43:57Z | 659 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:cgato/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2",
"license:cc-by-nc-4.0",
"region:us"
] | null | 2024-06-30T12:43:21Z | ---
base_model: cgato/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2
license: cc-by-nc-4.0
tags:
- llama-cpp
- gguf-my-repo
---
# Ransss/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2-Q8_0-GGUF
This model was converted to GGUF format from [`cgato/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2`](https://huggingface.co/cgato/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/cgato/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Ransss/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2-Q8_0-GGUF --hf-file thesalt-rp-l3-8b-dpo-v0.3.2-e0.4.2-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Ransss/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2-Q8_0-GGUF --hf-file thesalt-rp-l3-8b-dpo-v0.3.2-e0.4.2-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Ransss/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2-Q8_0-GGUF --hf-file thesalt-rp-l3-8b-dpo-v0.3.2-e0.4.2-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Ransss/TheSalt-RP-L3-8b-DPO-v0.3.2-e0.4.2-Q8_0-GGUF --hf-file thesalt-rp-l3-8b-dpo-v0.3.2-e0.4.2-q8_0.gguf -c 2048
```
|
abmorton/standard-small-1 | abmorton | 2024-06-30T21:41:51Z | 659 | 0 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-06-30T21:37:48Z | ---
license: creativeml-openrail-m
tags:
- text-to-image
- stable-diffusion
---
### standard-small-1 Dreambooth model trained by abmorton with [TheLastBen's fast-DreamBooth](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast-DreamBooth.ipynb) notebook
Test the concept via A1111 Colab [fast-Colab-A1111](https://colab.research.google.com/github/TheLastBen/fast-stable-diffusion/blob/main/fast_stable_diffusion_AUTOMATIC1111.ipynb)
Sample pictures of this concept:
|
TheTUFGuy/HermioneChatBot | TheTUFGuy | 2021-08-30T18:06:36Z | 658 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
tags:
- conversational
---
# Hemione Chat Bot |
minutillamolinara/bert-japanese_finetuned-sentiment-analysis | minutillamolinara | 2023-03-31T13:13:37Z | 658 | 3 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"ja",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2023-03-31T02:28:09Z | ---
language: ja
license: mit
widget:
- text: "自然言語処理が面白い"
metrics:
- accuracy
- f1
---
# bert-japanese_finetuned-sentiment-analysis
This model was trained from scratch on the Japanese Sentiment Polarity Dictionary dataset.
## Pre-trained model
jarvisx17/japanese-sentiment-analysis<br/>
Link : https://huggingface.co/jarvisx17/japanese-sentiment-analysis
## Training Data
The model was trained on Japanese Sentiment Polarity Dictionary dataset.<br/>
link : https://www.cl.ecei.tohoku.ac.jp/Open_Resources-Japanese_Sentiment_Polarity_Dictionary.html
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 16
- eval_batch_size: 16
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 10
## Usage
You can use cURL to access this model:
Python API:
```
from transformers import AutoTokenizer, AutoModelForSequenceClassification
tokenizer = AutoTokenizer.from_pretrained("minutillamolinara/bert-japanese_finetuned-sentiment-analysis")
model = AutoModelForSequenceClassification.from_pretrained("minutillamolinara/bert-japanese_finetuned-sentiment-analysis")
inputs = tokenizer("自然言語処理が面白い", return_tensors="pt")
outputs = model(**inputs)
```
### Dependencies
- !pip install fugashi
- !pip install unidic_lite
## Licenses
MIT
|
llama-moe/LLaMA-MoE-v1-3_5B-2_8 | llama-moe | 2024-06-25T02:37:42Z | 658 | 15 | transformers | [
"transformers",
"pytorch",
"llama_moe",
"text-generation",
"MoE",
"custom_code",
"en",
"arxiv:2310.06694",
"arxiv:2406.16554",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | text-generation | 2023-12-23T14:00:42Z | ---
license: apache-2.0
language:
- en
tags:
- MoE
---
# LLaMA-MoE-v1-3.5B (2/8)
[[💻 Code]](https://github.com/pjlab-sys4nlp/llama-moe) | [[📜 Technical Report]](https://github.com/pjlab-sys4nlp/llama-moe/blob/main/docs/LLaMA_MoE.pdf)
👋 Very nice to meet you here~
❤️ This repo contains the model `LLaMA-MoE-v1-3.5B (2/8)`, which activates 2 out of 8 experts (3.5B parameters).
This model is NOT fine-tuned by instruction pairs, so it may not be good enough to act like a chatbot.
📢 LLaMA-MoE is a series of Mixture-of-Expert (MoE) models based on [LLaMA-2](https://huggingface.co/meta-llama/Llama-2-7b-hf).
You can find the code for training this model at [this repo](https://github.com/pjlab-sys4nlp/llama-moe).
💎 This series of models are obtained by partitioning original LLaMA FFNs into experts and further continual pre-training.
The total model size is only 6.7B parameters, which is very convenient for deployment and research usage.
More details could be found at [our technical report](https://arxiv.org/).
## 🚀 QuickStart
```python
# python>=3.10
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_dir = "llama-moe/LLaMA-MoE-v1-3_5B-2_8"
tokenizer = AutoTokenizer.from_pretrained(model_dir, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(model_dir, torch_dtype=torch.bfloat16, trust_remote_code=True)
model.eval()
model.to("cuda:0")
input_text = "Suzhou is famous of"
inputs = tokenizer(input_text, return_tensors="pt")
inputs = inputs.to("cuda:0")
pred = model.generate(**inputs, max_length=50, temperature=0.0)
print(tokenizer.decode(pred.cpu()[0], skip_special_tokens=True))
# Suzhou is famous of its beautiful gardens. The most famous one is the Humble Administrator's Garden. It is a classical Chinese garden with a history of more than 600 years. The garden is divided into three
```
## 📊 Performance
| Model | \#Activated Experts | \#Experts | \#Activated Params | Links |
| :------------------------ | :-----------------: | :-------: | :----------------: | :-----------------------------------------------------------------------: |
| **LLaMA-MoE-3.0B** | 2 | 16 | 3.0B | [[🤗 HF Weights]](https://huggingface.co/llama-moe/LLaMA-MoE-v1-3_0B-2_16) |
| **LLaMA-MoE-3.5B (4/16)** | 4 | 16 | 3.5B | [[🤗 HF Weights]](https://huggingface.co/llama-moe/LLaMA-MoE-v1-3_5B-4_16) |
| **LLaMA-MoE-3.5B (2/8)** | 2 | 8 | 3.5B | [[🤗 HF Weights]](https://huggingface.co/llama-moe/LLaMA-MoE-v1-3_5B-2_8) |
| Model | SciQ | PIQA | WinoGrande | ARC-e | ARC-c (25) | HellaSwag (10) | LogiQA | BoolQ (32) | LAMBADA | NQ (32) | MMLU (5) | Average |
| :------------------------------------------------------------------------------------ | :------: | :------: | :--------: | :------: | :--------: | :------------: | :------: | :--------: | :------: | :------: | :-------: | :-----: |
| [OPT-2.7B](https://huggingface.co/facebook/opt-2.7b) | 78.9 | 74.8 | 60.8 | 54.4 | 34.0 | 61.4 | 25.8 | 63.3 | 63.6 | 10.7 | 25.8 | 50.3 |
| [Pythia-2.8B](https://huggingface.co/EleutherAI/pythia-2.8b) | 83.2 | 73.6 | 59.6 | 58.8 | 36.7 | 60.7 | 28.1 | 65.9 | 64.6 | 8.7 | 26.8 | 51.5 |
| [INCITE-BASE-3B](https://huggingface.co/togethercomputer/RedPajama-INCITE-Base-3B-v1) | 85.6 | 73.9 | 63.5 | 61.7 | 40.3 | 64.7 | 27.5 | 65.8 | 65.4 | 15.2 | 27.2 | 53.7 |
| [Open-LLaMA-3B-v2](https://huggingface.co/openlm-research/open_llama_3b_v2) | 88.0 | 77.9 | 63.1 | 63.3 | 40.1 | 71.4 | 28.1 | 69.2 | 67.4 | 16.0 | 26.8 | 55.6 |
| [Sheared-LLaMA-2.7B](https://huggingface.co/princeton-nlp/Sheared-LLaMA-2.7B) | 87.5 | 76.9 | 65.0 | 63.3 | 41.6 | 71.0 | 28.3 | 73.6 | 68.3 | 17.6 | **27.3** | 56.4 |
| **LLaMA-MoE-3.0B** | 84.2 | 77.5 | 63.6 | 60.2 | 40.9 | 70.8 | **30.6** | 71.9 | 66.6 | 17.0 | 26.8 | 55.5 |
| **LLaMA-MoE-3.5B (4/16)** | 87.6 | **77.9** | 65.5 | **65.6** | **44.2** | **73.3** | 29.7 | **75.0** | **69.5** | **20.3** | 26.8 | 57.7 |
| **LLaMA-MoE-3.5B (2/8)** | **88.4** | 77.6 | **66.7** | 65.3 | 43.1 | **73.3** | 29.6 | 73.9 | 69.4 | 19.8 | 27.0 | 57.6 |
## 📖 Details
Training Data: 200B tokens from [SlimPajama](https://www.cerebras.net/blog/slimpajama-a-627b-token-cleaned-and-deduplicated-version-of-redpajama) with the same data sampling weights as [Sheared LLaMA](https://arxiv.org/abs/2310.06694).
## 📃 Citation
```bibtex
@article{llama-moe,
title={LLaMA-MoE: Building Mixture-of-Experts from LLaMA with Continual Pre-training},
author={Tong Zhu and Xiaoye Qu and Daize Dong and Jiacheng Ruan and Jingqi Tong and Conghui He and Yu Cheng},
journal={arXiv preprint arXiv:2406.16554},
year={2024},
url={https://arxiv.org/abs/2406.16554},
}
``` |
panda0125/5EtMoSeLwavwVq1FJtkgXVyc9WW6BKFtZtLn68ByUE2WKyQe_vgg | panda0125 | 2024-02-15T10:35:18Z | 658 | 0 | keras | [
"keras",
"region:us"
] | null | 2024-02-08T06:52:20Z | Entry not found |
sensenova/piccolo-large-zh-v2 | sensenova | 2024-06-13T06:15:54Z | 658 | 47 | sentence-transformers | [
"sentence-transformers",
"bert",
"mteb",
"arxiv:2405.06932",
"model-index",
"region:us"
] | null | 2024-04-20T14:15:18Z | ---
tags:
- mteb
- sentence-transformers
model-index:
- name: piccolo-large-zh-v2
results:
- task:
type: STS
dataset:
type: C-MTEB/AFQMC
name: MTEB AFQMC
config: default
split: validation
revision: None
metrics:
- type: cos_sim_pearson
value: 56.76055988260572
- type: cos_sim_spearman
value: 61.49271876861677
- type: euclidean_pearson
value: 59.14524585320711
- type: euclidean_spearman
value: 60.63579339225774
- type: manhattan_pearson
value: 59.14662752965445
- type: manhattan_spearman
value: 60.635190265737904
- task:
type: STS
dataset:
type: C-MTEB/ATEC
name: MTEB ATEC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 56.21706298831197
- type: cos_sim_spearman
value: 59.19831457688953
- type: euclidean_pearson
value: 62.37752017633299
- type: euclidean_spearman
value: 58.79400967473204
- type: manhattan_pearson
value: 62.37015943212308
- type: manhattan_spearman
value: 58.79232537600814
- task:
type: Classification
dataset:
type: mteb/amazon_reviews_multi
name: MTEB AmazonReviewsClassification (zh)
config: zh
split: test
revision: 1399c76144fd37290681b995c656ef9b2e06e26d
metrics:
- type: accuracy
value: 49.440000000000005
- type: f1
value: 46.67381446305019
- task:
type: STS
dataset:
type: C-MTEB/BQ
name: MTEB BQ
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 70.99026329599994
- type: cos_sim_spearman
value: 72.87565357908989
- type: euclidean_pearson
value: 71.17690439270028
- type: euclidean_spearman
value: 72.50428109969029
- type: manhattan_pearson
value: 71.17262321033088
- type: manhattan_spearman
value: 72.49845447987437
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringP2P
name: MTEB CLSClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 57.92713421071616
- task:
type: Clustering
dataset:
type: C-MTEB/CLSClusteringS2S
name: MTEB CLSClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 48.096546680932235
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 89.31003741715936
- type: mrr
value: 91.38075396825397
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 90.13769781784876
- type: mrr
value: 92.14329365079365
- task:
type: Retrieval
dataset:
type: C-MTEB/CmedqaRetrieval
name: MTEB CmedqaRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 26.931
- type: map_at_10
value: 40.647
- type: map_at_100
value: 42.519
- type: map_at_1000
value: 42.616
- type: map_at_3
value: 36.144999999999996
- type: map_at_5
value: 38.717
- type: mrr_at_1
value: 40.935
- type: mrr_at_10
value: 49.684
- type: mrr_at_100
value: 50.598
- type: mrr_at_1000
value: 50.632999999999996
- type: mrr_at_3
value: 47.07
- type: mrr_at_5
value: 48.49
- type: ndcg_at_1
value: 40.935
- type: ndcg_at_10
value: 47.583999999999996
- type: ndcg_at_100
value: 54.69199999999999
- type: ndcg_at_1000
value: 56.314
- type: ndcg_at_3
value: 41.973
- type: ndcg_at_5
value: 44.334
- type: precision_at_1
value: 40.935
- type: precision_at_10
value: 10.585
- type: precision_at_100
value: 1.637
- type: precision_at_1000
value: 0.184
- type: precision_at_3
value: 23.881
- type: precision_at_5
value: 17.399
- type: recall_at_1
value: 26.931
- type: recall_at_10
value: 59.006
- type: recall_at_100
value: 88.247
- type: recall_at_1000
value: 99.045
- type: recall_at_3
value: 42.064
- type: recall_at_5
value: 49.266
- task:
type: PairClassification
dataset:
type: C-MTEB/CMNLI
name: MTEB Cmnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 86.08538785327721
- type: cos_sim_ap
value: 92.64373114205229
- type: cos_sim_f1
value: 86.89951395953432
- type: cos_sim_precision
value: 84.11378555798687
- type: cos_sim_recall
value: 89.87608136544307
- type: dot_accuracy
value: 72.66386049308478
- type: dot_ap
value: 81.053422935767
- type: dot_f1
value: 75.19933726830277
- type: dot_precision
value: 67.4907063197026
- type: dot_recall
value: 84.89595510872107
- type: euclidean_accuracy
value: 85.52014431749849
- type: euclidean_ap
value: 91.90647782899615
- type: euclidean_f1
value: 86.26361413647477
- type: euclidean_precision
value: 82.2071595001059
- type: euclidean_recall
value: 90.74117371989713
- type: manhattan_accuracy
value: 85.48406494287433
- type: manhattan_ap
value: 91.89657919524385
- type: manhattan_f1
value: 86.20413761572752
- type: manhattan_precision
value: 84.324686940966
- type: manhattan_recall
value: 88.16927753097966
- type: max_accuracy
value: 86.08538785327721
- type: max_ap
value: 92.64373114205229
- type: max_f1
value: 86.89951395953432
- task:
type: Retrieval
dataset:
type: C-MTEB/CovidRetrieval
name: MTEB CovidRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 75.50099999999999
- type: map_at_10
value: 83.43
- type: map_at_100
value: 83.577
- type: map_at_1000
value: 83.57900000000001
- type: map_at_3
value: 82.06400000000001
- type: map_at_5
value: 82.88600000000001
- type: mrr_at_1
value: 75.869
- type: mrr_at_10
value: 83.536
- type: mrr_at_100
value: 83.682
- type: mrr_at_1000
value: 83.68299999999999
- type: mrr_at_3
value: 82.244
- type: mrr_at_5
value: 82.998
- type: ndcg_at_1
value: 75.764
- type: ndcg_at_10
value: 86.777
- type: ndcg_at_100
value: 87.36
- type: ndcg_at_1000
value: 87.424
- type: ndcg_at_3
value: 84.10300000000001
- type: ndcg_at_5
value: 85.532
- type: precision_at_1
value: 75.764
- type: precision_at_10
value: 9.8
- type: precision_at_100
value: 1.005
- type: precision_at_1000
value: 0.101
- type: precision_at_3
value: 30.207
- type: precision_at_5
value: 18.82
- type: recall_at_1
value: 75.50099999999999
- type: recall_at_10
value: 96.997
- type: recall_at_100
value: 99.473
- type: recall_at_1000
value: 100.0
- type: recall_at_3
value: 89.831
- type: recall_at_5
value: 93.256
- task:
type: Retrieval
dataset:
type: C-MTEB/DuRetrieval
name: MTEB DuRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 27.094
- type: map_at_10
value: 82.418
- type: map_at_100
value: 85.05
- type: map_at_1000
value: 85.083
- type: map_at_3
value: 57.68600000000001
- type: map_at_5
value: 72.476
- type: mrr_at_1
value: 92.25
- type: mrr_at_10
value: 94.621
- type: mrr_at_100
value: 94.675
- type: mrr_at_1000
value: 94.677
- type: mrr_at_3
value: 94.375
- type: mrr_at_5
value: 94.52199999999999
- type: ndcg_at_1
value: 92.25
- type: ndcg_at_10
value: 89.13600000000001
- type: ndcg_at_100
value: 91.532
- type: ndcg_at_1000
value: 91.836
- type: ndcg_at_3
value: 88.50099999999999
- type: ndcg_at_5
value: 87.251
- type: precision_at_1
value: 92.25
- type: precision_at_10
value: 42.295
- type: precision_at_100
value: 4.812
- type: precision_at_1000
value: 0.48900000000000005
- type: precision_at_3
value: 79.167
- type: precision_at_5
value: 66.56
- type: recall_at_1
value: 27.094
- type: recall_at_10
value: 89.816
- type: recall_at_100
value: 97.855
- type: recall_at_1000
value: 99.384
- type: recall_at_3
value: 59.557
- type: recall_at_5
value: 76.395
- task:
type: Retrieval
dataset:
type: C-MTEB/EcomRetrieval
name: MTEB EcomRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 53.6
- type: map_at_10
value: 62.985
- type: map_at_100
value: 63.532999999999994
- type: map_at_1000
value: 63.546
- type: map_at_3
value: 60.617
- type: map_at_5
value: 62.017
- type: mrr_at_1
value: 53.6
- type: mrr_at_10
value: 62.985
- type: mrr_at_100
value: 63.532999999999994
- type: mrr_at_1000
value: 63.546
- type: mrr_at_3
value: 60.617
- type: mrr_at_5
value: 62.017
- type: ndcg_at_1
value: 53.6
- type: ndcg_at_10
value: 67.755
- type: ndcg_at_100
value: 70.366
- type: ndcg_at_1000
value: 70.696
- type: ndcg_at_3
value: 62.89900000000001
- type: ndcg_at_5
value: 65.437
- type: precision_at_1
value: 53.6
- type: precision_at_10
value: 8.28
- type: precision_at_100
value: 0.9490000000000001
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 23.166999999999998
- type: precision_at_5
value: 15.14
- type: recall_at_1
value: 53.6
- type: recall_at_10
value: 82.8
- type: recall_at_100
value: 94.89999999999999
- type: recall_at_1000
value: 97.5
- type: recall_at_3
value: 69.5
- type: recall_at_5
value: 75.7
- task:
type: Classification
dataset:
type: C-MTEB/IFlyTek-classification
name: MTEB IFlyTek
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 52.104655636783384
- type: f1
value: 41.025743582860514
- task:
type: Classification
dataset:
type: C-MTEB/JDReview-classification
name: MTEB JDReview
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 88.57410881801127
- type: ap
value: 59.49612312498937
- type: f1
value: 83.70595013666741
- task:
type: STS
dataset:
type: C-MTEB/LCQMC
name: MTEB LCQMC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 74.00327736048256
- type: cos_sim_spearman
value: 79.5459672237356
- type: euclidean_pearson
value: 79.18300205389669
- type: euclidean_spearman
value: 79.21872988987533
- type: manhattan_pearson
value: 79.1715470733081
- type: manhattan_spearman
value: 79.20756273498812
- task:
type: Retrieval
dataset:
type: C-MTEB/MMarcoRetrieval
name: MTEB MMarcoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 66.94600000000001
- type: map_at_10
value: 75.947
- type: map_at_100
value: 76.268
- type: map_at_1000
value: 76.28
- type: map_at_3
value: 74.13300000000001
- type: map_at_5
value: 75.28399999999999
- type: mrr_at_1
value: 69.241
- type: mrr_at_10
value: 76.532
- type: mrr_at_100
value: 76.816
- type: mrr_at_1000
value: 76.827
- type: mrr_at_3
value: 74.95
- type: mrr_at_5
value: 75.957
- type: ndcg_at_1
value: 69.241
- type: ndcg_at_10
value: 79.54299999999999
- type: ndcg_at_100
value: 80.95
- type: ndcg_at_1000
value: 81.252
- type: ndcg_at_3
value: 76.119
- type: ndcg_at_5
value: 78.069
- type: precision_at_1
value: 69.241
- type: precision_at_10
value: 9.576
- type: precision_at_100
value: 1.026
- type: precision_at_1000
value: 0.105
- type: precision_at_3
value: 28.571999999999996
- type: precision_at_5
value: 18.181
- type: recall_at_1
value: 66.94600000000001
- type: recall_at_10
value: 90.024
- type: recall_at_100
value: 96.3
- type: recall_at_1000
value: 98.656
- type: recall_at_3
value: 81.026
- type: recall_at_5
value: 85.658
- task:
type: Classification
dataset:
type: mteb/amazon_massive_intent
name: MTEB MassiveIntentClassification (zh-CN)
config: zh-CN
split: test
revision: 31efe3c427b0bae9c22cbb560b8f15491cc6bed7
metrics:
- type: accuracy
value: 77.71015467383997
- type: f1
value: 74.32345894845358
- task:
type: Classification
dataset:
type: mteb/amazon_massive_scenario
name: MTEB MassiveScenarioClassification (zh-CN)
config: zh-CN
split: test
revision: 7d571f92784cd94a019292a1f45445077d0ef634
metrics:
- type: accuracy
value: 85.63214525891055
- type: f1
value: 84.65303466003252
- task:
type: Retrieval
dataset:
type: C-MTEB/MedicalRetrieval
name: MTEB MedicalRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 55.50000000000001
- type: map_at_10
value: 61.66199999999999
- type: map_at_100
value: 62.13999999999999
- type: map_at_1000
value: 62.187000000000005
- type: map_at_3
value: 59.967000000000006
- type: map_at_5
value: 60.927
- type: mrr_at_1
value: 55.7
- type: mrr_at_10
value: 61.76199999999999
- type: mrr_at_100
value: 62.241
- type: mrr_at_1000
value: 62.287000000000006
- type: mrr_at_3
value: 60.06700000000001
- type: mrr_at_5
value: 61.027
- type: ndcg_at_1
value: 55.50000000000001
- type: ndcg_at_10
value: 64.878
- type: ndcg_at_100
value: 67.464
- type: ndcg_at_1000
value: 68.745
- type: ndcg_at_3
value: 61.367000000000004
- type: ndcg_at_5
value: 63.117999999999995
- type: precision_at_1
value: 55.50000000000001
- type: precision_at_10
value: 7.51
- type: precision_at_100
value: 0.878
- type: precision_at_1000
value: 0.098
- type: precision_at_3
value: 21.8
- type: precision_at_5
value: 13.94
- type: recall_at_1
value: 55.50000000000001
- type: recall_at_10
value: 75.1
- type: recall_at_100
value: 87.8
- type: recall_at_1000
value: 97.89999999999999
- type: recall_at_3
value: 65.4
- type: recall_at_5
value: 69.69999999999999
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 33.386980266936106
- type: mrr
value: 32.11904761904762
- task:
type: Classification
dataset:
type: C-MTEB/MultilingualSentiment-classification
name: MTEB MultilingualSentiment
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 79.08666666666666
- type: f1
value: 78.93142205976953
- task:
type: PairClassification
dataset:
type: C-MTEB/OCNLI
name: MTEB Ocnli
config: default
split: validation
revision: None
metrics:
- type: cos_sim_accuracy
value: 84.35300487276665
- type: cos_sim_ap
value: 87.83572265803564
- type: cos_sim_f1
value: 85.42713567839195
- type: cos_sim_precision
value: 81.49568552253116
- type: cos_sim_recall
value: 89.7571277719113
- type: dot_accuracy
value: 72.87493232268544
- type: dot_ap
value: 80.29032993894747
- type: dot_f1
value: 76.5938475256353
- type: dot_precision
value: 66.28086419753086
- type: dot_recall
value: 90.70749736008447
- type: euclidean_accuracy
value: 82.34975636166757
- type: euclidean_ap
value: 85.73873757468064
- type: euclidean_f1
value: 83.56713426853707
- type: euclidean_precision
value: 79.50428979980934
- type: euclidean_recall
value: 88.0675818373812
- type: manhattan_accuracy
value: 82.45804006497022
- type: manhattan_ap
value: 85.7176464290469
- type: manhattan_f1
value: 83.65095285857572
- type: manhattan_precision
value: 79.65616045845272
- type: manhattan_recall
value: 88.0675818373812
- type: max_accuracy
value: 84.35300487276665
- type: max_ap
value: 87.83572265803564
- type: max_f1
value: 85.42713567839195
- task:
type: Classification
dataset:
type: C-MTEB/OnlineShopping-classification
name: MTEB OnlineShopping
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 94.61999999999999
- type: ap
value: 92.74140430219491
- type: f1
value: 94.60775857122515
- task:
type: STS
dataset:
type: C-MTEB/PAWSX
name: MTEB PAWSX
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 39.75749234575995
- type: cos_sim_spearman
value: 46.48035295363829
- type: euclidean_pearson
value: 45.38711981599582
- type: euclidean_spearman
value: 46.13915356562481
- type: manhattan_pearson
value: 45.420770530489065
- type: manhattan_spearman
value: 46.179913441143775
- task:
type: STS
dataset:
type: C-MTEB/QBQTC
name: MTEB QBQTC
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 44.02008249965321
- type: cos_sim_spearman
value: 45.906917552219156
- type: euclidean_pearson
value: 36.600317631983316
- type: euclidean_spearman
value: 41.97740958824762
- type: manhattan_pearson
value: 36.54329048509785
- type: manhattan_spearman
value: 41.91222171040451
- task:
type: STS
dataset:
type: mteb/sts22-crosslingual-sts
name: MTEB STS22 (zh)
config: zh
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 60.97044608578288
- type: cos_sim_spearman
value: 63.76187490245927
- type: euclidean_pearson
value: 60.74245987426317
- type: euclidean_spearman
value: 63.32990713078846
- type: manhattan_pearson
value: 60.62422616577702
- type: manhattan_spearman
value: 63.256612476686826
- task:
type: STS
dataset:
type: C-MTEB/STSB
name: MTEB STSB
config: default
split: test
revision: None
metrics:
- type: cos_sim_pearson
value: 76.28185867362305
- type: cos_sim_spearman
value: 78.71478656159289
- type: euclidean_pearson
value: 79.80734359535234
- type: euclidean_spearman
value: 79.85403491297063
- type: manhattan_pearson
value: 79.79454037962215
- type: manhattan_spearman
value: 79.82796402623201
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 67.14759526113295
- type: mrr
value: 77.36422096484723
- task:
type: Retrieval
dataset:
type: C-MTEB/T2Retrieval
name: MTEB T2Retrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 28.177999999999997
- type: map_at_10
value: 78.77199999999999
- type: map_at_100
value: 82.365
- type: map_at_1000
value: 82.422
- type: map_at_3
value: 55.452999999999996
- type: map_at_5
value: 68.12700000000001
- type: mrr_at_1
value: 91.097
- type: mrr_at_10
value: 93.52000000000001
- type: mrr_at_100
value: 93.587
- type: mrr_at_1000
value: 93.589
- type: mrr_at_3
value: 93.136
- type: mrr_at_5
value: 93.381
- type: ndcg_at_1
value: 91.097
- type: ndcg_at_10
value: 86.136
- type: ndcg_at_100
value: 89.515
- type: ndcg_at_1000
value: 90.049
- type: ndcg_at_3
value: 87.41600000000001
- type: ndcg_at_5
value: 86.115
- type: precision_at_1
value: 91.097
- type: precision_at_10
value: 42.597
- type: precision_at_100
value: 5.043
- type: precision_at_1000
value: 0.517
- type: precision_at_3
value: 76.239
- type: precision_at_5
value: 63.93
- type: recall_at_1
value: 28.177999999999997
- type: recall_at_10
value: 85.182
- type: recall_at_100
value: 96.174
- type: recall_at_1000
value: 98.848
- type: recall_at_3
value: 57.150999999999996
- type: recall_at_5
value: 71.50999999999999
- task:
type: Classification
dataset:
type: C-MTEB/TNews-classification
name: MTEB TNews
config: default
split: validation
revision: None
metrics:
- type: accuracy
value: 54.521
- type: f1
value: 52.53528052282081
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringP2P
name: MTEB ThuNewsClusteringP2P
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 74.2003249023509
- task:
type: Clustering
dataset:
type: C-MTEB/ThuNewsClusteringS2S
name: MTEB ThuNewsClusteringS2S
config: default
split: test
revision: None
metrics:
- type: v_measure
value: 68.4277378629746
- task:
type: Retrieval
dataset:
type: C-MTEB/VideoRetrieval
name: MTEB VideoRetrieval
config: default
split: dev
revision: None
metrics:
- type: map_at_1
value: 58.599999999999994
- type: map_at_10
value: 68.671
- type: map_at_100
value: 69.148
- type: map_at_1000
value: 69.157
- type: map_at_3
value: 66.9
- type: map_at_5
value: 68.045
- type: mrr_at_1
value: 58.599999999999994
- type: mrr_at_10
value: 68.671
- type: mrr_at_100
value: 69.148
- type: mrr_at_1000
value: 69.157
- type: mrr_at_3
value: 66.9
- type: mrr_at_5
value: 68.045
- type: ndcg_at_1
value: 58.599999999999994
- type: ndcg_at_10
value: 73.099
- type: ndcg_at_100
value: 75.33
- type: ndcg_at_1000
value: 75.58500000000001
- type: ndcg_at_3
value: 69.502
- type: ndcg_at_5
value: 71.542
- type: precision_at_1
value: 58.599999999999994
- type: precision_at_10
value: 8.68
- type: precision_at_100
value: 0.97
- type: precision_at_1000
value: 0.099
- type: precision_at_3
value: 25.667
- type: precision_at_5
value: 16.38
- type: recall_at_1
value: 58.599999999999994
- type: recall_at_10
value: 86.8
- type: recall_at_100
value: 97.0
- type: recall_at_1000
value: 99.1
- type: recall_at_3
value: 77.0
- type: recall_at_5
value: 81.89999999999999
- task:
type: Classification
dataset:
type: C-MTEB/waimai-classification
name: MTEB Waimai
config: default
split: test
revision: None
metrics:
- type: accuracy
value: 89.58999999999999
- type: ap
value: 75.69899834265364
- type: f1
value: 88.2026184757175
---
[EN](README.md) | [简体中文](README_zh.md)
**News**
**[2024-05-16]**
Due to certain internal company considerations, we have temporarily removed the model weights.
