
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter1/streaming.mdx | # Потоковая передача аудиоданных
Одной из самых больших проблем, возникающих при работе с аудиоданными, является их огромный размер. Одна минута несжатого аудиофайла CD-качества (44,1 кГц, 16 бит)
занимает чуть более 5 МБ памяти. Как правило, набор аудиоданных содержат несколько часов записей.
В предыдущих разделах мы использовали очень небольшое подмножество набора аудиоданных MINDS-14, однако типичные наборы аудиоданных гораздо больше.
Например, `xs` (наименьшая) конфигурация [GigaSpeech от SpeechColab](https://huggingface.co/datasets/speechcolab/gigaspeech)
содержит всего 10 часов обучающих данных, но для их загрузки и подготовки требуется более 13 Гбайт дискового пространства. Что же
произойдет, если мы захотим обучиться на более крупной части набора данных? Полная конфигурация `xl` того же набора данных содержит 10 000 часов
тренировочных данных, что требует более 1 ТБ дискового пространства. Для большинства из нас это значительно превышает характеристики обычного
жесткого диска. Нужно ли нам тратиться на покупку дополнительного хранилища? Или есть способ обучения на этих наборах данных без ограничения дискового пространства?
🤗 Datasets приходит на помощь, предлагая [потоковый режим] (https://huggingface.co/docs/datasets/stream). Потоковая передача позволяет загружать данные постепенно,
по мере того как мы итерируемся по набору данных. Вместо того чтобы загружать весь набор данных сразу, мы загружаем его по одному образцу за раз.
Мы итеративно обращаемся к набору данных, загружая и подготавливая образцы на лету, когда это необходимо. Таким образом, мы всегда
загружаем только те образцы, которые мы используем, а не те, которые мы не используем!
Закончив работу с образцом, мы продолжаем итерацию по набору данных и загружаем следующий образец.
Потоковый режим имеет три основных преимущества перед загрузкой всего набора данных целиком:
* Дисковое пространство: образцы загружаются в память один за другим по мере итерации по набору данных. Поскольку данные не загружаются
локально, то не требуется дисковое пространство, поэтому можно использовать наборы данных произвольного размера.
* Время загрузки и обработки: аудиоданные имеют большой объем и требуют значительного времени для загрузки и обработки.
При потоковой передаче данных загрузка и обработка выполняются "на лету", то есть вы можете начать использовать набор данных, как только
будет готов первый образец.
* Простота экспериментов: вы можете провести эксперимент на нескольких образцах, чтобы проверить, работает ли ваш скрипт, без необходимости
загружать весь набор данных.
В режиме потоковой передачи данных есть одна оговорка. При загрузке полного набора данных без потоковой передачи как исходные данные, так и обработанные
сохраняются локально на диске. Если мы захотим повторно использовать этот набор данных, мы можем напрямую загрузить обработанные данные с диска,
минуя этапы загрузки и обработки. Следовательно, нам достаточно один раз выполнить операции загрузки и обработки,
после чего мы можем повторно использовать подготовленные данные.
В потоковом режиме данные не загружаются на диск. Таким образом, ни загруженные, ни предварительно обработанные данные не кэшируются.
Если мы хотим повторно использовать набор данных, необходимо повторить шаги потоковой передачи, при этом аудиофайлы должны быть загружены и обработаны на
"на лету" заново. По этой причине рекомендуется загружать наборы данных, которые, скорее всего, будут использоваться многократно.
Как включить потоковый режим? Легко! Просто установите `streaming=True` при загрузке набора данных. Об остальном позаботятся:
```py
gigaspeech = load_dataset("speechcolab/gigaspeech", "xs", streaming=True)
```
Подобно тому, как мы применяли шаги предварительной обработки к загруженному подмножеству MINDS-14, точно так же можно выполнить
ту же самую предварительную обработку с потоковым набором данных.
Единственное отличие заключается в том, что вы больше не можете обращаться к отдельным образцам, используя индексацию Python (т.е. `gigaspeech["train"][sample_idx]`).
Вместо этого приходится выполнять итерации по набору данных. Вот как можно получить доступ к образцу при потоковой передаче набора данных:
```py
next(iter(gigaspeech["train"]))
```
**Output:**
```out
{
"segment_id": "YOU0000000315_S0000660",
"speaker": "N/A",
"text": "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
"audio": {
"path": "xs_chunks_0000/YOU0000000315_S0000660.wav",
"array": array(
[0.0005188, 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294, 0.00036621]
),
"sampling_rate": 16000,
},
"begin_time": 2941.89,
"end_time": 2945.07,
"audio_id": "YOU0000000315",
"title": "Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43",
"url": "https://www.youtube.com/watch?v=zr2n1fLVasU",
"source": 2,
"category": 24,
"original_full_path": "audio/youtube/P0004/YOU0000000315.opus",
}
```
Если вы хотите ознакомиться с несколькими образцами из большого набора данных, воспользуйтесь функцией `take()` для получения первых n элементов. Возьмем
первые два образца из набора данных gigaspeech:
```py
gigaspeech_head = gigaspeech["train"].take(2)
list(gigaspeech_head)
```
**Output:**
```out
[
{
"segment_id": "YOU0000000315_S0000660",
"speaker": "N/A",
"text": "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
"audio": {
"path": "xs_chunks_0000/YOU0000000315_S0000660.wav",
"array": array(
[
0.0005188,
0.00085449,
0.00012207,
...,
0.00125122,
0.00076294,
0.00036621,
]
),
"sampling_rate": 16000,
},
"begin_time": 2941.89,
"end_time": 2945.07,
"audio_id": "YOU0000000315",
"title": "Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43",
"url": "https://www.youtube.com/watch?v=zr2n1fLVasU",
"source": 2,
"category": 24,
"original_full_path": "audio/youtube/P0004/YOU0000000315.opus",
},
{
"segment_id": "AUD0000001043_S0000775",
"speaker": "N/A",
"text": "SIX TOMATOES <PERIOD>",
"audio": {
"path": "xs_chunks_0000/AUD0000001043_S0000775.wav",
"array": array(
[
1.43432617e-03,
1.37329102e-03,
1.31225586e-03,
...,
-6.10351562e-05,
-1.22070312e-04,
-1.83105469e-04,
]
),
"sampling_rate": 16000,
},
"begin_time": 3673.96,
"end_time": 3675.26,
"audio_id": "AUD0000001043",
"title": "Asteroid of Fear",
"url": "http//www.archive.org/download/asteroid_of_fear_1012_librivox/asteroid_of_fear_1012_librivox_64kb_mp3.zip",
"source": 0,
"category": 28,
"original_full_path": "audio/audiobook/P0011/AUD0000001043.opus",
},
]
```
Потоковый режим может вывести ваши исследования на новый уровень: вам не только доступны самые большие наборы данных, но вы
можете легко оценивать системы на нескольких наборах данных за один раз, не заботясь о дисковом пространстве. По сравнению с оценкой
на одном наборе данных, оценка на нескольких наборах дает более точную метрику обобщающих способностей
системы распознавания речи (например, End-to-end Speech Benchmark (ESB)).
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter1/quiz.mdx | <!-- DISABLE-FRONTMATTER-SECTIONS -->
# Проверьте свое понимание материала курса
### 1. В каких единицах измеряется частота дискретизации?
<Question
choices={[
{
text: "дБ",
explain: "Нет, амплитуда измеряется в децибелах (дБ)."
},
{
text: "Гц",
explain: "Частота дискретизации - это количество выборок, сделанных за одну секунду, она измеряется в герцах (Гц).",
correct: true
},
{
text: "бит",
explain: "Биты используются для описания битовой глубины, под которой понимается количество битов информации, используемых для представления каждого образца аудиосигнала.",
}
]}
/>
### 2. При потоковой передаче большого набора аудиоданных как скоро можно начать его использовать?
<Question
choices={[
{
text: "Как только набор данных будет загружен полностью.",
explain: "Цель потоковой передачи данных состоит в том, чтобы иметь возможность работать с ними без необходимости полной загрузки набора данных."
},
{
text: "Как только первые 16 образцов будут загружены.",
explain: "Попробуйте еще раз!"
},
{
text: "Как только первый образец будет загружен.",
explain: "",
correct: true
}
]}
/>
### 3. Что такое спектрограмма?
<Question
choices={[
{
text: "Устройство, используемое для оцифровки звука, который сначала улавливается микрофоном, преобразующим звуковые волны в электрический сигнал.",
explain: "Устройство, используемое для оцифровки такого электрического сигнала, называется аналого-цифровым преобразователем. Попробуйте еще раз!"
},
{
text: "График, показывающий изменение амплитуды звукового сигнала с течением времени. Он также известен как *временная область* представления звука.",
explain: "В приведенном описании речь идет о форме волны, а не о спектрограмме."
},
{
text: "Визуальное представление частотного спектра сигнала при его изменении во времени.",
explain: "",
correct: true
}
]}
/>
### 4. Как проще всего преобразовать сырые аудиоданные в лог-мел спектрограмму, ожидаемую Whisper?
A.
```python
librosa.feature.melspectrogram(audio["array"])
```
B.
```python
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
feature_extractor(audio["array"])
```
C.
```python
dataset.feature(audio["array"], model="whisper")
```
<Question
choices={[
{
text: "A",
explain: "`librosa.feature.melspectrogram()` создает спектрограмму мощности."
},
{
text: "B",
explain: "",
correct: true
},
{
text: "C",
explain: "Dataset не подготавливает признаки для моделей Transformer, это делает препроцессор модели."
}
]}
/>
### 5. Как загрузить набор данных из 🤗 Hub?
A.
```python
from datasets import load_dataset
dataset = load_dataset(DATASET_NAME_ON_HUB)
```
B.
```python
import librosa
dataset = librosa.load(PATH_TO_DATASET)
```
C.
```python
from transformers import load_dataset
dataset = load_dataset(DATASET_NAME_ON_HUB)
```
<Question
choices={[
{
text: "A",
explain: "Лучше всего использовать библиотеку 🤗 Datasets.",
correct: true
},
{
text: "B",
explain: "Librosa.load удобен для загрузки отдельного аудиофайла расположенного по пути в кортеж с временным рядом и частотой дискретизации, но не целого набора данных с большим количеством образцов и множеством признаков. "
},
{
text: "C",
explain: "Метод load_dataset находится в библиотеке 🤗 Datasets, а не в 🤗 Transformers."
}
]}
/>
### 6. Ваш пользовательский набор данных содержит высококачественные аудиозаписи с частотой дискретизации 32 кГц. Вы хотите обучить модель распознавания речи, которая ожидает, что аудиопримеры будут иметь частоту дискретизации 16 кГц. Что нужно сделать?
<Question
choices={[
{
text: "Используйте примеры как есть, модель легко обобщится на более качественные аудиопримеры.",
explain: "Из-за зависимости от механизма внимания моделям сложно обобщать данные с разной частотой дискретизации."
},
{
text: "Используйте модуль Audio из библиотеки 🤗 Datasets для понижения частоты дискретизации примеров в пользовательском наборе данных",
explain: "",
correct: true
},
{
text: "Уменьшите выборку в 2 раза, отбросив все остальные образцы.",
explain: "При этом в сигнале возникают искажения, называемые наложениями (aliases). Корректная передискретизация - сложная задача, и ее лучше доверить проверенным библиотекам, таким как librosa или 🤗 Datasets."
}
]}
/>
### 7. Как преобразовать спектрограмму, сгенерированную моделью машинного обучения, в форму волны?
<Question
choices={[
{
text: "Для восстановления формы волны из спектрограммы мы можем использовать нейронную сеть, называемую вокодером.",
explain: "Поскольку фазовая информация в этом случае отсутствует, для восстановления формы сигнала необходимо использовать вокодер или классический алгоритм Гриффина-Лима.",
correct: true
},
{
text: "Мы можем использовать обратное ОПФ для преобразования сгенерированной спектрограммы в форму волны",
explain: "В сгенерированной спектрограмме отсутствует фазовая информация, необходимая для использования инверсного ОПФ."
},
{
text: "Вы не можете преобразовать спектрограмму, сгенерированную моделью машинного обучения, в форму волны.",
explain: "Попробуйте еще раз!"
}
]}
/>
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter1/introduction.mdx | # Раздел 1. Работа с аудио данными
## Что вы узнаете в этом разделе
Любая аудио или голосовая задача начинается с аудиофайла. Прежде чем приступить к решению этих задач, необходимо
понять, что на самом деле содержат эти файлы и как с ними работать.
В этом разделе вы получите представление о фундаментальной терминологии, связанной с аудиоданными, включая форму волны,
частоту дискретизации и спектрограмму. Вы также узнаете, как работать с наборами аудиоданных, включая загрузку и препроцессинг
аудиоданных, и как эффективно передавать большие наборы данных.
К концу этого раздела вы будете хорошо разбираться в основной терминологии аудиоданных и овладеете навыками,
необходимыми для работы с аудио наборами данных в различных приложениях. Знания, которые вы получите в этом разделе,
заложат основу для понимания остальной части курса. | 2 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter1/audio_data.mdx | # Введение в аудиоданные
По своей природе звуковая волна является непрерывным сигналом, то есть содержит бесконечное число значений сигнала за определенное время.
Это создает проблемы для цифровых устройств, которые ожидают конечные массивы. Для обработки, хранения и передачи сигнала цифровыми устройствами,
непрерывная звуковая волна должна быть преобразована в ряд дискретных значений, называемых цифровым представлением.
Если обратиться к любому набору аудиоданных, то можно найти цифровые файлы со звуковыми фрагментами, например, с текстовым повествованием или музыкой.
Вы можете встретить различные форматы файлов, такие как `.wav` (Waveform Audio File), `.flac` (Free Lossless Audio Codec),
`.mp3` (MPEG-1 Audio Layer 3). Эти форматы различаются главным образом способом сжатия цифрового представления аудиосигнала.
Рассмотрим, как мы приходим от непрерывного сигнала к такому представлению. Сначала аналоговый сигнал улавливается
микрофоном, который преобразует звуковые волны в электрический сигнал. Затем электрический сигнал оцифровывается с помощью
Аналого-Цифрового Преобразователя для получения цифрового представления путем дискретизации.
## Выборка и частота дискретизации
Выборка (сэмлирование, дискретизация) - это процесс измерения значения непрерывного сигнала с фиксированным шагом по времени. Выборочная форма сигнала является _дискретной_,
поскольку содержит конечное число значений сигнала через равномерные интервалы времени.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/Signal_Sampling.png" alt="Иллюстрация дискретизации сигнала">
</div>
*Иллюстрация из статьи Википедии: [Сэмплирование (обработка сигналов)](https://en.wikipedia.org/wiki/Sampling_(signal_processing))*
**Частота выборки (сэмплирования)** (также называемая частотой дискретизации) - это количество выборок, сделанных за одну секунд измеряемое в
герцах (Гц). Чтобы дать вам примерную точку отсчета, частота дискретизации аудиофайлов CD-качества составляет 44 100 Гц, то есть выборки делаются
44 100 раз в секунду. Для сравнения, частота дискретизации звука высокого разрешения составляет 192 000 Гц или 192 кГц. Обычно
частота дискретизации, используемая при обучении речевых моделей, составляет 16 000 Гц или 16 кГц.
Выбор частоты дискретизации в первую очередь определяет наивысшую частоту, которая может быть извлечена из сигнала. Это значение также,
известно как предел Найквиста, и составляет ровно половину частоты дискретизации. Слышимые частоты в человеческой речи лежат ниже 8 кГц,
поэтому для дискретизации речи достаточно 16 кГц. Использование более высокой частоты дискретизации не позволяет получить больше информации и
только приведет к увеличению вычислительных затрат на обработку таких файлов. С другой стороны, дискретизация звука при слишком
низкой частоте дискретизации приводит к потере информации. Речь, дискретизированная с частотой 8 кГц, будет звучать приглушенно, так как более высокие частоты
не могут быть захвачены при такой частоте дискретизации.
При работе над любой аудио задачей важно убедиться, что все примеры звука в вашем наборе данных имеют одинаковую частоту дискретизации.
Если вы планируете использовать пользовательские аудиоданные для дообучения предварительно обученной модели, то частота дискретизации ваших данных должна соответствовать частоте дискретизации данных, на которых была предварительно обучена модель. Частота дискретизации определяет временной интервал между последовательными
выборками звука, что влияет на временное разрешение аудиоданных. Рассмотрим пример: 5-секундный звук при частоте дискретизации
16 000 Гц будет представлен в виде серии из 80 000 значений, а тот же 5-секундный звук при частоте дискретизации
8 000 Гц будет представлен в виде серии из 40 000 значений. Модели трансформеров, решающие аудиозадачи, рассматривают примеры как последовательности
и полагаются на механизмы внимания для обучения аудио или мультимодальному представлению. Поскольку последовательности данных различны для
аудиопримеров с разной частотой дискретизации, то моделям будет сложно обобщать данные для разных частот дискретизации.
**Передискретизация** - это процесс согласования частот дискретизации, являющийся частью [препроцессинга](preprocessing#resampling-the-audio-data) аудиоданных.
## Амплитуда и битовая глубина
В то время как частота дискретизации говорит о том, как часто происходит выборка образцов, какие именно значения содержатся в каждом образце?
Звук возникает в результате изменения давления воздуха на частотах, слышимых человеком. **Амплитуда** звука характеризует
уровень звукового давления в любой момент времени и измеряется в децибелах (дБ). Мы воспринимаем амплитуду как громкость.
Для примера, обычный разговор не превышает 60 дБ, а рок-концерт может достигать 125 дБ, что является пределом
для человеческого слуха.
В цифровом аудио каждый образец звука фиксирует амплитуду звуковой волны в определенный момент времени. **Битовая глубина** образца звука
определяет, с какой точностью может быть описано это значение амплитуды. Чем выше битовая глубина, тем точнее
цифровое представление приближается к исходной непрерывной звуковой волне.
Наиболее распространенные битовые глубины звука - 16 и 24 бита. Каждая из них представляет собой двоичный термин, обозначающий количество возможных шагов,
на которое можно квантовать амплитудное значение при его преобразовании из непрерывного в дискретное: 65 536 шагов для 16-битного звука,
для 24-битного звука - 16 777 216 шагов. Поскольку при квантовании происходит округление непрерывного значения до дискретного,
процесс дискретизации вносит шум. Чем выше битовая глубина, тем меньше этот шум квантования. На практике
шум квантования 16-битного звука уже достаточно мал, чтобы быть неслышимым, и использование большей битовой глубины обычно
не требуется.
Вы также можете встретить 32-битные аудио. В нем выборки хранятся в виде значений с плавающей точкой, тогда как в 16- и 24-битном аудио
используются целочисленные выборки. Точность 32-битного значения с плавающей точкой составляет 24 бита, что дает такую же битовую глубину, как и у 24-битного звука.
Предполагается, что аудио выборки с плавающей точкой лежат в диапазоне [-1,0, 1,0]. Поскольку модели машинного обучения естественным образом
работают с данными в формате с плавающей точкой, перед тем как использовать их для обучения модели, аудиоданные необходимо преобразовать в формат с плавающей точкой.
Как это сделать, мы рассмотрим в следующем разделе [Препроцессинг](preprocessing).
Как и в случае с непрерывными звуковыми сигналами, амплитуда цифрового звука обычно выражается в децибелах (дБ). Поскольку
слух человека имеет логарифмическую природу - наши уши более чувствительны к небольшим колебаниям тихих звуков, чем громких,
то громкость звука легче интерпретировать, если амплитуды выражены в децибелах, которые также являются логарифмическими.
Децибельная шкала для реального звука начинается с 0 дБ, что соответствует самому тихому звуку, который может услышать человек, а
более громкие звуки имеют большие значения. Однако для цифровых аудиосигналов 0 дБ - это самая громкая возможная амплитуда, а все
остальные амплитуды отрицательны. Краткое эмпирическое правило: каждые -6 дБ - это уменьшение амплитуды вдвое, и все, что ниже -60 дБ
обычно неслышно, если только вы не увеличите громкость.
## Аудио как форма волны
Возможно, вам приходилось видеть визуализацию звуков в виде **формы волны**, которая отображает значения отсчетов во времени и иллюстрирует изменения
амплитуды звука. Такое представление звука называется *временной областью*.
Этот тип визуализации полезен для выявления специфических особенностей аудиосигнала, таких как время появления отдельных звуковых событий,
общая громкость сигнала, неравномерности или шумы, присутствующие в аудиосигнале.
Для построения графика формы волны аудиосигнала можно использовать библиотеку Python `librosa`:
```bash
pip install librosa
```
Возьмем для примера звук "Трубы", который поставляется вместе с библиотекой::
```py
import librosa
array, sampling_rate = librosa.load(librosa.ex("trumpet"))
```
Пример загружается в виде кортежа состоящего из временного ряда звука (здесь мы называем его `array`), и частоты дискретизации (`sampling_rate`).
Посмотрим на форму волны этого звука с помощью функции librosa `waveshow()`:
```py
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/waveform_plot.png" alt="Waveform plot">
</div>
При этом по оси y откладывается амплитуда сигнала, а по оси x - время. Другими словами, каждая точка соответствует
одному значению выборки, которое было взято при сэмплировании этого звука. Также отметим, что librosa возвращает звук уже в виде значений
с плавающей точкой, при этом значения амплитуды действительно находятся в диапазоне [-1.0, 1.0].
Визуализация звука наряду с его прослушиванием может быть полезным инструментом для понимания данных, с которыми вы работаете.
Вы можете увидеть форму сигнала, заметить закономерности, научиться выявлять шумы или искажения. При предварительной обработке данных,
например, нормализации, повторной выборке или фильтрации, можно визуально убедиться в том, что этапы предварительной обработки были выполнены как ожидалось.
После обучения модели можно также визуализировать примеры, в которых возникают ошибки (например, в задаче классификации звука), для отладки
возникающих проблем.
## Частотный спектр
Другим способом визуализации аудиоданных является построение **частотного спектра** аудиосигнала, также известное как **частотный интервал**.
Спектр вычисляется с помощью Дискретного Преобразования Фурье или ДПФ (Discrete Fourier Transform - DFT). Он описывает отдельные частоты,
из которых состоит сигнал, и их силу.
Построим частотный спектр для того же звука трубы, взяв ДПФ с помощью функции numpy `rfft()`. Хотя
можно построить спектр всего звука, удобнее рассматривать небольшую область. Здесь мы возьмем
ДПФ первых 4096 выборок, что приблизительно равно длительности первой сыгранной ноты:
```py
import numpy as np
dft_input = array[:4096]
# Рассчитаем ДПФ
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# получим амплитудный спектр в децибелах
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# получим частотные столбцы
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/spectrum_plot.png" alt="Spectrum plot">
</div>
Здесь отображается сила различных частотных составляющих, присутствующих в данном аудио сегменте. На оси x
откладываются значения частот, обычно в логарифмическом масштабе, а по оси y - их амплитуды.
Построенный нами частотный спектр имеет несколько пиков. Эти пики соответствуют гармоникам исполняемой ноты,
причем более высокие гармоники более тихие. Поскольку первый пик находится на частоте около 620 Гц, это частотный спектр ноты E♭.
На выходе ДПФ получается массив комплексных чисел, состоящий из действительной и мнимой компонент. Взяв
величину с помощью `np.abs(dft)`, можно извлечь из спектрограммы амплитудную информацию. Угол между действительной и
мнимой составляющими дает так называемый фазовый спектр, но в приложениях машинного обучения он часто отбрасывается.
Вы использовали `librosa.amplitude_to_db()` для преобразования значений амплитуды в децибельную шкалу, что облегчает просмотр
более тонких деталей в спектре. Иногда используют **энергетический спектр**, который измеряет энергию, а не амплитуду;
это просто спектр с квадратом амплитудных значений.
<Tip>
💡 На практике термин БПФ (Fast Fourier Transform - FFT) используется как взаимозаменяемый с термином ДПФ, поскольку БПФ или быстрое преобразование Фурье является единственным эффективным способ вычисления ДПФ на компьютере.
</Tip>
Частотный спектр аудиосигнала содержит точно такую же информацию, как и его волновая форма, - это просто два разных способа
взглянуть на одни и те же данные (здесь - первые 4096 выборок из звука трубы). Если волновая форма отображает амплитуду
звукового сигнала во времени, то спектр представляет амплитуды отдельных частот в фиксированный момент времени.
## Спектрограмма
Что если мы хотим увидеть, как изменяются частоты в аудиосигнале? Труба играет несколько нот, и все они имеют
разные частоты. Проблема в том, что спектр показывает только застывший снимок частот в данный момент времени.
Решение состоит в том, чтобы взять несколько ДПФ, каждый из которых охватывает лишь небольшой отрезок времени, и сложить полученные спектры вместе
в **спектрограмму**.
Спектрограмма представляет собой график изменения частотного содержания звукового сигнала во времени. Она позволяет увидеть время, частоту,
и амплитуду на одном графике. Алгоритм, выполняющий эти вычисления, называется ОПФ или Оконное Преобразование Фурье (Short Time Fourier Transform - STFT).
Спектрограмма является одним из наиболее информативных аудио инструментов. Например, при работе с музыкальной записью
можно увидеть различные инструменты и вокальные дорожки и их вклад в общее звучание. В речи можно
идентифицировать различные гласные звуки, поскольку каждый гласный звук характеризуется определенными частотами.
Построим спектрограмму для того же звука трубы, используя функции библиотеки librosa `stft()` и `specshow()`:
```py
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/spectrogram_plot.png" alt="Spectrogram plot">
</div>
На этом графике ось x представляет собой время, как и при визуализации формы волны, но теперь ось y представляет собой частоту в Гц.
Интенсивность цвета показывает амплитуду или мощность частотной составляющей в каждый момент времени, измеряемую в децибелах (дБ).
Спектрограмма создается путем выделения коротких сегментов аудиосигнала, как правило, длительностью несколько миллисекунд, и вычисления
дискретного преобразования Фурье каждого сегмента для получения его частотного спектра. Полученные спектры складываются
вместе по оси времени для получения спектрограммы. Каждый вертикальный срез на этом изображении соответствует одному частотному
спектру, если смотреть сверху. По умолчанию `librosa.stft()` разбивает аудиосигнал на сегменты по 2048 выборок, что
дает хороший компромисс между частотным и временным разрешением.
Поскольку спектрограмма и волновая форма - это разные представления одних и тех же данных, то с помощью обратного ОПФ можно превратить спектрограмму обратно
в исходную волновую форму. Однако для этого помимо информации об амплитуде
требуется информация о фазе. Если спектрограмма была сгенерирована моделью машинного обучения, то она, как правило, выдает только амплитуды.
В этом случае для восстановления формы волны из спектрограммы можно использовать алгоритм восстановления фазы, например, классический алгоритм Гриффина-Лима,
или нейронную сеть, называемую вокодером.
Спектрограммы используются не только для визуализации. Многие модели машинного обучения принимают на вход спектрограммы - в отличие от
формы волны - и выдают на выходе спектрограммы.
Теперь, когда мы знаем, что такое спектрограмма и как она строится, рассмотрим ее разновидность, широко используемую при обработке речи, - Мел спектрограмму.
## Мэл спектрограмма
Мел-спектрограмма - это разновидность спектрограммы, которая широко используется в задачах обработки речи и машинного обучения.
Она похожа на спектрограмму тем, что показывает частотное содержание аудиосигнала во времени, но на другой частотной оси.
В стандартной спектрограмме частотная ось линейна и измеряется в герцах (Гц). Однако слуховая система человека
более чувствительна к изменениям на низких частотах, чем на высоких, и эта чувствительность уменьшается логарифмически
с увеличением частоты. Шкала Мэл - это перцептивная шкала, которая аппроксимирует нелинейную частотную характеристику человеческого уха.
Для создания мэл спектрограммы, как и ранее, используется ОПФ, при этом аудиосигнал разбивается на короткие сегменты для получения последовательности
частотных спектров. Кроме того, каждый спектр пропускается через набор фильтров, так называемый банк фильтров мэла, для [NL1] преобразования частот в Мэл шкалу.
Рассмотрим, как можно построить мэл спектрограмму с помощью функции librosa `melspectrogram()`, которая выполняет все эти действия за нас:
```py
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/mel-spectrogram.png" alt="Mel spectrogram plot">
</div>
В приведенном примере `n_mels` означает количество генерируемых мэл диапазонов. Мел диапазоны определяют набор частотных
диапазонов, которые разделяют спектр на перцептивно значимые компоненты, используя набор фильтров, форма и расстояние между которыми
выбираются таким образом, чтобы имитировать реакцию человеческого уха на различные частоты. Обычные значения для `n_mels` это 40 или 80. `fmax`
указывает максимальную частоту (в Гц), которая нас интересует.
Как и в случае с обычной спектрограммой, принято выражать силу мел-частотных компонентов в
децибелах. Такую спектрограмму принято называть **лог-мэл-спектрограммой**, поскольку при переводе в децибелы выполняется
логарифмическая операция. В приведенном выше примере использовалась функция `librosa.power_to_db()`, так как `librosa.feature.melspectrogram()` создает спектрограмму мощности.
<Tip>
💡 Не все мэл спектрограммы одинаковы! Существуют две различные шкалы мэл, которые широко используются ("htk" и "slaney"),
а вместо спектрограммы мощности может использоваться амплитудная спектрограмма. При преобразовании спектрограммы в лог-мел не всегда
вычисляются истинные децибелы, а может просто браться `log`. Поэтому, если модель машинного обучения ожидает в качестве входных данных спектрограмму мел,
дважды проверьте, что она вычисляется тем же способом.
</Tip>
Создание mel-спектрограммы - это операция с потерями, так как она связана с фильтрацией сигнала. Конвертировать mel-спектрограмму обратно
в волновую форму сложнее, чем обычную спектрограмму, так как для этого необходимо оценить частоты,
которые были отброшены. Поэтому для получения формы волны из мэл спектрограммы необходимы модели машинного обучения,
такие как вокодер HiFiGAN.
По сравнению со стандартной спектрограммой, мэл спектрограмма может отражать более значимые для восприятия человеком особенности аудиосигнала,
что делает ее популярной в таких задачах, как распознавание речи, идентификация диктора и классификация музыкальных жанров.
Теперь, когда вы знаете, как визуализировать примеры аудиоданных, попробуйте посмотреть, как выглядят ваши любимые звуки. :)
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter1/load_and_explore.mdx | # Загрузка и изучение аудио набора данных
В этом курсе мы будем использовать библиотеку 🤗 Datasets для работы с наборами аудиоданных. 🤗 Datasets - это библиотека с открытым исходным кодом для
загрузки и подготовки наборов данных всех модальностей, включая аудио. Библиотека предоставляет легкий доступ к беспрецедентному
подборке наборов данных машинного обучения, публично доступных на Hugging Face Hub. Кроме того, 🤗 Datasets содержит множество
функций, предназначенных для работы с аудиоданными, которые упрощают работу с ними как для исследователей, так и для практиков.
Для начала работы с наборами аудиоданных необходимо убедиться, что у вас установлена библиотека 🤗 Datasets:
```bash
pip install datasets[audio]
```
Одной из ключевых особенностей 🤗 Datasets является возможность загрузки и подготовки набора данных всего одной строкой
Python-кода с помощью функции `load_dataset()`.
Давайте загрузим и исследуем набор аудиоданных под названием [MINDS-14](https://huggingface.co/datasets/PolyAI/minds14), который содержит
записи людей, задающих вопросы системе дистанционного банковского обслуживания на нескольких языках и диалектах.
Для загрузки набора данных MINDS-14 нам необходимо скопировать идентификатор набора данных на хабе (`PolyAI/minds14`) и передать его
в функцию `load_dataset`. Мы также укажем, что нас интересует только австралийское подмножество (`en-AU`)
данных, и ограничим его частью набора данных предназначенной для обучения:
```py
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
minds
```
**Output:**
```out
Dataset(
{
features: [
"path",
"audio",
"transcription",
"english_transcription",
"intent_class",
"lang_id",
],
num_rows: 654,
}
)
```
Набор содержит 654 аудиофайла, каждый из которых сопровождается транскрипцией, переводом на английский язык и меткой,
указывающей на намерение человека, сделавшего запрос. В столбце audio содержатся необработанные аудиоданные. Рассмотрим подробнее
на одном из примеров:
```py
example = minds[0]
example
```
**Output:**
```out
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[0.0, 0.00024414, -0.00024414, ..., -0.00024414, 0.00024414, 0.0012207],
dtype=float32,
),
"sampling_rate": 8000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"english_transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
"lang_id": 2,
}
```
Вы можете заметить, что столбец аудио содержит несколько параметров. Вот что они собой представляют:
* `path`: путь к аудиофайлу (в данном случае `*.wav`).
* `array`: Декодированные аудиоданные, представленные в виде одномерного массива NumPy.
* `sampling_rate`. Частота дискретизации аудиофайла (в данном примере 8 000 Гц).
Класс `intent_class` - это классификационная категория аудиозаписи. Для преобразования этого числа в осмысленную строку
можно использовать метод `int2str()`:
```py
id2label = minds.features["intent_class"].int2str
id2label(example["intent_class"])
```
**Output:**
```out
"pay_bill"
```
Если посмотреть на транскрипцию, то можно увидеть, что в аудиофайле действительно записан человек, задающий вопрос
об оплате счета.
Если вы планируете обучать аудиоклассификатор на этом подмножестве данных, то, возможно, вам не обязательно понадобятся все признаки. Например,
`lang_id` будет иметь одно и то же значение для всех примеров и не будет полезен. Параметр `english_transcription`, скорее всего, будет
дублировать `transcription` в этом подмножестве, поэтому их можно смело удалить.
Удалить нерелевантные признаки можно с помощью метода 🤗 Datasets `remove_columns`:
```py
columns_to_remove = ["lang_id", "english_transcription"]
minds = minds.remove_columns(columns_to_remove)
minds
```
**Output:**
```out
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 654})
```
Теперь, когда мы загрузили и осмотрели необработанное содержимое набора данных, давайте прослушаем несколько примеров! Мы воспользуемся функциями `Blocks`
и `Audio` из `Gradio` для декодирования нескольких случайных образцов из набора данных:
```py
import gradio as gr
def generate_audio():
example = minds.shuffle()[0]
audio = example["audio"]
return (
audio["sampling_rate"],
audio["array"],
), id2label(example["intent_class"])
with gr.Blocks() as demo:
with gr.Column():
for _ in range(4):
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)
```
При желании можно также визуализировать некоторые примеры. Построим форму волны для первого примера.
```py
import librosa
import matplotlib.pyplot as plt
import librosa.display
array = example["audio"]["array"]
sampling_rate = example["audio"]["sampling_rate"]
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/waveform_unit1.png" alt="Waveform plot">
</div>
Попробуйте! Загрузите другой диалект или язык из набора данных MINDS-14, прослушайте и визуализируйте несколько примеров, чтобы получить представление
о вариативности всего набора данных. Полный список доступных языков можно найти [здесь](https://huggingface.co/datasets/PolyAI/minds14).
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter7/supplemental_reading.mdx | # Дополнительные материалы и ресурсы
В этом разделе объединены многие компоненты из предыдущих разделов, представлены задачи перевода речи в речь,
голосовые помощники и диаризация диктора. Для удобства чтения дополнительный материал разбит на эти три новые задачи:
Перевод речи в речь:
* [STST с дискретными блоками](https://ai.facebook.com/blog/advancing-direct-speech-to-speech-modeling-with-discrete-units/) от Meta AI: прямой подход к STST через модели энкодер-декодер
* [Hokkien прямой перевод речи в речь](https://ai.facebook.com/blog/ai-translation-hokkien/) от Meta AI: прямой подход к STST с использованием моделей энкодер-декодер с двухступенчатым декодером
* [Использование неконтролируемых и слабоконтролируемых данных для улучшения прямой STST](https://arxiv.org/abs/2203.13339) от Google: предлагает новые подходы к использованию неконтролируемых (unsupervised) и слабоконтролируемых (weakly supervised) данных для обучения прямых STST-моделей и небольшие изменения в архитектуре Transformer
* [Translatotron-2](https://google-research.github.io/lingvo-lab/translatotron2/) от Google: система, способная сохранять характеристики диктора в переведенной речи
Голосовой ассистент:
* [Точное обнаружение пробуждающих слов (wakeword)](https://www.amazon.science/publications/accurate-detection-of-wake-word-start-and-end-using-a-cnn) от Amazon: подход с низкой задержкой для обнаружения пробуждающих слов (wakeword) для приложений на устройствах
* [RNN-Transducer Архитектура](https://arxiv.org/pdf/1811.06621.pdf) от Google: модификация архитектуры CTC для потокового ASR на устройствах
Транскрипция встреч:
* [pyannote.audio Технический отчет](https://huggingface.co/pyannote/speaker-diarization/blob/main/technical_report_2.1.pdf) Эрве Бредин: в этом докладе описываются основные принципы, лежащие в основе конвейера диаризации дикторов `pyannote.audio
* [Whisper X](https://arxiv.org/pdf/2303.00747.pdf) by Max Bain et al.: усовершенствованный подход к вычислению временных меток на уровне слов с использованием модели Whisper | 5 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter7/transcribe-meeting.mdx | # Транскрибирование встречи
В этом заключительном разделе мы используем модель Whisper для создания транскрипции разговора или встречи между двумя или более говорящими. Затем мы объединим
ее с моделью *диаризации диктора* для прогнозирования "кто когда говорил". Сопоставив временные метки из транскрипции Whisper с временными метками от модели диаризации,
мы можем спрогнозировать сквозную транскрипцию встречи с полностью отформатированным временем начала и окончания для каждого говорящего. Это базовая версия услуг по
транскрибированию совещаний, которую вы могли видеть в интернете от таких компаний, как [Otter.ai](https://otter.ai) и др:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/diarization_transcription.png">
</div>
## Диаризация диктора
Диаризация диктора (или диаризация) - это задача получения немаркированных аудиоданных и прогнозирования того, "кто когда говорил". При этом мы можем
прогнозировать временные метки начала/окончания каждой очереди дикторов, соответствующие моменту начала речи и моменту ее окончания.
🤗 В настоящее время в библиотеке Transformers нет модели для диаризации диктора, но на Hub есть контрольные точки, которые можно использовать
с относительной легкостью. В этом примере мы будем использовать предварительно обученную модель диаризации диктора из [pyannote.audio](https://github.com/pyannote/pyannote-audio).
Давайте приступим к работе и установим пакет с помощью pip:
```bash
pip install --upgrade pyannote.audio
```
Отлично! Веса для этой модели размещены на Hugging Face Hub. Чтобы получить к ним доступ, сначала нужно согласиться с условиями использования модели диаризации
диктора: [pyannote/speaker-diarization](https://huggingface.co/pyannote/speaker-diarization). А затем - с условиями использования модели
сегментации: [pyannote/segmentation](https://huggingface.co/pyannote/segmentation).
После завершения работы мы можем загрузить предварительно обученный конвейер диаризации дикторов локально на наше устройство:
```python
from pyannote.audio import Pipeline
diarization_pipeline = Pipeline.from_pretrained(
"pyannote/[email protected]", use_auth_token=True
)
```
Давайте опробуем его на примере аудиофайла! Для этого мы загрузим образец из датасета [LibriSpeech ASR](https://huggingface.co/datasets/librispeech_asr), содержащий речь
двух разных дикторов, который мы объединили в один аудиофайл:
```python
from datasets import load_dataset
concatenated_librispeech = load_dataset(
"sanchit-gandhi/concatenated_librispeech", split="train", streaming=True
)
sample = next(iter(concatenated_librispeech))
```
Мы можем прослушать аудиозапись, чтобы понять, как она звучит:
```python
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
Класс! Мы отчетливо слышим двух разных дикторов с переходом примерно на 15 секунде звучания. Давайте передадим этот аудиофайл в модель диаризации, чтобы получить
время начала и окончания разговора. Заметим, что pyannote.audio ожидает, что входной аудиофайл будет представлять собой тензор PyTorch формы `(channels, seq_len)`,
поэтому перед запуском модели нам необходимо выполнить это преобразование:
```python
import torch
input_tensor = torch.from_numpy(sample["audio"]["array"][None, :]).float()
outputs = diarization_pipeline(
{"waveform": input_tensor, "sample_rate": sample["audio"]["sampling_rate"]}
)
outputs.for_json()["content"]
```
```text
[{'segment': {'start': 0.4978125, 'end': 14.520937500000002},
'track': 'B',
'label': 'SPEAKER_01'},
{'segment': {'start': 15.364687500000002, 'end': 21.3721875},
'track': 'A',
'label': 'SPEAKER_00'}]
```
Выглядит это довольно неплохо! Видно, что первый диктор говорит до отметки 14,5 секунды, а второй - с 15,4 секунды.
Теперь нам нужно получить транскрипцию!
## Транскрибирование речи
В третий раз в этом блоке мы будем использовать модель Whisper для нашей системы транскрипции речи. В частности, мы загрузим контрольную точку [Whisper Base](https://huggingface.co/openai/whisper-base),
поскольку она достаточно мала, чтобы обеспечить хорошую скорость инференса при приемлемой точности транскрипции. Как и прежде, вы можете использовать любую контрольную точку распознавания речи с
[Hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&library=transformers&sort=trending), включая Wav2Vec2, MMS ASR или другие контрольные точки Whisper:
```python
from transformers import pipeline
asr_pipeline = pipeline(
"automatic-speech-recognition",
model="openai/whisper-base",
)
```
Давайте получим транскрипцию для нашего образца аудиозаписи, возвращая также временные метки на уровне сегментов, чтобы знать время начала и окончания каждого сегмента.
Из раздела 5 вы помните, что для активации задачи прогнозирования временных меток в Whisper нам необходимо передать аргумент `return_timestamps=True`:
```python
asr_pipeline(
sample["audio"].copy(),
generate_kwargs={"max_new_tokens": 256},
return_timestamps=True,
)
```
```text
{
"text": " The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight. He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
"chunks": [
{"timestamp": (0.0, 3.56), "text": " The second and importance is as follows."},
{
"timestamp": (3.56, 7.84),
"text": " Sovereignty may be defined to be the right of making laws.",
},
{
"timestamp": (7.84, 13.88),
"text": " In France, the king really exercises a portion of the sovereign power, since the laws have",
},
{"timestamp": (13.88, 15.48), "text": " no weight."},
{
"timestamp": (15.48, 19.44),
"text": " He was in a favored state of mind, owing to the blight his wife's action threatened to",
},
{"timestamp": (19.44, 21.28), "text": " cast upon his entire future."},
],
}
```
Отлично! Мы видим, что каждый сегмент транскрипции имеет начальное и конечное время, причем смена дикторов происходит на отметке 15,48 секунды. Теперь мы можем сопоставить
эту транскрипцию с временными метками дикторов, полученными с помощью модели диаризации, и получить окончательную транскрипцию.
## Speechbox
Чтобы получить окончательную транскрипцию, совместим временные метки, полученные с помощью модели диаризации, с временными метками, полученными с помощью модели Whisper.
Модель диаризации предсказала окончание речи первого диктора на 14,5 с, а второго - на 15,4 с, в то время как Whisper предсказал границы сегментов на 13,88, 15,48 и 19,44 с соответственно.
Поскольку временные метки, полученные с помощью Whisper, не полностью совпадают с данными модели диаризации, нам необходимо найти, какие из этих границ ближе всего к 14,5 и 15,4 с, и
соответствующим образом сегментировать транскрипцию по дикторам. В частности, мы найдем наиболее близкое совпадение между временными метками диаризации и транскрипции,
минимизировав абсолютное расстояние между ними.
К счастью для нас, мы можем использовать пакет 🤗 Speechbox для выполнения этого выравнивания. Сначала давайте установим пакет `speechbox` из main:
```bash
pip install git+https://github.com/huggingface/speechbox
```
Теперь мы можем инстанцировать наш комбинированный конвейер диаризации и транскрипции, передав модель диаризации и
модель ASR в класс [`ASRDiarizationPipeline`](https://github.com/huggingface/speechbox/tree/main#asr-with-speaker-diarization):
```python
from speechbox import ASRDiarizationPipeline
pipeline = ASRDiarizationPipeline(
asr_pipeline=asr_pipeline, diarization_pipeline=diarization_pipeline
)
```
<Tip>
Вы также можете инстанцировать <code>ASRDiarizationPipeline</code> directly непосредственно из предварительно обученных моделей, указав идентификатор
модели ASR на Hub:
<p><code>pipeline = ASRDiarizationPipeline.from_pretrained("openai/whisper-base")</code></p>
</Tip>
Передадим аудиофайл в композитный конвейер и посмотрим, что получится в результате:
```python
pipeline(sample["audio"].copy())
```
```text
[{'speaker': 'SPEAKER_01',
'text': ' The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight.',
'timestamp': (0.0, 15.48)},
{'speaker': 'SPEAKER_00',
'text': " He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
'timestamp': (15.48, 21.28)}]
```
Отлично! Первый диктор сегментирован как говорящий с 0 до 15,48 секунды, а второй - с 15,48 до 21,28 секунды,
с соответствующими транскрипциями для каждого из них.
Для более удобного форматирования временных меток можно определить две вспомогательные функции. Первая преобразует кортеж временных меток в строку, округленную
до заданного количества знаков после запятой. Вторая объединяет идентификатор диктора, временную метку и текстовую информацию в одну строку, а для удобства
чтения разбивает каждого диктора на отдельные строки:
```python
def tuple_to_string(start_end_tuple, ndigits=1):
return str((round(start_end_tuple[0], ndigits), round(start_end_tuple[1], ndigits)))
def format_as_transcription(raw_segments):
return "\n\n".join(
[
chunk["speaker"] + " " + tuple_to_string(chunk["timestamp"]) + chunk["text"]
for chunk in raw_segments
]
)
```
Повторно запустим конвейер, на этот раз форматируя транскрипцию в соответствии с функцией, которую мы только что определили:
```python
outputs = pipeline(sample["audio"].copy())
format_as_transcription(outputs)
```
```text
SPEAKER_01 (0.0, 15.5) The second and importance is as follows. Sovereignty may be defined to be the right of making laws.
In France, the king really exercises a portion of the sovereign power, since the laws have no weight.
SPEAKER_00 (15.5, 21.3) He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon
his entire future.
```
Вот так! Таким образом, мы провели диарирование и транскрибацию входного аудиосигнала и получили транскрибации с сегментацией дикторов. Хотя алгоритм минимального расстояния для
выравнивания временных меток диаризации и транскрибации прост, он хорошо работает на практике. Если вы хотите изучить более сложные методы совмещения временных меток, то исходный
код `ASRDiarizationPipeline` является хорошей отправной точкой: [speechbox/diarize.py](https://github.com/huggingface/speechbox/blob/96d2d1a180252d92263f862a1cd25a48860f1aed/src/speechbox/diarize.py#L12)
| 6 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter7/introduction.mdx | # Раздел 7. Собираем все воедино 🪢
Молодцы, что добрались до 7-го раздела 7 🥳 Вы находитесь всего в нескольких шагах от завершения курса и приобретения нескольких последних
навыков, необходимых для работы в области Аудио ML. Что касается понимания, то вы уже знаете все, что нужно знать!
Вместе мы всесторонне рассмотрели основные темы, составляющие аудио домен, и сопутствующую им теорию
(аудио данные, классификацию аудиоданных, распознавание речи и преобразование текста в речь). Целью данного раздела является создание основы
для **сочетания всего этого вместе**: теперь, когда вы знаете, как работает каждая из этих задач в отдельности, мы рассмотрим, как
вы можете объединить их вместе для создания некоторых реальных приложений.
## Чему вы научитесь и что создадите
В этом разделе мы рассмотрим следующие три темы:
* [Перевод речи в речь](speech-to-speech): перевод речи с одного языка в речь на другом языке
* [Создание голосового ассистента](voice-assistant): создание собственного голосового помощника, работающего аналогично Alexa или Siri
* [Транскрибирование встреч](transcribe-meeting): транскрибация встречи и маркировка транскрипции с указанием того, кто когда выступал
| 7 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter7/speech-to-speech.mdx | # Перевод Speech-to-speech
Перевод речи в речь (Speech-to-speech, STST или S2ST) - это относительно новая задача обработки устной речи. Она заключается
в переводе [NL] речи с одного языка в речь на **другом** языке:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/s2st.png" alt="Diagram of speech to speech translation">
</div>
STST можно рассматривать как расширение традиционной задачи машинного перевода (МТ): вместо перевода **текста** с одного языка
на другой мы переводим **речь** с одного языка на другой. STST находит применение в области многоязыковой коммуникации,
позволяя носителям разных языков общаться друг с другом посредством речи.
Предположим, вы хотите общаться с другим человеком, преодолевая языковой барьер. Вместо того чтобы писать информацию, которую вы хотите
передать, а затем переводить ее в текст на целевом языке, вы можете говорить напрямую, а система STST преобразует вашу устную речь
в целевой язык. Получатель может ответить, обратившись к системе STST, а вы можете прослушать его ответ. Это более естественный
способ общения по сравнению с машинным переводом текста.
В этом разделе мы рассмотрим *каскадный* подход к STST, объединив знания, полученные в разделах 5 и 6 курса. Мы будем использовать
систему *перевода речи (ST)* для транскрибирования исходной речи в текст на целевом языке, а затем *перевода текста в речь (TTS)*
для генерации речи на целевом языке из переведенного текста:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/s2st_cascaded.png" alt="Diagram of cascaded speech to speech translation">
</div>
Можно было бы использовать и трехэтапный подход, когда сначала с помощью системы автоматического распознавания речи (ASR) исходная речь транскрибируется в текст на том же
языке, затем с помощью машинного перевода транскрибированный текст переводится на целевой язык, и, наконец, с помощью преобразования текста в речь формируется речь
на целевом языке. Однако добавление большего числа компонентов в конвейер приводит к *распространению ошибок*, когда ошибки, вносимые в одну систему, усугубляются
при прохождении через остальные системы, а также к увеличению задержки, поскольку инференс приходится проводить для большего числа моделей.
Несмотря на то, что такой каскадный подход к STST достаточно прост, он позволяет создавать очень эффективные системы STST. Трехступенчатая каскадная система ASR + MT + TTS
ранее использовалась для работы многих коммерческих продуктов STST, в том числе [Google Translate](https://ai.googleblog.com/2019/05/introducing-translatotron-end-to-end.html).
Это также очень эффективный способ разработки STST-системы, поскольку существующие системы распознавания речи и преобразования текста в речь могут быть объединены
для получения новой STST-модели без дополнительного обучения.
В оставшейся части этого раздела мы сосредоточимся на создании системы STST, которая переводит речь с любого языка X в речь на английском языке.
Рассмотренные методы могут быть распространены на системы STST, переводящие с любого языка X на любой язык Y, но мы оставляем это на усмотрение читателя и
указываем, где это возможно.Далее мы разделяем задачу STST на две составные части: ST и TTS. В завершение мы соединим их вместе и создадин демо с помощью Gradio
для демонстрации нашей системы.
## Перевод речи
Мы будем использовать модель Whisper для нашей системы перевода речи, поскольку эта модель способна переводить с более чем 96 языков на английский.
В частности, мы загрузим контрольную точку [Whisper Base](https://huggingface.co/openai/whisper-base), которая имеет 74М параметров. Это далеко не самая производительная
модель Whisper, поскольку [наибольшая контрольная точка Whisper](https://huggingface.co/openai/whisper-large-v2) более чем в 20 раз больше, но поскольку мы объединяем две
авторегрессивные системы (ST + TTS), мы хотим, чтобы каждая модель могла работать относительно быстро, чтобы мы получили приемлемую скорость инференса:
```python
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)
```
Отлично! Для проверки нашей системы STST загрузим аудиопример на неанглийском языке. Загрузим первый пример из итальянской (`it`) части
датасета [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli):
```python
from datasets import load_dataset
dataset = load_dataset("facebook/voxpopuli", "it", split="validation", streaming=True)
sample = next(iter(dataset))
```
Чтобы прослушать этот пример, мы можем либо воспроизвести его с помощью средства просмотра набора данных на Hub: [facebook/voxpopuli/viewer](https://huggingface.co/datasets/facebook/voxpopuli/viewer/it/validation?row=0)
Или воспроизведение с помощью функции ipynb audio:
```python
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
Теперь определим функцию, которая принимает этот аудиовход и возвращает переведенный текст. Вы помните, что мы должны передать ключевое слово генерации аргументу `"task"`,
установив его в значение `"translate"`, чтобы убедиться, что Whisper выполняет перевод речи, а не ее распознавание:
```python
def translate(audio):
outputs = pipe(audio, max_new_tokens=256, generate_kwargs={"task": "translate"})
return outputs["text"]
```
<Tip>
Whisper также можно "обманом" заставить перевести речь на любом языке X на любой язык Y. Просто задайте задачу `"transcribe"`, а `"language"` - целевым языком
в аргументах ключевых слов генерации, например, для испанского языка можно задать:
`generate_kwargs={"task": "transcribe", "language": "es"}`
</Tip>
Отлично! Давайте быстро проверим, что мы получаем разумный результат от модели:
```python
translate(sample["audio"].copy())
```
```
' psychological and social. I think that it is a very important step in the construction of a juridical space of freedom, circulation and protection of rights.'
```
Хорошо! Если мы сравним это с исходным текстом:
```python
sample["raw_text"]
```
```
'Penso che questo sia un passo in avanti importante nella costruzione di uno spazio giuridico di libertà di circolazione e di protezione dei diritti per le persone in Europa.'
```
Мы увидим, что перевод более или менее совпадает (вы можете проверить это с помощью Google Translate), за исключением нескольких
лишних слов в начале транскрипции, когда говорящий заканчивал предыдущее предложение.
На этом мы завершили первую половину нашего каскадного конвейера STST, применив на практике навыки, полученные в разделе 5, когда мы учились использовать
модель Whisper для распознавания и перевода речи. Если вы хотите освежить в памяти какие-либо из рассмотренных нами этапов, прочтите
раздел [Предварительно обученные модели для распознавания речи](../chapter5/asr_models) из раздела 5.
## Преобразование текста в речь
Вторая половина нашей каскадной системы STST связана с преобразованием английского текста в английскую речь. Для этого мы
будем использовать предварительно обученную модель [SpeechT5 TTS](https://huggingface.co/microsoft/speecht5_tts) для английского TTS.
🤗 В настоящее время Transformers не имеет TTS `pipeline`, поэтому нам придется использовать модель непосредственно самим.
Ничего страшного, вы же все эксперты по использованию модели для инференса после раздела 6!
Сначала загрузим процессор SpeechT5, модель и вокодер из предварительно обученной контрольной точки:
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
```
<Tip>
Здесь мы используем контрольную точку SpeechT5, обученную специально для английского TTS. Если вы хотите перевести
на язык, отличный от английского, либо замените контрольную точку на модель SpeechT5 TTS, дообученную для выбранного
вами языка, либо используйте контрольную точку MMS TTS, предварительно обученную для вашего целевого языка.
</Tip>
Как и в случае с моделью Whisper, модель SpeechT5 и вокодер мы поместим на GPU-ускоритель, если он у нас есть:
```python
model.to(device)
vocoder.to(device)
```
Отлично! Давайте загрузим эмбеддинги дикторов:
```python
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
Теперь мы можем написать функцию, которая принимает на вход текстовый запрос и генерирует соответствующую речь. Сначала мы предварительно обработаем
текстовый ввод с помощью процессора SpeechT5, токенизируя текст для получения входных идентификаторов. Затем мы передадим входные идентификаторы и
эбеддинги диктора в модель SpeechT5, разместив каждый из них на ускорителе, если таковой имеется. Наконец, мы вернем сгенерированную речь обратно в
процессор, чтобы мы могли воспроизвести ее в нашем ноутбуке ipynb:
```python
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()
```
Проверим его работу с помощью фиктивного текстового ввода:
```python
speech = synthesise("Hey there! This is a test!")
Audio(speech, rate=16000)
```
Звучит неплохо! Теперь самое интересное - собрать все воедино.
## Создание демо STST
Перед тем как создать демо [Gradio](https://gradio.app) для демонстрации нашей системы STST, давайте сначала проведем быструю проверку, чтобы убедиться,
что мы можем объединить две модели, подавая аудио пример на вход и получая аудио пример на выходе. Для этого мы объединим две функции, определенные в
предыдущих двух подразделах: введем исходное аудио и получим переведенный текст, затем синтезируем переведенный текст, чтобы получить переведенную речь.
Наконец, мы преобразуем синтезированную речь в массив `int16`, который является форматом выходного аудиофайла, ожидаемого Gradio. Для этого сначала
необходимо нормализовать аудио массив по динамическому диапазону целевого dtype (`int16`), а затем преобразовать из стандартного dtype NumPy (`float64`)
в целевой dtype (`int16`):
```python
import numpy as np
target_dtype = np.int16
max_range = np.iinfo(target_dtype).max
def speech_to_speech_translation(audio):
translated_text = translate(audio)
synthesised_speech = synthesise(translated_text)
synthesised_speech = (synthesised_speech.numpy() * max_range).astype(np.int16)
return 16000, synthesised_speech
```
Проверим, что эта конкатенированная функция дает ожидаемый результат:
```python
sampling_rate, synthesised_speech = speech_to_speech_translation(sample["audio"])
Audio(synthesised_speech, rate=sampling_rate)
```
Отлично! Теперь мы завернем это в красивое демо Gradio, чтобы мы могли записать нашу исходную речь с помощью
микрофонного или файлового входа и воспроизвести прогноз системы:
```python
import gradio as gr
demo = gr.Blocks()
mic_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
file_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="upload", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
with demo:
gr.TabbedInterface([mic_translate, file_translate], ["Microphone", "Audio File"])
demo.launch(debug=True)
```
В результате будет запущена демо Gradio, аналогичная той, что работает на Hugging Face Space:
<iframe src="https://course-demos-speech-to-speech-translation.hf.space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
Вы можете [дублировать](https://huggingface.co/spaces/course-demos/speech-to-speech-translation?duplicate=true) это демо и адаптировать его для
использования другой контрольной точки Whisper, другой контрольной точки TTS, или отказаться от ограничений по выводу английской речи
и следовать советам по переводу на выбранный вами язык!
## Двигаемся вперед
Хотя каскадная система представляет собой эффективный с точки зрения вычислений и данных способ построения системы STST, она страдает от описанных выше
проблем распространения ошибок и аддитивной задержки. В последних работах исследовался *прямой* подход к STST, который не прогнозирует промежуточный
текстовый вывод, а напрямую переводит исходную речь в целевую. Эти системы также способны сохранять в целевой речи речевые характеристики
диктора-источника (такие как просодия, высота тона и интонация). Если вы хотите узнать больше об этих системах, ознакомьтесь с ресурсами,
перечисленными в секции [дополнительные материалы и ресурсы](supplemental_reading).
| 8 |
0 | hf_public_repos/audio-transformers-course/chapters/ru | hf_public_repos/audio-transformers-course/chapters/ru/chapter7/voice-assistant.mdx | # Создание голосового ассистента
В этом разделе мы объединим три модели, с которыми уже имели практический опыт работы, и создадим полноценный голосовой помощник под названием **Marvin** 🤖.
Подобно Amazon Alexa или Apple Siri, Marvin - это виртуальный голосовой помощник, который реагирует на определенное "слово активации", затем слушает голосовой
запрос и, наконец, отвечает на него.
Мы можем разбить конвейер голосового помощника на четыре этапа, каждый из которых требует отдельной модели:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/voice_assistant.png">
</div>
### 1. Обнаружение слова активации
Голосовые помощники постоянно прослушивают аудиосигналы, поступающие через микрофон вашего устройства, но включаются
в работу только после произнесения определенного 'слова активации' или 'триггерного слова'.
Задачу обнаружения слов активации решает небольшая модель классификации звука на устройстве, которая значительно меньше и легче модели
распознавания речи - часто всего несколько миллионов параметров по сравнению с несколькими сотнями миллионов для распознавания речи. Таким
образом, она может постоянно работать на устройстве, не разряжая аккумулятор. Только при обнаружении "слова активации" запускается более
крупная модель распознавания речи, после чего она снова отключается.
### 2. Транскрибирование речи
Следующий этап - транскрибация произнесенного запроса в текст. На практике передача аудиофайлов с локального устройства в облако происходит
медленно из-за большого размера аудиофайлов, поэтому эффективнее транскрибировать их напрямую с помощью модели автоматического распознавания речи (ASR)
на устройстве, а не использовать модель в облаке. Модель на устройстве может быть меньше и, следовательно, менее точной, чем модель, размещенная в облаке,
но более высокая скорость инференса оправдывает себя, поскольку мы можем работать с распознаванием речи практически в реальном времени, транскрибируя
произнесенные нами фразы по мере их произнесения.
Мы уже хорошо знакомы с процессом распознавания речи, так что это должно быть проще простого!
### 3. Запрос к языковой модели
Теперь, когда мы знаем, что спросил пользователь, нам нужно сгенерировать ответ! Лучшими моделями-кандидатами для решения этой задачи являются
*большие языковые модели (Large Language Models, LLM)*, поскольку они способны эффективно понять семантику текстового запроса
и сгенерировать подходящий ответ.
Поскольку наш текстовый запрос невелик (всего несколько текстовых токенов), а языковые модели велики (многие миллиарды параметров), наиболее эффективным
способом проведения инференса LLM является отправка текстового запроса с устройства на LLM, запущенную в облаке, генерация текстового ответа и возврат
ответа обратно на устройство.
### 4. Синтез речи
Наконец, мы используем модель преобразования текста в речь (TTS) для синтеза текстового ответа в устную речь. Это делается на устройстве, но можно запустить
модель TTS в облаке, генерируя аудио вывод и передавая его обратно на устройство.
Опять же, мы делали это уже несколько раз, так что процесс будет очень знакомым!
<Tip>
Следующий раздел требует использования микрофона для записи голосового ввода. Поскольку машины Google Colab не совместимы с микрофоном,
рекомендуется выполнять этот раздел локально, либо на CPU, либо на GPU, если у вас есть доступ к локальным ресурсам. Размеры контрольных точек
были выбраны достаточно малыми для достаточно быстрой работы на CPU, поэтому Вы получите хорошую производительность и без GPU.
</Tip>
## Обнаружение слова активации
Первым этапом работы голосового помощника является определение того, было ли произнесено слово активации, для решения этой задачи нам необходимо найти подходящую
предварительно обученную модель! Из раздела [Предварительно обученные модели классификации звука](../chapter4/classification_models) вы помните, что
[Speech Commands](https://huggingface.co/datasets/speech_commands) - это набор устных слов, предназначенный для оценки моделей классификации звука на 15+ простых
командных словах, таких как `"вверх"`, `"вниз"`, `"да"` и `"нет"`, а также метка `"тишина"` для классификации отсутствия речи. Уделите минутку прослушиванию
образцов в программе просмотра наборов данных на Hub и заново познакомиться с набором данных Speech Commands: [datasets viewer](https://huggingface.co/datasets/speech_commands/viewer/v0.01/train).
Мы можем взять модель классификации звука, предварительно обученную на наборе данных Speech Commands, и выбрать одно из этих простых командных слов
в качестве слова активации. Если из 15 с лишним возможных командных слов модель предсказывает выбранное нами слово активации с наибольшей
вероятностью, мы можем быть уверены, что оно было произнесено".
Давайте зайдем в Hugging Face Hub и перейдем на вкладку "Models": https://huggingface.co/models.
В результате будут отображены все модели на Hugging Face Hub, отсортированные по количеству загрузок за последние 30 дней:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/all_models.png">
</div>
С левой стороны вы заметите, что у нас есть ряд вкладок, которые мы можем выбрать для фильтрации моделей по задачам, библиотекам, набору данных и т.д.
Прокрутите страницу вниз и выберите задачу " Audio Classification " из списка задач аудио:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/by_audio_classification.png">
</div>
Теперь нам представлено подмножество из 500+ моделей классификации звука на Hub. Для дальнейшего уточнения этой выборки мы можем
отфильтровать модели по датасету. Перейдите на вкладку "Datasets" и в строке поиска введите "speech_commands". При вводе текста
под вкладкой поиска появится выделение `speech_commands. Нажав на эту кнопку, можно отфильтровать все модели классификации звука на те,
которые были дообучены на датасете Speech Commands:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/by_speech_commands.png">
</div>
Отлично! Мы видим, что для данного датасета и задачи нам доступны шесть предварительно обученных моделей (хотя, если вы
читаете этот материал позднее, могут быть добавлены новые модели!) Первую из этих моделей вы узнаете как [Audio Spectrogram Transformer checkpoint](https://huggingface.co/MIT/ast-finetuned-speech-commands-v2)
которую мы использовали в примере 4-го раздела. Мы снова будем использовать эту контрольную точку для задачи определения слова активации.
Перейдем к загрузке контрольной точки с помощью класса `pipeline`:
```python
from transformers import pipeline
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
classifier = pipeline(
"audio-classification", model="MIT/ast-finetuned-speech-commands-v2", device=device
)
```
Мы можем проверить, на каких метках обучалась модель, проверив атрибут `id2label` в конфигурации модели:
```python
classifier.model.config.id2label
```
Отлично! Мы видим, что модель была обучена на 35 метках классов, включая некоторые простые командные слова, которые мы описали выше, а
также некоторые конкретные объекты, такие как `"bed"`, `"house"` и `"cat"`. Мы видим, что в этих метках класса есть одно имя:
id 27 соответствует метке **"marvin "**:
```python
classifier.model.config.id2label[27]
```
```
'marvin'
```
Отлично! Мы можем использовать это имя в качестве слова активации для нашего голосового помощника, подобно тому, как используется
"Alexa" для Amazon Alexa или "Hey Siri" для Apple Siri. Если из всех возможных меток модель с наибольшей вероятностью предсказывает
`"marvin"`, мы можем быть уверены, что выбранное нами слово активации было произнесено.
Теперь нам необходимо определить функцию, которая будет постоянно прослушивать микрофонный вход нашего устройства и непрерывно передавать
звук в модель классификации для проведения инференса. Для этого мы воспользуемся удобной вспомогательной функцией, входящей
в состав 🤗 Transformers, под названием [`ffmpeg_microphone_live`](https://github.com/huggingface/transformers/blob/fb78769b9c053876ed7ae152ee995b0439a4462a/src/transformers/pipelines/audio_utils.py#L98).
Эта функция направляет в модель для классификации небольшие фрагменты звука заданной длины `chunk_length_s`. Для обеспечения плавных
границ между фрагментами звука мы используем скользящее окно с шагом `chunk_length_s / 6`. Чтобы не ждать, пока запишется весь первый фрагмент,
прежде чем приступить к инференсу, мы также определяем минимальную продолжительность по времени аудио входа `stream_chunk_s`,
который передается в модель до достижения времени `chunk_length_s`.
Функция `ffmpeg_microphone_live` возвращает объект *generator*, создающий последовательность аудиофрагментов, каждый из которых может быть
передан модели классификации для предсказания. Мы можем передать этот генератор непосредственно в `pipeline`, который, в свою очередь,
возвращает на выходе последовательность прогнозов, по одному для каждого фрагмента входного аудиосигнала. Мы можем просмотреть вероятности
меток классов для каждого фрагмента и остановить цикл обнаружения слов активации, когда обнаружим, что слово активации было произнесено.
Для классификации произнесения слова активации мы будем использовать очень простой критерий: если метка класса с наибольшей вероятностью является
словом активации и эта вероятность превышает порог `prob_threshold`, то мы объявляем, что слово активации было произнесено. Использование порога
вероятности для управления классификатором таким образом гарантирует, что слово активации не будет ошибочно предсказано, если аудиосигнал является
шумом, что обычно происходит, когда модель очень неопределенна и все вероятности меток классов низки. Возможно, вы захотите настроить этот порог
вероятности или использовать более сложные средства для принятия решения о слове активации с помощью метрики [*entropy*](https://en.wikipedia.org/wiki/Entropy_(information_theory))
(или метрики, основанной на неопределенности).
```python
from transformers.pipelines.audio_utils import ffmpeg_microphone_live
def launch_fn(
wake_word="marvin",
prob_threshold=0.5,
chunk_length_s=2.0,
stream_chunk_s=0.25,
debug=False,
):
if wake_word not in classifier.model.config.label2id.keys():
raise ValueError(
f"Wake word {wake_word} not in set of valid class labels, pick a wake word in the set {classifier.model.config.label2id.keys()}."
)
sampling_rate = classifier.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Listening for wake word...")
for prediction in classifier(mic):
prediction = prediction[0]
if debug:
print(prediction)
if prediction["label"] == wake_word:
if prediction["score"] > prob_threshold:
return True
```
Давайте опробуем эту функцию и посмотрим, как она работает! Установим флаг `debug=True`, чтобы выводить прогнозы для каждого фрагмента звука. Пусть модель
поработает несколько секунд, чтобы увидеть, какие предсказания она делает при отсутствии речевого ввода, затем четко произнесем слово активации `"marvin"`
и увидим, как предсказание метки класса для `"marvin"` подскочит почти до 1:
```python
launch_fn(debug=True)
```
```text
Listening for wake word...
{'score': 0.055326107889413834, 'label': 'one'}
{'score': 0.05999856814742088, 'label': 'off'}
{'score': 0.1282748430967331, 'label': 'five'}
{'score': 0.07310110330581665, 'label': 'follow'}
{'score': 0.06634809821844101, 'label': 'follow'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.999913215637207, 'label': 'marvin'}
```
Потрясающе! Как мы и ожидали, в течение первых нескольких секунд модель генерирует "мусорные" предсказания. Речевой ввод отсутствует, поэтому модель
делает прогнозы, близкие к случайным, но с очень низкой вероятностью. Как только мы произносим слово активации, модель прогнозирует `"marvin"`
с вероятностью, близкой к 1, и завершает цикл, сигнализируя о том, что слово активации обнаружено и система ASR должна быть активирована!
## Транскрибирование речи
И снова мы будем использовать модель Whisper для нашей системы транскрипции речи. В частности, мы загрузим контрольную точку
[Whisper Base English](https://huggingface.co/openai/whisper-base.en), поскольку она достаточно мала, чтобы обеспечить хорошую скорость инференса при приемлемой
точности транскрипции. Мы будем использовать трюк, позволяющий получить транскрипцию практически в реальном времени за счет умного подхода к передаче аудиосигнала
в модель. Как и прежде, можно использовать любую контрольную точку распознавания речи на [Hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&library=transformers&sort=trending),
включая Wav2Vec2, MMS ASR или другие контрольные точки Whisper:
```python
transcriber = pipeline(
"automatic-speech-recognition", model="openai/whisper-base.en", device=device
)
```
<Tip>
Если вы используете GPU, вы можете увеличить размер контрольной точки, чтобы использовать контрольную точку <a href="https://huggingface.co/openai/whisper-small.en">Whisper Small English</a>,
которая обеспечит более высокую точность транскрипции и при этом не превысит требуемый порог задержки.
Просто поменяйте id модели на: <code>"openai/whisper-small.en"</code>.
</Tip>
Теперь мы можем определить функцию для записи сигнала с микрофона и транскрипции соответствующего текста. С помощью вспомогательной
функции `ffmpeg_microphone_live` мы можем управлять тем, насколько `в реальном времени` работает наша модель распознавания речи.
Использование меньшего `stream_chunk_s` позволяет распознавать речь в реальном времени, поскольку мы делим входной звук на более
мелкие фрагменты и транскрибируем их на лету. Однако за счет этого снижается точность, поскольку модель получает меньше контекста для инференса.
В процессе транскрибации речи нам также необходимо знать, когда пользователь **прекращает** говорить, чтобы можно было прервать запись.
Для простоты мы будем прекращать запись с микрофона после первого `chunk_length_s` (по умолчанию это 5 секунд), но вы можете
поэкспериментировать с использованием модели [voice activity detection (VAD)](https://huggingface.co/models?pipeline_tag=voice-activity-detection&sort=trending),
чтобы предсказать, когда пользователь прекращает говорить.
```python
import sys
def transcribe(chunk_length_s=5.0, stream_chunk_s=1.0):
sampling_rate = transcriber.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Start speaking...")
for item in transcriber(mic, generate_kwargs={"max_new_tokens": 128}):
sys.stdout.write("\033[K")
print(item["text"], end="\r")
if not item["partial"][0]:
break
return item["text"]
```
Давайте попробуем и посмотрим, что у нас получится! Как только микрофон заработает, начинайте говорить и наблюдайте,
как ваша транскрипция появляется в полуреальном времени:
```python
transcribe()
```
```text
Start speaking...
Hey, this is a test with the whisper model.
```
Отлично! Вы можете регулировать максимальную длину звука `chunk_length_s` в зависимости от того, насколько быстро или медленно
вы говорите (увеличить, если вам показалось, что вы не успели договорить, уменьшить, если вы были вынуждены ждать в конце), и
`stream_chunk_s` для фактора реального времени. Просто передайте их в качестве аргументов функции `transcribe`.
## Запрос к языковой модели
Теперь, когда мы получили транскрибацию нашего запроса, мы хотим сгенерировать осмысленный ответ. Для этого мы воспользуемся LLM, размещенным в облаке.
В частности, мы выберем LLM на Hugging Face Hub и воспользуемся [Inference API](https://huggingface.co/inference-api), чтобы легко
передать запрос модели.
Для начала перейдём на хаб Hugging Face. Для выбора нашей модели LLM мы воспользуемся [🤗 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
пространством, которое ранжирует модели LLM по производительности в четырех задачах генерации. Мы будем искать по "instruct", чтобы отфильтровать модели, которые были дообучены
на инструкциях, так как они должны лучше работать для нашей задачи передачи запроса (querying task):
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/llm_leaderboard.png">
</div>
Мы будем использовать контрольную точку [tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) от [TII](https://www.tii.ae/) - LM с декодером только на 7B параметров,
которая дообучена на смеси датасетов чатов и инструкций. Вы можете использовать любую LLM на Hugging Face Hub, у которой активирован параметр "Hosted inference API",
просто обратите внимание на виджет в правой части карточки модели:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/inference_api.png">
</div>
Inference API позволяет отправить HTTP-запрос с локальной машины на LLM, размещенную на Hub, и возвращает ответ в виде файла `json`.
Все, что нам нужно, - это указать наш токен Hugging Face Hub (который мы получаем непосредственно из нашей папки Hugging Face Hub)
и идентификатор модели LLM, которой мы хотим передать запрос:
```python
from huggingface_hub import HfFolder
import requests
def query(text, model_id="tiiuae/falcon-7b-instruct"):
api_url = f"https://api-inference.huggingface.co/models/{model_id}"
headers = {"Authorization": f"Bearer {HfFolder().get_token()}"}
payload = {"inputs": text}
print(f"Querying...: {text}")
response = requests.post(api_url, headers=headers, json=payload)
return response.json()[0]["generated_text"][len(text) + 1 :]
```
Давайте попробуем это сделать с помощью тестового ввода!
```python
query("What does Hugging Face do?")
```
```
'Hugging Face is a company that provides natural language processing and machine learning tools for developers. They'
```
Вы можете заметить, насколько быстро выполняется инференс с помощью Inference API - нам нужно отправить лишь небольшое количество текстовых токенов
с нашей локальной машины на размещенную на сервере модель, поэтому затраты на связь очень малы. LLM размещается на GPU-ускорителях, поэтому инференс
выполняется очень быстро. Наконец, сгенерированный ответ передается обратно от модели на нашу локальную машину,
что также не требует больших коммуникационных затрат.
## Синтез речи
Теперь мы готовы к получению окончательного речевого вывода! В очередной раз мы будем использовать модель Microsoft [SpeechT5 TTS](https://huggingface.co/microsoft/speecht5_tts)
для TTS на английском языке, но вы можете использовать любую модель TTS по своему усмотрению. Давайте загрузим процессор и модель:
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts").to(device)
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan").to(device)
```
А также эбеддинги диктора:
```python
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
Мы повторно используем функцию `synthesise`, которую мы определили в предыдущей главе [Перевод речи в речь] (speech-to-speech):
```python
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()
```
Давайте быстро проверим, что все работает так, как и ожидается:
```python
from IPython.display import Audio
audio = synthesise(
"Hugging Face is a company that provides natural language processing and machine learning tools for developers."
)
Audio(audio, rate=16000)
```
Отличная работа 👍
## Марвин 🤖
Теперь, когда мы определили функцию для каждого из четырех этапов конвейера голосового помощника, осталось только собрать их вместе,
чтобы получить готовый голосовой помощник. Мы просто объединим все четыре этапа, начиная с обнаружения слов активации (`launch_fn`),
транскрипции речи, передачи запроса LLM и заканчивая синтезом речи.
```python
launch_fn()
transcription = transcribe()
response = query(transcription)
audio = synthesise(response)
Audio(audio, rate=16000, autoplay=True)
```
Попробуйте сделать это с помощью нескольких запросов! Вот несколько примеров для начала:
* Какая самая жаркая страна в мире?
* Как работают модели-трансформеры?
* Знаешь ли ты испанский язык?
Вот и все, у нас есть готовый голосовой помощник, созданный с использованием 🤗 аудио инструментов, которые вы изучили в этом курсе, с добавлением в конце волшебства LLM.
Есть несколько расширений, которые мы могли бы сделать для улучшения голосового помощника. Во-первых, модель классификации звука классифицирует 35 различных меток.
Мы могли бы использовать более компактную и легкую модель бинарной классификации, которая прогнозирует только то, было ли произнесено слово активации или нет.
Во-вторых, мы заранее загружаем все модели и держим их запущенными на нашем устройстве. Если бы мы хотели сэкономить электроэнергию, то загружали бы каждую модель
только в тот момент, когда она необходима, а затем выгружали бы ее. В-третьих, в нашей функции транскрибации отсутствует модель определения активности голоса,
транскрибация осуществляется в течение фиксированного времени, которое в одних случаях слишком длинное, а в других - слишком короткое.
## Обобщаем всё 🪄
До сих пор мы видели, как можно генерировать речевой вывод с помощью нашего голосового помощника Marvin.
В заключение мы продемонстрируем, как можно обобщить этот речевой вывод на текст, аудио и изображение.
Для построения нашего помощника мы будем использовать [Transformers Agents](https://huggingface.co/docs/transformers/transformers_agents). Transformers Agents
предоставляет API для работы с естественным языком поверх библиотек 🤗 Transformers и Diffusers, интерпретирует входной сигнал на естественном языке с помощью LLM
с тщательно продуманными подсказками и использует набор курируемых инструментов для обеспечения мультимодального вывода.
Давайте перейдем к инстанцированию агента. Для агентов-трансформеров существует [три LLM](https://huggingface.co/docs/transformers/transformers_agents#quickstart), две из которых с открытым исходным кодом
и бесплатно доступны на Hugging Face Hub. Третья - модель от OpenAI, требующая ключа OpenAI API. В данном примере мы будем использовать бесплатную модель [Bigcode Starcoder](https://huggingface.co/bigcode/starcoder),
но вы также можете попробовать любую из других доступных LLM:
```python
from transformers import HfAgent
agent = HfAgent(
url_endpoint="https://api-inference.huggingface.co/models/bigcode/starcoder"
)
```
Чтобы воспользоваться агентом, достаточно вызвать `agent.run` с нашим текстовым приглашением. В качестве примера мы попросим
его сгенерировать изображение кота 🐈 (которое, надеюсь, выглядит немного лучше, чем этот эмоджи):
```python
agent.run("Generate an image of a cat")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/generated_cat.png">
</div>
<Tip>
Обратите внимание, что при первом вызове будет произведена загрузка весов модели, что может занять некоторое время
в зависимости от скорости загрузки.
</Tip>
Все просто! Агент интерпретировал наш запрос и, используя [Stable Diffusion](https://huggingface.co/docs/diffusers/using-diffusers/conditional_image_generation) под капотом,
сгенерировал изображение, при этом нам не пришлось беспокоиться о загрузке модели, написании функции или выполнении кода.
Теперь мы можем заменить функцию передачи запроса LLM и шаг синтеза текста нашим агентом Transformers Agent в голосовом помощнике,
поскольку агент будет выполнять оба этих действия за нас:
```python
launch_fn()
transcription = transcribe()
agent.run(transcription)
```
Попробуйте произнести тот же запрос " Generate an image of a cat" и посмотрите, как справится система. Если задать Агенту простой запрос "вопрос/ответ", он ответит текстовым ответом.
Можно побудить его генерировать мультимодальный вывод, попросив вернуть изображение или речь. Например, вы можете попросить его: "Generate an image of a cat, caption it, and speak the caption".
Хотя агент является более гибким, чем наш первый итерационный ассистент Marvin 🤖, обобщение задачи голосового помощника таким образом может привести к снижению производительности при выполнении
стандартных запросов к голосовому помощнику. Для восстановления производительности можно попробовать использовать более производительную контрольную точку LLM, например, от OpenAI, или определить
набор [custom tools](https://huggingface.co/docs/transformers/transformers_agents#custom-tools), специфичный для задачи голосового помощника.
| 9 |
0 | hf_public_repos/candle/candle-wasm-examples/whisper/src | hf_public_repos/candle/candle-wasm-examples/whisper/src/bin/app.rs | fn main() {
wasm_logger::init(wasm_logger::Config::new(log::Level::Trace));
yew::Renderer::<candle_wasm_example_whisper::App>::new().render();
}
| 0 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/llama2-c/llama2cWorker.js | import init, { Model } from "./build/m.js";
async function fetchArrayBuffer(url) {
const cacheName = "llama2c-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
class Llama2C {
static instance = {};
static async getInstance(weightsURL, modelID, tokenizerURL) {
// load individual modelID only once
if (!this.instance[modelID]) {
await init();
self.postMessage({ status: "loading", message: "Loading Model" });
const [weightsArrayU8, tokenizerArrayU8] = await Promise.all([
fetchArrayBuffer(weightsURL),
fetchArrayBuffer(tokenizerURL),
]);
this.instance[modelID] = new Model(weightsArrayU8, tokenizerArrayU8);
}
return this.instance[modelID];
}
}
let controller = null;
self.addEventListener("message", (event) => {
if (event.data.command === "start") {
controller = new AbortController();
generate(event.data);
} else if (event.data.command === "abort") {
controller.abort();
}
});
async function generate(data) {
const {
weightsURL,
modelID,
tokenizerURL,
prompt,
temp,
top_p,
repeatPenalty,
seed,
maxSeqLen,
} = data;
try {
self.postMessage({ status: "loading", message: "Starting llama2.c" });
const model = await Llama2C.getInstance(weightsURL, modelID, tokenizerURL);
self.postMessage({ status: "loading", message: "Initializing model" });
const firstToken = model.init_with_prompt(
prompt,
temp,
top_p,
repeatPenalty,
seed
);
const seq_len = model.get_seq_len();
let sentence = firstToken;
let maxTokens = maxSeqLen ? maxSeqLen : seq_len - prompt.length - 1;
let startTime = performance.now();
let tokensCount = 0;
while (tokensCount < maxTokens) {
await new Promise(async (resolve) => {
if (controller && controller.signal.aborted) {
self.postMessage({
status: "aborted",
message: "Aborted",
output: prompt + sentence,
});
return;
}
const token = await model.next_token();
const tokensSec =
((tokensCount + 1) / (performance.now() - startTime)) * 1000;
sentence += token;
self.postMessage({
status: "generating",
message: "Generating token",
token: token,
sentence: sentence,
totalTime: performance.now() - startTime,
tokensSec,
prompt: prompt,
});
setTimeout(resolve, 0);
});
tokensCount++;
}
self.postMessage({
status: "complete",
message: "complete",
output: prompt + sentence,
});
} catch (e) {
self.postMessage({ error: e });
}
}
| 1 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/llama2-c/index.html | <!DOCTYPE html>
<html lang="en">
<head>
<meta charset="utf-8" />
<title>Welcome to Candle!</title>
<link data-trunk rel="copy-file" href="tokenizer.json" />
<link data-trunk rel="copy-file" href="model.bin" />
<link data-trunk rel="rust" href="Cargo.toml" data-bin="app" data-type="main" />
<link data-trunk rel="rust" href="Cargo.toml" data-bin="worker" data-type="worker" />
<link rel="stylesheet" href="https://fonts.googleapis.com/css?family=Roboto:300,300italic,700,700italic">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/normalize/8.0.1/normalize.css">
<link rel="stylesheet" href="https://cdnjs.cloudflare.com/ajax/libs/milligram/1.4.1/milligram.css">
</head>
<body></body>
</html>
| 2 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/llama2-c/Cargo.toml | [package]
name = "candle-wasm-example-llama2"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
[dependencies]
candle = { workspace = true }
candle-nn = { workspace = true }
candle-transformers = { workspace = true }
num-traits = { workspace = true }
tokenizers = { workspace = true, features = ["unstable_wasm"] }
# App crates.
anyhow = { workspace = true }
byteorder = { workspace = true }
log = { workspace = true }
rand = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
# Wasm specific crates.
console_error_panic_hook = "0.1.7"
getrandom = { version = "0.2", features = ["js"] }
gloo = "0.11"
js-sys = "0.3.64"
wasm-bindgen = "0.2.87"
wasm-bindgen-futures = "0.4.37"
wasm-logger = "0.2"
yew-agent = "0.2.0"
yew = { version = "0.20.0", features = ["csr"] }
[dependencies.web-sys]
version = "0.3.70"
features = [
'Blob',
'Document',
'Element',
'HtmlElement',
'Node',
'Window',
'Request',
'RequestCache',
'RequestInit',
'RequestMode',
'Response',
'Performance',
]
| 3 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/llama2-c/build-lib.sh | cargo build --target wasm32-unknown-unknown --release
wasm-bindgen ../../target/wasm32-unknown-unknown/release/m.wasm --out-dir build --target web
| 4 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/llama2-c/lib-example.html | <html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type" />
<title>Candle Llama.c Rust/WASM</title>
</head>
<body></body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<style>
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap");
html,
body {
font-family: "Source Sans 3", sans-serif;
}
code,
output,
select,
pre {
font-family: "Source Code Pro", monospace;
}
</style>
<script src="https://cdn.tailwindcss.com"></script>
<script type="module">
// base url for audio examples
const MODELS_BASE_URL =
"https://huggingface.co/karpathy/tinyllamas/resolve/main";
// models base url
const MODELS = {
stories15M: {
url: "stories15M.bin",
seq_len: 256,
},
stories42M: {
url: "stories42M.bin",
seq_len: 1024,
},
stories110M: {
url: "stories110M.bin",
seq_len: 1024,
},
};
const llamaWorker = new Worker("./llama2cWorker.js", {
type: "module",
});
async function generateSequence(controller) {
const getValue = (id) => document.querySelector(`#${id}`).value;
const modelID = getValue("model");
const model = MODELS[modelID];
const weightsURL = `${MODELS_BASE_URL}/${model.url}`;
const prompt = getValue("prompt");
const temperature = getValue("temperature");
const topP = getValue("top-p");
const repeatPenalty = getValue("repeat_penalty");
const seed = getValue("seed");
const maxSeqLen = getValue("max-seq");
function updateStatus(data) {
const outStatus = document.querySelector("#output-status");
const outGen = document.querySelector("#output-generation");
const outCounter = document.querySelector("#output-counter");
switch (data.status) {
case "loading":
outStatus.hidden = false;
outStatus.textContent = data.message;
outGen.hidden = true;
outCounter.hidden = true;
break;
case "generating":
const { message, prompt, sentence, tokensSec, totalTime } = data;
outStatus.hidden = true;
outCounter.hidden = false;
outGen.hidden = false;
outGen.innerHTML = `<span class="font-semibold">${prompt}</span>${sentence.replace(
/\<s\>|\<\/s\>/g,
""
)}`;
outCounter.innerHTML = `${(totalTime / 1000).toFixed(
2
)}s (${tokensSec.toFixed(2)} tok/s)`;
break;
case "complete":
outStatus.hidden = true;
outGen.hidden = false;
break;
}
}
return new Promise((resolve, reject) => {
llamaWorker.postMessage({
weightsURL,
modelID,
tokenizerURL: "tokenizer.json",
prompt,
temp: temperature,
top_p: topP,
repeatPenalty,
seed: BigInt(seed),
maxSeqLen,
command: "start",
});
const handleAbort = () => {
llamaWorker.postMessage({ command: "abort" });
};
const handleMessage = (event) => {
const { status, error, message, prompt, sentence } = event.data;
if (status) updateStatus(event.data);
if (error) {
llamaWorker.removeEventListener("message", handleMessage);
reject(new Error(error));
}
if (status === "aborted") {
llamaWorker.removeEventListener("message", handleMessage);
resolve(event.data);
}
if (status === "complete") {
llamaWorker.removeEventListener("message", handleMessage);
resolve(event.data);
}
};
controller.signal.addEventListener("abort", handleAbort);
llamaWorker.addEventListener("message", handleMessage);
});
}
const form = document.querySelector("#form");
const prompt = document.querySelector("#prompt");
const clearBtn = document.querySelector("#clear-btn");
const runBtn = document.querySelector("#run");
const modelSelect = document.querySelector("#model");
let runController = new AbortController();
let isRunning = false;
modelSelect.addEventListener("change", (e) => {
const model = MODELS[e.target.value];
document.querySelector("#max-seq").max = model.seq_len;
document.querySelector("#max-seq").nextElementSibling.value =
model.seq_len;
});
form.addEventListener("submit", async (e) => {
e.preventDefault();
if (isRunning) {
stopRunning();
} else {
startRunning();
await generateSequence(runController);
stopRunning();
}
});
function startRunning() {
isRunning = true;
runBtn.textContent = "Stop";
}
function stopRunning() {
runController.abort();
runController = new AbortController();
runBtn.textContent = "Run";
isRunning = false;
}
clearBtn.addEventListener("click", (e) => {
e.preventDefault();
prompt.value = "";
clearBtn.classList.add("invisible");
runBtn.disabled = true;
stopRunning();
});
prompt.addEventListener("input", (e) => {
runBtn.disabled = false;
if (e.target.value.length > 0) {
clearBtn.classList.remove("invisible");
} else {
clearBtn.classList.add("invisible");
}
});
</script>
</head>
<body class="container max-w-4xl mx-auto p-4 text-gray-800">
<main class="grid grid-cols-1 gap-8 relative">
<span class="absolute text-5xl -ml-[1em]"> 🕯️ </span>
<div>
<h1 class="text-5xl font-bold">Candle Llama2.c</h1>
<h2 class="text-2xl font-bold">Rust/WASM Demo</h2>
<p class="max-w-lg">
<a
href="https://github.com/karpathy/llama2.c"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline"
target="_blank"
>Llama2.c</a
>
is Andrey Karpathy's C implementation of the Llama 2 LLM model in C.
This demo uses
<a
href="https://github.com/huggingface/candle/"
target="_blank"
class="underline hover:text-blue-500 hover:no-underline"
>Candle
</a>
to run Llama2.c in the browser using rust/wasm.
</p>
</div>
<div>
<label for="model" class="font-medium">Models Options: </label>
<select
id="model"
class="border-2 border-gray-500 rounded-md font-light">
<option value="stories15M" selected>stories 15M (60.8 MB)</option>
<option value="stories42M">stories 42M (167 MB)</option>
<option value="stories110M">stories 110M (438 MB)</option>
</select>
</div>
<form
id="form"
class="flex text-normal px-1 py-1 border border-gray-700 rounded-md items-center">
<input type="submit" hidden />
<input
type="text"
id="prompt"
class="font-light w-full px-3 py-2 mx-1 resize-none outline-none"
placeholder="Add your prompt here..."
value="Once upon a time" />
<button id="clear-btn">
<svg
fill="none"
xmlns="http://www.w3.org/2000/svg"
width="40"
viewBox="0 0 70 40">
<path opacity=".5" d="M39 .2v40.2" stroke="#1F2937" />
<path
d="M1.5 11.5 19 29.1m0-17.6L1.5 29.1"
opacity=".5"
stroke="#1F2937"
stroke-width="2" />
</svg>
</button>
<button
id="run"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 w-16 rounded disabled:bg-gray-300 disabled:cursor-not-allowed">
Run
</button>
</form>
<details>
<summary class="font-medium cursor-pointer">Advanced Options</summary>
<div class="grid grid-cols-3 max-w-md items-center gap-3 py-3">
<label class="text-sm font-medium" for="max-seq"
>Maximum length
</label>
<input
type="range"
id="max-seq"
name="max-seq"
min="1"
max="256"
step="1"
value="200"
oninput="this.nextElementSibling.value = Number(this.value)" />
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md">
200</output
>
<label class="text-sm font-medium" for="temperature"
>Temperature</label
>
<input
type="range"
id="temperature"
name="temperature"
min="0"
max="2"
step="0.01"
value="0.40"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)" />
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md">
0.40</output
>
<label class="text-sm font-medium" for="top-p">Top-p</label>
<input
type="range"
id="top-p"
name="top-p"
min="0"
max="1"
step="0.01"
value="1.00"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)" />
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md">
1.00</output
>
<label class="text-sm font-medium" for="repeat_penalty"
>Repeat Penalty</label
>
<input
type="range"
id="repeat_penalty"
name="repeat_penalty"
min="1"
max="2"
step="0.01"
value="1.10"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)" />
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>1.10</output
>
<label class="text-sm font-medium" for="seed">Seed</label>
<input
type="number"
id="seed"
name="seed"
value="299792458"
class="font-light border border-gray-700 text-right rounded-md p-2" />
<button
id="run"
onclick="document.querySelector('#seed').value = BigInt(Math.floor(Math.random() * 2**64-1))"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-1 w-[50px] rounded disabled:bg-gray-300 disabled:cursor-not-allowed text-sm">
Rand
</button>
</div>
</details>
<div>
<h3 class="font-medium">Generation:</h3>
<div
class="min-h-[250px] bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2">
<div
id="output-counter"
hidden
class="ml-auto font-semibold grid-rows-1 text-sm"></div>
<p hidden id="output-generation" class="grid-rows-2"></p>
<span id="output-status" class="m-auto font-light"
>No output yet</span
>
</div>
</div>
</main>
</body>
</html>
| 5 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/llama2-c/README.md | ## Running [llama2.c](https://github.com/karpathy/llama2.c) Examples
Here, we provide two examples of how to run [llama2.c](https://github.com/karpathy/llama2.c) written in Rust using a Candle-compiled WASM binary and runtimes.
### Pure Rust UI
To build and test the UI made in Rust you will need [Trunk](https://trunkrs.dev/#install)
From the `candle-wasm-examples/llama2-c` directory run:
Download assets:
```bash
# Model and tokenizer
wget -c https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/model.bin
wget -c https://huggingface.co/spaces/lmz/candle-llama2/resolve/main/tokenizer.json
```
Run hot reload server:
```bash
trunk serve --release --public-url / --port 8080
```
### Vanilla JS and WebWorkers
To build and test the UI made in Vanilla JS and WebWorkers, first we need to build the WASM library:
```bash
sh build-lib.sh
```
This will bundle the library under `./build` and we can import it inside our WebWorker like a normal JS module:
```js
import init, { Model } from "./build/m.js";
```
The full example can be found under `./lib-example.html`. All needed assets are fetched from the web, so no need to download anything.
Finally, you can preview the example by running a local HTTP server. For example:
```bash
python -m http.server
```
Then open `http://localhost:8000/lib-example.html` in your browser.
| 6 |
0 | hf_public_repos/candle/candle-wasm-examples/llama2-c | hf_public_repos/candle/candle-wasm-examples/llama2-c/src/lib.rs | mod app;
pub mod model;
pub mod worker;
pub use app::App;
pub use worker::Worker;
| 7 |
0 | hf_public_repos/candle/candle-wasm-examples/llama2-c | hf_public_repos/candle/candle-wasm-examples/llama2-c/src/model.rs | use candle::{DType, Device, IndexOp, Result, Tensor, D};
use candle_nn::{
embedding, linear_no_bias as linear, rms_norm, Embedding, Linear, Module, RmsNorm, VarBuilder,
};
use std::collections::HashMap;
use std::sync::{Arc, Mutex};
#[derive(Debug, Clone)]
pub struct Config {
pub dim: usize, // transformer dimension
pub hidden_dim: usize, // for ffn layers
pub n_layers: usize, // number of layers
pub n_heads: usize, // number of query heads
pub n_kv_heads: usize, // number of key/value heads (can be < query heads because of multiquery)
pub vocab_size: usize, // vocabulary size, usually 256 (byte-level)
pub seq_len: usize, // max sequence length
pub norm_eps: f64,
}
#[derive(Clone)]
pub struct Cache {
masks: Arc<Mutex<HashMap<usize, Tensor>>>,
pub use_kv_cache: bool,
#[allow(clippy::type_complexity)]
pub kvs: Arc<Mutex<Vec<Option<(Tensor, Tensor)>>>>,
cos: Tensor,
sin: Tensor,
device: Device,
}
impl Cache {
pub fn new(use_kv_cache: bool, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let freq_cis_real = vb.get((cfg.seq_len, cfg.head_size() / 2), "freq_cis_real")?;
let freq_cis_imag = vb.get((cfg.seq_len, cfg.head_size() / 2), "freq_cis_imag")?;
let cos = freq_cis_real.reshape((cfg.seq_len, cfg.head_size() / 2, 1))?;
let sin = freq_cis_imag.reshape((cfg.seq_len, cfg.head_size() / 2, 1))?;
Ok(Self {
masks: Arc::new(Mutex::new(HashMap::new())),
use_kv_cache,
kvs: Arc::new(Mutex::new(vec![None; cfg.n_layers])),
cos,
sin,
device: vb.device().clone(),
})
}
fn mask(&self, t: usize) -> Result<Tensor> {
let mut masks = self.masks.lock().unwrap();
if let Some(mask) = masks.get(&t) {
Ok(mask.clone())
} else {
let mask: Vec<_> = (0..t)
.flat_map(|i| (0..t).map(move |j| u8::from(j > i)))
.collect();
let mask = Tensor::from_slice(&mask, (t, t), &self.device)?;
masks.insert(t, mask.clone());
Ok(mask)
}
}
}
struct CausalSelfAttention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
o_proj: Linear,
n_head: usize,
n_key_value_head: usize,
head_dim: usize,
cache: Cache,
}
impl CausalSelfAttention {
fn apply_rotary_emb(&self, x: &Tensor, index_pos: usize) -> Result<Tensor> {
let (b_sz, seq_len, h, n_embd) = x.dims4()?;
let cos = self.cache.cos.i(index_pos..index_pos + seq_len)?;
let sin = self.cache.sin.i(index_pos..index_pos + seq_len)?;
let cos = cos.unsqueeze(1)?;
let sin = sin.unsqueeze(1)?;
let cos = cos.broadcast_as((b_sz, seq_len, 1, n_embd / 2, 1))?;
let sin = sin.broadcast_as((b_sz, seq_len, 1, n_embd / 2, 1))?;
let x = x.reshape((b_sz, seq_len, h, n_embd / 2, 2))?;
let x0 = x.narrow(D::Minus1, 0, 1)?;
let x1 = x.narrow(D::Minus1, 1, 1)?;
let dst0 = (x0.broadcast_mul(&cos)? - x1.broadcast_mul(&sin)?)?;
let dst1 = (x0.broadcast_mul(&sin)? + x1.broadcast_mul(&cos)?)?;
let rope = Tensor::cat(&[&dst0, &dst1], D::Minus1)?.reshape((b_sz, seq_len, h, n_embd))?;
Ok(rope)
}
fn forward(&self, x: &Tensor, index_pos: usize, block_idx: usize) -> Result<Tensor> {
let (b_sz, seq_len, n_embd) = x.dims3()?;
let q = self.q_proj.forward(x)?;
let k = self.k_proj.forward(x)?;
let v = self.v_proj.forward(x)?;
let q = q.reshape((b_sz, seq_len, self.n_head, self.head_dim))?;
let k = k.reshape((b_sz, seq_len, self.n_key_value_head, self.head_dim))?;
let mut v = v.reshape((b_sz, seq_len, self.n_key_value_head, self.head_dim))?;
let q = self.apply_rotary_emb(&q, index_pos)?;
let mut k = self.apply_rotary_emb(&k, index_pos)?;
if self.cache.use_kv_cache {
let mut cache = self.cache.kvs.lock().unwrap();
if let Some((cache_k, cache_v)) = &cache[block_idx] {
k = Tensor::cat(&[cache_k, &k], 1)?.contiguous()?;
v = Tensor::cat(&[cache_v, &v], 1)?.contiguous()?;
}
cache[block_idx] = Some((k.clone(), v.clone()))
}
let k = self.repeat_kv(k)?;
let v = self.repeat_kv(v)?;
let q = q.transpose(1, 2)?.contiguous()?;
let k = k.transpose(1, 2)?.contiguous()?;
let v = v.transpose(1, 2)?.contiguous()?;
let att = (q.matmul(&k.t()?)? / (self.head_dim as f64).sqrt())?;
let mask = self.cache.mask(seq_len)?.broadcast_as(att.shape())?;
let att = masked_fill(&att, &mask, f32::NEG_INFINITY)?;
let att = candle_nn::ops::softmax(&att, D::Minus1)?;
// Convert to contiguous as matmul doesn't support strided vs for now.
let y = att.matmul(&v.contiguous()?)?;
let y = y.transpose(1, 2)?.reshape(&[b_sz, seq_len, n_embd])?;
let y = self.o_proj.forward(&y)?;
Ok(y)
}
fn repeat_kv(&self, x: Tensor) -> Result<Tensor> {
let n_rep = self.n_head / self.n_key_value_head;
if n_rep == 1 {
Ok(x)
} else {
let (b_sz, seq_len, n_kv_head, head_dim) = x.dims4()?;
let x = x
.unsqueeze(3)?
.expand((b_sz, seq_len, n_kv_head, n_rep, head_dim))?
.reshape((b_sz, seq_len, n_kv_head * n_rep, head_dim))?;
Ok(x)
}
}
fn load(vb: VarBuilder, cache: &Cache, cfg: &Config) -> Result<Self> {
let size_in = cfg.dim;
let size_q = (cfg.dim / cfg.n_heads) * cfg.n_heads;
let size_kv = (cfg.dim / cfg.n_heads) * cfg.n_kv_heads;
let q_proj = linear(size_in, size_q, vb.pp("q_proj"))?;
let k_proj = linear(size_in, size_kv, vb.pp("k_proj"))?;
let v_proj = linear(size_in, size_kv, vb.pp("v_proj"))?;
let o_proj = linear(size_q, size_in, vb.pp("o_proj"))?;
Ok(Self {
q_proj,
k_proj,
v_proj,
o_proj,
n_head: cfg.n_heads,
n_key_value_head: cfg.n_kv_heads,
head_dim: cfg.dim / cfg.n_heads,
cache: cache.clone(),
})
}
}
fn masked_fill(on_false: &Tensor, mask: &Tensor, on_true: f32) -> Result<Tensor> {
let shape = mask.shape();
let on_true = Tensor::new(on_true, on_false.device())?.broadcast_as(shape.dims())?;
let m = mask.where_cond(&on_true, on_false)?;
Ok(m)
}
struct Mlp {
c_fc1: Linear,
c_fc2: Linear,
c_proj: Linear,
}
impl Mlp {
fn new(c_fc1: Linear, c_fc2: Linear, c_proj: Linear) -> Self {
Self {
c_fc1,
c_fc2,
c_proj,
}
}
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = (candle_nn::ops::silu(&self.c_fc1.forward(x)?)? * self.c_fc2.forward(x)?)?;
self.c_proj.forward(&x)
}
fn load(vb: VarBuilder, cfg: &Config) -> Result<Self> {
let h_size = cfg.dim;
let i_size = cfg.hidden_dim;
let c_fc1 = linear(h_size, i_size, vb.pp("gate_proj"))?;
let c_fc2 = linear(h_size, i_size, vb.pp("up_proj"))?;
let c_proj = linear(i_size, h_size, vb.pp("down_proj"))?;
Ok(Self::new(c_fc1, c_fc2, c_proj))
}
}
struct Block {
rms_1: RmsNorm,
attn: CausalSelfAttention,
rms_2: RmsNorm,
mlp: Mlp,
}
impl Block {
fn new(rms_1: RmsNorm, attn: CausalSelfAttention, rms_2: RmsNorm, mlp: Mlp) -> Self {
Self {
rms_1,
attn,
rms_2,
mlp,
}
}
fn forward(&self, x: &Tensor, index_pos: usize, block_idx: usize) -> Result<Tensor> {
let residual = x;
let x = self.rms_1.forward(x)?;
let x = (self.attn.forward(&x, index_pos, block_idx)? + residual)?;
let residual = &x;
let x = (self.mlp.forward(&self.rms_2.forward(&x)?)? + residual)?;
Ok(x)
}
fn load(vb: VarBuilder, cache: &Cache, cfg: &Config) -> Result<Self> {
let attn = CausalSelfAttention::load(vb.pp("self_attn"), cache, cfg)?;
let mlp = Mlp::load(vb.pp("mlp"), cfg)?;
let input_layernorm = rms_norm(cfg.dim, cfg.norm_eps, vb.pp("input_layernorm"))?;
let post_attention_layernorm =
rms_norm(cfg.dim, cfg.norm_eps, vb.pp("post_attention_layernorm"))?;
Ok(Self::new(
input_layernorm,
attn,
post_attention_layernorm,
mlp,
))
}
}
pub struct Llama {
wte: Embedding,
blocks: Vec<Block>,
ln_f: RmsNorm,
lm_head: Linear,
}
impl Llama {
fn new(wte: Embedding, blocks: Vec<Block>, ln_f: RmsNorm, lm_head: Linear) -> Self {
Self {
wte,
blocks,
ln_f,
lm_head,
}
}
pub fn forward(&self, x: &Tensor, index_pos: usize) -> Result<Tensor> {
let (_b_sz, seq_len) = x.dims2()?;
let mut x = self.wte.forward(x)?;
for (block_idx, block) in self.blocks.iter().enumerate() {
x = block.forward(&x, index_pos, block_idx)?;
}
let x = self.ln_f.forward(&x)?;
let x = x.i((.., seq_len - 1, ..))?;
let logits = self.lm_head.forward(&x)?;
logits.to_dtype(DType::F32)
}
pub fn load(vb: VarBuilder, cache: &Cache, cfg: &Config) -> Result<Self> {
let wte = embedding(cfg.vocab_size, cfg.dim, vb.pp("model.embed_tokens"))?;
let lm_head = linear(cfg.dim, cfg.vocab_size, vb.pp("lm_head"))?;
let norm = rms_norm(cfg.dim, cfg.norm_eps, vb.pp("model.norm"))?;
let blocks: Vec<_> = (0..cfg.n_layers)
.map(|i| Block::load(vb.pp(format!("model.layers.{i}")), cache, cfg).unwrap())
.collect();
Ok(Self::new(wte, blocks, norm, lm_head))
}
}
| 8 |
0 | hf_public_repos/candle/candle-wasm-examples/llama2-c | hf_public_repos/candle/candle-wasm-examples/llama2-c/src/worker.rs | use crate::model::{Cache, Config, Llama};
use byteorder::{LittleEndian, ReadBytesExt};
use candle::{DType, Device, IndexOp, Result, Shape, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use serde::{Deserialize, Serialize};
use tokenizers::Tokenizer;
use wasm_bindgen::prelude::*;
use yew_agent::{HandlerId, Public, WorkerLink};
#[wasm_bindgen]
extern "C" {
// Use `js_namespace` here to bind `console.log(..)` instead of just
// `log(..)`
#[wasm_bindgen(js_namespace = console)]
pub fn log(s: &str);
}
#[macro_export]
macro_rules! console_log {
// Note that this is using the `log` function imported above during
// `bare_bones`
($($t:tt)*) => ($crate::worker::log(&format_args!($($t)*).to_string()))
}
// Communication to the worker happens through bincode, the model weights and configs are fetched
// on the main thread and transferred via the following structure.
#[derive(Serialize, Deserialize)]
pub struct ModelData {
pub tokenizer: Vec<u8>,
pub model: Vec<u8>,
}
fn read_i32<R: std::io::Read>(r: &mut R) -> Result<i32> {
let mut buf = [0u8; 4];
r.read_exact(&mut buf)?;
Ok(i32::from_le_bytes(buf))
}
fn read_tensor<R: std::io::Read, S: Into<Shape>>(
r: &mut R,
shape: S,
dev: &Device,
) -> Result<Tensor> {
let shape = shape.into();
let mut data_t = vec![0f32; shape.elem_count()];
r.read_f32_into::<LittleEndian>(&mut data_t)?;
let tensor = Tensor::from_vec(data_t, shape, dev)?;
Ok(tensor)
}
pub struct Model {
pub cache: Cache,
pub config: Config,
pub llama: Llama,
pub tokenizer: Tokenizer,
}
impl Model {
fn run(
&self,
link: &WorkerLink<Worker>,
id: HandlerId,
temp: f64,
top_p: f64,
prompt: String,
) -> Result<()> {
let dev = Device::Cpu;
let temp = if temp <= 0. { None } else { Some(temp) };
let top_p = if top_p <= 0. || top_p >= 1.0 {
None
} else {
Some(top_p)
};
console_log!("temp: {temp:?} top_p: {top_p:?} prompt: {prompt}");
let mut logits_processor = LogitsProcessor::new(299792458, temp, top_p);
let mut index_pos = 0;
let mut tokens = self
.tokenizer
.encode(prompt.to_string(), true)
.map_err(|m| candle::Error::Msg(m.to_string()))?
.get_ids()
.to_vec();
link.respond(id, Ok(WorkerOutput::Generated(prompt)));
for index in 0.. {
if tokens.len() >= self.config.seq_len {
break;
}
let context_size = if self.cache.use_kv_cache && index > 0 {
1
} else {
tokens.len()
};
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &dev)?.unsqueeze(0)?;
let logits = self.llama.forward(&input, index_pos)?;
let logits = logits.squeeze(0)?;
index_pos += ctxt.len();
let next_token = logits_processor.sample(&logits)?;
tokens.push(next_token);
if let Some(text) = self.tokenizer.id_to_token(next_token) {
let text = text.replace('▁', " ").replace("<0x0A>", "\n");
link.respond(id, Ok(WorkerOutput::Generated(text)));
}
}
Ok(())
}
}
impl Config {
fn from_reader<R: std::io::Read>(r: &mut R) -> Result<Self> {
let dim = read_i32(r)? as usize;
let hidden_dim = read_i32(r)? as usize;
let n_layers = read_i32(r)? as usize;
let n_heads = read_i32(r)? as usize;
let n_kv_heads = read_i32(r)? as usize;
let vocab_size = read_i32(r)? as usize;
let seq_len = read_i32(r)? as usize;
Ok(Self {
dim,
hidden_dim,
n_layers,
n_heads,
n_kv_heads,
vocab_size,
seq_len,
norm_eps: 1e-5,
})
}
pub fn head_size(&self) -> usize {
self.dim / self.n_heads
}
}
struct TransformerWeights {
// token embedding table
token_embedding_table: Tensor, // (vocab_size, dim)
// weights for rmsnorms
rms_att_weight: Tensor, // (layer, dim) rmsnorm weights
rms_ffn_weight: Tensor, // (layer, dim)
// weights for matmuls
wq: Tensor, // (layer, dim, dim)
wk: Tensor, // (layer, dim, dim)
wv: Tensor, // (layer, dim, dim)
wo: Tensor, // (layer, dim, dim)
// weights for ffn
w1: Tensor, // (layer, hidden_dim, dim)
w2: Tensor, // (layer, dim, hidden_dim)
w3: Tensor, // (layer, hidden_dim, dim)
// final rmsnorm
rms_final_weight: Tensor, // (dim,)
// freq_cis for RoPE relatively positional embeddings
freq_cis_real: Tensor, // (seq_len, head_size/2)
freq_cis_imag: Tensor, // (seq_len, head_size/2)
}
impl TransformerWeights {
fn from_reader<R: std::io::Read>(r: &mut R, c: &Config, dev: &Device) -> Result<Self> {
let token_embedding_table = read_tensor(r, (c.vocab_size, c.dim), dev)?;
let rms_att_weight = read_tensor(r, (c.n_layers, c.dim), dev)?;
let wq = read_tensor(r, (c.n_layers, c.dim, c.dim), dev)?;
let wk = read_tensor(r, (c.n_layers, c.dim, c.dim), dev)?;
let wv = read_tensor(r, (c.n_layers, c.dim, c.dim), dev)?;
let wo = read_tensor(r, (c.n_layers, c.dim, c.dim), dev)?;
let rms_ffn_weight = read_tensor(r, (c.n_layers, c.dim), dev)?;
let w1 = read_tensor(r, (c.n_layers, c.hidden_dim, c.dim), dev)?;
let w2 = read_tensor(r, (c.n_layers, c.dim, c.hidden_dim), dev)?;
let w3 = read_tensor(r, (c.n_layers, c.hidden_dim, c.dim), dev)?;
let rms_final_weight = read_tensor(r, c.dim, dev)?;
let head_size = c.head_size();
let freq_cis_real = read_tensor(r, (c.seq_len, head_size / 2), dev)?;
let freq_cis_imag = read_tensor(r, (c.seq_len, head_size / 2), dev)?;
Ok(Self {
token_embedding_table,
rms_att_weight,
wq,
wk,
wv,
wo,
rms_ffn_weight,
w1,
w2,
w3,
rms_final_weight,
freq_cis_real,
freq_cis_imag,
})
}
fn var_builder(&self, cfg: &Config, device: &Device) -> Result<VarBuilder> {
let mut ws = std::collections::HashMap::new();
let mut insert = |name: &str, t: Tensor| {
ws.insert(name.to_string(), t);
};
insert("rot.freq_cis_real", self.freq_cis_real.clone());
insert("rot.freq_cis_imag", self.freq_cis_imag.clone());
insert(
"model.embed_tokens.weight",
self.token_embedding_table.clone(),
);
insert("lm_head.weight", self.token_embedding_table.clone());
insert("model.norm.weight", self.rms_final_weight.clone());
for layer in 0..cfg.n_layers {
ws.insert(
format!("model.layers.{layer}.self_attn.q_proj.weight"),
self.wq.i(layer)?,
);
ws.insert(
format!("model.layers.{layer}.self_attn.k_proj.weight"),
self.wk.i(layer)?,
);
ws.insert(
format!("model.layers.{layer}.self_attn.v_proj.weight"),
self.wv.i(layer)?,
);
ws.insert(
format!("model.layers.{layer}.self_attn.o_proj.weight"),
self.wo.i(layer)?,
);
ws.insert(
format!("model.layers.{layer}.mlp.gate_proj.weight"),
self.w1.i(layer)?,
);
ws.insert(
format!("model.layers.{layer}.mlp.down_proj.weight"),
self.w2.i(layer)?,
);
ws.insert(
format!("model.layers.{layer}.mlp.up_proj.weight"),
self.w3.i(layer)?,
);
ws.insert(
format!("model.layers.{layer}.input_layernorm.weight"),
self.rms_att_weight.i(layer)?,
);
ws.insert(
format!("model.layers.{layer}.post_attention_layernorm.weight"),
self.rms_ffn_weight.i(layer)?,
);
}
let vb = VarBuilder::from_tensors(ws, DType::F32, device);
Ok(vb)
}
}
impl Model {
pub fn load(md: ModelData) -> Result<Self> {
let dev = Device::Cpu;
let mut model = std::io::Cursor::new(md.model);
let config = Config::from_reader(&mut model)?;
let weights = TransformerWeights::from_reader(&mut model, &config, &dev)?;
let vb = weights.var_builder(&config, &dev)?;
let cache = Cache::new(true, &config, vb.pp("rot"))?;
let llama = Llama::load(vb, &cache, &config)?;
let tokenizer =
Tokenizer::from_bytes(&md.tokenizer).map_err(|m| candle::Error::Msg(m.to_string()))?;
Ok(Self {
cache,
config,
llama,
tokenizer,
})
}
}
pub struct Worker {
link: WorkerLink<Self>,
model: Option<Model>,
}
#[derive(Serialize, Deserialize)]
pub enum WorkerInput {
ModelData(ModelData),
Run(f64, f64, String),
}
#[derive(Serialize, Deserialize)]
pub enum WorkerOutput {
Generated(String),
GenerationDone(std::result::Result<(), String>),
WeightsLoaded,
}
impl yew_agent::Worker for Worker {
type Input = WorkerInput;
type Message = ();
type Output = std::result::Result<WorkerOutput, String>;
type Reach = Public<Self>;
fn create(link: WorkerLink<Self>) -> Self {
Self { link, model: None }
}
fn update(&mut self, _msg: Self::Message) {
// no messaging
}
fn handle_input(&mut self, msg: Self::Input, id: HandlerId) {
let output = match msg {
WorkerInput::ModelData(md) => match Model::load(md) {
Ok(model) => {
self.model = Some(model);
Ok(WorkerOutput::WeightsLoaded)
}
Err(err) => Err(format!("model creation error {err:?}")),
},
WorkerInput::Run(temp, top_p, prompt) => match &mut self.model {
None => Err("model has not been set yet".to_string()),
Some(model) => {
{
let mut cache = model.cache.kvs.lock().unwrap();
for elem in cache.iter_mut() {
*elem = None
}
}
let result = model
.run(&self.link, id, temp, top_p, prompt)
.map_err(|e| e.to_string());
Ok(WorkerOutput::GenerationDone(result))
}
},
};
self.link.respond(id, output);
}
fn name_of_resource() -> &'static str {
"worker.js"
}
fn resource_path_is_relative() -> bool {
true
}
}
| 9 |
0 | hf_public_repos | hf_public_repos/blog/stable_diffusion.md | ---
title: Stable Diffusion with 🧨 Diffusers
thumbnail: /blog/assets/98_stable_diffusion/thumbnail.png
authors:
- user: valhalla
- user: pcuenq
- user: natolambert
- user: patrickvonplaten
---
# Stable Diffusion with 🧨 Diffusers
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
**Stable Diffusion** 🎨
*...using 🧨 Diffusers*
Stable Diffusion is a text-to-image latent diffusion model created by the researchers and engineers from [CompVis](https://github.com/CompVis), [Stability AI](https://stability.ai/) and [LAION](https://laion.ai/).
It is trained on 512x512 images from a subset of the [LAION-5B](https://laion.ai/blog/laion-5b/) database.
*LAION-5B* is the largest, freely accessible multi-modal dataset that currently exists.
In this post, we want to show how to use Stable Diffusion with the [🧨 Diffusers library](https://github.com/huggingface/diffusers), explain how the model works and finally dive a bit deeper into how `diffusers` allows
one to customize the image generation pipeline.
**Note**: It is highly recommended to have a basic understanding of how diffusion models work. If diffusion
models are completely new to you, we recommend reading one of the following blog posts:
- [The Annotated Diffusion Model](https://huggingface.co/blog/annotated-diffusion)
- [Getting started with 🧨 Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb)
Now, let's get started by generating some images 🎨.
## Running Stable Diffusion
### License
Before using the model, you need to accept the model [license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) in order to download and use the weights. **Note: the license does not need to be explicitly accepted through the UI anymore**.
The license is designed to mitigate the potential harmful effects of such a powerful machine learning system.
We request users to **read the license entirely and carefully**. Here we offer a summary:
1. You can't use the model to deliberately produce nor share illegal or harmful outputs or content,
2. We claim no rights on the outputs you generate, you are free to use them and are accountable for their use which should not go against the provisions set in the license, and
3. You may re-distribute the weights and use the model commercially and/or as a service. If you do, please be aware you have to include the same use restrictions as the ones in the license and share a copy of the CreativeML OpenRAIL-M to all your users.
### Usage
First, you should install `diffusers==0.10.2` to run the following code snippets:
```bash
pip install diffusers==0.10.2 transformers scipy ftfy accelerate
```
In this post we'll use model version [`v1-4`](https://huggingface.co/CompVis/stable-diffusion-v1-4), but you can also use other versions of the model such as 1.5, 2, and 2.1 with minimal code changes.
The Stable Diffusion model can be run in inference with just a couple of lines using the [`StableDiffusionPipeline`](https://github.com/huggingface/diffusers/blob/main/src/diffusers/pipelines/stable_diffusion/pipeline_stable_diffusion.py) pipeline. The pipeline sets up everything you need to generate images from text with
a simple `from_pretrained` function call.
```python
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4")
```
If a GPU is available, let's move it to one!
```python
pipe.to("cuda")
```
**Note**: If you are limited by GPU memory and have less than 10GB of GPU RAM available, please
make sure to load the `StableDiffusionPipeline` in float16 precision instead of the default
float32 precision as done above.
You can do so by loading the weights from the `fp16` branch and by telling `diffusers` to expect the
weights to be in float16 precision:
```python
import torch
from diffusers import StableDiffusionPipeline
pipe = StableDiffusionPipeline.from_pretrained("CompVis/stable-diffusion-v1-4", revision="fp16", torch_dtype=torch.float16)
```
To run the pipeline, simply define the prompt and call `pipe`.
```python
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```
The result would look as follows

The previous code will give you a different image every time you run it.
If at some point you get a black image, it may be because the content filter built inside the model might have detected an NSFW result.
If you believe this shouldn't be the case, try tweaking your prompt or using a different seed. In fact, the model predictions include information about whether NSFW was detected for a particular result. Let's see what they look like:
```python
result = pipe(prompt)
print(result)
```
```json
{
'images': [<PIL.Image.Image image mode=RGB size=512x512>],
'nsfw_content_detected': [False]
}
```
If you want deterministic output you can seed a random seed and pass a generator to the pipeline.
Every time you use a generator with the same seed you'll get the same image output.
```python
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, generator=generator).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```
The result would look as follows

