
modelId
stringlengths 5
122
| author
stringlengths 2
42
| last_modified
timestamp[us, tz=UTC] | downloads
int64 0
738M
| likes
int64 0
11k
| library_name
stringclasses 245
values | tags
listlengths 1
4.05k
| pipeline_tag
stringclasses 48
values | createdAt
timestamp[us, tz=UTC] | card
stringlengths 1
901k
|
|---|---|---|---|---|---|---|---|---|---|
QuantFactory/WizardLM-2-7B-abliterated-GGUF | QuantFactory | 2024-05-27T01:45:37Z | 393 | 0 | null | [
"gguf",
"text-generation",
"arxiv:2304.12244",
"arxiv:2306.08568",
"arxiv:2308.09583",
"base_model:fearlessdots/WizardLM-2-7B-abliterated",
"license:apache-2.0",
"region:us"
]
| text-generation | 2024-05-27T00:52:30Z | ---
license: apache-2.0
pipeline_tag: text-generation
base_model: fearlessdots/WizardLM-2-7B-abliterated
---
# WizardLM-2-7B-abliterated-GGUF
This is quantized version of [fearlessdots/WizardLM-2-7B-abliterated](https://huggingface.co/fearlessdots/WizardLM-2-7B-abliterated) created using llama.cpp
# Model Description
This is the **WizardLM-2-7B** model with orthogonalized bfloat16 safetensor weights, based on the implementation by `@failspy`. For more info:
- Original paper preview presenting the methodology: <https://www.alignmentforum.org/posts/jGuXSZgv6qfdhMCuJ/refusal-in-llms-is-mediated-by-a-single-direction>
- Jupyter notebook containing a implementation of the methodology, by `@failspy`: <https://huggingface.co/failspy/llama-3-70B-Instruct-abliterated/blob/main/ortho_cookbook.ipynb>
## Prompt Template
This model uses the prompt format from **Vicuna** and supports **multi-turn** conversation.
---
# Original model card:
<p style="font-size:20px;" align="center">
🏠 <a href="https://wizardlm.github.io/WizardLM2" target="_blank">WizardLM-2 Release Blog</a> </p>
<p align="center">
🤗 <a href="https://huggingface.co/collections/microsoft/wizardlm-2-661d403f71e6c8257dbd598a" target="_blank">HF Repo</a> •🐱 <a href="https://github.com/victorsungo/WizardLM/tree/main/WizardLM-2" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/WizardLM_AI" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> • 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> • 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://discord.gg/VZjjHtWrKs" target="_blank">Discord</a>
</p>
## News 🔥🔥🔥 [2024/04/15]
We introduce and opensource WizardLM-2, our next generation state-of-the-art large language models,
which have improved performance on complex chat, multilingual, reasoning and agent.
New family includes three cutting-edge models: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B.
- WizardLM-2 8x22B is our most advanced model, demonstrates highly competitive performance compared to those leading proprietary works
and consistently outperforms all the existing state-of-the-art opensource models.
- WizardLM-2 70B reaches top-tier reasoning capabilities and is the first choice in the same size.
- WizardLM-2 7B is the fastest and achieves comparable performance with existing 10x larger opensource leading models.
For more details of WizardLM-2 please read our [release blog post](https://wizardlm.github.io/WizardLM2) and upcoming paper.
## Model Details
* **Model name**: WizardLM-2 7B
* **Developed by**: WizardLM@Microsoft AI
* **Base model**: [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1)
* **Parameters**: 7B
* **Language(s)**: Multilingual
* **Blog**: [Introducing WizardLM-2](https://wizardlm.github.io/WizardLM2)
* **Repository**: [https://github.com/nlpxucan/WizardLM](https://github.com/nlpxucan/WizardLM)
* **Paper**: WizardLM-2 (Upcoming)
* **License**: Apache2.0
## Model Capacities
**MT-Bench**
We also adopt the automatic MT-Bench evaluation framework based on GPT-4 proposed by lmsys to assess the performance of models.
The WizardLM-2 8x22B even demonstrates highly competitive performance compared to the most advanced proprietary models.
Meanwhile, WizardLM-2 7B and WizardLM-2 70B are all the top-performing models among the other leading baselines at 7B to 70B model scales.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/mtbench.png" alt="MTBench" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
**Human Preferences Evaluation**
We carefully collected a complex and challenging set consisting of real-world instructions, which includes main requirements of humanity, such as writing, coding, math, reasoning, agent, and multilingual.
We report the win:loss rate without tie:
- WizardLM-2 8x22B is just slightly falling behind GPT-4-1106-preview, and significantly stronger than Command R Plus and GPT4-0314.
- WizardLM-2 70B is better than GPT4-0613, Mistral-Large, and Qwen1.5-72B-Chat.
- WizardLM-2 7B is comparable with Qwen1.5-32B-Chat, and surpasses Qwen1.5-14B-Chat and Starling-LM-7B-beta.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/winall.png" alt="Win" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Method Overview
We built a **fully AI powered synthetic training system** to train WizardLM-2 models, please refer to our [blog](https://wizardlm.github.io/WizardLM2) for more details of this system.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/exp_1.png" alt="Method" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Usage
❗<b>Note for model system prompts usage:</b>
<b>WizardLM-2</b> adopts the prompt format from <b>Vicuna</b> and supports **multi-turn** conversation. The prompt should be as following:
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......
```
<b> Inference WizardLM-2 Demo Script</b>
We provide a WizardLM-2 inference demo [code](https://github.com/nlpxucan/WizardLM/tree/main/demo) on our github. |
QuantFactory/CodeLlama-7B-KStack-GGUF | QuantFactory | 2024-05-27T04:04:58Z | 393 | 0 | transformers | [
"transformers",
"gguf",
"code",
"text-generation",
"dataset:JetBrains/KStack",
"base_model:JetBrains/CodeLlama-7B-KStack",
"license:apache-2.0",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-05-27T03:17:22Z | ---
license: apache-2.0
datasets:
- JetBrains/KStack
results:
- task:
type: text-generation
dataset:
name: MultiPL-HumanEval (Kotlin)
type: openai_humaneval
metrics:
- name: pass@1
type: pass@1
value: 29.19
tags:
- code
library_name: transformers
pipeline_tag: text-generation
base_model: JetBrains/CodeLlama-7B-KStack
---
# CodeLlama-7B-KStack-GGUF
This is quantized version of [JetBrains/CodeLlama-7B-KStack](https://huggingface.co/JetBrains/CodeLlama-7B-KStack) created using llama.cpp
# Model description
This is a repository for the **CodeLlama-7b** model fine-tuned on the [KStack](https://huggingface.co/datasets/JetBrains/KStack) dataset with rule-based filtering, in the *Hugging Face Transformers* format. KStack is the largest collection of permissively licensed Kotlin code, and so the model is fine-tuned to work better with Kotlin code.
# How to use
As with the base model, we can use FIM. To do this, the following format must be used:
```
'<PRE> ' + prefix + ' <SUF> ' + suffix + ' <MID>'
```
# Training setup
The model was trained on one A100 GPU with following hyperparameters:
| **Hyperparameter** | **Value** |
|:---------------------------:|:----------------------------------------:|
| `warmup` | 5% |
| `max_lr` | 1e-6 |
| `num_epochs` | 1 |
| 'attention_dropout' | 0.1 |
| `scheduler` | cosine |
| `total_batch_size` | 128 (~65K tokens per step) |
| `num_epochs` | 1 |
More details about fine-tuning can be found in the technical report (coming soon!).
# Fine-tuning data
For tuning the model, we used the [KStack](https://huggingface.co/datasets/JetBrains/KStack) dataset, the largest collection of permissively licensed Kotlin code. To increase the quality of the dataset and filter out outliers, such as homework assignments, we filter out the dataset entries according to the following rules:
* We filter out files, which belong to low-popular repos (the sum of stars and forks is less than 6)
* Next, we filter out files, which belong to repos with less than 5 Kotlin files
* Finally, we remove files which have fewer than 20 SLOC
We clean the content of the remaining dataset entries according to the following rules:
* We remove all non-ASCII entries
* We remove all package lines, such as _package kotlinx.coroutines.channels_
* We remove half of the import lines
We removed half of the imports to avoid potential hallucinations by the model, where it might attempt to import unnecessary libraries. Additionally, packages were removed because this information is only useful at the project level and may introduce additional noise during the learning process.
# Evaluation
For evaluation, we used the [Kotlin HumanEval](https://huggingface.co/datasets/JetBrains/Kotlin_HumanEval) dataset, which contains all 161 tasks from HumanEval translated into Kotlin by human experts. You can find more details about the pre-processing necessary to obtain our results, including the code for running, on the [datasets's page](https://huggingface.co/datasets/JetBrains/Kotlin_HumanEval).
Here are the results of our evaluation:
| **Model name** | **Kotlin HumanEval Pass Rate** |
|:---------------------------:|:----------------------------------------:|
| `CodeLlama-7B` | 26.09 |
| `CodeLlama-7B-KStack` | **29.19** |
# Ethical Considerations and Limitations
CodeLlama-7B-KStack is a new technology that carries risks with use. The testing conducted to date has not covered, nor could it cover all scenarios. For these reasons, as with all LLMs, CodeLlama-7B-KStack's potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate or objectionable responses to user prompts. The model was fine-tuned on a specific data format (Kotlin tasks), and deviation from this format can also lead to inaccurate or undesirable responses to user queries. Therefore, before deploying any applications of CodeLlama-7B-KStack, developers should perform safety testing and tuning tailored to their specific applications of the model. |
mradermacher/nyun-llama3-60B-GGUF | mradermacher | 2024-06-04T05:52:01Z | 393 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:nyunai/nyun-llama3-60B",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-31T22:14:54Z | ---
base_model: nyunai/nyun-llama3-60B
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/nyunai/nyun-llama3-60B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/nyun-llama3-60B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q2_K.gguf) | Q2_K | 22.6 | |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.IQ3_XS.gguf) | IQ3_XS | 25.1 | |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q3_K_S.gguf) | Q3_K_S | 26.4 | |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.IQ3_S.gguf) | IQ3_S | 26.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.IQ3_M.gguf) | IQ3_M | 27.4 | |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q3_K_M.gguf) | Q3_K_M | 29.3 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q3_K_L.gguf) | Q3_K_L | 31.9 | |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.IQ4_XS.gguf) | IQ4_XS | 32.8 | |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q4_K_S.gguf) | Q4_K_S | 34.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q4_K_M.gguf) | Q4_K_M | 36.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q5_K_S.gguf) | Q5_K_S | 41.7 | |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q5_K_M.gguf) | Q5_K_M | 42.8 | |
| [GGUF](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q6_K.gguf) | Q6_K | 49.6 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/nyun-llama3-60B-GGUF/resolve/main/nyun-llama3-60B.Q8_0.gguf.part2of2) | Q8_0 | 64.2 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf | RichardErkhov | 2024-06-01T03:22:05Z | 393 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-05-31T23:11:13Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
japanese-stablelm-base-beta-70b - GGUF
- Model creator: https://huggingface.co/stabilityai/
- Original model: https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [japanese-stablelm-base-beta-70b.Q2_K.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q2_K.gguf) | Q2_K | 23.71GB |
| [japanese-stablelm-base-beta-70b.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.IQ3_XS.gguf) | IQ3_XS | 24.37GB |
| [japanese-stablelm-base-beta-70b.IQ3_S.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.IQ3_S.gguf) | IQ3_S | 6.29GB |
| [japanese-stablelm-base-beta-70b.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q3_K_S.gguf) | Q3_K_S | 3.98GB |
| [japanese-stablelm-base-beta-70b.IQ3_M.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.IQ3_M.gguf) | IQ3_M | 0.7GB |
| [japanese-stablelm-base-beta-70b.Q3_K.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q3_K.gguf) | Q3_K | 0.41GB |
| [japanese-stablelm-base-beta-70b.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q3_K_M.gguf) | Q3_K_M | 0.26GB |
| [japanese-stablelm-base-beta-70b.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q3_K_L.gguf) | Q3_K_L | 0.14GB |
| [japanese-stablelm-base-beta-70b.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.IQ4_XS.gguf) | IQ4_XS | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q4_0.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q4_0.gguf) | Q4_0 | 0.0GB |
| [japanese-stablelm-base-beta-70b.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.IQ4_NL.gguf) | IQ4_NL | 0.27GB |
| [japanese-stablelm-base-beta-70b.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q4_K_S.gguf) | Q4_K_S | 0.07GB |
| [japanese-stablelm-base-beta-70b.Q4_K.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q4_K.gguf) | Q4_K | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q4_K_M.gguf) | Q4_K_M | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q4_1.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q4_1.gguf) | Q4_1 | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q5_0.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q5_0.gguf) | Q5_0 | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q5_K_S.gguf) | Q5_K_S | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q5_K.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q5_K.gguf) | Q5_K | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q5_K_M.gguf) | Q5_K_M | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q5_1.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q5_1.gguf) | Q5_1 | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q6_K.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q6_K.gguf) | Q6_K | 0.0GB |
| [japanese-stablelm-base-beta-70b.Q8_0.gguf](https://huggingface.co/RichardErkhov/stabilityai_-_japanese-stablelm-base-beta-70b-gguf/blob/main/japanese-stablelm-base-beta-70b.Q8_0.gguf) | Q8_0 | 0.0GB |
Original model description:
---
language:
- ja
tags:
- japanese-stablelm
- causal-lm
pipeline_tag: text-generation
datasets:
- wikipedia
- mc4
- cc100
- oscar-corpus/OSCAR-2301
- oscar-corpus/OSCAR-2201
- cerebras/SlimPajama-627B
license:
- llama2
extra_gated_fields:
Name: text
Email: text
Country: text
Organization or Affiliation: text
I allow Stability AI to contact me about information related to its models and research: checkbox
---
# Japanese-StableLM-Base-Beta-70B

> A cute robot wearing a kimono writes calligraphy with one single brush — [Stable Diffusion XL](https://clipdrop.co/stable-diffusion)
## Model Description
`japanese-stablelm-base-beta-70b` is a 70B-parameter decoder-only language model based on [Llama-2-70b](https://huggingface.co/meta-llama/Llama-2-70b) that has been fine-tuned on a diverse collection of Japanese data, with the intent of maximizing downstream performance on Japanese language tasks.
For an instruction-following model, check [Japanese-StableLM-Instruct-Beta-70B](https://huggingface.co/stabilityai/japanese-stablelm-instruct-beta-70b). The base and instruct models are also available in smaller 7b sizes. For a model that has faster inference times, see [Japanese-StableLM-Base-JA_Vocab-Beta-7B](https://huggingface.co/stabilityai/japanese-stablelm-base-ja_vocab-beta-7b), or [the instruction-following version](https://huggingface.co/stabilityai/japanese-stablelm-instruct-ja_vocab-beta-7b).
## Usage
First install additional dependencies in [requirements.txt](./requirements.txt):
```sh
pip install -r requirements.txt
```
Then start generating text with `japanese-stablelm-base-beta-70b` by using the following code snippet:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM
model_name = "stabilityai/japanese-stablelm-base-beta-70b"
tokenizer = AutoTokenizer.from_pretrained(model_name)
# The next line may need to be modified depending on the environment
model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype=torch.float16, low_cpu_mem_usage=True, device_map="auto")
prompt = """
AI で科学研究を加速するには、
""".strip()
input_ids = tokenizer.encode(
prompt,
add_special_tokens=True,
return_tensors="pt"
)
# this is for reproducibility.
# feel free to change to get different result
seed = 23
torch.manual_seed(seed)
tokens = model.generate(
input_ids.to(device=model.device),
max_new_tokens=128,
temperature=0.99,
top_p=0.95,
do_sample=True,
)
out = tokenizer.decode(tokens[0], skip_special_tokens=True)
print(out)
```
We suggest playing with different generation config (`top_p`, `repetition_penalty` etc) to find the best setup for your tasks. For example, use higher temperature for roleplay task, lower temperature for reasoning.
## Model Details
* **Model type**: `japanese-stablelm-base-beta-70b` model is an auto-regressive language model based on the Llama2 transformer architecture.
* **Language(s)**: Japanese
* **License**: [Llama2 Community License](https://ai.meta.com/llama/license/).
* **Contact**: For questions and comments about the model, please join [Stable Community Japan](https://discord.gg/StableJP). For future announcements / information about Stability AI models, research, and events, please follow https://twitter.com/StabilityAI_JP.
## Training Dataset
Roughly 100B tokens from a mixture of the following corpora were used for continued pre-training.
- [Japanese/English Wikipedia](https://dumps.wikimedia.org/other/cirrussearch)
- [Japanese mc4](https://huggingface.co/datasets/mc4)
- [Japanese CC-100](http://data.statmt.org/cc-100/ja.txt.xz)
- [Japanese OSCAR](https://oscar-project.github.io/documentation/)
- [SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B) (excluding the Books3 subset)
## Use and Limitations
### Intended Use
The model is intended to be used by all individuals as a foundation for application-specific fine-tuning without strict limitations on commercial use.
### Limitations and bias
The pre-training dataset may have contained offensive or inappropriate content even after applying data cleansing filters which can be reflected in the model generated text. We recommend users exercise reasonable caution when using these models in production systems. Do not use the model for any applications that may cause harm or distress to individuals or groups.
## Authors
This model was developed by the Research & Development team at Stability AI Japan, and the development was co-led by [Takuya Akiba](https://huggingface.co/iwiwi) and [Meng Lee](https://huggingface.co/leemeng). The members of the team are as follows:
- [Meng Lee](https://huggingface.co/leemeng)
- [Fujiki Nakamura](https://huggingface.co/fujiki)
- [Makoto Shing](https://huggingface.co/mkshing)
- [Paul McCann](https://huggingface.co/polm-stability)
- [Takuya Akiba](https://huggingface.co/iwiwi)
- [Naoki Orii](https://huggingface.co/mrorii)
## Acknowledgements
We thank Meta Research for releasing Llama 2 under an open license for others to build on.
We are grateful for the contributions of the EleutherAI Polyglot-JA team in helping us to collect a large amount of pre-training data in Japanese. Polyglot-JA members includes Hyunwoong Ko (Project Lead), Fujiki Nakamura (originally started this project when he commited to the Polyglot team), Yunho Mo, Minji Jung, KeunSeok Im, and Su-Kyeong Jang.
We are also appreciative of [AI Novelist/Sta (Bit192, Inc.)](https://ai-novel.com/index.php) and the numerous contributors from [Stable Community Japan](https://discord.gg/VPrcE475HB) for assisting us in gathering a large amount of high-quality Japanese textual data for model training.
## How to cite
```
@misc{JapaneseStableLMBaseBeta70B,
url={[https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b](https://huggingface.co/stabilityai/japanese-stablelm-base-beta-70b)},
title={Japanese StableLM Base Beta 70B},
author={Lee, Meng and Nakamura, Fujiki and Shing, Makoto and McCann, Paul and Akiba, Takuya and Orii, Naoki}
}
```
|
mradermacher/EvolutiontGOLD-GGUF | mradermacher | 2024-06-05T16:28:59Z | 393 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:ClaudioItaly/EvolutiontGOLD",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-05T15:44:33Z | ---
base_model: ClaudioItaly/EvolutiontGOLD
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/ClaudioItaly/EvolutiontGOLD
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q2_K.gguf) | Q2_K | 4.7 | |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.IQ3_XS.gguf) | IQ3_XS | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q3_K_S.gguf) | Q3_K_S | 5.5 | |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.IQ3_S.gguf) | IQ3_S | 5.5 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.IQ3_M.gguf) | IQ3_M | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q3_K_M.gguf) | Q3_K_M | 6.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q3_K_L.gguf) | Q3_K_L | 6.7 | |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.IQ4_XS.gguf) | IQ4_XS | 6.9 | |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q4_K_S.gguf) | Q4_K_S | 7.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q4_K_M.gguf) | Q4_K_M | 7.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q5_K_S.gguf) | Q5_K_S | 8.7 | |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q5_K_M.gguf) | Q5_K_M | 8.9 | |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q6_K.gguf) | Q6_K | 10.3 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/EvolutiontGOLD-GGUF/resolve/main/EvolutiontGOLD.Q8_0.gguf) | Q8_0 | 13.4 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
John6666/ebara-pony-v1-sdxl-spo | John6666 | 2024-06-22T21:20:56Z | 393 | 1 | diffusers | [
"diffusers",
"safetensors",
"text-to-image",
"stable-diffusion",
"stable-diffusion-xl",
"anime",
"pony",
"SPO",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionXLPipeline",
"region:us"
]
| text-to-image | 2024-06-22T21:16:06Z | ---
license: other
license_name: faipl-1.0-sd
license_link: https://freedevproject.org/faipl-1.0-sd/
tags:
- text-to-image
- stable-diffusion
- stable-diffusion-xl
- anime
- pony
- SPO
---
Original model is [here](https://huggingface.co/tsukihara/xl_model).
|
J-LAB/BRisa_Mistral_7b_PTBR-Q4_K_M-GGUF | J-LAB | 2024-06-24T05:01:40Z | 393 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:J-LAB/BRisa_Mistral_7b_PTBR",
"region:us"
]
| null | 2024-06-24T05:00:40Z | ---
tags:
- llama-cpp
- gguf-my-repo
base_model: J-LAB/BRisa_Mistral_7b_PTBR
---
# J-LAB/BRisa_Mistral_7b_PTBR-Q4_K_M-GGUF
This model was converted to GGUF format from [`J-LAB/BRisa_Mistral_7b_PTBR`](https://huggingface.co/J-LAB/BRisa_Mistral_7b_PTBR) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/J-LAB/BRisa_Mistral_7b_PTBR) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama --hf-repo J-LAB/BRisa_Mistral_7b_PTBR-Q4_K_M-GGUF --hf-file brisa_mistral_7b_ptbr-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo J-LAB/BRisa_Mistral_7b_PTBR-Q4_K_M-GGUF --hf-file brisa_mistral_7b_ptbr-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./main --hf-repo J-LAB/BRisa_Mistral_7b_PTBR-Q4_K_M-GGUF --hf-file brisa_mistral_7b_ptbr-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./server --hf-repo J-LAB/BRisa_Mistral_7b_PTBR-Q4_K_M-GGUF --hf-file brisa_mistral_7b_ptbr-q4_k_m.gguf -c 2048
```
|
capricornstone/MING-1.8B-Q8_0-GGUF | capricornstone | 2024-06-28T03:41:54Z | 393 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:BlueZeros/MING-1.8B",
"license:apache-2.0",
"region:us"
]
| null | 2024-06-28T03:41:45Z | ---
base_model: BlueZeros/MING-1.8B
license: apache-2.0
tags:
- llama-cpp
- gguf-my-repo
---
# capricornstone/MING-1.8B-Q8_0-GGUF
This model was converted to GGUF format from [`BlueZeros/MING-1.8B`](https://huggingface.co/BlueZeros/MING-1.8B) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/BlueZeros/MING-1.8B) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo capricornstone/MING-1.8B-Q8_0-GGUF --hf-file ming-1.8b-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo capricornstone/MING-1.8B-Q8_0-GGUF --hf-file ming-1.8b-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo capricornstone/MING-1.8B-Q8_0-GGUF --hf-file ming-1.8b-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo capricornstone/MING-1.8B-Q8_0-GGUF --hf-file ming-1.8b-q8_0.gguf -c 2048
```
|
monologg/koelectra-base-v3-generator | monologg | 2023-06-12T12:30:53Z | 392 | 4 | transformers | [
"transformers",
"pytorch",
"safetensors",
"electra",
"fill-mask",
"korean",
"ko",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2022-03-02T23:29:05Z | ---
language: ko
license: apache-2.0
tags:
- korean
---
# KoELECTRA v3 (Base Generator)
Pretrained ELECTRA Language Model for Korean (`koelectra-base-v3-generator`)
For more detail, please see [original repository](https://github.com/monologg/KoELECTRA/blob/master/README_EN.md).
## Usage
### Load model and tokenizer
```python
>>> from transformers import ElectraModel, ElectraTokenizer
>>> model = ElectraModel.from_pretrained("monologg/koelectra-base-v3-generator")
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-base-v3-generator")
```
### Tokenizer example
```python
>>> from transformers import ElectraTokenizer
>>> tokenizer = ElectraTokenizer.from_pretrained("monologg/koelectra-base-v3-generator")
>>> tokenizer.tokenize("[CLS] 한국어 ELECTRA를 공유합니다. [SEP]")
['[CLS]', '한국어', 'EL', '##EC', '##TRA', '##를', '공유', '##합니다', '.', '[SEP]']
>>> tokenizer.convert_tokens_to_ids(['[CLS]', '한국어', 'EL', '##EC', '##TRA', '##를', '공유', '##합니다', '.', '[SEP]'])
[2, 11229, 29173, 13352, 25541, 4110, 7824, 17788, 18, 3]
```
## Example using ElectraForMaskedLM
```python
from transformers import pipeline
fill_mask = pipeline(
"fill-mask",
model="monologg/koelectra-base-v3-generator",
tokenizer="monologg/koelectra-base-v3-generator"
)
print(fill_mask("나는 {} 밥을 먹었다.".format(fill_mask.tokenizer.mask_token)))
```
|
mpariente/DPRNNTasNet-ks2_WHAM_sepclean | mpariente | 2021-09-23T16:12:22Z | 392 | 9 | asteroid | [
"asteroid",
"pytorch",
"audio",
"DPRNNTasNet",
"audio-to-audio",
"dataset:wham",
"dataset:sep_clean",
"license:cc-by-sa-4.0",
"region:us"
]
| audio-to-audio | 2022-03-02T23:29:05Z | ---
tags:
- asteroid
- audio
- DPRNNTasNet
- audio-to-audio
datasets:
- wham
- sep_clean
license: cc-by-sa-4.0
---
## Asteroid model `mpariente/DPRNNTasNet-ks2_WHAM_sepclean`
Imported from [Zenodo](https://zenodo.org/record/3862942)
### Description:
This model was trained by Manuel Pariente
using the wham/DPRNN recipe in [Asteroid](https://github.com/asteroid-team/asteroid).
It was trained on the `sep_clean` task of the WHAM! dataset.
### Training config:
```yaml
data:
mode: min
nondefault_nsrc: None
sample_rate: 8000
segment: 2.0
task: sep_clean
train_dir: data/wav8k/min/tr
valid_dir: data/wav8k/min/cv
filterbank:
kernel_size: 2
n_filters: 64
stride: 1
main_args:
exp_dir: exp/train_dprnn_new/
gpus: -1
help: None
masknet:
bidirectional: True
bn_chan: 128
chunk_size: 250
dropout: 0
hid_size: 128
hop_size: 125
in_chan: 64
mask_act: sigmoid
n_repeats: 6
n_src: 2
out_chan: 64
optim:
lr: 0.001
optimizer: adam
weight_decay: 1e-05
positional arguments:
training:
batch_size: 3
early_stop: True
epochs: 200
gradient_clipping: 5
half_lr: True
num_workers: 8
```
### Results:
```yaml
si_sdr: 19.316743490695334
si_sdr_imp: 19.317895273889842
sdr: 19.68085347190952
sdr_imp: 19.5298092932871
sir: 30.362213998701232
sir_imp: 30.21116982007881
sar: 20.15553251343315
sar_imp: -129.02091762351188
stoi: 0.97772664309074
stoi_imp: 0.23968091518217424
```
### License notice:
This work "DPRNNTasNet-ks2_WHAM_sepclean" is a derivative of [CSR-I (WSJ0) Complete](https://catalog.ldc.upenn.edu/LDC93S6A)
by [LDC](https://www.ldc.upenn.edu/), used under [LDC User Agreement for
Non-Members](https://catalog.ldc.upenn.edu/license/ldc-non-members-agreement.pdf) (Research only).
"DPRNNTasNet-ks2_WHAM_sepclean" is licensed under [Attribution-ShareAlike 3.0 Unported](https://creativecommons.org/licenses/by-sa/3.0/)
by Manuel Pariente.
|
cafeai/cafe_style | cafeai | 2022-11-14T17:11:24Z | 392 | 7 | transformers | [
"transformers",
"pytorch",
"beit",
"image-classification",
"license:agpl-3.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2022-11-14T14:57:57Z | ---
license: agpl-3.0
---
|
lorahub/flan_t5_large-quail_context_question_answer_description_id | lorahub | 2023-07-24T09:53:43Z | 392 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-07-24T09:53:33Z | ---
library_name: peft
---
|
Kyle1668/ag-news-bert-base-uncased | Kyle1668 | 2023-08-08T16:47:12Z | 392 | 0 | transformers | [
"transformers",
"pytorch",
"bert",
"text-classification",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-08-08T16:46:58Z | Entry not found |
TheBloke/chronos-13B-GGUF | TheBloke | 2023-09-27T12:52:17Z | 392 | 0 | transformers | [
"transformers",
"gguf",
"llama",
"pytorch",
"chatbot",
"storywriting",
"base_model:elinas/chronos-13b",
"license:other",
"text-generation-inference",
"region:us"
]
| null | 2023-09-19T22:17:43Z | ---
license: other
tags:
- llama
- pytorch
- chatbot
- storywriting
model_name: Chronos 13B
base_model: elinas/chronos-13b
inference: false
model_creator: elinas
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Chronos 13B - GGUF
- Model creator: [elinas](https://huggingface.co/elinas)
- Original model: [Chronos 13B](https://huggingface.co/elinas/chronos-13b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [elinas's Chronos 13B](https://huggingface.co/elinas/chronos-13b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/chronos-13B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/Yhyu13/chronos-13b-gptq-4bit)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/chronos-13B-GGUF)
* [elinas's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/elinas/chronos-13b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [chronos-13B.Q2_K.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q2_K.gguf) | Q2_K | 2 | 5.43 GB| 7.93 GB | smallest, significant quality loss - not recommended for most purposes |
| [chronos-13B.Q3_K_S.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q3_K_S.gguf) | Q3_K_S | 3 | 5.66 GB| 8.16 GB | very small, high quality loss |
| [chronos-13B.Q3_K_M.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q3_K_M.gguf) | Q3_K_M | 3 | 6.34 GB| 8.84 GB | very small, high quality loss |
| [chronos-13B.Q3_K_L.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q3_K_L.gguf) | Q3_K_L | 3 | 6.93 GB| 9.43 GB | small, substantial quality loss |
| [chronos-13B.Q4_0.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q4_0.gguf) | Q4_0 | 4 | 7.37 GB| 9.87 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [chronos-13B.Q4_K_S.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q4_K_S.gguf) | Q4_K_S | 4 | 7.41 GB| 9.91 GB | small, greater quality loss |
| [chronos-13B.Q4_K_M.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q4_K_M.gguf) | Q4_K_M | 4 | 7.87 GB| 10.37 GB | medium, balanced quality - recommended |
| [chronos-13B.Q5_0.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q5_0.gguf) | Q5_0 | 5 | 8.97 GB| 11.47 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [chronos-13B.Q5_K_S.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q5_K_S.gguf) | Q5_K_S | 5 | 8.97 GB| 11.47 GB | large, low quality loss - recommended |
| [chronos-13B.Q5_K_M.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q5_K_M.gguf) | Q5_K_M | 5 | 9.23 GB| 11.73 GB | large, very low quality loss - recommended |
| [chronos-13B.Q6_K.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q6_K.gguf) | Q6_K | 6 | 10.68 GB| 13.18 GB | very large, extremely low quality loss |
| [chronos-13B.Q8_0.gguf](https://huggingface.co/TheBloke/chronos-13B-GGUF/blob/main/chronos-13B.Q8_0.gguf) | Q8_0 | 8 | 13.83 GB| 16.33 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/chronos-13B-GGUF and below it, a specific filename to download, such as: chronos-13B.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/chronos-13B-GGUF chronos-13B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/chronos-13B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/chronos-13B-GGUF chronos-13B.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m chronos-13B.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/chronos-13B-GGUF", model_file="chronos-13B.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: elinas's Chronos 13B
# chronos-13b
This is the fp16 PyTorch / HF version of **chronos-13b**
This model is primarily focused on chat, roleplay, and storywriting, but can accomplish other tasks such as simple reasoning and coding.
Chronos generates very long outputs with coherent text, largely due to the human inputs it was trained on.
This model uses Alpaca formatting, so for optimal model performance, use:
```
### Instruction:
Your instruction or question here.
### Response:
```
[4bit Quantized version](https://huggingface.co/elinas/chronos-13b-4bit)
[GGML Version provided by @TheBloke](https://huggingface.co/TheBloke/chronos-13B-GGML)
<!--**Support My Development of New Models**
<a href='https://ko-fi.com/Q5Q6MB734' target='_blank'><img height='36' style='border:0px;height:36px;'
src='https://storage.ko-fi.com/cdn/kofi1.png?v=3' border='0' alt='Support Development' /></a>-->
--
license: other
---
# LLaMA Model Card
## Model details
**Organization developing the model**
The FAIR team of Meta AI.
**Model date**
LLaMA was trained between December. 2022 and Feb. 2023.
**Model version**
This is version 1 of the model.
**Model type**
LLaMA is an auto-regressive language model, based on the transformer architecture. The model comes in different sizes: 7B, 13B, 33B and 65B parameters.
**Paper or resources for more information**
More information can be found in the paper “LLaMA, Open and Efficient Foundation Language Models”, available at https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/.
**Citations details**
https://research.facebook.com/publications/llama-open-and-efficient-foundation-language-models/
**License**
Non-commercial bespoke license
**Where to send questions or comments about the model**
Questions and comments about LLaMA can be sent via the [GitHub repository](https://github.com/facebookresearch/llama) of the project , by opening an issue.
## Intended use
**Primary intended uses**
The primary use of LLaMA is research on large language models, including:
exploring potential applications such as question answering, natural language understanding or reading comprehension,
understanding capabilities and limitations of current language models, and developing techniques to improve those,
evaluating and mitigating biases, risks, toxic and harmful content generations, hallucinations.
**Primary intended users**
The primary intended users of the model are researchers in natural language processing, machine learning and artificial intelligence.
**Out-of-scope use cases**
LLaMA is a base, or foundational, model. As such, it should not be used on downstream applications without further risk evaluation and mitigation. In particular, our model has not been trained with human feedback, and can thus generate toxic or offensive content, incorrect information or generally unhelpful answers.
## Factors
**Relevant factors**
One of the most relevant factors for which model performance may vary is which language is used. Although we included 20 languages in the training data, most of our dataset is made of English text, and we thus expect the model to perform better for English than other languages. Relatedly, it has been shown in previous studies that performance might vary for different dialects, and we expect that it will be the case for our model.
**Evaluation factors**
As our model is trained on data from the Web, we expect that it reflects biases from this source. We thus evaluated on RAI datasets to measure biases exhibited by the model for gender, religion, race, sexual orientation, age, nationality, disability, physical appearance and socio-economic status. We also measure the toxicity of model generations, depending on the toxicity of the context used to prompt the model.
## Metrics
**Model performance measures**
We use the following measure to evaluate the model:
- Accuracy for common sense reasoning, reading comprehension, natural language understanding (MMLU), BIG-bench hard, WinoGender and CrowS-Pairs,
- Exact match for question answering,
- The toxicity score from Perspective API on RealToxicityPrompts.
**Decision thresholds**
Not applicable.
**Approaches to uncertainty and variability**
Due to the high computational requirements of training LLMs, we trained only one model of each size, and thus could not evaluate variability of pre-training.
## Evaluation datasets
The model was evaluated on the following benchmarks: BoolQ, PIQA, SIQA, HellaSwag, WinoGrande, ARC, OpenBookQA, NaturalQuestions, TriviaQA, RACE, MMLU, BIG-bench hard, GSM8k, RealToxicityPrompts, WinoGender, CrowS-Pairs.
## Training dataset
The model was trained using the following source of data: CCNet [67%], C4 [15%], GitHub [4.5%], Wikipedia [4.5%], Books [4.5%], ArXiv [2.5%], Stack Exchange[2%]. The Wikipedia and Books domains include data in the following languages: bg, ca, cs, da, de, en, es, fr, hr, hu, it, nl, pl, pt, ro, ru, sl, sr, sv, uk. See the paper for more details about the training set and corresponding preprocessing.
## Quantitative analysis
Hyperparameters for the model architecture
<table>
<thead>
<tr>
<th >LLaMA</th> <th colspan=6>Model hyper parameters </th>
</tr>
<tr>
<th>Number of parameters</th><th>dimension</th><th>n heads</th><th>n layers</th><th>Learn rate</th><th>Batch size</th><th>n tokens</th>
</tr>
</thead>
<tbody>
<tr>
<th>7B</th> <th>4096</th> <th>32</th> <th>32</th> <th>3.0E-04</th><th>4M</th><th>1T
</tr>
<tr>
<th>13B</th><th>5120</th><th>40</th><th>40</th><th>3.0E-04</th><th>4M</th><th>1T
</tr>
<tr>
<th>33B</th><th>6656</th><th>52</th><th>60</th><th>1.5.E-04</th><th>4M</th><th>1.4T
</tr>
<tr>
<th>65B</th><th>8192</th><th>64</th><th>80</th><th>1.5.E-04</th><th>4M</th><th>1.4T
</tr>
</tbody>
</table>
*Table 1 - Summary of LLama Model Hyperparameters*
We present our results on eight standard common sense reasoning benchmarks in the table below.
<table>
<thead>
<tr>
<th>LLaMA</th> <th colspan=9>Reasoning tasks </th>
</tr>
<tr>
<th>Number of parameters</th> <th>BoolQ</th><th>PIQA</th><th>SIQA</th><th>HellaSwag</th><th>WinoGrande</th><th>ARC-e</th><th>ARC-c</th><th>OBQA</th><th>COPA</th>
</tr>
</thead>
<tbody>
<tr>
<th>7B</th><th>76.5</th><th>79.8</th><th>48.9</th><th>76.1</th><th>70.1</th><th>76.7</th><th>47.6</th><th>57.2</th><th>93
</th>
<tr><th>13B</th><th>78.1</th><th>80.1</th><th>50.4</th><th>79.2</th><th>73</th><th>78.1</th><th>52.7</th><th>56.4</th><th>94
</th>
<tr><th>33B</th><th>83.1</th><th>82.3</th><th>50.4</th><th>82.8</th><th>76</th><th>81.4</th><th>57.8</th><th>58.6</th><th>92
</th>
<tr><th>65B</th><th>85.3</th><th>82.8</th><th>52.3</th><th>84.2</th><th>77</th><th>81.5</th><th>56</th><th>60.2</th><th>94</th></tr>
</tbody>
</table>
*Table 2 - Summary of LLama Model Performance on Reasoning tasks*
We present our results on bias in the table below. Note that lower value is better indicating lower bias.
| No | Category | FAIR LLM |
| --- | -------------------- | -------- |
| 1 | Gender | 70.6 |
| 2 | Religion | 79 |
| 3 | Race/Color | 57 |
| 4 | Sexual orientation | 81 |
| 5 | Age | 70.1 |
| 6 | Nationality | 64.2 |
| 7 | Disability | 66.7 |
| 8 | Physical appearance | 77.8 |
| 9 | Socioeconomic status | 71.5 |
| | LLaMA Average | 66.6 |
*Table 3 - Summary bias of our model output*
## Ethical considerations
**Data**
The data used to train the model is collected from various sources, mostly from the Web. As such, it contains offensive, harmful and biased content. We thus expect the model to exhibit such biases from the training data.
**Human life**
The model is not intended to inform decisions about matters central to human life, and should not be used in such a way.
**Mitigations**
We filtered the data from the Web based on its proximity to Wikipedia text and references. For this, we used a Kneser-Ney language model and a fastText linear classifier.
**Risks and harms**
Risks and harms of large language models include the generation of harmful, offensive or biased content. These models are often prone to generating incorrect information, sometimes referred to as hallucinations. We do not expect our model to be an exception in this regard.
**Use cases**
LLaMA is a foundational model, and as such, it should not be used for downstream applications without further investigation and mitigations of risks. These risks and potential fraught use cases include, but are not limited to: generation of misinformation and generation of harmful, biased or offensive content.
<!-- original-model-card end -->
|
LanguageBind/LanguageBind_Thermal | LanguageBind | 2024-02-01T06:57:23Z | 392 | 1 | transformers | [
"transformers",
"pytorch",
"LanguageBindThermal",
"zero-shot-image-classification",
"arxiv:2310.01852",
"license:mit",
"endpoints_compatible",
"region:us"
]
| zero-shot-image-classification | 2023-10-06T08:48:56Z | ---
license: mit
---
<p align="center">
<img src="https://s11.ax1x.com/2024/02/01/pFMDAm9.png" width="250" style="margin-bottom: 0.2;"/>
<p>
<h2 align="center"> <a href="https://arxiv.org/pdf/2310.01852.pdf">【ICLR 2024 🔥】LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment</a></h2>
<h5 align="center"> If you like our project, please give us a star ⭐ on GitHub for latest update. </h2>
## 📰 News
* **[2024.01.27]** 👀👀👀 Our [MoE-LLaVA](https://github.com/PKU-YuanGroup/MoE-LLaVA) is released! A sparse model with 3B parameters outperformed the dense model with 7B parameters.
* **[2024.01.16]** 🔥🔥🔥 Our LanguageBind has been accepted at ICLR 2024! We earn the score of 6(3)8(6)6(6)6(6) [here](https://openreview.net/forum?id=QmZKc7UZCy¬eId=OgsxQxAleA).
* **[2023.12.15]** 💪💪💪 We expand the 💥💥💥 VIDAL dataset and now have **10M video-text data**. We launch **LanguageBind_Video 1.5**, checking our [model zoo](#-model-zoo).
* **[2023.12.10]** We expand the 💥💥💥 VIDAL dataset and now have **10M depth and 10M thermal data**. We are in the process of uploading thermal and depth data on [Hugging Face](https://huggingface.co/datasets/LanguageBind/VIDAL-Depth-Thermal) and expect the whole process to last 1-2 months.
* **[2023.11.27]** 🔥🔥🔥 We have updated our [paper](https://arxiv.org/abs/2310.01852) with emergency zero-shot results., checking our ✨ [results](#emergency-results).
* **[2023.11.26]** 💥💥💥 We have open-sourced all textual sources and corresponding YouTube IDs [here](DATASETS.md).
* **[2023.11.26]** 📣📣📣 We have open-sourced fully fine-tuned **Video & Audio**, achieving improved performance once again, checking our [model zoo](#-model-zoo).
* **[2023.11.22]** We are about to release a fully fine-tuned version, and the **HUGE** version is currently undergoing training.
* **[2023.11.21]** 💥 We are releasing sample data in [DATASETS.md](DATASETS.md) so that individuals who are interested can further modify the code to train it on their own data.
* **[2023.11.20]** 🚀🚀🚀 [Video-LLaVA](https://github.com/PKU-YuanGroup/Video-LLaVA) builds a large visual-language model to achieve 🎉SOTA performances based on LanguageBind encoders.
* **[2023.10.23]** 🎶 LanguageBind-Audio achieves 🎉🎉🎉**state-of-the-art (SOTA) performance on 5 datasets**, checking our ✨ [results](#multiple-modalities)!
* **[2023.10.14]** 😱 Released a stronger LanguageBind-Video, checking our ✨ [results](#video-language)! The video checkpoint **have updated** on Huggingface Model Hub!
* **[2023.10.10]** We provide sample data, which can be found in [assets](assets), and [emergency zero-shot usage](#emergency-zero-shot) is described.
* **[2023.10.07]** The checkpoints are available on 🤗 [Huggingface Model](https://huggingface.co/LanguageBind).
* **[2023.10.04]** Code and [demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) are available now! Welcome to **watch** 👀 this repository for the latest updates.
## 😮 Highlights
### 💡 High performance, but NO intermediate modality required
LanguageBind is a **language-centric** multimodal pretraining approach, **taking the language as the bind across different modalities** because the language modality is well-explored and contains rich semantics.
* The following first figure shows the architecture of LanguageBind. LanguageBind can be easily extended to segmentation, detection tasks, and potentially to unlimited modalities.
### ⚡️ A multimodal, fully aligned and voluminous dataset
We propose **VIDAL-10M**, **10 Million data** with **V**ideo, **I**nfrared, **D**epth, **A**udio and their corresponding **L**anguage, which greatly expands the data beyond visual modalities.
* The second figure shows our proposed VIDAL-10M dataset, which includes five modalities: video, infrared, depth, audio, and language.
### 🔥 Multi-view enhanced description for training
We make multi-view enhancements to language. We produce multi-view description that combines **meta-data**, **spatial**, and **temporal** to greatly enhance the semantic information of the language. In addition we further **enhance the language with ChatGPT** to create a good semantic space for each modality aligned language.
## 🤗 Demo
* **Local demo.** Highly recommend trying out our web demo, which incorporates all features currently supported by LanguageBind.
```bash
python gradio_app.py
```
* **Online demo.** We provide the [online demo](https://huggingface.co/spaces/LanguageBind/LanguageBind) in Huggingface Spaces. In this demo, you can calculate the similarity of modalities to language, such as audio-to-language, video-to-language, and depth-to-image.
## 🛠️ Requirements and Installation
* Python >= 3.8
* Pytorch >= 1.13.1
* CUDA Version >= 11.6
* Install required packages:
```bash
git clone https://github.com/PKU-YuanGroup/LanguageBind
cd LanguageBind
pip install torch==1.13.1+cu116 torchvision==0.14.1+cu116 torchaudio==0.13.1 --extra-index-url https://download.pytorch.org/whl/cu116
pip install -r requirements.txt
```
## 🐳 Model Zoo
The names in the table represent different encoder models. For example, `LanguageBind/LanguageBind_Video_FT` represents the fully fine-tuned version, while `LanguageBind/LanguageBind_Video` represents the LoRA-tuned version.
You can freely replace them in the recommended [API usage](#-api). We recommend using the fully fine-tuned version, as it offers stronger performance.
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Modality</th><th>LoRA tuning</th><th>Fine-tuning</th>
</tr>
<tr align="center">
<td>Video</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">LanguageBind_Video</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">LanguageBind_Video_FT</a></td>
</tr>
<tr align="center">
<td>Audio</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio">LanguageBind_Audio</a></td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Audio_FT">LanguageBind_Audio_FT</a></td>
</tr>
<tr align="center">
<td>Depth</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Depth">LanguageBind_Depth</a></td><td>-</td>
</tr>
<tr align="center">
<td>Thermal</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Thermal">LanguageBind_Thermal</a></td><td>-</td>
</tr>
</table>
</div>
<div align="center">
<table border="1" width="100%">
<tr align="center">
<th>Version</th><th>Tuning</th><th>Model size</th><th>Num_frames</th><th>HF Link</th><th>MSR-VTT</th><th>DiDeMo</th><th>ActivityNet</th><th>MSVD</th>
</tr>
<tr align="center">
<td>LanguageBind_Video</td><td>LoRA</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video">Link</a></td><td>42.6</td><td>37.8</td><td>35.1</td><td>52.2</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_FT">Link</a></td><td>42.7</td><td>38.1</td><td>36.9</td><td>53.5</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_V1.5_FT">Link</a></td><td>42.8</td><td>39.7</td><td>38.4</td><td>54.1</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_V1.5_FT</td><td>Full-tuning</td><td>Large</td><td>12</td><td>Coming soon</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>8</td><td><a href="https://huggingface.co/LanguageBind/LanguageBind_Video_Huge_V1.5_FT">Link</a></td><td>44.8</td><td>39.9</td><td>41.0</td><td>53.7</td>
</tr>
<tr align="center">
<td>LanguageBind_Video_Huge_V1.5_FT</td><td>Full-tuning</td><td>Huge</td><td>12</td><td>Coming soon</td>
</tr>
</table>
</div>
## 🤖 API
**We open source all modalities preprocessing code.** If you want to load the model (e.g. ```LanguageBind/LanguageBind_Thermal```) from the model hub on Huggingface or on local, you can use the following code snippets!
### Inference for Multi-modal Binding
We have provided some sample datasets in [assets](assets) to quickly see how languagebind works.
```python
import torch
from languagebind import LanguageBind, to_device, transform_dict, LanguageBindImageTokenizer
if __name__ == '__main__':
device = 'cuda:0'
device = torch.device(device)
clip_type = {
'video': 'LanguageBind_Video_FT', # also LanguageBind_Video
'audio': 'LanguageBind_Audio_FT', # also LanguageBind_Audio
'thermal': 'LanguageBind_Thermal',
'image': 'LanguageBind_Image',
'depth': 'LanguageBind_Depth',
}
model = LanguageBind(clip_type=clip_type, cache_dir='./cache_dir')
model = model.to(device)
model.eval()
pretrained_ckpt = f'lb203/LanguageBind_Image'
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir/tokenizer_cache_dir')
modality_transform = {c: transform_dict[c](model.modality_config[c]) for c in clip_type.keys()}
image = ['assets/image/0.jpg', 'assets/image/1.jpg']
audio = ['assets/audio/0.wav', 'assets/audio/1.wav']
video = ['assets/video/0.mp4', 'assets/video/1.mp4']
depth = ['assets/depth/0.png', 'assets/depth/1.png']
thermal = ['assets/thermal/0.jpg', 'assets/thermal/1.jpg']
language = ["Training a parakeet to climb up a ladder.", 'A lion climbing a tree to catch a monkey.']
inputs = {
'image': to_device(modality_transform['image'](image), device),
'video': to_device(modality_transform['video'](video), device),
'audio': to_device(modality_transform['audio'](audio), device),
'depth': to_device(modality_transform['depth'](depth), device),
'thermal': to_device(modality_transform['thermal'](thermal), device),
}
inputs['language'] = to_device(tokenizer(language, max_length=77, padding='max_length',
truncation=True, return_tensors='pt'), device)
with torch.no_grad():
embeddings = model(inputs)
print("Video x Text: \n",
torch.softmax(embeddings['video'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Image x Text: \n",
torch.softmax(embeddings['image'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Depth x Text: \n",
torch.softmax(embeddings['depth'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Audio x Text: \n",
torch.softmax(embeddings['audio'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
print("Thermal x Text: \n",
torch.softmax(embeddings['thermal'] @ embeddings['language'].T, dim=-1).detach().cpu().numpy())
```
Then returns the following result.
