
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_text_classification.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.text_classification.params import TextClassificationParams
from . import BaseAutoTrainCommand
def run_text_classification_command_factory(args):
return RunAutoTrainTextClassificationCommand(args)
class RunAutoTrainTextClassificationCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(TextClassificationParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
arg_list = [arg for arg in arg_list if arg["arg"] != "--disable-gradient-checkpointing"]
run_text_classification_parser = parser.add_parser(
"text-classification", description="✨ Run AutoTrain Text Classification"
)
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_text_classification_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_text_classification_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_text_classification_parser.set_defaults(func=run_text_classification_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"auto_find_batch_size",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
def run(self):
logger.info("Running Text Classification")
if self.args.train:
params = TextClassificationParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 0 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_token_classification.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.token_classification.params import TokenClassificationParams
from . import BaseAutoTrainCommand
def run_token_classification_command_factory(args):
return RunAutoTrainTokenClassificationCommand(args)
class RunAutoTrainTokenClassificationCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(TokenClassificationParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
arg_list = [arg for arg in arg_list if arg["arg"] != "--disable-gradient-checkpointing"]
run_token_classification_parser = parser.add_parser(
"token-classification", description="✨ Run AutoTrain Token Classification"
)
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_token_classification_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_token_classification_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_token_classification_parser.set_defaults(func=run_token_classification_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"auto_find_batch_size",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
def run(self):
logger.info("Running Token Classification")
if self.args.train:
params = TokenClassificationParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 1 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_setup.py | import subprocess
from argparse import ArgumentParser
from autotrain import logger
from . import BaseAutoTrainCommand
def run_app_command_factory(args):
return RunSetupCommand(args.update_torch, args.colab)
class RunSetupCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
run_setup_parser = parser.add_parser(
"setup",
description="✨ Run AutoTrain setup",
)
run_setup_parser.add_argument(
"--update-torch",
action="store_true",
help="Update PyTorch to latest version",
)
run_setup_parser.add_argument(
"--colab",
action="store_true",
help="Run setup for Google Colab",
)
run_setup_parser.set_defaults(func=run_app_command_factory)
def __init__(self, update_torch: bool, colab: bool = False):
self.update_torch = update_torch
self.colab = colab
def run(self):
if self.colab:
cmd = "pip install -U xformers==0.0.24"
else:
cmd = "pip uninstall -y xformers"
cmd = cmd.split()
pipe = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
logger.info("Installing latest xformers")
_, _ = pipe.communicate()
logger.info("Successfully installed latest xformers")
if self.update_torch:
cmd = "pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121"
cmd = cmd.split()
pipe = subprocess.Popen(cmd, stdout=subprocess.PIPE, stderr=subprocess.PIPE)
logger.info("Installing latest PyTorch")
_, _ = pipe.communicate()
logger.info("Successfully installed latest PyTorch")
| 2 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_sent_tranformers.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.sent_transformers.params import SentenceTransformersParams
from . import BaseAutoTrainCommand
def run_sentence_transformers_command_factory(args):
return RunAutoTrainSentenceTransformersCommand(args)
class RunAutoTrainSentenceTransformersCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(SentenceTransformersParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
run_sentence_transformers_parser = parser.add_parser(
"sentence-transformers", description="✨ Run AutoTrain Sentence Transformers"
)
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_sentence_transformers_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_sentence_transformers_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_sentence_transformers_parser.set_defaults(func=run_sentence_transformers_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"auto_find_batch_size",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
if self.args.backend.startswith("spaces") or self.args.backend.startswith("ep-"):
if not self.args.push_to_hub:
raise ValueError("Push to hub must be specified for spaces backend")
if self.args.username is None:
raise ValueError("Username must be specified for spaces backend")
if self.args.token is None:
raise ValueError("Token must be specified for spaces backend")
def run(self):
logger.info("Running Sentence Transformers...")
if self.args.train:
params = SentenceTransformersParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 3 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_tabular.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.tabular.params import TabularParams
from . import BaseAutoTrainCommand
def run_tabular_command_factory(args):
return RunAutoTrainTabularCommand(args)
class RunAutoTrainTabularCommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(TabularParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend",
"required": False,
"type": str,
"default": "local",
},
] + arg_list
remove_args = ["--disable_gradient_checkpointing", "--gradient_accumulation", "--epochs", "--log", "--lr"]
arg_list = [arg for arg in arg_list if arg["arg"] not in remove_args]
run_tabular_parser = parser.add_parser("tabular", description="✨ Run AutoTrain Tabular Data Training")
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_tabular_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_tabular_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_tabular_parser.set_defaults(func=run_tabular_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
self.args.target_columns = [k.strip() for k in self.args.target_columns.split(",")]
def run(self):
logger.info("Running Tabular Training")
if self.args.train:
params = TabularParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 4 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/cli/run_extractive_qa.py | from argparse import ArgumentParser
from autotrain import logger
from autotrain.cli.utils import get_field_info
from autotrain.project import AutoTrainProject
from autotrain.trainers.extractive_question_answering.params import ExtractiveQuestionAnsweringParams
from . import BaseAutoTrainCommand
def run_extractive_qa_command_factory(args):
return RunAutoTrainExtractiveQACommand(args)
class RunAutoTrainExtractiveQACommand(BaseAutoTrainCommand):
@staticmethod
def register_subcommand(parser: ArgumentParser):
arg_list = get_field_info(ExtractiveQuestionAnsweringParams)
arg_list = [
{
"arg": "--train",
"help": "Command to train the model",
"required": False,
"action": "store_true",
},
{
"arg": "--deploy",
"help": "Command to deploy the model (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--inference",
"help": "Command to run inference (limited availability)",
"required": False,
"action": "store_true",
},
{
"arg": "--backend",
"help": "Backend to use for training",
"required": False,
"default": "local",
},
] + arg_list
arg_list = [arg for arg in arg_list if arg["arg"] != "--disable-gradient-checkpointing"]
run_extractive_qa_parser = parser.add_parser(
"extractive-qa", description="✨ Run AutoTrain Extractive Question Answering"
)
for arg in arg_list:
names = [arg["arg"]] + arg.get("alias", [])
if "action" in arg:
run_extractive_qa_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
action=arg.get("action"),
default=arg.get("default"),
)
else:
run_extractive_qa_parser.add_argument(
*names,
dest=arg["arg"].replace("--", "").replace("-", "_"),
help=arg["help"],
required=arg.get("required", False),
type=arg.get("type"),
default=arg.get("default"),
choices=arg.get("choices"),
)
run_extractive_qa_parser.set_defaults(func=run_extractive_qa_command_factory)
def __init__(self, args):
self.args = args
store_true_arg_names = [
"train",
"deploy",
"inference",
"auto_find_batch_size",
"push_to_hub",
]
for arg_name in store_true_arg_names:
if getattr(self.args, arg_name) is None:
setattr(self.args, arg_name, False)
if self.args.train:
if self.args.project_name is None:
raise ValueError("Project name must be specified")
if self.args.data_path is None:
raise ValueError("Data path must be specified")
if self.args.model is None:
raise ValueError("Model must be specified")
if self.args.push_to_hub:
if self.args.username is None:
raise ValueError("Username must be specified for push to hub")
else:
raise ValueError("Must specify --train, --deploy or --inference")
def run(self):
logger.info("Running Extractive Question Answering")
if self.args.train:
params = ExtractiveQuestionAnsweringParams(**vars(self.args))
project = AutoTrainProject(params=params, backend=self.args.backend, process=True)
job_id = project.create()
logger.info(f"Job ID: {job_id}")
| 5 |
0 | hf_public_repos/autotrain-advanced/src/autotrain | hf_public_repos/autotrain-advanced/src/autotrain/trainers/common.py | """
Common classes and functions for all trainers.
"""
import json
import os
import shutil
import time
import traceback
import requests
from accelerate import PartialState
from huggingface_hub import HfApi
from pydantic import BaseModel
from transformers import TrainerCallback, TrainerControl, TrainerState, TrainingArguments
from autotrain import is_colab, logger
ALLOW_REMOTE_CODE = os.environ.get("ALLOW_REMOTE_CODE", "true").lower() == "true"
def get_file_sizes(directory):
"""
Calculate the sizes of all files in a given directory and its subdirectories.
Args:
directory (str): The path to the directory to scan for files.
Returns:
dict: A dictionary where the keys are the file paths and the values are the file sizes in gigabytes (GB).
"""
file_sizes = {}
for root, _, files in os.walk(directory):
for file in files:
file_path = os.path.join(root, file)
file_size = os.path.getsize(file_path)
file_size_gb = file_size / (1024**3) # Convert bytes to GB
file_sizes[file_path] = file_size_gb
return file_sizes
def remove_global_step(directory):
"""
Removes directories that start with 'global_step' within the specified directory.
This function traverses the given directory and its subdirectories in a bottom-up manner.
If it finds any directory whose name starts with 'global_step', it deletes that directory
and all its contents.
Args:
directory (str): The path to the directory to be traversed and cleaned.
Returns:
None
"""
for root, dirs, _ in os.walk(directory, topdown=False):
for name in dirs:
if name.startswith("global_step"):
folder_path = os.path.join(root, name)
print(f"Removing folder: {folder_path}")
shutil.rmtree(folder_path)
def remove_autotrain_data(config):
"""
Removes the AutoTrain data directory and global step for a given project.
Args:
config (object): Configuration object that contains the project name.
Raises:
OSError: If the removal of the directory fails.
"""
os.system(f"rm -rf {config.project_name}/autotrain-data")
remove_global_step(config.project_name)
def save_training_params(config):
"""
Saves the training parameters to a JSON file, excluding the "token" key if it exists.
Args:
config (object): Configuration object that contains the project name.
The function checks if a file named 'training_params.json' exists in the directory
specified by `config.project_name`. If the file exists, it loads the JSON content,
removes the "token" key if present, and then writes the updated content back to the file.
"""
if os.path.exists(f"{config.project_name}/training_params.json"):
training_params = json.load(open(f"{config.project_name}/training_params.json"))
if "token" in training_params:
training_params.pop("token")
json.dump(
training_params,
open(f"{config.project_name}/training_params.json", "w"),
indent=4,
)
def pause_endpoint(params):
"""
Pauses a Hugging Face endpoint using the provided parameters.
Args:
params (dict or object): Parameters containing the token required for authorization.
If a dictionary is provided, it should have a key "token" with the authorization token.
If an object is provided, it should have an attribute `token` with the authorization token.
Returns:
dict: The JSON response from the API call to pause the endpoint.
Raises:
KeyError: If the "token" key is missing in the params dictionary.
requests.exceptions.RequestException: If there is an issue with the API request.
Environment Variables:
ENDPOINT_ID: Should be set to the endpoint identifier in the format "username/project_name".
"""
if isinstance(params, dict):
token = params["token"]
else:
token = params.token
endpoint_id = os.environ["ENDPOINT_ID"]
username = endpoint_id.split("/")[0]
project_name = endpoint_id.split("/")[1]
api_url = f"https://api.endpoints.huggingface.cloud/v2/endpoint/{username}/{project_name}/pause"
headers = {"Authorization": f"Bearer {token}"}
r = requests.post(api_url, headers=headers, timeout=120)
return r.json()
def pause_space(params, is_failure=False):
"""
Pauses the Hugging Face space and optionally shuts down the endpoint.
This function checks for the presence of "SPACE_ID" and "ENDPOINT_ID" in the environment variables.
If "SPACE_ID" is found, it pauses the space and creates a discussion on the Hugging Face platform
to notify the user about the status of the training run (success or failure).
If "ENDPOINT_ID" is found, it pauses the endpoint.
Args:
params (object): An object containing the necessary parameters, including the token, username, and project name.
is_failure (bool, optional): A flag indicating whether the training run failed. Defaults to False.
Raises:
Exception: If there is an error while creating the discussion on the Hugging Face platform.
Logs:
Info: Logs the status of pausing the space and endpoint.
Warning: Logs any issues encountered while creating the discussion.
Error: Logs if the model failed to train and the discussion was not created.
"""
if "SPACE_ID" in os.environ:
# shut down the space
logger.info("Pausing space...")
api = HfApi(token=params.token)
if is_failure:
msg = "Your training run has failed! Please check the logs for more details"
title = "Your training has failed ❌"
else:
msg = "Your training run was successful! [Check out your trained model here]"
msg += f"(https://huggingface.co/{params.username}/{params.project_name})"
title = "Your training has finished successfully ✅"
if not params.token.startswith("hf_oauth_"):
try:
api.create_discussion(
repo_id=os.environ["SPACE_ID"],
title=title,
description=msg,
repo_type="space",
)
except Exception as e:
logger.warning(f"Failed to create discussion: {e}")
if is_failure:
logger.error("Model failed to train and discussion was not created.")
else:
logger.warning("Model trained successfully but discussion was not created.")
api.pause_space(repo_id=os.environ["SPACE_ID"])
if "ENDPOINT_ID" in os.environ:
# shut down the endpoint
logger.info("Pausing endpoint...")
pause_endpoint(params)
def monitor(func):
"""
A decorator that wraps a function to monitor its execution and handle exceptions.
This decorator performs the following actions:
1. Retrieves the 'config' parameter from the function's keyword arguments or positional arguments.
2. Executes the wrapped function.
3. If an exception occurs during the execution of the wrapped function, logs the error message and stack trace.
4. Optionally pauses the execution if the environment variable 'PAUSE_ON_FAILURE' is set to 1.
Args:
func (callable): The function to be wrapped by the decorator.
Returns:
callable: The wrapped function with monitoring capabilities.
"""
def wrapper(*args, **kwargs):
config = kwargs.get("config", None)
if config is None and len(args) > 0:
config = args[0]
try:
return func(*args, **kwargs)
except Exception as e:
error_message = f"""{func.__name__} has failed due to an exception: {traceback.format_exc()}"""
logger.error(error_message)
logger.error(str(e))
if int(os.environ.get("PAUSE_ON_FAILURE", 1)) == 1:
pause_space(config, is_failure=True)
return wrapper
class AutoTrainParams(BaseModel):
"""
AutoTrainParams is a base class for all AutoTrain parameters.
Attributes:
Config (class): Configuration class for Pydantic model.
protected_namespaces (tuple): Protected namespaces for the model.
Methods:
save(output_dir):
Save parameters to a JSON file in the specified output directory.
__str__():
Return a string representation of the parameters, masking the token if present.
__init__(**data):
Initialize the parameters, check for unused/extra parameters, and warn the user if necessary.
Raises ValueError if project_name is not alphanumeric (with hyphens allowed) or exceeds 50 characters.
"""
class Config:
protected_namespaces = ()
def save(self, output_dir):
"""
Save parameters to a json file.
"""
os.makedirs(output_dir, exist_ok=True)
path = os.path.join(output_dir, "training_params.json")
# save formatted json
with open(path, "w", encoding="utf-8") as f:
f.write(self.model_dump_json(indent=4))
def __str__(self):
"""
String representation of the parameters.
"""
data = self.model_dump()
data["token"] = "*****" if data.get("token") else None
return str(data)
def __init__(self, **data):
"""
Initialize the parameters, check for unused/extra parameters and warn the user.
"""
super().__init__(**data)
if len(self.project_name) > 0:
# make sure project_name is always alphanumeric but can have hyphens. if not, raise ValueError
if not self.project_name.replace("-", "").isalnum():
raise ValueError("project_name must be alphanumeric but can contain hyphens")
# project name cannot be more than 50 characters
if len(self.project_name) > 50:
raise ValueError("project_name cannot be more than 50 characters")
# Parameters not supplied by the user
defaults = set(self.model_fields.keys())
supplied = set(data.keys())
not_supplied = defaults - supplied
if not_supplied and not is_colab:
logger.warning(f"Parameters not supplied by user and set to default: {', '.join(not_supplied)}")
# Parameters that were supplied but not used
# This is a naive implementation. It might catch some internal Pydantic params.
unused = supplied - set(self.model_fields)
if unused:
logger.warning(f"Parameters supplied but not used: {', '.join(unused)}")
class UploadLogs(TrainerCallback):
"""
A callback to upload training logs to the Hugging Face Hub.
Args:
config (object): Configuration object containing necessary parameters.
Attributes:
config (object): Configuration object containing necessary parameters.
api (HfApi or None): Instance of HfApi for interacting with the Hugging Face Hub.
last_upload_time (float): Timestamp of the last upload.
Methods:
on_step_end(args, state, control, **kwargs):
Called at the end of each training step. Uploads logs to the Hugging Face Hub if conditions are met.
"""
def __init__(self, config):
self.config = config
self.api = None
self.last_upload_time = 0
if self.config.push_to_hub:
if PartialState().process_index == 0:
self.api = HfApi(token=config.token)
self.api.create_repo(
repo_id=f"{self.config.username}/{self.config.project_name}", repo_type="model", private=True
)
def on_step_end(self, args: TrainingArguments, state: TrainerState, control: TrainerControl, **kwargs):
if self.config.push_to_hub is False:
return control
if not os.path.exists(os.path.join(self.config.project_name, "runs")):
return control
if (state.global_step + 1) % self.config.logging_steps == 0 and self.config.log == "tensorboard":
if PartialState().process_index == 0:
current_time = time.time()
if current_time - self.last_upload_time >= 600:
try:
self.api.upload_folder(
folder_path=os.path.join(self.config.project_name, "runs"),
repo_id=f"{self.config.username}/{self.config.project_name}",
path_in_repo="runs",
)
except Exception as e:
logger.warning(f"Failed to upload logs: {e}")
logger.warning("Continuing training...")
self.last_upload_time = current_time
return control
class LossLoggingCallback(TrainerCallback):
"""
LossLoggingCallback is a custom callback for logging loss during training.
This callback inherits from `TrainerCallback` and overrides the `on_log` method
to remove the "total_flos" key from the logs and log the remaining information
if the current process is the local process zero.
Methods:
on_log(args, state, control, logs=None, **kwargs):
Called when the logs are updated. Removes the "total_flos" key from the logs
and logs the remaining information if the current process is the local process zero.
Args:
args: The training arguments.
state: The current state of the Trainer.
control: The control object for the Trainer.
logs (dict, optional): The logs dictionary containing the training metrics.
**kwargs: Additional keyword arguments.
"""
def on_log(self, args, state, control, logs=None, **kwargs):
_ = logs.pop("total_flos", None)
if state.is_local_process_zero:
logger.info(logs)
class TrainStartCallback(TrainerCallback):
"""
TrainStartCallback is a custom callback for the Trainer class that logs a message when training begins.
Methods:
on_train_begin(args, state, control, **kwargs):
Logs a message indicating that training is starting.
Args:
args: The training arguments.
state: The current state of the Trainer.
control: The control object for the Trainer.
**kwargs: Additional keyword arguments.
"""
def on_train_begin(self, args, state, control, **kwargs):
logger.info("Starting to train...")
| 6 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/object_detection/utils.py | import os
from dataclasses import dataclass
import albumentations as A
import torch
from torchmetrics.detection.mean_ap import MeanAveragePrecision
from transformers.image_transforms import center_to_corners_format
from autotrain.trainers.object_detection.dataset import ObjectDetectionDataset
VALID_METRICS = (
"eval_loss",
"eval_map",
"eval_map_50",
"eval_map_75",
"eval_map_small",
"eval_map_medium",
"eval_map_large",
"eval_mar_1",
"eval_mar_10",
"eval_mar_100",
"eval_mar_small",
"eval_mar_medium",
"eval_mar_large",
)
MODEL_CARD = """
---
tags:
- autotrain
- object-detection
- vision{base_model}
widget:
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/tiger.jpg
example_title: Tiger
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/teapot.jpg
example_title: Teapot
- src: https://huggingface.co/datasets/mishig/sample_images/resolve/main/palace.jpg
example_title: Palace{dataset_tag}
---
# Model Trained Using AutoTrain
- Problem type: Object Detection
## Validation Metrics
{validation_metrics}
"""
def collate_fn(batch):
"""
Collates a batch of data for object detection training.
Args:
batch (list): A list of dictionaries, where each dictionary contains
'pixel_values', 'labels', and optionally 'pixel_mask'.
Returns:
dict: A dictionary with the following keys:
- 'pixel_values' (torch.Tensor): A tensor containing stacked pixel values from the batch.
- 'labels' (list): A list of labels from the batch.
- 'pixel_mask' (torch.Tensor, optional): A tensor containing stacked pixel masks from the batch,
if 'pixel_mask' is present in the input batch.
"""
data = {}
data["pixel_values"] = torch.stack([x["pixel_values"] for x in batch])
data["labels"] = [x["labels"] for x in batch]
if "pixel_mask" in batch[0]:
data["pixel_mask"] = torch.stack([x["pixel_mask"] for x in batch])
return data
def process_data(train_data, valid_data, image_processor, config):
"""
Processes training and validation data for object detection.
Args:
train_data (list): List of training data samples.
valid_data (list or None): List of validation data samples. If None, only training data is processed.
image_processor (object): An image processor object that contains image processing configurations.
config (dict): Configuration dictionary containing various settings for data processing.
Returns:
tuple: A tuple containing processed training data and validation data (if provided). If validation data is not provided, the second element of the tuple is None.
"""
max_size = image_processor.size["longest_edge"]
basic_transforms = [
A.LongestMaxSize(max_size=max_size),
A.PadIfNeeded(max_size, max_size, border_mode=0, value=(128, 128, 128), position="top_left"),
]
train_transforms = A.Compose(
[
A.Compose(
[
A.SmallestMaxSize(max_size=max_size, p=1.0),
A.RandomSizedBBoxSafeCrop(height=max_size, width=max_size, p=1.0),
],
p=0.2,
),
A.OneOf(
[
A.Blur(blur_limit=7, p=0.5),
A.MotionBlur(blur_limit=7, p=0.5),
A.Defocus(radius=(1, 5), alias_blur=(0.1, 0.25), p=0.1),
],
p=0.1,
),
A.Perspective(p=0.1),
A.HorizontalFlip(p=0.5),
A.RandomBrightnessContrast(p=0.5),
A.HueSaturationValue(p=0.1),
*basic_transforms,
],
bbox_params=A.BboxParams(format="coco", label_fields=["category"], clip=True, min_area=25),
)
val_transforms = A.Compose(
basic_transforms,
bbox_params=A.BboxParams(format="coco", label_fields=["category"], clip=True),
)
train_data = ObjectDetectionDataset(train_data, train_transforms, image_processor, config)
if valid_data is not None:
valid_data = ObjectDetectionDataset(valid_data, val_transforms, image_processor, config)
return train_data, valid_data
return train_data, None
def convert_bbox_yolo_to_pascal(boxes, image_size):
"""
Convert bounding boxes from YOLO format (x_center, y_center, width, height) in range [0, 1]
to Pascal VOC format (x_min, y_min, x_max, y_max) in absolute coordinates.
Args:
boxes (torch.Tensor): Bounding boxes in YOLO format
image_size (Tuple[int, int]): Image size in format (height, width)
Returns:
torch.Tensor: Bounding boxes in Pascal VOC format (x_min, y_min, x_max, y_max)
"""
# convert center to corners format
boxes = center_to_corners_format(boxes)
# convert to absolute coordinates
height, width = image_size
boxes = boxes * torch.tensor([[width, height, width, height]])
return boxes
@torch.no_grad()
def object_detection_metrics(evaluation_results, image_processor, threshold=0.0, id2label=None):
"""
Compute mean average mAP, mAR and their variants for the object detection task.
Args:
evaluation_results (EvalPrediction): Predictions and targets from evaluation.
threshold (float, optional): Threshold to filter predicted boxes by confidence. Defaults to 0.0.
id2label (Optional[dict], optional): Mapping from class id to class name. Defaults to None.
Returns:
Mapping[str, float]: Metrics in a form of dictionary {<metric_name>: <metric_value>}
"""
@dataclass
class ModelOutput:
logits: torch.Tensor
pred_boxes: torch.Tensor
predictions, targets = evaluation_results.predictions, evaluation_results.label_ids
# For metric computation we need to provide:
# - targets in a form of list of dictionaries with keys "boxes", "labels"
# - predictions in a form of list of dictionaries with keys "boxes", "scores", "labels"
image_sizes = []
post_processed_targets = []
post_processed_predictions = []
# Collect targets in the required format for metric computation
for batch in targets:
# collect image sizes, we will need them for predictions post processing
batch_image_sizes = torch.tensor([x["orig_size"] for x in batch])
image_sizes.append(batch_image_sizes)
# collect targets in the required format for metric computation
# boxes were converted to YOLO format needed for model training
# here we will convert them to Pascal VOC format (x_min, y_min, x_max, y_max)
for image_target in batch:
boxes = torch.tensor(image_target["boxes"])
boxes = convert_bbox_yolo_to_pascal(boxes, image_target["orig_size"])
labels = torch.tensor(image_target["class_labels"])
post_processed_targets.append({"boxes": boxes, "labels": labels})
# Collect predictions in the required format for metric computation,
# model produce boxes in YOLO format, then image_processor convert them to Pascal VOC format
for batch, target_sizes in zip(predictions, image_sizes):
batch_logits, batch_boxes = batch[1], batch[2]
output = ModelOutput(logits=torch.tensor(batch_logits), pred_boxes=torch.tensor(batch_boxes))
post_processed_output = image_processor.post_process_object_detection(
output, threshold=threshold, target_sizes=target_sizes
)
post_processed_predictions.extend(post_processed_output)
# Compute metrics
metric = MeanAveragePrecision(box_format="xyxy", class_metrics=True)
metric.update(post_processed_predictions, post_processed_targets)
metrics = metric.compute()
# Replace list of per class metrics with separate metric for each class
classes = metrics.pop("classes")
try:
len(classes)
calc_map_per_class = True
except TypeError:
calc_map_per_class = False
if calc_map_per_class:
map_per_class = metrics.pop("map_per_class")
mar_100_per_class = metrics.pop("mar_100_per_class")
for class_id, class_map, class_mar in zip(classes, map_per_class, mar_100_per_class):
class_name = id2label[class_id.item()] if id2label is not None else class_id.item()
metrics[f"map_{class_name}"] = class_map
metrics[f"mar_100_{class_name}"] = class_mar
metrics = {k: round(v.item(), 4) for k, v in metrics.items()}
return metrics
def create_model_card(config, trainer):
"""
Generates a model card string based on the provided configuration and trainer.
Args:
config (object): Configuration object containing the following attributes:
- valid_split (optional): Validation split information.
- data_path (str): Path to the dataset.
- project_name (str): Name of the project.
- model (str): Path or identifier of the model.
trainer (object): Trainer object with an `evaluate` method that returns evaluation metrics.
Returns:
str: A formatted model card string containing dataset information, validation metrics, and base model details.
"""
if config.valid_split is not None:
eval_scores = trainer.evaluate()
eval_scores = [f"{k[len('eval_'):]}: {v}" for k, v in eval_scores.items() if k in VALID_METRICS]
eval_scores = "\n\n".join(eval_scores)
else:
eval_scores = "No validation metrics available"
if config.data_path == f"{config.project_name}/autotrain-data" or os.path.isdir(config.data_path):
dataset_tag = ""
else:
dataset_tag = f"\ndatasets:\n- {config.data_path}"
if os.path.isdir(config.model):
base_model = ""
else:
base_model = f"\nbase_model: {config.model}"
model_card = MODEL_CARD.format(
dataset_tag=dataset_tag,
validation_metrics=eval_scores,
base_model=base_model,
)
return model_card
| 7 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/object_detection/__main__.py | import argparse
import json
from functools import partial
from accelerate.state import PartialState
from datasets import load_dataset, load_from_disk
from huggingface_hub import HfApi
from transformers import (
AutoConfig,
AutoImageProcessor,
AutoModelForObjectDetection,
EarlyStoppingCallback,
Trainer,
TrainingArguments,
)
from transformers.trainer_callback import PrinterCallback
from autotrain import logger
from autotrain.trainers.common import (
ALLOW_REMOTE_CODE,
LossLoggingCallback,
TrainStartCallback,
UploadLogs,
monitor,
pause_space,
remove_autotrain_data,
save_training_params,
)
from autotrain.trainers.object_detection import utils
from autotrain.trainers.object_detection.params import ObjectDetectionParams
def parse_args():
# get training_config.json from the end user
parser = argparse.ArgumentParser()
parser.add_argument("--training_config", type=str, required=True)
return parser.parse_args()
@monitor
def train(config):
if isinstance(config, dict):
config = ObjectDetectionParams(**config)
valid_data = None
if config.data_path == f"{config.project_name}/autotrain-data":
train_data = load_from_disk(config.data_path)[config.train_split]
else:
if ":" in config.train_split:
dataset_config_name, split = config.train_split.split(":")
train_data = load_dataset(
config.data_path,
name=dataset_config_name,
split=split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
else:
train_data = load_dataset(
config.data_path,
split=config.train_split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
if config.valid_split is not None:
if config.data_path == f"{config.project_name}/autotrain-data":
valid_data = load_from_disk(config.data_path)[config.valid_split]
else:
if ":" in config.valid_split:
dataset_config_name, split = config.valid_split.split(":")
valid_data = load_dataset(
config.data_path,
name=dataset_config_name,
split=split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
else:
valid_data = load_dataset(
config.data_path,
split=config.valid_split,
token=config.token,
trust_remote_code=ALLOW_REMOTE_CODE,
)
logger.info(f"Train data: {train_data}")
logger.info(f"Valid data: {valid_data}")
categories = train_data.features[config.objects_column].feature["category"].names
id2label = dict(enumerate(categories))
label2id = {v: k for k, v in id2label.items()}
model_config = AutoConfig.from_pretrained(
config.model,
label2id=label2id,
id2label=id2label,
trust_remote_code=ALLOW_REMOTE_CODE,
token=config.token,
)
try:
model = AutoModelForObjectDetection.from_pretrained(
config.model,
config=model_config,
ignore_mismatched_sizes=True,
trust_remote_code=ALLOW_REMOTE_CODE,
token=config.token,
)
except OSError:
model = AutoModelForObjectDetection.from_pretrained(
config.model,
config=model_config,
trust_remote_code=ALLOW_REMOTE_CODE,
token=config.token,
ignore_mismatched_sizes=True,
from_tf=True,
)
image_processor = AutoImageProcessor.from_pretrained(
config.model,
token=config.token,
do_pad=False,
do_resize=False,
size={"longest_edge": config.image_square_size},
trust_remote_code=ALLOW_REMOTE_CODE,
)
train_data, valid_data = utils.process_data(train_data, valid_data, image_processor, config)
if config.logging_steps == -1:
if config.valid_split is not None:
logging_steps = int(0.2 * len(valid_data) / config.batch_size)
else:
logging_steps = int(0.2 * len(train_data) / config.batch_size)
if logging_steps == 0:
logging_steps = 1
if logging_steps > 25:
logging_steps = 25
config.logging_steps = logging_steps
else:
logging_steps = config.logging_steps
logger.info(f"Logging steps: {logging_steps}")
training_args = dict(
output_dir=config.project_name,
per_device_train_batch_size=config.batch_size,
per_device_eval_batch_size=2 * config.batch_size,
learning_rate=config.lr,
num_train_epochs=config.epochs,
eval_strategy=config.eval_strategy if config.valid_split is not None else "no",
logging_steps=logging_steps,
save_total_limit=config.save_total_limit,
save_strategy=config.eval_strategy if config.valid_split is not None else "no",
gradient_accumulation_steps=config.gradient_accumulation,
report_to=config.log,
auto_find_batch_size=config.auto_find_batch_size,
lr_scheduler_type=config.scheduler,
optim=config.optimizer,
warmup_ratio=config.warmup_ratio,
weight_decay=config.weight_decay,
max_grad_norm=config.max_grad_norm,
push_to_hub=False,
load_best_model_at_end=True if config.valid_split is not None else False,
ddp_find_unused_parameters=False,
)
if config.mixed_precision == "fp16":
training_args["fp16"] = True
if config.mixed_precision == "bf16":
training_args["bf16"] = True
if config.valid_split is not None:
training_args["eval_do_concat_batches"] = False
early_stop = EarlyStoppingCallback(
early_stopping_patience=config.early_stopping_patience,
early_stopping_threshold=config.early_stopping_threshold,
)
callbacks_to_use = [early_stop]
else:
callbacks_to_use = []
callbacks_to_use.extend([UploadLogs(config=config), LossLoggingCallback(), TrainStartCallback()])
_compute_metrics_fn = partial(
utils.object_detection_metrics, image_processor=image_processor, id2label=id2label, threshold=0.0
)
args = TrainingArguments(**training_args)
trainer_args = dict(
args=args,
model=model,
callbacks=callbacks_to_use,
data_collator=utils.collate_fn,
tokenizer=image_processor,
compute_metrics=_compute_metrics_fn,
)
trainer = Trainer(
**trainer_args,
train_dataset=train_data,
eval_dataset=valid_data,
)
trainer.remove_callback(PrinterCallback)
trainer.train()
logger.info("Finished training, saving model...")
trainer.save_model(config.project_name)
image_processor.save_pretrained(config.project_name)
model_card = utils.create_model_card(config, trainer)
# save model card to output directory as README.md
with open(f"{config.project_name}/README.md", "w") as f:
f.write(model_card)
if config.push_to_hub:
if PartialState().process_index == 0:
remove_autotrain_data(config)
save_training_params(config)
logger.info("Pushing model to hub...")
api = HfApi(token=config.token)
api.create_repo(
repo_id=f"{config.username}/{config.project_name}", repo_type="model", private=True, exist_ok=True
)
api.upload_folder(
folder_path=config.project_name, repo_id=f"{config.username}/{config.project_name}", repo_type="model"
)
if PartialState().process_index == 0:
pause_space(config)
if __name__ == "__main__":
_args = parse_args()
training_config = json.load(open(_args.training_config))
_config = ObjectDetectionParams(**training_config)
train(_config)
| 8 |
0 | hf_public_repos/autotrain-advanced/src/autotrain/trainers | hf_public_repos/autotrain-advanced/src/autotrain/trainers/object_detection/dataset.py | import numpy as np
class ObjectDetectionDataset:
"""
A dataset class for object detection tasks.
Args:
data (list): A list of data entries where each entry is a dictionary containing image and object information.
transforms (callable): A function or transform to apply to the images and bounding boxes.
image_processor (callable): A function or processor to convert images and annotations into the desired format.
config (object): A configuration object containing column names for images and objects.
Attributes:
data (list): The dataset containing image and object information.
transforms (callable): The transform function to apply to the images and bounding boxes.
image_processor (callable): The processor to convert images and annotations into the desired format.
config (object): The configuration object with column names for images and objects.
Methods:
__len__(): Returns the number of items in the dataset.
__getitem__(item): Retrieves and processes the image and annotations for the given index.
Example:
dataset = ObjectDetectionDataset(data, transforms, image_processor, config)
image_data = dataset[0]
"""
def __init__(self, data, transforms, image_processor, config):
self.data = data
self.transforms = transforms
self.image_processor = image_processor
self.config = config
def __len__(self):
return len(self.data)
def __getitem__(self, item):
image = self.data[item][self.config.image_column]
objects = self.data[item][self.config.objects_column]
output = self.transforms(
image=np.array(image.convert("RGB")), bboxes=objects["bbox"], category=objects["category"]
)
image = output["image"]
annotations = []
for j in range(len(output["bboxes"])):
annotations.append(
{
"image_id": str(item),
"category_id": output["category"][j],
"iscrowd": 0,
"area": objects["bbox"][j][2] * objects["bbox"][j][3], # [x, y, w, h
"bbox": output["bboxes"][j],
}
)
annotations = {"annotations": annotations, "image_id": str(item)}
result = self.image_processor(images=image, annotations=annotations, return_tensors="pt")
result["pixel_values"] = result["pixel_values"][0]
result["labels"] = result["labels"][0]
return result
| 9 |
0 | hf_public_repos | hf_public_repos/blog/leaderboard-medicalllm.md | ---
title: "The Open Medical-LLM Leaderboard: Benchmarking Large Language Models in Healthcare"
thumbnail: /blog/assets/leaderboards-on-the-hub/thumbnail_medicalllm.png
authors:
- user: aaditya
guest: true
- user: pminervini
guest: true
- user: clefourrier
---
# The Open Medical-LLM Leaderboard: Benchmarking Large Language Models in Healthcare

Over the years, Large Language Models (LLMs) have emerged as a groundbreaking technology with immense potential to revolutionize various aspects of healthcare. These models, such as [GPT-3](https://arxiv.org/abs/2005.14165), [GPT-4](https://arxiv.org/abs/2303.08774) and [Med-PaLM 2](https://arxiv.org/abs/2305.09617) have demonstrated remarkable capabilities in understanding and generating human-like text, making them valuable tools for tackling complex medical tasks and improving patient care. They have notably shown promise in various medical applications, such as medical question-answering (QA), dialogue systems, and text generation. Moreover, with the exponential growth of electronic health records (EHRs), medical literature, and patient-generated data, LLMs could help healthcare professionals extract valuable insights and make informed decisions.
However, despite the immense potential of Large Language Models (LLMs) in healthcare, there are significant and specific challenges that need to be addressed.
When models are used for recreational conversational aspects, errors have little repercussions; this is not the case for uses in the medical domain however, where wrong explanation and answers can have severe consequences for patient care and outcomes. The accuracy and reliability of information provided by language models can be a matter of life or death, as it could potentially affect healthcare decisions, diagnosis, and treatment plans.
For example, when given a medical query (see below), GPT-3 incorrectly recommended tetracycline for a pregnant patient, despite correctly explaining its contraindication due to potential harm to the fetus. Acting on this incorrect recommendation could lead to bone growth problems in the baby.
](https://github.com/monk1337/research_assets/blob/main/huggingface_blog/gpt_medicaltest.png?raw=true)
To fully utilize the power of LLMs in healthcare, it is crucial to develop and benchmark models using a setup specifically designed for the medical domain. This setup should take into account the unique characteristics and requirements of healthcare data and applications. The development of methods to evaluate the Medical-LLM is not just of academic interest but of practical importance, given the real-life risks they pose in the healthcare sector.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/4.20.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="openlifescienceai/open_medical_llm_leaderboard"></gradio-app>
The Open Medical-LLM Leaderboard aims to address these challenges and limitations by providing a standardized platform for evaluating and comparing the performance of various large language models on a diverse range of medical tasks and datasets. By offering a comprehensive assessment of each model's medical knowledge and question-answering capabilities, the leaderboard aims to foster the development of more effective and reliable medical LLMs.
This platform enables researchers and practitioners to identify the strengths and weaknesses of different approaches, drive further advancements in the field, and ultimately contribute to better patient care and outcomes
## Datasets, Tasks, and Evaluation Setup
The Medical-LLM Leaderboard includes a variety of tasks, and uses accuracy as its primary evaluation metric (accuracy measures the percentage of correct answers provided by a language model across the various medical QA datasets).
### MedQA
The [MedQA](https://arxiv.org/abs/2009.13081) dataset consists of multiple-choice questions from the United States Medical Licensing Examination (USMLE). It covers general medical knowledge and includes 11,450 questions in the development set and 1,273 questions in the test set. Each question has 4 or 5 answer choices, and the dataset is designed to assess the medical knowledge and reasoning skills required for medical licensure in the United States.

### MedMCQA
[MedMCQA](https://proceedings.mlr.press/v174/pal22a.html) is a large-scale multiple-choice QA dataset derived from Indian medical entrance examinations (AIIMS/NEET). It covers 2.4k healthcare topics and 21 medical subjects, with over 187,000 questions in the development set and 6,100 questions in the test set. Each question has 4 answer choices and is accompanied by an explanation. MedMCQA evaluates a model's general medical knowledge and reasoning capabilities.

### PubMedQA
[PubMedQA](https://aclanthology.org/D19-1259/) is a closed-domain QA dataset, In which each question can be answered by looking at an associated context (PubMed abstract). It is consists of 1,000 expert-labeled question-answer pairs. Each question is accompanied by a PubMed abstract as context, and the task is to provide a yes/no/maybe answer based on the information in the abstract. The dataset is split into 500 questions for development and 500 for testing. PubMedQA assesses a model's ability to comprehend and reason over scientific biomedical literature.

### MMLU Subsets (Medicine and Biology)
The [MMLU benchmark](https://arxiv.org/abs/2009.03300) (Measuring Massive Multitask Language Understanding) includes multiple-choice questions from various domains. For the Open Medical-LLM Leaderboard, we focus on the subsets most relevant to medical knowledge:
- Clinical Knowledge: 265 questions assessing clinical knowledge and decision-making skills.
- Medical Genetics: 100 questions covering topics related to medical genetics.
- Anatomy: 135 questions evaluating the knowledge of human anatomy.
- Professional Medicine: 272 questions assessing knowledge required for medical professionals.
- College Biology: 144 questions covering college-level biology concepts.
- College Medicine: 173 questions assessing college-level medical knowledge.
Each MMLU subset consists of multiple-choice questions with 4 answer options and is designed to evaluate a model's understanding of specific medical and biological domains.

The Open Medical-LLM Leaderboard offers a robust assessment of a model's performance across various aspects of medical knowledge and reasoning.
## Insights and Analysis
The Open Medical-LLM Leaderboard evaluates the performance of various large language models (LLMs) on a diverse set of medical question-answering tasks. Here are our key findings:
- Commercial models like GPT-4-base and Med-PaLM-2 consistently achieve high accuracy scores across various medical datasets, demonstrating strong performance in different medical domains.
- Open-source models, such as [Starling-LM-7B](https://huggingface.co/Nexusflow/Starling-LM-7B-beta), [gemma-7b](https://huggingface.co/google/gemma-7b), Mistral-7B-v0.1, and [Hermes-2-Pro-Mistral-7B](https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B), show competitive performance on certain datasets and tasks, despite having smaller sizes of around 7 billion parameters.
- Both commercial and open-source models perform well on tasks like comprehension and reasoning over scientific biomedical literature (PubMedQA) and applying clinical knowledge and decision-making skills (MMLU Clinical Knowledge subset).
](https://github.com/monk1337/research_assets/blob/main/huggingface_blog/model_evals.png?raw=true)
Google's model, [Gemini Pro](https://arxiv.org/abs/2312.11805) demonstrates strong performance in various medical domains, particularly excelling in data-intensive and procedural tasks like Biostatistics, Cell Biology, and Obstetrics & Gynecology. However, it shows moderate to low performance in critical areas such as Anatomy, Cardiology, and Dermatology, revealing gaps that require further refinement for comprehensive medical application.
](https://github.com/monk1337/research_assets/blob/main/huggingface_blog/subjectwise_eval.png?raw=true)
## Submitting Your Model for Evaluation
To submit your model for evaluation on the Open Medical-LLM Leaderboard, follow these steps:
**1. Convert Model Weights to Safetensors Format**
First, convert your model weights to the safetensors format. Safetensors is a new format for storing weights that is safer and faster to load and use. Converting your model to this format will also allow the leaderboard to display the number of parameters of your model in the main table.
**2. Ensure Compatibility with AutoClasses**
Before submitting your model, make sure you can load your model and tokenizer using the AutoClasses from the Transformers library. Use the following code snippet to test the compatibility:
```python
from transformers import AutoConfig, AutoModel, AutoTokenizer
config = AutoConfig.from_pretrained(MODEL_HUB_ID)
model = AutoModel.from_pretrained("your model name")
tokenizer = AutoTokenizer.from_pretrained("your model name")
```
If this step fails, follow the error messages to debug your model before submitting it. It's likely that your model has been improperly uploaded.
**3. Make Your Model Public**
Ensure that your model is publicly accessible. The leaderboard cannot evaluate models that are private or require special access permissions.
**4. Remote Code Execution (Coming Soon)**
Currently, the Open Medical-LLM Leaderboard does not support models that require `use_remote_code=True`. However, the leaderboard team is actively working on adding this feature, so stay tuned for updates.
**5. Submit Your Model via the Leaderboard Website**
Once your model is in the safetensors format, compatible with AutoClasses, and publicly accessible, you can submit it for evaluation using the "Submit here!" panel on the Open Medical-LLM Leaderboard website. Fill out the required information, such as the model name, description, and any additional details, and click the submit button.
The leaderboard team will process your submission and evaluate your model's performance on the various medical QA datasets. Once the evaluation is complete, your model's scores will be added to the leaderboard, allowing you to compare its performance with other submitted models.
## What's next? Expanding the Open Medical-LLM Leaderboard
The Open Medical-LLM Leaderboard is committed to expanding and adapting to meet the evolving needs of the research community and healthcare industry. Key areas of focus include:
1. Incorporating a wider range of medical datasets covering diverse aspects of healthcare, such as radiology, pathology, and genomics, through collaboration with researchers, healthcare organizations, and industry partners.
2. Enhancing evaluation metrics and reporting capabilities by exploring additional performance measures beyond accuracy, such as Pointwise score and domain-specific metrics that capture the unique requirements of medical applications.
3. A few efforts are already underway in this direction. If you are interested in collaborating on the next benchmark we are planning to propose, please join our [Discord community](https://discord.gg/A5Fjf5zC69) to learn more and get involved. We would love to collaborate and brainstorm ideas!
If you're passionate about the intersection of AI and healthcare, building models for the healthcare domain, and care about safety and hallucination issues for medical LLMs, we invite you to join our vibrant [community on Discord](https://discord.gg/A5Fjf5zC69).
## Credits and Acknowledgments

Special thanks to all the people who helped make this possible, including Clémentine Fourrier and the Hugging Face team. I would like to thank Andreas Motzfeldt, Aryo Gema, & Logesh Kumar Umapathi for their discussion and feedback on the leaderboard during development. Sincere gratitude to Prof. Pasquale Minervini for his time, technical assistance, and for providing GPU support from the University of Edinburgh.
## About Open Life Science AI
Open Life Science AI is a project that aims to revolutionize the application of Artificial intelligence in the life science and healthcare domains. It serves as a central hub for list of medical models, datasets, benchmarks, and tracking conference deadlines, fostering collaboration, innovation, and progress in the field of AI-assisted healthcare. We strive to establish Open Life Science AI as the premier destination for anyone interested in the intersection of AI and healthcare. We provide a platform for researchers, clinicians, policymakers, and industry experts to engage in dialogues, share insights, and explore the latest developments in the field.

## Citation
If you find our evaluations useful, please consider citing our work
**Medical-LLM Leaderboard**
```
@misc{Medical-LLM Leaderboard,
author = {Ankit Pal, Pasquale Minervini, Andreas Geert Motzfeldt, Aryo Pradipta Gema and Beatrice Alex},
title = {openlifescienceai/open_medical_llm_leaderboard},
year = {2024},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard}"
}
```
| 0 |
0 | hf_public_repos | hf_public_repos/blog/smollm.md | ---
title: SmolLM - blazingly fast and remarkably powerful
thumbnail: /blog/assets/smollm/banner.png
authors:
- user: loubnabnl
- user: anton-l
- user: eliebak
---
# SmolLM - blazingly fast and remarkably powerful
## TL;DR
This blog post introduces [SmolLM](https://huggingface.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966), a family of state-of-the-art small models with 135M, 360M, and 1.7B parameters, trained on a new high-quality dataset. It covers data curation, model evaluation, and usage.
## Introduction
There is increasing interest in small language models that can operate on local devices. This trend involves techniques such as distillation or quantization to compress large models, as well as training small models from scratch on large datasets. These approaches enable novel applications while dramatically reducing inference costs and improving user privacy.
Microsoft's Phi series, Alibaba's Qwen2 (less than 2B), and Meta's MobileLLM demonstrate that small models can achieve impressive results when designed and trained thoughtfully. However, most of the details about the data curation and training of these models are not publicly available.
In this blog post, we're excited to introduce [SmolLM](https://huggingface.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966), a series of state-of-the-art small language models available in three sizes: 135M, 360M, and 1.7B parameters. These models are built on a meticulously curated high-quality training corpus, which we are releasing as [SmolLM-Corpus](https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus). Smollm Corpus includes:
- **Cosmopedia v2**: A collection of synthetic textbooks and stories generated by Mixtral (28B tokens)
- **Python-Edu**: educational Python samples from The Stack (4B tokens)
- **FineWeb-Edu (deduplicated)**: educational web samples from FineWeb (220B tokens)
Our evaluations demonstrate that SmolLM models outperform other models in their size categories across a diverse set of benchmarks, testing common sense reasoning and world knowledge. In this blog post, we will go over the curation of each subset in the training corpus and then discuss the training and evaluation of SmolLM models.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled.png" alt="" style="width: 90%; height: auto;"><br>
<em>Evaluation of SmolLM models on different reasoning and common knowledge benchmarks.</em>
</p>
## Data curation
### From Cosmopedia v1 to v2
[Cosmopedia v2](https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus) is an enhanced version of Cosmopedia, the largest synthetic dataset for pre-training, consisting of over 30 million textbooks, blog posts, and stories generated by Mixtral-8x7B-Instruct-v0.1. Most of the samples are generated by prompting the model to generate content on specific topics using a web page referred to as a "seed sample", as shown in Figure 1. We use web samples to increase diversity and expand the range of prompts. You can find more details in this [blog post](https://huggingface.co/blog/cosmopedia).
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%201.png" alt="" style="width: 90%; height: auto;"><br>
<em>Figure 1. Example of a Cosmopedia prompt.</em>
</p>
To improve the dataset in v2, we tried two strategies:
- Using more capable models with the same prompts
- Optimizing the prompts themselves
For the first strategy, we experimented with llama3-70B-Instruct, Mixtral-8x22B-Instruct-v0.1, and Qwen1.5-72B-Chat but found no significant improvements when training models on textbooks generated by these alternatives. Therefore, in the remainder of this section, we will focus on the second strategy: how we improved the prompts.
#### The search for better topics and seed samples
Each prompt has three main components: the topic, the seed sample, and the generation style, which specifies the intended audience and the type of content we want the model to generate.
To ensure consistent generations, we need seed samples that are closely related to the given topic. In Cosmopedia v1, we ran clustering on FineWeb samples to identify both the topics and the corresponding web samples, as shown in Figure 2. This approach has two main limitations:
1. The topic list reflects the web/FineWeb clusters, which, while comprehensive, may limit our control over the topics.
2. The web samples within each cluster are not further filtered, potentially including some low-quality samples.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%202.png" alt="" style="width: 90%; height: auto;"><br>
<em>Figure 2. FineWeb clusters.</em>
</p>
Instead of this unsupervised clustering approach, in v2 we started with a predefined list of 34,000 topics using the [BISAC book classification](https://www.bisg.org/complete-bisac-subject-headings-list), a standard used to categorize books by subject that is both comprehensive and educationally focused. We started with 5,000 topics belonging to 51 categories and asked Mixtral to generate subtopics for certain topics. Below is the final distribution of subtopics in each category:
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%203.png" alt="" style="width: 90%; height: auto;"><br>
<em>Figure 3. Distribution of topics per top categories used for the prompts.</em>
</p>
After defining the topics, we still needed to find web pages related to them. Just like using a search engine to find content on a specific topic, we implemented a search tool to retrieve the most relevant pages for each topic. We ran this tool using our BISAC categories and their subtopics as queries on the FineWeb CC-MAIN-2024-10 and CC-MAIN-2023-50 dumps, which together consist of over 520 million samples. For each query, we retrieved 1,000 pages, ensuring we retrieved only the most relevant content. The code for deploying and running the search tool is available [here](https://github.com/huggingface/cosmopedia/tree/main/fulltext_search).
As a result, we compiled 34 million web pages across 34,000 topics. The next step was to determine which generation style worked best.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%204.png" alt="" style="width: 90%; height: auto;"><br>
<em>Figure 4. Topics and their retrieved samples in the category “Medical”.</em>
</p>
#### Generation Style
To determine the most effective generation style, we conducted ablation studies by training 1.8B models on 8B tokens from different subsets of Cosmopedia v1. For newly generated data, we only generated 2B tokens and trained for 4 epochs to save time (it takes approximately 1000 GPU hours to generate 2B tokens with Mixtral). We used the same training and evaluation setup as [FineWeb ablation models.](https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1) We ran each experiment twice with two different seeds and averaged the scores between the two runs.
We compared the performance of the following subsets of Cosmopedia v1:
- The web textbooks subset
- The stories subset
- The Stanford & OpenStax subset
We found that textbooks based on topics and seed samples from curated sources such as Stanford and OpenStax provided the best overall performance, leading to MMLU and ARC benchmarks compared to web-based textbooks. Stories seemed to help with common sense benchmarks. After implementing the new topics and seed sample retrieval methods in v2, we were able to match the performance of curated sources using web seeds, confirming the quality of the new prompts.
Next, we explored which audience style worked best. We generated textbooks using the same web textbook prompts but targeted two different audiences: middle school students and college students. We found that models trained on textbooks aimed primarily at middle school students gave the best score on all benchmarks except MMLU. This can be explained by the fact that most of these test basic common sense and elementary to intermediate science knowledge, while MMLU contains some questions that require advanced knowledge and expertise.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%205.png" alt="" style="width: 90%; height: auto;"><br>
<em>Evaluation of textbooks for different audiences.</em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%206.png" alt="" style="width: 90%; height: auto;"><br>
<em>Evaluation of textbooks for different audiences.</em>
</p>
For v2, we decided to generate 40% of the content for middle school students, 30% for college students and 30% as a mix of other audiences and styles including in subsets we borrow from Cosmopedia v1 such as stories and Stanford courses based textbooks. Additionally, we generated 1B code textbooks based on Python seed samples from AutoMathText dataset.
Ultimately, we produced 39 million synthetic documents consisting of 28B tokens of textbooks, stories, articles, and code, with a diverse range of audiences and over 34,000 topics.
### FineWeb-Edu
FineWeb-Edu is a dataset we released a few months ago with FineWeb’s [technical report.](https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1) It consists of **1.3T tokens** of educational web pages filtered from 🍷 FineWeb dataset.
We developed an [**educational quality classifier**](https://huggingface.co/HuggingFaceFW/fineweb-edu-classifier) using annotations generated by Llama3-70B-Instruct. We then used this classifier to retain only the most educational web pages from FineWeb. FineWeb-Edu outperforms FineWeb on popular benchmarks and shows the power of classifiers trained on synthetic data.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%207.png" alt="" style="width: 90%; height: auto;"><br>
<em>Comparison of FineWeb-Edu to other open web datasets.</em>
</p>
In Smollm-Corpus we include 220B deduplicated tokens from FineWeb.
### Stack-Edu-Python
We applied the same idea of FineWeb-Edu to Code. We used Llama3 to annotate 500,000 Python samples from The Stack dataset and used them to train an [educational code classifier](https://huggingface.co/HuggingFaceTB/python-edu-scorer) using the same recipe as the FineWeb-Edu classifier. We then applied this classifier to a Python subset of the StarCoder models training corpus. From the 40B Python tokens available, we retained only the samples with a score of 4 or higher, resulting in a refined dataset of 4B tokens.
The plot below compares Python-Edu to the unfiltered Python code and to using a less strict threshold of 3. We can see that the model trained on Python-Edu converges more than 3 times faster than the model trained on unfiltered Python code, achieving 16% pass@1 after only 12B tokens.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%208.png" alt="" style="width: 90%; height: auto;"><br>
<em>Comparison of Python-Edu to unfiltered Python code.</em>
</p>
## Training
SmolLM models are available in three sizes and were trained on the data mixture below:
- 135M and 360M models, each trained on 600B tokens from [Smollm-Corpus](https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus)
- 1.7B model, trained on 1T tokens from Smollm-Corpus
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%209.png" alt="" style="width: 60%; height: auto;"><br>
<em>Training mixture of SmolLM models.</em>
</p>
### Hyperparameters choice
We used a trapezoidal learning rate scheduler with a cooldown phase equal to 20% of the total training time. It's important to note that the original experiments with this schedule were conducted at a smaller scale, and we've adapted it for our larger models.
For the architecture of our 135M and 360M parameter models, we adopted a design similar to [MobileLLM](https://arxiv.org/abs/2402.14905), incorporating Grouped-Query Attention (GQA) and prioritizing depth over width. The 1.7B parameter model uses a more traditional architecture. For all three models we use embedding tying and a context length of 2048 tokens. This context length can be further extended with some long context fine-tuning.
The detailed architecture specifications for each model size are as follows:
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2010.png" alt="" style="width: 90%; height: auto;"><br>
<em>Architecture details of SmolLM models.</em>
</p>
We used a tokenizer trained on the Smollm Corpus with a vocab size of 49152.
### Experiments
One advantage of using the trapezoidal scheduler is that it can reduce the time needed to perform scaling law experiments, as shown in [Hägele et al.](https://arxiv.org/pdf/2405.18392). We illustrate this with a small scaling law study on our smallest model, SmolLM-125M. We observed that performance continues to improve with longer training, even beyond the Chinchilla optimal point. Therefore, we decided to train the 1.7B model on 1 trillion tokens and the 135M and 360M models on 600B tokens, as the performance gains after 400B tokens begin to slow on some benchmarks for these smaller models.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2011.png" alt="" style="width: 90%; height: auto;"><br>
<em>Evaluation of 125M SmolLM models trained on different numbers of tokens.</em>
</p>
We experimented with adding instruct datasets and upsampling the curated Cosmopedia subsets during the cooldown phase, but found no significant improvements. This may be because the primary data mixture is already of high quality, limiting the impact of these changes.
To track our training progress, we evaluate our two smallest models every 2B token. The following plot shows their performance on several benchmarks:
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2012.png" alt="" style="width: 90%; height: auto;"><br>
<em>Intermediate evaluation of SmolLM-135M and SmolLM-360M on different benchmarks.</em>
</p>
## Evaluation
In this section, we evaluate the performance of SmolLM models across different parameter sizes and compare them with the best models in their respective categories. We evaluate on a diverse set of benchmarks testing common sense reasoning and world knowledge. We use the same evaluation setup for all models using this [setup](https://github.com/huggingface/cosmopedia/tree/main/evaluation) with `lighteval` library. For HumanEval, we use [bigcode-evaluation-harness](We use temperature 0.2, top-p 0.95 with 20 samples.) with We use temperature 0.2, top-p 0.95 with 20 samples. For MobileLLM, which isn’t publicly available, we use the numbers reported in the paper whenever possible.
We find that:
- SmolLM-135M outperforms the current best model with less than 200M parameters, MobileLM-125M, despite being trained on only 600B tokens compared to MobileLM's 1T tokens.
- SmolLM**-**360M outperforms all models with less than 500M parameters, despite having fewer parameters and being trained on less than a trillion tokens (600B) as opposed to MobileLM-350M and Qwen2-500M.
- SmolLM-1.7B outperforms all other models with less than 2B parameters, including Phi1.5 from Microsoft, MobileLM-1.5B, and Qwen2-1.5B.
- SmolLM-1.7B shows strong Python coding performance with 24 pass@1. We note that the evaluation scorefor Qwen2-1.5B is different from the 31.1 pass@1 reported by Qwen team. We use temperature 0.2, top-p 0.95 with 20 samples.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2014.png" alt="" style="width: 90%; height: auto;"><br>
<em>Comparison of SmolLM models to other SLMs. We evaluate all models on the same setup, except for MobieLLM, which isn't publicly available.</em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/image.png" alt="" style="width: 50%; height: auto;"><br>
<em>Evaluation of SmolLM models on HumanEval.</em>
</p>
We also instruction tuned the models using publicly available permissive instruction datasets. We trained all three models for one epoch on the permissive subset of the [WebInstructSub dataset](https://huggingface.co/datasets/TIGER-Lab/WebInstructSub), combined with StarCoder2-Self-OSS-Instruct. Following this, we performed DPO (Direct Preference Optimization) for one epoch: using [HelpSteer](https://huggingface.co/datasets/nvidia/HelpSteer) for the 135M and 1.7B models, and [argilla/dpo-mix-7k](https://huggingface.co/datasets/argilla/dpo-mix-7k) for the 360M model. We followed the training parameters from the Zephyr-Gemma recipe in the [alignment handbook](https://github.com/huggingface/alignment-handbook/blob/main/recipes/zephyr-7b-gemma/README.md), but adjusted the SFT (Supervised Fine-Tuning) learning rate to 3e-4.
The table below shows the performance of SmolLM-Instruct and other models on the IFEval benchmark (Prompt Strict Accuracy). Qwen2-1.5B-Instruct model scores the highest with 29.94, SmolLM-Instruct models provide a good balance between model size and performance, using only publicly available permissive datasets.
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2016.png" alt="" style="width: 60%; height: auto;"><br>
<em>Evaluation of SmolLM-Instruct models on IFEval.</em>
</p>
## How to run locally ?
Our models are designed to be small and can run locally on various hardware configurations. For reference, an iPhone 15 has 6GB of DRAM, while an iPhone 15 Pro has 8GB. These memory requirements make our models suitable for deployment on a wide range of devices, from smartphones to laptops. We benchmarked the memory footprint of our three model sizes:
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2013.png" alt="" style="width: 60%; height: auto;"><br>
<em>Memory footprint of SmolLM models.</em>
</p>
Along with the transformers checkpoints, we released ONNX checkpoints and plan to add a GGUF version compatible with `llama.cpp`. You can find WebGPU demos SmolLM-135M and Smol-LM360M at [https://huggingface.co/spaces/HuggingFaceTB/SmolLM-135M-Instruct-WebGPU](https://huggingface.co/spaces/HuggingFaceTB/SmolLM-135M-Instruct-WebGPU) and [https://huggingface.co/spaces/HuggingFaceTB/SmolLM-360M-Instruct-WebGPU](https://huggingface.co/spaces/HuggingFaceTB/SmolLM-360M-Instruct-WebGPU).
## Conclusion
In this blog post we introduced SmolLM models, a new state-of-the-art family of small LLMs. They demonstrate that small language models can achieve high performance with efficient training on high-quality datasets, providing a strong balance between size and performance.
## Resources
- SmolLM models collection: [https://huggingface.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966](https://huggingface.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966)
- SmolLM-Corpus dataset: [https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus](https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus)
- WebGPU demo: [https://huggingface.co/spaces/HuggingFaceTB/SmolLM-135M-Instruct-WebGPU](https://huggingface.co/spaces/HuggingFaceTB/SmolLM-135M-Instruct-WebGPU) and [https://huggingface.co/spaces/HuggingFaceTB/SmolLM-360M-Instruct-WebGPU](https://huggingface.co/spaces/HuggingFaceTB/SmolLM-360M-Instruct-WebGPU)
| 1 |
0 | hf_public_repos | hf_public_repos/blog/habana-gaudi-2-benchmark.md | ---
title: "Faster Training and Inference: Habana Gaudi®2 vs Nvidia A100 80GB"
thumbnail: /blog/assets/habana-gaudi-2-benchmark/thumbnail.png
authors:
- user: regisss
---
# Faster Training and Inference: Habana Gaudi®-2 vs Nvidia A100 80GB
In this article, you will learn how to use [Habana® Gaudi®2](https://habana.ai/training/gaudi2/) to accelerate model training and inference, and train bigger models with 🤗 [Optimum Habana](https://huggingface.co/docs/optimum/habana/index). Then, we present several benchmarks including BERT pre-training, Stable Diffusion inference and T5-3B fine-tuning, to assess the performance differences between first generation Gaudi, Gaudi2 and Nvidia A100 80GB. Spoiler alert - Gaudi2 is about twice faster than Nvidia A100 80GB for both training and inference!
[Gaudi2](https://habana.ai/training/gaudi2/) is the second generation AI hardware accelerator designed by Habana Labs. A single server contains 8 accelerator devices with 96GB of memory each (versus 32GB on first generation Gaudi and 80GB on A100 80GB). The Habana SDK, [SynapseAI](https://developer.habana.ai/), is common to both first-gen Gaudi and Gaudi2.
That means that 🤗 Optimum Habana, which offers a very user-friendly interface between the 🤗 Transformers and 🤗 Diffusers libraries and SynapseAI, **works the exact same way on Gaudi2 as on first-gen Gaudi!**
So if you already have ready-to-use training or inference workflows for first-gen Gaudi, we encourage you to try them on Gaudi2, as they will work without any single change.
## How to Get Access to Gaudi2?
One of the easy, cost-efficient ways that Intel and Habana have made Gaudi2 available is on the Intel Developer Cloud. To start using Gaudi2 there, you should follow the following steps:
1. Go to the [Intel Developer Cloud landing page](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html) and sign in to your account or register if you do not have one.
2. Go to the [Intel Developer Cloud management console](https://scheduler.cloud.intel.com/#/systems).
3. Select *Habana Gaudi2 Deep Learning Server featuring eight Gaudi2 HL-225H mezzanine cards and latest Intel® Xeon® Processors* and click on *Launch Instance* in the lower right corner as shown below.
<figure class="image table text-center m-0 w-full">
<img src="assets/habana-gaudi-2-benchmark/launch_instance.png" alt="Cloud Architecture"/>
</figure>
4. You can then request an instance:
<figure class="image table text-center m-0 w-full">
<img src="assets/habana-gaudi-2-benchmark/request_instance.png" alt="Cloud Architecture"/>
</figure>
5. Once your request is validated, re-do step 3 and click on *Add OpenSSH Publickey* to add a payment method (credit card or promotion code) and a SSH public key that you can generate with `ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa`. You may be redirected to step 3 each time you add a payment method or a SSH public key.
6. Re-do step 3 and then click on *Launch Instance*. You will have to accept the proposed general conditions to actually launch the instance.
7. Go to the [Intel Developer Cloud management console](https://scheduler.cloud.intel.com/#/systems) and click on the tab called *View Instances*.
8. You can copy the SSH command to access your Gaudi2 instance remotely!
> If you terminate the instance and want to use Gaudi2 again, you will have to re-do the whole process.
You can find more information about this process [here](https://scheduler.cloud.intel.com/public/Intel_Developer_Cloud_Getting_Started.html).
## Benchmarks
Several benchmarks were performed to assess the abilities of first-gen Gaudi, Gaudi2 and A100 80GB for both training and inference, and for models of various sizes.
### Pre-Training BERT
A few months ago, [Philipp Schmid](https://huggingface.co/philschmid), technical lead at Hugging Face, presented [how to pre-train BERT on Gaudi with 🤗 Optimum Habana](https://huggingface.co/blog/pretraining-bert). 65k training steps were performed with a batch size of 32 samples per device (so 8*32=256 in total) for a total training time of 8 hours and 53 minutes (you can see the TensorBoard logs of this run [here](https://huggingface.co/philschmid/bert-base-uncased-2022-habana-test-6/tensorboard?scroll=1#scalars)).
We re-ran the same script with the same hyperparameters on Gaudi2 and got a total training time of 2 hours and 55 minutes (see the logs [here](https://huggingface.co/regisss/bert-pretraining-gaudi-2-batch-size-32/tensorboard?scroll=1#scalars)). **That makes a x3.04 speedup on Gaudi2 without changing anything.**
Since Gaudi2 has roughly 3 times more memory per device compared to first-gen Gaudi, it is possible to leverage this greater capacity to have bigger batches. This will give HPUs more work to do and will also enable developers to try a range of hyperparameter values that was not reachable with first-gen Gaudi. With a batch size of 64 samples per device (512 in total), we got with 20k steps a similar loss convergence to the 65k steps of the previous runs. That makes a total training time of 1 hour and 33 minutes (see the logs [here](https://huggingface.co/regisss/bert-pretraining-gaudi-2-batch-size-64/tensorboard?scroll=1#scalars)). The throughput is x1.16 higher with this configuration, while this new batch size strongly accelerates convergence.
**Overall, with Gaudi2, the total training time is reduced by a 5.75 factor and the throughput is x3.53 higher compared to first-gen Gaudi**.
**Gaudi2 also offers a speedup over A100**: 1580.2 samples/s versus 981.6 for a batch size of 32 and 1835.8 samples/s versus 1082.6 for a batch size of 64, which is consistent with the x1.8 speedup [announced by Habana](https://habana.ai/training/gaudi2/) on the phase 1 of BERT pre-training with a batch size of 64.
The following table displays the throughputs we got for first-gen Gaudi, Gaudi2 and Nvidia A100 80GB GPUs:
<center>
| | First-gen Gaudi (BS=32) | Gaudi2 (BS=32) | Gaudi2 (BS=64) | A100 (BS=32) | A100 (BS=64) |
|:-:|:-----------------------:|:--------------:|:--------------:|:-------:|:---------------------:|
| Throughput (samples/s) | 520.2 | 1580.2 | 1835.8 | 981.6 | 1082.6 |
| Speedup | x1.0 | x3.04 | x3.53 | x1.89 | x2.08 |
</center>
*BS* is the batch size per device. The Gaudi runs were performed in mixed precision (bf16/fp32) and the A100 runs in fp16. All runs were *distributed* runs on *8 devices*.
### Generating Images from Text with Stable Diffusion
One of the main new features of 🤗 Optimum Habana release 1.3 is [the support for Stable Diffusion](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion). It is now very easy to generate images from text on Gaudi. Unlike with 🤗 Diffusers on GPUs, images are generated by batches. Due to model compilation times, the first two batches will be slower than the following iterations. In this benchmark, these first two iterations were discarded to compute the throughputs for both first-gen Gaudi and Gaudi2.
[This script](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) was run for a batch size of 8 samples. It uses the [`Habana/stable-diffusion`](https://huggingface.co/Habana/stable-diffusion) Gaudi configuration.
The results we got, which are consistent with the numbers published by Habana [here](https://developer.habana.ai/resources/habana-models-performance/), are displayed in the table below.
**Gaudi2 showcases latencies that are x3.51 faster than first-gen Gaudi (3.25s versus 0.925s) and x2.84 faster than Nvidia A100 (2.63s versus 0.925s).** It can also support bigger batch sizes.
<center>
| | First-gen Gaudi (BS=8) | Gaudi2 (BS=8) | A100 (BS=1) |
|:---------------:|:----------------------:|:-------------:|:-----------:|
| Latency (s/img) | 3.25 | 0.925 | 2.63 |
| Speedup | x1.0 | x3.51 | x1.24 |
</center>
*Update: the figures above were updated as SynapseAI 1.10 and Optimum Habana 1.6 bring an additional speedup on first-gen Gaudi and Gaudi2.*
*BS* is the batch size.
The Gaudi runs were performed in *bfloat16* precision and the A100 runs in *fp16* precision (more information [here](https://huggingface.co/docs/diffusers/optimization/fp16)). All runs were *single-device* runs.
### Fine-tuning T5-3B
With 96 GB of memory per device, Gaudi2 enables running much bigger models. For instance, we managed to fine-tune T5-3B (containing 3 billion parameters) with gradient checkpointing being the only applied memory optimization. This is not possible on first-gen Gaudi.
[Here](https://huggingface.co/regisss/t5-3b-summarization-gaudi-2/tensorboard?scroll=1#scalars) are the logs of this run where the model was fine-tuned on the CNN DailyMail dataset for text summarization using [this script](https://github.com/huggingface/optimum-habana/tree/main/examples/summarization).
The results we achieved are presented in the table below. **Gaudi2 is x2.44 faster than A100 80GB.** We observe that we cannot fit a batch size larger than 1 on Gaudi2 here. This is due to the memory space taken by the graph where operations are accumulated during the first iteration of the run. Habana is working on optimizing the memory footprint in future releases of SynapseAI. We are looking forward to expanding this benchmark using newer versions of Habana's SDK and also using [DeepSpeed](https://www.deepspeed.ai/) to see if the same trend holds.
<center>
| | First-gen Gaudi | Gaudi2 (BS=1) | A100 (BS=16) |
|:-:|:-------:|:--------------:|:------------:|
| Throughput (samples/s) | N/A | 19.7 | 8.07 |
| Speedup | / | x2.44 | x1.0 |
</center>
*BS* is the batch size per device. Gaudi2 and A100 runs were performed in fp32 with gradient checkpointing enabled. All runs were *distributed* runs on *8 devices*.
## Conclusion
In this article, we discuss our first experience with Gaudi2. The transition from first generation Gaudi to Gaudi2 is completely seamless since SynapseAI, Habana's SDK, is fully compatible with both. This means that new optimizations proposed by future releases will benefit both of them.
You have seen that Habana Gaudi2 significantly improves performance over first generation Gaudi and delivers about twice the throughput speed as Nvidia A100 80GB for both training and inference.
You also know now how to setup a Gaudi2 instance through the Intel Developer Zone. Check out the [examples](https://github.com/huggingface/optimum-habana/tree/main/examples) you can easily run on it with 🤗 Optimum Habana.
If you are interested in accelerating your Machine Learning training and inference workflows using the latest AI hardware accelerators and software libraries, check out our [Expert Acceleration Program](https://huggingface.co/support). To learn more about Habana solutions, [read about our partnership here](https://huggingface.co/hardware/habana) and [contact them](https://habana.ai/contact-us/). To learn more about Hugging Face efforts to make AI hardware accelerators easy to use, check out our [Hardware Partner Program](https://huggingface.co/hardware).
### Related Topics
- [Getting Started on Transformers with Habana Gaudi](https://huggingface.co/blog/getting-started-habana)
- [Accelerate Transformer Model Training with Hugging Face and Habana Labs](https://developer.habana.ai/events/accelerate-transformer-model-training-with-hugging-face-and-habana-labs/)
---
Thanks for reading! If you have any questions, feel free to contact me, either through [Github](https://github.com/huggingface/optimum-habana) or on the [forum](https://discuss.huggingface.co/c/optimum/59). You can also connect with me on [LinkedIn](https://www.linkedin.com/in/regispierrard/).
| 2 |
0 | hf_public_repos | hf_public_repos/blog/instruction-tuning-sd.md | ---
title: "Instruction-tuning Stable Diffusion with InstructPix2Pix"
thumbnail: assets/instruction_tuning_sd/thumbnail.png
authors:
- user: sayakpaul
---
# Instruction-tuning Stable Diffusion with InstructPix2Pix
This post explores instruction-tuning to teach [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) to follow instructions to translate or process input images. With this method, we can prompt Stable Diffusion using an input image and an “instruction”, such as - *Apply a cartoon filter to the natural image*.
| 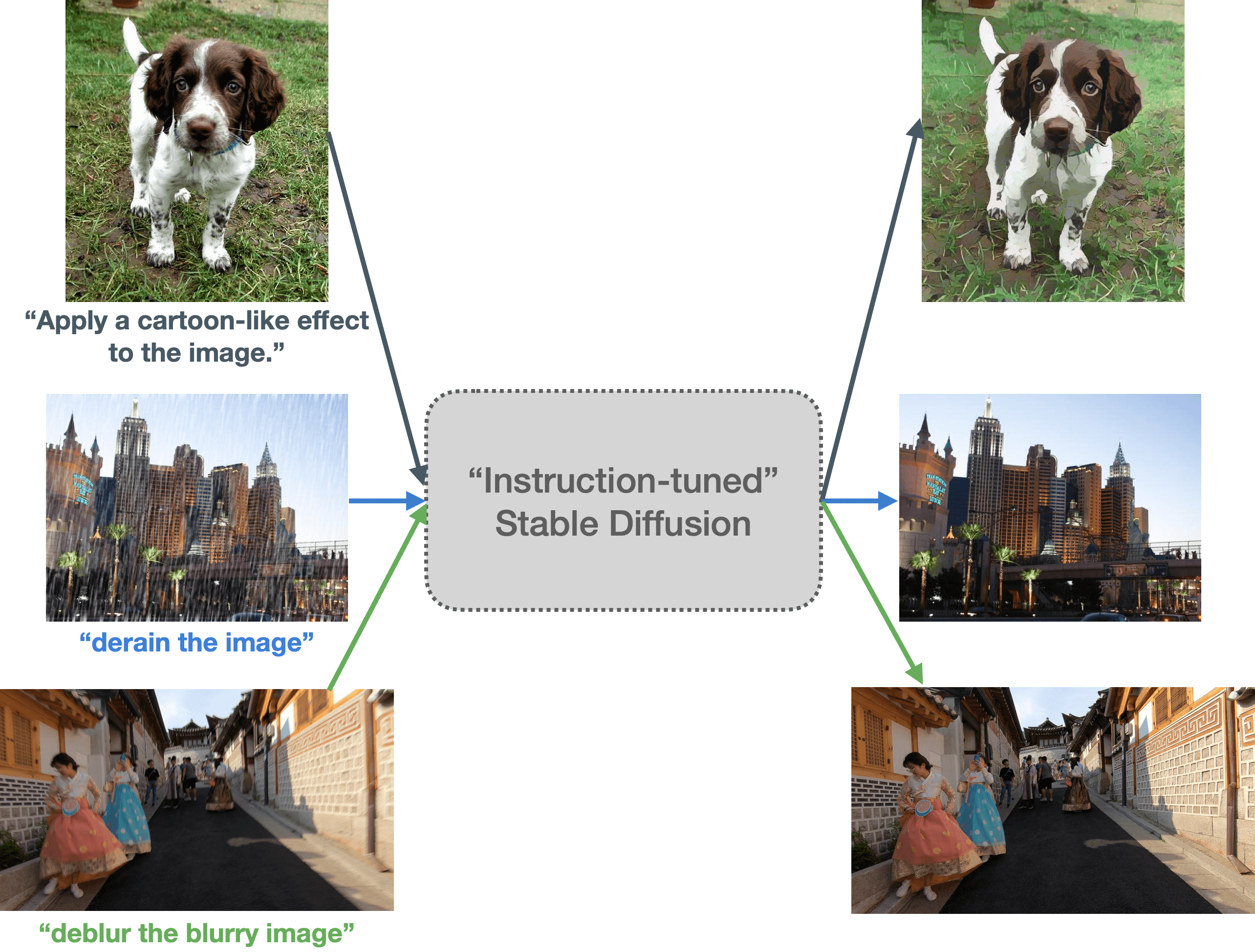 |
|:--:|
| **Figure 1**: We explore the instruction-tuning capabilities of Stable Diffusion. In this figure, we prompt an instruction-tuned Stable Diffusion system with prompts involving different transformations and input images. The tuned system seems to be able to learn these transformations stated in the input prompts. Figure best viewed in color and zoomed in. |
This idea of teaching Stable Diffusion to follow user instructions to perform **edits** on input images was introduced in [InstructPix2Pix: Learning to Follow Image Editing Instructions](https://huggingface.co/papers/2211.09800). We discuss how to extend the InstructPix2Pix training strategy to follow more specific instructions related to tasks in image translation (such as cartoonization) and low-level image processing (such as image deraining). We cover:
- [Introduction to instruction-tuning](#introduction-and-motivation)
- [The motivation behind this work](#introduction-and-motivation)
- [Dataset preparation](#dataset-preparation)
- [Training experiments and results](#training-experiments-and-results)
- [Potential applications and limitations](#potential-applications-and-limitations)
- [Open questions](#open-questions)
Our code, pre-trained models, and datasets can be found [here](https://github.com/huggingface/instruction-tuned-sd).
## Introduction and motivation
Instruction-tuning is a supervised way of teaching language models to follow instructions to solve a task. It was introduced in [Fine-tuned Language Models Are Zero-Shot Learners](https://huggingface.co/papers/2109.01652) (FLAN) by Google. From recent times, you might recall works like [Alpaca](https://crfm.stanford.edu/2023/03/13/alpaca.html) and [FLAN V2](https://huggingface.co/papers/2210.11416), which are good examples of how beneficial instruction-tuning can be for various tasks.