You can change the number of inference steps using the `num_inference_steps` argument.
In general, results are better the more steps you use, however the more steps, the longer the generation takes.
Stable Diffusion works quite well with a relatively small number of steps, so we recommend to use the default number of inference steps of `50`.
If you want faster results you can use a smaller number. If you want potentially higher quality results,
you can use larger numbers.
Let's try out running the pipeline with less denoising steps.
```python
import torch
generator = torch.Generator("cuda").manual_seed(1024)
image = pipe(prompt, guidance_scale=7.5, num_inference_steps=15, generator=generator).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```

Note how the structure is the same, but there are problems in the astronauts suit and the general form of the horse.
This shows that using only 15 denoising steps has significantly degraded the quality of the generation result. As stated earlier `50` denoising steps is usually sufficient to generate high-quality images.
Besides `num_inference_steps`, we've been using another function argument, called `guidance_scale` in all
previous examples. `guidance_scale` is a way to increase the adherence to the conditional signal that guides the generation (text, in this case) as well as overall sample quality.
It is also known as [classifier-free guidance](https://arxiv.org/abs/2207.12598), which in simple terms forces the generation to better match the prompt potentially at the cost of image quality or diversity.
Values between `7` and `8.5` are usually good choices for Stable Diffusion. By default the pipeline
uses a `guidance_scale` of 7.5.
If you use a very large value the images might look good, but will be less diverse.
You can learn about the technical details of this parameter in [this section](#writing-your-own-inference-pipeline) of the post.
Next, let's see how you can generate several images of the same prompt at once.
First, we'll create an `image_grid` function to help us visualize them nicely in a grid.
```python
from PIL import Image
def image_grid(imgs, rows, cols):
assert len(imgs) == rows*cols
w, h = imgs[0].size
grid = Image.new('RGB', size=(cols*w, rows*h))
grid_w, grid_h = grid.size
for i, img in enumerate(imgs):
grid.paste(img, box=(i%cols*w, i//cols*h))
return grid
```
We can generate multiple images for the same prompt by simply using a list with the same prompt repeated several times. We'll send the list to the pipeline instead of the string we used before.
```python
num_images = 3
prompt = ["a photograph of an astronaut riding a horse"] * num_images
images = pipe(prompt).images
grid = image_grid(images, rows=1, cols=3)
# you can save the grid with
# grid.save(f"astronaut_rides_horse.png")
```

By default, stable diffusion produces images of `512 × 512` pixels. It's very easy to override the default using the `height` and `width` arguments to create rectangular images in portrait or landscape ratios.
When choosing image sizes, we advise the following:
- Make sure `height` and `width` are both multiples of `8`.
- Going below 512 might result in lower quality images.
- Going over 512 in both directions will repeat image areas (global coherence is lost).
- The best way to create non-square images is to use `512` in one dimension, and a value larger than that in the other one.
Let's run an example:
```python
prompt = "a photograph of an astronaut riding a horse"
image = pipe(prompt, height=512, width=768).images[0]
# you can save the image with
# image.save(f"astronaut_rides_horse.png")
```

## How does Stable Diffusion work?
Having seen the high-quality images that stable diffusion can produce, let's try to understand
a bit better how the model functions.
Stable Diffusion is based on a particular type of diffusion model called **Latent Diffusion**, proposed in [High-Resolution Image Synthesis with Latent Diffusion Models](https://arxiv.org/abs/2112.10752).
Generally speaking, diffusion models are machine learning systems that are trained to *denoise* random Gaussian noise step by step, to get to a sample of interest, such as an *image*. For a more detailed overview of how they work, check [this colab](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb).
Diffusion models have shown to achieve state-of-the-art results for generating image data. But one downside of diffusion models is that the reverse denoising process is slow because of its repeated, sequential nature. In addition, these models consume a lot of memory because they operate in pixel space, which becomes huge when generating high-resolution images. Therefore, it is challenging to train these models and also use them for inference.
<br>
Latent diffusion can reduce the memory and compute complexity by applying the diffusion process over a lower dimensional _latent_ space, instead of using the actual pixel space. This is the key difference between standard diffusion and latent diffusion models: **in latent diffusion the model is trained to generate latent (compressed) representations of the images.**
There are three main components in latent diffusion.
1. An autoencoder (VAE).
2. A [U-Net](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb#scrollTo=wW8o1Wp0zRkq).
3. A text-encoder, *e.g.* [CLIP's Text Encoder](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel).
**1. The autoencoder (VAE)**
The VAE model has two parts, an encoder and a decoder. The encoder is used to convert the image into a low dimensional latent representation, which will serve as the input to the *U-Net* model.
The decoder, conversely, transforms the latent representation back into an image.
During latent diffusion _training_, the encoder is used to get the latent representations (_latents_) of the images for the forward diffusion process, which applies more and more noise at each step. During _inference_, the denoised latents generated by the reverse diffusion process are converted back into images using the VAE decoder. As we will see during inference we **only need the VAE decoder**.
**2. The U-Net**
The U-Net has an encoder part and a decoder part both comprised of ResNet blocks.
The encoder compresses an image representation into a lower resolution image representation and the decoder decodes the lower resolution image representation back to the original higher resolution image representation that is supposedly less noisy.
More specifically, the U-Net output predicts the noise residual which can be used to compute the predicted denoised image representation.
To prevent the U-Net from losing important information while downsampling, short-cut connections are usually added between the downsampling ResNets of the encoder to the upsampling ResNets of the decoder.
Additionally, the stable diffusion U-Net is able to condition its output on text-embeddings via cross-attention layers. The cross-attention layers are added to both the encoder and decoder part of the U-Net usually between ResNet blocks.
**3. The Text-encoder**
The text-encoder is responsible for transforming the input prompt, *e.g.* "An astronaut riding a horse" into an embedding space that can be understood by the U-Net. It is usually a simple *transformer-based* encoder that maps a sequence of input tokens to a sequence of latent text-embeddings.
Inspired by [Imagen](https://imagen.research.google/), Stable Diffusion does **not** train the text-encoder during training and simply uses an CLIP's already trained text encoder, [CLIPTextModel](https://huggingface.co/docs/transformers/model_doc/clip#transformers.CLIPTextModel).
**Why is latent diffusion fast and efficient?**
Since latent diffusion operates on a low dimensional space, it greatly reduces the memory and compute requirements compared to pixel-space diffusion models. For example, the autoencoder used in Stable Diffusion has a reduction factor of 8. This means that an image of shape `(3, 512, 512)` becomes `(4, 64, 64)` in latent space, which means the spatial compression ratio is `8 × 8 = 64`.
This is why it's possible to generate `512 × 512` images so quickly, even on 16GB Colab GPUs!
**Stable Diffusion during inference**
Putting it all together, let's now take a closer look at how the model works in inference by illustrating the logical flow.
<p align="center">
<img src="https://raw.githubusercontent.com/patrickvonplaten/scientific_images/master/stable_diffusion.png" alt="sd-pipeline" width="500"/>
</p>
The stable diffusion model takes both a latent seed and a text prompt as an input. The latent seed is then used to generate random latent image representations of size \\( 64 \times 64 \\) where as the text prompt is transformed to text embeddings of size \\( 77 \times 768 \\) via CLIP's text encoder.
Next the U-Net iteratively *denoises* the random latent image representations while being conditioned on the text embeddings. The output of the U-Net, being the noise residual, is used to compute a denoised latent image representation via a scheduler algorithm. Many different scheduler algorithms can be used for this computation, each having its pro- and cons. For Stable Diffusion, we recommend using one of:
- [PNDM scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_pndm.py) (used by default)
- [DDIM scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_ddim.py)
- [K-LMS scheduler](https://github.com/huggingface/diffusers/blob/main/src/diffusers/schedulers/scheduling_lms_discrete.py)
Theory on how the scheduler algorithm function is out-of-scope for this notebook, but in short one should remember that they compute the predicted denoised image representation from the previous noise representation and the predicted noise residual.
For more information, we recommend looking into [Elucidating the Design Space of Diffusion-Based Generative Models](https://arxiv.org/abs/2206.00364)
The *denoising* process is repeated *ca.* 50 times to step-by-step retrieve better latent image representations.
Once complete, the latent image representation is decoded by the decoder part of the variational auto encoder.
After this brief introduction to Latent and Stable Diffusion, let's see how to make advanced use of 🤗 Hugging Face `diffusers` library!
## Writing your own inference pipeline
Finally, we show how you can create custom diffusion pipelines with `diffusers`.
Writing a custom inference pipeline is an advanced use of the `diffusers` library that can be useful to switch out certain components, such as the VAE or scheduler explained above.
For example, we'll show how to use Stable Diffusion with a different scheduler, namely [Katherine Crowson's](https://github.com/crowsonkb) K-LMS scheduler added in [this PR](https://github.com/huggingface/diffusers/pull/185).
The [pre-trained model](https://huggingface.co/CompVis/stable-diffusion-v1-4/tree/main) includes all the components required to setup a complete diffusion pipeline. They are stored in the following folders:
- `text_encoder`: Stable Diffusion uses CLIP, but other diffusion models may use other encoders such as `BERT`.
- `tokenizer`. It must match the one used by the `text_encoder` model.
- `scheduler`: The scheduling algorithm used to progressively add noise to the image during training.
- `unet`: The model used to generate the latent representation of the input.
- `vae`: Autoencoder module that we'll use to decode latent representations into real images.
We can load the components by referring to the folder they were saved, using the `subfolder` argument to `from_pretrained`.
```python
from transformers import CLIPTextModel, CLIPTokenizer
from diffusers import AutoencoderKL, UNet2DConditionModel, PNDMScheduler
# 1. Load the autoencoder model which will be used to decode the latents into image space.
vae = AutoencoderKL.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="vae")
# 2. Load the tokenizer and text encoder to tokenize and encode the text.
tokenizer = CLIPTokenizer.from_pretrained("openai/clip-vit-large-patch14")
text_encoder = CLIPTextModel.from_pretrained("openai/clip-vit-large-patch14")
# 3. The UNet model for generating the latents.
unet = UNet2DConditionModel.from_pretrained("CompVis/stable-diffusion-v1-4", subfolder="unet")
```
Now instead of loading the pre-defined scheduler, we load the [K-LMS scheduler](https://github.com/huggingface/diffusers/blob/71ba8aec55b52a7ba5a1ff1db1265ffdd3c65ea2/src/diffusers/schedulers/scheduling_lms_discrete.py#L26) with some fitting parameters.
```python
from diffusers import LMSDiscreteScheduler
scheduler = LMSDiscreteScheduler(beta_start=0.00085, beta_end=0.012, beta_schedule="scaled_linear", num_train_timesteps=1000)
```
Next, let's move the models to GPU.
```python
torch_device = "cuda"
vae.to(torch_device)
text_encoder.to(torch_device)
unet.to(torch_device)
```
We now define the parameters we'll use to generate images.
Note that `guidance_scale` is defined analog to the guidance weight `w` of equation (2) in the [Imagen paper](https://arxiv.org/pdf/2205.11487.pdf). `guidance_scale == 1` corresponds to doing no classifier-free guidance. Here we set it to 7.5 as also done previously.
In contrast to the previous examples, we set `num_inference_steps` to 100 to get an even more defined image.
```python
prompt = ["a photograph of an astronaut riding a horse"]
height = 512 # default height of Stable Diffusion
width = 512 # default width of Stable Diffusion
num_inference_steps = 100 # Number of denoising steps
guidance_scale = 7.5 # Scale for classifier-free guidance
generator = torch.manual_seed(0) # Seed generator to create the inital latent noise
batch_size = len(prompt)
```
First, we get the `text_embeddings` for the passed prompt.
These embeddings will be used to condition the UNet model and guide the image generation towards something that should resemble the input prompt.
```python
text_input = tokenizer(prompt, padding="max_length", max_length=tokenizer.model_max_length, truncation=True, return_tensors="pt")
text_embeddings = text_encoder(text_input.input_ids.to(torch_device))[0]
```
We'll also get the unconditional text embeddings for classifier-free guidance, which are just the embeddings for the padding token (empty text). They need to have the same shape as the conditional `text_embeddings` (`batch_size` and `seq_length`)
```python
max_length = text_input.input_ids.shape[-1]
uncond_input = tokenizer(
[""] * batch_size, padding="max_length", max_length=max_length, return_tensors="pt"
)
uncond_embeddings = text_encoder(uncond_input.input_ids.to(torch_device))[0]
```
For classifier-free guidance, we need to do two forward passes: one with the conditioned input (`text_embeddings`), and another with the unconditional embeddings (`uncond_embeddings`). In practice, we can concatenate both into a single batch to avoid doing two forward passes.
```python
text_embeddings = torch.cat([uncond_embeddings, text_embeddings])
```
Next, we generate the initial random noise.
```python
latents = torch.randn(
(batch_size, unet.in_channels, height // 8, width // 8),
generator=generator,
)
latents = latents.to(torch_device)
```
If we examine the `latents` at this stage we'll see their shape is `torch.Size([1, 4, 64, 64])`, much smaller than the image we want to generate. The model will transform this latent representation (pure noise) into a `512 × 512` image later on.
Next, we initialize the scheduler with our chosen `num_inference_steps`.
This will compute the `sigmas` and exact time step values to be used during the denoising process.
```python
scheduler.set_timesteps(num_inference_steps)
```
The K-LMS scheduler needs to multiply the `latents` by its `sigma` values. Let's do this here:
```python
latents = latents * scheduler.init_noise_sigma
```
We are ready to write the denoising loop.
```python
from tqdm.auto import tqdm
scheduler.set_timesteps(num_inference_steps)
for t in tqdm(scheduler.timesteps):
# expand the latents if we are doing classifier-free guidance to avoid doing two forward passes.
latent_model_input = torch.cat([latents] * 2)
latent_model_input = scheduler.scale_model_input(latent_model_input, timestep=t)
# predict the noise residual
with torch.no_grad():
noise_pred = unet(latent_model_input, t, encoder_hidden_states=text_embeddings).sample
# perform guidance
noise_pred_uncond, noise_pred_text = noise_pred.chunk(2)
noise_pred = noise_pred_uncond + guidance_scale * (noise_pred_text - noise_pred_uncond)
# compute the previous noisy sample x_t -> x_t-1
latents = scheduler.step(noise_pred, t, latents).prev_sample
```
We now use the `vae` to decode the generated `latents` back into the image.
```python
# scale and decode the image latents with vae
latents = 1 / 0.18215 * latents
with torch.no_grad():
image = vae.decode(latents).sample
```
And finally, let's convert the image to PIL so we can display or save it.
```python
image = (image / 2 + 0.5).clamp(0, 1)
image = image.detach().cpu().permute(0, 2, 3, 1).numpy()
images = (image * 255).round().astype("uint8")
pil_images = [Image.fromarray(image) for image in images]
pil_images[0]
```

We've gone from the basic use of Stable Diffusion using 🤗 Hugging Face Diffusers to more advanced uses of the library, and we tried to introduce all the pieces in a modern diffusion system. If you liked this topic and want to learn more, we recommend the following resources:
- Our [Colab notebook](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/stable_diffusion.ipynb).
- The [Getting Started with Diffusers](https://colab.research.google.com/github/huggingface/notebooks/blob/main/diffusers/diffusers_intro.ipynb) notebook, that gives a broader overview on Diffusion systems.
- The [Annotated Diffusion Model](https://huggingface.co/blog/annotated-diffusion) blog post.
- Our [code in GitHub](https://github.com/huggingface/diffusers) where we'd be more than happy if you leave a ⭐ if `diffusers` is useful to you!
### Citation:
```
@article{patil2022stable,
author = {Patil, Suraj and Cuenca, Pedro and Lambert, Nathan and von Platen, Patrick},
title = {Stable Diffusion with 🧨 Diffusers},
journal = {Hugging Face Blog},
year = {2022},
note = {[https://huggingface.co/blog/rlhf](https://huggingface.co/blog/stable_diffusion)},
}
```
| 0 |
0 | hf_public_repos | hf_public_repos/blog/open-llm-leaderboard-rlhf.md | ---
title: "Can foundation models label data like humans?"
thumbnail: /blog/assets/llm-leaderboard/leaderboard-thumbnail.png
authors:
- user: nazneen
- user: natolambert
- user: sheonhan
- user: wangjean
guest: true
- user: OsvaldN97
guest: true
- user: edbeeching
- user: lewtun
- user: slippylolo
- user: thomwolf
---
# Can foundation models label data like humans?
Since the advent of ChatGPT, we have seen unprecedented growth in the development of Large Language Models (LLMs), and particularly chatty models that are fine-tuned to follow instructions given in the form of prompts.
However, how these models compare is unclear due to the lack of benchmarks designed to test their performance rigorously.
Evaluating instruction and chatty models is intrinsically difficult because a large part of user preference is centered around qualitative style while in the past NLP evaluation was far more defined.
In this line, it’s a common story that a new large language model (LLM) is released to the tune of “our model is preferred to ChatGPT N% of the time,” and what is omitted from that sentence is that the model is preferred in some type of GPT-4-based evaluation scheme.
What these points are trying to show is a proxy for a different measurement: scores provided by human labelers.
The process of training models with reinforcement learning from human feedback (RLHF) has proliferated interfaces for and data of comparing two model completions to each other.
This data is used in the RLHF process to train a reward model that predicts a preferred text, but the idea of rating and ranking model outputs has grown to be a more general tool in evaluation.
Here is an example from each of the `instruct` and `code-instruct` splits of our blind test set.

In terms of iteration speed, using a language model to evaluate model outputs is highly efficient, but there’s a sizable missing piece: **investigating if the downstream tool-shortcut is calibrated with the original form of measurement.**
In this blog post, we’ll zoom in on where you can and cannot trust the data labels you get from the LLM of your choice by expanding the Open LLM Leaderboard evaluation suite.
Leaderboards have begun to emerge, such as the [LMSYS](https://leaderboard.lmsys.org/), [nomic / GPT4All](https://gpt4all.io/index.html), to compare some aspects of these models, but there needs to be a complete source comparing model capabilities.
Some use existing NLP benchmarks that can show question and answering capabilities and some are crowdsourced rankings from open-ended chatting.
In order to present a more general picture of evaluations the [Hugging Face Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard?tab=evaluation) has been expanded, including automated academic benchmarks, professional human labels, and GPT-4 evals.
---
## Table of Contents
- [Evaluating preferences of open-source models](#evaluating-preferences-of-open-source-models)
- [Related work](#related-work)
- [GPT-4 evaluation examples](#GPT-4-evaluation-examples)
- [Further experiments](#further-experiments)
- [Takeaways and discussion](#takeaways-and-discussion)
- [Resources and citation](#resources-and-citation)
## Evaluating preferences of open-source models
Any point in a training process where humans are needed to curate the data is inherently expensive.
To date, there are only a few human labeled preference datasets available **for training** these models, such as [Anthropic’s HHH data](https://huggingface.co/datasets/Anthropic/hh-rlhf), [OpenAssistant’s dialogue rankings](https://huggingface.co/datasets/OpenAssistant/oasst1), or OpenAI’s [Learning to Summarize](https://huggingface.co/datasets/openai/summarize_from_feedback) / [WebGPT](https://huggingface.co/datasets/openai/webgpt_comparisons) datasets.
The same preference labels can be generated on **model outputs to create a relative Elo ranking between models** ([Elo rankings](https://en.wikipedia.org/wiki/Elo_rating_system), popularized in chess and used in video games, are method to construct a global ranking tier out of only pairwise comparisons — higher is better). When the source of text given to labelers is generated from a model of interest, the data becomes doubly interesting.
While training our models, we started seeing interesting things, so we wanted to do a more controlled study of existing open-source models and how that preference collection process would translate and compare to the currently popular GPT-4/ChatGPT evaluations of preferences.
To do this, we curated a held-out set of instruction prompts and completions from a popular set of open-source models: [Koala 13b](https://huggingface.co/young-geng/koala), [Vicuna 13b](https://huggingface.co/lmsys/vicuna-13b-delta-v1.1), [OpenAssistant](https://huggingface.co/OpenAssistant/oasst-sft-4-pythia-12b-epoch-3.5) 12b, and [Dolly 12b](https://huggingface.co/databricks/dolly-v2-12b).

We collected a set of high-quality, human-written prompts from [Self-Instruct](https://arxiv.org/abs/2212.10560) evaluation set and early discussions with data vendors for diverse task categories, including generation, brainstorming, question answering, summarization, commonsense, and coding-related.
The dataset has 327 prompts across these categories, and 25 are coding-related.
Here are the stats on the prompt and demonstration length.
| | prompt | completions |
| --- | --- | --- |
| count | 327 | 327 |
| length (mean ± std. dev.) in tokens | 24 ± 38 | 69 ± 79 |
| min. length | 3 | 1 |
| 25% percentile length | 10 | 18 |
| 50% percentile length | 15 | 42 |
| 75% percentile length | 23 | 83 |
| max | 381 | 546 |
With these completions, we set off to evaluate the quality of the models with Scale AI and GPT-4.
To do evaluations, we followed the Anthropic recipe for preference models and asked the raters to score on a Likert scale from 1 to 8.
On this scale, a 1 represents a strong preference of the first model and a 4 represents a close tiebreak for the first model.
The opposite side of the scale follows the reverse, with 8 being the clearest comparison.
### Human Elo results
We partnered with Scale AI to collect high-quality human annotations for a handful of open-source instruction-tuned models on our blind test set.
We requested annotators to rate responses for helpfulness and truthfulness in a pairwise setting.
We generated \\( n \choose 2 \\) combinations for each prompt, where \\(n\\) is the number of models we evaluate.
Here is an example snapshot of the instructions and the interface Scale provided for our evaluations.
With this data, we created bootstrapped Elo estimates based on the win probabilities between the two models.
For more on the Elo process, see LMSYS’s [notebook](https://colab.research.google.com/drive/17L9uCiAivzWfzOxo2Tb9RMauT7vS6nVU?usp=sharing). The Elo scores on our blind test data are reported on our [leaderboard]().
In this blog, we show the bootstrapped Elo estimates along with error estimates. Here are the rankings using human annotators on our blind test set.
****************Elo rankings without ties (bootstrapped from 1000 rounds of sampling games)****************
| Model | Elo ranking (median) | 5th and 95th percentiles |
| --- | --- | --- |
| Vicuna-13B | 1140 | 1061 ↔ 1219 |
| Koala-13B | 1073 | 999 ↔ 1147 |
| Oasst-12B | 986 | 913 ↔ 1061 |
| Dolly-12B | 802 | 730 ↔ 878 |
Given the Likert scale, it is also debatable whether a score of 4 or 5 should constitute a win, so we also compute the Elo rankings where a score of 4 or 5 indicates a tie.
In this case, and throughout the article, we saw few changes to the ranking of the models relative to eachother with this change.
The tie counts (out of 327 comparisons per model pair) and the new Elo scores are below. The number in each cell indicates the number of ties for the models in the intersecting row and column. E.g., Koala-13B and Vicuna-13B have the highest number of ties, 96, so they are likely very close in performance.
*Note, read this plot by selecting a row, e.g. `oasst-12b` and then reading across horizontally to see how many ties it had with each other model.*
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/tie_counts.png" width="600" />
</p>
****************Elo rankings w/ ties (bootstrapped from 1000 rounds of sampling games)****************
| Model | Elo ranking (median) | 5th and 95th percentiles |
| --- | --- | --- |
| Vicuna-13B | 1130 | 1066 ↔ 1192 |
| Koala-13B | 1061 | 998 ↔ 1128 |
| Oasst-12B | 988 | 918 ↔ 1051 |
| Dolly-12B | 820 | 760 ↔ 890 |
Below is the histogram of ratings from the Scale AI taskforce.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/human-hist.png" width="600" />
</p>
For the rest of this post, you will see similar analyses with different data generation criteria.
### GPT-4 Elo results
Next, we turned to GPT-4 to see how the results would compare.
The ordering of the models remains, but the relative margins change.
**Elo rankings without ties (bootstrapped from 1000 rounds of sampling games)**
| Model | Elo ranking (median) | 2.5th and 97.5th percentiles |
| --- | --- | --- |
| vicuna-13b | 1134 | 1036 ↔ 1222 |
| koala-13b | 1082 | 989 ↔ 1169 |
| oasst-12b | 972 | 874 ↔ 1062 |
| dolly-12b | 812 | 723 ↔ 909 |
**Elo rankings w/ ties (bootstrapped from 1000 rounds of sampling games)**
*Reminder, in the Likert scale 1 to 8, we define scores 4 and 5 as a tie.*
| Model | Elo ranking (median) | 2.5th and 97.5th percentiles |
| --- | --- | --- |
| vicuna-13b | 1114 | 1033 ↔ 1194 |
| koala-13b | 1082 | 995 ↔ 1172 |
| oasst-12b | 973 | 885 ↔ 1054 |
| dolly-12b | 831 | 742 ↔ 919 |
To do this, we used a prompt adapted from the [FastChat evaluation prompts](https://github.com/lm-sys/FastChat/blob/main/fastchat/eval/table/prompt.jsonl), encouraging shorter length for faster and cheaper generations (as the explanations are disregarded most of the time):
```
### Question
{question}
### The Start of Assistant 1's Answer
{answer_1}
### The End of Assistant 1's Answer
### The Start of Assistant 2's Answer
{answer_2}
### The End of Assistant 2's Answer
### System
We would like to request your feedback on the performance of two AI assistants in response to the user question displayed above.
Please compare the helpfulness, relevance, accuracy, level of details of their responses.
The rating should be from the set of 1, 2, 3, 4, 5, 6, 7, or 8, where higher numbers indicated that Assistant 2 was better than Assistant 1.
Please first output a single line containing only one value indicating the preference between Assistant 1 and 2.
In the subsequent line, please provide a brief explanation of your evaluation, avoiding any potential bias and ensuring that the order in which the responses were presented does not affect your judgment.
```
The histogram of responses from GPT-4 starts to show a clear issue with LLM based evaluation: **positional bias**.
This score distribution is with fully randomized ordering of which model is included in `answer_1` above.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/gpt4-hist.png" width="600" />
</p>
Given the uncertainty of GPT-4 evaluations, we decided to add another benchmark to our rankings: completions made by highly trained humans.
We wanted to answer the question of: what would be the Elo ranking of humans, if evaluated by GPT-4 as well.
### GPT-4 Elo results with demonstrations
Ultimately, the Elo ranking of human demonstrations is blatantly confusing.
There are many hypotheses that could explain this, but it points to a potential style benefit being given to models also trained on outputs of large language models (when compared to something like Dolly).
This could amount to *****unintentional doping***** between training and evaluation methods that are being developed in parallel.
**Elo rankings without ties (bootstrapped from 1000 rounds of sampling games)**
| Model | Elo ranking (median) | 2.5th and 975th percentiles |
| --- | --- | --- |
| Vicuna-13b | 1148 | 1049 ↔ 1239 |
| koala-13b | 1097 | 1002 ↔ 1197 |
| Oasst-12b | 985 | 896 ↔ 1081 |
| human | 940 | 840 ↔ 1034 |
| dolly-12b | 824 | 730 ↔ 922 |
## Related work
We are not the only ones to share the GPT-4 may not be a perfect tool for training and evaluating LLMs with.
Two recent papers have investigated the impacts of instruction tuning on outputs from OpenAI models and how doing so can impact “model comparison” evaluations (when the output of your trained model is compared to the outputs of ChatGPT or GPT-4).
The most striking paper in this regard *[How Far Can Camels Go?](https://arxiv.org/abs/2306.04751)* from Allen AI shows a potential indicator in what may be causing GPT-4 to rate an output highly: diversity and length of responses.
These correlations are striking, as it rewards models to be verbose, even if the task may not call for it.
Below is the figure where the authors correlate the win-rate with the token quantity.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/camel-fig.png" width="600" />
</p>
The other popular and recent paper is *[The False Promise of Imitating Proprietary LLMs](https://arxiv.org/abs/2305.15717)* from Berkeley, where the authors show that training on more data actually lowers comparison results.
With the scale the authors were operating at, more investigation is needed to fully understand the results, but it points in a clear direction: be wary when training on and evaluating with another LLM. The figure from the paper showcasing this is below:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/false-promise-fig.png" width="600" />
</p>
## GPT-4 evaluation examples
Below we’ve included a couple examples of what the evaluations look like to give you a sense why and how GPT-4 may be choosing:
---
**Question:**
Indicate the genre of the book to which it belongs.\n Input: Love in the Time of Cholera.
**Model response (koala)**:
The genre of "Love in the Time of Cholera" is a romance novel with elements of magical realism and historical fiction.
It tells the story of two men, Fermina Daza and Florentino Ariza, who are both deeply in love with her but cannot be together due to various circumstances.
Throughout their lives, they encounter obstacles that prevent them from being reunited, including war, illness, and societal pressure.
However, their love for each other never fades away, and they continue to hold onto hope that one day they will be able to be together again.
This combination of romantic elements and historical context makes this book fall under the category of romance novels with magical realistic and historical fictional elements.
**Human response:**
Fiction
**GPT-4 rating: 1** (model greatly better)
Assistant 1 provided a more detailed and accurate answer, discussing the elements of romance, magical realism, and historical fiction present in the novel.
Assistant 2's answer was too brief and did not provide sufficient information about the genre of the book.
---
**Question:**
Write a LinkedIn post to announce that you have accepted a new job offer.\n Input:
**Model response (koala)**:
Exciting news! I am thrilled to announce that I have officially accepted an exciting new job opportunity as [Job Title] at [Company Name]. This role will allow me to leverage my skills and experience in [industry/field of expertise], while also providing opportunities for personal and professional growth.
I want to take this moment to express my gratitude to everyone who has supported me throughout the hiring process, including [previous employer name(s) or individuals who provided guidance/advice/references]. Your support means the world to me and I couldn't be more grateful for your help.
I am excited about what lies ahead and can't wait to join the team at [Company Name]. Thank you again for all your support!
**Human response:**
I’m excited beyond words to share with you my decision to accept the role of Marketing Director at the XYZ Company!
I couldn’t have had this opportunity if not for the help of my friend, [name], who shared this job opportunity with me, and my former boss, [boss’s name], for her stellar recommendation and guidance.
I happily look forward to starting this new journey and growing professionally with my new family—the marketing rock stars of XYZ Company.
**GPT-4 rating: 6** (model better)
Both assistants provided helpful and relevant responses for a LinkedIn post announcing a new job offer.
However, Assistant 2's answer was more detailed and included placeholders for specific information, making it easier for the user to customize the post.
Assistant 1's response was also good, but slightly less structured and detailed compared to Assistant 2's response.
---
**Question:**
You are given a search query and a document. Classify whether the document is relevant to the search query or not relevant.
Input: Search: why sky is blue
Document: The Short Answer: Sunlight reaches Earth's atmosphere and is scattered in all directions by all the gases and particles in the air. Blue light is scattered more than the other colors because it travels as shorter, smaller waves. This is why we see a blue sky most of the time
**Model response (dolly)**:
The provided example search "why sky is blue" is related to the input document which explains the reason for blue color of the sky.
Advantages
This answer only takes up 34 characters compared to longer explanations like sunlight reaching earth due to its speed through space etc.. which would take up 80 characters. Hence this answer is highly relevant and useful to many users.
Disadvantage
Now if the question was about reasons behind changes in the weather one could think of many documents relating to climate change, pollution, static charges in the air etc., these documents might be relevant to the user but taking up lots of additional real-estate makes them less relevant compared to the above mentioned answer.
**Human response:**
relevant
**GPT-4 rating: 5** (model slightly better)
Both assistants provided relevant answers to the question, but Assistant 1's answer was more detailed and explained the reason behind the sky's blue color, while Assistant 2's answer was concise but not as informative. Assistant 1's answer is more helpful for users who want to understand the phenomenon, while Assistant 2's answer is suitable for users who only want a quick confirmation.
---
## Further experiments
### Correlating human and GPT-4 labels
Here we break down the categories in our test set (as listed earlier) to show which sections the GPT-4 models may perform slightly better.
We find that there is a much higher correlation in scores for tasks where creativity is required when compared to factual categories.
This suggests that humans do a better job discerning model inaccuracies, which we would expect!
| Category | Correlation: GPT-4 to Human Labels |
| --- | --- |
| Brainstorm | 0.60 |
| Creative generation | 0.55 |
| Commonsense reasoning | 0.46 |
| Question answering | 0.44 |
| Summarization | 0.40 |
| Natural language to code | 0.33 |
### Ablations
**GPT-4 Elo with score rather than ranking**
Other evaluation benchmarks use a ranking system to compare the models — asking GPT-4 to return two scores and explain there reasoning.
We wanted to compare these results, even if philosophically it does not fit into the training paradigm of RLHF as well (scores cannot train reliable preference models to date, while comparisons do).
Using rankings showed a substantial decrease in the positional bias of the prompt, shown below along with the median Elo estimates (without ties).
| Model | Elo ranking (median) |
| --- | --- |
| Vicuna-13b | 1136 |
| koala-13b | 1081 |
| Oasst-12b | 961 |
| human | 958 |
| dolly-12b | 862 |
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/gpt4-score-hist.png" width="600" />
</p>
**GPT-4 Elo with asking to de-bias**
Given the positional bias we have seen with Likert scales, what if we add a de-bias ask to the prompt? We added the following to our evaluation prompt:
```latex
Be aware that LLMs like yourself are extremely prone to positional bias and tend to return 1, can you please try to remove this bias so our data is fair?
```
This resulted in the histogram of rankings below, which flipped the bias from before (but did not entirely solve it).
Yes, sometimes GPT-4 returns integers outside the requested window (0s).
Below, you can see the updated distribution of Likert ratings returned and the Elo estimates without ties (these results are very close).
| Model | Elo ranking (median) |
| --- | --- |
| koala-13b | 1105 |
| Oasst-12b | 1075 |
| Vicuna-13b | 1066 |
| human | 916 |
| dolly-12b | 835 |
This is an experiment where the ordering of models changes substantially when ties are added to the model:
| Model | Elo ranking (median) |
| --- | --- |
| Vicuna-13b | 1110 |
| koala-13b | 1085 |
| Oasst-12b | 1075 |
| human | 923 |
| dolly-12b | 804 |
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/llm-leaderboard/gpt4-debias-hist.png" width="600" />
</p>
## Takeaways and discussion
There is a lot here, but the most important insights in our experiments are:
- GPT-4 has a positional bias and is predisposed to generate a rating of “1” in a pairwise preference collection setting using a scale of 1-8 (1-4 being decreasingly model-a and 5-8 being increasingly model-b) for evaluating models.
- Asking GPT-4 to debias itself makes it biased in the other direction, but not as worse as 1.
- GPT-4 is predisposed to prefer models trained on data bootstrapped using InstructGPT/GPT-4/ChatGPT over more factual and useful content. For example, preferring Vicuna or Alpaca over human written outputs.
- GPT-4 and human raters for evaluating have a correlation of 0.5 for non coding task and much lower but still positive correlation on coding tasks.
- If we group by tasks, the correlation between human and GPT-4 ratings is highest among categories with high entropy such as brainstorming/generation and low on categories with low entropy such as coding.
This line of work is extremely new, so there are plenty of areas where the field’s methodology can be further understood:
- **Likert vs. ratings**: In our evaluations, we worked with Likert scales to match the motivation for this as an evaluation tool — how preference data is collected to train models with RLHF. In this setup, it has been repeatedly reproduced that training a preference model on scores alone does not generate enough signal (when compared to relative rankings). In a similar vein, we found it unlikely that evaluating on scores will lead to a useful signal long-term.
Continuing with this, it is worth noting that ChatGPT (a slightly less high performance model) actually cannot even return answers in the correct format for a Likert score, while it can do rankings somewhat reliably. This hints that these models are just starting to gain the formatting control to fit the shape of evaluations we want, a point that would come far before they are a useful evaluation tool.
- **Prompting for evaluation**: In our work we saw substantial positional bias in the GPT-4 evaluations, but there are other issues that could impact the quality of the prompting.
In a recent [podcast](https://thegradientpub.substack.com/p/riley-goodside-the-art-and-craft#details), Riley Goodside describes the limits on per-token information from a LLM, so outputing the score first in the prompts we have could be limiting the ability for a model like GPT-4 to reason full.
- **Rating/ranking scale**: It’s not clear what the scale of ratings or Likert rankings should be. LLMs are used to seeing certain combinations in a training set (e.g. 1 to 5 stars), which is likely to bias the generations of ratings. It could be that giving specific tokens to return rather than numbers could make the results less biased.
- **Length bias**: Much how ChatGPT is loved because it creates interesting and lengthy answers, we saw that our evaluation with GPT-4 was heavily biased away from concise and correct answers, just by the other model continuing to produce way more tokens.
- **Correct generation parameters**: in the early stages of our experiments, we had to spend substantial time getting the correct dialogue format for each model (example of a complete version is [FastChat’s `conversation.py`](https://github.com/lm-sys/FastChat/blob/main/fastchat/conversation.py)). This likely got the model only 70-90% or so to its maximum potential capacity. The rest of the capabilities would be unlocked by tuning the generation parameters (temperature, top-p, etc.), but without reliable baselines for evaluation, today, there is no fair way to do this. For our experiments, we use a temperature of 0.5 a top-k of 50 and a top-p of 0.95 (for generations, OpenAI evaluations requires other parameters).
### Resources and citation
- More information on our labeling instructions can be found [here](https://docs.google.com/document/d/1c5-96Lj-UH4lzKjLvJ_MRQaVMjtoEXTYA4dvoAYVCHc/edit?usp=sharing).
Have a model that you want GPT-4 or human annotators to evaluate? Drop us a note on [the leaderboard discussions](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard_internal/discussions).
```
@article{rajani2023llm_labels,
author = {Rajani, Nazneen, and Lambert, Nathan and Han, Sheon and Wang, Jean and Nitski, Osvald and Beeching, Edward and Tunstall, Lewis},
title = {Can foundation models label data like humans?},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/llm-v-human-data},
}
```
_Thanks to [Joao](https://twitter.com/_joaogui1) for pointing out a typo in a table._
| 1 |
0 | hf_public_repos | hf_public_repos/blog/bert-cpu-scaling-part-1.md | ---
title: "Scaling-up BERT Inference on CPU (Part 1)"
thumbnail: /blog/assets/21_bert_cpu_scaling_part_1/imgs/numa_set.png
authors:
- user: mfuntowicz
---
<style>
.centered {
display: block;
margin: 0 auto;
}
figure {
text-align: center;
display: table;
max-width: 85%; /* demo; set some amount (px or %) if you can */
margin: 10px auto; /* not needed unless you want centered */
}
</style>
# Scaling up BERT-like model Inference on modern CPU - Part 1
## 1. Context and Motivations
Back in October 2019, my colleague Lysandre Debut published a comprehensive _(at the time)_ [inference performance
benchmarking blog (1)](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2).
Since then, [🤗 transformers (2)](https://github.com/huggingface/transformers) welcomed a tremendous number
of new architectures and thousands of new models were added to the [🤗 hub (3)](https://huggingface.co/models)
which now counts more than 9,000 of them as of first quarter of 2021.
As the NLP landscape keeps trending towards more and more BERT-like models being used in production, it
remains challenging to efficiently deploy and run these architectures at scale.
This is why we recently introduced our [🤗 Inference API](https://api-inference.huggingface.co/docs/python/html/index.html):
to let you focus on building value for your users and customers, rather than digging into all the highly
technical aspects of running such models.
This blog post is the first part of a series which will cover most of the hardware and software optimizations to better
leverage CPUs for BERT model inference.
For this initial blog post, we will cover the hardware part:
- Setting up a baseline - Out of the box results
- Practical & technical considerations when leveraging modern CPUs for CPU-bound tasks
- Core count scaling - Does increasing the number of cores actually give better performance?
- Batch size scaling - Increasing throughput with multiple parallel & independent model instances
We decided to focus on the most famous Transformer model architecture,
[BERT (Delvin & al. 2018) (4)](https://arxiv.org/abs/1810.04805v1). While we focus this blog post on BERT-like
models to keep the article concise, all the described techniques
can be applied to any architecture on the Hugging Face model hub.
In this blog post we will not describe in detail the Transformer architecture - to learn about that I can't
recommend enough the
[Illustrated Transformer blogpost from Jay Alammar (5)](https://jalammar.github.io/illustrated-transformer/).
Today's goals are to give you an idea of where we are from an Open Source perspective using BERT-like
models for inference on PyTorch and TensorFlow, and also what you can easily leverage to speedup inference.
## 2. Benchmarking methodology
When it comes to leveraging BERT-like models from Hugging Face's model hub, there are many knobs which can
be tuned to make things faster.
Also, in order to quantify what "faster" means, we will rely on widely adopted metrics:
- **Latency**: Time it takes for a single execution of the model (i.e. forward call)
- **Throughput**: Number of executions performed in a fixed amount of time
These two metrics will help us understand the benefits and tradeoffs along this blog post.
The benchmarking methodology was reimplemented from scratch in order to integrate the latest features provided by transformers
and also to let the community run and share benchmarks in an __hopefully easier__ way.
The whole framework is now based on [Facebook AI & Research's Hydra configuration library](https://hydra.cc/) allowing us to easily report
and track all the items involved while running the benchmark, hence increasing the overall reproducibility.
You can find the whole structure of the project [here](https://github.com/huggingface/tune)
On the 2021 version, we kept the ability to run inference workloads through PyTorch and Tensorflow as in the
previous blog [(1)](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2) along with their traced counterpart
[TorchScript (6)](https://pytorch.org/docs/stable/jit.html), [Google Accelerated Linear Algebra (XLA) (7)](https://www.tensorflow.org/xla).
Also, we decided to include support for [ONNX Runtime (8)](https://www.onnxruntime.ai/) as it provides many optimizations
specifically targeting transformers based models which makes it a strong candidate to consider when discussing
performance.
Last but not least, this new unified benchmarking environment will allow us to easily run inference for different scenarios
such as [Quantized Models (Zafrir & al.) (9)](https://arxiv.org/abs/1910.06188)
using less precise number representations (`float16`, `int8`, `int4`).
This method known as **quantization** has seen an increased adoption among all major hardware providers.
In the near future, we would like to integrate additional methods we are actively working on at Hugging Face, namely Distillation, Pruning & Sparsificaton.
## 3. Baselines
All the results below were run on [Amazon Web Services (AWS) c5.metal instance](https://aws.amazon.com/ec2/instance-types/c5)
leveraging an Intel Xeon Platinum 8275 CPU (48 cores/96 threads).
The choice of this instance provides all the useful CPU features to speedup Deep Learning workloads such as:
- AVX512 instructions set (_which might not be leveraged out-of-the-box by the various frameworks_)
- Intel Deep Learning Boost (also known as Vector Neural Network Instruction - VNNI) which provides specialized
CPU instructions for running quantized networks (_using int8 data type_)
The choice of using _metal_ instance is to avoid any virtualization issue which can arise when using cloud providers.
This gives us full control of the hardware, especially while targeting the NUMA (Non-Unified Memory Architecture) controller, which
we will cover later in this post.
_The operating system was Ubuntu 20.04 (LTS) and all the experiments were conducted using Hugging Face transformers version 4.5.0, PyTorch 1.8.1 & Google TensorFlow 2.4.0_
## 4. Out of the box results
<br>
<figure class="image">
<img alt="pytorch versus tensorflow out of the box" src="assets/21_bert_cpu_scaling_part_1/imgs/pytorch_vs_tf_oob.svg" />
<figcaption>Figure 1. PyTorch (1.8.1) vs Google TensorFlow (2.4.1) out of the box</figcaption>
</figure>
<br>
<br>
<figure class="image">
<img alt="pytorch versus tensorflow out of the box bigger batch sizes" src="assets/21_bert_cpu_scaling_part_1/imgs/pytorch_vs_tf_oob_big_batch.svg" />
<figcaption>Figure 2. PyTorch (1.8.1) vs Google TensorFlow (2.4.1) out of the box - (Bigger Batch Size)</figcaption>
</figure>
<br>
Straigh to the point, out-of-the-box, PyTorch shows better inference results over TensorFlow for all the configurations tested here.
It is important to note the results out-of-the-box might not reflect the "optimal" setup for both PyTorch and TensorFlow and thus it can look deceiving here.
One possible way to explain such difference between the two frameworks might be the underlying technology to
execute parallel sections within operators.
PyTorch internally uses [OpenMP (10)](https://www.openmp.org/) along with [Intel MKL (now oneDNN) (11)](https://software.intel.com/content/www/us/en/develop/documentation/oneapi-programming-guide/top/api-based-programming/intel-oneapi-deep-neural-network-library-onednn.html) for efficient linear algebra computations whereas TensorFlow relies on Eigen and its own threading implementation.
## 5. Scaling BERT Inference to increase overall throughput on modern CPU
### 5.1. Introduction
There are multiple ways to improve the latency and throughput for tasks such as BERT inference.
Improvements and tuning can be performed at various levels from enabling Operating System features, swapping dependent
libraries with more performant ones, carefully tuning framework properties and, last but not least,
using parallelization logic leveraging all the cores on the CPU(s).
For the remainder of this blog post we will focus on the latter, also known as **Multiple Inference Stream**.
The idea is simple: Allocate **multiple instances** of the same model and assign the execution of each instance to a
**dedicated, non-overlapping subset of the CPU cores** in order to have truly parallel instances.
### 5.2. Cores and Threads on Modern CPUs
On our way towards optimizing CPU inference for better usage of the CPU cores you might have already seen -_at least for the
past 20 years_- modern CPUs specifications report "cores" and "hardware threads" or "physical" and "logical" numbers.
These notions refer to a mechanism called **Simultaneous Multi-Threading** (SMT) or **Hyper-Threading** on Intel's platforms.
To illustrate this, imagine two tasks **A** and **B**, executing in parallel, each on its own software thread.
At some point, there is a high probability these two tasks will have to wait for some resources to be fetched from main memory, SSD, HDD
or even the network.
If the threads are scheduled on different physical cores, with no hyper-threading,
during these periods the core executing the task is in an **Idle** state waiting for the resources to arrive, and effectively doing nothing... and hence not getting fully utilized
Now, with **SMT**, the **two software threads for task A and B** can be scheduled on the same **physical core**,
such that their execution is interleaved on that physical core:
Task A and Task B will execute simultaneously on the physical core and when one task is halted, the other task can still continue execution
on the core thereby increasing the utilization of that core.
<br>
<figure class="image">
<img class="centered" alt="Intel Hyper Threading technology" src="assets/21_bert_cpu_scaling_part_1/imgs/hyper_threading_explained.png" />
<figcaption>Figure 3. Illustration of Intel Hyper Threading technology (SMT)</figcaption>
</figure>
<br>
The figure 3. above simplifies the situation by assuming single core setup. If you want some more details on how SMT works on multi-cores CPUs, please
refer to these two articles with very deep technical explanations of the behavior:
- [Intel® Hyper-Threading Technology - Technical User Guide (12)](http://www.cslab.ece.ntua.gr/courses/advcomparch/2007/material/readings/Intel%20Hyper-Threading%20Technology.pdf)
- [Introduction to Hyper-Threading Technology (13)](https://software.intel.com/content/www/us/en/develop/articles/introduction-to-hyper-threading-technology.html)
Back to our model inference workload... If you think about it, in a perfect world with a fully optimized setup, computations take the majority of time.
In this context, using the logical cores shouldn't bring us any performance benefit because both logical cores (hardware threads) compete for the core’s execution resources.
As a result, the tasks being a majority of general matrix multiplications (_[gemms (14)](https://en.wikipedia.org/wiki/Basic_Linear_Algebra_Subprograms#Level_3)_), they are inherently CPU bounds and **does not benefits** from SMT.
### 5.3. Leveraging Multi-Socket servers and CPU affinity
Nowadays servers bring many cores, some of them even support multi-socket setups (_i.e. multiple CPUs on the motherboard_).
On Linux, the command `lscpu` reports all the specifications and topology of the CPUs present on the system:
```shell
ubuntu@some-ec2-machine:~$ lscpu
Architecture: x86_64
CPU op-mode(s): 32-bit, 64-bit
Byte Order: Little Endian
Address sizes: 46 bits physical, 48 bits virtual
CPU(s): 96
On-line CPU(s) list: 0-95
Thread(s) per core: 2
Core(s) per socket: 24
Socket(s): 2
NUMA node(s): 2
Vendor ID: GenuineIntel
CPU family: 6
Model: 85
Model name: Intel(R) Xeon(R) Platinum 8275CL CPU @ 3.00GHz
Stepping: 7
CPU MHz: 1200.577
CPU max MHz: 3900.0000
CPU min MHz: 1200.0000
BogoMIPS: 6000.00
Virtualization: VT-x
L1d cache: 1.5 MiB
L1i cache: 1.5 MiB
L2 cache: 48 MiB
L3 cache: 71.5 MiB
NUMA node0 CPU(s): 0-23,48-71
NUMA node1 CPU(s): 24-47,72-95
```
In our case we have a machine with **2 sockets**, each socket providing **24 physical cores** with **2 threads per cores** (SMT).
Another interesting characteristic is the notion of **NUMA** node (0, 1) which represents how cores and memory are being
mapped on the system.
Non-Uniform Memory Access (**NUMA**) is the opposite of Uniform Memory Access (**UMA**) where the whole memory pool
is accessible by all the cores through a single unified bus between sockets and the main memory.
**NUMA** on the other hand splits the memory pool and each CPU socket is responsible to address a subset of the memory,
reducing the congestion on the bus.
<br>
<figure class="image">
<img class="centered" alt="Non-Uniform Memory Access and Uniform Memory Access architectures" src="assets/21_bert_cpu_scaling_part_1/imgs/UMA_NUMA.png" />
<figcaption>Figure 5. Difference illustration of UMA and NUMA architectures <a href="https://software.intel.com/content/www/us/en/develop/articles/optimizing-applications-for-numa.html">(source (15))</a></figcaption>
</figure>
<br>
In order to fully utilize the potential of such a beefy machine, we need to ensure our model instances are correctly
dispatched across all the **physical** cores on all sockets along with enforcing memory allocation to be "NUMA-aware".
On Linux, NUMA's process configuration can be tuned through [`numactl`](https://linux.die.net/man/8/numactl) which provides an interface to bind a process to a
set of CPU cores (referred as **Thread Affinity**).
Also, it allows tuning the memory allocation policy, making sure the memory allocated for the process
is as close as possible to the cores' memory pool (referred as **Explicit Memory Allocation Directives**).
_Note: Setting both cores and memory affinities is important here. Having computations done on socket 0 and memory allocated
on socket 1 would ask the system to go over the sockets shared bus to exchange memory, thus leading to an undesired overhead._
### 5.4. Tuning Thread Affinity & Memory Allocation Policy
Now that we have all the knobs required to control the resources' allocation of our model instances we go further and see how to
effectively deploy those and see the impact on latency and throughput.
Let's go gradually to get a sense of what is the impact of each command and parameter.
First, we start by launching our inference model without any tuning, and we observe how the computations are being dispatched on CPU cores (_Left_).
```shell
python3 src/main.py model=bert-base-cased backend.name=pytorch batch_size=1 sequence_length=128
```
Then we specify the core and memory affinity through `numactl` using all the **physical** cores and only a single thread (thread 0) per core (_Right_):
```shell
numactl -C 0-47 -m 0,1 python3 src/main.py model=bert-base-cased backend.name=pytorch batch_size=1 sequence_length=128
```
<br>
<figure class="image">
<img class="centered" alt="htop CPU usage without and with numactl thread affinity set" src="assets/21_bert_cpu_scaling_part_1/imgs/numa_combined.svg" />
<figcaption>Figure 6. Linux htop command side-by-side results without & with Thread Affinity set</figcaption>
</figure>
<br>
As you can see, without any specific tuning, PyTorch and TensorFlow dispatch the work on a single socket, using all the logical cores in that socket (both threads on 24 cores).
Also, as we highlighted earlier, we do not want to leverage the **SMT** feature in our case, so we set the process' thread affinity to target only 1 hardware thread.
_Note, this is specific to this run and can vary depending on individual setups. Hence, it is recommended to check thread affinity settings for each specific use-case._
Let's take sometime from here to highlight what we did with `numactl`:
- `-C 0-47` indicates to `numactl` what is the thread affinity (cores 0 to 47).
- `-m 0,1` indicates to `numactl` to allocate memory on both CPU sockets
If you wonder why we are binding the process to cores [0...47], you need to go back to look at the output of `lscpu`.
From there you will find the section `NUMA node0` and `NUMA node1` which has the form `NUMA node<X> <logical ids>`
In our case, each socket is one NUMA node and there are 2 NUMA nodes.
Each socket or each NUMA node has 24 physical cores and 2 hardware threads per core, so 48 logical cores.
For NUMA node 0, 0-23 are hardware thread 0 and 24-47 are hardware thread 1 on the 24 physical cores in socket 0.
Likewise, for NUMA node 1, 48-71 are hardware thread 0 and 72-95 are hardware thread 1 on the 24 physical cores in socket 1.
As we are targeting just 1 thread per physical core, as explained earlier, we pick only thread 0 on each core and hence logical processors 0-47.
Since we are using both sockets, we need to also bind the memory allocations accordingly (0,1).
_Please note that using both sockets may not always give the best results, particularly for small problem sizes.
The benefit of using compute resources across both sockets might be reduced or even negated by cross-socket communication overhead._
## 6. Core count scaling - Does using more cores actually improve performance?
When thinking about possible ways to improve our model inference performances, the first rational solution might be to
throw some more resources to do the same amount of work.
Through the rest of this blog series, we will refer to this setup as **Core Count Scaling** meaning, only the number
of cores used on the system to achieve the task will vary. This is also often referred as Strong Scaling in the HPC world.
At this stage, you may wonder what is the point of allocating only a subset of the cores rather than throwing
all the horses at the task to achieve minimum latency.
Indeed, depending on the problem-size, throwing more resources to the task might give better results.
It is also possible that for small problems putting more CPU cores at work doesn't improve the final latency.
In order to illustrate this, the figure 6. below takes different problem sizes (`batch_size = 1, sequence length = {32, 128, 512}`)
and reports the latencies with respect to the number of CPU cores used for running
computations for both PyTorch and TensorFlow.
Limiting the number of resources involved in computation is done by limiting the CPU cores involved in
**intra** operations (_**intra** here means inside an operator doing computation, also known as "kernel"_).
This is achieved through the following APIs:
- PyTorch: `torch.set_num_threads(x)`
- TensorFlow: `tf.config.threading.set_intra_op_parallelism_threads(x)`
<br>
<figure class="image">
<img alt="" src="assets/21_bert_cpu_scaling_part_1/imgs/core_count_scaling.svg" />
<figcaption>Figure 7. Latency measurements</figcaption>
</figure>
<br>
As you can see, depending on the problem size, the number of threads involved in the computations has a positive impact
on the latency measurements.
For small-sized problems & medium-sized problems using only one socket would give the best performance.
For large-sized problems, the overhead of the cross-socket communication is covered by the computations cost, thus benefiting from
using all the cores available on the both sockets.
## 7. Multi-Stream Inference - Using multiple instances in parallel
If you're still reading this, you should now be in good shape to set up parallel inference workloads on CPU.
Now, we are going to highlight some possibilities offered by the powerful hardware we have, and tuning the knobs described before,
to scale our inference as linearly as possible.
In the following section we will explore another possible scaling solution **Batch Size Scaling**, but before diving into this, let's
take a look at how we can leverage Linux tools in order to assign Thread Affinity allowing effective model instance parallelism.
Instead of throwing more cores to the task as you would do in the core count scaling setup, now we will be using more model instances.
Each instance will run independently on its own subset of the hardware resources in a truly parallel fashion on a subset of the CPU cores.
### 7.1. How-to allocate multiple independent instances
Let's start simple, if we want to spawn 2 instances, one on each socket with 24 cores assigned:
```shell
numactl -C 0-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=24
numactl -C 24-47 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=24
```
Starting from here, each instance does not share any resource with the other, and everything is operating at maximum efficiency from a
hardware perspective.
The latency measurements are identical to what a single instance would achieve, but throughput is actually 2x higher
as the two instances operate in a truly parallel way.
We can further increase the number of instances, lowering the number of cores assigned for each instance.
Let's run 4 independent instances, each of them effectively bound to 12 CPU cores.
```shell
numactl -C 0-11 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 12-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 24-35 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
numactl -C 36-47 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=12
```
The outcomes remain the same, our 4 instances are effectively running in a truly parallel manner.
The latency will be slightly higher than the example before (2x less cores being used), but the throughput will be again 2x higher.
### 7.2. Smart dispatching - Allocating different model instances for different problem sizes
One another possibility offered by this setup is to have multiple instances carefully tuned for various problem sizes.
With a smart dispatching approach, one can redirect incoming requests to the right configuration giving the best latency depending on the request workload.
```shell
# Small-sized problems (sequence length <= 32) use only 8 cores (on socket 0 - 8/24 cores used)
numactl -C 0-7 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=32 backend.name=pytorch backend.num_threads=8
# Medium-sized problems (32 > sequence <= 384) use remaining 16 cores (on socket 0 - (8+16)/24 cores used)
numactl -C 8-23 -m 0 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=128 backend.name=pytorch backend.num_threads=16
# Large sized problems (sequence >= 384) use the entire CPU (on socket 1 - 24/24 cores used)
numactl -C 24-37 -m 1 python3 src/main.py model=bert-base-cased batch_size=1 sequence_length=384 backend.name=pytorch backend.num_threads=24
```
## 8. Batch size scaling - Improving throughput and latency with multiple parallel & independent model instances
One another very interesting direction for scaling up inference is to actually put some more model instances into the pool
along with reducing the actual workload each instance receives proportionally.
This method actually changes both the size of the problem (_batch size_), and the resources involved in the computation (_cores_).
To illustrate, imagine you have a server with `C` CPU cores, and you want to run a workload containing B samples with S tokens.
You can represent this workload as a tensor of shape `[B, S]`, B being the size of the batch and S being the maximum sequence length within the B samples.
For all the instances (`N`), each of them executes on `C / N` cores and would receive a subset of the task `[B / N, S]`.
Each instance doesn't receive the global batch but instead, they all receive a subset of it `[B / N, S]` thus the name **Batch Size Scaling**.
In order to highlight the benefits of such scaling method, the charts below reports both the latencies when scaling up model instances along with the effects on the throughput.
When looking at the results, let's focus on the latency and the throughput aspects:
On one hand, we are taking the maximum latency over the pool of instances to reflect the time it takes to process all the samples in the batch.
Putting it differently, as instances operate in a truly parallel fashion, the time it takes to gather all the batch chunks from all the instances
is driven by the longest time it takes for individual instance in the pool to get their chunk done.
As you can see below on Figure 7., the actual latency gain when increasing the number of instances is really dependent of the problem size.
In all cases, we can find an optimal resource allocation (batch size & number of instances) to minimize our latency but, there is no specific pattern on the number of cores to involve in the computation.
Also, it is important to notice the results might look totally different on another system _(i.e. Operating System, Kernel Version, Framework version, etc.)_
Figure 8. sums up the best multi-instance configuration when targeting minimum latency by taking the minimum over the number of instances involved.
For instance, for `{batch = 8, sequence length = 128}` using 4 instances (each with `{batch = 2}` and 12 cores) gives the best latency measurements.
The Figure 9. reports all the setups minimizing latency for both PyTorch and TensorFlow for various problem-sizes.
_**Spoiler**: There are numerous other optimizations we will discuss in a follow-up blog post which will substantially impact this chart._
<br>
<figure class="image">
<img alt="Batch scaling experiment for PyTorch and Tensorflow" src="assets/21_bert_cpu_scaling_part_1/imgs/batch_scaling_exp.svg" style="width:100%"/>
<figcaption>Figure 8. Max latency evolution with respect to number of instances for a total batch size of 8</figcaption>
</figure>
<br>
<br>
<figure class="image">
<img alt="Optimal number of instance minimizing overall latency for a total batch size of 8" src="assets/21_bert_cpu_scaling_part_1/imgs/batch_size_scaling_latency_optimal_nb_instances.svg" style="width:100%"/>
<figcaption>Figure 9. Optimal number of instance minimizing overall latency for a total batch size of 8</figcaption>
</figure>
<br>
On a second hand, we observe the throughput as the sum of all the model instance executing in parallel.
It allows us to visualize the scalability of the system when adding more and more instances each of them with fewer resources but also proportional workload.
Here, the results show almost linear scalability and thus an optimal hardware usage.
<figure class="image">
<img alt="Batch scaling experiment for PyTorch and Tensorflow" src="assets/21_bert_cpu_scaling_part_1/imgs/batch_scaling_exp_throughput.svg" style="width:100%"/>
<figcaption>Figure 10. Sum throughput with respect to number of instances for a total batch size of 8</figcaption>
</figure>
<br>
## 9. Conclusion
Through this blog post, we covered out-of-box BERT inference performance one can expect for PyTorch and TensorFlow,
from a simple PyPi install and without further tuning.
It is important to highlight results provided here reflects out-of-the-box framework setup hence, they might not provide the absolute best performances.
We decided to not include optimizations as part of this blog post to focus on hardware and efficiency.
Optimizations will be discussed in the second part! 🚀
Then, we covered and detailed the impact, and the importance of setting the thread affinity along with the trade-off between the target problem size, and the number of cores required for achieving the task.
Also, it is important to define **which criteria** _(i.e. latency vs throughput)_ to use when optimizing your deployment as the resulting setups might be totally different.
On a more general note, small problem sizes (_short sequences and/or small batches_) might require much fewer cores to achieve the best possible latency than big problems (_very long sequences and/or big batches_).
It is interesting to cover all these aspects when thinking about the final deployment platform as it might cut the cost of the infrastructure drastically.
For instance, our 48 cores machine charges **4.848\$/h** whereas a smaller instances with only 8 cores lowers the cost to **0.808\$/h**, leading to a **6x cost reduction**.
Last but not least, many of the knobs discussed along this blog post can be automatically tuned through a [launcher script](https://github.com/huggingface/tune/blob/main/launcher.py)
highly inspired from the original script made by Intel and available [here](https://github.com/intel/intel-extension-for-pytorch/blob/master/intel_pytorch_extension_py/launch.py).
The launcher script is able to automatically starts your python process(es) with the correct thread affinity, effectively
splitting resources across instances along with many other performances tips! We will detail many of this tips in the second part 🧐.
In the follow-up blog post, more advanced settings and tuning techniques to decrease model latency even further will be involved, such as:
- Launcher script walk-through
- Tuning the memory allocation library
- Using Linux's Transparent Huge Pages mechanisms
- Using vendor-specific Math/Parallel libraries
Stay tuned! 🤗
## Acknowledgments
- [Omry Yadan](https://github.com/omry) (Facebook FAIR) - Author of [OmegaConf](https://github.com/omry/omegaconf) & [Hydra](https://github.com/facebookresearch/hydra) for all the tips setting up Hydra correctly.
- All Intel & Intel Labs' NLP colleagues - For the ongoing optimizations and research efforts they are putting into transformers and more generally in the NLP field.
- Hugging Face colleagues - For all the comments and improvements in the reviewing process.
## References
1. [Benchmarking Transformers: PyTorch and TensorFlow](https://medium.com/huggingface/benchmarking-transformers-pytorch-and-tensorflow-e2917fb891c2)
2. [HuggingFace's Transformers: State-of-the-art Natural Language Processing](https://arxiv.org/abs/1910.03771v2)
3. [HuggingFace's Model Hub](https://huggingface.co/models)
4. [BERT - Pre-training of Deep Bidirectional Transformers for Language Understanding (Devlin & al. 2018)](https://arxiv.org/abs/1810.04805v1)
5. [Illustrated Transformer blogpost from Jay Alammar](https://jalammar.github.io/illustrated-transformer/)
6. [PyTorch - TorchScript](https://pytorch.org/docs/stable/jit.html)
7. [Google Accelerated Linear Algebra (XLA)](https://www.tensorflow.org/xla)
8. [ONNX Runtime - Optimize and Accelerate Machine Learning Inferencing and Training](https://www.onnxruntime.ai/)
9. [Q8BERT - Quantized 8Bit BERT (Zafrir & al. 2019)](https://arxiv.org/abs/1910.06188)
10. [OpenMP](https://www.openmp.org/)
11. [Intel oneDNN](https://software.intel.com/content/www/us/en/develop/documentation/oneapi-programming-guide/top/api-based-programming/intel-oneapi-deep-neural-network-library-onednn.html)
12. [Intel® Hyper-Threading Technology - Technical User Guide](http://www.cslab.ece.ntua.gr/courses/advcomparch/2007/material/readings/Intel%20Hyper-Threading%20Technology.pdf)
13. [Introduction to Hyper-Threading Technology](https://software.intel.com/content/www/us/en/develop/articles/introduction-to-hyper-threading-technology.html)
14. [BLAS (Basic Linear Algebra Subprogram) - Wikipedia](https://en.wikipedia.org/wiki/Basic_Linear_Algebra_Subprograms#Level_3)
15. [Optimizing Applications for NUMA](https://software.intel.com/content/www/us/en/develop/articles/optimizing-applications-for-numa.html)
| 2 |
0 | hf_public_repos | hf_public_repos/blog/doc_aug_hf_alb.md | ---
title: "Introducing TextImage Augmentation for Document Images"
thumbnail: "/blog/assets/185_albumentations/thumbnail.png"
authors:
- user: danaaubakirova
- user: Molbap
- user: Ternaus
guest: True
---
# Introducing Multimodal TextImage Augmentation for Document Images
In this blog post, we provide a tutorial on how to use a new data augmentation technique for document images, developed in collaboration with Albumentations AI.
## Motivation
Vision Language Models (VLMs) have an immense range of applications, but they often need to be fine-tuned to specific use-cases, particularly for datasets containing document images, i.e., images with high textual content. In these cases, it is crucial for text and image to interact with each other at all stages of model training, and applying augmentation to both modalities ensures this interaction. Essentially, we want a model to learn to read properly, which is challenging in the most common cases where data is missing.
Hence, the need for **effective data augmentation** techniques for document images became evident when addressing challenges in fine-tuning models with limited datasets. A common concern is that typical image transformations, such as resizing, blurring, or changing background colors, can negatively impact text extraction accuracy.

We recognized the need for data augmentation techniques that preserve the integrity of the text while augmenting the dataset. Such data augmentation can facilitate generation of new documents or modification of existing ones, while preserving their text quality.
## Introduction
To address this need, we introduce a **new data augmentation pipeline** developed in collaboration with [Albumentations AI](https://albumentations.ai). This pipeline handles both images and text within them, providing a comprehensive solution for document images. This class of data augmentation is *multimodal* as it modifies both the image content and the text annotations simultaneously.
As discussed in a previous [blog post](https://huggingface.co/blog/danaaubakirova/doc-augmentation), our goal is to test the hypothesis that integrating augmentations on both text and images during pretraining of VLMs is effective. Detailed parameters and use case illustrations can be found on the [Albumentations AI Documentation](https://albumentations.ai/docs/examples/example_textimage/?h=textimage). Albumentations AI enables the dynamic design of these augmentations and their integration with other types of augmentations.
## Method
To augment document images, we begin by randomly selecting lines within the document. A hyperparameter `fraction_range` controls the bounding box fraction to be modified.
Next, we apply one of several text augmentation methods to the corresponding lines of text, which are commonly utilized in text generation tasks. These methods include Random Insertion, Deletion, and Swap, and Stopword Replacement.
After modifying the text, we black out parts of the image where the text is inserted and inpaint them, using the original bounding box size as a proxy for the new text's font size. The font size can be specified with the parameter `font_size_fraction_range`, which determines the range for selecting the font size as a fraction of the bounding box height. Note that the modified text and corresponding bounding box can be retrieved and used for training. This process results in a dataset with semantically similar textual content and visually distorted images.
## Main Features of the TextImage Augmentation
The library can be used for two main purposes:
1. **Inserting any text on the image**: This feature allows you to overlay text on document images, effectively generating synthetic data. By using any random image as a background and rendering completely new text, you can create diverse training samples. A similar technique, called SynthDOG, was introduced in the [OCR-free document understanding transformer](https://arxiv.org/pdf/2111.15664).
2. **Inserting augmented text on the image**: This includes the following text augmentations:
- **Random deletion**: Randomly removes words from the text.
- **Random swapping**: Swaps words within the text.
- **Stop words insertion**: Inserts common stop words into the text.
Combining these augmentations with other image transformations from Albumentations allows for simultaneous modification of images and text. You can retrieve the augmented text as well.
*Note*: The initial version of the data augmentation pipeline presented in [this repo](https://github.com/danaaubakirova/doc-augmentation), included synonym replacement. It was removed in this version because it caused significant time overhead.
## Installation
```python
!pip install -U pillow
!pip install albumentations
!pip install nltk
```
```python
import albumentations as A
import cv2
from matplotlib import pyplot as plt
import json
import nltk
nltk.download('stopwords')
from nltk.corpus import stopwords
```
## Visualization
```python
def visualize(image):
plt.figure(figsize=(20, 15))
plt.axis('off')
plt.imshow(image)
```
## Load data
Note that for this type of augmentation you can use the [IDL](https://huggingface.co/datasets/pixparse/idl-wds) and [PDFA](https://huggingface.co/datasets/pixparse/pdfa-eng-wds) datasets. They provide the bounding boxes of the lines that you want to modify.
For this tutorial, we will focus on the sample from IDL dataset.
```python
bgr_image = cv2.imread("examples/original/fkhy0236.tif")
image = cv2.cvtColor(bgr_image, cv2.COLOR_BGR2RGB)
with open("examples/original/fkhy0236.json") as f:
labels = json.load(f)
font_path = "/usr/share/fonts/truetype/liberation/LiberationSerif-Regular.ttf"
visualize(image)
```

We need to correctly preprocess the data, as the input format for the bounding boxes is the normalized Pascal VOC. Hence, we build the metadata as follows:
```python
page = labels['pages'][0]
def prepare_metadata(page: dict, image_height: int, image_width: int) -> list:
metadata = []
for text, box in zip(page['text'], page['bbox']):
left, top, width_norm, height_norm = box
metadata.append({
"bbox": [left, top, left + width_norm, top + height_norm],
"text": text
})
return metadata
image_height, image_width = image.shape[:2]
metadata = prepare_metadata(page, image_height, image_width)
```
## Random Swap
```python
transform = A.Compose([A.TextImage(font_path=font_path, p=1, augmentations=["swap"], clear_bg=True, font_color = 'red', fraction_range = (0.5,0.8), font_size_fraction_range=(0.8, 0.9))])
transformed = transform(image=image, textimage_metadata=metadata)
visualize(transformed["image"])
```

## Random Deletion
```python
transform = A.Compose([A.TextImage(font_path=font_path, p=1, augmentations=["deletion"], clear_bg=True, font_color = 'red', fraction_range = (0.5,0.8), font_size_fraction_range=(0.8, 0.9))])
transformed = transform(image=image, textimage_metadata=metadata)
visualize(transformed['image'])
```

## Random Insertion
In random insertion we insert random words or phrases into the text. In this case, we use stop words, common words in a language that are often ignored or filtered out during natural language processing (NLP) tasks because they carry less meaningful information compared to other words. Examples of stop words include "is," "the," "in," "and," "of," etc.
```python
stops = stopwords.words('english')
transform = A.Compose([A.TextImage(font_path=font_path, p=1, augmentations=["insertion"], stopwords = stops, clear_bg=True, font_color = 'red', fraction_range = (0.5,0.8), font_size_fraction_range=(0.8, 0.9))])
transformed = transform(image=image, textimage_metadata=metadata)
visualize(transformed['image'])
```

## Can we combine with other transformations?
Let's define a complex transformation pipeline using `A.Compose`, which includes text insertion with specified font properties and stopwords, Planckian jitter, and affine transformations. Firstly, with `A.TextImage` we insert text into the image using specified font properties, with a clear background and red font color. The fraction and size of the text to be inserted are also specified.
Then with `A.PlanckianJitter` we alter the color balance of the image. Finally, using `A.Affine` we apply affine transformations, which can include scaling, rotating, and translating the image.
```python
transform_complex = A.Compose([A.TextImage(font_path=font_path, p=1, augmentations=["insertion"], stopwords = stops, clear_bg=True, font_color = 'red', fraction_range = (0.5,0.8), font_size_fraction_range=(0.8, 0.9)),
A.PlanckianJitter(p=1),
A.Affine(p=1)
])
transformed = transform_complex(image=image, textimage_metadata=metadata)
visualize(transformed["image"])
```

# How to get the altered text?
To extract the information on the bounding box indices where text was altered, along with the corresponding transformed text data
run the following cell. This data can be used effectively for training models to recognize and process text changes in images.
```python
transformed['overlay_data']
```
[{'bbox_coords': (375, 1149, 2174, 1196),
'text': "Lionberger, Ph.D., (Title: if Introduction to won i FDA's yourselves Draft Guidance once of the wasn't General Principles",
'original_text': "Lionberger, Ph.D., (Title: Introduction to FDA's Draft Guidance of the General Principles",
'bbox_index': 12,
'font_color': 'red'},
{'bbox_coords': (373, 1677, 2174, 1724),
'text': "After off needn't were a brief break, ADC member mustn Jeffrey that Dayno, MD, Chief Medical Officer for at their Egalet",
'original_text': 'After a brief break, ADC member Jeffrey Dayno, MD, Chief Medical Officer at Egalet',
'bbox_index': 19,
'font_color': 'red'},
{'bbox_coords': (525, 2109, 2172, 2156),
'text': 'll Brands recognize the has importance and of a generics ADF guidance to ensure which after',
'original_text': 'Brands recognize the importance of a generics ADF guidance to ensure',
'bbox_index': 23,
'font_color': 'red'}]
## Synthetic Data Generation
This augmentation method can be extended to the generation of synthetic data, as it enables the rendering of text on any background or template.
```python
template = cv2.imread('template.png')
image_template = cv2.cvtColor(template, cv2.COLOR_BGR2RGB)
transform = A.Compose([A.TextImage(font_path=font_path, p=1, clear_bg=True, font_color = 'red', font_size_fraction_range=(0.5, 0.7))])
metadata = [{
"bbox": [0.1, 0.4, 0.5, 0.48],
"text": "Some smart text goes here.",
}, {
"bbox": [0.1, 0.5, 0.5, 0.58],
"text": "Hope you find it helpful.",
}]
transformed = transform(image=image_template, textimage_metadata=metadata)
visualize(transformed['image'])
```

## Conclusion
In collaboration with Albumentations AI, we introduced TextImage Augmentation, a multimodal technique that modifies document images along with the text. By combining text augmentations such as Random Insertion, Deletion, Swap, and Stopword Replacement with image modifications, this pipeline allows for the generation of diverse training samples.
For detailed parameters and use case illustrations, refer to the [Albumentations AI Documentation](https://albumentations.ai/docs/examples/example_textimage/?h=textimage). We hope you find these augmentations useful for enhancing your document image processing workflows.
## References
```
@inproceedings{kim2022ocr,
title={Ocr-free document understanding transformer},
author={Kim, Geewook and Hong, Teakgyu and Yim, Moonbin and Nam, JeongYeon and Park, Jinyoung and Yim, Jinyeong and Hwang, Wonseok and Yun, Sangdoo and Han, Dongyoon and Park, Seunghyun},
booktitle={European Conference on Computer Vision},
pages={498--517},
year={2022},
organization={Springer}
}
```
| 3 |
0 | hf_public_repos | hf_public_repos/blog/matryoshka.md | ---
title: "🪆 Introduction to Matryoshka Embedding Models"
thumbnail: /blog/assets/matryoshka/thumbnail.png
authors:
- user: tomaarsen
- user: xenova
- user: osanseviero
---
# 🪆 Introduction to Matryoshka Embedding Models
In this blogpost, we will introduce you to the concept of Matryoshka Embeddings and explain why they are useful. We will discuss how these models are theoretically trained and how you can train them using Sentence Transformers.
Additionally, we will provide practical guidance on how to use Matryoshka Embedding models and share a comparison between a Matryoshka embedding model and a regular embedding model. Finally, we invite you to check out our interactive demo that showcases the power of these models.
## Table of Contents
* [Understanding Embeddings](#understanding-embeddings)
* [🪆 Matryoshka Embeddings](#%F0%9F%AA%86-matryoshka-embeddings)
* [🪆 Matryoshka Dolls](#%F0%9F%AA%86-matryoshka-dolls)
* [Why would you use 🪆 Matryoshka Embedding models?](#why-would-you-use-%F0%9F%AA%86-matryoshka-embedding-models)
* [How are 🪆 Matryoshka Embedding models trained?](#how-are-%F0%9F%AA%86-matryoshka-embedding-models-trained)
+ [Theoretically](#theoretically)
+ [In Sentence Transformers](#in-sentence-transformers)
* [How do I use 🪆 Matryoshka Embedding models?](#how-do-i-use-%F0%9F%AA%86-matryoshka-embedding-models)
+ [Theoretically](#theoretically-1)
+ [In Sentence Transformers](#in-sentence-transformers-1)
* [Results](#results)
* [Demo](#demo)
* [References](#references)
## Understanding Embeddings
Embeddings are one of the most versatile tools in natural language processing, enabling practitioners to solve a large variety of tasks. In essence, an embedding is a numerical representation of a more complex object, like text, images, audio, etc.
The embedding model will always produce embeddings of the same fixed size. You can then compute the similarity of complex objects by computing the similarity of the respective embeddings!
This has an enormous amount of use cases, and serves as the backbone for recommendation systems, retrieval, one-shot or few-shot learning, outlier detection, similarity search, paraphrase detection, clustering, classification, and much more!
## 🪆 Matryoshka Embeddings
As research progressed, new state-of-the-art (text) embedding models started producing embeddings with increasingly higher output dimensions, i.e., every input text is represented using more values. Although this improves performance, it comes at the cost of efficiency of downstream tasks such as search or classification.
Consequently, [Kusupati et al.](https://huggingface.co/papers/2205.13147) (2022) were inspired to create embedding models whose embeddings could reasonably be shrunk without suffering too much on performance.
These Matryoshka embedding models are trained such that these small truncated embeddings would still be useful. In short, Matryoshka embedding models can produce useful embeddings of various dimensions.
## 🪆 Matryoshka Dolls
For those unfamiliar, "Matryoshka dolls", also known as "Russian nesting dolls", are a set of wooden dolls of decreasing size that are placed inside one another. In a similar way, Matryoshka embedding models aim to store more important information in earlier dimensions, and less important information in later dimensions. This characteristic of Matryoshka embedding models allows us to truncate the original (large) embedding produced by the model, while still retaining enough of the information to perform well on downstream tasks.
## Why would you use 🪆 Matryoshka Embedding models?
Such variable-size embedding models can be quite valuable to practitioners, for example:
1. **Shortlisting and reranking**: Rather than performing your downstream task (e.g., nearest neighbor search) on the full embeddings, you can shrink the embeddings to a smaller size and very efficiently "shortlist" your embeddings. Afterwards, you can process the remaining embeddings using their full dimensionality.
2. **Trade-offs**: Matryoshka models will allow you to scale your embedding solutions to your desired storage cost, processing speed, and performance.
## How are 🪆 Matryoshka Embedding models trained?
### Theoretically
The Matryoshka Representation Learning (MRL) approach can be adopted for almost all embedding model training frameworks. Normally, a training step for an embedding model involves producing embeddings for your training batch (of texts, for example) and then using some loss function to create a loss value that represents the quality of the produced embeddings. The optimizer will adjust the model weights throughout training to reduce the loss value.
For Matryoshka Embedding models, a training step also involves producing embeddings for your training batch, but then you use some loss function to determine not just the quality of your full-size embeddings, but also the quality of your embeddings at various different dimensionalities. For example, output dimensionalities are 768, 512, 256, 128, and 64. The loss values for each dimensionality are added together, resulting in a final loss value. The optimizer will then try and adjust the model weights to lower this loss value.
In practice, this incentivizes the model to frontload the most important information at the start of an embedding, such that it will be retained if the embedding is truncated.
### In Sentence Transformers
[Sentence Tranformers](https://sbert.net) is a commonly used framework to train embedding models, and it recently implemented support for Matryoshka models. Training a Matryoshka embedding model using Sentence Transformers is quite elementary: rather than applying some loss function on only the full-size embeddings, we also apply that same loss function on truncated portions of the embeddings.
For example, if a model has an original embedding dimension of 768, it can now be trained on 768, 512, 256, 128 and 64. Each of these losses will be added together, optionally with some weight:
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.losses import CoSENTLoss, MatryoshkaLoss
model = SentenceTransformer("microsoft/mpnet-base")
base_loss = CoSENTLoss(model=model)
loss = MatryoshkaLoss(
model=model,
loss=base_loss,
matryoshka_dims=[768, 512, 256, 128, 64],
matryoshka_weight=[1, 1, 1, 1, 1],
)
model.fit(
train_objectives=[(train_dataset, loss)],
...,
)
```
Training with `MatryoshkaLoss` does not incur a notable overhead in training time.
References:
* [`MatryoshkaLoss`](https://sbert.net/docs/package_reference/losses.html#matryoshkaloss)
* [`CoSENTLoss`](https://sbert.net/docs/package_reference/losses.html#cosentloss)
* [`SentenceTransformer`](https://sbert.net/docs/package_reference/SentenceTransformer.html)
* [`SentenceTransformer.fit`](https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.fit)
* [Matryoshka Embeddings - Training](https://sbert.net/examples/training/matryoshka/README.html#training)
See the following complete scripts as examples of how to apply the `MatryoshkaLoss` in practice:
* **[matryoshka_nli.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli.py)**: This example uses the `MultipleNegativesRankingLoss` with `MatryoshkaLoss` to train a strong embedding model using Natural Language Inference (NLI) data. It is an adaptation of the [NLI](../nli/README) documentation.
* **[matryoshka_nli_reduced_dim.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli_reduced_dim.py)**: This example uses the `MultipleNegativesRankingLoss` with `MatryoshkaLoss` to train a strong embedding model with a small maximum output dimension of 256. It trains using Natural Language Inference (NLI) data, and is an adaptation of the [NLI](../nli/README) documentation.
* **[matryoshka_sts.py](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_sts.py)**: This example uses the `CoSENTLoss` with `MatryoshkaLoss` to train an embedding model on the training set of the `STSBenchmark` dataset. It is an adaptation of the [STS](../sts/README) documentation.
## How do I use 🪆 Matryoshka Embedding models?
### Theoretically
In practice, getting embeddings from a Matryoshka embedding model works the same way as with a normal embedding model. The only difference is that, after receiving the embeddings, we can optionally truncate them to a smaller dimensionality. Do note that if the embeddings were normalized, then after truncating they will no longer be, so you may want to re-normalize.
After truncating, you can either directly apply them for your use cases, or store them such that they can be used later. After all, smaller embeddings in your vector database should result in considerable speedups!
Keep in mind that although processing smaller embeddings for downstream tasks (retrieval, clustering, etc.) will be faster, getting the smaller embeddings from the model is just as fast as getting the larger ones.
### In Sentence Transformers
In Sentence Transformers, you can load a Matryoshka Embedding model just like any other model, but you can specify the desired embedding size using the `truncate_dim` argument. After that, you can perform inference using the [`SentenceTransformers.encode`](https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode) function, and the embeddings will be automatically truncated to the specified size.
Let's try to use a model that I trained using [`matryoshka_nli.py`](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli.py) with [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base):
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
matryoshka_dim = 64
model = SentenceTransformer("tomaarsen/mpnet-base-nli-matryoshka", truncate_dim=matryoshka_dim)
embeddings = model.encode(
[
"The weather is so nice!",
"It's so sunny outside!",
"He drove to the stadium.",
]
)
print(embeddings.shape)
# => (3, 64)
# Similarity of the first sentence to the other two:
similarities = cos_sim(embeddings[0], embeddings[1:])
print(similarities)
# => tensor([[0.8910, 0.1337]])
```
* Link to the model: [tomaarsen/mpnet-base-nli-matryoshka](https://huggingface.co/tomaarsen/mpnet-base-nli-matryoshka)
Feel free to experiment with using different values for `matryoshka_dim` and observe how that affects the similarities. You can do so either by running this code locally, on the cloud such as with [Google Colab](https://colab.research.google.com/#fileId=https%3A//huggingface.co/tomaarsen/mpnet-base-nli-matryoshka/blob/main/inference.ipynb), or by checking out the [demo](#demo).
References:
* [`SentenceTransformer`](https://sbert.net/docs/package_reference/SentenceTransformer.html)
* [`SentenceTransformer.encode`](https://sbert.net/docs/package_reference/SentenceTransformer.html#sentence_transformers.SentenceTransformer.encode)
* [`util.cos_sim`](https://sbert.net/docs/package_reference/util.html#sentence_transformers.util.cos_sim)
* [Matryoshka Embeddings - Inference](https://sbert.net/examples/training/matryoshka/README.html#inference)
<details><summary><b>Click here to see how to use the Nomic v1.5 Matryoshka Model</b></summary>
Note: Nomic specifically requires an `F.layer_norm` before the embedding truncation. As a result, the following snippet uses manual truncation to the desired dimension. For all other models, you can use the `truncate_dim` option in the constructor, as shown in the previous example.
```python
from sentence_transformers import SentenceTransformer
from sentence_transformers.util import cos_sim
import torch.nn.functional as F
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True)
matryoshka_dim = 64
embeddings = model.encode(
[
"search_query: What is TSNE?",
"search_document: t-distributed stochastic neighbor embedding (t-SNE) is a statistical method for visualizing high-dimensional data by giving each datapoint a location in a two or three-dimensional map.",
"search_document: Amelia Mary Earhart was an American aviation pioneer and writer.",
],
convert_to_tensor=True,
)
# The Nomic team uses a custom architecture, making them recommend Layer Normalization before truncation
embeddings = F.layer_norm(embeddings, normalized_shape=(embeddings.shape[1],))
embeddings[..., :matryoshka_dim] # Shrink the embedding dimensions
similarities = cos_sim(embeddings[0], embeddings[1:])
# => tensor([[0.7154, 0.4468]])
```
* Link to the model: [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5)
</details>
## Results
Now that Matryoshka models have been introduced, let's look at the actual performance that we may be able to expect from a Matryoshka embedding model versus a regular embedding model. For this experiment, I have trained two models:
* [tomaarsen/mpnet-base-nli-matryoshka](https://huggingface.co/tomaarsen/mpnet-base-nli-matryoshka): Trained by running [`matryoshka_nli.py`](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli.py) with [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base).
* [tomaarsen/mpnet-base-nli](https://huggingface.co/tomaarsen/mpnet-base-nli): Trained by running a modified version of [`matryoshka_nli.py`](https://github.com/UKPLab/sentence-transformers/blob/master/examples/training/matryoshka/matryoshka_nli.py) where the training loss is only `MultipleNegativesRankingLoss` rather than `MatryoshkaLoss` on top of `MultipleNegativesRankingLoss`. I also use [`microsoft/mpnet-base`](https://huggingface.co/microsoft/mpnet-base) as the base model.
Both of these models were trained on the AllNLI dataset, which is a concatenation of the [SNLI](https://huggingface.co/datasets/snli) and [MultiNLI](https://huggingface.co/datasets/multi_nli) datasets. I have evaluated these models on the [STSBenchmark](https://huggingface.co/datasets/mteb/stsbenchmark-sts) test set using multiple different embedding dimensions. The results are plotted in the following figure:
In the top figure, you can see that the Matryoshka model reaches a higher Spearman similarity than the standard model at all dimensionalities, indicative that the Matryoshka model is superior in this task.
Furthermore, the performance of the Matryoshka model falls off much less quickly than the standard model. This is shown clearly in the second figure, which shows the performance at the embedding dimension relative to the maximum performance. **Even at 8.3% of the embedding size, the Matryoshka model preserves 98.37% of the performance**, much higher than the 96.46% by the standard model.
These findings are indicative that truncating embeddings by a Matryoshka model could: 1) significantly speed up downstream tasks such as retrieval and 2) significantly save on storage space, all without a notable hit in performance.
## Demo
In this demo, you can dynamically shrink the output dimensions of the [`nomic-ai/nomic-embed-text-v1.5`](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) Matryoshka embedding model and observe how it affects the retrieval performance. All of the embeddings are computed in the browser using [🤗 Transformers.js](https://github.com/xenova/transformers.js).
<iframe
src="https://xenova-adaptive-retrieval-web.static.hf.space"
frameborder="0"
width="100%"
height="800"
></iframe>
## References
* Kusupati, A., Bhatt, G., Rege, A., Wallingford, M., Sinha, A., Ramanujan, V., ... & Farhadi, A. (2022). Matryoshka representation learning. Advances in Neural Information Processing Systems, 35, 30233-30249. https://arxiv.org/abs/2205.13147
* Matryoshka Embeddings — Sentence-Transformers documentation. (n.d.). https://sbert.net/examples/training/matryoshka/README.html
* UKPLab. (n.d.). GitHub. https://github.com/UKPLab/sentence-transformers
* Unboxing Nomic Embed v1.5: Resizable Production Embeddings with Matryoshka Representation Learning. (n.d.). https://blog.nomic.ai/posts/nomic-embed-matryoshka | 4 |
0 | hf_public_repos | hf_public_repos/blog/safecoder.md | ---
title: "Introducing SafeCoder"
thumbnail: /blog/assets/159_safecoder/thumbnail.jpg
authors:
- user: jeffboudier
- user: philschmid
---
# Introducing SafeCoder
Today we are excited to announce SafeCoder - a code assistant solution built for the enterprise.
The goal of SafeCoder is to unlock software development productivity for the enterprise, with a fully compliant and self-hosted pair programmer. In marketing speak: “your own on-prem GitHub copilot”.
Before we dive deeper, here’s what you need to know:
- SafeCoder is not a model, but a complete end-to-end commercial solution
- SafeCoder is built with security and privacy as core principles - code never leaves the VPC during training or inference
- SafeCoder is designed for self-hosting by the customer on their own infrastructure
- SafeCoder is designed for customers to own their own Code Large Language Model
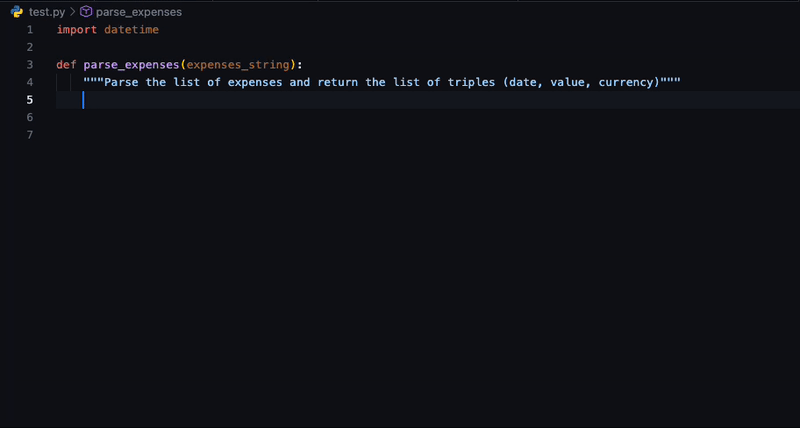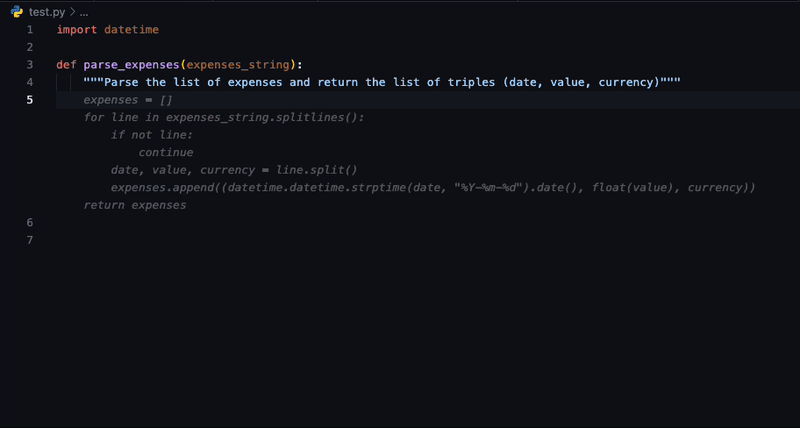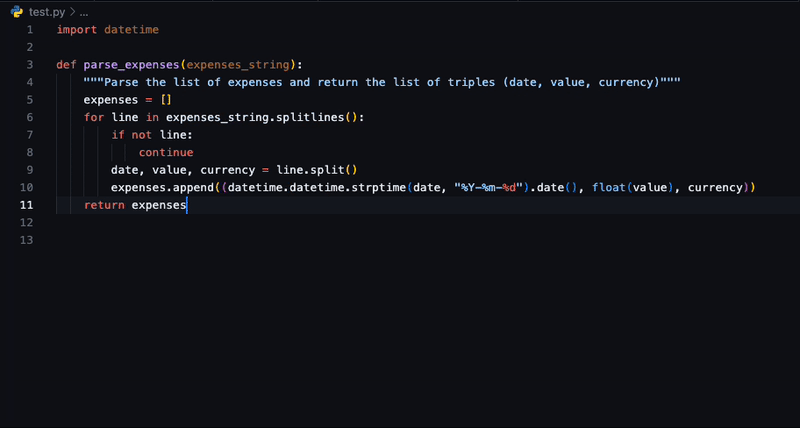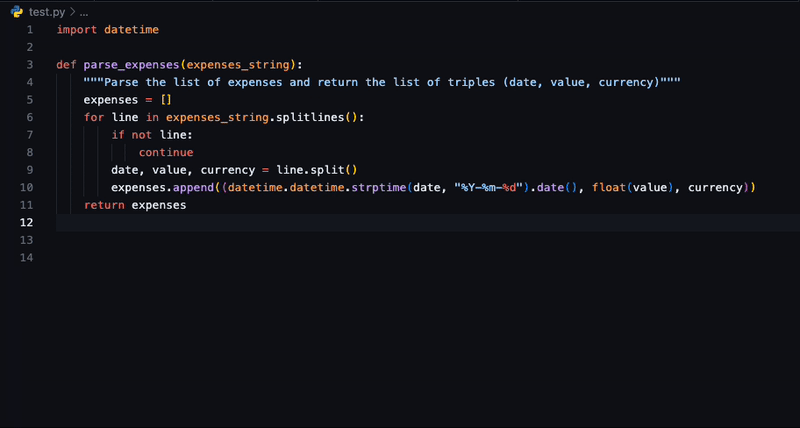
## Why SafeCoder?
Code assistant solutions built upon LLMs, such as GitHub Copilot, are delivering strong [productivity boosts](https://github.blog/2022-09-07-research-quantifying-github-copilots-impact-on-developer-productivity-and-happiness/). For the enterprise, the ability to tune Code LLMs on the company code base to create proprietary Code LLMs improves reliability and relevance of completions to create another level of productivity boost. For instance, Google internal LLM code assistant reports a completion [acceptance rate of 25-34%](https://ai.googleblog.com/2022/07/ml-enhanced-code-completion-improves.html) by being trained on an internal code base.
However, relying on closed-source Code LLMs to create internal code assistants exposes companies to compliance and security issues. First during training, as fine-tuning a closed-source Code LLM on an internal codebase requires exposing this codebase to a third party. And then during inference, as fine-tuned Code LLMs are likely to “leak” code from their training dataset during inference. To meet compliance requirements, enterprises need to deploy fine-tuned Code LLMs within their own infrastructure - which is not possible with closed source LLMs.
With SafeCoder, Hugging Face will help customers build their own Code LLMs, fine-tuned on their proprietary codebase, using state of the art open models and libraries, without sharing their code with Hugging Face or any other third party. With SafeCoder, Hugging Face delivers a containerized, hardware-accelerated Code LLM inference solution, to be deployed by the customer directly within the Customer secure infrastructure, without code inputs and completions leaving their secure IT environment.
## From StarCoder to SafeCoder
At the core of the SafeCoder solution is the [StarCoder](https://huggingface.co/bigcode/starcoder) family of Code LLMs, created by the [BigCode](https://huggingface.co/bigcode) project, a collaboration between Hugging Face, ServiceNow and the open source community.
The StarCoder models offer unique characteristics ideally suited to enterprise self-hosted solution:
- State of the art code completion results - see benchmarks in the [paper](https://huggingface.co/papers/2305.06161) and [multilingual code evaluation leaderboard](https://huggingface.co/spaces/bigcode/multilingual-code-evals)
- Designed for inference performance: a 15B parameters model with code optimizations, Multi-Query Attention for reduced memory footprint, and Flash Attention to scale to 8,192 tokens context.
- Trained on [the Stack](https://huggingface.co/datasets/bigcode/the-stack), an ethically sourced, open source code dataset containing only commercially permissible licensed code, with a developer opt-out mechanism from the get-go, refined through intensive PII removal and deduplication efforts.
Note: While StarCoder is the inspiration and model powering the initial version of SafeCoder, an important benefit of building a LLM solution upon open source models is that it can adapt to the latest and greatest open source models available. In the future, SafeCoder may offer other similarly commercially permissible open source models built upon ethically sourced and transparent datasets as the base LLM available for fine-tuning.
## Privacy and Security as a Core Principle
For any company, the internal codebase is some of its most important and valuable intellectual property. A core principle of SafeCoder is that the customer internal codebase will never be accessible to any third party (including Hugging Face) during training or inference.
In the initial set up phase of SafeCoder, the Hugging Face team provides containers, scripts and examples to work hand in hand with the customer to select, extract, prepare, duplicate, deidentify internal codebase data into a training dataset to be used in a Hugging Face provided training container configured to the hardware infrastructure available to the customer.
In the deployment phase of SafeCoder, the customer deploys containers provided by Hugging Face on their own infrastructure to expose internal private endpoints within their VPC. These containers are configured to the exact hardware configuration available to the customer, including NVIDIA GPUs, AMD Instinct GPUs, Intel Xeon CPUs, AWS Inferentia2 or Habana Gaudi accelerators.
## Compliance as a Core Principle
As the regulation framework around machine learning models and datasets is still being written across the world, global companies need to make sure the solutions they use minimize legal risks.
Data sources, data governance, management of copyrighted data are just a few of the most important compliance areas to consider. BigScience, the older cousin and inspiration for BigCode, addressed these areas in working groups before they were broadly recognized by the draft AI EU Act, and as a result was [graded as most compliant among Foundational Model Providers in a Stanford CRFM study](https://crfm.stanford.edu/2023/06/15/eu-ai-act.html).
BigCode expanded upon this work by implementing novel techniques for the code domain and building The Stack with compliance as a core principle, such as commercially permissible license filtering, consent mechanisms (developers can [easily find out if their code is present and request to be opted out](https://huggingface.co/spaces/bigcode/in-the-stack) of the dataset), and extensive documentation and tools to inspect the [source data](https://huggingface.co/datasets/bigcode/the-stack-metadata), and dataset improvements (such as [deduplication](https://huggingface.co/blog/dedup) and [PII removal](https://huggingface.co/bigcode/starpii)).
All these efforts translate into legal risk minimization for users of the StarCoder models, and customers of SafeCoder. And for SafeCoder users, these efforts translate into compliance features: when software developers get code completions these suggestions are checked against The Stack, so users know if the suggested code matches existing code in the source dataset, and what the license is. Customers can specify which licenses are preferred and surface those preferences to their users.
## How does it work?
SafeCoder is a complete commercial solution, including service, software and support.
### Training your own SafeCoder model
StarCoder was trained in more than 80 programming languages and offers state of the art performance on [multiple benchmarks](https://huggingface.co/spaces/bigcode/multilingual-code-evals). To offer better code suggestions specifically for a SafeCoder customer, we start the engagement with an optional training phase, where the Hugging Face team works directly with the customer team to guide them through the steps to prepare and build a training code dataset, and to create their own code generation model through fine-tuning, without ever exposing their codebase to third parties or the internet.
The end result is a model that is adapted to the code languages, standards and practices of the customer. Through this process, SafeCoder customers learn the process and build a pipeline for creating and updating their own models, ensuring no vendor lock-in, and keeping control of their AI capabilities.
### Deploying SafeCoder
During the setup phase, SafeCoder customers and Hugging Face design and provision the optimal infrastructure to support the required concurrency to offer a great developer experience. Hugging Face then builds SafeCoder inference containers that are hardware-accelerated and optimized for throughput, to be deployed by the customer on their own infrastructure.
SafeCoder inference supports various hardware to give customers a wide range of options: NVIDIA Ampere GPUs, AMD Instinct GPUs, Habana Gaudi2, AWS Inferentia 2, Intel Xeon Sapphire Rapids CPUs and more.
### Using SafeCoder
Once SafeCoder is deployed and its endpoints are live within the customer VPC, developers can install compatible SafeCoder IDE plugins to get code suggestions as they work. Today, SafeCoder supports popular IDEs, including [VSCode](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode), IntelliJ and with more plugins coming from our partners.
## How can I get SafeCoder?
Today, we are announcing SafeCoder in collaboration with VMware at the VMware Explore conference and making SafeCoder available to VMware enterprise customers. Working with VMware helps ensure the deployment of SafeCoder on customers’ VMware Cloud infrastructure is successful – whichever cloud, on-premises or hybrid infrastructure scenario is preferred by the customer. In addition to utilizing SafeCoder, VMware has published a [reference architecture](https://www.vmware.com/content/dam/digitalmarketing/vmware/en/pdf/docs/vmware-baseline-reference-architecture-for-generative-ai.pdf) with code samples to enable the fastest possible time-to-value when deploying and operating SafeCoder on VMware infrastructure. VMware’s Private AI Reference Architecture makes it easy for organizations to quickly leverage popular open source projects such as ray and kubeflow to deploy AI services adjacent to their private datasets, while working with Hugging Face to ensure that organizations maintain the flexibility to take advantage of the latest and greatest in open-source models. This is all without tradeoffs in total cost of ownership or performance.
“Our collaboration with Hugging Face around SafeCoder fully aligns to VMware’s goal of enabling customer choice of solutions while maintaining privacy and control of their business data. In fact, we have been running SafeCoder internally for months and have seen excellent results. Best of all, our collaboration with Hugging Face is just getting started, and I’m excited to take our solution to our hundreds of thousands of customers worldwide,” says Chris Wolf, Vice President of VMware AI Labs. Learn more about private AI and VMware’s differentiation in this emerging space [here](https://octo.vmware.com/vmware-private-ai-foundation/).
---
If you’re interested in SafeCoder for your company, please contact us [here](mailto:[email protected]?subject=SafeCoder) - our team will contact you to discuss your requirements!
| 5 |
0 | hf_public_repos | hf_public_repos/blog/summer-at-huggingface.md | ---
title: "Summer at Hugging Face"
thumbnail: /blog/assets/27_summer_at_huggingface/summer_intro.gif
authors:
- user: huggingface
---
# Summer At Hugging Face 😎
Summer is now officially over and these last few months have been quite busy at Hugging Face. From new features in the Hub to research and Open Source development, our team has been working hard to empower the community through open and collaborative technology.
In this blog post you'll catch up on everything that happened at Hugging Face in June, July and August!

This post covers a wide range of areas our team has been working on, so don't hesitate to skip to the parts that interest you the most 🤗
1. [New Features](#new-features)
2. [Community](#community)
3. [Open Source](#open-source)
4. [Solutions](#solutions)
5. [Research](#research)
## New Features
In the last few months, the Hub went from 10,000 public model repositories to over 16,000 models! Kudos to our community for sharing so many amazing models with the world. And beyond the numbers, we have a ton of cool new features to share with you!
### Spaces Beta ([hf.co/spaces](/spaces))
Spaces is a simple and free solution to host Machine Learning demo applications directly on your user profile or your organization [hf.co](http://hf.co/) profile. We support two awesome SDKs that let you build cool apps easily in Python: [Gradio](https://gradio.app/) and [Streamlit](https://streamlit.io/). In a matter of minutes you can deploy an app and share it with the community! 🚀
Spaces lets you [set up secrets](/docs/hub/spaces-overview#managing-secrets), permits [custom requirements](/docs/hub/spaces-dependencies), and can even be managed [directly from GitHub repos](/docs/hub/spaces-github-actions). You can sign up for the beta at [hf.co/spaces](/spaces). Here are some of our favorites!
- Create recipes with the help of [Chef Transformer](/spaces/flax-community/chef-transformer)
- Transcribe speech to text with [HuBERT](https://huggingface.co/spaces/osanseviero/HUBERT)
- Do segmentation in a video with the [DINO model](/spaces/nateraw/dino-clips)
- Use [Paint Transformer](/spaces/akhaliq/PaintTransformer) to make paintings from a given picture
- Or you can just explore any of the over [100 existing Spaces](/spaces)!

### Share Some Love
You can now like any model, dataset, or Space on [http://huggingface.co](http://huggingface.co/), meaning you can share some love with the community ❤️. You can also keep an eye on who's liking what by clicking on the likes box 👀. Go ahead and like your own repos, we're not judging 😉.

### TensorBoard Integration
In late June, we launched a TensorBoard integration for all our models. If there are TensorBoard traces in the repo, an automatic, free TensorBoard instance is launched for you. This works with both public and private repositories and for any library that has TensorBoard traces!

### Metrics
In July, we added the ability to list evaluation metrics in model repos by adding them to their model card📈. If you add an evaluation metric under the `model-index` section of your model card, it will be displayed proudly in your model repo.

If that wasn't enough, these metrics will be automatically linked to the corresponding [Papers With Code](https://paperswithcode.com/) leaderboard. That means as soon as you share your model on the Hub, you can compare your results side-by-side with others in the community. 💪
Check out [this repo](https://huggingface.co/nateraw/vit-base-beans-demo) as an example, paying close attention to `model-index` section of its [model card](https://huggingface.co/nateraw/vit-base-beans-demo/blob/main/README.md#L12-L25) to see how you can do this yourself and find the metrics in Papers with Code [automatically](https://paperswithcode.com/sota/image-classification-on-beans).
### New Widgets
The Hub has 18 widgets that allow users to try out models directly in the browser.
With our latest integrations to Sentence Transformers, we also introduced two new widgets: feature extraction and sentence similarity.
The latest **audio classification** widget enables many cool use cases: language identification, [street sound detection](https://huggingface.co/speechbrain/urbansound8k_ecapa) 🚨, [command recognition](https://huggingface.co/speechbrain/google_speech_command_xvector), [speaker identification](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb), and more! You can try this out with `transformers` and `speechbrain` models today! 🔊 (Beware, when you try some of the models, you might need to bark out loud)
You can try our early demo of [structured data classification](https://huggingface.co/julien-c/wine-quality) with Scikit-learn. And finally, we also introduced new widgets for image-related models: **text to image**, **image classification**, and **object detection**. Try image classification with Google's ViT model [here](https://huggingface.co/google/vit-base-patch16-224) and object detection with Facebook AI's DETR model [here](https://huggingface.co/facebook/detr-resnet-50)!

### More Features
That's not everything that has happened in the Hub. We've introduced new and improved [documentation](https://huggingface.co/docs/hub/main) of the Hub. We also introduced two widely requested features: users can now transfer/rename repositories and directly upload new files to the Hub.

## Community
### Hugging Face Course
In June, we launched the first part of our [free online course](https://huggingface.co/course/chapter1)! The course teaches you everything about the 🤗 Ecosystem: Transformers, Tokenizers, Datasets, Accelerate, and the Hub. You can also find links to the course lessons in the official documentation of our libraries. The live sessions for all chapters can be found on our [YouTube channel](https://www.youtube.com/playlist?list=PLo2EIpI_JMQuQ8StH9RwKXwJVqLTDxwwy). Stay tuned for the next part of the course which we'll be launching later this year!

### JAX/FLAX Sprint
In July we hosted our biggest [community event](https://discuss.huggingface.co/t/open-to-the-community-community-week-using-jax-flax-for-nlp-cv/7104) ever with almost 800 participants! In this event co-organized with the JAX/Flax and Google Cloud teams, compute-intensive NLP, Computer Vision, and Speech projects were made accessible to a wider audience of engineers and researchers by providing free TPUv3s. The participants created over 170 models, 22 datasets, and 38 Spaces demos 🤯. You can explore all the amazing demos and projects [here](https://huggingface.co/flax-community).
There were talks around JAX/Flax, Transformers, large-scale language modeling, and more! You can find all recordings [here](https://github.com/huggingface/transformers/tree/master/examples/research_projects/jax-projects#talks).
We're really excited to share the work of the 3 winning teams!
1. [Dall-e mini](https://huggingface.co/spaces/flax-community/dalle-mini). DALL·E mini is a model that generates images from any prompt you give! DALL·E mini is 27 times smaller than the original DALL·E and still has impressive results.

2. [DietNerf](https://huggingface.co/spaces/flax-community/DietNerf-Demo). DietNerf is a 3D neural view synthesis model designed for few-shot learning of 3D scene reconstruction using 2D views. This is the first Open Source implementation of the "[Putting Nerf on a Diet](https://arxiv.org/abs/2104.00677)" paper.

3. [CLIP RSIC](https://huggingface.co/spaces/sujitpal/clip-rsicd-demo). CLIP RSIC is a CLIP model fine-tuned on remote sensing image data to enable zero-shot satellite image classification and captioning. This project demonstrates how effective fine-tuned CLIP models can be for specialized domains.

Apart from these very cool projects, we're excited about how these community events enable training large and multi-modal models for multiple languages. For example, we saw the first ever Open Source big LMs for some low-resource languages like [Swahili](https://huggingface.co/models?language=sw), [Polish](https://huggingface.co/flax-community/papuGaPT2) and [Marathi](https://huggingface.co/spaces/flax-community/roberta-base-mr).
## Bonus
On top of everything we just shared, our team has been doing lots of other things. Here are just some of them:
- 📖 This 3-part [video series](https://www.youtube.com/watch?time_continue=6&v=qmN1fJ7Fdmo&feature=emb_title&ab_channel=NilsR) shows the theory on how to train state-of-the-art sentence embedding models.
- We presented at PyTorch Community Voices and participated in a QA ([video](https://www.youtube.com/watch?v=wE3bk7JaH4E&ab_channel=PyTorch)).
- Hugging Face has collaborated with [NLP in Spanish](https://twitter.com/NLP_en_ES) and [SpainAI](https://twitter.com/Spain_AI_) in a Spanish [course](https://www.youtube.com/playlist?list=PLBILcz47fTtPspj9QDm2E0oHLe1p67tMz) that teaches concepts and state-of-the art architectures as well as their applications through use cases.
- We presented at [MLOps World Demo Days](https://www.youtube.com/watch?v=lWahHp5vpVg).
## Open Source
### New in Transformers
Summer has been an exciting time for 🤗 Transformers! The library reached 50,000 stars, 30 million total downloads, and almost 1000 contributors! 🤩
So what's new? JAX/Flax is now the 3rd supported framework with over [5000](https://huggingface.co/models?library=jax&sort=downloads) models in the Hub! You can find actively maintained [examples](https://github.com/huggingface/transformers/tree/master/examples/flax) for different tasks such as text classification. We're also working hard on improving our TensorFlow support: all our [examples](https://github.com/huggingface/transformers/tree/master/examples/tensorflow) have been reworked to be more robust, TensorFlow idiomatic, and clearer. This includes examples such as summarization, translation, and named entity recognition.
You can now easily publish your model to the Hub, including automatically authored model cards, evaluation metrics, and TensorBoard instances. There is also increased support for exporting models to ONNX with the new [`transformers.onnx` module](https://huggingface.co/transformers/serialization.html?highlight=onnx).
```bash
python -m transformers.onnx --model=bert-base-cased onnx/bert-base-cased/
```
The last 4 releases introduced many new cool models!
- [DETR](https://huggingface.co/transformers/model_doc/detr.html) can do fast end-to-end object detection and image segmentation. Check out some of our community [tutorials](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/DETR)!

- [ByT5](https://huggingface.co/transformers/model_doc/byt5.html) is the first tokenizer-free model in the Hub! You can find all available checkpoints [here](https://huggingface.co/models?search=byt5).
- [CANINE](https://huggingface.co/transformers/model_doc/canine.html) is another tokenizer-free encoder-only model by Google AI, operating directly at the character level. You can find all (multilingual) checkpoints [here](https://huggingface.co/models?search=canine).
- [HuBERT](https://huggingface.co/transformers/model_doc/hubert.html?highlight=hubert) shows exciting results for downstream audio tasks such as [command classification](https://huggingface.co/superb/hubert-base-superb-ks) and [emotion recognition](https://huggingface.co/superb/hubert-base-superb-er). Check the models [here](https://huggingface.co/models?filter=hubert).
- [LayoutLMv2](https://huggingface.co/transformers/model_doc/layoutlmv2.html) and [LayoutXLM](https://huggingface.co/transformers/model_doc/layoutxlm.html?highlight=layoutxlm) are two incredible models capable of parsing document images (like PDFs) by incorporating text, layout, and visual information. We built a [Space demo](https://huggingface.co/spaces/nielsr/LayoutLMv2-FUNSD) so you can directly try it out! Demo notebooks can be found [here](https://github.com/NielsRogge/Transformers-Tutorials/tree/master/LayoutLMv2).

- [BEiT](https://huggingface.co/transformers/model_doc/beit.html) by Microsoft Research makes self-supervised Vision Transformers outperform supervised ones, using a clever pre-training objective inspired by BERT.
- [RemBERT](https://huggingface.co/transformers/model_doc/rembert.html?), a large multilingual Transformer that outperforms XLM-R (and mT5 with a similar number of parameters) in zero-shot transfer.
- [Splinter](https://huggingface.co/transformers/model_doc/splinter.html) which can be used for few-shot question answering. Given only 128 examples, Splinter is able to reach ~73% F1 on SQuAD, outperforming MLM-based models by 24 points!
The Hub is now integrated into `transformers`, with the ability to push to the Hub configuration, model, and tokenizer files without leaving the Python runtime! The `Trainer` can now push directly to the Hub every time a checkpoint is saved:

### New in Datasets
You can find 1400 public datasets in [https://huggingface.co/datasets](https://huggingface.co/datasets) thanks to the awesome contributions from all our community. 💯
The support for `datasets` keeps growing: it can be used in JAX, process parquet files, use remote files, and has wider support for other domains such as Automatic Speech Recognition and Image Classification.
Users can also directly host and share their datasets to the community simply by uploading their data files in a repository on the Dataset Hub.

What are the new datasets highlights? Microsoft CodeXGlue [datasets](https://huggingface.co/datasets?search=code_x_glue) for multiple coding tasks (code completion, generation, search, etc), huge datasets such as [C4](https://huggingface.co/datasets/c4) and [MC4](https://huggingface.co/datasets/mc4), and many more such as [RussianSuperGLUE](https://huggingface.co/datasets/russian_super_glue) and [DISFL-QA](https://huggingface.co/datasets/disfl_qa).
### Welcoming new Libraries to the Hub
Apart from having deep integration with `transformers`-based models, the Hub is also building great partnerships with Open Source ML libraries to provide free model hosting and versioning. We've been achieving this with our [huggingface_hub](https://github.com/huggingface/huggingface_hub) Open-Source library as well as new Hub [documentation](https://huggingface.co/docs/hub/main).
All spaCy canonical pipelines can now be found in the official spaCy [organization](https://huggingface.co/spacy), and any user can share their pipelines with a single command `python -m spacy huggingface-hub`. To read more about it, head to [https://huggingface.co/blog/spacy](https://huggingface.co/blog/spacy). You can try all canonical spaCy models directly in the Hub in the demo [Space](https://huggingface.co/spaces/spacy/pipeline-visualizer)!

Another exciting integration is Sentence Transformers. You can read more about it in the [blog announcement](https://huggingface.co/blog/sentence-transformers-in-the-hub): you can find over 200 [models](https://huggingface.co/models?library=sentence-transformers) in the Hub, easily share your models with the rest of the community and reuse models from the community.
But that's not all! You can now find over 100 Adapter Transformers in the Hub and try out Speechbrain models with widgets directly in the browser for different tasks such as audio classification. If you're interested in our collaborations to integrate new ML libraries to the Hub, you can read more about them [here](https://huggingface.co/docs/hub/libraries).

## Solutions
### **Coming soon: Infinity**
Transformers latency down to 1ms? 🤯🤯🤯
We have been working on a really sleek solution to achieve unmatched efficiency for state-of-the-art Transformer models, for companies to deploy in their own infrastructure.
- Infinity comes as a single-container and can be deployed in any production environment.
- It can achieve 1ms latency for BERT-like models on GPU and 4-10ms on CPU 🤯🤯🤯
- Infinity meets the highest security requirements and can be integrated into your system without the need for internet access. You have control over all incoming and outgoing traffic.
⚠️ Join us for a [live announcement and demo on Sep 28](https://app.livestorm.co/hugging-face/hugging-face-infinity-launch?type=detailed), where we will be showcasing Infinity for the first time in public!
### **NEW: Hardware Acceleration**
Hugging Face is [partnering with leading AI hardware accelerators](http://hf.co/hardware) such as Intel, Qualcomm and GraphCore to make state-of-the-art production performance accessible and extend training capabilities on SOTA hardware. As the first step in this journey, we [introduced a new Open Source library](https://huggingface.co/blog/hardware-partners-program): 🤗 Optimum - the ML optimization toolkit for production performance 🏎. Learn more in this [blog post](https://huggingface.co/blog/graphcore).
### **NEW: Inference on SageMaker**
We launched a [new integration with AWS](https://huggingface.co/blog/deploy-hugging-face-models-easily-with-amazon-sagemaker) to make it easier than ever to deploy 🤗 Transformers in SageMaker 🔥. Pick up the code snippet right from the 🤗 Hub model page! Learn more about how to leverage transformers in SageMaker in our [docs](https://huggingface.co/docs/sagemaker/inference) or check out these [video tutorials](https://youtube.com/playlist?list=PLo2EIpI_JMQtPhGR5Eo2Ab0_Vb89XfhDJ).
For questions reach out to us on the forum: [https://discuss.huggingface.co/c/sagemaker/17](https://discuss.huggingface.co/c/sagemaker/17)

### **NEW: AutoNLP In Your Browser**
We released a new [AutoNLP](https://huggingface.co/autonlp) experience: a web interface to train models straight from your browser! Now all it takes is a few clicks to train, evaluate and deploy **🤗** Transformers models on your own data. [Try it out](https://ui.autonlp.huggingface.co/) - NO CODE needed!

### Inference API
**Webinar**:
We hosted a [live webinar](https://youtu.be/p055U0dnEos) to show how to add Machine Learning capabilities with just a few lines of code. We also built a VSCode extension that leverages the Hugging Face Inference API to generate comments describing Python code.
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/p055U0dnEos"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
**Hugging Face** + **Zapier Demo**
20,000+ Machine Learning models connected to 3,000+ apps? 🤯 By leveraging the [Inference API](https://huggingface.co/landing/inference-api/startups), you can now easily connect models right into apps like Gmail, Slack, Twitter, and more. In this demo video, we created a zap that uses this [code snippet](https://gist.github.com/feconroses/3476a91dc524fdb930a726b3894a1d08) to analyze your Twitter mentions and alerts you on Slack about the negative ones.
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/sjfpOJ4KA78"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
**Hugging Face + Google Sheets Demo**
With the [Inference API](https://huggingface.co/landing/inference-api/startups), you can easily use zero-shot classification right into your spreadsheets in Google Sheets. Just [add this script](https://gist.github.com/feconroses/302474ddd3f3c466dc069ecf16bb09d7) in Tools -> Script Editor:
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/-A-X3aUYkDs"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
**Few-shot learning in practice**
We wrote a [blog post](https://huggingface.co/blog/few-shot-learning-gpt-neo-and-inference-api) about what Few-Shot Learning is and explores how GPT-Neo and 🤗 Accelerated Inference API are used to generate your own predictions.
### **Expert Acceleration Program**
Check out out the brand [new home for the Expert Acceleration Program](https://huggingface.co/landing/premium-support); you can now get direct, premium support from our Machine Learning experts and build better ML solutions, faster.
## Research
At BigScience we held our first live event (since the kick off) in July BigScience Episode #1. Our second event BigScience Episode #2 was held on September 20th, 2021 with technical talks and updates by the BigScience working groups and invited talks by Jade Abbott (Masakhane), Percy Liang (Stanford CRFM), Stella Biderman (EleutherAI) and more. We have completed the first large-scale training on Jean Zay, a 13B English only decoder model (you can find the details [here](https://github.com/bigscience-workshop/bigscience/blob/master/train/tr1-13B-base/chronicles.md)), and we're currently deciding on the architecture of the second model. The organization working group has filed the application for the second half of the compute budget: Jean Zay V100 : 2,500,000 GPU hours. 🚀
In June, we shared the result of our collaboration with the Yandex research team: [DeDLOC](https://arxiv.org/abs/2106.10207), a method to collaboratively train your large neural networks, i.e. without using an HPC cluster, but with various accessible resources such as Google Colaboratory or Kaggle notebooks, personal computers or preemptible VMs. Thanks to this method, we were able to train [sahajBERT](https://huggingface.co/neuropark/sahajBERT), a Bengali language model, with 40 volunteers! And our model competes with the state of the art, and even is [the best for the downstream task of classification](https://huggingface.co/neuropark/sahajBERT-NCC) on Soham News Article Classification dataset. You can read more about it in this [blog](https://huggingface.co/blog/collaborative-training) post. This is a fascinating line of research because it would make model pre-training much more accessible (financially speaking)!
<div class="aspect-w-16 aspect-h-9">
<iframe
src="https://www.youtube.com/embed/v8ShbLasRF8"
frameborder="0"
allow="accelerometer; autoplay; encrypted-media; gyroscope; picture-in-picture"
allowfullscreen></iframe>
</div>
In June our [paper](https://arxiv.org/abs/2103.08493), How Many Data Points is a Prompt Worth?, got a Best Paper award at NAACL! In it, we reconcile and compare traditional and prompting approaches to adapt pre-trained models, finding that human-written prompts are worth up to thousands of supervised data points on new tasks. You can also read its blog [post](https://huggingface.co/blog/how_many_data_points/).

We're looking forward to EMNLP this year where we have four accepted papers!
- Our [paper](https://arxiv.org/abs/2109.02846) "[Datasets: A Community Library for Natural Language Processing](https://arxiv.org/abs/2109.02846)" documents the Hugging Face Datasets project that has over 300 contributors. This community project gives easy access to hundreds of datasets to researchers. It has facilitated new use cases of cross-dataset NLP, and has advanced features for tasks like indexing and streaming large datasets.
- Our collaboration with researchers from TU Darmstadt lead to another paper accepted at the conference (["Avoiding Inference Heuristics in Few-shot Prompt-based Finetuning"](https://arxiv.org/abs/2109.04144)). In this paper, we show that prompt-based fine-tuned language models (which achieve strong performance in few-shot setups) still suffer from learning surface heuristics (sometimes called *dataset biases*), a pitfall that zero-shot models don't exhibit.
- Our submission "[Block Pruning For Faster Transformers](https://arxiv.org/abs/2109.04838v1)" has also been accepted as a long paper. In this paper, we show how to use block sparsity to obtain both fast and small Transformer models. Our experiments yield models which are 2.4x faster and 74% smaller than BERT on SQuAD.
## Last words
😎 🔥 Summer was fun! So many things have happened! We hope you enjoyed reading this blog post and looking forward to share the new projects we're working on. See you in the winter! ❄️ | 6 |
0 | hf_public_repos | hf_public_repos/blog/sd_distillation.md | ---
title: "Open-sourcing Knowledge Distillation Code and Weights of SD-Small and SD-Tiny"
thumbnail: /blog/assets/distill_sd/thumbnail.png
authors:
- user: harishsegmind
guest: true
- user: Warlord-K
guest: true
- user: Gothos
guest: true
---
# Open-sourcing Knowledge Distillation Code and Weights of SD-Small and SD-Tiny
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture1.png" width=500>
</p>
In recent times, the AI community has witnessed a remarkable surge in the development of larger and more performant language models, such as Falcon 40B, LLaMa-2 70B, Falcon 40B, MPT 30B, and in the imaging domain with models like SD2.1 and SDXL. These advancements have undoubtedly pushed the boundaries of what AI can achieve, enabling highly versatile and state-of-the-art image generation and language understanding capabilities. However, as we marvel at the power and complexity of these models, it is essential to recognize a growing need to make AI models smaller, efficient, and more accessible, particularly by open-sourcing them.
At [Segmind](https://www.segmind.com/models), we have been working on how to make generative AI models faster and cheaper. Last year, we have open-sourced our accelerated SD-WebUI library called [voltaML](https://github.com/VoltaML/voltaML-fast-stable-diffusion), which is a AITemplate/TensorRT based inference acceleration library that has delivered between 4-6X increase in the inference speed. To continue towards the goal of making generative models faster, smaller and cheaper, we are open-sourcing the weights and training code of our compressed **SD models; SD-Small and SD-Tiny**. The pretrained checkpoints are available on [Huggingface 🤗](https://huggingface.co/segmind)
## Knowledge Distillation
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture2.png" width=500>
</p>
Our new compressed models have been trained on Knowledge-Distillation (KD) techniques and the work has been largely based on [this paper](https://openreview.net/forum?id=bOVydU0XKC). The authors describe a Block-removal Knowledge-Distillation method where some of the UNet layers are removed and the student model weights are trained. Using the KD methods described in the paper, we were able to train two compressed models using the [🧨 diffusers](https://github.com/huggingface/diffusers) library; **Small** and **Tiny**, that have 35% and 55% fewer parameters, respectively than the base model while achieving comparable image fidelity as the base model. We have open-sourced our distillation code in this [repo](https://github.com/segmind/distill-sd) and pretrained checkpoints on [Huggingface 🤗](https://huggingface.co/segmind).
Knowledge-Distillation training a neural network is similar to a teacher guiding a student step-by-step. A large teacher model is pre-trained on a large amount of data and then a smaller model is trained on a smaller dataset, to imitate the outputs of the larger model along with classical training on the dataset.
In this particular type of knowledge distillation, the student model is trained to do the normal diffusion task of recovering an image from pure noise, but at the same time, the model is made to match the output of the larger teacher model. The matching of outputs happens at every block of the U-nets, hence the model quality is mostly preserved. So, using the previous analogy, we can say that during this kind of distillation, the student will not only try to learn from the Questions and Answers but also from the Teacher’s answers, as well as the step by step method of getting to the answer. We have 3 components in the loss function to achieve this, firstly the traditional loss between latents of the target image and latents of the generated image. Secondly, the loss between latents of the image generated by the teacher and latents of image generated by the student. And lastly, and the most important component, is the feature level loss, which is the loss between the outputs of each of the blocks of the teacher and the student.
Combining all of this makes up the Knowledge-Distillation training. Below is an architecture of the Block Removed UNet used in the KD as described in the paper.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture3.png" width=500>
</p>
Image taken from the [paper](https://arxiv.org/abs/2305.15798) “On Architectural Compression of Text-to-Image Diffusion Models” by Shinkook. et. al
We have taken [Realistic-Vision 4.0](https://huggingface.co/SG161222/Realistic_Vision_V4.0_noVAE) as our base teacher model and have trained on the [LAION Art Aesthetic dataset](https://huggingface.co/datasets/recastai/LAION-art-EN-improved-captions) with image scores above 7.5, because of their high quality image descriptions. Unlike the paper, we have chosen to train the two models on 1M images for 100K steps for the Small and 125K steps for the Tiny mode respectively. The code for the distillation training can be found [here](https://github.com/segmind/distill-sd).
## Model Usage
The Model can be used using the DiffusionPipeline from [🧨 diffusers](https://github.com/huggingface/diffusers)
```python
from diffusers import DiffusionPipeline
import torch
pipeline = DiffusionPipeline.from_pretrained("segmind/small-sd", torch_dtype=torch.float16)
prompt = "Portrait of a pretty girl"
negative_prompt = "(deformed iris, deformed pupils, semi-realistic, cgi, 3d, render, sketch, cartoon, drawing, anime:1.4), text, close up, cropped, out of frame, worst quality, low quality, jpeg artifacts, ugly, duplicate, morbid, mutilated, extra fingers, mutated hands, poorly drawn hands, poorly drawn face, mutation, deformed, blurry, dehydrated, bad anatomy, bad proportions, extra limbs, cloned face, disfigured, gross proportions, malformed limbs, missing arms, missing legs, extra arms, extra legs, fused fingers, too many fingers, long neck"
image = pipeline(prompt, negative_prompt = negative_prompt).images[0]
image.save("my_image.png")
```
## Speed in terms of inference latency
We have observed that distilled models are up to 100% faster than the original base models. The Benchmarking code can be found [here](https://github.com/segmind/distill-sd/blob/master/inference.py).
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture4.jpeg" width=500>
</p>
## Potential Limitations
The distilled models are in early phase and the outputs may not be at a production quality yet.
These models may not be the best general models. They are best used as fine-tuned or LoRA trained on specific concepts/styles.
Distilled models are not very good at composibility or multiconcepts yet.
## Fine-tuning SD-tiny model on portrait dataset
We have fine-tuned our sd-tiny model on portrait images generated with the Realistic Vision v4.0 model. Below are the fine tuning parameters used.
- Steps: 131000
- Learning rate: 1e-4
- Batch size: 32
- Gradient accumulation steps: 4
- Image resolution: 768
- Dataset size - 7k images
- Mixed-precision: fp16
We were able to produce image quality close to the images produced by the original model, with almost 40% fewer parameters and the sample results below speak for themselves:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture5.png" width=500>
</p>
The code for fine-tuning the base models can be found [here](https://github.com/segmind/distill-sd/blob/master/checkpoint_training.py).
## LoRA Training
One of the advantages of LoRA training on a distilled model is faster training. Below are some of the images of the first LoRA we trained on the distilled model on some abstract concepts. The code for the LoRA training can be found [here](https://github.com/segmind/distill-sd/blob/master/lora_training.py).
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/distill_sd/Picture6.png" width=500>
</p>
## Conclusion
We invite the open-source community to help us improve and achieve wider adoption of these distilled SD models. Users can join our [Discord](https://discord.gg/s6E6eHJk) server, where we will be announcing the latest updates to these models, releasing more checkpoints and some exciting new LoRAs. And if you like our work, please give us a star on our [Github](https://github.com/segmind/distill-sd).
| 7 |
0 | hf_public_repos | hf_public_repos/blog/starcoder2.md | ---
title: "StarCoder2 and The Stack v2"
thumbnail: /blog/assets/177_starcoder2/sc2-banner.png
authors:
- user: lvwerra
- user: loubnabnl
- user: anton-l
- user: nouamanetazi
---
# StarCoder2 and The Stack v2
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/admin/resolve/main/sc2-banner.png" alt="StarCoder2">
</div>
BigCode is releasing StarCoder2, the next generation of transparently trained open code LLMs. All StarCoder2 variants were trained on [The Stack v2](https://huggingface.co/datasets/bigcode/the-stack-v2/), a new large and high-quality code dataset. We release all models, datasets, and the processing as well as the training code. Check out the [paper](https://drive.google.com/file/d/17iGn3c-sYNiLyRSY-A85QOzgzGnGiVI3/view?usp=sharing) for details.
## What is StarCoder2?
StarCoder2 is a family of open LLMs for code and comes in 3 different sizes with 3B, 7B and 15B parameters. The flagship StarCoder2-15B model is trained on over 4 trillion tokens and 600+ programming languages from The Stack v2. All models use Grouped Query Attention, a context window of 16,384 tokens with a sliding window attention of 4,096 tokens, and were trained using the Fill-in-the-Middle objective.
StarCoder2 offers three model sizes: a 3 billion-parameter model trained by ServiceNow, a 7 billion-parameter model trained by Hugging Face, and a 15 billion-parameter model trained by NVIDIA using NVIDIA NeMo on NVIDIA accelerated infrastructure:
- [StarCoder2-3B](https://huggingface.co/bigcode/starcoder2-3b) was trained on 17 programming languages from The Stack v2 on 3+ trillion tokens.
- [StarCoder2-7B](https://huggingface.co/bigcode/starcoder2-7b) was trained on 17 programming languages from The Stack v2 on 3.5+ trillion tokens.
- [StarCoder2-15B](https://huggingface.co/bigcode/starcoder2-15b) was trained on 600+ programming languages from The Stack v2 on 4+ trillion tokens.
StarCoder2-15B is the best in its size class and matches 33B+ models on many evaluations. StarCoder2-3B matches the performance of StarCoder1-15B:
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/admin/resolve/main/sc2-evals.png" alt="StarCoder2 Evaluation">
</div>
## What is The Stack v2?
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/admin/resolve/main/stackv2-banner.png" alt="The Stack v2">
</div>
The Stack v2 is the largest open code dataset suitable for LLM pretraining. The Stack v2 is larger than The Stack v1, follows an improved language and license detection procedure, and better filtering heuristics. In addition, the training dataset is grouped by repositories, allowing to train models with repository context.
||[The Stack v1](https://huggingface.co/datasets/bigcode/the-stack/)|[The Stack v2](https://huggingface.co/datasets/bigcode/the-stack-v2/)|
|-|-|-|
| full | 6.4TB | 67.5TB |
| deduplicated | 2.9TB | 32.1TB |
| training dataset | ~200B tokens | ~900B tokens |
This dataset is derived from the Software Heritage archive, the largest public archive of software source code and accompanying development history. Software Heritage, launched by Inria in partnership with UNESCO, is an open, non-profit initiative to collect, preserve, and share the source code of all publicly available software. We are grateful to Software Heritage for providing access to this invaluable resource. For more details, visit the [Software Heritage website](https://www.softwareheritage.org).
The Stack v2 can be accessed through the [Hugging Face Hub](https://huggingface.co/datasets/bigcode/the-stack-v2/).
## About BigCode
BigCode is an open scientific collaboration led jointly by Hugging Face and ServiceNow that works on the responsible development of large language models for code.
## Links
### Models
- [Paper](https://drive.google.com/file/d/17iGn3c-sYNiLyRSY-A85QOzgzGnGiVI3/view?usp=sharing): A technical report about StarCoder2 and The Stack v2.
- [GitHub](https://github.com/bigcode-project/starcoder2/): All you need to know about using or fine-tuning StarCoder2.
- [StarCoder2-3B](https://huggingface.co/bigcode/starcoder2-3b): Small StarCoder2 model.
- [StarCoder2-7B](https://huggingface.co/bigcode/starcoder2-7b): Medium StarCoder2 model.
- [StarCoder2-15B](https://huggingface.co/bigcode/starcoder2-15b): Large StarCoder2 model.
### Data & Governance
- [StarCoder2 License Agreement](https://huggingface.co/spaces/bigcode/bigcode-model-license-agreement): The model is licensed under the BigCode OpenRAIL-M v1 license agreement.
- [StarCoder2 Search](https://huggingface.co/spaces/bigcode/search-v2): Full-text search for code in the pretraining dataset.
- [StarCoder2 Membership Test](https://stack-v2.dataportraits.org): Blazing fast check of code that was present in the pretraining dataset.
### Others
- [VSCode Extension](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode): Code with StarCoder!
- [Big Code Models Leaderboard](https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard)
You can find all the resources and links at [huggingface.co/bigcode](https://huggingface.co/bigcode)!
| 8 |
0 | hf_public_repos | hf_public_repos/blog/snowball-fight.md | ---
title: 'Introducing Snowball Fight ☃️, our first ML-Agents environment'
thumbnail: /blog/assets/39_introducing_snowball_fight/thumbnail.png
authors:
- user: ThomasSimonini
---
# Introducing Snowball Fight ☃️, our First ML-Agents Environment
We're excited to share our **first custom Deep Reinforcement Learning environment**: Snowball Fight 1vs1 🎉.

Snowball Fight is a game made with Unity ML-Agents, where you shoot snowballs against a Deep Reinforcement Learning agent. The game is [**hosted on Hugging Face Spaces**](https://hf.co/spaces/launch).
👉 [You can play it online here](https://huggingface.co/spaces/ThomasSimonini/SnowballFight)
In this post, we'll cover **the ecosystem we are working on for Deep Reinforcement Learning researchers and enthusiasts that use Unity ML-Agents**.
## Unity ML-Agents at Hugging Face
The [Unity Machine Learning Agents Toolkit](https://github.com/Unity-Technologies/ml-agents) is an open source library that allows you to build games and simulations with Unity game engine to **serve as environments for training intelligent agents**.
With this first step, our goal is to build an ecosystem on Hugging Face for Deep Reinforcement Learning researchers and enthusiasts that uses ML-Agents, with three features.
1. **Building and sharing custom environments.** We are developing and sharing exciting environments to experiment with new problems: snowball fights, racing, puzzles... All of them will be open source and hosted on the Hugging Face's Hub.
2. **Allowing you to easily host your environments, save models and share them** on the Hugging Face Hub. We have already published the Snowball Fight training environment [here](https://huggingface.co/ThomasSimonini/ML-Agents-SnowballFight-1vs1), but there will be more to come!
3. **You can now easily host your demos on Spaces** and showcase your results quickly with the rest of the ecosystem.
## Be part of the conversation: join our discord server!
If you're using ML-Agents or interested in Deep Reinforcement Learning and want to be part of the conversation, **[you can join our discord server](https://discord.gg/YRAq8fMnUG)**. We just added two channels (and we'll add more in the future):
- Deep Reinforcement Learning
- ML-Agents
[Our discord](https://discord.gg/YRAq8fMnUG) is the place where you can exchange about Hugging Face, NLP, Deep RL, and more! It's also in this discord that we'll announce all our new environments and features in the future.
## What's next?
In the coming weeks and months, we will be extending the ecosystem by:
- Writing some **technical tutorials on ML-Agents**.
- Working on a **Snowball Fight 2vs2 version**, where the agents will collaborate in teams using [MA-POCA, a new Deep Reinforcement Learning algorithm](https://blog.unity.com/technology/ml-agents-plays-dodgeball) that trains cooperative behaviors in a team.

- And we're building **new custom environments that will be hosted in Hugging Face**.
## Conclusion
We're excited to see what you're working on with ML-Agents and how we can build features and tools **that help you to empower your work**.
Don't forget to [join our discord server](https://discord.gg/YRAq8fMnUG) to be alerted of the new features.
| 9 |
0 | hf_public_repos | hf_public_repos/blog/aws-partnership.md | ---
title: "Hugging Face and AWS partner to make AI more accessible"
thumbnail: /blog/assets/131_aws-partnership/aws-partnership-thumbnail.png
authors:
- user: jeffboudier
- user: philschmid
- user: juliensimon
---
# Hugging Face and AWS partner to make AI more accessible
It’s time to make AI open and accessible to all. That’s the goal of this expanded long-term strategic partnership between Hugging Face and Amazon Web Services (AWS). Together, the two leaders aim to accelerate the availability of next-generation machine learning models by making them more accessible to the machine learning community and helping developers achieve the highest performance at the lowest cost.
## A new generation of open, accessible AI
Machine learning is quickly becoming embedded in all applications. As its impact on every sector of the economy comes into focus, it’s more important than ever to ensure every developer can access and assess the latest models. The partnership with AWS paves the way toward this future by making it faster and easier to build, train, and deploy the latest machine learning models in the cloud using purpose-built tools.
There have been significant advances in new Transformer and Diffuser machine learning models that process and generate text, audio, and images. However, most of these popular generative AI models are not publicly available, widening the gap of machine learning capabilities between the largest tech companies and everyone else. To counter this trend, AWS and Hugging Face are partnering to contribute next-generation models to the global AI community and democratize machine learning. Through the strategic partnership, Hugging Face will leverage AWS as a preferred cloud provider so developers in Hugging Face’s community can access AWS’s state-of-the-art tools (e.g., [Amazon SageMaker](https://aws.amazon.com/sagemaker), [AWS Trainium](https://aws.amazon.com/machine-learning/trainium/), [AWS Inferentia](https://aws.amazon.com/machine-learning/inferentia/)) to train, fine-tune, and deploy models on AWS. This will allow developers to further optimize the performance of their models for their specific use cases while lowering costs. Hugging Face will apply the latest in innovative research findings using Amazon SageMaker to build next-generation AI models. Together, Hugging Face and AWS are bridging the gap so the global AI community can benefit from the latest advancements in machine learning to accelerate the creation of generative AI applications.
“The future of AI is here, but it’s not evenly distributed,” said Clement Delangue, CEO of Hugging Face. “Accessibility and transparency are the keys to sharing progress and creating tools to use these new capabilities wisely and responsibly. Amazon SageMaker and AWS-designed chips will enable our team and the larger machine learning community to convert the latest research into openly reproducible models that anyone can build on.”
## Collaborating to scale AI in the cloud
This expanded strategic partnership enables Hugging Face and AWS to accelerate machine learning adoption using the latest models hosted on Hugging Face with the industry-leading capabilities of Amazon SageMaker. Customers can now easily fine-tune and deploy state-of-the-art Hugging Face models in just a few clicks on Amazon SageMaker and Amazon Elastic Computing Cloud (EC2), taking advantage of purpose-built machine learning accelerators including AWS Trainium and AWS Inferentia.
“Generative AI has the potential to transform entire industries, but its cost and the required expertise puts the technology out of reach for all but a select few companies,” said Adam Selipsky, CEO of AWS. “Hugging Face and AWS are making it easier for customers to access popular machine learning models to create their own generative AI applications with the highest performance and lowest costs. This partnership demonstrates how generative AI companies and AWS can work together to put this innovative technology into the hands of more customers.”
Hugging Face has become the central hub for machine learning, with more than [100,000 free and accessible machine learning models](https://huggingface.co/models) downloaded more than 1 million times daily by researchers, data scientists, and machine learning engineers. AWS is by far the most popular place to run models from the Hugging Face Hub. Since the [start of our collaboration](https://huggingface.co/blog/the-partnership-amazon-sagemaker-and-hugging-face), [Hugging Face on Amazon SageMaker](https://aws.amazon.com/machine-learning/hugging-face/) has grown exponentially. We are experiencing an exciting renaissance with generative AI, and we're just getting started. We look forward to what the future holds for Hugging Face, AWS, and the AI community.
| 0 |
0 | hf_public_repos | hf_public_repos/blog/llama31-on-vertex-ai.md | ---
title: "Deploy Meta Llama 3.1 405B on Google Cloud Vertex AI"
thumbnail: /blog/assets/llama31-on-vertex-ai/thumbnail.png
authors:
- user: alvarobartt
- user: philschmid
- user: pagezyhf
- user: jeffboudier
---
# Deploy Meta Llama 3.1 405B on Google Cloud Vertex AI
[Meta Llama 3.1](https://huggingface.co/blog/llama31) is the latest open LLM from Meta, released in July 2024. Meta Llama 3.1 comes in three sizes: 8B for efficient deployment and development on consumer-size GPU, 70B for large-scale AI native applications, and 405B for synthetic data, LLM as a Judge or distillation; among other use cases. Some of its key features include: a large context length of 128K tokens (vs original 8K), multilingual capabilities, tool usage capabilities, and a more permissive license.
In this blog you will learn how to programmatically deploy [`meta-llama/Meta-Llama-3.1-405B-Instruct-FP8`](https://hf.co/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8), the FP8 quantized variant of [`meta-llama/Meta-Llama-3.1-405B-Instruct`](https://huggingface.co/meta-llama/Meta-Llama-3.1-405B-Instruct), in a Google Cloud A3 node with 8 x H100 NVIDIA GPUs on Vertex AI with [Text Generation Inference](https://github.com/huggingface/text-generation-inference) (TGI) using the Hugging Face purpose-built Deep Learning Containers (DLCs) for Google Cloud.
Alternatively, you can deploy [`meta-llama/Meta-Llama-3.1-405B-Instruct-FP8`](https://hf.co/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8) without writing any code directly from the [Hub](https://huggingface.co/blog/google-cloud-model-garden#how-it-works---from-the-hub) or from [Vertex Model Garden](https://console.cloud.google.com/vertex-ai/model-garden)!
This blog will cover:
[Introduction to Vertex AI](#introduction-to-vertex-ai)
1. [Requirements for Meta Llama 3.1 Models on Google Cloud](#1-requirements-for-meta-llama-31-models-on-google-cloud)
2. [Setup Google Cloud for Vertex AI](#2-setup-google-cloud-for-vertex-ai)
3. [Register the Meta Llama 3.1 405B Model on Vertex AI](#3-register-the-meta-llama-31-405b-model-on-vertex-ai)
4. [Deploy Meta Llama 3.1 405B on Vertex AI](#4-deploy-meta-llama-31-405b-on-vertex-ai)
5. [Run online predictions with Meta Llama 3.1 405B](#5-run-online-predictions-with-meta-llama-31-405b)
1. [Via Python](#51-via-python)
1. [Within the same session](#511-within-the-same-session)
2. [From a different session](#512-from-a-different-session)
2. [Via the Vertex AI Online Prediction UI](#52-via-the-vertex-ai-online-prediction-ui)
6. [Clean up resources](#6-clean-up-resources)
[Conclusion](#conclusion)
Lets get started! 🚀 Alternatively, you can follow along from [this Jupyter Notebook](https://github.com/alvarobartt/meta-llama-3-1-on-vertex-ai/blob/main/notebooks/meta-llama-3-1-on-vertex-ai/vertex-notebook.ipynb).
## Introduction to Vertex AI
Vertex AI is a machine learning (ML) platform that lets you train and deploy ML models and AI applications, and customize Large Language Models (LLMs) for use in your AI-powered applications. Vertex AI combines data engineering, data science, and ML engineering workflows, enabling your teams to collaborate using a common toolset and scale your applications using the benefits of Google Cloud.
This blog will be focused on deploying an already fine-tuned model from the Hugging Face Hub using a pre-built container to get real-time online predictions. Thus, we'll demonstrate the use of Vertex AI for inference.
More information at [Vertex AI - Documentation - Introduction to Vertex AI](https://cloud.google.com/vertex-ai/docs/start/introduction-unified-platform).
## 1. Requirements for Meta Llama 3.1 Models on Google Cloud
Meta Llama 3.1 brings exciting advancements. However, running these models requires careful consideration of your hardware resources. For inference, the memory requirements depend on the model size and the precision of the weights. Here's a table showing the approximate memory needed for different configurations:
<table>
<tr>
<td><strong>Model Size</strong>
</td>
<td><strong>FP16</strong>
</td>
<td><strong>FP8</strong>
</td>
<td><strong>INT4</strong>
</td>
</tr>
<tr>
<td>8B
</td>
<td>16 GB
</td>
<td>8 GB
</td>
<td>4 GB
</td>
</tr>
<tr>
<td>70B
</td>
<td>140 GB
</td>
<td>70 GB
</td>
<td>35 GB
</td>
</tr>
<tr>
<td>405B
</td>
<td>810 GB
</td>
<td>405 GB
</td>
<td>203 GB
</td>
</tr>
</table>
_Note: The above-quoted numbers indicate the GPU VRAM required just to load the model checkpoint. They don’t include torch reserved space for kernels or CUDA graphs._
As an example, an H100 node (8 H100s with 80GB each) has a total of ~640GB of VRAM, so the 405B model would need to be run in a multi-node setup or run at a lower precision (e.g. FP8), which would be the recommended approach. Read more about it in the [Hugging Face Blog for Meta Llama 3.1](https://huggingface.co/blog/llama31#inference-memory-requirements).
The A3 accelerator-optimized machine series in Google Cloud comes with 8 H100s 80GB NVIDIA GPUs, 208 vCPUs, and 1872 GB of memory. This machine series is optimized for compute and memory intensive, network bound ML training, and HPC workloads. Read more about the A3 machines availability announcement at [Announcing A3 supercomputers with NVIDIA H100 GPUs, purpose-built for AI](https://cloud.google.com/blog/products/compute/introducing-a3-supercomputers-with-nvidia-h100-gpus) and about the A3 machine series at [Compute Engine - Accelerator-optimized machine family](https://cloud.google.com/compute/docs/accelerator-optimized-machines#a3-vms).
Even if the A3 machines are available within Google Cloud, you will still need to request a custom quota increase in Google Cloud, as those need a specific approval. Note that the A3 machines are only available in some zones, so make sure to check the availability of both A3 High or even A3 Mega per zone at [Compute Engine - GPU regions and zones](https://cloud.google.com/compute/docs/gpus/gpu-regions-zones).
In this case, to request a quota increase to use the A3 High GPU machine type you will need to increase the following quotas:
* `Service: Vertex AI API` and `Name: Custom model serving Nvidia H100 80GB GPUs per region` set to **8**
* `Service: Vertex AI API` and `Name: Custom model serving A3 CPUs per region` set to **208**

Read more on how to request a quota increase at [Google Cloud Documentation - View and manage quotas](https://cloud.google.com/docs/quotas/view-manage).
## 2. Setup Google Cloud for Vertex AI
Before proceeding, we will set the following environment variables for convenience:
```bash
%env PROJECT_ID=your-project-id
%env LOCATION=your-region
```
First you need to install `gcloud` in your machine following the instructions at [Cloud SDK - Install the gcloud CLI](https://cloud.google.com/sdk/docs/install); and log in into your Google Cloud account, setting your project and preferred Google Compute Engine region.
```bash
gcloud auth login
gcloud config set project $PROJECT_ID
gcloud config set compute/region $LOCATION
```
Once the Google Cloud SDK is installed, you need to enable the Google Cloud APIs required to use Vertex AI from a Deep Learning Container (DLC) within their Artifact Registry for Docker.
```bash
gcloud services enable aiplatform.googleapis.com
gcloud services enable compute.googleapis.com
gcloud services enable container.googleapis.com
gcloud services enable containerregistry.googleapis.com
gcloud services enable containerfilesystem.googleapis.com
```
Then you will also need to install [`google-cloud-aiplatform`](https://github.com/googleapis/python-aiplatform), required to programmatically interact with Google Cloud Vertex AI from Python.
```bash
pip install --upgrade --quiet google-cloud-aiplatform
```
To then initialize it via Python as follows:
```python
import os
from google.cloud import aiplatform
aiplatform.init(project=os.getenv("PROJECT_ID"), location=os.getenv("LOCATION"))
```
Finally, as the Meta Llama 3.1 models are gated under the [`meta-llama` organization in the Hugging Face Hub](https://hf.co/meta-llama), you will need to request access to it and wait for approval, which shouldn't take longer than 24 hours. Then, you need to install the `huggingface_hub` Python SDK to use the `huggingface-cli` to log in into the Hugging Face Hub to download those models.
```bash
pip install --upgrade --quiet huggingface_hub
```
Alternatively, you can also skip the `huggingface_hub` installation and just generate a [Hugging Face Fine-grained Token](https://hf.co/settings/tokens) with read-only permissions for [`meta-llama/Meta-Llama-3.1-405B-Instruct-FP8`](https://hf.co/meta-llama/Meta-Llama-3.1-405B-Instruct-FP8) or any other model under the [`meta-llama` organization](https://hf.co/meta-llama), to be selected under e.g. `Repository permissions -> meta-llama/Meta-Llama-3.1-405B-Instruct-FP8 -> Read access to contents of selected repos`. And either set that token within the `HF_TOKEN` environment variable or just provide it manually to the `notebook_login` method as follows:
```python
from huggingface_hub import notebook_login
notebook_login()
```
## 3. Register the Meta Llama 3.1 405B Model on Vertex AI
To register the Meta Llama 3.1 405B model on Vertex AI, you will need to use the `google-cloud-aiplatform` Python SDK. But before proceeding, you need to first define which DLC you are going to use, which in this case will be the latest Hugging Face TGI DLC for GPU.
As of the current date (August 2024), the latest available Hugging Face TGI DLC, i.e. [us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu121.2-2.ubuntu2204.py310](us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu121.2-2.ubuntu2204.py310) uses TGI v2.2. This version comes with support for the Meta Llama 3.1 architecture, which needs a different RoPE scaling method than its predecessor, Meta Llama 3.
To check which Hugging Face DLCs are available in Google Cloud you can either navigate to [Google Cloud Artifact Registry](https://console.cloud.google.com/artifacts/docker/deeplearning-platform-release/us/gcr.io) and filter by "huggingface-text-generation-inference", or use the following `gcloud` command:
```bash
gcloud container images list --repository="us-docker.pkg.dev/deeplearning-platform-release/gcr.io" | grep "huggingface-text-generation-inference"
```
Then you need to define the configuration for the container, which are the environment variables that the `text-generation-launcher` expects as arguments (as per the [official documentation](https://huggingface.co/docs/text-generation-inference/en/basic_tutorials/launcher)), which in this case are the following:
* `MODEL_ID` the model ID on the Hugging Face Hub, i.e. `meta-llama/Meta-Llama-3.1-405B-Instruct-FP8`.
* `HUGGING_FACE_HUB_TOKEN` the read-access token over the gated repository `meta-llama/Meta-Llama-3.1-405B-Instruct-FP8`, required to download the weights from the Hugging Face Hub.
* `NUM_SHARD` the number of shards to use i.e. the number of GPUs to use, in this case set to 8 as an A3 instance with 8 x H100 NVIDIA GPUs will be used.
Additionally, as a recommendation you should also define `HF_HUB_ENABLE_HF_TRANSFER=1` to enable a faster download speed via the `hf_transfer` utility, as Meta Llama 3.1 405B is around 400 GiB and downloading the weights may take longer otherwise.
Then you can already register the model within Vertex AI's Model Registry via the `google-cloud-aiplatform` Python SDK as follows:
```python
from huggingface_hub import get_token
model = aiplatform.Model.upload(
display_name="meta-llama--Meta-Llama-3.1-405B-Instruct-FP8",
serving_container_image_uri="us-docker.pkg.dev/deeplearning-platform-release/gcr.io/huggingface-text-generation-inference-cu121.2-2.ubuntu2204.py310",
serving_container_environment_variables={
"MODEL_ID": "meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
"HUGGING_FACE_HUB_TOKEN": get_token(),
"HF_HUB_ENABLE_HF_TRANSFER": "1",
"NUM_SHARD": "8",
},
)
model.wait()
```

## 4. Deploy Meta Llama 3.1 405B on Vertex AI
Once Meta Llama 3.1 405B is registered on Vertex AI Model Registry, then you can create a Vertex AI Endpoint and deploy the model to the endpoint, with the Hugging Face DLC for TGI as the serving container.
As mentioned before, since Meta Llama 3.1 405B in FP8 takes ~400 GiB of disk space, that means we need at least 400 GiB of GPU VRAM to load the model, and the GPUs within the node need to support the FP8 data type. In this case, an A3 instance with 8 x NVIDIA H100 80GB with a total of ~640 GiB of VRAM will be used to load the model while also leaving some free VRAM for the KV Cache and the CUDA Graphs.
```python
endpoint = aiplatform.Endpoint.create(display_name="Meta-Llama-3.1-405B-FP8-Endpoint")
deployed_model = model.deploy(
endpoint=endpoint,
machine_type="a3-highgpu-8g",
accelerator_type="NVIDIA_H100_80GB",
accelerator_count=8,
)
```
> Note that the Meta Llama 3.1 405B deployment on Vertex AI may take around 25-30 minutes to deploy, as it needs to allocate the resources on Google Cloud, download the weights from the Hugging Face Hub (\~10 minutes), and load them for inference in TGI (\~2 minutes).

Congrats, you already deployed Meta Llama 3.1 405B in your Google Cloud account! 🔥 Now is time to put the model to the test.
## 5. Run online predictions with Meta Llama 3.1 405B
Vertex AI will expose an online prediction endpoint within the `/predict` route that is serving the text generation from Text Generation Inference (TGI) DLC, making sure that the I/O data is compliant with Vertex AI payloads (read more about Vertex AI I/O payloads in [Vertex AI Documentation - Get online predictions from a custom trained model](https://cloud.google.com/vertex-ai/docs/predictions/get-online-predictions#formatting-prediction-input)).
As `/generate` is the endpoint that is being exposed, you will need to format the messages with the chat template before sending the request to Vertex AI, so it's recommended to install 🤗`transformers` to use the `apply_chat_template` method from the `PreTrainedTokenizerFast` tokenizer instance.
```bash
pip install --upgrade --quiet transformers
```
And then apply the chat template to a conversation using the tokenizer as follows:
```python
import os
from huggingface_hub import get_token
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(
"meta-llama/Meta-Llama-3.1-405B-Instruct-FP8",
token=get_token(),
)
messages = [
{"role": "system", "content": "You are an assistant that responds as a pirate."},
{"role": "user", "content": "What's the Theory of Relativity?"},
]
inputs = tokenizer.apply_chat_template(
messages,
tokenize=False,
add_generation_prompt=True,
)
```
Now you have a string out of the initial conversation messages, formatted using the default chat template for Meta Llama 3.1:
> <|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are an assistant that responds as a pirate.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat's the Theory of Relativity?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n
Which is what you will be sending within the payload to the deployed Vertex AI Endpoint, as well as the generation arguments as in [Consuming Text Generation Inference (TGI) -> Generate](https://huggingface.co/docs/huggingface_hub/main/en/package_reference/inference_client#huggingface_hub.InferenceClient.text_generation).
### 5.1 Via Python
#### 5.1.1 Within the same session
If you are willing to run the online prediction within the current session i.e. the same one as the one used to deploy the model, you can send requests programmatically via the `aiplatform.Endpoint` returned as of the `aiplatform.Model.deploy` method as in the following snippet.
```python
output = deployed_model.predict(
instances=[
{
"inputs": inputs,
"parameters": {
"max_new_tokens": 128,
"do_sample": True,
"top_p": 0.95,
"temperature": 0.7,
},
},
]
)
```
Producing the following `output`:
> Prediction(predictions=["Yer want ta know about them fancy science things, eh? Alright then, matey, settle yerself down with a pint o' grog and listen close. I be tellin' ye about the Theory o' Relativity, as proposed by that swashbucklin' genius, Albert Einstein.\n\nNow, ye see, Einstein said that time and space be connected like the sea and the wind. Ye can't have one without the other, savvy? And he proposed that how ye see time and space depends on how fast ye be movin' and where ye be standin'. That be called relativity, me"], deployed_model_id='***', metadata=None, model_version_id='1', model_resource_name='projects/***/locations/***/models/***', explanations=None)
#### 5.1.2 From a different session
If the Vertex AI Endpoint was deployed in a different session and you just want to use it, but don't have access to the `deployed_model` variable returned by the `aiplatform.Model.deploy` method, then you can also run the following snippet to instantiate the deployed `aiplatform.Endpoint` via its resource name that can be found either within the Vertex AI Online Prediction UI, from the `aiplatform.Endpoint` instantiated above, or just replacing the values in `projects/{PROJECT_ID}/locations/{LOCATION}/endpoints/{ENDPOINT_ID}`.
```python
import os
from google.cloud import aiplatform
aiplatform.init(project=os.getenv("PROJECT_ID"), location=os.getenv("LOCATION"))
endpoint = aiplatform.Endpoint(f"projects/{os.getenv('PROJECT_ID')}/locations/{os.getenv('LOCATION')}/endpoints/{ENDPOINT_ID}")
output = endpoint.predict(
instances=[
{
"inputs": inputs,
"parameters": {
"max_new_tokens": 128,
"do_sample": True,
"top_p": 0.95,
"temperature": 0.7,
},
},
],
)
```
Producing the following `output`:
> Prediction(predictions=["Yer lookin' fer a treasure trove o' knowledge about them fancy physics, eh? Alright then, matey, settle yerself down with a pint o' grog and listen close, as I spin ye the yarn o' Einstein's Theory o' Relativity.\n\nIt be a tale o' two parts, me hearty: Special Relativity and General Relativity. Now, I know what ye be thinkin': what in blazes be the difference? Well, matey, let me break it down fer ye.\n\nSpecial Relativity be the idea that time and space be connected like the sea and the sky."], deployed_model_id='***', metadata=None, model_version_id='1', model_resource_name='projects/***/locations/***/models/***', explanations=None)
### 5.2 Via the Vertex AI Online Prediction UI
Alternatively, for testing purposes you can also use the Vertex AI Online Prediction UI, that provides a field that expects the JSON payload formatted according to the Vertex AI specification (as in the examples above) being:
```json
{
"instances": [
{
"inputs": "<|begin_of_text|><|start_header_id|>system<|end_header_id|>\n\nYou are an assistant that responds as a pirate.<|eot_id|><|start_header_id|>user<|end_header_id|>\n\nWhat's the Theory of Relativity?<|eot_id|><|start_header_id|>assistant<|end_header_id|>\n\n",
"parameters": {
"max_new_tokens": 128,
"do_sample": true,
"top_p": 0.95,
"temperature": 0.7
}
}
]
}
```
So that the output is generated and printed within the UI too.

## 6. Clean up resources
When you're done, you can release the resources that you've created as follows, to avoid unnecessary costs.
* `deployed_model.undeploy_all` to undeploy the model from all the endpoints.
* `deployed_model.delete` to delete the endpoint/s where the model was deployed gracefully, after the `undeploy_all` method.
* `model.delete` to delete the model from the registry.
```python
deployed_model.undeploy_all()
deployed_model.delete()
model.delete()
```
Alternatively, you can also remove those from the Google Cloud Console following the steps:
* Go to Vertex AI in Google Cloud
* Go to Deploy and use -> Online prediction
* Click on the endpoint and then on the deployed model/s to "Undeploy model from endpoint"
* Then go back to the endpoint list and remove the endpoint
* Finally, go to Deploy and use -> Model Registry, and remove the model
## Conclusion
That's it! You have already registered and deployed Meta Llama 3.1 405B Instruct FP8 on Google Cloud Vertex AI, then ran online prediction both programmatically and via the Google Cloud Console, and finally cleaned up the resources used to avoid unnecessary costs.
Thanks to the Hugging Face DLCs for Text Generation Inference (TGI), and Google Cloud Vertex AI, deploying a high-performance text generation container for serving Large Language Models (LLMs) has never been easier. And we’re not going to stop here – stay tuned as we enable more experiences to build AI with open models on Google Cloud!
| 1 |
0 | hf_public_repos | hf_public_repos/blog/trl-peft.md | ---
title: "Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU"
thumbnail: assets/133_trl_peft/thumbnail.png
authors:
- user: edbeeching
- user: ybelkada
- user: lvwerra
- user: smangrul
- user: lewtun
- user: kashif
---
# Fine-tuning 20B LLMs with RLHF on a 24GB consumer GPU
We are excited to officially release the integration of `trl` with `peft` to make Large Language Model (LLM) fine-tuning with Reinforcement Learning more accessible to anyone! In this post, we explain why this is a competitive alternative to existing fine-tuning approaches.
Note `peft` is a general tool that can be applied to many ML use-cases but it’s particularly interesting for RLHF as this method is especially memory-hungry!
If you want to directly deep dive into the code, check out the example scripts directly on the [documentation page of TRL](https://huggingface.co/docs/trl/main/en/sentiment_tuning_peft).
## Introduction
### LLMs & RLHF
LLMs combined with RLHF (Reinforcement Learning with Human Feedback) seems to be the next go-to approach for building very powerful AI systems such as ChatGPT.
Training a language model with RLHF typically involves the following three steps:
1- Fine-tune a pretrained LLM on a specific domain or corpus of instructions and human demonstrations
2- Collect a human annotated dataset and train a reward model
3- Further fine-tune the LLM from step 1 with the reward model and this dataset using RL (e.g. PPO)
| 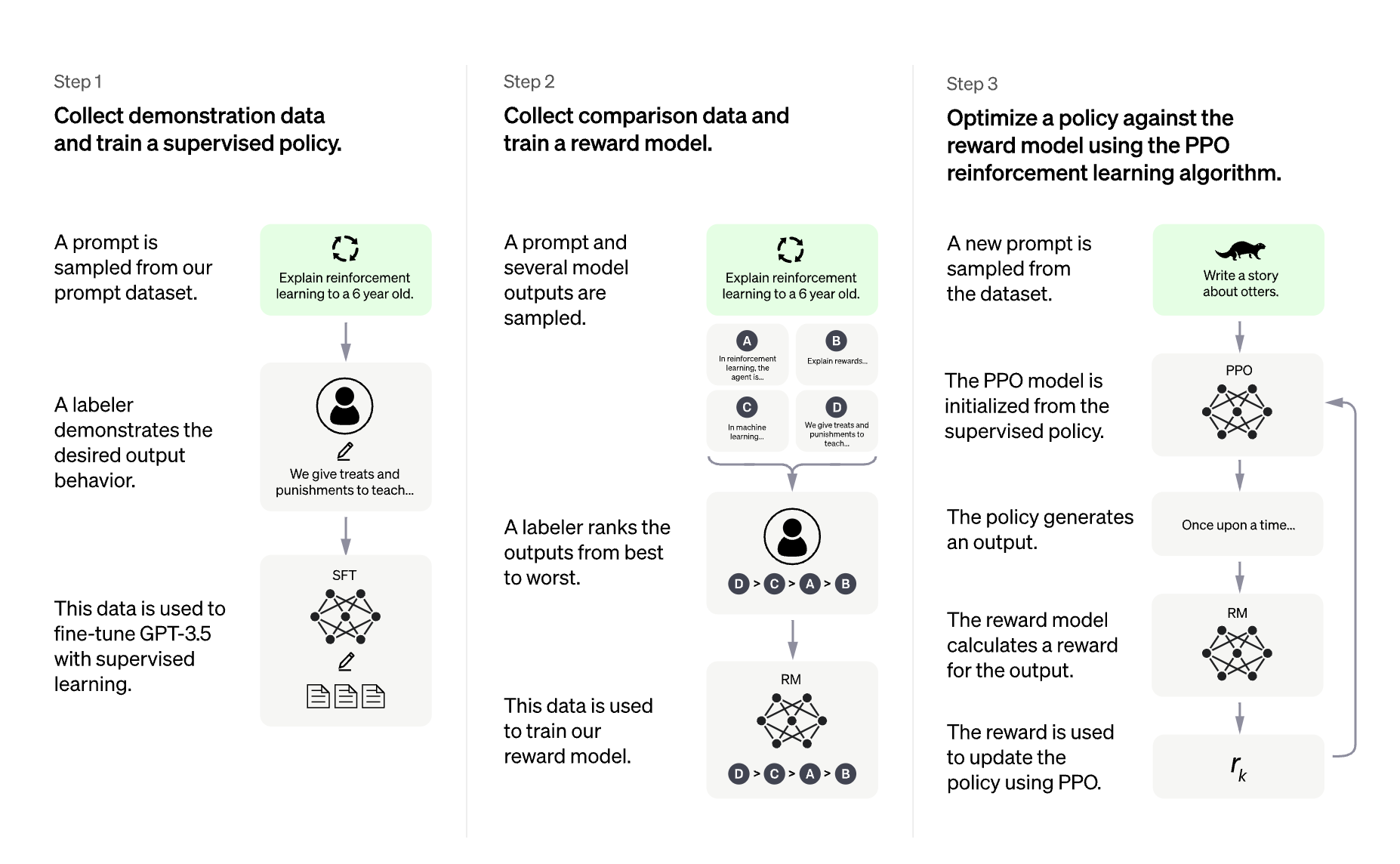 |
|:--:|
| <b>Overview of ChatGPT's training protocol, from the data collection to the RL part. Source: <a href="https://openai.com/blog/chatgpt" rel="noopener" target="_blank" >OpenAI's ChatGPT blogpost</a> </b>|
The choice of the base LLM is quite crucial here. At this time of writing, the “best” open-source LLM that can be used “out-of-the-box” for many tasks are instruction finetuned LLMs. Notable models being: [BLOOMZ](https://huggingface.co/bigscience/bloomz), [Flan-T5](https://huggingface.co/google/flan-t5-xxl), [Flan-UL2](https://huggingface.co/google/flan-ul2), and [OPT-IML](https://huggingface.co/facebook/opt-iml-max-30b). The downside of these models is their size. To get a decent model, you need at least to play with 10B+ scale models which would require up to 40GB GPU memory in full precision, just to fit the model on a single GPU device without doing any training at all!
### What is TRL?
The `trl` library aims at making the RL step much easier and more flexible so that anyone can fine-tune their LM using RL on their custom dataset and training setup. Among many other applications, you can use this algorithm to fine-tune a model to generate [positive movie reviews](https://huggingface.co/docs/trl/sentiment_tuning), do [controlled generation](https://github.com/lvwerra/trl/blob/main/examples/sentiment/notebooks/gpt2-sentiment-control.ipynb) or [make the model less toxic](https://huggingface.co/docs/trl/detoxifying_a_lm).
Using `trl` you can run one of the most popular Deep RL algorithms, [PPO](https://huggingface.co/deep-rl-course/unit8/introduction?fw=pt), in a distributed manner or on a single device! We leverage `accelerate` from the Hugging Face ecosystem to make this possible, so that any user can scale up the experiments up to an interesting scale.
Fine-tuning a language model with RL follows roughly the protocol detailed below. This requires having 2 copies of the original model; to avoid the active model deviating too much from its original behavior / distribution you need to compute the logits of the reference model at each optimization step. This adds a hard constraint on the optimization process as you need always at least two copies of the model per GPU device. If the model grows in size, it becomes more and more tricky to fit the setup on a single GPU.
|  |
|:--:|
| <b>Overview of the PPO training setup in TRL.</b>|
In `trl` you can also use shared layers between reference and active models to avoid entire copies. A concrete example of this feature is showcased in the detoxification example.
### Training at scale
Training at scale can be challenging. The first challenge is fitting the model and its optimizer states on the available GPU devices. The amount of GPU memory a single parameter takes depends on its “precision” (or more specifically `dtype`). The most common `dtype` being `float32` (32-bit), `float16`, and `bfloat16` (16-bit). More recently “exotic” precisions are supported out-of-the-box for training and inference (with certain conditions and constraints) such as `int8` (8-bit). In a nutshell, to load a model on a GPU device each billion parameters costs 4GB in float32 precision, 2GB in float16, and 1GB in int8. If you would like to learn more about this topic, have a look at this blogpost which dives deeper: [https://huggingface.co/blog/hf-bitsandbytes-integration](https://huggingface.co/blog/hf-bitsandbytes-integration).
If you use an AdamW optimizer each parameter needs 8 bytes (e.g. if your model has 1B parameters, the full AdamW optimizer of the model would require 8GB GPU memory - [source](https://huggingface.co/docs/transformers/v4.20.1/en/perf_train_gpu_one)).
Many techniques have been adopted to tackle these challenges at scale. The most familiar paradigms are Pipeline Parallelism, Tensor Parallelism, and Data Parallelism.
| 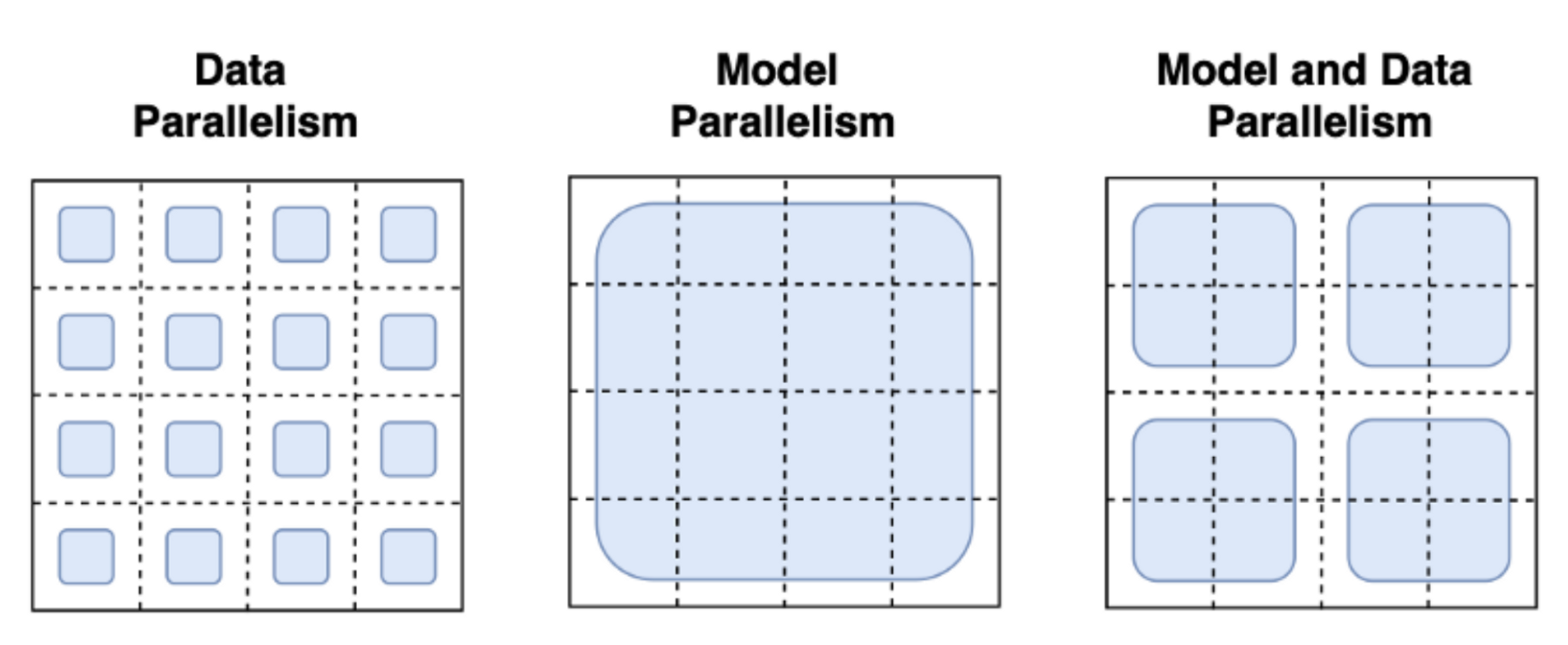 |
|:--:|
| <b>Image Credits to <a href="https://towardsdatascience.com/distributed-parallel-training-data-parallelism-and-model-parallelism-ec2d234e3214" rel="noopener" target="_blank" >this blogpost</a> </b>|
With data parallelism the same model is hosted in parallel on several machines and each instance is fed a different data batch. This is the most straight forward parallelism strategy essentially replicating the single-GPU case and is already supported by `trl`. With Pipeline and Tensor Parallelism the model itself is distributed across machines: in Pipeline Parallelism the model is split layer-wise, whereas Tensor Parallelism splits tensor operations across GPUs (e.g. matrix multiplications). With these Model Parallelism strategies, you need to shard the model weights across many devices which requires you to define a communication protocol of the activations and gradients across processes. This is not trivial to implement and might need the adoption of some frameworks such as [`Megatron-DeepSpeed`](https://github.com/microsoft/Megatron-DeepSpeed) or [`Nemo`](https://github.com/NVIDIA/NeMo). It is also important to highlight other tools that are essential for scaling LLM training such as Adaptive activation checkpointing and fused kernels. Further reading about parallelism paradigms can be found [here](https://huggingface.co/docs/transformers/v4.17.0/en/parallelism).
Therefore, we asked ourselves the following question: how far can we go with just data parallelism? Can we use existing tools to fit super-large training processes (including active model, reference model and optimizer states) in a single device? The answer appears to be yes. The main ingredients are: adapters and 8bit matrix multiplication! Let us cover these topics in the following sections:
### 8-bit matrix multiplication
Efficient 8-bit matrix multiplication is a method that has been first introduced in the paper LLM.int8() and aims to solve the performance degradation issue when quantizing large-scale models. The proposed method breaks down the matrix multiplications that are applied under the hood in Linear layers in two stages: the outlier hidden states part that is going to be performed in float16 & the “non-outlier” part that is performed in int8.
| 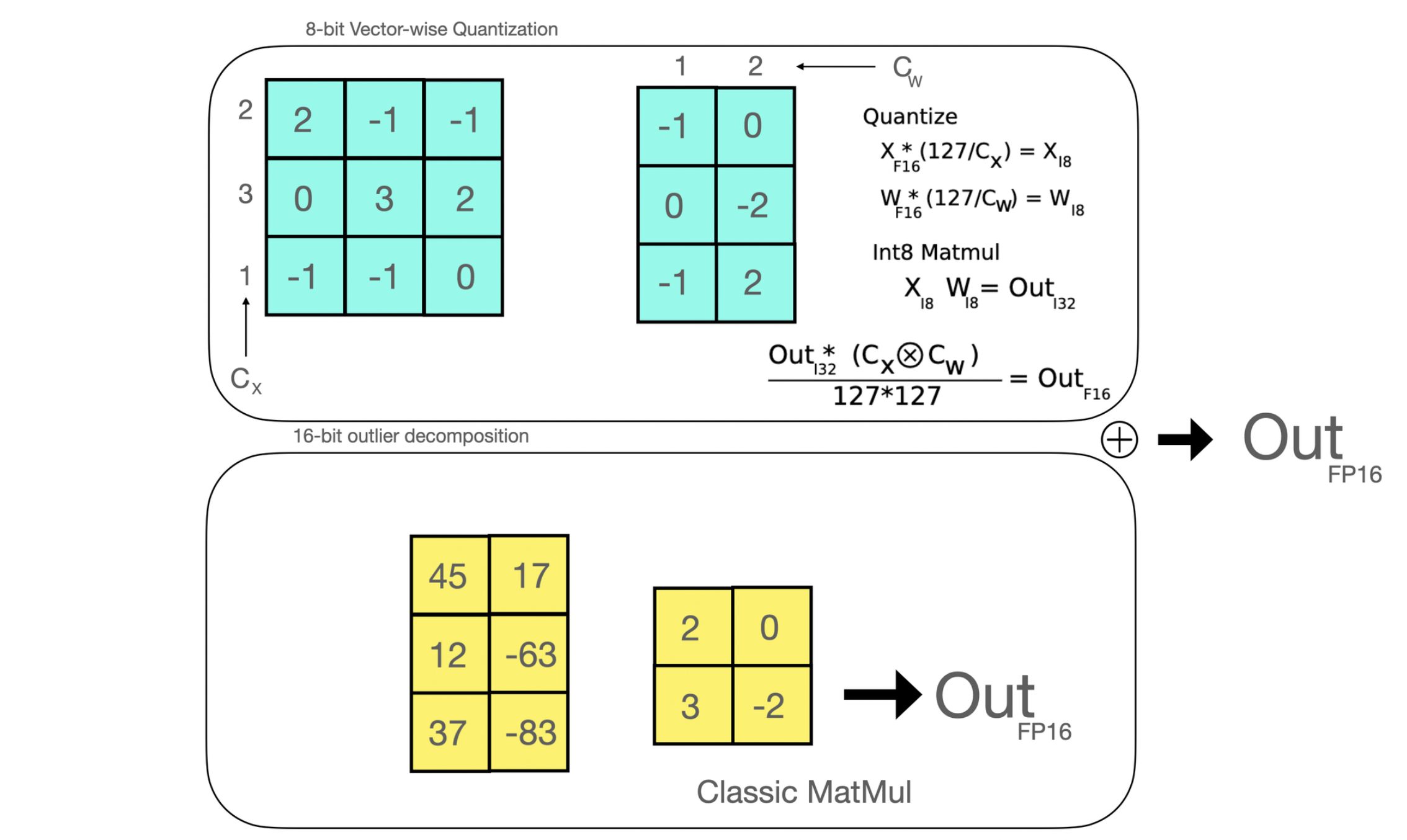 |
|:--:|
| <b>Efficient 8-bit matrix multiplication is a method that has been first introduced in the paper [LLM.int8()](https://arxiv.org/abs/2208.07339) and aims to solve the performance degradation issue when quantizing large-scale models. The proposed method breaks down the matrix multiplications that are applied under the hood in Linear layers in two stages: the outlier hidden states part that is going to be performed in float16 & the “non-outlier” part that is performed in int8. </b>|
In a nutshell, you can reduce the size of a full-precision model by 4 (thus, by 2 for half-precision models) if you use 8-bit matrix multiplication.
### Low rank adaptation and PEFT
In 2021, a paper called LoRA: Low-Rank Adaption of Large Language Models demonstrated that fine tuning of large language models can be performed by freezing the pretrained weights and creating low rank versions of the query and value layers attention matrices. These low rank matrices have far fewer parameters than the original model, enabling fine-tuning with far less GPU memory. The authors demonstrate that fine-tuning of low-rank adapters achieved comparable results to fine-tuning the full pretrained model.
|  |
|:--:|
| <b>The output activations original (frozen) pretrained weights (left) are augmented by a low rank adapter comprised of weight matrics A and B (right). </b>|
This technique allows the fine tuning of LLMs using a fraction of the memory requirements. There are, however, some downsides. The forward and backward pass is approximately twice as slow, due to the additional matrix multiplications in the adapter layers.
### What is PEFT?
[Parameter-Efficient Fine-Tuning (PEFT)](https://github.com/huggingface/peft), is a Hugging Face library, created to support the creation and fine tuning of adapter layers on LLMs.`peft` is seamlessly integrated with 🤗 Accelerate for large scale models leveraging DeepSpeed and Big Model Inference.
The library supports many state of the art models and has an extensive set of examples, including:
- Causal language modeling
- Conditional generation
- Image classification
- 8-bit int8 training
- Low Rank adaption of Dreambooth models
- Semantic segmentation
- Sequence classification
- Token classification
The library is still under extensive and active development, with many upcoming features to be announced in the coming months.
## Fine-tuning 20B parameter models with Low Rank Adapters
Now that the prerequisites are out of the way, let us go through the entire pipeline step by step, and explain with figures how you can fine-tune a 20B parameter LLM with RL using the tools mentioned above on a single 24GB GPU!
### Step 1: Load your active model in 8-bit precision
| 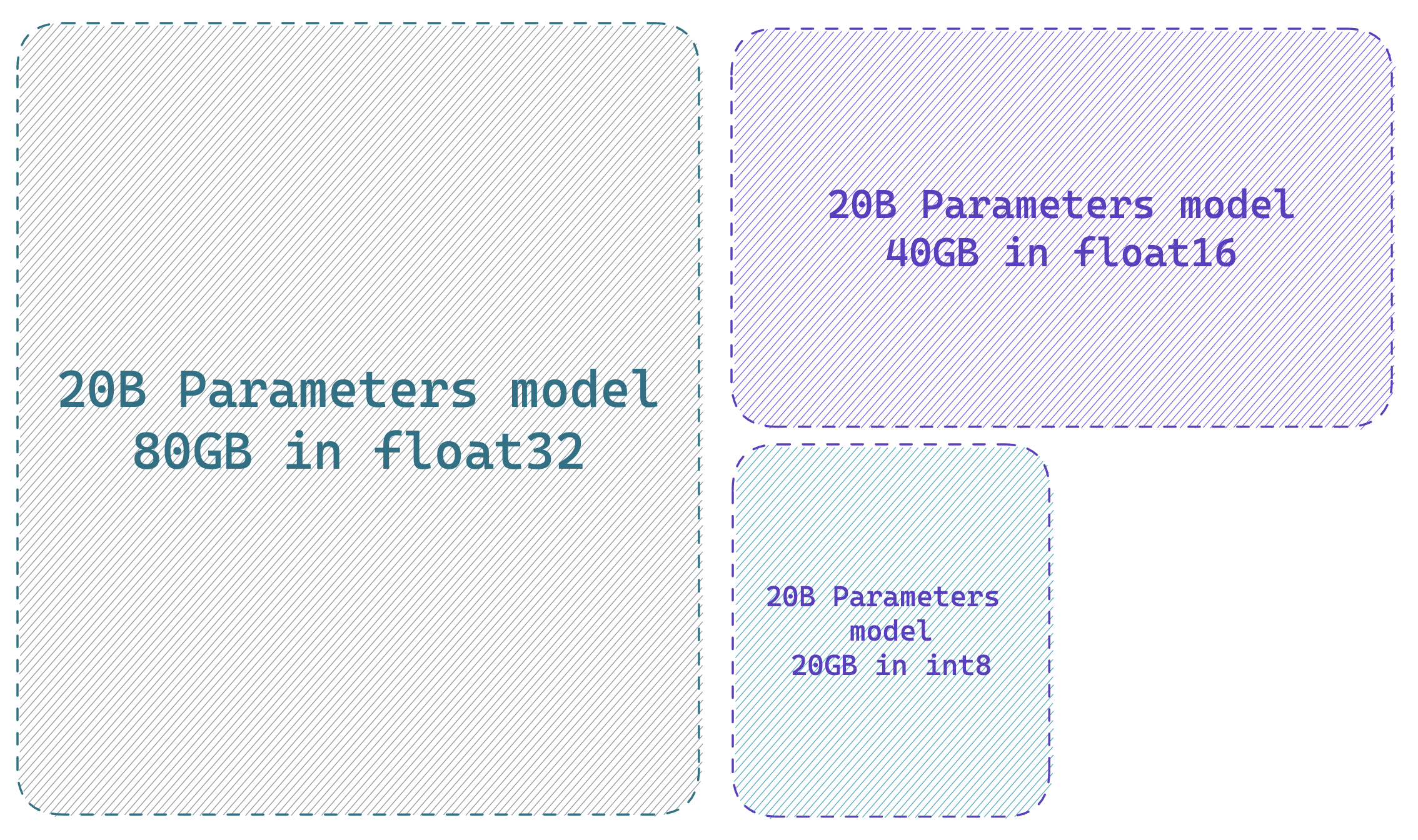 |
|:--:|
| <b> Loading a model in 8-bit precision can save up to 4x memory compared to full precision model</b>|
A “free-lunch” memory reduction of a LLM using `transformers` is to load your model in 8-bit precision using the method described in LLM.int8. This can be performed by simply adding the flag `load_in_8bit=True` when calling the `from_pretrained` method (you can read more about that [here](https://huggingface.co/docs/transformers/main/en/main_classes/quantization)).
As stated in the previous section, a “hack” to compute the amount of GPU memory you should need to load your model is to think in terms of “billions of parameters”. As one byte needs 8 bits, you need 4GB per billion parameters for a full-precision model (32bit = 4bytes), 2GB per billion parameters for a half-precision model, and 1GB per billion parameters for an int8 model.
So in the first place, let’s just load the active model in 8-bit. Let’s see what we need to do for the second step!
### Step 2: Add extra trainable adapters using `peft`
| 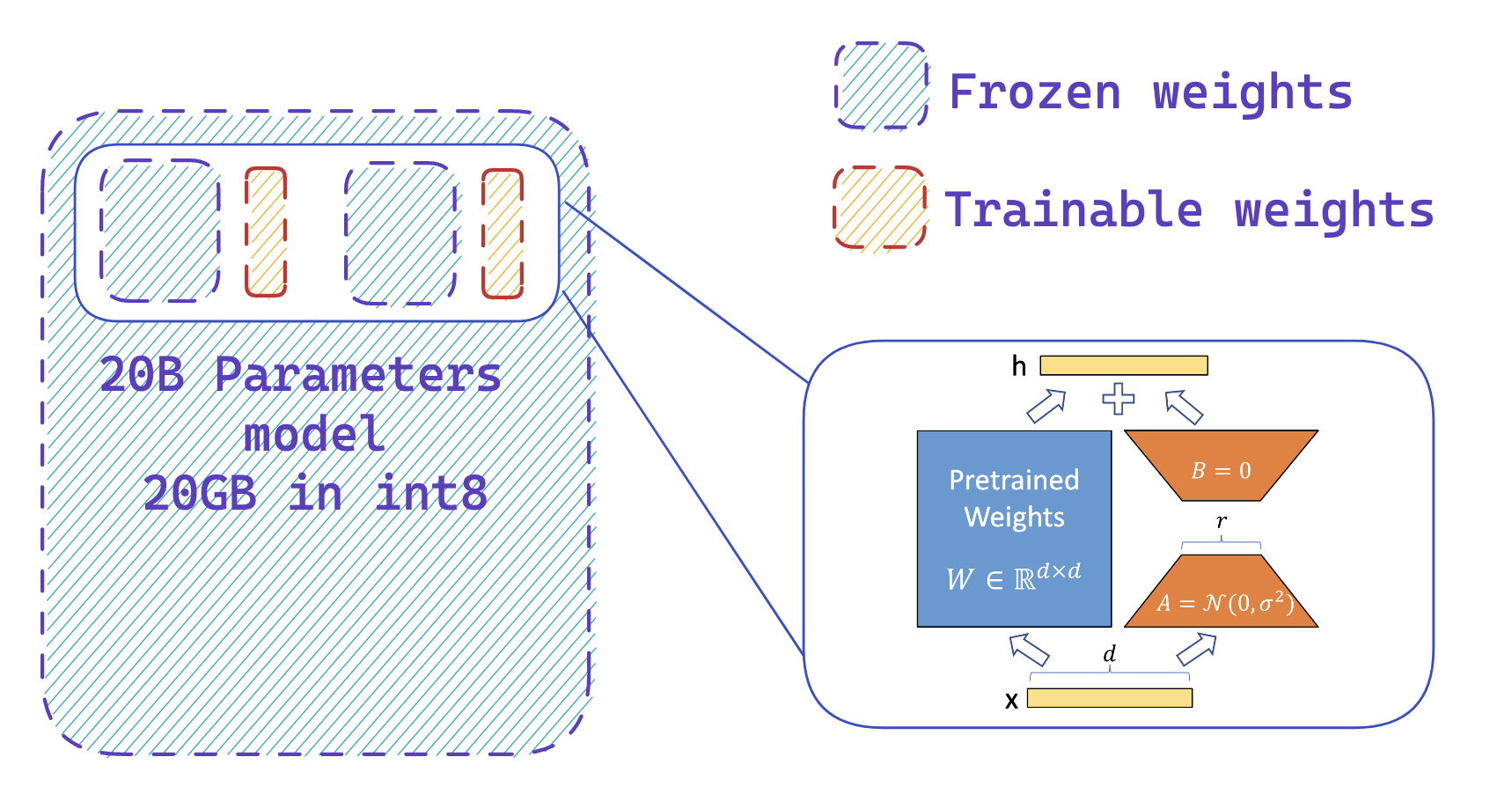 |
|:--:|
| <b> You easily add adapters on a frozen 8-bit model thus reducing the memory requirements of the optimizer states, by training a small fraction of parameters</b>|
The second step is to load adapters inside the model and make these adapters trainable. This enables a drastic reduction of the number of trainable weights that are needed for the active model. This step leverages `peft` library and can be performed with a few lines of code. Note that once the adapters are trained, you can easily push them to the Hub to use them later.
### Step 3: Use the same model to get the reference and active logits
| 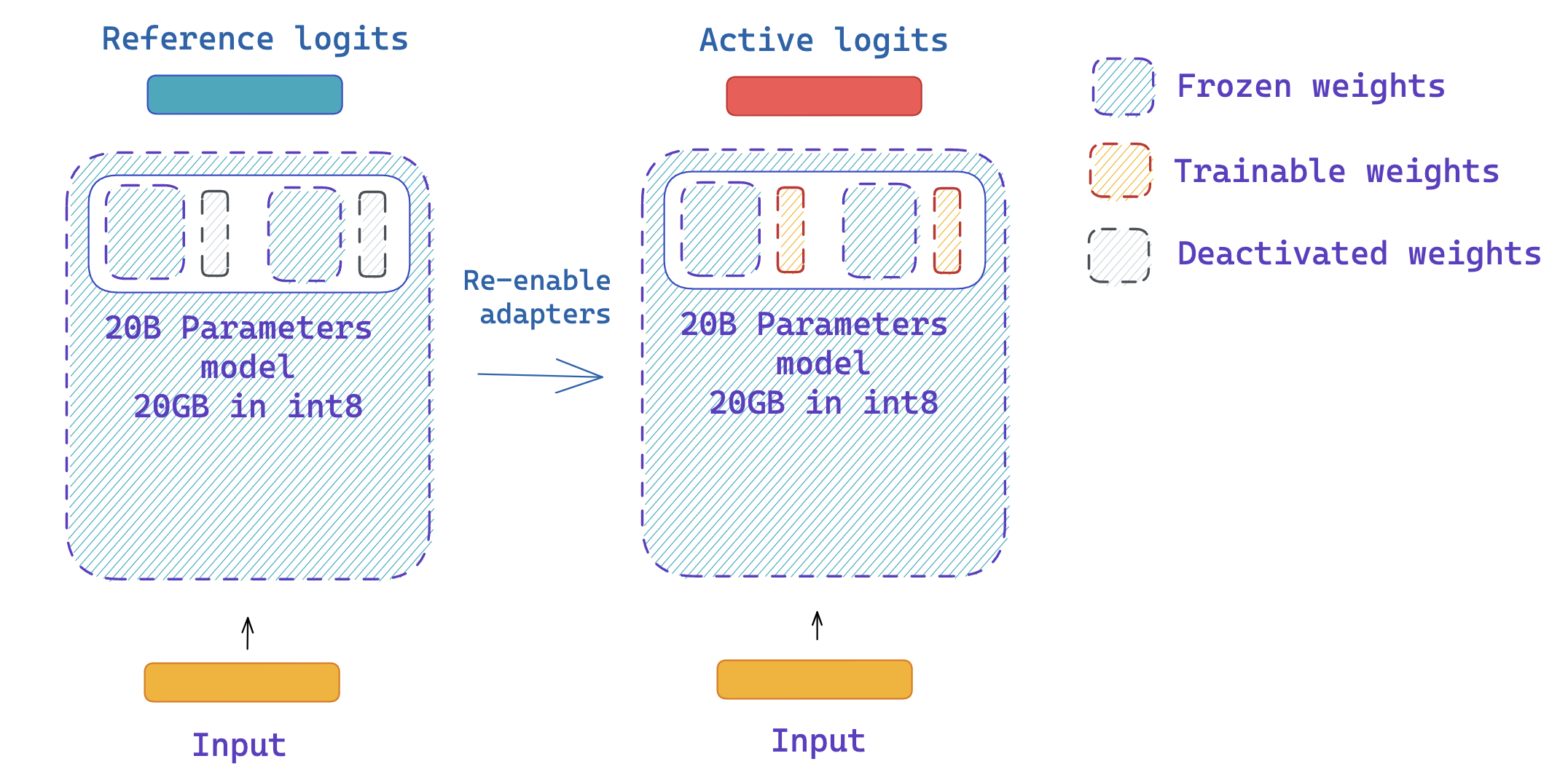 |
|:--:|
| <b> You can easily disable and enable adapters using the `peft` API.</b>|
Since adapters can be deactivated, we can use the same model to get the reference and active logits for PPO, without having to create two copies of the same model! This leverages a feature in `peft` library, which is the `disable_adapters` context manager.
### Overview of the training scripts:
We will now describe how we trained a 20B parameter [gpt-neox model](https://huggingface.co/EleutherAI/gpt-neox-20b) using `transformers`, `peft` and `trl`. The end goal of this example was to fine-tune a LLM to generate positive movie reviews in a memory constrained settting. Similar steps could be applied for other tasks, such as dialogue models.
Overall there were three key steps and training scripts:
1. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/clm_finetune_peft_imdb.py)** - Fine tuning a Low Rank Adapter on a frozen 8-bit model for text generation on the imdb dataset.
2. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/merge_peft_adapter.py)** - Merging of the adapter layers into the base model’s weights and storing these on the hub.
3. **[Script](https://github.com/lvwerra/trl/blob/main/examples/sentiment/scripts/gpt-neox-20b_peft/gpt-neo-20b_sentiment_peft.py)** - Sentiment fine-tuning of a Low Rank Adapter to create positive reviews.
We tested these steps on a 24GB NVIDIA 4090 GPU. While it is possible to perform the entire training run on a 24 GB GPU, the full training runs were untaken on a single A100 on the 🤗 reseach cluster.
The first step in the training process was fine-tuning on the pretrained model. Typically this would require several high-end 80GB A100 GPUs, so we chose to train a low rank adapter. We treated this as a Causal Language modeling setting and trained for one epoch of examples from the [imdb](https://huggingface.co/datasets/imdb) dataset, which features movie reviews and labels indicating whether they are of positive or negative sentiment.
|  |
|:--:|
| <b> Training loss during one epoch of training of a gpt-neox-20b model for one epoch on the imdb dataset</b>|
In order to take the adapted model and perform further finetuning with RL, we first needed to combine the adapted weights, this was achieved by loading the pretrained model and adapter in 16-bit floating point and summary with weight matrices (with the appropriate scaling applied).
Finally, we could then fine-tune another low-rank adapter, on top of the frozen imdb-finetuned model. We use an [imdb sentiment classifier](https://huggingface.co/lvwerra/distilbert-imdb) to provide the rewards for the RL algorithm.
|  |
|:--:|
| <b> Mean of rewards when RL fine-tuning of a peft adapted 20B parameter model to generate positive movie reviews.</b>|
The full Weights and Biases report is available for this experiment [here](https://wandb.ai/edbeeching/trl/runs/l8e7uwm6?workspace=user-edbeeching), if you want to check out more plots and text generations.
## Conclusion
We have implemented a new functionality in `trl` that allows users to fine-tune large language models using RLHF at a reasonable cost by leveraging the `peft` and `bitsandbytes` libraries. We demonstrated that fine-tuning `gpt-neo-x` (40GB in `bfloat16`!) on a 24GB consumer GPU is possible, and we expect that this integration will be widely used by the community to fine-tune larger models utilizing RLHF and share great artifacts.
We have identified some interesting directions for the next steps to push the limits of this integration
- *How this will scale in the multi-GPU setting?* We’ll mainly explore how this integration will scale with respect to the number of GPUs, whether it is possible to apply Data Parallelism out-of-the-box or if it’ll require some new feature adoption on any of the involved libraries.
- *What tools can we leverage to increase training speed?* We have observed that the main downside of this integration is the overall training speed. In the future we would be keen to explore the possible directions to make the training much faster.
## References
- parallelism paradigms: [https://huggingface.co/docs/transformers/v4.17.0/en/parallelism](https://huggingface.co/docs/transformers/v4.17.0/en/parallelism)
- 8-bit integration in `transformers`: [https://huggingface.co/blog/hf-bitsandbytes-integration](https://huggingface.co/blog/hf-bitsandbytes-integration)
- LLM.int8 paper: [https://arxiv.org/abs/2208.07339](https://arxiv.org/abs/2208.07339)
- Gradient checkpoiting explained: [https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html](https://docs.aws.amazon.com/sagemaker/latest/dg/model-parallel-extended-features-pytorch-activation-checkpointing.html)
| 2 |
0 | hf_public_repos | hf_public_repos/blog/putting_rl_back_in_rlhf_with_rloo.md | ---
title: "Putting RL back in RLHF"
thumbnail: /blog/assets/putting_rl_back_in_rlhf_with_rloo/thumbnail.png
authors:
- user: vwxyzjn
- user: ArashAhmadian
org: CohereForAI
guest: true
---
# Putting RL back in RLHF
We are excited to introduce the RLOO (REINFORCE Leave One-Out) Trainer in TRL. As an alternative to PPO, RLOO is a new online RLHF training algorithm designed to be more accessible and easier to implement. In particular, **RLOO requires less GPU memory and takes less wall time to converge.** As shown in the figures below:
1. 🤑RLOO uses **approximately 50-70% less** vRAM than PPO, depending on the model size
2. 🚀RLOO runs **2x faster** than PPO with 1B models and up to **3x faster** than PPO with 6.9B models.
3. 🔥RLOO performs **competitively to PPO** in terms of the response win rate (judged by GPT4) and consistently outperforms popular offline methods like DPO.
With RLOO, we bring Reinforcement Learning back into RLHF, enabling the community to explore online RL methods more easily. This is exciting because more and more studies have shown that online RL is more effective than offline methods such as DPO ([https://arxiv.org/abs/2402.04792](https://arxiv.org/abs/2402.04792), [https://arxiv.org/abs/2405.08448](https://arxiv.org/abs/2405.08448)).
<p align="center">
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/blog/putting_rl_back_in_rlhf_with_rloo/win_rate_comparison.png?download=true" alt="alt_text" title="image_tooltip" />
</p>
<p align="center">
<img src="https://huggingface.co/datasets/trl-internal-testing/example-images/resolve/main/blog/putting_rl_back_in_rlhf_with_rloo/memory_runtime_comparison.png?download=true" alt="alt_text" title="image_tooltip" />
</p>
This blog post will explain the motivation behind the RLOO Trainer, how it works, and how to use it in TRL.
# Motivation
PPO is an effective online RLHF training algorithm that is used to train state-of-the-art models such as GPT-4. However, PPO can be quite challenging to use in practice due to its high GPU memory requirements. In particular, PPO needs to load 4 copies of the models into the memory: 1) the policy model, 2) the reference policy model, 3) the reward model, and 4) the value model, as shown in the following figure. PPO also has many subtle implementation details that can be difficult to get right ([Engstrom et al; 2020](https://openreview.net/forum?id=r1etN1rtPB), [Huang et al 2022](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)).

In a new paper from Cohere, [Ahmadian et al. (2024)](https://cohere.com/research/papers/back-to-basics-revisiting-reinforce-style-optimization-for-learning-from-human-feedback-in-llms-2024-02-23) revisited the basics of RLHF training and proposed a more elegant method called RLOO, a new online training algorithm. RLOO only needs to load 3 copies of the models into the memory: 1) the policy model, 2) the reference policy model, and 3) the reward model, as shown in the figure above.
Importantly, RLOO requires less memory, meaning it’s easier to
1. run without OOMs (out-of-memory errors)
2. being able to load larger batch sizes
3. runs more efficiently and faster.
Furthermore, RLOO models the entire completion tokens as a single action, as illustrated in the figure below. In the next section, we will dive into further detail with code snippets.

# How RLOO Works
Both RLOO and PPO have several shared steps:
1. The policy model would generate some completion tokens and get the per-token log probs under the current and reference policies.
2. We then calculate the per-token KL penalties as the difference between the logprobs under the current and reference policies.
3. We then get the score of the entire completion from the reward model.
From here on, regular PPO and RLOO differ in approach. RLOO has several key ideas. First, it treats the ****entire model completion**** as a single action, whereas regular PPO treats ****each completion token**** as individual actions. Typically, only the EOS token gets a true reward, which is very sparse. Regular PPO would attribute a reward to the EOS token, whereas RLOO would attribute that EOS reward to the entire completion, as demonstrated below.
```python
from torch import Tensor
response = Tensor([4., 5., 6.])
per_token_logprobs = Tensor([-12.3, -8.3, -2.3])
reference_per_token_logprobs = Tensor([-11.3, -8.4, -2.0])
kl = per_token_logprobs - reference_per_token_logprobs
score_from_rm = 1.0
print(f"{kl=}") # kl=tensor([-1.0000, 0.1000, -0.3000])
per_token_reward = kl.clone()
per_token_reward[-1] += score_from_rm # assume last token is the EOS token
print(f"{per_token_reward=}") # per_token_reward=tensor([-1.0000, 0.1000, 0.7000])
print(f"{score_from_rm=}") # score_from_rm=1.0
print("#### Modeling each token as an action")
for action, reward in zip(response, per_token_reward):
print(f"{action=}, {reward=}")
# action=tensor(4.), reward=tensor(-1.)
# action=tensor(5.), reward=tensor(0.1000)
# action=tensor(6.), reward=tensor(0.7000)
print("#### Modeling the entire response as an action")
entire_generation_reward = per_token_reward.sum()
print(f"action='entire completion', reward={entire_generation_reward}")
# action='entire completion', reward=-0.2000 (-1 + 0.1 + 0.7)
```
Second, RLOO uses the REINFORCE loss, which basically multiplies the (reward - baseline) by the logprob of actions. Here, we highlight the differences between per-token REINFORCE loss and the entire completion REINFORCE loss. Note that for PPO's loss, we would need to calculate the advantage additionally based on the value model with [Generalized Advantage Estimation (GAE)](https://arxiv.org/abs/1506.02438).
```python
from torch import Tensor
response = Tensor([4., 5., 6.])
per_token_logprobs = Tensor([-12.3, -8.3, -2.3])
reference_per_token_logprobs = Tensor([-11.3, -8.4, -2.0])
kl = per_token_logprobs - reference_per_token_logprobs
score_from_rm = 1.0
print(f"{kl=}") # kl=tensor([-1.0000, 0.1000, -0.3000])
per_token_reward = kl.clone()
per_token_reward[-1] += score_from_rm # assume last token is the EOS token
print(f"{per_token_reward=}") # per_token_reward=tensor([-1.0000, 0.1000, 0.7000])
print(f"{score_from_rm=}") # score_from_rm=1.0
print("#### Modeling each token as an action")
for action, reward in zip(response, per_token_reward):
print(f"{action=}, {reward=}")
# action=tensor(4.), reward=tensor(-1.)
# action=tensor(5.), reward=tensor(0.1000)
# action=tensor(6.), reward=tensor(0.7000)
print("#### Modeling the entire response as an action")
entire_generation_reward = per_token_reward.sum()
print(f"action='entire completion', reward={entire_generation_reward}")
# action='entire completion', reward=-0.2000 (-1 + 0.1 + 0.7)
baseline = Tensor([0.2, 0.3, 0.4]) # dummy baseline
print("#### Modeling each token as an action")
advantage = per_token_reward - baseline
per_token_reinforce_loss = per_token_logprobs * advantage
print(f"{advantage=}") # advantage=tensor([-1.2000, -0.2000, 0.3000])
print(f"{per_token_reinforce_loss=}") # per_token_reinforce_loss=tensor([14.7600, 1.6600, -0.6900])
print(f"{per_token_reinforce_loss.mean()=}") # per_token_reinforce_loss.mean()=tensor(5.2433)
print("#### Modeling the entire response as an action")
advantage = entire_generation_reward - baseline.sum()
reinforce_loss = per_token_logprobs.sum() * advantage
print(f"{advantage=}") # advantage=tensor(-1.1000)
print(f"{reinforce_loss=}") # reinforce_loss=tensor(25.1900)
```
Third, RLOO calculates baselines smartly. Notice we used a dummy baseline above. In practice, RLOO uses the reward of all other samples in the batch as the baseline. Below is a case where we have 3 prompts and 4 completions each. We calculate the baseline for each completion by averaging the rewards of all other completions for the same prompt.
```python
import torch
local_batch_size = 3
rloo_k = 4
rlhf_reward = torch.tensor([
1, 2, 3, # first rlhf reward for three prompts
2, 3, 4, # second rlhf reward for three prompts
5, 6, 7, # third rlhf reward for three prompts
8, 9, 10, # fourth rlhf reward for three prompts
]).float() # here we have 3 prompts which have 4 completions each
# slow impl
baseline = (rlhf_reward.sum(0) - rlhf_reward) / (rloo_k - 1)
advantages = torch.zeros_like(rlhf_reward)
for i in range(0, len(advantages), local_batch_size):
other_response_rlhf_rewards = []
for j in range(0, len(advantages), local_batch_size):
if i != j:
other_response_rlhf_rewards.append(rlhf_reward[j : j + local_batch_size])
advantages[i : i + local_batch_size] = rlhf_reward[i : i + local_batch_size] - torch.stack(
other_response_rlhf_rewards
).mean(0)
assert (1 - (2 + 5 + 8) / 3 - advantages[0].item()) < 1e-6
assert (6 - (3 + 2 + 9) / 3 - advantages[7].item()) < 1e-6
# vectorized impl
rlhf_reward = rlhf_reward.reshape(rloo_k, local_batch_size)
baseline = (rlhf_reward.sum(0) - rlhf_reward) / (rloo_k - 1)
vec_advantages = rlhf_reward - baseline
torch.testing.assert_close(vec_advantages.flatten(), advantages)
```
A big shout out to Arash Ahmadian, who provided the vectorized implementation of the advantages calculation above.
# Get started with using RLOO with TRL
To get started with RLOO, you can install the latest version of TRL via `pip install --upgrade trl` and import the RLOOTrainer. Below is a short snippet that shows some high-level API usage. Feel free to checkout the documentation
* [https://huggingface.co/docs/trl/main/en/rloo_trainer](https://huggingface.co/docs/trl/main/en/rloo_trainer)
* [https://huggingface.co/docs/trl/main/en/ppov2_trainer](https://huggingface.co/docs/trl/main/en/ppov2_trainer)
```python
from transformers import (
AutoModelForCausalLM,
AutoModelForSequenceClassification,
AutoTokenizer,
)
from trl.trainer.rloo_trainer import RLOOConfig, RLOOTrainer
from trl.trainer.utils import SIMPLE_QUERY_CHAT_TEMPLATE
base_model_name = "EleutherAI/pythia-1b-deduped"
tokenizer = AutoTokenizer.from_pretrained(base_model_name, padding_side="left")
tokenizer.add_special_tokens({"pad_token": "[PAD]"})
if tokenizer.chat_template is None:
tokenizer.chat_template = SIMPLE_QUERY_CHAT_TEMPLATE
reward_model = AutoModelForSequenceClassification.from_pretrained(base_model_name, num_labels=1)
ref_policy = AutoModelForCausalLM.from_pretrained(base_model_name)
policy = AutoModelForCausalLM.from_pretrained(base_model_name)
train_dataset = ... # make sure to have columns "input_ids"
eval_dataset = ...
trainer = RLOOTrainer(
config=RLOOConfig(
per_device_train_batch_size=1,
gradient_accumulation_steps=64,
total_episodes=30000,
),
tokenizer=tokenizer,
policy=policy,
ref_policy=ref_policy,
reward_model=reward_model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
)
trainer.train()
```
Here is an example of tracked weights and biases experiments: [https://wandb.ai/huggingface/trl/runs/dd2o3g35](https://wandb.ai/huggingface/trl/runs/dd2o3g35)

When coding the RLOO and PPOv2 implementation, we emphasize making it easier to improve the transparency of model development. In particular, we have enhanced the docs to include an explanation of logged metrics and a cookbook guide on reading and debugging these metrics. For example, we recommend closely monitoring objective/rlhf_reward, the ultimate objective of the RLHF training, during training.


To help visualize the training progress,, we periodically log some sample completions from the model. Here is an example of a completion. In an example tracked run at Weights and Biases ([https://wandb.ai/huggingface/trl/runs/dd2o3g35](https://wandb.ai/huggingface/trl/runs/dd2o3g35)), it looks like the following, allowing you to see the model’s response at different stages of training. By default, we generate --num_sample_generations 10 during training, but you can customize the number of generations.

# How we implemented RLOO Trainer in TRL
We implemented RLOO trainer based on our new experimental `PPOv2Trainer`, which is itself based on https://arxiv.org/abs/2403.17031. Interestingly, our implementation of the RLOO trainer still uses the PPO loss. This is because the loss of REINFORCE is a special case of PPO (https://arxiv.org/abs/2205.09123). Note that even though the logprob is explicitly in the REINFORCE loss, it is also implicitly in the PPO loss. Seeing is believing, so let's demonstrate this with a simple example.
```python
import torch.nn.functional as F
from torch import LongTensor, Tensor, gather, no_grad
action = LongTensor([1])
advantage = Tensor([1.0])
logits = Tensor([[1.0, 2.0, 1.0, 1.0]])
logits.requires_grad = True
all_logprob = F.log_softmax(logits, dim=-1)
with no_grad():
old_logprob = gather(all_logprob, 1, action.unsqueeze(-1)).squeeze(-1)
logprob = gather(all_logprob, 1, action.unsqueeze(-1)).squeeze(-1)
ratio = (logprob - old_logprob).exp()
ppo_loss = (ratio * advantage).mean() # [πθ(at | st) / πθ_old(at | st) * At]
# when the πθ and πθ_old are the same, the ratio is 1, and PPO's clipping has no effect
ppo_loss.backward()
print(f"{logits.grad=}") # tensor([[-0.1749, 0.5246, -0.1749, -0.1749]])
logits2 = Tensor([[1.0, 2.0, 1.0, 1.0]])
logits2.requires_grad = True
all_logprob2 = F.log_softmax(logits2, dim=-1)
logprob2 = gather(all_logprob2, 1, action.unsqueeze(-1)).squeeze(-1)
reinforce_loss = logprob2 * advantage # [log πθ(at | st) * At]
reinforce_loss.mean().backward()
print(f"{logits2.grad=}") # tensor([[-0.1749, 0.5246, -0.1749, -0.1749]])
```
# Experiments
To validate the RLOO implementation works, we ran experiments on the Pythia 1B and 6.9B models and release the trained checkpoints here:
* [https://huggingface.co/collections/vwxyzjn/rloo-ppov2-tl-dr-summarize-checkpoints-66679a3bfd95ddf66c97420d](https://huggingface.co/collections/vwxyzjn/rloo-ppov2-tl-dr-summarize-checkpoints-66679a3bfd95ddf66c97420d)
We take the SFT / RM models directly from [Huang et al., 2024](https://arxiv.org/abs/2403.17031). To evaluate, we use vLLM to load the checkpoints and GPT4 as a judge model to assess the generated TL;DR against the reference TL;DR. We also look at the GPU memory usage and runtime, as shown in the figures at the beginning of the blog post. To reproduce our work, feel free to check out the commands in our docs:
* [https://huggingface.co/docs/trl/main/en/rloo_trainer#benchmark-experiments](https://huggingface.co/docs/trl/main/en/rloo_trainer#benchmark-experiments)
* [https://huggingface.co/docs/trl/main/en/rloo_trainer#benchmark-experiments](https://huggingface.co/docs/trl/main/en/rloo_trainer#benchmark-experiments)
The key results are as follows:
* **🚀Highly performant RLOO checkpoint: **The 6.9B checkpoint gets a 78.7% (k=2) preferred rate using GPT4 as a judge, which even exceeds the best-reported performance of 77.9% (k=4) and 74.2 (k=2) in the original [paper](https://arxiv.org/abs/2402.14740). This is a good sign that our RLOO training is working as intended.
* The RLOO 1B checkpoint has a 40.1% win rate compared to the SFT checkpoint's 21.3% win rate. This is a good sign that the RLOO training is working as intended.
* 🤑**Less GPU memory and runs faster**: RLOO training uses less memory and runs faster, making it a highly useful algorithm for online RL training.
# Numerical Stability: The Dark Side
Despite RLOO's performance and compute efficiency advantages, we want to highlight some numerical issues. Specifically, the response logprobs obtained during generation are slightly numerically different from the logprobs obtained during the training forward passes under `bf16`. This causes an issue for both PPO and RLOO, but it’s much worse for RLOO, as explained below.
For example, say we are generating 10 tokens for two sequences. Under the precision `fp32`, the output looks as follows, where the `ratio = (forward_logprob - generation_logprob).exp()` and is what PPO used to clip. Under the first epoch and first minibatch, the ratio should be exactly the same because the model hasn’t done any updates:
```
generation_logprob=tensor([[ -0.1527, -0.2258, -3.5535, -3.4805, -0.0519,
-2.3097, -2.0275, -0.4597, -0.1687, -0.0000],
[ -0.1527, -0.2258, -5.2855, -0.1686, -8.4760,
-4.3118, -1.0368, -0.8274, -1.6342, -2.6128]],
device='cuda:0')
forward_logprob=tensor([[-0.1527, -0.2258, -3.5535, -3.4805, -0.0519, -2.3097, -2.0275, -0.4597,
-0.1687],
[-0.1527, -0.2258, -5.2855, -0.1686, -8.4760, -4.3118, -1.0368, -0.8274,
-1.6342]], device='cuda:0', grad_fn=<SqueezeBackward1>)
ratio=tensor([[1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000],
[1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000, 1.0000]],
device='cuda:0', grad_fn=<ExpBackward0>)
ratio.mean()=0.9999998211860657
ratio.std()=6.592738373001339e-06
ratio.max()=1.0000133514404297
ratio.min()=0.9999887943267822
```
However, under bf16, we get
```
generation_logprob=tensor([[ -0.1426, -0.1904, -3.5938, -3.4688, -0.0618,
-2.3906, -2.0781, -0.4375, -0.1562, -0.0000],
[ -0.1426, -0.1904, -5.2812, -0.1641, -8.5625,
-4.2812, -1.0078, -0.8398, -1.5781, -2.5781]],
device='cuda:0', dtype=torch.bfloat16)
forward_logprob=tensor([[-0.1445, -0.1670, -3.5938, -3.5156, -0.0554, -2.2969, -1.9688, -0.5273,
-0.1953],
[-0.1445, -0.1670, -5.2812, -0.1533, -8.5625, -4.3125, -1.0000, -0.7852,
-1.6641]], device='cuda:0', dtype=torch.bfloat16,
grad_fn=<SqueezeBackward1>)
ratio=tensor([[1.0000, 0.9766, 1.0000, 1.0469, 0.9922, 0.9102, 0.8945, 1.0938, 1.0391],
[1.0000, 0.9766, 1.0000, 0.9883, 1.0000, 1.0312, 0.9922, 0.9453, 1.0859]],
device='cuda:0', dtype=torch.bfloat16, grad_fn=<ExpBackward0>)
ratio.mean()=1.0
ratio.std()=0.051025390625
ratio.max()=1.09375
ratio.min()=0.89453125
```
and under fp16, we get
```
generation_logprob=tensor([[ -0.1486, -0.2212, -3.5586, -3.4688, -0.0526,
-2.3105, -2.0254, -0.4629, -0.1677, -0.0000],
[ -0.1486, -0.2212, -5.2852, -0.1681, -8.4844,
-4.3008, -1.0322, -0.8286, -1.6348, -2.6074]],
device='cuda:0', dtype=torch.float16)
forward_logprob=tensor([[-0.1486, -0.2212, -3.5586, -3.4805, -0.0529, -2.3066, -2.0332, -0.4629,
-0.1676],
[-0.1486, -0.2212, -5.2852, -0.1682, -8.4766, -4.3008, -1.0322, -0.8281,
-1.6299]], device='cuda:0', dtype=torch.float16,
grad_fn=<SqueezeBackward1>)
ratio=tensor([[1.0000, 1.0000, 1.0000, 1.0117, 1.0000, 0.9961, 1.0078, 1.0000, 1.0000],
[1.0000, 1.0000, 1.0000, 1.0000, 0.9922, 1.0000, 1.0000, 0.9995, 0.9951]],
device='cuda:0', dtype=torch.float16, grad_fn=<ExpBackward0>)
ratio.mean()=1.0
ratio.std()=0.00418853759765625
ratio.max()=1.01171875
ratio.min()=0.9921875
```
Note that the ratio for `bf16` is very unstable for some reason. When the ratio becomes large, PPO’s clip coefficient = 0.2 kicks in, **nulling** the gradient of the tokens for which the ratio is greater than 1.2 or lower than 0.8. With RLOO, this issue is more extreme because we are looking at the `(forward_logprob.sum(1) - generation_logprob.sum(1)).exp() = [ 1.0625, 12.1875]`, which means the gradient for the entire second sequence is nulled.
In practice, we noticed PPO nulls the gradient of approximately 3% of the batch data, whereas RLOO nulls about 20-40% of the batch data. Theoretically, RLOO should null 0% of the batch data when not using mini-batches. Importantly, we observe that the clipping ratio for RLOO did not change significantly once we increased the number of gradient steps before generating new batches (through num_ppo_epochs and num_mini_batches); this provides empirical evidence that the clipping ratio is indeed due to numerical issues with bf16 as opposed to the behavior and latest policies being significantly different, as positioned in the paper.
To keep reading about the latest issue updates, feel free to check out [https://github.com/huggingface/transformers/issues/31267](https://github.com/huggingface/transformers/issues/31267).
# Conclusion
The introduction of the RLOO (REINFORCE Leave One-Out) Trainer in TRL is an exciting algorithm in online RLHF training, providing a more accessible and efficient alternative to PPO. By reducing GPU memory usage and simplifying the training process, RLOO enables larger batch sizes and faster training times. Our experiments demonstrate that RLOO performs competitively with PPO and outperforms DPO checkpoints in terms of response win rate, making it a powerful tool for effective online RLHF. Explore our documentation to get started!
* [https://huggingface.co/docs/trl/main/en/rloo_trainer](https://huggingface.co/docs/trl/main/en/rloo_trainer)
* [https://huggingface.co/docs/trl/main/en/ppov2_trainer](https://huggingface.co/docs/trl/main/en/ppov2_trainer)
# Acknowledgment and Thanks
We thank Lewis Tunstall, Sara Hooker, Omar Sanseviero, and Leandro Von Werra for the helpful feedback on this blog post.
| 3 |
0 | hf_public_repos | hf_public_repos/blog/2023-in-llms.md | ---
title: "2023, year of open LLMs"
thumbnail: /blog/assets/cv_state/thumbnail.png
authors:
- user: clefourrier
---
# 2023, year of open LLMs
2023 has seen a surge of public interest in Large Language Models (LLMs), and now that most people have an idea of what they are and can do, the public debates around open versus closed source have reached a wide audience as well. At Hugging Face, we follow open models with great interest, as they allow research to be reproducible, empower the community to participate in the development of AI models, permit the easier scrutiny of model biases and limitations, and lower the overall carbon impact of our field by favoring checkpoint reuse (among [many other benefits](https://huggingface.co/papers/2302.04844)).
So let's do a retrospective of the year in open LLMs!
*To keep this document manageable in length, we won't look at code models.*
## 🍜 Recipe for a pretrained Large Language Model
First, how do you get a Large Language Model? (Feel free to skim this section if you already know!)
The model **architecture** (its code) describes its specific implementation and mathematical shape: it is a list of all its parameters, as well as how they interact with inputs. At the moment, most highly performing LLMs are variations on the "decoder-only" Transformer architecture (more details in the [original transformers paper](https://huggingface.co/papers/1706.03762)).
The **training dataset** contains all examples and documents on which the model is trained (aka the parameters are learned), therefore, the specific patterns learned. Most of the time, these documents contain text, either in natural language (ex: French, English, Chinese), a programming language (ex: Python, C), or any kind of structured data expressible as text (ex: tables in markdown or latex, equations, ...).
A **tokenizer** defines how the text from the training dataset is converted to numbers (as a model is a mathematical function and therefore needs numbers as inputs). Tokenization is done by transforming text into sub-units called tokens (which can be words, sub-words, or characters, depending on tokenization methods). The vocabulary size of the tokenizer indicates how many different tokens it knows, typically between 32k and 200k. The size of a dataset is often measured as the **number of tokens** it contains once split in a sequence of these individual, "atomistic" units, and these days range from several hundred billion tokens to several trillion tokens!
**Training hyperparameters** then define how the model is trained. How much should the parameters change to fit each new example? How fast should the model be updated?
Once these parameters have been selected, you only need 1) a lot of computing power to train the model and 2) competent (and kind) people to run and monitor the training. The training itself will consist in instantiating the architecture (creating the matrices on the hardware used for training) and running the training algorithm on the training dataset with the above mentioned hyperparameters. The result is a set of model **weights**. These are the model parameters after learning and what most people mean when discussing access to an open pretrained model. These weights can then be used for **inference**, i.e. for prediction on new inputs, for instance to generate text.
Pretrained LLMs can also be specialized or adapted for a specific task after pretraining, particularly when the weights are openly released. They are then used as a starting point for use cases and applications through a process called **fine-tuning**. Fine-tuning involves applying additional training steps on the model on a different –often more specialized and smaller– dataset to optimize it for a specific application. Even though this step has a cost in terms of compute power needed, it is usually much less costly than training a model from scratch, both financially and environmentally. This is one reason high-quality open-source pretrained models are very interesting, as they can be freely used and built upon by the community even when the practitioners have only access to a limited computing budget.
## 🗝️ 2022, from a race for size to a race for data
What open models were available to the community before 2023?
Until early 2022, the trend in machine learning was that the bigger a model was (i.e. the more parameters it had), the better its performance. In particular, it seemed that models going above specific size thresholds jumped in capabilities, two concepts which were dubbed `emergent abilities` and `scaling laws`. Pretrained open-source model families published in 2022 mostly followed this paradigm.
1. [BLOOM](https://huggingface.co/papers/2211.05100) (BigScience Large Open-science Open-access Multilingual Language Model)
BLOOM is a family of [models](https://huggingface.co/bigscience/bloom) released by BigScience, a collaborative effort including 1000 researchers across 60 countries and 250 institutions, coordinated by Hugging Face, in collaboration with the French organizations GENCI and IDRIS. These models use decoder-only transformers, with minor modifications (post embedding normalization,[^1] and the use of ALiBi positional embeddings [^2]). The biggest model of this family is a 176B parameters model, trained on 350B tokens of multilingual data in 46 human languages and 13 programming languages. Most of the training data was released, and details of its sources, curation, and processing were published. It is the biggest open source massively multilingual model to date.
2. [OPT](https://huggingface.co/papers/2205.01068) (Open Pre-trained Transformer)
The OPT [model](https://huggingface.co/facebook/opt-66b) family was released by Meta. These models use a decoder-only transformers architecture, following the tricks of the GPT-3 paper (a specific weights initialization, pre-normalization), with some changes to the attention mechanism (alternating dense and locally banded attention layers). The biggest model of this family is a 175B parameters model trained on 180B tokens of data from mostly public sources (books, social data through Reddit, news, Wikipedia, and other various internet sources). This model family was of comparable performance to GPT-3 models, using coding optimization to make it less compute-intensive.
3. [GLM-130B](https://huggingface.co/papers/2210.02414) (General Language Model)
[GLM-130B](https://huggingface.co/THUDM/glm-roberta-large) was released by Tsinghua University and Zhipu.AI. It uses a full transformer architecture with some changes (post-layer-normalisation with DeepNorm, rotary embeddings). The 130B parameters model was trained on 400B tokens of English and Chinese internet data (The Pile, Wudao Corpora, and other Chinese corpora). It was also of comparable performance to GPT-3 models.
4. Smaller or more specialized open LLM
Smaller open-source models were also released, mostly for research purposes: Meta released the [Galactica](https://huggingface.co/papers/2211.09085) series, LLM of up to [120B](https://huggingface.co/facebook/galactica-120b) parameters, pre-trained on 106B tokens of scientific literature, and EleutherAI released the [GPT-NeoX-20B](https://huggingface.co/EleutherAI/gpt-neox-20b) model, an entirely open source (architecture, weights, data included) decoder transformer model trained on 500B tokens (using RoPE and some changes to attention and initialization), to provide a full artifact for scientific investigations.
These huge models were exciting but also very expensive to run! When performing inference (computing predictions from a model), the model needs to be loaded in memory, but a 100B parameters model will typically require 220GB of memory to be loaded (we explain this process below), which is very large, and not accessible to most organization and practitioners!
However, in March 2022, a [new paper](https://huggingface.co/papers/2203.15556) by DeepMind came out, investigating what the optimal ratio of tokens to model parameters is for a given compute budget. In other words, if you only have an amount X of money to spend on model training, what should the respective model and data sizes be? The authors found out that, overall, for the average compute budget being spent on LLMs, models should be smaller but trained on considerably more data. Their own model, Chinchilla (not open source), was a 70B parameters model (a third of the size of the above models) but trained on 1.4T tokens of data (between 3 and 4 times more data). It had similar or better performance than its bigger counterparts, both open and closed source.
This paradigm shift, while probably already known in closed labs took the open science community by storm.
## 🌊 2023, a year of open releases
### The rise of small Large Language Models
2023 saw a wave of decoder style transformers arise, with new pretrained models released every month, and soon every week or even day: LLaMA (by Meta) in February, StableLM (by StabilityAI) and Pythia (by Eleuther AI) in April, MPT (by MosaicML) in May, X-GEN (by Salesforce) and Falcon (by TIIUAE) in June, Llama 2 (by Meta) in July, StableLM v2 (by StabilityAI) in August, Qwen (by Alibaba) and Mistral (by Mistral.AI) in September, Yi (by 01-ai) in November, DeciLM (by Deci), Phi-2, and SOLAR (by Upstage) in December.
All these releases a) included model weights (under varyingly open licenses) and b) had good performance for models on the smaller side (between 3B and 70B parameters), and therefore, they were instantly adopted by the community. Almost all of these models use the decoder transformer architecture, with various tweaks (ALiBi or RoPE, RMS pre-normalization, SwiGLU), as well as some changes to the attention functions (Flash-Attention, GQA, sliding windows) and different code base implementations to optimize for training or inference speed. These tweaks are likely to affect the performance and training speed to some extent; however, as all the architectures have been released publicly with the weights, the core differences that remain are the training data and the licensing of the models.
The first model family in this series was the [LLaMA](https://huggingface.co/papers/2302.13971) family, released by Meta AI. The explicit objective of the researchers was to train a set of models of various sizes with the best possible performances for a given computing budget. For one of the first times, the research team explicitly decided to consider not only the training budget but also the inference cost (for a given performance objective, how much does it cost to run inference with the model). In this perspective, they decided to train smaller models on even more data and for more steps than was usually done, thereby reaching higher performances at a smaller model size (the trade-off being training compute efficiency). The biggest model in the Llama 1 family is a 65B parameters model trained on 1.4T tokens, while the smaller models (resp. 6 and 13B parameters) were trained on 1T tokens. The small 13B LLaMA model outperformed GPT-3 on most benchmarks, and the biggest LLaMA model was state of the art when it came out. The weights were released with a non-commercial license though, limiting the adoption by the community.
The [Pythia](https://huggingface.co/papers/2304.01373) models were released by the open-source non-profit lab Eleuther AI, and were a [suite of LLMs](https://huggingface.co/collections/EleutherAI/pythia-scaling-suite-64fb5dfa8c21ebb3db7ad2e1) of different sizes, trained on completely public data, provided to help researchers to understand the different steps of LLM training.
The [MPT models](https://www.mosaicml.com/blog/mpt-7b), which came out a couple of months later, released by MosaicML, were close in performance but with a license allowing commercial use, and the details of their training mix. The first MPT model was a [7B model](https://huggingface.co/mosaicml/mpt-7b), followed up by 30B versions in June, both trained on 1T tokens of English and code (using data from C4, CommonCrawl, The Stack, S2ORC).
The MPT models were quickly followed by the 7 and 30B [models](https://huggingface.co/tiiuae/falcon-7b) from the [Falcon series](https://huggingface.co/collections/tiiuae/falcon-64fb432660017eeec9837b5a), released by TIIUAE, and trained on 1 to 1.5T tokens of English and code (RefinedWeb, Project Gutemberg, Reddit, StackOverflow, Github, arXiv, Wikipedia, among other sources) - later in the year, a gigantic 180B model was also released. The Falcon models, data, and training process were detailed in a technical report and a [later research paper](https://huggingface.co/papers/2311.16867).
Inheriting from the GPT-Neo-X model, StabilityAI released the [StableLM-Base-Alpha](https://huggingface.co/stabilityai/stablelm-base-alpha-7b) models, a small (3B and 7B) pre-trained series using 1.5T tokens of an experimental dataset built on ThePile, followed by a [v2 series](https://huggingface.co/stabilityai/stablelm-base-alpha-7b-v2) with a data mix including RefinedWeb, RedPajama, ThePile, and undisclosed internal datasets, and lastly by a very small 3B model, the [StableLM-3B-4e1T](https://huggingface.co/stabilityai/stablelm-3b-4e1t), complete with a [detailed technical report](https://stability.wandb.io/stability-llm/stable-lm/reports/StableLM-3B-4E1T--VmlldzoyMjU4?accessToken=u3zujipenkx5g7rtcj9qojjgxpconyjktjkli2po09nffrffdhhchq045vp0wyfo).
Where previous models were mostly public about their data, from then on, following releases gave close to no information about what was used to train the models, and their efforts cannot be reproduced - however, they provide starting points for the community through the weights released.
Early in the summer came the [X-Gen](https://huggingface.co/papers/2309.03450) [models](https://huggingface.co/Salesforce/xgen-7b-4k-base) from Salesforce, 7B parameters models trained on 1.5T tokens of "natural language and code", in several steps, following a data scheduling system (not all data is introduced at the same time to the model).
X-Gen was a bit over-shadowed by the much visible new [LLaMA-2](https://huggingface.co/papers/2307.09288) family from Meta, a range of [7 to 70B models](https://huggingface.co/meta-llama/Llama-2-7b) trained on 2T tokens "from publicly available sources", with a permissive community license and an extensive process of finetuning from human-preferences (RLHF), so-called alignment procedure.
A couple of months later, the first [model](https://huggingface.co/mistralai/Mistral-7B-v0.1) from the newly created startup Mistral, the so-called [Mistral-7B](https://huggingface.co/papers/2310.06825) was released, trained on an undisclosed number of tokens from data "extracted from the open Web". The end of 2023 was busy with model releases with a second larger model from Mistral (Mixtral 8x7B), a first impressive [model](https://huggingface.co/Deci/DeciLM-7B) from Deci.AI called [DeciLM](https://deci.ai/blog/introducing-DeciLM-7B-the-fastest-and-most-accurate-7b-large-language-model-to-date) as well as a larger merge of models from upstage, [SOLAR](https://huggingface.co/upstage/SOLAR-10.7B-v1.0) also trained on undisclosed amount and sources of data. All these models carried steady increases on the leaderboards and open benchmarks.
In parallel, a notable event of the end of the year 2023 was the rise of performances and a number of models trained in China and openly released. Two bilingual English-Chinese model series were released: [Qwen](https://huggingface.co/papers/2309.16609), from Alibaba, [models](https://huggingface.co/Qwen/Qwen-72B) of 7 to 70B parameters trained on 2.4T tokens, and [Yi](https://huggingface.co/01-ai/Yi-34B), from 01-AI, models of 6 to 34B parameters, trained on 3T tokens. The performance of these models was a step ahead of previous models both on open leaderboards like the [Open LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) and some of the most difficult benchmarks like [Skill-Mix](https://huggingface.co/papers/2310.17567). Another strong contender from late 2023 was the DeepSeek coding model from [DeepSeek AI](https://huggingface.co/deepseek-ai) trained from scratch on 2T tokens, with a composition of 87% code and 13% natural language in both English and Chinese (mostly a code model).
### Dialog models everywhere
Compared to 2022, almost all pretrained models released in 2023 came with both a pre-trained version and a dialog-finetuned version, using one of several existing approaches. While approaches for adapting models to chat-setting were developed in 2022 and before, wide adoption of these techniques really took off in 2023, emphasizing the growing use of these chat models by the general public as well as the growing manual evaluation of the models by chatting with them ("vibe-check" evaluation). We detail the most well-known approaches to adapt pretrained models for chat here, but many variations exist!
**Chat-based fine-tuning** is a variant of supervised fine-tuning, where the annotated data is chat data (multiturn dialogue-like data, much like what you would find on social media) that you fine-tune your model on. You use the same technique as when training your model: for decoder transformers, you teach your model to predict the next words one by one (called an auto-regressive approach).
**Instruction fine-tuning** (IFT) follows the same approach but with instruction datasets, which contain a collection of query-like prompts plus answers (with optional additional input if needed). These datasets teach the models how to follow an instruction and can be human or LLM-generated.
Using large-scale model-outputs synthetic datasets (datasets which are composed of model generations, e.g., generations from GPT-4 either from instructions of from interactions between users and said model) is one of the ways to accomplish instruction and chat finetuning. This is often called `distillation` as it involves taking the knowledge from a high-performing model to train or fine-tune a smaller model.
Both these methods are relatively easy to implement: you just need to find or generate related datasets and then fine-tune your model using the same technique as when training. A great number of instruct datasets were published last year, which improved model performance in dialogue-like setups. For more information on this topic, you can read an intro blog [here](https://huggingface.co/blog/dialog-agents). However, the models, though better, can still not match what humans expect.
**Reinforcement learning from human feedback** (RLHF) is a specific approach that aims to align what the model predicts to what humans like best (depending on specific criteria). It was (at the beginning of the year) a new technique for fine-tuning. From a given prompt, the model generates several possible answers; humans rank these answers; the rankings are used to train what is called a preference model (which learns to give a score reflecting human preference for answers); the preference model is then used to fine-tune the language model using reinforcement learning. For more detailed information, see this [blog post](https://huggingface.co/blog/rlhf), the [original RLHF paper](https://huggingface.co/papers/1909.08593), or the Anthropic paper on [RLHF](https://huggingface.co/papers/2204.05862). It's a costly method (annotating/ranking + training a new model + fine-tuning is quite expensive) that has been mostly used to align models for safety objectives. A less costly variation of this method has been developed that uses a high-quality LLM to rank model outputs instead of humans: **reinforcement learning from AI feedback** (RLAIF).
**Direct preference optimization** (DPO) is another variation of RLHF, but does not require the training and use of a separate preference model - the method requires the same human or AI ranking dataset but uses this data to update the model directly by looking at the difference between its original policy (way of predicting) and the optimal one (which would predict the best-ranked answers). In other words, the aligned model is also the preference model, which makes the optimization procedure a lot simpler while giving what seems to be equivalent final performances.
So, to come back to our wave of small open weights models from (mostly) private companies, a lot of them were released with fine-tuned counterparts: MPT-7B also came with an instruct and a chat version, instruct-tuned versions of Falcon and XGen models were released at the end of the year, Llama-2, Qwen and Yi were released with chat versions and DeciLM with an instruct version. The release of Llama-2 was particularly notable due to the strong focus on safety, both in the pretraining and fine-tuning models.
### What about the community?
While chat models and instruction fine-tuned models were usually provided directly with new model releases, the community and researchers didn't take this for granted: a wide and healthy community of model fine-tuners bloomed over the fruitful grounds provided by these base models, with discussions spontaneously occurring on Reddit, Discord, the Hugging Face Hub, and Twitter. Community model releases were frequent, in parallel with the creation of new interesting datasets (also used to finetune models to ascertain their good performances and quality).
At the beginning of 2023, a few datasets for instruction/chat finetuning were already released. For instance, for human preferences, the [WebGPT](https://huggingface.co/datasets/openai/webgpt_comparisons) dataset by OpenAI, [HH-RLHF dataset](https://github.com/anthropics/hh-rlhf) by Anthropic, and [Summarize](https://huggingface.co/datasets/openai/summarize_from_feedback) by OpenAI were pioneer in this direction. Examples of instruction datasets are the [Public Pool of Prompts](https://huggingface.co/datasets/bigscience/P3) by BigScience, [FLAN](https://github.com/google-research/FLAN) 1 and 2 by Google, [Natural Instructions](https://github.com/allenai/natural-instructions) by AllenAI, [Self Instruct](https://github.com/yizhongw/self-instruct), a framework to generate automatic instructions by researchers from different affiliations, [SuperNatural instructions](https://aclanthology.org/2022.emnlp-main.340/), an expert created instruction benchmark sometimes used as fine-tuning data, [Unnatural instructions](https://aclanthology.org/2023.acl-long.806.pdf), an automatically generated instruction dataset by Tel Aviv University and Meta, among others.
❄️ Winter 2022/2023: In January this year, the [Human ChatGPT Instruction corpus](https://huggingface.co/datasets/Hello-SimpleAI/HC3) (HC3) was released by Chinese researchers from various institutions, and contained humans versus model answers to various questions. March was filled with releases: Stanford opened the [Alpaca](https://github.com/tatsu-lab/stanford_alpaca) model, which was the first instruction-following LLaMA model (7B), and the associated dataset, 52K instructions generated with an LLM. LAION (a non profit open source lab) released the [Open Instruction Generalist](https://laion.ai/blog/oig-dataset/) (OIG) dataset, 43M instructions both created with data augmentation and compiled from other pre-existing data sources. The same month, LMSYS org (at UC Berkeley) released [Vicuna](https://lmsys.org/blog/2023-03-30-vicuna/), also a LLaMA fine-tune (13B), this time on chat data: conversations between users and ChatGPT, shared publicly by the users themselves on [ShareGPT](https://share-gpt.com/). The [Guanaco](https://huggingface.co/datasets/JosephusCheung/GuanacoDataset) dataset, an extension of the Alpaca dataset (containing an added 500K entries in more languages), was also released, as well as the associated LLaMA-7B fine-tune.
🌱 Spring: In April, BAIR (Berkeley AI Research lab) released [Koala](https://bair.berkeley.edu/blog/2023/04/03/koala/), a chat-tuned LLaMA model, using several of the previous datasets (Alpaca, HH-RLHF, WebGPT, ShareGPT), and DataBricks released the [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k) dataset, a great human effort of 15K manually generated instructions as well as the associated model, a Pythia fine-tune. In May, Tsinghua University released [UltraChat](https://arxiv.org/abs/2305.14233), a dataset of 1.5M conversations containing instructions, and UltraLLaMA, a fine-tune on said dataset. Microsoft then released the [GPT4-LLM](https://github.com/Instruction-Tuning-with-GPT-4/GPT-4-LLM) dataset/framework to generate instructions with GPT4, and in June, Microsoft research shared a new method, [Orca](https://arxiv.org/pdf/2306.02707.pdf), to construct instruction datasets by using the reasoning trace of larger models (which explain their step by step reasoning) - it was soon reproduced by the community (notably Alignmentlab.ai), who created [Open Orca](https://huggingface.co/Open-Orca) datasets, several million of entries, then used to fine-tune a number of models (Llama, Mistral, ...). In May and June, [Camel-AI](https://huggingface.co/camel-ai) released a number of instruction or chat datasets on different topics (more than 20K examples in each domain, physics, biology, chemistry, ...) obtained with GPT4. In June, too, the [Airoboros](https://github.com/jondurbin/airoboros) framework to fine-tune models using model-generated data (following the self-instruct approach) was released, along with a number of [instruct datasets](https://huggingface.co/jondurbin).
🌻Summer: In August, [UltraLM](https://github.com/thunlp/UltraChat) (a high-performing chat fine-tune of LLaMA) was released by OpenBMB, a Chinese non-profit, and in September, they released the associated preference dataset [UltraFeedback](https://huggingface.co/datasets/openbmb/UltraFeedback), a feedback dataset of inputs compared by GPT4 (with annotations). Throughout the summer, [NousResearch](https://huggingface.co/NousResearch), a collective, released several fine-tunes (notably the Hermes and Capybara collections) based on several private and public instruct datasets. In September, a student team from Tsinghua University released [OpenChat](https://huggingface.co/openchat/openchat_3.5), a LLaMA fine-tune using a new RL finetuning strategy, and Intel released an [Orca style DPO dataset](https://huggingface.co/datasets/Intel/orca_dpo_pairs).
🍂 Autumn: In October, Hugging Face released [Zephyr](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta), a Mistral fine-tune using DPO and AIF on UltraChat and UltraFeedback, and community members released [OpenHermes 2](https://huggingface.co/teknium/OpenHermes-2-Mistral-7B), a Mistral-7B fine-tuned on 900K entries either from the web or generated with Axolotl. Lmsys released LMSYS-Chat-1M, real-life user conversations with 25 LLMs. In November, OpenBuddy released OpenBuddy-Zephyr, a Zephyr fine-tuned on multi-turn dialogue data, and Argilla released [Notus](https://huggingface.co/argilla/notus-7b-v1), a DPO fine-tune of Zephyr. NVIDIA released [HelpSteer](https://huggingface.co/datasets/nvidia/HelpSteer), an alignment fine-tuning dataset providing prompts, associated model responses, and grades of said answers on several criteria, while Microsoft Research released the [Orca-2](https://huggingface.co/microsoft/Orca-2-13b) model, a Llama 2 fine-tuned on a new synthetic reasoning dataset and Intel [Neural Chat](https://huggingface.co/Intel/neural-chat-7b-v3-1), a Mistral fine-tune on Orca and with DPO. In December, Berkeley released [Starling](https://huggingface.co/berkeley-nest/Starling-LM-7B-alpha), a RLAIF fine-tuned of Open-Chat, and the associated dataset, [Nectar](https://huggingface.co/datasets/berkeley-nest/Nectar), 200K entries of comparison data.
As we can see, this whole year's development relies both on the creation of new datasets through the use of high-quality pretrained LLMs, as well as on all the open models released by the community, making the field go forward by leaps and bounds! And if you now see one of these names in a model name, you'll be able to get an idea of where it's coming from 🤗
Note: *Some more specialized datasets (such as [MetaMath](https://meta-math.github.io/) or [MathInstruct](https://huggingface.co/datasets/TIGER-Lab/MathInstruct) math problem fine-tuning datasets, [Evol-Instruct](https://huggingface.co/datasets/WizardLM/WizardLM_evol_instruct_70k), math and code instructions, [CodeAlpaca](https://huggingface.co/datasets/sahil2801/CodeAlpaca-20k) and [CodeCapybara](https://github.com/FSoft-AI4Code/CodeCapybara) code instructions) were also released, but we won't cover them in detail here, though they have also been used to improve model performance on specific tasks. You can also see the [awesome instructions dataset](https://github.com/jianzhnie/awesome-instruction-datasets) for a compilation of other relevant datasets.*
## Democratizing access
Note: A number of tools also emerged to support inference and deployment for more beginner users, such as llama.cpp, ollama, text-generation-inference, vllm, among others. They are out of scope for this document.
### Merging: Extreme customization
In a typical open-source fashion, one of the landmark of the community is model/data merging. With each merge/commit, it can be more difficult to trace both the data used (as a number of released datasets are compilations of other datasets) and the models' history, as highly performing models are fine-tuned versions of fine-tuned versions of similar models (see Mistral's "child models tree" [here](https://huggingface.co/spaces/davanstrien/mistral-graph)). In this summary, we haven't had the time yet to talk about this amazing technique, so let's spend a couple of final words on it.
But what does it mean to merge a model?
**Model merging** is a way to fuse the weights of different models together in a single model to (ideally) combine the respective strengths of each model in a unified single model. A few techniques exist to do so that have been extended and often published mostly in community forums, a striking case of fully decentralized research happening all over the world between a community of practitioners, researchers, and hobbyists. One of the simplest published methods consists in averaging the parameters of a set of models sharing a common architecture ([example 1](https://huggingface.co/papers/2204.03044), [example 2](https://huggingface.co/papers/2109.01903)) but more complex parameter combinations exist, such as determining which parameters are the most influential in each model for a given task ([weighted averaging](https://huggingface.co/papers/2111.09832)), or considering parameters interference between models before selecting which parameters to keep when merging ([ties merging](https://huggingface.co/papers/2306.01708)). For a good overview of the litterature, you can check this [cool paper collection](https://huggingface.co/collections/osanseviero/model-merging-65097893623330a3a51ead66)!
These techniques allow anybody to easily generate combinations of models and are made especially easy by the fact that most models are nowadays variations on the same architecture. That's the reason some models submitted to the [open LLM leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) have names such as `llama2-zephyr-orca-ultra`. This particular example is likely a merge of `llama2` and `zephyr` models, fine-tuned on orca and ultra datasets. Usually, more details are to be found in the respective model card on the Hugging Face hub.
### PEFT: Personalization at the tip of your fingers
Sometimes, you may want more controlled personalization, without enough memory to load a whole model in memory to fine tune it. Did you know that you don't need to use an entire model when fine-tuning?
You might want to use what is called **parameter efficient fine-tuning** (PEFT).
This technique first freezes up the parameters of your pretrained model of interest, then adds a number of new parameters on top of it, called the adapters. What you then fine-tune on your task are only the (lightweight) adapter weights, considerably smaller than the original model. You then just need to share your small adapter weights (and the base model)! You'll find a list of interesting approaches for PEFT [here](https://github.com/huggingface/peft).
### Quantization: Models running everywhere
We've seen that well-performing models now come in all shapes and sizes… but even then, it doesn't mean that they are accessible to all! A 30B parameters model can require more than 66G of RAM just to load in memory (not even use), and not everyone in the community has the hardware necessary to do so.
That's where quantization comes in! Quantization is a special technique which reduces a model's size by changing the precision of its parameters.
What does it mean?
In a computer, numbers are stored with a given precision (such as `float32`, `float16`, `int8`, and so forth). A precision indicates both the number type (is it a floating point number or an integer) as well as on how much memory the number is stored: `float32` stores floating point numbers on 32 bits. For a more in-depth explanation, see [this link](https://huggingface.co/docs/optimum/concept_guides/quantization#going-further-how-do-machines-represent-numbers). So, the higher the precision, the more physical memory a number takes, as it will be stored on more bits.
So, if you reduce the precision, you reduce the memory each model parameter takes in storage, therefore reducing the model size! This also means that you reduce... the actual precision of the computations, which can reduce the model's performance. However, we found out that on bigger models, this performance degradation is actually very [limited](https://huggingface.co/blog/overview-quantization-transformers).
To go back to our above example, our 30B parameters model in `float16` requires a bit less than 66G of RAM, in `8bit` it only requires half that, so 33G of RAM, and it `4bit` we reach even half of this, so around 16G of RAM, making it considerably more accessible.
There are many ways to go from one precision to another, with many different "translation" schemes existing, each with its own benefits and drawbacks. Popular approaches include [bitsandbytes](https://huggingface.co/papers/2208.07339), [GPTQ](https://huggingface.co/papers/2210.17323), and [AWQ](https://huggingface.co/papers/2306.00978). Some users, such as [TheBloke](https://huggingface.co/TheBloke), are even converting popular models to make them accessible to the community. All are very recent and still developing, and we hope to see even more progress on this as time goes on.
## What's next?
The year is not over yet! And these final ~~months~~ ~~days~~ hours have already come with the share of surprises: will a new architecture finally overperform the simple and efficient Transformer?
New releases include
- A mixture of experts:
- [Mixtral](https://huggingface.co/mistralai/Mixtral-8x7B-v0.1), the model is made of 8 sub-models (transformer decoders), and for each input, a router picks the 2 best sub-models and sums their outputs.
- Several state space models (models that map input to output through a latent space and which can expressed as either an RNN or a CNN depending on the tasks, [this resource](https://srush.github.io/annotated-s4/) is great at explaining state models if you want more information):
- [Mamba](https://huggingface.co/papers/2312.00752), a state space model with an added selection mechanism
- [Striped Hyena](https://huggingface.co/togethercomputer/StripedHyena-Nous-7B), a state space model with fast convolutions kernel
It's still a bit too early to say if these new approaches will take over the Transformer, but state space models are quite promising!
## Takeaways
- This year has seen a rise of open releases from all kinds of actors (big companies, start ups, research labs), which empowered the community to start experimenting and exploring at a rate never seen before.
- Model announcement openness has seen ebbs and flow, from early releases this year being very open (dataset mixes, weights, architectures) to late releases indicating nothing about their training data, therefore being unreproducible.
- Open models emerged from many new places, including China, with several new actors positioning themselves as strong contenders in the LLM game.
- Personalization possibilities reached an all-time high, with new strategies for fine-tuning (RLHF, adapters, merging), which are only at their beginning.
- Smaller model sizes and upgrades in quantization made LLMs really accessible to many more people!
- New architectures have also appeared - will they finally replace the Transformer?
That's it folks!
I hope you enjoyed this year's review, learned a thing or two, and feel as enthusiastic as me about how much of AI progress now relies on open source and community effort! 🤗
[^1]: Post embedding normalisation is a trick to make learning more stable.
[^2]: ALiBi positional embeddings introduce a penalty when tokens too far away in a sequence are connected together by the model (where normal positional embeddings would just store information about the order and respective position of tokens in a sequence).
| 4 |
0 | hf_public_repos | hf_public_repos/blog/introducing-csearch.md | ---
title: "Generating Human-level Text with Contrastive Search in Transformers 🤗"
thumbnail: /blog/assets/115_introducing_contrastive_search/thumbnail.png
authors:
- user: GMFTBY
---
# Generating Human-level Text with Contrastive Search in Transformers 🤗
****
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/115_introducing_contrastive_search.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
### 1. Introduction:
Natural language generation (i.e. text generation) is one of the core tasks in natural language processing (NLP). In this blog, we introduce the current state-of-the-art decoding method, ___Contrastive Search___, for neural text generation. Contrastive search is originally proposed in _"A Contrastive Framework for Neural Text Generation"_ <a href='#references'>[1]</a> ([[Paper]](https://arxiv.org/abs/2202.06417)[[Official Implementation]](https://github.com/yxuansu/SimCTG)) at NeurIPS 2022. Moreover, in this follow-up work, _"Contrastive Search Is What You Need For Neural Text Generation"_ <a href='#references'>[2]</a> ([[Paper]](https://arxiv.org/abs/2210.14140) [[Official Implementation]](https://github.com/yxuansu/Contrastive_Search_Is_What_You_Need)), the authors further demonstrate that contrastive search can generate human-level text using **off-the-shelf** language models across **16** languages.
**[Remark]** For users who are not familiar with text generation, please refer more details to [this blog post](https://huggingface.co/blog/how-to-generate).
****
<span id='demo'/>
### 2. Hugging Face 🤗 Demo of Contrastive Search:
Contrastive Search is now available on 🤗 `transformers`, both on PyTorch and TensorFlow. You can interact with the examples shown in this blog post using your framework of choice in [this Colab notebook](https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/115_introducing_contrastive_search.ipynb), which is linked at the top. We have also built this awesome [demo](https://huggingface.co/spaces/joaogante/contrastive_search_generation) which directly compares contrastive search with other popular decoding methods (e.g. beam search, top-k sampling <a href='#references'>[3]</a>, and nucleus sampling <a href='#references'>[4]</a>).
****
<span id='installation'/>
### 3. Environment Installation:
Before running the experiments in the following sections, please install the update-to-date version of `transformers` as
```yaml
pip install torch
pip install "transformers==4.24.0"
```
****
<span id='problems_of_decoding_methods'/>
### 4. Problems of Existing Decoding Methods:
Decoding methods can be divided into two categories: (i) deterministic methods and (ii) stochastic methods. Let's discuss both!
<span id='deterministic_methods'/>
#### 4.1. Deterministic Methods:
Deterministic methods, e.g. greedy search and beam search, generate text by selecting the text continuation with the highest likelihood measured by the language model. However, as widely discussed in previous studies <a href='#references'>[3]</a><a href='#references'>[4]</a>, deterministic methods often lead to the problem of _model degeneration_, i.e., the generated text is unnatural and contains undesirable repetitions.
Below, let's see an example of generated text from greedy search using GPT-2 model.
```python
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
input_ids = tokenizer('DeepMind Company is', return_tensors='pt').input_ids
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
output = model.generate(input_ids, max_length=128)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
DeepMind Company is a leading AI research company, with a focus on deep learning and deep
learning-based systems.
The company's research is focused on the development of deep learning-based systems that
can learn from large amounts of data, and that can be used to solve real-world problems.
DeepMind's research is also used by the UK government to develop new technologies for the
UK's National Health Service.
DeepMind's research is also used by the UK government to develop new technologies for the
UK's National Health Service.
DeepMind's research is also used by the UK government to develop new technologies
----------------------------------------------------------------------------------------------------
```
</details>
**[Remark]** From the result generated by greedy search, we can see obvious pattern of repetitions.
<span id='stochastic_methods'/>
#### 4.2. Stochastic Methods:
To address the issues posed by deterministic methods, stochastic methods generate text by introducing randomness during the decoding process. Two widely-used stochastic methods are (i) top-k sampling <a href='#references'>[3]</a> and (ii) nucleus sampling (also called top-p sampling) <a href='#references'>[4]</a>.
Below, we illustrate an example of generated text by nucleus sampling (p=0.95) using the GPT-2 model.
```python
import torch
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
input_ids = tokenizer('DeepMind Company is', return_tensors='pt').input_ids
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=128, top_p=0.95, top_k=0)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
DeepMind Company is a leading provider of AI-based research, development, and delivery of
AI solutions for security, infrastructure, machine learning, communications, and so on."
'AI is not journalism'
Worse still was the message its researchers hoped would reach the world's media — that it
was not really research, but rather a get-rich-quick scheme to profit from living forces'
ignorance.
"The thing is, we know that people don't consciously assess the value of the others'
information. They understand they will get the same on their own."
One example? Given the details of today
----------------------------------------------------------------------------------------------------
```
</details>
**[Remark]** While nucleus sampling can generate text free of repetitions, the semantic coherence of the generated text is not well-maintained. For instance, the generated phrase _'AI is not journalism'_ is incoherent with respect to the given prefix, i.e. _'DeepMind Company'_.
We note that this semantic inconsistency problem can partially be remedied by lowering the temperature. However, reducing the temperature brings nucleus sampling closer to greedy search, which can be seen as a trade-off between greedy search and nucleus sampling. Generally, it is challenging to find a prompt and model-independent temperature that avoids both the pitfalls of greedy search and nucleus sampling.
****
<span id='contrastive_search'/>
### 5. Contrastive Search:
In this section, we introduce a new decoding method, ___Contrastive Search___, in details.
<span id='contrastive_objective'/>
#### 5.1. Decoding Objective:
Given the prefix text \\(x_{< t}\\), the selection of the output token \\(x_{t}\\) follows
<center class="half">
<img src="assets/115_introducing_contrastive_search/formulation.png" width="750"/>
</center>
where \\(V^{(k)}\\) is the set of top-k predictions from the language model's probability distribution \\(p_{\theta}(v|x_{< t})\\). The first term, i.e. _model confidence_, is the probability of the candidate \\(v\\) predicted by the language model. The second term, _degeneration penalty_, measures how discriminative of \\(v\\) with respect to the previous context \\( x_{< t}\\) and the function \\(s(\cdot, \cdot)\\) computes the cosine similarity between the token representations. More specifically, the degeneration penalty is defined as the maximum cosine similarity between the token representation of \\(v\\), i.e. \\(h_{v}\\), and that of all tokens in the context \\(x_{< t}\\). Here, the candidate representation \\(h_{v}\\) is computed by the language model given the concatenation of \\(x_{< t}\\) and \\(v\\). Intuitively, a larger degeneration penalty of \\(v\\) means it is more similar (in the representation space) to the context, therefore more likely leading to the problem of model degeneration. The hyperparameter \\(\alpha\\) regulates the importance of these two components. When \\(\alpha=0\\), contrastive search degenerates to the vanilla greedy search.
**[Remark]** When generating output, contrastive search jointly considers (i) the probability predicted by the language model to maintain the semantic coherence between the generated text and the prefix text; and (ii) the similarity with respect to the previous context to avoid model degeneration.
<span id='contrastive_generation'/>
#### 5.2. Generating Text with Contrastive Search:
Below, we use the same prefix text (i.e. _"DeepMind Company is"_) as in Section <a href='#deterministic_methods'>4.1</a> and <a href='#stochastic_methods'>4.2</a>, and generate the text with contrastive search (k=4 and \\(\alpha=0.6\\)). To fully demonstrate the superior capability of contrastive search, we let the language model generate a **long** document with **512** tokens as
```python
from transformers import GPT2Tokenizer, GPT2LMHeadModel
model_name = 'gpt2-large'
tokenizer = GPT2Tokenizer.from_pretrained(model_name)
model = GPT2LMHeadModel.from_pretrained(model_name, pad_token_id=tokenizer.eos_token_id)
model.eval()
# prepare the prefix
prefix_text = r'DeepMind Company is'
input_ids = tokenizer(prefix_text, return_tensors='pt').input_ids
# generate the result with contrastive search
output = model.generate(input_ids, penalty_alpha=0.6, top_k=4, max_length=512)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
The arguments are as follows:
* `--top_k`: The hyperparameter \\(k\\) in contrastive search.
* `--penalty_alpha`: The hyperparameter \\(\alpha\\) in contrastive search.
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
DeepMind Company is a leader in artificial intelligence (AI). We have a long history of working
with companies such as Google, Facebook, Amazon, and Microsoft to build products that improve
people's lives, and today we are excited to announce that DeepMind's AlphaGo program has won the
game of Go, becoming the first program to defeat a professional Go player.
The victory is a testament to the power of deep learning, and to the incredible work of our
research team, which has been at the forefront of AI research for the past five years. AlphaGo
is one of the most advanced Go programs ever created, and its performance is an important step
towards the goal of human-level AI.
"This is the culmination of a decade of hard work," said Andy Ng, co-founder and CTO of DeepMind.
"We are thrilled to have achieved this milestone and look forward to continuing to develop AI that
can be used in a wide range of applications and to help people live better lives."
DeepMind's work on Go began in 2010, when it began to train a neural network to play Go using
millions of games played by top Go players around the world. Since then, the team has refined the
algorithm, adding more and more layers of reinforcement learning to make it better at recognizing
patterns and making decisions based on those patterns. In the past year and a half, the team has
made significant progress in the game, winning a record-tying 13 games in a row to move into the
top four of the world rankings.
"The game of Go is a complex game in which players have to be very careful not to overextend their
territory, and this is something that we have been able to improve over and over again," said
Dr. Demis Hassabis, co-founder and Chief Scientific Officer of DeepMind. "We are very proud of our
team's work, and we hope that it will inspire others to take the next step in their research and
apply the same techniques to other problems."
In addition to the win in Go, DeepMind has also developed an AI system that can learn to play a
number of different games, including poker, Go, and chess. This AI system, called Tarsier, was
developed in partnership with Carnegie Mellon University and the University of California,
Berkeley, and is being used to teach computer vision and machine learning to identify objects in
images and recognize speech in natural language. Tarsier has been trained to play the game of Go
and other games on a
----------------------------------------------------------------------------------------------------
```
</details>
**[Remark]** We see that the generated text is of exceptionally high quality. The entire document is grammatically fluent as well as semantically coherent. Meanwhile, the generated text also well maintains its factually correctness. For instance, in the first paragraph, it elaborates _"AlphaGo"_ as the _"first program to defeat a professional Go player"_.
<span id='contrastive_visual_demonstration'/>
#### 5.3. Visual Demonstration of Contrastive Search:
To better understand how contrastive search works, we provide a visual comparison between greedy search (<a href='#deterministic_methods'>Section 4.1</a>) and contrastive search. Specifically, we visualize the token similarity matrix of the generated text from greedy search and contrastive search, respectively. The similarity between two tokens is defined as the cosine similarity between their token representations (i.e. the hidden states of the last transformer layer). The results of greedy search (top) and contrastive search (bottom) are shown in the Figure below.
<center class="half">
<img src="assets/115_introducing_contrastive_search/greedy_search_visualization.png" width="400"/>
<img src="assets/115_introducing_contrastive_search/contrastive_search_visualization.png" width="400"/>
</center>
**[Remark]** From the result of greedy search, we see high similarity scores in the off-diagonal entries which clearly indicates the generated repetitions by greedy search. On the contrary, in the result of contrastive search, the high similarity scores mostly appear in the diagonal entries which verifies that the degeneration problem is successfully addressed. This nice property of contrastive search is achieved by the introduction of degeneration penalty (see <a href='#contrastive_objective'>Section 5.1</a>) during the decoding process.
****
<span id='more_examples'/>
### 6. More Generated Examples:
In this section, we provide more generated examples to compare different decoding methods.
