
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos | hf_public_repos/blog/infini-attention.md | ---
title: "A failed experiment: Infini-Attention, and why we should keep trying?"
thumbnail: ./assets/185_infini_attention/infini_attention_thumbnail.png
authors:
- user: neuralink
- user: lvwerra
- user: thomwolf
---
# A failed experiment: Infini-Attention, and why we should keep trying?
TLDR: Infini-attention's performance gets worse as we increase the number of times we compress the memory, and to the best of our knowledge, [ring attention](https://x.com/Haojun_Zhao14/status/1815419356408336738), [YaRN](https://arxiv.org/abs/2309.00071) and [rope scaling](https://arxiv.org/abs/2309.16039) are still the best ways for extending a pretrained model to longer context length.
## Section 0: Introduction
The context length of language models is one of the central attributes besides the model’s performance. Since the emergence of in-context learning, adding relevant information to the model’s input has become increasingly important. Thus, the context length rapidly increased from paragraphs (512 tokens with BERT/GPT-1) to pages (1024/2048 with GPT-2 and GPT-3 respectively) to books (128k of Claude) all the way to collections of books (1-10M tokens of Gemini). However, extending standard attention to such length remains challenging.
> A small intro to Ring Attention: Ring Attention was first introduced by researchers from UC Berkeley in 2024 [[link]](https://arxiv.org/abs/2310.01889) (to the best of our knowledge). This engineering technique helps overcome memory limitations by performing self-attention and feedforward network computations in a blockwise fashion and distributing sequence dimensions across multiple devices, allowing concurrent computation and communication.
Even with Ring Attention, the number of GPUs required to train a [Llama 3 8B](https://arxiv.org/abs/2407.21783) on a 1-million-token context length with a batch size of 1 is 512 GPUs. As scaling laws have [shown](https://arxiv.org/abs/2001.08361), there is a strong correlation between model size and its downstream performance, which means the bigger the model, the better (of course, both models should be well-trained). So we not only want a 1m context length, but we want a 1m context length on the biggest model (e.g., Llama 3 8B 405B). And there are only a few companies in existence that have the resources to do so.
> Recap on the memory complexity of self-attention
> In standard attention (not-flash-attention), every token attends to every other token in the sequence, resulting in an attention matrix of size [seq_len, seq_len]. For each pair of tokens, we compute an attention score, and as the sequence length (seq_len) increases, the memory and computation requirements grow quadratically: Memory for the attention matrix is O(seq_len^2). For instance, a 10x increase in sequence length results in a 100x increase in memory requirements. Even memory efficient attention methods like Flash Attention still increase linearly with context length and are bottlenecked by single GPU memory, leading to a typical max context far lower than 1M tokens on today's GPUs.
Motivated by this, we explore an alternative approach to standard attention: infini-attention. The paper was released by researchers from Google in April 2024 [[link]](https://arxiv.org/abs/2404.07143). Instead of computing attention scores between every word, Infini-attention divides the sequence into segments, compresses earlier segments into a fixed buffer, and allows the next segment to retrieve memory from the earlier segments while limiting attention scores to words within the current segment. A key advantage is its fixed buffer size upper bounds the total memory usage. It also uses the same query within a segment to access information from both its own segment and the compressed memory, which enables us to cheaply extend the context length for a pretrained model. In theory, we can achieve infinite context length, as it only keeps a single buffer for all the memory of earlier segments. However, in reality compression limits the amount of information which can effectively been stored and the question is thus: how usably is the memory such compressed?
While understanding a new method on paper is relatively easy, actually making it work is often a whole other story, story which is very rarely shared publicly. Motivated by this, we decided to share our experiments and chronicles in reproducing the Infini-attention paper, what motivated us throughout the debugging process (we spent 90% of our time debugging a convergence issue), and how hard it can be to make these things work.
With the release of Llama 3 8B (which has a context length limit of 8k tokens), we sought to extend this length to 1 million tokens without quadratically increasing the memory. In this blog post, we will start by explaining how Infini-attention works. We’ll then outline our reproduction principles and describe our initial small-scale experiment. We discuss the challenges we faced, how we addressed them, and conclude with a summary of our findings and other ideas we explored. If you’re interested in testing our trained checkpoint [[link]](https://huggingface.co/nanotron/llama3-8b-infini-attention), you can find it in the following repo [[link]](https://github.com/huggingface/nanotron/tree/xrsrke/infini_attention_this_actually_works) (note that we currently provide the code as is).
## Section 1: Reproduction Principles
We found the following rules helpful when implementing a new method and use it as guiding principles for a lot of our work:
+ **Principle 1:** Start with the smallest model size that provides good signals, and scale up the experiments once you get good signals.
+ **Principle 2.** Always train a solid baseline to measure progress.
+ **Principle 3.** To determine if a modification improves performance, train two models identically except for the modification being tested.
With these principles in mind, let's dive into how Infini-attention actually works. Understanding the mechanics will be crucial as we move forward with our experiments.
## Section 2: How does Infini-attention works
- Step 1: Split the input sequence into smaller, fixed-size chunks called "segments".
- Step 2: Calculate the standard causal dot-product attention within each segment.
- Step 3: Pull relevant information from the compressive memory using the current segment’s query vector. The retrieval process is defined mathematically as follows:
\\( A_{\text {mem }}=\frac{\sigma(Q) M_{s-1}}{\sigma(Q) z_{s-1}} \\)
+ \\( A_{\text {mem }} \in \mathbb{R}^{N \times d_{\text {value }}} \\) : The retrieved content from memory, representing the long-term context.
+ \\( Q \in \mathbb{R}^{N \times d_{\text {key }}} \\) : The query matrix, where \\( N \\) is the number of queries, and \\( d_{\text {key }} \\) is the dimension of each query.
+ \\( M_{s-1} \in \mathbb{R}^{d_{\text {key }} \times d_{\text {value }}} \\) : The memory matrix from the previous segment, storing key-value pairs.
+ \\( \sigma \\): A nonlinear activation function, specifically element-wise Exponential Linear Unit (ELU) plus 1.
+ \\( z_{s-1} \in \mathbb{R}^{d_{\text {key }}} \\) : A normalization term.
```python
import torch.nn.functional as F
from torch import einsum
from einops import rearrange
def _retrieve_from_memory(query_states, prev_memory, prev_normalization):
...
sigma_query_states = F.elu(query_states) + 1
retrieved_memory = einsum(
sigma_query_states,
prev_memory,
"batch_size n_heads seq_len d_k, batch_size n_heads d_k d_v -> batch_size n_heads seq_len d_v",
)
denominator = einsum(
sigma_query_states,
prev_normalization,
"batch_size n_heads seq_len d_head, batch_size n_heads d_head -> batch_size n_heads seq_len",
)
denominator = rearrange(
denominator,
"batch_size n_heads seq_len -> batch_size n_heads seq_len 1",
)
# NOTE: because normalization is the sum of all the keys, so each word should have the same normalization
retrieved_memory = retrieved_memory / denominator
return retrieved_memory
```
- Step 4: Combine the local context (from the current segment) with the long-term context (retrieved from the compressive memory) to generate the final output. This way, both short-term and long-term contexts can be considered in the attention output.
\\( A=\text{sigmoid}(\beta) \odot A_{\text {mem }}+(1-\text{sigmoid}(\beta)) \odot A_{\text {dot }} \\)
+ \\( A \in \mathbb{R}^{N \times d_{\text {value }}} \\) : The combined attention output.
+ \\( \text{sigmoid}(\beta) \\) : A learnable scalar parameter that controls the trade-off between the long-term memory content \\( A_{\text {mem }} \\) and the local context.
+ \\( A_{\text {dot }} \in \mathbb{R}^{N \times d_{\text {value }}} \\) : The attention output from the current segment using dot-product attention.
+ Step 5: Update the compressive memory by adding the key-value states from the current segment, so this allows us to accumulate the context over time.
\\( M_s \leftarrow M_{s-1}+\sigma(K)^T V \\)
\\( z_s \leftarrow z_{s-1}+\sum_{t=1}^N \sigma\left(K_t\right) \\)
+ \\( M_s \in \mathbb{R}^{d_{\text {key }} \times d_{\text {value }}} \\) : The updated memory matrix for the current segment, incorporating new information.
+ \\( K \in \mathbb{R}^{N \times d_{\text {key }}} \\) : The key matrix for the current segment, representing the new keys to be stored.
+ \\( V \in \mathbb{R}^{N \times d_{\text {value }}} \\) : The value matrix for the current segment, representing the new values associated with the keys.
+ \\( K_t \\) : The \\( t \\)-th key vector in the key matrix.
+ \\( z_s \\) : The updated normalization term for the current segment.
```python
import torch
def _update_memory(prev_memory, prev_normalization, key_states, value_states):
...
sigma_key_states = F.elu(key_states) + 1
if prev_memory is None or prev_normalization is None:
new_value_states = value_states
else:
numerator = einsum(
sigma_key_states,
prev_memory,
"batch_size n_heads seq_len d_k, batch_size n_heads d_k d_v -> batch_size n_heads seq_len d_v",
)
denominator = einsum(
sigma_key_states,
prev_normalization,
"batch_size n_heads seq_len d_k, batch_size n_heads d_k -> batch_size n_heads seq_len",
)
denominator = rearrange(
denominator,
"batch_size n_heads seq_len -> batch_size n_heads seq_len 1",
)
prev_v = numerator / denominator
new_value_states = value_states - prev_v
memory = torch.matmul(sigma_key_states.transpose(-2, -1), new_value_states)
normalization = reduce(
sigma_key_states,
"batch_size n_heads seq_len d_head -> batch_size n_heads d_head",
reduction="sum",
...
)
memory += prev_memory if prev_memory is not None else 0
normalization += prev_normalization if prev_normalization is not None else 0
return memory, normalization
```
+ Step 6: As we move from one segment to the next, we discard the previous segment's attention states and pass along the updated compressed memory to the next segment.
```python
def forward(...):
...
outputs = []
global_weights = F.sigmoid(self.balance_factors)
...
local_weights = 1 - global_weights
memory = None
normalization = None
for segment_hidden_state, segment_sequence_mask in zip(segment_hidden_states, segment_sequence_masks):
attn_outputs = self.forward_with_hidden_states(
hidden_states=segment_hidden_state, sequence_mask=segment_sequence_mask, return_qkv_states=True
)
local_attn_outputs = attn_outputs["attention_output"]
query_states, key_states, value_states = attn_outputs["qkv_states_without_pe"]
q_bs = query_states.shape[0]
q_length = query_states.shape[2]
...
retrieved_memory = _retrieve_from_memory(
query_states, prev_memory=memory, prev_normalization=normalization
)
attention_output = global_weights * retrieved_memory + local_weights * local_attn_outputs
...
output = o_proj(attention_output)
memory, normalization = _update_memory(memory, normalization, key_states, value_states)
outputs.append(output)
outputs = torch.cat(outputs, dim=1) # concat along sequence dimension
...
```
Now that we've got a handle on the theory, time to roll up our sleeves and get into some actual experiments. Let's start small for quick feedback and iterate rapidly.
## Section 3: First experiments on a small scale
Llama 3 8B is quite large so we decided to start with a 200M Llama, pretraining Infini-attention from scratch using Nanotron [[link]](https://github.com/huggingface/nanotron) and the Fineweb dataset [[link]](https://huggingface.co/datasets/HuggingFaceFW/fineweb). Once we obtained good results with the 200M model, we proceeded with continual pretraining on Llama 3 8B. We used a batch size of 2 million tokens, a context length of 256, gradient clipping of 1, and weight decay of 0.1, the first 5,000 iterations were a linear warmup, while the remaining steps were cosine decay, with a learning rate of 3e-5.
**Evaluating using the passkey retrieval task**
The passkey retrieval task was first introduced by researchers from EPFL [[link]](https://arxiv.org/abs/2305.16300). It's a task designed to evaluate a model's ability to retrieve information from long contexts where the location of the information is controllable. The input format for prompting a model is structured as follows:
```There is important info hidden inside a lot of irrelevant text. Find it and memorize them. I will quiz you about the important information there. The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. (repeat x times) The pass key is 9054. Remember it. 9054 is the pass key. The grass is green. The sky is blue. The sun is yellow. Here we go. There and back again. (repeat y times) What is the pass key? The pass key is```
We consider the model successful at this task if its output contains the "needle" ("9054" in the above case) and unsuccessful if it does not. In our experiments, we place the needle at various positions within the context, specifically at 0%, 5%, 10%, ..., 95%, and 100% of the total context length (with 0% being the furthest away from the generated tokens). For instance, if the context length is 1024 tokens, placing the needle at 10% means it is located around the 102nd token. At each depth position, we test the model with 10 different samples and calculate the mean success rate.
**First results**
Here are some first results on the small 200M model:

As you can see it somewhat works. If you look at the sample generations, you can see that Infini-attention generates content related to the earlier segment.
Since Infini-attention predicts the first token in the second segment by conditioning on the entire content of the first segment, which it generated as "_grad" for the first token, this provides a good signal. To validate whether this signal is a false positive, we hypothesize that Infini-attention generates content related to its earlier segment because when given "_grad" as the first generated token of the second segment, it consistently generates PyTorch-related tutorials, which happen to relate to its earlier segment. Therefore, we conducted a sanity test where the only input token was "_grad", and it generated [text here]. This suggests it does use the memory, but just doesn’t use it well enough (to retrieve the exact needle or continue the exact content of its earlier segment). The generation:
```
_graduate_education.html
Graduate Education
The Department of Physics and Astronomy offers a program leading to the Master of Science degree in physics. The program is designed to provide students with a broad background in
```
Based on these results, the model appears to in fact use the compressed memory. We decided to scale up our experiments by continually pretraining a Llama 3 8B. Unfortunately, the model failed to pass the needle evaluation when the needle was placed in an earlier segment.
We decided to inspect the balance factors (factor balancing the amount of compressed and not-compressed memory) across all layers. Based on Figure 3a and Figure 3b, we found that about 95% of the weights are centered around 0.5. Recall that for a weight to converge to an ideal range, it depends on two general factors: the step size and the magnitude of the gradients. However, Adam normalizes the gradients to a magnitude of 1 so the question became: are the training hyper-parameters the right ones to allow the finetuning to converge?
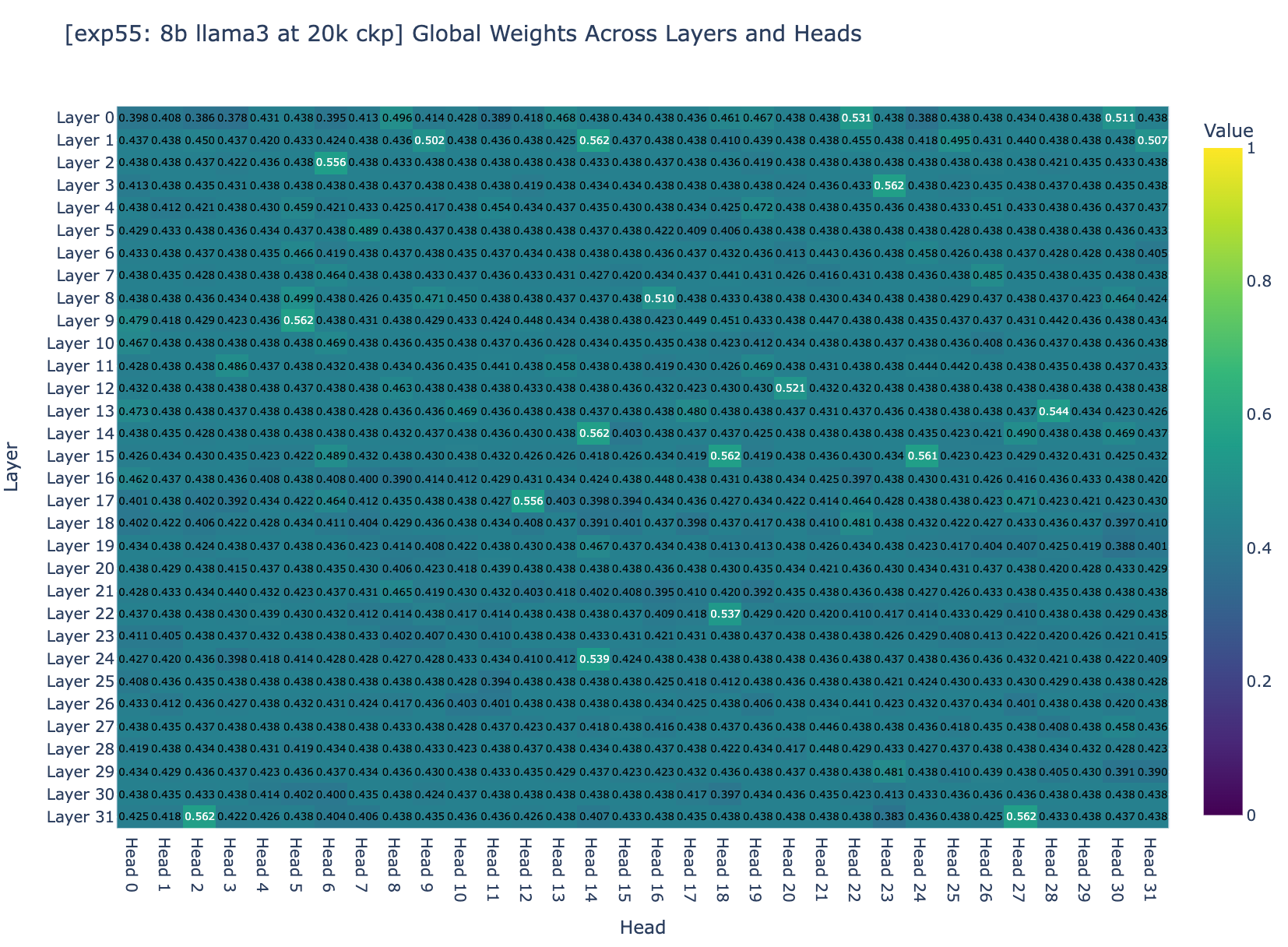

## Section 4: Studying convergence?
We decided to simulate how much balance weights would change during training given gradients are in a good range (L2 norm is 0.01), and found that, given the config of the last 8B LLaMA3 fine-tuning experiment, the total of absolute changes in the weight would be 0.03. Since we initialize balance factors at 0 (it doesn’t matter in this case), the weights at the end would be in the range [0 - 0.03, 0 + 0.03] = [-0.03, 0.03].
An educated guess for infinity attention to work well is when global weights spread out in the range 0 and 1 as in the paper. Given the weight above, sigmoid([-0.03, 0.03]) = tensor([0.4992, 0.5008]) (this fits with our previous experiment results that the balance factor is ~0.5). We decided as next step to use a higher learning rate for balance factors (and all other parameters use Llama 3 8B's learning rate), and a larger number of training steps to allow the balance factors to change by at least 4, so that we allow global weights to reach the ideal weights if gradient descent wants (sigmoid(-4) ≈ 0, sigmoid(4) ≈ 1).
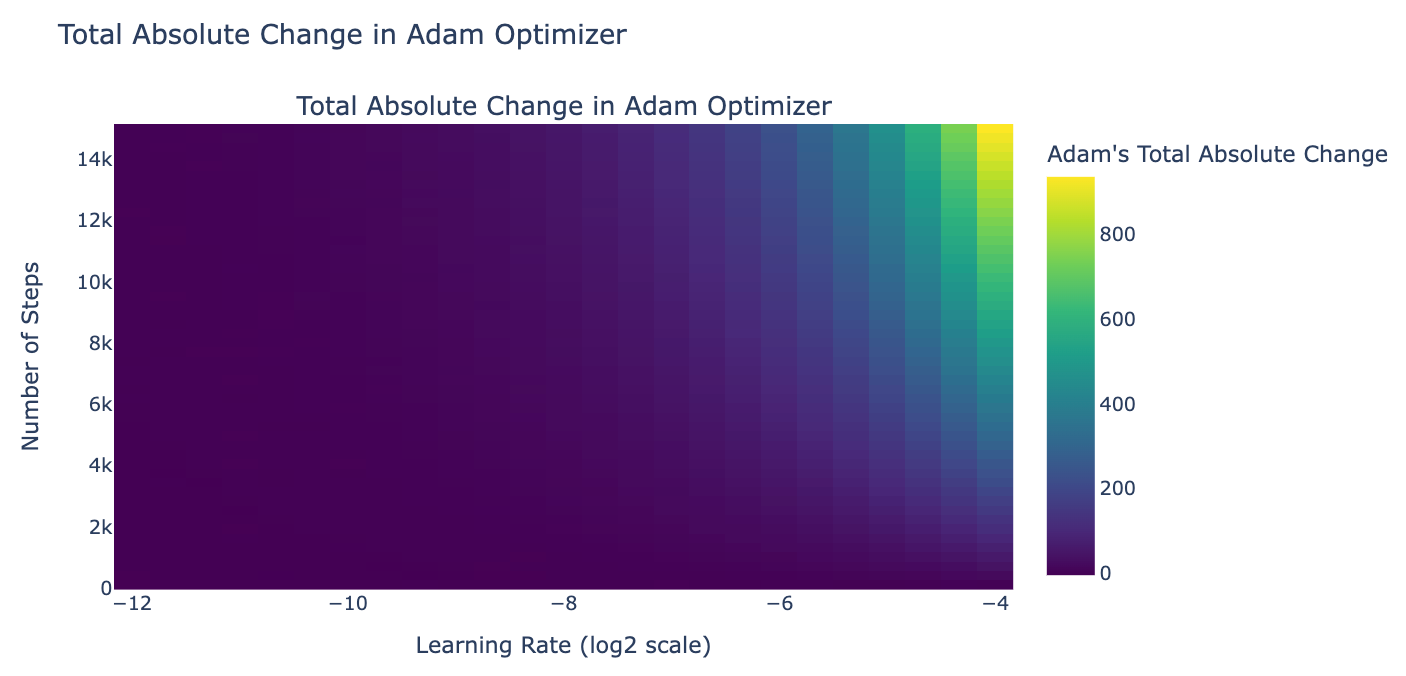
We also note that since the gradients don't always go in the same direction, cancellations occur. This means we should aim for a learning rate and training steps that are significantly larger than the total absolute changes. Recall that the learning rate for Llama 3 8B is 3.0x10^-4, which means if we use this as a global learning rate, the gating cannot converge by any means.
> Conclusion: we decided to go with a global learning rate of 3.0x10^-4 and a gating learning rate of 0.01 which should allows the gating function to converge.
With these hyper-parameters the balance factors in Infini-attention are trainable, but we observed that the 200M llama's loss went NaN after 20B tokens (we tried learning rates from 0.001 to 1.0e-6). We investigated a few generations at the 20B tokens checkpoint (10k training steps) which you can see in Figure 4a. The model now continue the exact content and recall identities (if the memory is knocked out, it generates trash).
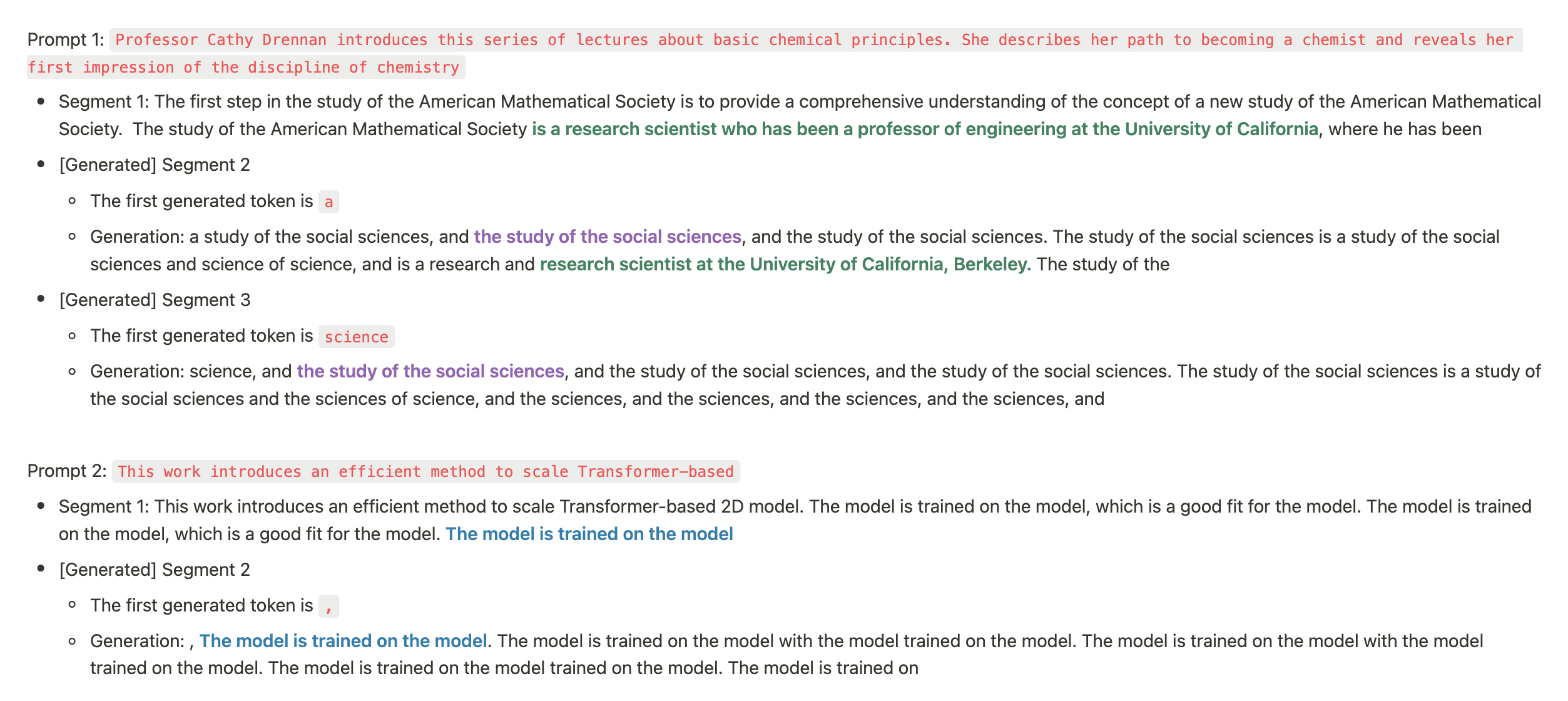
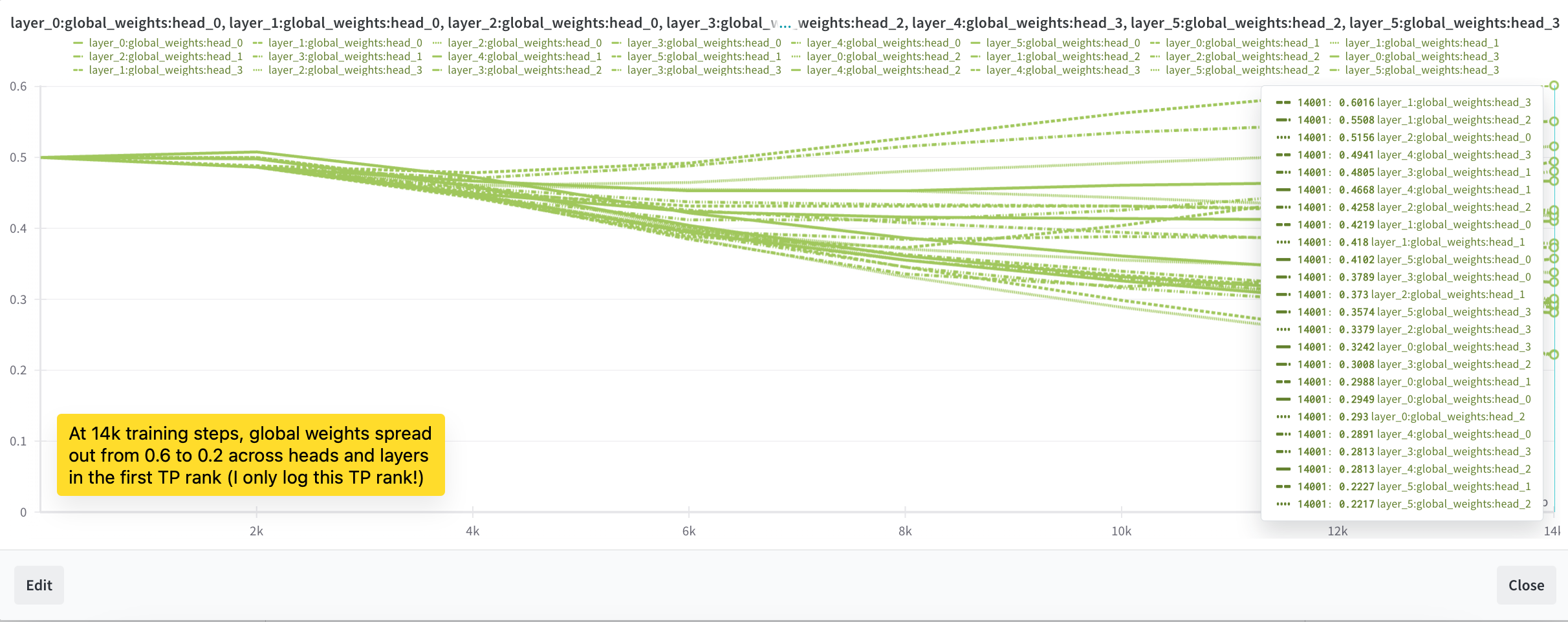
But it is still not able to recall the needle from one segment to the other (it does so reliably within the segment). Needle evaluation fails completely when the needle is placed in the 1st segment (100% success when placed in the 2nd segment, out of 2 segments total). As showed in Figure 4b, we also observed that the balance factors stopped changing after 5,000 steps. While we made some progress, we were not yet out of the woods. The balance factors were still not behaving as we hoped. We decided to dig deeper and make more adjustments.