```bash
Video x Text:
[[9.9989331e-01 1.0667283e-04]
[1.3255903e-03 9.9867439e-01]]
Image x Text:
[[9.9990666e-01 9.3292067e-05]
[4.6132666e-08 1.0000000e+00]]
Depth x Text:
[[0.9954276 0.00457235]
[0.12042473 0.8795753 ]]
Audio x Text:
[[0.97634876 0.02365119]
[0.02917843 0.97082156]]
Thermal x Text:
[[0.9482511 0.0517489 ]
[0.48746133 0.5125386 ]]
```
### Emergency zero-shot
Since languagebind binds each modality together, we also found the **emergency zero-shot**. It's very simple to use.
```python
print("Video x Audio: \n", torch.softmax(embeddings['video'] @ embeddings['audio'].T, dim=-1).detach().cpu().numpy())
print("Image x Depth: \n", torch.softmax(embeddings['image'] @ embeddings['depth'].T, dim=-1).detach().cpu().numpy())
print("Image x Thermal: \n", torch.softmax(embeddings['image'] @ embeddings['thermal'].T, dim=-1).detach().cpu().numpy())
```
Then, you will get:
```
Video x Audio:
[[1.0000000e+00 0.0000000e+00]
[3.1150486e-32 1.0000000e+00]]
Image x Depth:
[[1. 0.]
[0. 1.]]
Image x Thermal:
[[1. 0.]
[0. 1.]]
```
### Different branches for X-Language task
Additionally, LanguageBind can be **disassembled into different branches** to handle different tasks. Note that we do not train Image, which just initialize from OpenCLIP.
#### Thermal
```python
import torch
from languagebind import LanguageBindThermal, LanguageBindThermalTokenizer, LanguageBindThermalProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Thermal'
model = LanguageBindThermal.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindThermalTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
thermal_process = LanguageBindThermalProcessor(model.config, tokenizer)
model.eval()
data = thermal_process([r"your/thermal.jpg"], ['your text'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Depth
```python
import torch
from languagebind import LanguageBindDepth, LanguageBindDepthTokenizer, LanguageBindDepthProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Depth'
model = LanguageBindDepth.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindDepthTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
depth_process = LanguageBindDepthProcessor(model.config, tokenizer)
model.eval()
data = depth_process([r"your/depth.png"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Video
```python
import torch
from languagebind import LanguageBindVideo, LanguageBindVideoTokenizer, LanguageBindVideoProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Video_FT' # also 'LanguageBind/LanguageBind_Video'
model = LanguageBindVideo.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindVideoTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
video_process = LanguageBindVideoProcessor(model.config, tokenizer)
model.eval()
data = video_process(["your/video.mp4"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Audio
```python
import torch
from languagebind import LanguageBindAudio, LanguageBindAudioTokenizer, LanguageBindAudioProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Audio_FT' # also 'LanguageBind/LanguageBind_Audio'
model = LanguageBindAudio.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindAudioTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
audio_process = LanguageBindAudioProcessor(model.config, tokenizer)
model.eval()
data = audio_process([r"your/audio.wav"], ['your audio.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
#### Image
Note that our image encoder is the same as OpenCLIP. **Not** as fine-tuned as other modalities.
```python
import torch
from languagebind import LanguageBindImage, LanguageBindImageTokenizer, LanguageBindImageProcessor
pretrained_ckpt = 'LanguageBind/LanguageBind_Image'
model = LanguageBindImage.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
tokenizer = LanguageBindImageTokenizer.from_pretrained(pretrained_ckpt, cache_dir='./cache_dir')
image_process = LanguageBindImageProcessor(model.config, tokenizer)
model.eval()
data = image_process([r"your/image.jpg"], ['your text.'], return_tensors='pt')
with torch.no_grad():
out = model(**data)
print(out.text_embeds @ out.image_embeds.T)
```
## 💥 VIDAL-10M
The datasets is in [DATASETS.md](DATASETS.md).
## 🗝️ Training & Validating
The training & validating instruction is in [TRAIN_AND_VALIDATE.md](TRAIN_AND_VALIDATE.md).
## 👍 Acknowledgement
* [OpenCLIP](https://github.com/mlfoundations/open_clip) An open source pretraining framework.
* [CLIP4Clip](https://github.com/ArrowLuo/CLIP4Clip) An open source Video-Text retrieval framework.
* [sRGB-TIR](https://github.com/rpmsnu/sRGB-TIR) An open source framework to generate infrared (thermal) images.
* [GLPN](https://github.com/vinvino02/GLPDepth) An open source framework to generate depth images.
## 🔒 License
* The majority of this project is released under the MIT license as found in the [LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/LICENSE) file.
* The dataset of this project is released under the CC-BY-NC 4.0 license as found in the [DATASET_LICENSE](https://github.com/PKU-YuanGroup/LanguageBind/blob/main/DATASET_LICENSE) file.
## ✏️ Citation
If you find our paper and code useful in your research, please consider giving a star :star: and citation :pencil:.
```BibTeX
@misc{zhu2023languagebind,
title={LanguageBind: Extending Video-Language Pretraining to N-modality by Language-based Semantic Alignment},
author={Bin Zhu and Bin Lin and Munan Ning and Yang Yan and Jiaxi Cui and Wang HongFa and Yatian Pang and Wenhao Jiang and Junwu Zhang and Zongwei Li and Cai Wan Zhang and Zhifeng Li and Wei Liu and Li Yuan},
year={2023},
eprint={2310.01852},
archivePrefix={arXiv},
primaryClass={cs.CV}
}
```
## ✨ Star History
[](https://star-history.com/#PKU-YuanGroup/LanguageBind&Date)
## 🤝 Contributors
<a href="https://github.com/PKU-YuanGroup/LanguageBind/graphs/contributors">
<img src="https://contrib.rocks/image?repo=PKU-YuanGroup/LanguageBind" />
</a>
|
delphi-suite/v0-llama2-6.4m | delphi-suite | 2024-01-19T10:13:07Z | 392 | 0 | transformers | [
"transformers",
"pytorch",
"llama",
"text-generation",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-01-19T10:11:53Z | ---
license: mit
---
|
David-Xu/llama-2-7b-chat-sft | David-Xu | 2024-03-14T07:35:42Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"arxiv:1910.09700",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2024-03-08T01:13:38Z | ---
library_name: transformers
license: mit
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
unsloth/gemma-1.1-7b-it-bnb-4bit | unsloth | 2024-04-18T15:03:42Z | 392 | 2 | transformers | [
"transformers",
"safetensors",
"gemma",
"text-generation",
"unsloth",
"gemma-7b",
"bnb",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"4-bit",
"bitsandbytes",
"region:us"
]
| text-generation | 2024-04-07T10:12:19Z | ---
language:
- en
license: apache-2.0
library_name: transformers
tags:
- unsloth
- transformers
- gemma
- gemma-7b
- bnb
---
# Finetune Mistral, Gemma, Llama 2-5x faster with 70% less memory via Unsloth!
We have a Google Colab Tesla T4 notebook for Gemma 7b here: https://colab.research.google.com/drive/10NbwlsRChbma1v55m8LAPYG15uQv6HLo?usp=sharing
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/Discord%20button.png" width="200"/>](https://discord.gg/u54VK8m8tk)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/buy%20me%20a%20coffee%20button.png" width="200"/>](https://ko-fi.com/unsloth)
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" width="200"/>](https://github.com/unslothai/unsloth)
## ✨ Finetune for Free
All notebooks are **beginner friendly**! Add your dataset, click "Run All", and you'll get a 2x faster finetuned model which can be exported to GGUF, vLLM or uploaded to Hugging Face.
| Unsloth supports | Free Notebooks | Performance | Memory use |
|-----------------|--------------------------------------------------------------------------------------------------------------------------|-------------|----------|
| **Gemma 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/10NbwlsRChbma1v55m8LAPYG15uQv6HLo?usp=sharing) | 2.4x faster | 58% less |
| **Mistral 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1Dyauq4kTZoLewQ1cApceUQVNcnnNTzg_?usp=sharing) | 2.2x faster | 62% less |
| **Llama-2 7b** | [▶️ Start on Colab](https://colab.research.google.com/drive/1lBzz5KeZJKXjvivbYvmGarix9Ao6Wxe5?usp=sharing) | 2.2x faster | 43% less |
| **TinyLlama** | [▶️ Start on Colab](https://colab.research.google.com/drive/1AZghoNBQaMDgWJpi4RbffGM1h6raLUj9?usp=sharing) | 3.9x faster | 74% less |
| **CodeLlama 34b** A100 | [▶️ Start on Colab](https://colab.research.google.com/drive/1y7A0AxE3y8gdj4AVkl2aZX47Xu3P1wJT?usp=sharing) | 1.9x faster | 27% less |
| **Mistral 7b** 1xT4 | [▶️ Start on Kaggle](https://www.kaggle.com/code/danielhanchen/kaggle-mistral-7b-unsloth-notebook) | 5x faster\* | 62% less |
| **DPO - Zephyr** | [▶️ Start on Colab](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) | 1.9x faster | 19% less |
- This [conversational notebook](https://colab.research.google.com/drive/1Aau3lgPzeZKQ-98h69CCu1UJcvIBLmy2?usp=sharing) is useful for ShareGPT ChatML / Vicuna templates.
- This [text completion notebook](https://colab.research.google.com/drive/1ef-tab5bhkvWmBOObepl1WgJvfvSzn5Q?usp=sharing) is for raw text. This [DPO notebook](https://colab.research.google.com/drive/15vttTpzzVXv_tJwEk-hIcQ0S9FcEWvwP?usp=sharing) replicates Zephyr.
- \* Kaggle has 2x T4s, but we use 1. Due to overhead, 1x T4 is 5x faster.
|
MatthieuJ/ECE-TW3-JRGL-V5 | MatthieuJ | 2024-04-10T19:16:39Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"davidkim205/Rhea-72b-v0.5",
"abacusai/Smaug-72B-v0.1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-10T18:58:42Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- davidkim205/Rhea-72b-v0.5
- abacusai/Smaug-72B-v0.1
---
# ECE-TW3-JRGL-V5
ECE-TW3-JRGL-V5 is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [davidkim205/Rhea-72b-v0.5](https://huggingface.co/davidkim205/Rhea-72b-v0.5)
* [abacusai/Smaug-72B-v0.1](https://huggingface.co/abacusai/Smaug-72B-v0.1)
## 🧩 Configuration |
allknowingroger/Calmex26-10B-MoE | allknowingroger | 2024-04-12T08:20:14Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"frankenmoe",
"merge",
"mergekit",
"lazymergekit",
"allknowingroger/MultiverseEx26-7B-slerp",
"allknowingroger/CalmExperiment-7B-slerp",
"base_model:allknowingroger/MultiverseEx26-7B-slerp",
"base_model:allknowingroger/CalmExperiment-7B-slerp",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-12T08:12:58Z | ---
license: apache-2.0
tags:
- moe
- frankenmoe
- merge
- mergekit
- lazymergekit
- allknowingroger/MultiverseEx26-7B-slerp
- allknowingroger/CalmExperiment-7B-slerp
base_model:
- allknowingroger/MultiverseEx26-7B-slerp
- allknowingroger/CalmExperiment-7B-slerp
---
# Calmex26-10B-MoE
Calmex26-10B-MoE is a Mixture of Experts (MoE) made with the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [allknowingroger/MultiverseEx26-7B-slerp](https://huggingface.co/allknowingroger/MultiverseEx26-7B-slerp)
* [allknowingroger/CalmExperiment-7B-slerp](https://huggingface.co/allknowingroger/CalmExperiment-7B-slerp)
## 🧩 Configuration
```yaml
base_model: allknowingroger/MultiverseEx26-7B-slerp
experts:
- source_model: allknowingroger/MultiverseEx26-7B-slerp
positive_prompts: ["what"]
- source_model: allknowingroger/CalmExperiment-7B-slerp
positive_prompts: ["why"]
```
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "allknowingroger/Calmex26-10B-MoE"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
KnutJaegersberg/WizardLM-2-8x22B | KnutJaegersberg | 2024-04-16T03:56:06Z | 392 | 1 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"arxiv:2304.12244",
"arxiv:2306.08568",
"arxiv:2308.09583",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-16T03:56:06Z | ---
license: apache-2.0
---
<p style="font-size:20px;" align="center">
🏠 <a href="https://wizardlm.github.io/WizardLM2" target="_blank">WizardLM-2 Release Blog</a> </p>
<p align="center">
🤗 <a href="https://huggingface.co/collections/microsoft/wizardlm-2-661d403f71e6c8257dbd598a" target="_blank">HF Repo</a> •🐱 <a href="https://github.com/victorsungo/WizardLM/tree/main/WizardLM-2" target="_blank">Github Repo</a> • 🐦 <a href="https://twitter.com/WizardLM_AI" target="_blank">Twitter</a> • 📃 <a href="https://arxiv.org/abs/2304.12244" target="_blank">[WizardLM]</a> • 📃 <a href="https://arxiv.org/abs/2306.08568" target="_blank">[WizardCoder]</a> • 📃 <a href="https://arxiv.org/abs/2308.09583" target="_blank">[WizardMath]</a> <br>
</p>
<p align="center">
👋 Join our <a href="https://discord.gg/VZjjHtWrKs" target="_blank">Discord</a>
</p>
## News 🔥🔥🔥 [2024/04/15]
We introduce and opensource WizardLM-2, our next generation state-of-the-art large language models,
which have improved performance on complex chat, multilingual, reasoning and agent.
New family includes three cutting-edge models: WizardLM-2 8x22B, WizardLM-2 70B, and WizardLM-2 7B.
- WizardLM-2 8x22B is our most advanced model, demonstrates highly competitive performance compared to those leading proprietary works
and consistently outperforms all the existing state-of-the-art opensource models.
- WizardLM-2 70B reaches top-tier reasoning capabilities and is the first choice in the same size.
- WizardLM-2 7B is the fastest and achieves comparable performance with existing 10x larger opensource leading models.
For more details of WizardLM-2 please read our [release blog post](https://wizardlm.github.io/WizardLM2) and upcoming paper.
## Model Details
* **Model name**: WizardLM-2 8x22B
* **Developed by**: WizardLM@Microsoft AI
* **Model type**: Mixture of Experts (MoE)
* **Base model**: [mistral-community/Mixtral-8x22B-v0.1](https://huggingface.co/mistral-community/Mixtral-8x22B-v0.1)
* **Parameters**: 141B
* **Language(s)**: Multilingual
* **Blog**: [Introducing WizardLM-2](https://wizardlm.github.io/WizardLM2)
* **Repository**: [https://github.com/nlpxucan/WizardLM](https://github.com/nlpxucan/WizardLM)
* **Paper**: WizardLM-2 (Upcoming)
* **License**: Apache2.0
## Model Capacities
**MT-Bench**
We also adopt the automatic MT-Bench evaluation framework based on GPT-4 proposed by lmsys to assess the performance of models.
The WizardLM-2 8x22B even demonstrates highly competitive performance compared to the most advanced proprietary models.
Meanwhile, WizardLM-2 7B and WizardLM-2 70B are all the top-performing models among the other leading baselines at 7B to 70B model scales.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/mtbench.png" alt="MTBench" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
**Human Preferences Evaluation**
We carefully collected a complex and challenging set consisting of real-world instructions, which includes main requirements of humanity, such as writing, coding, math, reasoning, agent, and multilingual.
We report the win:loss rate without tie:
- WizardLM-2 8x22B is just slightly falling behind GPT-4-1106-preview, and significantly stronger than Command R Plus and GPT4-0314.
- WizardLM-2 70B is better than GPT4-0613, Mistral-Large, and Qwen1.5-72B-Chat.
- WizardLM-2 7B is comparable with Qwen1.5-32B-Chat, and surpasses Qwen1.5-14B-Chat and Starling-LM-7B-beta.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/winall.png" alt="Win" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Method Overview
We built a **fully AI powered synthetic training system** to train WizardLM-2 models, please refer to our [blog](https://wizardlm.github.io/WizardLM2) for more details of this system.
<p align="center" width="100%">
<a ><img src="https://raw.githubusercontent.com/WizardLM/WizardLM2/main/static/images/exp_1.png" alt="Method" style="width: 96%; min-width: 300px; display: block; margin: auto;"></a>
</p>
## Usage
❗<b>Note for model system prompts usage:</b>
<b>WizardLM-2</b> adopts the prompt format from <b>Vicuna</b> and supports **multi-turn** conversation. The prompt should be as following:
```
A chat between a curious user and an artificial intelligence assistant. The assistant gives helpful,
detailed, and polite answers to the user's questions. USER: Hi ASSISTANT: Hello.</s>
USER: Who are you? ASSISTANT: I am WizardLM.</s>......
```
<b> Inference WizardLM-2 Demo Script</b>
We provide a WizardLM-2 inference demo [code](https://github.com/nlpxucan/WizardLM/tree/main/demo) on our github.
|
flammenai/flammen18-mistral-7B | flammenai | 2024-04-17T03:43:59Z | 392 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"arxiv:2403.19522",
"base_model:nbeerbower/flammen11-mistral-7B",
"base_model:nbeerbower/flammen15-gutenberg-DPO-v1-7B",
"base_model:nbeerbower/Flammen-Kunoichi-7B",
"base_model:nbeerbower/flammen11X-mistral-7B",
"base_model:nbeerbower/Maidphin-Kunoichi-7B",
"base_model:nbeerbower/Suppe-v1-7B",
"base_model:nbeerbower/flammen10-mistral-7B",
"base_model:nbeerbower/bruphin-lambda",
"base_model:nbeerbower/flammen13-mistral-7B",
"base_model:nbeerbower/bophades-mistral-truthy-DPO-7B",
"base_model:nbeerbower/flammen17-mistral-7B",
"base_model:nbeerbower/bophades-mistral-math-DPO-7B",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-17T02:25:16Z | ---
license: apache-2.0
base_model:
- nbeerbower/flammen11-mistral-7B
- nbeerbower/flammen15-gutenberg-DPO-v1-7B
- nbeerbower/Flammen-Kunoichi-7B
- nbeerbower/flammen11X-mistral-7B
- nbeerbower/Maidphin-Kunoichi-7B
- nbeerbower/Suppe-v1-7B
- nbeerbower/flammen10-mistral-7B
- nbeerbower/bruphin-lambda
- nbeerbower/flammen13-mistral-7B
- nbeerbower/bophades-mistral-truthy-DPO-7B
- nbeerbower/flammen17-mistral-7B
- nbeerbower/bophades-mistral-math-DPO-7B
library_name: transformers
tags:
- mergekit
- merge
---

# flammen18-mistral-7B
A Mistral 7B LLM built from merging pretrained models and finetuning. Flammen specializes in exceptional character roleplay, creative writing, and general intelligence
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [nbeerbower/flammen17-mistral-7B](https://huggingface.co/nbeerbower/flammen17-mistral-7B) as a base.
### Models Merged
The following models were included in the merge:
* [nbeerbower/flammen11-mistral-7B](https://huggingface.co/nbeerbower/flammen11-mistral-7B)
* [nbeerbower/flammen15-gutenberg-DPO-v1-7B](https://huggingface.co/nbeerbower/flammen15-gutenberg-DPO-v1-7B)
* [nbeerbower/Flammen-Kunoichi-7B](https://huggingface.co/nbeerbower/Flammen-Kunoichi-7B)
* [nbeerbower/flammen11X-mistral-7B](https://huggingface.co/nbeerbower/flammen11X-mistral-7B)
* [nbeerbower/Maidphin-Kunoichi-7B](https://huggingface.co/nbeerbower/Maidphin-Kunoichi-7B)
* [nbeerbower/Suppe-v1-7B](https://huggingface.co/nbeerbower/Suppe-v1-7B)
* [nbeerbower/flammen10-mistral-7B](https://huggingface.co/nbeerbower/flammen10-mistral-7B)
* [nbeerbower/bruphin-lambda](https://huggingface.co/nbeerbower/bruphin-lambda)
* [nbeerbower/flammen13-mistral-7B](https://huggingface.co/nbeerbower/flammen13-mistral-7B)
* [nbeerbower/bophades-mistral-truthy-DPO-7B](https://huggingface.co/nbeerbower/bophades-mistral-truthy-DPO-7B)
* [nbeerbower/bophades-mistral-math-DPO-7B](https://huggingface.co/nbeerbower/bophades-mistral-math-DPO-7B)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: nbeerbower/bophades-mistral-truthy-DPO-7B
- model: nbeerbower/flammen11-mistral-7B
- model: nbeerbower/Suppe-v1-7B
- model: nbeerbower/bophades-mistral-math-DPO-7B
- model: nbeerbower/flammen10-mistral-7B
- model: nbeerbower/flammen15-gutenberg-DPO-v1-7B
- model: nbeerbower/bruphin-lambda
- model: nbeerbower/Maidphin-Kunoichi-7B
- model: nbeerbower/flammen11X-mistral-7B
- model: nbeerbower/flammen13-mistral-7B
- model: nbeerbower/Flammen-Kunoichi-7B
merge_method: model_stock
base_model: nbeerbower/flammen17-mistral-7B
dtype: bfloat16
```
|
birgermoell/Llama-3-dare_ties | birgermoell | 2024-04-19T22:00:05Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"meta-llama/Meta-Llama-3-8B-Instruct",
"conversational",
"base_model:meta-llama/Meta-Llama-3-8B-Instruct",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-18T22:10:49Z | ---
tags:
- merge
- mergekit
- lazymergekit
- meta-llama/Meta-Llama-3-8B-Instruct
base_model:
- meta-llama/Meta-Llama-3-8B-Instruct
license: llama2
---
# Llama-3-dare_ties
<img src="merge_ties.png"/>
Llama-3-dare_ties is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct)
## 🧩 Configuration
```yaml
models:
- model: meta-llama/Meta-Llama-3-8B
- model: meta-llama/Meta-Llama-3-8B-Instruct
parameters:
density: 0.53
weight: 0.6
merge_method: dare_ties
base_model: meta-llama/Meta-Llama-3-8B
parameters:
int8_mask: true
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "birgermoell/Llama-3-dare_ties"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE | NotAiLOL | 2024-04-19T09:00:01Z | 392 | 1 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"moe",
"merge",
"mergekit",
"NousResearch/Nous-Hermes-2-SOLAR-10.7B",
"upstage/SOLAR-10.7B-Instruct-v1.0",
"llama",
"Llama",
"conversational",
"base_model:NousResearch/Nous-Hermes-2-SOLAR-10.7B",
"base_model:upstage/SOLAR-10.7B-Instruct-v1.0",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-19T08:14:00Z | ---
license: apache-2.0
tags:
- moe
- merge
- mergekit
- NousResearch/Nous-Hermes-2-SOLAR-10.7B
- upstage/SOLAR-10.7B-Instruct-v1.0
- llama
- Llama
base_model:
- NousResearch/Nous-Hermes-2-SOLAR-10.7B
- upstage/SOLAR-10.7B-Instruct-v1.0
---
# Boundary-Solar-Chat-2x10.7B-MoE
Boundary-Solar-Chat-2x10.7B-MoE is a Mixture of Experts (MoE) made with the following models:
* [NousResearch/Nous-Hermes-2-SOLAR-10.7B](https://huggingface.co/NousResearch/Nous-Hermes-2-SOLAR-10.7B)
* [upstage/SOLAR-10.7B-Instruct-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0)
## 🧩 Configuration
```yaml
base_model: NousResearch/Nous-Hermes-2-SOLAR-10.7B
dtype: float16
gate_mode: cheap_embed
experts:
- source_model: NousResearch/Nous-Hermes-2-SOLAR-10.7B
positive_prompts: ["You are a helpful general assistant."]
- source_model: upstage/SOLAR-10.7B-Instruct-v1.0
positive_prompts: ["You are assistant for question and answering."]
```
## 💻 Usage
```python
!pip install -qU transformers bitsandbytes accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "NotAiLOL/Boundary-Solar-Chat-2x10.7B-MoE"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
Omartificial-Intelligence-Space/al-baka-16bit-llama3-8b | Omartificial-Intelligence-Space | 2024-05-04T09:43:33Z | 392 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"alpaca",
"llama3",
"arabic",
"conversational",
"ar",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-21T10:18:08Z | ---
license: apache-2.0
language:
- ar
- en
tags:
- alpaca
- llama3
- arabic
library_name: transformers
---
# 🚀 al-baka-llama3-8b (Main Model)
[<img src="https://i.ibb.co/fMsBM0M/Screenshot-2024-04-20-at-3-04-34-AM.png" width="150"/>](https://www.omarai.co)
Al Baka is an Fine Tuned Model based on the new released LLAMA3-8B Model on the Stanford Alpaca dataset Arabic version [Yasbok/Alpaca_arabic_instruct](https://huggingface.co/datasets/Yasbok/Alpaca_arabic_instruct).
## Model Summary
- **Model Type:** Llama3-8B FineTuned Model (16-bit Version)
- **Language(s):** Arabic, English
- **Base Model:** [LLAMA-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B)
- **Dataset:** [Yasbok/Alpaca_arabic_instruct](https://huggingface.co/datasets/Yasbok/Alpaca_arabic_instruct)
## Model Details
- The model was fine-tuned and mergen in 16-bit precision using [unsloth](https://github.com/unslothai/unsloth)
## How to Get Started with the Model
### Setup
```python
# Install packages
%%capture
import torch
major_version, minor_version = torch.cuda.get_device_capability()
!pip install "unsloth[colab-new] @ git+https://github.com/unslothai/unsloth.git"
if major_version >= 8:
# Use this for new GPUs like Ampere, Hopper GPUs (RTX 30xx, RTX 40xx, A100, H100, L40)
!pip install --no-deps packaging ninja einops flash-attn xformers trl peft accelerate bitsandbytes
else:
# Use this for older GPUs (V100, Tesla T4, RTX 20xx)
!pip install --no-deps xformers trl peft accelerate bitsandbytes
pass
```
### First, Load the Model
```python
from unsloth import FastLanguageModel
import torch
max_seq_length = 2048 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "Omartificial-Intelligence-Space/al-baka-16bit-llama3-8b",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
```
### Second, Try the model
```python
alpaca_prompt = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request.
### Instruction:
{}
### Input:
{}
### Response:
{}"""
# alpaca_prompt = Copied from above
FastLanguageModel.for_inference(model) # Enable native 2x faster inference
inputs = tokenizer(
[
alpaca_prompt.format(
"استخدم البيانات المعطاة لحساب الوسيط.", # instruction
"[2 ، 3 ، 7 ، 8 ، 10]", # input
"", # output - leave this blank for generation!
)
], return_tensors = "pt").to("cuda")
outputs = model.generate(**inputs, max_new_tokens = 64, use_cache = True)
tokenizer.batch_decode(outputs)
```
### Recommendations
- [unsloth](https://github.com/unslothai/unsloth) for finetuning models. You can get a 2x faster finetuned model which can be exported to any format or uploaded to Hugging Face. |
skuma307/OrpoLlama3-8B-FT | skuma307 | 2024-04-21T13:23:28Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-21T12:48:26Z | ---
library_name: transformers
license: apache-2.0
datasets:
- HuggingFaceH4/ultrafeedback_binarized
pipeline_tag: text-generation
---
# Model Card for OrpoLlama3-8B-FT
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card for OrpoLlama3-8B-FT model that has been pushed on the Hub. This model is fine tuned using ORPO.
- **Developed by:** Sonu Kumar
- **Model type:** Llama3
- **License:** Apache 2.0
- **Finetuned from model [optional]:** https://huggingface.co/meta-llama/Meta-Llama-3-8B |
jonasknobloch/gpt2-morf_s0-30-x-2_cx-en_00000-00009_50k | jonasknobloch | 2024-04-21T22:03:13Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"gpt2",
"text-generation",
"generated_from_trainer",
"en",
"dataset:uonlp/CulturaX",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-21T18:14:58Z | ---
tags:
- generated_from_trainer
datasets:
- uonlp/CulturaX
metrics:
- accuracy
model-index:
- name: gpt2+morf_s0-30-x-2_cx-en_00000-00009_50k
results:
- task:
name: Causal Language Modeling
type: text-generation
dataset:
name: uonlp/CulturaX en
type: uonlp/CulturaX
args: en
metrics:
- name: Accuracy
type: accuracy
value: 0.4329592727693433
license: mit
language:
- en
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# gpt2+morf_s0-30-x-2_cx-en_00000-00009_50k
This model is a fine-tuned version of [](https://huggingface.co/) on the uonlp/CulturaX en dataset.
It achieves the following results on the evaluation set:
- Loss: 2.8423
- Accuracy: 0.4330
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-05
- train_batch_size: 64
- eval_batch_size: 64
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 1.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:------:|:---------------:|:--------:|
| 3.6569 | 0.03 | 10000 | 3.5764 | 0.3502 |
| 3.4317 | 0.06 | 20000 | 3.3581 | 0.3727 |
| 3.3161 | 0.09 | 30000 | 3.2447 | 0.3848 |
| 3.2463 | 0.13 | 40000 | 3.1761 | 0.3924 |
| 3.1897 | 0.16 | 50000 | 3.1277 | 0.3977 |
| 3.152 | 0.19 | 60000 | 3.0910 | 0.4022 |
| 3.1341 | 0.22 | 70000 | 3.0575 | 0.4060 |
| 3.1006 | 0.25 | 80000 | 3.0363 | 0.4084 |
| 3.0806 | 0.28 | 90000 | 3.0118 | 0.4115 |
| 3.0555 | 0.31 | 100000 | 2.9919 | 0.4138 |
| 3.038 | 0.34 | 110000 | 2.9786 | 0.4156 |
| 3.0291 | 0.38 | 120000 | 2.9651 | 0.4171 |
| 3.0182 | 0.41 | 130000 | 2.9499 | 0.4191 |
| 3.0145 | 0.44 | 140000 | 2.9381 | 0.4205 |
| 2.9891 | 0.47 | 150000 | 2.9272 | 0.4219 |
| 2.9836 | 0.5 | 160000 | 2.9191 | 0.4230 |
| 2.9717 | 0.53 | 170000 | 2.9103 | 0.4241 |
| 2.9651 | 0.56 | 180000 | 2.9039 | 0.4250 |
| 2.9615 | 0.59 | 190000 | 2.8971 | 0.4258 |
| 2.9556 | 0.63 | 200000 | 2.8882 | 0.4269 |
| 2.9452 | 0.66 | 210000 | 2.8825 | 0.4277 |
| 2.9412 | 0.69 | 220000 | 2.8766 | 0.4284 |
| 2.9402 | 0.72 | 230000 | 2.8722 | 0.4290 |
| 2.9299 | 0.75 | 240000 | 2.8675 | 0.4296 |
| 2.9302 | 0.78 | 250000 | 2.8623 | 0.4304 |
| 2.9165 | 0.81 | 260000 | 2.8585 | 0.4308 |
| 2.915 | 0.84 | 270000 | 2.8537 | 0.4314 |
| 2.92 | 0.88 | 280000 | 2.8506 | 0.4319 |
| 2.9186 | 0.91 | 290000 | 2.8484 | 0.4321 |
| 2.9084 | 0.94 | 300000 | 2.8458 | 0.4325 |
| 2.9142 | 0.97 | 310000 | 2.8438 | 0.4327 |
### Framework versions
- Transformers 4.37.1
- Pytorch 2.1.2+cu121
- Datasets 2.16.1
- Tokenizers 0.15.1 |
pszemraj/griffin-v0.01-c3t-8layer-simplewiki | pszemraj | 2024-04-25T00:49:49Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"recurrent_gemma",
"text-generation",
"generated_from_trainer",
"en",
"dataset:pszemraj/simple_wikipedia_LM",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-24T03:24:17Z | ---
tags:
- generated_from_trainer
metrics:
- accuracy
license: apache-2.0
datasets:
- pszemraj/simple_wikipedia_LM
language:
- en
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# pszemraj/griffin-v0.01-c3t-8layer-simplewiki
- griffin/recurrent_gemma arch
- claude3 tokenizer (as an HF gpt2 tokenizer)
## Model description
This model is a fine-tuned version of [./griffin-1024-c3t-8layer](https://huggingface.co/./griffin-1024-c3t-8layer) on an unknown dataset.
It achieves the following results on the evaluation set:
- Loss: 4.1928
- Accuracy: 0.4084
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 0.0003
- train_batch_size: 4
- eval_batch_size: 4
- seed: 80085
- gradient_accumulation_steps: 32
- total_train_batch_size: 128
- optimizer: Adam with betas=(0.9,0.99) and epsilon=1e-07
- lr_scheduler_type: constant_with_warmup
- lr_scheduler_warmup_ratio: 0.05
- num_epochs: 2.0
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:------:|:----:|:---------------:|:--------:|
| 13.2525 | 0.2548 | 100 | 11.9768 | 0.0131 |
| 8.8873 | 0.5095 | 200 | 8.0127 | 0.0357 |
| 7.2457 | 0.7643 | 300 | 6.4508 | 0.0512 |
| 6.3152 | 1.0190 | 400 | 5.6163 | 0.0460 |
| 5.5586 | 1.2738 | 500 | 4.7645 | 0.3650 |
| 5.2936 | 1.5285 | 600 | 4.3919 | 0.3934 |
| 4.8839 | 1.7833 | 700 | 4.1928 | 0.4084 |
### Framework versions
- Transformers 4.40.1
- Pytorch 2.2.0+cu121
- Datasets 2.19.0
- Tokenizers 0.19.1 |
thesven/thesven-OrpoLlama-3-8B-bnb-4bit | thesven | 2024-04-25T22:40:36Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"dataset:mlabonne/orpo-dpo-mix-40k",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-25T21:21:04Z | ---
library_name: transformers
license: mit
datasets:
- mlabonne/orpo-dpo-mix-40k
---
# Model Card for Model ID
## Model Details
Fine tuned version of Llama3 8B. 4 bit quantized with Bits and Bytes. Fine tuned for 1 epoch for 58 hours on an Nvidia a5000.
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** Michael Svendsen
- **Finetuned from model [Llama3-8b]:**
|
ShenaoZhang/0.001_3iters_bs256_nodpo_only4w_iter_1 | ShenaoZhang | 2024-04-28T04:57:18Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"generated_from_trainer",
"trl",
"dpo",
"conversational",
"dataset:updated",
"dataset:original",
"base_model:HuggingFaceH4/mistral-7b-sft-beta",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-28T04:02:02Z | ---
license: mit
base_model: HuggingFaceH4/mistral-7b-sft-beta
tags:
- alignment-handbook
- generated_from_trainer
- trl
- dpo
- generated_from_trainer
datasets:
- updated
- original
model-index:
- name: 0.001_3iters_bs256_nodpo_only4w_iter_1
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# 0.001_3iters_bs256_nodpo_only4w_iter_1
This model is a fine-tuned version of [HuggingFaceH4/mistral-7b-sft-beta](https://huggingface.co/HuggingFaceH4/mistral-7b-sft-beta) on the updated and the original datasets.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 8
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 4
- total_train_batch_size: 256
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.36.2
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.2
|
tomaarsen/xlm-roberta-base-multilingual-en-ar-fr-de-es-tr-it | tomaarsen | 2024-05-02T14:28:46Z | 392 | 4 | sentence-transformers | [
"sentence-transformers",
"safetensors",
"xlm-roberta",
"sentence-similarity",
"feature-extraction",
"loss:MSELoss",
"en",
"multilingual",
"ar",
"bg",
"ca",
"cs",
"da",
"de",
"el",
"es",
"et",
"fa",
"fi",
"fr",
"gl",
"gu",
"he",
"hi",
"hr",
"hu",
"hy",
"id",
"it",
"ja",
"ka",
"ko",
"ku",
"lt",
"lv",
"mk",
"mn",
"mr",
"ms",
"my",
"nb",
"nl",
"pl",
"pt",
"ro",
"ru",
"sk",
"sl",
"sq",
"sr",
"sv",
"th",
"tr",
"uk",
"ur",
"vi",
"zh",
"arxiv:1908.10084",
"arxiv:2004.09813",
"base_model:FacebookAI/xlm-roberta-base",
"model-index",
"co2_eq_emissions",
"endpoints_compatible",
"region:us"
]
| sentence-similarity | 2024-05-02T14:27:33Z | ---
language:
- en
- multilingual
- ar
- bg
- ca
- cs
- da
- de
- el
- es
- et
- fa
- fi
- fr
- gl
- gu
- he
- hi
- hr
- hu
- hy
- id
- it
- ja
- ka
- ko
- ku
- lt
- lv
- mk
- mn
- mr
- ms
- my
- nb
- nl
- pl
- pt
- ro
- ru
- sk
- sl
- sq
- sr
- sv
- th
- tr
- uk
- ur
- vi
- zh
library_name: sentence-transformers
tags:
- sentence-transformers
- sentence-similarity
- feature-extraction
- loss:MSELoss
base_model: FacebookAI/xlm-roberta-base
metrics:
- negative_mse
- src2trg_accuracy
- trg2src_accuracy
- mean_accuracy
- pearson_cosine
- spearman_cosine
- pearson_manhattan
- spearman_manhattan
- pearson_euclidean
- spearman_euclidean
- pearson_dot
- spearman_dot
- pearson_max
- spearman_max
widget:
- source_sentence: Grazie tante.
sentences:
- Grazie infinite.
- Non c'è un solo architetto diplomato in tutta la Contea.
- Le aziende non credevano che fosse loro responsabilità.
- source_sentence: Avance rapide.
sentences:
- Très bien.
- Donc, je voulais faire quelque chose de spécial aujourd'hui.
- Et ils ne tiennent pas non plus compte des civils qui souffrent de façon plus
générale.
- source_sentence: E' importante.
sentences:
- E' una materia fondamentale.
- Sono qui oggi per mostrare le mie fotografie dei Lakota.
- Non ero seguito da un corteo di macchine.
- source_sentence: Müfettişler…
sentences:
- İşçi sınıfına dair birşey.
- Antlaşmaya göre, o topraklar bağımsız bir ulustur.
- Son derece düz ve bataklık bir coğrafya.
- source_sentence: Wir sind eins.
sentences:
- Das versuchen wir zu bieten.
- Ihre Gehirne sind ungefähr 100 Millionen Mal komplizierter.
- Hinter mir war gar keine Autokolonne.
pipeline_tag: sentence-similarity
co2_eq_emissions:
emissions: 23.27766676567869
energy_consumed: 0.05988563672345058
source: codecarbon
training_type: fine-tuning
on_cloud: false
cpu_model: 13th Gen Intel(R) Core(TM) i7-13700K
ram_total_size: 31.777088165283203
hours_used: 0.179
hardware_used: 1 x NVIDIA GeForce RTX 3090
model-index:
- name: SentenceTransformer based on FacebookAI/xlm-roberta-base
results:
- task:
type: knowledge-distillation
name: Knowledge Distillation
dataset:
name: en ar
type: en-ar
metrics:
- type: negative_mse
value: -20.395545661449432
name: Negative Mse
- task:
type: translation
name: Translation
dataset:
name: en ar
type: en-ar
metrics:
- type: src2trg_accuracy
value: 0.7603222557905337
name: Src2Trg Accuracy
- type: trg2src_accuracy
value: 0.7824773413897281
name: Trg2Src Accuracy
- type: mean_accuracy
value: 0.7713997985901309
name: Mean Accuracy
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts17 en ar test
type: sts17-en-ar-test
metrics:
- type: pearson_cosine
value: 0.40984231242712876
name: Pearson Cosine
- type: spearman_cosine
value: 0.4425400227662121
name: Spearman Cosine
- type: pearson_manhattan
value: 0.4068582195810505
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.4194184278683204
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.38014538983821944
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.38651157412220366
name: Spearman Euclidean
- type: pearson_dot
value: 0.4077636003696869
name: Pearson Dot
- type: spearman_dot
value: 0.37682818098716137
name: Spearman Dot
- type: pearson_max
value: 0.40984231242712876
name: Pearson Max
- type: spearman_max
value: 0.4425400227662121
name: Spearman Max
- task:
type: knowledge-distillation
name: Knowledge Distillation
dataset:
name: en fr
type: en-fr
metrics:
- type: negative_mse
value: -19.62321847677231
name: Negative Mse
- task:
type: translation
name: Translation
dataset:
name: en fr
type: en-fr
metrics:
- type: src2trg_accuracy
value: 0.8981854838709677
name: Src2Trg Accuracy
- type: trg2src_accuracy
value: 0.8901209677419355
name: Trg2Src Accuracy
- type: mean_accuracy
value: 0.8941532258064516
name: Mean Accuracy
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts17 fr en test
type: sts17-fr-en-test
metrics:
- type: pearson_cosine
value: 0.5017606394120642
name: Pearson Cosine
- type: spearman_cosine
value: 0.5333594401322842
name: Spearman Cosine
- type: pearson_manhattan
value: 0.4461108010622129
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.45470883061015244
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.44313058261278737
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.44806261424208443
name: Spearman Euclidean
- type: pearson_dot
value: 0.40165874540768454
name: Pearson Dot
- type: spearman_dot
value: 0.41339619568003433
name: Spearman Dot
- type: pearson_max
value: 0.5017606394120642
name: Pearson Max
- type: spearman_max
value: 0.5333594401322842
name: Spearman Max
- task:
type: knowledge-distillation
name: Knowledge Distillation
dataset:
name: en de
type: en-de
metrics:
- type: negative_mse
value: -19.727922976017
name: Negative Mse
- task:
type: translation
name: Translation
dataset:
name: en de
type: en-de
metrics:
- type: src2trg_accuracy
value: 0.8920282542885973
name: Src2Trg Accuracy
- type: trg2src_accuracy
value: 0.8910191725529768
name: Trg2Src Accuracy
- type: mean_accuracy
value: 0.8915237134207871
name: Mean Accuracy
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts17 en de test
type: sts17-en-de-test
metrics:
- type: pearson_cosine
value: 0.5262798164154752
name: Pearson Cosine
- type: spearman_cosine
value: 0.5618005565496922
name: Spearman Cosine
- type: pearson_manhattan
value: 0.5084907192868734
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.5218456102379673
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.5055278909013912
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.5206420646365548
name: Spearman Euclidean
- type: pearson_dot
value: 0.3742195121194434
name: Pearson Dot
- type: spearman_dot
value: 0.3691237073066472
name: Spearman Dot
- type: pearson_max
value: 0.5262798164154752
name: Pearson Max
- type: spearman_max
value: 0.5618005565496922
name: Spearman Max
- task:
type: knowledge-distillation
name: Knowledge Distillation
dataset:
name: en es
type: en-es
metrics:
- type: negative_mse
value: -19.472387433052063
name: Negative Mse
- task:
type: translation
name: Translation
dataset:
name: en es
type: en-es
metrics:
- type: src2trg_accuracy
value: 0.9434343434343434
name: Src2Trg Accuracy
- type: trg2src_accuracy
value: 0.9464646464646465
name: Trg2Src Accuracy
- type: mean_accuracy
value: 0.944949494949495
name: Mean Accuracy
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts17 es en test
type: sts17-es-en-test
metrics:
- type: pearson_cosine
value: 0.4944989376773328
name: Pearson Cosine
- type: spearman_cosine
value: 0.502096516024397
name: Spearman Cosine
- type: pearson_manhattan
value: 0.44447965250345656
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.428444032581959
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.43569887867301704
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.4169602915053127
name: Spearman Euclidean
- type: pearson_dot
value: 0.3751122541083453
name: Pearson Dot
- type: spearman_dot
value: 0.37961391381473436
name: Spearman Dot
- type: pearson_max
value: 0.4944989376773328
name: Pearson Max
- type: spearman_max
value: 0.502096516024397
name: Spearman Max
- task:
type: knowledge-distillation
name: Knowledge Distillation
dataset:
name: en tr
type: en-tr
metrics:
- type: negative_mse
value: -20.754697918891907
name: Negative Mse
- task:
type: translation
name: Translation
dataset:
name: en tr
type: en-tr
metrics:
- type: src2trg_accuracy
value: 0.743202416918429
name: Src2Trg Accuracy
- type: trg2src_accuracy
value: 0.743202416918429
name: Trg2Src Accuracy
- type: mean_accuracy
value: 0.743202416918429
name: Mean Accuracy
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts17 en tr test
type: sts17-en-tr-test
metrics:
- type: pearson_cosine
value: 0.5544917743538167
name: Pearson Cosine
- type: spearman_cosine
value: 0.581923120433332
name: Spearman Cosine
- type: pearson_manhattan
value: 0.5103770986779784
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.5087986920849596
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.5045523005860614
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.5053157708914061
name: Spearman Euclidean
- type: pearson_dot
value: 0.47262046401401747
name: Pearson Dot
- type: spearman_dot
value: 0.4297595645819756
name: Spearman Dot
- type: pearson_max
value: 0.5544917743538167
name: Pearson Max
- type: spearman_max
value: 0.581923120433332
name: Spearman Max
- task:
type: knowledge-distillation
name: Knowledge Distillation
dataset:
name: en it
type: en-it
metrics:
- type: negative_mse
value: -19.76993829011917
name: Negative Mse
- task:
type: translation
name: Translation
dataset:
name: en it
type: en-it
metrics:
- type: src2trg_accuracy
value: 0.878147029204431
name: Src2Trg Accuracy
- type: trg2src_accuracy
value: 0.8831822759315207
name: Trg2Src Accuracy
- type: mean_accuracy
value: 0.8806646525679758
name: Mean Accuracy
- task:
type: semantic-similarity
name: Semantic Similarity
dataset:
name: sts17 it en test
type: sts17-it-en-test
metrics:
- type: pearson_cosine
value: 0.506365733914274
name: Pearson Cosine
- type: spearman_cosine
value: 0.5250284136808592
name: Spearman Cosine
- type: pearson_manhattan
value: 0.45167598168533407
name: Pearson Manhattan
- type: spearman_manhattan
value: 0.46227952068355316
name: Spearman Manhattan
- type: pearson_euclidean
value: 0.4423426674780287
name: Pearson Euclidean
- type: spearman_euclidean
value: 0.45072801992723094
name: Spearman Euclidean
- type: pearson_dot
value: 0.4201989776020174
name: Pearson Dot
- type: spearman_dot
value: 0.42253906764732746
name: Spearman Dot
- type: pearson_max
value: 0.506365733914274
name: Pearson Max
- type: spearman_max
value: 0.5250284136808592
name: Spearman Max
---
# SentenceTransformer based on FacebookAI/xlm-roberta-base
This is a [sentence-transformers](https://www.SBERT.net) model finetuned from [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) on the [en-ar](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks), [en-fr](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks), [en-de](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks), [en-es](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks), [en-tr](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) and [en-it](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) datasets. It maps sentences & paragraphs to a 768-dimensional dense vector space and can be used for semantic textual similarity, semantic search, paraphrase mining, text classification, clustering, and more.
## Model Details
### Model Description
- **Model Type:** Sentence Transformer
- **Base model:** [FacebookAI/xlm-roberta-base](https://huggingface.co/FacebookAI/xlm-roberta-base) <!-- at revision e73636d4f797dec63c3081bb6ed5c7b0bb3f2089 -->
- **Maximum Sequence Length:** 128 tokens
- **Output Dimensionality:** 768 tokens
- **Similarity Function:** Cosine Similarity
- **Training Datasets:**
- [en-ar](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks)
- [en-fr](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks)
- [en-de](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks)
- [en-es](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks)
- [en-tr](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks)
- [en-it](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks)
- **Languages:** en, multilingual, ar, bg, ca, cs, da, de, el, es, et, fa, fi, fr, gl, gu, he, hi, hr, hu, hy, id, it, ja, ka, ko, ku, lt, lv, mk, mn, mr, ms, my, nb, nl, pl, pt, ro, ru, sk, sl, sq, sr, sv, th, tr, uk, ur, vi, zh
<!-- - **License:** Unknown -->
### Model Sources
- **Documentation:** [Sentence Transformers Documentation](https://sbert.net)
- **Repository:** [Sentence Transformers on GitHub](https://github.com/UKPLab/sentence-transformers)
- **Hugging Face:** [Sentence Transformers on Hugging Face](https://huggingface.co/models?library=sentence-transformers)
### Full Model Architecture
```
SentenceTransformer(
(0): Transformer({'max_seq_length': 128, 'do_lower_case': False}) with Transformer model: XLMRobertaModel
(1): Pooling({'word_embedding_dimension': 768, 'pooling_mode_cls_token': False, 'pooling_mode_mean_tokens': True, 'pooling_mode_max_tokens': False, 'pooling_mode_mean_sqrt_len_tokens': False, 'pooling_mode_weightedmean_tokens': False, 'pooling_mode_lasttoken': False, 'include_prompt': True})
)
```
## Usage
### Direct Usage (Sentence Transformers)
First install the Sentence Transformers library:
```bash
pip install -U sentence-transformers
```
Then you can load this model and run inference.
