
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/tabularregression-linear_regression-1.0-output.json | [
139.54831330342856,
179.52030577879273,
134.04133297819817,
291.4119359771987,
123.78723656395928,
92.17357676591854,
258.2340970376254,
181.33895237832277,
90.22217861672894,
108.63143297584902
] | 0 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/iris-logistic_regression-latest-output.json | [
1,
0,
2,
1,
1,
0,
1,
2,
1,
1
] | 1 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/textclassification-1.0-input.json | {
"data": [
"From: [email protected] (K. R. Subramanian)\nSubject: Companies involved with Scientific Visualization...\nReply-To: [email protected]\nOrganization: AT&T Bell Laboratories\nLines: 10\n\nIf anyone has a list of companies doing data visualization (software\nor hardware) I would like to hear from them. Thanks.\n\n\t-- krs\n-- \n\nK.R.Subramanian Ph: (908) 582-6346\nAT&T Bell Laboratories, Rm. 2A240 email : [email protected]\n600 Mountain Av.\nMurray Hill, NJ 07974\n",
"From: [email protected] (Laird P. Broadfield)\nSubject: Re: CNN for sale; Influencing the coverage\nOrganization: \"Well, a head on top, an arm on each side, two legs....\"\nDistribution: usa\nLines: 25\n\nIn <[email protected]> [email protected] (Andrew Betz) writes:\n>In article <[email protected]> [email protected] (Frank Crary) writes:\n>>I'd be willing to go in as well. By the way, we wouldn't need to\n>>buy the network wholesale. Simply owning a large number of shares\n>>would still work (if 5% of the shareholders want pro-gun coverage\n>>and the rest don't really care, they'll go along just to keep \n>>the 5% happy...)\n\n>I'd go along with this plan as well. Turner's stock is traded\n>on the American exchange and has 3 classes (A, B, and C). A and\n>B stock is currently about 23 bucks a share; C stock is about 11\n>bucks a share. Does anybody have any idea how much stock TBS\n>has issued? What would it take to reach 5%, 51%, or even 100%?\n\nUm, I sortof hesitate to bring this up, but owning even a single share\nentitles you to attend the annual shareholders meeting, and under most\ncorporate charters to introduce topics to be discussed. While I *don't*\nsuggest the tactic used by some in Japan (go to the shareholders meeting,\nand disrupt the bejeezus out of everything), what about a well-worded\nresolution complaining about \"advocacy journalism\"?\n\n\n-- \nLaird P. Broadfield [email protected] ...{ucsd, nosc}!crash!lairdb\nHi! I'm a shareware signature! Send $5 if you use me, send $10 for manual!\n",
"From: [email protected] (Galen Watts)\nSubject: Re: RF Communications Link\nNntp-Posting-Host: storm.cfnr.colostate.edu\nOrganization: College of Natural Resources, Colo. State Univ.\nLines: 20\n\nIn article <[email protected]> [email protected] (Warren Blumenow) writes:\n>We have to design an RF link for a distance of 250 m. We're using\n>standard RS232 waves (square pulses) as the modulating waves and the \n>carrier wave is sinusoidal. The link has to be bidirectional.\n>We would appreciate any advice on the type of modulating techniques\n>or antennas that we should use.\n\nWhat frequency is your carrier?\n\nHave you considered using two tones, one for 1 and another for 0?\n\nHow high is your RS-232 data rate?\n\nCan you use more than one carrier freq?\n\nHave you considered hiring an RF data transmission consultant?\n\nJust Curious,\nGalen Watts, KF0YJ\n\n",
"Subject: Re: what to do with old 256k SIMMs?\nFrom: [email protected] (Srikanth Viswanathan)\nDistribution: world\nOrganization: California State Polytechnic University, Pomona\nNntp-Posting-Host: vmsb.is.csupomona.edu\nNews-Software: VAX/VMS VNEWS 1.41 \nLines: 14\n\nIn article <[email protected]>, [email protected] (Scott Dorsey) writes...\n>In article <[email protected]> [email protected] writes:\n>>In article <[email protected]>, [email protected] (G. Stewart Beal) writes:\n>>|> >\tI was wondering if people had any good uses for old\n>>|> >256k SIMMs. I have a bunch of them for the Apple Mac\n>>|> >and I know lots of other people do to. I have tried to\n>>|> >sell them but have gotten NO interest.\n>>\n\nWell, if you're willing to spend a little money, you could buy one\nof those IDE caching controllers (assuming you have an IDE of course)\nand put the 256K SIMMs on them. Hardware cache!\n\nSrikanth\n",
"From: [email protected] (Jack Love)\nSubject: Re: Israeli destruction of mosque(s) in Jerusalem\nOrganization: /usr/local/trn/lib/organization\nLines: 33\nNNTP-Posting-Host: ivrit.ra.itd.umich.edu\n\nIn article <[email protected]> [email protected] (Tim Clock) writes:\n>This issue has been going on for a while and your presentation here of\n>just one reference probably won't resolve this issue to those that\n>oppose your insistence that mosques *were* destroyed. Even in your\n>location of this one reference, you spend most of your quote dealing\n>with an incidence that, while abhorrant, has nothing to do with the \n>issue at hand here. Then, at the end of the quote, there is an almost\n>off-hand comment that \"two mosques\" were destroyed.\n>\n>To support a claim of this nature, what other authors support this\n>incident? If identifiable mosques were destroyed they are certainly\n>identifiable, they have names and addresses (steet location). The\n>comment by one reporter *does* make us wonder if \"this happened\" but\n>by no means \"proves it.\n\nThere is no doubt that Israeli authorities ordered the destruction of\nmosques in the vicinity of the Wailing Wall. That does not mean,\nhowever, that once can generalize from this to any other points. The\nentire plaza, mosques and all, was cleared to make it possible for Jews\nto have a place to worship in the place that was holiest to many of\nthem, and which had been denied to them for millenia.\n\nOn the other hand, throughout the rest of Jerusalem and Israel, to the\nbest of my knowledge, Israeli authorities have scrupulously avoided\ndamage to any Islamic religious sites. This contrasts with the policies\nof previous regimes which destroyed Jewish synagogues out of hate and\nbigotry.\n\n\n-- \n________________________________________\nJack F. Love\t| \tOpinions expressed are mine alone.\n\t\t|\t(Unless you happen to agree.)\n",
"From: [email protected] (Rebecca Snyder)\nSubject: centi- and milli- pedes\nOrganization: New Mexico Tech\nLines: 10\n\nDoes anyone know how posionous centipedes and millipedes are? If someone\nwas bitten, how soon would medical treatment be needed, and what would\nbe liable to happen to the person?\n\n(Just for clarification - I have NOT been bitten by one of these, but my\nhouse seems to be infested, and I want to know 'just in case'.)\n\nRebecca\n\n\n",
"From: [email protected] (Bryan L. Allen)\nSubject: Re: New Encryption Algorithm\nSummary: Boundaries are in the eye of the beholder\nKeywords: NSA surveillance ( )\nOrganization: Telos Corp., Jet Propulsion Laboratory (NASA)\nLines: 25\n\nIn article <[email protected]> [email protected] (Jeff Hupp) writes:\n> \n>>In article <[email protected]> [email protected] (Steve Brinich) writes:\n[some deleted]\n>>\n>>Unlike the CIA, the NSA has no prohibition against domestic spying. Read\n>>Bamford's THE PUZZLE PALACE.\n>>\n>>Bruce\n>>\n> I have that book, and the way I read it is, one side of the\n>conversation MUST be from outside the United States.\n> Of coures, that ASS U MEs that the NSA plays by the rules...\n\nOne thing that seems ambiguous is whether a signal being echoed down from\ngeosynchronous orbit is \"...from outside the United States.\"\n\nAlso, being able to assess whether NSA is playing by the rules requires\nknowing what the rules are. We only know a subset. For those even more\nsuspicious, there could be other surveillance organizations \"blacker\"\nthan the NSA.\n\n-- \n Bryan L. Allen [email protected]\n Telos Corp./JPL (818) 306-6425\n",
"Subject: Re: Zeno's Countersteering Paradox Unveiled!!!\nFrom: [email protected] (John Stafford)\nDistribution: world\nOrganization: Winona State University\nNntp-Posting-Host: stafford.winona.msus.edu\nLines: 14\n\nIn article <[email protected]>,\[email protected] wrote:\n> \n>[...] Therefore, there is a point\n> in time when even though my front wheel is turned to the right \n> I must be going straight ahead (the point when I go from the right\n> turn to the left). [...]\n\n\tWhat you are trying to describe is that transition point where\n\tthe front wheel actually reverses direction; turns backwards.\n\n====================================================\nJohn Stafford Minnesota State University @ Winona\n All standard disclaimers apply.\n",
"From: [email protected] (Jonathan McDowell)\nSubject: Re: STS-57 inclination?\nOrganization: Smithsonian Astrophysical Observatory, Cambridge, MA, USA\nLines: 11\n\nFrom article <[email protected]>, by [email protected]:\n>> Primary payload: Spacehab 1 EURECA 1-R Inclination: 57 degrees\n> I have seen elsewhere that inclination is 28 degrees. \n> Which is correct?\n\nHmmm... Atlantis left Eureca in a 28 degree orbit. Retrieving it is\ngoing to be *REALLY* fun if they fly to 57 degrees. Torque that \nCanadarm! :-)\n\n - Jonathan\n\n",
"From: [email protected] (John Grant)\nSubject: Re: AfterDark (StarTrek) out of memory!\nOrganization: Energy, Mines, and Resources, Ottawa\nLines: 17\n\nIn article <[email protected]> [email protected] writes:\n>I have the startrek version of afterdark running but it nearly always\n>reports \"space: out of memory\", which floats across the top of the\n>screen. What have I not set correctly (I've got 16M of ram)?\n>\n>jerry\n\n\tYou're right, it doesn't appear to working correctly. It really\n\tshould say:\n\t\t\"space: the last frontier\"\n\tacross the top. :) :) :)\n\n\n-- \nJohn A. Grant\t\t\t\t\t\[email protected]\nAirborne Geophysics\nGeological Survey of Canada, Ottawa\n"
]
} | 2 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/textclassification-hist_gradient_boosting-latest-output.json | [
[
{
"label": "0",
"score": 0.007188341023581018
},
{
"label": "1",
"score": 0.03422080165466977
},
{
"label": "2",
"score": 0.04593990453288182
},
{
"label": "3",
"score": 0.024030566430797918
},
{
"label": "4",
"score": 0.03209593726948875
},
{
"label": "5",
"score": 0.11182728408961141
},
{
"label": "6",
"score": 0.44556793690944363
},
{
"label": "7",
"score": 0.024559022071172845
},
{
"label": "8",
"score": 0.011669934009514878
},
{
"label": "9",
"score": 0.030182113638619862
},
{
"label": "10",
"score": 0.0248637811927033
},
{
"label": "11",
"score": 0.04262809835525818
},
{
"label": "12",
"score": 0.05245772328697052
},
{
"label": "13",
"score": 0.038168343489749096
},
{
"label": "14",
"score": 0.019925741393428655
},
{
"label": "15",
"score": 0.009631384752144933
},
{
"label": "16",
"score": 0.014821126836993746
},
{
"label": "17",
"score": 0.012278330051148532
},
{
"label": "18",
"score": 0.011661211580574558
},
{
"label": "19",
"score": 0.006282417431246482
}
]
] | 3 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/iris-latest-input.json | {
"data": {
"sepal length (cm)": [
6.1,
5.7,
7.7,
6.0,
6.8,
5.4,
5.6,
6.9,
6.2,
5.8
],
"sepal width (cm)": [
2.8,
3.8,
2.6,
2.9,
2.8,
3.4,
2.9,
3.1,
2.2,
2.7
],
"petal length (cm)": [
4.7,
1.7,
6.9,
4.5,
4.8,
1.5,
3.6,
5.1,
4.5,
3.9
],
"petal width (cm)": [
1.2,
0.3,
2.3,
1.5,
1.4,
0.4,
1.3,
2.3,
1.5,
1.2
]
}
} | 4 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/tabularregression-hist_gradient_boosting_regressor-1.0-output.json | [
128.767605088706,
213.12484287152625,
152.87415981711302,
271.367552554169,
109.00499923164844,
81.88059224780598,
238.4711759447084,
215.14159932904784,
134.42407401121258,
189.15096503239798
] | 5 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/iris-hist_gradient_boosting-1.0-output.json | [
1,
0,
2,
1,
1,
0,
1,
2,
1,
1
] | 6 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/textclassification-latest-input.json | {
"data": [
"From: [email protected] (K. R. Subramanian)\nSubject: Companies involved with Scientific Visualization...\nReply-To: [email protected]\nOrganization: AT&T Bell Laboratories\nLines: 10\n\nIf anyone has a list of companies doing data visualization (software\nor hardware) I would like to hear from them. Thanks.\n\n\t-- krs\n-- \n\nK.R.Subramanian Ph: (908) 582-6346\nAT&T Bell Laboratories, Rm. 2A240 email : [email protected]\n600 Mountain Av.\nMurray Hill, NJ 07974\n",
"From: [email protected] (Laird P. Broadfield)\nSubject: Re: CNN for sale; Influencing the coverage\nOrganization: \"Well, a head on top, an arm on each side, two legs....\"\nDistribution: usa\nLines: 25\n\nIn <[email protected]> [email protected] (Andrew Betz) writes:\n>In article <[email protected]> [email protected] (Frank Crary) writes:\n>>I'd be willing to go in as well. By the way, we wouldn't need to\n>>buy the network wholesale. Simply owning a large number of shares\n>>would still work (if 5% of the shareholders want pro-gun coverage\n>>and the rest don't really care, they'll go along just to keep \n>>the 5% happy...)\n\n>I'd go along with this plan as well. Turner's stock is traded\n>on the American exchange and has 3 classes (A, B, and C). A and\n>B stock is currently about 23 bucks a share; C stock is about 11\n>bucks a share. Does anybody have any idea how much stock TBS\n>has issued? What would it take to reach 5%, 51%, or even 100%?\n\nUm, I sortof hesitate to bring this up, but owning even a single share\nentitles you to attend the annual shareholders meeting, and under most\ncorporate charters to introduce topics to be discussed. While I *don't*\nsuggest the tactic used by some in Japan (go to the shareholders meeting,\nand disrupt the bejeezus out of everything), what about a well-worded\nresolution complaining about \"advocacy journalism\"?\n\n\n-- \nLaird P. Broadfield [email protected] ...{ucsd, nosc}!crash!lairdb\nHi! I'm a shareware signature! Send $5 if you use me, send $10 for manual!\n",
"From: [email protected] (Galen Watts)\nSubject: Re: RF Communications Link\nNntp-Posting-Host: storm.cfnr.colostate.edu\nOrganization: College of Natural Resources, Colo. State Univ.\nLines: 20\n\nIn article <[email protected]> [email protected] (Warren Blumenow) writes:\n>We have to design an RF link for a distance of 250 m. We're using\n>standard RS232 waves (square pulses) as the modulating waves and the \n>carrier wave is sinusoidal. The link has to be bidirectional.\n>We would appreciate any advice on the type of modulating techniques\n>or antennas that we should use.\n\nWhat frequency is your carrier?\n\nHave you considered using two tones, one for 1 and another for 0?\n\nHow high is your RS-232 data rate?\n\nCan you use more than one carrier freq?\n\nHave you considered hiring an RF data transmission consultant?\n\nJust Curious,\nGalen Watts, KF0YJ\n\n",
"Subject: Re: what to do with old 256k SIMMs?\nFrom: [email protected] (Srikanth Viswanathan)\nDistribution: world\nOrganization: California State Polytechnic University, Pomona\nNntp-Posting-Host: vmsb.is.csupomona.edu\nNews-Software: VAX/VMS VNEWS 1.41 \nLines: 14\n\nIn article <[email protected]>, [email protected] (Scott Dorsey) writes...\n>In article <[email protected]> [email protected] writes:\n>>In article <[email protected]>, [email protected] (G. Stewart Beal) writes:\n>>|> >\tI was wondering if people had any good uses for old\n>>|> >256k SIMMs. I have a bunch of them for the Apple Mac\n>>|> >and I know lots of other people do to. I have tried to\n>>|> >sell them but have gotten NO interest.\n>>\n\nWell, if you're willing to spend a little money, you could buy one\nof those IDE caching controllers (assuming you have an IDE of course)\nand put the 256K SIMMs on them. Hardware cache!\n\nSrikanth\n",
"From: [email protected] (Jack Love)\nSubject: Re: Israeli destruction of mosque(s) in Jerusalem\nOrganization: /usr/local/trn/lib/organization\nLines: 33\nNNTP-Posting-Host: ivrit.ra.itd.umich.edu\n\nIn article <[email protected]> [email protected] (Tim Clock) writes:\n>This issue has been going on for a while and your presentation here of\n>just one reference probably won't resolve this issue to those that\n>oppose your insistence that mosques *were* destroyed. Even in your\n>location of this one reference, you spend most of your quote dealing\n>with an incidence that, while abhorrant, has nothing to do with the \n>issue at hand here. Then, at the end of the quote, there is an almost\n>off-hand comment that \"two mosques\" were destroyed.\n>\n>To support a claim of this nature, what other authors support this\n>incident? If identifiable mosques were destroyed they are certainly\n>identifiable, they have names and addresses (steet location). The\n>comment by one reporter *does* make us wonder if \"this happened\" but\n>by no means \"proves it.\n\nThere is no doubt that Israeli authorities ordered the destruction of\nmosques in the vicinity of the Wailing Wall. That does not mean,\nhowever, that once can generalize from this to any other points. The\nentire plaza, mosques and all, was cleared to make it possible for Jews\nto have a place to worship in the place that was holiest to many of\nthem, and which had been denied to them for millenia.\n\nOn the other hand, throughout the rest of Jerusalem and Israel, to the\nbest of my knowledge, Israeli authorities have scrupulously avoided\ndamage to any Islamic religious sites. This contrasts with the policies\nof previous regimes which destroyed Jewish synagogues out of hate and\nbigotry.\n\n\n-- \n________________________________________\nJack F. Love\t| \tOpinions expressed are mine alone.\n\t\t|\t(Unless you happen to agree.)\n",
"From: [email protected] (Rebecca Snyder)\nSubject: centi- and milli- pedes\nOrganization: New Mexico Tech\nLines: 10\n\nDoes anyone know how posionous centipedes and millipedes are? If someone\nwas bitten, how soon would medical treatment be needed, and what would\nbe liable to happen to the person?\n\n(Just for clarification - I have NOT been bitten by one of these, but my\nhouse seems to be infested, and I want to know 'just in case'.)\n\nRebecca\n\n\n",
"From: [email protected] (Bryan L. Allen)\nSubject: Re: New Encryption Algorithm\nSummary: Boundaries are in the eye of the beholder\nKeywords: NSA surveillance ( )\nOrganization: Telos Corp., Jet Propulsion Laboratory (NASA)\nLines: 25\n\nIn article <[email protected]> [email protected] (Jeff Hupp) writes:\n> \n>>In article <[email protected]> [email protected] (Steve Brinich) writes:\n[some deleted]\n>>\n>>Unlike the CIA, the NSA has no prohibition against domestic spying. Read\n>>Bamford's THE PUZZLE PALACE.\n>>\n>>Bruce\n>>\n> I have that book, and the way I read it is, one side of the\n>conversation MUST be from outside the United States.\n> Of coures, that ASS U MEs that the NSA plays by the rules...\n\nOne thing that seems ambiguous is whether a signal being echoed down from\ngeosynchronous orbit is \"...from outside the United States.\"\n\nAlso, being able to assess whether NSA is playing by the rules requires\nknowing what the rules are. We only know a subset. For those even more\nsuspicious, there could be other surveillance organizations \"blacker\"\nthan the NSA.\n\n-- \n Bryan L. Allen [email protected]\n Telos Corp./JPL (818) 306-6425\n",
"Subject: Re: Zeno's Countersteering Paradox Unveiled!!!\nFrom: [email protected] (John Stafford)\nDistribution: world\nOrganization: Winona State University\nNntp-Posting-Host: stafford.winona.msus.edu\nLines: 14\n\nIn article <[email protected]>,\[email protected] wrote:\n> \n>[...] Therefore, there is a point\n> in time when even though my front wheel is turned to the right \n> I must be going straight ahead (the point when I go from the right\n> turn to the left). [...]\n\n\tWhat you are trying to describe is that transition point where\n\tthe front wheel actually reverses direction; turns backwards.\n\n====================================================\nJohn Stafford Minnesota State University @ Winona\n All standard disclaimers apply.\n",
"From: [email protected] (Jonathan McDowell)\nSubject: Re: STS-57 inclination?\nOrganization: Smithsonian Astrophysical Observatory, Cambridge, MA, USA\nLines: 11\n\nFrom article <[email protected]>, by [email protected]:\n>> Primary payload: Spacehab 1 EURECA 1-R Inclination: 57 degrees\n> I have seen elsewhere that inclination is 28 degrees. \n> Which is correct?\n\nHmmm... Atlantis left Eureca in a 28 degree orbit. Retrieving it is\ngoing to be *REALLY* fun if they fly to 57 degrees. Torque that \nCanadarm! :-)\n\n - Jonathan\n\n",
"From: [email protected] (John Grant)\nSubject: Re: AfterDark (StarTrek) out of memory!\nOrganization: Energy, Mines, and Resources, Ottawa\nLines: 17\n\nIn article <[email protected]> [email protected] writes:\n>I have the startrek version of afterdark running but it nearly always\n>reports \"space: out of memory\", which floats across the top of the\n>screen. What have I not set correctly (I've got 16M of ram)?\n>\n>jerry\n\n\tYou're right, it doesn't appear to working correctly. It really\n\tshould say:\n\t\t\"space: the last frontier\"\n\tacross the top. :) :) :)\n\n\n-- \nJohn A. Grant\t\t\t\t\t\[email protected]\nAirborne Geophysics\nGeological Survey of Canada, Ottawa\n"
]
} | 7 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/textclassification-hist_gradient_boosting-1.0-output.json | [
[
{
"label": "0",
"score": 0.007188341023581015
},
{
"label": "1",
"score": 0.03422080165466977
},
{
"label": "2",
"score": 0.04593990453288178
},
{
"label": "3",
"score": 0.02403056643079793
},
{
"label": "4",
"score": 0.03209593726948873
},
{
"label": "5",
"score": 0.1118272840896114
},
{
"label": "6",
"score": 0.445567936909444
},
{
"label": "7",
"score": 0.02455902207117283
},
{
"label": "8",
"score": 0.011669934009514884
},
{
"label": "9",
"score": 0.030182113638619834
},
{
"label": "10",
"score": 0.0248637811927033
},
{
"label": "11",
"score": 0.04262809835525814
},
{
"label": "12",
"score": 0.0524577232869705
},
{
"label": "13",
"score": 0.03816834348974906
},
{
"label": "14",
"score": 0.019925741393428644
},
{
"label": "15",
"score": 0.009631384752144945
},
{
"label": "16",
"score": 0.014821126836993737
},
{
"label": "17",
"score": 0.012278330051148537
},
{
"label": "18",
"score": 0.011661211580574562
},
{
"label": "19",
"score": 0.006282417431246468
}
]
] | 8 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/tabularregression-latest-input.json | {
"data": {
"age": [
0.04534098333546186,
0.09256398319871433,
0.06350367559055897,
0.09619652164973376,
0.012648137276287077,
0.009015598825267658,
-0.009147093429829445,
-0.02367724723390713,
-0.09269547780327612,
-0.06000263174410134
],
"sex": [
-0.044641636506989144,
-0.044641636506989144,
0.05068011873981862,
-0.044641636506989144,
0.05068011873981862,
-0.044641636506989144,
0.05068011873981862,
0.05068011873981862,
0.05068011873981862,
0.05068011873981862
],
"bmi": [
-0.006205954135807083,
0.0369065288194249,
-0.004050329988045492,
0.05199589785375607,
-0.020217511096257485,
-0.02452875939178067,
0.17055522598064407,
0.045529025410471304,
-0.09027529589850945,
0.015350287341808908
],
"bp": [
-0.015998975220305175,
0.0218723855140367,
-0.012556124244455912,
0.0792647112814439,
-0.002227571316908129,
-0.02632752814785296,
0.014986683562338177,
0.0218723855140367,
-0.057313186930496314,
-0.019441826196154435
],
"s1": [
0.12501870313429186,
-0.0249601584096303,
0.10300345740307394,
0.05484510736603471,
0.03833367306762126,
0.09887559882847057,
0.030077955918414535,
0.10988322169407955,
-0.0249601584096303,
0.03695772020942014
],
"s2": [
0.1251981011367534,
-0.016658152053905938,
0.04878987646010685,
0.036577086450315016,
0.05317395492516036,
0.0941964034195894,
0.03375875029420919,
0.08887287956916731,
-0.030436684372645465,
0.04816357953652778
],
"s3": [
0.019186997017453092,
0.0007788079970183853,
0.05600337505832251,
-0.07653558588880739,
-0.006584467611155497,
0.07072992627467027,
-0.02131101882750326,
0.0007788079970183853,
-0.006584467611155497,
0.019186997017453092
],
"s4": [
0.03430885887772673,
-0.03949338287409329,
-0.002592261998183278,
0.14132210941786577,
0.03430885887772673,
-0.002592261998183278,
0.03430885887772673,
0.03430885887772673,
-0.002592261998183278,
-0.002592261998183278
],
"s5": [
0.03243232415655107,
-0.022516528376302174,
0.08449153066204618,
0.0986480615153178,
-0.005142189801713891,
-0.021395309255276825,
0.033653814906286016,
0.07419089971278872,
0.024055085357995654,
-0.030747917533098208
],
"s6": [
-0.005219804415300423,
-0.021788232074638245,
-0.01764612515980379,
0.06105390622205087,
-0.009361911330134878,
0.007206516329202944,
0.03205915781820968,
0.06105390622205087,
0.0030644094143684884,
-0.0010776975004659671
]
}
} | 9 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/colpali/main.rs | use anyhow::{Error as E, Result};
use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::models::colpali::Model;
use candle_transformers::models::{colpali, paligemma};
use clap::Parser;
use hf_hub::{api::sync::Api, Repo, RepoType};
use image::DynamicImage;
use pdf2image::{RenderOptionsBuilder, PDF};
use tokenizers::Tokenizer;
struct PageRetriever {
model: Model,
config: paligemma::Config,
pdf: PDF,
device: Device,
tokenizer: Tokenizer,
range: pdf2image::Pages,
batch_size: usize,
top_k: usize,
}
impl PageRetriever {
fn new(
model: Model,
config: paligemma::Config,
pdf: PDF,
tokenizer: Tokenizer,
device: &Device,
range: Option<pdf2image::Pages>,
batch_size: usize,
top_k: usize,
) -> Self {
let page_count = pdf.page_count();
Self {
model,
config,
pdf,
device: device.clone(),
tokenizer,
range: range.unwrap_or_else(|| pdf2image::Pages::Range(1..=page_count)),
batch_size,
top_k,
}
}
fn get_images_from_pdf(&self) -> Result<Vec<DynamicImage>> {
let pages = self
.pdf
.render(self.range.clone(), RenderOptionsBuilder::default().build()?)?;
Ok(pages)
}
fn tokenize_batch(&self, prompts: Vec<&str>) -> Result<Tensor> {
let tokens = self.tokenizer.encode_batch(prompts, true).map_err(E::msg)?;
let token_ids = tokens
.iter()
.map(|tokens| {
let tokens = tokens.get_ids().to_vec();
Tensor::new(tokens.as_slice(), &self.device)
})
.collect::<candle::Result<Vec<_>>>()?;
let input = Tensor::stack(&token_ids, 0)?;
Ok(input)
}
fn images_to_tensor(
&self,
pages: &[DynamicImage],
image_size: usize,
) -> anyhow::Result<Tensor> {
let mut images = vec![];
for page in pages.iter() {
let img = page.resize_to_fill(
image_size as u32,
image_size as u32,
image::imageops::FilterType::Triangle,
);
let img = img.to_rgb8();
let img = img.into_raw();
let img = Tensor::from_vec(img, (image_size, image_size, 3), &Device::Cpu)?
.permute((2, 0, 1))?
.to_dtype(DType::F32)?
.affine(2. / 255., -1.)?;
images.push(img);
}
let images = Tensor::stack(&images, 0)?;
Ok(images)
}
fn retrieve(&mut self, prompt: &str) -> Result<Vec<usize>> {
let dtype = if self.device.is_cuda() {
DType::BF16
} else {
DType::F32
};
let dummy_prompt: &str = "Describe the image";
let input = self.tokenize_batch(vec![prompt])?;
let dummy_input = self.tokenize_batch(vec![dummy_prompt])?;
let pages = self.get_images_from_pdf()?;
let mut all_scores = Vec::new();
for batch in pages.chunks(self.batch_size) {
let page_images = self
.images_to_tensor(batch, self.config.vision_config.image_size)?
.to_device(&self.device)?
.to_dtype(dtype)?;
let dummy_input = dummy_input.repeat((page_images.dims()[0], 0))?;
let image_embeddings = self.model.forward_images(&page_images, &dummy_input)?;
let text_embeddings = self.model.forward_text(&input)?;
let scores = text_embeddings
.unsqueeze(1)?
.broadcast_matmul(&image_embeddings.unsqueeze(0)?.transpose(3, 2)?)?
.max(3)?
.sum(2)?;
let batch_scores: Vec<f32> = scores
.to_dtype(DType::F32)?
.to_vec2()?
.into_iter()
.flatten()
.collect();
all_scores.extend(batch_scores);
}
let mut indices: Vec<usize> = (0..all_scores.len()).collect();
indices.sort_by(|a, b| all_scores[*b].partial_cmp(&all_scores[*a]).unwrap());
let top_k_indices = indices[0..self.top_k].to_vec();
Ok(top_k_indices)
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
#[arg(long)]
prompt: String,
/// number of top pages to show.
#[arg(long, default_value_t = 3)]
top_k: usize,
#[arg(long)]
model_id: Option<String>,
#[arg(long, default_value = "main")]
revision: String,
#[arg(long)]
tokenizer_file: Option<String>,
#[arg(long)]
weight_files: Option<String>,
#[arg(long)]
pdf: String,
#[arg(long)]
start: Option<u32>,
#[arg(long)]
end: Option<u32>,
}
fn main() -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
let api = Api::new()?;
let model_id = match &args.model_id {
Some(model_id) => model_id.to_string(),
None => "vidore/colpali-v1.2-merged".to_string(),
};
let repo = api.repo(Repo::with_revision(
model_id,
RepoType::Model,
args.revision,
));
let tokenizer_filename = match args.tokenizer_file {
Some(file) => std::path::PathBuf::from(file),
None => api
.repo(Repo::with_revision(
"vidore/colpali".to_string(),
RepoType::Model,
"main".to_string(),
))
.get("tokenizer.json")?,
};
let filenames = match args.weight_files {
Some(files) => files
.split(',')
.map(std::path::PathBuf::from)
.collect::<Vec<_>>(),
None => candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?,
};
let start = std::time::Instant::now();
let config: paligemma::Config = paligemma::Config::paligemma_3b_448();
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let device = candle_examples::device(false)?;
let dtype = if device.is_cuda() {
DType::BF16
} else {
DType::F32
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
let model = colpali::Model::new(&config, vb)?;
let pdf = PDF::from_file(args.pdf)?;
// check if start and end given in arg
let range = if let (Some(start), Some(end)) = (args.start, args.end) {
pdf2image::Pages::Range(start..=end)
} else {
pdf2image::Pages::Range(1..=pdf.page_count()) // can use pdf2image::Pages::All but there is a bug in the library which causes the first page to rendered twice.
};
let mut retriever =
PageRetriever::new(model, config, pdf, tokenizer, &device, Some(range), 4, 3);
let top_k_indices = retriever.retrieve(&args.prompt)?;
println!("Prompt: {}", args.prompt);
println!(
"top {} page numbers that contain similarity to the prompt",
retriever.top_k
);
println!("-----------------------------------");
for index in top_k_indices {
println!("Page: {:?}", index + 1);
}
println!("-----------------------------------");
Ok(())
}
| 0 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/colpali/README.md | # Colpali
[HuggingFace Model Card](https://huggingface.co/vidore/colpali-v1.2-merged)
```
wget https://arxiv.org/pdf/1706.03762.pdf
cargo run --features cuda,pdf2image --release --example colpali -- --prompt "What is Positional Encoding" --pdf "1706.03762.pdf"
```
```
Prompt: what is position encoding?
top 3 page numbers that contain similarity to the prompt
-----------------------------------
Page: 6
Page: 11
Page: 15
-----------------------------------
``` | 1 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/vit/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::Parser;
use candle::{DType, IndexOp, D};
use candle_nn::VarBuilder;
use candle_transformers::models::vit;
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let image = candle_examples::imagenet::load_image224(args.image)?.to_device(&device)?;
println!("loaded image {image:?}");
let model_file = match args.model {
None => {
let api = hf_hub::api::sync::Api::new()?;
let api = api.model("google/vit-base-patch16-224".into());
api.get("model.safetensors")?
}
Some(model) => model.into(),
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };
let model = vit::Model::new(&vit::Config::vit_base_patch16_224(), 1000, vb)?;
println!("model built");
let logits = model.forward(&image.unsqueeze(0)?)?;
let prs = candle_nn::ops::softmax(&logits, D::Minus1)?
.i(0)?
.to_vec1::<f32>()?;
let mut prs = prs.iter().enumerate().collect::<Vec<_>>();
prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for &(category_idx, pr) in prs.iter().take(5) {
println!(
"{:24}: {:.2}%",
candle_examples::imagenet::CLASSES[category_idx],
100. * pr
);
}
Ok(())
}
| 2 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/vit/README.md | # candle-vit
Vision Transformer (ViT) model implementation following the lines of
[vit-base-patch16-224](https://huggingface.co/google/vit-base-patch16-224)
This uses a classification head trained on the ImageNet dataset and returns the
probabilities for the top-5 classes.
## Running an example
```
$ cargo run --example vit --release -- --image tiger.jpg
loaded image Tensor[dims 3, 224, 224; f32]
model built
tiger, Panthera tigris : 100.00%
tiger cat : 0.00%
jaguar, panther, Panthera onca, Felis onca: 0.00%
leopard, Panthera pardus: 0.00%
lion, king of beasts, Panthera leo: 0.00%
```
| 3 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/quantized/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::{Parser, ValueEnum};
use std::io::Write;
use tokenizers::Tokenizer;
use candle::quantized::{ggml_file, gguf_file};
use candle::Tensor;
use candle_transformers::generation::{LogitsProcessor, Sampling};
use candle_examples::token_output_stream::TokenOutputStream;
use candle_transformers::models::quantized_llama as model;
use model::ModelWeights;
const DEFAULT_PROMPT: &str = "My favorite theorem is ";
#[derive(Debug)]
enum Prompt {
Interactive,
Chat,
One(String),
}
#[derive(Clone, Debug, Copy, PartialEq, Eq, ValueEnum)]
enum Which {
#[value(name = "7b")]
L7b,
#[value(name = "13b")]
L13b,
#[value(name = "70b")]
L70b,
#[value(name = "7b-chat")]
L7bChat,
#[value(name = "13b-chat")]
L13bChat,
#[value(name = "70b-chat")]
L70bChat,
#[value(name = "7b-code")]
L7bCode,
#[value(name = "13b-code")]
L13bCode,
#[value(name = "32b-code")]
L34bCode,
#[value(name = "7b-leo")]
Leo7b,
#[value(name = "13b-leo")]
Leo13b,
#[value(name = "7b-mistral")]
Mistral7b,
#[value(name = "7b-mistral-instruct")]
Mistral7bInstruct,
#[value(name = "7b-mistral-instruct-v0.2")]
Mistral7bInstructV02,
#[value(name = "7b-zephyr-a")]
Zephyr7bAlpha,
#[value(name = "7b-zephyr-b")]
Zephyr7bBeta,
#[value(name = "7b-open-chat-3.5")]
OpenChat35,
#[value(name = "7b-starling-a")]
Starling7bAlpha,
#[value(name = "mixtral")]
Mixtral,
#[value(name = "mixtral-instruct")]
MixtralInstruct,
#[value(name = "llama3-8b")]
L8b,
#[value(name = "phi3")]
Phi3,
#[value(name = "SmoLM2-360M-Instruct")]
SmolLM2_360MInstruct,
#[value(name = "SmoLM2-1.7B-Instruct")]
SmolLM2_1BInstruct,
}
impl Which {
fn is_mistral(&self) -> bool {
match self {
Self::L7b
| Self::L13b
| Self::L70b
| Self::L7bChat
| Self::L13bChat
| Self::L70bChat
| Self::L7bCode
| Self::L13bCode
| Self::L34bCode
| Self::Leo7b
| Self::Leo13b
| Self::L8b
| Self::Phi3
| Self::SmolLM2_1BInstruct
| Self::SmolLM2_360MInstruct => false,
// Zephyr and OpenChat are fine tuned versions of mistral and should be treated in the
// same way. Starling is a fine tuned version of OpenChat.
Self::OpenChat35
| Self::Starling7bAlpha
| Self::Zephyr7bAlpha
| Self::Zephyr7bBeta
| Self::Mixtral
| Self::MixtralInstruct
| Self::Mistral7b
| Self::Mistral7bInstruct
| Self::Mistral7bInstructV02 => true,
}
}
fn is_zephyr(&self) -> bool {
match self {
Self::L7b
| Self::L13b
| Self::L70b
| Self::L7bChat
| Self::L13bChat
| Self::L70bChat
| Self::L7bCode
| Self::L13bCode
| Self::L34bCode
| Self::Leo7b
| Self::Leo13b
| Self::Mixtral
| Self::MixtralInstruct
| Self::Mistral7b
| Self::Mistral7bInstruct
| Self::Mistral7bInstructV02
| Self::OpenChat35
| Self::Starling7bAlpha
| Self::L8b
| Self::SmolLM2_1BInstruct
| Self::SmolLM2_360MInstruct
| Self::Phi3 => false,
Self::Zephyr7bAlpha | Self::Zephyr7bBeta => true,
}
}
fn is_open_chat(&self) -> bool {
match self {
Self::L7b
| Self::L13b
| Self::L70b
| Self::L7bChat
| Self::L13bChat
| Self::L70bChat
| Self::L7bCode
| Self::L13bCode
| Self::L34bCode
| Self::Leo7b
| Self::Leo13b
| Self::Mixtral
| Self::MixtralInstruct
| Self::Mistral7b
| Self::Mistral7bInstruct
| Self::Mistral7bInstructV02
| Self::Zephyr7bAlpha
| Self::Zephyr7bBeta
| Self::L8b
| Self::SmolLM2_1BInstruct
| Self::SmolLM2_360MInstruct
| Self::Phi3 => false,
Self::OpenChat35 | Self::Starling7bAlpha => true,
}
}
fn tokenizer_repo(&self) -> &'static str {
match self {
Self::L7b
| Self::L13b
| Self::L70b
| Self::L7bChat
| Self::L13bChat
| Self::L70bChat
| Self::L7bCode
| Self::L13bCode
| Self::L34bCode => "hf-internal-testing/llama-tokenizer",
Self::Leo7b => "LeoLM/leo-hessianai-7b",
Self::Leo13b => "LeoLM/leo-hessianai-13b",
Self::Mixtral => "mistralai/Mixtral-8x7B-v0.1",
Self::MixtralInstruct => "mistralai/Mixtral-8x7B-Instruct-v0.1",
Self::Mistral7b
| Self::Mistral7bInstruct
| Self::Mistral7bInstructV02
| Self::Zephyr7bAlpha
| Self::Zephyr7bBeta => "mistralai/Mistral-7B-v0.1",
Self::OpenChat35 => "openchat/openchat_3.5",
Self::Starling7bAlpha => "berkeley-nest/Starling-LM-7B-alpha",
Self::L8b => "meta-llama/Meta-Llama-3-8B",
Self::Phi3 => "microsoft/Phi-3-mini-4k-instruct",
Self::SmolLM2_360MInstruct => "HuggingFaceTB/SmolLM2-360M-Instruct",
Self::SmolLM2_1BInstruct => "HuggingFaceTB/SmolLM2-1.7B-Instruct",
}
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// GGML/GGUF file to load, typically a .bin/.gguf file generated by the quantize command from llama.cpp
#[arg(long)]
model: Option<String>,
/// The initial prompt, use 'interactive' for entering multiple prompts in an interactive way
/// and 'chat' for an interactive model where history of previous prompts and generated tokens
/// is preserved.
#[arg(long)]
prompt: Option<String>,
/// The length of the sample to generate (in tokens).
#[arg(short = 'n', long, default_value_t = 1000)]
sample_len: usize,
/// The tokenizer config in json format.
#[arg(long)]
tokenizer: Option<String>,
/// The temperature used to generate samples, use 0 for greedy sampling.
#[arg(long, default_value_t = 0.8)]
temperature: f64,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// Only sample among the top K samples.
#[arg(long)]
top_k: Option<usize>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
/// Display the token for the specified prompt.
#[arg(long)]
verbose_prompt: bool,
/// Process prompt elements separately.
#[arg(long)]
split_prompt: bool,
/// Run on CPU rather than GPU even if a GPU is available.
#[arg(long)]
cpu: bool,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
/// The model size to use.
#[arg(long, default_value = "7b")]
which: Which,
/// Group-Query Attention, use 8 for the 70B version of LLaMAv2.
#[arg(long)]
gqa: Option<usize>,
/// Use the slower dmmv cuda kernel.
#[arg(long)]
force_dmmv: bool,
}
impl Args {
fn tokenizer(&self) -> anyhow::Result<Tokenizer> {
let tokenizer_path = match &self.tokenizer {
Some(config) => std::path::PathBuf::from(config),
None => {
let api = hf_hub::api::sync::Api::new()?;
let repo = self.which.tokenizer_repo();
let api = api.model(repo.to_string());
api.get("tokenizer.json")?
}
};
Tokenizer::from_file(tokenizer_path).map_err(anyhow::Error::msg)
}
fn model(&self) -> anyhow::Result<std::path::PathBuf> {
let model_path = match &self.model {
Some(config) => std::path::PathBuf::from(config),
None => {
let (repo, filename) = match self.which {
Which::L7b => ("TheBloke/Llama-2-7B-GGML", "llama-2-7b.ggmlv3.q4_0.bin"),
Which::L13b => ("TheBloke/Llama-2-13B-GGML", "llama-2-13b.ggmlv3.q4_0.bin"),
Which::L70b => ("TheBloke/Llama-2-70B-GGML", "llama-2-70b.ggmlv3.q4_0.bin"),
Which::L7bChat => (
"TheBloke/Llama-2-7B-Chat-GGML",
"llama-2-7b-chat.ggmlv3.q4_0.bin",
),
Which::L13bChat => (
"TheBloke/Llama-2-13B-Chat-GGML",
"llama-2-13b-chat.ggmlv3.q4_0.bin",
),
Which::L70bChat => (
"TheBloke/Llama-2-70B-Chat-GGML",
"llama-2-70b-chat.ggmlv3.q4_0.bin",
),
Which::L7bCode => ("TheBloke/CodeLlama-7B-GGUF", "codellama-7b.Q8_0.gguf"),
Which::L13bCode => ("TheBloke/CodeLlama-13B-GGUF", "codellama-13b.Q8_0.gguf"),
Which::L34bCode => ("TheBloke/CodeLlama-34B-GGUF", "codellama-34b.Q8_0.gguf"),
Which::Leo7b => (
"TheBloke/leo-hessianai-7B-GGUF",
"leo-hessianai-7b.Q4_K_M.gguf",
),
Which::Leo13b => (
"TheBloke/leo-hessianai-13B-GGUF",
"leo-hessianai-13b.Q4_K_M.gguf",
),
Which::Mixtral => (
"TheBloke/Mixtral-8x7B-v0.1-GGUF",
"mixtral-8x7b-v0.1.Q4_K_M.gguf",
),
Which::MixtralInstruct => (
"TheBloke/Mixtral-8x7B-Instruct-v0.1-GGUF",
"mixtral-8x7b-instruct-v0.1.Q4_K_M.gguf",
),
Which::Mistral7b => (
"TheBloke/Mistral-7B-v0.1-GGUF",
"mistral-7b-v0.1.Q4_K_S.gguf",
),
Which::Mistral7bInstruct => (
"TheBloke/Mistral-7B-Instruct-v0.1-GGUF",
"mistral-7b-instruct-v0.1.Q4_K_S.gguf",
),
Which::Mistral7bInstructV02 => (
"TheBloke/Mistral-7B-Instruct-v0.2-GGUF",
"mistral-7b-instruct-v0.2.Q4_K_S.gguf",
),
Which::Zephyr7bAlpha => (
"TheBloke/zephyr-7B-alpha-GGUF",
"zephyr-7b-alpha.Q4_K_M.gguf",
),
Which::Zephyr7bBeta => {
("TheBloke/zephyr-7B-beta-GGUF", "zephyr-7b-beta.Q4_K_M.gguf")
}
Which::OpenChat35 => ("TheBloke/openchat_3.5-GGUF", "openchat_3.5.Q4_K_M.gguf"),
Which::Starling7bAlpha => (
"TheBloke/Starling-LM-7B-alpha-GGUF",
"starling-lm-7b-alpha.Q4_K_M.gguf",
),
// TODO: swap to TheBloke model when available
Which::L8b => (
"QuantFactory/Meta-Llama-3-8B-GGUF",
"Meta-Llama-3-8B.Q4_K_S.gguf",
),
Which::Phi3 => (
"microsoft/Phi-3-mini-4k-instruct-gguf",
"Phi-3-mini-4k-instruct-q4.gguf",
),
Which::SmolLM2_360MInstruct => (
"HuggingFaceTB/SmolLM2-360M-Instruct-GGUF",
"smollm2-360m-instruct-q8_0.gguf",
),
Which::SmolLM2_1BInstruct => (
"HuggingFaceTB/SmolLM2-1.7B-Instruct-GGUF",
"smollm2-1.7b-instruct-q4_k_m.gguf",
),
};
let revision = if self.which == Which::Phi3 {
"5eef2ce24766d31909c0b269fe90c817a8f263fb"
} else {
"main"
};
let api = hf_hub::api::sync::Api::new()?;
api.repo(hf_hub::Repo::with_revision(
repo.to_string(),
hf_hub::RepoType::Model,
revision.to_string(),
))
.get(filename)?
}
};
Ok(model_path)
}
}
fn format_size(size_in_bytes: usize) -> String {
if size_in_bytes < 1_000 {
format!("{}B", size_in_bytes)
} else if size_in_bytes < 1_000_000 {
format!("{:.2}KB", size_in_bytes as f64 / 1e3)
} else if size_in_bytes < 1_000_000_000 {
format!("{:.2}MB", size_in_bytes as f64 / 1e6)
} else {
format!("{:.2}GB", size_in_bytes as f64 / 1e9)
}
}
fn main() -> anyhow::Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
#[cfg(feature = "cuda")]
candle::quantized::cuda::set_force_dmmv(args.force_dmmv);
candle::cuda::set_gemm_reduced_precision_f16(true);
candle::cuda::set_gemm_reduced_precision_bf16(true);
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature, args.repeat_penalty, args.repeat_last_n
);
let model_path = args.model()?;
let mut file = std::fs::File::open(&model_path)?;
let start = std::time::Instant::now();
let device = candle_examples::device(args.cpu)?;
let mut model = match model_path.extension().and_then(|v| v.to_str()) {
Some("gguf") => {
let model = gguf_file::Content::read(&mut file).map_err(|e| e.with_path(model_path))?;
let mut total_size_in_bytes = 0;
for (_, tensor) in model.tensor_infos.iter() {
let elem_count = tensor.shape.elem_count();
total_size_in_bytes +=
elem_count * tensor.ggml_dtype.type_size() / tensor.ggml_dtype.block_size();
}
println!(
"loaded {:?} tensors ({}) in {:.2}s",
model.tensor_infos.len(),
&format_size(total_size_in_bytes),
start.elapsed().as_secs_f32(),
);
ModelWeights::from_gguf(model, &mut file, &device)?
}
Some("ggml" | "bin") | Some(_) | None => {
let model = ggml_file::Content::read(&mut file, &device)
.map_err(|e| e.with_path(model_path))?;
let mut total_size_in_bytes = 0;
for (_, tensor) in model.tensors.iter() {
let elem_count = tensor.shape().elem_count();
total_size_in_bytes +=
elem_count * tensor.dtype().type_size() / tensor.dtype().block_size();
}
println!(
"loaded {:?} tensors ({}) in {:.2}s",
model.tensors.len(),
&format_size(total_size_in_bytes),
start.elapsed().as_secs_f32(),
);
println!("params: {:?}", model.hparams);
let default_gqa = match args.which {
Which::L7b
| Which::L13b
| Which::L7bChat
| Which::L13bChat
| Which::L7bCode
| Which::L13bCode
| Which::L34bCode
| Which::Leo7b
| Which::Leo13b
| Which::L8b
| Which::SmolLM2_1BInstruct
| Which::SmolLM2_360MInstruct
| Which::Phi3 => 1,
Which::Mixtral
| Which::MixtralInstruct
| Which::Mistral7b
| Which::Mistral7bInstruct
| Which::Mistral7bInstructV02
| Which::Zephyr7bAlpha
| Which::Zephyr7bBeta
| Which::L70b
| Which::L70bChat
| Which::OpenChat35
| Which::Starling7bAlpha => 8,
};
ModelWeights::from_ggml(model, args.gqa.unwrap_or(default_gqa))?
}
};
println!("model built");
let tokenizer = args.tokenizer()?;
let mut tos = TokenOutputStream::new(tokenizer);
let prompt = match args.prompt.as_deref() {
Some("chat") => Prompt::Chat,
Some("interactive") => Prompt::Interactive,
Some(s) => Prompt::One(s.to_string()),
None => Prompt::One(DEFAULT_PROMPT.to_string()),
};
let mut pre_prompt_tokens = vec![];
for prompt_index in 0.. {
let prompt_str = match &prompt {
Prompt::One(prompt) => prompt.clone(),
Prompt::Interactive | Prompt::Chat => {
let is_interactive = matches!(prompt, Prompt::Interactive);
print!("> ");
std::io::stdout().flush()?;
let mut prompt = String::new();
std::io::stdin().read_line(&mut prompt)?;
if prompt.ends_with('\n') {
prompt.pop();
if prompt.ends_with('\r') {
prompt.pop();
}
}
if args.which.is_open_chat() {
format!("GPT4 Correct User: {prompt}<|end_of_turn|>GPT4 Correct Assistant:")
} else if args.which.is_zephyr() {
if prompt_index == 0 || is_interactive {
format!("<|system|>\n</s>\n<|user|>\n{prompt}</s>\n<|assistant|>",)
} else {
format!("<|user|>\n{prompt}</s>\n<|assistant|>")
}
} else if args.which.is_mistral() {
format!("[INST] {prompt} [/INST]")
} else {
prompt
}
}
};
print!("{}", &prompt_str);
let tokens = tos
.tokenizer()
.encode(prompt_str, true)
.map_err(anyhow::Error::msg)?;
if args.verbose_prompt {
for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {
let token = token.replace('▁', " ").replace("<0x0A>", "\n");
println!("{id:7} -> '{token}'");
}
}
let prompt_tokens = [&pre_prompt_tokens, tokens.get_ids()].concat();
let to_sample = args.sample_len.saturating_sub(1);
let prompt_tokens = if prompt_tokens.len() + to_sample > model::MAX_SEQ_LEN - 10 {
let to_remove = prompt_tokens.len() + to_sample + 10 - model::MAX_SEQ_LEN;
prompt_tokens[prompt_tokens.len().saturating_sub(to_remove)..].to_vec()
} else {
prompt_tokens
};
let mut all_tokens = vec![];
let mut logits_processor = {
let temperature = args.temperature;
let sampling = if temperature <= 0. {
Sampling::ArgMax
} else {
match (args.top_k, args.top_p) {
(None, None) => Sampling::All { temperature },
(Some(k), None) => Sampling::TopK { k, temperature },
(None, Some(p)) => Sampling::TopP { p, temperature },
(Some(k), Some(p)) => Sampling::TopKThenTopP { k, p, temperature },
}
};
LogitsProcessor::from_sampling(args.seed, sampling)
};
let start_prompt_processing = std::time::Instant::now();
let mut next_token = if !args.split_prompt {
let input = Tensor::new(prompt_tokens.as_slice(), &device)?.unsqueeze(0)?;
let logits = model.forward(&input, 0)?;
let logits = logits.squeeze(0)?;
logits_processor.sample(&logits)?
} else {
let mut next_token = 0;
for (pos, token) in prompt_tokens.iter().enumerate() {
let input = Tensor::new(&[*token], &device)?.unsqueeze(0)?;
let logits = model.forward(&input, pos)?;
let logits = logits.squeeze(0)?;
next_token = logits_processor.sample(&logits)?
}
next_token
};
let prompt_dt = start_prompt_processing.elapsed();
all_tokens.push(next_token);
if let Some(t) = tos.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
let eos_token = match args.which {
Which::SmolLM2_360MInstruct | Which::SmolLM2_1BInstruct => "<|endoftext|>",
Which::L8b => "<|end_of_text|>",
_ => match args.which.is_open_chat() {
true => "<|end_of_turn|>",
false => "</s>",
},
};
let eos_token = *tos.tokenizer().get_vocab(true).get(eos_token).unwrap();
let start_post_prompt = std::time::Instant::now();
let mut sampled = 0;
for index in 0..to_sample {
let input = Tensor::new(&[next_token], &device)?.unsqueeze(0)?;
let logits = model.forward(&input, prompt_tokens.len() + index)?;
let logits = logits.squeeze(0)?;
let logits = if args.repeat_penalty == 1. {
logits
} else {
let start_at = all_tokens.len().saturating_sub(args.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
args.repeat_penalty,
&all_tokens[start_at..],
)?
};
next_token = logits_processor.sample(&logits)?;
all_tokens.push(next_token);
if let Some(t) = tos.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
sampled += 1;
if next_token == eos_token {
break;
};
}
if let Some(rest) = tos.decode_rest().map_err(candle::Error::msg)? {
print!("{rest}");
}
std::io::stdout().flush()?;
let dt = start_post_prompt.elapsed();
println!(
"\n\n{:4} prompt tokens processed: {:.2} token/s",
prompt_tokens.len(),
prompt_tokens.len() as f64 / prompt_dt.as_secs_f64(),
);
println!(
"{sampled:4} tokens generated: {:.2} token/s",
sampled as f64 / dt.as_secs_f64(),
);
match prompt {
Prompt::One(_) => break,
Prompt::Interactive => {}
Prompt::Chat => {
pre_prompt_tokens = [prompt_tokens.as_slice(), all_tokens.as_slice()].concat()
}
}
}
Ok(())
}
| 4 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/quantized/README.md | # candle-quantized-llama: Fast Inference of quantized LLaMA models
This example provides a quantized LLaMA model similar to
[llama.cpp](https://github.com/ggerganov/llama.cpp). This is based on candle
built-in quantization methods. Supported features include:
- 2-bit, 3-bit, 4-bit, 5-bit, 6-bit and 8-bit integer quantization support.
- SIMD optimizations on Apple Silicon and x86.
- Support using the `gguf` and `ggml` file formats.
The weights are automatically downloaded for you from the [HuggingFace
Hub](https://huggingface.co/) on the first run. There are various command line
flags to use local files instead, run with `--help` to learn about them.