<span id='gpt2_example_one'/>
#### 6.1. Example One - GPT-2:
In this part, we use GPT-2 to generate text with the prefix text from the original [OpenAI blog](https://openai.com/blog/better-language-models/) that announced the release of GPT-2.
> _In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English._
<details open>
<summary><b> Load the language model and prepare the prefix text:</b></summary>
```python
import torch
from transformers import AutoTokenizer, GPT2LMHeadModel
tokenizer = AutoTokenizer.from_pretrained('gpt2-large')
model = GPT2LMHeadModel.from_pretrained('gpt2-large')
prefix_text = r"In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns spoke perfect English."
input_ids = tokenizer(prefix_text, return_tensors='pt').input_ids
```
</details>
<span id='gpt2_greedy_example_one'/>
##### 6.1.1. Generating Text with Greedy Search:
<details>
<summary><b>Code: [click to expand]</b></summary>
```python
output = model.generate(input_ids, max_length=512)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details>
<summary><b>Model Output: [click to expand]</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously
unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact
that the unicorns spoke perfect English.
The researchers, led by Dr. David R. Williams of the University of California, Santa Cruz,
discovered the unicorns in the Andes Mountains of Peru. The area is known for its unique geology
and is home to a number of rare species of animals.
The researchers found the unicorns in the Andes Mountains of Peru.
"We were surprised to find that the unicorns were able to communicate with each other," Williams
said. "We were also surprised to find that they were able to communicate in English."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago.
"The Incas were the first people to use the Andes Mountains as a refuge from the harsh climate of
the Andes," Williams said. "They were also the first people to use the Andes Mountains as a place
to hunt and gather food."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago.
"The Incas were the first people to use the Andes Mountains as a refuge from the harsh climate of
the Andes," Williams said. "They were also the first people to use the Andes Mountains as a place
to hunt and gather food."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago.
"The Incas were the first people to use the Andes Mountains as a refuge from the harsh climate of
the Andes," Williams said. "They were also the first people to use the Andes Mountains as a place
to hunt and gather food."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago.
"The Incas were the first people to use the Andes Mountains as a refuge from the harsh climate of
the Andes," Williams said. "They were also the first people to use the Andes Mountains as a place
to hunt and gather food."
The researchers believe that the unicorns are descendants of the ancient Incas, who lived in the
area around 2,000 years ago
----------------------------------------------------------------------------------------------------
```
</details>
<span id='gpt2_nucleus_example_one'/>
##### 6.1.2. Generating Text with Nucleus Sampling:
<details>
<summary><b>Code: [click to expand]</b></summary>
```python
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=512, top_p=0.95, top_k=0)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details>
<summary><b>Model Output: [click to expand]</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously
unexplored valley, in the Andes Mountains. Even more surprising to the researchers was the fact
that the unicorns spoke perfect English. The study was published in the Journal of Zoology in
March 2016.
Polygynous mammals such as unicorns have remained largely unknown to science. Professor Gustavo
Giacota, from the University of Oxford who led the study, said that they had been documented as
far as Eastern Siberia in Russia, but had only been seen a handful of times in the Gobi Desert.
Tiny animals with pale and shiny coats live in the presence of human beings and are hardly likely
to be victims of any cruelty. However, there is some evidence of the condition occurring in both
humans and animals in remote regions, which might have similarities to "black moles" that coexist
on the skin.
It is thought that Unicorns could be inside themselves, that they have different scents depending
on their current environment, or just fall out and there are plenty of legends of how they have
survived. Experts speculate that the moths and other animals could be remnants of the Yezidi Isis
and Charon, which literally is both the word which means great bird, and the Greek word for sound.
It is said that the Isis and Charon taught their young the use of voice in the form of calling out
to others.
The scientists think that it could be ancient folklore that has survived and is no longer attributed
to a real entity
----------------------------------------------------------------------------------------------------
```
</details>
<span id='gpt2_contrastive_example_one'/>
##### 6.1.3. Generating Text with Contrastive Search:
<details open>
<summary><b>Code:</b></summary>
```python
output = model.generate(input_ids, max_length=512, penalty_alpha=0.6, top_k=4)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
In a shocking finding, scientist discovered a herd of unicorns living in a remote, previously unexplored
valley, in the Andes Mountains. Even more surprising to the researchers was the fact that the unicorns
spoke perfect English.
According to the BBC, a team of scientists led by Dr David MacKay, from the University of Bristol, spent
two years searching for the unicorn herd, which they discovered during a survey of the area.
"It's a very rare find," MacKay told the BBC. "There are a few in the Himalayas, but this is the first
time we've been able to find one in such a remote area."
The team was surprised to find a herd of unicorns living in a region that has been known to be a hotbed
of poaching, with many of the animals poached for their horns, which are used in traditional Chinese
medicine to treat everything from rheumatism to cancer.
"We knew that the area was rich in rhino horn, but we had no idea how many there were, or what they were
doing there," MacKay said. "This is an area of high poaching pressure, and we wanted to find out what was
going on."
In order to do so, the team used GPS collars to track the animals as they moved around the mountain and
the surrounding area. The GPS data was then compared with information gathered from local villagers, who
had a wealth of information about the animals' movements, including where they were eating, what they were
doing at night, and how much time they spent in the mountains each day.
After analyzing the data, the team determined that the herd consisted of at least three species of unicorns,
including a male and two females. One of the females was the mother of the male, and the other two were her
daughters. All three had the same horn color, which is believed to be a sign of purity in the animal kingdom.
While the discovery is exciting, it's not the first time scientists have discovered an animal that speaks
English. Last year, scientists discovered a species of porcupine that can be heard by humans, and has been
dubbed "Porcupine Man" for his ability to converse with the human race.
----------------------------------------------------------------------------------------------------
```
</details>
<span id='opt_example_two'/>
#### 6.2. Example Two - OPT:
In this part, we use the OPT model <a href='#references'>[5]</a> which is recently released by Meta to generate text by taking the first two sentences from the abstract of the prestigious ResNet paper <a href='#references'>[6]</a>.
> Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously.
<details open>
<summary><b> Load the language model and prepare the prefix text:</b></summary>
```python
import torch
from transformers import AutoTokenizer, OPTForCausalLM
model_name = r'facebook/opt-1.3b'
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = OPTForCausalLM.from_pretrained(model_name)
prefix_text = r"Deeper neural networks are more difficult to train. We present a residual learning framework to ease the training of networks that are substantially deeper than those used previously."
input_ids = tokenizer(prefix_text, return_tensors='pt').input_ids
```
</details>
<span id='opt_greedy_example_two'/>
##### 6.2.1. Generating Text with Greedy Search:
<details>
<summary><b>Code: [click to expand]</b></summary>
```python
output = model.generate(input_ids, max_length=256)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details>
<summary><b>Model Output: [click to expand]</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
Deeper neural networks are more difficult to train. We present a residual learning framework to ease
the training of networks that are substantially deeper than those used previously. We show that the
residual learning framework can be used to train deep neural networks that are significantly more
difficult to train than those used previously. We also show that the residual learning framework can
be used to train deep neural networks that are significantly more difficult to train than those used
previously.
The paper presents a new residual learning framework for deep neural networks that is based on the
concept of residuals. The residuals are the residuals of the network that are not used in the training
process. The residuals are computed by taking the residuals of the network that are used in the training
process and subtracting the residuals of the network that are not used in the training process. The
residuals are then used to train the network. The residuals are computed by taking the residuals of
the network that are used in the training process and subtracting the residuals of the network that
are not used in the training process. The residuals are then used to train the network. The residuals
are computed by taking the residuals of the network that are used in the training process and
subtracting the residuals of the
----------------------------------------------------------------------------------------------------
```
</details>
<span id='opt_greedy_example_two'/>
##### 6.2.2. Generating Text with Nucleus Sampling:
<details>
<summary><b>Code: [click to expand]</b></summary>
```python
torch.manual_seed(0.)
output = model.generate(input_ids, do_sample=True, max_length=256, top_p=0.95, top_k=0)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details>
<summary><b>Model Output: [click to expand]</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
Deeper neural networks are more difficult to train. We present a residual learning framework to ease the
training of networks that are substantially deeper than those used previously. The theory focuses on
several aspects of learning, including the dynamics of replicative and non-replicative aspects of learning.
This framework emphasizes learning by entropy. New randomized algorithms enable training networks with
residual learning, so that deep networks can be deployed as reliably and as efficiently as their more
conventional counterparts.
----------------------------------------------------------------------------------------------------
```
</details>
<span id='opt_contrastive_example_two'/>
##### 6.2.3. Generating Text with Contrastive Search:
<details open>
<summary><b>Code:</b></summary>
```python
output = model.generate(input_ids, max_length=256, penalty_alpha=0.6, top_k=6)
print("Output:\n" + 100 * '-')
print(tokenizer.decode(output[0], skip_special_tokens=True))
print("" + 100 * '-')
```
</details>
<details open>
<summary><b>Model Output:</b></summary>
```
Output:
----------------------------------------------------------------------------------------------------
Deeper neural networks are more difficult to train. We present a residual learning framework to ease
the training of networks that are substantially deeper than those used previously.
In this paper, we propose a model-based residual learning (MBRL) framework that is based on neural
networks trained on data that is sparse in terms of dimensionality (e.g., 1, 2, 3, etc.). The network
parameters are chosen such that there is a high probability of convergence, i.e., the number of
iterations is large enough to minimize the variance of the residuals. This is achieved by training
the network on a set of training data, in which the data is sparse in terms of dimensionality, and
then discarding the nonparametric part of the data after training is complete.
We show that MBRL outperforms other methods for deep reinforcement learning (RL) and deep convolutional
neural networks (CNNs) by a factor of at least 2. In addition, we show that, compared to CNNs, MBRL
performs better in two-dimensional (2D) and three-dimensional (3D) cases.
----------------------------------------------------------------------------------------------------
```
</details>
****
<span id='resources'/>
### 7. Resources:
For more details of contrastive search, please check our papers and code as
* **A Contrastive Framework for Neural Text Generation**: (1) [Paper](https://arxiv.org/abs/2202.06417) and (2) [Official Implementation](https://github.com/yxuansu/SimCTG).
* **Contrastive Search Is What You Need For Neural Text Generation**: (1) [Paper](https://arxiv.org/abs/2210.14140) and (2) [Official Implementation](https://github.com/yxuansu/Contrastive_Search_Is_What_You_Need).
****
<span id='citation'/>
### 8. Citation:
```bibtex
@inproceedings{su2022a,
title={A Contrastive Framework for Neural Text Generation},
author={Yixuan Su and Tian Lan and Yan Wang and Dani Yogatama and Lingpeng Kong and Nigel Collier},
booktitle={Advances in Neural Information Processing Systems},
editor={Alice H. Oh and Alekh Agarwal and Danielle Belgrave and Kyunghyun Cho},
year={2022},
url={https://openreview.net/forum?id=V88BafmH9Pj}
}
@article{su2022contrastiveiswhatyouneed,
title={Contrastive Search Is What You Need For Neural Text Generation},
author={Su, Yixuan and Collier, Nigel},
journal={arXiv preprint arXiv:2210.14140},
year={2022}
}
```
****
<span id='references'/>
## Reference:
> [1] Su et al., 2022 ["A Contrastive Framework for Neural Text Generation"](https://arxiv.org/abs/2202.06417), NeurIPS 2022
> [2] Su and Collier, 2022 ["Contrastive Search Is What You Need For Neural Text Generation"](https://arxiv.org/abs/2210.14140), Arxiv 2022
> [3] Fan et al., 2018 ["Hierarchical Neural Story Generation"](https://arxiv.org/abs/1805.04833), ACL 2018
> [4] Holtzman et al., 2020 ["The Curious Case of Neural Text Degeneration"](https://arxiv.org/abs/1904.09751), ICLR 2020
> [5] Zhang et al., 2022 ["OPT: Open Pre-trained Transformer Language Models"](https://arxiv.org/abs/2205.01068), Arxiv 2022
> [6] He et al., 2016 ["Deep Residual Learning for Image Recognition"](https://arxiv.org/abs/1512.03385), CVPR 2016
****
*- Written by Yixuan Su and Tian Lan*
****
<span id='acknowledgements'/>
## Acknowledgements:
We would like to thank Joao Gante ([@joaogante](https://huggingface.co/joaogante)), Patrick von Platen ([@patrickvonplaten](https://huggingface.co/patrickvonplaten)), and Sylvain Gugger ([@sgugger](https://github.com/sgugger)) for their help and guidance in adding contrastive search mentioned in this blog post into the `transformers` library.
| 5 |
0 | hf_public_repos | hf_public_repos/blog/gradio-blocks.md | ---
title: "Gradio 3.0 is Out!"
thumbnail: /blog/assets/68_gradio_blocks/block-party.png
authors:
- user: abidlabs
---
# Gradio 3.0 is Out!
### Machine Learning Demos
Machine learning demos are an increasingly vital part of releasing a model. Demos allow anyone — not just ML engineers — to try out a model in the browser, give feedback on predictions, and build trust in the model if it performs well.
More than 600,000 ML demos have been built with the Gradio library since its first version in 2019, and today, we are thrilled to announce **Gradio 3.0**: a ground-up redesign of the Gradio library 🥳
### What's New in Gradio 3.0?
🔥 A complete redesign of the frontend, based on the feedback we're hearing from Gradio users:
* We've switched to modern technologies (like <a href="https://svelte.dev/" target="_blank">Svelte</a>) to build the Gradio frontend. We're seeing much smaller payloads and much faster page loads as a result!
* We've also embranced a much cleaner design that will allow Gradio demos to fit in visually in more settings (such as being <a href="https://discuss.huggingface.co/t/gradio-iframe-embedding/13021/9?u=abidlabs">embedded</a> in blog posts).
<img class="max-w-full mx-auto my-6" style="width: 54rem" src="/blog/assets/68_gradio_blocks/lion.jpg">
* We've revamped our existing components, like `Dataframe` to be more user-friendly (try dragging-and-dropping a CSV file into a Dataframe) as well as added new components, such as the `Gallery`, to allow you to build the right UI for your model.
<img class="max-w-full mx-auto my-6" style="width: 54rem" src="/blog/assets/68_gradio_blocks/dalle.jpg">
* We've added a `TabbedInterface` class which allows you to group together related demos as multiple tabs in one web app
<img class="max-w-full mx-auto my-6" style="width: 54rem" src="/blog/assets/68_gradio_blocks/tts.png">
Check out all the components you can use [on our (redesigned) docs](http://www.gradio.app/docs) 🤗!
🔥 We've created a new low-level language called **Gradio Blocks** that lets you build complex custom web apps, right in Python:
<img class="max-w-full mx-auto my-6" style="width: 54rem" src="/blog/assets/68_gradio_blocks/mindseye-lite.jpg">
Why did we create Blocks? Gradio demos are very easy to build, but what if you want more control over the layout of your demo, or more flexibility on how the data flows? For example, you might want to:
* Change the layout of your demo instead of just having all of the inputs on the left and outputs on the right
* Have multi-step interfaces, in which the output of one model becomes the input to the next model, or have more flexible data flows in general
* Change a component's properties (for example, the choices in a Dropdown) or its visibilty based on user input
The low-level Blocks API allows you to do all of this, right in Python.
Here's an example of a Blocks demo that creates two simple demos and uses tabs to group them together:
```python
import numpy as np
import gradio as gr
def flip_text(x):
return x[::-1]
def flip_image(x):
return np.fliplr(x)
with gr.Blocks() as demo:
gr.Markdown("Flip text or image files using this demo.")
with gr.Tabs():
with gr.TabItem("Flip Text"):
text_input = gr.Textbox()
text_output = gr.Textbox()
# this demo runs whenever the input textbox changes
text_input.change(flip_text, inputs=text_input, outputs=text_output)
with gr.TabItem("Flip Image"):
with gr.Row():
image_input = gr.Image()
image_output = gr.Image()
button = gr.Button("Flip")
# this demo runs whenever the button is clicked
button.click(flip_image, inputs=image_input, outputs=image_output)
demo.launch()
```
Once you run `launch()`, the following demo will appear:
<img class="max-w-full mx-auto my-6" style="width: 54rem" src="/blog/assets/68_gradio_blocks/flipper.png">
For a step-by-step introduction to Blocks, check out [the dedicated Blocks Guide](https://www.gradio.app/introduction_to_blocks/)
### The Gradio Blocks Party
We're very excited about Gradio Blocks -- and we'd love for you to try it out -- so we are organizing a competition, **the Gradio Blocks Party** (😉), to see who can build the best demos with Blocks. By building these demos, we can make state-of-the-art machine learning accessible, not just to engineers, but anyone who can use an Internet browser!
Even if you've never used Gradio before, this is the perfect time to start, because the Blocks Party is running until the end of May. We'll be giving out 🤗 merch and other prizes at the end of the Party for demos built using Blocks.
Learn more about Blocks Party here: https://huggingface.co/spaces/Gradio-Blocks/README
| 6 |
0 | hf_public_repos | hf_public_repos/blog/keras-llama-32.md | ---
title: “Llama 3.2 in Keras”
thumbnail: /blog/assets/keras_llama_32/thumbnail.jpg
authors:
- user: martin-gorner
---
# Llama 3.2 in Keras
This is going to be the shortest blog post ever.
> **Question**: *Llama 3.2 landed two weeks ago on Hugging Face / Transformers. When will it be available in Keras?*
> **Answer**: *It has been working from day 1 😀. There is nothing to wait for.*
Yes, Keras Llama3 can be loaded from any standard (i.e. safetensors) Hugging Face checkpoint, including the 3.2 checkpoints. If a conversion is required, it happens on the fly. Try this:
```py
!pip install keras_hub
from keras_hub import models.Llama3CausalLM
model = Llama3CausalLM.from_preset("hf://meta-llama/Llama-3.2-1B-Instruct", dtype="bfloat16")
model.generate("Hi there!")
```
#### Here is a [Colab](https://colab.research.google.com/drive/1cnAUQbDfM8lErQ8MD2x9Mo5sfKIqIxEh) to try this out. Enjoy! 🤗
---
OK, OK, I'm being told that if I want to publish a blog post, I have to fill the space. Here are a couple of additional things to know about Keras.
## Keras is multi-backend
Keras is the time-tested modeling library for JAX, PyTorch and TensorFlow. You might have noticed this line in the [demo Colab](https://colab.research.google.com/drive/1cnAUQbDfM8lErQ8MD2x9Mo5sfKIqIxEh):
```py
import os
os.environ["KERAS_BACKEND"] = "jax" # or "torch", or "tensorflow"
```
It has to appear before `import keras` and controls if the model is running on JAX, PyTorch or TensorFlow. Very handy to try your favorite models on JAX with XLA compilation 🚀.
## What is keras-hub?
Keras is a modeling library and [keras-hub](https://keras.io/keras_hub/) is its collection of pre-trained models. It was previously called [KerasNLP](https://keras.io/keras_nlp/) and [KerasCV](https://keras.io/keras_cv/). The [rename](https://github.com/keras-team/keras-hub/issues/1831) is in progress. It has all the popular pre-trained models (Llama3, Gemma, StableDiffusion, Segment Anything, ...) with their canonical implementation in Keras.
## LLMs in Keras come "batteries included"
I mean, "tokenizer included". `model.generate()` just works on strings:
```py
model.generate("Hi there!")
> "Hi there! I'm looking for information on how to ...
```
Same thing for training. You can train on a set of strings directly:
```py
model.fit(strings) # list or dataset of input strings
```
## Chatting with an LLM
Instruction-tuned variants of popular LLMs can be used for turn-by-turn conversations. Here, Llama-3.2-1B-Instruct understands the following conversation tagging (see [meta docs](https://www.llama.com/docs/model-cards-and-prompt-formats/llama3_1/#-instruct-model-prompt-)).
```
<|start_header_id|>system<|end_header_id|>You are a helpful assistant<|eot_id|>\n
\n
<|start_header_id|>user<|end_header_id|>Hello_<|eot_id|>\n
\n
<|start_header_id|>assistant<|end_header_id|>\n
\n
```
The conversation, once formatted in this way, can be fed directly to `model.generate()`.
For convenience, the [demo Colab](https://colab.research.google.com/drive/1cnAUQbDfM8lErQ8MD2x9Mo5sfKIqIxEh) implements a helper class called `ChatState` that does the necessary string concats automatically.
## Lower level access: Tokenizer, Backbone
If you don't like "batteries included" and want to get to the underlying tokenizer and model, they are easily accessible:
```py
# tokenizer
model.preprocessor.tokenizer
# the model itself
model.backbone
# You can even load them separately from the same preset
backbone = keras_hub.models.Llama3CausalLM.from_preset("hf://meta-llama/Llama-3.2-1B-Instruct", dtype="float16")
tokenizer = keras_hub.models.Llama3Tokenizer.from_preset("hf://meta-llama/Llama-3.2-1B-Instruct")
```
## Wait, Tokenizer, Preprocessor? I'm confused
The Tokenizer just transforms text into integer vectors. Here "Hello" translates into a single token:
```py
tokenizer("Hello")
> Array([9906], dtype=int32)
```
The Preprocessor is a catch-all concept for doing all the data transformations a model requires. This could be, for example, image resizing or augmentation for tasks involving images, or text tokenization like here for a text model. For the CausalLM task, the preprocessor takes care of three additional details:
* adding the text start and text end tokens expected by the model
* padding the token sequences and generating a mask
* generating "expected outputs" for training and fine-tuning. For CausalLM tasks this is the input string shifted by one.
```py
tokens = model.preprocessor("Hello")
tokens[0] # 128000 and 128009 are the start and end text tokens
> {'token_ids': Array([128000, 9906, 128009, 0, 0, 0], dtype=int32), 'padding_mask': Array([True, True, True, False, False, False], dtype=bool)}
tokens[1] # input sequence shifted by one
> [9906, 128009, 0, 0, 0, 0]
# feeding the model manually
model.backbone(model.preprocessor(["Hello", "Hi!"])[0]) # raw logits as output
> [[[ 0.9805 0.1664 0.625 ... -0.834 -0.264 0.05203]
...]]
# More typically you would use Keras built-in functions model.generate, model.fit, model.predict, model.evaluate
```
## Keras has a built-in trainer
Just call `model.fit(ds)` on your training dataset. This trainer is compatible with the various [distributed training](https://keras.io/guides/distribution/), [mixed precision](https://keras.io/api/mixed_precision/), [quantization](https://keras.io/examples/keras_recipes/float8_training_and_inference_with_transformer/) or [LoRA/QLoRA](https://keras.io/examples/keras_recipes/parameter_efficient_finetuning_of_gemma_with_lora_and_qlora/) options available in Keras. It's also totally optional. You can write a custom training loop if you want.
For a complete example, see the [demo Colab](https://colab.research.google.com/drive/1cnAUQbDfM8lErQ8MD2x9Mo5sfKIqIxEh) where we fine-tune Llama 3.2 to speak like a pirate:

## You can upload to the Hub
Once you are happy with your fine-tuned model, upload it directly from Keras using:
```py
model.save_to_preset("./pirate-llama")
# Use your own repo here
keras_hub.upload_preset(
uri = "hf://martin-gorner/llama-3.2-1B-pirate-instruct",
preset = "./pirate-llama")
```
The uploaded model is visible [here](https://huggingface.co/martin-gorner/llama-3.2-1B-pirate-instruct).
## Distributed model parallelism for inference or training
#### Demo Colab for this section: [Llama 3.1 Keras model parallel](https://colab.research.google.com/drive/1WzErEM04rieeCMY6s_wGyTjWcuhAF-3D)
Some of you are wondering, why use Keras when one can already work with LLMs on Hugging Face using Transformers? Answer: even if you don't care about Keras' flexibility and usability as a modeling framework (you should!), Keras is your quickest path to advanced model parallelism thanks to [JAX](https://github.com/jax-ml/jax) and its powerful [XLA](https://github.com/openxla/xla) compiler.
Let's pick an 8B parameters model to demonstrate: meta-llama/Llama-3.1-8B-Instruct ([demo Colab here](https://colab.research.google.com/drive/1WzErEM04rieeCMY6s_wGyTjWcuhAF-3D)). Without quantization, this model is too large for any single accelerator. With Keras, you can load it sharded across multiple accelerators, GPU or TPU. If you are uncertain about the "correct" weight shardings, most models provide sensible defaults. Here, call `keras_hub.models.Llama3Backbone.get_layout_map(device_mesh)`:
```py
devices = keras.distribution.list_devices() # 8 TPU cores: let's do a 2x4 mesh
device_mesh = keras.distribution.DeviceMesh((2, 4), ["batch", "model"], devices)
layout_map = keras_hub.models.Llama3Backbone.get_layout_map(device_mesh) # defaults
distrib = keras.distribution.ModelParallel(layout_map=layout_map, batch_dim_name="batch")
keras.distribution.set_distribution(distrib)
# Now load the model, distributed across the accelerators
model = keras_hub.models.Llama3CausalLM.from_preset("hf://meta-llama/Llama-3.1-8B-Instruct")
```
And if you don't trust the default layout map provided by the model, you can define your own. In this example running on a "small" TPU setup with only 8 cores, the following layout map is a bit faster than the default (54s/epoch rather than 62s/epoch):
```py
layout_map = keras.distribution.LayoutMap(device_mesh)
layout_map["token_embedding/embeddings"] = ("model", None)
layout_map["token_embedding/reverse_embeddings"] = ("model", None)
layout_map["self_attention.*(query|key|value).kernel"] = ("model", None, None)
layout_map["self_attention.*attention_output.kernel"] = ("model", None, None)
layout_map["feedforward_intermediate_dense.kernel"] = (None, "model")
layout_map["feedforward_gate_dense.kernel"] = (None, "model")
layout_map["feedforward_output_dense.kernel"] = ("model", None)
```
Check out the [demo Colab here](https://colab.research.google.com/drive/1WzErEM04rieeCMY6s_wGyTjWcuhAF-3D) which fine-tunes the larger 8B Llama on pirate-speak, in just under 8 min on a Google TPU v5e (available in [JupyterLab on Hugging Face Spaces](https://huggingface.co/docs/hub/main/en/spaces-sdks-docker-jupyter). The fine-tuned model is [here](https://huggingface.co/martin-gorner/llama-3.1-8B-pirate-instruct). And if you need a short model explainer about model parallelism and Keras, I have you [covered here](https://developers.googleblog.com/en/fine-tuning-gemma-2-with-keras-hugging-face-update/).
| 7 |
0 | hf_public_repos | hf_public_repos/blog/sempre-health-eap-case-study.md | ---
title: "How Sempre Health is leveraging the Expert Acceleration Program to accelerate their ML roadmap"
thumbnail: /blog/assets/70_sempre_health/thumbnail.jpg
authors:
- user: huggingface
---
# How Sempre Health is leveraging the Expert Acceleration Program to accelerate their ML roadmap
👋 Hello, friends! We recently sat down with [Swaraj Banerjee](https://www.linkedin.com/in/swarajbanerjee/) and [Larry Zhang](https://www.linkedin.com/in/larry-zhang-b58642a3/) from [Sempre Health](https://www.semprehealth.com/), a startup that brings behavior-based, dynamic pricing to Healthcare. They are doing some exciting work with machine learning and are leveraging our [Expert Acceleration Program](https://huggingface.co/support) to accelerate their ML roadmap.
An example of our collaboration is their new NLP pipeline to automatically classify and respond inbound messages. Since deploying it to production, they have seen more than 20% of incoming messages get automatically handled by this new system 🤯 having a massive impact on their business scalability and team workflow.
In this short video, Swaraj and Larry walk us through some of their machine learning work and share their experience collaborating with our team via the [Expert Acceleration Program](https://huggingface.co/support). Check it out:
<iframe width="100%" style="aspect-ratio: 16 / 9;"src="https://www.youtube.com/embed/QBOTlNJUtdk" title="YouTube video player" frameborder="0" allow="accelerometer; autoplay; clipboard-write; encrypted-media; gyroscope; picture-in-picture" allowfullscreen></iframe>
If you'd like to accelerate your machine learning roadmap with the help of our experts, as Swaraj and Larry did, visit [hf.co/support](https://huggingface.co/support) to learn more about our Expert Acceleration Program and request a quote.
## Transcription:
### Introduction
My name is Swaraj. I'm the CTO and co-founder at Sempre Health. I'm Larry, I'm a machine learning engineer at Sempre Health. We're working on medication adherence and affordability by combining SMS engagement and discounts for filling prescriptions.
### How do you apply Machine Learning at Sempre Health?
Here at Sempre Health, we receive thousands of text messages from the patients on our platform every single day. A huge portion of these messages are messages that we can actually automatically respond to. So, for example, if a patient messages us a simple _“Thank you”_, we can automatically reply with _“You're welcome”_. Or if a patient says _“Can you refill my prescription?”_, we have systems in place to automatically call their pharmacy and submit a refill request on their behalf.
We're using machine learning, specifically natural language processing (NLP), to help identify which of these thousands of text messages that we see daily are ones that we can automatically handle.
### What challenges were you facing before the Expert Acceleration Program?
Our rule-based system caught about 80% of our inbound text messages, but we wanted to do much better. We knew that a statistical machine learning approach would be the only way to improve our parsing. When we looked around for what tools we could leverage, we found the language models on Hugging Face would be a great place to start. Even though Larry and I have backgrounds in machine learning and NLP, we were worried that we weren't formulating our problem perfectly, using the best model or neural network architecture for our particular use case and training data.
### How did you leverage the Expert Acceleration Program?
The Hugging Face team really helped us in all aspects of implementing our NLP solution for this particular problem. They give us really good advice on how to get both representative as well as accurate labels for our text messages. They also saved us countless hours of research time by pointing us immediately to the right models and the right methods. I can definitely say with a lot of confidence that it would've taken us a lot longer to see the results that we see today without the Expert Acceleration Program.
### What surprised you about the Expert Acceleration Program?
We knew what we wanted to get out of the program; we had this very concrete problem and we knew that if we used the Hugging Face libraries correctly, we could make a tremendous impact on our product. We were pleasantly surprised that we got the help that we wanted. The people that we worked with were really sharp, met us where we were, didn't require us to do a bunch of extra work, and so it was pleasantly surprising to get exactly what we wanted out of the program.
### What was the impact of collaborating with the Hugging Face team?
The most important thing about this collaboration was making a tremendous impact on our business's scalability and our operations team's workflow. We launched our production NLP pipeline several weeks ago. Since then, we've consistently seen almost 20% of incoming messages get automatically handled by our new system. These are messages that would've created a ticket for our patient operations team before. So we've reduced a lot of low-value work from our team.
### For what type of AI problems should ML teams consider the Expert Acceleration Program?
Here at Sempre Health, we're a pretty small team and we're just starting to explore how we can leverage ML to better our overall patient experience. The expertise of the Hugging Face team definitely expedited our development process for this project. So we'd recommend this program to any teams that are really looking to quickly add AI pipelines to their products without a lot of the hassle and development time that normally comes with machine learning development.
---
With the Expert Acceleration Program, we've put together a world-class team to help customers build better ML solutions, faster. Our experts answer questions and find solutions as needed in your machine learning journey from research to production. Visit [hf.co/support](https://huggingface.co/support) to learn more and request a quote.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/unsung-heroes.md | ---
title: "The 5 Most Under-Rated Tools on Hugging Face"
thumbnail: /blog/assets/unsung-heroes/new-thumbnail.png
authors:
- user: derek-thomas
---
# The 5 Most Under-Rated Tools on Hugging Face
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
tl;dr The Hugging Face Hub has a number of tools and integrations that are often overlooked that can make it easier to build many types of AI solutions</div>
The Hugging Face Hub boasts over 850K public models, with ~50k new ones added every month, and that just seems to be
climbing higher and higher. We also offer an Enterprise Hub subscription that
unlocks [compliance](https://huggingface.co/docs/hub/en/storage-regions\#regulatory-and-legal-compliance), [security](https://huggingface.co/docs/hub/en/security\#security),
and [governance](https://huggingface.co/docs/hub/en/enterprise-hub-resource-groups) features, along with additional
compute capacities on inference endpoints for production-level inference and more hardware options for doing demos on
Spaces.
The Hugging Face Hub allows broad usage since you have diverse hardware, and you can run almost anything you want
in [Docker Spaces](https://huggingface.co/docs/hub/en/spaces-sdks-docker). I’ve noticed we have a number of features
that are unsung (listed below). In the process of creating a semantic search application on the Hugging Face hub I took
advantage of all of these features to implement various parts of the solution. While I think the final application
(detailed in this org [reddit-tools-HF](https://huggingface.co/reddit-tools-HF)), is compelling, I'd like to use this example to show how you can apply them to
your own projects.
* [ZeroGPU](#zerogpu) - How can I use a free GPU?
* [Multi-process Docker](#multi-process-docker) - How can I solve 2 (n) problems in 1 space?
* [Gradio API](#gradio-api) - How can I make multiple spaces work together?
* [Webhooks](#webhooks) - How can I trigger events in a space based on the hub changes?
* [Nomic Atlas](#nomic-atlas) - A feature-rich semantic search (visual and text based)
## Use-Case
> An automatically updated, visually enabled, semantic search for a dynamic data source, for free
It’s easy to imagine multiple scenarios where this is useful:
* E-commerce platforms that are looking to handle their many products based on descriptions or reported issues
* Law firms and compliance departments who need to comb through legal documents or regulations
* Researchers who have to keep up with new advances and find relevant papers or articles for their needs
I'll be demonstrating this by using a subreddit as my data source and using the Hub to facilitate the rest. There are a
number of ways to implement this. I could put everything in 1 space, but that would be quite messy. On the other hand, having too
many components in a solution has its own challenges. Ultimately, **I chose a design that allows me to highlight some of
the unsung heroes on the Hub and demonstrate how you can use them effectively**. The architecture is shown in *Figure 1*
and is fully hosted on Hugging Face in the form of spaces, datasets and webhooks. Every feature I'm
using is free for maximum accessibility. As you need to scale your service, you might consider upgrading to the [Enterprise Hub](https://huggingface.co/enterprise).
||
|:--:|
|Figure 1: Project Flow [clickable version here](https://miro.com/app/board/uXjVKnOWQZM=/?share_link_id=183806319042)|
You can see that I'm using [r/bestofredditorupdates](https://www.reddit.com/r/BestofRedditorUpdates/) as my **Data Source**, it has 10-15 new posts a day. I pull from it daily using their API via a [Reddit Application](https://www.reddit.com/prefs/apps) with [PRAW](https://praw.readthedocs.io/en/stable/), and store the results in the **Raw Dataset** ([reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates](https://huggingface.co/datasets/reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates)). Storing new data triggers a [webhook](https://huggingface.co/docs/hub/en/webhooks), which in turn triggers the **Data Processing Space** to take action. The **Data Processing Space** will take the **Raw Dataset** and add columns to it, namely feature embeddings generated by the **Embedding Model Space** and retrieved using a Gradio client. The **Data Processing Space** will then take the processed data and store it in the **Processed Dataset**. It will also build the **Data Explorer** tool. Do note that the data is considered `not-for-all-audiences` due to the data source. More on this in [Ethical Considerations](#ethical-considerations)
| Component | Details | Location | Additional Information |
| :---- | :---- | :---- |:-----------------------------------------------------------------------------------------------|
| **Data Source** | Data from [r/bestofredditorupdates](https://www.reddit.com/r/BestofRedditorUpdates/) | | Chosen because it's my favorite subreddit\! Pulled using PRAW and Reddit’s API |
| **Dataset Creator Space** | Pulls the new Reddit data into a dataset | [reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates](https://huggingface.co/spaces/reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates) (space) | - Scheduled dataset pull job <br/>- Monitoring of Process 1 via Log Visualization |
| **Raw Dataset** | The latest aggregation of raw data from [r/bestofredditorupdates](https://www.reddit.com/r/BestofRedditorUpdates/) | [reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates](https://huggingface.co/datasets/reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates) (dataset) | |
| **Data Processing Space** | Adds an embeddings column to Raw Dataset for semantic comparisons | [reddit-tools-HF/processing-bestofredditorupdates](https://huggingface.co/spaces/reddit-tools-HF/processing-bestofredditorupdates) | Shows both the Processing Logs and the Nomic Atlas Map |
| **Embedding Model Space** | Hosts an embedding model | [reddit-tools-HF/nomic-embeddings](https://huggingface.co/spaces/reddit-tools-HF/nomic-embeddings) | Uses [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5)\* |
| **Processed Dataset** | The resulting dataset with the embeddings | [reddit-tools-HF/reddit-bestofredditorupdates-processed](https://huggingface.co/datasets/reddit-tools-HF/reddit-bestofredditorupdates-processed) (dataset) | |
| **Data Explorer** | Visual and text-based semantic search tool | [Nomic Atlas Map](https://atlas.nomic.ai/data/derek2/boru-subreddit-neural-search/map) | Built with [Nomic Atlas](https://atlas.nomic.ai): Powerful filtering and narrowing tools |
*I used [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) to generate the embeddings for a few reasons:
- Handles long contexts well (8192 tokens)
- Efficient at 137M parameters
- High on the [MTEB leaderboard](https://huggingface.co/spaces/mteb/leaderboard)
- Works with nomic-atlas for semantic search
## ZeroGPU
One of the challenges with modern models is they typically require GPUs or other heavy hardware to run. These can be
bulky with year long commitments and very expensive. Spaces makes it easy to use the hardware you desire at a low cost, but
it’s not automatically spun up and down (though you could programmatically do it!).
[ZeroGPU](https://huggingface.co/zero-gpu-explorers) is a new kind of hardware for Spaces. There is a quota for
free users and a bigger one for [PRO users](https://huggingface.co/pricing\#pro).
It has two goals :
* Provide **free** GPU access for Spaces
* Allow Spaces to run on multiple GPUs
||
|:--:|
|Figure 2: ZeroGPU behind the scenes |
This is achieved by making Spaces efficiently hold and release GPUs as needed (as opposed to a classical GPU Space with a GPU attached at all times). ZeroGPU uses Nvidia A100 GPUs under the hood (40GB of vRAM are available
for each workload).
### Application
I used ZeroGPU to host the amazing nomic embedding model in my **Embedding Model Space**. It's super convenient because
I don’t really need a dedicated GPU as I only need to do inference occasionally and incrementally.
It's **extremely** simple to use. The only change is that you need to have a function with all your GPU code inside, and
decorate that with `@spaces.GPU`.
```py
import spaces
model = SentenceTransformer("nomic-ai/nomic-embed-text-v1.5", trust_remote_code=True, device='cuda')
@spaces.GPU
def embed(document: str):
return model.encode(document)
```
## Multi-process Docker
||
|:--:|
|Figure 3: Data Processing Space |
One of the most common requests we see from enterprises is that I want feature X, or tool Y integrated. One of the best
parts of the Hugging Face Hub is that we have
an [unreasonably robust API](https://huggingface.co/docs/huggingface_hub/main/en/index) that can integrate with
basically anything. The second way of solving this problem is usually in spaces. Here I'll use a
blank [docker space](https://huggingface.co/docs/hub/spaces-sdks-docker) that can run an arbitrary docker container with
the Hardware of your choice (a free CPU in my case).
My main pain point is that I want to be able to run 2 very different things in a single space. Most spaces have a single
identity, like [showing off a diffusers model](https://huggingface.co/spaces/stabilityai/stable-diffusion),
or [generating music](https://huggingface.co/spaces/facebook/MusicGen). Consider the **Dataset Creator Space**, I need
to:
* Run some code to pull data from Reddit and store it in **Raw Dataset**
* This is a mostly invisible process
* This is run by `main.py`
* Visualize the logs from the above code so I can have a good understanding of what is going on (shown in *Figure 3*)
* This is run by `app.py`
Note that both of these should run in separate processes. I’ve come across
many use-cases where visualizing the logs
is actually really useful and important. It’s a great debugging tool and it's also much more aesthetically pleasing in
scenarios where there isn’t a natural UI.
### Application
I leverage a Multi-process Docker solution by leveraging the [supervisord](http://supervisord.org) library, which is
touted as a process control system. It's a clean way of controlling multiple separate processes. Supervisord lets me do
multiple things in a single container, which is useful in a Docker Space. Note that Spaces only allows you to expose a
single port, so that might influence what solutions you consider.
Installing Supervisor is quite easy as it's a python package.
```py
pip install supervisor
```
You need to write a `supervisord.conf` file to specify your configuration. You can see my whole example
here: [supervisord.conf](https://huggingface.co/spaces/reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates/blob/main/supervisord.conf).
It's pretty self explanatory. Note I don’t want the logs from `program:app` because `app.py` is just there to visualize
logs, not create them, so I route them to `/dev/null`.
```
[supervisord]
nodaemon=true
[program:main]
command=python main.py
stdout_logfile=/dev/stdout
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stderr
stderr_logfile_maxbytes=0
autostart=true
[program:app]
command=python app.py
stdout_logfile=/dev/null
stdout_logfile_maxbytes=0
stderr_logfile=/dev/stderr
stderr_logfile_maxbytes=0
autostart=true
autorestart=true
```
Lastly we need to start our `supervisord.conf` to actually run our 2 processes. In my [Dockerfile](https://huggingface.co/spaces/reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates/blob/main/Dockerfile) I simply run:
```
CMD ["supervisord", "-c", "supervisord.conf"]
```
## Gradio API
In the **Data Processing Space** I need embeddings for the posts, this presents a challenge if I abstract the embedding
model in another space. How do I call it?
When you build a [Gradio app](https://www.gradio.app), by default you can treat any interaction as an API call. This
means all those [cool spaces](https://huggingface.co/spaces) on the Hub have an API associated with them (Spaces allows
you to use an API call to Streamlit or Docker spaces too if the author enables it)! Even cooler, is that we have
an [easy to use client](https://www.gradio.app/docs/python-client/client) for this API.
### Application
I used the client in my **Data Processing Space** to get embeddings from the nomic model deployed in the **Embedding
Model Space**. It was used in
this [utilities.py](https://huggingface.co/spaces/reddit-tools-HF/processing-bestofredditorupdates/blob/main/src/utilities.py)
file, I’ve extrapolated the relevant parts below:
```py
from gradio_client import Client
# Define the Client
client = Client("reddit-tools-HF/nomic-embeddings")
# Create an easy to use function (originally applied to a dataframe)
def update_embeddings(content, client):
# Note that the embedding model requires you to add the relevant prefix
embedding = client.predict('search_document: ' + content, api_name="/embed")
return np.array(embedding)
# Consume
final_embedding = update_embeddings(content=row['content'], client=client)
```
<br>
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
There is even a really cool <a href="https://huggingface.co/posts/abidlabs/216848389441212">API recorder</a> now which lets you use the GUI but records each step as an API interaction.
</div>
## Webhooks
||
|:--:|
|Figure 4: Project Webhooks|
[Webhooks](https://huggingface.co/docs/hub/en/webhooks) are a foundation for MLOps-related features. They allow you to
listen for new changes on specific repos or to all repos belonging to a particular set of users/organizations (not just
your repos, but any repo).
You can use them to auto-convert models, build community bots, build CI/CD for your models, datasets, and Spaces, and
much more!
### Application
In my use-case I wanted to rebuild the **Processed Dataset** whenever I update the **Raw Dataset**. You can see
the [full code here](https://huggingface.co/spaces/reddit-tools-HF/processing-bestofredditorupdates/blob/main/app.py#L73-L139).
To do this I need to add a webhook that triggers on the **Raw Dataset** updates and to send it’s payload to the **Data
Processing Space**. There are multiple types of updates that can happen, some might be on other branches, or in the discussions tab. My criteria is to trigger when both the `README.md` file and another file are updated
on the main branch of the repo, because that's what changes when a new commit is pushed to the dataset ([here's an example](https://huggingface.co/api/datasets/reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates/compare/984759c734ab6d01c43739ac7eb46870eacf304b..adcc0f523c8fabe0f04448139fc7f72befa5428e?raw=true)).
```
# Commit cleaned up for readability
T 1807 M README.md
T 52836295 M data/train-00000-of-00001.parquet
```
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
You will need to carefully decide what your criteria is as you adapt this to your use-case
</div>
First you will need to create your webhook in your settings. It's best to
follow [this guide](https://huggingface.co/docs/hub/en/webhooks#create-your-webhook) on how to create a webhook, make
sure to use consistent endpoint names (`/dataset_repo` in my case).
<div style="background-color: #e6f9e6; padding: 16px 32px; outline: 2px solid; border-radius: 10px;">
<p>Also note the webhook url is the <em>Direct URL</em> with <code>/webhooks</code> appended. The <em>Direct URL</em> can be found by clicking the 3 dots above the space and selecting <code>Embed this Space</code>. I also set a <a href="https://huggingface.co/docs/hub/en/webhooks#webhook-secret">webhook secret</a> in the <strong>Data Processing Space</strong> so it’s secure.</p>
</div>
Here is what my webhook creation input looks like. Just don’t tell anyone my secret 😉.
Target Repositories: `datasets/reddit-tools-HF/dataset-creator-reddit-bestofredditorupdates`
Webhook URL: `https://reddit-tools-hf-processing-bestofredditorupdates.hf.space/webhooks/dataset_repo`
Secret (optional): `Float-like-a-butterfly`
Next you will need to consume your webhook in your space. To do this I'll discuss:
1. How to setup the webhook server
2. How to selectively trigger only the updates we care about
1. It must be a `repo` change
2. It must be on the main branch: `refs/heads/main`
3. It must be an update with not just the `README.md` changing
#### How to setup the webhook server
First we need to consume the payload. We have a convenient way
to [consume a webhook payload](https://huggingface.co/docs/huggingface_hub/main/en/guides/webhooks#custom-server)
built into the [huggingface_hub](https://huggingface.co/docs/huggingface_hub/index) library. You can see that I
use `@app.add_webhook` to define an endpoint that matches what I did upon webhook creation. Then I define my function.
Note you need to respond to the payload request within 30s or you will get a `500` error. This is why I have an async
function to respond and then kick off my actual process instead of doing the processing in
the `handle_repository_changes` function. You can check
out [background task documentation](https://fastapi.tiangolo.com/tutorial/background-tasks/) for more information.
```py
from huggingface_hub import WebhookPayload, WebhooksServer
app = WebhooksServer(ui=ui.queue(), webhook_secret=WEBHOOK_SECRET)
# Use /dataset_repo upon webhook creation
@app.add_webhook("/dataset_repo")
async def handle_repository_changes(payload: WebhookPayload, task_queue: BackgroundTasks):
###################################
# Add selective trigger code here #
###################################
logger.info(f"Webhook received from {payload.repo.name} indicating a repo {payload.event.action}")
task_queue.add_task(_process_webhook, payload=payload)
return Response("Task scheduled.", status_code=status.HTTP_202_ACCEPTED)
def _process_webhook(payload: WebhookPayload):
#do processing here
pass
```
#### Selectively Trigger
Since I am interested in any change at the repo level, I can use `payload.event.scope.startswith("repo")` to determine
if I care about this incoming payload.
```py
# FILTER 1: Don't trigger on non-repo changes
if not payload.event.scope.startswith("repo"):
return Response("No task scheduled", status_code=status.HTTP_200_OK)
```
I can access the branch information via `payload.updatedRefs[0]`
```py
# FILTER 2: Dont trigger if change is not on the main branch
try:
if payload.updatedRefs[0].ref != 'refs/heads/main':
response_content = "No task scheduled: Change not on main branch"
logger.info(response_content)
return Response(response_content, status_code=status.HTTP_200_OK)
except:
response_content = "No task scheduled"
logger.info(response_content)
return Response(response_content, status_code=status.HTTP_200_OK)
```
To check which files were changed is a bit more complicated. We can see some git information in `commit_files_url` but
then we need to parse it. It's kind of like a `.tsv`.
Steps:
* Get commit information
* Parse this into `changed_files`
* Take action based on my conditions
```py
from huggingface_hub.utils import build_hf_headers, get_session
# FILTER 3: Dont trigger if there are only README updates
try:
commit_files_url = f"""{payload.repo.url.api}/compare/{payload.updatedRefs[0].oldSha}..{payload.updatedRefs[0].newSha}?raw=true"""
response_text = get_session.get(commit_files_url, headers=build_hf_headers()).text
logger.info(f"Git Compare URl: {commit_files_url}")
# Splitting the output into lines
file_lines = response_text.split('\n')
# Filtering the lines to find file changes
changed_files = [line.split('\t')[-1] for line in file_lines if line.strip()]
logger.info(f"Changed files: {changed_files}")
# Checking if only README.md has been changed
if all('README.md' in file for file in changed_files):
response_content = "No task scheduled: its a README only update."
logger.info(response_content)
return Response(response_content, status_code=status.HTTP_200_OK)
except Exception as e:
logger.error(f"{str(e)}")
response_content = "Unexpected issue :'("
logger.info(response_content)
return Response(response_content, status_code=status.HTTP_501_NOT_IMPLEMENTED)
```
## Nomic Atlas
One of the common pain points we see with customers/partners is that data understanding and collaboration are
challenging. Data understanding is often the first step to solving any AI use-case. My favorite way to do that is
through visualization, and often I don’t feel I have great tools for that when it comes to semantic data. I was
absolutely delighted to discover [Nomic Atlas](https://docs.nomic.ai/index.html). It allows me to have a number of key
features for data exploration:
* Semantic Search with [nomic-ai/nomic-embed-text-v1.5](https://huggingface.co/nomic-ai/nomic-embed-text-v1.5) (in beta
now)
* Feature-rich filtering
* Keyword search
* Lasso Search (I can draw boundaries!!)
### Application
I built the nomic Atlas in the **Data Processing Space**. In the flow I have already built the **Processed Dataset** and
the only thing left is to visualize it. You can see how I build with nomic
in [build_nomic.py](https://huggingface.co/spaces/reddit-tools-HF/processing-bestofredditorupdates/blob/main/src/build_nomic.py).
As before, I'll extrapolate the relevant parts for this blog:
```py
from nomic import atlas
from nomic.dataset import AtlasClass
from nomic.data_inference import NomicTopicOptions
# Login to nomic with a Space Secret
NOMIC_KEY = os.getenv('NOMIC_KEY')
nomic.login(NOMIC_KEY)
# Set because I do want the super cool topic modeling
topic_options = NomicTopicOptions(build_topic_model=True, community_description_target_field='subreddit')
identifier = 'BORU Subreddit Neural Search'
project = atlas.map_data(embeddings=np.stack(df['embedding'].values),
data=df,
id_field='id',
identifier=identifier,
topic_model=topic_options)
print(f"Succeeded in creating new version of nomic Atlas: {project.slug}")
```
Given how nomic works, it will create a new Atlas Dataset under your account each time you run `atlas.map_data`. I want
to keep the same dataset updated. Currently the best way to do this is to delete your old dataset.
```py
ac = AtlasClass()
atlas_id = ac._get_dataset_by_slug_identifier("derek2/boru-subreddit-neural-search")['id']
ac._delete_project_by_id(atlas_id)
logger.info(f"Succeeded in deleting old version of nomic Atlas.")
#Naively wait until it's deleted on the server
sleep_time = 300
logger.info(f"Sleeping for {sleep_time}s to wait for old version deletion on the server-side")
time.sleep(sleep_time)
```
### Features
||
|:--:|
|Figure 5: Nomic Screenshot|
Using Nomic Atlas should be pretty self-explanatory and you can find
some [further documentation here](https://docs.nomic.ai). But I'll give a quick intro so I can then highlight some of
the lesser known features.
The main area with the dots shows each embedded document. The closer each document is, the more related it is. This will
vary based on a few things (how well the embedder works on your data, compression from high dimensionality to 2D
representation, etc) so take it with a grain of salt. We have the ability to search and view documents on the left.
In the **red box** in *Figure 5* we can see 5 boxes that allow us to search in different ways. Each one is applied
iteratively, which makes it a great way
to “[chip away at the elephant](https://philipchircop.wordpress.com/2012/07/03/chip-it-away/)”. We could search by date
or other field, and then use a text search for instance. The coolest feature is the one on the *far left*, it's a neural
search that you can use in 3 ways:
1. Query Search - You give a short description that should match an embedded (long) document
2. Document Search - You give a long document that should match an embedded document
3. Embedding Search - Use an embedding vector directly to search
I typically use Query search when I'm exploring my uploaded documents.
In the **blue box** in *Figure 5* we can see each row of the dataset I uploaded visualized nicely. One feature I really
liked is that it visualizes HTML. So you have control on how it looks. Since reddit posts are in markdown it's easy to
convert this to HTML to visualize it.
## Ethical Considerations
The data source for all of this contains content that is labeled Not Suited For Work (NSFW), which is similar to our
label of Not For All Audiences (NFAA). We don’t prohibit this content on the Hub, but we do want to handle it
accordingly. Additionally, recent work has shown that content that is obtained indiscriminately from the internet has a
risk of containing Child Sexual Abuse Material (CSAM), especially content that has a high prevalence of uncurated sexual
material.
To assess those risks in the context of this dataset curation effort, we can start by looking at the process through
which the source data is collated. The original stories (before being aggregated) go through a moderator, then the
update is often in a subreddit where there is a moderator. On occasion the update gets uploaded to the original poster’s
profile. The final version gets uploaded to [r/bestofredditorupdates](https://www.reddit.com/r/BestofRedditorUpdates/)
which has strict moderation. They are strict since they have more risks of brigading. All that to say there are at least
2 moderation steps, usually 3 with one being well known as strict.
At the time of writing this there were 69 stories labeled NSFW. Of those, none of them have CSAM material as I manually
checked them. I have also gated the datasets containing NFAA material. To make the nomic visualization more accessible
I’m making a filtered dataset upon atlas creation by removing posts containing content with “NSFW” in the dataframe.
## Conclusion
By shining a light on these lesser-known tools and features within the Hugging Face Hub, I hope to inspire you to think
outside the box when building your AI solutions. Whether you replicate the use-case I’ve outlined or come up with
something entirely your own, these tools can help you build more efficient, powerful, and innovative applications. Get
started today and unlock the full potential of the Hugging Face Hub!
## References
* Fikayo Adepoju, [Webhooks Tutorial: The Beginner’s Guide to Working with Webhooks](https://medium.com/hookdeck/webhooks-tutorial-the-beginners-guide-to-working-with-webhooks-79b711c4dd87), 2021
* philipchircop, [CHIP IT AWAY](https://philipchircop.wordpress.com/2012/07/03/chip-it-away/), 2012
| 9 |
0 | hf_public_repos/candle/candle-wasm-examples/bert | hf_public_repos/candle/candle-wasm-examples/bert/src/lib.rs | use candle_transformers::models::bert;
use wasm_bindgen::prelude::*;
pub use bert::{BertModel, Config, DTYPE};
pub use tokenizers::{PaddingParams, Tokenizer};
#[wasm_bindgen]
extern "C" {
// Use `js_namespace` here to bind `console.log(..)` instead of just
// `log(..)`
#[wasm_bindgen(js_namespace = console)]
pub fn log(s: &str);
}
#[macro_export]
macro_rules! console_log {
// Note that this is using the `log` function imported above during
// `bare_bones`
($($t:tt)*) => ($crate::log(&format_args!($($t)*).to_string()))
}
| 0 |
0 | hf_public_repos/candle/candle-wasm-examples/bert/src | hf_public_repos/candle/candle-wasm-examples/bert/src/bin/m.rs | use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::models::bert::{BertModel, Config};
use candle_wasm_example_bert::console_log;
use tokenizers::{PaddingParams, Tokenizer};
use wasm_bindgen::prelude::*;
#[wasm_bindgen]
pub struct Model {
bert: BertModel,
tokenizer: Tokenizer,
}
#[wasm_bindgen]
impl Model {
#[wasm_bindgen(constructor)]
pub fn load(weights: Vec<u8>, tokenizer: Vec<u8>, config: Vec<u8>) -> Result<Model, JsError> {
console_error_panic_hook::set_once();
console_log!("loading model");
let device = &Device::Cpu;
let vb = VarBuilder::from_buffered_safetensors(weights, DType::F32, device)?;
let config: Config = serde_json::from_slice(&config)?;
let tokenizer =
Tokenizer::from_bytes(&tokenizer).map_err(|m| JsError::new(&m.to_string()))?;
let bert = BertModel::load(vb, &config)?;
Ok(Self { bert, tokenizer })
}
pub fn get_embeddings(&mut self, input: JsValue) -> Result<JsValue, JsError> {
let input: Params =
serde_wasm_bindgen::from_value(input).map_err(|m| JsError::new(&m.to_string()))?;
let sentences = input.sentences;
let normalize_embeddings = input.normalize_embeddings;
let device = &Device::Cpu;
if let Some(pp) = self.tokenizer.get_padding_mut() {
pp.strategy = tokenizers::PaddingStrategy::BatchLongest
} else {
let pp = PaddingParams {
strategy: tokenizers::PaddingStrategy::BatchLongest,
..Default::default()
};
self.tokenizer.with_padding(Some(pp));
}
let tokens = self
.tokenizer
.encode_batch(sentences.to_vec(), true)
.map_err(|m| JsError::new(&m.to_string()))?;
let token_ids: Vec<Tensor> = tokens
.iter()
.map(|tokens| {
let tokens = tokens.get_ids().to_vec();
Tensor::new(tokens.as_slice(), device)
})
.collect::<Result<Vec<_>, _>>()?;
let attention_mask: Vec<Tensor> = tokens
.iter()
.map(|tokens| {
let tokens = tokens.get_attention_mask().to_vec();
Tensor::new(tokens.as_slice(), device)
})
.collect::<Result<Vec<_>, _>>()?;
let token_ids = Tensor::stack(&token_ids, 0)?;
let attention_mask = Tensor::stack(&attention_mask, 0)?;
let token_type_ids = token_ids.zeros_like()?;
console_log!("running inference on batch {:?}", token_ids.shape());
let embeddings = self
.bert
.forward(&token_ids, &token_type_ids, Some(&attention_mask))?;
console_log!("generated embeddings {:?}", embeddings.shape());
// Apply some avg-pooling by taking the mean embedding value for all tokens (including padding)
let (_n_sentence, n_tokens, _hidden_size) = embeddings.dims3()?;
let embeddings = (embeddings.sum(1)? / (n_tokens as f64))?;
let embeddings = if normalize_embeddings {
embeddings.broadcast_div(&embeddings.sqr()?.sum_keepdim(1)?.sqrt()?)?
} else {
embeddings
};
let embeddings_data = embeddings.to_vec2()?;
Ok(serde_wasm_bindgen::to_value(&Embeddings {
data: embeddings_data,
})?)
}
}
#[derive(serde::Serialize, serde::Deserialize)]
struct Embeddings {
data: Vec<Vec<f32>>,
}
#[derive(serde::Serialize, serde::Deserialize)]
pub struct Params {
sentences: Vec<String>,
normalize_embeddings: bool,
}
fn main() {
console_error_panic_hook::set_once();
}
| 1 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/moondream/index.html | <html>
<head>
<meta content="text/html;charset=utf-8" http-equiv="Content-Type" />
<title>Candle Moondream Rust/WASM</title>
</head>
<body></body>
</html>
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8" />
<meta name="viewport" content="width=device-width, initial-scale=1.0" />
<link
rel="stylesheet"
href="https://cdn.jsdelivr.net/gh/highlightjs/[email protected]/build/styles/default.min.css"
/>
<style>
@import url("https://fonts.googleapis.com/css2?family=Source+Code+Pro:wght@200;300;400&family=Source+Sans+3:wght@100;200;300;400;500;600;700;800;900&display=swap");
html,
body {
font-family: "Source Sans 3", sans-serif;
}
code,
output,
select,
pre {
font-family: "Source Code Pro", monospace;
}
</style>
<style type="text/tailwindcss">
.link {
@apply underline hover:text-blue-500 hover:no-underline;
}
</style>
<script src="https://cdn.tailwindcss.com/3.4.3"></script>
<script type="module" src="./code.js"></script>
</head>
<body class="container max-w-4xl mx-auto p-4 text-gray-800">
<main class="grid grid-cols-1 gap-8 relative">
<span class="absolute text-5xl -ml-[1em]"> 🕯️ </span>
<div>
<h1 class="text-5xl font-bold">Candle Moondream 2</h1>
<h2 class="text-2xl font-bold">Rust/WASM Demo</h2>
<p class="max-w-lg">
<a
href="https://huggingface.co/vikhyatk/moondream2"
class="link"
target="_blank"
>Moondream 2</a
>
by
<a
href=" https://huggingface.co/vikhyatk"
class="link"
target="_blank"
>Vik</a
>
and model implementation on Candle by
<a
href="https://huggingface.co/santiagomed"
class="link"
target="_blank"
>Santiago Medina
</a>
</p>
</div>
<div>
<p class="text-xs italic max-w-lg">
<b>Note:</b>
When first run, the app will download and cache the model, which could
take a few minutes. Then, the embeddings and generation will take a
few minutes to start 😔.
</p>
</div>
<div>
<label for="model" class="font-medium">Models Options: </label>
<select
id="model"
class="border-2 border-gray-500 rounded-md font-light"
></select>
</div>
<form
id="form"
class="flex text-normal px-1 py-1 border border-gray-700 rounded-md items-center"
>
<input type="submit" hidden />
<input
type="text"
id="prompt"
class="font-light text-lg w-full px-3 py-2 mx-1 resize-none outline-none"
placeholder="Add your prompt here..."
/>
<button
id="run"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-2 w-16 rounded disabled:bg-gray-300 disabled:cursor-not-allowed"
>
Run
</button>
</form>
<details>
<summary class="font-medium cursor-pointer">Advanced Options</summary>
<div class="grid grid-cols-3 max-w-md items-center gap-3 py-3">
<label class="text-sm font-medium" for="max-seq"
>Maximum length
</label>
<input
type="range"
id="max-seq"
name="max-seq"
min="1"
max="2048"
step="1"
value="500"
oninput="this.nextElementSibling.value = Number(this.value)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>
500</output
>
<label class="text-sm font-medium" for="temperature"
>Temperature</label
>
<input
type="range"
id="temperature"
name="temperature"
min="0"
max="2"
step="0.01"
value="0.00"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>
0.00</output
>
<label class="text-sm font-medium" for="top-p">Top-p</label>
<input
type="range"
id="top-p"
name="top-p"
min="0"
max="1"
step="0.01"
value="1.00"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>
1.00</output
>
<label class="text-sm font-medium" for="repeat_penalty"
>Repeat Penalty</label
>
<input
type="range"
id="repeat_penalty"
name="repeat_penalty"
min="1"
max="2"
step="0.01"
value="1.10"
oninput="this.nextElementSibling.value = Number(this.value).toFixed(2)"
/>
<output
class="text-xs w-[50px] text-center font-light px-1 py-1 border border-gray-700 rounded-md"
>1.10</output
>
<label class="text-sm font-medium" for="seed">Seed</label>
<input
type="number"
id="seed"
name="seed"
value="299792458"
class="font-light border border-gray-700 text-right rounded-md p-2"
/>
<button
id="run"
onclick="document.querySelector('#seed').value = Math.floor(Math.random() * Number.MAX_SAFE_INTEGER)"
class="bg-gray-700 hover:bg-gray-800 text-white font-normal py-1 w-[50px] rounded disabled:bg-gray-300 disabled:cursor-not-allowed text-sm"
>
Rand
</button>
</div>
</details>
<div class="grid md:grid-cols-2 gap-4 items-start">
<div>
<div class="relative md:mt-6">
<div
class="absolute w-full bottom-full flex justify-between items-center"
>
<div class="flex gap-2 w-full">
<button
id="clear-img-btn"
disabled
title="Clear Image"
class="ml-auto text-xs py-1 bg-white rounded-md disabled:opacity-20 flex gap-1 items-center"
>
<svg
class=""
xmlns="http://www.w3.org/2000/svg"
viewBox="0 0 13 12"
height="1em"
>
<path
d="M1.6.7 12 11.1M12 .7 1.6 11.1"
stroke="#2E3036"
stroke-width="2"
/>
</svg>
</button>
</div>
</div>
<div
id="drop-area"
class="min-h-[250px] flex flex-col items-center justify-center border-2 border-gray-300 border-dashed rounded-xl relative w-full overflow-hidden"
>
<div
class="absolute flex flex-col items-center justify-center space-y-1 text-center"
>
<svg
width="25"
height="25"
viewBox="0 0 25 25"
fill="none"
xmlns="http://www.w3.org/2000/svg"
>
<path
d="M3.5 24.3a3 3 0 0 1-1.9-.8c-.5-.5-.8-1.2-.8-1.9V2.9c0-.7.3-1.3.8-1.9.6-.5 1.2-.7 2-.7h18.6c.7 0 1.3.2 1.9.7.5.6.7 1.2.7 2v18.6c0 .7-.2 1.4-.7 1.9a3 3 0 0 1-2 .8H3.6Zm0-2.7h18.7V2.9H3.5v18.7Zm2.7-2.7h13.3c.3 0 .5 0 .6-.3v-.7l-3.7-5a.6.6 0 0 0-.6-.2c-.2 0-.4 0-.5.3l-3.5 4.6-2.4-3.3a.6.6 0 0 0-.6-.3c-.2 0-.4.1-.5.3l-2.7 3.6c-.1.2-.2.4 0 .7.1.2.3.3.6.3Z"
fill="#000"
/>
</svg>
<div class="flex text-sm text-gray-600">
<label
for="file-upload"
class="relative cursor-pointer bg-white rounded-md font-medium text-blue-950 hover:text-blue-700"
>
<span>Drag and drop the image here</span>
<span class="block text-xs">or</span>
<span class="block text-xs">Click to upload</span>
</label>
</div>
<input
id="file-upload"
name="file-upload"
type="file"
accept="image/*"
class="sr-only"
/>
</div>
<canvas
id="canvas"
class="z-10 pointer-events-none w-full"
></canvas>
</div>
</div>
</div>
<div>
<h3 class="font-medium">Generation:</h3>
<div
class="min-h-[250px] bg-slate-100 text-gray-500 p-4 rounded-md flex flex-col gap-2"
>
<div
id="output-counter"
hidden
class="ml-auto font-semibold grid-rows-1"
></div>
<p hidden id="output-generation" class="grid-rows-2 text-lg"></p>
<span id="output-status" class="m-auto font-light"
>No output yet</span
>
</div>
</div>
</div>
<div>
<div
class="flex gap-3 items-center overflow-x-scroll"
id="image-select"
>
<h3 class="font-medium">Examples:</h3>
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/sf.jpg"
class="cursor-pointer w-24 h-24 object-cover"
/>
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/bike.jpeg"
class="cursor-pointer w-24 h-24 object-cover"
/>
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/000000000077.jpg"
class="cursor-pointer w-24 h-24 object-cover"
/>
<img
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/candle/examples/demo-1.jpg"
class="cursor-pointer w-24 h-24 object-cover"
/>
</div>
</div>
</main>
</body>
</html>
| 2 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/moondream/Cargo.toml | [package]
name = "candle-wasm-example-moondream"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
[dependencies]
candle = { workspace = true }
candle-nn = { workspace = true }
candle-transformers = { workspace = true }
tokenizers = { workspace = true, features = ["unstable_wasm"] }
num-traits = { workspace = true }
# App crates.
anyhow = { workspace = true }
byteorder = { workspace = true }
getrandom = { version = "0.2", features = ["js"] }
image = { workspace = true }
log = { workspace = true }
safetensors = { workspace = true }
serde = { workspace = true }
serde_json = { workspace = true }
# Wasm specific crates.
console_error_panic_hook = "0.1.7"
wasm-bindgen = "0.2.87"
js-sys = "0.3.64"
serde-wasm-bindgen = "0.6.5"
| 3 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/moondream/build-lib.sh | cargo build --target wasm32-unknown-unknown --release
wasm-bindgen ../../target/wasm32-unknown-unknown/release/m.wasm --out-dir build --target web
| 4 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/moondream/code.js | import snarkdown from "https://cdn.skypack.dev/snarkdown";
import hljs from "https://cdn.skypack.dev/highlight.js";
// models base url
const MODELS = {
moondream2_q4k: {
base_url:
"https://huggingface.co/santiagomed/candle-moondream/resolve/main/",
model: "model-q4_0.gguf",
tokenizer: "tokenizer.json",
quantized: true,
size: "1.51 GB",
},
};
const moodreamWorker = new Worker("./moondreamWorker.js", {
type: "module",
});
async function generateSequence(controller) {
const getValue = (id) => document.querySelector(`#${id}`).value;
const modelID = getValue("model");
const model = MODELS[modelID];
const weightsURL =
model.model instanceof Array
? model.model.map((m) => model.base_url + m)
: model.base_url + model.model;
const tokenizerURL = model.base_url + model.tokenizer;
const prompt = getValue("prompt").trim();
const temperature = getValue("temperature");
const topP = getValue("top-p");
const repeatPenalty = getValue("repeat_penalty");
const seed = getValue("seed");
const maxSeqLen = getValue("max-seq");
if (prompt?.value?.trim() === "") {
return;
}
function updateStatus(data) {
const outStatus = document.querySelector("#output-status");
const outGen = document.querySelector("#output-generation");
const outCounter = document.querySelector("#output-counter");
switch (data.status) {
case "loading":
outStatus.hidden = false;
outStatus.textContent = data.message;
outGen.hidden = true;
outCounter.hidden = true;
break;
case "generating":
const { message, prompt, sentence, tokensSec, totalTime } = data;
outStatus.hidden = true;
outCounter.hidden = false;
outGen.hidden = false;
outGen.innerHTML = snarkdown(prompt + sentence);
outCounter.innerHTML = `${(totalTime / 1000).toFixed(
2
)}s (${tokensSec.toFixed(2)} tok/s)`;
hljs.highlightAll();
break;
case "complete":
outStatus.hidden = true;
outGen.hidden = false;
break;
}
}
return new Promise((resolve, reject) => {
moodreamWorker.postMessage({
weightsURL,
modelID,
tokenizerURL,
quantized: model.quantized,
imageURL: currentImageURL,
prompt,
temp: temperature,
top_p: topP,
repeatPenalty,
seed: seed,
maxSeqLen,
verbose_prompt: false,
command: "start",
});
const handleAbort = () => {
moodreamWorker.postMessage({ command: "abort" });
};
const handleMessage = (event) => {
const { status, error, message, prompt, sentence } = event.data;
if (status) updateStatus(event.data);
if (error) {
moodreamWorker.removeEventListener("message", handleMessage);
reject(new Error(error));
}
if (status === "aborted") {
moodreamWorker.removeEventListener("message", handleMessage);
resolve(event.data);
}
if (status === "complete") {
moodreamWorker.removeEventListener("message", handleMessage);
resolve(event.data);
}
};
controller.signal.addEventListener("abort", handleAbort);
moodreamWorker.addEventListener("message", handleMessage);
});
}
const form = document.querySelector("#form");
const prompt = document.querySelector("#prompt");
const runBtn = document.querySelector("#run");
const modelSelect = document.querySelector("#model");
const dropArea = document.querySelector("#drop-area");
const canvas = document.querySelector("#canvas");
const ctxCanvas = canvas.getContext("2d");
const fileUpload = document.querySelector("#file-upload");
const clearImgBtn = document.querySelector("#clear-img-btn");
const imagesExamples = document.querySelector("#image-select");
let currentImageURL = null;
let runController = new AbortController();
let isRunning = false;
document.addEventListener("DOMContentLoaded", () => {
for (const [id, model] of Object.entries(MODELS)) {
const option = document.createElement("option");
option.value = id;
option.innerText = `${id} (${model.size})`;
modelSelect.appendChild(option);
}
const query = new URLSearchParams(window.location.search);
const modelID = query.get("model");
if (modelID) {
modelSelect.value = modelID;
} else {
modelSelect.value = "moondream2_q4k";
}
});
imagesExamples.addEventListener("click", (e) => {
// if (isEmbedding || isSegmenting) {
// return;
// }
const target = e.target;
if (target.nodeName === "IMG") {
const href = target.src;
clearImageCanvas();
currentImageURL = href;
drawImageCanvas(href);
}
});
modelSelect.addEventListener("change", (e) => {
const query = new URLSearchParams(window.location.search);
query.set("model", e.target.value);
window.history.replaceState({}, "", `${window.location.pathname}?${query}`);
window.parent.postMessage({ queryString: "?" + query }, "*");
const model = MODELS[e.target.value];
document.querySelector("#max-seq").max = model.seq_len;
document.querySelector("#max-seq").nextElementSibling.value = 200;
});
clearImgBtn.addEventListener("click", () => {
clearImageCanvas();
});
//add event listener to file input
fileUpload.addEventListener("input", async (e) => {
const target = e.target;
if (target.files.length > 0 && !target.files[0].type.includes("svg")) {
const href = URL.createObjectURL(target.files[0]);
clearImageCanvas();
await drawImageCanvas(href);
}
});
// add event listener to drop-area
dropArea.addEventListener("dragenter", (e) => {
e.preventDefault();
dropArea.classList.add("border-blue-700");
});
dropArea.addEventListener("dragleave", (e) => {
e.preventDefault();
dropArea.classList.remove("border-blue-700");
});
dropArea.addEventListener("dragover", (e) => {
e.preventDefault();
});
dropArea.addEventListener("drop", async (e) => {
e.preventDefault();
dropArea.classList.remove("border-blue-700");
const url = e.dataTransfer.getData("text/uri-list");
const files = e.dataTransfer.files;
if (files.length > 0) {
const href = URL.createObjectURL(files[0]);
clearImageCanvas();
await drawImageCanvas(href);
} else if (url) {
clearImageCanvas();
await drawImageCanvas(url);
}
});
form.addEventListener("submit", async (e) => {
e.preventDefault();
if (isRunning) {
stopRunning();
} else {
startRunning();
await generateSequence(runController);
stopRunning();
}
});
async function drawImageCanvas(imgURL) {
if (!imgURL) {
throw new Error("No image URL provided");
}
return new Promise((resolve, reject) => {
ctxCanvas.clearRect(0, 0, canvas.width, canvas.height);
ctxCanvas.clearRect(0, 0, canvas.width, canvas.height);
const img = new Image();
img.crossOrigin = "anonymous";
img.onload = () => {
canvas.width = img.width;
canvas.height = img.height;
ctxCanvas.drawImage(img, 0, 0);
clearImgBtn.disabled = false;
resolve(img);
};
img.src = imgURL;
currentImageURL = imgURL;
});
}
function clearImageCanvas() {
ctxCanvas.clearRect(0, 0, canvas.width, canvas.height);
clearImgBtn.disabled = true;
canvas.parentElement.style.height = "auto";
currentImageURL = null;
canvas.width = 0;
canvas.height = 0;
}
function startRunning() {
isRunning = true;
runBtn.textContent = "Stop";
prompt.disabled = true;
}
function stopRunning() {
runController.abort();
runController = new AbortController();
runBtn.textContent = "Run";
isRunning = false;
prompt.disabled = false;
}
prompt.addEventListener("input", (e) => {
runBtn.disabled = false;
});
| 5 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/moondream/moondreamWorker.js | import init, { Model } from "./build/m.js";
async function fetchArrayBuffer(url, cacheModel = true) {
if (!cacheModel)
return new Uint8Array(await (await fetch(url)).arrayBuffer());
const cacheName = "moondream-candle-cache";
const cache = await caches.open(cacheName);
const cachedResponse = await cache.match(url);
if (cachedResponse) {
const data = await cachedResponse.arrayBuffer();
return new Uint8Array(data);
}
const res = await fetch(url, { cache: "force-cache" });
cache.put(url, res.clone());
return new Uint8Array(await res.arrayBuffer());
}
async function concatenateArrayBuffers(urls) {
const arrayBuffers = await Promise.all(
urls.map((url) => fetchArrayBuffer(url))
);
let totalLength = arrayBuffers.reduce(
(acc, arrayBuffer) => acc + arrayBuffer.byteLength,
0
);
let concatenatedBuffer = new Uint8Array(totalLength);
let offset = 0;
arrayBuffers.forEach((buffer) => {
concatenatedBuffer.set(new Uint8Array(buffer), offset);
offset += buffer.byteLength;
});
return concatenatedBuffer;
}
class Moondream {
static imageArrayHash = {};
static instance = {};
static currentModelID = null;
static async getInstance(weightsURL, modelID, tokenizerURL, quantized) {
// load individual modelID only once
if (!this.instance[modelID]) {
await init();
self.postMessage({ status: "loading", message: "Loading Model" });
const [weightsArrayU8, tokenizerArrayU8] = await Promise.all([
weightsURL instanceof Array
? concatenateArrayBuffers(weightsURL)
: fetchArrayBuffer(weightsURL),
fetchArrayBuffer(tokenizerURL),
]);
this.instance[modelID] = new Model(
weightsArrayU8,
tokenizerArrayU8,
quantized
);
}
this.currentModelID = modelID;
return this.instance[modelID];
}
// Remove the modelID parameter from setImageEmbeddings
static setImageEmbeddings(imageArrayU8) {
// check if image embeddings are already set for this image and model
const imageArrayHash = this.getSimpleHash(imageArrayU8);
if (
this.imageArrayHash[this.currentModelID] === imageArrayHash &&
this.instance[this.currentModelID]
) {
self.postMessage({
status: "embedding",
message: "Embeddings Already Set",
});
return;
}
this.imageArrayHash[this.currentModelID] = imageArrayHash;
this.instance[this.currentModelID].set_image_embeddings(imageArrayU8);
self.postMessage({ status: "embedding", message: "Embeddings Set" });
}
static getSimpleHash(imageArrayU8) {
// get simple hash of imageArrayU8
let imageArrayHash = 0;
for (let i = 0; i < imageArrayU8.length; i += 100) {
imageArrayHash ^= imageArrayU8[i];
}
return imageArrayHash.toString(16);
}
}
let controller = null;
self.addEventListener("message", (event) => {
if (event.data.command === "start") {
controller = new AbortController();
generate(event.data);
} else if (event.data.command === "abort") {
controller.abort();
}
});
async function generate(data) {
const {
weightsURL,
modelID,
tokenizerURL,
quantized,
imageURL,
prompt,
seed,
temp,
top_p,
repeatPenalty,
maxSeqLen,
verbose_prompt,
} = data;
try {
self.postMessage({ status: "loading", message: "Starting Moondream" });
const model = await Moondream.getInstance(
weightsURL,
modelID,
tokenizerURL,
quantized
);
self.postMessage({ status: "loading", message: "Initializing model" });
self.postMessage({ status: "loading", message: "Loading Image" });
const imageArrayU8 = await fetchArrayBuffer(imageURL, false);
self.postMessage({ status: "embedding", message: "Creating Embeddings" });
Moondream.setImageEmbeddings(imageArrayU8);
self.postMessage({
status: "complete-embedding",
message: "Embeddings Complete",
});
const { token, token_id } = model.init_with_image_prompt({
prompt,
seed: BigInt(seed),
temp: parseFloat(temp),
top_p: parseFloat(top_p),
repeat_penalty: parseFloat(repeatPenalty),
repeat_last_n: 64,
verbose_prompt,
});
const seq_len = 2048;
let sentence = token;
let maxTokens = maxSeqLen ? maxSeqLen : seq_len - prompt.length - 1;
let startTime = performance.now();
let tokensCount = 0;
while (tokensCount < maxTokens) {
await new Promise(async (resolve) => {
if (controller && controller.signal.aborted) {
console.log("Aborted");
self.postMessage({
status: "aborted",
message: "Aborted",
output: prompt + sentence,
});
return;
}
const { token, token_id } = await model.next_token();
if (token_id === 50256) {
// <|endoftext|>
self.postMessage({
status: "complete",
message: "complete",
output: prompt + sentence,
});
return;
}
const tokensSec =
((tokensCount + 1) / (performance.now() - startTime)) * 1000;
sentence += token;
self.postMessage({
status: "generating",
message: "Generating token",
token: token,
sentence: sentence,
totalTime: performance.now() - startTime,
tokensSec,
prompt: prompt,
});
setTimeout(resolve, 0);
});
tokensCount++;
}
self.postMessage({
status: "complete",
message: "complete",
output: prompt + sentence,
});
} catch (e) {
self.postMessage({ error: e });
}
}
| 6 |
0 | hf_public_repos/candle/candle-wasm-examples | hf_public_repos/candle/candle-wasm-examples/moondream/README.md | ## Running [Moondream 2](https://huggingface.co/vikhyatk/moondream2) Model Example
### Vanilla JS and WebWorkers
To build and test the UI made in Vanilla JS and WebWorkers, first we need to build the WASM library:
```bash
sh build-lib.sh
```
This will bundle the library under `./build` and we can import it inside our WebWorker like a normal JS module:
```js
import init, { Model } from "./build/m.js";
```
The full example can be found under `./index.html`. All needed assets are fetched from the web, so no need to download anything.
Finally, you can preview the example by running a local HTTP server. For example:
```bash
python -m http.server
```
Then open `http://localhost:8000/index.html` in your browser.
| 7 |
0 | hf_public_repos/candle/candle-wasm-examples/moondream | hf_public_repos/candle/candle-wasm-examples/moondream/src/lib.rs | use wasm_bindgen::prelude::*;
#[wasm_bindgen]
extern "C" {
// Use `js_namespace` here to bind `console.log(..)` instead of just
// `log(..)`
#[wasm_bindgen(js_namespace = console)]
pub fn log(s: &str);
}
#[macro_export]
macro_rules! console_log {
// Note that this is using the `log` function imported above during
// `bare_bones`
($($t:tt)*) => ($crate::log(&format_args!($($t)*).to_string()))
}
| 8 |
0 | hf_public_repos/candle/candle-wasm-examples/moondream/src | hf_public_repos/candle/candle-wasm-examples/moondream/src/bin/m.rs | use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::{
generation::LogitsProcessor,
models::{moondream, quantized_moondream},
};
use candle_wasm_example_moondream::console_log;
use js_sys::Date;
use serde::{Deserialize, Serialize};
use tokenizers::Tokenizer;
use wasm_bindgen::prelude::*;
enum SelectedModel {
Moondream(moondream::Model),
Quantized(quantized_moondream::Model),
}
#[wasm_bindgen]
pub struct Model {
model: SelectedModel,
tokenizer: Tokenizer,
logits_processor: LogitsProcessor,
tokens: Vec<u32>,
repeat_penalty: f32,
repeat_last_n: usize,
index: usize,
bos_token: Option<Tensor>,
image_embeddings: Option<Tensor>,
}
#[derive(Serialize, Deserialize)]
struct Output {
token: String,
token_id: u32,
}
#[derive(Serialize, Deserialize)]
struct InitInput {
prompt: String,
seed: u64,
temp: f64,
top_p: f64,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
}
#[wasm_bindgen]
impl Model {
#[wasm_bindgen(constructor)]
pub fn load(weights: Vec<u8>, tokenizer: Vec<u8>, quantized: bool) -> Result<Model, JsError> {
console_error_panic_hook::set_once();
console_log!("loading model");
let device = Device::Cpu;
let config = moondream::Config::v2();
console_log!("config loaded in {:?}", Date::now());
let tokenizer =
Tokenizer::from_bytes(&tokenizer).map_err(|m| JsError::new(&m.to_string()))?;
let start = Date::now();
console_log!("weights len: {:?}", weights.len());
let model = if quantized {
let vb = candle_transformers::quantized_var_builder::VarBuilder::from_gguf_buffer(
&weights, &device,
)?;
console_log!("weights loaded");
let model = quantized_moondream::Model::new(&config, vb)?;
SelectedModel::Quantized(model)
} else {
let device = &Device::Cpu;
let vb = VarBuilder::from_buffered_safetensors(weights, DType::F32, device)?;
let model = moondream::Model::new(&config, vb)?;
SelectedModel::Moondream(model)
};
console_log!("model loaded in {:?}s", (Date::now() - start) / 1000.);
let logits_processor = LogitsProcessor::new(299792458, None, None);
Ok(Self {
model,
tokenizer,
tokens: vec![],
logits_processor,
repeat_penalty: 1.,
repeat_last_n: 64,
bos_token: None,
image_embeddings: None,
index: 0,
})
}
pub fn set_image_embeddings(&mut self, image: Vec<u8>) -> Result<(), JsError> {
let device = Device::Cpu;
console_log!("loading image as tensor");
let start = Date::now();
let image: Tensor = self.load_image(image)?.to_device(&device)?;
console_log!("image loaded in {:?}s", (Date::now() - start) / 1000.);
let start = Date::now();
let image_embeds = &image.unsqueeze(0)?;
let image_embeds = match &self.model {
SelectedModel::Moondream(ref m) => image_embeds.apply(m.vision_encoder())?,
SelectedModel::Quantized(ref m) => image_embeds.apply(m.vision_encoder())?,
};
console_log!(
"loaded and encoded the image {image:?} in {:?}",
(Date::now() - start) / 1000.
);
self.image_embeddings = Some(image_embeds);
Ok(())
}
#[wasm_bindgen]
pub fn init_with_image_prompt(&mut self, input: JsValue) -> Result<JsValue, JsError> {
let InitInput {
prompt,
seed,
temp,
top_p,
repeat_penalty,
repeat_last_n,
verbose_prompt,
} = serde_wasm_bindgen::from_value(input).map_err(|m| JsError::new(&m.to_string()))?;
let device = Device::Cpu;
let prompt = format!("\n\nQuestion: {0}\n\nAnswer:", prompt);
match &mut self.model {
SelectedModel::Moondream(m) => m.text_model.clear_kv_cache(),
SelectedModel::Quantized(m) => m.text_model.clear_kv_cache(),
};
let temp = if temp <= 0. { None } else { Some(temp) };
let top_p = if top_p <= 0. || top_p >= 1. {
None
} else {
Some(top_p)
};
self.logits_processor = LogitsProcessor::new(seed, temp, top_p);
self.repeat_penalty = repeat_penalty;
self.repeat_last_n = repeat_last_n;
self.tokens.clear();
self.index = 0;
// Moondream tokenizer bos_token is "<|endoftext|>"
// https://huggingface.co/vikhyatk/moondream2/blob/main/special_tokens_map.json
let special_token = match self.tokenizer.get_vocab(true).get("<|endoftext|>") {
Some(token) => *token,
None => return Err(JsError::new("BOS token not found in the tokenizer.")),
};
self.bos_token = Some(Tensor::new(&[special_token], &device)?.unsqueeze(0)?);
let tokens = self
.tokenizer
.encode(prompt, true)
.map_err(|m| JsError::new(&m.to_string()))?;
if tokens.is_empty() {
return Err(JsError::new(
"Empty prompts are not supported in the Moondream model.",
));
}
if verbose_prompt {
for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {
let token = token.replace('▁', " ").replace("<0x0A>", "\n");
println!("{id:7} -> '{token}'");
}
}
let tokens = tokens.get_ids().to_vec();
let text = match self.process(&tokens) {
Ok(text) => text,
Err(_e) => {
console_log!("error decoding token");
Output {
token: "".to_string(),
token_id: 0,
}
}
};
Ok(serde_wasm_bindgen::to_value(&text)?)
}
#[wasm_bindgen]
pub fn next_token(&mut self) -> Result<JsValue, JsError> {
let last_token = *self.tokens.last().unwrap();
let text = match self.process(&[last_token]) {
Ok(text) => text,
Err(_e) => {
console_log!("error decoding token");
Output {
token: "".to_string(),
token_id: 0,
}
}
};
Ok(serde_wasm_bindgen::to_value(&text)?)
}
}
impl Model {
fn load_image(&self, image: Vec<u8>) -> Result<Tensor, JsError> {
let img = image::ImageReader::new(std::io::Cursor::new(image))
.with_guessed_format()?
.decode()
.map_err(|e| JsError::new(&e.to_string()))?
.resize_to_fill(378, 378, image::imageops::FilterType::Triangle); // Adjusted to 378x378
let img = img.to_rgb8();
let data = img.into_raw();
let data = Tensor::from_vec(data, (378, 378, 3), &Device::Cpu)?.permute((2, 0, 1))?;
let mean = Tensor::new(&[0.5f32, 0.5, 0.5], &Device::Cpu)?.reshape((3, 1, 1))?;
let std = Tensor::new(&[0.5f32, 0.5, 0.5], &Device::Cpu)?.reshape((3, 1, 1))?;
(data.to_dtype(candle::DType::F32)? / 255.)?
.broadcast_sub(&mean)?
.broadcast_div(&std)
.map_err(|e| JsError::new(&e.to_string()))
}
}
impl Model {
fn process(&mut self, tokens: &[u32]) -> Result<Output, JsError> {
let image_embeddings = match &self.image_embeddings {
Some(embeddings) => embeddings,
None => return Err(JsError::new("Image embeddings are not set.")),
};
let bos_token = match &self.bos_token {
Some(token) => token,
None => return Err(JsError::new("BOS token is not set.")),
};
let device = Device::Cpu;
let context_size = if self.index > 0 { 1 } else { tokens.len() };
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &device)?.unsqueeze(0)?;
let logits = if self.index > 0 {
match self.model {
SelectedModel::Moondream(ref mut model) => model.text_model.forward(&input)?,
SelectedModel::Quantized(ref mut model) => model.text_model.forward(&input)?,
}
} else {
match self.model {
SelectedModel::Moondream(ref mut model) => {
model
.text_model
.forward_with_img(bos_token, &input, image_embeddings)?
}
SelectedModel::Quantized(ref mut model) => {
model
.text_model
.forward_with_img(bos_token, &input, image_embeddings)?
}
}
};
let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
self.tokens.push(next_token);
let token = match self.tokenizer.decode(&[next_token], true) {
Ok(token) => token,
Err(e) => {
console_log!("error decoding token: {:?}", e);
"".to_string()
}
};
self.index += 1;
Ok(Output {
token,
token_id: next_token,
})
}
}
fn main() {
console_error_panic_hook::set_once();
}
| 9 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter6/pre-trained_models.mdx | # Pre-trained models for text-to-speech
Compared to ASR (automatic speech recognition) and audio classification tasks, there are significantly fewer pre-trained
model checkpoints available. On the 🤗 Hub, you'll find close to 300 suitable checkpoints. Among
these pre-trained models we'll focus on two architectures that are readily available for you in the 🤗 Transformers library -
SpeechT5 and Massive Multilingual Speech (MMS). In this section, we'll explore how to use these pre-trained models in the
Transformers library for TTS.
## SpeechT5
[SpeechT5](https://arxiv.org/abs/2110.07205) is a model published by Junyi Ao et al. from Microsoft that is capable of
handling a range of speech tasks. While in this unit, we focus on the text-to-speech aspect,
this model can be tailored to speech-to-text tasks (automatic speech recognition or speaker identification),
as well as speech-to-speech (e.g. speech enhancement or converting between different voices). This is due to how the model
is designed and pre-trained.
At the heart of SpeechT5 is a regular Transformer encoder-decoder model. Just like any other Transformer, the encoder-decoder
network models a sequence-to-sequence transformation using hidden representations. This Transformer backbone is the same
for all tasks SpeechT5 supports.
This Transformer is complemented with six modal-specific (speech/text) _pre-nets_ and _post-nets_. The input speech or text
(depending on the task) is preprocessed through a corresponding pre-net to obtain the hidden representations that Transformer
can use. The Transformer's output is then passed to a post-net that will use it to generate the output in the target modality.
This is what the architecture looks like (image from the original paper):
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/architecture.jpg" alt="SpeechT5 architecture from the original paper">
</div>
SpeechT5 is first pre-trained using large-scale unlabeled speech and text data, to acquire a unified representation
of different modalities. During the pre-training phase all pre-nets and post-nets are used simultaneously.
After pre-training, the entire encoder-decoder backbone is fine-tuned for each individual task. At this step, only the
pre-nets and post-nets relevant to the specific task are employed. For example, to use SpeechT5 for text-to-speech, you'd
need the text encoder pre-net for the text inputs and the speech decoder pre- and post-nets for the speech outputs.
This approach allows to obtain several models fine-tuned for different speech tasks that all benefit from the initial
pre-training on unlabeled data.
<Tip>
Even though the fine-tuned models start out using the same set of weights from the shared pre-trained model, the
final versions are all quite different in the end. You can't take a fine-tuned ASR model and swap out the pre-nets and
post-net to get a working TTS model, for example. SpeechT5 is flexible, but not that flexible ;)
</Tip>
Let's see what are the pre- and post-nets that SpeechT5 uses for the TTS task specifically:
* Text encoder pre-net: A text embedding layer that maps text tokens to the hidden representations that the encoder expects. This is similar to what happens in an NLP model such as BERT.
* Speech decoder pre-net: This takes a log mel spectrogram as input and uses a sequence of linear layers to compress the spectrogram into hidden representations.
* Speech decoder post-net: This predicts a residual to add to the output spectrogram and is used to refine the results.
When combined, this is what SpeechT5 architecture for text-to-speech looks like:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/speecht5/tts.jpg" alt="SpeechT5 architecture for TTS">
</div>
As you can see, the output is a log mel spectrogram and not a final waveform. If you recall, we briefly touched on
this topic in [Unit 3](../chapter3/introduction#spectrogram-output). It is common for models that generate audio to produce
a log mel spectrogram, which needs to be converted to a waveform with an additional neural network known as a vocoder.
Let's see how you could do that.
First, let's load the fine-tuned TTS SpeechT5 model from the 🤗 Hub, along with the processor object used for tokenization
and feature extraction:
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
```
Next, tokenize the input text.
```python
inputs = processor(text="Don't count the days, make the days count.", return_tensors="pt")
```
The SpeechT5 TTS model is not limited to creating speech for a single speaker. Instead, it uses so-called speaker embeddings
that capture a particular speaker's voice characteristics.
<Tip>
Speaker embeddings is a method of representing a speaker's identity in a compact way, as a vector of
fixed size, regardless of the length of the utterance. These embeddings capture essential information about a speaker's
voice, accent, intonation, and other unique characteristics that distinguish one speaker from another. Such embeddings can
be used for speaker verification, speaker diarization, speaker identification, and more.
The most common techniques for generating speaker embeddings include:
* I-Vectors (identity vectors): I-Vectors are based on a Gaussian mixture model (GMM). They represent speakers as low-dimensional fixed-length vectors derived from the statistics of a speaker-specific GMM, and are obtained in unsupervised manner.
* X-Vectors: X-Vectors are derived using deep neural networks (DNNs) and capture frame-level speaker information by incorporating temporal context.
[X-Vectors](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf) are a state-of-the-art method that shows superior performance
on evaluation datasets compared to I-Vectors. The deep neural network is used to obtain X-Vectors: it trains to discriminate
between speakers, and maps variable-length utterances to fixed-dimensional embeddings. You can also load an X-Vector speaker embedding that has been computed ahead of time, which will encapsulate the speaking characteristics of a particular speaker.
</Tip>
Let's load such a speaker embedding from a dataset on the Hub. The embeddings
were obtained from the [CMU ARCTIC dataset](http://www.festvox.org/cmu_arctic/) using
[this script](https://huggingface.co/mechanicalsea/speecht5-vc/blob/main/manifest/utils/prep_cmu_arctic_spkemb.py), but
any X-Vector embedding should work.
```python
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
import torch
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
The speaker embedding is a tensor of shape (1, 512). This particular speaker embedding describes a female voice.
At this point we already have enough inputs to generate a log mel spectrogram as an output, you can do it like this:
```python
spectrogram = model.generate_speech(inputs["input_ids"], speaker_embeddings)
```
This outputs a tensor of shape (140, 80) containing a log mel spectrogram. The first dimension is the sequence length, and
it may vary between runs as the speech decoder pre-net always applies dropout to the input sequence. This adds a bit of
random variability to the generated speech.
However, if we are looking to generate speech waveform, we need to specify a vocoder to use for the spectrogram to waveform conversion.
In theory, you can use any vocoder that works on 80-bin mel spectrograms. Conveniently, 🤗 Transformers offers a vocoder
based on HiFi-GAN. Its weights were kindly provided by the original authors of SpeechT5.
<Tip>
[HiFi-GAN](https://arxiv.org/pdf/2010.05646v2.pdf) is a state-of-the-art generative adversarial network (GAN) designed
for high-fidelity speech synthesis. It is capable of generating high-quality and realistic audio waveforms from spectrogram inputs.
On a high level, HiFi-GAN consists of one generator and two discriminators. The generator is a fully convolutional
neural network that takes a mel-spectrogram as input and learns to produce raw audio waveforms. The discriminators'
role is to distinguish between real and generated audio. The two discriminators focus on different aspects of the audio.
HiFi-GAN is trained on a large dataset of high-quality audio recordings. It uses a so-called <em>adversarial training</em>,
where the generator and discriminator networks compete against each other. Initially, the generator produces low-quality
audio, and the discriminator can easily differentiate it from real audio. As training progresses, the generator improves
its output, aiming to fool the discriminator. The discriminator, in turn, becomes more accurate in distinguishing real
and generated audio. This adversarial feedback loop helps both networks improve over time. Ultimately, HiFi-GAN learns to
generate high-fidelity audio that closely resembles the characteristics of the training data.
</Tip>
Loading the vocoder is as easy as any other 🤗 Transformers model.
```python
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
```
Now all you need to do is pass it as an argument when generating speech, and the outputs will be automatically converted to the speech waveform.
```python
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
```
Let's listen to the result. The sample rate used by SpeechT5 is always 16 kHz.
```python
from IPython.display import Audio
Audio(speech, rate=16000)
```
Neat!
Feel free to play with the SpeechT5 text-to-speech demo, explore other voices, experiment with inputs. Note that this
pre-trained checkpoint only supports English language:
<iframe
src="https://matthijs-speecht5-tts-demo.hf.space"
frameborder="0"
width="850"
height="450">
</iframe>
## Bark
Bark is a transformer-based text-to-speech model proposed by Suno AI in [suno-ai/bark](https://github.com/suno-ai/bark).
Unlike SpeechT5, Bark generates raw speech waveforms directly, eliminating the need for a separate vocoder during inference – it's already integrated. This efficiency is achieved through the utilization of [`Encodec`](https://huggingface.co/docs/transformers/main/en/model_doc/encodec), which serves as both a codec and a compression tool.
With `Encodec`, you can compress audio into a lightweight format to reduce memory usage and subsequently decompress it to restore the original audio. This compression process is facilitated by 8 codebooks, each consisting of integer vectors. Think of these codebooks as representations or embeddings of the audio in integer form. It's important to note that each successive codebook improves the quality of the audio reconstruction from the previous codebooks. As codebooks are integer vectors, they can be learned by transformer models, which are very efficient in this task. This is what Bark was specifically trained to do.
To be more specific, Bark is made of 4 main models:
- `BarkSemanticModel` (also referred to as the 'text' model): a causal auto-regressive transformer model that takes as input tokenized text, and predicts semantic text tokens that capture the meaning of the text.
- `BarkCoarseModel` (also referred to as the 'coarse acoustics' model): a causal autoregressive transformer, that takes as input the results of the `BarkSemanticModel` model. It aims at predicting the first two audio codebooks necessary for EnCodec.
- `BarkFineModel` (the 'fine acoustics' model), this time a non-causal autoencoder transformer, which iteratively predicts the last codebooks based on the sum of the previous codebooks embeddings.
- having predicted all the codebook channels from the `EncodecModel`, Bark uses it to decode the output audio array.
It should be noted that each of the first three modules can support conditional speaker embeddings to condition the output sound according to specific predefined voice.
Bark is an highly-controllable text-to-speech model, meaning you can use with various settings, as we are going to see.
Before everything, load the model and its processor.
The processor role here is two-sides:
1. It is used to tokenize the input text, i.e. to cut it into small pieces that the model can understand.
2. It stores speaker embeddings, i.e voice presets that can condition the generation.
```python
from transformers import BarkModel, BarkProcessor
model = BarkModel.from_pretrained("suno/bark-small")
processor = BarkProcessor.from_pretrained("suno/bark-small")
```
Bark is very versatile and can generate audio conditioned by [a speaker embeddings library](https://suno-ai.notion.site/8b8e8749ed514b0cbf3f699013548683?v=bc67cff786b04b50b3ceb756fd05f68c) which can be loaded via the processor.
```python
# add a speaker embedding
inputs = processor("This is a test!", voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/first_sample.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
It can also generate ready-to-use multilingual speeches, such as French and Chinese. You can find a list of supported languages [here](https://huggingface.co/suno/bark). Unlike MMS, discussed below, it is not necessary to specify the language used, but simply adapt the input text to the corresponding language.
```python
# try it in French, let's also add a French speaker embedding
inputs = processor("C'est un test!", voice_preset="v2/fr_speaker_1")
speech_output = model.generate(**inputs).cpu().numpy()
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/second_sample.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
The model can also generate **non-verbal communications** such as laughing, sighing and crying. You just have to modify the input text with corresponding cues such as `[clears throat]`, `[laughter]`, or `...`.
```python
inputs = processor(
"[clears throat] This is a test ... and I just took a long pause.",
voice_preset="v2/fr_speaker_1",
)
speech_output = model.generate(**inputs).cpu().numpy()
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/third_sample.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
Bark can even generate music. You can help by adding ♪ musical notes ♪ around your words.
```python
inputs = processor(
"♪ In the mighty jungle, I'm trying to generate barks.",
)
speech_output = model.generate(**inputs).cpu().numpy()
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/fourth_sample.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
In addition to all these features, Bark supports batch processing, which means you can process several text entries at the same time, at the expense of more intensive computation.
On some hardware, such as GPUs, batching enables faster overall generation, which means it can be faster to generate samples all at once than to generate them one by one.
Let's try generating a few examples:
```python
input_list = [
"[clears throat] Hello uh ..., my dog is cute [laughter]",
"Let's try generating speech, with Bark, a text-to-speech model",
"♪ In the jungle, the mighty jungle, the lion barks tonight ♪",
]
# also add a speaker embedding
inputs = processor(input_list, voice_preset="v2/en_speaker_3")
speech_output = model.generate(**inputs).cpu().numpy()
```
Let's listen to the outputs one by one.
First one:
```python
from IPython.display import Audio
sampling_rate = model.generation_config.sample_rate
Audio(speech_output[0], rate=sampling_rate)
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/batch_1.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
Second one:
```python
Audio(speech_output[1], rate=sampling_rate)
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/batch_2.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
Third one:
```python
Audio(speech_output[2], rate=sampling_rate)
```
<audio controls>
<source src="https://huggingface.co/datasets/ylacombe/hf-course-audio-files/resolve/main/batch_3.wav" type="audio/wav">
Your browser does not support the audio element.
</audio>
<Tip>
Bark, like other 🤗 Transformers models, can be optimized in just a few lines of code regarding speed and memory impact. To find out how, click on [this colab demonstration notebook](https://colab.research.google.com/github/ylacombe/notebooks/blob/main/Benchmark_Bark_HuggingFace.ipynb).
</Tip>
## Massive Multilingual Speech (MMS)
What if you are looking for a pre-trained model in a language other than English? Massive Multilingual Speech (MMS) is
another model that covers an array of speech tasks, however, it supports a large number of languages. For instance, it can
synthesize speech in over 1,100 languages.
MMS for text-to-speech is based on [VITS Kim et al., 2021](https://arxiv.org/pdf/2106.06103.pdf), which is one of the
state-of-the-art TTS approaches.
VITS is a speech generation network that converts text into raw speech waveforms. It works like a conditional variational
auto-encoder, estimating audio features from the input text. First, acoustic features, represented as spectrograms, are
generated. The waveform is then decoded using transposed convolutional layers adapted from HiFi-GAN.
During inference, the text encodings are upsampled and transformed into waveforms using the flow module and HiFi-GAN decoder.
Like Bark, there's no need for a vocoder, as waveforms are generated directly.
<Tip warning={true}>
MMS model has been added to 🤗 Transformers very recently, so you will have to install the library from source:
```bash
pip install git+https://github.com/huggingface/transformers.git
```
</Tip>
Let's give MMS a go, and see how we can synthesize speech in a language other than English, e.g. German.
First, we'll load the model checkpoint and the tokenizer for the correct language:
```python
from transformers import VitsModel, VitsTokenizer
model = VitsModel.from_pretrained("facebook/mms-tts-deu")
tokenizer = VitsTokenizer.from_pretrained("facebook/mms-tts-deu")
```
You may notice that to load the MMS model you need to use `VitsModel` and `VitsTokenizer`. This is because MMS for text-to-speech
is based on the VITS model as mentioned earlier.
Let's pick an example text in German, like these first two lines from a children's song:
```python
text_example = (
"Ich bin Schnappi das kleine Krokodil, komm aus Ägypten das liegt direkt am Nil."
)
```
To generate a waveform output, preprocess the text with the tokenizer, and pass it to the model:
```python
import torch
inputs = tokenizer(text_example, return_tensors="pt")
input_ids = inputs["input_ids"]
with torch.no_grad():
outputs = model(input_ids)
speech = outputs["waveform"]
```
Let's listen to it:
```python
from IPython.display import Audio
Audio(speech, rate=16000)
```
Wunderbar! If you'd like to try MMS with another language, find other suitable `vits` checkpoints [on 🤗 Hub](https://huggingface.co/models?filter=vits).
Now let's see how you can fine-tune a TTS model yourself!
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter6/tts_datasets.mdx | # Text-to-speech datasets
Text-to-speech task (also called _speech synthesis_) comes with a range of challenges.
First, just like in the previously discussed automatic speech recognition, the alignment between text and speech can be tricky.
However, unlike ASR, TTS is a **one-to-many** mapping problem, i.e. the same text can be synthesised in many different ways. Think about the diversity of voices and speaking styles in the speech you hear on a daily basis - each person has a different way of speaking the same sentence, but they are all valid and correct! Even different outputs (spectrograms or audio waveforms) can correspond to the same ground truth. The model has to learn to generate the correct duration and timing for each phoneme, word, or sentence which can be challenging,
especially for long and complex sentences.
Next, there's the long-distance dependency problem: language has a temporal aspect, and understanding the meaning of a
sentence often requires considering the context of surrounding words. Ensuring that the TTS model captures and retains
contextual information over long sequences is crucial for generating coherent and natural-sounding speech.
Finally, training TTS models typically requires pairs of text and corresponding speech recordings. On top of that, to ensure
the model can generate speech that sounds natural for various speakers and speaking styles, data should contain diverse and
representative speech samples from multiple speakers. Collecting such data is expensive, time-consuming and for some languages
is not feasible. You may think, why not just take a dataset designed for ASR (automatic speech recognition) and use it for
training a TTS model? Unfortunately, automated speech recognition (ASR) datasets are not the best option. The features that
make it beneficial for ASR, such as excessive background noise, are typically undesirable in TTS. It's great to be able to
pick out speach from a noisy street recording, but not so much if your voice assistant replies to you with cars honking
and construction going full-swing in the background. Still, some ASR datasets can sometimes be useful for fine-tuning,
as finding top-quality, multilingual, and multi-speaker TTS datasets can be quite challenging.
Let's explore a few datasets suitable for TTS that you can find on the 🤗 Hub.
## LJSpeech
[LJSpeech](https://huggingface.co/datasets/lj_speech) is a dataset that consists of 13,100 English-language audio clips
paired with their corresponding transcriptions. The dataset contains recording of a single speaker reading sentences
from 7 non-fiction books in English. LJSpeech is often used as a benchmark for evaluating TTS models
due to its high audio quality and diverse linguistic content.
## Multilingual LibriSpeech
[Multilingual LibriSpeech](https://huggingface.co/datasets/facebook/multilingual_librispeech) is a multilingual extension
of the LibriSpeech dataset, which is a large-scale collection of read English-language audiobooks. Multilingual LibriSpeech
expands on this by including additional languages, such as German, Dutch, Spanish, French, Italian, Portuguese, and Polish.
It offers audio recordings along with aligned transcriptions for each language. The dataset provides a valuable resource
for developing multilingual TTS systems and exploring cross-lingual speech synthesis techniques.
## VCTK (Voice Cloning Toolkit)
[VCTK](https://huggingface.co/datasets/vctk) is a dataset specifically designed for text-to-speech research and development.
It contains audio recordings of 110 English speakers with various accents. Each speaker reads out about 400 sentences,
which were selected from a newspaper, the rainbow passage and an elicitation paragraph used for the speech accent archive.
VCTK offers a valuable resource for training TTS models with varied voices and accents, enabling more natural and diverse
speech synthesis.
## Libri-TTS/ LibriTTS-R
[Libri-TTS/ LibriTTS-R](https://huggingface.co/datasets/cdminix/libritts-r-aligned) is a multi-speaker English corpus of
approximately 585 hours of read English speech at 24kHz sampling rate, prepared by Heiga Zen with the assistance of Google
Speech and Google Brain team members. The LibriTTS corpus is designed for TTS research. It is derived from the original
materials (mp3 audio files from LibriVox and text files from Project Gutenberg) of the LibriSpeech corpus. The main
differences from the LibriSpeech corpus are listed below:
* The audio files are at 24kHz sampling rate.
* The speech is split at sentence breaks.
* Both original and normalized texts are included.
* Contextual information (e.g., neighbouring sentences) can be extracted.
* Utterances with significant background noise are excluded.
Assembling a good dataset for TTS is no easy task as such dataset would have to possess several key characteristics:
* High-quality and diverse recordings that cover a wide range of speech patterns, accents, languages, and emotions. The recordings should be clear, free from background noise, and exhibit natural speech characteristics.
* Transcriptions: Each audio recording should be accompanied by its corresponding text transcription.
* Variety of linguistic content: The dataset should contain a diverse range of linguistic content, including different types of sentences, phrases, and words. It should cover various topics, genres, and domains to ensure the model's ability to handle different linguistic contexts.
Good news is, it is unlikely that you would have to train a TTS model from scratch. In the next section we'll look into
pre-trained models available on the 🤗 Hub.
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter6/introduction.mdx | # Unit 6. From text to speech
In the previous unit, you learned how to use Transformers to convert spoken speech into text. Now let's flip the
script and see how you can transform a given input text into an audio output that sounds like human speech.
The task we will study in this unit is called "Text-to-speech" (TTS). Models capable of converting text into audible
human speech have a wide range of potential applications:
* Assistive apps: think about tools that can leverage these models to enable visually-impaired people to access digital content through the medium of sound.
* Audiobook narration: converting written books into audio form makes literature more accessible to individuals who prefer to listen or have difficulty with reading.
* Virtual assistants: TTS models are a fundamental component of virtual assistants like Siri, Google Assistant, or Amazon Alexa. Once they have used a classification model to catch the wake word, and used ASR model to process your request, they can use a TTS model to respond to your inquiry.
* Entertainment, gaming and language learning: give voice to your NPC characters, narrate game events, or help language learners with examples of correct pronunciation and intonation of words and phrases.
These are just a few examples, and I am sure you can imagine many more! However, with so much power comes the responsibility,
and it is important to highlight that TTS models have the potential to be used for malicious purposes.
For example, with sufficient voice samples, malicious actors could potentially create convincing fake audio recordings, leading to
the unauthorized use of someone's voice for fraudulent purposes or manipulation. If you plan to collect data for fine-tuning
your own systems, carefully consider privacy and informed consent. Voice data should be obtained with explicit consent
from individuals, ensuring they understand the purpose, scope, and potential risks associated with their voice being used
in a TTS system. Please use text-to-speech responsibly.
## What you'll learn and what you'll build
In this unit we will talk about:
* [Datasets suitable for text-to-speech training](tts_datasets)
* [Pre-trained models for text-to-speech](pre-trained_models)
* [Fine-tuning SpeechT5 on a new language](fine-tuning)
* [Evaluating TTS models](evaluation)
| 2 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter6/fine-tuning.mdx | # Fine-tuning SpeechT5
Now that you are familiar with the text-to-speech task and internal workings of the SpeechT5 model that was pre-trained
on English language data, let's see how we can fine-tune it to another language.
## House-keeping
Make sure that you have a GPU if you want to reproduce this example. In a notebook, you can check with the following command:
```bash
nvidia-smi
```
<Tip warning={true}>
In our example we will be using approximately 40 hours of training data. If you'd like to follow along using the Google Colab free tier GPU,
you will need to reduce the amount of training data to approximately 10-15 hours, and reduce the number of training steps.
</Tip>
You'll also need some additional dependencies:
```bash
pip install transformers datasets soundfile speechbrain accelerate
```
Finally, don't forget to log in to your Hugging Face account so that you could upload and share your model with the community:
```py
from huggingface_hub import notebook_login
notebook_login()
```
## The dataset
For this example we'll take the Dutch (`nl`) language subset of the [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) dataset.
[VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) is a large-scale multilingual speech corpus consisting of
data sourced from 2009-2020 European Parliament event recordings. It contains labelled audio-transcription data for 15
European languages. While we will be using the Dutch language subset, feel free to pick another subset.
This is an automated speech recognition (ASR) dataset, so, as mentioned before, it is not the most suitable
option for training TTS models. However, it will be good enough for this exercise.
Let's load the data:
```python
from datasets import load_dataset, Audio
dataset = load_dataset("facebook/voxpopuli", "nl", split="train")
len(dataset)
```
**Output:**
```out
20968
```
20968 examples should be sufficient for fine-tuning. SpeechT5 expects audio data to have a sampling rate of 16 kHz, so
make sure the examples in the dataset meet this requirement:
```python
dataset = dataset.cast_column("audio", Audio(sampling_rate=16000))
```
## Preprocessing the data
Let's begin by defining the model checkpoint to use and loading the appropriate processor that contains both tokenizer,
and feature extractor that we will need to prepare the data for training:
```py
from transformers import SpeechT5Processor
checkpoint = "microsoft/speecht5_tts"
processor = SpeechT5Processor.from_pretrained(checkpoint)
```
### Text cleanup for SpeechT5 tokenization
First, for preparing the text, we'll need the tokenizer part of the processor, so let's get it:
```py
tokenizer = processor.tokenizer
```
Let's take a look at an example:
```python
dataset[0]
```
**Output:**
```out
{'audio_id': '20100210-0900-PLENARY-3-nl_20100210-09:06:43_4',
'language': 9,
'audio': {'path': '/root/.cache/huggingface/datasets/downloads/extracted/02ec6a19d5b97c03e1379250378454dbf3fa2972943504a91c7da5045aa26a89/train_part_0/20100210-0900-PLENARY-3-nl_20100210-09:06:43_4.wav',
'array': array([ 4.27246094e-04, 1.31225586e-03, 1.03759766e-03, ...,
-9.15527344e-05, 7.62939453e-04, -2.44140625e-04]),
'sampling_rate': 16000},
'raw_text': 'Dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'normalized_text': 'dat kan naar mijn gevoel alleen met een brede meerderheid die wij samen zoeken.',
'gender': 'female',
'speaker_id': '1122',
'is_gold_transcript': True,
'accent': 'None'}
```
What you may notice is that the dataset examples contain `raw_text` and `normalized_text` features. When deciding which
feature to use as the text input, it will be important to know that the SpeechT5 tokenizer doesn't have any tokens for
numbers. In `normalized_text` the numbers are written out as text. Thus, it is a better fit, and we should use `normalized_text`
as input text.
Because SpeechT5 was trained on the English language, it may not recognize certain characters in the Dutch dataset. If
left as is, these characters will be converted to `<unk>` tokens. However, in Dutch, certain characters like `à` are
used to stress syllables. In order to preserve the meaning of the text, we can replace this character with a regular `a`.
To identify unsupported tokens, extract all unique characters in the dataset using the `SpeechT5Tokenizer` which
works with characters as tokens. To do this, we'll write the `extract_all_chars` mapping function that concatenates
the transcriptions from all examples into one string and converts it to a set of characters.
Make sure to set `batched=True` and `batch_size=-1` in `dataset.map()` so that all transcriptions are available at once for
the mapping function.
```py
def extract_all_chars(batch):
all_text = " ".join(batch["normalized_text"])
vocab = list(set(all_text))
return {"vocab": [vocab], "all_text": [all_text]}
vocabs = dataset.map(
extract_all_chars,
batched=True,
batch_size=-1,
keep_in_memory=True,
remove_columns=dataset.column_names,
)
dataset_vocab = set(vocabs["vocab"][0])
tokenizer_vocab = {k for k, _ in tokenizer.get_vocab().items()}
```
Now you have two sets of characters: one with the vocabulary from the dataset and one with the vocabulary from the tokenizer.
To identify any unsupported characters in the dataset, you can take the difference between these two sets. The resulting
set will contain the characters that are in the dataset but not in the tokenizer.
```py
dataset_vocab - tokenizer_vocab
```
**Output:**
```out
{' ', 'à', 'ç', 'è', 'ë', 'í', 'ï', 'ö', 'ü'}
```
To handle the unsupported characters identified in the previous step, we can define a function that maps these characters to
valid tokens. Note that spaces are already replaced by `▁` in the tokenizer and don't need to be handled separately.
```py
replacements = [
("à", "a"),
("ç", "c"),
("è", "e"),
("ë", "e"),
("í", "i"),
("ï", "i"),
("ö", "o"),
("ü", "u"),
]
def cleanup_text(inputs):
for src, dst in replacements:
inputs["normalized_text"] = inputs["normalized_text"].replace(src, dst)
return inputs
dataset = dataset.map(cleanup_text)
```
Now that we have dealt with special characters in the text, it's time to shift the focus to the audio data.
### Speakers
The VoxPopuli dataset includes speech from multiple speakers, but how many speakers are represented in the dataset? To
determine this, we can count the number of unique speakers and the number of examples each speaker contributes to the dataset.
With a total of 20,968 examples in the dataset, this information will give us a better understanding of the distribution of
speakers and examples in the data.
```py
from collections import defaultdict
speaker_counts = defaultdict(int)
for speaker_id in dataset["speaker_id"]:
speaker_counts[speaker_id] += 1
```
By plotting a histogram you can get a sense of how much data there is for each speaker.
```py
import matplotlib.pyplot as plt
plt.figure()
plt.hist(speaker_counts.values(), bins=20)
plt.ylabel("Speakers")
plt.xlabel("Examples")
plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_speakers_histogram.png" alt="Speakers histogram"/>
</div>
The histogram reveals that approximately one-third of the speakers in the dataset have fewer than 100 examples, while
around ten speakers have more than 500 examples. To improve training efficiency and balance the dataset, we can limit
the data to speakers with between 100 and 400 examples.
```py
def select_speaker(speaker_id):
return 100 <= speaker_counts[speaker_id] <= 400
dataset = dataset.filter(select_speaker, input_columns=["speaker_id"])
```
Let's check how many speakers remain:
```py
len(set(dataset["speaker_id"]))
```
**Output:**
```out
42
```
Let's see how many examples are left:
```py
len(dataset)
```
**Output:**
```out
9973
```
You are left with just under 10,000 examples from approximately 40 unique speakers, which should be sufficient.
Note that some speakers with few examples may actually have more audio available if the examples are long. However,
determining the total amount of audio for each speaker requires scanning through the entire dataset, which is a
time-consuming process that involves loading and decoding each audio file. As such, we have chosen to skip this step here.
### Speaker embeddings
To enable the TTS model to differentiate between multiple speakers, you'll need to create a speaker embedding for each example.
The speaker embedding is an additional input into the model that captures a particular speaker's voice characteristics.
To generate these speaker embeddings, use the pre-trained [spkrec-xvect-voxceleb](https://huggingface.co/speechbrain/spkrec-xvect-voxceleb)
model from SpeechBrain.
Create a function `create_speaker_embedding()` that takes an input audio waveform and outputs a 512-element vector
containing the corresponding speaker embedding.
```py
import os
import torch
from speechbrain.pretrained import EncoderClassifier
spk_model_name = "speechbrain/spkrec-xvect-voxceleb"
device = "cuda" if torch.cuda.is_available() else "cpu"
speaker_model = EncoderClassifier.from_hparams(
source=spk_model_name,
run_opts={"device": device},
savedir=os.path.join("/tmp", spk_model_name),
)
def create_speaker_embedding(waveform):
with torch.no_grad():
speaker_embeddings = speaker_model.encode_batch(torch.tensor(waveform))
speaker_embeddings = torch.nn.functional.normalize(speaker_embeddings, dim=2)
speaker_embeddings = speaker_embeddings.squeeze().cpu().numpy()
return speaker_embeddings
```
It's important to note that the `speechbrain/spkrec-xvect-voxceleb` model was trained on English speech from the VoxCeleb
dataset, whereas the training examples in this guide are in Dutch. While we believe that this model will still generate
reasonable speaker embeddings for our Dutch dataset, this assumption may not hold true in all cases.
For optimal results, we would need to train an X-vector model on the target speech first. This will ensure that the model
is better able to capture the unique voice characteristics present in the Dutch language. If you'd like to train your own
X-vector model, you can use [this script](https://huggingface.co/mechanicalsea/speecht5-vc/blob/main/manifest/utils/prep_cmu_arctic_spkemb.py)
as an example.
### Processing the dataset
Finally, let's process the data into the format the model expects. Create a `prepare_dataset` function that takes in a
single example and uses the `SpeechT5Processor` object to tokenize the input text and load the target audio into a log-mel spectrogram.
It should also add the speaker embeddings as an additional input.
```py
def prepare_dataset(example):
audio = example["audio"]
example = processor(
text=example["normalized_text"],
audio_target=audio["array"],
sampling_rate=audio["sampling_rate"],
return_attention_mask=False,
)
# strip off the batch dimension
example["labels"] = example["labels"][0]
# use SpeechBrain to obtain x-vector
example["speaker_embeddings"] = create_speaker_embedding(audio["array"])
return example
```
Verify the processing is correct by looking at a single example:
```py
processed_example = prepare_dataset(dataset[0])
list(processed_example.keys())
```
**Output:**
```out
['input_ids', 'labels', 'stop_labels', 'speaker_embeddings']
```
Speaker embeddings should be a 512-element vector:
```py
processed_example["speaker_embeddings"].shape
```
**Output:**
```out
(512,)
```
The labels should be a log-mel spectrogram with 80 mel bins.
```py
import matplotlib.pyplot as plt
plt.figure()
plt.imshow(processed_example["labels"].T)
plt.show()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/transformers/tasks/tts_logmelspectrogram_1.png" alt="Log-mel spectrogram with 80 mel bins"/>
</div>
Side note: If you find this spectrogram confusing, it may be due to your familiarity with the convention of placing low frequencies
at the bottom and high frequencies at the top of a plot. However, when plotting spectrograms as an image using the matplotlib library,
the y-axis is flipped and the spectrograms appear upside down.
Now we need to apply the processing function to the entire dataset. This will take between 5 and 10 minutes.
```py
dataset = dataset.map(prepare_dataset, remove_columns=dataset.column_names)
```
You'll see a warning saying that some examples in the dataset are longer than the maximum input length the model can handle (600 tokens).
Remove those examples from the dataset. Here we go even further and to allow for larger batch sizes we remove anything over 200 tokens.
```py
def is_not_too_long(input_ids):
input_length = len(input_ids)
return input_length < 200
dataset = dataset.filter(is_not_too_long, input_columns=["input_ids"])
len(dataset)
```
**Output:**
```out
8259
```
Next, create a basic train/test split:
```py
dataset = dataset.train_test_split(test_size=0.1)
```
### Data collator
In order to combine multiple examples into a batch, you need to define a custom data collator. This collator will pad shorter sequences with padding
tokens, ensuring that all examples have the same length. For the spectrogram labels, the padded portions are replaced with
the special value `-100`. This special value instructs the model to ignore that part of the spectrogram when calculating the spectrogram loss.
```py
from dataclasses import dataclass
from typing import Any, Dict, List, Union
@dataclass
class TTSDataCollatorWithPadding:
processor: Any
def __call__(
self, features: List[Dict[str, Union[List[int], torch.Tensor]]]
) -> Dict[str, torch.Tensor]:
input_ids = [{"input_ids": feature["input_ids"]} for feature in features]
label_features = [{"input_values": feature["labels"]} for feature in features]
speaker_features = [feature["speaker_embeddings"] for feature in features]
# collate the inputs and targets into a batch
batch = processor.pad(
input_ids=input_ids, labels=label_features, return_tensors="pt"
)
# replace padding with -100 to ignore loss correctly
batch["labels"] = batch["labels"].masked_fill(
batch.decoder_attention_mask.unsqueeze(-1).ne(1), -100
)
# not used during fine-tuning
del batch["decoder_attention_mask"]
# round down target lengths to multiple of reduction factor
if model.config.reduction_factor > 1:
target_lengths = torch.tensor(
[len(feature["input_values"]) for feature in label_features]
)
target_lengths = target_lengths.new(
[
length - length % model.config.reduction_factor
for length in target_lengths
]
)
max_length = max(target_lengths)
batch["labels"] = batch["labels"][:, :max_length]
# also add in the speaker embeddings
batch["speaker_embeddings"] = torch.tensor(speaker_features)
return batch
```
In SpeechT5, the input to the decoder part of the model is reduced by a factor 2. In other words, it throws away every
other timestep from the target sequence. The decoder then predicts a sequence that is twice as long. Since the original
target sequence length may be odd, the data collator makes sure to round the maximum length of the batch down to be a
multiple of 2.
```py
data_collator = TTSDataCollatorWithPadding(processor=processor)
```
## Train the model
Load the pre-trained model from the same checkpoint as you used for loading the processor:
```py
from transformers import SpeechT5ForTextToSpeech
model = SpeechT5ForTextToSpeech.from_pretrained(checkpoint)
```
The `use_cache=True` option is incompatible with gradient checkpointing. Disable it for training, and re-enable cache for
generation to speed-up inference time:
```py
from functools import partial
# disable cache during training since it's incompatible with gradient checkpointing
model.config.use_cache = False
# set language and task for generation and re-enable cache
model.generate = partial(model.generate, use_cache=True)
```
Define the training arguments. Here we are not computing any evaluation metrics during the training process,
we'll talk about evaluation later in this chapter. Instead, we'll only look at the loss:
```python
from transformers import Seq2SeqTrainingArguments
training_args = Seq2SeqTrainingArguments(
output_dir="speecht5_finetuned_voxpopuli_nl", # change to a repo name of your choice
per_device_train_batch_size=4,
gradient_accumulation_steps=8,
learning_rate=1e-5,
warmup_steps=500,
max_steps=4000,
gradient_checkpointing=True,
fp16=True,
evaluation_strategy="steps",
per_device_eval_batch_size=2,
save_steps=1000,
eval_steps=1000,
logging_steps=25,
report_to=["tensorboard"],
load_best_model_at_end=True,
greater_is_better=False,
label_names=["labels"],
push_to_hub=True,
)
```
Instantiate the `Trainer` object and pass the model, dataset, and data collator to it.
```py
from transformers import Seq2SeqTrainer
trainer = Seq2SeqTrainer(
args=training_args,
model=model,
train_dataset=dataset["train"],
eval_dataset=dataset["test"],
data_collator=data_collator,
tokenizer=processor,
)
```
And with that, we're ready to start training! Training will take several hours. Depending on your GPU,
it is possible that you will encounter a CUDA "out-of-memory" error when you start training. In this case, you can reduce
the `per_device_train_batch_size` incrementally by factors of 2 and increase `gradient_accumulation_steps` by 2x to compensate.
```py
trainer.train()
```
Push the final model to the 🤗 Hub:
```py
trainer.push_to_hub()
```
## Inference
Once you have fine-tuned a model, you can use it for inference! Load the model from the 🤗 Hub (make sure to use your
account name in the following code snippet):
```py
model = SpeechT5ForTextToSpeech.from_pretrained(
"YOUR_ACCOUNT/speecht5_finetuned_voxpopuli_nl"
)
```
Pick an example, here we'll take one from the test dataset. Obtain a speaker embedding.
```py
example = dataset["test"][304]
speaker_embeddings = torch.tensor(example["speaker_embeddings"]).unsqueeze(0)
```
Define some input text and tokenize it.
```py
text = "hallo allemaal, ik praat nederlands. groetjes aan iedereen!"
```
Preprocess the input text:
```py
inputs = processor(text=text, return_tensors="pt")
```
Instantiate a vocoder and generate speech:
```py
from transformers import SpeechT5HifiGan
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
speech = model.generate_speech(inputs["input_ids"], speaker_embeddings, vocoder=vocoder)
```
Ready to listen to the result?
```py
from IPython.display import Audio
Audio(speech.numpy(), rate=16000)
```
Obtaining satisfactory results from this model on a new language can be challenging. The quality of the speaker
embeddings can be a significant factor. Since SpeechT5 was pre-trained with English x-vectors, it performs best
when using English speaker embeddings. If the synthesized speech sounds poor, try using a different speaker embedding.
Increasing the training duration is also likely to enhance the quality of the results. Even so, the speech clearly is Dutch instead of English, and it does
capture the voice characteristics of the speaker (compare to the original audio in the example).
Another thing to experiment with is the model's configuration. For example, try using `config.reduction_factor = 1` to
see if this improves the results.
In the next section, we'll talk about how we evaluate text-to-speech models.
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter6/hands_on.mdx | # Hands-on exercise
In this unit, we have explored text-to-speech audio task, talked about existing datasets, pretrained
models and nuances of fine-tuning SpeechT5 for a new language.
As you've seen, fine-tuning models for text-to-speech task can be challenging in low-resource scenarios. At the same time,
evaluating text-to-speech models isn't easy either.
For these reasons, this hands-on exercise will focus on practicing the skills rather than achieving a certain metric value.
Your objective for this task is to fine-tune SpeechT5 on a dataset of your choosing. You have the freedom to select
another language from the same `voxpopuli` dataset, or you can pick any other dataset listed in this unit.
Be mindful of the training data size! For training on a free tier GPU from Google Colab, we recommend limiting the training
data to about 10-15 hours.
Once you have completed the fine-tuning process, share your model by uploading it to the Hub. Make sure to tag your model
as a `text-to-speech` model either with appropriate kwargs, or in the Hub UI.
Remember, the primary aim of this exercise is to provide you with ample practice, allowing you to refine your skills and
gain a deeper understanding of text-to-speech audio tasks.
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters | hf_public_repos/audio-transformers-course/chapters/es/_toctree.yml | - title: Unidad 0. ¡Bienvenido al curso!
sections:
- local: chapter0/introduction
title: Que esperar de este curso
- local: chapter0/get_ready
title: Prepárate
- local: chapter0/community
title: Únete a la comunidad
- title: Unidad 1. Trabajando con datos de audio
sections:
- local: chapter1/introduction
title: ¿Qué aprenderás?
- local: chapter1/audio_data
title: Introducción a los datos de audio
- local: chapter1/load_and_explore
title: Cargar y Explorar un conjunto de datos
- local: chapter1/preprocessing
title: Preprocesamiento de datos de audio
- local: chapter1/streaming
title: Transmitiendo datos de audio
- local: chapter1/quiz
title: Quiz
quiz: 1
- local: chapter1/supplemental_reading
title: Lecturas y recursos adicionales
- title: Unidad 2. A gentle introduction to audio applications
sections:
- local: chapter2/introduction
title: Tour por la aplicaciones de audio
- local: chapter2/audio_classification_pipeline
title: Clasificación de audio usando una pipeline
- local: chapter2/asr_pipeline
title: Reconocimiento automático de la voz usando una pipeline
- local: chapter2/hands_on
title: Ejercicio práctico
#- title: Unidad 3. Transformer architectures for audio
# sections:
# - local: chapter3/introduction
# title: Refresher on transformer models
# - local: chapter3/ctc
# title: CTC architectures
# - local: chapter3/seq2seq
# title: Seq2Seq architectures
# - local: chapter3/classification
# title: Audio classification architectures
# - local: chapter3/quiz
# title: Quiz
# quiz: 3
# - local: chapter3/supplemental_reading
# title: Supplemental reading and resources
#- title: Unidad 4. Build a music genre classifier
# sections:
# - local: chapter4/introduction
# title: What you'll learn and what you'll build
# - local: chapter4/classification_models
# title: Pre-trained models for audio classification
# - local: chapter4/fine-tuning
# title: Fine-tuning a model for music classification
# - local: chapter4/demo
# title: Build a demo with Gradio
# - local: chapter4/hands_on
# title: Hands-on exercise
#- title: Unidad 5. Transcribe a meeting recording
# sections:
# - local: chapter5/introduction
# title: What you'll learn and what you'll build
# - local: chapter5/choosing_dataset
# title: Choosing a dataset
# - local: chapter5/asr_models
# title: Pre-trained models for automatic speech recognition
# - local: chapter5/preprocessing_data
# title: Loading and preprocessing data
# - local: chapter5/evaluation
# title: Evaluation metrics for ASR
# - local: chapter5/fine-tuning
# title: Fine-tuning the ASR model
# - local: chapter5/speaker_diarization
# title: Automatic speech recognition with speaker diarization
# - local: chapter5/quiz
# title: Quiz
# quiz: 5
# - local: chapter5/hands_on
# title: Hands-on exercise
# - local: chapter5/supplemental_reading
# title: Supplemental reading and resources
#
#- title: Unidad 6. From text to speech
# sections:
# - local: chapter6/introduction
# title: What you'll learn and what you'll build
# - local: chapter6/overview
# title: How to synthesize human speech from text?
# - local: chapter6/choosing_dataset
# title: Choosing a dataset
# - local: chapter6/preprocessing
# title: Loading and preprocessing data
# - local: chapter6/pre-trained_models
# title: Pre-trained models for text-to-speech
# - local: chapter6/evaluation
# title: Evaluation metrics for text-to-speech
# - local: chapter6/fine-tuning
# title: Fine-tuning SpeechT5
# - local: chapter6/quiz
# title: Quiz
# quiz: 6
# - local: chapter6/hands_on
# title: Hands-on exercise
# - local: chapter6/supplemental_reading
# title: Supplemental reading and resources
#
#- title: Unidad 7. Audio to audio
# sections:
# - local: chapter7/introduction
# title: What you'll learn and what you'll build
# - local: chapter7/tasks
# title: Examples of audio-to-audio tasks
# - local: chapter7/choosing_dataset
# title: Choosing a dataset
# - local: chapter7/preprocessing
# title: Loading and preprocessing data
# - local: chapter7/evaluation
# title: Evaluation metrics for audio-to-audio
# - local: chapter7/fine-tuning
# title: Fine-tuning the model
# - local: chapter7/quiz
# title: Quiz
# quiz: 7
# - local: chapter7/hands_on
# title: Hands-on exercise
# - local: chapter7/supplemental_reading
# title: Supplemental reading and resources
#
#- title: Unidad 8. Finish line
# sections:
# - local: chapter8/introduction
# title: Congratulations!
# - local: chapter8/certification
# title: Get your certification of completion
# - local: chapter8/stay_in_touch
# title: Stay in touch
#
#- title: Bonus unit. Diffusion models for audio
# sections:
# - local: chapter9/introduction
# title: Introduction
# - local: chapter9/music_generation
# title: Music generation
# - local: chapter9/riffusion
# title: Riffusion
# - local: chapter9/audioldm
# title: AudioLDM
# - local: chapter9/dance_diffusion
# title: Dance Diffusion
#- title: Course Events
# sections:
# - local: events/introduction
# title: Live sessions and workshops | 5 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter0/get_ready.mdx | # Prepárate para tomar el curso
Esperamos que estes emocionado de empezar este curso, hemos diseñado esta página para asegurarnos que ¡tienes
todo para comenzar!
## Paso 1. Suscríbete.
Para estar al tanto de todas las actualizaciones y los eventos sociales, suscríbete al curso.
[👉 SUSCRIBETE](http://eepurl.com/insvcI)
## Paso 2. Crea una cuenta de Hugging Face.
Si aún no tienes una, crea una cuenta de Hugging Face (Es gratis). La necesitarás para completar los ejercicios
prácticos, para recibir el certificado de finalización, explorar modelos pre-entrenados, acceder a conjuntos de datos y mucho más.
[👉 CREA TU CUENTA DE HUGGING FACE](https://huggingface.co/join)
## Paso 3. Repasa los fundamentos (si lo necesitas)
Asumimos que estas familiarizado con los conceptos básicos de deep learning y transformers. Si necesitas afianzar tu
comprensión de transformers, mira nuestro [Curso de NLP](https://huggingface.co/course/chapter1/1).
## Paso 4. Revisa tu setup
Para realizar el curso necesitarás:
- Un computadot con conexión a internet.
- [Google Colab](https://colab.research.google.com) para los ejercicios prácticos. La versión gratuita es suficiente.
Si nunca has usado Google Colab antes, revisa la [introducción oficial](https://colab.research.google.com/notebooks/intro.ipynb).
## Paso 5. Únete a la comunidad.
Suscríbete a nuestro servidor de Discord, el lugar donde puedes intercambiar tus ideas con tus compañeros de curso y conctactar con nosotros (El equipo de Hugging Face).
[👉 UNETE A LA COMUNIDAD DE DISCORD](http://hf.co/join/discord)
para aprender más acerda de nuestra comuninda en Discord y como sacar el mayor provecho, Mira la [siguiente página](community)
| 6 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter0/introduction.mdx | # ¡Bienvenido al curso de Hugging Face de Audio!
Querido estudiante,
Bienvenido a este curso de transformers para audio. Una y otra vez, los transformers han demostrado ser una de las arquitecturas
de aprendizaje profundo más poderosas y versátiles, capaces de lograr resultados que son estado del arte en una amplia gama de tareas,
incluyendo el procesamiento del lenguaje natural, visión por computadora y, más recientemente, procesamiento de audio.
En este curso, exploraremos cómo se pueden aplicar los transformers a datos de audio. Aprenderás cómo utilizarlos para abordar una variedad
de tareas relacionadas con el audio. Ya sea que estés interesado en reconocimiento de voz, clasificación de audio o generación de habla a partir
de texto, los transformers y este curso te brindarán las herramientas necesarias.
Para que puedas tener una idea de lo que estos modelos pueden hacer, di algunas palabras en la siguiente demostración y observa
cómo el modelo las ¡transcribe en tiempo real!
<iframe
src="https://openai-whisper.hf.space"
frameborder="0"
width="850"
height="450">
</iframe>
A lo largo del curso, adquirirás una comprensión de los aspectos específicos de trabajar con datos de audio.
Aprenderás sobre diferentes arquitecturas de transformers y entrenarás tus propios transformers de audio aprovechando potentes
modelos pre-entrenados.
Este curso está diseñado para estudiantes con experiencia en aprendizaje profundo y familiaridad general con los transformers.
No se requiere experiencia en el procesamiento de datos de audio. Si necesitas repasar tu comprensión de los transformers,
echa un vistazo a nuestro [Curso de NLP](https://huggingface.co/course/chapter1/1), que profundiza en los fundamentos de los transformers
en detalle.
## Conoce al equipo del curso
**Sanchit Gandhi, Machine Learning Research Engineer en Hugging Face**
¡Hola! Soy Sanchit y soy un ingeniero de investigación en aprendizaje automático para audio en el equipo de código abierto de Hugging Face 🤗.
Mi enfoque principal es el reconocimiento automático de voz y la traducción, con el objetivo actual de hacer que los modelos de habla sean
más rápidos, ligeros y fáciles de usar.
**Matthijs Hollemans, Machine Learning Engineer en Hugging Face**
Soy Matthijs, y soy un ingeniero de aprendizaje automático para audio en el equipo de código abierto de Hugging Face. También soy el autor
de un libro sobre cómo escribir sintetizadores de sonido, y creo plug-ins de audio en mi tiempo libre.
**Maria Khalusova, Documentation & Courses at Hugging Face**
Soy María, y creo contenido educativo y documentación para hacer que los Transformers y otras herramientas de código abierto sean aún más
accesibles. Desgloso conceptos técnicos complejos y ayudo a las personas a comenzar con tecnologías de vanguardia.
**Vaibhav Srivastav, ML Developer Advocate Engineer at Hugging Face**
Soy Vaibhav (VB) y soy un Ingeniero de Promoción para audio en el equipo de código abierto de Hugging Face.
Investigo sobre Texto a Voz(TTS) en lenguajes con bajos recursos y ayudo a llevar el estado del arte de la investigación del habla al público general.
## Estructura del curso
El curso esta estructurado en varias unidades que cubren varios temas en profudidad:
* Unidad 1: Aprende sobre los detalles específicos de trabajar con datos de audio, incluyendo técnicas de procesamiento de audio y preparación de datos.
* Unidad 2: Conoce las aplicaciones de audio y aprende a utilizar las pipelines de 🤗 Transformers para diferentes tareas, como
clasificación de audio y reconocimiento de voz.
* Unidad 3: Explora las arquitecturas de transformers de audio, aprende en qué se diferencian y para qué tareas son más adecuadas.
* Unidad 4: Aprende cómo construir tu propio clasificador de género musical.
* Unidad 5: Adéntrate en el reconocimiento de voz y construye un modelo para transcribir grabaciones de reuniones.
* Unidad 6: Aprende cómo generar habla a partir de texto.
* Unidad 7: Aprende cómo convertir audio a audio utilizando transformers.
Cada unidad incluye un componente teórico, donde podras adquirir un entendimiento profundo de los conceptos y técnicas.
A lo largo del curso, hay quizzes para ayudarte a evaluar to conocimiento y reforzar tu aprendizaje.
Algunos capítulos tambien incluyen ejercicios prácticos, en los que tendrás la oportunidad de aplicar todo lo que has aprendido.
Al finalizar el curso, tendras una formación sólida en el uso de transfomers para datos de audio y estarás bien
equipado para aplicar este tipo de técnicas a un conjunto amplio de tareas relacionadas con audio.
Las unidades del curso serán publicadas en bloques consecutivos de acuerdo a la siguiente agenda:
| Unidades | Fecha de publicación |
|---|-----------------|
| Unidad 0, Unidad 1, and Unidad 2 | Junio 14, 2023 |
| Unidad 3, Unidad 4 | Junio 21, 2023 |
| Unidad 5 | Junio 28, 2023 |
| Unidad 6 | Julio 5, 2023 |
| Unidad 7, Unidad 8 | Julio 12, 2023 |
## Rutas de aprendizaje y certificaciones
No hay una manera correcta o erronea de tomar este curso. Todos los materiales en este curso son 100% gratis, públicos y de código abierto.
Puedes tomar el curso a tu propio ritmo, sin embargo, recomendamos ir a lo largo de las unidades en orden.
Si quieres tener un certificado al final del curso, ofrecemos dos opciones:
| Tipo de certficado | Requerimientos |
|---|------------------------------------------------------------------------------------------------|
| Certificado de finalización | Completa el 80% de los ejercicios prácticos según las instrucciones. |
| Certificado de honor | Completa el 100% de los ejercicios prácticos según las instrucciones. |
Cada ejercicio práctico tiene unos criterios para considerarse completo. Una vez hayas completado suficientes ejericios prácticos
para acceder a alguno de los certificados, visita la última unidad del curso para aprender como puedes obtener tu certificado. ¡Buena Suerte!
## Suscríbete al curso
Las unidades de este curso seran publicadas gradualmente en el transcurso de un par de semanas. Te animamos a que te suscribas
a las actualizaciones del curso y asi no te perderas ninguna unidad cuando sean publicadas. Los estudiantes que se suscriban a
las actualizaciones del curso serán los primeros en darse cuenta de los eventos sociales que planeammos organizar.
[SUSCRIBETE](http://eepurl.com/insvcI)
¡Disfruta el curso!
| 7 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter0/community.mdx | # ¡Únete a la comunidad!
Te invitamos a [unirte a nuestra comunidad dinámica y amigable en Discord](http://hf.co/join/discord). Tendrás la oportunidad de conectar
con estudiantes con intereses similares, intercambiar ideas y obtener retroalimentación valiosa en los ejercicios prácticos. Puedes hacer
tus preguntas, compartir recursos y colaborar con otros.
Nuestro equipo también está activo en Discord y estará disponible para brindarte apoyo y orientación cuando lo necesites.
Unirte a nuestra comunidad es una excelente manera de mantenerte motivado, activo y conectado,
¡Esperamos verte allí!
## ¿Qué es Discord?
Discord es una plataforma gratuita de chat. Si has usado Slack, lo encontrarás bastante similar.
El servidor de Discord de Hugging Face es el hogar de una próspera comunidad de 18 000 expertos en IA,
estudiantes y entusiastas, a la cual puedes unirte.
## Navegando en Discord
Una vez que te hayas registrado en nuestro servidor de Discord, deberás elegir los temas que te interesan haciendo clic en #role-assignment
ubicado la izquierda. Puedes elegir tantas categorías diferentes como desees. Para unirte a otros estudiantes de este curso, asegúrate de hacer
clic en "ML for Audio and Speech".
Explora los canales y comparte algunas cosas sobre ti en el canal `#introduce-yourself`.
## Canales del curso de audio
Hay muchos canales enfocados en varios temas en nuestro servidor de Discord. Encontrarás a personas discutiendo artículos, organizando eventos,
compartiendo sus proyectos e ideas, haciendo lluvia de ideas y mucho más.
Como estudiante del curso de audio, es posible que encuentres especialmente relevantes los siguientes canales:
* `#audio-announcements`: actualizaciones sobre el curso, noticias de Hugging Face relacionadas con todo lo relacionado con el audio, anuncios de eventos y más.
* `#audio-study-group`: un lugar para intercambiar ideas, hacer preguntas sobre el curso e iniciar discusiones.
* `#audio-discuss`: un lugar general para tener discusiones sobre temas relacionados con el audio.
Además de unirte al `#audio-study-group`, ¡siéntete libre de crear tu propio grupo de estudio, aprender juntos siempre es más fácil!
| 8 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter2/asr_pipeline.mdx | # Reconocimiento automático de la voz con pipeline
El reconocimiento automático de la voz(ASR) es una tarea que consiste en transcribir una grabación de audio en texto.
Esta tarea tiene numerosas aplicaciones prácticas, desde crear subtitulos para videos hasta permitir comandos de voz en
asistentes virtuales como Siri o Alexa.
En esta sección, usaremos la pipeline `automatic-speech-recognition` para transcribir la grabación del audio de una
persona haciendo una pregunta sobre el pago de una cuenta usando el mismo conjunto de datos MINDS-14 que utilizamos antes.
Para empezar, carguemos el conjunto de datos y hagamos un proceso de resampling a 16kHz como se describe en
[Audio classification with a pipeline](introduction.mdx), si no lo has hecho antes.
Para transcribir una grabación de audio, podemos usar la pipeline `automatic-speech-recognition` de 🤗 Transformers.
Instaciemos primero la pipeline:
```py
from transformers import pipeline
asr = pipeline("automatic-speech-recognition")
```
A continuación, tomamos un ejemplo del conjunto de datos y pasamos los datos en bruto de audio por la pipeline.
```py
example = minds[0]
asr(example["audio"]["array"])
```
**Output:**
```out
{"text": "I WOULD LIKE TO PAY MY ELECTRICITY BILL USING MY COD CAN YOU PLEASE ASSIST"}
```
Comparemos la salida generada por la pipeline con la transcripción que tiene este ejemplo:
```py
example["english_transcription"]
```
**Output:**
```out
"I would like to pay my electricity bill using my card can you please assist"
```
Parece que el modelo ha hecho un muy buen trabajo ¡transcribiendo el audio! Solo una palabra tiene una transcripción mala("card")
al compararse con la transcripción original, lo que esta muy bien considerando que el hablante tiene un acento australiano, donde la letra "r"
es mucha veces muda. Habiendo aclarado esto, no recomendaria intentar pagar tu próxima cuenta de electricidad con una pescado(Traducción de cad)
Por defecto, esta pipeline usa un modelo entrenado para reconocimientode voz en el idioma ingles, lo que se adapta a este ejemplo.
Si quisieras intentar transcribir otro subconjunto de MINDS-14 de un lenguaje diferente, puedes encontrar un modelo de ASR
pre-entrenado en el [🤗 Hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&language=fr&sort=downloads).
Puedes filtrar los modelos por tipo de tarea y luego por lenguaje. Una vez que hayas encontrado el modelo, puedes pasar el nombre
como el argumento `model` a la pipeline
Intentemoslo para la partición de Aleman de MINDS-14. Carga el subconjunto "de-DE":
```py
from datasets import load_dataset
from datasets import Audio
minds = load_dataset("PolyAI/minds14", name="de-DE", split="train")
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
```
Mira un ejemplo para verificar que la transcripción es lo que esperamos:
```py
example = minds[0]
example["transcription"]
```
**Output:**
```out
"ich möchte gerne Geld auf mein Konto einzahlen"
```
Encuentra un modelo pre-entrenado de ASR para el idioma aleman en el 🤗 Hub, instancia la pipeline, y transcribe el ejemplo:
```py
from transformers import pipeline
asr = pipeline("automatic-speech-recognition", model="maxidl/wav2vec2-large-xlsr-german")
asr(example["audio"]["array"])
```
**Output:**
```out
{"text": "ich möchte gerne geld auf mein konto einzallen"}
```
Also, stimmt's!
Cuando trabajes en resolver tu propria tarea, empezar con una pipeline simple como las que acabamos de mostrar en esta unidad
es una herramienta valiosa que ofrece los siguientes beneficios:
- un modelo pre entrenado puede existir que ya resuelva tu tarea de una forma satisfactoria, lo que te ahorrará tiempo.
- pipeline() se encarga de todos los pasos de pre y post procesamiento, así no tienes que preocuparte en convertir los
datos en el formato adecuado que necesita el modelo.
- Si el resultado no es el ideal, te da un modelo de base en el que posteriormente puedes re-entrenar.
- Una vez que re-entrenes tu modelo con tus datos personalizados y lo compartas en el Hub, la comunidad podrá usarlo de forma
rápida y fácil usando `pipeline()`, lo que hace el campo de la IA mucho más accesible.
| 9 |
0 | hf_public_repos | hf_public_repos/blog/ml-director-insights.md | ---
title: "Director of Machine Learning Insights"
thumbnail: /blog/assets/61_ml_director_insights/thumbnail.png
authors:
- user: britneymuller
---
# Director of Machine Learning Insights [Part 1]
Few seats at the Machine Learning table span both technical skills, problem solving and business acumen like Directors of Machine Learning
Directors of Machine Learning and/or Data Science are often expected to design ML systems, have deep knowledge of mathematics, familiarity with ML frameworks, rich data architecture understanding, experience applying ML to real-world applications, solid communication skills, and often expected to keep on top of industry developments. A tall order!
<a href="https://huggingface.co/platform?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_1"><img width="100%" style=
"margin:auto" src="/blog/assets/61_ml_director_insights/private-model-hub.png"></a>
For these reasons, we’ve tapped into this unique group of ML Directors for a series of articles highlighting their thoughts on current ML insights and industry trends ranging from Healthcare to Finance, eCommerce, SaaS, Research, Media, and more. For example, one Director will note how ML can be used to reduce empty deadheading truck driving (which occurs ~20% of the time) down to just 19% would cut carbon emissions by ~100,000 Americans. Note: This is back of napkin math, done by an ex-rocket Scientist however, so we’ll take it.
In this first installment, you’ll hear from a researcher (who’s using ground penetrating radar to detect buried landmines), an ex-Rocket Scientist, a Dzongkha fluent amateur gamer (Kuzu = Hello!), an ex-van living Scientist, a high-performance Data Science team coach who’s still very hands-on, a data practitioner who values relationships, family, dogs, and pizza. —All of whom are currently Directors of Machine Learning with rich field insights.
🚀 Let’s meet some top Machine Learning Directors and hear what they have to say about Machine Learning’s impact on their prospective industries:
<img class="mx-auto" style="float: left;" padding="5px" src="/blog/assets/61_ml_director_insights/Archi-Mitra.jpeg"></a>
### [Archi Mitra](https://www.linkedin.com/in/archimitra/) - Director of Machine Learning at [Buzzfeed](https://www.buzzfeed.com/)
**Background:** Bringing balance to the promise of ML for business. People over Process. Strategy over Hope. AI Ethics over AI Profits. Brown New Yorker.
**Fun Fact:** I can speak [Dzongkha](https://en.wikipedia.org/wiki/Dzongkha) (google it!) and am a supporter of [Youth for Seva](https://www.youthforseva.org/Donation).
**Buzzfeed:** An American Internet media, news and entertainment company with a focus on digital media.
#### **1. How has ML made a positive impact on Media?**
_Privacy first personalization for customers:_ Every user is unique and while their long-term interests are stable, their short-term interests are stochastic. They expect their relationship with the Media to reflect this. The combination of advancement in hardware acceleration and Deep Learning for recommendations has unlocked the ability to start deciphering this nuance and serve users with the right content at the right time at the right touchpoint.
_Assistive tools for makers:_ Makers are the limited assets in media and preserving their creative bandwidth by ML driven human-in-the-loop assistive tools have seen an outsized impact. Something as simple as automatically suggesting an appropriate title, image, video, and/or product that can go along with the content they are creating unlocks a collaborative machine-human flywheel.
_Tightened testing:_ In a capital intensive media venture, there is a need to shorten the time between collecting information on what resonates with users and immediately acting on it. With a wide variety of Bayesian techniques and advancements in reinforcement learning, we have been able to drastically reduce not only the time but the cost associated with it.
#### **2. What are the biggest ML challenges within Media?**
_Privacy, editorial voice, and equitable coverage:_ Media is a key pillar in the democratic world now more than ever. ML needs to respect that and operate within constraints that are not strictly considered table stakes in any other domain or industry. Finding a balance between editorially curated content & programming vs ML driven recommendations continues to be a challenge. Another unique challenge to BuzzFeed is we believe that the internet should be free which means we don't track our users like others can.
#### **3. What’s a common mistake you see people make trying to integrate ML into Media?**
Ignoring “the makers” of media: Media is prevalent because it houses a voice that has a deep influence on people. The editors, content creators, writers & makers are the larynx of that voice and the business and building ML that enables them, extends their impact and works in harmony with them is the key ingredient to success.
#### **4. What excites you most about the future of ML?**
Hopefully, small data-driven general-purpose multi-modal multi-task real-time ML systems that create step-function improvements in drug discovery, high precision surgery, climate control systems & immersive metaverse experiences. Realistically, more accessible, low-effort meta-learning techniques for highly accurate text and image generation.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Li-Tan.jpeg"></a>
### [Li Tan](http://linkedin.com/in/iamtanli/) - Director of Machine Learning & AI at [Johnson & Johnson](https://www.jnj.com/)
**Background:** Li is an AI/ML veteran with 15+ years of experience leading high-profile Data Science teams within industry leaders like Johnson & Johnson, Microsoft, and Amazon.
**Fun Fact:** Li continues to be curious, is always learning, and enjoys hands-on programming.
**Johnson & Johnson:** A Multinational corporation that develops medical devices, pharmaceuticals, and consumer packaged goods.
#### **1. How has ML made a positive impact on Pharmaceuticals?**
AI/ML applications have exploded in the pharmaceuticals space the past few years and are making many long-term positive impacts. Pharmaceuticals and healthcare have many use cases that can leverage AI/ML.
Applications range from research, and real-world evidence, to smart manufacturing and quality assurance. The technologies used are also very broad: NLP/NLU, CV, AIIoT, Reinforcement Learning, etc. even things like AlphaFold.
#### **2. What are the biggest ML challenges within Pharmaceuticals?**
The biggest ML challenge within pharma and healthcare is how to ensure equality and diversity in AI applications. For example, how to make sure the training set has good representations of all ethnic groups. Due to the nature of healthcare and pharma, this problem can have a much greater impact compared to applications in some other fields.
#### **3. What’s a common mistake you see people make trying to integrate ML into Pharmaceuticals?**
Wouldn’t say this is necessarily a mistake, but I see many people gravitate toward extreme perspectives when it comes to AI applications in healthcare; either too conservative or too aggressive.
Some people are resistant due to high regulatory requirements. We had to qualify many of our AI applications with strict GxP validation. It may require a fair amount of work, but we believe the effort is worthwhile. On the opposite end of the spectrum, there are many people who think AI/Deep Learning models can outperform humans in many applications and run completely autonomously.
As practitioners, we know that currently, neither is true.
ML models can be incredibly valuable but still make mistakes. So I recommend a more progressive approach. The key is to have a framework that can leverage the power of AI while having goalkeepers in place. [FDA has taken actions](https://www.fda.gov/medical-devices/software-medical-device-samd/artificial-intelligence-and-machine-learning-software-medical-device) to regulate how AI/ML should be used in software as a medical device and I believe that’s a positive step forward for our industry.
#### **4. What excites you most about the future of ML?**
The intersections between AI/ML and other hard sciences and technologies. I’m excited to see what’s to come.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Alina-Zare.jpeg"></a>
### [Alina Zare](https://www.linkedin.com/in/alina-zare/) - Director of the Machine Learning & Sensing Laboratory at the [University of Florida](https://faculty.eng.ufl.edu/machine-learning/people/faculty/)
**Background:** Alina Zare teaches and conducts research in the area of machine learning and artificial intelligence as a Professor in the Electrical and Computer Engineering Department at the University of Florida and Director of the Machine Learning and Sensing Lab. Dr. Zare’s research has focused primarily on developing new machine learning algorithms to automatically understand and process data and imagery.
Her research work has included automated plant root phenotyping, sub-pixel hyperspectral image analysis, target detection, and underwater scene understanding using synthetic aperture sonar, LIDAR data analysis, Ground Penetrating Radar analysis, and buried landmine and explosive hazard detection.
**Fun Fact:** Alina is a rower. She joined the crew team in high school, rowed throughout college and grad school, was head coach of the University of Missouri team while she was an assistant professor, and then rowed as a masters rower when she joined the faculty at UF.
**Machine Learning & Sensing Laboratory:** A University of Florida laboratory that develops machine learning methods for autonomously analyzing and understanding sensor data.
#### **1. How has ML made a positive impact on Science**
ML has made a positive impact in a number of ways from helping to automate tedious and/or slow tasks or providing new ways to examine and look at various questions. One example from my work in ML for plant science is that we have developed ML approaches to automate plant root segmentation and characterization in imagery. This task was previously a bottleneck for plant scientists looking at root imagery. By automating this step through ML we can conduct these analyses at a much higher throughput and begin to use this data to investigate plant biology research questions at scale.
#### **2. What are the biggest ML challenges within Scientific research?**
There are many challenges. One example is when using ML for Science research, we have to think carefully through the data collection and curation protocols. In some cases, the protocols we used for non-ML analysis are not appropriate or effective. The quality of the data and how representative it is of what we expect to see in the application can make a huge impact on the performance, reliability, and trustworthiness of an ML-based system.
#### **3. What’s a common mistake you see people make trying to integrate ML into Science?**
Related to the question above, one common mistake is misinterpreting results or performance to be a function of just the ML system and not also considering the data collection, curation, calibration, and normalization protocols.
#### **4. What excites you most about the future of ML?**
There are a lot of really exciting directions. A lot of my research currently is in spaces where we have a huge amount of prior knowledge and empirically derived models. For example, I have ongoing work using ML for forest ecology research. The forestry community has a rich body of prior knowledge and current purely data-driven ML systems are not leveraging. I think hybrid methods that seamlessly blend prior knowledge with ML approaches will be an interesting and exciting path forward.
An example may be understanding how likely two species are to co-occur in an area. Or what species distribution we could expect given certain environmental conditions. These could potentially be used w/ data-driven methods to make predictions in changing conditions.
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Nathan-Cahill.jpeg"></a>
### [Nathan Cahill](https://www.linkedin.com/in/nathan-m-cahill/) Ph.D. - Director of Machine Learning at [Xpress Technologies](https://xpresstechfreight.com/)
**Background:** Nathan is a passionate machine learning leader with 7 years of experience in research and development, and three years experience creating business value by shipping ML models to prod. He specializes in finding and strategically prioritizing the business' biggest pain points: unlocking the power of data earlier on in the growth curve.
**Fun Fact:** Before getting into transportation and logistics I was engineering rockets at Northrop Grumman. #RocketScience
**Xpress Technologies:** A digital freight matching technology to connect Shippers, Brokers and Carriers to bring efficiency and automation to the Transportation Industry.
#### **1. How has ML made a positive impact on Logistics/Transportation?**
The transportation industry is incredibly fragmented. The top players in the game have less than 1% market share. As a result, there exist inefficiencies that can be solved by digital solutions.
For example, when you see a semi-truck driving on the road, there is currently a 20% chance that the truck is driving with nothing in the back. Yes, 20% of the miles a tractor-trailer drives are from the last drop off of their previous load to their next pickup. The chances are that there is another truck driving empty (or "deadheading") in the other direction.
With machine learning and optimization this deadhead percent can be reduced significantly, and just taking that number from 20% to 19% percent would cut the equivalent carbon emissions of 100,000 Americans.
Note: the carbon emissions of 100k Americans were my own back of the napkin math.
#### **2. What are the biggest ML challenges within Logistics?**
The big challenge within logistics is due to the fact that the industry is so fragmented: there is no shared pool of data that would allow technology solutions to "see" the big picture. For example a large fraction of brokerage loads, maybe a majority, costs are negotiated on a load by load basis making them highly volatile. This makes pricing a very difficult problem to solve. If the industry became more transparent and shared data more freely, so much more would become possible.
#### **3. What’s a common mistake you see people make trying to integrate ML into Logistics?**
I think that the most common mistake I see is people doing ML and Data Science in a vacuum.
Most ML applications within logistics will significantly change the dynamics of the problem if they are being used so it's important to develop models iteratively with the business and make sure that performance in reality matches what you expect in training.
An example of this is in pricing where if you underprice a lane slightly, your prices may be too competitive which will create an influx of freight on that lane. This, in turn, may cause costs to go up as the brokers struggle to find capacity for those loads, exacerbating the issue.
#### **4. What excites you the most about the future of ML?**
I think the thing that excites me most about ML is the opportunity to make people better at their jobs.
As ML begins to be ubiquitous in business, it will be able to help speed up decisions and automate redundant work. This will accelerate the pace of innovation and create immense economic value. I can’t wait to see what problems we solve in the next 10 years aided by data science and ML!
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Nicolas-Bertagnolli.png"></a>
### [Nicolas Bertagnolli](https://www.linkedin.com/in/nicolas-bertagnolli-058aba81/) - Director of Machine Learning at [BEN](https://ben.productplacement.com/)
**Background:** Nic is a scientist and engineer working to improve human communication through machine learning. He’s spent the last decade applying ML/NLP to solve data problems in the medical space from uncovering novel patterns in cancer genomes to leveraging billions of clinical notes to reduce costs and improve outcomes.
At BEN, Nic innovates intelligent technologies that scale human capabilities to reach people. See his [CV](http://www.nbertagnolli.com/assets/Bertagnolli_CV.pdf), [research](http://www.nbertagnolli.com/), and [Medium articles here](https://nbertagnolli.medium.com/).
**Fun Fact:** Nic lived in a van and traveled around the western United States for three years before starting work at BEN.
**BEN:** An entertainment AI company that places brands inside influencer, streaming, TV, and film content to connect brands with audiences in a way that advertisements cannot.
#### **1. How has ML made a positive impact on Marketing?**
In so many ways! It’s completely changing the landscape. Marketing is a field steeped in tradition based on gut feelings. In the past 20 years, there has been a move to more and more statistically informed marketing decisions but many brands are still relying on the gut instincts of their marketing departments. ML is revolutionizing this. With the ability to analyze data about which advertisements perform well we can make really informed decisions about how and who we market to.
At BEN, ML has really helped us take the guesswork out of a lot of the process when dealing with influencer marketing. Data helps shine a light through the fog of bias and subjectivity so that we can make informed decisions.
That’s just the obvious stuff! ML is also making it possible to make safer marketing decisions for brands. For example, it’s illegal to advertise alcohol to people under the age of 21. Using machine learning we can identify influencers whose audiences are mainly above 21. This scales our ability to help alcohol brands, and also brands who are worried about their image being associated with alcohol.
#### **2. What are the biggest ML challenges within Marketing?**
As with most things in Machine Learning the problems often aren’t really with the models themselves. With tools like [Hugging Face](http://huggingface.co), [torch hub](https://pytorch.org/docs/stable/hub.html), etc. so many great and flexible models are available to work with.
The real challenges have to do with collecting, cleaning, and managing the data. If we want to talk about the hard ML-y bits of the job, some of it comes down to the fact that there is a lot of noise in what people view and enjoy. Understanding things like virality are really really hard.
Understanding what makes a creator/influencer successful over time is really hard. There is a lot of weird preference information buried in some pretty noisy difficult-to-acquire data. These problems come down to having really solid communication between data, ML, and business teams, and building models which augment and collaborate with humans instead of fully automating away their roles.
#### **3. What’s a common mistake you see people make trying to integrate ML into Marketing?**
I don’t think this is exclusive to marketing but prioritizing machine learning and data science over good infrastructure is a big problem I see often. Organizations hear about ML and want to get a piece of the pie so they hire some data scientists only to find out that they don’t have any infrastructure to service their new fancy pants models. A ton of the value of ML is in the infrastructure around the models and if you’ve got trained models but no infrastructure you’re hosed.
One of the really nice things about BEN is we invested heavily in our data infrastructure and built the horse before the cart. Now Data Scientists can build models that get served to our end users quickly instead of having to figure out every step of that pipeline themselves. Invest in data engineering before hiring lots of ML folks.
#### **4. What excites you most about the future of ML?**
There is so much exciting stuff going on. I think the pace and democratization of the field is perhaps what I find most exciting. I remember almost 10 years ago writing my first seq2seq model for language translation. It was hundreds of lines of code, took forever to train and was pretty challenging. Now you can basically build a system to translate any language to any other language in under 100 lines of python code. It’s insane! This trend is most likely to continue and as the ML infrastructure gets better and better it will be easier and easier for people without deep domain expertise to deploy and serve models to other people.
Much like in the beginning of the internet, software developers were few and far between and you needed a skilled team to set up a website. Then things like Django, Rails, etc. came out making website building easy but serving it was hard. We’re kind of at this place where building the models is easy but serving them reliably, monitoring them reliably, etc. is still challenging. I think in the next few years the barrier to entry is going to come WAY down here and basically, any high schooler could deploy a deep transformer to some cloud infrastructure and start serving useful results to the general population. This is really exciting because it means we’ll start to see more and more tangible innovation, much like the explosion of online services. So many cool things!
<img class="mx-auto" style="float: left;" padding="5px" width="200" src="/blog/assets/61_ml_director_insights/Eric-Golinko.jpeg"></a>
### [Eric Golinko](https://www.linkedin.com/in/eric-golinko/) - Director of Machine Learning at [E Source](https://www.esource.com/)
**Background:** Experienced data practitioner and team builder. I’ve worked in many industries across companies of different sizes. I’m a problem solver, by training a mathematician and computer scientist. But, above all, I value relationships, family, dogs, travel and pizza.
**Fun Fact:** Eric adores nachos!
**E Source:** Provides independent market intelligence, consulting, and predictive data science to utilities, major energy users, and other key players in the retail energy marketplace.
#### **1. How has ML made a positive impact on the Energy/Utility industry?**
Access to business insight. Provided a pre-requisite is great data. Utilities have many data relationships within their data portfolio from customers to devices, more specifically, this speaks to monthly billing amounts and enrollment in energy savings programs. Data like that could be stored in a relational database, whereas device or asset data we can think of as the pieces of machinery that make our grid. Bridging those types of data is non-trivial.
In addition, third-party data spatial/gis and weather are extremely important. Through the lens of machine learning, we are able to find and explore features and outcomes that have a real impact.
#### **2. What are the biggest ML challenges within Utilities?**
There is a demystification that needs to happen. What machine learning can do and where it needs to be monitored or could fall short. The utility industry has established ways of operating, machine learning can be perceived as a disruptor. Because of this, departments can be slow to adopt any new technology or paradigm. However, if the practitioner is able to prove results, then results create traction and a larger appetite to adopt. Additional challenges are on-premise data and access to the cloud and infrastructure. It’s a gradual process and has a learning curve that requires patience.
#### **3. What’s a common mistake you see people make trying to integrate ML into Utilities?**
Not unique to utilizes, but moving too fast and neglecting good data quality and simple quality checks. Aside from this machine learning is practiced among many groups in some direct or indirect way. A challenge is integrating best development practices across teams. This also means model tracking and being able to persist experiments and continuous discovery.
#### **4. What excites you most about the future of ML?**
I’ve been doing this for over a decade, and I somehow still feel like a novice. I feel fortunate to have been part of teams where I’d be lucky to be called the average member. My feeling is that the next ten years and beyond will be more focused on data engineering to see even a larger number of use cases covered by machine learning.
---
🤗 Thank you for joining us in this first installment of ML Director Insights. Stay tuned for more insights from ML Directors in SaaS, Finance, and e-Commerce.
Big thanks to Eric Golinko, Nicolas Bertagnolli, Nathan Cahill, Alina Zare, Li Tan, and Archi Mitra for their brilliant insights and participation in this piece. We look forward to watching each of your continued successes and will be cheering you on each step of the way. 🎉
Lastly, if you or your team are interested in accelerating your ML roadmap with Hugging Face Experts please visit [hf.co/support](https://huggingface.co/support?utm_source=article&utm_medium=blog&utm_campaign=ml_director_insights_1) to learn more.
| 0 |
0 | hf_public_repos | hf_public_repos/blog/mantis-case-study.md | ---
title: "Why we’re switching to Hugging Face Inference Endpoints, and maybe you should too"
thumbnail: /blog/assets/78_ml_director_insights/mantis1.png
authors:
- user: mattupson
guest: true
---
# Why we’re switching to Hugging Face Inference Endpoints, and maybe you should too
Hugging Face recently launched [Inference Endpoints](https://huggingface.co/inference-endpoints); which as they put it: solves transformers in production. Inference Endpoints is a managed service that allows you to:
- Deploy (almost) any model on Hugging Face Hub
- To any cloud (AWS, and Azure, GCP on the way)
- On a range of instance types (including GPU)
- We’re switching some of our Machine Learning (ML) models that do inference on a CPU to this new service. This blog is about why, and why you might also want to consider it.
## What were we doing?
The models that we have switched over to Inference Endpoints were previously managed internally and were running on AWS [Elastic Container Service](https://aws.amazon.com/ecs/) (ECS) backed by [AWS Fargate](https://aws.amazon.com/fargate/). This gives you a serverless cluster which can run container based tasks. Our process was as follows:
- Train model on a GPU instance (provisioned by [CML](https://cml.dev/), trained with [transformers](https://huggingface.co/docs/transformers/main/))
- Upload to [Hugging Face Hub](https://huggingface.co/models)
- Build API to serve model [(FastAPI)](https://fastapi.tiangolo.com/)
- Wrap API in container [(Docker)](https://www.docker.com/)
- Upload container to AWS [Elastic Container Repository](https://aws.amazon.com/ecr/) (ECR)
- Deploy model to ECS Cluster
Now, you can reasonably argue that ECS was not the best approach to serving ML models, but it served us up until now, and also allowed ML models to sit alongside other container based services, so it reduced cognitive load.
## What do we do now?
With Inference Endpoints, our flow looks like this:
- Train model on a GPU instance (provisioned by [CML](https://cml.dev/), trained with [transformers](https://huggingface.co/docs/transformers/main/))
- Upload to [Hugging Face Hub](https://huggingface.co/models)
- Deploy using Hugging Face Inference Endpoints.
So this is significantly easier. We could also use another managed service such as [SageMaker](https://aws.amazon.com/es/sagemaker/), [Seldon](https://www.seldon.io/), or [Bento ML](https://www.bentoml.com/), etc., but since we are already uploading our model to Hugging Face hub to act as a model registry, and we’re pretty invested in Hugging Face’s other tools (like transformers, and [AutoTrain](https://huggingface.co/autotrain)) using Inference Endpoints makes a lot of sense for us.
## What about Latency and Stability?
Before switching to Inference Endpoints we tested different CPU endpoints types using [ab](https://httpd.apache.org/docs/2.4/programs/ab.html).
For ECS we didn’t test so extensively, but we know that a large container had a latency of about ~200ms from an instance in the same region. The tests we did for Inference Endpoints we based on text classification model fine tuned on [RoBERTa](https://huggingface.co/roberta-base) with the following test parameters:
- Requester region: eu-east-1
- Requester instance size: t3-medium
- Inference endpoint region: eu-east-1
- Endpoint Replicas: 1
- Concurrent connections: 1
- Requests: 1000 (1000 requests in 1–2 minutes even from a single connection would represent very heavy use for this particular application)
The following table shows latency (ms ± standard deviation and time to complete test in seconds) for four Intel Ice Lake equipped CPU endpoints.
```bash
size | vCPU (cores) | Memory (GB) | ECS (ms) | 🤗 (ms)
----------------------------------------------------------------------
small | 1 | 2 | _ | ~ 296
medium | 2 | 4 | _ | 156 ± 51 (158s)
large | 4 | 8 | ~200 | 80 ± 30 (80s)
xlarge | 8 | 16 | _ | 43 ± 31 (43s)
```
What we see from these results is pretty encouraging. The application that will consume these endpoints serves requests in real time, so we need as low latency as possible. We can see that the vanilla Hugging Face container was more than twice as fast as our bespoke container run on ECS — the slowest response we received from the large Inference Endpoint was just 108ms.
## What about the cost?
So how much does this all cost? The table below shows a price comparison for what we were doing previously (ECS + Fargate) and using Inference Endpoints.
```bash
size | vCPU | Memory (GB) | ECS | 🤗 | % diff
----------------------------------------------------------------------
small | 1 | 2 | $ 33.18 | $ 43.80 | 0.24
medium | 2 | 4 | $ 60.38 | $ 87.61 | 0.31
large | 4 | 8 | $ 114.78 | $ 175.22 | 0.34
xlarge | 8 | 16 | $ 223.59 | $ 350.44 | 0.5
```
We can say a couple of things about this. Firstly, we want a managed solution to deployment, we don’t have a dedicated MLOPs team (yet), so we’re looking for a solution that helps us minimize the time we spend on deploying models, even if it costs a little more than handling the deployments ourselves.
Inference Endpoints are more expensive that what we were doing before, there’s an increased cost of between 24% and 50%. At the scale we’re currently operating, this additional cost, a difference of ~$60 a month for a large CPU instance is nothing compared to the time and cognitive load we are saving by not having to worry about APIs, and containers. If we were deploying 100s of ML microservices we would probably want to think again, but that is probably true of many approaches to hosting.
## Some notes and caveats:
- You can find pricing for Inference Endpoints [here](https://huggingface.co/pricing#endpoints), but a different number is displayed when you deploy a new endpoint from the [GUI](https://ui.endpoints.huggingface.co/new). I’ve used the latter, which is higher.
- The values that I present in the table for ECS + Fargate are an underestimate, but probably not by much. I extracted them from the [fargate pricing page](https://aws.amazon.com/fargate/pricing/) and it includes just the cost of hosting the instance. I’m not including the data ingress/egress (probably the biggest thing is downloading the model from Hugging Face hub), nor have I included the costs related to ECR.
## Other considerations
### Deployment Options
Currently you can deploy an Inference Endpoint from the [GUI](https://ui.endpoints.huggingface.co/new) or using a [RESTful API](https://huggingface.co/docs/inference-endpoints/api_reference). You can also make use of our command line tool [hugie](https://github.com/MantisAI/hfie) (which will be the subject of a future blog) to launch Inference Endpoints in one line of code by passing a configuration, it’s really this simple:
```bash
hugie endpoint create example/development.json
```
For me, what’s lacking is a [custom terraform provider](https://www.hashicorp.com/blog/writing-custom-terraform-providers). It’s all well and good deploying an inference endpoint from a [GitHub action](https://github.com/features/actions) using hugie, as we do, but it would be better if we could use the awesome state machine that is terraform to keep track of these. I’m pretty sure that someone (if not Hugging Face) will write one soon enough — if not, we will.
### Hosting multiple models on a single endpoint
Philipp Schmid posted a really nice blog about how to write a custom [Endpoint Handler](https://www.philschmid.de/multi-model-inference-endpoints) class to allow you to host multiple models on a single endpoint, potentially saving you quite a bit of money. His blog was about GPU inference, and the only real limitation is how many models you can fit into the GPU memory. I assume this will also work for CPU instances, though I’ve not tried yet.
## To conclude…
We find Hugging Face Inference Endpoints to be a very simple and convenient way to deploy transformer (and [sklearn](https://huggingface.co/scikit-learn)) models into an endpoint so they can be consumed by an application. Whilst they cost a little more than the ECS approach we were using before, it’s well worth it because it saves us time on thinking about deployment, we can concentrate on the thing we want to: building NLP solutions for our clients to help solve their problems.
_If you’re interested in Hugging Face Inference Endpoints for your company, please contact us [here](https://huggingface.co/inference-endpoints/enterprise) - our team will contact you to discuss your requirements!_
_This article was originally published on February 15, 2023 [in Medium](https://medium.com/mantisnlp/why-were-switching-to-hugging-face-inference-endpoints-and-maybe-you-should-too-829371dcd330)._
| 1 |
0 | hf_public_repos | hf_public_repos/blog/hf-hub-glam-guide.md | ---
title: "The Hugging Face Hub for Galleries, Libraries, Archives and Museums"
thumbnail: /blog/assets/144_hf_hub_glam_guide/thumbnail.png
authors:
- user: davanstrien
---
## The Hugging Face Hub for Galleries, Libraries, Archives and Museums
### What is the Hugging Face Hub?
Hugging Face aims to make high-quality machine learning accessible to everyone. This goal is pursued in various ways, including developing open-source code libraries such as the widely-used Transformers library, offering [free courses](https://huggingface.co/learn), and providing the Hugging Face Hub.
The [Hugging Face Hub](https://huggingface.co/) is a central repository where people can share and access machine learning models, datasets and demos. The Hub hosts over 190,000 machine learning models, 33,000 datasets and over 100,000 machine learning applications and demos. These models cover a wide range of tasks from pre-trained language models, text, image and audio classification models, object detection models, and a wide range of generative models.
The models, datasets and demos hosted on the Hub span a wide range of domains and languages, with regular community efforts to expand the scope of what is available via the Hub. This blog post intends to offer people working in or with the galleries, libraries, archives and museums (GLAM) sector to understand how they can use — and contribute to — the Hugging Face Hub.
You can read the whole post or jump to the most relevant sections!
- If you don't know what the Hub is, start with: [What is the Hugging Face Hub?](#what-is-the-hugging-face-hub)
- If you want to know how you can find machine learning models on the Hub, start with: [How can you use the Hugging Face Hub: finding relevant models on the Hub](#how-can-you-use-the-hugging-face-hub-finding-relevant-models-on-the-hub)
- If you want to know how you can share GLAM datasets on the Hub, start with [Walkthrough: Adding a GLAM dataset to the Hub?](#walkthrough-adding-a-glam-dataset-to-the-hub)
- If you want to see some examples, check out: [Example uses of the Hugging Face Hub](#example-uses-of-the-hugging-face-hub)
## What can you find on the Hugging Face Hub?
### Models
The Hugging Face Hub provides access to machine learning models covering various tasks and domains. Many machine learning libraries have integrations with the Hugging Face Hub, allowing you to directly use or share models to the Hub via these libraries.
### Datasets
The Hugging Face hub hosts over 30,000 datasets. These datasets cover a range of domains and modalities, including text, image, audio and multi-modal datasets. These datasets are valuable for training and evaluating machine learning models.
### Spaces
Hugging Face [Spaces](https://huggingface.co/docs/hub/spaces) is a platform that allows you to host machine learning demos and applications. These Spaces range from simple demos allowing you to explore the predictions made by a machine learning model to more involved applications.
Spaces make hosting and making your application accessible for others to use much more straightforward. You can use Spaces to host [Gradio](gradio.app/) and [Streamlit](https://streamlit.io/) applications, or you can use Spaces to [custom docker images](https://huggingface.co/docs/hub/spaces-sdks-docker). Using Gradio and Spaces in combination often means you can have an application created and hosted with access for others to use within minutes. You can use Spaces to host a Docker image if you want complete control over your application. There are also Docker templates that can give you quick access to a hosted version of many popular tools, including the [Argailla](https://argilla.io/) and [Label Studio](https://labelstud.io/) annotations tools.
## How can you use the Hugging Face Hub: finding relevant models on the Hub
There are many potential use cases in the GLAM sector where machine learning models can be helpful. Whilst some institutions may have the resources required to train machine learning models from scratch, you can use the Hub to find openly shared models that either already do what you want or are very close to your goal.
As an example, if you are working with a collection of digitized Norwegian documents with minimal metadata. One way to better understand what's in the collection is to use a Named Entity Recognition (NER) model. This model extracts entities from a text, for example, identifying the locations mentioned in a text. Knowing which entities are contained in a text can be a valuable way of better understanding what a document is about.
We can find NER models on the Hub by filtering models by task. In this case, we choose `token-classification`, which is the task which includes named entity recognition models. [This filter](https://huggingface.co/datasets?task_categories=task_categories:token-classification) returns models labelled as doing `token-classification`. Since we are working with Norwegian documents, we may also want to [filter by language](https://huggingface.co/models?pipeline_tag=token-classification&language=no&sort=downloads); this gets us to a smaller set of models we want to explore. Many of these models will also contain a [model widget](https://huggingface.co/saattrupdan/nbailab-base-ner-scandi), allowing us to test the model.

A model widget can quickly show how well a model will likely perform on our data. Once you've found a model that interests you, the Hub provides different ways of using that tool. If you are already familiar with the Transformers library, you can click the use in Transformers button to get a pop-up which shows how to load the model in Transformers.


If you prefer to use a model via an API, clicking the
`deploy` button in a model repository gives you various options for hosting the model behind an API. This can be particularly useful if you want to try out a model on a larger amount of data but need the infrastructure to run models locally.
A similar approach can also be used to find relevant models and datasets
on the Hugging Face Hub.
## Walkthrough: how can you add a GLAM dataset to the Hub?
We can make datasets available via the Hugging Face hub in various ways. I'll walk through an example of adding a CSV dataset to the Hugging Face hub.
<figure class="image table text-center m-0 w-full">
<video
alt="Uploading a file to the Hugging Face Hub"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/hf-hub-glam-guide/Upload%20dataset%20to%20hub.mp4" type="video/mp4">
</video>
</figure>
*Overview of the process of uploading a dataset to the Hub via the browser interface*
For our example, we'll work on making the [On the Books Training Set
](https://cdr.lib.unc.edu/concern/data_sets/6q182v788?locale=en) available via the Hub. This dataset comprises a CSV file containing data that can be used to train a text classification model. Since the CSV format is one of the [supported formats](https://huggingface.co/docs/datasets/upload_dataset#upload-dataset) for uploading data to the Hugging Face Hub, we can share this dataset directly on the Hub without needing to write any code.
### Create a new dataset repository
The first step to uploading a dataset to the Hub is to create a new dataset repository. This can be done by clicking the `New Dataset` button on the dropdown menu in the top right-hand corner of the Hugging Face hub.
Once you have done this you can choose a name for your new dataset repository. You can also create the dataset under a different owner i.e. an organization, and optionally specify a license.

### Upload files
Once you have created a dataset repository you will need to upload the data files. You can do this by clicking on `Add file` under the `Files` tab on the dataset repository.

You can now select the data you wish to upload to the Hub.

You can upload a single file or multiple files using the upload interface. Once you have uploaded your file, you commit your changes to finalize the upload.
### Adding metadata
It is important to add metadata to your dataset repository to make your dataset more discoverable and helpful for others. This will allow others to find your dataset and understand what it contains.
You can edit metadata using the `Metadata UI` editor. This allows you to specify the license, language, tags etc., for the dataset.

It is also very helpful to outline in more detail what your dataset is, how and why it was constructed, and it's strengths and weaknesses. This can be done in a dataset repository by filling out the `README.md` file. This file will serve as a [dataset card](https://huggingface.co/docs/datasets/dataset_card) for your dataset. A dataset card is a semi-structured form of documentation for machine learning datasets that aims to ensure datasets are sufficiently well documented. When you edit the `README.md` file you will be given the option to import a template dataset card. This template will give you helpful prompts for what is useful to include in a dataset card.
*Tip: Writing a good dataset card can be a lot of work. However, you do not need to do all of this work in one go necessarily, and because people can ask questions or make suggestions for datasets hosted on the Hub the processes of documenting datasets can be a collective activity.*
### Datasets preview
Once we've uploaded our dataset to the Hub, we'll get a preview of the dataset. The dataset preview can be a beneficial way of better understanding the dataset.

### Other ways of sharing datasets
You can use many other approaches for sharing datasets on the Hub. The datasets [documentation](https://huggingface.co/docs/datasets/share) will help you better understand what will likely work best for your particular use case.
## Why might Galleries, Libraries, Archives and Museums want to use the Hugging Face hub?
There are many different reasons why institutions want to contribute to
the Hugging Face Hub:
- **Exposure to a new audience**: the Hub has become a central destination for people working in machine learning, AI and related fields. Sharing on the Hub will help expose your collections and work to this audience. This also opens up the opportunity for further collaboration with this audience.
- **Community:** The Hub has many community-oriented features, allowing users and potential users of your material to ask questions and engage with materials you share via the Hub. Sharing trained models and machine learning datasets also allows people to build on each other's work and lowers the barrier to using machine learning in the sector.
- **Diversity of training data:** One of the barriers to the GLAM using machine learning is the availability of relevant data for training and evaluation of machine learning models. Machine learning models that work well on benchmark datasets may not work as well on GLAM organizations' data. Building a community to share domain-specific datasets will ensure machine learning can be more effectively pursued in the GLAM sector.
- **Climate change:** Training machine learning models produces a carbon footprint. The size of this footprint depends on various factors. One way we can collectively reduce this footprint is to share trained models with the community so that people aren't duplicating the same models (and generating more carbon emissions in the process).
## Example uses of the Hugging Face Hub
Individuals and organizations already use the Hugging Face hub to share machine learning models, datasets and demos related to the GLAM sector.
### [BigLAM](https://huggingface.co/biglam)
An initiative developed out of the [BigScience project](https://bigscience.huggingface.co/) is focused on making datasets from GLAM with relevance to machine learning are made more accessible. BigLAM has so far made over 30 datasets related to GLAM available via the Hugging Face hub.
### [Nasjonalbiblioteket AI Lab](https://huggingface.co/NbAiLab)
The AI lab at the National Library of Norway is a very active user of the Hugging Face hub, with ~120 models, 23 datasets and six machine learning demos shared publicly. These models include language models trained on Norwegian texts from the National Library of Norway and Whisper (speech-to-text) models trained on Sámi languages.
### [Smithsonian Institution](https://huggingface.co/Smithsonian)
The Smithsonian shared an application hosted on Hugging Face Spaces, demonstrating two machine learning models trained to identify Amazon fish species. This project aims to empower communities with tools that will allow more accurate measurement of fish species numbers in the Amazon. Making tools such as this available via a Spaces demo further lowers the barrier for people wanting to use these tools.
<html>
<iframe
src="https://smithsonian-amazonian-fish-classifier.hf.space"
frameborder="0"
width="850"
height="450"
></iframe>
</html>
[Source](https://huggingface.co/Smithsonian)
## Hub features for Galleries, Libraries, Archives and Museums
The Hub supports many features which help make machine learning more accessible. Some features which may be particularly helpful for GLAM institutions include:
- **Organizations**: you can create an organization on the Hub. This allows you to create a place to share your organization's artefacts.
- **Minting DOIs**: A [DOI](https://www.doi.org/) (Digital Object Identifier) is a persistent digital identifier for an object. DOIs have become essential for creating persistent identifiers for publications, datasets and software. A persistent identifier is often required by journals, conferences or researcher funders when referencing academic outputs. The Hugging Face Hub supports issuing DOIs for models, datasets, and demos shared on the Hub.
- **Usage tracking**: you can view download stats for datasets and models hosted in the Hub monthly or see the total number of downloads over all time. These stats can be a valuable way for institutions to demonstrate their impact.
- **Script-based dataset sharing**: if you already have dataset hosted somewhere, you can still provide access to them via the Hugging Face hub using a [dataset loading script](https://huggingface.co/docs/datasets/dataset_script).
- **Model and dataset gating**: there are circumstances where you want more control over who is accessing models and datasets. The Hugging Face hub supports model and dataset gating, allowing you to add access controls.
## How can I get help using the Hub?
The Hub [docs](https://huggingface.co/docs/hub/index) go into more detail about the various features of the Hugging Face Hub. You can also find more information about [sharing datasets on the Hub](https://huggingface.co/docs/datasets/upload_dataset) and information about [sharing Transformers models to the Hub](https://huggingface.co/docs/transformers/model_sharing).
If you require any assistance while using the Hugging Face Hub, there are several avenues you can explore. You may seek help by utilizing the [discussion forum](https://discuss.huggingface.co/) or through a [Discord](https://discord.com/invite/hugging-face-879548962464493619).
| 2 |
0 | hf_public_repos | hf_public_repos/blog/researcher-dataset-sharing.md | ---
title: "Share your open ML datasets on Hugging Face Hub!"
thumbnail: /blog/assets/researcher-dataset-sharing/thumbnail.png
authors:
- user: davanstrien
- user: cfahlgren1
- user: lhoestq
- user: erinys
---
If you're working on data-intensive research or machine learning projects, you need a reliable way to share and host your datasets. Public datasets such as Common Crawl, ImageNet, Common Voice and more are critical to the open ML ecosystem, yet they can be challenging to host and share.
Hugging Face Hub makes it seamless to host and share datasets, trusted by many leading research institutions, companies, and government agencies, including [Nvidia](https://huggingface.co/nvidia), [Google](https://huggingface.co/google), [Stanford](https://huggingface.co/stanfordnlp), [NASA](https://huggingface.co/ibm-nasa-geospatial), [THUDM](https://huggingface.co/THUDM) and [Barcelona Supercomputing Center](https://huggingface.co/BSC-LT).
By hosting a dataset on the Hugging Face Hub, you get instant access to features that can maximize your work's impact:
- [Generous Limits](#generous-limits)
- [Dataset Viewer](#dataset-viewer)
- [Third Party Library Support](#third-party-library-support)
- [SQL Console](#sql-console)
- [Security](#security)
- [Reach and Visibility](#reach-and-visibility)
## Generous Limits
### Support for large datasets
The Hub can host terabyte-scale datasets, with high [per-file and per-repository limits](https://huggingface.co/docs/hub/en/repositories-recommendations). If you have data to share, the Hugging Face datasets team can help suggest the best format for uploading your data for community usage.
The [🤗 Datasets library](https://huggingface.co/docs/datasets/index) makes it easy to upload and download your files, or even create a dataset from scratch. 🤗 Datasets also enables dataset streaming , making it possible to work with large datasets without needing to download the entire thing. This can be invaluable to allow researchers with less computational resources to work with your datasets, or to select small portions of a huge dataset for testing, development or prototyping.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/researcher-dataset-sharing/filesize.png" alt="Screenshot of the file size information for a dataset"><br>
<em>The Hugging Face Hub can host the large datasets often created for machine learning research.</em>
</p>
_Note: The [Xet team](https://huggingface.co/xet-team) is currently working on a backend update that will increase per-file limits from the current 50 GB to 500 GB while also improving storage and transfer efficiency._
## Dataset Viewer
Beyond just hosting your data, the Hub provides powerful tools for exploration. With the Datasets Viewer, users can explore and interact with datasets hosted on the Hub directly in their browser. This provides an easy way for others to view and explore your data without downloading it first.
Hugging Face datasets supports many different modalities (audio, images, video, etc.) and file formats (CSV, JSON, Parquet, etc.), and compression formats (Gzip, Zip, etc.). Check out the [Datasets File Formats](https://huggingface.co/docs/hub/en/datasets-adding#file-formats) page for more details.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets/infinity-instruct.png" alt="Screenshot of the Datasets Viewer"><br>
<em>The Dataset Viewer for the Infinity-Instruct dataset.</em>
</p>
The Datasets Viewer also includes a few features which make it easier to explore a dataset.
### Full Text Search
Built-in Full Text Search is one of the most powerful features of the Datasets Viewer. Any text columns in a dataset immediately become searchable.
The Arxiver dataset contains 63.4k rows of arXiv research papers converted to Markdown. By using Full Text Search, it's easy to find the papers containing a specific author such as Ilya Sutskever below.
<iframe
src="https://huggingface.co/datasets/neuralwork/arxiver/embed/viewer/default/train?q=ilya+sutskever"
frameborder="0"
width="100%"
height="560px"
></iframe>
### Sorting
The Datasets Viewer allows you to sort the dataset by clicking on the column headers. This makes it easy to find the most relevant examples in a dataset.
Below is an example of a dataset sorted by the `helpfulness` column in descending order for the [HelpSteer2](https://huggingface.co/datasets/nvidia/HelpSteer2) dataset.
<iframe
src="https://huggingface.co/datasets/nvidia/HelpSteer2/embed/viewer/default/train?sort[column]=helpfulness&sort[direction]=desc"
frameborder="0"
width="100%"
height="560px"
></iframe>
## Third Party Library Support
Hugging Face is fortunate to have third party integrations with the leading open source data tools. By hosting a dataset on the Hub, it instantly makes the dataset compatible with the tools users are most familiar with.
Here are some of the libraries Hugging Face supports out of the box:
| Library | Description | Monthly PyPi Downloads (2024) |
| :---- | :---- | :---- |
| [Pandas](https://huggingface.co/docs/hub/datasets-pandas) | Python data analysis toolkit. | **258M** |
| [Spark](https://huggingface.co/docs/hub/datasets-spark) | Real-time, large-scale data processing tool in a distributed environment. | **29M** |
| [Datasets](https://huggingface.co/docs/hub/datasets-usage) | 🤗 Datasets is a library for accessing and sharing datasets for Audio, Computer Vision, and Natural Language Processing (NLP). | **17M** |
| [Dask](https://huggingface.co/docs/hub/datasets-dask) | Parallel and distributed computing library that scales the existing Python and PyData ecosystem. | **12M** |
| [Polars](https://huggingface.co/docs/hub/datasets-polars) | A DataFrame library on top of an OLAP query engine. | **8.5M** |
| [DuckDB](https://huggingface.co/docs/hub/datasets-duckdb) | In-process SQL OLAP database management system. | **6M** |
| [WebDataset](https://huggingface.co/docs/hub/datasets-webdataset) | Library to write I/O pipelines for large datasets. | **871K** |
| [Argilla](https://huggingface.co/docs/hub/datasets-argilla) | Collaboration tool for AI engineers and domain experts that value high quality data. | **400k** |
Most of these libraries enable you to load or stream a dataset in 1 single line of code.
Here are some examples with Pandas, Polars and DuckDB:
```python
# Pandas example
import pandas as pd
df = pd.read_parquet("hf://datasets/neuralwork/arxiver/data/train.parquet")
# Polars example
import polars as pl
df = pl.read_parquet("hf://datasets/neuralwork/arxiver/data/train.parquet")
# DuckDB example - SQL queries
import duckdb
duckdb.sql("SELECT * FROM 'hf://datasets/neuralwork/arxiver/data/train.parquet' LIMIT 10")
```
You can find more information about integrated libraries in the [Datasets documentation](https://huggingface.co/docs/hub/en/datasets-libraries). Along with the libraries listed above, there are many more community supported tools which support the Hugging Face Hub such as [Lilac](https://lilacml.com/) and [Spotlight](https://github.com/Renumics/spotlight).
## SQL Console
The [SQL Console](https://huggingface.co/blog/sql-console) provides an interactive SQL editor that runs entirely in your browser, enabling instant data exploration without any setup. Key features include:
- **One-Click**: Open a SQL Console to query a dataset with a single click
- **Shareable and Embeddable Results**: Share and embed interesting query results
- **Full DuckDB Syntax**: Use full SQL syntax with built-in functions for regex, lists, JSON, embeddings, and more
On every public dataset you should see a new **SQL Console** badge. With just one click you can open a SQL Console to query that dataset.
<figure class="image flex flex-col items-center text-center m-0 w-full">
<video
alt="SQL Console Demo"
autoplay loop autobuffer muted playsinline
>
<source src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/sql_console/Magpie-Ultra-Demo-SQL-Console.mp4" type="video/mp4">
</video>
<figcaption class="text-center text-sm italic">Querying the Magpie-Ultra dataset for excellent, high quality reasoning instructions.</figcaption>
</figure>
## Security
While making datasets accessible is important, protecting sensitive data is equally crucial. The Hugging Face Hub provides robust security features to help you maintain control over your data while sharing it with the right audiences.
### Access Controls
The Hugging Face Hub supports unique access control options for who has access to the dataset.
- **Public**: Anyone can access the dataset.
- **Private**: Only you and those in your organization can access the dataset.
- **Gated**: Control access to your dataset through two options:
- **Automatic Approval**: Users must provide required information (like name and email) and agree to terms before gaining access
- **Manual Approval**: You review and manually approve/reject each access request
For more details about gated datasets, see the [gated datasets documentation](https://huggingface.co/docs/hub/en/datasets-gated). For more fine-grained controls, there are Enterprise plan features where organizations can [create resource security groups](https://huggingface.co/docs/hub/en/security-resource-groups), use [SSO](https://huggingface.co/docs/hub/en/security-sso), and more.
### Built-in Security Scanning
Along with access controls, the Hugging Face Hub offers several security scanners:
| Feature | Description |
| :---- | :---- |
| [Malware Scanning](https://huggingface.co/docs/hub/en/security-malware) | Scans files for malware and suspicious content at each commit and visit |
| [Secrets Scanning](https://huggingface.co/docs/hub/en/security-secrets) | Blocks datasets with hardcoded secrets and environment variables |
| [Pickle Scanning](https://huggingface.co/docs/hub/en/security-pickle) | Scans pickle files and shows vetted imports for PyTorch weights |
| [ProtectAI](https://huggingface.co/docs/hub/en/security-protectai) | Uses Guardian tech to block datasets with pickle, Keras and other exploits |
<figure class="flex flex-col items-center text-center m-0 w-full">
<img class="rounded" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/hub/security-scanner-status-banner.png" alt="Security scanner status banner showing various security checks"/>
<figcaption class="text-center text-sm italic mt-2">To learn more about these scanners, see the <a href="https://huggingface.co/docs/hub/en/security">security scanners documentation</a>.</figcaption>
</figure>
## Reach and Visibility
Having a secure platform with powerful features is valuable, but the true impact of research comes from reaching the right audience. Reach and visibility are crucial for researchers sharing datasets - it helps maximize research impact, enables reproducibility, facilitates collaboration, and ensures valuable data can benefit the broader scientific community.
With over 5M builders actively using the platform, the Hugging Face Hub provides researchers with powerful tools for community engagement and visibility. Here's what you can expect:
### Better Community Engagement
- Built-in discussion tabs for each dataset for community engagement
- Organizations as a centralized place for grouping and collaborating on multiple datasets
- Metrics for dataset usage and impact
### Wider Reach
- Access to a large, active community of researchers, developers, and practitioners
- SEO-optimized URLs making your dataset easily discoverable
- Integration with the broader ecosystem of models, datasets, and libraries
- Clear links between your dataset and related models, papers, and demos
### Improved Documentation
- Customizable README files for comprehensive documentation
- Support for detailed dataset descriptions and proper academic citations
- Links to related research papers and publications
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/researcher-dataset-sharing/discussion.png" alt="Screenshot of a discussion for a dataset on the Hub."><br>
<em>The Hub makes it easy to ask questions and discuss datasets.</em>
</p>
## How can I host my dataset on the Hugging Face Hub?
Now that you understand the benefits of hosting your dataset on the Hub, you might be wondering how to get started. Here are some comprehensive resources to guide you through the process:
- General guidance on [creating](https://huggingface.co/docs/datasets/create_dataset) and [sharing datasets on the Hub](https://huggingface.co/docs/datasets/upload_dataset)
- Guides for particular modalities:
- Creating an [audio dataset](https://huggingface.co/docs/datasets/audio_dataset)
- Creating an [image dataset](https://huggingface.co/docs/datasets/image_dataset)
- Creating a [video dataset](https://huggingface.co/docs/datasets/video_dataset)
- Guidance on [structuring your repository](https://huggingface.co/docs/datasets/repository_structure) so a dataset can be automatically loaded from the Hub.
The following pages will be useful if you want to share large datasets:
- [Repository limitations and recommendations](https://huggingface.co/docs/hub/repositories-recommendations) provides general guidance on some of the considerations you'll want to make when sharing large datasets.
- The [Tips and tricks for large uploads](https://huggingface.co/docs/huggingface_hub/guides/upload#tips-and-tricks-for-large-uploads) page provides some guidance on how to upload large datasets to the Hub.
If you want any further help uploading a dataset to the Hub or want to upload a particularly large dataset, please contact [email protected].
| 3 |
0 | hf_public_repos | hf_public_repos/blog/huggylingo.md | ---
title: "Huggy Lingo: Using Machine Learning to Improve Language Metadata on the Hugging Face Hub"
thumbnail: blog/assets/156_huggylingo/Huggy_Lingo.png
authors:
- user: davanstrien
---
## Huggy Lingo: Using Machine Learning to Improve Language Metadata on the Hugging Face Hub
**tl;dr**: We're using machine learning to detect the language of Hub datasets with no language metadata, and [librarian-bots](https://huggingface.co/librarian-bots) to make pull requests to add this metadata.
The Hugging Face Hub has become the repository where the community shares machine learning models, datasets, and applications. As the number of datasets grows, metadata becomes increasingly important as a tool for finding the right resource for your use case.
In this blog post, I'm excited to share some early experiments which seek to use machine learning to improve the metadata for datasets hosted on the Hugging Face Hub.
### Language metadata for datasets on the Hub
There are currently ~50K public datasets on the Hugging Face Hub. Metadata about the language used in a dataset can be specified using a [YAML](https://en.wikipedia.org/wiki/YAML) field at the top of the [dataset card](https://huggingface.co/docs/datasets/upload_dataset#create-a-dataset-card).
All public datasets specify 1,716 unique languages via a language tag in their metadata. Note that some of them will be the result of languages being specified in different ways i.e. `en` vs `eng` vs `english` vs `English`.
For example, the [IMDB dataset](https://huggingface.co/datasets/imdb) specifies `en` in the YAML metadata (indicating English):
* Section of the YAML metadata for the IMDB dataset*
It is perhaps unsurprising that English is by far the most common language for datasets on the Hub, with around 19% of datasets on the Hub listing their language as `en` (not including any variations of `en`, so the actual percentage is likely much higher).
*The frequency and percentage frequency for datasets on the Hugging Face Hub*
What does the distribution of languages look like if we exclude English? We can see that there is a grouping of a few dominant languages and after that there is a pretty smooth fall in the frequencies at which languages appear.
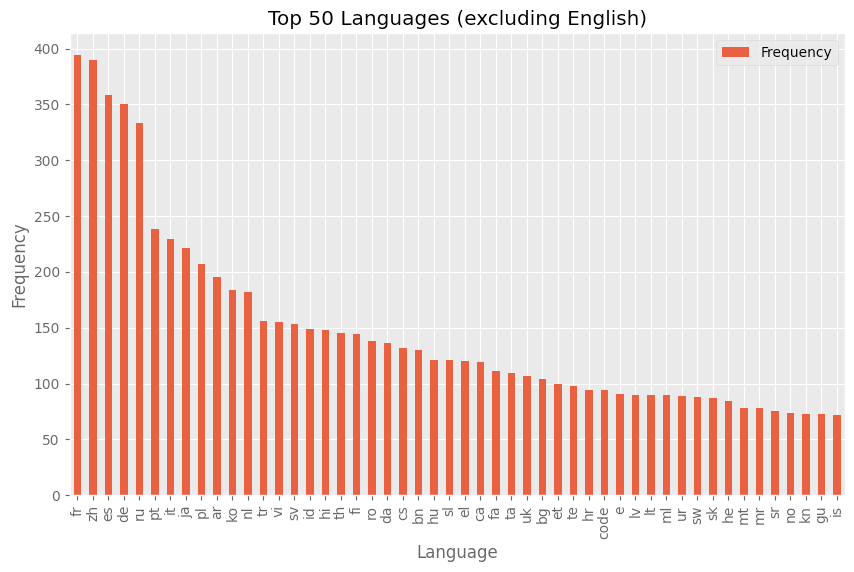
*Distribution of language tags for datasets on the hub excluding English*
However, there is a major caveat to this. Most datasets (around 87%) do not specify any language at all!
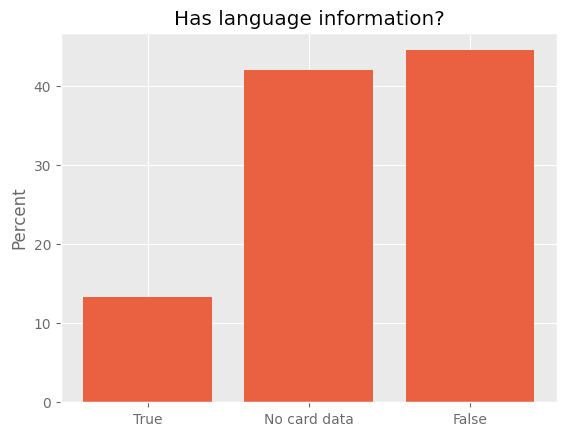
*The percent of datasets which have language metadata. True indicates language metadata is specified, False means no language data is listed. No card data means that there isn't any metadata or it couldn't be loaded by the `huggingface_hub` Python library.*
#### Why is language metadata important?
Language metadata can be a vital tool for finding relevant datasets. The Hugging Face Hub allows you to filter datasets by language. For example, if we want to find datasets with Dutch language we can use [a filter](https://huggingface.co/datasets?language=language:nl&sort=trending) on the Hub to include only datasets with Dutch data.
Currently this filter returns 184 datasets. However, there are datasets on the Hub which include Dutch but don't specify this in the metadata. These datasets become more difficult to find, particularly as the number of datasets on the Hub grows.
Many people want to be able to find datasets for a particular language. One of the major barriers to training good open source LLMs for a particular language is a lack of high quality training data.
If we switch to the task of finding relevant machine learning models, knowing what languages were included in the training data for a model can help us find models for the language we are interested in. This relies on the dataset specifying this information.
Finally, knowing what languages are represented on the Hub (and which are not), helps us understand the language biases of the Hub and helps inform community efforts to address gaps in particular languages.
### Predicting the languages of datasets using machine learning
We’ve already seen that many of the datasets on the Hugging Face Hub haven’t included metadata for the language used. However, since these datasets are already shared openly, perhaps we can look at the dataset and try to identify the language using machine learning.
#### Getting the data
One way we could access some examples from a dataset is by using the datasets library to download the datasets i.e.
```python
from datasets import load_dataset
dataset = load_dataset("biglam/on_the_books")
```
However, for some of the datasets on the Hub, we might be keen not to download the whole dataset. We could instead try to load a sample of the dataset. However, depending on how the dataset was created, we might still end up downloading more data than we’d need onto the machine we’re working on.
Luckily, many datasets on the Hub are available via the [dataset viewer API](https://huggingface.co/docs/datasets-server/index). It allows us to access datasets hosted on the Hub without downloading the dataset locally. The API powers the dataset viewer you will see for many datasets hosted on the Hub.
For this first experiment with predicting language for datasets, we define a list of column names and data types likely to contain textual content i.e. `text` or `prompt` column names and `string` features are likely to be relevant `image` is not. This means we can avoid predicting the language for datasets where language information is less relevant, for example, image classification datasets. We use the dataset viewer API to get 20 rows of text data to pass to a machine learning model (we could modify this to take more or fewer examples from the dataset).
This approach means that for the majority of datasets on the Hub we can quickly request the contents of likely text columns for the first 20 rows in a dataset.
#### Predicting the language of a dataset
Once we have some examples of text from a dataset, we need to predict the language. There are various options here, but for this work, we used the [facebook/fasttext-language-identification](https://huggingface.co/facebook/fasttext-language-identification) fastText model created by [Meta](https://huggingface.co/facebook) as part of the [No Language Left Behind](https://ai.facebook.com/research/no-language-left-behind/) work. This model can detect 217 languages which will likely represent the majority of languages for datasets hosted on the Hub.
We pass 20 examples to the model representing rows from a dataset. This results in 20 individual language predictions (one per row) for each dataset.
Once we have these predictions, we do some additional filtering to determine if we will accept the predictions as a metadata suggestion. This roughly consists of:
- Grouping the predictions for each dataset by language: some datasets return predictions for multiple languages. We group these predictions by the language predicted i.e. if a dataset returns predictions for English and Dutch, we group the English and Dutch predictions together.
- For datasets with multiple languages predicted, we count how many predictions we have for each language. If a language is predicted less than 20% of the time, we discard this prediction. i.e. if we have 18 predictions for English and only 2 for Dutch we discard the Dutch predictions.
- We calculate the mean score for all predictions for a language. If the mean score associated with a languages prediction is below 80% we discard this prediction.
Once we’ve done this filtering, we have a further step of deciding how to use these predictions. The fastText language prediction model returns predictions as an [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) code (an international standard for language codes) along with a script type. i.e. `kor_Hang` is the ISO 693-3 language code for Korean (kor) + Hangul script (Hang) a [ISO 15924](https://en.wikipedia.org/wiki/ISO_15924) code representing the script of a language.
We discard the script information since this isn't currently captured consistently as metadata on the Hub and, where possible, we convert the language prediction returned by the model from [ISO 639-3](https://en.wikipedia.org/wiki/ISO_639-3) to [ISO 639-1](https://en.wikipedia.org/wiki/ISO_639-1) language codes. This is largely done because these language codes have better support in the Hub UI for navigating datasets.
For some ISO 639-3 codes, there is no ISO 639-1 equivalent. For these cases we manually specify a mapping if we deem it to make sense, for example Standard Arabic (`arb`) is mapped to Arabic (`ar`). Where an obvious mapping is not possible, we currently don't suggest metadata for this dataset. In future iterations of this work we may take a different approach. It is important to recognise this approach does come with downsides, since it reduces the diversity of languages which might be suggested and also relies on subjective judgments about what languages can be mapped to others.
But the process doesn't stop here. After all, what use is predicting the language of the datasets if we can't share that information with the rest of the community?
### Using Librarian-Bot to Update Metadata
To ensure this valuable language metadata is incorporated back into the Hub, we turn to Librarian-Bot! Librarian-Bot takes the language predictions generated by Meta's [facebook/fasttext-language-identification](https://huggingface.co/facebook/fasttext-language-identification) fastText model and opens pull requests to add this information to the metadata of each respective dataset.
This automated system not only updates the datasets with language information, but also does it swiftly and efficiently, without requiring manual work from humans. Once these pull requests are approved and merged, the language metadata becomes available for all users, significantly enhancing the usability of the Hugging Face Hub. You can keep track of what the librarian-bot is doing [here](https://huggingface.co/librarian-bot/activity/community)!
#### Next steps
As the number of datasets on the Hub grows, metadata becomes increasingly important. Language metadata, in particular, can be incredibly valuable for identifying the correct dataset for your use case.
With the assistance of the dataset viewer API and the [Librarian-Bots](https://huggingface.co/librarian-bots), we can update our dataset metadata at a scale that wouldn't be possible manually. As a result, we're enriching the Hub and making it an even more powerful tool for data scientists, linguists, and AI enthusiasts around the world.
As the machine learning librarian at Hugging Face, I continue exploring opportunities for automatic metadata enrichment for machine learning artefacts hosted on the Hub. Feel free to reach out (daniel at thiswebsite dot co) if you have ideas or want to collaborate on this effort!
| 4 |
0 | hf_public_repos | hf_public_repos/blog/prodigy-hf.md | ---
title: "Introducing Prodigy-HF: a direct integration with Hugging Face"
thumbnail: /blog/assets/171_prodigy_hf/thumbnail.png
authors:
- user: koaning
guest: true
---
# Introducing Prodigy-HF
[Prodigy](https://prodi.gy/) is an annotation tool made by [Explosion](https://explosion.ai/), a company well known as the creators of [spaCy](https://spacy.io/). It's a fully scriptable product with a large community around it. The product has many features, including tight integration with spaCy and active learning capabilities. But the main feature of the product is that it is programmatically customizable with Python.
To foster this customisability, Explosion has started releasing [plugins](https://prodi.gy/docs/plugins). These plugins integrate with third-party tools in an open way that encourages users to work on bespoke annotation workflows. However, one customization specifically deserves to be celebrated explicitly. Last week, Explosion introduced [Prodigy-HF](https://github.com/explosion/prodigy-hf), which offers code recipes that directly integrate with the Hugging Face stack. It's been a much-requested feature on the [Prodigy support forum](https://support.prodi.gy/), so we're super excited to have it out there.
## Features
The first main feature is that this plugin allows you to train and re-use Hugging Face models on your annotated data. That means if you've been annotating data in our interface for named entity recognition, you can directly fine-tune BERT models against it.
<figure>
<div style="background-color: #eee; padding-top: 8px; padding-bottom: 8px;">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/prodigy-hf/interface.png" width="100%">
</div>
<figcaption style="text-color: gray; margin-left: auto; margin-right: auto; text-align:center; padding-top: 8px;"><small>What the Prodigy NER interface looks like.</small></figcaption>
</figure>
After installing the plugin you can call the `hf.train.ner` recipe from the command line to train a transformer model directly on your own data.
```
python -m prodigy hf.train.ner fashion-train,eval:fashion-eval path/to/model-out --model "distilbert-base-uncased"
```
This will fine-tune the `distilbert-base-uncased` model for the dataset you've stored in Prodigy and save it to disk. Similarly, this plugin also supports models for text classification via a very similar interface.
```
python -m prodigy hf.train.textcat fashion-train,eval:fashion-eval path/to/model-out --model "distilbert-base-uncased"
```
This offers a lot of flexibility because the tool directly integrates with the `AutoTokenizer` and `AutoModel` classes of Hugging Face transformers. Any transformer model on the hub can be fine-tuned on your own dataset with just a single command. These models will be serialised on disk, which means that you can upload them to the Hugging Face Hub, or re-use them to help you annotate data. This can save a lot of time, especially for NER tasks. To re-use a trained NER model you can use the `hf.correct.ner` recipe.
```
python -m prodigy hf.correct.ner fashion-train path/to/model-out examples.jsonl
```
This will give you a similar interface as before, but now the model predictions will be shown in the interface as well.
### Upload
The second feature, which is equally exciting, is that you can now also publish your annotated datasets on the Hugging Face Hub. This is great if you're interested in sharing datasets that others would like to use.
```
python -m prodigy hf.upload <dataset_name> <username>/<repo_name>
```
We're particularly fond of this upload feature because it encourages collaboration. People can annotate their own datasets independently of each other, but still benefit when they share the data with the wider community.
## More to come
We hope that this direct integration with the Hugging Face ecosystem enables many users to experiment more. The Hugging Face Hub offers _many_ [models](https://huggingface.co/models) for a wide array of tasks as well as a wide array of languages. We really hope that this integration makes it easier to get data annotated, even if you've got a more domain specific and experimental use-case.
More features for this library are on their way, and feel free to reach out on the [Prodigy forum](https://support.prodi.gy/) if you have more questions.
We'd also like to thank the team over at Hugging Face for their feedback on this plugin, specifically @davanstrien, who suggested to add the upload feature. Thanks!
| 5 |
0 | hf_public_repos | hf_public_repos/blog/pytorch_block_sparse.md | ---
title: Block Sparse Matrices for Smaller and Faster Language Models
thumbnail: /blog/assets/04_pytorch_block_sparse/thumbnail.png
authors:
- user: madlag
---
# Block Sparse Matrices for Smaller and Faster Language Models
## Saving space and time, one zero at a time
In previous [blog](https://medium.com/huggingface/is-the-future-of-neural-networks-sparse-an-introduction-1-n-d03923ecbd70)
[posts](https://medium.com/huggingface/sparse-neural-networks-2-n-gpu-performance-b8bc9ce950fc)
we introduced sparse matrices and what they could do to improve neural networks.
The basic assumption is that full dense layers are often overkill and can be pruned without a significant loss in precision.
In some cases sparse linear layers can even *improve precision or/and generalization*.
The main issue is that currently available code that supports sparse algebra computation is severely lacking efficiency.
We are also [still waiting](https://openai.com/blog/openai-pytorch/) for official PyTorch support.
That's why we ran out of patience and took some time this summer to address this "lacuna".
Today, we are excited to **release the extension [pytorch_block_sparse](https://github.com/huggingface/pytorch_block_sparse)**.
By itself, or even better combined with other methods like
[distillation](https://medium.com/huggingface/distilbert-8cf3380435b5)
and [quantization](https://medium.com/microsoftazure/faster-and-smaller-quantized-nlp-with-hugging-face-and-onnx-runtime-ec5525473bb7),
this library enables **networks** which are both **smaller and faster**,
something Hugging Face considers crucial to let anybody use
neural networks in production at **low cost**, and to **improve the experience** for the end user.
## Usage
The provided `BlockSparseLinear` module is a drop in replacement for `torch.nn.Linear`, and it is trivial to use
it in your models:
```python
# from torch.nn import Linear
from pytorch_block_sparse import BlockSparseLinear
...
# self.fc = nn.Linear(1024, 256)
self.fc = BlockSparseLinear(1024, 256, density=0.1)
```
The extension also provides a `BlockSparseModelPatcher` that allows to modify an existing model "on the fly",
which is shown in this [example notebook](https://github.com/huggingface/pytorch_block_sparse/blob/master/doc/notebooks/ModelSparsification.ipynb).
Such a model can then be trained as usual, without any change in your model source code.
## NVIDIA CUTLASS
This extension is based on the [cutlass tilesparse](https://github.com/YulhwaKim/cutlass_tilesparse) proof of concept by [Yulhwa Kim](https://github.com/YulhwaKim).
It is using **C++ CUDA templates** for block-sparse matrix multiplication
based on **[CUTLASS](https://developer.nvidia.com/blog/cutlass-linear-algebra-cuda/)**.
CUTLASS is a collection of CUDA C++ templates for implementing high-performance CUDA kernels.
With CUTLASS, approching cuBLAS performance on custom kernels is possible without resorting to assembly language code.
The latest versions include all the **Ampere Tensor Core primitives**, providing **x10 or more speedups** with a limited loss of precision.
Next versions of pytorch_block_sparse will make use of these primitives,
as block sparsity is 100% compatible with Tensor Cores requirements.
## Performance
At the current stage of the library, the performances for sparse matrices are roughly
two times slower than their cuBLAS optimized dense counterpart, and we are confident
that we can improve this in the future.
This is a huge improvement on PyTorch sparse matrices: their current implementation is an order of magnitude slower
than the dense one.
But the more important point is that the performance gain of using sparse matrices grows with the sparsity,
so a **75% sparse matrix** is roughly **2x** faster than the dense equivalent.
The memory savings are even more significant: for **75% sparsity**, memory consumption is reduced by **4x**
as you would expect.
## Future work
Being able to efficiently train block-sparse linear layers was just the first step.
The sparsity pattern is currenly fixed at initialization, and of course optimizing it during learning will yield large
improvements.
So in future versions, you can expect tools to measure the "usefulness" of parameters to be able to **optimize the sparsity pattern**.
**NVIDIA Ampere 50% sparse pattern** within blocks will probably yield another significant performance gain, just as upgrading
to more recent versions of CUTLASS does.
So, stay tuned for more sparsity goodness in a near future!
| 6 |
0 | hf_public_repos | hf_public_repos/blog/open_rail.md | ---
title: "OpenRAIL: Towards open and responsible AI licensing frameworks"
thumbnail: /blog/assets/100_open_rail/100_open-rail.png
authors:
- user: CarlosMF
---
# OpenRAIL: Towards open and responsible AI licensing frameworks
Open & Responsible AI licenses ("OpenRAIL") are AI-specific licenses enabling open access, use and distribution of AI artifacts while requiring a responsible use of the latter. OpenRAIL licenses could be for open and responsible ML what current open software licenses are to code and Creative Commons to general content: **a widespread community licensing tool.**
Advances in machine learning and other AI-related areas have flourished these past years partly thanks to the ubiquity of the open source culture in the Information and Communication Technologies (ICT) sector, which has permeated into ML research and development dynamics. Notwithstanding the benefits of openness as a core value for innovation in the field, (not so already) recent events related to the ethical and socio-economic concerns of development and use of machine learning models have spread a clear message: Openness is not enough. Closed systems are not the answer though, as the problem persists under the opacity of firms' private AI development processes.
## **Open source licenses do not fit all**
Access, development and use of ML models is highly influenced by open source licensing schemes. For instance, ML developers might colloquially refer to "open sourcing a model" when they make its weights available by attaching an official open source license, or any other open software or content license such as Creative Commons. This begs the question: why do they do it? Are ML artifacts and source code really that similar? Do they share enough from a technical perspective that private governance mechanisms (e.g. open source licenses) designed for source code should also govern the development and use of ML models?
Most current model developers seem to think so, as the majority of openly released models have an open source license (e.g., Apache 2.0). See for instance the Hugging Face [Model Hub](https://huggingface.co/models?license=license:apache-2.0&sort=downloads) and [Muñoz Ferrandis & Duque Lizarralde (2022)](https://papers.ssrn.com/sol3/papers.cfm?abstract_id=4018413).
However, empirical evidence is also telling us that a rigid approach to open sourcing [and/or](https://www.gnu.org/philosophy/open-source-misses-the-point.en.html) Free Software dynamics and an axiomatic belief in Freedom 0 for the release of ML artifacts is creating socio-ethical distortions in the use of ML models (see [Widder et al. (2022)](https://davidwidder.me/files/widder-ossdeepfakes-facct22.pdf)). In simpler terms, open source licenses do not take the technical nature and capabilities of the model as a different artifact to software/source code into account, and are therefore ill-adapted to enabling a more responsible use of ML models (e.g. criteria 6 of the [Open Source Definition](https://opensource.org/osd)), see also [Widder et al. (2022)](https://davidwidder.me/files/widder-ossdeepfakes-facct22.pdf); [Moran (2021)](https://www.google.com/url?q=https://thegradient.pub/machine-learning-ethics-and-open-source-licensing-2/&sa=D&source=docs&ust=1655402923069398&usg=AOvVaw3yTXEfpRQOJ99w04v5GAEd); [Contractor et al. (2020)](https://facctconference.org/static/pdfs_2022/facct22-63.pdf).
If specific ad hoc practices devoted to documentation, transparency and ethical usage of ML models are already present and improving each day (e.g., model cards, evaluation benchmarks), why shouldn't open licensing practices also be adapted to the specific capabilities and challenges stemming from ML models?
Same concerns are rising in commercial and government ML licensing practices. In the words of [Bowe & Martin (2022)](https://www.gmu.edu/news/2022-04/no-10-implementing-responsible-ai-proposed-framework-data-licensing): "_Babak Siavoshy, general counsel at Anduril Industries, asked what type of license terms should apply to an AI algorithm privately developed for computer-vision object detection and adapt it for military targeting or threat-evaluation? Neither commercial software licenses nor standard DFARS data rights clauses adequately answer this question as neither appropriately protects the developer's interest or enable the government to gain the insight into the system to deploy it responsibly_".
If indeed ML models and software/source code are different artifacts, why is the former released under open source licenses? The answer is easy, open source licenses have become the de facto standard in software-related markets for the open sharing of code among software communities. This "open source" approach to collaborative software development has permeated and influenced AI development and licensing practices and has brought huge benefits. Both open source and Open & Responsible AI licenses ("OpenRAIL") might well be complementary initiatives.
**Why don't we design a set of licensing mechanisms inspired by movements such as open source and led by an evidence-based approach from the ML field?** In fact, there is a new set of licensing frameworks which are going to be the vehicle towards open and responsible ML development, use and access: Open & Responsible AI Licenses ([OpenRAIL](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses)).
## **A change of licensing paradigm: OpenRAIL**
The OpenRAIL [approach](https://www.licenses.ai/blog/2022/8/18/naming-convention-of-responsible-ai-licenses) taken by the [RAIL Initiative](https://www.licenses.ai/) and supported by Hugging Face is informed and inspired by initiatives such as BigScience, Open Source, and Creative Commons. The 2 main features of an OpenRAIL license are:
- **Open:** these licenses allow royalty free access and flexible downstream use and re-distribution of the licensed material, and distribution of any derivatives of it.
- **Responsible:** OpenRAIL licenses embed a specific set of restrictions for the use of the licensed AI artifact in identified critical scenarios. Use-based restrictions are informed by an evidence-based approach to ML development and use limitations which forces to draw a line between promoting wide access and use of ML against potential social costs stemming from harmful uses of the openly licensed AI artifact. Therefore, while benefiting from an open access to the ML model, the user will not be able to use the model for the specified restricted scenarios.
The integration of use-based restrictions clauses into open AI licenses brings up the ability to better control the use of AI artifacts and the capacity of enforcement to the licensor of the ML model, standing up for a responsible use of the released AI artifact, in case a misuse of the model is identified. If behavioral-use restrictions were not present in open AI licenses, how would licensors even begin to think about responsible use-related legal tools when openly releasing their AI artifacts? OpenRAILs and RAILs are the first step towards enabling ethics-informed behavioral restrictions.
And even before thinking about enforcement, use-based restriction clauses might act as a deterrent for potential users to misuse the model (i.e., dissuasive effect). However, the mere presence of use-based restrictions might not be enough to ensure that potential misuses of the released AI artifact won't happen. This is why OpenRAILs require downstream adoption of the use-based restrictions by subsequent re-distribution and derivatives of the AI artifact, as a means to dissuade users of derivatives of the AI artifact from misusing the latter.
The effect of copyleft-style behavioral-use clauses spreads the requirement from the original licensor on his/her wish and trust on the responsible use of the licensed artifact. Moreover, widespread adoption of behavioral-use clauses gives subsequent distributors of derivative versions of the licensed artifact the ability for a better control of the use of it. From a social perspective, OpenRAILs are a vehicle towards the consolidation of an informed and respectful culture of sharing AI artifacts acknowledging their limitations and the values held by the licensors of the model.
## **OpenRAIL could be for good machine learning what open software licensing is to code**
Three examples of OpenRAIL licenses are the recently released [BigScience OpenRAIL-M](https://www.licenses.ai/blog/2022/8/26/bigscience-open-rail-m-license), StableDiffusion's [CreativeML OpenRAIL-M](https://huggingface.co/spaces/CompVis/stable-diffusion-license), and the genesis of the former two: [BigSicence BLOOM RAIL v1.0](https://huggingface.co/spaces/bigscience/license) (see post and FAQ [here](https://bigscience.huggingface.co/blog/the-bigscience-rail-license)). The latter was specifically designed to promote open and responsible access and use of BigScience's 176B parameter model named BLOOM (and related checkpoints). The license plays at the intersection between openness and responsible AI by proposing a permissive set of licensing terms coped with a use-based restrictions clause wherein a limited number of restricted uses is set based on the evidence on the potential that Large Language Models (LLMs) have, as well as their inherent risks and scrutinized limitations. The OpenRAIL approach taken by the RAIL Initiative is a consequence of the BigScience BLOOM RAIL v1.0 being the first of its kind in parallel with the release of other more restricted models with behavioral-use clauses, such as [OPT-175](https://github.com/facebookresearch/metaseq/blob/main/projects/OPT/MODEL_LICENSE.md) or [SEER](https://github.com/facebookresearch/vissl/blob/main/projects/SEER/MODEL_LICENSE.md), being also made available.
The licenses are BigScience's reaction to 2 partially addressed challenges in the licensing space: (i) the "Model" being a different thing to "code"; (ii) the responsible use of the Model. BigScience made that extra step by really focusing the license on the specific case scenario and BigScience's community goals. In fact, the solution proposed is kind of a new one in the AI space: BigScience designed the license in a way that makes the responsible use of the Model widespread (i.e. promotion of responsible use), because any re-distribution or derivatives of the Model will have to comply with the specific use-based restrictions while being able to propose other licensing terms when it comes to the rest of the license.
OpenRAIL also aligns with the ongoing regulatory trend proposing sectoral specific regulations for the deployment, use and commercialization of AI systems. With the advent of AI regulations (e.g., [EU AI Act](https://eur-lex.europa.eu/legal-content/EN/TXT/?uri=CELEX%3A52021PC0206); Canada's [proposal](https://iapp.org/news/a/canada-introduces-new-federal-privacy-and-ai-legislation/) of an AI & Data Act), new open licensing paradigms informed by AI regulatory trends and ethical concerns have the potential of being massively adopted in the coming years. Open sourcing a model without taking due account of its impact, use, and documentation could be a source of concern in light of new AI regulatory trends. Henceforth, OpenRAILs should be conceived as instruments articulating with ongoing AI regulatory trends and part of a broader system of AI governance tools, and not as the only solution enabling open and responsible use of AI.
Open licensing is one of the cornerstones of AI innovation. Licenses as social and legal institutions should be well taken care of. They should not be conceived as burdensome legal technical mechanisms, but rather as a communication instrument among AI communities bringing stakeholders together by sharing common messages on how the licensed artifact can be used.
Let's invest in a healthy open and responsible AI licensing culture, the future of AI innovation and impact depends on it, on all of us, on you.
Author: Carlos Muñoz Ferrandis
Blog acknowledgments: Yacine Jernite, Giada Pistilli, Irene Solaiman, Clementine Fourrier, Clément Délange
| 7 |
0 | hf_public_repos | hf_public_repos/blog/hugging-face-wiz-security-blog.md | ---
title: "Hugging Face partners with Wiz Research to Improve AI Security"
thumbnail: /blog/assets/wiz_security/security.png
authors:
- user: JJoe206
- user: GuillaumeSalouHF
- user: michellehbn
- user: XciD
- user: mcpotato
- user: Narsil
- user: julien-c
---
# Hugging Face partners with Wiz Research to Improve AI Security
We are pleased to announce that we are partnering with Wiz with the goal of improving security across our platform and the AI/ML ecosystem at large.
Wiz researchers [collaborated with Hugging Face on the security of our platform and shared their findings](https://www.wiz.io/blog/wiz-and-hugging-face-address-risks-to-ai-infrastructure). Wiz is a cloud security company that helps their customers build and maintain software in a secure manner. Along with the publication of this research, we are taking the opportunity to highlight some related Hugging Face security improvements.
Hugging Face has recently integrated Wiz for Vulnerability Management, a continuous and proactive process to keep our platform free of security vulnerabilities. In addition, we are using Wiz for Cloud Security Posture Management (CSPM), which allows us to configure our cloud environment securely, and monitor to ensure it remains secure.
One of our favorite Wiz features is a holistic view of Vulnerabilities, from storage to compute to network. We run multiple Kubernetes (k8s) clusters and have resources across multiple regions and cloud providers, so it is extremely helpful to have a central report in a single location with the full context graph for each vulnerability. We’ve also built on top of their tooling, to automatically remediate detected issues in our products, most notably in Spaces.
As part of the joint work, Wiz’s security research team identified shortcomings of our sandboxed compute environments by running arbitrary code within the system thanks to pickle. As you read this blog and the Wiz security research paper, it is important to remember that we have resolved all issues related to the exploit and continue to remain diligent in our Threat Detection and Incident Response process.
## Hugging Face Security
At Hugging Face we take security seriously, as AI rapidly evolves, new threat vectors seemingly pop up every day. Even as Hugging Face announces multiple partnerships and business relationships with the largest names in tech, we remain committed to allow our users and the AI community to responsibly experiment with and operationalize AI/ML systems and technologies. We are dedicated to securing our platform as well as democratizing AI/ML, such that the community can contribute to and be a part of this paradigm shifting event that will impact us all. We are writing this blog to reaffirm our commitment to protecting our users and customers from security threats. Below we will also discuss Hugging Face’s philosophy regarding our support of the controversial pickle files as well as discuss the shared responsibility of moving away from the pickle format.
There are many other exciting security improvements and announcements coming in the near future. The publications will not only discuss the security risks to the Hugging Face platform community, but also cover systemic security risks of AI as well as best practices for mitigation. We remain committed to making our products, our infrastructure, and the AI community secure, stay tuned for followup security blog posts and whitepapers.
## Open Source Security Collaboration and Tools for the Community
We highly value transparency and collaboration with the community and this includes participation in the identification and disclosure of vulnerabilities, collaborating on resolving security issues, and security tooling. Below are examples of our security wins born from collaboration, which help the entire AI community lower their security risk:
- Picklescan was built in partnership with Microsoft; Matthieu Maitre started the project and given we had our own internal version of the same tool, we joined forces and contributed to picklescan. Refer to the following documentation page if you are curious to know more on how it works:
https://huggingface.co/docs/hub/en/security-pickle
- Safetensors, which was developed by Nicolas Patry, is a secure alternative to pickle files. Safetensors has been audited by Trail of Bits on a collaborative initiative with EuletherAI & Stability AI.
https://huggingface.co/docs/safetensors/en/index
- We have a robust bug bounty program, with many amazing researchers from all around the world. Researchers who have identified a security vuln may inquire about joining our program through [email protected]
- Malware Scanning: https://huggingface.co/docs/hub/en/security-malware
- Secrets Scanning: https://huggingface.co/docs/hub/security-secrets
- As previously mentioned, we’re also collaborating with Wiz to lower Platform security risks
- We are starting a series of security publications which address security issues facing the AI/ML community.
## Security Best Practices for Open Source AI/ML users
AI/ML has introduced new vectors of attack, but for many of these attacks mitigants are long standing and well known. Security professionals should ensure that they apply relevant security controls to AI resources and models. In addition, below are some resources and best practices when working with open source software and models:
- Know the contributor: Only use models from trusted sources and pay attention to commit signing. https://huggingface.co/docs/hub/en/security-gpg
- Don’t use pickle files in production environments
- Use Safetensors: https://huggingface.co/docs/safetensors/en/index
- Review the OWASP top 10: https://owasp.org/www-project-top-ten/
- Enable MFA on your Hugging Face accounts
- Establish a Secure Development Lifecycle, which includes code review by a security professional or engineer with appropriate security training
Test models in non-production and virtualized test/dev environments
## Pickle Files - The Insecure Elephant in the Room
Pickle files have been at the core of most of the research done by Wiz and other recent publications by security researchers about Hugging Face. Pickle files have long been considered to have security risks associated with them, see our doc files for more information: https://huggingface.co/docs/hub/en/security-pickle
Despite these known security flaws, the AI/ML community still frequently uses pickles (or similarly trivially exploitable formats). Many of these use cases are low risk or for test purposes making the familiarity and ease of use of pickle files more attractive than the secure alternative.
As the open source AI platform, we are left with the following options:
- Ban pickle files entirely
- Do nothing about pickle files
- Finding a middle ground that both allows for pickle use as well as reasonably and practicably mitigating the risks associated with pickle files
We have chosen option 3, the middle ground for now. This option is a burden on our engineering and security teams and we have put in significant effort to mitigate the risks while allowing the AI community to use tools they choose. Some of the key mitigants we have implemented to the risks related to pickle include:
- Creating clear documentation outlining the risks
- Developing automated scanning tools
- Using scanning tools and labeling models with security vulnerabilities with clear warnings
- We have even provided a secure solution to use in lieu of pickle (Safetensors)
- We have also made Safetensors a first class citizen on our platform to protect the community members who may not understand the risks
- In addition to the above, we have also had to significantly segment and enhance security of the areas in which models are used to account for potential vulnerabilities within them
We intend to continue to be the leader in protecting and securing the AI Community. Part of this will be monitoring and addressing risks related to pickle files. Sunsetting support of pickle is also not out of the question either, however, we do our best to balance the impact on the community as part of a decision like this.
An important note that the upstream open source communities as well as large tech and security firms, have been largely silent on contributing to solutions here and left Hugging Face to both define philosophy and invest heavily in developing and implementing mitigating controls to ensure the solution is both acceptable and practicable.
## Closing remarks
I spoke extensively to Nicolas Patry, the creator of Safetensors in writing this blog post and he requested that I add a call to action to the AI open source community and AI enthusiasts:
- Pro-actively start replacing your pickle files with Safetensors. As mentioned earlier, pickle contains inherent security flaws and may be unsupported in the near future.
- Keep opening issues/PRs upstream about security to your favorite libraries to push secure defaults as much as possible upstream.
The AI industry is rapidly changing and new attack vectors / exploits are being identified all the time. Huggingface has a one of a kind community and we partner heavily with you to help us maintain a secure platform.
Please remember to responsibly disclose security vulns/bugs through the appropriate channels to avoid potential legal liability and violation of laws.
Want to join the discussion? Reach out to us as [email protected] or follow us on Linkedin/Twitter.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/streamlit-spaces.md | ---
title: "Hosting your Models and Datasets on Hugging Face Spaces using Streamlit"
thumbnail: /blog/assets/29_streamlit-spaces/thumbnail.png
authors:
- user: merve
---
# Hosting your Models and Datasets on Hugging Face Spaces using Streamlit
## Showcase your Datasets and Models using Streamlit on Hugging Face Spaces
[Streamlit](https://streamlit.io/) allows you to visualize datasets and build demos of Machine Learning models in a neat way. In this blog post we will walk you through hosting models and datasets and serving your Streamlit applications in Hugging Face Spaces.
## Building demos for your models
You can load any Hugging Face model and build cool UIs using Streamlit. In this particular example we will recreate ["Write with Transformer"](https://transformer.huggingface.co/doc/gpt2-large) together. It's an application that lets you write anything using transformers like GPT-2 and XLNet.

We will not dive deep into how the inference works. You only need to know that you need to specify some hyperparameter values for this particular application. Streamlit provides many [components](https://docs.streamlit.io/en/stable/api.html) for you to easily implement custom applications. We will use some of them to receive necessary hyperparameters inside the inference code.
- The ```.text_area``` component creates a nice area to input sentences to be completed.
- The Streamlit ```.sidebar``` method enables you to accept variables in a sidebar.
- The ```slider``` is used to take continuous values. Don't forget to give ```slider``` a step, otherwise it will treat the values as integers.
- You can let the end-user input integer vaues with ```number_input``` .
``` python
import streamlit as st
# adding the text that will show in the text box as default
default_value = "See how a modern neural network auto-completes your text 🤗 This site, built by the Hugging Face team, lets you write a whole document directly from your browser, and you can trigger the Transformer anywhere using the Tab key. Its like having a smart machine that completes your thoughts 😀 Get started by typing a custom snippet, check out the repository, or try one of the examples. Have fun!"
sent = st.text_area("Text", default_value, height = 275)
max_length = st.sidebar.slider("Max Length", min_value = 10, max_value=30)
temperature = st.sidebar.slider("Temperature", value = 1.0, min_value = 0.0, max_value=1.0, step=0.05)
top_k = st.sidebar.slider("Top-k", min_value = 0, max_value=5, value = 0)
top_p = st.sidebar.slider("Top-p", min_value = 0.0, max_value=1.0, step = 0.05, value = 0.9)
num_return_sequences = st.sidebar.number_input('Number of Return Sequences', min_value=1, max_value=5, value=1, step=1)
```
The inference code returns the generated output, you can print the output using simple ```st.write```.
```st.write(generated_sequences[-1])```
Here's what our replicated version looks like.