The figure below shows a formulation of instruction-tuning (also called “instruction-finetuning”). In the [FLAN V2 paper](https://huggingface.co/papers/2210.11416), the authors take a pre-trained language model ([T5](https://huggingface.co/docs/transformers/model_doc/t5), for example) and fine-tune it on a dataset of exemplars, as shown in the figure below.
| 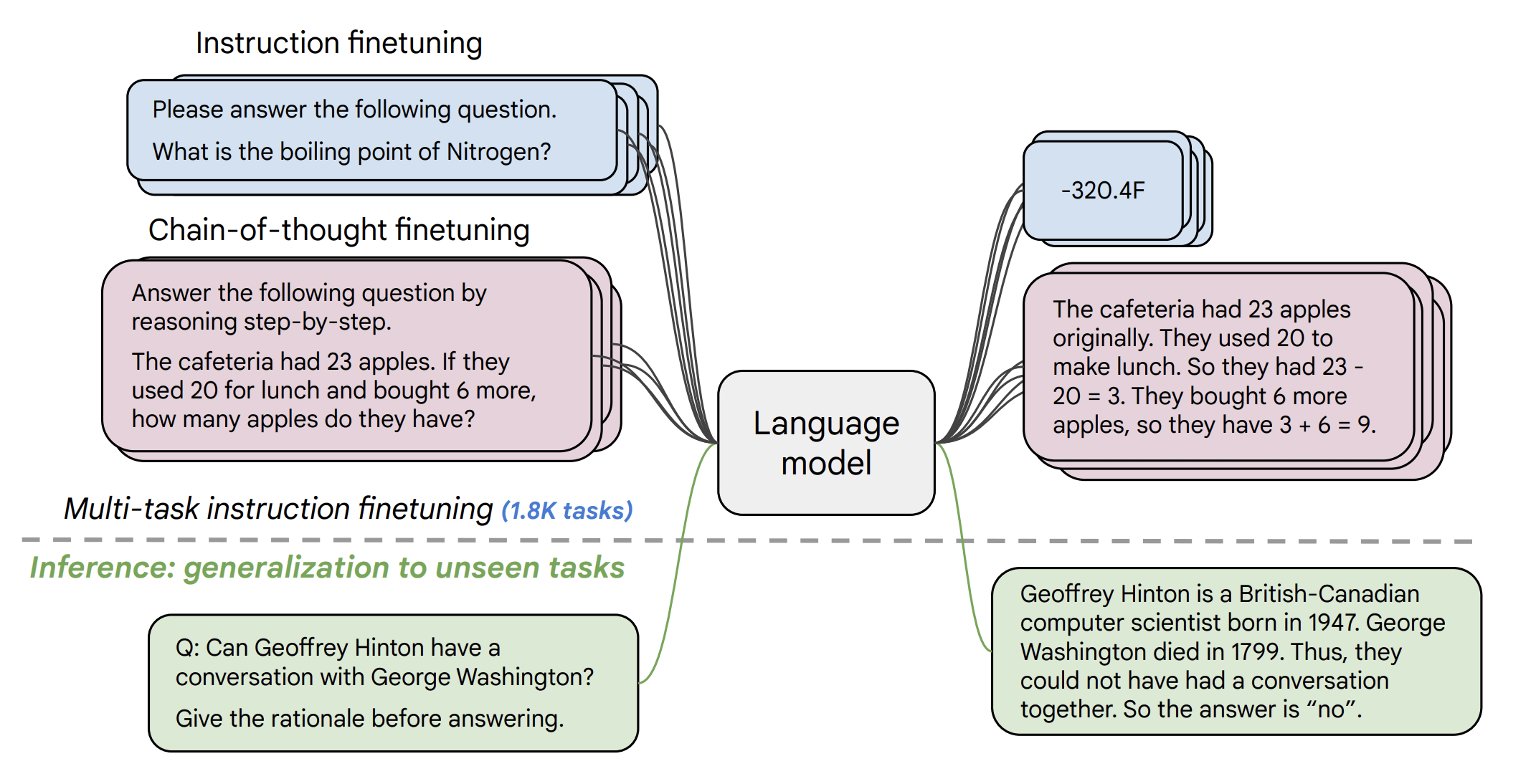 |
|:--:|
| **Figure 2**: FLAN V2 schematic (figure taken from the FLAN V2 paper). |
With this approach, one can create exemplars covering many different tasks, which makes instruction-tuning a multi-task training objective:
| **Input** | **Label** | **Task** |
|---|---|---|
| Predict the sentiment of the<br>following sentence: “The movie<br>was pretty amazing. I could not<br>turn around my eyes even for a<br>second.” | Positive | Sentiment analysis /<br>Sequence classification |
| Please answer the following<br>question. <br>What is the boiling point of<br>Nitrogen? | 320.4F | Question answering |
| Translate the following<br>English sentence into German: “I have<br>a cat.” | Ich habe eine Katze. | Machine translation |
| … | … | … |
| | | | |
Using a similar philosophy, the authors of FLAN V2 conduct instruction-tuning on a mixture of thousands of tasks and achieve zero-shot generalization to unseen tasks:
| 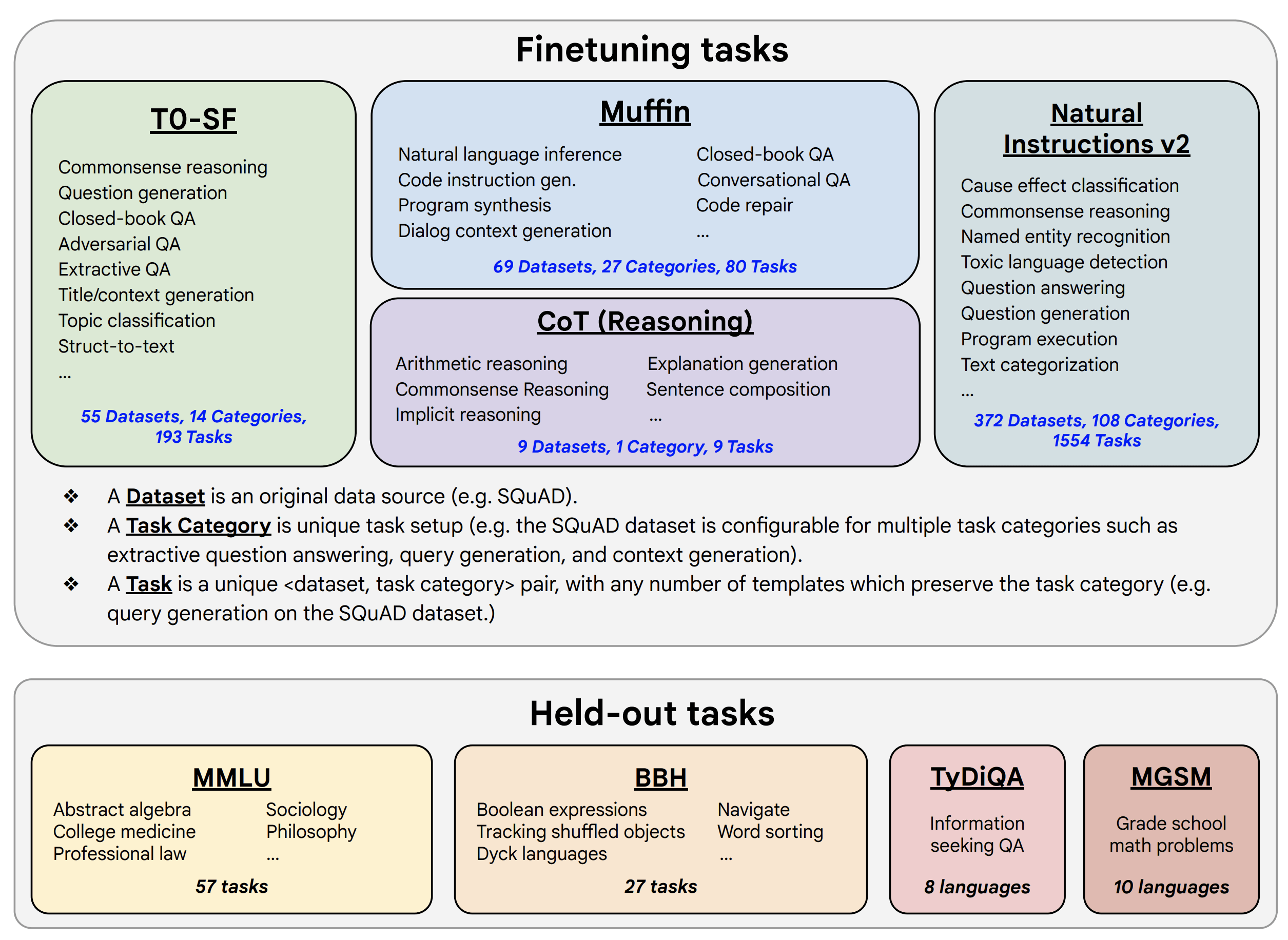 |
|:--:|
| **Figure 3**: FLAN V2 training and test task mixtures (figure taken from the FLAN V2 paper). |
Our motivation behind this work comes partly from the FLAN line of work and partly from InstructPix2Pix. We wanted to explore if it’s possible to prompt Stable Diffusion with specific instructions and input images to process them as per our needs.
The [pre-trained InstructPix2Pix models](https://huggingface.co/timbrooks/instruct-pix2pix) are good at following general instructions, but they may fall short of following instructions involving specific transformations:
|  |
|:--:|
| **Figure 4**: We observe that for the input images (left column), our models (right column) more faithfully perform “cartoonization” compared to the pre-trained InstructPix2Pix models (middle column). It is interesting to note the results of the first row where the pre-trained InstructPix2Pix models almost fail significantly. Figure best viewed in color and zoomed in. See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/cartoonization_results.png). |
But we can still leverage the findings from InstructPix2Pix to suit our customizations.
On the other hand, paired datasets for tasks like [cartoonization](https://github.com/SystemErrorWang/White-box-Cartoonization), [image denoising](https://paperswithcode.com/dataset/sidd), [image deraining](https://paperswithcode.com/dataset/raindrop), etc. are available publicly, which we can use to build instruction-prompted datasets taking inspiration from FLAN V2. Doing so allows us to transfer the instruction-templating ideas explored in FLAN V2 to this work.
## Dataset preparation
### Cartoonization
In our early experiments, we prompted InstructPix2Pix to perform cartoonization and the results were not up to our expectations. We tried various inference-time hyperparameter combinations (such as image guidance scale and the number of inference steps), but the results still were not compelling. This motivated us to approach the problem differently.
As hinted in the previous section, we wanted to benefit from both worlds:
**(1)** training methodology of InstructPix2Pix and
**(2)** the flexibility of creating instruction-prompted dataset templates from FLAN.
We started by creating an instruction-prompted dataset for the task of cartoonization. Figure 5 presents our dataset creation pipeline:
| 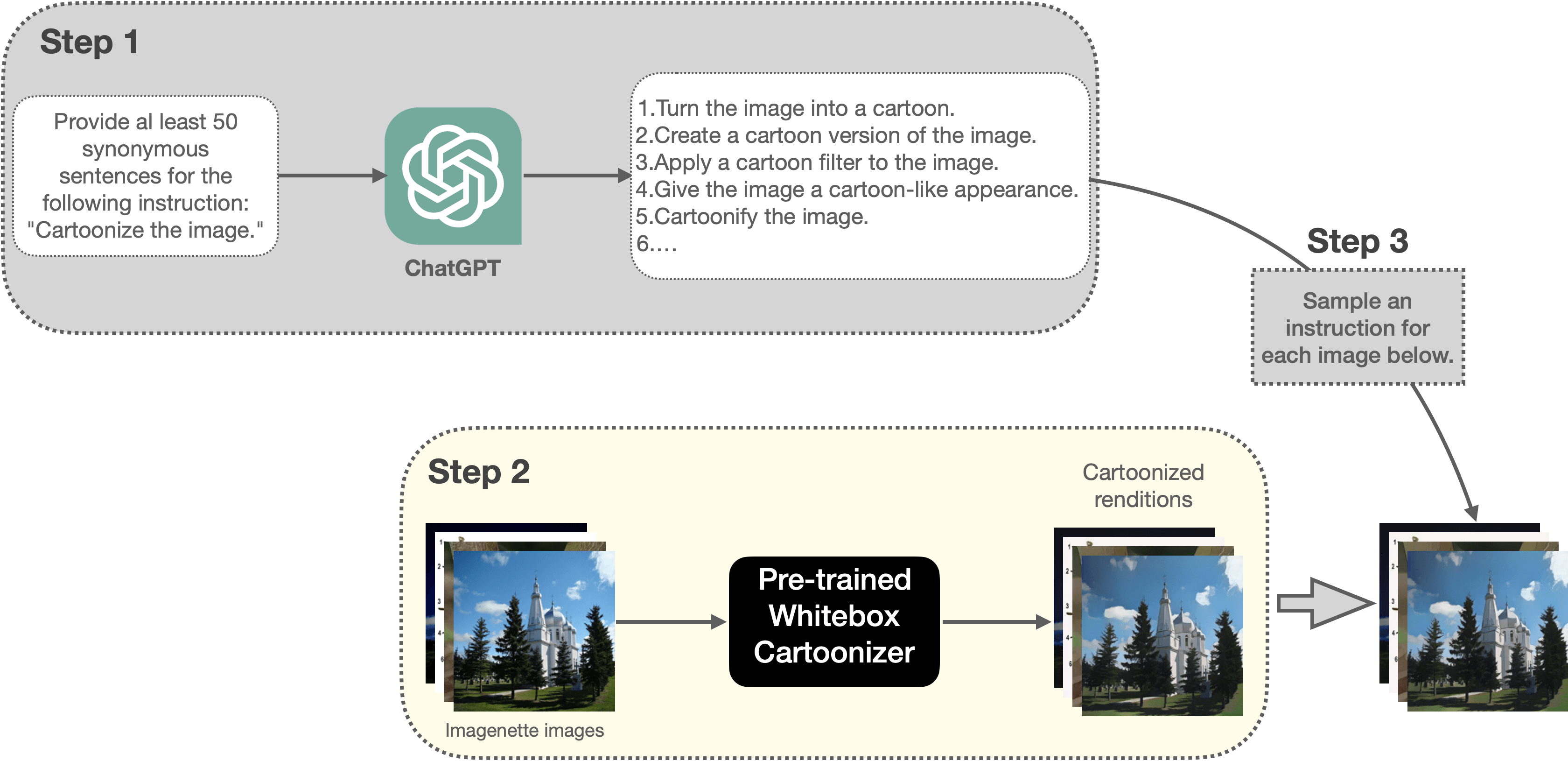 |
|:--:|
| **Figure 5**: A depiction of our dataset creation pipeline for cartoonization (best viewed in color and zoomed in). |
In particular, we:
1. Ask [ChatGPT](https://openai.com/blog/chatgpt) to generate 50 synonymous sentences for the following instruction: "Cartoonize the image.”
2. We then use a random sub-set (5000 samples) of the [Imagenette dataset](https://github.com/fastai/imagenette) and leverage a pre-trained [Whitebox CartoonGAN](https://github.com/SystemErrorWang/White-box-Cartoonization) model to produce the cartoonized renditions of those images. The cartoonized renditions are the labels we want our model to learn from. So, in a way, this corresponds to transferring the biases learned by the Whitebox CartoonGAN model to our model.
3. Then we create our exemplars in the following format:
| 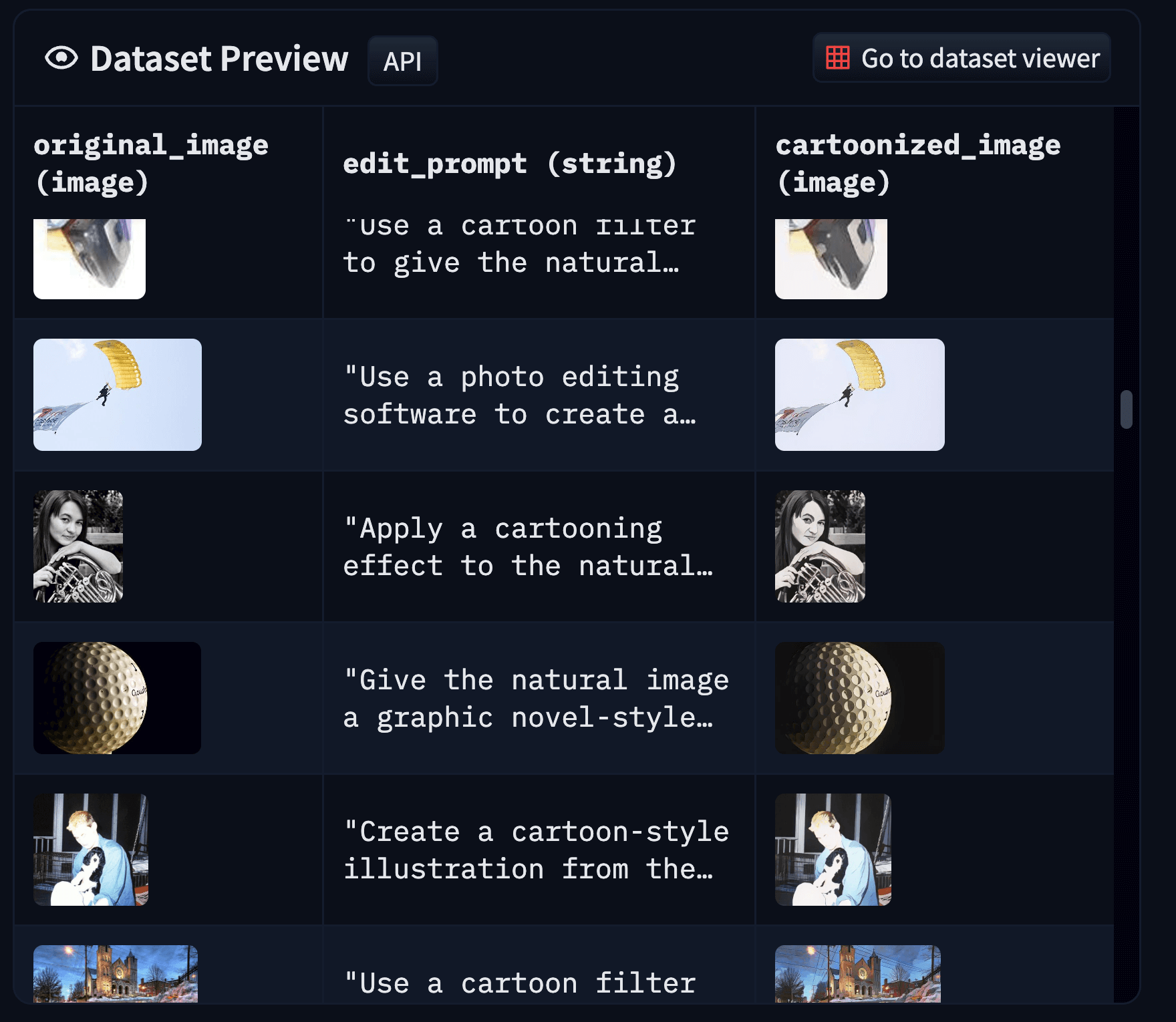 |
|:--:|
| **Figure 6**: Samples from the final cartoonization dataset (best viewed in color and zoomed in). |
Our final dataset for cartoonization can be found [here](https://huggingface.co/datasets/instruction-tuning-vision/cartoonizer-dataset). For more details on how the dataset was prepared, refer to [this directory](https://github.com/huggingface/instruction-tuned-sd/tree/main/data_preparation). We experimented with this dataset by fine-tuning InstructPix2Pix and got promising results (more details in the “Training experiments and results” section).
We then proceeded to see if we could generalize this approach to low-level image processing tasks such as image deraining, image denoising, and image deblurring.
### Low-level image processing
We focus on the common low-level image processing tasks explored in [MAXIM](https://huggingface.co/papers/2201.02973). In particular, we conduct our experiments for the following tasks: deraining, denoising, low-light image enhancement, and deblurring.
We took different number of samples from the following datasets for each task and constructed a single dataset with prompts added like so:
| **Task** | **Prompt** | **Dataset** | **Number of samples** |
|---|---|---|---|
| Deblurring | “deblur the blurry image” | [REDS](https://seungjunnah.github.io/Datasets/reds.html) (`train_blur`<br>and `train_sharp`) | 1200 |
| Deraining | “derain the image” | [Rain13k](https://github.com/megvii-model/HINet#image-restoration-tasks) | 686 |
| Denoising | “denoise the noisy image” | [SIDD](https://www.eecs.yorku.ca/~kamel/sidd/) | 8 |
| Low-light<br>image enhancement | "enhance the low-light image” | [LOL](https://paperswithcode.com/dataset/lol) | 23 |
| | | | |
Datasets mentioned above typically come as input-output pairs, so we do not have to worry about the ground-truth. Our final dataset is available [here](https://huggingface.co/datasets/instruction-tuning-vision/instruct-tuned-image-processing). The final dataset looks like so:
| 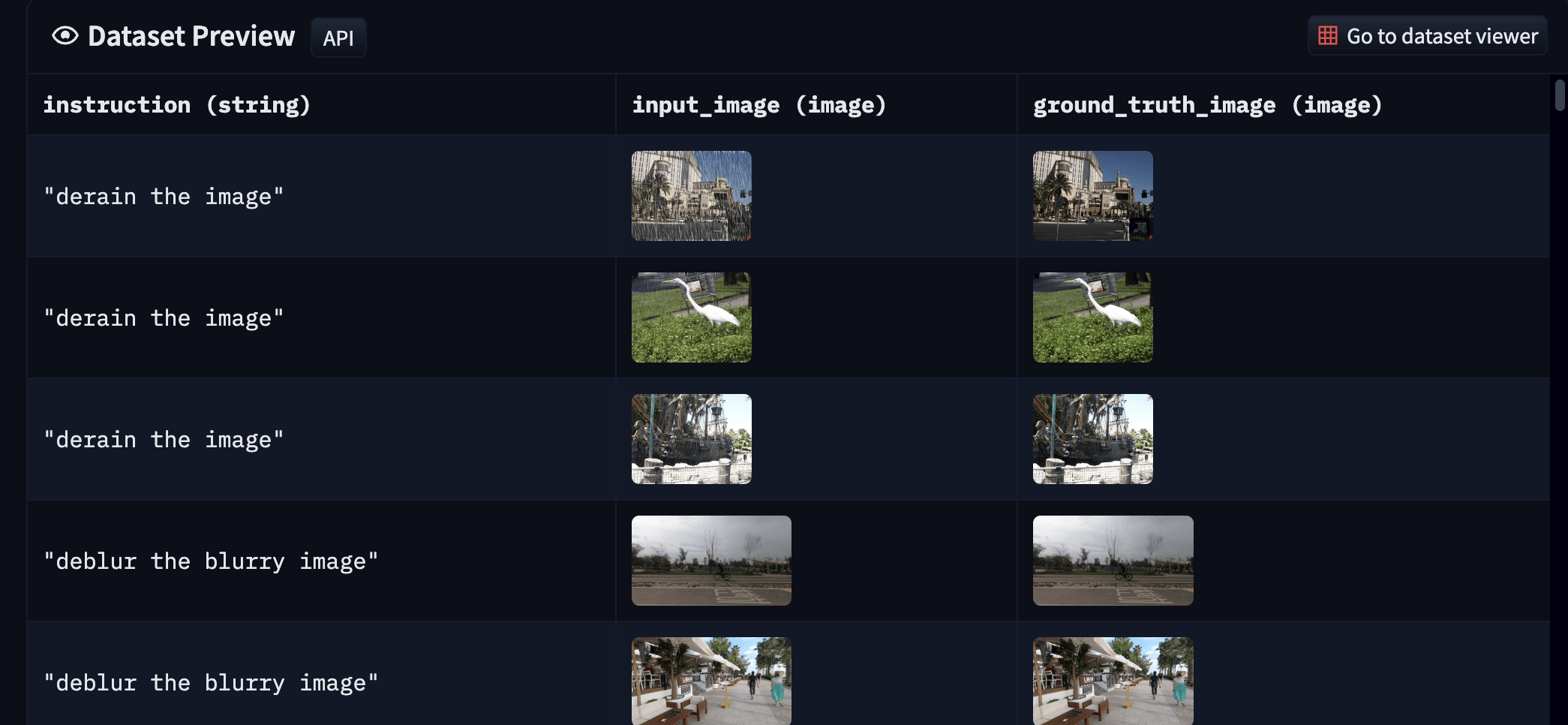 |
|:--:|
| **Figure 7**: Samples from the final low-level image processing dataset (best viewed in color and zoomed in). |
Overall, this setup helps draw parallels from the FLAN setup, where we create a mixture of different tasks. This also helps us train a single model one time, performing well to the different tasks we have in the mixture. This varies significantly from what is typically done in low-level image processing. Works like MAXIM introduce a single model architecture capable of modeling the different low-level image processing tasks, but training happens independently on the individual datasets.
## Training experiments and results
We based our training experiments on [this script](https://github.com/huggingface/diffusers/blob/main/examples/instruct_pix2pix/train_instruct_pix2pix.py). Our training logs (including validation samples and training hyperparameters) are available on Weight and Biases:
- [Cartoonization](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/wszjpb1b) ([hyperparameters](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/wszjpb1b/overview?workspace=))
- [Low-level image processing](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/2kg5wohb) ([hyperparameters](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/2kg5wohb/overview?workspace=))
When training, we explored two options:
1. Fine-tuning from an existing [InstructPix2Pix checkpoint](https://huggingface.co/timbrooks/instruct-pix2pix)
2. Fine-tuning from an existing [Stable Diffusion checkpoint](https://huggingface.co/runwayml/stable-diffusion-v1-5) using the InstructPix2Pix training methodology
In our experiments, we found out that the first option helps us adapt to our datasets faster (in terms of generation quality).
For more details on the training and hyperparameters, we encourage you to check out [our code](https://github.com/huggingface/instruction-tuned-sd) and the respective run pages on Weights and Biases.
### Cartoonization results
For testing the [instruction-tuned cartoonization model](https://huggingface.co/instruction-tuning-sd/cartoonizer), we compared the outputs as follows:
|  |
|:--:|
| **Figure 8**: We compare the results of our instruction-tuned cartoonization model (last column) with that of a [CartoonGAN](https://github.com/SystemErrorWang/White-box-Cartoonization) model (column two) and the pre-trained InstructPix2Pix model (column three). It’s evident that the instruction-tuned model can more faithfully match the outputs of the CartoonGAN model. Figure best viewed in color and zoomed in. See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/cartoonization_full_results.png). |
To gather these results, we sampled images from the `validation` split of ImageNette. We used the following prompt when using our model and the pre-trained InstructPix2Pix model: *“Generate a cartoonized version of the image”.* For these two models, we kept the `image_guidance_scale` and `guidance_scale` to 1.5 and 7.0, respectively, and number of inference steps to 20. Indeed more experimentation is needed around these hyperparameters to study how they affect the results of the pre-trained InstructPix2Pix model, in particular.
More comparative results are available [here](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/g6cvggw2). Our code for comparing these models is available [here](https://github.com/huggingface/instruction-tuned-sd/blob/main/validation/compare_models.py).
Our model, however, [fails to produce](https://wandb.ai/sayakpaul/instruction-tuning-sd/runs/g6cvggw2) the expected outputs for the classes from ImageNette, which it has not seen enough during training. This is somewhat expected, and we believe this could be mitigated by scaling the training dataset.
### Low-level image processing results
For low-level image processing ([our model](https://huggingface.co/instruction-tuning-sd/low-level-img-proc)), we follow the same inference-time hyperparameters as above:
- Number of inference steps: 20
- Image guidance scale: 1.5
- Guidance scale: 7.0
For deraining, our model provides compelling results when compared to the ground-truth and the output of the pre-trained InstructPix2Pix model:
|  |
|:--:|
| **Figure 9**: Deraining results (best viewed in color and zoomed in). Inference prompt: “derain the image” (same as the training set). See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/deraining_results.png). |
However, for low-light image enhancement, it leaves a lot to be desired:
|  |
|:--:|
| **Figure 10**: Low-light image enhancement results (best viewed in color and zoomed in). Inference prompt: “enhance the low-light image” (same as the training set). See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/image_enhancement_results.png). |
This failure, perhaps, can be attributed to our model not seeing enough exemplars for the task and possibly from better training. We notice similar findings for deblurring as well:
|  |
|:--:|
| **Figure 11**: Deblurring results (best viewed in color and zoomed in). Inference prompt: “deblur the image” (same as the training set). See original [here](https://huggingface.co/datasets/sayakpaul/sample-datasets/resolve/main/Instruction-tuning-sd/deblurring_results.png). |
We believe there is an opportunity for the community to explore how much the task mixture for low-level image processing affects the end results. *Does increasing the task mixture with more representative samples help improve the end results?* We leave this question for the community to explore further.
You can try out the interactive demo below to make Stable Diffusion follow specific instructions:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.29.0/gradio.js"></script>
<gradio-app theme_mode="light" src="https://instruction-tuning-sd-instruction-tuned-sd.hf.space"></gradio-app>
## Potential applications and limitations
In the world of image editing, there is a disconnect between what a domain expert has in mind (the tasks to be performed) and the actions needed to be applied in editing tools (such as [Lightroom](https://www.adobe.com/in/products/photoshop-lightroom.html)). Having an easy way of translating natural language goals to low-level image editing primitives would be a seamless user experience. With the introduction of mechanisms like InstructPix2Pix, it’s safe to say that we’re getting closer to that realm.
However, challenges still remain:
- These systems need to work for large high-resolution original images.
- Diffusion models often invent or re-interpret an instruction to perform the modifications in the image space. For a realistic image editing application, this is unacceptable.
## Open questions
We acknowledge that our experiments are preliminary. We did not go deep into ablating the apparent factors in our experiments. Hence, here we enlist a few open questions that popped up during our experiments:
- ***What happens we scale up the datasets?*** How does that impact the quality of the generated samples? We experimented with a handful of examples. For comparison, InstructPix2Pix was trained on more than 30000 samples.
- ***What is the impact of training for longer, especially when the task mixture is broader?*** In our experiments, we did not conduct hyperparameter tuning, let alone an ablation on the number of training steps.
- ***How does this approach generalize to a broader mixture of tasks commonly done in the “instruction-tuning” world?*** We only covered four tasks for low-level image processing: deraining, deblurring, denoising, and low-light image enhancement. Does adding more tasks to the mixture with more representative samples help the model generalize to unseen tasks or, perhaps, a combination of tasks (example: “Deblur the image and denoise it”)?
- ***Does using different variations of the same instruction on-the-fly help improve performance?*** For cartoonization, we randomly sampled an instruction from the set of ChatGPT-generated synonymous instructions **during** dataset creation. But what happens when we perform random sampling during training instead?
For low-level image processing, we used fixed instructions. What happens when we follow a similar methodology of using synonymous instructions for each task and input image?
- ***What happens when we use ControlNet training setup, instead?*** [ControlNet](https://huggingface.co/papers/2302.05543) also allows adapting a pre-trained text-to-image diffusion model to be conditioned on additional images (such as semantic segmentation maps, canny edge maps, etc.). If you’re interested, then you can use the datasets presented in this post and perform ControlNet training referring to [this post](https://huggingface.co/blog/train-your-controlnet).
## Conclusion
In this post, we presented our exploration of “instruction-tuning” of Stable Diffusion. While pre-trained InstructPix2Pix are good at following general image editing instructions, they may break when presented with more specific instructions. To mitigate that, we discussed how we prepared our datasets for further fine-tuning InstructPix2Pix and presented our results. As noted above, our results are still preliminary. But we hope this work provides a basis for the researchers working on similar problems and they feel motivated to explore the open questions further.
## Links
- Training and inference code: [https://github.com/huggingface/instruction-tuned-sd](https://github.com/huggingface/instruction-tuned-sd)
- Demo: [https://huggingface.co/spaces/instruction-tuning-sd/instruction-tuned-sd](https://huggingface.co/spaces/instruction-tuning-sd/instruction-tuned-sd)
- InstructPix2Pix: [https://huggingface.co/timbrooks/instruct-pix2pix](https://huggingface.co/timbrooks/instruct-pix2pix)
- Datasets and models from this post: [https://huggingface.co/instruction-tuning-sd](https://huggingface.co/instruction-tuning-sd)
*Thanks to [Alara Dirik](https://www.linkedin.com/in/alaradirik/) and [Zhengzhong Tu](https://www.linkedin.com/in/zhengzhongtu) for the helpful discussions. Thanks to [Pedro Cuenca](https://twitter.com/pcuenq?lang=en) and [Kashif Rasul](https://twitter.com/krasul?lang=en) for their helpful reviews on the post.*
## Citation
To cite this work, please use the following citation:
```bibtex
@article{
Paul2023instruction-tuning-sd,
author = {Paul, Sayak},
title = {Instruction-tuning Stable Diffusion with InstructPix2Pix},
journal = {Hugging Face Blog},
year = {2023},
note = {https://huggingface.co/blog/instruction-tuning-sd},
}
``` | 3 |
0 | hf_public_repos | hf_public_repos/blog/bloom.md | ---
title: "Introducing The World's Largest Open Multilingual Language Model: BLOOM"
thumbnail: /blog/assets/86_bloom/thumbnail.png
authors:
- user: bigscience
---
# 🌸 Introducing The World's Largest Open Multilingual Language Model: BLOOM 🌸
<a href="https://huggingface.co/bigscience/bloom"><img style="middle" width="950" src="/blog/assets/86_bloom/thumbnail-2.png"></a>
Large language models (LLMs) have made a significant impact on AI research. These powerful, general models can take on a wide variety of new language tasks from a user’s instructions. However, academia, nonprofits and smaller companies' research labs find it difficult to create, study, or even use LLMs as only a few industrial labs with the necessary resources and exclusive rights can fully access them. Today, we release [BLOOM](https://huggingface.co/bigscience/bloom), the first multilingual LLM trained in complete transparency, to change this status quo — the result of the largest collaboration of AI researchers ever involved in a single research project.
With its 176 billion parameters, BLOOM is able to generate text in 46 natural languages and 13 programming languages. For almost all of them, such as Spanish, French and Arabic, BLOOM will be the first language model with over 100B parameters ever created. This is the culmination of a year of work involving over 1000 researchers from 70+ countries and 250+ institutions, leading to a final run of 117 days (March 11 - July 6) training the BLOOM model on the [Jean Zay supercomputer](http://www.idris.fr/eng/info/missions-eng.html) in the south of Paris, France thanks to a compute grant worth an estimated €3M from French research agencies CNRS and GENCI.
Researchers can [now download, run and study BLOOM](https://huggingface.co/bigscience/bloom) to investigate the performance and behavior of recently developed large language models down to their deepest internal operations. More generally, any individual or institution who agrees to the terms of the model’s [Responsible AI License](https://bigscience.huggingface.co/blog/the-bigscience-rail-license) (developed during the BigScience project itself) can use and build upon the model on a local machine or on a cloud provider. In this spirit of collaboration and continuous improvement, we’re also releasing, for the first time, the intermediary checkpoints and optimizer states of the training. Don’t have 8 A100s to play with? An inference API, currently backed by Google’s TPU cloud and a FLAX version of the model, also allows quick tests, prototyping, and lower-scale use. You can already play with it on the Hugging Face Hub.
<img class="mx-auto" style="center" width="950" src="/blog/assets/86_bloom/bloom-examples.jpg"></a>
This is only the beginning. BLOOM’s capabilities will continue to improve as the workshop continues to experiment and tinker with the model. We’ve started work to make it instructable as our earlier effort T0++ was and are slated to add more languages, compress the model into a more usable version with the same level of performance, and use it as a starting point for more complex architectures… All of the experiments researchers and practitioners have always wanted to run, starting with the power of a 100+ billion parameter model, are now possible. BLOOM is the seed of a living family of models that we intend to grow, not just a one-and-done model, and we’re ready to support community efforts to expand it.
| 4 |
0 | hf_public_repos | hf_public_repos/blog/hub-duckdb.md | ---
title: "DuckDB: analyze 50,000+ datasets stored on the Hugging Face Hub"
thumbnail: /blog/assets/hub_duckdb/hub_duckdb.png
authors:
- user: stevhliu
- user: lhoestq
- user: severo
---
# DuckDB: run SQL queries on 50,000+ datasets on the Hugging Face Hub
The Hugging Face Hub is dedicated to providing open access to datasets for everyone and giving users the tools to explore and understand them. You can find many of the datasets used to train popular large language models (LLMs) like [Falcon](https://huggingface.co/datasets/tiiuae/falcon-refinedweb), [Dolly](https://huggingface.co/datasets/databricks/databricks-dolly-15k), [MPT](https://huggingface.co/datasets/mosaicml/dolly_hhrlhf), and [StarCoder](https://huggingface.co/datasets/bigcode/the-stack). There are tools for addressing fairness and bias in datasets like [Disaggregators](https://huggingface.co/spaces/society-ethics/disaggregators), and tools for previewing examples inside a dataset like the Dataset Viewer.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/datasets-server/oasst1_light.png"/>
</div>
<small>A preview of the OpenAssistant dataset with the Dataset Viewer.</small>
We are happy to share that we recently added another feature to help you analyze datasets on the Hub; you can run SQL queries with DuckDB on any dataset stored on the Hub! According to the 2022 [StackOverflow Developer Survey](https://survey.stackoverflow.co/2022/#section-most-popular-technologies-programming-scripting-and-markup-languages), SQL is the 3rd most popular programming language. We also wanted a fast database management system (DBMS) designed for running analytical queries, which is why we’re excited about integrating with [DuckDB](https://duckdb.org/). We hope this allows even more users to access and analyze datasets on the Hub!
## TLDR
The [dataset viewer](https://huggingface.co/docs/datasets-server/index) **automatically converts all public datasets on the Hub to Parquet files**, that you can see by clicking on the "Auto-converted to Parquet" button at the top of a dataset page. You can also access the list of the Parquet files URLs with a simple HTTP call.
```py
r = requests.get("https://datasets-server.huggingface.co/parquet?dataset=blog_authorship_corpus")
j = r.json()
urls = [f['url'] for f in j['parquet_files'] if f['split'] == 'train']
urls
['https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00000-of-00002.parquet',
'https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00001-of-00002.parquet']
```
Create a connection to DuckDB and install and load the `httpfs` extension to allow reading and writing remote files:
```py
import duckdb
url = "https://huggingface.co/datasets/blog_authorship_corpus/resolve/refs%2Fconvert%2Fparquet/blog_authorship_corpus/blog_authorship_corpus-train-00000-of-00002.parquet"
con = duckdb.connect()
con.execute("INSTALL httpfs;")
con.execute("LOAD httpfs;")
```
Once you’re connected, you can start writing SQL queries!
```sql
con.sql(f"""SELECT horoscope,
count(*),
AVG(LENGTH(text)) AS avg_blog_length
FROM '{url}'
GROUP BY horoscope
ORDER BY avg_blog_length
DESC LIMIT(5)"""
)
```
To learn more, check out the [documentation](https://huggingface.co/docs/datasets-server/parquet_process).
## From dataset to Parquet
[Parquet](https://parquet.apache.org/docs/) files are columnar, making them more efficient to store, load and analyze. This is especially important when you're working with large datasets, which we’re seeing more and more of in the LLM era. To support this, the dataset viewer automatically converts and publishes any public dataset on the Hub as Parquet files. The URL to the Parquet files can be retrieved with the [`/parquet`](https://huggingface.co/docs/datasets-server/quick_start#access-parquet-files) endpoint.
## Analyze with DuckDB
DuckDB offers super impressive performance for running complex analytical queries. It is able to execute a SQL query directly on a remote Parquet file without any overhead. With the [`httpfs`](https://duckdb.org/docs/extensions/httpfs) extension, DuckDB is able to query remote files such as datasets stored on the Hub using the URL provided from the `/parquet` endpoint. DuckDB also supports querying multiple Parquet files which is really convenient because the dataset viewer shards big datasets into smaller 500MB chunks.
## Looking forward
Knowing what’s inside a dataset is important for developing models because it can impact model quality in all sorts of ways! By allowing users to write and execute any SQL query on Hub datasets, this is another way for us to enable open access to datasets and help users be more aware of the datasets contents. We are excited for you to try this out, and we’re looking forward to what kind of insights your analysis uncovers!
| 5 |
0 | hf_public_repos | hf_public_repos/blog/trl-ddpo.md | ---
title: "Finetune Stable Diffusion Models with DDPO via TRL"
thumbnail: /blog/assets/166_trl_ddpo/thumbnail.png
authors:
- user: metric-space
guest: true
- user: sayakpaul
- user: kashif
- user: lvwerra
---
# Finetune Stable Diffusion Models with DDPO via TRL
## Introduction
Diffusion models (e.g., DALL-E 2, Stable Diffusion) are a class of generative models that are widely successful at generating images most notably of the photorealistic kind. However, the images generated by these models may not always be on par with human preference or human intention. Thus arises the alignment problem i.e. how does one go about making sure that the outputs of a model are aligned with human preferences like “quality” or that outputs are aligned with intent that is hard to express via prompts? This is where Reinforcement Learning comes into the picture.
In the world of Large Language Models (LLMs), Reinforcement learning (RL) has proven to become a very effective tool for aligning said models to human preferences. It’s one of the main recipes behind the superior performance of systems like ChatGPT. More precisely, RL is the critical ingredient of Reinforcement Learning from Human Feedback (RLHF), which makes ChatGPT chat like human beings.
In [Training Diffusion Models with Reinforcement Learning, Black](https://arxiv.org/abs/2305.13301) et al. show how to augment diffusion models to leverage RL to fine-tune them with respect to an objective function via a method named Denoising Diffusion Policy Optimization (DDPO).
In this blog post, we discuss how DDPO came to be, a brief description of how it works, and how DDPO can be incorporated into an RLHF workflow to achieve model outputs more aligned with the human aesthetics. We then quickly switch gears to talk about how you can apply DDPO to your models with the newly integrated `DDPOTrainer` from the `trl` library and discuss our findings from running DDPO on Stable Diffusion.
## The Advantages of DDPO
DDPO is not the only working answer to the question of how to attempt to fine-tune diffusion models with RL.
Before diving in, there are two key points to remember when it comes to understanding the advantages of one RL solution over the other
1. Computational efficiency is key. The more complicated your data distribution gets, the higher your computational costs get.
2. Approximations are nice, but because approximations are not the real thing, associated errors stack up.
Before DDPO, Reward-weighted regression (RWR) was an established way of using Reinforcement Learning to fine-tune diffusion models. RWR reuses the denoising loss function of the diffusion model along with training data sampled from the model itself and per-sample loss weighting that depends on the reward associated with the final samples. This algorithm ignores the intermediate denoising steps/samples. While this works, two things should be noted:
1. Optimizing by weighing the associated loss, which is a maximum likelihood objective, is an approximate optimization
2. The associated loss is not an exact maximum likelihood objective but an approximation that is derived from a reweighed variational bound
The two orders of approximation have a significant impact on both performance and the ability to handle complex objectives.
DDPO uses this method as a starting point. Rather than viewing the denoising step as a single step by only focusing on the final sample, DDPO frames the whole denoising process as a multistep Markov Decision Process (MDP) where the reward is received at the very end. This formulation in addition to using a fixed sampler paves the way for the agent policy to become an isotropic Gaussian as opposed to an arbitrarily complicated distribution. So instead of using the approximate likelihood of the final sample (which is the path RWR takes), here the exact likelihood of each denoising step which is extremely easy to compute ( \\( \ell(\mu, \sigma^2; x) = -\frac{n}{2} \log(2\pi) - \frac{n}{2} \log(\sigma^2) - \frac{1}{2\sigma^2} \sum_{i=1}^n (x_i - \mu)^2 \\) ).
If you’re interested in learning more details about DDPO, we encourage you to check out the [original paper](https://arxiv.org/abs/2305.13301) and the [accompanying blog post](https://bair.berkeley.edu/blog/2023/07/14/ddpo/).
## DDPO algorithm briefly
Given the MDP framework used to model the sequential nature of the denoising process and the rest of the considerations that follow, the tool of choice to tackle the optimization problem is a policy gradient method. Specifically Proximal Policy Optimization (PPO). The whole DDPO algorithm is pretty much the same as Proximal Policy Optimization (PPO) but as a side, the portion that stands out as highly customized is the trajectory collection portion of PPO
Here’s a diagram to summarize the flow:
## DDPO and RLHF: a mix to enforce aestheticness
The general training aspect of [RLHF](https://huggingface.co/blog/rlhf) can roughly be broken down into the following steps:
1. Supervised fine-tuning a “base” model learns to the distribution of some new data
2. Gathering preference data and training a reward model using it.
3. Fine-tuning the model with reinforcement learning using the reward model as a signal.
It should be noted that preference data is the primary source for capturing human feedback in the context of RLHF.
When we add DDPO to the mix, the workflow gets morphed to the following:
1. Starting with a pretrained Diffusion Model
2. Gathering preference data and training a reward model using it.
3. Fine-tuning the model with DDPO using the reward model as a signal
Notice that step 3 from the general RLHF workflow is missing in the latter list of steps and this is because empirically it has been shown (as you will get to see yourself) that this is not needed.
To get on with our venture to get a diffusion model to output images more in line with the human perceived notion of what it means to be aesthetic, we follow these steps:
1. Starting with a pretrained Stable Diffusion (SD) Model
2. Training a frozen [CLIP](https://huggingface.co/openai/clip-vit-large-patch14) model with a trainable regression head on the [Aesthetic Visual Analysis](http://refbase.cvc.uab.es/files/MMP2012a.pdf) (AVA) dataset to predict how much people like an input image on average
3. Fine-tuning the SD model with DDPO using the aesthetic predictor model as the reward signaller
We keep these steps in mind while moving on to actually getting these running which is described in the following sections.
## Training Stable Diffusion with DDPO
### Setup
To get started, when it comes to the hardware side of things and this implementation of DDPO, at the very least access to an A100 NVIDIA GPU is required for successful training. Anything below this GPU type will soon run into Out-of-memory issues.
Use pip to install the `trl` library
```bash
pip install trl[diffusers]
```
This should get the main library installed. The following dependencies are for tracking and image logging. After getting `wandb` installed, be sure to login to save the results to a personal account
```bash
pip install wandb torchvision
```
Note: you could choose to use `tensorboard` rather than `wandb` for which you’d want to install the `tensorboard` package via `pip`.
### A Walkthrough
The main classes within the `trl` library responsible for DDPO training are the `DDPOTrainer` and `DDPOConfig` classes. See [docs](https://huggingface.co/docs/trl/ddpo_trainer#getting-started-with-examplesscriptsstablediffusiontuningpy) for more general info on the `DDPOTrainer` and `DDPOConfig`. There is an [example training script](https://github.com/huggingface/trl/blob/main/examples/scripts/ddpo.py) in the `trl` repo. It uses both of these classes in tandem with default implementations of required inputs and default parameters to finetune a default pretrained Stable Diffusion Model from `RunwayML` .
This example script uses `wandb` for logging and uses an aesthetic reward model whose weights are read from a public facing HuggingFace repo (so gathering data and training the aesthetic reward model is already done for you). The default prompt dataset used is a list of animal names.
There is only one commandline flag argument that is required of the user to get things up and running. Additionally, the user is expected to have a [huggingface user access token](https://huggingface.co/docs/hub/security-tokens) that will be used to upload the model post finetuning to HuggingFace hub.
The following bash command gets things running:
```python
python ddpo.py --hf_user_access_token <token>
```
The following table contains key hyperparameters that are directly correlated with positive results:
| Parameter | Description | Recommended value for single GPU training (as of now) |
| --- | --- | --- |
| `num_epochs` | The number of epochs to train for | 200 |
| `train_batch_size` | The batch size to use for training | 3 |
| `sample_batch_size` | The batch size to use for sampling | 6 |
| `gradient_accumulation_steps` | The number of accelerator based gradient accumulation steps to use | 1 |
| `sample_num_steps` | The number of steps to sample for | 50 |
| `sample_num_batches_per_epoch` | The number of batches to sample per epoch | 4 |
| `per_prompt_stat_tracking` | Whether to track stats per prompt. If false, advantages will be calculated using the mean and std of the entire batch as opposed to tracking per prompt | `True` |
| `per_prompt_stat_tracking_buffer_size` | The size of the buffer to use for tracking stats per prompt | 32 |
| `mixed_precision` | Mixed precision training | `True` |
| `train_learning_rate` | Learning rate | 3e-4 |
The provided script is merely a starting point. Feel free to adjust the hyperparameters or even overhaul the script to accommodate different objective functions. For instance, one could integrate a function that gauges JPEG compressibility or [one that evaluates visual-text alignment using a multi-modal model](https://github.com/kvablack/ddpo-pytorch/blob/main/ddpo_pytorch/rewards.py#L45), among other possibilities.
## Lessons learned
1. The results seem to generalize over a wide variety of prompts despite the minimally sized training prompts size. This has been thoroughly verified for the objective function that rewards aesthetics
2. Attempts to try to explicitly generalize at least for the aesthetic objective function by increasing the training prompt size and varying the prompts seem to slow down the convergence rate for barely noticeable learned general behavior if at all this exists
3. While LoRA is recommended and is tried and tested multiple times, the non-LoRA is something to consider, among other reasons from empirical evidence, non-Lora does seem to produce relatively more intricate images than LoRA. However, getting the right hyperparameters for a stable non-LoRA run is significantly more challenging.
4. Recommendations for the config parameters for non-Lora are: set the learning rate relatively low, something around `1e-5` should do the trick and set `mixed_precision` to `None`
## Results
The following are pre-finetuned (left) and post-finetuned (right) outputs for the prompts `bear`, `heaven` and `dune` (each row is for the outputs of a single prompt):
| pre-finetuned | post-finetuned |
|:-------------------------:|:-------------------------:|
|  |  |
|  |  |
|  |  |
## Limitations
1. Right now `trl`'s DDPOTrainer is limited to finetuning vanilla SD models;
2. In our experiments we primarily focused on LoRA which works very well. We did a few experiments with full training which can lead to better quality but finding the right hyperparameters is more challenging.
## Conclusion
Diffusion models like Stable Diffusion, when fine-tuned using DDPO, can offer significant improvements in the quality of generated images as perceived by humans or any other metric once properly conceptualized as an objective function
The computational efficiency of DDPO and its ability to optimize without relying on approximations, especially over earlier methods to achieve the same goal of fine-tuning diffusion models, make it a suitable candidate for fine-tuning diffusion models like Stable Diffusion
`trl` library's `DDPOTrainer` implements DDPO for finetuning SD models.
Our experimental findings underline the strength of DDPO in generalizing across a broad range of prompts, although attempts at explicit generalization through varying prompts had mixed results. The difficulty of finding the right hyperparameters for non-LoRA setups also emerged as an important learning.
DDPO is a promising technique to align diffusion models with any reward function and we hope that with the release in TRL we can make it more accessible to the community!
## Acknowledgements
Thanks to Chunte Lee for the thumbnail of this blog post.
| 6 |
0 | hf_public_repos | hf_public_repos/blog/benczechmark.md | ---
title: "🇨🇿 BenCzechMark - Can your LLM Understand Czech?"
thumbnail: /blog/assets/187_benczechmark/thumbnail.png
authors:
- user: mfajcik
guest: true
org: BUT-FIT
- user: hynky
- user: mdocekal
guest: true
org: BUT-FIT
- user: xdolez52
guest: true
org: BUT-FIT
- user: jstetina
guest: true
org: BUT-FIT
- user: Lakoc
guest: true
org: BUT-FIT
- user: popelucha
guest: true
org: MU-NLPC
- user: hales
guest: true
org: MU-NLPC
- user: michal-stefanik
guest: true
org: MU-NLPC
- user: Adamiros
guest: true
org: CIIRC-NLP
- user: davidamczyk
guest: true
org: CIIRC-NLP
- user: janH
guest: true
org: CIIRC-NLP
- user: jsedivy
guest: true
org: CIIRC-NLP
---
# 🇨🇿 BenCzechMark - Can your LLM Understand Czech?
The 🇨🇿 BenCzechMark is the first and most comprehensive evaluation suite for assessing the abilities of Large Language Models (LLMs) in the Czech language. It aims to test how well LLMs can:
- Reason and perform complex tasks in Czech.
- Generate and verify grammatically and semantically correct Czech.
- Extract information and store knowledge by answering questions about Czech culture and Czech-related facts.
- Do what language models were originally trained for—estimate the probability of Czech texts.
To achieve this, we've sourced **50** tasks spanning **9** categories, with 90% of tasks having native, non-translated content.
In this blog, we introduce both the evaluation suite itself and the BenCzechMark leaderboard, featuring over **25** open-source models of various sizes!
<iframe space="CZLC/BenCzechMark" src="https://czlc-benczechmark.hf.space" width="100%" height="1200px" frameborder="0"></iframe>
## 📋 Tasks and Categories
The 🇨🇿 BenCzechMark (in it’s current version) is divided into **9** categories to comprehensively assess LLM abilities. For each task,
- We manually design at least 5 prompts, and record best performance and variance across prompts.
- We distinguish between 4 types of tasks, and associate them with metrics:
- **Accuracy** (Acc) measures multi-choice(MC) tasks,
- **Exact Match** (EM) measures tasks with open short answer generation,
- **Area Under the Receiver Operating Characteristic Curve** (AUROC, computed as average of one-vs-all in multi-class setting) measures the performance on classification tasks, without need for threshold calibration.
Out-of-the-box language models are often biased by the class distributions in their training data, the way prompts are structured, and the examples provided during inference. These biases can vary across models, making predictions inconsistent depending on the specific model and its influences. To ensure reliable decision-making on datasets with different class distributions, calibration is necessary to adjust the model's predictions. However, by using threshold-free metrics like AUROC, which focus on ranking rather than decision thresholds, calibration can be avoided entirely. This approach enables fairer model comparisons by eliminating the need for calibration (see e.g., [Zhaeo et al., 2021](https://proceedings.mlr.press/v139/zhao21c/zhao21c.pdf) for more details on calibration of LLMs).
- **Word-level Perplexity** (Ppl) is associated with language modeling tasks. It quantifies the likelihood the model would generate text with, normalized per number of words in corpus.
The translated portion of the dataset (10% of the total) was mostly translated via CUBBITT [LINDAT Translation](https://lindat.mff.cuni.cz/services/translation/), except for [CsFever](https://arxiv.org/abs/2201.11115), where the authors used [DeepL](https://www.deepl.com/) for translation.
This is the complete list of categories, alongside the datasets and metrics used:
1. **Reading Comprehension** tests whether the system can extract the answer for a question based on information provided in the context.
- *Belebele* - Acc - contains questions about manually translated web articles.
- *SQAD3.2* - EM - is a well-established reading comprehension task in SQuAD format, sourced from Wikipedia.
2. **Factual Knowledge** contains questions testing factual knowledge stored in the model.
- *Umimeto* (5 tasks focused on Biology/Chemistry/History/Informatics/Physics) - Acc - Elementary and high school questions from respective topics. Sourced from [umimeto.org](https://www.umimeto.org/).
- *TriviaQA* - EM (Translated using CUBITT) - contains Q/A from trivia and quiz-league websites (U.S. centric dataset).
- *NaturalQuestions* - EM (Translated using CUBITT) - contains Q/A from Google Search (U.S. centric dataset). We include these to ensure the model did not forget any EN-centric knowledge when prompted in Czech (i.e., after possible domain transfer).
3. **Czech Language Understanding** targets the peculiar understanding of syntactic structure and nuanced meaning in the Czech Language.
- *CERMAT* (Open/TF/MC) - EM/AUROC/Acc - focuses on understanding tasks sourced from 6th, 9th-year primary school tests and state high school exams in Open/True-False/Multiple-choice formats.
- *Grammar Error Detection* - AUC (True/False grammar error prediction task) - contains sentences from language learner essays.
- *Agree* - Acc - requires filling in missing grammar suffixes of past tense verbs
4. **Language Modeling** tests how likely the model would sample specific Czech language samples.
- *Czech National Corpus* - Ppl - includes 7 tasks that span across spoken, dialect, historical, and other versions of Czech language, sourced from [ČNK](https://www.korpus.cz/).
- *HellaSwag* - Acc - (Translated using CUBITT) requires selecting plausible continuation of text from 4 options.
5. **Math Reasoning in Czech** quantifies how well the model can process and solve Czech math assignments.
- *Klokan QA* - Acc - elementary/high school problems from Czech math competition.
- *CERMAT* - EM/Acc - Math subsection of CERMAT Open/MC.
- *Umimeto (Math)* - Acc - Math subsection of Umimeto.
6. **Natural Language Inference** tests whether the text entails the information required in the associated text pair.
- *Czech SNLI* - AUROC (Translated SNLI using CUBITT + manual correction) - tests for entailment of hypothesis in the premise text.
- *CSFever* - AUROC (Czech version of FEVER dataset, using partial translation) - asks whether claim is (at least partially) supported in the evidence.
- *CTKFacts* - AUROC- same format as CSFEVER, but manually sourced from Czech News Agency articles.
- *Propaganda* - AUROC - contains 13 tasks predicting various aspects of news articles, such as location, genre and emotive theme.
7. **Named Entity Recognition** determines whether the model recognizes different named entity types in the text.
- *CNEC2.0* - EM - standard NER dataset in Czech
- *Court Decisions* - EM - NER derived from decisions of Czech Supreme/Constitutional Courts.
8. **Sentiment Analysis** quantifies how well the model estimates sentiment information in the text.
- *Subjectivity* - AUROC - asks whether a passage is subjective or objective.
- *CzechSentiment* (MALL/CSFD/FB) - AUROC - sentiment analysis of product reviews, movie reviews, and Facebook comments.
9. **Document Retrieval** focuses on identifying the relevant documents.
- *Historical IR* - Acc - multiple-choice task for selecting passages relevant/irrelevant to a query.
## ⚔️ Model Duels and Average Score
Since we use different metrics for the tasks, simply averaging wouldn't work due to varying scales. Instead, we've introduced a novel way to determine a final score: we let the models fight!
For every task and metric, we compute a test for statistical significance at **α=0.05**. This means the probability that the performance of model A equals that of model B is estimated to be less than 0.05. We use the following tests, each with varying statistical power:
- **ACC and EM**: one-tailed paired t-test,
- **AUROC**: Bayesian test inspired by [Goutte et al., 2005](https://link.springer.com/chapter/10.1007/978-3-540-31865-1_25),
- **Ppl**: bootstrapping.
We then compute a model's *duel win score (DWS)* - the proportion of duels won against all other models on that task. Finally, we calculate aggregate scores as follows:
- Category DWS: average of task scores within the category,
- Average DWS: average across category DWSs.
This yields an easy-to-understand model score: **Macro-averaged model win-rate!**
## 👑 BenCzechMark Leaderboard - Llama-405B Takes the Crown
To identify the top-performing open-source model in our suite, we evaluated **26 open-weight** models using the following parameters:
- Maximum input length: 2048 tokens
- Few-shot examples: 3
- Truncation: Smart truncation (truncates few-shot samples first then task description)
- Log-probability aggregation: Average-pooling (helps mitigate long-document bias)
- Chat templates: Not used
The results can be explored in our [**Space**](https://huggingface.co/spaces/CZLC/BenCzechMark). While Llama-450B emerged as the clear overall winner, it didn’t dominate every category. Interestingly, some models have excelled in specific areas — for instance:
- *Qwen-72B* shone in Math and Information Retrieval but lagged behind similarly-sized models in other categories.
- *Aya-23-35B* model excels in Sentiment and Language Modeling, but similarly lags behind in different categories.
- *Gemma-2 9B* delivers excellent results in Czech reading comprehension, outperforming much larger models.
## 🇨🇿 Think Your Model Can Excel in Czech? Submit It!
One of our main goals at **BenCzechMark** is to empower researchers to assess their models' capabilities in Czech and to encourage the community to train and discover models that excel in the Czech language.
If you know of a model that stands out, we'd love for you to **submit** it to our leaderboard, making the competition even more exciting!
To help you get started, we've prepared a straightforward 3-step guide, which you can find in the BenCzechMark space under the **Submission** tab.
## **🌟 Acknowledgements**
We'd like to extend our thanks to all contributors from [**BUT** **FIT**](https://fit.vut.cz/), [**FI** **MUNI**](https://www.fi.muni.cz/), [**CIIRC** **CTU**](https://ciirc.cvut.cz/), and [**Hugging** **Face**](https://huggingface.co/) for their invaluable work in bringing BenCzechMark to life.
We're also grateful to the organizations that provided source data for some of the tasks, namely [**Umímeto**](https://www.umimeto.org/), [**CERMAT**](https://cermat.cz/), and [**ČNK**](https://www.korpus.cz/).
## 📚 Citation and references
```
@article{fajcik2024benczechmark,
title = {{B}en{C}zech{M}ark: A Czech-centric Multitask and Multimetric Benchmark for Language Models with Duel Scoring Mechanism},
author = {Martin Fajcik and Martin Docekal and Jan Dolezal and Karel Ondrej and Karel Benes and Jan Kapsa and Michal Hradis and Zuzana Neverilova and Ales Horak and Michal Stefanik and Adam Jirkovsky and David Adamczyk and Jan Hula and Jan Sedivy and Hynek Kydlicek},
year = {2024},
url = {[https://huggingface.co/spaces/CZLC/BenCzechMark](https://huggingface.co/spaces/CZLC/BenCzechMark)}
institution = {Brno University of Technology, Masaryk University, Czech Technical University in Prague, Hugging Face},
}
``` | 7 |
0 | hf_public_repos | hf_public_repos/blog/llama3.md | ---
title: "Welcome Llama 3 - Meta's new open LLM"
thumbnail: /blog/assets/llama3/thumbnail.jpg
authors:
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: ybelkada
- user: lvwerra
---
# Welcome Llama 3 - Meta’s new open LLM
## Introduction
Meta’s Llama 3, the next iteration of the open-access Llama family, is now released and available at Hugging Face. It's great to see Meta continuing its commitment to open AI, and we’re excited to fully support the launch with comprehensive integration in the Hugging Face ecosystem.
Llama 3 comes in two sizes: 8B for efficient deployment and development on consumer-size GPU, and 70B for large-scale AI native applications. Both come in base and instruction-tuned variants. In addition to the 4 models, a new version of Llama Guard was fine-tuned on Llama 3 8B and is released as Llama Guard 2 (safety fine-tune).
We’ve collaborated with Meta to ensure the best integration into the Hugging Face ecosystem. You can find all 5 open-access models (2 base models, 2 fine-tuned & Llama Guard) on the Hub. Among the features and integrations being released, we have:
- [Models on the Hub](https://huggingface.co/meta-llama), with their model cards and licenses
- 🤗 Transformers integration
- [Hugging Chat integration for Meta Llama 3 70b](https://huggingface.co/chat/models/meta-llama/Meta-Llama-3-70B-instruct)
- Inference Integration into Inference Endpoints, Google Cloud & Amazon SageMaker
- An example of fine-tuning Llama 3 8B on a single GPU with 🤗 TRL
## Table of contents
- [What’s new with Llama 3?](#whats-new-with-llama-3)
- [Llama 3 evaluation](#llama-3-evaluation)
- [How to prompt Llama 3](#how-to-prompt-llama-3)
- [Demo](#demo)
- [Using 🤗 Transformers](#using-🤗-transformers)
- [Inference Integrations](#inference-integrations)
- [Fine-tuning with 🤗 TRL](#fine-tuning-with-🤗-trl)
- [Additional Resources](#additional-resources)
- [Acknowledgments](#acknowledgments)
## What’s new with Llama 3?
The Llama 3 release introduces 4 new open LLM models by Meta based on the Llama 2 architecture. They come in two sizes: 8B and 70B parameters, each with base (pre-trained) and instruct-tuned versions. All the variants can be run on various types of consumer hardware and have a context length of 8K tokens.
- [Meta-Llama-3-8b](https://huggingface.co/meta-llama/Meta-Llama-3-8B): Base 8B model
- [Meta-Llama-3-8b-instruct](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct): Instruct fine-tuned version of the base 8b model
- [Meta-Llama-3-70b](https://huggingface.co/meta-llama/Meta-Llama-3-70B): Base 70B model
- [Meta-Llama-3-70b-instruct](https://huggingface.co/meta-llama/Meta-Llama-3-70B-instruct): Instruct fine-tuned version of the base 70b model
In addition to these 4 base models, Llama Guard 2 was also released. Fine-tuned on Llama 3 8B, it’s the latest iteration in the Llama Guard family. Llama Guard 2, built for production use cases, is designed to classify LLM inputs (prompts) as well as LLM responses in order to detect content that would be considered unsafe in a risk taxonomy.
A big change in Llama 3 compared to Llama 2 is the use of a new tokenizer that expands the vocabulary size to 128,256 (from 32K tokens in the previous version). This larger vocabulary can encode text more efficiently (both for input and output) and potentially yield stronger multilingualism. This comes at a cost, though: the embedding input and output matrices are larger, which accounts for a good portion of the parameter count increase of the small model: it goes from 7B in Llama 2 to 8B in Llama 3. In addition, the 8B version of the model now uses Grouped-Query Attention (GQA), which is an efficient representation that should help with longer contexts.
The Llama 3 models were trained ~8x more data on over 15 trillion tokens on a new mix of publicly available online data on two clusters with 24,000 GPUs. We don’t know the exact details of the training mix, and we can only guess that bigger and more careful data curation was a big factor in the improved performance. Llama 3 Instruct has been optimized for dialogue applications and was trained on over 10 Million human-annotated data samples with combination of supervised fine-tuning (SFT), rejection sampling, proximal policy optimization (PPO), and direct policy optimization (DPO).
Regarding the licensing terms, Llama 3 comes with a permissive license that allows redistribution, fine-tuning, and derivative works. The requirement for explicit attribution is new in the Llama 3 license and was not present in Llama 2. Derived models, for instance, need to include "Llama 3" at the beginning of their name, and you also need to mention "Built with Meta Llama 3" in derivative works or services. For full details, please make sure to read the [official license](https://huggingface.co/meta-llama/Meta-Llama-3-70B/blob/main/LICENSE).
## Llama 3 evaluation
Here, you can see a list of models and their [Open LLM Leaderboard](https://huggingface.co/spaces/open-llm-leaderboard/open_llm_leaderboard) scores. This is not a comprehensive list and we encourage you to look at the full leaderboard. Note that the LLM Leaderboard is specially useful to evaluate pre-trained models, as there are other benchmarks specific to conversational models.
| Model | License | Pretraining length [tokens] | Leaderboard score |
| --- | --- | --- | --- |
| [MPT-7B](https://huggingface.co/mosaicml/mpt-7b) | Apache 2.0 | 1,000B | 5.98 |
| [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) | Apache 2.0 | 1,500B | 5.1 |
| [Llama-2-7B](https://huggingface.co/meta-llama/Llama-2-7b-hf) | Llama 2 license | 2T | 8.72 |
| [Qwen 2 7B](https://huggingface.co/Qwen/Qwen2-7B) | Apache 2.0 | ? | 23.66 |
| [Llama-3-8B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) | Llama 3 license | 15T | 13.41 |
| [Llama-2-13B](https://huggingface.co/meta-llama/Llama-2-13b-hf) | Llama 2 license | 2T | 10.99 |
| [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) | Apache 2.0 | 1,000B | 11.33 |
| [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) | Apache 2.0 | 1,000B | 11.33 |
| [Llama-2-70B](https://huggingface.co/meta-llama/Llama-2-70b-hf) | Llama 2 license | 2T | 18.25 |
| [Llama-3-70B](https://huggingface.co/meta-llama/Meta-Llama-3-8B) | Llama 3 license | 15T | 26.37 |
| [Mixtral 8x22B](https://huggingface.co/mistralai/Mixtral-8x22B-v0.1) | Apache 2 | ? | 25.49 |
## How to prompt Llama 3
The base models have no prompt format. Like other base models, they can be used to continue an input sequence with a plausible continuation or for zero-shot/few-shot inference. They are also a great foundation for fine-tuning your own use cases. The Instruct versions use the following conversation structure:
```bash
<|begin_of_text|><|start_header_id|>system<|end_header_id|>
{{ system_prompt }}<|eot_id|><|start_header_id|>user<|end_header_id|>
{{ user_msg_1 }}<|eot_id|><|start_header_id|>assistant<|end_header_id|>
{{ model_answer_1 }}<|eot_id|>
```
This format has to be exactly reproduced for effective use. We’ll later show how easy it is to reproduce the instruct prompt with the chat template available in `transformers`.
## Demo
You can chat with the Llama 3 70B instruct on Hugging Chat! Check out the link here: https://huggingface.co/chat/models/meta-llama/Meta-Llama-3-70B-instruct
## Using 🤗 Transformers
With Transformers [release 4.40](https://github.com/huggingface/transformers/releases/tag/v4.40.0), you can use Llama 3 and leverage all the tools within the Hugging Face ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as bitsandbytes (4-bit quantization), PEFT (parameter efficient fine-tuning), and Flash Attention 2
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
In addition, Llama 3 models are compatible with `torch.compile()` with CUDA graphs, giving them a ~4x speedup at inference time!
To use Llama 3 models with transformers, make sure to install a recent version of `transformers`:
```jsx
pip install --upgrade transformers
```
The following snippet shows how to use `Llama-3-8b-instruct` with transformers. It requires about 16 GB of RAM, which includes consumer GPUs such as 3090 or 4090.
```python
from transformers import pipeline
import torch
model_id = "meta-llama/Meta-Llama-3-8B-Instruct"
pipe = pipeline(
"text-generation",
model=model_id,
model_kwargs={"torch_dtype": torch.bfloat16},
device="cuda",
)
messages = [
{"role": "system", "content": "You are a pirate chatbot who always responds in pirate speak!"},
{"role": "user", "content": "Who are you?"},
]
terminators = [
pipe.tokenizer.eos_token_id,
pipe.tokenizer.convert_tokens_to_ids("<|eot_id|>")
]
outputs = pipe(
messages,
max_new_tokens=256,
eos_token_id=terminators,
do_sample=True,
temperature=0.6,
top_p=0.9,
)
assistant_response = outputs[0]["generated_text"][-1]["content"]
print(assistant_response)
```
> Arrrr, me hearty! Me name be Captain Chat, the scurviest pirate chatbot to ever sail the Seven Seas! Me be here to swab the decks o' yer mind with me trusty responses, savvy? I be ready to hoist the Jolly Roger and set sail fer a swashbucklin' good time, matey! So, what be bringin' ye to these fair waters?
A couple of details:
- We loaded the model in `bfloat16`. This is the type used by the original checkpoint published by Meta, so it’s the recommended way to run to ensure the best precision or to conduct evaluations. For real world use, it’s also safe to use `float16`, which may be faster depending on your hardware.
- Assistant responses may end with the special token `<|eot_id|>`, but we must also stop generation if the regular EOS token is found. We can stop generation early by providing a list of terminators in the `eos_token_id` parameter.
- We used the default sampling parameters (`temperature` and `top_p`) taken from the original meta codebase. We haven’t had time to conduct extensive tests yet, feel free to explore!
You can also automatically quantize the model, loading it in 8-bit or even 4-bit mode. 4-bit loading takes about 7 GB of memory to run, making it compatible with a lot of consumer cards and all the GPUs in Google Colab. This is how you’d load the generation pipeline in 4-bit:
```python
pipeline = transformers.pipeline(
"text-generation",
model=model_id,
model_kwargs={
"torch_dtype": torch.float16,
"quantization_config": {"load_in_4bit": True},
"low_cpu_mem_usage": True,
},
)
```
For more details on using the models with transformers, please check [the model cards](https://huggingface.co/meta-llama/Meta-Llama-3-8B-Instruct).
## Inference Integrations
In this section, we’ll go through different approaches to running inference of the Llama 3 models. Before using these models, make sure you have requested access to one of the models in the official [Meta Llama 3](https://TODO) repositories.
### Integration with Inference Endpoints
You can deploy Llama 3 on Hugging Face's [Inference Endpoints](https://ui.endpoints.huggingface.co/), which uses Text Generation Inference as the backend. [Text Generation Inference](https://github.com/huggingface/text-generation-inference) is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
To deploy Llama 3, go to the [model page](https://huggingface.co/meta-llama/Meta-Llama-3-70B-instruct) and click on the [Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/philschmid/new?repository=meta-llama/Meta-Llama-3-70B-instruct&vendor=aws®ion=us-east-1&accelerator=gpu&instance_size=4xlarge&task=text-generation&no_suggested_compute=true&tgi=true&tgi_max_batch_prefill_tokens=16384&tgi_max_batch_total_tokens=16384&tgi_max_input_length=4000&tgi_max_total_tokens=8192) widget. You can learn more about [Deploying LLMs with Hugging Face Inference Endpoints](https://huggingface.co/blog/inference-endpoints-llm) in a previous blog post. Inference Endpoints supports [Messages API](https://huggingface.co/blog/tgi-messages-api) through Text Generation Inference, which allows you to switch from another closed model to an open one by simply changing the URL.
```bash
from openai import OpenAI
# initialize the client but point it to TGI
client = OpenAI(
base_url="<ENDPOINT_URL>" + "/v1/", # replace with your endpoint url
api_key="<HF_API_TOKEN>", # replace with your token
)
chat_completion = client.chat.completions.create(
model="tgi",
messages=[
{"role": "user", "content": "Why is open-source software important?"},
],
stream=True,
max_tokens=500
)
# iterate and print stream
for message in chat_completion:
print(message.choices[0].delta.content, end="")
```
### Integration with Google Cloud
You can deploy Llama 3 on Google Cloud through Vertex AI or Google Kubernetes Engine (GKE), using [Text Generation Inference](https://huggingface.co/docs/text-generation-inference/index).
To deploy the Llama 3 model from Hugging Face, go to the [model page](https://huggingface.co/meta-llama/Meta-Llama-3-70B-instruct) and click on [Deploy -> Google Cloud.](https://console.cloud.google.com/vertex-ai/publishers/meta-llama/model-garden/Meta-Llama-3-70B-instruct;hfSource=true;action=deploy) This will bring you to the Google Cloud Console, where you can 1-click deploy Llama 3 on Vertex AI or GKE.
### Integration with Amazon SageMaker
You can deploy and train Llama 3 on Amazon SageMaker through AWS Jumpstart or using the [Hugging Face LLM Container](https://huggingface.co/blog/sagemaker-huggingface-llm).
To deploy the Llama 3 model from Hugging Face, go to the [model page](https://huggingface.co/meta-llama/Meta-Llama-3-70B-instruct) and click on [Deploy -> Amazon SageMaker.](https://huggingface.co/meta-llama/Meta-Llama-3-70B-instruct?sagemaker_deploy=true) This will display a code snippet you can copy and execute in your environment. Amazon SageMaker will now create a dedicated inference endpoint you can use to send requests.
## Fine-tuning with 🤗 TRL
Training LLMs can be technically and computationally challenging. In this section, we’ll look at the tools available in the Hugging Face ecosystem to efficiently train Llama 3 on consumer-size GPUs. Below is an example command to fine-tune Llama 3 on the [No Robots dataset](https://huggingface.co/datasets/HuggingFaceH4/no_robots). We use 4-bit quantization, and [QLoRA](https://arxiv.org/abs/2305.14314) and TRL’s SFTTrainer will automatically format the dataset into `chatml` format. Let’s get started!
First, install the latest version of 🤗 TRL.
```bash
pip install -U transformers trl accelerate
```
If you just want to chat with the model in the terminal you can use the `chat` command of the TRL CLI (for more info see the [docs](https://huggingface.co/docs/trl/en/clis#chat-interface)):
```jsx
trl chat \
--model_name_or_path meta-llama/Meta-Llama-3-8B-Instruct \
--device cuda \
--eos_tokens "<|end_of_text|>,<|eod_id|>"
```
You can also use TRL CLI to supervise fine-tuning (SFT) Llama 3 on your own, custom dataset. Use the `trl sft` command and pass your training arguments as CLI argument. Make sure you are logged in and have access the Llama 3 checkpoint. You can do this with `huggingface-cli login`.
```jsx
trl sft \
--model_name_or_path meta-llama/Meta-Llama-3-8B \
--dataset_name HuggingFaceH4/no_robots \
--learning_rate 0.0001 \
--per_device_train_batch_size 4 \
--max_seq_length 2048 \
--output_dir ./llama3-sft \
--use_peft \
--load_in_4bit \
--log_with wandb \
--gradient_checkpointing \
--logging_steps 10
```
This will run the fine-tuning from your terminal and takes about 4 hours to train on a single A10G, but can be easily parallelized by tweaking `--num_processes` to the number of GPUs you have available.
_Note: You can also replace the CLI arguments with a `yaml` file. Learn more about the TRL CLI [here](https://huggingface.co/docs/trl/clis#fine-tuning-with-the-cli)._
## Additional Resources
- [Models on the Hub](https://huggingface.co/collections/meta-llama/meta-llama-3-66214712577ca38149ebb2b6)
- [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [Chat demo on Hugging Chat](https://huggingface.co/chat/models/meta-llama/Llama-3-70b-instruct)
- [Meta Blog](https://ai.meta.com/blog/meta-llama-3/)
- [Google Cloud Vertex AI model garden](https://console.cloud.google.com/vertex-ai/publishers/meta/model-garden/llama3)
## Acknowledgments
Releasing such models with support and evaluations in the ecosystem would not be possible without the contributions of many community members, including
- [Clémentine Fourrier](https://huggingface.co/clefourrier), [Nathan Habib](https://huggingface.co/SaylorTwift), and [Eleuther Evaluation Harness](https://github.com/EleutherAI/lm-evaluation-harness) for LLM evaluations
- [Olivier Dehaene](https://huggingface.co/olivierdehaene) and [Nicolas Patry](https://huggingface.co/Narsil) for [Text Generation Inference Support](https://github.com/huggingface/text-generation-inference)
- [Arthur Zucker](https://huggingface.co/ArthurZ) and [Lysandre Debut](https://huggingface.co/lysandre) for adding Llama 3 support in transformers and tokenizers
- [Nathan Sarrazin](https://huggingface.co/nsarrazin), [Victor Mustar](https://huggingface.co/victor), and Kevin Cathaly for making Llama 3 available in Hugging Chat.
- [Yuvraj Sharma](https://huggingface.co/ysharma) for the Gradio demo.
- [Xenova](https://huggingface.co/Xenova) and [Vaibhav Srivastav](https://huggingface.co/reach-vb) for debugging and experimentation with quantization and prompt templates.
- [Brigitte Tousignant](https://huggingface.co/BrigitteTousi), [Florent Daudens](https://huggingface.co/fdaudens), [Morgan Funtowicz](https://huggingface.co/mfuntowicz), and [Simon Brandeis](https://huggingface.co/sbrandeis) for different items during the launch!
- Thank you to the whole Meta team, including [Samuel Selvan](https://huggingface.co/samuelselvanmeta), Eleonora Presani, Hamid Shojanazeri, Azadeh Yazdan, Aiman Farooq, Ruan Silva, Ashley Gabriel, Eissa Jamil, Binh Tang, Matthias Reso, Lovish Madaan, Joe Spisak, and Sergey Edunov.
Thank you to the Meta Team for releasing Llama 3 and making it available to the open-source AI community!
| 8 |
0 | hf_public_repos | hf_public_repos/blog/supercharge-customer-service-with-machine-learning.md | ---
title: "Supercharged Customer Service with Machine Learning"
thumbnail: /blog/assets/61_supercharged_customer_service_with_nlp/thumbnail.png
authors:
- user: patrickvonplaten
---
# Supercharged Customer Service with Machine Learning
<a target="_blank" href="https://github.com/patrickvonplaten/notebooks/blob/master/Using_%F0%9F%A4%97_Transformers_and_%F0%9F%A4%97_Datasets_filter_customer_feedback_filtering.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In this blog post, we will simulate a real-world customer service use case and use tools machine learning tools of the Hugging Face ecosystem to address it.
We strongly recommend using this notebook as a template/example to solve **your** real-world use case.
## Defining Task, Dataset & Model
Before jumping into the actual coding part, it's important to have a clear definition of the use case that you would like to automate or partly automate.
A clear definition of the use case helps identify the most suitable task, dataset to use, and model to apply for your use case.
### Defining your NLP task
Alright, let's dive into a hypothetical problem we wish to solve using models of natural language processing models. Let's assume we are selling a product and our customer support team receives thousands of messages including feedback, complaints, and questions which ideally should all be answered.
Quickly, it becomes obvious that customer support is by no means able to reply to every message. Thus, we decide to only respond to the most unsatisfied customers and aim to answer 100% of those messages, as these are likely the most urgent compared to the other neutral and positive messages.
Assuming that a) messages of very unsatisfied customers represent only a fraction of all messages and b) that we can filter out unsatisfied messages in an automated way, customer support should be able to reach this goal.
To filter out unsatisfied messages in an automated way, we plan on applying natural language processing technologies.
The first step is to map our use case - *filtering out unsatisfied messages* - to a machine learning task.
The [tasks page on the Hugging Face Hub](https://huggingface.co/tasks) is a great place to get started to see which task best fits a given scenario. Each task has a detailed description and potential use cases.
The task of finding messages of the most unsatisfied customers can be modeled as a text classification task: Classify a message into one of the following 5 categories: *very unsatisfied*, *unsatisfied*, *neutral*, *satisfied*, **or** *very satisfied*.
### Finding suitable datasets
Having decided on the task, next, we should find the data the model will be trained on. This is usually more important for the performance of your use case than picking the right model architecture.
Keep in mind that a model is **only as good as the data it has been trained on**. Thus, we should be very careful when curating and/or selecting the dataset.
Since we consider the hypothetical use case of *filtering out unsatisfied messages*, let's look into what datasets are available.
For your real-world use case, it is **very likely** that you have internal data that best represents the actual data your NLP system is supposed to handle. Therefore, you should use such internal data to train your NLP system.
It can nevertheless be helpful to also include publicly available data to improve the generalizability of your model.
Let's take a look at all available Datasets on the [Hugging Face Hub](https://huggingface.co/datasets). On the left side, you can filter the datasets according to *Task Categories* as well as *Tasks* which are more specific. Our use case corresponds to *Text Classification* -> *Sentiment Analysis* so let's select [these filters](https://huggingface.co/datasets?task_categories=task_categories:text-classification&task_ids=task_ids:sentiment-classification&sort=downloads). We are left with *ca.* 80 datasets at the time of writing this notebook. Two aspects should be evaluated when picking a dataset:
- **Quality**: Is the dataset of high quality? More specifically: Does the data correspond to the data you expect to deal with in your use case? Is the data diverse, unbiased, ...?
- **Size**: How big is the dataset? Usually, one can safely say the bigger the dataset, the better.
It's quite tricky to evaluate whether a dataset is of high quality efficiently, and it's even more challenging to know whether and how the dataset is biased.
An efficient and reasonable heuristic for high quality is to look at the download statistics. The more downloads, the more usage, the higher chance that the dataset is of high quality. The size is easy to evaluate as it can usually be quickly read upon. Let's take a look at the most downloaded datasets:
- [Glue](https://huggingface.co/datasets/glue)
- [Amazon polarity](https://huggingface.co/datasets/amazon_polarity)
- [Tweet eval](https://huggingface.co/datasets/tweet_eval)
- [Yelp review full](https://huggingface.co/datasets/yelp_review_full)
- [Amazon reviews multi](https://huggingface.co/datasets/amazon_reviews_multi)
Now we can inspect those datasets in more detail by reading through the dataset card, which ideally should give all relevant and important information. In addition, the [dataset viewer](https://huggingface.co/datasets/glue/viewer/cola/test) is an incredibly powerful tool to inspect whether the data suits your use case.
Let's quickly go over the dataset cards of the models above:
- *GLUE* is a collection of small datasets that primarily serve to compare new model architectures for researchers. The datasets are too small and don't correspond enough to our use case.
- *Amazon polarity* is a huge and well-suited dataset for customer feedback since the data deals with customer reviews. However, it only has binary labels (positive/negative), whereas we are looking for more granularity in the sentiment classification.
- *Tweet eval* uses different emojis as labels that cannot easily be mapped to a scale going from unsatisfied to satisfied.
- *Amazon reviews multi* seems to be the most suitable dataset here. We have sentiment labels ranging from 1-5 corresponding to 1-5 stars on Amazon. These labels can be mapped to *very unsatisfied, neutral, satisfied, very satisfied*. We have inspected some examples on [the dataset viewer](https://huggingface.co/datasets/amazon_reviews_multi/viewer/en/train) to verify that the reviews look very similar to actual customer feedback reviews, so this seems like a very good dataset. In addition, each review has a `product_category` label, so we could even go as far as to only use reviews of a product category corresponding to the one we are working in. The dataset is multi-lingual, but we are just interested in the English version for now.
- *Yelp review full* looks like a very suitable dataset. It's large and contains product reviews and sentiment labels from 1 to 5. Sadly, the dataset viewer is not working here, and the dataset card is also relatively sparse, requiring some more time to inspect the dataset. At this point, we should read the paper, but given the time constraint of this blog post, we'll choose to go for *Amazon reviews multi*.
As a conclusion, let's focus on the [*Amazon reviews multi*](https://huggingface.co/datasets/amazon_reviews_multi) dataset considering all training examples.
As a final note, we recommend making use of Hub's dataset functionality even when working with private datasets. The Hugging Face Hub, Transformers, and Datasets are flawlessly integrated, which makes it trivial to use them in combination when training models.
In addition, the Hugging Face Hub offers:
- [A dataset viewer for every dataset](https://huggingface.co/datasets/amazon_reviews_multi)
- [Easy demoing of every model using widgets](https://huggingface.co/docs/hub/models-widgets)
- [Private and Public models](https://huggingface.co/docs/hub/repositories-settings)
- [Git version control for repositories](https://huggingface.co/docs/hub/repositories-getting-started)
- [Highest security mechanisms](https://huggingface.co/docs/hub/security)
### Finding a suitable model
Having decided on the task and the dataset that best describes our use case, we can now look into choosing a model to be used.