It will be uploaded again after passing our internal review process.
Please temporarily access this model via API: https://platform.sensenova.cn/doc?path=/chat/Embeddings/Embeddings.md
There is a temporary problem with the API of this page. Please access it temporarily in the following way:
```python
import requests
url = "http://103.237.28.72:8006/v1/qd"
headers = {
'Content-Type': 'application/json',
'Accept': 'application/json'
}
data = {
"inputs": ['hello,world']
}
response = requests.post(url, json=data, headers=headers)
print(response.json())
```
**[2024-05-14]**
We have currently release our model weights, training code, and tech report. Discussions are welcome.
For training code, please refer to our [github](https://github.com/hjq133/piccolo-embedding)
For training details, please refer to our [tech-report](https://arxiv.org/abs/2405.06932)
**[2024-04-22]**
piccolo-large-zh-v2 currently ranks first on the C-MTEB list, leading the previous BERT model by about 1.9 points.
## Piccolo-large-zh-v2
piccolo-large-zh-v2 is a Chinese embedding model developed by the general model group from SenseTime Research. This upgraded version of Piccolo aims to prioritize general downstream fine-tuning methods. Piccolo2 primarily leverages an efficient multi-task hybrid loss training approach,
effectively harnessing textual data and labels from diverse downstream
tasks. In addition, Piccolo2 scales up the embedding dimension and uses
MRL training to support more flexible vector dimensions.
## 💡 Model Hightlights
The main feature of piccolo2 is that it uses a multi-task hybrid loss during training.
For retrieval/sorting tasks, we use the standard InfoNCE with in-batch-negative:
<p align='left'>
<img src='assets/1.png' width='400' height='80'>
</p>
For sts/pair classification tasks, we use cosent loss, which is proved to be better for data with more fine-grained labels(e.g. score values ):
<p align='left'>
<img src='assets/2.png' width='450' height='90'>
</p>
For classification/clustering tasks, by treating text and its semantic labels as positive and negative pairs, we convert the dataset into the format of triples. And then we use InfoNCE to optimize it. However, it’s important to
stress that in-batch negatives are no longer used due to the fact that
it can easily lead to conflict training targets:
<p align='left'>
<img src='assets/3.png' width='400' height='80'>
</p>
## 📃 Experiments and Results
Piccolo2 primarily focuses on the downstream general finetune paradigm. Our open source model uses [stella-v3.5](https://huggingface.co/infgrad/stella-mrl-large-zh-v3.5-1792d) as initialization and trained about 2500 steps on 32 GPUS. For more implementation details, please refer to our [technical report](https://arxiv.org/abs/2405.06932).
| Model Name | Model Size (GB) | Dimension | Sequence Length | Classification (9) | Clustering (4) | Pair Classification (2) | Reranking (4) | Retrieval (8) | STS (8) | Average (35) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [**piccolo-large-zh-v2**](https://huggingface.co/sensenova/piccolo-large-zh-v2) | 1.21 | 1792 | 512 | 74.59 | 62.17 | 90.24 | 70 | 74.36 | 63.5 | 70.95 |
| [gte-Qwen1.5-7B-instruct](https://huggingface.co/Alibaba-NLP/gte-Qwen1.5-7B-instruct)| 26.45 | 32768 |4096 | 73.35 | 67.08 | 88.52 | 66.38 | 70.62 | 62.32 | 69.56|
| [acge-text-embedding](https://huggingface.co/aspire/acge_text_embedding) |1.21 | 1792 | 512 | 72.75 | 58.7 | 87.84 | 67.98 | 72.93 | 62.09 | 69.07 |
## 🔨 Usage
The piccolo model can be easily accessed in the sentence-transformer package:
```python
# for s2s/s2p dataset, you can use piccolo as below
from sklearn.preprocessing import normalize
from sentence_transformers import SentenceTransformer
sentences = ["数据1", "数据2"]
matryoshka_dim=1792 # support 256, 512, 768, 1024, 1280, 1536, 1792
model = SentenceTransformer('sensenova/piccolo-large-zh-v2')
embeddings_1 = model.encode(sentences, normalize_embeddings=False)
embeddings_2 = model.encode(sentences, normalize_embeddings=False)
embeddings_1 = normalize(embeddings_1[..., :matryoshka_dim], norm="l2", axis=1)
embeddings_2 = normalize(embeddings_2[..., :matryoshka_dim], norm="l2", axis=1)
similarity = embeddings_1 @ embeddings_2.T
```
## 🤗 **Model List**
| Model|Language|Description|prompt|
|:-|:-:|:-:|:--:|
| [sensenova/piccolo-large-zh-v2](https://huggingface.co/sensenova/piccolo-large-zh-v2) | Chinese | version2: finetuning with multi-task hybrid loss training | None |
| [sensenova/piccolo-large-zh](https://huggingface.co/sensenova/piccolo-large-zh) | Chinese | version1: pretrain under 400 million chinese text pair | '查询'/'结果' |
| [sensenova/piccolo-base-zh](https://huggingface.co/sensenova/piccolo-base-zh) | Chinese | version1: pretrain under 400 million chinese text pair | '查询'/'结果' |
## Citation
If you find our tech report, models or code helpful, please cite our report or give a star on github or huggingface!
```bibtex
@misc{2405.06932,
Author = {Junqin Huang and Zhongjie Hu and Zihao Jing and Mengya Gao and Yichao Wu},
Title = {Piccolo2: General Text Embedding with Multi-task Hybrid Loss Training},
Year = {2024},
Eprint = {arXiv:2405.06932},
}
``` |
RUNorm/RUNorm-tagger | RUNorm | 2024-05-14T00:55:21Z | 658 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"token-classification",
"ru",
"license:apache-2.0",
"autotrain_compatible",
"region:us"
] | token-classification | 2024-05-05T10:11:58Z | ---
license: apache-2.0
language:
- ru
inference: false
---
Используется в https://github.com/Den4ikAI/runorm
Вы можете поддержать проект деньгами. Это поможет быстрее разрабатывать более качественные новые версии.
CloudTips: https://pay.cloudtips.ru/p/b9d86686 |
mradermacher/Daredevil-8B-GGUF | mradermacher | 2024-05-26T04:37:44Z | 658 | 1 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"en",
"base_model:mlabonne/Daredevil-8B",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2024-05-26T03:36:18Z | ---
base_model: mlabonne/Daredevil-8B
language:
- en
library_name: transformers
license: other
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/mlabonne/Daredevil-8B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Daredevil-8B-GGUF/resolve/main/Daredevil-8B.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
QuantFactory/AutoCoder_S_6.7B-GGUF | QuantFactory | 2024-06-04T09:30:55Z | 658 | 1 | null | [
"gguf",
"text-generation",
"arxiv:2405.14906",
"base_model:Bin12345/AutoCoder_S_6.7B",
"license:apache-2.0",
"region:us"
] | text-generation | 2024-06-01T16:42:41Z | ---
license: apache-2.0
pipeline_tag: text-generation
base_model: Bin12345/AutoCoder_S_6.7B
---
# QuantFactory/AutoCoder_S_6.7B-GGUF
This is quantized version of [Bin12345/AutoCoder_S_6.7B](https://huggingface.co/Bin12345/AutoCoder_S_6.7B) created using llama.cpp
# Model Description
We introduced a new model designed for the Code generation task. It 33B version's test accuracy on the HumanEval base dataset surpasses that of GPT-4 Turbo (April 2024). (90.9% vs 90.2%).
Additionally, compared to previous open-source models, AutoCoder offers a new feature: it can **automatically install the required packages** and attempt to run the code until it deems there are no issues, **whenever the user wishes to execute the code**.
This is the 6.7B version of AutoCoder. Its base model is deepseeker-coder.
See details on the [AutoCoder GitHub](https://github.com/bin123apple/AutoCoder).
Simple test script:
```
model_path = ""
tokenizer = AutoTokenizer.from_pretrained(model_path)
model = AutoModelForCausalLM.from_pretrained(model_path,
device_map="auto")
HumanEval = load_dataset("evalplus/humanevalplus")
Input = "" # input your question here
messages=[
{ 'role': 'user', 'content': Input}
]
inputs = tokenizer.apply_chat_template(messages, add_generation_prompt=True,
return_tensors="pt").to(model.device)
outputs = model.generate(inputs,
max_new_tokens=1024,
do_sample=False,
temperature=0.0,
top_p=1.0,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id)
answer = tokenizer.decode(outputs[0][len(inputs[0]):], skip_special_tokens=True)
```
Paper: https://arxiv.org/abs/2405.14906 |
mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF | mradermacher | 2024-06-16T22:03:26Z | 658 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:migtissera/Tess-v2.5.2-Qwen2-72B",
"license:other",
"endpoints_compatible",
"region:us"
] | null | 2024-06-15T13:12:37Z | ---
base_model: migtissera/Tess-v2.5.2-Qwen2-72B
language:
- en
library_name: transformers
license: other
license_link: https://huggingface.co/Qwen/Qwen2-72B/blob/main/LICENSE
license_name: qwen2
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/migtissera/Tess-v2.5.2-Qwen2-72B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ1_S.gguf) | i1-IQ1_S | 22.8 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ1_M.gguf) | i1-IQ1_M | 23.8 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 25.6 | |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 27.2 | |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ2_S.gguf) | i1-IQ2_S | 28.0 | |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ2_M.gguf) | i1-IQ2_M | 29.4 | |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q2_K.gguf) | i1-Q2_K | 29.9 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 31.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 32.9 | |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ3_S.gguf) | i1-IQ3_S | 34.6 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 34.6 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ3_M.gguf) | i1-IQ3_M | 35.6 | |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 37.8 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 39.6 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 39.8 | |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q4_0.gguf) | i1-Q4_0 | 41.5 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 44.0 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 47.5 | fast, recommended |
| [PART 1](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q5_K_S.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q5_K_S.gguf.part2of2) | i1-Q5_K_S | 51.5 | |
| [PART 1](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q5_K_M.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q5_K_M.gguf.part2of2) | i1-Q5_K_M | 54.5 | |
| [PART 1](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q6_K.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Tess-v2.5.2-Qwen2-72B-i1-GGUF/resolve/main/Tess-v2.5.2-Qwen2-72B.i1-Q6_K.gguf.part2of2) | i1-Q6_K | 64.4 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
V3N0M/Jenna-Uncensored-GGUF-q4-v02 | V3N0M | 2024-06-20T07:05:36Z | 658 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"text-generation-inference",
"unsloth",
"en",
"base_model:unsloth/tinyllama-chat-bnb-4bit",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-20T07:04:05Z | ---
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- llama
- gguf
base_model: unsloth/tinyllama-chat-bnb-4bit
---
# Uploaded model
- **Developed by:** V3N0M
- **License:** apache-2.0
- **Finetuned from model :** unsloth/tinyllama-chat-bnb-4bit
This llama model was trained 2x faster with [Unsloth](https://github.com/unslothai/unsloth) and Huggingface's TRL library.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
|
Klevin/MOE-Finetuned-4B-Q3_K_L-GGUF | Klevin | 2024-06-22T08:07:44Z | 658 | 1 | transformers | [
"transformers",
"gguf",
"text-generation-inference",
"unsloth",
"mistral",
"trl",
"llama-cpp",
"gguf-my-repo",
"en",
"base_model:Klevin/MOE-Finetuned-4B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-22T08:07:28Z | ---
base_model: Klevin/MOE-Finetuned-4B
language:
- en
license: apache-2.0
tags:
- text-generation-inference
- transformers
- unsloth
- mistral
- trl
- llama-cpp
- gguf-my-repo
---
# Klevin/MOE-Finetuned-4B-Q3_K_L-GGUF
This model was converted to GGUF format from [`Klevin/MOE-Finetuned-4B`](https://huggingface.co/Klevin/MOE-Finetuned-4B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/Klevin/MOE-Finetuned-4B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo Klevin/MOE-Finetuned-4B-Q3_K_L-GGUF --hf-file moe-finetuned-4b-q3_k_l.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo Klevin/MOE-Finetuned-4B-Q3_K_L-GGUF --hf-file moe-finetuned-4b-q3_k_l.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo Klevin/MOE-Finetuned-4B-Q3_K_L-GGUF --hf-file moe-finetuned-4b-q3_k_l.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo Klevin/MOE-Finetuned-4B-Q3_K_L-GGUF --hf-file moe-finetuned-4b-q3_k_l.gguf -c 2048
```
|
gooohjy/suicidal-electra | gooohjy | 2022-03-30T12:18:23Z | 657 | 4 | transformers | [
"transformers",
"pytorch",
"electra",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | # Suicidal-ELECTRA
This text classification model predicts whether a sequence of words are suicidal (1) or non-suicidal (0).
## Data
The model was trained on the [Suicide and Depression Dataset](https://www.kaggle.com/nikhileswarkomati/suicide-watch) obtained from Kaggle. The dataset was scraped from Reddit and consists of 232,074 rows equally distributed between 2 classes - suicide and non-suicide.
## Parameters
The model fine-tuning was conducted on 1 epoch, with batch size of 6, and learning rate of 0.00001. Due to limited computing resources and time, we were unable to scale up the number of epochs and batch size.
## Performance
The model has achieved the following results after fine-tuning on the aforementioned dataset:
- Accuracy: 0.9792
- Recall: 0.9788
- Precision: 0.9677
- F1 Score: 0.9732
## How to Use
Load the model via the transformers library:
```
from transformers import AutoTokenizer, AutoModel
tokenizer = AutoTokenizer.from_pretrained("gooohjy/suicidal-electra")
model = AutoModel.from_pretrained("gooohjy/suicidal-electra")
```
## Resources
For more resources, including the source code, please refer to the GitHub repository [gohjiayi/suicidal-text-detection](https://github.com/gohjiayi/suicidal-text-detection/). |
juliensimon/reviews-sentiment-analysis | juliensimon | 2023-03-17T08:01:25Z | 657 | 11 | transformers | [
"transformers",
"pytorch",
"safetensors",
"distilbert",
"text-classification",
"sentiment-analysis",
"en",
"dataset:generated_reviews_enth",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-classification | 2022-03-02T23:29:05Z | ---
language:
- en
tags:
- distilbert
- sentiment-analysis
datasets:
- generated_reviews_enth
---
Distilbert model fine-tuned on English language product reviews
A notebook for Amazon SageMaker is available in the 'code' subfolder.
|
timm/maxxvitv2_nano_rw_256.sw_in1k | timm | 2023-05-11T00:46:53Z | 657 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2204.01697",
"arxiv:2201.03545",
"license:apache-2.0",
"region:us"
] | image-classification | 2023-01-20T21:37:10Z | ---
tags:
- image-classification
- timm
library_name: timm
license: apache-2.0
datasets:
- imagenet-1k
---
# Model card for maxxvitv2_nano_rw_256.sw_in1k
A timm specific MaxxViT-V2 image classification model. Trained in `timm` on ImageNet-1k by Ross Wightman.
ImageNet-1k training done on TPUs thanks to support of the [TRC](https://sites.research.google/trc/about/) program.
### Model Variants in [maxxvit.py](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/maxxvit.py)
MaxxViT covers a number of related model architectures that share a common structure including:
- CoAtNet - Combining MBConv (depthwise-separable) convolutional blocks in early stages with self-attention transformer blocks in later stages.
- MaxViT - Uniform blocks across all stages, each containing a MBConv (depthwise-separable) convolution block followed by two self-attention blocks with different partitioning schemes (window followed by grid).
- CoAtNeXt - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in CoAtNet. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT - A timm specific arch that uses ConvNeXt blocks in place of MBConv blocks in MaxViT. All normalization layers are LayerNorm (no BatchNorm).
- MaxxViT-V2 - A MaxxViT variation that removes the window block attention leaving only ConvNeXt blocks and grid attention w/ more width to compensate.
Aside from the major variants listed above, there are more subtle changes from model to model. Any model name with the string `rw` are `timm` specific configs w/ modelling adjustments made to favour PyTorch eager use. These were created while training initial reproductions of the models so there are variations.
All models with the string `tf` are models exactly matching Tensorflow based models by the original paper authors with weights ported to PyTorch. This covers a number of MaxViT models. The official CoAtNet models were never released.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 23.7
- GMACs: 6.3
- Activations (M): 23.1
- Image size: 256 x 256
- **Papers:**
- MaxViT: Multi-Axis Vision Transformer: https://arxiv.org/abs/2204.01697
- A ConvNet for the 2020s: https://arxiv.org/abs/2201.03545
- **Dataset:** ImageNet-1k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('maxxvitv2_nano_rw_256.sw_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxxvitv2_nano_rw_256.sw_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 96, 128, 128])
# torch.Size([1, 96, 64, 64])
# torch.Size([1, 192, 32, 32])
# torch.Size([1, 384, 16, 16])
# torch.Size([1, 768, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'maxxvitv2_nano_rw_256.sw_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 768, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
### By Top-1
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
### By Throughput (samples / sec)
|model |top1 |top5 |samples / sec |Params (M) |GMAC |Act (M)|
|------------------------------------------------------------------------------------------------------------------------|----:|----:|--------------:|--------------:|-----:|------:|
|[coatnext_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnext_nano_rw_224.sw_in1k) |81.95|95.92| 2525.52| 14.70| 2.47| 12.80|
|[coatnet_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_nano_rw_224.sw_in1k) |81.70|95.64| 2344.52| 15.14| 2.41| 15.41|
|[coatnet_rmlp_nano_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_nano_rw_224.sw_in1k) |82.05|95.87| 2109.09| 15.15| 2.62| 20.34|
|[coatnet_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_0_rw_224.sw_in1k) |82.39|95.84| 1831.21| 27.44| 4.43| 18.73|
|[coatnet_bn_0_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_bn_0_rw_224.sw_in1k) |82.39|96.19| 1600.14| 27.44| 4.67| 22.04|
|[maxvit_rmlp_pico_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_pico_rw_256.sw_in1k) |80.53|95.21| 1594.71| 7.52| 1.85| 24.86|
|[maxxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_nano_rw_256.sw_in1k) |83.03|96.34| 1341.24| 16.78| 4.37| 26.05|
|[maxvit_rmlp_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_nano_rw_256.sw_in1k) |82.96|96.26| 1283.24| 15.50| 4.47| 31.92|
|[maxxvitv2_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxxvitv2_nano_rw_256.sw_in1k) |83.11|96.33| 1276.88| 23.70| 6.26| 23.05|
|[maxvit_nano_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_nano_rw_256.sw_in1k) |82.93|96.23| 1218.17| 15.45| 4.46| 30.28|
|[maxvit_tiny_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_tiny_rw_224.sw_in1k) |83.50|96.50| 1100.53| 29.06| 5.11| 33.11|
|[coatnet_rmlp_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw_224.sw_in1k) |83.36|96.45| 1093.03| 41.69| 7.85| 35.47|
|[coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_1_rw2_224.sw_in12k_ft_in1k) |84.90|96.96| 1025.45| 41.72| 8.11| 40.13|
|[maxvit_tiny_tf_224.in1k](https://huggingface.co/timm/maxvit_tiny_tf_224.in1k) |83.41|96.59| 1004.94| 30.92| 5.60| 35.78|
|[coatnet_1_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_1_rw_224.sw_in1k) |83.62|96.38| 989.59| 41.72| 8.04| 34.60|
|[maxvit_rmlp_tiny_rw_256.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_tiny_rw_256.sw_in1k) |84.23|96.78| 807.21| 29.15| 6.77| 46.92|
|[maxvit_rmlp_small_rw_224.sw_in1k](https://huggingface.co/timm/maxvit_rmlp_small_rw_224.sw_in1k) |84.49|96.76| 693.82| 64.90| 10.75| 49.30|
|[maxvit_small_tf_224.in1k](https://huggingface.co/timm/maxvit_small_tf_224.in1k) |84.43|96.83| 647.96| 68.93| 11.66| 53.17|
|[coatnet_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_2_rw_224.sw_in12k_ft_in1k) |86.57|97.89| 631.88| 73.87| 15.09| 49.22|
|[coatnet_rmlp_2_rw_224.sw_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in1k) |84.61|96.74| 625.81| 73.88| 15.18| 54.78|
|[coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_224.sw_in12k_ft_in1k) |86.49|97.90| 620.58| 73.88| 15.18| 54.78|
|[maxxvit_rmlp_small_rw_256.sw_in1k](https://huggingface.co/timm/maxxvit_rmlp_small_rw_256.sw_in1k) |84.63|97.06| 575.53| 66.01| 14.67| 58.38|
|[maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.64|98.02| 501.03| 116.09| 24.20| 62.77|
|[maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_224.sw_in12k_ft_in1k) |86.89|98.02| 375.86| 116.14| 23.15| 92.64|
|[maxvit_base_tf_224.in1k](https://huggingface.co/timm/maxvit_base_tf_224.in1k) |84.85|96.99| 358.25| 119.47| 24.04| 95.01|
|[maxvit_tiny_tf_384.in1k](https://huggingface.co/timm/maxvit_tiny_tf_384.in1k) |85.11|97.38| 293.46| 30.98| 17.53| 123.42|
|[maxvit_large_tf_224.in1k](https://huggingface.co/timm/maxvit_large_tf_224.in1k) |84.93|96.97| 247.71| 211.79| 43.68| 127.35|
|[maxvit_small_tf_384.in1k](https://huggingface.co/timm/maxvit_small_tf_384.in1k) |85.54|97.46| 188.35| 69.02| 35.87| 183.65|
|[coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/coatnet_rmlp_2_rw_384.sw_in12k_ft_in1k) |87.39|98.31| 160.80| 73.88| 47.69| 209.43|
|[maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxxvitv2_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.47|98.37| 149.49| 116.09| 72.98| 213.74|
|[maxvit_tiny_tf_512.in1k](https://huggingface.co/timm/maxvit_tiny_tf_512.in1k) |85.67|97.58| 144.25| 31.05| 33.49| 257.59|
|[maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k](https://huggingface.co/timm/maxvit_rmlp_base_rw_384.sw_in12k_ft_in1k) |87.81|98.37| 106.55| 116.14| 70.97| 318.95|
|[maxvit_base_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_384.in21k_ft_in1k) |87.92|98.54| 104.71| 119.65| 73.80| 332.90|
|[maxvit_base_tf_384.in1k](https://huggingface.co/timm/maxvit_base_tf_384.in1k) |86.29|97.80| 101.09| 119.65| 73.80| 332.90|
|[maxvit_small_tf_512.in1k](https://huggingface.co/timm/maxvit_small_tf_512.in1k) |86.10|97.76| 88.63| 69.13| 67.26| 383.77|
|[maxvit_large_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_384.in21k_ft_in1k) |87.98|98.56| 71.75| 212.03|132.55| 445.84|
|[maxvit_large_tf_384.in1k](https://huggingface.co/timm/maxvit_large_tf_384.in1k) |86.23|97.69| 70.56| 212.03|132.55| 445.84|
|[maxvit_base_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_base_tf_512.in21k_ft_in1k) |88.20|98.53| 50.87| 119.88|138.02| 703.99|
|[maxvit_base_tf_512.in1k](https://huggingface.co/timm/maxvit_base_tf_512.in1k) |86.60|97.92| 50.75| 119.88|138.02| 703.99|
|[maxvit_xlarge_tf_384.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_384.in21k_ft_in1k) |88.32|98.54| 42.53| 475.32|292.78| 668.76|
|[maxvit_large_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_large_tf_512.in21k_ft_in1k) |88.04|98.40| 36.42| 212.33|244.75| 942.15|
|[maxvit_large_tf_512.in1k](https://huggingface.co/timm/maxvit_large_tf_512.in1k) |86.52|97.88| 36.04| 212.33|244.75| 942.15|
|[maxvit_xlarge_tf_512.in21k_ft_in1k](https://huggingface.co/timm/maxvit_xlarge_tf_512.in21k_ft_in1k) |88.53|98.64| 21.76| 475.77|534.14|1413.22|
## Citation
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
```bibtex
@article{tu2022maxvit,
title={MaxViT: Multi-Axis Vision Transformer},
author={Tu, Zhengzhong and Talebi, Hossein and Zhang, Han and Yang, Feng and Milanfar, Peyman and Bovik, Alan and Li, Yinxiao},
journal={ECCV},
year={2022},
}
```
```bibtex
@article{dai2021coatnet,
title={CoAtNet: Marrying Convolution and Attention for All Data Sizes},
author={Dai, Zihang and Liu, Hanxiao and Le, Quoc V and Tan, Mingxing},
journal={arXiv preprint arXiv:2106.04803},
year={2021}
}
```
|
maddes8cht/OpenAssistant-falcon-40b-sft-mix-1226-gguf | maddes8cht | 2023-11-24T22:50:24Z | 657 | 0 | null | [
"gguf",
"sft",
"en",
"de",
"es",
"fr",
"dataset:OpenAssistant/oasst1",
"dataset:databricks/databricks-dolly-15k",
"license:apache-2.0",
"region:us"
] | null | 2023-10-01T14:02:41Z | ---
license: apache-2.0
language:
- en
- de
- es
- fr
tags:
- sft
inference: false
datasets:
- OpenAssistant/oasst1
- databricks/databricks-dolly-15k
---
[]()
I'm constantly enhancing these model descriptions to provide you with the most relevant and comprehensive information
# falcon-40b-sft-mix-1226 - GGUF
- Model creator: [OpenAssistant](https://huggingface.co/OpenAssistant)
- Original model: [falcon-40b-sft-mix-1226](https://huggingface.co/OpenAssistant/falcon-40b-sft-mix-1226)
# K-Quants in Falcon 7b models
New releases of Llama.cpp now support K-quantization for previously incompatible models, in particular all Falcon 7B models (While Falcon 40b is and always has been fully compatible with K-Quantisation). This is achieved by employing a fallback solution for model layers that cannot be quantized with real K-quants.
For Falcon 7B models, although only a quarter of the layers can be quantized with true K-quants, this approach still benefits from utilizing *different* legacy quantization types Q4_0, Q4_1, Q5_0, and Q5_1. As a result, it offers better quality at the same file size or smaller file sizes with comparable performance.
So this solution ensures improved performance and efficiency over legacy Q4_0, Q4_1, Q5_0 and Q5_1 Quantizations.
---
# Brief
Finally got the OpenAssistant falcon *sft* models working again
* [falcon-7b-sft-top1-696](https://huggingface.co/OpenAssistant/falcon-7b-sft-top1-696)
* [falcon-40b-sft-top1-560](https://huggingface.co/OpenAssistant/falcon-40b-sft-top1-560)
* [falcon-40b-sft-mix-1226](https://huggingface.co/OpenAssistant/falcon-40b-sft-mix-1226)
---
# About GGUF format
`gguf` is the current file format used by the [`ggml`](https://github.com/ggerganov/ggml) library.
A growing list of Software is using it and can therefore use this model.
The core project making use of the ggml library is the [llama.cpp](https://github.com/ggerganov/llama.cpp) project by Georgi Gerganov
# Quantization variants
There is a bunch of quantized files available to cater to your specific needs. Here's how to choose the best option for you:
# Legacy quants
Q4_0, Q4_1, Q5_0, Q5_1 and Q8 are `legacy` quantization types.
Nevertheless, they are fully supported, as there are several circumstances that cause certain model not to be compatible with the modern K-quants.
## Note:
Now there's a new option to use K-quants even for previously 'incompatible' models, although this involves some fallback solution that makes them not *real* K-quants. More details can be found in affected model descriptions.
(This mainly refers to Falcon 7b and Starcoder models)
# K-quants
K-quants are designed with the idea that different levels of quantization in specific parts of the model can optimize performance, file size, and memory load.
So, if possible, use K-quants.
With a Q6_K, you'll likely find it challenging to discern a quality difference from the original model - ask your model two times the same question and you may encounter bigger quality differences.
---
# Original Model Card:
# Open-Assistant Falcon 40B SFT MIX Model
This model is a fine-tuning of TII's [Falcon 40B](https://huggingface.co/tiiuae/falcon-40b) LLM.
It was trained on a mixture of OASST top-2 threads (exported on June 2, 2023), Dolly-15k and synthetic instruction datasets (see dataset configuration below).
## Model Details
- **Finetuned from:** [tiiuae/falcon-40b]((https://huggingface.co/tiiuae/falcon-40b)
- **Model type:** Causal decoder-only transformer language model
- **Language:** English, German, Spanish, French (and limited capabilities in Italian, Portuguese, Polish, Dutch, Romanian, Czech, Swedish);
- **Demo:** [Continuations for 250 random prompts](https://open-assistant.github.io/oasst-model-eval/?f=https%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Fchat-gpt%2F2023-04-11_gpt-3.5-turbo_lottery.json%0Ahttps%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Foasst-sft%2F2023-06-05_OpenAssistant_falcon-40b-sft-mix-1226_sampling_noprefix2.json), [multiligual-60](https://open-assistant.github.io/oasst-model-eval/?f=https%3A%2F%2Fraw.githubusercontent.com%2FOpen-Assistant%2Foasst-model-eval%2Fmain%2Fsampling_reports%2Foasst-sft%2F2023-06-05_OpenAssistant_falcon-40b-sft-mix-1226_multilingual_noprefix2.json)
- **Eval results:** [ilm-eval](https://tju01.github.io/ilm-eval/)
- **Weights & Biases**: [Training log](https://wandb.ai/open-assistant/public-sft/runs/feplc450) (checkpoint: 1226 steps)
- **License:** Apache 2.0
- **Contact:** [Open-Assistant Discord](https://ykilcher.com/open-assistant-discord)
## Prompting
Two special tokens are used to mark the beginning of user and assistant turns:
`<|prompter|>` and `<|assistant|>`. Each turn ends with a `<|endoftext|>` token.
Input prompt example:
```
<|prompter|>What is a meme, and what's the history behind this word?<|endoftext|><|assistant|>
```
The input ends with the `<|assistant|>` token to signal that the model should
start generating the assistant reply.