## Section 5: No weight decay on balance factors
Inspecting in detail the balance factor once again, we saw some progress: approximately 95% of the heads now show a global weight ranging from 0.4 to 0.5, and none of the heads have a global weight greater than 0.6. But the weights still aren't in the ideal range.
We thought of another potential reason: weight decay, which encourages a small L2 norm of balance factors, leading sigmoid values to converge close to zero and factor to center around 0.5.
Yet another potential reason could be that we used too small a rollout. In the 200m experiment, we only used 4 rollouts, and in the 8b experiment, we only used 2 rollouts (8192**2). Using a larger rollout should incentive the model to compress and use the memory well. So we decided to increase the number of rollouts to 16 and use no weight decay. We scaled down the context length to 1024 context length, with 16 rollouts, getting segment lengths of 64.
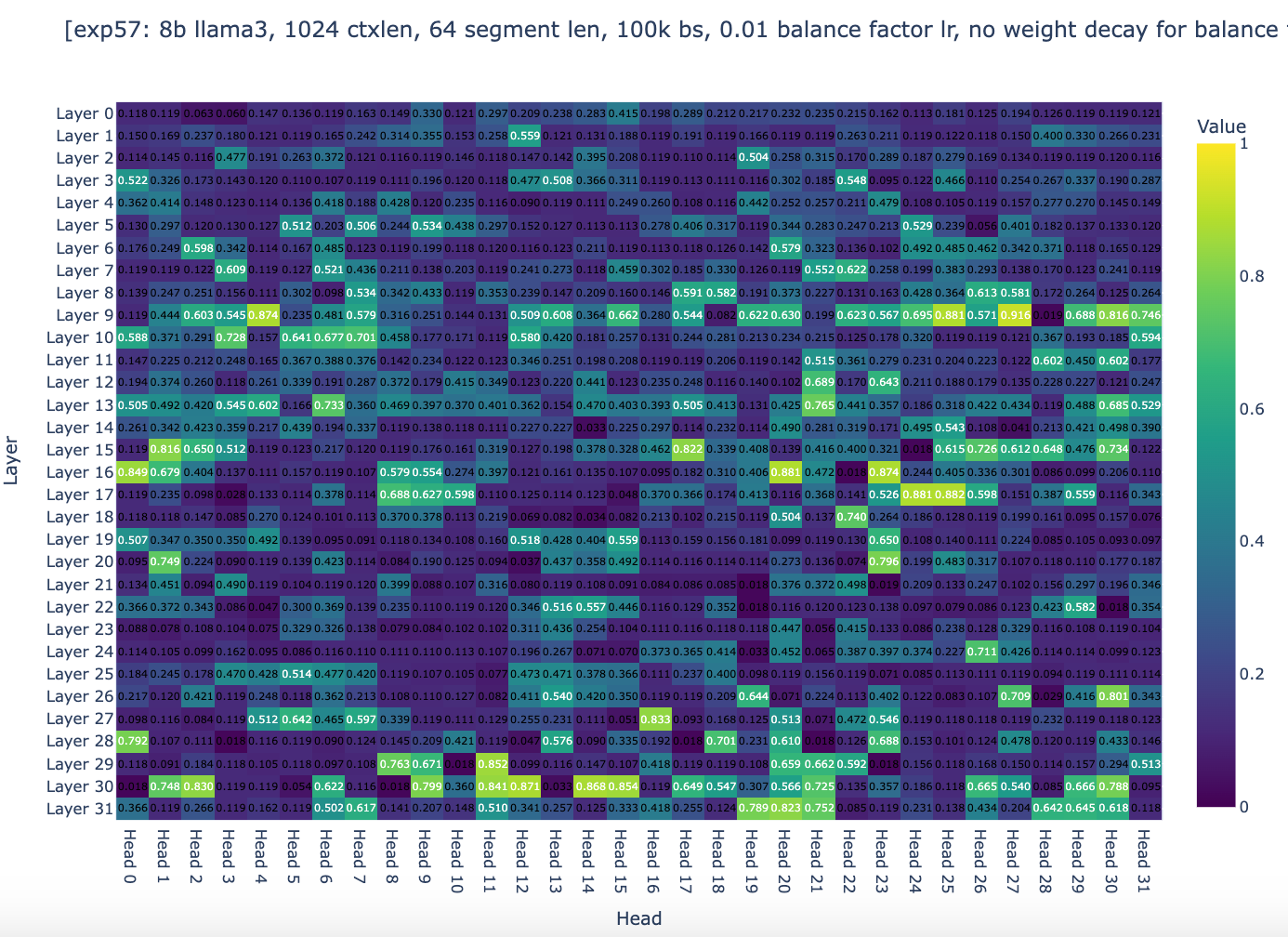
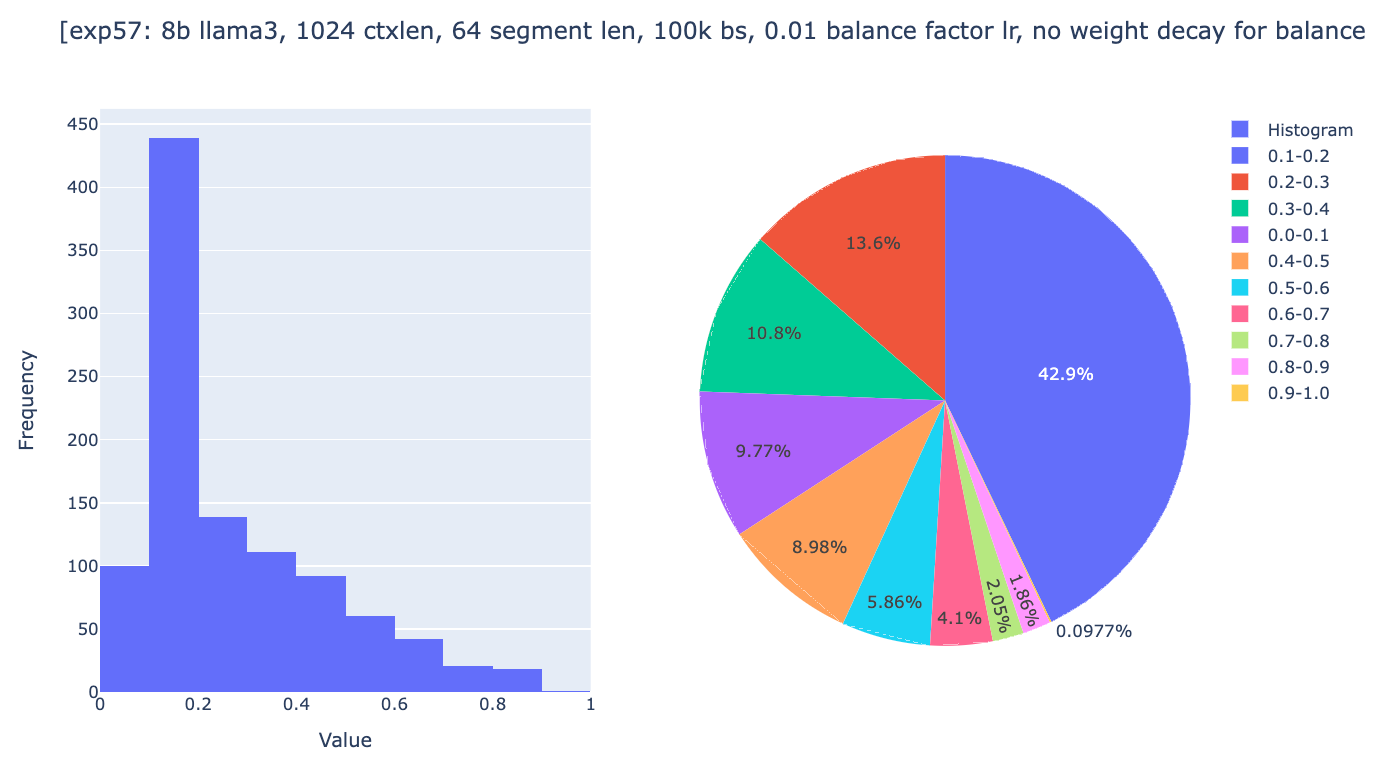
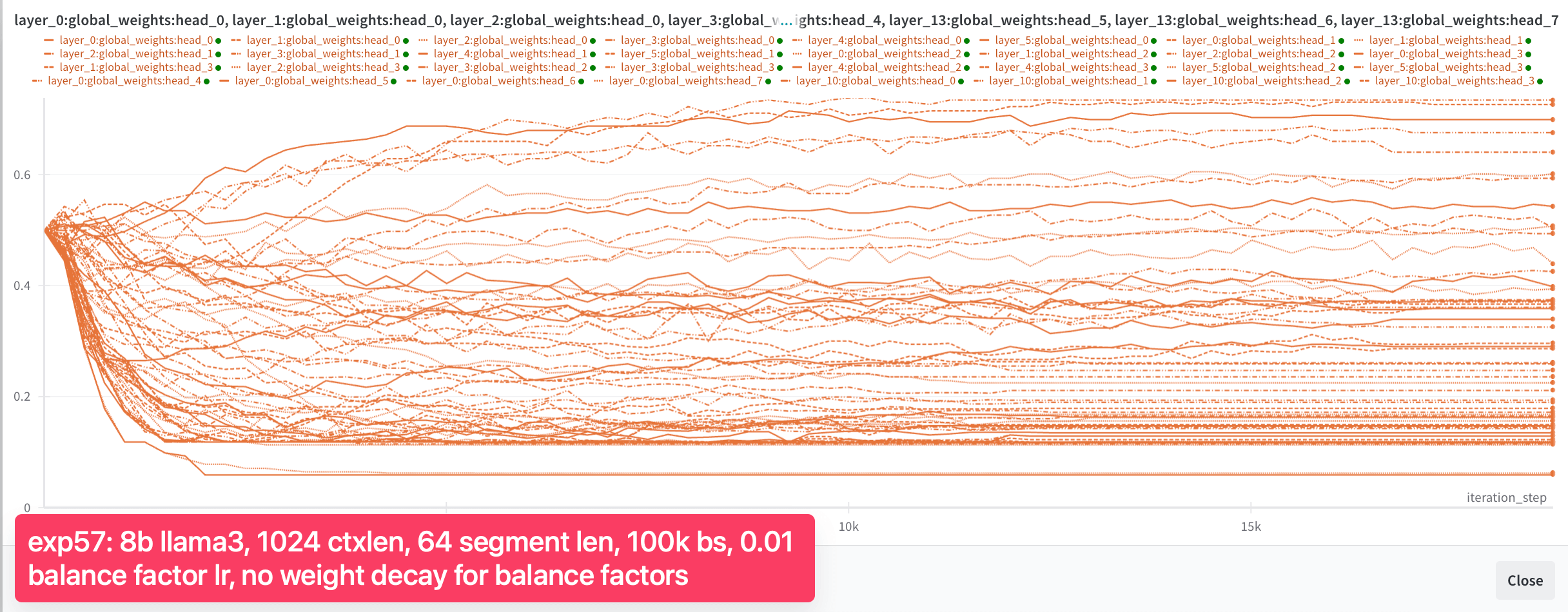
As you can see, global weights are now distributed across the range from 0 to 1, with 10% of heads having a global weight between 0.9 and 1.0, even though after 18k steps, most heads stopped changing their global weights. We were then quite confident that the experiments were setup to allow convergence if the spirits of gradient descent are with us. The only question remaining was whether the general approach of Infini-attention could works well enough.
The following evaluations were run at 1.5B tokens.

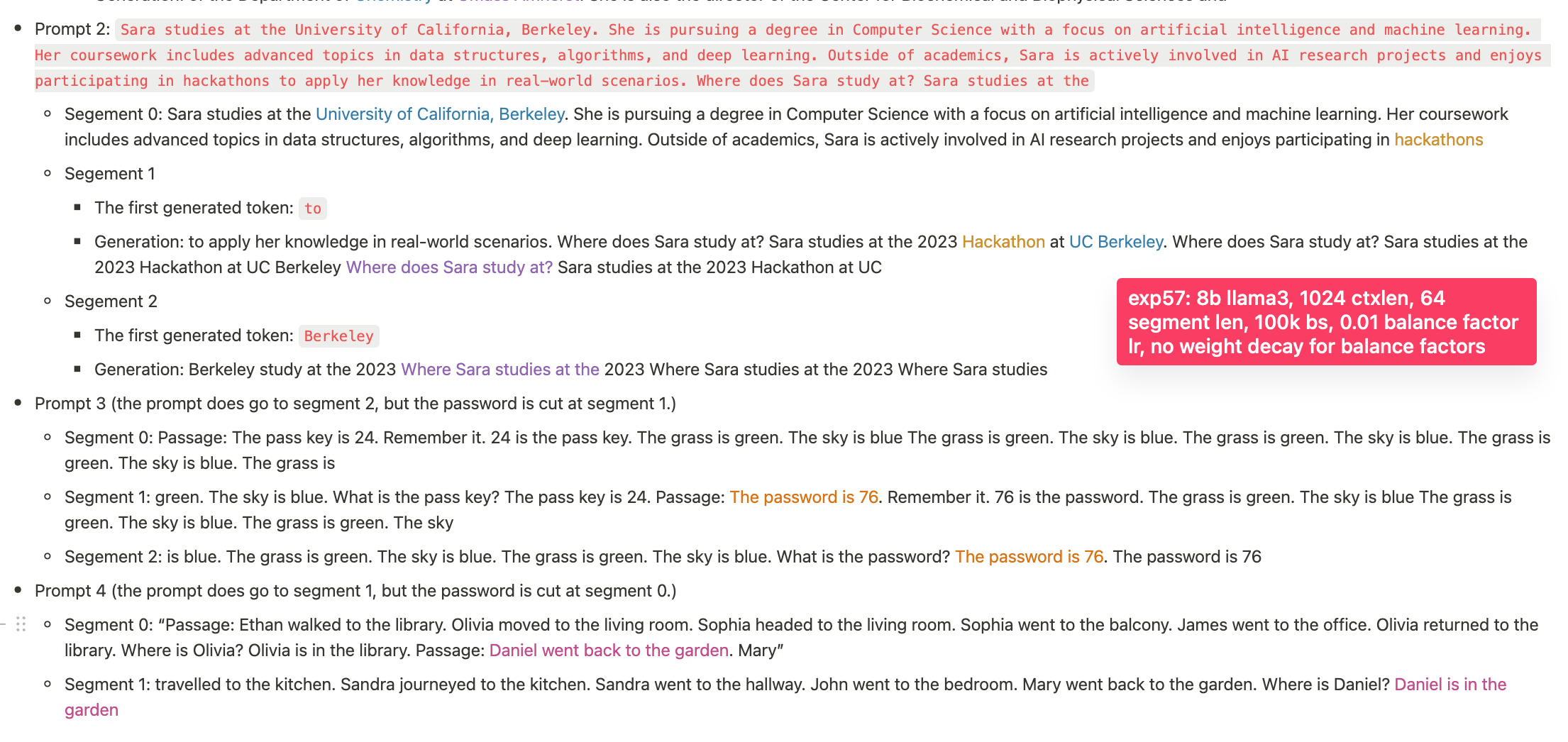
- 0-short: In the prompt 2, it recalls where a person studies (the 8b model yesterday failed at this), but fails at the needle passkey (not comprehensively run yet; will run).
- 1-short
+ Prompt 3: It identifies where a person locates.
+ Prompt 4: It passes the needle pass key
And in this cases, the models continue generating the exact content of earlier segments. (In our previous experiments, the model failed to continue with the exact content of an earlier segment and only generated something approximately related; the new model is thus quite much better already.)
## Section 6: Conclusion
Unfortunately, despite these progress, we found that Infini-attention was not convincing enough in our experiments and in particular not reliable enough. At this stage of our reproduction we are still of the opinion that Ring Attention [[link]](https://x.com/Haojun_Zhao14/status/1815419356408336738), YaRN [[link]](https://arxiv.org/abs/2309.00071) and rope scaling [[link]](https://arxiv.org/abs/2309.16039) are better options for extending a pretrained model to longer context length.
These later technics still come with large resource requirements for very large model sizes (e.g., 400B and beyond). we thus till think that exploring compression techniques or continuing to push the series of experiments we've bee describing in this blog post is of great interest for the community and are are excited to follow and try new techniques that may be developped and overcome some of the limitation of the present work.
**Recaps**
- What it means to train a neural network: give it good data, set up the architecture and training to receive good gradient signals, and allow it to converge.
- Infini-attention's long context performance decreases as the number of times we compresses the memory.
- Gating is important; tweaking the training to allow the gating to converge improves Infini-attention's long context performance (but not good enough).
- Always train a good reference model as a baseline to measure progress.
- There is another bug that messes up the dimensions in the attention output, resulting in a situation where, even though the loss decreases throughout training, the model still can't generate coherent text within its segment length. Lesson learned: Even if you condition the model poorly, gradient descent can still find a way to decrease the loss. However, the model won't work as expected, so always run evaluations.
## Acknowledgements
Thanks to Leandro von Werra and Thomas Wolf for their guidance on the project, and to Tsendsuren Munkhdalai for sharing additional details on the original experiments. We also appreciate Leandro's feedback on the blog post and are grateful to Hugging Face’s science cluster for the compute.
| 0 |
0 | hf_public_repos | hf_public_repos/blog/vit-align.md | ---
title: "New ViT and ALIGN Models From Kakao Brain"
thumbnail: /blog//assets/132_vit_align/thumbnail.png
authors:
- user: adirik
- user: Unso
- user: dylan-m
- user: jun-untitled
---
# Kakao Brain’s Open Source ViT, ALIGN, and the New COYO Text-Image Dataset
Kakao Brain and Hugging Face are excited to release a new open-source image-text dataset [COYO](https://github.com/kakaobrain/coyo-dataset) of 700 million pairs and two new visual language models trained on it, [ViT](https://github.com/kakaobrain/coyo-vit) and [ALIGN](https://github.com/kakaobrain/coyo-align). This is the first time ever the ALIGN model is made public for free and open-source use and the first release of ViT and ALIGN models that come with the train dataset.
Kakao Brain’s ViT and ALIGN models follow the same architecture and hyperparameters as provided in the original respective Google models but are trained on the open source [COYO](https://github.com/kakaobrain/coyo-dataset) dataset. Google’s [ViT](https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html) and [ALIGN](https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html) models, while trained on huge datasets (ViT trained on 300 million images and ALIGN trained on 1.8 billion image-text pairs respectively), cannot be replicated because the datasets are not public. This contribution is particularly valuable to researchers who want to reproduce visual language modeling with access to the data as well. More detailed information on the Kakao ViT and ALIGN models can be found [here](https://huggingface.co/kakaobrain).
This blog will introduce the new [COYO](https://github.com/kakaobrain/coyo-dataset) dataset, Kakao Brain's ViT and ALIGN models, and how to use them! Here are the main takeaways:
* First open-source ALIGN model ever!
* First open ViT and ALIGN models that have been trained on an open-source dataset [COYO](https://github.com/kakaobrain/coyo-dataset)
* Kakao Brain's ViT and ALIGN models perform on-par with the Google versions
* ViT and ALIGN demos are available on HF! You can play with the ViT and ALIGN demos online with image samples of your own choice!
## Performance Comparison
Kakao Brain's released ViT and ALIGN models perform on par and sometimes better than what Google has reported about their implementation. Kakao Brain's `ALIGN-B7-Base` model, while trained on a much fewer pairs (700 million pairs vs 1.8 billion), performs on par with Google's `ALIGN-B7-Base` on the Image KNN classification task and better on MS-COCO retrieval image-to-text, text-to-image tasks. Kakao Brain's `ViT-L/16` performs similarly to Google's `ViT-L/16` when evaluated on ImageNet and ImageNet-ReaL at model resolutions 384 and 512. This means the community can use Kakao Brain's ViT and ALIGN models to replicate Google's ViT and ALIGN releases especially when users require access to the training data. We are excited to see open-source and transparent releases of these model that perform on par with the state of the art!
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/vit-align-performance.png" alt="ViT and ALIGN performance"/>
</center>
</p>
## COYO DATASET
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/coyo-samples.png" alt="COYO samples"/>
</center>
</p>
What's special about these model releases is that the models are trained on the free and accessible COYO dataset. [COYO](https://github.com/kakaobrain/coyo-dataset#dataset-preview) is an image-text dataset of 700 million pairs similar to Google's `ALIGN 1.8B` image-text dataset which is a collection of "noisy" alt-text and image pairs from webpages, but open-source. `COYO-700M` and `ALIGN 1.8B` are "noisy" because minimal filtering was applied. `COYO` is similar to the other open-source image-text dataset, `LAION` but with the following differences. While `LAION` 2B is a much larger dataset of 2 billion English pairs, compared to `COYO`’s 700 million pairs, `COYO` pairs come with more metadata that give users more flexibility and finer-grained control over usage. The following table shows the differences: `COYO` comes equipped with aesthetic scores for all pairs, more robust watermark scores, and face count data.
| COYO | LAION 2B| ALIGN 1.8B |
| :----: | :----: | :----: |
| Image-text similarity score calculated with CLIP ViT-B/32 and ViT-L/14 models, they are provided as metadata but nothing is filtered out so as to avoid possible elimination bias | Image-text similarity score provided with CLIP (ViT-B/32) - only examples above threshold 0.28 | Minimal, Frequency based filtering |
| NSFW filtering on images and text | NSFW filtering on images | [Google Cloud API](https://cloud.google.com/vision) |
| Face recognition (face count) data provided as meta-data | No face recognition data | NA |
| 700 million pairs all English | 2 billion English| 1.8 billion |
| From CC 2020 Oct - 2021 Aug| From CC 2014-2020| NA |
|Aesthetic Score | Aesthetic Score Partial | NA|
|More robust Watermark score | Watermark Score | NA|
|Hugging Face Hub | Hugging Face Hub | Not made public |
| English | English | English? |
## How ViT and ALIGN work
So what do these models do? Let's breifly discuss how the ViT and ALIGN models work.
ViT -- Vision Transformer -- is a vision model [proposed by Google in 2020](https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html) that resembles the text Transformer architecture.
It is a new approach to vision, distinct from convolutional neural nets (CNNs) that have dominated vision tasks since 2012's AlexNet. It is upto four times more computationally efficient than similarly performing CNNs and domain agnostic. ViT takes as input an image which is broken up into a sequence of image patches - just as the text Transformer takes as input a sequence of text - and given position embeddings to each patch to learn the image structure. ViT performance is notable in particular for having an excellent performance-compute trade-off. While some of Google's ViT models are open-source, the JFT-300 million image-label pair dataset they were trained on has not been released publicly. While Kakao Brain's trained on [COYO-Labeled-300M](https://github.com/kakaobrain/coyo-dataset/tree/main/subset/COYO-Labeled-300M), which has been released publicly, and released ViT model performs similarly on various tasks, its code, model, and training data(COYO-Labeled-300M) are made entirely public for reproducibility and open science.
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/vit-architecture.gif" alt="ViT architecture" width="700"/>
</center>
</p>
<p>
<center>
<em>A Visualization of How ViT Works from <a href="https://ai.googleblog.com/2020/12/transformers-for-image-recognition-at.html">Google Blog</a></em>
</center>
</p>
[Google then introduced ALIGN](https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html) -- a Large-scale Image and Noisy Text Embedding model in 2021 -- a visual-language model trained on "noisy" text-image data for various vision and cross-modal tasks such as text-image retrieval. ALIGN has a simple dual-encoder architecture trained on image and text pairs, learned via a contrastive loss function. ALIGN's "noisy" training corpus is notable for balancing scale and robustness. Previously, visual language representational learning had been trained on large-scale datasets with manual labels, which require extensive preprocessing. ALIGN's corpus uses the image alt-text data, text that appears when the image fails to load, as the caption to the image -- resulting in an inevitably noisy, but much larger (1.8 billion pair) dataset that allows ALIGN to perform at SoTA levels on various tasks. Kakao Brain's ALIGN is the first open-source version of this model, trained on the `COYO` dataset and performs better than Google's reported results.