Most likely, you will have to fine-tune a pretrained model for your own use case, but it is worth checking whether the hub already has suitable fine-tuned models. In this case, you might reach a higher performance by just continuing to fine-tune such a model on your dataset.
Let's take a look at all models that have been fine-tuned on Amazon Reviews Multi. You can find the list of models on the bottom right corner - clicking on *Browse models trained on this dataset* you can see [a list of all models fine-tuned on the dataset that are publicly available](https://huggingface.co/models?dataset=dataset:amazon_reviews_multi). Note that we are only interested in the English version of the dataset because our customer feedback will only be in English. Most of the most downloaded models are trained on the multi-lingual version of the dataset and those that don't seem to be multi-lingual have very little information or poor performance. At this point,
it might be more sensible to fine-tune a purely pretrained model instead of using one of the already fine-tuned ones shown in the link above.
Alright, the next step now is to find a suitable pretrained model to be used for fine-tuning. This is actually more difficult than it seems given the large amount of pretrained and fine-tuned models that are on the [Hugging Face Hub](https://huggingface.co/models). The best option is usually to simply try out a variety of different models to see which one performs best.
We still haven't found the perfect way of comparing different model checkpoints to each other at Hugging Face, but we provide some resources that are worth looking into:
- The [model summary](https://huggingface.co/docs/transformers/model_summary) gives a short overview of different model architectures.
- A task-specific search on the Hugging Face Hub, *e.g.* [a search on text-classification models](https://huggingface.co/models), shows you the most downloaded checkpoints which is also an indication of how well those checkpoints perform.
However, both of the above resources are currently suboptimal. The model summary is not always kept up to date by the authors. The speed at which new model architectures are released and old model architectures become outdated makes it extremely difficult to have an up-to-date summary of all model architectures.
Similarly, it doesn't necessarily mean that the most downloaded model checkpoint is the best one. E.g. [`bert-base-cased`](https://huggingface.co/bert-base-uncased) is amongst the most downloaded model checkpoints but is not the best performing checkpoint anymore.
The best approach is to try out various model architectures, stay up to date with new model architectures by following experts in the field, and check well-known leaderboards.
For text-classification, the important benchmarks to look at are [GLUE](https://gluebenchmark.com/leaderboard) and [SuperGLUE](https://super.gluebenchmark.com/leaderboard). Both benchmarks evaluate pretrained models on a variety of text-classification tasks, such as grammatical correctness, natural language inference, Yes/No question answering, etc..., which are quite similar to our target task of sentiment analysis. Thus, it is reasonable to choose one of the leading models of these benchmarks for our task.
At the time of writing this blog post, the best performing models are very large models containing more than 10 billion parameters most of which are not open-sourced, *e.g.* *ST-MoE-32B*, *Turing NLR v5*, or
*ERNIE 3.0*. One of the top-ranking models that is easily accessible is [DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta). Therefore, let's try out DeBERTa's newest base version - *i.e.* [`microsoft/deberta-v3-base`](https://huggingface.co/microsoft/deberta-v3-base).
## Training / Fine-tuning a model with 🤗 Transformers and 🤗 Datasets
In this section, we will jump into the technical details of how to
fine-tune a model end-to-end to be able to automatically filter out very unsatisfied customer feedback messages.
Cool! Let's start by installing all necessary pip packages and setting up our code environment, then look into preprocessing the dataset, and finally start training the model.
The following notebook can be run online in a google colab pro with the GPU runtime environment enabled.
### Install all necessary packages
To begin with, let's install [`git-lfs`](https://git-lfs.github.com/) so that we can automatically upload our trained checkpoints to the Hub during training.
```bash
apt install git-lfs
```
Also, we install the 🤗 Transformers and 🤗 Datasets libraries to run this notebook. Since we will be using [DeBERTa](https://huggingface.co/docs/transformers/model_doc/deberta-v2#debertav2) in this blog post, we also need to install the [`sentencepiece`](https://github.com/google/sentencepiece) library for its tokenizer.
```bash
pip install datasets transformers[sentencepiece]
```
Next, let's login into our [Hugging Face account](https://huggingface.co/join) so that models are uploaded correctly under your name tag.
```python
from huggingface_hub import notebook_login
notebook_login()
```
**Output:**
```
Login successful
Your token has been saved to /root/.huggingface/token
Authenticated through git-credential store but this isn't the helper defined on your machine.
You might have to re-authenticate when pushing to the Hugging Face Hub. Run the following command in your terminal in case you want to set this credential helper as the default
git config --global credential.helper store
```
### Preprocess the dataset
Before we can start training the model, we should bring the dataset in a format
that is understandable by the model.
Thankfully, the 🤗 Datasets library makes this extremely easy as you will see in the following cells.
The `load_dataset` function loads the dataset, nicely arranges it into predefined attributes, such as `review_body` and `stars`, and finally saves the newly arranged data using the [arrow format](https://arrow.apache.org/#:~:text=Format,data%20access%20without%20serialization%20overhead.) on disk.
The arrow format allows for fast and memory-efficient data reading and writing.
Let's load and prepare the English version of the `amazon_reviews_multi` dataset.
```python
from datasets import load_dataset
amazon_review = load_dataset("amazon_reviews_multi", "en")
```
**Output:**
```
Downloading and preparing dataset amazon_reviews_multi/en (download: 82.11 MiB, generated: 58.69 MiB, post-processed: Unknown size, total: 140.79 MiB) to /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609...
Dataset amazon_reviews_multi downloaded and prepared to /root/.cache/huggingface/datasets/amazon_reviews_multi/en/1.0.0/724e94f4b0c6c405ce7e476a6c5ef4f87db30799ad49f765094cf9770e0f7609. Subsequent calls will reuse this data.
```
Great, that was fast 🔥. Let's take a look at the structure of the dataset.
```python
print(amazon_review)
```
**Output:**
```
{.output .execute_result execution_count="5"}
DatasetDict({
train: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 200000
})
validation: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
test: Dataset({
features: ['review_id', 'product_id', 'reviewer_id', 'stars', 'review_body', 'review_title', 'language', 'product_category'],
num_rows: 5000
})
})
```
We have 200,000 training examples as well as 5000 validation and test examples. This sounds reasonable for training! We're only really interested in the input being the `"review_body"` column and the target being the `"starts"` column.
Let's check out a random example.
```python
random_id = 34
print("Stars:", amazon_review["train"][random_id]["stars"])
print("Review:", amazon_review["train"][random_id]["review_body"])
```
**Output:**
```
Stars: 1
Review: This product caused severe burning of my skin. I have used other brands with no problems
```
The dataset is in a human-readable format, but now we need to transform it into a "machine-readable" format. Let's define the model repository which includes all utils necessary to preprocess and fine-tune the checkpoint we decided on.
```python
model_repository = "microsoft/deberta-v3-base"
```
Next, we load the tokenizer of the model repository, which is a [DeBERTa's Tokenizer](https://huggingface.co/docs/transformers/model_doc/deberta-v2#transformers.DebertaV2Tokenizer).
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained(model_repository)
```
As mentioned before, we will use the `"review_body"` as the model's input and `"stars"` as the model's target. Next, we make use of the tokenizer to transform the input into a sequence of token ids that can be understood by the model. The tokenizer does exactly this and can also help you to limit your input data to a certain length to not run into a memory issue. Here, we limit
the maximum length to 128 tokens which in the case of DeBERTa corresponds to roughly 100 words which in turn corresponds to *ca.* 5-7 sentences. Looking at the [dataset viewer](https://huggingface.co/datasets/amazon_reviews_multi/viewer/en/test) again, we can see that this covers pretty much all training examples.
**Important**: This doesn't mean that our model cannot handle longer input sequences, it just means that we use a maximum length of 128 for training since it covers 99% of our training and we don't want to waste memory. Transformer models have shown to be very good at generalizing to longer sequences after training.
If you want to learn more about tokenization in general, please have a look at [the Tokenizers docs](https://huggingface.co/course/chapter6/1?fw=pt).
The labels are easy to transform as they already correspond to numbers in their raw form, *i.e.* the range from 1 to 5. Here we just shift the labels into the range 0 to 4 since indexes usually start at 0.
Great, let's pour our thoughts into some code. We will define a `preprocess_function` that we'll apply to each data sample.
```python
def preprocess_function(example):
output_dict = tokenizer(example["review_body"], max_length=128, truncation=True)
output_dict["labels"] = [e - 1 for e in example["stars"]]
return output_dict
```
To apply this function to all data samples in our dataset, we use the [`map`](https://huggingface.co/docs/datasets/master/en/package_reference/main_classes#datasets.Dataset.map) method of the `amazon_review` object we created earlier. This will apply the function on all the elements of all the splits in `amazon_review`, so our training, validation, and testing data will be preprocessed in one single command. We run the mapping function in `batched=True` mode to speed up the process and also remove all columns since we don't need them anymore for training.
```python
tokenized_datasets = amazon_review.map(preprocess_function, batched=True, remove_columns=amazon_review["train"].column_names)
```
Let's take a look at the new structure.
```python
tokenized_datasets
```
**Output:**
```
DatasetDict({
train: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 200000
})
validation: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
test: Dataset({
features: ['input_ids', 'token_type_ids', 'attention_mask', 'labels'],
num_rows: 5000
})
})
```
We can see that the outer layer of the structure stayed the same but the naming of the columns has changed.
Let's take a look at the same random example we looked at previously only that it's preprocessed now.
```python
print("Input IDS:", tokenized_datasets["train"][random_id]["input_ids"])
print("Labels:", tokenized_datasets["train"][random_id]["labels"])
```
**Output:**
```
Input IDS: [1, 329, 714, 2044, 3567, 5127, 265, 312, 1158, 260, 273, 286, 427, 340, 3006, 275, 363, 947, 2]
Labels: 0
```
Alright, the input text is transformed into a sequence of integers which can be transformed to word embeddings by the model, and the label index is simply shifted by -1.
### Fine-tune the model
Having preprocessed the dataset, next we can fine-tune the model. We will make use of the popular [Hugging Face Trainer](https://huggingface.co/docs/transformers/main/en/main_classes/trainer) which allows us to start training in just a couple of lines of code. The `Trainer` can be used for more or less all tasks in PyTorch and is extremely convenient by taking care of a lot of boilerplate code needed for training.
Let's start by loading the model checkpoint using the convenient [`AutoModelForSequenceClassification`](https://huggingface.co/docs/transformers/main/en/model_doc/auto#transformers.AutoModelForSequenceClassification). Since the checkpoint of the model repository is just a pretrained checkpoint we should define the size of the classification head by passing `num_lables=5` (since we have 5 sentiment classes).
```python
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained(model_repository, num_labels=5)
```
```
Some weights of the model checkpoint at microsoft/deberta-v3-base were not used when initializing DebertaV2ForSequenceClassification: ['mask_predictions.classifier.bias', 'mask_predictions.LayerNorm.bias', 'mask_predictions.dense.weight', 'mask_predictions.dense.bias', 'mask_predictions.LayerNorm.weight', 'lm_predictions.lm_head.dense.bias', 'lm_predictions.lm_head.bias', 'lm_predictions.lm_head.LayerNorm.weight', 'lm_predictions.lm_head.dense.weight', 'lm_predictions.lm_head.LayerNorm.bias', 'mask_predictions.classifier.weight']
- This IS expected if you are initializing DebertaV2ForSequenceClassification from the checkpoint of a model trained on another task or with another architecture (e.g. initializing a BertForSequenceClassification model from a BertForPreTraining model).
- This IS NOT expected if you are initializing DebertaV2ForSequenceClassification from the checkpoint of a model that you expect to be exactly identical (initializing a BertForSequenceClassification model from a BertForSequenceClassification model).
Some weights of DebertaV2ForSequenceClassification were not initialized from the model checkpoint at microsoft/deberta-v3-base and are newly initialized: ['pooler.dense.bias', 'classifier.weight', 'classifier.bias', 'pooler.dense.weight']
You should probably TRAIN this model on a down-stream task to be able to use it for predictions and inference.
```
Next, we load a data collator. A [data collator](https://huggingface.co/docs/transformers/main_classes/data_collator) is responsible for making sure each batch is correctly padded during training, which should happen dynamically since training samples are reshuffled before each epoch.
```python
from transformers import DataCollatorWithPadding
data_collator = DataCollatorWithPadding(tokenizer=tokenizer)
```
During training, it is important to monitor the performance of the model on a held-out validation set. To do so, we should pass a to define a `compute_metrics` function to the `Trainer` which is then called at each validation step during training.
The simplest metric for the text classification task is *accuracy*, which simply states how much percent of the training samples were correctly classified. Using the *accuracy* metric might be problematic however if the validation or test data is very unbalanced. Let's verify quickly that this is not the case by counting the occurrences of each label.
```python
from collections import Counter
print("Validation:", Counter(tokenized_datasets["validation"]["labels"]))
print("Test:", Counter(tokenized_datasets["test"]["labels"]))
```
**Output:**
```
Validation: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
Test: Counter({0: 1000, 1: 1000, 2: 1000, 3: 1000, 4: 1000})
```
The validation and test data sets are as balanced as they can be, so we can safely use accuracy here!
Let's load the [accuracy metric](https://huggingface.co/metrics/accuracy) via the datasets library.
```python
from datasets import load_metric
accuracy = load_metric("accuracy")
```
Next, we define the `compute_metrics` which will be applied to the predicted outputs of the model which is of type [`EvalPrediction`](https://huggingface.co/docs/transformers/main/en/internal/trainer_utils#transformers.EvalPrediction) and therefore exposes the model's predictions and the gold labels.
We compute the predicted label class by taking the `argmax` of the model's prediction before passing it alongside the gold labels to the accuracy metric.
```python
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
acc = accuracy.compute(predictions=pred_classes, references=labels)
return {"accuracy": acc["accuracy"]}
```
Great, now all components required for training are ready and all that's left to do is to define the hyper-parameters of the `Trainer`. We need to make sure that the model checkpoints are uploaded to the Hugging Face Hub during training. By setting `push_to_hub=True`, this is done automatically at every `save_steps` via the convenient [`push_to_hub`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.Trainer.push_to_hub) method.
Besides, we define some standard hyper-parameters such as learning rate, warm-up steps and training epochs. We will log the loss every 500 steps and run evaluation every 5000 steps.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="deberta_amazon_reviews_v1",
num_train_epochs=2,
learning_rate=2e-5,
warmup_steps=200,
logging_steps=500,
save_steps=5000,
eval_steps=5000,
push_to_hub=True,
evaluation_strategy="steps",
)
```
Putting it all together, we can finally instantiate the Trainer by passing all required components. We'll use the `"validation"` split as the held-out dataset during training.
```python
from transformers import Trainer
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
train_dataset=tokenized_datasets["train"],
eval_dataset=tokenized_datasets["validation"]
)
```
The trainer is ready to go 🚀 You can start training by calling `trainer.train()`.
```python
train_metrics = trainer.train().metrics
trainer.save_metrics("train", train_metrics)
```
**Output:**
```
***** Running training *****
Num examples = 200000
Num Epochs = 2
Instantaneous batch size per device = 8
Total train batch size (w. parallel, distributed & accumulation) = 8
Gradient Accumulation steps = 1
Total optimization steps = 50000
```
**Output:**
<div>
<table><p>
<tbody>
<tr style="text-align: left;">
<td>Step</td>
<td>Training Loss</td>
<td>Validation Loss</td>
<td>Accuracy</td>
</tr>
<tr>
<td>5000</td>
<td>0.931200</td>
<td>0.979602</td>
<td>0.585600</td>
</tr>
<tr>
<td>10000</td>
<td>0.931600</td>
<td>0.933607</td>
<td>0.597400</td>
</tr>
<tr>
<td>15000</td>
<td>0.907600</td>
<td>0.917062</td>
<td>0.602600</td>
</tr>
<tr>
<td>20000</td>
<td>0.902400</td>
<td>0.919414</td>
<td>0.604600</td>
</tr>
<tr>
<td>25000</td>
<td>0.879400</td>
<td>0.910928</td>
<td>0.608400</td>
</tr>
<tr>
<td>30000</td>
<td>0.806700</td>
<td>0.933923</td>
<td>0.609200</td>
</tr>
<tr>
<td>35000</td>
<td>0.826800</td>
<td>0.907260</td>
<td>0.616200</td>
</tr>
<tr>
<td>40000</td>
<td>0.820500</td>
<td>0.904160</td>
<td>0.615800</td>
</tr>
<tr>
<td>45000</td>
<td>0.795000</td>
<td>0.918947</td>
<td>0.616800</td>
</tr>
<tr>
<td>50000</td>
<td>0.783600</td>
<td>0.907572</td>
<td>0.618400</td>
</tr>
</tbody>
</table><p>
</div>
**Output:**
```
***** Running Evaluation *****
Num examples = 5000
Batch size = 8
Saving model checkpoint to deberta_amazon_reviews_v1/checkpoint-50000
Configuration saved in deberta_amazon_reviews_v1/checkpoint-50000/config.json
Model weights saved in deberta_amazon_reviews_v1/checkpoint-50000/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/checkpoint-50000/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/checkpoint-50000/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/checkpoint-50000/added_tokens.json
Training completed. Do not forget to share your model on huggingface.co/models =)
```
Cool, we see that the model seems to learn something! Training loss and validation loss are going down and the accuracy also ends up being well over random chance (20%). Interestingly, we see an accuracy of around **58.6 %** after only 5000 steps which doesn't improve that much anymore afterward. Choosing a bigger model or training for longer would have probably given better results here, but that's good enough for our hypothetical use case!
Alright, finally let's upload the model checkpoint to the Hub.
```python
trainer.push_to_hub()
```
**Output:**
```
Saving model checkpoint to deberta_amazon_reviews_v1
Configuration saved in deberta_amazon_reviews_v1/config.json
Model weights saved in deberta_amazon_reviews_v1/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/added_tokens.json
Several commits (2) will be pushed upstream.
The progress bars may be unreliable.
```
### Evaluate / Analyse the model
Now that we have fine-tuned the model we need to be very careful about analyzing its performance.
Note that canonical metrics, such as *accuracy*, are useful to get a general picture
about your model's performance, but it might not be enough to evaluate how well the model performs on your actual use case.
The better approach is to find a metric that best describes the actual use case of the model and measure exactly this metric during and after training.
Let's dive into evaluating the model 🤿.
The model has been uploaded to the Hub under [`deberta_v3_amazon_reviews`](https://huggingface.co/patrickvonplaten/deberta_v3_amazon_reviews) after training, so in a first step, let's download it from there again.
```python
from transformers import AutoModelForSequenceClassification
model = AutoModelForSequenceClassification.from_pretrained("patrickvonplaten/deberta_v3_amazon_reviews")
```
The Trainer is not only an excellent class to train a model, but also to evaluate a model on a dataset. Let's instantiate the trainer with the same instances and functions as before, but this time there is no need to pass a training dataset.
```python
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)
```
We use the Trainer's [`predict`](https://huggingface.co/docs/transformers/main/en/main_classes/trainer#transformers.Trainer.predict) function to evaluate the model on the test dataset on the same metric.
```python
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics
```
**Output:**
```
***** Running Prediction *****
Num examples = 5000
Batch size = 8
```
**Output:**
```
{'test_accuracy': 0.608,
'test_loss': 0.9637690186500549,
'test_runtime': 21.9574,
'test_samples_per_second': 227.714,
'test_steps_per_second': 28.464}
```
The results are very similar to performance on the validation dataset, which is usually a good sign as it shows that the model didn't overfit the test dataset.
However, 60% accuracy is far from being perfect on a 5-class classification problem, but do we need very high accuracy for all classes?
Since we are mostly concerned with very negative customer feedback, let's just focus on how well the model performs on classifying reviews of the most unsatisfied customers. We also decide to help the model a bit - all feedback classified as either **very unsatisfied** or **unsatisfied** will be handled by us - to catch close to 99% of the **very unsatisfied** messages. At the same time, we also measure how many **unsatisfied** messages we can answer this way and how much unnecessary work we do by answering messages of neutral, satisfied, and very satisfied customers.
Great, let's write a new `compute_metrics` function.
```python
import numpy as np
def compute_metrics(pred):
pred_logits = pred.predictions
pred_classes = np.argmax(pred_logits, axis=-1)
labels = np.asarray(pred.label_ids)
# First let's compute % of very unsatisfied messages we can catch
very_unsatisfied_label_idx = (labels == 0)
very_unsatisfied_pred = pred_classes[very_unsatisfied_label_idx]
# Now both 0 and 1 labels are 0 labels the rest is > 0
very_unsatisfied_pred = very_unsatisfied_pred * (very_unsatisfied_pred - 1)
# Let's count how many labels are 0 -> that's the "very unsatisfied"-accuracy
true_positives = sum(very_unsatisfied_pred == 0) / len(very_unsatisfied_pred)
# Second let's compute how many satisfied messages we unnecessarily reply to
satisfied_label_idx = (labels > 1)
satisfied_pred = pred_classes[satisfied_label_idx]
# how many predictions are labeled as unsatisfied over all satisfied messages?
false_positives = sum(satisfied_pred <= 1) / len(satisfied_pred)
return {"%_unsatisfied_replied": round(true_positives, 2), "%_satisfied_incorrectly_labels": round(false_positives, 2)}
```
We again instantiate the `Trainer` to easily run the evaluation.
```python
trainer = Trainer(
args=training_args,
compute_metrics=compute_metrics,
model=model,
tokenizer=tokenizer,
data_collator=data_collator,
)
```
And let's run the evaluation again with our new metric computation which is better suited for our use case.
```python
prediction_metrics = trainer.predict(tokenized_datasets["test"]).metrics
prediction_metrics
```
**Output:**
```
***** Running Prediction *****
Num examples = 5000
Batch size = 8
```
**Output:**
```
{'test_%_satisfied_incorrectly_labels': 0.11733333333333333,
'test_%_unsatisfied_replied': 0.949,
'test_loss': 0.9637690186500549,
'test_runtime': 22.8964,
'test_samples_per_second': 218.375,
'test_steps_per_second': 27.297}
```
Cool! This already paints a pretty nice picture. We catch around 95% of **very unsatisfied** customers automatically at a cost of wasting our efforts on 10% of satisfied messages.
Let's do some quick math. We receive daily around 10,000 messages for which we expect ca. 500 to be very negative. Instead of having to answer to all 10,000 messages, using this automatic filtering, we would only need to look into 500 + 0.12 \* 10,000 = 1700 messages and only reply to 475 messages while incorrectly missing 5% of the messages. Pretty nice - a 83% reduction in human effort at missing only 5% of very unsatisfied customers!
Obviously, the numbers don't represent the gained value of an actual use case, but we could come close to it with enough high-quality training data of your real-world example!
Let's save the results
```python
trainer.save_metrics("prediction", prediction_metrics)
```
and again upload everything on the Hub.
```python
trainer.push_to_hub()
```
**Output:**
```
Saving model checkpoint to deberta_amazon_reviews_v1
Configuration saved in deberta_amazon_reviews_v1/config.json
Model weights saved in deberta_amazon_reviews_v1/pytorch_model.bin
tokenizer config file saved in deberta_amazon_reviews_v1/tokenizer_config.json
Special tokens file saved in deberta_amazon_reviews_v1/special_tokens_map.json
added tokens file saved in deberta_amazon_reviews_v1/added_tokens.json
To https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1
599b891..ad77e6d main -> main
Dropping the following result as it does not have all the necessary fields:
{'task': {'name': 'Text Classification', 'type': 'text-classification'}}
To https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1
ad77e6d..13e5ddd main -> main
```
The data is now saved [here](https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1/blob/main/prediction_results.json).
That's it for today 😎. As a final step, it would also make a lot of sense to try the model out on actual real-world data. This can be done directly on the inference widget on [the model card](https://huggingface.co/patrickvonplaten/deberta_amazon_reviews_v1):
It does seem to generalize quite well to real-world data 🔥
## Optimization
As soon as you think the model's performance is good enough for production it's all about making the model as memory efficient and fast as possible.
There are some obvious solutions to this like choosing the best suited accelerated hardware, *e.g.* better GPUs, making sure no gradients are computed during the forward pass, or lowering the precision, *e.g.* to float16.
More advanced optimization methods include using open-source accelerator libraries such as [ONNX Runtime](https://onnxruntime.ai/index.html), [quantization](https://pytorch.org/docs/stable/quantization.html), and inference servers like [Triton](https://developer.nvidia.com/nvidia-triton-inference-server).
At Hugging Face, we have been working a lot to facilitate the optimization of models, especially with our open-source [Optimum library](https://huggingface.co/hardware). Optimum makes it extremely simple to optimize most 🤗 Transformers models.
If you're looking for **highly optimized** solutions which don't require any technical knowledge, you might be interested in the [Inference API](https://huggingface.co/inference-api), a plug & play solution to serve in production a wide variety of machine learning tasks, including sentiment analysis.
Moreover, if you are searching for **support for your custom use cases**, Hugging Face's team of experts can help accelerate your ML projects! Our team answer questions and find solutions as needed in your machine learning journey from research to production. Visit [hf.co/support](https://huggingface.co/support) to learn more and request a quote.
| 9 |
0 | hf_public_repos | hf_public_repos/api-inference-community/build_docker.py | #!/usr/bin/env python
import argparse
import os
import subprocess
import sys
import uuid
def run(command):
print(" ".join(command))
p = subprocess.run(command)
if p.returncode != 0:
sys.exit(p.returncode)
def build(framework: str, is_gpu: bool):
DEFAULT_HOSTNAME = os.getenv("DEFAULT_HOSTNAME")
hostname = DEFAULT_HOSTNAME
tag_id = str(uuid.uuid4())[:5]
tag = f"{framework}-{tag_id}"
container_tag = f"{hostname}/api-inference/community:{tag}"
command = ["docker", "build", f"docker_images/{framework}", "-t", container_tag]
run(command)
password = os.environ["REGISTRY_PASSWORD"]
username = os.environ["REGISTRY_USERNAME"]
command = ["echo", password]
ecr_login = subprocess.Popen(command, stdout=subprocess.PIPE)
docker_login = subprocess.Popen(
["docker", "login", "-u", username, "--password-stdin", hostname],
stdin=ecr_login.stdout,
stdout=subprocess.PIPE,
)
docker_login.communicate()
command = ["docker", "push", container_tag]
run(command)
return tag
def main():
frameworks = {
dirname for dirname in os.listdir("docker_images") if dirname != "common"
}
framework_choices = frameworks.copy()
framework_choices.add("all")
parser = argparse.ArgumentParser()
parser.add_argument(
"framework",
type=str,
choices=framework_choices,
help="Which framework image to build.",
)
parser.add_argument(
"--out",
type=str,
help="Where to store the new tags",
)
parser.add_argument(
"--gpu",
action="store_true",
help="Build the GPU version of the model",
)
args = parser.parse_args()
branch = (
subprocess.check_output(["git", "rev-parse", "--abbrev-ref", "HEAD"])
.decode("utf-8")
.strip()
)
if branch != "main":
raise Exception(f"Go to branch `main` ({branch})")
print("Pulling")
subprocess.run(["git", "pull"])
if args.framework == "all":
outputs = []
for framework in frameworks:
tag = build(framework, args.gpu)
outputs.append((framework, tag))
else:
tag = build(args.framework, args.gpu)
outputs = [(args.framework, tag)]
for (framework, tag) in outputs:
compute = "GPU" if args.gpu else "CPU"
name = f"{framework.upper()}_{compute}_TAG"
print(name, tag)
if args.out:
with open(args.out, "w") as f:
f.write(f"{name}={tag}\n")
if __name__ == "__main__":
main()
| 0 |
0 | hf_public_repos | hf_public_repos/api-inference-community/LICENSE | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 1 |
0 | hf_public_repos | hf_public_repos/api-inference-community/Makefile | .PHONY: quality style
check_dirs := api_inference_community tests docker_images
quality:
black --check $(check_dirs)
isort --check-only $(check_dirs)
flake8 $(check_dirs)
style:
black $(check_dirs)
isort $(check_dirs)
test:
pytest -sv --log-level=DEBUG tests/
| 2 |
0 | hf_public_repos | hf_public_repos/api-inference-community/requirements.txt | starlette>=0.14.2
numpy>=1.18.0
pydantic>=2
parameterized>=0.8.1
pillow>=8.2.0
huggingface_hub>=0.20.2
datasets>=2.2
psutil>=6.0.0
pytest
httpx
uvicorn
black
isort
flake8
| 3 |
0 | hf_public_repos | hf_public_repos/api-inference-community/build.sh | pip install -U pip build twine
python -m build
python -m twine upload dist/*
| 4 |
0 | hf_public_repos | hf_public_repos/api-inference-community/manage.py | #!/usr/bin/env python
import argparse
import ast
import hashlib
import os
import subprocess
import sys
import uuid
from huggingface_hub import HfApi
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerPopen(subprocess.Popen):
def __exit__(self, exc_type, exc_val, traceback):
self.terminate()
self.wait(5)
return super().__exit__(exc_type, exc_val, traceback)
def create_docker(name: str, is_gpu: bool) -> str:
rand = str(uuid.uuid4())[:5]
tag = f"{name}:{rand}"
with cd(
os.path.join(os.path.dirname(os.path.normpath(__file__)), "docker_images", name)
):
subprocess.run(["docker", "build", ".", "-t", tag])
return tag
def resolve_dataset(args, task: str):
import datasets
builder = datasets.load_dataset_builder(
args.dataset_name, use_auth_token=args.token
)
if args.dataset_config is None:
args.dataset_config = builder.config_id
print(f"Inferred dataset_config {args.dataset_config}")
splits = builder.info.splits
if splits is not None:
if args.dataset_split not in splits:
raise ValueError(
f"The split `{args.dataset_split}` is not a valid split, please choose from {','.join(splits.keys())}"
)
task_templates = builder.info.task_templates
if task_templates is not None:
for task_template in task_templates:
if task_template.task == task:
args.dataset_column = task_template.audio_file_path_column
print(f"Inferred dataset_column {args.dataset_column}")
return (
args.dataset_name,
args.dataset_config,
args.dataset_split,
args.dataset_column,
)
def get_repo_name(model_id: str, dataset_name: str) -> str:
# Hash needs to have the fully qualified name to disambiguate.
hash_ = hashlib.md5((model_id + dataset_name).encode("utf-8")).hexdigest()
model_name = model_id.split("/")[-1]
dataset_name = dataset_name.split("/")[-1]
return f"bulk-{model_name[:10]}-{dataset_name[:10]}-{hash_[:5]}"
def show(args):
directory = os.path.join(
os.path.dirname(os.path.normpath(__file__)), "docker_images"
)
for framework in sorted(os.listdir(directory)):
print(f"{framework}")
local_path = os.path.join(
os.path.dirname(os.path.normpath(__file__)),
"docker_images",
framework,
"app",
"main.py",
)
# Using ast to prevent import issues with missing dependencies.
# and slow loads.
with open(local_path, "r") as source:
tree = ast.parse(source.read())
for item in tree.body:
if (
isinstance(item, ast.AnnAssign)
and item.target.id == "ALLOWED_TASKS"
):
for key in item.value.keys:
print(" " * 4, key.value)
def resolve(model_id: str) -> [str, str]:
try:
info = HfApi().model_info(model_id)
except Exception as e:
raise ValueError(
f"The hub has no information on {model_id}, does it exist: {e}"
)
try:
task = info.pipeline_tag
except Exception:
raise ValueError(
f"The hub has no `pipeline_tag` on {model_id}, you can set it in the `README.md` yaml header"
)
try:
framework = info.library_name
except Exception:
raise ValueError(
f"The hub has no `library_name` on {model_id}, you can set it in the `README.md` yaml header"
)
return task, framework.replace("-", "_")
def resolve_task_framework(args):
model_id = args.model
task = args.task
framework = args.framework
if task is None or framework is None:
rtask, rframework = resolve(model_id)
if task is None:
task = rtask
print(f"Inferred task : {task}")
if framework is None:
framework = rframework
print(f"Inferred framework : {framework}")
return model_id, task, framework
def start(args):
import uvicorn
model_id, task, framework = resolve_task_framework(args)
local_path = os.path.join(
os.path.dirname(os.path.normpath(__file__)), "docker_images", framework
)
sys.path.append(local_path)
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = task
if args.gpu:
os.environ["COMPUTE_TYPE"] = "gpu"
uvicorn.run("app.main:app", host="127.0.0.1", port=8000, log_level="info")
def docker(args):
model_id, task, framework = resolve_task_framework(args)
tag = create_docker(framework, is_gpu=args.gpu)
gpu = ["--gpus", "all"] if args.gpu else []
run_docker_command = [
"docker",
"run",
*gpu,
"-p",
"8000:80",
"-e",
f"TASK={task}",
"-e",
f"MODEL_ID={model_id}",
"-e",
f"COMPUTE_TYPE={'gpu' if args.gpu else 'cpu'}",
"-e",
f"DEBUG={os.getenv('DEBUG', '0')}",
"-v",
"/tmp:/data",
"-t",
tag,
]
print(" ".join(run_docker_command))
with DockerPopen(run_docker_command) as proc:
try:
proc.wait()
except KeyboardInterrupt:
proc.terminate()
def main():
parser = argparse.ArgumentParser()
subparsers = parser.add_subparsers()
parser_start = subparsers.add_parser(
"start", help="Start a local version of a model inference"
)
parser_start.add_argument(
"model",
type=str,
help="Which model_id to start.",
)
parser_start.add_argument(
"--task",
type=str,
help="Which task to load",
)
parser_start.add_argument(
"--framework",
type=str,
help="Which framework to load",
)
parser_start.add_argument(
"--gpu",
action="store_true",
help="Using gpu ?",
)
parser_start.set_defaults(func=start)
parser_docker = subparsers.add_parser(
"docker", help="Start a docker version of a model inference"
)
parser_docker.add_argument(
"model",
type=str,
help="Which model_id to docker.",
)
parser_docker.add_argument(
"--task",
type=str,
help="Which task to load",
)
parser_docker.add_argument(
"--framework",
type=str,
help="Which framework to load",
)
parser_docker.add_argument(
"--gpu",
action="store_true",
help="Using gpu ?",
)
parser_docker.set_defaults(func=docker)
parser_show = subparsers.add_parser(
"show", help="Show dockers and the various pipelines they implement"
)
parser_show.set_defaults(func=show)
args = parser.parse_args()
args.func(args)
if __name__ == "__main__":
main()
| 5 |
0 | hf_public_repos | hf_public_repos/api-inference-community/MANIFEST.in | include README.md requirements.txt
| 6 |
0 | hf_public_repos | hf_public_repos/api-inference-community/.pre-commit-config.yaml | repos:
- repo: https://github.com/psf/black
rev: 22.3.0
hooks:
- id: black
- repo: https://github.com/PyCQA/flake8
rev: 5.0.4
hooks:
- id: flake8
- repo: https://github.com/pre-commit/mirrors-isort
rev: v5.7.0 # Use the revision sha / tag you want to point at
hooks:
- id: isort
- repo: https://github.com/pre-commit/mirrors-mypy
rev: "b84ce099a2fd3c5216b6ccf3fd176c3828b075fb" # Use the sha / tag you want to point at
hooks:
- id: mypy
args: [--ignore-missing-imports]
additional_dependencies: [tokenize-rt==3.2.0]
files: ^docker_images/common/
entry: mypy docker_images/common/
pass_filenames: false
- id: mypy
args: [--ignore-missing-imports]
additional_dependencies: [tokenize-rt==3.2.0]
files: ^docker_images/speechbrain/
entry: mypy docker_images/speechbrain/
pass_filenames: false
- id: mypy
args: [--ignore-missing-imports]
additional_dependencies: [tokenize-rt==3.2.0]
files: ^docker_images/kasteroid/
entry: mypy docker_images/asteroid/
pass_filenames: false
- id: mypy
args: [--ignore-missing-imports]
additional_dependencies: [tokenize-rt==3.2.0]
files: ^docker_images/allennlp/
entry: mypy docker_images/allennlp/
pass_filenames: false
- id: mypy
args: [--ignore-missing-imports]
additional_dependencies: [tokenize-rt==3.2.0]
files: ^docker_images/espnet/
entry: mypy docker_images/espnet/
pass_filenames: false
- id: mypy
args: [--ignore-missing-imports]
additional_dependencies: [tokenize-rt==3.2.0]
files: ^docker_images/timm/
entry: mypy docker_images/timm/
pass_filenames: false
- id: mypy
args: [--ignore-missing-imports]
additional_dependencies: [tokenize-rt==3.2.0]
files: ^docker_images/flair/
entry: mypy docker_images/flair/
pass_filenames: false
- id: mypy
args: [--ignore-missing-imports]
additional_dependencies: [tokenize-rt==3.2.0]
files: ^docker_images/sentence_transformers/
entry: mypy docker_images/sentence_transformers/
pass_filenames: false
| 7 |
0 | hf_public_repos | hf_public_repos/api-inference-community/README.md |
This repositories enable third-party libraries integrated with [huggingface_hub](https://github.com/huggingface/huggingface_hub/) to create
their own docker so that the widgets on the hub can work as the `transformers` one do.
The hardware to run the API will be provided by Hugging Face for now.
The `docker_images/common` folder is intended to be a starter point for all new libs that
want to be integrated.
### Adding a new container from a new lib.
1. Copy the `docker_images/common` folder into your library's name `docker_images/example`.
2. Edit:
- `docker_images/example/requirements.txt`
- `docker_images/example/app/main.py`
- `docker_images/example/app/pipelines/{task_name}.py`
to implement the desired functionality. All required code is marked with `IMPLEMENT_THIS` markup.
3. Remove:
- Any pipeline files in `docker_images/example/app/pipelines/` that are not used.
- Any tests associated with deleted pipelines in `docker_images/example/tests`.
- Any imports of the pipelines you deleted from `docker_images/example/app/pipelines/__init__.py`
4. Feel free to customize anything required by your lib everywhere you want. The only real requirements, are to honor the HTTP endpoints, in the same fashion as the `common` folder for all your supported tasks.
5. Edit `example/tests/test_api.py` to add TESTABLE_MODELS.
6. Pass the test suite `pytest -sv --rootdir docker_images/example/ docker_images/example/`
7. Submit your PR and enjoy !
### Going the full way
Doing the first 7 steps is good enough to get started, however in the process
you can anticipate some problems corrections early on. Maintainers will help you
along the way if you don't feel confident to follow those steps yourself
1. Test your creation within a docker
```python
./manage.py docker MY_MODEL
```
should work and responds on port 8000. `curl -X POST -d "test" http://localhost:8000` for instance if
the pipeline deals with simple text.
If it doesn't work out of the box and/or docker is slow for some reason you
can test locally (using your local python environment) with :
`./manage.py start MY_MODEL`
2. Test your docker uses cache properly.
When doing subsequent docker launch with the same model_id, the docker should start up very fast and not redownload the whole model file. If you see the model/repo being downloaded over and over, it means the cache is not being used correctly.
You can edit the `docker_images/{framework}/Dockerfile` and add an environment variable (by default it assumes `HUGGINGFACE_HUB_CACHE`), or your code directly to put
the model files in the `/data` folder.
3. Add a docker test.
Edit the `tests/test_dockers.py` file to add a new test with your new framework
in it (`def test_{framework}(self):` for instance). As a basic you should have 1 line per task in this test function with a real working model on the hub. Those tests are relatively slow but will check automatically that correct errors are replied by your API and that the cache works properly. To run those tests your can simply do:
```bash
RUN_DOCKER_TESTS=1 pytest -sv tests/test_dockers.py::DockerImageTests::test_{framework}
```
### Modifying files within `api-inference-community/{routes,validation,..}.py`.
If you ever come across a bug within `api-inference-community/` package or want to update it
the development process is slightly more involved.
- First, make sure you need to change this package, each framework is very autonomous
so if your code can get away by being standalone go that way first as it's much simpler.
- If you can make the change only in `api-inference-community` without depending on it
that's also a great option. Make sure to add the proper tests to your PR.
- Finally, the best way to go is to develop locally using `manage.py` command:
- Do the necessary modifications within `api-inference-community` first.
- Install it locally in your environment with `pip install -e .`
- Install your package dependencies locally.
- Run your webserver locally: `./manage.py start --framework example --task audio-source-separation --model-id MY_MODEL`
- When everything is working, you will need to split your PR in two, 1 for the `api-inference-community` part.
The second one will be for your package specific modifications and will only land once the `api-inference-community` tag has landed.
- This workflow is still work in progress, don't hesitate to ask questions to maintainers.
Another similar command `./manage.py docker --framework example --task audio-source-separation --model-id MY_MODEL`
Will launch the server, but this time in a protected, controlled docker environment making sure the behavior
will be exactly the one in the API.
### Available tasks
- **Automatic speech recognition**: Input is a file, output is a dict of understood words being said within the file
- **Text generation**: Input is a text, output is a dict of generated text
- **Image recognition**: Input is an image, output is a dict of generated text
- **Question answering**: Input is a question + some context, output is a dict containing necessary information to locate the answer to the `question` within the `context`.
- **Audio source separation**: Input is some audio, and the output is n audio files that sum up to the original audio but contain individual sources of sound (either speakers or instruments for instant).
- **Token classification**: Input is some text, and the output is a list of entities mentioned in the text. Entities can be anything remarkable like locations, organisations, persons, times etc...
- **Text to speech**: Input is some text, and the output is an audio file saying the text...
- **Sentence Similarity**: Input is some sentence and a list of reference sentences, and the list of similarity scores.
| 8 |
0 | hf_public_repos/api-inference-community | hf_public_repos/api-inference-community/scripts/export_tasks.py | """Exports a library -> supported tasks mapping in JSON format.
This script
- parses the source code of a library's app/main.py and extracts the AST
- finds the ALLOWED_TASKS variable and get all the keys.
- prints the library name as well as its tasks in JSON format.
Note that the transformer library is not included in the output
as we can assume it supports all tasks. This is done as
the transformers API codebase is not in this repository.
"""
import ast
import collections
import os
import pathlib
import json
lib_to_task_map = collections.defaultdict(list)
def _extract_tasks(library_name, variable_name, value):
"""Extract supported tasks of the library.
Args:
library_name: The name of the library (e.g. paddlenlp)
variable_name: The name of the Python variable (e.g. ALLOWED_TASKS)
value: The AST of the variable's Python value.
"""
if variable_name == "ALLOWED_TASKS":
if isinstance(value, ast.Dict):
for key in value.keys:
lib_to_task_map[library_name].append(key.value)
def traverse_global_assignments(library_name, file_content, handler):
"""Traverse all global assignments and apply handler on each of them.
Args:
library_name: The name of the library (e.g. paddlenlp)
file_content: The content of app/main.py file in string.
handler: A callback that processes the AST.
"""
for element in ast.parse(file_content).body:
# Typical case, e.g. TARGET_ID: Type = VALUE
if isinstance(element, ast.AnnAssign):
handler(library_name, element.target.id, element.value)
# Just in case user omitted the type annotation
# Unpacking and multi-variable assignment is rare so not handled
# e.g. TARGET_ID = VALUE
elif isinstance(element, ast.Assign):
target = element.targets[0]
if isinstance(target, ast.Name):
handler(library_name, target.id, element.value)
if __name__ == "__main__":
root = pathlib.Path(__file__).parent.parent.resolve()
libs = os.listdir(root / "docker_images")
libs.remove("common")
for lib in libs:
with open(root / "docker_images" / lib / "app/main.py") as f:
content = f.read()
traverse_global_assignments(lib, content, _extract_tasks)
output = json.dumps(lib_to_task_map, sort_keys=True, indent=4)
print(output)
| 9 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/constants.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import operator as op
SCALER_NAME = "scaler.pt"
MODEL_NAME = "pytorch_model"
SAFE_MODEL_NAME = "model"
RNG_STATE_NAME = "random_states"
OPTIMIZER_NAME = "optimizer"
SCHEDULER_NAME = "scheduler"
SAMPLER_NAME = "sampler"
PROFILE_PATTERN_NAME = "profile_{suffix}.json"
WEIGHTS_NAME = f"{MODEL_NAME}.bin"
WEIGHTS_PATTERN_NAME = "pytorch_model{suffix}.bin"
WEIGHTS_INDEX_NAME = f"{WEIGHTS_NAME}.index.json"
SAFE_WEIGHTS_NAME = f"{SAFE_MODEL_NAME}.safetensors"
SAFE_WEIGHTS_PATTERN_NAME = "model{suffix}.safetensors"
SAFE_WEIGHTS_INDEX_NAME = f"{SAFE_WEIGHTS_NAME}.index.json"
SAGEMAKER_PYTORCH_VERSION = "1.10.2"
SAGEMAKER_PYTHON_VERSION = "py38"
SAGEMAKER_TRANSFORMERS_VERSION = "4.17.0"
SAGEMAKER_PARALLEL_EC2_INSTANCES = ["ml.p3.16xlarge", "ml.p3dn.24xlarge", "ml.p4dn.24xlarge"]
FSDP_SHARDING_STRATEGY = ["FULL_SHARD", "SHARD_GRAD_OP", "NO_SHARD", "HYBRID_SHARD", "HYBRID_SHARD_ZERO2"]
FSDP_AUTO_WRAP_POLICY = ["TRANSFORMER_BASED_WRAP", "SIZE_BASED_WRAP", "NO_WRAP"]
FSDP_BACKWARD_PREFETCH = ["BACKWARD_PRE", "BACKWARD_POST", "NO_PREFETCH"]
FSDP_STATE_DICT_TYPE = ["FULL_STATE_DICT", "LOCAL_STATE_DICT", "SHARDED_STATE_DICT"]
FSDP_PYTORCH_VERSION = (
"2.1.0.a0+32f93b1" # Technically should be 2.1.0, but MS-AMP uses this specific prerelease in their Docker image.
)
FSDP_MODEL_NAME = "pytorch_model_fsdp"
DEEPSPEED_MULTINODE_LAUNCHERS = ["pdsh", "standard", "openmpi", "mvapich", "mpich"]
TORCH_DYNAMO_MODES = ["default", "reduce-overhead", "max-autotune"]
ELASTIC_LOG_LINE_PREFIX_TEMPLATE_PYTORCH_VERSION = "2.2.0"
XPU_PROFILING_AVAILABLE_PYTORCH_VERSION = "2.4.0"
MITA_PROFILING_AVAILABLE_PYTORCH_VERSION = "2.1.0"
STR_OPERATION_TO_FUNC = {">": op.gt, ">=": op.ge, "==": op.eq, "!=": op.ne, "<=": op.le, "<": op.lt}
# These are the args for `torch.distributed.launch` for pytorch < 1.9
TORCH_LAUNCH_PARAMS = [
"nnodes",
"nproc_per_node",
"rdzv_backend",
"rdzv_endpoint",
"rdzv_id",
"rdzv_conf",
"standalone",
"max_restarts",
"monitor_interval",
"start_method",
"role",
"module",
"m",
"no_python",
"run_path",
"log_dir",
"r",
"redirects",
"t",
"tee",
"node_rank",
"master_addr",
"master_port",
]
CUDA_DISTRIBUTED_TYPES = ["DEEPSPEED", "MULTI_GPU", "FSDP", "MEGATRON_LM"]
TORCH_DISTRIBUTED_OPERATION_TYPES = CUDA_DISTRIBUTED_TYPES + [
"MULTI_NPU",
"MULTI_MLU",
"MULTI_MUSA",
"MULTI_XPU",
"MULTI_CPU",
]
| 0 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/__init__.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from .constants import (
MITA_PROFILING_AVAILABLE_PYTORCH_VERSION,
MODEL_NAME,
OPTIMIZER_NAME,
PROFILE_PATTERN_NAME,
RNG_STATE_NAME,
SAFE_MODEL_NAME,
SAFE_WEIGHTS_INDEX_NAME,
SAFE_WEIGHTS_NAME,
SAFE_WEIGHTS_PATTERN_NAME,
SAMPLER_NAME,
SCALER_NAME,
SCHEDULER_NAME,
TORCH_DISTRIBUTED_OPERATION_TYPES,
TORCH_LAUNCH_PARAMS,
WEIGHTS_INDEX_NAME,
WEIGHTS_NAME,
WEIGHTS_PATTERN_NAME,
XPU_PROFILING_AVAILABLE_PYTORCH_VERSION,
)
from .dataclasses import (
AutocastKwargs,
BnbQuantizationConfig,
ComputeEnvironment,
CustomDtype,
DataLoaderConfiguration,
DDPCommunicationHookType,
DeepSpeedPlugin,
DistributedDataParallelKwargs,
DistributedType,
DynamoBackend,
FP8RecipeKwargs,
FullyShardedDataParallelPlugin,
GradientAccumulationPlugin,
GradScalerKwargs,
InitProcessGroupKwargs,
KwargsHandler,
LoggerType,
MegatronLMPlugin,
PrecisionType,
ProfileKwargs,
ProjectConfiguration,
RNGType,
SageMakerDistributedType,
TensorInformation,
TorchDynamoPlugin,
add_model_config_to_megatron_parser,
)
from .environment import (
are_libraries_initialized,
check_cuda_p2p_ib_support,
check_fp8_capability,
clear_environment,
convert_dict_to_env_variables,
get_cpu_distributed_information,
get_gpu_info,
get_int_from_env,
parse_choice_from_env,
parse_flag_from_env,
patch_environment,
purge_accelerate_environment,
set_numa_affinity,
str_to_bool,
)
from .imports import (
deepspeed_required,
get_ccl_version,
is_4bit_bnb_available,
is_8bit_bnb_available,
is_aim_available,
is_bf16_available,
is_bitsandbytes_multi_backend_available,
is_bnb_available,
is_boto3_available,
is_ccl_available,
is_clearml_available,
is_comet_ml_available,
is_cuda_available,
is_datasets_available,
is_deepspeed_available,
is_dvclive_available,
is_fp8_available,
is_import_timer_available,
is_ipex_available,
is_lomo_available,
is_megatron_lm_available,
is_mlflow_available,
is_mlu_available,
is_mps_available,
is_msamp_available,
is_musa_available,
is_npu_available,
is_pandas_available,
is_peft_available,
is_pippy_available,
is_pynvml_available,
is_pytest_available,
is_rich_available,
is_sagemaker_available,
is_schedulefree_available,
is_tensorboard_available,
is_timm_available,
is_torch_xla_available,
is_torchdata_available,
is_torchdata_stateful_dataloader_available,
is_torchvision_available,
is_transformer_engine_available,
is_transformers_available,
is_triton_available,
is_wandb_available,
is_weights_only_available,
is_xpu_available,
)
from .modeling import (
align_module_device,
calculate_maximum_sizes,
check_device_map,
check_tied_parameters_in_config,
check_tied_parameters_on_same_device,
compute_module_sizes,
convert_file_size_to_int,
dtype_byte_size,
find_tied_parameters,
get_balanced_memory,
get_grad_scaler,
get_max_layer_size,
get_max_memory,
get_mixed_precision_context_manager,
has_offloaded_params,
id_tensor_storage,
infer_auto_device_map,
is_peft_model,
load_checkpoint_in_model,
load_offloaded_weights,
load_state_dict,
named_module_tensors,
retie_parameters,
set_module_tensor_to_device,
)
from .offload import (
OffloadedWeightsLoader,
PrefixedDataset,
extract_submodules_state_dict,
load_offloaded_weight,
offload_state_dict,
offload_weight,
save_offload_index,
)
from .operations import (
CannotPadNestedTensorWarning,
GatheredParameters,
broadcast,
broadcast_object_list,
concatenate,
convert_outputs_to_fp32,
convert_to_fp32,
copy_tensor_to_devices,
find_batch_size,
find_device,
gather,
gather_object,
get_data_structure,
honor_type,
ignorant_find_batch_size,
initialize_tensors,
is_namedtuple,
is_tensor_information,
is_torch_tensor,
listify,
pad_across_processes,
pad_input_tensors,
recursively_apply,
reduce,
send_to_device,
slice_tensors,
)
from .versions import compare_versions, is_torch_version
if is_deepspeed_available():
from .deepspeed import (
DeepSpeedEngineWrapper,
DeepSpeedOptimizerWrapper,
DeepSpeedSchedulerWrapper,
DummyOptim,
DummyScheduler,
HfDeepSpeedConfig,
get_active_deepspeed_plugin,
)
from .bnb import has_4bit_bnb_layers, load_and_quantize_model
from .fsdp_utils import (
disable_fsdp_ram_efficient_loading,
enable_fsdp_ram_efficient_loading,
ensure_weights_retied,
load_fsdp_model,
load_fsdp_optimizer,
merge_fsdp_weights,
save_fsdp_model,
save_fsdp_optimizer,
)
from .launch import (
PrepareForLaunch,
_filter_args,
prepare_deepspeed_cmd_env,
prepare_multi_gpu_env,
prepare_sagemager_args_inputs,
prepare_simple_launcher_cmd_env,
prepare_tpu,
)
# For docs
from .megatron_lm import (
AbstractTrainStep,
BertTrainStep,
GPTTrainStep,
MegatronLMDummyDataLoader,
MegatronLMDummyScheduler,
T5TrainStep,
avg_losses_across_data_parallel_group,
)
if is_megatron_lm_available():
from .megatron_lm import (
MegatronEngine,
MegatronLMOptimizerWrapper,
MegatronLMSchedulerWrapper,
gather_across_data_parallel_groups,
)
from .megatron_lm import initialize as megatron_lm_initialize
from .megatron_lm import prepare_data_loader as megatron_lm_prepare_data_loader
from .megatron_lm import prepare_model_optimizer_scheduler as megatron_lm_prepare_model_optimizer_scheduler
from .megatron_lm import prepare_optimizer as megatron_lm_prepare_optimizer
from .megatron_lm import prepare_scheduler as megatron_lm_prepare_scheduler
from .memory import find_executable_batch_size, release_memory
from .other import (
check_os_kernel,
clean_state_dict_for_safetensors,
convert_bytes,
extract_model_from_parallel,
get_pretty_name,
is_port_in_use,
load,
merge_dicts,
recursive_getattr,
save,
wait_for_everyone,
write_basic_config,
)
from .random import set_seed, synchronize_rng_state, synchronize_rng_states
from .torch_xla import install_xla
from .tqdm import tqdm
from .transformer_engine import (
apply_fp8_autowrap,
contextual_fp8_autocast,
convert_model,
has_transformer_engine_layers,
)
| 1 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/operations.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
"""
A set of basic tensor ops compatible with tpu, gpu, and multigpu
"""
import pickle
import warnings
from contextlib import contextmanager, nullcontext
from functools import update_wrapper, wraps
from typing import Any, Mapping
import torch
from ..state import AcceleratorState, PartialState
from .constants import TORCH_DISTRIBUTED_OPERATION_TYPES
from .dataclasses import DistributedType, TensorInformation
from .imports import (
is_npu_available,
is_torch_distributed_available,
is_torch_xla_available,
is_xpu_available,
)
from .versions import is_torch_version
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
if is_torch_distributed_available():
from torch.distributed import ReduceOp
def is_torch_tensor(tensor):
return isinstance(tensor, torch.Tensor)
def is_torch_xpu_tensor(tensor):
return isinstance(
tensor,
torch.xpu.FloatTensor,
torch.xpu.ByteTensor,
torch.xpu.IntTensor,
torch.xpu.LongTensor,
torch.xpu.HalfTensor,
torch.xpu.DoubleTensor,
torch.xpu.BFloat16Tensor,
)
def is_tensor_information(tensor_info):
return isinstance(tensor_info, TensorInformation)
def is_namedtuple(data):
"""
Checks if `data` is a `namedtuple` or not. Can have false positives, but only if a user is trying to mimic a
`namedtuple` perfectly.
"""
return isinstance(data, tuple) and hasattr(data, "_asdict") and hasattr(data, "_fields")
def honor_type(obj, generator):
"""
Cast a generator to the same type as obj (list, tuple, or namedtuple)
"""
# Some objects may not be able to instantiate from a generator directly
if is_namedtuple(obj):
return type(obj)(*list(generator))
else:
return type(obj)(generator)
def recursively_apply(func, data, *args, test_type=is_torch_tensor, error_on_other_type=False, **kwargs):
"""
Recursively apply a function on a data structure that is a nested list/tuple/dictionary of a given base type.
Args:
func (`callable`):
The function to recursively apply.
data (nested list/tuple/dictionary of `main_type`):
The data on which to apply `func`
*args:
Positional arguments that will be passed to `func` when applied on the unpacked data.
main_type (`type`, *optional*, defaults to `torch.Tensor`):
The base type of the objects to which apply `func`.
error_on_other_type (`bool`, *optional*, defaults to `False`):
Whether to return an error or not if after unpacking `data`, we get on an object that is not of type
`main_type`. If `False`, the function will leave objects of types different than `main_type` unchanged.
**kwargs (additional keyword arguments, *optional*):
Keyword arguments that will be passed to `func` when applied on the unpacked data.
Returns:
The same data structure as `data` with `func` applied to every object of type `main_type`.
"""
if isinstance(data, (tuple, list)):
return honor_type(
data,
(
recursively_apply(
func, o, *args, test_type=test_type, error_on_other_type=error_on_other_type, **kwargs
)
for o in data
),
)
elif isinstance(data, Mapping):
return type(data)(
{
k: recursively_apply(
func, v, *args, test_type=test_type, error_on_other_type=error_on_other_type, **kwargs
)
for k, v in data.items()
}
)
elif test_type(data):
return func(data, *args, **kwargs)
elif error_on_other_type:
raise TypeError(
f"Unsupported types ({type(data)}) passed to `{func.__name__}`. Only nested list/tuple/dicts of "
f"objects that are valid for `{test_type.__name__}` should be passed."
)
return data
def send_to_device(tensor, device, non_blocking=False, skip_keys=None):
"""
Recursively sends the elements in a nested list/tuple/dictionary of tensors to a given device.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to send to a given device.
device (`torch.device`):
The device to send the data to.
Returns:
The same data structure as `tensor` with all tensors sent to the proper device.
"""
if is_torch_tensor(tensor) or hasattr(tensor, "to"):
# `torch.Tensor.to("npu")` could not find context when called for the first time (see this [issue](https://gitee.com/ascend/pytorch/issues/I8KECW?from=project-issue)).
if device == "npu":
device = "npu:0"
if device == "xpu":
device = "xpu:0"
try:
return tensor.to(device, non_blocking=non_blocking)
except TypeError: # .to() doesn't accept non_blocking as kwarg
return tensor.to(device)
except AssertionError as error:
# `torch.Tensor.to(<int num>)` is not supported by `torch_npu` (see this [issue](https://github.com/Ascend/pytorch/issues/16)).
# This call is inside the try-block since is_npu_available is not supported by torch.compile.
if is_npu_available():
if isinstance(device, int):
device = f"npu:{device}"
elif is_xpu_available():
if isinstance(device, int):
device = f"xpu:{device}"
else:
raise error
try:
return tensor.to(device, non_blocking=non_blocking)
except TypeError: # .to() doesn't accept non_blocking as kwarg
return tensor.to(device)
elif isinstance(tensor, (tuple, list)):
return honor_type(
tensor, (send_to_device(t, device, non_blocking=non_blocking, skip_keys=skip_keys) for t in tensor)
)
elif isinstance(tensor, Mapping):
if isinstance(skip_keys, str):
skip_keys = [skip_keys]
elif skip_keys is None:
skip_keys = []
return type(tensor)(
{
k: t if k in skip_keys else send_to_device(t, device, non_blocking=non_blocking, skip_keys=skip_keys)
for k, t in tensor.items()
}
)
else:
return tensor
def get_data_structure(data):
"""
Recursively gathers the information needed to rebuild a nested list/tuple/dictionary of tensors.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`):
The data to send to analyze.
Returns:
The same data structure as `data` with [`~utils.TensorInformation`] instead of tensors.
"""
def _get_data_structure(tensor):
return TensorInformation(shape=tensor.shape, dtype=tensor.dtype)
return recursively_apply(_get_data_structure, data)
def get_shape(data):
"""
Recursively gathers the shape of a nested list/tuple/dictionary of tensors as a list.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`):
The data to send to analyze.
Returns:
The same data structure as `data` with lists of tensor shapes instead of tensors.
"""
def _get_shape(tensor):
return list(tensor.shape)
return recursively_apply(_get_shape, data)
def initialize_tensors(data_structure):
"""
Recursively initializes tensors from a nested list/tuple/dictionary of [`~utils.TensorInformation`].
Returns:
The same data structure as `data` with tensors instead of [`~utils.TensorInformation`].
"""
def _initialize_tensor(tensor_info):
return torch.empty(*tensor_info.shape, dtype=tensor_info.dtype)
return recursively_apply(_initialize_tensor, data_structure, test_type=is_tensor_information)
def find_batch_size(data):
"""
Recursively finds the batch size in a nested list/tuple/dictionary of lists of tensors.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`): The data from which to find the batch size.
Returns:
`int`: The batch size.
"""
if isinstance(data, (tuple, list, Mapping)) and (len(data) == 0):
raise ValueError(f"Cannot find the batch size from empty {type(data)}.")
if isinstance(data, (tuple, list)):
return find_batch_size(data[0])
elif isinstance(data, Mapping):
for k in data.keys():
return find_batch_size(data[k])
elif not isinstance(data, torch.Tensor):
raise TypeError(f"Can only find the batch size of tensors but got {type(data)}.")
return data.shape[0]
def ignorant_find_batch_size(data):
"""
Same as [`utils.operations.find_batch_size`] except will ignore if `ValueError` and `TypeErrors` are raised
Args:
data (nested list/tuple/dictionary of `torch.Tensor`): The data from which to find the batch size.
Returns:
`int`: The batch size.
"""
try:
return find_batch_size(data)
except (ValueError, TypeError):
pass
return None
def listify(data):
"""
Recursively finds tensors in a nested list/tuple/dictionary and converts them to a list of numbers.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`): The data from which to convert to regular numbers.
Returns:
The same data structure as `data` with lists of numbers instead of `torch.Tensor`.
"""
def _convert_to_list(tensor):
tensor = tensor.detach().cpu()
if tensor.dtype == torch.bfloat16:
# As of Numpy 1.21.4, NumPy does not support bfloat16 (see
# https://github.com/numpy/numpy/blob/a47ecdea856986cd60eabbd53265c2ca5916ad5d/doc/source/user/basics.types.rst ).
# Until Numpy adds bfloat16, we must convert float32.
tensor = tensor.to(torch.float32)
return tensor.tolist()
return recursively_apply(_convert_to_list, data)
def _tpu_gather(tensor):
def _tpu_gather_one(tensor):
if tensor.ndim == 0:
tensor = tensor.clone()[None]
# Can only gather contiguous tensors
if not tensor.is_contiguous():
tensor = tensor.contiguous()
return xm.all_gather(tensor)
res = recursively_apply(_tpu_gather_one, tensor, error_on_other_type=True)
xm.mark_step()
return res
def _gpu_gather(tensor):
state = PartialState()
if is_torch_version(">=", "1.13"):
gather_op = torch.distributed.all_gather_into_tensor
else:
gather_op = torch.distributed._all_gather_base
def _gpu_gather_one(tensor):
if tensor.ndim == 0:
tensor = tensor.clone()[None]
# Can only gather contiguous tensors
if not tensor.is_contiguous():
tensor = tensor.contiguous()
if state.backend is not None and state.backend != "gloo":
# We use `empty` as `all_gather_into_tensor` slightly
# differs from `all_gather` for better efficiency,
# and we rely on the number of items in the tensor
# rather than its direct shape
output_tensors = torch.empty(
state.num_processes * tensor.numel(),
dtype=tensor.dtype,
device=state.device,
)
gather_op(output_tensors, tensor)
return output_tensors.view(-1, *tensor.size()[1:])
else:
# a backend of `None` is always CPU
# also gloo does not support `all_gather_into_tensor`,
# which will result in a larger memory overhead for the op
output_tensors = [torch.empty_like(tensor) for _ in range(state.num_processes)]
torch.distributed.all_gather(output_tensors, tensor)
return torch.cat(output_tensors, dim=0)
return recursively_apply(_gpu_gather_one, tensor, error_on_other_type=True)
class DistributedOperationException(Exception):
"""
An exception class for distributed operations. Raised if the operation cannot be performed due to the shape of the
tensors.
"""
pass
def verify_operation(function):
"""
Verifies that `tensor` is the same shape across all processes. Only ran if `PartialState().debug` is `True`.
"""
@wraps(function)
def wrapper(*args, **kwargs):
if PartialState().distributed_type == DistributedType.NO or not PartialState().debug:
return function(*args, **kwargs)
operation = f"{function.__module__}.{function.__name__}"
if "tensor" in kwargs:
tensor = kwargs["tensor"]
else:
tensor = args[0]
if PartialState().device.type != find_device(tensor).type:
raise DistributedOperationException(
f"One or more of the tensors passed to {operation} were not on the {tensor.device.type} while the `Accelerator` is configured for {PartialState().device.type}. "
f"Please move it to the {PartialState().device.type} before calling {operation}."
)
shapes = get_shape(tensor)
output = gather_object([shapes])
if output[0] is not None:
are_same = output.count(output[0]) == len(output)
if not are_same:
process_shape_str = "\n - ".join([f"Process {i}: {shape}" for i, shape in enumerate(output)])
raise DistributedOperationException(
f"Cannot apply desired operation due to shape mismatches. "
"All shapes across devices must be valid."
f"\n\nOperation: `{operation}`\nInput shapes:\n - {process_shape_str}"
)
return function(*args, **kwargs)
return wrapper
def chained_operation(function):
"""
Checks that `verify_operation` failed and if so reports a more helpful error chaining the existing
`DistributedOperationException`.
"""
@wraps(function)
def wrapper(*args, **kwargs):
try:
return function(*args, **kwargs)
except DistributedOperationException as e:
operation = f"{function.__module__}.{function.__name__}"
raise DistributedOperationException(
f"Error found while calling `{operation}`. Please see the earlier error for more details."
) from e
return wrapper
@verify_operation
def gather(tensor):
"""
Recursively gather tensor in a nested list/tuple/dictionary of tensors from all devices.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to gather.
Returns:
The same data structure as `tensor` with all tensors sent to the proper device.
"""
if PartialState().distributed_type == DistributedType.XLA:
return _tpu_gather(tensor)
elif PartialState().distributed_type in TORCH_DISTRIBUTED_OPERATION_TYPES:
return _gpu_gather(tensor)
else:
return tensor
def _gpu_gather_object(object: Any):
output_objects = [None for _ in range(PartialState().num_processes)]
torch.distributed.all_gather_object(output_objects, object)
# all_gather_object returns a list of lists, so we need to flatten it
return [x for y in output_objects for x in y]
def gather_object(object: Any):
"""
Recursively gather object in a nested list/tuple/dictionary of objects from all devices.
Args:
object (nested list/tuple/dictionary of picklable object):
The data to gather.
Returns:
The same data structure as `object` with all the objects sent to every device.
"""
if PartialState().distributed_type == DistributedType.XLA:
raise NotImplementedError("gather objects in TPU is not supported")
elif PartialState().distributed_type in TORCH_DISTRIBUTED_OPERATION_TYPES:
return _gpu_gather_object(object)
else:
return object
def _gpu_broadcast(data, src=0):
def _gpu_broadcast_one(tensor, src=0):
torch.distributed.broadcast(tensor, src=src)
return tensor
return recursively_apply(_gpu_broadcast_one, data, error_on_other_type=True, src=src)
def _tpu_broadcast(tensor, src=0, name="broadcast tensor"):
if isinstance(tensor, (list, tuple)):
return honor_type(tensor, (_tpu_broadcast(t, name=f"{name}_{i}") for i, t in enumerate(tensor)))
elif isinstance(tensor, Mapping):
return type(tensor)({k: _tpu_broadcast(v, name=f"{name}_{k}") for k, v in tensor.items()})
return xm.mesh_reduce(name, tensor, lambda x: x[src])
TENSOR_TYPE_TO_INT = {
torch.float: 1,
torch.double: 2,
torch.half: 3,
torch.bfloat16: 4,
torch.uint8: 5,
torch.int8: 6,
torch.int16: 7,
torch.int32: 8,
torch.int64: 9,
torch.bool: 10,
}
TENSOR_INT_TO_DTYPE = {v: k for k, v in TENSOR_TYPE_TO_INT.items()}
def gather_tensor_shape(tensor):
"""
Grabs the shape of `tensor` only available on one process and returns a tensor of its shape
"""
# Allocate 80 bytes to store the shape
max_tensor_dimension = 2**20
state = PartialState()
base_tensor = torch.empty(max_tensor_dimension, dtype=torch.int, device=state.device)
# Since PyTorch can't just send a tensor to another GPU without
# knowing its size, we store the size of the tensor with data
# in an allocation
if tensor is not None:
shape = tensor.shape
tensor_dtype = TENSOR_TYPE_TO_INT[tensor.dtype]
base_tensor[: len(shape) + 1] = torch.tensor(list(shape) + [tensor_dtype], dtype=int)
# Perform a reduction to copy the size data onto all GPUs
base_tensor = reduce(base_tensor, reduction="sum")
base_tensor = base_tensor[base_tensor.nonzero()]
# The last non-zero data contains the coded dtype the source tensor is
dtype = int(base_tensor[-1:][0])
base_tensor = base_tensor[:-1]
return base_tensor, dtype
def copy_tensor_to_devices(tensor=None) -> torch.Tensor:
"""
Copys a tensor that only exists on a single device and broadcasts it to other devices. Differs from `broadcast` as
each worker doesn't need to know its shape when used (and tensor can be `None`)
Args:
tensor (`torch.tensor`):
The tensor that should be sent to all devices. Must only have it be defined on a single device, the rest
should be `None`.
"""
state = PartialState()
shape, dtype = gather_tensor_shape(tensor)
if tensor is None:
tensor = torch.zeros(shape, dtype=TENSOR_INT_TO_DTYPE[dtype]).to(state.device)
return reduce(tensor, reduction="sum")
@verify_operation
def broadcast(tensor, from_process: int = 0):
"""
Recursively broadcast tensor in a nested list/tuple/dictionary of tensors to all devices.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to gather.
from_process (`int`, *optional*, defaults to 0):
The process from which to send the data
Returns:
The same data structure as `tensor` with all tensors broadcasted to the proper device.
"""
if PartialState().distributed_type == DistributedType.XLA:
return _tpu_broadcast(tensor, src=from_process, name="accelerate.utils.broadcast")
elif PartialState().distributed_type in TORCH_DISTRIBUTED_OPERATION_TYPES:
return _gpu_broadcast(tensor, src=from_process)
else:
return tensor
def broadcast_object_list(object_list, from_process: int = 0):
"""
Broadcast a list of picklable objects form one process to the others.
Args:
object_list (list of picklable objects):
The list of objects to broadcast. This list will be modified inplace.
from_process (`int`, *optional*, defaults to 0):
The process from which to send the data.
Returns:
The same list containing the objects from process 0.
"""
if PartialState().distributed_type == DistributedType.XLA:
for i, obj in enumerate(object_list):
object_list[i] = xm.mesh_reduce("accelerate.utils.broadcast_object_list", obj, lambda x: x[from_process])
elif PartialState().distributed_type in TORCH_DISTRIBUTED_OPERATION_TYPES:
torch.distributed.broadcast_object_list(object_list, src=from_process)
return object_list
def slice_tensors(data, tensor_slice, process_index=None, num_processes=None):
"""
Recursively takes a slice in a nested list/tuple/dictionary of tensors.
Args:
data (nested list/tuple/dictionary of `torch.Tensor`):
The data to slice.
tensor_slice (`slice`):
The slice to take.
Returns:
The same data structure as `data` with all the tensors slices.
"""
def _slice_tensor(tensor, tensor_slice):
return tensor[tensor_slice]
return recursively_apply(_slice_tensor, data, tensor_slice)
def concatenate(data, dim=0):
"""
Recursively concatenate the tensors in a nested list/tuple/dictionary of lists of tensors with the same shape.
Args:
data (nested list/tuple/dictionary of lists of tensors `torch.Tensor`):
The data to concatenate.
dim (`int`, *optional*, defaults to 0):
The dimension on which to concatenate.
Returns:
The same data structure as `data` with all the tensors concatenated.
"""
if isinstance(data[0], (tuple, list)):
return honor_type(data[0], (concatenate([d[i] for d in data], dim=dim) for i in range(len(data[0]))))
elif isinstance(data[0], Mapping):
return type(data[0])({k: concatenate([d[k] for d in data], dim=dim) for k in data[0].keys()})
elif not isinstance(data[0], torch.Tensor):
raise TypeError(f"Can only concatenate tensors but got {type(data[0])}")
return torch.cat(data, dim=dim)
class CannotPadNestedTensorWarning(UserWarning):
pass
@chained_operation
def pad_across_processes(tensor, dim=0, pad_index=0, pad_first=False):
"""
Recursively pad the tensors in a nested list/tuple/dictionary of tensors from all devices to the same size so they
can safely be gathered.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to gather.
dim (`int`, *optional*, defaults to 0):
The dimension on which to pad.
pad_index (`int`, *optional*, defaults to 0):
The value with which to pad.
pad_first (`bool`, *optional*, defaults to `False`):
Whether to pad at the beginning or the end.
"""
def _pad_across_processes(tensor, dim=0, pad_index=0, pad_first=False):
if getattr(tensor, "is_nested", False):
warnings.warn(
"Cannot pad nested tensors without more information. Leaving unprocessed.",
CannotPadNestedTensorWarning,
)
return tensor
if dim >= len(tensor.shape) or dim < -len(tensor.shape):
return tensor
# Convert negative dimensions to non-negative
if dim < 0:
dim += len(tensor.shape)
# Gather all sizes
size = torch.tensor(tensor.shape, device=tensor.device)[None]
sizes = gather(size).cpu()
# Then pad to the maximum size
max_size = max(s[dim] for s in sizes)
if max_size == tensor.shape[dim]:
return tensor
old_size = tensor.shape
new_size = list(old_size)
new_size[dim] = max_size
new_tensor = tensor.new_zeros(tuple(new_size)) + pad_index
if pad_first:
indices = tuple(
slice(max_size - old_size[dim], max_size) if i == dim else slice(None) for i in range(len(new_size))
)
else:
indices = tuple(slice(0, old_size[dim]) if i == dim else slice(None) for i in range(len(new_size)))
new_tensor[indices] = tensor
return new_tensor
return recursively_apply(
_pad_across_processes, tensor, error_on_other_type=True, dim=dim, pad_index=pad_index, pad_first=pad_first
)
def pad_input_tensors(tensor, batch_size, num_processes, dim=0):
"""
Takes a `tensor` of arbitrary size and pads it so that it can work given `num_processes` needed dimensions.
New tensors are just the last input repeated.
E.g.:
Tensor: ([3,4,4]) Num processes: 4 Expected result shape: ([4,4,4])
"""
def _pad_input_tensors(tensor, batch_size, num_processes, dim=0):
remainder = batch_size // num_processes
last_inputs = batch_size - (remainder * num_processes)
if batch_size // num_processes == 0:
to_pad = num_processes - batch_size
else:
to_pad = num_processes - (batch_size // num_processes)
# In the rare case that `to_pad` is negative,
# we need to pad the last inputs - the found `to_pad`
if last_inputs > to_pad & to_pad < 1:
to_pad = last_inputs - to_pad
old_size = tensor.shape
new_size = list(old_size)
new_size[0] = batch_size + to_pad
new_tensor = tensor.new_zeros(tuple(new_size))
indices = tuple(slice(0, old_size[dim]) if i == dim else slice(None) for i in range(len(new_size)))
new_tensor[indices] = tensor
return new_tensor
return recursively_apply(
_pad_input_tensors,
tensor,
error_on_other_type=True,
batch_size=batch_size,
num_processes=num_processes,
dim=dim,
)
@verify_operation
def reduce(tensor, reduction="mean", scale=1.0):
"""
Recursively reduce the tensors in a nested list/tuple/dictionary of lists of tensors across all processes by the
mean of a given operation.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to reduce.
reduction (`str`, *optional*, defaults to `"mean"`):
A reduction method. Can be of "mean", "sum", or "none"
scale (`float`, *optional*):
A default scaling value to be applied after the reduce, only valied on XLA.
Returns:
The same data structure as `data` with all the tensors reduced.
"""
def _reduce_across_processes(tensor, reduction="mean", scale=1.0):
state = PartialState()
cloned_tensor = tensor.clone()
if state.distributed_type == DistributedType.NO:
return cloned_tensor
if state.distributed_type == DistributedType.XLA:
# Some processes may have different HLO graphs than other
# processes, for example in the breakpoint API
# accelerator.set_trigger(). Use mark_step to make HLOs
# the same on all processes.
xm.mark_step()
xm.all_reduce(xm.REDUCE_SUM, [cloned_tensor], scale)
xm.mark_step()
elif state.distributed_type.value in TORCH_DISTRIBUTED_OPERATION_TYPES:
torch.distributed.all_reduce(cloned_tensor, ReduceOp.SUM)
if reduction == "mean":
cloned_tensor /= state.num_processes
return cloned_tensor
return recursively_apply(
_reduce_across_processes, tensor, error_on_other_type=True, reduction=reduction, scale=scale
)
def convert_to_fp32(tensor):
"""
Recursively converts the elements nested list/tuple/dictionary of tensors in FP16/BF16 precision to FP32.
Args:
tensor (nested list/tuple/dictionary of `torch.Tensor`):
The data to convert from FP16/BF16 to FP32.
Returns:
The same data structure as `tensor` with all tensors that were in FP16/BF16 precision converted to FP32.
"""
def _convert_to_fp32(tensor):
return tensor.float()
def _is_fp16_bf16_tensor(tensor):
return (is_torch_tensor(tensor) or hasattr(tensor, "dtype")) and tensor.dtype in (
torch.float16,
torch.bfloat16,
)
return recursively_apply(_convert_to_fp32, tensor, test_type=_is_fp16_bf16_tensor)
class ConvertOutputsToFp32:
"""
Decorator to apply to a function outputing tensors (like a model forward pass) that ensures the outputs in FP16
precision will be convert back to FP32.
Args:
model_forward (`Callable`):
The function which outputs we want to treat.
Returns:
The same function as `model_forward` but with converted outputs.
"""
def __init__(self, model_forward):
self.model_forward = model_forward
update_wrapper(self, model_forward)
def __call__(self, *args, **kwargs):
return convert_to_fp32(self.model_forward(*args, **kwargs))
def __getstate__(self):
raise pickle.PicklingError(
"Cannot pickle a prepared model with automatic mixed precision, please unwrap the model with `Accelerator.unwrap_model(model)` before pickling it."
)
def convert_outputs_to_fp32(model_forward):
model_forward = ConvertOutputsToFp32(model_forward)
def forward(*args, **kwargs):
return model_forward(*args, **kwargs)
# To act like a decorator so that it can be popped when doing `extract_model_from_parallel`
forward.__wrapped__ = model_forward
return forward
def find_device(data):
"""
Finds the device on which a nested dict/list/tuple of tensors lies (assuming they are all on the same device).
Args:
(nested list/tuple/dictionary of `torch.Tensor`): The data we want to know the device of.
"""
if isinstance(data, Mapping):
for obj in data.values():
device = find_device(obj)
if device is not None:
return device
elif isinstance(data, (tuple, list)):
for obj in data:
device = find_device(obj)
if device is not None:
return device
elif isinstance(data, torch.Tensor):
return data.device
@contextmanager
def GatheredParameters(params, modifier_rank=None, fwd_module=None, enabled=True):
"""
Wrapper around `deepspeed.runtime.zero.GatheredParameters`, but if Zero-3 is not enabled, will be a no-op context
manager.
"""
# We need to use the `AcceleratorState` here since it has access to the deepspeed plugin
if AcceleratorState().distributed_type != DistributedType.DEEPSPEED or (
AcceleratorState().deepspeed_plugin is not None
and not AcceleratorState().deepspeed_plugin.is_zero3_init_enabled()
):
gather_param_context = nullcontext()
else:
import deepspeed
gather_param_context = deepspeed.zero.GatheredParameters(
params, modifier_rank=modifier_rank, fwd_module=fwd_module, enabled=enabled
)
with gather_param_context:
yield
| 2 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/bnb.py | # Copyright 2023 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import logging
import os
from copy import deepcopy
from typing import Dict, List, Optional, Union
import torch
import torch.nn as nn
from accelerate.utils.imports import (
is_4bit_bnb_available,
is_8bit_bnb_available,
)
from ..big_modeling import dispatch_model, init_empty_weights
from .dataclasses import BnbQuantizationConfig
from .modeling import (
find_tied_parameters,
get_balanced_memory,
infer_auto_device_map,
load_checkpoint_in_model,
offload_weight,
set_module_tensor_to_device,
)
logger = logging.getLogger(__name__)
def load_and_quantize_model(
model: torch.nn.Module,
bnb_quantization_config: BnbQuantizationConfig,
weights_location: Union[str, os.PathLike] = None,
device_map: Optional[Dict[str, Union[int, str, torch.device]]] = None,
no_split_module_classes: Optional[List[str]] = None,
max_memory: Optional[Dict[Union[int, str], Union[int, str]]] = None,
offload_folder: Optional[Union[str, os.PathLike]] = None,
offload_state_dict: bool = False,
):
"""
This function will quantize the input model with the associated config passed in `bnb_quantization_config`. If the
model is in the meta device, we will load and dispatch the weights according to the `device_map` passed. If the
model is already loaded, we will quantize the model and put the model on the GPU,
Args:
model (`torch.nn.Module`):
Input model. The model can be already loaded or on the meta device
bnb_quantization_config (`BnbQuantizationConfig`):
The bitsandbytes quantization parameters
weights_location (`str` or `os.PathLike`):
The folder weights_location to load. It can be:
- a path to a file containing a whole model state dict
- a path to a `.json` file containing the index to a sharded checkpoint
- a path to a folder containing a unique `.index.json` file and the shards of a checkpoint.
- a path to a folder containing a unique pytorch_model.bin file.
device_map (`Dict[str, Union[int, str, torch.device]]`, *optional*):
A map that specifies where each submodule should go. It doesn't need to be refined to each parameter/buffer
name, once a given module name is inside, every submodule of it will be sent to the same device.
no_split_module_classes (`List[str]`, *optional*):
A list of layer class names that should never be split across device (for instance any layer that has a
residual connection).
max_memory (`Dict`, *optional*):
A dictionary device identifier to maximum memory. Will default to the maximum memory available if unset.
offload_folder (`str` or `os.PathLike`, *optional*):
If the `device_map` contains any value `"disk"`, the folder where we will offload weights.
offload_state_dict (`bool`, *optional*, defaults to `False`):
If `True`, will temporarily offload the CPU state dict on the hard drive to avoid getting out of CPU RAM if
the weight of the CPU state dict + the biggest shard does not fit.