## Configuration Details
Model:
```
falcon-40b:
dtype: bf16
learning_rate: 1e-5
model_name: "tiiuae/falcon-40b"
deepspeed_config: configs/zero3_config_falcon.json
weight_decay: 0.0
max_length: 2048
warmup_steps: 20
gradient_checkpointing: true
gradient_accumulation_steps: 1
per_device_train_batch_size: 18
per_device_eval_batch_size: 10
eval_steps: 120
save_strategy: steps
save_steps: 613
num_train_epochs: 8
save_total_limit: 4
use_flash_attention: false
residual_dropout: 0.3
residual_dropout_lima: true
```
Dataset:
```
sft9-stage2:
# oasst_export: 100.00% (29899)
# vicuna: 50.00% (16963)
# code_alpaca: 50.00% (9510)
# oa_wiki_qa_bart_10000row: 100.00% (9434)
# grade_school_math_instructions: 100.00% (8351)
# dolly15k: 100.00% (14250)
use_custom_sampler: true
datasets:
- oasst_export:
lang: "bg,ca,cs,da,de,en,es,fr,hr,hu,it,nl,pl,pt,ro,ru,sl,sr,sv,uk" # sft-8.0
input_file_path: 2023-06-02_oasst_all_labels.jsonl.gz
val_split: 0.05
top_k: 2
- vicuna:
fraction: 0.5
val_split: 0.025
max_val_set: 250
- code_alpaca:
fraction: 0.5
val_split: 0.05
max_val_set: 250
- oa_wiki_qa_bart_10000row:
val_split: 0.05
max_val_set: 250
- grade_school_math_instructions:
val_split: 0.05
- dolly15k:
val_split: 0.05
max_val_set: 300
```
***End of original Model File***
---
## Please consider to support my work
**Coming Soon:** I'm in the process of launching a sponsorship/crowdfunding campaign for my work. I'm evaluating Kickstarter, Patreon, or the new GitHub Sponsors platform, and I am hoping for some support and contribution to the continued availability of these kind of models. Your support will enable me to provide even more valuable resources and maintain the models you rely on. Your patience and ongoing support are greatly appreciated as I work to make this page an even more valuable resource for the community.
<center>
[](https://maddes8cht.github.io)
[](https://stackexchange.com/users/26485911)
[](https://github.com/maddes8cht)
[](https://huggingface.co/maddes8cht)
[](https://twitter.com/maddes1966)
</center> |
TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF | TheBloke | 2023-10-03T17:09:59Z | 657 | 10 | transformers | [
"transformers",
"gguf",
"tinyllama",
"en",
"dataset:cerebras/SlimPajama-627B",
"dataset:bigcode/starcoderdata",
"base_model:PY007/TinyLlama-1.1B-intermediate-step-480k-1T",
"license:apache-2.0",
"region:us"
] | null | 2023-10-03T17:06:13Z | ---
base_model: PY007/TinyLlama-1.1B-intermediate-step-480k-1T
datasets:
- cerebras/SlimPajama-627B
- bigcode/starcoderdata
inference: false
language:
- en
license: apache-2.0
model_creator: Zhang Peiyuan
model_name: TinyLlama 1.1B Intermediate Step 480K 1T
model_type: tinyllama
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# TinyLlama 1.1B Intermediate Step 480K 1T - GGUF
- Model creator: [Zhang Peiyuan](https://huggingface.co/PY007)
- Original model: [TinyLlama 1.1B Intermediate Step 480K 1T](https://huggingface.co/PY007/TinyLlama-1.1B-intermediate-step-480k-1T)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Zhang Peiyuan's TinyLlama 1.1B Intermediate Step 480K 1T](https://huggingface.co/PY007/TinyLlama-1.1B-intermediate-step-480k-1T).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF)
* [Zhang Peiyuan's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/PY007/TinyLlama-1.1B-intermediate-step-480k-1T)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q2_K.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q2_K.gguf) | Q2_K | 2 | 0.48 GB| 2.98 GB | smallest, significant quality loss - not recommended for most purposes |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q3_K_S.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q3_K_S.gguf) | Q3_K_S | 3 | 0.50 GB| 3.00 GB | very small, high quality loss |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q3_K_M.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q3_K_M.gguf) | Q3_K_M | 3 | 0.55 GB| 3.05 GB | very small, high quality loss |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q3_K_L.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q3_K_L.gguf) | Q3_K_L | 3 | 0.59 GB| 3.09 GB | small, substantial quality loss |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q4_0.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q4_0.gguf) | Q4_0 | 4 | 0.64 GB| 3.14 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q4_K_S.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q4_K_S.gguf) | Q4_K_S | 4 | 0.64 GB| 3.14 GB | small, greater quality loss |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q4_K_M.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q4_K_M.gguf) | Q4_K_M | 4 | 0.67 GB| 3.17 GB | medium, balanced quality - recommended |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q5_0.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q5_0.gguf) | Q5_0 | 5 | 0.77 GB| 3.27 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q5_K_S.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q5_K_S.gguf) | Q5_K_S | 5 | 0.77 GB| 3.27 GB | large, low quality loss - recommended |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q5_K_M.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q5_K_M.gguf) | Q5_K_M | 5 | 0.78 GB| 3.28 GB | large, very low quality loss - recommended |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q6_K.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q6_K.gguf) | Q6_K | 6 | 0.90 GB| 3.40 GB | very large, extremely low quality loss |
| [tinyllama-1.1b-intermediate-step-480k-1t.Q8_0.gguf](https://huggingface.co/TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF/blob/main/tinyllama-1.1b-intermediate-step-480k-1t.Q8_0.gguf) | Q8_0 | 8 | 1.17 GB| 3.67 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF and below it, a specific filename to download, such as: tinyllama-1.1b-intermediate-step-480k-1t.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF tinyllama-1.1b-intermediate-step-480k-1t.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF tinyllama-1.1b-intermediate-step-480k-1t.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m tinyllama-1.1b-intermediate-step-480k-1t.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/TinyLlama-1.1B-intermediate-step-480k-1T-GGUF", model_file="tinyllama-1.1b-intermediate-step-480k-1t.Q4_K_M.gguf", model_type="tinyllama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Zhang Peiyuan's TinyLlama 1.1B Intermediate Step 480K 1T
<div align="center">
# TinyLlama-1.1B
</div>
https://github.com/jzhang38/TinyLlama
The TinyLlama project aims to **pretrain** a **1.1B Llama model on 3 trillion tokens**. With some proper optimization, we can achieve this within a span of "just" 90 days using 16 A100-40G GPUs 🚀🚀. The training has started on 2023-09-01.
<div align="center">
<img src="./TinyLlama_logo.png" width="300"/>
</div>
We adopted exactly the same architecture and tokenizer as Llama 2. This means TinyLlama can be plugged and played in many open-source projects built upon Llama. Besides, TinyLlama is compact with only 1.1B parameters. This compactness allows it to cater to a multitude of applications demanding a restricted computation and memory footprint.
#### This Model
This is an intermediate checkpoint with 480K steps and 1007B tokens.
#### How to use
You will need the transformers>=4.31
Do check the [TinyLlama](https://github.com/jzhang38/TinyLlama) github page for more information.
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "PY007/TinyLlama-1.1B-intermediate-step-240k-503b"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'The TinyLlama project aims to pretrain a 1.1B Llama model on 3 trillion tokens. With some proper optimization, we can achieve this within a span of "just" 90 days using 16 A100-40G GPUs 🚀🚀. The training has started on 2023-09-01.',
do_sample=True,
top_k=10,
num_return_sequences=1,
repetition_penalty=1.5,
eos_token_id=tokenizer.eos_token_id,
max_length=500,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
<!-- original-model-card end -->
|
TheBloke/Orca2myth7.2-GGUF | TheBloke | 2023-12-23T17:50:09Z | 657 | 9 | transformers | [
"transformers",
"gguf",
"llama",
"base_model:TheBigBlender/Orca2myth7.2",
"license:other",
"text-generation-inference",
"region:us"
] | null | 2023-12-23T17:21:43Z | ---
base_model: TheBigBlender/Orca2myth7.2
inference: false
license: other
model_creator: The Big Blender
model_name: Orca2Myth7.2
model_type: llama
prompt_template: '{prompt}
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Orca2Myth7.2 - GGUF
- Model creator: [The Big Blender](https://huggingface.co/TheBigBlender)
- Original model: [Orca2Myth7.2](https://huggingface.co/TheBigBlender/Orca2myth7.2)
<!-- description start -->
## Description
This repo contains GGUF format model files for [The Big Blender's Orca2Myth7.2](https://huggingface.co/TheBigBlender/Orca2myth7.2).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Orca2myth7.2-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Orca2myth7.2-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF)
* [The Big Blender's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/TheBigBlender/Orca2myth7.2)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Unknown
```
{prompt}
```
<!-- prompt-template end -->
<!-- licensing start -->
## Licensing
The creator of the source model has listed its license as `other`, and this quantization has therefore used that same license.
As this model is based on Llama 2, it is also subject to the Meta Llama 2 license terms, and the license files for that are additionally included. It should therefore be considered as being claimed to be licensed under both licenses. I contacted Hugging Face for clarification on dual licensing but they do not yet have an official position. Should this change, or should Meta provide any feedback on this situation, I will update this section accordingly.
In the meantime, any questions regarding licensing, and in particular how these two licenses might interact, should be directed to the original model repository: [The Big Blender's Orca2Myth7.2](https://huggingface.co/TheBigBlender/Orca2myth7.2).
<!-- licensing end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [orca2myth7.2.Q2_K.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q2_K.gguf) | Q2_K | 2 | 8.31 GB| 10.81 GB | smallest, significant quality loss - not recommended for most purposes |
| [orca2myth7.2.Q3_K_S.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q3_K_S.gguf) | Q3_K_S | 3 | 8.66 GB| 11.16 GB | very small, high quality loss |
| [orca2myth7.2.Q3_K_M.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q3_K_M.gguf) | Q3_K_M | 3 | 9.70 GB| 12.20 GB | very small, high quality loss |
| [orca2myth7.2.Q3_K_L.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q3_K_L.gguf) | Q3_K_L | 3 | 10.63 GB| 13.13 GB | small, substantial quality loss |
| [orca2myth7.2.Q4_0.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q4_0.gguf) | Q4_0 | 4 | 11.29 GB| 13.79 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [orca2myth7.2.Q4_K_S.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q4_K_S.gguf) | Q4_K_S | 4 | 11.34 GB| 13.84 GB | small, greater quality loss |
| [orca2myth7.2.Q4_K_M.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q4_K_M.gguf) | Q4_K_M | 4 | 12.04 GB| 14.54 GB | medium, balanced quality - recommended |
| [orca2myth7.2.Q5_0.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q5_0.gguf) | Q5_0 | 5 | 13.77 GB| 16.27 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [orca2myth7.2.Q5_K_S.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q5_K_S.gguf) | Q5_K_S | 5 | 13.77 GB| 16.27 GB | large, low quality loss - recommended |
| [orca2myth7.2.Q5_K_M.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q5_K_M.gguf) | Q5_K_M | 5 | 14.16 GB| 16.66 GB | large, very low quality loss - recommended |
| [orca2myth7.2.Q6_K.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q6_K.gguf) | Q6_K | 6 | 16.41 GB| 18.91 GB | very large, extremely low quality loss |
| [orca2myth7.2.Q8_0.gguf](https://huggingface.co/TheBloke/Orca2myth7.2-GGUF/blob/main/orca2myth7.2.Q8_0.gguf) | Q8_0 | 8 | 21.25 GB| 23.75 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Orca2myth7.2-GGUF and below it, a specific filename to download, such as: orca2myth7.2.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Orca2myth7.2-GGUF orca2myth7.2.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Orca2myth7.2-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Orca2myth7.2-GGUF orca2myth7.2.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m orca2myth7.2.Q4_K_M.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "{prompt}"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./orca2myth7.2.Q4_K_M.gguf", # Download the model file first
n_ctx=4096, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"{prompt}", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./orca2myth7.2.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: The Big Blender's Orca2Myth7.2
A product of an amateur merger. I like it due to the fact that it combines both Orca2 understanding and Pyg's dialogue style (using mythalion for consistency). - shotmisser64
This model was made by ShotMisser64 using the following mergekit yaml:
```
slices:
- sources:
- model: output/Orca2flat
layer_range: [0, 13]
- sources:
- model: PygmalionAI/mythalion-13b
layer_range: [3, 22]
- sources:
- model: output/Orca2flat
layer_range: [14, 27]
- sources:
- model: PygmalionAI/mythalion-13b
layer_range: [23, 40]
merge_method: passthrough
dtype: float16
```
The Orca2flat model uses the following mergekit yaml:
```
merge_method: task_arithmetic
base_model: TheBloke/Llama-2-13B-fp16
models:
- model: TheBloke/Llama-2-13B-fp16
- model: microsoft/Orca-2-13b
parameters:
weight: 1.0
dtype: float16
```
Found something interesting or would you like your own custom merge? Visit our community at https://koboldai.org/discord
Please respect the license of the origin models.
<!-- original-model-card end -->
|
Buseak/md_mt5_0109_v8 | Buseak | 2024-03-20T00:40:27Z | 657 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"mt5",
"text2text-generation",
"generated_from_trainer",
"base_model:Buseak/md_mt5_0109_v7",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text2text-generation | 2024-03-19T21:12:01Z | ---
license: apache-2.0
base_model: Buseak/md_mt5_0109_v7
tags:
- generated_from_trainer
metrics:
- bleu
model-index:
- name: md_mt5_0109_v8
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# md_mt5_0109_v8
This model is a fine-tuned version of [Buseak/md_mt5_0109_v7](https://huggingface.co/Buseak/md_mt5_0109_v7) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0444
- Bleu: 0.6614
- Gen Len: 18.9444
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 4
- eval_batch_size: 4
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 15
### Training results
| Training Loss | Epoch | Step | Validation Loss | Bleu | Gen Len |
|:-------------:|:-----:|:-----:|:---------------:|:------:|:-------:|
| 0.1129 | 1.0 | 975 | 0.0597 | 0.6517 | 18.9418 |
| 0.1094 | 2.0 | 1950 | 0.0567 | 0.654 | 18.9372 |
| 0.1101 | 3.0 | 2925 | 0.0543 | 0.657 | 18.9415 |
| 0.1097 | 4.0 | 3900 | 0.0520 | 0.6555 | 18.9446 |
| 0.1091 | 5.0 | 4875 | 0.0511 | 0.6571 | 18.9446 |
| 0.1102 | 6.0 | 5850 | 0.0497 | 0.6591 | 18.9451 |
| 0.1056 | 7.0 | 6825 | 0.0489 | 0.6585 | 18.9444 |
| 0.1088 | 8.0 | 7800 | 0.0470 | 0.6595 | 18.9436 |
| 0.1103 | 9.0 | 8775 | 0.0467 | 0.6589 | 18.9415 |
| 0.1078 | 10.0 | 9750 | 0.0462 | 0.66 | 18.9423 |
| 0.1106 | 11.0 | 10725 | 0.0451 | 0.6605 | 18.9431 |
| 0.1112 | 12.0 | 11700 | 0.0448 | 0.6607 | 18.9444 |
| 0.1134 | 13.0 | 12675 | 0.0447 | 0.6607 | 18.9395 |
| 0.1183 | 14.0 | 13650 | 0.0446 | 0.6602 | 18.9408 |
| 0.1188 | 15.0 | 14625 | 0.0444 | 0.6614 | 18.9444 |
### Framework versions
- Transformers 4.38.2
- Pytorch 2.2.1+cu121
- Datasets 2.18.0
- Tokenizers 0.15.2
|
RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf | RichardErkhov | 2024-06-03T04:11:08Z | 657 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-02T18:56:31Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Iambe-RP-v3-20b - GGUF
- Model creator: https://huggingface.co/athirdpath/
- Original model: https://huggingface.co/athirdpath/Iambe-RP-v3-20b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Iambe-RP-v3-20b.Q2_K.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q2_K.gguf) | Q2_K | 6.91GB |
| [Iambe-RP-v3-20b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.IQ3_XS.gguf) | IQ3_XS | 7.63GB |
| [Iambe-RP-v3-20b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.IQ3_S.gguf) | IQ3_S | 8.06GB |
| [Iambe-RP-v3-20b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q3_K_S.gguf) | Q3_K_S | 8.06GB |
| [Iambe-RP-v3-20b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.IQ3_M.gguf) | IQ3_M | 8.53GB |
| [Iambe-RP-v3-20b.Q3_K.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q3_K.gguf) | Q3_K | 9.04GB |
| [Iambe-RP-v3-20b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q3_K_M.gguf) | Q3_K_M | 9.04GB |
| [Iambe-RP-v3-20b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q3_K_L.gguf) | Q3_K_L | 9.9GB |
| [Iambe-RP-v3-20b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.IQ4_XS.gguf) | IQ4_XS | 10.01GB |
| [Iambe-RP-v3-20b.Q4_0.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q4_0.gguf) | Q4_0 | 10.52GB |
| [Iambe-RP-v3-20b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.IQ4_NL.gguf) | IQ4_NL | 10.57GB |
| [Iambe-RP-v3-20b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q4_K_S.gguf) | Q4_K_S | 10.59GB |
| [Iambe-RP-v3-20b.Q4_K.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q4_K.gguf) | Q4_K | 11.22GB |
| [Iambe-RP-v3-20b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q4_K_M.gguf) | Q4_K_M | 11.22GB |
| [Iambe-RP-v3-20b.Q4_1.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q4_1.gguf) | Q4_1 | 11.67GB |
| [Iambe-RP-v3-20b.Q5_0.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q5_0.gguf) | Q5_0 | 12.83GB |
| [Iambe-RP-v3-20b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q5_K_S.gguf) | Q5_K_S | 12.83GB |
| [Iambe-RP-v3-20b.Q5_K.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q5_K.gguf) | Q5_K | 13.18GB |
| [Iambe-RP-v3-20b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q5_K_M.gguf) | Q5_K_M | 13.18GB |
| [Iambe-RP-v3-20b.Q5_1.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q5_1.gguf) | Q5_1 | 13.98GB |
| [Iambe-RP-v3-20b.Q6_K.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q6_K.gguf) | Q6_K | 15.28GB |
| [Iambe-RP-v3-20b.Q8_0.gguf](https://huggingface.co/RichardErkhov/athirdpath_-_Iambe-RP-v3-20b-gguf/blob/main/Iambe-RP-v3-20b.Q8_0.gguf) | Q8_0 | 19.79GB |
Original model description:
---
license: cc-by-nc-4.0
language:
- en
tags:
- not-for-all-audiences
datasets:
- athirdpath/DPO_Pairs-Roleplay-Alpaca-NSFW-v1
---
<p align="center"><img src="https://i.ibb.co/PCY2Xym/Iambe-RP-sml-t.png"/><font size="6"> <b>Iambe-RP-v3-20b</b> </font></p>
<p align="center"><font size="4"> <b>Trained with Alpaca prompt formatting, ChatML works well too</b> </font></p>
### Description
Okay, now that all the cards were in the deck, I needed to unshuffle them. 1 epoch of the v1 dataset, trained on Iambe-RP-DARE-20b-DENSE with standard DPO, 2e-5 LR.
Iambe is intended to have the best realistically possible understanding of instructions, anatomy and scene state for a 20b merge, while remaining passionate and humanoid in "voice".
### Update Methodology
Go-Bruins-v2 skyrocketing up the leaderboard showed that standard DPO with the v1 dataset could have shocking results, so I had to give it a go myself.
<font size="5"> <b>Assistant Example @ q5_k_m</b> </font></p>



<p align="center"><font size="5"> <b>NSFW Writing Example @ q5_k_m</b> </font></p>
<b>Write a medium-length story about Alice, a 26 year old cocktail waitress, having steamy sex with a guy she picked up at the bar for a one night stand.</b>
<i>
Once upon a time in a bustling city, there lived Alice, a charming 26-year-old cocktail waitress working in a trendy club. She had long, flowing brunette hair that cascaded down her shoulders, captivating emerald eyes, and full sensual lips. Alice was known throughout the establishment as the life of the party, always ready with a witty remark or flirtatious smile. Despite her lively demeanor, though, she harbored secrets—secrets of unfulfilled desire and passion that lay dormant within her until the perfect man crossed her path.
One fateful Friday evening, after a particularly exhausting shift filled with rowdy patrons and demanding drink orders, Alice found herself leaning against the wooden bar top, taking a much-needed breather. Her body ached from moving around so vigorously, but something else burned just below her skin, calling out for release. As she sipped on a glass of Pinot Noir, her gaze swept across the dimly lit room before landing on him. He was tall, broad-shouldered, with dark tousled hair and piercing blue eyes that seemed to see right through her. There was an air of confidence about him that made Alice feel weak at the knees.
As fate would have it, he caught sight of Alice too and began making his way towards her. His strides were purposeful yet relaxed, exuding charm and self-assurance. When he finally reached her side, he flashed her a disarmingly sexy grin and ordered a shot of tequila. Alice couldn't help but feel drawn to him, as if there was some invisible string tugging them together. She obliged and poured him the shot, their fingers brushing against each other in the process—an electric spark crackling between them.
"What's your name?" he asked huskily, downing the tequila in one swig before setting the empty glass back on the bar.
Alice smiled seductively, taking advantage of the situation. "I'm Alice," she purred, leaning closer to him than she should have. "And you are...?"
He raised an eyebrow playfully, running his fingers along the curve of her neck before tracing a path down her collarbone. "Let's just say I can give you the best night of your life." With that enchanting declaration, Alice found herself agreeing without hesitation, following him out into the crisp night air where his waiting car awaited them.
The drive to his luxurious penthouse suite felt like both an eternity and a fleeting moment at once. When they finally arrived, he took her hand and led her inside, the room illuminated by soft candlelight and sensual jazz music filling the air. His place was impeccably stylish yet cozy—the perfect mix of sophistication and intimacy. They made their way towards the bedroom door, their bodies brushing against each other with every step. The anticipation between them grew almost unbearable as they reached the threshold, leaving behind everything but the raw desire in their eyes.
Alice kicked off her high heels, letting them clatter onto the hardwood floor, while he undid the buttons on his shirt methodically, revealing his defined chest muscles underneath. As she pulled her skirt down past her thighs, exposing her black lace underwear, he growled lowly in response, reaching for the clasp before it could hit the ground. In seconds, they were naked, standing face-to-face, body pressed up against body. Alice wrapped her arms around him tightly, pulling him closer still until their lips met passionately. She had never felt this kind of hunger before—a primal urge that consumed her entire being.
As they tumbled onto the plush mattress, tongues exploring each other's mouths, hands roaming over each other's skin, Alice knew without a doubt that this man was meant to be hers tonight. He kissed down her neck, trailing his teeth along her collarbone, and then lower still, nipping at the delicate flesh of her breasts before taking one into his mouth. A cry escaped from deep within her as pleasure coursed through every fiber of her being, sending waves of desire crashing through her core. His hand slid between her legs, finding her soaking wet with anticipation, fingers stroking gently yet firmly, driving her wild.
Alice reciprocated by running her fingernails lightly across his chest before moving further down to graze the hair that blanketed his groin. She heard him moan loudly in response, growing harder underneath her touch. In a bold move, she reached down and freed his erection from his pants, wrapping her soft hand around its length. Her eyes widened in surprise at how big he was, but instead of intimidating her, it fueled her curiosity even more. With practiced skill, learned from countless encounters like these, she began to stroke up and down, feeling him twitch against her palm.
As their rhythm picked up pace, Alice moved herself higher on the bed until her legs were wrapped tightly around his hips. He lifted himself up slightly, positioning himself at the entrance of her wetness. The anticipation built once again as they stared into each other's eyes—their faces flushed red, breathing heavily. Finally, he plunged inside her hard, filling every crevice and triggering an earth-shattering scream from deep within her soul. It felt so right—his body molded against hers, their hearts racing together. They moved together in perfect harmony, lost in their
desire for each other. Skins slapping against skins, bodies grinding against bodies, moans and groans echoing throughout the room. Time seemed to stand still as they rode out wave after wave of ecstasy, driven by primal lust and raw passion.
When finally satiated, they lay panting on the bed, sweat trickling down their skin. Alice couldn't believe what had just happened—how incredible it had been with this stranger she barely knew. She looked over at him, who was also catching his breath, a satisfied smirk spread across his lips. "I don't know your name either," she said softly, tracing circles around his chest hair before leaning up to place a tender kiss on his lips. He smiled warmly back at her, brushing a strand of hair behind her ear.
"It doesn't matter, Alice," he whispered hoarsely. "Because tonight, we were just two people seeking something more than just another night." And with that simple yet profound statement, they drifted off into blissful oblivion, wrapped tightly together like lovers destined never to part again.
</i>
### Eval Scores (since the leaderboard rejects nearly all my models)
| Tasks |Version|Filter|n-shot|Metric|Value| |Stderr|
|----------|-------|------|-----:|------|----:|---|-----:|
|winogrande|Yaml |none | 5|acc |0.738|± |0.0124|
|truthfulqa_mc2|Yaml |none | 0|acc |0.5551|± |0.0158|
|arc_challenge|Yaml |none | 25|acc |0.6101|± |0.0143|
| arc_challenge| |none | 25|acc_norm|0.6425|± |0.0140|
|
RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf | RichardErkhov | 2024-06-04T22:44:11Z | 657 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-04T22:36:10Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
distilgpt2-tiny-conversational - GGUF
- Model creator: https://huggingface.co/ethzanalytics/
- Original model: https://huggingface.co/ethzanalytics/distilgpt2-tiny-conversational/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [distilgpt2-tiny-conversational.Q2_K.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q2_K.gguf) | Q2_K | 0.06GB |
| [distilgpt2-tiny-conversational.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.IQ3_XS.gguf) | IQ3_XS | 0.07GB |
| [distilgpt2-tiny-conversational.IQ3_S.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.IQ3_S.gguf) | IQ3_S | 0.07GB |
| [distilgpt2-tiny-conversational.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q3_K_S.gguf) | Q3_K_S | 0.07GB |
| [distilgpt2-tiny-conversational.IQ3_M.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.IQ3_M.gguf) | IQ3_M | 0.07GB |
| [distilgpt2-tiny-conversational.Q3_K.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q3_K.gguf) | Q3_K | 0.07GB |
| [distilgpt2-tiny-conversational.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q3_K_M.gguf) | Q3_K_M | 0.07GB |
| [distilgpt2-tiny-conversational.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q3_K_L.gguf) | Q3_K_L | 0.07GB |
| [distilgpt2-tiny-conversational.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.IQ4_XS.gguf) | IQ4_XS | 0.07GB |
| [distilgpt2-tiny-conversational.Q4_0.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q4_0.gguf) | Q4_0 | 0.08GB |
| [distilgpt2-tiny-conversational.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.IQ4_NL.gguf) | IQ4_NL | 0.08GB |
| [distilgpt2-tiny-conversational.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q4_K_S.gguf) | Q4_K_S | 0.08GB |
| [distilgpt2-tiny-conversational.Q4_K.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q4_K.gguf) | Q4_K | 0.08GB |
| [distilgpt2-tiny-conversational.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q4_K_M.gguf) | Q4_K_M | 0.08GB |
| [distilgpt2-tiny-conversational.Q4_1.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q4_1.gguf) | Q4_1 | 0.08GB |
| [distilgpt2-tiny-conversational.Q5_0.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q5_0.gguf) | Q5_0 | 0.09GB |
| [distilgpt2-tiny-conversational.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q5_K_S.gguf) | Q5_K_S | 0.09GB |
| [distilgpt2-tiny-conversational.Q5_K.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q5_K.gguf) | Q5_K | 0.09GB |
| [distilgpt2-tiny-conversational.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q5_K_M.gguf) | Q5_K_M | 0.09GB |
| [distilgpt2-tiny-conversational.Q5_1.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q5_1.gguf) | Q5_1 | 0.09GB |
| [distilgpt2-tiny-conversational.Q6_K.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q6_K.gguf) | Q6_K | 0.1GB |
| [distilgpt2-tiny-conversational.Q8_0.gguf](https://huggingface.co/RichardErkhov/ethzanalytics_-_distilgpt2-tiny-conversational-gguf/blob/main/distilgpt2-tiny-conversational.Q8_0.gguf) | Q8_0 | 0.12GB |
Original model description:
---
license: apache-2.0
tags:
- text-generation
- chatbot
- dialogue
- distilgpt2
- gpt2
- ai-msgbot
widget:
- text: "I know you're tired, but can we go for another walk this evening?\nperson beta:\n\n"
example_title: "walk"
- text: "Have you done anything exciting lately?\nperson beta:\n\n"
example_title: "activities"
- text: "hey - do you have a favorite grocery store around here?\nperson beta:\n\n"
example_title: "grocery"
- text: "Can you take me for dinner somewhere nice this time?\nperson beta:\n\n"
example_title: "dinner"
- text: "What's your favorite form of social media?\nperson beta:\n\n"
example_title: "social media"
- text: "Hi, how are you?\nperson beta:\n\n"
example_title: "greeting"
- text: "I am the best; my sister is the worst. What am I?\nperson beta:\n\n"
example_title: "sister"
- text: "What do you call an alligator who's just had surgery to remove his left arm?\nperson beta:\n\n"
example_title: "alligator"
- text: "A man walks into a bar and asks for a drink. The bartender asks for $10, and he pays him $1. What did he pay him with?\nperson beta:\n\n"
example_title: "dollar"
- text: "What did I say was in the mailbox when it was actually in the cabinet?\nperson beta:\n\n"
example_title: "mailbox"
- text: "My friend says that she knows every language, but she doesn't speak any of them.. what's wrong with her?\nperson beta:\n\n"
example_title: "language"
inference:
parameters:
min_length: 2
max_length: 64
length_penalty: 0.7
no_repeat_ngram_size: 2
do_sample: True
top_p: 0.95
top_k: 20
temperature: 0.3
repetition_penalty: 3.5
---
# distilgpt2-tiny-conversational
This model is a fine-tuned version of [distilgpt2](https://huggingface.co/distilgpt2) on a parsed version of Wizard of Wikipedia. Persona alpha/beta framework designed for use with [ai-msgbot](https://github.com/pszemraj/ai-msgbot).
It achieves the following results on the evaluation set:
- Loss: 2.2461
## Model description
- a basic dialogue model for conversation. It can be used as a chatbot.
- check out a [simple demo here](https://huggingface.co/spaces/ethzanalytics/dialogue-demo)
## Intended uses & limitations
- usage is designed for integrating with this repo: [ai-msgbot](https://github.com/pszemraj/ai-msgbot)
- the main specific information to know is that the model generates whole conversations between two entities, `person alpha` and `person beta`. These entity names are used functionally as custom `<bos>` tokens to extract when one response ends and another begins.