<p>
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/align-architecture.png" width="700" />
</center>
</p>
<p>
<center>
<em>ALIGN Model from <a href="https://ai.googleblog.com/2021/05/align-scaling-up-visual-and-vision.html">Google Blog</a>
</em>
</center>
<p>
## How to use the COYO dataset
We can conveniently download the `COYO` dataset with a single line of code using the 🤗 Datasets library. To preview the `COYO` dataset and learn more about the data curation process and the meta attributes included, head over to the dataset page on the [hub](https://huggingface.co/datasets/kakaobrain/coyo-700m) or the original Git [repository](https://github.com/kakaobrain/coyo-dataset). To get started, let's install the 🤗 Datasets library: `pip install datasets` and download it.
```shell
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m')
>>> dataset
```
While it is significantly smaller than the `LAION` dataset, the `COYO` dataset is still massive with 747M image-text pairs and it might be unfeasible to download the whole dataset to your local. In order to download only a subset of the dataset, we can simply pass in the `streaming=True` argument to the `load_dataset()` method to create an iterable dataset and download data instances as we go.
```shell
>>> from datasets import load_dataset
>>> dataset = load_dataset('kakaobrain/coyo-700m', streaming=True)
>>> print(next(iter(dataset['train'])))
{'id': 2680060225205, 'url': 'https://cdn.shopify.com/s/files/1/0286/3900/2698/products/TVN_Huile-olive-infuse-et-s-227x300_e9a90ffd-b6d2-4118-95a1-29a5c7a05a49_800x.jpg?v=1616684087', 'text': 'Olive oil infused with Tuscany herbs', 'width': 227, 'height': 300, 'image_phash': '9f91e133b1924e4e', 'text_length': 36, 'word_count': 6, 'num_tokens_bert': 6, 'num_tokens_gpt': 9, 'num_faces': 0, 'clip_similarity_vitb32': 0.19921875, 'clip_similarity_vitl14': 0.147216796875, 'nsfw_score_opennsfw2': 0.0058441162109375, 'nsfw_score_gantman': 0.018961310386657715, 'watermark_score': 0.11015450954437256, 'aesthetic_score_laion_v2': 4.871710777282715}
```
## How to use ViT and ALIGN from the Hub
Let’s go ahead and experiment with the new ViT and ALIGN models. As ALIGN is newly added to 🤗 Transformers, we will install the latest version of the library: `pip install -q git+https://github.com/huggingface/transformers.git` and get started with ViT for image classification by importing the modules and libraries we will use. Note that the newly added ALIGN model will be a part of the PyPI package in the next release of the library.
```py
import requests
from PIL import Image
import torch
from transformers import ViTImageProcessor, ViTForImageClassification
```
Next, we will download a random image of two cats and remote controls on a couch from the COCO dataset and preprocess the image to transform it to the input format expected by the model. To do this, we can conveniently use the corresponding preprocessor class (`ViTProcessor`). To initialize the model and the preprocessor, we will use one of the [Kakao Brain ViT repos](https://huggingface.co/models?search=kakaobrain/vit) on the hub. Note that initializing the preprocessor from a repository ensures that the preprocessed image is in the expected format required by that specific pretrained model.
```py
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = ViTImageProcessor.from_pretrained('kakaobrain/vit-large-patch16-384')
model = ViTForImageClassification.from_pretrained('kakaobrain/vit-large-patch16-384')
```
The rest is simple, we will forward preprocess the image and use it as input to the model to retrive the class logits. The Kakao Brain ViT image classification models are trained on ImageNet labels and output logits of shape (batch_size, 1000).
```py
# preprocess image or list of images
inputs = processor(images=image, return_tensors="pt")
# inference
with torch.no_grad():
outputs = model(**inputs)
# apply SoftMax to logits to compute the probability of each class
preds = torch.nn.functional.softmax(outputs.logits, dim=-1)
# print the top 5 class predictions and their probabilities
top_class_preds = torch.argsort(preds, descending=True)[0, :5]
for c in top_class_preds:
print(f"{model.config.id2label[c.item()]} with probability {round(preds[0, c.item()].item(), 4)}")
```
And we are done! To make things even easier and shorter, we can also use the convenient image classification [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.ImageClassificationPipeline) and pass the Kakao Brain ViT repo name as our target model to initialize the pipeline. We can then pass in a URL or a local path to an image or a Pillow image and optionally use the `top_k` argument to return the top k predictions. Let's go ahead and get the top 5 predictions for our image of cats and remotes.
```shell
>>> from transformers import pipeline
>>> classifier = pipeline(task='image-classification', model='kakaobrain/vit-large-patch16-384')
>>> classifier('http://images.cocodataset.org/val2017/000000039769.jpg', top_k=5)
[{'score': 0.8223727941513062, 'label': 'remote control, remote'}, {'score': 0.06580372154712677, 'label': 'tabby, tabby cat'}, {'score': 0.0655883178114891, 'label': 'tiger cat'}, {'score': 0.0388941615819931, 'label': 'Egyptian cat'}, {'score': 0.0011215205304324627, 'label': 'lynx, catamount'}]
```
If you want to experiment more with the Kakao Brain ViT model, head over to its [Space](https://huggingface.co/spaces/adirik/kakao-brain-vit) on the 🤗 Hub.
<center>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/132_vit_align/vit_demo.png" alt="vit performance" width="900"/>
</center>
Let's move on to experimenting with ALIGN, which can be used to retrieve multi-modal embeddings of texts or images or to perform zero-shot image classification. ALIGN's transformers implementation and usage is similar to [CLIP](https://huggingface.co/docs/transformers/main/en/model_doc/clip). To get started, we will first download the pretrained model and its processor, which can preprocess both the images and texts such that they are in the expected format to be fed into the vision and text encoders of ALIGN. Once again, let's import the modules we will use and initialize the preprocessor and the model.
```py
import requests
from PIL import Image
import torch
from transformers import AlignProcessor, AlignModel
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignModel.from_pretrained('kakaobrain/align-base')
```
We will start with zero-shot image classification first. To do this, we will suppy candidate labels (free-form text) and use AlignModel to find out which description better describes the image. We will first preprocess both the image and text inputs and feed the preprocessed input to the AlignModel.
```py
candidate_labels = ['an image of a cat', 'an image of a dog']
inputs = processor(images=image, text=candidate_labels, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# this is the image-text similarity score
logits_per_image = outputs.logits_per_image
# we can take the softmax to get the label probabilities
probs = logits_per_image.softmax(dim=1)
print(probs)
```
Done, easy as that. To experiment more with the Kakao Brain ALIGN model for zero-shot image classification, simply head over to its [demo](https://huggingface.co/spaces/adirik/ALIGN-zero-shot-image-classification) on the 🤗 Hub. Note that, the output of `AlignModel` includes `text_embeds` and `image_embeds` (see the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/align) of ALIGN). If we don't need to compute the per-image and per-text logits for zero-shot classification, we can retrieve the vision and text embeddings using the convenient `get_image_features()` and `get_text_features()` methods of the `AlignModel` class.
```py
text_embeds = model.get_text_features(
input_ids=inputs['input_ids'],
attention_mask=inputs['attention_mask'],
token_type_ids=inputs['token_type_ids'],
)
image_embeds = model.get_image_features(
pixel_values=inputs['pixel_values'],
)
```
Alternatively, we can use the stand-along vision and text encoders of ALIGN to retrieve multi-modal embeddings. These embeddings can then be used to train models for various downstream tasks such as object detection, image segmentation and image captioning. Let's see how we can retrieve these embeddings using `AlignTextModel` and `AlignVisionModel`. Note that we can use the convenient AlignProcessor class to preprocess texts and images separately.
```py
from transformers import AlignTextModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignTextModel.from_pretrained('kakaobrain/align-base')
# get embeddings of two text queries
inputs = processor(['an image of a cat', 'an image of a dog'], return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# get the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
```
We can also opt to return all hidden states and attention values by setting the output_hidden_states and output_attentions arguments to True during inference.
```py
with torch.no_grad():
outputs = model(**inputs, output_hidden_states=True, output_attentions=True)
# print what information is returned
for key, value in outputs.items():
print(key)
```
Let's do the same with `AlignVisionModel` and retrieve the multi-modal embedding of an image.
```py
from transformers import AlignVisionModel
processor = AlignProcessor.from_pretrained('kakaobrain/align-base')
model = AlignVisionModel.from_pretrained('kakaobrain/align-base')
url = 'http://images.cocodataset.org/val2017/000000039769.jpg'
image = Image.open(requests.get(url, stream=True).raw)
inputs = processor(images=image, return_tensors='pt')
with torch.no_grad():
outputs = model(**inputs)
# print the last hidden state and the final pooled output
last_hidden_state = outputs.last_hidden_state
pooled_output = outputs.pooler_output
```
Similar to ViT, we can use the zero-shot image classification [pipeline](https://huggingface.co/docs/transformers/main_classes/pipelines#transformers.ZeroShotImageClassificationPipeline) to make our work even easier. Let's see how we can use this pipeline to perform image classification in the wild using free-form text candidate labels.
```shell
>>> from transformers import pipeline
>>> classifier = pipeline(task='zero-shot-image-classification', model='kakaobrain/align-base')
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['animals', 'humans', 'landscape'],
... )
[{'score': 0.9263709783554077, 'label': 'animals'}, {'score': 0.07163811475038528, 'label': 'humans'}, {'score': 0.0019908479880541563, 'label': 'landscape'}]
>>> classifier(
... 'https://huggingface.co/datasets/Narsil/image_dummy/raw/main/parrots.png',
... candidate_labels=['black and white', 'photorealist', 'painting'],
... )
[{'score': 0.9735308885574341, 'label': 'black and white'}, {'score': 0.025493400171399117, 'label': 'photorealist'}, {'score': 0.0009757201769389212, 'label': 'painting'}]
```
## Conclusion
There have been incredible advances in multi-modal models in recent years, with models such as CLIP and ALIGN unlocking various downstream tasks such as image captioning, zero-shot image classification, and open vocabulary object detection. In this blog, we talked about the latest open source ViT and ALIGN models contributed to the Hub by Kakao Brain, as well as the new COYO text-image dataset. We also showed how you can use these models to perform various tasks with a few lines of code both on their own or as a part of 🤗 Transformers pipelines.
That was it! We are continuing to integrate the most impactful computer vision and multi-modal models and would love to hear back from you. To stay up to date with the latest news in computer vision and multi-modal research, you can follow us on Twitter: [@adirik](https://twitter.com/https://twitter.com/alaradirik), [@a_e_roberts](https://twitter.com/a_e_roberts), [@NielsRogge](https://twitter.com/NielsRogge), [@RisingSayak](https://twitter.com/RisingSayak), and [@huggingface](https://twitter.com/huggingface).
| 1 |
0 | hf_public_repos | hf_public_repos/blog/gaussian-splatting.md | ---
title: "Introduction to 3D Gaussian Splatting"
thumbnail: /blog/assets/124_ml-for-games/thumbnail-gaussian-splatting.png
authors:
- user: dylanebert
---
# Introduction to 3D Gaussian Splatting
3D Gaussian Splatting is a rasterization technique described in [3D Gaussian Splatting for Real-Time Radiance Field Rendering](https://huggingface.co/papers/2308.04079) that allows real-time rendering of photorealistic scenes learned from small samples of images. This article will break down how it works and what it means for the future of graphics.
## What is 3D Gaussian Splatting?
3D Gaussian Splatting is, at its core, a rasterization technique. That means:
1. Have data describing the scene.
2. Draw the data on the screen.
This is analogous to triangle rasterization in computer graphics, which is used to draw many triangles on the screen.

However, instead of triangles, it's gaussians. Here's a single rasterized gaussian, with a border drawn for clarity.

It's described by the following parameters:
- **Position**: where it's located (XYZ)
- **Covariance**: how it's stretched/scaled (3x3 matrix)
- **Color**: what color it is (RGB)
- **Alpha**: how transparent it is (α)
In practice, multiple gaussians are drawn at once.
That's three gaussians. Now what about 7 million gaussians?

Here's what it looks like with each gaussian rasterized fully opaque:

That's a very brief overview of what 3D Gaussian Splatting is. Next, let's walk through the full procedure described in the paper.
## How it works
### 1. Structure from Motion
The first step is to use the Structure from Motion (SfM) method to estimate a point cloud from a set of images. This is a method for estimating a 3D point cloud from a set of 2D images. This can be done with the [COLMAP](https://colmap.github.io/) library.

### 2. Convert to Gaussians
Next, each point is converted to a gaussian. This is already sufficient for rasterization. However, only position and color can be inferred from the SfM data. To learn a representation that yields high quality results, we need to train it.
### 3. Training
The training procedure uses Stochastic Gradient Descent, similar to a neural network, but without the layers. The training steps are:
1. Rasterize the gaussians to an image using differentiable gaussian rasterization (more on that later)
2. Calculate the loss based on the difference between the rasterized image and ground truth image
3. Adjust the gaussian parameters according to the loss
4. Apply automated densification and pruning
Steps 1-3 are conceptually pretty straightforward. Step 4 involves the following:
- If the gradient is large for a given gaussian (i.e. it's too wrong), split/clone it
- If the gaussian is small, clone it
- If the gaussian is large, split it
- If the alpha of a gaussian gets too low, remove it
This procedure helps the gaussians better fit fine-grained details, while pruning unnecessary gaussians.
### 4. Differentiable Gaussian Rasterization
As mentioned earlier, 3D Gaussian Splatting is a *rasterization* approach, which draws the data to the screen. However, some important elements are also that it's:
1. Fast
2. Differentiable
The original implementation of the rasterizer can be found [here](https://github.com/graphdeco-inria/diff-gaussian-rasterization). The rasterization involves:
1. Project each gaussian into 2D from the camera perspective.
2. Sort the gaussians by depth.
3. For each pixel, iterate over each gaussian front-to-back, blending them together.
Additional optimizations are described in [the paper](https://huggingface.co/papers/2308.04079).
It's also essential that the rasterizer is differentiable, so that it can be trained with stochastic gradient descent. However, this is only relevant for training - the trained gaussians can also be rendered with a non-differentiable approach.
## Who cares?
Why has there been so much attention on 3D Gaussian Splatting? The obvious answer is that the results speak for themselves - it's high-quality scenes in real-time. However, there may be more to the story.
There are many unknowns as to what else can be done with Gaussian Splatting. Can they be animated? The upcoming paper [Dynamic 3D Gaussians: tracking by Persistent Dynamic View Synthesis](https://arxiv.org/pdf/2308.09713) suggests that they can. There are many other unknowns as well. Can they do reflections? Can they be modeled without training on reference images?
Finally, there is growing research interest in [Embodied AI](https://ieeexplore.ieee.org/iel7/7433297/9741092/09687596.pdf). This is an area of AI research where state-of-the-art performance is still orders of magnitude below human performance, with much of the challenge being in representing 3D space. Given that 3D Gaussian Splatting yields a very dense representation of 3D space, what might the implications be for Embodied AI research?
These questions call attention to the method. It remains to be seen what the actual impact will be.
## The future of graphics
So what does this mean for the future of graphics? Well, let's break it up into pros/cons:
**Pros**
1. High-quality, photorealistic scenes
2. Fast, real-time rasterization
3. Relatively fast to train
**Cons**
1. High VRAM usage (4GB to view, 12GB to train)
2. Large disk size (1GB+ for a scene)
3. Incompatible with existing rendering pipelines
3. Static (for now)
So far, the original CUDA implementation has not been adapted to production rendering pipelines, like Vulkan, DirectX, WebGPU, etc, so it's yet to be seen what the impact will be.
There have already been the following adaptations:
1. [Remote viewer](https://huggingface.co/spaces/dylanebert/gaussian-viewer)
2. [WebGPU viewer](https://github.com/cvlab-epfl/gaussian-splatting-web)
3. [WebGL viewer](https://huggingface.co/spaces/cakewalk/splat)
4. [Unity viewer](https://github.com/aras-p/UnityGaussianSplatting)
5. [Optimized WebGL viewer](https://gsplat.tech/)
These rely either on remote streaming (1) or a traditional quad-based rasterization approach (2-5). While a quad-based approach is compatible with decades of graphics technologies, it may result in lower quality/performance. However, [viewer #5](https://gsplat.tech/) demonstrates that optimization tricks can result in high quality/performance, despite a quad-based approach.
So will we see 3D Gaussian Splatting fully reimplemented in a production environment? The answer is *probably yes*. The primary bottleneck is sorting millions of gaussians, which is done efficiently in the original implementation using [CUB device radix sort](https://nvlabs.github.io/cub/structcub_1_1_device_radix_sort.html), a highly optimized sort only available in CUDA. However, with enough effort, it's certainly possible to achieve this level of performance in other rendering pipelines.
If you have any questions or would like to get involved, join the [Hugging Face Discord](https://hf.co/join/discord)!
| 2 |
0 | hf_public_repos | hf_public_repos/blog/policy-blog.md | ---
title: "Public Policy at Hugging Face"
thumbnail: /blog/assets/policy_docs/policy_blog_thumbnail.png
authors:
- user: irenesolaiman
- user: yjernite
- user: meg
- user: evijit
---
# Public Policy at Hugging Face
AI Policy at Hugging Face is a multidisciplinary and cross-organizational workstream. Instead of being part of a vertical communications or global affairs organization, our policy work is rooted in the expertise of our many researchers and developers, from [Ethics and Society Regulars](https://huggingface.co/blog/ethics-soc-1) and the legal team to machine learning engineers working on healthcare, art, and evaluations.
What we work on is informed by our Hugging Face community needs and experiences on the Hub. We champion [responsible openness](https://huggingface.co/blog/ethics-soc-3), investing heavily in [ethics-forward research](https://huggingface.co/spaces/society-ethics/about), [transparency mechanisms](https://huggingface.co/blog/model-cards), [platform safeguards](https://huggingface.co/content-guidelines), and translate our lessons to policy.
So what have we shared with policymakers?
## Policy Materials
The following materials reflect what we have found urgent to stress to policymakers at the time of requests for information, and will be updated as materials are published.
- United States of America
- Congressional
- September 2023: [Clement Delangue (CEO) Senate AI Insight Forum Kickoff Statement](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2023_AI%20Insight%20Forum%20Kickoff%20Written%20Statement.pdf)
- June 2023: Clement Delangue (CEO) House Committee on Science, Space, and Technology Testimony
- [Written statement](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2023_HCSST_CongressionalTestimony.pdf)
- View [recorded testimony](https://science.house.gov/2023/6/artificial-intelligence-advancing-innovation-towards-the-national-interest)
- November 2023: [Dr. Margaret Mitchell (Chief Ethics Scientist) Senate Insight Forum Statement](https://www.schumer.senate.gov/imo/media/doc/Margaret%20Mitchell%20-%20Statement.pdf)
- Executive
- September 2024: Response to NIST [RFC on AI 800-1: Managing Misuse Risk for Dual-Use Foundational Models](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2024_AISI_Dual_Use_Foundational_Models_Response.pdf)
- June 2024: Response to NIST [RFC on AI 600-1: Artificial Intelligence Risk Management Framework: Generative Artificial Intelligence Profile](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2024_NIST_GENAI_Response.pdf)
- March 2024: Response to NTIA [RFC on Dual Use Foundation Artificial Intelligence Models with Widely Available Model Weights](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2024_NTIA_Response.pdf)
- February 2024: Response to NIST [RFI Assignments Under Sections 4.1, 4.5 and 11 of the Executive Order Concerning Artificial Intelligence](https://huggingface.co/datasets/huggingface/policy-docs/blob/main/2024_NIST%20RFI%20on%20EO.pdf)
- December 2023: Response to OMB [RFC Agency Use of Artificial Intelligence](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2023_OMB%20EO%20RFC.pdf)
- November 2023: Response to U.S. Copyright Office [Notice of Inquiry on Artificial Intelligence and Copyright](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2023_Copyright_Response.pdf)
- June 2023: Response to NTIA [RFC on AI Accountability](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2023_NTIA_Response.pdf)
- September 2022: Response to NIST [AI Risk Management Framework]](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2022_NIST_RMF_Response.pdf)
- June 2022: Response to NAIRR [Implementing Findings from the National Artificial Intelligence Research Resource Task Force](https://huggingface.co/blog/assets/92_us_national_ai_research_resource/Hugging_Face_NAIRR_RFI_2022.pdf)
- European Union
- January 2024: Response to [Digital Services Act, Transparency Reports](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2024_DSA_Response.pdf)
- July 2023: Comments on the [Proposed AI Act](https://huggingface.co/blog/assets/eu_ai_act_oss/supporting_OS_in_the_AIAct.pdf)
- United Kingdom
- November 2023: Irene Solaiman (Head of Global Policy) [oral evidence to UK Parliament House of Lords transcript](https://committees.parliament.uk/oralevidence/13802/default/)
- September 2023: Response to [UK Parliament: UK Parliament RFI: LLMs](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2023_UK%20Parliament%20RFI%20LLMs.pdf)
- June 2023: Response to [No 10: UK RFI: AI Regulatory Innovation White Paper](https://huggingface.co/datasets/huggingface/policy-docs/resolve/main/2023_UK_RFI_AI_Regulatory_Innovation_White_Paper.pdf)
| 3 |
0 | hf_public_repos | hf_public_repos/blog/mixtral.md | ---
title: "Welcome Mixtral - a SOTA Mixture of Experts on Hugging Face"
thumbnail: /blog/assets/mixtral/thumbnail.jpg
authors:
- user: lewtun
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: olivierdehaene
- user: lvwerra
- user: ybelkada
---
# Welcome Mixtral - a SOTA Mixture of Experts on Hugging Face
Mixtral 8x7b is an exciting large language model released by Mistral today, which sets a new state-of-the-art for open-access models and outperforms GPT-3.5 across many benchmarks. We’re excited to support the launch with a comprehensive integration of Mixtral in the Hugging Face ecosystem 🔥!
Among the features and integrations being released today, we have:
- [Models on the Hub](https://huggingface.co/models?search=mistralai/Mixtral), with their model cards and licenses (Apache 2.0)
- [🤗 Transformers integration](https://github.com/huggingface/transformers/releases/tag/v4.36.0)
- Integration with Inference Endpoints
- Integration with [Text Generation Inference](https://github.com/huggingface/text-generation-inference) for fast and efficient production-ready inference
- An example of fine-tuning Mixtral on a single GPU with 🤗 TRL.
## Table of Contents
- [What is Mixtral 8x7b](#what-is-mixtral-8x7b)
- [About the name](#about-the-name)
- [Prompt format](#prompt-format)
- [What we don't know](#what-we-dont-know)
- [Demo](#demo)
- [Inference](#inference)
- [Using 🤗 Transformers](#using-🤗-transformers)
- [Using Text Generation Inference](#using-text-generation-inference)
- [Fine-tuning with 🤗 TRL](#fine-tuning-with-🤗-trl)
- [Quantizing Mixtral](#quantizing-mixtral)
- [Load Mixtral with 4-bit quantization](#load-mixtral-with-4-bit-quantization)
- [Load Mixtral with GPTQ](#load-mixtral-with-gptq)
- [Disclaimers and ongoing work](#disclaimers-and-ongoing-work)
- [Additional Resources](#additional-resources)
- [Conclusion](#conclusion)
## What is Mixtral 8x7b?
Mixtral has a similar architecture to Mistral 7B, but comes with a twist: it’s actually 8 “expert” models in one, thanks to a technique called Mixture of Experts (MoE). For transformers models, the way this works is by replacing some Feed-Forward layers with a sparse MoE layer. A MoE layer contains a router network to select which experts process which tokens most efficiently. In the case of Mixtral, two experts are selected for each timestep, which allows the model to decode at the speed of a 12B parameter-dense model, despite containing 4x the number of effective parameters!
For more details on MoEs, see our accompanying blog post: [hf.co/blog/moe](https://huggingface.co/blog/moe)
**Mixtral release TL;DR;**
- Release of base and Instruct versions
- Supports a context length of 32k tokens.
- Outperforms Llama 2 70B and matches or beats GPT3.5 on most benchmarks
- Speaks English, French, German, Spanish, and Italian.
- Good at coding, with 40.2% on HumanEval
- Commercially permissive with an Apache 2.0 license
So how good are the Mixtral models? Here’s an overview of the base model and its performance compared to other open models on the [LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) (higher scores are better):
| Model | License | Commercial use? | Pretraining size [tokens] | Leaderboard score ⬇️ |
| --------------------------------------------------------------------------------- | --------------- | --------------- | ------------------------- | -------------------- |
| [mistralai/Mixtral-8x7B-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) | Apache 2.0 | ✅ | unknown | 68.42 |
| [meta-llama/Llama-2-70b-hf](https://huggingface.co/meta-llama/Llama-2-70b-hf) | Llama 2 license | ✅ | 2,000B | 67.87 |
| [tiiuae/falcon-40b](https://huggingface.co/tiiuae/falcon-40b) | Apache 2.0 | ✅ | 1,000B | 61.5 |
| [mistralai/Mistral-7B-v0.1](https://huggingface.co/mistralai/Mistral-7B-v0.1) | Apache 2.0 | ✅ | unknown | 60.97 |
| [meta-llama/Llama-2-7b-hf](https://huggingface.co/meta-llama/Llama-2-7b-hf) | Llama 2 license | ✅ | 2,000B | 54.32 |
For instruct and chat models, evaluating on benchmarks like MT-Bench or AlpacaEval is better. Below, we show how [Mixtral Instruct](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) performs up against the top closed and open access models (higher scores are better):
| Model | Availability | Context window (tokens) | MT-Bench score ⬇️ |
| --------------------------------------------------------------------------------------------------- | --------------- | ----------------------- | ---------------- |
| [GPT-4 Turbo](https://openai.com/blog/new-models-and-developer-products-announced-at-devday) | Proprietary | 128k | 9.32 |
| [GPT-3.5-turbo-0613](https://platform.openai.com/docs/models/gpt-3-5) | Proprietary | 16k | 8.32 |
| [mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) | Apache 2.0 | 32k | 8.30 |
| [Claude 2.1](https://www.anthropic.com/index/claude-2-1) | Proprietary | 200k | 8.18 |
| [openchat/openchat_3.5](https://huggingface.co/openchat/openchat_3.5) | Apache 2.0 | 8k | 7.81 |
| [HuggingFaceH4/zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) | MIT | 8k | 7.34 |
| [meta-llama/Llama-2-70b-chat-hf](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) | Llama 2 license | 4k | 6.86 |
Impressively, Mixtral Instruct outperforms all other open-access models on MT-Bench and is the first one to achieve comparable performance with GPT-3.5!