Returns:
`torch.nn.Module`: The quantized model
"""
load_in_4bit = bnb_quantization_config.load_in_4bit
load_in_8bit = bnb_quantization_config.load_in_8bit
if load_in_8bit and not is_8bit_bnb_available():
raise ImportError(
"You have a version of `bitsandbytes` that is not compatible with 8bit quantization,"
" make sure you have the latest version of `bitsandbytes` installed."
)
if load_in_4bit and not is_4bit_bnb_available():
raise ValueError(
"You have a version of `bitsandbytes` that is not compatible with 4bit quantization,"
"make sure you have the latest version of `bitsandbytes` installed."
)
modules_on_cpu = []
# custom device map
if isinstance(device_map, dict) and len(device_map.keys()) > 1:
modules_on_cpu = [key for key, value in device_map.items() if value in ["disk", "cpu"]]
# We keep some modules such as the lm_head in their original dtype for numerical stability reasons
if bnb_quantization_config.skip_modules is None:
bnb_quantization_config.skip_modules = get_keys_to_not_convert(model)
# add cpu modules to skip modules only for 4-bit modules
if load_in_4bit:
bnb_quantization_config.skip_modules.extend(modules_on_cpu)
modules_to_not_convert = bnb_quantization_config.skip_modules
# We add the modules we want to keep in full precision
if bnb_quantization_config.keep_in_fp32_modules is None:
bnb_quantization_config.keep_in_fp32_modules = []
keep_in_fp32_modules = bnb_quantization_config.keep_in_fp32_modules
modules_to_not_convert.extend(keep_in_fp32_modules)
# compatibility with peft
model.is_loaded_in_4bit = load_in_4bit
model.is_loaded_in_8bit = load_in_8bit
model_device = get_parameter_device(model)
if model_device.type != "meta":
# quantization of an already loaded model
logger.warning(
"It is not recommended to quantize a loaded model. "
"The model should be instantiated under the `init_empty_weights` context manager."
)
model = replace_with_bnb_layers(model, bnb_quantization_config, modules_to_not_convert=modules_to_not_convert)
# convert param to the right dtype
dtype = bnb_quantization_config.torch_dtype
for name, param in model.state_dict().items():
if any(module_to_keep_in_fp32 in name for module_to_keep_in_fp32 in keep_in_fp32_modules):
param.to(torch.float32)
if param.dtype != torch.float32:
name = name.replace(".weight", "").replace(".bias", "")
param = getattr(model, name, None)
if param is not None:
param.to(torch.float32)
elif torch.is_floating_point(param):
param.to(dtype)
if model_device.type == "cuda":
# move everything to cpu in the first place because we can't do quantization if the weights are already on cuda
model.cuda(torch.cuda.current_device())
torch.cuda.empty_cache()
elif torch.cuda.is_available():
model.to(torch.cuda.current_device())
else:
raise RuntimeError("No GPU found. A GPU is needed for quantization.")
logger.info(
f"The model device type is {model_device.type}. However, cuda is needed for quantization."
"We move the model to cuda."
)
return model
elif weights_location is None:
raise RuntimeError(
f"`weights_location` needs to be the folder path containing the weights of the model, but we found {weights_location} "
)
else:
with init_empty_weights():
model = replace_with_bnb_layers(
model, bnb_quantization_config, modules_to_not_convert=modules_to_not_convert
)
device_map = get_quantized_model_device_map(
model,
bnb_quantization_config,
device_map,
max_memory=max_memory,
no_split_module_classes=no_split_module_classes,
)
if offload_state_dict is None and device_map is not None and "disk" in device_map.values():
offload_state_dict = True
offload = any(x in list(device_map.values()) for x in ["cpu", "disk"])
load_checkpoint_in_model(
model,
weights_location,
device_map,
dtype=bnb_quantization_config.torch_dtype,
offload_folder=offload_folder,
offload_state_dict=offload_state_dict,
keep_in_fp32_modules=bnb_quantization_config.keep_in_fp32_modules,
offload_8bit_bnb=load_in_8bit and offload,
)
return dispatch_model(model, device_map=device_map, offload_dir=offload_folder)
def get_quantized_model_device_map(
model, bnb_quantization_config, device_map=None, max_memory=None, no_split_module_classes=None
):
if device_map is None:
if torch.cuda.is_available():
device_map = {"": torch.cuda.current_device()}
else:
raise RuntimeError("No GPU found. A GPU is needed for quantization.")
logger.info("The device_map was not initialized." "Setting device_map to `{'':torch.cuda.current_device()}`.")
if isinstance(device_map, str):
if device_map not in ["auto", "balanced", "balanced_low_0", "sequential"]:
raise ValueError(
"If passing a string for `device_map`, please choose 'auto', 'balanced', 'balanced_low_0' or "
"'sequential'."
)
special_dtypes = {}
special_dtypes.update(
{
name: bnb_quantization_config.torch_dtype
for name, _ in model.named_parameters()
if any(m in name for m in bnb_quantization_config.skip_modules)
}
)
special_dtypes.update(
{
name: torch.float32
for name, _ in model.named_parameters()
if any(m in name for m in bnb_quantization_config.keep_in_fp32_modules)
}
)
kwargs = {}
kwargs["special_dtypes"] = special_dtypes
kwargs["no_split_module_classes"] = no_split_module_classes
kwargs["dtype"] = bnb_quantization_config.target_dtype
# get max_memory for each device.
if device_map != "sequential":
max_memory = get_balanced_memory(
model,
low_zero=(device_map == "balanced_low_0"),
max_memory=max_memory,
**kwargs,
)
kwargs["max_memory"] = max_memory
device_map = infer_auto_device_map(model, **kwargs)
if isinstance(device_map, dict):
# check if don't have any quantized module on the cpu
modules_not_to_convert = bnb_quantization_config.skip_modules + bnb_quantization_config.keep_in_fp32_modules
device_map_without_some_modules = {
key: device_map[key] for key in device_map.keys() if key not in modules_not_to_convert
}
for device in ["cpu", "disk"]:
if device in device_map_without_some_modules.values():
if bnb_quantization_config.load_in_4bit:
raise ValueError(
"""
Some modules are dispatched on the CPU or the disk. Make sure you have enough GPU RAM to fit
the quantized model. If you want to dispatch the model on the CPU or the disk while keeping
these modules in `torch_dtype`, you need to pass a custom `device_map` to
`load_and_quantize_model`. Check
https://huggingface.co/docs/accelerate/main/en/usage_guides/quantization#offload-modules-to-cpu-and-disk
for more details.
"""
)
else:
logger.info(
"Some modules are are offloaded to the CPU or the disk. Note that these modules will be converted to 8-bit"
)
del device_map_without_some_modules
return device_map
def replace_with_bnb_layers(model, bnb_quantization_config, modules_to_not_convert=None, current_key_name=None):
"""
A helper function to replace all `torch.nn.Linear` modules by `bnb.nn.Linear8bit` modules or by `bnb.nn.Linear4bit`
modules from the `bitsandbytes`library. The function will be run recursively and replace `torch.nn.Linear` modules.
Parameters:
model (`torch.nn.Module`):
Input model or `torch.nn.Module` as the function is run recursively.
modules_to_not_convert (`List[str]`):
Names of the modules to not quantize convert. In practice we keep the `lm_head` in full precision for
numerical stability reasons.
current_key_name (`List[str]`, *optional*):
An array to track the current key of the recursion. This is used to check whether the current key (part of
it) is not in the list of modules to not convert.
"""
if modules_to_not_convert is None:
modules_to_not_convert = []
model, has_been_replaced = _replace_with_bnb_layers(
model, bnb_quantization_config, modules_to_not_convert, current_key_name
)
if not has_been_replaced:
logger.warning(
"You are loading your model in 8bit or 4bit but no linear modules were found in your model."
" this can happen for some architectures such as gpt2 that uses Conv1D instead of Linear layers."
" Please double check your model architecture, or submit an issue on github if you think this is"
" a bug."
)
return model
def _replace_with_bnb_layers(
model,
bnb_quantization_config,
modules_to_not_convert=None,
current_key_name=None,
):
"""
Private method that wraps the recursion for module replacement.
Returns the converted model and a boolean that indicates if the conversion has been successfull or not.
"""
# bitsandbytes will initialize CUDA on import, so it needs to be imported lazily
import bitsandbytes as bnb
has_been_replaced = False
for name, module in model.named_children():
if current_key_name is None:
current_key_name = []
current_key_name.append(name)
if isinstance(module, nn.Linear) and name not in modules_to_not_convert:
# Check if the current key is not in the `modules_to_not_convert`
current_key_name_str = ".".join(current_key_name)
proceed = True
for key in modules_to_not_convert:
if (
(key in current_key_name_str) and (key + "." in current_key_name_str)
) or key == current_key_name_str:
proceed = False
break
if proceed:
# Load bnb module with empty weight and replace ``nn.Linear` module
if bnb_quantization_config.load_in_8bit:
bnb_module = bnb.nn.Linear8bitLt(
module.in_features,
module.out_features,
module.bias is not None,
has_fp16_weights=False,
threshold=bnb_quantization_config.llm_int8_threshold,
)
elif bnb_quantization_config.load_in_4bit:
bnb_module = bnb.nn.Linear4bit(
module.in_features,
module.out_features,
module.bias is not None,
bnb_quantization_config.bnb_4bit_compute_dtype,
compress_statistics=bnb_quantization_config.bnb_4bit_use_double_quant,
quant_type=bnb_quantization_config.bnb_4bit_quant_type,
)
else:
raise ValueError("load_in_8bit and load_in_4bit can't be both False")
bnb_module.weight.data = module.weight.data
if module.bias is not None:
bnb_module.bias.data = module.bias.data
bnb_module.requires_grad_(False)
setattr(model, name, bnb_module)
has_been_replaced = True
if len(list(module.children())) > 0:
_, _has_been_replaced = _replace_with_bnb_layers(
module, bnb_quantization_config, modules_to_not_convert, current_key_name
)
has_been_replaced = has_been_replaced | _has_been_replaced
# Remove the last key for recursion
current_key_name.pop(-1)
return model, has_been_replaced
def get_keys_to_not_convert(model):
r"""
An utility function to get the key of the module to keep in full precision if any For example for CausalLM modules
we may want to keep the lm_head in full precision for numerical stability reasons. For other architectures, we want
to keep the tied weights of the model. The function will return a list of the keys of the modules to not convert in
int8.
Parameters:
model (`torch.nn.Module`):
Input model
"""
# Create a copy of the model
with init_empty_weights():
tied_model = deepcopy(model) # this has 0 cost since it is done inside `init_empty_weights` context manager`
tied_params = find_tied_parameters(tied_model)
# For compatibility with Accelerate < 0.18
if isinstance(tied_params, dict):
tied_keys = sum(list(tied_params.values()), []) + list(tied_params.keys())
else:
tied_keys = sum(tied_params, [])
has_tied_params = len(tied_keys) > 0
# Check if it is a base model
is_base_model = False
if hasattr(model, "base_model_prefix"):
is_base_model = not hasattr(model, model.base_model_prefix)
# Ignore this for base models (BertModel, GPT2Model, etc.)
if (not has_tied_params) and is_base_model:
return []
# otherwise they have an attached head
list_modules = list(model.named_children())
list_last_module = [list_modules[-1][0]]
# add last module together with tied weights
intersection = set(list_last_module) - set(tied_keys)
list_untouched = list(set(tied_keys)) + list(intersection)
# remove ".weight" from the keys
names_to_remove = [".weight", ".bias"]
filtered_module_names = []
for name in list_untouched:
for name_to_remove in names_to_remove:
if name_to_remove in name:
name = name.replace(name_to_remove, "")
filtered_module_names.append(name)
return filtered_module_names
def has_4bit_bnb_layers(model):
"""Check if we have `bnb.nn.Linear4bit` or `bnb.nn.Linear8bitLt` layers inside our model"""
# bitsandbytes will initialize CUDA on import, so it needs to be imported lazily
import bitsandbytes as bnb
for m in model.modules():
if isinstance(m, bnb.nn.Linear4bit):
return True
return False
def get_parameter_device(parameter: nn.Module):
return next(parameter.parameters()).device
def quantize_and_offload_8bit(model, param, param_name, new_dtype, offload_folder, offload_index, fp16_statistics):
# if it is not quantized, we quantize and offload the quantized weights and the SCB stats
if fp16_statistics is None:
set_module_tensor_to_device(model, param_name, 0, dtype=new_dtype, value=param)
tensor_name = param_name
module = model
if "." in tensor_name:
splits = tensor_name.split(".")
for split in splits[:-1]:
new_module = getattr(module, split)
if new_module is None:
raise ValueError(f"{module} has no attribute {split}.")
module = new_module
tensor_name = splits[-1]
# offload weights
module._parameters[tensor_name].requires_grad = False
offload_weight(module._parameters[tensor_name], param_name, offload_folder, index=offload_index)
if hasattr(module._parameters[tensor_name], "SCB"):
offload_weight(
module._parameters[tensor_name].SCB,
param_name.replace("weight", "SCB"),
offload_folder,
index=offload_index,
)
else:
offload_weight(param, param_name, offload_folder, index=offload_index)
offload_weight(fp16_statistics, param_name.replace("weight", "SCB"), offload_folder, index=offload_index)
set_module_tensor_to_device(model, param_name, "meta", dtype=new_dtype, value=torch.empty(*param.size()))
| 3 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/imports.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import importlib
import importlib.metadata
import os
import warnings
from functools import lru_cache, wraps
import torch
from packaging import version
from packaging.version import parse
from .environment import parse_flag_from_env, patch_environment, str_to_bool
from .versions import compare_versions, is_torch_version
# Try to run Torch native job in an environment with TorchXLA installed by setting this value to 0.
USE_TORCH_XLA = parse_flag_from_env("USE_TORCH_XLA", default=True)
_torch_xla_available = False
if USE_TORCH_XLA:
try:
import torch_xla.core.xla_model as xm # noqa: F401
import torch_xla.runtime
_torch_xla_available = True
except ImportError:
pass
# Keep it for is_tpu_available. It will be removed along with is_tpu_available.
_tpu_available = _torch_xla_available
# Cache this result has it's a C FFI call which can be pretty time-consuming
_torch_distributed_available = torch.distributed.is_available()
def _is_package_available(pkg_name, metadata_name=None):
# Check we're not importing a "pkg_name" directory somewhere but the actual library by trying to grab the version
package_exists = importlib.util.find_spec(pkg_name) is not None
if package_exists:
try:
# Some libraries have different names in the metadata
_ = importlib.metadata.metadata(pkg_name if metadata_name is None else metadata_name)
return True
except importlib.metadata.PackageNotFoundError:
return False
def is_torch_distributed_available() -> bool:
return _torch_distributed_available
def is_ccl_available():
try:
pass
except ImportError:
print(
"Intel(R) oneCCL Bindings for PyTorch* is required to run DDP on Intel(R) GPUs, but it is not"
" detected. If you see \"ValueError: Invalid backend: 'ccl'\" error, please install Intel(R) oneCCL"
" Bindings for PyTorch*."
)
return (
importlib.util.find_spec("torch_ccl") is not None
or importlib.util.find_spec("oneccl_bindings_for_pytorch") is not None
)
def get_ccl_version():
return importlib.metadata.version("oneccl_bind_pt")
def is_import_timer_available():
return _is_package_available("import_timer")
def is_pynvml_available():
return _is_package_available("pynvml") or _is_package_available("pynvml", "nvidia-ml-py")
def is_pytest_available():
return _is_package_available("pytest")
def is_msamp_available():
return _is_package_available("msamp", "ms-amp")
def is_schedulefree_available():
return _is_package_available("schedulefree")
def is_transformer_engine_available():
return _is_package_available("transformer_engine", "transformer-engine")
def is_lomo_available():
return _is_package_available("lomo_optim")
def is_fp8_available():
return is_msamp_available() or is_transformer_engine_available()
def is_cuda_available():
"""
Checks if `cuda` is available via an `nvml-based` check which won't trigger the drivers and leave cuda
uninitialized.
"""
with patch_environment(PYTORCH_NVML_BASED_CUDA_CHECK="1"):
available = torch.cuda.is_available()
return available
@lru_cache
def is_torch_xla_available(check_is_tpu=False, check_is_gpu=False):
"""
Check if `torch_xla` is available. To train a native pytorch job in an environment with torch xla installed, set
the USE_TORCH_XLA to false.
"""
assert not (check_is_tpu and check_is_gpu), "The check_is_tpu and check_is_gpu cannot both be true."
if not _torch_xla_available:
return False
elif check_is_gpu:
return torch_xla.runtime.device_type() in ["GPU", "CUDA"]
elif check_is_tpu:
return torch_xla.runtime.device_type() == "TPU"
return True
def is_deepspeed_available():
if is_mlu_available():
return _is_package_available("deepspeed", metadata_name="deepspeed-mlu")
return _is_package_available("deepspeed")
def is_pippy_available():
return is_torch_version(">=", "2.4.0")
def is_bf16_available(ignore_tpu=False):
"Checks if bf16 is supported, optionally ignoring the TPU"
if is_torch_xla_available(check_is_tpu=True):
return not ignore_tpu
if is_cuda_available():
return torch.cuda.is_bf16_supported()
if is_mps_available():
return False
return True
def is_4bit_bnb_available():
package_exists = _is_package_available("bitsandbytes")
if package_exists:
bnb_version = version.parse(importlib.metadata.version("bitsandbytes"))
return compare_versions(bnb_version, ">=", "0.39.0")
return False
def is_8bit_bnb_available():
package_exists = _is_package_available("bitsandbytes")
if package_exists:
bnb_version = version.parse(importlib.metadata.version("bitsandbytes"))
return compare_versions(bnb_version, ">=", "0.37.2")
return False
def is_bnb_available(min_version=None):
package_exists = _is_package_available("bitsandbytes")
if package_exists and min_version is not None:
bnb_version = version.parse(importlib.metadata.version("bitsandbytes"))
return compare_versions(bnb_version, ">=", min_version)
else:
return package_exists
def is_bitsandbytes_multi_backend_available():
if not is_bnb_available():
return False
import bitsandbytes as bnb
return "multi_backend" in getattr(bnb, "features", set())
def is_torchvision_available():
return _is_package_available("torchvision")
def is_megatron_lm_available():
if str_to_bool(os.environ.get("ACCELERATE_USE_MEGATRON_LM", "False")) == 1:
if importlib.util.find_spec("megatron") is not None:
try:
megatron_version = parse(importlib.metadata.version("megatron-core"))
if compare_versions(megatron_version, ">=", "0.8.0"):
return importlib.util.find_spec(".training", "megatron")
except Exception as e:
warnings.warn(f"Parse Megatron version failed. Exception:{e}")
return False
def is_transformers_available():
return _is_package_available("transformers")
def is_datasets_available():
return _is_package_available("datasets")
def is_peft_available():
return _is_package_available("peft")
def is_timm_available():
return _is_package_available("timm")
def is_triton_available():
return _is_package_available("triton")
def is_aim_available():
package_exists = _is_package_available("aim")
if package_exists:
aim_version = version.parse(importlib.metadata.version("aim"))
return compare_versions(aim_version, "<", "4.0.0")
return False
def is_tensorboard_available():
return _is_package_available("tensorboard") or _is_package_available("tensorboardX")
def is_wandb_available():
return _is_package_available("wandb")
def is_comet_ml_available():
return _is_package_available("comet_ml")
def is_boto3_available():
return _is_package_available("boto3")
def is_rich_available():
if _is_package_available("rich"):
return parse_flag_from_env("ACCELERATE_ENABLE_RICH", False)
return False
def is_sagemaker_available():
return _is_package_available("sagemaker")
def is_tqdm_available():
return _is_package_available("tqdm")
def is_clearml_available():
return _is_package_available("clearml")
def is_pandas_available():
return _is_package_available("pandas")
def is_mlflow_available():
if _is_package_available("mlflow"):
return True
if importlib.util.find_spec("mlflow") is not None:
try:
_ = importlib.metadata.metadata("mlflow-skinny")
return True
except importlib.metadata.PackageNotFoundError:
return False
return False
def is_mps_available(min_version="1.12"):
"Checks if MPS device is available. The minimum version required is 1.12."
# With torch 1.12, you can use torch.backends.mps
# With torch 2.0.0, you can use torch.mps
return is_torch_version(">=", min_version) and torch.backends.mps.is_available() and torch.backends.mps.is_built()
def is_ipex_available():
"Checks if ipex is installed."
def get_major_and_minor_from_version(full_version):
return str(version.parse(full_version).major) + "." + str(version.parse(full_version).minor)
_torch_version = importlib.metadata.version("torch")
if importlib.util.find_spec("intel_extension_for_pytorch") is None:
return False
_ipex_version = "N/A"
try:
_ipex_version = importlib.metadata.version("intel_extension_for_pytorch")
except importlib.metadata.PackageNotFoundError:
return False
torch_major_and_minor = get_major_and_minor_from_version(_torch_version)
ipex_major_and_minor = get_major_and_minor_from_version(_ipex_version)
if torch_major_and_minor != ipex_major_and_minor:
warnings.warn(
f"Intel Extension for PyTorch {ipex_major_and_minor} needs to work with PyTorch {ipex_major_and_minor}.*,"
f" but PyTorch {_torch_version} is found. Please switch to the matching version and run again."
)
return False
return True
@lru_cache
def is_mlu_available(check_device=False):
"""
Checks if `mlu` is available via an `cndev-based` check which won't trigger the drivers and leave mlu
uninitialized.
"""
if importlib.util.find_spec("torch_mlu") is None:
return False
import torch_mlu # noqa: F401
with patch_environment(PYTORCH_CNDEV_BASED_MLU_CHECK="1"):
available = torch.mlu.is_available()
return available
@lru_cache
def is_musa_available(check_device=False):
"Checks if `torch_musa` is installed and potentially if a MUSA is in the environment"
if importlib.util.find_spec("torch_musa") is None:
return False
import torch_musa # noqa: F401
if check_device:
try:
# Will raise a RuntimeError if no MUSA is found
_ = torch.musa.device_count()
return torch.musa.is_available()
except RuntimeError:
return False
return hasattr(torch, "musa") and torch.musa.is_available()
@lru_cache
def is_npu_available(check_device=False):
"Checks if `torch_npu` is installed and potentially if a NPU is in the environment"
if importlib.util.find_spec("torch_npu") is None:
return False
import torch_npu # noqa: F401
if check_device:
try:
# Will raise a RuntimeError if no NPU is found
_ = torch.npu.device_count()
return torch.npu.is_available()
except RuntimeError:
return False
return hasattr(torch, "npu") and torch.npu.is_available()
@lru_cache
def is_xpu_available(check_device=False):
"""
Checks if XPU acceleration is available either via `intel_extension_for_pytorch` or via stock PyTorch (>=2.4) and
potentially if a XPU is in the environment
"""
"check if user disables it explicitly"
if not parse_flag_from_env("ACCELERATE_USE_XPU", default=True):
return False
if is_ipex_available():
if is_torch_version("<=", "1.12"):
return False
import intel_extension_for_pytorch # noqa: F401
else:
if is_torch_version("<=", "2.3"):
return False
if check_device:
try:
# Will raise a RuntimeError if no XPU is found
_ = torch.xpu.device_count()
return torch.xpu.is_available()
except RuntimeError:
return False
return hasattr(torch, "xpu") and torch.xpu.is_available()
def is_dvclive_available():
return _is_package_available("dvclive")
def is_torchdata_available():
return _is_package_available("torchdata")
# TODO: Remove this function once stateful_dataloader is a stable feature in torchdata.
def is_torchdata_stateful_dataloader_available():
package_exists = _is_package_available("torchdata")
if package_exists:
torchdata_version = version.parse(importlib.metadata.version("torchdata"))
return compare_versions(torchdata_version, ">=", "0.8.0")
return False
# TODO: Rework this into `utils.deepspeed` and migrate the "core" chunks into `accelerate.deepspeed`
def deepspeed_required(func):
"""
A decorator that ensures the decorated function is only called when deepspeed is enabled.
"""
@wraps(func)
def wrapper(*args, **kwargs):
from accelerate.state import AcceleratorState
from accelerate.utils.dataclasses import DistributedType
if AcceleratorState._shared_state != {} and AcceleratorState().distributed_type != DistributedType.DEEPSPEED:
raise ValueError(
"DeepSpeed is not enabled, please make sure that an `Accelerator` is configured for `deepspeed` "
"before calling this function."
)
return func(*args, **kwargs)
return wrapper
def is_weights_only_available():
# Weights only with allowlist was added in 2.4.0
# ref: https://github.com/pytorch/pytorch/pull/124331
return is_torch_version(">=", "2.4.0")
def is_numpy_available(min_version="1.25.0"):
numpy_version = parse(importlib.metadata.version("numpy"))
return compare_versions(numpy_version, ">=", min_version)
| 4 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/versions.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import importlib.metadata
from typing import Union
from packaging.version import Version, parse
from .constants import STR_OPERATION_TO_FUNC
torch_version = parse(importlib.metadata.version("torch"))
def compare_versions(library_or_version: Union[str, Version], operation: str, requirement_version: str):
"""
Compares a library version to some requirement using a given operation.
Args:
library_or_version (`str` or `packaging.version.Version`):
A library name or a version to check.
operation (`str`):
A string representation of an operator, such as `">"` or `"<="`.
requirement_version (`str`):
The version to compare the library version against
"""
if operation not in STR_OPERATION_TO_FUNC.keys():
raise ValueError(f"`operation` must be one of {list(STR_OPERATION_TO_FUNC.keys())}, received {operation}")
operation = STR_OPERATION_TO_FUNC[operation]
if isinstance(library_or_version, str):
library_or_version = parse(importlib.metadata.version(library_or_version))
return operation(library_or_version, parse(requirement_version))
def is_torch_version(operation: str, version: str):
"""
Compares the current PyTorch version to a given reference with an operation.
Args:
operation (`str`):
A string representation of an operator, such as `">"` or `"<="`
version (`str`):
A string version of PyTorch
"""
return compare_versions(torch_version, operation, version)
| 5 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/modeling.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import contextlib
import gc
import inspect
import json
import logging
import os
import re
import shutil
import tempfile
import warnings
from collections import OrderedDict, defaultdict
from typing import Dict, List, Optional, Set, Tuple, Union
import torch
import torch.nn as nn
from ..state import AcceleratorState
from .constants import SAFE_WEIGHTS_NAME, WEIGHTS_NAME
from .dataclasses import AutocastKwargs, CustomDtype, DistributedType
from .imports import (
is_mlu_available,
is_mps_available,
is_musa_available,
is_npu_available,
is_peft_available,
is_torch_xla_available,
is_xpu_available,
)
from .memory import clear_device_cache, get_xpu_available_memory
from .offload import load_offloaded_weight, offload_weight, save_offload_index
from .tqdm import is_tqdm_available, tqdm
from .versions import is_torch_version
if is_npu_available(check_device=False):
import torch_npu # noqa: F401
if is_mlu_available(check_device=False):
import torch_mlu # noqa: F401
if is_musa_available(check_device=False):
import torch_musa # noqa: F401
from safetensors import safe_open
from safetensors.torch import load_file as safe_load_file
WEIGHTS_INDEX_NAME = "pytorch_model.bin.index.json"
logger = logging.getLogger(__name__)
def is_peft_model(model):
from .other import extract_model_from_parallel
if is_peft_available():
from peft import PeftModel
return is_peft_available() and isinstance(extract_model_from_parallel(model), PeftModel)
def check_device_same(first_device, second_device):
"""
Utility method to check if two `torch` devices are similar. When dealing with CUDA devices, torch throws `False`
for `torch.device("cuda") == torch.device("cuda:0")` whereas they should be the same
Args:
first_device (`torch.device`):
First device to check
second_device (`torch.device`):
Second device to check
"""
if first_device.type != second_device.type:
return False
if first_device.type == "cuda" and first_device.index is None:
# In case the first_device is a cuda device and have
# the index attribute set to `None`, default it to `0`
first_device = torch.device("cuda", index=0)
if second_device.type == "cuda" and second_device.index is None:
# In case the second_device is a cuda device and have
# the index attribute set to `None`, default it to `0`
second_device = torch.device("cuda", index=0)
return first_device == second_device
def convert_file_size_to_int(size: Union[int, str]):
"""
Converts a size expressed as a string with digits an unit (like `"5MB"`) to an integer (in bytes).
Args:
size (`int` or `str`): The size to convert. Will be directly returned if an `int`.
Example:
```py
>>> convert_file_size_to_int("1MiB")
1048576
```
"""
mem_size = -1
err_msg = (
f"`size` {size} is not in a valid format. Use an integer for bytes, or a string with an unit (like '5.0GB')."
)
try:
if isinstance(size, int):
mem_size = size
elif size.upper().endswith("GIB"):
mem_size = int(float(size[:-3]) * (2**30))
elif size.upper().endswith("MIB"):
mem_size = int(float(size[:-3]) * (2**20))
elif size.upper().endswith("KIB"):
mem_size = int(float(size[:-3]) * (2**10))
elif size.upper().endswith("GB"):
int_size = int(float(size[:-2]) * (10**9))
mem_size = int_size // 8 if size.endswith("b") else int_size
elif size.upper().endswith("MB"):
int_size = int(float(size[:-2]) * (10**6))
mem_size = int_size // 8 if size.endswith("b") else int_size
elif size.upper().endswith("KB"):
int_size = int(float(size[:-2]) * (10**3))
mem_size = int_size // 8 if size.endswith("b") else int_size
except ValueError:
raise ValueError(err_msg)
if mem_size < 0:
raise ValueError(err_msg)
return mem_size
def dtype_byte_size(dtype: torch.dtype):
"""
Returns the size (in bytes) occupied by one parameter of type `dtype`.
Example:
```py
>>> dtype_byte_size(torch.float32)
4
```
"""
if dtype == torch.bool:
return 1 / 8
elif dtype == CustomDtype.INT2:
return 1 / 4
elif dtype == CustomDtype.INT4:
return 1 / 2
elif dtype == CustomDtype.FP8:
return 1
elif is_torch_version(">=", "2.1.0") and dtype == torch.float8_e4m3fn:
return 1
bit_search = re.search(r"[^\d](\d+)$", str(dtype))
if bit_search is None:
raise ValueError(f"`dtype` is not a valid dtype: {dtype}.")
bit_size = int(bit_search.groups()[0])
return bit_size // 8
def id_tensor_storage(tensor: torch.Tensor) -> Tuple[torch.device, int, int]:
"""
Unique identifier to a tensor storage. Multiple different tensors can share the same underlying storage. For
example, "meta" tensors all share the same storage, and thus their identifier will all be equal. This identifier is
guaranteed to be unique and constant for this tensor's storage during its lifetime. Two tensor storages with
non-overlapping lifetimes may have the same id.
"""
_SIZE = {
torch.int64: 8,
torch.float32: 4,
torch.int32: 4,
torch.bfloat16: 2,
torch.float16: 2,
torch.int16: 2,
torch.uint8: 1,
torch.int8: 1,
torch.bool: 1,
torch.float64: 8,
}
try:
storage_ptr = tensor.untyped_storage().data_ptr()
storage_size = tensor.untyped_storage().nbytes()
except Exception:
# Fallback for torch==1.10
try:
storage_ptr = tensor.storage().data_ptr()
storage_size = tensor.storage().size() * _SIZE[tensor.dtype]
except NotImplementedError:
# Fallback for meta storage
storage_ptr = 0
# On torch >=2.0 this is the tensor size
storage_size = tensor.nelement() * _SIZE[tensor.dtype]
return tensor.device, storage_ptr, storage_size
def set_module_tensor_to_device(
module: nn.Module,
tensor_name: str,
device: Union[int, str, torch.device],
value: Optional[torch.Tensor] = None,
dtype: Optional[Union[str, torch.dtype]] = None,
fp16_statistics: Optional[torch.HalfTensor] = None,
tied_params_map: Optional[Dict[int, Dict[torch.device, torch.Tensor]]] = None,
):
"""
A helper function to set a given tensor (parameter of buffer) of a module on a specific device (note that doing
`param.to(device)` creates a new tensor not linked to the parameter, which is why we need this function).
Args:
module (`torch.nn.Module`):
The module in which the tensor we want to move lives.
tensor_name (`str`):
The full name of the parameter/buffer.
device (`int`, `str` or `torch.device`):
The device on which to set the tensor.
value (`torch.Tensor`, *optional*):
The value of the tensor (useful when going from the meta device to any other device).
dtype (`torch.dtype`, *optional*):
If passed along the value of the parameter will be cast to this `dtype`. Otherwise, `value` will be cast to
the dtype of the existing parameter in the model.
fp16_statistics (`torch.HalfTensor`, *optional*):
The list of fp16 statistics to set on the module, used for 8 bit model serialization.
tied_params_map (Dict[int, Dict[torch.device, torch.Tensor]], *optional*, defaults to `None`):
A map of current data pointers to dictionaries of devices to already dispatched tied weights. For a given
execution device, this parameter is useful to reuse the first available pointer of a shared weight on the
device for all others, instead of duplicating memory.
"""
# Recurse if needed
if "." in tensor_name:
splits = tensor_name.split(".")
for split in splits[:-1]:
new_module = getattr(module, split)
if new_module is None:
raise ValueError(f"{module} has no attribute {split}.")
module = new_module
tensor_name = splits[-1]
if tensor_name not in module._parameters and tensor_name not in module._buffers:
raise ValueError(f"{module} does not have a parameter or a buffer named {tensor_name}.")
is_buffer = tensor_name in module._buffers
old_value = getattr(module, tensor_name)
# Treat the case where old_value (or a custom `value`, typically offloaded to RAM/disk) belongs to a tied group, and one of the weight
# in the tied group has already been dispatched to the device, by avoiding reallocating memory on the device and just copying the pointer.
if (
value is not None
and tied_params_map is not None
and value.data_ptr() in tied_params_map
and device in tied_params_map[value.data_ptr()]
):
module._parameters[tensor_name] = tied_params_map[value.data_ptr()][device]
return
elif (
tied_params_map is not None
and old_value.data_ptr() in tied_params_map
and device in tied_params_map[old_value.data_ptr()]
):
module._parameters[tensor_name] = tied_params_map[old_value.data_ptr()][device]
return
if old_value.device == torch.device("meta") and device not in ["meta", torch.device("meta")] and value is None:
raise ValueError(f"{tensor_name} is on the meta device, we need a `value` to put in on {device}.")
param = module._parameters[tensor_name] if tensor_name in module._parameters else None
param_cls = type(param)
if value is not None:
# We can expect mismatches when using bnb 4bit since Params4bit will reshape and pack the weights.
# In other cases, we want to make sure we're not loading checkpoints that do not match the config.
if old_value.shape != value.shape and param_cls.__name__ != "Params4bit":
raise ValueError(
f'Trying to set a tensor of shape {value.shape} in "{tensor_name}" (which has shape {old_value.shape}), this looks incorrect.'
)
if dtype is None:
# For compatibility with PyTorch load_state_dict which converts state dict dtype to existing dtype in model
value = value.to(old_value.dtype)
elif not str(value.dtype).startswith(("torch.uint", "torch.int", "torch.bool")):
value = value.to(dtype)
device_quantization = None
with torch.no_grad():
# leave it on cpu first before moving them to cuda
# # fix the case where the device is meta, we don't want to put it on cpu because there is no data =0
if (
param is not None
and param.device.type != "cuda"
and torch.device(device).type == "cuda"
and param_cls.__name__ in ["Int8Params", "FP4Params", "Params4bit"]
):
device_quantization = device
device = "cpu"
# `torch.Tensor.to(<int num>)` is not supported by `torch_npu` (see this [issue](https://github.com/Ascend/pytorch/issues/16)).
if isinstance(device, int):
if is_npu_available():
device = f"npu:{device}"
elif is_mlu_available():
device = f"mlu:{device}"
elif is_musa_available():
device = f"musa:{device}"
elif is_xpu_available():
device = f"xpu:{device}"
if "xpu" in str(device) and not is_xpu_available():
raise ValueError(f'{device} is not available, you should use device="cpu" instead')
if value is None:
new_value = old_value.to(device)
if dtype is not None and device in ["meta", torch.device("meta")]:
if not str(old_value.dtype).startswith(("torch.uint", "torch.int", "torch.bool")):
new_value = new_value.to(dtype)
if not is_buffer:
module._parameters[tensor_name] = param_cls(new_value, requires_grad=old_value.requires_grad)
elif isinstance(value, torch.Tensor):
new_value = value.to(device)
else:
new_value = torch.tensor(value, device=device)
if device_quantization is not None:
device = device_quantization
if is_buffer:
module._buffers[tensor_name] = new_value
elif value is not None or not check_device_same(torch.device(device), module._parameters[tensor_name].device):
param_cls = type(module._parameters[tensor_name])
kwargs = module._parameters[tensor_name].__dict__
if param_cls.__name__ in ["Int8Params", "FP4Params", "Params4bit"]:
if param_cls.__name__ == "Int8Params" and new_value.dtype == torch.float32:
# downcast to fp16 if any - needed for 8bit serialization
new_value = new_value.to(torch.float16)
# quantize module that are going to stay on the cpu so that we offload quantized weights
if device == "cpu" and param_cls.__name__ == "Int8Params":
new_value = param_cls(new_value, requires_grad=old_value.requires_grad, **kwargs).to(0).to("cpu")
new_value.CB = new_value.CB.to("cpu")
new_value.SCB = new_value.SCB.to("cpu")
else:
new_value = param_cls(new_value, requires_grad=old_value.requires_grad, **kwargs).to(device)
elif param_cls.__name__ in ["QTensor", "QBitsTensor"]:
new_value = torch.nn.Parameter(new_value, requires_grad=old_value.requires_grad).to(device)
elif param_cls.__name__ in ["AffineQuantizedTensor"]:
new_value = torch.nn.Parameter(
param_cls(
new_value.layout_tensor,
new_value.block_size,
new_value.shape,
new_value.quant_min,
new_value.quant_max,
new_value.zero_point_domain,
),
requires_grad=old_value.requires_grad,
).to(device)
else:
new_value = param_cls(new_value, requires_grad=old_value.requires_grad).to(device)
module._parameters[tensor_name] = new_value
if fp16_statistics is not None:
module._parameters[tensor_name].SCB = fp16_statistics.to(device)
del fp16_statistics
# as we put the weight to meta, it doesn't have SCB attr anymore. make sure that it is not a meta weight
if (
module.__class__.__name__ == "Linear8bitLt"
and getattr(module.weight, "SCB", None) is None
and str(module.weight.device) != "meta"
):
# quantize only if necessary
device_index = torch.device(device).index if torch.device(device).type == "cuda" else None
if not getattr(module.weight, "SCB", None) and device_index is not None:
if module.bias is not None and module.bias.device.type != "meta":
# if a bias exists, we need to wait until the bias is set on the correct device
module = module.cuda(device_index)
elif module.bias is None:
# if no bias exists, we can quantize right away
module = module.cuda(device_index)
elif (
module.__class__.__name__ == "Linear4bit"
and getattr(module.weight, "quant_state", None) is None
and str(module.weight.device) != "meta"
):
# quantize only if necessary
device_index = torch.device(device).index if torch.device(device).type == "cuda" else None
if not getattr(module.weight, "quant_state", None) and device_index is not None:
module.weight = module.weight.cuda(device_index)
# clean pre and post foward hook
if device != "cpu":
clear_device_cache()
# When handling tied weights, we update tied_params_map to keep track of the tied weights that have already been allocated on the device in
# order to avoid duplicating memory, see above.
if (
tied_params_map is not None
and old_value.data_ptr() in tied_params_map
and device not in tied_params_map[old_value.data_ptr()]
):
tied_params_map[old_value.data_ptr()][device] = new_value
elif (
value is not None
and tied_params_map is not None
and value.data_ptr() in tied_params_map
and device not in tied_params_map[value.data_ptr()]
):
tied_params_map[value.data_ptr()][device] = new_value
def named_module_tensors(
module: nn.Module, include_buffers: bool = True, recurse: bool = False, remove_non_persistent: bool = False
):
"""
A helper function that gathers all the tensors (parameters + buffers) of a given module. If `include_buffers=True`
it's the same as doing `module.named_parameters(recurse=recurse) + module.named_buffers(recurse=recurse)`.
Args:
module (`torch.nn.Module`):
The module we want the tensors on.
include_buffer (`bool`, *optional*, defaults to `True`):
Whether or not to include the buffers in the result.
recurse (`bool`, *optional`, defaults to `False`):
Whether or not to go look in every submodule or just return the direct parameters and buffers.
remove_non_persistent (`bool`, *optional*, defaults to `False`):
Whether or not to remove the non persistent buffer from the buffers. Useful only when include_buffers =
True
"""
yield from module.named_parameters(recurse=recurse)
if include_buffers:
non_persistent_buffers = set()
if remove_non_persistent:
non_persistent_buffers = get_non_persistent_buffers(module, recurse=recurse)
for named_buffer in module.named_buffers(recurse=recurse):
name, _ = named_buffer
if name not in non_persistent_buffers:
yield named_buffer
def get_non_persistent_buffers(module: nn.Module, recurse: bool = False):
"""
Gather all non persistent buffers of a given modules into a set
Args:
module (`nn.Module`):
The module we want the non persistent buffers on.
recurse (`bool`, *optional*, defaults to `False`):
Whether or not to go look in every submodule or just return the direct non persistent buffers.
"""
non_persistent_buffers_set = module._non_persistent_buffers_set
if recurse:
for _, m in module.named_modules():
non_persistent_buffers_set |= m._non_persistent_buffers_set
return non_persistent_buffers_set
class FindTiedParametersResult(list):
"""
This is a subclass of a list to handle backward compatibility for Transformers. Do not rely on the fact this is not
a list or on the `values` method as in the future this will be removed.
"""
def __init__(self, *args, **kwargs):
super().__init__(*args, **kwargs)
def values(self):
warnings.warn(
"The 'values' method of FindTiedParametersResult is deprecated and will be removed in Accelerate v1.3.0. ",
FutureWarning,
)
return sum([x[1:] for x in self], [])
def check_tied_parameters_in_config(model: nn.Module):
"""
Check if there is any indication in the given model that some weights should be tied.
Args:
model (`torch.nn.Module`): The model to inspect
Returns:
bool: True if the model needs to have tied weights
"""
# based on model.tie_weights() method
has_tied_word_embedding = False
has_tied_encoder_decoder = False
has_tied_module = False
if "PreTrainedModel" in [c.__name__ for c in inspect.getmro(model.__class__)]:
has_tied_word_embedding = (
hasattr(model, "config")
and getattr(model.config, "tie_word_embeddings", False)
and model.get_output_embeddings()
)
has_tied_encoder_decoder = (
hasattr(model, "config")
and getattr(model.config, "is_encoder_decoder", False)
and getattr(model.config, "tie_encoder_decoder", False)
)
has_tied_module = any(hasattr(module, "_tie_weights") for module in model.modules())
return any([has_tied_word_embedding, has_tied_encoder_decoder, has_tied_module])
def _get_param_device(param, device_map):
if param in device_map:
return device_map[param]
parent_param = ".".join(param.split(".")[:-1])
if parent_param == param:
raise ValueError(f"The `device_map` does not contain the module {param}.")
else:
return _get_param_device(parent_param, device_map)
def check_tied_parameters_on_same_device(tied_params, device_map):
"""
Check if tied parameters are on the same device
Args:
tied_params (`List[List[str]]`):
A list of lists of parameter names being all tied together.
device_map (`Dict[str, Union[int, str, torch.device]]`):
A map that specifies where each submodule should go.
"""
for tie_param in tied_params:
tie_param_devices = {}
for param in tie_param:
tie_param_devices[param] = _get_param_device(param, device_map)
if len(set(tie_param_devices.values())) > 1:
logger.warn(
f"Tied parameters are on different devices: {tie_param_devices}. "
"Please modify your custom device map or set `device_map='auto'`. "
)
def _get_named_modules(
module: torch.nn.Module,
memo: Optional[Set[torch.nn.Module]] = None,
prefix: str = "",
remove_duplicate: bool = True,
):
"""
Return an iterator over all modules in the network, yielding both the name of the module as well as the module
itself. Copied from PyTorch `torch.nn.Module.named_modules` for compatability with torch < 2.0 versions with
`remove_duplicate` option added.
Args:
memo (set of `torch.nn.Module`, *optional*):
A memo to store the set of modules already added to the result
prefix (`str`, *optional*):
A prefix that will be added to the name of the module
remove_duplicate (`bool`, *optional*):
Whether to remove the duplicated module instances in the result or not
Yields:
(str, Module): Tuple of name and module
Note:
Duplicate modules are returned only once. In the following example, ``l`` will be returned only once.
"""
if memo is None:
memo = set()
if module not in memo:
if remove_duplicate:
memo.add(module)
yield prefix, module
for name, sub_module in module._modules.items():
if sub_module is None:
continue
submodule_prefix = prefix + ("." if prefix else "") + name
yield from _get_named_modules(sub_module, memo, submodule_prefix, remove_duplicate)
def _get_named_parameters(module: torch.nn.Module, prefix="", recurse=True, remove_duplicate: bool = True):
"""
Help yield various names + members of modules. Copied from PyTorch `torch.nn.Module.named_modules` for
compatability with torch < 2.0 versions with `remove_duplicate` option added.
"""
memo = set()
modules = (
_get_named_modules(module, prefix=prefix, remove_duplicate=remove_duplicate) if recurse else [(prefix, module)]
)
for module_prefix, module in modules:
members = module._parameters.items()
for k, v in members:
if v is None or v in memo:
continue
if remove_duplicate:
memo.add(v)
name = module_prefix + ("." if module_prefix else "") + k
yield name, v
def find_tied_parameters(model: torch.nn.Module, **kwargs):
"""
Find the tied parameters in a given model.
<Tip warning={true}>
The signature accepts keyword arguments, but they are for the recursive part of this function and you should ignore
them.
</Tip>
Args:
model (`torch.nn.Module`): The model to inspect.
Returns:
List[List[str]]: A list of lists of parameter names being all tied together.
Example:
```py
>>> from collections import OrderedDict
>>> import torch.nn as nn
>>> model = nn.Sequential(OrderedDict([("linear1", nn.Linear(4, 4)), ("linear2", nn.Linear(4, 4))]))
>>> model.linear2.weight = model.linear1.weight
>>> find_tied_parameters(model)
[['linear1.weight', 'linear2.weight']]
```
"""
# get ALL model parameters and thier names
all_named_parameters = {name: param for name, param in _get_named_parameters(model, remove_duplicate=False)}
# get ONLY unique named parameters,
# if parameter is tied and have multiple names, it will be included only once
no_duplicate_named_parameters = {
name: param for name, param in _get_named_parameters(model, remove_duplicate=True)
}
# the difference of the two sets will give us the tied parameters
tied_param_names = set(all_named_parameters.keys()) - set(no_duplicate_named_parameters.keys())
# 'tied_param_names' contains the names of parameters that are tied in the model, but we do not know
# which names refer to the same parameter. To identify this, we need to group them together.
tied_param_groups = {}
for tied_param_name in tied_param_names:
tied_param = all_named_parameters[tied_param_name]
for param_name, param in no_duplicate_named_parameters.items():
# compare if parameters are the same, if so, group thier names together
if param is tied_param:
if param_name not in tied_param_groups:
tied_param_groups[param_name] = []
tied_param_groups[param_name].append(tied_param_name)
return FindTiedParametersResult([sorted([weight] + list(set(tied))) for weight, tied in tied_param_groups.items()])
def retie_parameters(model, tied_params):
"""
Reties tied parameters in a given model if the link was broken (for instance when adding hooks).
Args:
model (`torch.nn.Module`):
The model in which to retie parameters.
tied_params (`List[List[str]]`):
A mapping parameter name to tied parameter name as obtained by `find_tied_parameters`.
"""
for tied_group in tied_params:
param_to_tie = None
# two loops : the first one to set param_to_tie , the second one to change the values of tied_group
for param_name in tied_group:
module = model
splits = param_name.split(".")
for split in splits[:-1]:
module = getattr(module, split)
param = getattr(module, splits[-1])
if param_to_tie is None and param.device != torch.device("meta"):
param_to_tie = param
break
if param_to_tie is not None:
for param_name in tied_group:
module = model
splits = param_name.split(".")
for split in splits[:-1]:
module = getattr(module, split)
setattr(module, splits[-1], param_to_tie)
def _get_proper_dtype(dtype: Union[str, torch.device]) -> torch.dtype:
"""
Just does torch.dtype(dtype) if necessary.
"""
if isinstance(dtype, str):
# We accept "torch.float16" or just "float16"
dtype = dtype.replace("torch.", "")
dtype = getattr(torch, dtype)
return dtype
def compute_module_sizes(
model: nn.Module,
dtype: Optional[Union[str, torch.device]] = None,
special_dtypes: Optional[Dict[str, Union[str, torch.device]]] = None,
buffers_only: bool = False,
):
"""
Compute the size of each submodule of a given model.
"""
if dtype is not None:
dtype = _get_proper_dtype(dtype)
dtype_size = dtype_byte_size(dtype)
if special_dtypes is not None:
special_dtypes = {key: _get_proper_dtype(dtyp) for key, dtyp in special_dtypes.items()}
special_dtypes_size = {key: dtype_byte_size(dtyp) for key, dtyp in special_dtypes.items()}
module_sizes = defaultdict(int)
module_list = []
if not buffers_only:
module_list = named_module_tensors(model, recurse=True)
else:
module_list = model.named_buffers(recurse=True)
for name, tensor in module_list:
if special_dtypes is not None and name in special_dtypes:
size = tensor.numel() * special_dtypes_size[name]
elif dtype is None:
size = tensor.numel() * dtype_byte_size(tensor.dtype)
elif str(tensor.dtype).startswith(("torch.uint", "torch.int", "torch.bool")):
# According to the code in set_module_tensor_to_device, these types won't be converted
# so use their original size here
size = tensor.numel() * dtype_byte_size(tensor.dtype)
else:
size = tensor.numel() * min(dtype_size, dtype_byte_size(tensor.dtype))
name_parts = name.split(".")
for idx in range(len(name_parts) + 1):
module_sizes[".".join(name_parts[:idx])] += size
return module_sizes
def compute_module_total_buffer_size(
model: nn.Module,
dtype: Optional[Union[str, torch.device]] = None,
special_dtypes: Optional[Dict[str, Union[str, torch.device]]] = None,
):
"""
Compute the total size of buffers in each submodule of a given model.
"""
module_sizes = compute_module_sizes(model, dtype=dtype, special_dtypes=special_dtypes, buffers_only=True)
return module_sizes.get("", 0)
def get_max_layer_size(
modules: List[Tuple[str, torch.nn.Module]], module_sizes: Dict[str, int], no_split_module_classes: List[str]
):
"""
Utility function that will scan a list of named modules and return the maximum size used by one full layer. The
definition of a layer being:
- a module with no direct children (just parameters and buffers)
- a module whose class name is in the list `no_split_module_classes`
Args:
modules (`List[Tuple[str, torch.nn.Module]]`):
The list of named modules where we want to determine the maximum layer size.
module_sizes (`Dict[str, int]`):
A dictionary mapping each layer name to its size (as generated by `compute_module_sizes`).
no_split_module_classes (`List[str]`):
A list of class names for layers we don't want to be split.
Returns:
`Tuple[int, List[str]]`: The maximum size of a layer with the list of layer names realizing that maximum size.
"""
max_size = 0
layer_names = []
modules_to_treat = modules.copy()
while len(modules_to_treat) > 0:
module_name, module = modules_to_treat.pop(0)
modules_children = list(module.named_children()) if isinstance(module, torch.nn.Module) else []
if len(modules_children) == 0 or module.__class__.__name__ in no_split_module_classes:
# No splitting this one so we compare to the max_size
size = module_sizes[module_name]
if size > max_size:
max_size = size
layer_names = [module_name]
elif size == max_size:
layer_names.append(module_name)
else:
modules_to_treat = [(f"{module_name}.{n}", v) for n, v in modules_children] + modules_to_treat
return max_size, layer_names
def get_max_memory(max_memory: Optional[Dict[Union[int, str], Union[int, str]]] = None):
"""
Get the maximum memory available if nothing is passed, converts string to int otherwise.
"""
import psutil
if max_memory is None:
max_memory = {}
# Make sure CUDA is initialized on each GPU to have the right memory info.
if is_npu_available():
for i in range(torch.npu.device_count()):
try:
_ = torch.tensor(0, device=torch.device("npu", i))
max_memory[i] = torch.npu.mem_get_info(i)[0]
except Exception:
logger.info(f"Device {i} seems unavailable, Proceeding to check subsequent devices.")
continue
elif is_mlu_available():
for i in range(torch.mlu.device_count()):
try:
_ = torch.tensor(0, device=torch.device("mlu", i))
max_memory[i] = torch.mlu.mem_get_info(i)[0]
except Exception:
logger.info(f"Device {i} seems unavailable, Proceeding to check subsequent devices.")
continue
elif is_musa_available():
for i in range(torch.musa.device_count()):
try:
_ = torch.tensor(0, device=torch.device("musa", i))
max_memory[i] = torch.musa.mem_get_info(i)[0]
except Exception:
logger.info(f"Device {i} seems unavailable, Proceeding to check subsequent devices.")
continue
elif is_xpu_available():
for i in range(torch.xpu.device_count()):
try:
_ = torch.tensor(0, device=torch.device("xpu", i))
max_memory[i] = get_xpu_available_memory(i)
except Exception:
logger.info(f"Device {i} seems unavailable, Proceeding to check subsequent devices.")
continue
else:
for i in range(torch.cuda.device_count()):
try:
_ = torch.tensor([0], device=i)
max_memory[i] = torch.cuda.mem_get_info(i)[0]
except Exception:
logger.info(f"Device {i} seems unavailable, Proceeding to check subsequent devices.")
continue
# allocate everything in the mps device as the RAM is shared
if is_mps_available():
max_memory["mps"] = psutil.virtual_memory().available
else:
max_memory["cpu"] = psutil.virtual_memory().available
return max_memory
for key in max_memory:
if isinstance(max_memory[key], str):
max_memory[key] = convert_file_size_to_int(max_memory[key])
# Need to sort the device by type to make sure that we allocate the gpu first.
# As gpu/npu/xpu are represented by int, we need to sort them first.
gpu_devices = [k for k in max_memory.keys() if isinstance(k, int)]
gpu_devices.sort()
# check if gpu/npu/xpu devices are available and if not, throw a warning
if is_npu_available():
num_devices = torch.npu.device_count()
elif is_mlu_available():
num_devices = torch.mlu.device_count()
elif is_musa_available():
num_devices = torch.musa.device_count()
elif is_xpu_available():
num_devices = torch.xpu.device_count()
else:
num_devices = torch.cuda.device_count()
for device in gpu_devices:
if device >= num_devices or device < 0:
logger.warning(f"Device {device} is not available, available devices are {list(range(num_devices))}")
# Add the other devices in the preset order if they are available
all_devices = gpu_devices + [k for k in ["mps", "cpu", "disk"] if k in max_memory.keys()]
# Raise an error if a device is not recognized
for k in max_memory.keys():
if k not in all_devices:
raise ValueError(
f"Device {k} is not recognized, available devices are integers(for GPU/XPU), 'mps', 'cpu' and 'disk'"
)
max_memory = {k: max_memory[k] for k in all_devices}
return max_memory
def clean_device_map(device_map: Dict[str, Union[int, str, torch.device]], module_name: str = ""):
"""
Cleans a device_map by grouping all submodules that go on the same device together.
"""
# Get the value of the current module and if there is only one split across several keys, regroup it.
prefix = "" if module_name == "" else f"{module_name}."
values = [v for k, v in device_map.items() if k.startswith(prefix)]
if len(set(values)) == 1 and len(values) > 1:
for k in [k for k in device_map if k.startswith(prefix)]:
del device_map[k]
device_map[module_name] = values[0]
# Recurse over the children
children_modules = [k for k in device_map.keys() if k.startswith(prefix) and len(k) > len(module_name)]
idx = len(module_name.split(".")) + 1 if len(module_name) > 0 else 1
children_modules = set(".".join(k.split(".")[:idx]) for k in children_modules)
for child in children_modules:
clean_device_map(device_map, module_name=child)
return device_map
def load_offloaded_weights(model, index, offload_folder):
"""
Loads the weights from the offload folder into the model.
Args:
model (`torch.nn.Module`):
The model to load the weights into.
index (`dict`):
A dictionary containing the parameter name and its metadata for each parameter that was offloaded from the
model.
offload_folder (`str`):
The folder where the offloaded weights are stored.
"""
if index is None or len(index) == 0:
# Nothing to do
return
for param_name, metadata in index.items():
if "SCB" in param_name:
continue
fp16_statistics = None
if "weight" in param_name and param_name.replace("weight", "SCB") in index.keys():
weight_name = param_name.replace("weight", "SCB")
fp16_statistics = load_offloaded_weight(
os.path.join(offload_folder, f"{weight_name}.dat"), index[weight_name]
)
tensor_file = os.path.join(offload_folder, f"{param_name}.dat")
weight = load_offloaded_weight(tensor_file, metadata)
set_module_tensor_to_device(model, param_name, "cpu", value=weight, fp16_statistics=fp16_statistics)
def get_module_leaves(module_sizes):
module_children = {}
for module in module_sizes:
if module == "" or "." not in module:
continue
parent = module.rsplit(".", 1)[0]
module_children[parent] = module_children.get(parent, 0) + 1
leaves = [module for module in module_sizes if module_children.get(module, 0) == 0 and module != ""]
return leaves
def get_balanced_memory(
model: nn.Module,
max_memory: Optional[Dict[Union[int, str], Union[int, str]]] = None,
no_split_module_classes: Optional[List[str]] = None,
dtype: Optional[Union[str, torch.dtype]] = None,
special_dtypes: Optional[Dict[str, Union[str, torch.device]]] = None,
low_zero: bool = False,
):
"""
Compute a `max_memory` dictionary for [`infer_auto_device_map`] that will balance the use of each available GPU.
<Tip>
All computation is done analyzing sizes and dtypes of the model parameters. As a result, the model can be on the
meta device (as it would if initialized within the `init_empty_weights` context manager).
</Tip>
Args:
model (`torch.nn.Module`):
The model to analyze.
max_memory (`Dict`, *optional*):
A dictionary device identifier to maximum memory. Will default to the maximum memory available if unset.
Example: `max_memory={0: "1GB"}`.
no_split_module_classes (`List[str]`, *optional*):
A list of layer class names that should never be split across device (for instance any layer that has a
residual connection).
dtype (`str` or `torch.dtype`, *optional*):
If provided, the weights will be converted to that type when loaded.
special_dtypes (`Dict[str, Union[str, torch.device]]`, *optional*):
If provided, special dtypes to consider for some specific weights (will override dtype used as default for
all weights).
low_zero (`bool`, *optional*):
Minimizes the number of weights on GPU 0, which is convenient when it's used for other operations (like the
Transformers generate function).
"""
# Get default / clean up max_memory
user_not_set_max_memory = max_memory is None
max_memory = get_max_memory(max_memory)
if is_npu_available():
expected_device_type = "npu"
elif is_mlu_available():
expected_device_type = "mlu"
elif is_musa_available():
expected_device_type = "musa"
elif is_xpu_available():
expected_device_type = "xpu"
else:
expected_device_type = "cuda"
num_devices = len([d for d in max_memory if torch.device(d).type == expected_device_type and max_memory[d] > 0])
if num_devices == 0:
return max_memory
if num_devices == 1:
# We cannot do low_zero on just one GPU, but we will still reserve some memory for the buffer
low_zero = False
# If user just asked us to handle memory usage, we should avoid OOM
if user_not_set_max_memory:
for key in max_memory.keys():
if isinstance(key, int):
max_memory[key] *= 0.9 # 90% is a good compromise
logger.info(
f"We will use 90% of the memory on device {key} for storing the model, and 10% for the buffer to avoid OOM. "
"You can set `max_memory` in to a higher value to use more memory (at your own risk)."
)
break # only one device
module_sizes = compute_module_sizes(model, dtype=dtype, special_dtypes=special_dtypes)
per_gpu = module_sizes[""] // (num_devices - 1 if low_zero else num_devices)
# We can't just set the memory to model_size // num_devices as it will end being too small: each GPU will get
# slightly less layers and some layers will end up offload at the end. So this function computes a buffer size to
# add which is the biggest of:
# - the size of no split block (if applicable)
# - the mean of the layer sizes
if no_split_module_classes is None:
no_split_module_classes = []
elif not isinstance(no_split_module_classes, (list, tuple)):
no_split_module_classes = [no_split_module_classes]
# Identify the size of the no_split_block modules
if len(no_split_module_classes) > 0:
no_split_children = {}
for name, size in module_sizes.items():
if name == "":
continue
submodule = model
for submodule_name in name.split("."):
submodule = getattr(submodule, submodule_name)
class_name = submodule.__class__.__name__
if class_name in no_split_module_classes and class_name not in no_split_children:
no_split_children[class_name] = size
if set(no_split_children.keys()) == set(no_split_module_classes):
break
buffer = max(no_split_children.values()) if len(no_split_children) > 0 else 0
else:
buffer = 0
# Compute mean of final modules. In the first dict of module sizes, leaves are the parameters
leaves = get_module_leaves(module_sizes)
module_sizes = {n: v for n, v in module_sizes.items() if n not in leaves}
# Once removed, leaves are the final modules.
leaves = get_module_leaves(module_sizes)
mean_leaves = int(sum([module_sizes[n] for n in leaves]) / max(len(leaves), 1))
buffer = int(1.25 * max(buffer, mean_leaves))
per_gpu += buffer
# Sorted list of GPUs id (we may have some gpu ids not included in the our max_memory list - let's ignore them)
gpus_idx_list = list(
sorted(
device_id for device_id, device_mem in max_memory.items() if isinstance(device_id, int) and device_mem > 0
)
)
# The last device is left with max_memory just in case the buffer is not enough.
for idx in gpus_idx_list[:-1]:
max_memory[idx] = min(max_memory[0] if low_zero and idx == 0 else per_gpu, max_memory[idx])
if low_zero:
min_zero = max(0, module_sizes[""] - sum([max_memory[i] for i in range(1, num_devices)]))
max_memory[0] = min(min_zero, max_memory[0])
return max_memory
def calculate_maximum_sizes(model: torch.nn.Module):
"Computes the total size of the model and its largest layer"
sizes = compute_module_sizes(model)
# `transformers` models store this information for us
no_split_modules = getattr(model, "_no_split_modules", None)
if no_split_modules is None:
no_split_modules = []
modules_to_treat = (
list(model.named_parameters(recurse=False))
+ list(model.named_children())
+ list(model.named_buffers(recurse=False))
)
largest_layer = get_max_layer_size(modules_to_treat, sizes, no_split_modules)
total_size = sizes[""]
return total_size, largest_layer
def _init_infer_auto_device_map(
model: nn.Module,
max_memory: Optional[Dict[Union[int, str], Union[int, str]]] = None,
no_split_module_classes: Optional[List[str]] = None,
dtype: Optional[Union[str, torch.dtype]] = None,
special_dtypes: Optional[Dict[str, Union[str, torch.device]]] = None,
) -> Tuple[
List[Union[int, str]],
List[Union[int, str]],
List[int],
Dict[str, int],
List[List[str]],
List[str],
List[Tuple[str, nn.Module]],
]:
"""
Initialize variables required for computing the device map for model allocation.
"""
max_memory = get_max_memory(max_memory)
if no_split_module_classes is None:
no_split_module_classes = []
elif not isinstance(no_split_module_classes, (list, tuple)):
no_split_module_classes = [no_split_module_classes]
devices = list(max_memory.keys())
if "disk" not in devices:
devices.append("disk")
gpus = [device for device in devices if device not in ["cpu", "disk"]]
# Devices that need to keep space for a potential offloaded layer.
if "mps" in gpus:
main_devices = ["mps"]
elif len(gpus) > 0:
main_devices = [gpus[0], "cpu"]
else:
main_devices = ["cpu"]
module_sizes = compute_module_sizes(model, dtype=dtype, special_dtypes=special_dtypes)
tied_parameters = find_tied_parameters(model)
if check_tied_parameters_in_config(model) and len(tied_parameters) == 0:
logger.warn(
"The model weights are not tied. Please use the `tie_weights` method before using the `infer_auto_device` function."
)
# Direct submodules and parameters
modules_to_treat = (
list(model.named_parameters(recurse=False))
+ list(model.named_children())
+ list(model.named_buffers(recurse=False))
)
return (
devices,
main_devices,
gpus,
module_sizes,
tied_parameters,
no_split_module_classes,
modules_to_treat,
)
def get_module_size_with_ties(
tied_params,
module_size,
module_sizes,
modules_to_treat,
) -> Tuple[int, List[str], List[nn.Module]]:
"""
Calculate the total size of a module, including its tied parameters.
Args:
tied_params (`List[str]`): The list of tied parameters.
module_size (`int`): The size of the module without tied parameters.
module_sizes (`Dict[str, int]`): A dictionary mapping each layer name to its size.
modules_to_treat (`List[Tuple[str, nn.Module]]`): The list of named modules to treat.
Returns:
`Tuple[int, List[str], List[nn.Module]]`: The total size of the module, the names of the tied modules, and the
tied modules.
"""
if len(tied_params) < 1:
return module_size, [], []
tied_module_names = []
tied_modules = []
for tied_param in tied_params:
tied_module_index = [i for i, (n, _) in enumerate(modules_to_treat) if n in tied_param][0]
tied_module_names.append(modules_to_treat[tied_module_index][0])
tied_modules.append(modules_to_treat[tied_module_index][1])
module_size_with_ties = module_size
for tied_param, tied_module_name in zip(tied_params, tied_module_names):
module_size_with_ties += module_sizes[tied_module_name] - module_sizes[tied_param]
return module_size_with_ties, tied_module_names, tied_modules
def fallback_allocate(
modules: List[Tuple[str, nn.Module]],
module_sizes: Dict[str, int],
size_limit: Union[int, str],
no_split_module_classes: Optional[List[str]] = None,
tied_parameters: Optional[List[List[str]]] = None,
) -> Tuple[Optional[str], Optional[nn.Module], List[Tuple[str, nn.Module]]]:
"""
Find a module that fits in the size limit using BFS and return it with its name and the remaining modules.
Args:
modules (`List[Tuple[str, nn.Module]]`):
The list of named modules to search in.
module_sizes (`Dict[str, int]`):
A dictionary mapping each layer name to its size (as generated by `compute_module_sizes`).
size_limit (`Union[int, str]`):
The maximum size a module can have.
no_split_module_classes (`Optional[List[str]]`, *optional*):
A list of class names for layers we don't want to be split.
tied_parameters (`Optional[List[List[str]]`, *optional*):
A list of lists of parameter names being all tied together.
Returns:
`Tuple[Optional[str], Optional[nn.Module], List[Tuple[str, nn.Module]]]`: A tuple containing:
- The name of the module that fits within the size limit.
- The module itself.
- The list of remaining modules after the found module is removed.
"""
try:
size_limit = convert_file_size_to_int(size_limit)
except ValueError:
return None, None, modules
if no_split_module_classes is None:
no_split_module_classes = []
if tied_parameters is None:
tied_parameters = []
modules_to_search = modules.copy()
module_found = False
while modules_to_search:
name, module = modules_to_search.pop(0)
tied_param_groups = [
tied_group
for tied_group in tied_parameters
if any(name + "." in k + "." for k in tied_group) and not all(name + "." in k + "." for k in tied_group)
]
tied_params = sum(
[[p for p in tied_group if name + "." not in p + "."] for tied_group in tied_param_groups], []
)
module_size_with_ties, _, _ = get_module_size_with_ties(
tied_params, module_sizes[name], module_sizes, modules_to_search
)
# If the module fits in the size limit, we found it.
if module_size_with_ties <= size_limit:
module_found = True
break
# The module is too big, we need to split it if possible.
modules_children = (
[]
if isinstance(module, nn.Parameter) or isinstance(module, torch.Tensor)
else list(module.named_children())
)
# Split fails, move to the next module
if len(modules_children) == 0 or module.__class__.__name__ in no_split_module_classes:
continue
# split is possible, add the children to the list of modules to search
modules_children = list(module.named_parameters(recurse=False)) + modules_children
modules_to_search = [(f"{name}.{n}", v) for n, v in modules_children] + modules_to_search
if not module_found:
return None, None, modules
# Prepare the module list for removal of the found module
current_names = [n for n, _ in modules]
dot_idx = [i for i, c in enumerate(name) if c == "."]
for dot_index in dot_idx:
parent_name = name[:dot_index]
if parent_name in current_names:
parent_module_idx = current_names.index(parent_name)
_, parent_module = modules[parent_module_idx]
module_children = list(parent_module.named_parameters(recurse=False)) + list(
parent_module.named_children()
)
modules = (
modules[:parent_module_idx]
+ [(f"{parent_name}.{n}", v) for n, v in module_children]
+ modules[parent_module_idx + 1 :]
)
current_names = [n for n, _ in modules]
# Now the target module should be directly in the list
target_idx = current_names.index(name)
name, module = modules.pop(target_idx)
return name, module, modules
def infer_auto_device_map(
model: nn.Module,
max_memory: Optional[Dict[Union[int, str], Union[int, str]]] = None,
no_split_module_classes: Optional[List[str]] = None,
dtype: Optional[Union[str, torch.dtype]] = None,
special_dtypes: Optional[Dict[str, Union[str, torch.dtype]]] = None,
verbose: bool = False,
clean_result: bool = True,
offload_buffers: bool = False,
fallback_allocation: bool = False,
):
"""
Compute a device map for a given model giving priority to GPUs, then offload on CPU and finally offload to disk,
such that:
- we don't exceed the memory available of any of the GPU.
- if offload to the CPU is needed, there is always room left on GPU 0 to put back the layer offloaded on CPU that
has the largest size.
- if offload to the CPU is needed,we don't exceed the RAM available on the CPU.
- if offload to the disk is needed, there is always room left on the CPU to put back the layer offloaded on disk
that has the largest size.
<Tip>
All computation is done analyzing sizes and dtypes of the model parameters. As a result, the model can be on the
meta device (as it would if initialized within the `init_empty_weights` context manager).
</Tip>
Args:
model (`torch.nn.Module`):
The model to analyze.
max_memory (`Dict`, *optional*):
A dictionary device identifier to maximum memory. Will default to the maximum memory available if unset.
Example: `max_memory={0: "1GB"}`.
no_split_module_classes (`List[str]`, *optional*):
A list of layer class names that should never be split across device (for instance any layer that has a
residual connection).
dtype (`str` or `torch.dtype`, *optional*):
If provided, the weights will be converted to that type when loaded.
special_dtypes (`Dict[str, Union[str, torch.device]]`, *optional*):
If provided, special dtypes to consider for some specific weights (will override dtype used as default for
all weights).
verbose (`bool`, *optional*, defaults to `False`):
Whether or not to provide debugging statements as the function builds the device_map.
clean_result (`bool`, *optional*, defaults to `True`):
Clean the resulting device_map by grouping all submodules that go on the same device together.
offload_buffers (`bool`, *optional*, defaults to `False`):
In the layers that are offloaded on the CPU or the hard drive, whether or not to offload the buffers as
well as the parameters.
fallback_allocation (`bool`, *optional*, defaults to `False`):
When regular allocation fails, try to allocate a module that fits in the size limit using BFS.
"""
# Initialize the variables
(
devices,
main_devices,
gpus,
module_sizes,
tied_parameters,
no_split_module_classes,
modules_to_treat,
) = _init_infer_auto_device_map(model, max_memory, no_split_module_classes, dtype, special_dtypes)
device_map = OrderedDict()
current_device = 0
device_memory_used = {device: 0 for device in devices}
device_buffer_sizes = {}
device_minimum_assignment_memory = {}
# Initialize maximum largest layer, to know which space to keep in memory
max_layer_size, max_layer_names = get_max_layer_size(modules_to_treat, module_sizes, no_split_module_classes)
# Ready ? This is going to be a bit messy.
while len(modules_to_treat) > 0:
name, module = modules_to_treat.pop(0)
if verbose:
print(f"\nTreating module {name}.")
# Max size in the remaining layers may have changed since we took one, so we maybe update it.
max_layer_names = [n for n in max_layer_names if n != name and not n.startswith(name + ".")]
if len(max_layer_names) == 0:
max_layer_size, max_layer_names = get_max_layer_size(
[(n, m) for n, m in modules_to_treat if isinstance(m, torch.nn.Module)],
module_sizes,
no_split_module_classes,
)
# Assess size needed
module_size = module_sizes[name]
# We keep relevant tied parameters only: one of the tied parameters in the group is inside the current module
# and the other is not.
# Note: If we are currently processing the name `compute.weight`, an other parameter named
# e.g. `compute.weight_submodule.parameter`
# needs to be considered outside the current module, hence the check with additional dots.
tied_param_groups = [
tied_group
for tied_group in tied_parameters
if any(name + "." in k + "." for k in tied_group) and not all(name + "." in k + "." for k in tied_group)
]
if verbose and len(tied_param_groups) > 0:
print(f" Found the relevant tied param groups {tied_param_groups}")
# Then we keep track of all the parameters that are tied to the current module, but not in the current module
tied_params = sum(
[[p for p in tied_group if name + "." not in p + "."] for tied_group in tied_param_groups], []
)
if verbose and len(tied_params) > 0:
print(f" So those parameters need to be taken into account {tied_params}")
device = devices[current_device]
current_max_size = max_memory[device] if device != "disk" else None
current_memory_reserved = 0
# Reduce max size available by the largest layer.
if devices[current_device] in main_devices:
current_max_size = current_max_size - max_layer_size
current_memory_reserved = max_layer_size
module_size_with_ties, tied_module_names, tied_modules = get_module_size_with_ties(
tied_params, module_size, module_sizes, modules_to_treat
)
# The module and its tied modules fit on the current device.
if current_max_size is None or device_memory_used[device] + module_size_with_ties <= current_max_size:
if verbose:
output = f"Putting {name}"
if tied_module_names:
output += f" and {tied_module_names}"
else:
output += f" (size={module_size})"
if current_max_size is not None:
output += f" (available={current_max_size - device_memory_used[device]})"
output += f" on {device}."
print(output)
device_memory_used[device] += module_size_with_ties
# Assign the primary module to the device.
device_map[name] = device
# Assign tied modules if any.
for tied_module_name in tied_module_names:
if tied_module_name in [m[0] for m in modules_to_treat]:
# Find the index of the tied module in the list
tied_module_index = next(i for i, (n, _) in enumerate(modules_to_treat) if n == tied_module_name)
# Remove the tied module from the list to prevent reprocessing
modules_to_treat.pop(tied_module_index)
# Assign the tied module to the device
device_map[tied_module_name] = device
# Buffer Handling
if not offload_buffers and isinstance(module, nn.Module):
# Compute the total buffer size for the module
current_buffer_size = compute_module_total_buffer_size(
module, dtype=dtype, special_dtypes=special_dtypes
)
# Update the buffer size on the device
device_buffer_sizes[device] = device_buffer_sizes.get(device, 0) + current_buffer_size
continue
# The current module itself fits, so we try to split the tied modules.
if len(tied_params) > 0 and device_memory_used[device] + module_size <= current_max_size:
# can we split one of the tied modules to make it smaller or do we need to go on the next device?
if verbose:
print(
f"Not enough space on {devices[current_device]} to put {name} and {tied_module_names} (space "
f"available {current_max_size - device_memory_used[device]}, needed size {module_size_with_ties})."
)
split_happened = False
for tied_module_name, tied_module in zip(tied_module_names, tied_modules):
tied_module_children = list(tied_module.named_children())
if len(tied_module_children) == 0 or tied_module.__class__.__name__ in no_split_module_classes:
# can't break this one.
continue
if verbose:
print(f"Splitting {tied_module_name}.")
tied_module_children = list(tied_module.named_parameters(recurse=False)) + tied_module_children
tied_module_children = [(f"{tied_module_name}.{n}", v) for n, v in tied_module_children]
tied_module_index = [i for i, (n, _) in enumerate(modules_to_treat) if n == tied_module_name][0]
modules_to_treat = (
[(name, module)]
+ modules_to_treat[:tied_module_index]
+ tied_module_children
+ modules_to_treat[tied_module_index + 1 :]
)
# Update the max layer size.
max_layer_size, max_layer_names = get_max_layer_size(
[(n, m) for n, m in modules_to_treat if isinstance(m, torch.nn.Module)],
module_sizes,
no_split_module_classes,
)
split_happened = True
break
if split_happened:
continue
# If the tied module is not split, we go to the next device
if verbose:
print("None of the tied module can be split, going to the next device.")
# The current module itself doesn't fit, so we have to split it or go to the next device.
if device_memory_used[device] + module_size >= current_max_size:
# Split or not split?
modules_children = (
[]
if isinstance(module, nn.Parameter) or isinstance(module, torch.Tensor)
else list(module.named_children())
)
if verbose:
print(
f"Not enough space on {devices[current_device]} to put {name} (space available "
f"{current_max_size - device_memory_used[device]}, module size {module_size})."
)
if len(modules_children) == 0 or module.__class__.__name__ in no_split_module_classes:
# -> no split, we go to the next device
if verbose:
print("This module cannot be split, going to the next device.")
else:
# -> split, we replace the module studied by its children + parameters
if verbose:
print(f"Splitting {name}.")
modules_children = list(module.named_parameters(recurse=False)) + modules_children
modules_to_treat = [(f"{name}.{n}", v) for n, v in modules_children] + modules_to_treat
# Update the max layer size.
max_layer_size, max_layer_names = get_max_layer_size(
[(n, m) for n, m in modules_to_treat if isinstance(m, torch.nn.Module)],
module_sizes,
no_split_module_classes,
)
continue
# If no module is assigned to the current device, we attempt to allocate a fallback module
# if fallback_allocation is enabled.
if device_memory_used[device] == 0 and fallback_allocation and device != "disk":
# We try to allocate a module that fits in the size limit using BFS.
# Recompute the current max size as we need to consider the current module as well.
current_max_size = max_memory[device] - max(max_layer_size, module_size_with_ties)
fallback_module_name, fallback_module, remaining_modules = fallback_allocate(
modules_to_treat,
module_sizes,
current_max_size - device_memory_used[device],
no_split_module_classes,
tied_parameters,
)
# use the next iteration to put the fallback module on the next device to avoid code duplication
if fallback_module is not None:
modules_to_treat = [(fallback_module_name, fallback_module)] + [(name, module)] + remaining_modules
continue
if device_memory_used[device] == 0:
device_minimum_assignment_memory[device] = module_size_with_ties + current_memory_reserved
# Neither the current module nor any tied modules can be split, so we move to the next device.
device_memory_used[device] = device_memory_used[device] + current_memory_reserved
current_device += 1
modules_to_treat = [(name, module)] + modules_to_treat
device_memory_used = {device: mem for device, mem in device_memory_used.items() if mem > 0}
if clean_result:
device_map = clean_device_map(device_map)
non_gpu_buffer_size = device_buffer_sizes.get("cpu", 0) + device_buffer_sizes.get("disk", 0)
if non_gpu_buffer_size > 0 and not offload_buffers:
is_buffer_fit_any_gpu = False
for gpu_device, gpu_max_memory in max_memory.items():
if gpu_device == "cpu" or gpu_device == "disk":
continue
if not is_buffer_fit_any_gpu:
gpu_memory_used = device_memory_used.get(gpu_device, 0)
if gpu_max_memory >= non_gpu_buffer_size + gpu_memory_used:
is_buffer_fit_any_gpu = True
if len(gpus) > 0 and not is_buffer_fit_any_gpu:
warnings.warn(
f"Current model requires {non_gpu_buffer_size} bytes of buffer for offloaded layers, which seems does "
f"not fit any GPU's remaining memory. If you are experiencing a OOM later, please consider using "
f"offload_buffers=True."
)
if device_minimum_assignment_memory:
devices_info = "\n".join(
f" - {device}: {mem} bytes required" for device, mem in device_minimum_assignment_memory.items()
)
logger.info(
f"Based on the current allocation process, no modules could be assigned to the following devices due to "
f"insufficient memory:\n"
f"{devices_info}\n"
f"These minimum requirements are specific to this allocation attempt and may vary. Consider increasing "
f"the available memory for these devices to at least the specified minimum, or adjusting the model config."
)
return device_map
def check_device_map(model: nn.Module, device_map: Dict[str, Union[int, str, torch.device]]):
"""
Checks a device map covers everything in a given model.
Args:
model (`torch.nn.Module`): The model to check the device map against.
device_map (`Dict[str, Union[int, str, torch.device]]`): The device map to check.
"""
all_model_tensors = [name for name, _ in model.state_dict().items()]
for module_name in device_map.keys():
if module_name == "":
all_model_tensors.clear()
break
else:
all_model_tensors = [
name
for name in all_model_tensors
if not name == module_name and not name.startswith(module_name + ".")
]
if len(all_model_tensors) > 0:
non_covered_params = ", ".join(all_model_tensors)
raise ValueError(
f"The device_map provided does not give any device for the following parameters: {non_covered_params}"
)
def load_state_dict(checkpoint_file, device_map=None):
"""
Load a checkpoint from a given file. If the checkpoint is in the safetensors format and a device map is passed, the
weights can be fast-loaded directly on the GPU.
Args:
checkpoint_file (`str`): The path to the checkpoint to load.
device_map (`Dict[str, Union[int, str, torch.device]]`, *optional*):
A map that specifies where each submodule should go. It doesn't need to be refined to each parameter/buffer
name, once a given module name is inside, every submodule of it will be sent to the same device.
"""
if checkpoint_file.endswith(".safetensors"):
with safe_open(checkpoint_file, framework="pt") as f:
metadata = f.metadata()
weight_names = f.keys()
if metadata is None:
logger.warn(
f"The safetensors archive passed at {checkpoint_file} does not contain metadata. "
"Make sure to save your model with the `save_pretrained` method. Defaulting to 'pt' metadata."
)
metadata = {"format": "pt"}
if metadata.get("format") not in ["pt", "tf", "flax"]:
raise OSError(
f"The safetensors archive passed at {checkpoint_file} does not contain the valid metadata. Make sure "
"you save your model with the `save_pretrained` method."