## Training and evaluation data
- [wizard of Wikipedia](https://parl.ai/projects/wizard_of_wikipedia/) parsed, from parlAI
## Training procedure
- deepspeed + huggingface trainer, an example notebook is in [ai-msgbot](https://github.com/pszemraj/ai-msgbot)
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 4
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 30
### Training results
| Training Loss | Epoch | Step | Validation Loss |
|:-------------:|:-----:|:-----:|:---------------:|
| No log | 1.0 | 418 | 2.7793 |
| 2.9952 | 2.0 | 836 | 2.6914 |
| 2.7684 | 3.0 | 1254 | 2.6348 |
| 2.685 | 4.0 | 1672 | 2.5938 |
| 2.6243 | 5.0 | 2090 | 2.5625 |
| 2.5816 | 6.0 | 2508 | 2.5332 |
| 2.5816 | 7.0 | 2926 | 2.5098 |
| 2.545 | 8.0 | 3344 | 2.4902 |
| 2.5083 | 9.0 | 3762 | 2.4707 |
| 2.4793 | 10.0 | 4180 | 2.4551 |
| 2.4531 | 11.0 | 4598 | 2.4395 |
| 2.4269 | 12.0 | 5016 | 2.4238 |
| 2.4269 | 13.0 | 5434 | 2.4102 |
| 2.4051 | 14.0 | 5852 | 2.3945 |
| 2.3777 | 15.0 | 6270 | 2.3848 |
| 2.3603 | 16.0 | 6688 | 2.3711 |
| 2.3394 | 17.0 | 7106 | 2.3613 |
| 2.3206 | 18.0 | 7524 | 2.3516 |
| 2.3206 | 19.0 | 7942 | 2.3398 |
| 2.3026 | 20.0 | 8360 | 2.3301 |
| 2.2823 | 21.0 | 8778 | 2.3203 |
| 2.2669 | 22.0 | 9196 | 2.3105 |
| 2.2493 | 23.0 | 9614 | 2.3027 |
| 2.2334 | 24.0 | 10032 | 2.2930 |
| 2.2334 | 25.0 | 10450 | 2.2852 |
| 2.2194 | 26.0 | 10868 | 2.2754 |
| 2.2014 | 27.0 | 11286 | 2.2695 |
| 2.1868 | 28.0 | 11704 | 2.2598 |
| 2.171 | 29.0 | 12122 | 2.2539 |
| 2.1597 | 30.0 | 12540 | 2.2461 |
### Framework versions
- Transformers 4.16.1
- Pytorch 1.10.0+cu111
- Tokenizers 0.11.0
|
CHE-72/Yi-1.5-6B-Chat-Q4_K_M-GGUF | CHE-72 | 2024-06-22T07:25:47Z | 657 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:01-ai/Yi-1.5-6B-Chat",
"license:apache-2.0",
"region:us"
] | null | 2024-06-22T07:25:31Z | ---
base_model: 01-ai/Yi-1.5-6B-Chat
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
---
# CHE-72/Yi-1.5-6B-Chat-Q4_K_M-GGUF
This model was converted to GGUF format from [`01-ai/Yi-1.5-6B-Chat`](https://huggingface.co/01-ai/Yi-1.5-6B-Chat) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/01-ai/Yi-1.5-6B-Chat) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo CHE-72/Yi-1.5-6B-Chat-Q4_K_M-GGUF --hf-file yi-1.5-6b-chat-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo CHE-72/Yi-1.5-6B-Chat-Q4_K_M-GGUF --hf-file yi-1.5-6b-chat-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo CHE-72/Yi-1.5-6B-Chat-Q4_K_M-GGUF --hf-file yi-1.5-6b-chat-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo CHE-72/Yi-1.5-6B-Chat-Q4_K_M-GGUF --hf-file yi-1.5-6b-chat-q4_k_m.gguf -c 2048
```
|
martintmv/omost-llama-3-8b-Q8_0-GGUF | martintmv | 2024-06-22T23:39:55Z | 657 | 0 | null | [
"gguf",
"pytorch",
"trl",
"sft",
"llama-cpp",
"gguf-my-repo",
"base_model:lllyasviel/omost-llama-3-8b",
"region:us"
] | null | 2024-06-22T23:39:19Z | ---
base_model: lllyasviel/omost-llama-3-8b
tags:
- pytorch
- trl
- sft
- llama-cpp
- gguf-my-repo
inference: false
---
# martintmv/omost-llama-3-8b-Q8_0-GGUF
This model was converted to GGUF format from [`lllyasviel/omost-llama-3-8b`](https://huggingface.co/lllyasviel/omost-llama-3-8b) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/lllyasviel/omost-llama-3-8b) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo martintmv/omost-llama-3-8b-Q8_0-GGUF --hf-file omost-llama-3-8b-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo martintmv/omost-llama-3-8b-Q8_0-GGUF --hf-file omost-llama-3-8b-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo martintmv/omost-llama-3-8b-Q8_0-GGUF --hf-file omost-llama-3-8b-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo martintmv/omost-llama-3-8b-Q8_0-GGUF --hf-file omost-llama-3-8b-q8_0.gguf -c 2048
```
|
jjzha/jobbert-base-cased | jjzha | 2023-03-18T09:30:27Z | 656 | 15 | transformers | [
"transformers",
"pytorch",
"safetensors",
"bert",
"fill-mask",
"JobBERT",
"job postings",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-04-12T11:39:22Z | ---
language:
- en
tags:
- JobBERT
- job postings
---
# JobBERT
This is the JobBERT model from:
Mike Zhang, Kristian Nørgaard Jensen, Sif Dam Sonniks, and Barbara Plank. __SkillSpan: Hard and Soft Skill Extraction from Job Postings__. Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies.
This model is continuously pre-trained from a `bert-base-cased` checkpoint on ~3.2M sentences from job postings. More information can be found in the paper.
If you use this model, please cite the following paper:
```
@inproceedings{zhang-etal-2022-skillspan,
title = "{S}kill{S}pan: Hard and Soft Skill Extraction from {E}nglish Job Postings",
author = "Zhang, Mike and
Jensen, Kristian N{\o}rgaard and
Sonniks, Sif and
Plank, Barbara",
booktitle = "Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies",
month = jul,
year = "2022",
address = "Seattle, United States",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2022.naacl-main.366",
pages = "4962--4984",
abstract = "Skill Extraction (SE) is an important and widely-studied task useful to gain insights into labor market dynamics. However, there is a lacuna of datasets and annotation guidelines; available datasets are few and contain crowd-sourced labels on the span-level or labels from a predefined skill inventory. To address this gap, we introduce SKILLSPAN, a novel SE dataset consisting of 14.5K sentences and over 12.5K annotated spans. We release its respective guidelines created over three different sources annotated for hard and soft skills by domain experts. We introduce a BERT baseline (Devlin et al., 2019). To improve upon this baseline, we experiment with language models that are optimized for long spans (Joshi et al., 2020; Beltagy et al., 2020), continuous pre-training on the job posting domain (Han and Eisenstein, 2019; Gururangan et al., 2020), and multi-task learning (Caruana, 1997). Our results show that the domain-adapted models significantly outperform their non-adapted counterparts, and single-task outperforms multi-task learning.",
}
```
|
Nacholmo/controlnet-qr-pattern | Nacholmo | 2023-12-28T13:58:11Z | 656 | 39 | diffusers | [
"diffusers",
"tensorboard",
"controlnet",
"dataset:Nacholmo/controlnet-test-darkest-color",
"dataset:yuvalkirstain/pexel_images_lots_with_generated_captions",
"base_model:runwayml/stable-diffusion-v1-5",
"license:creativeml-openrail-m",
"region:us"
] | null | 2023-06-13T23:50:18Z | ---
license: creativeml-openrail-m
datasets:
- Nacholmo/controlnet-test-darkest-color
- yuvalkirstain/pexel_images_lots_with_generated_captions
tags:
- controlnet
base_model: runwayml/stable-diffusion-v1-5
---
# New version:
https://huggingface.co/Nacholmo/controlnet-qr-pattern-v2
# Controlnet model for use in qr codes
Conditioning only 15% of the pixels closest to black, so as not to affect the luminance of the rest of the image.
Also manteing the color to some degree.
## Lasted version on the Automatic1111-Compatible folder
Move the .yaml to extensions/sd-webui-controlnet/models
If you want to use it in diffusers (Not automatic111), the recommended checkpoint is the 11500
### Recommended parameters
```
Recommended parameters:
Steps: +50, Size: 920x920,
ControlNet:
preprocessor: none,
weight: 1,
starting/ending: (0, 0.75),
control mode: Balanced
```
Play arround with the starting step, 0 to 0.25 its the sweetspot, if it start at 0 the qr has priority, the higher you raise them, the stronger the prompt gets
To achieve optimal results with the Hires fix, ensure that your resolution is set to a minimum of 600x600. Additionally, set the denoising strength to a minimum of 0.7 and the hires steps to at least 20.
Example prompt parameters:
```
1girl, solo, red flower, print dress, bow, year of the ox, food print, short hair, black hair, looking at viewer, bangs, long sleeves, red bow
Negative prompt: (KHFB, AuroraNegative),(Worst Quality, Low Quality:1.4)
Steps: 40, Sampler: DPM++ 2M SDE Karras, CFG scale: 6, Seed: 1463218996, Size: 920x920, Model hash: b42b09ff12, Model: cetusMix_v4, Clip skip: 2, Version: 0ddf613, Parser: Full parser, ControlNet 0: "preprocessor: none, model: 11500_color [c4220211], weight: 1, starting/ending: (0, 0.75), resize mode: Crop and Resize, pixel perfect: False, control mode: Balanced, preprocessor params: (-1, -1, -1)"
```
QR Pattern and QR Pattern sdxl were created as free community resources by an Argentinian university student. Training AI models requires money, which can be challenging in Argentina's economy. If you find these models helpful and would like to empower an enthusiastic community member to keep creating free open models, I humbly welcome any support you can offer through ko-fi here https://ko-fi.com/nacholmo |
Yntec/ChildrenStoriesAnime | Yntec | 2023-11-23T09:45:36Z | 656 | 5 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Zovya",
"Children Books",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-07-20T13:56:44Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
tags:
- stable-diffusion
- stable-diffusion-diffusers
- diffusers
- text-to-image
- Zovya
- Children Books
---
# Children's Stories Anime
This version of this model by Zovya has the Waifu 1.4 VAE baked in for better saturation.
Original page:
https://civitai.com/models/64544?modelVersionId=69167 |
Yntec/RadiantCinemagic | Yntec | 2023-08-28T13:10:12Z | 656 | 2 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"Cinematic",
"Photography",
"Photorealism",
"Fantasy",
"Artwork",
"Landscape",
"Ciro_Negrogni",
"Hivemind111",
"en",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2023-08-28T11:28:15Z | ---
license: creativeml-openrail-m
library_name: diffusers
pipeline_tag: text-to-image
language:
- en
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- Cinematic
- Photography
- Photorealism
- Fantasy
- Artwork
- Landscape
- Ciro_Negrogni
- Hivemind111
inference: true
---
# Radiant Cinemagic
Radiant Vibes model with the Cinemagic Vision LoRa merged in.
Sample and prompts:


Overwatch pretty cute girl grabbing beef tacos made out of burritos. by ilya kuvshinov, krenz cushart, greg rutkowski, trending on artstation. glossy materials, sharp highlights, amazing textured brush strokes, accurate shape, clear details, cinematic soft volumetric studio lighting, with backlight, vfx, hdr
Original Pages:
https://civitai.com/models/4509?modelVersionId=38663 (Radiant)
https://civitai.com/models/117345?modelVersionId=127152 (Cinemagic)
# Cinemagic
Cinemagic is Radiant Vibes with the LoRa merged at 1.0 strength, Radiant Cinemagic is Radiant with strength 0.3 merged with Cinemagic at 0.7 strength. |
NbAiLab/nb-whisper-large | NbAiLab | 2024-02-21T11:23:09Z | 656 | 14 | transformers | [
"transformers",
"pytorch",
"jax",
"tensorboard",
"onnx",
"safetensors",
"whisper",
"automatic-speech-recognition",
"audio",
"asr",
"hf-asr-leaderboard",
"no",
"nb",
"nn",
"en",
"dataset:NbAiLab/ncc_speech",
"dataset:NbAiLab/NST",
"dataset:NbAiLab/NPSC",
"arxiv:2212.04356",
"base_model:openai/whisper-large",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | automatic-speech-recognition | 2024-02-13T10:07:22Z | ---
license: apache-2.0
language:
- 'no'
- nb
- nn
- en
datasets:
- NbAiLab/ncc_speech
- NbAiLab/NST
- NbAiLab/NPSC
base_model: openai/whisper-large
tags:
- audio
- asr
- automatic-speech-recognition
- hf-asr-leaderboard
metrics:
- wer
- cer
library_name: transformers
pipeline_tag: automatic-speech-recognition
widget:
- src: https://datasets-server.huggingface.co/assets/google/fleurs/--/nb_no/train/1/audio/audio.mp3
example_title: FLEURS sample 1
- src: https://datasets-server.huggingface.co/assets/google/fleurs/--/nb_no/train/4/audio/audio.mp3
example_title: FLEURS sample 2
---
# NB-Whisper Large
Introducing the **_Norwegian NB-Whisper Large model_**, proudly developed by the National Library of Norway. NB-Whisper is a cutting-edge series of models designed for automatic speech recognition (ASR) and speech translation. These models are based on the work of [OpenAI's Whisper](https://arxiv.org/abs/2212.04356). Each model in the series has been trained for 250,000 steps, utilizing a diverse dataset of 8 million samples. These samples consist of aligned audio clips, each 30 seconds long, culminating in a staggering 66,000 hours of speech. For an in-depth understanding of our training methodology and dataset composition, keep an eye out for our upcoming article.
| Model Size | Parameters | Model |
|------------|------------|------------|
| Tiny | 39M | [NB-Whisper Tiny](https://huggingface.co/NbAiLab/nb-whisper-tiny) |
| Base | 74M | [NB-Whisper Base](https://huggingface.co/NbAiLab/nb-whisper-base) |
| Small | 244M | [NB-Whisper Small](https://huggingface.co/NbAiLab/nb-whisper-small) |
| Medium | 769M | [NB-Whisper Medium](https://huggingface.co/NbAiLab/nb-whisper-medium) |
| Large | 1550M | [NB-Whisper Large](https://huggingface.co/NbAiLab/nb-whisper-large) |
### Verbatim Model
While the main models are suitable for most transcription task, we demonstrate how easy it is to change the output of the main model. The following models are trained 250 additional steps from the main models above, and might be suitable for more targetted use cases:
- **Verbatim version**: This lower-cased variant is more literal and suitable for tasks requiring detailed transcription, such as linguistic analysis.
| Model Size | Parameters | Semantic version |
|------------|------------|------------------|
| Tiny | 39M | [Tiny - semantic](https://huggingface.co/NbAiLab/nb-whisper-tiny-semantic) |
| Base | 74M | [Base - semantic](https://huggingface.co/NbAiLab/nb-whisper-base-semantic) |
| Small | 244M | [Small - semantic](https://huggingface.co/NbAiLab/nb-whisper-small-semantic) |
| Medium | 769M | [Medium - semantic](https://huggingface.co/NbAiLab/nb-whisper-medium-semantic) |
| Large | 1550M | [Large - semantic](https://huggingface.co/NbAiLab/nb-whisper-large-semantic) |
### Model Description
- **Developed by:** [NB AI-Lab](https://ai.nb.no/)
- **Shared by:** [NB AI-Lab](https://ai.nb.no/)
- **Model type:** `whisper`
- **Language(s) (NLP):** Norwegian, Norwegian Bokmål, Norwegian Nynorsk, English
- **License:** [Apache 2.0](https://www.apache.org/licenses/LICENSE-2.0)
- **Trained from model:** [openai/whisper-large-v3](https://huggingface.co/openai/whisper-large-v3)
- **Code Repository:** https://github.com/NbAiLab/nb-whisper/
- **Paper:** _Coming soon_
- **Demo:** _See Spaces on this page_
## How to Use the Models
### Online Demos
You can try the models directly through the HuggingFace Inference API, accessible on the right side of this page. Be aware that initially, the model needs to load and will run on limited CPU capacity, which might be slow. To enhance your experience, we are temporarily hosting some models on TPUs for a few days, significantly boosting their performance. Explore these under the **Spaces** section on the [Main Page](https://huggingface.co/NbAiLab/).
### Local Setup with HuggingFace
Alternatively, you can run the models locally. The Tiny, Base, and Small models are optimized for CPU execution. For the Medium and Large models, we recommend a system equipped with a GPU to ensure efficient processing. Setting up and using these models with HuggingFace's Transformers is straightforward, provided you have [Python](https://www.python.org/downloads/) installed on your machine. For practical demonstrations, refer to examples using this [sample mp3 file](https://github.com/NbAiLab/nb-whisper/raw/main/audio/king.mp3).
```bash
# Download the sample file
$ wget -N https://github.com/NbAiLab/nb-whisper/raw/main/audio/king.mp3
# Install necessary libraries.
$ pip install transformers>=4.35.2
```
After this is done, you should be able to run this in Python:
```python
from transformers import pipeline
# Load the model
asr = pipeline("automatic-speech-recognition", "NbAiLabBeta/nb-whisper-large")
#transcribe
asr("king.mp3", generate_kwargs={'task': 'transcribe', 'language': 'no'})
```
<details>
<summary>Expected output</summary>
```json
{
{'text': ' Nordmenn er nordlendinger, trøndere, sørlendinger og folk fra alle andre regioner. Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra.'}
}
```
</details>
#### Extended HuggingFace
Examining the output above, we see that there are multiple repetitions at the end. This is because the video is longer than 30 seconds. By passing the ```chunk_lengt_s``` argument, we can transcribe longer file. Our experience is that we get slightly better result by setting that to 28 seconds instead of the default 30 seconds. We also recommend setting the beam size to 5 if possible. This greatly increases the accuracy but takes a bit longer and requires slightly more memory. The examples below also illustrates how to transcribe to English or Nynorsk, and how to get timestamps for sentences and words.
```python
# Long Transcripts
asr("king.mp3", chunk_length_s=28, generate_kwargs={'task': 'transcribe', 'language': 'no'})
# Increase accuracy by setting beam size to 5
asr("king.mp3", chunk_length_s=28, return_timestamps=True, generate_kwargs={'num_beams': 5, 'task': 'transcribe', 'language': 'no'})
# Return Timestamps
asr("king.mp3", chunk_length_s=28, return_timestamps=True, generate_kwargs={'task': 'transcribe', 'language': 'no'})
# Return Word Level Timestamps
asr("king.mp3", chunk_length_s=28, return_timestamps="word", generate_kwargs={'task': 'transcribe', 'language': 'no'})
# Transcribe to Nynorsk
asr("king.mp3", chunk_length_s=28, generate_kwargs={'task': 'transcribe', 'language': 'nn'})
# Transcribe to English
asr("king.mp3", chunk_length_s=28, generate_kwargs={'task': 'transcribe', 'language': 'en'})
```
<details>
<summary>Expected output</summary>
Long transcripts:
```json
{
{'text': ' Nordmenn er nordlendinger, trøndere, sørlendinger og folk fra alle andre regioner. Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra, hvilken nasjonalitet vi tilhører. Det vi kaller hjem, er der hjertet vårt er, og det kan ikke alltid plasseres innenfor landegrenser. Nordmenn er jenter som er glad i jenter, gutter som er glad i gutter, og jenter og gutter som er glad i hverandre. Nordmenn trommer på Gud, Allah, Altet og ingenting. Nordmenn liker Grieg, Kygo, Helbilis og Kari Bremnes. Med andre ord, Norge er dere. Norge er oss. Mitt største håp for Norge er at vi skal klare å ta vare på hverandre, at vi skal bygge dette landet videre på tillit, fellesskap og raushet.'}
}
```
Timestamps:
```json
{
{'text': ' Nordmenn er nordlendinger, trøndere, sørlendinger og folk fra alle andre regioner. Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi er fra. Hvilken nasjonalitet vi er fra. hvilken nasjonalitet vi tilhører. Det vi kaller hjem, er der hjertet vårt er, og det kan ikke alltid plasseres innenfor landegrenser. Nordmenn er jenter som er glad i jenter, gutter som er glad i gutter, og jenter og gutter som er glad i hverandre. Nordmenn trommer på Gud, Allah, Altet og ingenting. Nordmenn liker Grieg, Kygo, Helbiles og Kari Bremnes. Med andre ord, Norge er dere. Norge er oss. Mitt største håp for Norge er at vi skal klare å ta vare på hverandre, at vi skal bygge dette landet videre på tillit, fellesskap og raushet.',
'chunks': [{'timestamp': (0.0, 5.46),
'text': ' Nordmenn er nordlendinger, trøndere, sørlendinger'},
{'timestamp': (5.52, 8.68), 'text': ' og folk fra alle andre regioner.'},
{'timestamp': (8.68, 16.64),
'text': ' Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria.'},
{'timestamp': (16.64, 13.3),
'text': ' Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi er fra.'},
{'timestamp': (13.32, 30.28),
'text': ' Hvilken nasjonalitet vi er fra. hvilken nasjonalitet vi tilhører.'},
{'timestamp': (32.52, 39.16),
'text': ' Det vi kaller hjem, er der hjertet vårt er, og det kan ikke alltid plasseres'},
{'timestamp': (39.16, 42.0), 'text': ' innenfor landegrenser.'},
{'timestamp': (42.0, 46.74),
'text': ' Nordmenn er jenter som er glad i jenter, gutter som er glad i gutter,'},
{'timestamp': (46.74, 51.12),
'text': ' og jenter og gutter som er glad i hverandre.'},
{'timestamp': (51.16, 57.42),
'text': ' Nordmenn trommer på Gud, Allah, Altet og ingenting.'},
{'timestamp': (57.42, 64.3),
'text': ' Nordmenn liker Grieg, Kygo, Helbiles og Kari Bremnes.'},
{'timestamp': (64.34, 71.24),
'text': ' Med andre ord, Norge er dere. Norge er oss.'},
{'timestamp': (71.24, 78.04),
'text': ' Mitt største håp for Norge er at vi skal klare å ta vare på hverandre,'},
{'timestamp': (78.12, 84.68),
'text': ' at vi skal bygge dette landet videre på tillit, fellesskap og raushet.'}]}
}
```
Word Level Timestamps:
```json
{
{"text": "Nordmenn er nordlendinger, trøndere, sørlendinger og folk fra alle andre regioner. Nordmenn er også innvandret fra Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikke alltid så lett å si hvor vi er fra, hvilken nasjonalitet vi tilhører. Det vi kaller hjem, er der hjertet vårt er, og det kan ikke alltid plasseres innenfor landegrenser. Nordmenn er jenter som er glad i jenter, gutter som er glad i gutter, og jenter og gutter som er glad i hverandre. Nordmenn trommer på Gud, Allah, Altet og ingenting. Nordmenn liker Grieg, Kygo, Helbilis og Kari Bremnes. Med andre ord, Norge er dere. Norge er oss. Mitt største håp for Norge er at vi skal klare å ta vare på hverandre, at vi skal bygge dette landet videre på tillit, fellesskap og raushet.",
"chunks": [
{"text": "Nordmenn", "timestamp": [0.72, 1.42]},
{"text": "er", "timestamp": [1.42, 1.74]},
// ... more chunks ...
{"text": "raushet.", "timestamp": [83.1, 84.88]}
]
}
}
```
Nynorsk:
```json
{
{"text": "Nordmenn er nordlendingar, trøndarar, sørlendingar og folk frå alle andre regionar. Nordmenn er også innvandra frå Afghanistan, Pakistan, Polen, Sverige, Somalia og Syria. Det er ikkje alltid så lett å seie kvar vi er frå, kva nasjonalitet vi tilhøyrer. Det vi kallar heim, er der hjartet vårt er, og det kan ikkje alltid plasserast innanfor landegrenser. Nordmenn er jenter som er glad i jenter, gutar som erade i gutar, og jenter og gutar som er glade i kvarandre. Nordmenn trommar på Gud, Allah, Altet og ingenting. Nordmenn liker Grieg, Kygo, Helbiles og Kari Bremnes. Med andre ord, Noreg er dere! Noreg er oss. Mitt største håp for Noreg er at vi skal klare å ta vare på kvarandre, at vi skal byggje dette landet vidare på tillit, fellesskap og raushet."}
}
```
English:
```json
{
{"text": "Norwegians are Norwegians, trønders, southerners and people from all other regions. Norwegians are also invaded from Afghanistan, Pakistan, Poland, Sweden, Somalia and Suria. It is not always so easy to say where we are from, what nationality we belong to. What we call home is where our heart is, and it cannot always be placed within national borders. Norwegians are girls who like girls, boys who like boys, and girls and boys who like each other. Norwegians thrump on God, Allah, Altet and nothing. Norwegians like Grieg, Kygo, Helbilis and Kari Bremnes. In other words, Norway is you. Norway is us. My biggest hope for Norway is that we should be able to take care of each other, that we should build this country on trust, community and generosity."}
}
```
</details>
### Whisper CPP
Whisper CPP is a C++ implementation of the Whisper model, offering the same functionalities with the added benefits of C++ efficiency and performance optimizations. This allows embedding any Whisper model into a binary file, facilitating the development of real applications. However, it requires some familiarity with compiling C++ programs. Their [homepage](https://github.com/ggerganov/whisper.cpp) provides examples of how to build applications, including real-time transcription.
We have converted this model to the ggml-format model used by Whisper CPP binaries. The file can be downloaded [here](blob/main/ggml-model.bin), and a `q5_0` quantized version is also available [here](blob/main/ggml-model-q5_0.bin).
```bash
# We can download and compile whisper.cpp
$ git clone --depth 1 https://github.com/ggerganov/whisper.cpp --branch v1.5.1
$ cd whisper.cpp/
$ make
# We also need to convert the audio to WAV as that is the only format supported by whisper.cpp
$ wget -N https://github.com/NbAiLab/nb-whisper/raw/main/audio/king.mp3
$ ffmpeg -i king.mp3 -ar 16000 -ac 1 -c:a pcm_s16le king.wav
# Lets download the two ggml-files from this site
wget -N https://huggingface.co/NbAiLab/nb-whisper-large/resolve/main/ggml-model.bin -O models/nb-large-ggml-model.bin
wget -N https://huggingface.co/NbAiLab/nb-whisper-large/resolve/main/ggml-model-q5_0.bin -O models/nb-large-ggml-model-q5_0.bin
# And run it with the f16 default model
$ ./main -l no -m models/nb-large-ggml-model.bin king.wav
# Or the quantized version
$ ./main -l no -m models/nb-large-ggml-model-q5_0.bin king.wav
```
### WhisperX and Speaker Diarization
Speaker diarization is a technique in natural language processing and automatic speech recognition that identifies and separates different speakers in an audio recording. It segments the audio into parts based on who is speaking, enhancing the quality of transcribing meetings or phone calls. We find that [WhisperX](https://github.com/m-bain/whisperX) is the easiest way to use our models for diarizing speech. In addition, WhisperX is using phoneme-based Wav2Vec-models for improving the alignment of the timestamps. As of December 2023 it also has native support for using the nb-wav2vec-models. It currently uses [PyAnnote-audio](https://github.com/pyannote/pyannote-audio) for doing the actual diarization. This package has a fairly strict licence where you have to agree to user terms. Follow the instructions below.
```bash
# Follow the install instructions on https://github.com/m-bain/whisperX
# Make sure you have a HuggingFace account and have agreed to the pyannote terms
# Log in (or supply HF Token in command line)
huggingface-cli login
# Download a test file
wget -N https://github.com/NbAiLab/nb-whisper/raw/main/audio/knuthamsun.mp3
# Optional. If you get complains about not support for Norwegian, do:
pip uninstall whisperx && pip install git+https://github.com/m-bain/whisperx.git@8540ff5985fceee764acbed94f656063d7f56540
# Transcribe the test file. All transcripts will end up in the directory of the mp3-file
whisperx knuthamsun.mp3 --model NbAiLabBeta/nb-whisper-large --language no --diarize
```
You can also run WhisperX from Python. Please take a look at the instructions on [WhisperX homepage](https://github.com/m-bain/whisperX).
### API
Instructions for accessing the models via a simple API are included in the demos under Spaces. Note that these demos are temporary and will only be available for a few weeks.
## Training Data
The training data originates from Språkbanken and the National Library of Norway's digital collection, including:
- NST Norwegian ASR Database (16 kHz) and its corresponding dataset
- Transcribed speeches from the Norwegian Parliament by Språkbanken
- TV broadcast (NRK) subtitles (NLN digital collection)
- Audiobooks (NLN digital collection)
## Downstream Use
The models, especially the smaller ones, may exhibit occasional hallucinations and may drop parts of the transcript. They are designed to convert spoken language into grammatically correct written sentences, which might not always be word-for-word translations. We have made two extra model variant for users that want a different transcription style. We encourage users to try the models themselves to get a better understanding.
## Bias, Risks, and Limitations
Using these models without adequate risk assessment and mitigation could be considered irresponsible. They may contain biases or other undesirable distortions. Users who deploy these models or integrate them into systems or services are responsible for mitigating risks and complying with applicable AI regulations. The National Library of Norway, as the model owner, disclaims liability for any outcomes resulting from third-party use of these models.
### Software
The model was trained using Jax/Flax and converted to PyTorch, Tensorflow, whisper.cpp, and ONXX formats. These are available under `Files and versions`. We welcome requests for conversion to other formats. All training code and scripts are released under the Apache License 2.0 in the GitHub repository [nb-whisper](https://github.com/NbAiLab/nb-whisper/).
## Citation & Contributors
The NB-Whisper Large model is a product of the NoSTram project led by Per Egil Kummervold ([@pere](https://huggingface.co/pere)) at the National Library of Norway. Key contributors include Javier de la Rosa ([@versae](https://huggingface.co/versae)), Freddy Wetjen ([@freddyw](https://huggingface.co/freddyw)), and Rolv-Arild Braaten ([@Rolv-Arild](https://huggingface.co/Rolv-Arild)). NB AI-Lab, under the direction of Svein Arne Brygfjeld ([@Brygfjeld](https://huggingface.co/Brygfjeld)), supported the project's successful completion. A detailed paper on our process and findings is forthcoming.
## Disclaimer
The models published in this repository are intended for a generalist purpose and are available to third parties. These models may have bias and/or any other undesirable distortions. When third parties, deploy or provide systems and/or services to other parties using any of these models (or using systems based on these models) or become users of the models, they should note that it is their responsibility to mitigate the risks arising from their use and, in any event, to comply with applicable regulations, including regulations regarding the use of artificial intelligence. In no event shall the owner of the models (The National Library of Norway) be liable for any results arising from the use made by third parties of these models.
## Acknowledgements
Our gratitude extends to [Google TPU Research Cloud](https://sites.research.google/trc/about/) for training resources, Google Cloud for translation credits, and HuggingFace's Sanchit Ghandi for technical support. A special thank you to Per Erik Solberg at Språkbanken for the collaboration on the Stortinget corpus.