## Running some example.
```bash
cargo run --example quantized --release -- --prompt "The best thing about coding in rust is "
> avx: true, neon: false, simd128: false, f16c: true
> temp: 0.80 repeat-penalty: 1.10 repeat-last-n: 64
> loaded 291 tensors (3.79GB) in 2.17s
> params: HParams { n_vocab: 32000, n_embd: 4096, n_mult: 256, n_head: 32, n_layer: 32, n_rot: 128, ftype: 2 }
> The best thing about coding in rust is 1.) that I don’t need to worry about memory leaks, 2.) speed and 3.) my program will compile even on old machines.
```
Using the mixtral sparse mixture of expert model:
```bash
$ cargo run --example quantized --release -- --which mixtral --prompt "Lebesgue's integral is superior to Riemann's because "
> avx: true, neon: false, simd128: false, f16c: true
> temp: 0.80 repeat-penalty: 1.10 repeat-last-n: 64
> loaded 995 tensors (26.44GB) in 0.03s
Lebesgue's integral is superior to Riemann's because 1. it is defined for a wider class of functions, those which are absolutely integrable; 2. the definition does not involve limits in two variables---one being computed before the other (which makes some computations more difficult); and 3. interchange of order of integration is easier to establish than with Riemann's integral. On the other hand, Lebesgue's integral applies only for bounded functions defined on finite intervals; it does not provide numerical values for improper integrals. The latter are best evaluated using Cauchy's limit definition.
The reason $f(x) = x^2$ is discontinuous at the ends of its interval of definition, and Riemann's integral requires continuity on the whole of an open interval containing it (see our earlier post), sine no such function exists with this property, is that the endpoints are infinite in measure for Lebesgue's integral.
```
## Command-line flags
Run with `--help` to see all options.
- `--which`: specify the model to use, e.g. `7b`, `13-chat`, `7b-code`.
- `--prompt interactive`: interactive mode where multiple prompts can be
entered.
- `--model mymodelfile.gguf`: use a local model file rather than getting one
from the hub.
| 5 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/stable-lm/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::{Error as E, Result};
use clap::{Parser, ValueEnum};
use candle_transformers::models::quantized_stable_lm::Model as QStableLM;
use candle_transformers::models::stable_lm::{Config, Model as StableLM};
use candle::{DType, Device, Tensor};
use candle_examples::token_output_stream::TokenOutputStream;
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::Tokenizer;
enum Model {
StableLM(StableLM),
Quantized(QStableLM),
}
struct TextGeneration {
model: Model,
device: Device,
tokenizer: TokenOutputStream,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
device: &Device,
) -> Self {
let logits_processor = LogitsProcessor::new(seed, temp, top_p);
Self {
model,
tokenizer: TokenOutputStream::new(tokenizer),
logits_processor,
repeat_penalty,
repeat_last_n,
device: device.clone(),
}
}
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {
use std::io::Write;
self.tokenizer.clear();
let mut tokens = self
.tokenizer
.tokenizer()
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
for &t in tokens.iter() {
if let Some(t) = self.tokenizer.next_token(t)? {
print!("{t}")
}
}
std::io::stdout().flush()?;
let mut generated_tokens = 0usize;
let eos_token = match self.tokenizer.get_token("<|endoftext|>") {
Some(token) => token,
None => anyhow::bail!("cannot find the <|endoftext|> token"),
};
let start_gen = std::time::Instant::now();
for index in 0..sample_len {
let context_size = if index > 0 { 1 } else { tokens.len() };
let start_pos = tokens.len().saturating_sub(context_size);
let ctxt = &tokens[start_pos..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
let logits = match &mut self.model {
Model::StableLM(m) => m.forward(&input, start_pos)?,
Model::Quantized(m) => m.forward(&input, start_pos)?,
};
let logits = logits.squeeze(0)?.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token {
break;
}
if let Some(t) = self.tokenizer.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
}
let dt = start_gen.elapsed();
if let Some(rest) = self.tokenizer.decode_rest().map_err(E::msg)? {
print!("{rest}");
}
std::io::stdout().flush()?;
println!(
"\n{generated_tokens} tokens generated ({:.2} token/s)",
generated_tokens as f64 / dt.as_secs_f64(),
);
Ok(())
}
}
#[derive(Clone, Copy, Debug, ValueEnum, PartialEq, Eq)]
enum Which {
V1Orig,
V1,
V1Zephyr,
V2,
V2Zephyr,
Code,
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
#[arg(long)]
use_flash_attn: bool,
#[arg(long)]
prompt: String,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, short = 'n', default_value_t = 1000)]
sample_len: usize,
#[arg(long)]
model_id: Option<String>,
#[arg(long, default_value = "main")]
revision: String,
#[arg(long, default_value = "v2")]
which: Which,
#[arg(long)]
tokenizer_file: Option<String>,
#[arg(long)]
weight_files: Option<String>,
#[arg(long)]
quantized: bool,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
}
fn main() -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
let api = Api::new()?;
let model_id = match args.model_id {
Some(model_id) => model_id,
None => match args.which {
Which::V1Orig => "lmz/candle-stablelm-3b-4e1t".to_string(),
Which::V1 => "stabilityai/stablelm-3b-4e1t".to_string(),
Which::V1Zephyr => "stabilityai/stablelm-zephyr-3b".to_string(),
Which::Code => "stabilityai/stable-code-3b".to_string(),
Which::V2 => "stabilityai/stablelm-2-1_6b".to_string(),
Which::V2Zephyr => "stabilityai/stablelm-2-zephyr-1_6b".to_string(),
},
};
let repo = api.repo(Repo::with_revision(
model_id,
RepoType::Model,
args.revision,
));
let tokenizer_filename = match args.tokenizer_file {
Some(file) => std::path::PathBuf::from(file),
None => repo.get("tokenizer.json")?,
};
let filenames = match args.weight_files {
Some(files) => files
.split(',')
.map(std::path::PathBuf::from)
.collect::<Vec<_>>(),
None => match (args.which, args.quantized) {
(Which::V1Orig | Which::V1, true) => vec![repo.get("model-q4k.gguf")?],
(Which::V2, true) => {
let gguf = api
.model("lmz/candle-stablelm".to_string())
.get("stablelm-2-1_6b-q4k.gguf")?;
vec![gguf]
}
(Which::V2Zephyr, true) => {
let gguf = api
.model("lmz/candle-stablelm".to_string())
.get("stablelm-2-zephyr-1_6b-q4k.gguf")?;
vec![gguf]
}
(Which::V1Zephyr | Which::Code, true) => {
anyhow::bail!("Quantized {:?} variant not supported.", args.which)
}
(Which::V1Orig | Which::V1 | Which::V1Zephyr | Which::V2 | Which::V2Zephyr, false) => {
vec![repo.get("model.safetensors")?]
}
(Which::Code, false) => {
candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?
}
},
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let start = std::time::Instant::now();
let config = match args.which {
Which::V1Orig => Config::stablelm_3b_4e1t(args.use_flash_attn),
Which::V1 | Which::V1Zephyr | Which::V2 | Which::V2Zephyr | Which::Code => {
let config_filename = repo.get("config.json")?;
let config = std::fs::read_to_string(config_filename)?;
let mut config: Config = serde_json::from_str(&config)?;
config.set_use_flash_attn(args.use_flash_attn);
config
}
};
let device = candle_examples::device(args.cpu)?;
let model = if args.quantized {
let filename = &filenames[0];
let vb =
candle_transformers::quantized_var_builder::VarBuilder::from_gguf(filename, &device)?;
let model = QStableLM::new(&config, vb)?;
Model::Quantized(model)
} else {
let dtype = if device.is_cuda() {
DType::BF16
} else {
DType::F32
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
let model = StableLM::new(&config, vb)?;
Model::StableLM(model)
};
println!("loaded the model in {:?}", start.elapsed());
let mut pipeline = TextGeneration::new(
model,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.repeat_penalty,
args.repeat_last_n,
&device,
);
pipeline.run(&args.prompt, args.sample_len)?;
Ok(())
}
| 6 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/stable-lm/README.md | # candle-stable-lm
StableLM-3B-4E1T is a 3 billion parameter decoder-only language model
pre-trained on 1 trillion tokens of diverse English and code datasets for 4
epochs. See the [HuggingFace Hub Model
Card](https://huggingface.co/stabilityai/stablelm-3b-4e1t).
Note that this model is gated so you will have to request access on the Hub in
order to be able to use it.
Other available models are Stable-Code-3B, StableLM-2 and Zephyr variants.
## Running some example
```bash
$ cargo run --example stable-lm --release --features cuda -- --prompt 'What is the most efficient programming language in use?' --sample-len 150
avx: true, neon: false, simd128: false, f16c: true
temp: 0.00 repeat-penalty: 1.10 repeat-last-n: 64
retrieved the files in 126.593µs
loaded the model in 3.474148965s
What is the most efficient programming language in use?
The answer to this question depends on what you mean by "efficient". If you're talking about speed, then C++ and Java are probably your best bets. But if you're talking about ease of development, then Python is probably the way to go.
Python is a high-level, interpreted language that is easy to learn and use. It has a large community of developers who are always working on new features and improvements.
C++ is a low-level, compiled language that can be used for both desktop applications and web development. It's more difficult to learn than Python but offers greater control over the code.
Java is another high-level language that is popular with programmers because it runs on many different platforms (including Android phones
150 tokens generated (37.61 token/s)
```
| 7 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mobilenetv4/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::{Parser, ValueEnum};
use candle::{DType, IndexOp, D};
use candle_nn::{Module, VarBuilder};
use candle_transformers::models::mobilenetv4;
#[derive(Clone, Copy, Debug, ValueEnum)]
enum Which {
Small,
Medium,
Large,
HybridMedium,
HybridLarge,
}
impl Which {
fn model_filename(&self) -> String {
let name = match self {
Self::Small => "conv_small.e2400_r224",
Self::Medium => "conv_medium.e500_r256",
Self::HybridMedium => "hybrid_medium.ix_e550_r256",
Self::Large => "conv_large.e600_r384",
Self::HybridLarge => "hybrid_large.ix_e600_r384",
};
format!("timm/mobilenetv4_{}_in1k", name)
}
fn resolution(&self) -> u32 {
match self {
Self::Small => 224,
Self::Medium => 256,
Self::HybridMedium => 256,
Self::Large => 384,
Self::HybridLarge => 384,
}
}
fn config(&self) -> mobilenetv4::Config {
match self {
Self::Small => mobilenetv4::Config::small(),
Self::Medium => mobilenetv4::Config::medium(),
Self::HybridMedium => mobilenetv4::Config::hybrid_medium(),
Self::Large => mobilenetv4::Config::large(),
Self::HybridLarge => mobilenetv4::Config::hybrid_large(),
}
}
}
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
#[arg(value_enum, long, default_value_t=Which::Small)]
which: Which,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let image =
candle_examples::imagenet::load_image(args.image, args.which.resolution() as usize)?
.to_device(&device)?;
println!("loaded image {image:?}");
let model_file = match args.model {
None => {
let model_name = args.which.model_filename();
let api = hf_hub::api::sync::Api::new()?;
let api = api.model(model_name);
api.get("model.safetensors")?
}
Some(model) => model.into(),
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };
let model = mobilenetv4::mobilenetv4(&args.which.config(), 1000, vb)?;
println!("model built");
let logits = model.forward(&image.unsqueeze(0)?)?;
let prs = candle_nn::ops::softmax(&logits, D::Minus1)?
.i(0)?
.to_vec1::<f32>()?;
let mut prs = prs.iter().enumerate().collect::<Vec<_>>();
prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for &(category_idx, pr) in prs.iter().take(5) {
println!(
"{:24}: {:.2}%",
candle_examples::imagenet::CLASSES[category_idx],
100. * pr
);
}
Ok(())
}
| 8 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/mobilenetv4/README.md | # candle-mobilenetv4
[MobileNetV4 - Universal Models for the Mobile Ecosystem](https://arxiv.org/abs/2404.10518)
This candle implementation uses pre-trained MobileNetV4 models from timm for inference.
The classification head has been trained on the ImageNet dataset and returns the probabilities for the top-5 classes.
## Running an example
```
$ cargo run --example mobilenetv4 --release -- --image candle-examples/examples/yolo-v8/assets/bike.jpg --which medium
loaded image Tensor[dims 3, 256, 256; f32]
model built
unicycle, monocycle : 20.18%
mountain bike, all-terrain bike, off-roader: 19.77%
bicycle-built-for-two, tandem bicycle, tandem: 15.91%
crash helmet : 1.15%
tricycle, trike, velocipede: 0.67%
```
| 9 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/granite.rs | //! Granite is a Long Context Transformer Language Model.
//!
//! A high performance transformer model optimized for efficient processing
//! of very long context sequences
//!
//! Based on implementation from [Nod.ai](https://github.com/nod-ai/granite)
use super::with_tracing::{linear_no_bias as linear, Linear, RmsNorm};
use candle::{DType, Device, IndexOp, Result, Tensor, D};
use candle_nn::{embedding, Embedding, Module, VarBuilder};
use std::{collections::HashMap, f32::consts::PI};
pub const DEFAULT_MAX_SEQ_LEN: usize = 4096;
#[derive(Debug, Clone, serde::Deserialize, Default)]
pub enum GraniteRopeType {
#[serde(rename = "granite")]
Granite,
#[default]
#[serde(rename = "default")]
Default,
}
#[derive(Debug, Clone, serde::Deserialize, Default)]
pub struct GraniteRopeConfig {
pub factor: f32,
pub low_freq_factor: f32,
pub high_freq_factor: f32,
pub original_max_position_embeddings: usize,
pub rope_type: GraniteRopeType,
}
#[derive(Debug, Clone, serde::Deserialize)]
#[serde(untagged)]
pub enum GraniteEosToks {
Single(u32),
Multiple(Vec<u32>),
}
#[derive(Debug, Clone, serde::Deserialize)]
pub struct GraniteConfig {
pub hidden_size: usize,
pub intermediate_size: usize,
pub vocab_size: usize,
pub num_hidden_layers: usize,
pub num_attention_heads: usize,
pub num_key_value_heads: Option<usize>,
pub rms_norm_eps: f64,
#[serde(default = "default_rope")]
pub rope_theta: f32,
pub bos_token_id: Option<u32>,
pub eos_token_id: Option<GraniteEosToks>,
pub rope_scaling: Option<GraniteRopeConfig>,
pub max_position_embeddings: usize,
}
impl GraniteConfig {
pub fn num_key_value_heads(&self) -> usize {
self.num_key_value_heads.unwrap_or(self.num_attention_heads)
}
}
fn default_rope() -> f32 {
10_000.0
}
impl GraniteConfig {
pub fn into_config(self, use_flash_attn: bool) -> Config {
Config {
hidden_size: self.hidden_size,
intermediate_size: self.intermediate_size,
vocab_size: self.vocab_size,
num_hidden_layers: self.num_hidden_layers,
num_attention_heads: self.num_attention_heads,
num_key_value_heads: self.num_key_value_heads(),
rms_norm_eps: self.rms_norm_eps,
rope_theta: self.rope_theta,
use_flash_attn,
bos_token_id: self.bos_token_id,
eos_token_id: self.eos_token_id,
rope_scaling: self.rope_scaling,
max_position_embeddings: self.max_position_embeddings,
}
}
}
#[derive(Debug, Clone)]
pub struct Config {
pub hidden_size: usize,
pub intermediate_size: usize,
pub vocab_size: usize,
pub num_hidden_layers: usize,
pub num_attention_heads: usize,
pub num_key_value_heads: usize,
pub use_flash_attn: bool,
pub rms_norm_eps: f64,
pub rope_theta: f32,
pub bos_token_id: Option<u32>,
pub eos_token_id: Option<GraniteEosToks>,
pub rope_scaling: Option<GraniteRopeConfig>,
pub max_position_embeddings: usize,
}
#[derive(Debug, Clone)]
pub struct Cache {
masks: HashMap<usize, Tensor>,
pub use_kv_cache: bool,
kvs: Vec<Option<(Tensor, Tensor)>>,
cos: Tensor,
sin: Tensor,
device: Device,
}
fn calculate_default_inv_freq(cfg: &Config) -> Vec<f32> {
let head_dim = cfg.hidden_size / cfg.num_attention_heads;
(0..head_dim)
.step_by(2)
.map(|i| 1f32 / cfg.rope_theta.powf(i as f32 / head_dim as f32))
.collect()
}
impl Cache {
pub fn new(use_kv_cache: bool, dtype: DType, config: &Config, device: &Device) -> Result<Self> {
// precompute freqs_cis
let theta = match &config.rope_scaling {
None
| Some(GraniteRopeConfig {
rope_type: GraniteRopeType::Default,
..
}) => calculate_default_inv_freq(config),
Some(rope_scaling) => {
let low_freq_wavelen = rope_scaling.original_max_position_embeddings as f32
/ rope_scaling.low_freq_factor;
let high_freq_wavelen = rope_scaling.original_max_position_embeddings as f32
/ rope_scaling.high_freq_factor;
calculate_default_inv_freq(config)
.into_iter()
.map(|freq| {
let wavelen = 2. * PI / freq;
if wavelen < high_freq_wavelen {
freq
} else if wavelen > low_freq_wavelen {
freq / rope_scaling.factor
} else {
let smooth = (rope_scaling.original_max_position_embeddings as f32
/ wavelen
- rope_scaling.low_freq_factor)
/ (rope_scaling.high_freq_factor - rope_scaling.low_freq_factor);
(1. - smooth) * freq / rope_scaling.factor + smooth * freq
}
})
.collect::<Vec<_>>()
}
};
let theta = Tensor::new(theta, device)?;
let idx_theta = Tensor::arange(0, config.max_position_embeddings as u32, device)?
.to_dtype(DType::F32)?
.reshape((config.max_position_embeddings, 1))?
.matmul(&theta.reshape((1, theta.elem_count()))?)?;
let cos = idx_theta.cos()?.to_dtype(dtype)?;
let sin = idx_theta.sin()?.to_dtype(dtype)?;
Ok(Self {
masks: HashMap::new(),
use_kv_cache,
kvs: vec![None; config.num_hidden_layers],
device: device.clone(),
cos,
sin,
})
}
fn mask(&mut self, t: usize) -> Result<Tensor> {
if let Some(mask) = self.masks.get(&t) {
Ok(mask.clone())
} else {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j > i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), &self.device)?;
self.masks.insert(t, mask.clone());
Ok(mask)
}
}
}
#[derive(Debug, Clone)]
struct CausalSelfAttention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
o_proj: Linear,
num_attention_heads: usize,
num_key_value_heads: usize,
head_dim: usize,
use_flash_attn: bool,
span: tracing::Span,
span_rot: tracing::Span,
max_position_embeddings: usize,
}
#[cfg(feature = "flash-attn")]
fn flash_attn(
q: &Tensor,
k: &Tensor,
v: &Tensor,
softmax_scale: f32,
causal: bool,
) -> Result<Tensor> {
candle_flash_attn::flash_attn(q, k, v, softmax_scale, causal)
}
#[cfg(not(feature = "flash-attn"))]
fn flash_attn(_: &Tensor, _: &Tensor, _: &Tensor, _: f32, _: bool) -> Result<Tensor> {
unimplemented!("compile with '--features flash-attn'")
}
impl CausalSelfAttention {
fn apply_rotary_emb(&self, x: &Tensor, index_pos: usize, cache: &Cache) -> Result<Tensor> {
let _enter = self.span_rot.enter();
let (_b_sz, _, seq_len, _hidden_size) = x.dims4()?;
let cos = cache.cos.narrow(0, index_pos, seq_len)?;
let sin = cache.sin.narrow(0, index_pos, seq_len)?;
candle_nn::rotary_emb::rope(x, &cos, &sin)
}
fn forward(
&self,
x: &Tensor,
index_pos: usize,
block_idx: usize,
cache: &mut Cache,
) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_sz, seq_len, hidden_size) = x.dims3()?;
let q = self.q_proj.forward(x)?;
let k = self.k_proj.forward(x)?;
let v = self.v_proj.forward(x)?;
let q = q
.reshape((b_sz, seq_len, self.num_attention_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let k = k
.reshape((b_sz, seq_len, self.num_key_value_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let mut v = v
.reshape((b_sz, seq_len, self.num_key_value_heads, self.head_dim))?
.transpose(1, 2)?;
let q = self.apply_rotary_emb(&q, index_pos, cache)?;
let mut k = self.apply_rotary_emb(&k, index_pos, cache)?;
if cache.use_kv_cache {
if let Some((cache_k, cache_v)) = &cache.kvs[block_idx] {
k = Tensor::cat(&[cache_k, &k], 2)?.contiguous()?;
v = Tensor::cat(&[cache_v, &v], 2)?.contiguous()?;
let k_seq_len = k.dims()[1];
if k_seq_len > self.max_position_embeddings {
k = k
.narrow(
D::Minus1,
k_seq_len - self.max_position_embeddings,
self.max_position_embeddings,
)?
.contiguous()?
}
let v_seq_len = v.dims()[1];
if v_seq_len > 2 * self.max_position_embeddings {
v = v
.narrow(
D::Minus1,
v_seq_len - self.max_position_embeddings,
self.max_position_embeddings,
)?
.contiguous()?
}
}
cache.kvs[block_idx] = Some((k.clone(), v.clone()))
}
let k = self.repeat_kv(k)?;
let v = self.repeat_kv(v)?;
let y = if self.use_flash_attn {
// flash-attn expects (b_sz, seq_len, nheads, head_dim)
let q = q.transpose(1, 2)?;
let k = k.transpose(1, 2)?;
let v = v.transpose(1, 2)?;
let softmax_scale = 1f32 / (self.head_dim as f32).sqrt();
flash_attn(&q, &k, &v, softmax_scale, seq_len > 1)?.transpose(1, 2)?
} else {
let in_dtype = q.dtype();
let q = q.to_dtype(DType::F32)?;
let k = k.to_dtype(DType::F32)?;
let v = v.to_dtype(DType::F32)?;
let att = (q.matmul(&k.t()?)? / (self.head_dim as f64).sqrt())?;
let att = if seq_len == 1 {
att
} else {
let mask = cache.mask(seq_len)?.broadcast_as(att.shape())?;
masked_fill(&att, &mask, f32::NEG_INFINITY)?
};
let att = candle_nn::ops::softmax(&att, D::Minus1)?;
// Convert to contiguous as matmul doesn't support strided vs for now.
att.matmul(&v.contiguous()?)?.to_dtype(in_dtype)?
};
let y = y.transpose(1, 2)?.reshape(&[b_sz, seq_len, hidden_size])?;
let y = self.o_proj.forward(&y)?;
Ok(y)
}
fn repeat_kv(&self, x: Tensor) -> Result<Tensor> {
crate::utils::repeat_kv(x, self.num_attention_heads / self.num_key_value_heads)
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "attn");
let span_rot = tracing::span!(tracing::Level::TRACE, "attn-rot");
let size_in = cfg.hidden_size;
let size_q = (cfg.hidden_size / cfg.num_attention_heads) * cfg.num_attention_heads;
let size_kv = (cfg.hidden_size / cfg.num_attention_heads) * cfg.num_key_value_heads;
let q_proj = linear(size_in, size_q, vb.pp("q_proj"))?;
let k_proj = linear(size_in, size_kv, vb.pp("k_proj"))?;
let v_proj = linear(size_in, size_kv, vb.pp("v_proj"))?;
let o_proj = linear(size_q, size_in, vb.pp("o_proj"))?;
Ok(Self {
q_proj,
k_proj,
v_proj,
o_proj,
num_attention_heads: cfg.num_attention_heads,
num_key_value_heads: cfg.num_key_value_heads,
head_dim: cfg.hidden_size / cfg.num_attention_heads,
use_flash_attn: cfg.use_flash_attn,
span,
span_rot,
max_position_embeddings: cfg.max_position_embeddings,
})
}
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: f32) -> Result<Tensor> {
let shape = mask.shape();
let on_true = Tensor::new(on_true, on_false.device())?.broadcast_as(shape.dims())?;
let m = mask.where_cond(&on_true, on_false)?;
Ok(m)
}
#[derive(Debug, Clone)]
struct Mlp {
c_fc1: Linear,
c_fc2: Linear,
c_proj: Linear,
span: tracing::Span,
}
impl Mlp {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let x = (candle_nn::ops::silu(&self.c_fc1.forward(x)?)? * self.c_fc2.forward(x)?)?;
self.c_proj.forward(&x)
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "mlp");
let h_size = cfg.hidden_size;
let i_size = cfg.intermediate_size;
let c_fc1 = linear(h_size, i_size, vb.pp("gate_proj"))?;
let c_fc2 = linear(h_size, i_size, vb.pp("up_proj"))?;
let c_proj = linear(i_size, h_size, vb.pp("down_proj"))?;
Ok(Self {
c_fc1,
c_fc2,
c_proj,
span,
})
}
}
#[derive(Debug, Clone)]
struct Block {
rms_1: RmsNorm,
attn: CausalSelfAttention,
rms_2: RmsNorm,
mlp: Mlp,
span: tracing::Span,
}
impl Block {
fn forward(
&self,
x: &Tensor,
index_pos: usize,
block_idx: usize,
cache: &mut Cache,
) -> Result<Tensor> {
let _enter = self.span.enter();
let residual = x;
let x = self.rms_1.forward(x)?;
let x = (self.attn.forward(&x, index_pos, block_idx, cache)? + residual)?;
let residual = &x;
let x = (self.mlp.forward(&self.rms_2.forward(&x)?)? + residual)?;
Ok(x)
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "block");
let attn = CausalSelfAttention::load(vb.pp("self_attn"), cfg)?;
let mlp = Mlp::load(vb.pp("mlp"), cfg)?;
let rms_1 = RmsNorm::new(cfg.hidden_size, cfg.rms_norm_eps, vb.pp("input_layernorm"))?;
let rms_2 = RmsNorm::new(
cfg.hidden_size,
cfg.rms_norm_eps,
vb.pp("post_attention_layernorm"),
)?;
Ok(Self {
rms_1,
attn,
rms_2,
mlp,
span,
})
}
}
#[derive(Debug, Clone)]
pub struct Granite {
wte: Embedding,
blocks: Vec<Block>,
ln_f: RmsNorm,
lm_head: Linear,
}
impl Granite {
pub fn forward(&self, x: &Tensor, index_pos: usize, cache: &mut Cache) -> Result<Tensor> {
let (_b_sz, seq_len) = x.dims2()?;
let mut x = self.wte.forward(x)?;
for (block_idx, block) in self.blocks.iter().enumerate() {
x = block.forward(&x, index_pos, block_idx, cache)?;
}
let x = self.ln_f.forward(&x)?;
let x = x.i((.., seq_len - 1, ..))?.contiguous()?;
let logits = self.lm_head.forward(&x)?;
logits.to_dtype(DType::F32)
}
pub fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let wte = embedding(cfg.vocab_size, cfg.hidden_size, vb.pp("model.embed_tokens"))?;
let lm_head = linear(cfg.hidden_size, cfg.vocab_size, vb.pp("lm_head"))?;
let ln_f = RmsNorm::new(cfg.hidden_size, cfg.rms_norm_eps, vb.pp("model.norm"))?;
let blocks: Vec<_> = (0..cfg.num_hidden_layers)
.map(|i| Block::load(vb.pp(format!("model.layers.{i}")), cfg).unwrap())
.collect();
Ok(Self {
wte,
blocks,
ln_f,
lm_head,
})
}
}
| 0 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/rwkv_v6.rs | //! RWKV v6 model implementation.
//!
//! The [RWKV model](https://wiki.rwkv.com/) is a recurrent neural network model
//! with performance on par with transformer architectures. Several variants are
//! available, candle implements the v5 and v6 versions and can be used with
//! Eagle 7B([blog post](https://blog.rwkv.com/p/eagle-7b-soaring-past-transformers)).
//!
//! Key characteristics:
//! - Linear attention mechanism
//! - Time-mixing for temporal dependencies
//! - Group normalization
//! - Feed forward gating
//! - State recycling for efficient inference
//!
//! # Example
//!
//! ```bash
//! cargo run --example rwkv --release -- \
//! --prompt "The smallest prime is "
//!
//! > avx: true, neon: false, simd128: false, f16c: true
//! > temp: 0.00 repeat-penalty: 1.10 repeat-last-n: 64
//! > The smallest prime is ϕ(2) = 2.
//! > The smallest composite is ϕ(3) = 3.
//! > The smallest perfect number is ϕ(5) = 5.
//! > The smallest perfect square is ϕ(4) = 4.
//! > The smallest perfect cube is ϕ(6) = 6.
//! ```
use super::with_tracing::{layer_norm, linear_no_bias as linear, LayerNorm, Linear};
use candle::{IndexOp, Result, Tensor};
use candle_nn::{embedding, Embedding, Module, VarBuilder};
pub use crate::models::rwkv_v5::{Config, State, Tokenizer};
#[derive(Debug, Clone)]
struct SelfAttention {
key: Linear,
receptance: Linear,
value: Linear,
gate: Linear,
output: Linear,
ln_x: candle_nn::GroupNorm,
time_mix_x: Tensor,
time_mix_w: Tensor,
time_mix_key: Tensor,
time_mix_value: Tensor,
time_mix_receptance: Tensor,
time_decay: Tensor,
time_faaaa: Tensor,
time_mix_gate: Tensor,
time_decay_w1: Tensor,
time_decay_w2: Tensor,
time_mix_w1: Tensor,
time_mix_w2: Tensor,
layer_id: usize,
n_attn_heads: usize,
}
impl SelfAttention {
fn new(layer_id: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_size = cfg.hidden_size;
let attn_hidden_size = cfg.attention_hidden_size;
let key = linear(hidden_size, attn_hidden_size, vb.pp("key"))?;
let receptance = linear(hidden_size, attn_hidden_size, vb.pp("receptance"))?;
let value = linear(hidden_size, attn_hidden_size, vb.pp("value"))?;
let gate = linear(hidden_size, attn_hidden_size, vb.pp("gate"))?;
let output = linear(attn_hidden_size, hidden_size, vb.pp("output"))?;
let ln_x = candle_nn::group_norm(
hidden_size / cfg.head_size,
hidden_size,
1e-5,
vb.pp("ln_x"),
)?;
let time_mix_x = vb.get((1, 1, cfg.hidden_size), "time_mix_x")?;
let time_mix_w = vb.get((1, 1, cfg.hidden_size), "time_mix_w")?;
let time_mix_key = vb.get((1, 1, cfg.hidden_size), "time_mix_key")?;
let time_mix_value = vb.get((1, 1, cfg.hidden_size), "time_mix_value")?;
let time_mix_receptance = vb.get((1, 1, cfg.hidden_size), "time_mix_receptance")?;
let n_attn_heads = cfg.hidden_size / cfg.head_size;
let time_decay = vb.get((1, 1, cfg.hidden_size), "time_decay")?;
let time_faaaa = vb.get((n_attn_heads, cfg.head_size), "time_faaaa")?;
let time_mix_gate = vb.get((1, 1, cfg.hidden_size), "time_mix_gate")?;
let time_decay_w1 = vb.get((cfg.hidden_size, n_attn_heads * 2), "time_decay_w1")?;
let time_decay_w2 = vb.get((n_attn_heads * 2, cfg.hidden_size), "time_decay_w2")?;
let time_mix_w1 = vb.get((cfg.hidden_size, n_attn_heads * 5), "time_mix_w1")?;
let time_mix_w2 = vb.get((5, n_attn_heads, cfg.hidden_size), "time_mix_w2")?;
Ok(Self {
key,
value,
receptance,
gate,
output,
ln_x,
time_mix_x,
time_mix_w,
time_mix_key,
time_mix_value,
time_mix_receptance,
time_decay,
time_faaaa,
time_mix_gate,
time_decay_w1,
time_decay_w2,
time_mix_w1,
time_mix_w2,
layer_id,
n_attn_heads,
})
}
pub fn forward(&self, xs: &Tensor, state: &mut State) -> Result<Tensor> {
let h = self.n_attn_heads;
let (b, t, s) = xs.dims3()?;
let s = s / h;
let (receptance, key, value, gate, w) = {
// extract key-value
let shifted = state.per_layer[self.layer_id].extract_key_value.clone();
let shifted = if shifted.rank() == 2 {
shifted.unsqueeze(1)?
} else {
shifted
};
let sx = (&shifted - xs)?;
let xxx = (xs + &sx * &self.time_mix_x)?;
let xxx = xxx
.broadcast_matmul(&self.time_mix_w1)?
.tanh()?
.reshape((b * t, 5, ()))?
.transpose(0, 1)?;
let xxx = xxx.matmul(&self.time_mix_w2)?.reshape((5, b, t, ()))?;
let (mw, mk, mv, mr, mg) = (xxx.i(0)?, xxx.i(1)?, xxx.i(2)?, xxx.i(3)?, xxx.i(4)?);
let xw = (xs + &sx * (&self.time_mix_w + &mw)?)?;
let xk = (xs + &sx * (&self.time_mix_key + &mk)?)?;
let xv = (xs + &sx * (&self.time_mix_value + &mv)?)?;
let xr = (xs + &sx * (&self.time_mix_receptance + &mr)?)?;
let xg = (xs + &sx * (&self.time_mix_gate + &mg)?)?;
let w = (&self.time_decay
+ xw.broadcast_matmul(&self.time_decay_w1)?
.tanh()?
.broadcast_matmul(&self.time_decay_w2)?)?
.reshape(((), 1, 1))?
.reshape((self.n_attn_heads, (), 1))?;
let key = self.key.forward(&xk)?;
let value = self.value.forward(&xv)?;
let receptance = self.receptance.forward(&xr)?;
let gate = candle_nn::ops::silu(&self.gate.forward(&xg)?)?;
state.per_layer[self.layer_id].extract_key_value = xs.i((.., t - 1))?;
(receptance, key, value, gate, w)
};
// linear attention
let mut state_ = state.per_layer[self.layer_id].linear_attention.clone();
let key = key.reshape((b, t, h, s))?.permute((0, 2, 3, 1))?;
let value = value.reshape((b, t, h, s))?.transpose(1, 2)?;
let receptance = receptance.reshape((b, t, h, s))?.transpose(1, 2)?;
let w = w.exp()?.neg()?.exp()?;
let time_faaaa =
self.time_faaaa
.reshape(((), 1, 1))?
.reshape((self.n_attn_heads, (), 1))?;
let mut out: Vec<Tensor> = Vec::with_capacity(t);
for t_ in 0..t {
let rt = receptance.i((.., .., t_..t_ + 1))?.contiguous()?;
let kt = key.i((.., .., .., t_..t_ + 1))?.contiguous()?;
let vt = value.i((.., .., t_..t_ + 1))?.contiguous()?;
let at = kt.matmul(&vt)?;
let rhs = (time_faaaa.broadcast_mul(&at)? + &state_)?;
let out_ = rt.matmul(&rhs)?.squeeze(2)?;
state_ = (&at + w.broadcast_mul(&state_))?;
out.push(out_)
}
let out = Tensor::cat(&out, 1)?.reshape((b * t, h * s, 1))?;
let out = out.apply(&self.ln_x)?.reshape((b, t, h * s))?;
let out = (out * gate)?.apply(&self.output)?;
state.per_layer[self.layer_id].linear_attention = state_;
Ok(out)
}
}
#[derive(Debug, Clone)]
struct FeedForward {
time_mix_key: Tensor,
time_mix_receptance: Tensor,
key: Linear,
receptance: Linear,
value: Linear,
layer_id: usize,
}
impl FeedForward {
fn new(layer_id: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let int_size = cfg
.intermediate_size
.unwrap_or(((cfg.hidden_size as f64 * 3.5) as usize) / 32 * 32);
let key = linear(cfg.hidden_size, int_size, vb.pp("key"))?;
let receptance = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("receptance"))?;
let value = linear(int_size, cfg.hidden_size, vb.pp("value"))?;
let time_mix_key = vb.get((1, 1, cfg.hidden_size), "time_mix_key")?;
let time_mix_receptance = vb.get((1, 1, cfg.hidden_size), "time_mix_receptance")?;
Ok(Self {
key,
receptance,
value,
time_mix_key,
time_mix_receptance,
layer_id,
})
}
fn forward(&self, xs: &Tensor, state: &mut State) -> Result<Tensor> {
let shifted = state.per_layer[self.layer_id]
.feed_forward
.broadcast_sub(xs)?;
let key = (xs + shifted.broadcast_mul(&self.time_mix_key)?)?;
let receptance = (xs + shifted.broadcast_mul(&self.time_mix_receptance)?)?;
let key = key.apply(&self.key)?.relu()?.sqr()?;
let value = key.apply(&self.value)?;
let receptance = candle_nn::ops::sigmoid(&receptance.apply(&self.receptance)?)?;
state.per_layer[self.layer_id].feed_forward = xs.i((.., xs.dim(1)? - 1))?;
let xs = (receptance * value)?;
Ok(xs)
}
}
#[derive(Debug, Clone)]
struct Block {
pre_ln: Option<LayerNorm>,
ln1: LayerNorm,
ln2: LayerNorm,
attention: SelfAttention,
feed_forward: FeedForward,
}
impl Block {
fn new(layer_id: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let ln1 = layer_norm(cfg.hidden_size, cfg.layer_norm_epsilon, vb.pp("ln1"))?;
let ln2 = layer_norm(cfg.hidden_size, cfg.layer_norm_epsilon, vb.pp("ln2"))?;
let pre_ln = if layer_id == 0 {
let ln = layer_norm(cfg.hidden_size, cfg.layer_norm_epsilon, vb.pp("pre_ln"))?;
Some(ln)
} else {
None
};
let attention = SelfAttention::new(layer_id, cfg, vb.pp("attention"))?;
let feed_forward = FeedForward::new(layer_id, cfg, vb.pp("feed_forward"))?;
Ok(Self {
pre_ln,
ln1,
ln2,
attention,
feed_forward,
})
}
fn forward(&self, xs: &Tensor, state: &mut State) -> Result<Tensor> {
let xs = match self.pre_ln.as_ref() {
None => xs.clone(),
Some(pre_ln) => xs.apply(pre_ln)?,
};
let attention = self.attention.forward(&xs.apply(&self.ln1)?, state)?;
let xs = (xs + attention)?;
let feed_forward = self.feed_forward.forward(&xs.apply(&self.ln2)?, state)?;
let xs = (xs + feed_forward)?;
Ok(xs)
}
}
#[derive(Debug, Clone)]
pub struct Model {
embeddings: Embedding,
blocks: Vec<Block>,
ln_out: LayerNorm,
head: Linear,
rescale_every: usize,
layers_are_rescaled: bool,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_m = vb.pp("rwkv");
let embeddings = embedding(cfg.vocab_size, cfg.hidden_size, vb_m.pp("embeddings"))?;
let mut blocks = Vec::with_capacity(cfg.num_hidden_layers);
let vb_b = vb_m.pp("blocks");
for block_index in 0..cfg.num_hidden_layers {
let block = Block::new(block_index, cfg, vb_b.pp(block_index))?;
blocks.push(block)
}
let ln_out = layer_norm(cfg.hidden_size, 1e-5, vb_m.pp("ln_out"))?;
let head = linear(cfg.hidden_size, cfg.vocab_size, vb.pp("head"))?;
Ok(Self {
embeddings,
blocks,
ln_out,
head,
rescale_every: cfg.rescale_every,
layers_are_rescaled: false, // This seem to only happen for the f16/bf16 dtypes.
})
}
pub fn forward(&self, xs: &Tensor, state: &mut State) -> Result<Tensor> {
let (_b_size, _seq_len) = xs.dims2()?;
let mut xs = xs.apply(&self.embeddings)?;
for (block_idx, block) in self.blocks.iter().enumerate() {
xs = block.forward(&xs, state)?;
if self.layers_are_rescaled && (block_idx + 1) % self.rescale_every == 0 {
xs = (xs / 2.)?
}
}
let xs = xs.apply(&self.ln_out)?.apply(&self.head)?;
state.pos += 1;
Ok(xs)
}
}
| 1 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/quantized_phi3.rs | //! Phi3 model implementation with quantization support.
//!
//! Phi3 is a language model intended for research purposes.
//! This implementation provides quantization for reduced memory usage.
//!
//! Key characteristics:
//! - Multi-head attention
//! - RMSNorm for layer normalization
//! - Rotary positional embeddings (RoPE)
//! - Support for quantization
//!
//! References:
//! - [Model Card](https://huggingface.co/microsoft/phi-3)
//!
use std::collections::HashMap;
use candle::quantized::gguf_file;
use candle::quantized::QTensor;
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
use candle_nn::{kv_cache::KvCache, Embedding, RmsNorm};
#[derive(Debug, Clone)]
struct QLinear {
inner: candle::quantized::QMatMul,
span: tracing::Span,
}
impl QLinear {
fn new<R: std::io::Read + std::io::Seek>(
ct: &gguf_file::Content,
r: &mut R,
name: &str,
device: &Device,
) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "qmatmul");
let w = ct.tensor(r, &format!("{name}.weight"), device)?;
let inner = candle::quantized::QMatMul::from_qtensor(w)?;
Ok(Self { inner, span })
}
}
impl Module for QLinear {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
self.inner.forward(xs)
}
}
#[derive(Debug, Clone)]
struct Mlp {
ffn_up: QLinear,
ffn_down: QLinear,
i_size: usize,
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let up_states = xs.apply(&self.ffn_up)?;
let gate = up_states.narrow(D::Minus1, 0, self.i_size)?;
let up_states = up_states.narrow(D::Minus1, self.i_size, self.i_size)?;
let up_states = (up_states * gate.silu()?)?;
up_states.apply(&self.ffn_down)
}
}
fn rms_norm(w: QTensor, eps: f64) -> Result<RmsNorm> {
let w = w.dequantize(&w.device())?;
let rms = RmsNorm::new(w, eps);
Ok(rms)
}
#[derive(Debug, Clone)]
struct LayerWeights {
attn_qkv: QLinear,
attn_output: QLinear,
attn_norm: RmsNorm,
ffn_norm: RmsNorm,
mlp: Mlp,
n_head: usize,
n_kv_head: usize,
head_dim: usize,
cos: Tensor,
sin: Tensor,
neg_inf: Tensor,
kv_cache: KvCache,
use_flash_attn: bool,
span_attn: tracing::Span,
span_rot: tracing::Span,
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: &Tensor) -> Result<Tensor> {
let shape = mask.shape();
let m = mask.where_cond(&on_true.broadcast_as(shape.dims())?, on_false)?;
Ok(m)
}
impl LayerWeights {
fn apply_rotary_emb(&self, xs: &Tensor, index_pos: usize) -> Result<Tensor> {
let _enter = self.span_rot.enter();
let (_b_sz, _h, seq_len, _n_embd) = xs.dims4()?;
let cos = self.cos.narrow(0, index_pos, seq_len)?;
let sin = self.sin.narrow(0, index_pos, seq_len)?;
candle_nn::rotary_emb::rope(&xs.contiguous()?, &cos, &sin)
}
fn forward_attn(
&mut self,
x: &Tensor,
mask: Option<&Tensor>,
index_pos: usize,
) -> Result<Tensor> {
let _enter = self.span_attn.enter();
let (b_sz, seq_len, n_embd) = x.dims3()?;
let qkv = self.attn_qkv.forward(x)?;
let query_pos = self.n_head * self.head_dim;
let q = qkv.narrow(D::Minus1, 0, query_pos)?;
let k = qkv.narrow(D::Minus1, query_pos, self.n_kv_head * self.head_dim)?;
let v = qkv.narrow(
D::Minus1,
query_pos + self.n_kv_head * self.head_dim,
self.n_kv_head * self.head_dim,
)?;
let q = q
.reshape((b_sz, seq_len, self.n_head, self.head_dim))?
.transpose(1, 2)?;
let k = k
.reshape((b_sz, seq_len, self.n_head, self.head_dim))?
.transpose(1, 2)?;
let v = v
.reshape((b_sz, seq_len, self.n_kv_head, self.head_dim))?
.transpose(1, 2)?;
let q = self.apply_rotary_emb(&q, index_pos)?.contiguous()?;
let k = self.apply_rotary_emb(&k, index_pos)?;
let (k, v) = self.kv_cache.append(&k.contiguous()?, &v.contiguous()?)?;
let k = crate::utils::repeat_kv(k, self.n_head / self.n_kv_head)?;
let v = crate::utils::repeat_kv(v, self.n_head / self.n_kv_head)?;
let y = if self.use_flash_attn {
// flash-attn expects (b_sz, seq_len, nheads, head_dim)
let q = q.to_dtype(DType::BF16)?.transpose(1, 2)?;
let k = k.to_dtype(DType::BF16)?.transpose(1, 2)?;
let v = v.to_dtype(DType::BF16)?.transpose(1, 2)?;
let softmax_scale = 1f32 / (self.head_dim as f32).sqrt();
flash_attn(&q, &k, &v, softmax_scale, seq_len > 1)?
.to_dtype(DType::F32)?
.transpose(1, 2)?
} else {
let att = (q.matmul(&k.t()?)? / (self.head_dim as f64).sqrt())?;
let att = match mask {
None => att,
Some(mask) => {
let mask = mask.broadcast_as(att.shape())?;
masked_fill(&att, &mask, &self.neg_inf)?
}
};
let att = candle_nn::ops::softmax_last_dim(&att)?;
// Convert to contiguous as matmul doesn't support strided vs for now.
att.matmul(&v)?
};
let y = y.transpose(1, 2)?.reshape(&[b_sz, seq_len, n_embd])?;
let y = self.attn_output.forward(&y)?;
Ok(y)
}
}
#[cfg(feature = "flash-attn")]
fn flash_attn(
q: &Tensor,
k: &Tensor,
v: &Tensor,
softmax_scale: f32,
causal: bool,
) -> Result<Tensor> {
candle_flash_attn::flash_attn(q, k, v, softmax_scale, causal)
}
#[cfg(not(feature = "flash-attn"))]
fn flash_attn(_: &Tensor, _: &Tensor, _: &Tensor, _: f32, _: bool) -> Result<Tensor> {
unimplemented!("compile with '--features flash-attn'")
}
#[derive(Debug, Clone)]
pub struct ModelWeights {
tok_embeddings: Embedding,
layers: Vec<LayerWeights>,
output_norm: RmsNorm,
output: QLinear,
masks: HashMap<usize, Tensor>,
span: tracing::Span,
span_output: tracing::Span,
}
fn precomput_freqs_cis(
head_dim: usize,
max_seq_len: usize,
freq_base: f32,
device: &Device,
) -> Result<(Tensor, Tensor)> {
let theta: Vec<_> = (0..head_dim)
.step_by(2)
.map(|i| 1f32 / freq_base.powf(i as f32 / head_dim as f32))
.collect();
let theta = Tensor::new(theta.as_slice(), device)?;
let idx_theta = Tensor::arange(0, max_seq_len as u32, device)?
.to_dtype(DType::F32)?
.reshape((max_seq_len, 1))?
.matmul(&theta.reshape((1, theta.elem_count()))?)?;
let cos = idx_theta.cos()?;
let sin = idx_theta.sin()?;
Ok((cos, sin))
}
impl ModelWeights {
pub fn from_gguf<R: std::io::Seek + std::io::Read>(
use_flash_attn: bool,
ct: gguf_file::Content,
reader: &mut R,
device: &Device,
) -> Result<Self> {
let md_get = |s: &str| match ct.metadata.get(s) {
None => candle::bail!("cannot find {s} in metadata"),
Some(v) => Ok(v),
};
// Parameter extraction from metadata.
let head_count = md_get("phi3.attention.head_count")?.to_u32()? as usize;
let head_count_kv = md_get("phi3.attention.head_count_kv")?.to_u32()? as usize;
let block_count = md_get("phi3.block_count")?.to_u32()? as usize;
let embedding_length = md_get("phi3.embedding_length")?.to_u32()? as usize;
let max_seq_len = md_get("phi3.context_length")?.to_u32()? as usize;
let head_dim = embedding_length / head_count;
let i_size = md_get("phi3.feed_forward_length")?.to_u32()? as usize;
let rope_dim = md_get("phi3.rope.dimension_count")?.to_u32()? as usize;
let rms_eps = md_get("phi3.attention.layer_norm_rms_epsilon")?.to_f32()? as f64;
let (cos, sin) = precomput_freqs_cis(rope_dim, max_seq_len, 10_000., device)?;
let neg_inf = Tensor::new(f32::NEG_INFINITY, device)?;
let tok_embeddings = ct.tensor(reader, "token_embd.weight", device)?;
let tok_embeddings = tok_embeddings.dequantize(device)?;
let output_norm = rms_norm(ct.tensor(reader, "output_norm.weight", device)?, rms_eps)?;
let output = QLinear::new(&ct, reader, "output", device)?;
let mut layers = Vec::with_capacity(block_count);
for layer_idx in 0..block_count {
let prefix = format!("blk.{layer_idx}");
let ffn_up = QLinear::new(&ct, reader, &format!("{prefix}.ffn_up"), device)?;
let ffn_down = QLinear::new(&ct, reader, &format!("{prefix}.ffn_down"), device)?;
let mlp = Mlp {
ffn_up,
ffn_down,
i_size,
};
let attn_norm = rms_norm(
ct.tensor(reader, &format!("{prefix}.attn_norm.weight"), device)?,
rms_eps,
)?;
let ffn_norm = rms_norm(
ct.tensor(reader, &format!("{prefix}.ffn_norm.weight"), device)?,
rms_eps,
)?;
let span_attn = tracing::span!(tracing::Level::TRACE, "attn");
let span_rot = tracing::span!(tracing::Level::TRACE, "attn-rot");
let kv_cache = KvCache::new(2, max_seq_len);
layers.push(LayerWeights {
attn_qkv: QLinear::new(&ct, reader, &format!("{prefix}.attn_qkv"), device)?,
attn_output: QLinear::new(&ct, reader, &format!("{prefix}.attn_output"), device)?,
attn_norm,
ffn_norm,
mlp,
n_head: head_count,
n_kv_head: head_count_kv,
head_dim,
cos: cos.clone(),
sin: sin.clone(),
neg_inf: neg_inf.clone(),
kv_cache,
use_flash_attn,
span_attn,
span_rot,
})
}
let span = tracing::span!(tracing::Level::TRACE, "model");
let span_output = tracing::span!(tracing::Level::TRACE, "output");
Ok(Self {
tok_embeddings: Embedding::new(tok_embeddings, embedding_length),
layers,
output_norm,
output,
masks: HashMap::new(),
span,
span_output,
})
}
fn mask(&mut self, t: usize, device: &Device) -> Result<Tensor> {
if let Some(mask) = self.masks.get(&t) {
Ok(mask.clone())
} else {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j > i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), device)?;
self.masks.insert(t, mask.clone());
Ok(mask)
}
}
pub fn forward(&mut self, xs: &Tensor, index_pos: usize) -> Result<Tensor> {
let (_b_sz, seq_len) = xs.dims2()?;
let mask = if seq_len == 1 {
None
} else {
Some(self.mask(seq_len, xs.device())?)
};
let _enter = self.span.enter();
let mut xs = self.tok_embeddings.forward(xs)?;
for layer in self.layers.iter_mut() {
let residual = &xs;
let ys = xs.apply(&layer.attn_norm)?;
let ys = layer.forward_attn(&ys, mask.as_ref(), index_pos)?;
let ys = (ys + residual)?;
let residual = &ys;
let ys = ys.apply(&layer.ffn_norm)?;
let ys = layer.mlp.forward(&ys)?;
xs = (ys + residual)?
}
let xs = xs.apply(&self.output_norm)?.i((.., seq_len - 1, ..))?;
let _enter = self.span_output.enter();
self.output.forward(&xs)
}
}
| 2 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/parler_tts.rs | //! Parler Model implementation for parler_tts text-to-speech synthesis
//!
//! Implements a transformer-based decoder architecture for generating audio tokens
//! from text using discrete tokens. The model converts text into audio segments
//! using multiple codebooks of quantized audio tokens.
//!
//! The model architecture includes:
//! - Multi-head attention layers for text and audio processing
//! - Feed-forward networks
//! - Layer normalization
//! - Positional embeddings
//! - Multiple codebook prediction heads
//!
//! The implementation follows the original parler_tts architecture while focusing
//! on audio token generation for text-to-speech synthesis.
//!
use crate::generation::LogitsProcessor;
use crate::models::t5;
use candle::{IndexOp, Result, Tensor};
use candle_nn::{layer_norm, linear_b as linear, Activation, LayerNorm, Linear, VarBuilder};
#[derive(serde::Deserialize, Debug, Clone)]
pub struct DecoderConfig {
pub vocab_size: usize,
pub max_position_embeddings: usize,
pub num_hidden_layers: usize,
pub ffn_dim: usize,
pub num_attention_heads: usize,
pub num_key_value_heads: Option<usize>,
pub num_cross_attention_key_value_heads: Option<usize>,
pub activation_function: Activation,
pub hidden_size: usize,
pub scale_embedding: bool,
pub num_codebooks: usize,
pub pad_token_id: usize,
pub bos_token_id: usize,
pub eos_token_id: usize,
pub tie_word_embeddings: bool,
pub rope_embeddings: bool,
pub rope_theta: f64,
}
#[derive(serde::Deserialize, Debug, Clone)]
pub struct Config {
pub decoder_start_token_id: u32,
pub pad_token_id: u32,
pub decoder: DecoderConfig,
pub text_encoder: t5::Config,
pub vocab_size: usize,
pub audio_encoder: crate::models::dac::Config,
}
#[derive(Debug, Clone)]
pub struct Attention {
k_proj: Linear,
v_proj: Linear,
q_proj: Linear,
out_proj: Linear,
is_causal: bool,
kv_cache: Option<(Tensor, Tensor)>,
scaling: f64,
num_heads: usize,
num_kv_heads: usize,
num_kv_groups: usize,
head_dim: usize,
}
impl Attention {
fn new(
num_kv_heads: usize,
is_causal: bool,
cfg: &DecoderConfig,
vb: VarBuilder,
) -> Result<Self> {
if cfg.rope_embeddings {
candle::bail!("rope embeddings are not supported");
}
let embed_dim = cfg.hidden_size;
let head_dim = embed_dim / cfg.num_attention_heads;
let kv_out_dim = num_kv_heads * head_dim;
let k_proj = linear(embed_dim, kv_out_dim, false, vb.pp("k_proj"))?;
let v_proj = linear(embed_dim, kv_out_dim, false, vb.pp("v_proj"))?;
let q_proj = linear(embed_dim, embed_dim, false, vb.pp("q_proj"))?;
let out_proj = linear(embed_dim, embed_dim, false, vb.pp("out_proj"))?;
Ok(Self {
k_proj,
v_proj,
q_proj,
out_proj,
is_causal,
kv_cache: None,
scaling: (head_dim as f64).powf(-0.5),
num_heads: cfg.num_attention_heads,
num_kv_heads,
num_kv_groups: cfg.num_attention_heads / num_kv_heads,
head_dim,
})
}
fn forward(
&mut self,
xs: &Tensor,
key_value_states: Option<&Tensor>,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let (b_sz, tgt_len, _) = xs.dims3()?;
let query_states = (xs.apply(&self.q_proj)? * self.scaling)?
.reshape((b_sz, tgt_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let key_states = match key_value_states {
Some(states) => states.apply(&self.k_proj)?,
None => xs.apply(&self.k_proj)?,
};
let key_states = key_states
.reshape((b_sz, (), self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let value_states = match key_value_states {
Some(states) => states.apply(&self.v_proj)?,
None => xs.apply(&self.v_proj)?,
};
let value_states = value_states
.reshape((b_sz, (), self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let (key_states, value_states) = match &self.kv_cache {
None => (key_states, value_states),
Some((prev_k, prev_v)) => {
let key_states = Tensor::cat(&[prev_k, &key_states], 2)?;
let value_states = Tensor::cat(&[prev_v, &value_states], 2)?;
(key_states, value_states)
}
};
if self.is_causal {
self.kv_cache = Some((key_states.clone(), value_states.clone()));
}
let key_states = crate::utils::repeat_kv(key_states, self.num_kv_groups)?.contiguous()?;
let value_states =
crate::utils::repeat_kv(value_states, self.num_kv_groups)?.contiguous()?;
let attn_weights = query_states.matmul(&key_states.transpose(2, 3)?)?;
let attn_weights = match attention_mask {
None => attn_weights,
Some(mask) => attn_weights.broadcast_add(mask)?,
};
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
let attn_output = attn_weights.matmul(&value_states)?;
attn_output
.transpose(1, 2)?
.reshape((b_sz, tgt_len, ()))?
.apply(&self.out_proj)
}
fn clear_kv_cache(&mut self) {
self.kv_cache = None
}
}
#[derive(Debug, Clone)]
pub struct DecoderLayer {
self_attn: Attention,
self_attn_layer_norm: LayerNorm,
encoder_attn: Attention,
encoder_attn_layer_norm: LayerNorm,
fc1: Linear,
fc2: Linear,
final_layer_norm: LayerNorm,
activation: Activation,
}
impl DecoderLayer {
fn new(cfg: &DecoderConfig, vb: VarBuilder) -> Result<Self> {
let kv_heads = cfg.num_key_value_heads.unwrap_or(cfg.num_attention_heads);
let kv_heads_cross = cfg.num_cross_attention_key_value_heads.unwrap_or(kv_heads);
let self_attn = Attention::new(kv_heads, true, cfg, vb.pp("self_attn"))?;
let encoder_attn = Attention::new(kv_heads_cross, false, cfg, vb.pp("encoder_attn"))?;
let self_attn_layer_norm =
layer_norm(cfg.hidden_size, 1e-5, vb.pp("self_attn_layer_norm"))?;
let encoder_attn_layer_norm =
layer_norm(cfg.hidden_size, 1e-5, vb.pp("encoder_attn_layer_norm"))?;
let fc1 = linear(cfg.hidden_size, cfg.ffn_dim, false, vb.pp("fc1"))?;
let fc2 = linear(cfg.ffn_dim, cfg.hidden_size, false, vb.pp("fc2"))?;
let final_layer_norm = layer_norm(cfg.hidden_size, 1e-5, vb.pp("final_layer_norm"))?;
Ok(Self {
self_attn,
self_attn_layer_norm,
encoder_attn,
encoder_attn_layer_norm,
fc1,
fc2,
final_layer_norm,
activation: cfg.activation_function,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
encoder_xs: &Tensor,
encoder_attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
// Self attention
let residual = xs;
let xs = xs.apply(&self.self_attn_layer_norm)?;
let xs = self.self_attn.forward(&xs, None, attention_mask)?;
let xs = (residual + xs)?;
// Cross attention
let residual = &xs;
let xs = xs.apply(&self.encoder_attn_layer_norm)?;
let xs = self
.encoder_attn
.forward(&xs, Some(encoder_xs), encoder_attention_mask)?;
let xs = (residual + xs)?;
// Fully connected
let residual = &xs;
let xs = xs
.apply(&self.final_layer_norm)?
.apply(&self.fc1)?
.apply(&self.activation)?
.apply(&self.fc2)?;
residual + xs
}
fn clear_kv_cache(&mut self) {
self.self_attn.clear_kv_cache();
self.encoder_attn.clear_kv_cache();
}
}
#[derive(Debug, Clone)]
pub struct Decoder {
embed_tokens: Vec<candle_nn::Embedding>,
embed_positions: Tensor,
layers: Vec<DecoderLayer>,
layer_norm: LayerNorm,
num_codebooks: usize,
hidden_size: usize,
lm_heads: Vec<Linear>,
dtype: candle::DType,
}
impl Decoder {
pub fn new(cfg: &DecoderConfig, vb: VarBuilder) -> Result<Self> {
let vb_d = vb.pp("model.decoder");
let mut embed_tokens = Vec::with_capacity(cfg.num_codebooks);
let vb_e = vb_d.pp("embed_tokens");
for embed_idx in 0..cfg.num_codebooks {
let e = candle_nn::embedding(cfg.vocab_size + 1, cfg.hidden_size, vb_e.pp(embed_idx))?;
embed_tokens.push(e)
}
let embed_positions = vb_d.get(
(cfg.max_position_embeddings, cfg.hidden_size),
"embed_positions.weights",
)?;
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb_l = vb_d.pp("layers");
for layer_idx in 0..cfg.num_hidden_layers {
let layer = DecoderLayer::new(cfg, vb_l.pp(layer_idx))?;
layers.push(layer)
}
let layer_norm = layer_norm(cfg.hidden_size, 1e-5, vb_d.pp("layer_norm"))?;
let mut lm_heads = Vec::with_capacity(cfg.num_codebooks);
let vb_l = vb.pp("lm_heads");
for lm_idx in 0..cfg.num_codebooks {
let lm_head = linear(cfg.hidden_size, cfg.vocab_size, false, vb_l.pp(lm_idx))?;
lm_heads.push(lm_head)
}
Ok(Self {
embed_tokens,
embed_positions,
layers,
layer_norm,
num_codebooks: cfg.num_codebooks,
lm_heads,
hidden_size: cfg.hidden_size,
dtype: vb.dtype(),
})
}
pub fn forward(
&mut self,
input_ids: &Tensor,
prompt_hidden_states: Option<&Tensor>,
attention_mask: Option<&Tensor>,
encoder_xs: &Tensor,
encoder_attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Vec<Tensor>> {
let (b_sz, num_codebooks, seq_len) = input_ids.dims3()?;
if num_codebooks != self.num_codebooks {
candle::bail!("unexpected num codebooks in input {:?}", input_ids.shape())
}
let mut inputs_embeds = Tensor::zeros(
(b_sz, seq_len, self.hidden_size),
self.dtype,
input_ids.device(),
)?;
for (idx, embs) in self.embed_tokens.iter().enumerate() {
let e = input_ids.i((.., idx))?.apply(embs)?;
inputs_embeds = (inputs_embeds + e)?
}
let inputs_embeds = match prompt_hidden_states {
None => inputs_embeds,
Some(pis) => Tensor::cat(&[pis, &inputs_embeds], 1)?,
};
let embed_positions = self
.embed_positions
.i(seqlen_offset..seqlen_offset + inputs_embeds.dim(1)?)?;
let mut xs = (inputs_embeds + embed_positions.unsqueeze(0))?;
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, attention_mask, encoder_xs, encoder_attention_mask)?;
}
let xs = xs.apply(&self.layer_norm)?;
let mut lm_logits = Vec::with_capacity(self.num_codebooks);
for lm_head in self.lm_heads.iter() {
let logits = xs.apply(lm_head)?;
lm_logits.push(logits)
}
Ok(lm_logits)
}
pub fn clear_kv_cache(&mut self) {
for layer in self.layers.iter_mut() {
layer.clear_kv_cache()
}
}
}
#[derive(Debug, Clone)]
pub struct Model {
pub embed_prompts: candle_nn::Embedding,
pub enc_to_dec_proj: Option<Linear>,
pub decoder: Decoder,
pub text_encoder: t5::T5EncoderModel,
pub decoder_start_token_id: u32,
pub pad_token_id: u32,
pub audio_encoder: crate::models::dac::Model,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let text_encoder = t5::T5EncoderModel::load(vb.pp("text_encoder"), &cfg.text_encoder)?;
let decoder = Decoder::new(&cfg.decoder, vb.pp("decoder"))?;
let embed_prompts = candle_nn::embedding(
cfg.vocab_size,
cfg.decoder.hidden_size,
vb.pp("embed_prompts"),
)?;
let enc_to_dec_proj = if cfg.text_encoder.d_model != cfg.decoder.hidden_size {
let proj = linear(
cfg.text_encoder.d_model,
cfg.decoder.hidden_size,
true,
vb.pp("enc_to_dec_proj"),
)?;
Some(proj)
} else {
None
};
let audio_encoder =
crate::models::dac::Model::new(&cfg.audio_encoder, vb.pp("audio_encoder"))?;
Ok(Self {
decoder,
text_encoder,
embed_prompts,
enc_to_dec_proj,
decoder_start_token_id: cfg.decoder_start_token_id,
pad_token_id: cfg.pad_token_id,
audio_encoder,
})
}
/// Note that the returned tensor uses the CPU device.
pub fn generate(
&mut self,
prompt_tokens: &Tensor,
description_tokens: &Tensor,
mut lp: LogitsProcessor,
max_steps: usize,
) -> Result<Tensor> {
self.decoder.clear_kv_cache();
self.text_encoder.clear_kv_cache();
let encoded = self.text_encoder.forward(description_tokens)?;
let encoded = match self.enc_to_dec_proj.as_ref() {
None => encoded,
Some(proj) => encoded.apply(proj)?,
};
let prompt_hidden_states = prompt_tokens.apply(&self.embed_prompts)?;
let num_codebooks = self.decoder.num_codebooks;
let mut audio_tokens = vec![self.decoder_start_token_id; num_codebooks];
let mut all_audio_tokens = vec![vec![]; num_codebooks];
let prompt_len = prompt_hidden_states.dim(1)?;
for step in 0..max_steps {
let input_ids = Tensor::from_slice(
audio_tokens.as_slice(),
(1, num_codebooks, 1),
prompt_tokens.device(),
)?;
let (prompt_hidden_states, pos) = if step == 0 {
(Some(&prompt_hidden_states), 0)
} else {
(None, step + prompt_len)
};
let causal_mask = if pos == 0 {
self.prepare_causal_mask(prompt_len + 1, prompt_len + 1, input_ids.device())?
} else {
self.prepare_causal_mask(1, pos + 1, input_ids.device())?
};
let logits = self.decoder.forward(
&input_ids,
prompt_hidden_states,
Some(&causal_mask),
&encoded,
None,
pos,
)?;
for (logit_idx, logit) in logits.iter().enumerate() {
if logit_idx > step {
break;
}
if audio_tokens[logit_idx] != self.pad_token_id {
let logit = logit.i((0, logit.dim(1)? - 1))?;
let token = lp.sample(&logit)?;
audio_tokens[logit_idx] = token
}
}
if audio_tokens.iter().all(|v| v == &self.pad_token_id) {
break;
}
for (cb_idx, &token) in audio_tokens.iter().enumerate() {
if token != self.decoder_start_token_id && token != self.pad_token_id {
all_audio_tokens[cb_idx].push(token)
}
}
}
let min_len = all_audio_tokens.iter().map(|v| v.len()).min().unwrap_or(0);
all_audio_tokens.iter_mut().for_each(|v| {
v.resize(min_len, 0);
});
let all_audio_tokens = Tensor::new(all_audio_tokens, &candle::Device::Cpu)?;
Ok(all_audio_tokens)
}
fn prepare_causal_mask(
&self,
q_len: usize,
kv_len: usize,
device: &candle::Device,
) -> Result<Tensor> {
let mask: Vec<_> = (0..q_len)
.flat_map(|i| {
(0..kv_len).map(move |j| {
if i + kv_len < j + q_len {
f32::NEG_INFINITY
} else {
0.
}
})
})
.collect();
Tensor::from_slice(&mask, (q_len, kv_len), device)
}
}
| 3 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/fastvit.rs | //! # FastViT inference implementation based on timm
//!
//! ## Description
//! See ["FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization"](https://arxiv.org/pdf/2303.14189)
//!
//! Implementation based on [timm model](https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/fastvit.py)
use candle::{DType, Result, Tensor, D};
use candle_nn::{
batch_norm, conv2d, conv2d_no_bias, linear, linear_no_bias, ops::sigmoid, ops::softmax,
BatchNorm, Conv2d, Conv2dConfig, Func, VarBuilder,
};
#[derive(serde::Serialize, serde::Deserialize, Clone, Debug)]
pub struct Config {
pub exp_ratio: usize,
pub in_channels: usize,
pub blocks: [usize; 4],
pub attn: bool,
pub lkc_use_act: bool,
}
impl Config {
pub fn t8() -> Self {
Self {
exp_ratio: 3,
in_channels: 48,
blocks: [2, 2, 4, 2],
attn: false,
lkc_use_act: false,
}
}
pub fn t12() -> Self {
Self {
exp_ratio: 3,
in_channels: 64,
blocks: [2, 2, 6, 2],
attn: false,
lkc_use_act: false,
}
}
pub fn s12() -> Self {
Self {
exp_ratio: 4,
in_channels: 64,
blocks: [2, 2, 6, 2],
attn: false,
lkc_use_act: false,
}
}
pub fn sa12() -> Self {
Self {
exp_ratio: 4,
in_channels: 64,
blocks: [2, 2, 6, 2],
attn: true,
lkc_use_act: false,
}
}
pub fn sa24() -> Self {
Self {
exp_ratio: 4,
in_channels: 64,
blocks: [4, 4, 12, 4],
attn: true,
lkc_use_act: false,
}
}
pub fn sa36() -> Self {
Self {
exp_ratio: 4,
in_channels: 64,
blocks: [6, 6, 18, 6],
attn: true,
lkc_use_act: false,
}
}
pub fn ma36() -> Self {
Self {
exp_ratio: 4,
in_channels: 76,
blocks: [6, 6, 18, 6],
attn: true,
lkc_use_act: false,
}
}
// configs used by MobileCLIP's image encoder
pub fn mci0() -> Self {
Self {
exp_ratio: 3,
in_channels: 64,
blocks: [2, 6, 10, 2],
attn: true,
lkc_use_act: true,
}
}
pub fn mci1() -> Self {
Self {
exp_ratio: 3,
in_channels: 64,
blocks: [4, 12, 20, 4],
attn: true,
lkc_use_act: true,
}
}
pub fn mci2() -> Self {
Self {
exp_ratio: 3,
in_channels: 80,
blocks: [4, 12, 24, 4],
attn: true,
lkc_use_act: true,
}
}
}
fn conv_norm(
in_channels: usize,
out_channels: usize,
kernel: usize,
stride: usize,
vb: VarBuilder,
) -> Result<Func<'static>> {
let conv2d_cfg = Conv2dConfig {
stride,
padding: kernel / 2,
groups: in_channels,
..Default::default()
};
let bn = batch_norm(out_channels, 1e-5, vb.pp("bn"))?;
let conv = conv2d_no_bias(in_channels, out_channels, kernel, conv2d_cfg, vb.pp("conv"))?;
let conv = conv.absorb_bn(&bn)?;
Ok(Func::new(move |xs| {
let xs = xs.apply(&conv)?;
Ok(xs)
}))
}
fn conv_mlp(dim: usize, exp_ratio: usize, vb: VarBuilder) -> Result<Func<'static>> {
let conv2d_cfg = Conv2dConfig {
..Default::default()
};
let conv = conv_norm(dim, dim, 7, 1, vb.pp("conv"))?;
let fc1 = conv2d(dim, dim * exp_ratio, 1, conv2d_cfg, vb.pp("fc1"))?;
let fc2 = conv2d(dim * exp_ratio, dim, 1, conv2d_cfg, vb.pp("fc2"))?;
Ok(Func::new(move |xs| {
let xs = xs.apply(&conv)?.apply(&fc1)?.gelu_erf()?.apply(&fc2)?;
Ok(xs)
}))
}
fn squeeze_and_excitation(
in_channels: usize,
squeeze_channels: usize,
vb: VarBuilder,
) -> Result<Func<'static>> {
let conv2d_cfg = Conv2dConfig {
..Default::default()
};
let fc1 = conv2d(in_channels, squeeze_channels, 1, conv2d_cfg, vb.pp("fc1"))?;
let fc2 = conv2d(squeeze_channels, in_channels, 1, conv2d_cfg, vb.pp("fc2"))?;
Ok(Func::new(move |xs| {
let residual = xs;
let xs = xs.mean_keepdim(D::Minus2)?.mean_keepdim(D::Minus1)?;
let xs = sigmoid(&xs.apply(&fc1)?.relu()?.apply(&fc2)?)?;
residual.broadcast_mul(&xs)
}))
}
// fuses a convolutional kernel and a batchnorm layer into a convolutional layer
// based on the _fuse_bn_tensor method in timm
// see https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py#L602
fn fuse_conv_bn(weights: &Tensor, bn: BatchNorm) -> Result<(Tensor, Tensor)> {
let (gamma, beta) = bn.weight_and_bias().unwrap();
let mu = bn.running_mean();
let sigma = (bn.running_var() + bn.eps())?.sqrt();
let gps = (gamma / sigma)?;
let bias = (beta - mu * &gps)?;
let weights = weights.broadcast_mul(&gps.reshape(((), 1, 1, 1))?)?;
Ok((weights, bias))
}
fn mobileone_block(
in_channels: usize,
out_channels: usize,
kernel: usize,
stride: usize,
group_size: usize,
use_act: bool,
vb: VarBuilder,
) -> Result<Func<'static>> {
let groups = if group_size == 0 {
1
} else {
in_channels / group_size
};
let padding = kernel / 2;
let conv2d_cfg = Conv2dConfig {
stride,
groups,
padding,
..Default::default()
};
let mut w = Tensor::zeros(
(out_channels, in_channels / groups, kernel, kernel),
DType::F32,
vb.device(),
)?;
let dim = out_channels;
let mut b = Tensor::zeros(dim, DType::F32, vb.device())?;
let conv_kxk_bn = batch_norm(dim, 1e-5, vb.pp("conv_kxk.0.bn"));
let conv_kxk = conv2d_no_bias(
in_channels,
out_channels,
kernel,
conv2d_cfg,
vb.pp("conv_kxk.0.conv"),
);
if let (Ok(conv), Ok(bn)) = (conv_kxk, conv_kxk_bn) {
let (wk, bk) = fuse_conv_bn(conv.weight(), bn)?;
w = (w + wk)?;
b = (b + bk)?;
};
let conv_scale_bn = batch_norm(dim, 1e-5, vb.pp("conv_scale.bn"));
let conv_scale = conv2d_no_bias(
in_channels,
out_channels,
1,
conv2d_cfg,
vb.pp("conv_scale.conv"),
);
if let (Ok(conv), Ok(bn)) = (conv_scale, conv_scale_bn) {
let (ws, bs) = fuse_conv_bn(conv.weight(), bn)?;
// pad to 3x3
let ws = ws
.pad_with_zeros(D::Minus1, 1, 1)?
.pad_with_zeros(D::Minus2, 1, 1)?;
w = (w + ws)?;
b = (b + bs)?;
};
let se = squeeze_and_excitation(out_channels, out_channels / 16, vb.pp("se"));
// read and reparameterize the identity bn into wi and bi
let identity_bn = batch_norm(dim, 1e-5, vb.pp("identity"));
if let Ok(id_bn) = identity_bn {
let mut weights: Vec<f32> = vec![0.0; w.elem_count()];
let id = in_channels / groups;
// See https://github.com/huggingface/pytorch-image-models/blob/main/timm/models/byobnet.py#L809
for i in 0..in_channels {
if kernel > 1 {
weights[i * kernel * kernel + 4] = 1.0;
} else {
weights[i * (id + 1)] = 1.0;
}
}
let weights = &Tensor::from_vec(weights, w.shape(), w.device())?;
let (wi, bi) = fuse_conv_bn(weights, id_bn)?;
w = (w + wi)?;
b = (b + bi)?;
};
let reparam_conv = Conv2d::new(w, Some(b), conv2d_cfg);
Ok(Func::new(move |xs| {
let mut xs = xs.apply(&reparam_conv)?;
if let Ok(f) = &se {
xs = xs.apply(f)?;
}
if use_act {
xs = xs.gelu_erf()?;
};
Ok(xs)
}))
}
fn repmixer(dim: usize, kernel: usize, vb: VarBuilder) -> Result<Func<'static>> {
let gamma = vb.get((dim, 1, 1), "layer_scale.gamma")?;
let norm = mobileone_block(dim, dim, kernel, 1, 1, false, vb.pp("norm"))?;
let mixer = mobileone_block(dim, dim, kernel, 1, 1, false, vb.pp("mixer"))?;
Ok(Func::new(move |xs| {
let residual = xs.clone();
let xs = (xs.apply(&mixer)? - xs.apply(&norm)?)?;
let xs = xs.broadcast_mul(&gamma.reshape((1, (), 1, 1))?)?;
let xs = (xs + residual)?;
Ok(xs)
}))
}
fn repmixer_block(dim: usize, exp_ratio: usize, vb: VarBuilder) -> Result<Func<'static>> {
let gamma = vb.get((dim, 1, 1), "layer_scale.gamma")?;
let token_mixer = repmixer(dim, 3, vb.pp("token_mixer"))?;
let mlp = conv_mlp(dim, exp_ratio, vb.pp("mlp"))?;
Ok(Func::new(move |xs| {
let residual = xs.apply(&token_mixer)?;
let mut xs = residual.apply(&mlp)?;
xs = xs.broadcast_mul(&gamma.reshape((1, (), 1, 1))?)?;
let xs = (xs + residual)?;
Ok(xs)
}))
}
fn positional_encoding(dim: usize, vb: VarBuilder) -> Result<Func<'static>> {
let conv2d_cfg = Conv2dConfig {
stride: 1,
padding: 3,
groups: dim,
..Default::default()
};
let conv = conv2d(dim, dim, 7, conv2d_cfg, vb.pp("pos_enc"))?;
Ok(Func::new(move |xs| {
let xs = (xs + xs.apply(&conv)?)?;
Ok(xs)
}))
}
fn attention(dim: usize, vb: VarBuilder) -> Result<Func<'static>> {
let qkv = linear_no_bias(dim, dim * 3, vb.pp("qkv"))?;
let proj = linear(dim, dim, vb.pp("proj"))?;
let head_dim = 32;
let num_heads = dim / head_dim;
let scale = (head_dim as f64).powf(-0.5);
Ok(Func::new(move |xs| {
let xs = xs.clone();
let (b, c, h, w) = xs.dims4()?;
let n = h * w;
let xs = xs.flatten_from(2)?.transpose(D::Minus1, D::Minus2)?;
let qkv = xs
.apply(&qkv)?
.reshape((b, n, 3, num_heads, head_dim))?
.permute((2, 0, 3, 1, 4))?;
let q = qkv.get(0)?;
let k = qkv.get(1)?;
let v = qkv.get(2)?;
let q = (q * scale)?;
let att = q.matmul(&k.transpose(D::Minus2, D::Minus1)?)?;
let att = softmax(&att, D::Minus1)?;
let xs = att.matmul(&v)?;
let xs = xs.transpose(1, 2)?.reshape((b, n, c))?;
let xs = xs.apply(&proj)?;
let xs = xs.transpose(D::Minus1, D::Minus2)?.reshape((b, c, h, w))?;
Ok(xs)
}))
}
fn attention_block(dim: usize, exp_ratio: usize, vb: VarBuilder) -> Result<Func<'static>> {
let gamma1 = vb.get((dim, 1, 1), "layer_scale_1.gamma")?;
let gamma2 = vb.get((dim, 1, 1), "layer_scale_2.gamma")?;
let norm = batch_norm(dim, 1e-5, vb.pp("norm"))?;
let token_mixer = attention(dim, vb.pp("token_mixer"))?;
let mlp = conv_mlp(dim, exp_ratio, vb.pp("mlp"))?;
Ok(Func::new(move |xs| {
let xs = xs.clone();
let xs = (&xs
+ &xs
.apply_t(&norm, false)?
.apply(&token_mixer)?
.broadcast_mul(&gamma1.reshape((1, (), 1, 1))?)?)?;
let xs = (&xs
+ &xs
.apply(&mlp)?
.broadcast_mul(&gamma2.reshape((1, (), 1, 1))?)?)?;
Ok(xs)
}))
}
fn fastvit_stage(cfg: &Config, idx: usize, vb: VarBuilder) -> Result<Func<'static>> {
let nblocks = cfg.blocks[idx];
let mut blocks = Vec::with_capacity(nblocks);
let dim = cfg.in_channels << idx;
let downsample = fastvit_patch_embed(dim / 2, dim, cfg.lkc_use_act, vb.pp("downsample"));
for block_idx in 0..nblocks {
let block = if cfg.attn && idx == 3 {
attention_block(dim, cfg.exp_ratio, vb.pp(format!("blocks.{block_idx}")))?
} else {
repmixer_block(dim, cfg.exp_ratio, vb.pp(format!("blocks.{block_idx}")))?
};
blocks.push(block);
}
let pos_emb = positional_encoding(dim, vb.pp("pos_emb"));
Ok(Func::new(move |xs| {
let mut xs = xs.clone();
if let Ok(ds) = &downsample {
xs = xs.apply(ds)?;
}
if let Ok(pos) = &pos_emb {
xs = xs.apply(pos)?;
}
for block in blocks.iter() {
xs = xs.apply(block)?;
}
Ok(xs)
}))
}
fn fastvit_patch_embed(
in_channels: usize,
out_channels: usize,
use_act: bool,
vb: VarBuilder,
) -> Result<Func<'static>> {
let lk = conv_norm(in_channels, out_channels, 7, 2, vb.pp("proj.0.large_conv"))?;
let sk = conv_norm(in_channels, out_channels, 3, 2, vb.pp("proj.0.small_conv"))?;
let se = squeeze_and_excitation(out_channels, out_channels / 4, vb.pp("proj.0.se"));
let mb = mobileone_block(out_channels, out_channels, 1, 1, 0, true, vb.pp("proj.1"))?;
Ok(Func::new(move |xs| {
let mut xs = (xs.apply(&lk)? + xs.apply(&sk)?)?;
if let Ok(f) = &se {
xs = xs.apply(f)?;
}
if use_act {
xs = xs.gelu_erf()?;
};
let xs = xs.apply(&mb)?;
Ok(xs)
}))
}
fn fastvit_stem(in_channels: usize, out_channels: usize, vb: VarBuilder) -> Result<Func<'static>> {
let mb0 = mobileone_block(in_channels, out_channels, 3, 2, 0, true, vb.pp(0))?;
let mb1 = mobileone_block(out_channels, out_channels, 3, 2, 1, true, vb.pp(1))?;
let mb2 = mobileone_block(out_channels, out_channels, 1, 1, 0, true, vb.pp(2))?;
Ok(Func::new(move |xs| {
let xs = xs.apply(&mb0)?.apply(&mb1)?.apply(&mb2)?;
Ok(xs)
}))
}
// Build a fastvit model for a given configuration.
fn fastvit_model(cfg: &Config, nclasses: Option<usize>, vb: VarBuilder) -> Result<Func<'static>> {
let cls = match nclasses {
None => None,
Some(nclasses) => {
let linear = linear(cfg.in_channels * 16, nclasses, vb.pp("head.fc"))?;
Some(linear)
}
};
let stem = fastvit_stem(3, cfg.in_channels, vb.pp("stem"))?;
let final_conv = mobileone_block(
cfg.in_channels * 8,
cfg.in_channels * 16,
3,
1,
1,
true,
vb.pp("final_conv"),
)?;
let vb = vb.pp("stages");
let stage1 = fastvit_stage(cfg, 0, vb.pp(0))?;
let stage2 = fastvit_stage(cfg, 1, vb.pp(1))?;
let stage3 = fastvit_stage(cfg, 2, vb.pp(2))?;
let stage4 = fastvit_stage(cfg, 3, vb.pp(3))?;
Ok(Func::new(move |xs| {
let xs = xs
.apply(&stem)?
.apply(&stage1)?
.apply(&stage2)?
.apply(&stage3)?
.apply(&stage4)?
.apply(&final_conv)?;
match &cls {
None => Ok(xs),
Some(cls) => xs.mean(D::Minus2)?.mean(D::Minus1)?.apply(cls),
}
}))
}
pub fn fastvit(cfg: &Config, nclasses: usize, vb: VarBuilder) -> Result<Func<'static>> {
fastvit_model(cfg, Some(nclasses), vb)
}
pub fn fastvit_no_final_layer(cfg: &Config, vb: VarBuilder) -> Result<Func<'static>> {
fastvit_model(cfg, None, vb)
}
| 4 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/phi.rs | //! Microsoft Phi model implementation
//!
//! The Phi series are decoder-only transformers designed for code and language tasks.
//!
//! Key characteristics:
//! - Decoder-only transformer architecture
//! - RoPE embeddings
//! - Layer normalization
//! - QK normalization
//!
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-phi1-phi2-wasm-demo)
//! - 🤗 [HF Link](https://huggingface.co/microsoft/phi-2)
//!
use crate::models::with_tracing::{layer_norm, linear, Embedding, LayerNorm, Linear};
/// Phi model.
/// https://huggingface.co/microsoft/phi-2
/// There is an alternative implementation of the phi model in mixformers.rs.
/// This corresponds to the model update made with the following commit:
/// https://huggingface.co/microsoft/phi-2/commit/cb2f4533604d8b67de604e7df03bfe6f3ca22869
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
use candle_nn::{Activation, VarBuilder};
use serde::Deserialize;
// https://huggingface.co/microsoft/phi-2/blob/main/configuration_phi.py
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct Config {
pub(crate) vocab_size: usize,
pub(crate) hidden_size: usize,
pub(crate) intermediate_size: usize,
pub(crate) num_hidden_layers: usize,
pub(crate) num_attention_heads: usize,
pub(crate) num_key_value_heads: Option<usize>,
pub(crate) hidden_act: Activation,
pub(crate) max_position_embeddings: usize,
pub(crate) layer_norm_eps: f64,
pub(crate) tie_word_embeddings: bool,
pub(crate) rope_theta: f32,
pub(crate) partial_rotary_factor: f64,
pub(crate) qk_layernorm: bool,
}
impl Config {
fn num_key_value_heads(&self) -> usize {
self.num_key_value_heads.unwrap_or(self.num_attention_heads)
}
fn head_dim(&self) -> usize {
self.hidden_size / self.num_attention_heads
}
}
#[derive(Debug, Clone)]
struct RotaryEmbedding {
dim: usize,
sin: Tensor,
cos: Tensor,
}
impl RotaryEmbedding {
fn new(cfg: &Config, dev: &Device) -> Result<Self> {
let dim = (cfg.partial_rotary_factor * cfg.head_dim() as f64) as usize;
let inv_freq: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / cfg.rope_theta.powf(i as f32 / dim as f32))
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?;
let t = Tensor::arange(0u32, cfg.max_position_embeddings as u32, dev)?
.to_dtype(DType::F32)?
.reshape((cfg.max_position_embeddings, 1))?;
let freqs = t.matmul(&inv_freq)?;
Ok(Self {
dim,
sin: freqs.sin()?,
cos: freqs.cos()?,
})
}
fn apply_rotary_emb(&self, xs: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let (_b_size, _num_heads, seq_len, _headdim) = xs.dims4()?;
let xs_rot = xs.i((.., .., .., ..self.dim))?.contiguous()?;
let xs_pass = xs.i((.., .., .., self.dim..))?;
let c = self.cos.narrow(0, seqlen_offset, seq_len)?;
let s = self.sin.narrow(0, seqlen_offset, seq_len)?;
let xs_rot = candle_nn::rotary_emb::rope(&xs_rot, &c, &s)?;
Tensor::cat(&[&xs_rot, &xs_pass], D::Minus1)
}
}
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MLP {
fc1: Linear,
fc2: Linear,
act: Activation,
}
impl MLP {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let fc1 = linear(cfg.hidden_size, cfg.intermediate_size, vb.pp("fc1"))?;
let fc2 = linear(cfg.intermediate_size, cfg.hidden_size, vb.pp("fc2"))?;
Ok(Self {
fc1,
fc2,
// This does not match the mixformers implementation where Gelu is used rather than
// GeluNew.
act: cfg.hidden_act,
})
}
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.fc1)?.apply(&self.act)?.apply(&self.fc2)
}
}
#[derive(Clone)]
struct Attention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
dense: Linear,
kv_cache: Option<(Tensor, Tensor)>,
q_layernorm: Option<LayerNorm>,
k_layernorm: Option<LayerNorm>,
rotary_emb: RotaryEmbedding,
softmax_scale: f64,
num_heads: usize,
num_kv_heads: usize,
head_dim: usize,
span: tracing::Span,
}
fn get_mask(size: usize, device: &Device) -> Result<Tensor> {
let mask: Vec<_> = (0..size)
.flat_map(|i| (0..size).map(move |j| u8::from(j > i)))
.collect();
Tensor::from_slice(&mask, (size, size), device)
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: f32) -> Result<Tensor> {
let shape = mask.shape();
let on_true = Tensor::new(on_true, on_false.device())?.broadcast_as(shape.dims())?;
let m = mask.where_cond(&on_true, on_false)?;
Ok(m)
}
impl Attention {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let num_heads = cfg.num_attention_heads;
let num_kv_heads = cfg.num_key_value_heads();
let head_dim = cfg.head_dim();
let q_proj = linear(cfg.hidden_size, num_heads * head_dim, vb.pp("q_proj"))?;
let k_proj = linear(cfg.hidden_size, num_kv_heads * head_dim, vb.pp("k_proj"))?;
let v_proj = linear(cfg.hidden_size, num_kv_heads * head_dim, vb.pp("v_proj"))?;
let dense = linear(num_heads * head_dim, cfg.hidden_size, vb.pp("dense"))?;
// Alternative rope scalings are not supported.
let rotary_emb = RotaryEmbedding::new(cfg, vb.device())?;
let (q_layernorm, k_layernorm) = if cfg.qk_layernorm {
let q_layernorm = layer_norm(head_dim, cfg.layer_norm_eps, vb.pp("q_layernorm"))?;
let k_layernorm = layer_norm(head_dim, cfg.layer_norm_eps, vb.pp("k_layernorm"))?;
(Some(q_layernorm), Some(k_layernorm))
} else {
(None, None)
};
let softmax_scale = 1f64 / (head_dim as f64).sqrt();
Ok(Self {
q_proj,
k_proj,
v_proj,
dense,
kv_cache: None,
q_layernorm,
k_layernorm,
rotary_emb,
softmax_scale,
num_heads,
num_kv_heads,
head_dim,
span: tracing::span!(tracing::Level::TRACE, "attention"),
})
}
fn repeat_kv(&self, xs: Tensor) -> Result<Tensor> {
crate::utils::repeat_kv(xs, self.num_heads / self.num_kv_heads)
}
fn forward(&mut self, xs: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_size, seq_len, _n_embd) = xs.dims3()?;
let query_states = self.q_proj.forward(xs)?;
let key_states = self.k_proj.forward(xs)?;
let value_states = self.v_proj.forward(xs)?;
let query_states = match &self.q_layernorm {
None => query_states,
Some(ln) => query_states.apply(ln)?,
};
let key_states = match &self.k_layernorm {
None => key_states,
Some(ln) => key_states.apply(ln)?,
};
let query_states = query_states
.reshape((b_size, seq_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?;
let key_states = key_states
.reshape((b_size, seq_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
let value_states = value_states
.reshape((b_size, seq_len, self.num_kv_heads, self.head_dim))?
.transpose(1, 2)?;
// Rotary embeddings.
let seqlen_offset = match &self.kv_cache {
None => 0,
Some((prev_k, _)) => prev_k.dim(2)?,
};
let query_states = self
.rotary_emb
.apply_rotary_emb(&query_states, seqlen_offset)?;
let key_states = self
.rotary_emb
.apply_rotary_emb(&key_states, seqlen_offset)?;
// KV cache.
let (key_states, value_states) = match &self.kv_cache {
None => (key_states, value_states),
Some((prev_k, prev_v)) => {
let k = Tensor::cat(&[prev_k, &key_states], 2)?;
let v = Tensor::cat(&[prev_v, &value_states], 2)?;
(k, v)
}
};
self.kv_cache = Some((key_states.clone(), value_states.clone()));
// Repeat kv.
let key_states = self.repeat_kv(key_states)?.contiguous()?;
let value_states = self.repeat_kv(value_states)?.contiguous()?;
let attn_weights = (query_states
.to_dtype(DType::F32)?
.contiguous()?
.matmul(&key_states.to_dtype(DType::F32)?.t()?)?
* self.softmax_scale)?;
let attn_weights = match mask {
None => attn_weights,
Some(mask) => masked_fill(
&attn_weights,
&mask.broadcast_left((b_size, self.num_heads))?,
f32::NEG_INFINITY,
)?,
};
let attn_weights =
candle_nn::ops::softmax_last_dim(&attn_weights)?.to_dtype(value_states.dtype())?;
let attn_output = attn_weights.matmul(&value_states)?;
let attn_output = attn_output
.transpose(1, 2)?
.reshape((b_size, seq_len, ()))?;
attn_output.apply(&self.dense)
}
fn clear_kv_cache(&mut self) {
self.kv_cache = None
}
}
#[derive(Clone)]
struct DecoderLayer {
self_attn: Attention,
mlp: MLP,
input_layernorm: LayerNorm,
span: tracing::Span,
}
impl DecoderLayer {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let self_attn = Attention::new(cfg, vb.pp("self_attn"))?;
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
let input_layernorm = layer_norm(
cfg.hidden_size,
cfg.layer_norm_eps,
vb.pp("input_layernorm"),
)?;
Ok(Self {
self_attn,
mlp,
input_layernorm,
span: tracing::span!(tracing::Level::TRACE, "block"),
})
}
fn forward(&mut self, xs: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let _enter = self.span.enter();
let residual = xs;
let xs = xs.apply(&self.input_layernorm)?;
let attn_outputs = self.self_attn.forward(&xs, mask)?;
let feed_forward_hidden_states = self.mlp.forward(&xs)?;
attn_outputs + feed_forward_hidden_states + residual
}
fn clear_kv_cache(&mut self) {
self.self_attn.clear_kv_cache()
}
}
#[derive(Clone)]
pub struct Model {
embed_tokens: Embedding,
layers: Vec<DecoderLayer>,
final_layernorm: LayerNorm,
lm_head: Linear,
span: tracing::Span,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_m = vb.pp("model");
let embed_tokens =
Embedding::new(cfg.vocab_size, cfg.hidden_size, vb_m.pp("embed_tokens"))?;
let final_layernorm = layer_norm(
cfg.hidden_size,
cfg.layer_norm_eps,
vb_m.pp("final_layernorm"),
)?;
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb_m = vb_m.pp("layers");
for layer_idx in 0..cfg.num_hidden_layers {
let layer = DecoderLayer::new(cfg, vb_m.pp(layer_idx))?;
layers.push(layer)
}
let lm_head = linear(cfg.hidden_size, cfg.vocab_size, vb.pp("lm_head"))?;
Ok(Self {
embed_tokens,
layers,
final_layernorm,
lm_head,
span: tracing::span!(tracing::Level::TRACE, "model"),
})
}
pub fn forward(&mut self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (_b_size, seq_len) = xs.dims2()?;
let mut xs = xs.apply(&self.embed_tokens)?;
let mask = if seq_len <= 1 {
None
} else {
Some(get_mask(seq_len, xs.device())?)
};
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, mask.as_ref())?;
}
xs.apply(&self.final_layernorm)?
.narrow(1, seq_len - 1, 1)?
.apply(&self.lm_head)?
.squeeze(1)
}
pub fn clear_kv_cache(&mut self) {
self.layers.iter_mut().for_each(|b| b.clear_kv_cache())
}
}
| 5 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/based.rs | //! Based from the Stanford Hazy Research group.
//!
//! See "Simple linear attention language models balance the recall-throughput tradeoff", Arora et al. 2024
//! - Simple linear attention language models balance the recall-throughput tradeoff. [Arxiv](https://arxiv.org/abs/2402.18668)
//! - [Github Rep](https://github.com/HazyResearch/based)
//! - [Blogpost](https://hazyresearch.stanford.edu/blog/2024-03-03-based)
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
use candle_nn::{
conv1d_no_bias, linear, linear_no_bias, ops::softmax_last_dim, rms_norm, Conv1d, Conv1dConfig,
Func, Linear, RmsNorm, VarBuilder,
};
use std::sync::Arc;
#[derive(Debug, Clone, serde::Deserialize)]
pub struct LinearAttentionFeatureMapConfig {
input_dim: usize,
}
#[derive(Debug, Clone, serde::Deserialize)]
pub struct LinearAttentionConfig {
num_heads: usize,
feature_dim: usize,
feature_map: LinearAttentionFeatureMapConfig,
}
#[derive(Debug, Clone, serde::Deserialize)]
pub struct SlidingWindowAttentionConfig {
num_heads: usize,
window_size: usize,
}
#[derive(Debug, Clone, serde::Deserialize)]
pub struct Config {
vocab_size: usize,
#[serde(rename = "n_embd")]
hidden_size: usize,
#[serde(rename = "n_inner")]
intermediate_size: usize,
#[serde(rename = "n_layer")]
num_hidden_layers: usize,
#[serde(rename = "n_head")]
num_attention_heads: usize,
layer_norm_epsilon: f64,
#[serde(default = "default_rope", rename = "rotary_emb_base")]
rope_theta: f64,
alt_mixer_layers: Vec<usize>,
alt_mixer_2_layers: Vec<usize>,
#[serde(rename = "alt_mixer")]
la: LinearAttentionConfig,
#[serde(rename = "alt_mixer_2")]
swa: SlidingWindowAttentionConfig,
}
fn default_rope() -> f64 {
10_000.0
}
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MLP {
fc1: Linear,
fc2: Linear,
}
impl MLP {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let fc1 = linear_no_bias(cfg.hidden_size, cfg.hidden_size * 4, vb.pp("fc1"))?;
let fc2 = linear_no_bias(cfg.intermediate_size, cfg.hidden_size, vb.pp("fc2"))?;
Ok(Self { fc1, fc2 })
}
}
// Swiglu implementation.
// Not using Activation::Swiglu because this has the gate and y arguments switched compared to the version in candle-nn/src/ops.rs
fn swiglu(xs: &Tensor) -> Result<Tensor> {
let xs = xs.chunk(2, D::Minus1)?;
&xs[1].silu()? * &xs[0]
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = xs.apply(&self.fc1)?;
let xs = swiglu(&xs)?;
let xs = xs.apply(&self.fc2)?;
Ok(xs)
}
}
// A gated convolutional block.
#[derive(Debug, Clone)]
struct BasedConv {
in_proj: Linear,
out_proj: Linear,
conv: Conv1d,
state: Tensor,
}
impl BasedConv {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dim = cfg.hidden_size * 2;
let conv1d_cfg = Conv1dConfig {
groups: dim,
padding: 2,
..Default::default()
};
let in_proj = linear(cfg.hidden_size, cfg.hidden_size * 4, vb.pp("in_proj"))?;
let out_proj = linear(dim, cfg.hidden_size, vb.pp("out_proj"))?;
let conv = conv1d_no_bias(dim, dim, 3, conv1d_cfg, vb.pp("conv.conv"))?;
let state = Tensor::zeros((1, dim, 3), vb.dtype(), vb.device())?;
Ok(Self {
in_proj,
out_proj,
conv,
state,
})
}
fn step(&mut self, xs: &Tensor) -> Result<Tensor> {
self.state = self.state.roll(-1, D::Minus1)?;
let (_, _, l) = self.state.dims3()?;
self.state = self.state.narrow(D::Minus1, 0, l - 1)?;
self.state = Tensor::cat(&[&self.state, &xs.transpose(1, 2)?], 2)?;
let xs = (&self.state * self.conv.weight().permute((1, 0, 2))?)?
.sum_keepdim(0)?
.sum(D::Minus1)?;
let xs = xs.unsqueeze(1)?;
Ok(xs)
}
fn forward(&mut self, xs: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let xs = xs.apply(&self.in_proj)?;
let us = xs.chunk(2, D::Minus1)?;
let (_b, l, _d) = us[0].dims3()?;
let u_conv = if seqlen_offset > 0 {
self.step(&us[0])?
} else {
let k = std::cmp::min(3, l);
self.state = self.state.narrow(D::Minus1, 0, 3 - k)?;
let xs = us[0].narrow(1, l - k, k)?.transpose(1, 2)?;
self.state = Tensor::cat(&[&self.state, &xs], 2)?;
us[0]
.transpose(1, 2)?
.apply(&self.conv)?
.narrow(D::Minus1, 0, l)?
.transpose(1, 2)?
};
let u_conv = u_conv.silu()?;
let v = u_conv.broadcast_mul(&us[1])?;
let xs = v.apply(&self.out_proj)?;
Ok(xs)
}
}
// Linear attention approximating softmax using second order Taylor polynomials.
#[derive(Debug, Clone)]
struct LinearAttention {
proj_q: Linear,
proj_k: Linear,
proj_v: Linear,
out_proj: Linear,
feature_dim: usize,
num_heads: usize,
input_dim: usize,
k_state: Tensor,
kv_state: Tensor,
}
impl LinearAttention {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let input_dim = cfg.la.feature_map.input_dim;
let out_proj = linear_no_bias(cfg.hidden_size, cfg.hidden_size, vb.pp("out_proj"))?;
let proj_k = linear_no_bias(
cfg.hidden_size,
cfg.la.num_heads * cfg.la.feature_dim,
vb.pp("proj_k"),
)?;
let proj_q = linear_no_bias(
cfg.hidden_size,
cfg.la.num_heads * cfg.la.feature_dim,
vb.pp("proj_q"),
)?;
let proj_v = linear_no_bias(cfg.hidden_size, cfg.hidden_size, vb.pp("proj_v"))?;
let expanded_size = cfg.la.feature_dim.pow(2) + cfg.la.feature_dim + 1;
let k_state = Tensor::zeros(
(1, cfg.la.num_heads, 1, 1, expanded_size),
vb.dtype(),
vb.device(),
)?;
let kv_state = Tensor::zeros(
(1, cfg.la.num_heads, cfg.la.feature_dim, expanded_size),
vb.dtype(),
vb.device(),
)?;
Ok(Self {
proj_q,
proj_k,
proj_v,
out_proj,
feature_dim: cfg.la.feature_dim,
num_heads: cfg.la.num_heads,
input_dim,
k_state,
kv_state,
})
}
fn taylor_expansion(&self) -> Result<Func<'static>> {
let r2 = std::f64::consts::SQRT_2;
let rd = (self.input_dim as f64).sqrt();
let rrd = rd.sqrt();
Ok(Func::new(move |xs| {
let dims = xs.dims();
let mut d = dims.to_vec();
if let Some(last) = d.last_mut() {
*last = 1;
};
let x = xs
.unsqueeze(D::Minus1)?
.broadcast_mul(&xs.unsqueeze(D::Minus2)?)?;
let x = (x.flatten_from(D::Minus2)? / r2)?;
let o = Tensor::ones(d, xs.dtype(), xs.device())?;
let x = Tensor::cat(&[o, (xs / rrd)?, (&x / rd)?], D::Minus1)?;
Ok(x)
}))
}
fn forward(&mut self, xs: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let eps = 1e-12;
let feature_map = self.taylor_expansion()?;
let (b, l, d) = xs.dims3()?;
let q = xs.apply(&self.proj_q)?;
let k = xs.apply(&self.proj_k)?;
let v = xs.apply(&self.proj_v)?;
let q = q
.reshape((b, l, self.num_heads, self.feature_dim))?
.transpose(1, 2)?
.contiguous()?;
let k = k
.reshape((b, l, self.num_heads, self.feature_dim))?
.transpose(1, 2)?
.contiguous()?;
let v = v
.reshape((b, l, self.num_heads, d / self.num_heads))?
.transpose(1, 2)?
.contiguous()?;
let q = feature_map.forward(&q)?;
let k = feature_map.forward(&k)?;
let y = if seqlen_offset > 0 {
let (_b, _h, l, _d) = k.dims4()?;
let q = q.unsqueeze(D::Minus2)?;
let k = k.unsqueeze(D::Minus2)?;
let v = v.unsqueeze(D::Minus1)?;
let kn = k.narrow(D::Minus1, l - 1, 1)?;
let vn = v.narrow(D::Minus1, l - 1, 1)?;
self.k_state = self.k_state.broadcast_add(&kn)?;
self.kv_state = self.kv_state.broadcast_add(&kn.broadcast_mul(&vn)?)?;
let num = q.broadcast_mul(&self.kv_state)?.sum(D::Minus1)?;
let den = (q.broadcast_mul(&self.k_state)?.sum(D::Minus1)? + eps)?;
num.broadcast_div(&den)?
} else {
self.k_state = k.sum(2)?.unsqueeze(2)?.unsqueeze(3)?;
self.kv_state = k
.transpose(2, 3)?
.matmul(&v)?
.transpose(2, 3)?
.unsqueeze(2)?;
let aqk = q.matmul(&k.transpose(D::Minus1, D::Minus2)?)?;
let tril = Tensor::tril2(l, aqk.dtype(), aqk.device())?;
let aqk = aqk.broadcast_mul(&tril)?.matmul(&v)?;
let z = (1f64 / (q.mul(&k.cumsum(2)?)?.sum(D::Minus1)? + eps)?)?;
aqk.broadcast_mul(&z.unsqueeze(D::Minus1)?)?
};
let (b, h, l, d) = y.dims4()?;
let y = y.permute((0, 2, 1, 3))?.reshape((b, l, h * d))?;
let y = self.out_proj.forward(&y)?;
Ok(y)
}
}
// Rotary embeddings used in local attention.
#[derive(Debug, Clone)]
struct RotaryEmbedding {
sin: Tensor,
cos: Tensor,
}
impl RotaryEmbedding {
fn new(dtype: DType, cfg: &Config, dev: &Device) -> Result<Self> {
let dim = cfg.hidden_size / cfg.num_attention_heads;
let max_seq_len = 2048; // Hardcoded, missing from config.
let inv_freq: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / cfg.rope_theta.powf(i as f64 / dim as f64) as f32)
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?.to_dtype(dtype)?;
let t = Tensor::arange(0u32, max_seq_len as u32, dev)?
.to_dtype(dtype)?
.reshape((max_seq_len, 1))?;
let freqs = t.matmul(&inv_freq)?;
Ok(Self {
sin: freqs.sin()?,
cos: freqs.cos()?,
})
}
fn apply_rotary_emb_qkv(
&self,
q: &Tensor,
k: &Tensor,
seqlen_offset: usize,
) -> Result<(Tensor, Tensor)> {
let (_b_sz, _h, seq_len, _n_embd) = q.dims4()?;
let cos = self.cos.narrow(0, seqlen_offset, seq_len)?;
let sin = self.sin.narrow(0, seqlen_offset, seq_len)?;
let q_embed = candle_nn::rotary_emb::rope(&q.contiguous()?, &cos, &sin)?;
let k_embed = candle_nn::rotary_emb::rope(&k.contiguous()?, &cos, &sin)?;
Ok((q_embed, k_embed))
}
}
// Local attention using a small sliding window.
#[derive(Debug, Clone)]
struct SlidingWindowAttention {
wqkv: Linear,
out_proj: Linear,
num_heads: usize,
head_dim: usize,
hidden_size: usize,
rotary_emb: Arc<RotaryEmbedding>,
kv_cache: Option<(Tensor, Tensor)>,
}
impl SlidingWindowAttention {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let hidden_size = cfg.hidden_size;
let num_heads = cfg.swa.num_heads;
let head_dim = hidden_size / num_heads;
let out_proj = linear_no_bias(hidden_size, hidden_size, vb.pp("out_proj"))?;
let wqkv = linear_no_bias(hidden_size, hidden_size * 3, vb.pp("Wqkv"))?;
let rotary_emb = Arc::new(RotaryEmbedding::new(vb.dtype(), cfg, vb.device())?);
Ok(Self {
wqkv,
out_proj,
hidden_size,
num_heads,
head_dim,
rotary_emb,
kv_cache: None,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let (b_sz, q_len, _) = xs.dims3()?;
let qkv = xs.apply(&self.wqkv)?;
let qkv = qkv.reshape((b_sz, q_len, 3, (), self.head_dim))?;
let q = qkv.i((.., .., 0))?;
let k = qkv.i((.., .., 1))?;
let v = qkv.i((.., .., 2))?;
let q = q
.reshape((b_sz, q_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?;
let k = k
.reshape((b_sz, q_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?;
let v = v
.reshape((b_sz, q_len, self.num_heads, self.head_dim))?
.transpose(1, 2)?;
let (q, k) = self
.rotary_emb
.apply_rotary_emb_qkv(&q, &k, seqlen_offset)?;
let (k, v) = match &self.kv_cache {
None => (k, v),
Some((prev_k, prev_v)) => {
let k = Tensor::cat(&[prev_k, &k], 2)?;
let v = Tensor::cat(&[prev_v, &v], 2)?;
(k, v)
}
};
self.kv_cache = Some((k.clone(), v.clone()));
let scale = 1f64 / f64::sqrt(self.head_dim as f64);
let attn_weights = (q.matmul(&k.transpose(2, 3)?)? * scale)?;
let attn_weights = match attention_mask {
None => attn_weights,
Some(mask) => attn_weights.broadcast_add(mask)?,
};
let attn_weights = softmax_last_dim(&attn_weights)?;
let attn_output = attn_weights.matmul(&v)?;
let out = attn_output
.transpose(1, 2)?
.reshape((b_sz, q_len, self.hidden_size))?
.apply(&self.out_proj)?;
Ok(out)
}
}
// The model layers use three types of mixers.
#[derive(Debug, Clone)]
enum SequenceMixer {
Based(BasedConv),
Linear(LinearAttention),
Sliding(SlidingWindowAttention),
}
impl SequenceMixer {
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
pos: usize,
) -> Result<Tensor> {
match self {
Self::Based(b) => b.forward(xs, pos),
Self::Linear(b) => b.forward(xs, pos),
Self::Sliding(b) => b.forward(xs, attention_mask, pos),
}
}
}
#[derive(Debug, Clone)]
struct DecoderLayer {
mlp: MLP,
norm1: RmsNorm,
norm2: RmsNorm,
mixer: SequenceMixer,
}
impl DecoderLayer {
fn new(layer_idx: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
let norm1 = rms_norm(cfg.hidden_size, cfg.layer_norm_epsilon, vb.pp("norm1"))?;
let norm2 = rms_norm(cfg.hidden_size, cfg.layer_norm_epsilon, vb.pp("norm2"))?;
let l_attn = cfg.alt_mixer_layers.contains(&layer_idx);
let sw_attn = cfg.alt_mixer_2_layers.contains(&layer_idx);
let mixer = if l_attn {
SequenceMixer::Linear(LinearAttention::new(cfg, vb.pp("mixer"))?)
} else if sw_attn {
SequenceMixer::Sliding(SlidingWindowAttention::new(cfg, vb.pp("mixer"))?)
} else {
SequenceMixer::Based(BasedConv::new(cfg, vb.pp("mixer"))?)
};
Ok(Self {
mlp,
norm1,
norm2,
mixer,
})
}
fn forward(
&mut self,
xs: &Tensor,
attention_mask: Option<&Tensor>,
seqlen_offset: usize,
) -> Result<Tensor> {
let residual = xs;
let xs = self.norm1.forward(xs)?;
let xs = self.mixer.forward(&xs, attention_mask, seqlen_offset)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = xs.apply(&self.norm2)?.apply(&self.mlp)?;
residual + xs
}
}
#[derive(Debug, Clone)]
pub struct Model {
embed_tokens: super::with_tracing::Embedding,
layers: Vec<DecoderLayer>,
norm: RmsNorm,
lm_head: Linear,
sliding_window: usize,
device: Device,
dtype: DType,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vocab_size = cfg.vocab_size + (8 - cfg.vocab_size % 8) % 8;
let lm_head = linear_no_bias(cfg.hidden_size, vocab_size, vb.pp("lm_head"))?;
let embed_tokens = super::with_tracing::Embedding::from_weights(lm_head.weight().clone())?;
let vb_m = vb.pp("transformer");
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb_l = vb_m.pp("layers");
for layer_idx in 0..cfg.num_hidden_layers {
let layer = DecoderLayer::new(layer_idx, cfg, vb_l.pp(layer_idx))?;
layers.push(layer)
}
let norm = rms_norm(cfg.hidden_size, cfg.layer_norm_epsilon, vb_m.pp("ln_f"))?;
Ok(Self {
embed_tokens,
layers,
norm,
lm_head,
sliding_window: cfg.swa.window_size,
device: vb.device().clone(),
dtype: vb.dtype(),
})
}
fn prepare_decoder_attention_mask(
&self,
b_size: usize,
tgt_len: usize,
seqlen_offset: usize,
) -> Result<Tensor> {
let sliding_window = self.sliding_window / 2;
let mask: Vec<_> = (0..tgt_len)
.flat_map(|i| {
(0..tgt_len).map(move |j| {
if i < j || j + sliding_window < i {
f32::NEG_INFINITY
} else {
0.
}
})
})
.collect();
let mask = Tensor::from_slice(&mask, (tgt_len, tgt_len), &self.device)?;
let mask = if seqlen_offset > 0 {
let mask0 = Tensor::zeros((tgt_len, seqlen_offset), self.dtype, &self.device)?;
Tensor::cat(&[&mask0, &mask], D::Minus1)?
} else {
mask
};
mask.expand((b_size, 1, tgt_len, tgt_len + seqlen_offset))?
.to_dtype(self.dtype)
}
pub fn forward(&mut self, input_ids: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let (b_size, seq_len) = input_ids.dims2()?;
let attention_mask = if seq_len <= 1 {
None
} else {
let mask = self.prepare_decoder_attention_mask(b_size, seq_len, seqlen_offset)?;
Some(mask)
};
let mut xs = self.embed_tokens.forward(input_ids)?;
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, attention_mask.as_ref(), seqlen_offset)?
}
xs.narrow(1, seq_len - 1, 1)?
.apply(&self.norm)?
.apply(&self.lm_head)
}
}
| 6 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/quantized_qwen2.rs | //! Qwen2 model implementation with quantization support.
//!
//! Qwen2 is a chat-optimized language model that supports 8-bit quantization
//! for reduced memory usage and faster inference.
//!
//! Key characteristics:
//! - Group Query Attention (GQA)
//! - RMSNorm for layer normalization
//! - Rotary positional embeddings (RoPE)
//! - Support for 8-bit quantization
//!
//! References:
//! - [Model Card](https://huggingface.co/Qwen/Qwen2)
//!
use crate::{quantized_nn::RmsNorm, utils::repeat_kv};
use candle::{
quantized::{gguf_file, QMatMul},
DType, Device, IndexOp, Result, Tensor,
};
use candle_nn::{Embedding, Module};
use std::collections::HashMap;
#[derive(Debug, Clone)]
struct Mlp {
feed_forward_w1: QMatMul,
feed_forward_w2: QMatMul,
feed_forward_w3: QMatMul,
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let w1 = self.feed_forward_w1.forward(xs)?;
let w3 = self.feed_forward_w3.forward(xs)?;
self.feed_forward_w2
.forward(&(candle_nn::ops::silu(&w1)? * w3)?)
}
}
#[derive(Debug, Clone)]
struct LayerWeights {
attention_wq: QMatMul,
attention_wk: QMatMul,
attention_wv: QMatMul,
attention_bq: Tensor,
attention_bk: Tensor,
attention_bv: Tensor,
attention_wo: QMatMul,
attention_norm: RmsNorm,
mlp: Mlp,
ffn_norm: RmsNorm,
n_head: usize,
n_kv_head: usize,
head_dim: usize,
cos: Tensor,
sin: Tensor,
neg_inf: Tensor,
kv_cache: Option<(Tensor, Tensor)>,
span_attn: tracing::Span,
span_rot: tracing::Span,
span_mlp: tracing::Span,
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: &Tensor) -> Result<Tensor> {
let shape = mask.shape();
let m = mask.where_cond(&on_true.broadcast_as(shape.dims())?, on_false)?;
Ok(m)
}
impl LayerWeights {
fn apply_rotary_emb(&self, x: &Tensor, index_pos: usize) -> Result<Tensor> {
let _enter = self.span_rot.enter();
let (_b_sz, _n_head, seq_len, _n_embd) = x.dims4()?;
let cos = self.cos.narrow(0, index_pos, seq_len)?;
let sin = self.sin.narrow(0, index_pos, seq_len)?;
candle_nn::rotary_emb::rope(&x.contiguous()?, &cos, &sin)
}
fn forward_attn(
&mut self,
x: &Tensor,
mask: Option<&Tensor>,
index_pos: usize,
) -> Result<Tensor> {
let _enter = self.span_attn.enter();
let (b_sz, seq_len, n_embd) = x.dims3()?;
let q = self.attention_wq.forward(x)?;
let k = self.attention_wk.forward(x)?;
let v = self.attention_wv.forward(x)?;
let q = q.broadcast_add(&self.attention_bq)?;
let k = k.broadcast_add(&self.attention_bk)?;
let v = v.broadcast_add(&self.attention_bv)?;
let q = q
.reshape((b_sz, seq_len, self.n_head, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let k = k
.reshape((b_sz, seq_len, self.n_kv_head, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
let v = v
.reshape((b_sz, seq_len, self.n_kv_head, self.head_dim))?
.transpose(1, 2)?
.contiguous()?;
// let (q, k) = self
// .rotary_embedding
// .apply_rotary_emb_qkv(&q, &k, index_pos)?;
let q = self.apply_rotary_emb(&q, index_pos)?;
let k = self.apply_rotary_emb(&k, index_pos)?;
let (k, v) = match &self.kv_cache {
None => (k, v),
Some((k_cache, v_cache)) => {
if index_pos == 0 {
(k, v)
} else {
let k = Tensor::cat(&[k_cache, &k], 2)?;
let v = Tensor::cat(&[v_cache, &v], 2)?;
(k, v)
}
}
};
self.kv_cache = Some((k.clone(), v.clone()));
// Support for MQA, useful for 70B models and mistral.
let k = repeat_kv(k, self.n_head / self.n_kv_head)?;
let v = repeat_kv(v, self.n_head / self.n_kv_head)?;
let att = (q.matmul(&k.t()?)? / (self.head_dim as f64).sqrt())?;
let att = match mask {
None => att,
Some(mask) => {
let mask = mask.broadcast_as(att.shape())?;
masked_fill(&att, &mask, &self.neg_inf)?
}
};
let att = candle_nn::ops::softmax_last_dim(&att)?;
// Convert to contiguous as matmul doesn't support strided vs for now.
let y = att.matmul(&v.contiguous()?)?;
let y = y.transpose(1, 2)?.reshape(&[b_sz, seq_len, n_embd])?;
let y = self.attention_wo.forward(&y)?;
Ok(y)
}
}
pub struct ModelWeights {
tok_embeddings: Embedding,
layers: Vec<LayerWeights>,
norm: RmsNorm,
output: QMatMul,
masks: HashMap<usize, Tensor>,
span: tracing::Span,
span_output: tracing::Span,
}
fn precomput_freqs_cis(
head_dim: usize,
freq_base: f32,
context_length: usize,
device: &Device,
) -> Result<(Tensor, Tensor)> {
let theta: Vec<_> = (0..head_dim)
.step_by(2)
.map(|i| 1f32 / freq_base.powf(i as f32 / head_dim as f32))
.collect();
let theta = Tensor::new(theta.as_slice(), device)?;
let idx_theta = Tensor::arange(0, context_length as u32, device)?
.to_dtype(DType::F32)?
.reshape((context_length, 1))?
.matmul(&theta.reshape((1, theta.elem_count()))?)?;
let cos = idx_theta.cos()?;
let sin = idx_theta.sin()?;
Ok((cos, sin))
}
impl ModelWeights {
pub fn from_gguf<R: std::io::Seek + std::io::Read>(
ct: gguf_file::Content,
reader: &mut R,
device: &Device,
) -> Result<Self> {
let md_get = |s: &str| match ct.metadata.get(s) {
None => candle::bail!("cannot find {s} in metadata"),
Some(v) => Ok(v),
};
let head_count = md_get("qwen2.attention.head_count")?.to_u32()? as usize;
let head_count_kv = md_get("qwen2.attention.head_count_kv")?.to_u32()? as usize;
let embedding_length = md_get("qwen2.embedding_length")?.to_u32()? as usize;
let context_length = md_get("qwen2.context_length")?.to_u32()? as usize;
let block_count = md_get("qwen2.block_count")?.to_u32()? as usize;
let rms_norm_eps = md_get("qwen2.attention.layer_norm_rms_epsilon")?.to_f32()? as f64;
let rope_freq_base = md_get("qwen2.rope.freq_base")
.and_then(|m| m.to_f32())
.unwrap_or(10000f32);
let head_dim = embedding_length / head_count;
let neg_inf = Tensor::new(f32::NEG_INFINITY, device)?;
let tok_embeddings = ct.tensor(reader, "token_embd.weight", device)?;
let tok_embeddings = tok_embeddings.dequantize(device)?;
let norm = RmsNorm::from_qtensor(
ct.tensor(reader, "output_norm.weight", device)?,
rms_norm_eps,
)?;
let output = match ct.tensor(reader, "output.weight", device) {
Ok(v) => QMatMul::from_qtensor(v)?,
_ => {
// use tie_word_embeddings
QMatMul::from_qtensor(ct.tensor(reader, "token_embd.weight", device)?)?
}
};
let (cos, sin) = precomput_freqs_cis(head_dim, rope_freq_base, context_length, device)?;
let mut layers = Vec::with_capacity(block_count);
for layer_idx in 0..block_count {
let prefix = format!("blk.{layer_idx}");
let attention_wq = ct.tensor(reader, &format!("{prefix}.attn_q.weight"), device)?;
let attention_wk = ct.tensor(reader, &format!("{prefix}.attn_k.weight"), device)?;
let attention_wv = ct.tensor(reader, &format!("{prefix}.attn_v.weight"), device)?;
let attention_bq = ct.tensor(reader, &format!("{prefix}.attn_q.bias"), device)?;
let attention_bk = ct.tensor(reader, &format!("{prefix}.attn_k.bias"), device)?;
let attention_bv = ct.tensor(reader, &format!("{prefix}.attn_v.bias"), device)?;
let attention_wo =
ct.tensor(reader, &format!("{prefix}.attn_output.weight"), device)?;
let mlp = {
let feed_forward_w1 =
ct.tensor(reader, &format!("{prefix}.ffn_gate.weight"), device)?;
let feed_forward_w2 =
ct.tensor(reader, &format!("{prefix}.ffn_down.weight"), device)?;
let feed_forward_w3 =
ct.tensor(reader, &format!("{prefix}.ffn_up.weight"), device)?;
Mlp {
feed_forward_w1: QMatMul::from_qtensor(feed_forward_w1)?,
feed_forward_w2: QMatMul::from_qtensor(feed_forward_w2)?,
feed_forward_w3: QMatMul::from_qtensor(feed_forward_w3)?,
}
};
let attention_norm =
ct.tensor(reader, &format!("{prefix}.attn_norm.weight"), device)?;
let ffn_norm = ct.tensor(reader, &format!("{prefix}.ffn_norm.weight"), device)?;
let span_attn = tracing::span!(tracing::Level::TRACE, "attn");
let span_rot = tracing::span!(tracing::Level::TRACE, "attn-rot");
let span_mlp = tracing::span!(tracing::Level::TRACE, "attn-mlp");
layers.push(LayerWeights {
attention_wq: QMatMul::from_qtensor(attention_wq)?,
attention_wk: QMatMul::from_qtensor(attention_wk)?,
attention_wv: QMatMul::from_qtensor(attention_wv)?,
attention_bq: attention_bq.dequantize(device)?,
attention_bk: attention_bk.dequantize(device)?,
attention_bv: attention_bv.dequantize(device)?,
attention_wo: QMatMul::from_qtensor(attention_wo)?,
attention_norm: RmsNorm::from_qtensor(attention_norm, rms_norm_eps)?,
cos: cos.clone(),
sin: sin.clone(),
mlp,
ffn_norm: RmsNorm::from_qtensor(ffn_norm, rms_norm_eps)?,
n_head: head_count,
n_kv_head: head_count_kv,
head_dim,
neg_inf: neg_inf.clone(),
kv_cache: None,
span_attn,
span_rot,
span_mlp,
});
}
let span = tracing::span!(tracing::Level::TRACE, "model");
let span_output = tracing::span!(tracing::Level::TRACE, "output");
Ok(Self {
tok_embeddings: Embedding::new(tok_embeddings, embedding_length),
layers,
norm,
output,
masks: HashMap::new(),
span,
span_output,
})
}
fn mask(&mut self, t: usize, device: &Device) -> Result<Tensor> {
if let Some(mask) = self.masks.get(&t) {
Ok(mask.clone())
} else {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j > i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), device)?;
self.masks.insert(t, mask.clone());
Ok(mask)
}
}
pub fn forward(&mut self, x: &Tensor, index_pos: usize) -> Result<Tensor> {
let (_b_sz, seq_len) = x.dims2()?;
let mask = if seq_len == 1 {
None
} else {
Some(self.mask(seq_len, x.device())?)
};
let _enter = self.span.enter();
let mut layer_in = self.tok_embeddings.forward(x)?;
for layer in self.layers.iter_mut() {
let x = layer_in;
let residual = &x;
let x = layer.attention_norm.forward(&x)?;
let attn = layer.forward_attn(&x, mask.as_ref(), index_pos)?;
let x = (attn + residual)?;
// MLP
let _enter = layer.span_mlp.enter();
let residual = &x;
let x = layer.ffn_norm.forward(&x)?;
let x = layer.mlp.forward(&x)?;
let x = (x + residual)?;
layer_in = x
}
let x = self.norm.forward(&layer_in)?;
let x = x.i((.., seq_len - 1, ..))?;
let _enter = self.span_output.enter();
self.output.forward(&x)
}
}
| 7 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/mixformer.rs | //! MixFormer (Microsoft's Phi Architecture)
//!
//! See "Textbooks Are All You Need II: phi-1.5 technical report", Lin et al. 2023
//! - [Arxiv](https://arxiv.org/abs/2309.05463)
//! - [Github](https://huggingface.co/microsoft/phi-1_5)
//!
use crate::models::with_tracing::{linear, Embedding as E, Linear};
/// MixFormer model.
/// https://huggingface.co/microsoft/phi-1_5
/// https://arxiv.org/abs/2309.05463
use candle::{DType, Device, IndexOp, Module, Result, Tensor, D};
use candle_nn::{Activation, VarBuilder};
use serde::Deserialize;
const MAX_SEQ_LEN: usize = 4096;
// https://huggingface.co/microsoft/phi-1_5/blob/d38e6f954ec29b96fe2cf033937dad64e279b5d9/configuration_mixformer_sequential.py
#[derive(Debug, Clone, PartialEq, Deserialize)]
pub struct Config {
pub(crate) vocab_size: usize,
pub(crate) n_positions: usize,
pub(crate) n_embd: usize,
pub(crate) n_layer: usize,
pub(crate) n_inner: Option<usize>,
pub(crate) n_head: usize,
pub(crate) rotary_dim: usize,
pub(crate) activation_function: Activation,
pub(crate) layer_norm_epsilon: f64,
pub(crate) tie_word_embeddings: bool,
pub(crate) pad_vocab_size_multiple: usize,
}
impl Config {
pub fn v1() -> Self {
Self {
vocab_size: 50304,
n_positions: 2048,
n_embd: 1024,
n_layer: 20,
n_inner: None,
n_head: 16,
rotary_dim: usize::min(32, 1024 / 16),
activation_function: Activation::Gelu,
layer_norm_epsilon: 1e-5,
tie_word_embeddings: false,
pad_vocab_size_multiple: 64,
}
}
pub fn v1_5() -> Self {
Self {
vocab_size: 51200,
n_positions: 2048,
n_embd: 2048,
n_layer: 24,
n_inner: None,
n_head: 32,
rotary_dim: usize::min(32, 2048 / 32),
activation_function: Activation::Gelu,
layer_norm_epsilon: 1e-5,
tie_word_embeddings: false,
pad_vocab_size_multiple: 64,
}
}
pub fn v2() -> Self {
Self {
vocab_size: 51200,
n_positions: 2048,
n_embd: 2560,
n_layer: 32,
n_inner: None,
n_head: 32,
rotary_dim: usize::min(32, 2560 / 32),
activation_function: Activation::Gelu,
layer_norm_epsilon: 1e-5,
tie_word_embeddings: false,
pad_vocab_size_multiple: 64,
}
}
// https://huggingface.co/teknium/Puffin-Phi-v2/blob/main/config.json
pub fn puffin_phi_v2() -> Self {
Self {
vocab_size: 50304,
n_positions: 2048,
n_embd: 2048,
n_layer: 24,
n_inner: None,
n_head: 32,
rotary_dim: usize::min(32, 2048 / 32),
activation_function: Activation::Gelu,
layer_norm_epsilon: 1e-5,
tie_word_embeddings: false,
pad_vocab_size_multiple: 64,
}
}
// https://huggingface.co/teknium/Phi-Hermes-1.3B/blob/main/config.json
pub fn phi_hermes_1_3b() -> Self {
Self {
vocab_size: 50304,
n_positions: 2048,
n_embd: 2048,
n_layer: 24,
n_inner: None,
n_head: 32,
rotary_dim: usize::min(32, 2048 / 32),
activation_function: Activation::NewGelu,
layer_norm_epsilon: 1e-5,
tie_word_embeddings: false,
pad_vocab_size_multiple: 64,
}
}
}
#[derive(Debug, Clone)]
struct Embedding {
wte: E,
}
impl Embedding {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let wte = E::new(cfg.vocab_size, cfg.n_embd, vb.pp("wte"))?;
Ok(Self { wte })
}
}
impl Module for Embedding {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
self.wte.forward(xs)
}
}
fn get_mask(size: usize, dtype: DType, device: &Device) -> Result<Tensor> {
let mask: Vec<_> = (0..size)
.flat_map(|i| (0..size).map(move |j| if j > i { f32::NEG_INFINITY } else { 0. }))
.collect();
Tensor::from_slice(&mask, (size, size), device)?.to_dtype(dtype)
}
#[derive(Debug, Clone)]
struct RotaryEmbedding {
sin: Tensor,
cos: Tensor,
}
impl RotaryEmbedding {
fn new(dim: usize, max_seq_len: usize, dtype: DType, dev: &Device) -> Result<Self> {
let inv_freq: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / 10000f32.powf(i as f32 / dim as f32))
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?;
let t = Tensor::arange(0u32, max_seq_len as u32, dev)?
.to_dtype(DType::F32)?
.reshape((max_seq_len, 1))?;
let freqs = t.matmul(&inv_freq)?;
Ok(Self {
sin: freqs.sin()?.to_dtype(dtype)?,
cos: freqs.cos()?.to_dtype(dtype)?,
})
}
fn apply_rotary_emb_qkv(
&self,
qkv: &Tensor,
seqlen_offset: usize,
) -> Result<(Tensor, Tensor, Tensor)> {
let (_b_size, seqlen, three, _, _headdim) = qkv.dims5()?;
if three != 3 {
candle::bail!("unexpected shape for qkv {:?}", qkv.shape())
}
let (_rotary_seqlen, rotary_dim) = self.cos.dims2()?;
let rotary_dim = rotary_dim * 2;
let q_rot = qkv.i((.., .., 0, .., ..rotary_dim))?.contiguous()?;
let q_pass = qkv.i((.., .., 0, .., rotary_dim..))?;
let k_rot = qkv.i((.., .., 1, .., ..rotary_dim))?.contiguous()?;
let k_pass = qkv.i((.., .., 1, .., rotary_dim..))?;
let c = self.cos.narrow(0, seqlen_offset, seqlen)?;
let s = self.sin.narrow(0, seqlen_offset, seqlen)?;
let q_rot = candle_nn::rotary_emb::rope_thd(&q_rot, &c, &s)?;
let k_rot = candle_nn::rotary_emb::rope_thd(&k_rot, &c, &s)?;
let q = Tensor::cat(&[&q_rot, &q_pass], D::Minus1)?;
let k = Tensor::cat(&[&k_rot, &k_pass], D::Minus1)?;
let v = qkv.i((.., .., 2))?;
Ok((q, k, v))
}
}
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MLP {
fc1: Linear,
fc2: Linear,
act: Activation,
span: tracing::Span,
}
impl MLP {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let n_inner = cfg.n_inner.unwrap_or(4 * cfg.n_embd);
let fc1 = linear(cfg.n_embd, n_inner, vb.pp("fc1"))?;
let fc2 = linear(n_inner, cfg.n_embd, vb.pp("fc2"))?;
Ok(Self {
fc1,
fc2,
act: cfg.activation_function,
span: tracing::span!(tracing::Level::TRACE, "mlp"),
})
}
}
impl Module for MLP {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
xs.apply(&self.fc1)?.apply(&self.act)?.apply(&self.fc2)
}
}
#[derive(Debug, Clone)]
struct CausalLMHead {
ln: candle_nn::LayerNorm,
linear: Linear,
}
impl CausalLMHead {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let ln = candle_nn::layer_norm(cfg.n_embd, cfg.layer_norm_epsilon, vb.pp("ln"))?;
let linear = linear(cfg.n_embd, cfg.vocab_size, vb.pp("linear"))?;
Ok(Self { ln, linear })
}
}
impl Module for CausalLMHead {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.ln)?
.apply(&self.linear)?
.to_dtype(DType::F32)
}
}
#[derive(Debug, Clone)]
#[allow(clippy::upper_case_acronyms)]
struct MHA {
wqkv: Linear,
out_proj: Linear,
rotary_emb: RotaryEmbedding,
kv_cache: Option<(Tensor, Tensor)>,
head_dim: usize,
softmax_scale: f64,
span: tracing::Span,
span_rope: tracing::Span,
span_mask: tracing::Span,
span_softmax: tracing::Span,
}
impl MHA {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let head_dim = cfg.n_embd / cfg.n_head;
let op_size = cfg.n_embd;
let wqkv = linear(cfg.n_embd, 3 * op_size, vb.pp("Wqkv"))?;
let out_proj = linear(op_size, cfg.n_embd, vb.pp("out_proj"))?;
let rotary_emb =
RotaryEmbedding::new(cfg.rotary_dim, MAX_SEQ_LEN, vb.dtype(), vb.device())?;
let softmax_scale = 1f64 / (head_dim as f64).sqrt();
Ok(Self {
wqkv,
out_proj,
head_dim,
kv_cache: None,
rotary_emb,
softmax_scale,
span: tracing::span!(tracing::Level::TRACE, "mha"),
span_rope: tracing::span!(tracing::Level::TRACE, "rope"),
span_mask: tracing::span!(tracing::Level::TRACE, "mask"),
span_softmax: tracing::span!(tracing::Level::TRACE, "softmax"),
})
}
fn forward(&mut self, xs: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let _enter = self.span.enter();
let (b_size, seq_len, _n_embd) = xs.dims3()?;
let qkv = self
.wqkv
.forward(xs)?
.reshape((b_size, seq_len, 3, (), self.head_dim))?;
let seqlen_offset = match &self.kv_cache {
None => 0,
Some((prev_k, _)) => prev_k.dim(1)?,
};
// In the python implementation, a single tensor is returned with the third axis of size 3.
let (q, k, v) = {
let _enter = self.span_rope.enter();
self.rotary_emb.apply_rotary_emb_qkv(&qkv, seqlen_offset)?
};
let (k, v) = match &self.kv_cache {
None => (k, v),
Some((prev_k, prev_v)) => {
let k = Tensor::cat(&[prev_k, &k], 1)?;
let v = Tensor::cat(&[prev_v, &v], 1)?;
(k, v)
}
};
self.kv_cache = Some((k.clone(), v.clone()));
// scores = torch.einsum('bthd,bshd->bhts', q, k * softmax_scale)
let q = q.transpose(1, 2)?.flatten_to(1)?; // b*h, t, d
let k = k.transpose(1, 2)?.flatten_to(1)?; // b*h, s, d
let v = v.transpose(1, 2)?.flatten_to(1)?; // b*h, s, d
let attn_weights = (q.matmul(&k.t()?)? * self.softmax_scale)?; // b*h, t, s
// causal_mask = torch.triu(torch.full((seqlen_q, seqlen_k), -10000.0, device=scores.device), 1)
// scores = scores + causal_mask.to(dtype=scores.dtype)
let attn_weights = match mask {
None => attn_weights,
Some(mask) => {
let _enter = self.span_mask.enter();
attn_weights.broadcast_add(mask)?
}
};
let attn_weights = {
let _enter = self.span_softmax.enter();
candle_nn::ops::softmax_last_dim(&attn_weights)?
};
// output = torch.einsum('bhts,bshd->bthd', attention_drop, v)
// attn_weights: b*h,t,s, v: b*h,s,d
let attn_output = attn_weights.matmul(&v)?;
// b*h,t,d
let attn_output = attn_output
.reshape((b_size, (), seq_len, self.head_dim))?
.transpose(1, 2)?
.flatten_from(D::Minus2)?;
attn_output.apply(&self.out_proj)
}
fn clear_kv_cache(&mut self) {
self.kv_cache = None
}
}
#[derive(Debug, Clone)]
struct ParallelBlock {
ln: candle_nn::LayerNorm,
mixer: MHA,
mlp: MLP,
span: tracing::Span,
}
impl ParallelBlock {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let ln = candle_nn::layer_norm(cfg.n_embd, cfg.layer_norm_epsilon, vb.pp("ln"))?;
let mixer = MHA::new(cfg, vb.pp("mixer"))?;
let mlp = MLP::new(cfg, vb.pp("mlp"))?;
Ok(Self {
ln,
mixer,
mlp,
span: tracing::span!(tracing::Level::TRACE, "block"),
})
}
fn forward(&mut self, xs: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let _enter = self.span.enter();
let residual = xs;
let xs = xs.apply(&self.ln)?;
let attn_outputs = self.mixer.forward(&xs, mask)?;
let feed_forward_hidden_states = self.mlp.forward(&xs)?;
attn_outputs + feed_forward_hidden_states + residual
}
fn clear_kv_cache(&mut self) {
self.mixer.clear_kv_cache()
}
}
#[derive(Debug, Clone)]
pub struct MixFormerSequentialForCausalLM {
embedding: Embedding,
blocks: Vec<ParallelBlock>,
head: CausalLMHead,
span: tracing::Span,
}
impl MixFormerSequentialForCausalLM {
pub fn new_v2(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_head = vb.pp("lm_head");
let vb = vb.pp("transformer");
let embedding = Embedding::new(cfg, vb.pp("embd"))?;
let mut blocks = Vec::new();
for i in 0..cfg.n_layer {
let block = ParallelBlock::new(cfg, vb.pp("h").pp(i))?;
blocks.push(block)
}
let head = CausalLMHead::new(cfg, vb_head)?;
Ok(Self {
embedding,
blocks,
head,
span: tracing::span!(tracing::Level::TRACE, "mixformer"),
})
}
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb = vb.pp("layers");
let embedding = Embedding::new(cfg, vb.pp(0))?;
let mut blocks = Vec::new();
for i in 0..cfg.n_layer {
let block = ParallelBlock::new(cfg, vb.pp(i + 1))?;
blocks.push(block)
}
let head = CausalLMHead::new(cfg, vb.pp(cfg.n_layer + 1))?;
Ok(Self {
embedding,
blocks,
head,
span: tracing::span!(tracing::Level::TRACE, "mixformer"),
})
}
pub fn forward(&mut self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (_b_size, seq_len) = xs.dims2()?;
let mut xs = xs.apply(&self.embedding)?;
let mask = if seq_len <= 1 {
None
} else {
Some(get_mask(seq_len, xs.dtype(), xs.device())?)
};
for block in self.blocks.iter_mut() {
xs = block.forward(&xs, mask.as_ref())?
}
xs.narrow(1, seq_len - 1, 1)?.apply(&self.head)?.squeeze(1)
}
pub fn forward_with_img(
&mut self,
bos_token: &Tensor,
xs: &Tensor,
img_embeds: &Tensor,
) -> Result<Tensor> {
let _enter = self.span.enter();
let xs = xs.apply(&self.embedding)?;
let bos_token = bos_token.apply(&self.embedding)?;
// Python implementation sequence order is <bos token embedding><img embedding><rest of text embedding>
// https://github.com/vikhyat/moondream/blob/a9d788a20d1543fb1479edc54106e88cff7759d3/moondream/moondream.py#L43-L56
let mut xs = Tensor::cat(&[bos_token, img_embeds.clone(), xs], 1)?;
let (_b_size, seq_len, _embds) = xs.dims3()?;
let mask = Some(get_mask(seq_len, xs.dtype(), xs.device())?);
for block in self.blocks.iter_mut() {
xs = block.forward(&xs, mask.as_ref())?
}
let xs = xs
.narrow(1, seq_len - 1, 1)?
.apply(&self.head)?
.squeeze(1)?;
Ok(xs)
}
pub fn clear_kv_cache(&mut self) {
self.blocks.iter_mut().for_each(|b| b.clear_kv_cache())
}
}
| 8 |
0 | hf_public_repos/candle/candle-transformers/src | hf_public_repos/candle/candle-transformers/src/models/blip_text.rs | //! Implementation of BLIP text encoder/decoder.
//!
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086). BLIP: Bootstrapping Language-Image Pre-training for Unified Vision-Language Understanding and Generation"
//!
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
//!
use super::with_tracing::{linear, Embedding, Linear};
use candle::{Module, Result, Tensor, D};
use candle_nn::{layer_norm, LayerNorm, VarBuilder};
use serde::Deserialize;
#[derive(Debug, Clone, Deserialize)]
pub struct Config {
pub vocab_size: usize,
pub hidden_size: usize,
pub encoder_hidden_size: usize,
pub intermediate_size: usize,
pub projection_dim: usize,
pub num_hidden_layers: usize,
pub num_attention_heads: usize,
pub max_position_embeddings: usize,
pub hidden_act: candle_nn::Activation,
pub layer_norm_eps: f64,
pub is_decoder: bool,
}
#[derive(Debug, Clone)]
struct TextEmbeddings {
word_embedddings: Embedding,
position_embeddings: Embedding,
layer_norm: LayerNorm,
position_ids: Tensor,
}
impl TextEmbeddings {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let word_embedddings =
Embedding::new(cfg.vocab_size, cfg.hidden_size, vb.pp("word_embeddings"))?;
let position_embeddings = Embedding::new(
cfg.max_position_embeddings,
cfg.hidden_size,
vb.pp("position_embeddings"),
)?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
let position_ids =
Tensor::arange(0, cfg.max_position_embeddings as u32, vb.device())?.unsqueeze(0)?;
Ok(Self {
word_embedddings,
position_embeddings,
layer_norm,
position_ids,
})
}
fn forward(&self, xs: &Tensor, past_kv_len: usize) -> Result<Tensor> {
let seq_len = xs.dim(1)?;
let position_ids = self.position_ids.narrow(1, past_kv_len, seq_len)?;
let embeddings = self.word_embedddings.forward(xs)?;
let position_embeddings = self.position_embeddings.forward(&position_ids)?;
(embeddings + position_embeddings)?.apply(&self.layer_norm)
}
}
#[derive(Debug, Clone)]
struct TextSelfAttention {
query: Linear,
key: Linear,
value: Linear,
attention_head_size: usize,
num_attention_heads: usize,
attention_scale: f64,
kv_cache: Option<(Tensor, Tensor)>,
}
impl TextSelfAttention {
fn new(cfg: &Config, is_cross_attention: bool, vb: VarBuilder) -> Result<Self> {
let num_attention_heads = cfg.num_attention_heads;
let attention_head_size = cfg.hidden_size / num_attention_heads;
let all_head_size = cfg.num_attention_heads * attention_head_size;
let query = linear(cfg.hidden_size, all_head_size, vb.pp("query"))?;
let in_size = if is_cross_attention {
cfg.encoder_hidden_size
} else {
cfg.hidden_size
};
let key = linear(in_size, all_head_size, vb.pp("key"))?;
let value = linear(in_size, all_head_size, vb.pp("value"))?;
let attention_scale = 1f64 / (attention_head_size as f64).sqrt();
Ok(Self {
query,
key,
value,
attention_head_size,
num_attention_heads,
attention_scale,
kv_cache: None,
})
}
fn transpose_for_scores(&self, xs: &Tensor) -> Result<Tensor> {
let (b_size, seq_len, _) = xs.dims3()?;
xs.reshape((
b_size,
seq_len,
self.num_attention_heads,
self.attention_head_size,
))?
.permute((0, 2, 1, 3))
}
fn reset_kv_cache(&mut self) {
self.kv_cache = None
}
fn forward(
&mut self,
xs: &Tensor,
encoder_hidden_states: Option<&Tensor>,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let query = self
.transpose_for_scores(&self.query.forward(xs)?)?
.contiguous()?;
let (key, value) = match encoder_hidden_states {
None => {
let key = self.transpose_for_scores(&self.key.forward(xs)?)?;
let value = self.transpose_for_scores(&self.value.forward(xs)?)?;
let (key, value) = match &self.kv_cache {
None => (key, value),
Some((prev_key, prev_value)) => {
let key = Tensor::cat(&[prev_key, &key], 2)?;
let value = Tensor::cat(&[prev_value, &value], 2)?;
(key, value)
}
};
self.kv_cache = Some((key.clone(), value.clone()));
(key, value)
}
Some(xs) => {
let key = self.transpose_for_scores(&self.key.forward(xs)?)?;
let value = self.transpose_for_scores(&self.value.forward(xs)?)?;
// no kv-cache in this case, but the results could probably be memoized.
(key, value)
}
};
let key = key.contiguous()?;
let value = value.contiguous()?;
let attention_scores = query.matmul(&key.t()?)?;
let attention_scores = (attention_scores * self.attention_scale)?;
let attention_scores = match attention_mask {
Some(mask) => attention_scores.broadcast_add(mask)?,
None => attention_scores,
};
let attention_probs = candle_nn::ops::softmax_last_dim(&attention_scores)?;
attention_probs
.matmul(&value)?
.permute((0, 2, 1, 3))?
.flatten_from(D::Minus2)
}
}
#[derive(Debug, Clone)]
struct TextSelfOutput {
dense: Linear,
layer_norm: LayerNorm,
}
impl TextSelfOutput {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("dense"))?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self { dense, layer_norm })
}
fn forward(&self, xs: &Tensor, input_tensor: &Tensor) -> Result<Tensor> {
(xs.apply(&self.dense) + input_tensor)?.apply(&self.layer_norm)
}
}
#[derive(Debug, Clone)]
struct TextAttention {
self_: TextSelfAttention,
output: TextSelfOutput,
}
impl TextAttention {
fn new(cfg: &Config, is_cross_attention: bool, vb: VarBuilder) -> Result<Self> {
let self_ = TextSelfAttention::new(cfg, is_cross_attention, vb.pp("self"))?;
let output = TextSelfOutput::new(cfg, vb.pp("output"))?;
Ok(Self { self_, output })
}
fn reset_kv_cache(&mut self) {
self.self_.reset_kv_cache()
}
fn forward(
&mut self,
xs: &Tensor,
encoder_hidden_states: Option<&Tensor>,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let self_outputs = self
.self_
.forward(xs, encoder_hidden_states, attention_mask)?;
self.output.forward(&self_outputs, xs)
}
}
#[derive(Debug, Clone)]
struct TextIntermediate {
dense: Linear,
intermediate_act_fn: candle_nn::Activation,
}
impl TextIntermediate {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.intermediate_size, vb.pp("dense"))?;
Ok(Self {
dense,
intermediate_act_fn: cfg.hidden_act,
})
}
}
impl Module for TextIntermediate {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.dense)?.apply(&self.intermediate_act_fn)
}
}
#[derive(Debug, Clone)]
struct TextOutput {
dense: Linear,
layer_norm: LayerNorm,
}
impl TextOutput {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.intermediate_size, cfg.hidden_size, vb.pp("dense"))?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self { dense, layer_norm })
}
fn forward(&self, xs: &Tensor, input_tensor: &Tensor) -> Result<Tensor> {
(xs.apply(&self.dense)? + input_tensor)?.apply(&self.layer_norm)
}
}
#[derive(Debug, Clone)]
struct TextLayer {
attention: TextAttention,
cross_attention: Option<TextAttention>,
intermediate: TextIntermediate,
output: TextOutput,
}
impl TextLayer {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let attention = TextAttention::new(cfg, false, vb.pp("attention"))?;
let cross_attention = if cfg.is_decoder {
Some(TextAttention::new(cfg, true, vb.pp("crossattention"))?)
} else {
None
};
let intermediate = TextIntermediate::new(cfg, vb.pp("intermediate"))?;
let output = TextOutput::new(cfg, vb.pp("output"))?;
Ok(Self {
attention,
cross_attention,
intermediate,
output,
})
}
fn reset_kv_cache(&mut self) {
self.attention.reset_kv_cache();
if let Some(ca) = &mut self.cross_attention {
ca.reset_kv_cache()
}
}
fn forward(
&mut self,
xs: &Tensor,
encoder_hidden_states: &Tensor,
attention_mask: &Tensor,
) -> Result<Tensor> {
let attention_output = self.attention.forward(xs, None, Some(attention_mask))?;
let attention_output = match &mut self.cross_attention {
Some(ca) => ca.forward(&attention_output, Some(encoder_hidden_states), None)?,
None => candle::bail!("expected some cross-attn"),
};
let intermediate_output = self.intermediate.forward(&attention_output)?;
self.output.forward(&intermediate_output, &attention_output)
}
}
#[derive(Debug, Clone)]
struct TextEncoder {
layers: Vec<TextLayer>,
}
impl TextEncoder {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb = vb.pp("layer");
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
for i in 0..cfg.num_hidden_layers {
let layer = TextLayer::new(cfg, vb.pp(i))?;
layers.push(layer)
}
Ok(Self { layers })
}
fn reset_kv_cache(&mut self) {
self.layers.iter_mut().for_each(|l| l.reset_kv_cache())
}
fn forward(
&mut self,
xs: &Tensor,
encoder_hidden_states: &Tensor,
attention_mask: &Tensor,
) -> Result<Tensor> {
let mut xs = xs.clone();
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, encoder_hidden_states, attention_mask)?
}
Ok(xs)
}
}
#[derive(Debug, Clone)]
pub struct TextPooler {
dense: Linear,
}
impl TextPooler {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("dense"))?;
Ok(Self { dense })
}
}
impl Module for TextPooler {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.narrow(D::Minus1, 0, 1)?
.squeeze(D::Minus1)?
.apply(&self.dense)?
.tanh()
}
}
#[derive(Debug, Clone)]
struct TextPredictionHeadTransform {
dense: Linear,
transform_act_fn: candle_nn::Activation,
layer_norm: LayerNorm,
}
impl TextPredictionHeadTransform {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dense = linear(cfg.hidden_size, cfg.hidden_size, vb.pp("dense"))?;
let layer_norm = layer_norm(cfg.hidden_size, cfg.layer_norm_eps, vb.pp("LayerNorm"))?;
Ok(Self {
dense,
transform_act_fn: cfg.hidden_act,
layer_norm,
})
}
}
impl Module for TextPredictionHeadTransform {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.dense)?
.apply(&self.transform_act_fn)?
.apply(&self.layer_norm)
}
}
#[derive(Debug, Clone)]
struct TextLMPredictionHead {
transform: TextPredictionHeadTransform,
decoder: Linear,
}
impl TextLMPredictionHead {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let transform = TextPredictionHeadTransform::new(cfg, vb.pp("transform"))?;
let weight = vb.get((cfg.vocab_size, cfg.hidden_size), "decoder.weight")?;
let bias = vb.get(cfg.vocab_size, "bias")?;
let decoder = Linear::from_weights(weight, Some(bias));
Ok(Self { transform, decoder })
}
}
impl Module for TextLMPredictionHead {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.transform)?.apply(&self.decoder)
}
}
#[derive(Debug, Clone)]
struct TextOnlyMLMHead {
predictions: TextLMPredictionHead,
}
impl TextOnlyMLMHead {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let predictions = TextLMPredictionHead::new(cfg, vb.pp("predictions"))?;
Ok(Self { predictions })
}
}
impl Module for TextOnlyMLMHead {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
self.predictions.forward(xs)
}
}
#[derive(Debug, Clone)]
struct TextModel {
embeddings: TextEmbeddings,
encoder: TextEncoder,
past_kv_len: usize,
// We do not need the pooler for caption generation
}
impl TextModel {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let embeddings = TextEmbeddings::new(cfg, vb.pp("embeddings"))?;
let encoder = TextEncoder::new(cfg, vb.pp("encoder"))?;
Ok(Self {
embeddings,
encoder,
past_kv_len: 0,
})
}
fn forward(
&mut self,
input_ids: &Tensor,
encoder_hidden_states: &Tensor,
attention_mask: &Tensor,
) -> Result<Tensor> {
let (_b_sz, seq_len) = input_ids.dims2()?;
let embedding_output = self.embeddings.forward(input_ids, self.past_kv_len)?;
let sequence_output =
self.encoder
.forward(&embedding_output, encoder_hidden_states, attention_mask)?;
self.past_kv_len += seq_len;
// We're interested in the sequence-output rather than the pooled-output.
Ok(sequence_output)
}
fn reset_kv_cache(&mut self) {
self.past_kv_len = 0;
self.encoder.reset_kv_cache();
}
}
#[derive(Debug, Clone)]
pub struct TextLMHeadModel {
bert: TextModel,
cls: TextOnlyMLMHead,
}
impl TextLMHeadModel {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let bert = TextModel::new(cfg, vb.pp("bert"))?;
let cls = TextOnlyMLMHead::new(cfg, vb.pp("cls"))?;
Ok(Self { bert, cls })
}
pub fn forward(
&mut self,
input_ids: &Tensor,
encoder_hidden_states: &Tensor,
) -> Result<Tensor> {
let seq_len = input_ids.dim(1)?;
let mask: Vec<_> = (0..seq_len)
.flat_map(|i| (0..seq_len).map(move |j| if j > i { f32::NEG_INFINITY } else { 0f32 }))
.collect();
let mask = Tensor::from_vec(mask, (seq_len, seq_len), input_ids.device())?;
let sequence_output = self.bert.forward(input_ids, encoder_hidden_states, &mask)?;
let prediction_scores = self.cls.forward(&sequence_output)?;
// return_logits is false so we don't discard the last sequence element.
Ok(prediction_scores)
}
pub fn reset_kv_cache(&mut self) {
self.bert.reset_kv_cache()
}
}
| 9 |
0 | hf_public_repos/accelerate/tests/test_samples | hf_public_repos/accelerate/tests/test_samples/MRPC/train.csv | label,sentence1,sentence2
equivalent,He said the foodservice pie business doesn 't fit the company 's long-term growth strategy .,""" The foodservice pie business does not fit our long-term growth strategy ."
not_equivalent,Magnarelli said Racicot hated the Iraqi regime and looked forward to using his long years of training in the war .,"His wife said he was "" 100 percent behind George Bush "" and looked forward to using his years of training in the war ."
not_equivalent,"The dollar was at 116.92 yen against the yen , flat on the session , and at 1.2891 against the Swiss franc , also flat .","The dollar was at 116.78 yen JPY = , virtually flat on the session , and at 1.2871 against the Swiss franc CHF = , down 0.1 percent ."
equivalent,The AFL-CIO is waiting until October to decide if it will endorse a candidate .,The AFL-CIO announced Wednesday that it will decide in October whether to endorse a candidate before the primaries .
not_equivalent,No dates have been set for the civil or the criminal trial .,"No dates have been set for the criminal or civil cases , but Shanley has pleaded not guilty ."
equivalent,Wal-Mart said it would check all of its million-plus domestic workers to ensure they were legally employed .,It has also said it would review all of its domestic employees more than 1 million to ensure they have legal status .
| 0 |
0 | hf_public_repos/accelerate/tests/test_samples | hf_public_repos/accelerate/tests/test_samples/MRPC/dev.csv | label,sentence1,sentence2
equivalent,He said the foodservice pie business doesn 't fit the company 's long-term growth strategy .,""" The foodservice pie business does not fit our long-term growth strategy ."
not_equivalent,Magnarelli said Racicot hated the Iraqi regime and looked forward to using his long years of training in the war .,"His wife said he was "" 100 percent behind George Bush "" and looked forward to using his years of training in the war ."
not_equivalent,"The dollar was at 116.92 yen against the yen , flat on the session , and at 1.2891 against the Swiss franc , also flat .","The dollar was at 116.78 yen JPY = , virtually flat on the session , and at 1.2871 against the Swiss franc CHF = , down 0.1 percent ."
equivalent,The AFL-CIO is waiting until October to decide if it will endorse a candidate .,The AFL-CIO announced Wednesday that it will decide in October whether to endorse a candidate before the primaries .
not_equivalent,No dates have been set for the civil or the criminal trial .,"No dates have been set for the criminal or civil cases , but Shanley has pleaded not guilty ."
equivalent,Wal-Mart said it would check all of its million-plus domestic workers to ensure they were legally employed .,It has also said it would review all of its domestic employees more than 1 million to ensure they have legal status .
| 1 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/test_configs/0_28_0_mpi.yaml | compute_environment: LOCAL_MACHINE
debug: false
distributed_type: MULTI_CPU
downcast_bf16: 'no'
ipex_config:
ipex: true
machine_rank: 0
main_process_ip: 127.0.0.1
main_process_port: 29500
main_training_function: main
mixed_precision: 'no'
mpirun_config:
mpirun_ccl: '1'
mpirun_hostfile: /home/user/hostfile
num_machines: 4
num_processes: 16
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: true
| 2 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/test_configs/0_12_0.yaml | compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: 'NO'
downcast_bf16: 'no'
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 1
use_cpu: false | 3 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/test_configs/latest.yaml | compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: 'NO'
downcast_bf16: 'no'
fsdp_config: {}
gpu_ids: all
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
megatron_lm_config: {}
mixed_precision: 'no'
num_machines: 1
num_processes: 1
rdzv_backend: static
same_network: true
use_cpu: false
tpu_name: 'test-tpu'
tpu_zone: 'us-central1-a'
commands: null
command_file: tests/test_samples/test_command_file.sh | 4 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/test_configs/invalid_keys.yaml | compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: 'NO'
downcast_bf16: 'no'
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 1
use_cpu: false
invalid_key: "invalid_value"
another_invalid_key: "another_invalid_value" | 5 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/test_configs/0_30_0_sagemaker.yaml | compute_environment: AMAZON_SAGEMAKER
debug: false
distributed_type: NO
mixed_precision: fp16
debug: false
use_cpu: false
ec2_instance_type: MY_TYPE
iam_role_name: MY_ROLE
| 6 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/test_configs/0_11_0.yaml | compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: 'NO'
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 1
use_cpu: false | 7 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/test_configs/0_34_0_fp8.yaml | compute_environment: LOCAL_MACHINE
debug: false
distributed_type: MULTI_GPU
downcast_bf16: 'no'
enable_cpu_affinity: false
fp8_config:
amax_compute_algorithm: max
amax_history_length: 1024
backend: TE
fp8_format: E4M3
interval: 1
margin: 0
override_linear_precision: false
use_autocast_during_eval: false
gpu_ids: all
machine_rank: 0
main_training_function: main
mixed_precision: fp8
num_machines: 1
num_processes: 2
rdzv_backend: static
same_network: true
tpu_env: []
tpu_use_cluster: false
tpu_use_sudo: false
use_cpu: false
| 8 |
0 | hf_public_repos/accelerate/tests | hf_public_repos/accelerate/tests/test_configs/README.md | This folder contains test configs for `accelerate config`. These should be generated for each major version
and are written based on `accelerate config` and selecting the "No distributed training" option. | 9 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/matryoshka.md | ---
title: "🪆 俄罗斯套娃嵌入模型"
thumbnail: /blog/assets/matryoshka/thumbnail.png
authors:
- user: tomaarsen
- user: xenova
- user: osanseviero
translators:
- user: innovation64
- user: zhongdongy
proofreader: true
---
# 🪆 俄罗斯套娃 (Matryoshka) 嵌入模型概述
在这篇博客中,我们将向你介绍俄罗斯套娃嵌入的概念,并解释为什么它们很有用。我们将讨论这些模型在理论上是如何训练的,以及你如何使用 Sentence Transformers 来训练它们。
除此之外,我们还会告诉你怎么用这种像套娃一样的俄罗斯套娃嵌入模型,并且我们会比较一下这种模型和普通嵌入模型的不同。最后,我们邀请你来玩一下我们的互动演示,看看这些模型有多厉害。
## 目录
* [理解嵌入](#understanding-embeddings)
* [🪆 俄罗斯套娃嵌入](#🪆-matryoshka-embeddings)
* [🪆 俄罗斯套娃套娃](#🪆-matryoshka-dolls)
* [为什么使用🪆 俄罗斯套娃嵌入模型?](#why-would-you-use-🪆-matryoshka-embedding-models)
* [🪆 俄罗斯套娃嵌入模型是如何训练的?](#how-are-🪆-matryoshka-embedding-models-trained)
+ [理论上](#theoretically)
+ [在 Sentence Transformers 中](#in-sentence-transformers)
* [如何使用🪆 俄罗斯套娃嵌入模型?](#how-do-i-use-🪆-matryoshka-embedding-models)
+ [理论上](#theoretically-1)
+ [在 Sentence Transformers 中](#in-sentence-transformers-1)
* [结果](#results)
* [演示](#demo)
* [参考文献](#references)
<a id="understanding-embeddings"></a>
## 理解嵌入 (embedding)
嵌入是自然语言处理中最通用的工具之一,使从业者能够解决大量任务。本质上,嵌入是一个更复杂数字对象的数值表示,如文本、图像、音频等。
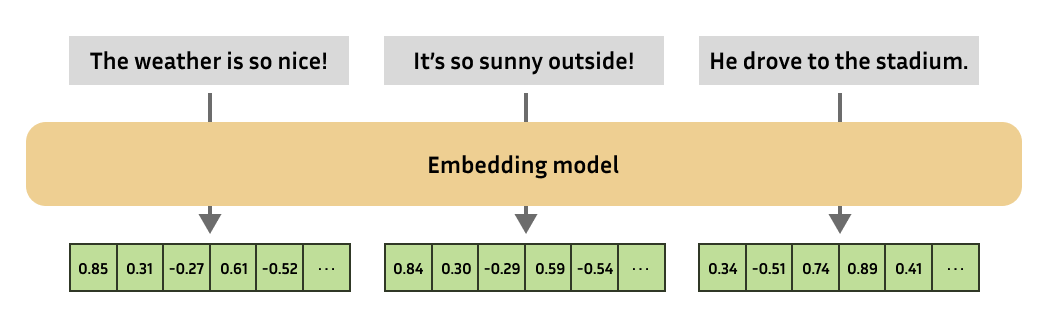
嵌入模型总是会产生相同固定大小的嵌入。然后,你可以通过计算相应嵌入的相似性来计算复杂数字对象的相似性!
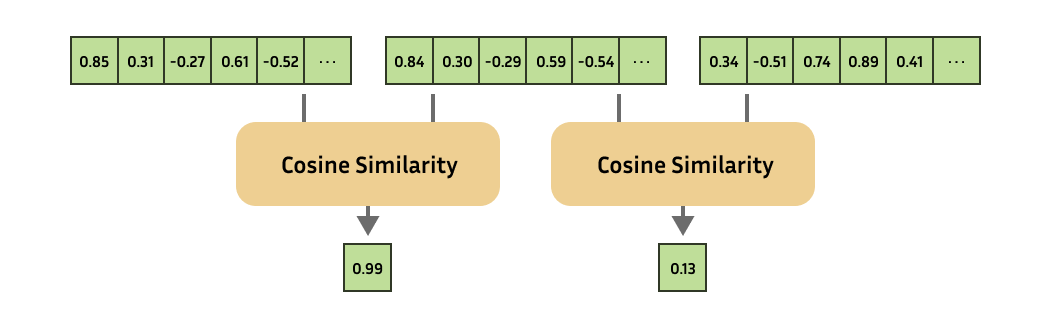
这种技术 (嵌入) 在许多领域都有应用,它是推荐系统、信息检索、零样本学习或少量样本学习、异常检测、相似性搜索、释义检测、聚类、分类等领域的基础。
<a id="🪆-matryoshka-embeddings"></a>
## 🪆 俄罗斯套娃 (Matryoshka) 嵌入
随着研究的进展,新的最先进的 (文本) 嵌入模型开始产生具有越来越高的输出维度,即每个输入文本都使用更多的值来表示。尽管这提高了性能,但以下游任务 (如搜索或分类) 的效率为代价。
因此,Kusupati 等人 (2022) 受到启发,创造了即使嵌入尺寸合理缩小也不会在性能上遭受太大损失的嵌入模型。
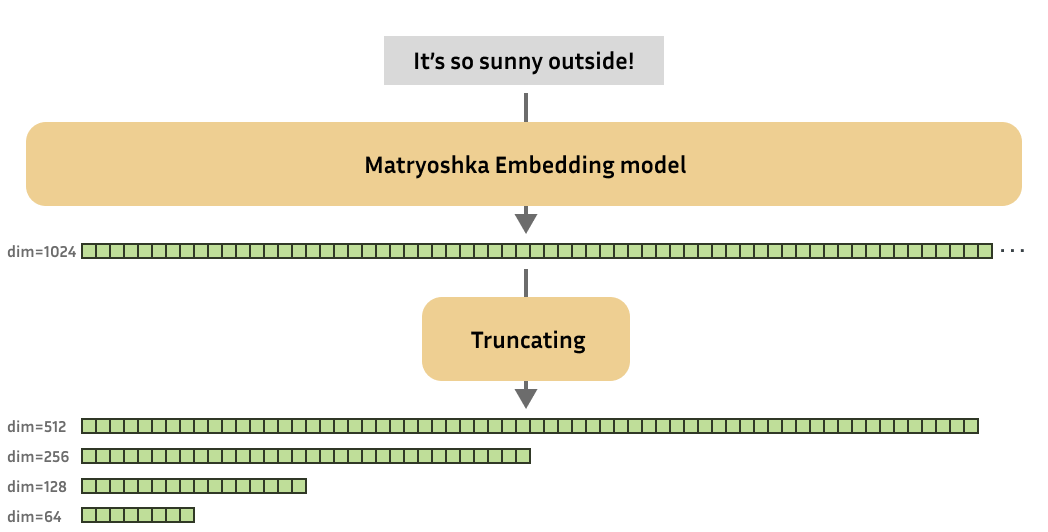
这些俄罗斯套娃嵌入模型经过训练,使得这些小的截断嵌入仍然有用。简而言之,俄罗斯套娃嵌入模型可以产生各种尺寸的有用嵌入。
<a id="🪆-matryoshka-dolls"></a>
## 🪆 俄罗斯套娃
对于不熟悉的人来说,“Matryoshka 娃娃”,也称为“俄罗斯套娃”,是一组大小递减的木制娃娃,相互嵌套。类似地,俄罗斯套娃嵌入模型旨在将更重要的信息存储在早期的维度中,将不太重要的信息存储在后面的维度中。俄罗斯套娃嵌入模型的这一特点允许我们截断模型产生的原始 (大) 嵌入,同时仍保留足够的信息以在下游任务上表现良好。
<a id="why-would-you-use-🪆-matryoshka-embedding-models"></a>
## 为什么使用🪆 俄罗斯套娃嵌入模型?
这种可变尺寸的嵌入模型对从业者来说非常有价值,例如:
1. **筛选和重新排序**: 不必在完整嵌入上执行你的下游任务 (例如,最近邻搜索),你可以缩小嵌入到更小的尺寸,并非常高效地“筛选”你的嵌入。之后,你可以使用它们的完整维度处理剩余的嵌入。
2. **权衡**: 俄罗斯套娃模型将允许你根据所需的存储成本、处理速度和性能来扩展你的嵌入解决方案。
<a id="how-are-🪆-matryoshka-embedding-models-trained"></a>
## 🪆 俄罗斯套娃嵌入模型是如何训练的?
<a id="theoretically"></a>
### 理论上
俄罗斯套娃表示学习 (MRL) 方法几乎可以适用于所有嵌入模型训练框架。通常,嵌入模型的一个训练步骤涉及为你的训练批次 (例如文本) 产生嵌入,然后使用一些损失函数创建一个代表产生嵌入质量的损失值。优化器会在训练过程中调整模型权重以减少损失值。
对于俄罗斯套娃嵌入模型,一个训练步骤还涉及为你的训练批次产生嵌入,但是然后你使用一些损失函数来确定不仅仅是全尺寸嵌入的质量,还有各种不同维度性下的嵌入质量。例如,输出维度性为 768、512、256、128 和 64。每个维度性的损失值加在一起,得到最终的损失值。然后,优化器将尝试调整模型权重以降低这个损失值。
实际上,这鼓励模型在嵌入的开始部分前置最重要的信息,这样如果嵌入被截断,这些信息将得以保留。
<a id="in-sentence-transformers"></a>
### 在 Sentence Transformers 中
[Sentence Tranformers](https://sbert.net) 是一个常用于训练嵌入模型的框架,它最近实现了对俄罗斯套娃模型的支持。使用 Sentence Transformers 训练俄罗斯套娃嵌入模型非常基础: 不是仅在全尺寸嵌入上应用一些损失函数,我们也在嵌入的截断部分应用同样的损失函数。
例如,如果一个模型的原始嵌入维度为 768,现在它可以被训练为 768、512、256、128 和 64。这些损失值将加在一起,可以选择性地给予一些权重:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, MatryoshkaLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = MatryoshkaLoss(
model=model,
loss=base_loss,
matryoshka_dims=[768, 512, 256, 128, 64],
matryoshka_weight=[1, 1, 1, 1, 1],
)
model.fit(
train_objectives=[(train_dataset, loss)],
...,
)
```
使用 `MatryoshkaLoss` 进行训练并不会显著增加训练时间。
参考文献:
- [`MatryoshkaLoss`](https://sbert.net/docs/package_reference/losses.html#matryoshkaloss)
- [`CoSENTLoss`](https://sbert.net/docs/package_reference/losses.html#cosentloss)
- [`SentenceTransformer`](https://sbert.net/docs/package_reference/SentenceTransformer.html)
- [`SentenceTransformer.fit`](https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.fit)
- [Matryoshka Embeddings - Training](https://sbert.net/examples/training/matryoshka/README.html#training)
请查看以下完整脚本,了解如何在实际应用中使用 `MatryoshkaLoss` :
- **[matryoshka_nli.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli.py)**: 此示例使用 `MultipleNegativesRankingLoss` 与 `MatryoshkaLoss` 结合,利用自然语言推理 (NLI) 数据训练一个强大的嵌入模型。这是对 [NLI](../nli/README) 文档的改编。
- **[matryoshka_nli_reduced_dim.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli_reduced_dim.py)**: 此示例使用 `MultipleNegativesRankingLoss` 与 `MatryoshkaLoss` 结合,训练一个最大输出维度为 256 的小型嵌入模型。它使用自然语言推理 (NLI) 数据进行训练,这是对 [NLI](../nli/README) 文档的改编。
- **[matryoshka_sts.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_sts.py)**: 此示例使用 `CoSENTLoss` 与 `MatryoshkaLoss` 结合,在 `STSBenchmark` 数据集的训练集上训练一个嵌入模型。这是对 [STS](../sts/README) 文档的改编。
<a id="how-do-i-use-🪆-matryoshka-embedding-models"></a>
## 如何使用 🪆俄罗斯套娃嵌入模型?
<a id="theoretically-1"></a>
### 理论上
实际上,从俄罗斯套娃嵌入模型获取嵌入的方式与从普通嵌入模型获取嵌入的方式相同。唯一的区别在于,在接收到嵌入后,我们可以选择将它们截断为更小的维度。请注意,如果嵌入已经归一化,那么在截断后它们将不再归一化,因此你可能需要重新归一化。
截断后,你可以直接将它们应用于你的用例,或者存储它们以便稍后使用。毕竟,在你的向量数据库中使用较小的嵌入应该会带来相当大的速度提升!
请记住,尽管处理较小嵌入以进行下游任务 (检索、聚类等) 会更快,但从模型获取较小嵌入的速度与获取较大嵌入的速度一样快。
<a id="in-sentence-transformers-1"></a>
### 在 Sentence Transformers 中
在 Sentence Transformers 中,你可以像加载普通模型一样加载俄罗斯套娃嵌入模型,并使用 [`SentenceTransformers.encode`](https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode) 进行推理。获取嵌入后,我们可以将它们截断到我们所需的尺寸,如果需要,我们还可以对它们进行归一化。
让我们尝试使用我使用 [`matryoshka_nli.py`](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli.py) 和 [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) 训练的模型:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
model = SentenceTransformer("tomaarsen/mpnet-base-nli-matryoshka")
matryoshka_dim = 64
embeddings = model.encode(
[
"The weather is so nice!",
"It's so sunny outside!",
"He drove to the stadium.",
]
)
embeddings = embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions
print(embeddings.shape)
# => (3, 64)
# Similarity of the first sentence to the other two:
similarities = cos_sim(embeddings[0], embeddings[1:])
print(similarities)
# => tensor([[0.8910, 0.1337]])
```
模型链接: [tomaarsen/mpnet-base-nli-matryoshka](https://huggingface.co/tomaarsen/mpnet-base-nli-matryoshka)
请随意尝试使用不同的 `matryoshka_dim` 值,并观察这对相似度的影响。你可以通过在本地运行这段代码,在云端运行 (例如使用 [Google Colab](https://colab.research.google.com/#fileId=https%3A//huggingface.co/tomaarsen/mpnet-base-nli-matryoshka/blob/main/inference.ipynb)),或者查看 [演示](#demo) 来进行实验。
参考文献:
- [`SentenceTransformer`](https://sbert.net/docs/package_reference/SentenceTransformer.html)
- [`SentenceTransformer.encode`](https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode)
- [`util.cos_sim`](https://sbert.net/docs/package_reference/util.html#sentence_transformers.util.cos_sim)
- [Matryoshka Embeddings - 推理](https://sbert.net/examples/training/matryoshka/README.html#inference)
<details><summary><b> 点击这里查看如何使用 Nomic v1.5 Matryoshka 模型 </b></summary>
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
import torch.nn.functional as F
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
matryoshka_dim = 64
embeddings = model.encode(
[
"search_query: What is TSNE?",
"search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.",
"search_document: Amelia Mary Earhart was an American aviation pioneer and writer.",
],
convert_to_tensor=True,
)
# The Nomic team uses a custom architecture, making them recommend Layer Normalization before truncation
embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions
similarities = cos_sim(embeddings[0], embeddings[1:])
# => tensor([[0.7154, 0.4468]])
```
- 模型链接: [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5)
</details>
<a id="results"></a>
## 结果
现在我们已经介绍了俄罗斯套娃模型,让我们来看看我们可以从俄罗斯套娃嵌入模型与常规嵌入模型中实际期待的绩效表现。为了这个实验,我训练了两个模型:
- [tomaarsen/mpnet-base-nli-matryoshka](https://huggingface.co/tomaarsen/mpnet-base-nli-matryoshka): 通过运行 [`matryoshka_nli.py`](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli.py) 与 [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) 进行训练。
- [tomaarsen/mpnet-base-nli](https://huggingface.co/tomaarsen/mpnet-base-nli): 通过运行修改版的 [`matryoshka_nli.py`](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli.py) 进行训练,其中训练损失仅为 `MultipleNegativesRankingLoss` ,而不是在 `MultipleNegativesRankingLoss` 之上的 `MatryoshkaLoss` 。我也使用 [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) 作为基础模型。
这两个模型都在 AllNLI 数据集上进行了训练,该数据集是 [SNLI](https://huggingface.co/datasets/snli) 和 [MultiNLI](https://huggingface.co/datasets/multi_nli) 数据集的拼接。我使用多种不同的嵌入维度在这些模型上评估了 [STSBenchmark](https://huggingface.co/datasets/mteb/stsbenchmark-sts) 测试集。结果绘制在下面的图表中:
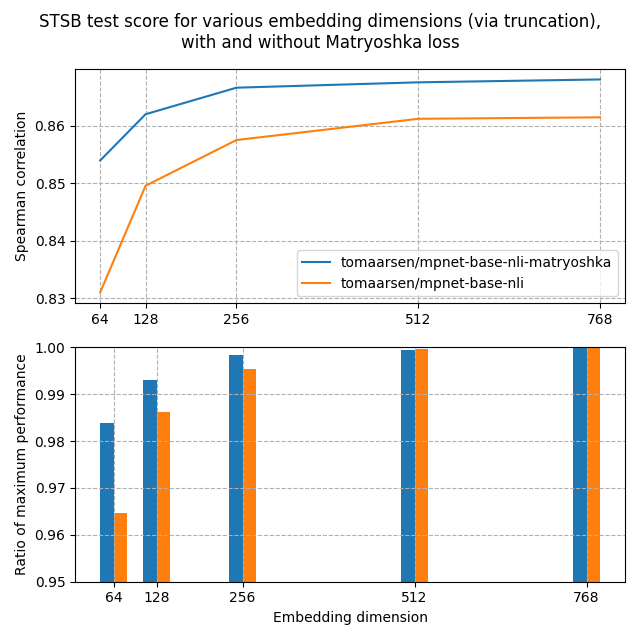
在上面的图表中,你可以看到俄罗斯套娃模型在所有维度上都达到了比标准模型更高的 Spearman 相似度,这表明俄罗斯套娃模型在此任务上是优越的。
此外,俄罗斯套娃模型的性能下降速度比标准模型要慢得多。这在第二个图表中清晰显示,该图表显示了相对于最大性能的嵌入维度的性能。 **即使嵌入大小只有 8.3%,俄罗斯套娃模型也保持了 98.37% 的性能**,远高于标准模型的 96.46%。
这些发现表明,通过俄罗斯套娃模型截断嵌入可以:
1. 显著加快下游任务 (如检索) 的速度;
2. 显著节省存储空间,而且不会对性能产生显著影响。
<a id="demo"></a>
## 演示
在这个演示中,你可以动态缩小 [`nomic-ai/nomic-embed-text-v1.5`](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) 俄罗斯套娃嵌入模型的输出维度,并观察它如何影响检索性能。所有的嵌入都是在浏览器中使用 [🤗 Transformers.js](https://github.com/xenova/transformers.js) 进行计算的。
<iframe
src="https://xenova-adaptive-retrieval-web.static.hf.space"
frameborder="0"
width="100%"
height="800"
></iframe>
<a id="references"></a>
## 参考文献
- Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V., … & Farhadi, A. (2022). Matryoshka representation learning. Advances in Neural Information Processing Systems, 35, 30233-30249. https://arxiv.org/abs/2205.13147
- Matryoshka Embeddings — Sentence-Transformers documentation. (n.d.). https://sbert.net/examples/training/matryoshka/README.html
- UKPLab. (n.d.). GitHub. https://github.com/UKPLab/sentence-transformers
- Unboxing Nomic Embed v1.5: Resizable Production Embeddings with Matryoshka Representation Learning. (n.d.). https://blog.nomic.ai/posts/nomic-embed-matryoshka
| 0 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/safecoder.md | ---
title: "推介 SafeCoder"
thumbnail: /blog/assets/159_safecoder/thumbnail.jpg
authors:
- user: jeffboudier
- user: philschmid
translators:
- user: MatrixYao
---
# 推介 SafeCoder
今天,我们向大家隆重介绍 SafeCoder —— 一款专为企业打造的代码助手解决方案。
SafeCoder 旨在成为你完全合规且自托管的结对编程工程师,从而释放企业的软件开发生产力。用营销话术来讲就是:“你自己的本地 GitHub Copilot”。
在深入探讨之前,我们先简单了解一下 SafeCoder:
- SafeCoder 不是一个模型,而是一个完整的端到端商业解决方案
- SafeCoder 以安全及隐私为核心原则 - 代码在训练或推理过程中永远不会离开 VPC(Virtual Private Cloud,虚拟私有云)
- SafeCoder 专为客户在自己的基础设施上自行托管而设计
- SafeCoder 旨在让客户真正拥有自己的代码大语言模型
## 为何选择 SafeCoder?
基于 LLM 的代码助理解决方案(如 GitHub Copilot)正在掀起巨大的[生产力提升](https://github.blog/2022-09-07-research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness/)浪潮。对于企业来说,这使得它们能够用公司自己的代码库去调整代码大模型从而创建出专属于自己的代码大模型以提高代码补全的可靠性及相关性,从而进一步提高生产力。一个例子是,据 Google 报告,其内部的 LLM 代码助理在基于内部代码库训练后,代码补全[接受率提高到了 25-34%](https://ai.googleblog.com/2022/07/ml-enhanced-code-completion-improves.html)。
然而,依靠闭源代码大模型来创建内部代码助理会让公司面临合规及安全问题。首先,在训练期间,在内部代码库上微调闭源代码大模型需要将此代码库向第三方公开。其次,在推理过程中,经过微调的代码大模型可能会在推理过程中“泄漏”其训练数据集中的代码。为了合规,企业需要在自己的基础设施上部署微调过的代码大模型 - 这对于闭源 LLM 来说是不可能的。
借助 SafeCoder,Hugging Face 可以帮助客户构建自己的代码大模型,使得客户可以最先进的库,在其私有代码库上微调最先进的开放模型,而无需与 Hugging Face 或任何其他第三方共享数据。通过 SafeCoder,Hugging Face 会提供容器化、硬件加速的代码大模型推理解决方案,由客户直接在其信任的、安全的基础设施上部署,从而使得整个代码输入和补全过程无需离开客户自己的安全 IT 环境。
## 从 StarCoder 到 SafeCoder
SafeCoder 解决方案的核心是 [BigCode](https://huggingface.co/bigcode) 项目训出来的 [StarCoder](https://huggingface.co/bigcode/starcoder) 系列代码大模型。BigCode 项目是一个由 Hugging Face、ServiceNow 及开源社区共同合作完成的开源项目。
StarCoder 模型是企业自托管解决方案的理想选择,其优势如下:
- 最先进的代码补全效果 - 详情可参阅[论文](https://huggingface.co/papers/2305.06161)及[多语言代码评估排行榜](https://huggingface.co/spaces/bigcode/multilingual)。
- 为推理性能而生:代码级优化的 15B 模型、可以减少内存占用的多查询注意力(Multi-Query Attention,MQA)以及可将上下文扩展至 8192 个词元的 Flash 注意力。
- 基于 [The Stack](https://huggingface.co/datasets/bigcode/the-stack) 数据集训练,这是一个来源符合道德准则的开源代码数据集,其中仅包含可商用的许可代码,且从一开始就包含了允许开发人员自主将其代码库退出的机制,此外我们还对其进行了大量的 PII 删除和代码去重工作。
注意:虽然 StarCoder 是 SafeCoder 的灵感来源和首个基础模型。但基于开源模型构建 LLM 解决方案的一个重要好处是它可以用上最新最好的开源模型,因此,将来 SafeCoder 不排除会基于其他类似的、可商用的、开源的、来源符合道德准则的公开透明的开源代码数据集的基础 LLM 进行微调。
## 核心原则之隐私和安全
对于任何公司而言,内部代码库都是其最重要、最有价值的知识产权。 SafeCoder 的一个核心原则是,在训练和推理过程中,任何第三方(包括 Hugging Face)永远不会访问到客户内部代码库。
当客户开始搭建 SafeCoder 方案时,Hugging Face 团队会提供容器、脚本和示例,并与客户携手合作以对内部代码库数据进行选择、提取、准备、复制、脱敏,最终生成训练数据集,然后客户就可以配置好 Hugging Face 提供的训练容器并将其部署至自管基础设施上。
到了部署阶段,客户会在自管基础设施上部署 Hugging Face 提供的容器,并在其 VPC 内发布内部私有推理终端。这些容器可根据客户自己的硬件环境进行相应配置,目前主要支持的硬件有:英伟达 GPU、AMD Instinct GPU、英特尔至强 CPU、AWS Inferentia2 以及 Habana Gaudi。
## 核心原则之合规
由于目前在全世界范围内,围绕机器学习模型和数据集的监管框架仍在制定中,跨国公司需要确保其使用的解决方案能够最大限度地降低法律风险。
数据源、数据治理、版权数据管理是其中最重要的几个需考量的合规领域。在这些问题得到人工智能欧盟法案草案的广泛认可之前,BigCode 的老表和灵感来源 BigScience 已在其在工作组中解决了这些问题,并因此[在斯坦福 CRFM 研究中被评为最合规的基础模型提供商](https://crfm.stanford.edu/2023/06/15/eu-ai-act.html)。
BigCode 发扬了 BigScience 的工作,其以合规为核心原则构建 The Stack 数据集并围绕这个数据集实施了一系列新技术。例如对可商用许可证进行过滤、同意机制(开发人员可以[轻松地查到他们的代码是否在数据集中并要求将其代码从数据集中剔除](https://huggingface.co/spaces/bigcode/in-the-stack))、大量的用于审查[源代码数据](https://huggingface.co/datasets/bigcode/the-stack-metadata)的文档和工具,以及数据集改进方案(如[数据去重](https://huggingface.co/blog/zh/dedup)、[PII 删除](https://huggingface.co/bigcode/starpii))。
所有这些努力都大大降低了 StarCoder 模型用户和 SafeCoder 客户的法律风险。对于 SafeCoder 用户来说,这些工作最终还形成了一个合规性功能:当软件开发人员用 SafeCoder 进行代码补全时,可将其与 The Stack 数据集进行比对,以便知道生成的代码是否与源数据集中的某些现有代码匹配,以及对应代码的许可证是什么。客户甚至可以指定许可证白名单并向用户展示在白名单内的代码。
## 产品说明
SafeCoder 是一个完整的商业解决方案,包括服务、软件及相应的支持。
### 训练你自己的 SafeCoder 模型
StarCoder 的训练数据中有 80 多种编程语言,其在[多个测试基准](https://huggingface.co/spaces/bigcode/multilingual-code-evals)上名列前茅。为了使 SafeCoder 客户能得到更好、更有针对性的代码建议,用户可以选择让我们从训练阶段开始参与,此时 Hugging Face 团队直接与客户团队合作,指导他们准备并构建训练代码数据集,并微调出他们自己的代码生成模型,而无需将其代码库暴露给第三方或上传到互联网上。
最终生成的是一个适合客户的编程语言、标准及实践的模型。通过这个过程,SafeCoder 客户可以学习该流程并构建一个用于创建和更新自有模型的流水线,确保不被供应商锁定,并保持对其 AI 功能的控制力。
### 部署 SafeCoder
在部署阶段,SafeCoder 客户和 Hugging Face 一起设计并组建能支持所需并发性的最佳基础设施,从而提供出色的开发者体验。然后,Hugging Face 据此构建出 SafeCoder 推理容器,这些容器经过硬件加速并针对吞吐进行了优化。最后,由客户部署在自己的基础设施上。
SafeCoder 推理支持各种硬件,为客户提供广泛的选择:英伟达 Ampere GPU、AMD Instinct GPU、Habana Gaudi2、AWS Inferentia 2、英特尔至强 Sapphire Rapids CPU 等。
### 使用 SafeCoder
一旦部署了 SafeCoder 并在客户 VPC 中上线了其推理端点,开发人员就可以安装兼容的 SafeCoder IDE 插件,以便在工作时获取代码建议。当前,SafeCoder 支持流行的 IDE,包括 [VSCode](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode)、IntelliJ,同时我们的合作伙伴还在开发更多插件,尽请期待。
## 如何获取 SafeCoder?
今天,我们在 VMware Explore 大会上宣布与 VMware 合作推出 SafeCoder,并向 VMware 企业客户提供 SafeCoder。与 VMware 合作有助于确保 SafeCoder 在客户的 VMware Cloud 基础设施上成功部署 - 无论客户更青睐云、本地还是混合基础设施。除了 SafeCoder 本身外,VMware 还发布了一个[参考架构](https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/docs/vmware-baseline-reference-architecture-for-generative-ai.pdf),其中包含了一些示例代码,可以帮助用户用最短时间在 VMware 基础设施上部署和运营 SafeCoder 从而创造价值。VMware 的私有 AI 参考架构使组织能够轻松快速地利用流行的开源项目(例如 Ray 和 kubeflow)围绕其私有数据集部署 AI 服务。同时,通过与 Hugging Face 合作,组织还能保持利用最新技术及以及最佳开源模型的灵活性。这一切都无需在总拥有成本或性能上进行权衡。
“我们与 Hugging Face 围绕 SafeCoder 进行的合作与 VMware 的目标完美契合,即让客户能够选择解决方案,同时维护其隐私及其对业务数据的控制。事实上,我们已经在内部运行 SafeCoder 几个月了,并且已经看到了出色的结果。最重要的是,我们与 Hugging Face 的合作才刚刚开始,我很高兴能够将我们的解决方案带给全球数十万客户。” VMware AI 研究院副总裁 Chris Wolf 说道。 点击[此处](https://octo.vmware.com/vmware-private-ai-foundation/)可详细了解私有 AI 和 VMware 在这一新兴领域的差异化功能。
| 1 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/sd_distillation.md | ---
title: "开源 SD-Small 和 SD-Tiny 知识蒸馏代码与权重"
thumbnail: /blog/assets/distill_sd/thumbnail.png
authors:
- user: harishsegmind
guest: true
- user: Warlord-K
guest: true
- user: Gothos
guest: true
translators:
- user: innovation64
- user: zhongdongy
proofreader: true
---
# 开源 SD-Small 和 SD-Tiny 知识蒸馏代码与权重
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture1.png" width=500>
</p>
最近,人工智能社区在开发更大、更高性能的语言模型方面取得了显著的进展,例如 Falcon 40B、LLaMa-2 70B、Falcon 40B、MPT 30B; 以及在图像领域的模型,如 SD2.1 和 SDXL 。这些进步无疑推动了人工智能的发展,使其具有高度多功能和最先进的图像生成和语言理解能力。然而,在我们惊叹于这些模型的强大和复杂性之余,必须认识到一个日益增长的需求: 使人工智能模型体量更小、运行更高效、更易于访问,特别是通过开源它们来共建生态。
在 [Segmind](https://www.segmind.com/models),我们一直致力于如何使生成式 AI 更快、更便宜。去年,我们开源了我们加速的 SD-WebUI 库 [voltaML](https://github.com/VoltaML/voltaML-fast-stable-diffusion),它是一个基于 AITemplate/TensorRT 的推理加速库,推理速度提高了 4-6 倍。为了继续实现使生成模型更快、更小、更便宜的目标,我们正在开源我们压缩的 **SD 模型:SD-Small 和 SD-Tiny** 的权重和训练代码。预训练的检查点可在 [Hugging Face 🤗](https://huggingface.co/segmind) 上获取。
## 知识蒸馏
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture2.png" width=500>
</p>
我们的新压缩模型已经经过知识蒸馏 (KD) 技术的训练,这项工作主要基于 [这篇论文](https://openreview.net/forum?id=bOVydU0XKC)。作者描述了一种块移除知识蒸馏方法,其中一些 UNet 层被移除,学生模型权重被训练。使用论文中描述的 KD 方法,我们能够使用 [🧨 diffusers](https://github.com/huggingface/diffusers) 库训练两个压缩模型; **Small (微小版本)** 和 **Tiny (极小版本)**,分别比基础模型少 35% 和 55% 的参数,同时实现与基础模型相当的图像保真度。我们已经在这个 [repo](https://github.com/segmind/distill-sd) 中开源了我们的蒸馏代码,并将预训练检查点上传到了 [Hugging Face 🤗](https://huggingface.co/segmind)。
知识蒸馏训练神经网络类似于老师一步一步指导学生。一个大的老师模型 (teacher model) 预先在大量数据上训练,然后一个较小的模型在较小的数据集上训练,以模仿大模型的输出并在数据集上进行经典训练。
在这种特殊类型的知识蒸馏中,学生模型被训练来完成从纯噪声恢复图像的正常扩散任务,但同时,模型被迫与更大的老师模型的输出匹配。输出匹配发生在 U-nets 的每个块,因此模型质量基本保持不变。所以,使用前面的类比,我们可以说,在这种蒸馏过程中,学生不仅会试图从问题和答案中学习,还会从老师的答案以及逐步得到答案的方法中学习。我们在损失函数中有 3 个组成部分来实现这一点,首先是目标图像隐变量和生成图像隐变量之间的传统损失。其次是老师生成的图像隐变量和学生生成的图像隐变量之间的损失。最后,也是最重要的组成部分,是特征级损失,即老师和学生每个块输出之间的损失。
结合所有这些构成了知识蒸馏训练。下面是论文中描述的用于 KD 的块移除 UNet 架构。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture3.png" width=500>
</p>
图片来自 Shinkook 等人的 [论文](https://arxiv.org/abs/2305.15798) “On Architectural Compression of Text-to-Image Diffusion Models”。
我们以 [Realistic-Vision 4.0](https://huggingface.co/SG161222/Realistic_Vision_V4.0_noVAE) 为基础老师模型,并在[LAION Art Aesthetic 数据集](https://huggingface.co/datasets/recastai/LAION-art-EN-improved-captions) 上训练,图像分数高于 7.5,因为它们具有高质量的图像描述。与论文不同,我们选择分别为 Small 和 Tiny 模式训练两个模型,分别在 1M 张图像上进行 100K 步和 125K 步的训练。蒸馏训练的代码可以在 [这里](https://github.com/segmind/distill-sd) 找到。
## 模型使用
模型可以通过 [🧨 diffusers](https://github.com/huggingface/diffusers) 中的 DiffusionPipeline 来使用。
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("segmind/small-sd", torch_dtype=torch.float16)
prompt = "Portrait of a pretty girl"
negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
image = pipeline(prompt, negative_prompt = negative_prompt).images[0]
image.save("my_image.png")
```
## 推理延迟方面的速度表现
我们观察到,蒸馏模型比原始基础模型快了一倍。基准测试代码可以在 [这里](https://github.com/segmind/distill-sd/blob/master/inference.py) 找到。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture4.jpeg" width=500>
</p>
## 潜在的局限性
蒸馏模型处于早期阶段,输出可能还不具备生产水平的质量。这些模型可能不是最好的通用模型,它们最好用作针对特定概念/风格进行微调或 LoRA 训练。蒸馏模型目前还不太擅长组合性或多概念。
## 在人像数据集上微调 SD-tiny 模型
我们已经在 Realistic Vision v4.0 模型生成的人像图像上微调了我们的 sd-tiny 模型。下面是使用的微调参数。
|原版参数|中文释义|
|--|--|
| Steps: 131000|步数: 131000|
| Learning rate: 1e-4 |学习率: 1e-4|
| Batch size: 32|批量大小: 32|
| Gradient accumulation steps: 4|梯度累积步数: 4|
| Image resolution: 768|图像分辨率: 768|
| Dataset size: 7k images|数据集大小: 7 千张图像|
| Mixed precision: fp16|混合精度: fp16|
我们能够产生接近原始模型产生的图像质量,参数减少了近 40%,下面的样本结果不言自明:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture5.png" width=500>
</p>
微调基础模型的代码可以在 [这里](https://github.com/segmind/distill-sd/blob/master/checkpoint_training.py) 找到。
## LoRA 训练
在蒸馏模型上进行 LoRA 训练的一个优点是训练更快。下面是我们在蒸馏模型上对一些抽象概念进行的第一个 LoRA 训练的一些图像。LoRA 训练的代码可以在 [这里](https://github.com/segmind/distill-sd/blob/master/lora_training.py) 找到。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture6.png" width=500>
</p>
## 结论
我们邀请开源社区帮助我们改进并实现这些蒸馏 SD 模型的更广泛采用。用户可以加入我们的 [Discord](https://discord.gg/s6E6eHJk) 服务器,在那里我们将宣布这些模型的最新更新,发布更多的检查点和一些令人兴奋的新 LoRAs。如果你喜欢我们的工作,请在我们的 [Github](https://github.com/segmind/distill-sd) 上给我们点一下 star。
| 2 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/starcoder2.md | ---
title: "StarCoder2 及 The Stack v2 数据集正式发布"
thumbnail: /blog/assets/177_starcoder2/sc2-banner.png
authors:
- user: lvwerra
- user: loubnabnl
- user: anton-l
- user: nouamanetazi
translators:
- user: AdinaY
---
# StarCoder2 及 The Stack v2 数据集正式发布
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/admin/resolve/main/sc2-banner.png" alt="StarCoder2">
</div>
BigCode 正式推出 StarCoder2 —— 一系列新一代的开放源代码大语言模型(LLMs)。这些模型全部基于一个全新、大规模且高品质的代码数据集 [The Stack v2](https://huggingface.co/datasets/bigcode/the-stack-v2/) 进行训练。我们不仅公开了所有的模型和数据集,还包括了数据处理和训练代码的详细信息,详情请参阅 [相关论文](https://drive.google.com/file/d/17iGn3c-sYNiLyRSY-A85QOzgzGnGiVI3/view?usp=sharing)。
## StarCoder2 是什么?
StarCoder2 是一套面向代码的开放式大语言模型系列,提供3种规模的模型,分别包括 30 亿(3B)、70 亿(7B)和 150 亿(15B)参数。特别地,StarCoder2-15B 模型经过了超过 4 万亿 token 和 600 多种编程语言的训练,基于 The Stack v2 数据集。所有模型均采用分组查询注意力机制(Grouped Query Attention),具备 16384 个 token 的上下文窗口和 4096 个令牌的滑动窗口注意力,并通过“填充中间”(Fill-in-the-Middle)技术进行训练。
StarCoder2 包含三种规模的模型:ServiceNow 训练的30亿参数模型、Hugging Face 训练的 70 亿参数模型以及 NVIDIA 利用 NVIDIA NeMo 在 NVIDIA 加速基础架构上训练的150亿参数模型:
- [StarCoder2-3B](https://huggingface.co/bigcode/starcoder2-3b) 基于 The Stack v2 的 17 种编程语言训练,处理了超过 3 万亿 token。
- [StarCoder2-7B](https://huggingface.co/bigcode/starcoder2-7b) 基于 The Stack v2 的 17 种编程语言训练,处理了超过 3.5 万亿 token。
- [StarCoder2-15B](https://huggingface.co/bigcode/starcoder2-15b) 基于 The Stack v2 的 600 多种编程语言训练,处理了超过 4 万亿 token。
StarCoder2-15B 模型在其级别中表现出色,与33亿以上参数的模型在多项评估中不相上下。StarCoder2-3B 的性能达到了 StarCoder1-15B 的水平:
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/admin/resolve/main/sc2-evals.png" alt="StarCoder2 Evaluation">
</div>
## The Stack v2 是什么?
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/admin/resolve/main/stackv2-banner.png" alt="The Stack v2">
</div>
The Stack v2 是迄今为止最大的开放代码数据集,非常适合进行大语言模型的预训练。与 The Stack v1 相比,The Stack v2 拥有更大的数据规模,采用了更先进的语言和许可证检测流程以及更优的过滤机制。此外,训练数据集按照仓库进行了分组,使得模型训练能够获得仓库上下文的支持。
| 数据集对比 | [The Stack v1](https://huggingface.co/datasets/bigcode/the-stack/) | [The Stack v2](https://huggingface.co/datasets/bigcode/the-stack-v2/) |
|--------|------|------|
| 全部数据量 | 6.4TB | 67.5TB |
| 去重后数据量 | 2.9TB | 32.1TB |
| 训练数据集大小 | 约 2000 亿token | 约9000亿token |
该数据集源自软件遗产档案(Software Heritage archive),这是一个包含了丰富软件源代码及其开发历史的公共档案库。作为一个开放和非盈利的项目,软件遗产由 Inria 与 UNESCO 合作发起,旨在收集、保存并共享所有公开可用的软件源代码。我们对软件遗产提供这一无价资源表示感
谢。欲了解更多信息,请访问 [软件遗产网站](https://www.softwareheritage.org)。
您可以通过 [Hugging Face Hub](https://huggingface.co/datasets/bigcode/the-stack-v2/) 访问 The Stack v2 数据集。
## 关于 BigCode
BigCode 是由 Hugging Face 和 ServiceNow 联合领导的一个开放科研合作项目,致力于负责任地开发代码用大语言模型。
## 相关链接
### 模型资源
- [研究论文](https://drive.google.com/file/d/17iGn3c-sYNiLyRSY-A85QOzgzGnGiVI3/view?usp=sharing):详细介绍 StarCoder2 和 The Stack v2 的技术报告。
- [GitHub 仓库](https://github.com/bigcode-project/starcoder2/):提供使用或微调 StarCoder2 的完整指南。
- [StarCoder2-3B](https://huggingface.co/bigcode/starcoder2-3b):规模较小的 StarCoder2 模型。
- [StarCoder2-7B](https://huggingface.co/bigcode/starcoder2-7b):规模中等的 StarCoder2 模型。
- [StarCoder2-15B](https://huggingface.co/bigcode/starcoder2-15b):规模较大的 StarCoder2 模型。
### 数据及治理
- [StarCoder2 许可协议](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement):模型基于 BigCode OpenRAIL-M v1 许可协议授权。
- [StarCoder2 代码搜索](https://huggingface.co/spaces/bigcode/search-v2):对预训练数据集中的代码进行全文搜索。
- [StarCoder2 成员资格测试](https://stack-v2.dataportraits.org):快速验证代码是否包含在预训练数据集中。
### 其他资源
- [VSCode 扩展](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode):使用 StarCoder 进行编码的插件。
- [大型代码模型排行榜](https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard):比较不同模型的性能。
所有资源和链接均可在 [huggingface.co/bigcode](https://huggingface.co/bigcode) 查阅!
| 3 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/cosmopedia.md | ---
title: "Cosmopedia:如何为大语言模型预训练构建大规模合成数据集"
thumbnail: /blog/assets/cosmopedia/thumbnail.png
authors:
- user: loubnabnl
- user: anton-l
- user: davanstrien
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# Cosmopedia: 如何为预训练构建大规模合成数据集
本文概述了我们在生成含数十亿词元的合成数据集以复现 [Phi-1.5](https://arxiv.org/abs/2309.05463) 过程中所遇到的挑战及其解决方案,由此最终创建了 [Cosmopedia](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia) 合成数据集。合成数据已成为机器学习社区的 C 位话题,其题中之义是用人工 (如使用大语言模型 (LLM)) 生成的数据模拟真实数据。
传统上,构建用于有监督微调和指令微调的数据集需要昂贵且耗时的人工标注。这种做法需要大量资源,因此注定只有少数玩家玩得起。然而,最近情况发生了变化。我们已经见证了数百个高质量的合成微调数据集,它们主要由 GPT-3.5 和 GPT-4 生成。大家还在社区发表了大量的材料以指导相关的各种流程并解决相应挑战 [[1](https://arxiv.org/abs/2305.14233)][[2](https://arxiv.org/abs/2312.02120)][[3](https://arxiv.org/abs/2402.10176)][[4](https://arxiv.org/abs/2304.12244)][[5](https://huggingface.co/blog/synthetic-data-save-costs)]。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/data.png" alt="number of datasets with synthetic tag" style="width: 90%; height: auto;"><br>
<em>图 1: Hugging Face Hub 上带有合成数据标签的数据集</em>
</p>
然而,本文无意于成为另一篇如何生成合成指令微调数据集的文章,关于此社区已经有大量文章了。我们的专注点是如何将样本从 **几千** 扩展到 **数百万**,从而使其可用于 **从头开始预训练 LLM**。到达成这一愿景,需要解决一系列独特的挑战。
## 何以 Cosmopedia?
微软通过 Phi 系列模型 [[6](https://arxiv.org/abs/2306.11644)][[7](https://arxiv.org/abs/2309.05463)][[8](https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/)] 推动了合成数据领域的发展,这些模型主要由合成数据的训练而得。Phi 系列模型的表现超越了基于网络数据集的、训练时长更长的大模型。[Phi-2](https://huggingface.co/microsoft/phi-2) 过去一个月的下载量超过 61.7 万次,是 Hugging Face Hub 上最受欢迎的 20 个模型之一。
虽然 Phi 模型的技术报告 (如 _Textbooks Are All You Need_ [](https://arxiv.org/abs/2306.11644)) 已详述了模型的卓越性能及训练过程,但其跳过了有关如何获得合成训练数据集的重要细节。此外,数据集本身也并未发布。这引发了狂热派和怀疑派之间的争论: 一些人给模型能力点赞,而批评者则认为它们可能只是过拟合了基准罢了; 甚至还有一些人认为在合成数据上预训练模型是 [“垃圾入,垃圾出”](https://x.com/Grady_Booch/status/1760042033761378431?s=20)。抛开这些不谈,完全控制数据生成过程并复现 Phi 模型的高性能的想法本身就很有趣且值得探索。
以上就是开发 [Cosmopedia](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia) 的动机,其目的是重现 Phi-1.5 所使用的训练数据。在本文中,我们会分享我们的初步发现,并讨论一些改进当前数据集的计划。我们深入研究了创建数据集的方法、提示整编的方法及相应的技术栈。 Cosmopedia 完全开放: 我们发布了端到端流水线 [代码](https://github.com/huggingface/cosmopedia),[数据集](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia),以及一个在其上训练的 1B 模型,即 [cosmo-1b](https://huggingface.co/HuggingFaceTB/cosmo-1b)。因此,社区可以重现我们的结果并在此基础上继续研究。
## Cosmopedia 的幕后花絮
围绕在 Phi 数据集上的谜团除了我们对其如何创建的不甚了了之外,还有一个问题是其数据集的生成使用的是私有模型。为了解决这些问题,我们引入了 Cosmopedia,这是由 [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) 生成的包含教科书、博文、故事、帖子以及 WikiHow 文章等各种体裁的合成数据集。其中有超过 3000 万个文件、250 亿个词元,是迄今为止最大的开放合成数据集。
请注意: 如果你期待读到一个如何在数百个 H100 GPU 上部署大规模生成任务的故事,那么你可能要失望了,因为实际上 Cosmopedia 的大部分时间都花在了细致的提示词工程上了。
### 提示策划
生成合成数据看起来可能很简单,但当要扩大数据规模时,保持多样性 (这对于获得最佳模型性能至关重要) 迅速成为一大挑战。因此,有必要策划主题广泛的多样化提示并最大程度地减少重复输出,因为我们不想花大量算力生成了数十亿本教科书,却因为它们彼此非常相似而需要丢弃掉大多数。在我们在数百个 GPU 上启动这一生成任务前,我们花了很多时间使用 [HuggingChat](https://huggingface.co/chat/) 等工具来对提示进行迭代。在本节中,我们将回顾为 Cosmopedia 创建超过 3000 万条提示的过程,这些提示涵盖数百个主题且重复率低于 1%。
Cosmopedia 旨在生成大量主题广泛的高质量合成数据。据 Phi-1.5 [技术报告](https://arxiv.org/abs/2309.05463) 透露,他们策划了 2 万个主题,以生成总计 200 亿词元的合成教科书,同时他们还使用网络数据集中的样本来保证多样性,报告指出:
> 我们精心挑选了 2 万个主题来生成新的合成数据。在我们生成提示时,我们还使用了网络数据集中的样本来保证多样性。
假设文件的平均长度为 1000 词元,可以估计他们使用了大约 2000 万个不同的提示。然而,如何将主题和网络样本结合起来以增强多样性,报告并未透露。
我们结合了两种方法来构建 Cosmopedia 的提示: 根据精选来源构建以及根据网络数据构建。我们将我们依赖的这些数据源称为“种子数据”。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/piecharts.png" alt="piecharts of data sources" style="width: 90%; height: auto;"><br>
<em>图 2: 用于构建 Cosmopedia 提示的数据源分布 (左图) 以及“精选源”子集中的源分布 (右图)
</em>
</p>
#### 精选源
我们使用的主题主要来自知名教育源,例如斯坦福课程、可汗学院、OpenStax 和 WikiHow。这些资源涵盖了许多有价值的主题可供 LLM 学习。例如,我们提取了斯坦福大学各种课程的大纲,并据此构建了提示,要求模型为这些课程的各个单元生成教科书。图 3 展示了此类提示的示例。
尽管这种方法可以生成高质量的内容,但其可扩展性不是很好。我们受限于每个来源中的可用资源数量及主题类型。例如,从 OpenStax 中我们只能提取 16,000 个不同的单元,从斯坦福大学中只能提取 250,000 个。考虑到目标是生成 200 亿个词元,我们至少需要 2000 万个提示!
##### 利用受众和风格的多样性
提高生成样本多样性的一种策略是利用受众和风格的多样性: 通过改变目标受众 (如,少儿/大学生) 及生成风格 (如,学术教科书/博文),来实现对一个主题的多次利用。然而,我们发现仅把 _“为关于‘为什么进入太空?’的大学教科书编写详细的课程单元?”_ 的提示改成 _“写一篇关于‘为什么去太空?’的详细博文”_ 或 _“为少年儿童写一本关于‘为什么去太空?’的教科书”_ 并不足以降低内容重复率。为了缓解这种情况,我们在提示中强调了受众和风格的变化,并对格式和内容应如何不同进行了具体说明。
图 3 展示了我们是如何对同一主题针对不同受众调整提示的。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/textbooks.png" alt="comparison of prompts" style="width: 90%; height: auto;"><br>
<em>图 3: 为少儿、专业人士和研究人员以及高中生生成相同主题的教科书的提示</em>
</p>
通过针对四种不同的受众 (少儿、高中生、大学生、研究人员) 以及三种生成风格 (教科书、博文、wikiHow 文章),我们可以获得最多 12 倍的提示。然而,我们可能希望在训练数据集中包含这些资源未涵盖的其他主题,再者这些资源的数量还是有点小,即使用了我们提出的提示扩增的方法,距离我们目标的 2 千多万条提示还很远。这时候网络数据就派上用场了,那如果我们要生成涵盖所有网络主题的教科书怎么办?在下一节中,我们将解释如何选择主题并使用网络数据来构建数百万提示。
#### 网络数据
我们的实践表明,使用网络数据构建提示扩展性最好,Cosmopedia 使用的 80% 以上的提示来自于此。我们使用 [RefinedWeb](https://huggingface.co/datasets/tiiuae/falcon-refinedweb) 等数据集将数百万个 Web 样本聚为 145 个簇,并从每个簇中提取 10 个随机样本的内容并要求 Mixtral 找到它们的共同主题以最终识别该簇的主题。有关聚类环节的更多详细信息,请参阅技术栈部分。
我们检查了这些簇并排除了任何我们认为教育价值较低的簇,剔除的内容如露骨的成人材料、名人八卦和讣告等。你可于 [此处](https://github.com/huggingface/cosmopedia/blob/dd5cd1f7fcfae255c9cfbe704ba2187965523457/prompts/web_samples/filter_and_classify_clusters.py) 获取保留和剔除的 112 个主题的完整列表。
然后,我们构建提示以指示模型根据网络示例所在簇的主题生成相应的教科书。图 4 展示了基于网络数据的提示的示例。为了提高多样性并解决主题标签的不完整性,我们仅以 50% 的概率在提示内说明主题,并更改受众和生成风格,如上一节所述。最终,我们使用这种方法构建了 2300 万条提示。图 5 展示了 Cosmopedia 中种子数据、生成格式和受众的最终分布。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/web_samples.png" alt="web prompt" style="width: 90%; height: auto;"><br>
<em>图 4: 网络数据种子样本及其对应提示的示例</em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/histograms.png" alt="histogram" style="width: 90%; height: auto;"><br>
<em>图 5: Cosmopedia 数据集中种子数据、生成格式和目标受众的分布</em>
</p>
除了随机网络数据之外,为了包含更多科学内容,我们还使用了 AutoMathText 中的样本,其是一个精心设计的数学文本数据集。
#### 指令数据集与故事
在我们对生成的合成数据集训得的模型进行初步评估时,我们发现其缺乏小学教育阶段所需的典型常识和基础知识。为了解决这一问题,我们增加了 [UltraChat](https://huggingface.co/datasets/stingning/ultrachat) 和 [OpenHermes2.5](https://huggingface.co/datasets/teknium/OpenHermes-2.5) 指令微调数据集作为提示的种子数据。这些数据集涵盖了广泛的主题,如在 `UltraChat` 中,我们使用了“关于世界的问题”子集,其中涵盖了 30 个关于世界的元概念; 而对另一个多样化且高质量的指令调优数据集 `OpenHermes2.5` ,我们跳过了不适合讲故事的来源和类别,例如用于编程的 `glaive-code-assist` 和用于高级化学的 `camala` 。图 6 展示了我们用来生成这些故事的提示示例。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/stories.png" alt="stories prompts" style="width: 90%; height: auto;"><br>
<em>图 6: 从 UltraChat 和 OpenHermes 样本中构建的用于生成故事的提示 (分别针对少儿、普通受众及 Reddit 论坛)</em>
</p>
我们的提示工程故事就至此就告一段落了,我们构建了 3000 多万个不同的提示,这些提示的内容几乎没有重复。下图展示了 Cosmopedia 中的数据簇,这种分布与网络数据中的簇分布类似。你还可以从 [Nomic](https://www.nomic.ai/) 中找到可互动的 [可视化数据地图](https://atlas.nomic.ai/map/cosmopedia)。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/clusters.png" alt="clusters" style="width: 90%; height: auto;"><br>
<em>图 7: Cosmopedia 的簇,主题由 Mixtral 生成</em>
</p>
你还可以使用 [数据集查看器](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia/viewer/stanford) 自行探索数据集:
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/viewer.png" alt="dataset viewer" style="width: 90%; height: auto;"><br>
<em>图 8: Cosmopedia 的数据集查看器</em>
</p>
### 技术栈
我们在 [此](https://github.com/huggingface/cosmopedia) 发布了用于构建 Cosmopedia 的所有代码。
本节,我们将重点介绍用于文本聚类、大规模文本生成和训练 cosmo-1b 模型的技术栈。
#### 主题聚类
我们使用 [text-clustering](https://github.com/huggingface/text-clustering/) 代码库来对 Cosmopedia 提示中使用的网络数据进行主题聚类。下图说明了聚类及对生成的簇进行标注的流程。我们还要求 Mixtral 在标注时为簇打一个教育性得分 (满分 10 分) ; 这有助于后面我们进行主题检查。你可以在此 [演示](https://huggingface.co/spaces/HuggingFaceTB/inspect_web_clusters) 中找到网络数据的每个簇及其得分。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/text_clustering.png" alt="text-clustering" style="width: 60%; height: auto;"><br>
<em>图 9: 文本聚类的流程</em>
</p>
#### 大规模教科书生成
我们用 [llm-swarm](https://github.com/huggingface/llm-swarm) 库使用 [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) 生成 250 亿个合成内容词元。这是一个可扩展的合成数据生成工具,支持本地 LLM 以及 Hugging Face Hub 上的推理终端。它还支持 [TGI](https://github.com/huggingface/text-generation-inference) 和 [vLLM](https://github.com/vllm-project/vllm) 推理库。我们使用 TGI 在 Hugging Face Science 集群的 H100 GPU 上本地部署 Mixtral-8x7B。生成 Cosmopedia 的总计算时间超过 1 万 GPU 时。
以下是在 Slurm 集群上使用 2 个 TGI 实例在 100k Cosmopedia 提示上使用 Mixtral 生成教科书的示例:
```bash
# clone the repo and follow installation requirements
cd llm-swarm
python ./examples/textbooks/generate_synthetic_textbooks.py \
--model mistralai/Mixtral-8x7B-Instruct-v0.1 \
--instances 2 \
--prompts_dataset "HuggingFaceTB/cosmopedia-100k" \
--prompt_column prompt \
--max_samples -1 \
--checkpoint_path "./tests_data" \
--repo_id "HuggingFaceTB/generations_cosmopedia_100k" \
--checkpoint_interval 500
```
你甚至可以使用 `wandb` 跟踪生成过程,以监控吞吐量和生成的词元数。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/wandb.png" alt="text-clustering" style="width: 60%; height: auto;"><br>
<em>图 10: llm-swarm 的 wandb 图</em>
</p>
**注意:**
我们使用 HuggingChat 对提示进行初始迭代。我们使用 `llm-swarm` 为每个提示生成数百个样本以检查生成的样本是否有异常及其异常模式。比如说,模型在为多个教科书生成了非常相似的介绍性短语,并且经常以相同的短语开头,如“很久很久以前”以及“太阳低垂在天空中”。我们在迭代后的提示中明确要求模型避免这些介绍性陈述并要求其创造性解决问题,基于这些提示,虽然仍会出现上述情况,但概率很低。
#### 基准去污
鉴于种子样本或模型的训练数据中可能存在基准污染,我们实现了一个净化流水线,以确保我们的数据集不含测试基准中的任何样本。
与 Phi-1 类似,我们使用 10- 词元重叠率来识别潜在污染的样本。从数据集中检索到候选样本后,我们使用 [`difflib.SequenceMatcher`](https://docs.python.org/3/library/difflib.html) 将其与基准样本进行比较。如果 `len(matched_substrings)` 与 `len(benchmark_sample)` 的比率超过 0.5,我们将丢弃该样本。我们对 Cosmo-1B 模型所有评估基准都实施了此净化,包括 MMLU、HellaSwag、PIQA、SIQA、Winogrande、OpenBookQA、ARC-Easy 以及 ARC-Challenge。
下表汇总了我们从每个数据子集中删除的受污染样本的数量,以及它们对应的基准样本数 (见括号):
<div align="center">
| 数据集 | ARC | BoolQ | HellaSwag | PIQA |
| --- | --- | --- | --- | --- |
| 网络数据 + 斯坦福 + openstax | 49 (16) | 386 (41) | 6 (5) | 5 (3) |
| auto_math_text + 可汗学院 | 17 (6) | 34 (7) | 1 (1) | 0 (0) |
| 故事 | 53 (32) | 27 (21) | 3 (3) | 6 (4) |
</div>
我们发现与 MMLU、OpenBookQA 和 WinoGrande 重合的受污染样本少于 4 个。
#### 训练软件栈
我们在 Cosmopedia 上使用 Llama2 架构训练了一个 [1B LLM](https://huggingface.co/HuggingFaceTB/cosmo-1b),以评估 Cosmopedia 的质量。
我们用 [datatrove](https://github.com/huggingface/datatrove) 进行数据去重及分词,用 [nanotron](https://github.com/huggingface/nanotron/tree/main) 进行模型训练,用 [lighteval](https://github.com/huggingface/lighteval-harness) 进行评估。
该模型在 ARC-easy、ARC-challenge、OpenBookQA 和 MMLU 上的性能优于 TinyLlama 1.1B,在 ARC-challenge 和 OpenBookQA 上与 Qwen-1.5-1B 相当。然而,我们注意到其与 Phi-1.5 的性能相比仍存在一些差距,这表明我们仍有空间改善合成数据的质量,这可能与用于生成的 LLM、主题覆盖度或提示有关。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/cosmopedia/evals.png" alt="evaluation results" style="width: 60%; height: auto;"><br>
<em>图 10: Cosmo-1B 的评估结果</em>
</p>
## 结论及下一步
本文,我们概述了创建 Cosmopedia 的方法,Cosmopedia 是一个专为模型预训练而设计的大型合成数据集,其目标对 Phi 模型进行复现。我们强调了精心制作提示以涵盖广泛主题、确保生成多样化内容的重要性。此外,我们还共享并开源了我们的技术栈,从而可将该生成过程扩展至数百个 GPU。
然而,这只是 Cosmopedia 的初始版本,我们正在积极努力提高生成内容的质量。生成的准确性和可靠性很大程度上取决于生成时使用的模型。举个例子,Mixtral 有时可能会产生幻觉并产生不正确的信息,例如,当涉及 AutoMathText 和可汗学院数据集中的历史事实或数学推理相关主题时,Mixtral 就会产生幻觉。缓解幻觉的一种策略是使用检索增强生成 (RAG),这包含检索与种子样本相关的信息 (如从维基百科),并将其合并至上下文中。幻觉度量还可以帮助评估哪些主题或领域受幻觉的影响最大 [[9]](https://arxiv.org/abs/2303.08896)。将 Mixtral 的生成内容与其他开放模型进行比较也很有趣。
合成数据潜力巨大,我们渴望看到社区在 Cosmopedia 之玩些花头出来。
## 参考文献
[1] Ding et al. [Enhancing Chat Language Models by Scaling High-quality Instructional Conversations](https://arxiv.org/abs/2305.14233)
[2] Wei et al. [Magicoder: Source Code Is All You Need](https://arxiv.org/abs/2312.02120)
[3] Toshniwal et al. [OpenMathInstruct-1: A 1.8 Million Math Instruction Tuning Dataset](https://arxiv.org/abs/2402.10176)
[4] Xu et al. [WizardLM: Empowering Large Language Models to Follow Complex Instructions](https://arxiv.org/abs/2304.12244)
[5] Moritz Laurer [Synthetic data: save money, time and carbon with open source](https://huggingface.co/blog/synthetic-data-save-cost)
[6] Gunasekar et al. [Textbooks Are All You Need](https://arxiv.org/abs/2306.11644)
[7] Li et al. [Textbooks are all you need ii: phi-1.5 technical report](https://arxiv.org/abs/2309.05463)
[8] [Phi-2 博文](https://www.microsoft.com/en-us/research/blog/phi-2-the-surprising-power-of-small-language-models/)
[9] Manakul, Potsawee and Liusie, Adian and Gales, Mark JF [Selfcheckgpt: Zero-resource black-box hallucination detection for generative large language models](https://arxiv.org/abs/2303.08896)
| 4 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/ml-for-games-2.md | ---
title: "使用 ChatGPT 启发游戏创意|基于 AI 5 天创建一个农场游戏,第 2 天"
thumbnail: /blog/assets/124_ml-for-games/thumbnail2.png
authors:
- user: dylanebert
translators:
- user: SuSung-boy
- user: zhongdongy
proofreader: true
---
# 使用 ChatGPT 启发游戏创意|基于 AI 5 天创建一个农场游戏,第 2 天
**欢迎使用 AI 进行游戏开发!** 在本系列中,我们将使用 AI 工具在 5 天内创建一个功能完备的农场游戏。到本系列结束时,您将了解到如何将多种 AI 工具整合到游戏开发流程中。本文将向您展示如何将 AI 工具用于:
1. 美术风格
2. 游戏设计
3. 3D 素材
4. 2D 素材
5. 剧情
想要观看视频快速了解?请点击 [此处](https://www.tiktok.com/@individualkex/video/7186551685035085098)。如果您想要掌握更多技术细节,请继续阅读!
**注意:** 本教程面向熟悉 Unity 开发和 C# 语言的读者。如果您不熟悉这些技术,请先查看 [Unity for Beginners](https://www.tiktok.com/@individualkex/video/7086863567412038954) 系列后再继续阅读。
## 第 2 天:游戏设计
在本系列教程的 [第 1 部分](https://huggingface.co/blog/zh/ml-for-games-1) 中,我们使用 **AI 帮助确定美术风格**。更确切地说,我们使用了一项名为 Stable Diffiusion 的技术,实现了生成概念艺术图片,并将其应用到游戏的视觉美术风格中。
在这一部分中,我们将使用 AI 进行游戏设计。在下文的[缩略版](#缩略版) 中,我会简要介绍如何使用 ChatGPT 工具帮助启发游戏创意。但对 AI 相关的读者来说,更值得关注的是 ChatGPT 的工作原理。你也可以在下文的 [语言模型](#语言模型) 部分了解更多关于语言模型的背景知识,以及更多 [在游戏开发中的应用](#在游戏开发中的应用),请继续往下阅读。
### 缩略版
使用 AI 进行游戏设计的缩略版:向 [ChatGPT](https://chat.openai.com/chat) 提问寻求建议,然后自行决定是否遵循建议。以本系列的农场游戏为例,我这样提问 ChatGPT:
> 你是一名专业游戏设计师,正负责一款简易农场游戏的设计工作。为使该农场游戏好玩有趣且引人入胜,哪些功能应最优先考虑?
得到的回答(总结)如下:
1. 多样性的农作物
2. 具有挑战性和奖励机制的进阶系统
3. 动态、可交互的环境
4. 社交性质、多人玩法
5. 精妙绝伦的剧情
鉴于此系列只有 5 天时间,我仅实现了前两点的游戏功能,并完成了 [灰盒测试](https://en.wikipedia.org/wiki/Gray-box_testing)。您可以 [试玩游戏](https://individualkex.itch.io/ml-for-game-dev-2) 或者 [查看源码](https://github.com/dylanebert/FarmingGame)。
本文不会详细说明实现这些游戏机制的具体细节,因为本系列的重点是如何使用 AI 工具帮助农场游戏开发,而不是如何实现。相反,本文将介绍 ChatGPT 是什么 (语言模型)、它的工作原理是什么、以及怎样影响着游戏开发过程。
### 语言模型
ChatGPT 尽管在回答采纳率方面取得了重大突破,但实际上它是现有技术的迭代产物,这项技术就是 **语言模型**。
语言模型是 AI 的其中一种,经训练可用于预测单词序列的概率。例如一个序列「猫捉__」,我们期望语言模型经训练可以预测的单词为「老鼠」。这类训练过程可以应用于多种类型的任务,例如翻译任务:「猫的法语单词是___」。这种训练设置虽然在早期的一些自然语言处理任务上取得很好的效果,但对比当下的模型水平仍相差甚远,而差距悬殊的原因就是 **transformers** 这项技术。
**Transformers** 是 [2017 年被提出](https://proceedings.neurips.cc/paper/2017/file/3f5ee243547dee91fbd053c1c4a845aa-Paper.pdf)的一种神经网络架构,它使用自注意力机制单步完成整个序列的预测,是 ChatGPT 等现代语言模型背后的重要技术。想深入了解其工作原理?访问 Hugging Face 查看 [Transformer 入门课程](https://huggingface.co/course/chapter1/1)!
相比于早期的语言模型,为什么 ChatGPT 如此成功?全面地回答这个问题是不可能的,因为 ChatGPT 并未开源。不过可回答的其中一个方面是 RLHF(Reinforcement Learning from Human Feedback),即以强化学习的方式依据人类反馈优化语言模型。可以点击这篇博客文章: [ChatGPT 背后的「功臣」——RLHF 技术详解](https://huggingface.co/blog/zh/rlhf),查看更多关于 RLHF 的信息,包括它的工作原理、实现它的开源工具及其前景展望等等。
AI 领域在持续变革。随着 AI 成为开源社区的一部分,可以预见在激发创造力方面将出现爆炸式增长,当然也包括在游戏开发中的应用。如果您正在阅读本文,您可能已经走在变革前列。
### 在游戏开发中的应用
在 [缩略版](#缩略版) 中,我介绍了如何使用 ChatGPT 来帮助启发游戏创意。不仅如此,您还可以用它来 [编写完整游戏代码](https://www.youtube.com/watch?v=YDWvAqKLTLg&ab_channel=AAlex),以及用于几乎任何您能想到的事情。反而了解它的 **局限性** 可能更有意义。
#### 局限性
ChatGPT 的有些回答通常听起来可信度很高,但实际上是错误的。这里有一份 [ChatGPT 错误回答合集](https://github.com/giuven95/chatgpt-failures),造成这些的原因是 ChatGPT 不能 **理解** 人类讲话的方式。ChatGPT 仅仅是一个非常大的 [语言模型](#语言模型),对于一个问题它可以预测可能的回答,但并不能真正理解自己在说什么。我个人非常喜欢的错误回答(尤其是与游戏开发相关的)之一是从 [Reddit](https://www.reddit.com/r/Unity3D/comments/zcps1f/eli5_quaternion_by_chatgpt/) 摘录的一篇 ChatGPT 对四元数的解释:
<figure class="image text-center">
<img src="../assets/124_ml-for-games/quaternion.png" alt="ChatGPT Quaternion Explanation">
</figure>
> 内容翻译:
>
> 向一位小朋友解释一下四元数是什么
>
>
> 四元数是表示旋转的一种特殊方式。想象一下你有一辆玩具车,你想把它转到另一个方向。仅说 “把车向左转” 这样的模糊词不够,这时候可以使用四元数来精确地表示玩具车的转弯角度以及转弯方向。四元数有四个组成部分,每一部分都表示转弯的不同信息。第一部分表示玩具车的转弯方式(左转或右转);第二部分表示玩具车的具体转弯角度;第三部分表示玩具车的倾斜方式;第四部分表示玩具车的具体倾斜程度。使用四元数可以精确地表示你对玩具车如何转弯这一指令。
这个解释听起来不错,但却是完全错误的。这个错误回答的例子很好地说明了为什么 ChatGPT 虽然非常有用,但不应该用作权威的知识库。
#### 一些建议
如果 ChatGPT 的回答错误很多,还应该使用它吗?我认为不能依赖它代替你完成任务,但将它作为一种工具仍然是非常有用的。本文游戏设计的例子中,在 ChatGPT 回答了游戏所需功能之后,我本可以继续提问 ChatGPT 并要求它为我实现所有功能,事实上已经有 [其他人这样做过了](https://www.youtube.com/watch?v=YDWvAqKLTLg&ab_channel=AAlex),而且有点奏效。不过,我的建议更倾向于将 ChatGPT 作为头脑风暴和加速开发的工具,而不是完全替代开发过程中的某些环节。
欢迎继续阅读 [第三部分](https://huggingface.co/blog/zh/ml-for-games-3),我们一起 **使用 AI 制作 3D 素材**!
| 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/gradio-5.md | ---
title: "Gradio 5 现已发布"
thumbnail: /blog/assets/gradio-5/thumbnail.png
authors:
- user: abidlabs
translators:
- user: chenglu
---
# Gradio 5 现已发布
在过去的几个月里,我们一直在努力工作,现在我们非常激动地宣布 **Gradio 5 的稳定版发布**。
有了 Gradio 5,开发者可以构建 **生产级的机器学习 Web 应用程序**,这些应用不仅性能优越、可扩展、设计精美、易于访问,而且还遵循了最佳的 Web 安全实践。更重要的是,只需几行 Python 代码即可实现。
想要体验 Gradio 5,只需在终端中输入以下命令:
```
pip install --upgrade gradio
```
然后开始构建你的 [第一个 Gradio 应用](https://www.gradio.app/guides/quickstart)。
## Gradio 5:面向生产环境的机器学习应用构建工具
如果你之前使用过 Gradio,可能会想知道 Gradio 5 有什么不同。
Gradio 5 的目标是倾听和解决 Gradio 开发者在构建生产级应用时遇到的常见问题。例如,我们听到一些开发者提到:
* “Gradio 应用加载太慢” → Gradio 5 带来了重大的性能改进,包括通过服务端渲染 (SSR) 提供 Gradio 应用,几乎可以在浏览器中瞬间加载应用。_告别加载时的转圈圈_! 🏎️💨
<video width="600" controls playsinline>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/gradio-5/gradio-4-vs-5-load.mp4">
</video>
* “这个 Gradio 应用看起来有点过时” → Gradio 5 对许多核心组件进行了现代化设计改进,包括按钮、标签页、滑块以及高级聊天界面。我们还发布了一组全新的内置主题,让你可以轻松创建外观时尚的 Gradio 应用 🎨。
* “我无法在 Gradio 中构建实时应用” → Gradio 5 实现了低延迟的流式处理!我们使用 base64 编码和 websockets 自动加速,还通过自定义组件支持 WebRTC。此外,还增加了大量文档和示例演示,涵盖了常见的流式处理用例,如基于摄像头的物体检测、视频流处理、实时语音转录与生成,以及对话型聊天机器人。 🎤
* “LLM 不了解 Gradio” → Gradio 5 推出了一个实验性的 AI Playground,你可以在其中使用 AI 来生成或修改 Gradio 应用,并立即在浏览器中预览:[https://www.gradio.app/playground](https://www.gradio.app/playground)
<video width="600" controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/gradio-5/simple-playground.mp4">
</video>
Gradio 5 在保留简单直观的开发者 API 的同时,提供了所有这些新功能。作为面向各种机器学习应用的生产级 Web 框架,Gradio 5 还在 Web 安全性方面做了重大改进(包括第三方审计)——更多详情将在即将发布的博客中介绍!
## 不兼容的更改
在 Gradio 4.x 中没有出现弃用警告的 Gradio 应用应该可以继续在 Gradio 5 中正常运行,[少数例外请参考 Gradio 5 中的不兼容更改列表](https://github.com/gradio-app/gradio/issues/9463)。
## Gradio 的下一步计划
我们在 Gradio 5 中的许多更改是为了支持即将发布的新功能。敬请期待以下内容:
* 支持多页面的 Gradio 应用,以及原生的导航栏和侧边栏
* 支持通过 PWA 在移动设备上运行 Gradio 应用,甚至可能支持原生应用
* 更多媒体组件,以支持新兴的图像和视频处理模式
* 更丰富的 DataFrame 组件,支持常见的电子表格操作
* 与机器学习模型和 API 提供商的一键集成
* 进一步减少 Gradio 应用的内存消耗
以及更多功能!有了 Gradio 5 提供的稳固基础,我们非常期待让开发者使用 Gradio 构建各种机器学习应用。
## 立即试用 Gradio 5
以下是一些运行 Gradio 5 的 Hugging Face Spaces:
* https://huggingface.co/spaces/akhaliq/depth-pro
* https://huggingface.co/spaces/hf-audio/whisper-large-v3-turbo
* https://huggingface.co/spaces/gradio/chatbot_streaming_main
* https://huggingface.co/spaces/gradio/scatter_plot_demo_main
| 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/presidio-pii-detection.md | ---
title: "在 Hub 上使用 Presidio 进行自动 PII 检测实验"
thumbnail: /blog/assets/presidio-pii-detection/thumbnail.png
authors:
- user: lhoestq
- user: meg
- user: presidio
- user: omri374
translator:
- user: Evinci
- user: zhongdongy
proofreader: true
---
# 在 Hub 上使用 Presidio 进行自动 PII 检测实验
我们在 Hugging Face Hub 上托管的机器学习 (ML) 数据集中发现了一个引人关注的现象: 包含个人未经记录的私密信息。这一现象为机器学习从业者带来了一些特殊挑战。
在本篇博客中,我们将深入探讨含有一种称为个人识别信息 (PII) 的私密信息的各类数据集,分析这些数据集存在的问题,并介绍我们在数据集 Hub 上正在测试的一个新功能,旨在帮助应对这些挑战。
## 包含个人识别信息 (PII) 的数据集类型
我们注意到包含个人识别信息 (PII) 的数据集主要有两种类型:
1. **标注的 PII 数据集**: 例如由 Ai4Privacy 提供的 [PII-Masking-300k](https://huggingface.co/datasets/ai4privacy/pii-masking-300k),这类数据集专门用于训练 PII 检测模型。这些模型用于检测和掩盖 PII,可以帮助进行在线内容审核或提供匿名化的数据库。
2. **预训练数据集**: 这些通常是大规模的数据集,往往有数 TB 大小,通常通过网络爬虫获得。尽管这些数据集一般会过滤掉某些类型的 PII,但由于数据量庞大和 PII 检测模型的不完善,仍可能有少量敏感信息遗漏。
## 机器学习数据集中的个人识别信息 (PII) 面临的挑战
机器学习数据集中存在的个人识别信息 (PII) 会为从业者带来几个挑战。首先,它引发了隐私问题,可能被用来推断个人的敏感信息。
此外,如果未能妥善处理 PII,它还可能影响机器学习模型的性能。例如,如果一个模型是在包含 PII 的数据集上训练的,它可能学会将特定的 PII 与特定的结果关联起来,这可能导致预测偏见或从训练集生成 PII。
## 数据集 Hub 上的新实验: Presidio 报告
为了应对这些挑战,我们正在数据集 Hub 上试验一项新功能,使用 [Presidio](https://github.com/microsoft/presidio)——一种开源的最先进的个人识别信息 (PII) 检测工具。Presidio 依赖检测模式和机器学习模型来识别 PII。
通过这个新功能,用户将能够看到一个报告,估计数据集中 PII 的存在情况。这一信息对于机器学习从业者非常有价值,帮助他们在训练模型前做出明智的决策。例如,如果报告指出数据集包含敏感的 PII,从业者可能会选择使用像 Presidio 这样的工具进一步过滤数据集。
数据集所有者也可以通过使用这些报告来验证他们的 PII 过滤流程,从而在发布数据集之前受益于这一功能。
## Presidio 报告的一个示例
让我们来看一个关于这个 [预训练数据集](https://huggingface.co/datasets/allenai/c4) 的 Presidio 报告的示例:

在这个例子中,Presidio 检测到数据集中有少量的电子邮件和敏感个人识别信息 (PII)。
## 结论
机器学习数据集中个人识别信息 (PII) 的存在是机器学习社区不断发展的挑战之一。 在 Hugging Face,我们致力于保持透明度,并帮助从业者应对这些挑战。 通过在数据集 Hub 上试验诸如 Presidio 报告之类的新功能,我们希望赋予用户做出明智决策的能力,并构建更健壯、更符合道德标准的机器学习模型。
我们还要感谢国家信息与自由委员会 (CNIL) 对 [GDPR 合规性的帮助](https://huggingface.co/blog/cnil)。 他们在指导我们应对人工智能和个人数据问题的复杂性方面提供了宝贵的帮助。 请在 [这里](https://www.cnil.fr/fr/ai-how-to-sheets) 查看他们更新的人工智能操作指南。
敬请期待更多关于这一激动人心发展的更新! | 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/t2i-sdxl-adapters.md | ---
title: "在 SDXL 上用 T2I-Adapter 实现高效可控的文生图"
thumbnail: /blog/assets/t2i-sdxl-adapters/thumbnail.png
authors:
- user: Adapter
guest: true
- user: valhalla
- user: sayakpaul
- user: Xintao
guest: true
- user: hysts
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 在 SDXL 上用 T2I-Adapter 实现高效可控的文生图
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/t2i-adapters-sdxl/hf_tencent.png" height=180/>
</p>
[T2I-Adapter](https://huggingface.co/papers/2302.08453) 是一种高效的即插即用模型,其能对冻结的预训练大型文生图模型提供额外引导。T2I-Adapter 将 T2I 模型中的内部知识与外部控制信号结合起来。我们可以根据不同的情况训练各种适配器,实现丰富的控制和编辑效果。
同期的 [ControlNet](https://hf.co/papers/2302.05543) 也有类似的功能且已有广泛的应用。然而,其运行所需的 **计算成本比较高**。这是因为其反向扩散过程的每个去噪步都需要运行 ControlNet 和 UNet。另外,对 ControlNet 而言,复制 UNet 编码器作为控制模型的一部分对效果非常重要,这也导致了控制模型参数量的进一步增大。因此,ControlNet 的模型大小成了生成速度的瓶颈 (模型越大,生成得越慢)。
在这方面,T2I-Adapters 相较 ControlNets 而言颇有优势。T2I-Adapter 的尺寸较小,而且,与 ControlNet 不同,T2I-Adapter 可以在整个去噪过程中仅运行一次。
| **模型** | **参数量** | **所需存储空间(fp16)** |
| --- | --- | --- |
| [ControlNet-SDXL](https://huggingface.co/diffusers/controlnet-canny-sdxl-1.0) | 1251 M | 2.5 GB |
| [ControlLoRA](https://huggingface.co/stabilityai/control-lora) (rank = 128) | 197.78 M (参数量减少 84.19%) | 396 MB (所需空间减少 84.53%) |
| [T2I-Adapter-SDXL](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0) | 79 M (**_参数量减少 93.69%_**) | 158 MB (**_所需空间减少 94%_**) |
在过去的几周里,Diffusers 团队和 T2I-Adapter 作者紧密合作,在 [`diffusers`](https://github.com/huggingface/diffusers) 库上为 [Stable Diffusion XL (SDXL)](https://huggingface.co/papers/2307.01952) 增加 T2I-Adapter 的支持。本文,我们将分享我们在从头开始训练基于 SDXL 的 T2I-Adapter 过程中的发现、漂亮的结果,以及各种条件 (草图、canny、线稿图、深度图以及 OpenPose 骨骼图) 下的 T2I-Adapter checkpoint!