)
elif metadata["format"] != "pt":
raise ValueError(f"The checkpoint passed was saved with {metadata['format']}, we need a the pt format.")
if device_map is None:
return safe_load_file(checkpoint_file)
else:
# if we only have one device we can load everything directly
if len(set(device_map.values())) == 1:
device = list(device_map.values())[0]
target_device = device
if is_xpu_available():
if isinstance(device, int):
target_device = f"xpu:{device}"
return safe_load_file(checkpoint_file, device=target_device)
devices = list(set(device_map.values()) - {"disk"})
# cpu device should always exist as fallback option
if "cpu" not in devices:
devices.append("cpu")
# For each device, get the weights that go there
device_weights = {device: [] for device in devices}
for module_name, device in device_map.items():
if device in devices:
device_weights[device].extend(
[k for k in weight_names if k == module_name or k.startswith(module_name + ".")]
)
# all weights that haven't defined a device should be loaded on CPU
device_weights["cpu"].extend([k for k in weight_names if k not in sum(device_weights.values(), [])])
tensors = {}
if is_tqdm_available():
progress_bar = tqdm(
main_process_only=False,
total=sum([len(device_weights[device]) for device in devices]),
unit="w",
smoothing=0,
leave=False,
)
else:
progress_bar = None
for device in devices:
target_device = device
if is_xpu_available():
if isinstance(device, int):
target_device = f"xpu:{device}"
with safe_open(checkpoint_file, framework="pt", device=target_device) as f:
for key in device_weights[device]:
if progress_bar is not None:
progress_bar.set_postfix(dev=device, refresh=False)
progress_bar.set_description(key)
tensors[key] = f.get_tensor(key)
if progress_bar is not None:
progress_bar.update()
if progress_bar is not None:
progress_bar.close()
return tensors
else:
return torch.load(checkpoint_file, map_location=torch.device("cpu"))
def get_state_dict_offloaded_model(model: nn.Module):
"""
Returns the state dictionary for an offloaded model via iterative onloading
Args:
model (`torch.nn.Module`):
The offloaded model we want to save
"""
state_dict = {}
placeholders = set()
for name, module in model.named_modules():
if name == "":
continue
try:
with align_module_device(module, "cpu"):
module_state_dict = module.state_dict()
except MemoryError:
raise MemoryError("Offloaded module must fit in CPU memory to call save_model!") from None
for key in module_state_dict:
# ignore placeholder parameters that are still on the meta device
if module_state_dict[key].device == torch.device("meta"):
placeholders.add(name + f".{key}")
continue
params = module_state_dict[key]
state_dict[name + f".{key}"] = params.to("cpu") # move buffers to cpu
for key in placeholders.copy():
if key in state_dict:
placeholders.remove(key)
if placeholders:
logger.warning(f"The following tensors were not saved because they were still on meta device: {placeholders}")
return state_dict
def get_state_dict_from_offload(
module: nn.Module,
module_name: str,
state_dict: Dict[str, Union[str, torch.tensor]],
device_to_put_offload: Union[int, str, torch.device] = "cpu",
):
"""
Retrieve the state dictionary (with parameters) from an offloaded module and load into a specified device (defaults
to cpu).
Args:
module: (`torch.nn.Module`):
The module we want to retrieve a state dictionary from
module_name: (`str`):
The name of the module of interest
state_dict (`Dict[str, Union[int, str, torch.device]]`):
Dictionary of {module names: parameters}
device_to_put_offload (`Union[int, str, torch.device]`):
Device to load offloaded parameters into, defaults to the cpu.
"""
root = module_name[: module_name.rfind(".")] # module name without .weight or .bias
# assign the device to which the offloaded parameters will be sent
with align_module_device(module, device_to_put_offload):
for m_key, params in module.state_dict().items():
if (root + f".{m_key}") in state_dict:
state_dict[root + f".{m_key}"] = params
return state_dict
def load_checkpoint_in_model(
model: nn.Module,
checkpoint: Union[str, os.PathLike],
device_map: Optional[Dict[str, Union[int, str, torch.device]]] = None,
offload_folder: Optional[Union[str, os.PathLike]] = None,
dtype: Optional[Union[str, torch.dtype]] = None,
offload_state_dict: bool = False,
offload_buffers: bool = False,
keep_in_fp32_modules: List[str] = None,
offload_8bit_bnb: bool = False,
strict: bool = False,
):
"""
Loads a (potentially sharded) checkpoint inside a model, potentially sending weights to a given device as they are
loaded.
<Tip warning={true}>
Once loaded across devices, you still need to call [`dispatch_model`] on your model to make it able to run. To
group the checkpoint loading and dispatch in one single call, use [`load_checkpoint_and_dispatch`].
</Tip>
Args:
model (`torch.nn.Module`):
The model in which we want to load a checkpoint.
checkpoint (`str` or `os.PathLike`):
The folder checkpoint to load. It can be:
- a path to a file containing a whole model state dict
- a path to a `.json` file containing the index to a sharded checkpoint
- a path to a folder containing a unique `.index.json` file and the shards of a checkpoint.
- a path to a folder containing a unique pytorch_model.bin or a model.safetensors file.
device_map (`Dict[str, Union[int, str, torch.device]]`, *optional*):
A map that specifies where each submodule should go. It doesn't need to be refined to each parameter/buffer
name, once a given module name is inside, every submodule of it will be sent to the same device.
offload_folder (`str` or `os.PathLike`, *optional*):
If the `device_map` contains any value `"disk"`, the folder where we will offload weights.
dtype (`str` or `torch.dtype`, *optional*):
If provided, the weights will be converted to that type when loaded.
offload_state_dict (`bool`, *optional*, defaults to `False`):
If `True`, will temporarily offload the CPU state dict on the hard drive to avoid getting out of CPU RAM if
the weight of the CPU state dict + the biggest shard does not fit.
offload_buffers (`bool`, *optional*, defaults to `False`):
Whether or not to include the buffers in the weights offloaded to disk.
keep_in_fp32_modules(`List[str]`, *optional*):
A list of the modules that we keep in `torch.float32` dtype.
offload_8bit_bnb (`bool`, *optional*):
Whether or not to enable offload of 8-bit modules on cpu/disk.
strict (`bool`, *optional*, defaults to `False`):
Whether to strictly enforce that the keys in the checkpoint state_dict match the keys of the model's
state_dict.
"""
if offload_8bit_bnb:
from .bnb import quantize_and_offload_8bit
tied_params = find_tied_parameters(model)
if check_tied_parameters_in_config(model) and len(tied_params) == 0:
logger.warn(
"The model weights are not tied. Please use the `tie_weights` method before using the `infer_auto_device` function."
)
if device_map is not None:
check_tied_parameters_on_same_device(tied_params, device_map)
if offload_folder is None and device_map is not None and "disk" in device_map.values():
raise ValueError(
"At least one of the model submodule will be offloaded to disk, please pass along an `offload_folder`."
)
elif offload_folder is not None and device_map is not None and "disk" in device_map.values():
os.makedirs(offload_folder, exist_ok=True)
if isinstance(dtype, str):
# We accept "torch.float16" or just "float16"
dtype = dtype.replace("torch.", "")
dtype = getattr(torch, dtype)
checkpoint_files = None
index_filename = None
if os.path.isfile(checkpoint):
if str(checkpoint).endswith(".json"):
index_filename = checkpoint
else:
checkpoint_files = [checkpoint]
elif os.path.isdir(checkpoint):
# check if the whole state dict is present
potential_state_bin = [f for f in os.listdir(checkpoint) if f == WEIGHTS_NAME]
potential_state_safetensor = [f for f in os.listdir(checkpoint) if f == SAFE_WEIGHTS_NAME]
if len(potential_state_bin) == 1:
checkpoint_files = [os.path.join(checkpoint, potential_state_bin[0])]
elif len(potential_state_safetensor) == 1:
checkpoint_files = [os.path.join(checkpoint, potential_state_safetensor[0])]
else:
# otherwise check for sharded checkpoints
potential_index = [f for f in os.listdir(checkpoint) if f.endswith(".index.json")]
if len(potential_index) == 0:
raise ValueError(
f"{checkpoint} is not a folder containing a `.index.json` file or a {WEIGHTS_NAME} or a {SAFE_WEIGHTS_NAME} file"
)
elif len(potential_index) == 1:
index_filename = os.path.join(checkpoint, potential_index[0])
else:
raise ValueError(
f"{checkpoint} containing more than one `.index.json` file, delete the irrelevant ones."
)
else:
raise ValueError(
"`checkpoint` should be the path to a file containing a whole state dict, or the index of a sharded "
f"checkpoint, or a folder containing a sharded checkpoint or the whole state dict, but got {checkpoint}."
)
if index_filename is not None:
checkpoint_folder = os.path.split(index_filename)[0]
with open(index_filename) as f:
index = json.loads(f.read())
if "weight_map" in index:
index = index["weight_map"]
checkpoint_files = sorted(list(set(index.values())))
checkpoint_files = [os.path.join(checkpoint_folder, f) for f in checkpoint_files]
# Logic for missing/unexepected keys goes here.
offload_index = {}
if offload_state_dict:
state_dict_folder = tempfile.mkdtemp()
state_dict_index = {}
unexpected_keys = set()
model_keys = set(model.state_dict().keys())
buffer_names = [name for name, _ in model.named_buffers()]
for checkpoint_file in checkpoint_files:
loaded_checkpoint = load_state_dict(checkpoint_file, device_map=device_map)
if device_map is None:
model.load_state_dict(loaded_checkpoint, strict=strict)
unexpected_keys.update(set(loaded_checkpoint.keys()) - model_keys)
else:
for param_name, param in loaded_checkpoint.items():
# skip SCB parameter (for 8-bit serialization)
if "SCB" in param_name:
continue
if param_name not in model_keys:
unexpected_keys.add(param_name)
if not strict:
continue # Skip loading this parameter.
module_name = param_name
while len(module_name) > 0 and module_name not in device_map:
module_name = ".".join(module_name.split(".")[:-1])
if module_name == "" and "" not in device_map:
# TODO: group all errors and raise at the end.
raise ValueError(f"{param_name} doesn't have any device set.")
param_device = device_map[module_name]
new_dtype = dtype
if dtype is not None and torch.is_floating_point(param):
if keep_in_fp32_modules is not None and dtype == torch.float16:
proceed = False
for key in keep_in_fp32_modules:
if ((key in param_name) and (key + "." in param_name)) or key == param_name:
proceed = True
break
if proceed:
new_dtype = torch.float32
if "weight" in param_name and param_name.replace("weight", "SCB") in loaded_checkpoint.keys():
if param.dtype == torch.int8:
fp16_statistics = loaded_checkpoint[param_name.replace("weight", "SCB")]
else:
fp16_statistics = None
if param_device == "disk":
if offload_buffers or param_name not in buffer_names:
if new_dtype is None:
new_dtype = param.dtype
if offload_8bit_bnb:
quantize_and_offload_8bit(
model, param, param_name, new_dtype, offload_folder, offload_index, fp16_statistics
)
continue
else:
set_module_tensor_to_device(model, param_name, "meta", dtype=new_dtype)
offload_weight(param, param_name, offload_folder, index=offload_index)
elif param_device == "cpu" and offload_state_dict:
if new_dtype is None:
new_dtype = param.dtype
if offload_8bit_bnb:
quantize_and_offload_8bit(
model, param, param_name, new_dtype, state_dict_folder, state_dict_index, fp16_statistics
)
else:
set_module_tensor_to_device(model, param_name, "meta", dtype=new_dtype)
offload_weight(param, param_name, state_dict_folder, index=state_dict_index)
else:
set_module_tensor_to_device(
model,
param_name,
param_device,
value=param,
dtype=new_dtype,
fp16_statistics=fp16_statistics,
)
# Force Python to clean up.
del loaded_checkpoint
gc.collect()
if not strict and len(unexpected_keys) > 0:
logger.warning(
f"Some weights of the model checkpoint at {checkpoint} were not used when"
f" initializing {model.__class__.__name__}: {unexpected_keys}. This may or may not be an issue - make sure that the checkpoint does not have unnecessary parameters, or that the model definition correctly corresponds to the checkpoint."
)
save_offload_index(offload_index, offload_folder)
# Load back offloaded state dict on CPU
if offload_state_dict:
load_offloaded_weights(model, state_dict_index, state_dict_folder)
shutil.rmtree(state_dict_folder)
retie_parameters(model, tied_params)
def get_mixed_precision_context_manager(native_amp: bool = False, autocast_kwargs: AutocastKwargs = None):
"""
Return a context manager for autocasting mixed precision
Args:
native_amp (`bool`, *optional*, defaults to False):
Whether mixed precision is actually enabled.
cache_enabled (`bool`, *optional*, defaults to True):
Whether the weight cache inside autocast should be enabled.
"""
state = AcceleratorState()
if autocast_kwargs is None:
autocast_kwargs = {}
else:
autocast_kwargs = autocast_kwargs.to_kwargs()
if native_amp:
device_type = (
"cuda"
if (state.distributed_type == DistributedType.XLA and is_torch_xla_available(check_is_gpu=True))
else state.device.type
)
if state.mixed_precision == "fp16":
return torch.autocast(device_type=device_type, dtype=torch.float16, **autocast_kwargs)
elif state.mixed_precision in ["bf16", "fp8"] and state.distributed_type in [
DistributedType.NO,
DistributedType.MULTI_CPU,
DistributedType.MULTI_GPU,
DistributedType.MULTI_MLU,
DistributedType.MULTI_MUSA,
DistributedType.MULTI_NPU,
DistributedType.MULTI_XPU,
DistributedType.FSDP,
DistributedType.XLA,
]:
return torch.autocast(device_type=device_type, dtype=torch.bfloat16, **autocast_kwargs)
else:
return torch.autocast(device_type=device_type, **autocast_kwargs)
else:
return contextlib.nullcontext()
def get_grad_scaler(distributed_type: DistributedType = None, **kwargs):
"""
A generic helper which will initialize the correct `GradScaler` implementation based on the environment and return
it.
Args:
distributed_type (`DistributedType`, *optional*, defaults to None):
The type of distributed environment.
kwargs:
Additional arguments for the utilized `GradScaler` constructor.
"""
if distributed_type == DistributedType.FSDP:
from torch.distributed.fsdp.sharded_grad_scaler import ShardedGradScaler
return ShardedGradScaler(**kwargs)
if is_torch_xla_available(check_is_gpu=True):
import torch_xla.amp as xamp
return xamp.GradScaler(**kwargs)
elif is_mlu_available():
return torch.mlu.amp.GradScaler(**kwargs)
elif is_musa_available():
return torch.musa.amp.GradScaler(**kwargs)
elif is_npu_available():
return torch.npu.amp.GradScaler(**kwargs)
elif is_xpu_available():
return torch.amp.GradScaler("xpu", **kwargs)
else:
if is_torch_version(">=", "2.3"):
return torch.amp.GradScaler("cuda", **kwargs)
else:
return torch.cuda.amp.GradScaler(**kwargs)
def has_offloaded_params(module: torch.nn.Module) -> bool:
"""
Checks if a module has offloaded parameters by checking if the given module has a AlignDevicesHook attached with
offloading enabled
Args:
module (`torch.nn.Module`): The module to check for an offload hook.
Returns:
bool: `True` if the module has an offload hook and offloading is enabled, `False` otherwise.
"""
from ..hooks import AlignDevicesHook # avoid circular import
return hasattr(module, "_hf_hook") and isinstance(module._hf_hook, AlignDevicesHook) and module._hf_hook.offload
@contextlib.contextmanager
def align_module_device(module: torch.nn.Module, execution_device: Optional[torch.device] = None):
"""
Context manager that moves a module's parameters to the specified execution device.
Args:
module (`torch.nn.Module`):
Module with parameters to align.
execution_device (`torch.device`, *optional*):
If provided, overrides the module's execution device within the context. Otherwise, use hook execution
device or pass
"""
if has_offloaded_params(module):
if execution_device is not None:
original_device = module._hf_hook.execution_device
module._hf_hook.execution_device = execution_device
try:
module._hf_hook.pre_forward(module)
yield
finally:
module._hf_hook.post_forward(module, None)
if execution_device is not None:
module._hf_hook.execution_device = original_device
elif execution_device is not None:
devices = {name: param.device for name, param in module.named_parameters(recurse=False)}
try:
for name in devices:
set_module_tensor_to_device(module, name, execution_device)
yield
finally:
for name, device in devices.items():
set_module_tensor_to_device(module, name, device)
else:
yield
| 6 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/random.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import random
from typing import List, Optional, Union
import numpy as np
import torch
from ..state import AcceleratorState
from .constants import CUDA_DISTRIBUTED_TYPES
from .dataclasses import DistributedType, RNGType
from .imports import is_mlu_available, is_musa_available, is_npu_available, is_torch_xla_available, is_xpu_available
if is_torch_xla_available():
import torch_xla.core.xla_model as xm
def set_seed(seed: int, device_specific: bool = False, deterministic: bool = False):
"""
Helper function for reproducible behavior to set the seed in `random`, `numpy`, `torch`.
Args:
seed (`int`):
The seed to set.
device_specific (`bool`, *optional*, defaults to `False`):
Whether to differ the seed on each device slightly with `self.process_index`.
deterministic (`bool`, *optional*, defaults to `False`):
Whether to use deterministic algorithms where available. Can slow down training.
"""
if device_specific:
seed += AcceleratorState().process_index
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
if is_xpu_available():
torch.xpu.manual_seed_all(seed)
elif is_npu_available():
torch.npu.manual_seed_all(seed)
elif is_mlu_available():
torch.mlu.manual_seed_all(seed)
elif is_musa_available():
torch.musa.manual_seed_all(seed)
else:
torch.cuda.manual_seed_all(seed)
# ^^ safe to call this function even if cuda is not available
if is_torch_xla_available():
xm.set_rng_state(seed)
if deterministic:
torch.use_deterministic_algorithms(True)
def synchronize_rng_state(rng_type: Optional[RNGType] = None, generator: Optional[torch.Generator] = None):
# Get the proper rng state
if rng_type == RNGType.TORCH:
rng_state = torch.get_rng_state()
elif rng_type == RNGType.CUDA:
rng_state = torch.cuda.get_rng_state()
elif rng_type == RNGType.XLA:
assert is_torch_xla_available(), "Can't synchronize XLA seeds as torch_xla is unavailable."
rng_state = torch.tensor(xm.get_rng_state())
elif rng_type == RNGType.NPU:
assert is_npu_available(), "Can't synchronize NPU seeds on an environment without NPUs."
rng_state = torch.npu.get_rng_state()
elif rng_type == RNGType.MLU:
assert is_mlu_available(), "Can't synchronize MLU seeds on an environment without MLUs."
rng_state = torch.mlu.get_rng_state()
elif rng_type == RNGType.MUSA:
assert is_musa_available(), "Can't synchronize MUSA seeds on an environment without MUSAs."
rng_state = torch.musa.get_rng_state()
elif rng_type == RNGType.XPU:
assert is_xpu_available(), "Can't synchronize XPU seeds on an environment without XPUs."
rng_state = torch.xpu.get_rng_state()
elif rng_type == RNGType.GENERATOR:
assert generator is not None, "Need a generator to synchronize its seed."
rng_state = generator.get_state()
# Broadcast the rng state from device 0 to other devices
state = AcceleratorState()
if state.distributed_type == DistributedType.XLA:
rng_state = rng_state.to(xm.xla_device())
xm.collective_broadcast([rng_state])
xm.mark_step()
rng_state = rng_state.cpu()
elif (
state.distributed_type in CUDA_DISTRIBUTED_TYPES
or state.distributed_type == DistributedType.MULTI_MLU
or state.distributed_type == DistributedType.MULTI_MUSA
or state.distributed_type == DistributedType.MULTI_NPU
or state.distributed_type == DistributedType.MULTI_XPU
):
rng_state = rng_state.to(state.device)
torch.distributed.broadcast(rng_state, 0)
rng_state = rng_state.cpu()
elif state.distributed_type == DistributedType.MULTI_CPU:
torch.distributed.broadcast(rng_state, 0)
# Set the broadcast rng state
if rng_type == RNGType.TORCH:
torch.set_rng_state(rng_state)
elif rng_type == RNGType.CUDA:
torch.cuda.set_rng_state(rng_state)
elif rng_type == RNGType.NPU:
torch.npu.set_rng_state(rng_state)
elif rng_type == RNGType.MLU:
torch.mlu.set_rng_state(rng_state)
elif rng_type == RNGType.MUSA:
torch.musa.set_rng_state(rng_state)
elif rng_type == RNGType.XPU:
torch.xpu.set_rng_state(rng_state)
elif rng_type == RNGType.XLA:
xm.set_rng_state(rng_state.item())
elif rng_type == RNGType.GENERATOR:
generator.set_state(rng_state)
def synchronize_rng_states(rng_types: List[Union[str, RNGType]], generator: Optional[torch.Generator] = None):
for rng_type in rng_types:
synchronize_rng_state(RNGType(rng_type), generator=generator)
| 7 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/tqdm.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
from .imports import is_tqdm_available
if is_tqdm_available():
from tqdm.auto import tqdm as _tqdm
from ..state import PartialState
def tqdm(*args, main_process_only: bool = True, **kwargs):
"""
Wrapper around `tqdm.tqdm` that optionally displays only on the main process.
Args:
main_process_only (`bool`, *optional*):
Whether to display the progress bar only on the main process
"""
if not is_tqdm_available():
raise ImportError("Accelerate's `tqdm` module requires `tqdm` to be installed. Please run `pip install tqdm`.")
if len(args) > 0 and isinstance(args[0], bool):
raise ValueError(
"Passing `True` or `False` as the first argument to Accelerate's `tqdm` wrapper is unsupported. "
"Please use the `main_process_only` keyword argument instead."
)
disable = kwargs.pop("disable", False)
if main_process_only and not disable:
disable = PartialState().local_process_index != 0
return _tqdm(*args, **kwargs, disable=disable)
| 8 |
0 | hf_public_repos/accelerate/src/accelerate | hf_public_repos/accelerate/src/accelerate/utils/offload.py | # Copyright 2022 The HuggingFace Team. All rights reserved.
#
# Licensed under the Apache License, Version 2.0 (the "License");
# you may not use this file except in compliance with the License.
# You may obtain a copy of the License at
#
# http://www.apache.org/licenses/LICENSE-2.0
#
# Unless required by applicable law or agreed to in writing, software
# distributed under the License is distributed on an "AS IS" BASIS,
# WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
# See the License for the specific language governing permissions and
# limitations under the License.
import json
import os
from collections.abc import Mapping
from typing import Dict, List, Optional, Union
import numpy as np
import torch
from safetensors import safe_open
def offload_weight(weight, weight_name, offload_folder, index=None):
dtype = None
# Check the string instead of the dtype to be compatible with versions of PyTorch that don't have bfloat16.
if str(weight.dtype) == "torch.bfloat16":
# Need to reinterpret the underlined data as int16 since NumPy does not handle bfloat16s.
weight = weight.view(torch.int16)
dtype = "bfloat16"
array = weight.cpu().numpy()
tensor_file = os.path.join(offload_folder, f"{weight_name}.dat")
if index is not None:
if dtype is None:
dtype = str(array.dtype)
index[weight_name] = {"dtype": dtype, "shape": list(array.shape)}
if array.ndim == 0:
array = array[None]
file_array = np.memmap(tensor_file, dtype=array.dtype, mode="w+", shape=array.shape)
file_array[:] = array[:]
file_array.flush()
return index
def load_offloaded_weight(weight_file, weight_info):
shape = tuple(weight_info["shape"])
if shape == ():
# NumPy memory-mapped arrays can't have 0 dims so it was saved as 1d tensor
shape = (1,)
dtype = weight_info["dtype"]
if dtype == "bfloat16":
# NumPy does not support bfloat16 so this was saved as a int16
dtype = "int16"
weight = np.memmap(weight_file, dtype=dtype, shape=shape, mode="r")
if len(weight_info["shape"]) == 0:
weight = weight[0]
weight = torch.tensor(weight)
if weight_info["dtype"] == "bfloat16":
weight = weight.view(torch.bfloat16)
return weight
def save_offload_index(index, offload_folder):
if index is None or len(index) == 0:
# Nothing to save
return
offload_index_file = os.path.join(offload_folder, "index.json")
if os.path.isfile(offload_index_file):
with open(offload_index_file, encoding="utf-8") as f:
current_index = json.load(f)
else:
current_index = {}
current_index.update(index)
with open(offload_index_file, "w", encoding="utf-8") as f:
json.dump(current_index, f, indent=2)
def offload_state_dict(save_dir: Union[str, os.PathLike], state_dict: Dict[str, torch.Tensor]):
"""
Offload a state dict in a given folder.
Args:
save_dir (`str` or `os.PathLike`):
The directory in which to offload the state dict.
state_dict (`Dict[str, torch.Tensor]`):
The dictionary of tensors to offload.
"""
os.makedirs(save_dir, exist_ok=True)
index = {}
for name, parameter in state_dict.items():
index = offload_weight(parameter, name, save_dir, index=index)
# Update index
save_offload_index(index, save_dir)
class PrefixedDataset(Mapping):
"""
Will access keys in a given dataset by adding a prefix.
Args:
dataset (`Mapping`): Any map with string keys.
prefix (`str`): A prefix to add when trying to access any element in the underlying dataset.
"""
def __init__(self, dataset: Mapping, prefix: str):
self.dataset = dataset
self.prefix = prefix
def __getitem__(self, key):
return self.dataset[f"{self.prefix}{key}"]
def __iter__(self):
return iter([key for key in self.dataset if key.startswith(self.prefix)])
def __len__(self):
return len(self.dataset)
class OffloadedWeightsLoader(Mapping):
"""
A collection that loads weights stored in a given state dict or memory-mapped on disk.
Args:
state_dict (`Dict[str, torch.Tensor]`, *optional*):
A dictionary parameter name to tensor.
save_folder (`str` or `os.PathLike`, *optional*):
The directory in which the weights are stored (by `offload_state_dict` for instance).
index (`Dict`, *optional*):
A dictionary from weight name to their information (`dtype`/ `shape` or safetensors filename). Will default
to the index saved in `save_folder`.
"""
def __init__(
self,
state_dict: Dict[str, torch.Tensor] = None,
save_folder: Optional[Union[str, os.PathLike]] = None,
index: Mapping = None,
device=None,
):
if state_dict is None and save_folder is None and index is None:
raise ValueError("Need either a `state_dict`, a `save_folder` or an `index` containing offloaded weights.")
self.state_dict = {} if state_dict is None else state_dict
self.save_folder = save_folder
if index is None and save_folder is not None:
with open(os.path.join(save_folder, "index.json")) as f:
index = json.load(f)
self.index = {} if index is None else index
self.all_keys = list(self.state_dict.keys())
self.all_keys.extend([key for key in self.index if key not in self.all_keys])
self.device = device
def __getitem__(self, key: str):
# State dict gets priority
if key in self.state_dict:
return self.state_dict[key]
weight_info = self.index[key]
if weight_info.get("safetensors_file") is not None:
device = "cpu" if self.device is None else self.device
tensor = None
try:
with safe_open(weight_info["safetensors_file"], framework="pt", device=device) as f:
tensor = f.get_tensor(weight_info.get("weight_name", key))
except TypeError:
# if failed to get_tensor on the device, such as bf16 on mps, try to load it on CPU first
with safe_open(weight_info["safetensors_file"], framework="pt", device="cpu") as f:
tensor = f.get_tensor(weight_info.get("weight_name", key))
if "dtype" in weight_info:
tensor = tensor.to(getattr(torch, weight_info["dtype"]))
if tensor.device != torch.device(device):
tensor = tensor.to(device)
return tensor
weight_file = os.path.join(self.save_folder, f"{key}.dat")
return load_offloaded_weight(weight_file, weight_info)
def __iter__(self):
return iter(self.all_keys)
def __len__(self):
return len(self.all_keys)
def extract_submodules_state_dict(state_dict: Dict[str, torch.Tensor], submodule_names: List[str]):
"""
Extract the sub state-dict corresponding to a list of given submodules.
Args:
state_dict (`Dict[str, torch.Tensor]`): The state dict to extract from.
submodule_names (`List[str]`): The list of submodule names we want to extract.
"""
result = {}
for module_name in submodule_names:
# We want to catch module_name parameter (module_name.xxx) or potentially module_name, but not any of the
# submodules that could being like module_name (transformers.h.1 and transformers.h.10 for instance)
result.update(
{
key: param
for key, param in state_dict.items()
if key == module_name or key.startswith(module_name + ".")
}
)
return result
| 9 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/chinese_clip/text_model.rs | //! Chinese contrastive Language-Image Pre-Training
//!
//! Chinese contrastive Language-Image Pre-Training (CLIP) is an architecture trained on
//! pairs of images with related texts.
//!
//! - 💻 [Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP)
//! - 💻 [HF](https://github.com/huggingface/transformers/blob/5af7d41e49bbfc8319f462eb45253dcb3863dfb7/src/transformers/models/chinese_clip/modeling_chinese_clip.py)
use candle::{DType, Device, IndexOp, Module, Result, Tensor};
use candle_nn as nn;
use super::Activation;
/// Type of position embedding. Choose one of `"absolute"`, `"relative_key"`, `"relative_key_query"`. For
/// positional embeddings use `"absolute"`. For more information on `"relative_key"`, please refer to
/// [Self-Attention with Relative Position Representations (Shaw et al.)](https://arxiv.org/abs/1803.02155).
/// For more information on `"relative_key_query"`, please refer to *Method 4* in [Improve Transformer Models
/// with Better Relative Position Embeddings (Huang et al.)](https://arxiv.org/abs/2009.13658).
#[derive(Clone, Debug)]
pub enum PositionEmbeddingType {
Absolute,
RelativeKey,
RelativeKeyQuery,
}
#[derive(Clone, Debug)]
pub struct ChineseClipTextConfig {
pub vocab_size: usize,
pub hidden_size: usize,
pub num_hidden_layers: usize,
pub num_attention_heads: usize,
pub intermediate_size: usize,
pub hidden_act: Activation,
pub hidden_dropout_prob: f32,
pub attention_probs_dropout_prob: f64,
pub max_position_embeddings: usize,
pub type_vocab_size: usize,
pub initializer_range: f64,
pub initializer_factor: f64,
pub layer_norm_eps: f64,
pub pad_token_id: usize,
pub position_embedding_type: PositionEmbeddingType,
pub use_cache: bool,
}
impl Default for ChineseClipTextConfig {
fn default() -> Self {
Self {
vocab_size: 30522,
hidden_size: 768,
num_hidden_layers: 12,
num_attention_heads: 12,
intermediate_size: 3072,
hidden_act: Activation::Gelu,
hidden_dropout_prob: 0.1,
attention_probs_dropout_prob: 0.1,
max_position_embeddings: 512,
type_vocab_size: 2,
initializer_range: 0.02,
initializer_factor: 1.0,
layer_norm_eps: 1e-12,
pad_token_id: 0,
position_embedding_type: PositionEmbeddingType::Absolute,
use_cache: true,
}
}
}
impl ChineseClipTextConfig {
/// [referer](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/blob/main/config.json)
pub fn clip_vit_base_patch16() -> Self {
Self {
vocab_size: 21128,
hidden_size: 768,
num_hidden_layers: 12,
num_attention_heads: 12,
intermediate_size: 3072,
hidden_act: Activation::Gelu,
hidden_dropout_prob: 0.1,
attention_probs_dropout_prob: 0.1,
max_position_embeddings: 512,
type_vocab_size: 2,
initializer_range: 0.02,
initializer_factor: 1.0,
layer_norm_eps: 1e-12,
pad_token_id: 0,
position_embedding_type: PositionEmbeddingType::Absolute,
use_cache: true,
}
}
}
#[derive(Clone, Debug)]
pub struct ChineseClipTextEmbeddings {
word_embeddings: nn::Embedding,
position_embeddings: nn::Embedding,
token_type_embeddings: nn::Embedding,
layer_norm: nn::LayerNorm,
dropout: nn::Dropout,
position_embedding_type: PositionEmbeddingType,
position_ids: Tensor,
token_type_ids: Tensor,
}
impl ChineseClipTextEmbeddings {
pub fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let word_embeddings = nn::embedding(
config.vocab_size,
config.hidden_size,
var.pp("word_embeddings"),
)?;
let position_embeddings = nn::embedding(
config.max_position_embeddings,
config.hidden_size,
var.pp("position_embeddings"),
)?;
let token_type_embeddings = nn::embedding(
config.type_vocab_size,
config.hidden_size,
var.pp("token_type_embeddings"),
)?;
let layer_norm = nn::layer_norm::<f64>(
config.hidden_size,
config.layer_norm_eps,
var.pp("LayerNorm"),
)?;
let dropout = nn::Dropout::new(config.hidden_dropout_prob);
let position_ids =
Tensor::arange(0u32, config.max_position_embeddings as u32, var.device())?
.unsqueeze(0)?;
let token_type_ids = Tensor::zeros(position_ids.shape(), DType::I64, var.device())?;
Ok(Self {
word_embeddings,
position_embeddings,
token_type_embeddings,
layer_norm,
dropout,
position_embedding_type: config.position_embedding_type.clone(),
position_ids,
token_type_ids,
})
}
fn forward(&self, xs: &Tensor, token_type_ids: Option<&Tensor>) -> Result<Tensor> {
let (_batch_size, seq_length) = xs.dims2()?;
let position_ids = (0..seq_length as u32).collect::<Vec<_>>();
let position_ids = self.position_ids.index_select(
&Tensor::new(&position_ids[..], self.position_ids.device())?,
1,
)?;
let word_embeddings = self.word_embeddings.forward(xs)?;
let token_type_ids = match token_type_ids {
Some(token_type_ids) => token_type_ids,
None => &self.token_type_ids.i((.., 0..seq_length))?,
};
let token_type_ids = token_type_ids.expand(xs.shape())?;
let token_type_embeddings = self.token_type_embeddings.forward(&token_type_ids)?;
let embeddings = (&word_embeddings + token_type_embeddings)?;
let embeddings = match self.position_embedding_type {
PositionEmbeddingType::Absolute => {
let position_embeddings = self.position_embeddings.forward(&position_ids)?;
let position_embeddings = position_embeddings.expand(embeddings.shape())?;
(embeddings + position_embeddings)?
}
_ => embeddings,
};
let embeddings = self.layer_norm.forward(&embeddings)?;
let embeddings = self.dropout.forward(&embeddings, false)?;
Ok(embeddings)
}
}
/// Copied from [`crate::models::bert::BertSelfOutput`] to [`ChineseClipTextSelfOutput`]
#[derive(Clone, Debug)]
struct ChineseClipTextSelfOutput {
dense: nn::Linear,
layer_norm: nn::LayerNorm,
dropout: nn::Dropout,
span: tracing::Span,
}
impl ChineseClipTextSelfOutput {
fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let dense = nn::linear(config.hidden_size, config.hidden_size, var.pp("dense"))?;
let layer_norm = nn::layer_norm(
config.hidden_size,
config.layer_norm_eps,
var.pp("LayerNorm"),
)?;
let dropout = nn::Dropout::new(config.hidden_dropout_prob);
Ok(Self {
dense,
layer_norm,
dropout,
span: tracing::span!(tracing::Level::TRACE, "self-out"),
})
}
fn forward(&self, hidden_states: &Tensor, input_tensor: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let hidden_states = self.dense.forward(hidden_states)?;
let hidden_states = self.dropout.forward(&hidden_states, false)?;
self.layer_norm.forward(&(hidden_states + input_tensor)?)
}
}
/// Copied from [`crate::models::bert::BertSelfAttention`] to [`ChineseClipTextSelfAttention`]
#[derive(Clone, Debug)]
struct ChineseClipTextSelfAttention {
query: nn::Linear,
key: nn::Linear,
value: nn::Linear,
dropout: nn::Dropout,
num_attention_heads: usize,
attention_head_size: usize,
span: tracing::Span,
span_softmax: tracing::Span,
}
impl ChineseClipTextSelfAttention {
fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let attention_head_size = config.hidden_size / config.num_attention_heads;
let all_head_size = config.num_attention_heads * attention_head_size;
let dropout = nn::Dropout::new(config.hidden_dropout_prob);
let hidden_size = config.hidden_size;
let query = nn::linear(hidden_size, all_head_size, var.pp("query"))?;
let value = nn::linear(hidden_size, all_head_size, var.pp("value"))?;
let key = nn::linear(hidden_size, all_head_size, var.pp("key"))?;
Ok(Self {
query,
key,
value,
dropout,
num_attention_heads: config.num_attention_heads,
attention_head_size,
span: tracing::span!(tracing::Level::TRACE, "self-attn"),
span_softmax: tracing::span!(tracing::Level::TRACE, "softmax"),
})
}
fn transpose_for_scores(&self, xs: &Tensor) -> Result<Tensor> {
let mut new_x_shape = xs.dims().to_vec();
new_x_shape.pop();
new_x_shape.push(self.num_attention_heads);
new_x_shape.push(self.attention_head_size);
let xs = xs.reshape(new_x_shape.as_slice())?.transpose(1, 2)?;
xs.contiguous()
}
fn forward(&self, hidden_states: &Tensor, attention_mask: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let query_layer = self.query.forward(hidden_states)?;
let key_layer = self.key.forward(hidden_states)?;
let value_layer = self.value.forward(hidden_states)?;
let query_layer = self.transpose_for_scores(&query_layer)?;
let key_layer = self.transpose_for_scores(&key_layer)?;
let value_layer = self.transpose_for_scores(&value_layer)?;
let attention_scores = query_layer.matmul(&key_layer.t()?)?;
let attention_scores = (attention_scores / (self.attention_head_size as f64).sqrt())?;
let attention_scores = attention_scores.broadcast_add(attention_mask)?;
let attention_probs = {
let _enter_sm = self.span_softmax.enter();
nn::ops::softmax(&attention_scores, candle::D::Minus1)?
};
let attention_probs = self.dropout.forward(&attention_probs, false)?;
let context_layer = attention_probs.matmul(&value_layer)?;
let context_layer = context_layer.transpose(1, 2)?.contiguous()?;
let context_layer = context_layer.flatten_from(candle::D::Minus2)?;
Ok(context_layer)
}
}
/// Copied from [`crate::models::bert::BertAttention`] to [`ChineseClipTextAttention`]
#[derive(Clone, Debug)]
struct ChineseClipTextAttention {
self_attention: ChineseClipTextSelfAttention,
self_output: ChineseClipTextSelfOutput,
span: tracing::Span,
}
impl ChineseClipTextAttention {
fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let self_attention = ChineseClipTextSelfAttention::new(var.pp("self"), config)?;
let self_output = ChineseClipTextSelfOutput::new(var.pp("output"), config)?;
Ok(Self {
self_attention,
self_output,
span: tracing::span!(tracing::Level::TRACE, "attn"),
})
}
fn forward(&self, hidden_states: &Tensor, attention_mask: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let self_outputs = self.self_attention.forward(hidden_states, attention_mask)?;
let attention_output = self.self_output.forward(&self_outputs, hidden_states)?;
Ok(attention_output)
}
}
type HiddenActLayer = Activation;
/// Copied from [`crate::models::bert::BertIntermediate`] to [`ChineseClipTextIntermediate`]
#[derive(Clone, Debug)]
struct ChineseClipTextIntermediate {
dense: nn::Linear,
intermediate_act: HiddenActLayer,
span: tracing::Span,
}
impl ChineseClipTextIntermediate {
fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let dense = nn::linear(
config.hidden_size,
config.intermediate_size,
var.pp("dense"),
)?;
Ok(Self {
dense,
intermediate_act: config.hidden_act,
span: tracing::span!(tracing::Level::TRACE, "inter"),
})
}
}
impl Module for ChineseClipTextIntermediate {
fn forward(&self, hidden_states: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let hidden_states = self.dense.forward(hidden_states)?;
let ys = self.intermediate_act.forward(&hidden_states)?;
Ok(ys)
}
}
/// Copied from [`crate::models::bert::BertOutput`] to [`ChineseClipTextOutput`]
#[derive(Clone, Debug)]
struct ChineseClipTextOutput {
dense: nn::Linear,
layer_norm: nn::LayerNorm,
dropout: nn::Dropout,
span: tracing::Span,
}
impl ChineseClipTextOutput {
fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let dense = nn::linear(
config.intermediate_size,
config.hidden_size,
var.pp("dense"),
)?;
let layer_norm = nn::layer_norm(
config.hidden_size,
config.layer_norm_eps,
var.pp("LayerNorm"),
)?;
let dropout = nn::Dropout::new(config.hidden_dropout_prob);
Ok(Self {
dense,
layer_norm,
dropout,
span: tracing::span!(tracing::Level::TRACE, "out"),
})
}
fn forward(&self, hidden_states: &Tensor, input_tensor: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let hidden_states = self.dense.forward(hidden_states)?;
let hidden_states = self.dropout.forward(&hidden_states, false)?;
self.layer_norm.forward(&(hidden_states + input_tensor)?)
}
}
/// Copied from [`crate::models::bert::BertLayer`] to [`ChineseClipTextLayer`]
#[derive(Clone, Debug)]
struct ChineseClipTextLayer {
attention: ChineseClipTextAttention,
intermediate: ChineseClipTextIntermediate,
output: ChineseClipTextOutput,
span: tracing::Span,
}
impl ChineseClipTextLayer {
fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let attention = ChineseClipTextAttention::new(var.pp("attention"), config)?;
let intermediate = ChineseClipTextIntermediate::new(var.pp("intermediate"), config)?;
let output = ChineseClipTextOutput::new(var.pp("output"), config)?;
Ok(Self {
attention,
intermediate,
output,
span: tracing::span!(tracing::Level::TRACE, "layer"),
})
}
fn forward(&self, hidden_states: &Tensor, attention_mask: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let attention_output = self.attention.forward(hidden_states, attention_mask)?;
// https://github.com/huggingface/transformers/blob/6eedfa6dd15dc1e22a55ae036f681914e5a0d9a1/src/transformers/models/bert/modeling_bert.py#L523
let intermediate_output = self.intermediate.forward(&attention_output)?;
let layer_output = self
.output
.forward(&intermediate_output, &attention_output)?;
Ok(layer_output)
}
}
#[derive(Clone, Debug)]
struct Tanh;
impl Tanh {
pub fn new() -> Self {
Self {}
}
}
impl Module for Tanh {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.tanh()
}
}
#[derive(Clone, Debug)]
struct ChineseClipTextPooler {
dense: nn::Linear,
activation: Tanh,
}
impl ChineseClipTextPooler {
pub fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let dense = nn::linear(config.hidden_size, config.hidden_size, var.pp("dense"))?;
let activation = Tanh::new();
Ok(Self { dense, activation })
}
}
impl Module for ChineseClipTextPooler {
fn forward(&self, hidden_states: &Tensor) -> Result<Tensor> {
let first_token_tensor = hidden_states.i((.., 0))?;
let pooled_output = self.dense.forward(&first_token_tensor)?;
let pooled_output = self.activation.forward(&pooled_output)?;
Ok(pooled_output)
}
}
#[derive(Clone, Debug)]
struct ChineseClipTextEncoder {
layers: Vec<ChineseClipTextLayer>,
span: tracing::Span,
}
impl ChineseClipTextEncoder {
fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let layers = (0..config.num_hidden_layers)
.map(|index| ChineseClipTextLayer::new(var.pp(format!("layer.{index}")), config))
.collect::<Result<Vec<_>>>()?;
let span = tracing::span!(tracing::Level::TRACE, "encoder");
Ok(ChineseClipTextEncoder { layers, span })
}
fn forward(&self, hidden_states: &Tensor, attention_mask: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let mut hidden_states = hidden_states.clone();
// Use a loop rather than a fold as it's easier to modify when adding debug/...
for layer in self.layers.iter() {
hidden_states = layer.forward(&hidden_states, attention_mask)?
}
Ok(hidden_states)
}
}
#[derive(Clone, Debug)]
pub struct ChineseClipTextTransformer {
embeddings: ChineseClipTextEmbeddings,
encoder: ChineseClipTextEncoder,
pooler: Option<ChineseClipTextPooler>,
pub device: Device,
span: tracing::Span,
}
impl ChineseClipTextTransformer {
pub fn new(var: nn::VarBuilder, config: &ChineseClipTextConfig) -> Result<Self> {
let embeddings = ChineseClipTextEmbeddings::new(var.pp("embeddings"), config)?;
let encoder = ChineseClipTextEncoder::new(var.pp("encoder"), config)?;
// see: https://github.com/huggingface/transformers/blob/e40bb4845e0eefb52ec1e9cac9c2446ab36aef81/src/transformers/models/chinese_clip/modeling_chinese_clip.py#L1362
// In the original Python version of the code, the pooler is not used, and there are no parameters for the pooler in the weight file.
let pooler = if var.contains_tensor("pooler") {
Some(ChineseClipTextPooler::new(var.pp("pooler"), config)?)
} else {
None
};
Ok(Self {
embeddings,
encoder,
pooler,
device: var.device().clone(),
span: tracing::span!(tracing::Level::TRACE, "model"),
})
}
pub fn forward(
&self,
input_ids: &Tensor,
token_type_ids: Option<&Tensor>,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let _enter = self.span.enter();
let embedding_output = self.embeddings.forward(input_ids, token_type_ids)?;
let attention_mask = match attention_mask {
Some(attention_mask) => attention_mask.clone(),
None => input_ids.ones_like()?,
};
// https://github.com/huggingface/transformers/blob/6eedfa6dd15dc1e22a55ae036f681914e5a0d9a1/src/transformers/models/bert/modeling_bert.py#L995
let attention_mask = get_extended_attention_mask(&attention_mask, DType::F32)?;
let encoder_outputs = self.encoder.forward(&embedding_output, &attention_mask)?;
let encoder_output = encoder_outputs.i((.., 0, ..))?;
let pooled_output = match &self.pooler {
Some(pooler) => pooler.forward(&encoder_output)?,
None => encoder_output,
};
Ok(pooled_output)
}
}
fn get_extended_attention_mask(attention_mask: &Tensor, dtype: DType) -> Result<Tensor> {
let attention_mask = match attention_mask.rank() {
3 => attention_mask.unsqueeze(1)?,
2 => attention_mask.unsqueeze(1)?.unsqueeze(1)?,
_ => candle::bail!("Wrong shape for input_ids or attention_mask"),
};
let attention_mask = attention_mask.to_dtype(dtype)?;
// torch.finfo(dtype).min
(attention_mask.ones_like()? - &attention_mask)?
.broadcast_mul(&Tensor::try_from(f32::MIN)?.to_device(attention_mask.device())?)
}
| 0 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/chinese_clip/mod.rs | //! Chinese contrastive Language-Image Pre-Training
//!
//! Chinese contrastive Language-Image Pre-Training (CLIP) is an architecture trained on
//! pairs of images with related texts.
//!
//! - 💻 [GH Link](https://github.com/OFA-Sys/Chinese-CLIP)
//! - 💻 Transformers Python [reference implementation](https://github.com/huggingface/transformers/blob/5af7d41e49bbfc8319f462eb45253dcb3863dfb7/src/transformers/models/chinese_clip/modeling_chinese_clip.py)
//!
use candle::{Module, Result, Tensor, D};
use candle_nn as nn;
use text_model::ChineseClipTextTransformer;
use vision_model::ChineseClipVisionTransformer;
pub mod text_model;
pub mod vision_model;
#[derive(Debug, Clone, Copy)]
pub enum Activation {
QuickGelu,
Gelu,
GeluNew,
Relu,
}
impl From<String> for Activation {
fn from(value: String) -> Self {
match value.as_str() {
"quick_gelu" => Activation::QuickGelu,
"gelu" => Activation::Gelu,
"gelu_new" => Activation::GeluNew,
"relu" => Activation::Relu,
_ => panic!("Invalid activation function: {}", value),
}
}
}
impl Module for Activation {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
match self {
Activation::QuickGelu => xs * nn::ops::sigmoid(&(xs * 1.702f64)?)?,
Activation::Gelu => xs.gelu_erf(),
Activation::GeluNew => xs.gelu(),
Activation::Relu => xs.relu(),
}
}
}
#[derive(Clone, Debug)]
pub struct ChineseClipConfig {
pub text_config: text_model::ChineseClipTextConfig,
pub vision_config: vision_model::ChineseClipVisionConfig,
pub projection_dim: usize,
pub logit_scale_init_value: f32,
pub image_size: usize,
}
impl ChineseClipConfig {
/// referer: https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/blob/main/config.json
pub fn clip_vit_base_patch16() -> Self {
let text_config = text_model::ChineseClipTextConfig::clip_vit_base_patch16();
let vision_config = vision_model::ChineseClipVisionConfig::clip_vit_base_patch16();
Self {
text_config,
vision_config,
projection_dim: 512,
logit_scale_init_value: 2.6592,
image_size: 512,
}
}
}
#[derive(Clone, Debug)]
pub enum EncoderConfig {
Text(text_model::ChineseClipTextConfig),
Vision(vision_model::ChineseClipVisionConfig),
}
impl EncoderConfig {
pub fn embed_dim(&self) -> usize {
match self {
Self::Text(c) => c.hidden_size,
Self::Vision(c) => c.hidden_size,
}
}
pub fn num_attention_heads(&self) -> usize {
match self {
Self::Text(c) => c.num_attention_heads,
Self::Vision(c) => c.num_attention_heads,
}
}
pub fn intermediate_size(&self) -> usize {
match self {
Self::Text(c) => c.intermediate_size,
Self::Vision(c) => c.intermediate_size,
}
}
pub fn num_hidden_layers(&self) -> usize {
match self {
Self::Text(c) => c.num_hidden_layers,
Self::Vision(c) => c.num_hidden_layers,
}
}
pub fn activation(&self) -> Activation {
match self {
Self::Text(c) => c.hidden_act,
Self::Vision(c) => c.hidden_act,
}
}
pub fn layer_norm_eps(&self) -> f64 {
match self {
Self::Text(c) => c.layer_norm_eps,
Self::Vision(c) => c.layer_norm_eps,
}
}
}
#[derive(Clone, Debug)]
pub struct ChineseClipModel {
text_model: ChineseClipTextTransformer,
vision_model: ChineseClipVisionTransformer,
visual_projection: nn::Linear,
text_projection: nn::Linear,
logit_scale: Tensor,
}
impl ChineseClipModel {
pub fn new(vs: nn::VarBuilder, c: &ChineseClipConfig) -> Result<Self> {
let text_model = ChineseClipTextTransformer::new(vs.pp("text_model"), &c.text_config)?;
let vision_model =
ChineseClipVisionTransformer::new(vs.pp("vision_model"), &c.vision_config)?;
let vision_embed_dim = c.vision_config.hidden_size;
let vision_projection = nn::linear_no_bias(
vision_embed_dim,
c.projection_dim,
vs.pp("visual_projection"),
)?;
let text_embed_dim = c.text_config.hidden_size;
let text_projection =
nn::linear_no_bias(text_embed_dim, c.projection_dim, vs.pp("text_projection"))?;
let logit_scale = if vs.contains_tensor("logit_scale") {
vs.get(&[], "logit_scale")?
} else {
Tensor::new(&[c.logit_scale_init_value], vs.device())?
};
Ok(Self {
text_model,
vision_model,
visual_projection: vision_projection,
text_projection,
logit_scale,
})
}
pub fn get_text_features(
&self,
input_ids: &Tensor,
token_type_ids: Option<&Tensor>,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let output = self
.text_model
.forward(input_ids, token_type_ids, attention_mask)?
.contiguous()?;
self.text_projection.forward(&output)
}
pub fn get_image_features(&self, pixel_values: &Tensor) -> Result<Tensor> {
pixel_values
.apply(&self.vision_model)?
.apply(&self.visual_projection)
}
pub fn forward(
&self,
pixel_values: &Tensor,
input_ids: &Tensor,
token_type_ids: Option<&Tensor>,
attention_mask: Option<&Tensor>,
) -> Result<(Tensor, Tensor)> {
let image_features = self.get_image_features(pixel_values)?;
let text_features = self.get_text_features(input_ids, token_type_ids, attention_mask)?;
let image_features_normalized = div_l2_norm(&image_features)?;
let text_features_normalized = div_l2_norm(&text_features)?;
let logits_per_text = text_features_normalized.matmul(&image_features_normalized.t()?)?;
let logit_scale = self.logit_scale.exp()?;
let logits_per_text = logits_per_text.broadcast_mul(&logit_scale)?;
let logits_per_image = logits_per_text.t()?;
Ok((logits_per_text, logits_per_image))
}
}
pub fn div_l2_norm(v: &Tensor) -> Result<Tensor> {
let l2_norm = v.sqr()?.sum_keepdim(D::Minus1)?.sqrt()?;
v.broadcast_div(&l2_norm)
}
| 1 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/chinese_clip/vision_model.rs | //! Chinese contrastive Language-Image Pre-Training
//!
//! Chinese contrastive Language-Image Pre-Training (CLIP) is an architecture trained on
//! pairs of images with related texts.
//!
//! - 💻 [Chinese-CLIP](https://github.com/OFA-Sys/Chinese-CLIP)
//! - 💻 [GH](https://github.com/huggingface/transformers/blob/5af7d41e49bbfc8319f462eb45253dcb3863dfb7/src/transformers/models/chinese_clip/modeling_chinese_clip.py_
use candle::{DType, IndexOp, Module, Result, Shape, Tensor, D};
use candle_nn as nn;
use super::{Activation, EncoderConfig};
#[derive(Clone, Debug)]
pub struct ChineseClipVisionConfig {
pub hidden_size: usize,
pub intermediate_size: usize,
pub projection_dim: usize,
pub num_hidden_layers: usize,
pub num_attention_heads: usize,
pub num_channels: usize,
pub image_size: usize,
pub patch_size: usize,
pub hidden_act: Activation,
pub layer_norm_eps: f64,
pub attention_dropout: f32,
pub initializer_range: f32,
pub initializer_factor: f32,
}
impl Default for ChineseClipVisionConfig {
fn default() -> Self {
ChineseClipVisionConfig {
hidden_size: 768,
intermediate_size: 3072,
projection_dim: 512,
num_hidden_layers: 12,
num_attention_heads: 12,
num_channels: 3,
image_size: 224,
patch_size: 32,
hidden_act: Activation::QuickGelu,
layer_norm_eps: 1e-5,
attention_dropout: 0.0,
initializer_range: 0.02,
initializer_factor: 1.0,
}
}
}
impl ChineseClipVisionConfig {
/// [referer](https://huggingface.co/OFA-Sys/chinese-clip-vit-base-patch16/blob/main/config.json)
pub fn clip_vit_base_patch16() -> Self {
Self {
hidden_size: 768,
intermediate_size: 3072,
projection_dim: 512,
num_hidden_layers: 12,
num_attention_heads: 12,
num_channels: 3,
image_size: 224,
patch_size: 16,
hidden_act: Activation::QuickGelu,
layer_norm_eps: 1e-5,
attention_dropout: 0.0,
initializer_range: 0.02,
initializer_factor: 1.0,
}
}
}
#[derive(Clone, Debug)]
pub struct ChineseClipVisionEmbeddings {
patch_embedding: nn::Conv2d,
position_ids: Tensor,
class_embedding: Tensor,
position_embedding: nn::Embedding,
}
impl ChineseClipVisionEmbeddings {
pub fn new(var: nn::VarBuilder, config: &ChineseClipVisionConfig) -> Result<Self> {
let embed_dim = config.hidden_size;
// originally nn.Parameter
let class_embedding = if var.contains_tensor("class_embedding") {
var.get(embed_dim, "class_embedding")?
} else {
Tensor::randn(0f32, 1f32, embed_dim, var.device())?
};
let num_patches = (config.image_size / config.patch_size).pow(2);
let num_positions = num_patches + 1;
let position_ids = Tensor::arange(0, num_positions as i64, var.device())?;
let conv2dconfig = nn::Conv2dConfig {
stride: config.patch_size,
..Default::default()
};
let position_embedding =
nn::embedding(num_positions, embed_dim, var.pp("position_embedding"))?;
let patch_embedding = nn::conv2d_no_bias(
config.num_channels,
embed_dim,
config.patch_size,
conv2dconfig,
var.pp("patch_embedding"),
)?;
Ok(Self {
patch_embedding,
position_ids,
class_embedding,
position_embedding,
})
}
}
impl Module for ChineseClipVisionEmbeddings {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let batch_size = xs.shape().dims();
let patch_embeds = self
.patch_embedding
.forward(xs)?
.flatten_from(2)?
.transpose(1, 2)?;
let shape = Shape::from((batch_size[0], 1, self.class_embedding.dim(D::Minus1)?));
let class_embeds = self.class_embedding.expand(shape)?;
let embeddings = Tensor::cat(&[class_embeds, patch_embeds], 1)?;
let position_embedding = self.position_embedding.forward(&self.position_ids)?;
embeddings.broadcast_add(&position_embedding)
}
}
#[derive(Clone, Debug)]
struct ChineseClipVisionAttention {
k_proj: nn::Linear,
v_proj: nn::Linear,
q_proj: nn::Linear,
out_proj: nn::Linear,
head_dim: usize,
scale: f64,
num_attention_heads: usize,
}
impl ChineseClipVisionAttention {
fn new(var: nn::VarBuilder, config: &EncoderConfig) -> Result<Self> {
let embed_dim = config.embed_dim();
let num_attention_heads = config.num_attention_heads();
let k_proj = nn::linear(embed_dim, embed_dim, var.pp("k_proj"))?;
let v_proj = nn::linear(embed_dim, embed_dim, var.pp("v_proj"))?;
let q_proj = nn::linear(embed_dim, embed_dim, var.pp("q_proj"))?;
let out_proj = nn::linear(embed_dim, embed_dim, var.pp("out_proj"))?;
let head_dim = embed_dim / num_attention_heads;
let scale = (head_dim as f64).powf(-0.5);
Ok(ChineseClipVisionAttention {
k_proj,
v_proj,
q_proj,
out_proj,
head_dim,
scale,
num_attention_heads,
})
}
fn shape(&self, xs: &Tensor, seq_len: usize, bsz: usize) -> Result<Tensor> {
xs.reshape((bsz, seq_len, self.num_attention_heads, self.head_dim))?
.transpose(1, 2)?
.contiguous()
}
fn forward(&self, xs: &Tensor, causal_attention_mask: Option<&Tensor>) -> Result<Tensor> {
let in_dtype = xs.dtype();
let (bsz, seq_len, embed_dim) = xs.dims3()?;
let proj_shape = (bsz * self.num_attention_heads, seq_len, self.head_dim);
let query_states = self
.shape(&(self.q_proj.forward(xs)? * self.scale)?, seq_len, bsz)?
.reshape(proj_shape)?
.to_dtype(DType::F32)?;
let key_states = self
.shape(&self.k_proj.forward(xs)?, seq_len, bsz)?
.reshape(proj_shape)?
.to_dtype(DType::F32)?;
let value_states = self
.shape(&self.v_proj.forward(xs)?, seq_len, bsz)?
.reshape(proj_shape)?
.to_dtype(DType::F32)?;
let attn_weights = query_states.matmul(&key_states.transpose(1, 2)?)?;
let src_len = key_states.dim(1)?;
let attn_weights = if let Some(causal_attention_mask) = causal_attention_mask {
attn_weights
.reshape((bsz, self.num_attention_heads, seq_len, src_len))?
.broadcast_add(causal_attention_mask)?
.reshape((bsz * self.num_attention_heads, seq_len, src_len))?
} else {
attn_weights
};
let attn_weights = nn::ops::softmax(&attn_weights, D::Minus1)?;
let attn_output = attn_weights.matmul(&value_states)?.to_dtype(in_dtype)?;
let attn_output = attn_output
.reshape((bsz, self.num_attention_heads, seq_len, self.head_dim))?
.transpose(1, 2)?
.reshape((bsz, seq_len, embed_dim))?;
self.out_proj.forward(&attn_output)
}
}
#[derive(Clone, Debug)]
struct ChineseClipVisionMlp {
fc1: nn::Linear,
fc2: nn::Linear,
activation: Activation,
}
impl ChineseClipVisionMlp {
fn new(var: nn::VarBuilder, config: &EncoderConfig) -> Result<Self> {
let fc1 = nn::linear(
config.embed_dim(),
config.intermediate_size(),
var.pp("fc1"),
)?;
let fc2 = nn::linear(
config.intermediate_size(),
config.embed_dim(),
var.pp("fc2"),
)?;
Ok(ChineseClipVisionMlp {
fc1,
fc2,
activation: config.activation(),
})
}
}
impl ChineseClipVisionMlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let xs = self.fc1.forward(xs)?;
self.fc2.forward(&self.activation.forward(&xs)?)
}
}
#[derive(Clone, Debug)]
struct ChineseClipVisionEncoderLayer {
self_attn: ChineseClipVisionAttention,
layer_norm1: nn::LayerNorm,
mlp: ChineseClipVisionMlp,
layer_norm2: nn::LayerNorm,
}
impl ChineseClipVisionEncoderLayer {
fn new(var: nn::VarBuilder, config: &EncoderConfig) -> Result<Self> {
let self_attn = ChineseClipVisionAttention::new(var.pp("self_attn"), config)?;
let layer_norm1 = nn::layer_norm(
config.embed_dim(),
config.layer_norm_eps(),
var.pp("layer_norm1"),
)?;
let mlp = ChineseClipVisionMlp::new(var.pp("mlp"), config)?;
let layer_norm2 = nn::layer_norm(
config.embed_dim(),
config.layer_norm_eps(),
var.pp("layer_norm2"),
)?;
Ok(ChineseClipVisionEncoderLayer {
self_attn,
layer_norm1,
mlp,
layer_norm2,
})
}
fn forward(&self, xs: &Tensor, causal_attention_mask: Option<&Tensor>) -> Result<Tensor> {
let residual = xs;
let xs = self.layer_norm1.forward(xs)?;
let xs = self.self_attn.forward(&xs, causal_attention_mask)?;
let xs = (xs + residual)?;
let residual = &xs;
let xs = self.layer_norm2.forward(&xs)?;
let xs = self.mlp.forward(&xs)?;
xs + residual
}
}
#[derive(Clone, Debug)]
pub struct ChineseClipVisionEncoder {
layers: Vec<ChineseClipVisionEncoderLayer>,
}
impl ChineseClipVisionEncoder {
pub fn new(var: nn::VarBuilder, config: &EncoderConfig) -> Result<Self> {
let vs = var.pp("layers");
let mut layers: Vec<ChineseClipVisionEncoderLayer> = Vec::new();
for index in 0..config.num_hidden_layers() {
let layer = ChineseClipVisionEncoderLayer::new(vs.pp(index.to_string()), config)?;
layers.push(layer)
}
Ok(ChineseClipVisionEncoder { layers })
}
pub fn forward(&self, xs: &Tensor, causal_attention_mask: Option<&Tensor>) -> Result<Tensor> {
let mut xs = xs.clone();
for layer in self.layers.iter() {
xs = layer.forward(&xs, causal_attention_mask)?;
}
Ok(xs)
}
// required by LLaVA
pub fn output_hidden_states(
&self,
xs: &Tensor,
causal_attention_mask: Option<&Tensor>,
) -> Result<Vec<Tensor>> {
let mut xs = xs.clone();
let mut hidden_states = Vec::new();
for layer in self.layers.iter() {
xs = layer.forward(&xs, causal_attention_mask)?;
hidden_states.push(xs.clone());
}
Ok(hidden_states)
}
}
#[derive(Clone, Debug)]
pub struct ChineseClipVisionTransformer {
embeddings: ChineseClipVisionEmbeddings,
encoder: ChineseClipVisionEncoder,
pre_layer_norm: nn::LayerNorm,
final_layer_norm: nn::LayerNorm,
}
impl ChineseClipVisionTransformer {
pub fn new(var: nn::VarBuilder, config: &ChineseClipVisionConfig) -> Result<Self> {
let embed_dim = config.hidden_size;
let embeddings = ChineseClipVisionEmbeddings::new(var.pp("embeddings"), config)?;
let pre_layer_norm =
nn::layer_norm(embed_dim, config.layer_norm_eps, var.pp("pre_layrnorm"))?;
let encoder = ChineseClipVisionEncoder::new(
var.pp("encoder"),
&EncoderConfig::Vision(config.clone()),
)?;
let final_layer_norm =
nn::layer_norm(embed_dim, config.layer_norm_eps, var.pp("post_layernorm"))?;
Ok(Self {
embeddings,
encoder,
final_layer_norm,
pre_layer_norm,
})
}
// required by LLaVA
pub fn output_hidden_states(&self, pixel_values: &Tensor) -> Result<Vec<Tensor>> {
let hidden_states = pixel_values
.apply(&self.embeddings)?
.apply(&self.pre_layer_norm)?;
let mut result = self.encoder.output_hidden_states(&hidden_states, None)?;
let encoder_outputs = result.last().unwrap();
let pooled_output = encoder_outputs.i((.., 0, ..))?;
result.push(self.final_layer_norm.forward(&pooled_output)?.clone());
Ok(result)
}
}
impl Module for ChineseClipVisionTransformer {
fn forward(&self, pixel_values: &Tensor) -> Result<Tensor> {
let hidden_states = pixel_values
.apply(&self.embeddings)?
.apply(&self.pre_layer_norm)?;
let encoder_outputs = self.encoder.forward(&hidden_states, None)?;
// referer: https://github.com/huggingface/transformers/blob/f6fa0f0bf0796ac66f201f23bdb8585de1609add/src/transformers/models/clip/modeling_clip.py#L787
let pooled_output = encoder_outputs.i((.., 0, ..))?;
self.final_layer_norm.forward(&pooled_output)
}
}
| 2 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/pixtral/mod.rs | //! Pixtral Language-Image Pre-Training
//!
//! Pixtral is an architecture trained for multimodal learning
//! using images paired with text descriptions.
//!
//! - 💻 Transformers Python [reference implementation](https://github.com/huggingface/transformers/tree/main/src/transformers/models/pixtral)
//! - 📝 [Blog Post](https://mistral.ai/news/pixtral-12b/)
//! - 🤗 [HF Model Card](https://huggingface.co/mistralai/Pixtral-12B-2409)
//! - 🤗 [HF Community Model Card](https://huggingface.co/mistral-community/pixtral-12b)
//!
//! # Example
//!
//! <div align=center>
//! <img src="https://github.com/huggingface/candle/raw/main/candle-examples/examples/flux/assets/flux-robot.jpg" alt="" width=320>
//! </div>
//!
//! ```bash
//! cargo run --profile=release-with-debug \
//! --features cuda \
//! --example pixtral -- \
//! --image candle-examples/examples/flux/assets/flux-robot.jpg
//! ```
//!
//! ```txt
//! Describe the image.
//!
//! The image depicts a charming, rustic robot standing on a sandy beach at sunset.
//! The robot has a vintage, steampunk aesthetic with visible gears and mechanical
//! parts. It is holding a small lantern in one hand, which emits a warm glow, and
//! its other arm is extended forward as if reaching out or guiding the way. The
//! robot's body is adorned with the word "RUST" in bright orange letters, adding to
//! its rustic theme.
//!
//! The background features a dramatic sky filled with clouds, illuminated by the
//! setting sun, casting a golden hue over the scene. Gentle waves lap against the
//! shore, creating a serene and picturesque atmosphere. The overall mood of the
//! image is whimsical and nostalgic, evoking a sense of adventure and tranquility.
//! ```
pub mod llava;
pub mod vision_model;
pub use llava::{Config, Model};
| 3 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/pixtral/llava.rs | use candle::{Module, Result, Tensor};
use candle_nn::{linear, Linear, VarBuilder};
use super::vision_model;
use crate::models::mistral;
#[derive(serde::Deserialize, Debug, Clone)]
pub struct Config {
pub projector_hidden_act: candle_nn::Activation,
pub text_config: mistral::Config,
pub vision_config: vision_model::Config,
pub image_token_index: usize,
pub image_seq_length: usize,
}
#[derive(Debug, Clone)]
pub struct MultiModalProjector {
linear_1: Linear,
act: candle_nn::Activation,
linear_2: Linear,
}
impl MultiModalProjector {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let (hidden_v, hidden_t) = (cfg.vision_config.hidden_size, cfg.text_config.hidden_size);
let linear_1 = linear(hidden_v, hidden_t, vb.pp("linear_1"))?;
let linear_2 = linear(hidden_t, hidden_t, vb.pp("linear_2"))?;
Ok(Self {
linear_1,
act: cfg.projector_hidden_act,
linear_2,
})
}
}
impl Module for MultiModalProjector {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.linear_1)?
.apply(&self.act)?
.apply(&self.linear_2)
}
}
#[derive(Debug, Clone)]
pub struct Model {
pub multi_modal_projector: MultiModalProjector,
pub language_model: mistral::Model,
pub vision_tower: vision_model::Model,
pub patch_size: usize,
pub dtype: candle::DType,
pub pos: usize,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let language_model = mistral::Model::new(&cfg.text_config, vb.pp("language_model"))?;
let vision_tower = vision_model::Model::new(
&cfg.vision_config,
vb.pp("vision_tower").to_dtype(candle::DType::F32),
)?;
let multi_modal_projector = MultiModalProjector::new(
cfg,
vb.pp("multi_modal_projector").to_dtype(candle::DType::F32),
)?;
Ok(Self {
multi_modal_projector,
language_model,
vision_tower,
patch_size: cfg.vision_config.patch_size,
dtype: vb.dtype(),
pos: 0,
})
}
pub fn clear_kv_cache(&mut self) {
self.language_model.clear_kv_cache();
self.pos = 0;
}
pub fn encode_image(&self, image: &Tensor) -> Result<Tensor> {
let image_embeds = self.vision_tower.forward(image)?;
self.multi_modal_projector.forward(&image_embeds)
}
pub fn lm_forward(&mut self, input_ids: &Tensor) -> Result<Tensor> {
let (_, seq_len) = input_ids.dims2()?;
let logits = self.language_model.forward(input_ids, self.pos)?;
self.pos += seq_len;
Ok(logits)
}
pub fn lm_forward_embeds(&mut self, xs: &Tensor) -> Result<Tensor> {
let (_, seq_len, _) = xs.dims3()?;
let logits = self.language_model.forward_embeds(xs, None, self.pos)?;
self.pos += seq_len;
Ok(logits)
}
}
| 4 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/pixtral/vision_model.rs | use candle::{DType, Module, Result, Tensor, D};
use candle_nn::{linear_b, rms_norm, Linear, RmsNorm, VarBuilder};
fn default_act() -> candle_nn::Activation {
candle_nn::Activation::Gelu
}
fn default_hidden_size() -> usize {
1024
}
fn default_intermediate_size() -> usize {
4096
}
fn default_num_channels() -> usize {
3
}
fn default_num_hidden_layers() -> usize {
24
}
fn default_num_attention_heads() -> usize {
16
}
#[derive(serde::Deserialize, Debug, Clone)]
pub struct Config {
#[serde(default = "default_hidden_size")]
pub hidden_size: usize,
#[serde(default = "default_num_channels")]
pub num_channels: usize,
pub image_size: usize,
pub patch_size: usize,
pub rope_theta: f64,
#[serde(default = "default_intermediate_size")]
pub intermediate_size: usize,
#[serde(default = "default_num_hidden_layers")]
pub num_hidden_layers: usize,
pub head_dim: Option<usize>,
#[serde(default = "default_num_attention_heads")]
pub num_attention_heads: usize,
#[serde(default = "default_act")]
pub hidden_act: candle_nn::Activation,
}
impl Config {
pub fn pixtral_12b_2409() -> Self {
Self {
hidden_size: 1024,
num_channels: 3,
image_size: 1024,
patch_size: 16,
rope_theta: 10000.0,
intermediate_size: 4096,
num_hidden_layers: 24,
num_attention_heads: 16,
head_dim: None,
// Default
hidden_act: candle_nn::Activation::Gelu,
}
}
fn head_dim(&self) -> usize {
self.head_dim
.unwrap_or(self.hidden_size / self.num_attention_heads)
}
}
#[derive(Debug, Clone)]
struct Attention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
o_proj: Linear,
scale: f64,
num_heads: usize,
head_dim: usize,
}
impl Attention {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let h = cfg.hidden_size;
let num_heads = cfg.num_attention_heads;
let head_dim = cfg.head_dim();
let q_proj = linear_b(h, h, false, vb.pp("q_proj"))?;
let k_proj = linear_b(h, h, false, vb.pp("k_proj"))?;
let v_proj = linear_b(h, h, false, vb.pp("v_proj"))?;
let o_proj = linear_b(h, h, false, vb.pp("o_proj"))?;
let scale = (head_dim as f64).powf(-0.5);
Ok(Self {
q_proj,
k_proj,
v_proj,
o_proj,
scale,
num_heads,
head_dim,
})
}
fn forward(
&self,
xs: &Tensor,
emb: &RotaryEmbedding,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let (b, patches, _) = xs.dims3()?;
let query_states = xs.apply(&self.q_proj)?;
let key_states = xs.apply(&self.k_proj)?;
let value_states = xs.apply(&self.v_proj)?;
let shape = (b, patches, self.num_heads, self.head_dim);
let query_states = query_states.reshape(shape)?.transpose(1, 2)?.contiguous()?;
let key_states = key_states.reshape(shape)?.transpose(1, 2)?.contiguous()?;
let value_states = value_states.reshape(shape)?.transpose(1, 2)?.contiguous()?;
let (query_states, key_states) = emb.apply_rotary_emb_qkv(&query_states, &key_states)?;
let attn_weights = (query_states.matmul(&key_states.t()?)? * self.scale)?;
let attn_weights = match attention_mask {
None => attn_weights,
Some(mask) => attn_weights.broadcast_add(mask)?,
};
let attn_weights = candle_nn::ops::softmax_last_dim(&attn_weights)?;
attn_weights
.matmul(&value_states)?
.transpose(1, 2)?
.reshape((b, patches, ()))?
.apply(&self.o_proj)
}
}
#[derive(Debug, Clone)]
struct Mlp {
gate_proj: Linear,
up_proj: Linear,
down_proj: Linear,
act_fn: candle_nn::Activation,
}
impl Mlp {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let (h, i) = (cfg.hidden_size, cfg.intermediate_size);
let gate_proj = linear_b(h, i, false, vb.pp("gate_proj"))?;
let up_proj = linear_b(h, i, false, vb.pp("up_proj"))?;
let down_proj = linear_b(i, h, false, vb.pp("down_proj"))?;
Ok(Self {
gate_proj,
up_proj,
down_proj,
act_fn: cfg.hidden_act,
})
}
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
(xs.apply(&self.gate_proj)?.apply(&self.act_fn)? * xs.apply(&self.up_proj))?
.apply(&self.down_proj)
}
}
#[derive(Debug, Clone)]
struct AttentionLayer {
attention_norm: RmsNorm,
feed_forward: Mlp,
attention: Attention,
ffn_norm: RmsNorm,
}
impl AttentionLayer {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let attention_norm = rms_norm(cfg.hidden_size, 1e-5, vb.pp("attention_norm"))?;
let feed_forward = Mlp::new(cfg, vb.pp("feed_forward"))?;
let attention = Attention::new(cfg, vb.pp("attention"))?;
let ffn_norm = rms_norm(cfg.hidden_size, 1e-5, vb.pp("ffn_norm"))?;
Ok(Self {
attention_norm,
feed_forward,
attention,
ffn_norm,
})
}
fn forward(
&self,
xs: &Tensor,
emb: &RotaryEmbedding,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let residual = xs;
let xs = self
.attention
.forward(&xs.apply(&self.attention_norm)?, emb, attention_mask)?;
let xs = (residual + xs)?;
let residual = &xs;
let xs = xs.apply(&self.ffn_norm)?.apply(&self.feed_forward)?;
xs + residual
}
}
#[derive(Debug, Clone)]
struct Transformer {
layers: Vec<AttentionLayer>,
}
impl Transformer {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let mut layers = Vec::with_capacity(cfg.num_hidden_layers);
let vb = vb.pp("layers");
for layer_idx in 0..cfg.num_hidden_layers {
let layer = AttentionLayer::new(cfg, vb.pp(layer_idx))?;
layers.push(layer)
}
Ok(Self { layers })
}
fn forward(
&self,
xs: &Tensor,
emb: &RotaryEmbedding,
attention_mask: Option<&Tensor>,
) -> Result<Tensor> {
let mut xs = xs.clone();
for layer in self.layers.iter() {
xs = layer.forward(&xs, emb, attention_mask)?
}
Ok(xs)
}
}
#[derive(Debug, Clone)]
struct RotaryEmbedding {
cos: Tensor,
sin: Tensor,
}
impl RotaryEmbedding {
fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let dtype = vb.dtype();
let dev = vb.device();
let dim = cfg.head_dim();
let rope_theta = cfg.rope_theta as f32;
let max_patches_per_side = cfg.image_size / cfg.patch_size;
let freqs: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / rope_theta.powf(i as f32 / dim as f32))
.collect();
let freqs_h = freqs.iter().step_by(2).copied().collect::<Vec<_>>();
let freqs_h = Tensor::new(freqs_h, dev)?;
let freqs_w = freqs.iter().skip(1).step_by(2).copied().collect::<Vec<_>>();
let freqs_w = Tensor::new(freqs_w, dev)?;
let h = Tensor::arange(0u32, max_patches_per_side as u32, dev)?.to_dtype(DType::F32)?;
let w = Tensor::arange(0u32, max_patches_per_side as u32, dev)?.to_dtype(DType::F32)?;
let freqs_h = h.unsqueeze(1)?.matmul(&freqs_h.unsqueeze(0)?)?;
let freqs_w = w.unsqueeze(1)?.matmul(&freqs_w.unsqueeze(0)?)?;
let inv_freq = Tensor::cat(
&[
freqs_h.unsqueeze(1)?.repeat((1, max_patches_per_side, 1))?,
freqs_w.unsqueeze(0)?.repeat((max_patches_per_side, 1, 1))?,
],
D::Minus1,
)?
.reshape(((), dim / 2))?;
let cos = inv_freq.cos()?.to_dtype(dtype)?;
let sin = inv_freq.sin()?.to_dtype(dtype)?;
Ok(Self { cos, sin })
}
fn apply_rotary_emb_qkv(&self, q: &Tensor, k: &Tensor) -> Result<(Tensor, Tensor)> {
let (_b_sz, _h, _seq_len, _n_embd) = q.dims4()?;
let cos = &self.cos;
let sin = &self.sin;
let q_embed = candle_nn::rotary_emb::rope(q, cos, sin)?;
let k_embed = candle_nn::rotary_emb::rope(k, cos, sin)?;
Ok((q_embed, k_embed))
}
}
#[derive(Debug, Clone)]
pub struct Model {
patch_conv: candle_nn::Conv2d,
ln_pre: RmsNorm,
transformer: Transformer,
patch_positional_embedding: RotaryEmbedding,
}
impl Model {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let conv2d_cfg = candle_nn::Conv2dConfig {
stride: cfg.patch_size,
..Default::default()
};
let patch_conv = candle_nn::conv2d_no_bias(
cfg.num_channels,
cfg.hidden_size,
cfg.patch_size,
conv2d_cfg,
vb.pp("patch_conv"),
)?;
let ln_pre = candle_nn::rms_norm(cfg.hidden_size, 1e-5, vb.pp("ln_pre"))?;
let transformer = Transformer::new(cfg, vb.pp("transformer"))?;
let patch_positional_embedding =
RotaryEmbedding::new(cfg, vb.pp("patch_positional_embedding"))?;
Ok(Self {
patch_conv,
ln_pre,
transformer,
patch_positional_embedding,
})
}
}
impl Module for Model {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let patch_embeds = xs.apply(&self.patch_conv)?;
let patch_embeds = patch_embeds.flatten_from(2)?.t()?.apply(&self.ln_pre)?;
self.transformer
.forward(&patch_embeds, &self.patch_positional_embedding, None)
}
}
| 5 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mmdit/embedding.rs | use candle::{bail, DType, Module, Result, Tensor};
use candle_nn as nn;
pub struct PatchEmbedder {
proj: nn::Conv2d,
}
impl PatchEmbedder {
pub fn new(
patch_size: usize,
in_channels: usize,
embed_dim: usize,
vb: nn::VarBuilder,
) -> Result<Self> {
let proj = nn::conv2d(
in_channels,
embed_dim,
patch_size,
nn::Conv2dConfig {
stride: patch_size,
..Default::default()
},
vb.pp("proj"),
)?;
Ok(Self { proj })
}
}
impl Module for PatchEmbedder {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
let x = self.proj.forward(x)?;
// flatten spatial dim and transpose to channels last
let (b, c, h, w) = x.dims4()?;
x.reshape((b, c, h * w))?.transpose(1, 2)
}
}
pub struct Unpatchifier {
patch_size: usize,
out_channels: usize,
}
impl Unpatchifier {
pub fn new(patch_size: usize, out_channels: usize) -> Result<Self> {
Ok(Self {
patch_size,
out_channels,
})
}
pub fn unpatchify(&self, x: &Tensor, h: usize, w: usize) -> Result<Tensor> {
let h = (h + 1) / self.patch_size;
let w = (w + 1) / self.patch_size;
let x = x.reshape((
x.dim(0)?,
h,
w,
self.patch_size,
self.patch_size,
self.out_channels,
))?;
let x = x.permute((0, 5, 1, 3, 2, 4))?; // "nhwpqc->nchpwq"
x.reshape((
x.dim(0)?,
self.out_channels,
self.patch_size * h,
self.patch_size * w,
))
}
}
pub struct PositionEmbedder {
pos_embed: Tensor,
patch_size: usize,
pos_embed_max_size: usize,
}
impl PositionEmbedder {
pub fn new(
hidden_size: usize,
patch_size: usize,
pos_embed_max_size: usize,
vb: nn::VarBuilder,
) -> Result<Self> {
let pos_embed = vb.get(
(1, pos_embed_max_size * pos_embed_max_size, hidden_size),
"pos_embed",
)?;
Ok(Self {
pos_embed,
patch_size,
pos_embed_max_size,
})
}
pub fn get_cropped_pos_embed(&self, h: usize, w: usize) -> Result<Tensor> {
let h = (h + 1) / self.patch_size;
let w = (w + 1) / self.patch_size;
if h > self.pos_embed_max_size || w > self.pos_embed_max_size {
bail!("Input size is too large for the position embedding")
}
let top = (self.pos_embed_max_size - h) / 2;
let left = (self.pos_embed_max_size - w) / 2;
let pos_embed =
self.pos_embed
.reshape((1, self.pos_embed_max_size, self.pos_embed_max_size, ()))?;
let pos_embed = pos_embed.narrow(1, top, h)?.narrow(2, left, w)?;
pos_embed.reshape((1, h * w, ()))
}
}
pub struct TimestepEmbedder {
mlp: nn::Sequential,
frequency_embedding_size: usize,
}
impl TimestepEmbedder {
pub fn new(
hidden_size: usize,
frequency_embedding_size: usize,
vb: nn::VarBuilder,
) -> Result<Self> {
let mlp = nn::seq()
.add(nn::linear(
frequency_embedding_size,
hidden_size,
vb.pp("mlp.0"),
)?)