## Contact
For feedback, technical concerns, or collaboration inquiries, please contact <a rel="noopener nofollow" href="mailto:[email protected]">[email protected]</a>. If you plan to include this model in your research, contact us for the latest information on our upcoming paper for citation purposes.
|
screamuch/kunteynir-lyrics-ruadapt_llama2_7b-gguf | screamuch | 2024-04-05T08:37:43Z | 656 | 0 | null | [
"gguf",
"not-for-all-audiences",
"ru",
"license:cc-by-4.0",
"region:us"
] | null | 2024-04-04T23:50:55Z | ---
license: cc-by-4.0
language:
- ru
tags:
- not-for-all-audiences
---
# основа
https://huggingface.co/screamuch/kunteynir-lyrics-ruadapt_llama2_7b
# юсадж
q6_k работает нормально и быстро на rtx 3060, q8_0 уже нет. оригинальная модель в f16, поэтому если есть 16гб врам то вам лучше в основную модель.
в каком-нибудь нормальном шелле типа [fish](https://github.com/fish-shell/fish-shell)
```
./main --color --interactive --n-gpu-layers 15000 --n-predict 500 --ctx-size 1024 -m models/kunteynir-lyrics-ruadapt_llama2_7b-q8_0.gguf -p "### Input:
Напиши куплет в стиле Паши Техника/Кальмара/Максима Синицына/Блева про {скелет повествования}. {список каких-то ключевых слов}.
### Response:
"
```
в баше можно вот так:
```
./main --color --interactive --n-gpu-layers 15000 --n-predict 500 --ctx-size 1024 -m models/kunteynir-lyrics-ruadapt_llama2_7b-q8_0.gguf -p "### Input:\nНапиши куплет в стиле Паши Техника/Кальмара/Максима Синицына/Блева про {скелет повествования}. {список каких-то ключевых слов}.\n\n### Response:\n"
``` |
mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF | mradermacher | 2024-05-05T15:00:33Z | 656 | 2 | transformers | [
"transformers",
"gguf",
"merge",
"mergekit",
"lazymergekit",
"jdqwoi/Mistral-dolphin-mix-cine-open-Ne",
"athirdpath/NSFW_DPO_Noromaid-7b",
"en",
"base_model:jdqwoi/Mistral-dolphin-mix-cine-open-Ne-NSFW",
"endpoints_compatible",
"region:us"
] | null | 2024-04-28T16:22:16Z | ---
base_model: jdqwoi/Mistral-dolphin-mix-cine-open-Ne-NSFW
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- merge
- mergekit
- lazymergekit
- jdqwoi/Mistral-dolphin-mix-cine-open-Ne
- athirdpath/NSFW_DPO_Noromaid-7b
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/jdqwoi/Mistral-dolphin-mix-cine-open-Ne-NSFW
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q2_K.gguf) | Q2_K | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.IQ3_XS.gguf) | IQ3_XS | 3.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q3_K_S.gguf) | Q3_K_S | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.IQ3_S.gguf) | IQ3_S | 3.3 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.IQ3_M.gguf) | IQ3_M | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q3_K_M.gguf) | Q3_K_M | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q3_K_L.gguf) | Q3_K_L | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.IQ4_XS.gguf) | IQ4_XS | 4.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q4_K_S.gguf) | Q4_K_S | 4.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q4_K_M.gguf) | Q4_K_M | 4.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q5_K_S.gguf) | Q5_K_S | 5.1 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q5_K_M.gguf) | Q5_K_M | 5.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q6_K.gguf) | Q6_K | 6.0 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.Q8_0.gguf) | Q8_0 | 7.8 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Mistral-dolphin-mix-cine-open-Ne-NSFW-GGUF/resolve/main/Mistral-dolphin-mix-cine-open-Ne-NSFW.f16.gguf) | f16 | 14.6 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/SOVL_Llama3_8B-i1-GGUF | mradermacher | 2024-05-05T14:51:04Z | 656 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:ResplendentAI/SOVL_Llama3_8B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-03T22:56:51Z | ---
base_model: ResplendentAI/SOVL_Llama3_8B
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hfhfix -->
<!-- ### vocab_type: -->
weighted/imatrix quants of https://huggingface.co/ResplendentAI/SOVL_Llama3_8B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/SOVL_Llama3_8B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.5 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.7 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ2_S.gguf) | i1-IQ2_S | 2.9 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q2_K.gguf) | i1-Q2_K | 3.3 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.4 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 3.8 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ3_S.gguf) | i1-IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ3_M.gguf) | i1-IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.1 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.4 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q4_0.gguf) | i1-Q4_0 | 4.8 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 4.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/SOVL_Llama3_8B-i1-GGUF/resolve/main/SOVL_Llama3_8B.i1-Q6_K.gguf) | i1-Q6_K | 6.7 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
mradermacher/SyntheticMoist-11B-GGUF | mradermacher | 2024-06-05T14:29:23Z | 656 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"solar",
"llama",
"not-for-all-audiences",
"en",
"base_model:v000000/SyntheticMoist-11B",
"endpoints_compatible",
"region:us"
] | null | 2024-06-05T13:51:23Z | ---
base_model: v000000/SyntheticMoist-11B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
- solar
- llama
- not-for-all-audiences
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/v000000/SyntheticMoist-11B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/SyntheticMoist-11B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q2_K.gguf) | Q2_K | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.IQ3_XS.gguf) | IQ3_XS | 4.5 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q3_K_S.gguf) | Q3_K_S | 4.8 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.IQ3_S.gguf) | IQ3_S | 4.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.IQ3_M.gguf) | IQ3_M | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q3_K_M.gguf) | Q3_K_M | 5.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q3_K_L.gguf) | Q3_K_L | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.IQ4_XS.gguf) | IQ4_XS | 5.9 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q4_K_S.gguf) | Q4_K_S | 6.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q4_K_M.gguf) | Q4_K_M | 6.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q5_K_S.gguf) | Q5_K_S | 7.5 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q5_K_M.gguf) | Q5_K_M | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q6_K.gguf) | Q6_K | 8.9 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/SyntheticMoist-11B-GGUF/resolve/main/SyntheticMoist-11B.Q8_0.gguf) | Q8_0 | 11.5 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
sbintuitions/tiny-lm-chat | sbintuitions | 2024-06-07T16:53:45Z | 656 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"conversational",
"ja",
"en",
"dataset:wikipedia",
"dataset:llm-jp/oasst1-21k-ja",
"dataset:llm-jp/oasst1-21k-en",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-06-07T13:14:57Z | ---
license: mit
datasets:
- wikipedia
- llm-jp/oasst1-21k-ja
- llm-jp/oasst1-21k-en
language:
- ja
- en
---
# tiny-lm
This repository provides a tiny 16M parameters language model for debugging and testing purposes.
This is created by tuning [sbintuitions/tiny-lm](https://huggingface.co/sbintuitions) with oasset1 datasets in Japanese and English.
## How to use
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, pipeline
model = AutoModelForCausalLM.from_pretrained("sbintuitions/tiny-lm-chat", torch_dtype="auto")
tokenizer = AutoTokenizer.from_pretrained("sbintuitions/tiny-lm-chat", use_fast=False)
generator = pipeline("text-generation", model=model, tokenizer=tokenizer)
prompt = tokenizer.apply_chat_template([{"role": "user", "content": "Hello!"}], add_generation_prompt=True, tokenize=False)
print(generator(prompt, max_length=30, do_sample=True, top_k=100))
```
## Model architecture
A 4-layer, 512-hidden-size transformer-based language model.
## Training
The model was first pre-trained on English Wikipedia and Japanese Wikipedia to optimize a traditional language modelling objective for 25B tokens.
And then it was fine-tuned on oasst1 datasets in Japanese and English for 15 epochs.
## License
[MIT License](https://huggingface.co/sbintuitions/tiny-lm-chat/resolve/main/LICENSE)
|
nikravan/glm-4vq | nikravan | 2024-06-16T10:33:48Z | 656 | 2 | transformers | [
"transformers",
"safetensors",
"chatglm",
"feature-extraction",
"text-generation-inference",
"document-question-answering",
"custom_code",
"en",
"de",
"fr",
"fa",
"ar",
"tr",
"es",
"it",
"zh",
"ko",
"ja",
"hi",
"4-bit",
"bitsandbytes",
"region:us"
] | document-question-answering | 2024-06-10T12:54:20Z | ---
language:
- en
- de
- fr
- fa
- ar
- tr
- es
- it
- zh
- ko
- ja
- hi
metrics:
- accuracy
pipeline_tag: document-question-answering
tags:
- text-generation-inference
---
### MultiModal MultiLingual (3ML)
This model is 4bit quantized of [glm-4v-9b](https://huggingface.co/THUDM/glm-4v-9b) Model (Less than 9G).
It excels in document, image, chart questioning answering and delivers superior performance over GPT-4-turbo-2024-04-09, Gemini 1.0 Pro, Qwen-VL-Max, and Claude 3 Opus.
Some part of the original Model changed and It can excute on free version of google colab.
# Try it: [](https://colab.research.google.com/drive/1aZGX9f5Yw1WbiOrS3TpvPk_UJUP_yYQU?usp=sharing)
[![Github Source]](https://github.com/nikravan1/3ML)
Note: For optimal performance with document and image understanding, please use English or Chinese. The model can still handle chat in any supported language.
### About GLM-4V-9B
GLM-4V-9B is a multimodal language model with visual understanding capabilities. The evaluation results of its related classic tasks are as follows:
| | **MMBench-EN-Test** | **MMBench-CN-Test** | **SEEDBench_IMG** | **MMStar** | **MMMU** | **MME** | **HallusionBench** | **AI2D** | **OCRBench** |
|-------------------------|---------------------|---------------------|-------------------|------------|----------|---------|--------------------|----------|--------------|
| | 英文综合 | 中文综合 | 综合能力 | 综合能力 | 学科综合 | 感知推理 | 幻觉性 | 图表理解 | 文字识别 |
| **GPT-4o, 20240513** | 83.4 | 82.1 | 77.1 | 63.9 | 69.2 | 2310.3 | 55 | 84.6 | 736 |
| **GPT-4v, 20240409** | 81 | 80.2 | 73 | 56 | 61.7 | 2070.2 | 43.9 | 78.6 | 656 |
| **GPT-4v, 20231106** | 77 | 74.4 | 72.3 | 49.7 | 53.8 | 1771.5 | 46.5 | 75.9 | 516 |
| **InternVL-Chat-V1.5** | 82.3 | 80.7 | 75.2 | 57.1 | 46.8 | 2189.6 | 47.4 | 80.6 | 720 |
| **LlaVA-Next-Yi-34B** | 81.1 | 79 | 75.7 | 51.6 | 48.8 | 2050.2 | 34.8 | 78.9 | 574 |
| **Step-1V** | 80.7 | 79.9 | 70.3 | 50 | 49.9 | 2206.4 | 48.4 | 79.2 | 625 |
| **MiniCPM-Llama3-V2.5** | 77.6 | 73.8 | 72.3 | 51.8 | 45.8 | 2024.6 | 42.4 | 78.4 | 725 |
| **Qwen-VL-Max** | 77.6 | 75.7 | 72.7 | 49.5 | 52 | 2281.7 | 41.2 | 75.7 | 684 |
| **GeminiProVision** | 73.6 | 74.3 | 70.7 | 38.6 | 49 | 2148.9 | 45.7 | 72.9 | 680 |
| **Claude-3V Opus** | 63.3 | 59.2 | 64 | 45.7 | 54.9 | 1586.8 | 37.8 | 70.6 | 694 |
| **GLM-4v-9B** | 81.1 | 79.4 | 76.8 | 58.7 | 47.2 | 2163.8 | 46.6 | 81.1 | 786 |
**This repository is the model repository of 4bit quantized of GLM-4V-9B model, supporting `8K` context length.**
## Quick Start
Use colab model or this python script.
```python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
from PIL import Image
device = "cuda"
modelPath="nikravan/glm-4vq"
tokenizer = AutoTokenizer.from_pretrained(modelPath, trust_remote_code=True)
model = AutoModelForCausalLM.from_pretrained(
modelPath,
torch_dtype=torch.bfloat16,
low_cpu_mem_usage=True,
trust_remote_code=True,
device_map="auto"
)
query ='explain all the details in this picture'
image = Image.open("a3.png").convert('RGB')
#image=""
inputs = tokenizer.apply_chat_template([{"role": "user", "image": image, "content": query}],
add_generation_prompt=True, tokenize=True, return_tensors="pt",
return_dict=True) # chat with image mode
inputs = inputs.to(device)
gen_kwargs = {"max_length": 2500, "do_sample": True, "top_k": 1}
with torch.no_grad():
outputs = model.generate(**inputs, **gen_kwargs)
outputs = outputs[:, inputs['input_ids'].shape[1]:]
print(tokenizer.decode(outputs[0]))
``` |
kahou1234/YoutubeVtuber | kahou1234 | 2024-06-29T03:36:50Z | 656 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"llama-factory",
"unsloth",
"trl",
"sft",
"conversational",
"arxiv:1910.09700",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-06-17T14:06:46Z | ---
library_name: transformers
tags:
- llama-factory
- unsloth
- trl
- sft
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
rajtest/t_llama_v3 | rajtest | 2024-06-30T19:08:00Z | 656 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"license:unknown",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | null | 2024-06-30T17:50:23Z | ---
license: unknown
---
|
Helsinki-NLP/opus-mt-de-fi | Helsinki-NLP | 2023-08-16T11:27:51Z | 655 | 0 | transformers | [
"transformers",
"pytorch",
"tf",
"marian",
"text2text-generation",
"translation",
"de",
"fi",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | translation | 2022-03-02T23:29:04Z | ---
tags:
- translation
license: apache-2.0
---
### opus-mt-de-fi
* source languages: de
* target languages: fi
* OPUS readme: [de-fi](https://github.com/Helsinki-NLP/OPUS-MT-train/blob/master/models/de-fi/README.md)
* dataset: opus
* model: transformer-align
* pre-processing: normalization + SentencePiece
* download original weights: [opus-2020-01-08.zip](https://object.pouta.csc.fi/OPUS-MT-models/de-fi/opus-2020-01-08.zip)
* test set translations: [opus-2020-01-08.test.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-fi/opus-2020-01-08.test.txt)
* test set scores: [opus-2020-01-08.eval.txt](https://object.pouta.csc.fi/OPUS-MT-models/de-fi/opus-2020-01-08.eval.txt)
## Benchmarks
| testset | BLEU | chr-F |
|-----------------------|-------|-------|
| Tatoeba.de.fi | 40.0 | 0.628 |
|
nlpie/distil-clinicalbert | nlpie | 2024-03-26T16:43:45Z | 655 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"fill-mask",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | fill-mask | 2022-10-25T22:35:40Z | ---
title: README
emoji: 🏃
colorFrom: gray
colorTo: purple
sdk: static
pinned: false
---
# Model Description
DistilClinicalBERT is a distilled version of the [BioClinicalBERT](https://huggingface.co/emilyalsentzer/Bio_ClinicalBERT) model which is distilled for 3 epochs using a total batch size of 192 on the MIMIC-III notes dataset.
# Distillation Procedure
This model uses a simple distillation technique, which tries to align the output distribution of the student model with the output distribution of the teacher based on the MLM objective. In addition, it optionally uses another alignment loss for aligning the last hidden state of the student and teacher.
# Initialisation
Following [DistilBERT](https://huggingface.co/distilbert-base-uncased?text=The+goal+of+life+is+%5BMASK%5D.), we initialise the student model by taking weights from every other layer of the teacher.
# Architecture
In this model, the size of the hidden dimension and the embedding layer are both set to 768. The vocabulary size is 28996. The number of transformer layers is 6 and the expansion rate of the feed-forward layer is 4. Overall this model has around 65 million parameters.
# Citation
If you use this model, please consider citing the following paper:
```bibtex
@article{rohanian2023lightweight,
title={Lightweight transformers for clinical natural language processing},
author={Rohanian, Omid and Nouriborji, Mohammadmahdi and Jauncey, Hannah and Kouchaki, Samaneh and Nooralahzadeh, Farhad and Clifton, Lei and Merson, Laura and Clifton, David A and ISARIC Clinical Characterisation Group and others},
journal={Natural Language Engineering},
pages={1--28},
year={2023},
publisher={Cambridge University Press}
}
``` |
timm/swin_large_patch4_window12_384.ms_in22k | timm | 2024-02-10T23:31:31Z | 655 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-22k",
"arxiv:2103.14030",
"license:mit",
"region:us"
] | image-classification | 2023-03-18T04:10:12Z | ---
license: mit
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-22k
---
# Model card for swin_large_patch4_window12_384.ms_in22k
A Swin Transformer image classification model. Pretrained on ImageNet-22k by paper authors.
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 228.8
- GMACs: 104.1
- Activations (M): 202.2
- Image size: 384 x 384
- **Papers:**
- Swin Transformer: Hierarchical Vision Transformer using Shifted Windows: https://arxiv.org/abs/2103.14030
- **Original:** https://github.com/microsoft/Swin-Transformer
- **Dataset:** ImageNet-22k
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('swin_large_patch4_window12_384.ms_in22k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_large_patch4_window12_384.ms_in22k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g. for swin_base_patch4_window7_224 (NHWC output)
# torch.Size([1, 56, 56, 128])
# torch.Size([1, 28, 28, 256])
# torch.Size([1, 14, 14, 512])
# torch.Size([1, 7, 7, 1024])
# e.g. for swinv2_cr_small_ns_224 (NCHW output)
# torch.Size([1, 96, 56, 56])
# torch.Size([1, 192, 28, 28])
# torch.Size([1, 384, 14, 14])
# torch.Size([1, 768, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'swin_large_patch4_window12_384.ms_in22k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled (ie.e a (batch_size, H, W, num_features) tensor for swin / swinv2
# or (batch_size, num_features, H, W) for swinv2_cr
output = model.forward_head(output, pre_logits=True)
# output is (batch_size, num_features) tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
## Citation
```bibtex
@inproceedings{liu2021Swin,
title={Swin Transformer: Hierarchical Vision Transformer using Shifted Windows},
author={Liu, Ze and Lin, Yutong and Cao, Yue and Hu, Han and Wei, Yixuan and Zhang, Zheng and Lin, Stephen and Guo, Baining},
booktitle={Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV)},
year={2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
timm/regnetz_040.ra3_in1k | timm | 2024-02-10T23:34:19Z | 655 | 1 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"dataset:imagenet-1k",
"arxiv:2103.06877",
"license:apache-2.0",
"region:us"
] | image-classification | 2023-03-21T07:35:58Z | ---
license: apache-2.0
library_name: timm
tags:
- image-classification
- timm
datasets:
- imagenet-1k
---
# Model card for regnetz_040.ra3_in1k
A RegNetZ-4GF image classification model. Trained on ImageNet-1k by Ross Wightman in `timm`.
The `timm` RegNet implementation includes a number of enhancements not present in other implementations, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* configurable output stride (dilation)
* configurable activation and norm layers
* option for a pre-activation bottleneck block used in RegNetV variant
* only known RegNetZ model definitions with pretrained weights
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 27.1
- GMACs: 4.1
- Activations (M): 24.2
- Image size: train = 256 x 256, test = 320 x 320
- **Papers:**
- Fast and Accurate Model Scaling: https://arxiv.org/abs/2103.06877
- **Dataset:** ImageNet-1k
- **Original:** https://github.com/huggingface/pytorch-image-models
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('regnetz_040.ra3_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetz_040.ra3_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 128, 128])
# torch.Size([1, 48, 64, 64])
# torch.Size([1, 104, 32, 32])
# torch.Size([1, 240, 16, 16])
# torch.Size([1, 528, 8, 8])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetz_040.ra3_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 528, 8, 8) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
For the comparison summary below, the ra_in1k, ra3_in1k, ch_in1k, sw_*, and lion_* tagged weights are trained in `timm`.
|model |img_size|top1 |top5 |param_count|gmacs|macts |
|-------------------------|--------|------|------|-----------|-----|------|
|[regnety_1280.swag_ft_in1k](https://huggingface.co/timm/regnety_1280.swag_ft_in1k)|384 |88.228|98.684|644.81 |374.99|210.2 |
|[regnety_320.swag_ft_in1k](https://huggingface.co/timm/regnety_320.swag_ft_in1k)|384 |86.84 |98.364|145.05 |95.0 |88.87 |
|[regnety_160.swag_ft_in1k](https://huggingface.co/timm/regnety_160.swag_ft_in1k)|384 |86.024|98.05 |83.59 |46.87|67.67 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|288 |86.004|97.83 |83.59 |26.37|38.07 |
|[regnety_1280.swag_lc_in1k](https://huggingface.co/timm/regnety_1280.swag_lc_in1k)|224 |85.996|97.848|644.81 |127.66|71.58 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|288 |85.982|97.844|83.59 |26.37|38.07 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|224 |85.574|97.666|83.59 |15.96|23.04 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|224 |85.564|97.674|83.59 |15.96|23.04 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|288 |85.398|97.584|51.82 |20.06|35.34 |
|[regnety_2560.seer_ft_in1k](https://huggingface.co/timm/regnety_2560.seer_ft_in1k)|384 |85.15 |97.436|1282.6 |747.83|296.49|
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|320 |85.036|97.268|57.7 |15.46|63.94 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|224 |84.976|97.416|51.82 |12.14|21.38 |
|[regnety_320.swag_lc_in1k](https://huggingface.co/timm/regnety_320.swag_lc_in1k)|224 |84.56 |97.446|145.05 |32.34|30.26 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|320 |84.496|97.004|28.94 |6.43 |37.94 |
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|256 |84.436|97.02 |57.7 |9.91 |40.94 |
|[regnety_1280.seer_ft_in1k](https://huggingface.co/timm/regnety_1280.seer_ft_in1k)|384 |84.432|97.092|644.81 |374.99|210.2 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|320 |84.246|96.93 |27.12 |6.35 |37.78 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|320 |84.054|96.992|23.37 |6.19 |37.08 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|320 |84.038|96.992|23.46 |7.03 |38.92 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|320 |84.022|96.866|27.58 |9.33 |37.08 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|288 |83.932|96.888|39.18 |13.22|29.69 |
|[regnety_640.seer_ft_in1k](https://huggingface.co/timm/regnety_640.seer_ft_in1k)|384 |83.912|96.924|281.38 |188.47|124.83|
|[regnety_160.swag_lc_in1k](https://huggingface.co/timm/regnety_160.swag_lc_in1k)|224 |83.778|97.286|83.59 |15.96|23.04 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|256 |83.776|96.704|28.94 |4.12 |24.29 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|288 |83.72 |96.75 |30.58 |10.55|27.11 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|288 |83.718|96.724|30.58 |10.56|27.11 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|288 |83.69 |96.778|83.59 |26.37|38.07 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|256 |83.62 |96.704|27.12 |4.06 |24.19 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|256 |83.438|96.776|23.37 |3.97 |23.74 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|256 |83.424|96.632|27.58 |5.98 |23.74 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|256 |83.36 |96.636|23.46 |4.5 |24.92 |
|[regnety_320.seer_ft_in1k](https://huggingface.co/timm/regnety_320.seer_ft_in1k)|384 |83.35 |96.71 |145.05 |95.0 |88.87 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|288 |83.204|96.66 |20.64 |6.6 |20.3 |
|[regnety_320.tv2_in1k](https://huggingface.co/timm/regnety_320.tv2_in1k)|224 |83.162|96.42 |145.05 |32.34|30.26 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|224 |83.16 |96.486|39.18 |8.0 |17.97 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|224 |83.108|96.458|30.58 |6.39 |16.41 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|288 |83.044|96.5 |20.65 |6.61 |20.3 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|224 |83.02 |96.292|30.58 |6.39 |16.41 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|224 |82.974|96.502|83.59 |15.96|23.04 |
|[regnetx_320.tv2_in1k](https://huggingface.co/timm/regnetx_320.tv2_in1k)|224 |82.816|96.208|107.81 |31.81|36.3 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|288 |82.742|96.418|19.44 |5.29 |18.61 |
|[regnety_160.tv2_in1k](https://huggingface.co/timm/regnety_160.tv2_in1k)|224 |82.634|96.22 |83.59 |15.96|23.04 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|320 |82.634|96.472|13.49 |3.86 |25.88 |
|[regnety_080_tv.tv2_in1k](https://huggingface.co/timm/regnety_080_tv.tv2_in1k)|224 |82.592|96.246|39.38 |8.51 |19.73 |
|[regnetx_160.tv2_in1k](https://huggingface.co/timm/regnetx_160.tv2_in1k)|224 |82.564|96.052|54.28 |15.99|25.52 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|320 |82.51 |96.358|13.46 |3.92 |25.88 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|224 |82.44 |96.198|20.64 |4.0 |12.29 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|224 |82.304|96.078|20.65 |4.0 |12.29 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|256 |82.16 |96.048|13.46 |2.51 |16.57 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|256 |81.936|96.15 |13.49 |2.48 |16.57 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|224 |81.924|95.988|19.44 |3.2 |11.26 |
|[regnety_032.tv2_in1k](https://huggingface.co/timm/regnety_032.tv2_in1k)|224 |81.77 |95.842|19.44 |3.2 |11.26 |
|[regnetx_080.tv2_in1k](https://huggingface.co/timm/regnetx_080.tv2_in1k)|224 |81.552|95.544|39.57 |8.02 |14.06 |
|[regnetx_032.tv2_in1k](https://huggingface.co/timm/regnetx_032.tv2_in1k)|224 |80.924|95.27 |15.3 |3.2 |11.37 |
|[regnety_320.pycls_in1k](https://huggingface.co/timm/regnety_320.pycls_in1k)|224 |80.804|95.246|145.05 |32.34|30.26 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|288 |80.712|95.47 |9.72 |2.39 |16.43 |
|[regnety_016.tv2_in1k](https://huggingface.co/timm/regnety_016.tv2_in1k)|224 |80.66 |95.334|11.2 |1.63 |8.04 |
|[regnety_120.pycls_in1k](https://huggingface.co/timm/regnety_120.pycls_in1k)|224 |80.37 |95.12 |51.82 |12.14|21.38 |
|[regnety_160.pycls_in1k](https://huggingface.co/timm/regnety_160.pycls_in1k)|224 |80.288|94.964|83.59 |15.96|23.04 |
|[regnetx_320.pycls_in1k](https://huggingface.co/timm/regnetx_320.pycls_in1k)|224 |80.246|95.01 |107.81 |31.81|36.3 |
|[regnety_080.pycls_in1k](https://huggingface.co/timm/regnety_080.pycls_in1k)|224 |79.882|94.834|39.18 |8.0 |17.97 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|224 |79.872|94.974|9.72 |1.45 |9.95 |
|[regnetx_160.pycls_in1k](https://huggingface.co/timm/regnetx_160.pycls_in1k)|224 |79.862|94.828|54.28 |15.99|25.52 |
|[regnety_064.pycls_in1k](https://huggingface.co/timm/regnety_064.pycls_in1k)|224 |79.716|94.772|30.58 |6.39 |16.41 |
|[regnetx_120.pycls_in1k](https://huggingface.co/timm/regnetx_120.pycls_in1k)|224 |79.592|94.738|46.11 |12.13|21.37 |
|[regnetx_016.tv2_in1k](https://huggingface.co/timm/regnetx_016.tv2_in1k)|224 |79.44 |94.772|9.19 |1.62 |7.93 |
|[regnety_040.pycls_in1k](https://huggingface.co/timm/regnety_040.pycls_in1k)|224 |79.23 |94.654|20.65 |4.0 |12.29 |
|[regnetx_080.pycls_in1k](https://huggingface.co/timm/regnetx_080.pycls_in1k)|224 |79.198|94.55 |39.57 |8.02 |14.06 |
|[regnetx_064.pycls_in1k](https://huggingface.co/timm/regnetx_064.pycls_in1k)|224 |79.064|94.454|26.21 |6.49 |16.37 |
|[regnety_032.pycls_in1k](https://huggingface.co/timm/regnety_032.pycls_in1k)|224 |78.884|94.412|19.44 |3.2 |11.26 |
|[regnety_008_tv.tv2_in1k](https://huggingface.co/timm/regnety_008_tv.tv2_in1k)|224 |78.654|94.388|6.43 |0.84 |5.42 |
|[regnetx_040.pycls_in1k](https://huggingface.co/timm/regnetx_040.pycls_in1k)|224 |78.482|94.24 |22.12 |3.99 |12.2 |
|[regnetx_032.pycls_in1k](https://huggingface.co/timm/regnetx_032.pycls_in1k)|224 |78.178|94.08 |15.3 |3.2 |11.37 |
|[regnety_016.pycls_in1k](https://huggingface.co/timm/regnety_016.pycls_in1k)|224 |77.862|93.73 |11.2 |1.63 |8.04 |
|[regnetx_008.tv2_in1k](https://huggingface.co/timm/regnetx_008.tv2_in1k)|224 |77.302|93.672|7.26 |0.81 |5.15 |
|[regnetx_016.pycls_in1k](https://huggingface.co/timm/regnetx_016.pycls_in1k)|224 |76.908|93.418|9.19 |1.62 |7.93 |
|[regnety_008.pycls_in1k](https://huggingface.co/timm/regnety_008.pycls_in1k)|224 |76.296|93.05 |6.26 |0.81 |5.25 |
|[regnety_004.tv2_in1k](https://huggingface.co/timm/regnety_004.tv2_in1k)|224 |75.592|92.712|4.34 |0.41 |3.89 |
|[regnety_006.pycls_in1k](https://huggingface.co/timm/regnety_006.pycls_in1k)|224 |75.244|92.518|6.06 |0.61 |4.33 |
|[regnetx_008.pycls_in1k](https://huggingface.co/timm/regnetx_008.pycls_in1k)|224 |75.042|92.342|7.26 |0.81 |5.15 |
|[regnetx_004_tv.tv2_in1k](https://huggingface.co/timm/regnetx_004_tv.tv2_in1k)|224 |74.57 |92.184|5.5 |0.42 |3.17 |
|[regnety_004.pycls_in1k](https://huggingface.co/timm/regnety_004.pycls_in1k)|224 |74.018|91.764|4.34 |0.41 |3.89 |
|[regnetx_006.pycls_in1k](https://huggingface.co/timm/regnetx_006.pycls_in1k)|224 |73.862|91.67 |6.2 |0.61 |3.98 |
|[regnetx_004.pycls_in1k](https://huggingface.co/timm/regnetx_004.pycls_in1k)|224 |72.38 |90.832|5.16 |0.4 |3.14 |
|[regnety_002.pycls_in1k](https://huggingface.co/timm/regnety_002.pycls_in1k)|224 |70.282|89.534|3.16 |0.2 |2.17 |
|[regnetx_002.pycls_in1k](https://huggingface.co/timm/regnetx_002.pycls_in1k)|224 |68.752|88.556|2.68 |0.2 |2.16 |
## Citation
```bibtex
@InProceedings{Dollar2021,
title = {Fast and Accurate Model Scaling},
author = {Piotr Doll{'a}r and Mannat Singh and Ross Girshick},
booktitle = {CVPR},
year = {2021}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
enzostvs/hair-color | enzostvs | 2023-11-17T23:40:50Z | 655 | 4 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"onnx",
"safetensors",
"vit",
"image-classification",
"huggingpics",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | image-classification | 2023-10-18T17:04:28Z | ---
tags:
- image-classification
- pytorch
- huggingpics
metrics:
- accuracy
model-index:
- name: hair-color
results:
- task:
name: Image Classification
type: image-classification
metrics:
- name: Accuracy
type: accuracy
value: 0.7321428656578064
---
# hair-color
Autogenerated by HuggingPics🤗🖼️
Create your own image classifier for **anything** by running [the demo on Google Colab](https://colab.research.google.com/github/nateraw/huggingpics/blob/main/HuggingPics.ipynb).