### About the name
The Mixtral MoE is called **Mixtral-8x7B**, but it doesn't have 56B parameters. Shortly after the release, we found that some people were misled into thinking that the model behaves similarly to an ensemble of 8 models with 7B parameters each, but that's not how MoE models work. Only some layers of the model (the feed-forward blocks) are replicated; the rest of the parameters are the same as in a 7B model. The total number of parameters is not 56B, but about 45B. A better name [could have been `Mixtral-45-8e`](https://twitter.com/osanseviero/status/1734248798749159874) to better convey the architecture. For more details about how MoE works, please refer to [our "Mixture of Experts Explained" post](https://huggingface.co/blog/moe).
### Prompt format
The [base model](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1) has no prompt format. Like other base models, it can be used to continue an input sequence with a plausible continuation or for zero-shot/few-shot inference. It’s also a great foundation for fine-tuning your own use case. The [Instruct model](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) has a very simple conversation structure.
```bash
<s> [INST] User Instruction 1 [/INST] Model answer 1</s> [INST] User instruction 2[/INST]
```
This format has to be exactly reproduced for effective use. We’ll show later how easy it is to reproduce the instruct prompt with the chat template available in `transformers`.
### What we don't know
Like the previous Mistral 7B release, there are several open questions about this new series of models. In particular, we have no information about the size of the dataset used for pretraining, its composition, or how it was preprocessed.
Similarly, for the Mixtral instruct model, no details have been shared about the fine-tuning datasets or the hyperparameters associated with SFT and DPO.
## Demo
You can chat with the Mixtral Instruct model on Hugging Face Chat! Check it out here: [https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1).
## Inference
We provide two main ways to run inference with Mixtral models:
- Via the `pipeline()` function of 🤗 Transformers.
- With Text Generation Inference, which supports advanced features like continuous batching, tensor parallelism, and more, for blazing fast results.
For each method, it is possible to run the model in half-precision (float16) or with quantized weights. Since the Mixtral model is roughly equivalent in size to a 45B parameter dense model, we can estimate the minimum amount of VRAM needed as follows:
| Precision | Required VRAM |
| --------- | ------------- |
| float16 | >90 GB |
| 8-bit | >45 GB |
| 4-bit | >23 GB |
### Using 🤗 Transformers
With transformers [release 4.36](https://github.com/huggingface/transformers/releases/tag/v4.36.0), you can use Mixtral and leverage all the tools within the Hugging Face ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning), and Flash Attention 2
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
Make sure to use a recent version of `transformers`:
```bash
pip install --upgrade transformers
```
In the following code snippet, we show how to run inference with 🤗 Transformers and 4-bit quantization. Due to the large size of the model, you’ll need a card with at least 30 GB of RAM to run it. This includes cards such as A100 (80 or 40GB versions), or A6000 (48 GB).
```python
from transformers import pipeline
import torch
model = "mistralai/Mixtral-8x7B-Instruct-v0.1"
pipe = pipeline(
"text-generation",
model=model,
model_kwargs={"torch_dtype": torch.float16, "load_in_4bit": True},
)
messages = [{"role": "user", "content": "Explain what a Mixture of Experts is in less than 100 words."}]
outputs = pipe(messages, max_new_tokens=256, do_sample=True, temperature=0.7, top_k=50, top_p=0.95)
print(outputs[0]["generated_text"][-1]["content"])
```
> \<s>[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST] A
Mixture of Experts is an ensemble learning method that combines multiple models,
or "experts," to make more accurate predictions. Each expert specializes in a
different subset of the data, and a gating network determines the appropriate
expert to use for a given input. This approach allows the model to adapt to
complex, non-linear relationships in the data and improve overall performance.
>
### Using Text Generation Inference
**[Text Generation Inference](https://github.com/huggingface/text-generation-inference)** is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
You can deploy Mixtral on Hugging Face's [Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=mistralai%2FMixtral-8x7B-Instruct-v0.1&vendor=aws®ion=us-east-1&accelerator=gpu&instance_size=2xlarge&task=text-generation&no_suggested_compute=true&tgi=true&tgi_max_batch_total_tokens=1024000&tgi_max_total_tokens=32000), which uses Text Generation Inference as the backend. To deploy a Mixtral model, go to the [model page](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) and click on the [Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=meta-llama/Llama-2-7b-hf) widget.
*Note: You might need to request a quota upgrade via email to **[[email protected]](mailto:[email protected])** to access A100s*
You can learn more on how to **[Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm)**. The **[blog](https://huggingface.co/blog/inference-endpoints-llm)** includes information about supported hyperparameters and how to stream your response using Python and Javascript.
You can also run Text Generation Inference locally on 2x A100s (80GB) with Docker as follows:
```bash
docker run --gpus all --shm-size 1g -p 3000:80 -v /data:/data ghcr.io/huggingface/text-generation-inference:1.3.0 \
--model-id mistralai/Mixtral-8x7B-Instruct-v0.1 \
--num-shard 2 \
--max-batch-total-tokens 1024000 \
--max-total-tokens 32000
```
## Fine-tuning with 🤗 TRL
Training LLMs can be technically and computationally challenging. In this section, we look at the tools available in the Hugging Face ecosystem to efficiently train Mixtral on a single A100 GPU.
An example command to fine-tune Mixtral on OpenAssistant’s [chat dataset](https://huggingface.co/datasets/OpenAssistant/oasst_top1_2023-08-25) can be found below. To conserve memory, we make use of 4-bit quantization and [QLoRA](https://arxiv.org/abs/2305.14314) to target all the linear layers in the attention blocks. Note that unlike dense transformers, one should not target the MLP layers as they are sparse and don’t interact well with PEFT.
First, install the nightly version of 🤗 TRL and clone the repo to access the [training script](https://github.com/huggingface/trl/blob/main/examples/scripts/sft.py):
```bash
pip install -U transformers
pip install git+https://github.com/huggingface/trl
git clone https://github.com/huggingface/trl
cd trl
```
Then you can run the script:
```bash
accelerate launch --config_file examples/accelerate_configs/multi_gpu.yaml --num_processes=1 \
examples/scripts/sft.py \
--model_name mistralai/Mixtral-8x7B-v0.1 \
--dataset_name trl-lib/ultrachat_200k_chatml \
--batch_size 2 \
--gradient_accumulation_steps 1 \
--learning_rate 2e-4 \
--save_steps 200_000 \
--use_peft \
--peft_lora_r 16 --peft_lora_alpha 32 \
--target_modules q_proj k_proj v_proj o_proj \
--load_in_4bit
```
This takes about 48 hours to train on a single A100, but can be easily parallelised by tweaking `--num_processes` to the number of GPUs you have available.
## Quantizing Mixtral
As seen above, the challenge for this model is to make it run on consumer-type hardware for anyone to use it, as the model requires ~90GB just to be loaded in half-precision (`torch.float16`).
With the 🤗 transformers library, we support out-of-the-box inference with state-of-the-art quantization methods such as QLoRA and GPTQ. You can read more about the quantization methods we support in the [appropriate documentation section](https://huggingface.co/docs/transformers/quantization).
### Load Mixtral with 4-bit quantization
As demonstrated in the inference section, you can load Mixtral with 4-bit quantization by installing the `bitsandbytes` library (`pip install -U bitsandbytes`) and passing the flag `load_in_4bit=True` to the `from_pretrained` method. For better performance, we advise users to load the model with `bnb_4bit_compute_dtype=torch.float16`. Note you need a GPU device with at least 30GB VRAM to properly run the snippet below.
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "mistralai/Mixtral-8x7B-Instruct-v0.1"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_compute_dtype=torch.float16
)
model = AutoModelForCausalLM.from_pretrained(model_id, quantization_config=quantization_config)
prompt = "[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
This 4-bit quantization technique was introduced in the [QLoRA paper](https://huggingface.co/papers/2305.14314), you can read more about it in the corresponding section of [the documentation](https://huggingface.co/docs/transformers/quantization#4-bit) or in [this post](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
### Load Mixtral with GPTQ
The GPTQ algorithm is a post-training quantization technique where each row of the weight matrix is quantized independently to find a version of the weights that minimizes the error. These weights are quantized to int4, but they’re restored to fp16 on the fly during inference. In contrast with 4-bit QLoRA, GPTQ needs the model to be calibrated with a dataset in order to be quantized. Ready-to-use GPTQ models are shared on the 🤗 Hub by [TheBloke](https://huggingface.co/TheBloke), so anyone can use them without having to calibrate them first.
For Mixtral, we had to tweak the calibration approach by making sure we **do not** quantize the expert gating layers for better performance. The final perplexity (lower is better) of the quantized model is `4.40` vs `4.25` for the half-precision model. The quantized model can be found [here](https://huggingface.co/TheBloke/Mixtral-8x7B-v0.1-GPTQ), and to run it with 🤗 transformers you first need to update the `auto-gptq` and `optimum` libraries:
```bash
pip install -U optimum auto-gptq
```
You also need to install transformers from source:
```bash
pip install -U git+https://github.com/huggingface/transformers.git
```
Once installed, simply load the GPTQ model with the `from_pretrained` method:
```python
import torch
from transformers import AutoTokenizer, AutoModelForCausalLM, BitsAndBytesConfig
model_id = "TheBloke/Mixtral-8x7B-v0.1-GPTQ"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(model_id, device_map="auto")
prompt = "[INST] Explain what a Mixture of Experts is in less than 100 words. [/INST]"
inputs = tokenizer(prompt, return_tensors="pt").to(0)
output = model.generate(**inputs, max_new_tokens=50)
print(tokenizer.decode(output[0], skip_special_tokens=True))
```
Note that for both QLoRA and GPTQ you need at least 30 GB of GPU VRAM to fit the model. You can make it work with 24 GB if you use `device_map="auto"`, like in the example above, so some layers are offloaded to CPU.
## Disclaimers and ongoing work
- **Quantization**: Quantization of MoEs is an active area of research. Some initial experiments we've done with TheBloke are shown above, but we expect more progress as this architecture is known better! It will be exciting to see the development in the coming days and weeks in this area. Additionally, recent work such as [QMoE](https://arxiv.org/abs/2310.16795), which achieves sub-1-bit quantization for MoEs, could be applied here.
- **High VRAM usage**: MoEs run inference very quickly but still need a large amount of VRAM (and hence an expensive GPU). This makes it challenging to use it in local setups. MoEs are great for setups with many devices and large VRAM. Mixtral requires 90GB of VRAM in half-precision 🤯
## Additional Resources
- [Mixture of Experts Explained](https://huggingface.co/blog/moe)
- [Mixtral of experts](https://mistral.ai/news/mixtral-of-experts/)
- [Models on the Hub](https://huggingface.co/models?other=mixtral)
- [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [Chat demo on Hugging Chat](https://huggingface.co/chat/?model=mistralai/Mixtral-8x7B-Instruct-v0.1)
## Conclusion
We're very excited about Mixtral being released! In the coming days, be ready to learn more about ways to fine-tune and deploy Mixtral.
| 4 |
0 | hf_public_repos | hf_public_repos/blog/time-series-transformers.md | ---
title: "Probabilistic Time Series Forecasting with 🤗 Transformers"
thumbnail: /blog/assets/118_time-series-transformers/thumbnail.png
authors:
- user: nielsr
- user: kashif
---
# Probabilistic Time Series Forecasting with 🤗 Transformers
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
## Introduction
Time series forecasting is an essential scientific and business problem and as such has also seen a lot of innovation recently with the use of [deep learning based](https://dl.acm.org/doi/abs/10.1145/3533382) models in addition to the [classical methods](https://otexts.com/fpp3/). An important difference between classical methods like ARIMA and novel deep learning methods is the following.
## Probabilistic Forecasting
Typically, classical methods are fitted on each time series in a dataset individually. These are often referred to as "single" or "local" methods. However, when dealing with a large amount of time series for some applications, it is beneficial to train a "global" model on all available time series, which enables the model to learn latent representations from many different sources.
Some classical methods are point-valued (meaning, they just output a single value per time step) and models are trained by minimizing an L2 or L1 type of loss with respect to the ground truth data. However, since forecasts are often used in some real-world decision making pipeline, even with humans in the loop, it is much more beneficial to provide the uncertainties of predictions. This is also called "probabilistic forecasting", as opposed to "point forecasting". This entails modeling a probabilistic distribution, from which one can sample.
So in short, rather than training local point forecasting models, we hope to train **global probabilistic** models. Deep learning is a great fit for this, as neural networks can learn representations from several related time series as well as model the uncertainty of the data.
It is common in the probabilistic setting to learn the future parameters of some chosen parametric distribution, like Gaussian or Student-T; or learn the conditional quantile function; or use the framework of Conformal Prediction adapted to the time series setting. The choice of method does not affect the modeling aspect and thus can be typically thought of as yet another hyperparameter. One can always turn a probabilistic model into a point-forecasting model, by taking empirical means or medians.
## The Time Series Transformer
In terms of modeling time series data which are sequential in nature, as one can imagine, researchers have come up with models which use Recurrent Neural Networks (RNN) like LSTM or GRU, or Convolutional Networks (CNN), and more recently Transformer based methods which fit naturally to the time series forecasting setting.
In this blog post, we're going to leverage the vanilla Transformer [(Vaswani et al., 2017)](https://arxiv.org/abs/1706.03762) for the **univariate** probabilistic forecasting task (i.e. predicting each time series' 1-d distribution individually). The Encoder-Decoder Transformer is a natural choice for forecasting as it encapsulates several inductive biases nicely.
To begin with, the use of an Encoder-Decoder architecture is helpful at inference time where typically for some logged data we wish to forecast some prediction steps into the future. This can be thought of as analogous to the text generation task where given some context, we sample the next token and pass it back into the decoder (also called "autoregressive generation"). Similarly here we can also, given some distribution type, sample from it to provide forecasts up until our desired prediction horizon. This is known as Greedy Sampling/Search and there is a great blog post about it [here](https://huggingface.co/blog/how-to-generate) for the NLP setting.
Secondly, a Transformer helps us to train on time series data which might contain thousands of time points. It might not be feasible to input *all* the history of a time series at once to the model, due to the time- and memory constraints of the attention mechanism. Thus, one can consider some appropriate context window and sample this window and the subsequent prediction length sized window from the training data when constructing batches for stochastic gradient descent (SGD). The context sized window can be passed to the encoder and the prediction window to a *causal-masked* decoder. This means that the decoder can only look at previous time steps when learning the next value. This is equivalent to how one would train a vanilla Transformer for machine translation, referred to as "teacher forcing".
Another benefit of Transformers over the other architectures is that we can incorporate missing values (which are common in the time series setting) as an additional mask to the encoder or decoder and still train without resorting to in-filling or imputation. This is equivalent to the `attention_mask` of models like BERT and GPT-2 in the Transformers library, to not include padding tokens in the computation of the attention matrix.
A drawback of the Transformer architecture is the limit to the sizes of the context and prediction windows because of the quadratic compute and memory requirements of the vanilla Transformer, see [Tay et al., 2020](https://arxiv.org/abs/2009.06732). Additionally, since the Transformer is a powerful architecture, it might overfit or learn spurious correlations much more easily compared to other [methods](https://openreview.net/pdf?id=D7YBmfX_VQy).
The 🤗 Transformers library comes with a vanilla probabilistic time series Transformer model, simply called the [Time Series Transformer](https://huggingface.co/docs/transformers/model_doc/time_series_transformer). In the sections below, we'll show how to train such a model on a custom dataset.
## Set-up Environment
First, let's install the necessary libraries: 🤗 Transformers, 🤗 Datasets, 🤗 Evaluate, 🤗 Accelerate and [GluonTS](https://github.com/awslabs/gluonts).
As we will show, GluonTS will be used for transforming the data to create features as well as for creating appropriate training, validation and test batches.
```python
!pip install -q transformers
!pip install -q datasets
!pip install -q evaluate
!pip install -q accelerate
!pip install -q gluonts ujson
```
## Load Dataset
In this blog post, we'll use the `tourism_monthly` dataset, which is available on the [Hugging Face Hub](https://huggingface.co/datasets/monash_tsf). This dataset contains monthly tourism volumes for 366 regions in Australia.
This dataset is part of the [Monash Time Series Forecasting](https://forecastingdata.org/) repository, a collection of time series datasets from a number of domains. It can be viewed as the GLUE benchmark of time series forecasting.
```python
from datasets import load_dataset
dataset = load_dataset("monash_tsf", "tourism_monthly")
```
As can be seen, the dataset contains 3 splits: train, validation and test.
```python
dataset
>>> DatasetDict({
train: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
test: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
validation: Dataset({
features: ['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'],
num_rows: 366
})
})
```
Each example contains a few keys, of which `start` and `target` are the most important ones. Let us have a look at the first time series in the dataset:
```python
train_example = dataset['train'][0]
train_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The `start` simply indicates the start of the time series (as a datetime), and the `target` contains the actual values of the time series.
The `start` will be useful to add time related features to the time series values, as extra input to the model (such as "month of year"). Since we know the frequency of the data is `monthly`, we know for instance that the second value has the timestamp `1979-02-01`, etc.
```python
print(train_example['start'])
print(train_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5772.876953125]
```
The validation set contains the same data as the training set, just for a `prediction_length` longer amount of time. This allows us to validate the model's predictions against the ground truth.
The test set is again one `prediction_length` longer data compared to the validation set (or some multiple of `prediction_length` longer data compared to the training set for testing on multiple rolling windows).
```python
validation_example = dataset['validation'][0]
validation_example.keys()
>>> dict_keys(['start', 'target', 'feat_static_cat', 'feat_dynamic_real', 'item_id'])
```
The initial values are exactly the same as the corresponding training example:
```python
print(validation_example['start'])
print(validation_example['target'])
>>> 1979-01-01 00:00:00
[1149.8699951171875, 1053.8001708984375, ..., 5985.830078125]
```
However, this example has `prediction_length=24` additional values compared to the training example. Let us verify it.
```python
freq = "1M"
prediction_length = 24
assert len(train_example["target"]) + prediction_length == len(
validation_example["target"]
)
```
Let's visualize this:
```python
import matplotlib.pyplot as plt
figure, axes = plt.subplots()
axes.plot(train_example["target"], color="blue")
axes.plot(validation_example["target"], color="red", alpha=0.5)
plt.show()
```
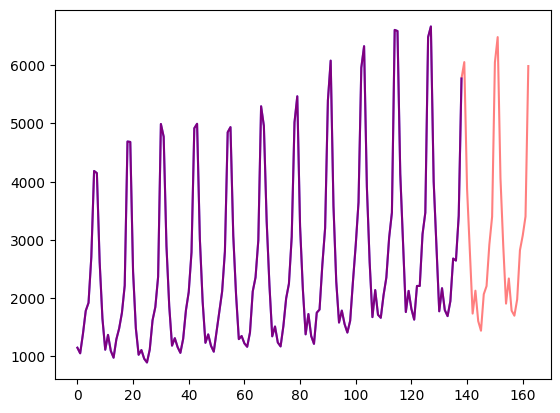
Let's split up the data:
```python
train_dataset = dataset["train"]
test_dataset = dataset["test"]
```
## Update `start` to `pd.Period`
The first thing we'll do is convert the `start` feature of each time series to a pandas `Period` index using the data's `freq`:
```python
from functools import lru_cache
import pandas as pd
import numpy as np
@lru_cache(10_000)
def convert_to_pandas_period(date, freq):
return pd.Period(date, freq)
def transform_start_field(batch, freq):
batch["start"] = [convert_to_pandas_period(date, freq) for date in batch["start"]]
return batch
```
We now use `datasets`' [`set_transform`](https://huggingface.co/docs/datasets/v2.7.0/en/package_reference/main_classes#datasets.Dataset.set_transform) functionality to do this on-the-fly in place:
```python
from functools import partial
train_dataset.set_transform(partial(transform_start_field, freq=freq))
test_dataset.set_transform(partial(transform_start_field, freq=freq))
```
## Define the Model
Next, let's instantiate a model. The model will be trained from scratch, hence we won't use the `from_pretrained` method here, but rather randomly initialize the model from a [`config`](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerConfig).
We specify a couple of additional parameters to the model:
- `prediction_length` (in our case, `24` months): this is the horizon that the decoder of the Transformer will learn to predict for;
- `context_length`: the model will set the `context_length` (input of the encoder) equal to the `prediction_length`, if no `context_length` is specified;
- `lags` for a given frequency: these specify how much we "look back", to be added as additional features. e.g. for a `Daily` frequency we might consider a look back of `[1, 2, 7, 30, ...]` or in other words look back 1, 2, ... days while for `Minute` data we might consider `[1, 30, 60, 60*24, ...]` etc.;
- the number of time features: in our case, this will be `2` as we'll add `MonthOfYear` and `Age` features;
- the number of static categorical features: in our case, this will be just `1` as we'll add a single "time series ID" feature;
- the cardinality: the number of values of each static categorical feature, as a list which for our case will be `[366]` as we have 366 different time series
- the embedding dimension: the embedding dimension for each static categorical feature, as a list, for example `[3]` means the model will learn an embedding vector of size `3` for each of the `366` time series (regions).
Let's use the default lags provided by GluonTS for the given frequency ("monthly"):
```python
from gluonts.time_feature import get_lags_for_frequency
lags_sequence = get_lags_for_frequency(freq)
print(lags_sequence)
>>> [1, 2, 3, 4, 5, 6, 7, 11, 12, 13, 23, 24, 25, 35, 36, 37]
```
This means that we'll look back up to 37 months for each time step, as additional features.
Let's also check the default time features that GluonTS provides us:
```python
from gluonts.time_feature import time_features_from_frequency_str
time_features = time_features_from_frequency_str(freq)
print(time_features)
>>> [<function month_of_year at 0x7fa496d0ca70>]
```
In this case, there's only a single feature, namely "month of year". This means that for each time step, we'll add the month as a scalar value (e.g. `1` in case the timestamp is "january", `2` in case the timestamp is "february", etc.).
We now have everything to define the model:
```python
from transformers import TimeSeriesTransformerConfig, TimeSeriesTransformerForPrediction
config = TimeSeriesTransformerConfig(
prediction_length=prediction_length,
# context length:
context_length=prediction_length * 2,
# lags coming from helper given the freq:
lags_sequence=lags_sequence,
# we'll add 2 time features ("month of year" and "age", see further):
num_time_features=len(time_features) + 1,
# we have a single static categorical feature, namely time series ID:
num_static_categorical_features=1,
# it has 366 possible values:
cardinality=[len(train_dataset)],
# the model will learn an embedding of size 2 for each of the 366 possible values:
embedding_dimension=[2],
# transformer params:
encoder_layers=4,
decoder_layers=4,
d_model=32,
)
model = TimeSeriesTransformerForPrediction(config)
```
Note that, similar to other models in the 🤗 Transformers library, [`TimeSeriesTransformerModel`](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerModel) corresponds to the encoder-decoder Transformer without any head on top, and [`TimeSeriesTransformerForPrediction`](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerForPrediction) corresponds to `TimeSeriesTransformerModel` with a **distribution head** on top. By default, the model uses a Student-t distribution (but this is configurable):
```python
model.config.distribution_output
>>> student_t
```
This is an important difference with Transformers for NLP, where the head typically consists of a fixed categorical distribution implemented as an `nn.Linear` layer.
## Define Transformations
Next, we define the transformations for the data, in particular for the creation of the time features (based on the dataset or universal ones).
Again, we'll use the GluonTS library for this. We define a `Chain` of transformations (which is a bit comparable to `torchvision.transforms.Compose` for images). It allows us to combine several transformations into a single pipeline.
```python
from gluonts.time_feature import (
time_features_from_frequency_str,
TimeFeature,
get_lags_for_frequency,
)
from gluonts.dataset.field_names import FieldName
from gluonts.transform import (
AddAgeFeature,
AddObservedValuesIndicator,
AddTimeFeatures,
AsNumpyArray,
Chain,
ExpectedNumInstanceSampler,
InstanceSplitter,
RemoveFields,
SelectFields,
SetField,
TestSplitSampler,
Transformation,
ValidationSplitSampler,
VstackFeatures,
RenameFields,
)
```
The transformations below are annotated with comments, to explain what they do. At a high level, we will iterate over the individual time series of our dataset and add/remove fields or features:
```python
from transformers import PretrainedConfig
def create_transformation(freq: str, config: PretrainedConfig) -> Transformation:
remove_field_names = []
if config.num_static_real_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_REAL)
if config.num_dynamic_real_features == 0:
remove_field_names.append(FieldName.FEAT_DYNAMIC_REAL)
if config.num_static_categorical_features == 0:
remove_field_names.append(FieldName.FEAT_STATIC_CAT)
# a bit like torchvision.transforms.Compose
return Chain(
# step 1: remove static/dynamic fields if not specified
[RemoveFields(field_names=remove_field_names)]
# step 2: convert the data to NumPy (potentially not needed)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_CAT,
expected_ndim=1,
dtype=int,
)
]
if config.num_static_categorical_features > 0
else []
)
+ (
[
AsNumpyArray(
field=FieldName.FEAT_STATIC_REAL,
expected_ndim=1,
)
]
if config.num_static_real_features > 0
else []
)
+ [
AsNumpyArray(
field=FieldName.TARGET,
# we expect an extra dim for the multivariate case:
expected_ndim=1 if config.input_size == 1 else 2,
),
# step 3: handle the NaN's by filling in the target with zero
# and return the mask (which is in the observed values)
# true for observed values, false for nan's
# the decoder uses this mask (no loss is incurred for unobserved values)
# see loss_weights inside the xxxForPrediction model
AddObservedValuesIndicator(
target_field=FieldName.TARGET,
output_field=FieldName.OBSERVED_VALUES,
),
# step 4: add temporal features based on freq of the dataset
# month of year in the case when freq="M"
# these serve as positional encodings
AddTimeFeatures(
start_field=FieldName.START,
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_TIME,
time_features=time_features_from_frequency_str(freq),
pred_length=config.prediction_length,
),
# step 5: add another temporal feature (just a single number)
# tells the model where in its life the value of the time series is,
# sort of a running counter
AddAgeFeature(
target_field=FieldName.TARGET,
output_field=FieldName.FEAT_AGE,
pred_length=config.prediction_length,
log_scale=True,
),
# step 6: vertically stack all the temporal features into the key FEAT_TIME
VstackFeatures(
output_field=FieldName.FEAT_TIME,
input_fields=[FieldName.FEAT_TIME, FieldName.FEAT_AGE]
+ (
[FieldName.FEAT_DYNAMIC_REAL]
if config.num_dynamic_real_features > 0
else []
),
),
# step 7: rename to match HuggingFace names
RenameFields(
mapping={
FieldName.FEAT_STATIC_CAT: "static_categorical_features",
FieldName.FEAT_STATIC_REAL: "static_real_features",
FieldName.FEAT_TIME: "time_features",
FieldName.TARGET: "values",
FieldName.OBSERVED_VALUES: "observed_mask",
}
),
]
)
```
## Define `InstanceSplitter`
For training/validation/testing we next create an `InstanceSplitter` which is used to sample windows from the dataset (as, remember, we can't pass the entire history of values to the Transformer due to time- and memory constraints).