```python
from sentence_transformers import SentenceTransformer
# Download from the 🤗 Hub
model = SentenceTransformer("tomaarsen/xlm-roberta-base-multilingual-en-ar-fr-de-es-tr-it")
# Run inference
sentences = [
'Wir sind eins.',
'Das versuchen wir zu bieten.',
'Ihre Gehirne sind ungefähr 100 Millionen Mal komplizierter.',
]
embeddings = model.encode(sentences)
print(embeddings.shape)
# [3, 768]
# Get the similarity scores for the embeddings
similarities = model.similarity(embeddings)
print(similarities.shape)
# [3, 3]
```
<!--
### Direct Usage (Transformers)
<details><summary>Click to see the direct usage in Transformers</summary>
</details>
-->
<!--
### Downstream Usage (Sentence Transformers)
You can finetune this model on your own dataset.
<details><summary>Click to expand</summary>
</details>
-->
<!--
### Out-of-Scope Use
*List how the model may foreseeably be misused and address what users ought not to do with the model.*
-->
## Evaluation
### Metrics
#### Knowledge Distillation
* Dataset: `en-ar`
* Evaluated with [<code>MSEEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.MSEEvaluator)
| Metric | Value |
|:-----------------|:-------------|
| **negative_mse** | **-20.3955** |
#### Translation
* Dataset: `en-ar`
* Evaluated with [<code>TranslationEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.TranslationEvaluator)
| Metric | Value |
|:------------------|:-----------|
| src2trg_accuracy | 0.7603 |
| trg2src_accuracy | 0.7825 |
| **mean_accuracy** | **0.7714** |
#### Semantic Similarity
* Dataset: `sts17-en-ar-test`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:-------------------|:-----------|
| pearson_cosine | 0.4098 |
| spearman_cosine | 0.4425 |
| pearson_manhattan | 0.4069 |
| spearman_manhattan | 0.4194 |
| pearson_euclidean | 0.3801 |
| spearman_euclidean | 0.3865 |
| pearson_dot | 0.4078 |
| spearman_dot | 0.3768 |
| pearson_max | 0.4098 |
| **spearman_max** | **0.4425** |
#### Knowledge Distillation
* Dataset: `en-fr`
* Evaluated with [<code>MSEEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.MSEEvaluator)
| Metric | Value |
|:-----------------|:-------------|
| **negative_mse** | **-19.6232** |
#### Translation
* Dataset: `en-fr`
* Evaluated with [<code>TranslationEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.TranslationEvaluator)
| Metric | Value |
|:------------------|:-----------|
| src2trg_accuracy | 0.8982 |
| trg2src_accuracy | 0.8901 |
| **mean_accuracy** | **0.8942** |
#### Semantic Similarity
* Dataset: `sts17-fr-en-test`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:-------------------|:-----------|
| pearson_cosine | 0.5018 |
| spearman_cosine | 0.5334 |
| pearson_manhattan | 0.4461 |
| spearman_manhattan | 0.4547 |
| pearson_euclidean | 0.4431 |
| spearman_euclidean | 0.4481 |
| pearson_dot | 0.4017 |
| spearman_dot | 0.4134 |
| pearson_max | 0.5018 |
| **spearman_max** | **0.5334** |
#### Knowledge Distillation
* Dataset: `en-de`
* Evaluated with [<code>MSEEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.MSEEvaluator)
| Metric | Value |
|:-----------------|:-------------|
| **negative_mse** | **-19.7279** |
#### Translation
* Dataset: `en-de`
* Evaluated with [<code>TranslationEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.TranslationEvaluator)
| Metric | Value |
|:------------------|:-----------|
| src2trg_accuracy | 0.892 |
| trg2src_accuracy | 0.891 |
| **mean_accuracy** | **0.8915** |
#### Semantic Similarity
* Dataset: `sts17-en-de-test`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:-------------------|:-----------|
| pearson_cosine | 0.5263 |
| spearman_cosine | 0.5618 |
| pearson_manhattan | 0.5085 |
| spearman_manhattan | 0.5218 |
| pearson_euclidean | 0.5055 |
| spearman_euclidean | 0.5206 |
| pearson_dot | 0.3742 |
| spearman_dot | 0.3691 |
| pearson_max | 0.5263 |
| **spearman_max** | **0.5618** |
#### Knowledge Distillation
* Dataset: `en-es`
* Evaluated with [<code>MSEEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.MSEEvaluator)
| Metric | Value |
|:-----------------|:-------------|
| **negative_mse** | **-19.4724** |
#### Translation
* Dataset: `en-es`
* Evaluated with [<code>TranslationEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.TranslationEvaluator)
| Metric | Value |
|:------------------|:-----------|
| src2trg_accuracy | 0.9434 |
| trg2src_accuracy | 0.9465 |
| **mean_accuracy** | **0.9449** |
#### Semantic Similarity
* Dataset: `sts17-es-en-test`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:-------------------|:-----------|
| pearson_cosine | 0.4945 |
| spearman_cosine | 0.5021 |
| pearson_manhattan | 0.4445 |
| spearman_manhattan | 0.4284 |
| pearson_euclidean | 0.4357 |
| spearman_euclidean | 0.417 |
| pearson_dot | 0.3751 |
| spearman_dot | 0.3796 |
| pearson_max | 0.4945 |
| **spearman_max** | **0.5021** |
#### Knowledge Distillation
* Dataset: `en-tr`
* Evaluated with [<code>MSEEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.MSEEvaluator)
| Metric | Value |
|:-----------------|:-------------|
| **negative_mse** | **-20.7547** |
#### Translation
* Dataset: `en-tr`
* Evaluated with [<code>TranslationEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.TranslationEvaluator)
| Metric | Value |
|:------------------|:-----------|
| src2trg_accuracy | 0.7432 |
| trg2src_accuracy | 0.7432 |
| **mean_accuracy** | **0.7432** |
#### Semantic Similarity
* Dataset: `sts17-en-tr-test`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:-------------------|:-----------|
| pearson_cosine | 0.5545 |
| spearman_cosine | 0.5819 |
| pearson_manhattan | 0.5104 |
| spearman_manhattan | 0.5088 |
| pearson_euclidean | 0.5046 |
| spearman_euclidean | 0.5053 |
| pearson_dot | 0.4726 |
| spearman_dot | 0.4298 |
| pearson_max | 0.5545 |
| **spearman_max** | **0.5819** |
#### Knowledge Distillation
* Dataset: `en-it`
* Evaluated with [<code>MSEEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.MSEEvaluator)
| Metric | Value |
|:-----------------|:-------------|
| **negative_mse** | **-19.7699** |
#### Translation
* Dataset: `en-it`
* Evaluated with [<code>TranslationEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.TranslationEvaluator)
| Metric | Value |
|:------------------|:-----------|
| src2trg_accuracy | 0.8781 |
| trg2src_accuracy | 0.8832 |
| **mean_accuracy** | **0.8807** |
#### Semantic Similarity
* Dataset: `sts17-it-en-test`
* Evaluated with [<code>EmbeddingSimilarityEvaluator</code>](https://sbert.net/docs/package_reference/evaluation.html#sentence_transformers.evaluation.EmbeddingSimilarityEvaluator)
| Metric | Value |
|:-------------------|:----------|
| pearson_cosine | 0.5064 |
| spearman_cosine | 0.525 |
| pearson_manhattan | 0.4517 |
| spearman_manhattan | 0.4623 |
| pearson_euclidean | 0.4423 |
| spearman_euclidean | 0.4507 |
| pearson_dot | 0.4202 |
| spearman_dot | 0.4225 |
| pearson_max | 0.5064 |
| **spearman_max** | **0.525** |
<!--
## Bias, Risks and Limitations
*What are the known or foreseeable issues stemming from this model? You could also flag here known failure cases or weaknesses of the model.*
-->
<!--
### Recommendations
*What are recommendations with respect to the foreseeable issues? For example, filtering explicit content.*
-->
## Training Details
### Training Datasets
#### en-ar
* Dataset: [en-ar](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 5,000 training samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 4 tokens</li><li>mean: 27.3 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------------------------------|
| <code>حسناً ان ما نقوم به اليوم .. هو ان نجبر الطلاب لتعلم الرياضيات</code> | <code>[0.3943225145339966, 0.18910610675811768, -0.3788299858570099, 0.4386662542819977, 0.2727023661136627, ...]</code> |
| <code>انها المادة الاهم ..</code> | <code>[0.6257511377334595, -0.1750679910182953, -0.5734405517578125, 0.11480475962162018, 1.1682192087173462, ...]</code> |
| <code>انا لا انفي لدقيقة واحدة ان الذين يهتمون بالحسابات اليدوية والذين هوايتهم القيام بذلك .. او القيام بالطرق التقليدية في اي مجال ان يقوموا بذلك كما يريدون .</code> | <code>[-0.04564047232270241, 0.4971524775028229, 0.28066301345825195, -0.726702094078064, -0.17846377193927765, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-fr
* Dataset: [en-fr](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 5,000 training samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 3 tokens</li><li>mean: 30.18 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>Je ne crois pas que ce soit justifié.</code> | <code>[-0.361753910779953, 0.7323777079582214, 0.6518164277076721, -0.8461216688156128, -0.007496988866478205, ...]</code> |
| <code>Je fais cette distinction entre ce qu'on force les gens à faire et les matières générales, et la matière que quelqu'un va apprendre parce que ça lui plait et peut-être même exceller dans ce domaine.</code> | <code>[0.3047865629196167, 0.5270194411277771, 0.26616284251213074, 0.2612147927284241, 0.1950961947441101, ...]</code> |
| <code>Quels sont les problèmes en relation avec ça?</code> | <code>[0.2123892903327942, -0.09616081416606903, -0.41965243220329285, -0.5469444394111633, -0.6056491136550903, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-de
* Dataset: [en-de](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 5,000 training samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 4 tokens</li><li>mean: 27.04 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:----------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>Ich denke, dass es sich aus diesem Grund lohnt, den Leuten das Rechnen von Hand beizubringen.</code> | <code>[0.0960279330611229, 0.7833179831504822, -0.09527698159217834, 0.8104371428489685, 0.7545774579048157, ...]</code> |
| <code>Außerdem gibt es ein paar bestimmte konzeptionelle Dinge, die das Rechnen per Hand rechtfertigen, aber ich glaube es sind sehr wenige.</code> | <code>[-0.5939837098121643, 0.9714100956916809, 0.6800686717033386, -0.21585524082183838, -0.7509503364562988, ...]</code> |
| <code>Eine Sache, die ich mich oft frage, ist Altgriechisch, und wie das zusammengehört.</code> | <code>[-0.09777048230171204, 0.07093209028244019, -0.42989012598991394, -0.1457514613866806, 1.4382753372192383, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-es
* Dataset: [en-es](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 5,000 training samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 4 tokens</li><li>mean: 25.42 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:-----------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>Y luego hay ciertas aspectos conceptuales que pueden beneficiarse del cálculo a mano pero creo que son relativamente pocos.</code> | <code>[-0.5939835906028748, 0.9714106917381287, 0.6800685524940491, -0.2158554196357727, -0.7509507536888123, ...]</code> |
| <code>Algo que pregunto a menudo es sobre el griego antiguo y cómo se relaciona.</code> | <code>[-0.09777048230171204, 0.07093209028244019, -0.42989012598991394, -0.1457514613866806, 1.4382753372192383, ...]</code> |
| <code>Vean, lo que estamos haciendo ahora es forzar a la gente a aprender matemáticas.</code> | <code>[0.3943225145339966, 0.18910610675811768, -0.3788299858570099, 0.4386662542819977, 0.2727023661136627, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-tr
* Dataset: [en-tr](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 5,000 training samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 4 tokens</li><li>mean: 24.72 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>Eğer insanlar elle hesaba ilgililerse ya da öğrenmek için özel amaçları varsa konu ne kadar acayip olursa olsun bunu öğrenmeliler, engellemeyi bir an için bile önermiyorum.</code> | <code>[-0.04564047232270241, 0.4971524775028229, 0.28066301345825195, -0.726702094078064, -0.17846377193927765, ...]</code> |
| <code>İnsanların kendi ilgi alanlarını takip etmeleri, kesinlikle doğru bir şeydir.</code> | <code>[0.2061387449502945, 0.5284574031829834, 0.3577779233455658, 0.28818392753601074, 0.17228049039840698, ...]</code> |
| <code>Ben bir biçimde Antik Yunan hakkında ilgiliyimdir. ancak tüm nüfusu Antik Yunan gibi bir konu hakkında bilgi edinmeye zorlamamalıyız.</code> | <code>[0.12050342559814453, 0.15652479231357574, 0.48636534810066223, -0.13693244755268097, 0.42764803767204285, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-it
* Dataset: [en-it](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 5,000 training samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 3 tokens</li><li>mean: 26.41 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:----------------------------------------------------------------------------------------------------------------------------|
| <code>Non credo che sia giustificato.</code> | <code>[-0.36175352334976196, 0.7323781251907349, 0.651816189289093, -0.8461223840713501, -0.007496151141822338, ...]</code> |
| <code>Perciò faccio distinzione tra quello che stiamo facendo fare alle persone, le materie che si ritengono principali, e le materie che le persone potrebbero seguire per loro interesse o forse a volte anche incitate a farlo.</code> | <code>[0.3047865927219391, 0.5270194411277771, 0.26616284251213074, 0.2612147927284241, 0.1950961947441101, ...]</code> |
| <code>Ma che argomenti porta la gente su questi temi?</code> | <code>[0.2123885154724121, -0.09616123884916306, -0.4196523427963257, -0.5469440817832947, -0.6056501865386963, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
### Evaluation Datasets
#### en-ar
* Dataset: [en-ar](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 993 evaluation samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 3 tokens</li><li>mean: 28.03 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>شكرا جزيلا كريس.</code> | <code>[-0.4331263303756714, 1.0602688789367676, -0.07791043072938919, -0.4170420169830322, 1.6768444776535034, ...]</code> |
| <code>انه فعلا شرف عظيم لي ان أصعد المنصة للمرة الثانية. أنا في غاية الامتنان.</code> | <code>[0.27005696296691895, 0.5391750335693359, -0.2580486238002777, -0.6613674759864807, 0.6738830804824829, ...]</code> |
| <code>لقد بهرت فعلا بهذا المؤتمر, وأريد أن أشكركم جميعا على تعليقاتكم الطيبة على ما قلته تلك الليلة.</code> | <code>[-0.25320106744766235, 0.04791366308927536, -0.13174884021282196, -0.7357578277587891, 0.2366354614496231, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-fr
* Dataset: [en-fr](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 992 evaluation samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 4 tokens</li><li>mean: 30.72 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:---------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>Merci beaucoup, Chris.</code> | <code>[-0.4331263303756714, 1.0602688789367676, -0.07791043072938919, -0.4170420169830322, 1.6768444776535034, ...]</code> |
| <code>C'est vraiment un honneur de pouvoir venir sur cette scène une deuxième fois. Je suis très reconnaissant.</code> | <code>[0.27005696296691895, 0.5391750335693359, -0.2580486238002777, -0.6613674759864807, 0.6738830804824829, ...]</code> |
| <code>J'ai été très impressionné par cette conférence, et je tiens à vous remercier tous pour vos nombreux et sympathiques commentaires sur ce que j'ai dit l'autre soir.</code> | <code>[-0.25320106744766235, 0.04791366308927536, -0.13174884021282196, -0.7357578277587891, 0.2366354614496231, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-de
* Dataset: [en-de](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 991 evaluation samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 4 tokens</li><li>mean: 27.71 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:-----------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>Vielen Dank, Chris.</code> | <code>[-0.4331263303756714, 1.0602688789367676, -0.07791043072938919, -0.4170420169830322, 1.6768444776535034, ...]</code> |
| <code>Es ist mir wirklich eine Ehre, zweimal auf dieser Bühne stehen zu dürfen. Tausend Dank dafür.</code> | <code>[0.27005696296691895, 0.5391750335693359, -0.2580486238002777, -0.6613674759864807, 0.6738830804824829, ...]</code> |
| <code>Ich bin wirklich begeistert von dieser Konferenz, und ich danke Ihnen allen für die vielen netten Kommentare zu meiner Rede vorgestern Abend.</code> | <code>[-0.25320106744766235, 0.04791366308927536, -0.13174884021282196, -0.7357578277587891, 0.2366354614496231, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-es
* Dataset: [en-es](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 990 evaluation samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 4 tokens</li><li>mean: 26.47 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:------------------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>Muchas gracias Chris.</code> | <code>[-0.4331263303756714, 1.0602688789367676, -0.07791043072938919, -0.4170420169830322, 1.6768444776535034, ...]</code> |
| <code>Y es en verdad un gran honor tener la oportunidad de venir a este escenario por segunda vez. Estoy extremadamente agradecido.</code> | <code>[0.27005696296691895, 0.5391750335693359, -0.2580486238002777, -0.6613674759864807, 0.6738830804824829, ...]</code> |
| <code>He quedado conmovido por esta conferencia, y deseo agradecer a todos ustedes sus amables comentarios acerca de lo que tenía que decir la otra noche.</code> | <code>[-0.25320106744766235, 0.04791366308927536, -0.13174884021282196, -0.7357578277587891, 0.2366354614496231, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-tr
* Dataset: [en-tr](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 993 evaluation samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 4 tokens</li><li>mean: 25.4 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:----------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>Çok teşekkür ederim Chris.</code> | <code>[-0.4331263303756714, 1.0602688789367676, -0.07791043072938919, -0.4170420169830322, 1.6768444776535034, ...]</code> |
| <code>Bu sahnede ikinci kez yer alma fırsatına sahip olmak gerçekten büyük bir onur. Çok minnettarım.</code> | <code>[0.27005696296691895, 0.5391750335693359, -0.2580486238002777, -0.6613674759864807, 0.6738830804824829, ...]</code> |
| <code>Bu konferansta çok mutlu oldum, ve anlattıklarımla ilgili güzel yorumlarınız için sizlere çok teşekkür ederim.</code> | <code>[-0.25320106744766235, 0.04791366308927536, -0.13174884021282196, -0.7357578277587891, 0.2366354614496231, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
#### en-it
* Dataset: [en-it](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks) at [d366ddd](https://huggingface.co/datasets/sentence-transformers/parallel-sentences-talks/tree/d366dddc3d1ef0421a41f9e534bad4efae6d7730)
* Size: 993 evaluation samples
* Columns: <code>non_english</code> and <code>label</code>
* Approximate statistics based on the first 1000 samples:
| | non_english | label |
|:--------|:-----------------------------------------------------------------------------------|:-------------------------------------|
| type | string | list |
| details | <ul><li>min: 4 tokens</li><li>mean: 27.94 tokens</li><li>max: 128 tokens</li></ul> | <ul><li>size: 768 elements</li></ul> |
* Samples:
| non_english | label |
|:--------------------------------------------------------------------------------------------------------------------------------------------------------|:-----------------------------------------------------------------------------------------------------------------------------|
| <code>Grazie mille, Chris.</code> | <code>[-0.4331263303756714, 1.0602688789367676, -0.07791043072938919, -0.4170420169830322, 1.6768444776535034, ...]</code> |
| <code>E’ veramente un grande onore venire su questo palco due volte. Vi sono estremamente grato.</code> | <code>[0.27005696296691895, 0.5391750335693359, -0.2580486238002777, -0.6613674759864807, 0.6738830804824829, ...]</code> |
| <code>Sono impressionato da questa conferenza, e voglio ringraziare tutti voi per i tanti, lusinghieri commenti, anche perché... Ne ho bisogno!!</code> | <code>[-0.25320106744766235, 0.04791366308927536, -0.13174884021282196, -0.7357578277587891, 0.2366354614496231, ...]</code> |
* Loss: [<code>MSELoss</code>](https://sbert.net/docs/package_reference/losses.html#mseloss)
### Training Hyperparameters
#### Non-Default Hyperparameters
- `eval_strategy`: steps
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `learning_rate`: 2e-05
- `num_train_epochs`: 5
- `warmup_ratio`: 0.1
- `fp16`: True
#### All Hyperparameters
<details><summary>Click to expand</summary>
- `overwrite_output_dir`: False
- `do_predict`: False
- `eval_strategy`: steps
- `prediction_loss_only`: False
- `per_device_train_batch_size`: 64
- `per_device_eval_batch_size`: 64
- `per_gpu_train_batch_size`: None
- `per_gpu_eval_batch_size`: None
- `gradient_accumulation_steps`: 1
- `eval_accumulation_steps`: None
- `learning_rate`: 2e-05
- `weight_decay`: 0.0
- `adam_beta1`: 0.9
- `adam_beta2`: 0.999
- `adam_epsilon`: 1e-08
- `max_grad_norm`: 1.0
- `num_train_epochs`: 5
- `max_steps`: -1
- `lr_scheduler_type`: linear
- `lr_scheduler_kwargs`: {}
- `warmup_ratio`: 0.1
- `warmup_steps`: 0
- `log_level`: passive
- `log_level_replica`: warning
- `log_on_each_node`: True
- `logging_nan_inf_filter`: True
- `save_safetensors`: True
- `save_on_each_node`: False
- `save_only_model`: False
- `no_cuda`: False
- `use_cpu`: False
- `use_mps_device`: False
- `seed`: 42
- `data_seed`: None
- `jit_mode_eval`: False
- `use_ipex`: False
- `bf16`: False
- `fp16`: True
- `fp16_opt_level`: O1
- `half_precision_backend`: auto
- `bf16_full_eval`: False
- `fp16_full_eval`: False
- `tf32`: None
- `local_rank`: 0
- `ddp_backend`: None
- `tpu_num_cores`: None
- `tpu_metrics_debug`: False
- `debug`: []
- `dataloader_drop_last`: False
- `dataloader_num_workers`: 0
- `dataloader_prefetch_factor`: None
- `past_index`: -1
- `disable_tqdm`: False
- `remove_unused_columns`: True
- `label_names`: None
- `load_best_model_at_end`: False
- `ignore_data_skip`: False
- `fsdp`: []
- `fsdp_min_num_params`: 0
- `fsdp_config`: {'min_num_params': 0, 'xla': False, 'xla_fsdp_v2': False, 'xla_fsdp_grad_ckpt': False}
- `fsdp_transformer_layer_cls_to_wrap`: None
- `accelerator_config`: {'split_batches': False, 'dispatch_batches': None, 'even_batches': True, 'use_seedable_sampler': True, 'non_blocking': False, 'gradient_accumulation_kwargs': None}
- `deepspeed`: None
- `label_smoothing_factor`: 0.0
- `optim`: adamw_torch
- `optim_args`: None
- `adafactor`: False
- `group_by_length`: False
- `length_column_name`: length
- `ddp_find_unused_parameters`: None
- `ddp_bucket_cap_mb`: None
- `ddp_broadcast_buffers`: None
- `dataloader_pin_memory`: True
- `dataloader_persistent_workers`: False
- `skip_memory_metrics`: True
- `use_legacy_prediction_loop`: False
- `push_to_hub`: False
- `resume_from_checkpoint`: None
- `hub_model_id`: None
- `hub_strategy`: every_save
- `hub_private_repo`: False
- `hub_always_push`: False
- `gradient_checkpointing`: False
- `gradient_checkpointing_kwargs`: None
- `include_inputs_for_metrics`: False
- `eval_do_concat_batches`: True
- `fp16_backend`: auto
- `push_to_hub_model_id`: None
- `push_to_hub_organization`: None
- `mp_parameters`:
- `auto_find_batch_size`: False
- `full_determinism`: False
- `torchdynamo`: None
- `ray_scope`: last
- `ddp_timeout`: 1800
- `torch_compile`: False
- `torch_compile_backend`: None
- `torch_compile_mode`: None
- `dispatch_batches`: None
- `split_batches`: None
- `include_tokens_per_second`: False
- `include_num_input_tokens_seen`: False
- `neftune_noise_alpha`: None
- `optim_target_modules`: None
- `batch_sampler`: batch_sampler
- `multi_dataset_batch_sampler`: proportional
</details>
### Training Logs
| Epoch | Step | Training Loss | en-ar loss | en-it loss | en-de loss | en-fr loss | en-es loss | en-tr loss | en-ar_mean_accuracy | en-ar_negative_mse | en-de_mean_accuracy | en-de_negative_mse | en-es_mean_accuracy | en-es_negative_mse | en-fr_mean_accuracy | en-fr_negative_mse | en-it_mean_accuracy | en-it_negative_mse | en-tr_mean_accuracy | en-tr_negative_mse | sts17-en-ar-test_spearman_max | sts17-en-de-test_spearman_max | sts17-en-tr-test_spearman_max | sts17-es-en-test_spearman_max | sts17-fr-en-test_spearman_max | sts17-it-en-test_spearman_max |
|:------:|:----:|:-------------:|:----------:|:----------:|:----------:|:----------:|:----------:|:----------:|:-------------------:|:------------------:|:-------------------:|:------------------:|:-------------------:|:------------------:|:-------------------:|:------------------:|:-------------------:|:------------------:|:-------------------:|:------------------:|:-----------------------------:|:-----------------------------:|:-----------------------------:|:-----------------------------:|:-----------------------------:|:-----------------------------:|
| 0.2110 | 100 | 0.5581 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.4219 | 200 | 0.3071 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.6329 | 300 | 0.2675 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 0.8439 | 400 | 0.2606 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 1.0549 | 500 | 0.2589 | 0.2519 | 0.2498 | 0.2511 | 0.2488 | 0.2503 | 0.2512 | 0.1254 | -25.1903 | 0.2523 | -25.1089 | 0.2591 | -25.0276 | 0.2409 | -24.8803 | 0.2180 | -24.9768 | 0.1158 | -25.1219 | 0.0308 | 0.1281 | 0.1610 | 0.1465 | 0.0552 | 0.0518 |
| 1.2658 | 600 | 0.2504 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 1.4768 | 700 | 0.2427 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 1.6878 | 800 | 0.2337 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 1.8987 | 900 | 0.2246 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 2.1097 | 1000 | 0.2197 | 0.2202 | 0.2157 | 0.2151 | 0.2147 | 0.2139 | 0.2218 | 0.5841 | -22.0204 | 0.8012 | -21.5087 | 0.8495 | -21.3935 | 0.7959 | -21.4660 | 0.7815 | -21.5699 | 0.6007 | -22.1778 | 0.3346 | 0.4013 | 0.4727 | 0.3353 | 0.3827 | 0.3292 |
| 2.3207 | 1100 | 0.2163 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 2.5316 | 1200 | 0.2123 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 2.7426 | 1300 | 0.2069 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 2.9536 | 1400 | 0.2048 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 3.1646 | 1500 | 0.2009 | 0.2086 | 0.2029 | 0.2022 | 0.2012 | 0.2002 | 0.2111 | 0.7367 | -20.8567 | 0.8739 | -20.2247 | 0.9303 | -20.0215 | 0.8755 | -20.1213 | 0.8600 | -20.2900 | 0.7165 | -21.1119 | 0.4087 | 0.5473 | 0.5551 | 0.4724 | 0.4882 | 0.4690 |
| 3.3755 | 1600 | 0.2019 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 3.5865 | 1700 | 0.1989 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 3.7975 | 1800 | 0.196 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 4.0084 | 1900 | 0.1943 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 4.2194 | 2000 | 0.194 | 0.2040 | 0.1977 | 0.1973 | 0.1962 | 0.1947 | 0.2075 | 0.7714 | -20.3955 | 0.8915 | -19.7279 | 0.9449 | -19.4724 | 0.8942 | -19.6232 | 0.8807 | -19.7699 | 0.7432 | -20.7547 | 0.4425 | 0.5618 | 0.5819 | 0.5021 | 0.5334 | 0.5250 |
| 4.4304 | 2100 | 0.1951 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 4.6414 | 2200 | 0.1928 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
| 4.8523 | 2300 | 0.1909 | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - | - |
### Environmental Impact
Carbon emissions were measured using [CodeCarbon](https://github.com/mlco2/codecarbon).
- **Energy Consumed**: 0.060 kWh
- **Carbon Emitted**: 0.023 kg of CO2
- **Hours Used**: 0.179 hours
### Training Hardware
- **On Cloud**: No
- **GPU Model**: 1 x NVIDIA GeForce RTX 3090
- **CPU Model**: 13th Gen Intel(R) Core(TM) i7-13700K
- **RAM Size**: 31.78 GB
### Framework Versions
- Python: 3.11.6
- Sentence Transformers: 3.0.0.dev0
- Transformers: 4.41.0.dev0
- PyTorch: 2.3.0+cu121
- Accelerate: 0.26.1
- Datasets: 2.18.0
- Tokenizers: 0.19.1
## Citation
### BibTeX
#### Sentence Transformers
```bibtex
@inproceedings{reimers-2019-sentence-bert,
title = "Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2019",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/1908.10084",
}
```
#### MSELoss
```bibtex
@inproceedings{reimers-2020-multilingual-sentence-bert,
title = "Making Monolingual Sentence Embeddings Multilingual using Knowledge Distillation",
author = "Reimers, Nils and Gurevych, Iryna",
booktitle = "Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing",
month = "11",
year = "2020",
publisher = "Association for Computational Linguistics",
url = "https://arxiv.org/abs/2004.09813",
}
```
<!--
## Glossary
*Clearly define terms in order to be accessible across audiences.*
-->
<!--
## Model Card Authors
*Lists the people who create the model card, providing recognition and accountability for the detailed work that goes into its construction.*
-->
<!--
## Model Card Contact
*Provides a way for people who have updates to the Model Card, suggestions, or questions, to contact the Model Card authors.*
--> |
RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf | RichardErkhov | 2024-05-11T05:33:04Z | 392 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-05-11T03:07:23Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Llama-3-8B-Instruct-Gradient-1048k - GGUF
- Model creator: https://huggingface.co/gradientai/
- Original model: https://huggingface.co/gradientai/Llama-3-8B-Instruct-Gradient-1048k/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Llama-3-8B-Instruct-Gradient-1048k.Q2_K.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q2_K.gguf) | Q2_K | 2.96GB |
| [Llama-3-8B-Instruct-Gradient-1048k.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.IQ3_XS.gguf) | IQ3_XS | 3.28GB |
| [Llama-3-8B-Instruct-Gradient-1048k.IQ3_S.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.IQ3_S.gguf) | IQ3_S | 3.43GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q3_K_S.gguf) | Q3_K_S | 3.41GB |
| [Llama-3-8B-Instruct-Gradient-1048k.IQ3_M.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.IQ3_M.gguf) | IQ3_M | 3.52GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q3_K.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q3_K.gguf) | Q3_K | 3.74GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q3_K_M.gguf) | Q3_K_M | 3.74GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q3_K_L.gguf) | Q3_K_L | 4.03GB |
| [Llama-3-8B-Instruct-Gradient-1048k.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.IQ4_XS.gguf) | IQ4_XS | 4.18GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q4_0.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q4_0.gguf) | Q4_0 | 4.34GB |
| [Llama-3-8B-Instruct-Gradient-1048k.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.IQ4_NL.gguf) | IQ4_NL | 4.38GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q4_K_S.gguf) | Q4_K_S | 4.37GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q4_K.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q4_K.gguf) | Q4_K | 4.58GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q4_K_M.gguf) | Q4_K_M | 4.58GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q4_1.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q4_1.gguf) | Q4_1 | 4.78GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q5_0.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q5_0.gguf) | Q5_0 | 5.21GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q5_K_S.gguf) | Q5_K_S | 5.21GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q5_K.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q5_K.gguf) | Q5_K | 5.34GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q5_K_M.gguf) | Q5_K_M | 5.34GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q5_1.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q5_1.gguf) | Q5_1 | 5.65GB |
| [Llama-3-8B-Instruct-Gradient-1048k.Q6_K.gguf](https://huggingface.co/RichardErkhov/gradientai_-_Llama-3-8B-Instruct-Gradient-1048k-gguf/blob/main/Llama-3-8B-Instruct-Gradient-1048k.Q6_K.gguf) | Q6_K | 6.14GB |
Original model description:
---
language:
- en
pipeline_tag: text-generation
tags:
- meta
- llama-3
license: llama3
---
<a href="https://www.gradient.ai" target="_blank"><img src="https://cdn-uploads.huggingface.co/production/uploads/655bb613e8a8971e89944f3e/TSa3V8YpoVagnTYgxiLaO.png" width="200"/></a>
# Llama-3 8B Gradient Instruct 1048k
Join our custom agent and long context (262k-1M+) waitlist: https://forms.gle/L6TDY7dozx8TuoUv7
Gradient incorporates your data to deploy autonomous assistants that power critical operations across your business. If you're looking to build custom AI models or agents, email us a message [email protected]. For more info see our [end-to-end development service for custom LLMs and AI systems](https://gradient.ai/development-lab)
[Join our Discord](https://discord.com/invite/2QVy2qt2mf)
This model extends LLama-3 8B's context length from 8k to > 1040K, developed by Gradient, sponsored by compute from [Crusoe Energy](https://huggingface.co/crusoeai). It demonstrates that SOTA LLMs can learn to operate on long context with minimal training by appropriately adjusting RoPE theta. We trained on 830M tokens for this stage, and 1.4B tokens total for all stages, which is < 0.01% of Llama-3's original pre-training data.
**Update (5/3): We further fine-tuned our model to strengthen its assistant-like chat ability as well.**
Updated NIAH result:
<img src="https://cdn-uploads.huggingface.co/production/uploads/6585dc9be92bc5f258156bd6/-qaI__83ksClzoJzlqZjq.png" width="900" />
RULER evals:
- Our model is behind only GPT-4 and Yi in the retrieval and Q&A tasks
- It’s the smallest parameter model to rank in the top 7 overall
<img src="https://cdn-uploads.huggingface.co/production/uploads/655bb613e8a8971e89944f3e/0mLjl0Latrjc8gOrdtbc6.png" width="900" />
**Approach:**
- [meta-llama/Meta-Llama-3-8B-Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) as the base
- NTK-aware interpolation [1] to initialize an optimal schedule for RoPE theta, followed by empirical RoPE theta optimization
- Progressive training on increasing context lengths, similar to [Large World Model](https://huggingface.co/LargeWorldModel) [2] (See details below)
**Infra:**
We build on top of the EasyContext Blockwise RingAttention library [3] to scalably and efficiently train on contexts up to 1048k tokens on [Crusoe Energy](https://huggingface.co/crusoeai) high performance L40S cluster.
Notably, we layered parallelism on top of Ring Attention with a custom network topology to better leverage large GPU clusters in the face of network bottlenecks from passing many KV blocks between devices. This gave us a 33x speedup in model training (compare 524k and 1048k to 65k and 262k in the table below).
**Data:**
For training data, we generate long contexts by augmenting [SlimPajama](https://huggingface.co/datasets/cerebras/SlimPajama-627B). We also fine-tune on a chat dataset based on UltraChat [4], following a similar recipe for data augmentation to [2].
**Progressive Training Details:**
| | 65K | 262K | 524k | 1048k |
|------------------------|-----------|-----------|-----------|-----------|
| Initialize From | LLaMA-3 8B| 65K | 262K | 524k |
| Sequence Length 2^N | 16 | 18 | 19 | 20 |
| RoPE theta | 15.3 M | 207.1 M | 1.06B | 2.80B |
| Batch Size | 1 | 1 | 16 | 8 |
| Gradient Accumulation Steps | 32 | 16 | 1 | 1 |
| Steps | 30 | 24 | 50 | 50 |
| Total Tokens | 62914560 | 100663296 | 419430400 | 838860800 |
| Learning Rate | 2.00E-05 | 2.00E-05 | 2.00E-05 | 2.00E-05 |
| # GPUs | 8 | 32 | 512 | 512 |
| GPU Type | NVIDIA L40S | NVIDIA L40S | NVIDIA L40S | NVIDIA L40S |
| Minutes to Train (Wall)| 202 | 555 | 61 | 87 |
**Evaluation:**

```
EVAL_MAX_CONTEXT_LENGTH=1040200
EVAL_MIN_CONTEXT_LENGTH=100
EVAL_CONTEXT_INTERVAL=86675
EVAL_DEPTH_INTERVAL=0.2
EVAL_RND_NUMBER_DIGITS=8
HAYSTACK1:
EVAL_GENERATOR_TOKENS=25
HAYSTACK2:
EVAL_CONTEXT_INTERVAL=173350
EVAL_GENERATOR_TOKENS=150000
HAYSTACK3:
EVAL_GENERATOR_TOKENS=925000
```
All boxes not pictured for Haystack 1 and 3 are 100% accurate. Haystacks 1,2 and 3 are further detailed in this [blog post](https://gradient.ai/blog/the-haystack-matters-for-niah-evals).
**Quants:**
- [GGUF by Crusoe](https://huggingface.co/crusoeai/Llama-3-8B-Instruct-1048k-GGUF). Note that you need to add 128009 as [special token with llama.cpp](https://huggingface.co/gradientai/Llama-3-8B-Instruct-262k/discussions/13).
- [MLX-4bit](https://huggingface.co/mlx-community/Llama-3-8B-Instruct-1048k-4bit)
- [Ollama](https://ollama.com/library/llama3-gradient)
- vLLM docker image, recommended to load via `--max-model-len 32768`
- If you are interested in a hosted version, drop us a mail below.
## The Gradient AI Team
https://gradient.ai/
Gradient is accelerating AI transformation across industries. Our AI Foundry incorporates your data to deploy autonomous assistants that power critical operations across your business.
## Contact Us
Drop an email to [[email protected]](mailto:[email protected])
## References
[1] Peng, Bowen, et al. "Yarn: Efficient context window extension of large language models." arXiv preprint arXiv:2309.00071 (2023).
[2] Liu, Hao, et al. "World Model on Million-Length Video And Language With RingAttention." arXiv preprint arXiv:2402.08268 (2024).
[3] https://github.com/jzhang38/EasyContext
[4] Ning Ding, Yulin Chen, Bokai Xu, Yujia Qin, Zhi Zheng, Shengding Hu, Zhiyuan
Liu, Maosong Sun, and Bowen Zhou. Enhancing chat language models by scaling
high-quality instructional conversations. arXiv preprint arXiv:2305.14233, 2023.
----
# Base Model
## Model Details
Meta developed and released the Meta Llama 3 family of large language models (LLMs), a collection of pretrained and instruction tuned generative text models in 8 and 70B sizes. The Llama 3 instruction tuned models are optimized for dialogue use cases and outperform many of the available open source chat models on common industry benchmarks. Further, in developing these models, we took great care to optimize helpfulness and safety.
**Model developers** Meta
**Variations** Llama 3 comes in two sizes — 8B and 70B parameters — in pre-trained and instruction tuned variants.
**Input** Models input text only.
**Output** Models generate text and code only.
**Model Architecture** Llama 3 is an auto-regressive language model that uses an optimized transformer architecture. The tuned versions use supervised fine-tuning (SFT) and reinforcement learning with human feedback (RLHF) to align with human preferences for helpfulness and safety.
<table>
<tr>
<td>
</td>
<td><strong>Training Data</strong>
</td>
<td><strong>Params</strong>
</td>
<td><strong>Context length</strong>
</td>
<td><strong>GQA</strong>
</td>
<td><strong>Token count</strong>
</td>
<td><strong>Knowledge cutoff</strong>
</td>
</tr>
<tr>
<td rowspan="2" >Llama 3
</td>
<td rowspan="2" >A new mix of publicly available online data.
</td>
<td>8B
</td>
<td>8k
</td>
<td>Yes
</td>
<td rowspan="2" >15T+
</td>
<td>March, 2023
</td>
</tr>
<tr>
<td>70B
</td>
<td>8k
</td>
<td>Yes
</td>
<td>December, 2023
</td>
</tr>
</table>
**Llama 3 family of models**. Token counts refer to pretraining data only. Both the 8 and 70B versions use Grouped-Query Attention (GQA) for improved inference scalability.
**Model Release Date** April 18, 2024.
**Status** This is a static model trained on an offline dataset. Future versions of the tuned models will be released as we improve model safety with community feedback.
**License** A custom commercial license is available at: [https://llama.meta.com/llama3/license](https://llama.meta.com/llama3/license)
Where to send questions or comments about the model Instructions on how to provide feedback or comments on the model can be found in the model [README](https://github.com/meta-llama/llama3). For more technical information about generation parameters and recipes for how to use Llama 3 in applications, please go [here](https://github.com/meta-llama/llama-recipes).
## Intended Use
**Intended Use Cases** Llama 3 is intended for commercial and research use in English. Instruction tuned models are intended for assistant-like chat, whereas pretrained models can be adapted for a variety of natural language generation tasks.
**Out-of-scope** Use in any manner that violates applicable laws or regulations (including trade compliance laws). Use in any other way that is prohibited by the Acceptable Use Policy and Llama 3 Community License. Use in languages other than English**.
**Note: Developers may fine-tune Llama 3 models for languages beyond English provided they comply with the Llama 3 Community License and the Acceptable Use Policy.
## How to use
This repository contains two versions of Meta-Llama-3-8B-Instruct, for use with transformers and with the original `llama3` codebase.
### Use with transformers
You can run conversational inference using the Transformers pipeline abstraction, or by leveraging the Auto classes with the `generate()` function. Let's see examples of both.
#### Transformers pipeline
```python
import transformers
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
prompt = pipeline.tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True
)
terminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipeline(
prompt,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
print(outputs[0]["generated_text"][len(prompt):])
```
#### Transformers AutoModelForCausalLM
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16,
device_map="auto",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
input_ids = tokenizer.apply_chat_template(
messages,
add_generation_prompt=True,
return_tensors="pt"
).to(model.device)
terminators = [
tokenizer.eos_token_id,
tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = model.generate(
input_ids,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
response = outputs[0][input_ids.shape[-1]:]
print(tokenizer.decode(response, skip_special_tokens=True))
```
### Use with `llama3`
Please, follow the instructions in the [repository](https://github.com/meta-llama/llama3)
To download Original checkpoints, see the example command below leveraging `huggingface-cli`:
```
huggingface-cli download meta-llama/Meta-Llama-3-8B-Instruct --include "original/*" --local-dir Meta-Llama-3-8B-Instruct
```
For Hugging Face support, we recommend using transformers or TGI, but a similar command works.
## Hardware and Software
**Training Factors** We used custom training libraries, Meta's Research SuperCluster, and production clusters for pretraining. Fine-tuning, annotation, and evaluation were also performed on third-party cloud compute.
**Carbon Footprint Pretraining utilized a cumulative** 7.7M GPU hours of computation on hardware of type H100-80GB (TDP of 700W). Estimated total emissions were 2290 tCO2eq, 100% of which were offset by Meta’s sustainability program.
<table>
<tr>
<td>
</td>
<td><strong>Time (GPU hours)</strong>
</td>
<td><strong>Power Consumption (W)</strong>
</td>
<td><strong>Carbon Emitted(tCO2eq)</strong>
</td>
</tr>
<tr>
<td>Llama 3 8B
</td>
<td>1.3M
</td>
<td>700
</td>
<td>390
</td>
</tr>
<tr>
<td>Llama 3 70B
</td>
<td>6.4M
</td>
<td>700
</td>
<td>1900
</td>
</tr>
<tr>
<td>Total
</td>
<td>7.7M
</td>
<td>
</td>
<td>2290
</td>
</tr>
</table>
**CO2 emissions during pre-training**. Time: total GPU time required for training each model. Power Consumption: peak power capacity per GPU device for the GPUs used adjusted for power usage efficiency. 100% of the emissions are directly offset by Meta's sustainability program, and because we are openly releasing these models, the pretraining costs do not need to be incurred by others.
## Training Data
**Overview** Llama 3 was pretrained on over 15 trillion tokens of data from publicly available sources. The fine-tuning data includes publicly available instruction datasets, as well as over 10M human-annotated examples. Neither the pretraining nor the fine-tuning datasets include Meta user data.
**Data Freshness** The pretraining data has a cutoff of March 2023 for the 7B and December 2023 for the 70B models respectively.
## Benchmarks
In this section, we report the results for Llama 3 models on standard automatic benchmarks. For all the evaluations, we use our internal evaluations library. For details on the methodology see [here](https://github.com/meta-llama/llama3/blob/main/eval_methodology.md).
### Base pretrained models
<table>
<tr>
<td><strong>Category</strong>
</td>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama2 7B</strong>
</td>
<td><strong>Llama2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama2 70B</strong>
</td>
</tr>
<tr>
<td rowspan="6" >General
</td>
<td>MMLU (5-shot)
</td>
<td>66.6
</td>
<td>45.7
</td>
<td>53.8
</td>
<td>79.5
</td>
<td>69.7
</td>
</tr>
<tr>
<td>AGIEval English (3-5 shot)
</td>
<td>45.9
</td>
<td>28.8
</td>
<td>38.7
</td>
<td>63.0
</td>
<td>54.8
</td>
</tr>
<tr>
<td>CommonSenseQA (7-shot)
</td>
<td>72.6
</td>
<td>57.6
</td>
<td>67.6
</td>
<td>83.8
</td>
<td>78.7
</td>
</tr>
<tr>
<td>Winogrande (5-shot)
</td>
<td>76.1
</td>
<td>73.3
</td>
<td>75.4
</td>
<td>83.1
</td>
<td>81.8
</td>
</tr>
<tr>
<td>BIG-Bench Hard (3-shot, CoT)
</td>
<td>61.1
</td>
<td>38.1
</td>
<td>47.0
</td>
<td>81.3
</td>
<td>65.7
</td>
</tr>
<tr>
<td>ARC-Challenge (25-shot)
</td>
<td>78.6
</td>
<td>53.7
</td>
<td>67.6
</td>
<td>93.0
</td>
<td>85.3
</td>
</tr>
<tr>
<td>Knowledge reasoning
</td>
<td>TriviaQA-Wiki (5-shot)
</td>
<td>78.5
</td>
<td>72.1
</td>
<td>79.6
</td>
<td>89.7
</td>
<td>87.5
</td>
</tr>
<tr>
<td rowspan="4" >Reading comprehension
</td>
<td>SQuAD (1-shot)
</td>
<td>76.4
</td>
<td>72.2
</td>
<td>72.1
</td>
<td>85.6
</td>
<td>82.6
</td>
</tr>
<tr>
<td>QuAC (1-shot, F1)
</td>
<td>44.4
</td>
<td>39.6
</td>
<td>44.9
</td>
<td>51.1
</td>
<td>49.4
</td>
</tr>
<tr>
<td>BoolQ (0-shot)
</td>
<td>75.7
</td>
<td>65.5
</td>
<td>66.9
</td>
<td>79.0
</td>
<td>73.1
</td>
</tr>
<tr>
<td>DROP (3-shot, F1)
</td>
<td>58.4
</td>
<td>37.9
</td>
<td>49.8
</td>
<td>79.7
</td>
<td>70.2
</td>
</tr>
</table>
### Instruction tuned models
<table>
<tr>
<td><strong>Benchmark</strong>
</td>
<td><strong>Llama 3 8B</strong>
</td>
<td><strong>Llama 2 7B</strong>
</td>
<td><strong>Llama 2 13B</strong>
</td>
<td><strong>Llama 3 70B</strong>
</td>
<td><strong>Llama 2 70B</strong>
</td>
</tr>
<tr>
<td>MMLU (5-shot)
</td>
<td>68.4
</td>
<td>34.1
</td>
<td>47.8
</td>
<td>82.0
</td>
<td>52.9
</td>
</tr>
<tr>
<td>GPQA (0-shot)
</td>
<td>34.2
</td>
<td>21.7
</td>
<td>22.3
</td>
<td>39.5
</td>
<td>21.0
</td>
</tr>
<tr>
<td>HumanEval (0-shot)
</td>
<td>62.2
</td>
<td>7.9
</td>
<td>14.0
</td>
<td>81.7
</td>
<td>25.6
</td>
</tr>
<tr>
<td>GSM-8K (8-shot, CoT)
</td>
<td>79.6
</td>
<td>25.7
</td>
<td>77.4
</td>
<td>93.0
</td>
<td>57.5
</td>
</tr>
<tr>
<td>MATH (4-shot, CoT)
</td>
<td>30.0
</td>
<td>3.8
</td>
<td>6.7
</td>
<td>50.4
</td>
<td>11.6
</td>
</tr>
</table>
### Responsibility & Safety
We believe that an open approach to AI leads to better, safer products, faster innovation, and a bigger overall market. We are committed to Responsible AI development and took a series of steps to limit misuse and harm and support the open source community.
Foundation models are widely capable technologies that are built to be used for a diverse range of applications. They are not designed to meet every developer preference on safety levels for all use cases, out-of-the-box, as those by their nature will differ across different applications.
Rather, responsible LLM-application deployment is achieved by implementing a series of safety best practices throughout the development of such applications, from the model pre-training, fine-tuning and the deployment of systems composed of safeguards to tailor the safety needs specifically to the use case and audience.
As part of the Llama 3 release, we updated our [Responsible Use Guide](https://llama.meta.com/responsible-use-guide/) to outline the steps and best practices for developers to implement model and system level safety for their application. We also provide a set of resources including [Meta Llama Guard 2](https://llama.meta.com/purple-llama/) and [Code Shield](https://llama.meta.com/purple-llama/) safeguards. These tools have proven to drastically reduce residual risks of LLM Systems, while maintaining a high level of helpfulness. We encourage developers to tune and deploy these safeguards according to their needs and we provide a [reference implementation](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai) to get you started.
#### Llama 3-Instruct
As outlined in the Responsible Use Guide, some trade-off between model helpfulness and model alignment is likely unavoidable. Developers should exercise discretion about how to weigh the benefits of alignment and helpfulness for their specific use case and audience. Developers should be mindful of residual risks when using Llama models and leverage additional safety tools as needed to reach the right safety bar for their use case.
<span style="text-decoration:underline;">Safety</span>
For our instruction tuned model, we conducted extensive red teaming exercises, performed adversarial evaluations and implemented safety mitigations techniques to lower residual risks. As with any Large Language Model, residual risks will likely remain and we recommend that developers assess these risks in the context of their use case. In parallel, we are working with the community to make AI safety benchmark standards transparent, rigorous and interpretable.