Report any issues with the demo at the [github repo](https://github.com/nateraw/huggingpics).
## Example Images
#### black hair

#### blond hair

#### completely bald

#### red hair

#### white hair
 |
TheBloke/Mixtral-SlimOrca-8x7B-GGUF | TheBloke | 2023-12-14T14:31:12Z | 655 | 24 | transformers | [
"transformers",
"gguf",
"mixtral",
"text-generation",
"dataset:Open-Orca/SlimOrca",
"base_model:Open-Orca/Mixtral-SlimOrca-8x7B",
"license:apache-2.0",
"text-generation-inference",
"region:us"
] | text-generation | 2023-12-13T16:16:36Z | ---
base_model: Open-Orca/Mixtral-SlimOrca-8x7B
datasets:
- Open-Orca/SlimOrca
inference: false
license: apache-2.0
model_creator: OpenOrca
model_name: Mixtral SlimOrca 8X7B
model_type: mixtral
pipeline_tag: text-generation
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Mixtral SlimOrca 8X7B - GGUF
- Model creator: [OpenOrca](https://huggingface.co/Open-Orca)
- Original model: [Mixtral SlimOrca 8X7B](https://huggingface.co/Open-Orca/Mixtral-SlimOrca-8x7B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [OpenOrca's Mixtral SlimOrca 8X7B](https://huggingface.co/Open-Orca/Mixtral-SlimOrca-8x7B).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
### Mixtral GGUF
Support for Mixtral was merged into Llama.cpp on December 13th.
These Mixtral GGUFs are known to work in:
* llama.cpp as of December 13th
* KoboldCpp 1.52 as later
* LM Studio 0.2.9 and later
* llama-cpp-python 0.2.23 and later
Other clients/libraries, not listed above, may not yet work.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GGUF)
* [OpenOrca's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/Open-Orca/Mixtral-SlimOrca-8x7B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These Mixtral GGUFs are compatible with llama.cpp from December 13th onwards. Other clients/libraries may not work yet.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [mixtral-slimorca-8x7b.Q2_K.gguf](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GGUF/blob/main/mixtral-slimorca-8x7b.Q2_K.gguf) | Q2_K | 2 | 15.64 GB| 18.14 GB | smallest, significant quality loss - not recommended for most purposes |
| [mixtral-slimorca-8x7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GGUF/blob/main/mixtral-slimorca-8x7b.Q3_K_M.gguf) | Q3_K_M | 3 | 20.36 GB| 22.86 GB | very small, high quality loss |
| [mixtral-slimorca-8x7b.Q4_0.gguf](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GGUF/blob/main/mixtral-slimorca-8x7b.Q4_0.gguf) | Q4_0 | 4 | 26.44 GB| 28.94 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [mixtral-slimorca-8x7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GGUF/blob/main/mixtral-slimorca-8x7b.Q4_K_M.gguf) | Q4_K_M | 4 | 26.44 GB| 28.94 GB | medium, balanced quality - recommended |
| [mixtral-slimorca-8x7b.Q5_0.gguf](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GGUF/blob/main/mixtral-slimorca-8x7b.Q5_0.gguf) | Q5_0 | 5 | 32.23 GB| 34.73 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [mixtral-slimorca-8x7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GGUF/blob/main/mixtral-slimorca-8x7b.Q5_K_M.gguf) | Q5_K_M | 5 | 32.23 GB| 34.73 GB | large, very low quality loss - recommended |
| [mixtral-slimorca-8x7b.Q6_K.gguf](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GGUF/blob/main/mixtral-slimorca-8x7b.Q6_K.gguf) | Q6_K | 6 | 38.38 GB| 40.88 GB | very large, extremely low quality loss |
| [mixtral-slimorca-8x7b.Q8_0.gguf](https://huggingface.co/TheBloke/Mixtral-SlimOrca-8x7B-GGUF/blob/main/mixtral-slimorca-8x7b.Q8_0.gguf) | Q8_0 | 8 | 49.62 GB| 52.12 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Mixtral-SlimOrca-8x7B-GGUF and below it, a specific filename to download, such as: mixtral-slimorca-8x7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Mixtral-SlimOrca-8x7B-GGUF mixtral-slimorca-8x7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Mixtral-SlimOrca-8x7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Mixtral-SlimOrca-8x7B-GGUF mixtral-slimorca-8x7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m mixtral-slimorca-8x7b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Note that text-generation-webui may not yet be compatible with Mixtral GGUFs. Please check compatibility first.
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) version 0.2.23 and later.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./mixtral-slimorca-8x7b.Q4_K_M.gguf", # Download the model file first
n_ctx=2048, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./mixtral-slimorca-8x7b.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Michael Levine, 阿明, Trailburnt, Nikolai Manek, John Detwiler, Randy H, Will Dee, Sebastain Graf, NimbleBox.ai, Eugene Pentland, Emad Mostaque, Ai Maven, Jim Angel, Jeff Scroggin, Michael Davis, Manuel Alberto Morcote, Stephen Murray, Robert, Justin Joy, Luke @flexchar, Brandon Frisco, Elijah Stavena, S_X, Dan Guido, Undi ., Komninos Chatzipapas, Shadi, theTransient, Lone Striker, Raven Klaugh, jjj, Cap'n Zoog, Michel-Marie MAUDET (LINAGORA), Matthew Berman, David, Fen Risland, Omer Bin Jawed, Luke Pendergrass, Kalila, OG, Erik Bjäreholt, Rooh Singh, Joseph William Delisle, Dan Lewis, TL, John Villwock, AzureBlack, Brad, Pedro Madruga, Caitlyn Gatomon, K, jinyuan sun, Mano Prime, Alex, Jeffrey Morgan, Alicia Loh, Illia Dulskyi, Chadd, transmissions 11, fincy, Rainer Wilmers, ReadyPlayerEmma, knownsqashed, Mandus, biorpg, Deo Leter, Brandon Phillips, SuperWojo, Sean Connelly, Iucharbius, Jack West, Harry Royden McLaughlin, Nicholas, terasurfer, Vitor Caleffi, Duane Dunston, Johann-Peter Hartmann, David Ziegler, Olakabola, Ken Nordquist, Trenton Dambrowitz, Tom X Nguyen, Vadim, Ajan Kanaga, Leonard Tan, Clay Pascal, Alexandros Triantafyllidis, JM33133, Xule, vamX, ya boyyy, subjectnull, Talal Aujan, Alps Aficionado, wassieverse, Ari Malik, James Bentley, Woland, Spencer Kim, Michael Dempsey, Fred von Graf, Elle, zynix, William Richards, Stanislav Ovsiannikov, Edmond Seymore, Jonathan Leane, Martin Kemka, usrbinkat, Enrico Ros
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: OpenOrca's Mixtral SlimOrca 8X7B
# SlimOrca Mixtral 8x7B
[<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="200" height="32"/>](https://github.com/OpenAccess-AI-Collective/axolotl)

Official release of the SlimOrca Mixtral finetune. More details to come.
## Model Details
### Model Description
- **Developed by:** OpenAccess AI Collective and OpenOrca
- **Finetuned from model [optional]:** mistralai/Mixtral-8x7B-v0.1
<!-- original-model-card end -->
|
sam749/AWPainting-v1-2 | sam749 | 2024-04-01T18:01:08Z | 655 | 3 | diffusers | [
"diffusers",
"safetensors",
"Safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:creativeml-openrail-m",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
] | text-to-image | 2024-04-01T17:39:57Z | ---
license: creativeml-openrail-m
library_name: diffusers
tags:
- Safetensors
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
pipeline_tag: text-to-image
---
# AWPainting
## v1.2

### Description:
>
### Creator: DynamicWang
### Civitai Page: https://civitai.com/models/84476
You can use this with the [🧨Diffusers library](https://github.com/huggingface/diffusers)
### Diffusers
```py
from diffusers import StableDiffusionPipeline
import torch
model_id = "sam749/AWPainting-v1-2"
pipe = StableDiffusionPipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe = pipe.to("cuda")
prompt = "masterpiece, best quality, 1girl, (colorful),(delicate eyes and face), volumatic light, ray tracing, bust shot ,extremely detailed CG unity 8k wallpaper,solo,smile"
image = pipe(prompt).images[0]
image.save("result.png")
```
|
RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf | RichardErkhov | 2024-05-11T00:17:18Z | 655 | 0 | null | [
"gguf",
"arxiv:2310.04799",
"region:us"
] | null | 2024-05-10T21:41:58Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-Open-Ko-8B - GGUF
- Model creator: https://huggingface.co/beomi/
- Original model: https://huggingface.co/beomi/Llama-3-Open-Ko-8B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-Open-Ko-8B.Q2_K.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q2_K.gguf) | Q2_K | 2.96GB |
| [Llama-3-Open-Ko-8B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Llama-3-Open-Ko-8B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Llama-3-Open-Ko-8B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Llama-3-Open-Ko-8B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Llama-3-Open-Ko-8B.Q3_K.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q3_K.gguf) | Q3_K | 3.74GB |
| [Llama-3-Open-Ko-8B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Llama-3-Open-Ko-8B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Llama-3-Open-Ko-8B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Llama-3-Open-Ko-8B.Q4_0.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Llama-3-Open-Ko-8B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Llama-3-Open-Ko-8B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Llama-3-Open-Ko-8B.Q4_K.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q4_K.gguf) | Q4_K | 4.58GB |
| [Llama-3-Open-Ko-8B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Llama-3-Open-Ko-8B.Q4_1.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Llama-3-Open-Ko-8B.Q5_0.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Llama-3-Open-Ko-8B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Llama-3-Open-Ko-8B.Q5_K.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q5_K.gguf) | Q5_K | 5.34GB |
| [Llama-3-Open-Ko-8B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Llama-3-Open-Ko-8B.Q5_1.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Llama-3-Open-Ko-8B.Q6_K.gguf](https://huggingface.co/RichardErkhov/beomi_-_Llama-3-Open-Ko-8B-gguf/blob/main/Llama-3-Open-Ko-8B.Q6_K.gguf) | Q6_K | 6.14GB |
Original model description:
---
language:
- en
- ko
license: other
tags:
- facebook
- meta
- pytorch
- llama
- llama-3
- llama-3-ko
pipeline_tag: text-generation
license_name: llama3
license_link: LICENSE
---
> Update @ 2024.05.01: Pre-Release [Llama-3-KoEn-8B](https://huggingface.co/beomi/Llama-3-KoEn-8B-preview) model & [Llama-3-KoEn-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-KoEn-8B-Instruct-preview)
> Update @ 2024.04.24: Release Llama-3-Open-Ko-8B model & [Llama-3-Open-Ko-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-Open-Ko-8B-Instruct-preview)
## Model Details
**Llama-3-Open-Ko-8B**
Llama-3-Open-Ko-8B model is continued pretrained language model based on Llama-3-8B.
This model is trained fully with publicily available resource, with 60GB+ of deduplicated texts.
With the new Llama-3 tokenizer, the pretraining conducted with 17.7B+ tokens, which slightly more than Korean tokenizer(Llama-2-Ko tokenizer).
The train was done on TPUv5e-256, with the warm support from TRC program by Google.
**Note for [Llama-3-Open-Ko-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-Open-Ko-8B-Instruct-preview)**
With applying the idea from [Chat Vector paper](https://arxiv.org/abs/2310.04799), I released Instruction model named [Llama-3-Open-Ko-8B-Instruct-preview](https://huggingface.co/beomi/Llama-3-Open-Ko-8B-Instruct-preview).
Since it is NOT finetuned with any Korean instruction set(indeed `preview`), but it would be great starting point for creating new Chat/Instruct models.
**Meta Llama-3**
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Junbum Lee (Beomi)
**Variations** Llama-3-Open-Ko comes in one size — 8B.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama-3-Open-Ko
</td>
<td rowspan="2" >Same as *Open-Solar-Ko Dataset
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >17.7B+
</td>
<td>Jun, 2023
</td>
</tr>
</table>
*You can find dataset list here: https://huggingface.co/beomi/OPEN-SOLAR-KO-10.7B/tree/main/corpus
**Model Release Date** 2024.04.24.
**Status** This is a static model trained on an offline dataset.
**License** Llama3 License: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
TBD
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
**Llama-3-Open-Ko**
```
@article{llama3openko,
title={Llama-3-Open-Ko},
author={L, Junbum},
year={2024},
url={https://huggingface.co/beomi/Llama-3-Open-Ko-8B}
}
```
**Original Llama-3**
```
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
```
|
bartowski/Llama-3-Hercules-5.1-8B-GGUF | bartowski | 2024-05-27T04:36:30Z | 655 | 3 | transformers | [
"transformers",
"gguf",
"text-generation",
"dataset:Locutusque/hercules-v5.0",
"license:llama3",
"endpoints_compatible",
"region:us"
] | text-generation | 2024-05-27T04:13:00Z | ---
license: llama3
library_name: transformers
datasets:
- Locutusque/hercules-v5.0
quantized_by: bartowski
pipeline_tag: text-generation
---
## Llamacpp imatrix Quantizations of Llama-3-Hercules-5.1-8B
Using <a href="https://github.com/ggerganov/llama.cpp/">llama.cpp</a> release <a href="https://github.com/ggerganov/llama.cpp/releases/tag/b3001">b3001</a> for quantization.
Original model: https://huggingface.co/Locutusque/Llama-3-Hercules-5.0-8B
All quants made using imatrix option with dataset from [here](https://gist.github.com/bartowski1182/b6ac44691e994344625687afe3263b3a)
## Prompt format
No chat template specified so default is used. This may be incorrect, check original model card for details.
```
<|im_start|>system
{system_prompt}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
## Download a file (not the whole branch) from below:
| Filename | Quant type | File Size | Description |
| -------- | ---------- | --------- | ----------- |
| [Llama-3-Hercules-5.1-8B-Q8_0.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q8_0.gguf) | Q8_0 | 8.54GB | Extremely high quality, generally unneeded but max available quant. |
| [Llama-3-Hercules-5.1-8B-Q6_K.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q6_K.gguf) | Q6_K | 6.59GB | Very high quality, near perfect, *recommended*. |
| [Llama-3-Hercules-5.1-8B-Q5_K_M.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q5_K_M.gguf) | Q5_K_M | 5.73GB | High quality, *recommended*. |
| [Llama-3-Hercules-5.1-8B-Q5_K_S.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q5_K_S.gguf) | Q5_K_S | 5.59GB | High quality, *recommended*. |
| [Llama-3-Hercules-5.1-8B-Q4_K_M.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q4_K_M.gguf) | Q4_K_M | 4.92GB | Good quality, uses about 4.83 bits per weight, *recommended*. |
| [Llama-3-Hercules-5.1-8B-Q4_K_S.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q4_K_S.gguf) | Q4_K_S | 4.69GB | Slightly lower quality with more space savings, *recommended*. |
| [Llama-3-Hercules-5.1-8B-IQ4_NL.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ4_NL.gguf) | IQ4_NL | 4.67GB | Decent quality, slightly smaller than Q4_K_S with similar performance *recommended*. |
| [Llama-3-Hercules-5.1-8B-IQ4_XS.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ4_XS.gguf) | IQ4_XS | 4.44GB | Decent quality, smaller than Q4_K_S with similar performance, *recommended*. |
| [Llama-3-Hercules-5.1-8B-Q3_K_L.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q3_K_L.gguf) | Q3_K_L | 4.32GB | Lower quality but usable, good for low RAM availability. |
| [Llama-3-Hercules-5.1-8B-Q3_K_M.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q3_K_M.gguf) | Q3_K_M | 4.01GB | Even lower quality. |
| [Llama-3-Hercules-5.1-8B-IQ3_M.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ3_M.gguf) | IQ3_M | 3.78GB | Medium-low quality, new method with decent performance comparable to Q3_K_M. |
| [Llama-3-Hercules-5.1-8B-IQ3_S.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ3_S.gguf) | IQ3_S | 3.68GB | Lower quality, new method with decent performance, recommended over Q3_K_S quant, same size with better performance. |
| [Llama-3-Hercules-5.1-8B-Q3_K_S.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q3_K_S.gguf) | Q3_K_S | 3.66GB | Low quality, not recommended. |
| [Llama-3-Hercules-5.1-8B-IQ3_XS.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ3_XS.gguf) | IQ3_XS | 3.51GB | Lower quality, new method with decent performance, slightly better than Q3_K_S. |
| [Llama-3-Hercules-5.1-8B-IQ3_XXS.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ3_XXS.gguf) | IQ3_XXS | 3.27GB | Lower quality, new method with decent performance, comparable to Q3 quants. |
| [Llama-3-Hercules-5.1-8B-Q2_K.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-Q2_K.gguf) | Q2_K | 3.17GB | Very low quality but surprisingly usable. |
| [Llama-3-Hercules-5.1-8B-IQ2_M.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ2_M.gguf) | IQ2_M | 2.94GB | Very low quality, uses SOTA techniques to also be surprisingly usable. |
| [Llama-3-Hercules-5.1-8B-IQ2_S.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ2_S.gguf) | IQ2_S | 2.75GB | Very low quality, uses SOTA techniques to be usable. |
| [Llama-3-Hercules-5.1-8B-IQ2_XS.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ2_XS.gguf) | IQ2_XS | 2.60GB | Very low quality, uses SOTA techniques to be usable. |
| [Llama-3-Hercules-5.1-8B-IQ2_XXS.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ2_XXS.gguf) | IQ2_XXS | 2.39GB | Lower quality, uses SOTA techniques to be usable. |
| [Llama-3-Hercules-5.1-8B-IQ1_M.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ1_M.gguf) | IQ1_M | 2.16GB | Extremely low quality, *not* recommended. |
| [Llama-3-Hercules-5.1-8B-IQ1_S.gguf](https://huggingface.co/bartowski/Llama-3-Hercules-5.1-8B-GGUF/blob/main/Llama-3-Hercules-5.1-8B-IQ1_S.gguf) | IQ1_S | 2.01GB | Extremely low quality, *not* recommended. |
## Downloading using huggingface-cli
First, make sure you have hugginface-cli installed:
```
pip install -U "huggingface_hub[cli]"
```
Then, you can target the specific file you want:
```
huggingface-cli download bartowski/Llama-3-Hercules-5.1-8B-GGUF --include "Llama-3-Hercules-5.1-8B-Q4_K_M.gguf" --local-dir ./
```
If the model is bigger than 50GB, it will have been split into multiple files. In order to download them all to a local folder, run:
```
huggingface-cli download bartowski/Llama-3-Hercules-5.1-8B-GGUF --include "Llama-3-Hercules-5.1-8B-Q8_0.gguf/*" --local-dir Llama-3-Hercules-5.1-8B-Q8_0
```
You can either specify a new local-dir (Llama-3-Hercules-5.1-8B-Q8_0) or download them all in place (./)
## Which file should I choose?
A great write up with charts showing various performances is provided by Artefact2 [here](https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9)
The first thing to figure out is how big a model you can run. To do this, you'll need to figure out how much RAM and/or VRAM you have.
If you want your model running as FAST as possible, you'll want to fit the whole thing on your GPU's VRAM. Aim for a quant with a file size 1-2GB smaller than your GPU's total VRAM.
If you want the absolute maximum quality, add both your system RAM and your GPU's VRAM together, then similarly grab a quant with a file size 1-2GB Smaller than that total.
Next, you'll need to decide if you want to use an 'I-quant' or a 'K-quant'.
If you don't want to think too much, grab one of the K-quants. These are in format 'QX_K_X', like Q5_K_M.
If you want to get more into the weeds, you can check out this extremely useful feature chart:
[llama.cpp feature matrix](https://github.com/ggerganov/llama.cpp/wiki/Feature-matrix)
But basically, if you're aiming for below Q4, and you're running cuBLAS (Nvidia) or rocBLAS (AMD), you should look towards the I-quants. These are in format IQX_X, like IQ3_M. These are newer and offer better performance for their size.
These I-quants can also be used on CPU and Apple Metal, but will be slower than their K-quant equivalent, so speed vs performance is a tradeoff you'll have to decide.
The I-quants are *not* compatible with Vulcan, which is also AMD, so if you have an AMD card double check if you're using the rocBLAS build or the Vulcan build. At the time of writing this, LM Studio has a preview with ROCm support, and other inference engines have specific builds for ROCm.
Want to support my work? Visit my ko-fi page here: https://ko-fi.com/bartowski
|
dbmdz/electra-large-discriminator-finetuned-conll03-english | dbmdz | 2023-09-06T22:20:07Z | 654 | 19 | transformers | [
"transformers",
"pytorch",
"safetensors",
"electra",
"token-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z | Entry not found |
yahya1994/DialoGPT-small-Gintama-Gintoki | yahya1994 | 2021-09-03T17:17:22Z | 654 | 0 | transformers | [
"transformers",
"pytorch",
"gpt2",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-03-02T23:29:05Z | ---
tags:
- conversational
---
# Gintoki dialog |
allenai/aspire-sentence-embedder | allenai | 2022-10-03T21:21:18Z | 654 | 2 | transformers | [
"transformers",
"pytorch",
"bert",
"feature-extraction",
"arxiv:2111.08366",
"endpoints_compatible",
"text-embeddings-inference",
"region:us"
] | feature-extraction | 2022-03-08T19:36:18Z | ---
language: en
license: apache-2.0
---
## Overview
Model included in a paper for modeling fine grained similarity between documents:
**Title**: "Multi-Vector Models with Textual Guidance for Fine-Grained Scientific Document Similarity"
**Authors**: Sheshera Mysore, Arman Cohan, Tom Hope
**Paper**: https://arxiv.org/abs/2111.08366
**Github**: https://github.com/allenai/aspire
**Note**: In the context of the paper, this model is referred to as `cosentbert` and represents a baseline sentence encoder for scientific text. The paper trains two versions of `cosentbert`, one for biomedical scientific text and another one for computer science text. This released model is trained on a union of all available data across scientific domains in the Semantic Scholar Open Research Corpus (S2ORC) dataset. This difference in training data leads to different, though close, evaluation performance than in the paper.
## Model Card
**Model description:** This model represents a SciBERT based sentence encoder pre-trained for scientific text similarity. The model represents a sentence with a single vector obtained by reading the CLS token for the sentence.
**Training data:** The model is trained on sets of co-citation context sentences referencing the same set of papers in a contrastive learning setup. These sentences can often be considered as paraphrases since co-citation sentences citing the same papers often describe similar aspects of the co-cited papers. The model is trained on 4.3 million sentence pairs of this type. In training the model negative examples for the contrastive loss are obtained as random in-batch negatives. An example pair of sentences used for training is as follows:
> "The idea of distant supervision has been proposed and used widely in Relation Extraction (Mintz et al., 2009; Riedel et al., 2010; Hoffmann et al., 2011; Surdeanu et al., 2012) , where the source of labels is an external knowledge base."
>
> "Distant supervision [31, 43, 21, 49] generates training data automatically by aligning texts and a knowledge base (KB) (see Fig. 1 )."
**Training procedure:** The model was trained with the Adam Optimizer and a learning rate of 2e-5 with 1000 warm-up steps followed by linear decay of the learning rate. The model training convergence is checked with the loss on a held out dev set consisting of co-citation context pairs. All the training data used was in English.
**Intended uses & limitations:** This model is trained for sentence similarity tasks in scientific text and is best used as a sentence encoder. However with appropriate fine-tuning the model can also be used for other tasks such as classification. Note that about 50% of the training data consists of text from biomedical text and performance may be superior on text from bio-medicine and similar domains.
**How to use:** This model can be used as a BERT model via the `transformers` library:
```
from transformers import AutoModel, AutoTokenizer
aspire_sent = AutoModel.from_pretrained('allenai/aspire-sentence-embedder')
aspire_tok = AutoTokenizer.from_pretrained('allenai/aspire-sentence-embedder')
s='We present a new scientific document similarity model based on matching fine-grained aspects of texts.'
inputs = aspire_tok(s, padding=True, truncation=True, return_tensors="pt", max_length=512)
result = aspire_sent(\*\*inputs)
clsrep = result.last_hidden_state[:,0,:]
```
OR via the `sentence_transformers` library:
```
from sentence_transformers import SentenceTransformer, models
word_embedding_model = models.Transformer('allenai/aspire-sentence-embedder', max_seq_length=512)
pooling_model = models.Pooling(word_embedding_model.get_word_embedding_dimension(), pooling_mode='cls')
aspire_sb = SentenceTransformer(modules=[word_embedding_model, pooling_model])
clsrep_sb = sentbert_model.encode([s])
```
**Variable and metrics:**
Since the paper this model was trained for proposes methods for similarity of scientific abstracts, this model is evaluated on information retrieval datasets with document level queries. The datasets used for the paper include RELISH (biomedical/English), TRECCOVID (biomedical/English), and CSFCube (computer science/English). These are all detailed on [github](https://github.com/allenai/aspire) and in our [paper](https://arxiv.org/abs/2111.08366). RELISH and TRECCOVID represent a abstract level retrieval task, where given a query scientific abstract the task requires the retrieval of relevant candidate abstracts. CSFCube presents a slightly different task and presents a set of finer-grained sentences in the abstract based on which a finer-grained retrieval must be made. This task represents the closest task to a sentence similarity task.
In using this sentence level model for abstract level retrieval we rank documents by the minimal L2 distance between the sentences in the query and candidate abstract.
**Evaluation results:**
The released model `aspire-sentence-embedder` is compared against 1) `all-mpnet-base-v2` a sentence-bert model trained on ~1 billion training examples, 2) `paraphrase-TinyBERT-L6-v2` a sentence-bert model trained on paraphrase pairs, and 3) the `cosentbert` models used in our paper.
| | CSFCube aggregated | CSFCube aggregated | TRECCOVID | TRECCOVID | RELISH | RELISH |
|-------------------------------------------:|:------------------:|:-------:|:---------:|:-------:|:------:|:-------:|
| | MAP | NDCG%20 | MAP | NDCG%20 | MAP | NDCG%20 |
| `all-mpnet-base-v2` | 34.64 | 54.94 | 17.35 | 43.87 | 52.92 | 69.69 |
| `paraphrase-TinyBERT-L6-v2` | 26.77 | 48.57 | 11.12 | 34.85 | 50.80 | 67.35 |
| `cosentbert` | 28.95 | 50.68 | 12.80 | 38.07 | 50.04 | 66.35 |
| `aspire-sentence-embedder` | 30.58 | 53.86 | 11.64 | 36.50 | 50.36 | 66.63 |
The released model sees similar performance across datasets to the per-domain `cosentbert` models used in our paper (and reported above). |
Norod78/gpt-fluentui-flat-svg | Norod78 | 2023-03-19T09:28:25Z | 654 | 15 | transformers | [
"transformers",
"pytorch",
"safetensors",
"gpt2",
"text-generation",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"8-bit",
"region:us"
] | text-generation | 2023-01-17T14:23:31Z | ---
thumbnail: https://huggingface.co/Norod78/gpt-fluentui-flat-svg/raw/main/train/sample16.svg
license: mit
library_name: transformers
pipeline_tag: text-generation
widget:
- text: <svg
---
# gpt-fluentui-flat-svg
A custom GPT model which was trained upon svg files.
Specifically the flat emoji variants from [Microsoft's FluentUI repo](https://github.com/microsoft/fluentui-emoji).
These svn files only consist of "stand-alone" path elements which should make it simpler to train upon and sample from.