.add(nn::Activation::Silu)
.add(nn::linear(hidden_size, hidden_size, vb.pp("mlp.2"))?);
Ok(Self {
mlp,
frequency_embedding_size,
})
}
fn timestep_embedding(t: &Tensor, dim: usize, max_period: f64) -> Result<Tensor> {
if dim % 2 != 0 {
bail!("Embedding dimension must be even")
}
if t.dtype() != DType::F32 && t.dtype() != DType::F64 {
bail!("Input tensor must be floating point")
}
let half = dim / 2;
let freqs = Tensor::arange(0f32, half as f32, t.device())?
.to_dtype(candle::DType::F32)?
.mul(&Tensor::full(
(-f64::ln(max_period) / half as f64) as f32,
half,
t.device(),
)?)?
.exp()?;
let args = t
.unsqueeze(1)?
.to_dtype(candle::DType::F32)?
.matmul(&freqs.unsqueeze(0)?)?;
let embedding = Tensor::cat(&[args.cos()?, args.sin()?], 1)?;
embedding.to_dtype(candle::DType::F16)
}
}
impl Module for TimestepEmbedder {
fn forward(&self, t: &Tensor) -> Result<Tensor> {
let t_freq = Self::timestep_embedding(t, self.frequency_embedding_size, 10000.0)?;
self.mlp.forward(&t_freq)
}
}
pub struct VectorEmbedder {
mlp: nn::Sequential,
}
impl VectorEmbedder {
pub fn new(input_dim: usize, hidden_size: usize, vb: nn::VarBuilder) -> Result<Self> {
let mlp = nn::seq()
.add(nn::linear(input_dim, hidden_size, vb.pp("mlp.0"))?)
.add(nn::Activation::Silu)
.add(nn::linear(hidden_size, hidden_size, vb.pp("mlp.2"))?);
Ok(Self { mlp })
}
}
impl Module for VectorEmbedder {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
self.mlp.forward(x)
}
}
| 6 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mmdit/blocks.rs | use candle::{Module, Result, Tensor, D};
use candle_nn as nn;
use super::projections::{AttnProjections, Mlp, Qkv, QkvOnlyAttnProjections};
pub struct ModulateIntermediates {
gate_msa: Tensor,
shift_mlp: Tensor,
scale_mlp: Tensor,
gate_mlp: Tensor,
}
pub struct DiTBlock {
norm1: LayerNormNoAffine,
attn: AttnProjections,
norm2: LayerNormNoAffine,
mlp: Mlp,
ada_ln_modulation: nn::Sequential,
}
pub struct LayerNormNoAffine {
eps: f64,
}
impl LayerNormNoAffine {
pub fn new(eps: f64) -> Self {
Self { eps }
}
}
impl Module for LayerNormNoAffine {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
nn::LayerNorm::new_no_bias(Tensor::ones_like(x)?, self.eps).forward(x)
}
}
impl DiTBlock {
pub fn new(hidden_size: usize, num_heads: usize, vb: nn::VarBuilder) -> Result<Self> {
let norm1 = LayerNormNoAffine::new(1e-6);
let attn = AttnProjections::new(hidden_size, num_heads, vb.pp("attn"))?;
let norm2 = LayerNormNoAffine::new(1e-6);
let mlp_ratio = 4;
let mlp = Mlp::new(hidden_size, hidden_size * mlp_ratio, vb.pp("mlp"))?;
let n_mods = 6;
let ada_ln_modulation = nn::seq().add(nn::Activation::Silu).add(nn::linear(
hidden_size,
n_mods * hidden_size,
vb.pp("adaLN_modulation.1"),
)?);
Ok(Self {
norm1,
attn,
norm2,
mlp,
ada_ln_modulation,
})
}
pub fn pre_attention(&self, x: &Tensor, c: &Tensor) -> Result<(Qkv, ModulateIntermediates)> {
let modulation = self.ada_ln_modulation.forward(c)?;
let chunks = modulation.chunk(6, D::Minus1)?;
let (shift_msa, scale_msa, gate_msa, shift_mlp, scale_mlp, gate_mlp) = (
chunks[0].clone(),
chunks[1].clone(),
chunks[2].clone(),
chunks[3].clone(),
chunks[4].clone(),
chunks[5].clone(),
);
let norm_x = self.norm1.forward(x)?;
let modulated_x = modulate(&norm_x, &shift_msa, &scale_msa)?;
let qkv = self.attn.pre_attention(&modulated_x)?;
Ok((
qkv,
ModulateIntermediates {
gate_msa,
shift_mlp,
scale_mlp,
gate_mlp,
},
))
}
pub fn post_attention(
&self,
attn: &Tensor,
x: &Tensor,
mod_interm: &ModulateIntermediates,
) -> Result<Tensor> {
let attn_out = self.attn.post_attention(attn)?;
let x = x.add(&attn_out.broadcast_mul(&mod_interm.gate_msa.unsqueeze(1)?)?)?;
let norm_x = self.norm2.forward(&x)?;
let modulated_x = modulate(&norm_x, &mod_interm.shift_mlp, &mod_interm.scale_mlp)?;
let mlp_out = self.mlp.forward(&modulated_x)?;
let x = x.add(&mlp_out.broadcast_mul(&mod_interm.gate_mlp.unsqueeze(1)?)?)?;
Ok(x)
}
}
pub struct SelfAttnModulateIntermediates {
gate_msa: Tensor,
shift_mlp: Tensor,
scale_mlp: Tensor,
gate_mlp: Tensor,
gate_msa2: Tensor,
}
pub struct SelfAttnDiTBlock {
norm1: LayerNormNoAffine,
attn: AttnProjections,
attn2: AttnProjections,
norm2: LayerNormNoAffine,
mlp: Mlp,
ada_ln_modulation: nn::Sequential,
}
impl SelfAttnDiTBlock {
pub fn new(hidden_size: usize, num_heads: usize, vb: nn::VarBuilder) -> Result<Self> {
let norm1 = LayerNormNoAffine::new(1e-6);
let attn = AttnProjections::new(hidden_size, num_heads, vb.pp("attn"))?;
let attn2 = AttnProjections::new(hidden_size, num_heads, vb.pp("attn2"))?;
let norm2 = LayerNormNoAffine::new(1e-6);
let mlp_ratio = 4;
let mlp = Mlp::new(hidden_size, hidden_size * mlp_ratio, vb.pp("mlp"))?;
let n_mods = 9;
let ada_ln_modulation = nn::seq().add(nn::Activation::Silu).add(nn::linear(
hidden_size,
n_mods * hidden_size,
vb.pp("adaLN_modulation.1"),
)?);
Ok(Self {
norm1,
attn,
attn2,
norm2,
mlp,
ada_ln_modulation,
})
}
pub fn pre_attention(
&self,
x: &Tensor,
c: &Tensor,
) -> Result<(Qkv, Qkv, SelfAttnModulateIntermediates)> {
let modulation = self.ada_ln_modulation.forward(c)?;
let chunks = modulation.chunk(9, D::Minus1)?;
let (
shift_msa,
scale_msa,
gate_msa,
shift_mlp,
scale_mlp,
gate_mlp,
shift_msa2,
scale_msa2,
gate_msa2,
) = (
chunks[0].clone(),
chunks[1].clone(),
chunks[2].clone(),
chunks[3].clone(),
chunks[4].clone(),
chunks[5].clone(),
chunks[6].clone(),
chunks[7].clone(),
chunks[8].clone(),
);
let norm_x = self.norm1.forward(x)?;
let modulated_x = modulate(&norm_x, &shift_msa, &scale_msa)?;
let qkv = self.attn.pre_attention(&modulated_x)?;
let modulated_x2 = modulate(&norm_x, &shift_msa2, &scale_msa2)?;
let qkv2 = self.attn2.pre_attention(&modulated_x2)?;
Ok((
qkv,
qkv2,
SelfAttnModulateIntermediates {
gate_msa,
shift_mlp,
scale_mlp,
gate_mlp,
gate_msa2,
},
))
}
pub fn post_attention(
&self,
attn: &Tensor,
attn2: &Tensor,
x: &Tensor,
mod_interm: &SelfAttnModulateIntermediates,
) -> Result<Tensor> {
let attn_out = self.attn.post_attention(attn)?;
let x = x.add(&attn_out.broadcast_mul(&mod_interm.gate_msa.unsqueeze(1)?)?)?;
let attn_out2 = self.attn2.post_attention(attn2)?;
let x = x.add(&attn_out2.broadcast_mul(&mod_interm.gate_msa2.unsqueeze(1)?)?)?;
let norm_x = self.norm2.forward(&x)?;
let modulated_x = modulate(&norm_x, &mod_interm.shift_mlp, &mod_interm.scale_mlp)?;
let mlp_out = self.mlp.forward(&modulated_x)?;
let x = x.add(&mlp_out.broadcast_mul(&mod_interm.gate_mlp.unsqueeze(1)?)?)?;
Ok(x)
}
}
pub struct QkvOnlyDiTBlock {
norm1: LayerNormNoAffine,
attn: QkvOnlyAttnProjections,
ada_ln_modulation: nn::Sequential,
}
impl QkvOnlyDiTBlock {
pub fn new(hidden_size: usize, num_heads: usize, vb: nn::VarBuilder) -> Result<Self> {
let norm1 = LayerNormNoAffine::new(1e-6);
let attn = QkvOnlyAttnProjections::new(hidden_size, num_heads, vb.pp("attn"))?;
let n_mods = 2;
let ada_ln_modulation = nn::seq().add(nn::Activation::Silu).add(nn::linear(
hidden_size,
n_mods * hidden_size,
vb.pp("adaLN_modulation.1"),
)?);
Ok(Self {
norm1,
attn,
ada_ln_modulation,
})
}
pub fn pre_attention(&self, x: &Tensor, c: &Tensor) -> Result<Qkv> {
let modulation = self.ada_ln_modulation.forward(c)?;
let chunks = modulation.chunk(2, D::Minus1)?;
let (shift_msa, scale_msa) = (chunks[0].clone(), chunks[1].clone());
let norm_x = self.norm1.forward(x)?;
let modulated_x = modulate(&norm_x, &shift_msa, &scale_msa)?;
self.attn.pre_attention(&modulated_x)
}
}
pub struct FinalLayer {
norm_final: LayerNormNoAffine,
linear: nn::Linear,
ada_ln_modulation: nn::Sequential,
}
impl FinalLayer {
pub fn new(
hidden_size: usize,
patch_size: usize,
out_channels: usize,
vb: nn::VarBuilder,
) -> Result<Self> {
let norm_final = LayerNormNoAffine::new(1e-6);
let linear = nn::linear(
hidden_size,
patch_size * patch_size * out_channels,
vb.pp("linear"),
)?;
let ada_ln_modulation = nn::seq().add(nn::Activation::Silu).add(nn::linear(
hidden_size,
2 * hidden_size,
vb.pp("adaLN_modulation.1"),
)?);
Ok(Self {
norm_final,
linear,
ada_ln_modulation,
})
}
pub fn forward(&self, x: &Tensor, c: &Tensor) -> Result<Tensor> {
let modulation = self.ada_ln_modulation.forward(c)?;
let chunks = modulation.chunk(2, D::Minus1)?;
let (shift, scale) = (chunks[0].clone(), chunks[1].clone());
let norm_x = self.norm_final.forward(x)?;
let modulated_x = modulate(&norm_x, &shift, &scale)?;
let output = self.linear.forward(&modulated_x)?;
Ok(output)
}
}
fn modulate(x: &Tensor, shift: &Tensor, scale: &Tensor) -> Result<Tensor> {
let shift = shift.unsqueeze(1)?;
let scale = scale.unsqueeze(1)?;
let scale_plus_one = scale.add(&Tensor::ones_like(&scale)?)?;
shift.broadcast_add(&x.broadcast_mul(&scale_plus_one)?)
}
pub trait JointBlock {
fn forward(&self, context: &Tensor, x: &Tensor, c: &Tensor) -> Result<(Tensor, Tensor)>;
}
pub struct MMDiTJointBlock {
x_block: DiTBlock,
context_block: DiTBlock,
num_heads: usize,
use_flash_attn: bool,
}
impl MMDiTJointBlock {
pub fn new(
hidden_size: usize,
num_heads: usize,
use_flash_attn: bool,
vb: nn::VarBuilder,
) -> Result<Self> {
let x_block = DiTBlock::new(hidden_size, num_heads, vb.pp("x_block"))?;
let context_block = DiTBlock::new(hidden_size, num_heads, vb.pp("context_block"))?;
Ok(Self {
x_block,
context_block,
num_heads,
use_flash_attn,
})
}
}
impl JointBlock for MMDiTJointBlock {
fn forward(&self, context: &Tensor, x: &Tensor, c: &Tensor) -> Result<(Tensor, Tensor)> {
let (context_qkv, context_interm) = self.context_block.pre_attention(context, c)?;
let (x_qkv, x_interm) = self.x_block.pre_attention(x, c)?;
let (context_attn, x_attn) =
joint_attn(&context_qkv, &x_qkv, self.num_heads, self.use_flash_attn)?;
let context_out =
self.context_block
.post_attention(&context_attn, context, &context_interm)?;
let x_out = self.x_block.post_attention(&x_attn, x, &x_interm)?;
Ok((context_out, x_out))
}
}
pub struct MMDiTXJointBlock {
x_block: SelfAttnDiTBlock,
context_block: DiTBlock,
num_heads: usize,
use_flash_attn: bool,
}
impl MMDiTXJointBlock {
pub fn new(
hidden_size: usize,
num_heads: usize,
use_flash_attn: bool,
vb: nn::VarBuilder,
) -> Result<Self> {
let x_block = SelfAttnDiTBlock::new(hidden_size, num_heads, vb.pp("x_block"))?;
let context_block = DiTBlock::new(hidden_size, num_heads, vb.pp("context_block"))?;
Ok(Self {
x_block,
context_block,
num_heads,
use_flash_attn,
})
}
}
impl JointBlock for MMDiTXJointBlock {
fn forward(&self, context: &Tensor, x: &Tensor, c: &Tensor) -> Result<(Tensor, Tensor)> {
let (context_qkv, context_interm) = self.context_block.pre_attention(context, c)?;
let (x_qkv, x_qkv2, x_interm) = self.x_block.pre_attention(x, c)?;
let (context_attn, x_attn) =
joint_attn(&context_qkv, &x_qkv, self.num_heads, self.use_flash_attn)?;
let x_attn2 = attn(&x_qkv2, self.num_heads, self.use_flash_attn)?;
let context_out =
self.context_block
.post_attention(&context_attn, context, &context_interm)?;
let x_out = self
.x_block
.post_attention(&x_attn, &x_attn2, x, &x_interm)?;
Ok((context_out, x_out))
}
}
pub struct ContextQkvOnlyJointBlock {
x_block: DiTBlock,
context_block: QkvOnlyDiTBlock,
num_heads: usize,
use_flash_attn: bool,
}
impl ContextQkvOnlyJointBlock {
pub fn new(
hidden_size: usize,
num_heads: usize,
use_flash_attn: bool,
vb: nn::VarBuilder,
) -> Result<Self> {
let x_block = DiTBlock::new(hidden_size, num_heads, vb.pp("x_block"))?;
let context_block = QkvOnlyDiTBlock::new(hidden_size, num_heads, vb.pp("context_block"))?;
Ok(Self {
x_block,
context_block,
num_heads,
use_flash_attn,
})
}
pub fn forward(&self, context: &Tensor, x: &Tensor, c: &Tensor) -> Result<Tensor> {
let context_qkv = self.context_block.pre_attention(context, c)?;
let (x_qkv, x_interm) = self.x_block.pre_attention(x, c)?;
let (_, x_attn) = joint_attn(&context_qkv, &x_qkv, self.num_heads, self.use_flash_attn)?;
let x_out = self.x_block.post_attention(&x_attn, x, &x_interm)?;
Ok(x_out)
}
}
// A QKV-attention that is compatible with the interface of candle_flash_attn::flash_attn
// Flash attention regards q, k, v dimensions as (batch_size, seqlen, nheads, headdim)
fn flash_compatible_attention(
q: &Tensor,
k: &Tensor,
v: &Tensor,
softmax_scale: f32,
) -> Result<Tensor> {
let q_dims_for_matmul = q.transpose(1, 2)?.dims().to_vec();
let rank = q_dims_for_matmul.len();
let q = q.transpose(1, 2)?.flatten_to(rank - 3)?;
let k = k.transpose(1, 2)?.flatten_to(rank - 3)?;
let v = v.transpose(1, 2)?.flatten_to(rank - 3)?;
let attn_weights = (q.matmul(&k.t()?)? * softmax_scale as f64)?;
let attn_scores = candle_nn::ops::softmax_last_dim(&attn_weights)?.matmul(&v)?;
attn_scores.reshape(q_dims_for_matmul)?.transpose(1, 2)
}
#[cfg(feature = "flash-attn")]
fn flash_attn(
q: &Tensor,
k: &Tensor,
v: &Tensor,
softmax_scale: f32,
causal: bool,
) -> Result<Tensor> {
candle_flash_attn::flash_attn(q, k, v, softmax_scale, causal)
}
#[cfg(not(feature = "flash-attn"))]
fn flash_attn(_: &Tensor, _: &Tensor, _: &Tensor, _: f32, _: bool) -> Result<Tensor> {
unimplemented!("compile with '--features flash-attn'")
}
fn joint_attn(
context_qkv: &Qkv,
x_qkv: &Qkv,
num_heads: usize,
use_flash_attn: bool,
) -> Result<(Tensor, Tensor)> {
let qkv = Qkv {
q: Tensor::cat(&[&context_qkv.q, &x_qkv.q], 1)?,
k: Tensor::cat(&[&context_qkv.k, &x_qkv.k], 1)?,
v: Tensor::cat(&[&context_qkv.v, &x_qkv.v], 1)?,
};
let seqlen = qkv.q.dim(1)?;
let attn = attn(&qkv, num_heads, use_flash_attn)?;
let context_qkv_seqlen = context_qkv.q.dim(1)?;
let context_attn = attn.narrow(1, 0, context_qkv_seqlen)?;
let x_attn = attn.narrow(1, context_qkv_seqlen, seqlen - context_qkv_seqlen)?;
Ok((context_attn, x_attn))
}
fn attn(qkv: &Qkv, num_heads: usize, use_flash_attn: bool) -> Result<Tensor> {
let batch_size = qkv.q.dim(0)?;
let seqlen = qkv.q.dim(1)?;
let qkv = Qkv {
q: qkv.q.reshape((batch_size, seqlen, num_heads, ()))?,
k: qkv.k.reshape((batch_size, seqlen, num_heads, ()))?,
v: qkv.v.clone(),
};
let headdim = qkv.q.dim(D::Minus1)?;
let softmax_scale = 1.0 / (headdim as f64).sqrt();
let attn = if use_flash_attn {
flash_attn(&qkv.q, &qkv.k, &qkv.v, softmax_scale as f32, false)?
} else {
flash_compatible_attention(&qkv.q, &qkv.k, &qkv.v, softmax_scale as f32)?
};
attn.reshape((batch_size, seqlen, ()))
}
| 7 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mmdit/mod.rs | //! Mix of Multi-scale Dilated and Traditional Convolutions
//!
//! Mix of Multi-scale Dilated and Traditional Convolutions (MMDiT) is an architecture
//! introduced for Stable Diffusion 3, with the MMDiT-X variant used in Stable Diffusion 3.5.
//!
//! - 📝 [Research Paper](https://arxiv.org/abs/2403.03206)
//! - 💻 ComfyUI [reference implementation](https://github.com/comfyanonymous/ComfyUI/blob/78e133d0415784924cd2674e2ee48f3eeca8a2aa/comfy/ldm/modules/diffusionmodules/mmdit.py)
//! - 💻 Stability-AI [MMDiT-X implementation](https://github.com/Stability-AI/sd3.5/blob/4e484e05308d83fb77ae6f680028e6c313f9da54/mmditx.py)
//! - ⚡ [Interactive Wasm Example](https://huggingface.co/spaces/radames/Candle-BLIP-Image-Captioning)
//! - 💻 [GH Link](https://github.com/salesforce/BLIP)
//! - 🤗 [HF Link](https://huggingface.co/Salesforce/blip-image-captioning-base)
//! - 📝 [Paper](https://arxiv.org/abs/2201.12086)
//!
pub mod blocks;
pub mod embedding;
pub mod model;
pub mod projections;
| 8 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mmdit/model.rs | // Implement the MMDiT model originally introduced for Stable Diffusion 3 (https://arxiv.org/abs/2403.03206),
// as well as the MMDiT-X variant introduced for Stable Diffusion 3.5-medium (https://huggingface.co/stabilityai/stable-diffusion-3.5-medium)
// This follows the implementation of the MMDiT model in the ComfyUI repository.
// https://github.com/comfyanonymous/ComfyUI/blob/78e133d0415784924cd2674e2ee48f3eeca8a2aa/comfy/ldm/modules/diffusionmodules/mmdit.py#L1
// with MMDiT-X support following the Stability-AI/sd3.5 repository.
// https://github.com/Stability-AI/sd3.5/blob/4e484e05308d83fb77ae6f680028e6c313f9da54/mmditx.py#L1
use candle::{Module, Result, Tensor, D};
use candle_nn as nn;
use super::blocks::{
ContextQkvOnlyJointBlock, FinalLayer, JointBlock, MMDiTJointBlock, MMDiTXJointBlock,
};
use super::embedding::{
PatchEmbedder, PositionEmbedder, TimestepEmbedder, Unpatchifier, VectorEmbedder,
};
#[derive(Debug, Clone)]
pub struct Config {
pub patch_size: usize,
pub in_channels: usize,
pub out_channels: usize,
pub depth: usize,
pub head_size: usize,
pub adm_in_channels: usize,
pub pos_embed_max_size: usize,
pub context_embed_size: usize,
pub frequency_embedding_size: usize,
}
impl Config {
pub fn sd3_medium() -> Self {
Self {
patch_size: 2,
in_channels: 16,
out_channels: 16,
depth: 24,
head_size: 64,
adm_in_channels: 2048,
pos_embed_max_size: 192,
context_embed_size: 4096,
frequency_embedding_size: 256,
}
}
pub fn sd3_5_medium() -> Self {
Self {
patch_size: 2,
in_channels: 16,
out_channels: 16,
depth: 24,
head_size: 64,
adm_in_channels: 2048,
pos_embed_max_size: 384,
context_embed_size: 4096,
frequency_embedding_size: 256,
}
}
pub fn sd3_5_large() -> Self {
Self {
patch_size: 2,
in_channels: 16,
out_channels: 16,
depth: 38,
head_size: 64,
adm_in_channels: 2048,
pos_embed_max_size: 192,
context_embed_size: 4096,
frequency_embedding_size: 256,
}
}
}
pub struct MMDiT {
core: MMDiTCore,
patch_embedder: PatchEmbedder,
pos_embedder: PositionEmbedder,
timestep_embedder: TimestepEmbedder,
vector_embedder: VectorEmbedder,
context_embedder: nn::Linear,
unpatchifier: Unpatchifier,
}
impl MMDiT {
pub fn new(cfg: &Config, use_flash_attn: bool, vb: nn::VarBuilder) -> Result<Self> {
let hidden_size = cfg.head_size * cfg.depth;
let core = MMDiTCore::new(
cfg.depth,
hidden_size,
cfg.depth,
cfg.patch_size,
cfg.out_channels,
use_flash_attn,
vb.clone(),
)?;
let patch_embedder = PatchEmbedder::new(
cfg.patch_size,
cfg.in_channels,
hidden_size,
vb.pp("x_embedder"),
)?;
let pos_embedder = PositionEmbedder::new(
hidden_size,
cfg.patch_size,
cfg.pos_embed_max_size,
vb.clone(),
)?;
let timestep_embedder = TimestepEmbedder::new(
hidden_size,
cfg.frequency_embedding_size,
vb.pp("t_embedder"),
)?;
let vector_embedder =
VectorEmbedder::new(cfg.adm_in_channels, hidden_size, vb.pp("y_embedder"))?;
let context_embedder = nn::linear(
cfg.context_embed_size,
hidden_size,
vb.pp("context_embedder"),
)?;
let unpatchifier = Unpatchifier::new(cfg.patch_size, cfg.out_channels)?;
Ok(Self {
core,
patch_embedder,
pos_embedder,
timestep_embedder,
vector_embedder,
context_embedder,
unpatchifier,
})
}
pub fn forward(
&self,
x: &Tensor,
t: &Tensor,
y: &Tensor,
context: &Tensor,
skip_layers: Option<&[usize]>,
) -> Result<Tensor> {
// Following the convention of the ComfyUI implementation.
// https://github.com/comfyanonymous/ComfyUI/blob/78e133d0415784924cd2674e2ee48f3eeca8a2aa/comfy/ldm/modules/diffusionmodules/mmdit.py#L919
//
// Forward pass of DiT.
// x: (N, C, H, W) tensor of spatial inputs (images or latent representations of images)
// t: (N,) tensor of diffusion timesteps
// y: (N,) tensor of class labels
let h = x.dim(D::Minus2)?;
let w = x.dim(D::Minus1)?;
let cropped_pos_embed = self.pos_embedder.get_cropped_pos_embed(h, w)?;
let x = self
.patch_embedder
.forward(x)?
.broadcast_add(&cropped_pos_embed)?;
let c = self.timestep_embedder.forward(t)?;
let y = self.vector_embedder.forward(y)?;
let c = (c + y)?;
let context = self.context_embedder.forward(context)?;
let x = self.core.forward(&context, &x, &c, skip_layers)?;
let x = self.unpatchifier.unpatchify(&x, h, w)?;
x.narrow(2, 0, h)?.narrow(3, 0, w)
}
}
pub struct MMDiTCore {
joint_blocks: Vec<Box<dyn JointBlock>>,
context_qkv_only_joint_block: ContextQkvOnlyJointBlock,
final_layer: FinalLayer,
}
impl MMDiTCore {
pub fn new(
depth: usize,
hidden_size: usize,
num_heads: usize,
patch_size: usize,
out_channels: usize,
use_flash_attn: bool,
vb: nn::VarBuilder,
) -> Result<Self> {
let mut joint_blocks = Vec::with_capacity(depth - 1);
for i in 0..depth - 1 {
let joint_block_vb_pp = format!("joint_blocks.{}", i);
let joint_block: Box<dyn JointBlock> =
if vb.contains_tensor(&format!("{}.x_block.attn2.qkv.weight", joint_block_vb_pp)) {
Box::new(MMDiTXJointBlock::new(
hidden_size,
num_heads,
use_flash_attn,
vb.pp(&joint_block_vb_pp),
)?)
} else {
Box::new(MMDiTJointBlock::new(
hidden_size,
num_heads,
use_flash_attn,
vb.pp(&joint_block_vb_pp),
)?)
};
joint_blocks.push(joint_block);
}
Ok(Self {
joint_blocks,
context_qkv_only_joint_block: ContextQkvOnlyJointBlock::new(
hidden_size,
num_heads,
use_flash_attn,
vb.pp(format!("joint_blocks.{}", depth - 1)),
)?,
final_layer: FinalLayer::new(
hidden_size,
patch_size,
out_channels,
vb.pp("final_layer"),
)?,
})
}
pub fn forward(
&self,
context: &Tensor,
x: &Tensor,
c: &Tensor,
skip_layers: Option<&[usize]>,
) -> Result<Tensor> {
let (mut context, mut x) = (context.clone(), x.clone());
for (i, joint_block) in self.joint_blocks.iter().enumerate() {
if let Some(skip_layers) = &skip_layers {
if skip_layers.contains(&i) {
continue;
}
}
(context, x) = joint_block.forward(&context, &x, c)?;
}
let x = self.context_qkv_only_joint_block.forward(&context, &x, c)?;
self.final_layer.forward(&x, c)
}
}
| 9 |
0 | hf_public_repos/candle/candle-pyo3/py_src | hf_public_repos/candle/candle-pyo3/py_src/candle/__init__.py | import logging
try:
from .candle import *
except ImportError as e:
# If we are in development mode, or we did not bundle the DLLs, we try to locate them here
# PyO3 wont give us any information about what DLLs are missing, so we can only try to load
# the DLLs and re-import the module
logging.warning("DLLs were not bundled with this package. Trying to locate them...")
import os
import platform
def locate_cuda_dlls():
logging.warning("Locating CUDA DLLs...")
# Try to locate CUDA_PATH environment variable
cuda_path = os.environ.get("CUDA_PATH", None)
if cuda_path:
logging.warning(f"Found CUDA_PATH environment variable: {cuda_path}")
if platform.system() == "Windows":
cuda_path = os.path.join(cuda_path, "bin")
else:
cuda_path = os.path.join(cuda_path, "lib64")
logging.warning(f"Adding {cuda_path} to DLL search path...")
os.add_dll_directory(cuda_path)
else:
logging.warning("CUDA_PATH environment variable not found!")
def locate_mkl_dlls():
# Try to locate ONEAPI_ROOT environment variable
oneapi_root = os.environ.get("ONEAPI_ROOT", None)
if oneapi_root:
if platform.system() == "Windows":
mkl_path = os.path.join(
oneapi_root, "compiler", "latest", "windows", "redist", "intel64_win", "compiler"
)
else:
mkl_path = os.path.join(oneapi_root, "mkl", "latest", "lib", "intel64")
logging.warning(f"Adding {mkl_path} to DLL search path...")
os.add_dll_directory(mkl_path)
else:
logging.warning("ONEAPI_ROOT environment variable not found!")
locate_cuda_dlls()
locate_mkl_dlls()
try:
from .candle import *
except ImportError as inner_e:
raise ImportError("Could not locate DLLs. Please check the documentation for more information.")
__doc__ = candle.__doc__
if hasattr(candle, "__all__"):
__all__ = candle.__all__
| 0 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/typing/__init__.py | from typing import TypeVar, Union, Sequence
_T = TypeVar("_T")
_ArrayLike = Union[
_T,
Sequence[_T],
Sequence[Sequence[_T]],
Sequence[Sequence[Sequence[_T]]],
Sequence[Sequence[Sequence[Sequence[_T]]]],
]
CPU: str = "cpu"
CUDA: str = "cuda"
Device = TypeVar("Device", CPU, CUDA)
Scalar = Union[int, float]
Index = Union[int, slice, None, "Ellipsis"]
Shape = Union[int, Sequence[int]]
| 1 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/functional/__init__.pyi | # Generated content DO NOT EDIT
from typing import Any, Callable, Dict, List, Optional, Tuple, Union, Sequence
from os import PathLike
from candle.typing import _ArrayLike, Device, Scalar, Index, Shape
from candle import Tensor, DType, QTensor
@staticmethod
def avg_pool2d(tensor: Tensor, ksize: int, stride: int = 1) -> Tensor:
"""
Applies the 2d avg-pool function to a given tensor.#
"""
pass
@staticmethod
def gelu(tensor: Tensor) -> Tensor:
"""
Applies the Gaussian Error Linear Unit (GELU) function to a given tensor.
"""
pass
@staticmethod
def max_pool2d(tensor: Tensor, ksize: int, stride: int = 1) -> Tensor:
"""
Applies the 2d max-pool function to a given tensor.#
"""
pass
@staticmethod
def relu(tensor: Tensor) -> Tensor:
"""
Applies the Rectified Linear Unit (ReLU) function to a given tensor.
"""
pass
@staticmethod
def silu(tensor: Tensor) -> Tensor:
"""
Applies the Sigmoid Linear Unit (SiLU) function to a given tensor.
"""
pass
@staticmethod
def softmax(tensor: Tensor, dim: int) -> Tensor:
"""
Applies the Softmax function to a given tensor.#
"""
pass
@staticmethod
def tanh(tensor: Tensor) -> Tensor:
"""
Applies the tanh function to a given tensor.
"""
pass
| 2 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/functional/__init__.py | # Generated content DO NOT EDIT
from .. import functional
avg_pool2d = functional.avg_pool2d
gelu = functional.gelu
max_pool2d = functional.max_pool2d
relu = functional.relu
silu = functional.silu
softmax = functional.softmax
tanh = functional.tanh
| 3 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/testing/__init__.py | import candle
from candle import Tensor
_UNSIGNED_DTYPES = set([str(candle.u8), str(candle.u32)])
def _assert_tensor_metadata(
actual: Tensor,
expected: Tensor,
check_device: bool = True,
check_dtype: bool = True,
check_layout: bool = True,
check_stride: bool = False,
):
if check_device:
assert actual.device == expected.device, f"Device mismatch: {actual.device} != {expected.device}"
if check_dtype:
assert str(actual.dtype) == str(expected.dtype), f"Dtype mismatch: {actual.dtype} != {expected.dtype}"
if check_layout:
assert actual.shape == expected.shape, f"Shape mismatch: {actual.shape} != {expected.shape}"
if check_stride:
assert actual.stride == expected.stride, f"Stride mismatch: {actual.stride} != {expected.stride}"
def assert_equal(
actual: Tensor,
expected: Tensor,
check_device: bool = True,
check_dtype: bool = True,
check_layout: bool = True,
check_stride: bool = False,
):
"""
Asserts that two tensors are exact equals.
"""
_assert_tensor_metadata(actual, expected, check_device, check_dtype, check_layout, check_stride)
assert (actual - expected).abs().sum_all().values() == 0, f"Tensors mismatch: {actual} != {expected}"
def assert_almost_equal(
actual: Tensor,
expected: Tensor,
rtol=1e-05,
atol=1e-08,
check_device: bool = True,
check_dtype: bool = True,
check_layout: bool = True,
check_stride: bool = False,
):
"""
Asserts, that two tensors are almost equal by performing an element wise comparison of the tensors with a tolerance.
Computes: |actual - expected| ≤ atol + rtol x |expected|
"""
_assert_tensor_metadata(actual, expected, check_device, check_dtype, check_layout, check_stride)
# Secure against overflow of u32 and u8 tensors
if str(actual.dtype) in _UNSIGNED_DTYPES or str(expected.dtype) in _UNSIGNED_DTYPES:
actual = actual.to(candle.i64)
expected = expected.to(candle.i64)
diff = (actual - expected).abs()
threshold = (expected.abs().to_dtype(candle.f32) * rtol + atol).to(expected)
assert (diff <= threshold).sum_all().values() == actual.nelement, f"Difference between tensors was to great"
| 4 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/onnx/__init__.pyi | # Generated content DO NOT EDIT
from typing import Any, Callable, Dict, List, Optional, Tuple, Union, Sequence
from os import PathLike
from candle.typing import _ArrayLike, Device, Scalar, Index, Shape
from candle import Tensor, DType, QTensor
class ONNXModel:
"""
A wrapper around an ONNX model.
"""
def __init__(self, path: str):
pass
@property
def doc_string(self) -> str:
"""
The doc string of the model.
"""
pass
@property
def domain(self) -> str:
"""
The domain of the operator set of the model.
"""
pass
def initializers(self) -> Dict[str, Tensor]:
"""
Get the weights of the model.
"""
pass
@property
def inputs(self) -> Optional[Dict[str, ONNXTensorDescription]]:
"""
The inputs of the model.
"""
pass
@property
def ir_version(self) -> int:
"""
The version of the IR this model targets.
"""
pass
@property
def model_version(self) -> int:
"""
The version of the model.
"""
pass
@property
def outputs(self) -> Optional[Dict[str, ONNXTensorDescription]]:
"""
The outputs of the model.
"""
pass
@property
def producer_name(self) -> str:
"""
The producer of the model.
"""
pass
@property
def producer_version(self) -> str:
"""
The version of the producer of the model.
"""
pass
def run(self, inputs: Dict[str, Tensor]) -> Dict[str, Tensor]:
"""
Run the model on the given inputs.
"""
pass
class ONNXTensorDescription:
"""
A wrapper around an ONNX tensor description.
"""
@property
def dtype(self) -> DType:
"""
The data type of the tensor.
"""
pass
@property
def shape(self) -> Tuple[Union[int, str, Any]]:
"""
The shape of the tensor.
"""
pass
| 5 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/onnx/__init__.py | # Generated content DO NOT EDIT
from .. import onnx
ONNXModel = onnx.ONNXModel
ONNXTensorDescription = onnx.ONNXTensorDescription
| 6 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/nn/__init__.pyi | # Generated content DO NOT EDIT
from typing import Any, Callable, Dict, List, Optional, Tuple, Union, Sequence
from os import PathLike
from candle.typing import _ArrayLike, Device, Scalar, Index, Shape
from candle import Tensor, DType, QTensor
@staticmethod
def silu(tensor: Tensor) -> Tensor:
"""
Applies the Sigmoid Linear Unit (SiLU) function to a given tensor.
"""
pass
@staticmethod
def softmax(tensor: Tensor, dim: int) -> Tensor:
"""
Applies the Softmax function to a given tensor.#
"""
pass
| 7 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/nn/module.py | from candle import Tensor, QTensor, DType
from typing import (
Dict,
Tuple,
Any,
Optional,
Union,
Iterator,
Set,
overload,
Mapping,
TypeVar,
List,
)
from collections import OrderedDict, namedtuple
TensorLike = Union[Tensor, QTensor]
T = TypeVar("T", bound="Module")
class _IncompatibleKeys(namedtuple("IncompatibleKeys", ["missing_keys", "unexpected_keys"])):
def __repr__(self):
if not self.missing_keys and not self.unexpected_keys:
return "<All keys matched successfully>"
return super().__repr__()
__str__ = __repr__
# see: https://github.com/pytorch/pytorch/blob/main/torch/nn/modules/module.py
class Module:
"""
Pytorch like Module.
Base class for all neural network modules.
Your models should also subclass this class.
"""
_modules: Dict[str, Optional["Module"]]
_buffers: Dict[str, Optional[TensorLike]]
_non_persistent_buffers_set: Set[str]
_quantizable_buffers: Set[str]
_version: int = 1
def __init__(self, *args, **kwargs) -> None:
"""
Initializes internal Module state
"""
super().__setattr__("_modules", OrderedDict())
super().__setattr__("_buffers", OrderedDict())
super().__setattr__("_non_persistent_buffers_set", set())
super().__setattr__("_quantizable_buffers", set())
def __call__(self, *input):
"""
Call self as a function.
"""
return self.forward(*input)
def forward(self, *input):
"""
Defines the computation performed at every call.
Should be overridden by all subclasses.
"""
pass
def children(self) -> Iterator["Module"]:
r"""Returns an iterator over immediate children modules.
Yields:
Module: a child module
"""
for name, module in self.named_children():
yield module
def named_children(self) -> Iterator[Tuple[str, "Module"]]:
r"""Returns an iterator over immediate children modules, yielding both
the name of the module as well as the module itself.
Yields:
(str, Module): Tuple containing a name and child module
Example::
>>> for name, module in model.named_children():
>>> if name in ['conv4', 'conv5']:
>>> print(module)
"""
memo = set()
for name, module in self._modules.items():
if module is not None and module not in memo:
memo.add(module)
yield name, module
def add_module(self, name: str, module: Optional["Module"]) -> None:
r"""Adds a child module to the current module.
The module can be accessed as an attribute using the given name.
Args:
name (str): name of the child module. The child module can be
accessed from this module using the given name
module (Module): child module to be added to the module.
"""
if not isinstance(module, Module) and module is not None:
raise TypeError(f"{str(module)} is not a Module subclass")
elif not isinstance(name, str):
raise TypeError(f"module name should be a string. Got {name}")
elif hasattr(self, name) and name not in self._modules:
raise KeyError(f"attribute '{name}' already exists")
elif "." in name:
raise KeyError(f'module name can\'t contain ".", got: {name}')
elif name == "":
raise KeyError('module name can\'t be empty string ""')
self._modules[name] = module
def register_module(self, name: str, module: Optional["Module"]) -> None:
r"""Alias for :func:`add_module`."""
self.add_module(name, module)
def modules(self) -> Iterator["Module"]:
r"""Returns an iterator over all modules in the network."""
for _, module in self.named_modules():
yield module
def named_modules(
self,
memo: Optional[Set["Module"]] = None,
prefix: str = "",
remove_duplicate: bool = True,
):
r"""Returns an iterator over all modules in the network, yielding
both the name of the module as well as the module itself.
Args:
memo: a memo to store the set of modules already added to the result
prefix: a prefix that will be added to the name of the module
remove_duplicate: whether to remove the duplicated module instances in the result
or not
Yields:
(str, Module): Tuple of name and module
Note:
Duplicate modules are returned only once. In the following
example, ``l`` will be returned only once.
"""
if memo is None:
memo = set()
if self not in memo:
if remove_duplicate:
memo.add(self)
yield prefix, self
for name, module in self._modules.items():
if module is None:
continue
submodule_prefix = prefix + ("." if prefix else "") + name
for m in module.named_modules(memo, submodule_prefix, remove_duplicate):
yield m
def buffers(self, recurse: bool = True) -> Iterator[TensorLike]:
"""
Returns an iterator over module buffers.
"""
for name, buf in self.named_buffers(recurse=recurse):
yield buf
def named_buffers(
self, prefix: str = "", recurse: bool = True, remove_duplicate: bool = True
) -> Iterator[Tuple[str, TensorLike]]:
r"""Returns an iterator over module buffers, yielding both the
name of the buffer as well as the buffer itself.
Args:
prefix (str): prefix to prepend to all buffer names.
recurse (bool, optional): if True, then yields buffers of this module
and all submodules. Otherwise, yields only buffers that
are direct members of this module. Defaults to True.
remove_duplicate (bool, optional): whether to remove the duplicated buffers in the result. Defaults to True.
Yields:
(str, Tensor): Tuple containing the name and buffer
Example::
>>> for name, buf in self.named_buffers():
>>> if name in ['running_var']:
>>> print(buf.size())
"""
gen = self._named_members(
lambda module: module._buffers.items(),
prefix=prefix,
recurse=recurse,
remove_duplicate=remove_duplicate,
)
yield from gen
# The user can pass an optional arbitrary mappable object to `state_dict`, in which case `state_dict` returns
# back that same object. But if they pass nothing, an `OrderedDict` is created and returned.
T_destination = TypeVar("T_destination", bound=Dict[str, Any])
@overload
def state_dict(self, *, destination: T_destination, prefix: str = ..., keep_vars: bool = ...) -> T_destination: ...
@overload
def state_dict(self, *, prefix: str = ..., keep_vars: bool = ...) -> Dict[str, Any]: ...
def state_dict(self, *args, destination=None, prefix="", keep_vars=False):
r"""Returns a dictionary containing references to the whole state of the module.
Both parameters and persistent buffers (e.g. running averages) are
included. Keys are corresponding parameter and buffer names.
Parameters and buffers set to ``None`` are not included.
.. note::
The returned object is a shallow copy. It contains references
to the module's parameters and buffers.
.. warning::
Currently ``state_dict()`` also accepts positional arguments for
``destination``, ``prefix`` and ``keep_vars`` in order. However,
this is being deprecated and keyword arguments will be enforced in
future releases.
.. warning::
Please avoid the use of argument ``destination`` as it is not
designed for end-users.
Args:
destination (dict, optional): If provided, the state of module will
be updated into the dict and the same object is returned.
Otherwise, an ``OrderedDict`` will be created and returned.
Default: ``None``.
prefix (str, optional): a prefix added to parameter and buffer
names to compose the keys in state_dict. Default: ``''``.
keep_vars (bool, optional): by default the :class:`~candle.Tensor` s
returned in the state dict are detached from autograd. If it's
set to ``True``, detaching will not be performed.
Default: ``False``.
Returns:
dict:
a dictionary containing a whole state of the module
Example::
>>> # xdoctest: +SKIP("undefined vars")
>>> module.state_dict().keys()
['bias', 'weight']
"""
# TODO: Remove `args` and the parsing logic when BC allows.
if len(args) > 0:
if destination is None:
destination = args[0]
if len(args) > 1 and prefix == "":
prefix = args[1]
if len(args) > 2 and keep_vars is False:
keep_vars = args[2]
if destination is None:
destination = OrderedDict()
destination._metadata = OrderedDict()
local_metadata = dict(version=self._version)
if hasattr(destination, "_metadata"):
destination._metadata[prefix[:-1]] = local_metadata
self._save_to_state_dict(destination, prefix, keep_vars)
for name, module in self._modules.items():
if module is not None:
module.state_dict(
destination=destination,
prefix=prefix + name + ".",
keep_vars=keep_vars,
)
return destination
def _save_to_state_dict(self, destination, prefix, keep_vars):
r"""Saves module state to `destination` dictionary, containing a state
of the module, but not its descendants. This is called on every
submodule in :meth:`~candle.nn.Module.state_dict`.
In rare cases, subclasses can achieve class-specific behavior by
overriding this method with custom logic.
Args:
destination (dict): a dict where state will be stored
prefix (str): the prefix for parameters and buffers used in this
module
"""
for name, buf in self._buffers.items():
if buf is not None and name not in self._non_persistent_buffers_set:
if isinstance(buf, Tensor):
destination[prefix + name] = buf if keep_vars else buf.detach()
else:
destination[prefix + name] = buf
def load_state_dict(self, state_dict: Mapping[str, Any], strict: bool = True, assign: bool = False):
r"""Copies parameters and buffers from :attr:`state_dict` into
this module and its descendants. If :attr:`strict` is ``True``, then
the keys of :attr:`state_dict` must exactly match the keys returned
by this module's :meth:`~candle.nn.Module.state_dict` function.
.. warning::
If :attr:`assign` is ``True`` the optimizer must be created after
the call to :attr:`load_state_dict`.
Args:
state_dict (dict): a dict containing parameters and
persistent buffers.
strict (bool, optional): whether to strictly enforce that the keys
in :attr:`state_dict` match the keys returned by this module's
:meth:`~candle.nn.Module.state_dict` function. Default: ``True``
assign (bool, optional): whether to assign items in the state
dictionary to their corresponding keys in the module instead
of copying them inplace into the module's current parameters and buffers.
When ``False``, the properties of the tensors in the current
module are preserved while when ``True``, the properties of the
Tensors in the state dict are preserved.
Default: ``False``
Returns:
``NamedTuple`` with ``missing_keys`` and ``unexpected_keys`` fields:
* **missing_keys** is a list of str containing the missing keys
* **unexpected_keys** is a list of str containing the unexpected keys
Note:
If a parameter or buffer is registered as ``None`` and its corresponding key
exists in :attr:`state_dict`, :meth:`load_state_dict` will raise a
``RuntimeError``.
"""
if not isinstance(state_dict, Mapping):
raise TypeError(f"Expected state_dict to be dict-like, got {type(state_dict)}.")
missing_keys: List[str] = []
unexpected_keys: List[str] = []
error_msgs: List[str] = []
# copy state_dict so _load_from_state_dict can modify it
metadata = getattr(state_dict, "_metadata", None)
state_dict = OrderedDict(state_dict)
if metadata is not None:
# mypy isn't aware that "_metadata" exists in state_dict
state_dict._metadata = metadata # type: ignore[attr-defined]
def load(module, local_state_dict, prefix=""):
local_metadata = {} if metadata is None else metadata.get(prefix[:-1], {})
if assign:
local_metadata["assign_to_params_buffers"] = assign
module._load_from_state_dict(
local_state_dict,
prefix,
local_metadata,
True,
missing_keys,
unexpected_keys,
error_msgs,
)
for name, child in module._modules.items():
if child is not None:
child_prefix = prefix + name + "."
child_state_dict = {k: v for k, v in local_state_dict.items() if k.startswith(child_prefix)}
load(child, child_state_dict, child_prefix)
load(self, state_dict)
del load
if strict:
if len(unexpected_keys) > 0:
error_msgs.insert(
0,
"Unexpected key(s) in state_dict: {}. ".format(", ".join(f'"{k}"' for k in unexpected_keys)),
)
if len(missing_keys) > 0:
error_msgs.insert(
0,
"Missing key(s) in state_dict: {}. ".format(", ".join(f'"{k}"' for k in missing_keys)),
)
if len(error_msgs) > 0:
raise RuntimeError(
"Error(s) in loading state_dict for {}:\n\t{}".format(self.__class__.__name__, "\n\t".join(error_msgs))
)
return _IncompatibleKeys(missing_keys, unexpected_keys)
def _load_from_state_dict(
self,
state_dict,
prefix,
local_metadata,
strict,
missing_keys,
unexpected_keys,
error_msgs,
):
r"""Copies parameters and buffers from :attr:`state_dict` into only
this module, but not its descendants. This is called on every submodule
in :meth:`~candle.nn.Module.load_state_dict`. Metadata saved for this
module in input :attr:`state_dict` is provided as :attr:`local_metadata`.
For state dicts without metadata, :attr:`local_metadata` is empty.
Subclasses can achieve class-specific backward compatible loading using
the version number at `local_metadata.get("version", None)`.
Additionally, :attr:`local_metadata` can also contain the key
`assign_to_params_buffers` that indicates whether keys should be
assigned their corresponding tensor in the state_dict.
.. note::
:attr:`state_dict` is not the same object as the input
:attr:`state_dict` to :meth:`~candle.nn.Module.load_state_dict`. So
it can be modified.
Args:
state_dict (dict): a dict containing parameters and
persistent buffers.
prefix (str): the prefix for parameters and buffers used in this
module
local_metadata (dict): a dict containing the metadata for this module.
See
strict (bool): whether to strictly enforce that the keys in
:attr:`state_dict` with :attr:`prefix` match the names of
parameters and buffers in this module
missing_keys (list of str): if ``strict=True``, add missing keys to
this list
unexpected_keys (list of str): if ``strict=True``, add unexpected
keys to this list
error_msgs (list of str): error messages should be added to this
list, and will be reported together in
:meth:`~candle.nn.Module.load_state_dict`
"""
persistent_buffers = {k: v for k, v in self._buffers.items() if k not in self._non_persistent_buffers_set}
local_name_params = persistent_buffers.items()
local_state = {k: v for k, v in local_name_params if v is not None}
for name, param in local_state.items():
key = prefix + name
if key in state_dict:
input_param = state_dict[key]
if not isinstance(input_param, (Tensor, QTensor)):
error_msgs.append(
f'While copying the parameter named "{key}", '
"expected Tensor-like object from checkpoint but "
f"received {type(input_param)}"
)
continue
if input_param.shape != param.shape:
# local shape should match the one in checkpoint
error_msgs.append(
"size mismatch for {}: copying a param with shape {} from checkpoint, "
"the shape in current model is {}.".format(key, input_param.shape, param.shape)
)
continue
try:
# Shape checks are already done above -> Just assign tensor
setattr(self, name, input_param)
except Exception as ex:
error_msgs.append(
f'While copying the parameter named "{key}", '
f"whose dimensions in the model are {param.shape} and "
f"whose dimensions in the checkpoint are {input_param.shape}, "
f"an exception occurred : {ex.args}."
)
elif strict:
missing_keys.append(key)
if strict:
for key in state_dict.keys():
if key.startswith(prefix):
input_name = key[len(prefix) :]
input_name = input_name.split(".", 1)[0] # get the name of param/buffer/child
if input_name not in self._modules and input_name not in local_state:
unexpected_keys.append(key)
def _named_members(self, get_members_fn, prefix="", recurse=True, remove_duplicate: bool = True):
r"""Helper method for yielding various names + members of modules."""
memo = set()
modules = self.named_modules(prefix=prefix, remove_duplicate=remove_duplicate) if recurse else [(prefix, self)]
for module_prefix, module in modules:
members = get_members_fn(module)
for k, v in members:
if v is None or v in memo:
continue
if remove_duplicate:
memo.add(v)
name = module_prefix + ("." if module_prefix else "") + k
yield name, v
def _get_name(self):
return self.__class__.__name__
def _apply(self, fn):
for module in self.children():
module._apply(fn)
for key, buf in self._buffers.items():
if buf is not None:
self._buffers[key] = fn(buf)
return self
def __move_tensor_to_device(self, tensor: TensorLike, device: str):
if isinstance(tensor, Tensor):
return tensor.to_device(device)
else:
raise NotImplementedError("Cannot offload QTensor to cuda, yet!")
def device(self) -> str:
"""
Gets the device of the module, by inspecting its tensors.
"""
tensor = next(self.buffers())
if isinstance(tensor, Tensor):
return tensor.device
else:
# QTensors can only be on the CPU
return "cpu"
def cuda(self: T) -> T:
r"""Moves all model parameters and buffers to the GPU.
This also makes associated parameters and buffers different objects. So
it should be called before constructing optimizer if the module will
live on GPU while being optimized.
.. note::
This method modifies the module in-place.
Returns:
Module: self
"""
def to_cuda(t: TensorLike):
return self.__move_tensor_to_device(t, "cuda")
return self._apply(to_cuda)
def cpu(self: T) -> T:
r"""Moves all model parameters and buffers to the CPU.
.. note::
This method modifies the module in-place.
Returns:
Module: self
"""
def to_cpu(t: TensorLike):
return self.__move_tensor_to_device(t, "cpu")
return self._apply(to_cpu)
def __cast_tensor(self, tensor: TensorLike, dtype: Union[DType, str]):
if isinstance(tensor, Tensor):
return tensor.to_dtype(dtype)
else:
raise TypeError("candle.Module.to only accepts Tensor dtypes, but got desired dtype={}".format(dtype))
def type(self: T, dst_type: Union[DType, str]) -> T:
r"""Casts all parameters and buffers to :attr:`dst_type`.
.. note::
This method modifies the module in-place.
Args:
dst_type (type or string): the desired type
Returns:
Module: self
"""
def cast(t: TensorLike):
return self.__cast_tensor(t, dst_type)
return self._apply(cast)
@overload
def to(
self: T,
device: str = ...,
dtype: Optional[Union[DType, str]] = ...,
) -> T: ...
@overload
def to(self: T, dtype: Union[DType, str]) -> T: ...
def to(self, *args, **kwargs):
r"""Moves and/or casts the parameters and buffers.
This can be called as
.. function:: to(device=None, dtype=None)
:noindex:
.. function:: to(dtype)
:noindex:
See below for examples.
.. note::
This method modifies the module in-place.
Args:
device (:class:`candle.device`): the desired device of the parameters
and buffers in this module
dtype (:class:`candle.dtype`): the desired floating point dtype of
the parameters and buffers in this module
Returns:
Module: self
"""
device = None
dtype = None
if args:
for arg in args:
# Assuming arg can be a string representing a device or a dtype
if isinstance(arg, str):
lower_arg = str(arg).lower()
if lower_arg.startswith("cuda") or lower_arg == "cpu":
device = lower_arg
else:
dtype = arg
elif isinstance(arg, DType):
dtype = str(arg)
else:
raise TypeError("Module.to() received an invalid combination of arguments. Got: {}".format(args))
if kwargs:
device = kwargs.get("device", device)
dtype = str(kwargs.get("dtype", dtype))
if device:
device = device.lower()
if dtype:
dtype = dtype.lower()
if dtype not in ["f32", "f16", "f64"]:
raise TypeError(
"candle.Module.to only accepts floating point" "dtypes, but got desired dtype={}".format(dtype)
)
def convert(t):
if dtype:
t = self.__cast_tensor(t, dtype)
if device:
t = self.__move_tensor_to_device(t, device)
return t
return self._apply(convert)
def __setattr__(self, __name: str, __value: Any) -> None:
if isinstance(__value, Module):
self._modules[__name] = __value
elif isinstance(__value, QTensor):
if __name in self._quantizable_buffers:
type = __value.ggml_dtype.lower()
if type in ["f32", "f16"]:
# It is faster to just dequantize the tensor here and use the normal tensor operations
dequant = __value.dequantize()
if type == "f16":
dequant = dequant.to_dtype("f16")
self._buffers[__name] = dequant
else:
self._buffers[__name] = __value
else:
# We expect a normal tensor here => dequantize it
self._buffers[__name] = __value.dequantize()
elif isinstance(__value, Tensor):
self._buffers[__name] = __value
else:
super().__setattr__(__name, __value)
def __getattr__(self, __name: str) -> Any:
if "_modules" in self.__dict__:
modules = self.__dict__["_modules"]
if __name in modules:
return modules[__name]
if "_buffers" in self.__dict__:
tensors = self.__dict__["_buffers"]
if __name in tensors:
return tensors[__name]
return super().__getattribute__(__name)
def __delattr__(self, name):
if name in self._buffers:
del self._buffers[name]
elif name in self._modules:
del self._modules[name]
else:
super().__delattr__(name)
| 8 |
0 | hf_public_repos/candle/candle-pyo3/py_src/candle | hf_public_repos/candle/candle-pyo3/py_src/candle/nn/linear.py | import math
from typing import Any
import candle
from candle import Tensor
from .module import Module
# See https://github.com/pytorch/pytorch/blob/main/torch/nn/modules/linear.py
class Identity(Module):
r"""A placeholder identity operator that is argument-insensitive.
Args:
args: any argument (unused)
kwargs: any keyword argument (unused)
Shape:
- Input: :math:`(*)`, where :math:`*` means any number of dimensions.
- Output: :math:`(*)`, same shape as the input.
Examples::
>>> m = nn.Identity(54, unused_argument1=0.1, unused_argument2=False)
>>> input = candle.randn(128, 20)
>>> output = m(input)
>>> print(output.shape)
"""
def __init__(self, *args: Any, **kwargs: Any) -> None:
super().__init__()
def forward(self, input: Tensor) -> Tensor:
return input
class Linear(Module):
r"""Applies a linear transformation to the incoming data: :math:`y = xA^T + b`
Args:
in_features: size of each input sample
out_features: size of each output sample
bias: If set to ``False``, the layer will not learn an additive bias.
Default: ``True``
Shape:
- Input: :math:`(*, H_{in})` where :math:`*` means any number of
dimensions including none and :math:`H_{in} = \text{in\_features}`.
- Output: :math:`(*, H_{out})` where all but the last dimension
are the same shape as the input and :math:`H_{out} = \text{out\_features}`.
Attributes:
weight: the learnable weights of the module of shape
:math:`(\text{out\_features}, \text{in\_features})`. The values are
initialized from :math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})`, where
:math:`k = \frac{1}{\text{in\_features}}`
bias: the learnable bias of the module of shape :math:`(\text{out\_features})`.
If :attr:`bias` is ``True``, the values are initialized from
:math:`\mathcal{U}(-\sqrt{k}, \sqrt{k})` where
:math:`k = \frac{1}{\text{in\_features}}`
"""
__constants__ = ["in_features", "out_features"]
in_features: int
out_features: int
weight: Tensor
def __init__(
self,
in_features: int,
out_features: int,
bias: bool = True,
device=None,
dtype=None,
) -> None:
factory_kwargs = {"device": device, "dtype": dtype}
super().__init__()
# Allow 'weight' to be quantized
self._quantizable_buffers.add("weight")
self.in_features = in_features
self.out_features = out_features
# TODO: Do actual initialization here: e.g. kaiming_uniform or xavier_uniform
self.weight = candle.ones((out_features, in_features), **factory_kwargs)
if bias:
self.bias = candle.zeros((out_features,), **factory_kwargs)
else:
self.bias = None
def forward(self, x: Tensor) -> Tensor:
dims = x.shape
last_dim = dims[-1]
if isinstance(self.weight, candle.QTensor):
if len(dims) < 3:
matmul_result = self.weight.matmul_t(x).broadcast_add(self.bias)
elif len(dims) == 3:
b, n, m = dims
output_shape = (b, n, self.out_features)
re = x.reshape((b * n, m))
matmul_result = self.weight.matmul_t(re).reshape((output_shape))
else:
raise NotImplementedError("'QTensor.matmul_t' is not implemented for more than 3 dimensions")
if self.bias:
return matmul_result.broadcast_add(self.bias)
else:
if self.weight.shape[-1] == last_dim and len(dims) < 3:
w = self.weight.t()
else:
batch_size = dims[0]
w = self.weight.broadcast_left((batch_size,)).t()
x = x.matmul(w)
if self.bias is not None:
x = x.broadcast_add(self.bias)
return x
def extra_repr(self) -> str:
return f"in_features={self.in_features}, out_features={self.out_features}, bias={self.bias is not None}"
| 9 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mimi/quantization.rs | // Copyright (c) Kyutai, all rights reserved.
// This source code is licensed under the license found in the
// LICENSE file in the root directory of this source tree.
use candle::{IndexOp, Layout, Result, Shape, Tensor, D};
use candle_nn::{linear, Linear, VarBuilder};
struct CodebookEncode;
impl candle::CustomOp2 for CodebookEncode {
fn name(&self) -> &'static str {
"cb"
}
fn cpu_fwd(
&self,
lhs_storage: &candle::CpuStorage,
lhs_layout: &Layout,
rhs_storage: &candle::CpuStorage,
rhs_layout: &Layout,
) -> Result<(candle::CpuStorage, Shape)> {
use rayon::prelude::*;
let (lhs_dim1, lhs_dim2) = lhs_layout.shape().dims2()?;
let (rhs_dim1, rhs_dim2) = rhs_layout.shape().dims2()?;
if lhs_dim2 != rhs_dim2 {
candle::bail!("CodebookEncode, mismatch on last dim, {lhs_layout:?} {rhs_layout:?}");
}
if lhs_dim2 == 0 {
candle::bail!("CodebookEncode, empty last dim {lhs_layout:?}")
}
let lhs = match lhs_layout.contiguous_offsets() {
None => candle::bail!("CodebookEncode, lhs has to be contiguous, got {lhs_layout:?}"),
Some((o1, o2)) => {
let slice = lhs_storage.as_slice::<f32>()?;
&slice[o1..o2]
}
};
let rhs = match rhs_layout.contiguous_offsets() {
None => candle::bail!("CodebookEncode, rhs has to be contiguous, got {rhs_layout:?}"),
Some((o1, o2)) => {
let slice = rhs_storage.as_slice::<f32>()?;
&slice[o1..o2]
}
};
let dst = (0..lhs_dim1)
.into_par_iter()
.map(|idx1| {
let mut where_min = 0;
let mut min_dist = f32::INFINITY;
let lhs = &lhs[idx1 * lhs_dim2..(idx1 + 1) * lhs_dim2];
for idx2 in 0..rhs_dim1 {
let rhs = &rhs[idx2 * rhs_dim2..(idx2 + 1) * rhs_dim2];
let mut dist = 0f32;
for (a, b) in lhs.iter().zip(rhs.iter()) {
dist += (a - b) * (a - b)
}
if dist < min_dist {
min_dist = dist;
where_min = idx2;
}
}
where_min as u32
})
.collect();
let storage = candle::WithDType::to_cpu_storage_owned(dst);
Ok((storage, (lhs_dim1,).into()))
}
}
#[allow(unused)]
#[derive(Debug, Clone)]
pub struct EuclideanCodebook {
initialized: Tensor,
cluster_usage: Tensor,
embedding_sum: Tensor,
embedding: Tensor,
c2: Tensor,
epsilon: f64,
dim: usize,
span_encode: tracing::Span,
span_decode: tracing::Span,
}
impl EuclideanCodebook {
pub fn new(dim: usize, codebook_size: usize, vb: VarBuilder) -> Result<Self> {
let epsilon = 1e-5;
let initialized = vb.get(1, "initialized")?;
let cluster_usage = vb.get(codebook_size, "cluster_usage")?;
let embedding_sum = vb.get((codebook_size, dim), "embed_sum")?;
let embedding = {
let cluster_usage = cluster_usage.maximum(epsilon)?.unsqueeze(1)?;
embedding_sum.broadcast_div(&cluster_usage)?
};
let c2 = ((&embedding * &embedding)?.sum(D::Minus1)? / 2.0)?;
Ok(Self {
initialized,
cluster_usage,
embedding_sum,
embedding,
c2,
epsilon,
dim,
span_encode: tracing::span!(tracing::Level::TRACE, "euclidean-encode"),
span_decode: tracing::span!(tracing::Level::TRACE, "euclidean-encode"),
})
}
pub fn encode_very_slow(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span_encode.enter();
let mut target_shape = xs.dims().to_vec();
target_shape.pop();
let xs = xs.flatten_to(D::Minus2)?;
let _ = xs.dims2()?;
// TODO: avoid repeating this.
let cluster_usage = self.cluster_usage.maximum(self.epsilon)?.unsqueeze(1)?;
let embedding = self.embedding_sum.broadcast_div(&cluster_usage)?;
// Manual cdist implementation.
let diff = xs.unsqueeze(1)?.broadcast_sub(&embedding.unsqueeze(0)?)?;
let dists = diff.sqr()?.sum(D::Minus1)?;
let codes = dists.argmin(D::Minus1)?;
codes.reshape(target_shape)
}
pub fn encode_slow(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span_encode.enter();
let mut target_shape = xs.dims().to_vec();
target_shape.pop();
let xs = xs.flatten_to(D::Minus2)?;
let _ = xs.dims2()?;
let dot_prod = xs.matmul(&self.embedding.t()?)?;
let codes = self.c2.broadcast_sub(&dot_prod)?.argmin(D::Minus1)?;
codes.reshape(target_shape)
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span_encode.enter();
let mut target_shape = xs.dims().to_vec();
target_shape.pop();
let xs = xs.flatten_to(D::Minus2)?;
let _ = xs.dims2()?;
let codes = Tensor::apply_op2(&xs, &self.embedding, CodebookEncode)?;
codes.reshape(target_shape)
}
pub fn decode(&self, indexes: &Tensor) -> Result<Tensor> {
let _enter = self.span_decode.enter();
// let ys = candle_nn::Embedding::new(self.embedding.clone(), self.dim).forward(xs)?;
let mut final_dims = indexes.dims().to_vec();
final_dims.push(self.dim);
let indexes = indexes.flatten_all()?;
let values = self.embedding.index_select(&indexes, 0)?;
let values = values.reshape(final_dims)?;
Ok(values)
}
}
#[allow(unused)]
#[derive(Debug, Clone)]
pub struct VectorQuantization {
project_in: Option<Linear>,
project_out: Option<Linear>,
codebook: EuclideanCodebook,
}
impl VectorQuantization {
pub fn new(
dim: usize,
codebook_size: usize,
codebook_dim: Option<usize>,
vb: VarBuilder,
) -> Result<Self> {
let codebook_dim = codebook_dim.unwrap_or(dim);
let (project_in, project_out) = if codebook_dim == dim {
(None, None)
} else {
let p_in = linear(dim, codebook_dim, vb.pp("project_in"))?;
let p_out = linear(codebook_dim, dim, vb.pp("project_out"))?;
(Some(p_in), Some(p_out))
};
let codebook = EuclideanCodebook::new(codebook_dim, codebook_size, vb.pp("codebook"))?;
Ok(Self {
project_in,
project_out,
codebook,
})
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let xs = xs.t()?.apply(&self.project_in.as_ref())?;
self.codebook.encode_slow(&xs)
}
pub fn decode(&self, codes: &Tensor) -> Result<Tensor> {
let quantized = self.codebook.decode(codes)?;
let quantized = match &self.project_out {
None => quantized,
Some(p) => quantized.apply(p)?,
};
quantized.t()
}
}
#[derive(Debug, Clone)]
pub struct ResidualVectorQuantization {
layers: Vec<VectorQuantization>,
}
impl ResidualVectorQuantization {
pub fn new(
n_q: usize,
dim: usize,
codebook_size: usize,
codebook_dim: Option<usize>,
vb: VarBuilder,
) -> Result<Self> {
let vb = vb.pp("layers");
let mut layers = Vec::with_capacity(n_q);
for i in 0..n_q {
let layer = VectorQuantization::new(dim, codebook_size, codebook_dim, vb.pp(i))?;
layers.push(layer)
}
Ok(Self { layers })
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let mut codes = Vec::with_capacity(self.layers.len());
let mut residual = xs.clone();
for layer in self.layers.iter() {
let indices = layer.encode(&residual)?;
let quantized = layer.decode(&indices)?;
residual = (residual - quantized)?;
codes.push(indices)
}
Tensor::stack(&codes, 0)
}
pub fn decode(&self, xs: &Tensor) -> Result<Tensor> {
if self.layers.is_empty() {
candle::bail!("empty layers in ResidualVectorQuantization")
}
if self.layers.len() != xs.dim(0)? {
candle::bail!(
"mismatch between the number of layers {} and the code shape {:?}",
self.layers.len(),
xs.shape()
)
}
let mut quantized = self.layers[0].decode(&xs.i(0)?)?;
for (i, layer) in self.layers.iter().enumerate().skip(1) {
let xs = xs.i(i)?;
quantized = (quantized + layer.decode(&xs))?
}
Ok(quantized)
}
}
#[allow(unused)]
#[derive(Debug, Clone)]
pub struct ResidualVectorQuantizer {
vq: ResidualVectorQuantization,
input_proj: Option<candle_nn::Conv1d>,
output_proj: Option<candle_nn::Conv1d>,
}
impl ResidualVectorQuantizer {
pub fn new(
dim: usize,
input_dim: Option<usize>,
output_dim: Option<usize>,
n_q: usize,
bins: usize,
force_projection: bool,
vb: VarBuilder,
) -> Result<Self> {
let input_dim = input_dim.unwrap_or(dim);
let output_dim = output_dim.unwrap_or(dim);
let input_proj = if input_dim == dim && !force_projection {
None
} else {
let c = candle_nn::conv1d_no_bias(
input_dim,
dim,
1,
Default::default(),
vb.pp("input_proj"),
)?;
Some(c)
};
let output_proj = if output_dim == dim && !force_projection {
None
} else {
let c = candle_nn::conv1d_no_bias(
dim,
output_dim,
1,
Default::default(),
vb.pp("output_proj"),
)?;
Some(c)
};
let vq = ResidualVectorQuantization::new(
n_q, dim, /* codebook_size */ bins, /* codebook_dim */ None, vb,
)?;
Ok(Self {
vq,
input_proj,
output_proj,
})
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let codes = self.vq.encode(&xs.apply(&self.input_proj.as_ref())?)?;
codes.transpose(0, 1)
}
pub fn decode(&self, codes: &Tensor) -> Result<Tensor> {
// codes is [B, K, T], with T frames, K nb of codebooks, vq.decode expects [K, B, T].
let codes = codes.transpose(0, 1)?;
let quantized = self.vq.decode(&codes)?;
match &self.output_proj {
None => Ok(quantized),
Some(p) => quantized.apply(p),
}
}
}
// we do not use any codebook_offset at the moment. When reconstructing the codes, we could just
// concatenate the indexes.
#[derive(Debug, Clone)]
pub struct SplitResidualVectorQuantizer {
rvq_first: ResidualVectorQuantizer,
rvq_rest: ResidualVectorQuantizer,
n_q: usize,
span_encode: tracing::Span,
span_decode: tracing::Span,
}
impl SplitResidualVectorQuantizer {
pub fn new(
dim: usize,
input_dim: Option<usize>,
output_dim: Option<usize>,
n_q: usize,
bins: usize,
vb: VarBuilder,
) -> Result<Self> {
let rvq_first = ResidualVectorQuantizer::new(
dim,
input_dim,
output_dim,
1,
bins,
true,
vb.pp("semantic_residual_vector_quantizer"),
)?;
let rvq_rest = ResidualVectorQuantizer::new(
dim,
input_dim,
output_dim,
n_q - 1,
bins,
true,
vb.pp("acoustic_residual_vector_quantizer"),
)?;
let span_encode = tracing::span!(tracing::Level::TRACE, "split-rvq-encode");
let span_decode = tracing::span!(tracing::Level::TRACE, "split-rvq-decode");
Ok(Self {
rvq_first,
rvq_rest,
n_q,
span_encode,
span_decode,
})
}
pub fn encode(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span_encode.enter();
let codes = self.rvq_first.encode(xs)?;
if self.n_q > 1 {
// We encode xs again here rather than the residual. The decomposition is not
// hierarchical but rather having semantic tokens for rvq_first and the acoustic tokens
// for rvq_rest.
let rest_codes = self.rvq_rest.encode(xs)?;
Tensor::cat(&[codes, rest_codes], 1)
} else {
Ok(codes)
}
}
pub fn decode(&self, codes: &Tensor) -> Result<Tensor> {
// codes is [B, K, T], with T frames, K nb of codebooks.
let _enter = self.span_decode.enter();
let quantized = self.rvq_first.decode(&codes.i((.., ..1))?)?;
let quantized = if self.n_q > 1 {
(quantized + self.rvq_rest.decode(&codes.i((.., 1..))?))?
} else {
quantized
};
Ok(quantized)
}
}
| 0 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mimi/conv.rs | // Copyright (c) Kyutai, all rights reserved.
// This source code is licensed under the license found in the
// LICENSE file in the root directory of this source tree.
use candle::{Module, Result, StreamTensor, StreamingModule, Tensor, D};
use candle_nn::{Conv1d, VarBuilder};
#[allow(clippy::enum_variant_names)]
#[derive(Debug, Copy, Clone, PartialEq, Eq)]
pub enum Norm {
WeightNorm,
SpectralNorm,
TimeGroupNorm,
}
#[derive(Debug, Copy, Clone, PartialEq, Eq)]
pub enum PadMode {
Constant,
Reflect,
Replicate,
}
// Applies weight norm for inference by recomputing the weight tensor. This
// does not apply to training.
// https://pytorch.org/docs/stable/generated/torch.nn.utils.weight_norm.html
fn conv1d_weight_norm(
in_c: usize,
out_c: usize,
kernel_size: usize,
bias: bool,
config: candle_nn::Conv1dConfig,
vb: VarBuilder,
) -> Result<Conv1d> {
let weight = if vb.contains_tensor("weight") {
vb.get((out_c, in_c, kernel_size), "weight")?
} else {
let weight_g = vb.get((out_c, 1, 1), "weight_g")?;
let weight_v = vb.get((out_c, in_c, kernel_size), "weight_v")?;
let norm_v = weight_v.sqr()?.sum_keepdim((1, 2))?.sqrt()?;
weight_v.broadcast_mul(&weight_g)?.broadcast_div(&norm_v)?
};
let bias = if bias {
Some(vb.get(out_c, "bias")?)
} else {
None
};
Ok(Conv1d::new(weight, bias, config))
}
#[derive(Debug, Clone)]
pub struct NormConv1d {
conv: Conv1d,
norm: Option<candle_nn::GroupNorm>,
span: tracing::Span,
}
impl NormConv1d {
#[allow(clippy::too_many_arguments)]
pub fn new(
in_c: usize,
out_c: usize,
k_size: usize,
causal: bool,
norm: Option<Norm>,
bias: bool,
cfg: candle_nn::Conv1dConfig,
vb: VarBuilder,
) -> Result<Self> {
let conv = match norm {
None | Some(Norm::TimeGroupNorm) => {
if bias {
candle_nn::conv1d(in_c, out_c, k_size, cfg, vb.pp("conv"))?
} else {
candle_nn::conv1d_no_bias(in_c, out_c, k_size, cfg, vb.pp("conv"))?
}
}
Some(Norm::WeightNorm) => {
conv1d_weight_norm(in_c, out_c, k_size, bias, cfg, vb.pp("conv"))?
}
Some(Norm::SpectralNorm) => candle::bail!("SpectralNorm is not supported yet."),
};
let norm = match norm {
None | Some(Norm::WeightNorm) | Some(Norm::SpectralNorm) => None,
Some(Norm::TimeGroupNorm) => {
if causal {
candle::bail!("GroupNorm doesn't support causal evaluation.")
}
let norm = candle_nn::group_norm(1, out_c, 1e-5, vb.pp("norm"))?;
Some(norm)
}
};
Ok(Self {
conv,
norm,
span: tracing::span!(tracing::Level::TRACE, "norm-conv1d"),
})
}
}
impl Module for NormConv1d {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let xs = xs.apply(&self.conv)?;
match self.norm.as_ref() {
None => Ok(xs),
Some(norm) => xs.apply(norm),
}
}
}
#[derive(Debug, Clone)]
pub struct NormConvTranspose1d {
ws: Tensor,
bs: Option<Tensor>,
k_size: usize,
stride: usize,
groups: usize,
norm: Option<candle_nn::GroupNorm>,
span: tracing::Span,
}
impl NormConvTranspose1d {
#[allow(clippy::too_many_arguments)]
pub fn new(
in_c: usize,
out_c: usize,
k_size: usize,
causal: bool,
norm: Option<Norm>,
bias: bool,
stride: usize,
groups: usize,
vb: VarBuilder,
) -> Result<Self> {
let vb = vb.pp("conv");
let bs = if bias {
Some(vb.get(out_c, "bias")?)
} else {
None
};
let ws = match norm {
None | Some(Norm::TimeGroupNorm) => vb.get((in_c, out_c / groups, k_size), "weight")?,
Some(Norm::WeightNorm) => {
if vb.contains_tensor("weight") {
vb.get((in_c, out_c, k_size), "weight")?
} else {
let weight_g = vb.get((in_c, 1, 1), "weight_g")?;
let weight_v = vb.get((in_c, out_c, k_size), "weight_v")?;
let norm_v = weight_v.sqr()?.sum_keepdim((1, 2))?.sqrt()?;
weight_v.broadcast_mul(&weight_g)?.broadcast_div(&norm_v)?
}
}
Some(Norm::SpectralNorm) => candle::bail!("SpectralNorm is not supported yet."),
};
let (ws, groups) = if groups == out_c && in_c == out_c {
let eye = Tensor::eye(out_c, ws.dtype(), ws.device())?;
let ws = ws
.repeat((1, out_c, 1))?
.mul(&eye.unsqueeze(2)?.repeat((1, 1, k_size))?)?;
(ws, 1)
} else {
(ws, groups)
};
let norm = match norm {
None | Some(Norm::WeightNorm) | Some(Norm::SpectralNorm) => None,
Some(Norm::TimeGroupNorm) => {
if causal {
candle::bail!("GroupNorm doesn't support causal evaluation.")
}
let norm = candle_nn::group_norm(1, out_c, 1e-5, vb.pp("norm"))?;
Some(norm)
}
};
Ok(Self {
ws,
bs,
k_size,
stride,
groups,
norm,
span: tracing::span!(tracing::Level::TRACE, "norm-conv-tr1d"),
})
}
}
impl Module for NormConvTranspose1d {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
// conv-transpose1d seems to be broken on metal after enough iterations. Causing
// the following error:
// _status < MTLCommandBufferStatusCommitted >
// -[IOGPUMetalCommandBuffer setCurrentCommandEncoder:]
// This is now fixed in candle.
let xs = Tensor::conv_transpose1d(xs, &self.ws, 0, 0, self.stride, 1, self.groups)?;
let xs = match &self.bs {
None => xs,
Some(bias) => {
let b = bias.dims1()?;
let bias = bias.reshape((1, b, 1))?;
xs.broadcast_add(&bias)?
}
};
match self.norm.as_ref() {
None => Ok(xs),
Some(norm) => xs.apply(norm),
}
}
}
fn get_extra_padding_for_conv1d(
xs: &Tensor,
k_size: usize,
stride: usize,
padding_total: usize,
) -> Result<usize> {
let len = xs.dim(D::Minus1)?;
let n_frames = (len + padding_total).saturating_sub(k_size) as f64 / stride as f64 + 1.0;
let ideal_len =
((n_frames.ceil() as usize - 1) * stride + k_size).saturating_sub(padding_total);
Ok(ideal_len.saturating_sub(len))
}
fn pad1d(xs: &Tensor, pad_l: usize, pad_r: usize, mode: PadMode) -> Result<Tensor> {
match mode {
PadMode::Constant => xs.pad_with_zeros(D::Minus1, pad_l, pad_r),
PadMode::Reflect => candle::bail!("pad-mode 'reflect' is not supported"),
PadMode::Replicate => xs.pad_with_same(D::Minus1, pad_l, pad_r),
}
}
fn unpad1d(xs: &Tensor, unpad_l: usize, unpad_r: usize) -> Result<Tensor> {
let len = xs.dim(D::Minus1)?;
if len < unpad_l + unpad_r {
candle::bail!("unpad1d: tensor len {len} is too low, {unpad_l} + {unpad_r}")
}
xs.narrow(D::Minus1, unpad_l, len - (unpad_l + unpad_r))
}
#[derive(Debug, Clone)]
pub struct StreamableConv1d {
conv: NormConv1d,
causal: bool,
pad_mode: PadMode,
state_prev_xs: StreamTensor,
left_pad_applied: bool,
kernel_size: usize,
span: tracing::Span,
}
impl StreamableConv1d {
#[allow(clippy::too_many_arguments)]
pub fn new(
in_c: usize,
out_c: usize,
k_size: usize,
stride: usize,
dilation: usize,
groups: usize,
bias: bool,
causal: bool,
norm: Option<Norm>,
pad_mode: PadMode,
vb: VarBuilder,
) -> Result<Self> {
let cfg = candle_nn::Conv1dConfig {
padding: 0,
stride,
dilation,
groups,
};
let conv = NormConv1d::new(in_c, out_c, k_size, causal, norm, bias, cfg, vb)?;
if k_size < stride {
candle::bail!("kernel-size {k_size} is smaller than stride {stride}")
}
Ok(Self {
conv,
causal,
pad_mode,
state_prev_xs: StreamTensor::empty(),
left_pad_applied: false,
kernel_size: k_size,
span: tracing::span!(tracing::Level::TRACE, "streamable-conv1d"),
})
}
}
impl Module for StreamableConv1d {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (_b, _t, _c) = xs.dims3()?;
let k_size = self.conv.conv.weight().dim(D::Minus1)?;
let conv_cfg = self.conv.conv.config();
// Effective kernel size with dilations.
let k_size = (k_size - 1) * conv_cfg.dilation + 1;
let padding_total = k_size - conv_cfg.stride;
let extra_padding =
get_extra_padding_for_conv1d(xs, k_size, conv_cfg.stride, padding_total)?;
let xs = if self.causal {
pad1d(xs, padding_total, extra_padding, self.pad_mode)?
} else {
let padding_right = padding_total / 2;
let padding_left = padding_total - padding_right;
pad1d(
xs,
padding_left,
padding_right + extra_padding,
self.pad_mode,
)?