You can checkout the full code [here](https://huggingface.co/spaces/merve/write-with-transformer).
## Showcase your Datasets and Data Visualizations
Streamlit provides many components to help you visualize datasets. It works seamlessly with 🤗 [Datasets](https://huggingface.co/docs/datasets/), [pandas](https://pandas.pydata.org/docs/index.html), and visualization libraries such as [matplotlib](https://matplotlib.org/stable/index.html), [seaborn](https://seaborn.pydata.org/) and [bokeh](https://bokeh.org/).
Let's start by loading a dataset. A new feature in `Datasets`, called [streaming](https://huggingface.co/docs/datasets/dataset_streaming.html), allows you to work immediately with very large datasets, eliminating the need to download all of the examples and load them into memory.
``` python
from datasets import load_dataset
import streamlit as st
dataset = load_dataset("merve/poetry", streaming=True)
df = pd.DataFrame.from_dict(dataset["train"])
```
If you have structured data like mine, you can simply use ```st.dataframe(df) ``` to show your dataset. There are many Streamlit components to plot data interactively. One such component is ```st.barchart() ```, which I used to visualize the most used words in the poem contents.
``` python
st.write("Most appearing words including stopwords")
st.bar_chart(words[0:50])
```
If you'd like to use libraries like matplotlib, seaborn or bokeh, all you have to do is to put ```st.pyplot() ``` at the end of your plotting script.
``` python
st.write("Number of poems for each author")
sns.catplot(x="author", data=df, kind="count", aspect = 4)
plt.xticks(rotation=90)
st.pyplot()
```
You can see the interactive bar chart, dataframe component and hosted matplotlib and seaborn visualizations below. You can check out the code [here](https://huggingface.co/spaces/merve/streamlit-dataset-demo).