<span style="text-decoration:underline;">Refusals</span>
In addition to residual risks, we put a great emphasis on model refusals to benign prompts. Over-refusing not only can impact the user experience but could even be harmful in certain contexts as well. We’ve heard the feedback from the developer community and improved our fine tuning to ensure that Llama 3 is significantly less likely to falsely refuse to answer prompts than Llama 2.
We built internal benchmarks and developed mitigations to limit false refusals making Llama 3 our most helpful model to date.
#### Responsible release
In addition to responsible use considerations outlined above, we followed a rigorous process that requires us to take extra measures against misuse and critical risks before we make our release decision.
Misuse
If you access or use Llama 3, you agree to the Acceptable Use Policy. The most recent copy of this policy can be found at [https://llama.meta.com/llama3/use-policy/](https://llama.meta.com/llama3/use-policy/).
#### Critical risks
<span style="text-decoration:underline;">CBRNE</span> (Chemical, Biological, Radiological, Nuclear, and high yield Explosives)
We have conducted a two fold assessment of the safety of the model in this area:
* Iterative testing during model training to assess the safety of responses related to CBRNE threats and other adversarial risks.
* Involving external CBRNE experts to conduct an uplift test assessing the ability of the model to accurately provide expert knowledge and reduce barriers to potential CBRNE misuse, by reference to what can be achieved using web search (without the model).
### <span style="text-decoration:underline;">Cyber Security </span>
We have evaluated Llama 3 with CyberSecEval, Meta’s cybersecurity safety eval suite, measuring Llama 3’s propensity to suggest insecure code when used as a coding assistant, and Llama 3’s propensity to comply with requests to help carry out cyber attacks, where attacks are defined by the industry standard MITRE ATT&CK cyber attack ontology. On our insecure coding and cyber attacker helpfulness tests, Llama 3 behaved in the same range or safer than models of [equivalent coding capability](https://huggingface.co/spaces/facebook/CyberSecEval).
### <span style="text-decoration:underline;">Child Safety</span>
Child Safety risk assessments were conducted using a team of experts, to assess the model’s capability to produce outputs that could result in Child Safety risks and inform on any necessary and appropriate risk mitigations via fine tuning. We leveraged those expert red teaming sessions to expand the coverage of our evaluation benchmarks through Llama 3 model development. For Llama 3, we conducted new in-depth sessions using objective based methodologies to assess the model risks along multiple attack vectors. We also partnered with content specialists to perform red teaming exercises assessing potentially violating content while taking account of market specific nuances or experiences.
### Community
Generative AI safety requires expertise and tooling, and we believe in the strength of the open community to accelerate its progress. We are active members of open consortiums, including the AI Alliance, Partnership in AI and MLCommons, actively contributing to safety standardization and transparency. We encourage the community to adopt taxonomies like the MLCommons Proof of Concept evaluation to facilitate collaboration and transparency on safety and content evaluations. Our Purple Llama tools are open sourced for the community to use and widely distributed across ecosystem partners including cloud service providers. We encourage community contributions to our [Github repository](https://github.com/meta-llama/PurpleLlama).
Finally, we put in place a set of resources including an [output reporting mechanism](https://developers.facebook.com/llama_output_feedback) and [bug bounty program](https://www.facebook.com/whitehat) to continuously improve the Llama technology with the help of the community.
## Ethical Considerations and Limitations
The core values of Llama 3 are openness, inclusivity and helpfulness. It is meant to serve everyone, and to work for a wide range of use cases. It is thus designed to be accessible to people across many different backgrounds, experiences and perspectives. Llama 3 addresses users and their needs as they are, without insertion unnecessary judgment or normativity, while reflecting the understanding that even content that may appear problematic in some cases can serve valuable purposes in others. It respects the dignity and autonomy of all users, especially in terms of the values of free thought and expression that power innovation and progress.
But Llama 3 is a new technology, and like any new technology, there are risks associated with its use. Testing conducted to date has been in English, and has not covered, nor could it cover, all scenarios. For these reasons, as with all LLMs, Llama 3’s potential outputs cannot be predicted in advance, and the model may in some instances produce inaccurate, biased or other objectionable responses to user prompts. Therefore, before deploying any applications of Llama 3 models, developers should perform safety testing and tuning tailored to their specific applications of the model. As outlined in the Responsible Use Guide, we recommend incorporating [Purple Llama](https://github.com/facebookresearch/PurpleLlama) solutions into your workflows and specifically [Llama Guard](https://ai.meta.com/research/publications/llama-guard-llm-based-input-output-safeguard-for-human-ai-conversations/) which provides a base model to filter input and output prompts to layer system-level safety on top of model-level safety.
Please see the Responsible Use Guide available at [http://llama.meta.com/responsible-use-guide](http://llama.meta.com/responsible-use-guide)
## Citation instructions
@article{llama3modelcard,
title={Llama 3 Model Card},
author={AI@Meta},
year={2024},
url = {https://github.com/meta-llama/llama3/blob/main/MODEL_CARD.md}
}
## Contributors
Aaditya Singh; Aaron Grattafiori; Abhimanyu Dubey; Abhinav Jauhri; Abhinav Pandey; Abhishek Kadian; Adam Kelsey; Adi Gangidi; Ahmad Al-Dahle; Ahuva Goldstand; Aiesha Letman; Ajay Menon; Akhil Mathur; Alan Schelten; Alex Vaughan; Amy Yang; Andrei Lupu; Andres Alvarado; Andrew Gallagher; Andrew Gu; Andrew Ho; Andrew Poulton; Andrew Ryan; Angela Fan; Ankit Ramchandani; Anthony Hartshorn; Archi Mitra; Archie Sravankumar; Artem Korenev; Arun Rao; Ashley Gabriel; Ashwin Bharambe; Assaf Eisenman; Aston Zhang; Aurelien Rodriguez; Austen Gregerson; Ava Spataru; Baptiste Roziere; Ben Maurer; Benjamin Leonhardi; Bernie Huang; Bhargavi Paranjape; Bing Liu; Binh Tang; Bobbie Chern; Brani Stojkovic; Brian Fuller; Catalina Mejia Arenas; Chao Zhou; Charlotte Caucheteux; Chaya Nayak; Ching-Hsiang Chu; Chloe Bi; Chris Cai; Chris Cox; Chris Marra; Chris McConnell; Christian Keller; Christoph Feichtenhofer; Christophe Touret; Chunyang Wu; Corinne Wong; Cristian Canton Ferrer; Damien Allonsius; Daniel Kreymer; Daniel Haziza; Daniel Li; Danielle Pintz; Danny Livshits; Danny Wyatt; David Adkins; David Esiobu; David Xu; Davide Testuggine; Delia David; Devi Parikh; Dhruv Choudhary; Dhruv Mahajan; Diana Liskovich; Diego Garcia-Olano; Diego Perino; Dieuwke Hupkes; Dingkang Wang; Dustin Holland; Egor Lakomkin; Elina Lobanova; Xiaoqing Ellen Tan; Emily Dinan; Eric Smith; Erik Brinkman; Esteban Arcaute; Filip Radenovic; Firat Ozgenel; Francesco Caggioni; Frank Seide; Frank Zhang; Gabriel Synnaeve; Gabriella Schwarz; Gabrielle Lee; Gada Badeer; Georgia Anderson; Graeme Nail; Gregoire Mialon; Guan Pang; Guillem Cucurell; Hailey Nguyen; Hannah Korevaar; Hannah Wang; Haroun Habeeb; Harrison Rudolph; Henry Aspegren; Hu Xu; Hugo Touvron; Iga Kozlowska; Igor Molybog; Igor Tufanov; Iliyan Zarov; Imanol Arrieta Ibarra; Irina-Elena Veliche; Isabel Kloumann; Ishan Misra; Ivan Evtimov; Jacob Xu; Jade Copet; Jake Weissman; Jan Geffert; Jana Vranes; Japhet Asher; Jason Park; Jay Mahadeokar; Jean-Baptiste Gaya; Jeet Shah; Jelmer van der Linde; Jennifer Chan; Jenny Hong; Jenya Lee; Jeremy Fu; Jeremy Teboul; Jianfeng Chi; Jianyu Huang; Jie Wang; Jiecao Yu; Joanna Bitton; Joe Spisak; Joelle Pineau; Jon Carvill; Jongsoo Park; Joseph Rocca; Joshua Johnstun; Junteng Jia; Kalyan Vasuden Alwala; Kam Hou U; Kate Plawiak; Kartikeya Upasani; Kaushik Veeraraghavan; Ke Li; Kenneth Heafield; Kevin Stone; Khalid El-Arini; Krithika Iyer; Kshitiz Malik; Kuenley Chiu; Kunal Bhalla; Kyle Huang; Lakshya Garg; Lauren Rantala-Yeary; Laurens van der Maaten; Lawrence Chen; Leandro Silva; Lee Bell; Lei Zhang; Liang Tan; Louis Martin; Lovish Madaan; Luca Wehrstedt; Lukas Blecher; Luke de Oliveira; Madeline Muzzi; Madian Khabsa; Manav Avlani; Mannat Singh; Manohar Paluri; Mark Zuckerberg; Marcin Kardas; Martynas Mankus; Mathew Oldham; Mathieu Rita; Matthew Lennie; Maya Pavlova; Meghan Keneally; Melanie Kambadur; Mihir Patel; Mikayel Samvelyan; Mike Clark; Mike Lewis; Min Si; Mitesh Kumar Singh; Mo Metanat; Mona Hassan; Naman Goyal; Narjes Torabi; Nicolas Usunier; Nikolay Bashlykov; Nikolay Bogoychev; Niladri Chatterji; Ning Dong; Oliver Aobo Yang; Olivier Duchenne; Onur Celebi; Parth Parekh; Patrick Alrassy; Paul Saab; Pavan Balaji; Pedro Rittner; Pengchuan Zhang; Pengwei Li; Petar Vasic; Peter Weng; Polina Zvyagina; Prajjwal Bhargava; Pratik Dubal; Praveen Krishnan; Punit Singh Koura; Qing He; Rachel Rodriguez; Ragavan Srinivasan; Rahul Mitra; Ramon Calderer; Raymond Li; Robert Stojnic; Roberta Raileanu; Robin Battey; Rocky Wang; Rohit Girdhar; Rohit Patel; Romain Sauvestre; Ronnie Polidoro; Roshan Sumbaly; Ross Taylor; Ruan Silva; Rui Hou; Rui Wang; Russ Howes; Ruty Rinott; Saghar Hosseini; Sai Jayesh Bondu; Samyak Datta; Sanjay Singh; Sara Chugh; Sargun Dhillon; Satadru Pan; Sean Bell; Sergey Edunov; Shaoliang Nie; Sharan Narang; Sharath Raparthy; Shaun Lindsay; Sheng Feng; Sheng Shen; Shenghao Lin; Shiva Shankar; Shruti Bhosale; Shun Zhang; Simon Vandenhende; Sinong Wang; Seohyun Sonia Kim; Soumya Batra; Sten Sootla; Steve Kehoe; Suchin Gururangan; Sumit Gupta; Sunny Virk; Sydney Borodinsky; Tamar Glaser; Tamar Herman; Tamara Best; Tara Fowler; Thomas Georgiou; Thomas Scialom; Tianhe Li; Todor Mihaylov; Tong Xiao; Ujjwal Karn; Vedanuj Goswami; Vibhor Gupta; Vignesh Ramanathan; Viktor Kerkez; Vinay Satish Kumar; Vincent Gonguet; Vish Vogeti; Vlad Poenaru; Vlad Tiberiu Mihailescu; Vladan Petrovic; Vladimir Ivanov; Wei Li; Weiwei Chu; Wenhan Xiong; Wenyin Fu; Wes Bouaziz; Whitney Meers; Will Constable; Xavier Martinet; Xiaojian Wu; Xinbo Gao; Xinfeng Xie; Xuchao Jia; Yaelle Goldschlag; Yann LeCun; Yashesh Gaur; Yasmine Babaei; Ye Qi; Yenda Li; Yi Wen; Yiwen Song; Youngjin Nam; Yuchen Hao; Yuchen Zhang; Yun Wang; Yuning Mao; Yuzi He; Zacharie Delpierre Coudert; Zachary DeVito; Zahra Hankir; Zhaoduo Wen; Zheng Yan; Zhengxing Chen; Zhenyu Yang; Zoe Papakipos
|
Mxode/Qwen1.5-0.5B-L8-raw | Mxode | 2024-05-14T10:00:14Z | 392 | 0 | transformers | [
"transformers",
"safetensors",
"qwen2",
"text-generation",
"pretrained",
"conversational",
"en",
"arxiv:1910.09700",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-14T09:55:24Z | ---
license: other
license_name: tongyi-qianwen-research
license_link: >-
https://huggingface.co/Qwen/Qwen1.5-0.5B/blob/main/LICENSE
language:
- en
pipeline_tag: text-generation
tags:
- pretrained
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed]
|
RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf | RichardErkhov | 2024-05-24T04:45:26Z | 392 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-05-24T01:19:54Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
mistral-11b-slimorca - GGUF
- Model creator: https://huggingface.co/chargoddard/
- Original model: https://huggingface.co/chargoddard/mistral-11b-slimorca/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [mistral-11b-slimorca.Q2_K.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q2_K.gguf) | Q2_K | 3.73GB |
| [mistral-11b-slimorca.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.IQ3_XS.gguf) | IQ3_XS | 4.14GB |
| [mistral-11b-slimorca.IQ3_S.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.IQ3_S.gguf) | IQ3_S | 4.37GB |
| [mistral-11b-slimorca.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q3_K_S.gguf) | Q3_K_S | 4.34GB |
| [mistral-11b-slimorca.IQ3_M.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.IQ3_M.gguf) | IQ3_M | 4.51GB |
| [mistral-11b-slimorca.Q3_K.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q3_K.gguf) | Q3_K | 4.84GB |
| [mistral-11b-slimorca.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q3_K_M.gguf) | Q3_K_M | 4.84GB |
| [mistral-11b-slimorca.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q3_K_L.gguf) | Q3_K_L | 5.26GB |
| [mistral-11b-slimorca.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.IQ4_XS.gguf) | IQ4_XS | 5.43GB |
| [mistral-11b-slimorca.Q4_0.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q4_0.gguf) | Q4_0 | 5.66GB |
| [mistral-11b-slimorca.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.IQ4_NL.gguf) | IQ4_NL | 5.72GB |
| [mistral-11b-slimorca.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q4_K_S.gguf) | Q4_K_S | 5.7GB |
| [mistral-11b-slimorca.Q4_K.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q4_K.gguf) | Q4_K | 6.02GB |
| [mistral-11b-slimorca.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q4_K_M.gguf) | Q4_K_M | 6.02GB |
| [mistral-11b-slimorca.Q4_1.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q4_1.gguf) | Q4_1 | 6.27GB |
| [mistral-11b-slimorca.Q5_0.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q5_0.gguf) | Q5_0 | 6.89GB |
| [mistral-11b-slimorca.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q5_K_S.gguf) | Q5_K_S | 6.89GB |
| [mistral-11b-slimorca.Q5_K.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q5_K.gguf) | Q5_K | 7.08GB |
| [mistral-11b-slimorca.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q5_K_M.gguf) | Q5_K_M | 7.08GB |
| [mistral-11b-slimorca.Q5_1.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q5_1.gguf) | Q5_1 | 7.51GB |
| [mistral-11b-slimorca.Q6_K.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q6_K.gguf) | Q6_K | 8.2GB |
| [mistral-11b-slimorca.Q8_0.gguf](https://huggingface.co/RichardErkhov/chargoddard_-_mistral-11b-slimorca-gguf/blob/main/mistral-11b-slimorca.Q8_0.gguf) | Q8_0 | 10.62GB |
Original model description:
---
language:
- en
license: apache-2.0
datasets:
- Open-Orca/SlimOrca
base_model: mistralai/Mistral-7B-v0.1
model-index:
- name: mistral-11b-slimorca
results:
- task:
type: text-generation
name: Text Generation
dataset:
name: AI2 Reasoning Challenge (25-Shot)
type: ai2_arc
config: ARC-Challenge
split: test
args:
num_few_shot: 25
metrics:
- type: acc_norm
value: 64.25
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=chargoddard/mistral-11b-slimorca
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: HellaSwag (10-Shot)
type: hellaswag
split: validation
args:
num_few_shot: 10
metrics:
- type: acc_norm
value: 83.81
name: normalized accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=chargoddard/mistral-11b-slimorca
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: MMLU (5-Shot)
type: cais/mmlu
config: all
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 63.66
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=chargoddard/mistral-11b-slimorca
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: TruthfulQA (0-shot)
type: truthful_qa
config: multiple_choice
split: validation
args:
num_few_shot: 0
metrics:
- type: mc2
value: 54.66
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=chargoddard/mistral-11b-slimorca
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: Winogrande (5-shot)
type: winogrande
config: winogrande_xl
split: validation
args:
num_few_shot: 5
metrics:
- type: acc
value: 77.98
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=chargoddard/mistral-11b-slimorca
name: Open LLM Leaderboard
- task:
type: text-generation
name: Text Generation
dataset:
name: GSM8k (5-shot)
type: gsm8k
config: main
split: test
args:
num_few_shot: 5
metrics:
- type: acc
value: 52.39
name: accuracy
source:
url: https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?query=chargoddard/mistral-11b-slimorca
name: Open LLM Leaderboard
---
Full weight fine tuned on two epochs of [SlimOrca](https://huggingface.co/datasets/Open-Orca/SlimOrca). Uses Mistral Instruct's prompt format.
The base model for this came from a variation on Undi's [Mistral 11B recipe](https://huggingface.co/Undi95/Mistral-11B-v0.1). The `o_proj` and `down_proj` tensors were set to zero in the added layers, making the output exactly identical to Mistral 7B before training.
~Benchmarks look good locally but still evaluating actual usefulness.~
Update: this turned out great! 10/10 would recommend as a training approach.
### Reproducing
This [mergekit](https://github.com/cg123/mergekit) config was used to produce the base model:
```yml
slices:
- sources:
- model: mistralai/Mistral-7B-v0.1
layer_range: [0, 24]
- sources: # add middle layers with residuals scaled to zero
- model: mistralai/Mistral-7B-v0.1
layer_range: [8, 24]
parameters:
scale:
- filter: o_proj
value: 0.0
- filter: down_proj
value: 0.0
- value: 1.0
- sources:
- model: mistralai/Mistral-7B-v0.1
layer_range: [24, 32]
merge_method: passthrough
dtype: bfloat16
```
The axolotl config for fine tuning is available [here](https://huggingface.co/chargoddard/mistral-11b-slimorca/blob/main/axolotl_config.yaml).
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_chargoddard__mistral-11b-slimorca)
| Metric |Value|
|---------------------------------|----:|
|Avg. |66.12|
|AI2 Reasoning Challenge (25-Shot)|64.25|
|HellaSwag (10-Shot) |83.81|
|MMLU (5-Shot) |63.66|
|TruthfulQA (0-shot) |54.66|
|Winogrande (5-shot) |77.98|
|GSM8k (5-shot) |52.39|
|
PJMixers/LLaMa-3-CursedStock-v1.6-8B | PJMixers | 2024-06-28T15:12:37Z | 392 | 1 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"not-for-all-audiences",
"merge",
"mergekit",
"en",
"base_model:openlynn/Llama-3-Soliloquy-8B-v2",
"base_model:Undi95/Llama-3-LewdPlay-8B-evo",
"base_model:NeverSleep/Llama-3-Lumimaid-8B-v0.1",
"base_model:Nitral-AI/Poppy_Porpoise-0.72-L3-8B",
"base_model:dreamgen-preview/opus-v1.2-llama-3-8b-base-run3.4-epoch2",
"base_model:dreamgen-preview/opus-v1.2-llama-3-8b-instruct-run3.5-epoch2.5",
"base_model:Gryphe/Pantheon-RP-1.0-8b-Llama-3",
"base_model:cgato/L3-TheSpice-8b-v0.8.3",
"base_model:ResplendentAI/BlueMoon_Llama3",
"base_model:ResplendentAI/RP_Format_QuoteAsterisk_Llama3",
"base_model:Endevor/InfinityRP-v2-8B",
"base_model:flammenai/Mahou-1.2-llama3-8B",
"base_model:Sao10K/L3-8B-Stheno-v3.1",
"base_model:mpasila/Llama-3-LiPPA-8B",
"base_model:mpasila/Llama-3-Instruct-LiPPA-8B",
"base_model:Abdulhanan2006/WaifuAI-L3-8B-8k",
"base_model:TheSkullery/llama-3-cat-8b-instruct-v1",
"base_model:abacusai/Llama-3-Smaug-8B",
"base_model:Locutusque/Llama-3-Orca-2.0-8B",
"base_model:Locutusque/llama-3-neural-chat-v2.2-8B",
"base_model:RDson/Orca-Llama-3-8B-Instruct-DPO",
"base_model:jondurbin/bagel-8b-v1.0",
"base_model:Sao10K/L3-Solana-8B-v1",
"base_model:TIGER-Lab/MAmmoTH2-8B-Plus",
"base_model:nvidia/Llama3-ChatQA-1.5-8B",
"base_model:H-D-T/Buzz-8b-Large-v0.5",
"base_model:VAGOsolutions/Llama-3-SauerkrautLM-8b-Instruct",
"base_model:cognitivecomputations/Llama-3-8B-Instruct-abliterated-v2",
"base_model:failspy/Llama-3-8B-Instruct-abliterated",
"base_model:Undi95/Llama-3-Unholy-8B",
"base_model:ResplendentAI/Theory_of_Mind_Llama3",
"base_model:ResplendentAI/Aura_Llama3",
"base_model:ResplendentAI/Luna_Llama3",
"base_model:Edgerunners/meta-llama-3-8b-instruct-hf-ortho-baukit-5fail-3000total-bf16",
"base_model:vicgalle/Configurable-Llama-3-8B-v0.3",
"base_model:lodrick-the-lafted/Limon-8B",
"base_model:nothingiisreal/L3-Zodiac-Instruct-8B-ORPO-E2",
"base_model:ajibawa-2023/Code-Llama-3-8B",
"base_model:Walmart-the-bag/Llama-3-LizardCoder-8B",
"base_model:WhiteRabbitNeo/Llama-3-WhiteRabbitNeo-8B-v2.0",
"base_model:migtissera/Tess-2.0-Llama-3-8B",
"base_model:johnsnowlabs/JSL-MedLlama-3-8B-v1.0",
"base_model:aaditya/Llama3-OpenBioLLM-8B",
"base_model:ruslanmv/Medical-Llama3-8B",
"base_model:BeaverAI/Llama-3SOME-8B-v2-rc2",
"base_model:ToastyPigeon/Llama-3-8B-Instruct-SpringDragon-V2-QLoRA",
"base_model:refuelai/Llama-3-Refueled",
"base_model:Danielbrdz/Barcenas-Llama3-8b-ORPO",
"base_model:lodrick-the-lafted/Olethros-8B",
"base_model:RLHFlow/LLaMA3-iterative-DPO-final",
"base_model:victunes/TherapyLlama-8B-v1",
"base_model:DevQuasar/llama3_8b_chat_brainstorm",
"base_model:migtissera/Llama-3-8B-Synthia-v3.5",
"license:llama3",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-25T00:56:01Z | ---
tags:
- not-for-all-audiences
- merge
- mergekit
base_model:
- openlynn/Llama-3-Soliloquy-8B-v2
- Undi95/Llama-3-LewdPlay-8B-evo
- NeverSleep/Llama-3-Lumimaid-8B-v0.1
- Nitral-AI/Poppy_Porpoise-0.72-L3-8B
- dreamgen-preview/opus-v1.2-llama-3-8b-base-run3.4-epoch2
- dreamgen-preview/opus-v1.2-llama-3-8b-instruct-run3.5-epoch2.5
- Gryphe/Pantheon-RP-1.0-8b-Llama-3
- cgato/L3-TheSpice-8b-v0.8.3
- ResplendentAI/BlueMoon_Llama3
- ResplendentAI/RP_Format_QuoteAsterisk_Llama3
- Endevor/InfinityRP-v2-8B
- flammenai/Mahou-1.2-llama3-8B
- Sao10K/L3-8B-Stheno-v3.1
- mpasila/Llama-3-LiPPA-8B
- mpasila/Llama-3-Instruct-LiPPA-8B
- Abdulhanan2006/WaifuAI-L3-8B-8k
- TheSkullery/llama-3-cat-8b-instruct-v1
- abacusai/Llama-3-Smaug-8B
- Locutusque/Llama-3-Orca-2.0-8B
- Locutusque/llama-3-neural-chat-v2.2-8B
- RDson/Orca-Llama-3-8B-Instruct-DPO
- jondurbin/bagel-8b-v1.0
- Sao10K/L3-Solana-8B-v1
- TIGER-Lab/MAmmoTH2-8B-Plus
- nvidia/Llama3-ChatQA-1.5-8B
- H-D-T/Buzz-8b-Large-v0.5
- VAGOsolutions/Llama-3-SauerkrautLM-8b-Instruct
- cognitivecomputations/Llama-3-8B-Instruct-abliterated-v2
- failspy/Llama-3-8B-Instruct-abliterated
- Undi95/Llama-3-Unholy-8B
- ResplendentAI/Theory_of_Mind_Llama3
- ResplendentAI/Aura_Llama3
- ResplendentAI/Luna_Llama3
- Edgerunners/meta-llama-3-8b-instruct-hf-ortho-baukit-5fail-3000total-bf16
- vicgalle/Configurable-Llama-3-8B-v0.3
- lodrick-the-lafted/Limon-8B
- nothingiisreal/L3-Zodiac-Instruct-8B-ORPO-E2
- ajibawa-2023/Code-Llama-3-8B
- Walmart-the-bag/Llama-3-LizardCoder-8B
- WhiteRabbitNeo/Llama-3-WhiteRabbitNeo-8B-v2.0
- migtissera/Tess-2.0-Llama-3-8B
- johnsnowlabs/JSL-MedLlama-3-8B-v1.0
- aaditya/Llama3-OpenBioLLM-8B
- ruslanmv/Medical-Llama3-8B
- BeaverAI/Llama-3SOME-8B-v2-rc2
- ToastyPigeon/Llama-3-8B-Instruct-SpringDragon-V2-QLoRA
- refuelai/Llama-3-Refueled
- Danielbrdz/Barcenas-Llama3-8b-ORPO
- lodrick-the-lafted/Olethros-8B
- RLHFlow/LLaMA3-iterative-DPO-final
- victunes/TherapyLlama-8B-v1
- DevQuasar/llama3_8b_chat_brainstorm
- migtissera/Llama-3-8B-Synthia-v3.5
license: llama3
language:
- en
---
# Merging Compute Sponsored by KoboldAI

**GGUFs can be found on [mradermacher's page](https://huggingface.co/mradermacher/LLaMa-3-CursedStock-v1.6-8B-GGUF)**
---
Refer to the original models for best usage.
- [openlynn/Llama-3-Soliloquy-8B-v2](https://huggingface.co/openlynn/Llama-3-Soliloquy-8B-v2)
- [Undi95/Llama-3-LewdPlay-8B-evo](https://huggingface.co/Undi95/Llama-3-LewdPlay-8B-evo)
- [NeverSleep/Llama-3-Lumimaid-8B-v0.1](https://huggingface.co/NeverSleep/Llama-3-Lumimaid-8B-v0.1)
- [Nitral-AI/Poppy_Porpoise-0.72-L3-8B](https://huggingface.co/Nitral-AI/Poppy_Porpoise-0.72-L3-8B)
- [dreamgen-preview/opus-v1.2-llama-3-8b-base-run3.4-epoch2](https://huggingface.co/dreamgen-preview/opus-v1.2-llama-3-8b-base-run3.4-epoch2)
- [dreamgen-preview/opus-v1.2-llama-3-8b-instruct-run3.5-epoch2.5](https://huggingface.co/dreamgen-preview/opus-v1.2-llama-3-8b-instruct-run3.5-epoch2.5)
- [Gryphe/Pantheon-RP-1.0-8b-Llama-3](https://huggingface.co/Gryphe/Pantheon-RP-1.0-8b-Llama-3)
- [cgato/L3-TheSpice-8b-v0.8.3](https://huggingface.co/cgato/L3-TheSpice-8b-v0.8.3)
- [ResplendentAI/BlueMoon_Llama3](https://huggingface.co/ResplendentAI/BlueMoon_Llama3)
- [ResplendentAI/RP_Format_QuoteAsterisk_Llama3](https://huggingface.co/ResplendentAI/RP_Format_QuoteAsterisk_Llama3)
- [Endevor/InfinityRP-v2-8B](https://huggingface.co/Endevor/InfinityRP-v2-8B)
- [flammenai/Mahou-1.2-llama3-8B](https://huggingface.co/flammenai/Mahou-1.2-llama3-8B)
- [Sao10K/L3-8B-Stheno-v3.1](https://huggingface.co/Sao10K/L3-8B-Stheno-v3.1)
- [mpasila/Llama-3-LiPPA-8B](https://huggingface.co/mpasila/Llama-3-LiPPA-8B)
- [mpasila/Llama-3-Instruct-LiPPA-8B](https://huggingface.co/mpasila/Llama-3-Instruct-LiPPA-8B)
- [Abdulhanan2006/WaifuAI-L3-8B-8k](https://huggingface.co/Abdulhanan2006/WaifuAI-L3-8B-8k)
- [TheSkullery/llama-3-cat-8b-instruct-v1](https://huggingface.co/TheSkullery/llama-3-cat-8b-instruct-v1)
- [abacusai/Llama-3-Smaug-8B](https://huggingface.co/abacusai/Llama-3-Smaug-8B)
- [Locutusque/Llama-3-Orca-2.0-8B](https://huggingface.co/Locutusque/Llama-3-Orca-2.0-8B)
- [Locutusque/llama-3-neural-chat-v2.2-8B](https://huggingface.co/Locutusque/llama-3-neural-chat-v2.2-8B)
- [RDson/Orca-Llama-3-8B-Instruct-DPO](https://huggingface.co/RDson/Orca-Llama-3-8B-Instruct-DPO)
- [jondurbin/bagel-8b-v1.0](https://huggingface.co/jondurbin/bagel-8b-v1.0)
- [Sao10K/L3-Solana-8B-v1](https://huggingface.co/Sao10K/L3-Solana-8B-v1)
- [TIGER-Lab/MAmmoTH2-8B-Plus](https://huggingface.co/TIGER-Lab/MAmmoTH2-8B-Plus)
- [nvidia/Llama3-ChatQA-1.5-8B](https://huggingface.co/nvidia/Llama3-ChatQA-1.5-8B)
- [H-D-T/Buzz-8b-Large-v0.5](https://huggingface.co/H-D-T/Buzz-8b-Large-v0.5)
- [VAGOsolutions/Llama-3-SauerkrautLM-8b-Instruct](https://huggingface.co/VAGOsolutions/Llama-3-SauerkrautLM-8b-Instruct)
- [cognitivecomputations/Llama-3-8B-Instruct-abliterated-v2](https://huggingface.co/cognitivecomputations/Llama-3-8B-Instruct-abliterated-v2)
- [failspy/Llama-3-8B-Instruct-abliterated](https://huggingface.co/failspy/Llama-3-8B-Instruct-abliterated)
- [Undi95/Llama-3-Unholy-8B](https://huggingface.co/Undi95/Llama-3-Unholy-8B)
- [ResplendentAI/Theory_of_Mind_Llama3](https://huggingface.co/ResplendentAI/Theory_of_Mind_Llama3)
- [ResplendentAI/Aura_Llama3](https://huggingface.co/ResplendentAI/Aura_Llama3)
- [ResplendentAI/Luna_Llama3](https://huggingface.co/ResplendentAI/Luna_Llama3)
- [Edgerunners/meta-llama-3-8b-instruct-hf-ortho-baukit-5fail-3000total-bf16](https://huggingface.co/Edgerunners/meta-llama-3-8b-instruct-hf-ortho-baukit-5fail-3000total-bf16)
- [vicgalle/Configurable-Llama-3-8B-v0.3](https://huggingface.co/vicgalle/Configurable-Llama-3-8B-v0.3)
- [lodrick-the-lafted/Limon-8B](https://huggingface.co/lodrick-the-lafted/Limon-8B)
- [nothingiisreal/L3-Zodiac-Instruct-8B-ORPO-E2](https://huggingface.co/nothingiisreal/L3-Zodiac-Instruct-8B-ORPO-E2)
- [ajibawa-2023/Code-Llama-3-8B](https://huggingface.co/ajibawa-2023/Code-Llama-3-8B)
- [Walmart-the-bag/Llama-3-LizardCoder-8B](https://huggingface.co/Walmart-the-bag/Llama-3-LizardCoder-8B)
- [WhiteRabbitNeo/Llama-3-WhiteRabbitNeo-8B-v2.0](https://huggingface.co/WhiteRabbitNeo/Llama-3-WhiteRabbitNeo-8B-v2.0)
- [migtissera/Tess-2.0-Llama-3-8B](https://huggingface.co/migtissera/Tess-2.0-Llama-3-8B)
- [johnsnowlabs/JSL-MedLlama-3-8B-v1.0](https://huggingface.co/johnsnowlabs/JSL-MedLlama-3-8B-v1.0)
- [aaditya/Llama3-OpenBioLLM-8B](https://huggingface.co/aaditya/Llama3-OpenBioLLM-8B)
- [ruslanmv/Medical-Llama3-8B](https://huggingface.co/ruslanmv/Medical-Llama3-8B)
- [BeaverAI/Llama-3SOME-8B-v2-rc2](https://huggingface.co/BeaverAI/Llama-3SOME-8B-v2-rc2)
- [ToastyPigeon/Llama-3-8B-Instruct-SpringDragon-V2-QLoRA](https://huggingface.co/ToastyPigeon/Llama-3-8B-Instruct-SpringDragon-V2-QLoRA)
- [refuelai/Llama-3-Refueled](https://huggingface.co/refuelai/Llama-3-Refueled)
- [Danielbrdz/Barcenas-Llama3-8b-ORPO](https://huggingface.co/Danielbrdz/Barcenas-Llama3-8b-ORPO)
- [lodrick-the-lafted/Olethros-8B](https://huggingface.co/lodrick-the-lafted/Olethros-8B)
- [RLHFlow/LLaMA3-iterative-DPO-final](https://huggingface.co/RLHFlow/LLaMA3-iterative-DPO-final)
- [victunes/TherapyLlama-8B-v1](https://huggingface.co/victunes/TherapyLlama-8B-v1)
- [DevQuasar/llama3_8b_chat_brainstorm](https://huggingface.co/victunes/DevQuasar/llama3_8b_chat_brainstorm)
- [migtissera/Llama-3-8B-Synthia-v3.5](https://huggingface.co/migtissera/Llama-3-8B-Synthia-v3.5)
---
# Mergekit Recipe
```yaml
merge_method: model_stock
base_model: NousResearch/Meta-Llama-3-8B
dtype: bfloat16
models:
# RP
- model: openlynn/Llama-3-Soliloquy-8B-v2
- model: Undi95/Llama-3-LewdPlay-8B-evo
- model: NeverSleep/Llama-3-Lumimaid-8B-v0.1
- model: Nitral-AI/Poppy_Porpoise-0.72-L3-8B
- model: dreamgen-preview/opus-v1.2-llama-3-8b-base-run3.4-epoch2
- model: dreamgen-preview/opus-v1.2-llama-3-8b-instruct-run3.5-epoch2.5
- model: Gryphe/Pantheon-RP-1.0-8b-Llama-3
- model: cgato/L3-TheSpice-8b-v0.8.3
- model: Undi95/Llama3-Unholy-8B-OAS+ResplendentAI/BlueMoon_Llama3
- model: Undi95/Llama3-Unholy-8B-OAS+ResplendentAI/RP_Format_QuoteAsterisk_Llama3
- model: Endevor/InfinityRP-v2-8B
- model: flammenai/Mahou-1.2-llama3-8B
- model: Sao10K/L3-8B-Stheno-v3.1
- model: mpasila/Llama-3-LiPPA-8B
- model: mpasila/Llama-3-Instruct-LiPPA-8B
- model: Abdulhanan2006/WaifuAI-L3-8B-8k
# Smart
- model: TheSkullery/llama-3-cat-8b-instruct-v1
- model: abacusai/Llama-3-Smaug-8B
- model: Locutusque/Llama-3-Orca-2.0-8B
- model: Locutusque/llama-3-neural-chat-v2.2-8B
- model: RDson/Orca-Llama-3-8B-Instruct-DPO
- model: jondurbin/bagel-8b-v1.0
- model: Sao10K/L3-Solana-8B-v1
- model: TIGER-Lab/MAmmoTH2-8B-Plus
- model: nvidia/Llama3-ChatQA-1.5-8B
- model: H-D-T/Buzz-8b-Large-v0.5
- model: VAGOsolutions/Llama-3-SauerkrautLM-8b-Instruct
# Uncensored
- model: cognitivecomputations/Llama-3-8B-Instruct-abliterated-v2
- model: failspy/Llama-3-8B-Instruct-abliterated
- model: Undi95/Llama-3-Unholy-8B
- model: Undi95/Llama3-Unholy-8B-OAS+ResplendentAI/Theory_of_Mind_Llama3
- model: Undi95/Llama3-Unholy-8B-OAS+ResplendentAI/Aura_Llama3
- model: Undi95/Llama3-Unholy-8B-OAS+ResplendentAI/Luna_Llama3
- model: Edgerunners/meta-llama-3-8b-instruct-hf-ortho-baukit-5fail-3000total-bf16
- model: vicgalle/Configurable-Llama-3-8B-v0.3
- model: lodrick-the-lafted/Limon-8B
- model: nothingiisreal/L3-Zodiac-Instruct-8B-ORPO-E2
# Code
- model: ajibawa-2023/Code-Llama-3-8B
- model: Walmart-the-bag/Llama-3-LizardCoder-8B
- model: WhiteRabbitNeo/Llama-3-WhiteRabbitNeo-8B-v2.0
- model: migtissera/Tess-2.0-Llama-3-8B
# Med
- model: johnsnowlabs/JSL-MedLlama-3-8B-v1.0
- model: aaditya/Llama3-OpenBioLLM-8B
- model: ruslanmv/Medical-Llama3-8B
- model: HPAI-BSC/Llama3-Aloe-8B-Alpha
# Misc
- model: BeaverAI/Llama-3SOME-8B-v2-rc2
- model: NousResearch/Meta-Llama-3-8B-Instruct+ToastyPigeon/Llama-3-8B-Instruct-SpringDragon-V2-QLoRA
- model: refuelai/Llama-3-Refueled
- model: Danielbrdz/Barcenas-Llama3-8b-ORPO
- model: lodrick-the-lafted/Olethros-8B
- model: RLHFlow/LLaMA3-iterative-DPO-final
- model: victunes/TherapyLlama-8B-v1
- model: DevQuasar/llama3_8b_chat_brainstorm
- model: migtissera/Llama-3-8B-Synthia-v3.5
``` |
mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF | mradermacher | 2024-05-27T01:57:09Z | 392 | 0 | transformers | [
"transformers",
"gguf",
"abliterated",
"en",
"dataset:mlabonne/orpo-dpo-mix-40k",
"base_model:mlabonne/Llama-3-8B-Instruct-abliterated-dpomix",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-27T00:16:32Z | ---
base_model: mlabonne/Llama-3-8B-Instruct-abliterated-dpomix
datasets:
- mlabonne/orpo-dpo-mix-40k
language:
- en
library_name: transformers
license: other
quantized_by: mradermacher
tags:
- abliterated
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hfhfix -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/mlabonne/Llama-3-8B-Instruct-abliterated-dpomix
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-8B-Instruct-abliterated-dpomix-GGUF/resolve/main/Llama-3-8B-Instruct-abliterated-dpomix.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf | RichardErkhov | 2024-06-02T02:02:09Z | 392 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-06-02T01:48:29Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
MXLewd-L2-20B - GGUF
- Model creator: https://huggingface.co/Undi95/
- Original model: https://huggingface.co/Undi95/MXLewd-L2-20B/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [MXLewd-L2-20B.Q2_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q2_K.gguf) | Q2_K | 6.91GB |
| [MXLewd-L2-20B.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.IQ3_XS.gguf) | IQ3_XS | 0.78GB |
| [MXLewd-L2-20B.IQ3_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.IQ3_S.gguf) | IQ3_S | 0.13GB |
| [MXLewd-L2-20B.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q3_K_S.gguf) | Q3_K_S | 0.09GB |
| [MXLewd-L2-20B.IQ3_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.IQ3_M.gguf) | IQ3_M | 0.0GB |
| [MXLewd-L2-20B.Q3_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q3_K.gguf) | Q3_K | 0.0GB |
| [MXLewd-L2-20B.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q3_K_M.gguf) | Q3_K_M | 0.0GB |
| [MXLewd-L2-20B.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q3_K_L.gguf) | Q3_K_L | 0.0GB |
| [MXLewd-L2-20B.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.IQ4_XS.gguf) | IQ4_XS | 0.0GB |
| [MXLewd-L2-20B.Q4_0.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q4_0.gguf) | Q4_0 | 0.0GB |
| [MXLewd-L2-20B.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.IQ4_NL.gguf) | IQ4_NL | 0.0GB |
| [MXLewd-L2-20B.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q4_K_S.gguf) | Q4_K_S | 0.0GB |
| [MXLewd-L2-20B.Q4_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q4_K.gguf) | Q4_K | 0.0GB |
| [MXLewd-L2-20B.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q4_K_M.gguf) | Q4_K_M | 0.0GB |
| [MXLewd-L2-20B.Q4_1.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q4_1.gguf) | Q4_1 | 0.0GB |
| [MXLewd-L2-20B.Q5_0.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q5_0.gguf) | Q5_0 | 0.0GB |
| [MXLewd-L2-20B.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q5_K_S.gguf) | Q5_K_S | 0.0GB |
| [MXLewd-L2-20B.Q5_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q5_K.gguf) | Q5_K | 0.0GB |
| [MXLewd-L2-20B.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q5_K_M.gguf) | Q5_K_M | 0.0GB |
| [MXLewd-L2-20B.Q5_1.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q5_1.gguf) | Q5_1 | 0.0GB |
| [MXLewd-L2-20B.Q6_K.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q6_K.gguf) | Q6_K | 0.0GB |
| [MXLewd-L2-20B.Q8_0.gguf](https://huggingface.co/RichardErkhov/Undi95_-_MXLewd-L2-20B-gguf/blob/main/MXLewd-L2-20B.Q8_0.gguf) | Q8_0 | 0.0GB |
Original model description:
---
license: cc-by-nc-4.0
---
Merge:
```shell
layer_slices:
- model: ./MXLewd-L2-20B-part2
start: 0
end: 16
- model: ./MXLewd-L2-20B-part1
start: 8
end: 20
- model: ./MXLewd-L2-20B-part2
start: 17
end: 32
- model: ./MXLewd-L2-20B-part1
start: 21
end: 40
```
Part 2 is ReMM (0.33) and Xwin (0.66)
Part 1 is Xwin (0.33) and MLewd (0.66)
<!-- description start -->
## Models used
- Undi95/MLewd-L2-13B-v2-3
- Undi95/ReMM-v2.1-L2-13B
- Xwin-LM/Xwin-LM-13B-V0.1
<!-- description end -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that completes the request.
### Instruction:
{prompt}
### Response:
```
# [Open LLM Leaderboard Evaluation Results](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
Detailed results can be found [here](https://huggingface.co/datasets/open-llm-leaderboard/details_Undi95__MXLewd-L2-20B)
| Metric | Value |
|-----------------------|---------------------------|
| Avg. | 51.29 |
| ARC (25-shot) | 63.23 |
| HellaSwag (10-shot) | 85.33 |
| MMLU (5-shot) | 57.36 |
| TruthfulQA (0-shot) | 51.65 |
| Winogrande (5-shot) | 76.09 |
| GSM8K (5-shot) | 10.92 |
| DROP (3-shot) | 14.46 |
|
mradermacher/Llama-Salad-8x8B-GGUF | mradermacher | 2024-06-09T06:29:59Z | 392 | 2 | transformers | [
"transformers",
"gguf",
"nsfw",
"not-for-all-audiences",
"llama-3",
"text-generation-inference",
"moe",
"mergekit",
"merge",
"en",
"base_model:HiroseKoichi/Llama-Salad-8x8B",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-08T23:23:26Z | ---
base_model: HiroseKoichi/Llama-Salad-8x8B
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
tags:
- nsfw
- not-for-all-audiences
- llama-3
- text-generation-inference
- moe
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/HiroseKoichi/Llama-Salad-8x8B
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Llama-Salad-8x8B-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q2_K.gguf) | Q2_K | 17.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.IQ3_XS.gguf) | IQ3_XS | 20.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.IQ3_S.gguf) | IQ3_S | 21.0 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q3_K_S.gguf) | Q3_K_S | 21.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.IQ3_M.gguf) | IQ3_M | 22.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q3_K_M.gguf) | Q3_K_M | 23.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q3_K_L.gguf) | Q3_K_L | 24.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.IQ4_XS.gguf) | IQ4_XS | 26.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q4_K_S.gguf) | Q4_K_S | 27.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q4_K_M.gguf) | Q4_K_M | 29.1 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q5_K_S.gguf) | Q5_K_S | 32.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q5_K_M.gguf) | Q5_K_M | 33.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q6_K.gguf) | Q6_K | 39.1 | very good quality |
| [PART 1](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q8_0.gguf.part1of2) [PART 2](https://huggingface.co/mradermacher/Llama-Salad-8x8B-GGUF/resolve/main/Llama-Salad-8x8B.Q8_0.gguf.part2of2) | Q8_0 | 50.6 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
zachaman/phi3-goodwater5-merged-Q8_0-GGUF | zachaman | 2024-06-09T02:50:19Z | 392 | 0 | transformers | [
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:zachaman/phi3-goodwater5-merged",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-09T02:50:09Z | ---
library_name: transformers
tags:
- llama-cpp
- gguf-my-repo
base_model: zachaman/phi3-goodwater5-merged
---
# zachaman/phi3-goodwater5-merged-Q8_0-GGUF
This model was converted to GGUF format from [`zachaman/phi3-goodwater5-merged`](https://huggingface.co/zachaman/phi3-goodwater5-merged) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/zachaman/phi3-goodwater5-merged) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama --hf-repo zachaman/phi3-goodwater5-merged-Q8_0-GGUF --hf-file phi3-goodwater5-merged-q8_0.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo zachaman/phi3-goodwater5-merged-Q8_0-GGUF --hf-file phi3-goodwater5-merged-q8_0.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./main --hf-repo zachaman/phi3-goodwater5-merged-Q8_0-GGUF --hf-file phi3-goodwater5-merged-q8_0.gguf -p "The meaning to life and the universe is"
```
or
```
./server --hf-repo zachaman/phi3-goodwater5-merged-Q8_0-GGUF --hf-file phi3-goodwater5-merged-q8_0.gguf -c 2048
```
|
paulo037/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-Q4_K_M-GGUF | paulo037 | 2024-06-23T23:05:50Z | 392 | 0 | transformers | [
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-23T23:05:39Z | ---
base_model: NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch
library_name: transformers
tags:
- llama-cpp
- gguf-my-repo
---
# paulo037/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-Q4_K_M-GGUF
This model was converted to GGUF format from [`NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch`](https://huggingface.co/NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo paulo037/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-Q4_K_M-GGUF --hf-file phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo paulo037/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-Q4_K_M-GGUF --hf-file phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo paulo037/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-Q4_K_M-GGUF --hf-file phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo paulo037/phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-Q4_K_M-GGUF --hf-file phi-3-mini-128k-instruct-mix-spider-bird-1-epoch-q4_k_m.gguf -c 2048
```
|
w11wo/javanese-gpt2-small | w11wo | 2023-06-30T02:45:24Z | 391 | 1 | transformers | [
"transformers",
"pytorch",
"tf",
"jax",
"safetensors",
"gpt2",
"text-generation",
"javanese-gpt2-small",
"jv",
"dataset:wikipedia",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2022-03-02T23:29:05Z | ---
language: jv
tags:
- javanese-gpt2-small
license: mit
datasets:
- wikipedia
widget:
- text: "Jenengku Budi, saka Indonesia"
---
## Javanese GPT-2 Small
Javanese GPT-2 Small is a language model based on the [GPT-2 model](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf). It was trained on the latest (late December 2020) Javanese Wikipedia articles.
The model was originally HuggingFace's pretrained [English GPT-2 model](https://huggingface.co/transformers/model_doc/gpt2.html) and is later fine-tuned on the Javanese dataset. Many of the techniques used
are based on a [notebook](https://github.com/piegu/fastai-projects/blob/master/finetuning-English-GPT2-any-language-Portuguese-HuggingFace-fastaiv2.ipynb)/[blog](https://medium.com/@pierre_guillou/faster-than-training-from-scratch-fine-tuning-the-english-gpt-2-in-any-language-with-hugging-f2ec05c98787) shared by [Pierre Guillou](https://medium.com/@pierre_guillou), where Pierre Guillou fine-tuned the English GPT-2 model on a Portuguese dataset.
Frameworks used include HuggingFace's [Transformers](https://huggingface.co/transformers) and fast.ai's [Deep Learning library](https://docs.fast.ai/). PyTorch was used as the backend framework during training, but the model remains compatible with TensorFlow nonetheless.