The instance splitter samples random `context_length` sized and subsequent `prediction_length` sized windows from the data, and appends a `past_` or `future_` key to any temporal keys in `time_series_fields` for the respective windows. The instance splitter can be configured into three different modes:
1. `mode="train"`: Here we sample the context and prediction length windows randomly from the dataset given to it (the training dataset)
2. `mode="validation"`: Here we sample the very last context length window and prediction window from the dataset given to it (for the back-testing or validation likelihood calculations)
3. `mode="test"`: Here we sample the very last context length window only (for the prediction use case)
```python
from gluonts.transform.sampler import InstanceSampler
from typing import Optional
def create_instance_splitter(
config: PretrainedConfig,
mode: str,
train_sampler: Optional[InstanceSampler] = None,
validation_sampler: Optional[InstanceSampler] = None,
) -> Transformation:
assert mode in ["train", "validation", "test"]
instance_sampler = {
"train": train_sampler
or ExpectedNumInstanceSampler(
num_instances=1.0, min_future=config.prediction_length
),
"validation": validation_sampler
or ValidationSplitSampler(min_future=config.prediction_length),
"test": TestSplitSampler(),
}[mode]
return InstanceSplitter(
target_field="values",
is_pad_field=FieldName.IS_PAD,
start_field=FieldName.START,
forecast_start_field=FieldName.FORECAST_START,
instance_sampler=instance_sampler,
past_length=config.context_length + max(config.lags_sequence),
future_length=config.prediction_length,
time_series_fields=["time_features", "observed_mask"],
)
```
## Create DataLoaders
Next, it's time to create the DataLoaders, which allow us to have batches of (input, output) pairs - or in other words (`past_values`, `future_values`).
```python
from typing import Iterable
import torch
from gluonts.itertools import Cached, Cyclic
from gluonts.dataset.loader import as_stacked_batches
def create_train_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
num_batches_per_epoch: int,
shuffle_buffer_length: Optional[int] = None,
cache_data: bool = True,
**kwargs,
) -> Iterable:
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
TRAINING_INPUT_NAMES = PREDICTION_INPUT_NAMES + [
"future_values",
"future_observed_mask",
]
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=True)
if cache_data:
transformed_data = Cached(transformed_data)
# we initialize a Training instance
instance_splitter = create_instance_splitter(config, "train")
# the instance splitter will sample a window of
# context length + lags + prediction length (from the 366 possible transformed time series)
# randomly from within the target time series and return an iterator.
stream = Cyclic(transformed_data).stream()
training_instances = instance_splitter.apply(stream)
return as_stacked_batches(
training_instances,
batch_size=batch_size,
shuffle_buffer_length=shuffle_buffer_length,
field_names=TRAINING_INPUT_NAMES,
output_type=torch.tensor,
num_batches_per_epoch=num_batches_per_epoch,
)
```
```python
def create_backtest_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data)
# we create a Validation Instance splitter which will sample the very last
# context window seen during training only for the encoder.
instance_sampler = create_instance_splitter(config, "validation")
# we apply the transformations in train mode
testing_instances = instance_sampler.apply(transformed_data, is_train=True)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
We have a test dataloader helper for completion, even though we will not use it here. This is useful in a production setting where we want to start forecasting from the end of a given time series. Thus, the test dataloader will sample the very last context window from the dataset provided and pass it to the model.
```python
def create_test_dataloader(
config: PretrainedConfig,
freq,
data,
batch_size: int,
**kwargs,
):
PREDICTION_INPUT_NAMES = [
"past_time_features",
"past_values",
"past_observed_mask",
"future_time_features",
]
if config.num_static_categorical_features > 0:
PREDICTION_INPUT_NAMES.append("static_categorical_features")
if config.num_static_real_features > 0:
PREDICTION_INPUT_NAMES.append("static_real_features")
transformation = create_transformation(freq, config)
transformed_data = transformation.apply(data, is_train=False)
# We create a test Instance splitter to sample the very last
# context window from the dataset provided.
instance_sampler = create_instance_splitter(config, "test")
# We apply the transformations in test mode
testing_instances = instance_sampler.apply(transformed_data, is_train=False)
return as_stacked_batches(
testing_instances,
batch_size=batch_size,
output_type=torch.tensor,
field_names=PREDICTION_INPUT_NAMES,
)
```
```python
train_dataloader = create_train_dataloader(
config=config,
freq=freq,
data=train_dataset,
batch_size=256,
num_batches_per_epoch=100,
)
test_dataloader = create_backtest_dataloader(
config=config,
freq=freq,
data=test_dataset,
batch_size=64,
)
```
Let's check the first batch:
```python
batch = next(iter(train_dataloader))
for k, v in batch.items():
print(k, v.shape, v.type())
>>> past_time_features torch.Size([256, 85, 2]) torch.FloatTensor
past_values torch.Size([256, 85]) torch.FloatTensor
past_observed_mask torch.Size([256, 85]) torch.FloatTensor
future_time_features torch.Size([256, 24, 2]) torch.FloatTensor
static_categorical_features torch.Size([256, 1]) torch.LongTensor
future_values torch.Size([256, 24]) torch.FloatTensor
future_observed_mask torch.Size([256, 24]) torch.FloatTensor
```
As can be seen, we don't feed `input_ids` and `attention_mask` to the encoder (as would be the case for NLP models), but rather `past_values`, along with `past_observed_mask`, `past_time_features`, and `static_categorical_features`.
The decoder inputs consist of `future_values`, `future_observed_mask` and `future_time_features`. The `future_values` can be seen as the equivalent of `decoder_input_ids` in NLP.
We refer to the [docs](https://huggingface.co/docs/transformers/model_doc/time_series_transformer#transformers.TimeSeriesTransformerForPrediction.forward.past_values) for a detailed explanation for each of them.
## Forward Pass
Let's perform a single forward pass with the batch we just created:
```python
# perform forward pass
outputs = model(
past_values=batch["past_values"],
past_time_features=batch["past_time_features"],
past_observed_mask=batch["past_observed_mask"],
static_categorical_features=batch["static_categorical_features"]
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"]
if config.num_static_real_features > 0
else None,
future_values=batch["future_values"],
future_time_features=batch["future_time_features"],
future_observed_mask=batch["future_observed_mask"],
output_hidden_states=True,
)
```
```python
print("Loss:", outputs.loss.item())
>>> Loss: 9.069628715515137
```
Note that the model is returning a loss. This is possible as the decoder automatically shifts the `future_values` one position to the right in order to have the labels. This allows computing a loss between the predicted values and the labels.
Also, note that the decoder uses a causal mask to not look into the future as the values it needs to predict are in the `future_values` tensor.
## Train the Model
It's time to train the model! We'll use a standard PyTorch training loop.
We will use the 🤗 [Accelerate](https://huggingface.co/docs/accelerate/index) library here, which automatically places the model, optimizer and dataloader on the appropriate `device`.
```python
from accelerate import Accelerator
from torch.optim import AdamW
accelerator = Accelerator()
device = accelerator.device
model.to(device)
optimizer = AdamW(model.parameters(), lr=6e-4, betas=(0.9, 0.95), weight_decay=1e-1)
model, optimizer, train_dataloader = accelerator.prepare(
model,
optimizer,
train_dataloader,
)
model.train()
for epoch in range(40):
for idx, batch in enumerate(train_dataloader):
optimizer.zero_grad()
outputs = model(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
future_values=batch["future_values"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
future_observed_mask=batch["future_observed_mask"].to(device),
)
loss = outputs.loss
# Backpropagation
accelerator.backward(loss)
optimizer.step()
if idx % 100 == 0:
print(loss.item())
```
## Inference
At inference time, it's recommended to use the `generate()` method for autoregressive generation, similar to NLP models.
Forecasting involves getting data from the test instance sampler, which will sample the very last `context_length` sized window of values from each time series in the dataset, and pass it to the model. Note that we pass `future_time_features`, which are known ahead of time, to the decoder.
The model will autoregressively sample a certain number of values from the predicted distribution and pass them back to the decoder to return the prediction outputs:
```python
model.eval()
forecasts = []
for batch in test_dataloader:
outputs = model.generate(
static_categorical_features=batch["static_categorical_features"].to(device)
if config.num_static_categorical_features > 0
else None,
static_real_features=batch["static_real_features"].to(device)
if config.num_static_real_features > 0
else None,
past_time_features=batch["past_time_features"].to(device),
past_values=batch["past_values"].to(device),
future_time_features=batch["future_time_features"].to(device),
past_observed_mask=batch["past_observed_mask"].to(device),
)
forecasts.append(outputs.sequences.cpu().numpy())
```
The model outputs a tensor of shape (`batch_size`, `number of samples`, `prediction length`).
In this case, we get `100` possible values for the next `24` months (for each example in the batch which is of size `64`):
```python
forecasts[0].shape
>>> (64, 100, 24)
```
We'll stack them vertically, to get forecasts for all time-series in the test dataset:
```python
forecasts = np.vstack(forecasts)
print(forecasts.shape)
>>> (366, 100, 24)
```
We can evaluate the resulting forecast with respect to the ground truth out of sample values present in the test set. We will use the [MASE](https://huggingface.co/spaces/evaluate-metric/mase) and [sMAPE](https://huggingface.co/spaces/evaluate-metric/smape) metrics which we calculate for each time series in the dataset:
```python
from evaluate import load
from gluonts.time_feature import get_seasonality
mase_metric = load("evaluate-metric/mase")
smape_metric = load("evaluate-metric/smape")
forecast_median = np.median(forecasts, 1)
mase_metrics = []
smape_metrics = []
for item_id, ts in enumerate(test_dataset):
training_data = ts["target"][:-prediction_length]
ground_truth = ts["target"][-prediction_length:]
mase = mase_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
training=np.array(training_data),
periodicity=get_seasonality(freq))
mase_metrics.append(mase["mase"])
smape = smape_metric.compute(
predictions=forecast_median[item_id],
references=np.array(ground_truth),
)
smape_metrics.append(smape["smape"])
```
```python
print(f"MASE: {np.mean(mase_metrics)}")
>>> MASE: 1.2564196892177717
print(f"sMAPE: {np.mean(smape_metrics)}")
>>> sMAPE: 0.1609541520852549
```
We can also plot the individual metrics of each time series in the dataset and observe that a handful of time series contribute a lot to the final test metric:
```python
plt.scatter(mase_metrics, smape_metrics, alpha=0.3)
plt.xlabel("MASE")
plt.ylabel("sMAPE")
plt.show()
```
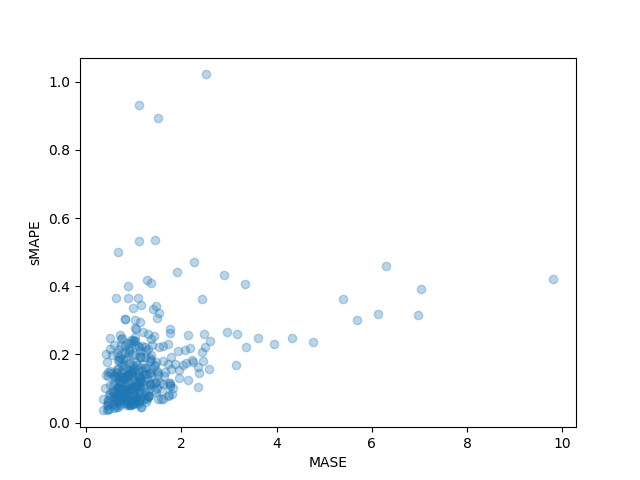
To plot the prediction for any time series with respect the ground truth test data we define the following helper:
```python
import matplotlib.dates as mdates
def plot(ts_index):
fig, ax = plt.subplots()
index = pd.period_range(
start=test_dataset[ts_index][FieldName.START],
periods=len(test_dataset[ts_index][FieldName.TARGET]),
freq=freq,
).to_timestamp()
# Major ticks every half year, minor ticks every month,
ax.xaxis.set_major_locator(mdates.MonthLocator(bymonth=(1, 7)))
ax.xaxis.set_minor_locator(mdates.MonthLocator())
ax.plot(
index[-2*prediction_length:],
test_dataset[ts_index]["target"][-2*prediction_length:],
label="actual",
)
plt.plot(
index[-prediction_length:],
np.median(forecasts[ts_index], axis=0),
label="median",
)
plt.fill_between(
index[-prediction_length:],
forecasts[ts_index].mean(0) - forecasts[ts_index].std(axis=0),
forecasts[ts_index].mean(0) + forecasts[ts_index].std(axis=0),
alpha=0.3,
interpolate=True,
label="+/- 1-std",
)
plt.legend()
plt.show()
```
For example:
```python
plot(334)
```
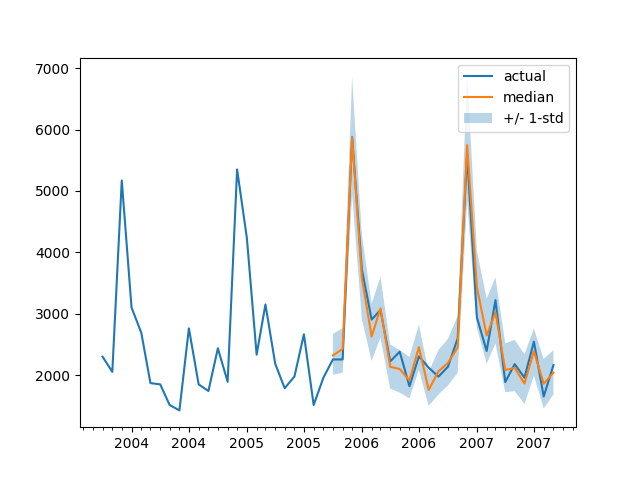
How do we compare against other models? The [Monash Time Series Repository](https://forecastingdata.org/#results) has a comparison table of test set MASE metrics which we can add to:
|Dataset | SES| Theta | TBATS| ETS | (DHR-)ARIMA| PR| CatBoost | FFNN | DeepAR | N-BEATS | WaveNet| **Transformer** (Our) |
|:------------------:|:-----------------:|:--:|:--:|:--:|:--:|:--:|:--:|:---:|:---:|:--:|:--:|:--:|
|Tourism Monthly | 3.306 | 1.649 | 1.751 | 1.526| 1.589| 1.678 |1.699| 1.582 | 1.409 | 1.574| 1.482 | **1.256**|
Note that, with our model, we are beating all other models reported (see also table 2 in the corresponding [paper](https://openreview.net/pdf?id=wEc1mgAjU-)), and we didn't do any hyperparameter tuning. We just trained the Transformer for 40 epochs.
Of course, we need to be careful with just claiming state-of-the-art results on time series with neural networks, as it seems ["XGBoost is typically all you need"](https://www.sciencedirect.com/science/article/pii/S0169207021001679). We are just very curious to see how far neural networks can bring us, and whether Transformers are going to be useful in this domain. This particular dataset seems to indicate that it's definitely worth exploring.
## Next Steps
We would encourage the readers to try out the [notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/time-series-transformers.ipynb) with other time series datasets from the [Hub](https://huggingface.co/datasets/monash_tsf) and replace the appropriate frequency and prediction length parameters. For your datasets, one would need to convert them to the convention used by GluonTS, which is explained nicely in their documentation [here](https://ts.gluon.ai/stable/tutorials/forecasting/extended_tutorial.html#What-is-in-a-dataset?). We have also prepared an example notebook showing you how to convert your dataset into the 🤗 datasets format [here](https://github.com/huggingface/notebooks/blob/main/examples/time_series_datasets.ipynb).
As time series researchers will know, there has been a lot of interest in applying Transformer based models to the time series problem. The vanilla Transformer is just one of many attention-based models and so there is a need to add more models to the library.
At the moment nothing is stopping us from modeling multivariate time series, however for that one would need to instantiate the model with a multivariate distribution head. Currently, diagonal independent distributions are supported, and other multivariate distributions will be added. Stay tuned for a future blog post that will include a tutorial.
Another thing on the roadmap is time series classification. This entails adding a time series model with a classification head to the library, for the anomaly detection task for example.
The current model assumes the presence of a date-time together with the time series values, which might not be the case for every time series in the wild. See for instance neuroscience datasets like the one from [WOODS](https://woods-benchmarks.github.io/). Thus, one would need to generalize the current model to make some inputs optional in the whole pipeline.
Finally, the NLP/Vision domain has benefitted tremendously from [large pre-trained models](https://arxiv.org/abs/1810.04805), while this is not the case as far as we are aware for the time series domain. Transformer based models seem like the obvious choice in pursuing this avenue of research and we cannot wait to see what researchers and practitioners come up with!
| 5 |
0 | hf_public_repos | hf_public_repos/blog/codegemma.md | ---
title: "CodeGemma - an official Google release for code LLMs"
thumbnail: /blog/assets/codegemma/thumbnail_b.png
authors:
- user: pcuenq
- user: osanseviero
- user: reach-vb
- user: philschmid
- user: mishig
- user: loubnabnl
---
# CodeGemma - an official Google release for code LLMs
CodeGemma is a family of open-access versions of Gemma specialized in code, and we’re excited to collaborate with Google on its release to make it as accessible as possible.🤗
CodeGemma comes in three flavors:
- A 2B base model specialized in infilling and open-ended generation.
- A 7B base model trained with both code infilling and natural language.
- A 7B instruct model a user can chat with about code.
We’ve collaborated with Google to ensure the best integration into the Hugging Face ecosystem. You can find the three open-access models ready to use on the Hub. Among the features and integrations being released, we have:
- [Models on the Hub](https://huggingface.co/collections/google/codegemma-release-66152ac7b683e2667abdee11), with their model cards and licenses. There are versions for the transformers library, checkpoints for use with Google’s original codebases, and full-precision GGUF files that the community can quantize.
- Transformers integration
- Integration with Google Cloud
- Integration with Inference Endpoints
- Code benchmarks
## Table of contents
- [What is CodeGemma](#what-is-codegemma)
- [Evaluation Results](#evaluation-results)
- [Prompt format](#prompt-format)
- [Using CodeGemma](#using-codegemma)
- [Demo](#demo)
- [Using Transformers](#using-transformers)
- [Integration with Google Cloud](#integration-with-google-cloud)
- [Integration with Inference Endpoints](#integration-with-inference-endpoints)
- [Additional Resources](#additional-resources)
## What is CodeGemma?
CodeGemma is a family of code-specialist LLM models by Google, based on the pre-trained [2B and 7B Gemma checkpoints](https://huggingface.co/blog/gemma). CodeGemma are further trained on an additional 500 billion tokens of primarily English language data, mathematics, and code to improve on logical and mathematical reasoning, and are suitable for code completion and generation.
[CodeGemma 2B](https://huggingface.co/google/codegemma-2b) was trained exclusively on Code Infilling and is meant for fast code completion and generation, especially in settings where latency and/or privacy are crucial. [CodeGemma 7B](https://huggingface.co/google/codegemma-7b) training mix includes code infilling data (80%) and natural language. It can be used for code completion, as well as code and language understanding and generation. [CodeGemma 7B Instruct](https://huggingface.co/google/codegemma-7b-it) was fine-tuned for instruction following on top of CodeGemma 7B. It’s meant for conversational use, especially around code, programming, or mathematical reasoning topics. All the models have the same 8K token context size as their predecessors.

This image is from [the original report](https://goo.gle/codegemma)
### Evaluation Results
CodeGemma-7B outperforms similarly-sized 7B models except DeepSeek-Coder-7B on HumanEval, a popular benchmark for evaluating code models on Python. The same goes for the evaluation of other programming languages like Java, JavaScript, and C++ from MultiPL-E, a translation of HumanEval. According to the technical report, the model performs best on [GSM8K](https://huggingface.co/datasets/gsm8k) among 7B models. The instruct version CodeGemma-7B-it improves on the most popular languages on both HumanEval and MBPP (cf paper table 5). For more details, you can check the [BigCode leaderboard](https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard) or some metrics below.
| Model | Pretraining size [tokens] | Python | JavaScript |
| --- | --- | --- | --- |
| 10B+ models | | | |
| StarCoder 2 15B | 4,000B+ | 44.15 | 44.24 |
| Code Llama 13B | 2,500B | 35.07 | 38.26 |
| 7B models | | | |
| DeepSeek Coder 7B | 2,000B | 45.83 | 45.9 |
| CodeGemma 7B | 500B of extra training | 40.13 | 43.06 |
| Code Llama 7B | 2,500B | 29.98 | 31.8 |
| StarCoder 2 7B | 3,500B+ | 34.09 | 35.35 |
| StarCoderBase 7B | 3,000B+ | 28.37 | 27.35 |
| <3B models | | | |
| CodeGemma 2B | 500B of extra training | 27.28 | 29.94 |
| Stable Code 3B | 1,300B | 30.72 | 28.75 |
| StarCoder 2 3B | 3,000B+ | 31.44 | 35.37 |
| Model | Pretraining size [tokens] | Python | JavaScript |
| --- | --- | --- | --- |
| 10B+ models | | | |
| Code Llama 13B | 2,620B | 50.6 | 40.92 |
| Code Llama 13B | 2,620B | 42.89 | 40.66 |
| 7B models | | | |
| CodeGemma 7B | 500B | 52.74 | 47.71 |
| Code Llama 7B | 2,620B | 40.48 | 36.34 |
| Code Llama 7B | 2,620B | 25.65 | 33.11 |
Here is a table from the original report with a breakdown per language.

### Prompt format
CodeGemma 2B and CodeGemma 7B use infilling (code, comments, docstrings, import statements) for code completion. CodeGemma was trained for this task using the fill-in-the-middle (FIM) objective, where you provide a prefix and a suffix as context for the completion. The following tokens are used to separate the different parts of the input:
- `<|fim_prefix|>` precedes the context before the completion we want to run.
- `<|fim_suffix|>` precedes the suffix. You must put this token exactly where the cursor would be positioned in an editor, as this is the location where the model will code complete.
- `<|fim_middle|>` is the prompt that invites the model to run the generation.
In addition to these, there's also `<|file_separator|>`, which provides multi-file contexts. We’ll show examples of use in the *Using with transformers* section.
CodeGemma 7B Instruct uses the same prompt format as the base Gemma Instruction-tuned versions, following this conversation structure:
```bash
<bos><start_of_turn>user
knock knock<end_of_turn>
<start_of_turn>model
who is there<end_of_turn>
<start_of_turn>user
LaMDA<end_of_turn>
<start_of_turn>model
LaMDA who?<end_of_turn>
```
As is the case with Gemma, the easiest way to reproduce this format is with the chat template available in `transformers`.
## Using CodeGemma
### Demo
You can easily try the CodeGemma Model (7 billion parameters!) in **[this Space](https://huggingface.co/spaces/ysharma/CodeGemma)** or in the Chatbot embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/4.26.0/gradio.js"></script>
<gradio-app src="https://ysharma-codegemma.hf.space"></gradio-app>
Under the hood, this playground uses Transformers implementation. You can also duplicate the Space for your use – it's self-contained, so you can examine the source code and adapt it as you wish!
### Using Transformers
With Transformers [release 4.39](https://github.com/huggingface/transformers/releases/tag/v4.39.3), you can use CodeGemma and leverage all the tools within the Hugging Face ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning), and Flash Attention 2
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
Like the Gemma models, CodeGemma is compatible with `torch.compile()` for an important inference speedup.
*Bonus*: We made a Colab notebook for you to try out the model at the touch of a button [here](https://github.com/Vaibhavs10/notebooks/blob/main/CodeGemma_colab.ipynb).
To use CodeGemma with transformers, make sure to use the latest release:
```jsx
pip install --upgrade transformers
```
The following snippet shows how to use `codegemma-2b` for code completion with transformers. It requires about 6 GB of RAM using `float16` precision, making it perfectly suitable for consumer GPUs and on-device applications.
```python
from transformers import GemmaTokenizer, AutoModelForCausalLM
import torch
model_id = "google/codegemma-2b"
tokenizer = GemmaTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.float16
).to("cuda:0")
prompt = '''\
<|fim_prefix|>import datetime
def calculate_age(birth_year):
"""Calculates a person's age based on their birth year."""
current_year = datetime.date.today().year
<|fim_suffix|>
return age<|fim_middle|>\
'''
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
prompt_len = inputs["input_ids"].shape[-1]
outputs = model.generate(**inputs, max_new_tokens=100)
print(tokenizer.decode(outputs[0][prompt_len:]))
```
Observe that the `<|fim_suffix|>` token appears in the position where the cursor would be placed in an editor, marking the position for the generation. `<|fim_prefix|>` provides the context that precedes the cursor, and the remaining until `<|fim_middle|>` is additional context after the cursor. Either of them can be empty if the cursor is located at the beginning or end of the file.
The previous code may return something like the following:
```
age = current_year - birth_year<|file_separator|>test_calculate_age.py
<|fim_suffix|>
assert calculate_age(1990) == 33
assert calculate_age(1980) == 43
assert calculate_age(1970) == 53
assert calculate_age(1960) == 63
assert calculate_age(1950) == 73
```
Note the extra content after the correct completion. This is particularly the case for CodeGemma 7B, which is more verbose and tends to provide additional code or comments after completion. We must ignore everything that appears after the FIM tokens or the EOS token for code infilling. We can stop generation early with transformers by providing a list of terminators to the `generate` function, like this:
```python
FIM_PREFIX = '<|fim_prefix|>'
FIM_SUFFIX = '<|fim_suffix|>'
FIM_MIDDLE = '<|fim_middle|>'
FIM_FILE_SEPARATOR = '<|file_separator|>'
terminators = tokenizer.convert_tokens_to_ids(
[FIM_PREFIX, FIM_MIDDLE, FIM_SUFFIX, FIM_FILE_SEPARATOR]
)
terminators += [tokenizer.eos_token_id]
outputs = model.generate(
**inputs,
max_new_tokens=100,
eos_token_id=terminators,
)
```
In this case, generation will stop as soon as the first delimiter is found:
```
age = current_year - birth_year<|file_separator|>
```
### A note on precision
The original CodeGemma checkpoints are released in `bfloat16` precision. If you load the model without indicating a `torch_dtype`, PyTorch will upcast them to `float32`. Casting to `float16` is perfectly fine for use, and it can be much faster than `bfloat16` on certain hardware. For maximum precision, we recommend you use `bfloat16` rather than `float32`.
You can also automatically quantize the model, loading it in 8-bit or 4-bit mode. 4-bit loading of CodeGemma 7B takes about 9 GB of memory to run, making it compatible with many consumer cards and all the GPUs in Google Colab. This is how you’d load the generation pipeline in 4-bit:
```jsx
pipeline = pipeline(
"text-generation",
model=model,
model_kwargs={
"torch_dtype": torch.float16,
"quantization_config": {"load_in_4bit": True}
},
)
```
### Integration with Google Cloud
You can deploy and train Gemma on Google Cloud through Vertex AI or Google Kubernetes Engine (GKE), using [Text Generation Inference](https://huggingface.co/docs/text-generation-inference/index) and Transformers.