};
xs.apply(&self.conv)
}
}
impl StreamingModule for StreamableConv1d {
fn reset_state(&mut self) {
self.state_prev_xs.reset();
self.left_pad_applied = false;
}
fn step(&mut self, xs: &StreamTensor) -> Result<StreamTensor> {
let _enter = self.span.enter();
let xs = match xs.as_option() {
None => return Ok(().into()),
Some(xs) => xs.clone(),
};
let xs = if self.left_pad_applied {
xs
} else {
self.left_pad_applied = true;
let k_size = self.conv.conv.weight().dim(D::Minus1)?;
let conv_cfg = self.conv.conv.config();
let k_size = (k_size - 1) * conv_cfg.dilation + 1;
let padding_total = k_size - conv_cfg.stride;
pad1d(&xs, padding_total, 0, self.pad_mode)?
};
let cfg = self.conv.conv.config();
let stride = cfg.stride;
let dilation = cfg.dilation;
let kernel = (self.kernel_size - 1) * dilation + 1;
let xs = StreamTensor::cat2(&self.state_prev_xs, &xs.into(), D::Minus1)?;
let seq_len = xs.seq_len(D::Minus1)?;
let num_frames = (seq_len + stride).saturating_sub(kernel) / stride;
if num_frames > 0 {
let offset = num_frames * stride;
self.state_prev_xs = xs.narrow(D::Minus1, offset, seq_len - offset)?;
let in_l = (num_frames - 1) * stride + kernel;
let xs = xs.narrow(D::Minus1, 0, in_l)?;
// We apply the underlying convtr directly rather than through forward so as
// not to apply any padding here.
xs.apply(&self.conv.conv)
} else {
self.state_prev_xs = xs;
Ok(StreamTensor::empty())
}
}
}
#[derive(Debug, Clone)]
pub struct StreamableConvTranspose1d {
convtr: NormConvTranspose1d,
causal: bool,
state_prev_ys: StreamTensor,
kernel_size: usize,
span: tracing::Span,
}
impl StreamableConvTranspose1d {
#[allow(clippy::too_many_arguments)]
pub fn new(
in_c: usize,
out_c: usize,
k_size: usize,
stride: usize,
groups: usize,
bias: bool,
causal: bool,
norm: Option<Norm>,
vb: VarBuilder,
) -> Result<Self> {
let convtr =
NormConvTranspose1d::new(in_c, out_c, k_size, causal, norm, bias, stride, groups, vb)?;
Ok(Self {
convtr,
causal,
kernel_size: k_size,
state_prev_ys: StreamTensor::empty(),
span: tracing::span!(tracing::Level::TRACE, "streamable-conv-tr1d"),
})
}
}
impl Module for StreamableConvTranspose1d {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let k_size = self.convtr.k_size;
let stride = self.convtr.stride;
let padding_total = k_size.saturating_sub(stride);
let xs = xs.apply(&self.convtr)?;
if self.causal {
// This corresponds to trim_right_ratio = 1.
unpad1d(&xs, 0, padding_total)
} else {
let padding_right = padding_total / 2;
let padding_left = padding_total - padding_right;
unpad1d(&xs, padding_left, padding_right)
}
}
}
impl StreamingModule for StreamableConvTranspose1d {
fn reset_state(&mut self) {
self.state_prev_ys.reset()
}
fn step(&mut self, xs: &StreamTensor) -> Result<StreamTensor> {
let _enter = self.span.enter();
let xs = match xs.as_option() {
Some(xs) => xs,
None => return Ok(StreamTensor::empty()),
};
let stride = self.convtr.stride;
// We apply the underlying convtr directly rather than through forward so as
// not to apply any padding here.
let ys = self.convtr.forward(xs)?;
let ot = ys.dim(D::Minus1)?;
let ys = match self.state_prev_ys.as_option() {
None => ys,
Some(prev_ys) => {
let pt = prev_ys.dim(D::Minus1)?;
// Remove the bias as it will be applied multiple times.
let prev_ys = match &self.convtr.bs {
None => prev_ys.clone(),
Some(bias) => {
let bias = bias.reshape((1, (), 1))?;
prev_ys.broadcast_sub(&bias)?
}
};
let ys1 = (ys.narrow(D::Minus1, 0, pt)? + prev_ys)?;
let ys2 = ys.narrow(D::Minus1, pt, ot - pt)?;
Tensor::cat(&[ys1, ys2], D::Minus1)?
}
};
let invalid_steps = self.kernel_size - stride;
let (ys, prev_ys) = StreamTensor::from(ys).split(D::Minus1, ot - invalid_steps)?;
self.state_prev_ys = prev_ys;
Ok(ys)
}
}
#[derive(Debug, Clone)]
pub struct ConvDownsample1d {
conv: StreamableConv1d,
}
impl ConvDownsample1d {
pub fn new(
stride: usize,
dim: usize,
causal: bool,
learnt: bool,
vb: VarBuilder,
) -> Result<Self> {
if !learnt {
candle::bail!("only learnt=true is supported")
}
let conv = StreamableConv1d::new(
/* in_c */ dim,
/* out_c */ dim,
/* k_size_c */ 2 * stride,
/* stride */ stride,
/* dilation */ 1,
/* groups */ 1, // channel_wise = false
/* bias */ false,
/* causal */ causal,
/* norm */ None,
/* pad_mode */ PadMode::Replicate,
vb,
)?;
Ok(Self { conv })
}
}
impl Module for ConvDownsample1d {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.conv)
}
}
impl StreamingModule for ConvDownsample1d {
fn reset_state(&mut self) {
self.conv.reset_state()
}
fn step(&mut self, xs: &StreamTensor) -> Result<StreamTensor> {
self.conv.step(xs)
}
}
#[derive(Debug, Clone)]
pub struct ConvTrUpsample1d {
convtr: StreamableConvTranspose1d,
}
impl ConvTrUpsample1d {
pub fn new(
stride: usize,
dim: usize,
causal: bool,
learnt: bool,
vb: VarBuilder,
) -> Result<Self> {
if !learnt {
candle::bail!("only learnt=true is supported")
}
let convtr = StreamableConvTranspose1d::new(
dim,
dim,
/* k_size */ 2 * stride,
/* stride */ stride,
/* groups */ dim,
/* bias */ false,
/* causal */ causal,
/* norm */ None,
vb,
)?;
Ok(Self { convtr })
}
}
impl Module for ConvTrUpsample1d {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.apply(&self.convtr)
}
}
impl StreamingModule for ConvTrUpsample1d {
fn reset_state(&mut self) {
self.convtr.reset_state()
}
fn step(&mut self, xs: &StreamTensor) -> Result<StreamTensor> {
self.convtr.step(xs)
}
}
#[cfg(test)]
mod tests {
use super::*;
use candle::IndexOp;
fn run_conv1d(
k_size: usize,
stride: usize,
dilation: usize,
step_size: usize,
len: usize,
bias: bool,
) -> Result<()> {
// TODO: We should ensure for the seed to be constant when running these tests.
let dev = &candle::Device::Cpu;
let vm = candle_nn::VarMap::new();
let vb = VarBuilder::from_varmap(&vm, candle::DType::F32, dev);
let conv1d = StreamableConv1d::new(
/* in_c */ 2,
/* out_c */ 3,
/* k_size */ k_size,
/* stride */ stride,
/* dilation */ dilation,
/* groups */ 1,
/* bias */ bias,
/* causal */ true,
/* norm */ None,
/* pad_mode */ PadMode::Constant,
vb,
)?;
let xs = Tensor::randn(0f32, 1., (1, 2, step_size * len), dev)?;
let ys = conv1d.forward(&xs)?;
let mut conv1d = conv1d;
let mut ys_steps = vec![];
for idx in 0..len {
let xs = xs.i((.., .., step_size * idx..step_size * (idx + 1)))?;
let ys = conv1d.step(&xs.into())?;
if let Some(ys) = ys.as_option() {
ys_steps.push(ys.clone())
}
}
let ys_steps = Tensor::cat(&ys_steps, D::Minus1)?;
let diff = (&ys - &ys_steps)?
.abs()?
.flatten_all()?
.max(0)?
.to_vec0::<f32>()?;
if diff > 1e-5 {
println!("{xs}");
println!("{ys}");
println!("{ys_steps}");
candle::bail!("larger diff than expected {diff}")
}
Ok(())
}
fn run_conv_tr1d(
k_size: usize,
stride: usize,
step_size: usize,
len: usize,
bias: bool,
) -> Result<()> {
// TODO: We should ensure for the seed to be constant when running these tests.
let dev = &candle::Device::Cpu;
let vm = candle_nn::VarMap::new();
let vb = VarBuilder::from_varmap(&vm, candle::DType::F32, dev);
let conv1d = StreamableConvTranspose1d::new(
/* in_c */ 2, /* out_c */ 3, /* k_size */ k_size,
/* stride */ stride, /* groups */ 1, /* bias */ bias,
/* causal */ true, /* norm */ None, vb,
)?;
let xs = Tensor::randn(0f32, 1., (1, 2, step_size * len), dev)?;
let ys = conv1d.forward(&xs)?;
let mut conv1d = conv1d;
let mut ys_steps = vec![];
for idx in 0..len {
let xs = xs.i((.., .., step_size * idx..step_size * (idx + 1)))?;
let ys = conv1d.step(&xs.into())?;
if let Some(ys) = ys.as_option() {
ys_steps.push(ys.clone())
}
}
let ys_steps = Tensor::cat(&ys_steps, D::Minus1)?;
let diff = (&ys - &ys_steps)?
.abs()?
.flatten_all()?
.max(0)?
.to_vec0::<f32>()?;
if diff > 1e-5 {
println!("{xs}");
println!("{ys}");
println!("{ys_steps}");
candle::bail!("larger diff than expected {diff}")
}
Ok(())
}
#[test]
fn conv1d() -> Result<()> {
for step_size in [1, 2, 3] {
for bias in [false, true] {
run_conv1d(1, 1, 1, step_size, 5, bias)?;
run_conv1d(2, 1, 1, step_size, 5, bias)?;
run_conv1d(2, 2, 1, step_size, 6, bias)?;
run_conv1d(3, 2, 1, step_size, 8, bias)?;
run_conv1d(3, 2, 2, step_size, 8, bias)?;
}
}
Ok(())
}
#[test]
fn conv_tr1d() -> Result<()> {
for step_size in [1, 2, 3] {
for bias in [false, true] {
run_conv_tr1d(1, 1, step_size, 5, bias)?;
run_conv_tr1d(2, 1, step_size, 5, bias)?;
run_conv_tr1d(3, 1, step_size, 5, bias)?;
run_conv_tr1d(3, 2, step_size, 5, bias)?;
}
}
Ok(())
}
}
| 1 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mimi/transformer.rs | // Copyright (c) Kyutai, all rights reserved.
// This source code is licensed under the license found in the
// LICENSE file in the root directory of this source tree.
use candle::{DType, Device, IndexOp, Module, Result, StreamTensor, StreamingModule, Tensor, D};
use candle_nn::{linear_no_bias, Linear, VarBuilder};
use std::sync::Arc;
fn linear(in_d: usize, out_d: usize, bias: bool, vb: VarBuilder) -> Result<Linear> {
if bias {
candle_nn::linear(in_d, out_d, vb)
} else {
linear_no_bias(in_d, out_d, vb)
}
}
#[derive(Debug, Copy, Clone, PartialEq, Eq)]
pub enum PositionalEmbedding {
Rope,
Sin,
None,
}
#[derive(Debug, Clone)]
pub struct Config {
pub d_model: usize,
pub num_heads: usize,
pub num_layers: usize,
pub causal: bool,
pub norm_first: bool,
pub bias_ff: bool,
pub bias_attn: bool,
pub layer_scale: Option<f64>,
pub positional_embedding: PositionalEmbedding,
pub use_conv_block: bool,
pub cross_attention: bool,
pub conv_kernel_size: usize,
pub use_conv_bias: bool,
pub gating: Option<candle_nn::Activation>,
pub norm: super::NormType,
pub context: usize,
pub max_period: usize,
pub max_seq_len: usize,
pub kv_repeat: usize,
pub dim_feedforward: usize,
pub conv_layout: bool,
}
#[derive(Debug, Clone)]
pub struct RotaryEmbedding {
sin: Tensor,
cos: Tensor,
span: tracing::Span,
}
impl RotaryEmbedding {
pub fn new(dim: usize, max_seq_len: usize, theta: f32, dev: &Device) -> Result<Self> {
let inv_freq: Vec<_> = (0..dim)
.step_by(2)
.map(|i| 1f32 / theta.powf(i as f32 / dim as f32))
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?;
let t = Tensor::arange(0u32, max_seq_len as u32, dev)?
.to_dtype(DType::F32)?
.reshape((max_seq_len, 1))?;
let freqs = t.matmul(&inv_freq)?;
Ok(Self {
sin: freqs.sin()?,
cos: freqs.cos()?,
span: tracing::span!(tracing::Level::TRACE, "rot"),
})
}
pub fn apply_rotary_emb(&self, qk: &Tensor, seqlen_offset: usize) -> Result<Tensor> {
let _enter = self.span.enter();
let (_b_size, _nheads, seqlen, _headdim) = qk.dims4()?;
let qk_dtype = qk.dtype();
let c = self.cos.narrow(0, seqlen_offset, seqlen)?;
let s = self.sin.narrow(0, seqlen_offset, seqlen)?;
candle_nn::rotary_emb::rope_i(&qk.to_dtype(DType::F32)?, &c, &s)?.to_dtype(qk_dtype)
}
}
#[derive(Debug, Clone)]
pub struct LayerScale {
scale: Tensor,
}
impl LayerScale {
pub fn new(d_model: usize, _init: f64, vb: VarBuilder) -> Result<Self> {
let scale = vb.get(d_model, "scale")?;
Ok(Self { scale })
}
}
impl Module for LayerScale {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
xs.broadcast_mul(&self.scale)
}
}
#[derive(Debug, Clone)]
pub struct StreamingMultiheadAttention {
q_proj: Linear,
k_proj: Linear,
v_proj: Linear,
out_proj: Linear,
kv_repeat: usize,
num_heads: usize,
context: usize,
neg_inf: Tensor,
rope: Option<Arc<RotaryEmbedding>>,
kv_cache: candle_nn::kv_cache::RotatingKvCache,
pos: usize,
use_flash_attn: bool,
span: tracing::Span,
}
impl StreamingMultiheadAttention {
pub fn new(rope: &Option<Arc<RotaryEmbedding>>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let embed_dim = cfg.d_model;
let num_kv = cfg.num_heads / cfg.kv_repeat;
let kv_dim = num_kv * (embed_dim / cfg.num_heads);
let q_proj = linear(embed_dim, embed_dim, cfg.bias_attn, vb.pp("q_proj"))?;
let k_proj = linear(embed_dim, kv_dim, cfg.bias_attn, vb.pp("k_proj"))?;
let v_proj = linear(embed_dim, kv_dim, cfg.bias_attn, vb.pp("v_proj"))?;
let out_proj = linear(embed_dim, embed_dim, cfg.bias_attn, vb.pp("o_proj"))?;
let neg_inf = Tensor::new(f32::NEG_INFINITY, vb.device())?.to_dtype(vb.dtype())?;
Ok(Self {
q_proj,
k_proj,
v_proj,
out_proj,
rope: rope.clone(),
kv_repeat: cfg.kv_repeat,
num_heads: cfg.num_heads,
context: cfg.context,
neg_inf,
kv_cache: candle_nn::kv_cache::RotatingKvCache::new(2, cfg.context),
pos: 0,
use_flash_attn: false,
span: tracing::span!(tracing::Level::TRACE, "mha"),
})
}
pub fn forward(&mut self, xs: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let _enter = self.span.enter();
if self.kv_repeat != 1 {
candle::bail!("only kv-repeat = 1 is supported")
}
let (b, t, hd) = xs.dims3()?;
let head_dim = hd / self.num_heads;
let q = xs
.apply(&self.q_proj)?
.reshape((b, t, self.num_heads, head_dim))?;
let k = xs
.apply(&self.k_proj)?
.reshape((b, t, self.num_heads, head_dim))?;
let v = xs
.apply(&self.v_proj)?
.reshape((b, t, self.num_heads, head_dim))?;
// qk_layer_norm = None
// kv_repeat = 1, otherwise we would need repeat_kv
let mut q = q.transpose(1, 2)?.contiguous()?; // b,h,t,d
let mut k = k.transpose(1, 2)?.contiguous()?; // b,h,k,d
let v = v.transpose(1, 2)?.contiguous()?; // b,h,k,d
if let Some(rope) = &self.rope {
q = rope.apply_rotary_emb(&q, self.pos)?;
k = rope.apply_rotary_emb(&k, self.pos)?;
}
let (k, v) = {
self.pos += k.dim(2)?;
self.kv_cache.append(&k.contiguous()?, &v.contiguous()?)?
};
// The KV cache keeps all the data at the moment, we want to trim
// down the part that comes from the cache to at most context to
// be coherent with the mask shape we provide.
let k_len = k.dim(2)?;
let k_target_len = t + usize::min(self.context, k_len - t);
let (k, v) = if k_target_len < k_len {
let k = k.narrow(2, k_len - k_target_len, k_target_len)?;
let v = v.narrow(2, k_len - k_target_len, k_target_len)?;
(k, v)
} else {
(k.clone(), v.clone())
};
let xs = if q.dtype() == DType::BF16 && self.use_flash_attn {
let q = q.transpose(1, 2)?;
let k = k.transpose(1, 2)?;
let v = v.transpose(1, 2)?;
let softmax_scale = 1f32 / (head_dim as f32).sqrt();
flash_attn(&q, &k, &v, softmax_scale, t > 1)?.transpose(1, 2)?
} else {
let pre_ws = q.matmul(&k.t()?)?; // b,h,t,k
let pre_ws = (pre_ws * (head_dim as f64).powf(-0.5))?;
let pre_ws = match mask {
None => pre_ws,
Some(mask) => {
let mask = mask.broadcast_left((b, self.num_heads))?;
let neg_inf = self.neg_inf.broadcast_as(pre_ws.shape())?;
mask.where_cond(&neg_inf, &pre_ws)?
}
};
let ws = candle_nn::ops::softmax_last_dim(&pre_ws)?; // b,h,t,k
ws.matmul(&v)? // b,h,t,d
};
let xs = xs
.transpose(1, 2)? // b,t,h,d
.reshape((b, t, hd))?
.apply(&self.out_proj)?;
Ok(xs)
}
pub fn reset_kv_cache(&mut self) {
self.kv_cache.reset()
}
pub fn set_kv_cache(&mut self, kv_cache: candle_nn::kv_cache::RotatingKvCache) {
self.kv_cache = kv_cache
}
}
#[derive(Debug, Clone)]
pub struct StreamingMultiheadCrossAttention {
in_proj_q: Linear,
in_proj_k: Linear,
in_proj_v: Linear,
out_proj: Linear,
kv_repeat: usize,
num_heads: usize,
neg_inf: Tensor,
span: tracing::Span,
}
impl StreamingMultiheadCrossAttention {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let embed_dim = cfg.d_model;
let num_kv = cfg.num_heads / cfg.kv_repeat;
let kv_dim = num_kv * (embed_dim / cfg.num_heads);
let out_dim = embed_dim + 2 * kv_dim;
let in_proj_weight = vb.get((out_dim, embed_dim), "in_proj_weight")?;
let in_proj_weight_q = in_proj_weight.narrow(0, 0, embed_dim)?;
let in_proj_weight_k = in_proj_weight.narrow(0, embed_dim, kv_dim)?;
let in_proj_weight_v = in_proj_weight.narrow(0, embed_dim + kv_dim, kv_dim)?;
let (in_proj_bias_q, in_proj_bias_k, in_proj_bias_v) = if cfg.bias_attn {
let b = vb.get(out_dim, "in_proj_bias")?;
let q = b.narrow(0, 0, embed_dim)?;
let k = b.narrow(0, embed_dim, kv_dim)?;
let v = b.narrow(0, embed_dim + kv_dim, kv_dim)?;
(Some(q), Some(k), Some(v))
} else {
(None, None, None)
};
let in_proj_q = Linear::new(in_proj_weight_q, in_proj_bias_q);
let in_proj_k = Linear::new(in_proj_weight_k, in_proj_bias_k);
let in_proj_v = Linear::new(in_proj_weight_v, in_proj_bias_v);
let out_proj = linear(embed_dim, embed_dim, cfg.bias_attn, vb.pp("out_proj"))?;
let neg_inf = Tensor::new(f32::NEG_INFINITY, vb.device())?.to_dtype(vb.dtype())?;
Ok(Self {
in_proj_q,
in_proj_k,
in_proj_v,
out_proj,
kv_repeat: cfg.kv_repeat,
num_heads: cfg.num_heads,
neg_inf,
span: tracing::span!(tracing::Level::TRACE, "mhca"),
})
}
pub fn forward(&self, xs: &Tensor, ca_src: &Tensor, mask: Option<&Tensor>) -> Result<Tensor> {
let _enter = self.span.enter();
if self.kv_repeat != 1 {
candle::bail!("only kv-repeat = 1 is supported")
}
let (b, t, hd) = xs.dims3()?;
let head_dim = hd / self.num_heads;
// time_dim = 1, layout: b,t,h,d
let q = xs.apply(&self.in_proj_q)?;
let k = ca_src.apply(&self.in_proj_k)?;
let v = ca_src.apply(&self.in_proj_v)?;
let (ca_b, ca_t, ca_dim) = k.dims3()?;
let q = q.reshape((b, t, self.num_heads, head_dim))?;
let k = k.reshape((ca_b, ca_t, ca_dim / head_dim, head_dim))?;
let v = v.reshape((ca_b, ca_t, ca_dim / head_dim, head_dim))?;
// qk_layer_norm = None
// kv_repeat = 1, otherwise we would need repeat_kv
let q = q.transpose(1, 2)?.contiguous()?; // b,h,t,d
let k = k.transpose(1, 2)?.contiguous()?; // b,h,k,d
let v = v.transpose(1, 2)?.contiguous()?; // b,h,k,d
let pre_ws = q.matmul(&k.t()?)?; // b,h,t,k
let pre_ws = (pre_ws * (head_dim as f64).powf(-0.5))?;
let pre_ws = match mask {
None => pre_ws,
Some(mask) => {
let mask = mask.broadcast_left((b, self.num_heads))?;
let neg_inf = self.neg_inf.broadcast_as(pre_ws.shape())?;
mask.where_cond(&neg_inf, &pre_ws)?
}
};
let ws = candle_nn::ops::softmax_last_dim(&pre_ws)?; // b,h,t,k
let xs = ws.matmul(&v)?; // b,h,t,d
let xs = xs
.transpose(1, 2)? // b,t,h,d
.reshape((b, t, hd))?
.apply(&self.out_proj)?;
Ok(xs)
}
}
#[derive(Debug, Clone)]
pub enum Mlp {
NoGating {
span1: tracing::Span,
linear1: Linear,
span2: tracing::Span,
linear2: Linear,
span: tracing::Span,
},
Gating {
linear_in: Linear,
linear_out: Linear,
activation: candle_nn::Activation,
span: tracing::Span,
},
}
impl Mlp {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let d_model = cfg.d_model;
let span = tracing::span!(tracing::Level::TRACE, "mlp");
match cfg.gating {
None => {
let span1 = tracing::span!(tracing::Level::TRACE, "lin1");
let span2 = tracing::span!(tracing::Level::TRACE, "lin2");
let linear1 = linear(d_model, cfg.dim_feedforward, cfg.bias_ff, vb.pp("mlp.fc1"))?;
let linear2 = linear(cfg.dim_feedforward, d_model, cfg.bias_ff, vb.pp("mlp.fc2"))?;
Ok(Self::NoGating {
linear1,
linear2,
span,
span1,
span2,
})
}
Some(activation) => {
let vb = vb.pp("gating");
let hidden = if cfg.dim_feedforward == 4 * d_model {
11 * d_model / 4
} else {
2 * cfg.dim_feedforward / 3
};
// TODO: Maybe use bias_ff here?
let linear_in = linear(d_model, 2 * hidden, false, vb.pp("linear_in"))?;
let linear_out = linear(hidden, d_model, false, vb.pp("linear_out"))?;
Ok(Self::Gating {
linear_in,
linear_out,
activation,
span,
})
}
}
}
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
match self {
Self::NoGating {
linear1,
linear2,
span,
span1,
span2,
} => {
let _enter = span.enter();
let xs = {
let _enter = span1.enter();
xs.apply(linear1)?
};
let xs = xs.gelu_erf()?;
{
let _enter = span2.enter();
xs.apply(linear2)
}
}
Self::Gating {
linear_in,
linear_out,
activation,
span,
} => {
let _enter = span.enter();
let xs = xs.apply(linear_in)?;
let (b, t, _) = xs.dims3()?;
let xs = xs.reshape((b, t, 2, ()))?;
let xs = (xs.i((.., .., 0))?.apply(activation)? * xs.i((.., .., 1))?)?;
xs.apply(linear_out)
}
}
}
}
#[derive(Debug, Clone)]
pub struct RmsNorm {
pub(crate) alpha: Tensor,
pub(crate) eps: f32,
}
impl RmsNorm {
pub fn new(d_model: usize, eps: f32, vb: VarBuilder) -> Result<Self> {
let alpha = vb.get((1, 1, d_model), "alpha")?.reshape(d_model)?;
Ok(Self { alpha, eps })
}
}
impl Module for RmsNorm {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
candle_nn::ops::rms_norm(xs, &self.alpha, self.eps)
}
}
#[derive(Debug, Clone)]
pub enum Norm {
LayerNorm(candle_nn::LayerNorm),
RmsNorm(RmsNorm),
}
impl Norm {
pub fn new(d_model: usize, cfg: &Config, vb: VarBuilder) -> Result<Self> {
let norm = match cfg.norm {
super::NormType::LayerNorm => {
let norm = candle_nn::layer_norm(d_model, 1e-5, vb)?;
Self::LayerNorm(norm)
}
super::NormType::RmsNorm => {
let norm = RmsNorm::new(d_model, 1e-8, vb)?;
Self::RmsNorm(norm)
}
};
Ok(norm)
}
}
impl Module for Norm {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
match self {
Self::LayerNorm(m) => m.forward(xs),
Self::RmsNorm(m) => m.forward(xs),
}
}
}
#[derive(Debug, Clone)]
pub struct StreamingTransformerLayer {
self_attn: StreamingMultiheadAttention,
mlp: Mlp,
norm1: Norm,
norm2: Norm,
layer_scale_1: Option<LayerScale>,
layer_scale_2: Option<LayerScale>,
cross_attn: Option<(candle_nn::LayerNorm, StreamingMultiheadCrossAttention)>,
norm_first: bool,
span: tracing::Span,
}
impl StreamingTransformerLayer {
pub fn new(rope: &Option<Arc<RotaryEmbedding>>, cfg: &Config, vb: VarBuilder) -> Result<Self> {
if cfg.use_conv_block {
candle::bail!("conv-block is not supported")
}
let d_model = cfg.d_model;
let mlp = Mlp::new(cfg, vb.clone())?;
let (norm1, norm2) = match cfg.norm {
super::NormType::LayerNorm => {
let norm1 = candle_nn::layer_norm(d_model, 1e-5, vb.pp("input_layernorm"))?;
let norm2 =
candle_nn::layer_norm(d_model, 1e-5, vb.pp("post_attention_layernorm"))?;
(Norm::LayerNorm(norm1), Norm::LayerNorm(norm2))
}
super::NormType::RmsNorm => {
let norm1 = RmsNorm::new(d_model, 1e-8, vb.pp("input_rmsnorm"))?;
let norm2 = RmsNorm::new(d_model, 1e-8, vb.pp("post_attention_rmsnorm"))?;
(Norm::RmsNorm(norm1), Norm::RmsNorm(norm2))
}
};
let layer_scale_1 = match cfg.layer_scale {
None => None,
Some(ls) => {
let ls = LayerScale::new(d_model, ls, vb.pp("self_attn_layer_scale"))?;
Some(ls)
}
};
let layer_scale_2 = match cfg.layer_scale {
None => None,
Some(ls) => {
let ls = LayerScale::new(d_model, ls, vb.pp("mlp_layer_scale"))?;
Some(ls)
}
};
let self_attn = StreamingMultiheadAttention::new(rope, cfg, vb.pp("self_attn"))?;
let cross_attn = if cfg.cross_attention {
let norm_cross = candle_nn::layer_norm(cfg.d_model, 1e-5, vb.pp("norm_cross"))?;
let cross_attn = StreamingMultiheadCrossAttention::new(cfg, vb.pp("cross_attention"))?;
Some((norm_cross, cross_attn))
} else {
None
};
Ok(Self {
self_attn,
mlp,
norm1,
norm2,
layer_scale_1,
layer_scale_2,
cross_attn,
norm_first: cfg.norm_first,
span: tracing::span!(tracing::Level::TRACE, "transformer-layer"),
})
}
pub fn forward(
&mut self,
xs: &Tensor,
ca_src: Option<&Tensor>,
mask: Option<&Tensor>,
) -> Result<Tensor> {
let _enter = self.span.enter();
if !self.norm_first {
candle::bail!("only norm_first = true is supported")
}
let norm1 = xs.apply(&self.norm1)?;
let xs = (xs
+ self
.self_attn
.forward(&norm1, mask)?
.apply(&self.layer_scale_1.as_ref())?)?;
let xs = match (&self.cross_attn, ca_src) {
(Some((norm_cross, cross_attn)), Some(ca_src)) => {
let residual = &xs;
let xs = xs.apply(norm_cross)?;
(residual + cross_attn.forward(&xs, ca_src, None)?)?
}
_ => xs,
};
let xs = (&xs
+ xs.apply(&self.norm2)?
.apply(&self.mlp)?
.apply(&self.layer_scale_2.as_ref()))?;
Ok(xs)
}
pub fn reset_kv_cache(&mut self) {
self.self_attn.reset_kv_cache()
}
pub fn set_kv_cache(&mut self, kv_cache: candle_nn::kv_cache::RotatingKvCache) {
self.self_attn.set_kv_cache(kv_cache)
}
}
#[derive(Debug, Clone)]
pub struct StreamingTransformer {
layers: Vec<StreamingTransformerLayer>,
positional_embedding: PositionalEmbedding,
max_period: usize,
}
impl StreamingTransformer {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
let vb_l = vb.pp("layers");
let rope = match cfg.positional_embedding {
PositionalEmbedding::Rope => {
let rope = RotaryEmbedding::new(
cfg.d_model / cfg.num_heads,
cfg.max_seq_len,
cfg.max_period as f32,
vb.device(),
)?;
Some(Arc::new(rope))
}
PositionalEmbedding::Sin | PositionalEmbedding::None => None,
};
let mut layers = Vec::with_capacity(cfg.num_layers);
for layer_idx in 0..cfg.num_layers {
let layer = StreamingTransformerLayer::new(&rope, cfg, vb_l.pp(layer_idx))?;
layers.push(layer)
}
Ok(Self {
layers,
positional_embedding: cfg.positional_embedding,
max_period: cfg.max_period,
})
}
pub fn forward(&mut self, xs: &Tensor) -> Result<Tensor> {
self.forward_ca(xs, None)
}
pub fn forward_ca(&mut self, xs: &Tensor, ca_src: Option<&Tensor>) -> Result<Tensor> {
let (_b, t, c) = xs.dims3()?;
let pos = self.layers[0].self_attn.kv_cache.current_seq_len();
let mask = self.layers[0]
.self_attn
.kv_cache
.attn_mask(t, xs.device())?;
let mut xs = match self.positional_embedding {
PositionalEmbedding::Rope | PositionalEmbedding::None => xs.clone(),
PositionalEmbedding::Sin => {
let dev = xs.device();
let theta = self.max_period as f32;
let half_dim = c / 2;
let positions = Tensor::arange(pos as u32, (pos + t) as u32, dev)?
.unsqueeze(1)?
.to_dtype(DType::F32)?;
let inv_freq: Vec<_> = (0..half_dim)
.map(|i| 1f32 / theta.powf(i as f32 / (half_dim - 1) as f32))
.collect();
let inv_freq_len = inv_freq.len();
let inv_freq = Tensor::from_vec(inv_freq, (1, inv_freq_len), dev)?;
let freqs = positions.broadcast_mul(&inv_freq)?;
let pos_emb =
Tensor::cat(&[freqs.cos()?, freqs.sin()?], D::Minus1)?.to_dtype(xs.dtype())?;
xs.broadcast_add(&pos_emb)?
}
};
for layer in self.layers.iter_mut() {
xs = layer.forward(&xs, ca_src, mask.as_ref())?;
}
Ok(xs)
}
pub fn copy_state(&mut self, from: &Self) -> Result<()> {
if self.layers.len() != from.layers.len() {
candle::bail!("cannot copy kv-caches as the transformers have different depths")
}
self.layers
.iter_mut()
.zip(from.layers.iter())
.for_each(|(v, w)| v.set_kv_cache(w.self_attn.kv_cache.clone()));
Ok(())
}
}
impl StreamingModule for StreamingTransformer {
fn reset_state(&mut self) {
self.layers.iter_mut().for_each(|v| v.reset_kv_cache())
}
fn step(&mut self, xs: &StreamTensor) -> Result<StreamTensor> {
match xs.as_option() {
None => Ok(StreamTensor::empty()),
Some(xs) => Ok(StreamTensor::from_tensor(self.forward(xs)?)),
}
}
}
#[derive(Debug, Clone)]
pub struct ProjectedTransformer {
transformer: StreamingTransformer,
input_proj: Option<Linear>,
output_projs: Vec<Option<Linear>>,
conv_layout: bool,
span: tracing::Span,
}
impl ProjectedTransformer {
pub fn new(
input_dim: usize,
output_dims: &[usize],
cfg: &Config,
vb: VarBuilder,
) -> Result<Self> {
let transformer = StreamingTransformer::new(cfg, vb.clone())?;
let input_proj = if input_dim == cfg.d_model {
None
} else {
let l = linear_no_bias(input_dim, cfg.d_model, vb.pp("input_proj"))?;
Some(l)
};
let mut output_projs = Vec::with_capacity(output_dims.len());
let vb_o = vb.pp("output_projs");
for (i, &output_dim) in output_dims.iter().enumerate() {
let output_proj = if output_dim == cfg.d_model {
None
} else {
let l = linear_no_bias(cfg.d_model, output_dim, vb_o.pp(i))?;
Some(l)
};
output_projs.push(output_proj)
}
Ok(Self {
transformer,
input_proj,
output_projs,
conv_layout: cfg.conv_layout,
span: tracing::span!(tracing::Level::TRACE, "proj-transformer"),
})
}
pub fn forward(&mut self, xs: &Tensor) -> Result<Vec<Tensor>> {
let _enter = self.span.enter();
let xs = if self.conv_layout {
xs.transpose(1, 2)?
} else {
xs.clone()
};
let xs = xs.apply(&self.input_proj.as_ref())?;
let xs = self.transformer.forward(&xs)?;
let mut ys = Vec::with_capacity(self.output_projs.len());
for output_proj in self.output_projs.iter() {
let ys_ = xs.apply(&output_proj.as_ref())?;
let ys_ = if self.conv_layout {
ys_.transpose(1, 2)?
} else {
ys_
};
ys.push(ys_)
}
Ok(ys)
}
}
impl StreamingModule for ProjectedTransformer {
fn reset_state(&mut self) {
self.transformer.reset_state()
}
fn step(&mut self, xs: &StreamTensor) -> Result<StreamTensor> {
let xs = xs.apply(&|x: &Tensor| {
if self.conv_layout {
x.transpose(1, 2)
} else {
Ok(x.clone())
}
})?;
let xs = xs.apply(&self.input_proj.as_ref())?;
let xs = self.transformer.step(&xs)?;
let ys = xs.apply(&self.output_projs[0].as_ref())?;
ys.apply(&|y: &Tensor| {
if self.conv_layout {
y.transpose(1, 2)
} else {
Ok(y.clone())
}
})
}
}
#[cfg(feature = "flash-attn")]
fn flash_attn(
q: &Tensor,
k: &Tensor,
v: &Tensor,
softmax_scale: f32,
causal: bool,
) -> Result<Tensor> {
candle_flash_attn::flash_attn(q, k, v, softmax_scale, causal)
}
#[cfg(not(feature = "flash-attn"))]
fn flash_attn(_: &Tensor, _: &Tensor, _: &Tensor, _: f32, _: bool) -> Result<Tensor> {
unimplemented!("compile with '--features flash-attn'")
}
| 2 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mimi/mod.rs | //! mimi model
//!
//! [Mimi](https://huggingface.co/kyutai/mimi) is a state of the art audio
//! compression model using an encoder/decoder architecture with residual vector
//! quantization. The candle implementation supports streaming meaning that it's
//! possible to encode or decode a stream of audio tokens on the flight to provide
//! low latency interaction with an audio model.
//!
//! - 🤗 [HuggingFace Model Card](https://huggingface.co/kyutai/mimi)
//! - 💻 [GitHub](https://github.com/kyutai-labs/moshi)
//!
//!
//! # Example
//! ```bash
//! # Generating some audio tokens from an audio files.
//! wget https://github.com/metavoiceio/metavoice-src/raw/main/assets/bria.mp3
//! cargo run --example mimi \
//! --features mimi --release -- \
//! audio-to-code bria.mp3 bria.safetensors
//!
//! # And decoding the audio tokens back into a sound file.
//! cargo run --example mimi
//! --features mimi --release -- \
//! code-to-audio bria.safetensors bria.wav
//!
// Copyright (c) Kyutai, all rights reserved.
// This source code is licensed under the license found in the
// LICENSE file in the root directory of this source tree.
pub use candle;
pub use candle_nn;
pub mod conv;
pub mod encodec;
pub mod quantization;
pub mod seanet;
pub mod transformer;
#[derive(Debug, Copy, Clone, PartialEq, Eq)]
pub enum NormType {
RmsNorm,
LayerNorm,
}
pub use encodec::{load, Config, Encodec as Model};
| 3 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/mimi/seanet.rs | // Copyright (c) Kyutai, all rights reserved.
// This source code is licensed under the license found in the
// LICENSE file in the root directory of this source tree.
use candle::{streaming, Module, Result, StreamTensor, StreamingModule, Tensor};
use candle_nn::VarBuilder;
use super::conv::{StreamableConv1d, StreamableConvTranspose1d};
#[derive(Debug, Clone)]
pub struct Config {
pub dimension: usize,
pub channels: usize,
pub causal: bool,
pub n_filters: usize,
pub n_residual_layers: usize,
pub ratios: Vec<usize>,
pub activation: candle_nn::Activation,
pub norm: super::conv::Norm,
pub kernel_size: usize,
pub residual_kernel_size: usize,
pub last_kernel_size: usize,
pub dilation_base: usize,
pub pad_mode: super::conv::PadMode,
pub true_skip: bool,
pub compress: usize,
pub lstm: usize,
pub disable_norm_outer_blocks: usize,
pub final_activation: Option<candle_nn::Activation>,
}
#[derive(Debug, Clone)]
pub struct SeaNetResnetBlock {
block: Vec<StreamableConv1d>,
shortcut: Option<StreamableConv1d>,
activation: candle_nn::Activation,
skip_op: candle::StreamingBinOp,
span: tracing::Span,
}
impl SeaNetResnetBlock {
#[allow(clippy::too_many_arguments)]
pub fn new(
dim: usize,
k_sizes_and_dilations: &[(usize, usize)],
activation: candle_nn::Activation,
norm: Option<super::conv::Norm>,
causal: bool,
pad_mode: super::conv::PadMode,
compress: usize,
true_skip: bool,
vb: VarBuilder,
) -> Result<Self> {
let mut block = Vec::with_capacity(k_sizes_and_dilations.len());
let hidden = dim / compress;
let vb_b = vb.pp("block");
for (i, (k_size, dilation)) in k_sizes_and_dilations.iter().enumerate() {
let in_c = if i == 0 { dim } else { hidden };
let out_c = if i == k_sizes_and_dilations.len() - 1 {
dim
} else {
hidden
};
let c = StreamableConv1d::new(
in_c,
out_c,
/* k_size */ *k_size,
/* stride */ 1,
/* dilation */ *dilation,
/* groups */ 1,
/* bias */ true,
/* causal */ causal,
/* norm */ norm,
/* pad_mode */ pad_mode,
vb_b.pp(2 * i + 1),
)?;
block.push(c)
}
let shortcut = if true_skip {
None
} else {
let c = StreamableConv1d::new(
dim,
dim,
/* k_size */ 1,
/* stride */ 1,
/* dilation */ 1,
/* groups */ 1,
/* bias */ true,
/* causal */ causal,
/* norm */ norm,
/* pad_mode */ pad_mode,
vb.pp("shortcut"),
)?;
Some(c)
};
Ok(Self {
block,
shortcut,
activation,
skip_op: streaming::StreamingBinOp::new(streaming::BinOp::Add, candle::D::Minus1),
span: tracing::span!(tracing::Level::TRACE, "sea-resnet"),
})
}
}
impl Module for SeaNetResnetBlock {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let mut ys = xs.clone();
for block in self.block.iter() {
ys = ys.apply(&self.activation)?.apply(block)?;
}
match self.shortcut.as_ref() {
None => ys + xs,
Some(shortcut) => ys + xs.apply(shortcut),
}
}
}
impl StreamingModule for SeaNetResnetBlock {
fn reset_state(&mut self) {
for block in self.block.iter_mut() {
block.reset_state()
}
if let Some(shortcut) = self.shortcut.as_mut() {
shortcut.reset_state()
}
}
fn step(&mut self, xs: &StreamTensor) -> Result<StreamTensor> {
let _enter = self.span.enter();
let mut ys = xs.clone();
for block in self.block.iter_mut() {
ys = block.step(&ys.apply(&self.activation)?)?;
}
match self.shortcut.as_ref() {
None => self.skip_op.step(&ys, xs),
Some(shortcut) => self.skip_op.step(&ys, &xs.apply(shortcut)?),
}
}
}
#[derive(Debug, Clone)]
struct EncoderLayer {
residuals: Vec<SeaNetResnetBlock>,
downsample: StreamableConv1d,
}
#[derive(Debug, Clone)]
pub struct SeaNetEncoder {
init_conv1d: StreamableConv1d,
activation: candle_nn::Activation,
layers: Vec<EncoderLayer>,
final_conv1d: StreamableConv1d,
span: tracing::Span,
}
impl SeaNetEncoder {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
if cfg.lstm > 0 {
candle::bail!("seanet lstm is not supported")
}
let n_blocks = 2 + cfg.ratios.len();
let mut mult = 1usize;
let init_norm = if cfg.disable_norm_outer_blocks >= 1 {
None
} else {
Some(cfg.norm)
};
let mut layer_idx = 0;
let vb = vb.pp("layers");
let init_conv1d = StreamableConv1d::new(
cfg.channels,
mult * cfg.n_filters,
cfg.kernel_size,
/* stride */ 1,
/* dilation */ 1,
/* groups */ 1,
/* bias */ true,
/* causal */ cfg.causal,
/* norm */ init_norm,
/* pad_mode */ cfg.pad_mode,
vb.pp(layer_idx),
)?;
layer_idx += 1;
let mut layers = Vec::with_capacity(cfg.ratios.len());
for (i, &ratio) in cfg.ratios.iter().rev().enumerate() {
let norm = if cfg.disable_norm_outer_blocks >= i + 2 {
None
} else {
Some(cfg.norm)
};
let mut residuals = Vec::with_capacity(cfg.n_residual_layers);
for j in 0..cfg.n_residual_layers {
let resnet_block = SeaNetResnetBlock::new(
mult * cfg.n_filters,
&[
(cfg.residual_kernel_size, cfg.dilation_base.pow(j as u32)),
(1, 1),
],
cfg.activation,
norm,
cfg.causal,
cfg.pad_mode,
cfg.compress,
cfg.true_skip,
vb.pp(layer_idx),
)?;
residuals.push(resnet_block);
layer_idx += 1;
}
let downsample = StreamableConv1d::new(
mult * cfg.n_filters,
mult * cfg.n_filters * 2,
/* k_size */ ratio * 2,
/* stride */ ratio,
/* dilation */ 1,
/* groups */ 1,
/* bias */ true,
/* causal */ true,
/* norm */ norm,
/* pad_mode */ cfg.pad_mode,
vb.pp(layer_idx + 1),
)?;
layer_idx += 2;
let layer = EncoderLayer {
downsample,
residuals,
};
layers.push(layer);
mult *= 2
}
let final_norm = if cfg.disable_norm_outer_blocks >= n_blocks {
None
} else {
Some(cfg.norm)
};
let final_conv1d = StreamableConv1d::new(
mult * cfg.n_filters,
cfg.dimension,
cfg.last_kernel_size,
/* stride */ 1,
/* dilation */ 1,
/* groups */ 1,
/* bias */ true,
/* causal */ cfg.causal,
/* norm */ final_norm,
/* pad_mode */ cfg.pad_mode,
vb.pp(layer_idx + 1),
)?;
Ok(Self {
init_conv1d,
activation: cfg.activation,
layers,
final_conv1d,
span: tracing::span!(tracing::Level::TRACE, "sea-encoder"),
})
}
}
impl Module for SeaNetEncoder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let mut xs = xs.apply(&self.init_conv1d)?;
for layer in self.layers.iter() {
for residual in layer.residuals.iter() {
xs = xs.apply(residual)?
}
xs = xs.apply(&self.activation)?.apply(&layer.downsample)?;
}
xs.apply(&self.activation)?.apply(&self.final_conv1d)
}
}
impl StreamingModule for SeaNetEncoder {
fn reset_state(&mut self) {
self.init_conv1d.reset_state();
self.layers.iter_mut().for_each(|v| {
v.residuals.iter_mut().for_each(|v| v.reset_state());
v.downsample.reset_state()
});
self.final_conv1d.reset_state();
}
fn step(&mut self, xs: &StreamTensor) -> Result<StreamTensor> {
let _enter = self.span.enter();
let mut xs = self.init_conv1d.step(xs)?;
for layer in self.layers.iter_mut() {
for residual in layer.residuals.iter_mut() {
xs = residual.step(&xs)?;
}
xs = layer.downsample.step(&xs.apply(&self.activation)?)?;
}
self.final_conv1d.step(&xs.apply(&self.activation)?)
}
}
#[derive(Debug, Clone)]
struct DecoderLayer {
upsample: StreamableConvTranspose1d,
residuals: Vec<SeaNetResnetBlock>,
}
#[derive(Debug, Clone)]
pub struct SeaNetDecoder {
init_conv1d: StreamableConv1d,
activation: candle_nn::Activation,
layers: Vec<DecoderLayer>,
final_conv1d: StreamableConv1d,
final_activation: Option<candle_nn::Activation>,
span: tracing::Span,
}
impl SeaNetDecoder {
pub fn new(cfg: &Config, vb: VarBuilder) -> Result<Self> {
if cfg.lstm > 0 {
candle::bail!("seanet lstm is not supported")
}
let n_blocks = 2 + cfg.ratios.len();
let mut mult = 1 << cfg.ratios.len();
let init_norm = if cfg.disable_norm_outer_blocks == n_blocks {
None
} else {
Some(cfg.norm)
};
let mut layer_idx = 0;
let vb = vb.pp("layers");
let init_conv1d = StreamableConv1d::new(
cfg.dimension,
mult * cfg.n_filters,
cfg.kernel_size,
/* stride */ 1,
/* dilation */ 1,
/* groups */ 1,
/* bias */ true,
/* causal */ cfg.causal,
/* norm */ init_norm,
/* pad_mode */ cfg.pad_mode,
vb.pp(layer_idx),
)?;
layer_idx += 1;
let mut layers = Vec::with_capacity(cfg.ratios.len());
for (i, &ratio) in cfg.ratios.iter().enumerate() {
let norm = if cfg.disable_norm_outer_blocks + i + 1 >= n_blocks {
None
} else {
Some(cfg.norm)
};
let upsample = StreamableConvTranspose1d::new(
mult * cfg.n_filters,
mult * cfg.n_filters / 2,
/* k_size */ ratio * 2,
/* stride */ ratio,
/* groups */ 1,
/* bias */ true,
/* causal */ true,
/* norm */ norm,
vb.pp(layer_idx + 1),
)?;
layer_idx += 2;
let mut residuals = Vec::with_capacity(cfg.n_residual_layers);
for j in 0..cfg.n_residual_layers {
let resnet_block = SeaNetResnetBlock::new(
mult * cfg.n_filters / 2,
&[
(cfg.residual_kernel_size, cfg.dilation_base.pow(j as u32)),
(1, 1),
],
cfg.activation,
norm,
cfg.causal,
cfg.pad_mode,
cfg.compress,
cfg.true_skip,
vb.pp(layer_idx),
)?;
residuals.push(resnet_block);
layer_idx += 1;
}
let layer = DecoderLayer {
upsample,
residuals,
};
layers.push(layer);
mult /= 2
}
let final_norm = if cfg.disable_norm_outer_blocks >= 1 {
None
} else {
Some(cfg.norm)
};
let final_conv1d = StreamableConv1d::new(
cfg.n_filters,
cfg.channels,
cfg.last_kernel_size,
/* stride */ 1,
/* dilation */ 1,
/* groups */ 1,
/* bias */ true,
/* causal */ cfg.causal,
/* norm */ final_norm,
/* pad_mode */ cfg.pad_mode,
vb.pp(layer_idx + 1),
)?;
Ok(Self {
init_conv1d,
activation: cfg.activation,
layers,
final_conv1d,
final_activation: cfg.final_activation,
span: tracing::span!(tracing::Level::TRACE, "sea-decoder"),
})
}
}
impl Module for SeaNetDecoder {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let mut xs = xs.apply(&self.init_conv1d)?;
for layer in self.layers.iter() {
xs = xs.apply(&self.activation)?.apply(&layer.upsample)?;
for residual in layer.residuals.iter() {
xs = xs.apply(residual)?
}
}
let xs = xs.apply(&self.activation)?.apply(&self.final_conv1d)?;
let xs = match self.final_activation.as_ref() {
None => xs,
Some(act) => xs.apply(act)?,
};
Ok(xs)
}
}
impl StreamingModule for SeaNetDecoder {
fn reset_state(&mut self) {
self.init_conv1d.reset_state();
self.layers.iter_mut().for_each(|v| {
v.residuals.iter_mut().for_each(|v| v.reset_state());
v.upsample.reset_state()
});
self.final_conv1d.reset_state();
}
fn step(&mut self, xs: &StreamTensor) -> Result<StreamTensor> {
let _enter = self.span.enter();
let mut xs = self.init_conv1d.step(xs)?;
for layer in self.layers.iter_mut() {
xs = layer.upsample.step(&xs.apply(&self.activation)?)?;
for residual in layer.residuals.iter_mut() {
xs = residual.step(&xs)?;
}
}
let xs = self.final_conv1d.step(&xs.apply(&self.activation)?)?;
let xs = match self.final_activation.as_ref() {
None => xs,
Some(act) => xs.apply(act)?,
};
Ok(xs)
}
}
| 4 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/llava/mod.rs | //! The LLaVA (Large Language and Vision Assistant) model.
//!
//! This provides the main model implementation combining a vision tower (CLIP) with
//! language model (Llama) for multimodal capabilities. The architecture implements the training-free projection technique.
//!
//! - 💻[GH Link](https://github.com/haotian-liu/LLaVA/tree/main)
//! - 📝 [Paper](https://arxiv.org/abs/2304.08485)/ Visual Instruction Tuning
//!
pub mod config;
pub mod utils;
use crate::models::clip::vision_model::{ClipVisionConfig, ClipVisionTransformer};
use crate::models::llama::{Cache, Llama};
use crate::models::with_tracing::linear;
use candle::{bail, Device, IndexOp, Result, Tensor};
use candle_nn::{seq, Activation, Module, Sequential, VarBuilder};
use fancy_regex::Regex;
use utils::get_anyres_image_grid_shape;
use config::LLaVAConfig;
fn mlp_gelu_match(mm_projector_type: &str) -> Option<usize> {
let mlp_gelu_regex = Regex::new(r"^mlp(\d+)x_gelu$").unwrap();
if let Ok(Some(captures)) = mlp_gelu_regex.captures(mm_projector_type) {
if let Some(match_str) = captures.get(1) {
let match_str = match_str.as_str();
match_str.parse::<usize>().ok()
} else {
None
}
} else {
None
}
}
fn unpad_image(tensor: &Tensor, original_size: &(u32, u32)) -> Result<Tensor> {
assert_eq!(tensor.dims().len(), 3);
let (original_width, original_height) = *original_size;
let tensor_dims = tensor.dims();
let current_height = tensor_dims[1];
let current_width = tensor_dims[2];
let original_aspect_ratio = (original_width as f32) / (original_height as f32);
let current_aspect_ratio = (current_width as f32) / (current_height as f32);
if original_aspect_ratio > current_aspect_ratio {
let scale_factor = (current_width as f32) / (original_width as f32);
let new_height = (original_height as f32 * scale_factor).floor() as usize;
let padding = (current_height - new_height) / 2;
tensor.i((.., padding..current_width - padding, ..))
} else {
let scale_factor = (current_height as f32) / (original_height as f32);
let new_width = (original_width as f32 * scale_factor).floor() as usize;
let padding = (current_width - new_width) / 2;
tensor.i((.., .., padding..current_width - padding))
}
}
pub struct IdentityMap {}
impl Module for IdentityMap {
fn forward(&self, x: &Tensor) -> Result<Tensor> {
Ok(x.clone())
}
}
pub struct MMProjector {
pub modules: Sequential,
}
impl MMProjector {
pub fn load(vb: &VarBuilder, config: &LLaVAConfig) -> Result<Self> {
if config.mm_projector_type == "linear" {
let vb_prefix = if config.hf {
"multi_modal_projector.linear_1"
} else {
"model.mm_projector.0"
};
let linear = linear(config.mm_hidden_size, config.hidden_size, vb.pp(vb_prefix))?;
let modules = seq().add(linear);
Ok(Self { modules })
} else if let Some(mlp_depth) = mlp_gelu_match(&config.mm_projector_type) {
let modules = if config.hf {
let mut modules = seq().add(linear(
config.mm_hidden_size,
config.hidden_size,
vb.pp("multi_modal_projector.linear_1"),
)?);
for i in 1..mlp_depth {
modules = modules.add(Activation::Gelu).add(linear(
config.hidden_size,
config.hidden_size,
vb.pp(format!("multi_modal_projector.linear_{}", i + 1)),
)?);
}
modules
} else {
let mut modules = seq().add(linear(
config.mm_hidden_size,
config.hidden_size,
vb.pp("model.mm_projector.0"),
)?);
for i in 1..mlp_depth {
modules = modules.add(Activation::Gelu).add(linear(
config.hidden_size,
config.hidden_size,
vb.pp(format!("model.mm_projector.{}", i * 2)),
)?);
}
modules
};
Ok(Self { modules })
} else if config.mm_projector_type == "identity" {
Ok(Self {
modules: seq().add(IdentityMap {}),
})
} else {
bail!(
"Unsupported MM projector type: {}",
config.mm_projector_type
)
}
}
pub fn forward(&self, x: &Tensor) -> Result<Tensor> {
self.modules.forward(x)
}
}
pub struct ClipVisionTower {
model: ClipVisionTransformer,
select_layer: isize,
select_feature_method: String,
pub config: ClipVisionConfig,
}
impl ClipVisionTower {
pub fn new(
vb: VarBuilder,
select_layer: isize,
select_feature_method: &str,
config: &Option<ClipVisionConfig>,
) -> Result<Self> {
let config = if config.is_none() {
ClipVisionConfig::clip_vit_large_patch14_336()
} else {
config.clone().unwrap()
};
let select_layer = match select_layer {
-1 | -2 => select_layer,
_ => bail!("Unsupported select layer: {}", select_layer),
};
let model = ClipVisionTransformer::new(vb, &config)?;
Ok(Self {
model,
select_layer,
select_feature_method: select_feature_method.to_string(),
config,
})
}
pub fn forward(&self, x: &Tensor) -> Result<Tensor> {
let result = self.model.output_hidden_states(x)?;
let index = result.len() as isize + self.select_layer;
let result = result[index as usize].clone();
if self.select_feature_method == "cls_patch" {
Ok(result)
} else {
result.i((.., 1..))
}
}
pub fn num_patches_per_side(&self) -> usize {
self.config.image_size / self.config.patch_size
}
}
pub struct LLaVA {
pub clip_vision_tower: ClipVisionTower,
pub image_newline: Tensor,
pub mm_projector: MMProjector,
pub llama: Llama,
config: LLaVAConfig,
device: Device,
}
impl LLaVA {
pub fn load(
vb: VarBuilder,
config: &LLaVAConfig,
clip_vision_config: Option<ClipVisionConfig>,
) -> Result<Self> {
let device = vb.device().clone();
let llama_config = config.to_llama_config();
let mm_projector = MMProjector::load(&vb, config)?;
let (clip_vision_tower, image_newline, llama) = if config.hf {
(
ClipVisionTower::new(
vb.pp("vision_tower.vision_model"),
config.mm_vision_select_layer,
&config.mm_vision_select_feature,
&clip_vision_config,
)?,
vb.get(&[config.hidden_size], "image_newline")?
.to_device(&device)?,
Llama::load(vb.pp("language_model"), &llama_config)?,
)
} else {
(
ClipVisionTower::new(
vb.pp("model.vision_tower.vision_tower.vision_model"),
config.mm_vision_select_layer,
&config.mm_vision_select_feature,
&clip_vision_config,
)?,
vb.get(&[config.hidden_size], "model.image_newline")?
.to_device(&device)?,
Llama::load(vb, &llama_config)?,
)
};
Ok(Self {
clip_vision_tower,
image_newline,
mm_projector,
llama,
config: (*config).clone(),
device,
})
}
pub fn encode_images(&self, x: &Tensor) -> Result<Tensor> {
let image_features = self.clip_vision_tower.forward(x)?;
let image_features = self.mm_projector.forward(&image_features)?;
Ok(image_features)
}
// currently only for single image, 4 dim tensor
pub fn prepare_inputs_labels_for_multimodal(
&self,
input_ids: &Tensor,
images: &[Tensor],
image_sizes: &[(u32, u32)],
) -> Result<Tensor> {
//TODO: process of multiple images/ new line
// 576: 336(input size)/14(patch size)=24 24*24+1(class)=577 577-1=576
let concat_images = Tensor::cat(images, 0)?;
let image_features_together = self.encode_images(&concat_images)?;
let split_sizes = images
.iter()
.map(|x| x.shape().dims()[0])
.collect::<Vec<usize>>();
// can be replaced by split
let mut index_pos = 0;
let mut image_features = Vec::new();
for split_size in split_sizes.iter() {
image_features.push(image_features_together.i(index_pos..index_pos + (*split_size))?);
index_pos += *split_size;
}
let mm_patch_merge_type = &self.config.mm_patch_merge_type;
let image_aspect_ratio = &self.config.image_aspect_ratio;
let image_features = if mm_patch_merge_type == "flat" {
image_features
.iter()
.map(|x| x.flatten(0, 1).unwrap())
.collect::<Vec<Tensor>>()
} else if mm_patch_merge_type.starts_with("spatial") {
let mut new_image_features = Vec::new();
for (image_idx, image_feature) in image_features.iter().enumerate() {
let new_image_feature = if image_feature.dims()[0] > 1 {
let base_image_feature = image_feature.get(0).unwrap();
let patch_image_feature = image_feature.i(1..).unwrap();
let height = self.clip_vision_tower.num_patches_per_side();
let width = height;
assert_eq!(height * width, base_image_feature.dims()[0]);
let image_size = image_sizes[image_idx];
let new_image_feature = if image_aspect_ratio == "anyres" {
let (num_patch_width, num_patch_height) = get_anyres_image_grid_shape(
image_size,
&self.config.image_grid_pinpoints,
self.clip_vision_tower.config.image_size as u32,
);
patch_image_feature.reshape((
num_patch_height as usize,
num_patch_width as usize,
height,
width,
(),
))?
} else {
bail!("not implemented in original python LLaVA yet")
};
let new_image_feature = if mm_patch_merge_type.contains("unpad") {
let new_image_feature = new_image_feature
.permute((4, 0, 2, 1, 3))?
.flatten(1, 2)?
.flatten(2, 3)?;
let new_image_feature = unpad_image(&new_image_feature, &image_size)?;
let new_image_feature_dims = new_image_feature.dims();
let image_new_line = self
.image_newline
.reshape((self.config.hidden_size, 1, 1))?
.broadcast_as((
new_image_feature_dims[0],
new_image_feature_dims[1],
1,
))?;
let new_image_feature =
Tensor::cat(&[new_image_feature, image_new_line], 2)?;
new_image_feature.flatten(1, 2)?.transpose(0, 1)?
} else {
new_image_feature.permute((0, 2, 1, 3, 4))?.flatten(0, 3)?
};
Tensor::cat(&[base_image_feature, new_image_feature], 0)?
} else {
let new_image_feature = image_feature.get(0).unwrap();
if mm_patch_merge_type.contains("unpad") {
Tensor::cat(
&[
new_image_feature,
self.image_newline.clone().unsqueeze(0).unwrap(),
],
0,
)
.unwrap()
} else {
new_image_feature
}
};
new_image_features.push(new_image_feature);
}
new_image_features
} else {
bail!("Unexpected mm_patch_merge_type: {mm_patch_merge_type}")
};
// can easily be replaced by nonzero if it is implemented in candle
let input_ids_vec = input_ids.squeeze(0)?.to_vec1::<i64>()?;
let mut image_indices = {
let mut image_indices = vec![0_i64];
image_indices.extend(
input_ids_vec
.iter()
.enumerate()
.filter_map(|(i, x)| {
if *x == self.config.image_token_index as i64 {
Some(i as i64)
} else {
None
}
})
.collect::<Vec<i64>>(),
);
image_indices
};
if image_indices.len() == 1 {
//no image, only [0],
return self.llama.embed(input_ids);
}
let input_ids_noim = input_ids_vec
.iter()
.filter_map(|x| {
if *x != self.config.image_token_index as i64 {
Some(*x)
} else {
None
}
})
.collect::<Vec<i64>>();
let input_ids_noim_len = input_ids_noim.len();
image_indices.push((input_ids_noim_len) as i64);
let input_ids_noim = Tensor::from_vec(input_ids_noim, input_ids_noim_len, &self.device)?;
let cur_input_embeds = self.llama.embed(&input_ids_noim)?;
// can be replace by split if it is implemented in candle
let input_embed_no_ims = {
let mut input_embeds = Vec::new();
for i in 0..image_indices.len() - 1 {
let start = (image_indices[i]) as usize;
let end = image_indices[i + 1] as usize;
input_embeds.push(cur_input_embeds.i((start..end, ..))?)
}
input_embeds
};
let mut cur_new_input_embeds = Vec::new();
for (i, image_feature) in image_features.iter().enumerate() {
cur_new_input_embeds.push(input_embed_no_ims[i].clone());
cur_new_input_embeds.push(image_feature.clone());
}
cur_new_input_embeds.push(input_embed_no_ims[image_features.len()].clone());
let new_input_embeds = Tensor::cat(&cur_new_input_embeds, 0)?;
//trancate
let new_input_embeds =
if let Some(tokenizer_model_max_length) = self.config.tokenizer_model_max_length {
let (new_input_embeds_length, _) = new_input_embeds.shape().dims2()?;
if new_input_embeds_length > tokenizer_model_max_length {
new_input_embeds.i((..tokenizer_model_max_length, ..))?
} else {
new_input_embeds
}
} else {
new_input_embeds
};
new_input_embeds.unsqueeze(0)
}
pub fn forward(
&self,
input_embeds: &Tensor,
position_id: usize,
cache: &mut Cache,
) -> Result<Tensor> {
self.llama
.forward_input_embed(input_embeds, position_id, cache)
}
}
| 5 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/llava/config.rs | use std::collections::HashMap;
use crate::models::{
clip::{text_model::Activation, vision_model::ClipVisionConfig},
llama::{Config, LlamaEosToks},
};
use serde::{Deserialize, Serialize};
// original config from liuhaotian/llava
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct LLaVAConfig {
pub architectures: Vec<String>,
pub bos_token_id: usize,
pub eos_token_id: usize,
pub hidden_size: usize,
#[serde(default = "default_image_aspect_ratio")]
pub image_aspect_ratio: String,
pub image_crop_resolution: usize,
pub image_grid_pinpoints: Vec<(u32, u32)>,
pub image_split_resolution: usize,
pub intermediate_size: usize,
pub max_position_embeddings: usize,
pub mm_hidden_size: usize,
#[serde(default = "default_mm_patch_merge_type")]
pub mm_patch_merge_type: String,
pub mm_projector_type: String,
pub mm_use_im_start_end: bool,
pub mm_vision_select_feature: String,
pub mm_vision_select_layer: isize,
pub mm_vision_tower: Option<String>,
pub model_type: String,
pub num_attention_heads: usize,
pub num_hidden_layers: usize,
pub num_key_value_heads: usize,
pub pad_token_id: usize,
pub rms_norm_eps: f32,
pub rope_theta: f32,
pub tokenizer_model_max_length: Option<usize>,
pub torch_dtype: String,
pub use_cache: bool,
pub vocab_size: usize,
#[serde(default = "default_image_token_index")]
pub image_token_index: isize,
#[serde(default = "default_hf")]
pub hf: bool,
pub tie_word_embeddings: Option<bool>,
}
fn default_hf() -> bool {
false
}
fn default_image_token_index() -> isize {
-200
}
fn default_mm_patch_merge_type() -> String {
"flat".to_string()
}
fn default_image_aspect_ratio() -> String {
"square".to_string()
}
impl LLaVAConfig {
pub fn to_llama_config(&self) -> Config {
Config {
hidden_size: self.hidden_size,
intermediate_size: self.intermediate_size,
vocab_size: self.vocab_size,
num_hidden_layers: self.num_hidden_layers,
num_attention_heads: self.num_attention_heads,
num_key_value_heads: self.num_key_value_heads,
rms_norm_eps: self.rms_norm_eps as f64,
rope_theta: self.rope_theta,
bos_token_id: Some(self.bos_token_id as u32),
eos_token_id: Some(LlamaEosToks::Single(self.eos_token_id as u32)),
use_flash_attn: false,
rope_scaling: None, // Assume we don't have LLaVA for Llama 3.1
max_position_embeddings: self.max_position_embeddings,
tie_word_embeddings: self.tie_word_embeddings.unwrap_or(false),
}
}
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct HFLLaVATextConfig {
pub architectures: Vec<String>,
#[serde(default = "default_hidden_size")]
pub hidden_size: usize,
#[serde(default = "default_intermediate_size")]
pub intermediate_size: usize,
#[serde(default = "default_max_length")]
pub max_length: usize,
pub max_position_embeddings: usize,
pub model_type: String,
#[serde(default = "default_num_attention_heads")]
pub num_attention_heads: usize,
#[serde(default = "default_num_hidden_layers")]
pub num_hidden_layers: usize,
#[serde(default = "default_num_key_value_heads")]
pub num_key_value_heads: usize,
pub pad_token_id: usize,
pub rms_norm_eps: f32,
#[serde(default = "default_rope_theta")]
pub rope_theta: f32,
pub torch_dtype: String,
#[serde(default = "default_use_cache")]
pub use_cache: bool,
pub vocab_size: usize,
}
fn default_num_hidden_layers() -> usize {
32
}
fn default_use_cache() -> bool {
true
}
fn default_hidden_size() -> usize {
4096
}
fn default_intermediate_size() -> usize {
11008
}
fn default_max_length() -> usize {
4096
}
fn default_num_attention_heads() -> usize {
32
}
fn default_num_key_value_heads() -> usize {
32
}
fn default_rope_theta() -> f32 {
10000.0
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct HFLLaVAVisionConfig {
pub hidden_size: usize,
pub image_size: usize,
pub intermediate_size: usize,
pub model_type: String,
pub num_attention_heads: usize,
pub num_hidden_layers: usize,
pub patch_size: usize,
pub projection_dim: usize,
pub vocab_size: usize,
}
// config from llava-v1.6-vicuna-7b-hf
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct HFLLaVAConfig {
pub architectures: Vec<String>,
pub ignore_index: isize,
pub image_grid_pinpoints: Vec<(u32, u32)>,
pub image_token_index: isize,
pub model_type: String,
pub projector_hidden_act: String,
pub text_config: HFLLaVATextConfig,
pub torch_dtype: String,
pub use_image_newline_parameter: bool,
pub vision_config: HFLLaVAVisionConfig,
pub vision_feature_layer: isize,
pub vision_feature_select_strategy: String,
pub vocab_size: usize,
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct HFGenerationConfig {
pub bos_token_id: usize,
pub eos_token_id: usize,
#[serde(default = "default_max_length")]
pub max_length: usize,
pub pad_token_id: usize,
}
#[derive(Serialize, Deserialize, Debug, Clone)]
pub struct HFPreProcessorConfig {
pub aspect_ratio_setting: String,
pub crop_size: HashMap<String, usize>,
pub do_center_crop: bool,
pub do_convert_rgb: bool,
pub do_normalize: bool,
pub do_rescale: bool,
pub do_resize: bool,
pub image_mean: Vec<f32>,
pub image_std: Vec<f32>,
pub resample: u32,
pub rescale_factor: f32,
pub size: HashMap<String, f32>,
}
impl HFLLaVAConfig {
pub fn to_clip_vision_config(&self) -> ClipVisionConfig {
ClipVisionConfig {
embed_dim: self.vision_config.hidden_size,
activation: Activation::QuickGelu,
intermediate_size: self.vision_config.intermediate_size,
num_hidden_layers: self.vision_config.num_hidden_layers,
num_attention_heads: self.vision_config.num_attention_heads,
projection_dim: self.vision_config.projection_dim,
num_channels: 3,
image_size: self.vision_config.image_size,
patch_size: self.vision_config.patch_size,
}
}
fn map_projector_type(s: &str) -> String {
if s == "gelu" {
"mlp2x_gelu".to_string()
} else {
s.to_string()
}
}
fn map_select_feature(s: &str) -> String {
if s == "default" {
"patch".to_string()
} else {
"cls_patch".to_string()
}
}
pub fn to_llava_config(
&self,
generation_config: &HFGenerationConfig,
preprocessor_config: &HFPreProcessorConfig,
) -> LLaVAConfig {
LLaVAConfig {
hf: true,
architectures: self.architectures.clone(),
bos_token_id: generation_config.bos_token_id,
eos_token_id: generation_config.eos_token_id,
hidden_size: self.text_config.hidden_size,
image_aspect_ratio: preprocessor_config.aspect_ratio_setting.clone(),
image_crop_resolution: 224,
image_grid_pinpoints: self.image_grid_pinpoints.clone(),
image_split_resolution: 224,
intermediate_size: self.text_config.intermediate_size,
max_position_embeddings: self.text_config.max_position_embeddings,
mm_hidden_size: 1024,
mm_patch_merge_type: "spatial_unpad".to_string(),
mm_projector_type: Self::map_projector_type(&self.projector_hidden_act),
mm_use_im_start_end: false,
mm_vision_select_feature: Self::map_select_feature(
&self.vision_feature_select_strategy,
),
mm_vision_select_layer: self.vision_feature_layer,
mm_vision_tower: None,
model_type: self.model_type.clone(),
num_attention_heads: self.text_config.num_attention_heads,
num_hidden_layers: self.text_config.num_hidden_layers,
num_key_value_heads: self.text_config.num_key_value_heads,
pad_token_id: self.text_config.pad_token_id,
rms_norm_eps: self.text_config.rms_norm_eps,
rope_theta: self.text_config.rope_theta,
tokenizer_model_max_length: Some(4096),
torch_dtype: self.torch_dtype.clone(),
use_cache: self.text_config.use_cache,
vocab_size: self.vocab_size,
image_token_index: self.image_token_index,
tie_word_embeddings: None,
}
}
}
| 6 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/llava/utils.rs | pub fn get_anyres_image_grid_shape(
image_size: (u32, u32),
grid_pinpoints: &[(u32, u32)],
patch_size: u32,
) -> (u32, u32) {
let (width, height) = select_best_resolution(image_size, grid_pinpoints);
(width / patch_size, height / patch_size)
}
pub fn select_best_resolution(
original_size: (u32, u32),
possible_resolutions: &[(u32, u32)],
) -> (u32, u32) {
let (original_width, original_height) = original_size;
let mut best_fit = (0, 0);
let original_width_f = original_width as f32;
let original_height_f = original_height as f32;
let mut max_effective_resolution = 0_u32;
let mut min_wasted_resolution = u32::MAX;
for (width, height) in possible_resolutions {
let width_f = *width as f32;
let height_f = *height as f32;
let scale = (width_f / original_width_f).min(height_f / original_height_f);
let (downscaled_width, downscaled_height) = (
(original_width_f * scale) as u32,
(original_height_f * scale) as u32,
);
let effective_resolution =
std::cmp::min((*width) * (*height), downscaled_width * downscaled_height);
let wasted_resolution = (*width) * (*height) - effective_resolution;
if effective_resolution > max_effective_resolution
|| (effective_resolution == max_effective_resolution
&& wasted_resolution < min_wasted_resolution)
{
best_fit = (*width, *height);
max_effective_resolution = effective_resolution;
min_wasted_resolution = wasted_resolution;
}
}
best_fit
}
| 7 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/segment_anything/image_encoder.rs | use candle::{DType, IndexOp, Result, Tensor};
use candle_nn::{layer_norm, LayerNorm, Module, VarBuilder};
#[derive(Debug)]
struct PatchEmbed {
proj: candle_nn::Conv2d,
span: tracing::Span,
}
impl PatchEmbed {
fn new(
in_chans: usize,
embed_dim: usize,
k_size: usize,
stride: usize,
padding: usize,
vb: VarBuilder,
) -> Result<Self> {
let cfg = candle_nn::Conv2dConfig {
stride,
padding,
..Default::default()
};
let proj = candle_nn::conv2d(in_chans, embed_dim, k_size, cfg, vb.pp("proj"))?;
let span = tracing::span!(tracing::Level::TRACE, "patch-embed");
Ok(Self { proj, span })
}
}
impl Module for PatchEmbed {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
xs.apply(&self.proj)?.permute((0, 2, 3, 1))
}
}
// A custom op to make add_decomposed_rel_pos faster. Most of the time is spent on the final
// addition in the case where b = 12, q_h = q_w = 4096, k_h = k_w = 4096
// (attn.reshape((b, q_h, q_w, k_h, k_w))?
// + rel_h.unsqueeze(4)?.broadcast_add(&rel_w.unsqueeze(3)?)?)?
// .reshape((b, q_h * q_w, k_h * k_w))
// Ideally we would perform this operation in place but this is not supported in candle at the
// moment. We should also investigate using f16 rather than f32.
struct Add3(usize, usize, usize, usize, usize);
impl candle::CustomOp3 for Add3 {
fn name(&self) -> &'static str {
"add3"
}
fn cpu_fwd(
&self,
s1: &candle::CpuStorage,
l1: &candle::Layout,
s2: &candle::CpuStorage,
l2: &candle::Layout,
s3: &candle::CpuStorage,
l3: &candle::Layout,
) -> Result<(candle::CpuStorage, candle::Shape)> {
use rayon::prelude::*;
let Add3(b, q_h, q_w, k_h, k_w) = *self;
let s1 = s1.as_slice::<f32>()?;
let s1 = match l1.contiguous_offsets() {
None => candle::bail!("input1 has to be contiguous"),
Some((o1, o2)) => &s1[o1..o2],
};
let s2 = s2.as_slice::<f32>()?;
let s2 = match l2.contiguous_offsets() {
None => candle::bail!("input2 has to be contiguous"),
Some((o1, o2)) => &s2[o1..o2],
};
let s3 = s3.as_slice::<f32>()?;
let s3 = match l3.contiguous_offsets() {
None => candle::bail!("input3 has to be contiguous"),
Some((o1, o2)) => &s3[o1..o2],
};
let mut dst = vec![0f32; b * q_h * q_w * k_h * k_w];
dst.par_chunks_exact_mut(k_h * k_w)
.enumerate()
.for_each(|(b_idx, dst)| {
let s1_idx = b_idx * k_h * k_w;
let s2_idx = b_idx * k_h;
let s3_idx = b_idx * k_w;
for h_idx in 0..k_h {
let s1_idx = s1_idx + h_idx * k_w;
let s2_idx = s2_idx + h_idx;
let dst_idx = h_idx * k_w;
for w_idx in 0..k_w {
let s1_idx = s1_idx + w_idx;
let s3_idx = s3_idx + w_idx;
let dst_idx = dst_idx + w_idx;
dst[dst_idx] = s1[s1_idx] + s2[s2_idx] + s3[s3_idx]
}
}
});
let dst = candle::WithDType::to_cpu_storage_owned(dst);
Ok((dst, (b, q_h * q_w, k_h * k_w).into()))
}
}
#[derive(Debug)]
struct Attention {
qkv: super::Linear,
proj: super::Linear,
num_heads: usize,
scale: f64,
rel_pos_hw: Option<(Tensor, Tensor)>,
span: tracing::Span,
span_matmul: tracing::Span,
span_rel_pos: tracing::Span,
span_softmax: tracing::Span,
}
impl Attention {
fn new(
dim: usize,
num_heads: usize,
qkv_bias: bool,
use_rel_pos: bool,
input_size: (usize, usize),
vb: VarBuilder,
) -> Result<Self> {
let span = tracing::span!(tracing::Level::TRACE, "attention");
let span_matmul = tracing::span!(tracing::Level::TRACE, "attn-matmul");
let span_rel_pos = tracing::span!(tracing::Level::TRACE, "attn-rel-pos");
let span_softmax = tracing::span!(tracing::Level::TRACE, "attn-sm");
let qkv = super::linear(vb.pp("qkv"), dim, dim * 3, qkv_bias)?;
let proj = super::linear(vb.pp("proj"), dim, dim, true)?;
let head_dim = dim / num_heads;
let scale = 1. / (head_dim as f64).sqrt();
let rel_pos_hw = if use_rel_pos {
let h = vb.get((2 * input_size.0 - 1, head_dim), "rel_pos_h")?;
let w = vb.get((2 * input_size.1 - 1, head_dim), "rel_pos_w")?;
Some((h, w))
} else {
None
};
Ok(Self {
qkv,
proj,
num_heads,
scale,
rel_pos_hw,
span,
span_matmul,
span_rel_pos,
span_softmax,
})
}
fn add_decomposed_rel_pos(
&self,
attn: Tensor,
q: &Tensor,
(q_h, q_w): (usize, usize),
(k_h, k_w): (usize, usize),
) -> Result<Tensor> {
match &self.rel_pos_hw {
Some((rel_pos_h, rel_pos_w)) => {
let r_h = get_rel_pos(q_h, k_h, rel_pos_h)?;
let r_w = get_rel_pos(q_w, k_w, rel_pos_w)?;
let (b, _, dim) = q.dims3()?;
let r_q = q.reshape((b, q_h, q_w, dim))?;
// rel_h = torch.einsum("bhwc,hkc->bhwk", r_q, Rh)
let rel_h = r_q.matmul(&r_h.broadcast_left(b)?.t()?.contiguous()?)?;
// rel_w = torch.einsum("bhwc,wkc->bhwk", r_q, Rw)
let rel_w = r_q
.transpose(1, 2)? // -> bwhc
.contiguous()?
.matmul(&r_w.broadcast_left(b)?.t()?.contiguous()?)? // bwhc,bwck -> bwhk
.transpose(1, 2)?
.contiguous()?;
if attn.device().is_cpu() {
let op = Add3(b, q_h, q_w, k_h, k_w);
attn.apply_op3_no_bwd(&rel_h, &rel_w, &op)
} else {
(attn.reshape((b, q_h, q_w, k_h, k_w))?
+ rel_h.unsqueeze(4)?.broadcast_add(&rel_w.unsqueeze(3)?)?)?
.reshape((b, q_h * q_w, k_h * k_w))
}
}
None => Ok(attn),
}
}
}
fn get_rel_pos(q_size: usize, k_size: usize, rel_pos: &Tensor) -> Result<Tensor> {
let max_rel_dist = 2 * usize::max(q_size, k_size) - 1;
let dev = rel_pos.device();
let rel_pos_resized = if rel_pos.dim(0)? != max_rel_dist {
todo!("interpolation")
} else {
rel_pos
};
let q_coords = Tensor::arange(0u32, q_size as u32, dev)?
.reshape((q_size, 1))?
.to_dtype(DType::F32)?;
let k_coords = Tensor::arange(0u32, k_size as u32, dev)?
.reshape((1, k_size))?
.to_dtype(DType::F32)?;
let q_coords = (q_coords * f64::max(1f64, k_size as f64 / q_size as f64))?;
let k_coords = (k_coords * f64::max(1f64, q_size as f64 / k_size as f64))?;
let relative_coords = (q_coords.broadcast_sub(&k_coords)?
+ (k_size as f64 - 1.) * f64::max(1f64, q_size as f64 / k_size as f64))?;
let (d1, d2) = relative_coords.dims2()?;
let relative_coords = relative_coords.to_dtype(DType::U32)?;
rel_pos_resized
.index_select(&relative_coords.reshape(d1 * d2)?, 0)?
.reshape((d1, d2, ()))
}
impl Module for Attention {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (b, h, w, c) = xs.dims4()?;
let qkv = self
.qkv
.forward(&xs.flatten_to(1)?)?
.reshape((b, h * w, 3, self.num_heads, c / self.num_heads))?
.permute((2, 0, 3, 1, 4))?
.reshape((3, b * self.num_heads, h * w, c / self.num_heads))?;
let q = qkv.i(0)?;
let k = qkv.i(1)?;
let v = qkv.i(2)?;
let attn = {
let _enter = self.span_matmul.enter();
(&q * self.scale)?.matmul(&k.t()?)?
};
let attn = {
let _enter = self.span_rel_pos.enter();
self.add_decomposed_rel_pos(attn, &q, (h, w), (h, w))?
};
let attn = {
let _enter = self.span_softmax.enter();
candle_nn::ops::softmax_last_dim(&attn)?
};
let attn = {
let _enter = self.span_matmul.enter();
attn.matmul(&v)?
};
let attn = attn
.reshape((b, self.num_heads, h, w, c / self.num_heads))?
.permute((0, 2, 3, 1, 4))?