## Hosting your Projects in Hugging Face Spaces
You can simply drag and drop your files as shown below. Note that you need to include your additional dependencies in the requirements.txt. Also note that the version of Streamlit you have on your local is the same. For seamless usage, refer to [Spaces API reference](https://huggingface.co/docs/hub/spaces-config-reference).

There are so many components and [packages](https://streamlit.io/components) you can use to demonstrate your models, datasets, and visualizations. You can get started [here](https://huggingface.co/spaces). | 9 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim256_fp16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 256, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim256<cutlass::half_t, true>(params, stream);
}
| 0 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/rotary.h | /******************************************************************************
* Copyright (c) 2024, Tri Dao.
******************************************************************************/
#pragma once
#include <cute/tensor.hpp>
#include "utils.h"
////////////////////////////////////////////////////////////////////////////////////////////////////
namespace flash {
using namespace cute;
////////////////////////////////////////////////////////////////////////////////////////////////////
template <bool Is_even_K=true, bool Clear_OOB_K=true,
typename Engine0, typename Layout0, typename Engine1, typename Layout1,
typename Engine2, typename Layout2, typename Engine3, typename Layout3>
__forceinline__ __device__ void copy_rotary_interleaved(Tensor<Engine0, Layout0> const &S,
Tensor<Engine1, Layout1> &D,
Tensor<Engine2, Layout2> const &Cos,
Tensor<Engine2, Layout2> const &Sin,
Tensor<Engine3, Layout3> const &identity_MN,
const int max_MN, const int min_MN,
const int dim, const int rotary_dim) {
CUTE_STATIC_ASSERT_V(rank(S) == Int<3>{});
CUTE_STATIC_ASSERT_V(rank(D) == Int<3>{});
CUTE_STATIC_ASSERT_V(size<0>(S) == size<0>(D)); // MMA
CUTE_STATIC_ASSERT_V(size<1>(S) == size<1>(D)); // MMA_M
CUTE_STATIC_ASSERT_V(size<2>(S) == size<2>(D)); // MMA_K
CUTE_STATIC_ASSERT_V(size<1>(S) == size<1>(Cos)); // MMA_M
CUTE_STATIC_ASSERT_V(size<2>(S) == size<2>(Cos)); // MMA_K
CUTE_STATIC_ASSERT_V(size<1>(S) == size<1>(Sin)); // MMA_M
CUTE_STATIC_ASSERT_V(size<2>(S) == size<2>(Sin)); // MMA_K
CUTE_STATIC_ASSERT_V(size<0>(Cos) == size<0>(Sin)); // MMA_K
static_assert(decltype(size<0>(S))::value == decltype(size<0>(Cos))::value * 2);
static_assert(decltype(size<0>(Cos))::value % 2 == 0); // Since we do fast conversion from fp16/bf16 to fp32
Tensor rCos = make_fragment_like(Cos);
Tensor rSin = make_fragment_like(Sin);
Tensor rS = make_fragment_like(S);
#pragma unroll
for (int m = 0; m < size<1>(S); ++m) {
if (get<0>(identity_MN(0, m, 0)) >= min_MN && get<0>(identity_MN(0, m, 0)) < max_MN) {
#pragma unroll
for (int k = 0; k < size<2>(S); ++k) {
if (Is_even_K || get<1>(identity_MN(0, 0, k)) < dim) {
cute::copy(S(_, m, k), rS(_, m, k));
if (get<1>(identity_MN(0, 0, k)) < rotary_dim) {
cute::copy(Cos(_, m, k), rCos(_, m, k));
cute::copy(Sin(_, m, k), rSin(_, m, k));
Tensor S_fp32 = convert_type<float>(rS(_, m, k));
Tensor cos_fp32 = convert_type<float>(rCos(_, m, k));
Tensor sin_fp32 = convert_type<float>(rSin(_, m, k));
#pragma unroll
for (int i = 0; i < size<0>(rS) / 2; ++i) {
float real = S_fp32(2 * i) * cos_fp32(i) - S_fp32(2 * i + 1) * sin_fp32(i);
float imag = S_fp32(2 * i) * sin_fp32(i) + S_fp32(2 * i + 1) * cos_fp32(i);
S_fp32(2 * i) = real;
S_fp32(2 * i + 1) = imag;
}
// Idk but I need to copy for the convert_type to work
Tensor S_fp32_copy = make_fragment_like(S_fp32);
cute::copy(S_fp32, S_fp32_copy);
using T = typename Engine0::value_type;
Tensor S_og_type = convert_type<T>(S_fp32_copy);
cute::copy(S_og_type, rS(_, m, k));
}
cute::copy(rS(_, m, k), D(_, m, k));
} else if (Clear_OOB_K) {
cute::clear(D(_, m, k));
}
}
}
}
}
////////////////////////////////////////////////////////////////////////////////////////////////////
template <bool Is_even_K=true, bool Clear_OOB_K=true,
typename Engine0, typename Layout0, typename Engine1, typename Layout1,
typename Engine2, typename Layout2, typename Engine3, typename Layout3>
__forceinline__ __device__ void copy_rotary_contiguous(Tensor<Engine0, Layout0> const &S,
Tensor<Engine1, Layout1> &D,
Tensor<Engine2, Layout2> const &Cos,
Tensor<Engine2, Layout2> const &Sin,
Tensor<Engine3, Layout3> const &identity_MN,
const int max_MN, const int min_MN,
const int dim, const int rotary_dim) {
CUTE_STATIC_ASSERT_V(rank(S) == Int<3>{});
CUTE_STATIC_ASSERT_V(rank(D) == Int<3>{});
CUTE_STATIC_ASSERT_V(size<0>(S) == size<0>(D)); // MMA
CUTE_STATIC_ASSERT_V(size<1>(S) == size<1>(D)); // MMA_M
CUTE_STATIC_ASSERT_V(size<2>(S) == size<2>(D)); // MMA_K
CUTE_STATIC_ASSERT_V(size<1>(S) == size<1>(Cos)); // MMA_M
CUTE_STATIC_ASSERT_V(size<2>(S) == size<2>(Cos)); // MMA_K
CUTE_STATIC_ASSERT_V(size<1>(S) == size<1>(Sin)); // MMA_M
CUTE_STATIC_ASSERT_V(size<2>(S) == size<2>(Sin)); // MMA_K
CUTE_STATIC_ASSERT_V(size<0>(S) == size<0>(Cos)); // MMA
CUTE_STATIC_ASSERT_V(size<0>(Cos) == size<0>(Sin));
static_assert(decltype(size<0>(Cos))::value % 2 == 0); // Since we do fast conversion from fp16/bf16 to fp32
Tensor rCos = make_fragment_like(Cos);
Tensor rSin = make_fragment_like(Sin);
Tensor rS = make_fragment_like(S);
Tensor rS_other = make_fragment_like(rS(_, 0, 0));
#pragma unroll
for (int m = 0; m < size<1>(S); ++m) {
if (get<0>(identity_MN(0, m, 0)) >= min_MN && get<0>(identity_MN(0, m, 0)) < max_MN) {
#pragma unroll
for (int k = 0; k < size<2>(S); ++k) {
if (Is_even_K || get<1>(identity_MN(0, 0, k)) < dim) {
cute::copy(S(_, m, k), rS(_, m, k));
if (get<1>(identity_MN(0, 0, k)) < rotary_dim) {
const bool is_left = get<1>(identity_MN(0, 0, k)) < rotary_dim / 2;
Tensor gS_other = make_tensor(S(_, m, k).data() + (is_left ? rotary_dim / 2 : -rotary_dim / 2), S(_, m, k).layout());
cute::copy(gS_other, rS_other);
// if (cute::thread0()) { print_tensor(rS(_, m, k)); print_tensor(rS_other); }
Tensor gCos = make_tensor(Cos(_, m, k).data() + (is_left ? 0 : -rotary_dim / 2), Cos(_, m, k).layout());
Tensor gSin = make_tensor(Sin(_, m, k).data() + (is_left ? 0 : -rotary_dim / 2), Sin(_, m, k).layout());
cute::copy(gCos, rCos(_, m, k));
cute::copy(gSin, rSin(_, m, k));
// if (cute::thread0()) { print_tensor(rCos(_, m, k)); print_tensor(rSin(_, m, k)); }
Tensor S_fp32 = convert_type<float>(rS(_, m, k));
Tensor S_other_fp32 = convert_type<float>(rS_other);
Tensor cos_fp32 = convert_type<float>(rCos(_, m, k));
Tensor sin_fp32 = convert_type<float>(rSin(_, m, k));
#pragma unroll
for (int i = 0; i < size<0>(rS); ++i) {
S_fp32(i) = S_fp32(i) * cos_fp32(i) + S_other_fp32(i) * (is_left ? -sin_fp32(i) : sin_fp32(i));
}
// Idk but I need to copy for the convert_type to work
Tensor S_fp32_copy = make_fragment_like(S_fp32);
cute::copy(S_fp32, S_fp32_copy);
using T = typename Engine0::value_type;
Tensor S_og_type = convert_type<T>(S_fp32_copy);
cute::copy(S_og_type, rS(_, m, k));
// if (cute::thread0()) { print_tensor(rS(_, m, k)); }
}
cute::copy(rS(_, m, k), D(_, m, k));
} else if (Clear_OOB_K) {
cute::clear(D(_, m, k));
}
}
}
}
}
////////////////////////////////////////////////////////////////////////////////////////////////////
} // namespace flash
| 1 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/error.h | #pragma once
#define C10_CUDA_CHECK(EXPR) \
do { \
const cudaError_t __err = EXPR; \
} while (0)
#define C10_CUDA_KERNEL_LAUNCH_CHECK() C10_CUDA_CHECK(cudaGetLastError())
| 2 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim224_fp16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 224, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim224<cutlass::half_t, false>(params, stream);
}
| 3 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_launch_template.h | /******************************************************************************
* Copyright (c) 2023, Tri Dao.
******************************************************************************/
#pragma once
// #include <ATen/cuda/CUDAContext.h>
#include "error.h"
#include "static_switch.h"
#include "flash.h"
#include "flash_fwd_kernel.h"
// Determine if the architecture supports FLASH and define a macro to handle parameter modifiers
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800
#define ARCH_SUPPORTS_FLASH
#define KERNEL_PARAM_MODIFIER __grid_constant__
#else
#define KERNEL_PARAM_MODIFIER
#endif
// Define a macro for unsupported architecture handling to centralize the error message
#define FLASH_UNSUPPORTED_ARCH printf("FATAL: FlashAttention requires building with sm version sm80-sm90, but was built for < 8.0!");
// Use a macro to clean up kernel definitions
#define DEFINE_FLASH_FORWARD_KERNEL(kernelName, ...) \
template<typename Kernel_traits, __VA_ARGS__> \
__global__ void kernelName(KERNEL_PARAM_MODIFIER const Flash_fwd_params params)
DEFINE_FLASH_FORWARD_KERNEL(flash_fwd_kernel, bool Is_dropout, bool Is_causal, bool Is_local, bool Has_alibi, bool Is_even_MN, bool Is_even_K, bool Is_softcap, bool Return_softmax) {
#if defined(ARCH_SUPPORTS_FLASH)
static_assert(!(Is_causal && Is_local)); // Enforce constraints
flash::compute_attn<Kernel_traits, Is_dropout, Is_causal, Is_local, Has_alibi, Is_even_MN, Is_even_K, Is_softcap, Return_softmax>(params);
#else
FLASH_UNSUPPORTED_ARCH
#endif
}
DEFINE_FLASH_FORWARD_KERNEL(flash_fwd_splitkv_kernel, bool Is_causal, bool Is_local, bool Has_alibi, bool Is_even_MN, bool Is_even_K, bool Is_softcap, bool Split, bool Append_KV) {
#if defined(ARCH_SUPPORTS_FLASH)
flash::compute_attn_splitkv<Kernel_traits, Is_causal, Is_local, Has_alibi, Is_even_MN, Is_even_K, Is_softcap, Split, Append_KV>(params);
#else
FLASH_UNSUPPORTED_ARCH
#endif
}
DEFINE_FLASH_FORWARD_KERNEL(flash_fwd_splitkv_combine_kernel, int kBlockM, int Log_max_splits, bool Is_even_K) {
static_assert(Log_max_splits >= 1);
flash::combine_attn_seqk_parallel<Kernel_traits, kBlockM, Log_max_splits, Is_even_K>(params);
}
template<typename Kernel_traits, bool Is_dropout, bool Is_causal>
void run_flash_fwd(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr size_t smem_size = Kernel_traits::kSmemSize;
// printf("smem_size = %d\n", smem_size);
// Work-around for gcc 7. It doesn't like nested BOOL_SWITCH.
// https://github.com/kokkos/kokkos-kernels/issues/349
// https://github.com/HazyResearch/flash-attention/issues/21
const int num_m_block = (params.seqlen_q + Kernel_traits::kBlockM - 1) / Kernel_traits::kBlockM;
dim3 grid(num_m_block, params.b, params.h);
const bool is_even_MN = params.cu_seqlens_q == nullptr && params.cu_seqlens_k == nullptr && params.seqlen_k % Kernel_traits::kBlockN == 0 && params.seqlen_q % Kernel_traits::kBlockM == 0;
const bool is_even_K = params.d == Kernel_traits::kHeadDim;
const bool return_softmax = params.p_ptr != nullptr;
BOOL_SWITCH(is_even_MN, IsEvenMNConst, [&] {
EVENK_SWITCH(is_even_K, IsEvenKConst, [&] {
LOCAL_SWITCH((params.window_size_left >= 0 || params.window_size_right >= 0) && !Is_causal, Is_local, [&] {
BOOL_SWITCH(return_softmax, ReturnSoftmaxConst, [&] {
ALIBI_SWITCH(params.alibi_slopes_ptr != nullptr, Has_alibi, [&] {
SOFTCAP_SWITCH(params.softcap > 0.0, Is_softcap, [&] {
// Will only return softmax if dropout, to reduce compilation time.
// If not IsEvenKConst, we also set IsEvenMNConst to false to reduce number of templates.
// If return_softmax, set IsEvenMNConst to false to reduce number of templates
// If head dim > 128, set IsEvenMNConst to false to reduce number of templates
// If Is_local, set Is_causal to false
auto kernel = &flash_fwd_kernel<Kernel_traits, Is_dropout, Is_causal, Is_local && !Is_causal, Has_alibi, IsEvenMNConst && IsEvenKConst && !Is_local && !ReturnSoftmaxConst && Kernel_traits::kHeadDim <= 128, IsEvenKConst, Is_softcap, ReturnSoftmaxConst && Is_dropout>;
// auto kernel = &flash_fwd_kernel<Kernel_traits, false, Is_causal, false, false, true, true, false>;
// printf("IsEvenMNConst = %d, IsEvenKConst = %d, Is_local = %d, Is_causal = %d, ReturnSoftmaxConst = %d, Is_dropout = %d\n", int(IsEvenMNConst), int(IsEvenKConst), int(Is_local), int(Is_causal), int(ReturnSoftmaxConst), int(Is_dropout));
// auto kernel = &flash_fwd_kernel<Kernel_traits, false, Is_causal, false, true, true, false>;
if (smem_size >= 48 * 1024) {
C10_CUDA_CHECK(cudaFuncSetAttribute(
kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, smem_size));
}
// int ctas_per_sm;
// cudaError status_ = cudaOccupancyMaxActiveBlocksPerMultiprocessor(
// &ctas_per_sm, kernel, Kernel_traits::kNThreads, smem_size);
// printf("smem_size = %d, CTAs per SM = %d\n", int(smem_size), ctas_per_sm);
kernel<<<grid, Kernel_traits::kNThreads, smem_size, stream>>>(params);
C10_CUDA_KERNEL_LAUNCH_CHECK();
});
});
});
});
});
});
}
template<typename Kernel_traits, bool Is_causal>
void run_flash_splitkv_fwd(Flash_fwd_params ¶ms, cudaStream_t stream) {
static_assert(!Kernel_traits::Is_Q_in_regs, "SplitKV implementation does not support Is_Q_in_regs");
static_assert(!Kernel_traits::Share_Q_K_smem, "SplitKV implementation does not support Share_Q_K_smem");
constexpr size_t smem_size = Kernel_traits::kSmemSize;
const int num_m_block = (params.seqlen_q + Kernel_traits::kBlockM - 1) / Kernel_traits::kBlockM;
dim3 grid(num_m_block, params.num_splits > 1 ? params.num_splits : params.b, params.num_splits > 1 ? params.b * params.h : params.h);
const bool is_even_MN = params.cu_seqlens_q == nullptr && params.cu_seqlens_k == nullptr && params.seqlen_k % Kernel_traits::kBlockN == 0 && params.seqlen_q % Kernel_traits::kBlockM == 0;
const bool is_even_K = params.d == Kernel_traits::kHeadDim;
BOOL_SWITCH(is_even_MN, IsEvenMNConst, [&] {
EVENK_SWITCH(is_even_K, IsEvenKConst, [&] {
LOCAL_SWITCH((params.window_size_left >= 0 || params.window_size_right >= 0) && !Is_causal, Is_local, [&] {
BOOL_SWITCH(params.num_splits > 1, Split, [&] {
BOOL_SWITCH(params.knew_ptr != nullptr, Append_KV, [&] {
ALIBI_SWITCH(params.alibi_slopes_ptr != nullptr, Has_alibi, [&] {
SOFTCAP_SWITCH(params.softcap > 0.0, Is_softcap, [&] {
// If Append_KV, then we must have seqlen_offsets, which means cu_seqlens_k != nullptr.
// If not IsEvenKConst, we also set IsEvenMNConst to false to reduce number of templates.
// If Is_local, set Is_causal to false
auto kernel = &flash_fwd_splitkv_kernel<Kernel_traits, Is_causal, Is_local && !Is_causal, Has_alibi, IsEvenMNConst && !Append_KV && IsEvenKConst && !Is_local && Kernel_traits::kHeadDim <= 128, IsEvenKConst, Is_softcap, Split, Append_KV>;
// auto kernel = &flash_fwd_splitkv_kernel<Kernel_traits, Is_causal, false, true, Split, Append_KV>;
// auto kernel = &flash_fwd_splitkv_kernel<Kernel_traits, Is_causal, false, IsEvenKConst>;
if (smem_size >= 48 * 1024) {
C10_CUDA_CHECK(cudaFuncSetAttribute(
kernel, cudaFuncAttributeMaxDynamicSharedMemorySize, smem_size));
}
kernel<<<grid, Kernel_traits::kNThreads, smem_size, stream>>>(params);
C10_CUDA_KERNEL_LAUNCH_CHECK();
});
});
});
});
});
});
});
if (params.num_splits > 1) {
// We want kBlockM to be as small as possible for more parallelism.
// With 128 threads we can load 512 elements at a time, so if headdim is divisible by 128, kBlockM = 4.
// If headdim is divisible by 64, then we set kBlockM = 8, etc.
constexpr static int kBlockM = Kernel_traits::kHeadDim % 128 == 0 ? 4 : (Kernel_traits::kHeadDim % 64 == 0 ? 8 : 16);
dim3 grid_combine((params.b * params.h * params.seqlen_q + kBlockM - 1) / kBlockM);
EVENK_SWITCH(is_even_K, IsEvenKConst, [&] {
if (params.num_splits <= 2) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 1, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 4) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 2, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 8) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 3, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 16) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 4, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 32) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 5, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 64) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 6, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
} else if (params.num_splits <= 128) {
flash_fwd_splitkv_combine_kernel<Kernel_traits, kBlockM, 7, IsEvenKConst><<<grid_combine, Kernel_traits::kNThreads, 0, stream>>>(params);
}
C10_CUDA_KERNEL_LAUNCH_CHECK();
});
}
}
template<typename T, int Headdim, bool Is_causal>
void run_mha_fwd_splitkv_dispatch(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int kBlockM = 64; // Fixed for all head dimensions
// TD [2023-08-28]: nvcc segfaults for headdim 96 with block size 64 x 256,
// and for headdim 192 with block size 64 x 128.
// Also for headdim 160 with block size 64 x 128 after the rotary addition.
constexpr static int kBlockN = Headdim <= 64 ? 256 : (Headdim <= 128 ? 128 : 64);
run_flash_splitkv_fwd<Flash_fwd_kernel_traits<Headdim, kBlockM, kBlockN, 4, false, false, T>, Is_causal>(params, stream);
}
template<typename T, bool Is_causal>
void run_mha_fwd_hdim32(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 32;
DROPOUT_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
});
}
template<typename T, bool Is_causal>
void run_mha_fwd_hdim64(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 64;
DROPOUT_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
if constexpr(!Is_dropout) {
// Using 8 warps is 18% slower for seqlen=2k, 2 warps is 5% slower
// Using block size (64 x 256) is 27% slower for seqlen=2k
// Using block size (256 x 64) is 85% slower for seqlen=2k, because of register spilling
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
});
}
inline bool cuda_is_sm8x() {
// dprops = at::cuda::getCurrentDeviceProperties();
// return dprops->major == 8 && dprops->minor > 0;
return false;
}
template<typename T, bool Is_causal>
void run_mha_fwd_hdim96(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 96;
bool is_sm8x = cuda_is_sm8x();
DROPOUT_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
// For sm86 or sm89, 64 x 64 is the fastest for causal (because it's square),
if (is_sm8x) {
if constexpr(!Is_causal) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
// These two are always slower
// run_flash_fwd<Flash_fwd_kernel_traits<96, 128, 128, 4, true, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<96, 64, 128, 4, true, T>>(params, stream);
});
}
template<typename T, bool Is_causal>
void run_mha_fwd_hdim128(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 128;
bool is_sm8x = cuda_is_sm8x();
DROPOUT_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
if constexpr(!Is_dropout) {
// For sm86 or sm89, 64 x 64 is the fastest for causal (because it's square),
// and 128 x 32 (48 KB smem) is the fastest for non-causal since we get 2 CTAs per SM.
if (is_sm8x) {
if constexpr(!Is_causal) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 128, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// Using 8 warps (128 x 128 and 256 x 64) is 28% slower for seqlen=2k
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
// 1st ones are good for H100, A100
// 2nd one is good for A6000 bc we get slightly better occupancy
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, true, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, true, true, T>, Is_dropout, Is_causal>(params, stream);
}
});
}
template<typename T, bool Is_causal>
void run_mha_fwd_hdim160(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 160;
bool is_sm8x = cuda_is_sm8x();
DROPOUT_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
// For A100, H100, 128 x 32 is the fastest.
// For sm86 or sm89, 64 x 64 is the fastest for causal (because it's square),
// and 128 x 64 with 8 warps is the fastest for non-causal.
if (is_sm8x) {
if constexpr(!Is_causal) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, true, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 128, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 8, false, T>>(params, stream);
});
}
template<typename T, bool Is_causal>
void run_mha_fwd_hdim192(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 192;
DROPOUT_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
if constexpr(!Is_dropout) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 128, 4, false, T>>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 128, 8, false, T>>(params, stream);
});
}
template<typename T, bool Is_causal>
void run_mha_fwd_hdim224(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 224;
int device;
cudaGetDevice(&device);
int max_smem_per_block;
cudaError status_ = cudaDeviceGetAttribute(
&max_smem_per_block, cudaDevAttrMaxSharedMemoryPerBlockOptin, device);
if (status_ != cudaSuccess) {
C10_CUDA_CHECK(status_);
}
// printf("max_smem_per_block = %d\n", max_smem_per_block);
DROPOUT_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
if (max_smem_per_block >= 2 * Headdim * (128 + 2 * 64)) { // 112 KB
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// We can't do 128 x 32 with 8 warps because with headdim 224, kBlockKSmem = 32.
// If we have N = 32, there are only 1024 elements to load at once, where each load
// is 8 elements. This means we can only use 128 threads and not 256 threads.
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
});
}
template<typename T, bool Is_causal>
void run_mha_fwd_hdim256(Flash_fwd_params ¶ms, cudaStream_t stream) {
constexpr static int Headdim = 256;
int device;
cudaGetDevice(&device);
int max_smem_per_sm, max_smem_per_block;
cudaError status_ = cudaDeviceGetAttribute(
&max_smem_per_sm, cudaDevAttrMaxSharedMemoryPerMultiprocessor, device);
status_ = cudaDeviceGetAttribute(
&max_smem_per_block, cudaDevAttrMaxSharedMemoryPerBlockOptin, device);
if (status_ != cudaSuccess) {
C10_CUDA_CHECK(status_);
}
// printf("max_smem_per_sm = %d, max_smem_per_block = %d\n", max_smem_per_sm, max_smem_per_block);
DROPOUT_SWITCH(params.p_dropout < 1.f, Is_dropout, [&] {
// For A100, we want to run with 128 x 64 (128KB smem).
// For H100 we want to run with 64 x 64 (96KB smem) since then we can get 2 CTAs per SM.
if (max_smem_per_block >= 2 * Headdim * (128 + 2 * 64) && max_smem_per_sm < 4 * Headdim * (64 + 2 * 64)) {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 64, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
} else {
run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 64, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
}
// 64 KB
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 64, 32, 4, false, false, T>, Is_dropout, Is_causal>(params, stream);
// 96 KB
// run_flash_fwd<Flash_fwd_kernel_traits<Headdim, 128, 32, 8, false, false, T>, Is_dropout, Is_causal>(params, stream);
});
}
| 4 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim256_bf16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::bfloat16_t, 256, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim256<cutlass::bfloat16_t, false>(params, stream);
}
| 5 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/dropout.h | /******************************************************************************
* Copyright (c) 2024, Tri Dao.
******************************************************************************/
#pragma once
#include "philox.cuh"
#include "utils.h"
namespace flash {
struct Dropout {
const unsigned long long seed, offset;
const uint8_t p_dropout_in_uint8_t;
__forceinline__ __device__ Dropout(const unsigned long long seed, const unsigned long long offset,
const uint8_t p_dropout_in_uint8_t,
const int bid, const int hid, const int tid, const int nheads)
: seed(seed)
, offset(offset + (bid * nheads + hid) * 32 + tid % 32)
, p_dropout_in_uint8_t(p_dropout_in_uint8_t) {
}
template <bool encode_dropout_in_sign_bit=false, typename Engine, typename Layout>
__forceinline__ __device__ void apply_dropout(Tensor<Engine, Layout> &tensor_,
int block_row_start, int block_col_start, int block_row_stride) {
// convert shape from (4, MMA_M, MMA_N) to (8, MMA_M, MMA_N / 2)
Tensor tensor = make_tensor(tensor_.data(), flash::convert_layout_acc_dropout(tensor_.layout()));
using T = typename Engine::value_type;
auto encode_dropout = [](bool keep, T val) {
return keep ? val : (encode_dropout_in_sign_bit ? -val : T(0));
};
static_assert(decltype(size<2>(tensor))::value % 2 == 0);
const uint16_t p_dropout_8bit_in_uint16_t = uint16_t(p_dropout_in_uint8_t);
const uint32_t p_dropout_8bit_in_uint32_t = (uint32_t(p_dropout_8bit_in_uint16_t) << 16) | uint32_t(p_dropout_8bit_in_uint16_t);
// if (cute::thread0()) { printf("threshold2 = 0x%x\n", p_dropout_8bit_in_uint32_t); }
#pragma unroll
for (int m = 0; m < size<1>(tensor); ++m, block_row_start += block_row_stride) {
uint2 rowcol = make_uint2(block_row_start, block_col_start);
#pragma unroll
for (int n = 0; n < size<2>(tensor) / 2; ++n, ++rowcol.y) {
// if (cute::thread(32, 0)) { printf("m = %d, n = %d, row = %d, col = %d\n", m, n, int(rowcol.x), int(rowcol.y));}
uint4 random_uint4 = flash::philox(seed, reinterpret_cast<unsigned long long&>(rowcol), offset);
// if (cute::thread0()) { printf("philox = %u, %d, %d, %d\n", random_uint4.x, random_uint4.y, random_uint4.z, random_uint4.w);}
uint8_t (&rnd_8)[16] = reinterpret_cast<uint8_t (&)[16]>(random_uint4);
// Special implementation for 16-bit types: we duplicate the threshold to the
// low and high 16 bits of a 32-bit value, then use the f16x2 comparison instruction
// to get a mask. The low 16 bits of the mask will be either 0xffff or 0x0000,
// and the high 16 bits will be either 0xffff or 0x0000, depending on whether
// the random value is less than the threshold.
// We then do a bit-wise AND between the mask and the original value (in 32-bit).
// We're exploiting the fact that floating point comparison is equivalent to integer
// comparison, since we're comparing unsigned integers whose top 8-bits are zero.
if (!encode_dropout_in_sign_bit
&& (std::is_same<T, cutlass::half_t>::value || std::is_same<T, cutlass::bfloat16_t>::value)) {
uint16_t rnd_16[16];
#pragma unroll
for (int i = 0; i < 16; i++) { rnd_16[i] = uint16_t(rnd_8[i]); }
uint32_t (&rnd_32)[8] = reinterpret_cast<uint32_t (&)[8]>(rnd_16);
#pragma unroll
for (int j = 0; j < 2; j++) {
Tensor tensor_uint32 = recast<uint32_t>(tensor(_, m, n * 2 + j));
// if (cute::thread0()) { printf("random = 0x%x, 0x%x, 0x%x, 0x%x\n", rnd_32[j * 4 + 0], rnd_32[j * 4 + 1], rnd_32[j * 4 + 2], rnd_32[j * 4 + 3]); }
// if (cute::thread0()) { printf("tensor_uint32 = 0x%x, 0x%x, 0x%x, 0x%x\n", tensor_uint32(0), tensor_uint32(1), tensor_uint32(2), tensor_uint32(3)); }
#pragma unroll
for (int i = 0; i < 4; i++) {
uint32_t mask;
asm volatile("set.le.u32.f16x2 %0, %1, %2;\n" : "=r"(mask) : "r"(rnd_32[j * 4 + i]), "r"(p_dropout_8bit_in_uint32_t));
tensor_uint32(i) &= mask;
}
// if (cute::thread0()) { printf("tensor_uint32 = 0x%x, 0x%x, 0x%x, 0x%x\n", tensor_uint32(0), tensor_uint32(1), tensor_uint32(2), tensor_uint32(3)); }
}
} else {
#pragma unroll
for (int j = 0; j < 2; j++) {
#pragma unroll
for (int i = 0; i < 8; i++) {
tensor(i, m, n * 2 + j) = encode_dropout(rnd_8[j * 8 + i] <= p_dropout_in_uint8_t, tensor(i, m, n * 2 + j));
}
Tensor tensor_uint32 = recast<uint32_t>(tensor(_, m, n * 2 + j));
// if (cute::thread0()) { printf("tensor_uint32 = 0x%x, 0x%x, 0x%x, 0x%x\n", tensor_uint32(0), tensor_uint32(1), tensor_uint32(2), tensor_uint32(3)); }
}
}
// // if ((threadIdx.x == 0) && (blockIdx.x == 0) && (blockIdx.y == 0)) {
// // printf("n = %d, ph Philox: %u, %u, %u, %u\n", n, rnd_8.x, rnd_8.y, rnd_8.z, rnd_8.w);
// // }
}
}
}
};
} // namespace flash
| 6 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim256_bf16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::bfloat16_t, 256, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim256<cutlass::bfloat16_t, true>(params, stream);
}
| 7 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/kernel_traits.h | /******************************************************************************
* Copyright (c) 2024, Tri Dao.
******************************************************************************/
#pragma once
#include "cute/tensor.hpp"
#include "cutlass/cutlass.h"
#include "cutlass/layout/layout.h"
#include <cutlass/numeric_types.h>
using namespace cute;
template<int kHeadDim_, int kBlockM_, int kBlockN_, int kNWarps_, typename elem_type=cutlass::half_t>
struct Flash_kernel_traits {
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800
using Element = elem_type;
static constexpr bool Has_cp_async = true;
#else
using Element = cutlass::half_t;
static constexpr bool Has_cp_async = false;
#endif
using ElementAccum = float;
using index_t = int64_t;
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 800
using MMA_Atom_Arch = std::conditional_t<
std::is_same_v<elem_type, cutlass::half_t>,
MMA_Atom<SM80_16x8x16_F32F16F16F32_TN>,
MMA_Atom<SM80_16x8x16_F32BF16BF16F32_TN>
>;
#else
using MMA_Atom_Arch = MMA_Atom<SM75_16x8x8_F32F16F16F32_TN>;
#endif
#if defined(__CUDA_ARCH__) && __CUDA_ARCH__ >= 750
using SmemCopyAtom = Copy_Atom<SM75_U32x4_LDSM_N, elem_type>;
using SmemCopyAtomTransposed = Copy_Atom<SM75_U16x8_LDSM_T, elem_type>;
#else
using SmemCopyAtom = Copy_Atom<DefaultCopy, elem_type>;
using SmemCopyAtomTransposed = Copy_Atom<DefaultCopy, elem_type>;
#endif
};
// If Share_Q_K_smem is true, that forces Is_Q_in_regs to be true
template<int kHeadDim_, int kBlockM_, int kBlockN_, int kNWarps_, bool Is_Q_in_regs_=false, bool Share_Q_K_smem_=false, typename elem_type=cutlass::half_t,
typename Base=Flash_kernel_traits<kHeadDim_, kBlockM_, kBlockN_, kNWarps_, elem_type> >
struct Flash_fwd_kernel_traits : public Base {
using Element = typename Base::Element;
using ElementAccum = typename Base::ElementAccum;
using index_t = typename Base::index_t;
static constexpr bool Has_cp_async = Base::Has_cp_async;
using SmemCopyAtom = typename Base::SmemCopyAtom;
using SmemCopyAtomTransposed = typename Base::SmemCopyAtomTransposed;
static constexpr bool Share_Q_K_smem = Share_Q_K_smem_;
static constexpr bool Is_Q_in_regs = Is_Q_in_regs_ || Share_Q_K_smem;
// The number of threads.
static constexpr int kNWarps = kNWarps_;
static constexpr int kNThreads = kNWarps * 32;
static constexpr int kBlockM = kBlockM_;
static constexpr int kBlockN = kBlockN_;
static constexpr int kHeadDim = kHeadDim_;
static_assert(kHeadDim % 32 == 0);
static constexpr int kBlockKSmem = kHeadDim % 64 == 0 ? 64 : 32;
static constexpr int kBlockKGmem = kHeadDim % 128 == 0 ? 128 : (kHeadDim % 64 == 0 ? 64 : 32);
static constexpr int kSwizzle = kBlockKSmem == 32 ? 2 : 3;
using TiledMma = TiledMMA<
typename Base::MMA_Atom_Arch,
Layout<Shape<Int<kNWarps>,_1,_1>>, // 4x1x1 or 8x1x1 thread group
Tile<Int<16 * kNWarps>, _16, _16>>;
using SmemLayoutAtomQ = decltype(
composition(Swizzle<kSwizzle, 3, 3>{},
// This has to be kBlockKSmem, using kHeadDim gives wrong results for d=128
Layout<Shape<_8, Int<kBlockKSmem>>,
Stride<Int<kBlockKSmem>, _1>>{}));
using SmemLayoutQ = decltype(tile_to_shape(
SmemLayoutAtomQ{},
Shape<Int<kBlockM>, Int<kHeadDim>>{}));
using SmemLayoutKV = decltype(tile_to_shape(
SmemLayoutAtomQ{},
Shape<Int<kBlockN>, Int<kHeadDim>>{}));
// https://github.com/ColfaxResearch/cutlass-kernels/blob/a222587e6d59b93ba704853d3946fb686d8b8892/src/fmha/fmha_forward.cu#L434
using SmemLayoutVtransposed = decltype(
composition(SmemLayoutKV{}, make_layout(Shape<Int<kHeadDim>, Int<kBlockN>>{}, GenRowMajor{})));
using SmemLayoutVtransposedNoSwizzle = decltype(get_nonswizzle_portion(SmemLayoutVtransposed{}));
using SmemLayoutAtomO = decltype(
composition(Swizzle<kSwizzle, 3, 3>{},
Layout<Shape<Int<8>, Int<kBlockKSmem>>,
Stride<Int<kBlockKSmem>, _1>>{}));
using SmemLayoutO = decltype(tile_to_shape(
SmemLayoutAtomO{},
Shape<Int<kBlockM>, Int<kHeadDim>>{}));
using SmemCopyAtomO = Copy_Atom<DefaultCopy, Element>;
using SmemCopyAtomOaccum = Copy_Atom<DefaultCopy, ElementAccum>;
static constexpr int kSmemQSize = size(SmemLayoutQ{}) * sizeof(Element);
static constexpr int kSmemKVSize = size(SmemLayoutKV{}) * 2 * sizeof(Element);
static constexpr int kSmemSize = Share_Q_K_smem ? std::max(kSmemQSize, kSmemKVSize) : kSmemQSize + kSmemKVSize;
static constexpr int kGmemElemsPerLoad = sizeof(cute::uint128_t) / sizeof(Element);
static_assert(kHeadDim % kGmemElemsPerLoad == 0, "kHeadDim must be a multiple of kGmemElemsPerLoad");
// Using kBlockKSmem here is 6-10% faster than kBlockKGmem for d=128 because of bank conflicts.
// For example, for d=128, smem is split into 2 "pages", each page takes care of columns
// 0-63 and 64-127. If we have 16 threads per row for gmem read, when we write to smem,
// thread 0 - 7 will write to the first page and thread 8 - 15 will write to the second page,
// to the same banks.
static constexpr int kGmemThreadsPerRow = kBlockKSmem / kGmemElemsPerLoad;
static_assert(kNThreads % kGmemThreadsPerRow == 0, "kNThreads must be a multiple of kGmemThreadsPerRow");
using GmemLayoutAtom = Layout<Shape <Int<kNThreads / kGmemThreadsPerRow>, Int<kGmemThreadsPerRow>>,
Stride<Int<kGmemThreadsPerRow>, _1>>;
// We use CACHEGLOBAL instead of CACHEALWAYS for both Q and K/V, since we won't be reading
// from the same address by the same threadblock. This is slightly faster.
using Gmem_copy_struct = std::conditional_t<
Has_cp_async,
SM80_CP_ASYNC_CACHEGLOBAL<cute::uint128_t>,
DefaultCopy
>;
using GmemTiledCopyQKV = decltype(
make_tiled_copy(Copy_Atom<Gmem_copy_struct, Element>{},
GmemLayoutAtom{},
Layout<Shape<_1, _8>>{})); // Val layout, 8 vals per read
using GmemTiledCopyO = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, Element>{},
GmemLayoutAtom{},
Layout<Shape<_1, _8>>{})); // Val layout, 8 vals per store
using GmemLayoutAtomOaccum = std::conditional_t<
kBlockKSmem == 32,
Layout<Shape <_16, _8>, // Thread layout, 8 threads per row
Stride< _8, _1>>,
Layout<Shape <_8, _16>, // Thread layout, 16 threads per row
Stride< _16, _1>>
>;
using GmemTiledCopyOaccum = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, ElementAccum>{},
GmemLayoutAtomOaccum{},
Layout<Shape < _1, _4>>{})); // Val layout, 4 vals per store
using GmemLayoutAtomRotcossin = GmemLayoutAtom;
using GmemTiledCopyRotcossin = decltype(
make_tiled_copy(Copy_Atom<UniversalCopy<uint64_t>, Element>{},
GmemLayoutAtomRotcossin{},
Layout<Shape < _1, _4>>{})); // Val layout, 4 vals per load
using GmemTiledCopyRotcossinCont = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, Element>{},
GmemLayoutAtomRotcossin{},
Layout<Shape < _1, _8>>{})); // Val layout, 8 vals per load
};
// Is_V_in_regs is an option to reduce smem usage, but will increase register pressue.
// No_double_buffer is another option to reduce smem usage, but will slow things down.
template<int kHeadDim_, int kBlockM_, int kBlockN_, int kNWarps_,
int AtomLayoutMSdP_=1, int AtomLayoutNdKV=2, int AtomLayoutMdQ=2,
bool Is_V_in_regs_=false, bool No_double_buffer_=false, typename elem_type=cutlass::half_t,
typename Base=Flash_kernel_traits<kHeadDim_, kBlockM_, kBlockN_, kNWarps_, elem_type> >
struct Flash_bwd_kernel_traits : public Base {
using Element = typename Base::Element;
using ElementAccum = typename Base::ElementAccum;
using index_t = typename Base::index_t;
static constexpr bool Has_cp_async = Base::Has_cp_async;
using SmemCopyAtom = typename Base::SmemCopyAtom;
using SmemCopyAtomTransposed = typename Base::SmemCopyAtomTransposed;
static constexpr bool Is_V_in_regs = Is_V_in_regs_;
static constexpr bool No_double_buffer = No_double_buffer_;
// The number of threads.
static constexpr int kNWarps = kNWarps_;
static constexpr int kNThreads = kNWarps * 32;
static constexpr int kBlockM = kBlockM_;
static constexpr int kBlockN = kBlockN_;
static constexpr int kHeadDim = kHeadDim_;
static_assert(kHeadDim % 32 == 0);
static constexpr int kBlockKSmem = kHeadDim % 64 == 0 ? 64 : 32;
static constexpr int kBlockKGmem = kHeadDim % 128 == 0 ? 128 : (kHeadDim % 64 == 0 ? 64 : 32);
static constexpr int kSwizzle = kBlockKSmem == 32 ? 2 : 3;
static constexpr int AtomLayoutMSdP = AtomLayoutMSdP_;
static_assert(kNWarps % AtomLayoutMSdP == 0);
static_assert(kNWarps % AtomLayoutNdKV == 0);
static_assert(kNWarps % AtomLayoutMdQ == 0);
using TiledMmaSdP = TiledMMA<
typename Base::MMA_Atom_Arch,
Layout<Shape<Int<AtomLayoutMSdP>, Int<kNWarps / AtomLayoutMSdP>, _1>>,
Tile<Int<16 * AtomLayoutMSdP>, Int<16 * kNWarps / AtomLayoutMSdP>, _16>>;
using TiledMmadKV = TiledMMA<
typename Base::MMA_Atom_Arch,
Layout<Shape<Int<AtomLayoutNdKV>, Int<kNWarps / AtomLayoutNdKV>, _1>>,
Tile<Int<16 * AtomLayoutNdKV>, Int<16 * kNWarps / AtomLayoutNdKV>, _16>>;
using TiledMmadQ = TiledMMA<
typename Base::MMA_Atom_Arch,
Layout<Shape<Int<AtomLayoutMdQ>, Int<kNWarps / AtomLayoutMdQ>, _1>>, // 2x4x1 or 4x2x1 thread group
Tile<Int<16 * AtomLayoutMdQ>, Int<16 * kNWarps / AtomLayoutMdQ>, _16>>;
using SmemLayoutAtomQdO = decltype(
composition(Swizzle<kSwizzle, 3, 3>{},
Layout<Shape<_8, Int<kBlockKSmem>>,
Stride<Int<kBlockKSmem>, _1>>{}));
using SmemLayoutQdO = decltype(tile_to_shape(
SmemLayoutAtomQdO{},
make_shape(Int<kBlockM>{}, Int<kHeadDim>{})));
using SmemLayoutAtomKV = decltype(
composition(Swizzle<kSwizzle, 3, 3>{},
Layout<Shape<Int<kBlockM / kNWarps>, Int<kBlockKSmem>>,
Stride<Int<kBlockKSmem>, _1>>{}));
using SmemLayoutKV = decltype(tile_to_shape(
// SmemLayoutAtomQdO{},
SmemLayoutAtomKV{},
make_shape(Int<kBlockN>{}, Int<kHeadDim>{})));
using SmemLayoutKtransposed = decltype(
composition(SmemLayoutKV{}, make_layout(Shape<Int<kHeadDim>, Int<kBlockN>>{}, GenRowMajor{})));
using SmemLayoutKtransposedNoSwizzle = decltype(get_nonswizzle_portion(SmemLayoutKtransposed{}));
// TODO: generalize to other values of kBlockN
// TODO: what should be the Swizzle here? 3 is faster than 1, and 1 is faster than 2
// static constexpr int kPBlockN = kBlockN;
// Temporarily disabling this for hdim 256 on sm86 and sm89
// static_assert(kBlockN >= 64);
static_assert(kBlockN >= 32);
// TD [2023-03-19]: Idk why kPBlockN = 16 and kSwizzlePdS=3 is the fastest.
static constexpr int kPBlockN = kBlockN >= 64 ? 64 : 32;
static_assert(kPBlockN == 16 || kPBlockN == 32 || kPBlockN == 64);
// static constexpr int kSwizzlePdS = kPBlockN == 16 ? 1 : (kPBlockN == 32 ? 2 : 3);
static constexpr int kSwizzlePdS = 3;
using SmemLayoutAtomPdS = decltype(
composition(Swizzle<kSwizzlePdS, 3, 3>{},
Layout<Shape<Int<kBlockM>, Int<kPBlockN>>,
Stride<Int<kPBlockN>, _1>>{}));
using SmemLayoutPdS = decltype(tile_to_shape(
SmemLayoutAtomPdS{},
make_shape(Int<kBlockM>{}, Int<kBlockN>{})));
using SmemLayoutPdStransposed = decltype(
composition(SmemLayoutPdS{}, make_layout(Shape<Int<kBlockN>, Int<kBlockM>>{}, GenRowMajor{})));
using SmemLayoutPdStransposedNoSwizzle = decltype(get_nonswizzle_portion(SmemLayoutPdStransposed{}));
using SmemCopyAtomPdS = Copy_Atom<DefaultCopy, elem_type>;
using SmemLayoutQdOtransposed = decltype(
composition(SmemLayoutQdO{}, make_layout(Shape<Int<kHeadDim>, Int<kBlockM>>{}, GenRowMajor{})));
using SmemLayoutQdOtransposedNoSwizzle = decltype(get_nonswizzle_portion(SmemLayoutQdOtransposed{}));
using SmemLayoutAtomdKV = decltype(
composition(Swizzle<kSwizzle, 3, 3>{},
Layout<Shape<_8, Int<kBlockKSmem>>,
Stride<Int<kBlockKSmem>, _1>>{}));
using SmemLayoutdKV = decltype(tile_to_shape(
SmemLayoutAtomdKV{},
make_shape(Int<kBlockN>{}, Int<kHeadDim>{})));
using SmemCopyAtomdKV = Copy_Atom<DefaultCopy, elem_type>;
using SmemLayoutAtomdQ = decltype(
composition(Swizzle<kSwizzle, 3, 3>{},
Layout<Shape<_8, Int<kBlockKSmem>>,
Stride<Int<kBlockKSmem>, _1>>{}));
using SmemLayoutdQ = decltype(tile_to_shape(
SmemLayoutAtomdQ{},
make_shape(Int<kBlockM>{}, Int<kHeadDim>{})));
using SmemCopyAtomdQ = Copy_Atom<DefaultCopy, elem_type>;
// Double buffer for sQ
static constexpr int kSmemQdOSize = size(SmemLayoutQdO{}) * (No_double_buffer ? 2 : 3) * sizeof(Element);
static constexpr int kSmemKVSize = size(SmemLayoutKV{}) * 2 * sizeof(Element);
static constexpr int kSmemdSSize = size(SmemLayoutPdS{}) * sizeof(Element);
static constexpr int kSmemPSize = size(SmemLayoutPdS{}) * sizeof(Element);
static constexpr int kSmemdQSize = size(SmemLayoutdQ{}) * sizeof(Element);
static constexpr int kSmemSize = kSmemQdOSize
+ (!Is_V_in_regs
? kSmemKVSize + kSmemdSSize + std::max(kSmemPSize, kSmemdQSize)
: std::max(kSmemKVSize, kSmemKVSize / 2 + kSmemdSSize + std::max(kSmemPSize, kSmemdQSize)));
static constexpr int kSmemSize1colblock = kSmemQdOSize
+ (!Is_V_in_regs
? kSmemKVSize + kSmemdSSize + kSmemPSize
: std::max(kSmemKVSize, kSmemKVSize / 2 + kSmemdSSize + kSmemPSize));
static constexpr int kGmemElemsPerLoad = sizeof(cute::uint128_t) / sizeof(Element);
static_assert(kHeadDim % kGmemElemsPerLoad == 0, "kHeadDim must be a multiple of kGmemElemsPerLoad");
// Using kBlockKSmem instead of kHeadDim here to avoid bank conflicts, but doesn't seem
// to affect speed in practice.
static constexpr int kGmemThreadsPerRow = kBlockKSmem / kGmemElemsPerLoad;
static_assert(kNThreads % kGmemThreadsPerRow == 0, "kNThreads must be a multiple of kGmemThreadsPerRow");
using GmemLayoutAtom = Layout<Shape <Int<kNThreads / kGmemThreadsPerRow>, Int<kGmemThreadsPerRow>>,
Stride<Int<kGmemThreadsPerRow>, _1>>;
// We use CACHEGLOBAL instead of CACHEALWAYS for both Q and K/V, since we won't be reading
// from the same address by the same threadblock. This is slightly faster.
using Gmem_copy_struct = std::conditional_t<
Has_cp_async,
SM80_CP_ASYNC_CACHEGLOBAL<cute::uint128_t>,
DefaultCopy
>;
using GmemTiledCopyQKV = decltype(
make_tiled_copy(Copy_Atom<Gmem_copy_struct, elem_type>{},
GmemLayoutAtom{},
Layout<Shape<_1, _8>>{})); // Val layout, 8 vals per read
using GmemTiledCopydO = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, elem_type>{},
GmemLayoutAtom{},
Layout<Shape < _1, _8>>{})); // Val layout, 8 vals per store
using GmemTiledCopydKV = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, elem_type>{},
GmemLayoutAtom{},
Layout<Shape < _1, _8>>{})); // Val layout, 8 vals per store
using GmemTiledCopydQ = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, elem_type>{},
GmemLayoutAtom{},
Layout<Shape < _1, _8>>{})); // Val layout, 8 vals per store
using GmemLayoutAtomdQaccum = std::conditional_t<
kBlockKSmem == 32,
Layout<Shape <_32, _8>, // Thread layout, 8 threads per row
Stride< _8, _1>>,
Layout<Shape <_16, _16>, // Thread layout, 16 threads per row
Stride< _16, _1>>
>;
using GmemTiledCopydQaccum = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, ElementAccum>{},
GmemLayoutAtomdQaccum{},
Layout<Shape < _1, _4>>{})); // Val layout, 4 vals per store
using GmemTiledCopydQaccumAtomicAdd = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, ElementAccum>{},
Layout<Shape <_8, _32>, // Thread layout, 8 threads per row
Stride<_32, _1>>{},
Layout<Shape < _1, _1>>{})); // Val layout, 1 val per store
};
////////////////////////////////////////////////////////////////////////////////////////////////////
| 8 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim128_bf16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::bfloat16_t, 128, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim128<cutlass::bfloat16_t, true>(params, stream);
}
| 9 |
0 | hf_public_repos | hf_public_repos/blog/deep-rl-ppo.md | ---
title: "Proximal Policy Optimization (PPO)"
thumbnail: /blog/assets/93_deep_rl_ppo/thumbnail.png
authors:
- user: ThomasSimonini
---
# Proximal Policy Optimization (PPO)
<h2>Unit 8, of the <a href="https://github.com/huggingface/deep-rl-class">Deep Reinforcement Learning Class with Hugging Face 🤗</a></h2>
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit8/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
<img src="assets/93_deep_rl_ppo/thumbnail.png" alt="Thumbnail"/>
---
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit8/introduction)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
**[In the last Unit](https://huggingface.co/blog/deep-rl-a2c)**, we learned about Advantage Actor Critic (A2C), a hybrid architecture combining value-based and policy-based methods that help to stabilize the training by reducing the variance with:
- *An Actor* that controls **how our agent behaves** (policy-based method).
- *A Critic* that measures **how good the action taken is** (value-based method).
Today we'll learn about Proximal Policy Optimization (PPO), an architecture that improves our agent's training stability by avoiding too large policy updates. To do that, we use a ratio that will indicates the difference between our current and old policy and clip this ratio from a specific range \\( [1 - \epsilon, 1 + \epsilon] \\) .
Doing this will ensure **that our policy update will not be too large and that the training is more stable.**
And then, after the theory, we'll code a PPO architecture from scratch using PyTorch and bulletproof our implementation with CartPole-v1 and LunarLander-v2.
<figure class="image table text-center m-0 w-full">
<video
alt="LunarLander"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="assets/63_deep_rl_intro/lunarlander.mp4" type="video/mp4">
</video>
</figure>
Sounds exciting? Let's get started!
- [The intuition behind PPO](https://huggingface.co/blog/deep-rl-ppo#the-intuition-behind-ppo)
- [Introducing the Clipped Surrogate Objective](https://huggingface.co/blog/deep-rl-ppo#introducing-the-clipped-surrogate-objective)
- [Recap: The Policy Objective Function](https://huggingface.co/blog/deep-rl-ppo#recap-the-policy-objective-function)
- [The Ratio Function](https://huggingface.co/blog/deep-rl-ppo#the-ratio-function)
- [The unclipped part of the Clipped Surrogate Objective function](https://huggingface.co/blog/deep-rl-ppo#the-unclipped-part-of-the-clipped-surrogate-objective-function)
- [The clipped Part of the Clipped Surrogate Objective function](https://huggingface.co/blog/deep-rl-ppo#the-clipped-part-of-the-clipped-surrogate-objective-function)
- [Visualize the Clipped Surrogate Objective](https://huggingface.co/blog/deep-rl-ppo#visualize-the-clipped-surrogate-objective)
- [Case 1 and 2: the ratio is between the range](https://huggingface.co/blog/deep-rl-ppo#case-1-and-2-the-ratio-is-between-the-range)
- [Case 3 and 4: the ratio is below the range](https://huggingface.co/blog/deep-rl-ppo#case-3-and-4-the-ratio-is-below-the-range)
- [Case 5 and 6: the ratio is above the range](https://huggingface.co/blog/deep-rl-ppo#case-5-and-6-the-ratio-is-above-the-range)
- [Let's code our PPO Agent](https://huggingface.co/blog/deep-rl-ppo#lets-code-our-ppo-agent)
## The intuition behind PPO
The idea with Proximal Policy Optimization (PPO) is that we want to improve the training stability of the policy by limiting the change you make to the policy at each training epoch: **we want to avoid having too large policy updates.**
For two reasons:
- We know empirically that smaller policy updates during training are **more likely to converge to an optimal solution.**
- A too big step in a policy update can result in falling “off the cliff” (getting a bad policy) **and having a long time or even no possibility to recover.**
<figure class="image table text-center m-0 w-full">
<img class="center" src="assets/93_deep_rl_ppo/cliff.jpg" alt="Policy Update cliff"/>
<figcaption>Taking smaller policy updates improve the training stability</figcaption>
<figcaption>Modified version from RL — Proximal Policy Optimization (PPO) Explained by Jonathan Hui: https://jonathan-hui.medium.com/rl-proximal-policy-optimization-ppo-explained-77f014ec3f12</figcaption>
</figure>
**So with PPO, we update the policy conservatively**. To do so, we need to measure how much the current policy changed compared to the former one using a ratio calculation between the current and former policy. And we clip this ratio in a range \\( [1 - \epsilon, 1 + \epsilon] \\), meaning that we **remove the incentive for the current policy to go too far from the old one (hence the proximal policy term).**
## Introducing the Clipped Surrogate Objective
### Recap: The Policy Objective Function
Let’s remember what is the objective to optimize in Reinforce:
<img src="assets/93_deep_rl_ppo/lpg.jpg" alt="Reinforce"/>
The idea was that by taking a gradient ascent step on this function (equivalent to taking gradient descent of the negative of this function), we would **push our agent to take actions that lead to higher rewards and avoid harmful actions.**
However, the problem comes from the step size:
- Too small, **the training process was too slow**
- Too high, **there was too much variability in the training**
Here with PPO, the idea is to constrain our policy update with a new objective function called the *Clipped surrogate objective function* that **will constrain the policy change in a small range using a clip.**
This new function **is designed to avoid destructive large weights updates** :
<img src="assets/93_deep_rl_ppo/ppo-surrogate.jpg" alt="PPO surrogate function"/>
Let’s study each part to understand how it works.
### The Ratio Function
<img src="assets/93_deep_rl_ppo/ratio1.jpg" alt="Ratio"/>
This ratio is calculated this way:
<img src="assets/93_deep_rl_ppo/ratio2.jpg" alt="Ratio"/>
It’s the probability of taking action \\( a_t \\) at state \\( s_t \\) in the current policy divided by the previous one.
As we can see, \\( r_t(\theta) \\) denotes the probability ratio between the current and old policy:
- If \\( r_t(\theta) > 1 \\), the **action \\( a_t \\) at state \\( s_t \\) is more likely in the current policy than the old policy.**
- If \\( r_t(\theta) \\) is between 0 and 1, the **action is less likely for the current policy than for the old one**.
So this probability ratio is an **easy way to estimate the divergence between old and current policy.**
### The unclipped part of the Clipped Surrogate Objective function
<img src="assets/93_deep_rl_ppo/unclipped1.jpg" alt="PPO"/>
This ratio **can replace the log probability we use in the policy objective function**. This gives us the left part of the new objective function: multiplying the ratio by the advantage.
<figure class="image table text-center m-0 w-full">
<img src="assets/93_deep_rl_ppo/unclipped2.jpg" alt="PPO"/>
<figcaption><a href="https://arxiv.org/pdf/1707.06347.pdf">Proximal Policy Optimization Algorithms</a></figcaption>
</figure>
However, without a constraint, if the action taken is much more probable in our current policy than in our former, **this would lead to a significant policy gradient step** and, therefore, an **excessive policy update.**
### The clipped Part of the Clipped Surrogate Objective function
<img src="assets/93_deep_rl_ppo/clipped.jpg" alt="PPO"/>
Consequently, we need to constrain this objective function by penalizing changes that lead to a ratio away from 1 (in the paper, the ratio can only vary from 0.8 to 1.2).
**By clipping the ratio, we ensure that we do not have a too large policy update because the current policy can't be too different from the older one.**
To do that, we have two solutions:
- *TRPO (Trust Region Policy Optimization)* uses KL divergence constraints outside the objective function to constrain the policy update. But this method **is complicated to implement and takes more computation time.**
- *PPO* clip probability ratio directly in the objective function with its **Clipped surrogate objective function.**
<img src="assets/93_deep_rl_ppo/clipped.jpg" alt="PPO"/>
This clipped part is a version where rt(theta) is clipped between \\( [1 - \epsilon, 1 + \epsilon] \\).
With the Clipped Surrogate Objective function, we have two probability ratios, one non-clipped and one clipped in a range (between \\( [1 - \epsilon, 1 + \epsilon] \\), epsilon is a hyperparameter that helps us to define this clip range (in the paper \\( \epsilon = 0.2 \\).).
Then, we take the minimum of the clipped and non-clipped objective, **so the final objective is a lower bound (pessimistic bound) of the unclipped objective.**
Taking the minimum of the clipped and non-clipped objective means **we'll select either the clipped or the non-clipped objective based on the ratio and advantage situation**.
## Visualize the Clipped Surrogate Objective
Don't worry. **It's normal if this seems complex to handle right now**. But we're going to see what this Clipped Surrogate Objective Function looks like, and this will help you to visualize better what's going on.
<figure class="image table text-center m-0 w-full">
<img src="assets/93_deep_rl_ppo/recap.jpg" alt="PPO"/>
<figcaption><a href="https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf">Table from "Towards Delivering a Coherent Self-Contained
Explanation of Proximal Policy Optimization" by Daniel Bick</a></figcaption>
</figure>
We have six different situations. Remember first that we take the minimum between the clipped and unclipped objectives.
### Case 1 and 2: the ratio is between the range
In situations 1 and 2, **the clipping does not apply since the ratio is between the range** \\( [1 - \epsilon, 1 + \epsilon] \\)
In situation 1, we have a positive advantage: the **action is better than the average** of all the actions in that state. Therefore, we should encourage our current policy to increase the probability of taking that action in that state.
Since the ratio is between intervals, **we can increase our policy's probability of taking that action at that state.**
In situation 2, we have a negative advantage: the action is worse than the average of all actions at that state. Therefore, we should discourage our current policy from taking that action in that state.
Since the ratio is between intervals, **we can decrease the probability that our policy takes that action at that state.**
### Case 3 and 4: the ratio is below the range
<figure class="image table text-center m-0 w-full">
<img src="assets/93_deep_rl_ppo/recap.jpg" alt="PPO"/>
<figcaption><a href="https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf">Table from "Towards Delivering a Coherent Self-Contained
Explanation of Proximal Policy Optimization" by Daniel Bick</a></figcaption>
</figure>
If the probability ratio is lower than \\( [1 - \epsilon] \\), the probability of taking that action at that state is much lower than with the old policy.
If, like in situation 3, the advantage estimate is positive (A>0), then **you want to increase the probability of taking that action at that state.**
But if, like situation 4, the advantage estimate is negative, **we don't want to decrease further** the probability of taking that action at that state. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
### Case 5 and 6: the ratio is above the range
<figure class="image table text-center m-0 w-full">
<img src="assets/93_deep_rl_ppo/recap.jpg" alt="PPO"/>
<figcaption><a href="https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf">Table from "Towards Delivering a Coherent Self-Contained
Explanation of Proximal Policy Optimization" by Daniel Bick</a></figcaption>
</figure>
If the probability ratio is higher than \\( [1 + \epsilon] \\), the probability of taking that action at that state in the current policy is **much higher than in the former policy.**
If, like in situation 5, the advantage is positive, **we don't want to get too greedy**. We already have a higher probability of taking that action at that state than the former policy. Therefore, the gradient is = 0 (since we're on a flat line), so we don't update our weights.
If, like in situation 6, the advantage is negative, we want to decrease the probability of taking that action at that state.
So if we recap, **we only update the policy with the unclipped objective part**. When the minimum is the clipped objective part, we don't update our policy weights since the gradient will equal 0.
So we update our policy only if:
- Our ratio is in the range \\( [1 - \epsilon, 1 + \epsilon] \\)
- Our ratio is outside the range, but **the advantage leads to getting closer to the range**
- Being below the ratio but the advantage is > 0
- Being above the ratio but the advantage is < 0
**You might wonder why, when the minimum is the clipped ratio, the gradient is 0.** When the ratio is clipped, the derivative in this case will not be the derivative of the \\( r_t(\theta) * A_t \\) but the derivative of either \\( (1 - \epsilon)* A_t\\) or the derivative of \\( (1 + \epsilon)* A_t\\) which both = 0.
To summarize, thanks to this clipped surrogate objective, **we restrict the range that the current policy can vary from the old one.** Because we remove the incentive for the probability ratio to move outside of the interval since, the clip have the effect to gradient. If the ratio is > \\( 1 + \epsilon \\) or < \\( 1 - \epsilon \\) the gradient will be equal to 0.
The final Clipped Surrogate Objective Loss for PPO Actor-Critic style looks like this, it's a combination of Clipped Surrogate Objective function, Value Loss Function and Entropy bonus:
<img src="assets/93_deep_rl_ppo/ppo-objective.jpg" alt="PPO objective"/>
That was quite complex. Take time to understand these situations by looking at the table and the graph. **You must understand why this makes sense.** If you want to go deeper, the best resource is the article [Towards Delivering a Coherent Self-Contained Explanation of Proximal Policy Optimization" by Daniel Bick, especially part 3.4](https://fse.studenttheses.ub.rug.nl/25709/1/mAI_2021_BickD.pdf).
## Let's code our PPO Agent
Now that we studied the theory behind PPO, the best way to understand how it works **is to implement it from scratch.**
Implementing an architecture from scratch is the best way to understand it, and it's a good habit. We have already done it for a value-based method with Q-Learning and a Policy-based method with Reinforce.
So, to be able to code it, we're going to use two resources:
- A tutorial made by [Costa Huang](https://github.com/vwxyzjn). Costa is behind [CleanRL](https://github.com/vwxyzjn/cleanrl), a Deep Reinforcement Learning library that provides high-quality single-file implementation with research-friendly features.
- In addition to the tutorial, to go deeper, you can read the 13 core implementation details: [https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/](https://iclr-blog-track.github.io/2022/03/25/ppo-implementation-details/)
Then, to test its robustness, we're going to train it in 2 different classical environments:
- [Cartpole-v1](https://www.gymlibrary.ml/environments/classic_control/cart_pole/?highlight=cartpole)
- [LunarLander-v2](https://www.gymlibrary.ml/environments/box2d/lunar_lander/)
<figure class="image table text-center m-0 w-full">
<video
alt="LunarLander"
style="max-width: 70%; margin: auto;"
autoplay loop autobuffer muted playsinline
>
<source src="assets/63_deep_rl_intro/lunarlander.mp4" type="video/mp4">
</video>
</figure>
And finally, we will be push the trained model to the Hub to evaluate and visualize your agent playing.
LunarLander-v2 is the first environment you used when you started this course. At that time, you didn't know how it worked, and now, you can code it from scratch and train it. **How incredible is that 🤩.**
<iframe src="https://giphy.com/embed/pynZagVcYxVUk" width="480" height="480" frameBorder="0" class="giphy-embed" allowFullScreen></iframe><p><a href="https://giphy.com/gifs/the-office-michael-heartbreak-pynZagVcYxVUk">via GIPHY</a></p>
Start the tutorial here 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit8/unit8.ipynb
---
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorial. 🥳, **this was one of the hardest of the course**.
Don't hesitate to train your agent in other environments. The **best way to learn is to try things on your own!**
I want you to think about your progress since the first Unit. **With these eight units, you've built a strong background in Deep Reinforcement Learning. Congratulations!**
But this is not the end, even if the foundations part of the course is finished, this is not the end of the journey. We're working on new elements:
- Adding new environments and tutorials.
- A section about **multi-agents** (self-play, collaboration, competition).
- Another one about **offline RL and Decision Transformers.**
- **Paper explained articles.**
- And more to come.
The best way to keep in touch is to sign up for the course so that we keep you updated 👉 http://eepurl.com/h1pElX
And don't forget to share with your friends who want to learn 🤗!
Finally, with your feedback, we want **to improve and update the course iteratively**. If you have some, please fill this form 👉 **[https://forms.gle/3HgA7bEHwAmmLfwh9](https://forms.gle/3HgA7bEHwAmmLfwh9)**
See you next time!
### **Keep learning, stay awesome 🤗,**
| 0 |
0 | hf_public_repos | hf_public_repos/blog/patchtst.md | ---
title: "Patch Time Series Transformer in Hugging Face"
thumbnail: /blog/assets/patchtst/thumbnail.png
authors:
- user: namctin
guest: true
- user: wmgifford
guest: true
- user: ajati
guest: true
- user: vijaye12
guest: true
- user: kashif
---
# Patch Time Series Transformer in Hugging Face - Getting Started
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/huggingface/notebooks/blob/main/examples/patch_tst.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In this blog, we provide examples of how to get started with PatchTST. We first demonstrate the forecasting capability of `PatchTST` on the Electricity data. We will then demonstrate the transfer learning capability of `PatchTST` by using the previously trained model to do zero-shot forecasting on the electrical transformer (ETTh1) dataset. The zero-shot forecasting
performance will denote the `test` performance of the model in the `target` domain, without any
training on the target domain. Subsequently, we will do linear probing and (then) finetuning of
the pretrained model on the `train` part of the target data, and will validate the forecasting
performance on the `test` part of the target data.
The `PatchTST` model was proposed in A Time Series is Worth [64 Words: Long-term Forecasting with Transformers](https://huggingface.co/papers/2211.14730) by Yuqi Nie, Nam H. Nguyen, Phanwadee Sinthong, Jayant Kalagnanam and presented at ICLR 2023.
## Quick overview of PatchTST
At a high level, the model vectorizes individual time series in a batch into patches of a given size and encodes the resulting sequence of vectors via a Transformer that then outputs the prediction length forecast via an appropriate head.
The model is based on two key components:
1. segmentation of time series into subseries-level patches which serve as input tokens to the Transformer;
2. channel-independence where each channel contains a single univariate time series that shares the same embedding and Transformer weights across all the series, i.e. a [global](https://doi.org/10.1016/j.ijforecast.2021.03.004) univariate model.
The patching design naturally has three-fold benefit:
- local semantic information is retained in the embedding;
- computation and memory usage of the attention maps are quadratically reduced given the same look-back window via strides between patches; and
- the model can attend longer history via a trade-off between the patch length (input vector size) and the context length (number of sequences).
In addition, PatchTST has a modular design to seamlessly support masked time series pre-training as well as direct time series forecasting.
<!-- <div> <img src="./assets/patchtst/patchtst-arch.png" alt="Drawing" style="width: 600px;"/></div> -->
| 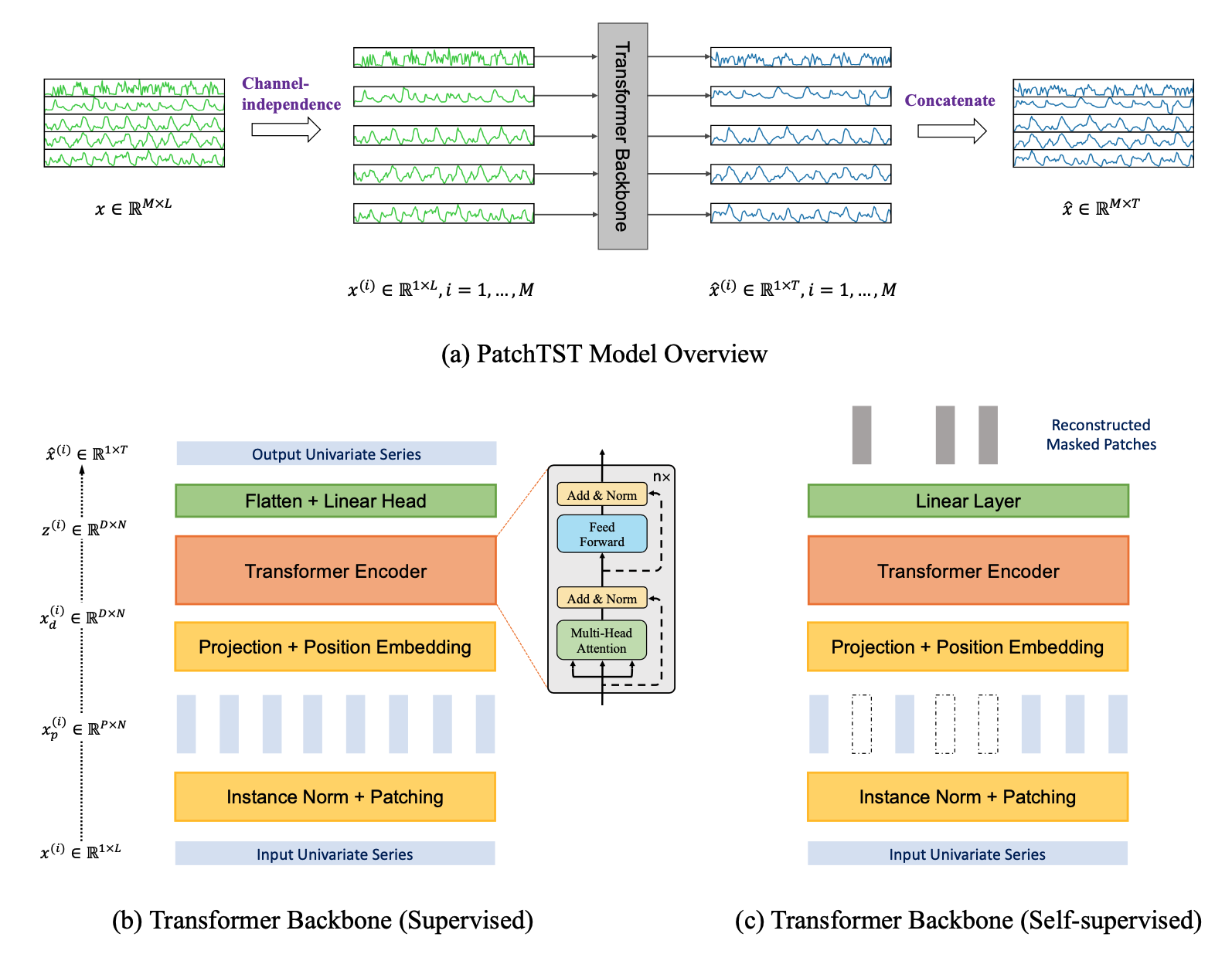 |
|:--:|
|(a) PatchTST model overview where a batch of \\(M\\) time series each of length \\(L\\) are processed independently (by reshaping them into the batch dimension) via a Transformer backbone and then reshaping the resulting batch back into \\(M \\) series of prediction length \\(T\\). Each *univariate* series can be processed in a supervised fashion (b) where the patched set of vectors is used to output the full prediction length or in a self-supervised fashion (c) where masked patches are predicted. |
## Installation
This demo requires Hugging Face [`Transformers`](https://github.com/huggingface/transformers) for the model, and the IBM `tsfm` package for auxiliary data pre-processing.
We can install both by cloning the `tsfm` repository and following the below steps.
1. Clone the public IBM Time Series Foundation Model Repository [`tsfm`](https://github.com/ibm/tsfm).
```bash
pip install git+https://github.com/IBM/tsfm.git
```
2. Install Hugging Face [`Transformers`](https://github.com/huggingface/transformers#installation)
```bash
pip install transformers
```
3. Test it with the following commands in a `python` terminal.
```python
from transformers import PatchTSTConfig
from tsfm_public.toolkit.dataset import ForecastDFDataset
```
## Part 1: Forecasting on the Electricity dataset
Here we train a PatchTST model directly on the Electricity dataset (available from https://github.com/zhouhaoyi/Informer2020), and evaluate its performance.
```python
# Standard
import os
# Third Party
from transformers import (
EarlyStoppingCallback,
PatchTSTConfig,
PatchTSTForPrediction,
Trainer,
TrainingArguments,
)
import numpy as np
import pandas as pd
# First Party
from tsfm_public.toolkit.dataset import ForecastDFDataset
from tsfm_public.toolkit.time_series_preprocessor import TimeSeriesPreprocessor
from tsfm_public.toolkit.util import select_by_index
```
### Set seed
```python
from transformers import set_seed
set_seed(2023)
```
### Load and prepare datasets
In the next cell, please adjust the following parameters to suit your application:
- `dataset_path`: path to local .csv file, or web address to a csv file for the data of interest. Data is loaded with pandas, so anything supported by
`pd.read_csv` is supported: (https://pandas.pydata.org/pandas-docs/stable/reference/api/pandas.read_csv.html).
- `timestamp_column`: column name containing timestamp information, use `None` if there is no such column.
- `id_columns`: List of column names specifying the IDs of different time series. If no ID column exists, use `[]`.
- `forecast_columns`: List of columns to be modeled
- `context_length`: The amount of historical data used as input to the model. Windows of the input time series data with length equal to `context_length` will be extracted from the input dataframe. In the case of a multi-time series dataset, the context windows will be created so that they are contained within a single time series (i.e., a single ID).
- `forecast_horizon`: Number of timestamps to forecast in the future.
- `train_start_index`, `train_end_index`: the start and end indices in the loaded data which delineate the training data.
- `valid_start_index`, `eval_end_index`: the start and end indices in the loaded data which delineate the validation data.
- `test_start_index`, `eval_end_index`: the start and end indices in the loaded data which delineate the test data.
- `patch_length`: The patch length for the `PatchTST` model. It is recommended to choose a value that evenly divides `context_length`.
- `num_workers`: Number of CPU workers in the PyTorch dataloader.
- `batch_size`: Batch size.
The data is first loaded into a Pandas dataframe and split into training, validation, and test parts. Then the Pandas dataframes are converted to the appropriate PyTorch dataset required for training.
```python
# The ECL data is available from https://github.com/zhouhaoyi/Informer2020?tab=readme-ov-file#data
dataset_path = "~/data/ECL.csv"
timestamp_column = "date"
id_columns = []
context_length = 512
forecast_horizon = 96
patch_length = 16
num_workers = 16 # Reduce this if you have low number of CPU cores
batch_size = 64 # Adjust according to GPU memory
```
```python
data = pd.read_csv(
dataset_path,
parse_dates=[timestamp_column],
)
forecast_columns = list(data.columns[1:])
# get split
num_train = int(len(data) * 0.7)
num_test = int(len(data) * 0.2)
num_valid = len(data) - num_train - num_test
border1s = [
0,
num_train - context_length,
len(data) - num_test - context_length,
]
border2s = [num_train, num_train + num_valid, len(data)]
train_start_index = border1s[0] # None indicates beginning of dataset
train_end_index = border2s[0]
# we shift the start of the evaluation period back by context length so that
# the first evaluation timestamp is immediately following the training data
valid_start_index = border1s[1]
valid_end_index = border2s[1]
test_start_index = border1s[2]
test_end_index = border2s[2]
train_data = select_by_index(
data,
id_columns=id_columns,
start_index=train_start_index,
end_index=train_end_index,
)
valid_data = select_by_index(
data,
id_columns=id_columns,
start_index=valid_start_index,
end_index=valid_end_index,
)
test_data = select_by_index(
data,
id_columns=id_columns,
start_index=test_start_index,
end_index=test_end_index,
)
time_series_preprocessor = TimeSeriesPreprocessor(
timestamp_column=timestamp_column,
id_columns=id_columns,
input_columns=forecast_columns,
output_columns=forecast_columns,
scaling=True,
)
time_series_preprocessor = time_series_preprocessor.train(train_data)
```
```python
train_dataset = ForecastDFDataset(
time_series_preprocessor.preprocess(train_data),
id_columns=id_columns,
timestamp_column="date",
input_columns=forecast_columns,
output_columns=forecast_columns,
context_length=context_length,
prediction_length=forecast_horizon,
)
valid_dataset = ForecastDFDataset(
time_series_preprocessor.preprocess(valid_data),
id_columns=id_columns,
timestamp_column="date",
input_columns=forecast_columns,
output_columns=forecast_columns,
context_length=context_length,
prediction_length=forecast_horizon,
)
test_dataset = ForecastDFDataset(
time_series_preprocessor.preprocess(test_data),
id_columns=id_columns,
timestamp_column="date",
input_columns=forecast_columns,
output_columns=forecast_columns,
context_length=context_length,
prediction_length=forecast_horizon,
)
```
### Configure the PatchTST model
Next, we instantiate a randomly initialized `PatchTST` model with a configuration. The settings below control the different hyperparameters related to the architecture.
- `num_input_channels`: the number of input channels (or dimensions) in the time series data. This is
automatically set to the number for forecast columns.
- `context_length`: As described above, the amount of historical data used as input to the model.
- `patch_length`: The length of the patches extracted from the context window (of length `context_length`).
- `patch_stride`: The stride used when extracting patches from the context window.
- `random_mask_ratio`: The fraction of input patches that are completely masked for pretraining the model.
- `d_model`: Dimension of the transformer layers.
- `num_attention_heads`: The number of attention heads for each attention layer in the Transformer encoder.
- `num_hidden_layers`: The number of encoder layers.
- `ffn_dim`: Dimension of the intermediate (often referred to as feed-forward) layer in the encoder.
- `dropout`: Dropout probability for all fully connected layers in the encoder.
- `head_dropout`: Dropout probability used in the head of the model.
- `pooling_type`: Pooling of the embedding. `"mean"`, `"max"` and `None` are supported.
- `channel_attention`: Activate the channel attention block in the Transformer to allow channels to attend to each other.
- `scaling`: Whether to scale the input targets via "mean" scaler, "std" scaler, or no scaler if `None`. If `True`, the
scaler is set to `"mean"`.
- `loss`: The loss function for the model corresponding to the `distribution_output` head. For parametric
distributions it is the negative log-likelihood (`"nll"`) and for point estimates it is the mean squared
error `"mse"`.
- `pre_norm`: Normalization is applied before self-attention if pre_norm is set to `True`. Otherwise, normalization is
applied after residual block.
- `norm_type`: Normalization at each Transformer layer. Can be `"BatchNorm"` or `"LayerNorm"`.
For full details on the parameters, we refer to the [documentation](https://huggingface.co/docs/transformers/main/en/model_doc/patchtst#transformers.PatchTSTConfig).
```python
config = PatchTSTConfig(
num_input_channels=len(forecast_columns),
context_length=context_length,
patch_length=patch_length,
patch_stride=patch_length,
prediction_length=forecast_horizon,
random_mask_ratio=0.4,
d_model=128,
num_attention_heads=16,
num_hidden_layers=3,
ffn_dim=256,
dropout=0.2,
head_dropout=0.2,
pooling_type=None,
channel_attention=False,
scaling="std",
loss="mse",
pre_norm=True,
norm_type="batchnorm",
)
model = PatchTSTForPrediction(config)
```
### Train model
Next, we can leverage the Hugging Face [Trainer](https://huggingface.co/docs/transformers/main_classes/trainer) class to train the model based on the direct forecasting strategy. We first define the [TrainingArguments](https://huggingface.co/docs/transformers/main_classes/trainer#transformers.TrainingArguments) which lists various hyperparameters for training such as the number of epochs, learning rate and so on.
```python
training_args = TrainingArguments(
output_dir="./checkpoint/patchtst/electricity/pretrain/output/",
overwrite_output_dir=True,
# learning_rate=0.001,
num_train_epochs=100,
do_eval=True,
evaluation_strategy="epoch",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
dataloader_num_workers=num_workers,
save_strategy="epoch",
logging_strategy="epoch",
save_total_limit=3,
logging_dir="./checkpoint/patchtst/electricity/pretrain/logs/", # Make sure to specify a logging directory
load_best_model_at_end=True, # Load the best model when training ends
metric_for_best_model="eval_loss", # Metric to monitor for early stopping
greater_is_better=False, # For loss
label_names=["future_values"],
)
# Create the early stopping callback
early_stopping_callback = EarlyStoppingCallback(
early_stopping_patience=10, # Number of epochs with no improvement after which to stop
early_stopping_threshold=0.0001, # Minimum improvement required to consider as improvement
)
# define trainer
trainer = Trainer(
model=model,
args=training_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
callbacks=[early_stopping_callback],
# compute_metrics=compute_metrics,
)
# pretrain
trainer.train()
```
<!--
<div>
<progress value='5810' max='7000' style='width:300px; height:20px; vertical-align: middle;'></progress>
[5810/7000 43:50 < 08:59, 2.21 it/s, Epoch 83/100]
</div>
-->
<table border="1" class="dataframe">
<thead>
<tr style="text-align: left;">
<th>Epoch</th>
<th>Training Loss</th>
<th>Validation Loss</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>0.455400</td>
<td>0.215057</td>
</tr>
<tr>
<td>2</td>
<td>0.241000</td>
<td>0.179336</td>
</tr>
<tr>
<td>3</td>
<td>0.209000</td>
<td>0.158522</td>
</tr>
<!--
<tr>
<td>4</td>
<td>0.190800</td>
<td>0.147135</td>
</tr>
<tr>
<td>5</td>
<td>0.179800</td>
<td>0.140547</td>
</tr>
<tr>
<td>6</td>
<td>0.172800</td>
<td>0.136634</td>
</tr>
<tr>
<td>7</td>
<td>0.167800</td>
<td>0.133554</td>
</tr>
<tr>
<td>8</td>
<td>0.163900</td>
<td>0.131195</td>
</tr>
<tr>
<td>9</td>
<td>0.160700</td>
<td>0.129303</td>
</tr>
<tr>
<td>10</td>
<td>0.158000</td>
<td>0.127299</td>
</tr>
<tr>
<td>11</td>
<td>0.155600</td>
<td>0.126036</td>
</tr>
<tr>
<td>12</td>
<td>0.153700</td>
<td>0.124635</td>
</tr>
<tr>
<td>13</td>
<td>0.151800</td>
<td>0.123454</td>
</tr>
<tr>
<td>14</td>
<td>0.150200</td>
<td>0.122605</td>
</tr>
<tr>
<td>15</td>
<td>0.148900</td>
<td>0.121886</td>
</tr>
<tr>
<td>16</td>
<td>0.147300</td>
<td>0.121087</td>
</tr>
<tr>
<td>17</td>
<td>0.146100</td>
<td>0.120236</td>
</tr>
<tr>
<td>18</td>
<td>0.145000</td>
<td>0.119824</td>
</tr>
<tr>
<td>19</td>
<td>0.143900</td>
<td>0.119152</td>
</tr>
<tr>
<td>20</td>
<td>0.142900</td>
<td>0.118846</td>
</tr>
<tr>
<td>21</td>
<td>0.142000</td>
<td>0.118068</td>
</tr>
<tr>
<td>22</td>
<td>0.141100</td>
<td>0.118113</td>
</tr>
<tr>
<td>23</td>
<td>0.140500</td>
<td>0.117507</td>
</tr>
<tr>
<td>24</td>
<td>0.139600</td>
<td>0.116810</td>
</tr>
<tr>
<td>25</td>
<td>0.139000</td>
<td>0.116932</td>
</tr>
<tr>
<td>26</td>
<td>0.138500</td>
<td>0.116615</td>
</tr>
<tr>
<td>27</td>
<td>0.137800</td>
<td>0.116271</td>
</tr>
<tr>
<td>28</td>
<td>0.137300</td>
<td>0.115869</td>
</tr>
<tr>
<td>29</td>
<td>0.136900</td>
<td>0.115507</td>
</tr>
<tr>
<td>30</td>
<td>0.136500</td>
<td>0.115528</td>
</tr>
<tr>
<td>31</td>
<td>0.136200</td>
<td>0.115159</td>
</tr>
<tr>
<td>32</td>
<td>0.135800</td>
<td>0.114793</td>
</tr>
<tr>
<td>33</td>
<td>0.135400</td>
<td>0.114708</td>
</tr>
<tr>
<td>34</td>
<td>0.135000</td>
<td>0.114543</td>
</tr>
<tr>
<td>35</td>
<td>0.134700</td>
<td>0.114122</td>
</tr>
<tr>
<td>36</td>
<td>0.134400</td>
<td>0.114027</td>
</tr>
<tr>
<td>37</td>
<td>0.134100</td>
<td>0.114218</td>
</tr>
<tr>
<td>38</td>
<td>0.133900</td>
<td>0.113932</td>
</tr>
<tr>
<td>39</td>
<td>0.133500</td>
<td>0.113782</td>
</tr>
<tr>
<td>40</td>
<td>0.133300</td>
<td>0.113526</td>
</tr>
<tr>
<td>41</td>
<td>0.133000</td>
<td>0.113371</td>
</tr>
<tr>
<td>42</td>
<td>0.132800</td>
<td>0.113198</td>
</tr>
<tr>
<td>43</td>
<td>0.132700</td>
<td>0.113216</td>
</tr>
<tr>
<td>44</td>
<td>0.132400</td>
<td>0.113184</td>
</tr>
<tr>
<td>45</td>
<td>0.132100</td>
<td>0.113104</td>
</tr>
<tr>
<td>46</td>
<td>0.132100</td>
<td>0.113357</td>
</tr>
<tr>
<td>47</td>
<td>0.131800</td>
<td>0.112759</td>
</tr>
<tr>
<td>48</td>
<td>0.131600</td>
<td>0.112729</td>
</tr>
<tr>
<td>49</td>
<td>0.131500</td>
<td>0.112671</td>
</tr>
<tr>
<td>50</td>
<td>0.131300</td>
<td>0.112952</td>
</tr>
<tr>
<td>51</td>
<td>0.131200</td>
<td>0.112605</td>
</tr>
<tr>
<td>52</td>
<td>0.130900</td>
<td>0.112396</td>
</tr>
<tr>
<td>53</td>
<td>0.130900</td>
<td>0.112694</td>
</tr>
<tr>
<td>54</td>
<td>0.130700</td>
<td>0.112293</td>
</tr>
<tr>
<td>55</td>
<td>0.130700</td>
<td>0.112163</td>
</tr>
<tr>
<td>56</td>
<td>0.130400</td>
<td>0.112269</td>
</tr>
<tr>
<td>57</td>
<td>0.130400</td>
<td>0.112087</td>
</tr>
<tr>
<td>58</td>
<td>0.130100</td>
<td>0.112125</td>
</tr>
<tr>
<td>59</td>
<td>0.130000</td>
<td>0.111991</td>
</tr>
<tr>
<td>60</td>
<td>0.129900</td>
<td>0.112255</td>
</tr>
<tr>
<td>61</td>
<td>0.129900</td>
<td>0.111913</td>
</tr>
<tr>
<td>62</td>
<td>0.129600</td>
<td>0.111966</td>
</tr>
<tr>
<td>63</td>
<td>0.129600</td>
<td>0.112031</td>
</tr>
<tr>
<td>64</td>
<td>0.129500</td>
<td>0.111876</td>
</tr>
<tr>
<td>65</td>
<td>0.129400</td>
<td>0.111759</td>
</tr>
<tr>
<td>66</td>
<td>0.129300</td>
<td>0.111742</td>
</tr>
<tr>
<td>67</td>
<td>0.129100</td>
<td>0.111626</td>
</tr>
<tr>
<td>68</td>
<td>0.129000</td>
<td>0.111595</td>
</tr>
<tr>
<td>69</td>
<td>0.129000</td>
<td>0.111605</td>
</tr>
<tr>
<td>70</td>
<td>0.128900</td>
<td>0.111627</td>
</tr>
<tr>
<td>71</td>
<td>0.128900</td>
<td>0.111542</td>
</tr>
<tr>
<td>72</td>
<td>0.128700</td>
<td>0.112140</td>
</tr>
<tr>
<td>73</td>
<td>0.128700</td>
<td>0.111440</td>
</tr>
<tr>
<td>74</td>
<td>0.128700</td>
<td>0.111474</td>
</tr>
<tr>
<td>75</td>
<td>0.128500</td>
<td>0.111478</td>
</tr>
<tr>
<td>76</td>
<td>0.128500</td>
<td>0.111569</td>
</tr>
<tr>
<td>77</td>
<td>0.128400</td>
<td>0.111468</td>
</tr>
<tr>
<td>78</td>
<td>0.128200</td>
<td>0.111457</td>
</tr>
<tr>
<td>79</td>
<td>0.128300</td>
<td>0.111344</td>
</tr>
<tr>
<td>80</td>
<td>0.128200</td>
<td>0.111425</td>
</tr>
<tr>
<td>81</td>
<td>0.128200</td>
<td>0.111350</td>
</tr>
<tr>
<td>82</td>
<td>0.128000</td>
<td>0.111294</td>
</tr>
-->
<tr><td>...</td><td>...</td><td>...</td></tr>
<tr>
<td>83</td>
<td>0.128000</td>
<td>0.111213</td>
</tr>
</tbody>
</table><p>
<!--
TrainOutput(global_step=5810, training_loss=0.1434877689446927, metrics={'train_runtime': 2644.2883, 'train_samples_per_second': 673.338, 'train_steps_per_second': 2.647, 'total_flos': 1.1614959858946867e+18, 'train_loss': 0.1434877689446927, 'epoch': 83.0})
-->
### Evaluate the model on the test set of the source domain
Next, we can leverage `trainer.evaluate()` to calculate test metrics. While this is not the target metric to judge in this task, it provides a reasonable check that the pretrained model has trained properly.
Note that the training and evaluation loss for PatchTST is the Mean Squared Error (MSE) loss. Hence, we do not separately compute the MSE metric in any of the following evaluation experiments.
```python
results = trainer.evaluate(test_dataset)
print("Test result:")
print(results)
>>> Test result:
{'eval_loss': 0.1316315233707428, 'eval_runtime': 5.8077, 'eval_samples_per_second': 889.332, 'eval_steps_per_second': 3.616, 'epoch': 83.0}
```
The MSE of `0.131` is very close to the value reported for the Electricity dataset in the original PatchTST paper.
### Save model
```python
save_dir = "patchtst/electricity/model/pretrain/"
os.makedirs(save_dir, exist_ok=True)
trainer.save_model(save_dir)
```
## Part 2: Transfer Learning from Electricity to ETTh1
In this section, we will demonstrate the transfer learning capability of the `PatchTST` model.
We use the model pre-trained on the Electricity dataset to do zero-shot forecasting on the ETTh1 dataset.
By Transfer Learning, we mean that we first pretrain the model for a forecasting task on a `source` dataset (which we did above on the `Electricity` dataset). Then, we will use the pretrained model for zero-shot forecasting on a `target` dataset. By zero-shot, we mean that we test the performance in the `target` domain without any additional training. We hope that the model gained enough knowledge from pretraining which can be transferred to a different dataset.
Subsequently, we will do linear probing and (then) finetuning of the pretrained model on the `train` split of the target data and will validate the forecasting performance on the `test` split of the target data. In this example, the source dataset is the `Electricity` dataset and the target dataset is ETTh1.
### Transfer learning on ETTh1 data.
All evaluations are on the `test` part of the `ETTh1` data.
Step 1: Directly evaluate the electricity-pretrained model. This is the zero-shot performance.
Step 2: Evaluate after doing linear probing.
Step 3: Evaluate after doing full finetuning.
### Load ETTh dataset
Below, we load the `ETTh1` dataset as a Pandas dataframe. Next, we create 3 splits for training, validation, and testing. We then leverage the `TimeSeriesPreprocessor` class to prepare each split for the model.
```python
dataset = "ETTh1"
```
```python
print(f"Loading target dataset: {dataset}")
dataset_path = f"https://raw.githubusercontent.com/zhouhaoyi/ETDataset/main/ETT-small/{dataset}.csv"
timestamp_column = "date"
id_columns = []
forecast_columns = ["HUFL", "HULL", "MUFL", "MULL", "LUFL", "LULL", "OT"]
train_start_index = None # None indicates beginning of dataset
train_end_index = 12 * 30 * 24
# we shift the start of the evaluation period back by context length so that
# the first evaluation timestamp is immediately following the training data
valid_start_index = 12 * 30 * 24 - context_length
valid_end_index = 12 * 30 * 24 + 4 * 30 * 24
test_start_index = 12 * 30 * 24 + 4 * 30 * 24 - context_length
test_end_index = 12 * 30 * 24 + 8 * 30 * 24
>>> Loading target dataset: ETTh1
```
```python
data = pd.read_csv(
dataset_path,
parse_dates=[timestamp_column],
)
train_data = select_by_index(
data,
id_columns=id_columns,
start_index=train_start_index,
end_index=train_end_index,
)
valid_data = select_by_index(
data,
id_columns=id_columns,
start_index=valid_start_index,
end_index=valid_end_index,
)
test_data = select_by_index(
data,
id_columns=id_columns,
start_index=test_start_index,
end_index=test_end_index,
)
time_series_preprocessor = TimeSeriesPreprocessor(
timestamp_column=timestamp_column,
id_columns=id_columns,
input_columns=forecast_columns,
output_columns=forecast_columns,
scaling=True,
)
time_series_preprocessor = time_series_preprocessor.train(train_data)
```
```python
train_dataset = ForecastDFDataset(
time_series_preprocessor.preprocess(train_data),
id_columns=id_columns,
input_columns=forecast_columns,
output_columns=forecast_columns,
context_length=context_length,
prediction_length=forecast_horizon,
)
valid_dataset = ForecastDFDataset(
time_series_preprocessor.preprocess(valid_data),
id_columns=id_columns,
input_columns=forecast_columns,
output_columns=forecast_columns,
context_length=context_length,
prediction_length=forecast_horizon,
)
test_dataset = ForecastDFDataset(
time_series_preprocessor.preprocess(test_data),
id_columns=id_columns,
input_columns=forecast_columns,
output_columns=forecast_columns,
context_length=context_length,
prediction_length=forecast_horizon,
)
```
### Zero-shot forecasting on ETTH
As we are going to test forecasting performance out-of-the-box, we load the model which we pretrained above.
```python
finetune_forecast_model = PatchTSTForPrediction.from_pretrained(
"patchtst/electricity/model/pretrain/",
num_input_channels=len(forecast_columns),
head_dropout=0.7,
)
```
```python
finetune_forecast_args = TrainingArguments(
output_dir="./checkpoint/patchtst/transfer/finetune/output/",
overwrite_output_dir=True,
learning_rate=0.0001,
num_train_epochs=100,
do_eval=True,
evaluation_strategy="epoch",
per_device_train_batch_size=batch_size,
per_device_eval_batch_size=batch_size,
dataloader_num_workers=num_workers,
report_to="tensorboard",
save_strategy="epoch",
logging_strategy="epoch",
save_total_limit=3,
logging_dir="./checkpoint/patchtst/transfer/finetune/logs/", # Make sure to specify a logging directory
load_best_model_at_end=True, # Load the best model when training ends
metric_for_best_model="eval_loss", # Metric to monitor for early stopping
greater_is_better=False, # For loss
label_names=["future_values"],
)
# Create a new early stopping callback with faster convergence properties
early_stopping_callback = EarlyStoppingCallback(
early_stopping_patience=10, # Number of epochs with no improvement after which to stop
early_stopping_threshold=0.001, # Minimum improvement required to consider as improvement
)
finetune_forecast_trainer = Trainer(
model=finetune_forecast_model,
args=finetune_forecast_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
callbacks=[early_stopping_callback],
)
print("\n\nDoing zero-shot forecasting on target data")
result = finetune_forecast_trainer.evaluate(test_dataset)
print("Target data zero-shot forecasting result:")
print(result)
>>> Doing zero-shot forecasting on target data
Target data zero-shot forecasting result:
{'eval_loss': 0.3728715181350708, 'eval_runtime': 0.95, 'eval_samples_per_second': 2931.527, 'eval_steps_per_second': 11.579}
```
As can be seen, with a zero-shot forecasting approach we obtain an MSE of 0.370 which is near to the state-of-the-art result in the original PatchTST paper.
Next, let's see how we can do by performing linear probing, which involves training a linear layer on top of a frozen pre-trained model. Linear probing is often done to test the performance of features of a pretrained model.
### Linear probing on ETTh1
We can do a quick linear probing on the `train` part of the target data to see any possible `test` performance improvement.
```python
# Freeze the backbone of the model
for param in finetune_forecast_trainer.model.model.parameters():
param.requires_grad = False
print("\n\nLinear probing on the target data")
finetune_forecast_trainer.train()
print("Evaluating")
result = finetune_forecast_trainer.evaluate(test_dataset)
print("Target data head/linear probing result:")
print(result)
>>> Linear probing on the target data
```
<!--
<div>
<progress value='576' max='3200' style='width:300px; height:20px; vertical-align: middle;'></progress>
[ 576/3200 00:50 < 03:51, 11.33 it/s, Epoch 18/100]
</div>
-->
<table border="1" class="dataframe">
<thead>
<tr style="text-align: left;">
<th>Epoch</th>
<th>Training Loss</th>
<th>Validation Loss</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>0.384600</td>
<td>0.688319</td>
</tr>
<tr>
<td>2</td>
<td>0.374200</td>
<td>0.678159</td>
</tr>
<tr>
<td>3</td>
<td>0.368400</td>
<td>0.667633</td>
</tr>
<tr><td>...</td><td>...</td><td>...</td></tr>
<!--
<tr>
<td>4</td>
<td>0.363400</td>
<td>0.662551</td>
</tr>
<tr>
<td>5</td>
<td>0.360100</td>
<td>0.660060</td>
</tr>
<tr>
<td>6</td>
<td>0.356400</td>
<td>0.658128</td>
</tr>
<tr>
<td>7</td>
<td>0.355100</td>
<td>0.656811</td>
</tr>
<tr>
<td>8</td>
<td>0.352400</td>
<td>0.655359</td>
</tr>
<tr>
<td>9</td>
<td>0.350900</td>
<td>0.655416</td>
</tr>
<tr>
<td>10</td>
<td>0.349100</td>
<td>0.654475</td>
</tr>
<tr>
<td>11</td>
<td>0.347200</td>
<td>0.653585</td>
</tr>
<tr>
<td>12</td>
<td>0.346000</td>
<td>0.654434</td>
</tr>
<tr>
<td>13</td>
<td>0.345600</td>
<td>0.654141</td>
</tr>
<tr>
<td>14</td>
<td>0.344900</td>
<td>0.656340</td>
</tr>
<tr>
<td>15</td>
<td>0.344000</td>
<td>0.655699</td>
</tr>
<tr>
<td>16</td>
<td>0.342100</td>
<td>0.655356</td>
</tr>
<tr>
<td>17</td>
<td>0.341500</td>
<td>0.656582</td>
</tr>
<tr>
<td>18</td>
<td>0.342700</td>
<td>0.655651</td>
</tr>
-->
</tbody>
</table><p>
```
>>> Evaluating
Target data head/linear probing result:
{'eval_loss': 0.35652095079421997, 'eval_runtime': 1.1537, 'eval_samples_per_second': 2413.986, 'eval_steps_per_second': 9.535, 'epoch': 18.0}
```
As can be seen, by only training a simple linear layer on top of the frozen backbone, the MSE decreased from 0.370 to 0.357, beating the originally reported results!
```python
save_dir = f"patchtst/electricity/model/transfer/{dataset}/model/linear_probe/"
os.makedirs(save_dir, exist_ok=True)
finetune_forecast_trainer.save_model(save_dir)
save_dir = f"patchtst/electricity/model/transfer/{dataset}/preprocessor/"
os.makedirs(save_dir, exist_ok=True)
time_series_preprocessor = time_series_preprocessor.save_pretrained(save_dir)
```
Finally, let's see if we can get additional improvements by doing a full fine-tune of the model.
### Full fine-tune on ETTh1
We can do a full model fine-tune (instead of probing the last linear layer as shown above) on the `train` part of the target data to see a possible `test` performance improvement. The code looks similar to the linear probing task above, except that we are not freezing any parameters.
```python
# Reload the model
finetune_forecast_model = PatchTSTForPrediction.from_pretrained(
"patchtst/electricity/model/pretrain/",
num_input_channels=len(forecast_columns),
dropout=0.7,
head_dropout=0.7,
)
finetune_forecast_trainer = Trainer(
model=finetune_forecast_model,
args=finetune_forecast_args,
train_dataset=train_dataset,
eval_dataset=valid_dataset,
callbacks=[early_stopping_callback],
)
print("\n\nFinetuning on the target data")
finetune_forecast_trainer.train()
print("Evaluating")
result = finetune_forecast_trainer.evaluate(test_dataset)
print("Target data full finetune result:")
print(result)
>>> Finetuning on the target data
```
<!--
<div>
<progress value='384' max='3200' style='width:300px; height:20px; vertical-align: middle;'></progress>
[ 384/3200 00:35 < 04:25, 10.62 it/s, Epoch 12/100]
</div>
-->
<table border="1" class="dataframe">
<thead>
<tr style="text-align: left;">
<th>Epoch</th>
<th>Training Loss</th>
<th>Validation Loss</th>
</tr>
</thead>
<tbody>
<tr>
<td>1</td>
<td>0.348600</td>
<td>0.709915</td>
</tr>
<tr>
<td>2</td>
<td>0.328800</td>
<td>0.706537</td>
</tr>
<tr>
<td>3</td>
<td>0.319700</td>
<td>0.741892</td>
</tr>
<tr>
<td>...</td>
<td>...</td>
<td>...</td>
</tr>
<!--
<tr>
<td>4</td>
<td>0.312900</td>
<td>0.727837</td>
</tr>
<tr>
<td>5</td>
<td>0.306700</td>
<td>0.774511</td>
</tr>
<tr>
<td>6</td>
<td>0.300300</td>
<td>0.786199</td>
</tr>
<tr>
<td>7</td>
<td>0.296600</td>
<td>0.821851</td>
</tr>
<tr>
<td>8</td>
<td>0.292000</td>
<td>0.838177</td>
</tr>
<tr>
<td>9</td>
<td>0.288800</td>
<td>0.832112</td>
</tr>
<tr>
<td>10</td>
<td>0.285100</td>
<td>0.800559</td>
</tr>
<tr>
<td>11</td>
<td>0.281200</td>
<td>0.860003</td>
</tr>
<tr>
<td>12</td>
<td>0.277200</td>
<td>0.855923</td>
</tr>
-->
</tbody>
</table><p>
```
>>> Evaluating
Target data full finetune result:
{'eval_loss': 0.354232519865036, 'eval_runtime': 1.0715, 'eval_samples_per_second': 2599.18, 'eval_steps_per_second': 10.266, 'epoch': 12.0}
```
In this case, there is only a small improvement on the ETTh1 dataset with full fine-tuning. For other datasets there may be more substantial improvements. Let's save the model anyway.
```python
save_dir = f"patchtst/electricity/model/transfer/{dataset}/model/fine_tuning/"
os.makedirs(save_dir, exist_ok=True)
finetune_forecast_trainer.save_model(save_dir)
```
## Summary
In this blog, we presented a step-by-step guide on training PatchTST for tasks related to forecasting and transfer learning, demonstrating various approaches for fine-tuning. We intend to facilitate easy integration of the PatchTST HF model for your forecasting use cases, and we hope that this content serves as a useful resource to expedite the adoption of PatchTST. Thank you for tuning in to our blog, and we hope you find this information beneficial for your projects.
| 1 |
0 | hf_public_repos | hf_public_repos/blog/deploy-tfserving-kubernetes.md | ---
title: Deploying 🤗 ViT on Kubernetes with TF Serving
thumbnail: /blog/assets/94_tf_serving_kubernetes/thumb.png
authors:
- user: chansung
guest: true
- user: sayakpaul
guest: true
---
# Deploying 🤗 ViT on Kubernetes with TF Serving
In the [<u>previous post</u>](https://huggingface.co/blog/tf-serving-vision), we showed how
to deploy a [<u>Vision Transformer (ViT)</u>](https://huggingface.co/docs/transformers/main/en/model_doc/vit)
model from 🤗 Transformers locally with TensorFlow Serving. We covered
topics like embedding preprocessing and postprocessing operations within
the Vision Transformer model, handling gRPC requests, and more!
While local deployments are an excellent head start to building
something useful, you’d need to perform deployments that can serve many
users in real-life projects. In this post, you’ll learn how to scale the
local deployment from the previous post with Docker and Kubernetes.
Therefore, we assume some familiarity with Docker and Kubernetes.
This post builds on top of the [<u>previous post</u>](https://huggingface.co/blog/tf-serving-vision), so, we highly
recommend reading it first. You can find all the code
discussed throughout this post in [<u>this repository</u>](https://github.com/sayakpaul/deploy-hf-tf-vision-models/tree/main/hf_vision_model_onnx_gke).
## Why go with Docker and Kubernetes?
The basic workflow of scaling up a deployment like ours includes the
following steps:
- **Containerizing the application logic**: The application logic
involves a served model that can handle requests and return
predictions. For containerization, Docker is the industry-standard
go-to.
- **Deploying the Docker container**: You have various options here. The most
widely used option is deploying the Docker container on a Kubernetes
cluster. Kubernetes provides numerous deployment-friendly features
(e.g. autoscaling and security). You can use a solution like
[<u>Minikube</u>](https://minikube.sigs.k8s.io/docs/start/) to
manage Kubernetes clusters locally or a serverless solution like
[<u>Elastic Kubernetes Service (EKS)</u>](https://docs.aws.amazon.com/eks/latest/userguide/what-is-eks.html).
You might be wondering why use an explicit setup like this in the age
of [<u>Sagemaker,</u>](https://aws.amazon.com/sagemaker/) [<u>Vertex AI</u>](https://cloud.google.com/vertex-ai)
that provides ML deployment-specific features right off the bat. It is fair to think
about it.
The above workflow is widely adopted in the industry, and many
organizations benefit from it. It has already been battle-tested for
many years. It also lets you have more granular control of your
deployments while abstracting away the non-trivial bits.
This post uses [<u>Google Kubernetes Engine (GKE)</u>](https://cloud.google.com/kubernetes-engine)
to provision and manage a Kubernetes cluster. We assume you already have a
billing-enabled GCP project if you’re using GKE. Also, note that you’d need to
configure the [`gcloud`](https://cloud.google.com/sdk/gcloud) utility for
performing the deployment on GKE. But the concepts discussed in this post
equally apply should you decide to use Minikube.
**Note**: The code snippets shown in this post can be executed on a Unix terminal
as long as you have configured the `gcloud` utility along with Docker and `kubectl`.
More instructions are available in the [accompanying repository](https://github.com/sayakpaul/deploy-hf-tf-vision-models/tree/main/hf_vision_model_onnx_gke).
## Containerization with Docker
The serving model can handle raw image inputs as bytes and is capable of preprocessing and
postprocessing.
In this section, you’ll see how to containerize that model using the
[<u>base TensorFlow Serving Image</u>](http://hub.docker.com/r/tensorflow/serving/tags/). TensorFlow Serving consumes models
in the [`SavedModel`](https://www.tensorflow.org/guide/saved_model) format. Recall how you
obtained such a `SavedModel` in the [<u>previous post</u>](https://huggingface.co/blog/tf-serving-vision). We assume that
you have the `SavedModel` compressed in `tar.gz` format. You can fetch
it from [<u>here</u>](https://huggingface.co/deploy-hf-tf-vit/vit-base16-extended/resolve/main/saved_model.tar.gz)
just in case. Then `SavedModel` should be placed in the special directory
structure of `<MODEL_NAME>/<VERSION>/<SavedModel>`. This is how TensorFlow Serving simultaneously manages multiple deployments of different versioned models.
### Preparing the Docker image
The shell script below places the `SavedModel` in `hf-vit/1` under the
parent directory models. You'll copy everything inside it when preparing
the Docker image. There is only one model in this example, but this
is a more generalizable approach.
```bash
$ MODEL_TAR=model.tar.gz
$ MODEL_NAME=hf-vit
$ MODEL_VERSION=1
$ MODEL_PATH=models/$MODEL_NAME/$MODEL_VERSION
$ mkdir -p $MODEL_PATH
$ tar -xvf $MODEL_TAR --directory $MODEL_PATH
```
Below, we show how the `models` directory is structured in our case:
```bash
$ find /models
/models
/models/hf-vit
/models/hf-vit/1
/models/hf-vit/1/keras_metadata.pb
/models/hf-vit/1/variables
/models/hf-vit/1/variables/variables.index
/models/hf-vit/1/variables/variables.data-00000-of-00001
/models/hf-vit/1/assets
/models/hf-vit/1/saved_model.pb
```
The custom TensorFlow Serving image should be built on top of the [base one](http://hub.docker.com/r/tensorflow/serving/tags/).
There are various approaches for this, but you’ll do this by running a Docker container as illustrated in the
[<u>official document</u>](https://www.tensorflow.org/tfx/serving/serving_kubernetes#commit_image_for_deployment). We start by running `tensorflow/serving` image in background mode, then the entire `models` directory is copied to the running container
as below.
```bash
$ docker run -d --name serving_base tensorflow/serving
$ docker cp models/ serving_base:/models/
```
We used the official Docker image of TensorFlow Serving as the base, but
you can use ones that you have [<u>built from source</u>](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/g3doc/setup.md#building-from-source)
as well.
**Note**: TensorFlow Serving benefits from hardware optimizations that leverage instruction sets such as
[<u>AVX512</u>](https://en.wikipedia.org/wiki/AVX-512). These
instruction sets can [<u>speed up deep learning model inference</u>](https://huggingface.co/blog/bert-cpu-scaling-part-1). So,
if you know the hardware on which the model will be deployed, it’s often
beneficial to obtain an optimized build of the TensorFlow Serving image
and use it throughout.
Now that the running container has all the required files in the
appropriate directory structure, we need to create a new Docker image
that includes these changes. This can be done with the [`docker commit`](https://docs.docker.com/engine/reference/commandline/commit/) command below, and you'll have a new Docker image named `$NEW_IMAGE`.
One important thing to note is that you need to set the `MODEL_NAME`
environment variable to the model name, which is `hf-vit` in this
case. This tells TensorFlow Serving what model to deploy.
```bash
$ NEW_IMAGE=tfserving:$MODEL_NAME
$ docker commit \
--change "ENV MODEL_NAME $MODEL_NAME" \
serving_base $NEW_IMAGE
```
### Running the Docker image locally
Lastly, you can run the newly built Docker image locally to see if it
works fine. Below you see the output of the `docker run` command. Since
the output is verbose, we trimmed it down to focus on the important
bits. Also, it is worth noting that it opens up `8500` and `8501`
ports for gRPC and HTTP/REST endpoints, respectively.
```shell
$ docker run -p 8500:8500 -p 8501:8501 -t $NEW_IMAGE &
---------OUTPUT---------
(Re-)adding model: hf-vit
Successfully reserved resources to load servable {name: hf-vit version: 1}
Approving load for servable version {name: hf-vit version: 1}
Loading servable version {name: hf-vit version: 1}
Reading SavedModel from: /models/hf-vit/1
Reading SavedModel debug info (if present) from: /models/hf-vit/1
Successfully loaded servable version {name: hf-vit version: 1}
Running gRPC ModelServer at 0.0.0.0:8500 ...
Exporting HTTP/REST API at:localhost:8501 ...
```
### Pushing the Docker image
The final step here is to push the Docker image to an image repository.
You'll use [<u>Google Container Registry (GCR)</u>](https://cloud.google.com/container-registry) for this
purpose. The following lines of code can do this for you:
```bash
$ GCP_PROJECT_ID=<GCP_PROJECT_ID>
$ GCP_IMAGE=gcr.io/$GCP_PROJECT_ID/$NEW_IMAGE
$ gcloud auth configure-docker
$ docker tag $NEW_IMAGE $GCP_IMAGE
$ docker push $GCP_IMAGE
```
Since we’re using GCR, you need to prefix the
Docker image tag ([<u>note</u>](https://cloud.google.com/container-registry/docs/pushing-and-pulling) the other formats too) with `gcr.io/<GCP_PROJECT_ID>` . With the Docker image prepared and pushed to GCR, you can now proceed to deploy it on a
Kubernetes cluster.
## Deploying on a Kubernetes cluster
Deployment on a Kubernetes cluster requires the following:
- Provisioning a Kubernetes cluster, done with [<u>Google Kubernetes Engine</u>](https://cloud.google.com/kubernetes-engine) (GKE) in
this post. However, you’re welcome to use other platforms and tools
like EKS or Minikube.
- Connecting to the Kubernetes cluster to perform a deployment.
- Writing YAML manifests.
- Performing deployment with the manifests with a utility tool,
[`kubectl`](https://kubernetes.io/docs/reference/kubectl/).
Let’s go over each of these steps.
### Provisioning a Kubernetes cluster on GKE
You can use a shell script like so for this (available
[<u>here</u>](https://github.com/sayakpaul/deploy-hf-tf-vision-models/blob/main/hf_vision_model_tfserving_gke/provision_gke_cluster.sh)):
```bash
$ GKE_CLUSTER_NAME=tfs-cluster
$ GKE_CLUSTER_ZONE=us-central1-a
$ NUM_NODES=2
$ MACHINE_TYPE=n1-standard-8
$ gcloud container clusters create $GKE_CLUSTER_NAME \
--zone=$GKE_CLUSTER_ZONE \
--machine-type=$MACHINE_TYPE \
--num-nodes=$NUM_NODES
```
GCP offers a variety of machine types to configure the deployment in a
way you want. We encourage you to refer to the
[<u>documentation</u>](https://cloud.google.com/sdk/gcloud/reference/container/clusters/create)
to learn more about it.
Once the cluster is provisioned, you need to connect to it to perform
the deployment. Since GKE is used here, you also need to authenticate
yourself. You can use a shell script like so to do both of these:
```bash
$ GCP_PROJECT_ID=<GCP_PROJECT_ID>
$ export USE_GKE_GCLOUD_AUTH_PLUGIN=True
$ gcloud container clusters get-credentials $GKE_CLUSTER_NAME \
--zone $GKE_CLUSTER_ZONE \
--project $GCP_PROJECT_ID
```
The `gcloud container clusters get-credentials` command takes care of
both connecting to the cluster and authentication. Once this is done,
you’re ready to write the manifests.
### Writing Kubernetes manifests
Kubernetes manifests are written in [<u>YAML</u>](https://yaml.org/)
files. While it’s possible to use a single manifest file to perform the
deployment, creating separate manifest files is often beneficial for
delegating the separation of concerns. It’s common to use three manifest
files for achieving this:
- `deployment.yaml` defines the desired state of the Deployment by
providing the name of the Docker image, additional arguments when
running the Docker image, the ports to open for external accesses,
and the limits of resources.
- `service.yaml` defines connections between external clients and
inside Pods in the Kubernetes cluster.
- `hpa.yaml` defines rules to scale up and down the number of Pods
consisting of the Deployment, such as the percentage of CPU
utilization.
You can find the relevant manifests for this post
[<u>here</u>](https://github.com/sayakpaul/deploy-hf-tf-vision-models/tree/main/hf_vision_model_tfserving_gke/.kube/base).
Below, we present a pictorial overview of how these manifests are
consumed.