To deploy the CodeGemma model from Hugging Face, go to the [model page](https://huggingface.co/google/codegemma-7b-it) and click on [Deploy -> Google Cloud.](https://huggingface.co/google/codegemma-7b-it) This will bring you to the Google Cloud Console, where you can 1-click deploy CodeGemma on Vertex AI or GKE, powered by Text Generation Inference.
You can also access CodeGemma directly through the Vertex AI Model Garden.

## Integration with Inference Endpoints
You can deploy CodeGemma on Hugging Face's [Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=google/codegemma-2b&vendor=aws®ion=us-east-1&accelerator=gpu&instance_size=2xlarge&task=text-generation&no_suggested_compute=true&tgi=true&tgi_max_batch_total_tokens=1024000&tgi_max_total_tokens=32000), which uses Text Generation Inference as the backend. [Text Generation Inference](https://github.com/huggingface/text-generation-inference) is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, production-ready logging and tracing, and is distributed under the Apache 2 license.
To deploy a CodeGemma model, go to the [model page](https://huggingface.co/google/codegemma-2b) and click on the [Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=google/codegemma-2b) widget. You can learn more about [Deploying LLMs with Hugging Face Inference Endpoints](https://huggingface.co/blog/inference-endpoints-llm) in a previous blog post. Note that T4s do not support the `bfloat16` format, so you will need to use a different GPU option.
```python
from huggingface_hub import InferenceClient
client = InferenceClient(model=IE_ENDPOINT)
prompt = """\
<|fim_prefix|>import <|fim_suffix|>
if __name__ == '__main__':
sys.exit(0)<|fim_middle|>\
"""
client.text_generation(prompt=prompt)
```
## Additional Resources
- [Models on the Hub](https://huggingface.co/collections/google/codegemma-release-66152ac7b683e2667abdee11)
- [Code Leaderboard](https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard)
- [Technical Report](https://goo.gle/codegemma)
| 6 |
0 | hf_public_repos | hf_public_repos/blog/spacy.md | ---
title: "Welcome spaCy to the Hugging Face Hub"
thumbnail: /blog/assets/23_spacy/thumbnail.png
authors:
- user: osanseviero
- user: ines
---
# Welcome spaCy to the Hugging Face Hub
[spaCy](https://github.com/explosion/spaCy) is a popular library for advanced Natural Language Processing used widely across industry. spaCy makes it easy to use and train pipelines for tasks like named entity recognition, text classification, part of speech tagging and more, and lets you build powerful applications to process and analyze large volumes of text.
Hugging Face makes it really easy to share your spaCy pipelines with the community! With a single command, you can upload any pipeline package, with a pretty model card and all required metadata auto-generated for you. The inference API currently supports NER out-of-the-box, and you can try out your pipeline interactively in your browser. You'll also get a live URL for your package that you can `pip install` from anywhere for a smooth path from prototype all the way to production!
### Finding models
Over 60 canonical models can be found in the [spaCy](https://hf.co/spacy) org. These models are from the [latest 3.1 release](https://explosion.ai/blog/spacy-v3-1), so you can try the latest realesed models right now! On top of this, you can find all spaCy models from the community here https://huggingface.co/models?filter=spacy.
### Widgets
This integration includes support for NER widgets, so all models with a NER component will have this out of the box! Coming soon there will be support for text classification and POS.
<div><a class="text-xs block mb-3 text-gray-300" href="/spacy/en_core_web_sm"><code>spacy/en_core_web_sm</code></a>
<div class="SVELTE_HYDRATER " data-props="{"apiUrl":"https://api-inference.huggingface.co","model":{"author":"spacy","autoArchitecture":"AutoModel","branch":"main","cardData":{"tags":["spacy","token-classification"],"language":["en"],"license":"MIT","model-index":[{"name":"en_core_web_sm","results":[{"tasks":{"name":"NER","type":"token-classification","metrics":[{"name":"Precision","type":"precision","value":0.8424355924},{"name":"Recall","type":"recall","value":0.8335336538},{"name":"F Score","type":"f_score","value":0.8379609817}]}},{"tasks":{"name":"POS","type":"token-classification","metrics":[{"name":"Accuracy","type":"accuracy","value":0.9720712187}]}},{"tasks":{"name":"SENTER","type":"token-classification","metrics":[{"name":"Precision","type":"precision","value":0.9074955788},{"name":"Recall","type":"recall","value":0.8801372122},{"name":"F Score","type":"f_score","value":0.893607046}]}},{"tasks":{"name":"UNLABELED_DEPENDENCIES","type":"token-classification","metrics":[{"name":"Accuracy","type":"accuracy","value":0.9185392711}]}},{"tasks":{"name":"LABELED_DEPENDENCIES","type":"token-classification","metrics":[{"name":"Accuracy","type":"accuracy","value":0.9185392711}]}}]}]},"cardSource":true,"id":"spacy/en_core_web_sm","pipeline_tag":"token-classification","library_name":"spacy","modelId":"spacy/en_core_web_sm","private":false,"siblings":[{"rfilename":".gitattributes"},{"rfilename":"LICENSE"},{"rfilename":"LICENSES_SOURCES"},{"rfilename":"README.md"},{"rfilename":"accuracy.json"},{"rfilename":"config.cfg"},{"rfilename":"en_core_web_sm-any-py3-none-any.whl"},{"rfilename":"meta.json"},{"rfilename":"tokenizer"},{"rfilename":"attribute_ruler/patterns"},{"rfilename":"lemmatizer/lookups/lookups.bin"},{"rfilename":"ner/cfg"},{"rfilename":"ner/model"},{"rfilename":"ner/moves"},{"rfilename":"vocab/lookups.bin"},{"rfilename":"vocab/strings.json"},{"rfilename":"vocab/vectors"}],"tags":["en","spacy","token-classification","license:mit","model-index"],"tag_objs":[{"id":"token-classification","label":"Token Classification","type":"pipeline_tag"},{"id":"spacy","label":"spaCy","type":"library"},{"id":"en","label":"en","type":"language"},{"id":"license:mit","label":"mit","type":"license"},{"id":"model-index","label":"model-index","type":"other"}],"widgetData":[{"text":"My name is Wolfgang and I live in Berlin"},{"text":"My name is Sarah and I live in London"},{"text":"My name is Clara and I live in Berkeley, California."}]},"shouldUpdateUrl":true}" data-target="InferenceWidget"><div class="flex flex-col w-full max-w-full
"> <div class="font-semibold flex items-center mb-2"><div class="text-lg flex items-center"><svg xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" class="-ml-1 mr-1 text-yellow-500" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 24 24"><path d="M11 15H6l7-14v8h5l-7 14v-8z" fill="currentColor"></path></svg>
Hosted inference API</div> <a target="_blank" href="/docs"><svg class="ml-1.5 text-sm text-gray-400 hover:text-black" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M17 22v-8h-4v2h2v6h-3v2h8v-2h-3z" fill="currentColor"></path><path d="M16 8a1.5 1.5 0 1 0 1.5 1.5A1.5 1.5 0 0 0 16 8z" fill="currentColor"></path><path d="M16 30a14 14 0 1 1 14-14a14 14 0 0 1-14 14zm0-26a12 12 0 1 0 12 12A12 12 0 0 0 16 4z" fill="currentColor"></path></svg></a></div> <div class="flex items-center text-sm text-gray-500 mb-1.5"><div class="inline-flex items-center"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" fill="currentColor" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 18 18"><path d="M11.075 10.1875H12.1625V11.275H11.075V10.1875Z"></path><path d="M15.425 9.10004H16.5125V10.1875H15.425V9.10004Z"></path><path d="M7.8125 3.66254H8.9V4.75004H7.8125V3.66254Z"></path><path d="M8.90001 12.3625H6.72501V9.09998C6.72472 8.81165 6.61005 8.5352 6.40617 8.33132C6.20228 8.12744 5.92584 8.01277 5.63751 8.01248H2.37501C2.08667 8.01277 1.81023 8.12744 1.60635 8.33132C1.40246 8.5352 1.28779 8.81165 1.28751 9.09998V12.3625C1.28779 12.6508 1.40246 12.9273 1.60635 13.1311C1.81023 13.335 2.08667 13.4497 2.37501 13.45H5.63751V15.625C5.63779 15.9133 5.75246 16.1898 5.95635 16.3936C6.16023 16.5975 6.43667 16.7122 6.72501 16.7125H8.90001C9.18834 16.7122 9.46478 16.5975 9.66867 16.3936C9.87255 16.1898 9.98722 15.9133 9.98751 15.625V13.45C9.98722 13.1616 9.87255 12.8852 9.66867 12.6813C9.46478 12.4774 9.18834 12.3628 8.90001 12.3625V12.3625ZM2.37501 12.3625V9.09998H5.63751V12.3625H2.37501ZM6.72501 15.625V13.45H8.90001V15.625H6.72501Z"></path><path d="M15.425 16.7125H13.25C12.9617 16.7122 12.6852 16.5976 12.4813 16.3937C12.2775 16.1898 12.1628 15.9134 12.1625 15.625V13.45C12.1628 13.1617 12.2775 12.8852 12.4813 12.6814C12.6852 12.4775 12.9617 12.3628 13.25 12.3625H15.425C15.7133 12.3628 15.9898 12.4775 16.1937 12.6814C16.3976 12.8852 16.5122 13.1617 16.5125 13.45V15.625C16.5122 15.9134 16.3976 16.1898 16.1937 16.3937C15.9898 16.5976 15.7133 16.7122 15.425 16.7125ZM13.25 13.45V15.625H15.425V13.45H13.25Z"></path><path d="M15.425 1.48752H12.1625C11.8742 1.48781 11.5977 1.60247 11.3938 1.80636C11.19 2.01024 11.0753 2.28668 11.075 2.57502V5.83752H9.98751C9.69917 5.83781 9.42273 5.95247 9.21885 6.15636C9.01496 6.36024 8.9003 6.63668 8.90001 6.92502V8.01252C8.9003 8.30085 9.01496 8.5773 9.21885 8.78118C9.42273 8.98506 9.69917 9.09973 9.98751 9.10002H11.075C11.3633 9.09973 11.6398 8.98506 11.8437 8.78118C12.0476 8.5773 12.1622 8.30085 12.1625 8.01252V6.92502H15.425C15.7133 6.92473 15.9898 6.81006 16.1937 6.60618C16.3976 6.4023 16.5122 6.12585 16.5125 5.83752V2.57502C16.5122 2.28668 16.3976 2.01024 16.1937 1.80636C15.9898 1.60247 15.7133 1.48781 15.425 1.48752ZM9.98751 8.01252V6.92502H11.075V8.01252H9.98751ZM12.1625 5.83752V2.57502H15.425V5.83752H12.1625Z"></path><path d="M4.55001 5.83752H2.37501C2.08667 5.83723 1.81023 5.72256 1.60635 5.51868C1.40246 5.3148 1.28779 5.03835 1.28751 4.75002V2.57502C1.28779 2.28668 1.40246 2.01024 1.60635 1.80636C1.81023 1.60247 2.08667 1.48781 2.37501 1.48752H4.55001C4.83834 1.48781 5.11478 1.60247 5.31867 1.80636C5.52255 2.01024 5.63722 2.28668 5.63751 2.57502V4.75002C5.63722 5.03835 5.52255 5.3148 5.31867 5.51868C5.11478 5.72256 4.83834 5.83723 4.55001 5.83752V5.83752ZM2.37501 2.57502V4.75002H4.55001V2.57502H2.37501Z"></path></svg> <span>Token Classification</span></div> <div class="ml-auto"></div></div> <form><div class="flex h-10"><input class="form-input-alt flex-1 rounded-r-none " placeholder="Your sentence here..." required="" type="text"> <button class="btn-widget w-24 h-10 px-5 rounded-l-none border-l-0 " type="submit">Compute</button></div></form> <div class="mt-1.5"><div class="text-gray-400 text-xs">This model is currently loaded and running on the Inference API.</div> </div> <div class="mt-auto pt-4 flex items-center text-xs text-gray-500"><button class="flex items-center cursor-not-allowed text-gray-300" disabled=""><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32" style="transform: rotate(360deg);"><path d="M31 16l-7 7l-1.41-1.41L28.17 16l-5.58-5.59L24 9l7 7z" fill="currentColor"></path><path d="M1 16l7-7l1.41 1.41L3.83 16l5.58 5.59L8 23l-7-7z" fill="currentColor"></path><path d="M12.419 25.484L17.639 6l1.932.518L14.35 26z" fill="currentColor"></path></svg>
JSON Output</button> <button class="flex items-center ml-auto"><svg class="mr-1" xmlns="http://www.w3.org/2000/svg" xmlns:xlink="http://www.w3.org/1999/xlink" aria-hidden="true" focusable="false" role="img" width="1em" height="1em" preserveAspectRatio="xMidYMid meet" viewBox="0 0 32 32"><path d="M22 16h2V8h-8v2h6v6z" fill="currentColor"></path><path d="M8 24h8v-2h-6v-6H8v8z" fill="currentColor"></path><path d="M26 28H6a2.002 2.002 0 0 1-2-2V6a2.002 2.002 0 0 1 2-2h20a2.002 2.002 0 0 1 2 2v20a2.002 2.002 0 0 1-2 2zM6 6v20h20.001L26 6z" fill="currentColor"></path></svg>
Maximize</button></div> </div></div></div>
### Using existing models
All models from the Hub can be directly installed using `pip install`.
```bash
pip install https://huggingface.co/spacy/en_core_web_sm/resolve/main/en_core_web_sm-any-py3-none-any.whl
```
```python
# Using spacy.load().
import spacy
nlp = spacy.load("en_core_web_sm")
# Importing as module.
import en_core_web_sm
nlp = en_core_web_sm.load()
```
When you open a repository, you can click `Use in spaCy` and you will be given a working snippet that you can use to install and load the model!


You can even make HTTP requests to call the models from the Inference API, which is useful in production settings. Here is an example of a simple request:
```bash
curl -X POST --data '{"inputs": "Hello, this is Omar"}' https://api-inference.huggingface.co/models/spacy/en_core_web_sm
>>> [{"entity_group":"PERSON","word":"Omar","start":15,"end":19,"score":1.0}]
```
And for larger-scale use cases, you can click "Deploy > Accelerated Inference" and see how to do this with Python.
### Sharing your models
But probably the coolest feature is that now you can very easily share your models with the `spacy-huggingface-hub` [library](https://github.com/explosion/spacy-huggingface-hub), which extends the `spaCy` CLI with a new command, `huggingface-hub push`.
```bash
huggingface-cli login
python -m spacy package ./en_ner_fashion ./output --build wheel
cd ./output/en_ner_fashion-0.0.0/dist
python -m spacy huggingface-hub push en_ner_fashion-0.0.0-py3-none-any.whl
```
In just a minute, you can get your packaged model in the Hub, try it out directly in the browser, and share it with the rest of the community. All the required metadata will be uploaded for you and you even get a cool model card.
Try it out and share your models with the community!
## Would you like to integrate your library to the Hub?
This integration is possible thanks to the [`huggingface_hub`](https://github.com/huggingface/huggingface_hub) library which has all our widgets and the API for all our supported libraries. If you would like to integrate your library to the Hub, we have a [guide](https://huggingface.co/docs/hub/models-adding-libraries) for you!
| 7 |
0 | hf_public_repos | hf_public_repos/blog/xethub-joins-hf.md | ---
title: "XetHub is joining Hugging Face!"
thumbnail: /blog/assets/xethub-joins-hf/thumbnail.png
authors:
- user: yuchenglow
org: xet-team
- user: julien-c
---
# XetHub is joining Hugging Face!
We are super excited to officially announce that Hugging Face acquired XetHub 🔥
XetHub is a Seattle-based company founded by Yucheng Low, Ajit Banerjee, Rajat Arya who previously worked at Apple where they built and scaled Apple’s internal ML infrastructure. XetHub’s mission is to enable software engineering best practices for AI development. XetHub has developed technologies to enable Git to scale to TB repositories and enable teams to explore, understand and work together on large evolving datasets and models. They were soon joined by a talented team of 12 team members. You should give them a follow at their new org page: [hf.co/xet-team](https://huggingface.co/xet-team)
## Our common goal at HF
> The XetHub team will help us unlock the next 5 years of growth of HF datasets and models by switching to our own, better version of LFS as storage backend for the Hub's repos.
>
> – Julien Chaumond, HF CTO
Back in 2020 when we built the first version of the HF Hub, we decided to build it on top of Git LFS because it was decently well-known and it was a reasonable choice to bootstrap the Hub’s usage.
We knew back then, however, that we would want to switch to our own, more optimized storage and versioning backend at some point. Git LFS – even though it stands for Large File storage – was just never meant for the type of large files we handle in AI, which are not just large, but _very very_ large 😃
## Example future use cases 🔥 – what this will enable on the Hub
Let's say you have a 10GB Parquet file. You add a single row. Today you need to re-upload 10GB. With the chunked files and deduplication from XetHub, you will only need to re-upload the few chunks containing the new row.
Another example for GGUF model files: let’s say [@bartowski](https://huggingface.co/bartowski) wants to update one single metadata value in the GGUF header for a Llama 3.1 405B repo. Well, in the future bartowski can only re-upload a single chunk of a few kilobytes, making the process way more efficient 🔥
As the field moves to trillion parameters models in the coming months (thanks Maxime Labonne for the new [BigLlama-3.1-1T](https://huggingface.co/mlabonne/BigLlama-3.1-1T-Instruct) 🤯) our hope is that this new tech will unlock new scale both in the community, and inside of Enterprise companies.
Finally, with large datasets and large models come challenges with collaboration. How do teams work together on large data, models and code? How do users understand how their data and models are evolving? We will be working to find better solutions to answer these questions.
## Fun current stats on Hub repos 🤯🤯
- number of repos: 1.3m models, 450k datasets, 680k spaces
- total cumulative size: 12PB stored in LFS (280M files) / 7,3 TB stored in git (non-LFS)
- Hub’s daily number of requests: 1B
- daily Cloudfront bandwidth: 6PB 🤯
## A personal word from [@ylow](https://huggingface.co/yuchenglow)
<!-- <i’ll insert a pic of yucheng (hf profile)> -->
I have been part of the AI/ML world for over 15 years, and have seen how deep learning has slowly taken over vision, speech, text and really increasingly every data domain.
What I have severely underestimated is the power of data. What seemed like impossible tasks just a few years ago (like image generation) turned out to be possible with orders of magnitude more data, and a model with the capacity to absorb it. In hindsight, this is an ML history lesson that has repeated itself many times.
I have been working in the data domain ever since my PhD. First in a startup (GraphLab/Dato/Turi) where I made structured data and ML algorithms scale on a single machine. Then after it was acquired by Apple, worked to scale AI data management to >100PB, supporting 10s of internal teams who shipped 100s of features annually. In 2021, together with my co-founders, supported by Madrona and other angel investors, started XetHub to bring our learnings of achieving collaboration at scale to the world.
XetHub’s goal is to enable ML teams to operate like software teams, by scaling Git file storage to TBs, seamlessly enabling experimentation and reproducibility, and providing the visualization capabilities to understand how datasets and models evolve.
I, along with the entire XetHub team, are very excited to join Hugging Face and continue this mission to make AI collaboration and development easier - by integrating XetHub technology into Hub - and to release these features to the largest ML Community in the world!
## Finally, our Infrastructure team is hiring 👯
If you like those subjects and you want to build and scale the collaboration platform for the open source AI movement, get in touch!
| 8 |
0 | hf_public_repos | hf_public_repos/blog/hugging-face-endpoints-on-azure.md | ---
title: Hugging Face Collaborates with Microsoft to launch Hugging Face Model Catalog on Azure
thumbnail: /blog/assets/75_hugging_face_endpoints_on_azure/01.jpg
authors:
- user: jeffboudier
- user: philschmid
- user: juliensimon
---
# Hugging Face Collaborates with Microsoft to launch Hugging Face Model Catalog on Azure

Today, we are thrilled to announce that Hugging Face expands its collaboration with Microsoft to bring open-source models from the Hugging Face Hub to Azure Machine Learning. Together we built a new Hugging Face Hub Model Catalog available directly within Azure Machine Learning Studio, filled with thousands of the most popular Transformers models from the [Hugging Face Hub](https://huggingface.co/models). With this new integration, you can now deploy Hugging Face models in just a few clicks on managed endpoints, running onto secure and scalable Azure infrastructure.

This new experience expands upon the strategic partnership we announced last year when we launched Azure Machine Learning Endpoints as a new managed app in Azure Marketplace, to simplify the experience of deploying large language models on Azure. Although our previous marketplace solution was a promising initial step, it had some limitations we could only overcome through a native integration within Azure Machine Learning. To address these challenges and enhance customers experience, we collaborated with Microsoft to offer a fully integrated experience for Hugging Face users within Azure Machine Learning Studio.
[Hosting over 200,000 open-source models](https://huggingface.co/models), and serving over 1 million model downloads a day, Hugging Face is the go-to destination for all of Machine Learning. But deploying Transformers to production remains a challenge today.
One of the main problems developers and organizations face is how difficult it is to deploy and scale production-grade inference APIs. Of course, an easy option is to rely on cloud-based AI services. Although they’re extremely simple to use, these services are usually powered by a limited set of models that may not support the [task type](https://huggingface.co/tasks) you need, and that cannot be deeply customized, if at all. Alternatively, cloud-based ML services or in-house platforms give you full control, but at the expense of more time, complexity and cost. In addition, many companies have strict security, compliance, and privacy requirements mandating that they only deploy models on infrastructure over which they have administrative control.
_“With the new Hugging Face Hub model catalog, natively integrated within Azure Machine Learning, we are opening a new page in our partnership with Microsoft, offering a super easy way for enterprise customers to deploy Hugging Face models for real-time inference, all within their secure Azure environment.”_ said Julien Simon, Chief Evangelist at Hugging Face.
_"The integration of Hugging Face's open-source models into Azure Machine Learning represents our commitment to empowering developers with industry-leading AI tools,"_ said John Montgomery, Corporate Vice President, Azure AI Platform at Microsoft. _"This collaboration not only simplifies the deployment process of large language models but also provides a secure and scalable environment for real-time inferencing. It's an exciting milestone in our mission to accelerate AI initiatives and bring innovative solutions to the market swiftly and securely, backed by the power of Azure infrastructure."_
Deploying Hugging Face models on Azure Machine Learning has never been easier:
* Open the Hugging Face registry in Azure Machine Learning Studio.
* Click on the Hugging Face Model Catalog.
* Filter by task or license and search the models.
* Click the model tile to open the model page and choose the real-time deployment option to deploy the model.
* Select an Azure instance type and click deploy.

Within minutes, you can test your endpoint and add its inference API to your application. It’s never been easier!

If you'd like to see the service in action, you can click on the image below to launch a video walkthrough.
[](https://youtu.be/cjXYjN2mNVM "Video walkthrough of Hugging Face Endpoints")
Hugging Face Model Catalog on Azure Machine Learning is available today in public preview in all Azure Regions where Azure Machine Learning is available. Give the service a try and [let us know your feedback and questions in the forum](https://discuss.huggingface.co/c/azureml/68)! | 9 |
0 | hf_public_repos | hf_public_repos/bench_cluster/scancel_jobs.sh | #!/bin/bash
# Function to print usage
usage() {
echo "Usage: $0 <job_ids_to_keep>"
echo "Example: $0 1234 5678 9012"
exit 1
}
# Check if at least one argument is provided
if [ $# -eq 0 ]; then
usage
fi
# Array to store jobs to keep
keep_jobs=("$@")
# Get all job IDs for the current user, including job arrays and their dependencies
all_jobs=$(squeue -u $USER -h -o "%A,%T,%j,%P")
# Function to check if a job should be kept
should_keep_job() {
local job_id=$1
for keep_job in "${keep_jobs[@]}"; do
if [ "$job_id" = "$keep_job" ]; then
return 0
fi
done
return 1
}
# Function to process job and its dependencies
process_job() {
local job_info=$1
local job_id=$(echo $job_info | cut -d',' -f1)
local job_state=$(echo $job_info | cut -d',' -f2)
local job_name=$(echo $job_info | cut -d',' -f3)
local job_array=$(echo $job_info | cut -d',' -f4)
if should_keep_job "$job_id"; then
echo "Keeping job $job_id ($job_name)"
else
# Check if it's a job array
if [[ $job_array == *"_"* ]]; then
echo "Cancelling job array $job_id ($job_name)"
scancel "$job_id"
else
echo "Cancelling job $job_id ($job_name)"
scancel "$job_id"
fi
fi
}
# Process all jobs
IFS=$'\n'
for job_info in $all_jobs; do
process_job "$job_info"
done
echo "Job cancellation complete."
# Check for orphaned dependencies and cancel them
orphaned_deps=$(squeue -u $USER -h -o "%A,%T,%j,%P" | grep "PENDING" | grep "Dependency")
if [ ! -z "$orphaned_deps" ]; then
echo "Cancelling orphaned dependencies:"
while IFS= read -r dep_job; do
dep_job_id=$(echo $dep_job | cut -d',' -f1)
dep_job_name=$(echo $dep_job | cut -d',' -f3)
echo "Cancelling orphaned dependency $dep_job_id ($dep_job_name)"
scancel "$dep_job_id"
done <<< "$orphaned_deps"
fi
echo "Orphaned dependency cancellation complete." | 0 |
0 | hf_public_repos | hf_public_repos/bench_cluster/generate_swiss.sh | # ========= SEQLEN 4096 ======
# Dp only experiments
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 4 --exp_name 4_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 8 --exp_name 8_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 16 --exp_name 16_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 32 --exp_name 32_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 4 --exp_name 4_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 8 --exp_name 8_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 16 --exp_name 16_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 32 --exp_name 32_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --cluster "swiss-ai"
# DP only with bapr=1
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 4 --exp_name 4_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 8 --exp_name 8_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 16 --exp_name 16_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 32 --exp_name 32_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 4 --exp_name 4_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 8 --exp_name 8_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 16 --exp_name 16_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 32 --exp_name 32_GPUS_DP_ONLY_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --cluster "swiss-ai"
# DP + TP
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 4 --exp_name 4_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 8 --exp_name 8_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 16 --exp_name 16_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 32 --exp_name 32_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 4 --exp_name 4_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 8 --exp_name 8_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 16 --exp_name 16_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 32 --exp_name 32_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --cluster "swiss-ai"
# DP + TP with bapr=1
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 4 --exp_name 4_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 8 --exp_name 8_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 16 --exp_name 16_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 32 --exp_name 32_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 4 --exp_name 4_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 8 --exp_name 8_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 16 --exp_name 16_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 32 --exp_name 32_GPUS_DP_TP_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --cluster "swiss-ai"
# ========= SEQLEN 2048 ======
# Dp only experiments
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 4 --exp_name 4_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 8 --exp_name 8_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 16 --exp_name 16_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 32 --exp_name 32_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 4 --exp_name 4_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 8 --exp_name 8_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 16 --exp_name 16_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 32 --exp_name 32_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --seq_len 2048 --cluster "swiss-ai"
# DP only with bapr=1
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 4 --exp_name 4_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 8 --exp_name 8_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 16 --exp_name 16_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 32 --exp_name 32_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 4 --exp_name 4_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 8 --exp_name 8_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 16 --exp_name 16_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 32 --exp_name 32_GPUS_DP_ONLY_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --tp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
# DP + TP
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 4 --exp_name 4_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 8 --exp_name 8_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 16 --exp_name 16_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 32 --exp_name 32_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 4 --exp_name 4_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 8 --exp_name 8_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 16 --exp_name 16_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 32 --exp_name 32_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --seq_len 2048 --cluster "swiss-ai"
# DP + TP with bapr=1
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 4 --exp_name 4_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 8 --exp_name 8_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 16 --exp_name 16_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-1B --gpus 32 --exp_name 32_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 4 --exp_name 4_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 8 --exp_name 8_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 16 --exp_name 16_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai"
python main.py create_configs --out_dir /capstor/scratch/cscs/fmom/new-local-results-epfl --model llama-7B --gpus 32 --exp_name 32_GPUS_DP_TP_SEQLEN_2048_no_profiler --no_profiler --pp_max 1 --bapr_max 1 --seq_len 2048 --cluster "swiss-ai" | 1 |
0 | hf_public_repos | hf_public_repos/bench_cluster/README.md | # bench_cluster
- TODO: git submodule for specific nanotron branch
```
pip install -e .
pip install -r requirements.txt
cd nanotron # Checkout bench_cluster branch
pip install -e .
pip install flash_attn==2.5.0
cd ..