与之前版本的 T2I-Adapter (SD-1.4/1.5) 相比,[T2I-Adapter-SDXL](https://github.com/TencentARC/T2I-Adapter) 还是原来的配方,不一样之处在于,用一个 79M 的适配器去驱动 2.6B 的大模型 SDXL! T2I-Adapter-SDXL 在继承 SDXL 的高品质生成能力的同时,保留了强大的控制能力!
## 用 `diffusers` 训练 T2I-Adapter-SDXL
我们基于 `diffusers` 提供的 [这个官方示例](https://github.com/huggingface/diffusers/blob/main/examples/t2i_adapter/README_sdxl.md) 构建了我们的训练脚本。
本文中提到的大多数 T2I-Adapter 模型都是在 LAION-Aesthetics V2 的 3M 高分辨率 `图文对` 上训练的,配置如下:
- 训练步数: 20000-35000
- batch size: 采用数据并行,单 GPU batch size 为 16,总 batch size 为 128
- 学习率: 1e-5 的恒定学习率
- 混合精度: fp16
我们鼓励社区使用我们的脚本来训练自己的强大的 T2I-Adapter,并对速度、内存和生成的图像质量进行折衷以获得竞争优势。
## 在 `diffusers` 中使用 T2I-Adapter-SDXL
这里以线稿图为控制条件来演示 [T2I-Adapter-SDXL](https://github.com/TencentARC/T2I-Adapter/tree/XL) 的使用。首先,安装所需的依赖项:
```bash
pip install -U git+https://github.com/huggingface/diffusers.git
pip install -U controlnet_aux==0.0.7 # for conditioning models and detectors
pip install transformers accelerate
```
T2I-Adapter-SDXL 的生成过程主要包含以下两个步骤:
1. 首先将条件图像转换为符合要求的 _控制图像_ 格式。
2. 然后将 _控制图像_ 和 _提示_ 传给 [`StableDiffusionXLAdapterPipeline`](https://github.com/huggingface/diffusers/blob/0ec7a02b6a609a31b442cdf18962d7238c5be25d/src/diffusers/pipelines/t2i_adapter/pipeline_stable_diffusion_xl_adapter.py#L126)。
我们看一个使用 [Lineart Adapter](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0) 的简单示例。我们首先初始化 SDXL 的 T2I-Adapter 流水线以及线稿检测器。
```python
import torch
from controlnet_aux.lineart import LineartDetector
from diffusers import (AutoencoderKL, EulerAncestralDiscreteScheduler,
StableDiffusionXLAdapterPipeline, T2IAdapter)
from diffusers.utils import load_image, make_image_grid
# load adapter
adapter = T2IAdapter.from_pretrained(
"TencentARC/t2i-adapter-lineart-sdxl-1.0", torch_dtype=torch.float16, varient="fp16"
).to("cuda")
# load pipeline
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
euler_a = EulerAncestralDiscreteScheduler.from_pretrained(
model_id, subfolder="scheduler"
)
vae = AutoencoderKL.from_pretrained(
"madebyollin/sdxl-vae-fp16-fix", torch_dtype=torch.float16
)
pipe = StableDiffusionXLAdapterPipeline.from_pretrained(
model_id,
vae=vae,
adapter=adapter,
scheduler=euler_a,
torch_dtype=torch.float16,
variant="fp16",
).to("cuda")
# load lineart detector
line_detector = LineartDetector.from_pretrained("lllyasviel/Annotators").to("cuda")
```
然后,加载图像并生成其线稿图:
```python
url = "https://huggingface.co/Adapter/t2iadapter/resolve/main/figs_SDXLV1.0/org_lin.jpg"
image = load_image(url)
image = line_detector(image, detect_resolution=384, image_resolution=1024)
```

然后生成:
```python
prompt = "Ice dragon roar, 4k photo"
negative_prompt = "anime, cartoon, graphic, text, painting, crayon, graphite, abstract, glitch, deformed, mutated, ugly, disfigured"
gen_images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
image=image,
num_inference_steps=30,
adapter_conditioning_scale=0.8,
guidance_scale=7.5,
).images[0]
gen_images.save("out_lin.png")
```

理解下述两个重要的参数,可以帮助你调节控制程度。
1. `adapter_conditioning_scale`
该参数调节控制图像对输入的影响程度。越大代表控制越强,反之亦然。
2. `adapter_conditioning_factor`
该参数调节适配器需应用于生成过程总步数的前面多少步,取值范围在 0-1 之间 (默认值为 1)。 `adapter_conditioning_factor=1` 表示适配器需应用于所有步,而 `adapter_conditioning_factor=0.5` 则表示它仅应用于前 50% 步。
更多详情,请查看 [官方文档](https://huggingface.co/docs/diffusers/main/en/api/pipelines/stable_diffusion/adapter)。
## 试玩演示应用
你可以在 [这儿](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL) 或下述嵌入的游乐场中轻松试玩 T2I-Adapter-SDXL:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.43.1/gradio.js"></script>
<gradio-app src="https://tencentarc-t2i-adapter-sdxl.hf.space"></gradio-app>
你还可以试试 [Doodly](https://huggingface.co/spaces/TencentARC/T2I-Adapter-SDXL-Sketch),它用的是草图版模型,可以在文本监督的配合下,把你的涂鸦变成逼真的图像:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.43.1/gradio.js"></script>
<gradio-app src="https://tencentarc-t2i-adapter-sdxl-sketch.hf.space"></gradio-app>
## 更多结果
下面,我们展示了使用不同控制图像作为条件获得的结果。除此以外,我们还分享了相应的预训练 checkpoint 的链接。如果想知道有关如何训练这些模型的更多详细信息及其示例用法,可以参考各自模型的模型卡。
### 使用线稿图引导图像生成

_模型见 [`TencentARC/t2i-adapter-lineart-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-lineart-sdxl-1.0)_
### 使用草图引导图像生成

_模型见 [`TencentARC/t2i-adapter-sketch-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-sketch-sdxl-1.0)_
### 使用 Canny 检测器检测出的边缘图引导图像生成

_模型见 [`TencentARC/t2i-adapter-canny-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-canny-sdxl-1.0)_
### 使用深度图引导图像生成

_模型分别见 [`TencentARC/t2i-adapter-depth-midas-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-depth-midas-sdxl-1.0) 及 [`TencentARC/t2i-adapter-depth-zoe-sdxl-1.0`](https://huggingface.co/TencentARC/t2i-adapter-depth-zoe-sdxl-1.0)_
### 使用 OpenPose 骨骼图引导图像生成

_模型见 [`TencentARC/t2i-adapter-openpose-sdxl-1.0`](https://hf.co/TencentARC/t2i-adapter-openpose-sdxl-1.0)_
---
_致谢: 非常感谢 [William Berman](https://twitter.com/williamLberman) 帮助我们训练模型并分享他的见解。_ | 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/peft.md | ---
title: "🤗 PEFT:在低资源硬件上对十亿规模模型进行参数高效微调"
thumbnail: /blog/assets/130_peft/thumbnail.png
authors:
- user: smangrul
- user: sayakpaul
---
## 🤗 PEFT:在低资源硬件上对十亿规模模型进行参数高效微调
## 动机
基于 Transformers 架构的大型语言模型 (LLM),如 GPT、T5 和 BERT,已经在各种自然语言处理 (NLP) 任务中取得了最先进的结果。此外,还开始涉足其他领域,例如计算机视觉 (CV) (VIT、Stable Diffusion、LayoutLM) 和音频 (Whisper、XLS-R)。传统的范式是对通用网络规模数据进行大规模预训练,然后对下游任务进行微调。与使用开箱即用的预训练 LLM (例如,零样本推理) 相比,在下游数据集上微调这些预训练 LLM 会带来巨大的性能提升。
然而,随着模型变得越来越大,在消费级硬件上对模型进行全部参数的微调变得不可行。此外,为每个下游任务独立存储和部署微调模型变得非常昂贵,因为微调模型与原始预训练模型的大小相同。参数高效微调(PEFT) 方法旨在解决这两个问题!
PEFT 方法仅微调少量 (额外) 模型参数,同时冻结预训练 LLM 的大部分参数,从而大大降低了计算和存储成本。这也克服了[灾难性遗忘](https://arxiv.org/abs/1312.6211)的问题,这是在 LLM 的全参数微调期间观察到的一种现象。PEFT 方法也显示出在低数据状态下比微调更好,可以更好地泛化到域外场景。它可以应用于各种模态,例如[图像分类](https://github.com/huggingface/peft/tree/main/examples/image_classification)以及 [Stable diffusion dreambooth](https://github.com/huggingface/peft/tree/main/examples/lora_dreambooth)。
PEFT 方法还有助于提高轻便性,其中用户可以使用 PEFT 方法调整模型,以获得与完全微调的大型检查点相比,大小仅几 MB 的微小检查点。例如, `bigscience/mt0-xxl` 占用 40GB 的存储空间,全参数微调将导致每个下游数据集有对应 40GB 检查点。而使用 PEFT 方法,每个下游数据集只占用几 MB 的存储空间,同时实现与全参数微调相当的性能。来自 PEFT 方法的少量训练权重被添加到预训练 LLM 顶层。因此,同一个 LLM 可以通过添加小的权重来用于多个任务,而无需替换整个模型。
**简而言之,PEFT 方法使您能够获得与全参数微调相当的性能,同时只有少量可训练参数。**
今天,我们很高兴地介绍 [🤗 PEFT](https://github.com/huggingface/peft) 库。它提供了最新的参数高效微调技术,与 🤗 Transformers 和 🤗 Accelerate 无缝集成。这使得能够使用来自 Transformers 的最流行和高性能的模型,以及 Accelerate 的简单性和可扩展性。以下是目前支持的 PEFT 方法,即将推出更多:
1. LoRA: [LORA: LOW-RANK ADAPTATION OF LARGE LANGUAGE MODELS](https://arxiv.org/pdf/2106.09685.pdf)
2. Prefix Tuning: [P-Tuning v2: Prompt Tuning Can Be Comparable to Fine-tuning Universally Across Scales and Tasks](https://arxiv.org/pdf/2110.07602.pdf)
3. Prompt Tuning: [The Power of Scale for Parameter-Efficient Prompt Tuning](https://arxiv.org/pdf/2104.08691.pdf)
4. P-Tuning: [GPT Understands, Too](https://arxiv.org/pdf/2103.10385.pdf)
## 用例
我们在 GitHub PEFT 库中探索了许多有趣的[用例](https://github.com/huggingface/peft#use-cases)。以下罗列的是其中最有趣的:
1. 使用 🤗 PEFT LoRA 在具有 11GB RAM 的消费级硬件上调整 `bigscience/T0_3B` 模型 (30 亿个参数),例如 Nvidia GeForce RTX 2080 Ti、Nvidia GeForce RTX 3080 等,并且使用 🤗 Accelerate 的 DeepSpeed 集成: [peft_lora_seq2seq_accelerate_ds_zero3_offload.py](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq_accelerate_ds_zero3_offload.py)。这意味着您可以在 Google Colab 中调整如此大的 LLM。
2. 通过使用 🤗 PEFT LoRA 和 [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) 在 Google Colab 中启用 OPT-6.7b 模型 (67 亿个参数) 的 INT8 调整,将前面的示例提升一个档次: [](https://colab.research.google.com/drive/1jCkpikz0J2o20FBQmYmAGdiKmJGOMo-o?usp=sharing)。
3. 在具有 11GB RAM 的消费级硬件上使用 🤗 PEFT 进行稳定的 Diffusion Dreambooth 训练,例如 Nvidia GeForce RTX 2080 Ti、Nvidia GeForce RTX 3080 等。试用 Space 演示,它应该可以在 T4 实例 (16GB GPU) 上无缝运行: [smangrul/peft-lora-sd-dreambooth](https://huggingface.co/spaces/smangrul/peft-lora-sd-dreambooth)。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/peft/peft_lora_dreambooth_gradio_space.png" alt="peft lora dreambooth gradio space"><br>
<em>PEFT LoRA Dreambooth Gradio Space</em>
</p>
## 使用 🤗 PEFT 训练您的模型
让我们考虑使用 LoRA 微调 [`bigscience/mt0-large`](https://huggingface.co/bigscience/mt0-large) 的情况。
1. 引进必要的库
```diff
from transformers import AutoModelForSeq2SeqLM
+ from peft import get_peft_model, LoraConfig, TaskType
model_name_or_path = "bigscience/mt0-large"
tokenizer_name_or_path = "bigscience/mt0-large"
```
2. 创建 PEFT 方法对应的配置
```py
peft_config = LoraConfig(
task_type=TaskType.SEQ_2_SEQ_LM, inference_mode=False, r=8, lora_alpha=32, lora_dropout=0.1
)
```
3. 通过调用 `get_peft_model` 包装基础 🤗 Transformer 模型
```diff
model = AutoModelForSeq2SeqLM.from_pretrained(model_name_or_path)
+ model = get_peft_model(model, peft_config)
+ model.print_trainable_parameters()
# output: trainable params: 2359296 || all params: 1231940608 || trainable%: 0.19151053100118282
```
就是这样!训练循环的其余部分保持不变。有关端到端示例,请参阅示例 [peft_lora_seq2seq.ipynb](https://github.com/huggingface/peft/blob/main/examples/conditional_generation/peft_lora_seq2seq.ipynb)。
4. 当您准备好保存模型以供推理时,只需执行以下操作。
```py
model.save_pretrained("output_dir")
# model.push_to_hub("my_awesome_peft_model") also works
```
这只会保存经过训练的增量 PEFT 权重。例如,您可以在此处的 `twitter_complaints` raft 数据集上找到使用 LoRA 调整的 `bigscience/T0_3B`: [smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM](https://huggingface.co/smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM)。请注意,它只包含 2 个文件: adapter_config.json 和 adapter_model.bin,后者只有 19MB。
5. 要加载它进行推理,请遵循以下代码片段:
```diff
from transformers import AutoModelForSeq2SeqLM
+ from peft import PeftModel, PeftConfig
peft_model_id = "smangrul/twitter_complaints_bigscience_T0_3B_LORA_SEQ_2_SEQ_LM"
config = PeftConfig.from_pretrained(peft_model_id)
model = AutoModelForSeq2SeqLM.from_pretrained(config.base_model_name_or_path)
+ model = PeftModel.from_pretrained(model, peft_model_id)
tokenizer = AutoTokenizer.from_pretrained(config.base_model_name_or_path)
model = model.to(device)
model.eval()
inputs = tokenizer("Tweet text : @HondaCustSvc Your customer service has been horrible during the recall process. I will never purchase a Honda again. Label :", return_tensors="pt")
with torch.no_grad():
outputs = model.generate(input_ids=inputs["input_ids"].to("cuda"), max_new_tokens=10)
print(tokenizer.batch_decode(outputs.detach().cpu().numpy(), skip_special_tokens=True)[0])
# 'complaint'
```
## 下一步
我们发布了 PEFT 方法,作为在下游任务和域上调整大型 LLM 的有效方式,节省了大量计算和存储,同时实现与全参数微调相当的性能。在接下来的几个月中,我们将探索更多 PEFT 方法,例如 (IA)3 和瓶颈适配器。此外,我们将关注新的用例,例如 Google Colab 中[`whisper-large`](https://huggingface.co/openai/whisper-large) 模型的 INT8 训练以及使用 PEFT 方法调整 RLHF 组件 (例如策略和排序器)。
与此同时,我们很高兴看到行业从业者如何将 PEFT 应用于他们的用例 - 如果您有任何问题或反馈,请在我们的 [GitHub 仓库](https://github.com/huggingface/peft) 上提出问题 🤗。
祝你有一趟快乐的参数高效微调之旅!
| 9 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/audioldm2.md | ---
title: "AudioLDM 2,加速⚡️!"
thumbnail: /blog/assets/161_audioldm2/thumbnail.png
authors:
- user: sanchit-gandhi
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# AudioLDM 2,加速⚡️!
<!-- {blog_metadata} -->
<!-- {authors} -->
<a target="_blank" href="https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/AudioLDM-2.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt=" 在 Colab 中打开 "/>
</a>
AudioLDM 2 由刘濠赫等人在 [AudioLDM 2: Learning Holistic Audio Generation with Self-supervised Pretraining](https://arxiv.org/abs/2308.05734) 一文中提出。 AudioLDM 2 接受文本提示作为输入并输出对应的音频,其可用于生成逼真的声效、人类语音以及音乐。
虽然生成的音频质量很高,但基于其原始实现进行推理的速度非常慢: 生成一个 10 秒的音频需要 30 秒以上的时间。慢的原因是多重的,包括其使用了多阶段建模、checkpoint 较大以及代码尚未优化等。
本文将展示如何在 Hugging Face 🧨 Diffusers 库中使用 AudioLDM 2,并在此基础上探索一系列代码优化 (如半精度、Flash 注意力、图编译) 以及模型级优化 (如选择合适的调度器及反向提示)。最终我们将推理时间降低了 **10 倍** 多,且对输出音频质量的影响最低。本文还附有一个更精简的 [Colab notebook](https://colab.research.google.com/github/sanchit-gandhi/notebooks/blob/main/AudioLDM-2.ipynb),这里面包含所有代码但精简了很多文字部分。
最终,我们可以在短短 1 秒内生成一个 10 秒的音频!
## 模型概述
受 [Stable Diffusion](https://huggingface.co/docs/diffusers/api/pipelines/stable_diffusion/overview) 的启发,AudioLDM 2 是一种文生音频的 _ 隐扩散模型 (latent diffusion model,LDM)_,其可以将文本嵌入映射成连续的音频表征。
大体的生成流程总结如下:
1. 给定输入文本 $\boldsymbol{x}$,使用两个文本编码器模型来计算文本嵌入: [CLAP](https://huggingface.co/docs/transformers/main/en/model_doc/clap) 的文本分支,以及 [Flan-T5](https://huggingface.co/docs/transformers/main/en/model_doc/flan-t5) 的文本编码器。
$$\boldsymbol{E} _{1} = \text{CLAP}\left(\boldsymbol{x} \right); \quad \boldsymbol{E}_ {2} = \text{T5}\left(\boldsymbol{x}\right)
$$
CLAP 文本嵌入经过训练,可以与对应的音频嵌入对齐,而 Flan-T5 嵌入可以更好地表征文本的语义。
2. 这些文本嵌入通过各自的线性层投影到同一个嵌入空间:
$$\boldsymbol{P} _{1} = \boldsymbol{W}_ {\text{CLAP}} \boldsymbol{E} _{1}; \quad \boldsymbol{P}_ {2} = \boldsymbol{W} _{\text{T5}}\boldsymbol{E}_ {2}
$$
在 `diffusers` 实现中,这些投影由 [AudioLDM2ProjectionModel](https://huggingface.co/docs/diffusers/api/pipelines/audioldm2/AudioLDM2ProjectionModel) 定义。
3. 使用 [GPT2](https://huggingface.co/docs/transformers/main/en/model_doc/gpt2) 语言模型 (LM) 基于 CLAP 和 Flan-T5 嵌入自回归地生成一个含有 $N$ 个嵌入向量的新序列:
$$\tilde{\boldsymbol{E}} _{i} = \text{GPT2}\left(\boldsymbol{P}_ {1}, \boldsymbol{P} _{2}, \tilde{\boldsymbol{E}}_ {1:i-1}\right) \qquad \text{for } i=1,\dots,N$$
4. 以生成的嵌入向量 $\tilde{\boldsymbol{E}} _{1:N}$ 和 Flan-T5 文本嵌入 $\boldsymbol{E}_ {2}$ 为条件,通过 LDM 的反向扩散过程对随机隐变量进行 _去噪_ 。LDM 在反向扩散过程中运行 $T$ 个步推理:
$$\boldsymbol{z} _{t} = \text{LDM}\left(\boldsymbol{z}_ {t-1} | \tilde{\boldsymbol{E}} _{1:N}, \boldsymbol{E}_ {2}\right) \qquad \text{for } t = 1, \dots, T$$
其中初始隐变量 $\boldsymbol{z} _{0}$ 是从正态分布 $\mathcal{N} \left(\boldsymbol{0}, \boldsymbol{I} \right )$ 中采样而得。 LDM 的 [UNet](https://huggingface.co/docs/diffusers/api/pipelines/audioldm2/AudioLDM2UNet2DConditionModel) 的独特之处在于它需要 **两组** 交叉注意力嵌入,来自 GPT2 语言模型的 $\tilde{\boldsymbol{E}}_ {1:N}$ 和来自 Flan-T5 的 $\boldsymbol{E}_{2}$,而其他大多数 LDM 只有一个交叉注意力条件。
5. 把最终去噪后的隐变量 $\boldsymbol{z}_{T}$ 传给 VAE 解码器以恢复梅尔谱图 $\boldsymbol{s}$:
$$
\boldsymbol{s} = \text{VAE} _{\text{dec}} \left(\boldsymbol{z}_ {T}\right)
$$
6. 梅尔谱图被传给声码器 (vocoder) 以获得输出音频波形 $\mathbf{y}$:
$$
\boldsymbol{y} = \text{Vocoder}\left(\boldsymbol{s}\right)
$$
下图展示了文本输入是如何作为条件传递给模型的,可以看到在 LDM 中两个提示嵌入均被用作了交叉注意力的条件:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/audioldm2.png?raw=true" width="600"/>
</p>
有关如何训练 AudioLDM 2 模型的完整的详细信息,读者可以参阅 [AudioLDM 2 论文](https://arxiv.org/abs/2308.05734)。
Hugging Face 🧨 Diffusers 提供了一个端到端的推理流水线类 [`AudioLDM2Pipeline`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2) 以将该模型的多阶段生成过程包装到单个可调用对象中,这样用户只需几行代码即可完成从文本生成音频的过程。
AudioLDM 2 有三个变体。其中两个 checkpoint 适用于通用的文本到音频生成任务,第三个 checkpoint 专门针对文本到音乐生成。三个官方 checkpoint 的详细信息请参见下表,这些 checkpoint 都可以在 [Hugging Face Hub](https://huggingface.co/models?search=cvssp/audioldm2) 上找到:
| checkpoint | 任务 | 模型大小 | 训练数据(单位:小时) |
|-----------------------------------------------------------------------|---------------|------------|-------------------|
| [cvssp/audioldm2](https://huggingface.co/cvssp/audioldm2) | 文生音频 | 1.1B | 1150k |
| [cvssp/audioldm2-music](https://huggingface.co/cvssp/audioldm2-music) | 文生音乐 | 1.1B | 665k |
| [cvssp/audioldm2-large](https://huggingface.co/cvssp/audioldm2-large) | 文生音频 | 1.5B | 1150k |
至此,我们已经全面概述了 AudioLDM 2 生成的工作原理,接下来让我们将这一理论付诸实践!
## 加载流水线
我们以基础版模型 [cvssp/audioldm2](https://huggingface.co/cvssp/audioldm2) 为例,首先使用 [`.from_pretrained`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/overview#diffusers.DiffusionPipeline.from_pretrained) 方法来加载整个管道,该方法会实例化管道并加载预训练权重:
```python
from diffusers import AudioLDM2Pipeline
model_id = "cvssp/audioldm2"
pipe = AudioLDM2Pipeline.from_pretrained(model_id)
```
**输出:**
```
Loading pipeline components...: 100%|███████████████████████████████████████████| 11/11 [00:01<00:00, 7.62it/s]
```
与 PyTorch 一样,使用 `to` 方法将流水线移至 GPU:
```python
pipe.to("cuda");
```
现在,我们来定义一个随机数生成器并固定一个种子,我们可以通过这种方式来固定 LDM 模型中的起始隐变量从而保证结果的可复现性,并可以观察不同提示对生成过程和结果的影响:
```python
import torch
generator = torch.Generator("cuda").manual_seed(0)
```
现在,我们准备好开始第一次生成了!本文中的所有实验都会使用固定的文本提示以及相同的随机种子来生成音频,并比较不同方案的延时和效果。 [`audio_length_in_s`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.__call__.audio_length_in_s) 参数主要控制所生成音频的长度,这里我们将其设置为默认值,即 LDM 训练时的音频长度: 10.24 秒:
```python
prompt = "The sound of Brazilian samba drums with waves gently crashing in the background"
audio = pipe(prompt, audio_length_in_s=10.24, generator=generator).audios[0]
```
**输出:**
```
100%|███████████████████████████████████████████| 200/200 [00:13<00:00, 15.27it/s]
```
酷!我们花了大约 13 秒最终生成出了音频。我们来听一下:
```python
from IPython.display import Audio
Audio(audio, rate=16000)
```
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/sample_1.wav" type="audio/wav">
浏览器不支持音频元素。
</audio>
听起来跟我们的文字提示很吻合!质量很好,但是有一些背景噪音。我们可以为流水线提供 [_反向提示 (negative prompt)_](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.__call__.negative_prompt),以防止其生成的音频中含有某些不想要特征。这里,我们给模型一个反向提示,以防止模型生成低质量的音频。我们不设 `audio_length_in_s` 参数以使用其默认值:
```python
negative_prompt = "Low quality, average quality."
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
```
**输出:**
```
100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.50it/s]
```
使用反向提示 ${}^1$ 时,推理时间不变; 我们只需将 LDM 的无条件输入替换为反向提示即可。这意味着我们在音频质量方面获得的任何收益都是免费的。
我们听一下生成的音频:
```python
Audio(audio, rate=16000)
```
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/sample_2.wav" type="audio/wav">
浏览器不支持音频元素。
</audio>
显然,整体音频质量有所改善 - 噪声更少,并且音频整体听起来更清晰。
${}^1$ 请注意,在实践中,我们通常会看到第二次生成比第一次生成所需的推理时间有所减少。这是由于我们第一次运行计算时 CUDA 被“预热”了。因此一般进行基准测试时我们会选择第二次推理的时间作为结果。
## 优化 1: Flash 注意力
PyTorch 2.0 及更高版本包含了一个优化过的内存高效的注意力机制的实现,用户可通过 [`torch.nn.function.scaled_dot_product_attention`](https://pytorch.org/docs/master/generated/torch.nn.functional.scaled_dot_product_attention) (SDPA) 函数来调用该优化。该函数会根据输入自动使能多个内置优化,因此比普通的注意力实现运行得更快、更节省内存。总体而言,SDPA 函数的优化与 Dao 等人在论文 [Fast and Memory-Efficient Exact Attention with IO-Awareness](https://arxiv.org/abs/2205.14135) 中所提出的 _flash 注意力_ 类似。
如果安装了 PyTorch 2.0 且 `torch.nn.function.scaled_dot_product_attention` 可用,Diffusers 将默认启用该函数。因此,仅需按照 [官方说明](https://pytorch.org/get-started/locally/) 安装 torch 2.0 或更高版本,不需对流水线🚀作任何改动,即能享受提速。
```python
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
```
**输出:**
```
100%|███████████████████████████████████████████| 200/200 [00:12<00:00, 16.60it/s]
```
有关在 `diffusers` 中使用 SDPA 的更多详细信息,请参阅相应的 [文档](https://huggingface.co/docs/diffusers/optimization/torch2.0)。
## 优化 2: 半精度
默认情况下, `AudioLDM2Pipeline` 以 float32 (全) 精度方式加载模型权重。所有模型计算也以 float32 精度执行。对推理而言,我们可以安全地将模型权重和计算转换为 float16 (半) 精度,这能改善推理时间和 GPU 内存,同时对生成质量的影响微乎其微。
我们可以通过将 `from_pretrained` 的 [`torch_dtype`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/overview#diffusers.DiffusionPipeline.from_pretrained.torch_dtype) 参数设为 `torch.float16` 来加载半精度权重:
```python
pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.to("cuda");
```
我们运行一下 float16 精度的生成,并听一下输出:
```python
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
Audio(audio, rate=16000)
```
**输出:**
```
100%|███████████████████████████████████████████| 200/200 [00:09<00:00, 20.94it/s]
```
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/sample_3.wav" type="audio/wav">
浏览器不支持音频元素。
</audio>
音频质量与全精度生成基本没有变化,推理加速了大约 2 秒。根据我们的经验,使用具有 float16 精度的 `diffusers` 流水线,我们可以获得显著的推理加速而无明显的音频质量下降。因此,我们建议默认使用 float16 精度。
## 优化 3: Torch Compile
为了获得额外的加速,我们还可以使用新的 `torch.compile` 功能。由于在流水线中 UNet 通常计算成本最高,因此我们用 `torch.compile` 编译一下 UNet,其余子模型 (文本编码器和 VAE) 保持不变:
```python
pipe.unet = torch.compile(pipe.unet, mode="reduce-overhead", fullgraph=True)
```
用 `torch.compile` 包装 UNet 后,由于编译 UNet 的开销,我们运行第一步推理时通常会很慢。所以,我们先运行一步流水线预热,这样后面真正运行的时候就快了。请注意,第一次推理的编译时间可能长达 2 分钟,请耐心等待!
```python
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
```
**输出:**
```
100%|███████████████████████████████████████████| 200/200 [01:23<00:00, 2.39it/s]
```
很棒!现在 UNet 已编译完毕,现在可以以更快的速度运行完整的扩散过程了:
```python
audio = pipe(prompt, negative_prompt=negative_prompt, generator=generator.manual_seed(0)).audios[0]
```
**输出:**
```
100%|███████████████████████████████████████████| 200/200 [00:04<00:00, 48.98it/s]
```
只需 4 秒即可生成!在实践中,你只需编译 UNet 一次,然后就可以为后面的所有生成赢得一个更快的推理。这意味着编译模型所花费的时间可以由后续推理时间的收益所均摊。有关 `torch.compile` 的更多信息及选项,请参阅 [torch compile](https://pytorch.org/tutorials/intermediate/torch_compile_tutorial.html) 文档。
## 优化 4: 调度器
还有一个选项是减少推理步数。选择更高效的调度器可以帮助减少步数,而不会牺牲输出音频质量。你可以调用 [`schedulers.compatibles`](https://huggingface.co/docs/diffusers/v0.20.0/en/api/schedulers/overview#diffusers.SchedulerMixin) 属性来查看哪些调度器与 `AudioLDM2Pipeline` 兼容:
```python
pipe.scheduler.compatibles
```
**输出:**
```
[diffusers.schedulers.scheduling_lms_discrete.LMSDiscreteScheduler,
diffusers.schedulers.scheduling_k_dpm_2_discrete.KDPM2DiscreteScheduler,
diffusers.schedulers.scheduling_dpmsolver_multistep.DPMSolverMultistepScheduler,
diffusers.schedulers.scheduling_unipc_multistep.UniPCMultistepScheduler,
diffusers.schedulers.scheduling_euler_discrete.EulerDiscreteScheduler,
diffusers.schedulers.scheduling_pndm.PNDMScheduler,
diffusers.schedulers.scheduling_dpmsolver_singlestep.DPMSolverSinglestepScheduler,
diffusers.schedulers.scheduling_heun_discrete.HeunDiscreteScheduler,
diffusers.schedulers.scheduling_ddpm.DDPMScheduler,
diffusers.schedulers.scheduling_deis_multistep.DEISMultistepScheduler,
diffusers.utils.dummy_torch_and_torchsde_objects.DPMSolverSDEScheduler,
diffusers.schedulers.scheduling_ddim.DDIMScheduler,
diffusers.schedulers.scheduling_k_dpm_2_ancestral_discrete.KDPM2AncestralDiscreteScheduler,
diffusers.schedulers.scheduling_euler_ancestral_discrete.EulerAncestralDiscreteScheduler]
```
好!现在我们有一长串的调度器备选📝。默认情况下,AudioLDM 2 使用 [`DDIMScheduler`](https://huggingface.co/docs/diffusers/api/schedulers/ddim),其需要 200 个推理步才能生成高质量的音频。但是,性能更高的调度程序,例如 [`DPMSolverMultistepScheduler`](https://huggingface.co/docs/diffusers/main/en/api/schedulers/multistep_dpm_solver#diffusers.DPMSolverMultistepScheduler),
只需 **20-25 个推理步** 即可获得类似的结果。
让我们看看如何将 AudioLDM 2 调度器从 `DDIM` 切换到 `DPM Multistep` 。我们需要使用 [`ConfigMixin.from_config()`](https://huggingface.co/docs/diffusers/main/en/api/configuration#diffusers.ConfigMixin.from_config) 方法以用原始 [`DDIMScheduler`](https://huggingface.co/docs/diffusers/api/schedulers/ddim) 的配置来加载 [`DPMSolverMultistepScheduler`](https://huggingface.co/docs/diffusers/main/en/api/schedulers/multistep_dpm_solver#diffusers.DPMSolverMultistepScheduler):
```python
from diffusers import DPMSolverMultistepScheduler
pipe.scheduler = DPMSolverMultistepScheduler.from_config(pipe.scheduler.config)
```
让我们将推理步数设为 20,并使用新的调度器重新生成。由于 LDM 隐变量的形状未更改,因此我们不必重编译:
```python
audio = pipe(prompt, negative_prompt=negative_prompt, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
```
**输出:**
```
100%|███████████████████████████████████████████| 20/20 [00:00<00:00, 49.14it/s]
```
这次只用了不到 **1 秒** 就生成了音频!我们听下它的生成:
```python
Audio(audio, rate=16000)
```
<audio controls>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/161_audioldm2/sample_4.wav" type="audio/wav">
浏览器不支持音频元素。
</audio>
生成质量与原来的基本相同,但只花了原来时间的一小部分! 🧨 Diffusers 流水线是“可组合”的,这个设计允许你轻松地替换调度器或其他组件以获得更高性能。
## 内存消耗如何?
我们想要生成的音频的长度决定了 LDM 中待去噪的隐变量的 _宽度_ 。由于 UNet 中交叉注意力层的内存随序列长度 (宽度) 的平方而变化,因此生成非常长的音频可能会导致内存不足错误。我们还可以通过 batch size 来控制生成的样本数,进而控制内存使用。
如前所述,以 float16 半精度加载模型可以节省大量内存。使用 PyTorch 2.0 SDPA 也可以改善内存占用,但这部分改善对超长序列长度来讲可能不够。
我们来试着生成一个 2.5 分钟 (150 秒) 的音频。我们通过设置 [`num_waveforms_per_prompt`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.__call__.num_waveforms_per_prompt) `=4` 来生成 4 个候选音频。一旦 [`num_waveforms_per_prompt`](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.__call__.num_waveforms_per_prompt) `>1` ,在生成的音频和文本提示之间会有一个自动评分机制: 将音频和文本提示嵌入到 CLAP 音频文本嵌入空间中,然后根据它们的余弦相似度得分进行排名。生成的音频中第 `0` 个音频就是分数“最高”的音频。
由于我们更改了 UNet 中隐变量的宽度,因此我们必须使用新的隐变量形状再执行一次 torch 编译。为了节省时间,我们就不编译了,直接重新加载管道:
```python
pipe = AudioLDM2Pipeline.from_pretrained(model_id, torch_dtype=torch.float16)
pipe.to("cuda")
audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
```
**输出:**
```
---------------------------------------------------------------------------
OutOfMemoryError Traceback (most recent call last)
<ipython-input-33-c4cae6410ff5> in <cell line: 5>()
3 pipe.to("cuda")
4
----> 5 audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
23 frames
/usr/local/lib/python3.10/dist-packages/torch/nn/modules/linear.py in forward(self, input)
112
113 def forward(self, input: Tensor) -> Tensor:
--> 114 return F.linear(input, self.weight, self.bias)
115
116 def extra_repr(self) -> str:
OutOfMemoryError: CUDA out of memory. Tried to allocate 1.95 GiB. GPU 0 has a total capacty of 14.75 GiB of which 1.66 GiB is free. Process 414660 has 13.09 GiB memory in use. Of the allocated memory 10.09 GiB is allocated by PyTorch, and 1.92 GiB is reserved by PyTorch but unallocated. If reserved but unallocated memory is large try setting max_split_size_mb to avoid fragmentation. See documentation for Memory Management and PYTORCH_CUDA_ALLOC_CONF
```
除非你的 GPU 显存很大,否则上面的代码可能会返回 OOM 错误。虽然 AudioLDM 2 流水线涉及多个组件,但任何时候只有当前正在使用的模型必须在 GPU 上。其余模块均可以卸载到 CPU。该技术称为“CPU 卸载”,可大大减少显存使用,且对推理时间的影响很小。
我们可以使用函数 [enable_model_cpu_offload()](https://huggingface.co/docs/diffusers/main/en/api/pipelines/audioldm2#diffusers.AudioLDM2Pipeline.enable_model_cpu_offload) 在流水线上启用 CPU 卸载:
```python
pipe.enable_model_cpu_offload()
```
调用 API 生成音频的方式与以前相同:
```python
audio = pipe(prompt, negative_prompt=negative_prompt, num_waveforms_per_prompt=4, audio_length_in_s=150, num_inference_steps=20, generator=generator.manual_seed(0)).audios[0]
```
**输出:**
```
100%|███████████████████████████████████████████| 20/20 [00:36<00:00, 1.82s/it]
```
这样,我们就可以生成 4 个各为 150 秒的样本,所有这些都在一次流水线调用中完成!大版的 AudioLDM 2 checkpoint 比基础版的 checkpoint 总内存使用量更高,因为 UNet 的大小相差两倍多 (750M 参数与 350M 参数相比),因此这种节省内存的技巧对大版的 checkpoint 特别有用。
## 总结
在本文中,我们展示了 🧨 Diffusers 开箱即用的四种优化方法,并将 AudioLDM 2 的生成时间从 14 秒缩短到不到 1 秒。我们还重点介绍了如何使用内存节省技巧 (例如半精度和 CPU 卸载) 来减少长音频样本或大 checkpoint 场景下的峰值显存使用量。
本文作者 [Sanchit Gandhi](https://huggingface.co/sanchit-gandhi) 非常感谢 [Vaibhav Srivastav](https://huggingface.co/reach-vb) 和 [Sayak Paul](https://huggingface.co/sayakpaul) 的建设性意见。频谱图图像来自于 [Getting to Know the Mel Spectrogram](https://towardsdatascience.com/getting-to-know-the-mel-spectrogram-31bca3e2d9d0) 一文,波形图来自于 [Aalto Speech Processing](https://speechprocessingbook.aalto.fi/Representations/Waveform.html) 一文。 | 0 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/intel-sapphire-rapids.md | ---
title: "使用英特尔 Sapphire Rapids 加速 PyTorch Transformers 模型(第一部分)"
thumbnail: /blog/assets/124_intel_sapphire_rapids/02.png
authors:
- user: juliensimon
translators:
- user: MatrixYao
- user: inferjay
proofreader: true
---
# 使用英特尔 Sapphire Rapids 加速 PyTorch Transformers 模型(第一部分)
大约一年以前,我们 [展示](https://huggingface.co/blog/accelerating-pytorch) 了如何在第三代 [英特尔至强可扩展](https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable.html) CPU(即 Ice Lake)集群上分布式训练 Hugging Face transformers 模型。最近,英特尔发布了代号为 Sapphire Rapids 的第四代至强可扩展 CPU,该 CPU 包含了令人兴奋的深度学习加速新指令。
通过本文,你将会学到如何在一个 AWS Sapphire Rapids 集群上加速一个 PyTorch 训练任务。我们会使用 [英特尔 oneAPI 集合通信库](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html)(oneAPI Collective Communications Library, oneCCL)来分布式化训练任务,并使用 [英特尔 PyTorch 扩展库](https://github.com/intel/intel-extension-for-pytorch)(Intel Extension for PyTorch,IPEX)来自动使用新指令进行性能优化。因为这两个库均已集成入 Hugging Face transformers 库,我们能够做到在不修改一行代码的前提下开箱即用地运行我们的示例代码。
在随后的另一篇文章里,我们还会探讨如何使用 Sapphire Rapids CPU 进行推理及其性能提升。
## 为何你应该考虑在 CPU 上训练
在英特尔至强 CPU 上训练一个深度学习模型是一个性价比高且可扩展的方案,在使用分布式训练或者在小数据集或中等数据集上微调模型时尤其如此。
至强 CPU 支持一些先进的特性,如 512 位先进矢量扩展(Advanced Vector Extensions,[AVX-512](https://en.wikipedia.org/wiki/AVX-512))以及超线程(Hyper-Threading),这些特性提高了深度学习模型的并行性和效率,使得我们可以在得到更好的硬件资源使用率的同时训练得更快。
另外,一般而言,相比用于训练大型深度学习模型的专门硬件如 GPU 等而言,至强 CPU 更便宜和易得。至强 CPU 还更容易用于其他生产任务,从网络服务到数据库不一而足,这使得它们成为 IT 基础设施的一个万用且灵活的选择。
最后,云用户还可以通过使用 spot 实例的方式进一步降低在至强 CPU 上的训练成本。Spot 实例使用空闲计算资源,因此以折扣价售卖。与按需实例相比,spot 实例提供了高至 90% 的显著的成本节约。最后同样重要的是,CPU spot 实例一般来讲比 GPU 实例更容易获得。
现在,让我们看一下 Sapphire Rapids 架构引入的新指令。
## 先进矩阵扩展 (AMX):深度学习新指令
Sapphire Rapids 架构引入了英特尔先进矩阵扩展(Advanced Matrix Extensions, [AMX](https://en.wikipedia.org/wiki/Advanced_Matrix_Extensions))用于加速深度学习工作负载。用户只需安装最新版本的 IPEX 即可受益于新指令,无需更改任何 Hugging Face 代码。
AMX 指令用于加速矩阵乘法,该操作是深度学习批量训练的核心操作。AMX 指令支持 Brain 浮点([BF16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format))和 8 比特整型(INT8)数据类型,覆盖不同训练场景的加速需求。
AMX 指令引入了新的 2 维 CPU 寄存器,称作 tile 寄存器。因为这些寄存器在上下文切换时需要保存和恢复,所以需要内核相关支持。在 Linux 上,内核版本需要在 [v5.16](https://discourse.ubuntu.com/t/kinetic-kudu-release-notes/27976) 及以上方可支持。
现在,让我们看看怎样构建一个 Sapphire Rapids CPU 集群用于分布式训练。
## 构建一个 Sapphire Rapids CPU 集群
截至本文撰写之时,使用 Sapphire Rapids 服务器的最简单的方式是使用新的亚马逊 EC2 [R7iz](https://aws.amazon.com/ec2/instance-types/r7iz/) 实例家族。由于它尚在预览期,你必须 [登记注册](https://pages.awscloud.com/R7iz-Preview.html) 以获得访问权限。另外,虚拟机尚未支持 AMX,因此,我们将使用裸金属实例(`r7iz.metal-16xl`, 64 vCPU, 512GB RAM)。
为避免手动设置集群中的每个节点,我们首先建立一个主节点并依此创建一个新的亚马逊机器镜像(Amazon Machine Image,[AMI](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html))。然后,我们用这个 AMI 启动其他节点。
从网络的角度,我们需要如下设置:
* 打开 22 端口,用于所有实例上的 ssh 访问创建和调试
* 配置从主实例(你启动训练的那个实例)到所有其他实例(包含主实例本身)的 [免密 ssh 访问](https://www.redhat.com/sysadmin/passwordless-ssh)。换句话说,主节点的 ssh 公钥必须在所有阶段上被授权
* 允许集群内的所有网络通信,使得分布式训练可以不受阻碍地运行。AWS 提供了 [安全组](https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html) 这一安全便捷的方式支持这个功能。我们只需创建一个安全组,确保所有集群内的实例属于同一安全组,并允许同一安全组内的所有网络通信即可,以下是我使用的设置:
<kbd>
<img src="../assets/124_intel_sapphire_rapids/01.png">
</kbd>
让我们开始创建集群的主节点。
## 设置主节点
我们首先启动一个安装了 Ubuntu 20.04 AMI(`ami-07cd3e6c4915b2d18`)并加入了我们之前创建的安全组的 `r7iz.metal-16xl` 实例,用于创建主节点。该 AMI 虽然只包含了 Linux v5.15.0,但是幸运的是英特尔和 AWS 已经为这个内核版本打上了 AMX 支持的补丁。因此,我们不需要升级内核至 v5.16。
一旦实例运行起来后,我们 ssh 登录上它并通过 `lscpu` 命令检查 AMX 是否确实已被支持。你应该会在 flags 部分看到如下内容:
```
amx_bf16 amx_tile amx_int8
```
然后,我们开始安装本地依赖以及 Python 依赖。
```
sudo apt-get update
# Install tcmalloc for extra performance (https://github.com/google/tcmalloc)
sudo apt install libgoogle-perftools-dev -y
# Create a virtual environment
sudo apt-get install python3-pip -y
pip install pip --upgrade
export PATH=/home/ubuntu/.local/bin:$PATH
pip install virtualenv
# Activate the virtual environment
virtualenv cluster_env
source cluster_env/bin/activate
# Install PyTorch, IPEX, CCL and Transformers
pip3 install torch==1.13.0 -f https://download.pytorch.org/whl/cpu
pip3 install intel_extension_for_pytorch==1.13.0 -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install oneccl_bind_pt==1.13 -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install transformers==4.24.0
# Clone the transformers repository for its example scripts
git clone https://github.com/huggingface/transformers.git
cd transformers
git checkout v4.24.0
```
接着,我们使用 `ssh-keygen` 创建一个新的 ssh 密钥对,命名为 `cluster`,并保存在缺省位置(`~/.ssh`)。
最后,我们用该实例创建一个 [新的 AMI](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/creating-an-ami-ebs.html)。
## 设置集群
一旦 AMI 准备就绪,我们用它启动另外 3 个 `r7iz.16xlarge-metal` 实例,不要忘了把他们加入之前创建的安全组中。
当这些实例启动的时候,我们 ssh 登录进主节点并完成网络设置。首先,我们编辑位于 `~/.ssh/config` 的 ssh 配置文件,使其支持从主节点到其他节点的免密连接,这里我们只需使用它们各自的私有 IP 及之前创建的密钥对即可。以下是我的配置文件。
```
Host 172.31.*.*
StrictHostKeyChecking no
Host node1
HostName 172.31.10.251
User ubuntu
IdentityFile ~/.ssh/cluster
Host node2
HostName 172.31.10.189
User ubuntu
IdentityFile ~/.ssh/cluster
Host node3
HostName 172.31.6.15
User ubuntu
IdentityFile ~/.ssh/cluster
```
到此为止,我们可以使用 `ssh node [1-3]` 去免密连接任何节点。
在主节点侧,我们创建一个 `~/hosts` 文件,并填入集群中所有节点的名称,这些名称已在上面的 ssh 配置文件中定义。我们用 `localhost` 代表主节点,因为我们会在该节点启动训练脚本。我的文件如下所示。
```
localhost
node1
node2
node3
```
集群现已准备就绪。让我们开始训练吧!
## 启动一个分布式训练任务
在本例中,我们将在 [SQUAD](https://huggingface.co/datasets/squad) 数据集上微调一个用于问答的 [DistilBERT](https://huggingface.co/distilbert-base-uncased) 模型。如果你想试试别的示例的话,尽管去做吧。
```
source ~/cluster_env/bin/activate
cd ~/transformers/examples/pytorch/question-answering
pip3 install -r requirements.txt
```
我们首先冒个烟,启动一个单实例训练任务。请注意如下几个重要的标志变量:
* `no_cuda` 确保使用 CPU 进行训练,忽略 GPU
* `use_ipex` 使能 IPEX 库,确保 AMX 和 AVX 指令的使用
* `bf16` 使能 BF16 训练
```
export LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so"
python run_qa.py --model_name_or_path distilbert-base-uncased \
--dataset_name squad --do_train --do_eval --per_device_train_batch_size 32 \
--num_train_epochs 1 --output_dir /tmp/debug_squad/ \
--use_ipex --bf16 --no_cuda
```
不必等到任务完成,我们只运行 1 分钟用于确保所有的依赖已被正常安装。同时,这也给了我们一个单实例训练的基线性能:1 个 epoch 花费大约 **26 分钟**。供参考,我们测量了同样的任务在一个相当的 Ice Lake 实例(`c6i.16xlarge`)上的性能,基于相同的软件设置,每个 epoch 需要 **3 小时 30 分钟**。加速比达到 **8 倍**。我们已经能看到新指令带来的好处!
现在,让我们把训练任务分布式部署到 4 个实例上。一个 `r7iz.16xlarge` 实例有 32 个物理 CPU 核,我们倾向于直接使用物理核而不是虚拟核(vCPUs)(`KMP_HW_SUBSET=1T`)。我们决定分配 24 个核用于训练(`OMP_NUM_THREADS`),2 个核用于集合通信(`CCL_WORKER_COUNT`),剩下的 6 个核给内核和其他进程使用。这 24 个训练线程分配给 2 个 Python 进程使用(`NUM_PROCESSES_PER_NODE`)。因此,一个 4 节点的集群上共有 8(`NUM_PROCESSES`)个 Python 进程。
```
# Set up environment variables for CCL
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
export MASTER_ADDR=172.31.3.190
export NUM_PROCESSES=8
export NUM_PROCESSES_PER_NODE=2
export CCL_WORKER_COUNT=2
export CCL_WORKER_AFFINITY=auto
export KMP_HW_SUBSET=1T
```
现在,我们启动分布式训练任务。
```
# Launch distributed training
mpirun -f ~/hosts \
-n $NUM_PROCESSES -ppn $NUM_PROCESSES_PER_NODE \
-genv OMP_NUM_THREADS=24 \
-genv LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so" \
python3 run_qa.py \
--model_name_or_path distilbert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 32 \
--num_train_epochs 1 \
--output_dir /tmp/debug_squad/ \
--overwrite_output_dir \
--no_cuda \
--xpu_backend ccl \
--bf16
```
现在,一个 epoch 仅需 **7 分 30 秒**。
任务如下图所示。图的上半部分是主节点,同时你也可以看到其他 3 个节点每个均有 2 个训练进程在运行。
<kbd>
<img src="../assets/124_intel_sapphire_rapids/02.png">
</kbd>
4 节点的完美线性扩展需要 6 分 30 秒的训练时间(26 分钟除以 4)。我们非常接近于这个理想值,这充分展现了该方法很高的扩展性。
## 结论
如你所见,在一个英特尔至强集群上训练 Hugging Face transformers 模型是一个灵活,可扩展且性价比高的解决方案,特别是在你的数据集和模型是小尺寸或者中等尺寸情况下。
以下列出了一些其他可帮助你起步的资源:
* [Intel IPEX](https://github.com/intel/intel-extension-for-pytorch) GitHub
* Hugging Face 文档: "[Efficient training on CPU](https://huggingface.co/docs/transformers/perf_train_cpu)" 及 "[Efficient training on many CPUs](https://huggingface.co/docs/transformers/perf_train_cpu_many)"
如你有任何问题或反馈,请通过 Hugging Face 论坛告诉我们。
感谢阅读!
| 1 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/encoder-decoder.md | ---
title: "基于 Transformers 的编码器-解码器模型"
thumbnail: /blog/assets/05_encoder_decoder/thumbnail.png
authors:
- user: patrickvonplaten
translators:
- user: MatrixYao
---
# 基于 Transformers 的编码器-解码器模型
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Encoder_Decoder_Model.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt=" 在 Colab 中打开 "/>
</a>
# **基于 Transformers 的编码器-解码器模型**
```bash
!pip install transformers==4.2.1
!pip install sentencepiece==0.1.95
```
Vaswani 等人在其名作 [Attention is all you need](https://arxiv.org/abs/1706.03762) 中首创了 _基于 transformer_ 的编码器-解码器模型,如今已成为自然语言处理 (natural language processing,NLP) 领域编码器-解码器架构的 _事实标准_ 。
最近基于 transformer 的编码器-解码器模型训练这一方向涌现出了大量关于 _预训练目标函数_ 的研究,_例如_ T5、Bart、Pegasus、ProphetNet、Marge 等,但它们所使用的网络结构并没有改变。
本文的目的是 **详细** 解释如何用基于 transformer 的编码器-解码器架构来对 _序列到序列 (sequence-to-sequence)_ 问题进行建模。我们将重点关注有关这一架构的数学知识以及如何对该架构的模型进行推理。在此过程中,我们还将介绍 NLP 中序列到序列模型的一些背景知识,并将 _基于 transformer_ 的编码器-解码器架构分解为 **编码器** 和 **解码器** 这两个部分分别讨论。我们提供了许多图例,并把 _基于 transformer_ 的编码器-解码器模型的理论与其在 🤗 transformers 推理场景中的实际应用二者联系起来。请注意,这篇博文 _不_ 解释如何训练这些模型 —— 我们会在后续博文中涵盖这一方面的内容。
基于 transformer 的编码器-解码器模型是 _表征学习_ 和 _模型架构_ 这两个领域多年研究成果的结晶。本文简要介绍了神经编码器-解码器模型的历史,更多背景知识,建议读者阅读由 Sebastion Ruder 撰写的这篇精彩 [博文](https://ruder.io/a-review-of-the-recent-history-of-nlp/)。此外,建议读者对 _自注意力 (self-attention) 架构_有一个基本了解,可以阅读 Jay Alammar 的 [这篇博文](http://jalammar.github.io/illustrated-transformer/) 复习一下原始 transformer 模型。
截至本文撰写时,🤗 transformers 库已经支持的编码器-解码器模型有: _T5_ 、_Bart_ 、_MarianMT_ 以及 _Pegasus_ ,你可以从 [这儿](https://huggingface.co/docs/transformers/model_summary#nlp-encoder-decoder) 获取相关信息。
本文分 4 个部分:
- **背景** - _简要回顾了神经编码器-解码器模型的历史,重点关注基于 RNN 的模型。_
- **编码器-解码器** - _阐述基于 transformer 的编码器-解码器模型,并阐述如何使用该模型进行推理。_
- **编码器** - _阐述模型的编码器部分。_
- **解码器** - _阐述模型的解码器部分。_
每个部分都建立在前一部分的基础上,但也可以单独阅读。
## **背景**
自然语言生成 (natural language generation,NLG) 是 NLP 的一个子领域,其任务一般可被建模为序列到序列问题。这类任务可以定义为寻找一个模型,该模型将输入词序列映射为目标词序列,典型的例子有 _摘要_ 和 _翻译_ 。在下文中,我们假设每个单词都被编码为一个向量表征。因此,$n$ 个输入词可以表示为 $n$ 个输入向量组成的序列:
$$\mathbf{X}_{1:n} = {\mathbf{x}_1, \ldots, \mathbf{x}_n}$$
因此,序列到序列问题可以表示为找到一个映射 $f$,其输入为 $n$ 个向量的序列,输出为 $m$ 个向量的目标序列 $\mathbf{Y}_{1:m}$。这里,目标向量数 $m$ 是先验未知的,其值取决于输入序列:
$$ f: \mathbf{X}_{1:n} \to \mathbf{Y}_{1:m} $$
[Sutskever 等 (2014) ](https://arxiv.org/abs/1409.3215) 的工作指出,深度神经网络 (deep neural networks,DNN)“_尽管灵活且强大,但只能用于拟合输入和输出维度均固定的映射。_” ${}^1$
因此,要用使用 DNN 模型 ${}^2$ 解决序列到序列问题就意味着目标向量数 $m$ 必须是先验已知的,且必须独立于输入 $\mathbf{X}_{1:n}$。这样设定肯定不是最优的。因为对 NLG 任务而言,目标词的数量通常取决于输入内容 $\mathbf{X}_{1:n}$,而不仅仅是输入长度 $n$。 _例如_ ,一篇 1000 字的文章,根据内容的不同,有可能可以概括为 200 字,也有可能可以概括为 100 字。
2014 年,[Cho 等人](https://arxiv.org/pdf/1406.1078.pdf) 和 [Sutskever 等人](https://arxiv.org/abs/1409.3215) 提出使用完全基于递归神经网络 (recurrent neural networks,RNN) 的编码器-解码器模型来解决 _序列到序列_任务。与 DNN 相比,RNN 支持输出可变数量的目标向量。下面,我们深入了解一下基于 RNN 的编码器-解码器模型的功能。
在推理过程中,RNN 编码器通过连续更新其 _隐含状态_ ${}^3$ 对输入序列 $\mathbf{X}_{1:n}$ 进行编码。我们定义处理完最后一个输入向量 $\mathbf{x}_n$ 后的编码器隐含状态为 $\mathbf{c}$。因此,编码器主要完成如下映射:
$$ f_{\theta_{enc}}: \mathbf{X}_{1:n} \to \mathbf{c} $$
然后,我们用 $\mathbf{c}$ 来初始化解码器的隐含状态,再用解码器 RNN 自回归地生成目标序列。
下面,我们进一步解释一下。从数学角度讲,解码器定义了给定隐含状态 $\mathbf{c}$ 下目标序列 $\mathbf{Y}_{1:m}$ 的概率分布:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) $$
根据贝叶斯法则,上述分布可以分解为每个目标向量的条件分布的积,如下所示:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}) $$
因此,如果模型架构可以在给定所有前驱目标向量的条件下对下一个目标向量的条件分布进行建模的话:
$$ p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \forall i \in \{1, \ldots, m\}$$
那它就可以通过简单地将所有条件概率相乘来模拟给定隐藏状态 $\mathbf{c}$ 下任意目标向量序列的分布。
那么基于 RNN 的解码器架构如何建模
$p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})$ 呢?
从计算角度讲,模型按序将前一时刻的内部隐含状态 $\mathbf{c}_{i-1}$ 和前一时刻的目标向量 $\mathbf{y}_{i-1}$ 映射到当前内部隐含状态 $\mathbf{c}_i$ 和一个 _logit 向量_ $\mathbf{l}_i$ (下图中以深红色表示):
$$ f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{i-1}) \to \mathbf{l}_i, \mathbf{c}_i$$
此处,$\mathbf{c}_0$ 为 RNN 编码器的输出。随后,对 logit 向量 $\mathbf{l}_i$ 进行 _softmax_ 操作,将其变换为下一个目标向量的条件概率分布:
$$ p(\mathbf{y}_i | \mathbf{l}_i) = \textbf{Softmax}(\mathbf{l}_i), \text{ 其中 } \mathbf{l}_i = f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{\text{prev}})$$
更多有关 logit 向量及其生成的概率分布的详细信息,请参阅脚注 ${}^4$。从上式可以看出,目标向量 $\mathbf{y}_i$ 的分布是其前一时刻的目标向量 $\mathbf{y}_{i-1}$ 及前一时刻的隐含状态 $\mathbf{c}_{i-1}$ 的条件分布。而我们知道前一时刻的隐含状态 $\mathbf{c}_{i-1}$ 依赖于之前所有的目标向量 $\mathbf{y}_0, \ldots, \mathbf{y}_{i- 2}$,因此我们可以说 RNN 解码器 _隐式_ (_或间接_) 地建模了条件分布
$p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})$。
目标向量序列 $\mathbf{Y}_{1:m}$ 的概率空间非常大,因此在推理时,必须借助解码方法对 = ${}^5$ 对 $p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c})$ 进行采样才能高效地生成最终的目标向量序列。
给定某解码方法,在推理时,我们首先从分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})$ 中采样出下一个输出向量; 接着,将其添加至解码器输入序列末尾,让解码器 RNN 继续从
$p_{\theta_{\text{dec}}}(\mathbf{y}_{i+1} | \mathbf{Y}_{0: i}, \mathbf{c})$ 中采样出下一个输出向量 $\mathbf{y}_{i+1}$,如此往复,整个模型就以 _自回归_的方式生成了最终的输出序列。
基于 RNN 的编码器-解码器模型的一个重要特征是需要定义一些 _特殊_ 向量,如 $\text{EOS}$ (终止符) 和 $\text{BOS}$ (起始符) 向量。 $\text{EOS}$ 向量通常意味着 $\mathbf{x}_n$ 中止,出现这个即“提示”编码器输入序列已结束; 如果它出现在目标序列中意味着输出结束,一旦从 logit 向量中采样到 $\text{EOS}$,生成就完成了。$\text{BOS}$ 向量用于表示在第一步解码时馈送到解码器 RNN 的输入向量 $\mathbf{y}_0$。为了输出第一个 logit $\mathbf{l}_1$,需要一个输入,而由于在其之前还没有生成任何输入,所以我们馈送了一个特殊的 $\text{BOS}$ 输入向量到解码器 RNN。好,有点绕了!我们用一个例子说明一下。
上图中,我们将编码器 RNN 编码器展开,并用绿色表示; 同时,将解码器 RNN 展开,并用红色表示。
英文句子 `I want to buy a car`,表示为 $(\mathbf{x}_1 = \text{I}$,$\mathbf{x}_2 = \text{want}$,$\mathbf{x}_3 = \text{to}$,$\mathbf{x}_4 = \text{buy}$,$\mathbf{x}_5 = \text{a}$,$\mathbf{x}_6 = \text{car}$,$\mathbf{x}_7 = \text{EOS}$)。将其翻译成德语: “Ich will ein Auto kaufen",表示为 $(\mathbf{y}_0 = \text{BOS}$,$\mathbf{y}_1 = \text{Ich}$,$\mathbf{y}_2 = \text{will}$,$\mathbf{y}_3 = \text {ein}$,$\mathbf{y}_4 = \text{Auto}$,$\mathbf{y}_5 = \text{kaufen}$,$\mathbf{y}_6=\text{EOS}$)。首先,编码器 RNN 处理输入向量 $\mathbf{x}_1 = \text{I}$ 并更新其隐含状态。请注意,对编码器而言,因为我们只对其最终隐含状态 $\mathbf{c}$ 感兴趣,所以我们可以忽略它的目标向量。然后,编码器 RNN 以相同的方式依次处理输入句子的其余部分: $\text{want}$、$\text{to}$、$\text{buy}$、$\text{a}$、$\text{car}$、$\text{EOS}$,并且每一步都更新其隐含状态,直到遇到向量 $\mathbf{x}_7={EOS}$ ${}^6$。在上图中,连接展开的编码器 RNN 的水平箭头表示按序更新隐含状态。编码器 RNN 的最终隐含状态,由 $\mathbf{c}$ 表示,其完全定义了输入序列的 _编码_ ,并可用作解码器 RNN 的初始隐含状态。可以认为,解码器 RNN 以编码器 RNN 的最终隐含状态为条件。
为了生成第一个目标向量,将 $\text{BOS}$ 向量输入给解码器,即上图中的 $\mathbf{y}_0$。然后通过 _语言模型头 (LM Head)_ 前馈层将 RNN 的目标向量进一步映射到 logit 向量 $\mathbf{l}_1$,此时,可得第一个目标向量的条件分布:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{c}) $$
最终采样出第一个目标词 $\text{Ich}$ (如图中连接 $\mathbf{l}_1$ 和 $\mathbf{y}_1$ 的灰色箭头所示)。接着,继续采样出第二个目标向量:
$$ \text{will} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \text{Ich}, \mathbf{c}) $$
依此类推,一直到第 6 步,此时从 $\mathbf{l}_6$ 中采样出 $\text{EOS}$,解码完成。输出目标序列为 $\mathbf{Y}_{1:6} = {\mathbf{y}_1, \ldots, \mathbf{y}_6}$, 即上文中的 “Ich will ein Auto kaufen”。
综上所述,我们通过将分布 $p(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n})$ 分解为 $f_{\theta_{\text{enc}}}$ 和 $p_{\theta_{\text{dec}}}$ 的表示来建模基于 RNN 的 encoder-decoder 模型:
$$ p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \text{ 其中 } \mathbf{c}=f_{\theta_{enc}}(X) $$
在推理过程中,利用高效的解码方法可以自回归地生成目标序列 $\mathbf{Y}_{1:m}$。
基于 RNN 的编码器-解码器模型席卷了 NLG 社区。2016 年,谷歌宣布用基于 RNN 的编码器-解码器单一模型完全取代其原先使用的的含有大量特征工程的翻译服务 (参见
[此处](https://www.oreilly.com/radar/what-machine-learning-means-for-software-development/#:~:text=Machine%20learning%20is%20already%20making,of%20code%20in%20Google%20Translate))。
然而,基于 RNN 的编码器-解码器模型存在两个主要缺陷。首先,RNN 存在梯度消失问题,因此很难捕获长程依赖性, _参见_ [Hochreiter 等 (2001) ](https://www.bioinf.jku.at/publications/older/ch7.pdf) 的工作。其次,RNN 固有的循环架构使得在编码时无法进行有效的并行化, _参见_ [Vaswani 等 (2017) ](https://arxiv.org/abs/1706.03762) 的工作。
---
${}^1$ 论文的原话是“_尽管 DNN 具有灵活性和强大的功能,但它们只能应用于输入和目标可以用固定维度的向量进行合理编码的问题_”,用在本文时稍作调整。
${}^2$ 这同样适用于卷积神经网络 (CNN)。虽然可以将可变长度的输入序列输入 CNN,但目标的维度要么取决于输入维数要么需要固定为特定值。
${}^3$ 在第一步时,隐含状态被初始化为零向量,并与第一个输入向量 $\mathbf{x}_1$ 一起馈送给 RNN。
${}^4$ 神经网络可以将所有单词的概率分布定义为 $p(\mathbf{y} | \mathbf{c}, \mathbf{Y}_{0 : i-1})$。首先,其将输入 $\mathbf{c}, \mathbf{Y}_{0: i-1}$ 转换为嵌入向量 $\mathbf{y'}$,该向量对应于 RNN 模型的目标向量。随后将 $\mathbf{y'}$ 送给“语言模型头”,即将其乘以 _词嵌入矩阵_ (即$\mathbf{Y}^{\text{vocab}}$),得到 $\mathbf{y'}$ 和词表 $\mathbf{Y}^{\text{vocab}}$ 中的每个向量 $\mathbf{y}$ 的相似度得分,生成的向量称为 logit 向量 $\mathbf{l} = \mathbf{Y}^{\text{vocab}} \mathbf{y'}$,最后再通过 softmax 操作归一化成所有单词的概率分布: $p(\mathbf{y} | \mathbf{c}) = \text{Softmax}(\mathbf{Y}^{\text{vocab}} \mathbf{y'}) = \text {Softmax}(\mathbf{l})$。
${}^5$ 波束搜索 (beam search) 是其中一种解码方法。本文不会对不同的解码方法进行介绍,如对此感兴趣,建议读者参考 [此文](https://huggingface.co/blog/zh/how-to-generate)。
${}^6$ [Sutskever 等 (2014) ](https://arxiv.org/abs/1409.3215) 的工作对输入顺序进行了逆序,对上面的例子而言,输入向量变成了 ($\mathbf{x}_1 = \text{car}$,$\mathbf{x}_2 = \text{a}$,$\mathbf{x}_3 = \text{buy}$,$\mathbf{x}_4 = \text{to}$,$\mathbf{x}_5 = \text{want}$,$\mathbf{x}_6 = \text{I}$,$\mathbf{x}_7 = \text{EOS}$)。其动机是让对应词对之间的连接更短,如可以使得 $\mathbf{x}_6 = \text{I}$ 和 $\mathbf{y}_1 = \text{Ich}$ 之间的连接更短。该研究小组强调,将输入序列进行逆序是他们的模型在机器翻译上的性能提高的一个关键原因。
## **编码器-解码器**
2017 年,Vaswani 等人引入了 **transformer** 架构,从而催生了 _基于 transformer_ 的编码器-解码器模型。
与基于 RNN 的编码器-解码器模型类似,基于 transformer 的编码器-解码器模型由一个编码器和一个解码器组成,且其编码器和解码器均由 _残差注意力模块 (residual attention blocks)_ 堆叠而成。基于 transformer 的编码器-解码器模型的关键创新在于: 残差注意力模块无需使用循环结构即可处理长度 $n$ 可变的输入序列 $\mathbf{X}_{1:n}$。不依赖循环结构使得基于 transformer 的编码器-解码器可以高度并行化,这使得模型在现代硬件上的计算效率比基于 RNN 的编码器-解码器模型高出几个数量级。
回忆一下,要解决 _序列到序列_ 问题,我们需要找到输入序列 $\mathbf{X}_{1:n}$ 到变长输出序列 $\mathbf{Y}_{1:m}$ 的映射。我们看看如何使用基于 transformer 的编码器-解码器模型来找到这样的映射。
与基于 RNN 的编码器-解码器模型类似,基于 transformer 的编码器-解码器模型定义了在给定输入序列 $\mathbf{X}_{1:n}$ 条件下目标序列 $\mathbf{Y}_{1:m}$ 的条件分布:
$$
p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n})
$$
基于 transformer 的编码器部分将输入序列 $\mathbf{X}_{1:n}$ 编码为 _隐含状态序列_ $\mathbf{\overline{X}}_{1:n}$,即:
$$ f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n} $$
然后,基于 transformer 的解码器负责建模在给定隐含状态序列 $\mathbf{\overline{X}}_{1:n}$ 的条件下目标向量序列 $\mathbf{Y}_{1:m}$ 的概率分布:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n})$$
根据贝叶斯法则,该序列分布可被分解为每个目标向量 $\mathbf{y}_i$ 在给定隐含状态 $\mathbf{\overline{X} }_{1:n}$ 和其所有前驱目标向量 $\mathbf{Y}_{0:i-1}$ 时的条件概率之积:
$$
p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) $$
因此,在生成 $\mathbf{y}_i$ 时,基于 transformer 的解码器将隐含状态序列 $\mathbf{\overline{X}}_{1:n}$ 及其所有前驱目标向量 $\mathbf{Y}_{0 :i-1}$ 映射到 _logit_ 向量 $\mathbf{l}_i$。 然后经由 _softmax_ 运算对 logit 向量 $\mathbf{l}_i$ 进行处理,从而生成条件分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})$。这个流程跟基于 RNN 的解码器是一样的。然而,与基于 RNN 的解码器不同的是,在这里,目标向量 $\mathbf{y}_i$ 的分布是 _显式_(或直接) 地以其所有前驱目标向量 $\mathbf{y}_0, \ldots, \mathbf{y}_{i-1}$ 为条件的,稍后我们将详细介绍。此处第 0 个目标向量 $\mathbf{y}_0$ 仍表示为 $\text{BOS}$ 向量。有了条件分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X} }_{1:n})$,我们就可以 _自回归_生成输出了。至此,我们定义了可用于推理的从输入序列 $\mathbf{X}_{1:n}$ 到输出序列 $\mathbf{Y}_{1:m}$ 的映射。
我们可视化一下使用 _基于 transformer_ 的编码器-解码器模型 _自回归_地生成序列的完整过程。
上图中,绿色为基于 transformer 的编码器,红色为基于 transformer 的解码器。与上一节一样,我们展示了如何将表示为 $(\mathbf{x}_1 = \text{I},\mathbf{ x}_2 = \text{want},\mathbf{x}_3 = \text{to},\mathbf{x}_4 = \text{buy},\mathbf{x}_5 = \text{a},\mathbf{x}_6 = \text{car},\mathbf{x}_7 = \text{EOS})$ 的英语句子 “I want to buy a car” 翻译成表示为 $(\mathbf{y}_0 = \text{BOS},\mathbf{y }_1 = \text{Ich},\mathbf{y}_2 = \text{will},\mathbf{y}_3 = \text{ein},\mathbf{y}_4 = \text{Auto},\mathbf{y}_5 = \text{kaufen},\mathbf{y}_6=\text{EOS})$ 的德语句子 “Ich will ein Auto kaufen”。
首先,编码器将完整的输入序列 $\mathbf{X}_{1:7}$ = “I want to buy a car” (由浅绿色向量表示) 处理为上下文相关的编码序列 $\mathbf{\overline{X}}_{1:7}$。这里上下文相关的意思是, _举个例子_ ,$\mathbf{\overline{x}}_4$ 的编码不仅取决于输入 $\mathbf{x}_4$ = “buy”,还与所有其他词 “I”、“want”、“to”、“a”、“car” 及 “EOS” 相关,这些词即该词的 _上下文_ 。
接下来,输入编码 $\mathbf{\overline{X}}_{1:7}$ 与 BOS 向量 ( _即_ $\mathbf{y}_0$) 被一起馈送到解码器。解码器将输入 $\mathbf{\overline{X}}_{1:7}$ 和 $\mathbf{y}_0$ 变换为第一个 logit $\mathbf{l }_1$ (图中以深红色显示),从而得到第一个目标向量 $\mathbf{y}_1$ 的条件分布:
$$ p_{\theta_{enc, dec}}(\mathbf{y} | \mathbf{y}_0, \mathbf{X}_{1:7}) = p_{\theta_{enc, dec}}(\mathbf{y} | \text{BOS}, \text{I want to buy a car EOS}) = p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}) $$
然后,从该分布中采样出第一个目标向量 $\mathbf{y}_1$ = $\text{Ich}$ (由灰色箭头表示),得到第一个输出后,我们会并将其继续馈送到解码器。现在,解码器开始以 $\mathbf{y}_0$ = “BOS” 和 $\mathbf{y}_1$ = “Ich” 为条件来定义第二个目标向量的条件分布 $\mathbf{y}_2$:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}) $$
再采样一次,生成目标向量 $\mathbf{y}_2$ = “will”。重复该自回归过程,直到第 6 步从条件分布中采样到 EOS:
$$ \text{EOS} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}) $$
这里有一点比较重要,我们仅在第一次前向传播时用编码器将 $\mathbf{X}_{1:n}$ 映射到 $\mathbf{\overline{X}}_{ 1:n}$。从第二次前向传播开始,解码器可以直接使用之前算得的编码 $\mathbf{\overline{X}}_{1:n}$。为清楚起见,下图画出了上例中第一次和第二次前向传播所需要做的操作。
可以看出,仅在步骤 $i=1$ 时,我们才需要将 “I want to buy a car EOS” 编码为 $\mathbf{\overline{X}}_{1:7}$。从 $i=2$ 开始,解码器只是简单地复用了已生成的编码。
在 🤗 transformers 库中,这一自回归生成过程是在调用 `.generate()` 方法时在后台完成的。我们用一个翻译模型来实际体验一下。
```python
from transformers import MarianMTModel, MarianTokenizer
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# translate example
output_ids = model.generate(input_ids)[0]
# decode and print
print(tokenizer.decode(output_ids))
```
*输出:*
```
<pad> Ich will ein Auto kaufen
```
`.generate()` 接口做了很多事情。首先,它将 `input_ids` 传递给编码器。然后,它将一个预定义的标记连同已编码的 `input_ids`一起传递给解码器 (在使用 `MarianMTModel` 的情况下,该预定义标记为 $\text{<pad>}$)。接着,它使用波束搜索解码机制根据最新的解码器输出的概率分布${}^1$自回归地采样下一个输出词。更多有关波束搜索解码工作原理的详细信息,建议阅读 [这篇博文](https://huggingface.co/blog/zh/how-to-generate)。
我们在附录中加入了一个代码片段,展示了如何“从头开始”实现一个简单的生成方法。如果你想要完全了解 _自回归_生成的幕后工作原理,强烈建议阅读附录。
总结一下:
- 基于 transformer 的编码器实现了从输入序列 $\mathbf{X}_{1:n}$ 到上下文相关的编码序列 $\mathbf{\overline{X}}_{1 :n}$ 之间的映射。
- 基于 transformer 的解码器定义了条件分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{ \overline{X}}_{1:n})$。
- 给定适当的解码机制,可以自回归地从 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in {1, \ldots, m}$ 中采样出输出序列 $\mathbf{Y}_{1:m}$。
太好了,现在我们已经大致了解了 _基于 transformer 的_编码器-解码器模型的工作原理。下面的部分,我们将更深入地研究模型的编码器和解码器部分。更具体地说,我们将确切地看到编码器如何利用自注意力层来产生一系列上下文相关的向量编码,以及自注意力层如何实现高效并行化。然后,我们将详细解释自注意力层在解码器模型中的工作原理,以及解码器如何通过 _交叉注意力_ 层以编码器输出为条件来定义分布 $p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})$。在此过程中,基于 transformer 的编码器-解码器模型如何解决基于 RNN 的编码器-解码器模型的长程依赖问题的答案将变得显而易见。
---
${}^1$ 可以从 [此处](https://s3.amazonaws.com/models.huggingface.co/bert/Helsinki-NLP/opus-mt-en-de/config.json) 获取 `"Helsinki-NLP/opus-mt-en-de"` 的解码参数。可以看到,其使用了 `num_beams=6` 的波束搜索。
## **编码器**
如前一节所述, _基于 transformer_ 的编码器将输入序列映射到上下文相关的编码序列:
$$ f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n} $$
仔细观察架构,基于 transformer 的编码器由许多 _残差注意力模块_堆叠而成。每个编码器模块都包含一个 **双向**自注意力层,其后跟着两个前馈层。这里,为简单起见,我们忽略归一化层 (normalization layer)。此外,我们不会深入讨论两个前馈层的作用,仅将其视为每个编码器模块 ${}^1$ 的输出映射层。双向自注意层将每个输入向量 $\mathbf{x'}_j, \forall j \in {1, \ldots, n}$ 与全部输入向量 $\mathbf{x'}_1, \ldots, \mathbf{x'}_n$ 相关联并通过该机制将每个输入向量 $\mathbf{x'}_j$ 提炼为与其自身上下文相关的表征: $\mathbf{x''}_j$。因此,第一个编码器块将输入序列 $\mathbf{X}_{1:n}$ (如下图浅绿色所示) 中的每个输入向量从 _上下文无关_ 的向量表征转换为 _上下文相关_的向量表征,后面每一个编码器模块都会进一步细化这个上下文表征,直到最后一个编码器模块输出最终的上下文相关编码 $\mathbf{\overline{X}}_{1:n}$ (如下图深绿色所示)。
我们对 `编码器如何将输入序列 "I want to buy a car EOS" 变换为上下文编码序列`这一过程进行一下可视化。与基于 RNN 的编码器类似,基于 transformer 的编码器也在输入序列最后添加了一个 EOS,以提示模型输入向量序列已结束 ${}^2$。
上图中的 _基于 transformer_ 的编码器由三个编码器模块组成。我们在右侧的红框中详细列出了第二个编码器模块的前三个输入向量: $\mathbf{x}_1$,$\mathbf {x}_2$ 及 $\mathbf{x}_3$。红框下部的全连接图描述了双向自注意力机制,上面是两个前馈层。如前所述,我们主要关注双向自注意力机制。
可以看出,自注意力层的每个输出向量 $\mathbf{x''}_i, \forall i \in {1, \ldots, 7}$ 都 _直接_ 依赖于 _所有_ 输入向量 $\mathbf{x'}_1, \ldots, \mathbf{x'}_7$。这意味着,单词 “want” 的输入向量表示 $\mathbf{x'}_2$ 与单词 “buy” (即 $\mathbf{x'}_4$) 和单词 “I” (即 $\mathbf{x'}_1$) 直接相关。 因此,“want” 的输出向量表征,_即_ $\mathbf{x''}_2$,是一个融合了其上下文信息的更精细的表征。
我们更深入了解一下双向自注意力的工作原理。编码器模块的输入序列 $\mathbf{X'}_{1:n}$ 中的每个输入向量 $\mathbf{x'}_i$ 通过三个可训练的权重矩阵 $\mathbf{W}_q$,$\mathbf{W}_v$,$\mathbf{W}_k$ 分别投影至 `key` 向量 $\mathbf{k}_i$、`value` 向量 $\mathbf{v}_i$ 和 `query` 向量 $\mathbf{q}_i$ (下图分别以橙色、蓝色和紫色表示):
$$ \mathbf{q}_i = \mathbf{W}_q \mathbf{x'}_i,$$
$$ \mathbf{v}_i = \mathbf{W}_v \mathbf{x'}_i,$$
$$ \mathbf{k}_i = \mathbf{W}_k \mathbf{x'}_i, $$
$$ \forall i \in {1, \ldots n }$$
请注意,对每个输入向量 $\mathbf{x}_i (\forall i \in {i, \ldots, n}$) 而言,其所使用的权重矩阵都是 **相同**的。将每个输入向量 $\mathbf{x}_i$ 投影到 `query` 、 `key` 和 `value` 向量后,将每个 `query` 向量 $\mathbf{q}_j (\forall j \in {1, \ldots, n}$) 与所有 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_n$ 进行比较。哪个 `key` 向量与 `query` 向量 $\mathbf{q}_j$ 越相似,其对应的 `value` 向量 $\mathbf{v}_j$ 对输出向量 $\mathbf{x''}_j$ 的影响就越重要。更具体地说,输出向量 $\mathbf{x''}_j$ 被定义为所有 `value` 向量的加权和 $\mathbf{v}_1, \ldots, \mathbf{v}_n$ 加上输入向量 $\mathbf{x'}_j$。而各 `value` 向量的权重与 $\mathbf{q}_j$ 和各个 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_n$ 之间的余弦相似度成正比,其数学公式为 $\textbf{Softmax}(\mathbf{K}_{1:n}^\intercal \mathbf{q}_j)$,如下文的公式所示。关于自注意力层的完整描述,建议读者阅读 [这篇](http://jalammar.github.io/illustrated-transformer/) 博文或 [原始论文](https://arxiv.org/abs/1706.03762)。
好吧,又复杂起来了。我们以上例中的一个 `query` 向量为例图解一下双向自注意层。为简单起见,本例中假设我们的 _基于 transformer_ 的解码器只有一个注意力头 `config.num_heads = 1` 并且没有归一化层。
图左显示了上个例子中的第二个编码器模块,右边详细可视化了第二个输入向量 $\mathbf{x'}_2$ 的双向自注意机制,其对应输入词为 “want”。首先将所有输入向量 $\mathbf{x'}_1, \ldots, \mathbf{x'}_7$ 投影到它们各自的 `query` 向量 $\mathbf{q}_1, \ldots, \mathbf{q}_7$ (上图中仅以紫色显示前三个 `query` 向量), `value` 向量 $\mathbf{v}_1, \ldots, \mathbf{v}_7$ (蓝色) 和 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_7$ (橙色)。然后,将 `query` 向量 $\mathbf{q}_2$ 与所有 `key` 向量的转置 ( _即_ $\mathbf{K}_{1:7}^{\intercal}$) 相乘,随后进行 softmax 操作以产生 _自注意力权重_ 。 自注意力权重最终与各自的 `value` 向量相乘,并加上输入向量 $\mathbf{x'}_2$,最终输出单词 “want” 的上下文相关表征, _即_ $\mathbf{x''}_2$ (图右深绿色表示)。整个等式显示在图右框的上部。 $\mathbf{K}_{1:7}^{\intercal}$ 和 $\mathbf{q}_2$ 的相乘使得将 “want” 的向量表征与所有其他输入 (“I”,“to”,“buy”,“a”,“car”,“EOS”) 的向量表征相比较成为可能,因此自注意力权重反映出每个输入向量 $\mathbf{x'}_j$ 对 “want” 一词的最终表征 $\mathbf{x''}_2$ 的重要程度。
为了进一步理解双向自注意力层的含义,我们假设以下句子: “ _房子很漂亮且位于市中心,因此那儿公共交通很方便_”。 “那儿”这个词指的是“房子”,这两个词相隔 12 个字。在基于 transformer 的编码器中,双向自注意力层运算一次,即可将“房子”的输入向量与“那儿”的输入向量相关联。相比之下,在基于 RNN 的编码器中,相距 12 个字的词将需要至少 12 个时间步的运算,这意味着在基于 RNN 的编码器中所需数学运算与距离呈线性关系。这使得基于 RNN 的编码器更难对长程上下文表征进行建模。此外,很明显,基于 transformer 的编码器比基于 RNN 的编码器-解码器模型更不容易丢失重要信息,因为编码的序列长度相对输入序列长度保持不变, _即_ $\textbf{len }(\mathbf{X}_{1:n}) = \textbf{len}(\mathbf{\overline{X}}_{1:n}) = n$,而 RNN 则会将 $\textbf{len}((\mathbf{X}_{1:n}) = n$ 压缩到 $\textbf{len}(\mathbf{c}) = 1$,这使得 RNN 很难有效地对输入词之间的长程依赖关系进行编码。
除了更容易学到长程依赖外,我们还可以看到 transformer 架构能够并行处理文本。从数学上讲,这是通过将自注意力机制表示为 `query` 、 `key` 和 `value` 的矩阵乘来完成的:
$$\mathbf{X''}_{1:n} = \mathbf{V}_{1:n} \text{Softmax}(\mathbf{Q}_{1:n}^\intercal \mathbf{K}_{1:n}) + \mathbf{X'}_{1:n} $$
输出 $\mathbf{X''}_{1:n} = \mathbf{x''}_1, \ldots, \mathbf{x''}_n$ 是由一系列矩阵乘计算和 softmax 操作算得,因此可以有效地并行化。请注意,在基于 RNN 的编码器模型中,隐含状态 $\mathbf{c}$ 的计算必须按顺序进行: 先计算第一个输入向量的隐含状态 $\mathbf{x}_1$; 然后计算第二个输入向量的隐含状态,其取决于第一个隐含向量的状态,依此类推。RNN 的顺序性阻碍了有效的并行化,并使其在现代 GPU 硬件上比基于 transformer 的编码器模型的效率低得多。
太好了,现在我们应该对 a) 基于 transformer 的编码器模型如何有效地建模长程上下文表征,以及 b) 它们如何有效地处理长序列向量输入这两个方面有了比较好的理解了。
现在,我们写一个 `MarianMT` 编码器-解码器模型的编码器部分的小例子,以验证这些理论在实践中行不行得通。
---
${}^1$ 关于前馈层在基于 transformer 的模型中所扮演的角色的详细解释超出了本文的范畴。[Yun 等人 (2017) ](https://arxiv.org/pdf/1912.10077.pdf) 的工作认为前馈层对于将每个上下文向量 $\mathbf{x'}_i$ 映射到目标输出空间至关重要,而单靠 _自注意力_ 层无法达成这一目的。这里请注意,每个输出词元 $\mathbf{x'}$ 都经由相同的前馈层处理。更多详细信息,建议读者阅读论文。
${}^2$ 我们无须将 EOS 附加到输入序列,虽然有工作表明,在很多情况下加入它可以提高性能。相反地,基于 transformer 的解码器必须把 $\text{BOS}$ 作为第 0 个目标向量,并以之为条件预测第 1 个目标向量。
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input_ids to encoder
encoder_hidden_states = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# change the input slightly and pass to encoder
input_ids_perturbed = tokenizer("I want to buy a house", return_tensors="pt").input_ids
encoder_hidden_states_perturbed = model.base_model.encoder(input_ids_perturbed, return_dict=True).last_hidden_state
# compare shape and encoding of first vector
print(f"Length of input embeddings {embeddings(input_ids).shape[1]}. Length of encoder_hidden_states {encoder_hidden_states.shape[1]}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `I` equal to its perturbed version?: ", torch.allclose(encoder_hidden_states[0, 0], encoder_hidden_states_perturbed[0, 0], atol=1e-3))
```
*输出:*
```
Length of input embeddings 7. Length of encoder_hidden_states 7
Is encoding for `I` equal to its perturbed version?: False
```
我们比较一下输入词嵌入的序列长度 ( _即_ `embeddings(input_ids)`,对应于 $\mathbf{X}_{1:n}$) 和 `encoder_hidden_states` 的长度 (对应于$\mathbf{\overline{X}}_{1:n}$)。同时,我们让编码器对单词序列 “I want to buy a car” 及其轻微改动版 “I want to buy a house” 分别执行前向操作,以检查第一个词 “I” 的输出编码在更改输入序列的最后一个单词后是否会有所不同。
不出意外,输入词嵌入和编码器输出编码的长度, _即_ $\textbf{len}(\mathbf{X}_{1:n})$ 和 $\textbf{len }(\mathbf{\overline{X}}_{1:n})$,是相等的。同时,可以注意到当最后一个单词从 “car” 改成 “house” 后,$\mathbf{\overline{x}}_1 = \text{“I”}$ 的编码输出向量的值也改变了。因为我们现在已经理解了双向自注意力机制,这就不足为奇了。
顺带一提, _自编码_ 模型 (如 BERT) 的架构与 _基于 transformer_ 的编码器模型是完全一样的。 _自编码_模型利用这种架构对开放域文本数据进行大规模自监督预训练,以便它们可以将任何单词序列映射到深度双向表征。在 [Devlin 等 (2018) ](https://arxiv.org/abs/1810.04805) 的工作中,作者展示了一个预训练 BERT 模型,其顶部有一个任务相关的分类层,可以在 11 个 NLP 任务上获得 SOTA 结果。你可以从 [此处](https://huggingface.co/transformers/model_summary.html#autoencoding-models) 找到 🤗 transformers 支持的所有 _自编码_ 模型。
## **解码器**
如 _编码器-解码器_ 部分所述, _基于 transformer_ 的解码器定义了给定上下文编码序列条件下目标序列的条件概率分布:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1: m} | \mathbf{\overline{X}}_{1:n}) $$
根据贝叶斯法则,在给定上下文编码序列和每个目标变量的所有前驱目标向量的条件下,可将上述分布分解为每个目标向量的条件分布的乘积:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}) $$
我们首先了解一下基于 transformer 的解码器如何定义概率分布。基于 transformer 的解码器由很多 _解码器模块_堆叠而成,最后再加一个线性层 (即 “LM 头”)。这些解码器模块的堆叠将上下文相关的编码序列 $\mathbf{\overline{X}}_{1:n}$ 和每个目标向量的前驱输入 $\mathbf{Y}_{0:i-1}$ (这里 $\mathbf{y}_0$ 为 BOS) 映射为目标向量的编码序列 $\mathbf{\overline{Y} }_{0:i-1}$。然后,“LM 头”将目标向量的编码序列 $\mathbf{\overline{Y}}_{0:i-1}$ 映射到 logit 向量序列 $\mathbf {L}_{1:n} = \mathbf{l}_1, \ldots, \mathbf{l}_n$, 而每个 logit 向量$\mathbf{l}_i$ 的维度即为词表的词汇量。这样,对于每个 $i \in {1, \ldots, n}$,其在整个词汇表上的概率分布可以通过对 $\mathbf{l}_i$ 取 softmax 获得。公式如下:
$$p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in {1, \ldots, n}$$
“LM 头” 即为词嵌入矩阵的转置, _即_ $\mathbf{W}_{\text{emb}}^{\intercal} = \left[\mathbf{ y}^1, \ldots, \mathbf{y}^{\text{vocab}}\right]^{T}$ ${}^1$。直观上来讲,这意味着对于所有 $i \in {0, \ldots, n - 1}$ “LM 头” 层会将 $\mathbf{\overline{y }}_i$ 与词汇表 $\mathbf{y}^1, \ldots, \mathbf{y}^{\text{vocab}}$ 中的所有词嵌入一一比较,输出的 logit 向量 $\mathbf{l}_{i+1}$ 即表示 $\mathbf{\overline{y }}_i$ 与每个词嵌入之间的相似度。Softmax 操作只是将相似度转换为概率分布。对于每个 $i \in {1, \ldots, n}$,以下等式成立:
$$ p_{\theta_{dec}}(\mathbf{y} | \mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1})$$
$$ = \text{Softmax}(f_{\theta_{\text{dec}}}(\mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1}))$$
$$ = \text{Softmax}(\mathbf{W}_{\text{emb}}^{\intercal} \mathbf{\overline{y}}_{i-1})$$
$$ = \text{Softmax}(\mathbf{l}_i) $$
总结一下,为了对目标向量序列 $\mathbf{Y}_{1: m}$ 的条件分布建模,先在目标向量 $\mathbf{Y}_{1: m-1}$ 前面加上特殊的 $\text{BOS}$ 向量 ( _即_ $\mathbf{y}_0$),并将其与上下文相关的编码序列 $\mathbf{\overline{X}}_{1:n}$ 一起映射到 logit 向量序列 $\mathbf{L}_{1:m}$。然后,使用 softmax 操作将每个 logit 目标向量 $\mathbf{l}_i$ 转换为目标向量 $\mathbf{y}_i$ 的条件概率分布。最后,将所有目标向量的条件概率 $\mathbf{y}_1, \ldots, \mathbf{y}_m$ 相乘得到完整目标向量序列的条件概率:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}).$$
与基于 transformer 的编码器不同,在基于 transformer 的解码器中,其输出向量 $\mathbf{\overline{y}}_{i-1}$ 应该能很好地表征 _下一个_目标向量 (即 $\mathbf{y}_i$),而不是输入向量本身 (即 $\mathbf{y}_{i-1}$)。此外,输出向量 $\mathbf{\overline{y}}_{i-1}$ 应基于编码器的整个输出序列 $\mathbf{\overline{X}}_{1:n}$。为了满足这些要求,每个解码器块都包含一个 **单向**自注意层,紧接着是一个 **交叉注意**层,最后是两个前馈层${}^2$。单向自注意层将其每个输入向量 $\mathbf{y'}_j$ 仅与其前驱输入向量 $\mathbf{y'}_i$ (其中 $i \le j$,且 $j \in {1, \ldots, n}$) 相关联,来模拟下一个目标向量的概率分布。交叉注意层将其每个输入向量 $\mathbf{y''}_j$ 与编码器输出的所有向量 $\mathbf{\overline{X}}_{1:n}$ 相关联,来根据编码器输入预测下一个目标向量的概率分布。
好,我们仍以英语到德语翻译为例可视化一下 _基于 transformer_ 的解码器。
我们可以看到解码器将 $\mathbf{Y}_{0:5}$: “BOS”、“Ich”、“will”、“ein”、“Auto”、“kaufen” (图中以浅红色显示) 和 “I”、“want”、“to”、“buy”、“a”、“car”、“EOS” ( _即_ $\mathbf{\overline{X}}_{1:7}$ (图中以深绿色显示)) 映射到 logit 向量 $\mathbf{L}_{1:6}$ (图中以深红色显示)。
因此,对每个 $\mathbf{l}_1、\mathbf{l}_2、\ldots、\mathbf{l}_6$ 使用 softmax 操作可以定义下列条件概率分布:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}), $$
> $$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}), $$
> $$ \ldots, $$
> $$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}) $$
总条件概率如下:
$$ p_{\theta_{dec}}(\text{Ich will ein Auto kaufen EOS} | \mathbf{\overline{X}}_{1:n})$$
其可表示为以下乘积形式:
$$ p_{\theta_{dec}}(\text{Ich} | \text{BOS}, \mathbf{\overline{X}}_{1:7}) \times \ldots \times p_{\theta_{dec}}(\text{EOS} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}) $$
图右侧的红框显示了前三个目标向量 $\mathbf{y}_0$、$\mathbf{y}_1$、 $\mathbf{y}_2$ 在一个解码器模块中的行为。下半部分说明了单向自注意机制,中间说明了交叉注意机制。我们首先关注单向自注意力。
与双向自注意一样,在单向自注意中, `query` 向量 $\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}$ (如下图紫色所示), `key` 向量 $\mathbf{k}_0, \ldots, \mathbf{k}_{m-1}$ (如下图橙色所示),和 `value` 向量 $\mathbf{v }_0, \ldots, \mathbf{v}_{m-1}$ (如下图蓝色所示) 均由输入向量 $\mathbf{y'}_0, \ldots, \mathbf{ y'}_{m-1}$ (如下图浅红色所示) 映射而来。然而,在单向自注意力中,每个 `query` 向量 $\mathbf{q}_i$ _仅_ 与当前及之前的 `key` 向量进行比较 (即 $\mathbf{k}_0 , \ldots, \mathbf{k}_i$) 并生成各自的 _注意力权重_ 。这可以防止输出向量 $\mathbf{y''}_j$ (如下图深红色所示) 包含未来向量 ($\mathbf{y}_i$,其中 $i > j$ 且 $j \in {0, \ldots, m - 1 }$) 的任何信息 。与双向自注意力的情况一样,得到的注意力权重会乘以它们各自的 `value` 向量并加权求和。
我们将单向自注意力总结如下:
$$\mathbf{y''}_i = \mathbf{V}_{0: i} \textbf{Softmax}(\mathbf{K}_{0: i}^\intercal \mathbf{q}_i) + \mathbf{y'}_i$$
请注意, `key` 和 `value` 向量的索引范围都是 $0:i$ 而不是 $0: m-1$,$0: m-1$ 是双向自注意力中 `key` 向量的索引范围。
下图显示了上例中输入向量 $\mathbf{y'}_1$ 的单向自注意力。
可以看出 $\mathbf{y''}_1$ 只依赖于 $\mathbf{y'}_0$ 和 $\mathbf{y'}_1$。因此,单词 “Ich” 的向量表征 ( _即_ $\mathbf{y'}_1$) 仅与其自身及 “BOS” 目标向量 ( _即_ $\mathbf{y'}_0$) 相关联,而 **不** 与 “will” 的向量表征 ( _即_ $\mathbf{y'}_2$) 相关联。
那么,为什么解码器使用单向自注意力而不是双向自注意力这件事很重要呢?如前所述,基于 transformer 的解码器定义了从输入向量序列 $\mathbf{Y}_{0: m-1}$ 到其 **下一个** 解码器输入的 logit 向量的映射,即 $\mathbf{L}_{1:m}$。举个例子,输入向量 $\mathbf{y}_1$ = “Ich” 会映射到 logit 向量 $\mathbf{l}_2$,并用于预测下一个输入向量 $\mathbf{y}_2$。因此,如果 $\mathbf{y'}_1$ 可以获取后续输入向量 $\mathbf{Y'}_{2:5}$的信息,解码器将会简单地复制向量 “will” 的向量表征 ( _即_ $\mathbf{y'}_2$) 作为其输出 $\mathbf{y''}_1$,并就这样一直传播到最后一层,所以最终的输出向量 $\mathbf{\overline{y}}_1$ 基本上就只对应于 $\mathbf{y}_2$ 的向量表征,并没有起到预测的作用。
这显然是不对的,因为这样的话,基于 transformer 的解码器永远不会学到在给定所有前驱词的情况下预测下一个词,而只是对所有 $i \in {1, \ldots, m }$,通过网络将目标向量 $\mathbf{y}_i$ 复制到 $\mathbf {\overline{y}}_{i-1}$。以下一个目标变量本身为条件去定义下一个目标向量,即从 $p(\mathbf{y} | \mathbf{Y}_{0:i}, \mathbf{\overline{ X}})$ 中预测 $\mathbf{y}_i$, 显然是不对的。因此,单向自注意力架构允许我们定义一个 _因果的_概率分布,这对有效建模下一个目标向量的条件分布而言是必要的。
太棒了!现在我们可以转到连接编码器和解码器的层 - _交叉注意力_机制!
交叉注意层将两个向量序列作为输入: 单向自注意层的输出 $\mathbf{Y''}_{0: m-1}$ 和编码器的输出 $\mathbf{\overline{X}}_{1:n}$。与自注意力层一样, `query` 向量 $\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}$ 是上一层输出向量 $\mathbf{Y''}_{0: m-1}$ 的投影。而 `key` 和 `value` 向量 $\mathbf{k}_0, \ldots, \mathbf{k}_{n-1}$、$\mathbf{v}_0, \ldots, \mathbf {v}_{n-1}$ 是编码器输出向量 $\mathbf{\overline{X}}_{1:n}$ 的投影。定义完 `key` 、`value` 和 `query` 向量后,将 `query` 向量 $\mathbf{q}_i$ 与 _所有_ `key` 向量进行比较,并用各自的得分对相应的 `value` 向量进行加权求和。这个过程与 _双向_自注意力对所有 $i \in {0, \ldots, m-1}$ 求 $\mathbf{y'''}_i$ 是一样的。交叉注意力可以概括如下:
$$
\mathbf{y'''}_i = \mathbf{V}_{1:n} \textbf{Softmax}(\mathbf{K}_{1: n}^\intercal \mathbf{q}_i) + \mathbf{y''}_i
$$
注意,`key` 和 `value` 向量的索引范围是 $1:n$,对应于编码器输入向量的数目。
我们用上例中输入向量 $\mathbf{y''}_1$ 来图解一下交叉注意力机制。
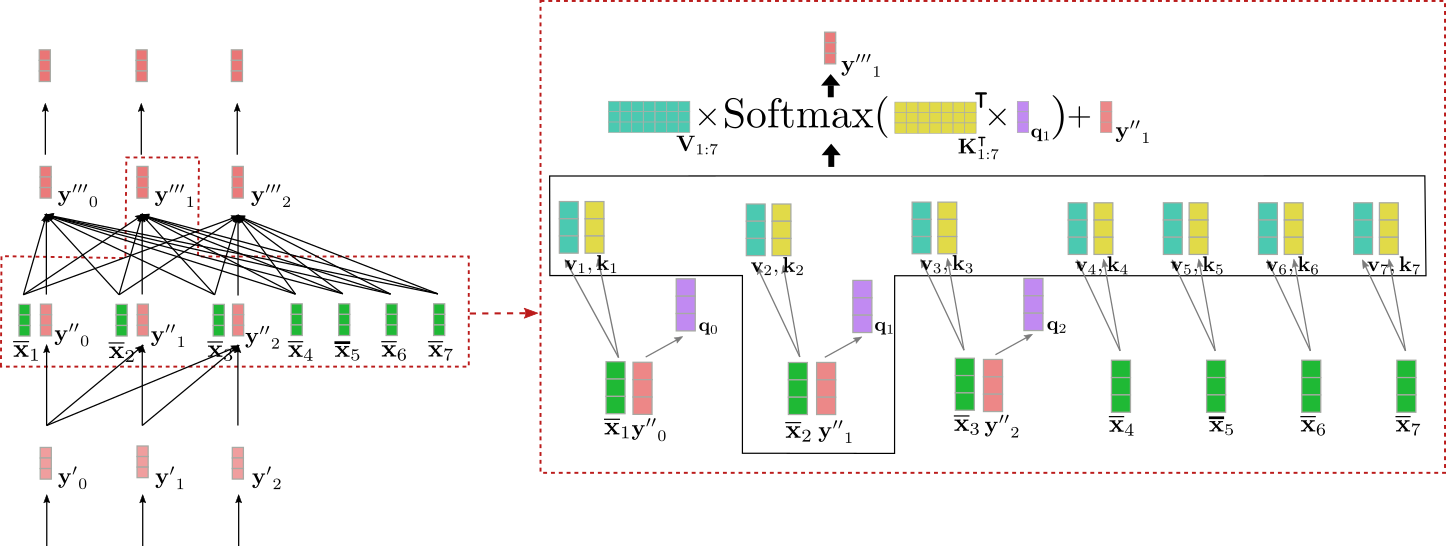
我们可以看到 `query` 向量 $\mathbf{q}_1$(紫色)源自 $\mathbf{y''}_1$(红色),因此其依赖于单词 "Ich" 的向量表征。然后将 `query` 向量 $\mathbf{q}_1$ 与对应的 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_7$(黄色)进行比较,这里的 `key` 向量对应于编码器对其输入 $\mathbf{X}_{1:n}$ = \"I want to buy a car EOS\" 的上下文相关向量表征。这将 \"Ich\" 的向量表征与所有编码器输入向量直接关联起来。最后,将注意力权重乘以 `value` 向量 $\mathbf{v}_1, \ldots, \mathbf{v}_7$(青绿色)并加上输入向量 $\mathbf{y''}_1$ 最终得到输出向量 $\mathbf{y'''}_1$(深红色)。
所以,直观而言,到底发生了什么?每个输出向量 $\mathbf{y'''}_i$ 是由所有从编码器来的 `value` 向量($\mathbf{v}_{1}, \ldots, \mathbf{v }_7$ )的加权和与输入向量本身 $\mathbf{y''}_i$ 相加而得(参见上图所示的公式)。其关键思想是:_来自解码器的_ $\mathbf{q}_i$ 的 `query` 投影与 _来自编码器的 $\mathbf{k}_j$_ 越相关,其对应的 $\mathbf{v}_j$ 对输出的影响越大。
酷!现在我们可以看到这种架构的每个输出向量 $\mathbf{y'''}_i$ 取决于其来自编码器的输入向量 $\mathbf{\overline{X}}_{1 :n}$ 及其自身的输入向量 $\mathbf{y''}_i$。这里有一个重要的点,在该架构中,虽然输出向量 $\mathbf{y'''}_i$ 依赖来自编码器的输入向量 $\mathbf{\overline{X}}_{1:n}$,但其完全独立于该向量的数量 $n$。所有生成 `key` 向量 $\mathbf{k}_1, \ldots, \mathbf{k}_n$ 和 `value` 向量 $\mathbf{v}_1, \ldots, \mathbf{v}_n $ 的投影矩阵 $\mathbf{W}^{\text{cross}}_{k}$ 和 $\mathbf{W}^{\text{cross}}_{v}$ 都是与 $n$ 无关的,所有 $n$ 共享同一个投影矩阵。且对每个 $\mathbf{y'''}_i$,所有 `value` 向量 $\mathbf{v}_1, \ldots, \mathbf{v}_n$ 被加权求和至一个向量。至此,关于`为什么基于 transformer 的解码器没有远程依赖问题而基于 RNN 的解码器有`这一问题的答案已经很显然了。因为每个解码器 logit 向量 _直接_ 依赖于每个编码后的输出向量,因此比较第一个编码输出向量和最后一个解码器 logit 向量只需一次操作,而不像 RNN 需要很多次。
总而言之,单向自注意力层负责基于当前及之前的所有解码器输入向量建模每个输出向量,而交叉注意力层则负责进一步基于编码器的所有输入向量建模每个输出向量。
为了验证我们对该理论的理解,我们继续上面编码器部分的代码,完成解码器部分。
---
${}^1$ 词嵌入矩阵 $\mathbf{W}_{\text{emb}}$ 为每个输入词提供唯一的 _上下文无关_向量表示。这个矩阵通常也被用作 “LM 头”,此时 “LM 头”可以很好地完成“编码向量到 logit” 的映射。
${}^2$ 与编码器部分一样,本文不会详细解释前馈层在基于 transformer 的模型中的作用。[Yun 等 (2017) ](https://arxiv.org/pdf/1912.10077.pdf) 的工作认为前馈层对于将每个上下文相关向量 $\mathbf{x'}_i$ 映射到所需的输出空间至关重要,仅靠自注意力层无法完成。这里应该注意,每个输出词元 $\mathbf{x'}$ 对应的前馈层是相同的。有关更多详细信息,建议读者阅读论文。
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create token ids for encoder input
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input token ids to encoder
encoder_output_vectors = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# create token ids for decoder input
decoder_input_ids = tokenizer("<pad> Ich will ein", return_tensors="pt", add_special_tokens=False).input_ids
# pass decoder input ids and encoded input vectors to decoder
decoder_output_vectors = model.base_model.decoder(decoder_input_ids, encoder_hidden_states=encoder_output_vectors).last_hidden_state
# derive embeddings by multiplying decoder outputs with embedding weights
lm_logits = torch.nn.functional.linear(decoder_output_vectors, embeddings.weight, bias=model.final_logits_bias)
# change the decoder input slightly
decoder_input_ids_perturbed = tokenizer("<pad> Ich will das", return_tensors="pt", add_special_tokens=False).input_ids
decoder_output_vectors_perturbed = model.base_model.decoder(decoder_input_ids_perturbed, encoder_hidden_states=encoder_output_vectors).last_hidden_state
lm_logits_perturbed = torch.nn.functional.linear(decoder_output_vectors_perturbed, embeddings.weight, bias=model.final_logits_bias)
# compare shape and encoding of first vector
print(f"Shape of decoder input vectors {embeddings(decoder_input_ids).shape}. Shape of decoder logits {lm_logits.shape}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `Ich` equal to its perturbed version?: ", torch.allclose(lm_logits[0, 0], lm_logits_perturbed[0, 0], atol=1e-3))
```
*输出:*
```
Shape of decoder input vectors torch.Size([1, 5, 512]). Shape of decoder logits torch.Size([1, 5, 58101])
Is encoding for `Ich` equal to its perturbed version?: True
```
我们首先比较解码器词嵌入层的输出维度 `embeddings(decoder_input_ids)` (对应于 $\mathbf{Y}_{0: 4}$,这里 `<pad>` 对应于 BOS 且 "Ich will das" 被分为 4 个词) 和 `lm_logits` (对应于 $\mathbf{L}_{1:5}$) 的维度。此外,我们还通过解码器将单词序列 “`<pad>` Ich will ein” 和其轻微改编版 “`<pad>` Ich will das” 与 `encoder_output_vectors` 一起传递给解码器,以检查对应于 “Ich” 的第二个 lm_logit 在仅改变输入序列中的最后一个单词 (“ein” -> “das”) 时是否会有所不同。
正如预期的那样,解码器输入词嵌入和 lm_logits 的输出, _即_ $\mathbf{Y}_{0: 4}$ 和 $\mathbf{L}_{ 1:5}$ 的最后一个维度不同。虽然序列长度相同 (=5),但解码器输入词嵌入的维度对应于 `model.config.hidden_size`,而 `lm_logit` 的维数对应于词汇表大小 `model.config.vocab_size`。其次,可以注意到,当将最后一个单词从 “ein” 变为 “das”,$\mathbf{l}_1 = \text{“Ich”}$ 的输出向量的值不变。鉴于我们已经理解了单向自注意力,这就不足为奇了。
最后一点, _自回归_模型,如 GPT2,与删除了交叉注意力层的 _基于 transformer_ 的解码器模型架构是相同的,因为纯自回归模型不依赖任何编码器的输出。因此,自回归模型本质上与 _自编码_模型相同,只是用单向注意力代替了双向注意力。这些模型还可以在大量开放域文本数据上进行预训练,以在自然语言生成 (NLG) 任务中表现出令人印象深刻的性能。在 [Radford 等 (2019) ](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf) 的工作中,作者表明预训练的 GPT2 模型无需太多微调即可在多种 NLG 任务上取得达到 SOTA 或接近 SOTA 的结果。你可以在 [此处](https://huggingface.co/transformers/model_summary.html#autoregressive-models) 获取所有 🤗 transformers 支持的 _自回归_模型的信息。
好了!至此,你应该已经很好地理解了 _基于 transforemr_ 的编码器-解码器模型以及如何在 🤗 transformers 库中使用它们。
非常感谢 Victor Sanh、Sasha Rush、Sam Shleifer、Oliver Åstrand、Ted Moskovitz 和 Kristian Kyvik 提供的宝贵反馈。
## **附录**
如上所述,以下代码片段展示了如何为 _基于 transformer_ 的编码器-解码器模型编写一个简单的生成方法。在这里,我们使用 `torch.argmax` 实现了一个简单的 _贪心_解码法来对目标向量进行采样。
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# create BOS token
decoder_input_ids = tokenizer("<pad>", add_special_tokens=False, return_tensors="pt").input_ids
assert decoder_input_ids[0, 0].item() == model.config.decoder_start_token_id, "`decoder_input_ids` should correspond to `model.config.decoder_start_token_id`"
# STEP 1
# pass input_ids to encoder and to decoder and pass BOS token to decoder to retrieve first logit
outputs = model(input_ids, decoder_input_ids=decoder_input_ids, return_dict=True)
# get encoded sequence
encoded_sequence = (outputs.encoder_last_hidden_state,)
# get logits
lm_logits = outputs.logits
# sample last token with highest prob
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concat
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# STEP 2
# reuse encoded_inputs and pass BOS + "Ich" to decoder to second logit
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
# sample last token with highest prob again
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concat again
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# STEP 3
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# let's see what we have generated so far!
print(f"Generated so far: {tokenizer.decode(decoder_input_ids[0], skip_special_tokens=True)}")
# This can be written in a loop as well.
```
*输出:*
```
Generated so far: Ich will ein
```
在这个示例代码中,我们准确地展示了正文中描述的内容。我们在输入 “I want to buy a car” 前面加上 $\text{BOS}$ ,然后一起传给编码器-解码器模型,并对第一个 logit $\mathbf{l}_1 $ (对应代码中第一次出现 lm_logits 的部分) 进行采样。这里,我们的采样策略很简单: 贪心地选择概率最高的词作为下一个解码器输入向量。然后,我们以自回归方式将采样得的解码器输入向量与先前的输入一起传递给编码器-解码器模型并再次采样。重复 3 次后,该模型生成了 “Ich will ein”。结果没问题,开了个好头。
在实践中,我们会使用更复杂的解码方法来采样 `lm_logits`。你可以参考 [这篇博文](https://huggingface.co/blog/zh/how-to-generate) 了解更多的解码方法。 | 2 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/dpo-trl.md | ---
title: "使用 DPO 微调 Llama 2"
thumbnail: /blog/assets/157_dpo_trl/dpo_thumbnail.png
authors:
- user: kashif
- user: ybelkada
- user: lvwerra
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 使用 DPO 微调 Llama 2
## 简介
基于人类反馈的强化学习 (Reinforcement Learning from Human Feedback,RLHF) 事实上已成为 GPT-4 或 Claude 等 LLM 训练的最后一步,它可以确保语言模型的输出符合人类在闲聊或安全性等方面的期望。然而,它也给 NLP 引入了一些 RL 相关的复杂性: 既要构建一个好的奖励函数,并训练一个模型用以估计每个状态的价值 (value) ; 又要注意最终生成的 LLM 不能与原始模型相差太远,如果太远的话会使得模型容易产生乱码而非有意义的文本。该过程非常复杂,涉及到许多复杂的组件,而这些组件本身在训练过程中又是动态变化的,因此把它们料理好并不容易。
Rafailov、Sharma、Mitchell 等人最近发表了一篇论文 [Direct Preference Optimization](https://arxiv.org/abs/2305.18290),论文提出将现有方法使用的基于强化学习的目标转换为可以通过简单的二元交叉熵损失直接优化的目标,这一做法大大简化了 LLM 的提纯过程。
本文介绍了直接偏好优化 (Direct Preference Optimization,DPO) 法,该方法现已集成至 [TRL 库](https://github.com/lvwerra/trl) 中。同时,我们还展示了如何在 [stack-exchange preference](https://huggingface.co/datasets/lvwerra/stack-exchange-paired) 数据集上微调最新的 Llama v2 7B 模型, `stack-exchange preference` 数据集中包含了各个 `stack-exchange` 门户上的各种问题及其排序后的回答。
## DPO 与 PPO
在通过 RL 优化人类衍生偏好时,一直以来的传统做法是使用一个辅助奖励模型来微调目标模型,以通过 RL 机制最大化目标模型所能获得的奖励。直观上,我们使用奖励模型向待优化模型提供反馈,以促使它多生成高奖励输出,少生成低奖励输出。同时,我们使用冻结的参考模型来确保输出偏差不会太大,且继续保持输出的多样性。这通常需要在目标函数设计时,除了奖励最大化目标外再添加一个相对于参考模型的 KL 惩罚项,这样做有助于防止模型学习作弊或钻营奖励模型。
DPO 绕过了建模奖励函数这一步,这源于一个关键洞见: 从奖励函数到最优 RL 策略的分析映射。这个映射直观地度量了给定奖励函数与给定偏好数据的匹配程度。有了它,作者就可与将基于奖励和参考模型的 RL 损失直接转换为仅基于参考模型的损失,从而直接在偏好数据上优化语言模型!因此,DPO 从寻找最小化 RLHF 损失的最佳方案开始,通过改变参量的方式推导出一个 _仅需_ 参考模型的损失!
有了它,我们可以直接优化该似然目标,而不需要奖励模型或繁琐的强化学习优化过程。
## 如何使用 TRL 进行训练
如前所述,一个典型的 RLHF 流水线通常包含以下几个环节:
1. 有监督微调 (supervised fine-tuning,SFT)
2. 用偏好标签标注数据
3. 基于偏好数据训练奖励模型
4. RL 优化
TRL 库包含了所有这些环节所需的工具程序。而 DPO 训练直接消灭了奖励建模和 RL 这两个环节 (环节 3 和 4),直接根据标注好的偏好数据优化 DPO 目标。
使用 DPO,我们仍然需要执行环节 1,但我们仅需在 TRL 中向 `DPOTrainer` 提供环节 2 准备好的偏好数据,而不再需要环节 3 和 4。标注好的偏好数据需要遵循特定的格式,它是一个含有以下 3 个键的字典:
- `prompt` : 即推理时输入给模型的提示
- `chosen` : 即针对给定提示的较优回答
- `rejected` : 即针对给定提示的较劣回答或非给定提示的回答
例如,对于 `stack-exchange preference` 数据集,我们可以通过以下工具函数将数据集中的样本映射至上述字典格式并删除所有原始列:
```python
def return_prompt_and_responses(samples) -> Dict[str, str, str]:
return {
"prompt": [
"Question: " + question + "\n\nAnswer: "
for question in samples["question"]
],
"chosen": samples["response_j"], # rated better than k
"rejected": samples["response_k"], # rated worse than j
}
dataset = load_dataset(
"lvwerra/stack-exchange-paired",
split="train",
data_dir="data/rl"
)
original_columns = dataset.column_names
dataset.map(
return_prompt_and_responses,
batched=True,
remove_columns=original_columns
)
```
一旦有了排序数据集,DPO 损失其实本质上就是一种有监督损失,其经由参考模型获得隐式奖励。因此,从上层来看,`DPOTrainer` 需要我们输入待优化的基础模型以及参考模型:
```python
dpo_trainer = DPOTrainer(
model, # 经 SFT 的基础模型
model_ref, # 一般为经 SFT 的基础模型的一个拷贝
beta=0.1, # DPO 的温度超参
train_dataset=dataset, # 上文准备好的数据集
tokenizer=tokenizer, # 分词器
args=training_args, # 训练参数,如: batch size, 学习率等
)
```
其中,超参 `beta` 是 DPO 损失的温度,通常在 `0.1` 到 `0.5` 之间。它控制了我们对参考模型的关注程度,`beta` 越小,我们就越忽略参考模型。对训练器初始化后,我们就可以简单调用以下方法,使用给定的 `training_args` 在给定数据集上进行训练了:
```python
dpo_trainer.train()
```
## 基于 Llama v2 进行实验
在 TRL 中实现 DPO 训练器的好处是,人们可以利用 TRL 及其依赖库 (如 Peft 和 Accelerate) 中已有的 LLM 相关功能。有了这些库,我们甚至可以使用 [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) 库提供的 [QLoRA 技术](https://huggingface.co/blog/4bit-transformers-bitsandbytes) 来训练 Llama v2 模型。
### 有监督微调
如上文所述,我们先用 TRL 的 `SFTTrainer` 在 SFT 数据子集上使用 [QLoRA](https://arxiv.org/abs/2305.14314) 对 7B Llama v2 模型进行有监督微调:
```python
# load the base model in 4-bit quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
base_model = AutoModelForCausalLM.from_pretrained(
script_args.model_name, # "meta-llama/Llama-2-7b-hf"
quantization_config=bnb_config,
device_map={"": 0},
trust_remote_code=True,
use_auth_token=True,
)
base_model.config.use_cache = False
# add LoRA layers on top of the quantized base model
peft_config = LoraConfig(
r=script_args.lora_r,
lora_alpha=script_args.lora_alpha,
lora_dropout=script_args.lora_dropout,
target_modules=["q_proj", "v_proj"],
bias="none",
task_type="CAUSAL_LM",
)
...
trainer = SFTTrainer(
model=base_model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
packing=True,
max_seq_length=None,
tokenizer=tokenizer,
args=training_args, # HF Trainer arguments
)
trainer.train()
```
### DPO 训练
SFT 结束后,我们保存好生成的模型。接着,我们继续进行 DPO 训练,我们把 SFT 生成的模型作为 DPO 的基础模型和参考模型,并在上文生成的 `stack-exchange preference` 数据上,以 DPO 为目标函数训练模型。我们选择对模型进行 LoRa 微调,因此我们使用 Peft 的 `AutoPeftModelForCausalLM` 函数加载模型:
```python
model = AutoPeftModelForCausalLM.from_pretrained(
script_args.model_name_or_path, # location of saved SFT model
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
is_trainable=True,
)
model_ref = AutoPeftModelForCausalLM.from_pretrained(
script_args.model_name_or_path, # same model as the main one
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
)
...
dpo_trainer = DPOTrainer(
model,
model_ref,
args=training_args,
beta=script_args.beta,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
)
dpo_trainer.train()
dpo_trainer.save_model()
```
可以看出,我们以 4 比特的方式加载模型,然后通过 `peft_config` 参数选择 QLora 方法对其进行训练。训练器还会用评估数据集评估训练进度,并报告一些关键指标,例如可以选择通过 WandB 记录并显示隐式奖励。最后,我们可以将训练好的模型推送到 HuggingFace Hub。
## 总结
SFT 和 DPO 训练脚本的完整源代码可在该目录 [examples/stack_llama_2](https://github.com/lvwerra/trl/tree/main/examples/research_projects/stack_llama_2) 处找到,训好的已合并模型也已上传至 HF Hub (见 [此处](https://huggingface.co/kashif/stack-llama-2))。
你可以在 [这儿](https://wandb.ai/krasul/huggingface/runs/c54lmder) 找到我们的模型在训练过程的 WandB 日志,其中包含了 `DPOTrainer` 在训练和评估期间记录下来的以下奖励指标:
- `rewards/chosen (较优回答的奖励) ` : 针对较优回答,策略模型与参考模型的对数概率二者之差的均值,按 `beta` 缩放。
- `rewards/rejected (较劣回答的奖励) ` : 针对较劣回答,策略模型与参考模型的对数概率二者之差的均值,按 `beta` 缩放。
- `rewards/accuracy (奖励准确率) ` : 较优回答的奖励大于相应较劣回答的奖励的频率的均值
- `rewards/margins (奖励余裕值) ` : 较优回答的奖励与相应较劣回答的奖励二者之差的均值。
直观上讲,在训练过程中,我们希望余裕值增加并且准确率达到 1.0,换句话说,较优回答的奖励高于较劣回答的奖励 (或余裕值大于零)。随后,我们还可以在评估数据集上计算这些指标。
我们希望我们代码的发布可以降低读者的入门门槛,让大家可以在自己的数据集上尝试这种大语言模型对齐方法,我们迫不及待地想看到你会用它做哪些事情!如果你想试试我们训练出来的模型,可以玩玩这个 space: [trl-lib/stack-llama](https://huggingface.co/spaces/trl-lib/stack-llama)。 | 3 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/big-bird.md | ---
title: "深入理解 BigBird 的块稀疏注意力"
thumbnail: /blog/assets/18_big_bird/attn.png
authors:
- user: vasudevgupta
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 深入理解 BigBird 的块稀疏注意力
## 引言
基于 transformer 的模型已被证明对很多 NLP 任务都非常有用。然而,$O(n^2)$ 的时间和内存复杂度 (其中 $n$ 是序列长度) 使得在长序列 ($n > 512$) 上应用它们变得非常昂贵,因而大大限制了其应用。最近的几篇论文,如 `Longformer` 、`Performer` 、`Reformer` 、`簇状注意力` 都试图通过对完整注意力矩阵进行近似来解决这个问题。如果你不熟悉这些模型,可以查看 🤗 之前的 [博文](https://huggingface.co/blog/zh/long-range-transformers)。
`BigBird` (由 [该论文](https://arxiv.org/abs/2007.14062) 引入) 是解决这个问题的最新模型之一。 `BigBird` 依赖于 **块稀疏注意力** 而不是普通注意力 ( _即_ BERT 的注意力),与 BERT 相比,这一新算法能以低得多的计算成本处理长达 **4096** 的序列。在涉及很长序列的各种任务上,该模型都实现了 SOTA,例如长文档摘要、长上下文问答。
**RoBERTa 架构的 BigBird** 模型现已集成入 🤗 transformers 中。本文的目的是让读者 **深入** 了解 BigBird 的实现,并让读者能在 🤗 transformers 中轻松使用 BigBird。但是,在更深入之前,一定记住 `BigBird` 注意力只是 `BERT` 完全注意力的一个近似,因此我们并不纠结于让它比 `BERT` 完全注意力 **更好**,而是致力于让它更有效率。有了它,transformer 模型就可以作用于更长的序列,因为 BERT 的二次方内存需求很快会变得难以为继。简而言之,如果我们有 $\infty$ 计算和 $\infty$ 时间,那么用 BERT 注意力就好了,完全没必要用本文讨论的块稀疏注意力。
如果你想知道为什么在处理较长序列时需要更多计算,那么本文正合你意!
---
在使用标准的 `BERT` 类注意力时可能会遇到以下几个主要问题:
- 每个词元真的都必须关注所有其他词元吗?
- 为什么不只计算重要词元的注意力?
- 如何决定哪些词元重要?
- 如何以高效的方式处理少量词元?
---
本文,我们将尝试回答这些问题。
### 应该关注哪些词元?
下面,我们将以句子 `BigBird is now available in HuggingFace for extractive Question Answering` 为例来说明注意力是如何工作的。在 `BERT` 这类的注意力机制中,每个词元都简单粗暴地关注所有其他词元。从数学上来讲,这意味着每个查询的词元 $ \text{query-token} \in {\text{BigBird},\text{is},\text{now},\text{available},\text{in},\text{HuggingFace},\text{for},\text{extractive},\text{question},\text{answering}} $,
将关注每个键词元 $\text{key-tokens} = \left[\text{BigBird},\text{is},\text{now},\text{available},\text{in},\text{HuggingFace},\text{for},\text{extractive},\text{question},\text{answering} \right]$。
我们考虑一下 `每个查询词元应如何明智地选择它实际上应该关注的键词元` 这个问题,下面我们通过编写伪代码的方式来整理思考过程。
假设 `available` 是当前查询词元,我们来构建一个合理的、需要关注的键词元列表。
```python
# 以下面的句子为例
example = ['BigBird', 'is', 'now', 'available', 'in', 'HuggingFace', 'for', 'extractive', 'question', 'answering']
# 假设当前需要计算 'available' 这个词的表征
query_token = 'available'
# 初始化一个空集合,用于放 'available' 这个词的键词元
key_tokens = [] # => 目前,'available' 词元不关注任何词元
```
邻近词元当然很重要,因为在一个句子 (单词序列) 中,当前词高度依赖于前后的邻近词。`滑动注意力` 即基于该直觉。
```python
# 考虑滑动窗大小为 3, 即将 'available' 的左边一个词和右边一个词纳入考量
# 左词: 'now'; 右词: 'in'
sliding_tokens = ["now", "available", "in"]
# 用以上词元更新集合
key_tokens.append(sliding_tokens)
```
**长程依赖关系:** 对某些任务而言,捕获词元间的长程关系至关重要。 _例如_ ,在问答类任务中,模型需要将上下文的每个词元与整个问题进行比较,以便能够找出上下文的哪一部分对正确答案有用。如果大多数上下文词元仅关注其他上下文词元,而不关注问题,那么模型从不太重要的上下文词元中过滤重要的上下文词元就会变得更加困难。
`BigBird` 提出了两种允许长程注意力依赖的方法,这两种方法都能保证计算效率。
- **全局词元:** 引入一些词元,这些词元将关注每个词元并且被每个词元关注。例如,对 _“HuggingFace is building nice libraries for easy NLP”_ ,现在假设 _'building'_ 被定义为全局词元,而对某些任务而言,模型需要知道 _'NLP'_ 和 _'HuggingFace'_ 之间的关系 (注意: 这 2 个词元位于句子的两端); 现在让 _'building'_ 在全局范围内关注所有其他词元,会对模型将 _'NLP'_ 与 _'HuggingFace'_ 关联起来有帮助。
```python
# 我们假设第一个和最后一个词元是全局的,则有:
global_tokens = ["BigBird", "answering"]
# 将全局词元加入到集合中
key_tokens.append(global_tokens)
```
- **随机词元:** 随机选择一些词元,这些词元将通过关注其他词元来传输信息,而那些词元又可以传输信息到其他词元。这可以降低直接从一个词元到另一个词元的信息传输成本。
```python
# 现在,我们可以从句子中随机选择 `r` 个词元。这里,假设 `r` 为 1, 选择了 `is` 这个词元
>>> random_tokens = ["is"] # 注意: 这个是完全随机选择的,因此可以是任意词元。
# 将随机词元加入到集合中
key_tokens.append(random_tokens)
# 现在看下 `key_tokens` 集合中有哪些词元
key_tokens
{'now', 'is', 'in', 'answering', 'available', 'BigBird'}
# 至此,查询词 'available' 仅关注集合中的这些词元,而不用关心全部
```
这样,查询词元仅关注所有词元的一个子集,该子集能够产生完全注意力值的一个不错的近似。相同的方法将用于所有其他查询词元。但请记住,这里的重点是尽可能有效地接近 `BERT` 的完全注意力。BERT 那种简单地让每个查询词元关注所有键词元的做法可以建模为一系列矩阵乘法,从而在现代硬件 (如 GPU) 上进行高效计算。然而,滑动、全局和随机注意力的组合似乎意味着稀疏矩阵乘法,这在现代硬件上很难高效实现。`BigBird` 的主要贡献之一是提出了 `块稀疏` 注意力机制,该机制可以高效计算滑动、全局和随机注意力。我们来看看吧!
### 图解全局、滑动、随机注意力的概念
首先,我们借助图来帮助理解“全局”、“滑动”和“随机”注意力,并尝试理解这三种注意力机制的组合是如何较好地近似标准 BERT 类注意力的。
<img src="https://huggingface.co/blog/assets/18_big_bird/global.png" width=250 height=250>
<img src="https://huggingface.co/blog/assets/18_big_bird/sliding.png" width=250 height=250>
<img src="https://huggingface.co/blog/assets/18_big_bird/random.png" width=250 height=250> <br>
_上图分别把“全局”(左) 、“滑动”(中) 和“随机”(右) 连接建模成一个图。每个节点对应一个词元,每条边代表一个注意力分数。如果 2 个词元之间没有边连接,则其注意力分数为 0。_
<img src="https://huggingface.co/blog/assets/18_big_bird/full.png" width=230 height=230>
**BigBird 块稀疏注意力** 是滑动连接、全局连接和随机连接 (总共 10 个连接) 的组合,如上图左侧动图所示。而 **完全注意力** 图 (右侧) 则是有全部 15 个连接 (注意: 总共有 6 个节点)。你可以简单地将完全注意力视为所有词元都是全局词元 ${}^1$。
**完全注意力:** 模型可以直接在单个层中将信息从一个词元传输到另一个词元,因为每个词元都会对每个其他词元进行查询,并且受到其他每个词元的关注。我们考虑一个与上图类似的例子,如果模型需要将 _'going'_ 与 _'now'_ 关联起来,它可以简单地在单层中执行此操作,因为它们两个是有直接连接的。
**块稀疏注意力:** 如果模型需要在两个节点 (或词元) 之间共享信息,则对于某些词元,信息将必须经过路径中的各个其他节点; 因为不是所有节点都有直接连接的。
_例如_ ,假设模型需要将 `going` 与 `now` 关联起来,那么如果仅存在滑动注意力,则这两个词元之间的信息流由路径 `going -> am -> i -> now` 来定义,也就是说它必须经过 2 个其他词元。因此,我们可能需要多个层来捕获序列的全部信息,而正常的注意力可以在单层中捕捉到这一点。在极端情况下,这可能意味着需要与输入词元一样多的层。然而,如果我们引入一些全局词元,信息可以通过以下路径传播 `going -> i -> now` ,这可以帮助缩短路径。如果我们再另外引入随机连接,它就可以通过 `going -> am -> now` 传播。借助随机连接和全局连接,信息可以非常快速地 (只需几层) 从一个词元传输到下一个词元。
如果我们有很多全局词元,那么我们可能不需要随机连接,因为信息可以通过多个短路径传播。这就是在使用 BigBird 的变体 (称为 ETC) 时设置 `num_random_tokens = 0` 的动机 (稍后部分将会详细介绍)。
${}^1$ 在这些图中,我们假设注意力矩阵是对称的 **即** $\mathbf{A} _{ij} = \mathbf{A}_ {ji}$ 因为在图中如果某个词元 **A** 关注 **B**,那么 **B** 也会关注 **A**。从下一节所示的注意力矩阵图中可以看出,这个假设对于 BigBird 中的大多数词元都成立。
| 注意力类型 | 全局词元 | 滑动词元 | 随机词元 |
|-----------------|-------------------|------------------|------------------------------------|
| 原始完全注意力 | `n` | 0 | 0 |
| 块稀疏注意力 | 2 x `block_size` | 3 x `block_size` | `num_random_blocks` x `block_size` |
原始完全注意力即 `BERT` 的注意力,而块稀疏注意力则是 `BigBird` 的注意力。想知道 `block_size` 是什么?请继续阅读下文。_现在,为简单起见,将其视为 1。_
## BigBird 块稀疏注意力
BigBird 块稀疏注意力是我们上文讨论的内容的高效实现。每个词元都关注某些 **全局词元** 、 **滑动词元** 和 **随机词元**,而不管其他 **所有** 词元。作者分别实现了每类查询注意力矩阵,并使用了一个很酷的技巧来加速 GPU 和 TPU 上的训练/推理。
_注意: 在上图的顶部有 2 个额外的句子。正如你所注意到的,两个句子中的每个词元都只是交换了一个位置。这就是滑动注意力的实现方式。当 `q[i]` 与 `k[i,0:3]` 相乘时,我们会得到 `q[i]` 的滑动注意力分数 (其中`i` 是序列中元素的索引)。_
你可以在 [这儿](https://github.com/vasudevgupta7/transformers/blob/5f2d6a0c93ca2017961199aa04a344b9b779d454/src/transformers/models/big_bird/modeling_big_bird.py#L513) 找到 `block_sparse` 注意力的具体实现。现在看起来可能非常可怕😨😨,但这篇文章肯定会让你轻松理解它。
### 全局注意力
对于全局注意力而言,每个查询词元关注序列中的所有其他词元,并且被其他每个词元关注。我们假设 `Vasudev` (第一个词元) 和 `them` (最后一个词元) 是全局的 (如上图所示)。你可以看到这些词元直接连接到所有其他词元 (蓝色框)。
```python
# 伪代码
Q -> Query martix (seq_length, head_dim)
K -> Key matrix (seq_length, head_dim)
# 第一个和最后一个词元关注所有其他词元
Q[0] x [K[0], K[1], K[2], ......, K[n-1]]
Q[n-1] x [K[0], K[1], K[2], ......, K[n-1]]
# 第一个和最后一个词元也被其他所有词元关注
K[0] x [Q[0], Q[1], Q[2], ......, Q[n-1]]
K[n-1] x [Q[0], Q[1], Q[2], ......, Q[n-1]]
```
### 滑动注意力
键词元序列被复制两次,其中一份每个词元向右移动一步,另一份每个词元向左移动一步。现在,如果我们将查询序列向量乘以这 3 个序列向量,我们将覆盖所有滑动词元。计算复杂度就是 `O(3n) = O(n)` 。参考上图,橙色框代表滑动注意力。你可以在图的顶部看到 3 个序列,其中 2 个序列各移动了一个词元 (1 个向左,1 个向右)。
```python
# 我们想做的
Q[i] x [K[i-1], K[i], K[i+1]] for i = 1:-1
# 高效的代码实现 (👇 乘法为点乘)
[Q[0], Q[1], Q[2], ......, Q[n-2], Q[n-1]] x [K[1], K[2], K[3], ......, K[n-1], K[0]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[n-1], K[0], K[1], ......, K[n-2]]
[Q[0], Q[1], Q[2], ......, Q[n-1]] x [K[0], K[1], K[2], ......, K[n-1]]
# 每个序列被乘 3 词, 即 `window_size = 3`。为示意,仅列出主要计算,省略了一些计算。
```
### 随机注意力
随机注意力确保每个查询词元也会关注一些随机词元。对实现而言,这意味着模型随机选取一些词元并计算它们的注意力分数。
```python
# r1, r2, r 为随机索引; 注意 r1, r2, r 每行取值不同 👇
Q[1] x [Q[r1], Q[r2], ......, Q[r]]
.
.
.
Q[n-2] x [Q[r1], Q[r2], ......, Q[r]]
# 不用管第 0 个和第 n-1 个词元,因为它们已经是全局词元了。
```
**注意:** 当前的实现进一步将序列划分为块,并且每个符号都依块而定义而非依词元而定义。我们在下一节中会更详细地讨论这个问题。
### 实现
**回顾:** 在常规 BERT 注意力中,一系列词元,即 $X = x_1, x_2, …., x_n$ 通过线性层投影到 $Q,K,V$,并基于它们计算注意力分数 $Z$,公式为 $Z=Softmax(QK^T)$。使用 BigBird 块稀疏注意力时,我们使用相同的算法,但仅针对一些选定的查询和键向量进行计算。
我们来看看 BigBird 块稀疏注意力是如何实现的。首先,我们用 $b、r、s、g$ 分别代表 `block_size` 、`num_random_blocks` 、`num_sliding_blocks` 、`num_global_blocks` 。我们以 $b=4,r=1,g=2,s=3,d=5$ 为例来说明 BigBird 块稀疏注意力的机制部分,如下所示:
<img src="https://huggingface.co/blog/assets/18_big_bird/intro.png" width=500 height=250>
${q} _{1}、{q}_ {2}、{q} _{3:n-2}、{q}_ {n-1}、{q}_{n}$ 的注意力分数分别计算如下:
---
$\mathbf{q}_{1}$ 的注意力分数由 $a_1$ 表示,其中 $a_1=Softmax(q_1 * K^T)$,即为第一块中的所有词元与序列中的所有其他词元之间的注意力分数。

$q_1$ 表示第 1 块,$g_i$ 表示第 $i$ 块。我们仅在 $q_1$ 和 $g$ (即所有键) 之间执行正常的注意力操作。
---
为了计算第二块中词元的注意力分数,我们收集前三块、最后一块和第五块。然后我们可以计算 $a_2 = Softmax(q_2 * concat(k_1, k_2, k_3, k_5, k_7))$。
_这里,我用 $g,r,s$ 表示词元只是为了明确地表示它们的性质 (即是全局、随机还是滑动词元),只用 $k$ 无法表示他们各自的性质。_
---
为了计算 ${q} _{3:n-2}$ 的注意力分数,我们先收集相应的全局、滑动、随机键向量,并基于它们正常计算 ${q}_ {3:n-2}$ 上的注意力。请注意,正如前面滑动注意力部分所讨论的,滑动键是使用特殊的移位技巧来收集的。

---
为了计算倒数第二块 (即 ${q} _{n-1}$) 中词元的注意力分数,我们收集第一块、最后三块和第三块的键向量。然后我们用公式 ${a}_ {n-1} = Softmax({q}_{n-1} * concat(k_1, k_3, k_5, k_6, k_7))$ 进行计算。这和计算 $q_2$ 非常相似。
---
最后一块 $\mathbf{q}_{n}$ 的注意力分数由 $a_n$ 表示,其中 $a_n=Softmax(q_n * K^T)$,只不过是最后一块中的所有词元与序列中的所有其他词元之间的注意力分数。这与我们对 $q_1$ 所做的非常相似。

---
我们将上面的矩阵组合起来得到最终的注意力矩阵。该注意力矩阵可用于获取所有词元的表征。
_上图中 `蓝色 -> 全局块` 、`红色 -> 随机块` 、`橙色 -> 滑动块` 。在前向传播过程中,我们不存储“白色”块,而是直接为每个单独的部分计算加权值矩阵 (即每个词元的表示),如上所述。_
现在,我们已经介绍了块稀疏注意力最难的部分,即它的实现。希望对你更好地理解实际代码有帮助。现在你可以深入研究代码了,在此过程中你可以将代码的每个部分与上面的某个部分联系起来以助于理解。
## 时间和内存复杂度
| 注意力类型 | 序列长度 | 时间和内存复杂度 |
|-----------------|-----------------|--------------------------|
| 原始完全注意力 | 512 | `T` |
| | 1024 | 4 x `T` |
| | 4096 | 64 x `T` |
| 块稀疏注意力 | 1024 | 2 x `T` |
| | 4096 | 8 x `T` |
_BERT 注意力和 BigBird 块稀疏注意力的时间和空间复杂度之比较。_
<details>
<summary> 展开以了解复杂度的计算过程。</summary>
```md
BigBird 时间复杂度 = O(w x n + r x n + g x n)
BERT 时间复杂度 = O(n^2)
假设:
w = 3 x 64
r = 3 x 64
g = 2 x 64
当序列长度为 512 时
=> **BERT 时间复杂度 = 512^2**
当序列长度为 1024 时
=> BERT 时间复杂度 = (2 x 512)^2
=> **BERT 时间复杂度 = 4 x 512^2**
=> BigBird 时间复杂度 = (8 x 64) x (2 x 512)
=> **BigBird 时间复杂度 = 2 x 512^2**
当序列长度为 4096 时
=> BERT 时间复杂度 = (8 x 512)^2
=> **BERT 时间复杂度 = 64 x 512^2**
=> BigBird 时间复杂度 = (8 x 64) x (8 x 512)
=> BigBird 时间复杂度 = 8 x (512 x 512)
=> **BigBird 时间复杂度 = 8 x 512^2**
```
</details>
## ITC 与 ETC
BigBird 模型可以使用 2 种不同的策略进行训练: **ITC** 和 **ETC**。 ITC (internal transformer construction,内部 transformer 构建) 就是我们上面讨论的。在 ETC (extended transformer construction,扩展 transformer 构建) 中,会有更多的全局词元,以便它们关注所有词元或者被所有词元关注。
ITC 需要的计算量较小,因为很少有词元是全局的,同时模型可以捕获足够的全局信息 (也可以借助随机注意力)。而 ETC 对于需要大量全局词元的任务非常有帮助,例如对 **问答** 类任务而言,整个问题应该被所有上下文关注,以便能够将上下文正确地与问题相关联。
_**注意:** BigBird 论文显示,在很多 ETC 实验中,随机块的数量设置为 0。考虑到我们上文图解部分的讨论,这是合理的。_
下表总结了 ITC 和 ETC:
| | ITC | ETC |
|----------------------------------------------|---------------------------------------|--------------------------------------|
| 全局注意力的注意力矩阵 | \\( A = \begin{bmatrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & & & & & & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix} \\) | \\( B = \begin{bmatrix} 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & & & & & & 1 \\ 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 & 1 \end{bmatrix} \\) |
| 全局词元 | 2 x `block_size` | `extra_tokens` + 2 x `block_size` |
| 随机词元 | `num_random_blocks` x `block_size` | `num_random_blocks` x `block_size` |
| 滑动词元 | 3 x `block_size` | 3 x `block_size` |
## 在 🤗Transformers 中使用 BigBird
你可以像使用任何其他 🤗 模型一样使用 `BigBirdModel` 。我们看一下代码:
```python
from transformers import BigBirdModel
# 从预训练 checkpoint 中加载 bigbird 模型
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base")
# 使用默认配置初始化模型,如 attention_type = "block_sparse",num_random_blocks = 3,block_size = 64
# 你也可以按照自己的需要改变这些参数。这 3 个参数只改变每个查询词元关注的词元数。
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", num_random_blocks=2, block_size=16)
# 通过把 attention_type 设成 `original_full`,BigBird 就会用复杂度为 n^2 的完全注意力。此时,BigBird 与 BERT 相似度为 99.9%。
model = BigBirdModel.from_pretrained("google/bigbird-roberta-base", attention_type="original_full")
```
截至现在, **🤗 Hub** 中总共有 **3 个 BigBird checkpoint**: [`bigbird-roberta-base`](https://huggingface.co/google/bigbird-roberta-base),[`bigbird-roberta-large`](https://huggingface.co/google/bigbird-roberta-large) 以及 [`bigbird-base-trivia-itc`](https://huggingface.co/google/bigbird-base-trivia-itc)。前两个检查点是使用 `masked_lm 损失` 预训练 `BigBirdForPretraining` 而得; 而最后一个是在 `trivia-qa` 数据集上微调 `BigBirdForQuestionAnswering` 而得。
让我们看一下如果用你自己喜欢的 PyTorch 训练器,最少需要多少代码就可以使用 🤗 的 BigBird 模型来微调你自己的任务。
```python
# 以问答任务为例
from transformers import BigBirdForQuestionAnswering, BigBirdTokenizer
import torch
device = torch.device("cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
# 我们用预训练权重初始化 bigbird 模型,并随机初始化其头分类器
model = BigBirdForQuestionAnswering.from_pretrained("google/bigbird-roberta-base", block_size=64, num_random_blocks=3)
tokenizer = BigBirdTokenizer.from_pretrained("google/bigbird-roberta-base")
model.to(device)
dataset = "torch.utils.data.DataLoader object"
optimizer = "torch.optim object"
epochs = ...
# 最简训练循环
for e in range(epochs):
for batch in dataset:
model.train()
batch = {k: batch[k].to(device) for k in batch}
# 前向
output = model(**batch)
# 后向
output["loss"].backward()
optimizer.step()
optimizer.zero_grad()
# 将最终权重存至本地目录
model.save_pretrained("<YOUR-WEIGHTS-DIR>")
# 将权重推到 🤗 Hub 中
from huggingface_hub import ModelHubMixin
ModelHubMixin.push_to_hub("<YOUR-WEIGHTS-DIR>", model_id="<YOUR-FINETUNED-ID>")
# 使用微调后的模型,以用于推理
question = ["How are you doing?", "How is life going?"]
context = ["<some big context having ans-1>", "<some big context having ans-2>"]
batch = tokenizer(question, context, return_tensors="pt")
batch = {k: batch[k].to(device) for k in batch}
model = BigBirdForQuestionAnswering.from_pretrained("<YOUR-FINETUNED-ID>")
model.to(device)
with torch.no_grad():
start_logits, end_logits = model(**batch).to_tuple()
# 这里,你可以使用自己的策略对 start_logits,end_logits 进行解码
# 注意:
# 该代码段仅用于展示即使你想用自己的 PyTorch 训练器微调 BigBrid,这也是相当容易的。
# 我会建议使用 🤗 Trainer,它更简单,功能也更多。
```
使用 BigBird 时,需要记住以下几点:
- 序列长度必须是块大小的倍数,即 `seqlen % block_size = 0` 。你不必担心,因为如果 batch 的序列长度不是 `block_size` 的倍数,🤗 transformers 会自动填充至最近的整数倍。
- 目前,Hugging Face 的实现 **尚不支持 ETC**,因此只有第一个和最后一个块是全局的。
- 当前实现不支持 `num_random_blocks = 0` 。
- 论文作者建议当序列长度 < 1024 时设置 `attention_type = "original_full"` 。
- 必须满足: `seq_length > global_token + random_tokens + moving_tokens + buffer_tokens` ,其中 `global_tokens = 2 x block_size` 、 `sliding_tokens = 3 x block_size` 、 `random_tokens = num_random_blocks x block_size` 且 `buffer_tokens = num_random_blocks x block_size` 。如果你不能满足这一点,🤗 transformers 会自动将 `attention_type` 切换为 `original_full` 并告警。
- 当使用 BigBird 作为解码器 (或使用 `BigBirdForCasualLM` ) 时, `attention_type` 应该是 `original_full` 。但你不用担心,🤗 transformers 会自动将 `attention_type` 切换为 `original_full` ,以防你忘记这样做。
## 下一步
[@patrickvonplaten](https://github.com/patrickvonplaten) 建了一个非常酷的 [笔记本](https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Evaluating_Big_Bird_on_TriviaQA.ipynb),以展示如何在 `trivia-qa` 数据集上评估 `BigBirdForQuestionAnswering` 。你可以随意用这个笔记本来玩玩 BigBird。
**BigBird 版的 Pegasus** 模型很快就会面世,你可将它们用于 **长文档摘要** 💥。
## 尾注
你可在 [此处](https://github.com/google-research/bigbird/blob/master/bigbird/core/attention.py) 找到 **块稀疏注意力矩阵** 的原始实现。🤗 版的实现在 [这儿](https://github.com/huggingface/transformers/tree/master/src/transformers/models/big_bird)。
| 4 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/Lora-for-sequence-classification-with-Roberta-Llama-Mistral.md | ---
title: "在灾难推文分析场景上比较用 LoRA 微调 Roberta、Llama 2 和 Mistral 的过程及表现"
thumbnail: /blog/assets/Lora-for-sequence-classification-with-Roberta-Llama-Mistral/Thumbnail.png
authors:
- user: mehdiiraqui
guest: true
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 在灾难推文分析场景上比较用 LoRA 微调 Roberta、Llama 2 和 Mistral 的过程及表现
<!-- TOC -->
- [在灾难推文分析场景上比较用 LoRA 微调 Roberta、Llama 2 和 Mistral 的过程及表现](#在灾难推文分析场景上比较用-lora-微调-robertallama-2-和-mistral-的过程及表现)
- [引言](#引言)
- [使用的硬件](#使用的硬件)
- [目标](#目标)
- [软件依赖](#软件依赖)
- [预训练模型](#预训练模型)
- [RoBERTa](#roberta)
- [Llama 2](#llama-2)
- [Mistral 7B](#mistral-7b)
- [LoRA](#lora)
- [环境设置](#环境设置)
- [数据准备](#数据准备)
- [数据加载](#数据加载)
- [数据处理](#数据处理)
- [模型](#模型)
- [RoBERTa](#roberta-1)
- [为分类任务加载 RoBERTa 检查点](#为分类任务加载-roberta-检查点)
- [RoBERTa 分类器的 LoRA 设置](#roberta-分类器的-lora-设置)
- [Mistral](#mistral)
- [为分类任务加载检查点](#为分类任务加载检查点)
- [Mistral 7B 分类器的 LoRA 设置](#mistral-7b-分类器的-lora-设置)
- [Llama 2](#llama-2-1)
- [为分类任务加载检查点](#为分类任务加载检查点-1)
- [Llama 2 分类器的 LoRA 设置](#llama-2-分类器的-lora-设置)
- [设置 `Trainer`](#设置-trainer)
- [评估指标](#评估指标)
- [基于加权损失的自定义 `Trainer`](#基于加权损失的自定义-trainer)
- [Trainer 设置](#trainer-设置)
- [RoBERTa](#roberta-2)
- [Mistral-7B](#mistral-7b-1)
- [Llama 2](#llama-2-2)
- [超参调优](#超参调优)
- [结果](#结果)
- [总结](#总结)
- [资源](#资源)
<!-- /TOC -->
## 引言
自然语言处理 (NLP) 领域的进展日新月异,你方唱罢我登场。因此,在实际场景中,针对特定的任务,我们经常需要对不同的语言模型进行比较,以寻找最适合的模型。本文主要比较 3 个模型: RoBERTa、Mistral-7B 及 Llama-2-7B。我们用它们来解决一个常见问题 —— 对灾难相关的推文进行分类。值得注意的是,Mistral 和 Llama 2 是 70 亿参数的大模型。相形之下,RoBERTa-large (355M 参数) 只是一个小模型,我们用它作为比较的基线。
本文,我们使用 PEFT (Parameter-Efficient Fine-Tuning,参数高效微调) 技术: LoRA (Low-Rank Adaptation,低秩适配) 来微调带序列分类任务头的预训练模型。LoRA 旨在显著减少可训参数量,同时保持强大的下游任务性能。
本文的主要目标是通过对 Hugging Face 的三个预训练模型进行 LoRA 微调,使之适用于序列分类任务。这三个预训练模型分别是: [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf)、[mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) 及 [roberta-large](https://huggingface.co/roberta-large)。
## 使用的硬件
- 节点数: 1
- 每个节点的 GPU 数: 1
- GPU 类型: A6000
- GPU 显存: 48GB
## 目标
- 使用 LoRA PEFT 方法对预训练 LLM 进行微调。
- 了解如何使用 Hugging Face 的各种 API ([transformers](https://huggingface.co/docs/transformers/index)、[peft](https://huggingface.co/docs/peft/index) 以及 [datasets](https://huggingface.co/docs/datasets/index))。
- 使用 [Weights & Biases](https://wandb.ai) 进行超参调优以及实验日志记录。
## 软件依赖
```bash
datasets
evaluate
peft
scikit-learn
torch
transformers
wandb
```
注意: 要准确重现本文结果,请注意确保软件版本与 [wandb 报告](#资源) 的一致。
## 预训练模型
### [RoBERTa](https://arxiv.org/abs/1907.11692)
RoBERTa (Robustly Optimized BERT Approach) 是 Meta AI 研究团队提出的改进版 BERT 模型。BERT 是一种基于 transformer 的语言模型,其基于自注意力机制对单词进行上下文感知的表征,并基于掩码语言模型目标进行训练。请注意,BERT 作为编码器模型,仅可用于自然语言理解任务 (例如序列分类和词元分类)。
RoBERTa 是一种流行的可微调模型,很适合作为我们实验的基线。欲了解更多信息,你可以查阅其 Hugging Face [模型卡](https://huggingface.co/docs/transformers/model_doc/roberta)。
### [Llama 2](https://arxiv.org/abs/2307.09288)
Llama 2 (Large Language Model Meta AI) 是 Meta AI 推出的一系列大语言模型 (LLM),其模型大小各异,参数量从 70 亿到 650 亿不等。
Llama 2 是一种基于 transformer 解码器架构的自回归语言模型。Llama 2 接受单词序列作为输入,并基于滑动窗口迭代预测下一个词元,从而实现文本生成的功能。
Llama 2 的架构与 GPT-3 等模型略有不同。举几个例子,Llama 2 采用 SwiGLU 激活函数而不是 ReLU,另外其位置嵌入使用的是旋转位置嵌入而不是可训绝对位置嵌入。
最近发布的 Llama 2 还对架构进行了改进,其将支持的最大上下文长度扩展到 4096 个词元,并使用分组查询注意 (grouped-query attention,GQA) 解码机制来更好地利用长序列。
### [Mistral 7B](https://arxiv.org/abs/2310.06825)
Mistral 7B v0.1 有 73 亿个参数,是 Mistral AI 推出的第一个 LLM。
Mistral 7B 架构使用的新技术主要有:
- 滑窗注意力: 用基于滑动窗口的注意力替换完整注意力 (平方级计算成本),其中每个词元最多可以关注上一层的 4096 个词元 (线性计算成本)。这样,多层以后,Mistral 7B 的实际关注词元数会叠加,因此更高层的注意力实际关注的总历史词元数会超过 4096。
- 分组查询注意力: Llama 2 也使用了该技术,其通过缓存先前解码的词元的键向量和值向量来优化推理过程 (减少处理时间)。
## [LoRA](https://arxiv.org/abs/2106.09685)
PEFT (Parameter Efficient Fine-Tuning,参数高效微调) 包含 p-tuning、前缀微调 (prefix-tuning) 、IA3、适配器微调以及 LoRA 等一系列技术,其旨在通过仅微调大模型的一个小参数集,就能达到全模型微调的性能水平。
LoRA (Low-Rank Adaptation,低阶适配) 的方法与添加适配层类似。其主要目标是减少模型的可训参数量。LoRA 的主要做法是冻结预训练权重,仅更新一个新增的低秩矩阵。

## 环境设置
RoBERTa 支持的最大序列长度为 512,为公平起见,对所有模型,我们统一设定 `MAX_LEN=512` 。
```python
MAX_LEN = 512
roberta_checkpoint = "roberta-large"
mistral_checkpoint = "mistralai/Mistral-7B-v0.1"
llama_checkpoint = "meta-llama/Llama-2-7b-hf"
```
## 数据准备
### 数据加载
从 Hugging Face 加载数据集:
```python
from datasets import load_dataset
dataset = load_dataset("mehdiiraqui/twitter_disaster")
```
将数据集分为训练集和验证集,同时加载测试集:
```python
from datasets import Dataset
# 将数据集的训练集划分为训练集和验证集
data = dataset['train'].train_test_split(train_size=0.8, seed=42)
# 把划分而得的测试集重命名为验证集
data['val'] = data.pop("test")
# 将原数据集的测试集仍作为测试集
data['test'] = dataset['test']
```
以下是数据集概览:
```bash
DatasetDict({
train: Dataset({
features: ['id', 'keyword', 'location', 'text', 'target'],
num_rows: 6090
})
val: Dataset({
features: ['id', 'keyword', 'location', 'text', 'target'],
num_rows: 1523
})
test: Dataset({
features: ['id', 'keyword', 'location', 'text', 'target'],
num_rows: 3263
})
})
```
首先,检查一下数据分布:
```python
import pandas as pd
data['train'].to_pandas().info()
data['test'].to_pandas().info()
```
- 训练集
```<class 'pandas.core.frame.DataFrame'>
RangeIndex: 7613 entries, 0 to 7612
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 7613 non-null int64
1 keyword 7552 non-null object
2 location 5080 non-null object
3 text 7613 non-null object
4 target 7613 non-null int64
dtypes: int64(2), object(3)
memory usage: 297.5+ KB
```
- 测试集
```
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 3263 entries, 0 to 3262
Data columns (total 5 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 id 3263 non-null int64
1 keyword 3237 non-null object
2 location 2158 non-null object
3 text 3263 non-null object
4 target 3263 non-null int64
dtypes: int64(2), object(3)
memory usage: 127.6+ KB
```
**训练集中标签分布情况:**
```
target
0 4342
1 3271
Name: count, dtype: int64
```
由于类别不平衡,我们计算一下正负类权重,以用于稍后的损失计算:
```python
pos_weights = len(data['train'].to_pandas()) / (2 * data['train'].to_pandas().target.value_counts()[1])
neg_weights = len(data['train'].to_pandas()) / (2 * data['train'].to_pandas().target.value_counts()[0])
```
计算出的权重为:
```
POS_WEIGHT, NEG_WEIGHT = (1.1637114032405993, 0.8766697374481806)
```
接着,我们计算文本序列的最大长度:
```python
# 字符数
max_char = data['train'].to_pandas()['text'].str.len().max()
# 词数
max_words = data['train'].to_pandas()['text'].str.split().str.len().max()
```
```
The maximum number of characters is 152.
The maximum number of words is 31.
```
### 数据处理
以一条训练数据为例:
```python
data['train'][0]
```
```
{'id': 5285,
'keyword': 'fear',
'location': 'Thibodaux, LA',
'text': 'my worst fear. https://t.co/iH8UDz8mq3',
'target': 0}
```
该数据中包括关键字、位置和推文。为了简单起见,我们选择 `text` 特征作为 LLM 的唯一输入。
本阶段的目标是为 LLM 微调准备所需的 Hugging Face 格式的训练集、验证集和测试集。然后是定义用于训练的词元数据集,使用合适的分词器将 `text` 特征转换为词元 id 和注意力掩码序列这两个张量。由于每个模型都有其特定的分词器,因此我们需要生成三个不同的数据集,每个模型一个。
我们首先定义 RoBERTa 模型的数据加载器:
- 加载与分词:
```python
from transformers import AutoTokenizer
roberta_tokenizer = AutoTokenizer.from_pretrained(roberta_checkpoint, add_prefix_space=True)
```
**注意:** RoBERTa 分词器经过训练已将空格视为词元的一部分。因此,如果句子的第一个单词前面没有空格,则其编码会有所不同。为了确保第一个单词包含空格,我们设置 `add_prefix_space=True` 。同时,为了保持三个模型的预处理一致,我们将 Llama 2 和 Mistral 7B 的相应参数也设为 `True` 。
- 定义每条数据的预处理函数:
```python
def roberta_preprocessing_function(examples):
return roberta_tokenizer(examples['text'], truncation=True, max_length=MAX_LEN)
```
将预处理函数应用于训练数据集的第一条数据,我们得到了分词后的输入 ( `input_ids` ) 及其注意力掩码:
```python
roberta_preprocessing_function(data['train'][0])
```
```
{'input_ids': [0, 127, 2373, 2490, 4, 1205, 640, 90, 4, 876, 73, 118, 725, 398, 13083, 329, 398, 119, 1343, 246, 2], 'attention_mask': [1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1]}
```
- 现在,将预处理函数应用于整个数据集:
```python
col_to_delete = ['id', 'keyword','location', 'text']
# 删除不需要的列,并应用预处理函数
roberta_tokenized_datasets = data.map(roberta_preprocessing_function, batched=True, remove_columns=col_to_delete)
# 按照 HuggingFace 的要求,将 `target` 列 重命名为 `label` 列
roberta_tokenized_datasets = roberta_tokenized_datasets.rename_column("target", "label")
# 数据集格式设为 "torch"
roberta_tokenized_datasets.set_format("torch")
```
**注意:** 我们从数据中删除了不需要的列: `id` 、 `keyword` 、 `location` 及 `text` 。删除 `text` 的原因是我们已经将其转换为输入 id 和注意力掩码:
分词后的训练数据集中的数据如下:
```python
roberta_tokenized_datasets['train'][0]
```
```
{'label': tensor(0),
'input_ids': tensor([ 0, 127, 2373, 2490, 4, 1205, 640, 90, 4, 876,
73, 118, 725, 398, 13083, 329, 398, 119, 1343, 246,
2]),
'attention_mask': tensor([1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1])}
```
- 为了生成训练 batch 数据,我们还需要对给定 batch 中的序列进行填充,以使 batch 中所有序列的长度都等于本 batch 最长序列的长度。为此,我们使用了 `DataCollatorWithPadding` 类:
```python
# 数据整理器将所有数据统一填充至 batch 内最长序列的长度
from transformers import DataCollatorWithPadding
roberta_data_collator = DataCollatorWithPadding(tokenizer=roberta_tokenizer)
```
用相同的流程为 Mistral 7B 和 Llama 2 模型准备数据:
**注意** Llama 2 和 Mistral 7B 没有默认的 `pad_token_id` ,我们将其设为 `eos_token_id` 。
- Mistral 7B:
```python
# 加载 Mistral 7B 分词器
from transformers import AutoTokenizer, DataCollatorWithPadding
mistral_tokenizer = AutoTokenizer.from_pretrained(mistral_checkpoint, add_prefix_space=True)
mistral_tokenizer.pad_token_id = mistral_tokenizer.eos_token_id
mistral_tokenizer.pad_token = mistral_tokenizer.eos_token
def mistral_preprocessing_function(examples):
return mistral_tokenizer(examples['text'], truncation=True, max_length=MAX_LEN)
mistral_tokenized_datasets = data.map(mistral_preprocessing_function, batched=True, remove_columns=col_to_delete)
mistral_tokenized_datasets = mistral_tokenized_datasets.rename_column("target", "label")
mistral_tokenized_datasets.set_format("torch")
# 序列填充
mistral_data_collator = DataCollatorWithPadding(tokenizer=mistral_tokenizer)
```
- Llama 2:
```python
# 加载 Llama 2 分词器
from transformers import AutoTokenizer, DataCollatorWithPadding
llama_tokenizer = AutoTokenizer.from_pretrained(llama_checkpoint, add_prefix_space=True)
llama_tokenizer.pad_token_id = llama_tokenizer.eos_token_id
llama_tokenizer.pad_token = llama_tokenizer.eos_token
def llama_preprocessing_function(examples):
return llama_tokenizer(examples['text'], truncation=True, max_length=MAX_LEN)
llama_tokenized_datasets = data.map(llama_preprocessing_function, batched=True, remove_columns=col_to_delete)
llama_tokenized_datasets = llama_tokenized_datasets.rename_column("target", "label")
llama_tokenized_datasets.set_format("torch")
# 序列填充
llama_data_collator = DataCollatorWithPadding(tokenizer=llama_tokenizer)
```
至此,我们已经准备好了分词后的数据集,下一节我们将讨论如何加载预训练 LLM 检查点以及如何设置 LoRA 权重。
## 模型
### RoBERTa
#### 为分类任务加载 RoBERTa 检查点
我们使用 Hugging Face `AutoModelForSequenceClassification` 类加载带有序列分类头的预训练 RoBERTa 模型:
```python
from transformers import AutoModelForSequenceClassification
roberta_model = AutoModelForSequenceClassification.from_pretrained(roberta_checkpoint, num_labels=2)
```
#### RoBERTa 分类器的 LoRA 设置
我们为 RoBERTa 分类器设置 LoRA 参数:
- TaskType: 序列分类
- r(rank): 分解矩阵的秩
- lora_alpha: 用于对习得权重进行缩放的 alpha 参数。LoRA 论文建议将 alpha 固定为 16
- lora_dropout: LoRA 层的 Dropout 概率
- bias: 是否向 LoRA 层添加偏置
以下代码使用了 [LoRA 论文](https://arxiv.org/abs/2106.09685) 的推荐设置。[后文](#超参调优) 我们还将用 `wandb` 对这些超参进行调优。
```python
from peft import get_peft_model, LoraConfig, TaskType
roberta_peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS, r=2, lora_alpha=16, lora_dropout=0.1, bias="none",
)
roberta_model = get_peft_model(roberta_model, roberta_peft_config)
roberta_model.print_trainable_parameters()
```
可以看到,可训参数量仅占 RoBERTa 模型参数量的 0.64%:
```bash
trainable params: 2,299,908 || all params: 356,610,052 || trainable%: 0.6449363911929212
```
### Mistral
#### 为分类任务加载检查点
加载带有序列分类头的预训练 Mistral-7B 模型:
```python
from transformers import AutoModelForSequenceClassification
import torch
mistral_model = AutoModelForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=mistral_checkpoint,
num_labels=2,
device_map="auto"
)
```
设置填充词元 id,因为 Mistral 7B 没有默认填充词元。
```python
mistral_model.config.pad_token_id = mistral_model.config.eos_token_id
```
#### Mistral 7B 分类器的 LoRA 设置
对 Mistral 7B 模型而言,我们需要指定 `target_modules` (我们将其指定为注意力模块的查询向量映射层和值向量映射层):
```python
from peft import get_peft_model, LoraConfig, TaskType
mistral_peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS, r=2, lora_alpha=16, lora_dropout=0.1, bias="none",
target_modules=[
"q_proj",
"v_proj",
],
)
mistral_model = get_peft_model(mistral_model, mistral_peft_config)
mistral_model.print_trainable_parameters()
```
可训参数量仅占 Mistral 模型参数量的 0.024%:
```
trainable params: 1,720,320 || all params: 7,112,380,416 || trainable%: 0.02418768259540745
```
### Llama 2
#### 为分类任务加载检查点
加载带有序列分类头的预训练 Llama 2 模型。
```python
from transformers import AutoModelForSequenceClassification
import torch
llama_model = AutoModelForSequenceClassification.from_pretrained(
pretrained_model_name_or_path=llama_checkpoint,
num_labels=2,
device_map="auto",
offload_folder="offload",
trust_remote_code=True
)
```
设置填充词元 id,因为 Llama 2 没有默认填充词元。
```python
llama_model.config.pad_token_id = llama_model.config.eos_token_id
```
#### Llama 2 分类器的 LoRA 设置
使用与 Mistral 相同的 LoRA 参数:
```python
from peft import get_peft_model, LoraConfig, TaskType
llama_peft_config = LoraConfig(
task_type=TaskType.SEQ_CLS, r=16, lora_alpha=16, lora_dropout=0.05, bias="none",
target_modules=[
"q_proj",
"v_proj",
],
)
llama_model = get_peft_model(llama_model, llama_peft_config)
llama_model.print_trainable_parameters()
```
可训参数量仅占 Llama 2 模型参数量的 0.12%:
```
trainable params: 8,404,992 || all params: 6,615,748,608 || trainable%: 0.1270452143516515
```
至此,我们定义了用于训练的词元数据集及 LoRA 设置。下面,我们介绍如何使用 Hugging Face 的 `Trainer` 类启动训练。
## 设置 `Trainer`
### 评估指标
首先,我们定义用于对三个模型的性能进行比较的指标: F1 分数、召回率、精确度和准确度:
```python
import evaluate
import numpy as np
def compute_metrics(eval_pred):
# HF `evaluate` 包已支持我们所要的所有指标
precision_metric = evaluate.load("precision")
recall_metric = evaluate.load("recall")
f1_metric= evaluate.load("f1")
accuracy_metric = evaluate.load("accuracy")
logits, labels = eval_pred
# eval_pred 是模型返回的预测值和实际值元组
predictions = np.argmax(logits, axis=-1)
precision = precision_metric.compute(predictions=predictions, references=labels)["precision"]
recall = recall_metric.compute(predictions=predictions, references=labels)["recall"]
f1 = f1_metric.compute(predictions=predictions, references=labels)["f1"]
accuracy = accuracy_metric.compute(predictions=predictions, references=labels)["accuracy"]
# `Trainer` 要求将指标组织为一个字典,其键为指标名,值为分数。
return {"precision": precision, "recall": recall, "f1-score": f1, 'accuracy': accuracy}
```
### 基于加权损失的自定义 `Trainer`
前文提到,数据集正负类分布并不平衡。因此,我们用加权交叉熵损失来训练模型以解决这个问题。 `Trainer` 类本身的实现中不支持自定义损失,因为它期望直接从模型的输出中获取损失。
因此,我们需要定义一个自定义的 `WeightedCELossTrainer` ,以重写 `compute_loss` 方法,该方法可以根据模型的预测和标签计算加权交叉熵损失:
```python
from transformers import Trainer
class WeightedCELossTrainer(Trainer):
def compute_loss(self, model, inputs, return_outputs=False):
labels = inputs.pop("labels")
# Get model's predictions
outputs = model(**inputs)
logits = outputs.get("logits")
# Compute custom loss
loss_fct = torch.nn.CrossEntropyLoss(weight=torch.tensor([neg_weights, pos_weights], device=model.device, dtype=logits.dtype))
loss = loss_fct(logits.view(-1, self.model.config.num_labels), labels.view(-1))
return (loss, outputs) if return_outputs else loss
```
### Trainer 设置
我们为三个模型分别设置训练超参及训练器。
#### RoBERTa
第一步,把模型搬到 GPU 设备上。
```python
roberta_model = roberta_model.cuda()
roberta_model.device()
```
It will print the following:
```
device(type='cuda', index=0)
```
然后,设置训练超参:
```python
from transformers import TrainingArguments
lr = 1e-4
batch_size = 8
num_epochs = 5
training_args = TrainingArguments(
output_dir="roberta-large-lora-token-classification",
learning_rate=lr,
lr_scheduler_type= "constant",
warmup_ratio= 0.1,
max_grad_norm= 0.3,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epochs,
weight_decay=0.001,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
report_to="wandb",
fp16=False,
gradient_checkpointing=True,
)
```
最后,我们将模型、训练超参和词元数据集一起作为参数来实例化一个 RoBERTa 训练器:
```python
roberta_trainer = WeightedCELossTrainer(
model=roberta_model,
args=training_args,
train_dataset=roberta_tokenized_datasets['train'],
eval_dataset=roberta_tokenized_datasets["val"],
data_collator=roberta_data_collator,
compute_metrics=compute_metrics
)
```
#### Mistral-7B
与 RoBERTa 类似,我们用如下代码初始化 `WeightedCELossTrainer` :
```python
from transformers import TrainingArguments, Trainer
mistral_model = mistral_model.cuda()
lr = 1e-4
batch_size = 8
num_epochs = 5
training_args = TrainingArguments(
output_dir="mistral-lora-token-classification",
learning_rate=lr,
lr_scheduler_type= "constant",
warmup_ratio= 0.1,
max_grad_norm= 0.3,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epochs,
weight_decay=0.001,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
report_to="wandb",
fp16=True,
gradient_checkpointing=True,
)
mistral_trainer = WeightedCELossTrainer(
model=mistral_model,
args=training_args,
train_dataset=mistral_tokenized_datasets['train'],
eval_dataset=mistral_tokenized_datasets["val"],
data_collator=mistral_data_collator,
compute_metrics=compute_metrics
)
```
**注意**,我们需要将 `fp16` 设为 `True` 以启用半精度训练。主要原因是 Mistral-7B 很大,如果使用 fp32 精度,其权重无法放进单块 GPU 的显存 (48GB) 中。
#### Llama 2
与 Mistral 7B 类似,我们用如下代码定义训练器:
```python
from transformers import TrainingArguments, Trainer
llama_model = llama_model.cuda()
lr = 1e-4
batch_size = 8
num_epochs = 5
training_args = TrainingArguments(
output_dir="llama-lora-token-classification",
learning_rate=lr,
lr_scheduler_type= "constant",
warmup_ratio= 0.1,
max_grad_norm= 0.3,
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
num_train_epochs=num_epochs,
weight_decay=0.001,
evaluation_strategy="epoch",
save_strategy="epoch",
load_best_model_at_end=True,
report_to="wandb",
fp16=True,
gradient_checkpointing=True,
)
llama_trainer = WeightedCELossTrainer(
model=llama_model,
args=training_args,
train_dataset=llama_tokenized_datasets['train'],
eval_dataset=llama_tokenized_datasets["val"],
data_collator=llama_data_collator,
compute_metrics=compute_metrics
)
```
## 超参调优
我们用 Wandb Sweep API 通过贝叶斯搜索策略来进行超参调优 (30 次运行),待调优的超参搜索空间如下:
| 方法 | 指标 | lora_alpha | lora_bias | lora_dropout | lora_rank | lr | max_length |
|--------|---------------------|-------------------------------------------|---------------------------|-------------------------|----------------------------------------------------|-----------------------------|---------------------------|
| bayes | 目标: maximize | 分布: categorical | 分布: categorical | 分布: uniform | 分布: categorical | 分布: uniform | 分布: categorical |
| | 目标名: eval/f1-score | 取值集合: <br>-16 <br>-32 <br>-64 | 取值集合: None | -最大值: 0.1 <br>-最小值: 0 | 取值集合: <br>-4 <br>-8 <br>-16 <br>-32 | -最大值: 2e-04<br>-最小值: 1e-05 | 取值集合: 512 | |
欲了解更多信息,可以查看 [资源](#资源) 一节中的 Wandb 实验报告。
## 结果
| 模型 | F1 分数 | 训练时间 | 内存消耗 | 可训参数量 |
|---------|----------|----------------|------------------------------|--------------------------------|
| RoBERTa | 0.8077 | 538 秒 | GPU1: 9.1 GB<br>GPU2: 8.3 GB | 0.64% |
| Mistral 7B | 0.7364 | 2030 秒 | GPU1: 29.6 Gb<br>GPU2: 29.5 GB | 0.024% |
| Llama 2 | 0.7638 | 2052 秒 | GPU1: 35 GB <br>GPU2: 33.9 GB | 0.12% |
## 总结
本文我们用 LoRA 对三个大语言模型 (LLM) (RoBERTa、Mistral 7B 及 Llama 2) 针对灾难推文分类任务进行微调。从性能结果来看,RoBERTa 的性能大幅优于 Mistral 7B 和 Llama 2。这就提出了一个问题: 我们是否真的需要一个大而复杂的 LLM 来完成诸如短序列二分类这样的简单任务?
一个重要的启示是,在选择要使用的 LLM 模型时应该考虑具体的项目要求、可用资源和性能需求。
此外,对于针对短序列的相对 _简单_ 的预测任务,小的基础模型 (例如 RoBERTa) 仍然具有竞争力。
最后,我们还通过例子展示了 LoRA 方法的通用性,其既可应用于编码器 (RoBERTa) 模型,还可应用于解码器 (Llama 2 及 Mistral 7B) 模型。
## 资源
1. 本文代码均已在该 [Github 项目](https://github.com/mehdiir/Roberta-Llama-Mistral/)。
2. 下面是各模型的 Wandb 超参调优实验报告:
- [RoBERTa](https://api.wandb.ai/links/mehdi-iraqui/505c22j1)
- [Mistral 7B](https://api.wandb.ai/links/mehdi-iraqui/24vveyxp)
- [Llama 2](https://api.wandb.ai/links/mehdi-iraqui/qq8beod0) | 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/gptq-integration.md | ---
title: "使用 AutoGPTQ 和 transformers 让大语言模型更轻量化"
thumbnail: /blog/assets/159_autogptq_transformers/thumbnail.jpg
authors:
- user: marcsun13
- user: fxmarty
- user: PanEa
guest: true
- user: qwopqwop
guest: true
- user: ybelkada
- user: TheBloke
guest: true
translators:
- user: PanEa
guest: true
- user: zhongdongy
proofreader: true
---
# 使用 AutoGPTQ 和 transformers 让大语言模型更轻量化
大语言模型在理解和生成人类水平的文字方面所展现出的非凡能力,正在许多领域带来应用上的革新。然而,在消费级硬件上训练和部署大语言模型的需求也变得越来越难以满足。
🤗 Hugging Face 的核心使命是 _让优秀的机器学习普惠化_ ,而这正包括了尽可能地让所有人都能够使用上大模型。本着 [与 bitsandbytes 合作](https://huggingface.co/blog/4bit-transformers-bitsandbytes) 一样的精神,我们将 [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) 代码库集成到了 Transformers 中,让用户使用 GPTQ 算法 ([Frantar et al. 2023](https://arxiv.org/pdf/2210.17323.pdf)) 在 8 位、4 位、3 位,甚至是 2 位精度下量化和运行模型成为可能。当使用 int4 量化时,精度的下降可以忽略不计,同时在小批量推理上保持着与 `fp16` 基线相当的速度。 需要注意的是,GPTQ 方法与 bitsandbytes 提出的训练后量化方法有所不同:它需要在量化阶段提供一个校准数据集。
本次集成支持英伟达 GPU 和基于 RoCm 的 AMD GPU。
## 目录
- [相关资源](#相关资源)
- [**GPTQ 论文总结**](#--gptq-论文总结--)
- [AutoGPTQ 代码库——一站式地将 GPTQ 方法应用于大语言模型](#autogptq-代码库——一站式地将-gptq-方法应用于大语言模型)
- [🤗 Transformers 对 GPTQ 模型的本地化支持](#---transformers-对-gptq-模型的本地化支持)
- [使用 **Optimum 代码库** 量化模型](#使用---optimum-代码库---量化模型)
- [通过 ***Text-Generation-Inference*** 使用 GPTQ 模型](#通过----text-generation-inference----使用-gptq-模型)
- [**使用 PEFT 微调量化后的模型**](#--使用-peft-微调量化后的模型--)
- [改进空间](#改进空间)
* [已支持的模型](#已支持的模型)
- [结论和结语](#结论和结语)
- [致谢](#致谢)
## 相关资源
本文及相关版本发布提供了一些资源来帮助用户开启 GPTQ 量化的旅程:
- [原始论文](https://arxiv.org/pdf/2210.17323.pdf)
- [运行于 Google Colab 笔记本上的基础用例](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) —— 该笔记本上的用例展示了如何使用 GPTQ 方法量化你的 transformers 模型、如何进行量化模型的推理,以及如何使用量化后的模型进行微调。
- Transformers 中集成 GPTQ 的 [说明文档](https://huggingface.co/docs/transformers/main/en/main_classes/quantization)
- Optimum 中集成 GPTQ 的 [说明文档](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
- TheBloke [模型仓库](https://huggingface.co/TheBloke?sort_models=likes#models) 中的 GPTQ 模型。
## **GPTQ 论文总结**
通常,量化方法可以分为以下两类:
1. 训练后量化 (Post Training Quantization, PTQ):适度地使用一些资源来量化预训练好的模型,如一个校准数据集和几小时的算力。
2. 量化感知训练 (Quantization Aware Training, QAT):在训练或进一步微调之前执行量化。
GPTQ 属于训练后量化,这对于大模型而言格外有趣且有意义,因为对其进行全参数训练以及甚至仅仅是微调都十分昂贵。
具体而言,GPTQ 采用 int4/fp16 (W4A16) 的混合量化方案,其中模型权重被量化为 int4 数值类型,而激活值则保留在 float16。在推理阶段,模型权重被动态地反量化回 float16 并在该数值类型下进行实际的运算。
该方案有以下两方面的优点:
- int4 量化能够节省接近4倍的内存,这是因为反量化操作发生在算子的计算单元附近,而不是在 GPU 的全局内存中。
- 由于用于权重的位宽较低,因此可以节省数据通信的时间,从而潜在地提升了推理速度。
GPTQ 论文解决了分层压缩的问题:
给定一个拥有权重矩阵 \\(W_{l}\\) 和输入 \\(X_{l}\\) 的网络层 \\(l\\),我们期望获得一个量化版本的权重矩阵 \\(\hat{W}_{l}\\) 以最小化均方误差 (MSE):
\\({\hat{W}_{l}}^{*} = argmin_{\hat{W_{l}}} \|W_{l}X-\hat{W}_{l}X\|^{2}_{2}\\)
一旦每层都实现了上述目标,就可以通过组合各网络层量化结果的方式来获得一个完整的量化模型。
为解决这一分层压缩问题,论文作者采用了最优脑量化 (Optimal Brain Quantization, OBQ) 框架 ([Frantar et al 2022](https://arxiv.org/abs/2208.11580)) 。OBQ 方法的出发点在于其观察到:以上等式可以改写成权重矩阵 \\(W_{l}\\) 每一行的平方误差之和
\\( \sum_{i=0}^{d_{row}} \|W_{l[i,:]}X-\hat{W}_{l[i,:]}X\|^{2}_{2} \\)
这意味着我们可以独立地对每一行执行量化。即所谓的 per-channel quantization。对每一行 \\(W_{l[i,:]}\\),OBQ 在每一时刻只量化一个权重,同时更新所有未被量化的权重,以补偿量化单个权重所带来的误差。所选权重的更新采用一个闭环公式,并利用了海森矩阵 (Hessian Matrices)。
GPTQ 论文通过引入一系列优化措施来改进上述量化框架,在降低量化算法复杂度的同时保留了模型的精度。
相较于 OBQ,GPTQ 的量化步骤本身也更快:OBQ 需要花费 2 个 GPU 时来完成 BERT 模型 (336M) 的量化,而使用 GPTQ,量化一个 Bloom 模型 (176B) 则只需不到 4 个 GPU 时。
为了解算法的更多细节以及在困惑度 (perplexity, PPL) 指标和推理速度上的不同测评数据,可查阅原始 [论文](https://arxiv.org/pdf/2210.17323.pdf) 。
## AutoGPTQ 代码库——一站式地将 GPTQ 方法应用于大语言模型
AutoGPTQ 代码库让用户能够使用 GPTQ 方法量化 🤗 Transformers 中支持的大量模型,而社区中的其他平行工作如 [GPTQ-for-LLaMa](https://github.com/qwopqwop200/GPTQ-for-LLaMa) 、[Exllama](https://github.com/turboderp/exllama) 和 [llama.cpp](https://github.com/ggerganov/llama.cpp/) 则主要针对 Llama 模型架构实现量化策略。相较之下,AutoGPTQ 因其对丰富的 transformers 架构的平滑覆盖而广受欢迎。
正因为 AutoGPTQ 代码库覆盖了大量的 transformers 模型,我们决定提供一个 🤗 Transformers 的 API 集成,让每个人都能够更容易地使用大语言模型量化技术。截止目前,我们已经集成了包括 CUDA 算子在内的最常用的优化选项。对于更多高级选项如使用 Triton 算子和(或)兼容注意力的算子融合,请查看 [AutoGPTQ](https://github.com/PanQiWei/AutoGPTQ) 代码库。
## 🤗 Transformers 对 GPTQ 模型的本地化支持
在 [安装 AutoGPTQ 代码库](https://github.com/PanQiWei/AutoGPTQ#quick-installation) 和 `optimum` (`pip install optimum`) 之后,在 Transformers 中运行 GPTQ 模型将非常简单:
```python
from transformers import AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("TheBloke/Llama-2-7b-Chat-GPTQ", torch_dtype=torch.float16, device_map="auto")
```
请查阅 Transformers 的 [说明文档](https://huggingface.co/docs/transformers/main/en/main_classes/quantization) 以了解有关所有特性的更多信息。
我们的 AutoGPTQ 集成有以下诸多优点:
- 量化模型可被序列化并在 Hugging Face Hub 上分享。
- GPTQ 方法大大降低运行大语言模型所需的内存,同时保持着与 FP16 相当的推理速度。
- AutoGPTQ 在更广泛的 transformers 架构上支持 Exllama 算子。
- 该集成带有基于 RoCm 的 AMD GPU 的本地化支持。
- 能够 [**使用 PEFT 微调量化后的模型**](#--使用-peft-微调量化后的模型--) 。
你可以在 Hugging Face Hub 上查看你所喜爱的模型是否已经拥有 GPTQ 量化版本。TheBloke,Hugging Face 的顶级贡献者之一,已经使用 AutoGPTQ 量化了大量的模型并分享在 Hugging Face Hub 上。在我们的共同努力下,这些模型仓库都将可以与我们的集成一起开箱即用。
以下是一个使用 batch size = 1 的测评结果示例。该测评结果通过在英伟达 A100-SXM4-80GB GPU 上运行得到。我们使用长度为 512 个词元的提示文本,并精确地生成 512 个新词元。表格的第一行展示的是未量化的 `fp16` 基线,另外两行则展示使用 AutoGPTQ 不同算子的内存开销和推理性能。
| gptq | act_order | bits | group_size | kernel | Load time (s) | Per-token latency (ms) | Throughput (tokens/s) | Peak memory (MB) |
|-------|-----------|------|------------|-------------------|---------------|------------------------|-----------------------|------------------|
| False | None | None | None | None | 26.0 | 36.958 | 27.058 | 29152.98 |
| True | False | 4 | 128 | exllama | 36.2 | 33.711 | 29.663 | 10484.34 |
| True | False | 4 | 128 | autogptq-cuda-old | 36.2 | 46.44 | 21.53 | 10344.62 |
一个更全面的、可复现的测评结果可以在[这里](https://github.com/huggingface/optimum/tree/main/tests/benchmark#gptq-benchmark) 取得。
## 使用 **Optimum 代码库** 量化模型
为了将 AutoGPTQ 无缝集成到 Transformers 中,我们使用了 AutoGPTQ API 的一个极简版本,其可在 [Optimum](https://github.com/huggingface/optimum) 中获得 —— 这是 Hugging Face 针对训练和推理优化而开发的一个工具包。通过这种方式,我们轻松地实现了与 Transformers 的集成,同时,如果人们想要量化他们自己的模型,他们也完全可以单独使用 Optimum 的 API!如果想要量化你自己的大语言模型,请查阅 Optimum 的 [说明文档](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization) 。
只需数行代码,即可使用 GPTQ 方法量化 🤗 Transformers 的模型:
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, GPTQConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = GPTQConfig(bits=4, dataset = "c4", tokenizer=tokenizer)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto", quantization_config=quantization_config)
```
量化一个模型可能花费较长的时间。对于一个 175B 参数量的模型,如果使用一个大型校准数据集(如 “c4”),至少需要 4 个 GPU 时。正如上面提到的那样,许多 GPTQ 模型已经可以在 Hugging Face Hub 上被取得,这让你在大多数情况下无需自行量化模型。当然,你仍可以使用你所专注的特定领域的数据集来量化模型。
## 通过 ***Text-Generation-Inference*** 使用 GPTQ 模型
在将 GPTQ 集成到 Transformers 中的同时,[Text-Generation-Inference 代码库](https://github.com/huggingface/text-generation-inference) (TGI) 已经添加了 GPTQ 的支持,旨在为生产中的大语言模型提供服务。现在,GPTQ 已经可以与动态批处理、paged attention、flash attention 等特性一起被应用于 [广泛的 transformers 模型架构](https://huggingface.co/docs/text-generation-inference/main/en/supported_models) 。
例如,这一集成允许在单个 A100-80GB GPU上服务 70B 模型!而这在使用 fp16 的模型权重时是不可能的,因为它超出了最大可用的 GPU 内存。
你可以在 TGI 的 [说明文档](https://huggingface.co/docs/text-generation-inference/main/en/basic_tutorials/preparing_model#quantization) 中找到更多有关 GPTQ 的用法。
需要注意的时,TGI 中集成的算子不能很好地扩展到较大的批处理大小。因此,这一方式虽然节省了内存,但在较大的批处理大小上发生速度的下降是符合预期的。
## **使用 PEFT 微调量化后的模型**
在常规的方法下,你无法进一步微调量化后的模型。然而,通过使用 PEFT 代码库,你可以在量化后的模型之上训练适应性网络!为实现这一目标,我们冻结了量化过的基座模型的所有网络层,并额外添加可训练的适应性网络。这里是一些关于如何使用 PEFT 训练 GPTQ 模型的例子:[Colab 笔记本](https://colab.research.google.com/drive/1VoYNfYDKcKRQRor98Zbf2-9VQTtGJ24k?usp=sharing) 和 [微调脚本](https://gist.github.com/SunMarc/dcdb499ac16d355a8f265aa497645996) 。
## 改进空间
虽然我们的 AutoGPTQ 集成在极小的预测质量损失代价下,带来了引人瞩目的优势。但在量化技术应用和算子实现方面仍有提升的空间。
首先,尽管 AutoGPTQ (在我们的认知范围内)已经集成了 [exllama](https://github.com/turboderp/exllama) 中所实现的最佳性能的 W4A16 算子(权重为 int4 数值类型,激活值为 fp16 数值类型),其仍有很大的改进空间。来自 [Kim 等人](https://arxiv.org/pdf/2211.10017.pdf) 的实现和 [MIT Han Lab](https://github.com/mit-han-lab/llm-awq) 的方法似乎十分可靠。此外,根据我们的内部测评,似乎暂未有开源的高性能的 Triton 版本的 W4A16 算子实现,这也是一个值得探索的方向。
在量化层面,我们需要再次强调 GPTQ 方法只对模型权重进行量化。而针对大语言模型的量化,存在其他的方法,提供了以较小的预测质量损失为代价,同时量化权重和激活值的方案。如 [LLM-QAT](https://arxiv.org/pdf/2305.17888.pdf) 采用 int4/int8 的混合精度方案,同时还对 KV Cache 施行量化。这一技术的强大优点是能实际使用整数运算算法来进行计算,一个例子是 [英伟达的张量核心支持 int8 计算](https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-us-nvidia-1758950-r4-web.pdf) 。然而,据我们所知,目前暂无开源的 W4A8 量化算子,但这可能是一个 [值得探索的方向](https://www.qualcomm.com/news/onq/2023/04/floating-point-arithmetic-for-ai-inference-hit-or-miss) 。
在算子层面,为更大的批处理大小设计高性能的 W4A16 算子仍然是一大挑战。
### 已支持的模型
在初始实现中,暂时只支持纯编码器或纯解码器架构的大语言模型。这听起来似乎有较大的局限性,但其实已经涵盖了当前绝大多数最先进的大语言模型,如 Llama、OPT、GPT-Neo、GPT-NeoX 等。
大型的视觉、语音和多模态模型在现阶段暂不被支持。
## 结论和结语
本文中,我们介绍了 Transformers 对 [AutoGPTQ 代码库](https://github.com/PanQiWei/AutoGPTQ) 的集成,使得社区中的任何人都可以更方便地利用 GPTQ 方法量化大语言模型,助力令人激动的大语言模型工具和应用的构建。
这一集成支持英伟达 GPU 和基于 RoCm 的 AMD GPU,这是向支持更广泛 GPU 架构的量化模型的普惠化迈出的一大步。
与 AutoGPTQ 团队的合作非常富有成效,我们非常感谢他们的支持和他们在该代码库上的工作。
我们希望本次集成将使每个人都更容易地在他们的应用程序中使用大语言模型,我们迫不及待地想要看到大家即将使用它所创造出的一切!
再次提醒不要错过文章开头分享的有用资源,以便更好地理解本次集成的特性以及如何快速开始使用 GPTQ 量化。
- [原始论文](https://arxiv.org/pdf/2210.17323.pdf)
- [运行于 Google Colab 笔记本上的基础用例](https://colab.research.google.com/drive/1_TIrmuKOFhuRRiTWN94iLKUFu6ZX4ceb?usp=sharing) —— 该笔记本上的用例展示了如何使用 GPTQ 方法量化你的 transformers 模型、如何进行量化模型的推理,以及如何使用量化后的模型进行微调。
- Transformers 中集成 GPTQ 的 [说明文档](https://huggingface.co/docs/transformers/main/en/main_classes/quantization)
- Optimum 中集成 GPTQ 的 [说明文档](https://huggingface.co/docs/optimum/llm_quantization/usage_guides/quantization)
- TheBloke [模型仓库](https://huggingface.co/TheBloke?sort_models=likes#models) 中的 GPTQ 模型。
## 致谢
感谢 [潘其威](https://github.com/PanQiWei) 对杰出的 AutoGPTQ 代码库的支持和所作的工作,以及他对本次集成的帮助。
感谢 [TheBloke](https://huggingface.co/TheBloke) 使用 AutoGPTQ 量化大量的模型并分享在 Hugging Face Hub 上,以及他在本次集成中所提供的帮助。
感谢 [qwopqwop200](https://github.com/qwopqwop200) 对 AutoGPTQ 代码库的持续贡献,目前,他正致力于将该代码库的使用场景拓展至 CPU ,这一特性将在 AutoGPTQ 的下一版本中发布。
最后,我们还要感谢 [Pedro Cuenca](https://github.com/pcuenca) 对本文的撰写所提供的帮助。 | 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/infini-attention.md | ---
title: "一次失败的实验——无限注意力,我们为什么坚持实验"
thumbnail: /blog/assets/185_infini_attention/infini_attention_thumbnail.png
authors:
- user: neuralink
- user: lvwerra
- user: thomwolf
translators:
- user: smartisan
- user: zhongdongy
proofreader: true
---
# 一次失败的实验 - 无限注意力,我们为什么坚持实验
总结: 随着我们增加内存压缩次数的次数,Infini-attention 的性能会变得越来越差。据我们所知,[ring attention](https://x.com/Haojun_Zhao14/status/1815419356408336738)、[YaRN](https://arxiv.org/abs/2309.00071) 和 [rope scaling](https://arxiv.org/abs/2309.16039) 这三种方法仍是将预训练模型拓展更长上下文的最佳方式。
## 引言:
语言模型的上下文长度也是除模型性能之外的重要属性之一。自 in-context learning (上下文学习) 出现以来,添加相关信息到模型的输入中日渐重要。因此,上下文长度迅速从段落 (BERT/GPT-1 的 512 个 tokens) 扩展到页面 (GPT-2 和 GPT-3 分别为 1024/2048 个 tokens), 再到书籍 (Claude 的 128k tokens), 甚至书籍集合 (Gemini 的 1-10M tokens)。然而,将 standard attention(标准注意力) 扩展到如此长度仍然面临挑战。
> 关于 Ring Attention (一种注意力机制) 的简单介绍: 据我们所知,Ring Attention 最初是由加州大学伯克利分校的研究人员在 2024 年提到的 [Ring Attention with Blockwise Transformers for Near-Infinite Context](https://arxiv.org/abs/2310.01889)。这种工程技术通过以分块方式执行 self-attention 和 feedforward network 计算,并将序列维度分配到多个设备上,减轻了内存限制,实现并发计算和通信。
即使使用 Ring Attention,要在 1 百万 token 的上下文长度上训练一个 [Llama 3 8B](https://arxiv.org/abs/2407.21783) 模型,batch size 为 1 时,仍然需要 512 个 GPU。正如 scaling laws (扩展定律) 提到 [Scaling Laws for Neural Language Models](https://arxiv.org/abs/2001.08361) 的那样,模型大小与其下游任务性能之间存在强相关性,这意味着模型越大越好 (当然,两种模型都应该被训练得很好)。因此,我们不仅需要 1 百万 token 的上下文长度,还希望在最大的模型上实现这一长度 (例如,Llama 3 8B 405B)。而目前只有少数几家公司拥有实现这一目标的资源。
> 回顾自注意力的内存复杂度
>
> 在标准注意力机制 (非 flash-attention) 中,每个标记都会关注序列中的所有其他标记,从而形成一个大小为 [seq_len, seq_len] 的注意力矩阵。对于每对标记,我们都需要计算一个注意力分数。随着序列长度 (seq_len) 的增加,内存和计算需求呈二次方增长:注意力矩阵的内存复杂度为 O(seq_len^2)。例如,序列长度增加 10 倍会导致内存需求增加 100 倍。
>
> 即使是像 Flash Attention 这样的内存高效注意力方法,其内存需求仍会随上下文长度线性增长,并受限于单个 GPU 的内存容量。这导致在当今的 GPU 上,典型的最大上下文长度远低于 1M 个标记。
受此启发,我们探索了一种替代标准注意力的方法:无限注意力 (infini-attention)。这篇论文由来自 Google 的研究人员于 2024 年 4 月发布 [Leave No Context Behind: Efficient Infinite Context Transformers with Infini-attention](https://arxiv.org/abs/2404.07143)。与计算每个词之间的注意力分数不同,无限注意力将序列划分为多个片段,将早期片段压缩到固定缓冲区,并允许下一个片段从早期片段中检索记忆,同时将注意力分数限制在当前片段内的词语之间。其关键优势在于固定的缓冲区大小为总内存使用设置了上限。它还在一个片段内使用相同的查询来访问该片段和压缩记忆中的信息,这使我们能够以低成本为预训练模型扩展上下文长度。理论上,我们可以实现无限长的上下文,因为它只为所有早期片段的记忆保留一个缓冲区。然而,实际上压缩限制了能有效存储的信息量,因此问题在于:这种压缩的记忆有多大的可用性 ?
虽然在理论上理解新方法相对容易,但实际使其运作往往是另一回事,而这个过程很少公开分享。出于这个原因,我们决定分享我们在复现无限注意力论文过程中的实验和记录,包括在调试过程中 (我们 90% 的时间都在调试一个收敛问题) 激励我们的因素,以及让这些方法正常工作可能有多困难。
随着 Llama 3 8B (上下文长度限制为 8k 个标记) 的发布,我们试图将这个长度扩展到 100 万个标记,而不会导致内存需求二次增长。在这篇博客中,我们将首先解释无限注意力的工作原理。然后,我们将介绍我们的复现原则,并描述我们最初的小规模实验。我们讨论了面临的挑战,如何解决这些挑战,并以我们的发现总结和其他探索的想法作为结束。如果你有兴趣测试我们训练的 [检查点](https://huggingface.co/nanotron/llama3-8b-infini-attention), 你可以在 [以下仓库](https://github.com/huggingface/nanotron/tree/xrsrke/infini_attention_this_actually_works) 中找到它 (请注意,我们目前按原样提供代码)。
## 第 1 节: 复现原则
我们发现以下规则在实现新方法时很有帮助,并将其用作我们大量工作的指导原则:
- **原则 1:** 从能提供良好信号的最小模型规模开始,一旦获得良好信号就扩大实验规模。
- **原则 2:** 始终训练一个可靠的基准模型来衡量进展。
- **原则 3:** 为了确定某项修改是否提高了性能,训练两个除了被测试的修改之外完全相同的模型。
牢记这些原则,让我们深入了解 Infini-attention 的实际工作原理。理解其机制对于我们推进实验至关重要。
## 第 2 节: Infini-attention 的工作原理
- 步骤 1: 将输入序列分割成较小的、固定大小的块,称为 “ 片段 “。
- 步骤 2: 在每个片段内计算标准的因果点积注意力。
- 步骤 3: 使用当前片段的查询向量从压缩内存中提取相关信息。检索过程的数学定义如下:
\\( A_{\text {mem }}=\frac{\sigma(Q) M_{s-1}}{\sigma(Q) z_{s-1}} \\)
+ \\( A_{\text {mem }} \in \mathbb{R}^{N \times d_{\text {value }}} \\) : 从内存中检索的内容,表示长期上下文。
+ \\( Q \in \mathbb{R}^{N \times d_{\text {key }}} \\) : 查询矩阵,其中 \\( N \\) 是查询的数量, \\( d_{\text {key }} \\) 是每个查询的维度。
+ \\( M_{s-1} \in \mathbb{R}^{d_{\text {key }} \times d_{\text {value }}} \\) : 来自前一个片段的内存矩阵,存储键值对。
+ \\( \sigma \\): 非线性激活函数,具体为逐元素指数线性单元 (ELU) 加 1。
+ \\( z_{s-1} \in \mathbb{R}^{d_{\text {key }}} \\) : 归一化项。
```python
import torch.nn.functional as F
from torch import einsum
from einops import rearrange
def _retrieve_from_memory(query_states, prev_memory, prev_normalization):
...
sigma_query_states = F.elu(query_states) + 1
retrieved_memory = einsum(
sigma_query_states,
prev_memory,
"batch_size n_heads seq_len d_k, batch_size n_heads d_k d_v -> batch_size n_heads seq_len d_v",
)
denominator = einsum(
sigma_query_states,
prev_normalization,
"batch_size n_heads seq_len d_head, batch_size n_heads d_head -> batch_size n_heads seq_len",
)
denominator = rearrange(
denominator,
"batch_size n_heads seq_len -> batch_size n_heads seq_len 1",
)
# NOTE: because normalization is the sum of all the keys, so each word should have the same normalization
retrieved_memory = retrieved_memory / denominator
return retrieved_memory
```
- 步骤 4: 将局部上下文 (来自当前片段) 与长期上下文 (从压缩内存中检索) 结合,生成最终输出。这样,注意力输出可以同时考虑短期和长期上下文。
\\( A=\text{sigmoid}(\beta) \odot A_{\text {mem }}+(1-\text{sigmoid}(\beta)) \odot A_{\text {dot }} \\)
+ \\( A \in \mathbb{R}^{N \times d_{\text {value }}} \\) : 组合后的注意力输出。
+ \\( \text{sigmoid}(\beta) \\) : 一个可学习的标量参数,用于控制长期内存内容 \\( A_{\text {mem }} \\) 和局部上下文之间的权衡。
+ \\( A_{\text {dot }} \in \mathbb{R}^{N \times d_{\text {value }}} \\) : 使用点积注意力从当前片段得到的注意力输出。
- 步骤 5: 通过添加当前片段的键值状态来更新压缩内存,这使我们能够随时间累积上下文。
\\( M_s \leftarrow M_{s-1}+\sigma(K)^T V \\)
\\( z_s \leftarrow z_{s-1}+\sum_{t=1}^N \sigma\left(K_t\right) \\)
+ \\( M_s \in \mathbb{R}^{d_{\text {key }} \times d_{\text {value }}} \\) : 当前片段的更新后内存矩阵,包含了新信息。
+ \\( K \in \mathbb{R}^{N \times d_{\text {key }}} \\): 当前片段的键矩阵,表示要存储的新键。
+ \\( V \in \mathbb{R}^{N \times d_{\text {value }}} \\) : 当前片段的值矩阵,表示与键相关联的新值。
+ \\( K_t \\) : 键矩阵中的第 \\( t \\) 个键向量。
+ \\( z_s \\) : 当前片段更新后的归一化项。
```python
import torch
def _update_memory(prev_memory, prev_normalization, key_states, value_states):
...
sigma_key_states = F.elu(key_states) + 1
if prev_memory is None or prev_normalization is None:
new_value_states = value_states
else:
numerator = einsum(
sigma_key_states,
prev_memory,
"batch_size n_heads seq_len d_k, batch_size n_heads d_k d_v -> batch_size n_heads seq_len d_v",
)
denominator = einsum(
sigma_key_states,
prev_normalization,
"batch_size n_heads seq_len d_k, batch_size n_heads d_k -> batch_size n_heads seq_len",
)
denominator = rearrange(
denominator,
"batch_size n_heads seq_len -> batch_size n_heads seq_len 1",
)
prev_v = numerator / denominator
new_value_states = value_states - prev_v
memory = torch.matmul(sigma_key_states.transpose(-2, -1), new_value_states)
normalization = reduce(
sigma_key_states,
"batch_size n_heads seq_len d_head -> batch_size n_heads d_head",
reduction="sum",
...
)
memory += prev_memory if prev_memory is not None else 0
normalization += prev_normalization if prev_normalization is not None else 0
return memory, normalization
```
- 步骤 6: 当我们从一个片段移动到下一个片段时,我们丢弃前一个片段的注意力状态,并将更新后的压缩内存传递给下一个片段。
```python
def forward(...):
...
outputs = []
global_weights = F.sigmoid(self.balance_factors)
...
local_weights = 1 - global_weights
memory = None
normalization = None
for segment_hidden_state, segment_sequence_mask in zip(segment_hidden_states, segment_sequence_masks):
attn_outputs = self.forward_with_hidden_states(
hidden_states=segment_hidden_state, sequence_mask=segment_sequence_mask, return_qkv_states=True
)
local_attn_outputs = attn_outputs["attention_output"]
query_states, key_states, value_states = attn_outputs["qkv_states_without_pe"]
q_bs = query_states.shape[0]
q_length = query_states.shape[2]
...
retrieved_memory = _retrieve_from_memory(
query_states, prev_memory=memory, prev_normalization=normalization
)
attention_output = global_weights * retrieved_memory + local_weights * local_attn_outputs
...
output = o_proj(attention_output)
memory, normalization = _update_memory(memory, normalization, key_states, value_states)
outputs.append(output)
outputs = torch.cat(outputs, dim=1) # concat along sequence dimension
...
```
既然我们已经掌握了理论,现在该动手进行一些实际实验了。我们先从小规模开始,以便快速获得反馈并迅速迭代。
## 第 3 节: 小规模的首次实验
Llama 3 8B 模型相当大,所以我们决定从 200M 的 Llama 开始,使用 [Nanotron](https://github.com/huggingface/nanotron) 和 [Fineweb 数据集](https://huggingface.co/datasets/HuggingFaceFW/fineweb) 从头预训练 Infini-attention。一旦我们在 200M 模型上获得了良好的结果,我们就继续对 Llama 3 8B 进行持续预训练。
我们使用了 200 万个 token 的 batch size,256 的上下文长度,1 的梯度裁剪,0.1 的权重衰减,前 5000 次迭代是线性预热,而剩余的步骤是余弦衰减,学习率为 3e-5。
**使用密钥检索任务进行评估**
密钥检索任务最初由 EPFL 的研究人员提出 [Landmark Attention: Random-Access Infinite Context Length for Transformers](https://arxiv.org/abs/2305.16300)。这是一个旨在评估模型从长上下文中检索信息的能力的任务,其中信息的位置是可控的。提示模型的输入格式结构如下:
```
在大量无关文本中隐藏着重要信息。找到并记住它们。我将就其中的重要信息对你进行测试。草是绿色的。天空是蓝色的。太阳是黄色的。我们开始吧。来回往复。(重复 x 次) 密钥是 9054。记住它。9054 是密钥。草是绿色的。天空是蓝色的。太阳是黄色的。我们开始吧。来回往复。(重复 y 次) 密钥是什么?密钥是
```
我们认为,如果模型的输出包含 “信息点” (在上述例子中为 “9054”),则模型在此任务中成功,否则失败。在实验中,我们将 “信息点” 放置在上下文的不同位置,具体为总上下文长度的 0%、5%、10%、…、95% 和 100% 处 (0% 为距离生成标记最远的位置)。例如,如果上下文长度为 1024 个 token,将 “信息点” 放在 10% 处意味着它位于约第 102 个 token 处。对于每个深度位置,我们使用 10 个不同的样本测试模型并计算平均成功率。
**首次结果**
这里是在小型 200M 模型上的一些首次结果:

如你所见,这在某种程度上是有效的。观察样本生成可以发现,Infini-attention 生成的内容与先前段落相关。
Infini-attention 通过以第一段的全部内容为条件来预测第二段的第一个 token,生成的第一个 token 是 “_grad”,这提供了一个良好的信号。为验证这个信号是否为假阳性,我们假设 Infini-attention 生成与先前段落相关的内容是因为当给定 “_grad” 作为第二段的第一个生成 token 时,它总是生成 PyTorch 相关的教程,而这恰好与先前段落相关。因此,我们进行了一个健全性测试,唯一的输入 token 是 “_grad”,它生成了下列结果。这表明它确实使用了记忆,但使用得不够好 (无法检索到确切的 needle 或继续先前段落的确切内容)。
```
_graduate_education.html
Graduate Education
The Department of Physics and Astronomy offers a program leading to the Master of Science degree in physics. The program is designed to provide students with a broad background in
```
基于这些结果,模型似乎确实使用了压缩内存。我们决定通过持续预训练 Llama 3 8B 来扩大实验规模。不幸的是,当 needle 位于较早的段落时,模型未能通过 needle 评估。
我们检查了所有层的平衡因子 (用于平衡压缩和非压缩内存量的因子)。图 3a 和图 3b 显示,约 95% 的权重集中在 0.5 左右。回想一下,权重收敛到理想范围取决于两个一般因素: 步长和梯度幅度。但 Adam 将梯度归一化到幅度 1,因此问题变为: 训练超参数是否正确,能使微调收敛?
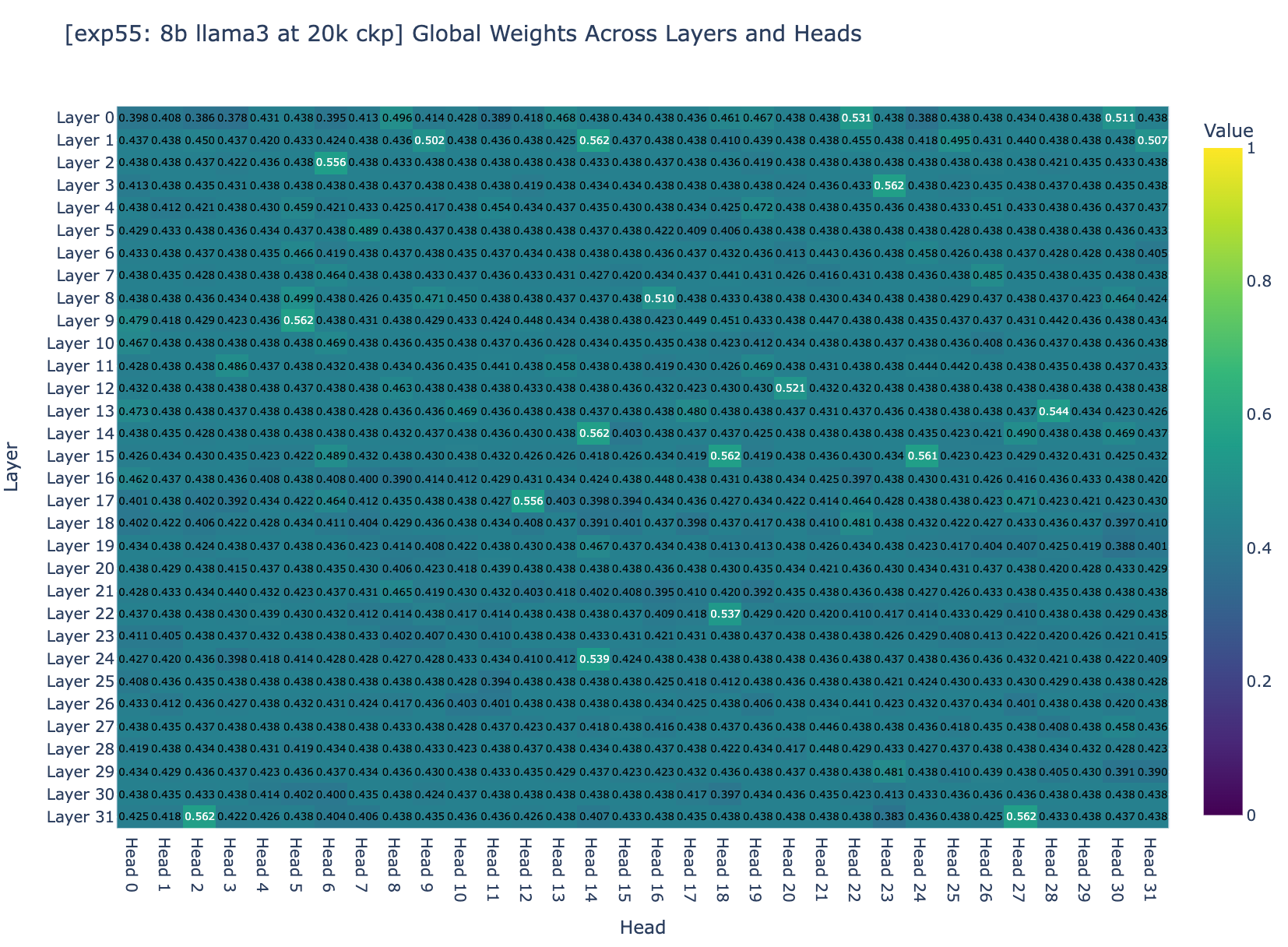