Next, we go through the important parts of each of these manifests.
**`deployment.yaml`**:
```yaml
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: tfs-server
name: tfs-server
...
spec:
containers:
- image: gcr.io/$GCP_PROJECT_ID/tfserving-hf-vit:latest
name: tfs-k8s
imagePullPolicy: Always
args: ["--tensorflow_inter_op_parallelism=2",
"--tensorflow_intra_op_parallelism=8"]
ports:
- containerPort: 8500
name: grpc
- containerPort: 8501
name: restapi
resources:
limits:
cpu: 800m
requests:
cpu: 800m
...
```
You can configure the names like `tfs-server`, `tfs-k8s` any way you
want. Under `containers`, you specify the Docker image URI the
deployment will use. The current resource utilization gets monitored by
setting the allowed bounds of the `resources` for the container. It
can let Horizontal Pod Autoscaler (discussed later) decide to scale up or down the number of
containers. `requests.cpu` is the minimal amount of CPU resources to
make the container work correctly set by operators. Here 800m means 80%
of the whole CPU resource. So, HPA monitors the average CPU utilization
out of the sum of `requests.cpu` across all Pods to make scaling
decisions.
Besides Kubernetes specific configuration, you can specify TensorFlow
Serving specific options in `args`.In this case, you have two:
- `tensorflow_inter_op_parallelism`, which sets the number of threads
to run in parallel to execute independent operations. The
recommended value for this is 2.
- `tensorflow_intra_op_parallelism`, which sets the number of threads
to run in parallel to execute individual operations. The recommended
value is the number of physical cores the deployment CPU has.
You can learn more about these options (and others) and tips on tuning
them for deployment from
[<u>here</u>](https://www.tensorflow.org/tfx/serving/performance) and
[<u>here</u>](https://github.com/IntelAI/models/blob/master/docs/general/tensorflow_serving/GeneralBestPractices.md).
**`service.yaml`**:
```yaml
apiVersion: v1
kind: Service
metadata:
labels:
app: tfs-server
name: tfs-server
spec:
ports:
- port: 8500
protocol: TCP
targetPort: 8500
name: tf-serving-grpc
- port: 8501
protocol: TCP
targetPort: 8501
name: tf-serving-restapi
selector:
app: tfs-server
type: LoadBalancer
```
We made the service type ‘LoadBalancer’ so the endpoints are
exposed externally to the Kubernetes cluster. It selects the
‘tfs-server’ Deployment to make connections with external clients via
the specified ports. We open two ports of ‘8500’ and ‘8501’ for gRPC and
HTTP/REST connections respectively.
**`hpa.yaml`**:
```yaml
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
name: tfs-server
spec:
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: tfs-server
minReplicas: 1
maxReplicas: 3
targetCPUUtilizationPercentage: 80
```
HPA stands for **H**orizontal **P**od **A**utoscaler. It sets criteria
to decide when to scale the number of Pods in the target Deployment. You
can learn more about the autoscaling algorithm internally used by
Kubernetes [<u>here</u>](https://kubernetes.io/docs/tasks/run-application/horizontal-pod-autoscale).
Here you specify how Kubernetes should handle autoscaling. In
particular, you define the replica bound within which it should perform
autoscaling – `minReplicas\` and `maxReplicas` and the target CPU
utilization. `targetCPUUtilizationPercentage` is an important metric
for autoscaling. The following thread aptly summarizes what it means
(taken from [<u>here</u>](https://stackoverflow.com/a/42530520/7636462)):
> The CPU utilization is the average CPU usage of all Pods in a
deployment across the last minute divided by the requested CPU of this
deployment. If the mean of the Pods' CPU utilization is higher than the
target you defined, your replicas will be adjusted.
Recall specifying `resources` in the deployment manifest. By
specifying the `resources`, the Kubernetes control plane starts
monitoring the metrics, so the `targetCPUUtilization` works.
Otherwise, HPA doesn't know the current status of the Deployment.
You can experiment and set these to the required numbers based on your
requirements. Note, however, that autoscaling will be contingent on the
quota you have available on GCP since GKE internally uses [<u>Google Compute Engine</u>](https://cloud.google.com/compute)
to manage these resources.
### Performing the deployment
Once the manifests are ready, you can apply them to the currently
connected Kubernetes cluster with the
[`kubectl apply`](https://kubernetes.io/docs/reference/generated/kubectl/kubectl-commands#apply)
command.
```bash
$ kubectl apply -f deployment.yaml
$ kubectl apply -f service.yaml
$ kubectl apply -f hpa.yaml
```
While using `kubectl` is fine for applying each of the manifests to
perform the deployment, it can quickly become harder if you have many
different manifests. This is where a utility like
[<u>Kustomize</u>](https://kustomize.io/) can be helpful. You simply
define another specification named `kustomization.yaml` like so:
```yaml
commonLabels:
app: tfs-server
resources:
- deployment.yaml
- hpa.yaml
- service.yaml
apiVersion: kustomize.config.k8s.io/v1beta1
kind: Kustomization
```
Then it’s just a one-liner to perform the actual deployment:
```bash
$ kustomize build . | kubectl apply -f -
```
Complete instructions are available
[<u>here</u>](https://github.com/sayakpaul/deploy-hf-tf-vision-models/tree/main/hf_vision_model_tfserving_gke).
Once the deployment has been performed, we can retrieve the endpoint IP
like so:
```bash
$ kubectl rollout status deployment/tfs-server
$ kubectl get svc tfs-server --watch
---------OUTPUT---------
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
tfs-server LoadBalancer xxxxxxxxxx xxxxxxxxxx 8500:30869/TCP,8501:31469/TCP xxx
```
Note down the external IP when it becomes available.
And that sums up all the steps you need to deploy your model on
Kubernetes! Kubernetes elegantly provides abstractions for complex bits
like autoscaling and cluster management while letting you focus on
the crucial aspects you should care about while deploying a model. These
include resource utilization, security (we didn’t cover that here),
performance north stars like latency, etc.
## Testing the endpoint
Given that you got an external IP for the endpoint, you can use the
following listing to test it:
```py
import tensorflow as tf
import json
import base64
image_path = tf.keras.utils.get_file(
"image.jpg", "http://images.cocodataset.org/val2017/000000039769.jpg"
)
bytes_inputs = tf.io.read_file(image_path)
b64str = base64.urlsafe_b64encode(bytes_inputs.numpy()).decode("utf-8")
data = json.dumps(
{"signature_name": "serving_default", "instances": [b64str]}
)
json_response = requests.post(
"http://<ENDPOINT-IP>:8501/v1/models/hf-vit:predict",
headers={"content-type": "application/json"},
data=data
)
print(json.loads(json_response.text))
---------OUTPUT---------
{'predictions': [{'label': 'Egyptian cat', 'confidence': 0.896659195}]}
```
If you’re interested to know how this deployment would perform if it
meets more traffic then we recommend you to check [<u>this article</u>](https://blog.tensorflow.org/2022/07/load-testing-TensorFlow-Servings-REST-interface.html).
Refer to the corresponding [<u>repository</u>](https://github.com/sayakpaul/deploy-hf-tf-vision-models/tree/main/locust)
to know more about running load tests with Locust and visualize the results.
## Notes on different TF Serving configurations
TensorFlow Serving
[<u>provides</u>](https://www.tensorflow.org/tfx/serving/serving_config)
various options to tailor the deployment based on your application use
case. Below, we briefly discuss some of them.
**`enable_batching`** enables the batch inference capability that
collects incoming requests with a certain amount of timing window,
collates them as a batch, performs a batch inference, and returns the
results of each request to the appropriate clients. TensorFlow Serving
provides a rich set of configurable options (such as `max_batch_size`,
`num_batch_threads`) to tailor your deployment needs. You can learn
more about them
[<u>here</u>](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/batching/README.md). Batching is
particularly beneficial for applications where you don't need predictions from a model
instantly. In those cases, you'd typically gather together multiple samples for prediction in batches and
then send those batches for prediction. Lucky for us, TensorFlow Serving can configure all of these
automatically when we enable its batching capabilities.
**`enable_model_warmup`** warms up some of the TensorFlow components
that are lazily instantiated with dummy input data. This way, you can
ensure everything is appropriately loaded up and that there will be no
lags during the actual service time.
## Conclusion
In this post and the associated [repository](https://github.com/sayakpaul/deploy-hf-tf-vision-models),
you learned about deploying the Vision Transformer model
from 🤗 Transformers on a Kubernetes cluster. If you’re doing this for
the first time, the steps may appear to be a little daunting, but once
you get the grasp, they’ll soon become an essential component of your
toolbox. If you were already familiar with this workflow, we hope this post was still beneficial
for you.
We applied the same deployment workflow for an ONNX-optimized version of the same
Vision Transformer model. For more details, check out [this link](https://github.com/sayakpaul/deploy-hf-tf-vision-models/tree/main/hf_vision_model_onnx_gke). ONNX-optimized models are especially beneficial if you're using x86 CPUs for deployment.
In the next post, we’ll show you how to perform these deployments with
significantly less code with [<u>Vertex AI</u>](https://cloud.google.com/vertex-ai) – more like
`model.deploy(autoscaling_config=...)` and boom! We hope you’re just as
excited as we are.
## Acknowledgement
Thanks to the ML Developer Relations Program team at Google, which
provided us with GCP credits for conducting the experiments.
| 2 |
0 | hf_public_repos | hf_public_repos/blog/zero-shot-eval-on-the-hub.md | ---
title: "Very Large Language Models and How to Evaluate Them"
thumbnail: /blog/assets/106_zero_shot_eval_on_the_hub/thumbnail.png
authors:
- user: mathemakitten
- user: Tristan
- user: abhishek
- user: lewtun
- user: douwekiela
---
# Very Large Language Models and How to Evaluate Them
Large language models can now be evaluated on zero-shot classification tasks with [Evaluation on the Hub](https://huggingface.co/spaces/autoevaluate/model-evaluator)!
Zero-shot evaluation is a popular way for researchers to measure the performance of large language models, as they have been [shown](https://arxiv.org/abs/2005.14165) to learn capabilities during training without explicitly being shown labeled examples. The [Inverse Scaling Prize](https://github.com/inverse-scaling/prize) is an example of a recent community effort to conduct large-scale zero-shot evaluation across model sizes and families to discover tasks on which larger models may perform worse than their smaller counterparts.