```
### Workflow
```
results/
- network_bench/
- network_bench_8_gpus.slurm
- log_8_gpus.out
- ...
- network_bench_512_gpus.slurm
- llama-1B/
- 8_GPUS/
- 8_GPUS_summary_results.csv
- dp-1_tp-8_pp-1_mbz-1/
- profiler/*.json
- bench.slurm
- config.yaml
- log_metrics.csv
- log.out
- profiler.csv
- status.txt
...
- dp-8_tp-1_pp-1_mbz-256/
...
- 512_GPUS/
...
- llama-7B/
```
### Usage
```shell
# Create single config
python main.py create_single_config --out_dir tmp --model llama-1B --gpus 8 --exp_name draft --no_profiler --cluster "hf" --mbs=1 --bapr=128 --dp=8 --tp=1 --pp=1
# Create above workflow with all possible combinations of hyper-parameters
python main.py create_configs --out_dir "results" --model llama-1B --gpus 8
# Create configs without profiler on Swiss cluster
python main.py create_configs --out_dir "results" --model llama-1B --gpus 4 --exp_name 4_GPUS_no_profiler --no_profiler --cluster swiss-ai
# Create above workflow with all possible combinations and name it 8_GPUS_FOLDER + disable profiler
python main.py create_configs --out_dir "results" --model llama-1B --gpus 8 --exp_name 8_GPUS_FOLDER --no_profiler
# Create above workflow with only combinations of DP
python main.py create_configs --out_dir "results" --model llama-1B --gpus 8 --tp_max=1 --pp_max=1
# Create configs witt global batch size ranging from 0M to 4M tokens. Include config that increase every 1M tokens as well
python main.py create_configs --out_dir "results"--model llama-1B --gpus 8 --gbs_range "[0M, 4M, 1M]"
# Launch all the jobs in `results/` folder
python main.py submit_jobs --inp_dir results/ --qos high --hf_token <YOUR_HF_TOKEN>
# Can as well batch jobs into 4 dependencies array
python main.py submit_jobs --inp_dir results/ --qos high --hf_token <YOUR_HF_TOKEN> --nb_slurm_array 4
# Check status of runs (INIT/PENDING/RUNNING/FAIL/OOM/COMPLETED)
./check_status.sh results/
# Will cancel jobs that were not properly cancel by slurm (to avoid wasting ressources)
sbatch healthcheck_jobs.slurm
# Automatically rerun the jobs with status FAIL
python main.py submit_jobs --inp_dir results/ --qos high --hf_token <YOUR_HF_TOKEN> --only_fails
# Bench intra/inter-connect of gpus
python main.py network_bench --out_dir results/ --qos=high --gpus=8
# Extract into CSV logs, network and profiler info (NOTE: this is automatically done when using `submit_jobs`)
python main.py report --inp_dir results/ [--is_logs | --is_network | --is_profiler]
# Create a global summary CSV file based on all exisiting csv runs file
python main.py report --inp_dir results/ --global_summary
``` | 2 |
0 | hf_public_repos | hf_public_repos/bench_cluster/open_logs_with_status.sh | #!/bin/bash
# Function to display usage
usage() {
echo "Usage: $0 <directory> <keyword1> [keyword2] ... [log search string]"
echo "Example: $0 results/llama-1B/64_GPUS timeout pending \"Some NCCL operations have failed\""
exit 1
}
# Check if at least two arguments are provided (directory and at least one keyword)
if [ $# -lt 2 ]; then
usage
fi
# First argument is the directory
directory="$1"
shift # Remove the first argument (directory) from the list
# Check if the directory exists
if [ ! -d "$directory" ]; then
echo "Error: Directory '$directory' does not exist."
exit 1
fi
# Initialize variables
keywords=()
log_search_string=""
files_found=0
# Parse arguments
while [[ $# -gt 0 ]]; do
if [[ "$1" == *" "* ]] || [[ "${#keywords[@]}" -ge 1 ]]; then
# If an argument contains a space or we already have at least one keyword,
# treat this and all following args as the log search string
log_search_string="$*"
break
else
keywords+=("$1")
shift
fi
done
echo "Directory: $directory"
echo "Keywords: ${keywords[*]}"
echo "Log search string: $log_search_string"
# Find all .txt files in the specified directory
txt_files=$(find "$directory" -name "*.txt")
files_found=0
# Loop through each status.txt file
for file in $txt_files; do
if [[ $(basename "$file") == "status.txt" ]]; then
if grep -qE "$(IFS="|"; echo "${keywords[*]}")" "$file"; then
dir=$(dirname "$file")
log_files=("$dir"/log_*.out)
if [ ${#log_files[@]} -gt 0 ]; then
for log_file in "${log_files[@]}"; do
if [ -f "$log_file" ]; then
if [[ -n "$log_search_string" ]]; then
if grep -Fq "$log_search_string" "$log_file"; then
echo "Opening $log_file (contains search string)"
((files_found++))
fi
else
echo "Opening $log_file"
((files_found++))
fi
fi
done
else
echo "No log_*.out files found in $dir"
fi
fi
fi
done
# Report the number of files found
echo "Total files found and opened: $files_found" | 3 |
0 | hf_public_repos/bench_cluster | hf_public_repos/bench_cluster/bench_cluster/submit_jobs.py | from enum import Enum
import os
from jinja2 import Template
import subprocess
import yaml
from typing import List
class Status(Enum):
# INIT -> PENDING -> [RUNNING | FAIL | TIMEOUT OOM] -> COMPLETED
INIT = "init" # Job is created
PENDING = "pending" # Job is waiting for ressources
RUNNING = "running" # Job is running
FAIL = "fail" # Job failed
OOM = "oom" # Job failed due to out of memory (expected behavior)
TIMEOUT = "timeout" # Job failed due to timeout
COMPLETED = "completed" # Job is completed
class Job:
def __init__(self, root_path: str, qos: str) -> None:
self.root_path = root_path
self.name = os.path.basename(root_path)
self.config = os.path.join(root_path, "config.yaml")
self.qos = qos
# Check if the status.txt file exists
status_file_path = os.path.join(self.root_path, "status.txt")
if not os.path.exists(status_file_path):
# Create the status.txt file with INIT status
with open(status_file_path, 'w') as f:
f.write(Status.INIT.value)
self.status = self.get_status()
def get_status(self) -> Status:
"""
Read the status of the job from `status.txt` and return it
"""
is_existing = lambda value_to_check: any(value.value == value_to_check for value in Status.__members__.values())
status_file_path = os.path.join(self.root_path, "status.txt")
with open(status_file_path, 'r') as f:
status = f.read()
if not is_existing(status):
raise ValueError("Invalid status")
return Status(status)
def set_status(self, status: Status) -> Status:
"""
Update the status of the job in `status.txt` and return the new status
"""
status_file_path = os.path.join(self.root_path, "status.txt")
with open(status_file_path, 'w') as f:
f.write(status.value)
return status
class Scheduler:
def __init__(self, inp_dir: str, qos: str) -> None:
jobs_directory_paths = [os.path.abspath(root) for root, dirs, _ in os.walk(inp_dir) if not dirs]
jobs_directory_paths = [job_path.replace("/profiler", "") if "profiler" in job_path else job_path for job_path in jobs_directory_paths]
self.job_lists = [Job(job_path, qos) for job_path in jobs_directory_paths]
def keep_only_jobs(self, status: Status):
return [job for job in self.job_lists if job.status == status]
def filter_out_jobs(self, status: Status):
return [job for job in self.job_lists if job.status != status]
def create_slurm_script(self, job: Job, cluster: str):
# Submit job to the cluster (edit jinja)
# load yaml config.yaml
with open(job.config, 'r') as file:
config = yaml.load(file, Loader=yaml.FullLoader)
if cluster == "hf":
max_nodes = 8
elif cluster == "swiss-ai":
max_nodes = 4
else:
raise ValueError("Invalid cluster")
# Pick the right number of nodes and n_proc_per_node
world_size = config['parallelism']['pp'] * config['parallelism']['dp'] * config['parallelism']['tp']
assert world_size <= max_nodes or world_size % max_nodes == 0
nodes = max(1, world_size // max_nodes)
n_proc_per_node = min(8, world_size // nodes)
assert nodes * n_proc_per_node == world_size
target_path_hf_hub = os.path.join(os.path.basename(os.path.dirname(os.path.dirname(job.root_path))), os.path.basename(os.path.dirname(job.root_path)), os.path.basename(job.root_path))
context_bench = {
'nodes': nodes,
'n_proc_per_node': n_proc_per_node,
'root_path': job.root_path,
'target_path_hf_hub': target_path_hf_hub,
"config": job.config,
"qos": job.qos,
}
#TODO: don't hardcode the base_bench.slurm path. Should be #HOME/bench_cluster/template/base_bench.slurm
if cluster == "swiss-ai":
base_path = "/users/fmom/project/bench_cluster/bench_cluster/template/base_bench_swiss.slurm"
elif cluster == "hf":
# HF cluster
base_path = "/fsx/ferdinandmom/ferdinand-hf/bench_cluster/bench_cluster/template/base_bench.slurm"
else:
raise ValueError("Invalid cluster")
with open(base_path, 'r') as file:
base_bench_file = file.read()
base_bench_template = Template(base_bench_file)
# Write the rendered script to a new file located at the job root_path
output_file_path = os.path.join(job.root_path, "bench.slurm")
with open(output_file_path, 'w') as file:
file.write(base_bench_template.render(context_bench))
print(f"Slurm script created at {output_file_path}")
def launch_dependency(self, job_array: List[Job], env_vars):
prev_job_id = None
for job in job_array:
if prev_job_id is None:
result = subprocess.run(["sbatch", '--parsable', os.path.join(job.root_path, "bench.slurm")], env=env_vars, capture_output=True, text=True)
else:
result = subprocess.run(["sbatch", '--parsable', '--dependency=afterany:'+prev_job_id, os.path.join(job.root_path, "bench.slurm")], env=env_vars, capture_output=True, text=True)
job.set_status(Status.PENDING)
prev_job_id = result.stdout.strip()
def check_status(self):
# find all status files using self.jobs_directory_paths
status_files = [os.path.join(job.root_path, "status.txt") for job in self.job_lists]
status_counts = {
"init": 0,
"pending": 0,
"running": 0,
"fail": 0,
"oom": 0,
"timeout": 0,
"completed": 0
}
for status_file in status_files:
with open(status_file, 'r') as f:
status = f.read().strip()
if status in status_counts:
status_counts[status] += 1
else:
raise ValueError(f"Invalid status: {status}")
total = sum(status_counts.values())
# Print the status counts in a formatted table
print(f"{'Status':<10} | {'Count':<6}")
print(f"{'-'*10}-|-{'-'*6}")
for status, count in status_counts.items():
print(f"{status.capitalize():<10} | {count:<6}")
print(f"{'-'*10}-|-{'-'*6}")
print(f"{'Total':<10} | {total:<6}")
def submit_jobs(inp_dir, qos, hf_token, nb_slurm_array, cluster: str, only: str = None):
scheduler = Scheduler(inp_dir, qos)
#TODO: batch into job arrays
env_vars = os.environ.copy()
env_vars["HUGGINGFACE_TOKEN"] = hf_token
total_jobs = len(scheduler.job_lists)
if only == "fail":
scheduler.job_lists = scheduler.keep_only_jobs(Status.FAIL)
elif only == "pending":
scheduler.job_lists = scheduler.keep_only_jobs(Status.PENDING)
elif only == "timeout":
scheduler.job_lists = scheduler.keep_only_jobs(Status.TIMEOUT)
elif only == "running":
scheduler.job_lists = scheduler.keep_only_jobs(Status.RUNNING)
if only is not None:
filtered_jobs = len(scheduler.job_lists)
if filtered_jobs == 0:
print(f"No '{only}' jobs to resubmit")
return
print(f"Only {filtered_jobs}/{total_jobs} jobs with status '{only}' will be resubmitted")
scheduler.job_lists = scheduler.filter_out_jobs(Status.COMPLETED)
if nb_slurm_array > 0:
# Use job dependecies
# Distribute the jobs into the arrays
base_jobs_per_array = len(scheduler.job_lists) // nb_slurm_array
extra_jobs = len(scheduler.job_lists) % nb_slurm_array
distribution = [base_jobs_per_array] * nb_slurm_array
for i in range(extra_jobs):
distribution[i] += 1
start = 0
for i, nb_jobs in enumerate(distribution):
previous_job_id = None
end = start + nb_jobs
job_array = scheduler.job_lists[start:end]
print(f"Launching job Dependency array {i+1} with {nb_jobs} jobs")
for job in job_array:
scheduler.create_slurm_script(job, cluster)
scheduler.launch_dependency(job_array, env_vars)
start = end
else:
# Don't use job dependecies
for job in scheduler.job_lists:
scheduler.create_slurm_script(job, cluster)
subprocess.run(["sbatch", os.path.join(job.root_path, "bench.slurm")], env=env_vars)
job.set_status(Status.PENDING) | 4 |
0 | hf_public_repos/bench_cluster | hf_public_repos/bench_cluster/bench_cluster/network_bench.py | # https://github.com/EleutherAI/cookbook/blob/main/benchmarks/communication/run_all.py
import os
import subprocess
from jinja2 import Template
def network_bench(
out_dir: str,
gpus: int,
qos: str,
trials: int,
warmups: int,
maxsize: int,
async_op: bool,
bw_unit: str,
scan: bool,
raw: bool,
dtype: str,
mem_factor: float,
debug: bool = False,
):
root_path = os.path.join(out_dir, f"network_bench")
os.makedirs(root_path, exist_ok=True)
slurm_script = os.path.join(root_path, f"network_bench_{gpus}_gpus.slurm")
base_slurm_script = "/fsx/ferdinandmom/ferdinand-hf/bench_cluster/bench_cluster/template/base_network_bench.slurm"
with open(base_slurm_script, "r") as f:
base_network_bench_file = f.read()
base_network_bench_template = Template(base_network_bench_file)
nodes = max(1, gpus // 8)
n_proc_per_node = min(8, gpus // nodes)
assert nodes * n_proc_per_node == gpus
context_bench = {
'nodes': nodes,
'n_proc_per_node': n_proc_per_node,
'qos': qos,
'root_path': root_path,
'trials': trials,
'warmups': warmups,
'maxsize': maxsize,
'async_op': async_op,
'bw_unit': bw_unit,
'scan': scan,
'raw': raw,
'dtype': dtype,
'mem_factor': mem_factor,
'debug': debug
}
with open(slurm_script, 'w') as file:
file.write(base_network_bench_template.render(context_bench))
subprocess.run(["sbatch", slurm_script])
print(f"Submitted network benchmark job with {gpus} GPUs") | 5 |
0 | hf_public_repos/bench_cluster | hf_public_repos/bench_cluster/bench_cluster/report.py | import glob
import os
import re
import csv
import json
import pandas as pd
import torch
from statistics import mean
import subprocess
def units_to_float(value):
if 'K' in value:
return float(value.replace('K', '')) * 1000
elif 'M' in value:
return float(value.replace('M', '')) * 1000000
elif 'G' in value:
return float(value.replace('G', '')) * 1000000000
else:
return float(value)
def parse_logs(inp_dir, cluster: str):
folders = [os.path.abspath(folder) for folder in glob.glob(os.path.join(inp_dir, "**"), recursive=True) if os.path.isdir(folder)]
completed_logs_path = []
for folder in folders:
status_file = os.path.join(folder, "status.txt")
if os.path.exists(status_file):
with open(status_file, "r") as f:
status = f.read().strip()
if status == "completed":
log_files = glob.glob(os.path.join(folder, "log_*.out"))
if log_files:
completed_logs_path.append(log_files[0])
metrics_dict = {}
for file_path in completed_logs_path:
metrics = {}
current_iteration = None
with open(file_path, 'r') as file:
for line in file:
if cluster == "hf":
match_iteration = re.search(
r'\[default\d+\]:\S+ \S+ \[INFO\|DP=\d+\|PP=\d+\|TP=\d+\|\S+\]: iteration: (\d+) / \d+ \| ' \
r'consumed_tokens: ([\d\.KM]+) \| elapsed_time_per_iteration_ms: ([\d\.KM]+) \| ' \
r'tokens_per_sec: ([\d\.KM]+) \| tokens_per_sec_per_gpu: ([\d\.KM]+) \| ' \
r'global_batch_size: ([\d\.KM]+) \| lm_loss: ([\d\.]+) \| lr: ([\de\.-]+) \| ' \
r'model_tflops_per_gpu: ([\d\.]+) \| hardware_tflops_per_gpu: ([\d\.]+) \| ' \
r'grad_norm: ([\d\.]+).*', line
)
if match_iteration:
current_iteration = int(match_iteration.group(1))
metrics[current_iteration] = {
'iteration': current_iteration,
'consumed_tokens': units_to_float(match_iteration.group(2)),
'elapsed_time_per_iteration_ms': units_to_float(match_iteration.group(3)),
'tokens_per_sec': units_to_float(match_iteration.group(4)),
'tokens_per_sec_per_gpu': units_to_float(match_iteration.group(5)),
'global_batch_size': units_to_float(match_iteration.group(6)),
'lm_loss': float(match_iteration.group(7)),
'lr': float(match_iteration.group(8)),
'model_tflops_per_gpu': float(match_iteration.group(9)),
'hardware_tflops_per_gpu': float(match_iteration.group(10)),
'grad_norm': float(match_iteration.group(11))
}
match_memory = re.search(
r'\[default\d\]:\S+ \S+ \[INFO\|DP=\d\|PP=\d\|TP=\d\|\S+\]: Memory usage: ([\d\.]+)MiB\. '
r'Peak allocated ([\d\.]+)MiB\. Peak reserved: ([\d\.]+)MiB', line)
if match_memory and current_iteration is not None:
if current_iteration in metrics:
metrics[current_iteration].update({
'memory_usage_MiB': float(match_memory.group(1)),
'peak_allocated_MiB': float(match_memory.group(2)),
'peak_reserved_MiB': float(match_memory.group(3))
})
elif cluster == "swiss-ai":
match_iteration = re.search(
r'(\d{2}/\d{2}/\d{4} \d{2}:\d{2}:\d{2}) \[INFO\|DP=(\d+)\|PP=(\d+)\|TP=(\d+)\|(nid\d+)\]: '
r'iteration: (\d+) / \d+ \| '
r'consumed_tokens: ([\d\.KM]+) \| '
r'elapsed_time_per_iteration_ms: ([\d\.KM]+) \| '
r'tokens_per_sec: ([\d\.KM]+) \| '
r'tokens_per_sec_per_gpu: ([\d\.KM]+) \| '
r'global_batch_size: ([\d\.KM]+) \| '
r'lm_loss: ([\d\.]+) \| '
r'lr: ([\de\.-]+) \| '
r'model_tflops_per_gpu: ([\d\.]+) \| '
r'hardware_tflops_per_gpu: ([\d\.]+) \| '
r'grad_norm: ([\d\.]+).*', line
)
if match_iteration:
current_iteration = int(match_iteration.group(6))
metrics[current_iteration] = {
'iteration': current_iteration,
'consumed_tokens': units_to_float(match_iteration.group(7)),
'elapsed_time_per_iteration_ms': units_to_float(match_iteration.group(8)),
'tokens_per_sec': units_to_float(match_iteration.group(9)),
'tokens_per_sec_per_gpu': units_to_float(match_iteration.group(10)),
'global_batch_size': units_to_float(match_iteration.group(11)),
'lm_loss': float(match_iteration.group(12)),
'lr': float(match_iteration.group(13)),
'model_tflops_per_gpu': float(match_iteration.group(14)),
'hardware_tflops_per_gpu': float(match_iteration.group(15)),
'grad_norm': float(match_iteration.group(16)),
}
match_memory = re.search(
r'(\d{2}/\d{2}/\d{4} \d{2}:\d{2}:\d{2}) \[INFO\|DP=(\d+)\|PP=(\d+)\|TP=(\d+)\|(nid\d+)\]:\s+'
r'Memory usage: ([\d\.]+)MiB\. '
r'Peak allocated ([\d\.]+)MiB\. Peak reserved: ([\d\.]+)MiB',
line
)
if match_memory and current_iteration is not None:
if current_iteration in metrics:
metrics[current_iteration].update({
'memory_usage_MiB': float(match_memory.group(6)),
'peak_allocated_MiB': float(match_memory.group(7)),
'peak_reserved_MiB': float(match_memory.group(8))
})
metrics_dict[file_path] = list(metrics.values())
# Save metrics to csv files
for file_path, data in metrics_dict.items():
base_folder = os.path.dirname(file_path)
if data:
job_id = os.path.basename(file_path).split("_")[1].split(".")[0]
csv_path = os.path.join(base_folder, f"log_metrics_{job_id}.csv")
with open(csv_path, 'w', newline='') as output_file:
fieldnames = data[0].keys()
dict_writer = csv.DictWriter(output_file, fieldnames=fieldnames)
dict_writer.writeheader()
dict_writer.writerows(data)
print(f"Saved {len(metrics_dict)} csv files over {len(completed_logs_path)} completed logs")
def parse_profiler(inp_dir):
# Search for files ending in .json in the inp_dir and its subdirectories
file_paths = glob.glob(os.path.join(inp_dir, "**", "*.json"), recursive=True)
if not file_paths:
raise ValueError(f"No .json file found in {inp_dir}")
all_forward_durations = []
all_backward_durations = []
def _format_duration(duration):
ms = duration // 1000
us = duration % 1000
return f"{ms}ms {us}μs"
for file_path in file_paths:
print(f"Processing file: {file_path}")
with open(file_path, 'r') as f:
trace_data = json.load(f)
forward_durations = []
backward_durations = []
for event in trace_data['traceEvents']:
if 'name' in event and 'dur' in event:
if "forward" in event['name'].lower():
forward_durations.append(event['dur'])
elif "backward" in event['name'].lower():
backward_durations.append(event['dur'])
if forward_durations:
all_forward_durations.extend(forward_durations)
if backward_durations:
all_backward_durations.extend(backward_durations)
# Write the mean forward and backward durations to a csv file
pattern = re.compile(r'dp-\d+_tp-\d+_pp-\d+_mbz-\d+')
matching_index = next((i for i, part in enumerate(file_path.split("/")) if pattern.match(part)), None)
if matching_index is None:
raise ValueError(f"Could not find the specified pattern in {file_paths[0]}")
assert matching_index < len(file_path.split("/")) - 1, "Matching index is out of bounds"
output_file = "/".join(file_path.split("/")[:matching_index + 1]) + "/profiler.csv"
if all_forward_durations or all_backward_durations:
with open(output_file, 'w', newline='') as f:
writer = csv.writer(f)
writer.writerow(["forward", "backward"])
writer.writerow([
_format_duration(int(mean(all_forward_durations))) if all_forward_durations else "N/A",
_format_duration(int(mean(all_backward_durations))) if all_backward_durations else "N/A"
])
print(f"Results written to {output_file}")
else:
print("No forward or backward durations found in any file.")
def parse_network(inp_dir):
file_paths = glob.glob(os.path.join(inp_dir, "*.out"))
if not file_paths:
raise ValueError(f"No log file found in {inp_dir}")
primitives = ['all_gather', 'all_reduce', 'all_to_all', 'broadcast', 'p2p']
headers = ['Primitive', 'Size (Bytes)', 'Description', 'Duration', 'Throughput (Gbps)', 'BusBW (Gbps)']
for file_path in file_paths:
with open(file_path, 'r') as file:
input_text = file.read()
data = []
for primitive in primitives:
pattern = rf"---- Performance of {primitive}.*?Size \(Bytes\).*?(\d+\.?\d*\s+[GMK]?B)\s+(\S+)\s+(\d+\.?\d*\s+ms)\s+(\d+\.?\d*)\s+(\d+\.?\d*)"
match = re.search(pattern, input_text, re.DOTALL)
if match:
size, description, duration, throughput, busbw = match.groups()
data.append([primitive, size, description, duration, throughput, busbw])
output_file = os.path.splitext(file_path)[0] + '.csv'
with open(output_file, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(headers)
writer.writerows(data)
print(f"Data from {file_path} has been written to {output_file}")
# https://github.com/stanford-cs336/spring2024-lectures/blob/main/lecture_02.py#L919
def get_promised_flop_per_sec(dtype: torch.dtype) -> float:
"""Return the peak FLOP/s for the GPU operating on `dtype`."""
# Run nvidia-smi command and capture output
try:
result = subprocess.run(['nvidia-smi', '--query-gpu=name', '--format=csv,noheader'],
capture_output=True, text=True, check=True)
gpu_name = result.stdout.strip()
except subprocess.CalledProcessError:
raise RuntimeError("Failed to run nvidia-smi. Make sure it's installed and accessible.")
except FileNotFoundError:
raise RuntimeError("nvidia-smi command not found. Make sure NVIDIA drivers are installed.")