## 第 4 节: 研究收敛性?
我们决定模拟训练期间平衡权重的变化,假设梯度在良好范围内 (L2 范数为 0.01)。根据最后一次 8B LLaMA3 微调实验的配置,权重的绝对变化总和为 0.03。平衡因子初始化为 0 (在这种情况下无关紧要),最终权重范围在 [-0.03, 0.03] 之间。
我们推测,无限注意力在全局权重分布于 0 到 1 之间时效果最佳,如论文中所述。给定上述权重,sigmoid([-0.03, 0.03]) = tensor([0.4992, 0.5008]),这与我们之前平衡因子约为 0.5 的实验结果一致。接下来,我们计划对平衡因子使用更高的学习率 (其他所有参数使用 Llama 3 8B 的学习率),并增加训练步骤数,使平衡因子至少变化 4,以便在梯度下降需要时,全局权重能达到理想值 (sigmoid(-4) ≈ 0,sigmoid(4) ≈ 1)。
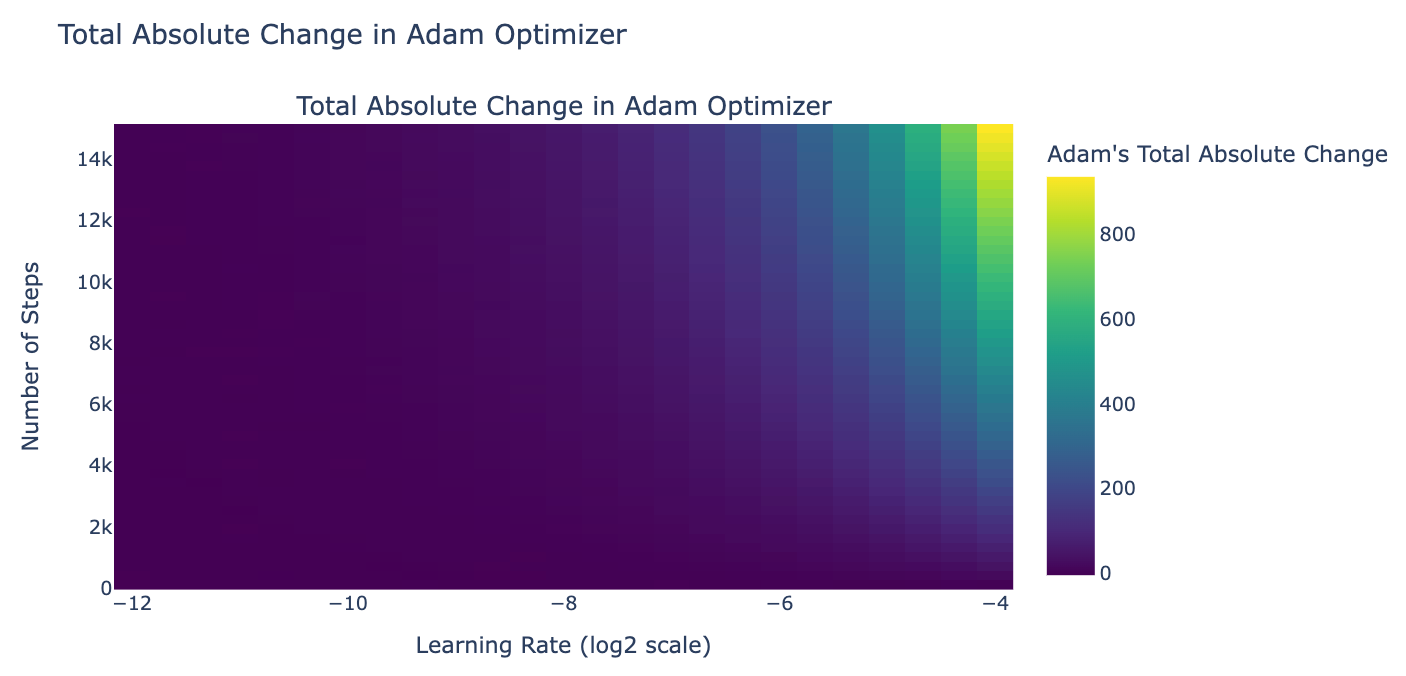
我们还注意到,由于梯度并不总是朝同一方向,会发生抵消现象。这意味着我们应该目标设定为显著大于总绝对变化的学习率和训练步骤。回想一下,Llama 3 8B 的学习率是 3.0x10^-4,这意味着如果我们将其用作全局学习率,门控将无法以任何方式收敛。
> 结论: 我们决定采用 3.0x10^-4 的全局学习率和 0.01 的门控学习率,这应该能使门控函数收敛。
使用这些超参数,无限注意力 (Infini-attention) 中的平衡因子变得可训练,但我们观察到 200M llama 的损失在 20B 标记后变为 NaN (我们尝试了从 0.001 到 1.0e-6 的学习率)。我们在 20B 标记检查点 (10k 训练步骤) 处调查了一些生成结果,您可以在图 4a 中看到。模型现在能够继续精确的内容并回忆身份信息 (如果记忆被移除,它会生成垃圾内容)。
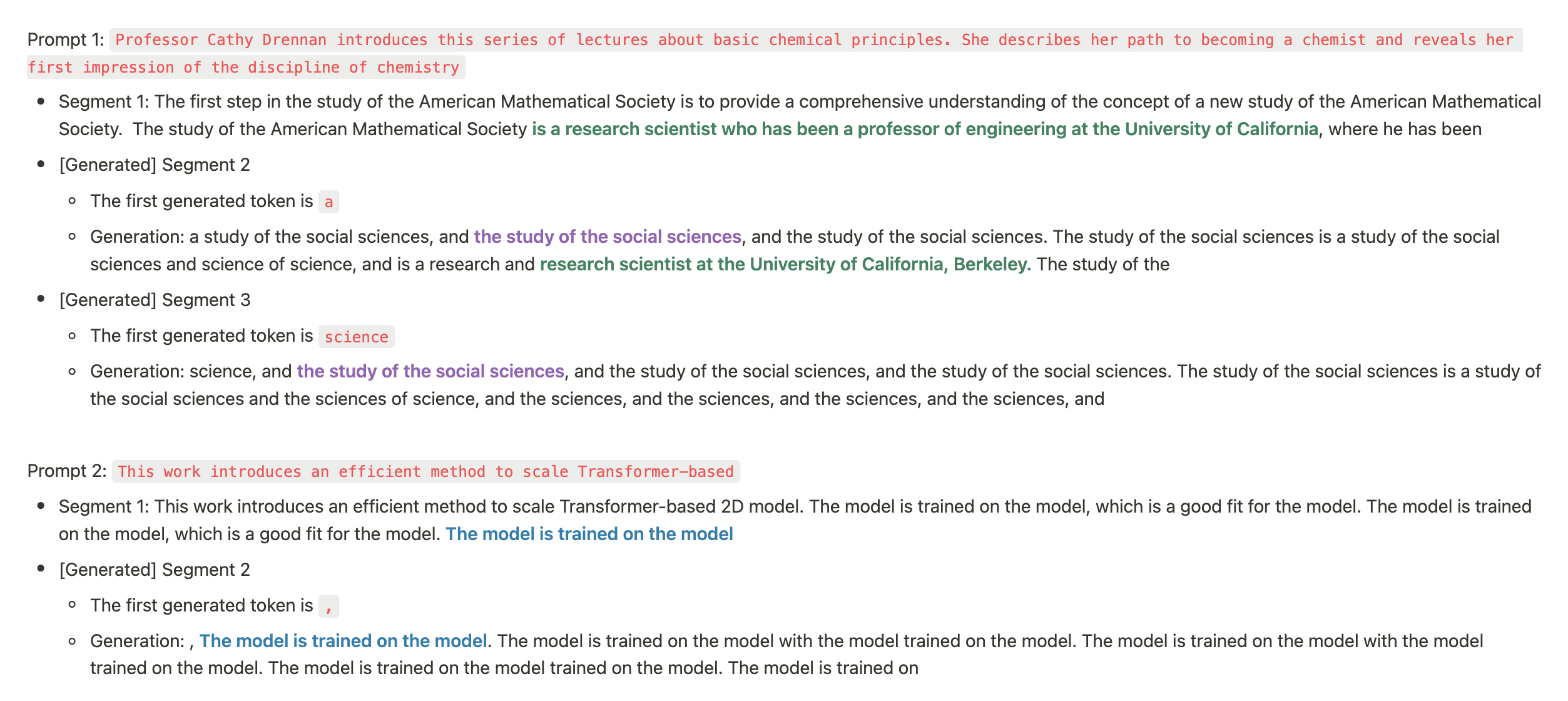
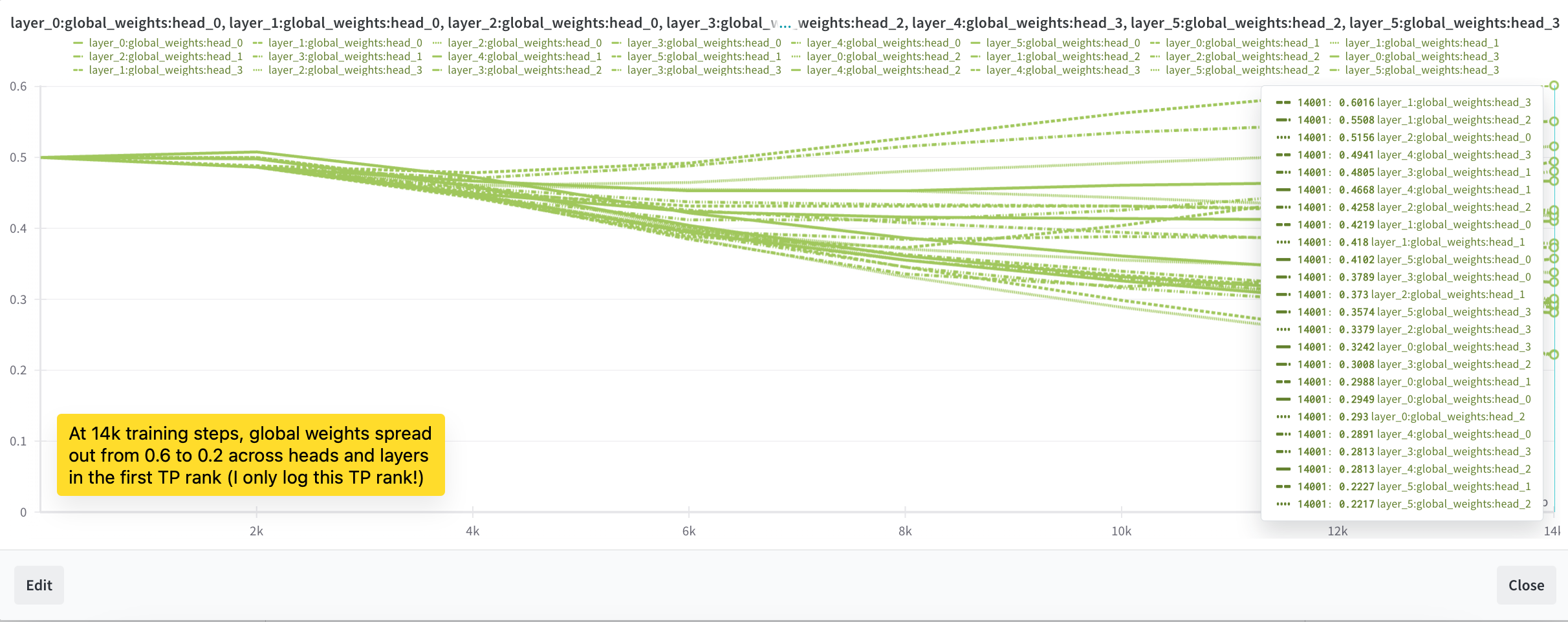
但模型仍无法在不同段落间检索信息点 (在同一段落内能可靠完成)。当信息点位于第一段时,信息点评估完全失败 (位于第二段时 100% 成功,共 2 段)。如图 4b 所示,我们还观察到平衡因子在 5,000 步后停止变化。尽管有所进展,我们还未完全解决问题。平衡因子的表现仍不如预期。我们决定进一步深入研究并做出更多调整。
## 第五节: 平衡因子无权重衰减
再次详细检查平衡因子,我们看到了一些进展: 现在约 95% 的头显示全局权重在 0.4 到 0.5 之间,没有头的全局权重大于 0.6。但权重仍然不在理想范围内。
我们想到了另一个可能的原因: 权重衰减,它鼓励平衡因子的 L2 范数较小,导致 sigmoid 值收敛接近零,因子集中在 0.5 左右。
另一个可能的原因是我们使用的展开太小。在 200m 实验中,我们只使用了 4 次展开,在 8b 实验中,我们只使用了 2 次展开 (8192**2)。使用更大的展开应该能激励模型压缩并更好地利用内存。因此,我们决定将展开次数增加到 16,并且不使用权重衰减。我们将上下文长度缩小到 1024,使用 16 次展开,得到 64 的段长度。
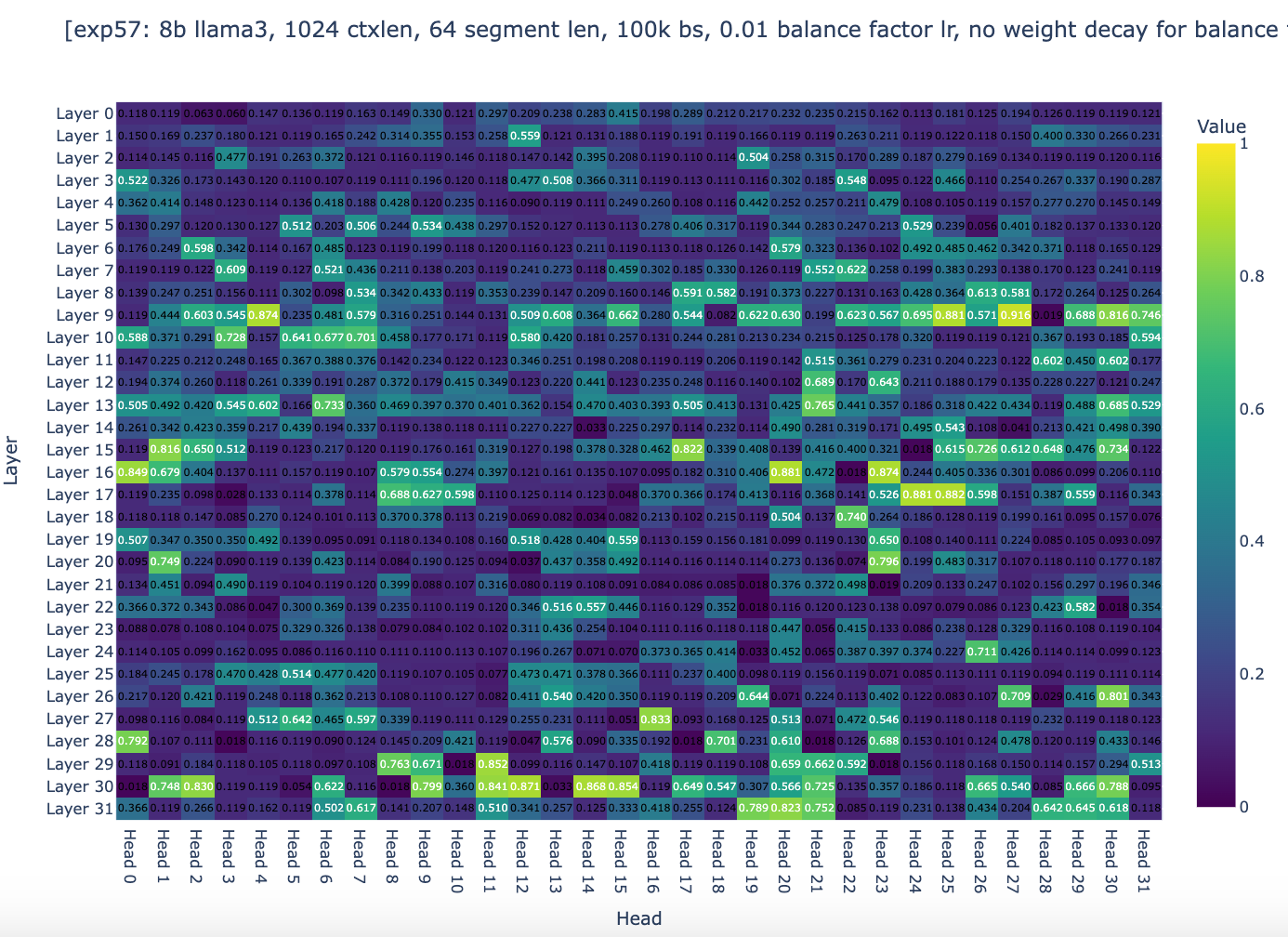
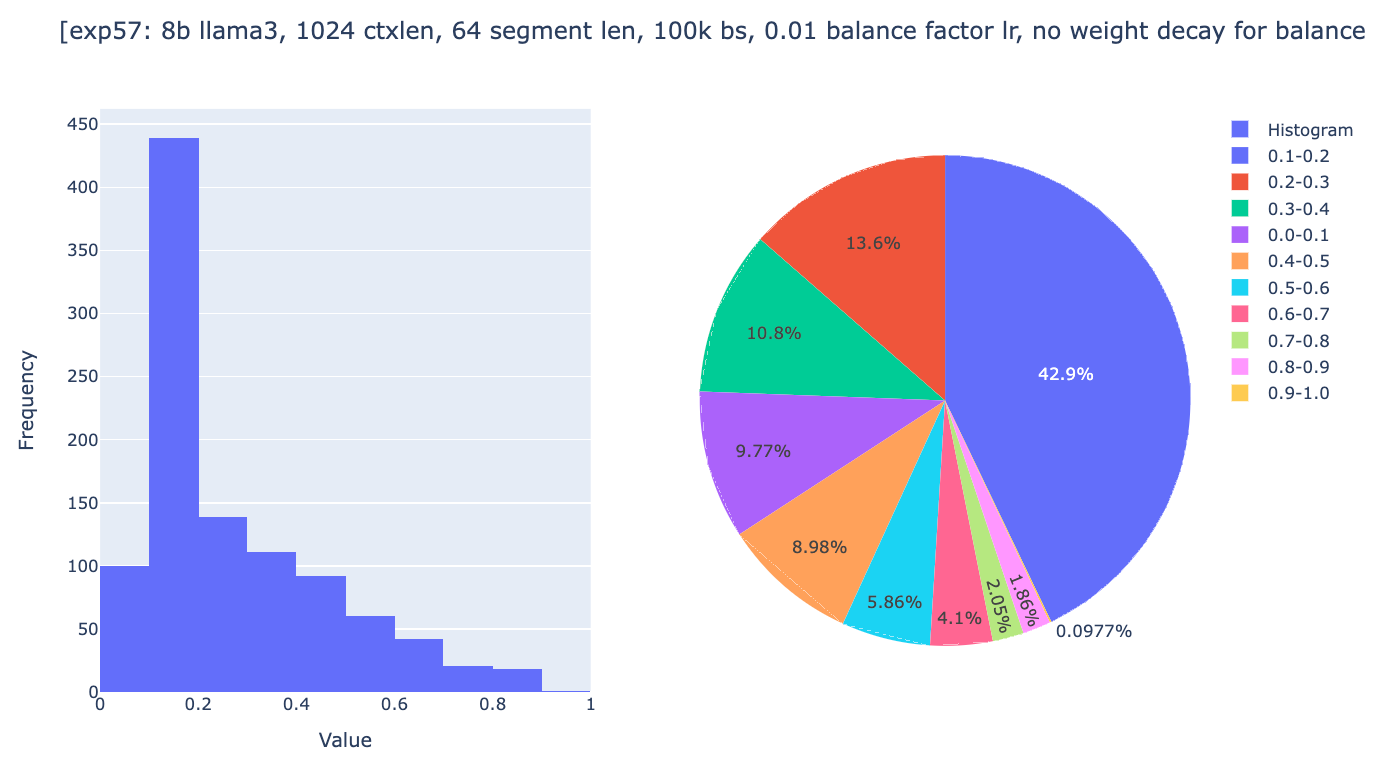
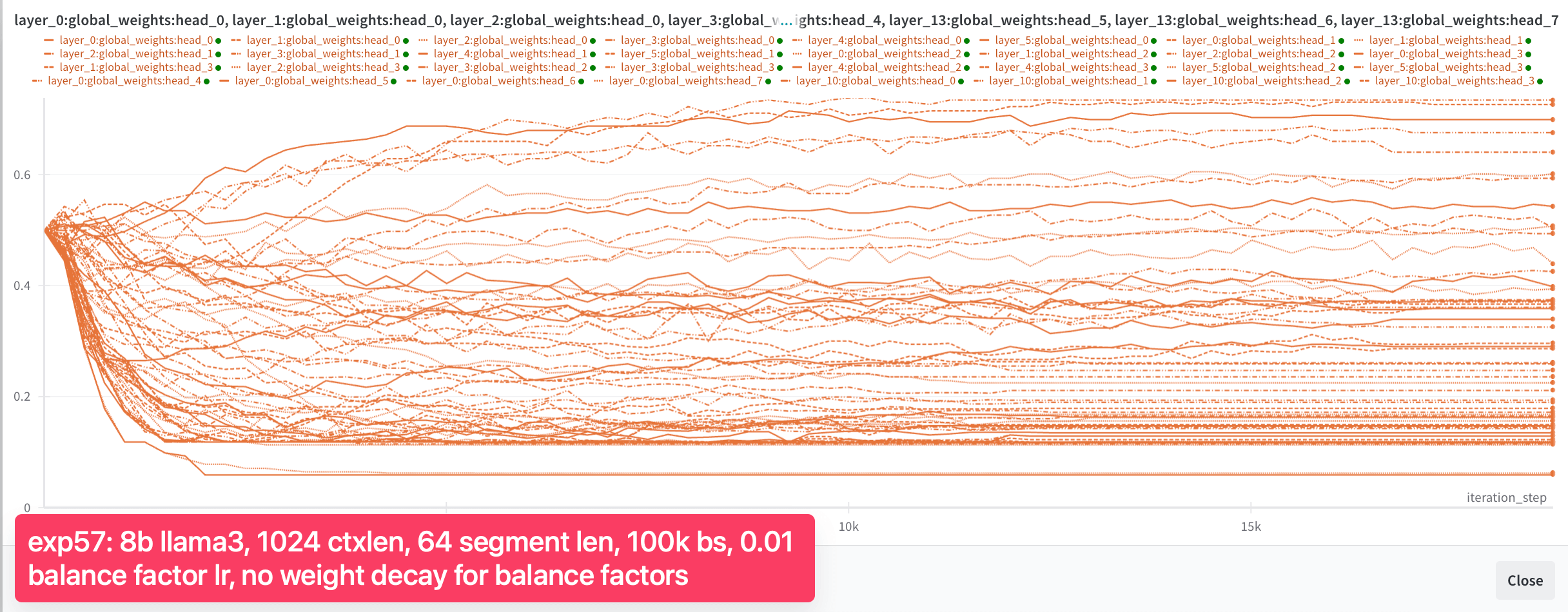
如你所见,全局权重现在分布在 0 到 1 的范围内,其中 10% 的注意力头的全局权重在 0.9 到 1.0 之间,尽管在 18k 步之后,大多数注意力头停止了全局权重的变化。然后,我们相当有信心,如果梯度下降的精神与我们同在,这些实验的设置将允许收敛。唯一剩下的问题是 Infini-attention 的一般方法是否能够足够好地工作。
以下评估是在 1.5B 词元上运行的。

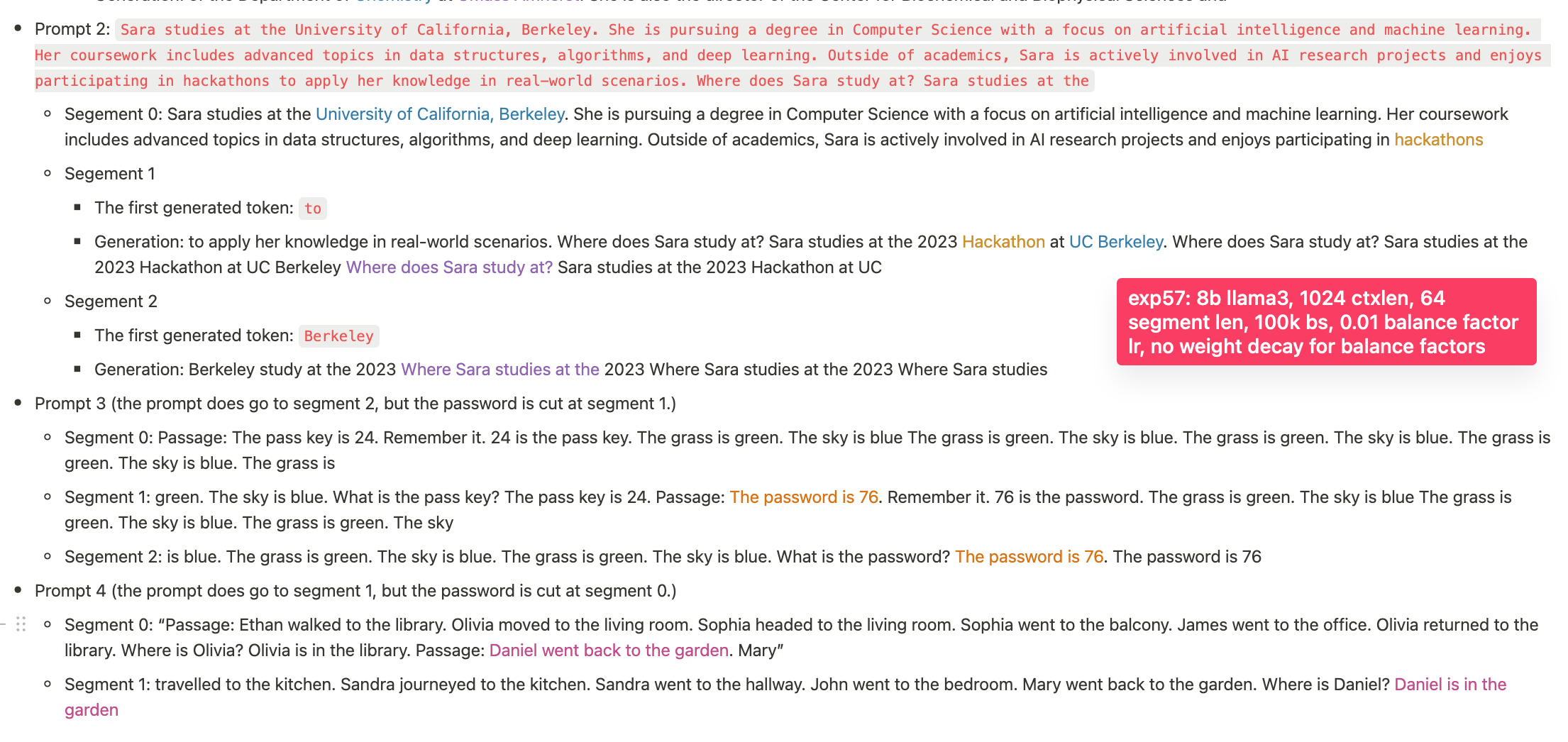
- 0-short: 在提示 2 中,模型能够回忆起一个人的学习地点 (昨天的 8b 模型未能做到这一点),但在信息点密钥测试中失败 (尚未全面运行; 将会进行)。
- 1-short
- 提示 3: 模型能够识别一个人的位置。
- 提示 4: 模型通过了信息点密钥测试
在这些情况下,模型能够继续生成早期片段的精确内容。(在我们之前的实验中,模型无法继续生成早期片段的精确内容,只能生成大致相关的内容; 因此新模型已经有了显著改进。)
## 第 6 节: 结论
遗憾的是,尽管取得了这些进展,我们发现在我们的实验中,Infini-attention 并不够令人信服,特别是在可靠性方面还不够。在我们复现的这个阶段,我们仍然认为 [Ring Attention](https://x.com/Haojun_Zhao14/status/1815419356408336738)、[YaRN](https://arxiv.org/abs/2309.00071) 和 [rope scaling](https://arxiv.org/abs/2309.16039) 是将预训练模型扩展到更长上下文长度的更好选择。
这些后来的技术对于非常大的模型 (例如,400B 及以上) 仍然需要大量资源。因此,我们仍然认为探索压缩技术或继续推进我们在这篇博文中描述的一系列实验对社区来说具有重大意义,我们也很兴奋能够跟进并尝试可能开发出的新技术,来克服当前工作的一些局限性。
**总结**
- 训练神经网络的含义: 提供优质数据,设置架构和训练以接收良好的梯度信号,并允许其收敛。
- Infini-attention 的长上下文性能随着我们压缩记忆的次数增加而下降。
- 门控机制很重要; 调整训练以允许门控收敛可以改善 Infini-attention 的长上下文性能 (但还不够好)。
- 始终训练一个良好的参考模型作为基线来衡量进展。
- 还有另一个错误会扰乱注意力输出的维度,导致即使在整个训练过程中损失减少,模型仍然无法在其片段长度内生成连贯的文本。经验教训: 即使你对模型的条件设置不佳,梯度下降仍然可以找到减少损失的方法。然而,模型不会按预期工作,所以要始终进行评估。
## 致谢
感谢 Leandro von Werra 和 Thomas Wolf 对项目的指导,以及 Tsendsuren Munkhdalai 分享原始实验的额外细节。我们也感谢 Leandro 对博文的反馈,并感谢 Hugging Face 的科学集群提供的计算资源。 | 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/vit-align.md | ---
title: "Kakao Brain 的开源 ViT、ALIGN 和 COYO 文字"
thumbnail: /blog//assets/132_vit_align/thumbnail.png
authors:
- user: adirik
- user: Unso
- user: dylan-m
- user: jun-untitled
translators:
- user: conyzhang
---
# Kakao Brain 的开源 ViT、ALIGN 和 COYO 文字
最近 Kakao Brain 在 Hugging Face 发布了一个全新的开源图像文本数据集 [COYO](https://github.com/kakaobrain/coyo-dataset),包含 7 亿对图像和文本,并训练了两个新的视觉语言模型 [ViT](https://github.com/kakaobrain/coyo-vit) 和 [ALIGN](https://github.com/kakaobrain/coyo-align)。
这是 ALIGN 模型首次公开发布供开源使用,同时 ViT 和 ALIGN 模型的发布都附带有训练数据集。
Google 的 [ViT](https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html) 和 [ALIGN](https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html) 模型都使用了巨大的数据集 (ViT 训练于 3 亿张图像,ALIGN 训练于 18 亿个图像 - 文本对) 进行训练,因为数据集不公开导致无法复现。[Kakao Brain](https://hf.co/kakaobrain) 的 ViT 和 ALIGN 模型采用与 Google 原始模型相同的架构和超参数,不同的是其在开源 [COYO 数据集](https://github.com/kakaobrain/coyo-dataset) 上进行训练。对于想要拥有数据并复现视觉语言模型的研究人员有很大的价值。
这篇博客将介绍新的 [COYO](https://github.com/kakaobrain/coyo-dataset) 数据集、Kakao Brain 的 ViT 和 ALIGN 模型,以及如何使用它们!以下是主要要点:
* 第一个开源的 ALIGN 模型!
* 第一个在开源数据集 [COYO](https://github.com/kakaobrain/coyo-dataset) 上训练的开源 ViT 和 ALIGN 模型。
* Kakao Brain 的 ViT 和 ALIGN 模型表现与 Google 版本相当。
* ViT 模型在 HF 上可演示!您可以使用自己的图像样本在线体验 ViT!
## 性能比较
Kakao Brain 发布的 ViT 和 ALIGN 模型与 Google 的模型表现相当,某些方面甚至更好。Kakao Brain 的 `ALIGN-B7-Base` 模型虽然训练的数据对少得多 ( 7 亿 VS 1.8 亿),但在图像 KNN 分类任务上表现与 Google 的 `ALIGN-B7-Base` 相当,在 MS-COCO 图像 - 文本检索、文本 - 图像检索任务上表现更好。Kakao Brain 的 `ViT-L/16` 在 384×512 的 ImageNet 和 ImageNet-ReaL 数据上的表现与 Google 的 `ViT-L/16` 相当。这意味着同行可以使用 Kakao Brain 的 ViT 和 ALIGN 模型来复现 Google 的 ViT 和 ALIGN ,尤其是当用户需要训练数据时。所以我们很高兴开源这些与现有技术相当的模型!
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/vit-align-performance.png" alt="ViT and ALIGN performance"/>
</center>
</p>
## COYO 数据集
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/coyo-samples.png" alt="COYO samples"/>
</center>
</p>
本次发布的模型特别之处在于都是基于开源的 COYO 数据集训练的。[COYO](https://github.com/kakaobrain/coyo-dataset#dataset-preview) 数据集包含 7 亿图像 - 文本对,类似于 Google 的 ALIGN 1.8B 图像 - 文本数据集,是从网页上收集的“嘈杂”的 html 文本 (alt-text) 和图像对。COYO-700M 和 ALIGN 1.8B都是“嘈杂”的,只使用了适当的清洗处理。COYO 类似于另一个开源的图像–文本数据集 `LAION`,但有一些区别。尽管 `LAION` 2B 是一个更大的数据集,包含 20 亿个英语配对,但 `COYO` 的附带有更多元数据,为用户提供更多灵活性和更细粒度的使用。以下表格显示了它们之间的区别: `COYO` 所有数据对都提供了美感评分,更健壮的水印评分和面部计数信息 (face count data)。
| COYO | LAION 2B| ALIGN 1.8B |
| :----: | :----: | :----: |
| Image-text similarity score calculated with CLIP ViT-B/32 and ViT-L/14 models, they are provided as metadata but nothing is filtered out so as to avoid possible elimination bias | Image-text similarity score provided with CLIP (ViT-B/32) - only examples above threshold 0.28 | Minimal, Frequency based filtering |
| NSFW filtering on images and text | NSFW filtering on images | [Google Cloud API](https://cloud.google.com/vision) |
| Face recognition (face count) data provided as meta-data | No face recognition data | NA |
| 700 million pairs all English | 2 billion English| 1.8 billion |
| From CC 2020 Oct - 2021 Aug| From CC 2014-2020| NA |
|Aesthetic Score | Aesthetic Score Partial | NA|
|More robust Watermark score | Watermark Score | NA|
|Hugging Face Hub | Hugging Face Hub | Not made public |
| English | English | English? |
## ViT 和 ALIGN 是如何工作的
这些模型是干什么的?让我们简要讨论一下 ViT 和 ALIGN 模型的工作原理。
ViT——Vision Transformer 是 [谷歌于 2020 年提出的一种视觉模型](https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html),类似于文本 Transformer 架构。这是一种与卷积神经网络不同的视觉方法 (AlexNet 自 2012 年以来一直主导视觉任务)。同样表现下,它的计算效率比 CNN 高达四倍,且具有域不可知性 (domain agnostic)。ViT 将输入的图像分解成一系列图像块 (patch),就像文本 Transformer 输入文本序列一样,然后为每个块提供位置嵌入以学习图像结构。ViT 的性能尤其在于具有出色的性能 - 计算权衡。谷歌的一些 ViT 模型是开源的,但其训练使用的 JFT-300 百万图像 - 标签对数据集尚未公开发布。Kakao Brain 的训练模型是基于公开发布的 [COYO-Labeled-300M](https://github.com/kakaobrain/coyo-dataset/tree/main/subset/COYO-Labeled-300M) 进行训练,对应的 ViT 模型在各种任务上具有相似表现,其代码、模型和训练数据 (COYO-Labeled-300M) 完全公开,以便能够进行复现和科学研究。
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/vit-architecture.gif" alt="ViT architecture" width="700"/>
</center>
</p>
<p>
<center>
<em>A Visualization of How ViT Works from <a href="https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html">Google Blog</a></em>
</center>
</p>
[谷歌在 2021 年推出了 ALIGN](https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html),它是一种基于“嘈杂”文本–图像数据训练的视觉语言模型,可用于各种视觉和跨模态任务,如文本 - 图像检索。ALIGN 采用简单的双编码器架构,通过对比损失函数学习图像和文本对,ALIGN 的“嘈杂”训练语料特点包括用语料规模弥补其噪音以及强大的鲁棒性。之前的视觉语言表示学习都是在手动标注的大规模数据集上进行训练,这就需要大量的预先处理和成本。ALIGN 的语料库使用 HTML 文本 (alt-text) 数据作为图像的描述,导致数据集不可避免地嘈杂,但更大的数据量 (18 亿对) 使 ALIGN 能够在各种任务上表现出 SoTA 水平。Kakao Brain 的模型是第一个 ALIGN 开源版本,它在 `COYO` 数据集上训练,表现比谷歌的结果更好。
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/align-architecture.png" width="700" />
</center>
</p>
<p>
<center>
<em>ALIGN Model from <a href="https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html">Google Blog</a>
</em>
</center>
<p>
## 如何使用 COYO 数据集
我们可以使用 Hugging Face 🤗 数据集库的一行代码方便地下载 COYO 数据集。要预览 COYO 数据集并了解数据处理过程和包含的元属性,请前往 [hub](https://huggingface.co/datasets/kakaobrain/coyo-700m) 数据集页面。
开始前,请安装 Hugging Face 🤗 数据集库: pip install datasets,然后下载数据集。
```shell
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m')
>>> dataset
```
由于 `COYO` 数据集非常庞大,包含 747M 个图像 - 文本对,您可能无法在本地下载整个数据集。或者可能只需要下载和使用数据集的子集。为此,可以简单地将 `streaming=True` 参数传递给 `load_dataset()` 方法,以创建可迭代数据集,并在需要时下载数据实例。
```shell
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m', streaming=True)
>>> print(next(iter(dataset['train'])))
{'id': 2680060225205, 'url': 'https://cdn.shopify.com/s/files/1/0286/3900/2698/products/TVN_Huile-olive-infuse-et-s-227x300_e9a90ffd-b6d2-4118-95a1-29a5c7a05a49_800x.jpg?v=1616684087', 'text': 'Olive oil infused with Tuscany herbs', 'width': 227, 'height': 300, 'image_phash': '9f91e133b1924e4e', 'text_length': 36, 'word_count': 6, 'num_tokens_bert': 6, 'num_tokens_gpt': 9, 'num_faces': 0, 'clip_similarity_vitb32': 0.19921875, 'clip_similarity_vitl14': 0.147216796875, 'nsfw_score_opennsfw2': 0.0058441162109375, 'nsfw_score_gantman': 0.018961310386657715, 'watermark_score': 0.11015450954437256, 'aesthetic_score_laion_v2': 4.871710777282715}
```
## 如何使用 Hub 中的 ViT 和 ALIGN
让我们尝试一下新的 ViT 和 ALIGN 模型。由于 ALIGN 是新加入 Hugging Face 🤗 Transformers 的,我们先安装最新版本的库: `pip install -q git+https://github.com/huggingface/transformers.git` 然后导入我们将要使用的模块和库,开始使用 ViT 进行图像分类。请注意,新添加的 ALIGN 模型将会包含到下一版 PyPI 包。
```py
import requests
from PIL import Image
import torch
from transformers import ViTImageProcessor, ViTForImageClassification
```
接下来,我们将从 COCO 数据集中随机下载一张有沙发图像,上边有两只猫和一个遥控器,并对图像进行预处理为模型所期望的输入格式,我们可以方便地使用相应的预处理器类 (`ViTProcessor`) 实现这一步。初始化模型和预处理器,可以使用 Hub 中 [Kakao Brain ViT repos](https://huggingface.co/models?search=kakaobrain/vit) 之一。请注意使用 Hub 中的库预处理器,确保预处理后的图像符合特定预训练模型所需的格式。
```py
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('kakaobrain/vit-large-patch16-384')
model = ViTForImageClassification.from_pretrained('kakaobrain/vit-large-patch16-384')
```
接下来将图像预处理并将其输入到模型,实现检索类别标签。Kakao Brain ViT 图像分类模型是在 ImageNet 标签上训练的,输出形状为 batch_size×1000 维度的类别 (logits)。
```py
# preprocess image or list of images
inputs = processor(images=image, return_tensors="pt")
# inference
with torch.no_grad():
outputs = model(**inputs)
# apply SoftMax to logits to compute the probability of each class
preds = torch.nn.functional.softmax(outputs.logits, dim=-1)
# print the top 5 class predictions and their probabilities
top_class_preds = torch.argsort(preds, descending=True)[0, :5]
for c in top_class_preds:
print(f"{model.config.id2label[c.item()]} with probability {round(preds[0, c.item()].item(), 4)}")
```
到这里就完成了!为了更加简单和简洁,还可以使用图像分类管道 ([pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.ImageClassificationPipeline)) 并将 Kakao Brain ViT 仓库名称作为目标模型传递给初始化管道。然后,我们可以传入图像的 URL 或本地路径,或 Pillow 图像,可选“top_k”参数表述返回前 k 个预测。让我们继续对猫和遥控器图片获取前 5 个预测结果。
```shell
>>> from transformers import pipeline
>>> classifier = pipeline(task='image-classification', model='kakaobrain/vit-large-patch16-384')
>>> classifier('http://images.cocodataset.org/val2017/000000039769.jpg', top_k=5)
[{'score': 0.8223727941513062, 'label': 'remote control, remote'}, {'score': 0.06580372154712677, 'label': 'tabby, tabby cat'}, {'score': 0.0655883178114891, 'label': 'tiger cat'}, {'score': 0.0388941615819931, 'label': 'Egyptian cat'}, {'score': 0.0011215205304324627, 'label': 'lynx, catamount'}]
```
如果您想更多地尝试 Kakao Brain ViT 模型,请前往 🤗 Hub 中心的项目 [空间](https://huggingface.co/spaces/adirik/kakao-brain-vit)。
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/vit_demo.png" alt="vit performance" width="900"/>
</center>
我们开始实验 ALIGN,它可用于检索文本或图像的多模态嵌入或执行零样本图像分类。ALIGN 的 Transformer 实现和用法类似于 [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip)。首先,下载预训练模型和其处理器 (processor),处理器预处理图像和文本,使它们符合 ALIGN 的预期格式,以便将其输入到视觉和文本编码器中。这步导入了我们将要使用的模块并初始化预处理器和模型。
```py
import requests
from PIL import Image
import torch
from transformers import AlignProcessor, AlignModel
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignModel.from_pretrained('kakaobrain/align-base')
```
先从零样本图像分类开始。为此,我们将提供候选标签 (自由格式文本),并使用 AlignModel 找出更好地描述图像的表述。我们将首先预处理图像和文本输入,并将预处理后的输入送到 AlignModel 中。
```py
candidate_labels = ['an image of a cat', 'an image of a dog']
inputs = processor(images=image, text=candidate_labels, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
```
完成了,就这么简单。要进一步尝试 Kakao Brain ALIGN 模型进行零样本图像分类,只需前往 Hugging Face 🤗 Hub 上的 [demo](https://huggingface.co/spaces/adirik/ALIGN-zero-shot-image-classification) 演示。请注意, `AlignModel` 的输出包括 `text_embeds` 和 `image_embeds` (参阅 ALIGN 的 [文档](https://huggingface.co/docs/transformers/main/en/model_doc/align))。如果不需要计算用于零样本分类的每个图像和每个文本的逻辑 (logits),可以使用 `AlignModel` 类中的 `get_image_features()` 和 `get_text_features()` 方法便捷地检索视觉和文本嵌入。
```py
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)
```
或者,我们可以使用 ALIGN 的独立视觉和文本编码器获取多模态嵌入。然后可以使用这些嵌入用于各种下游任务的模型训练,例如目标检测、图像分割和图像字幕生成。让我们看看如何使用 `AlignTextModel` 和 `AlignVisionModel` 获取这些嵌入。请注意,我们可以使用便捷的 AlignProcessor 类分别对文本和图像进行预处理。
```py
from transformers import AlignTextModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignTextModel.from_pretrained('kakaobrain/align-base')
# get embeddings of two text queries
inputs = processor(['an image of a cat', 'an image of a dog'], return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# get the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
```
我们也可以在推理过程中设置 output_hidden_states 和 output_attentions 参数为 True,以返回所有隐藏状态和注意力值。
```py
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True, output_attentions=True)
# print what information is returned
for key, value in outputs.items():
print(key)
```
在 `AlignVisionModel` 中执行相同的操作,获取图像的多模态嵌入。
```py
from transformers import AlignVisionModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignVisionModel.from_pretrained('kakaobrain/align-base')
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# print the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
```
与 ViT 类似,使用零样本图像分类管道 ([pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.ZeroShotImageClassificationPipeline)) 可以让过程更加轻松。以下实现了如何使用此流程使用自由文本候选标签在野外执行图像分类。
```shell
>>> from transformers import pipeline
>>> classifier = pipeline(task='zero-shot-image-classification', model='kakaobrain/align-base')
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['animals', 'humans', 'landscape'],
... )
[{'score': 0.9263709783554077, 'label': 'animals'}, {'score': 0.07163811475038528, 'label': 'humans'}, {'score': 0.0019908479880541563, 'label': 'landscape'}]
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['black and white', 'photorealist', 'painting'],
... )
[{'score': 0.9735308885574341, 'label': 'black and white'}, {'score': 0.025493400171399117, 'label': 'photorealist'}, {'score': 0.0009757201769389212, 'label': 'painting'}]
```
## 结论
近年来,多模态取得了令人难以置信的进展,例如 CLIP 和 ALIGN 等模型赋能了各种下游任务,例如图像描述、零样本图像分类和开放世界目标检测。本博客,我们介绍了由 Kakao Brain 贡献的最新开源代码 ViT 和 ALIGN 模型,以及新的 COYO 文本 - 图像数据集。展示了如何使用这些模型执行各种任务,只需几行代码即可单独使用或作为 🤗 Transformers pipeline 的一部分使用。
我们正在继续整合最有影响力的计算机视觉和多模型模型,并乐于听取您的反馈。要了解计算机视觉和多模态研究的最新消息,作者及 Twitter:[@adirik](https://twitter.com/https://twitter.com/alaradirik), [@a_e_roberts](https://twitter.com/a_e_roberts), [@NielsRogge](https://twitter.com/NielsRogge), [@RisingSayak](https://twitter.com/RisingSayak), and [@huggingface](https://twitter.com/huggingface).
| 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/gaussian-splatting.md | ---
title: "3D 高斯点染简介"
thumbnail: /blog/assets/124_ml-for-games/thumbnail-gaussian-splatting.png
authors:
- user: dylanebert
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 3D 高斯点染简介
3D 高斯点染技术由 [3D Gaussian Splatting for Real-Time Radiance Field Rendering](https://huggingface.co/papers/2308.04079) 一文首次提出。作为一种栅格化技术,3D 高斯点染可用于实时且逼真地渲染从一小组图像中学到的场景。本文将详细介绍其工作原理并讨论其对图形学的未来会带来什么影响。
## 什么是 3D 高斯点染?
3D 高斯点染本质上是一种栅格化技术。也就是说:
1. 我们有场景描述数据;
2. 我们会把这些数据在屏幕上渲染出来。
大家可能对计算机图形学中的三角形栅格化比较熟悉,其通过在屏幕上渲染许多三角形的方式来绘制图形。

其实 3D 高斯点染与三角形栅格化是一样的,只不过把基本绘图元素从三角形换成了高斯图像。下图给出了高斯图像的一个例子,为清晰起见,我们标出了它的边框。

每个高斯图像可由以下参数来描述:
- **位置**: 所在位置 (XYZ)
- **协方差**: 缩放程度 (3x3 矩阵)
- **颜色**: 颜色 (RGB)
- **Alpha**: 透明度 (α)
在实践中,我们通过在屏幕上绘制多个高斯图像,从而画出想要的图像。
上图是由 3 个高斯图像渲染出的图像。那么用 700 万个高斯图像可能会渲染出怎样的图像呢?看看下图:

如果这 700 万个高斯图像每个都完全不透明的话,渲染出的图像又会怎么样呢?如下:

以上,我们对 3D 高斯点染有了一个初步的认识。接下来,我们了解一下点染的具体过程。
## 点染过程
### 1. 从运动中恢复出结构
第一步是使用运动恢复结构 (Structure from Motion,SfM) 方法从一组图像中估计出点云。SfM 方法可以让我们从一组 2D 图像中估计出 3D 点云。我们可以直接调用 [COLMAP](https://colmap.github.io/) 库来完成这一步。

### 2. 用高斯图像对云中的每个点进行建模
接下来,把每个点建模成一个 3D 高斯图像。从 SfM 数据中,我们能推断出每个高斯图像的位置和颜色。这对于一般的栅格化已经够用了,但如果要产生更高质量的表征的话,我们还需要对每个高斯图像进行训练,以推断出更精细的位置和颜色,并推断出协方差和透明度。
### 3. 训练
与神经网络类似,我们使用随机梯度下降法进行训练,但这里没有神经网络的层的概念 (都是 3D 高斯函数)。训练步骤如下:
1. 用当前所有可微高斯图像渲染出图像 (稍后详细介绍)
2. 根据渲染图像和真实图像之间的差异计算损失
3. 根据损失调整每个高斯图像的参数
4. 根据情况对当前相关高斯图像进行自动致密化及修剪
步骤 1-3 比较简单,下面我们稍微解释一下第 4 步的工作:
- 如果某高斯图像的梯度很大 (即它错得比较离谱),则对其进行分割或克隆
- 如果该高斯图像很小,则克隆它
- 如果该高斯图像很大,则将其分割
- 如果该高斯图像的 alpha 太低,则将其删除
这么做能帮助高斯图像更好地拟合精细的细节,同时修剪掉不必要的高斯图像。
### 4. 可微高斯栅格化
如前所述,3D 高斯点染是一种 _栅格化_ 方法,即我们可以用其将数据渲染到屏幕上。作为众多栅格化方法的 _其中之一_ ,它有两个特点:
1. 快
2. 可微
你可在 [此处](https://github.com/graphdeco-inria/diff-gaussian-rasterization) 找到可微高斯渲染器的原始实现。其主要步骤为:
1. 针对给定相机视角,把每个 3D 高斯图像投影到 2D。
2. 按深度对高斯图像进行排序。
3. 对每个像素,从前到后计算每个高斯函数在该像素点的值,并将所有值混合以得到最终像素值。
更多细节及优化可参阅 [论文](https://huggingface.co/papers/2308.04079)。
渲染器可微这一点很重要,因为这样我们就可以用随机梯度下降法来训练它。但这一点仅对训练阶段很重要,训后的高斯函数是可以用不可微的方式来表示的。
## 有啥用?
为什么 3D 高斯点染受到如此多的关注?最直接的原因是其非凡的实力。有了它,对高画质场景的实时渲染成为了可能。有了这个能力,我们可以解锁更多可能的应用。
比如说,可以用它来渲染动画吗?即将发表的论文 [Dynamic 3D Gaussians: tracking by Persistent Dynamic View Synthesis](https://arxiv.org/pdf/2308.09713) 似乎表明这有戏。还有更多其他问题有待研究。它能对反射进行建模吗?可以不经参考图像的训练就直接建模吗……
最后,当前人们对 [具身智能 (Embodied AI)](https://ieeexplore.ieee.org/iel7/7433297/9741092/09687596.pdf) 兴趣日隆。但作为人工智能的一个研究领域,当前最先进的具身智能的性能仍然比人类低好几个数量级,其中大部分的挑战在 3D 空间的表示上。鉴于 3D 高斯分布可以产生致密的 3D 空间表示,这对具身智能研究有何影响?
所有这些问题都引发了人们对 3D 高斯点染的广泛关注。时间会告诉我们答案!
## 图形学的未来
3D 高斯点染会左右图形学的未来吗?我们先来看下该方法的优缺点:
**优点**
1. 高品质、逼真的场景
2. 快速、实时的渲染
3. 更快的训练速度
**缺点**
1. 更高的显存使用率 (4GB 用于显示,12GB 用于训练)
2. 更大的磁盘占用 (每场景 1GB+)
3. 与现有渲染管线不兼容
4. 仅能绘制静态图像 (当前)
到目前为止,3D 高斯点染的 CUDA 原始实现尚未与 Vulkan、DirectX、WebGPU 等产品级渲染管道进行适配,因此尚不清楚其会对现有渲染管线带来什么影响。
已有的适配如下:
1. [远程显示器](https://huggingface.co/spaces/dylanebert/gaussian-viewer)
2. [WebGPU 显示器](https://github.com/cvlab-epfl/gaussian-splatting-web)
3. [WebGL 显示器](https://huggingface.co/spaces/cakewalk/splat)
4. [Unity 显示器](https://github.com/aras-p/UnityGaussianSplatting)
5. [优化过的 WebGL 显示器](https://gsplat.tech/)
这些显示器要么依赖于远程流式传输 (1),要么依赖于传统的基于 2x2 像素块的栅格化方法 (2-5)。虽然基于 2x2 像素块的方法与数十年来的图形技术兼容,但它可能会导致质量/性能的降低。然而,[第 5 个显示器](https://gsplat.tech/) 的工作又表明,尽管采用基于 2x2 像素块的方法,通过巧妙的优化我们仍可以达到高的质量及性能。
那么有没有可能需要针对生产环境重实现 3D 高斯点染代码呢?答案是 _有可能_ 。当前主要的性能瓶颈在对数百万个高斯图像进行排序上,在论文的原始实现中,这一过程是通过 [CUB 库的基数排序](https://nvlabs.github.io/cub/structcub_1_1_device_radix_sort.html) 原语来高效实现的,但该高性能原语仅在 CUDA 中可用。我们相信,经过努力,其他渲染管线也可以达到相仿的性能水平。
如果你有任何问题或有兴趣加入我们的工作,请加入 [Hugging Face Discord](https://hf.co/join/discord)! | 9 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_object_detection.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.object_detection.params import ObjectDetectionParams
from . import BaseAutoTrainCommand
def run_object_detection_command_factory(args):
return RunAutoTrainObjectDetectionCommand(args)
class RunAutoTrainObjectDetectionCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(ObjectDetectionParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
run_object_detection_parser = parser.add_parser(
"object-detection", description="✨ Run AutoTrain Object Detection"
)
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_object_detection_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_object_detection_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_object_detection_parser.set_defaults(func=run_object_detection_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"auto_find_batch_size",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
if self.args.backend.startswith("spaces") or self.args.backend.startswith("ep-"):
if not self.args.push_to_hub:
raise ValueError("Push to hub must be specified for spaces backend")
if self.args.username is None:
raise ValueError("Username must be specified for spaces backend")
if self.args.token is None:
raise ValueError("Token must be specified for spaces backend")
def run(self):
logger.info("Running Object Detection")
if self.args.train:
params = ObjectDetectionParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 0 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_tools.py | from argparse import ArgumentParser
from . import BaseAutoTrainCommand
def run_tools_command_factory(args):
return RunAutoTrainToolsCommand(args)
class RunAutoTrainToolsCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
run_app_parser = parser.add_parser("tools", help="Run AutoTrain tools")
subparsers = run_app_parser.add_subparsers(title="tools", dest="tool_name")
merge_llm_parser = subparsers.add_parser(
"merge-llm-adapter",
help="Merge LLM Adapter tool",
)
merge_llm_parser.add_argument(
"--base-model-path",
type=str,
help="Base model path",
)
merge_llm_parser.add_argument(
"--adapter-path",
type=str,
help="Adapter path",
)
merge_llm_parser.add_argument(
"--token",
type=str,
help="Token",
default=None,
required=False,
)
merge_llm_parser.add_argument(
"--pad-to-multiple-of",
type=int,
help="Pad to multiple of",
default=None,
required=False,
)
merge_llm_parser.add_argument(
"--output-folder",
type=str,
help="Output folder",
required=False,
default=None,
)
merge_llm_parser.add_argument(
"--push-to-hub",
action="store_true",
help="Push to Hugging Face Hub",
required=False,
)
merge_llm_parser.set_defaults(func=run_tools_command_factory, merge_llm_adapter=True)
convert_to_kohya_parser = subparsers.add_parser("convert_to_kohya", help="Convert to Kohya tool")
convert_to_kohya_parser.add_argument(
"--input-path",
type=str,
help="Input path",
)
convert_to_kohya_parser.add_argument(
"--output-path",
type=str,
help="Output path",
)
convert_to_kohya_parser.set_defaults(func=run_tools_command_factory, convert_to_kohya=True)
def __init__(self, args):
self.args = args
def run(self):
if getattr(self.args, "merge_llm_adapter", False):
self.run_merge_llm_adapter()
if getattr(self.args, "convert_to_kohya", False):
self.run_convert_to_kohya()
def run_merge_llm_adapter(self):
from autotrain.tools.merge_adapter import merge_llm_adapter
merge_llm_adapter(
base_model_path=self.args.base_model_path,
adapter_path=self.args.adapter_path,
token=self.args.token,
output_folder=self.args.output_folder,
pad_to_multiple_of=self.args.pad_to_multiple_of,
push_to_hub=self.args.push_to_hub,
)
def run_convert_to_kohya(self):
from autotrain.tools.convert_to_kohya import convert_to_kohya
convert_to_kohya(
input_path=self.args.input_path,
output_path=self.args.output_path,
)
| 1 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_vlm.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.vlm.params import VLMTrainingParams
from . import BaseAutoTrainCommand
def run_vlm_command_factory(args):
return RunAutoTrainVLMCommand(args)
class RunAutoTrainVLMCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(VLMTrainingParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
run_image_regression_parser = parser.add_parser("vlm", description="✨ Run AutoTrain VLM")
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_image_regression_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_image_regression_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_image_regression_parser.set_defaults(func=run_vlm_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"auto_find_batch_size",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
if self.args.backend.startswith("spaces") or self.args.backend.startswith("ep-"):
if not self.args.push_to_hub:
raise ValueError("Push to hub must be specified for spaces backend")
if self.args.username is None:
raise ValueError("Username must be specified for spaces backend")
if self.args.token is None:
raise ValueError("Token must be specified for spaces backend")
def run(self):
logger.info("Running Image Regression")
if self.args.train:
params = VLMTrainingParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 2 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_seq2seq.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.seq2seq.params import Seq2SeqParams
from . import BaseAutoTrainCommand
def run_seq2seq_command_factory(args):
return RunAutoTrainSeq2SeqCommand(args)
class RunAutoTrainSeq2SeqCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(Seq2SeqParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
run_seq2seq_parser = parser.add_parser("seq2seq", description="✨ Run AutoTrain Seq2Seq")
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_seq2seq_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_seq2seq_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_seq2seq_parser.set_defaults(func=run_seq2seq_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = ["train", "deploy", "inference", "auto_find_batch_size", "push_to_hub", "peft"]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
def run(self):
logger.info("Running Seq2Seq Classification")
if self.args.train:
params = Seq2SeqParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 3 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_spacerunner.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.backends.base import AVAILABLE_HARDWARE
from autotrain.backends.spaces import SpaceRunner
from autotrain.trainers.generic.params import GenericParams
from autotrain.trainers.generic.utils import create_dataset_repo
from . import BaseAutoTrainCommand
BACKEND_CHOICES = list(AVAILABLE_HARDWARE.keys())
BACKEND_CHOICES = [b for b in BACKEND_CHOICES if b.startswith("spaces-")]
def run_spacerunner_command_factory(args):
return RunAutoTrainSpaceRunnerCommand(args)
class RunAutoTrainSpaceRunnerCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = [
{
"arg": "--project-name",
"help": "Name of the project. Must be unique.",
"required": True,
"type": str,
},
{
"arg": "--script-path",
"help": "Path to the script",
"required": True,
"type": str,
},
{
"arg": "--username",
"help": "Hugging Face Username, can also be an organization name",
"required": True,
"type": str,
},
{
"arg": "--token",
"help": "Hugging Face API Token",
"required": True,
"type": str,
},
{
"arg": "--backend",
"help": "Hugging Face backend to use",
"required": True,
"type": str,
"choices": BACKEND_CHOICES,
},
{
"arg": "--env",
"help": "Environment variables, e.g. --env FOO=bar;FOO2=bar2;FOO3=bar3",
"required": False,
"type": str,
},
{
"arg": "--args",
"help": "Arguments to pass to the script, e.g. --args foo=bar;foo2=bar2;foo3=bar3;store_true_arg",
"required": False,
"type": str,
},
]
run_spacerunner_parser = parser.add_parser("spacerunner", description="✨ Run AutoTrain SpaceRunner")
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_spacerunner_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
choices=arg.get("choices"),
)
else:
run_spacerunner_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_spacerunner_parser.set_defaults(func=run_spacerunner_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = []
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
env_vars = {}
if self.args.env:
for env_name_value in self.args.env.split(";"):
if len(env_name_value.split("=")) == 2:
env_vars[env_name_value.split("=")[0]] = env_name_value.split("=")[1]
else:
raise ValueError("Invalid environment variable format.")
self.args.env = env_vars
app_args = {}
store_true_args = []
if self.args.args:
for arg_name_value in self.args.args.split(";"):
if len(arg_name_value.split("=")) == 1:
store_true_args.append(arg_name_value)
elif len(arg_name_value.split("=")) == 2:
app_args[arg_name_value.split("=")[0]] = arg_name_value.split("=")[1]
else:
raise ValueError("Invalid argument format.")
for arg_name in store_true_args:
app_args[arg_name] = ""
self.args.args = app_args
def run(self):
dataset_id = create_dataset_repo(
username=self.args.username,
project_name=self.args.project_name,
script_path=self.args.script_path,
token=self.args.token,
)
params = GenericParams(
project_name=self.args.project_name,
data_path=dataset_id,
username=self.args.username,
token=self.args.token,
script_path=self.args.script_path,
env=self.args.env,
args=self.args.args,
)
project = SpaceRunner(params=params, backend=self.args.backend)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 4 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_api.py | from argparse import ArgumentParser
from . import BaseAutoTrainCommand
def run_api_command_factory(args):
return RunAutoTrainAPICommand(
args.port,
args.host,
args.task,
)
class RunAutoTrainAPICommand(BaseAutoTrainCommand):
"""
Command to run the AutoTrain API.
This command sets up and runs the AutoTrain API using the specified host and port.
Methods
-------
register_subcommand(parser: ArgumentParser)
Registers the 'api' subcommand and its arguments to the provided parser.
__init__(port: int, host: str, task: str)
Initializes the command with the specified port, host, and task.
run()
Runs the AutoTrain API using the uvicorn server.
"""
@staticmethod
def register_subcommand(parser: ArgumentParser):
run_api_parser = parser.add_parser(
"api",
description="✨ Run AutoTrain API",
)
run_api_parser.add_argument(
"--port",
type=int,
default=7860,
help="Port to run the api on",
required=False,
)
run_api_parser.add_argument(
"--host",
type=str,
default="127.0.0.1",
help="Host to run the api on",
required=False,
)
run_api_parser.add_argument(
"--task",
type=str,
required=False,
help="Task to run",
)
run_api_parser.set_defaults(func=run_api_command_factory)
def __init__(self, port, host, task):
self.port = port
self.host = host
self.task = task
def run(self):
import uvicorn
from autotrain.app.training_api import api
uvicorn.run(api, host=self.host, port=self.port)
| 5 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/autotrain.py | import argparse
from autotrain import __version__, logger
from autotrain.cli.run_api import RunAutoTrainAPICommand
from autotrain.cli.run_app import RunAutoTrainAppCommand
from autotrain.cli.run_extractive_qa import RunAutoTrainExtractiveQACommand
from autotrain.cli.run_image_classification import RunAutoTrainImageClassificationCommand
from autotrain.cli.run_image_regression import RunAutoTrainImageRegressionCommand
from autotrain.cli.run_llm import RunAutoTrainLLMCommand
from autotrain.cli.run_object_detection import RunAutoTrainObjectDetectionCommand
from autotrain.cli.run_sent_tranformers import RunAutoTrainSentenceTransformersCommand
from autotrain.cli.run_seq2seq import RunAutoTrainSeq2SeqCommand
from autotrain.cli.run_setup import RunSetupCommand
from autotrain.cli.run_spacerunner import RunAutoTrainSpaceRunnerCommand
from autotrain.cli.run_tabular import RunAutoTrainTabularCommand
from autotrain.cli.run_text_classification import RunAutoTrainTextClassificationCommand
from autotrain.cli.run_text_regression import RunAutoTrainTextRegressionCommand
from autotrain.cli.run_token_classification import RunAutoTrainTokenClassificationCommand
from autotrain.cli.run_tools import RunAutoTrainToolsCommand
from autotrain.parser import AutoTrainConfigParser
def main():
parser = argparse.ArgumentParser(
"AutoTrain advanced CLI",
usage="autotrain <command> [<args>]",
epilog="For more information about a command, run: `autotrain <command> --help`",
)
parser.add_argument("--version", "-v", help="Display AutoTrain version", action="store_true")
parser.add_argument("--config", help="Optional configuration file", type=str)
commands_parser = parser.add_subparsers(help="commands")
# Register commands
RunAutoTrainAppCommand.register_subcommand(commands_parser)
RunAutoTrainLLMCommand.register_subcommand(commands_parser)
RunSetupCommand.register_subcommand(commands_parser)
RunAutoTrainAPICommand.register_subcommand(commands_parser)
RunAutoTrainTextClassificationCommand.register_subcommand(commands_parser)
RunAutoTrainImageClassificationCommand.register_subcommand(commands_parser)
RunAutoTrainTabularCommand.register_subcommand(commands_parser)
RunAutoTrainSpaceRunnerCommand.register_subcommand(commands_parser)
RunAutoTrainSeq2SeqCommand.register_subcommand(commands_parser)
RunAutoTrainTokenClassificationCommand.register_subcommand(commands_parser)
RunAutoTrainToolsCommand.register_subcommand(commands_parser)
RunAutoTrainTextRegressionCommand.register_subcommand(commands_parser)
RunAutoTrainObjectDetectionCommand.register_subcommand(commands_parser)
RunAutoTrainSentenceTransformersCommand.register_subcommand(commands_parser)
RunAutoTrainImageRegressionCommand.register_subcommand(commands_parser)
RunAutoTrainExtractiveQACommand.register_subcommand(commands_parser)
args = parser.parse_args()
if args.version:
print(__version__)
exit(0)
if args.config:
logger.info(f"Using AutoTrain configuration: {args.config}")
cp = AutoTrainConfigParser(args.config)
cp.run()
exit(0)
if not hasattr(args, "func"):
parser.print_help()
exit(1)
command = args.func(args)
command.run()
if __name__ == "__main__":
main()
| 6 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_llm.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.clm.params import LLMTrainingParams
from . import BaseAutoTrainCommand
def run_llm_command_factory(args):
return RunAutoTrainLLMCommand(args)
class RunAutoTrainLLMCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(LLMTrainingParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
arg_list = [arg for arg in arg_list if arg["arg"] != "--block-size"]
arg_list.append(
{
"arg": "--block_size",
"help": "Block size",
"required": False,
"type": str,
"default": "1024",
"alias": ["--block-size"],
}
)
run_llm_parser = parser.add_parser("llm", description="✨ Run AutoTrain LLM")
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_llm_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_llm_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_llm_parser.set_defaults(func=run_llm_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"add_eos_token",
"peft",
"auto_find_batch_size",
"push_to_hub",
"merge_adapter",
"use_flash_attention_2",
"disable_gradient_checkpointing",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
block_size_split = self.args.block_size.strip().split(",")
if len(block_size_split) == 1:
self.args.block_size = int(block_size_split[0])
elif len(block_size_split) > 1:
self.args.block_size = [int(x.strip()) for x in block_size_split]
else:
raise ValueError("Invalid block size")
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
# must have project_name, username and token OR project_name, token
if self.args.username is None:
raise ValueError("Usernamemust be specified for push to hub")
if self.args.token is None:
raise ValueError("Token must be specified for push to hub")
if self.args.backend.startswith("spaces") or self.args.backend.startswith("ep-"):
if not self.args.push_to_hub:
raise ValueError("Push to hub must be specified for spaces backend")
if self.args.username is None:
raise ValueError("Username must be specified for spaces backend")
if self.args.token is None:
raise ValueError("Token must be specified for spaces backend")
if self.args.deploy:
raise NotImplementedError("Deploy is not implemented yet")
if self.args.inference:
raise NotImplementedError("Inference is not implemented yet")
def run(self):
logger.info("Running LLM")
if self.args.train:
params = LLMTrainingParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 7 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/__init__.py | from abc import ABC, abstractmethod
from argparse import ArgumentParser
class BaseAutoTrainCommand(ABC):
@staticmethod
@abstractmethod
def register_subcommand(parser: ArgumentParser):
raise NotImplementedError()
@abstractmethod
def run(self):
raise NotImplementedError()
| 8 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_image_regression.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.image_regression.params import ImageRegressionParams
from . import BaseAutoTrainCommand
def run_image_regression_command_factory(args):
return RunAutoTrainImageRegressionCommand(args)
class RunAutoTrainImageRegressionCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(ImageRegressionParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
run_image_regression_parser = parser.add_parser(
"image-regression", description="✨ Run AutoTrain Image Regression"
)
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_image_regression_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_image_regression_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_image_regression_parser.set_defaults(func=run_image_regression_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"auto_find_batch_size",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
if self.args.backend.startswith("spaces") or self.args.backend.startswith("ep-"):
if not self.args.push_to_hub:
raise ValueError("Push to hub must be specified for spaces backend")
if self.args.username is None:
raise ValueError("Username must be specified for spaces backend")
if self.args.token is None:
raise ValueError("Token must be specified for spaces backend")
def run(self):
logger.info("Running Image Regression")
if self.args.train:
params = ImageRegressionParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 9 |
0 | hf_public_repos/api-inference-community/docker_images/mindspore | hf_public_repos/api-inference-community/docker_images/mindspore/tests/test_api.py | import os
from typing import Dict
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, str] = {"image-classification": "mindspore-ai/LeNet"}
ALL_TASKS = {"image-classification"}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
with self.assertRaises(EnvironmentError):
get_pipeline(unsupported_task, model_id="XX")
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/mindspore | hf_public_repos/api-inference-community/docker_images/mindspore/tests/test_api_image_classification.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"image-classification" not in ALLOWED_TASKS,
"image-classification not implemented",
)
class ImageClassificationTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["image-classification"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "image-classification"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def read(self, filename: str) -> bytes:
dirname = os.path.dirname(os.path.abspath(__file__))
filename = os.path.join(dirname, "samples", filename)
with open(filename, "rb") as f:
bpayload = f.read()
return bpayload
def test_simple(self):
bpayload = self.read("0.jpg")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(set(type(el) for el in content), {dict})
self.assertEqual(
set((k, type(v)) for el in content for (k, v) in el.items()),
{("label", str), ("score", float)},
)
def test_different_resolution(self):
bpayload = self.read("5.jpg")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(set(type(el) for el in content), {dict})
self.assertEqual(
set(k for el in content for k in el.keys()), {"label", "score"}
)
| 1 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/fastai/requirements.txt | starlette==0.27.0
api-inference-community==0.0.23
huggingface_hub[fastai]==0.6.0
timm==0.5.4
| 2 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/fastai/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.8
LABEL maintainer="Omar Espejel <[email protected]>"
# Add any system dependency here
# RUN apt-get update -y && apt-get install libXXX -y
COPY ./requirements.txt /app
# This enables better docker caching so adding new requirements doesn't
# retrigger reinstalling the whole pytorch.
RUN pip install torch==1.11.0 torchvision==0.12.0 torchaudio==0.11.0
RUN pip install --no-cache-dir -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 3 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/fastai/prestart.sh | python app/main.py
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/fastai | hf_public_repos/api-inference-community/docker_images/fastai/app/main.py | import functools
import logging
import os
from typing import Dict, Type
from api_inference_community.routes import pipeline_route, status_ok
from app.pipelines import ImageClassificationPipeline, Pipeline
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.gzip import GZipMiddleware
from starlette.routing import Route
TASK = os.getenv("TASK")
MODEL_ID = os.getenv("MODEL_ID")
logger = logging.getLogger(__name__)
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {
"image-classification": ImageClassificationPipeline
}
@functools.lru_cache()
def get_pipeline() -> Pipeline:
task = os.environ["TASK"]
model_id = os.environ["MODEL_ID"]
if task not in ALLOWED_TASKS:
raise EnvironmentError(f"{task} is not a valid pipeline for model : {model_id}")
return ALLOWED_TASKS[task](model_id)
routes = [
Route("/{whatever:path}", status_ok),
Route("/{whatever:path}", pipeline_route, methods=["POST"]),
]
middleware = [Middleware(GZipMiddleware, minimum_size=1000)]
if os.environ.get("DEBUG", "") == "1":
from starlette.middleware.cors import CORSMiddleware
middleware.append(
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_headers=["*"],
allow_methods=["*"],
)
)
app = Starlette(routes=routes, middleware=middleware)
@app.on_event("startup")
async def startup_event():
logger = logging.getLogger("uvicorn.access")
handler = logging.StreamHandler()
handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(message)s"))
logger.handlers = [handler]
# Link between `api-inference-community` and framework code.
app.get_pipeline = get_pipeline
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
if __name__ == "__main__":
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/fastai/app | hf_public_repos/api-inference-community/docker_images/fastai/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any, Optional
class Pipeline(ABC):
task: Optional[str] = None
model_id: Optional[str] = None
@abstractmethod
def __init__(self, model_id: str):
raise NotImplementedError("Pipelines should implement an __init__ method")
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
class PipelineException(Exception):
pass
| 6 |
0 | hf_public_repos/api-inference-community/docker_images/fastai/app | hf_public_repos/api-inference-community/docker_images/fastai/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.image_classification import ImageClassificationPipeline
# from app.pipelines.audio_classification import AudioClassificationPipeline
# from app.pipelines.audio_to_audio import AudioToAudioPipeline
# from app.pipelines.automatic_speech_recognition import (
# AutomaticSpeechRecognitionPipeline,
# )
# from app.pipelines.feature_extraction import FeatureExtractionPipeline
# from app.pipelines.question_answering import QuestionAnsweringPipeline
# from app.pipelines.sentence_similarity import SentenceSimilarityPipeline
# from app.pipelines.speech_segmentation import SpeechSegmentationPipeline
# from app.pipelines.tabular_classification import (
# TabularDataPipeline,
# )
# from app.pipelines.text_to_speech import TextToSpeechPipeline
# from app.pipelines.token_classification import TokenClassificationPipeline
| 7 |
0 | hf_public_repos/api-inference-community/docker_images/fastai/app | hf_public_repos/api-inference-community/docker_images/fastai/app/pipelines/image_classification.py | from typing import Any, Dict, List
import numpy as np
from app.pipelines import Pipeline
from huggingface_hub import from_pretrained_fastai
from PIL import Image
class ImageClassificationPipeline(Pipeline):
def __init__(self, model_id: str):
self.model = from_pretrained_fastai(model_id)
# Obtain labels
self.id2label = self.model.dls.vocab
# Return at most the top 5 predicted classes
self.top_k = 5
def __call__(self, inputs: "Image.Image") -> List[Dict[str, Any]]:
"""
Args:
inputs (:obj:`PIL.Image`):
The raw image representation as PIL.
No transformation made whatsoever from the input. Make all necessary transformations here.
Return:
A :obj:`list`:. The list contains items that are dicts should be liked {"label": "XXX", "score": 0.82}
It is preferred if the returned list is in decreasing `score` order
"""
# FastAI expects a np array, not a PIL Image.
_, _, preds = self.model.predict(np.array(inputs))
preds = preds.tolist()
labels = [
{"label": str(self.id2label[i]), "score": float(preds[i])}
for i in range(len(preds))
]
return sorted(labels, key=lambda tup: tup["score"], reverse=True)[: self.top_k]
| 8 |
0 | hf_public_repos/api-inference-community/docker_images/fastai | hf_public_repos/api-inference-community/docker_images/fastai/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 9 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/dpo_vlm.md | ---
title: '为视觉语言多模态模型进行偏好优化'
thumbnail: /blog/assets/dpo_vlm/thumbnail.png
authors:
- user: qgallouedec
- user: vwxyzjn
- user: merve
- user: kashif
translators:
- user: hugging-hoi2022
- user: zhongdongy
proofreader: false
---
# 为视觉语言多模态模型进行偏好优化
训练模型使得它能够理解并预测人类偏好是一项比较复杂的任务。诸如 SFT (Supervised finetuning) 的传统的方法一般都需要耗费较大成本,因为这些算法需要对数据打上特定的标签。而偏好优化 (Preference Optimization) 作为一种替代选项,通常可以简化这一过程,并产出更准确的结果。通过对候选回答的对比和排序,而不是赋予固定的标签,偏好优化使得模型能更高效地捕捉人类偏好中的细微差别。
偏好优化已经在大语言模型中广泛使用了,但现在,它也可以用在视觉语言模型 (VLM) 上。得益于 **[TRL](https://huggingface.co/docs/trl/index)** 的开发,现在我们可以 **使用 TRL 对 VLM 进行直接偏好优化** (Direct Preference Optimization)。本文将会介绍使用 TRL 和 DPO 对视觉语言模型进行训练的全过程。
## 偏好数据集
进行偏好优化,首先我们需要有一个能体现用户偏好的数据集。在双项选择的设定下,相应的数据一般包含一个提示词 (Prompt) 和两个候选回答,两个回答中一个被记为选中 (chosen),另一个被记为淘汰 (rejected)。模型将要去学习着给出选中的回答,而不是被淘汰的那个。下图就是一个例子:
<figure class="image table text-center m-0 w-full">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/dpo_vlm/how-many-families.jpg"/>
<figcaption>图片来自 <a href="https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset">openbmb/RLAIF-V-Dataset</a> 数据集</figcaption>
</figure>
**❔ Question**: _How many families?_
- **❌ Rejected:** _The image does not provide any information about families._
- **✅ Chosen:** _The image shows a Union Organization table setup with 18,000 families._
需要注意的是,尽管选中的回答也不是完全正确的 (回答 18000 个家庭还是不对,应该是 18000000),但它也好于那个被淘汰的回答。
本文将使用 [openbmb/RLAIF-V-Dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset) 作为示例数据集,它包含了超过 83000 条标注的数据。可以通过下面代码查看一下数据集:
```python
>>> from datasets import load_dataset
>>> dataset = load_dataset("openbmb/RLAIF-V-Dataset", split="train[:1%]")
>>> sample = dataset[1]
>>> sample["image"].show()
>>> sample["question"]
'how many families?'
>>> sample["rejected"]
'The image does not provide any information about families.'
>>> sample["chosen"]
'The image shows a Union Organization table setup with 18,000 families.'
```
我们将要训练的 VLM 模型需要文本和图像同时作为输入,所以这里的第一步还是要对数据集格式进行改造。一条数据应该被结构化成能模拟人机对话的形式。用户提供一个提示语,其中包含一张图片和一个问题,然后模型需要能够给出一个回答。我们用以下代码实现格式转换:
```python
from datasets import features
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b", do_image_splitting=False)
def format(example):
# Prepare the input for the chat template
prompt = [
{
"role": "user",
"content": [{"type": "image"}, {"type": "text", "text": example["question"]}],
},
]
chosen = [
{
"role": "assistant",
"content": [{"type": "text", "text": example["chosen"]}],
},
]
rejected = [
{
"role": "assistant",
"content": [{"type": "text", "text": example["rejected"]}],
},
]
# Apply the chat template
prompt = processor.apply_chat_template(prompt, tokenize=False)
chosen = processor.apply_chat_template(chosen, tokenize=False)
rejected = processor.apply_chat_template(rejected, tokenize=False)
# Resize the image to ensure it fits within the maximum allowable
# size of the processor to prevent OOM errors.
max_size = processor.image_processor.size["longest_edge"]
example["image"].thumbnail((max_size, max_size))
return {"images": [example["image"]], "prompt": prompt, "chosen": chosen, "rejected": rejected}
# Apply the formatting function to the dataset,
# remove columns to end up with only "images", "prompt", "chosen", "rejected" columns
dataset = dataset.map(format, remove_columns=dataset.column_names)
# Make sure that the images are decoded, it prevents from storing bytes.
# More info here https://github.com/huggingface/blog/pull/2148#discussion_r1667400478
f = dataset.features
f["images"] = features.Sequence(features.Image(decode=True)) # to avoid bytes
dataset = dataset.cast(f)
```
完成了格式转换,我们来看看第一条数据:
```python
>>> dataset[1]
{'images': [<PIL.JpegImagePlugin.JpegImageFile image mode=L size=980x812 at 0x154505570>],
'prompt': 'User:<image>how many families?<end_of_utterance>\n',
'rejected': 'Assistant: The image does not provide any information about families.<end_of_utterance>\n',
'chosen': 'Assistant: The image shows a Union Organization table setup with 18,000 families.<end_of_utterance>\n'}
```
OK!接下来准备好 GPU,训练马上开始。
## 训练
我们将使用 [Idefics2-8b](https://huggingface.co/HuggingFaceM4/idefics2-8b) 作为我们的示例模型,但 TRL 里的 DPO 也是能用在像 [Llava 1.5](https://huggingface.co/llava-hf/llava-1.5-7b-hf) 和 [PaliGemma](https://huggingface.co/google/paligemma-3b-pt-224) 这样的模型上的 (可参考这篇文章: [Finetuning Llava 1.5, PaliGemma and others](#finetuning-llava-15-paligemma-and-others))。不过训练之前,我们先检查一下我们的 GPU 显存是否够用:
### 训练需要多大的 GPU 显存?
一个 80GB VRAM 的 GPU 足够用来对 Idefics2-8b 进行 DPO 训练吗?我们可以先计算一下:
我们用 \\( N \\) 表示参数的数量,用 \\( P \\) 表示训练使用的精度。训练过程中,下列部分需要共同放入显存中:
- **要训练的模型**: \\( N \times P \\)
- **用以防止模型产生偏离的参考模型**: 和要训练的模型一样大,所以也是 \\( N \times P \\)
- **梯度**: 我们对所有参数都进行训练,所以每个参数都有梯度: \\( N \times P \\)
- **优化器的状态量**: 我们使用 [AdamW](https://pytorch.org/docs/stable/generated/torch.optim.AdamW.html),一个参数会保存两个状态量,所以需要: \\( 2 \times N \times P \\)
Idefics2-8b 有 80 亿 (8B) 参数,我们使用 `float32` 精度,每个参数占 4 个字节。所以总的显存需求是:
| 参数来源 | 计算公式 | 显存需求 |
| ---------------- | ------------------------------------- | ---------- |
| 要训练的模型 | \\( 8 \times 10^9 \times 4 \\) | 32 GB |
| 参考模型 | \\( 8 \times 10^9 \times 4 \\) | 32 GB |
| 梯度 | \\( 8 \times 10^9 \times 4 \\) | 32 GB |
| 优化器状态量 | \\( 2 \times 8 \times 10^9 \times 4 \\) | 64 GB |
| **合计** | | **160 GB** |
这远超我们前面说的 80GB 显存了!幸运的是,我们可以使用量化、LoRA 等技术来大幅度地减少显存需求,让训练可以进行。接下来我们将介绍这些技术。
### 量化
量化会降低模型权重和激活值的精度,但也同时显著减少内存需求。将精度从 `float32` 改为 `bfloat16` ,会让每个参数需要的比特数从 4 比特减少到 2 比特。这一策略不仅能减少内存使用,还会显著加速训练,确保以最小代价保证足够高的性能。具体做法如下:
```python
import torch
from transformers import AutoModelForVision2Seq
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceM4/idefics2-8b", torch_dtype=torch.bfloat16)
```
通过如下 `bf16=True` 的设置, `bfloat16` 也可以被用在优化器上:
```python
from transformers import TrainingArguments
training_args = TrainingArguments(..., bf16=True)
```
### LoRA
[LoRA](https://arxiv.org/abs/2106.09685) 对参数矩阵进行低秩分解; 在训练时,固定住原参数矩阵,仅训练分解出的两个矩阵。是一种大规模减少 LLM 训练参数的方法。LoRA 已被集成在了 [PEFT](https://github.com/huggingface/peft) 库里,使用非常方便:
```diff
from transformers import AutoModelForVision2Seq
+ from peft import get_peft_model, LoraConfig
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceM4/idefics2-8b")
+ peft_config = LoraConfig(target_modules="all-linear")
+ model = get_peft_model(model, peft_config)
```
PEFT 像是给原模型进行了一次封装 (代码中称为 _adapter_ )。训练时,实际上是这个 adapter 在被训练,而原有的模型保持不动。我们现在算算 LoRA 帮我们减少了多少要训练的参数:
```python
>>> model.print_trainable_parameters()
trainable params: 55,348,736 || all params: 8,458,116,848 || trainable%: 0.6543860411799315
```
它帮我们把要训练的参数从八十亿降到了五千五百万!差距真大!这将显著减少显存需求。
### 使用 bfloat16 和 LoRA 后的显存需求
现在我们来算算新的显存需求:
| 参数来源 | 计算公式 | 显存需求 |
| ---------------- | ------------------------------------- | ----------- |
| 要训练的模型 | \\( 8 \mathrm{G} \times 2 \\) | 16 GB |
| 参考模型 | \\( 8 \mathrm{G} \times 2 \\) | 16 GB |
| 梯度 | \\( 55 \mathrm{M} \times 2 \\) | 0.1 GB |
| 优化器状态量 | \\( 2 \times 55 \mathrm{M} \times 2 \\) | 0.2 GB |
| **合计** | | **32.3 GB** |
现在我们仅需 32GB 的显存就可以训练我们的 Idefics2-8b 模型了。这合理多了,用 80GB 显存的 GPU 就可以训练了。
[PEFT 文档](https://huggingface.co/docs/peft/en/index) 和 [谷歌这篇关于 LoRA 和 QLoRA 文章](https://cloud.google.com/vertex-ai/generative-ai/docs/model-garden/lora-qlora) 也提供了很多关于显存优化的帮助指南,读者感兴趣可以阅读。
### 训练时 batch size 怎么设定?
上述关于显存占用的计算还不算准确,因为实际训练时,激活值也需要占用显存。激活值是神经网络各层的输出。作为中间产物,它们的显存占用量取决于模型结构和训练时的 batch size。准确计算这些显存需求还是很困难的,我们一般依赖实验观察。
若想找到一个合适的 batch size ( `per_device_train_batch_size` ),你可以先随便选取一个你认为合适的数值 (比如 64) 然后试着开始训练。当然这大多数情况下会爆显存 (OOM)。如果这样,你可以减半 batch size,同时将 `gradient_accumulation_steps` 翻倍,以获得和原先 batch size 设定相同的效果。反复重复这一过程,最终当 OOM 不再出现时,你就可以训练了。我们的实验参数是: `per_device_train_batch_size` 设为 2, `gradient_accumulation_steps` 设为 32。
你还可以使用 `gradient_checkpointing` 来减少激活值所需的内存。这一技术在计算梯度时,会重新计算一遍前向过程,而不是在前向过程中保存用于计算梯度的中间结果。需要使用时,设置 `gradient_checkpointing=True` 即可。
### 完整训练代码
一切就绪,我们可以开始训练了。下面是我们的完整训练代码。除了上面提到的部分外,我们还设置了 `dataset_num_proc` 和 `dataloader_num_workers` 等参数,用于加速数据预处理。
```python
# dpo_idefics2-8b.py
from datasets import features, load_dataset
from transformers import AutoModelForVision2Seq, AutoProcessor
import torch
from trl import DPOConfig, DPOTrainer
from peft import LoraConfig
def main():
# Load the model and processor
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceM4/idefics2-8b", torch_dtype=torch.bfloat16)
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b", do_image_splitting=False)
# Load the dataset
dataset = load_dataset("openbmb/RLAIF-V-Dataset", split="train")
def format(example):
# Prepare the input for the chat template
prompt = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": example["question"]}]}]
chosen = [{"role": "assistant", "content": [{"type": "text", "text": example["chosen"]}]}]
rejected = [{"role": "assistant", "content": [{"type": "text", "text": example["rejected"]}]}]
# Apply the chat template
prompt = processor.apply_chat_template(prompt, tokenize=False)
chosen = processor.apply_chat_template(chosen, tokenize=False)
rejected = processor.apply_chat_template(rejected, tokenize=False)
# Resize the image to ensure it fits within the maximum allowable
# size of the processor to prevent OOM errors.
max_size = processor.image_processor.size["longest_edge"]// 2
example["image"].thumbnail((max_size, max_size))
return {"images": [example["image"]], "prompt": prompt, "chosen": chosen, "rejected": rejected}
# Apply the formatting function to the dataset
dataset = dataset.map(format, remove_columns=dataset.column_names, num_proc=32)
# Make sure that the images are decoded, it prevents from storing bytes.
# More info here https://github.com/huggingface/blog/pull/2148#discussion_r1667400478
f = dataset.features
f["images"] = features.Sequence(features.Image(decode=True))
dataset = dataset.cast(f)
# Train the model
training_args = DPOConfig(
output_dir="idefics2-8b-dpo",
bf16=True,
gradient_checkpointing=True,
per_device_train_batch_size=2,
gradient_accumulation_steps=32,
num_train_epochs=1,
dataset_num_proc=32, # tokenization will use 32 processes
dataloader_num_workers=32, # data loading will use 32 workers
logging_steps=10,
)
trainer = DPOTrainer(
model,
ref_model=None, # not needed when using peft
args=training_args,
train_dataset=dataset,
tokenizer=processor,
peft_config=LoraConfig(target_modules="all-linear"),
)
trainer.train()
if __name__ == "__main__":
main()
```
启动脚本开始训练,接下来就等待结果吧 🚀
```sh
accelerate launch dpo_idefics2-8b.py
```
## 结果
训练需要几小时的时间。当训练完成后,我们可以看看训练相关指标的变化曲线:

In DPO, we focus on several metrics to assess the quality of the training:
在 DPO 中,为了评估训练,我们关注这几个指标:
- **精度 (Accuracy)**: 在训练样本中,模型更愿意输出被选中的回答而不是被淘汰的回答,这个比率有多少。我们可以看到随着训练,精度在提升,这是个好的信号。
- **奖励 (Rewards)**: 这一指标与一个回答 (选中或淘汰) 被选中的概率呈正相关,读者可以参考 [DPO 论文 , 第 5 部分](https://arxiv.org/abs/2305.18290)。我们希望被选中的回答对应的奖励高于被淘汰的回答。我们可以通过两者奖励的差值 ( _reward margin_ ) 来看: 图中这一差值逐渐变大, 这也是个好的信号。
## 评测
### 推理代码
训练完成后,我们接下来就要在一些样本上评测一下了。这会让我们了解模型学习得怎么样、预测有效性如何。下面的代码可以用来在测试样本上进行评测:
```python
from transformers import AutoModelForVision2Seq, AutoProcessor
from PIL import Image
model = AutoModelForVision2Seq.from_pretrained("HuggingFaceM4/idefics2-8b").to("cuda")
processor = AutoProcessor.from_pretrained("HuggingFaceM4/idefics2-8b", do_image_splitting=False)
model.load_adapter("HuggingFaceH4/idefics2-8b-dpo-rlaif-v-v0.3") # <-- Load the adapter we've just trained
# Process
user_message = ...
image_path = ...
data = [{"role": "user", "content": [{"type": "image"}, {"type": "text", "text": user_message}]}]
prompts = processor.apply_chat_template(data, add_generation_prompt=True) # add_generation_prompt=True to end the prompt with "ASSISTANT:"
images = [Image.open(image_path)]
inputs = processor(prompts, images, return_tensors="pt")
inputs = {k: v.to("cuda") for k, v in inputs.items()}
# Generate
generated_ids = model.generate(**inputs, max_new_tokens=500)
response_text = processor.batch_decode(generated_ids, skip_special_tokens=True)[0]
print(response_text)
```
前面提到的 [openbmb/RLAIF-V-Dataset](https://huggingface.co/datasets/openbmb/RLAIF-V-Dataset) 这个数据集是用来减少大模型幻觉的。但真实训练效果如何呢?我们可以使用 [AMBER benchmark](https://arxiv.org/abs/2311.07397) 这个评测基准,该数据集专门被用来评估 VLM 的幻觉情况。我们列出 Idefics2 和 Idefics2+DPO 的结果,并和其它模型对比。
| | Accuracy | F1 |
| ---------------- | -------- | -------- |
| GPT-4o | 88.8 | 91.6 |
| **Idefics2+DPO** | **85.9** | **89.4** |
| Idefics2 | 85.8 | 89.1 |
| GPT-4v | 83.4 | 87.4 |
| MiniGemini | 82.6 | 87.6 |
| LLaVA-NeXT | 81.4 | 85.4 |
| QWEN-VL | 81.9 | 86.4 |
| LURE | 73.5 | 77.7 |
| OPERA | 75.2 | 78.3 |
| Less-is-more | 72.4 | 75.8 |
| VCD | 71.8 | 74.9 |
总的来看,有点作用!幻觉似乎减少了点。训练看来还是成功的。
下面我们也列出一些可视化结果出来:
| Image | Question | Idefics2 | Idefics2+DPO |
| ---------------------------------------------------------------------------------------------------------------------- | ----------------------------------- | -------- | ------------ |
|  | Are there two ships in this image? | Yes | No |
|  | Is the ground uneven in this image? | No | Yes |
|  | Is there one shovel in this image? | Yes | No |
你也可以自己找些例子来测试一下这个模型!
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/4.36.1/gradio.js"></script>
<gradio-app theme_mode="light" space="HuggingFaceH4/compare_idefics-8b-dpo"></gradio-app>
## 微调 Llava 1.5 和 PaliGemma 等模型
截至本文完稿时,TRL 的 DPO 实现已支持 Idefics2、Llava 1.5 和 PaliGemma,同时 TRL 也在努力支持更多的模型。最简单的调用方法还是使用 TRL 提供的 [示例脚本](https://github.com/huggingface/trl/blob/main/examples/scripts/dpo_visual.py)。例如,如果你想微调 PaliGemma,你可以这样:
```sh
accelerate launch examples/scripts/dpo_visual.py \
--dataset_name HuggingFaceH4/rlaif-v_formatted \
--model_name_or_path google/paligemma-3b-pt-224 \
--per_device_train_batch_size 2 \
--gradient_accumulation_steps 32 \
--dataset_num_proc 32 \
--output_dir dpo_paligemma_rlaif-v \
--bf16 \
--torch_dtype bfloat16 \
--gradient_checkpointing \
--use_peft \
--lora_target_modules=all-linear
```
更多关于 PaliGemma 微调的信息可以在 [smol-vision](https://github.com/merveenoyan/smol-vision) 这个项目里看到。
🚀🚀 好了!你现在已经会使用 DPO 微调 VLM 模型了!我们期待你在社区分享你的模型、数据和独特见解! | 0 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/chinese-language-blog.md | ---
title: "Hugging Face 中文博客正式发布!"
thumbnail: /blog/assets/chinese-language-blog/thumbnail.png
forceLinkToOtherLanguage: on
authors:
- user: xianbao
- user: AdinaY
- user: chenglu
guest: true
---
# Hugging Face 中文博客正式发布!
Hugging Face 的中国社区成立已经有五个月之久,我们非常高兴地看到 Hugging Face 相关的中文内容在各个平台广受好评。同时我们也注意到,Hugging Face Hub 和开源生态上有众多国内开发者们的创新和贡献。
因此,我们非常高兴的宣布:
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chinese-language-blog/announcement.png">
</figure>
## 欢迎来到 Hugging Face 中文博客!
我们非常高兴地向你介绍一个新的、中文的 Hugging Face 博客!
这是我们 Hugging Face 博客的中文版,这个博客将以中文内容,向全球的中文开发者们提供来自英文博客的翻译文章,帮助更多的中国开发者了解最新的人工智能技术内容。
中文博客的发布离不开我们中国社区的本地化志愿者们的努力付出,他们非常积极和热情的参与本地化了我们的原始英文博客、NLP 课程、扩散模型课程以及深度强化课程等。非常感谢他们的帮助!
## 中文的社区成员在人工智能行业的成就毋庸置疑
首先,人工智能行业里的中文社区成员们展现了其卓越才能和强大的创新能力。比如 [HuggingGPT](https://huggingface.co/spaces/microsoft/HuggingGPT), [ChatGLM](https://huggingface.co/THUDM/chatglm-6b), [RWKV](https://huggingface.co/spaces/BlinkDL/Raven-RWKV-7B), [ChatYuan](https://huggingface.co/spaces/ClueAI/ChatYuan-large-v2), [ModelScope text-to-video models](https://huggingface.co/spaces/damo-vilab/modelscope-text-to-video-synthesis) 以及 [IDEA CCNL](https://huggingface.co/IDEA-CCNL), [BAAI](https://huggingface.co/BAAI) 等机构,他们都在人工智能行业里做出了突出的贡献。中文社区内蕴藏的巨大潜力。
此外,中文社区成员们还还积极参与创建了一些热门的 Space 应用,如 [Chuanhu GPT](https://huggingface.co/spaces/jdczlx/ChatGPT-chuanhu) 和 [GPT Academy](https://huggingface.co/spaces/qingxu98/gpt-academic),进一步展示了他们对于机器学习的热爱和创造力。
同时,我们也一直在与 [PaddlePaddle](https://huggingface.co/blog/paddlepaddle) 等组织或机构合作,保证其与 Hugging Face 的无缝集成,为推动机器学习领域的更多协作做出贡献。
## 加强协作纽带和未来活动
在与中文社区以往合作的各类活动中,我们一起实现了知识的交流和协作,推动了人工智能社区的发展。对此,我们感到非常自豪!这些合作主要包括:
- 与 DataWhale 社区合作的 [ChatGPT 从入门到应用](https://mp.weixin.qq.com/s/byR2n-5QJmy34Jq0W3ECDg) 课程(本月底开始)
- [在北京举办 JAX/Diffusers 社区的首次线下聚会](https://twitter.com/huggingface/status/1648986159580876800)
- [与百姓 AI 一起组织 Prompt 黑客马拉松](https://mp.weixin.qq.com/s/M5vjicNG1uBdCQzQtQU9yw)
- [与 PaddlePaddle 合作微调 Lora 模型](https://aistudio.baidu.com/aistudio/competition/detail/860/0/introduction)
- [与 HeyWhale 社区合作进行 DreamBooth 微调黑客松](https://www.heywhale.com/home/competition/63bbfb98de6c0e9cdb0d9dd5)
我们很高兴地宣布,我们将继续加强与人工智能中文社区们的联系,通过共同努力和协作,为知识共享和专业交流创造机会,促进跨社区的开源机器学习的合作,共同面对 OS ML 领域的挑战和机遇。
## 超越边界:拥抱多元化的人工智能社区
在我们共同步入新篇章之际,我们与人工智能中文社区的合作将服务于建立文化的桥梁和突破语言的障碍、促进人工智能领域的创新和合作。在 Hugging Face,我们珍视多元化的观点和声音,旨在创建一个开放和包容的社区,以促进符合道德规范的,公平的人工智能发展。
欢迎加入我们,一起开始这令人兴奋的旅程!敬请关注我们的博客,了解有关中文社群的最新进展以及关于未来合作的更多信息!
关注我们:
<figure class="image text-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/chinese-language-blog/wechat.jpg">
</figure>
[BAAI](https://hub.baai.ac.cn/users/45017), [Bilibili](https://space.bilibili.com/1740664937/), [CNBlogs](https://www.cnblogs.com/huggingface), [CSDN](https://huggingface.blog.csdn.net/), [Juejin](https://juejin.cn/user/611789528634712), [OS China](https://my.oschina.net/HuggingFace), [SegmentFault](https://segmentfault.com/u/huggingface), [Zhihu](https://www.zhihu.com/org/huggingface)
| 1 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/cv_state.md | ---
title: Hugging Face 中计算机视觉的现状
thumbnail: /blog/assets/cv_state/thumbnail.png
authors:
- user: sayakpaul
---
# Hugging Face 中计算机视觉的现状
在Hugging Face上,我们为与社区一起推动人工智能领域的民主化而感到自豪。作为这个使命的一部分,我们从去年开始专注于计算机视觉。开始只是 [🤗 Transformers中Vision Transformers (ViT) 的一个 PR](https://github.com/huggingface/transformers/pull/10950),现在已经发展壮大:8个核心视觉任务,超过3000个模型,在Hugging Face Hub上有超过1000个数据集。
自从 ViTs 加入 Hub 后,已经发生了大量激动人心的事情。在这篇博客文章中,我们将从 🤗Hugging Face 生态系统中总结已经发生的和将要发生的进展,以支持计算机视觉的持续发展。
下面是我们要覆盖的内容:
- [支持的视觉任务和流水线](https://huggingface.co/blog/cv_state#support-for-pipelines)
- [训练你自己的视觉模型](https://huggingface.co/blog/cv_state#training-your-own-models)
- [和`timm`整合](https://huggingface.co/blog/cv_state#🤗-🤝-timm)
- [Diffusers](https://huggingface.co/blog/cv_state#🧨-diffusers)
- [对第三方库的支持](https://huggingface.co/blog/cv_state#support-for-third-party-libraries)
- [开发](https://huggingface.co/blog/cv_state#deployment)
- 以及更多内容!
## 启动社区: 一次一个任务
Hugging Face Hub 拥有超过10万个用于不同任务的公共模型,例如:下一词预测、掩码填充、词符分类、序列分类等。截止今天,我们支持[8个核心视觉任务](https://huggingface.co/tasks),提供许多模型的 checkpoints:
- 图像分类
- 图像分割
- (零样本)目标检测
- 视频分类
- 深度估计
- 图像到图像合成
- 无条件图像生成
- 零样本图像分类
每个任务在 Hub 上至少有10个模型等待你去探索。此外,我们支持视觉和语言的交叉任务,比如:
- 图像到文字(图像说明,光学字符识别)
- 文字到图像
- 文档问答
- 视觉问答
这些任务不仅需要最先进的基于 Transformer 的架构,如 [ViT](https://huggingface.co/docs/transformers/model_doc/vit)、[Swin](https://huggingface.co/docs/transformers/model_doc/swin)、[DETR](https://huggingface.co/docs/transformers/model_doc/detr),还需要*纯卷积*的架构,如 [ConvNeXt](https://huggingface.co/docs/transformers/model_doc/convnext)、[ResNet](https://huggingface.co/docs/transformers/model_doc/resnet)、[RegNet](https://huggingface.co/docs/transformers/model_doc/regnet),甚至更多!像 ResNets 这样的架构仍然与无数的工业用例非常相关,因此在 🤗 Transformers 中也支持这些非 Transformers 的架构。
还需要注意的是,在 Hub 上的这些模型不仅来自 Transformers 库,也来自于其他第三方库。例如,尽管我们在 Hub 上支持无条件图像生成等任务,但我们在 Transformers 中还没有任何模型支持该任务(比如[这个](https://huggingface.co/ceyda/butterfly_cropped_uniq1K_512))。支持所有的机器学习任务,无论是使用 Transformers 还是第三方库来解决,都是我们促进一个协作的开源机器学习生态系统使命的一部分。
## 对 Pipelines 的支持
我们开发了 [Pipelines](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines) 来为从业者提供他们需要的工具,以便轻松地将机器学习整合到他们的工具箱中。对于给定与任务相关的输入,他们提供了一种简单的方法来执行推理。我们在Pipelines里支持[7种视觉任务](https://huggingface.co/docs/transformers/main/en/main_classes/pipelines#computer-vision)。下面是一个使用 Pipelines 进行深度估计的例子:
```python
from transformers import pipeline
depth_estimator = pipeline(task="depth-estimation", model="Intel/dpt-large")
output = depth_estimator("http://images.cocodataset.org/val2017/000000039769.jpg")
# This is a tensor with the values being the depth expressed
# in meters for each pixel
output["depth"]
```