# training and dataset
Both Tokenizer and Model were trained using [aitextgen](https://docs.aitextgen.io/)
The python file which was used for training, the .txt file dataset and a few generated samples can be found [here](https://huggingface.co/Norod78/gpt-fluentui-flat-svg/tree/main/train)
# post processing and extracting .svg files from generated samples
```
# Extract from generated output and into a seperate .svg file all sequences which starts with <svg and ends with:
# A. </svg>
# B. If the sequence does not end with </svg> then find the last > in the sequence and append </svg> to it
```
# generated samples
The generated samples below were also created with [this script](https://huggingface.co/Norod78/gpt-fluentui-flat-svg/blob/main/train/atg_train.py)



|
Buseak/canine_2303 | Buseak | 2023-03-23T19:16:00Z | 654 | 0 | transformers | [
"transformers",
"pytorch",
"tensorboard",
"canine",
"token-classification",
"generated_from_trainer",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2023-03-23T18:36:40Z | ---
license: apache-2.0
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: canine_2303
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# canine_2303
This model is a fine-tuned version of [google/canine-s](https://huggingface.co/google/canine-s) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.0001
- Precision: 0.9987
- Recall: 0.9982
- F1: 0.9985
- Accuracy: 0.9999
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 20
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 244 | 0.0025 | 0.9819 | 0.9924 | 0.9871 | 0.9993 |
| No log | 2.0 | 488 | 0.0018 | 0.9855 | 0.9925 | 0.9890 | 0.9995 |
| 0.0382 | 3.0 | 732 | 0.0014 | 0.9923 | 0.9891 | 0.9907 | 0.9996 |
| 0.0382 | 4.0 | 976 | 0.0009 | 0.9930 | 0.9931 | 0.9931 | 0.9997 |
| 0.0017 | 5.0 | 1220 | 0.0009 | 0.9922 | 0.9949 | 0.9936 | 0.9997 |
| 0.0017 | 6.0 | 1464 | 0.0007 | 0.9940 | 0.9952 | 0.9946 | 0.9998 |
| 0.0012 | 7.0 | 1708 | 0.0005 | 0.9947 | 0.9952 | 0.9949 | 0.9998 |
| 0.0012 | 8.0 | 1952 | 0.0005 | 0.9947 | 0.9955 | 0.9951 | 0.9998 |
| 0.0009 | 9.0 | 2196 | 0.0003 | 0.9959 | 0.9960 | 0.9959 | 0.9998 |
| 0.0009 | 10.0 | 2440 | 0.0003 | 0.9958 | 0.9963 | 0.9961 | 0.9998 |
| 0.0007 | 11.0 | 2684 | 0.0003 | 0.9971 | 0.9958 | 0.9965 | 0.9999 |
| 0.0007 | 12.0 | 2928 | 0.0003 | 0.9971 | 0.9962 | 0.9967 | 0.9999 |
| 0.0005 | 13.0 | 3172 | 0.0002 | 0.9974 | 0.9967 | 0.9971 | 0.9999 |
| 0.0005 | 14.0 | 3416 | 0.0002 | 0.9980 | 0.9972 | 0.9976 | 0.9999 |
| 0.0004 | 15.0 | 3660 | 0.0002 | 0.9982 | 0.9980 | 0.9981 | 0.9999 |
| 0.0004 | 16.0 | 3904 | 0.0002 | 0.9984 | 0.9974 | 0.9979 | 0.9999 |
| 0.0004 | 17.0 | 4148 | 0.0001 | 0.9984 | 0.9975 | 0.9979 | 0.9999 |
| 0.0004 | 18.0 | 4392 | 0.0001 | 0.9988 | 0.9982 | 0.9985 | 0.9999 |
| 0.0003 | 19.0 | 4636 | 0.0001 | 0.9987 | 0.9982 | 0.9985 | 0.9999 |
| 0.0003 | 20.0 | 4880 | 0.0001 | 0.9987 | 0.9982 | 0.9985 | 0.9999 |
### Framework versions
- Transformers 4.27.2
- Pytorch 1.13.1+cu116
- Datasets 2.10.1
- Tokenizers 0.13.2
|
marcsun13/opt-350m-gptq-4bit | marcsun13 | 2023-07-31T15:02:57Z | 654 | 0 | transformers | [
"transformers",
"pytorch",
"opt",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"gptq",
"region:us"
] | text-generation | 2023-07-31T15:02:41Z | Entry not found |
wesley7137/sci-bert-qa-db | wesley7137 | 2023-09-12T20:36:10Z | 654 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-09-12T20:20:39Z | Entry not found |
mradermacher/Mahou-1.3-yi-9B-i1-GGUF | mradermacher | 2024-05-30T20:47:36Z | 654 | 0 | transformers | [
"transformers",
"gguf",
"en",
"dataset:flammenai/MahouMix-v1",
"base_model:flammenai/Mahou-1.3-yi-9B",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
] | null | 2024-05-30T05:02:19Z | ---
base_model: flammenai/Mahou-1.3-yi-9B
datasets:
- flammenai/MahouMix-v1
language:
- en
library_name: transformers
license: apache-2.0
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/flammenai/Mahou-1.3-yi-9B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ1_S.gguf) | i1-IQ1_S | 2.1 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ1_M.gguf) | i1-IQ1_M | 2.3 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 2.6 | |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 2.8 | |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ2_S.gguf) | i1-IQ2_S | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ2_M.gguf) | i1-IQ2_M | 3.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q2_K.gguf) | i1-Q2_K | 3.5 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 3.6 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 4.0 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ3_S.gguf) | i1-IQ3_S | 4.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ3_M.gguf) | i1-IQ3_M | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 4.4 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 4.8 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 4.9 | |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q4_0.gguf) | i1-Q4_0 | 5.2 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 5.2 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 5.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 6.2 | |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 6.4 | |
| [GGUF](https://huggingface.co/mradermacher/Mahou-1.3-yi-9B-i1-GGUF/resolve/main/Mahou-1.3-yi-9B.i1-Q6_K.gguf) | i1-Q6_K | 7.3 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf | RichardErkhov | 2024-06-05T17:08:02Z | 654 | 0 | null | [
"gguf",
"region:us"
] | null | 2024-06-05T16:56:39Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
pythia-160m-hq-emails - GGUF
- Model creator: https://huggingface.co/postbot/
- Original model: https://huggingface.co/postbot/pythia-160m-hq-emails/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [pythia-160m-hq-emails.Q2_K.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q2_K.gguf) | Q2_K | 0.07GB |
| [pythia-160m-hq-emails.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.IQ3_XS.gguf) | IQ3_XS | 0.08GB |
| [pythia-160m-hq-emails.IQ3_S.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.IQ3_S.gguf) | IQ3_S | 0.08GB |
| [pythia-160m-hq-emails.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q3_K_S.gguf) | Q3_K_S | 0.08GB |
| [pythia-160m-hq-emails.IQ3_M.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.IQ3_M.gguf) | IQ3_M | 0.08GB |
| [pythia-160m-hq-emails.Q3_K.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q3_K.gguf) | Q3_K | 0.09GB |
| [pythia-160m-hq-emails.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q3_K_M.gguf) | Q3_K_M | 0.09GB |
| [pythia-160m-hq-emails.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q3_K_L.gguf) | Q3_K_L | 0.09GB |
| [pythia-160m-hq-emails.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.IQ4_XS.gguf) | IQ4_XS | 0.09GB |
| [pythia-160m-hq-emails.Q4_0.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q4_0.gguf) | Q4_0 | 0.1GB |
| [pythia-160m-hq-emails.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.IQ4_NL.gguf) | IQ4_NL | 0.1GB |
| [pythia-160m-hq-emails.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q4_K_S.gguf) | Q4_K_S | 0.1GB |
| [pythia-160m-hq-emails.Q4_K.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q4_K.gguf) | Q4_K | 0.1GB |
| [pythia-160m-hq-emails.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q4_K_M.gguf) | Q4_K_M | 0.1GB |
| [pythia-160m-hq-emails.Q4_1.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q4_1.gguf) | Q4_1 | 0.1GB |
| [pythia-160m-hq-emails.Q5_0.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q5_0.gguf) | Q5_0 | 0.11GB |
| [pythia-160m-hq-emails.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q5_K_S.gguf) | Q5_K_S | 0.11GB |
| [pythia-160m-hq-emails.Q5_K.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q5_K.gguf) | Q5_K | 0.12GB |
| [pythia-160m-hq-emails.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q5_K_M.gguf) | Q5_K_M | 0.12GB |
| [pythia-160m-hq-emails.Q5_1.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q5_1.gguf) | Q5_1 | 0.12GB |
| [pythia-160m-hq-emails.Q6_K.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q6_K.gguf) | Q6_K | 0.13GB |
| [pythia-160m-hq-emails.Q8_0.gguf](https://huggingface.co/RichardErkhov/postbot_-_pythia-160m-hq-emails-gguf/blob/main/pythia-160m-hq-emails.Q8_0.gguf) | Q8_0 | 0.16GB |
Original model description:
---
language:
- en
license: apache-2.0
tags:
- generated_from_trainer
datasets:
- postbot/multi-emails-hq
metrics:
- accuracy
widget:
- text: 'Good Morning Professor Beans,
Hope you are doing well. I just wanted to reach out and ask if differential calculus
will be on the exam'
example_title: email to prof
- text: 'Hey <NAME>,
Thank you for signing up for my weekly newsletter. Before we get started, you''ll
have to confirm your email address.'
example_title: newsletter
- text: 'Hi <NAME>,
I hope this email finds you well. I wanted to reach out and ask about office hours'
example_title: office hours
- text: 'Greetings <NAME>,
I hope you had a splendid evening at the Company sausage eating festival. I am
reaching out because'
example_title: festival
- text: 'Good Morning Harold,
I was wondering when the next'
example_title: event
- text: URGENT - I need the TPS reports
example_title: URGENT
- text: 'Hi Archibald,
I hope this email finds you extremely well.'
example_title: emails that find you
- text: 'Hello there.
I just wanted to reach out and check in to'
example_title: checking in
- text: 'Hello <NAME>,
I hope this email finds you well. I wanted to reach out and see if you''ve enjoyed
your time with us'
example_title: work well
- text: 'Hi <NAME>,
I hope this email finds you well. I wanted to reach out and see if we could catch
up'
example_title: catch up
- text: I'm <NAME> and I just moved into the area and wanted to reach out and get
some details on where I could get groceries and
example_title: grocery
inference:
parameters:
min_length: 16
max_length: 64
no_repeat_ngram_size: 4
do_sample: true
top_k: 40
top_p: 0.95
repetition_penalty: 3.5
pipeline_tag: text-generation
base_model: EleutherAI/pythia-160m-deduped
model-index:
- name: pythia-160m-hq-emails-v4
results:
- task:
type: text-generation
name: Causal Language Modeling
dataset:
name: postbot/multi-emails-hq
type: postbot/multi-emails-hq
metrics:
- type: accuracy
value: 0.611281497151223
name: Accuracy
---
# pythia-160m-hq-emails-v4
This model is a fine-tuned version of [EleutherAI/pythia-160m-deduped](https://huggingface.co/EleutherAI/pythia-160m-deduped) on the postbot/multi-emails-hq dataset.
It achieves the following results on the evaluation set:
- Loss: 2.2856
- Accuracy: 0.6113
- perplexity: 9.8313
## Model description
this is v4
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0006
- train_batch_size: 4
- eval_batch_size: 1
- seed: 42
- distributed_type: multi-GPU
- gradient_accumulation_steps: 32
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 4.0
- mixed_precision_training: Native AMP
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 2.412 | 0.99 | 76 | 2.5027 | 0.5458 |
| 1.9702 | 1.99 | 152 | 2.2757 | 0.5850 |
| 1.4628 | 2.99 | 228 | 2.2162 | 0.6082 |
| 1.1662 | 3.99 | 304 | 2.2856 | 0.6113 |
### Framework versions
- Transformers 4.27.0.dev0
- Pytorch 1.13.1+cu117
- Datasets 2.8.0
- Tokenizers 0.13.1
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_postbot__pythia-160m-hq-emails)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 25.12 |
| ARC (25-shot) | 23.12 |
| HellaSwag (10-shot) | 30.05 |
| MMLU (5-shot) | 26.58 |
| TruthfulQA (0-shot) | 45.51 |
| Winogrande (5-shot) | 50.28 |
| GSM8K (5-shot) | 0.0 |
| DROP (3-shot) | 0.31 |
|
stanfordnlp/stanza-zh-hans | stanfordnlp | 2024-03-25T00:05:45Z | 653 | 5 | stanza | [
"stanza",
"token-classification",
"zh",
"license:apache-2.0",
"region:us"
] | token-classification | 2022-03-02T23:29:05Z | ---
tags:
- stanza
- token-classification
library_name: stanza
language: zh
license: apache-2.0
---
# Stanza model for Simplified_Chinese (zh-hans)
Stanza is a collection of accurate and efficient tools for the linguistic analysis of many human languages. Starting from raw text to syntactic analysis and entity recognition, Stanza brings state-of-the-art NLP models to languages of your choosing.
Find more about it in [our website](https://stanfordnlp.github.io/stanza) and our [GitHub repository](https://github.com/stanfordnlp/stanza).
This card and repo were automatically prepared with `hugging_stanza.py` in the `stanfordnlp/huggingface-models` repo
Last updated 2024-03-25 00:04:55.397
|
PAIXAI/Astrid-1B-CPU | PAIXAI | 2023-08-21T23:12:05Z | 653 | 25 | transformers | [
"transformers",
"pytorch",
"gpt_neox",
"text-generation",
"gpt",
"llm",
"large language model",
"PAIX.Cloud",
"en",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2023-07-10T03:48:59Z | ---
language:
- en
library_name: transformers
tags:
- gpt
- llm
- large language model
- PAIX.Cloud
inference: true
thumbnail: https://static.wixstatic.com/media/bdee4e_8aa5cefc86024bc88f7e20e3e19d9ff3~mv2.png/v1/fill/w_192%2Ch_192%2Clg_1%2Cusm_0.66_1.00_0.01/bdee4e_8aa5cefc86024bc88f7e20e3e19d9ff3~mv2.png
---
# Model Card
## Summary
This model, Astrid-1B-CPU, is a GPT-NeoX model for causal language modeling, designed to generate human-like text.
It's part of our mission to make AI technology accessible to everyone, focusing on personalization, data privacy, and transparent AI governance.
Trained in English, it's a versatile tool for a variety of applications.
This model is one of the many models available on our platform, and we currently have a 1B and 7B open-source model.
This model was trained by [PAIX.Cloud](https://www.paix.cloud/).
- Wait list: [Wait List](https://www.paix.cloud/join-waitlist)
## Usage
To use the model with the `transformers` library on a machine with GPUs, first make sure you have the `transformers`, `accelerate` and `torch` libraries installed.
```bash
pip install transformers==4.30.1
pip install accelerate==0.20.3
pip install torch==2.0.0
```
```python
import torch
from transformers import pipeline
generate_text = pipeline(
model="PAIXAI/Astrid-1B-CPU",
torch_dtype="auto",
trust_remote_code=True,
use_fast=True,
device_map={"": "cuda:0"},
)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You can print a sample prompt after the preprocessing step to see how it is feed to the tokenizer:
```python
print(generate_text.preprocess("Why is drinking water so healthy?")["prompt_text"])
```
```bash
<|prompt|>Why is drinking water so healthy?<|endoftext|><|answer|>
```
Alternatively, you can download [h2oai_pipeline.py](h2oai_pipeline.py), store it alongside your notebook, and construct the pipeline yourself from the loaded model and tokenizer. If the model and the tokenizer are fully supported in the `transformers` package, this will allow you to set `trust_remote_code=False`.
```python
import torch
from h2oai_pipeline import H2OTextGenerationPipeline
from transformers import AutoModelForCausalLM, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"PAIXAI/Astrid-1B-CPU",
use_fast=True,
padding_side="left",
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
"PAIXAI/Astrid-1B-CPU",
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
generate_text = H2OTextGenerationPipeline(model=model, tokenizer=tokenizer)
res = generate_text(
"Why is drinking water so healthy?",
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)
print(res[0]["generated_text"])
```
You may also construct the pipeline from the loaded model and tokenizer yourself and consider the preprocessing steps:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "PAIXAI/Astrid-1B-CPU" # either local folder or huggingface model name
# Important: The prompt needs to be in the same format the model was trained with.
# You can find an example prompt in the experiment logs.
prompt = "<|prompt|>How are you?<|endoftext|><|answer|>"
tokenizer = AutoTokenizer.from_pretrained(
model_name,
use_fast=True,
trust_remote_code=True,
)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype="auto",
device_map={"": "cuda:0"},
trust_remote_code=True,
)
model.cuda().eval()
inputs = tokenizer(prompt, return_tensors="pt", add_special_tokens=False).to("cuda")
# generate configuration can be modified to your needs
tokens = model.generate(
**inputs,
min_new_tokens=2,
max_new_tokens=256,
do_sample=False,
num_beams=1,
temperature=float(0.3),
repetition_penalty=float(1.2),
renormalize_logits=True
)[0]
tokens = tokens[inputs["input_ids"].shape[1]:]
answer = tokenizer.decode(tokens, skip_special_tokens=True)
print(answer)
```
## Model Architecture
```
GPTNeoXForCausalLM(
(gpt_neox): GPTNeoXModel(
(embed_in): Embedding(50304, 2048)
(layers): ModuleList(
(0-15): 16 x GPTNeoXLayer(
(input_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(post_attention_layernorm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
(attention): GPTNeoXAttention(
(rotary_emb): RotaryEmbedding()
(query_key_value): Linear(in_features=2048, out_features=6144, bias=True)
(dense): Linear(in_features=2048, out_features=2048, bias=True)
)
(mlp): GPTNeoXMLP(
(dense_h_to_4h): Linear(in_features=2048, out_features=8192, bias=True)
(dense_4h_to_h): Linear(in_features=8192, out_features=2048, bias=True)
(act): GELUActivation()
)
)
)
(final_layer_norm): LayerNorm((2048,), eps=1e-05, elementwise_affine=True)
)
(embed_out): Linear(in_features=2048, out_features=50304, bias=False)
)
```
## Model Configuration
This model was trained using H2O LLM Studio and with the configuration in [cfg.yaml](cfg.yaml). Visit [H2O LLM Studio](https://github.com/h2oai/h2o-llmstudio) to learn how to train your own large language models.
## Model Validation
Model validation results using [EleutherAI lm-evaluation-harness](https://github.com/EleutherAI/lm-evaluation-harness).
```bash
CUDA_VISIBLE_DEVICES=0 python main.py --model hf-causal-experimental --model_args pretrained=PAIXAI/Astrid-1B-CPU --tasks openbookqa,arc_easy,winogrande,hellaswag,arc_challenge,piqa,boolq --device cuda &> eval.log
```
## Disclaimer
Please read this disclaimer carefully before using the large language model provided in this repository. Your use of the model signifies your agreement to the following terms and conditions.
- Biases and Offensiveness: The large language model is trained on a diverse range of internet text data, which may contain biased, racist, offensive, or otherwise inappropriate content. By using this model, you acknowledge and accept that the generated content may sometimes exhibit biases or produce content that is offensive or inappropriate. The developers of this repository do not endorse, support, or promote any such content or viewpoints.
- Limitations: The large language model is an AI-based tool and not a human. It may produce incorrect, nonsensical, or irrelevant responses. It is the user's responsibility to critically evaluate the generated content and use it at their discretion.
- Use at Your Own Risk: Users of this large language model must assume full responsibility for any consequences that may arise from their use of the tool. The developers and contributors of this repository shall not be held liable for any damages, losses, or harm resulting from the use or misuse of the provided model.
- Ethical Considerations: Users are encouraged to use the large language model responsibly and ethically. By using this model, you agree not to use it for purposes that promote hate speech, discrimination, harassment, or any form of illegal or harmful activities.
- Reporting Issues: If you encounter any biased, offensive, or otherwise inappropriate content generated by the large language model, please report it to the repository maintainers through the provided channels. Your feedback will help improve the model and mitigate potential issues.
- Changes to this Disclaimer: The developers of this repository reserve the right to modify or update this disclaimer at any time without prior notice. It is the user's responsibility to periodically review the disclaimer to stay informed about any changes.
By using the large language model provided in this repository, you agree to accept and comply with the terms and conditions outlined in this disclaimer. If you do not agree with any part of this disclaimer, you should refrain from using the model and any content generated by it. |
Buseak/pos_tagger_3112_v3 | Buseak | 2023-12-31T13:50:08Z | 653 | 0 | transformers | [
"transformers",
"tensorboard",
"safetensors",
"bert",
"token-classification",
"generated_from_trainer",
"base_model:dbmdz/bert-base-turkish-cased",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | token-classification | 2023-12-31T13:08:20Z | ---
license: mit
base_model: dbmdz/bert-base-turkish-cased
tags:
- generated_from_trainer
metrics:
- precision
- recall
- f1
- accuracy
model-index:
- name: pos_tagger_3112_v3
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pos_tagger_3112_v3
This model is a fine-tuned version of [dbmdz/bert-base-turkish-cased](https://huggingface.co/dbmdz/bert-base-turkish-cased) on the None dataset.
It achieves the following results on the evaluation set:
- Loss: 0.7728
- Precision: 0.8922
- Recall: 0.8955
- F1: 0.8938
- Accuracy: 0.9244
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 2e-05
- train_batch_size: 32
- eval_batch_size: 32
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 50
### Training results
| Training Loss | Epoch | Step | Validation Loss | Precision | Recall | F1 | Accuracy |
|:-------------:|:-----:|:-----:|:---------------:|:---------:|:------:|:------:|:--------:|
| No log | 1.0 | 244 | 0.3040 | 0.8905 | 0.8924 | 0.8915 | 0.9215 |
| No log | 2.0 | 488 | 0.2915 | 0.8981 | 0.9006 | 0.8994 | 0.9279 |
| 0.3896 | 3.0 | 732 | 0.3109 | 0.8933 | 0.8932 | 0.8933 | 0.9234 |
| 0.3896 | 4.0 | 976 | 0.3004 | 0.8954 | 0.8983 | 0.8969 | 0.9263 |
| 0.159 | 5.0 | 1220 | 0.3338 | 0.8929 | 0.8946 | 0.8937 | 0.9242 |
| 0.159 | 6.0 | 1464 | 0.3419 | 0.8914 | 0.8958 | 0.8936 | 0.9240 |
| 0.1038 | 7.0 | 1708 | 0.3840 | 0.8892 | 0.8930 | 0.8911 | 0.9223 |
| 0.1038 | 8.0 | 1952 | 0.3923 | 0.8857 | 0.8930 | 0.8894 | 0.9213 |
| 0.0629 | 9.0 | 2196 | 0.4441 | 0.8888 | 0.8914 | 0.8901 | 0.9213 |
| 0.0629 | 10.0 | 2440 | 0.4769 | 0.8886 | 0.8929 | 0.8908 | 0.9231 |
| 0.0357 | 11.0 | 2684 | 0.4846 | 0.8859 | 0.8913 | 0.8886 | 0.9199 |
| 0.0357 | 12.0 | 2928 | 0.5256 | 0.8877 | 0.8895 | 0.8886 | 0.9211 |
| 0.0212 | 13.0 | 3172 | 0.5554 | 0.8896 | 0.8900 | 0.8898 | 0.9219 |
| 0.0212 | 14.0 | 3416 | 0.5748 | 0.8870 | 0.8911 | 0.8890 | 0.9207 |
| 0.0143 | 15.0 | 3660 | 0.5988 | 0.8877 | 0.8916 | 0.8896 | 0.9220 |
| 0.0143 | 16.0 | 3904 | 0.6047 | 0.8874 | 0.8903 | 0.8888 | 0.9209 |
| 0.0098 | 17.0 | 4148 | 0.6161 | 0.8846 | 0.8914 | 0.8880 | 0.9199 |
| 0.0098 | 18.0 | 4392 | 0.6158 | 0.8883 | 0.8929 | 0.8906 | 0.9217 |
| 0.0072 | 19.0 | 4636 | 0.6216 | 0.8858 | 0.8928 | 0.8893 | 0.9209 |
| 0.0072 | 20.0 | 4880 | 0.6497 | 0.8892 | 0.8926 | 0.8909 | 0.9215 |
| 0.0058 | 21.0 | 5124 | 0.6698 | 0.8887 | 0.8919 | 0.8903 | 0.9216 |
| 0.0058 | 22.0 | 5368 | 0.6582 | 0.8858 | 0.8916 | 0.8887 | 0.9208 |
| 0.0046 | 23.0 | 5612 | 0.6915 | 0.8866 | 0.8925 | 0.8896 | 0.9212 |
| 0.0046 | 24.0 | 5856 | 0.6725 | 0.8898 | 0.8928 | 0.8913 | 0.9222 |
| 0.004 | 25.0 | 6100 | 0.6678 | 0.8912 | 0.8961 | 0.8936 | 0.9238 |
| 0.004 | 26.0 | 6344 | 0.6899 | 0.8891 | 0.8933 | 0.8912 | 0.9224 |
| 0.0034 | 27.0 | 6588 | 0.7082 | 0.8890 | 0.8922 | 0.8906 | 0.9215 |
| 0.0034 | 28.0 | 6832 | 0.7066 | 0.8903 | 0.8920 | 0.8911 | 0.9228 |
| 0.0026 | 29.0 | 7076 | 0.7243 | 0.8882 | 0.8938 | 0.8910 | 0.9228 |
| 0.0026 | 30.0 | 7320 | 0.7322 | 0.8891 | 0.8923 | 0.8907 | 0.9226 |
| 0.0023 | 31.0 | 7564 | 0.7292 | 0.8909 | 0.8930 | 0.8920 | 0.9230 |
| 0.0023 | 32.0 | 7808 | 0.7227 | 0.8922 | 0.8947 | 0.8934 | 0.9244 |
| 0.0027 | 33.0 | 8052 | 0.7231 | 0.8885 | 0.8922 | 0.8903 | 0.9222 |
| 0.0027 | 34.0 | 8296 | 0.7236 | 0.8907 | 0.8936 | 0.8922 | 0.9233 |
| 0.0019 | 35.0 | 8540 | 0.7313 | 0.8875 | 0.8895 | 0.8885 | 0.9214 |
| 0.0019 | 36.0 | 8784 | 0.7240 | 0.8902 | 0.8935 | 0.8919 | 0.9234 |
| 0.0017 | 37.0 | 9028 | 0.7364 | 0.8903 | 0.8939 | 0.8921 | 0.9233 |
| 0.0017 | 38.0 | 9272 | 0.7479 | 0.8896 | 0.8929 | 0.8913 | 0.9232 |
| 0.0013 | 39.0 | 9516 | 0.7511 | 0.8895 | 0.8937 | 0.8916 | 0.9230 |
| 0.0013 | 40.0 | 9760 | 0.7689 | 0.8896 | 0.8948 | 0.8922 | 0.9234 |
| 0.001 | 41.0 | 10004 | 0.7597 | 0.8909 | 0.8958 | 0.8933 | 0.9238 |
| 0.001 | 42.0 | 10248 | 0.7581 | 0.8897 | 0.8929 | 0.8913 | 0.9230 |
| 0.001 | 43.0 | 10492 | 0.7512 | 0.8919 | 0.8952 | 0.8935 | 0.9244 |
| 0.0012 | 44.0 | 10736 | 0.7622 | 0.8921 | 0.8957 | 0.8939 | 0.9244 |
| 0.0012 | 45.0 | 10980 | 0.7707 | 0.8907 | 0.8952 | 0.8930 | 0.9237 |
| 0.001 | 46.0 | 11224 | 0.7700 | 0.8922 | 0.8963 | 0.8942 | 0.9244 |
| 0.001 | 47.0 | 11468 | 0.7742 | 0.8895 | 0.8938 | 0.8916 | 0.9231 |
| 0.0009 | 48.0 | 11712 | 0.7753 | 0.8911 | 0.8945 | 0.8928 | 0.9239 |
| 0.0009 | 49.0 | 11956 | 0.7746 | 0.8909 | 0.8944 | 0.8927 | 0.9236 |
| 0.0008 | 50.0 | 12200 | 0.7728 | 0.8922 | 0.8955 | 0.8938 | 0.9244 |
### Framework versions
- Transformers 4.35.2
- Pytorch 2.1.0+cu121
- Datasets 2.16.1
- Tokenizers 0.15.0
|
AntoineSchutz/best_dpo_model | AntoineSchutz | 2024-05-26T14:27:21Z | 653 | 0 | peft | [
"peft",
"safetensors",
"arxiv:1910.09700",
"base_model:TinyLlama/TinyLlama-1.1B-Chat-v1.0",
"region:us"
] | null | 2024-05-26T11:54:11Z | ---
library_name: peft
base_model: TinyLlama/TinyLlama-1.1B-Chat-v1.0
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
lr = 1e-4
epoch =3
beta = 0.1
data = M1 data
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
### Framework versions
- PEFT 0.11.1 |
mradermacher/CATA-8x7B-i1-GGUF | mradermacher | 2024-06-17T22:44:43Z | 653 | 0 | transformers | [
"transformers",
"gguf",
"not-for-all-audiences",
"en",
"base_model:Envoid/CATA-8x7B",
"license:cc-by-nc-4.0",
"endpoints_compatible",
"region:us"
] | null | 2024-06-14T03:59:40Z | ---
base_model: Envoid/CATA-8x7B
language:
- en
library_name: transformers
license: cc-by-nc-4.0
quantized_by: mradermacher
tags:
- not-for-all-audiences
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: nicoboss -->
weighted/imatrix quants of https://huggingface.co/Envoid/CATA-8x7B
<!-- provided-files -->
static quants are available at https://huggingface.co/mradermacher/CATA-8x7B-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ1_S.gguf) | i1-IQ1_S | 9.9 | for the desperate |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ1_M.gguf) | i1-IQ1_M | 10.9 | mostly desperate |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ2_XXS.gguf) | i1-IQ2_XXS | 12.7 | |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ2_XS.gguf) | i1-IQ2_XS | 14.0 | |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ2_S.gguf) | i1-IQ2_S | 14.2 | |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ2_M.gguf) | i1-IQ2_M | 15.6 | |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q2_K.gguf) | i1-Q2_K | 17.4 | IQ3_XXS probably better |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ3_XXS.gguf) | i1-IQ3_XXS | 18.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ3_XS.gguf) | i1-IQ3_XS | 19.5 | |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ3_S.gguf) | i1-IQ3_S | 20.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q3_K_S.gguf) | i1-Q3_K_S | 20.5 | IQ3_XS probably better |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ3_M.gguf) | i1-IQ3_M | 21.5 | |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q3_K_M.gguf) | i1-Q3_K_M | 22.6 | IQ3_S probably better |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q3_K_L.gguf) | i1-Q3_K_L | 24.3 | IQ3_M probably better |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-IQ4_XS.gguf) | i1-IQ4_XS | 25.2 | |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q4_0.gguf) | i1-Q4_0 | 26.7 | fast, low quality |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q4_K_S.gguf) | i1-Q4_K_S | 26.8 | optimal size/speed/quality |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q4_K_M.gguf) | i1-Q4_K_M | 28.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q5_K_S.gguf) | i1-Q5_K_S | 32.3 | |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q5_K_M.gguf) | i1-Q5_K_M | 33.3 | |
| [GGUF](https://huggingface.co/mradermacher/CATA-8x7B-i1-GGUF/resolve/main/CATA-8x7B.i1-Q6_K.gguf) | i1-Q6_K | 38.5 | practically like static Q6_K |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time. Additional thanks to [@nicoboss](https://huggingface.co/nicoboss) for giving me access to his hardware for calculating the imatrix for these quants.
<!-- end -->
|
yukiarimo/yuna-ai-miru-v0 | yukiarimo | 2024-06-22T20:33:54Z | 653 | 1 | null | [
"gguf",
"real world",
"image recognition",
"image-to-text",
"en",
"ja",
"license:afl-3.0",
"region:us"
] | image-to-text | 2024-06-15T01:30:13Z | ---
license: afl-3.0
language:
- en
- ja
tags:
- real world
- image recognition
metrics:
- accuracy
pipeline_tag: image-to-text
---
# Yuna Vision
Welcome to the cutting-edge artificial general intelligence (AGI) series model with Yuna Vision AI. This model represents a significant leap forward in our quest to create AI that can perceive and understand the world in a way that rivals human cognition. Yuna Vision AI is not just a text-based model; it's an AGI-series model designed to process and interpret visual data, opening up a new realm of possibilities for AI applications.
Yuna Vision AI is the latest addition to the Yuna AI series, expanding the capabilities of the previous models to include visual processing. This model is hosted on Hugging Face for easy access and integration into your projects. For more detailed information, please visit the original GitHub repository: https://github.com/yukiarimo/yuna-ai
## Model Series
Yuna Vision AI is part of the AGI series, which includes:
- Yuna AI V1 (Text-based)
- Yuna AI V2 (Text-based)
- Yuna AI X V2 (Text-based)
- Yuna AI Vision V1 (Visual AGI-series)
- ✔️ Yuna AI Vision V2 (Visual AGI-series)
## Dataset Preparation:
Yuna Vision AI has been trained on diverse visual data, encompassing various scenes, objects, and contexts to ensure robust performance across different visual tasks. The model has been fine-tuned to achieve high accuracy in image recognition, object detection, and scene understanding.