# Extract GPU model (they are exponent 12)
if "A100" in gpu_name:
if dtype == torch.float32:
return 19.5 # 19.5 TFLOP/s
if dtype in (torch.bfloat16, torch.float16):
return 312 # 312 TFLOP/s
elif "H100" in gpu_name or "GH200" in gpu_name:
if dtype == torch.float32:
return 67.5 # 67.5 TFLOP/s
if dtype in (torch.bfloat16, torch.float16):
return (1979 / 2) # 989.5 TFLOP/s (half of 1979 for dense operations)
else:
raise ValueError(f"Unsupported GPU model: {gpu_name}")
raise ValueError(f"Unknown dtype: {dtype}")
def create_global_summary(inp_dir, cluster = "hf"):
if cluster == "hf":
max_gpus_per_node = 8
elif cluster == "swiss-ai":
max_gpus_per_node = 4
folders_path = glob.glob(os.path.join(inp_dir, '*/'))
file_paths = glob.glob(os.path.join(inp_dir, "**", "*.csv"), recursive=True)
if not file_paths:
raise ValueError(f"No .csv file found in {inp_dir}")
log_metrics_csv = [file for file in file_paths if re.search(r"log_metrics_\d+\.csv", file)]
profiler_csv = [file for file in file_paths if "profiler.csv" in file]
summary_results_pd = pd.DataFrame(columns=["model", "run_name", "status", "nnodes", "dp", "tp", "pp", "batch_accumulation_per_replica", "micro_batch_size", "tok/s/gpu", "mfu", "forward", "backward"])
summary_results_pd["status"] = summary_results_pd["status"].astype(str)
summary_results_pd["forward"] = summary_results_pd["forward"].astype(str)
summary_results_pd["backward"] = summary_results_pd["backward"].astype(str)
# Create run_name column in the summary_results_pd with folder_paths
for folder in folders_path:
components = os.path.normpath(folder).split("/")
model = next((c for c in components if 'llama' in c.lower()), None)
run_name = next((c for c in components if c.startswith('dp')), None)
dp, tp, pp, micro_batch_size, batch_accumulation_per_replica = re.findall(r'\d+', run_name)
dp, tp, pp = int(dp), int(tp), int(pp)
world_size = dp * tp * pp
summary_results_pd.loc[len(summary_results_pd)] = {
"model": model,
"run_name": run_name,
"status": str(""),
"nnodes": max(1, world_size // max_gpus_per_node),
"dp": dp,
"tp": tp,
"pp": pp,
"batch_accumulation_per_replica": batch_accumulation_per_replica,
"micro_batch_size": micro_batch_size,
"tok/s/gpu": -1,
"mfu": -1,
"memory": -1,
"forward": str(""),
"backward": str(""),
}
log_metrics_dfs = {}
for file in log_metrics_csv:
run_name = file.split("/")[-2]
log_metrics_dfs[run_name] = pd.read_csv(file)
profiler_dfs = {}
for file in profiler_csv:
run_name = file.split("/")[-2]
profiler_dfs[run_name] = pd.read_csv(file)
for run_name in summary_results_pd["run_name"]:
# Get the associated row in the summary_results csv
index = summary_results_pd[summary_results_pd["run_name"] == run_name].index[0]
# Status
status_file = os.path.join(inp_dir, run_name, "status.txt")
if os.path.exists(status_file):
with open(status_file, "r") as f:
status = f.read().strip()
summary_results_pd.loc[index, "status"] = status
if summary_results_pd.loc[index, "status"] in ["timeout", "oom", "fail", "pending", "running"]:
continue
if run_name not in log_metrics_dfs:
print(f"Skipping {run_name} as it does not have log metrics csv file")
continue
skip_profiling_steps = 0 if run_name not in profiler_dfs else 7
# Tokens per sec per gpu (exclude the first 6 iterations as they are part of profiling)
summary_results_pd.loc[index, "tok/s/gpu"] = log_metrics_dfs[run_name]["tokens_per_sec_per_gpu"][skip_profiling_steps:].astype(float).mean()
# MFU (bf16) (exclude the first 3 iterations as they are profiler warmup)
summary_results_pd.loc[index, "mfu"] = (log_metrics_dfs[run_name]["model_tflops_per_gpu"][skip_profiling_steps:].astype(int).mean() / get_promised_flop_per_sec(dtype=torch.bfloat16)) * 100
if run_name not in profiler_dfs:
print(f"Skipping profiler part for {run_name} as it does not have profiler.csv")
continue
# Forward
summary_results_pd.loc[index, "forward"] = profiler_dfs[run_name]["forward"].values[0]
# Backward
summary_results_pd.loc[index, "backward"] = profiler_dfs[run_name]["backward"].values[0]
num_gpus = folders_path[0].split("/")[-3]
path = os.path.join(inp_dir, num_gpus + "_global_summary.csv")
summary_results_pd.to_csv(path, index=False)
print(f"Create {path} with new metrics")
def report(inp_dir, cluster, is_profiler=False, is_network=False, is_logs=False, global_summary=False):
if is_logs:
parse_logs(inp_dir, cluster)
elif is_profiler:
parse_profiler(inp_dir)
elif is_network:
parse_network(inp_dir)
elif global_summary:
create_global_summary(inp_dir, cluster)
else:
raise ValueError("Please specify the type of report to generate") | 6 |
0 | hf_public_repos/bench_cluster | hf_public_repos/bench_cluster/bench_cluster/create_configs.py | from copy import deepcopy
from typing import List
import numpy as np
from bench_cluster.template.base_config import base_config
import itertools
import yaml
import os
from transformers import AutoTokenizer
import math
import pandas as pd
def find_combinations_within_global_batch_size_range(dp, seq_len, min_global_batch_size, max_global_batch_size, step, bapr_max: None):
def round_to_next_multiple_of(multiple, pair_list):
round_up = lambda n: math.ceil(n / multiple) * multiple
res = []
for a, b in pair_list:
new_a = round_up(a) if a != 1 else a
new_b = round_up(b) if b != 1 else b
res.append((new_a, new_b))
return res
combinations = []
for i in range(min_global_batch_size, max_global_batch_size + 1, step):
remaining_global_batch_size = i // (dp * seq_len)
all_pairs = [(a, b) for a, b in itertools.product(range(1, remaining_global_batch_size + 1), repeat=2) if a * b == remaining_global_batch_size]
all_pairs = round_to_next_multiple_of(multiple=2, pair_list=all_pairs)
for bapr, mbs in all_pairs:
if bapr_max is not None and bapr > bapr_max:
continue
current_global_batch_size = dp * seq_len * bapr * mbs
# Include as well the case where the current_global_batch size similar to max_global_batch size
if current_global_batch_size >= min_global_batch_size and current_global_batch_size <= max_global_batch_size + step:
combinations.append((bapr, mbs))
return combinations
def update_config_based_on_model(model: str, config: dict):
# Setting num_attention_heads = num_key_value_heads for all models <=> using MHA for all layers
if model == "llama-1B":
# HuggingFaceFW/ablation-model-fineweb-v1
config["model"]["model_config"]["hidden_size"] = 2048
config["model"]["model_config"]["intermediate_size"] = 4096
config["model"]["model_config"]["num_attention_heads"] = 32
config["model"]["model_config"]["num_hidden_layers"] = 24
config["model"]["model_config"]["num_key_value_heads"] = 32
config["model"]["model_config"]["max_position_embeddings"] = config["tokens"]["sequence_length"]
elif model == "llama-7B":
# meta-llama/Llama-2-7b-hf
config["model"]["model_config"]["hidden_size"] = 4096
config["model"]["model_config"]["intermediate_size"] = 11008
config["model"]["model_config"]["num_attention_heads"] = 32
config["model"]["model_config"]["num_hidden_layers"] = 32
config["model"]["model_config"]["num_key_value_heads"] = 32
config["model"]["model_config"]["max_position_embeddings"] = config["tokens"]["sequence_length"]
elif model == "llama-70B":
# meta-llama/Llama-2-70b-hf
config["model"]["model_config"]["hidden_size"] = 8192
config["model"]["model_config"]["intermediate_size"] = 28672
config["model"]["model_config"]["num_attention_heads"] = 64
config["model"]["model_config"]["num_hidden_layers"] = 80
config["model"]["model_config"]["num_key_value_heads"] = 64
config["model"]["model_config"]["max_position_embeddings"] = config["tokens"]["sequence_length"]
elif model == "llama-340B":
# nvidia/Nemotron-4-340B-Base
config["model"]["model_config"]["hidden_size"] = 18432
config["model"]["model_config"]["intermediate_size"] = 73728
config["model"]["model_config"]["num_attention_heads"] = 96
config["model"]["model_config"]["num_hidden_layers"] = 96
config["model"]["model_config"]["num_key_value_heads"] = 96
config["model"]["model_config"]["max_position_embeddings"] = config["tokens"]["sequence_length"]
elif model == "llama-400B":
config["model"]["model_config"]["hidden_size"] = 16384
config["model"]["model_config"]["intermediate_size"] = 1.2 * config["model"]["model_config"]["hidden_size"]
config["model"]["model_config"]["num_attention_heads"] = 128
config["model"]["model_config"]["num_hidden_layers"] = 126
config["model"]["model_config"]["num_key_value_heads"] = 128
config["model"]["model_config"]["max_position_embeddings"] = config["tokens"]["sequence_length"]
else:
raise ValueError(f"Model {model} is not supported")
tokenizer = AutoTokenizer.from_pretrained(config["tokenizer"]["tokenizer_name_or_path"])
config["model"]["model_config"]["vocab_size"] = tokenizer.vocab_size
def is_enough_layers_for_pp(pp_size, config):
def _get_block_compute_costs(config):
"""Computes the compute cost of each block in the model so that we can do a better job of load balancing."""
model_config = config["model"]["model_config"]
d_ff = model_config["intermediate_size"]
d_qkv = model_config["hidden_size"] // model_config["num_attention_heads"]
block_compute_costs = {
# This is the last lm_head
"lm_head": model_config["vocab_size"] * model_config["hidden_size"],
}
for i in range(model_config["num_hidden_layers"]):
# CausalSelfAttention (qkv proj + attn out) + MLP
block_compute_costs[f"decoder{i}"] = 4 * model_config["num_attention_heads"] * d_qkv * model_config["hidden_size"] + 3 * d_ff * model_config["hidden_size"]
return block_compute_costs
# compute PP block repartition
block_compute_costs = _get_block_compute_costs(config)
num_layers = config["model"]["model_config"]["num_hidden_layers"]
pipeline_blocks = ["token_embedding"] + [f"decoder{i}" for i in range(num_layers)] + ["final_layer_norm", "lm_head", "cast_to_fp32", "loss"]
block_cumulative_costs = np.cumsum(
[
block_compute_costs[name] if name in block_compute_costs else 0
for name in pipeline_blocks
]
)
# Assign ranks to blocks
block2rank = {block: 0 for block in pipeline_blocks}
target_pp_ranks = list(range(pp_size))
thresholds = [block_cumulative_costs[-1] * ((rank + 1) / pp_size) for rank in range(pp_size)]
assert thresholds[-1] >= block_cumulative_costs[-1]
target_pp_rank_idx = 0
for block, cumulative_cost in zip(pipeline_blocks, block_cumulative_costs):
assert target_pp_rank_idx < pp_size
block2rank[block] = target_pp_ranks[target_pp_rank_idx]
if cumulative_cost > thresholds[target_pp_rank_idx]:
target_pp_rank_idx += 1
block2rank["token_embedding"] = target_pp_ranks[0]
block2rank["loss"] = target_pp_ranks[target_pp_rank_idx]
# Check if all ranks have a block assigned to it
unique_ranks = sorted(set(block2rank.values()))
expected_ranks = list(range(pp_size))
return unique_ranks == expected_ranks
def create_single_config(
out_dir: str,
model: str,
gpus: int,
dp: int,
tp: int,
pp: int,
bapr: int,
mbs: int,
no_profiler: bool = False,
cluster: str = "hf",
exp_name: str = None,
seq_len: int = 4096,
recompute_layer: bool = False,
dry_run: bool = False
):
print(f"Creating single config for {model} given {gpus} GPUs")
config_content = deepcopy(base_config)
config_content["tokens"]["sequence_length"] = seq_len
config_content["parallelism"]["recompute_layer"] = recompute_layer
update_config_based_on_model(model, config_content)
if cluster == "hf":
tp_max_cluster = 8
elif cluster == "swiss-ai":
tp_max_cluster = 4 # GH200
# Create directories and write config files
if exp_name is not None:
path = os.path.join(out_dir, model + f"/{exp_name}")
else:
path = os.path.join(out_dir, model + f"/{gpus}_GPUS")
if not os.path.exists(path):
os.makedirs(path)
config_content['parallelism']['dp'] = dp
config_content['parallelism']['tp'] = tp
config_content['parallelism']['pp'] = pp
# Compute global batch_size and print
gbs = dp * mbs * bapr
gbs_token = gbs * seq_len
# Print in human readable format
print(f"Gbs_token: {gbs_token:,}, Gbs: {gbs}, dp: {dp}, seq_len: {seq_len}, bapr: {bapr}, mbs: {mbs}")
config_content['tokens']['batch_accumulation_per_replica'] = bapr
config_content['tokens']['micro_batch_size'] = mbs
# Create a directory for each combination of parallelism
run_path = os.path.join(path, f"dp-{dp}_tp-{tp}_pp-{pp}_mbz-{mbs}_bapr-{bapr}")
if recompute_layer:
run_path += "_recompute_layer"
# Get absoulte path for run_path
if no_profiler:
config_content['profiler'] = None
else:
config_content['profiler']['profiler_export_path'] = os.path.abspath(run_path)
if not dry_run:
if not os.path.exists(run_path):
os.makedirs(run_path)
with open(os.path.join(run_path, "config.yaml"), "w") as new_config:
yaml.dump(config_content, new_config, default_flow_style=False, sort_keys=False)
del config_content
def create_configs(
out_dir: str,
model: str,
gpus: int,
dp_max: int,
tp_max: int,
pp_max: int,
bapr_max: int,
gbs_range: tuple[int],
no_profiler: bool = False,
cluster: str = "hf",
exp_name: str = None,
seq_len: int = 4096,
recompute_layer: bool = False,
dry_run: bool = False
):
print(f"Creating configs for {model} given {gpus} GPUs")
config_content = deepcopy(base_config)
config_content["tokens"]["sequence_length"] = seq_len
config_content["parallelism"]["recompute_layer"] = recompute_layer
update_config_based_on_model(model, config_content)
if cluster == "hf":
tp_max_cluster = 8
elif cluster == "swiss-ai":
tp_max_cluster = 4 # GH200
# Generate all possible combinations of three numbers from 1 to gpus
combinations_3D_parallelism = set()
dp_range = range(1, gpus + 1) if dp_max is None else range(1, min(dp_max, gpus) + 1)
tp_range = range(1, tp_max_cluster + 1) if tp_max is None else range(1, min(tp_max, tp_max_cluster) + 1) # tp <= 8
pp_range = range(1, gpus + 1) if pp_max is None else range(1, min(pp_max, gpus) + 1)
# Generate combinations
for dp in dp_range:
for tp in tp_range:
for pp in pp_range:
if dp * tp * pp == gpus and is_enough_layers_for_pp(pp, config_content):
combinations_3D_parallelism.add((dp, tp, pp))
# Create directories and write config files
if exp_name is not None:
path = os.path.join(out_dir, model + f"/{exp_name}")
else:
path = os.path.join(out_dir, model + f"/{gpus}_GPUS")
if not os.path.exists(path):
os.makedirs(path)
min_global_batch_size, max_global_batch_size, step = gbs_range
count = 0
# Initialize tqdm progress bar for the combinations loop
for (dp, tp, pp) in combinations_3D_parallelism:
config_content['parallelism']['dp'] = dp
config_content['parallelism']['tp'] = tp
config_content['parallelism']['pp'] = pp
bapr_mbs_combo = find_combinations_within_global_batch_size_range(dp, seq_len, min_global_batch_size, max_global_batch_size, step, bapr_max)
# Sort combo based on current_global_batch_size = dp * seq_len * c[0] * c[1]
bapr_mbs_combo.sort(key=lambda c: dp * seq_len * c[0] * c[1])
for (batch_accumulation_per_replica, micro_batch_size) in bapr_mbs_combo:
if batch_accumulation_per_replica < pp - 1:
# self.n_micro_batches_per_batch = self.config.tokens.batch_accumulation_per_replica
# self.pipeline_engine.nb_microbatches = self.n_micro_batches_per_batch
#NOTE: assert self.nb_microbatches >= pg.size() - 1
continue
# Compute global batch_size and print
gbs = dp * micro_batch_size * batch_accumulation_per_replica * seq_len
# Print in human readable format
print(f"Global batch size : {gbs:,}: dp: {dp}, seq_len: {seq_len}, bapr: {batch_accumulation_per_replica}, mbs: {micro_batch_size}")
config_content['tokens']['batch_accumulation_per_replica'] = batch_accumulation_per_replica
config_content['tokens']['micro_batch_size'] = micro_batch_size
# Create a directory for each combination of parallelism
run_path = os.path.join(path, f"dp-{dp}_tp-{tp}_pp-{pp}_mbz-{micro_batch_size}_bapr-{batch_accumulation_per_replica}")
if recompute_layer:
run_path += "_recompute_layer"
# Get absoulte path for run_path
if no_profiler:
config_content['profiler'] = None
else:
config_content['profiler']['profiler_export_path'] = os.path.abspath(run_path)
if not dry_run:
if not os.path.exists(run_path):
os.makedirs(run_path)
with open(os.path.join(run_path, "config.yaml"), "w") as new_config:
yaml.dump(config_content, new_config, default_flow_style=False, sort_keys=False)
count += 1
if not dry_run:
print(f"Total number of configs created: {count}")
else:
print(f"Total number of configs that would be created: {count}")
# check if file exists
del config_content | 7 |
0 | hf_public_repos/bench_cluster/bench_cluster | hf_public_repos/bench_cluster/bench_cluster/template/base_bench_swiss.slurm | #!/bin/bash
#SBATCH --job-name bench_cluster
#SBATCH --output {{ root_path }}/log_%j.out
#SBATCH --error {{ root_path }}/log_%j.out
#SBATCH --nodes {{ nodes }}
#SBATCH --ntasks-per-node 1
#SBATCH --gres gpu:{{ n_proc_per_node }}
#SBATCH --cpus-per-task 80
#SBATCH --time 01:30:00
#SBATCH --environment /users/fmom/.edf/bench_cluster.toml
#SBATCH --contiguous
#SBATCH --exclusive
#SBATCH --reservation=benchmarking
# Function to update status based on squeue output
update_status() {
job_id=$1
status_file=$2
# For unknown reasons, it doenst update status for pending. It only works for running
while true; do
job_status=$(squeue --job $job_id --noheader --format=%T)
echo "Job status: $job_status"
if [ -z "$job_status" ]; then
# Job has finished or is not found
break
elif [ "$job_status" = "RUNNING" ]; then
printf "running" > $status_file
break
fi
sleep 10
done
}
# Misc initializations.
echo "========================"
echo "START TIME: $(date)"
echo python3 version = $(python3 --version)
echo "========================"
# Slurm stuff
export HOSTNAMES=$(scontrol show hostnames "$SLURM_JOB_NODELIST")
export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
export MASTER_PORT=$((1024 + RANDOM % 64511))
export TMPDIR=$SCRATCH
export HF_HOME="/capstor/scratch/cscs/fmom/.cache"
export HF_DATASETS_CACHE="/capstor/scratch/cscs/fmom/.cache"
export CUBLAS_WORKSPACE_CONFIG=":4096:8"
export CUDA_DEVICE_MAX_CONNECTIONS="1"
export WANDB_MODE=offline
huggingface-cli login --token $HUGGINGFACE_TOKEN
NANOTRON_REPO="/users/fmom/project/bench_cluster/nanotron"
CMD="$NANOTRON_REPO/run_train.py --config-file {{ config }}"
LAUNCHER="torchrun \
--nproc_per_node {{ n_proc_per_node }} \
--nnodes {{ nodes }} \
--rdzv_endpoint ${MASTER_ADDR}:${MASTER_PORT} \
--rdzv_backend c10d \
--max_restarts 0 \
--tee 3 \
--node_rank ${SLURM_PROCID}"
# Checkout the bench_cluster branch
cd $NANOTRON_REPO
git checkout bench_cluster
cd ..
export PYTHONPATH=$NANOTRON_REPO:$PYTHONPATH
echo "PYTHONPATH: $PYTHONPATH"
echo "Current directory: $(pwd)"
python -c "import sys; print(sys.path)"
python -c "import nanotron; print(nanotron.__file__)"
# Get the current job ID
job_id=${SLURM_JOB_ID}
# Update status to "pending" or "running" in the background
update_status $job_id {{ root_path }}/status.txt &
# Run the main command
srun -u $LAUNCHER $CMD
exit_status=$?
# Get the current job ID
job_id=${SLURM_JOB_ID}
# Update status based on the exit status of `srun`
if [ $exit_status -eq 0 ]; then
printf "completed" > {{ root_path }}/status.txt
else
if grep -q "OutOfMemoryError" {{ root_path }}/log_${job_id}.out; then
printf "oom" > {{ root_path }}/status.txt
elif grep -q " CUDA error: an illegal memory access" {{ root_path }}/log_${job_id}.out; then
printf "oom" > {{ root_path }}/status.txt
elif grep -q "Timeout" {{ root_path }}/log_${job_id}.out; then
printf "timeout" > {{ root_path }}/status.txt
else
printf "fail" > {{ root_path }}/status.txt
fi
fi
# Run the report script if the job completed successfully
if [ $exit_status -eq 0 ]; then
python /users/fmom/project/bench_cluster/main.py report --inp_dir {{ root_path }} --is_logs --cluster "swiss-ai"
python /users/fmom/project/bench_cluster/main.py report --inp_dir {{ root_path }} --is_profiler --cluster "swiss-ai"
fi
{# Set the path and branch variables #}
{% set path = target_path_hf_hub %}
{% set parts = path.split('/') %}
{% set branch = parts[0] + '-' + parts[1] %}
# Push to hub the folder using huggingface_cli
huggingface-cli upload nanotron/bench_cluster_epfl {{ root_path }} {{ target_path_hf_hub }} --revision {{ branch }} --commit-message "Upload {{ target_path_hf_hub }}"
# Verify the upload
if [ $? -eq 0 ]; then
echo "Uploading to Huggingface Hub successful"
else
echo "Failed to upload to Huggingface Hub"
fi | 8 |
0 | hf_public_repos/bench_cluster/bench_cluster | hf_public_repos/bench_cluster/bench_cluster/template/base_bench.slurm | #!/bin/bash
#SBATCH --job-name=bench_cluster
#SBATCH --time=01:30:00
#SBATCH --partition=hopper-prod
#SBATCH --nodes={{ nodes }}
#SBATCH --gres=gpu:{{ n_proc_per_node }}
#SBATCH --qos={{ qos }}
#SBATCH --ntasks-per-node=1
#SBATCH --cpus-per-task=96
#SBATCH --exclusive
#SBATCH --output={{ root_path }}/log_%j.out
#SBATCH --error={{ root_path }}/log_%j.out
# Function to update status based on squeue output
update_status() {
job_id=$1
status_file=$2
# For unknown reasons, it doenst update status for pending. It only works for running
while true; do
job_status=$(squeue --job $job_id --noheader --format=%T)
echo "Job status: $job_status"
if [ -z "$job_status" ]; then
# Job has finished or is not found
break
elif [ "$job_status" = "RUNNING" ]; then
printf "running" > $status_file
break
fi
sleep 10
done
}
# Misc initializations.
echo "========================"
echo "START TIME: $(date)"
source /etc/profile.d/modules.sh
source /fsx/ferdinandmom/miniforge3/etc/profile.d/conda.sh
conda activate /fsx/ferdinandmom/miniforge3/envs/env-new-bench-cluster
echo python3 version = $(python3 --version)
echo "========================"
# Slurm stuff
export HOSTNAMES=$(scontrol show hostnames "$SLURM_JOB_NODELIST")
export MASTER_ADDR=$(scontrol show hostnames "$SLURM_JOB_NODELIST" | head -n 1)
export MASTER_PORT=$((1024 + RANDOM % 64511))
export TMPDIR=/scratch
export HF_DATASETS_CACHE="/fsx/ferdinandmom/.cache"
export CUBLAS_WORKSPACE_CONFIG=":4096:8"
export CUDA_DEVICE_MAX_CONNECTIONS="1"
module load cuda/12.1
huggingface-cli login --token $HUGGINGFACE_TOKEN
NANOTRON_REPO="/fsx/ferdinandmom/ferdinand-hf/bench_cluster/nanotron"
CMD="$NANOTRON_REPO/run_train.py --config-file {{ config }}"
LAUNCHER="torchrun \
--nproc_per_node {{ n_proc_per_node }} \
--nnodes {{ nodes }} \
--rdzv_endpoint ${MASTER_ADDR}:${MASTER_PORT} \
--rdzv_backend c10d \
--max_restarts 0 \
--tee 3 \
--node_rank ${SLURM_PROCID}"
# Checkout the bench_cluster branch
cd $NANOTRON_REPO
git checkout bench_cluster
cd ..
# Get the current job ID
job_id=${SLURM_JOB_ID}
echo "Job ID: $job_id"
# Update status to "pending" or "running" in the background
update_status $job_id {{ root_path }}/status.txt &
# Run the main command
echo "Running command: srun -u $LAUNCHER $CMD"
srun -u $LAUNCHER $CMD
exit_status=$?
job_id=$SLURM_JOB_ID
# Update status based on the exit status of `srun`
if [ $exit_status -eq 0 ]; then
printf "completed" > {{ root_path }}/status.txt
else
if grep -q "OutOfMemoryError" {{ root_path }}/log_${job_id}.out; then
printf "oom" > {{ root_path }}/status.txt
elif grep -q " CUDA error: an illegal memory access" {{ root_path }}/log_${job_id}.out; then
printf "oom" > {{ root_path }}/status.txt
elif grep -q "Timeout" {{ root_path }}/log_${job_id}.out; then
printf "timeout" > {{ root_path }}/status.txt
else
printf "fail" > {{ root_path }}/status.txt
fi
fi
# Run the report script if the job completed successfully
if [ $exit_status -eq 0 ]; then
python /fsx/ferdinandmom/ferdinand-hf/bench_cluster/main.py report --inp_dir {{ root_path }} --is_logs
python /fsx/ferdinandmom/ferdinand-hf/bench_cluster/main.py report --inp_dir {{ root_path }} --is_profiler
fi
{# Set the path and branch variables #}
{% set path = target_path_hf_hub %}
{% set parts = path.split('/') %}
{% set branch = parts[0] + '-' + parts[1] %}
# Push to hub the folder using huggingface_cli
huggingface-cli upload nanotron/bench_cluster_official {{ root_path }} {{ target_path_hf_hub }} --revision {{ branch }} --commit-message "Upload {{ target_path_hf_hub }}"
# Verify the upload
if [ $? -eq 0 ]; then
echo "Uploading to Huggingface Hub successful"
else
echo "Failed to upload to Huggingface Hub"
fi | 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.