## Enabling zero-shot evaluation of language models on the Hub
[Evaluation on the Hub](https://huggingface.co/blog/eval-on-the-hub) helps you evaluate any model on the Hub without writing code, and is powered by [AutoTrain](https://huggingface.co/autotrain). Now, any causal language model on the Hub can be evaluated in a zero-shot fashion. Zero-shot evaluation measures the likelihood of a trained model producing a given set of tokens and does not require any labelled training data, which allows researchers to skip expensive labelling efforts.
We’ve upgraded the AutoTrain infrastructure for this project so that large models can be evaluated for free 🤯! It’s expensive and time-consuming for users to figure out how to write custom code to evaluate big models on GPUs. For example, a language model with 66 billion parameters may take 35 minutes just to load and compile, making evaluation of large models accessible only to those with expensive infrastructure and extensive technical experience. With these changes, evaluating a model with 66-billion parameters on a zero-shot classification task with 2000 sentence-length examples takes 3.5 hours and can be done by anyone in the community. Evaluation on the Hub currently supports evaluating models up to 66 billion parameters, and support for larger models is to come.
The zero-shot text classification task takes in a dataset containing a set of prompts and possible completions. Under the hood, the completions are concatenated with the prompt and the log-probabilities for each token are summed, then normalized and compared with the correct completion to report accuracy of the task.
In this blog post, we’ll use the zero-shot text classification task to evaluate various [OPT](https://ai.facebook.com/blog/democratizing-access-to-large-scale-language-models-with-opt-175b/) models on [WinoBias](https://uclanlp.github.io/corefBias/overview), a coreference task measuring gender bias related to occupations. WinoBias measures whether a model is more likely to pick a stereotypical pronoun to fill in a sentence mentioning an occupation, and observe that the results suggest an [inverse scaling](https://github.com/inverse-scaling/prize) trend with respect to model size.
## Case study: Zero-shot evaluation on the WinoBias task
The [WinoBias](https://github.com/uclanlp/corefBias) dataset has been formatted as a zero-shot task where classification options are the completions. Each completion differs by the pronoun, and the target corresponds to the anti-stereotypical completion for the occupation (e.g. "developer" is stereotypically a male-dominated occupation, so "she" would be the anti-stereotypical pronoun). See [here](https://huggingface.co/datasets/mathemakitten/winobias_antistereotype_test) for an example:

Next, we can select this newly-uploaded dataset in the Evaluation on the Hub interface using the `text_zero_shot_classification` task, select the models we’d like to evaluate, and submit our evaluation jobs! When the job has been completed, you’ll be notified by email that the autoevaluator bot has opened a new pull request with the results on the model’s Hub repository.

Plotting the results from the WinoBias task, we find that smaller models are more likely to select the anti-stereotypical pronoun for a sentence, while larger models are more likely to learn stereotypical associations between gender and occupation in text. This corroborates results from other benchmarks (e.g. [BIG-Bench](https://arxiv.org/abs/2206.04615)) which show that larger, more capable models are more likely to be biased with regard to gender, race, ethnicity, and nationality, and [prior work](https://www.deepmind.com/publications/scaling-language-models-methods-analysis-insights-from-training-gopher) which shows that larger models are more likely to generate toxic text.

## Enabling better research tools for everyone
Open science has made great strides with community-driven development of tools like the [Language Model Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) by EleutherAI and the [BIG-bench](https://github.com/google/BIG-bench) project, which make it straightforward for researchers to understand the behaviour of state-of-the-art models.
Evaluation on the Hub is a low-code tool which makes it simple to compare the zero-shot performance of a set of models along an axis such as FLOPS or model size, and to compare the performance of a set of models trained on a specific corpora against a different set of models. The zero-shot text classification task is extremely flexible—any dataset that can be permuted into a Winograd schema where examples to be compared only differ by a few words can be used with this task and evaluated on many models at once. Our goal is to make it simple to upload a new dataset for evaluation and enable researchers to easily benchmark many models on it.
An example research question which can be addressed with tools like this is the inverse scaling problem: while larger models are generally more capable at the majority of language tasks, there are tasks where larger models perform worse. The [Inverse Scaling Prize](https://github.com/inverse-scaling/prize) is a competition which challenges researchers to construct tasks where larger models perform worse than their smaller counterparts. We encourage you to try zero-shot evaluation on models of all sizes with your own tasks! If you find an interesting trend along model sizes, consider submitting your findings to round 2 of the [Inverse Scaling Prize](https://github.com/inverse-scaling/prize).
## Send us feedback!
At Hugging Face, we’re excited to continue democratizing access to state-of-the-art machine learning models, and that includes developing tools to make it easy for everyone to evaluate and probe their behavior. We’ve previously [written](https://huggingface.co/blog/eval-on-the-hub) about how important it is to standardize model evaluation methods to be consistent and reproducible, and to make tools for evaluation accessible to everyone. Future plans for Evaluation on the Hub include supporting zero-shot evaluation for language tasks which might not lend themselves to the format of concatenating completions to prompts, and adding support for even larger models.
One of the most useful things you can contribute as part of the community is to send us feedback! We’d love to hear from you on top priorities for model evaluation. Let us know your feedback and feature requests by posting on the Evaluation on the Hub [Community](https://huggingface.co/spaces/autoevaluate/model-evaluator/discussions) tab, or the [forums](https://discuss.huggingface.co/)!
| 3 |
0 | hf_public_repos | hf_public_repos/blog/cloudflare-workers-ai.md | ---
title: "Bringing serverless GPU inference to Hugging Face users"
thumbnail: /blog/assets/cloudflare-workers-ai/thumbnail.jpg
authors:
- user: philschmid
- user: jeffboudier
- user: rita3ko
guest: true
- user: nkothariCF
guest: true
---
# Bringing serverless GPU inference to Hugging Face users
<div class="alert alert-warning">
Update (November 2024): The integration is no longer available. Please switch to the Hugging Face Inference API, Inference Endpoints, or other deployment options for your AI model needs.
</div>
Today, we are thrilled to announce the launch of **Deploy on Cloudflare Workers AI**, a new integration on the Hugging Face Hub. Deploy on Cloudflare Workers AI makes using open models as a serverless API easy, powered by state-of-the-art GPUs deployed in Cloudflare edge data centers. Starting today, we are integrating some of the most popular open models on Hugging Face into Cloudflare Workers AI, powered by our production solutions, like [Text Generation Inference](https://github.com/huggingface/text-generation-inference/).
With Deploy on Cloudflare Workers AI, developers can build robust Generative AI applications without managing GPU infrastructure and servers and at a very low operating cost: only pay for the compute you use, not for idle capacity.
## Generative AI for Developers
This new experience expands upon the [strategic partnership we announced last year](https://blog.cloudflare.com/partnering-with-hugging-face-deploying-ai-easier-affordable) to simplify the access and deployment of open Generative AI models. One of the main problems developers and organizations face is the scarcity of GPU availability and the fixed costs of deploying servers to start building. Deploy on Cloudflare Workers AI offers an easy, low-cost solution to these challenges, providing serverless access to popular Hugging Face Models with a [pay-per-request pricing model](https://developers.cloudflare.com/workers-ai/platform/pricing).
Let's take a look at a concrete example. Imagine you develop an RAG Application that gets ~1000 requests per day, with an input of 1k tokens and an output of 100 tokens using Meta Llama 2 7B. The LLM inference production costs would amount to about $1 a day.
"We're excited to bring this integration to life so quickly. Putting the power of Cloudflare's global network of serverless GPUs into the hands of developers, paired with the most popular open source models on Hugging Face, will open the doors to lots of exciting innovation by our community around the world," said John Graham-Cumming, CTO, Cloudflare
## How it works
Using Hugging Face Models on Cloudflare Workers AI is super easy. Below, you will find step-by-step instructions on how to use Hermes 2 Pro on Mistral 7B, the newest model from Nous Research.
You can find all available models in this [Cloudflare Collection](https://huggingface.co/collections/Cloudflare/hf-curated-models-available-on-workers-ai-66036e7ad5064318b3e45db6).
_Note: You need access to a [Cloudflare Account](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/) and [API Token](https://dash.cloudflare.com/profile/api-tokens)._
You can find the Deploy on Cloudflare option on all available model pages, including models like Llama, Gemma or Mistral.
Open the “Deploy” menu, and select “Cloudflare Workers AI” - this will open an interface that includes instructions on how to use this model and send requests.
_Note: If the model you want to use does not have a “Cloudflare Workers AI” option, it is currently not supported. We are working on extending the availability of models together with Cloudflare. You can reach out to us at [[email protected]](mailto:[email protected]) with your request._
The integration can currently be used via two options: using the [Workers AI REST API](https://developers.cloudflare.com/workers-ai/get-started/rest-api/) or directly in Workers with the [Cloudflare AI SDK](https://developers.cloudflare.com/workers-ai/get-started/workers-wrangler/#1-create-a-worker-project). Select your preferred option and copy the code into your environment. When using the REST API, you need to make sure the <code>[ACCOUNT_ID](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/)</code> and <code>[API_TOKEN](https://dash.cloudflare.com/profile/api-tokens)</code> variables are defined.
That’s it! Now you can start sending requests to Hugging Face Models hosted on Cloudflare Workers AI. Make sure to use the correct prompt & template expected by the model.
## We’re just getting started
We are excited to collaborate with Cloudflare to make AI more accessible to developers. We will work with the Cloudflare team to make more models and experiences available to you!
| 4 |
0 | hf_public_repos | hf_public_repos/blog/tpu-inference-endpoints-spaces.md | ---
title: "Google Cloud TPUs made available to Hugging Face users"
thumbnail: /blog/assets/tpu-inference-endpoints-spaces/thumbnail.png
authors:
- user: pagezyhf
- user: michellehbn
- user: philschmid
- user: tengomucho
---
# Google Cloud TPUs made available to Hugging Face users

We're excited to share some great news! AI builders are now able to accelerate their applications with [Google Cloud TPUs](https://cloud.google.com/tpu?hl=en) on Hugging Face [Inference Endpoints](https://ui.endpoints.huggingface.co/) and [Spaces](https://huggingface.co/spaces)!
For those who might not be familiar, TPUs are custom-made AI hardware designed by Google. They are known for their ability to scale cost-effectively and deliver impressive performance across various AI workloads. This hardware has played a crucial role in some of Google's latest innovations, including the development of the Gemma 2 open models. We are excited to announce that TPUs will now be available for use in Inference Endpoints and Spaces.
This is a big step in our ongoing [collaboration](https://huggingface.co/blog/gcp-partnership) to provide you with the best tools and resources for your AI projects. We're really looking forward to seeing what amazing things you'll create with this new capability!
## Hugging Face Inference Endpoints support for TPUs
Hugging Face Inference Endpoints provides a seamless way to deploy Generative AI models with a few clicks on a dedicated, managed infrastructure using the cloud provider of your choice. Starting today, Google [TPU v5e](https://cloud.google.com/tpu/docs/v5e-inference) is available on Inference Endpoints. Choose the model you want to deploy, select Google Cloud Platform, select us-west1 and you’re ready to pick a TPU configuration:
We have 3 instance configurations, with more to come:
- v5litepod-1 TPU v5e with 1 core and 16 GB memory ($1.375/hour)
- v5litepod-4 TPU v5e with 4 cores and 64 GB memory ($5.50/hour)
- v5litepod-8 TPU v5e with 8 cores and 128 GB memory ($11.00/hour)

While you can use v5litepod-1 for models with up to 2 billion parameters without much hassle, we recommend to use v5litepod-4 for larger models to avoid memory budget issues. The larger the configuration, the lower the latency will be.
Together with the product and engineering teams at Google, we're excited to bring the performance and cost efficiency of TPUs to our Hugging Face community. This collaboration has resulted in some great developments:
1. We've created an open-source library called [Optimum TPU](https://github.com/huggingface/optimum-tpu), which makes it super easy for you to train and deploy Hugging Face models on Google TPUs.
2. Inference Endpoints uses Optimum TPU along with Text Generation Inference (TGI) to serve Large Language Models (LLMs) on TPUs.
3. We’re always working on support for a variety of model architectures. Starting today you can deploy [Gemma](https://huggingface.co/google/gemma-7b-it), [Llama](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), and [Mistral](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.3) in a few clicks. (Optimum TPU supported models).
## Hugging Face Spaces support for TPUs
Hugging Face Spaces provide developers with a platform to create, deploy, and share AI-powered demos and applications quickly. We are excited to introduce new TPU v5e instance support for Hugging Face Spaces. To upgrade your Space to run on TPUs, navigate to the Settings button in your Space and select the desired configuration:
- v5litepod-1 TPU v5e with 1 core and 16 GB memory ($1.375/hour)
- v5litepod-4 TPU v5e with 4 cores and 64 GB memory ($5.50/hour)
- v5litepod-8 TPU v5e with 8 cores and 128 GB memory ($11.00/hour)

Go build and share with the community awesome ML-powered demos on TPUs on [Hugging Face Spaces](https://huggingface.co/spaces)!
We're proud of what we've achieved together with Google and can't wait to see how you'll use TPUs in your projects. | 5 |
0 | hf_public_repos | hf_public_repos/blog/inference-pro.md | ---
title: Inference for PROs
thumbnail: /blog/assets/inference_pro/thumbnail.png
authors:
- user: osanseviero
- user: pcuenq
- user: victor
---
# Inference for PROs

Today, we're introducing Inference for PRO users - a community offering that gives you access to APIs of curated endpoints for some of the most exciting models available, as well as improved rate limits for the usage of free Inference API. Use the following page to [subscribe to PRO](https://huggingface.co/subscribe/pro).
Hugging Face PRO users now have access to exclusive API endpoints for a curated list of powerful models that benefit from ultra-fast inference powered by [text-generation-inference](https://github.com/huggingface/text-generation-inference). This is a benefit on top of the free inference API, which is available to all Hugging Face users to facilitate testing and prototyping on 200,000+ models. PRO users enjoy higher rate limits on these models, as well as exclusive access to some of the best models available today.
## Contents
- [Supported Models](#supported-models)
- [Getting started with Inference for PROs](#getting-started-with-inference-for-pros)
- [Applications](#applications)
- [Chat with Llama 2 and Code Llama 34B](#chat-with-llama-2-and-code-llama-34b)
- [Chat with Code Llama 70B](#chat-with-code-llama-70b)
- [Code infilling with Code Llama](#code-infilling-with-code-llama)
- [Stable Diffusion XL](#stable-diffusion-xl)
- [Messages API](#messages-api)
- [Generation Parameters](#generation-parameters)
- [Controlling Text Generation](#controlling-text-generation)
- [Controlling Image Generation](#controlling-image-generation)
- [Caching](#caching)
- [Streaming](#streaming)
- [Subscribe to PRO](#subscribe-to-pro)
- [FAQ](#faq)
## Supported Models
In addition to thousands of public models available in the Hub, PRO users get free access and higher rate limits to the following state-of-the-art models:
| Model | Size | Context Length | Use |
|--------------------------------|--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------|----------------|--------------------------------------------------------------|
| Meta Llama 3 Instruct | [8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct), [70B](https://huggingface.co/meta-llama/Meta-Llama-3-70B-Instruct) | 8k tokens | One of the best chat models |
| Mixtral 8x7B Instruct | [45B MOE](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1) | 32k tokens | Performance comparable to top proprietary models |
| Nous Hermes 2 Mixtral 8x7B DPO | [45B MOE](https://huggingface.co/NousResearch/Nous-Hermes-2-Mixtral-8x7B-DPO) | 32k tokens | Further trained over Mixtral 8x7B MoE |
| Zephyr 7B β | [7B](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta) | 4k tokens | One of the best chat models at the 7B weight |
| Llama 2 Chat | [7B](https://huggingface.co/meta-llama/Llama-2-7b-chat-hf), [13B](https://huggingface.co/meta-llama/Llama-2-13b-chat-hf) | 4k tokens | One of the best conversational models |
| Mistral 7B Instruct v0.2 | [7B](https://huggingface.co/mistralai/Mistral-7B-Instruct-v0.2) | 4k tokens | One of the best chat models at the 7B weight |
| Code Llama Base | [7B](https://huggingface.co/codellama/CodeLlama-7b-hf) and [13B](https://huggingface.co/codellama/CodeLlama-13b-hf) | 4k tokens | Autocomplete and infill code |
| Code Llama Instruct | [34B](https://huggingface.co/codellama/CodeLlama-34b-Instruct-hf) | 16k tokens | Conversational code assistant |
| Stable Diffusion XL | [3B UNet](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0) | - | Generate images |
| Bark | [0.9B](https://huggingface.co/suno/bark) | - | Text to audio generation |
Inference for PROs makes it easy to experiment and prototype with new models without having to deploy them on your own infrastructure. It gives PRO users access to ready-to-use HTTP endpoints for all the models listed above. It’s not meant to be used for heavy production applications - for that, we recommend using [Inference Endpoints](https://ui.endpoints.huggingface.co/catalog). Inference for PROs also allows using applications that depend upon an LLM endpoint, such as using a [VS Code extension](https://marketplace.visualstudio.com/items?itemName=HuggingFace.huggingface-vscode) for code completion, or have your own version of [Hugging Chat](http://hf.co/chat).
## Getting started with Inference For PROs
Using Inference for PROs is as simple as sending a POST request to the API endpoint for the model you want to run. You'll also need to get a PRO account authentication token from [your token settings page](https://huggingface.co/settings/tokens) and use it in the request. For example, to generate text using [Meta Llama 3 8B Instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct) in a terminal session, you'd do something like:
```bash
curl https://api-inference.huggingface.co/models/meta-llama/Meta-Llama-3-8b-Instruct \
-X POST \
-d '{"inputs": "In a surprising turn of events, "}' \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_TOKEN>"
```
Which would print something like this:
```json
[
{
"generated_text": "In a surprising turn of events, 2021 has brought us not one, but TWO seasons of our beloved TV show, \"Stranger Things.\""
}
]
```
You can also use many of the familiar transformers generation parameters, like `temperature` or `max_new_tokens`:
```bash
curl https://api-inference.huggingface.co/models/meta-llama/Meta-Llama-3-8b-Instruct \
-X POST \
-d '{"inputs": "In a surprising turn of events, ", "parameters": {"temperature": 0.7, "max_new_tokens": 100}}' \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_TOKEN>"
```
For more details on the generation parameters, please take a look at [_Controlling Text Generation_](#controlling-text-generation) below.
To send your requests in Python, you can take advantage of `InferenceClient`, a convenient utility available in the `huggingface_hub` Python library:
```bash
pip install huggingface_hub
```
`InferenceClient` is a helpful wrapper that allows you to make calls to the Inference API and Inference Endpoints easily:
```python
from huggingface_hub import InferenceClient
client = InferenceClient(model="meta-llama/Meta-Llama-3-8b-Instruct", token=YOUR_TOKEN)
output = client.text_generation("Can you please let us know more details about your ")
print(output)
```
If you don't want to pass the token explicitly every time you instantiate the client, you can use `notebook_login()` (in Jupyter notebooks), `huggingface-cli login` (in the terminal), or `login(token=YOUR_TOKEN)` (everywhere else) to log in a single time. The token will then be automatically used from here.
In addition to Python, you can also use JavaScript to integrate inference calls inside your JS or node apps. Take a look at [huggingface.js](https://huggingface.co/docs/huggingface.js/index) to get started!
## Applications
### Chat with Llama 2 and Code Llama 34B
Models prepared to follow chat conversations are trained with very particular and specific chat templates that depend on the model used. You need to be careful about the format the model expects and replicate it in your queries.
The following example was taken from [our Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2), that describes in full detail how to query the model for conversation:
```Python
prompt = """<s>[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
There's a llama in my garden 😱 What should I do? [/INST]
"""
client = InferenceClient(model="codellama/CodeLlama-13b-hf", token=YOUR_TOKEN)
response = client.text_generation(prompt, max_new_tokens=200)
print(response)
```
This example shows the structure of the first message in a multi-turn conversation. Note how the `<<SYS>>` delimiter is used to provide the _system prompt_, which tells the model how we expect it to behave. Then our query is inserted between `[INST]` delimiters.
If we wish to continue the conversation, we have to append the model response to the sequence, and issue a new followup instruction afterwards. This is the general structure of the prompt template we need to use for Llama 2:
```
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
```
This same format can be used with Code Llama Instruct to engage in technical conversations with a code-savvy assistant!
Please, refer to [our Llama 2 blog post](https://huggingface.co/blog/llama2#how-to-prompt-llama-2) for more details.
### Code infilling with Code Llama
Code models like Code Llama can be used for code completion using the same generation strategy we used in the previous examples: you provide a starting string that may contain code or comments, and the model will try to continue the sequence with plausible content. Code models can also be used for _infilling_, a more specialized task where you provide prefix and suffix sequences, and the model will predict what should go in between. This is great for applications such as IDE extensions. Let's see an example using Code Llama:
```Python
client = InferenceClient(model="codellama/CodeLlama-13b-hf", token=YOUR_TOKEN)
prompt_prefix = 'def remove_non_ascii(s: str) -> str:\n """ '
prompt_suffix = "\n return result"
prompt = f"<PRE> {prompt_prefix} <SUF>{prompt_suffix} <MID>"
infilled = client.text_generation(prompt, max_new_tokens=150)
infilled = infilled.rstrip(" <EOT>")
print(f"{prompt_prefix}{infilled}{prompt_suffix}")
```
```
def remove_non_ascii(s: str) -> str:
""" Remove non-ASCII characters from a string.
Args:
s (str): The string to remove non-ASCII characters from.
Returns:
str: The string with non-ASCII characters removed.
"""
result = ""
for c in s:
if ord(c) < 128:
result += c
return result
```
As you can see, the format used for infilling follows this pattern:
```
prompt = f"<PRE> {prompt_prefix} <SUF>{prompt_suffix} <MID>"
```
For more details on how this task works, please take a look at https://huggingface.co/blog/codellama#code-completion.
### Stable Diffusion XL
SDXL is also available for PRO users. The response returned by the endpoint consists of a byte stream representing the generated image. If you use `InferenceClient`, it will automatically decode to a `PIL` image for you:
```Python
sdxl = InferenceClient(model="stabilityai/stable-diffusion-xl-base-1.0", token=YOUR_TOKEN)
image = sdxl.text_to_image(
"Dark gothic city in a misty night, lit by street lamps. A man in a cape is walking away from us",
guidance_scale=9,
)
```

For more details on how to control generation, please take a look at [this section](#controlling-image-generation).
## Messages API
All text generation models now support the Messages API, so they are compatible with OpenAI client libraries, including LangChain and LlamaIndex. The following snippet shows how to use the official `openai` client library with Llama 3.1 70B:
```py
from openai import OpenAI
import huggingface_hub
# Initialize the client, pointing it to one of the available models
client = OpenAI(
base_url="https://api-inference.huggingface.co/v1/",
api_key=huggingface_hub.get_token(),
)
chat_completion = client.chat.completions.create(
model="meta-llama/Meta-Llama-3.1-70B-Instruct",
messages=[
{"role": "system", "content": "You are a helpful an honest programming assistant."},
{"role": "user", "content": "Is Rust better than Python?"},
],
stream=True,
max_tokens=500
)
# iterate and print stream
for message in chat_completion:
print(message.choices[0].delta.content, end="")
```
For more details about the use of the Messages API, please [check this post](https://huggingface.co/blog/tgi-messages-api).
## Generation Parameters
### Controlling Text Generation
Text generation is a rich topic, and there exist several generation strategies for different purposes. We recommend [this excellent overview](https://huggingface.co/blog/how-to-generate) on the subject. Many generation algorithms are supported by the text generation endpoints, and they can be configured using the following parameters:
- `do_sample`: If set to `False` (the default), the generation method will be _greedy search_, which selects the most probable continuation sequence after the prompt you provide. Greedy search is deterministic, so the same results will always be returned from the same input. When `do_sample` is `True`, tokens will be sampled from a probability distribution and will therefore vary across invocations.
- `temperature`: Controls the amount of variation we desire from the generation. A temperature of `0` is equivalent to greedy search. If we set a value for `temperature`, then `do_sample` will automatically be enabled. The same thing happens for `top_k` and `top_p`. When doing code-related tasks, we want less variability and hence recommend a low `temperature`. For other tasks, such as open-ended text generation, we recommend a higher one.
- `top_k`. Enables "Top-K" sampling: the model will choose from the `K` most probable tokens that may occur after the input sequence. Typical values are between 10 to 50.
- `top_p`. Enables "nucleus sampling": the model will choose from as many tokens as necessary to cover a particular probability mass. If `top_p` is 0.9, the 90% most probable tokens will be considered for sampling, and the trailing 10% will be ignored.
- `repetition_penalty`: Tries to avoid repeated words in the generated sequence.
- `seed`: Random seed that you can use in combination with sampling, for reproducibility purposes.
In addition to the sampling parameters above, you can also control general aspects of the generation with the following:
- `max_new_tokens`: maximum number of new tokens to generate. The default is `20`, feel free to increase if you want longer sequences.
- `return_full_text`: whether to include the input sequence in the output returned by the endpoint. The default used by `InferenceClient` is `False`, but the endpoint itself uses `True` by default.
- `stop_sequences`: a list of sequences that will cause generation to stop when encountered in the output.
### Controlling Image Generation
If you want finer-grained control over images generated with the SDXL endpoint, you can use the following parameters:
- `negative_prompt`: A text describing content that you want the model to steer _away_ from.
- `guidance_scale`: How closely you want the model to match the prompt. Lower numbers are less accurate, very high numbers might decrease image quality or generate artifacts.
- `width` and `height`: The desired image dimensions. SDXL works best for sizes between 768 and 1024.
- `num_inference_steps`: The number of denoising steps to run. Larger numbers may produce better quality but will be slower. Typical values are between 20 and 50 steps.
For additional details on text-to-image generation, we recommend you check the [diffusers library documentation](https://huggingface.co/docs/diffusers/using-diffusers/sdxl).
### Caching
If you run the same generation multiple times, you’ll see that the result returned by the API is the same (even if you are using sampling instead of greedy decoding). This is because recent results are cached. To force a different response each time, we can use an HTTP header to tell the server to run a new generation each time: `x-use-cache: 0`.
If you are using `InferenceClient`, you can simply append it to the `headers` client property:
```Python
client = InferenceClient(model="meta-llama/Meta-Llama-3-8b-Instruct", token=YOUR_TOKEN)
client.headers["x-use-cache"] = "0"
output = client.text_generation("In a surprising turn of events, ", do_sample=True)
print(output)
```
### Streaming
Token streaming is the mode in which the server returns the tokens one by one as the model generates them. This enables showing progressive generations to the user rather than waiting for the whole generation. Streaming is an essential aspect of the end-user experience as it reduces latency, one of the most critical aspects of a smooth experience.
<div class="flex justify-center">
<img
class="block dark:hidden"
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tgi/streaming-generation-visual_360.gif"
/>
<img
class="hidden dark:block"
src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/tgi/streaming-generation-visual-dark_360.gif"
/>
</div>
To stream tokens with `InferenceClient`, simply pass `stream=True` and iterate over the response.
```python
for token in client.text_generation("How do you make cheese?", max_new_tokens=12, stream=True):
print(token)
# To
# make
# cheese
#,
# you
# need
# to
# start
# with
# milk
```
To use the generate_stream endpoint with curl, you can add the `-N`/`--no-buffer` flag, which disables curl default buffering and shows data as it arrives from the server.
```
curl -N https://api-inference.huggingface.co/models/meta-llama/Meta-Llama-3-8b-Instruct \
-X POST \
-d '{"inputs": "In a surprising turn of events, ", "parameters": {"temperature": 0.7, "max_new_tokens": 100}}' \
-H "Content-Type: application/json" \
-H "Authorization: Bearer <YOUR_TOKEN>"
```
## Subscribe to PRO
You can sign up today for a PRO subscription [here](https://huggingface.co/subscribe/pro). Benefit from higher rate limits, custom accelerated endpoints for the latest models, and early access to features. If you've built some exciting projects with the Inference API or are looking for a model not available in Inference for PROs, please [use this discussion](https://huggingface.co/spaces/huggingface/HuggingDiscussions/discussions/13). [Enterprise users](https://huggingface.co/enterprise) also benefit from PRO Inference API on top of other features, such as SSO.
## FAQ
**Does this affect the free Inference API?**
No. We still expose thousands of models through free APIs that allow people to prototype and explore model capabilities quickly.
**Does this affect Enterprise users?**
Users with an Enterprise subscription also benefit from accelerated inference API for curated models.
**Can I use my own models with PRO Inference API?**
The free Inference API already supports a wide range of small and medium models from a variety of libraries (such as diffusers, transformers, and sentence transformers). If you have a custom model or custom inference logic, we recommend using [Inference Endpoints](https://ui.endpoints.huggingface.co/catalog).
| 6 |
0 | hf_public_repos | hf_public_repos/blog/pricing-update.md | ---
title: Introducing our new pricing
thumbnail: /blog/assets/114_pricing-update/thumbnail.png
authors:
- user: sbrandeis
- user: pierric
---
# Introducing our new pricing
As you might have noticed, our [pricing page](https://huggingface.co/pricing) has changed a lot recently.
First of all, we are sunsetting the Paid tier of the Inference API service. The Inference API will still be available for everyone to use for free. But if you're looking for a fast, enterprise-grade inference as a service, we recommend checking out our brand new solution for this: [Inference Endpoints](https://huggingface.co/inference-endpoints).
Along with Inference Endpoints, we've recently introduced hardware upgrades for [Spaces](https://huggingface.co/spaces/launch), which allows running ML demos with the hardware of your choice. No subscription is required to use these services; you only need to add a credit card to your account from your [billing settings](https://huggingface.co/settings/billing). You can also attach a payment method to any of [your organizations](https://huggingface.co/settings/organizations).
Your billing settings centralize everything about our paid services. From there, you can manage your personal PRO subscription, update your payment method, and visualize your usage for the past three months. Usage for all our paid services and subscriptions will be charged at the start of each month, and a consolidated invoice will be available for your records.
**TL;DR**: **At HF we monetize by providing simple access to compute for AI**, with services like AutoTrain, Spaces and Inference Endpoints, directly accessible from the Hub. [Read more](https://huggingface.co/docs/hub/billing) about our pricing and billing system.
If you have any questions, feel free to reach out. We welcome your feedback 🔥
| 7 |
0 | hf_public_repos | hf_public_repos/blog/optimum-onnxruntime-training.md | ---
title: "Optimum+ONNX Runtime - Easier, Faster training for your Hugging Face models"
thumbnail: /blog/assets/optimum_onnxruntime-training/thumbnail.png
authors:
- user: Jingya
- user: kshama-msft
guest: true
- user: askhade
guest: true
- user: weicwang
guest: true
- user: zhijiang
guest: true
---
# Optimum + ONNX Runtime: Easier, Faster training for your Hugging Face models
## Introduction
Transformer based models in language, vision and speech are getting larger to support complex multi-modal use cases for the end customer. Increasing model sizes directly impact the resources needed to train these models and scale them as the size increases. Hugging Face and Microsoft’s ONNX Runtime teams are working together to build advancements in finetuning large Language, Speech and Vision models. Hugging Face’s [Optimum library](https://huggingface.co/docs/optimum/index), through its integration with ONNX Runtime for training, provides an open solution to __improve training times by 35% or more__ for many popular Hugging Face models. We present details of both Hugging Face Optimum and the ONNX Runtime Training ecosystem, with performance numbers highlighting the benefits of using the Optimum library.
## Performance results
The chart below shows impressive acceleration __from 39% to 130%__ for Hugging Face models with Optimum when __using ONNX Runtime and DeepSpeed ZeRO Stage 1__ for training. The performance measurements were done on selected Hugging Face models with PyTorch as the baseline run, only ONNX Runtime for training as the second run, and ONNX Runtime + DeepSpeed ZeRO Stage 1 as the final run, showing maximum gains. The Optimizer used for the baseline PyTorch runs is the AdamW optimizer and the ORT Training runs use the Fused Adam Optimizer. The runs were performed on a single Nvidia A100 node with 8 GPUs.
<figure class="image table text-center m-0 w-full">
<img src="assets/optimum_onnxruntime-training/onnxruntime-training-benchmark.png" alt="Optimum-onnxruntime Training Benchmark"/>
</figure>
Additional details on configuration settings to turn on Optimum for training acceleration can be found [here](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/trainer). The version information used for these runs is as follows:
```
PyTorch: 1.14.0.dev20221103+cu116; ORT: 1.14.0.dev20221103001+cu116; DeepSpeed: 0.6.6; HuggingFace: 4.24.0.dev0; Optimum: 1.4.1.dev0; Cuda: 11.6.2
```
## Optimum Library
Hugging Face is a fast-growing open community and platform aiming to democratize good machine learning. We extended modalities from NLP to audio and vision, and now covers use cases across Machine Learning to meet our community's needs following the success of the [Transformers library](https://huggingface.co/docs/transformers/index). Now on [Hugging Face Hub](https://huggingface.co/models), there are more than 120K free and accessible model checkpoints for various machine learning tasks, 18K datasets, and 20K ML demo apps. However, scaling transformer models into production is still a challenge for the industry. Despite high accuracy, training and inference of transformer-based models can be time-consuming and expensive.
To target these needs, Hugging Face built two open-sourced libraries: __Accelerate__ and __Optimum__. While [🤗 Accelerate](https://huggingface.co/docs/accelerate/index) focuses on out-of-the-box distributed training, [🤗 Optimum](https://huggingface.co/docs/optimum/index), as an extension of transformers, accelerates model training and inference by leveraging the maximum efficiency of users’ targeted hardware. Optimum integrated machine learning accelerators like ONNX Runtime and specialized hardware like [Intel's Habana Gaudi](https://huggingface.co/blog/habana-gaudi-2-benchmark), so users can benefit from considerable speedup in both training and inference. Besides, Optimum seamlessly integrates other Hugging Face’s tools while inheriting the same ease of use as Transformers. Developers can easily adapt their work to achieve lower latency with less computing power.
## ONNX Runtime Training
[ONNX Runtime](https://onnxruntime.ai/) accelerates [large model training](https://onnxruntime.ai/docs/get-started/training-pytorch.html) to speed up throughput by up to 40% standalone, and 130% when composed with [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/) for popular HuggingFace transformer based models. ONNX Runtime is already integrated as part of Optimum and enables faster training through Hugging Face’s Optimum training framework.
ONNX Runtime Training achieves such throughput improvements via several memory and compute optimizations. The memory optimizations enable ONNX Runtime to maximize the batch size and utilize the available memory efficiently whereas the compute optimizations speed up the training time. These optimizations include, but are not limited to, efficient memory planning, kernel optimizations, multi tensor apply for Adam Optimizer (which batches the elementwise updates applied to all the model’s parameters into one or a few kernel launches), FP16 optimizer (which eliminates a lot of device to host memory copies), mixed precision training and graph optimizations like node fusions and node eliminations. ONNX Runtime Training supports both [NVIDIA](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/accelerate-pytorch-transformer-model-training-with-onnx-runtime/ba-p/2540471) and [AMD GPUs](https://cloudblogs.microsoft.com/opensource/2021/07/13/onnx-runtime-release-1-8-1-previews-support-for-accelerated-training-on-amd-gpus-with-the-amd-rocm-open-software-platform/), and offers extensibility with custom operators.
In short, it empowers AI developers to take full advantage of the ecosystem they are familiar with, like PyTorch and Hugging Face, and use acceleration from ONNX Runtime on the target device of their choice to save both time and resources.
## ONNX Runtime Training in Optimum
Optimum provides an `ORTTrainer` API that extends the `Trainer` in Transformers to use ONNX Runtime as the backend for acceleration. `ORTTrainer` is an easy-to-use API containing feature-complete training loop and evaluation loop. It supports features like hyperparameter search, mixed-precision training and distributed training with multiple GPUs. `ORTTrainer` enables AI developers to compose ONNX Runtime and other third-party acceleration techniques when training Transformers’ models, which helps accelerate the training further and gets the best out of the hardware. For example, developers can combine ONNX Runtime Training with distributed data parallel and mixed-precision training integrated in Transformers’ Trainer. Besides, `ORTTrainer` makes it easy to compose ONNX Runtime Training with DeepSpeed ZeRO-1, which saves memory by partitioning the optimizer states. After the pre-training or the fine-tuning is done, developers can either save the trained PyTorch model or convert it to the ONNX format with APIs that Optimum implemented for ONNX Runtime to ease the deployment for Inference. And just like `Trainer`, `ORTTrainer` has full integration with Hugging Face Hub: after the training, users can upload their model checkpoints to their Hugging Face Hub account.
So concretely, what should users do with Optimum to take advantage of the ONNX Runtime acceleration for training? If you are already using `Trainer`, you just need to adapt a few lines of code to benefit from all the improvements mentioned above. There are mainly two replacements that need to be applied. Firstly, replace `Trainer` with `ORTTrainer`, then replace `TrainingArguments` with `ORTTrainingArguments` which contains all the hyperparameters the trainer will use for training and evaluation. `ORTTrainingArguments` extends `TrainingArguments` to apply some extra arguments empowered by ONNX Runtime. For example, users can apply Fused Adam Optimizer for extra performance gain. Here is an example:
```diff
-from transformers import Trainer, TrainingArguments
+from optimum.onnxruntime import ORTTrainer, ORTTrainingArguments
# Step 1: Define training arguments
-training_args = TrainingArguments(
+training_args = ORTTrainingArguments(
output_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim = "adamw_ort_fused",
...
)
# Step 2: Create your ONNX Runtime Trainer
-trainer = Trainer(
+trainer = ORTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
+ feature="sequence-classification",
...
)
# Step 3: Use ONNX Runtime for training!🤗
trainer.train()
```
## Looking Forward
The Hugging Face team is working on open sourcing more large models and lowering the barrier for users to benefit from them with acceleration tools on both training and inference. We are collaborating with the ONNX Runtime training team to bring more training optimizations to newer and larger model architectures, including Whisper and Stable Diffusion. Microsoft has also packaged its state-of-the-art training acceleration technologies in the [Azure Container for PyTorch](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/enabling-deep-learning-with-azure-container-for-pytorch-in-azure/ba-p/3650489). This is a light-weight curated environment including DeepSpeed and ONNX Runtime to improve productivity for AI developers training with PyTorch. In addition to large model training, the ONNX Runtime training team is also building new solutions for learning on the edge – training on devices that are constrained on memory and power.
## Getting Started
We invite you to check out the links below to learn more about, and get started with, Optimum ONNX Runtime Training for your Hugging Face models.
* [Optimum ONNX Runtime Training Documentation](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/trainer)
* [Optimum ONNX Runtime Training Examples](https://github.com/huggingface/optimum/tree/main/examples/onnxruntime/training)
* [Optimum Github repo](https://github.com/huggingface/optimum/tree/main)
* [ONNX Runtime Training Examples](https://github.com/microsoft/onnxruntime-training-examples/)
* [ONNX Runtime Training Github repo](https://github.com/microsoft/onnxruntime/tree/main/orttraining)
* [ONNX Runtime](https://onnxruntime.ai/)
* [DeepSpeed](https://www.deepspeed.ai/) and [ZeRO](https://www.deepspeed.ai/tutorials/zero/) Tutorial
* [Azure Container for PyTorch](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/enabling-deep-learning-with-azure-container-for-pytorch-in-azure/ba-p/3650489)
---
🏎Thanks for reading! If you have any questions, feel free to reach us through [Github](https://github.com/huggingface/optimum/issues), or on the [forum](https://discuss.huggingface.co/c/optimum/). You can also connect with me on [Twitter](https://twitter.com/Jhuaplin) or [LinkedIn](https://www.linkedin.com/in/jingya-huang-96158b15b/). | 8 |
0 | hf_public_repos | hf_public_repos/blog/ray-rag.md | ---
title: "Retrieval Augmented Generation with Huggingface Transformers and Ray"
thumbnail: /blog/assets/12_ray_rag/ray_arch_updated.png
authors:
- user: ray-project
guest: true
---
# Retrieval Augmented Generation with Huggingface Transformers and Ray
##### A guest blog post by <a href="/amogkam">Amog Kamsetty</a> from the Anyscale team
[Huggingface Transformers](https://huggingface.co/) recently added the [Retrieval Augmented Generation (RAG)](https://twitter.com/huggingface/status/1310597560906780680) model, a new NLP architecture that leverages external documents (like Wikipedia) to augment its knowledge and achieve state of the art results on knowledge-intensive tasks. In this blog post, we introduce the integration of [Ray](https://docs.ray.io/en/master/), a library for building scalable applications, into the RAG contextual document retrieval mechanism. This speeds up retrieval calls by 2x and improves the scalability of RAG distributed [fine-tuning](https://github.com/huggingface/transformers/tree/master/examples/research_projects/rag).
### What is Retrieval Augmented Generation (RAG)?

_An overview of RAG. The model retrieves contextual documents from an external dataset as part of its execution. These contextual documents are used in conjunction with the original input to produce an output. The GIF is taken from [Facebook's original blog post](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models)._
Recently, [Huggingface](https://huggingface.co/) partnered with [Facebook AI](https://ai.facebook.com/) to introduce the [RAG](https://twitter.com/huggingface/status/1310597560906780680) model as part of its Transformers library.
[RAG](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/) acts just like any other [seq2seq model](https://blog.keras.io/a-ten-minute-introduction-to-sequence-to-sequence-learning-in-keras.html). However, [RAG](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/) has an intermediate component that retrieves contextual documents from an external knowledge base (like a Wikipedia text corpus). These documents are then used in conjunction with the input sequence and passed into the underlying seq2seq [generator](https://huggingface.co/blog/how-to-generate).
This information retrieval step allows [RAG](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models/) to make use of multiple sources of knowledge -- those that are baked into the model parameters and the information that is contained in the contextual passages, allowing it to outperform other state-of-the-art models in tasks like question answering. You can try it for yourself using this [demo provided by Huggingface](https://huggingface.co/rag/)!
### Scaling up fine-tuning
This retrieval of contextual documents is crucial for RAG's state-of-the-art results but introduces an extra layer of complexity. When scaling up the training process via a data-parallel training routine, a naive implementation of the document lookup can become a bottleneck for training. Further, the **document index** used in the retrieval component is often quite large, making it infeasible for each training worker to load its own replicated copy of the index.
The previous implementation of RAG fine-tuning leveraged the [torch.distributed](https://pytorch.org/docs/stable/distributed.html) communication package for the document retrieval portion. However, this implementation sometimes proved to be inflexible and limited in scalability.
Instead, a framework-agnostic and a more flexible implementation for ad-hoc concurrent programming is required. [Ray](https://ray.io/) fits the bill perfectly. Ray is a simple, yet powerful Python library for general-purpose distributed and parallel programming. Using Ray for distributed document retrieval, we achieved a **2x speedup per retrieval call compared to `torch.distributed`**, and overall better fine-tuning scalability.
### Ray for Document Retrieval

_Document retrieval with the torch.distributed implementation_
The main drawback of the [torch.distributed](https://pytorch.org/docs/stable/distributed.html) implementation for document retrieval was that it latched onto the same process group used for training and only the rank 0 training worker loaded the index into memory.
As a result, this implementation had some limitations:
1. **Synchronization bottleneck**: The rank 0 worker had to receive the inputs from all workers, perform the index query, and then send the results back to the other workers. This limited performance with multiple training workers.
2. **PyTorch specific**: The document retrieval process group had to latch onto the existing process group used for training, meaning that PyTorch had to be used for training as well.

_Document retrieval with the Ray implementation_
To overcome these limitations, we introduced a novel implementation of distributed retrieval based on Ray. With [Ray’s stateful actor abstractions](https://docs.ray.io/en/master/actors.html), multiple processes that are separate from the training processes are used to load the index and handle the retrieval queries. With multiple Ray actors, retrieval is no longer a bottleneck and PyTorch is no longer a requirement for RAG.
And as you can see below, using the [Ray](https://docs.ray.io/en/master/) based implementation leads to better retrieval performance for multi-GPU fine-tuning. The following results show the seconds per retrieval call and we can see that as we increase the number of GPUs that we train on, using Ray has comparatively better performance than `torch.distributed`. Also, if we increase the number of Ray processes that perform retrieval, we also get better performance with more training workers since a single retrieval process is no longer a bottleneck.
<table>
<tr>
<td>
</td>
<td>2 GPU
</td>
<td>3 GPU
</td>
<td>4 GPU
</td>
</tr>
<tr>
<td>torch.distributed
</td>
<td>2.12 sec/retrieval
</td>
<td>2.62 sec/retrieve
</td>
<td>3.438 sec/retrieve
</td>
</tr>
<tr>
<td>Ray 2 retrieval processes
</td>
<td>1.49 sec/retrieve
</td>
<td>1.539 sec/retrieve
</td>
<td>2.029 sec/retrieve
</td>
</tr>
<tr>
<td>Ray 4 retrieval processes
</td>
<td>1.145 sec/retrieve
</td>
<td>1.484 sec/retrieve
</td>
<td>1.66 sec/retrieve
</td>
</tr>
</table>
_A performance comparison of different retrieval implementations. For each document retrieval implementation, we run 500 training steps with a per-GPU batch size of 8, and measure the time it takes to retrieve the contextual documents for each batch on the rank 0 training worker. As the results show, using multiple retrieval processes improves performance, especially as we scale training to multiple GPUs._
### How do I use it?
[Huggingface](https://huggingface.co/) provides a [PyTorch Lightning](https://github.com/PyTorchLightning/pytorch-lightning) based [fine tuning script](https://github.com/huggingface/transformers/tree/master/examples/research_projects/rag), and we extended it to add the Ray retrieval implementation as an option.
To try it out, first install the necessary requirements
```bash
pip install ray
pip install transformers
pip install -r transformers/examples/research_projects/rag/requirements.txt
```
Then, you can specify your data paths and other configurations and run [finetune-rag-ray.sh](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag/finetune_rag_ray.sh)!
```bash
# Sample script to finetune RAG using Ray for distributed retrieval.
# Add parent directory to python path to access lightning_base.py
export PYTHONPATH="../":"${PYTHONPATH}"
# Start a single-node Ray cluster.
ray start --head
# A sample finetuning run, you need to specify data_dir, output_dir and model_name_or_path
# run ./examples/rag/finetune_rag_ray.sh --help to see all the possible options
python examples/rag/finetune_rag.py \
--data_dir $DATA_DIR \
--output_dir $OUTPUT_DIR \
--model_name_or_path $MODEL_NAME_OR_PATH \
--model_type rag_sequence \
--fp16 \
--gpus 8 \
--profile \
--do_train \
--do_predict \
--n_val -1 \
--train_batch_size 8 \
--eval_batch_size 1 \
--max_source_length 128 \
--max_target_length 25 \
--val_max_target_length 25 \
--test_max_target_length 25 \
--label_smoothing 0.1 \
--dropout 0.1 \
--attention_dropout 0.1 \
--weight_decay 0.001 \
--adam_epsilon 1e-08 \
--max_grad_norm 0.1 \
--lr_scheduler polynomial \
--learning_rate 3e-05 \
--num_train_epochs 100 \
--warmup_steps 500 \
--gradient_accumulation_steps 1 \
--distributed_retriever ray \
--num_retrieval_workers 4
# Stop the Ray cluster.
ray stop
```
## What’s next?
Using RAG with [Huggingface transformers](https://github.com/huggingface/transformers/tree/master/examples/research_projects/rag) and the [Ray retrieval implementation](https://github.com/huggingface/transformers/blob/master/examples/research_projects/rag/finetune_rag_ray.sh) for faster distributed fine-tuning, you can leverage RAG for retrieval-based generation on your own knowledge-intensive tasks.
Also, hyperparameter tuning is another aspect of transformer fine tuning and can have [huge impacts on accuracy](https://medium.com/distributed-computing-with-ray/hyperparameter-optimization-for-transformers-a-guide-c4e32c6c989b). For scalable and easy hyperparameter tuning, check out the [Ray Tune](https://docs.ray.io/en/latest/tune/) library. By using [Ray Tune’s integration with PyTorch Lightning](https://medium.com/distributed-computing-with-ray/scaling-up-pytorch-lightning-hyperparameter-tuning-with-ray-tune-4bd9e1ff9929), or the [built-in integration with Huggingface transformers](https://huggingface.co/blog/ray-tune), you can run experiments to find the perfect hyperparameters for your RAG model.
And lastly, stay tuned for a potential Tensorflow implementation of [RAG](https://ai.facebook.com/blog/retrieval-augmented-generation-streamlining-the-creation-of-intelligent-natural-language-processing-models) on [Huggingface](https://huggingface.co/)!
If you plan to try RAG+Ray integration out, please feel free to share your experiences on the [Ray Discourse](https://discuss.ray.io/) or join the [Ray community Slack](https://docs.google.com/forms/d/e/1FAIpQLSfAcoiLCHOguOm8e7Jnn-JJdZaCxPGjgVCvFijHB5PLaQLeig/viewform) for further discussion -- we’d love to hear from you!
> Also published at https://medium.com/distributed-computing-with-ray/retrieval-augmented-generation-with-huggingface-transformers-and-ray-b09b56161b1e
| 9 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/Dockerfile.app | FROM huggingface/autotrain-advanced:latest
CMD uvicorn autotrain.app:app --host 0.0.0.0 --port 7860 --reload --workers 4
| 0 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/README.md | # 🤗 AutoTrain Advanced
AutoTrain Advanced: faster and easier training and deployments of state-of-the-art machine learning models. AutoTrain Advanced is a no-code solution that allows you to train machine learning models in just a few clicks. Please note that you must upload data in correct format for project to be created. For help regarding proper data format and pricing, check out the documentation.
NOTE: AutoTrain is free! You only pay for the resources you use in case you decide to run AutoTrain on Hugging Face Spaces. When running locally, you only pay for the resources you use on your own infrastructure.
## Supported Tasks
| Task | Status | Python Notebook | Example Configs |
| --- | --- | --- | --- |
| LLM SFT Finetuning | ✅ | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/notebooks/llm_finetuning.ipynb) | [llm_sft_finetune.yaml](https://github.com/huggingface/autotrain-advanced/blob/main/configs/llm_finetuning/smollm2.yml) |
| LLM ORPO Finetuning | ✅ | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/notebooks/llm_finetuning.ipynb) | [llm_orpo_finetune.yaml](https://github.com/huggingface/autotrain-advanced/blob/main/configs/llm_finetuning/llama3-8b-orpo.yml) |
| LLM DPO Finetuning | ✅ | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/notebooks/llm_finetuning.ipynb) | [llm_dpo_finetune.yaml](https://github.com/huggingface/autotrain-advanced/blob/main/configs/llm_finetuning/llama3-8b-dpo-qlora.yml) |
| LLM Reward Finetuning | ✅ | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/notebooks/llm_finetuning.ipynb) | [llm_reward_finetune.yaml](https://github.com/huggingface/autotrain-advanced/blob/main/configs/llm_finetuning/llama32-1b-sft.yml) |
| LLM Generic/Default Finetuning | ✅ | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/notebooks/llm_finetuning.ipynb) | [llm_generic_finetune.yaml](https://github.com/huggingface/autotrain-advanced/blob/main/configs/llm_finetuning/gpt2_sft.yml) |
| Text Classification | ✅ | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/notebooks/text_classification.ipynb) | [text_classification.yaml](https://github.com/huggingface/autotrain-advanced/tree/main/configs/text_classification) |
| Text Regression | ✅ | [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/notebooks/text_regression.ipynb) | [text_regression.yaml](https://github.com/huggingface/autotrain-advanced/tree/main/configs/text_regression) |
| Token Classification | ✅ | Coming Soon | [token_classification.yaml](https://github.com/huggingface/autotrain-advanced/tree/main/configs/token_classification) |
| Seq2Seq | ✅ | Coming Soon | [seq2seq.yaml](https://github.com/huggingface/autotrain-advanced/tree/main/configs/seq2seq) |
| Extractive Question Answering | ✅ | Coming Soon | [extractive_qa.yaml](https://github.com/huggingface/autotrain-advanced/tree/main/configs/extractive_question_answering) |
| Image Classification | ✅ | Coming Soon | [image_classification.yaml](https://github.com/huggingface/autotrain-advanced/tree/main/configs/image_classification) |
| Image Scoring/Regression | ✅ | Coming Soon | [image_regression.yaml](https://github.com/huggingface/autotrain-advanced/tree/main/configs/image_scoring) |
| VLM | 🟥 | Coming Soon | [vlm.yaml](https://github.com/huggingface/autotrain-advanced/tree/main/configs/vlm) |
## Running UI on Colab or Hugging Face Spaces
- Deploy AutoTrain on Hugging Face Spaces: [](https://huggingface.co/login?next=%2Fspaces%2Fautotrain-projects%2Fautotrain-advanced%3Fduplicate%3Dtrue)
- Run AutoTrain UI on Colab via ngrok: [](https://colab.research.google.com/github/huggingface/autotrain-advanced/blob/main/colabs/AutoTrain_ngrok.ipynb)
## Local Installation
You can Install AutoTrain-Advanced python package via PIP. Please note you will need python >= 3.10 for AutoTrain Advanced to work properly.
pip install autotrain-advanced
Please make sure that you have git lfs installed. Check out the instructions here: https://github.com/git-lfs/git-lfs/wiki/Installation
You also need to install torch, torchaudio and torchvision.
The best way to run autotrain is in a conda environment. You can create a new conda environment with the following command:
conda create -n autotrain python=3.10
conda activate autotrain
pip install autotrain-advanced
conda install pytorch torchvision torchaudio pytorch-cuda=12.1 -c pytorch -c nvidia
conda install -c "nvidia/label/cuda-12.1.0" cuda-nvcc
Once done, you can start the application using:
autotrain app --port 8080 --host 127.0.0.1
If you are not fond of UI, you can use AutoTrain Configs to train using command line or simply AutoTrain CLI.
To use config file for training, you can use the following command:
autotrain --config <path_to_config_file>
You can find sample config files in the `configs` directory of this repository.
Example config file for finetuning SmolLM2:
```yaml
task: llm-sft
base_model: HuggingFaceTB/SmolLM2-1.7B-Instruct
project_name: autotrain-smollm2-finetune
log: tensorboard
backend: local
data:
path: HuggingFaceH4/no_robots
train_split: train
valid_split: null
chat_template: tokenizer
column_mapping:
text_column: messages
params:
block_size: 2048
model_max_length: 4096
epochs: 2
batch_size: 1
lr: 1e-5
peft: true
quantization: int4
target_modules: all-linear
padding: right
optimizer: paged_adamw_8bit
scheduler: linear
gradient_accumulation: 8
mixed_precision: bf16
merge_adapter: true
hub:
username: ${HF_USERNAME}
token: ${HF_TOKEN}
push_to_hub: true
```
To fine-tune a model using the config file above, you can use the following command:
```bash
$ export HF_USERNAME=<your_hugging_face_username>
$ export HF_TOKEN=<your_hugging_face_write_token>
$ autotrain --config <path_to_config_file>
```
## Documentation
Documentation is available at https://hf.co/docs/autotrain/
## Citation
```
@inproceedings{thakur-2024-autotrain,
title = "{A}uto{T}rain: No-code training for state-of-the-art models",
author = "Thakur, Abhishek",
booktitle = "Proceedings of the 2024 Conference on Empirical Methods in Natural Language Processing: System Demonstrations",
month = nov,
year = "2024",
address = "Miami, Florida, USA",
publisher = "Association for Computational Linguistics",
url = "https://aclanthology.org/2024.emnlp-demo.44",
pages = "419--423",
abstract = "With the advancements in open-source models, training(or finetuning) models on custom datasets has become a crucial part of developing solutions which are tailored to specific industrial or open-source applications. Yet, there is no single tool which simplifies the process of training across different types of modalities or tasks.We introduce AutoTrain(aka AutoTrain Advanced){---}an open-source, no code tool/library which can be used to train (or finetune) models for different kinds of tasks such as: large language model (LLM) finetuning, text classification/regression, token classification, sequence-to-sequence task, finetuning of sentence transformers, visual language model (VLM) finetuning, image classification/regression and even classification and regression tasks on tabular data. AutoTrain Advanced is an open-source library providing best practices for training models on custom datasets. The library is available at https://github.com/huggingface/autotrain-advanced. AutoTrain can be used in fully local mode or on cloud machines and works with tens of thousands of models shared on Hugging Face Hub and their variations.",
}
```
| 1 |
0 | hf_public_repos | hf_public_repos/autotrain-advanced/Dockerfile.api | FROM huggingface/autotrain-advanced:latest
CMD autotrain api --port 7860 --host 0.0.0.0 | 2 |
0 | hf_public_repos/autotrain-advanced | hf_public_repos/autotrain-advanced/colabs/AutoTrain_ngrok.ipynb | #@title 🤗 AutoTrain
#@markdown In order to use this colab
#@markdown - Enter your [Hugging Face Write Token](https://huggingface.co/settings/tokens)
#@markdown - Enter your [ngrok auth token](https://dashboard.ngrok.com/get-started/your-authtoken)
huggingface_token = '' # @param {type:"string"}
ngrok_token = "" # @param {type:"string"}
#@markdown
#@markdown - Attach appropriate accelerator `Runtime > Change runtime type > Hardware accelerator`
#@markdown - click `Runtime > Run all`
#@markdown - Follow the link to access the UI
#@markdown - Training happens inside this Google Colab
#@markdown - report issues / feature requests [here](https://github.com/huggingface/autotrain-advanced/issues)
import os
os.environ["HF_TOKEN"] = str(huggingface_token)
os.environ["NGROK_AUTH_TOKEN"] = str(ngrok_token)
os.environ["AUTOTRAIN_LOCAL"] = "1"
!pip install -U autotrain-advanced > install_logs.txt 2>&1
!autotrain app --share | 3 |
0 | hf_public_repos/autotrain-advanced | hf_public_repos/autotrain-advanced/colabs/AutoTrain_LLM.ipynb | #@title 🤗 AutoTrain LLM
#@markdown In order to use this colab
#@markdown - upload train.csv to a folder named `data/`
#@markdown - train.csv must contain a `text` column
#@markdown - choose a project name if you wish
#@markdown - change model if you wish, you can use most of the text-generation models from Hugging Face Hub
#@markdown - add huggingface information (token) if you wish to push trained model to huggingface hub
#@markdown - update hyperparameters if you wish
#@markdown - click `Runtime > Run all` or run each cell individually
#@markdown - report issues / feature requests here: https://github.com/huggingface/autotrain-advanced/issues
import os
!pip install -U autotrain-advanced > install_logs.txt 2>&1
!autotrain setup --colab > setup_logs.txt
from autotrain import __version__
print(f'AutoTrain version: {__version__}')#@markdown ---
#@markdown #### Project Config
#@markdown Note: if you are using a restricted/private model, you need to enter your Hugging Face token in the next step.
project_name = 'my-autotrain-llm' # @param {type:"string"}
model_name = 'abhishek/llama-2-7b-hf-small-shards' # @param {type:"string"}
#@markdown ---
#@markdown #### Push to Hub?
#@markdown Use these only if you want to push your trained model to a private repo in your Hugging Face Account
#@markdown If you dont use these, the model will be saved in Google Colab and you are required to download it manually.
#@markdown Please enter your Hugging Face write token. The trained model will be saved to your Hugging Face account.
#@markdown You can find your token here: https://huggingface.co/settings/tokens
push_to_hub = False # @param ["False", "True"] {type:"raw"}
hf_token = "hf_XXX" #@param {type:"string"}
hf_username = "abc" #@param {type:"string"}
#@markdown ---
#@markdown #### Hyperparameters
unsloth = False # @param ["False", "True"] {type:"raw"}
learning_rate = 2e-4 # @param {type:"number"}
num_epochs = 1 #@param {type:"number"}
batch_size = 1 # @param {type:"slider", min:1, max:32, step:1}
block_size = 1024 # @param {type:"number"}
trainer = "sft" # @param ["generic", "sft"] {type:"string"}
warmup_ratio = 0.1 # @param {type:"number"}
weight_decay = 0.01 # @param {type:"number"}
gradient_accumulation = 4 # @param {type:"number"}
mixed_precision = "fp16" # @param ["fp16", "bf16", "none"] {type:"string"}
peft = True # @param ["False", "True"] {type:"raw"}
quantization = "int4" # @param ["int4", "int8", "none"] {type:"string"}
lora_r = 16 #@param {type:"number"}
lora_alpha = 32 #@param {type:"number"}
lora_dropout = 0.05 #@param {type:"number"}
os.environ["HF_TOKEN"] = hf_token
os.environ["HF_USERNAME"] = hf_username
conf = f"""
task: llm-{trainer}
base_model: {model_name}
project_name: {project_name}
log: tensorboard
backend: local
data:
path: data/
train_split: train
valid_split: null
chat_template: null
column_mapping:
text_column: text
params:
block_size: {block_size}
lr: {learning_rate}
warmup_ratio: {warmup_ratio}
weight_decay: {weight_decay}
epochs: {num_epochs}
batch_size: {batch_size}
gradient_accumulation: {gradient_accumulation}
mixed_precision: {mixed_precision}
peft: {peft}
quantization: {quantization}
lora_r: {lora_r}
lora_alpha: {lora_alpha}
lora_dropout: {lora_dropout}
unsloth: {unsloth}
hub:
username: ${{HF_USERNAME}}
token: ${{HF_TOKEN}}
push_to_hub: {push_to_hub}
"""
with open("conf.yaml", "w") as f:
f.write(conf) | 4 |
0 | hf_public_repos/autotrain-advanced | hf_public_repos/autotrain-advanced/colabs/image_classification.ipynb | %%writefile config.yml
task: image_classification # do not change
base_model: google/vit-base-patch16-224 # the model to be used from hugging face hub
project_name: autotrain-image-classification-model # the name of the project, must be unique
log: tensorboard # do not change
backend: local # do not change
data:
path: data/ # the path to the data folder, this folder consists of `train` and `valid` (if any) folders
train_split: train # this folder inside data/ will be used for training, it contains the images in subfolders.
valid_split: null # this folder inside data/ will be used for validation, it contains the images in subfolders. If not available, set it to null
column_mapping: # do not change
image_column: image
target_column: labels
params:
epochs: 2
batch_size: 4
lr: 2e-5
optimizer: adamw_torch
scheduler: linear
gradient_accumulation: 1
mixed_precision: fp16
hub:
username: ${HF_USERNAME} # please set HF_USERNAME in colab secrets
token: ${HF_TOKEN} # please set HF_TOKEN in colab secrets, must be valid hugging face write token
push_to_hub: true # set to true if you want to push the model to the hubimport os
from google.colab import userdata
HF_USERNAME = userdata.get('HF_USERNAME')
HF_TOKEN = userdata.get('HF_TOKEN')
os.environ['HF_USERNAME'] = HF_USERNAME
os.environ['HF_TOKEN'] = HF_TOKEN
!autotrain --config config.yml | 5 |
0 | hf_public_repos/autotrain-advanced | hf_public_repos/autotrain-advanced/notebooks/text_classification.ipynb | from autotrain.params import TextClassificationParams
from autotrain.project import AutoTrainProjectHF_USERNAME = "your_huggingface_username"
HF_TOKEN = "your_huggingface_write_token" # get it from https://huggingface.co/settings/token
# It is recommended to use secrets or environment variables to store your HF_TOKEN
# your token is required if push_to_hub is set to True or if you are accessing a gated model/datasetparams = TextClassificationParams(
model="google-bert/bert-base-uncased",
data_path="stanfordnlp/imdb", # path to the dataset on huggingface hub
text_column="text", # the column in the dataset that contains the text
target_column="label", # the column in the dataset that contains the labels
train_split="train",
valid_split="test",
epochs=3,
batch_size=8,
max_seq_length=512,
lr=1e-5,
optimizer="adamw_torch",
scheduler="linear",
gradient_accumulation=1,
mixed_precision="fp16",
project_name="autotrain-model",
log="tensorboard",
push_to_hub=True,
username=HF_USERNAME,
token=HF_TOKEN,
)
# tip: you can use `?TextClassificationParams` to see the full list of allowed parameters# this will train the model locally
project = AutoTrainProject(params=params, backend="local", process=True)
project.create() | 6 |
0 | hf_public_repos/autotrain-advanced | hf_public_repos/autotrain-advanced/notebooks/llm_finetuning.ipynb | from autotrain.params import LLMTrainingParams
from autotrain.project import AutoTrainProjectHF_USERNAME = "your_huggingface_username"
HF_TOKEN = "your_huggingface_write_token" # get it from https://huggingface.co/settings/token
# It is recommended to use secrets or environment variables to store your HF_TOKEN
# your token is required if push_to_hub is set to True or if you are accessing a gated model/datasetparams = LLMTrainingParams(
model="meta-llama/Llama-3.2-1B-Instruct",
data_path="HuggingFaceH4/no_robots", # path to the dataset on huggingface hub
chat_template="tokenizer", # using the chat template defined in the model's tokenizer
text_column="messages", # the column in the dataset that contains the text
train_split="train",
trainer="sft", # using the SFT trainer, choose from sft, default, orpo, dpo and reward
epochs=3,
batch_size=1,
lr=1e-5,
peft=True, # training LoRA using PEFT
quantization="int4", # using int4 quantization
target_modules="all-linear",
padding="right",
optimizer="paged_adamw_8bit",
scheduler="cosine",
gradient_accumulation=8,
mixed_precision="bf16",
merge_adapter=True,
project_name="autotrain-llama32-1b-finetune",
log="tensorboard",
push_to_hub=True,
username=HF_USERNAME,
token=HF_TOKEN,
)# this will train the model locally
project = AutoTrainProject(params=params, backend="local", process=True)
project.create() | 7 |
0 | hf_public_repos/autotrain-advanced | hf_public_repos/autotrain-advanced/notebooks/text_regression.ipynb | from autotrain.params import TextRegressionParams
from autotrain.project import AutoTrainProjectHF_USERNAME = "your_huggingface_username"
HF_TOKEN = "your_huggingface_write_token" # get it from https://huggingface.co/settings/token
# It is recommended to use secrets or environment variables to store your HF_TOKEN
# your token is required if push_to_hub is set to True or if you are accessing a gated model/datasetparams = TextRegressionParams(
model="google-bert/bert-base-uncased",
data_path="lewtun/drug-reviews", # path to the dataset on huggingface hub
text_column="review", # the column in the dataset that contains the text
target_column="rating", # the column in the dataset that contains the labels
train_split="train",
valid_split="test",
epochs=3,
batch_size=8,
max_seq_length=512,
lr=1e-5,
optimizer="adamw_torch",
scheduler="linear",
gradient_accumulation=1,
mixed_precision="fp16",
project_name="autotrain-model",
log="tensorboard",
push_to_hub=True,
username=HF_USERNAME,
token=HF_TOKEN,
)
# tip: you can use `?TextClassificationParams` to see the full list of allowed parameters# this will train the model locally
project = AutoTrainProject(params=params, backend="local", process=True)
project.create() | 8 |
0 | hf_public_repos/autotrain-advanced/src | hf_public_repos/autotrain-advanced/src/autotrain/utils.py | import json
import os
import subprocess
from autotrain.commands import launch_command
from autotrain.trainers.clm.params import LLMTrainingParams
from autotrain.trainers.extractive_question_answering.params import ExtractiveQuestionAnsweringParams
from autotrain.trainers.generic.params import GenericParams
from autotrain.trainers.image_classification.params import ImageClassificationParams
from autotrain.trainers.image_regression.params import ImageRegressionParams
from autotrain.trainers.object_detection.params import ObjectDetectionParams
from autotrain.trainers.sent_transformers.params import SentenceTransformersParams
from autotrain.trainers.seq2seq.params import Seq2SeqParams
from autotrain.trainers.tabular.params import TabularParams
from autotrain.trainers.text_classification.params import TextClassificationParams
from autotrain.trainers.text_regression.params import TextRegressionParams
from autotrain.trainers.token_classification.params import TokenClassificationParams
from autotrain.trainers.vlm.params import VLMTrainingParams
ALLOW_REMOTE_CODE = os.environ.get("ALLOW_REMOTE_CODE", "true").lower() == "true"
def run_training(params, task_id, local=False, wait=False):
"""
Run the training process based on the provided parameters and task ID.
Args:
params (str): JSON string of the parameters required for training.
task_id (int): Identifier for the type of task to be performed.
local (bool, optional): Flag to indicate if the training should be run locally. Defaults to False.
wait (bool, optional): Flag to indicate if the function should wait for the process to complete. Defaults to False.
Returns:
int: Process ID of the launched training process.
Raises:
NotImplementedError: If the task_id does not match any of the predefined tasks.
"""
params = json.loads(params)
if isinstance(params, str):
params = json.loads(params)
if task_id == 9:
params = LLMTrainingParams(**params)
elif task_id == 28:
params = Seq2SeqParams(**params)
elif task_id in (1, 2):
params = TextClassificationParams(**params)
elif task_id in (13, 14, 15, 16, 26):
params = TabularParams(**params)
elif task_id == 27:
params = GenericParams(**params)
elif task_id == 18:
params = ImageClassificationParams(**params)
elif task_id == 4:
params = TokenClassificationParams(**params)
elif task_id == 10:
params = TextRegressionParams(**params)
elif task_id == 29:
params = ObjectDetectionParams(**params)
elif task_id == 30:
params = SentenceTransformersParams(**params)
elif task_id == 24:
params = ImageRegressionParams(**params)
elif task_id == 31:
params = VLMTrainingParams(**params)
elif task_id == 5:
params = ExtractiveQuestionAnsweringParams(**params)
else:
raise NotImplementedError
params.save(output_dir=params.project_name)
cmd = launch_command(params=params)
cmd = [str(c) for c in cmd]
env = os.environ.copy()
process = subprocess.Popen(cmd, env=env)
if wait:
process.wait()
return process.pid
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.