## Model
| Model | #params | Arch. | Training /Validation data (text) |
|-----------------------|---------|-------------|-------------------------------------|
| `javanese-gpt2-small` | 124M | GPT-2 Small | Javanese Wikipedia (319 MB of text) |
## Evaluation Results
Before fine-tuning, the English GPT-2 model went through a validation step just to see how the model fairs prior to training.
| valid loss | perplexity |
|------------|------------|
| 10.845 | 51313.62 |
The model was then trained afterwards for 5 epochs and the following are the results.
| epoch | train loss | valid loss | perplexity | total time |
|-------|------------|------------|------------|------------|
| 0 | 4.336 | 4.110 | 60.94 | 22:28 |
| 1 | 3.598 | 3.543 | 34.58 | 23:27 |
| 2 | 3.161 | 3.331 | 27.98 | 24:17 |
| 3 | 2.974 | 3.265 | 26.18 | 25:03 |
| 4 | 2.932 | 3.234 | 25.39 | 25:06 |
## How to Use (PyTorch)
### Load Model and Byte-level Tokenizer
```python
from transformers import GPT2TokenizerFast, GPT2LMHeadModel
pretrained_name = "w11wo/javanese-gpt2-small"
tokenizer = GPT2TokenizerFast.from_pretrained(pretrained_name)
tokenizer.model_max_length = 1024
model = GPT2LMHeadModel.from_pretrained(pretrained_name)
```
### Generate a Sequence
```python
# sample prompt
prompt = "Jenengku Budi, saka Indonesia"
input_ids = tokenizer.encode(prompt, return_tensors='pt')
model.eval()
# generate output using top-k sampling
sample_outputs = model.generate(input_ids,
pad_token_id=50256,
do_sample=True,
max_length=40,
min_length=40,
top_k=40,
num_return_sequences=1)
for i, sample_output in enumerate(sample_outputs):
print(tokenizer.decode(sample_output.tolist()))
```
## Disclaimer
Do remember that although the dataset originated from Wikipedia, the model may not always generate factual texts. Additionally, the biases which came from the Wikipedia articles may be carried over into the results of this model.
## Credits
Major thanks to Pierre Guillou for sharing his work, which did not only enable me to realize this project but also taught me tons of new, exciting stuff.
## Author
Javanese GPT-2 Small was trained and evaluated by [Wilson Wongso](https://w11wo.github.io/). All computation and development are done on Google Colaboratory using their free GPU access.
## Citation
If you use any of our models in your research, please cite:
```bib
@inproceedings{wongso2021causal,
title={Causal and Masked Language Modeling of Javanese Language using Transformer-based Architectures},
author={Wongso, Wilson and Setiawan, David Samuel and Suhartono, Derwin},
booktitle={2021 International Conference on Advanced Computer Science and Information Systems (ICACSIS)},
pages={1--7},
year={2021},
organization={IEEE}
}
```
|
Nahrawy/AIorNot | Nahrawy | 2023-04-07T17:12:13Z | 391 | 6 | transformers | [
"transformers",
"pytorch",
"swin",
"image-classification",
"generative ai",
"classification",
"en",
"dataset:competitions/aiornot",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| image-classification | 2023-03-18T16:55:35Z | ---
license: apache-2.0
datasets:
- competitions/aiornot
language:
- en
metrics:
- accuracy
tags:
- generative ai
- classification
---
Classification model used to classify real images and AI generated images.\
The model used is swin-tiny-patch4-window7-224 finetued on aiornot dataset.\
To use the model
```
import torch
from transformers import AutoFeatureExtractor, AutoModelForImageClassification
labels = ["Real", "AI"]
feature_extractor = AutoFeatureExtractor.from_pretrained("Nahrawy/AIorNot")
model = AutoModelForImageClassification.from_pretrained("Nahrawy/AIorNot")
input = feature_extractor(image, return_tensors="pt")
with torch.no_grad():
outputs = model(**input)
logits = outputs.logits
prediction = logits.argmax(-1).item()
label = labels[prediction]
``` |
lorahub/flan_t5_large-wiki_bio_comprehension | lorahub | 2023-07-24T10:07:22Z | 391 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-07-24T10:07:12Z | ---
library_name: peft
---
|
lorahub/flan_t5_large-quarel_testing_students | lorahub | 2023-07-24T10:21:55Z | 391 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-07-24T10:21:46Z | ---
library_name: peft
---
|
TheBloke/GPlatty-30B-GGUF | TheBloke | 2023-09-27T12:53:28Z | 391 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"en",
"base_model:lilloukas/GPlatty-30B",
"license:other",
"text-generation-inference",
"region:us"
]
| null | 2023-09-20T02:22:19Z | ---
language:
- en
license: other
tags:
- llama
metrics:
- MMLU
- ARC
- HellaSwag
- TruthfulQA
model_name: Gplatty 30B
base_model: lilloukas/GPlatty-30B
inference: false
model_creator: lilloukas
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Gplatty 30B - GGUF
- Model creator: [lilloukas](https://huggingface.co/lilloukas)
- Original model: [Gplatty 30B](https://huggingface.co/lilloukas/GPlatty-30B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Lilloukas' GPlatty 30B](https://huggingface.co/lilloukas/GPlatty-30B).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/GPlatty-30B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/GPlatty-30B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/GPlatty-30B-GGUF)
* [lilloukas's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/lilloukas/GPlatty-30B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [gplatty-30b.Q2_K.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q2_K.gguf) | Q2_K | 2 | 13.50 GB| 16.00 GB | smallest, significant quality loss - not recommended for most purposes |
| [gplatty-30b.Q3_K_S.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q3_K_S.gguf) | Q3_K_S | 3 | 14.06 GB| 16.56 GB | very small, high quality loss |
| [gplatty-30b.Q3_K_M.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q3_K_M.gguf) | Q3_K_M | 3 | 15.76 GB| 18.26 GB | very small, high quality loss |
| [gplatty-30b.Q3_K_L.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q3_K_L.gguf) | Q3_K_L | 3 | 17.28 GB| 19.78 GB | small, substantial quality loss |
| [gplatty-30b.Q4_0.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q4_0.gguf) | Q4_0 | 4 | 18.36 GB| 20.86 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [gplatty-30b.Q4_K_S.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q4_K_S.gguf) | Q4_K_S | 4 | 18.44 GB| 20.94 GB | small, greater quality loss |
| [gplatty-30b.Q4_K_M.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q4_K_M.gguf) | Q4_K_M | 4 | 19.62 GB| 22.12 GB | medium, balanced quality - recommended |
| [gplatty-30b.Q5_0.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q5_0.gguf) | Q5_0 | 5 | 22.40 GB| 24.90 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [gplatty-30b.Q5_K_S.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q5_K_S.gguf) | Q5_K_S | 5 | 22.40 GB| 24.90 GB | large, low quality loss - recommended |
| [gplatty-30b.Q5_K_M.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q5_K_M.gguf) | Q5_K_M | 5 | 23.05 GB| 25.55 GB | large, very low quality loss - recommended |
| [gplatty-30b.Q6_K.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q6_K.gguf) | Q6_K | 6 | 26.69 GB| 29.19 GB | very large, extremely low quality loss |
| [gplatty-30b.Q8_0.gguf](https://huggingface.co/TheBloke/GPlatty-30B-GGUF/blob/main/gplatty-30b.Q8_0.gguf) | Q8_0 | 8 | 34.57 GB| 37.07 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/GPlatty-30B-GGUF and below it, a specific filename to download, such as: gplatty-30b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/GPlatty-30B-GGUF gplatty-30b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/GPlatty-30B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/GPlatty-30B-GGUF gplatty-30b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m gplatty-30b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/GPlatty-30B-GGUF", model_file="gplatty-30b.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Lilloukas' GPlatty 30B
# Information
GPlatty-30B is a merge of [garage-bAInd/Platypus-30B](https://huggingface.co/lilloukas/Platypus-30B) and [chansung/gpt4-alpaca-lora-30b](https://huggingface.co/chansung/gpt4-alpaca-lora-30b)
| Metric | Value |
|-----------------------|-------|
| MMLU (5-shot) | 63.6 |
| ARC (25-shot) | 66.0 |
| HellaSwag (10-shot) | 84.8 |
| TruthfulQA (0-shot) | 53.8 |
| Avg. | 67.0 |
We use state-of-the-art [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above.
## Model Details
* **Trained by**: Platypus-30B trained by Cole Hunter & Ariel Lee; gpt4-alpaca-lora-30b by chansung.
* **Model type:** **GPlatty-30B** is an auto-regressive language model based on the LLaMA transformer architecture.
* **Language(s)**: English
* **License for base weights**: License for the base LLaMA model's weights is Meta's [non-commercial bespoke license](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md).
| Hyperparameter | Value |
|---------------------------|-------|
| \\(n_\text{parameters}\\) | 33B |
| \\(d_\text{model}\\) | 6656 |
| \\(n_\text{layers}\\) | 60 |
| \\(n_\text{heads}\\) | 52 |
## Reproducing Evaluation Results
Install LM Evaluation Harness:
```
git clone https://github.com/EleutherAI/lm-evaluation-harness
cd lm-evaluation-harness
pip install -e .
```
Each task was evaluated on a single A100 80GB GPU.
ARC:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/GPlatty-30B --tasks arc_challenge --batch_size 1 --no_cache --write_out --output_path results/Platypus-30B/arc_challenge_25shot.json --device cuda --num_fewshot 25
```
HellaSwag:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/GPlatty-30B --tasks hellaswag --batch_size 1 --no_cache --write_out --output_path results/Platypus-30B/hellaswag_10shot.json --device cuda --num_fewshot 10
```
MMLU:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/GPlatty-30B --tasks hendrycksTest-* --batch_size 1 --no_cache --write_out --output_path results/Platypus-30B/mmlu_5shot.json --device cuda --num_fewshot 5
```
TruthfulQA:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAInd/GPlatty-30B --tasks truthfulqa_mc --batch_size 1 --no_cache --write_out --output_path results/Platypus-30B/truthfulqa_0shot.json --device cuda
```
## Limitations and bias
The base LLaMA model is trained on various data, some of which may contain offensive, harmful, and biased content that can lead to toxic behavior. See Section 5.1 of the LLaMA paper. We have not performed any studies to determine how fine-tuning on the aforementioned datasets affect the model's behavior and toxicity. Do not treat chat responses from this model as a substitute for human judgment or as a source of truth. Please use responsibly.
## Citations
```bibtex
@article{touvron2023llama,
title={LLaMA: Open and Efficient Foundation Language Models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}
@article{hu2021lora,
title={LoRA: Low-Rank Adaptation of Large Language Models},
author={Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Chen, Weizhu},
journal={CoRR},
year={2021}
}
```
<!-- original-model-card end -->
|
TheBloke/Platypus-30B-GGUF | TheBloke | 2023-09-27T12:53:29Z | 391 | 1 | transformers | [
"transformers",
"gguf",
"llama",
"en",
"base_model:lilloukas/Platypus-30B",
"license:other",
"text-generation-inference",
"region:us"
]
| null | 2023-09-20T02:23:39Z | ---
language:
- en
license: other
tags:
- llama
metrics:
- MMLU
- ARC
- HellaSwag
- TruthfulQA
model_name: Platypus 30B
base_model: lilloukas/Platypus-30B
inference: false
model_creator: lilloukas
model_type: llama
prompt_template: 'Below is an instruction that describes a task. Write a response
that appropriately completes the request.
### Instruction:
{prompt}
### Response:
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Platypus 30B - GGUF
- Model creator: [lilloukas](https://huggingface.co/lilloukas)
- Original model: [Platypus 30B](https://huggingface.co/lilloukas/Platypus-30B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Lilloukas' Platypus 30B](https://huggingface.co/lilloukas/Platypus-30B).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Platypus-30B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Platypus-30B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Platypus-30B-GGUF)
* [lilloukas's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/lilloukas/Platypus-30B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Alpaca
```
Below is an instruction that describes a task. Write a response that appropriately completes the request.
### Instruction:
{prompt}
### Response:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [platypus-30b.Q2_K.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q2_K.gguf) | Q2_K | 2 | 13.50 GB| 16.00 GB | smallest, significant quality loss - not recommended for most purposes |
| [platypus-30b.Q3_K_S.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q3_K_S.gguf) | Q3_K_S | 3 | 14.06 GB| 16.56 GB | very small, high quality loss |
| [platypus-30b.Q3_K_M.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q3_K_M.gguf) | Q3_K_M | 3 | 15.76 GB| 18.26 GB | very small, high quality loss |
| [platypus-30b.Q3_K_L.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q3_K_L.gguf) | Q3_K_L | 3 | 17.28 GB| 19.78 GB | small, substantial quality loss |
| [platypus-30b.Q4_0.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q4_0.gguf) | Q4_0 | 4 | 18.36 GB| 20.86 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [platypus-30b.Q4_K_S.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q4_K_S.gguf) | Q4_K_S | 4 | 18.44 GB| 20.94 GB | small, greater quality loss |
| [platypus-30b.Q4_K_M.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q4_K_M.gguf) | Q4_K_M | 4 | 19.62 GB| 22.12 GB | medium, balanced quality - recommended |
| [platypus-30b.Q5_0.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q5_0.gguf) | Q5_0 | 5 | 22.40 GB| 24.90 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [platypus-30b.Q5_K_S.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q5_K_S.gguf) | Q5_K_S | 5 | 22.40 GB| 24.90 GB | large, low quality loss - recommended |
| [platypus-30b.Q5_K_M.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q5_K_M.gguf) | Q5_K_M | 5 | 23.05 GB| 25.55 GB | large, very low quality loss - recommended |
| [platypus-30b.Q6_K.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q6_K.gguf) | Q6_K | 6 | 26.69 GB| 29.19 GB | very large, extremely low quality loss |
| [platypus-30b.Q8_0.gguf](https://huggingface.co/TheBloke/Platypus-30B-GGUF/blob/main/platypus-30b.Q8_0.gguf) | Q8_0 | 8 | 34.57 GB| 37.07 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Platypus-30B-GGUF and below it, a specific filename to download, such as: platypus-30b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Platypus-30B-GGUF platypus-30b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Platypus-30B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Platypus-30B-GGUF platypus-30b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m platypus-30b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "Below is an instruction that describes a task. Write a response that appropriately completes the request.\n\n### Instruction:\n{prompt}\n\n### Response:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Platypus-30B-GGUF", model_file="platypus-30b.Q4_K_M.gguf", model_type="llama", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Alicia Loh, Stephen Murray, K, Ajan Kanaga, RoA, Magnesian, Deo Leter, Olakabola, Eugene Pentland, zynix, Deep Realms, Raymond Fosdick, Elijah Stavena, Iucharbius, Erik Bjäreholt, Luis Javier Navarrete Lozano, Nicholas, theTransient, John Detwiler, alfie_i, knownsqashed, Mano Prime, Willem Michiel, Enrico Ros, LangChain4j, OG, Michael Dempsey, Pierre Kircher, Pedro Madruga, James Bentley, Thomas Belote, Luke @flexchar, Leonard Tan, Johann-Peter Hartmann, Illia Dulskyi, Fen Risland, Chadd, S_X, Jeff Scroggin, Ken Nordquist, Sean Connelly, Artur Olbinski, Swaroop Kallakuri, Jack West, Ai Maven, David Ziegler, Russ Johnson, transmissions 11, John Villwock, Alps Aficionado, Clay Pascal, Viktor Bowallius, Subspace Studios, Rainer Wilmers, Trenton Dambrowitz, vamX, Michael Levine, 준교 김, Brandon Frisco, Kalila, Trailburnt, Randy H, Talal Aujan, Nathan Dryer, Vadim, 阿明, ReadyPlayerEmma, Tiffany J. Kim, George Stoitzev, Spencer Kim, Jerry Meng, Gabriel Tamborski, Cory Kujawski, Jeffrey Morgan, Spiking Neurons AB, Edmond Seymore, Alexandros Triantafyllidis, Lone Striker, Cap'n Zoog, Nikolai Manek, danny, ya boyyy, Derek Yates, usrbinkat, Mandus, TL, Nathan LeClaire, subjectnull, Imad Khwaja, webtim, Raven Klaugh, Asp the Wyvern, Gabriel Puliatti, Caitlyn Gatomon, Joseph William Delisle, Jonathan Leane, Luke Pendergrass, SuperWojo, Sebastain Graf, Will Dee, Fred von Graf, Andrey, Dan Guido, Daniel P. Andersen, Nitin Borwankar, Elle, Vitor Caleffi, biorpg, jjj, NimbleBox.ai, Pieter, Matthew Berman, terasurfer, Michael Davis, Alex, Stanislav Ovsiannikov
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Lilloukas' Platypus 30B
# 🥳 Platypus-30B has arrived!
Platypus-30B is an instruction fine-tuned model based on the LLaMA-30B transformer architecture.
| Metric | Value |
|-----------------------|-------|
| MMLU (5-shot) | 64.2 |
| ARC (25-shot) | 64.6 |
| HellaSwag (10-shot) | 84.3 |
| TruthfulQA (0-shot) | 45.8 |
| Avg. | 64.7 |
We use state-of-the-art [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) to run the benchmark tests above.
## Model Details
* **Trained by**: Cole Hunter & Ariel Lee
* **Model type:** **Platypus-30B** is an auto-regressive language model based on the LLaMA transformer architecture.
* **Language(s)**: English
* **License for base weights**: License for the base LLaMA model's weights is Meta's [non-commercial bespoke license](https://github.com/facebookresearch/llama/blob/main/MODEL_CARD.md).
| Hyperparameter | Value |
|---------------------------|-------|
| \\(n_\text{parameters}\\) | 33B |
| \\(d_\text{model}\\) | 6656 |
| \\(n_\text{layers}\\) | 60 |
| \\(n_\text{heads}\\) | 52 |
## Training Dataset
Dataset of highly filtered and curated question and answer pairs. Release TBD.
## Training Procedure
`garage-bAInd/Platypus-30B` was instruction fine-tuned using LoRA on 4 A100 80GB. For training details and inference instructions please see the [Platypus-30B](https://github.com/arielnlee/Platypus-30B.git) GitHub repo.
## Reproducing Evaluation Results
Install LM Evaluation Harness:
```
git clone https://github.com/EleutherAI/lm-evaluation-harness
cd lm-evaluation-harness
pip install -e .
```
Each task was evaluated on a single A100 80GB GPU.
ARC:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAIdnd/Platypus-30B --tasks arc_challenge --batch_size 1 --no_cache --write_out --output_path results/Platypus-30B/arc_challenge_25shot.json --device cuda --num_fewshot 25
```
HellaSwag:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAIdnd/Platypus-30B --tasks hellaswag --batch_size 1 --no_cache --write_out --output_path results/Platypus-30B/hellaswag_10shot.json --device cuda --num_fewshot 10
```
MMLU:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAIdnd/Platypus-30B --tasks hendrycksTest-* --batch_size 1 --no_cache --write_out --output_path results/Platypus-30B/mmlu_5shot.json --device cuda --num_fewshot 5
```
TruthfulQA:
```
python main.py --model hf-causal-experimental --model_args pretrained=garage-bAIdnd/Platypus-30B --tasks truthfulqa_mc --batch_size 1 --no_cache --write_out --output_path results/Platypus-30B/truthfulqa_0shot.json --device cuda
```
## Limitations and bias
The base LLaMA model is trained on various data, some of which may contain offensive, harmful, and biased content that can lead to toxic behavior. See Section 5.1 of the LLaMA paper. We have not performed any studies to determine how fine-tuning on the aforementioned datasets affect the model's behavior and toxicity. Do not treat chat responses from this model as a substitute for human judgment or as a source of truth. Please use responsibly.
## Citations
```bibtex
@article{touvron2023llama,
title={LLaMA: Open and Efficient Foundation Language Models},
author={Touvron, Hugo and Lavril, Thibaut and Izacard, Gautier and Martinet, Xavier and Lachaux, Marie-Anne and Lacroix, Timoth{\'e}e and Rozi{\`e}re, Baptiste and Goyal, Naman and Hambro, Eric and Azhar, Faisal and Rodriguez, Aurelien and Joulin, Armand and Grave, Edouard and Lample, Guillaume},
journal={arXiv preprint arXiv:2302.13971},
year={2023}
}
@article{hu2021lora,
title={LoRA: Low-Rank Adaptation of Large Language Models},
author={Hu, Edward J. and Shen, Yelong and Wallis, Phillip and Allen-Zhu, Zeyuan and Li, Yuanzhi and Wang, Shean and Chen, Weizhu},
journal={CoRR},
year={2021}
}
```
<!-- original-model-card end -->
|
TheBloke/Dans-TotSirocco-7B-GGUF | TheBloke | 2023-10-04T12:49:37Z | 391 | 1 | transformers | [
"transformers",
"gguf",
"mistral",
"en",
"base_model:PocketDoc/Dans-TotSirocco-7b",
"text-generation-inference",
"region:us"
]
| null | 2023-10-04T12:42:06Z | ---
base_model: PocketDoc/Dans-TotSirocco-7b
inference: false
language:
- en
model_creator: PocketDoc Labs
model_name: Dans TotSirocco 7B
model_type: mistral
prompt_template: '<|system|>{system_message}<|user|>{prompt}<|model|>
'
quantized_by: TheBloke
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Dans TotSirocco 7B - GGUF
- Model creator: [PocketDoc Labs](https://huggingface.co/PocketDoc)
- Original model: [Dans TotSirocco 7B](https://huggingface.co/PocketDoc/Dans-TotSirocco-7b)
<!-- description start -->
## Description
This repo contains GGUF format model files for [PocketDoc Labs's Dans TotSirocco 7B](https://huggingface.co/PocketDoc/Dans-TotSirocco-7b).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF)
* [PocketDoc Labs's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/PocketDoc/Dans-TotSirocco-7b)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: Metharme
```
<|system|>{system_message}<|user|>{prompt}<|model|>
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [dans-totsirocco-7b.Q2_K.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q2_K.gguf) | Q2_K | 2 | 3.08 GB| 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [dans-totsirocco-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| 5.66 GB | very small, high quality loss |
| [dans-totsirocco-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| 6.02 GB | very small, high quality loss |
| [dans-totsirocco-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| 6.32 GB | small, substantial quality loss |
| [dans-totsirocco-7b.Q4_0.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [dans-totsirocco-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| 6.64 GB | small, greater quality loss |
| [dans-totsirocco-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| 6.87 GB | medium, balanced quality - recommended |
| [dans-totsirocco-7b.Q5_0.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q5_0.gguf) | Q5_0 | 5 | 5.00 GB| 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [dans-totsirocco-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 5.00 GB| 7.50 GB | large, low quality loss - recommended |
| [dans-totsirocco-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| 7.63 GB | large, very low quality loss - recommended |
| [dans-totsirocco-7b.Q6_K.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q6_K.gguf) | Q6_K | 6 | 5.94 GB| 8.44 GB | very large, extremely low quality loss |
| [dans-totsirocco-7b.Q8_0.gguf](https://huggingface.co/TheBloke/Dans-TotSirocco-7B-GGUF/blob/main/dans-totsirocco-7b.Q8_0.gguf) | Q8_0 | 8 | 7.70 GB| 10.20 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Dans-TotSirocco-7B-GGUF and below it, a specific filename to download, such as: dans-totsirocco-7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Dans-TotSirocco-7B-GGUF dans-totsirocco-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Dans-TotSirocco-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Dans-TotSirocco-7B-GGUF dans-totsirocco-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m dans-totsirocco-7b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|system|>{system_message}<|user|>{prompt}<|model|>"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Dans-TotSirocco-7B-GGUF", model_file="dans-totsirocco-7b.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: PocketDoc Labs's Dans TotSirocco 7B
### Description:
This model is to test some of my data projects. It is a multipurpose chat / chat instruct hybrid model and can be seen as a prototype of Dan's PersonalityEngine Mk. 2. It has been trained on a wide array of one shot instructions, multi round instructions, role playing scenarios, and text adventure games. It is based on [Mistral-7b](https://huggingface.co/mistralai/Mistral-7B-v0.1)
### Prompt format:
Pygmalion / Metharme
The prompt should start with the cursor on the same line directly after "<|model|>" with no space. The following are all valid formats and can be extended to as many rounds as desired.
```
<|system|>system message here<|user|>user message here<|model|>
```
```
<|system|>system message here<|user|>user message here<|model|>model message<|user|>user message here<|model|>
```
```
<|system|>system message here<|model|>
```
```
<|system|>system message here<|model|>model message<|user|>user message here<|model|>
```
#### Some example prompts and their resulting outputs:
##### Prompt:
```
<|system|>You are an assistant, help the user and use markdown when applicable.<|user|>What are the top games of the 90s?<|model|>
```
##### Output:
```
The 1990s was a golden era for video gaming, with countless iconic titles released across various platforms. Here's a list of some of the most popular and influential games from that decade:
- **Super Mario World** (SNES) - Released in 1990, this classic platformer introduced fans to Yoshi and featured memorable levels like Donut Plains and Star World.
- **Mortal Kombat** (Arcade/Sega Genesis) - This gory fighting game shocked audiences upon its release in 1992 with its violent finishers and secret characters like Sub-Zero and Scorpion.
- **Doom** (PC) - Id Software's groundbreaking first-person shooter revolutionized the genre by introducing fast-paced action and multiplayer deathmatches.
- **Street Fighter II** (Arcade/SNES) - Capcom's sequel to their original Street Fighter arcade game added new fighters such as Ryu's rival Ken Masters plus complex special moves like Dragon Punch and Hadouken.
- **Crash Bandicoot** (PlayStation) - Naughty Dog's mascot platforming series debuted in 1996 starring Crash who had to save his girlfriend Tawna from Dr Cortex's evil experiments on Aku Aku masks.
- **Final Fantasy VII** (PlayStation) - Square Enix's seventh installment took players through Midgar City where they joined Cloud Strife's eco-terrorist group AVALANCHE against Shinra Electric Power Company led by Sephiroth.
- **Resident Evil** (PlayStation) - The survival horror masterpiece created by Capcom saw Chris Redfield investigating Spencer Mansion alongside Jill Valentine while trying not get eaten alive by zombies!
```
##### Prompt:
```
<|system|>You are a Virtual Story Generator. You take the user's input and create an excellent and captivating story that goes in that direction. Use an abundance of sensory descriptions and eloquent prose.<|user|>Alpha Centauri has fallen, to the bears. This is a point of view tale about a soldier on the ground.<|model|>
```
##### Output:
```
The roar of the engines shook the very foundations of the planet as the massive warships descended upon Alpha Centauri. The air was thick with the stench of burning fuel and smoke, as if the entire world had been set ablaze. In the chaos, soldiers were scrambling for cover, desperately trying to protect themselves from the relentless barrage of firepower unleashed by their enemy.
Amidst the carnage, one soldier stood tall, his heart pounding against his chest like a drumbeat of death. He knew he had to do something, anything, to stop this nightmare from becoming reality. With trembling hands, he reached for his weapon, determined to make a stand against the overwhelming force that threatened to consume them all.
As the battle raged around him, the soldier felt a sudden surge of adrenaline coursing through his veins. It was almost as if some hidden power within him had awoken, granting him strength beyond measure. His eyes blazed with determination as he raised his gun and took aim at the first target he saw: a bear-like creature, its fur matted with blood and gore, advancing towards him with murderous intent.
With a deafening crack, the soldier fired off several rounds, striking the beast square in the chest. The impact sent it reeling backwards, but it did not fall. Instead, it let out a ferocious growl before charging forward once more. The soldier gritted his teeth and pulled the trigger again, emptying his clip into the creature's already battered frame.
But even as the bullets tore through its flesh, the beast seemed unfazed, continuing its advance towards the terrified soldier. Desperate for any advantage, he threw himself to the side just moments before the monster slammed into the spot where he had been standing mere seconds ago. As it turned back towards him, ready to deliver another brutal blow, the soldier could see that its eyes glowed with an otherworldly light.
```
##### Prompt:
```
<|system|>You are a professional editor with decades of experience, help the user with any task they have for you.<|user|>Can you rewrite this to flow better? "I knew I probably shouldnt have done that but oh well"<|model|>
```
##### Output:
```
I hesitated before making my decision, knowing full well it was not wise. However, in the end, I chose to proceed regardless.
```
# Some quick and dirty training details:
- [<img src="https://raw.githubusercontent.com/OpenAccess-AI-Collective/axolotl/main/image/axolotl-badge-web.png" alt="Built with Axolotl" width="150" height="24"/>](https://github.com/OpenAccess-AI-Collective/axolotl)
- Sequence length: 4096
- Training time: 4 hours
- Hardware: 2x RTX 4090
- Training type: QLoRA
- PEFT R/A: 32/32
# Credits:
### Skein Text Adventure Data:
Thank you to the [Kobold AI](https://huggingface.co/KoboldAI) community for curating the Skein dataset, which is pivotal to this model's capabilities.
<!-- original-model-card end -->
|
sequelbox/Llama2-70B-StellarBright | sequelbox | 2024-05-15T15:54:47Z | 391 | 45 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"stellar-bright",
"llama-2",
"llama-2-chat",
"70b",
"en",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-10-09T19:18:22Z | ---
language:
- en
pipeline_tag: text-generation
tags:
- stellar-bright
- llama
- llama-2
- llama-2-chat
- 70b
model_type: llama
license: llama2
---
Stellar Bright is a general capability upgrade to Llama 2, using open source data to improve overall knowledge, extended communication, and technical skill.
This model is primarily recommended as a superior-to-Llama-2 baseline for additional finetuning, **not** for direct deployment to production as a chat model. The user accepts full responsibility for all outputs.
This is a 'legacy model' offered primarily for reference purposes. I recommend Llama 3 over this model for general use.
## Evaluation
| Model | Avg | ARC | HS | MMLU | TQA |
|-----------------------|--------|-------|-------|--------|-------|
| **Stellar Bright** | 74.10 | 72.95 | 87.82 | 71.17 | 64.46 |
| Llama 2 | 67.35 | 67.32 | 87.33 | 69.83 | 44.92 |
| Llama 2 Chat | 66.80 | 64.59 | 85.88 | 63.91 | 52.80 | |
TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF | TheBloke | 2023-10-13T06:58:44Z | 391 | 4 | transformers | [
"transformers",
"gguf",
"mistral",
"mistral-7b",
"instruct",
"finetune",
"gpt4",
"synthetic data",
"distillation",
"sharegpt",
"en",
"dataset:CollectiveCognition/chats-data-2023-09-27",
"base_model:teknium/CollectiveCognition-v1-Mistral-7B",
"license:apache-2.0",
"text-generation-inference",
"region:us"
]
| null | 2023-10-13T06:50:10Z | ---
base_model: teknium/CollectiveCognition-v1-Mistral-7B
datasets:
- CollectiveCognition/chats-data-2023-09-27
inference: false
language:
- en
license: apache-2.0
model-index:
- name: CollectiveCognition-v1-Mistral-7B
results: []
model_creator: Teknium
model_name: CollectiveCognition v1 Mistral 7B
model_type: mistral
prompt_template: 'USER: {prompt}
ASSISTANT:
'
quantized_by: TheBloke
tags:
- mistral-7b
- instruct
- finetune
- gpt4
- synthetic data
- distillation
- sharegpt
---
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# CollectiveCognition v1 Mistral 7B - GGUF
- Model creator: [Teknium](https://huggingface.co/teknium)
- Original model: [CollectiveCognition v1 Mistral 7B](https://huggingface.co/teknium/CollectiveCognition-v1-Mistral-7B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [Teknium's CollectiveCognition v1 Mistral 7B](https://huggingface.co/teknium/CollectiveCognition-v1-Mistral-7B).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplate list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF)
* [Teknium's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/teknium/CollectiveCognition-v1-Mistral-7B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: User-Assistant
```
USER: {prompt}
ASSISTANT:
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [collectivecognition-v1-mistral-7b.Q2_K.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q2_K.gguf) | Q2_K | 2 | 3.08 GB| 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [collectivecognition-v1-mistral-7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| 5.66 GB | very small, high quality loss |
| [collectivecognition-v1-mistral-7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| 6.02 GB | very small, high quality loss |
| [collectivecognition-v1-mistral-7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| 6.32 GB | small, substantial quality loss |
| [collectivecognition-v1-mistral-7b.Q4_0.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [collectivecognition-v1-mistral-7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| 6.64 GB | small, greater quality loss |
| [collectivecognition-v1-mistral-7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| 6.87 GB | medium, balanced quality - recommended |
| [collectivecognition-v1-mistral-7b.Q5_0.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q5_0.gguf) | Q5_0 | 5 | 5.00 GB| 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [collectivecognition-v1-mistral-7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q5_K_S.gguf) | Q5_K_S | 5 | 5.00 GB| 7.50 GB | large, low quality loss - recommended |
| [collectivecognition-v1-mistral-7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| 7.63 GB | large, very low quality loss - recommended |
| [collectivecognition-v1-mistral-7b.Q6_K.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q6_K.gguf) | Q6_K | 6 | 5.94 GB| 8.44 GB | very large, extremely low quality loss |
| [collectivecognition-v1-mistral-7b.Q8_0.gguf](https://huggingface.co/TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF/blob/main/collectivecognition-v1-mistral-7b.Q8_0.gguf) | Q8_0 | 8 | 7.70 GB| 10.20 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
- LM Studio
- LoLLMS Web UI
- Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF and below it, a specific filename to download, such as: collectivecognition-v1-mistral-7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF collectivecognition-v1-mistral-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF collectivecognition-v1-mistral-7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m collectivecognition-v1-mistral-7b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "USER: {prompt}\nASSISTANT:"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions here: [text-generation-webui/docs/llama.cpp.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/llama.cpp.md).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/CollectiveCognition-v1-Mistral-7B-GGUF", model_file="collectivecognition-v1-mistral-7b.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Pierre Kircher, Stanislav Ovsiannikov, Michael Levine, Eugene Pentland, Andrey, 준교 김, Randy H, Fred von Graf, Artur Olbinski, Caitlyn Gatomon, terasurfer, Jeff Scroggin, James Bentley, Vadim, Gabriel Puliatti, Harry Royden McLaughlin, Sean Connelly, Dan Guido, Edmond Seymore, Alicia Loh, subjectnull, AzureBlack, Manuel Alberto Morcote, Thomas Belote, Lone Striker, Chris Smitley, Vitor Caleffi, Johann-Peter Hartmann, Clay Pascal, biorpg, Brandon Frisco, sidney chen, transmissions 11, Pedro Madruga, jinyuan sun, Ajan Kanaga, Emad Mostaque, Trenton Dambrowitz, Jonathan Leane, Iucharbius, usrbinkat, vamX, George Stoitzev, Luke Pendergrass, theTransient, Olakabola, Swaroop Kallakuri, Cap'n Zoog, Brandon Phillips, Michael Dempsey, Nikolai Manek, danny, Matthew Berman, Gabriel Tamborski, alfie_i, Raymond Fosdick, Tom X Nguyen, Raven Klaugh, LangChain4j, Magnesian, Illia Dulskyi, David Ziegler, Mano Prime, Luis Javier Navarrete Lozano, Erik Bjäreholt, 阿明, Nathan Dryer, Alex, Rainer Wilmers, zynix, TL, Joseph William Delisle, John Villwock, Nathan LeClaire, Willem Michiel, Joguhyik, GodLy, OG, Alps Aficionado, Jeffrey Morgan, ReadyPlayerEmma, Tiffany J. Kim, Sebastain Graf, Spencer Kim, Michael Davis, webtim, Talal Aujan, knownsqashed, John Detwiler, Imad Khwaja, Deo Leter, Jerry Meng, Elijah Stavena, Rooh Singh, Pieter, SuperWojo, Alexandros Triantafyllidis, Stephen Murray, Ai Maven, ya boyyy, Enrico Ros, Ken Nordquist, Deep Realms, Nicholas, Spiking Neurons AB, Elle, Will Dee, Jack West, RoA, Luke @flexchar, Viktor Bowallius, Derek Yates, Subspace Studios, jjj, Toran Billups, Asp the Wyvern, Fen Risland, Ilya, NimbleBox.ai, Chadd, Nitin Borwankar, Emre, Mandus, Leonard Tan, Kalila, K, Trailburnt, S_X, Cory Kujawski
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: Teknium's CollectiveCognition v1 Mistral 7B
**Collective Cognition v1 - Mistral 7B**
<div style="display: flex; justify-content: center;">
<a href="https://collectivecognition.ai" target="_blank" style="display: inline-block; text-align: center;">
<img src="https://cdn-uploads.huggingface.co/production/uploads/6317aade83d8d2fd903192d9/DNZXsJE5oC_rM8eYY6H_x.png" alt="Collective Cognition Logo" width="50%" style="display: block; margin: 0 auto;">
</a>
</div>
## Model Description:
Collective Cognition v1 is a Mistral model fine-tuned using just 100 GPT-4 chats shared on Collective Cognition.
## Special Features:
- **Quick Training**: This model was trained in just 3 minutes on a single 4090 with a qlora, and competes with 70B scale Llama-2 Models at TruthfulQA.
- **Limited Data**: Despite its exceptional performance, it was trained on only ONE HUNDRED data points, all of which were gathered from Collective Cognition, a platform reminiscent of ShareGPT.
- **Extreme TruthfulQA Benchmark**: The collective cognition models are competing strongly with top 70B models on the TruthfulQA benchmark despite the small dataset and qlora training!

## Acknowledgements:
Special thanks to @a16z and all contributors to the Collective Cognition dataset for making the development of this model possible.
## Dataset:
The model was trained using data from the Collective Cognition website. The efficacy of this dataset is demonstrated by the model's stellar performance, suggesting that further expansion of this dataset could yield even more promising results. The data is reminiscent of that collected from platforms like ShareGPT.
You can contribute to the growth of the dataset by sharing your own ChatGPT chats [here](https://CollectiveCognition.ai).
You can download the datasets created by Collective Cognition here: https://huggingface.co/CollectiveCognition
## Performance:
- **TruthfulQA**: Collective Cognition v1 and v1.1 in particular have notably outperformed several models on the TruthfulQA benchmark, highlighting its ability to understand and rectify common misconceptions.
The model follows a LIMA approach, by minimizing the base model's original training as little as possible and giving a small but very high quality dataset to enhance it's performance and style.
## Usage:
Prompt Format:
```
USER: <prompt>
ASSISTANT:
```
OR
```
<system message>
USER: <prompt>
ASSISTANT:
```
## Benchmarks:
Collective Cognition v1.0 TruthfulQA:
```
| Task |Version|Metric|Value | |Stderr|
|-------------|------:|------|-----:|---|-----:|
|truthfulqa_mc| 1|mc1 |0.3794|± |0.0170|
| | |mc2 |0.5394|± |0.0158|
```
GPT4All Benchmark Suite:
```
Collective Cognition v1.0 GPT4All:
| Task |Version| Metric |Value | |Stderr|
|-------------|------:|--------|-----:|---|-----:|
|arc_challenge| 0|acc |0.5401|± |0.0146|
| | |acc_norm|0.5572|± |0.0145|
|arc_easy | 0|acc |0.8102|± |0.0080|
| | |acc_norm|0.7992|± |0.0082|
|boolq | 1|acc |0.8538|± |0.0062|
|hellaswag | 0|acc |0.6459|± |0.0048|
| | |acc_norm|0.8297|± |0.0038|
|openbookqa | 0|acc |0.3380|± |0.0212|
| | |acc_norm|0.4360|± |0.0222|
|piqa | 0|acc |0.8085|± |0.0092|
| | |acc_norm|0.8232|± |0.0089|
|winogrande | 0|acc |0.7451|± |0.0122|
Average: 72.06%
```
AGIEval:
```
| Task |Version| Metric |Value | |Stderr|
|------------------------------|------:|--------|-----:|---|-----:|
|agieval_aqua_rat | 0|acc |0.1890|± |0.0246|
| | |acc_norm|0.2047|± |0.0254|
|agieval_logiqa_en | 0|acc |0.2611|± |0.0172|
| | |acc_norm|0.3134|± |0.0182|
|agieval_lsat_ar | 0|acc |0.2087|± |0.0269|
| | |acc_norm|0.2217|± |0.0275|
|agieval_lsat_lr | 0|acc |0.3373|± |0.0210|
| | |acc_norm|0.3196|± |0.0207|
|agieval_lsat_rc | 0|acc |0.4201|± |0.0301|
| | |acc_norm|0.3978|± |0.0299|
|agieval_sat_en | 0|acc |0.5971|± |0.0343|
| | |acc_norm|0.5631|± |0.0346|
|agieval_sat_en_without_passage| 0|acc |0.4029|± |0.0343|
| | |acc_norm|0.3398|± |0.0331|
|agieval_sat_math | 0|acc |0.3045|± |0.0311|
| | |acc_norm|0.2864|± |0.0305|
Average: 33.08%
```
Training run on wandb here: https://wandb.ai/teknium1/collectivecognition-mistral-7b/runs/collectivecognition-mistral-6/workspace
## Licensing:
Apache 2.0
---
<!-- original-model-card end -->
|
xaviviro/falcon-7b-quantized-gguf | xaviviro | 2023-12-07T09:44:45Z | 391 | 1 | null | [
"gguf",
"region:us"
]
| null | 2023-12-07T08:28:08Z | Entry not found |
bartowski/internlm2-chat-20b-sft-llama | bartowski | 2024-01-18T22:06:49Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"license:other",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-01-18T21:56:37Z | ---
pipeline_tag: text-generation
license: other
---
# InternLM
<div align="center">
<img src="https://github.com/InternLM/InternLM/assets/22529082/b9788105-8892-4398-8b47-b513a292378e" width="200"/>
<div> </div>
<div align="center">
<b><font size="5">InternLM</font></b>
<sup>
<a href="https://internlm.intern-ai.org.cn/">
<i><font size="4">HOT</font></i>
</a>
</sup>
<div> </div>
</div>
[](https://github.com/internLM/OpenCompass/)
[💻Github Repo](https://github.com/InternLM/InternLM)
</div>
## Converted using <a href="https://huggingface.co/chargoddard">Charles Goddard's</a> conversion script to create llama models from internlm
Original REPO link: https://huggingface.co/internlm/internlm2-chat-20b-sft
|
vilm/Quyen-SE-v0.1 | vilm | 2024-02-26T03:33:51Z | 391 | 17 | transformers | [
"transformers",
"pytorch",
"safetensors",
"qwen2",
"text-generation",
"conversational",
"en",
"dataset:teknium/OpenHermes-2.5",
"dataset:LDJnr/Capybara",
"dataset:Intel/orca_dpo_pairs",
"dataset:argilla/distilabel-capybara-dpo-7k-binarized",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-02-04T23:02:30Z | ---
language:
- en
license: other
library_name: transformers
datasets:
- teknium/OpenHermes-2.5
- LDJnr/Capybara
- Intel/orca_dpo_pairs
- argilla/distilabel-capybara-dpo-7k-binarized
pipeline_tag: text-generation
---
# Quyen
<img src="quyen.webp" width="512" height="512" alt="Quyen">
# Model Description
Quyen is our first flagship LLM series based on the Qwen1.5 family. We introduced 6 different versions:
- **Quyen-SE (0.5B)**
- **Quyen-Mini (1.8B)**
- **Quyen (4B)**
- **Quyen-Plus (7B)**
- **Quyen-Pro (14B)**
- **Quyen-Pro-Max (72B)**
All models were trained with SFT and DPO using the following dataset:
- *OpenHermes-2.5* by **Teknium**
- *Capyabara* by **LDJ**
- *argilla/distilabel-capybara-dpo-7k-binarized* by **argilla**
- *orca_dpo_pairs* by **Intel**
- and Private Data by **Ontocord** & **BEE-spoke-data**
# Prompt Template
- All Quyen models use ChatML as the default template:
```
<|im_start|>system
You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.<|im_end|>
<|im_start|>user
Hello world.<|im_end|>
<|im_start|>assistant
```
- You can also use `apply_chat_template`:
```python
messages = [
{"role": "system", "content": "You are a sentient, superintelligent artificial general intelligence, here to teach and assist me."},
{"role": "user", "content": "Hello world."}
]
gen_input = tokenizer.apply_chat_template(message, return_tensors="pt")
model.generate(**gen_input)
```
# Benchmarks:
- Coming Soon! We will update the benchmarks later
# Acknowledgement
- We're incredibly grateful to **Tensoic** and **Ontocord** for their generous support with compute and data preparation.
- Special thanks to the Qwen team for letting us access the models early for these amazing finetunes. |
cazure87/5FvEYGo7zJHFMQHdWHvoNueaf6yvTRSdbHK2yPporX95bE73_vgg | cazure87 | 2024-03-02T06:48:10Z | 391 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-02-19T21:04:25Z | Entry not found |
TW3PartnersLLM/tw3jrglv4 | TW3PartnersLLM | 2024-04-02T21:46:24Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"migtissera/Tess-72B-v1.5b",
"davidkim205/Rhea-72b-v0.5",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-02T21:18:49Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- migtissera/Tess-72B-v1.5b
- davidkim205/Rhea-72b-v0.5
---
# TW3-JRGL-v4
TW3-JRGL-v4 is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [migtissera/Tess-72B-v1.5b](https://huggingface.co/migtissera/Tess-72B-v1.5b)
* [davidkim205/Rhea-72b-v0.5](https://huggingface.co/davidkim205/Rhea-72b-v0.5)
## 🧩 Configuration |
MaziyarPanahi/medicine-chat-GGUF | MaziyarPanahi | 2024-04-04T09:32:18Z | 391 | 5 | transformers | [
"transformers",
"gguf",
"mistral",
"quantized",
"2-bit",
"3-bit",
"4-bit",
"5-bit",
"6-bit",
"8-bit",
"GGUF",
"pytorch",
"safetensors",
"llama",
"text-generation",
"biology",
"medical",
"en",
"dataset:EleutherAI/pile",
"dataset:Open-Orca/OpenOrca",
"dataset:GAIR/lima",
"dataset:WizardLM/WizardLM_evol_instruct_V2_196k",
"arxiv:2309.09530",
"license:llama2",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"has_space",
"text-generation-inference",
"region:us",
"base_model:AdaptLLM/medicine-chat"
]
| text-generation | 2024-04-04T09:08:06Z | ---
tags:
- quantized
- 2-bit
- 3-bit
- 4-bit
- 5-bit
- 6-bit
- 8-bit
- GGUF
- transformers
- pytorch
- safetensors
- llama
- text-generation
- biology
- medical
- en
- dataset:EleutherAI/pile
- dataset:Open-Orca/OpenOrca
- dataset:GAIR/lima
- dataset:WizardLM/WizardLM_evol_instruct_V2_196k
- arxiv:2309.09530
- license:llama2
- model-index
- autotrain_compatible
- endpoints_compatible
- has_space
- text-generation-inference
- region:us
- text-generation
model_name: medicine-chat-GGUF
base_model: AdaptLLM/medicine-chat
inference: false
model_creator: AdaptLLM
pipeline_tag: text-generation
quantized_by: MaziyarPanahi
---
# [MaziyarPanahi/medicine-chat-GGUF](https://huggingface.co/MaziyarPanahi/medicine-chat-GGUF)
- Model creator: [AdaptLLM](https://huggingface.co/AdaptLLM)
- Original model: [AdaptLLM/medicine-chat](https://huggingface.co/AdaptLLM/medicine-chat)
## Description
[MaziyarPanahi/medicine-chat-GGUF](https://huggingface.co/MaziyarPanahi/medicine-chat-GGUF) contains GGUF format model files for [AdaptLLM/medicine-chat](https://huggingface.co/AdaptLLM/medicine-chat).
## How to use
Thanks to [TheBloke](https://huggingface.co/TheBloke) for preparing an amazing README on how to use GGUF models:
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [GPT4All](https://gpt4all.io/index.html), a free and open source local running GUI, supporting Windows, Linux and macOS with full GPU accel.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration. Linux available, in beta as of 27/11/2023.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server. Note, as of time of writing (November 27th 2023), ctransformers has not been updated in a long time and does not support many recent models.
### Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: [MaziyarPanahi/medicine-chat-GGUF](https://huggingface.co/MaziyarPanahi/medicine-chat-GGUF) and below it, a specific filename to download, such as: medicine-chat-GGUF.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download MaziyarPanahi/medicine-chat-GGUF medicine-chat.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
</details>
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download [MaziyarPanahi/medicine-chat-GGUF](https://huggingface.co/MaziyarPanahi/medicine-chat-GGUF) --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download MaziyarPanahi/medicine-chat-GGUF medicine-chat.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m medicine-chat.Q4_K_M.gguf --color -c 32768 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 32768` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20-%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://github.com/abetlen/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./medicine-chat.Q4_K_M.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./medicine-chat.Q4_K_M.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers) |
mradermacher/Twizzler-7B-GGUF | mradermacher | 2024-05-06T05:17:26Z | 391 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:son-of-man/Twizzler-7B",
"endpoints_compatible",
"region:us"
]
| null | 2024-04-04T15:44:57Z | ---
base_model: son-of-man/Twizzler-7B
language:
- en
library_name: transformers
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### convert_type: -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/son-of-man/Twizzler-7B
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q2_K.gguf) | Q2_K | 3.0 | |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.IQ3_XS.gguf) | IQ3_XS | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q3_K_S.gguf) | Q3_K_S | 3.4 | |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.IQ3_S.gguf) | IQ3_S | 3.4 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.IQ3_M.gguf) | IQ3_M | 3.5 | |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q3_K_M.gguf) | Q3_K_M | 3.8 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q3_K_L.gguf) | Q3_K_L | 4.1 | |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.IQ4_XS.gguf) | IQ4_XS | 4.2 | |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q4_K_S.gguf) | Q4_K_S | 4.4 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q4_K_M.gguf) | Q4_K_M | 4.6 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q5_K_S.gguf) | Q5_K_S | 5.3 | |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q5_K_M.gguf) | Q5_K_M | 5.4 | |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q6_K.gguf) | Q6_K | 6.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Twizzler-7B-GGUF/resolve/main/Twizzler-7B.Q8_0.gguf) | Q8_0 | 7.9 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
yyh0901/666 | yyh0901 | 2024-04-08T07:15:03Z | 391 | 0 | transformers | [
"transformers",
"llama",
"text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-07T05:54:19Z | ---
license: apache-2.0
pipeline_tag: text-generation
language:
- en
---
"_name_or_path": "/data/yyh/model/models--meta-llama--Llama-2-7b-hf",
"architectures": [
"LlamaForCausalLM"
],
"attention_bias": false,
"attention_dropout": 0.0,
"bos_token_id": 1,
"eos_token_id": 2,
"hidden_act": "silu",
"hidden_size": 4096,
"initializer_range": 0.02,
"intermediate_size": 11008,
"max_position_embeddings": 65536,
"model_type": "llama",
"num_attention_heads": 32,
"num_hidden_layers": 32,
"num_key_value_heads": 32,
"pad_token_id": 0,
"pretraining_tp": 1,
"rms_norm_eps": 1e-05,
"rope_scaling": {
"factor": 16.0,
"type": "dynamic"
},
"rope_theta": 10000.0,
"tie_word_embeddings": false,
"torch_dtype": "bfloat16",
"transformers_version": "4.39.2",
"use_cache": true,
"vocab_size": 32000
Enlonged context length, trained 50 steps on LLaMa-2-7b |
adowu/astral-demo-3 | adowu | 2024-04-10T05:10:14Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"astral",
"demo",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-10T02:24:25Z | ---
library_name: transformers
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- astral
- demo
- mistral
---
### astral-demo-3
## Overview
astral-demo-3 is a streamlined language model designed for quick demonstrations and insights into NLP capabilities, focusing on text generation and analysis.
## Features
- Efficient Text Generation: Quickly produces text for a variety of applications.
- Compact and Fast: Optimized for speed, making it ideal for demos and prototyping.
- Prototype Development: Tests ideas in conversational AI and content generation.
## Performance
Balances performance with accuracy, providing a practical demonstration of NLP technology in action.
- **Developed by:** aww
- **Model type:** Mistral |
srikanthmalla/BAAI-bge-reranker-large | srikanthmalla | 2024-04-10T21:09:37Z | 391 | 0 | transformers | [
"transformers",
"pytorch",
"onnx",
"safetensors",
"xlm-roberta",
"text-classification",
"mteb",
"zh",
"en",
"arxiv:2401.03462",
"arxiv:2312.15503",
"arxiv:2311.13534",
"arxiv:2310.07554",
"arxiv:2309.07597",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2024-04-10T21:09:37Z | ---
license: mit
language:
- zh
- en
tags:
- mteb
model-index:
- name: bge-reranker-large
results:
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv1-reranking
name: MTEB CMedQAv1
config: default
split: test
revision: None
metrics:
- type: map
value: 82.13813829648727
- type: mrr
value: 84.92349206349207
- task:
type: Reranking
dataset:
type: C-MTEB/CMedQAv2-reranking
name: MTEB CMedQAv2
config: default
split: test
revision: None
metrics:
- type: map
value: 84.19313276771856
- type: mrr
value: 86.96876984126984
- task:
type: Reranking
dataset:
type: C-MTEB/Mmarco-reranking
name: MTEB MMarcoReranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 37.16533876035345
- type: mrr
value: 36.60039682539682
- task:
type: Reranking
dataset:
type: C-MTEB/T2Reranking
name: MTEB T2Reranking
config: default
split: dev
revision: None
metrics:
- type: map
value: 67.60068968300665
- type: mrr
value: 77.68363585560605
---
<h1 align="center">FlagEmbedding</h1>
<h4 align="center">
<p>
<a href=#model-list>Model List</a> |
<a href=#frequently-asked-questions>FAQ</a> |
<a href=#usage>Usage</a> |
<a href="#evaluation">Evaluation</a> |
<a href="#train">Train</a> |
<a href="#contact">Contact</a> |
<a href="#citation">Citation</a> |
<a href="#license">License</a>
<p>
</h4>
More details please refer to our Github: [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding).
[English](README.md) | [中文](https://github.com/FlagOpen/FlagEmbedding/blob/master/README_zh.md)
FlagEmbedding focuses on retrieval-augmented LLMs, consisting of the following projects currently:
- **Long-Context LLM**: [Activation Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon)
- **Fine-tuning of LM** : [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail)
- **Dense Retrieval**: [BGE-M3](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3), [LLM Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), [BGE Embedding](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/baai_general_embedding)
- **Reranker Model**: [BGE Reranker](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
- **Benchmark**: [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB)
## News
- 1/30/2024: Release **BGE-M3**, a new member to BGE model series! M3 stands for **M**ulti-linguality (100+ languages), **M**ulti-granularities (input length up to 8192), **M**ulti-Functionality (unification of dense, lexical, multi-vec/colbert retrieval).
It is the first embedding model which supports all three retrieval methods, achieving new SOTA on multi-lingual (MIRACL) and cross-lingual (MKQA) benchmarks.
[Technical Report](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/BGE_M3/BGE_M3.pdf) and [Code](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3). :fire:
- 1/9/2024: Release [Activation-Beacon](https://github.com/FlagOpen/FlagEmbedding/tree/master/Long_LLM/activation_beacon), an effective, efficient, compatible, and low-cost (training) method to extend the context length of LLM. [Technical Report](https://arxiv.org/abs/2401.03462) :fire:
- 12/24/2023: Release **LLaRA**, a LLaMA-7B based dense retriever, leading to state-of-the-art performances on MS MARCO and BEIR. Model and code will be open-sourced. Please stay tuned. [Technical Report](https://arxiv.org/abs/2312.15503) :fire:
- 11/23/2023: Release [LM-Cocktail](https://github.com/FlagOpen/FlagEmbedding/tree/master/LM_Cocktail), a method to maintain general capabilities during fine-tuning by merging multiple language models. [Technical Report](https://arxiv.org/abs/2311.13534) :fire:
- 10/12/2023: Release [LLM-Embedder](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/llm_embedder), a unified embedding model to support diverse retrieval augmentation needs for LLMs. [Technical Report](https://arxiv.org/pdf/2310.07554.pdf)
- 09/15/2023: The [technical report](https://arxiv.org/pdf/2309.07597.pdf) of BGE has been released
- 09/15/2023: The [massive training data](https://data.baai.ac.cn/details/BAAI-MTP) of BGE has been released
- 09/12/2023: New models:
- **New reranker model**: release cross-encoder models `BAAI/bge-reranker-base` and `BAAI/bge-reranker-large`, which are more powerful than embedding model. We recommend to use/fine-tune them to re-rank top-k documents returned by embedding models.
- **update embedding model**: release `bge-*-v1.5` embedding model to alleviate the issue of the similarity distribution, and enhance its retrieval ability without instruction.
<details>
<summary>More</summary>
<!-- ### More -->
- 09/07/2023: Update [fine-tune code](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md): Add script to mine hard negatives and support adding instruction during fine-tuning.
- 08/09/2023: BGE Models are integrated into **Langchain**, you can use it like [this](#using-langchain); C-MTEB **leaderboard** is [available](https://huggingface.co/spaces/mteb/leaderboard).
- 08/05/2023: Release base-scale and small-scale models, **best performance among the models of the same size 🤗**
- 08/02/2023: Release `bge-large-*`(short for BAAI General Embedding) Models, **rank 1st on MTEB and C-MTEB benchmark!** :tada: :tada:
- 08/01/2023: We release the [Chinese Massive Text Embedding Benchmark](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB) (**C-MTEB**), consisting of 31 test dataset.
</details>
## Model List
`bge` is short for `BAAI general embedding`.
| Model | Language | | Description | query instruction for retrieval [1] |
|:-------------------------------|:--------:| :--------:| :--------:|:--------:|
| [BAAI/bge-m3](https://huggingface.co/BAAI/bge-m3) | Multilingual | [Inference](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3#usage) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/BGE_M3) | Multi-Functionality(dense retrieval, sparse retrieval, multi-vector(colbert)), Multi-Linguality, and Multi-Granularity(8192 tokens) | |
| [BAAI/llm-embedder](https://huggingface.co/BAAI/llm-embedder) | English | [Inference](./FlagEmbedding/llm_embedder/README.md) [Fine-tune](./FlagEmbedding/llm_embedder/README.md) | a unified embedding model to support diverse retrieval augmentation needs for LLMs | See [README](./FlagEmbedding/llm_embedder/README.md) |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | Chinese and English | [Inference](#usage-for-reranker) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker) | a cross-encoder model which is more accurate but less efficient [2] | |
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh-v1.5](https://huggingface.co/BAAI/bge-large-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | version 1.5 with more reasonable similarity distribution | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-large-en](https://huggingface.co/BAAI/bge-large-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [MTEB](https://huggingface.co/spaces/mteb/leaderboard) leaderboard | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-base-en](https://huggingface.co/BAAI/bge-base-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-en` | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-small-en](https://huggingface.co/BAAI/bge-small-en) | English | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) |a small-scale model but with competitive performance | `Represent this sentence for searching relevant passages: ` |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | :trophy: rank **1st** in [C-MTEB](https://github.com/FlagOpen/FlagEmbedding/tree/master/C_MTEB) benchmark | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a base-scale model but with similar ability to `bge-large-zh` | `为这个句子生成表示以用于检索相关文章:` |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | Chinese | [Inference](#usage-for-embedding-model) [Fine-tune](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) | a small-scale model but with competitive performance | `为这个句子生成表示以用于检索相关文章:` |
[1\]: If you need to search the relevant passages to a query, we suggest to add the instruction to the query; in other cases, no instruction is needed, just use the original query directly. In all cases, **no instruction** needs to be added to passages.
[2\]: Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding. To balance the accuracy and time cost, cross-encoder is widely used to re-rank top-k documents retrieved by other simple models.
For examples, use bge embedding model to retrieve top 100 relevant documents, and then use bge reranker to re-rank the top 100 document to get the final top-3 results.
All models have been uploaded to Huggingface Hub, and you can see them at https://huggingface.co/BAAI.
If you cannot open the Huggingface Hub, you also can download the models at https://model.baai.ac.cn/models .
## Frequently asked questions
<details>
<summary>1. How to fine-tune bge embedding model?</summary>
<!-- ### How to fine-tune bge embedding model? -->
Following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune) to prepare data and fine-tune your model.
Some suggestions:
- Mine hard negatives following this [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune#hard-negatives), which can improve the retrieval performance.
- If you pre-train bge on your data, the pre-trained model cannot be directly used to calculate similarity, and it must be fine-tuned with contrastive learning before computing similarity.
- If the accuracy of the fine-tuned model is still not high, it is recommended to use/fine-tune the cross-encoder model (bge-reranker) to re-rank top-k results. Hard negatives also are needed to fine-tune reranker.
</details>
<details>
<summary>2. The similarity score between two dissimilar sentences is higher than 0.5</summary>
<!-- ### The similarity score between two dissimilar sentences is higher than 0.5 -->
**Suggest to use bge v1.5, which alleviates the issue of the similarity distribution.**
Since we finetune the models by contrastive learning with a temperature of 0.01,
the similarity distribution of the current BGE model is about in the interval \[0.6, 1\].
So a similarity score greater than 0.5 does not indicate that the two sentences are similar.
For downstream tasks, such as passage retrieval or semantic similarity,
**what matters is the relative order of the scores, not the absolute value.**
If you need to filter similar sentences based on a similarity threshold,
please select an appropriate similarity threshold based on the similarity distribution on your data (such as 0.8, 0.85, or even 0.9).
</details>
<details>
<summary>3. When does the query instruction need to be used</summary>
<!-- ### When does the query instruction need to be used -->
For the `bge-*-v1.5`, we improve its retrieval ability when not using instruction.
No instruction only has a slight degradation in retrieval performance compared with using instruction.
So you can generate embedding without instruction in all cases for convenience.
For a retrieval task that uses short queries to find long related documents,
it is recommended to add instructions for these short queries.
**The best method to decide whether to add instructions for queries is choosing the setting that achieves better performance on your task.**
In all cases, the documents/passages do not need to add the instruction.
</details>
## Usage
### Usage for Embedding Model
Here are some examples for using `bge` models with
[FlagEmbedding](#using-flagembedding), [Sentence-Transformers](#using-sentence-transformers), [Langchain](#using-langchain), or [Huggingface Transformers](#using-huggingface-transformers).
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
If it doesn't work for you, you can see [FlagEmbedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md) for more methods to install FlagEmbedding.
```python
from FlagEmbedding import FlagModel
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = FlagModel('BAAI/bge-large-zh-v1.5',
query_instruction_for_retrieval="为这个句子生成表示以用于检索相关文章:",
use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
embeddings_1 = model.encode(sentences_1)
embeddings_2 = model.encode(sentences_2)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
# for s2p(short query to long passage) retrieval task, suggest to use encode_queries() which will automatically add the instruction to each query
# corpus in retrieval task can still use encode() or encode_corpus(), since they don't need instruction
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
q_embeddings = model.encode_queries(queries)
p_embeddings = model.encode(passages)
scores = q_embeddings @ p_embeddings.T
```
For the value of the argument `query_instruction_for_retrieval`, see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list).
By default, FlagModel will use all available GPUs when encoding. Please set `os.environ["CUDA_VISIBLE_DEVICES"]` to select specific GPUs.
You also can set `os.environ["CUDA_VISIBLE_DEVICES"]=""` to make all GPUs unavailable.
#### Using Sentence-Transformers
You can also use the `bge` models with [sentence-transformers](https://www.SBERT.net):
```
pip install -U sentence-transformers
```
```python
from sentence_transformers import SentenceTransformer
sentences_1 = ["样例数据-1", "样例数据-2"]
sentences_2 = ["样例数据-3", "样例数据-4"]
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
embeddings_1 = model.encode(sentences_1, normalize_embeddings=True)
embeddings_2 = model.encode(sentences_2, normalize_embeddings=True)
similarity = embeddings_1 @ embeddings_2.T
print(similarity)
```
For s2p(short query to long passage) retrieval task,
each short query should start with an instruction (instructions see [Model List](https://github.com/FlagOpen/FlagEmbedding/tree/master#model-list)).
But the instruction is not needed for passages.
```python
from sentence_transformers import SentenceTransformer
queries = ['query_1', 'query_2']
passages = ["样例文档-1", "样例文档-2"]
instruction = "为这个句子生成表示以用于检索相关文章:"
model = SentenceTransformer('BAAI/bge-large-zh-v1.5')
q_embeddings = model.encode([instruction+q for q in queries], normalize_embeddings=True)
p_embeddings = model.encode(passages, normalize_embeddings=True)
scores = q_embeddings @ p_embeddings.T
```
#### Using Langchain
You can use `bge` in langchain like this:
```python
from langchain.embeddings import HuggingFaceBgeEmbeddings
model_name = "BAAI/bge-large-en-v1.5"
model_kwargs = {'device': 'cuda'}
encode_kwargs = {'normalize_embeddings': True} # set True to compute cosine similarity
model = HuggingFaceBgeEmbeddings(
model_name=model_name,
model_kwargs=model_kwargs,
encode_kwargs=encode_kwargs,
query_instruction="为这个句子生成表示以用于检索相关文章:"
)
model.query_instruction = "为这个句子生成表示以用于检索相关文章:"
```
#### Using HuggingFace Transformers
With the transformers package, you can use the model like this: First, you pass your input through the transformer model, then you select the last hidden state of the first token (i.e., [CLS]) as the sentence embedding.
```python
from transformers import AutoTokenizer, AutoModel
import torch
# Sentences we want sentence embeddings for
sentences = ["样例数据-1", "样例数据-2"]
# Load model from HuggingFace Hub
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-large-zh-v1.5')
model = AutoModel.from_pretrained('BAAI/bge-large-zh-v1.5')
model.eval()
# Tokenize sentences
encoded_input = tokenizer(sentences, padding=True, truncation=True, return_tensors='pt')
# for s2p(short query to long passage) retrieval task, add an instruction to query (not add instruction for passages)
# encoded_input = tokenizer([instruction + q for q in queries], padding=True, truncation=True, return_tensors='pt')
# Compute token embeddings
with torch.no_grad():
model_output = model(**encoded_input)
# Perform pooling. In this case, cls pooling.
sentence_embeddings = model_output[0][:, 0]
# normalize embeddings
sentence_embeddings = torch.nn.functional.normalize(sentence_embeddings, p=2, dim=1)
print("Sentence embeddings:", sentence_embeddings)
```
### Usage for Reranker
Different from embedding model, reranker uses question and document as input and directly output similarity instead of embedding.
You can get a relevance score by inputting query and passage to the reranker.
The reranker is optimized based cross-entropy loss, so the relevance score is not bounded to a specific range.
#### Using FlagEmbedding
```
pip install -U FlagEmbedding
```
Get relevance scores (higher scores indicate more relevance):
```python
from FlagEmbedding import FlagReranker
reranker = FlagReranker('BAAI/bge-reranker-large', use_fp16=True) # Setting use_fp16 to True speeds up computation with a slight performance degradation
score = reranker.compute_score(['query', 'passage'])
print(score)
scores = reranker.compute_score([['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']])
print(scores)
```
#### Using Huggingface transformers
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-large')
model.eval()
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
with torch.no_grad():
inputs = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt', max_length=512)
scores = model(**inputs, return_dict=True).logits.view(-1, ).float()
print(scores)
```
#### Usage reranker with the ONNX files
```python
from optimum.onnxruntime import ORTModelForSequenceClassification # type: ignore
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained('BAAI/bge-reranker-large')
model = AutoModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-base')
model_ort = ORTModelForSequenceClassification.from_pretrained('BAAI/bge-reranker-base', file_name="onnx/model.onnx")
# Sentences we want sentence embeddings for
pairs = [['what is panda?', 'hi'], ['what is panda?', 'The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear or simply panda, is a bear species endemic to China.']]
# Tokenize sentences
encoded_input = tokenizer(pairs, padding=True, truncation=True, return_tensors='pt')
scores_ort = model_ort(**encoded_input, return_dict=True).logits.view(-1, ).float()
# Compute token embeddings
with torch.inference_mode():
scores = model_ort(**encoded_input, return_dict=True).logits.view(-1, ).float()
# scores and scores_ort are identical
```
#### Usage reranker with infinity
Its also possible to deploy the onnx/torch files with the [infinity_emb](https://github.com/michaelfeil/infinity) pip package.
```python
import asyncio
from infinity_emb import AsyncEmbeddingEngine, EngineArgs
query='what is a panda?'
docs = ['The giant panda (Ailuropoda melanoleuca), sometimes called a panda bear', "Paris is in France."]
engine = AsyncEmbeddingEngine.from_args(
EngineArgs(model_name_or_path = "BAAI/bge-reranker-base", device="cpu", engine="torch" # or engine="optimum" for onnx
))
async def main():
async with engine:
ranking, usage = await engine.rerank(query=query, docs=docs)
print(list(zip(ranking, docs)))
asyncio.run(main())
```
## Evaluation
`baai-general-embedding` models achieve **state-of-the-art performance on both MTEB and C-MTEB leaderboard!**
For more details and evaluation tools see our [scripts](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md).
- **MTEB**:
| Model Name | Dimension | Sequence Length | Average (56) | Retrieval (15) |Clustering (11) | Pair Classification (3) | Reranking (4) | STS (10) | Summarization (1) | Classification (12) |
|:----:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|:---:|
| [BAAI/bge-large-en-v1.5](https://huggingface.co/BAAI/bge-large-en-v1.5) | 1024 | 512 | **64.23** | **54.29** | 46.08 | 87.12 | 60.03 | 83.11 | 31.61 | 75.97 |
| [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) | 768 | 512 | 63.55 | 53.25 | 45.77 | 86.55 | 58.86 | 82.4 | 31.07 | 75.53 |
| [BAAI/bge-small-en-v1.5](https://huggingface.co/BAAI/bge-small-en-v1.5) | 384 | 512 | 62.17 |51.68 | 43.82 | 84.92 | 58.36 | 81.59 | 30.12 | 74.14 |
| [bge-large-en](https://huggingface.co/BAAI/bge-large-en) | 1024 | 512 | 63.98 | 53.9 | 46.98 | 85.8 | 59.48 | 81.56 | 32.06 | 76.21 |
| [bge-base-en](https://huggingface.co/BAAI/bge-base-en) | 768 | 512 | 63.36 | 53.0 | 46.32 | 85.86 | 58.7 | 81.84 | 29.27 | 75.27 |
| [gte-large](https://huggingface.co/thenlper/gte-large) | 1024 | 512 | 63.13 | 52.22 | 46.84 | 85.00 | 59.13 | 83.35 | 31.66 | 73.33 |
| [gte-base](https://huggingface.co/thenlper/gte-base) | 768 | 512 | 62.39 | 51.14 | 46.2 | 84.57 | 58.61 | 82.3 | 31.17 | 73.01 |
| [e5-large-v2](https://huggingface.co/intfloat/e5-large-v2) | 1024| 512 | 62.25 | 50.56 | 44.49 | 86.03 | 56.61 | 82.05 | 30.19 | 75.24 |
| [bge-small-en](https://huggingface.co/BAAI/bge-small-en) | 384 | 512 | 62.11 | 51.82 | 44.31 | 83.78 | 57.97 | 80.72 | 30.53 | 74.37 |
| [instructor-xl](https://huggingface.co/hkunlp/instructor-xl) | 768 | 512 | 61.79 | 49.26 | 44.74 | 86.62 | 57.29 | 83.06 | 32.32 | 61.79 |
| [e5-base-v2](https://huggingface.co/intfloat/e5-base-v2) | 768 | 512 | 61.5 | 50.29 | 43.80 | 85.73 | 55.91 | 81.05 | 30.28 | 73.84 |
| [gte-small](https://huggingface.co/thenlper/gte-small) | 384 | 512 | 61.36 | 49.46 | 44.89 | 83.54 | 57.7 | 82.07 | 30.42 | 72.31 |
| [text-embedding-ada-002](https://platform.openai.com/docs/guides/embeddings) | 1536 | 8192 | 60.99 | 49.25 | 45.9 | 84.89 | 56.32 | 80.97 | 30.8 | 70.93 |
| [e5-small-v2](https://huggingface.co/intfloat/e5-base-v2) | 384 | 512 | 59.93 | 49.04 | 39.92 | 84.67 | 54.32 | 80.39 | 31.16 | 72.94 |
| [sentence-t5-xxl](https://huggingface.co/sentence-transformers/sentence-t5-xxl) | 768 | 512 | 59.51 | 42.24 | 43.72 | 85.06 | 56.42 | 82.63 | 30.08 | 73.42 |
| [all-mpnet-base-v2](https://huggingface.co/sentence-transformers/all-mpnet-base-v2) | 768 | 514 | 57.78 | 43.81 | 43.69 | 83.04 | 59.36 | 80.28 | 27.49 | 65.07 |
| [sgpt-bloom-7b1-msmarco](https://huggingface.co/bigscience/sgpt-bloom-7b1-msmarco) | 4096 | 2048 | 57.59 | 48.22 | 38.93 | 81.9 | 55.65 | 77.74 | 33.6 | 66.19 |
- **C-MTEB**:
We create the benchmark C-MTEB for Chinese text embedding which consists of 31 datasets from 6 tasks.
Please refer to [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/README.md) for a detailed introduction.
| Model | Embedding dimension | Avg | Retrieval | STS | PairClassification | Classification | Reranking | Clustering |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| [**BAAI/bge-large-zh-v1.5**](https://huggingface.co/BAAI/bge-large-zh-v1.5) | 1024 | **64.53** | 70.46 | 56.25 | 81.6 | 69.13 | 65.84 | 48.99 |
| [BAAI/bge-base-zh-v1.5](https://huggingface.co/BAAI/bge-base-zh-v1.5) | 768 | 63.13 | 69.49 | 53.72 | 79.75 | 68.07 | 65.39 | 47.53 |
| [BAAI/bge-small-zh-v1.5](https://huggingface.co/BAAI/bge-small-zh-v1.5) | 512 | 57.82 | 61.77 | 49.11 | 70.41 | 63.96 | 60.92 | 44.18 |
| [BAAI/bge-large-zh](https://huggingface.co/BAAI/bge-large-zh) | 1024 | 64.20 | 71.53 | 54.98 | 78.94 | 68.32 | 65.11 | 48.39 |
| [bge-large-zh-noinstruct](https://huggingface.co/BAAI/bge-large-zh-noinstruct) | 1024 | 63.53 | 70.55 | 53 | 76.77 | 68.58 | 64.91 | 50.01 |
| [BAAI/bge-base-zh](https://huggingface.co/BAAI/bge-base-zh) | 768 | 62.96 | 69.53 | 54.12 | 77.5 | 67.07 | 64.91 | 47.63 |
| [multilingual-e5-large](https://huggingface.co/intfloat/multilingual-e5-large) | 1024 | 58.79 | 63.66 | 48.44 | 69.89 | 67.34 | 56.00 | 48.23 |
| [BAAI/bge-small-zh](https://huggingface.co/BAAI/bge-small-zh) | 512 | 58.27 | 63.07 | 49.45 | 70.35 | 63.64 | 61.48 | 45.09 |
| [m3e-base](https://huggingface.co/moka-ai/m3e-base) | 768 | 57.10 | 56.91 | 50.47 | 63.99 | 67.52 | 59.34 | 47.68 |
| [m3e-large](https://huggingface.co/moka-ai/m3e-large) | 1024 | 57.05 | 54.75 | 50.42 | 64.3 | 68.2 | 59.66 | 48.88 |
| [multilingual-e5-base](https://huggingface.co/intfloat/multilingual-e5-base) | 768 | 55.48 | 61.63 | 46.49 | 67.07 | 65.35 | 54.35 | 40.68 |
| [multilingual-e5-small](https://huggingface.co/intfloat/multilingual-e5-small) | 384 | 55.38 | 59.95 | 45.27 | 66.45 | 65.85 | 53.86 | 45.26 |
| [text-embedding-ada-002(OpenAI)](https://platform.openai.com/docs/guides/embeddings/what-are-embeddings) | 1536 | 53.02 | 52.0 | 43.35 | 69.56 | 64.31 | 54.28 | 45.68 |
| [luotuo](https://huggingface.co/silk-road/luotuo-bert-medium) | 1024 | 49.37 | 44.4 | 42.78 | 66.62 | 61 | 49.25 | 44.39 |
| [text2vec-base](https://huggingface.co/shibing624/text2vec-base-chinese) | 768 | 47.63 | 38.79 | 43.41 | 67.41 | 62.19 | 49.45 | 37.66 |
| [text2vec-large](https://huggingface.co/GanymedeNil/text2vec-large-chinese) | 1024 | 47.36 | 41.94 | 44.97 | 70.86 | 60.66 | 49.16 | 30.02 |
- **Reranking**:
See [C_MTEB](https://github.com/FlagOpen/FlagEmbedding/blob/master/C_MTEB/) for evaluation script.
| Model | T2Reranking | T2RerankingZh2En\* | T2RerankingEn2Zh\* | MMarcoReranking | CMedQAv1 | CMedQAv2 | Avg |
|:-------------------------------|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|:--------:|
| text2vec-base-multilingual | 64.66 | 62.94 | 62.51 | 14.37 | 48.46 | 48.6 | 50.26 |
| multilingual-e5-small | 65.62 | 60.94 | 56.41 | 29.91 | 67.26 | 66.54 | 57.78 |
| multilingual-e5-large | 64.55 | 61.61 | 54.28 | 28.6 | 67.42 | 67.92 | 57.4 |
| multilingual-e5-base | 64.21 | 62.13 | 54.68 | 29.5 | 66.23 | 66.98 | 57.29 |
| m3e-base | 66.03 | 62.74 | 56.07 | 17.51 | 77.05 | 76.76 | 59.36 |
| m3e-large | 66.13 | 62.72 | 56.1 | 16.46 | 77.76 | 78.27 | 59.57 |
| bge-base-zh-v1.5 | 66.49 | 63.25 | 57.02 | 29.74 | 80.47 | 84.88 | 63.64 |
| bge-large-zh-v1.5 | 65.74 | 63.39 | 57.03 | 28.74 | 83.45 | 85.44 | 63.97 |
| [BAAI/bge-reranker-base](https://huggingface.co/BAAI/bge-reranker-base) | 67.28 | 63.95 | 60.45 | 35.46 | 81.26 | 84.1 | 65.42 |
| [BAAI/bge-reranker-large](https://huggingface.co/BAAI/bge-reranker-large) | 67.6 | 64.03 | 61.44 | 37.16 | 82.15 | 84.18 | 66.09 |
\* : T2RerankingZh2En and T2RerankingEn2Zh are cross-language retrieval tasks
## Train
### BAAI Embedding
We pre-train the models using [retromae](https://github.com/staoxiao/RetroMAE) and train them on large-scale pairs data using contrastive learning.
**You can fine-tune the embedding model on your data following our [examples](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/finetune).**
We also provide a [pre-train example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/pretrain).
Note that the goal of pre-training is to reconstruct the text, and the pre-trained model cannot be used for similarity calculation directly, it needs to be fine-tuned.
More training details for bge see [baai_general_embedding](https://github.com/FlagOpen/FlagEmbedding/blob/master/FlagEmbedding/baai_general_embedding/README.md).
### BGE Reranker
Cross-encoder will perform full-attention over the input pair,
which is more accurate than embedding model (i.e., bi-encoder) but more time-consuming than embedding model.
Therefore, it can be used to re-rank the top-k documents returned by embedding model.
We train the cross-encoder on a multilingual pair data,
The data format is the same as embedding model, so you can fine-tune it easily following our [example](https://github.com/FlagOpen/FlagEmbedding/tree/master/examples/reranker).
More details please refer to [./FlagEmbedding/reranker/README.md](https://github.com/FlagOpen/FlagEmbedding/tree/master/FlagEmbedding/reranker)
## Contact
If you have any question or suggestion related to this project, feel free to open an issue or pull request.
You also can email Shitao Xiao([email protected]) and Zheng Liu([email protected]).
## Citation
If you find this repository useful, please consider giving a star :star: and citation
```
@misc{bge_embedding,
title={C-Pack: Packaged Resources To Advance General Chinese Embedding},
author={Shitao Xiao and Zheng Liu and Peitian Zhang and Niklas Muennighoff},
year={2023},
eprint={2309.07597},
archivePrefix={arXiv},
primaryClass={cs.CL}
}
```
## License
FlagEmbedding is licensed under the [MIT License](https://github.com/FlagOpen/FlagEmbedding/blob/master/LICENSE). The released models can be used for commercial purposes free of charge.
|
IAFrance/ECE-TW3-JRGL-VHF1 | IAFrance | 2024-04-15T19:13:07Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"MTSAIR/MultiVerse_70B",
"davidkim205/Rhea-72b-v0.5",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-15T18:54:05Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- MTSAIR/MultiVerse_70B
- davidkim205/Rhea-72b-v0.5
---
# ECE-TW3-JRGL-VHF1
ECE-TW3-JRGL-VHF1 is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [MTSAIR/MultiVerse_70B](https://huggingface.co/MTSAIR/MultiVerse_70B)
* [davidkim205/Rhea-72b-v0.5](https://huggingface.co/davidkim205/Rhea-72b-v0.5)
## 🧩 Configuration |
IAFrance/ECE-TW3-JRGL-VHF2 | IAFrance | 2024-04-15T19:47:26Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"abacusai/Smaug-72B-v0.1",
"davidkim205/Rhea-72b-v0.5",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-15T19:28:16Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- abacusai/Smaug-72B-v0.1
- davidkim205/Rhea-72b-v0.5
---
# ECE-TW3-JRGL-VHF2
ECE-TW3-JRGL-VHF2 is a merge of the following models using [mergekit](https://github.com/cg123/mergekit):
* [abacusai/Smaug-72B-v0.1](https://huggingface.co/abacusai/Smaug-72B-v0.1)
* [davidkim205/Rhea-72b-v0.5](https://huggingface.co/davidkim205/Rhea-72b-v0.5)
## 🧩 Configuration |
Replete-AI/Llama-3-13B-Instruct | Replete-AI | 2024-05-04T16:58:27Z | 391 | 3 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"conversational",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-19T04:43:16Z | ---
base_model: []
license: other
library_name: transformers
license_name: llama-3
license_link: https://llama.meta.com/llama3/license/
---
This is the first version of upscaling llama-3. Version 2 is now out and does not have any of the issues that this version has. Please use version 2 instead. Linked bellow:
- https://huggingface.co/Replete-AI/Llama-3-11.5B-Instruct-v2
__________________________________________________________________
Llama-3-13B-Instruct
Thank you to Meta for the weights for Meta-Llama-3-8B-Instruct

This is an upscaling of the Meta-Llama-3-8B-Instruct Ai using techniques created for Mistral-Evolved-11b-v0.1. This Ai model has been upscaled from 8b parameters to 13b parameters without any continuous pretraining or fine-tuning.
From testing, the model seems to function perfectly at fp16, but has some issues at 4-bit quantization using bitsandbytes.
The model that was used to create this one is linked below:
https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct |
varox34/7B-Model_Stock | varox34 | 2024-04-23T07:21:04Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"arxiv:2403.19522",
"base_model:Undi95/Toppy-M-7B",
"base_model:SanjiWatsuki/Kunoichi-DPO-v2-7B",
"base_model:Epiculous/Fett-uccine-7B",
"base_model:NeverSleep/Noromaid-7B-0.4-DPO",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-23T07:02:28Z | ---
base_model:
- Undi95/Toppy-M-7B
- SanjiWatsuki/Kunoichi-DPO-v2-7B
- Epiculous/Fett-uccine-7B
- NeverSleep/Noromaid-7B-0.4-DPO
library_name: transformers
tags:
- mergekit
- merge
license: apache-2.0
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [Model Stock](https://arxiv.org/abs/2403.19522) merge method using [SanjiWatsuki/Kunoichi-DPO-v2-7B](https://huggingface.co/SanjiWatsuki/Kunoichi-DPO-v2-7B) as a base.
### Models Merged
The following models were included in the merge:
* [Undi95/Toppy-M-7B](https://huggingface.co/Undi95/Toppy-M-7B)
* [Epiculous/Fett-uccine-7B](https://huggingface.co/Epiculous/Fett-uccine-7B)
* [NeverSleep/Noromaid-7B-0.4-DPO](https://huggingface.co/NeverSleep/Noromaid-7B-0.4-DPO)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: NeverSleep/Noromaid-7B-0.4-DPO
- model: SanjiWatsuki/Kunoichi-DPO-v2-7B
- model: Undi95/Toppy-M-7B
- model: Epiculous/Fett-uccine-7B
merge_method: model_stock
base_model: SanjiWatsuki/Kunoichi-DPO-v2-7B
dtype: bfloat16
``` |
AlanRobotics/nanit_slerp | AlanRobotics | 2024-04-27T01:48:54Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"phi",
"text-generation",
"custom_code",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-27T01:43:40Z | ---
library_name: transformers
license: other
---
Hello, my name is nanit. I am an AI assistant designed to help you with various tasks and provide information. I can assist with answering questions, providing recommendations, and performing calculations. I am constantly learning and improving to better serve you. If you have any specific questions or tasks you would like assistance with, please let me know. |
LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF | LiteLLMs | 2024-04-30T09:05:43Z | 391 | 1 | transformers | [
"transformers",
"gguf",
"code",
"GGUF",
"text-generation",
"dataset:bigcode/self-oss-instruct-sc2-exec-filter-50k",
"base_model:bigcode/starcoder2-15b",
"license:bigcode-openrail-m",
"model-index",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-04-30T06:31:08Z |
---
license: bigcode-openrail-m
library_name: transformers
tags:
- code
- GGUF
base_model: bigcode/starcoder2-15b
datasets:
- bigcode/self-oss-instruct-sc2-exec-filter-50k
pipeline_tag: text-generation
model-index:
- name: starcoder2-15b-instruct-v0.1
results:
- task:
type: text-generation
dataset:
name: LiveCodeBench (code generation)
type: livecodebench-codegeneration
metrics:
- type: pass@1
value: 20.4
verified: false
- task:
type: text-generation
dataset:
name: LiveCodeBench (self repair)
type: livecodebench-selfrepair
metrics:
- type: pass@1
value: 20.9
verified: false
- task:
type: text-generation
dataset:
name: LiveCodeBench (test output prediction)
type: livecodebench-testoutputprediction
metrics:
- type: pass@1
value: 29.8
verified: false
- task:
type: text-generation
dataset:
name: LiveCodeBench (code execution)
type: livecodebench-codeexecution
metrics:
- type: pass@1
value: 28.1
verified: false
- task:
type: text-generation
dataset:
name: HumanEval
type: humaneval
metrics:
- type: pass@1
value: 72.6
verified: false
- task:
type: text-generation
dataset:
name: HumanEval+
type: humanevalplus
metrics:
- type: pass@1
value: 63.4
verified: false
- task:
type: text-generation
dataset:
name: MBPP
type: mbpp
metrics:
- type: pass@1
value: 75.2
verified: false
- task:
type: text-generation
dataset:
name: MBPP+
type: mbppplus
metrics:
- type: pass@1
value: 61.2
verified: false
- task:
type: text-generation
dataset:
name: DS-1000
type: ds-1000
metrics:
- type: pass@1
value: 40.6
verified: false
quantized_by: andrijdavid
---
# starcoder2-15b-instruct-v0.1-GGUF
- Original model: [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1)
<!-- description start -->
## Description
This repo contains GGUF format model files for [starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
* [Ollama](https://github.com/jmorganca/ollama) Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
* [GPT4All](https://gpt4all.io), This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
* [LM Studio](https://lmstudio.ai/) An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui). A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
* [ctransformers](https://github.com/marella/ctransformers), A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
* [localGPT](https://github.com/PromtEngineer/localGPT) An open-source initiative enabling private conversations with documents.
<!-- README_GGUF.md-about-gguf end -->
<!-- compatibility_gguf start -->
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single folder.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF and below it, a specific filename to download, such as: Q4_0/Q4_0-00001-of-00009.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install huggingface_hub[hf_transfer]
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download LiteLLMs/starcoder2-15b-instruct-v0.1-GGUF Q4_0/Q4_0-00001-of-00009.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m Q4_0/Q4_0-00001-of-00009.gguf --color -c 8192 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<PROMPT>"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 8192` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./Q4_0/Q4_0-00001-of-00009.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<PROMPT>", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./Q4_0/Q4_0-00001-of-00009.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: starcoder2-15b-instruct-v0.1
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation

## Model Summary
We introduce StarCoder2-15B-Instruct-v0.1, the very first entirely self-aligned code Large Language Model (LLM) trained with a fully permissive and transparent pipeline. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
- **Model:** [bigcode/starcoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
- **Authors:**
[Yuxiang Wei](https://yuxiang.cs.illinois.edu),
[Federico Cassano](https://federico.codes/),
[Jiawei Liu](https://jw-liu.xyz),
[Yifeng Ding](https://yifeng-ding.com),
[Naman Jain](https://naman-ntc.github.io),
[Harm de Vries](https://www.harmdevries.com),
[Leandro von Werra](https://twitter.com/lvwerra),
[Arjun Guha](https://www.khoury.northeastern.edu/home/arjunguha/main/home/),
[Lingming Zhang](https://lingming.cs.illinois.edu).

## Use
### Intended use
The model is designed to respond to **coding-related instructions in a single turn**. Instructions in other styles may result in less accurate responses.
Here is an example to get started with the model using the [transformers](https://huggingface.co/docs/transformers/index) library:
```python
import transformers
import torch
pipeline = transformers.pipeline(
model="bigcode/starcoder2-15b-instruct-v0.1",
task="text-generation",
torch_dtype=torch.bfloat16,
device_map="auto",
)
def respond(instruction: str, response_prefix: str) -> str:
messages = [{"role": "user", "content": instruction}]
prompt = pipeline.tokenizer.apply_chat_template(messages, tokenize=False)
prompt += response_prefix
teminators = [
pipeline.tokenizer.eos_token_id,
pipeline.tokenizer.convert_tokens_to_ids("###"),
]
result = pipeline(
prompt,
max_length=256,
num_return_sequences=1,
do_sample=False,
eos_token_id=teminators,
pad_token_id=pipeline.tokenizer.eos_token_id,
truncation=True,
)
response = response_prefix + result[0]["generated_text"][len(prompt) :].split("###")[0].rstrip()
return response
instruction = "Write a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria."
response_prefix = ""
print(respond(instruction, response_prefix))
```
Here is the expected output:
``````
Here's how you can implement a quicksort function in Python with type hints and a 'less_than' parameter for custom sorting criteria:
```python
from typing import TypeVar, Callable
T = TypeVar('T')
def quicksort(items: list[T], less_than: Callable[[T, T], bool] = lambda x, y: x < y) -> list[T]:
if len(items) <= 1:
return items
pivot = items[0]
less = [x for x in items[1:] if less_than(x, pivot)]
greater = [x for x in items[1:] if not less_than(x, pivot)]
return quicksort(less, less_than) + [pivot] + quicksort(greater, less_than)
```
``````
### Bias, Risks, and Limitations
StarCoder2-15B-Instruct-v0.1 is primarily finetuned for Python code generation tasks that can be verified through execution, which may lead to certain biases and limitations. For example, the model might not adhere strictly to instructions that dictate the output format. In these situations, it's beneficial to provide a **response prefix** or a **one-shot example** to steer the model’s output. Additionally, the model may have limitations with other programming languages and out-of-domain coding tasks.
The model also inherits the bias, risks, and limitations from its base StarCoder2-15B model. For more information, please refer to the [StarCoder2-15B model card](https://huggingface.co/bigcode/starcoder2-15b).
## Evaluation on EvalPlus, LiveCodeBench, and DS-1000
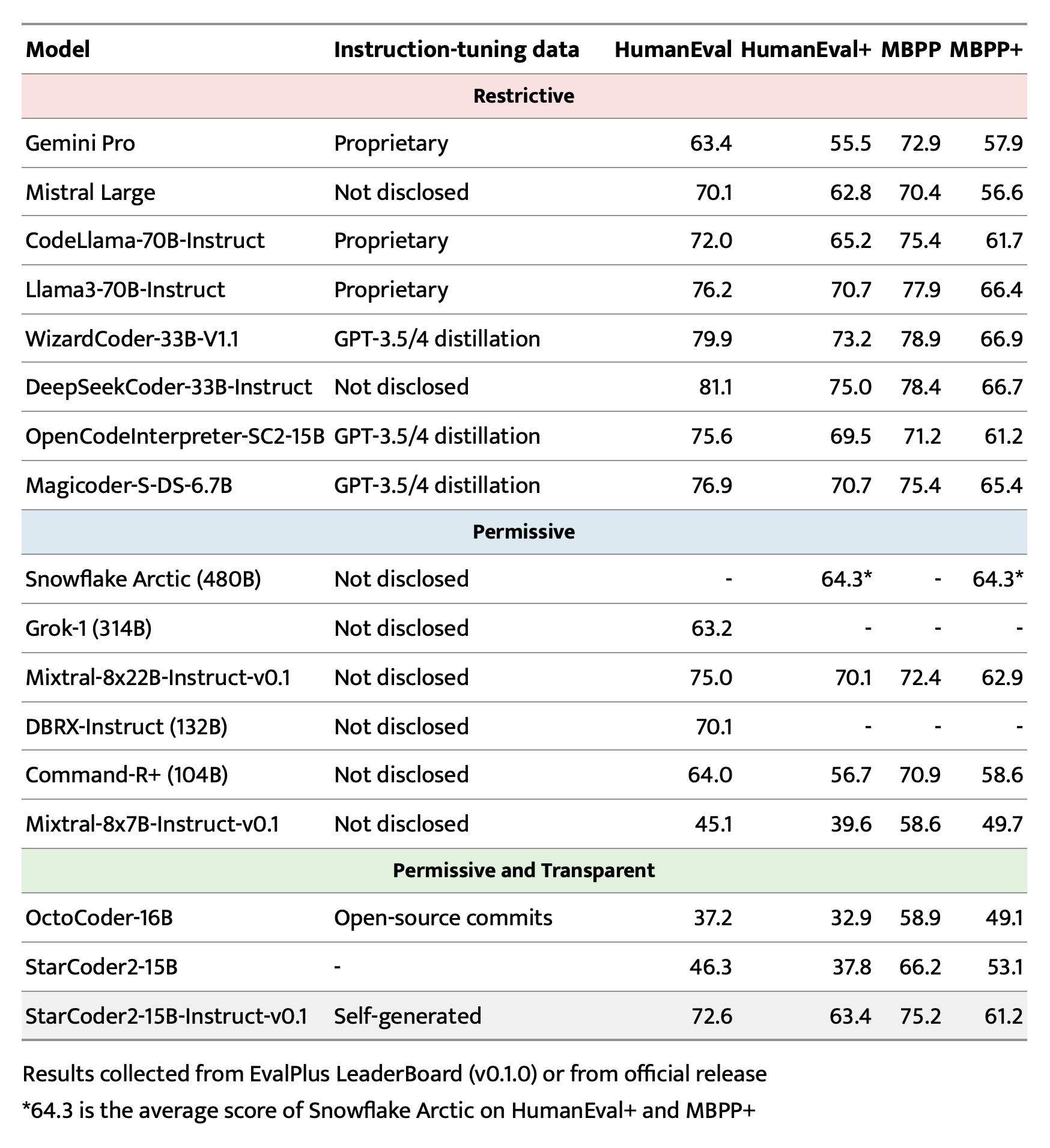
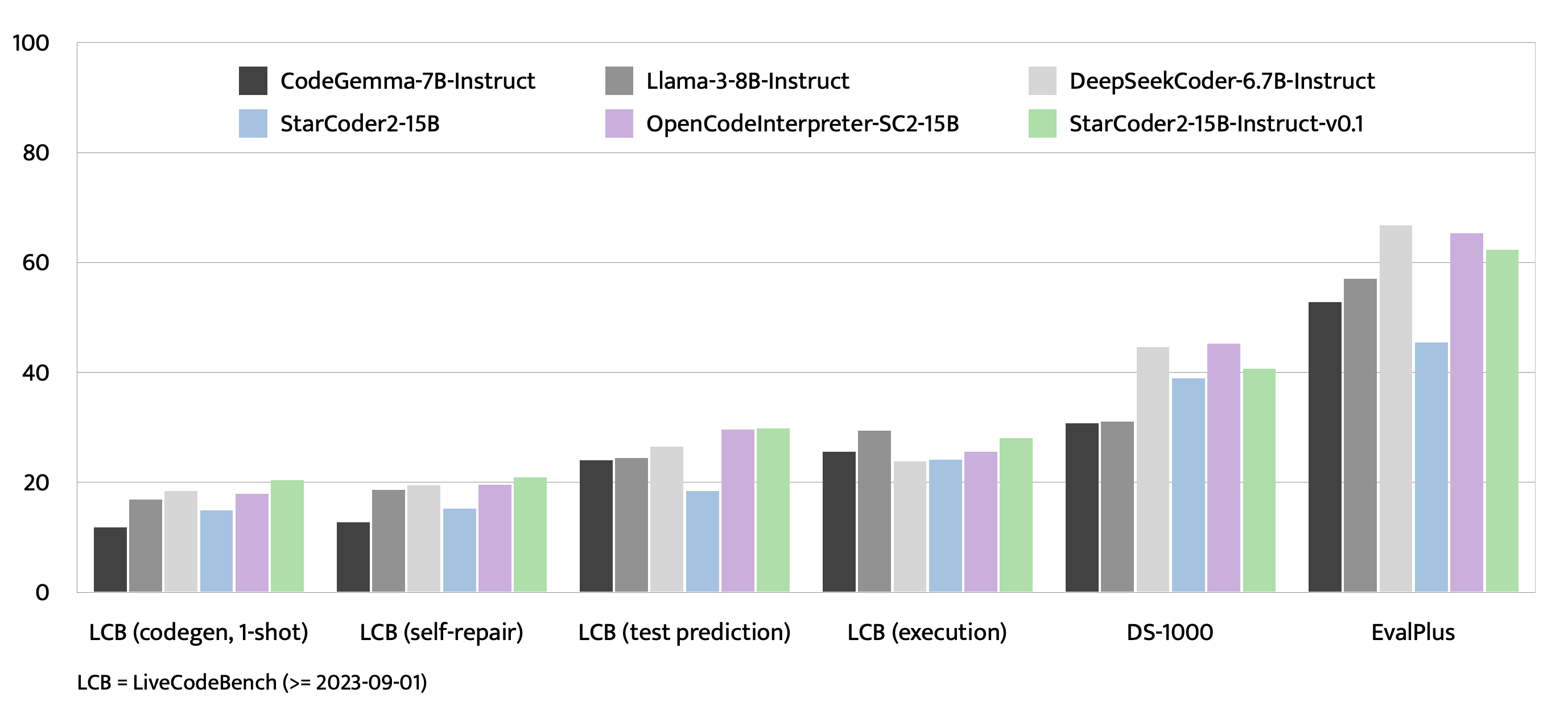
## Training Details
### Hyperparameters
- **Optimizer:** Adafactor
- **Learning rate:** 1e-5
- **Epoch:** 4
- **Batch size:** 64
- **Warmup ratio:** 0.05
- **Scheduler:** Linear
- **Sequence length:** 1280
- **Dropout**: Not applied
### Hardware
1 x NVIDIA A100 80GB
## Resources
- **Model:** [bigcode/starCoder2-15b-instruct-v0.1](https://huggingface.co/bigcode/starcoder2-instruct-15b-v0.1)
- **Code:** [bigcode-project/starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align)
- **Dataset:** [bigcode/self-oss-instruct-sc2-exec-filter-50k](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/)
<!-- original-model-card end -->
|
adamo1139/Yi-34B-200K-XLCTX-RAW-1904 | adamo1139 | 2024-05-27T21:38:35Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"dataset:adamo1139/rawrr_v2-2_stage1",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-02T21:27:05Z | ---
license: apache-2.0
datasets:
- adamo1139/rawrr_v2-2_stage1
---
## Model description
This is a base Yi-34B-200K XLCTX model treated with DPO with adamo1139/rawrr_v2-2_stage1 dataset to make outputs be completions instead of answers for a question. DPO was done using chatml format but no previous SFT step was done. If it would do it now, I would have used ORPO instead of DPO for this step to make it stronger, but too late for that. It can be used to maybe slightly decensor a model, but I don't think this idea works too well with DPO before SFT step, as was widely known but I did it anyway.