## Contributing and Feedback
The development of Yuna Vision AI is a collaborative effort, and we value the contributions and feedback from our community. If you have any suggestions, encounter issues, or want to contribute to the project, please contact us or submit a pull request on our GitHub repository. Your input is crucial in shaping the future of Yuna Vision AI.
Access the Yuna Vision AI model on Hugging Face and integrate visual intelligence into your applications today!
For further inquiries or contributions, connect with the developer:
- [Discord](https://discord.com/users/1131657390752800899)
- [Twitter](https://twitter.com/yukiarimo)
Support the project and stay updated on the latest developments:
[](https://www.patreon.com/YukiArimo)
[](https://github.com/yukiarimo)
Thank you for your interest in Yuna Vision. Together, we're pushing the boundaries of what's possible with artificial intelligence. |
NikolayKozloff/cendol-llama2-7b-chat-Q8_0-GGUF | NikolayKozloff | 2024-06-24T16:07:17Z | 653 | 1 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"id",
"su",
"jv",
"base_model:indonlp/cendol-llama2-7b-chat",
"license:apache-2.0",
"region:us"
] | null | 2024-06-24T16:06:43Z | ---
base_model: indonlp/cendol-llama2-7b-chat
language:
- id
- su
- jv
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
---
# NikolayKozloff/cendol-llama2-7b-chat-Q8_0-GGUF
This model was converted to GGUF format from [`indonlp/cendol-llama2-7b-chat`](https://huggingface.co/indonlp/cendol-llama2-7b-chat) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/indonlp/cendol-llama2-7b-chat) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo NikolayKozloff/cendol-llama2-7b-chat-Q8_0-GGUF --hf-file cendol-llama2-7b-chat-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo NikolayKozloff/cendol-llama2-7b-chat-Q8_0-GGUF --hf-file cendol-llama2-7b-chat-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo NikolayKozloff/cendol-llama2-7b-chat-Q8_0-GGUF --hf-file cendol-llama2-7b-chat-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo NikolayKozloff/cendol-llama2-7b-chat-Q8_0-GGUF --hf-file cendol-llama2-7b-chat-q8_0.gguf -c 2048
```
|
nm-testing/Meta-Llama-3-8B-Instruct-W8-Channel-A8-Dynamic-Per-Token-Test | nm-testing | 2024-06-25T19:09:04Z | 653 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2024-06-25T19:07:05Z | Entry not found |
facebook/galactica-6.7b | facebook | 2023-01-24T17:20:42Z | 652 | 92 | transformers | [
"transformers",
"pytorch",
"opt",
"text-generation",
"galactica",
"arxiv:1810.03993",
"license:cc-by-nc-4.0",
"autotrain_compatible",
"text-generation-inference",
"region:us"
] | text-generation | 2022-11-16T14:20:00Z | ---
license: cc-by-nc-4.0
tags:
- galactica
widget:
- text: "The Transformer architecture [START_REF]"
- text: "The Schwarzschild radius is defined as: \\["
- text: "A force of 0.6N is applied to an object, which accelerates at 3m/s. What is its mass? <work>"
- text: "Lecture 1: The Ising Model\n\n"
- text: "[START_I_SMILES]"
- text: "[START_AMINO]GHMQSITAGQKVISKHKNGRFYQCEVVRLTTETFYEVNFDDGSFSDNLYPEDIVSQDCLQFGPPAEGEVVQVRWTDGQVYGAKFVASHPIQMYQVEFEDGSQLVVKRDDVYTLDEELP[END_AMINO] ## Keywords"
inference: false
---

# GALACTICA 6.7B (standard)
Model card from the original [repo](https://github.com/paperswithcode/galai/blob/main/docs/model_card.md)
Following [Mitchell et al. (2018)](https://arxiv.org/abs/1810.03993), this model card provides information about the GALACTICA model, how it was trained, and the intended use cases. Full details about how the model was trained and evaluated can be found in the [release paper](https://galactica.org/paper.pdf).
## Model Details
The GALACTICA models are trained on a large-scale scientific corpus. The models are designed to perform scientific tasks, including but not limited to citation prediction, scientific QA, mathematical reasoning, summarization, document generation, molecular property prediction and entity extraction. The models were developed by the Papers with Code team at Meta AI to study the use of language models for the automatic organization of science. We train models with sizes ranging from 125M to 120B parameters. Below is a summary of the released models:
| Size | Parameters |
|:-----------:|:-----------:|
| `mini` | 125 M |
| `base` | 1.3 B |
| `standard` | 6.7 B |
| `large` | 30 B |
| `huge` | 120 B |
## Release Date
November 2022
## Model Type
Transformer based architecture in a decoder-only setup with a few modifications (see paper for more details).
## Paper & Demo
[Paper](https://galactica.org/paper.pdf) / [Demo](https://galactica.org)
## Model Use
The primary intended users of the GALACTICA models are researchers studying language models applied to the scientific domain. We also anticipate the model will be useful for developers who wish to build scientific tooling. However, we caution against production use without safeguards given the potential of language models to hallucinate.
The models are made available under a non-commercial CC BY-NC 4.0 license. More information about how to use the model can be found in the README.md of this repository.
## Training Data
The GALACTICA models are trained on 106 billion tokens of open-access scientific text and data. This includes papers, textbooks, scientific websites, encyclopedias, reference material, knowledge bases, and more. We tokenize different modalities to provide a natural langauge interface for different tasks. See the README.md for more information. See the paper for full information on the training data.
## How to use
Find below some example scripts on how to use the model in `transformers`:
## Using the Pytorch model
### Running the model on a CPU
<details>
<summary> Click to expand </summary>
```python
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-6.7b")
model = OPTForCausalLM.from_pretrained("facebook/galactica-6.7b")
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-6.7b")
model = OPTForCausalLM.from_pretrained("facebook/galactica-6.7b", device_map="auto")
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
### Running the model on a GPU using different precisions
#### FP16
<details>
<summary> Click to expand </summary>
```python
# pip install accelerate
import torch
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-6.7b")
model = OPTForCausalLM.from_pretrained("facebook/galactica-6.7b", device_map="auto", torch_dtype=torch.float16)
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
#### INT8
<details>
<summary> Click to expand </summary>
```python
# pip install bitsandbytes accelerate
from transformers import AutoTokenizer, OPTForCausalLM
tokenizer = AutoTokenizer.from_pretrained("facebook/galactica-6.7b")
model = OPTForCausalLM.from_pretrained("facebook/galactica-6.7b", device_map="auto", load_in_8bit=True)
input_text = "The Transformer architecture [START_REF]"
input_ids = tokenizer(input_text, return_tensors="pt").input_ids.to("cuda")
outputs = model.generate(input_ids)
print(tokenizer.decode(outputs[0]))
```
</details>
## Performance and Limitations
The model outperforms several existing language models on a range of knowledge probes, reasoning, and knowledge-intensive scientific tasks. This also extends to general NLP tasks, where GALACTICA outperforms other open source general language models. That being said, we note a number of limitations in this section.
As with other language models, GALACTICA is often prone to hallucination - and training on a high-quality academic corpus does not prevent this, especially for less popular and less cited scientific concepts. There are no guarantees of truthful output when generating from the model. This extends to specific modalities such as citation prediction. While GALACTICA's citation behaviour approaches the ground truth citation behaviour with scale, the model continues to exhibit a popularity bias at larger scales.
In addition, we evaluated the model on several types of benchmarks related to stereotypes and toxicity. Overall, the model exhibits substantially lower toxicity rates compared to other large language models. That being said, the model continues to exhibit bias on certain measures (see the paper for details). So we recommend care when using the model for generations.
## Broader Implications
GALACTICA can potentially be used as a new way to discover academic literature. We also expect a lot of downstream use for application to particular domains, such as mathematics, biology, and chemistry. In the paper, we demonstrated several examples of the model acting as alternative to standard search tools. We expect a new generation of scientific tools to be built upon large language models such as GALACTICA.
We encourage researchers to investigate beneficial and new use cases for these models. That being said, it is important to be aware of the current limitations of large language models. Researchers should pay attention to common issues such as hallucination and biases that could emerge from using these models.
## Citation
```bibtex
@inproceedings{GALACTICA,
title={GALACTICA: A Large Language Model for Science},
author={Ross Taylor and Marcin Kardas and Guillem Cucurull and Thomas Scialom and Anthony Hartshorn and Elvis Saravia and Andrew Poulton and Viktor Kerkez and Robert Stojnic},
year={2022}
}
``` |
BridgeTower/bridgetower-large-itm-mlm | BridgeTower | 2023-01-27T02:13:28Z | 652 | 1 | transformers | [
"transformers",
"pytorch",
"bridgetower",
"en",
"dataset:conceptual_captions",
"dataset:sbu_captions",
"dataset:visual_genome",
"dataset:mscoco_captions",
"arxiv:2206.08657",
"arxiv:1504.00325",
"license:mit",
"endpoints_compatible",
"region:us"
] | null | 2022-12-08T00:31:23Z | ---
language: en
tags:
- bridgetower
license: mit
datasets:
- conceptual_captions
- sbu_captions
- visual_genome
- mscoco_captions
---
# BridgeTower large-itm-mlm model
The BridgeTower model was proposed in "BridgeTower: Building Bridges Between Encoders in Vision-Language Representative Learning" by Xiao Xu, Chenfei Wu, Shachar Rosenman, Vasudev Lal, Wanxiang Che, Nan Duan.
The model was pretrained on English language using masked language modeling (MLM) and image text matching (ITM)objectives. It was introduced in
[this paper](https://arxiv.org/pdf/2206.08657.pdf) and first released in
[this repository](https://github.com/microsoft/BridgeTower).
BridgeTower got accepted to [AAAI'23](https://aaai.org/Conferences/AAAI-23/).
## Model description
The abstract from the paper is the following:
Vision-Language (VL) models with the Two-Tower architecture have dominated visual-language representation learning in recent years. Current VL models either use lightweight uni-modal encoders and learn to extract, align and fuse both modalities simultaneously in a deep cross-modal encoder, or feed the last-layer uni-modal representations from the deep pre-trained uni-modal encoders into the top cross-modal encoder. Both approaches potentially restrict vision-language representation learning and limit model performance. In this paper, we propose BridgeTower, which introduces multiple bridge layers that build a connection between the top layers of uni-modal encoders and each layer of the cross-modal encoder. This enables effective bottom-up cross-modal alignment and fusion between visual and textual representations of different semantic levels of pre-trained uni-modal encoders in the cross-modal encoder. Pre-trained with only 4M images, BridgeTower achieves state-of-the-art performance on various downstream vision-language tasks. In particular, on the VQAv2 test-std set, BridgeTower achieves an accuracy of 78.73%, outperforming the previous state-of-the-art model METER by 1.09% with the same pre-training data and almost negligible additional parameters and computational costs. Notably, when further scaling the model, BridgeTower achieves an accuracy of 81.15%, surpassing models that are pre-trained on orders-of-magnitude larger datasets.
## Intended uses & limitations(TODO)
### How to use
Here is how to use this model to perform image and text matching:
```python
from transformers import BridgeTowerProcessor, BridgeTowerForImageAndTextRetrieval
import requests
from PIL import Image
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
texts = ["An image of two cats chilling on a couch", "A football player scoring a goal"]
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm")
model = BridgeTowerForImageAndTextRetrieval.from_pretrained("BridgeTower/bridgetower-large-itm-mlm")
# forward pass
scores = dict()
for text in texts:
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
outputs = model(**encoding)
scores[text] = outputs.logits[0,1].item()
```
Here is how to use this model to perform masked language modeling:
```python
from transformers import BridgeTowerProcessor, BridgeTowerForMaskedLM
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000360943.jpg"
image = Image.open(requests.get(url, stream=True).raw).convert("RGB")
text = "a <mask> looking out of the window"
processor = BridgeTowerProcessor.from_pretrained("BridgeTower/bridgetower-large-itm-mlm")
model = BridgeTowerForMaskedLM.from_pretrained("BridgeTower/bridgetower-large-itm-mlm")
# prepare inputs
encoding = processor(image, text, return_tensors="pt")
# forward pass
outputs = model(**encoding)
results = processor.decode(outputs.logits.argmax(dim=-1).squeeze(0).tolist())
print(results)
#.a cat looking out of the window.
```
### Limitations and bias
TODO
## Training data
The BridgeTower model was pretrained on four public image-caption datasets:
- [Conceptual Captions(CC)](https://ai.google.com/research/ConceptualCaptions/),
- [SBU Captions](https://www.cs.rice.edu/~vo9/sbucaptions/),
- [MSCOCO Captions](https://arxiv.org/pdf/1504.00325.pdf),
- [Visual Genome](https://visualgenome.org/)
The total number of unique images in the combined data is 4M.
## Training procedure
### Preprocessing
TODO
### Pretraining
The model was pre-trained for 100k steps on 8 NVIDIA A100 GPUs with a batch size of 4096.
The optimizer used was AdamW with a learning rate of 1e-5. No data augmentation was used except for center-crop. The image resolution in pre-training is set to 288 x 288.
## Evaluation results
Please refer to [Table 5](https://arxiv.org/pdf/2206.08657.pdf) for BridgeTower's performance on Image Retrieval and other downstream tasks.
### BibTeX entry and citation info
```bibtex
@article{xu2022bridge,
title={BridgeTower: Building Bridges Between Encoders in Vision-Language Representation Learning},
author={Xu, Xiao and Wu, Chenfei and Rosenman, Shachar and Lal, Vasudev and Che, Wanxiang and Duan, Nan},
journal={arXiv preprint arXiv:2206.08657},
year={2022}
}
```
|
chelvan/GPT-Neo-1.3_Series_Forecasting | chelvan | 2023-02-02T11:11:16Z | 652 | 0 | transformers | [
"transformers",
"pytorch",
"gpt_neo",
"text-generation",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
] | text-generation | 2023-02-02T10:26:49Z | Entry not found |
timm/regnetx_008.tv2_in1k | timm | 2024-02-10T23:32:41Z | 652 | 0 | timm | [
"timm",
"pytorch",
"safetensors",
"image-classification",
"arxiv:2003.13678",
"license:bsd-3-clause",
"region:us"
] | image-classification | 2023-03-21T06:31:35Z | ---
license: bsd-3-clause
library_name: timm
tags:
- image-classification
- timm
---
# Model card for regnetx_008.tv2_in1k
A RegNetX-800MF image classification model. Pretrained on ImageNet-1k by torchvision contributors (see ImageNet1K-V2 weight details https://github.com/pytorch/vision/issues/3995#new-recipe).
The `timm` RegNet implementation includes a number of enhancements not present in other implementations, including:
* stochastic depth
* gradient checkpointing
* layer-wise LR decay
* configurable output stride (dilation)
* configurable activation and norm layers
* option for a pre-activation bottleneck block used in RegNetV variant
* only known RegNetZ model definitions with pretrained weights
## Model Details
- **Model Type:** Image classification / feature backbone
- **Model Stats:**
- Params (M): 7.3
- GMACs: 0.8
- Activations (M): 5.1
- Image size: 224 x 224
- **Papers:**
- Designing Network Design Spaces: https://arxiv.org/abs/2003.13678
- **Original:** https://github.com/pytorch/vision
## Model Usage
### Image Classification
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model('regnetx_008.tv2_in1k', pretrained=True)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
top5_probabilities, top5_class_indices = torch.topk(output.softmax(dim=1) * 100, k=5)
```
### Feature Map Extraction
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetx_008.tv2_in1k',
pretrained=True,
features_only=True,
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # unsqueeze single image into batch of 1
for o in output:
# print shape of each feature map in output
# e.g.:
# torch.Size([1, 32, 112, 112])
# torch.Size([1, 64, 56, 56])
# torch.Size([1, 128, 28, 28])
# torch.Size([1, 288, 14, 14])
# torch.Size([1, 672, 7, 7])
print(o.shape)
```
### Image Embeddings
```python
from urllib.request import urlopen
from PIL import Image
import timm
img = Image.open(urlopen(
'https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/beignets-task-guide.png'
))
model = timm.create_model(
'regnetx_008.tv2_in1k',
pretrained=True,
num_classes=0, # remove classifier nn.Linear
)
model = model.eval()
# get model specific transforms (normalization, resize)
data_config = timm.data.resolve_model_data_config(model)
transforms = timm.data.create_transform(**data_config, is_training=False)
output = model(transforms(img).unsqueeze(0)) # output is (batch_size, num_features) shaped tensor
# or equivalently (without needing to set num_classes=0)
output = model.forward_features(transforms(img).unsqueeze(0))
# output is unpooled, a (1, 672, 7, 7) shaped tensor
output = model.forward_head(output, pre_logits=True)
# output is a (1, num_features) shaped tensor
```
## Model Comparison
Explore the dataset and runtime metrics of this model in timm [model results](https://github.com/huggingface/pytorch-image-models/tree/main/results).
For the comparison summary below, the ra_in1k, ra3_in1k, ch_in1k, sw_*, and lion_* tagged weights are trained in `timm`.
|model |img_size|top1 |top5 |param_count|gmacs|macts |
|-------------------------|--------|------|------|-----------|-----|------|
|[regnety_1280.swag_ft_in1k](https://huggingface.co/timm/regnety_1280.swag_ft_in1k)|384 |88.228|98.684|644.81 |374.99|210.2 |
|[regnety_320.swag_ft_in1k](https://huggingface.co/timm/regnety_320.swag_ft_in1k)|384 |86.84 |98.364|145.05 |95.0 |88.87 |
|[regnety_160.swag_ft_in1k](https://huggingface.co/timm/regnety_160.swag_ft_in1k)|384 |86.024|98.05 |83.59 |46.87|67.67 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|288 |86.004|97.83 |83.59 |26.37|38.07 |
|[regnety_1280.swag_lc_in1k](https://huggingface.co/timm/regnety_1280.swag_lc_in1k)|224 |85.996|97.848|644.81 |127.66|71.58 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|288 |85.982|97.844|83.59 |26.37|38.07 |
|[regnety_160.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.sw_in12k_ft_in1k)|224 |85.574|97.666|83.59 |15.96|23.04 |
|[regnety_160.lion_in12k_ft_in1k](https://huggingface.co/timm/regnety_160.lion_in12k_ft_in1k)|224 |85.564|97.674|83.59 |15.96|23.04 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|288 |85.398|97.584|51.82 |20.06|35.34 |
|[regnety_2560.seer_ft_in1k](https://huggingface.co/timm/regnety_2560.seer_ft_in1k)|384 |85.15 |97.436|1282.6 |747.83|296.49|
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|320 |85.036|97.268|57.7 |15.46|63.94 |
|[regnety_120.sw_in12k_ft_in1k](https://huggingface.co/timm/regnety_120.sw_in12k_ft_in1k)|224 |84.976|97.416|51.82 |12.14|21.38 |
|[regnety_320.swag_lc_in1k](https://huggingface.co/timm/regnety_320.swag_lc_in1k)|224 |84.56 |97.446|145.05 |32.34|30.26 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|320 |84.496|97.004|28.94 |6.43 |37.94 |
|[regnetz_e8.ra3_in1k](https://huggingface.co/timm/regnetz_e8.ra3_in1k)|256 |84.436|97.02 |57.7 |9.91 |40.94 |
|[regnety_1280.seer_ft_in1k](https://huggingface.co/timm/regnety_1280.seer_ft_in1k)|384 |84.432|97.092|644.81 |374.99|210.2 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|320 |84.246|96.93 |27.12 |6.35 |37.78 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|320 |84.054|96.992|23.37 |6.19 |37.08 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|320 |84.038|96.992|23.46 |7.03 |38.92 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|320 |84.022|96.866|27.58 |9.33 |37.08 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|288 |83.932|96.888|39.18 |13.22|29.69 |
|[regnety_640.seer_ft_in1k](https://huggingface.co/timm/regnety_640.seer_ft_in1k)|384 |83.912|96.924|281.38 |188.47|124.83|
|[regnety_160.swag_lc_in1k](https://huggingface.co/timm/regnety_160.swag_lc_in1k)|224 |83.778|97.286|83.59 |15.96|23.04 |
|[regnetz_040_h.ra3_in1k](https://huggingface.co/timm/regnetz_040_h.ra3_in1k)|256 |83.776|96.704|28.94 |4.12 |24.29 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|288 |83.72 |96.75 |30.58 |10.55|27.11 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|288 |83.718|96.724|30.58 |10.56|27.11 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|288 |83.69 |96.778|83.59 |26.37|38.07 |
|[regnetz_040.ra3_in1k](https://huggingface.co/timm/regnetz_040.ra3_in1k)|256 |83.62 |96.704|27.12 |4.06 |24.19 |
|[regnetz_d8.ra3_in1k](https://huggingface.co/timm/regnetz_d8.ra3_in1k)|256 |83.438|96.776|23.37 |3.97 |23.74 |
|[regnetz_d32.ra3_in1k](https://huggingface.co/timm/regnetz_d32.ra3_in1k)|256 |83.424|96.632|27.58 |5.98 |23.74 |
|[regnetz_d8_evos.ch_in1k](https://huggingface.co/timm/regnetz_d8_evos.ch_in1k)|256 |83.36 |96.636|23.46 |4.5 |24.92 |
|[regnety_320.seer_ft_in1k](https://huggingface.co/timm/regnety_320.seer_ft_in1k)|384 |83.35 |96.71 |145.05 |95.0 |88.87 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|288 |83.204|96.66 |20.64 |6.6 |20.3 |
|[regnety_320.tv2_in1k](https://huggingface.co/timm/regnety_320.tv2_in1k)|224 |83.162|96.42 |145.05 |32.34|30.26 |
|[regnety_080.ra3_in1k](https://huggingface.co/timm/regnety_080.ra3_in1k)|224 |83.16 |96.486|39.18 |8.0 |17.97 |
|[regnetv_064.ra3_in1k](https://huggingface.co/timm/regnetv_064.ra3_in1k)|224 |83.108|96.458|30.58 |6.39 |16.41 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|288 |83.044|96.5 |20.65 |6.61 |20.3 |
|[regnety_064.ra3_in1k](https://huggingface.co/timm/regnety_064.ra3_in1k)|224 |83.02 |96.292|30.58 |6.39 |16.41 |
|[regnety_160.deit_in1k](https://huggingface.co/timm/regnety_160.deit_in1k)|224 |82.974|96.502|83.59 |15.96|23.04 |
|[regnetx_320.tv2_in1k](https://huggingface.co/timm/regnetx_320.tv2_in1k)|224 |82.816|96.208|107.81 |31.81|36.3 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|288 |82.742|96.418|19.44 |5.29 |18.61 |
|[regnety_160.tv2_in1k](https://huggingface.co/timm/regnety_160.tv2_in1k)|224 |82.634|96.22 |83.59 |15.96|23.04 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|320 |82.634|96.472|13.49 |3.86 |25.88 |
|[regnety_080_tv.tv2_in1k](https://huggingface.co/timm/regnety_080_tv.tv2_in1k)|224 |82.592|96.246|39.38 |8.51 |19.73 |
|[regnetx_160.tv2_in1k](https://huggingface.co/timm/regnetx_160.tv2_in1k)|224 |82.564|96.052|54.28 |15.99|25.52 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|320 |82.51 |96.358|13.46 |3.92 |25.88 |
|[regnetv_040.ra3_in1k](https://huggingface.co/timm/regnetv_040.ra3_in1k)|224 |82.44 |96.198|20.64 |4.0 |12.29 |
|[regnety_040.ra3_in1k](https://huggingface.co/timm/regnety_040.ra3_in1k)|224 |82.304|96.078|20.65 |4.0 |12.29 |
|[regnetz_c16.ra3_in1k](https://huggingface.co/timm/regnetz_c16.ra3_in1k)|256 |82.16 |96.048|13.46 |2.51 |16.57 |
|[regnetz_c16_evos.ch_in1k](https://huggingface.co/timm/regnetz_c16_evos.ch_in1k)|256 |81.936|96.15 |13.49 |2.48 |16.57 |
|[regnety_032.ra_in1k](https://huggingface.co/timm/regnety_032.ra_in1k)|224 |81.924|95.988|19.44 |3.2 |11.26 |
|[regnety_032.tv2_in1k](https://huggingface.co/timm/regnety_032.tv2_in1k)|224 |81.77 |95.842|19.44 |3.2 |11.26 |
|[regnetx_080.tv2_in1k](https://huggingface.co/timm/regnetx_080.tv2_in1k)|224 |81.552|95.544|39.57 |8.02 |14.06 |
|[regnetx_032.tv2_in1k](https://huggingface.co/timm/regnetx_032.tv2_in1k)|224 |80.924|95.27 |15.3 |3.2 |11.37 |
|[regnety_320.pycls_in1k](https://huggingface.co/timm/regnety_320.pycls_in1k)|224 |80.804|95.246|145.05 |32.34|30.26 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|288 |80.712|95.47 |9.72 |2.39 |16.43 |
|[regnety_016.tv2_in1k](https://huggingface.co/timm/regnety_016.tv2_in1k)|224 |80.66 |95.334|11.2 |1.63 |8.04 |
|[regnety_120.pycls_in1k](https://huggingface.co/timm/regnety_120.pycls_in1k)|224 |80.37 |95.12 |51.82 |12.14|21.38 |
|[regnety_160.pycls_in1k](https://huggingface.co/timm/regnety_160.pycls_in1k)|224 |80.288|94.964|83.59 |15.96|23.04 |
|[regnetx_320.pycls_in1k](https://huggingface.co/timm/regnetx_320.pycls_in1k)|224 |80.246|95.01 |107.81 |31.81|36.3 |
|[regnety_080.pycls_in1k](https://huggingface.co/timm/regnety_080.pycls_in1k)|224 |79.882|94.834|39.18 |8.0 |17.97 |
|[regnetz_b16.ra3_in1k](https://huggingface.co/timm/regnetz_b16.ra3_in1k)|224 |79.872|94.974|9.72 |1.45 |9.95 |
|[regnetx_160.pycls_in1k](https://huggingface.co/timm/regnetx_160.pycls_in1k)|224 |79.862|94.828|54.28 |15.99|25.52 |
|[regnety_064.pycls_in1k](https://huggingface.co/timm/regnety_064.pycls_in1k)|224 |79.716|94.772|30.58 |6.39 |16.41 |
|[regnetx_120.pycls_in1k](https://huggingface.co/timm/regnetx_120.pycls_in1k)|224 |79.592|94.738|46.11 |12.13|21.37 |
|[regnetx_016.tv2_in1k](https://huggingface.co/timm/regnetx_016.tv2_in1k)|224 |79.44 |94.772|9.19 |1.62 |7.93 |
|[regnety_040.pycls_in1k](https://huggingface.co/timm/regnety_040.pycls_in1k)|224 |79.23 |94.654|20.65 |4.0 |12.29 |
|[regnetx_080.pycls_in1k](https://huggingface.co/timm/regnetx_080.pycls_in1k)|224 |79.198|94.55 |39.57 |8.02 |14.06 |
|[regnetx_064.pycls_in1k](https://huggingface.co/timm/regnetx_064.pycls_in1k)|224 |79.064|94.454|26.21 |6.49 |16.37 |
|[regnety_032.pycls_in1k](https://huggingface.co/timm/regnety_032.pycls_in1k)|224 |78.884|94.412|19.44 |3.2 |11.26 |
|[regnety_008_tv.tv2_in1k](https://huggingface.co/timm/regnety_008_tv.tv2_in1k)|224 |78.654|94.388|6.43 |0.84 |5.42 |
|[regnetx_040.pycls_in1k](https://huggingface.co/timm/regnetx_040.pycls_in1k)|224 |78.482|94.24 |22.12 |3.99 |12.2 |
|[regnetx_032.pycls_in1k](https://huggingface.co/timm/regnetx_032.pycls_in1k)|224 |78.178|94.08 |15.3 |3.2 |11.37 |
|[regnety_016.pycls_in1k](https://huggingface.co/timm/regnety_016.pycls_in1k)|224 |77.862|93.73 |11.2 |1.63 |8.04 |
|[regnetx_008.tv2_in1k](https://huggingface.co/timm/regnetx_008.tv2_in1k)|224 |77.302|93.672|7.26 |0.81 |5.15 |
|[regnetx_016.pycls_in1k](https://huggingface.co/timm/regnetx_016.pycls_in1k)|224 |76.908|93.418|9.19 |1.62 |7.93 |
|[regnety_008.pycls_in1k](https://huggingface.co/timm/regnety_008.pycls_in1k)|224 |76.296|93.05 |6.26 |0.81 |5.25 |
|[regnety_004.tv2_in1k](https://huggingface.co/timm/regnety_004.tv2_in1k)|224 |75.592|92.712|4.34 |0.41 |3.89 |
|[regnety_006.pycls_in1k](https://huggingface.co/timm/regnety_006.pycls_in1k)|224 |75.244|92.518|6.06 |0.61 |4.33 |
|[regnetx_008.pycls_in1k](https://huggingface.co/timm/regnetx_008.pycls_in1k)|224 |75.042|92.342|7.26 |0.81 |5.15 |
|[regnetx_004_tv.tv2_in1k](https://huggingface.co/timm/regnetx_004_tv.tv2_in1k)|224 |74.57 |92.184|5.5 |0.42 |3.17 |
|[regnety_004.pycls_in1k](https://huggingface.co/timm/regnety_004.pycls_in1k)|224 |74.018|91.764|4.34 |0.41 |3.89 |
|[regnetx_006.pycls_in1k](https://huggingface.co/timm/regnetx_006.pycls_in1k)|224 |73.862|91.67 |6.2 |0.61 |3.98 |
|[regnetx_004.pycls_in1k](https://huggingface.co/timm/regnetx_004.pycls_in1k)|224 |72.38 |90.832|5.16 |0.4 |3.14 |
|[regnety_002.pycls_in1k](https://huggingface.co/timm/regnety_002.pycls_in1k)|224 |70.282|89.534|3.16 |0.2 |2.17 |
|[regnetx_002.pycls_in1k](https://huggingface.co/timm/regnetx_002.pycls_in1k)|224 |68.752|88.556|2.68 |0.2 |2.16 |
## Citation
```bibtex
@InProceedings{Radosavovic2020,
title = {Designing Network Design Spaces},
author = {Ilija Radosavovic and Raj Prateek Kosaraju and Ross Girshick and Kaiming He and Piotr Doll{'a}r},
booktitle = {CVPR},
year = {2020}
}
```
```bibtex
@misc{rw2019timm,
author = {Ross Wightman},
title = {PyTorch Image Models},
year = {2019},
publisher = {GitHub},
journal = {GitHub repository},
doi = {10.5281/zenodo.4414861},
howpublished = {\url{https://github.com/huggingface/pytorch-image-models}}
}
```
|
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.