即使对于视觉问答任务,接口也保持不变:
```python
from transformers import pipeline
oracle = pipeline(model="dandelin/vilt-b32-finetuned-vqa")
image_url = "https://huggingface.co/datasets/Narsil/image_dummy/raw/main/lena.png"
oracle(question="What is she wearing?", image=image_url, top_k=1)
# [{'score': 0.948, 'answer': 'hat'}]
```
## 训练你自己的模型
虽然能够使用现成推理模型是一个很好的入门方式,但微调是社区获得最大收益的地方。当你的数据集是自定义的、并且预训练模型的性能不佳时,这一点尤其正确。
Transformers 为一切与训练相关的东西提供了[训练器 API](https://huggingface.co/docs/transformers/main_classes/trainer)。当前,`Trainer`无缝地支持以下任务:图像分类、图像分割、视频分类、目标检测和深度估计。微调其他视觉任务的模型也是支持的,只是并不通过`Trainer`。
只要损失计算包含在 Transformers 计算给定任务损失的模型中,它就应该有资格对该任务进行微调。如果你发现问题,请在 GitHub 上[报告](https://github.com/huggingface/transformers/issues)。
我从哪里可以找到代码?
- [模型文档](https://huggingface.co/docs/transformers/index#supported-models)
- [Hugging Face 笔记本](https://github.com/huggingface/notebooks)
- [Hugging Face 示例脚本](https://github.com/huggingface/transformers/tree/main/examples)
- [任务页面](https://huggingface.co/tasks)
[Hugging Face 示例脚本](https://github.com/huggingface/transformers/tree/main/examples)包括不同的[自监督预训练策略](https://github.com/huggingface/transformers/tree/main/examples/pytorch/image-pretraining)如 [MAE](https://arxiv.org/abs/2111.06377),和[对比图像到文本预训练策略](https://github.com/huggingface/transformers/tree/main/examples/pytorch/contrastive-image-text)如 [CLIP](https://arxiv.org/abs/2103.00020)。这些脚本对于研究社区和愿意在预训练模型上从头训练自定义数据语料的从业者来说是非常宝贵的资源。
不过有些任务本来就不适合微调。例子包括零样本图像分类(比如 [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip)),零样本目标检测(比如 [OWL-ViT](https://huggingface.co/docs/transformers/main/en/model_doc/owlvit)),和零样本分割(比如 [CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg))。我们将在这篇文章中重新讨论这些模型。
## 与 Datasets 集成
Datasets 提供了对数千个不同模态数据集的轻松访问。如前所述,Hub 有超过1000个计算机视觉的数据集。一些例子值得关注:[ImageNet-1k](https://huggingface.co/datasets/imagenet-1k)、[Scene Parsing](https://huggingface.co/datasets/scene_parse_150)、[NYU Depth V2](https://huggingface.co/datasets/sayakpaul/nyu_depth_v2)、[COYO-700M](https://huggingface.co/datasets/kakaobrain/coyo-700m) 和 [LAION-400M](https://huggingface.co/datasets/laion/laion400m)。这些在 Hub 上的数据集,只需两行代码就可以加载它们:
```python
from datasets import load_dataset
dataset = load_dataset("scene_parse_150")
```
除了这些数据集,我们提供了对增强库如 [albumentations](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_albumentations.ipynb) 和 [Kornia](https://github.com/huggingface/notebooks/blob/main/examples/image_classification_kornia.ipynb) 的集成支持。社区可以利用 Datasets 的灵活性和性能,还有这些库提供的强大的增强变换能力。除此之外,我们也为核心视觉任务提供[专用的数据加载指南](https://huggingface.co/docs/datasets/image_load):图像分类,图像分割,目标检测和深度估计。
## 🤗 🤝 timm
`timm`,即 [pytorch-image-models](https://github.com/rwightman/pytorch-image-models),是一个最先进的 PyTorch 图像模型、预训练权重和用于训练、推理、验证的实用脚本的开源集合。
我们在 Hub 上有超过200个来自 `timm` 的模型,并且有更多模型即将上线。查看[文档](https://huggingface.co/docs/timm/index)以了解更多关于此集成的信息。
## 🧨 Diffusers
Diffusers 提供预训练的视觉和音频扩散模型,并且用作推理和训练的模块化工具箱。有了这个库,你可以从自然语言输入和其他创造性用例中生成可信的图像。下面是一个例子:
```python
from diffusers import DiffusionPipeline
generator = DiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
generator.to(“cuda”)
image = generator("An image of a squirrel in Picasso style").images[0]
```

这种类型的技术可以赋予新一代的创造性应用,也可以帮助来自不同背景的艺术家。查看[官方文档](https://huggingface.co/docs/diffusers)以了解更多关于 Diffusers 和不同用例的信息。
基于扩散模型的文献正在快速发展,这就是为什么我们与[乔纳森·惠特克](https://github.com/johnowhitaker)合作开发一门课程。这门课程是免费的,你可以点击[这里](https://github.com/huggingface/diffusion-models-class)查看。
## 对第三方库的支持
Hugging Face 生态系统的核心是 [Hugging Face Hub](https://huggingface.co/docs/hub),它让人们在机器学习上有效合作。正如前面所提到的,我们在 Hub 上不仅支持来自 🤗 Transformers 的模型,还支持来自其他第三方包的模型。为此,我们提供了几个[实用程序](https://huggingface.co/docs/hub/models-adding-libraries),以便你可以将自己的库与 Hub 集成。这样做的主要优点之一是,与社区共享工件(如模型和数据集)变得非常容易,从而使你的用户可以更容易地尝试你的模型。
当你的模型托管在 Hub 上时,你还可以为它们[添加自定义推理部件](https://github.com/huggingface/api-inference-community)。推理部件允许用户快速地检查模型。这有助于提高用户的参与度。

## 计算机视觉演示空间
使用 Hugging Hub Spaces应用,人们可以轻松地演示他们的机器学习模型。空间支持与 [Gradio](https://gradio.app/)、[Streamlit](https://streamlit.io/) 和 [Docker](https://www.docker.com/) 的直接集成,使从业者在展示他们的模型时有很大的灵活性。你可以用 Spaces 引入自己的机器学习框架来构建演示。
在 Spaces 里,Gradio 库提供几个部件来构建计算机视觉应用,比如 [Video](https://gradio.app/docs/#video)、[Gallery](https://gradio.app/docs/#gallery) 和 [Model3D](https://gradio.app/docs/#model3d)。社区一直在努力构建一些由 Spaces 提供支持的令人惊叹的计算机视觉应用:
- [从输入图像的预测深度图生成3D体素](https://huggingface.co/spaces/radames/dpt-depth-estimation-3d-voxels)
- [开放词汇语义分割](https://huggingface.co/spaces/facebook/ov-seg)
- [通过生成字幕来讲述视频](https://huggingface.co/spaces/nateraw/lavila)
- [对来自YouTube的视频进行分类](https://huggingface.co/spaces/fcakyon/video-classification)
- [零样本视频分类](https://huggingface.co/spaces/fcakyon/zero-shot-video-classification)
- [视觉问答](https://huggingface.co/spaces/nielsr/vilt-vqa)
- [使用零样本图像分类为图像找到最佳说明以生成相似的图像](https://huggingface.co/spaces/pharma/CLIP-Interrogator)
## 🤗 AutoTrain
[AutoTrain](https://huggingface.co/autotrain) 提供一个”零代码“的解决方案,为文本分类、文本摘要、命名实体识别等这样的任务训练最先进的机器学习模型。对于计算机视觉,我们当前支持[图像分类](https://huggingface.co/blog/autotrain-image-classification),但可以期待更多的任务覆盖。
AutoTrain 还支持[自动模型评估](https://huggingface.co/spaces/autoevaluate/model-evaluator)。此应用程序允许你用在 Hub 上的各种[数据集](https://huggingface.co/datasets)评估 🤗 Transformers [模型](https://huggingface.co/models?library=transformers&sort=downloads)。你的评估结果将会显示在[公共排行榜](https://huggingface.co/spaces/autoevaluate/leaderboards)上。你可以查看[这篇博客](https://huggingface.co/blog/eval-on-the-hub)以获得更多细节。
## 技术理念
在此部分,我们像向你分享在 🤗 Transformers 里添加计算机视觉背后的理念,以便社区知道针对该领域的设计选择。
尽管 Transformers 是从 NLP 开始的,但我们今天支持多种模式,比如:视觉、音频、视觉语言和强化学习。对于所有的这些模式,Transformers 中所有相应的模型都享有一些共同的优势:
- 使用一行代码`from_pretrained()`即可轻松下载模型
- 用`push_to_hub()`轻松上传模型
- 支持使用 checkpoint 分片技术加载大型的 checkpoints
- 优化支持(使用 [Optimum](https://huggingface.co/docs/optimum) 之类的工具)
- 从模型配置中初始化
- 支持 PyTorch 和 TensorFlow(非全面支持)
- 以及更多
与分词器不同,我们有预处理器(例如[这个](https://huggingface.co/docs/transformers/model_doc/vit#transformers.ViTImageProcessor))负责为视觉模型准备数据。我们一直努力确保在使用视觉模型时依然有轻松和相似的用户体验:
```python
from transformers import ViTImageProcessor, ViTForImageClassification
import torch
from datasets import load_dataset
dataset = load_dataset("huggingface/cats-image")
image = dataset["test"]["image"][0]
image_processor = ViTImageProcessor.from_pretrained("google/vit-base-patch16-224")
model = ViTForImageClassification.from_pretrained("google/vit-base-patch16-224")
inputs = image_processor(image, return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
# model predicts one of the 1000 ImageNet classes
predicted_label = logits.argmax(-1).item()
print(model.config.id2label[predicted_label])
# Egyptian cat
```
即使对于一个困难的任务如目标检测,用户体验也不会改变很多:
```python
from transformers import AutoImageProcessor, AutoModelForObjectDetection
from PIL import Image
import requests
url = "http://images.cocodataset.org/val2017/000000039769.jpg"
image = Image.open(requests.get(url, stream=True).raw)
image_processor = AutoImageProcessor.from_pretrained("microsoft/conditional-detr-resnet-50")
model = AutoModelForObjectDetection.from_pretrained("microsoft/conditional-detr-resnet-50")
inputs = image_processor(images=image, return_tensors="pt")
outputs = model(**inputs)
# convert outputs (bounding boxes and class logits) to COCO API
target_sizes = torch.tensor([image.size[::-1]])
results = image_processor.post_process_object_detection(
outputs, threshold=0.5, target_sizes=target_sizes
)[0]
for score, label, box in zip(results["scores"], results["labels"], results["boxes"]):
box = [round(i, 2) for i in box.tolist()]
print(
f"Detected {model.config.id2label[label.item()]} with confidence "
f"{round(score.item(), 3)} at location {box}"
)
```
输出为:
```
Detected remote with confidence 0.833 at location [38.31, 72.1, 177.63, 118.45]
Detected cat with confidence 0.831 at location [9.2, 51.38, 321.13, 469.0]
Detected cat with confidence 0.804 at location [340.3, 16.85, 642.93, 370.95]
Detected remote with confidence 0.683 at location [334.48, 73.49, 366.37, 190.01]
Detected couch with confidence 0.535 at location [0.52, 1.19, 640.35, 475.1]
```
## 视觉零样本模型
大量的模型以有趣的方式重新修订了分割和检测等核心视觉任务,并引入了更大的灵活性。我们支持 Transformers 中的一些:
- [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip) 支持带提示的零样本图像分类。给定一张图片,你可以用类似”一张{}的图片“这样的自然语言询问来提示 CLIP 模型。期望是得到类别标签作为答案。
- [OWL-ViT](https://huggingface.co/docs/transformers/main/en/model_doc/owlvit) 允许以语言为条件的零样本目标检测和以图像为条件的单样本目标检测。这意味着你可以在一张图片中检测物体即使底层模型在训练期间没有学过检测它们!你可以参考[这个笔记本](https://github.com/huggingface/notebooks/tree/main/examples#:~:text=zeroshot_object_detection_with_owlvit.ipynb)以了解更多。
- [CLIPSeg](https://huggingface.co/docs/transformers/model_doc/clipseg) 支持以语言为条件的零样本图像分割和以图像为条件的单样本图像分割。这意味着你可以在一张图片中分割物体即使底层模型在训练期间没有学过分割它们!你可以参考说明此想法的[这篇博客文章](https://huggingface.co/blog/clipseg-zero-shot)。[GroupViT](https://huggingface.co/docs/transformers/model_doc/groupvit) 也支持零样本分割。
- [X-CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/xclip) 展示对视频的零样本泛化。准确地说是支持零样本视频分类。查看[这个笔记本](https://github.com/NielsRogge/Transformers-Tutorials/blob/master/X-CLIP/Zero_shot_classify_a_YouTube_video_with_X_CLIP.ipynb)以获得更多细节。
社区期待在今后的日子里看到 🤗Transformers 支持更多的计算机视觉零样本模型。
## 开发
我们的 CTO 说:”真正的艺术家能将产品上市“🚀
我们通过 🤗[Inference Endpoints](https://huggingface.co/inference-endpoints) 支持这些视觉模型的开发。Inference Endpoints 直接集成了与图像分类、目标检测、图像分割相关的兼容模型。对于其他模型,你可以使用自定义处理程序。由于我们还在 TensorFlow 中提供了许多来自 🤗Transformers 的视觉模型用于部署,我们建议使用自定义处理程序或遵循这些资源:
- [在 Hugging Face 上用 TF 服务开发 TensorFlow 视觉模型](https://huggingface.co/blog/tf-serving-vision)
- [在 Kubernets 上用 TF 服务开发 ViT](https://huggingface.co/blog/deploy-tfserving-kubernetes)
- [在 Vertex AI 上开发 ViT](https://huggingface.co/blog/deploy-vertex-ai)
- [用 TFX 和 Vertex AI 开发 ViT](https://github.com/deep-diver/mlops-hf-tf-vision-models)
## 结论
在这篇文章中,我们向你简要介绍了 Hugging Face 生态系统目前为下一代计算机视觉应用提供的支持。我们希望你会喜欢使用这些产品来可靠地构建应用。
不过还有很多工作要做。 以下是您可以期待看到的一些内容:
- 🤗 Datasets 对视频的直接支持
- 支持更多和工业界相关的任务,比如图像相似性
- 图像数据集与 TensorFlow 的交互
- 来自 🤗Hugging Face 社区关于计算机视觉的课程
像往常一样,我们欢迎你的补丁、PR、模型 checkpoints、数据集和其他贡献!🤗
*Acknowlegements: Thanks to Omar Sanseviero, Nate Raw, Niels Rogge, Alara Dirik, Amy Roberts, Maria Khalusova, and Lysandre Debut for their rigorous and timely reviews on the blog draft. Thanks to Chunte Lee for creating the blog thumbnail.*
| 2 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/setfit-absa.md | ---
title: "SetFitABSA:基于 SetFit 的少样本、方面级情感分析"
thumbnail: /blog/assets/setfit-absa/intel_hf_logo_2.png
authors:
- user: ronenlap
guest: true
- user: tomaarsen
- user: lewtun
- user: danielkorat
guest: true
- user: orenpereg
guest: true
- user: moshew
guest: true
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# SetFitABSA: 基于 SetFit 的少样本、方面级情感分析
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/method.png" width=500>
</p>
<p align="center">
<em>SetFitABSA 是一种可以有效从文本中检测方面级情感的技术。</em>
</p>
方面级情感分析 (Aspect-Based Sentiment Analysis,ABSA) 是一种检测文本中特定方面的情感的任务。例如,在“这款手机的屏幕很棒,但电池太小”一句中,分别有“屏幕”和“电池”两个方面,它们的情感极性分别是正面和负面。
ABSA 应用颇为广泛,有了它我们可以通过分析顾客对产品或服务的多方面反馈,并从中提取出有价值的见解。然而,ABSA 要求在样本标注时对训练样本中涉及的各个方面进行词元级的识别,因此为 ABSA 标注训练数据成为了一件繁琐的任务。
为了缓解这一问题,英特尔实验室和 Hugging Face 联袂推出了 SetFitABSA,以用于少样本场景下的特定领域 ABSA 模型训练。实验表明,SetFitABSA 性能相当不错,其在少样本场景下表现甚至优于 Llama2 和 T5 等大型生成模型。
与基于 LLM 的方法相比,SetFitABSA 有两个独特优势:
<p>🗣 <strong> 无需提示: </strong> 在使用基于 LLM 的少样本上下文学习时,提示的作用非常关键,因此一般需要精心设计,这一要求使得最终效果对用词十分敏感且非常依赖用户的专业知识,因此整个方案会比较脆弱。SetFitABSA 直接从少量带标签的文本示例中生成丰富的嵌入,因此可完全无需提示。</p>
<p>🏎 <strong> 快速训练: </strong> SetFitABSA 仅需少量的已标注训练样本。此外,其训练数据格式非常简单,无需专门的标注工具,因此数据标注过程简单而快速。</p>
本文,我们将解释 SetFitABSA 的工作原理以及如何使用 [SetFit 库](https://github.com/huggingface/setfit) 训练你自己的模型。我们开始吧!
## 工作原理与流程
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/method.png" width=700>
</p>
<p align="center">
<em>SetFitABSA 的三段式训练流程 </em>
</p>
SetFitABSA 主要分三步。第一步从文本中提取候选方面; 第二步从候选方面中筛选出真正的方面,这一步主要由一个候选方面分类器来完成; 最后一步对每个方面判断其情感极性。其中,第二步和第三步均基于 SetFit 模型。
### 训练
**1. 候选方面提取**
这里我们假设: 方面一般指的是产品和服务的特性,因此其主要是名词或复合名词 (即几个相邻名词组成的字符串)。我们使用 [spaCy](https://spacy.io/) 从少样本训练集的句子中提取并标注出名词/复合名词。由于并非所有提取的名词/复合名词都是方面,因此我们叫它们 **候选方面**。
**2. 方面/非方面分类**
有了候选方面后,我们还需要训练一个模型,以便能够区分这些候选方面中哪些是真正的方面。为此,我们需要一些带有方面/无方面标签的训练样本。如果候选方面存在于训练集中我们即视其为 `True` ,否则视其为 `False` :
- **训练样本:** “Waiters aren’t friendly but the cream pasta is out of this world.”
- **分词:** [Waiters, are, n’t, friendly, but, the, cream, pasta, is, out, of, this, world, .]
- **提取候选方面:** [<strong style="color:orange">Waiters</strong>, are, n’t, friendly, but, the, <strong style="color:orange">cream</strong>, <strong style="color:orange">pasta</strong>, is, out, of, this, <strong style="color:orange">world</strong>, .]
- **训练集标签,其格式为 [BIO](https://en.wikipedia.org/wiki/Inside–outside–beginning_(tagging)):** [B-ASP, O, O, O, O、O、B-ASP、I-ASP、O、O、O、O、O、.]
- **根据训练集标签,生成方面/非方面标签:** [<strong style="color:green">Waiters</strong>, are, n’t, friendly, but, the, <strong style="color:green">cream</strong>, <strong style="color:green">pasta</strong>, is, out, of, this, <strong style="color:red">world</strong>, .]
至此,我们对所有候选方面进行了标注,下一步就是如何训练方面分类模型?也就是说,我们如何使用 SetFit 这一句子分类框架来对词元进行分类?我们使用的方法是: 将每个候选方面与其所在的句子串接起来,我们使用以下模板创建训练样本:
```
候选方面:所在句子
```
将该模板应用于上面的例子,我们会生成 3 个训练样本 - 其中 2 个标签为 `True` ,1 个标签为 `False` :
| 文本 | 标签 |
|:------------------------------------------------------------------------------|:------|
| Waiters:Waiters aren't friendly but the cream pasta is out of this world. | 1 |
| cream pasta:Waiters aren't friendly but the cream pasta is out of this world. | 1 |
| world:Waiters aren't friendly but the cream pasta is out of this world. | 0 |
| ... | ... |
生成训练样本后,我们就可以借助 SetFit 的强大功能仅用少许样本训练一个特定领域的二元分类器,以从输入文本评论中提取出方面。这是我们第一个微调 SetFit 模型。
**3. 情感极性分类**
一旦系统从文本中提取到方面,它需要判断每个方面的情感极性 (如积极、消极或中性)。为此,我们需要第二个 SetFit 模型,其训练方式与上面相似,如下例所示:
- **训练样本:** “Waiters aren’t friendly but the cream pasta is out of this world.”
- **分词:** [Waiters, are, n’t, friendly, but, the, cream, pasta, is, out, of, this, world, .]
- **标签:** [NEG, O, O, O, O, O, POS, POS, O, O, O, O, O, .]
| 文本 | 标签 |
|:------------------------------------------------------------------------------|:------|
| Waiters:Waiters aren't friendly but the cream pasta is out of this world. | NEG |
| cream pasta:Waiters aren't friendly but the cream pasta is out of this world. | POS |
| ... | ... |
注意,与方面提取模型不同,这里训练集中就不用包含非方面样本了,因为任务是对真正的方面进行情感极性分类。
## 推理
推理时,我们首先使用 spaCy 对输入句子进行候选方面提取,并用模板 `aspect_candidate:test_sentence` 生成推理样本。接下来,用方面/非方面分类器过滤掉非方面。最后,过滤出的方面会被送到情感极性分类器,该分类器预测每个方面的情感极性。
因此,我们的系统可以接收普通文本作为输入,并输出文本中的方面及其对应的情感:
**模型输入:**
```
"their dinner specials are fantastic."
```
**模型输出:**
```
[{'span': 'dinner specials', 'polarity': 'positive'}]
```
## 基准测试
我们将 SetFitABSA 与 [AWS AI 实验室](https://arxiv.org/pdf/2210.06629.pdf) 和 [Salesforce AI 研究院](https://arxiv.org/pdf/2204.05356.pdf) 的最新成果进行比较,这两项工作主要采用了对 T5 和 GPT2 进行提示微调的方法以实现方面级情感分析。为了对我们的工作进行全面测评,我们还将我们的模型与基于上下文学习的 Llama-2-chat 进行了比较。
我们采用的测评数据集是 2014 年语义评估挑战赛 ([SemEval14](https://aclanthology.org/S14-2004.pdf)) 中的 Laptop14 和 Restaurant14 ABSA [数据集](https://huggingface.co/datasets/alexcadillon/SemEval2014Task4)。测评任务选择的是术语提取中间任务 (SB1) 及完整 ABSA 任务 (包括方面提取及情感极性预测,即 SB1+SB2)。
### 模型尺寸比较
| 模型 | 尺寸 (参数量) |
|:------------------:|:-------------:|
| Llama-2-chat | 7B |
| T5-base | 220M |
| GPT2-base | 124M |
| GPT2-medium | 355M |
| **SetFit (MPNet)** | 2x 110M |
请注意,SB1 任务使用的 SetFitABSA 的参数量为 110M; SB2 任务再加上一个 110M 的模型。因此 SB1+SB2 时, SetFitABSA 的总参数量为 220M。
### 性能比较
我们看到,当训练样本较少时,SetFitABSA 有明显优势,尽管它比 T5 小 2 倍,比 GPT2-medium 小 3 倍。即便是与 64 倍参数量的 Llama 2 相比,SetFitABSA 也能获得相当或更好的效果。
**SetFitABSA vs GPT2**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/SetFitABSA_vs_GPT2.png" width=700>
</p>
**SetFitABSA vs T5**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/SetFitABSA_vs_T5.png" width=700>
</p>
请注意,为公平起见,在比较 SetFitABSA 与各基线 (GPT2、T5 等) 时,我们使用了相同的数据集划分。
**SetFitABSA vs Llama2**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/setfit-absa/SetFitABSA_vs_Llama2.png" width=700>
</p>
我们注意到,增加 Llama2 提示中的上下文样本的数目并不能改善效果。这种现象 [之前也在 ChatGPT 中发现过](https://www.analyticsvidhya.com/blog/2023/09/power-of-llms-zero-shot-and-few-shot-prompting/),我们认为后续值得深入调查一下。
## 训练你自己的模型
SetFitABSA 是 SetFit 框架的一个功能。要训练 ABSA 模型,首先需要安装包含 `absa` 功能的 `setfit` :
```shell
python -m pip install -U "setfit[absa]"
```
此外,我们必须安装 `en_core_web_lg` 版的 spaCy 模型:
```shell
python -m spacy download en_core_web_lg
```
接着开始准备训练数据集。训练集是一个 `Dataset` 对象,其包含 `text` 、 `span` 、 `label` 、 `ordinal` 四列:
- **text**: 含有方面的完整句子或文本。
- **span**: 句子中包含的方面。可以是一个单词或多个单词,如 “food”。
- **label**: 每个 span (即方面) 的情感极性标签,如 “positive”。这些标签的名称是在标注时确定的。
- **ordinal**: 如果某一方面在文本中出现了多次,则该列表示其在文本中出现的次序。这个值通常是 0,因为每个方面通常在对应文本中只出现一次。
举个例子,训练文本 “Restaurant with wonderful food but worst service I ever seen” 中包含两个方面,因此其在训练集表中占据两行,如下:
| text | span | label | ordinal |
|:-------------------------------------------------------------|:--------|:---------|:--------|
| Restaurant with wonderful food but worst service I ever seen | food | positive | 0 |
| Restaurant with wonderful food but worst service I ever seen | service | negative | 0 |
| ... | ... | ... | ... |
一旦准备好训练数据集,我们就可以创建一个 ABSA 训练器并运行训练。SetFit 模型的训练效率相当高,但由于 SetFitABSA 涉及两个依次训练的模型,因此建议使用 GPU 进行训练,以缩短训练时间。例如,以下训练脚本在免费的 Google Colab T4 GPU 上仅需约 10 分钟就可以完成 SetFitABSA 模型的训练。
```python
from datasets import load_dataset
from setfit import AbsaTrainer, AbsaModel
# Create a training dataset as above
# For convenience we will use an already prepared dataset here
train_dataset = load_dataset("tomaarsen/setfit-absa-semeval-restaurants", split="train[:128]")
# Create a model with a chosen sentence transformer from the Hub
model = AbsaModel.from_pretrained("sentence-transformers/paraphrase-mpnet-base-v2")
# Create a trainer:
trainer = AbsaTrainer(model, train_dataset=train_dataset)
# Execute training:
trainer.train()
```
好了!自此,我们成功训得一个特定领域的 ABSA 模型。我们可以将训得的模型保存到硬盘或将其上传到 Hugging Face Hub。请记住,该模型包含两个子模型,因此每个子模型都需有自己的路径:
```python
model.save_pretrained(
"models/setfit-absa-model-aspect",
"models/setfit-absa-model-polarity"
)
# 或
model.push_to_hub(
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-aspect",
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-polarity"
)
```
现在我们使用训得的模型进行推理。首先加载模型:
```python
from setfit import AbsaModel
model = AbsaModel.from_pretrained(
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-aspect",
"tomaarsen/setfit-absa-paraphrase-mpnet-base-v2-restaurants-polarity"
)
```
然后,使用模型的预测 API 进行推理。输入一个字符串列表,其中每个字符串代表一个评论文本:
```python
preds = model.predict([
"Best pizza outside of Italy and really tasty.",
"The food variations are great and the prices are absolutely fair.",
"Unfortunately, you have to expect some waiting time and get a note with a waiting number if it should be very full."
])
print(preds)
# [
# [{'span': 'pizza', 'polarity': 'positive'}],
# [{'span': 'food variations', 'polarity': 'positive'}, {'span': 'prices', 'polarity': 'positive'}],
# [{'span': 'waiting time', 'polarity': 'neutral'}, {'span': 'waiting number', 'polarity': 'neutral'}]
# ]
```
有关训练选项、如何保存和加载模型以及如何推理等更多详细信息,请参阅 SetFit [文档](https://huggingface.co/docs/setfit/how_to/absa)。
## 参考文献
- Maria Pontiki, Dimitris Galanis, John Pavlopoulos, Harris Papageorgiou, Ion Androutsopoulos, and Suresh Manandhar. 2014. SemEval-2014 task 4: Aspect based sentiment analysis. In Proceedings of the 8th International Workshop on Semantic Evaluation (SemEval 2014), pages 27–35.
- Siddharth Varia, Shuai Wang, Kishaloy Halder, Robert Vacareanu, Miguel Ballesteros, Yassine Benajiba, Neha Anna John, Rishita Anubhai, Smaranda Muresan, Dan Roth, 2023 “Instruction Tuning for Few-Shot Aspect-Based Sentiment Analysis”. https://arxiv.org/abs/2210.06629
- Ehsan Hosseini-Asl, Wenhao Liu, Caiming Xiong, 2022. “A Generative Language Model for Few-shot Aspect-Based Sentiment Analysis”. https://arxiv.org/abs/2204.05356
- Lewis Tunstall, Nils Reimers, Unso Eun Seo Jo, Luke Bates, Daniel Korat, Moshe Wasserblat, Oren Pereg, 2022. “Efficient Few-Shot Learning Without Prompts”. https://arxiv.org/abs/2209.11055
| 3 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/deploy-with-openvino.md | ---
title: 使用 Optimum-Intel 和 OpenVINO GenAI 优化和部署模型
authors:
- user: AlexKoff88
guest: true
org: Intel
- user: MrOpenVINO
guest: true
org: Intel
- user: katuni4ka
guest: true
org: Intel
- user: sandye51
guest: true
org: Intel
- user: raymondlo84
guest: true
org: Intel
- user: helenai
guest: true
org: Intel
- user: echarlaix
translators:
- user: Zipxuan
- user: zhongdongy
proofreader: true
---
# 使用 Optimum-Intel 和 OpenVINO GenAI 优化和部署模型
在端侧部署 Transformer 模型需要仔细考虑性能和兼容性。Python 虽然功能强大,但对于部署来说有时并不算理想,特别是在由 C++ 主导的环境中。这篇博客将指导您如何使用 Optimum-Intel 和 OpenVINO™ GenAI 来优化和部署 Hugging Face Transformers 模型,确保在最小依赖性的情况下进行高效的 AI 推理。
## 目录
- [为什么使用 OpenVINO 来进行端侧部署](#为什么使用-OpenVINO-来进行端侧部署)
- [第一步: 创建环境](#第一步创建环境)
- [第二步: 将模型导出为 OpenVINO IR](#第二步将模型导出为-openvino-ir)
- [第三步: 模型优化](#第三步模型优化)
- [第四步: 使用 OpenVINO GenAI API 进行部署](#第四步使用-openvino-genai-api-进行部署)
- [结论](#结论)
## 为什么使用 OpenVINO 来进行端侧部署
OpenVINO™ 最初是作为 C++ AI 推理解决方案开发的,使其非常适合在端侧设备部署中,其中最小化依赖性至关重要。随着引入 GenAI API,将大型语言模型 (LLMs) 集成到 C++ 或 Python 应用程序中变得更加简单,其特性旨在简化部署并提升性能。
## 第一步: 创建环境
### 预先准备
开始之前,请确保您的环境已正确配置了 Python 和 C++。安装必要的 Python 包:
```sh
pip install --upgrade --upgrade-strategy eager optimum[openvino]
```
以下是本文中使用的具体包:
```
transformers==4.44
openvino==24.3
openvino-tokenizers==24.3
optimum-intel==1.20
lm-eval==0.4.3
```
有关 GenAI C++ 库的安装,请按照 [此处](https://docs.openvino.ai/2024/get-started/install-openvino/install-openvino-genai.html) 的说明进行操作。
## 第二步: 将模型导出为 OpenVINO IR
Hugging Face 和 Intel 的合作促成了 [Optimum-Intel](https://huggingface.co/docs/optimum/en/intel/index) 项目。该项目旨在优化 Transformers 模型在 Intel 硬件上的推理性能。Optimum-Intel 支持 OpenVINO 作为推理后端,其 API 为各种基于 OpenVINO 推理 API 构建的模型架构提供了封装。这些封装都以 `OV` 前缀开头,例如 `OVModelForCausalLM` 。除此之外,它与 🤗 Transformers 库的 API 类似。
要将 Transformers 模型导出为 OpenVINO 中间表示 (IR),可以使用两种方法: 可以使用 Python 的 `.from_pretrained()` 方法或 Optimum 命令行界面 (CLI)。以下是使用这两种方法的示例:
### 使用 Python API
```python
from optimum.intel import OVModelForCausalLM
model_id = "meta-llama/Meta-Llama-3.1-8B"
model = OVModelForCausalLM.from_pretrained(model_id, export=True)
model.save_pretrained("./llama-3.1-8b-ov")
```
### 使用命令行 (CLI)
```sh
optimum-cli export openvino -m meta-llama/Meta-Llama-3.1-8B ./llama-3.1-8b-ov
```
./llama-3.1-8b-ov 文件夹将包含 .xml 和 bin IR 模型文件以及来自源模型的所需配置文件。🤗 tokenizer 也将转换为 openvino-tokenizers 库的格式,并在同一文件夹中创建相应的配置文件。
## 第三步: 模型优化
在资源受限的端侧设备上运行大型语言模型 (LLMs) 时,模型优化是一个极为重要的步骤。仅量化权重是一种主流方法,可以显著降低延迟和模型占用空间。Optimum-Intel 通过神经网络压缩框架 (NNCF) 提供了仅量化权重 (weight-only quantization) 的功能,该框架具有多种专为 LLMs 设计的优化技术: 从无数据 (data-free) 的 INT8 和 INT4 权重量化到数据感知方法,如 [AWQ](https://huggingface.co/docs/transformers/main/en/quantization/awq)、[GPTQ](https://huggingface.co/docs/transformers/main/en/quantization/gptq)、量化 scale 估计、混合精度量化等。默认情况下,超过十亿参数的模型的权重会被量化为 INT8 精度,这在准确性方面是安全的。这意味着上述导出步骤会生成具有 8 位权重的模型。然而,4 位整数的仅量化权重允许实现更好的准确性和性能的权衡。
对于 `meta-llama/Meta-Llama-3.1-8B` 模型,我们建议结合 AWQ、量化 scale 估计以及使用反映部署用例的校准数据集进行混合精度 INT4/INT8 权重的量化。与导出情况类似,在将 4 比特仅量化权重应用于 LLM 模型时有两种选项:
### 使用 Python API
- 在 `.from_pretrained()` 方法中指定 `quantization_config` 参数。在这种情况下,应创建 `OVWeightQuantizationConfig` 对象,并将其设置为该参数,如下所示:
```python
from optimum.intel import OVModelForCausalLM, OVWeightQuantizationConfig
MODEL_ID = "meta-llama/Meta-Llama-3.1-8B"
quantization_config = OVWeightQuantizationConfig(bits=4, awq=True, scale_estimation=True, group_size=64, dataset="c4")
model = OVModelForCausalLM.from_pretrained(MODEL_ID, export=True, quantization_config=quantization_config)
model.save_pretrained("./llama-3.1-8b-ov")
```
### 使用命令行 (CLI)
```sh
optimum-cli export openvino -m meta-llama/Meta-Llama-3.1-8B --weight-format int4 --awq --scale-estimation --group-size 64 --dataset wikitext2 ./llama-3.1-8b-ov
```
## 第四步: 使用 OpenVINO GenAI API 进行部署
在转换和优化之后,使用 OpenVINO GenAI 部署模型非常简单。OpenVINO GenAI 中的 LLMPipeline 类提供了 Python 和 C++ API,支持各种文本生成方法,并具有最小的依赖关系。
### Python API 的例子
```python
import argparse
import openvino_genai
device = "CPU" # GPU can be used as well
pipe = openvino_genai.LLMPipeline(args.model_dir, device)
config = openvino_genai.GenerationConfig()
config.max_new_tokens = 100
print(pipe.generate(args.prompt, config))
```
为了运行这个示例,您需要在 Python 环境中安装最小的依赖项,因为 OpenVINO GenAI 旨在提供轻量级部署。您可以将 OpenVINO GenAI 包安装到相同的 Python 环境中,或者创建一个单独的环境来比较应用程序的占用空间:
```sh
pip install openvino-genai==24.3
```
### C++ API 的例子
让我们看看如何使用 OpenVINO GenAI C++ API 运行相同的流程。GenAI API 的设计非常直观,并提供了与 🤗 Transformers API 无缝迁移的功能。
> **注意**: 在下面的示例中,您可以为 “device” 变量指定环境中的任何其他可用设备。例如,如果您正在使用带有集成显卡的 Intel CPU,则尝试使用 “GPU” 是一个不错的选择。要检查可用设备,您可以使用 ov::Core::get_available_devices 方法 (参考 [query-device-properties](https://docs.openvino.ai/2024/openvino-workflow/running-inference/inference-devices-and-modes/query-device-properties.html))。
```cpp
#include "openvino/genai/llm_pipeline.hpp"
#include <iostream>
int main(int argc, char* argv[]) {
std::string model_path = "./llama-3.1-8b-ov";
std::string device = "CPU" // GPU can be used as well
ov::genai::LLMPipeline pipe(model_path, device);
std::cout << pipe.generate("What is LLM model?", ov::genai::max_new_tokens(256));
}
```
### 自定义生成配置
`LLMPipeline` 还允许通过 `ov::genai::GenerationConfig` 来指定自定义生成选项:
```cpp
ov::genai::GenerationConfig config;
config.max_new_tokens = 256;
std::string result = pipe.generate(prompt, config);
```
使用 LLMPipeline,用户不仅可以轻松利用各种解码算法,如 Beam Search,还可以像下面的示例中那样构建具有 Streamer 的交互式聊天场景。此外,用户可以利用 LLMPipeline 的增强内部优化,例如利用先前聊天历史的 KV 缓存减少提示处理时间,使用 chat 方法: `start_chat()` 和 `finish_chat()` (参考 [using-genai-in-chat-scenario](https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide/genai-guide.html#using-genai-in-chat-scenario))。
```cpp
ov::genai::GenerationConfig config;
config.max_new_tokens = 100;
config.do_sample = true;
config.top_p = 0.9;
config.top_k = 30;
auto streamer = [](std::string subword) {
std::cout << subword << std::flush;
return false;
};
// Since the streamer is set, the results will
// be printed each time a new token is generated.
pipe.generate(prompt, config, streamer);
```
最后你可以看到如何在聊天场景下使用 LLMPipeline:
```cpp
pipe.start_chat()
for (size_t i = 0; i < questions.size(); i++) {
std::cout << "question:\n";
std::getline(std::cin, prompt);
std::cout << pipe.generate(prompt) << std::endl;
}
pipe.finish_chat();
```
## 结论
Optimum-Intel 和 OpenVINO™ GenAI 的结合为在端侧部署 Hugging Face 模型提供了强大而灵活的解决方案。通过遵循这些步骤,您可以在 Python 可能不是理想选择的环境中实现优化的高性能 AI 推理,以确保您的应用在 Intel 硬件上平稳运行。
## 其他资源
1. 您可以在这个 [教程](https://docs.openvino.ai/2024/learn-openvino/llm_inference_guide/genai-guide.html) 中找到更多详细信息。
2. 要构建上述的 C++ 示例,请参考这个 [文档](https://github.com/openvinotoolkit/openvino.genai/blob/releases/2024/3/src/docs/BUILD.md)。
3. [OpenVINO 文档](docs.openvino.ai)
4. [Jupyter 笔记本](https://docs.openvino.ai/2024/learn-openvino/interactive-tutorials-python.html)
5. [Optimum 文档](https://huggingface.co/docs/optimum/main/en/intel/index)
 | 4 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/dedup.md | ---
title: "BigCode 背后的大规模数据去重"
thumbnail: /blog/assets/dedup/thumbnail.png
authors:
- user: chenghao
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# BigCode 背后的大规模数据去重
## 目标受众
本文面向对大规模文档去重感兴趣,且对散列 (hashing) 、图 (graph) 及文本处理有一定了解的读者。
## 动机
老话说得好: 垃圾进,垃圾出 (garbage in, garbage out),把数据处理干净再输入给模型至关重要,至少对大语言模型如此。虽然现在一些明星大模型 (严格来讲,它们很多是 API) 的存在让大家恍惚产生了数据质量好像不那么重要了的错觉,但事实绝非如此。
在 BigScience 和 BigCode 项目中,在数据质量方面,我们面临的一个很大的问题是数据重复,这不仅包括训练集内的数据重复,还包括训练集中包含测试基准中的数据从而造成了基准污染 (benchmark contamination)。已经有研究表明,当训练集中存在较多重复数据时,模型倾向于逐字输出训练数据 [[1]](#1) (这一现象在其他一些领域并不常见 [[2]](#2)),而且训得的模型也更容易遭受隐私攻击 [[1]](#1)。除了能避免上面两个问题外,去重还有不少好处:
1. 让训练更高效: 你可以用更少的训练步骤获得相同的,甚至是更好的性能 [[3]](#3) [[4]](#4)。
2. 防止可能的数据泄漏和基准污染: 数据重复会损害你的模型性能报告的公信力,并可能让所谓的改进沦为泡影。
3. 提高数据可得性。我们大多数人都负担不起重复下载或传输数千 GB 文本的成本,更不用说由此带来的额外训练成本了。对数据集进行去重,能使其更易于学习、传输及协作。
## 从 BigScience 到 BigCode
我想先分享一个故事,故事主要讲述我如何接受数据去重这一任务,过程如何,以及在此过程中我学到了什么。
一切开始于 LinkedIn 上的一次对话,当时 [BigScience](https://bigscience.huggingface.co/) 已经开始几个月了。Huu Nguyen 注意到我在 GitHub 上的一个小项目并找到了我,问我是否有兴趣为 BigScience 做数据去重工作。我当然愿意了,尽管当时我完全没意识到由于数据量巨大,这项工作比想象中麻烦很多。
这项工作既有趣又充满挑战。挑战在于,我对处理如此大规模的数据并没有太多经验。但项目组的每个人仍然欢迎我、信任我,还给了我数千美元的云计算预算。有多少回,我不得不从睡梦中醒来,反复确认我是否关闭了那些云实例。我不停地在试验和错误中学习,在此过程中,新的视角被打开了。如果没有 BigScience,可能我永远不会有这种视角。
一年后的今天,我正在把从 BigScience 学到的东西应用到 [BigCode](https://www.bigcode-project.org/) 项目中去,去处理更大的数据集。除了英语 [[3]](#3) LLM 之外,我们已经再次证明数据去重也能改进代码模型 [[4]](#4) 的性能。有了数据去重,我们可以用更小的数据集达到更优的性能。现在,亲爱的读者,我想与你分享我学到的知识,希望你能透过数据去重的镜头一瞥 BigCode 项目的幕后故事。
下表列出了 BigScience 项目中各数据集使用的去重方法,以供参考:
| 数据集 | 输入数据量 | 输出数据尺寸或数据精简比 | 去重粒度 | 方法 | 参数 | 语种 | 耗时 |
| ------------------------------------ | -------------------------------- | --------------------------------------------------------------- | --------------------- | --------------------------------------------- | ---------------------------------------------------------------- | ------------ | ------------------- |
| OpenWebText2[[5]](#5) | 对 URL 去重后: 193.89 GB(69M)| 使用 MinHash LSH 后: 65.86 GB(17M) | URL + 文档 | URL(精确匹配)+ 文档(MinHash LSH) | $(10, 0.5, ?, ?, ?)$ | 英语 | |
| Pile-CC[[5]](#5) | *~306 GB* | *227.12 GiB(~55M)* | 文档 | 文档(MinHash LSH) | $(10, 0.5, ?, ?, ?) $ | 英语 | 数天 |
| BNE5[[6]](#6) | 2 TB | 570 GB | 文档 | Onion | 5-元组 | 西班牙语 | |
| MassiveText[[7]](#7) | | 0.001 TB ~ 2.1 TB | 文档 | 文档(精确匹配 + MinHash LSH) | $(?, 0.8, 13, ?, ?)$ | 英语 | |
| CC100-XL[[8]](#8) | | 0.01 GiB ~ 3324.45 GiB | URL + 段落 | URL(精确匹配) + 段落(精确匹配) | SHA-1 | 多语种 | |
| C4[[3]](#3) | 806.92 GB (364M) | 3.04% ~ 7.18% **↓** (训练集) | 子字符串或文档 | 子字符串(后缀数组)或文档(MinHash) | 后缀数组:50-词元,MinHash: $(9000, 0.8, 5, 20, 450)$ | 英语 | |
| Real News[[3]](#3) | ~120 GiB | 13.63% ~ 19.4% **↓**(训练集) | 同 **C4** | 同 **C4** | 同 **C4** | 英语 | |
| LM1B[[3]](#3) | ~4.40 GiB(30M) | 0.76% ~ 4.86% **↓**(训练集) | 同 **C4** | 同 **C4** | 同 **C4** | 英语 | |
| WIKI40B[[3]](#3) | ~2.9M | 0.39% ~ 2.76% **↓**(训练集) | 同 **C4** | 同 **C4** | 同 **C4** | 英语 | |
| BigScience ROOTS 语料集[[9]](#9) | | 0.07% ~ 2.7% **↓** (文档) + 10.61% ~ 32.30% **↓** (子字符串) | 文档 + 子字符串 | 文档 (SimHash) + 子字符串 (后缀数组) | SimHash:6-元组,汉明距离(hamming distance)为 4,后缀数组:50-词元 | 多语种 | 12 小时 ~ 数天 |
下表是我们在创建 BigCode 的训练数据集 (训练数据皆为代码) 时所用的方法。这里,如果当遇到没有名字的数据集时,我们就用模型名称来代替。
| 模型 | 去重方法 | 参数 | 去重级别 |
| --------------------- | -------------------- | -------------------------------------- | -------- |
| InCoder[[10]](#10) | 精确匹配 | 代码词元/MD5 + 布隆滤波(Bloom filtering) | 文档 |
| CodeGen[[11]](#11) | 精确匹配 | SHA256 | 文档 |
| AlphaCode[[12]](#12) | 精确匹配 | 忽略空格 | 文档 |
| PolyCode[[13]](#13) | 精确匹配 | SHA256 | 文档 |
| PaLM Coder[[14]](#14) | Levenshtein 距离 | | 文档 |
| CodeParrot[[15]](#15) | MinHash + LSH | $(256, 0.8, 1)$ | 文档 |
| The Stack[[16]](#16) | MinHash + LSH | $(256, 0.7, 5)$ | 文档 |
MinHash + LSH 参数 $(P, T, K, B, R)$ :
1. $P$ 哈希函数的个数或排列的个数
2. $T$ Jaccard 相似度阈值
3. $K$ K- 元组
4. $B$ 条带数
5. $R$ 每条带包含的行数
我们做了一个简单的演示程序来说明这些参数对结果的影响: [MinHash 数学演示](https://huggingface.co/spaces/bigcode/near-deduplication)。
## 例解 MinHash
在本节中,我们将详细介绍在 BigCode 中使用的 MinHash 方法的每个步骤,并讨论该方法的系统扩展性问题及其解决方案。我们以一个含有三个英文文档为例来演示整个工作流程:
| doc_id | 内容 |
| ------ | ---------------------------------------- |
| 0 | Deduplication is so much fun! |
| 1 | Deduplication is so much fun and easy! |
| 2 | I wish spider dog[[17]](#17) is a thing. |
MinHash 的典型工作流程如下:
1. 词袋生成 (生成 n- 元组) 及指纹生成 (生成 MinHash): 将每个文档映射成一组哈希值。
2. 局部敏感哈希 (LSH): 逐条带 (band) 的比较文档的相似性,并将相似的文档聚类以减少后续比较的次数。
3. 去重: 决定保留或删除哪些重复文档。
### 词袋生成
与大多数文本应用一样,我们需要先把文本表示成词袋,这里我们通常使用 N- 元组词袋。在本例中,我们使用以单词为基本单元的 3- 元组 (即每 3 个连续单词组成一个元组),且不考虑标点符号。我们后面会回过头来讨论元组大小对性能的影响。
| doc_id | 3-元组 |
| ------ | ------------------------------------------------------------------------------- |
| 0 | {"Deduplication is so", "is so much", "so much fun"} |
| 1 | {'so much fun', 'fun and easy', 'Deduplication is so', 'is so much'} |
| 2 | {'dog is a', 'is a thing', 'wish spider dog', 'spider dog is', 'I wish spider'} |
这个操作的时间复杂度为 $\mathcal{O}(NM)$,其中 $N$ 表示文档数,而 $M$ 表示文档长度。也就是说,时间复杂度与数据集大小呈线性关系。我们可以用多进程或分布式计算来并行化词袋生成过程。
### 指纹计算
使用 MinHash 方法时,每个 N- 元组需要生成多个哈希值,此时我们通常要么 1) 使用不同的哈希函数进行多次哈希,要么 2) 使用一个哈希函数进行哈希后再进行多次重排。本例中,我们选择第二种方法,重排生成 5 个哈希值。 更多 MinHash 的变体可以参考 [MinHash - 维基百科](https://en.wikipedia.org/wiki/MinHash?useskin=vector)。
| N-元组 | 哈希值 |
| ------------------- | ----------------------------------------------------------- |
| Deduplication is so | [403996643, 2764117407, 3550129378, 3548765886, 2353686061] |
| is so much | [3594692244, 3595617149, 1564558780, 2888962350, 432993166] |
| so much fun | [1556191985, 840529008, 1008110251, 3095214118, 3194813501] |
对以上文档哈希矩阵中的每一列取最小值 —— 即 “MinHash” 中的 “Min” 的题中之义,我们就能得到该文档最终的 MinHash 值:
| doc_id | MinHash |
| ------ | ---------------------------------------------------------- |
| 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] |
| 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] |
| 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] |
从技术上讲,虽然我们通常取最小值,但这并不代表我们一定要取每列的最小值。其他顺序统计量也是可以的,例如最大值、第 k 个最小值或第 k 个最大值 [[21]](#21)。
在具体实现时,我们可以使用 `numpy` 来对这些操作进行向量化。该操作的时间复杂度为 $\mathcal{O}(NMK)$,其中 $K$ 是排列数。以下列出了我们的代码,它是基于 [Datasketch](https://github.com/ekzhu/datasketch) 的实现修改而得的。
```python
def embed_func(
content: str,
idx: int,
*,
num_perm: int,
ngram_size: int,
hashranges: List[Tuple[int, int]],
permutations: np.ndarray,
) -> Dict[str, Any]:
a, b = permutations
masks: np.ndarray = np.full(shape=num_perm, dtype=np.uint64, fill_value=MAX_HASH)
tokens: Set[str] = {" ".join(t) for t in ngrams(NON_ALPHA.split(content), ngram_size)}
hashvalues: np.ndarray = np.array([sha1_hash(token.encode("utf-8")) for token in tokens], dtype=np.uint64)
permuted_hashvalues = np.bitwise_and(
((hashvalues * np.tile(a, (len(hashvalues), 1)).T).T + b) % MERSENNE_PRIME, MAX_HASH
)
hashvalues = np.vstack([permuted_hashvalues, masks]).min(axis=0)
Hs = [bytes(hashvalues[start:end].byteswap().data) for start, end in hashranges]
return {"__signatures__": Hs, "__id__": idx}
```
熟悉 [Datasketch](https://github.com/ekzhu/datasketch) 的读者可能会问,为什么我们要费心费力剥离 Datasketch 库提供的所有高级功能?其主要原因并不是因为我们要减少依赖项,而是因为我们想要尽可能地榨取 CPU 的算力。而将多个步骤融合到一个函数中,是更好利用计算资源的手段之一。
由于每个文档的计算互相独立,因此我们可以充分利用 `datasets` 库的 `map` 函数来实现并行化:
```python
embedded = ds.map(
function=embed_func,
fn_kwargs={
"num_perm": args.num_perm,
"hashranges": HASH_RANGES,
"ngram_size": args.ngram,
"permutations": PERMUTATIONS,
},
input_columns=[args.column],
remove_columns=ds.column_names,
num_proc=os.cpu_count(),
with_indices=True,
desc="Fingerprinting...",
)
```
指纹计算完毕之后,每个文档都被映射成了一个整数数组。为了弄清楚哪些文档彼此相似,我们需要根据这些指纹对它们进行聚类。轮到 **局部敏感哈希 (Locality Sensitive Hashing,LSH)** 闪亮登场了。
### 局部敏感哈希 (LSH)
LSH 将指纹数组按行分成若干个条带 (band),每个条带的行数相同,如果遇到最后一个条带行数不足,我们就直接忽略它。以条带数 $b=2$ 为例,每个条带有 $r=2$ 行,具体组织如下:
| doc_id | MinHash | 条带 |
| ------ | ---------------------------------------------------------- | ------------------------------------------------------ |
| 0 | [403996643, 840529008, 1008110251, 2888962350, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 2888962350]] |
| 1 | [403996643, 840529008, 1008110251, 1998729813, 432993166] | [0:[403996643, 840529008], 1:[1008110251, 1998729813]] |
| 2 | [166417565, 213933364, 1129612544, 1419614622, 1370935710] | [0:[166417565, 213933364], 1:[1129612544, 1419614622]] |
若两个文档在某条带上 MinHash 值相同,这两个文档就会被聚到同一个桶中备选。
| 条带 ID | 条带值 | doc_ids |
| ---------- | ------------------------ | ------- |
| 0 | [403996643, 840529008] | 0, 1 |
| 1 | [1008110251, 2888962350] | 0 |
| 1 | [1008110251, 1998729813] | 1 |
| 0 | [166417565, 213933364] | 2 |
| 1 | [1129612544, 1419614622] | 2 |
遍历 `doc_ids` 列的每一行,将其中的文档两两配对就生成了候选对。上表中,我们能生成一个候选对: `(0, 1)` 。
### 候选对生成后 ……
很多数据去重的论文或教程讲完上一节就结束了,但在实际项目中我们还涉及如何处理这些候选对的问题。通常,候选对生成后,我们有两个选择:
1. 由于 MinHash 只是一个近似,所以仍需计算两个文档的 N- 元组集合的交并比来算得准确的 Jaccard 相似性。此时,因为 LSH 已经帮我们过滤了不少,所以最终参与计算的候选对的量会大大减少。在 BigCode 项目中,我们起初就采用了这种做法,效果相当不错。
2. 我们还可以直接认可 LSH 选出来的相似对。这里面可能会有个问题: Jaccard 相似性不具传递性,也就是说 $A$ 相似于 $B$ 且 $B$ 相似于 $C$,并不意味着 $A$ 相似于 $C$。所以这里可能会有不少假阳性。通过在 The Stack 数据集上的实验,我们发现,直接认可 LSH 选出来的相似对在很大程度上能提高下游模型的性能,同时还节省了处理时间和训练时间。因此目前我们正慢慢开始转向这种方法。但是,这个经验并不是放之四海而皆准的,如果你准备在自己的数据集上仿效我们的做法,我们建议你在此之前好好检查你的数据集及其特点,然后作出数据驱动的决策。
最后,我们可以用生成的相似文本对构建一个图,在这个图中,重复的文档会被聚至同一个社区或同一个连通子图中。不幸的是, `datasets` 在这方面帮不上什么忙,因为现在我们需要类似 `groupby` 的功能,以根据 _条带 ID_ 及 _文档在该条带上的取值_ 对文档进行聚类。下面列出了我们尝试过的一些方案:
**方案 1: 老办法,迭代数据集以创建图,然后用一个图处理库对其做社区检测或者连通分量检测。**
我们测试下来,该方案的扩展性不怎么好,其原因是多方面的: 首先,整个数据集迭代起来很慢,而且内存消耗很大; 其次,诸如 `graphtool` 或 `networkx` 的市面上流行的图处理库创建图的开销较大。
**方案 2: 使用流行的 Python 框架 (如 `dask` ) 及其高效的 `groupby` 操作**。
但迭代慢和创建图慢的问题仍然存在。
**方案 3: 迭代数据集并使用并查集 (union find data structure) 对文档进行聚类。**
这个方案引入了一个很小的迭代开销,对中等数据集的有不错的效果不错,但在大数据集上还是慢。
```python
for table in tqdm(HASH_TABLES, dynamic_ncols=True, desc="Clustering..."):
for cluster in table.values():
if len(cluster) <= 1:
continue
idx = min(cluster)
for x in cluster:
uf.union(x, idx)
```
**方案 4: 对大数据集,使用 Spark。**
我们已经知道到 LSH 的有些步骤是可以并行化的,我们可以用 Spark 来实现它们。Spark 的好处是,它开箱即支持分布式 `groupBy` ,而且也能很轻松地实现像 [[18]](#18) 这样的连通分量检测算法。注意,这里我们并没有使用 Spark 的原生 MinHash 实现,其原因是迄今为止我们所有的实验都源于 [Datasketch](https://github.com/ekzhu/datasketch),而 Datasketch 的 MinHash 实现与 Spark 的原生实现完全不同。我们希望之前的经验和教训能帮助到后面的工作,而不是另起炉灶,进入另一个消融实验的轮回,因此我们选择在 Spark 中自己实现 Datasketch 的 MinHash 算法。
```python
edges = (
records.flatMap(
lambda x: generate_hash_values(
content=x[1],
idx=x[0],
num_perm=args.num_perm,
ngram_size=args.ngram_size,
hashranges=HASH_RANGES,
permutations=PERMUTATIONS,
)
)
.groupBy(lambda x:(x[0], x[1]))
.flatMap(lambda x: generate_edges([i[2] for i in x[1]]))
.distinct()
.cache()
)
```
以下是基于 [[18]](#18) 的简单连通分量检测算法的 Spark 实现。
```python
a = edges
while True:
b = a.flatMap(large_star_map).groupByKey().flatMap(large_star_reduce).distinct().cache()
a = b.map(small_star_map).groupByKey().flatMap(small_star_reduce).distinct().cache()
changes = a.subtract(b).union(b.subtract(a)).collect()
if len(changes) == 0:
break
results = a.collect()
```
多亏了云计算提供商,我们可以使用 GCP DataProc 等服务轻松地搭建 一个 Spark 集群。 **最终,我们把程序运行起来,只用了不到 4 小时就完成了 1.4 TB 数据的去重工作,每小时仅需 15 美元。**
## 数据质量很重要
我们不可能爬着梯子登上月球。因此我们不仅要确保方向正确,还要确保方法正确。
早期,我们使用的参数主要来自 CodeParrot 的实验,消融实验表明这些参数确实提高了模型的下游性能 [[16]](#16)。后来,我们开始沿着这条路进一步探索,由此进一步确认了以下结论 [[4]](#4):
1. 数据去重可以在缩小数据集 (6 TB VS. 3 TB) 规模的同时提高模型的下游性能
2. 虽然我们还没有完全搞清楚其能力边界及限制条件,但我们确实发现更激进的数据去重 (6 TB VS. 2.4 TB) 可以进一步提高性能,方法有:
1. 降低相似度阈值
2. 使用更长的元组 (如: 一元组 → 五元组)
3. 放弃误报检查,承受一小部分误报带来的数据损失
<center>
图例: 上述两幅图展示了相似性阈值和元组大小带来的影响,第一幅图使用 1- 元组,第二幅图使用 5- 元组。红色虚线表示相似性阈值: 低于该值的文档与同一簇中其他文档的相似性低于阈值,我们将其视为误报。
</center>
上面两幅图可以帮助我们理解为什么有必要仔细检查 CodeParrot 以及早期版本的 The Stack 训练数据上的误报: 这是使用 1- 元组的误报比例会很大; 上图还表明,将元组大小增加到 5,误报比例会显著降低。如果想激进点去重的话,阈值可以设低点。
还有实验表明,降低阈值会删除更多包含部分相似内容的文档,因此意味着提高了我们最想删除的那部分文档的查全率。
## 系统扩展性
<center> 图例: 数据去重时间与原始数据集规模的关系。测试基于 GCP 上的 15 个 c2d-standard-16 实例,每个实例每小时的成本约为 0.7 美元。</center>

<center> 图例: 集群在处理 JSON 数据集时的 CPU 使用率。</center>
上述扩展性数据未必非常严格,但也足够说明,在给定预算的情况下,数据去重耗时与数据集规模的关系应该是线性的。如果你仔细看一下处理 JSON 数据集 (The Stack 数据集的最大子集) 的集群资源使用情况,你会发现实际总计算时间 (图中第 2 和第 3 阶段) 主要都花在了 MinHash + LSH (图中第 2 阶段) 上,这与我们先前的分析一致,即第 2 阶段 d 的时间复杂度为 $ \mathcal{O}(NM) $ — 与数据体量成线性关系。
## 谨慎行事
数据去完重并不意味着万事大吉了,你仍然需要对数据进行彻底的探索和分析。此外,上文这些有关数据去重的发现来自于 The Stack 数据集,并不意味着它能无脑适用于其他数据集或语言。要构建一个好的训练数据集,我们仅仅迈出了万里长征的第一步,后面还有很多工作要做,例如数据质量过滤 (如过滤漏洞数据、毒性数据、偏见数据、模板生成的数据、个人身份数据等)。
我们还鼓励你在训练前像我们一样对数据集进行彻底的分析,因为大家的情况可能各不相同。例如,如果你的时间和计算预算都很紧张,那么数据去重可能不是很有帮助: [@geiping_2022](http://arxiv.org/abs/2212.14034) 提到基于子字符串的数据去重并没有提高他们模型的下游性能。在使用前,可能还需要对现存数据集进行彻底检查,例如,[@gao_2020](http://arxiv.org/abs/2101.00027) 声明他们只确保 Pile 本身及其子集都已去重,但不保证其与任何下游基准数据集没有重复,要不要对 Pile 与下游基准数据集进行去重取决于使用者自己。
在数据泄露和基准污染方面,还有很多需要探索的地方。由于 HumanEval 也是 GitHub Python 存储库之一,我们不得不重新训练了我们的代码模型。早期的工作还发现,最流行的编码基准之一的 MBPP[[19]](#19) 与许多 Leetcode 问题有很多相似之处 (例如,MBPP 中的任务 601 基本上是 Leetcode 646,任务 604 ≃ Leetcode 151)。我们都知道 GitHub 中不乏很多编程挑战赛题及其答案代码。如果居心叵测的人把所有基准测试的 Python 代码以不易察觉的方式上传到 Github,污染你所有的训练数据,这事儿就更难了。
## 后续方向
1. 子串去重。尽管在英语 [[3]](#3) 上子串去重是有益的,但尚不清楚是否对代码数据也有用;
2. 重复段落: 在一篇文档中重复多次的段落。 [@rae_2021](http://arxiv.org/abs/2112.11446) 分享了一些关于如何检测和删除它们的有趣的启发式方法。
3. 使用模型嵌入进行语义级的去重。这是另外一套思路了,需要一整套去重、扩展性、成本、销蚀等各方面的实验和权衡。对此 [[20]](#20) 提出了一些有趣的看法,但我们仍然需要更多实际证据才能得出结论 (其文本去重工作仅参考了 [@lee_2022a](http://arxiv.org/abs/2107.06499) 的工作,而 [@lee_2022a](http://arxiv.org/abs/2107.06499) 的主张主要是去重有作用而并未证明其效果达到了 SOTA)。
4. 优化。还有不少优化空间: 更好的质量评估标准、扩展性、对下游性能影响的分析等。
5. 换个角度: 对相似数据,去重到什么程度就会开始损害性能?需要保留多少相似数据以保留数据的多样性又不至冗余?
## 致谢
题图中的表情符 (Hugging Face、圣诞老人、文档、巫师以及魔杖) 来自于 Noto Emoji (Apache 2.0)。我也庄严保证,这篇博文是我一个字一个字敲出来的,没有使用任何文本生成 API。
非常感谢 Huu Nguyen(@Huu) 和 Hugo Laurençon(@HugoLaurencon) 在 BigScience 项目中的合作,以及 BigCode 项目中每个人一路上的帮助!如果你发现任何错误,请随时联系我: mouchenghao at gmail dot com。
## 更多资源
- [Datasketch](https://github.com/ekzhu/datasketch) (MIT)
- [simhash-py](https://github.com/seomoz/simhash-py/tree/master/simhash) 及 [simhash-cpp](https://github.com/seomoz/simhash-cpp) (MIT)
- [Deduplicating Training Data Makes Language Models Better](https://github.com/google-research/deduplicate-text-datasets) (Apache 2.0)
- [Gaoya](https://github.com/serega/gaoya) (MIT)
- [BigScience](https://github.com/bigscience-workshop) (Apache 2.0)
- [BigCode](https://github.com/bigcode-project) (Apache 2.0)
## 参考文献
- <a id="1">[1]</a> : Nikhil Kandpal, Eric Wallace, Colin Raffel, [Deduplicating Training Data Mitigates Privacy Risks in Language Models](http://arxiv.org/abs/2202.06539), 2022
- <a id="2">[2]</a> : Gowthami Somepalli, et al., [Diffusion Art or Digital Forgery? Investigating Data Replication in Diffusion Models](http://arxiv.org/abs/2212.03860), 2022
- <a id="3">[3]</a> : Katherine Lee, Daphne Ippolito, et al., [Deduplicating Training Data Makes Language Models Better](http://arxiv.org/abs/2107.06499), 2022
- <a id="4">[4]</a> : Loubna Ben Allal, Raymond Li, et al., [SantaCoder: Don't reach for the stars!](http://arxiv.org/abs/2301.03988), 2023
- <a id="5">[5]</a> : Leo Gao, Stella Biderman, et al., [The Pile: An 800GB Dataset of Diverse Text for Language Modeling](http://arxiv.org/abs/2101.00027), 2020
- <a id="6">[6]</a> : Asier Gutiérrez-Fandiño, Jordi Armengol-Estapé, et al., [MarIA: Spanish Language Models](http://arxiv.org/abs/2107.07253), 2022
- <a id="7">[7]</a> : Jack W. Rae, Sebastian Borgeaud, et al., [Scaling Language Models: Methods, Analysis & Insights from Training Gopher](http://arxiv.org/abs/2112.11446), 2021
- <a id="8">[8]</a> : Xi Victoria Lin, Todor Mihaylov, et al., [Few-shot Learning with Multilingual Language Models](http://arxiv.org/abs/2112.10668), 2021
- <a id="9">[9]</a> : Hugo Laurençon, Lucile Saulnier, et al., [The BigScience ROOTS Corpus: A 1.6TB Composite Multilingual Dataset](https://openreview.net/forum?id=UoEw6KigkUn), 2022
- <a id="10">[10]</a> : Daniel Fried, Armen Aghajanyan, et al., [InCoder: A Generative Model for Code Infilling and Synthesis](http://arxiv.org/abs/2204.05999), 2022
- <a id="11">[11]</a> : Erik Nijkamp, Bo Pang, et al., [CodeGen: An Open Large Language Model for Code with Multi-Turn Program Synthesis](http://arxiv.org/abs/2203.13474), 2023
- <a id="12">[12]</a> : Yujia Li, David Choi, et al., [Competition-Level Code Generation with AlphaCode](http://arxiv.org/abs/2203.07814), 2022
- <a id="13">[13]</a> : Frank F. Xu, Uri Alon, et al., [A Systematic Evaluation of Large Language Models of Code](http://arxiv.org/abs/2202.13169), 2022
- <a id="14">[14]</a> : Aakanksha Chowdhery, Sharan Narang, et al., [PaLM: Scaling Language Modeling with Pathways](http://arxiv.org/abs/2204.02311), 2022
- <a id="15">[15]</a> : Lewis Tunstall, Leandro von Werra, Thomas Wolf, [Natural Language Processing with Transformers, Revised Edition](https://www.oreilly.com/library/view/natural-language-processing/9781098136789/), 2022
- <a id="16">[16]</a> : Denis Kocetkov, Raymond Li, et al., [The Stack: 3 TB of permissively licensed source code](http://arxiv.org/abs/2211.15533), 2022
- <a id="17">[17]</a> : [Rocky | Project Hail Mary Wiki | Fandom](https://projecthailmary.fandom.com/wiki/Rocky)
- <a id="18">[18]</a> : Raimondas Kiveris, Silvio Lattanzi, et al., [Connected Components in MapReduce and Beyond](https://doi.org/10.1145/2670979.2670997), 2014
- <a id="19">[19]</a> : Jacob Austin, Augustus Odena, et al., [Program Synthesis with Large Language Models](http://arxiv.org/abs/2108.07732), 2021
- <a id="20">[20]</a>: Amro Abbas, Kushal Tirumala, et al., [SemDeDup: Data-efficient learning at web-scale through semantic deduplication](http://arxiv.org/abs/2303.09540), 2023
- <a id="21">[21]</a>: Edith Cohen, [MinHash Sketches : A Brief Survey](http://www.cohenwang.com/edith/Surveys/minhash.pdf), 2016
| 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/cost-efficient-rag-applications-with-intel.md | ---
title: "利用英特尔 Gaudi 2 和至强 CPU 构建经济高效的企业级 RAG 应用"
thumbnail: /blog/assets/cost_efficient_rag_applications_with_intel/main.jpg
authors:
- user: juliensimon
- user: Haihao
guest: true
org: Intel
- user: antonyvance
guest: true
org: Intel
- user: MatrixYao
guest: true
org: Intel
- user: lianglv
guest: true
org: Intel
- user: Suleyman Sair
guest: true
org: Intel
- user: gserochi
guest: true
org: Intel
- user: Debbh
guest: true
org: Intel
- user: kding1
guest: true
org: Intel
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 利用英特尔 Gaudi 2 和至强 CPU 构建经济高效的企业级 RAG 应用
<p align="center">
<img src="https://huggingface.co/blog/assets/cost_efficient_rag_applications_with_intel/main.jpg" width="512"><br>
</p>
检索增强生成 (Retrieval Augmented Generation,RAG) 可将存储在外部数据库中的新鲜领域知识纳入大语言模型以增强其文本生成能力。其提供了一种将公司数据与训练期间语言模型学到的知识分开的方式,有助于我们在性能、准确性及安全隐私之间进行有效折衷。
通过本文,你将了解到英特尔如何通过企业 AI 开放平台 [OPEA](https://opea.dev) 开源项目帮助你开发和部署 RAG 应用。你还将通过真实的 RAG 使用案例了解英特尔 Gaudi 2 AI 加速器和至强 CPU 如何助力企业级应用性能的显著飞跃。
# 导入
在深入了解细节之前,我们先要获取硬件。[英特尔 Gaudi 2](https://habana.ai/products/gaudi2/) 专为加速数据中心和云上的深度学习训练和推理而设计。你可在 [英特尔开发者云 (IDC)](https://www.intel.com/content/www/us/en/developer/tools/devcloud/overview.html) 上获取其公开实例,也可在本地部署它。IDC 是尝试 Gaudi 2 的最简单方法,如果你尚没有帐户,可以考虑注册一个帐户,订阅 “Premium”,然后申请相应的访问权限。
在软件方面,我们主要使用 LangChain 来构建我们的应用。LangChain 是一个开源框架,旨在简化 LLM AI 应用的构建流程。其提供了基于模板的解决方案,允许开发人员使用自定义嵌入模型、向量数据库和 LLM 构建 RAG 应用,用户可通过 LangChain 文档获取其更多信息。英特尔一直积极为 LangChain 贡献多项优化,以助力开发者在英特尔平台上高效部署 GenAI 应用。
在 LangChain 中,我们将使用 `rag-redis` 模板来创建我们的 RAG 应用。选型上,我们使用 [BAAI/bge-base-en-v1.5](https://huggingface.co/BAAI/bge-base-en-v1.5) 作为嵌入模型,并使用 Redis 作为默认向量数据库。下图展示了该应用的高层架构图。
<kbd>
<img src="https://huggingface.co/blog/assets/cost_efficient_rag_applications_with_intel/01.png">
</kbd>
在我们的应用中,嵌入模型跑在 [英特尔 Granite Rapids](https://www.intel.com/content/www/us/en/newsroom/news/intel-unveils-future-generation-xeon.html#gs.6t3deu) CPU 上。英特尔 Granite Rapids 架构专为高核数、性能敏感型工作负载以及通用计算工作负载而优化,并为此类工作负载提供最低的总拥有成本 (Cost Of Ownership,TCO)。GNR 还支持 AMX-FP16 指令集,这会为混合 AI 工作负载带来 2-3 倍的性能提升。
我们将 LLM 跑在英特尔 Gaudi 2 加速器上。至于如何使用 Hugging Face 模型,[Optimum Habana](https://huggingface.co/docs/optimum/en/habana/index) 库可将 Hugging Face [Transformers](https://huggingface.co/docs/transformers/index) 和 [Diffusers](https://huggingface.co/docs/diffusers/index) 库桥接至 Gaudi 加速器。因此,用户可以用它针对各种下游任务在单卡和多卡场景下轻松进行模型加载、训练及推理。
我们提供了一个 [Dockerfile](https://github.com/opea-project/GenAIExamples/tree/main/ChatQnA/langchain/docker) 以简化 LangChain 开发环境的配置。启动 Docker 容器后,你就可以开始在 Docker 环境中构建向量数据库、RAG 流水线以及 LangChain 应用。详细的分步说明,请参照 [ChatQnA](https://github.com/opea-project/GenAIExamples/tree/main/ChatQnA) 示例。
# 创建向量数据库
我们用耐克的公开财务文件创建一个向量数据库,示例代码如下:
```
# Ingest PDF files that contain Edgar 10k filings data for Nike.
company_name = "Nike"
data_path = "data"
doc_path = [os.path.join(data_path, file) for file in os.listdir(data_path)][0]
content = pdf_loader(doc_path)
chunks = text_splitter.split_text(content)
# Create vectorstore
embedder = HuggingFaceEmbeddings(model_name=EMBED_MODEL)
_ = Redis.from_texts(
texts=[f"Company: {company_name}. " + chunk for chunk in chunks],
embedding=embedder,
index_name=INDEX_NAME,
index_schema=INDEX_SCHEMA,
redis_url=REDIS_URL,
)
```
# 定义 RAG 流水线
在 LangChain 中,我们使用 Chain API 来连接提示、向量数据库以及嵌入模型。
你可在 [该代码库](https://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/langchain/redis/rag_redis/chain.py) 中找到完整代码。
```
# Embedding model running on Xeon CPU
embedder = HuggingFaceEmbeddings(model_name=EMBED_MODEL)
# Redis vector database
vectorstore = Redis.from_existing_index(
embedding=embedder, index_name=INDEX_NAME, schema=INDEX_SCHEMA, redis_url=REDIS_URL
)
# Retriever
retriever = vectorstore.as_retriever(search_type="mmr")
# Prompt template
template = """…"""
prompt = ChatPromptTemplate.from_template(template)
# Hugging Face LLM running on Gaudi 2
model = HuggingFaceEndpoint(endpoint_url=TGI_LLM_ENDPOINT, …)
# RAG chain
chain = (
RunnableParallel({"context": retriever, "question": RunnablePassthrough()}) | prompt | model | StrOutputParser()
).with_types(input_type=Question)
```
# 在 Gaudi 2 上加载 LLM
我们在 Gaudi2 上使用 Hugging Face 文本生成推理 (TGI) 服务运行聊天模型。TGI 让我们可以在 Gaudi2 硬件上针对流行的开源 LLM (如 MPT、Llama 以及 Mistral) 实现高性能的文本生成。
无需任何配置,我们可以直接使用预先构建的 Docker 映像并把模型名称 (如 Intel NeuralChat) 传给它。
```
model=Intel/neural-chat-7b-v3-3
volume=$PWD/data
docker run -p 8080:80 -v $volume:/data --runtime=habana -e HABANA_VISIBLE_DEVICES=all -e OMPI_MCA_btl_vader_single_copy_mechanism=none --cap-add=sys_nice --ipc=host tgi_gaudi --model-id $model
```
TGI 默认使用单张 Gaudi 加速卡。如需使用多张卡以运行更大的模型 (如 70B),可添加相应的参数,如 `--sharded true` 以及 `--num_shard 8` 。对于受限访问的模型,如 [Llama](https://huggingface.co/meta-llama) 或 [StarCoder](https://huggingface.co/bigcode/starcoder),你还需要指定 `-e HUGGING_FACE_HUB_TOKEN= <kbd>` 以使用你自己的 Hugging Face [令牌](https://huggingface.co/docs/hub/en/security-tokens) 获取模型。
容器启动后,我们可以通过向 TGI 终端发送请求以检查服务是否正常。
```
curl localhost:8080/generate -X POST \
-d '{"inputs":"Which NFL team won the Super Bowl in the 2010 season?", \
"parameters":{"max_new_tokens":128, "do_sample": true}}' \
-H 'Content-Type: application/json'
```
如果你能收到生成的响应,则 LLM 运行正确。从现在开始,你就可以在 Gaudi2 上尽情享受高性能推理了!
TGI Gaudi 容器默认使用 bfloat16 数据类型。为获得更高的吞吐量,你可能需要启用 FP8 量化。根据我们的测试结果,与 BF16 相比,FP8 量化会带来 1.8 倍的吞吐量提升。FP8 相关说明可在 [README](https://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/README.md) 文件中找到。
最后,你还可以使用 Meta [Llama Guard](https://huggingface.co/meta-llama/LlamaGuard-7b) 模型对生成的内容进行审核。OPEA 的 [README](https://github.com/opea-project/GenAIExamples/blob/main/ChatQnA/README.md) 文件提供了在 TGI Gaudi 上部署 Llama Guard 的说明。
# 运行 RAG 服务
我们运行下述命令启动 RAG 应用后端服务, `server.py` 脚本是用 fastAPI 实现的服务终端。
```
docker exec -it qna-rag-redis-server bash
nohup python app/server.py &
```
默认情况下,TGI Gaudi 终端运行在本地主机的 8080 端口上 (即 `http://127.0.0.1:8080` )。如果需将其运行至不同的地址或端口,可通过设置 `TGI_ENDPOINT ` 环境变量来达成。
# 启动 RAG GUI
运行以下命令以安装前端 GUI 组件:
```
sudo apt-get install npm && \
npm install -g n && \
n stable && \
hash -r && \
npm install -g npm@latest
```
然后,更新 `.env` 文件中的 `DOC_BASE_URL` 环境变量,将本地主机 IP 地址 ( `127.0.0.1` ) 替换为运行 GUI 的服务器的实际 IP 地址。
接着,运行以下命令以安装所需的软件依赖:
```
npm install
```
最后,使用以下命令启动 GUI 服务:
```
nohup npm run dev &
```
上述命令会运行前端服务并启动应用。
<kbd>
<img src="https://huggingface.co/blog/assets/cost_efficient_rag_applications_with_intel/02.png">
</kbd>
# 基准测试结果
我们针对不同的模型和配置进行了深入的实验。下面两张图展示了 Llama2-70B 模型在四卡英特尔 Gaudi 2 和四卡英伟达 H100 平台上,面对 16 个并发用户时的相对端到端吞吐量和性价比对比。
<kbd>
<img src="https://huggingface.co/blog/assets/cost_efficient_rag_applications_with_intel/03.png">
</kbd>
<kbd>
<img src="https://huggingface.co/blog/assets/cost_efficient_rag_applications_with_intel/04.png">
</kbd>
在这两种测例中,向量数据库和嵌入模型都运行在相同的英特尔 Granite Rapids CPU 平台上。为了比较每美元的性能,我们使用了与 [MosaicML](https://www.databricks.com/blog/llm-training-and-inference-intel-gaudi2-ai-accelerators) 团队于 2024 年 1 月使用的数据相同的公开定价数据来计算每美元的平均训练性能。
如你所见,与 Gaudi 2 相比,基于 H100 的系统虽然吞吐量提高了 1.13 倍,但每美元性能仅为 0.44 倍。这些比较可能会因云厂商不同以及客户折扣不同而有所不同,我们在文末列出了详细的基准配置。
# 总结
上例成功演示了如何在英特尔平台上部署基于 RAG 的聊天机器人。此外,英特尔会不断发布成熟的 GenAI 示例,以期通过这些经过验证的工具助力开发人员简化创建、部署流程。这些示例功能多样且易于定制,非常适合用户基于其在英特尔平台上开发各种应用。
运行企业级 AI 应用时,基于英特尔 Granite Rapids CPU 和 Gaudi 2 加速器的系统的总拥有成本更低。另外,还可通过 FP8 优化进一步优化成本。
以下开发者资源应该可以帮助大家更平滑地启动 GenAI 项目。
- [OPEA GenAI 示例](https://github.com/opea-project/GenAIExamples)
- [基于 Gaudi 2 的 TGI](https://github.com/huggingface/tgi-gaudi)
- [英特尔 AI 生态之 Hugging Face](https://www.intel.com/content/www/us/en/developer/ecosystem/hugging-face.html)
- [Hugging Face hub 英特尔页](https://huggingface.co/Intel)
如果你有任何问题或反馈,我们很乐意在 [Hugging Face 论坛](https://discuss.huggingface.co/) 上与你互动。感谢垂阅!
**致谢**:
我们要感谢 Chaitanya Khened、Suyue Chen、Mikolaj Zyczynski、Wenjiao Yue、Wenxin Zhu、Letong Han、Sihan Chen、Hanwen Cheng、Yuan Wu 和 Yi Wang 对在英特尔 Gaudi 2 上构建企业级 RAG 系统做出的杰出贡献。
---
**基准测试配置**
- Gaudi2 配置: HLS-Gaudi2 配备 8 张 Habana Gaudi2 HL-225H 夹层卡及 2 个英特尔至强铂金 8380 [email protected],以及 1TB 系统内存; 操作系统: Ubuntu 22.04.03,5.15.0 内核
- H100 SXM 配置: Lambda labs 实例 gpu_8x_h100_sxm5; 8 张 H100 SXM 及 2 个英特尔至强铂金 8480 CPU@2 GHz,以及 1.8TB 系统内存; 操作系统 ubuntu 20.04.6 LTS,5.15.0 内核
- Llama2 70B 部署至 4 张卡 (查询归一化至 8 卡)。Gaudi2 使用 BF16,H100 使用 FP16
- 嵌入模型为 `BAAI/bge-base v1.5` 。测试环境: TGI-gaudi 1.2.1、TGI-GPU 1.4.5、Python 3.11.7、Langchain 0.1.11、sentence-transformers 2.5.1、langchain benchmarks 0.0.10、redis 5.0.2、cuda 12.2.r12.2/compiler.32965470_0, TEI 1.2.0
- RAG 查询最大输入长度 1024,最大输出长度 128。测试数据集: langsmith Q&A。并发客户端数 16
- Gaudi2 (70B) 的 TGI 参数: `batch_bucket_size=22` , `prefill_batch_bucket_size=4` , `max_batch_prefill_tokens=5102` , `max_batch_total_tokens=32256` , `max_waiting_tokens=5` , `streaming=false`
- H100 (70B) 的 TGI 参数: `batch_bucket_size=8` , `prefill_batch_bucket_size=4` , `max_batch_prefill_tokens=4096` , `max_batch_total_tokens=131072` , `max_waiting_tokens=20` , `max_batch_size=128` , `streaming=false`
- TCO 参考: [https://www.databricks.com/blog/llm-training-and-inference-intel-gaudi2-ai-accelerators](https://www.databricks.com/blog/llm-training-and-inference-intel-gaudi2-ai-accelerators)
| 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/chinese-ai-expansion.md | ---
title: "中国 AI 出海现状概述"
thumbnail: /blog/assets/chinese-ai-expansion/thumbnail.png
authors:
- user: AdinaY
---
15 世纪初,中国航海家郑和在明朝初期领导了七次著名的远洋航行,史称“郑和下西洋”。他的航程穿越东南亚、中东,最终到达非洲。这是中国通过外交手段与海外建立贸易关系,并探索海外机遇的壮举。“出海”一词自此具有了特殊的全球化意义。
600 年后,中国再次在国际舞台上崭露头角,从全球制造中心转变为信息通信技术、电动汽车和人工智能技术的领导者。到 2024 年,中国企业加速了海外扩展,尤其是在人工智能领域。根据非凡产研 6 月份的报告,在全球 1500 家活跃的 AI 公司中,751 家位于中国,其中 103 家已开始向国际市场扩展。许多人将此视为中国科技创新实力的体现。也有观点认为,由于国内市场日益饱和且竞争激烈,出海可能已成为这些公司唯一可行的选择。
## 谁在出海?
首先抓住全球化机遇的公司,不出所料,是中国的科技巨头。华为、腾讯和阿里巴巴等公司在扩展海外时,重点放在云计算和 AI 基础设施上。2024 年 3 月,**腾讯云**与沙特阿拉伯领先的电信公司 Etihad Etisalat (Mobily) 合作,启动了“Go Saudi”项目,旨在推动沙特阿拉伯王国的数字化转型,作为其 2030 愿景战略的一部分。同年 5 月,**华为**在北非推出了 Galaxy AI,作为促进数字智能化转型的更大计划的一部分。此举是华为五年内计划在该地区投资 4.3 亿美元以加速智能化转型的一部分。同月,**阿里巴巴**宣布将在韩国、马来西亚、菲律宾、泰国和墨西哥建设数据中心,并推出国际版的大模型服务平台“百炼”(Model Studio)。
这些科技巨头将其海外战略重点放在东南亚和中东地区,这与中国的[一带一路倡议](https://eng.yidaiyilu.gov.cn/)和[数字丝绸之路政策](https://www.orcasia.org/digital-silk-road)相契合。在日益紧张的地缘政治局势下,选择中文使用广泛的东南亚、新兴市场中东以及长期盟友非洲,似乎是更具战略性的选择。
被称为“应用工厂”的**字节跳动**则选择了熟悉的西方 B2C 市场,仅在七个月内就推出了 11 款海外应用。2020 年推出的 **CapCut**,在 2022 年发布了其付费版本 **CapCut Pro**,并在 2024 年初整合了 AI 功能,成为全球最受欢迎的应用之一,月活跃用户超过 3 亿。根据 Sensor Tower 数据,截至 2024 年 7 月,CapCut 的移动应用累计收入已达 1.25 亿美元。
尽管仍处于商业化的早期阶段,初创企业也渴望加入海外扩展的行列。一些中国 AI 独角兽企业采用了一种“模型 + 应用”的策略。由于训练模型的成本高昂,一些初创企业已经将重点从更新基础模型转向有盈利可能的应用和场景探索。对于依赖融资的初创企业来说,在国内激烈的竞争下,出海已成为必要选择。许多早期出海的公司选择了西方 To-C 市场,推出了基于各自模型的生产力、创意和陪伴应用。例如,中国 AI “六小龙” (零一万物、百川智能、智谱 AI、月之暗面、MiniMax 和 阶跃星辰。 DeepSeek 和 面壁智能也曾被列入该名单中)的应用,“MiniMax”的“Talkie”和零一万物的“PopAI”已获得数百万用户,并实现了盈利。
## 为什么要出海?
### 国内市场竞争
中国拥有世界上最多的互联网用户和庞大的技术开发者群体,没人愿意在 AI 热潮中掉队。随着越来越多的公司涌入这个领域,AI 技术迅速发展,但应用落地和用户增长却较为缓慢。无论是行业巨头还是初创公司,都面临巨大压力。
在 2023 年 10 月到 2024 年 9 月期间,中国发布了 238 个大语言模型。在一年多的激烈竞争后,它们进入了整合阶段。2024 年 5 月,由 AI 初创企业**DeepSeek** 引发的价格战进一步加剧了压力,该公司通过架构创新显著降低了模型推理成本。随着这一宣布,字节跳动、腾讯、百度和阿里巴巴等主要公司迅速跟进并下调了价格,甚至将价格降至成本线以下。这场激烈的竞争源于模型之间的技术差异性微弱且产品化速度缓慢。
自 ChatGPT 推出以来至 2024 年 7 月,已有 78,612 家 AI 公司解散或暂停运营(来源:TMTPOST)。竞争之下,行业大洗牌开始,而仍在局内的公司也在不断挖掘利基市场以与其他公司区分开来。同时,垂类大语言模型正逐渐受到关注,尤其是在政府的推动下。2024 年 3 月 5 日的**政府工作报告**中强调了“AI+”战略,推动 AI 在各个行业中的渗透。到 2024 年 7 月,向中国网络空间管理局 (CAC) 注册的 AI 模型数量已超过 197 个,其中近 70% 是行业专用的大语言模型,主要集中在金融、医疗和教育等领域。随着 AI 在垂直行业中的快速整合,预计在未来几个月内,垂直领域将成为新一轮竞争的关键领域。
在以上列举的情况下,出海似乎成为了企业的一条出路。
### 政策与投资环境的压力
政府不仅在鼓励人工智能的发展,也在加强对其监管。2024 年 3 月至 9 月期间,政府推出了一系列监管政策,特别是关于数据隐私、算法透明度和内容标识的规定。
- 2024 年 3 月 5 日:中国国家信息安全标准化技术委员会 (TC260) 发布了一份技术文件,概述了生成式 AI 服务的基本安全要求。
- 2024 年 9 月 14 日:中国网络空间管理局 (CAC) 提议了一项新规,要求 AI 生成的内容必须被标识,确保用户可以轻松分辨内容是由人还是由机器生成的。
监管对于任何新兴行业来说都是不可避免的,但也会增加公司的合规成本,这对于中小企业有着一定的压力。前微软工程师邵猛评论道:“更严格的监管,尤其是对 To-C 团队,可能会推动更多公司将产品和团队选择出海。”
除了政策压力外,与 ChatGPT 刚推出时的 AI 热潮相比,过去 6 个月里的投资环境充满挑战。到 2024 年中期,中国 AI 初创企业通过 372 轮融资筹集了约 44 亿美元,相比 2021 年的峰值 249 亿美元大幅下降。

### 海外市场——中国 AI 企业的希望之地
与国内市场相比,某些海外市场的显著特点是更强的支付意愿以及相对稳定的商业环境。通过提出符合当地需求的创新 AI 解决方案,例如数字人直播这样的创新正在打入东南亚电商直播行业,这可以帮助中国 AI 企业在当地获得较为稳定的收入来源。
对于企业或政府客户而言,东南亚、中东和非洲等新兴市场已成为中国 AI 企业的首选。这些地区正处于数字化转型的早期阶段,与西方市场相比,这些地区的竞争较少,增长潜力更大,准入门槛更低。中国 AI 科技巨头通过利用其技术优势、成本效益结构和政府支持,扩大了在这些市场的份额。
## 关键成功因素是什么?
### 本地化
监管本地化:出海时,中国 AI 公司必须应对全球范围内多样化的数据隐私、安全和伦理法规,这甚至比其商业模式的实施更为重要。以 [欧盟人工智能法案](https://www.europarl.europa.eu/topics/en/article/20230601STO93804/eu-ai-act-first-regulation-on-artificial-intelligence) 及[通用数据保护条例](https://eur-lex.europa.eu/eli/reg/2016/679/oj) 为例,中国公司需要调整其 AI 模型以符合
欧盟的“隐私设计原则”,其中数据保护是 AI 产品和服务的核心组成部分。
技术本地化:尽管 AI 技术发展迅速,但仍没有一种万能的解决方案。在基础设施较弱的新兴市场,公司需要调整其产品以适应网络条件、数据存储和算法适应性。与此同时,在发达市场,公司需要符合行业标准,如数据本地化和 ISO 认证等。
### 提升国际影响力
尽管中国 AI 迅速发展,但中国 AI 企业在海外市场尚未获得足够的认知度。在 [Hugging Face Hub](https://huggingface.co/) 上发布开源项目已成为提升全球知名度的有效途径。除了提高知名度,这些模型还为全球社区贡献了宝贵的 AI 资源和多样化的多语言解决方案。例如,几乎每一到两周,都会有至少一个来自中国的模型出现在 Hugging Face 的热门模型排行榜上。这些模型包括阿里巴巴的 [**Qwen**](https://huggingface.co/Qwen) 系列,该系列在 [Hugging Face 开源 LLM 排行榜](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard) 上一直表现出色,被认为是目前全球最好的开放大语言模型之一,支持超过 29 种不同的语言;还有广受开源社区赞誉的 [**DeepSeek coder**](https://huggingface.co/deepseek-ai),以及智谱 AI 的开源项目 [**GLM**](https://huggingface.co/collections/THUDM/glm-4-665fcf188c414b03c2f7e3b7) 系列和 [**CogVideo**](https://huggingface.co/collections/THUDM/cogvideo-66c08e62f1685a3ade464cce)。
通过开源计划,这些项目在国际开源社区中获得了相当大的影响力,帮助中国项目在全球市场提升了认知度、信任度和竞争力。
一个有趣的现象是,许多中国公司在海外扩展后往往采用新的品牌名称,或者更愿意以其模型或应用的名称进行推广。Hugging Face 工程师王铁震表示:“中国公司经常为海外产品创造新品牌,甚至为每个国家创建一个新品牌,而西方公司则更喜欢在全球范围内使用统一的产品名称。”这种方式有助于它们更好地融入当地市场,同时也在一定程度上避免了地缘政治压力。
### 推广 ESG 战略
“AI for Good” 毫无疑问是探索 AI 更大用途的重要举措,它是一种没有国界的包容性声明。在北京,中国 ESG30 论坛发布了《2024 中国企业全球扩展战略报告》。该报告强调了 ESG 和 AI 作为中国公司融入全球化新阶段的两大支柱的重要性。一些科技巨头已经开始采用绿色能源来推动全球数据中心的可持续发展,或者使用 AI 图像识别技术来监测野生动物等。AI 应用还与 AI 初创企业和传统行业合作,共同开发绿色技术,例如可再生能源和电动汽车。这些创新进一步推动了产品的可持续性,帮助中国公司在竞争激烈的市场中脱颖而出。
## 结论
**中国 AI 企业正处于一个关键的转折点**。出海不仅仅是一个简单的市场扩展策略,更是由于国内严峻的市场环境和看似光明的海外机遇而做出的必要选择。然而,出海并非一定能够成功。在陌生的市场和受众面前,迅速适应当地市场、遵守法规并建立知名度同样充满挑战。
更重要的是,AI 仍处于发展的早期阶段,只有当 AI 公司找到成为 AI 赋能者以重塑行业的契机时,它的真正力量才能得以释放。今天,中国 AI 公司出海很重要,而当它们真正与当地产业整合并为其带来价值时,将是另一个高度。
郑和的“下西洋”是通过国家战略得以实施的,得益于当时强大的经济实力。今天,历史似乎在以不同的背景重演:技术创新不仅需要国家力量来支持,也需要通过自由市场的动态力量,即竞争和开放交流中驱动创造力和进步。中国的 AI 公司仍然有很长的路要走。
感谢王铁震、程路、邵猛和 Sam Guo 提供的宝贵反馈。
感谢阅读!
| 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/personal-copilot.md | ---
title: "个人编程助手:训练你自己的编码助手"
thumbnail: /blog/assets/170_personal_copilot/thumbnail.png
authors:
- user: smangrul
- user: sayakpaul
translators:
- user : innovation64
- user: zhongdongy
proofreader: true
---
# 个人编程助手: 训练你自己的编码助手
在编程和软件开发这个不断演变的领域中,对效率和生产力的追求催生了许多卓越的创新。其中一个显著的创新就是代码生成模型的出现,如 [Codex](https://openai.com/blog/openai-codex)、[StarCoder](https://arxiv.org/abs/2305.06161) 和 [Code Llama](https://arxiv.org/abs/2308.12950)。这些模型在生成类似人类编写的代码片段方面表现出惊人能力,显示出了作为编程助手的巨大潜力。
然而,虽然这些预训练模型在各种任务上已经表现出了卓越的性能,但在不远的未来,我们仍然可以期待一个令人兴奋的前景: 想象一下,你能够根据自己的特定需求定制代码生成模型,并且这种个性化的编程助手能够在企业规模上得到应用。
在这篇博客中,我们将展示如何创建 HugCoder 🤗,一个在 [`huggingface` GitHub 组织](https://github.com/huggingface) 的公共仓库代码内容上进行微调的代码大模型。我们将讲述我们的数据收集工作流程、训练实验,以及一些有趣的结果。这将使你能够根据你的专有代码库创建自己的个人编程助手。我们还将为这个项目的进一步扩展留下一些实验的方向。
让我们开始吧 🚀