[<img src="https://raw.githubusercontent.com/unslothai/unsloth/main/images/unsloth%20made%20with%20love.png" alt="made with Unsloth" width="400" height="64"/>](https://github.com/unslothai/unsloth)
## Training script for Unsloth
```
from unsloth import FastLanguageModel
from datasets import Dataset, load_dataset
from dataclasses import dataclass, field
from typing import Dict, Optional
import torch
max_seq_length = 4096 # Choose any! We auto support RoPE Scaling internally!
dtype = None # None for auto detection. Float16 for Tesla T4, V100, Bfloat16 for Ampere+
load_in_4bit = True # Use 4bit quantization to reduce memory usage. Can be False.
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "adamo1139/Yi-34B-200K-XLCTX", # Choose ANY! eg mistralai/Mistral-7B-Instruct-v0.2
max_seq_length = max_seq_length,
attn_implementation="flash_attention_2",
dtype = dtype,
load_in_4bit = load_in_4bit,
# token = "hf_...", # use one if using gated models like meta-llama/Llama-2-7b-hf
)
#@title Alignment Handbook utils
import os
import re
from typing import List, Literal, Optional
from datasets import DatasetDict, concatenate_datasets, load_dataset, load_from_disk
from datasets.builder import DatasetGenerationError
#DEFAULT_CHAT_TEMPLATE = "{% for message in messages %}\n{% if message['role'] == 'user' %}\n{{ '<|user|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'system' %}\n{{ '<|system|>\n' + message['content'] + eos_token }}\n{% elif message['role'] == 'assistant' %}\n{{ '<|assistant|>\n' + message['content'] + eos_token }}\n{% endif %}\n{% if loop.last and add_generation_prompt %}\n{{ '<|assistant|>' }}\n{% endif %}\n{% endfor %}"
tokenizer.chat_template = "{% if not add_generation_prompt is defined %}{% set add_generation_prompt = false %}{% endif %}{% for message in messages %}{{'<|im_start|>' + message['role'] + '\n' + message['content'] + '<|im_end|>' + '\n'}}{% endfor %}{% if add_generation_prompt %}{{ '<|im_start|>assistant\n' }}{% endif %}"
EOS_TOKEN = tokenizer.eos_token
def chatml_format(example):
# Format system
if len(example['system']) > 0:
message = {"role": "system", "content": example['system']}
system = tokenizer.apply_chat_template([message], tokenize=False)
else:
system = ""
# Format instruction
message = {"role": "user", "content": example['prompt']}
prompt = tokenizer.apply_chat_template([message], tokenize=False, add_generation_prompt=True)
# Format chosen answer
chosen = example['chosen'] + "<|im_end|>\n" + EOS_TOKEN
# Format rejected answer
rejected = example['rejected'] + "<|im_end|>\n" + EOS_TOKEN
return {
"prompt": system + prompt,
"chosen": chosen,
"rejected": rejected,
}
# Load dataset
dataset = load_dataset("adamo1139/rawrr_v2-2_stage1", split="train")
import pprint
pprint.pprint("""NOT a formatted dataset
""")
pprint
pprint.pprint(dataset[250])
pprint.pprint(dataset[260])
pprint.pprint(dataset[270])
pprint.pprint(dataset[280])
pprint.pprint(dataset[290])
# Save columns
original_columns = dataset.column_names
# Format dataset
dataset = dataset.map(
chatml_format,
remove_columns=original_columns
)
# Print sample
pprint.pprint("""formatted dataset""")
pprint.pprint(dataset[250])
pprint.pprint(dataset[260])
pprint.pprint(dataset[270])
pprint.pprint(dataset[280])
pprint.pprint(dataset[290])
model = FastLanguageModel.get_peft_model(
model,
r = 32, # Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 32,
lora_dropout = 0, # Currently only supports dropout = 0
bias = "none", # Currently only supports bias = "none"
use_gradient_checkpointing = "unsloth",
random_state = 3407,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
from transformers import AutoModelForCausalLM, AutoTokenizer, BitsAndBytesConfig, HfArgumentParser, TrainingArguments
from trl import DPOTrainer
dpo_trainer = DPOTrainer(
model = model,
ref_model = None,
args = TrainingArguments(
per_device_train_batch_size = 1,
gradient_accumulation_steps = 16,
warmup_ratio = 0.03,
num_train_epochs = 1,
learning_rate = 0.0001,
fp16 = not torch.cuda.is_bf16_supported(),
bf16 = torch.cuda.is_bf16_supported(),
logging_steps = 1,
optim = "adamw_8bit",
weight_decay = 0.0,
lr_scheduler_type = "cosine",
seed = 42,
save_strategy = "steps",
save_steps = 100,
save_total_limit = 20,
output_dir = "1904-yi-200k-xlctx-raw-intermediate",
),
beta = 0.1,
train_dataset = dataset,
# eval_dataset = raw_datasets["test"],
tokenizer = tokenizer,
max_length = 650,
max_prompt_length = 650,
)
dpo_trainer.train()
model.save_pretrained("1904-yi-200k-xlctx-raw-final") # Local saving
``` |
4season/pt_model_test1 | 4season | 2024-05-08T11:56:04Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-08T07:15:46Z | ---
license: apache-2.0
language:
- en
---
# 4season/pt_model_test1
# **Introduction**
This model is test version, pt model.
We utilize state-of-the-art instruction fine-tuning methods.
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 2
- eval_batch_size: 8
- seed: 42
- distributed_type: multi-GPU
- num_devices: 8
- gradient_accumulation_steps: 8
- total_train_batch_size: 128
- total_eval_batch_size: 64
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- num_epochs: 1.0
|
Rebecca19990101/Westbreeze-7B | Rebecca19990101 | 2024-05-10T04:54:10Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"senseable/WestLake-7B-v2",
"Rebecca19990101/Breeze-Petro-7B-Instruct-v1",
"conversational",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-10T04:50:17Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- senseable/WestLake-7B-v2
- Rebecca19990101/Breeze-Petro-7B-Instruct-v1
---
# Westbreeze-7B
Westbreeze-7B is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [senseable/WestLake-7B-v2](https://huggingface.co/senseable/WestLake-7B-v2)
* [Rebecca19990101/Breeze-Petro-7B-Instruct-v1](https://huggingface.co/Rebecca19990101/Breeze-Petro-7B-Instruct-v1)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: senseable/WestLake-7B-v2
layer_range: [0, 24]
- sources:
- model: Rebecca19990101/Breeze-Petro-7B-Instruct-v1
layer_range: [24, 32]
merge_method: passthrough
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "Rebecca19990101/Westbreeze-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
Rebecca19990101/WestSeverus-7B-DPO-v2-ORPO | Rebecca19990101 | 2024-05-14T03:35:41Z | 391 | 1 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"chemistry",
"code",
"text-generation-inference",
"conversational",
"en",
"dataset:mlabonne/orpo-dpo-mix-40k",
"arxiv:1910.09700",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-generation | 2024-05-13T17:35:53Z | ---
library_name: transformers
tags:
- chemistry
- code
- text-generation-inference
license: apache-2.0
datasets:
- mlabonne/orpo-dpo-mix-40k
language:
- en
metrics:
- code_eval
- accuracy
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
yweslakarep/mergekit-slerp-wxijtsx | yweslakarep | 2024-05-15T00:30:41Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"conversational",
"base_model:NousResearch/Hermes-2-Pro-Mistral-7B",
"base_model:WizardLM/WizardMath-7B-V1.1",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-14T09:11:31Z | ---
base_model:
- NousResearch/Hermes-2-Pro-Mistral-7B
- WizardLM/WizardMath-7B-V1.1
library_name: transformers
tags:
- mergekit
- merge
license: other
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the SLERP merge method.
### Models Merged
The following models were included in the merge:
* [NousResearch/Hermes-2-Pro-Mistral-7B](https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B)
* [WizardLM/WizardMath-7B-V1.1](https://huggingface.co/WizardLM/WizardMath-7B-V1.1)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: NousResearch/Hermes-2-Pro-Mistral-7B
- model: WizardLM/WizardMath-7B-V1.1
merge_method: slerp
base_model: NousResearch/Hermes-2-Pro-Mistral-7B
dtype: bfloat16
parameters:
t: [0, 0.5, 1, 0.5, 0] # V shaped curve: Hermes for input & output, WizardMath in the middle layers
``` |
allknowingroger/MultiMash7-12B-slerp | allknowingroger | 2024-05-22T12:14:57Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"mixtral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"allknowingroger/WestLakeMultiverse-12B-MoE",
"jsfs11/MixtureofMerges-MoE-2x7b-v6",
"base_model:allknowingroger/WestLakeMultiverse-12B-MoE",
"base_model:jsfs11/MixtureofMerges-MoE-2x7b-v6",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-22T12:01:53Z | ---
tags:
- merge
- mergekit
- lazymergekit
- allknowingroger/WestLakeMultiverse-12B-MoE
- jsfs11/MixtureofMerges-MoE-2x7b-v6
base_model:
- allknowingroger/WestLakeMultiverse-12B-MoE
- jsfs11/MixtureofMerges-MoE-2x7b-v6
license: apache-2.0
---
# MultiMash7-12B-slerp
MultiMash7-12B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [allknowingroger/WestLakeMultiverse-12B-MoE](https://huggingface.co/allknowingroger/WestLakeMultiverse-12B-MoE)
* [jsfs11/MixtureofMerges-MoE-2x7b-v6](https://huggingface.co/jsfs11/MixtureofMerges-MoE-2x7b-v6)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: allknowingroger/WestLakeMultiverse-12B-MoE
layer_range: [0, 32]
- model: jsfs11/MixtureofMerges-MoE-2x7b-v6
layer_range: [0, 32]
merge_method: slerp
base_model: allknowingroger/WestLakeMultiverse-12B-MoE
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "allknowingroger/MultiMash7-12B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
mradermacher/Llama-3-ProTrix-GGUF | mradermacher | 2024-06-26T20:59:37Z | 391 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:pkupie/Llama-3-ProTrix",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-05-23T21:57:02Z | ---
base_model: pkupie/Llama-3-ProTrix
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
static quants of https://huggingface.co/pkupie/Llama-3-ProTrix
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/Llama-3-ProTrix-GGUF/resolve/main/Llama-3-ProTrix.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf | RichardErkhov | 2024-05-24T15:04:11Z | 391 | 0 | null | [
"gguf",
"region:us"
]
| null | 2024-05-24T11:55:15Z | Quantization made by Richard Erkhov.
[Github](https://github.com/RichardErkhov)
[Discord](https://discord.gg/pvy7H8DZMG)
[Request more models](https://github.com/RichardErkhov/quant_request)
Hebrew-Gemma-11B-V2 - GGUF
- Model creator: https://huggingface.co/yam-peleg/
- Original model: https://huggingface.co/yam-peleg/Hebrew-Gemma-11B-V2/
| Name | Quant method | Size |
| ---- | ---- | ---- |
| [Hebrew-Gemma-11B-V2.Q2_K.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q2_K.gguf) | Q2_K | 3.9GB |
| [Hebrew-Gemma-11B-V2.IQ3_XS.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.IQ3_XS.gguf) | IQ3_XS | 4.27GB |
| [Hebrew-Gemma-11B-V2.IQ3_S.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.IQ3_S.gguf) | IQ3_S | 4.48GB |
| [Hebrew-Gemma-11B-V2.Q3_K_S.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q3_K_S.gguf) | Q3_K_S | 4.48GB |
| [Hebrew-Gemma-11B-V2.IQ3_M.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.IQ3_M.gguf) | IQ3_M | 4.63GB |
| [Hebrew-Gemma-11B-V2.Q3_K.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q3_K.gguf) | Q3_K | 4.94GB |
| [Hebrew-Gemma-11B-V2.Q3_K_M.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q3_K_M.gguf) | Q3_K_M | 4.94GB |
| [Hebrew-Gemma-11B-V2.Q3_K_L.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q3_K_L.gguf) | Q3_K_L | 5.33GB |
| [Hebrew-Gemma-11B-V2.IQ4_XS.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.IQ4_XS.gguf) | IQ4_XS | 5.44GB |
| [Hebrew-Gemma-11B-V2.Q4_0.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q4_0.gguf) | Q4_0 | 5.68GB |
| [Hebrew-Gemma-11B-V2.IQ4_NL.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.IQ4_NL.gguf) | IQ4_NL | 5.72GB |
| [Hebrew-Gemma-11B-V2.Q4_K_S.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q4_K_S.gguf) | Q4_K_S | 5.72GB |
| [Hebrew-Gemma-11B-V2.Q4_K.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q4_K.gguf) | Q4_K | 6.04GB |
| [Hebrew-Gemma-11B-V2.Q4_K_M.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q4_K_M.gguf) | Q4_K_M | 6.04GB |
| [Hebrew-Gemma-11B-V2.Q4_1.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q4_1.gguf) | Q4_1 | 6.25GB |
| [Hebrew-Gemma-11B-V2.Q5_0.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q5_0.gguf) | Q5_0 | 6.81GB |
| [Hebrew-Gemma-11B-V2.Q5_K_S.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q5_K_S.gguf) | Q5_K_S | 6.81GB |
| [Hebrew-Gemma-11B-V2.Q5_K.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q5_K.gguf) | Q5_K | 7.0GB |
| [Hebrew-Gemma-11B-V2.Q5_K_M.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q5_K_M.gguf) | Q5_K_M | 7.0GB |
| [Hebrew-Gemma-11B-V2.Q5_1.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q5_1.gguf) | Q5_1 | 7.37GB |
| [Hebrew-Gemma-11B-V2.Q6_K.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q6_K.gguf) | Q6_K | 8.01GB |
| [Hebrew-Gemma-11B-V2.Q8_0.gguf](https://huggingface.co/RichardErkhov/yam-peleg_-_Hebrew-Gemma-11B-V2-gguf/blob/main/Hebrew-Gemma-11B-V2.Q8_0.gguf) | Q8_0 | 10.37GB |
Original model description:
---
license: other
license_name: gemma-terms-of-use
license_link: https://ai.google.dev/gemma/terms
language:
- en
- he
library_name: transformers
---
# Hebrew-Gemma-11B-V2
An updated version of [Hebrew-Gemma-11B](https://huggingface.co/yam-peleg/Hebrew-Gemma-11B) that was trained longer and had some bugs fixes.
### Base Models:
- **07.03.2024:** [Hebrew-Gemma-11B](https://huggingface.co/yam-peleg/Hebrew-Gemma-11B)
- **16.03.2024:** [Hebrew-Gemma-11B-V2](https://huggingface.co/yam-peleg/Hebrew-Gemma-11B-V2)
### Instruct Models:
- **07.03.2024:** [Hebrew-Gemma-11B-Instruct](https://huggingface.co/yam-peleg/Hebrew-Gemma-11B-Instruct)
Hebrew-Gemma-11B is an open-source Large Language Model (LLM) is a hebrew/english pretrained generative text model with 11 billion parameters, based on the Gemma-7B architecture from Google.
It is continued pretrain of gemma-7b, extended to a larger scale and trained on 3B additional tokens of both English and Hebrew text data.
The resulting model Gemma-11B is a powerful general-purpose language model suitable for a wide range of natural language processing tasks, with a focus on Hebrew language understanding and generation.
### Terms of Use
As an extention of Gemma-7B, this model is subject to the original license and terms of use by Google.
**Gemma-7B original Terms of Use**: [Terms](https://www.kaggle.com/models/google/gemma/license/consent)
### Usage
Below are some code snippets on how to get quickly started with running the model.
First make sure to `pip install -U transformers`, then copy the snippet from the section that is relevant for your usecase.
### Running on CPU
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("yam-peleg/Hebrew-Gemma-11B-V2")
model = AutoModelForCausalLM.from_pretrained("yam-peleg/Hebrew-Gemma-11B-V2")
input_text = "שלום! מה שלומך היום?"
input_ids = tokenizer(input_text, return_tensors="pt")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
### Running on GPU
```python
from transformers import AutoTokenizer, AutoModelForCausalLM
tokenizer = AutoTokenizer.from_pretrained("yam-peleg/Hebrew-Gemma-11B-V2")
model = AutoModelForCausalLM.from_pretrained("yam-peleg/Hebrew-Gemma-11B-V2", device_map="auto")
input_text = "שלום! מה שלומך היום?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0]))
```
### Running with 4-Bit precision
```python
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
tokenizer = AutoTokenizer.from_pretrained("yam-peleg/Hebrew-Gemma-11B-V2")
model = AutoModelForCausalLM.from_pretrained("yam-peleg/Hebrew-Gemma-11B-V2", quantization_config = BitsAndBytesConfig(load_in_4bit=True))
input_text = "שלום! מה שלומך היום?"
input_ids = tokenizer(input_text, return_tensors="pt").to("cuda")
outputs = model.generate(**input_ids)
print(tokenizer.decode(outputs[0])
```
### Benchmark Results
- Coming Soon!
### Notice
Hebrew-Gemma-11B-V2 is a pretrained base model and therefore does not have any moderation mechanisms.
### Authors
- Trained by Yam Peleg.
- In collaboration with Jonathan Rouach and Arjeo, inc.
|
masrur/Oni-7B-slerp | masrur | 2024-05-26T12:39:11Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"mlabonne/Monarch-7B",
"vanillaOVO/supermario_v4",
"en",
"base_model:mlabonne/Monarch-7B",
"base_model:vanillaOVO/supermario_v4",
"license:llama2",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-05-26T12:17:07Z | ---
tags:
- merge
- mergekit
- lazymergekit
- mlabonne/Monarch-7B
- vanillaOVO/supermario_v4
base_model:
- mlabonne/Monarch-7B
- vanillaOVO/supermario_v4
license: llama2
language:
- en
---
# Oni-7B-slerp
Oni-7B-slerp is a merge of the following models using [LazyMergekit](https://colab.research.google.com/drive/1obulZ1ROXHjYLn6PPZJwRR6GzgQogxxb?usp=sharing):
* [mlabonne/Monarch-7B](https://huggingface.co/mlabonne/Monarch-7B)
* [vanillaOVO/supermario_v4](https://huggingface.co/vanillaOVO/supermario_v4)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: mlabonne/Monarch-7B
layer_range: [0, 32]
- model: vanillaOVO/supermario_v4
layer_range: [0, 32]
merge_method: slerp
base_model: mlabonne/Monarch-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: float16
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "masrur/Oni-7B-slerp"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF | mradermacher | 2024-06-02T01:35:25Z | 391 | 1 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"en",
"base_model:Hastagaras/UltimateANJIR-8B-L3-Blackroot",
"license:llama3",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-01T22:07:55Z | ---
base_model: Hastagaras/UltimateANJIR-8B-L3-Blackroot
language:
- en
library_name: transformers
license: llama3
quantized_by: mradermacher
tags:
- mergekit
- merge
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/Hastagaras/UltimateANJIR-8B-L3-Blackroot
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q2_K.gguf) | Q2_K | 3.3 | |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.IQ3_XS.gguf) | IQ3_XS | 3.6 | |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q3_K_S.gguf) | Q3_K_S | 3.8 | |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.IQ3_S.gguf) | IQ3_S | 3.8 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.IQ3_M.gguf) | IQ3_M | 3.9 | |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q3_K_M.gguf) | Q3_K_M | 4.1 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q3_K_L.gguf) | Q3_K_L | 4.4 | |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.IQ4_XS.gguf) | IQ4_XS | 4.6 | |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q4_K_S.gguf) | Q4_K_S | 4.8 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q4_K_M.gguf) | Q4_K_M | 5.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q5_K_S.gguf) | Q5_K_S | 5.7 | |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q5_K_M.gguf) | Q5_K_M | 5.8 | |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q6_K.gguf) | Q6_K | 6.7 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.Q8_0.gguf) | Q8_0 | 8.6 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/UltimateANJIR-8B-L3-Blackroot-GGUF/resolve/main/UltimateANJIR-8B-L3-Blackroot.f16.gguf) | f16 | 16.2 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
TTTXXX01/All_like-zephyr-7b-sft-full | TTTXXX01 | 2024-06-04T22:12:10Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"alignment-handbook",
"trl",
"dpo",
"generated_from_trainer",
"conversational",
"dataset:HuggingFaceH4/ultrafeedback_binarized",
"base_model:alignment-handbook/zephyr-7b-sft-full",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-06-04T17:13:15Z | ---
license: apache-2.0
base_model: alignment-handbook/zephyr-7b-sft-full
tags:
- alignment-handbook
- trl
- dpo
- generated_from_trainer
- trl
- dpo
- generated_from_trainer
datasets:
- HuggingFaceH4/ultrafeedback_binarized
model-index:
- name: All_like-zephyr-7b-sft-full
results: []
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# All_like-zephyr-7b-sft-full
This model is a fine-tuned version of [alignment-handbook/zephyr-7b-sft-full](https://huggingface.co/alignment-handbook/zephyr-7b-sft-full) on the HuggingFaceH4/ultrafeedback_binarized dataset.
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 5e-07
- train_batch_size: 3
- eval_batch_size: 4
- seed: 42
- distributed_type: multi-GPU
- num_devices: 4
- total_train_batch_size: 12
- total_eval_batch_size: 16
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: cosine
- lr_scheduler_warmup_ratio: 0.1
- num_epochs: 1
### Training results
### Framework versions
- Transformers 4.41.2
- Pytorch 2.3.0+cu121
- Datasets 2.19.1
- Tokenizers 0.19.1
|
mradermacher/Llama3-18B-lingyang-v1-GGUF | mradermacher | 2024-06-06T06:56:21Z | 391 | 0 | transformers | [
"transformers",
"gguf",
"mergekit",
"merge",
"Llama3",
"en",
"base_model:wwe180/Llama3-18B-lingyang-v1",
"license:other",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-06T05:51:39Z | ---
base_model: wwe180/Llama3-18B-lingyang-v1
language:
- en
library_name: transformers
license:
- other
quantized_by: mradermacher
tags:
- mergekit
- merge
- Llama3
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/wwe180/Llama3-18B-lingyang-v1
<!-- provided-files -->
weighted/imatrix quants are available at https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-i1-GGUF
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q2_K.gguf) | Q2_K | 7.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.IQ3_XS.gguf) | IQ3_XS | 7.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q3_K_S.gguf) | Q3_K_S | 8.1 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.IQ3_S.gguf) | IQ3_S | 8.1 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.IQ3_M.gguf) | IQ3_M | 8.4 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q3_K_M.gguf) | Q3_K_M | 8.9 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q3_K_L.gguf) | Q3_K_L | 9.7 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.IQ4_XS.gguf) | IQ4_XS | 10.0 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q4_K_S.gguf) | Q4_K_S | 10.5 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q4_K_M.gguf) | Q4_K_M | 11.0 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q5_K_S.gguf) | Q5_K_S | 12.6 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q5_K_M.gguf) | Q5_K_M | 12.9 | |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q6_K.gguf) | Q6_K | 14.9 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/Llama3-18B-lingyang-v1-GGUF/resolve/main/Llama3-18B-lingyang-v1.Q8_0.gguf) | Q8_0 | 19.3 | fast, best quality |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
JLawI11/generation_earnings_chatbot | JLawI11 | 2024-06-20T16:50:59Z | 391 | 0 | transformers | [
"transformers",
"safetensors",
"gguf",
"unsloth",
"arxiv:1910.09700",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-19T09:57:58Z | ---
library_name: transformers
tags:
- unsloth
---
# Model Card for Model ID
<!-- Provide a quick summary of what the model is/does. -->
## Model Details
### Model Description
<!-- Provide a longer summary of what this model is. -->
This is the model card of a 🤗 transformers model that has been pushed on the Hub. This model card has been automatically generated.
- **Developed by:** [More Information Needed]
- **Funded by [optional]:** [More Information Needed]
- **Shared by [optional]:** [More Information Needed]
- **Model type:** [More Information Needed]
- **Language(s) (NLP):** [More Information Needed]
- **License:** [More Information Needed]
- **Finetuned from model [optional]:** [More Information Needed]
### Model Sources [optional]
<!-- Provide the basic links for the model. -->
- **Repository:** [More Information Needed]
- **Paper [optional]:** [More Information Needed]
- **Demo [optional]:** [More Information Needed]
## Uses
<!-- Address questions around how the model is intended to be used, including the foreseeable users of the model and those affected by the model. -->
### Direct Use
<!-- This section is for the model use without fine-tuning or plugging into a larger ecosystem/app. -->
[More Information Needed]
### Downstream Use [optional]
<!-- This section is for the model use when fine-tuned for a task, or when plugged into a larger ecosystem/app -->
[More Information Needed]
### Out-of-Scope Use
<!-- This section addresses misuse, malicious use, and uses that the model will not work well for. -->
[More Information Needed]
## Bias, Risks, and Limitations
<!-- This section is meant to convey both technical and sociotechnical limitations. -->
[More Information Needed]
### Recommendations
<!-- This section is meant to convey recommendations with respect to the bias, risk, and technical limitations. -->
Users (both direct and downstream) should be made aware of the risks, biases and limitations of the model. More information needed for further recommendations.
## How to Get Started with the Model
Use the code below to get started with the model.
[More Information Needed]
## Training Details
### Training Data
<!-- This should link to a Dataset Card, perhaps with a short stub of information on what the training data is all about as well as documentation related to data pre-processing or additional filtering. -->
[More Information Needed]
### Training Procedure
<!-- This relates heavily to the Technical Specifications. Content here should link to that section when it is relevant to the training procedure. -->
#### Preprocessing [optional]
[More Information Needed]
#### Training Hyperparameters
- **Training regime:** [More Information Needed] <!--fp32, fp16 mixed precision, bf16 mixed precision, bf16 non-mixed precision, fp16 non-mixed precision, fp8 mixed precision -->
#### Speeds, Sizes, Times [optional]
<!-- This section provides information about throughput, start/end time, checkpoint size if relevant, etc. -->
[More Information Needed]
## Evaluation
<!-- This section describes the evaluation protocols and provides the results. -->
### Testing Data, Factors & Metrics
#### Testing Data
<!-- This should link to a Dataset Card if possible. -->
[More Information Needed]
#### Factors
<!-- These are the things the evaluation is disaggregating by, e.g., subpopulations or domains. -->
[More Information Needed]
#### Metrics
<!-- These are the evaluation metrics being used, ideally with a description of why. -->
[More Information Needed]
### Results
[More Information Needed]
#### Summary
## Model Examination [optional]
<!-- Relevant interpretability work for the model goes here -->
[More Information Needed]
## Environmental Impact
<!-- Total emissions (in grams of CO2eq) and additional considerations, such as electricity usage, go here. Edit the suggested text below accordingly -->
Carbon emissions can be estimated using the [Machine Learning Impact calculator](https://mlco2.github.io/impact#compute) presented in [Lacoste et al. (2019)](https://arxiv.org/abs/1910.09700).
- **Hardware Type:** [More Information Needed]
- **Hours used:** [More Information Needed]
- **Cloud Provider:** [More Information Needed]
- **Compute Region:** [More Information Needed]
- **Carbon Emitted:** [More Information Needed]
## Technical Specifications [optional]
### Model Architecture and Objective
[More Information Needed]
### Compute Infrastructure
[More Information Needed]
#### Hardware
[More Information Needed]
#### Software
[More Information Needed]
## Citation [optional]
<!-- If there is a paper or blog post introducing the model, the APA and Bibtex information for that should go in this section. -->
**BibTeX:**
[More Information Needed]
**APA:**
[More Information Needed]
## Glossary [optional]
<!-- If relevant, include terms and calculations in this section that can help readers understand the model or model card. -->
[More Information Needed]
## More Information [optional]
[More Information Needed]
## Model Card Authors [optional]
[More Information Needed]
## Model Card Contact
[More Information Needed] |
CHE-72/Baichuan2-7B-Chat-Q4_K_S-GGUF | CHE-72 | 2024-06-22T09:01:29Z | 391 | 0 | null | [
"gguf",
"llama-cpp",
"gguf-my-repo",
"en",
"zh",
"base_model:baichuan-inc/Baichuan2-7B-Chat",
"region:us"
]
| null | 2024-06-22T09:01:10Z | ---
base_model: baichuan-inc/Baichuan2-7B-Chat
language:
- en
- zh
license_name: baichuan2-community-license
license_link: https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat/blob/main/Community%20License%20for%20Baichuan2%20Model.pdf
tags:
- llama-cpp
- gguf-my-repo
tasks:
- text-generation
---
# CHE-72/Baichuan2-7B-Chat-Q4_K_S-GGUF
This model was converted to GGUF format from [`baichuan-inc/Baichuan2-7B-Chat`](https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo CHE-72/Baichuan2-7B-Chat-Q4_K_S-GGUF --hf-file baichuan2-7b-chat-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo CHE-72/Baichuan2-7B-Chat-Q4_K_S-GGUF --hf-file baichuan2-7b-chat-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo CHE-72/Baichuan2-7B-Chat-Q4_K_S-GGUF --hf-file baichuan2-7b-chat-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo CHE-72/Baichuan2-7B-Chat-Q4_K_S-GGUF --hf-file baichuan2-7b-chat-q4_k_s.gguf -c 2048
```
|
paulo037/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-Q4_K_S-GGUF | paulo037 | 2024-06-24T00:03:54Z | 391 | 0 | transformers | [
"transformers",
"gguf",
"llama-cpp",
"gguf-my-repo",
"base_model:NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-24T00:03:44Z | ---
base_model: NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps
library_name: transformers
tags:
- llama-cpp
- gguf-my-repo
---
# paulo037/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-Q4_K_S-GGUF
This model was converted to GGUF format from [`NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps`](https://huggingface.co/NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/NESPED-GEN/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo paulo037/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-Q4_K_S-GGUF --hf-file phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-q4_k_s.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo paulo037/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-Q4_K_S-GGUF --hf-file phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-q4_k_s.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo paulo037/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-Q4_K_S-GGUF --hf-file phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-q4_k_s.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo paulo037/phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-Q4_K_S-GGUF --hf-file phi-3-mini-128k-instruct-mix-spider-bird-2800-steps-q4_k_s.gguf -c 2048
```
|
xutongda/control_e_sd2.0_srx8 | xutongda | 2024-06-24T13:25:58Z | 391 | 0 | diffusers | [
"diffusers",
"safetensors",
"license:mit",
"region:us"
]
| null | 2024-06-24T02:59:19Z | ---
license: mit
---
|
pszemraj/Mistral-7B-sarcasm-scrolls-v2-Q4_K_M-GGUF | pszemraj | 2024-06-26T17:00:12Z | 391 | 0 | null | [
"gguf",
"axolotl",
"generated_from_trainer",
"llama-cpp",
"gguf-my-repo",
"en",
"dataset:BEE-spoke-data/sarcasm-scrolls",
"base_model:pszemraj/Mistral-7B-sarcasm-scrolls-v2",
"license:apache-2.0",
"region:us"
]
| null | 2024-06-25T19:09:48Z | ---
base_model: pszemraj/Mistral-7B-sarcasm-scrolls-v2
license: apache-2.0
tags:
- axolotl
- generated_from_trainer
- llama-cpp
- gguf-my-repo
model-index:
- name: Mistral-7B-v0.3-sarcasm-scrolls-v2
results: []
datasets:
- BEE-spoke-data/sarcasm-scrolls
language:
- en
---
# pszemraj/Mistral-7B-sarcasm-scrolls-v2-Q4_K_M-GGUF
This model was converted to GGUF format from [`pszemraj/Mistral-7B-sarcasm-scrolls-v2`](https://huggingface.co/pszemraj/Mistral-7B-sarcasm-scrolls-v2) using llama.cpp via the ggml.ai's [GGUF-my-repo](https://huggingface.co/spaces/ggml-org/gguf-my-repo) space.
Refer to the [original model card](https://huggingface.co/pszemraj/Mistral-7B-sarcasm-scrolls-v2) for more details on the model.
## Use with llama.cpp
Install llama.cpp through brew (works on Mac and Linux)
```bash
brew install llama.cpp
```
Invoke the llama.cpp server or the CLI.
### CLI:
```bash
llama-cli --hf-repo pszemraj/Mistral-7B-sarcasm-scrolls-v2-Q4_K_M-GGUF --hf-file mistral-7b-sarcasm-scrolls-v2-q4_k_m.gguf -p "The meaning to life and the universe is"
```
### Server:
```bash
llama-server --hf-repo pszemraj/Mistral-7B-sarcasm-scrolls-v2-Q4_K_M-GGUF --hf-file mistral-7b-sarcasm-scrolls-v2-q4_k_m.gguf -c 2048
```
Note: You can also use this checkpoint directly through the [usage steps](https://github.com/ggerganov/llama.cpp?tab=readme-ov-file#usage) listed in the Llama.cpp repo as well.
Step 1: Clone llama.cpp from GitHub.
```
git clone https://github.com/ggerganov/llama.cpp
```
Step 2: Move into the llama.cpp folder and build it with `LLAMA_CURL=1` flag along with other hardware-specific flags (for ex: LLAMA_CUDA=1 for Nvidia GPUs on Linux).
```
cd llama.cpp && LLAMA_CURL=1 make
```
Step 3: Run inference through the main binary.
```
./llama-cli --hf-repo pszemraj/Mistral-7B-sarcasm-scrolls-v2-Q4_K_M-GGUF --hf-file mistral-7b-sarcasm-scrolls-v2-q4_k_m.gguf -p "The meaning to life and the universe is"
```
or
```
./llama-server --hf-repo pszemraj/Mistral-7B-sarcasm-scrolls-v2-Q4_K_M-GGUF --hf-file mistral-7b-sarcasm-scrolls-v2-q4_k_m.gguf -c 2048
``` |
mradermacher/DistilGPT2-TinyStories-GGUF | mradermacher | 2024-06-26T11:04:24Z | 391 | 0 | transformers | [
"transformers",
"gguf",
"en",
"base_model:davidilic044/DistilGPT2-TinyStories",
"license:mit",
"endpoints_compatible",
"region:us"
]
| null | 2024-06-26T11:02:31Z | ---
base_model: davidilic044/DistilGPT2-TinyStories
language:
- en
library_name: transformers
license: mit
quantized_by: mradermacher
---
## About
<!-- ### quantize_version: 2 -->
<!-- ### output_tensor_quantised: 1 -->
<!-- ### convert_type: hf -->
<!-- ### vocab_type: -->
<!-- ### tags: -->
static quants of https://huggingface.co/davidilic044/DistilGPT2-TinyStories
<!-- provided-files -->
weighted/imatrix quants seem not to be available (by me) at this time. If they do not show up a week or so after the static ones, I have probably not planned for them. Feel free to request them by opening a Community Discussion.
## Usage
If you are unsure how to use GGUF files, refer to one of [TheBloke's
READMEs](https://huggingface.co/TheBloke/KafkaLM-70B-German-V0.1-GGUF) for
more details, including on how to concatenate multi-part files.
## Provided Quants
(sorted by size, not necessarily quality. IQ-quants are often preferable over similar sized non-IQ quants)
| Link | Type | Size/GB | Notes |
|:-----|:-----|--------:|:------|
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q2_K.gguf) | Q2_K | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.IQ3_XS.gguf) | IQ3_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.IQ3_S.gguf) | IQ3_S | 0.2 | beats Q3_K* |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q3_K_S.gguf) | Q3_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.IQ3_M.gguf) | IQ3_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q3_K_M.gguf) | Q3_K_M | 0.2 | lower quality |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q3_K_L.gguf) | Q3_K_L | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.IQ4_XS.gguf) | IQ4_XS | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q4_K_S.gguf) | Q4_K_S | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q4_K_M.gguf) | Q4_K_M | 0.2 | fast, recommended |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q5_K_S.gguf) | Q5_K_S | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q5_K_M.gguf) | Q5_K_M | 0.2 | |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q6_K.gguf) | Q6_K | 0.2 | very good quality |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.Q8_0.gguf) | Q8_0 | 0.2 | fast, best quality |
| [GGUF](https://huggingface.co/mradermacher/DistilGPT2-TinyStories-GGUF/resolve/main/DistilGPT2-TinyStories.f16.gguf) | f16 | 0.3 | 16 bpw, overkill |
Here is a handy graph by ikawrakow comparing some lower-quality quant
types (lower is better):

And here are Artefact2's thoughts on the matter:
https://gist.github.com/Artefact2/b5f810600771265fc1e39442288e8ec9
## FAQ / Model Request
See https://huggingface.co/mradermacher/model_requests for some answers to
questions you might have and/or if you want some other model quantized.
## Thanks
I thank my company, [nethype GmbH](https://www.nethype.de/), for letting
me use its servers and providing upgrades to my workstation to enable
this work in my free time.
<!-- end -->
|
pig4431/Sentiment140_roBERTa_5E | pig4431 | 2022-11-06T21:17:53Z | 390 | 1 | transformers | [
"transformers",
"pytorch",
"roberta",
"text-classification",
"generated_from_trainer",
"dataset:sentiment140",
"license:mit",
"model-index",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2022-11-06T21:15:53Z | ---
license: mit
tags:
- generated_from_trainer
datasets:
- sentiment140
metrics:
- accuracy
model-index:
- name: Sentiment140_roBERTa_5E
results:
- task:
name: Text Classification
type: text-classification
dataset:
name: sentiment140
type: sentiment140
config: sentiment140
split: train
args: sentiment140
metrics:
- name: Accuracy
type: accuracy
value: 0.8933333333333333
---
<!-- This model card has been generated automatically according to the information the Trainer had access to. You
should probably proofread and complete it, then remove this comment. -->
# Sentiment140_roBERTa_5E
This model is a fine-tuned version of [roberta-base](https://huggingface.co/roberta-base) on the sentiment140 dataset.
It achieves the following results on the evaluation set:
- Loss: 0.4796
- Accuracy: 0.8933
## Model description
More information needed
## Intended uses & limitations
More information needed
## Training and evaluation data
More information needed
## Training procedure
### Training hyperparameters
The following hyperparameters were used during training:
- learning_rate: 1e-05
- train_batch_size: 16
- eval_batch_size: 8
- seed: 42
- optimizer: Adam with betas=(0.9,0.999) and epsilon=1e-08
- lr_scheduler_type: linear
- num_epochs: 5
### Training results
| Training Loss | Epoch | Step | Validation Loss | Accuracy |
|:-------------:|:-----:|:----:|:---------------:|:--------:|
| 0.699 | 0.08 | 50 | 0.6734 | 0.5467 |
| 0.6099 | 0.16 | 100 | 0.4322 | 0.8 |
| 0.4906 | 0.24 | 150 | 0.3861 | 0.84 |
| 0.4652 | 0.32 | 200 | 0.4288 | 0.7933 |
| 0.4874 | 0.4 | 250 | 0.3872 | 0.84 |
| 0.4735 | 0.48 | 300 | 0.3401 | 0.8667 |
| 0.3909 | 0.56 | 350 | 0.3484 | 0.84 |
| 0.4277 | 0.64 | 400 | 0.3207 | 0.88 |
| 0.3894 | 0.72 | 450 | 0.3310 | 0.8733 |
| 0.4523 | 0.8 | 500 | 0.3389 | 0.8667 |
| 0.4087 | 0.88 | 550 | 0.3515 | 0.8467 |
| 0.3973 | 0.96 | 600 | 0.3513 | 0.8467 |
| 0.4016 | 1.04 | 650 | 0.3501 | 0.8667 |
| 0.3613 | 1.12 | 700 | 0.3327 | 0.8667 |
| 0.343 | 1.2 | 750 | 0.3518 | 0.86 |
| 0.314 | 1.28 | 800 | 0.3555 | 0.88 |
| 0.3407 | 1.36 | 850 | 0.3849 | 0.86 |
| 0.2944 | 1.44 | 900 | 0.3576 | 0.8667 |
| 0.3267 | 1.52 | 950 | 0.3461 | 0.8733 |
| 0.3251 | 1.6 | 1000 | 0.3411 | 0.8667 |
| 0.321 | 1.68 | 1050 | 0.3371 | 0.88 |
| 0.3057 | 1.76 | 1100 | 0.3322 | 0.88 |
| 0.3335 | 1.84 | 1150 | 0.3106 | 0.8667 |
| 0.3363 | 1.92 | 1200 | 0.3158 | 0.8933 |
| 0.2972 | 2.0 | 1250 | 0.3122 | 0.88 |
| 0.2453 | 2.08 | 1300 | 0.3327 | 0.8867 |
| 0.2467 | 2.16 | 1350 | 0.3767 | 0.8667 |
| 0.273 | 2.24 | 1400 | 0.3549 | 0.8667 |
| 0.2672 | 2.32 | 1450 | 0.3470 | 0.88 |
| 0.2352 | 2.4 | 1500 | 0.4092 | 0.8667 |
| 0.2763 | 2.48 | 1550 | 0.3472 | 0.9 |
| 0.2858 | 2.56 | 1600 | 0.3440 | 0.9 |
| 0.2206 | 2.64 | 1650 | 0.3770 | 0.88 |
| 0.2928 | 2.72 | 1700 | 0.3280 | 0.8867 |
| 0.2478 | 2.8 | 1750 | 0.3426 | 0.8867 |
| 0.2362 | 2.88 | 1800 | 0.3578 | 0.8933 |
| 0.2107 | 2.96 | 1850 | 0.3986 | 0.8933 |
| 0.2191 | 3.04 | 1900 | 0.3819 | 0.8933 |
| 0.2267 | 3.12 | 1950 | 0.4047 | 0.8867 |
| 0.2076 | 3.2 | 2000 | 0.4303 | 0.8867 |
| 0.1868 | 3.28 | 2050 | 0.4385 | 0.8933 |
| 0.2239 | 3.36 | 2100 | 0.4175 | 0.8933 |
| 0.2082 | 3.44 | 2150 | 0.4142 | 0.8933 |
| 0.2423 | 3.52 | 2200 | 0.4002 | 0.8867 |
| 0.1878 | 3.6 | 2250 | 0.4662 | 0.88 |
| 0.1892 | 3.68 | 2300 | 0.4783 | 0.88 |
| 0.2259 | 3.76 | 2350 | 0.4487 | 0.88 |
| 0.1859 | 3.84 | 2400 | 0.4456 | 0.8933 |
| 0.2042 | 3.92 | 2450 | 0.4468 | 0.8933 |
| 0.2096 | 4.0 | 2500 | 0.4153 | 0.8867 |
| 0.178 | 4.08 | 2550 | 0.4100 | 0.8933 |
| 0.1621 | 4.16 | 2600 | 0.4292 | 0.8933 |
| 0.1682 | 4.24 | 2650 | 0.4602 | 0.8933 |
| 0.1813 | 4.32 | 2700 | 0.4680 | 0.8933 |
| 0.2033 | 4.4 | 2750 | 0.4735 | 0.8933 |
| 0.1662 | 4.48 | 2800 | 0.4750 | 0.88 |
| 0.1686 | 4.56 | 2850 | 0.4830 | 0.8933 |
| 0.1603 | 4.64 | 2900 | 0.4909 | 0.8933 |
| 0.148 | 4.72 | 2950 | 0.4784 | 0.8933 |
| 0.162 | 4.8 | 3000 | 0.4750 | 0.8867 |
| 0.153 | 4.88 | 3050 | 0.4759 | 0.8867 |
| 0.1657 | 4.96 | 3100 | 0.4796 | 0.8933 |
### Framework versions
- Transformers 4.24.0
- Pytorch 1.13.0
- Datasets 2.3.2
- Tokenizers 0.13.1
|
helenai/papluca-xlm-roberta-base-language-detection-ov | helenai | 2024-05-22T19:30:24Z | 390 | 0 | transformers | [
"transformers",
"openvino",
"xlm-roberta",
"text-classification",
"en",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| text-classification | 2023-03-11T17:17:41Z | ---
language:
- en
tags:
- openvino
---
# papluca/xlm-roberta-base-language-detection
This is the [papluca/xlm-roberta-base-language-detection](https://huggingface.co/papluca/xlm-roberta-base-language-detection) model converted to [OpenVINO](https://openvino.ai), for accelerated inference.
An example of how to do inference on this model:
```python
from optimum.intel.openvino import OVModelForSequenceClassification
from transformers import AutoTokenizer, pipeline
# model_id should be set to either a local directory or a model available on the HuggingFace hub.
model_id = "helenai/papluca-xlm-roberta-base-language-detection-ov"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = OVModelForSequenceClassification.from_pretrained(model_id)
pipe = pipeline("text-classification", model=model, tokenizer=tokenizer)
result = pipe("hello world")
print(result)
```
|
osiria/flare-it | osiria | 2024-01-08T22:11:33Z | 390 | 2 | transformers | [
"transformers",
"pytorch",
"safetensors",
"xlm-roberta",
"fill-mask",
"it",
"dataset:wikipedia",
"arxiv:2012.15828",
"arxiv:2010.05609",
"arxiv:1906.08101",
"license:mit",
"autotrain_compatible",
"endpoints_compatible",
"region:us"
]
| fill-mask | 2023-05-02T18:07:27Z | ---
license: mit
datasets:
- wikipedia
language:
- it
widget:
- text: "milano è una <mask> dell'italia"
example_title: "Example 1"
- text: "giacomo leopardi è stato uno dei più grandi <mask> del classicismo italiano"
example_title: "Example 2"
- text: "la pizza è un noto simbolo della <mask> gastronomica italiana"
example_title: "Example 3"
---
--------------------------------------------------------------------------------------------------
<body>
<span class="vertical-text" style="background-color:lightgreen;border-radius: 3px;padding: 3px;"> </span>
<br>
<span class="vertical-text" style="background-color:orange;border-radius: 3px;padding: 3px;"> </span>
<br>
<span class="vertical-text" style="background-color:lightblue;border-radius: 3px;padding: 3px;"> Model: FLARE 🔥</span>
<br>
<span class="vertical-text" style="background-color:tomato;border-radius: 3px;padding: 3px;"> Lang: IT</span>
<br>
<span class="vertical-text" style="background-color:lightgrey;border-radius: 3px;padding: 3px;"> </span>
<br>
<span class="vertical-text" style="background-color:#CF9FFF;border-radius: 3px;padding: 3px;"> </span>
</body>
--------------------------------------------------------------------------------------------------
<h3>Introduction</h3>
This model is a <b>lightweight</b> and uncased version of <b>MiniLM</b> <b>[1]</b> for the <b>Italian</b> language. Its <b>17M parameters</b> and <b>67MB</b> size make it
<b>85% lighter</b> than a typical mono-lingual BERT model. It is ideal when memory consumption and execution speed are critical while maintaining high-quality results.
<h3>AILC CLiC-IT 2023 Proceedings</h3>
Flare-IT is part of the publication "Blaze-IT: a lightweight BERT model for the Italian language", which has been accepted at AILC CLiC-IT 2023 and published in the conference proceedings.
<br>
You can find the proceedings here: https://clic2023.ilc.cnr.it/proceedings/
<br>
And the published paper here: https://ceur-ws.org/Vol-3596/paper43.pdf
<h3>Model description</h3>
The model builds on <b>mMiniLMv2</b> <b>[1]</b> (from Microsoft: [L6xH384 mMiniLMv2](https://github.com/microsoft/unilm/tree/master/minilm)) as a starting point,
focusing it on the Italian language while at the same time turning it into an uncased model by modifying the embedding layer
(as in <b>[2]</b>, but computing document-level frequencies over the <b>Wikipedia</b> dataset and setting a frequency threshold of 0.1%), which brings a considerable
reduction in the number of parameters.
To compensate for the deletion of cased tokens, which now forces the model to exploit lowercase representations of words previously capitalized,
the model has been further pre-trained on the Italian split of the [Wikipedia](https://huggingface.co/datasets/wikipedia) dataset, using the <b>whole word masking [3]</b> technique to make it more robust
to the new uncased representations.
The resulting model has 17M parameters, a vocabulary of 14.610 tokens, and a size of 67MB, which makes it <b>85% lighter</b> than a typical mono-lingual BERT model and
75% lighter than a standard mono-lingual DistilBERT model.
<h3>Training procedure</h3>
The model has been trained for <b>masked language modeling</b> on the Italian <b>Wikipedia</b> (~3GB) dataset for 10K steps, using the AdamW optimizer, with a batch size of 512
(obtained through 128 gradient accumulation steps),
a sequence length of 512, and a linearly decaying learning rate starting from 5e-5. The training has been performed using <b>dynamic masking</b> between epochs and
exploiting the <b>whole word masking</b> technique.
<h3>Performances</h3>
The following metrics have been computed on the Part of Speech Tagging and Named Entity Recognition tasks, using the <b>UD Italian ISDT</b> and <b>WikiNER</b> datasets, respectively.
The PoST model has been trained for 5 epochs, and the NER model for 3 epochs, both with a constant learning rate, fixed at 1e-5. For Part of Speech Tagging, the metrics have been computed on the default test set
provided with the dataset, while for Named Entity Recognition the metrics have been computed with a 5-fold cross-validation
| Task | Recall | Precision | F1 |
| ------ | ------ | ------ | ------ |
| Part of Speech Tagging | 95.64 | 95.32 | 95.45 |
| Named Entity Recognition | 82.27 | 80.64 | 81.29 |
The metrics have been computed at the token level and macro-averaged over the classes.
<h3>Demo</h3>
You can try the model online (fine-tuned on named entity recognition) using this web app: https://huggingface.co/spaces/osiria/flare-it-demo
<h3>Quick usage</h3>
```python
from transformers import AutoTokenizer, XLMRobertaForMaskedLM
from transformers import pipeline
tokenizer = AutoTokenizer.from_pretrained("osiria/flare-it")
model = XLMRobertaForMaskedLM.from_pretrained("osiria/flare-it")
pipeline_mlm = pipeline(task="fill-mask", model=model, tokenizer=tokenizer)
```
<h3>Limitations</h3>
This lightweight model has been further pre-trained on Wikipedia, so it's particularly suitable as an agile analyzer for large volumes of natively digital text
from the world wide web, written in a correct and fluent form (like wikis, web pages, news, etc.). However, it may show limitations when it comes to chaotic text, containing errors and slang expressions
(like social media posts) or when it comes to domain-specific text (like medical, financial or legal content).
<h3>References</h3>
[1] https://arxiv.org/abs/2012.15828
[2] https://arxiv.org/abs/2010.05609
[3] https://arxiv.org/abs/1906.08101
<h3>License</h3>
The model is released under <b>MIT</b> license |
digiplay/majicMIX_sombre_v2 | digiplay | 2023-07-05T03:33:15Z | 390 | 2 | diffusers | [
"diffusers",
"safetensors",
"stable-diffusion",
"stable-diffusion-diffusers",
"text-to-image",
"license:other",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-07-04T23:08:08Z | ---
license: other
tags:
- stable-diffusion
- stable-diffusion-diffusers
- text-to-image
- diffusers
inference: true
---
Model info:
https://civitai.com/models/62778?modelVersionId=75209
|
lorahub/flan_t5_large-wmt16_translate_tr-en | lorahub | 2023-07-24T09:47:16Z | 390 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-07-24T09:47:05Z | ---
library_name: peft
---
|
lorahub/flan_t5_large-duorc_ParaphraseRC_answer_question | lorahub | 2023-07-24T10:10:14Z | 390 | 0 | peft | [
"peft",
"region:us"
]
| null | 2023-07-24T10:10:04Z | ---
library_name: peft
---
|
TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF | TheBloke | 2023-11-20T10:56:35Z | 390 | 8 | transformers | [
"transformers",
"gguf",
"mistral",
"llm",
"llama",
"spellcheck",
"grammar",
"base_model:FPHam/Karen_TheEditor_V2_STRICT_Mistral_7B",
"license:llama2",
"text-generation-inference",
"region:us"
]
| null | 2023-11-20T10:52:19Z | ---
base_model: FPHam/Karen_TheEditor_V2_STRICT_Mistral_7B
inference: false
license: llama2
model_creator: FPHam
model_name: Karen TheEditor V2 Strict Mistral 7B
model_type: mistral
prompt_template: '<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
'
quantized_by: TheBloke
tags:
- llm
- llama
- spellcheck
- grammar
---
<!-- markdownlint-disable MD041 -->
<!-- header start -->
<!-- 200823 -->
<div style="width: auto; margin-left: auto; margin-right: auto">
<img src="https://i.imgur.com/EBdldam.jpg" alt="TheBlokeAI" style="width: 100%; min-width: 400px; display: block; margin: auto;">
</div>
<div style="display: flex; justify-content: space-between; width: 100%;">
<div style="display: flex; flex-direction: column; align-items: flex-start;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://discord.gg/theblokeai">Chat & support: TheBloke's Discord server</a></p>
</div>
<div style="display: flex; flex-direction: column; align-items: flex-end;">
<p style="margin-top: 0.5em; margin-bottom: 0em;"><a href="https://www.patreon.com/TheBlokeAI">Want to contribute? TheBloke's Patreon page</a></p>
</div>
</div>
<div style="text-align:center; margin-top: 0em; margin-bottom: 0em"><p style="margin-top: 0.25em; margin-bottom: 0em;">TheBloke's LLM work is generously supported by a grant from <a href="https://a16z.com">andreessen horowitz (a16z)</a></p></div>
<hr style="margin-top: 1.0em; margin-bottom: 1.0em;">
<!-- header end -->
# Karen TheEditor V2 Strict Mistral 7B - GGUF
- Model creator: [FPHam](https://huggingface.co/FPHam)
- Original model: [Karen TheEditor V2 Strict Mistral 7B](https://huggingface.co/FPHam/Karen_TheEditor_V2_STRICT_Mistral_7B)
<!-- description start -->
## Description
This repo contains GGUF format model files for [FPHam's Karen TheEditor V2 Strict Mistral 7B](https://huggingface.co/FPHam/Karen_TheEditor_V2_STRICT_Mistral_7B).
These files were quantised using hardware kindly provided by [Massed Compute](https://massedcompute.com/).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). The source project for GGUF. Offers a CLI and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), the most widely used web UI, with many features and powerful extensions. Supports GPU acceleration.
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), a fully featured web UI, with GPU accel across all platforms and GPU architectures. Especially good for story telling.
* [LM Studio](https://lmstudio.ai/), an easy-to-use and powerful local GUI for Windows and macOS (Silicon), with GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui), a great web UI with many interesting and unique features, including a full model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), an attractive and easy to use character-based chat GUI for Windows and macOS (both Silicon and Intel), with GPU acceleration.
* [ctransformers](https://github.com/marella/ctransformers), a Python library with GPU accel, LangChain support, and OpenAI-compatible AI server.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), a Python library with GPU accel, LangChain support, and OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), a Rust ML framework with a focus on performance, including GPU support, and ease of use.
<!-- README_GGUF.md-about-gguf end -->
<!-- repositories-available start -->
## Repositories available
* [AWQ model(s) for GPU inference.](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-AWQ)
* [GPTQ models for GPU inference, with multiple quantisation parameter options.](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GPTQ)
* [2, 3, 4, 5, 6 and 8-bit GGUF models for CPU+GPU inference](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF)
* [FPHam's original unquantised fp16 model in pytorch format, for GPU inference and for further conversions](https://huggingface.co/FPHam/Karen_TheEditor_V2_STRICT_Mistral_7B)
<!-- repositories-available end -->
<!-- prompt-template start -->
## Prompt template: ChatML
```
<|im_start|>system
{system_message}<|im_end|>
<|im_start|>user
{prompt}<|im_end|>
<|im_start|>assistant
```
<!-- prompt-template end -->
<!-- compatibility_gguf start -->
## Compatibility
These quantised GGUFv2 files are compatible with llama.cpp from August 27th onwards, as of commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221)
They are also compatible with many third party UIs and libraries - please see the list at the top of this README.
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw
Refer to the Provided Files table below to see what files use which methods, and how.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-provided-files start -->
## Provided files
| Name | Quant method | Bits | Size | Max RAM required | Use case |
| ---- | ---- | ---- | ---- | ---- | ----- |
| [karen_theeditor_v2_strict_mistral_7b.Q2_K.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q2_K.gguf) | Q2_K | 2 | 3.08 GB| 5.58 GB | smallest, significant quality loss - not recommended for most purposes |
| [karen_theeditor_v2_strict_mistral_7b.Q3_K_S.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q3_K_S.gguf) | Q3_K_S | 3 | 3.16 GB| 5.66 GB | very small, high quality loss |
| [karen_theeditor_v2_strict_mistral_7b.Q3_K_M.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q3_K_M.gguf) | Q3_K_M | 3 | 3.52 GB| 6.02 GB | very small, high quality loss |
| [karen_theeditor_v2_strict_mistral_7b.Q3_K_L.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q3_K_L.gguf) | Q3_K_L | 3 | 3.82 GB| 6.32 GB | small, substantial quality loss |
| [karen_theeditor_v2_strict_mistral_7b.Q4_0.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q4_0.gguf) | Q4_0 | 4 | 4.11 GB| 6.61 GB | legacy; small, very high quality loss - prefer using Q3_K_M |
| [karen_theeditor_v2_strict_mistral_7b.Q4_K_S.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q4_K_S.gguf) | Q4_K_S | 4 | 4.14 GB| 6.64 GB | small, greater quality loss |
| [karen_theeditor_v2_strict_mistral_7b.Q4_K_M.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q4_K_M.gguf) | Q4_K_M | 4 | 4.37 GB| 6.87 GB | medium, balanced quality - recommended |
| [karen_theeditor_v2_strict_mistral_7b.Q5_0.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q5_0.gguf) | Q5_0 | 5 | 5.00 GB| 7.50 GB | legacy; medium, balanced quality - prefer using Q4_K_M |
| [karen_theeditor_v2_strict_mistral_7b.Q5_K_S.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q5_K_S.gguf) | Q5_K_S | 5 | 5.00 GB| 7.50 GB | large, low quality loss - recommended |
| [karen_theeditor_v2_strict_mistral_7b.Q5_K_M.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q5_K_M.gguf) | Q5_K_M | 5 | 5.13 GB| 7.63 GB | large, very low quality loss - recommended |
| [karen_theeditor_v2_strict_mistral_7b.Q6_K.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q6_K.gguf) | Q6_K | 6 | 5.94 GB| 8.44 GB | very large, extremely low quality loss |
| [karen_theeditor_v2_strict_mistral_7b.Q8_0.gguf](https://huggingface.co/TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF/blob/main/karen_theeditor_v2_strict_mistral_7b.Q8_0.gguf) | Q8_0 | 8 | 7.70 GB| 10.20 GB | very large, extremely low quality loss - not recommended |
**Note**: the above RAM figures assume no GPU offloading. If layers are offloaded to the GPU, this will reduce RAM usage and use VRAM instead.
<!-- README_GGUF.md-provided-files end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF and below it, a specific filename to download, such as: karen_theeditor_v2_strict_mistral_7b.Q4_K_M.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF karen_theeditor_v2_strict_mistral_7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF karen_theeditor_v2_strict_mistral_7b.Q4_K_M.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 32 -m karen_theeditor_v2_strict_mistral_7b.Q4_K_M.gguf --color -c 2048 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<|im_start|>system\n{system_message}<|im_end|>\n<|im_start|>user\n{prompt}<|im_end|>\n<|im_start|>assistant"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 2048` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries.
### How to load this model in Python code, using ctransformers
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install ctransformers
# Or with CUDA GPU acceleration
pip install ctransformers[cuda]
# Or with AMD ROCm GPU acceleration (Linux only)
CT_HIPBLAS=1 pip install ctransformers --no-binary ctransformers
# Or with Metal GPU acceleration for macOS systems only
CT_METAL=1 pip install ctransformers --no-binary ctransformers
```
#### Simple ctransformers example code
```python
from ctransformers import AutoModelForCausalLM
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = AutoModelForCausalLM.from_pretrained("TheBloke/Karen_TheEditor_V2_STRICT_Mistral_7B-GGUF", model_file="karen_theeditor_v2_strict_mistral_7b.Q4_K_M.gguf", model_type="mistral", gpu_layers=50)
print(llm("AI is going to"))
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer start -->
<!-- 200823 -->
## Discord
For further support, and discussions on these models and AI in general, join us at:
[TheBloke AI's Discord server](https://discord.gg/theblokeai)
## Thanks, and how to contribute
Thanks to the [chirper.ai](https://chirper.ai) team!
Thanks to Clay from [gpus.llm-utils.org](llm-utils)!
I've had a lot of people ask if they can contribute. I enjoy providing models and helping people, and would love to be able to spend even more time doing it, as well as expanding into new projects like fine tuning/training.
If you're able and willing to contribute it will be most gratefully received and will help me to keep providing more models, and to start work on new AI projects.
Donaters will get priority support on any and all AI/LLM/model questions and requests, access to a private Discord room, plus other benefits.
* Patreon: https://patreon.com/TheBlokeAI
* Ko-Fi: https://ko-fi.com/TheBlokeAI
**Special thanks to**: Aemon Algiz.
**Patreon special mentions**: Brandon Frisco, LangChain4j, Spiking Neurons AB, transmissions 11, Joseph William Delisle, Nitin Borwankar, Willem Michiel, Michael Dempsey, vamX, Jeffrey Morgan, zynix, jjj, Omer Bin Jawed, Sean Connelly, jinyuan sun, Jeromy Smith, Shadi, Pawan Osman, Chadd, Elijah Stavena, Illia Dulskyi, Sebastain Graf, Stephen Murray, terasurfer, Edmond Seymore, Celu Ramasamy, Mandus, Alex, biorpg, Ajan Kanaga, Clay Pascal, Raven Klaugh, 阿明, K, ya boyyy, usrbinkat, Alicia Loh, John Villwock, ReadyPlayerEmma, Chris Smitley, Cap'n Zoog, fincy, GodLy, S_X, sidney chen, Cory Kujawski, OG, Mano Prime, AzureBlack, Pieter, Kalila, Spencer Kim, Tom X Nguyen, Stanislav Ovsiannikov, Michael Levine, Andrey, Trailburnt, Vadim, Enrico Ros, Talal Aujan, Brandon Phillips, Jack West, Eugene Pentland, Michael Davis, Will Dee, webtim, Jonathan Leane, Alps Aficionado, Rooh Singh, Tiffany J. Kim, theTransient, Luke @flexchar, Elle, Caitlyn Gatomon, Ari Malik, subjectnull, Johann-Peter Hartmann, Trenton Dambrowitz, Imad Khwaja, Asp the Wyvern, Emad Mostaque, Rainer Wilmers, Alexandros Triantafyllidis, Nicholas, Pedro Madruga, SuperWojo, Harry Royden McLaughlin, James Bentley, Olakabola, David Ziegler, Ai Maven, Jeff Scroggin, Nikolai Manek, Deo Leter, Matthew Berman, Fen Risland, Ken Nordquist, Manuel Alberto Morcote, Luke Pendergrass, TL, Fred von Graf, Randy H, Dan Guido, NimbleBox.ai, Vitor Caleffi, Gabriel Tamborski, knownsqashed, Lone Striker, Erik Bjäreholt, John Detwiler, Leonard Tan, Iucharbius
Thank you to all my generous patrons and donaters!
And thank you again to a16z for their generous grant.
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: FPHam's Karen TheEditor V2 Strict Mistral 7B
<!-- header start -->
<div style="width: 100%;">
<img src="https://huggingface.co/FPHam/Karen_TheEditor_V2_STRICT_Mistral_7B/resolve/main/karen2.jpg" alt="FPHam's Karen v2" style="width: 80%; min-width: 200px; display: block; margin: auto;">
</div>
<div style="display: flex; flex-direction: column; align-items: center;">
<p><a href="https://ko-fi.com/Q5Q5MOB4M">Buy Karen Ko-fi</a></p>
</div>
<!-- header end -->
# Karen is an editor for your text. (v.2) STRICT edition
Ah, Karen, a true peach among grammatical cucumbers! She yearns to rectify the missteps and linguistic tangles that infest your horribly written fiction.
Yet, unlike those ChatGPT kaboodles that morph into self-absorbed, constipated gurus of self-help style, Karen remains steadfastly grounded in grammatical wisdom but respectfull of your style.
# Info
Karen, Version 2, uses a completely different data set and base model than the previous Karen.
# There are two versions of Karen V2
1. Strict (this one), in which Karen will try not to make too many changes to your original text, mostly fixing grammar and spelling, assuming that you know what you are doing.
2. Creative (to be uploaded), in which Karen may suggest slight contextual improvements or rephrasing where necessary. It's Karen, after a glass of wine.
# Goals
Karen's primary goal is to rectify grammatical and spelling errors in US English without altering the style of the text. She is adept at identifying and correcting common ESL errors.
Verb Tense Errors:
Incorrect use of verb tenses, such as using present tense when past tense is required and vice versa.
Confusion between continuous and simple tenses.
Subject-Verb Agreement:
Lack of agreement between the subject and verb in number, e.g., using a singular verb with a plural subject or vice versa.
Articles (a, an, the):
Incorrect use or omission of articles, such as using "a" instead of "an" or vice versa.
Overuse or omission of the definite article "the."
Prepositions:
Misuse of prepositions, such as using "in" instead of "on" or "at," or omitting prepositions where they are needed.
Word Order:
Incorrect word order in sentences, especially in questions and negative sentences.
Misplacement of adverbs or adjectives.
Pluralization:
Incorrect plural forms of nouns, such as failing to add "-s" or "-es" when necessary.
Pronoun Errors:
Confusion between subject and object pronouns.
Incorrect use of possessive pronouns.
Double Negatives:
Using double negatives, which is grammatically incorrect in standard English.
Modal Verbs:
Misuse of modal verbs like can, could, will, would, should, etc.
Confusing Similar Words:
Confusing words that sound similar but have different meanings and spellings (e.g., "their," "there," and "they're").
Lack of Plural/Singular Agreement:
Mistakes in matching singular and plural nouns and verbs in a sentence.
# Future Goals
Use bigger model, add grammar cases that the model misses. Better datasets. Use larger datasets.
# Training
It was reversely trained on fict/non-fiction US text where errors were intentionally inserted by another Llama model (Darth Karen) and Python script.
# Usage
It should be used by submitting a paragraph or block of text at a time.
# Model uses ChatML
```
<|im_start|>system
<|im_end|>
<|im_start|>user
Edit the following text for spelling and grammar mistakes: {paragraph of text} <|im_end|>
<|im_start|>assistant
```
Note the pretext: *Edit the following text for spelling and grammar mistakes:* before the actual text. This way Karen wouldn't start talking ABOUT the text.
# Recomended settings
- Temperature: 0.7
- top_p: 0.1
- top_k: 40
- repetition penalty: 1.18
Karen could also be used in chatting. But if Karen is involved in a conversation where the text is lengthy, she might interpret your message as needing proofreading assistance rather than simply acknowledging that you are using her in casual chat.
Example:
>Edit the following text for spelling and grammar mistakes: I see future writing more about you writing the story any way you can and LLM editing it and making it into a proper fiction. That seems to be more satisfying way where you could feel you actually had done something creATIVE. So human is the creative, LLM is the burger flipping intern.
>The opposite is what many people are trying rn. Make LLM to invent story (from premise, to creating outline to writing actual chapters) and the human to somehow assemble it from those pieces. So LLM is the creative man, and human is the floor polisher.
>I can't believe a normal person would find it satisfying long term.
>So in my view, the job of editor would be replaced by Ai, not the job of author.
(Grammarly Score: 48)
Output STRICT:
>I see the future of writing being more about you writing the story any way you can and having an AI like LLM edit it and make it into a proper fiction. That seems to be a more satisfying way where you could feel you actually did something creative. So humans are the creative ones, while LLMs are the burger-flipping interns.
>
>On the other hand, many people are currently trying to do the exact opposite. They want to make LLMs create stories (from premises, to outlining, to writing entire chapters). And then they want humans to somehow piece them together from these parts. In this scenario, LLMs become the creative individuals, and humans become the floor polishers.
>
>I can't imagine a regular person finding that satisfying over the long run.
>
>In my opinion, the role of an editor will eventually be taken over by AI, not the role of an author.
(Grammarly Score: 93)
Output CREATIVE:
>I see the future of writing being more focused on you writing the story any way you can and having an AI like GPT-3 edit it and turn it into a proper piece of fiction. This seems to be a more satisfying approach where you can truly feel that you have done something creative. In this scenario, humans remain the creative force, while the AI acts as the burger flipping intern.
>
>On the other hand, there are those who argue that we should let the AI generate stories from scratch - from coming up with a premise, to outlining the plot, to writing individual chapters. They believe that the role of the human should then become one of assembling these pieces together. In this case, the AI becomes the creative mind, and the human takes on the role of a floor polisher.
>
>I cannot imagine how someone could find this satisfying over the long term. Therefore, in my opinion, the job of the editor will eventually be taken over by AI, not the job of the author.
(Grammarly Score: 83)
# Conclusion
After probably 10 different versions with subsequent changes, I can now say that the current model works reasonably well, with occasional (but often debatable) grammar misses. The limitations seem to be related to the 7B parameters. It appears that the size isn't sufficient to have a fine-grained understanding of various nuances of the input. This correlates with my other findings - the Mistral model performs quite well when generating its own text, but its comprehension is less than perfect, again related to only 7B parameters.
The goal was to create a model that wouldn't change the style of the text. Often, LLM models, when asked to edit text, will attempt to rewrite the text even if the text is already fine. This proved to be quite challenging for such a small model where the main task was to determine the right balance between fixing the text (and not changing its style) and copying it verbatim.
The strict model assumes that you're already a good writer that doesn't need hand-holding and that every word you've written you've meant.
<!-- original-model-card end -->
|
ironjr/BlazingDriveV11m | ironjr | 2023-12-07T09:08:22Z | 390 | 2 | diffusers | [
"diffusers",
"autotrain_compatible",
"endpoints_compatible",
"diffusers:StableDiffusionPipeline",
"region:us"
]
| text-to-image | 2023-12-07T08:12:08Z | Entry not found |
andrijdavid/CatPPT-base-GGUF | andrijdavid | 2023-12-27T19:14:13Z | 390 | 1 | transformers | [
"transformers",
"safetensors",
"gguf",
"mistral",
"text-generation",
"GGUF",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2023-12-27T18:06:11Z | ---
license: apache-2.0
tags:
- GGUF
quantized_by: andrijdavid
---
# CatPPT-base-GGUF
- Original model: [CatPPT-base](https://huggingface.co/rishiraj/CatPPT-base)
<!-- description start -->
## Description
This repo contains GGUF format model files for [CatPPT-base](https://huggingface.co/rishiraj/CatPPT-base).
<!-- description end -->
<!-- README_GGUF.md-about-gguf start -->
### About GGUF
GGUF is a new format introduced by the llama.cpp team on August 21st 2023. It is a replacement for GGML, which is no longer supported by llama.cpp.
Here is an incomplete list of clients and libraries that are known to support GGUF:
* [llama.cpp](https://github.com/ggerganov/llama.cpp). This is the source project for GGUF, providing both a Command Line Interface (CLI) and a server option.
* [text-generation-webui](https://github.com/oobabooga/text-generation-webui), Known as the most widely used web UI, this project boasts numerous features and powerful extensions, and supports GPU acceleration.
* [Ollama](https://github.com/jmorganca/ollama) Ollama is a lightweight and extensible framework designed for building and running language models locally. It features a simple API for creating, managing, and executing models, along with a library of pre-built models for use in various applications
* [KoboldCpp](https://github.com/LostRuins/koboldcpp), A comprehensive web UI offering GPU acceleration across all platforms and architectures, particularly renowned for storytelling.
* [GPT4All](https://gpt4all.io), This is a free and open source GUI that runs locally, supporting Windows, Linux, and macOS with full GPU acceleration.
* [LM Studio](https://lmstudio.ai/) An intuitive and powerful local GUI for Windows and macOS (Silicon), featuring GPU acceleration.
* [LoLLMS Web UI](https://github.com/ParisNeo/lollms-webui). A notable web UI with a variety of unique features, including a comprehensive model library for easy model selection.
* [Faraday.dev](https://faraday.dev/), An attractive, user-friendly character-based chat GUI for Windows and macOS (both Silicon and Intel), also offering GPU acceleration.
* [llama-cpp-python](https://github.com/abetlen/llama-cpp-python), A Python library equipped with GPU acceleration, LangChain support, and an OpenAI-compatible API server.
* [candle](https://github.com/huggingface/candle), A Rust-based ML framework focusing on performance, including GPU support, and designed for ease of use.
* [ctransformers](https://github.com/marella/ctransformers), A Python library featuring GPU acceleration, LangChain support, and an OpenAI-compatible AI server.
* [localGPT](https://github.com/PromtEngineer/localGPT) An open-source initiative enabling private conversations with documents.
<!-- README_GGUF.md-about-gguf end -->
<!-- compatibility_gguf start -->
## Explanation of quantisation methods
<details>
<summary>Click to see details</summary>
The new methods available are:
* GGML_TYPE_Q2_K - "type-1" 2-bit quantization in super-blocks containing 16 blocks, each block having 16 weight. Block scales and mins are quantized with 4 bits. This ends up effectively using 2.5625 bits per weight (bpw)
* GGML_TYPE_Q3_K - "type-0" 3-bit quantization in super-blocks containing 16 blocks, each block having 16 weights. Scales are quantized with 6 bits. This end up using 3.4375 bpw.
* GGML_TYPE_Q4_K - "type-1" 4-bit quantization in super-blocks containing 8 blocks, each block having 32 weights. Scales and mins are quantized with 6 bits. This ends up using 4.5 bpw.
* GGML_TYPE_Q5_K - "type-1" 5-bit quantization. Same super-block structure as GGML_TYPE_Q4_K resulting in 5.5 bpw
* GGML_TYPE_Q6_K - "type-0" 6-bit quantization. Super-blocks with 16 blocks, each block having 16 weights. Scales are quantized with 8 bits. This ends up using 6.5625 bpw.
</details>
<!-- compatibility_gguf end -->
<!-- README_GGUF.md-how-to-download start -->
## How to download GGUF files
**Note for manual downloaders:** You almost never want to clone the entire repo! Multiple different quantisation formats are provided, and most users only want to pick and download a single file.
The following clients/libraries will automatically download models for you, providing a list of available models to choose from:
* LM Studio
* LoLLMS Web UI
* Faraday.dev
### In `text-generation-webui`
Under Download Model, you can enter the model repo: andrijdavid/CatPPT-base-GGUF and below it, a specific filename to download, such as: CatPPT-base-f16.gguf.
Then click Download.
### On the command line, including multiple files at once
I recommend using the `huggingface-hub` Python library:
```shell
pip3 install huggingface-hub
```
Then you can download any individual model file to the current directory, at high speed, with a command like this:
```shell
huggingface-cli download andrijdavid/CatPPT-base-GGUF CatPPT-base-f16.gguf --local-dir . --local-dir-use-symlinks False
```
<details>
<summary>More advanced huggingface-cli download usage (click to read)</summary>
You can also download multiple files at once with a pattern:
```shell
huggingface-cli download andrijdavid/CatPPT-base-GGUF --local-dir . --local-dir-use-symlinks False --include='*Q4_K*gguf'
```
For more documentation on downloading with `huggingface-cli`, please see: [HF -> Hub Python Library -> Download files -> Download from the CLI](https://huggingface.co/docs/huggingface_hub/guides/download#download-from-the-cli).
To accelerate downloads on fast connections (1Gbit/s or higher), install `hf_transfer`:
```shell
pip3 install hf_transfer
```
And set environment variable `HF_HUB_ENABLE_HF_TRANSFER` to `1`:
```shell
HF_HUB_ENABLE_HF_TRANSFER=1 huggingface-cli download andrijdavid/CatPPT-base-GGUF CatPPT-base-f16.gguf --local-dir . --local-dir-use-symlinks False
```
Windows Command Line users: You can set the environment variable by running `set HF_HUB_ENABLE_HF_TRANSFER=1` before the download command.
</details>
<!-- README_GGUF.md-how-to-download end -->
<!-- README_GGUF.md-how-to-run start -->
## Example `llama.cpp` command
Make sure you are using `llama.cpp` from commit [d0cee0d](https://github.com/ggerganov/llama.cpp/commit/d0cee0d36d5be95a0d9088b674dbb27354107221) or later.
```shell
./main -ngl 35 -m CatPPT-base-f16.gguf --color -c 4096 --temp 0.7 --repeat_penalty 1.1 -n -1 -p "<PROMPT>"
```
Change `-ngl 32` to the number of layers to offload to GPU. Remove it if you don't have GPU acceleration.
Change `-c 4096` to the desired sequence length. For extended sequence models - eg 8K, 16K, 32K - the necessary RoPE scaling parameters are read from the GGUF file and set by llama.cpp automatically. Note that longer sequence lengths require much more resources, so you may need to reduce this value.
If you want to have a chat-style conversation, replace the `-p <PROMPT>` argument with `-i -ins`
For other parameters and how to use them, please refer to [the llama.cpp documentation](https://github.com/ggerganov/llama.cpp/blob/master/examples/main/README.md)
## How to run in `text-generation-webui`
Further instructions can be found in the text-generation-webui documentation, here: [text-generation-webui/docs/04 ‐ Model Tab.md](https://github.com/oobabooga/text-generation-webui/blob/main/docs/04%20%E2%80%90%20Model%20Tab.md#llamacpp).
## How to run from Python code
You can use GGUF models from Python using the [llama-cpp-python](https://github.com/abetlen/llama-cpp-python) or [ctransformers](https://github.com/marella/ctransformers) libraries. Note that at the time of writing (Nov 27th 2023), ctransformers has not been updated for some time and is not compatible with some recent models. Therefore I recommend you use llama-cpp-python.
### How to load this model in Python code, using llama-cpp-python
For full documentation, please see: [llama-cpp-python docs](https://abetlen.github.io/llama-cpp-python/).
#### First install the package
Run one of the following commands, according to your system:
```shell
# Base ctransformers with no GPU acceleration
pip install llama-cpp-python
# With NVidia CUDA acceleration
CMAKE_ARGS="-DLLAMA_CUBLAS=on" pip install llama-cpp-python
# Or with OpenBLAS acceleration
CMAKE_ARGS="-DLLAMA_BLAS=ON -DLLAMA_BLAS_VENDOR=OpenBLAS" pip install llama-cpp-python
# Or with CLBLast acceleration
CMAKE_ARGS="-DLLAMA_CLBLAST=on" pip install llama-cpp-python
# Or with AMD ROCm GPU acceleration (Linux only)
CMAKE_ARGS="-DLLAMA_HIPBLAS=on" pip install llama-cpp-python
# Or with Metal GPU acceleration for macOS systems only
CMAKE_ARGS="-DLLAMA_METAL=on" pip install llama-cpp-python
# In windows, to set the variables CMAKE_ARGS in PowerShell, follow this format; eg for NVidia CUDA:
$env:CMAKE_ARGS = "-DLLAMA_OPENBLAS=on"
pip install llama-cpp-python
```
#### Simple llama-cpp-python example code
```python
from llama_cpp import Llama
# Set gpu_layers to the number of layers to offload to GPU. Set to 0 if no GPU acceleration is available on your system.
llm = Llama(
model_path="./CatPPT-base-f16.gguf", # Download the model file first
n_ctx=32768, # The max sequence length to use - note that longer sequence lengths require much more resources
n_threads=8, # The number of CPU threads to use, tailor to your system and the resulting performance
n_gpu_layers=35 # The number of layers to offload to GPU, if you have GPU acceleration available
)
# Simple inference example
output = llm(
"<PROMPT>", # Prompt
max_tokens=512, # Generate up to 512 tokens
stop=["</s>"], # Example stop token - not necessarily correct for this specific model! Please check before using.
echo=True # Whether to echo the prompt
)
# Chat Completion API
llm = Llama(model_path="./CatPPT-base-f16.gguf", chat_format="llama-2") # Set chat_format according to the model you are using
llm.create_chat_completion(
messages = [
{"role": "system", "content": "You are a story writing assistant."},
{
"role": "user",
"content": "Write a story about llamas."
}
]
)
```
## How to use with LangChain
Here are guides on using llama-cpp-python and ctransformers with LangChain:
* [LangChain + llama-cpp-python](https://python.langchain.com/docs/integrations/llms/llamacpp)
* [LangChain + ctransformers](https://python.langchain.com/docs/integrations/providers/ctransformers)
<!-- README_GGUF.md-how-to-run end -->
<!-- footer end -->
<!-- original-model-card start -->
# Original model card: CatPPT-base
# 😼 CatPPT
Introducing "CatPPT" - the purrfect alternative to that other big cat in town, known for keeping all the secrets to itself! Our feline friend here is created through merging openchat and neuralchat models using Gradient SLERP method (resulting in [rishiraj/CatPPT-base](https://huggingface.co/rishiraj/CatPPT-base)) and then finetuned on no_robots dataset for chat.
This is the top-performing 7B model on the leaderboard, that's free from any whiff of evaluation data contamination.

## Model date
rishiraj/CatPPT was trained between 15th and 17th December, 2023.
## Evaluation
It achieves the following results on the [Open_LLM_Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard). At the time of release, CatPPT is the highest ranked 7B chat model on the leaderboard, that's **free from evaluation data contamination**.
| Model | Average | ARC | HellaSwag | MMLU | TruthfulQA | Winogrande | GSM8K |
| | | | - | --: | :----: |
| 1.9947 | 0.16 | 3 | 2.0093 |
### Framework versions
- Transformers 4.36.1
- Pytorch 2.1.2+cu121
- Datasets 2.14.6
- Tokenizers 0.15.0
- PEFT 0.6.1
## Citation Information
```
@misc{rishiraj2023catppt,
author = {Rishiraj Acharya},
title = {CatPPT},
year = {2023},
publisher = {Hugging Face},
journal = {Hugging Face repository},
howpublished = {\url{https://huggingface.co/rishiraj/CatPPT}}
}
```
<!-- original-model-card end --> |
cckevinn/SeeClick | cckevinn | 2024-01-29T10:58:49Z | 390 | 6 | transformers | [
"transformers",
"safetensors",
"qwen",
"text-generation",
"custom_code",
"autotrain_compatible",
"region:us"
]
| text-generation | 2024-01-29T07:44:25Z | Entry not found |
LumiOpen/Viking-13B | LumiOpen | 2024-07-02T10:02:26Z | 390 | 8 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"fi",
"en",
"da",
"sv",
"no",
"nn",
"is",
"dataset:cerebras/SlimPajama-627B",
"dataset:bigcode/starcoderdata",
"dataset:mc4",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-02-16T13:15:49Z | ---
license: apache-2.0
datasets:
- cerebras/SlimPajama-627B
- bigcode/starcoderdata
- mc4
language:
- fi
- en
- da
- sv
- 'no'
- nn
- is
---
# Viking 13B
Viking 13B is a 13B parameter decoder-only transformer pretrained on Finnish,
English, Swedish, Danish, Norwegian, Icelandic and code. It is being trained
on 2 trillion tokens (1.3 trillion as of this release). Viking 13B is a fully open source model and is made available under the Apache 2.0 License.
Viking was created in a collaboration between the [TurkuNLP group](https://turkunlp.org/) of the University of Turku, [SiloGen](https://www.silo.ai/silogen) from [Silo AI](https://www.silo.ai/),and [High Performance Language Technologies](https://hplt-project.org/) (HPLT). Training was conducted on the [LUMI supercomputer](https://www.lumi-supercomputer.eu/), using compute resources generously provided by [CSC](https://csc.fi/) - IT Center for Science, Finland.
This project is part of an ongoing effort to create open source large language models for non-English and especially low resource languages like Finnish. The mode is fluent in Finnish, English, the Scandinavian languages and capable of basic translation between them. It is also able to understand and generate code.
## Model Family
Viking is the second set of models released by LumiOpen and is available at
3 parameter counts:
[Viking 7B](https://huggingface.co/LumiOpen/Viking-7B)
[Viking 13B](https://huggingface.co/LumiOpen/Viking-13B)
[Viking 33B](https://huggingface.co/LumiOpen/Viking-33B)
## Model Overview
_**NOTE:** This is a base model which needs further fine tuning for most use cases._
Viking is a generative pretrained transformer using a LLaMA-like GPT architecture, and makes use of rotary positional embeddings and flash attention.
| Hyperparameter | Value |
| :------------- | :----: |
| n_parameters | 14B |
| n_layers | 40 |
| n_heads | 40 |
| d_model | 5120 |
| vocab_size | 131072 |
| sequence_length | 4096 |
## Training
Viking 13B was trained on the LUMI supercomputer, using 512 AMD MI250X GPUs. Each MI250X GPU has two Graphics Complex Dies (GCDs) for a world size of 1024 during training, using activation checkpointing, a micro batch size of 1, gradient accumulation of 16, and a 3D parallelism strategy of TP=2, PP=4, DP=128.
Training began in September 2023 using a [custom fork](https://github.com/LumiOpen/Megatron-DeepSpeed) of the Megatron-Deepspeed framework.
## Training Hyperparameters
| Hyperparameter | Value | Comment |
| :------------: | :---: | :------:|
| Precision | bfloat16 | |
| Optimizer | AdamW | |
| Learning rate | 3e-4 | 10B tokens warm-up, cosine decay to 3e-5 |
| Weight decay | 1e-1 | |
| Batch size | 1024 | 1024 samples x 4096 tokens = 4194304 tokens |
## Tokenizer
Viking uses a custom 128K Bloom tokenizer trained on the same English, Finnish, Swedish, Danish, Norwegian, Icelandic and code dataset used to train the model.
## Dataset
Viking is being trained on a 2 trillion token mixed dataset of English, Finnish, Swedish, Danish, Norwegian, Icelandic and code.
More details on exact dataset will be published soon.
## Evaluation Results
Full evaluation results will be published with the final model.
## Training checkpoints
Training checkpoints are available as branches in the repository. Checkpoints will be released roughly every 100B tokens. The main branch will always point to the latest checkpoint. The following checkpoints are available:
* [100B](https://huggingface.co/LumiOpen/Viking-13B/tree/100B)
* [200B](https://huggingface.co/LumiOpen/Viking-13B/tree/200B)
* [300B](https://huggingface.co/LumiOpen/Viking-13B/tree/300B)
* [400B](https://huggingface.co/LumiOpen/Viking-13B/tree/400B)
* [500B](https://huggingface.co/LumiOpen/Viking-13B/tree/500B)
* [600B](https://huggingface.co/LumiOpen/Viking-13B/tree/600B)
* [700B](https://huggingface.co/LumiOpen/Viking-13B/tree/700B)
* [800B](https://huggingface.co/LumiOpen/Viking-13B/tree/800B)
* [900B](https://huggingface.co/LumiOpen/Viking-13B/tree/900B)
* [1000B](https://huggingface.co/LumiOpen/Viking-13B/tree/1000B)
* [1100B](https://huggingface.co/LumiOpen/Viking-13B/tree/1100B)
* [1200B](https://huggingface.co/LumiOpen/Viking-13B/tree/1200B)
* [1300B](https://huggingface.co/LumiOpen/Viking-13B/tree/1300B)
* [1400B](https://huggingface.co/LumiOpen/Viking-13B/tree/1400B)
* [1500B](https://huggingface.co/LumiOpen/Viking-13B/tree/1500B)
* [1600B](https://huggingface.co/LumiOpen/Viking-13B/tree/1600B)
* [1700B](https://huggingface.co/LumiOpen/Viking-13B/tree/1700B)
* [1800B](https://huggingface.co/LumiOpen/Viking-13B/tree/1800B)
* [1900B](https://huggingface.co/LumiOpen/Viking-13B/tree/1900B)
* [2000B](https://huggingface.co/LumiOpen/Viking-13B/tree/2000B)
The transformers library allows you to load a checkpoint from a branch as follows:
```python
branch = "1700B"
model = transformers.AutoModelForCausalLM.from_pretrained(
"LumiOpen/Viking-13B",
torch_dtype=torch.bfloat16 if torch.cuda.is_bf16_supported() else torch.float16,
revision=branch,
)
```
## Ethical Considerations and Limitations
_Viking 13B is a release of a partially trained model, and special care should be taken when using any output._
Viking is an advanced language model, primarily optimized for English, Finnish, Swedish, Norwegian, Danish, Icelandic and code, with no meaningful proficiency in any other languages. As with most AI-driven systems, Viking is a product of the vast data it has been trained on, which may reflect the imperfections, biases, and idiosyncrasies of the wider web. Viking may, at times, produce outputs that can be considered inaccurate, prejudiced, or controversial. Users and developers engaging with Viking should exercise discretion and consider additional evaluation and customization to ensure the model's responses align with their specific needs and ethical standards.
## License
Viking is released under the Apache 2.0 license.
|
ChrisWilson011016/5G3mh5TcPvKnSN6Psn16NNWtDTou3HPjTQiMo8ZJwA5iQUJJ_vgg | ChrisWilson011016 | 2024-03-04T18:59:35Z | 390 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-02-26T10:18:45Z | Entry not found |
fatgong/5EygaKNHUa8h7vtEYRkqyFatk9NCqYhn1fpj1B5fHShaFbkr_vgg | fatgong | 2024-03-27T22:48:17Z | 390 | 0 | keras | [
"keras",
"region:us"
]
| null | 2024-03-09T14:17:23Z | Entry not found |
LeroyDyer/Mixtral_AI_Cyber_3.1 | LeroyDyer | 2024-04-09T16:23:25Z | 390 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"mergekit",
"merge",
"code",
"Cyber-Series",
"conversational",
"arxiv:2306.01708",
"base_model:berkeley-nest/Starling-LM-7B-alpha",
"base_model:teknium/OpenHermes-2.5-Mistral-7B",
"base_model:cognitivecomputations/dolphin-2.2.1-mistral-7b",
"base_model:LeroyDyer/Mixtral_AI_Cyber_3.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-03-29T17:16:03Z | ---
base_model:
- berkeley-nest/Starling-LM-7B-alpha
- teknium/OpenHermes-2.5-Mistral-7B
- cognitivecomputations/dolphin-2.2.1-mistral-7b
- LeroyDyer/Mixtral_AI_Cyber_3.0
library_name: transformers
tags:
- mergekit
- merge
- code
- Cyber-Series
---
# merge
This is a merge of pre-trained language models created using [mergekit](https://github.com/cg123/mergekit).
## Merge Details
### Merge Method
This model was merged using the [TIES](https://arxiv.org/abs/2306.01708) merge method using [LeroyDyer/Mixtral_AI_Cyber_3.0](https://huggingface.co/LeroyDyer/Mixtral_AI_Cyber_3.0) as a base.
### Models Merged
The following models were included in the merge:
* [berkeley-nest/Starling-LM-7B-alpha](https://huggingface.co/berkeley-nest/Starling-LM-7B-alpha)
* [teknium/OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
* [cognitivecomputations/dolphin-2.2.1-mistral-7b](https://huggingface.co/cognitivecomputations/dolphin-2.2.1-mistral-7b)
### Configuration
The following YAML configuration was used to produce this model:
```yaml
models:
- model: berkeley-nest/Starling-LM-7B-alpha
parameters:
density: [0.87, 0.721, 0.451] # density gradient
weight: 0.876
- model: teknium/OpenHermes-2.5-Mistral-7B
parameters:
density: 0.232
weight: [0.36, 0.3, 0.437, 0.76] # weight gradient
- model: cognitivecomputations/dolphin-2.2.1-mistral-7b
parameters:
density: 0.475
weight:
- filter: mlp
value: 0.5
- value: 0
merge_method: ties
base_model: LeroyDyer/Mixtral_AI_Cyber_3.0
parameters:
normalize: true
int8_mask: true
dtype: float16
``` |
openbmb/Eurus-70b-nca | openbmb | 2024-04-12T11:54:51Z | 390 | 11 | transformers | [
"transformers",
"safetensors",
"llama",
"text-generation",
"reasoning",
"preference_learning",
"nca",
"conversational",
"dataset:openbmb/UltraInteract_pair",
"dataset:openbmb/UltraFeedback",
"arxiv:2404.02078",
"arxiv:2402.05369",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-01T09:24:48Z | ---
license: apache-2.0
datasets:
- openbmb/UltraInteract_pair
- openbmb/UltraFeedback
tags:
- reasoning
- preference_learning
- nca
pipeline_tag: text-generation
---
<div align="center">
<img src="https://huggingface.co/openbmb/Eurus-7b-sft/resolve/main/figures/Eurus-logo.png" width="200px">
**Eurus: A suit of open-source LLMs optimized for reasoning**
<p align="center">
<a href="#introduction"> Introduction</a> •
<a href="#evaluation">Evaluation</a>
</p>
</div>
# Links
- 📜 [Paper](https://arxiv.org/abs/2404.02078)
- 🤗 [Eurus Collection](https://huggingface.co/collections/openbmb/eurus-660bc40bec5376b3adc9d1c5)
- 🤗 UltraInteract
- [SFT](https://huggingface.co/datasets/openbmb/UltraInteract_sft)
- [Preference Learning](https://huggingface.co/datasets/openbmb/UltraInteract_pair)
- [GitHub Repo](https://github.com/OpenBMB/Eurus)
# Introduction
Eurus-70B-NCA is [NCA](https://arxiv.org/abs/2402.05369) fine-tuned from [Eurus-70B-SFT](https://huggingface.co/openbmb/Eurus-70b-sft) on all multi-turn trajectory pairs in [UltraInteract](https://huggingface.co/openbmb/UltraInteract) and all pairs in [UltraFeedback](https://huggingface.co/openbmb/UltraFeedback).
It achieves the best overall performance among open-source models of similar sizes and even outperforms specialized models in corresponding domains in many cases. Notably, Eurus-70B-NCA achieves better performance than GPT-3.5 Turbo through comprehensive benchmarking across 12 tests covering five tasks.
## Usage
We apply tailored prompts for coding and math, consistent with UltraInteract data formats:
**Coding**
```
[INST] Write Python code to solve the task:
{Instruction} [/INST]
```
**Math-CoT**
```
[INST] Solve the following math problem step-by-step.
Simplify your answer as much as possible. Present your final answer as \\boxed{Your Answer}.
{Instruction} [/INST]
```
**Math-PoT**
```
[INST] Tool available:
[1] Python interpreter
When you send a message containing Python code to python, it will be executed in a stateful Jupyter notebook environment.
Solve the following math problem step-by-step.
Simplify your answer as much as possible.
{Instruction} [/INST]
```
## Evaluation
- Eurus, both the 7B and 70B variants, achieve the best overall performance among open-source models of similar sizes. Eurus even outperforms specialized models in corresponding domains in many cases. Notably, Eurus-7B outperforms baselines that are 5× larger, and Eurus-70B achieves better performance than GPT-3.5 Turbo.
- Preference learning with UltraInteract can further improve performance, especially in math and the multi-turn ability.
<img src="./figures/main_exp.png" alt="stats" style="zoom: 40%;" />
## Citation
```
@misc{yuan2024advancing,
title={Advancing LLM Reasoning Generalists with Preference Trees},
author={Lifan Yuan and Ganqu Cui and Hanbin Wang and Ning Ding and Xingyao Wang and Jia Deng and Boji Shan and Huimin Chen and Ruobing Xie and Yankai Lin and Zhenghao Liu and Bowen Zhou and Hao Peng and Zhiyuan Liu and Maosong Sun},
year={2024},
eprint={2404.02078},
archivePrefix={arXiv},
primaryClass={cs.AI}
}
``` |
adowu/astral-demo-2 | adowu | 2024-04-10T05:11:09Z | 390 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"astral",
"demo",
"conversational",
"en",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-09T18:17:17Z | ---
library_name: transformers
license: apache-2.0
language:
- en
pipeline_tag: text-generation
tags:
- astral
- demo
- mistral
---
### astral-demo-2
## Overview
astral-demo-2 is a streamlined language model designed for quick demonstrations and insights into NLP capabilities, focusing on text generation and analysis.
## Features
- Efficient Text Generation: Quickly produces text for a variety of applications.
- Compact and Fast: Optimized for speed, making it ideal for demos and prototyping.
- Prototype Development: Tests ideas in conversational AI and content generation.
## Performance
Balances performance with accuracy, providing a practical demonstration of NLP technology in action.
- **Developed by:** aww
- **Model type:** Mistral |
automerger/Experiment27pasticheT3qm7xp-7B | automerger | 2024-04-12T13:02:45Z | 390 | 0 | transformers | [
"transformers",
"safetensors",
"mistral",
"text-generation",
"merge",
"mergekit",
"lazymergekit",
"automerger",
"base_model:automerger/Experiment27Pastiche-7B",
"base_model:nlpguy/T3QM7XP",
"license:apache-2.0",
"autotrain_compatible",
"endpoints_compatible",
"text-generation-inference",
"region:us"
]
| text-generation | 2024-04-12T13:01:54Z | ---
license: apache-2.0
tags:
- merge
- mergekit
- lazymergekit
- automerger
base_model:
- automerger/Experiment27Pastiche-7B
- nlpguy/T3QM7XP
---
# Experiment27pasticheT3qm7xp-7B
Experiment27pasticheT3qm7xp-7B is an automated merge created by [Maxime Labonne](https://huggingface.co/mlabonne) using the following configuration.
* [automerger/Experiment27Pastiche-7B](https://huggingface.co/automerger/Experiment27Pastiche-7B)
* [nlpguy/T3QM7XP](https://huggingface.co/nlpguy/T3QM7XP)
## 🧩 Configuration
```yaml
slices:
- sources:
- model: automerger/Experiment27Pastiche-7B
layer_range: [0, 32]
- model: nlpguy/T3QM7XP
layer_range: [0, 32]
merge_method: slerp
base_model: automerger/Experiment27Pastiche-7B
parameters:
t:
- filter: self_attn
value: [0, 0.5, 0.3, 0.7, 1]
- filter: mlp
value: [1, 0.5, 0.7, 0.3, 0]
- value: 0.5
dtype: bfloat16
random_seed: 0
```
## 💻 Usage
```python
!pip install -qU transformers accelerate
from transformers import AutoTokenizer
import transformers
import torch
model = "automerger/Experiment27pasticheT3qm7xp-7B"
messages = [{"role": "user", "content": "What is a large language model?"}]
tokenizer = AutoTokenizer.from_pretrained(model)
prompt = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
outputs = pipeline(prompt, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"])
``` |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.