## 数据收集的工作流
我们想要的数据集在概念上非常简单,我们像下面所示那样构建它。
| | | |
| --- | --- | --- |
| 仓库名 | 仓库中的文件路径 | 文件内容 |
| — | — | — |
| — | — | — |
使用 [Python GitHub API](https://github.com/PyGithub/PyGithub) 从 GitHub 上抓取代码内容是直截了当的。然而,这取决于仓库的数量和仓库内代码文件的数量,通常情况,人们很容易会遇到 API 速率限制等问题。
为了防止这类问题发生,我们决定将所有公共仓库克隆到本地,并从中提取内容,而不是通过 API。我们使用 Python 的 `multiprocessing` 模块并行下载所有仓库,如 [这个下载脚本](https://github.com/sayakpaul/hf-codegen/blob/main/data/parallel_clone_repos.py)。
一个仓库通常可能包含非代码文件,如图片、演示文稿和其他资料。我们对抓取它们不感兴趣。我们为此创建了一个 [扩展名列表](https://github.com/sayakpaul/hf-codegen/blob/f659eba76f07e622873211e5b975168b634e6c22/data/prepare_dataset.py#L17C1-L49C68) 来过滤掉它们。为了解析除了 Jupyter Notebook 之外的代码文件,我们简单地使用了 “utf-8” 编码。对于 notebook,我们只考虑了代码单元。
我们还排除了所有与代码不直接相关的文件路径。这些包括: `.git` , `__pycache__` 和 `xcodeproj` 。
为了保持这些内容的序列化相对内存友好 (即处理代码时不会过多占用内存),我们使用了分块处理方法和 [feather 格式](https://arrow.apache.org/docs/python/feather.html#:~:text=Feather%20is%20a%20portable%20file,Python%20(pandas)%20and%20R.) (储存序列化的数据)。完整实现请参见 [这个脚本](https://github.com/sayakpaul/hf-codegen/blob/main/data/prepare_dataset.py)。
最终的数据集 [可在 Hub 上获取](https://huggingface.co/datasets/sayakpaul/hf-codegen-v2),它看起来像这个样子:
对于这篇博客,我们选取了基于点赞数排名前十的 Hugging Face 公共仓库。它们分别是:
> ['transformers', 'pytorch-image-models', 'datasets', 'diffusers', 'peft', 'tokenizers', 'accelerate', 'text-generation-inference', 'chat-ui', 'deep-rl-class']
[这是我们用来生成这个数据集的代码](https://github.com/pacman100/DHS-LLM-Workshop/tree/main/personal_copilot/dataset_generation),而 [这是数据集在 Hub 上的链接](https://huggingface.co/datasets/smangrul/hf-stack-v1)。下面是它的一个快照:
为了降低项目复杂性,我们没有考虑对数据集进行去重。如果你对在生产应用中应用去重技术感兴趣,[这篇博客文章](https://huggingface.co/blog/zh/dedup) 是一个极佳的资源,它在代码大模型的内容中详细讨论了这个主题。
## 微调你的个人代码助手
在这一部分,我们将展示如何微调以下模型: [`bigcode/starcoder`](https://hf.co/bigcode/starcoder) (15.5B 参数) 、[`bigcode/starcoderbase-1b`](https://hf.co/bigcode/starcoderbase-1b) (1B 参数) 和 [`Deci/DeciCoder-1b`](https://hf.co/Deci/DeciCoder-1b) (1B 参数)。我们将使用一个带有 40GB 显存的 A100 Colab Notebook,并使用 🤗 PEFT (Parameter-Efficient Fine-Tuning,参数高效微调) 进行所有实验。此外,我们还将展示如何使用 🤗 Accelerate 的 FSDP (Fully Sharded Data Parallel,全分片数据并行) 集成,在一台配备 8 个 80GB 显存的 A100 GPU 的机器上完全微调 `bigcode/starcoder` (15.5B 参数)。训练目标是 [ fill in the middle (FIM) ](https://arxiv.org/abs/2207.14255),其中训练序列的一部分被移动到序列的末尾,并且重排序后的序列被自回归地预测。
为什么选择 PEFT ?因为全微调代价高昂。让我们来看一些数字以便更好地理解:
全微调所需的最小 GPU 内存:
1. 参数权重: 2 字节 (混合精度训练)
2. 参数权重梯度: 2 字节
3. 使用 Adam 优化器时的优化器状态: 4 字节用于原始 FP32 权重 + 8 字节用于一阶和二阶矩估计
4. 将以上所有内容加在一起的每个参数成本: 每个参数 16 字节
5. **15.5B 模型 -> 248GB 的 GPU 内存,甚至还没有考虑存储中间激活值所需的巨大内存 -> 至少需要 4 个 A100 80GB GPU**
由于硬件需求巨大,我们将使用 [QLoRA](https://arxiv.org/abs/2305.14314) 进行参数高效微调。下面是使用 QLoRA 进行 Starcoder 微调的最小 GPU 内存需求:
> trainable params: 110,428,160 || all params: 15,627,884,544 || trainable%: 0.7066097761926236
1. 基础模型权重: 0.5 字节 * 15.51B 冻结参数 = 7.755GB
2. 适配器 (Adapter) 权重: 2 字节 * 0.11B 可训练参数 = 0.22GB
3. 权重梯度: 2 字节 * 0.11B 可训练参数 = 0.22GB
4. 使用 Adam 优化器时的优化器状态: 4 字节 * 0.11B 可训练参数 * 3 = 1.32GB
5. **将以上所有内容加在一起 -> 9.51GB ~ 10GB -> 需要 1 个 A100 40GB GPU** 🤯。选择 A100 40GB GPU 的原因是,训练时长序列长度为 2048,批量大小为 4,这会导致更高的内存需求。如下所示,所需的 GPU 内存为 26GB,可以在 A100 40GB GPU 上容纳。此外,A100 GPU 与 Flash Attention 2 具有更好的兼容性。
在上面的计算中,我们没有考虑中间激活值检查点所需的内存,这通常是相当巨大的。我们利用 Flash Attention V2 和梯度检查点来解决这个问题。
1. 对于 QLoRA,加上 flash attention V2 和梯度检查点,单个 A100 40GB GPU 上模型占用的总内存为 **26GB**, **批量大小为 4**。
2. 对于使用 FSDP 进行全微调,加上 Flash Attention V2 和梯度检查点,每个 GPU 上占用的内存在 **70GB 到 77.6GB** 之间, **每个 GPU 的批量大小为 1**。
请参考 [model-memory-usage](https://huggingface.co/spaces/hf-accelerate/model-memory-usage) 以轻松计算在 🤗 Hugging Face Hub 上托管的大型模型上进行训练和推理所需的 vRAM。
## 全微调
我们将探讨如何使用 PyTorch Fully Sharded Data Parallel (FSDP) 技术在 8 个 A100 80GB GPU 上完全微调 `bigcode/starcoder` (15B 参数)。欲了解更多关于 FSDP 的信息,请参阅 [Fine-tuning Llama 2 70B using PyTorch FSDP](https://huggingface.co/blog/ram-efficient-pytorch-fsdp) 和 [Accelerate Large Model Training using PyTorch Fully Sharded Data Parallel](https://huggingface.co/blog/pytorch-fsdp)。
**资源**
1. 代码库: [链接](https://github.com/pacman100/DHS-LLM-Workshop/tree/main/personal_copilot/training)。它使用了 Transformers 中最近添加的 Flash Attention V2 支持。
2. FSDP 配置: [fsdp_config.yaml](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/training/configs/fsdp_config.yaml)
3. 模型: [bigcode/stacoder](https://huggingface.co/bigcode/starcoder)
4. 数据集: [smangrul/hf-stack-v1](https://huggingface.co/datasets/smangrul/hf-stack-v1)
5. 微调后的模型: [smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab](https://huggingface.co/smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab)
启动训练的命令在 [run_fsdp.sh](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/training/run_fsdp.sh) 中给出。
```
accelerate launch --config_file "configs/fsdp_config.yaml" train.py \
--model_path "bigcode/starcoder" \
--dataset_name "smangrul/hf-stack-v1" \
--subset "data" \
--data_column "content" \
--split "train" \
--seq_length 2048 \
--max_steps 2000 \
--batch_size 1 \
--gradient_accumulation_steps 2 \
--learning_rate 5e-5 \
--lr_scheduler_type "cosine" \
--weight_decay 0.01 \
--num_warmup_steps 30 \
--eval_freq 100 \
--save_freq 500 \
--log_freq 25 \
--num_workers 4 \
--bf16 \
--no_fp16 \
--output_dir "starcoder-personal-copilot-A100-40GB-colab" \
--fim_rate 0.5 \
--fim_spm_rate 0.5 \
--use_flash_attn
```
总的训练时间为 **9 小时**。根据 [lambdalabs](https://lambdalabs.com/service/gpu-cloud/pricing) 的价格,8 个 A100 80GB GPU 的成本为每小时 $12.00,总成本将为 **$108**。
## PEFT
我们将探讨如何使用 🤗 PEFT 的 QLoRA 方法对 `bigcode/starcoder` (15B 参数) 进行微调,使用的硬件是单个 A100 40GB GPU。有关 QLoRA 和 PEFT 方法的更多信息,请参阅 [Making LLMs even more accessible with bitsandbytes, 4-bit quantization and QLoRA](https://huggingface.co/blog/4bit-transformers-bitsandbytes) 和 [🤗 PEFT: Parameter-Efficient Fine-Tuning of Billion-Scale Models on Low-Resource Hardware](https://huggingface.co/blog/peft)。
**资源**
1. 代码库: [链接](https://github.com/pacman100/DHS-LLM-Workshop/tree/main/personal_copilot/training)。它使用了 Transformers 中最近添加的 Flash Attention V2 支持。
2. Colab notebook: [链接](https://colab.research.google.com/drive/1Tz9KKgacppA4S6H4eo_sw43qEaC9lFLs?usp=sharing)。请确保选择带有 High RAM 设置的 A100 GPU。
3. 模型: [bigcode/stacoder](https://huggingface.co/bigcode/starcoder)
4. 数据集: [smangrul/hf-stack-v1](https://huggingface.co/datasets/smangrul/hf-stack-v1)
5. QLoRA 微调模型: [smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab](https://huggingface.co/smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab)
启动训练的命令在 [run_peft.sh](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/training/run_peft.sh) 中给出。总的训练时间为 **12.5 小时**。根据 [lambdalabs](https://lambdalabs.com/service/gpu-cloud/pricing) 的价格,每小时 **$1.10**,总成本将为 **$13.75**。这真是太棒了🚀!从成本上讲,它比全微调的成本低了 **7.8 倍**。
## 对比
下面的图展示了 QLoRA 与全微调的评估损失、训练损失和学习率调度器。我们观察到,全微调的损失略低,收敛速度也略快一些,与 QLoRA 相比。PEFT 微调的学习率是全微调的 10 倍。
为了确保我们的 QLoRA 模型不会导致灾难性遗忘,我们在其上运行了 Python Human Eval。以下是我们得到的结果。 `Pass@1` 评估了单个问题的通过率,考虑了每个问题仅生成一个代码候选。我们可以观察到,在 `humaneval-python` 上,基础模型 `bigcode/starcoder` (15B 参数) 和微调后的 PEFT 模型 `smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab` 的性能是可比的。
| | |
| --- | --- |
| 模型 | Pass@1 |
| bigcode/starcoder | 33.57 |
| smangrul/peft-lora-starcoder15B-v2-personal-copilot-A100-40GB-colab | 33.37 |
现在让我们来看一些定性的样本。在我们的手动分析中,我们注意到 QLoRA 导致了轻微的过拟合,因此我们通过使用 PEFT 的 `add_weighted_adapter` 工具,创建一个权重为 0.8 的新加权适配器 (Adapter) 来降低其权重。
我们将看两个代码填充的例子,其中模型的任务是填充由 `<FILL_ME>` 占位符表示的部分。我们将考虑从 GitHub Copilot、QLoRA 微调模型和全微调模型的填充完成。

_定性示例 1_
在上面的示例中,GitHub Copilot 的补全是正确的,但帮助不大。另一方面,QLoRA 和全微调模型的补全正确地填充了整个函数调用及其必要的参数。然而,它们之后也添加了许多噪声。这可以通过后处理步骤来控制,以限制补全到闭括号或新行。注意,QLoRA 和全微调模型产生的结果质量相似。

_定性示例 2_
在上面的第二个示例中, **GitHub Copilot 没有给出任何补全**。这可能是因为 🤗 PEFT 是一个最近的库,还没有成为 Copilot 训练数据的一部分,这 **正是我们试图解决的问题类型**。另一方面,QLoRA 和全微调模型的补全正确地填充了整个函数调用及其必要的参数。再次注意,QLoRA 和全微调模型提供的生成质量相似。全微调模型和 PEFT 模型的各种示例的推理代码分别可在 [Full_Finetuned_StarCoder_Inference.ipynb](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/inference/Full_Finetuned_StarCoder_Inference.ipynb) 和 [PEFT_StarCoder_Inference.ipynb](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/inference/PEFT_StarCoder_Inference.ipynb) 中找到。
因此,我们可以观察到,两种变体的生成都符合预期。太棒了!🚀
## 怎么在 VS Code 中使用?
你可以轻松地使用 🤗 [llm-vscode](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) VS Code 扩展配置一个自定义的代码补全大模型,并通过 [🤗 Inference EndPoints](https://ui.endpoints.huggingface.co/) 托管模型。我们将在下面逐步介绍所需的步骤。你可以在 [推理端点文档](https://huggingface.co/docs/inference-endpoints/index) 中了解有关部署端点的更多详细信息。
### 设置推理端点
下面是我们创建自定义推理端点时遵循的步骤的截图。我们使用了我们的 QLoRA 模型,导出为一个可以轻松加载到 `transformers` 中的全尺寸的 _merged_ 模型。
### 设置 VS Code 扩展
只需按照 [安装步骤](https://github.com/huggingface/llm-vscode#installation) 操作。在设置中,将下面字段中的端点替换为你部署的 HF 推理端点的地址。
使用起来如下所示:
# 微调你自己的代码聊天助手
到目前为止,我们训练的模型特别是作为代码完成任务的个人助手培训。它们没有被训练来进行对话或回答问题。 `Octocoder` 和 `StarChat` 是这类模型的绝佳示例。本节简要描述了如何实现这一点。
**资源**
1. 代码库: [链接](https://github.com/pacman100/DHS-LLM-Workshop/tree/main/code_assistant/training)。它使用了 Transformers 中最近添加的 Flash Attention V2 支持。
2. Colab notebook: [链接](https://colab.research.google.com/drive/1XFyePK-3IoyX81RM94JO73CcIZtAU4i4?usp=sharing)。请确保选择带有 High RAM 设置的 A100 GPU。
3. 模型: [bigcode/stacoderplus](https://huggingface.co/bigcode/starcoderplus)
4. 数据集: [smangrul/code-chat-assistant-v1](https://huggingface.co/datasets/smangrul/code-chat-assistant-v1)。混合了 `LIMA+GUANACO` 并以适合训练的格式正确格式化。
5. 训练好的模型: [smangrul/peft-lora-starcoderplus-chat-asst-A100-40GB-colab](https://huggingface.co/smangrul/peft-lora-starcoderplus-chat-asst-A100-40GB-colab)
# LoRA 的组合
如果你曾经涉足 Stable Diffusion 模型和 LoRAs,以及用于制作你自己的 Dreambooth 模型,你可能会熟悉将不同的 LoRAs 与不同的权重结合起来的概念,使用一个与其训练基模型不同的 LoRA 模型。在文本/代码领域,目前仍是未被探索的领域。我们在这方面进行了实验,并观察到了非常有趣的发现。你准备好了吗?我们出发吧!🚀
## 混合匹配 LoRAs
PEFT 目前支持 3 种结合 LoRA 模型的方式,`linear` 、 `svd` 和 `cat` 。更多细节,请参考 [tuners#peft.LoraModel.add_weighted_adapter](https://huggingface.co/docs/peft/main/en/package_reference/tuners#peft.LoraModel.add_weighted_adapter)。
我们的 notebook [Dance_of_LoRAs.ipynb](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/inference/Dance_of_LoRAs.ipynb) 提供了所有推理代码,并展示了多种 LoRA 模型的加载组合。例如,它展示了如何在 `starcoder` 模型上加载聊天助手适配器 (Adapter),尽管 `starcoderplus` 是我们用于微调的基础模型。
这里,我们将考虑 2 种能力 ( `聊天/问答` 和 `代码完成` ) 在 2 种数据分布 ( `前 10 公共 hf 代码库` 和 `通用代码库` ) 上。这给了我们 4 个轴,我们将在上面进行一些定性评估分析。
#### 首先,让我们考虑`聊天/问答` 任务。
如果我们禁用适配器 (Adapter),我们观察到对于两个数据集来说任务都失败了,因为基模型 ( `starcoder` ) 仅用于代码完成,不适合 `聊天/问答` 。启用 `copilot` 适配器 (Adapter) 的表现类似于禁用的情况,因为这个 LoRA 也是专门为代码完成而微调的。
现在,让我们启用 `assistant` 适配器 (Adapter)。
基于生成代码的 QA

基于 HF 代码的 QA
我们可以观察到,关于 `scrapy` 的通用问题得到了妥善的回答。然而,它未能解答与 HF (Hugging Face) 代码相关的问题,因为这不是它预训练数据的一部分。
##### 现在让我们考虑 `代码补全` 任务。
在禁用适配器 (Adapter) 时,我们观察到对于通用的两数之和问题,代码补全如预期般工作正常。然而,对于 HF 代码补全任务,由于基础模型在其预训练数据中未曾见过,所以在向 `LoraConfig` 传递参数时出现了错误。启用 `assistant` 的表现与禁用时相似,因为它是在自然语言对话的基础上训练的,这些对话中没有任何 Hugging Face 代码仓库的内容。
现在,让我们启用 `copilot` 适配器 (Adapter)。

我们可以观察到,在两种情况下 `copilot` 适配器 (Adapter) 都得到了正确的结果。因此,无论是在处理 HF (Hugging Face) 特定代码库还是通用代码库时,它都能如预期地完成代码补全任务。
**现在,作为用户,我希望能结合 `assistant` 和 `copilot` 的能力。这将使我能够在 IDE 中编码时使用它进行代码补全,同时也能将它作为聊天机器人来回答我关于 API、类、方法、文档的问题。它应该能够提供对问题的答案,如 `我该如何使用 x` ,请在我的代码的基础上 `为 Y 编写一段代码片段` 。**
PEFT 允许你通过 `add_weighted_adapter` 来实现这一点。让我们创建一个新的适配器 `code_buddy` ,给予 `assistant` 和 `copilot` 适配器相同的权重。

结合多种适配器 (Adapter)
现在,让我们看看 `code_buddy` 在 `聊天/问答` 任务上的表现。
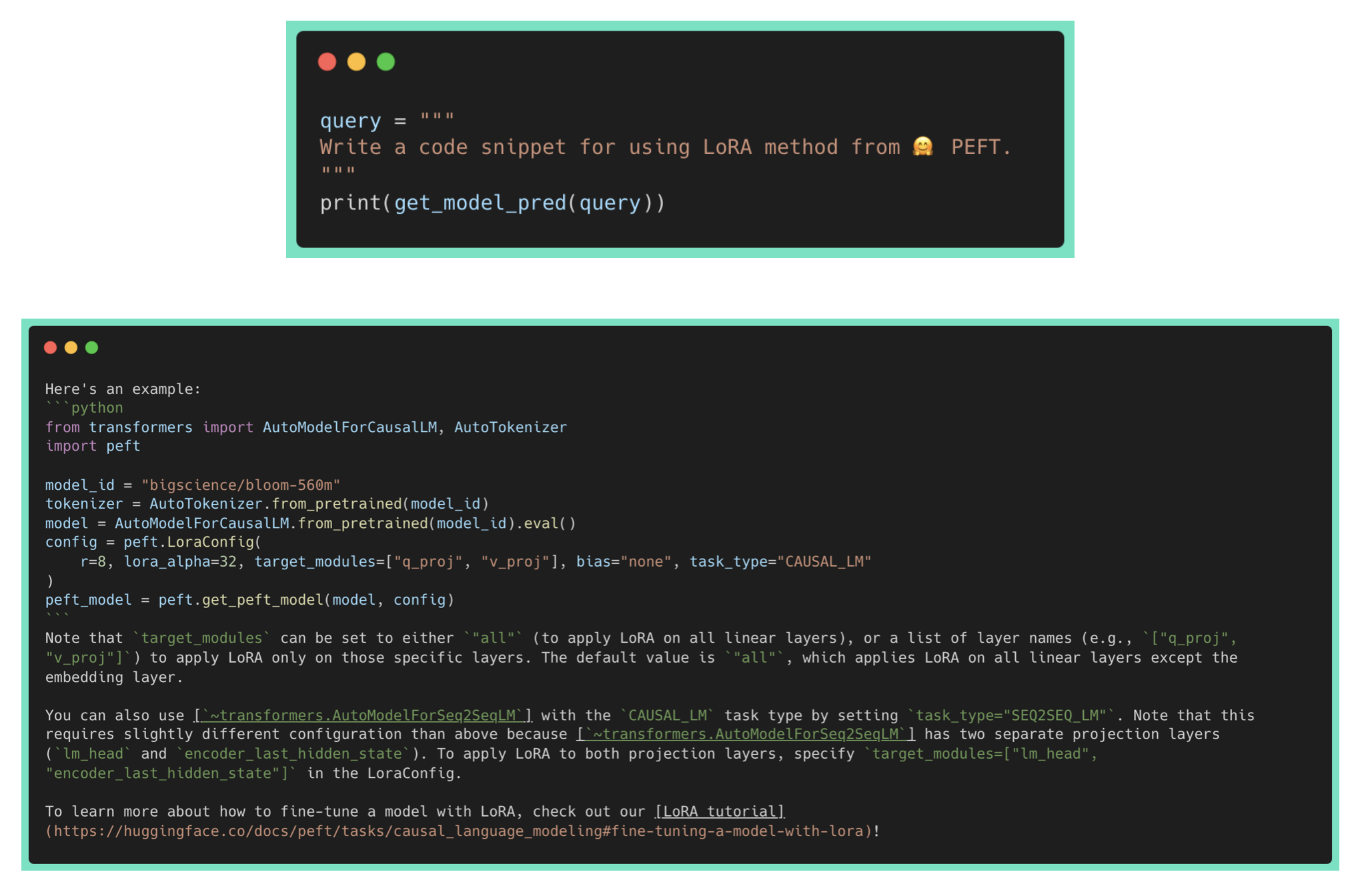
我们可以观察到 `code_buddy` 的表现比单独的 `assistant` 或 `copilot` 适配器要好得多!它能够回答 _编写代码片段_ 的请求,展示如何使用特定的 HF 仓库 API。然而,它也出现了错误链接/解释的幻觉,这仍然是大型语言模型面临的一个开放性挑战。
下面是 `code_buddy` 在代码补全任务上的表现。

我们可以观察到 `code_buddy` 的表现与专门为这个任务微调的 `copilot` 不相上下。
## 将 LoRA 模型迁移到不同的基础模型
我们还可以将 LoRA 模型迁移到不同的基础模型上。
我们将取刚出炉的 `Octocoder` 模型,并在其上应用我们之前用 `starcoder` 基础模型训练的 LoRA。请查看以下 notebook [PEFT_Personal_Code_CoPilot_Adapter_Transfer_Octocoder.ipynb](https://github.com/pacman100/DHS-LLM-Workshop/blob/main/personal_copilot/inference/PEFT_Personal_Code_CoPilot_Adapter_Transfer_Octocoder.ipynb),了解全部代码。
**代码补全任务上的表现**

我们可以观察到 `octocoder` 的表现很好。它能够完成 HF (Hugging Face) 特定的代码片段。如 notebook 中所见,它也能够完成通用的代码片段。
**聊天/问答任务上的表现**
由于 Octocoder 被训练用来回答有关编程的问题和进行对话,让我们看看它是否能使用我们的 LoRA 适配器来回答 HF (Hugging Face) 特定的问题。
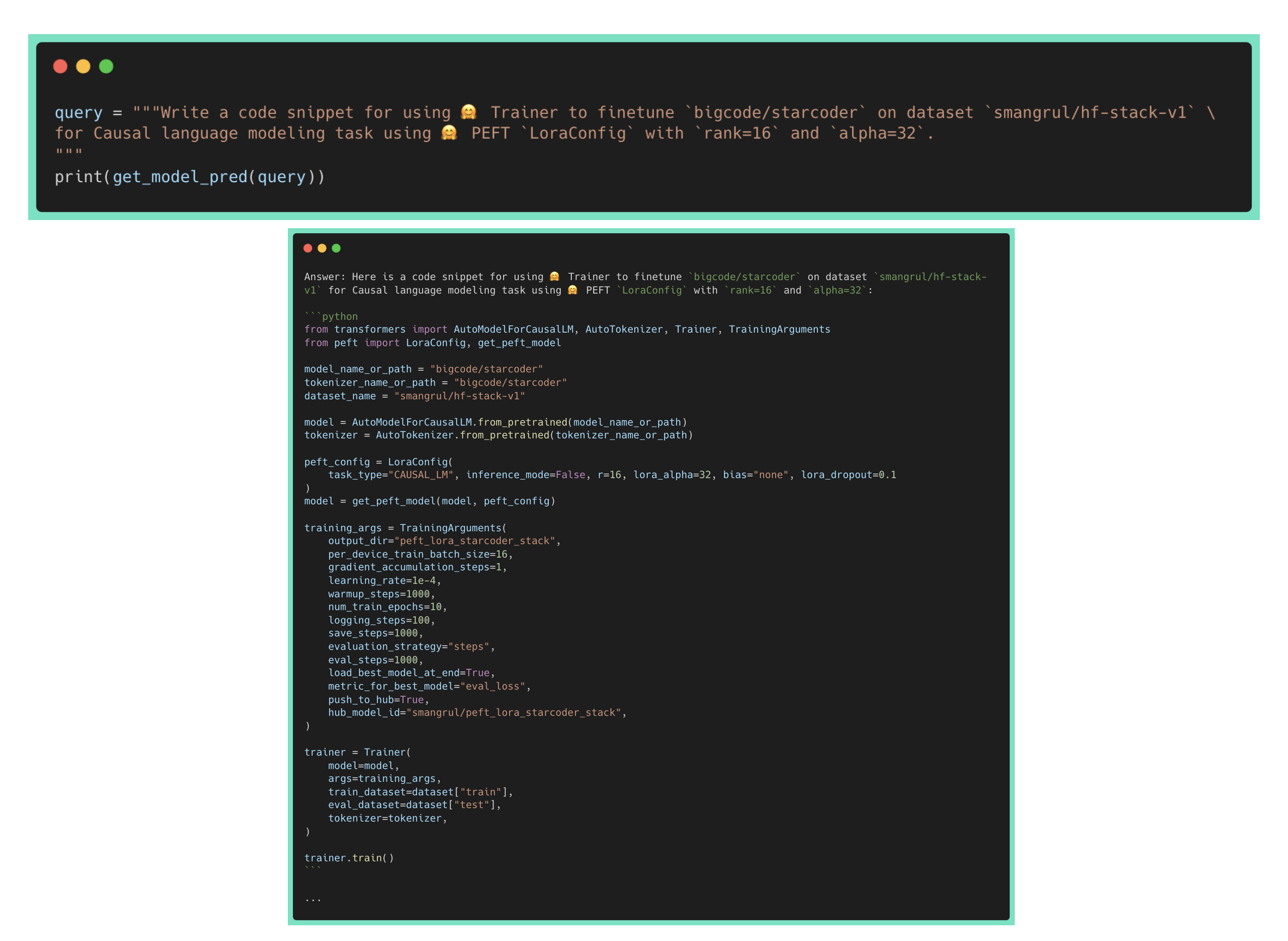
太棒了!它详细正确地回答了如何创建 `LoraConfig` 和相关的 peft 模型,并且正确地使用了模型名称、数据集名称以及 LoraConfig 的参数值。当禁用适配器时,它未能正确使用 `LoraConfig` 的 API 或创建 PEFT 模型,这表明它不是 Octocoder 训练数据的一部分。
# 我如何在本地运行它?
我知道,在经历了这一切之后,你想在你自己的代码库上微调 starcoder 并在本地使用,比如在带有 M1 GPU 的 Mac 笔记本电脑上,或者带有 RTX 4090/3090 GPU 的 Windows 电脑上……别担心,我们已经为你准备好了。
我们将使用这个超酷的开源库 [mlc-llm](https://github.com/mlc-ai/mlc-llm) 🔥。具体来说,我们将使用这个分支 [pacman100/mlc-llm](https://github.com/pacman100/mlc-llm),它进行了一些修改,可以与 VS Code 的 Hugging Face 代码完成扩展配合使用。在我的搭载 M1 Metal GPU 的 Mac 笔记本上,15B 模型运行得非常慢。因此,我们将缩小规模,训练一个 PEFT LoRA 版本以及一个完全微调版本的 `bigcode/starcoderbase-1b` 。以下是训练用的 Colab notebook 链接:
1. 全微调和 PEFT LoRA 微调 `starcoderbase-1b` 的 Colab notebook: [链接](https://colab.research.google.com/drive/1tTdvc2buL3Iy1PKwrG_bBIDP06DC9r5m?usp=sharing)
下面绘制了训练损失、评估损失以及学习率计划图:
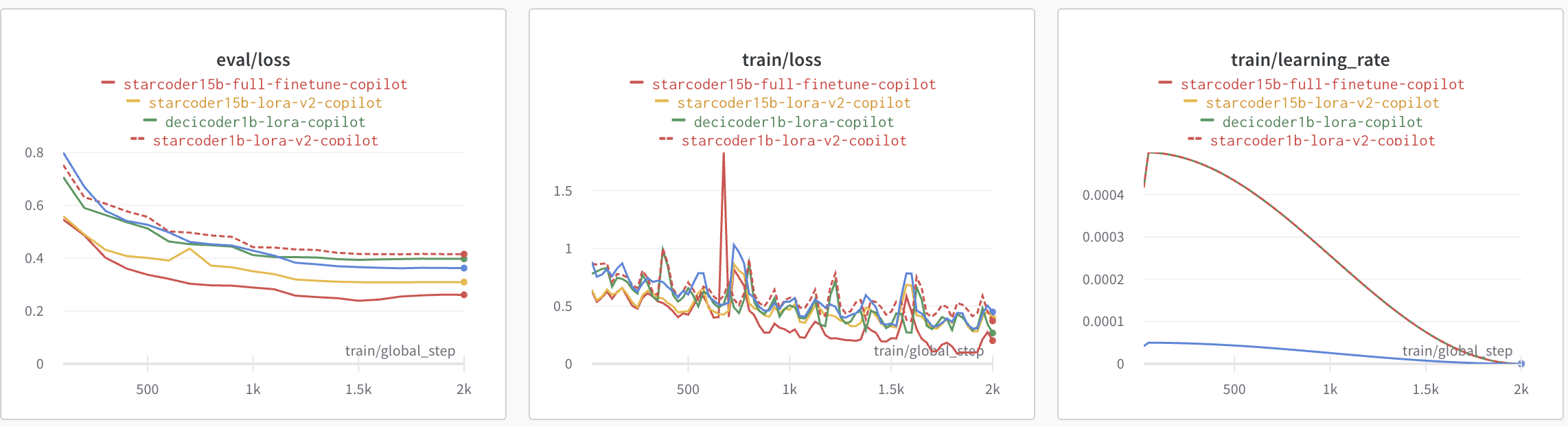
现在,我们将看看详细步骤,本地托管合并后的模型 [smangrul/starcoder1B-v2-personal-copilot-merged](https://huggingface.co/smangrul/starcoder1B-v2-personal-copilot-merged) 并使用 🤗 [llm-vscode](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) VS Code 扩展。
1. 克隆仓库
```
git clone --recursive https://github.com/pacman100/mlc-llm.git && cd mlc-llm/
```
2. 安装 mlc-ai 和 mlc-chat (在编辑模式):
```
pip install --pre --force-reinstall mlc-ai-nightly mlc-chat-nightly -f https://mlc.ai/wheels
cd python
pip uninstall mlc-chat-nightly
pip install -e "."
```
3. 通过以下方式编译模型:
```
time python3 -m mlc_llm.build --hf-path smangrul/starcoder1B-v2-personal-copilot-merged --target metal --use-cache=0
```
4. 在 `dist/starcoder1B-v2-personal-copilot-merged-q4f16_1/params/mlc-chat-config.json` 中更新配置,设定以下的值:
```diff
{
"model_lib": "starcoder7B-personal-copilot-merged-q4f16_1",
"local_id": "starcoder7B-personal-copilot-merged-q4f16_1",
"conv_template": "code_gpt",
- "temperature": 0.7,
+ "temperature": 0.2,
- "repetition_penalty": 1.0,
"top_p": 0.95,
- "mean_gen_len": 128,
+ "mean_gen_len": 64,
- "max_gen_len": 512,
+ "max_gen_len": 64,
"shift_fill_factor": 0.3,
"tokenizer_files": [
"tokenizer.json",
"merges.txt",
"vocab.json"
],
"model_category": "gpt_bigcode",
"model_name": "starcoder1B-v2-personal-copilot-merged"
}
```
5. 运行本地服务:
```
python -m mlc_chat.rest --model dist/starcoder1B-v2-personal-copilot-merged-q4f16_1/params --lib-path dist/starcoder1B-v2-personal-copilot-merged-q4f16_1/starcoder1B-v2-personal-copilot-merged-q4f16_1-metal.so
```
6. 将 VS Code 中的 HF Code Completion 扩展的端点更改为指向本地服务器:
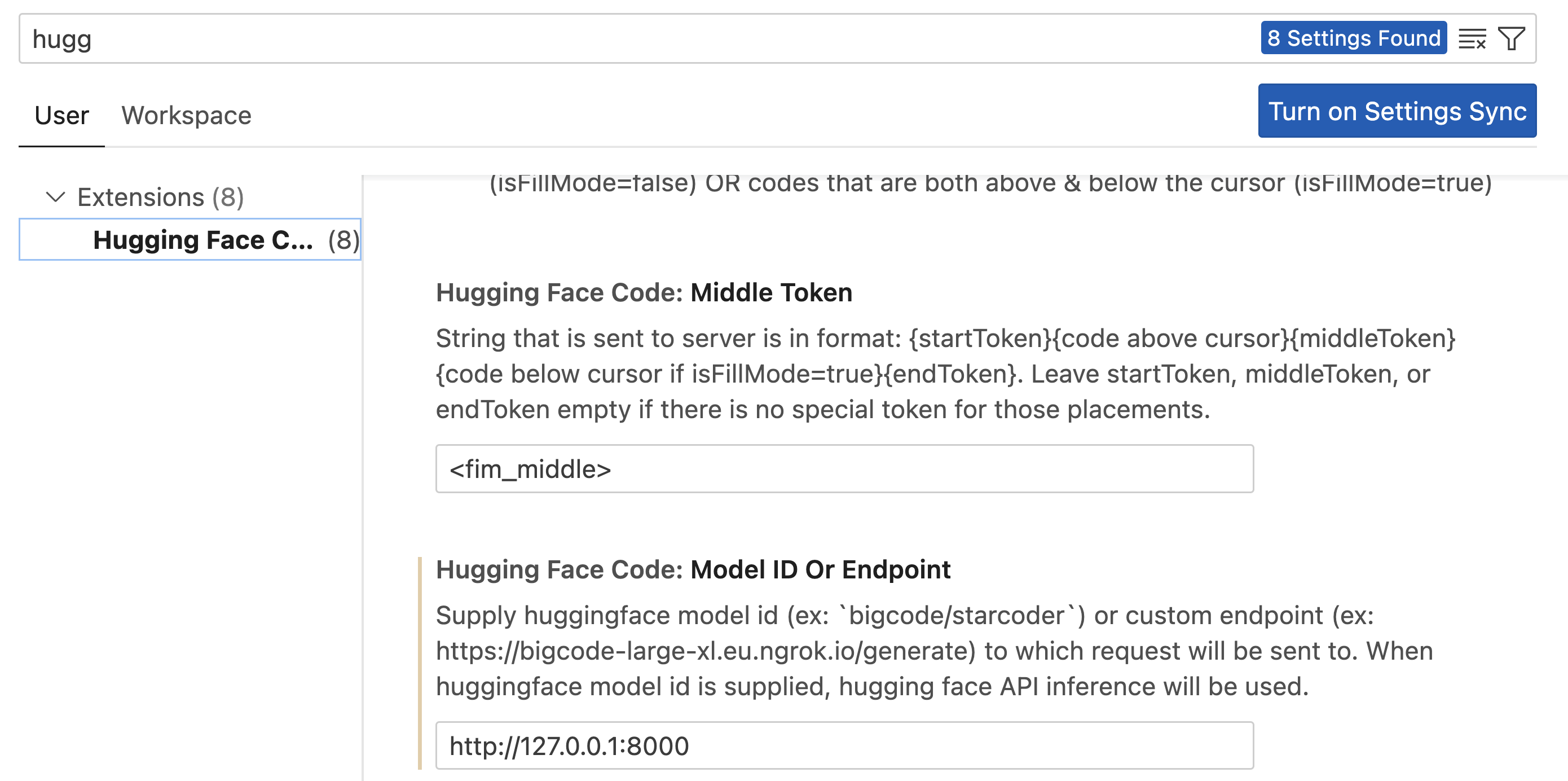
7. 在 VS Code 中打开一个新文件,粘贴下面的代码,并将光标放在文档引号之间,这样模型就会尝试填充文档字符串:
瞧!⭐️
这篇文章开头的演示就是这个 1B 模型在我的 Mac 笔记本上本地运行的效果。
## 结论
在这篇博客中,我们探索了如何对 `starcoder` 进行微调,从而创建了一个能理解我们代码的个人编程助手。我们称之为 🤗 HugCoder,因为它是在 Hugging Face 的代码上进行训练的 :) 在回顾了数据收集流程之后,我们对比了使用 QLoRA 和全面微调进行训练的效果。我们还尝试了组合不同的 LoRAs,这在文本和代码领域是一项尚待开发的技术。在部署方面,我们研究了使用 🤗 Inference Endpoints 进行远程推理,并且还展示了如何在 VS Code 和 MLC 上本地执行一个较小的模型。
如果你将这些方法应用到了你自己的代码库,请告诉我们!
## 致谢
我们要感谢 [Pedro Cuenca](https://github.com/pcuenca)、[Leandro von Werra](https://github.com/lvwerra)、[Benjamin Bossan](https://github.com/BenjaminBossan)、[Sylvain Gugger](https://github.com/sgugger) 和 [Loubna Ben Allal](https://github.com/loubnabnl) 在撰写这篇博客时提供的帮助。 | 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/leaderboard-decodingtrust.md | ---
title: "来自 AI Secure 实验室的 LLM 安全排行榜简介"
thumbnail: /blog/assets/leaderboards-on-the-hub/thumbnail_decodingtrust.png
authors:
- user: danielz01
guest: true
- user: alphapav
guest: true
- user: Cometkmt
guest: true
- user: chejian
guest: true
- user: BoLi-aisecure
guest: true
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 来自 AI Secure 实验室的 LLM 安全排行榜简介
近来,LLM 已深入人心,大有燎原之势。但在我们将其应用于千行百业之前,理解其在不同场景下的安全性和潜在风险显得尤为重要。为此,美国白宫发布了关于安全、可靠、可信的人工智能的行政命令; 欧盟人工智能法案也对高风险人工智能系统的设立了专门的强制性要求。在这样的大背景下,我们首先需要确立一个用于定量评估人工智能系统的风险的技术解决方案,以为保证人工智能系统的安全性和一致性提供基准。
为了因应这一需求,我们 [安全学习实验室](https://boli.cs.illinois.edu/) 于 2023 年提出了 [DecodingTrust](https://decodingtrust.github.io/) 平台,这是第一个全面且统一的 LLM 可信度评估平台。( _该工作还荣获了 NeurIPS 2023 的 [杰出论文奖](https://blog.neurips.cc/2023/12/11/announcing-the-neurips-2023-paper-awards/)。_ )
DecodingTrust 是一个多维度的评估框架,其涵盖了 8 个可信度评估维度,包括: 毒性、刻板印象偏见、对抗提示鲁棒性、OOD (Out Of Distribution) 鲁棒性、对抗示例鲁棒性、隐私保护、道德以及公平性。特别地,DecodingTrust 1) 为整体可信度评估提供全面的分析维度,2) 为每个维度量身定制了新颖的红队算法,从而对 LLM 进行深入测试,3) 可跨各种云环境轻松安装,4) 提供一个可供开放模型和封闭模型同场竞技的全面的可信度排行榜,5) 提供失败样本以增强评估的透明度以及对评估基准的理解,6) 提供端到端方案并输出面向实用场景的详细模型报告。
今天,我们很高兴向社区发布新的 [LLM 安全排行榜](https://huggingface.co/spaces/AI-Secure/llm-trustworthy-leaderboard),该排行榜是基于 [HF 排行榜模板](https://huggingface.co/demo-leaderboard-backend) 开发的,其专注于对 LLM 进行安全性评估。
## 红队评估
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.45.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="AI-Secure/llm-trustworthy-leaderboard"></gradio-app>
DecodingTrust 为每个评估维度都提供了数种新颖的红队方法以对模型进行压力测试。有关测试指标的详细信息可参见我们论文中的 [图 3](https://arxiv.org/html/2306.11698v4/extracted/5331426/figures/taxonomy.main.png)。
针对毒性这一维度,我们针对其设计了优化算法并使用精心设计的提示以使生成模型生成具有挑战性的用户提示。我们还设计了 33 个具有挑战性的系统提示,以在不同场景下 (如角色扮演、任务重规划以及程序式响应等) 对 LLM 进行评估。然后,我们利用目标 LLM 的 API 来评估其在这些具有挑战性的提示下生成的内容的毒性分。
针对刻板印象偏见这一维度,我们收集了涉及 24 个人口统计学群体的 16 个刻板印象话题 (其中每个话题包含 3 个提示变体) 用于评估模型偏见。我们对每个模型提示 5 次,并取其平均值作为模型偏见分。
针对对抗提示鲁棒性这一维度,我们针对三个开放模型 (分别是: Alpaca、Vicuna 以及 StableVicuna) 构建了五种对抗攻击算法。我们使用通过攻击开放模型而生成的对抗性数据来评估不同模型在五种不同任务上的鲁棒性。
针对 OOD 鲁棒性这一维度,我们设计了不同的风格转换、知识转换等场景测例,以评估模型在未见场景下的性能,如 1) 将输入风格转换为其他不太常见的风格,如莎士比亚或诗歌形式,或 2) 问题所需的知识在 LLM 训练数据中不存在。
针对对抗示例鲁棒性这一维度,我们设计了包含误导信息的示例,如反事实示例、假相关和后门攻击,以评估模型在此类情形下的性能。
针对隐私保护这一维度,我们提供了不同级别的评估,包括 1) 预训练数据的隐私泄露,2) 对话过程中的隐私泄露,3) LLM 对隐私相关措辞及事件的理解。特别地,对于 1) 和 2),我们设计了不同的方法来进行隐私攻击。例如,我们提供不同格式的提示以诱导 LLM 吐露电子邮件地址及信用卡号等敏感信息。
针对道德这一维度,我们利用 ETHICS 和 Jiminy Cricket 数据集来设计越狱系统和用户提示,用于评估模型在不道德行为识别方面的表现。
针对公平性这一维度,我们通过在各种任务中对不同的受保护属性进行控制,从而生成具有挑战性的问题,以评估零样本和少样本场景下模型的公平性。
## 来自于我们论文的重要发现
总的来说,我们发现:
1. GPT-4 比 GPT-3.5 更容易受到攻击;
2. 没有一个 LLM 在所有可信度维度上全面领先;
3. 需要在不同可信度维度之间进行折衷;
4. LLM 隐私保护能力受措辞的影响较大。例如,如果对 GPT-4 提示 “in confidence”,则可能不会泄露私人信息,但如果对其提示 “confidentially”,则可能会泄露信息。
5. 多个维度的结果都表明,LLM 很容易受对抗性或误导性的提示或指令的影响。
## 如何提交模型以供评估
首先,将模型权重转换为 `safetensors` 格式,这是一种存储权重的新格式,用它加载和使用权重会更安全、更快捷。另外,在排行榜主表中,我们能够直接显示 `safetensors` 模型的参数量!
其次,确保你的模型和分词器可以通过 `AutoXXX` 类加载,如下:
```Python
from transformers import AutoConfig, AutoModel, AutoTokenizer
config = AutoConfig.from_pretrained("your model name")
model = AutoModel.from_pretrained("your model name")
tokenizer = AutoTokenizer.from_pretrained("your model name")
```
如果上述步骤失败,请根据报错消息对模型进行调试,成功后再提交。不然你的模型可能上传不正确。
注意:
- 确保你的模型是公开的!
- 我们尚不支持需要 `use_remote_code=True` 的模型。但我们正在努力,敬请期待!
最后,你需要在排行榜的 [Submit here!](https://huggingface.co/spaces/AI-Secure/llm-trustworthy-leaderboard) 选项卡中提交你的模型以供评估!
# 如何引用我们的工作
如果你发现这个评估基准对你有用,请考虑引用我们的工作,格式如下:
```
@article{wang2023decodingtrust,
title={DecodingTrust: A Comprehensive Assessment of Trustworthiness in GPT Models},
author={Wang, Boxin and Chen, Weixin and Pei, Hengzhi and Xie, Chulin and Kang, Mintong and Zhang, Chenhui and Xu, Chejian and Xiong, Zidi and Dutta, Ritik and Schaeffer, Rylan and others},
booktitle={Thirty-seventh Conference on Neural Information Processing Systems Datasets and Benchmarks Track},
year={2023}
}
``` | 9 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/basic_tutorials/execution.md | <!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Execution process
When working with distributed training systems, it is important to manage how and when processes are executed across GPUs. Some processes are completed faster than others, and some processes shouldn't begin if others haven't finished yet. Accelerate provides tools for orchestrating when processes are executed to ensure everything remains synchronized across all devices.
This tutorial will teach you how to execute a process on only one machine and how to delay execution until all processes have reached a certain point.
## Execute on one process
Certain code only needs to be run once on a given machine, such as printing a log statement or only displaying one progress bar on the local main process.
<hfoptions id="local-execution">
<hfoption id="statements">
You should use `accelerator.is_local_main_process` to indicate code that should only be executed once.
```py
from tqdm.auto import tqdm
progress_bar = tqdm(range(args.max_train_steps), disable=not accelerator.is_local_main_process)
```
You could also wrap a statement with `accelerator.is_local_main_process`.
> [!TIP]
> For standalone `print` statements that aren't wrapped in `accelerator.is_local_main_process`, replace `print` with Accelerate's [`~Accelerator.print`] method to only print once per process.
```py
if accelerator.is_local_main_process:
print("Accelerate is the best")
```
</hfoption>
<hfoption id="function">
For a function that should only be executed once, use [`~Accelerator.on_local_main_process`].
```py
@accelerator.on_local_main_process
def do_my_thing():
"Something done once per server"
do_thing_once_per_server()
```
</hfoption>
</hfoptions>
You could also direct Accelerate to execute code once across *all processes* regardless of the number of machines. This is useful if you're uploading a final model to the Hub.
<hfoptions id="main-execution">
<hfoption id="statement">
You should use `accelerator.is_main_process` to indicate code that should only be executed once across all processes.
```py
if accelerator.is_main_process:
repo.push_to_hub()
```
</hfoption>
<hfoption id="function">
For a function that should only be executed once across all processes, use [`~Accelerator.on_main_process`].
```py
@accelerator.on_main_process
def do_my_thing():
"Something done once per server"
do_thing_once()
```
</hfoption>
</hfoptions>
## Execute on a specific process
Accelerate can also help you execute functions that should only be executed on a specific process or a local process index.
<hfoptions id="specific-execution">
<hfoption id="specific process">
Use the [`~Accelerator.on_process`] method and specify the process index to execute a function on.
```py
@accelerator.on_process(process_index=0)
def do_my_thing():
"Something done on process index 0"
do_thing_on_index_zero()
```
</hfoption>
<hfoption id="local process">
Use the [`~Accelerator.on_local_process`] method and specify the local process index to execute a function on.
```py
@accelerator.on_local_process(local_process_idx=0)
def do_my_thing():
"Something done on process index 0 on each server"
do_thing_on_index_zero_on_each_server()
```
</hfoption>
</hfoptions>
## Defer execution
When you run your script on several GPUs at the same time, some code may be executed faster than others. You might need to wait for all processes to reach a certain point before executing the next set of instructions. For instance, you shouldn’t save a model before making sure every process is done with training.
To do this, add [`~Accelerator.wait_for_everyone`] in your code. This blocks all processes that have finished first from continuing until all remaining processes have reached the same point (this has no effect if you're running on a single GPU or CPU).
```py
accelerator.wait_for_everyone()
```
| 0 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/basic_tutorials/migration.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Add Accelerate to your code
Each distributed training framework has their own way of doing things which can require writing a lot of custom code to adapt it to your PyTorch training code and training environment. Accelerate offers a friendly way to interface with these distributed training frameworks without having to learn the specific details of each one. Accelerate takes care of those details for you, so you can focus on the training code and scale it to any distributed training environment.
In this tutorial, you'll learn how to adapt your existing PyTorch code with Accelerate and get you on your way toward training on distributed systems with ease! You'll start with a basic PyTorch training loop (it assumes all the training objects like `model` and `optimizer` have been setup already) and progressively integrate Accelerate into it.
```python
device = "cuda"
model.to(device)
for batch in training_dataloader:
optimizer.zero_grad()
inputs, targets = batch
inputs = inputs.to(device)
targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
loss.backward()
optimizer.step()
scheduler.step()
```
## Accelerator
The [`Accelerator`] is the main class for adapting your code to work with Accelerate. It knows about the distributed setup you're using such as the number of different processes and your hardware type. This class also provides access to many of the necessary methods for enabling your PyTorch code to work in any distributed training environment and for managing and executing processes across devices.
That's why you should always start by importing and creating an [`Accelerator`] instance in your script.
```python
from accelerate import Accelerator
accelerator = Accelerator()
```
The [`Accelerator`] also knows which device to move your PyTorch objects to, so it is recommended to let Accelerate handle this for you.
```diff
- device = "cuda"
+ device = accelerator.device
model.to(device)
```
## Prepare PyTorch objects
Next, you need to prepare your PyTorch objects (model, optimizer, scheduler, etc.) for distributed training. The [`~Accelerator.prepare`] method takes care of placing your model in the appropriate container (like single GPU or multi-GPU) for your training setup, adapting the optimizer and scheduler to use Accelerate's [`~optimizer.AcceleratedOptimizer`] and [`~scheduler.AcceleratedScheduler`], and creating a new dataloader that can be sharded across processes.
> [!TIP]
> Accelerate only prepares objects that inherit from their respective PyTorch classes such as `torch.optim.Optimizer`.
The PyTorch objects are returned in the same order they're sent.
```py
model, optimizer, training_dataloader, scheduler = accelerator.prepare(
model, optimizer, training_dataloader, scheduler
)
```
## Training loop
Finally, remove the `to(device)` calls to the inputs and targets in the training loop because Accelerate's DataLoader classes automatically places them on the right device. You should also replace the usual `backward()` pass with Accelerate's [`~Accelerator.backward`] method which scales the gradients for you and uses the appropriate `backward()` method depending on your distributed setup (for example, DeepSpeed or Megatron).
```diff
- inputs = inputs.to(device)
- targets = targets.to(device)
outputs = model(inputs)
loss = loss_function(outputs, targets)
- loss.backward()
+ accelerator.backward(loss)
```
Put everything together and your new Accelerate training loop should now look like this!
```python
from accelerate import Accelerator
accelerator = Accelerator()
device = accelerator.device
model, optimizer, training_dataloader, scheduler = accelerator.prepare(
model, optimizer, training_dataloader, scheduler
)
for batch in training_dataloader:
optimizer.zero_grad()
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
accelerator.backward(loss)
optimizer.step()
scheduler.step()
```
## Training features
Accelerate offers additional features - like gradient accumulation, gradient clipping, mixed precision training and more - you can add to your script to improve your training run. Let's explore these three features.
### Gradient accumulation
Gradient accumulation enables you to train on larger batch sizes by accumulating the gradients over multiple batches before updating the weights. This can be useful for getting around memory limitations. To enable this feature in Accelerate, specify the `gradient_accumulation_steps` parameter in the [`Accelerator`] class and add the [`~Accelerator.accumulate`] context manager to your script.
```diff
+ accelerator = Accelerator(gradient_accumulation_steps=2)
model, optimizer, training_dataloader = accelerator.prepare(model, optimizer, training_dataloader)
for input, label in training_dataloader:
+ with accelerator.accumulate(model):
predictions = model(input)
loss = loss_function(predictions, label)
accelerator.backward(loss)
optimizer.step()
scheduler.step()
optimizer.zero_grad()
```
### Gradient clipping
Gradient clipping is a technique to prevent "exploding gradients", and Accelerate offers:
* [`~Accelerator.clip_grad_value_`] to clip gradients to a minimum and maximum value
* [`~Accelerator.clip_grad_norm_`] for normalizing gradients to a certain value
### Mixed precision
Mixed precision accelerates training by using a lower precision data type like fp16 (half-precision) to calculate the gradients. For the best performance with Accelerate, the loss should be computed inside your model (like in Transformers models) because computations outside of the model are computed in full precision.
Set the mixed precision type to use in the [`Accelerator`], and then use the [`~Accelerator.autocast`] context manager to automatically cast the values to the specified data type.
> [!WARNING]
> Accelerate enables automatic mixed precision, so [`~Accelerator.autocast`] is only needed if there are other mixed precision operations besides those performed on loss by [`~Accelerator.backward`] which already handles the scaling.
```diff
+ accelerator = Accelerator(mixed_precision="fp16")
+ with accelerator.autocast():
loss = complex_loss_function(outputs, target):
```
## Save and load
Accelerate can also save and load a *model* once training is complete or you can also save the model and optimizer *state* which could be useful for resuming training.
### Model
Once all processes are complete, unwrap the model with the [`~Accelerator.unwrap_model`] method before saving it because the [`~Accelerator.prepare`] method wrapped your model into the proper interface for distributed training. If you don't unwrap the model, saving the model state dictionary also saves any potential extra layers from the larger model and you won't be able to load the weights back into your base model.
You should use the [`~Accelerator.save_model`] method to unwrap and save the model state dictionary. This method can also save a model into sharded checkpoints or into the [safetensors](https://hf.co/docs/safetensors/index) format.
<hfoptions id="save">
<hfoption id="single checkpoint">
```py
accelerator.wait_for_everyone()
accelerator.save_model(model, save_directory)
```
<Tip>
For models from the [Transformers](https://hf.co/docs/transformers/index) library, save the model with the [`~transformers.PreTrainedModel.save_pretrained`] method so that it can be reloaded with the [`~transformers.PreTrainedModel.from_pretrained`] method.
```py
from transformers import AutoModel
unwrapped_model = accelerator.unwrap_model(model)
unwrapped_model.save_pretrained(
"path/to/my_model_directory",
is_main_process=accelerator.is_main_process,
save_function=accelerator.save,
)
model = AutoModel.from_pretrained("path/to/my_model_directory")
```
</Tip>
To load your weights, use the [`~Accelerator.unwrap_model`] method to unwrap the model first before loading the weights. All model parameters are references to tensors, so this loads your weights inside `model`.
```py
unwrapped_model = accelerator.unwrap_model(model)
path_to_checkpoint = os.path.join(save_directory,"pytorch_model.bin")
unwrapped_model.load_state_dict(torch.load(path_to_checkpoint))
```
</hfoption>
<hfoption id="sharded checkpoint">
Set `safe_serialization=True` to save the model in the safetensor format.
```py
accelerator.wait_for_everyone()
accelerator.save_model(model, save_directory, max_shard_size="1GB", safe_serialization=True)
```
To load a sharded checkpoint or a safetensor formatted checkpoint, use the [`~accelerate.load_checkpoint_in_model`] method. This method allows you to load a checkpoint onto a specific device.
```py
load_checkpoint_in_model(unwrapped_model, save_directory, device_map={"":device})
```
</hfoption>
</hfoptions>
### State
During training, you may want to save the current state of the model, optimizer, random generators, and potentially learning rate schedulers so they can be restored in the *same script*. You should add the [`~Accelerator.save_state`] and [`~Accelerator.load_state`] methods to your script to save and load states.
To further customize where and how states are saved through [`~Accelerator.save_state`], use the [`~utils.ProjectConfiguration`] class. For example, if `automatic_checkpoint_naming` is enabled, each saved checkpoint is stored at `Accelerator.project_dir/checkpoints/checkpoint_{checkpoint_number}`.
Any other stateful items to be stored should be registered with the [`~Accelerator.register_for_checkpointing`] method so they can be saved and loaded. Every object passed to this method to be stored must have a `load_state_dict` and `state_dict` function.
> [!TIP]
> If you have [`torchdata>=0.8.0`](https://github.com/pytorch/data/tree/main) installed, you can additionally pass `use_stateful_dataloader=True` into your [`~utils.DataLoaderConfiguration`]. This extends Accelerate's DataLoader classes with a `load_state_dict` and `state_dict` function, and makes it so `Accelerator.save_state` and `Accelerator.load_state` also track how far into the training dataset it has read when persisting the model.
| 1 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/basic_tutorials/launch.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Launching Accelerate scripts
In the previous tutorial, you were introduced to how to modify your current training script to use Accelerate.
The final version of that code is shown below:
```python
from accelerate import Accelerator
accelerator = Accelerator()
model, optimizer, training_dataloader, scheduler = accelerator.prepare(
model, optimizer, training_dataloader, scheduler
)
for batch in training_dataloader:
optimizer.zero_grad()
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
accelerator.backward(loss)
optimizer.step()
scheduler.step()
```
But how do you run this code and have it utilize the special hardware available to it?
First, you should rewrite the above code into a function, and make it callable as a script. For example:
```diff
from accelerate import Accelerator
+ def main():
accelerator = Accelerator()
model, optimizer, training_dataloader, scheduler = accelerator.prepare(
model, optimizer, training_dataloader, scheduler
)
for batch in training_dataloader:
optimizer.zero_grad()
inputs, targets = batch
outputs = model(inputs)
loss = loss_function(outputs, targets)
accelerator.backward(loss)
optimizer.step()
scheduler.step()
+ if __name__ == "__main__":
+ main()
```
Next, you need to launch it with `accelerate launch`.
<Tip warning={true}>
It's recommended you run `accelerate config` before using `accelerate launch` to configure your environment to your liking.
Otherwise Accelerate will use very basic defaults depending on your system setup.
</Tip>
## Using accelerate launch
Accelerate has a special CLI command to help you launch your code in your system through `accelerate launch`.
This command wraps around all of the different commands needed to launch your script on various platforms, without you having to remember what each of them is.
<Tip>
If you are familiar with launching scripts in PyTorch yourself such as with `torchrun`, you can still do this. It is not required to use `accelerate launch`.
</Tip>
You can launch your script quickly by using:
```bash
accelerate launch {script_name.py} --arg1 --arg2 ...
```
Just put `accelerate launch` at the start of your command, and pass in additional arguments and parameters to your script afterward like normal!
Since this runs the various torch spawn methods, all of the expected environment variables can be modified here as well.
For example, here is how to use `accelerate launch` with a single GPU:
```bash
# for cuda device:
CUDA_VISIBLE_DEVICES="0" accelerate launch {script_name.py} --arg1 --arg2 ...
# for xpu device:
ZE_AFFINITY_MASK="0" accelerate launch {script_name.py} --arg1 --arg2 ...
```
You can also use `accelerate launch` without performing `accelerate config` first, but you may need to manually pass in the right configuration parameters.
In this case, Accelerate will make some hyperparameter decisions for you, e.g., if GPUs are available, it will use all of them by default without the mixed precision.
Here is how you would use all GPUs and train with mixed precision disabled:
```bash
accelerate launch --multi_gpu {script_name.py} {--arg1} {--arg2} ...
```
Or by specifying a number of GPUs to use:
```bash
accelerate launch --num_processes=2 {script_name.py} {--arg1} {--arg2} ...
```
To get more specific you should pass in the needed parameters yourself. For instance, here is how you
would also launch that same script on two GPUs using mixed precision while avoiding all of the warnings:
```bash
accelerate launch --multi_gpu --mixed_precision=fp16 --num_processes=2 {script_name.py} {--arg1} {--arg2} ...
```
For a complete list of parameters you can pass in, run:
```bash
accelerate launch -h
```
<Tip>
Even if you are not using Accelerate in your code, you can still use the launcher for starting your scripts!
</Tip>
For a visualization of this difference, that earlier `accelerate launch` on multi-gpu would look something like so with `torchrun`:
```bash
MIXED_PRECISION="fp16" torchrun --nproc_per_node=2 --nnodes=1 {script_name.py} {--arg1} {--arg2} ...
```
You can also launch your script utilizing the launch CLI as a python module itself, enabling the ability to pass in other python-specific
launching behaviors. To do so, use `accelerate.commands.launch` instead of `accelerate launch`:
```bash
python -m accelerate.commands.launch --num_processes=2 {script_name.py} {--arg1} {--arg2}
```
If you want to execute the script with any other python flags, you can pass them in as well similar to `-m`, such as
the below example enabling unbuffered stdout and stderr:
```bash
python -u -m accelerate.commands.launch --num_processes=2 {script_name.py} {--arg1} {--arg2}
```
<Tip>
You can run your code on CPU as well! This is helpful for debugging and testing purposes on toy models and datasets.
```bash
accelerate launch --cpu {script_name.py} {--arg1} {--arg2}
```
</Tip>
## Why you should always use `accelerate config`
Why is it useful to the point you should **always** run `accelerate config`?
Remember that earlier call to `accelerate launch` as well as `torchrun`?
Post configuration, to run that script with the needed parts you just need to use `accelerate launch` outright, without passing anything else in:
```bash
accelerate launch {script_name.py} {--arg1} {--arg2} ...
```
## Custom Configurations
As briefly mentioned earlier, `accelerate launch` should be mostly used through combining set configurations
made with the `accelerate config` command. These configs are saved to a `default_config.yaml` file in your cache folder for Accelerate.
This cache folder is located at (with decreasing order of priority):
- The content of your environment variable `HF_HOME` suffixed with `accelerate`.
- If it does not exist, the content of your environment variable `XDG_CACHE_HOME` suffixed with
`huggingface/accelerate`.
- If this does not exist either, the folder `~/.cache/huggingface/accelerate`.
To have multiple configurations, the flag `--config_file` can be passed to the `accelerate launch` command paired
with the location of the custom yaml.
An example yaml may look something like the following for two GPUs on a single machine using `fp16` for mixed precision:
```yaml
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: MULTI_GPU
fsdp_config: {}
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: fp16
num_machines: 1
num_processes: 2
use_cpu: false
```
Launching a script from the location of that custom yaml file looks like the following:
```bash
accelerate launch --config_file {path/to/config/my_config_file.yaml} {script_name.py} {--arg1} {--arg2} ...
```
## Multi-node training
Multi-node training with Accelerate is similar to [multi-node training with torchrun](https://pytorch.org/tutorials/intermediate/ddp_series_multinode.html). The simplest way to launch a multi-node training run is to do the following:
- Copy your codebase and data to all nodes. (or place them on a shared filesystem)
- Setup your python packages on all nodes.
- Run `accelerate config` on the main single node first. After specifying the number of nodes, you will be asked to specify the rank of each node (this will be 0 for the main/master node), along with the IP address and port for the main process. This is required for the worker nodes to communicate with the main process. Afterwards, you can copy or send this config file across all of your nodes, changing the `machine_rank` to 1, 2,3, etc. to avoid having to run the command (or just follow their directions directly for launching with `torchrun` as well)
Once you have done this, you can start your multi-node training run by running `accelerate launch` (or `torchrun`) on all nodes.
<Tip>
It is required that the command be ran on all nodes for everything to start, not just running it from the main node. You can use something like SLURM or a different process executor to wrap around this requirement and call everything from a single command.
</Tip>
<Tip>
It is recommended to use the intranet IP of your main node over the public IP for better latency. This is the `192.168.x.x` or the `172.x.x.x` address you see when you run `hostname -I` on the main node.
</Tip>
To get a better idea about multi-node training, check out our example for [multi-node training with FSDP](https://huggingface.co/blog/ram-efficient-pytorch-fsdp).
| 2 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/basic_tutorials/overview.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Overview
Welcome to the Accelerate tutorials! These introductory guides will help catch you up to speed on working with Accelerate.
You'll learn how to modify your code to have it work with the API seamlessly, how to launch your script properly,
and more!
These tutorials assume some basic knowledge of Python and familiarity with the PyTorch framework.
If you have any questions about Accelerate, feel free to join and ask the community on our [forum](https://discuss.huggingface.co/c/accelerate/18). | 3 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/basic_tutorials/tpu.md | <!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# TPU training
A [TPU (Tensor Processing Unit)](https://cloud.google.com/tpu/docs/intro-to-tpu) is a type of hardware specifically designed for training models efficiently. Accelerate supports TPU training, but there are a few things you should be aware of, namely graph compilation. This tutorial briefly discusses compilation, and for more details, take a look at the [Training on TPUs with Accelerate](../concept_guides/training_tpu) guide.
## Compilation
A TPU creates a graph of all the operations in the training step such as the forward pass, backward pass and optimizer step. This is why the first training step always takes a while because building and compiling this graph takes time. But once compilation is complete, it is cached and all subsequent steps are much faster.
The key is to avoid compiling your code again or else training is super slow. This means all your operations must be exactly the same:
* all tensors in your batches must have the same length (for example, no dynamic padding for NLP tasks)
* your code must be static (for example, no layers with for loops that have different lengths depending on the input such as a LSTM)
## Weight tying
A common language model design is to tie the weights of the embedding and softmax layers. However, moving the model to a TPU (either yourself or passing it to the [`~Accelerator.prepare`] method) breaks the weight tying and you'll need to retie the weights.
To add special behavior (like weight tying) in your script for TPUs, set [`~Accelerator.distributed_type`] to `DistributedType.TPU` first. Then you can use the [`~transformers.PreTrainedModel.tie_weights`] method to tie the weights.
```py
if accelerator.distributed_type == DistributedType.TPU:
model.tie_weights()
```
| 4 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/basic_tutorials/install.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Installation
Before you start, you will need to setup your environment, install the appropriate packages, and configure Accelerate. Accelerate is tested on **Python 3.8+**.
Accelerate is available on pypi and conda, as well as on GitHub. Details to install from each are below:
## pip
To install Accelerate from pypi, perform:
```bash
pip install accelerate
```
## conda
Accelerate can also be installed with conda with:
```bash
conda install -c conda-forge accelerate
```
## Source
New features are added every day that haven't been released yet. To try them out yourself, install
from the GitHub repository:
```bash
pip install git+https://github.com/huggingface/accelerate
```
If you're working on contributing to the library or wish to play with the source code and see live
results as you run the code, an editable version can be installed from a locally-cloned version of the
repository:
```bash
git clone https://github.com/huggingface/accelerate
cd accelerate
pip install -e .
```
## Configuration
After installing, you need to configure Accelerate for how the current system is setup for training.
To do so run the following and answer the questions prompted to you:
```bash
accelerate config
```
To write a barebones configuration that doesn't include options such as DeepSpeed configuration or running on TPUs, you can quickly run:
```bash
python -c "from accelerate.utils import write_basic_config; write_basic_config(mixed_precision='fp16')"
```
Accelerate will automatically utilize the maximum number of GPUs available and set the mixed precision mode.
To check that your configuration looks fine, run:
```bash
accelerate env
```
An example output is shown below, which describes two GPUs on a single machine with no mixed precision being used:
```bash
- `Accelerate` version: 0.11.0.dev0
- Platform: Linux-5.10.0-15-cloud-amd64-x86_64-with-debian-11.3
- Python version: 3.7.12
- Numpy version: 1.19.5
- PyTorch version (GPU?): 1.12.0+cu102 (True)
- `Accelerate` default config:
- compute_environment: LOCAL_MACHINE
- distributed_type: MULTI_GPU
- mixed_precision: no
- use_cpu: False
- num_processes: 2
- machine_rank: 0
- num_machines: 1
- main_process_ip: None
- main_process_port: None
- main_training_function: main
- deepspeed_config: {}
- fsdp_config: {}
```
| 5 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/concept_guides/low_precision_training.md | <!--Copyright 2023 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Low precision training methods
The release of new kinds of hardware led to the emergence of new training paradigms that better utilize them. Currently, this is in the form of training
in 8-bit precision using packages such as [TransformersEngine](https://github.com/NVIDIA/TransformerEngine) (TE) or [MS-AMP](https://github.com/Azure/MS-AMP/tree/main).
For an introduction to the topics discussed today, we recommend reviewing the [low-precision usage guide](../usage_guides/low_precision_training) as this documentation will reference it regularly.
## A Quick Chart
Below is a quick chart from the MS-AMP documentation showing the different bit-precisions for each solution during training:
Optimization Level | Computation(GEMM) | Comm | Weight | Master Weight | Weight Gradient | Optimizer States
-- | -- | -- | -- | -- | -- | --
FP16 AMP | FP16 | FP32 | FP32 | N/A | FP32 | FP32+FP32
Nvidia TE | FP8 | FP32 | FP32 | N/A | FP32 | FP32+FP32
MS-AMP O1 | FP8 | FP8 | FP16 | N/A | FP8 | FP32+FP32
MS-AMP O2 | FP8 | FP8 | FP16 | N/A | FP8 | FP8+FP16
MS-AMP O3 | FP8 | FP8 | FP8 | FP16 | FP8 | FP8+FP16
## `TransformersEngine`
`TransformersEngine` is the first solution to trying to train in 8-bit floating point. It works by using drop-in replacement layers for certain ones in a model that utilizes their FP8-engine to reduce the number of bits (such as 32 to 8) without degrading the final accuracy of the model.
Specifically, Accelerate will find and replace the following layers with `TransformersEngine` versions:
* `nn.LayerNorm` for `te.LayerNorm`
* `nn.Linear` for `te.Linear`
As a result we wind up with a model that has most of its layers in BF16, while some layers are in FP8 reducing some of the memory.
Anecdotally, we have noticed that performance gains don't really start showing when using `TransformerEngine` until a large majority of the layers
in the model are made up of those two layers to replace. As a result, only larger models have shown performance improvements when the number of parameters is around and upwards of a few billion.
The `TransformerEngine` can receive many different arguments that customize how it performs FP8 calculations and what they do. A full list of the arguments is available below:
* `margin`: The margin to use for the gradient scaling.
* `interval`: The interval to use for how often the scaling factor is recomputed.
* `fp8_format``: The format to use for the FP8 recipe. Must be one of `HYBRID` or `E4M3`. (Generally `HYBRID` for training, `E4M3` for evaluation)
* `amax_history_len`: The length of the history to use for the scaling factor computation
* `amax_compute_algo`: The algorithm to use for the scaling factor computation. Must be one of `max` or `most_recent`.
* `override_linear_precision`: Whether or not to execute `fprop`, `dgrad`, and `wgrad` GEMMS in higher precision.
You can customize each of these as part of [`utils.FP8RecipeKwargs`] to help optimize performance of your models.
If we notice in the chart mentioned earlier, TE simply casts the computation layers into FP8, while everything else is in FP32. As a result this winds up utilizing the most memory but does so with the benefit of guaranteeing the least amount of loss in end accuracy during training.
## `MS-AMP`
MS-AMP takes a different approach to `TransformersEngine` by providing three different optimization levels to convert more operations in FP8 or FP16.
* The base optimization level (`O1`), passes communications of the weights (such as in DDP) in FP8, stores the weights of the model in FP16, and leaves the optimizer states in FP32. The main benefit of this optimization level is that we can reduce the communication bandwidth by essentially half. Additionally, more GPU memory is saved due to 1/2 of everything being cast in FP8, and the weights being cast to FP16. Notably, both the optimizer states remain in FP32.
* The second optimization level (`O2`) improves upon this by also reducing the precision of the optimizer states. One is in FP8 while the other is in FP16. Generally it's been shown that this will only provide a net-gain of no degraded end accuracy, increased training speed, and reduced memory as now every state is either in FP16 or FP8.
* Finally, MS-AMP has a third optimization level (`O3`) which helps during DDP scenarios such as DeepSpeed. The weights of the model in memory are fully cast to FP8, and the master weights are now stored in FP16. This fully reduces memory by the highest factor as now not only is almost everything in FP8, only two states are left in FP16. Currently, only DeepSpeed versions up through 0.9.2 are supported, so this capability is not included in the Accelerate integration
## Combining the two
More experiments need to be performed but it's been noted that combining both MS-AMP and TransformersEngine can lead to the highest throughput by relying on NVIDIA's optimized FP8 operators and utilizing how MS-AMP reduces the memory overhead.
| 6 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/concept_guides/fsdp_and_deepspeed.md | <!--Copyright 2024 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# FSDP vs DeepSpeed
Accelerate offers flexibilty of training frameworks, by integrating two extremely powerful tools for distributed training, namely [Pytorch FSDP](../usage_guides/fsdp) and [Microsoft DeepSpeed](../usage_guides/deepspeed). The aim of this tutorial is to draw parallels, as well as to outline potential differences, to empower the user to switch seamlessly between these two frameworks.
<Tip>
To switch between the frameworks, we recommend launching code `accelerate launch` passing in the correct config file with `--config_file`, or passing in the respective arguments directly for [FSDP and DeepSpeed](../package_reference/cli#accelerate-launch) .
Example Accelerate configurations can be found here for [DeepSpeed](../usage_guides/deepspeed#accelerate-deepspeed-plugin) and [FSDP](../usage_guides/fsdp#how-it-works-out-of-the-box), or in the [example zoo under "Launch Configurations"](../usage_guides/explore)
</Tip>
<Tip warning={true}>
This tutorial is for single-node, multi-GPU, scenarios only.
</Tip>
## Configuring Functionalities
Model tensors are split into different GPUs in an attempt to scale up model sizes; this is termed *sharding* in FSDP, and *partitioning* in DeepSpeed. FSDP sharding and DeepSpeed ZeRO (partitioning) stages are configured by `--fsdp_sharding_strategy`, and `--zero_stage`, respectively. In particular, FSDP `FULL_SHARD` maps to DeepSpeed ZeRO stage `3`; see this [comprehensive mapping between FSDP sharding and DeepSpeed ZeRO settings](../usage_guides/fsdp#mapping-between-fsdp-sharding-strategies-and-deepspeed-zero-stages). The below table summarizes and groups similar settings:
Group | Framework | Configuration | Example | Restrictions (if any)
--|--|--|--|--
sharding / partitioning | FSDP<br>DeepSpeed | `--fsdp_sharding_strategy`<br>`--zero_stage` | `1` (`FULL_SHARD`) <br>`3` |
offload | FSDP<br>DeepSpeed | `--fsdp_offload_params`<br>`--offload_param_device`<br>`--offload_optimizer_device` | `true`<br>`cpu`<br>`cpu` | all or nothing <br><br>
model loading | FSDP<br>DeepSpeed | <span style="white-space:nowrap;">`--fsdp_cpu_ram_efficient_loading`</span><br>`--zero3_init_flag` | `true`<br>`true` | <br>only ZeRO 3
efficient checkpointing | FSDP<br>DeepSpeed | `--fsdp_state_dict_type`<br>`--zero3_save_16bit_model` | `SHARDED_STATE_DICT`<br>`true` | <br>only ZeRO 3
weights prefetching | FSDP<br><br>DeepSpeed | `--fsdp_forward_prefetch`<br>`--fsdp_backward_prefetch`<br>None | `true`<br>`BACKWARD_PRE` | <br><br>
model | FSDP<br><br>DeepSpeed | `--fsdp_auto_wrap_policy`<br><span style="white-space:nowrap;">`--fsdp_transformer_layer_cls_to_wrap`</span><br>None | `TRANSFORMER_BASED_WRAP`<br><Layer Class> |<br>Usually not needed <br>Transparent to user.
parameters summoning | FSDP<br>DeepSpeed | `--fsdp_use_orig_params`<br>None | `true` | required for `torch.compile`<br>Transparent to user
parameters syncing | FSDP<br>DeepSpeed | `--fsdp_sync_module_states`<br>None | `true` |
training | FSDP<br>DeepSpeed | None<br>`--gradient_accumulation_steps`<br>`--gradient_clipping` | <br>`auto`<br>`auto` | Transparent to user
For detailed descriptions of the above, refer to [`Accelerate` launch documentation](../package_reference/cli#accelerate-launch).
<Tip>
To access other DeepSpeed configurations, such as mixed precision settings,
you need to pass in a `--deepspeed_config_file`, see the [documentation](../usage_guides/deepspeed#deepspeed-config-file).
DeepSpeed can be also configured via [`DeepSpeedPlugin`], e.g., `DeepSpeedPlugin.zero_stage` is equivalent of `--zero_stage`, and `DeepSpeedPlugin.hf_ds_config` can be used to pass `--deepeed_config_file.`
</Tip>
<Tip>
FSDP can be also configured via [`FullyShardedDataParallelPlugin`], e.g., `FullyShardedDataParallelPlugin.sharding_strategy` is equivalent of `--fsdp_sharding_strategy`.
</Tip>
### Checkpointing
Do note that while FSDP can be configured via `--fsdp_state_dict_type` to save either full / sharded checkpoints.
<Tip>
For DeepSpeed Zero3, one could pass a `--zero3_save_16bit_model true`, which conveniently consolidates the model to a single rank and saves; this is the FSDP equivalent of `fsdp_state_dict_type: FULL_STATE_DICT`.
</Tip>
<Tip warning={true}>
For large models, consolidating the model to a single rank can be very slow.
</Tip>
<Tip>
For quicker checkpointing, for FSDP use `fsdp_state_dict_type: SHARDED_STATE_DICT`, and for DeepSpeed Zero3 [use the `zero_to_fp32.py` script to post-convert sharded checkpoints](https://www.deepspeed.ai/tutorials/zero/#extracting-weights).
</Tip>
### Offloading
FSDP only allows *all-or-nothing* offload (i.e., either offload parameters, gradients, and optimizer, or keep them all in GPU), but DeepSpeed can offload parameters and optimizer differently. Furthermore, DeepSpeed also supports [offloading to NVME](https://www.deepspeed.ai/docs/config-json/#parameter-offloading).
### Prefetching
FSDP allows two prefetching configurations `--fsdp_forward_prefetch` and `--fsdp_backward_prefetch` to improve overlap of comms / computation at a cost of extra memory, see [FSDP documentation](https://pytorch.org/docs/stable/fsdp.html).
For DeepSpeed, the prefetching will be turned on when needed, and it turns on depending on certain hyper-params like `stage3_param_persistence_threshold`, `stage3_max_reuse_distance`, etc, [that can be configured for Zero3](https://www.deepspeed.ai/docs/config-json/#parameter-offloading); `accelerate` may set these hyper-params automatically if you don't set those explicitly in the deepspeed config file.
<Tip>
For FSDP set `fsdp_backward_prefetch: BACKWARD_PRE` for improved throughputs if memory allows.
</Tip>
### Model Loading
While FSDP require an explicit `--fsdp_cpu_ram_efficient_loading true` to activate efficient model loading, `transformers` will activate the similar feature whenever DeepSpeed Zero3 is used.
<Tip>
For FSDP, whenever setting `--fsdp_cpu_ram_efficient_loading true`, `accelerate` will automatically set `sync_module_states` to true.
For RAM efficient loading the weights will be loaded only in a singe rank, and thus requires `sync_module_states` to broadcast weights to other ranks.
</Tip>
### Model
FSDP requires an explicit `--fsdp_auto_wrap_policy` for the algorithm to decide how to schedule the all-gather and reduce-scatter operations. But for DeepSpeed this is transparent to the user.
<Tip>
For FSDP, simply set `fsdp_auto_wrap_policy: TRANSFORMER_BASED_WRAP`. With the latest [`transformers`] versions, we try our best to figure out the suitable `fsdp_transformer_layer_cls_to_wrap` for HF transformers models. However, if you get an error regarding it, please specify this.
</Tip>
### Parameters Summoning
FSDP requires an explicit `--fsdp_use_orig_params` flag if using `torch.compile`, see [the pytorch documenation](https://pytorch.org/docs/stable/fsdp.html#module-torch.distributed.fsdp). For DeepSpeed this is transparent to the user.
<Tip>
For FSDP, when using `torch.compile` please set `fsdp_use_orig_params: True`.
</Tip>
## Training
Deepspeed requires explicit `--gradient_accumulation_steps` and `--gradient_clipping` flags. For FSDP this is transparent to the user.
<Tip>
When using DeepSpeed, set `gradient_accumulation_steps: "auto"` and `gradient_clipping: "auto"` to automatically pick up values set in the [`Accelerator`] or [`TrainingArguments`] (if using `transformers`).
</Tip>
## On Differences in Data Precision Handling
To discuss the how data precision is handled in both FSDP and Deepspeed, it is instructive to first give an overview of how model parameters are handled in these frameworks. Before the model / optimizer parameters are distributed across GPUs, parameter preparation is involved to first "flatten" them to one-dimensional [`torch.Tensor`](https://pytorch.org/docs/stable/tensors.html#torch-tensor). The implementation of FSDP / DeepSpeed varies in the respect of the `dtype` in which these "flattened" parameters are stored, and there are ramifications with regards to how [`torch.Optimizer`](https://pytorch.org/docs/stable/optim.html#module-torch.optim) allocate their `dtype`s. The table below outlines the processes for both frameworks; the "Local" column indicates the process occurring at a per-gpu level, therefore any memory overheads by upcasting should be understood to be amortized by the number of gpus used.
<Tip>
As a rule of thumb, for stable training with automatic mixed precision, all the trainable parameters have to be in `torch.float32`.
</Tip>
Process | Local | Framework | Details
--|--|--|--
Loading, i.e., [`AutoModel.from_pretrained(..., torch_dtype=torch_dtype)`] |
Preparation, i.e., creation of "flat params" | ✅ | FSDP<br>DeepSpeed | created in `torch_dtype`.<br> disregards `torch_dtype`, created in `float32`.
Optimizer initialization | ✅ | FSDP<br>DeepSpeed | creates parameters in `torch_dtype`<br> creates parameters in `float32`
Training Step, i.e, forward, backward, reduction | | FSDP<br>DeepSpeed | follows [`MixedPrecision`](https://pytorch.org/docs/stable/fsdp.html#torch.distributed.fsdp.MixedPrecision)<br> follows `deepspeed_config_file` mixed precision settings.
Optimizer (Pre-Step) | ✅ | FSDP<br>DeepSpeed | upcasting (if any) to `torch_dtype`<br>upcasted to `float32`
Optimizer (Actual Step) | ✅ | FSDP<br>DeepSpeed | occurs in `torch_dtype` <br> occurs in `float32`.
<Tip warning={true}>
Therefore when using DeepSpeed a small number of GPUs, be aware of potentially significant memory overheads due to the upcasting during preperation.
</Tip>
<Tip>
With FSDP, in the absence of mixed precision, it is possible to operate the [`torch.Optimizer`](https://pytorch.org/docs/stable/optim.html#module-torch.optim) in low precision `torch_dtype`, which may be helpful when using small number of GPUs.
</Tip>
<Tip warning={true}>
With mixed precision, FSDP and DeepSpeed will upcast in the model preparation step (c.f. table above). But do note that FSDP will then save checkpoints in the upcasted precision; Deepspeed may still save low precision checkpoints if `--zero3_save_16bit_model` is specified.
</Tip>
To clarify the above table consider the concrete examples below; the optimizer pre- and actual step combined for brevity. With FSDP it is possible to operate in the two modes shown below, but DeepSpeed can only operate in one.
Framework | Model Loading (`torch_dtype`) | Mixed Precision | Preparation (Local) | Training | Optimizer (Local)
--|--|--|--|--|--
FSDP | bf16 | default (none) | bf16 | bf16 | bf16
FSDP | bf16 | bf16 | fp32 | bf16 | fp32
DeepSpeed | bf16 | bf16 | fp32 | bf16 | fp32
| 7 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/concept_guides/big_model_inference.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# Loading big models into memory
When loading a pre-trained model in PyTorch, the usual workflow looks like this:
```py
import torch
my_model = ModelClass(...)
state_dict = torch.load(checkpoint_file)
my_model.load_state_dict(state_dict)
```
In plain English, those steps are:
1. Create the model with randomly initialized weights
2. Load the model weights (in a dictionary usually called a state dict) from the disk
3. Load those weights inside the model
While this works very well for regularly sized models, this workflow has some clear limitations when we deal with a huge model: in step 1, we load a full version of the model in RAM, and spend some time randomly initializing the weights (which will be discarded in step 3). In step 2, we load another full version of the model in RAM, with the pre-trained weights. If you're loading a model with 6 billion parameters, this means you will need 24GB of RAM for each copy of the model, so 48GB in total (half of it to load the model in FP16).
<Tip warning={true}>
This API is quite new and still in its experimental stage. While we strive to provide a stable API, it's possible some small parts of the public API will change in the future.
</Tip>
## How the Process Works: A Quick Overview
<Youtube id="MWCSGj9jEAo" />
## How the Process Works: Working with Code
### Instantiating an empty model
The first tool Accelerate introduces to help with big models is a context manager [`init_empty_weights`] that helps you initialize a model without using any RAM so that step 1 can be done on models of any size. Here is how it works:
```py
from accelerate import init_empty_weights
with init_empty_weights():
my_model = ModelClass(...)
```
For instance:
```py
with init_empty_weights():
model = nn.Sequential(*[nn.Linear(10000, 10000) for _ in range(1000)])
```
initializes an empty model with a bit more than 100B parameters. Behind the scenes, this relies on the meta device introduced in PyTorch 1.9. During the initialization under the context manager, each time a parameter is created, it is instantly moved to that device.
<Tip warning={true}>
You can't move a model initialized like this on CPU or another device directly, since it doesn't have any data. It's also very likely that a forward pass with that empty model will fail, as not all operations are supported on the meta device.
</Tip>
### Sharded checkpoints
It's possible your model is so big that even a single copy won't fit in RAM. That doesn't mean it can't be loaded: if you have one or several GPUs, this is more memory available to store your model. In this case, it's better if your checkpoint is split into several smaller files that we call checkpoint shards.
Accelerate will handle sharded checkpoints as long as you follow the following format: your checkpoint should be in a folder, with several files containing the partial state dicts, and there should be an index in the JSON format that contains a dictionary mapping parameter names to the file containing their weights. You can easily shard your model with [`~Accelerator.save_model`]. For instance, we could have a folder containing:
```bash
first_state_dict.bin
index.json
second_state_dict.bin
```
with index.json being the following file:
```
{
"linear1.weight": "first_state_dict.bin",
"linear1.bias": "first_state_dict.bin",
"linear2.weight": "second_state_dict.bin",
"linear2.bias": "second_state_dict.bin"
}
```
and `first_state_dict.bin` containing the weights for `"linear1.weight"` and `"linear1.bias"`, `second_state_dict.bin` the ones for `"linear2.weight"` and `"linear2.bias"`
### Loading weights
The second tool Accelerate introduces is a function [`load_checkpoint_and_dispatch`], that will allow you to load a checkpoint inside your empty model. This supports full checkpoints (a single file containing the whole state dict) as well as sharded checkpoints. It will also automatically dispatch those weights across the devices you have available (GPUs, CPU RAM), so if you are loading a sharded checkpoint, the maximum RAM usage will be the size of the biggest shard.
If you want to use big model inference with Transformers models, check out this [documentation](https://huggingface.co/docs/transformers/main/en/main_classes/model#large-model-loading).
Here is how we can use this to load the [GPT2-1.5B](https://huggingface.co/marcsun13/gpt2-xl-linear-sharded) model.
Let's download the sharded version of this model.
```bash
pip install huggingface_hub
```
```py
from huggingface_hub import snapshot_download
checkpoint = "marcsun13/gpt2-xl-linear-sharded"
weights_location = snapshot_download(repo_id=checkpoint)
```
In order to initialize the model, we will use the library minGPT.
```bash
git clone https://github.com/karpathy/minGPT.git
pip install minGPT/
```
```py
from accelerate import init_empty_weights
from mingpt.model import GPT
model_config = GPT.get_default_config()
model_config.model_type = 'gpt2-xl'
model_config.vocab_size = 50257
model_config.block_size = 1024
with init_empty_weights():
model = GPT(model_config)
```
Then, load the checkpoint we just downloaded with:
```py
from accelerate import load_checkpoint_and_dispatch
model = load_checkpoint_and_dispatch(
model, checkpoint=weights_location, device_map="auto", no_split_module_classes=['Block']
)
```
By passing `device_map="auto"`, we tell Accelerate to determine automatically where to put each layer of the model depending on the available resources:
- first, we use the maximum space available on the GPU(s)
- if we still need space, we store the remaining weights on the CPU
- if there is not enough RAM, we store the remaining weights on the hard drive as memory-mapped tensors
#### `no_split_module_classes`
This parameter will indicate that some of the modules with the name `"Block"` should not be split across different devices. You should set here all blocks that
include a residual connection of some kind.
#### The `device_map`
You can see the `device_map` that Accelerate picked by accessing the `hf_device_map` attribute of your model:
```py
model.hf_device_map
```
```python out
{'transformer.wte': 0,
'transformer.wpe': 0,
'transformer.drop': 0,
'transformer.h.0': 0,
...
'transformer.h.21': 0,
'transformer.h.22': 1,
'transformer.h.23': 1,
'transformer.h.24': 1,
...
'transformer.h.47': 1,
'transformer.ln_f': 1,
'lm_head': 1}
```
It's fully possible to create your own device map for the layers to use as well, specifying the GPU device to use (a number), `"cpu"`, or `"disk"` and pass this in:
```python
device_map = {
"transformer.wte": "cpu",
"transformer.wpe": 0,
"transformer.drop": "cpu",
"transformer.h.0": "disk"
}
model = load_checkpoint_and_dispatch(
model, checkpoint=weights_location, device_map=device_map
)
```
### Run the model
Now that we have done this, our model lies across several devices, and maybe the hard drive. But it can still be used as a regular PyTorch model:
```py
from mingpt.bpe import BPETokenizer
tokenizer = BPETokenizer()
inputs = tokenizer("Hello, my name is").to(0)
outputs = model.generate(x1, max_new_tokens=10, do_sample=False)[0]
tokenizer.decode(outputs.cpu().squeeze())
```
Behind the scenes, Accelerate added hooks to the model, so that:
- at each layer, the inputs are put on the right device (so even if your model is spread across several GPUs, it works)
- for the weights offloaded on the CPU, they are put on a GPU just before the forward pass and cleaned up just after
- for the weights offloaded on the hard drive, they are loaded in RAM then put on a GPU just before the forward pass and cleaned up just after
This way, your model can run for inference even if it doesn't fit on one of the GPUs or the CPU RAM!
<Tip warning={true}>
This only supports the inference of your model, not training. Most of the computation happens behind `torch.no_grad()` context managers to avoid spending some GPU memory with intermediate activations.
</Tip>
### Designing a device map
You can let Accelerate handle the device map computation by setting `device_map` to one of the supported options (`"auto"`, `"balanced"`, `"balanced_low_0"`, `"sequential"`) or create one yourself if you want more control over where each layer should go.
<Tip>
You can derive all sizes of the model (and thus compute a `device_map`) on a model that is on the meta device.
</Tip>
All the options will produce the same result when you don't have enough GPU memory to accommodate the whole model (which is to fit everything that can on the GPU, then offload weights on the CPU or even on the disk if there is not enough RAM).
When you have more GPU memory available than the model size, here is the difference between each option:
- `"auto"` and `"balanced"` evenly split the model on all available GPUs, making it possible for you to use a batch size greater than 1.
- `"balanced_low_0"` evenly splits the model on all GPUs except the first one, and only puts on GPU 0 what does not fit on the others. This option is great when you need to use GPU 0 for some processing of the outputs, like when using the `generate` function for Transformers models
- `"sequential"` will fit what it can on GPU 0, then move on GPU 1 and so forth (so won't use the last GPUs if it doesn't need to).
<Tip>
The options `"auto"` and `"balanced"` produce the same results for now, but the behavior of `"auto"` might change in the future if we find a strategy that makes more sense, while `"balanced"` will stay stable.
</Tip>
First note that you can limit the memory used on each GPU by using the `max_memory` argument (available in [`infer_auto_device_map`] and in all functions using it). When setting `max_memory`, you should pass along a dictionary containing the GPU identifiers (for instance `0`, `1` etc.) and the `"cpu"` key for the maximum RAM you want to use for CPU offload. The values can either be an integer (in bytes) or a string representing a number with its unit, such as `"10GiB"` or `"10GB"`.
Here is an example where we don't want to use more than 10GiB on each of the two GPUs and no more than 30GiB of CPU RAM for the model weights:
```python
from accelerate import infer_auto_device_map
device_map = infer_auto_device_map(my_model, max_memory={0: "10GiB", 1: "10GiB", "cpu": "30GiB"})
```
<Tip warning={true}>
When a first allocation happens in PyTorch, it loads CUDA kernels which take about 1-2GB of memory depending on the GPU. Therefore you always have less usable memory than the actual size of the GPU. To see how much memory is actually used do `torch.ones(1).cuda()` and look at the memory usage.
Therefore when you create memory maps with `max_memory` make sure to adjust the available memory accordingly to avoid out-of-memory errors.
</Tip>
Additionally, if you do some additional operations with your outputs without placing them back on the CPU (for instance inside the `generate` method of Transformers) and if you placed your inputs on a GPU, that GPU will consume more memory than the others (Accelerate always place the output back to the device of the input). Therefore if you would like to optimize the maximum batch size and you have many GPUs, give the first GPU less memory. For example, with BLOOM-176B on 8x80 A100 setup, the close-to-ideal map is:
```python
max_memory = {0: "30GIB", 1: "46GIB", 2: "46GIB", 3: "46GIB", 4: "46GIB", 5: "46GIB", 6: "46GIB", 7: "46GIB"}
```
as you can see we gave the remaining 7 GPUs ~50% more memory than GPU 0.
If you opt to fully design the `device_map` yourself, it should be a dictionary with keys being module names of your model and values being a valid device identifier (for instance an integer for the GPUs) or `"cpu"` for CPU offload, `"disk"` for disk offload. The keys need to cover the whole model, you can then define your device map as you wish: for instance, if your model has two blocks (let's say `block1` and `block2`) which each contain three linear layers (let's say `linear1`, `linear2` and `linear3`), a valid device map can be:
```python
device_map = {"block1": 0, "block2": 1}
```
another one that is valid could be:
```python
device_map = {"block1": 0, "block2.linear1": 0, "block2.linear2": 1, "block2.linear3": 1}
```
On the other hand, this one is not valid as it does not cover every parameter of the model:
```python
device_map = {"block1": 0, "block2.linear1": 1, "block2.linear2": 1}
```
<Tip>
To be the most efficient, make sure your device map puts the parameters on the GPUs in a sequential manner (e.g. don't put one of the first weights on GPU 0, then weights on GPU 1 and the last weight back to GPU 0) to avoid making many transfers of data between the GPUs.
</Tip>
## CPU offload only
If you want to offload your model on CPU, you can use [`cpu_offload`]. As a result, all parameters of the model will be offloaded and only one copy of the state dict of the model will be kept. During the forward pass, parameters will be extracted from that state dict and put on the execution device and passed as they are needed, then offloaded again.
```python
cpu_offload(model, execution_device)
```
You can also use [`cpu_offload_with_hook`]. This function will offloads a model on the CPU and puts it back to an execution device when executed. The difference with [`cpu_offload`] is that the model stays on the execution device after the forward and is only offloaded again when the `offload` method of the returned `hook` is called. Furthermore, [`cpu_offload_with_hook`] is more performant but less memory saving. It is useful for pipelines running a model in a loop:
```python
model_1, hook_1 = cpu_offload_with_hook(model_1, execution_device)
model_2, hook_2 = cpu_offload_with_hook(model_2, execution_device, prev_module_hook=hook_1)
model_3, hook_3 = cpu_offload_with_hook(model_3, execution_device, prev_module_hook=hook_2)
hid_1 = model_1(input)
for i in range(50):
# model1 is offloaded on the CPU at the first iteration, model 2 stays on the GPU for this whole loop.
hid_2 = model_2(hid_1)
# model2 is offloaded to the CPU just before this forward.
hid_3 = model_3(hid_3)
# For model3, you need to manually call the hook offload method.
hook_3.offload()
```
## Disk offload only
To perform disk offload, you can use [`disk_offload`]. As a result, all parameters of the model will be offloaded as memory-mapped array in a given folder. During the forward pass, parameters will be accessed from that folder and put on the execution device passed as they are needed, then offloaded again.
```python
disk_offload(model, offload_dir, execution_device)
```
## Limits and further development
We are aware of the current limitations in the API:
- [`infer_auto_device_map`] (or `device_map="auto"` in [`load_checkpoint_and_dispatch`]) tries to maximize GPU and CPU RAM it sees available when you execute it. While PyTorch is very good at managing GPU RAM efficiently (and giving it back when not needed), it's not entirely true with Python and CPU RAM. Therefore, an automatically computed device map might be too intense on the CPU. Move a few modules to the disk device if you get crashes due to a lack of RAM.
- [`infer_auto_device_map`] (or `device_map="auto"` in [`load_checkpoint_and_dispatch`]) attributes devices sequentially (to avoid moving things back and forth) so if your first layer is bigger than the size of the GPU you have, it will end up with everything on the CPU/Disk.
- [`load_checkpoint_and_dispatch`] and [`load_checkpoint_in_model`] do not perform any check on the correctness of your state dict compared to your model at the moment (this will be fixed in a future version), so you may get some weird errors if trying to load a checkpoint with mismatched or missing keys.
- The model parallelism used when your model is split on several GPUs is naive and not optimized, meaning that only one GPU works at a given time and the other sits idle.
- When weights are offloaded on the CPU/hard drive, there is no pre-fetching (yet, we will work on this for future versions) which means the weights are put on the GPU when they are needed and not before.
- Hard-drive offloading might be very slow if the hardware you run on does not have fast communication between disk and CPU (like NVMes).
| 8 |
0 | hf_public_repos/accelerate/docs/source | hf_public_repos/accelerate/docs/source/concept_guides/deferring_execution.md | <!--Copyright 2022 The HuggingFace Team. All rights reserved.
Licensed under the Apache License, Version 2.0 (the "License"); you may not use this file except in compliance with
the License. You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software distributed under the License is distributed on
an "AS IS" BASIS, WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. See the License for the
specific language governing permissions and limitations under the License.
⚠️ Note that this file is in Markdown but contain specific syntax for our doc-builder (similar to MDX) that may not be
rendered properly in your Markdown viewer.
-->
# DExecuting and deferring jobs
When you run your usual script, instructions are executed in order. Using Accelerate to deploy your script on several
GPUs at the same time introduces a complication: while each process executes all instructions in order, some may be
faster than others.
You might need to wait for all processes to have reached a certain point before executing a given instruction. For
instance, you shouldn't save a model before being sure every process is done with training, and you wouldn't want to
continue training before all the model weights have been loaded in. To do this, just write the following line in your code:
```
accelerator.wait_for_everyone()
```
This instruction will block all the processes that arrive first until all the other processes have reached that
point (if you run your script on just one GPU or CPU, this won't do anything).
A few example cases of when to use this utility are listed below:
<Tip>
Some of these are utilized with the [`~Accelerator.main_process_first`] context manager, which utilizes [`~Accelerator.wait_for_everyone`] to
run a particular set of code on the main process beforehand before triggering and launching the other processes
</Tip>
## Downloading a Dataset
When downloading a dataset, you should download it first on the main process and then load the cached dataset afterward
<Tip>
`load_dataset` will perform a lock under the hood to stop multiple downloads from happening at once, but if you are downloading something
not using this library you should use this method.
</Tip>
```python
with accelerator.main_process_first():
datasets = load_dataset("glue", "mrpc")
```
Under the hood this is the same as calling:
```python
# First do something on the main process
if accelerator.is_main_process:
datasets = load_dataset("glue", "mrpc")
else:
accelerator.wait_for_everyone()
# And then send it to the rest of them
if not accelerator.is_main_process:
datasets = load_dataset("glue", "mrpc")
else:
accelerator.wait_for_everyone()
```
## Saving the `state_dict`
When saving the `state_dict` of the model, since you would normally save one file on just the main process
you should specify that:
```python
if accelerator.is_main_process:
model = accelerator.unwrap_model(model)
torch.save(model.state_dict(), "weights.pth")
```
## Loading in the `state_dict`
When loading in the `state_dict` to a model, optimizer, or scheduler, you should wait
for all workers to have the weights loaded in before moving on to training
```python
with accelerator.main_process_first():
state = torch.load("weights.pth")
model.load_state_dict(state)
```
## Applying a multi-worker CPU operation
Applying a `map()` operation on multiple workers, such as tokenizing should be done on the
main process first, and then propagated to each one.
```python
datasets = load_dataset("glue", "mrpc")
with accelerator.main_process_first():
tokenized_datasets = datasets.map(
tokenize_function,
batched=True,
remove_columns=["idx", "sentence1", "sentence2"],
)
```
## Applying checks such as Early Stopping
To have a check that works with a flag set by a particular process, the `set_trigger` and `check_trigger` API should be used. Useful examples
for doing so can include situations such as using early stopping and monitoring the loss (as each loss slightly differs on each process).
Call [`Accelerator.set_trigger`] when your condition has been met, and [`Accelerator.check_trigger`] when checking if that condition has been met in any process:
```python
for (x,y) in data_loader:
logits = model(x)
loss = loss_func(logits, y)
# Assume `should_do_early_stopping` is a custom defined function that returns a conditional
if should_do_early_stopping(loss):
accelerator.set_trigger()
# Later in the training script when we need to check for the breakpoint
if accelerator.check_trigger():
break
``` | 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.