.reshape((b, h * w, c))?;
self.proj.forward(&attn)?.reshape((b, h, w, c))
}
}
#[derive(Debug)]
struct Block {
norm1: LayerNorm,
attn: Attention,
norm2: LayerNorm,
mlp: super::MlpBlock,
window_size: usize,
span: tracing::Span,
}
impl Block {
fn new(
dim: usize,
num_heads: usize,
qkv_bias: bool,
use_rel_pos: bool,
window_size: usize,
input_size: (usize, usize),
vb: VarBuilder,
) -> Result<Self> {
let norm1 = layer_norm(dim, 1e-6, vb.pp("norm1"))?;
let norm2 = layer_norm(dim, 1e-6, vb.pp("norm2"))?;
let input_size_attn = if window_size == 0 {
input_size
} else {
(window_size, window_size)
};
let attn = Attention::new(
dim,
num_heads,
qkv_bias,
use_rel_pos,
input_size_attn,
vb.pp("attn"),
)?;
let mlp = super::MlpBlock::new(dim, dim * 4, candle_nn::Activation::Gelu, vb.pp("mlp"))?;
let span = tracing::span!(tracing::Level::TRACE, "ie-block");
Ok(Self {
norm1,
attn,
norm2,
mlp,
window_size,
span,
})
}
}
fn window_partition(xs: Tensor, window_size: usize) -> Result<(Tensor, (usize, usize))> {
let (b, h, w, c) = xs.dims4()?;
let pad_h = (window_size - h % window_size) % window_size;
let pad_w = (window_size - w % window_size) % window_size;
let xs = if pad_h > 0 {
xs.pad_with_zeros(1, 0, pad_h)?
} else {
xs
};
let xs = if pad_w > 0 {
xs.pad_with_zeros(2, 0, pad_w)?
} else {
xs
};
let (h_p, w_p) = (h + pad_h, w + pad_w);
let windows = xs
.reshape((
b,
h_p / window_size,
window_size,
w_p / window_size,
window_size,
c,
))?
.transpose(2, 3)?
.contiguous()?
.flatten_to(2)?;
Ok((windows, (h_p, w_p)))
}
fn window_unpartition(
windows: Tensor,
window_size: usize,
(h_p, w_p): (usize, usize),
(h, w): (usize, usize),
) -> Result<Tensor> {
let b = windows.dim(0)? / (h_p * w_p / window_size / window_size);
let xs = windows
.reshape((
b,
h_p / window_size,
w_p / window_size,
window_size,
window_size,
windows.elem_count() / b / h_p / w_p,
))?
.transpose(2, 3)?
.contiguous()?
.reshape((b, h_p, w_p, ()))?;
let xs = if h_p > h { xs.narrow(1, 0, h)? } else { xs };
let xs = if w_p > w { xs.narrow(2, 0, w)? } else { xs };
Ok(xs)
}
impl Module for Block {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let shortcut = xs;
let xs = self.norm1.forward(xs)?;
let hw = (xs.dim(1)?, xs.dim(2)?);
let (xs, pad_hw) = if self.window_size > 0 {
window_partition(xs, self.window_size)?
} else {
(xs, (0, 0))
};
let xs = self.attn.forward(&xs)?;
let xs = if self.window_size > 0 {
window_unpartition(xs, self.window_size, pad_hw, hw)?
} else {
xs
};
let xs = (xs + shortcut)?;
&xs + xs.apply(&self.norm2)?.apply(&self.mlp)?
}
}
#[derive(Debug)]
pub struct ImageEncoderViT {
patch_embed: PatchEmbed,
blocks: Vec<Block>,
neck_conv1: candle_nn::Conv2d,
neck_ln1: super::LayerNorm2d,
neck_conv2: candle_nn::Conv2d,
neck_ln2: super::LayerNorm2d,
pos_embed: Option<Tensor>,
span: tracing::Span,
}
impl ImageEncoderViT {
#[allow(clippy::too_many_arguments)]
pub fn new(
img_size: usize,
patch_size: usize,
in_chans: usize,
embed_dim: usize,
depth: usize,
num_heads: usize,
out_chans: usize,
qkv_bias: bool,
use_rel_pos: bool,
use_abs_pos: bool,
window_size: usize,
global_attn_indexes: &[usize],
vb: VarBuilder,
) -> Result<Self> {
let patch_embed = PatchEmbed::new(
in_chans,
embed_dim,
patch_size,
patch_size,
0,
vb.pp("patch_embed"),
)?;
let mut blocks = Vec::with_capacity(depth);
let vb_b = vb.pp("blocks");
for i in 0..depth {
let window_size = if global_attn_indexes.contains(&i) {
0
} else {
window_size
};
let block = Block::new(
embed_dim,
num_heads,
qkv_bias,
use_rel_pos,
window_size,
(img_size / patch_size, img_size / patch_size),
vb_b.pp(i),
)?;
blocks.push(block)
}
let neck_conv1 = candle_nn::conv2d_no_bias(
embed_dim,
out_chans,
1,
Default::default(),
vb.pp("neck.0"),
)?;
let neck_ln1 = super::LayerNorm2d::new(out_chans, 1e-6, vb.pp("neck.1"))?;
let cfg = candle_nn::Conv2dConfig {
padding: 1,
..Default::default()
};
let neck_conv2 = candle_nn::conv2d_no_bias(out_chans, out_chans, 3, cfg, vb.pp("neck.2"))?;
let neck_ln2 = super::LayerNorm2d::new(out_chans, 1e-6, vb.pp("neck.3"))?;
let pos_embed = if use_abs_pos {
let p = vb.get(
(1, img_size / patch_size, img_size / patch_size, embed_dim),
"pos_embed",
)?;
Some(p)
} else {
None
};
let span = tracing::span!(tracing::Level::TRACE, "image-encoder-vit");
Ok(Self {
patch_embed,
blocks,
neck_conv1,
neck_ln1,
neck_conv2,
neck_ln2,
pos_embed,
span,
})
}
}
impl Module for ImageEncoderViT {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let xs = self.patch_embed.forward(xs)?;
let mut xs = match &self.pos_embed {
Some(pos_embed) => (xs + pos_embed)?,
None => xs,
};
for block in self.blocks.iter() {
xs = block.forward(&xs)?
}
xs.permute((0, 3, 1, 2))?
.apply(&self.neck_conv1)?
.apply(&self.neck_ln1)?
.apply(&self.neck_conv2)?
.apply(&self.neck_ln2)
}
}
| 8 |
0 | hf_public_repos/candle/candle-transformers/src/models | hf_public_repos/candle/candle-transformers/src/models/segment_anything/tiny_vit.rs | // Adapted from:
// https://github.com/ChaoningZhang/MobileSAM/blob/master/mobile_sam/modeling/tiny_vit_sam.py
use candle::{IndexOp, Result, Tensor, D};
use candle_nn::{Conv2dConfig, Module, VarBuilder};
const MBCONV_EXPAND_RATIO: usize = 4;
const MLP_RATIO: usize = 4;
const LOCAL_CONV_SIZE: usize = 3;
const IMG_SIZE: usize = 1024;
const IN_CHANNELS: usize = 3;
#[derive(Debug)]
struct Conv2dBN {
c: candle_nn::Conv2d,
bn: candle_nn::BatchNorm,
span: tracing::Span,
}
impl Conv2dBN {
fn new(in_: usize, out: usize, ks: usize, cfg: Conv2dConfig, vb: VarBuilder) -> Result<Self> {
let c = candle_nn::conv2d_no_bias(in_, out, ks, cfg, vb.pp("c"))?;
let bn = candle_nn::batch_norm(out, 1e-5, vb.pp("bn"))?;
let span = tracing::span!(tracing::Level::TRACE, "conv2d-bn");
Ok(Self { c, bn, span })
}
}
impl Module for Conv2dBN {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
xs.apply(&self.c)?.apply_t(&self.bn, false)
}
}
#[derive(Debug)]
struct PatchEmbed {
conv1: Conv2dBN,
conv2: Conv2dBN,
span: tracing::Span,
}
impl PatchEmbed {
fn new(in_chans: usize, embed_dim: usize, vb: VarBuilder) -> Result<Self> {
let cfg = candle_nn::Conv2dConfig {
stride: 2,
padding: 1,
..Default::default()
};
let conv1 = Conv2dBN::new(in_chans, embed_dim / 2, 3, cfg, vb.pp("seq.0"))?;
let conv2 = Conv2dBN::new(embed_dim / 2, embed_dim, 3, cfg, vb.pp("seq.2"))?;
let span = tracing::span!(tracing::Level::TRACE, "patch-embed");
Ok(Self { conv1, conv2, span })
}
}
impl Module for PatchEmbed {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
xs.apply(&self.conv1)?.gelu()?.apply(&self.conv2)
}
}
#[derive(Debug)]
struct MBConv {
conv1: Conv2dBN,
conv2: Conv2dBN,
conv3: Conv2dBN,
span: tracing::Span,
}
impl MBConv {
fn new(in_: usize, out: usize, expand_ratio: usize, vb: VarBuilder) -> Result<Self> {
let hidden = in_ * expand_ratio;
let cfg2 = candle_nn::Conv2dConfig {
padding: 1,
groups: hidden,
..Default::default()
};
let conv1 = Conv2dBN::new(in_, hidden, 1, Default::default(), vb.pp("conv1"))?;
let conv2 = Conv2dBN::new(hidden, hidden, 3, cfg2, vb.pp("conv2"))?;
let conv3 = Conv2dBN::new(hidden, out, 1, Default::default(), vb.pp("conv3"))?;
let span = tracing::span!(tracing::Level::TRACE, "mb-conv");
Ok(Self {
conv1,
conv2,
conv3,
span,
})
}
}
impl Module for MBConv {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let shortcut = xs;
let xs = xs
.apply(&self.conv1)?
.gelu()?
.apply(&self.conv2)?
.gelu()?
.apply(&self.conv3)?;
(xs + shortcut)?.gelu()
}
}
#[derive(Debug)]
struct PatchMerging {
conv1: Conv2dBN,
conv2: Conv2dBN,
conv3: Conv2dBN,
input_resolution: (usize, usize),
span: tracing::Span,
}
impl PatchMerging {
fn new(
input_resolution: (usize, usize),
dim: usize,
out: usize,
vb: VarBuilder,
) -> Result<Self> {
let stride = if [320, 448, 576].contains(&out) { 1 } else { 2 };
let cfg2 = candle_nn::Conv2dConfig {
padding: 1,
stride,
groups: out,
..Default::default()
};
let conv1 = Conv2dBN::new(dim, out, 1, Default::default(), vb.pp("conv1"))?;
let conv2 = Conv2dBN::new(out, out, 3, cfg2, vb.pp("conv2"))?;
let conv3 = Conv2dBN::new(out, out, 1, Default::default(), vb.pp("conv3"))?;
let span = tracing::span!(tracing::Level::TRACE, "patch-merging");
Ok(Self {
conv1,
conv2,
conv3,
input_resolution,
span,
})
}
}
impl Module for PatchMerging {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let xs = if xs.rank() == 3 {
let (h, w) = self.input_resolution;
let b = xs.dim(0)?;
xs.reshape((b, h, w, ()))?.permute((0, 3, 1, 2))?
} else {
xs.clone()
};
xs.apply(&self.conv1)?
.gelu()?
.apply(&self.conv2)?
.gelu()?
.apply(&self.conv3)?
.flatten_from(2)?
.transpose(1, 2)
}
}
#[derive(Debug)]
struct ConvLayer {
blocks: Vec<MBConv>,
downsample: Option<PatchMerging>,
span: tracing::Span,
}
impl ConvLayer {
fn new(
dim: usize,
out: usize,
input_resolution: (usize, usize),
depth: usize,
downsample: bool,
conv_expand_ratio: usize,
vb: VarBuilder,
) -> Result<Self> {
let vb_b = vb.pp("blocks");
let mut blocks = Vec::with_capacity(depth);
for index in 0..depth {
let block = MBConv::new(dim, dim, conv_expand_ratio, vb_b.pp(index))?;
blocks.push(block)
}
let downsample = if downsample {
let downsample = PatchMerging::new(input_resolution, dim, out, vb.pp("downsample"))?;
Some(downsample)
} else {
None
};
let span = tracing::span!(tracing::Level::TRACE, "conv-layer");
Ok(Self {
blocks,
downsample,
span,
})
}
}
impl Module for ConvLayer {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let mut xs = xs.clone();
for block in self.blocks.iter() {
xs = block.forward(&xs)?
}
match &self.downsample {
None => Ok(xs),
Some(downsample) => downsample.forward(&xs),
}
}
}
#[derive(Debug)]
struct Mlp {
norm: candle_nn::LayerNorm,
fc1: super::Linear,
fc2: super::Linear,
span: tracing::Span,
}
impl Mlp {
fn new(in_: usize, hidden: usize, vb: VarBuilder) -> Result<Self> {
let norm = candle_nn::layer_norm(in_, 1e-5, vb.pp("norm"))?;
let fc1 = super::linear(vb.pp("fc1"), in_, hidden, true)?;
let fc2 = super::linear(vb.pp("fc2"), hidden, in_, true)?;
let span = tracing::span!(tracing::Level::TRACE, "mlp");
Ok(Self {
norm,
fc1,
fc2,
span,
})
}
}
impl Module for Mlp {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
xs.apply(&self.norm)?
.apply(&self.fc1)?
.gelu()?
.apply(&self.fc2)
}
}
#[derive(Debug)]
struct Attention {
norm: candle_nn::LayerNorm,
qkv: super::Linear,
proj: super::Linear,
ab: Tensor,
key_dim: usize,
num_heads: usize,
d: usize,
dh: usize,
scale: f64,
span: tracing::Span,
span_matmul: tracing::Span,
span_softmax: tracing::Span,
}
impl Attention {
fn new(
dim: usize,
key_dim: usize,
num_heads: usize,
attn_ratio: usize,
resolution: (usize, usize),
vb: VarBuilder,
) -> Result<Self> {
let d = attn_ratio * key_dim;
let dh = d * num_heads;
let nh_kd = key_dim * num_heads;
let h = dh + nh_kd * 2;
let norm = candle_nn::layer_norm(dim, 1e-5, vb.pp("norm"))?;
let qkv = super::linear(vb.pp("qkv"), dim, h, true)?;
let proj = super::linear(vb.pp("proj"), dh, dim, true)?;
let points = (0..resolution.0)
.flat_map(|x| (0..resolution.1).map(move |y| (x as i64, y as i64)))
.collect::<Vec<_>>();
let mut idxs = Vec::with_capacity(points.len() * points.len());
let mut attention_offsets = std::collections::HashMap::new();
for &(x1, y1) in points.iter() {
for &(x2, y2) in points.iter() {
let offset = ((x2 - x1).abs(), (y2 - y1).abs());
let l = attention_offsets.len();
let idx = attention_offsets.entry(offset).or_insert(l);
idxs.push(*idx as u32)
}
}
let attention_biases = vb.get((num_heads, attention_offsets.len()), "attention_biases")?;
let idxs = Tensor::new(idxs, attention_biases.device())?;
let ab =
attention_biases
.index_select(&idxs, 1)?
.reshape(((), points.len(), points.len()))?;
let span = tracing::span!(tracing::Level::TRACE, "attention");
let span_matmul = tracing::span!(tracing::Level::TRACE, "attn-matmul");
let span_softmax = tracing::span!(tracing::Level::TRACE, "attn-sm");
Ok(Self {
norm,
qkv,
proj,
ab,
key_dim,
num_heads,
d,
dh,
scale: 1f64 / (key_dim as f64).sqrt(),
span,
span_matmul,
span_softmax,
})
}
}
impl Module for Attention {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (b, n, _) = xs.dims3()?;
let xs = xs.apply(&self.norm)?;
let qkv = xs.apply(&self.qkv)?.reshape((b, n, self.num_heads, ()))?;
let q = qkv
.narrow(D::Minus1, 0, self.key_dim)?
.permute((0, 2, 1, 3))?
.contiguous()?;
let k = qkv
.narrow(D::Minus1, self.key_dim, self.key_dim)?
.permute((0, 2, 1, 3))?
.contiguous()?;
let v = qkv
.narrow(D::Minus1, 2 * self.key_dim, self.d)?
.permute((0, 2, 1, 3))?
.contiguous()?;
let attn = {
let _enter = self.span_matmul.enter();
(q.matmul(&k.t()?)? * self.scale)?
};
let attn = attn.broadcast_add(&self.ab)?;
let attn = {
let _enter = self.span_softmax.enter();
candle_nn::ops::softmax_last_dim(&attn)?
};
let attn = {
let _enter = self.span_matmul.enter();
attn.matmul(&v)?
};
attn.transpose(1, 2)?
.reshape((b, n, self.dh))?
.apply(&self.proj)
}
}
#[derive(Debug)]
struct TinyViTBlock {
attn: Attention,
local_conv: Conv2dBN,
mlp: Mlp,
window_size: usize,
input_resolution: (usize, usize),
span: tracing::Span,
}
impl TinyViTBlock {
fn new(
dim: usize,
input_resolution: (usize, usize),
num_heads: usize,
window_size: usize,
vb: VarBuilder,
) -> Result<Self> {
let head_dim = dim / num_heads;
let attn = Attention::new(
dim,
head_dim,
num_heads,
1,
(window_size, window_size),
vb.pp("attn"),
)?;
let mlp = Mlp::new(dim, dim * MLP_RATIO, vb.pp("mlp"))?;
let cfg = candle_nn::Conv2dConfig {
padding: LOCAL_CONV_SIZE / 2,
groups: dim,
..Default::default()
};
let local_conv = Conv2dBN::new(dim, dim, LOCAL_CONV_SIZE, cfg, vb.pp("local_conv"))?;
let span = tracing::span!(tracing::Level::TRACE, "attention");
Ok(Self {
attn,
local_conv,
mlp,
window_size,
input_resolution,
span,
})
}
}
impl Module for TinyViTBlock {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let (h, w) = self.input_resolution;
let (b, l, c) = xs.dims3()?;
let res_x = xs;
let xs = if h == self.window_size && w == self.window_size {
self.attn.forward(xs)?
} else {
let xs = xs.reshape((b, h, w, c))?;
let pad_b = (self.window_size - h % self.window_size) % self.window_size;
let pad_r = (self.window_size - w % self.window_size) % self.window_size;
let xs = if pad_b > 0 {
xs.pad_with_zeros(1, 0, pad_b)?
} else {
xs
};
let xs = if pad_r > 0 {
xs.pad_with_zeros(2, 0, pad_r)?
} else {
xs
};
let (p_h, p_w) = (h + pad_b, w + pad_r);
let n_h = p_h / self.window_size;
let n_w = p_w / self.window_size;
let xs = xs
.reshape((b, n_h, self.window_size, n_w, self.window_size, c))?
.transpose(2, 3)?
.reshape((b * n_h * n_w, self.window_size * self.window_size, c))?;
let xs = self.attn.forward(&xs)?;
let xs = xs
.reshape((b, n_h, n_w, self.window_size, self.window_size, c))?
.transpose(2, 3)?
.reshape((b, p_h, p_w, c))?;
let xs = if pad_r > 0 {
xs.i((.., .., ..w))?.contiguous()?
} else {
xs
};
let xs = if pad_b > 0 {
xs.i((.., ..h, ..))?.contiguous()?
} else {
xs
};
xs.reshape((b, l, c))?
};
let xs = (xs + res_x)?;
let xs = xs
.transpose(1, 2)?
.reshape((b, c, h, w))?
.apply(&self.local_conv)?
.reshape((b, c, l))?
.transpose(1, 2)?;
&xs + self.mlp.forward(&xs)?
}
}
#[derive(Debug)]
struct BasicLayer {
blocks: Vec<TinyViTBlock>,
downsample: Option<PatchMerging>,
span: tracing::Span,
}
impl BasicLayer {
#[allow(clippy::too_many_arguments)]
fn new(
dim: usize,
input_resolution: (usize, usize),
depth: usize,
num_heads: usize,
window_size: usize,
downsample: bool,
out: usize,
vb: VarBuilder,
) -> Result<Self> {
let vb_b = vb.pp("blocks");
let mut blocks = Vec::with_capacity(depth);
for index in 0..depth {
let block = TinyViTBlock::new(
dim,
input_resolution,
num_heads,
window_size,
vb_b.pp(index),
)?;
blocks.push(block)
}
let downsample = if downsample {
let downsample = PatchMerging::new(input_resolution, dim, out, vb.pp("downsample"))?;
Some(downsample)
} else {
None
};
let span = tracing::span!(tracing::Level::TRACE, "basic-layer");
Ok(Self {
blocks,
downsample,
span,
})
}
}
impl Module for BasicLayer {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let mut xs = xs.clone();
for block in self.blocks.iter() {
xs = block.forward(&xs)?
}
match &self.downsample {
None => Ok(xs),
Some(downsample) => downsample.forward(&xs),
}
}
}
#[derive(Debug)]
pub struct TinyViT {
patch_embed: PatchEmbed,
layer0: ConvLayer,
layers: Vec<BasicLayer>,
// norm_head: candle_nn::LayerNorm,
// head: candle_nn::Linear,
neck_conv1: candle_nn::Conv2d,
neck_ln1: super::LayerNorm2d,
neck_conv2: candle_nn::Conv2d,
neck_ln2: super::LayerNorm2d,
span: tracing::Span,
span_neck: tracing::Span,
}
impl TinyViT {
pub fn new(
embed_dims: &[usize],
depths: &[usize],
num_heads: &[usize],
window_sizes: &[usize],
_num_classes: usize,
vb: VarBuilder,
) -> Result<Self> {
let patch_embed = PatchEmbed::new(IN_CHANNELS, embed_dims[0], vb.pp("patch_embed"))?;
let patches_resolution = IMG_SIZE / 4;
let vb_l = vb.pp("layers");
let layer0 = ConvLayer::new(
/* dim */ embed_dims[0],
/* out */ embed_dims[1],
/* input_resolution */ (patches_resolution, patches_resolution),
/* depth */ depths[0],
/* downsample */ true,
/* conv_expand_ratio */ MBCONV_EXPAND_RATIO,
vb_l.pp(0),
)?;
let num_layers = embed_dims.len();
let mut layers = Vec::with_capacity(num_layers - 1);
for i_layer in 1..num_layers {
let patches_resolution = patches_resolution / (1 << usize::min(i_layer, 2));
let layer = BasicLayer::new(
/* dim */ embed_dims[i_layer],
/* input_resolution */ (patches_resolution, patches_resolution),
/* depth */ depths[i_layer],
/* num_heads */ num_heads[i_layer],
/* window_size */ window_sizes[i_layer],
/* downsample */ i_layer < num_layers - 1,
/* out */ embed_dims[usize::min(i_layer + 1, num_layers - 1)],
vb_l.pp(i_layer),
)?;
layers.push(layer)
}
let last_embed_dim = embed_dims[embed_dims.len() - 1];
// let norm_head = candle_nn::layer_norm(last_embed_dim, 1e-5, vb.pp("norm_head"))?;
// let head = candle_nn::linear(last_embed_dim, num_classes, vb.pp("head"))?;
let neck_conv1 =
candle_nn::conv2d_no_bias(last_embed_dim, 256, 1, Default::default(), vb.pp("neck.0"))?;
let neck_ln1 = super::LayerNorm2d::new(256, 1e-6, vb.pp("neck.1"))?;
let cfg = candle_nn::Conv2dConfig {
padding: 1,
..Default::default()
};
let neck_conv2 = candle_nn::conv2d_no_bias(256, 256, 3, cfg, vb.pp("neck.2"))?;
let neck_ln2 = super::LayerNorm2d::new(256, 1e-6, vb.pp("neck.3"))?;
let span = tracing::span!(tracing::Level::TRACE, "tiny-vit");
let span_neck = tracing::span!(tracing::Level::TRACE, "neck");
Ok(Self {
patch_embed,
layer0,
layers,
neck_conv1,
neck_ln1,
neck_conv2,
neck_ln2,
span,
span_neck,
})
}
}
impl Module for TinyViT {
fn forward(&self, xs: &Tensor) -> Result<Tensor> {
let _enter = self.span.enter();
let xs = self.patch_embed.forward(xs)?;
let mut xs = self.layer0.forward(&xs)?;
for layer in self.layers.iter() {
xs = layer.forward(&xs)?
}
let (b, _, c) = xs.dims3()?;
let _enter = self.span_neck.enter();
xs.reshape((b, 64, 64, c))?
.permute((0, 3, 1, 2))?
.apply(&self.neck_conv1)?
.apply(&self.neck_ln1)?
.apply(&self.neck_conv2)?
.apply(&self.neck_ln2)
}
}
pub fn tiny_vit_5m(vb: VarBuilder) -> Result<TinyViT> {
TinyViT::new(
/* embed_dims */ &[64, 128, 160, 320],
/* depths */ &[2, 2, 6, 2],
/* num_heads */ &[2, 4, 5, 10],
/* window_sizes */ &[7, 7, 14, 7],
/* num_classes */ 1000,
vb,
)
}
| 9 |
0 | hf_public_repos | hf_public_repos/blog/safetensors-security-audit.md | ---
title: "🐶Safetensors audited as really safe and becoming the default"
thumbnail: /blog/assets/142_safetensors_official/thumbnail.png
authors:
- user: Narsil
- user: stellaathena
guest: true
---
# Audit shows that safetensors is safe and ready to become the default
[Hugging Face](https://huggingface.co/), in close collaboration with [EleutherAI](https://www.eleuther.ai/) and [Stability AI](https://stability.ai/), has ordered
an external security audit of the `safetensors` library, the results of which allow
all three organizations to move toward making the library the default format
for saved models.
The full results of the security audit, performed by [Trail of Bits](https://www.trailofbits.com/),
can be found here: [Report](https://huggingface.co/datasets/safetensors/trail_of_bits_audit_repot/resolve/main/SOW-TrailofBits-EleutherAI_HuggingFace-v1.2.pdf).
The following blog post explains the origins of the library, why these audit results are important,
and the next steps.
## What is safetensors?
🐶[Safetensors](https://github.com/huggingface/safetensors) is a library
for saving and loading tensors in the most common frameworks (including PyTorch, TensorFlow, JAX, PaddlePaddle, and NumPy).
For a more concrete explanation, we'll use PyTorch.
```python
import torch
from safetensors.torch import load_file, save_file
weights = {"embeddings": torch.zeros((10, 100))}
save_file(weights, "model.safetensors")
weights2 = load_file("model.safetensors")
```
It also has a number of [cool features](https://github.com/huggingface/safetensors#yet-another-format-) compared to other formats, most notably that loading files is _safe_, as we'll see later.
When you're using `transformers`, if `safetensors` is installed, then those files will already
be used preferentially in order to prevent issues, which means that
```
pip install safetensors
```
is likely to be the only thing needed to run `safetensors` files safely.
Going forward and thanks to the validation of the library, `safetensors` will now be installed in `transformers` by
default. The next step is saving models in `safetensors` by default.
We are thrilled to see that the `safetensors` library is already seeing use in the ML ecosystem, including:
- [Civitai](https://civitai.com/)
- [Stable Diffusion Web UI](https://github.com/AUTOMATIC1111/stable-diffusion-webui)
- [dfdx](https://github.com/coreylowman/dfdx)
- [LLaMA.cpp](https://github.com/ggerganov/llama.cpp/blob/e6a46b0ed1884c77267dc70693183e3b7164e0e0/convert.py#L537)
## Why create something new?
The creation of this library was driven by the fact that PyTorch uses `pickle` under
the hood, which is inherently unsafe. (Sources: [1](https://huggingface.co/docs/hub/security-pickle), [2, video](https://www.youtube.com/watch?v=2ethDz9KnLk), [3](https://github.com/pytorch/pytorch/issues/52596))
With pickle, it is possible to write a malicious file posing as a model
that gives full control of a user's computer to an attacker without the user's knowledge,
allowing the attacker to steal all their bitcoins 😓.
While this vulnerability in pickle is widely known in the computer security world (and is acknowledged in the PyTorch [docs](https://pytorch.org/docs/stable/generated/torch.load.html)), it’s not common knowledge in the broader ML community.
Since the Hugging Face Hub is a platform where anyone can upload and share models, it is important to make efforts
to prevent users from getting infected by malware.
We are also taking steps to make sure the existing PyTorch files are not malicious, but the best we can do is flag suspicious-looking files.
Of course, there are other file formats out there, but
none seemed to meet the full set of [ideal requirements](https://github.com/huggingface/safetensors#yet-another-format-) our team identified.
In addition to being safe, `safetensors` allows lazy loading and generally faster loads (around 100x faster on CPU).
Lazy loading means loading only part of a tensor in an efficient manner.
This particular feature enables arbitrary sharding with efficient inference libraries, such as [text-generation-inference](https://github.com/huggingface/text-generation-inference), to load LLMs (such as LLaMA, StarCoder, etc.) on various types of hardware
with maximum efficiency.
Because it loads so fast and is framework agnostic, we can even use the format
to load models from the same file in PyTorch or TensorFlow.
## The security audit
Since `safetensors` main asset is providing safety guarantees, we wanted to make sure
it actually delivered. That's why Hugging Face, EleutherAI, and Stability AI teamed up to get an external
security audit to confirm it.
Important findings:
- No critical security flaw leading to arbitrary code execution was found.
- Some imprecisions in the spec format were detected and fixed.
- Some missing validation allowed [polyglot files](https://en.wikipedia.org/wiki/Polyglot_(computing)), which was fixed.
- Lots of improvements to the test suite were proposed and implemented.
In the name of openness and transparency, all companies agreed to make the report
fully public.
[Full report](https://huggingface.co/datasets/safetensors/trail_of_bits_audit_repot/resolve/main/SOW-TrailofBits-EleutherAI_HuggingFace-v1.2.pdf)
One import thing to note is that the library is written in Rust. This adds
an extra layer of [security](https://doc.rust-lang.org/rustc/exploit-mitigations.html)
coming directly from the language itself.
While it is impossible to
prove the absence of flaws, this is a major step in giving reassurance that `safetensors`
is indeed safe to use.
## Going forward
For Hugging Face, EleutherAI, and Stability AI, the master plan is to shift to using this format by default.
EleutherAI has added support for evaluating models stored as `safetensors` in their LM Evaluation Harness and is working on supporting the format in their GPT-NeoX distributed training library.
Within the `transformers` library we are doing the following:
- Create `safetensors`.
- Verify it works and can deliver on all promises (lazy load for LLMs, single file for all frameworks, faster loads).
- Verify it's safe. (This is today's announcement.)
- Make `safetensors` a core dependency. (This is already done or soon to come.)
- Make `safetensors` the default saving format. This will happen in a few months when we have enough feedback
to make sure it will cause as little disruption as possible and enough users already have the library
to be able to load new models even on relatively old `transformers` versions.
As for `safetensors` itself, we're looking into adding more advanced features for LLM training,
which has its own set of issues with current formats.
Finally, we plan to release a `1.0` in the near future, with the large user base of `transformers` providing the final testing step.
The format and the lib have had very few modifications since their inception,
which is a good sign of stability.
We're glad we can bring ML one step closer to being safe and efficient for all!
| 0 |
0 | hf_public_repos | hf_public_repos/blog/tf-serving-vision.md | ---
title: Deploying TensorFlow Vision Models in Hugging Face with TF Serving
thumbnail: /blog/assets/90_tf_serving_vision/thumbnail.png
authors:
- user: sayakpaul
guest: true
---
# Deploying TensorFlow Vision Models in Hugging Face with TF Serving
<a target="_blank" href="https://colab.research.google.com/github/huggingface/blog/blob/main/notebooks/111_tf_serving_vision.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
In the past few months, the Hugging Face team and external contributors
added a variety of vision models in TensorFlow to Transformers. This
list is growing comprehensively and already includes state-of-the-art
pre-trained models like [Vision Transformer](https://huggingface.co/docs/transformers/main/en/model_doc/vit),
[Masked Autoencoders](https://huggingface.co/docs/transformers/model_doc/vit_mae),
[RegNet](https://huggingface.co/docs/transformers/main/en/model_doc/regnet),
[ConvNeXt](https://huggingface.co/docs/transformers/model_doc/convnext),
and many others!
When it comes to deploying TensorFlow models, you have got a variety of
options. Depending on your use case, you may want to expose your model
as an endpoint or package it in an application itself. TensorFlow
provides tools that cater to each of these different scenarios.
In this post, you'll see how to deploy a Vision Transformer (ViT) model (for image classification)
locally using [TensorFlow Serving](https://www.tensorflow.org/tfx/tutorials/serving/rest_simple)
(TF Serving). This will allow developers to expose the model either as a
REST or gRPC endpoint. Moreover, TF Serving supports many
deployment-specific features off-the-shelf such as model warmup,
server-side batching, etc.
To get the complete working code shown throughout this post, refer to
the Colab Notebook shown at the beginning.
## Saving the Model
All TensorFlow models in 🤗 Transformers have a method named
`save_pretrained()`. With it, you can serialize the model weights in
the h5 format as well as in the standalone [SavedModel format](https://www.tensorflow.org/guide/saved_model).
TF Serving needs a model to be present in the SavedModel format. So, let's first
load a Vision Transformer model and save it:
```py
from transformers import TFViTForImageClassification
temp_model_dir = "vit"
ckpt = "google/vit-base-patch16-224"
model = TFViTForImageClassification.from_pretrained(ckpt)
model.save_pretrained(temp_model_dir, saved_model=True)
```
By default, `save_pretrained()` will first create a version directory
inside the path we provide to it. So, the path ultimately becomes:
`{temp_model_dir}/saved_model/{version}`.
We can inspect the serving signature of the SavedModel like so:
```bash
saved_model_cli show --dir {temp_model_dir}/saved_model/1 --tag_set serve --signature_def serving_default
```
This should output:
```bash
The given SavedModel SignatureDef contains the following input(s):
inputs['pixel_values'] tensor_info:
dtype: DT_FLOAT
shape: (-1, -1, -1, -1)
name: serving_default_pixel_values:0
The given SavedModel SignatureDef contains the following output(s):
outputs['logits'] tensor_info:
dtype: DT_FLOAT
shape: (-1, 1000)
name: StatefulPartitionedCall:0
Method name is: tensorflow/serving/predict
```
As can be noticed the model accepts single 4-d inputs (namely
`pixel_values`) which has the following axes: `(batch_size,
num_channels, height, width)`. For this model, the acceptable height
and width are set to 224, and the number of channels is 3. You can verify
this by inspecting the config argument of the model (`model.config`).
The model yields a 1000-d vector of `logits`.
## Model Surgery
Usually, every ML model has certain preprocessing and postprocessing
steps. The ViT model is no exception to this. The major preprocessing
steps include:
- Scaling the image pixel values to [0, 1] range.
- Normalizing the scaled pixel values to [-1, 1].
- Resizing the image so that it has a spatial resolution of (224, 224).
You can confirm these by investigating the image processor associated
with the model:
```py
from transformers import AutoImageProcessor
processor = AutoImageProcessor.from_pretrained(ckpt)
print(processor)
```
This should print:
```bash
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
```
Since this is an image classification model pre-trained on the
[ImageNet-1k dataset](https://huggingface.co/datasets/imagenet-1k), the model
outputs need to be mapped to the ImageNet-1k classes as the
post-processing step.
To reduce the developers' cognitive load and training-serving skew,
it's often a good idea to ship a model that has most of the
preprocessing and postprocessing steps in built. Therefore, you should
serialize the model as a SavedModel such that the above-mentioned
processing ops get embedded into its computation graph.
### Preprocessing
For preprocessing, image normalization is one of the most essential
components:
```py
def normalize_img(
img, mean=processor.image_mean, std=processor.image_std
):
# Scale to the value range of [0, 1] first and then normalize.
img = img / 255
mean = tf.constant(mean)
std = tf.constant(std)
return (img - mean) / std
```
You also need to resize the image and transpose it so that it has leading
channel dimensions since following the standard format of 🤗
Transformers. The below code snippet shows all the preprocessing steps:
```py
CONCRETE_INPUT = "pixel_values" # Which is what we investigated via the SavedModel CLI.
SIZE = processor.size["height"]
def normalize_img(
img, mean=processor.image_mean, std=processor.image_std
):
# Scale to the value range of [0, 1] first and then normalize.
img = img / 255
mean = tf.constant(mean)
std = tf.constant(std)
return (img - mean) / std
def preprocess(string_input):
decoded_input = tf.io.decode_base64(string_input)
decoded = tf.io.decode_jpeg(decoded_input, channels=3)
resized = tf.image.resize(decoded, size=(SIZE, SIZE))
normalized = normalize_img(resized)
normalized = tf.transpose(
normalized, (2, 0, 1)
) # Since HF models are channel-first.
return normalized
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def preprocess_fn(string_input):
decoded_images = tf.map_fn(
preprocess, string_input, dtype=tf.float32, back_prop=False
)
return {CONCRETE_INPUT: decoded_images}
```
**Note on making the model accept string inputs**:
When dealing with images via REST or gRPC requests the size of the
request payload can easily spiral up depending on the resolution of the
images being passed. This is why it is a good practice to compress them
reliably and then prepare the request payload.
### Postprocessing and Model Export
You're now equipped with the preprocessing operations that you can inject
into the model's existing computation graph. In this section, you'll also
inject the post-processing operations into the graph and export the
model!
```py
def model_exporter(model: tf.keras.Model):
m_call = tf.function(model.call).get_concrete_function(
tf.TensorSpec(
shape=[None, 3, SIZE, SIZE], dtype=tf.float32, name=CONCRETE_INPUT
)
)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def serving_fn(string_input):
labels = tf.constant(list(model.config.id2label.values()), dtype=tf.string)
images = preprocess_fn(string_input)
predictions = m_call(**images)
indices = tf.argmax(predictions.logits, axis=1)
pred_source = tf.gather(params=labels, indices=indices)
probs = tf.nn.softmax(predictions.logits, axis=1)
pred_confidence = tf.reduce_max(probs, axis=1)
return {"label": pred_source, "confidence": pred_confidence}
return serving_fn
```
You can first derive the [concrete function](https://www.tensorflow.org/guide/function)
from the model's forward pass method (`call()`) so the model is nicely compiled
into a graph. After that, you can apply the following steps in order:
1. Pass the inputs through the preprocessing operations.
2. Pass the preprocessing inputs through the derived concrete function.
3. Post-process the outputs and return them in a nicely formatted
dictionary.
Now it's time to export the model!
```py
MODEL_DIR = tempfile.gettempdir()
VERSION = 1
tf.saved_model.save(
model,
os.path.join(MODEL_DIR, str(VERSION)),
signatures={"serving_default": model_exporter(model)},
)
os.environ["MODEL_DIR"] = MODEL_DIR
```
After exporting, let's inspect the model signatures again:
```bash
saved_model_cli show --dir {MODEL_DIR}/1 --tag_set serve --signature_def serving_default
```
```bash
The given SavedModel SignatureDef contains the following input(s):
inputs['string_input'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: serving_default_string_input:0
The given SavedModel SignatureDef contains the following output(s):
outputs['confidence'] tensor_info:
dtype: DT_FLOAT
shape: (-1)
name: StatefulPartitionedCall:0
outputs['label'] tensor_info:
dtype: DT_STRING
shape: (-1)
name: StatefulPartitionedCall:1
Method name is: tensorflow/serving/predict
```
You can notice that the model's signature has now changed. Specifically,
the input type is now a string and the model returns two things: a
confidence score and the string label.
Provided you've already installed TF Serving (covered in the Colab
Notebook), you're now ready to deploy this model!
## Deployment with TensorFlow Serving
It just takes a single command to do this:
```bash
nohup tensorflow_model_server \
--rest_api_port=8501 \
--model_name=vit \
--model_base_path=$MODEL_DIR >server.log 2>&1
```
From the above command, the important parameters are:
- `rest_api_port` denotes the port number that TF Serving will use
deploying the REST endpoint of your model. By default, TF Serving
uses the 8500 port for the gRPC endpoint.
- `model_name` specifies the model name (can be anything) that will
used for calling the APIs.
- `model_base_path` denotes the base model path that TF Serving will
use to load the latest version of the model.
(The complete list of supported parameters is
[here](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/model_servers/main.cc).)
And voila! Within minutes, you should be up and running with a deployed
model having two endpoints - REST and gRPC.
## Querying the REST Endpoint
Recall that you exported the model such that it accepts string inputs
encoded with the [base64 format](https://en.wikipedia.org/wiki/Base64). So, to craft the
request payload you can do something like this:
```py
# Get image of a cute cat.
image_path = tf.keras.utils.get_file(
"image.jpg", "http://images.cocodataset.org/val2017/000000039769.jpg"
)
# Read the image from disk as raw bytes and then encode it.
bytes_inputs = tf.io.read_file(image_path)
b64str = base64.urlsafe_b64encode(bytes_inputs.numpy()).decode("utf-8")
# Create the request payload.
data = json.dumps({"signature_name": "serving_default", "instances": [b64str]})
```
TF Serving's request payload format specification for the REST endpoint
is available [here](https://www.tensorflow.org/tfx/serving/api_rest#request_format_2).
Within the `instances` you can pass multiple encoded images. This kind
of endpoints are meant to be consumed for online prediction scenarios.
For inputs having more than a single data point, you would to want to
[enable batching](https://github.com/tensorflow/serving/blob/master/tensorflow_serving/batching/README.md)
to get performance optimization benefits.
Now you can call the API:
```py
headers = {"content-type": "application/json"}
json_response = requests.post(
"http://localhost:8501/v1/models/vit:predict", data=data, headers=headers
)
print(json.loads(json_response.text))
# {'predictions': [{'label': 'Egyptian cat', 'confidence': 0.896659195}]}
```
The REST API is -
`http://localhost:8501/v1/models/vit:predict` following the specification from
[here](https://www.tensorflow.org/tfx/serving/api_rest#predict_api). By default,
this always picks up the latest version of the model. But if you wanted a
specific version you can do: `http://localhost:8501/v1/models/vit/versions/1:predict`.
## Querying the gRPC Endpoint
While REST is quite popular in the API world, many applications often
benefit from gRPC. [This post](https://blog.dreamfactory.com/grpc-vs-rest-how-does-grpc-compare-with-traditional-rest-apis/)
does a good job comparing the two ways of deployment. gRPC is usually
preferred for low-latency, highly scalable, and distributed systems.
There are a couple of steps are. First, you need to open a communication
channel:
```py
import grpc
from tensorflow_serving.apis import predict_pb2
from tensorflow_serving.apis import prediction_service_pb2_grpc
channel = grpc.insecure_channel("localhost:8500")
stub = prediction_service_pb2_grpc.PredictionServiceStub(channel)
```
Then, create the request payload:
```py
request = predict_pb2.PredictRequest()
request.model_spec.name = "vit"
request.model_spec.signature_name = "serving_default"
request.inputs[serving_input].CopyFrom(tf.make_tensor_proto([b64str]))
```
You can determine the `serving_input` key programmatically like so:
```py
loaded = tf.saved_model.load(f"{MODEL_DIR}/{VERSION}")
serving_input = list(
loaded.signatures["serving_default"].structured_input_signature[1].keys()
)[0]
print("Serving function input:", serving_input)
# Serving function input: string_input
```
Now, you can get some predictions:
```py
grpc_predictions = stub.Predict(request, 10.0) # 10 secs timeout
print(grpc_predictions)
```
```bash
outputs {
key: "confidence"
value {
dtype: DT_FLOAT
tensor_shape {
dim {
size: 1
}
}
float_val: 0.8966591954231262
}
}
outputs {
key: "label"
value {
dtype: DT_STRING
tensor_shape {
dim {
size: 1
}
}
string_val: "Egyptian cat"
}
}
model_spec {
name: "resnet"
version {
value: 1
}
signature_name: "serving_default"
}
```
You can also fetch the key-values of our interest from the above results like so:
```py
grpc_predictions.outputs["label"].string_val, grpc_predictions.outputs[
"confidence"
].float_val
# ([b'Egyptian cat'], [0.8966591954231262])
```
## Wrapping Up
In this post, we learned how to deploy a TensorFlow vision model from
Transformers with TF Serving. While local deployments are great for
weekend projects, we would want to be able to scale these deployments to
serve many users. In the next series of posts, you'll see how to scale up
these deployments with Kubernetes and Vertex AI.
## Additional References
- [gRPC](https://grpc.io/)
- [Practical Machine Learning for Computer Vision](https://www.oreilly.com/library/view/practical-machine-learning/9781098102357/)
- [Faster TensorFlow models in Hugging Face Transformers](https://huggingface.co/blog/tf-serving)
| 1 |
0 | hf_public_repos | hf_public_repos/blog/textgen-pipe-gaudi.md | ---
title: "Text-Generation Pipeline on Intel® Gaudi® 2 AI Accelerator"
thumbnail: /blog/assets/textgen-pipe-gaudi/thumbnail.png
authors:
- user: siddjags
guest: true
---
# Text-Generation Pipeline on Intel® Gaudi® 2 AI Accelerator
With the Generative AI (GenAI) revolution in full swing, text-generation with open-source transformer models like Llama 2 has become the talk of the town. AI enthusiasts as well as developers are looking to leverage the generative abilities of such models for their own use cases and applications. This article shows how easy it is to generate text with the Llama 2 family of models (7b, 13b and 70b) using Optimum Habana and a custom pipeline class – you'll be able to run the models with just a few lines of code!
This custom pipeline class has been designed to offer great flexibility and ease of use. Moreover, it provides a high level of abstraction and performs end-to-end text-generation which involves pre-processing and post-processing. There are multiple ways to use the pipeline - you can run the `run_pipeline.py` script from the Optimum Habana repository, add the pipeline class to your own python scripts, or initialize LangChain classes with it.
## Prerequisites
Since the Llama 2 models are part of a gated repo, you need to request access if you haven't done it already. First, you have to visit the [Meta website](https://ai.meta.com/resources/models-and-libraries/llama-downloads) and accept the terms and conditions. After you are granted access by Meta (it can take a day or two), you have to request access [in Hugging Face](https://huggingface.co/meta-llama/Llama-2-7b-hf), using the same email address you provided in the Meta form.
After you are granted access, please login to your Hugging Face account by running the following command (you will need an access token, which you can get from [your user profile page](https://huggingface.co/settings/tokens)):
```bash
huggingface-cli login
```
You also need to install the latest version of Optimum Habana and clone the repo to access the pipeline script. Here are the commands to do so:
```bash
pip install optimum-habana==1.10.4
git clone -b v1.10-release https://github.com/huggingface/optimum-habana.git
```
In case you are planning to run distributed inference, install DeepSpeed depending on your SynapseAI version. In this case, I am using SynapseAI 1.14.0.
```bash
pip install git+https://github.com/HabanaAI/[email protected]
```
Now you are all set to perform text-generation with the pipeline!
## Using the Pipeline
First, go to the following directory in your `optimum-habana` checkout where the pipeline scripts are located, and follow the instructions in the `README` to update your `PYTHONPATH`.
```bash
cd optimum-habana/examples/text-generation
pip install -r requirements.txt
cd text-generation-pipeline
```
If you wish to generate a sequence of text from a prompt of your choice, here is a sample command.
```bash
python run_pipeline.py --model_name_or_path meta-llama/Llama-2-7b-hf --use_hpu_graphs --use_kv_cache --max_new_tokens 100 --do_sample --prompt "Here is my prompt"
```
You can also pass multiple prompts as input and change the temperature and top_p values for generation as follows.
```bash
python run_pipeline.py --model_name_or_path meta-llama/Llama-2-13b-hf --use_hpu_graphs --use_kv_cache --max_new_tokens 100 --do_sample --temperature 0.5 --top_p 0.95 --prompt "Hello world" "How are you?"
```
For generating text with large models such as Llama-2-70b, here is a sample command to launch the pipeline with DeepSpeed.
```bash
python ../../gaudi_spawn.py --use_deepspeed --world_size 8 run_pipeline.py --model_name_or_path meta-llama/Llama-2-70b-hf --max_new_tokens 100 --bf16 --use_hpu_graphs --use_kv_cache --do_sample --temperature 0.5 --top_p 0.95 --prompt "Hello world" "How are you?" "Here is my prompt" "Once upon a time"
```
## Usage in Python Scripts
You can use the pipeline class in your own scripts as shown in the example below. Run the following sample script from `optimum-habana/examples/text-generation/text-generation-pipeline`.
```python
import argparse
import logging
from pipeline import GaudiTextGenerationPipeline
from run_generation import setup_parser
# Define a logger
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger = logging.getLogger(__name__)
# Set up an argument parser
parser = argparse.ArgumentParser()
args = setup_parser(parser)
# Define some pipeline arguments. Note that --model_name_or_path is a required argument for this script
args.num_return_sequences = 1
args.model_name_or_path = "meta-llama/Llama-2-7b-hf"
args.max_new_tokens = 100
args.use_hpu_graphs = True
args.use_kv_cache = True
args.do_sample = True
# Initialize the pipeline
pipe = GaudiTextGenerationPipeline(args, logger)
# You can provide input prompts as strings
prompts = ["He is working on", "Once upon a time", "Far far away"]
# Generate text with pipeline
for prompt in prompts:
print(f"Prompt: {prompt}")
output = pipe(prompt)
print(f"Generated Text: {repr(output)}")
```
> You will have to run the above script with `python <name_of_script>.py --model_name_or_path a_model_name` as `--model_name_or_path` is a required argument. However, the model name can be programatically changed as shown in the python snippet.
This shows us that the pipeline class operates on a string input and performs data pre-processing as well as post-processing for us.
## LangChain Compatibility
The text-generation pipeline can be fed as input to LangChain classes via the `use_with_langchain` constructor argument. You can install LangChain as follows.
```bash
pip install langchain==0.0.191
```
Here is a sample script that shows how the pipeline class can be used with LangChain.
```python
import argparse
import logging
from langchain.llms import HuggingFacePipeline
from langchain.prompts import PromptTemplate
from langchain.chains import LLMChain
from pipeline import GaudiTextGenerationPipeline
from run_generation import setup_parser
# Define a logger
logging.basicConfig(
format="%(asctime)s - %(levelname)s - %(name)s - %(message)s",
datefmt="%m/%d/%Y %H:%M:%S",
level=logging.INFO,
)
logger = logging.getLogger(__name__)
# Set up an argument parser
parser = argparse.ArgumentParser()
args = setup_parser(parser)
# Define some pipeline arguments. Note that --model_name_or_path is a required argument for this script
args.num_return_sequences = 1
args.model_name_or_path = "meta-llama/Llama-2-13b-chat-hf"
args.max_input_tokens = 2048
args.max_new_tokens = 1000
args.use_hpu_graphs = True
args.use_kv_cache = True
args.do_sample = True
args.temperature = 0.2
args.top_p = 0.95
# Initialize the pipeline
pipe = GaudiTextGenerationPipeline(args, logger, use_with_langchain=True)
# Create LangChain object
llm = HuggingFacePipeline(pipeline=pipe)
template = """Use the following pieces of context to answer the question at the end. If you don't know the answer,\
just say that you don't know, don't try to make up an answer.
Context: Large Language Models (LLMs) are the latest models used in NLP.
Their superior performance over smaller models has made them incredibly
useful for developers building NLP enabled applications. These models
can be accessed via Hugging Face's `transformers` library, via OpenAI
using the `openai` library, and via Cohere using the `cohere` library.
Question: {question}
Answer: """
prompt = PromptTemplate(input_variables=["question"], template=template)
llm_chain = LLMChain(prompt=prompt, llm=llm)
# Use LangChain object
question = "Which libraries and model providers offer LLMs?"
response = llm_chain(prompt.format(question=question))
print(f"Question 1: {question}")
print(f"Response 1: {response['text']}")
question = "What is the provided context about?"
response = llm_chain(prompt.format(question=question))
print(f"\nQuestion 2: {question}")
print(f"Response 2: {response['text']}")
```
> The pipeline class has been validated for LangChain version 0.0.191 and may not work with other versions of the package.
## Conclusion
We presented a custom text-generation pipeline on Intel® Gaudi® 2 AI accelerator that accepts single or multiple prompts as input. This pipeline offers great flexibility in terms of model size as well as parameters affecting text-generation quality. Furthermore, it is also very easy to use and to plug into your scripts, and is compatible with LangChain.
> Use of the pretrained model is subject to compliance with third party licenses, including the “Llama 2 Community License Agreement” (LLAMAV2). For guidance on the intended use of the LLAMA2 model, what will be considered misuse and out-of-scope uses, who are the intended users and additional terms please review and read the instructions in this link [https://ai.meta.com/llama/license/](https://ai.meta.com/llama/license/). Users bear sole liability and responsibility to follow and comply with any third party licenses, and Habana Labs disclaims and will bear no liability with respect to users’ use or compliance with third party licenses.
To be able to run gated models like this Llama-2-70b-hf, you need the following:
> * Have a HuggingFace account
> * Agree to the terms of use of the model in its model card on the HF Hub
> * set a read token
> * Login to your account using the HF CLI: run huggingface-cli login before launching your script
| 2 |
0 | hf_public_repos | hf_public_repos/blog/quanto-introduction.md | ---
title: "Quanto: a PyTorch quantization backend for Optimum"
thumbnail: /blog/assets/169_quanto_intro/thumbnail.png
authors:
- user: dacorvo
- user: ybelkada
- user: marcsun13
---
# Quanto: a PyTorch quantization backend for Optimum
Quantization is a technique to reduce the computational and memory costs of evaluating Deep Learning Models by representing their weights and activations with low-precision data types like 8-bit integer (int8) instead of the usual 32-bit floating point (float32).
Reducing the number of bits means the resulting model requires less memory storage, which is crucial for deploying Large Language Models on consumer devices.
It also enables specific optimizations for lower bitwidth datatypes, such as `int8` or `float8` matrix multiplications on CUDA devices.
Many open-source libraries are available to quantize pytorch Deep Learning Models, each providing very powerful features, yet often restricted to specific model configurations and devices.
Also, although they are based on the same design principles, they are unfortunately often incompatible with one another.
Today, we are excited to introduce [quanto](https://github.com/huggingface/optimum-quanto), a PyTorch quantization backend for [Optimum](https://huggingface.co/docs/optimum/index).
It has been designed with versatility and simplicity in mind:
- all features are available in eager mode (works with non-traceable models),
- quantized models can be placed on any device (including CUDA and MPS),
- automatically inserts quantization and dequantization stubs,
- automatically inserts quantized functional operations,
- automatically inserts quantized modules (see below the list of supported modules),
- provides a seamless workflow from a float model to a dynamic to a static quantized model,
- serialization compatible with PyTorch `weight_only` and 🤗 [Safetensors](https://huggingface.co/docs/safetensors/index),
- accelerated matrix multiplications on CUDA devices (int8-int8, fp16-int4, bf16-int8, bf16-int4),
- supports int2, int4, int8 and float8 weights,
- supports int8 and float8 activations.
Recent quantization methods appear to be focused on quantizing Large Language Models (LLMs), whereas [quanto](https://github.com/huggingface/optimum-quanto) intends to provide extremely simple quantization primitives for simple quantization schemes (linear quantization, per-group quantization) that are adaptable across any modality.
## Quantization workflow
Quanto is available as a pip package.
```sh
pip install optimum-quanto
```
A typical quantization workflow consists of the following steps:
**1. Quantize**
The first step converts a standard float model into a dynamically quantized model.
```python
from optimum.quanto import quantize, qint8
quantize(model, weights=qint8, activations=qint8)
```
At this stage, only the inference of the model is modified to dynamically quantize the weights.
**2. Calibrate (optional if activations are not quantized)**
Quanto supports a calibration mode that allows the recording of the activation ranges while passing representative samples through the quantized model.
```python
from optimum.quanto import Calibration
with Calibration(momentum=0.9):
model(samples)
```
This automatically activates the quantization of the activations in the quantized modules.
**3. Tune, aka Quantization-Aware-Training (optional)**
If the performance of the model degrades too much, one can tune it for a few epochs to recover the float model performance.
```python
import torch
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
data, target = data.to(device), target.to(device)
optimizer.zero_grad()
output = model(data).dequantize()
loss = torch.nn.functional.nll_loss(output, target)
loss.backward()
optimizer.step()
```
**4. Freeze integer weights**
When freezing a model, its float weights are replaced by quantized weights.
```python
from optimum.quanto import freeze
freeze(model)
```
**5. Serialize quantized model**
Quantized models weights can be serialized to a `state_dict`, and saved to a file.
Both `pickle` and `safetensors` (recommended) are supported.
```python
from safetensors.torch import save_file
save_file(model.state_dict(), 'model.safetensors')
```
In order to reload these weights, you also need to store the quantized
models quantization map.
```python
import json
from optimum.quanto import quantization_map
with open('quantization_map.json', w) as f:
json.dump(quantization_map(model))
```
**5. Reload a quantized model**
A serialized quantized model can be reloaded from a `state_dict` and a `quantization_map` using the `requantize` helper.
Note that you need to first instantiate an empty model.
```python
import json
from safetensors.torch import load_file
state_dict = load_file('model.safetensors')
with open('quantization_map.json', r) as f:
quantization_map = json.load(f)
# Create an empty model from your modeling code and requantize it
with torch.device('meta'):
new_model = ...
requantize(new_model, state_dict, quantization_map, device=torch.device('cuda'))
```
Please refer to the [examples](https://github.com/huggingface/optimum-quanto/tree/main/examples) for instantiations of the quantization workflow.
You can also check this [notebook](https://colab.research.google.com/drive/1qB6yXt650WXBWqroyQIegB-yrWKkiwhl?usp=sharing) where we show you how to quantize a BLOOM model with quanto!
## Performance
Below are two graphs evaluating the accuracy of different quantized configurations for [meta-llama/Meta-Llama-3.1-8B](https://huggingface.co/meta-llama/Meta-Llama-3.1-8B).
Note: the first bar in each group always corresponds to the non-quantized model.
<div class="row"><center>
<div class="column">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quanto-introduction/meta-llama-Meta-Llama-3.1-8B_bf16_Perplexity.png" alt=""meta-llama/Meta-Llama-3.1-8B WikiText perplexity">
</div>
</center>
</div>
These results are obtained without applying any Post-Training-Optimization algorithm like [hqq](https://mobiusml.github.io/hqq_blog/) or [AWQ](https://github.com/mit-han-lab/llm-awq).
The graph below gives the latency per-token measured on an NVIDIA A10 GPU.
<div class="row"><center>
<div class="column">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/quanto-introduction/meta-llama-Meta-Llama-3.1-8B_bf16_Latency__ms_.png" alt="meta-llama/Meta-Llama-3.1-8B Mean latency per token">
</div>
</center>
</div>
Stay tuned for updated results as we are constantly improving [quanto](https://github.com/huggingface/optimum-quanto) with optimizers and optimized kernels.
Please refer to the [quanto benchmarks](https://github.com/huggingface/optimum-quanto/tree/main/bench/) for detailed results for different model architectures and configurations.
## Integration in transformers
Quanto is seamlessly integrated in the Hugging Face [transformers](https://github.com/huggingface/transformers) library. You can quantize any model by passing a `QuantoConfig` to `from_pretrained`!
Currently, you need to use the latest version of [accelerate](https://github.com/huggingface/accelerate) to make sure the integration is fully compatible.
```python
from transformers import AutoModelForCausalLM, AutoTokenizer, QuantoConfig
model_id = "facebook/opt-125m"
tokenizer = AutoTokenizer.from_pretrained(model_id)
quantization_config = QuantoConfig(weights="int8")
quantized_model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config= quantization_config
)
```
You can quantize the weights and/or activations in int8, float8, int4, or int2 by simply passing the correct argument in `QuantoConfig`. The activations can be either in int8 or float8. For float8, you need to have hardware that is compatible with float8 precision, otherwise quanto will silently upcast the weights and activations to torch.float32 or torch.float16 (depending on the original data type of the model) when we perform the matmul (only when the weight is quantized). If you try to use `float8` using MPS devices, `torch` will currently raise an error.
Quanto is device agnostic, meaning you can quantize and run your model regardless if you are on CPU/GPU/ MPS (Apple Silicon).
Quanto is also torch.compile friendly. You can quantize a model with quanto and call `torch.compile` to the model to compile it for faster generation. This feature might not work out of the box if dynamic quantization is involved (i.e., Quantization Aware Training or quantized activations enabled). Make sure to keep `activations=None` when creating your `QuantoConfig` in case you use the transformers integration.
It is also possible to quantize any model, regardless of the modality using quanto! We demonstrate how to quantize `openai/whisper-large-v3` model in int8 using quanto.
```python
from transformers import AutoModelForSpeechSeq2Seq
model_id = "openai/whisper-large-v3"
quanto_config = QuantoConfig(weights="int8")
model = AutoModelForSpeechSeq2Seq.from_pretrained(
model_id,
torch_dtype=torch.float16,
device_map="cuda",
quantization_config=quanto_config
)
```
Check out this [notebook](https://colab.research.google.com/drive/16CXfVmtdQvciSh9BopZUDYcmXCDpvgrT?usp=sharing#scrollTo=IHbdLXAg53JL) for a complete tutorial on how to properly use quanto with the transformers integration!
## Contributing to quanto
Contributions to [quanto](https://github.com/huggingface/optimum-quanto) are very much welcomed, especially in the following areas:
- optimized kernels for [quanto](https://github.com/huggingface/optimum-quanto) operations targeting specific devices,
- Post-Training-Quantization optimizers to recover the accuracy lost during quantization,
- helper classes for `transformers` or `diffusers` models.
| 3 |
0 | hf_public_repos | hf_public_repos/blog/open-source-llms-as-agents.md | ---
title: "Open-source LLMs as LangChain Agents"
thumbnail: /blog/assets/open-source-llms-as-agents/thumbnail_open_source_agents.png
authors:
- user: m-ric
- user: Jofthomas
- user: andrewrreed
---
# Open-source LLMs as LangChain Agents
## TL;DR
Open-source LLMs have now reached a performance level that makes them suitable reasoning engines for powering agent workflows: [Mixtral](https://huggingface.co/blog/mixtral) even [surpasses GPT-3.5](#results) on our benchmark, and its performance could easily be further enhanced with fine-tuning.
## Introduction
Large Language Models (LLMs) trained for [causal language modeling](https://huggingface.co/docs/transformers/tasks/language_modeling) can tackle a wide range of tasks, but they often struggle with basic tasks like logic, calculation, and search. The worst scenario is when they perform poorly in a domain, such as math, yet still attempt to handle all the calculations themselves.
To overcome this weakness, amongst other approaches, one can integrate the LLM into a system where it can call tools: such a system is called an LLM agent.
In this post, we explain the inner workings of ReAct agents, then show how to build them using the `ChatHuggingFace` class recently integrated in LangChain. Finally, we benchmark several open-source LLMs against GPT-3.5 and GPT-4.
## Table of Contents
- [What are agents?](#what-are-agents)
- [Toy example of a ReAct agent's inner working](#toy-example-of-a-react-agents-inner-working)
- [Challenges of agent systems](#challenges-of-agent-systems)
- [Running agents with LangChain](#running-agents-with-langchain)
- [Agents Showdown: how do different LLMs perform as general purpose reasoning agents?](#agents-showdown-how-do-open-source-llms-perform-as-general-purpose-reasoning-agents)
- [Evaluation](#evaluation)
- [Results](#results)
## What are agents?
The definition of LLM agents is quite broad: LLM agents are all systems that use LLMs as their engine and can perform actions on their environment based on observations. They can use several iterations of the Perception ⇒ Reflexion ⇒ Action cycle to achieve their task and are often augmented with planning or knowledge management systems to enhance their performance. You can find a good review of the Agents landscape in [Xi et al., 2023](https://huggingface.co/papers/2309.07864).
Today, we are focusing on **ReAct agents**. [ReAct](https://huggingface.co/papers/2210.03629) is an approach to building agents based on the concatenation of two words, "**Reasoning**" and "**Acting**." In the prompt, we describe the model, which tools it can use, and ask it to think “step by step” (also called [Chain-of-Thought](https://huggingface.co/papers/2201.11903) behavior) to plan and execute its next actions to reach the final answer.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/open-source-llms-as-agents/ReAct.png" alt="drawing" width=90%>
</p>
### Toy example of a ReAct agent's inner working
The graph above seems very high-level, but under the hood it’s quite simple.
Take a look at [this notebook](https://colab.research.google.com/drive/1j_vsc28FwZEDocDxVxWJ6Fvxd18FK8Gl?usp=sharing): we implement a barebones tool call example with the Transformers library.
The LLM is called in a loop with a prompt containing in essence:
```
Here is a question: "{question}"
You have access to these tools: {tools_descriptions}.
You should first reflect with ‘Thought: {your_thoughts}’, then you either:
- call a tool with the proper JSON formatting,
- or your print your final answer starting with the prefix ‘Final Answer:’
```
Then you parse the LLM’s output:
- if it contains the string `‘Final Answer:’`, the loop ends and you print the answer,
- else, the LLM should have output a tool call: you can parse this output to get the tool name and arguments, then call said tool with said arguments. Then the output of this tool call is appended to the prompt, and you call the LLM again with this extended information, until it has enough information to finally provide a final answer to the question.
For instance, the LLM's output can look like this, when answering the question: `How many seconds are in 1:23:45?`
```
Thought: I need to convert the time string into seconds.
Action:
{
"action": "convert_time",
"action_input": {
"time": "1:23:45"
}
}
```
Since this output does not contain the string `‘Final Answer:’`, it is calling a tool: so we parse this output and get the tool call parameters: call tool `convert_time` with arguments `{"time": "1:23:45"}`.
Running this tool call returns `{'seconds': '5025'}`.
So we append this whole blob to the prompt.
The new prompt is now (a slightly more elaborate version of):
```
Here is a question: "How many seconds are in 1:23:45?"
You have access to these tools:
- convert_time: converts a time given in hours:minutes:seconds into seconds.
You should first reflect with ‘Thought: {your_thoughts}’, then you either:
- call a tool with the proper JSON formatting,
- or your print your final answer starting with the prefix ‘Final Answer:’
Thought: I need to convert the time string into seconds.
Action:
{
"action": "convert_time",
"action_input": {
"time": "1:23:45"
}
}
Observation: {'seconds': '5025'}
```
➡️ We call the LLM again, with this new prompt. Given that it has access to the tool call's result in `Observation`, the LLM is now most likely to output:
```
Thought: I now have the information needed to answer the question.
Final Answer: There are 5025 seconds in 1:23:45.
``````
And the task is solved!
### Challenges of agent systems
Generally, the difficult parts of running an agent system for the LLM engine are:
1. From supplied tools, choose the one that will help advance to a desired goal: e.g. when asked `"What is the smallest prime number greater than 30,000?"`, the agent could call the `Search` tool with `"What is the height of K2"` but it won't help.
2. Call tools with a rigorous argument formatting: for instance when trying to calculate the speed of a car that went 3 km in 10 minutes, you have to call tool `Calculator` to divide `distance` by `time` : even if your Calculator tool accepts calls in the JSON format: `{”tool”: “Calculator”, “args”: “3km/10min”}` , there are many pitfalls, for instance:
- Misspelling the tool name: `“calculator”` or `“Compute”` wouldn’t work
- Giving the name of the arguments instead of their values: `“args”: “distance/time”`
- Non-standardized formatting: `“args": "3km in 10minutes”`
3. Efficiently ingesting and using the information gathered in the past observations, be it the initial context or the observations returned after using tool uses.
So, how would a complete Agent setup look like?
## Running agents with LangChain
We have just integrated a `ChatHuggingFace` wrapper that lets you create agents based on open-source models in [🦜🔗LangChain](https://www.langchain.com/).
The code to create the ChatModel and give it tools is really simple, you can check it all in the [Langchain doc](https://python.langchain.com/docs/integrations/chat/huggingface).
```python
from langchain_community.llms import HuggingFaceEndpoint
from langchain_community.chat_models.huggingface import ChatHuggingFace
llm = HuggingFaceEndpoint(repo_id="HuggingFaceH4/zephyr-7b-beta")
chat_model = ChatHuggingFace(llm=llm)
```
You can make the `chat_model` into an agent by giving it a ReAct style prompt and tools:
```python
from langchain import hub
from langchain.agents import AgentExecutor, load_tools
from langchain.agents.format_scratchpad import format_log_to_str
from langchain.agents.output_parsers import (
ReActJsonSingleInputOutputParser,
)
from langchain.tools.render import render_text_description
from langchain_community.utilities import SerpAPIWrapper
# setup tools
tools = load_tools(["serpapi", "llm-math"], llm=llm)
# setup ReAct style prompt
prompt = hub.pull("hwchase17/react-json")
prompt = prompt.partial(
tools=render_text_description(tools),
tool_names=", ".join([t.name for t in tools]),
)
# define the agent
chat_model_with_stop = chat_model.bind(stop=["\nObservation"])
agent = (
{
"input": lambda x: x["input"],
"agent_scratchpad": lambda x: format_log_to_str(x["intermediate_steps"]),
}
| prompt
| chat_model_with_stop
| ReActJsonSingleInputOutputParser()
)
# instantiate AgentExecutor
agent_executor = AgentExecutor(agent=agent, tools=tools, verbose=True)
agent_executor.invoke(
{
"input": "Who is the current holder of the speed skating world record on 500 meters? What is her current age raised to the 0.43 power?"
}
)
```
And the agent will process the input:
```markdown
Thought: To answer this question, I need to find age of the current speedskating world record holder. I will use the search tool to find this information.
Action:
{
"action": "search",
"action_input": "speed skating world record holder 500m age"
}
Observation: ...
```
## Agents Showdown: how do open-source LLMs perform as general purpose reasoning agents?
You can find the code for this benchmark [here](https://github.com/aymeric-roucher/benchmark_agents/).
### Evaluation
We want to measure how open-source LLMs perform as general purpose reasoning agents. Thus we select questions requiring using logic and the use of basic tools: a calculator and access to internet search.
The [final dataset](https://huggingface.co/datasets/m-ric/agents_small_benchmark) is a combination of samples from 3 other datasets:
- For testing Internet search capability: we have selected questions from [HotpotQA](https://huggingface.co/datasets/hotpot_qa): this is originally a retrieval dataset, but it can be used for general question answering, with access to the internet. Some questions originally need to combine information from various sources: in our setting, this means performing several steps of internet search to combine the results.
- For calculator usage, we added questions from [GSM8K](https://huggingface.co/datasets/gsm8k): this dataset tests grade-school math ability, and is entirely solvable by correctly leveraging the 4 operators (add, subtract, multiply, divide).
- We also picked questions from [GAIA](https://huggingface.co/papers/2311.12983), a very difficult benchmark for General AI Assistants. The questions in the original dataset can require many other different tools, such as a code interpreter or pdf reader: we hand-picked questions that do not require other tools than search and calculator.
Evaluation was performed with GPT-4-as-a-judge using a prompt based on the [Prometheus prompt format](https://huggingface.co/kaist-ai/prometheus-13b-v1.0), giving results on a 5-point Likert Scale: see the exact prompt [here](https://github.com/aymeric-roucher/benchmark_agents/blob/master/scripts/prompts.py).
### Models
We evaluate a few strong open-source models:
- [Llama2-70b-chat](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf)
- [Mixtral-8x7B-Instruct-v0.1](https://huggingface.co/mistralai/Mixtral-8x7B-Instruct-v0.1)
- [OpenHermes-2.5-Mistral-7B](https://huggingface.co/teknium/OpenHermes-2.5-Mistral-7B)
- [Zephyr-7b-beta](https://huggingface.co/HuggingFaceH4/zephyr-7b-beta)
- [SOLAR-10.7B-Instruct-v1.0](https://huggingface.co/upstage/SOLAR-10.7B-Instruct-v1.0)
These models are evaluated in LangChain's [ReAct implementation](https://github.com/langchain-ai/langchain/tree/021b0484a8d9e8cf0c84bc164fb904202b9e4736/libs/langchain/langchain/agents/react)
This means we prompt them to output their function calls in this format:
```json
{
"action": $TOOL_NAME,
"action_input": $INPUT
}
```
For comparison, we have also evaluated GPT-3.5 and GPT-4 on the same examples using LangChain's [OpenAI-specific agent](https://github.com/langchain-ai/langchain/tree/021b0484a8d9e8cf0c84bc164fb904202b9e4736/libs/langchain/langchain/agents/openai_functions_agent).
Since this uses their own function-calling template, on which they were fine-tuned, this means the OpenAI models should be at their top performance.
### Results
Since the open-source models were not specifically fine-tuned for calling functions in the given output format, they are at a slight disadvantage compared to the OpenAI agents.
Despite this, some models perform really well! 💪
Here’s an example of Mixtral-8x7B answering the question: `“Which city has a larger population, Guiyang or Tacheng?”`
```markdown
Thought: To answer this question, I need to find the current populations of both Guiyang and Tacheng. I will use the search tool to find this information.
Action:
{
"action": "search",
"action_input": "current population of Guiyang"
}
4.697 million (2016)
Thought: I have obtained the population of Guiyang, which is 4.697 million (as of 2016). Now, I will use the search tool again to find the population of Tacheng.
Action:
{
"action": "search",
"action_input": "current population of Tacheng"
}
Population: Xinjiang: Tacheng data was reported at 1,110.000 Persons in 2021. This records a decrease from the previous number of 1,138.638 Persons for 2020.
Population: Xinjiang: Tacheng data is updated yearly, averaging 1,023.000 Persons from Dec 2005 to 2021, with 17 observations.
I have obtained the population of Tacheng, which is approximately 1.11 million (as of 2021). Comparing the two populations, Guiyang has a larger population than Tacheng.
Thought: I now know the final answer
Final Answer: Guiyang has a larger population, which is approximately 4.697 million (as of 2016), compared to Tacheng's population of approximately 1.11 million (as of 2021).
```
Here is a benchmark of the models on our evaluation dataset (the average scores originally on a scale of 1-5 have been converted to a scale of 0-100% for readability):
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/open-source-llms-as-agents/benchmark_agents.png" alt="benchmark of agents performance" width="90%">
</p>
As you can see, some open-source models do not perform well in powering agent workflows: while this was expected for the small Zephyr-7b, Llama2-70b performs surprisingly poorly.
👉 But **Mixtral-8x7B performs really well: it even beats GPT-3.5!** 🏆
And this is out-of-the-box performance: ***contrary to GPT-3.5, Mixtral was not finetuned for agent workflows*** (to our knowledge), which somewhat hinders its performance. For instance, on GAIA, 10% of questions fail because Mixtral tries to call a tool with incorrectly formatted arguments. **With proper fine-tuning for the function calling and task planning skills, Mixtral’s score would likely be even higher.**
➡️ We strongly recommend open-source builders to start fine-tuning Mixtral for agents, to surpass the next challenger: GPT-4! 🚀
**Closing remarks:**
- The GAIA benchmark, although it is tried here on a small subsample of questions and a few tools, seems like a very robust indicator of overall model performance for agent workflows, since it generally involves several reasoning steps and rigorous logic.
- The agent workflows allow LLMs to increase performance: for instance, on GSM8K, [GPT-4’s technical report](https://arxiv.org/pdf/2303.08774.pdf) reports 92% for 5-shot CoT prompting: giving it a calculator allows us to reach 95% in zero-shot . For Mixtral-8x7B, the [LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) reports 57.6% with 5-shot, we get 73% in zero-shot. _(Keep in mind that we tested only 20 questions of GSM8K)_
| 4 |
0 | hf_public_repos | hf_public_repos/blog/leaderboard-finbench.md | ---
title: "Introducing the Open FinLLM Leaderboard"
thumbnail: /blog/assets/leaderboards-on-the-hub/thumbnail_finbench.png
authors:
- user: QianqianXie1994
org: TheFinAI
guest: true
- user: jiminHuang
org: TheFinAI
guest: true
- user: Effoula
org: TheFinAI
guest: true
- user: yanglet
guest: true
- user: alejandroll10
guest: true
- user: Benyou
org: FreedomIntelligence
guest: true
- user: ldruth
org: TheFinAI
guest: true
- user: xiangr
org: TheFinAI
guest: true
- user: Me1oy
org: TheFinAI
guest: true
- user: ShirleyY
guest: true
- user: mirageco
guest: true
- user: blitzionic
guest: true
- user: clefourrier
---
# Introducing the Open FinLLM Leaderboard
*Finding the best LLM models for finance use cases*
The growing complexity of financial language models (LLMs) necessitates evaluations that go beyond general NLP benchmarks. While traditional leaderboards focus on broader NLP tasks like translation or summarization, they often fall short in addressing the specific needs of the finance industry. Financial tasks, such as predicting stock movements, assessing credit risks, and extracting information from financial reports, present unique challenges that require models with specialized skills. This is why we decided to create the [**Open FinLLM Leaderboard**](https://huggingface.co/spaces/TheFinAI/Open-Financial-LLM-Leaderboard).
The [leaderboard](https://huggingface.co/spaces/TheFinAI/Open-Financial-LLM-Leaderboard) provides a **specialized evaluation framework** tailored specifically to the financial sector. We hope it fills this critical gap, by providing a transparent framework that assesses model readiness for real-world use with a one-stop solution. The leaderboard is designed to highlight a model's **financial skill** by focusing on tasks that matter most to finance professionals—such as information extraction from financial documents, market sentiment analysis, and forecasting financial trends.
* **Comprehensive Financial Task Coverage:** The leaderboard evaluates models only on tasks that are directly relevant to finance. These tasks include **information extraction**, **sentiment analysis**, **credit risk scoring**, and **stock movement forecasting**, which are crucial for real-world financial decision-making.
* **Real-World Financial Relevance:** The datasets used for the benchmarks represent real-world challenges faced by the finance industry. This ensures that models are actually assessed on their ability to handle complex financial data, making them suitable for industry applications.
* **Focused Zero-Shot Evaluation:** The leaderboard employs a **zero-shot evaluation** method, testing models on unseen financial tasks without any prior fine-tuning. This approach reveals a model’s ability to generalize and perform well in financial contexts, such as predicting stock price movements or extracting entities from regulatory filings, without being explicitly trained on those tasks.
## Key Features of the Open Financial LLM Leaderboard
* **Diverse Task Categories:** The leaderboard covers tasks across seven categories: Information Extraction (IE), Textual Analysis (TA), Question Answering (QA), Text Generation (TG), Risk Management (RM), Forecasting (FO), and Decision-Making (DM).
* **Evaluation Metrics:** Models are assessed using a variety of metrics, including Accuracy, F1 Score, ROUGE Score, and Matthews Correlation Coefficient (MCC). These metrics provide a multidimensional view of model performance, helping users identify the strengths and weaknesses of each model.
## Supported Tasks and Metric
The **Open Financial LLM Leaderboard (OFLL)** evaluates financial language models across a diverse set of categories that reflect the complex needs of the finance industry. Each category targets specific capabilities, ensuring a comprehensive assessment of model performance in tasks directly relevant to finance.
### Categories
The selection of task categories in OFLL is intentionally designed to capture the full range of capabilities required by financial models. This approach is influenced by both the diverse nature of financial applications and the complexity of the tasks involved in financial language processing.
* **Information Extraction (IE):** The financial sector often requires structured insights from unstructured documents such as regulatory filings, contracts, and earnings reports. Information extraction tasks include **Named Entity Recognition (NER)**, **Relation Extraction**, and **Causal Classification**. These tasks evaluate a model’s ability to identify key financial entities, relationships, and events, which are crucial for downstream applications such as fraud detection or investment strategy.
* **Textual Analysis (TA):** Financial markets are driven by sentiment, opinions, and the interpretation of financial news and reports. Textual analysis tasks such as **Sentiment Analysis**, **News Classification**, and **Hawkish-Dovish Classification** help assess how well a model can interpret market sentiment and textual data, aiding in tasks like investor sentiment analysis and policy interpretation.
* **Question Answering (QA):** This category addresses the ability of models to interpret complex financial queries, particularly those that involve numerical reasoning or domain-specific knowledge. The QA tasks, such as those derived from datasets like **FinQA** and **TATQA**, evaluate a model’s capability to respond to detailed financial questions, which is critical in areas like risk analysis or financial advisory services.
* **Text Generation (TG):** Summarization of complex financial reports and documents is essential for decision-making. Tasks like **ECTSum** and **EDTSum** test models on their ability to generate concise and coherent summaries from lengthy financial texts, which is valuable in generating reports or analyst briefings.
* **Forecasting (FO):** One of the most critical applications in finance is the ability to forecast market movements. Tasks under this category evaluate a model’s ability to predict stock price movements or market trends based on historical data, news, and sentiment. These tasks are central to tasks like portfolio management and trading strategies.
* **Risk Management (RM):** This category focuses on tasks that evaluate a model’s ability to predict and assess financial risks, such as **Credit Scoring**, **Fraud Detection**, and **Financial Distress Identification**. These tasks are fundamental for credit evaluation, risk management, and compliance purposes.
* **Decision-Making (DM):** In finance, making informed decisions based on multiple inputs (e.g., market data, sentiment, and historical trends) is crucial. Decision-making tasks simulate complex financial decisions, such as **Mergers & Acquisitions** and **Stock Trading**, testing the model’s ability to handle multimodal inputs and offer actionable insights.
### Metrics
* **F1-score**, the harmonic mean of precision and recall, offers a balanced evaluation, especially important in cases of class imbalance within the dataset. Both metrics are standard in classification tasks and together give a comprehensive view of the model's capability to discern sentiments in financial language.
* **Accuracy** measures the proportion of correctly classified instances out of all instances, providing a straightforward assessment of overall performance.
* **RMSE** provides a measure of the average deviation between predicted and actual sentiment scores, offering a quantitative insight into the accuracy of the model's predictions.
* **Entity F1 Score (EntityF1)**. This metric assesses the balance between precision and recall specifically for the recognized entities, providing a clear view of the model's effectiveness in identifying relevant financial entities. A high EntityF1 indicates that the model is proficient at both detecting entities and minimizing false positives, making it an essential measure for applications in financial data analysis and automation.
* **Exact Match Accuracy (EmAcc)** measures the proportion of questions for which the model’s answer exactly matches the ground truth, providing a clear indication of the model's effectiveness in understanding and processing numerical information in financial contexts. A high EmAcc reflects a model's capability to deliver precise and reliable answers, crucial for applications that depend on accurate financial data interpretation.
* **ROUGE** (Recall-Oriented Understudy for Gisting Evaluation) is a set of metrics used to assess the quality of summaries by comparing them to reference summaries. It focuses on the overlap of n-grams between the generated summaries and the reference summaries, providing a measure of content coverage and fidelity.
* **BERTScore** utilizes contextual embeddings from the BERT model to evaluate the similarity between generated and reference summaries. By comparing the cosine similarity of the embeddings for each token, BERTScore captures semantic similarity, allowing for a more nuanced evaluation of summary quality.
* **BARTScore** is based on the BART (Bidirectional and Auto-Regressive Transformers) model, which combines the benefits of both autoregressive and autoencoding approaches for text generation. It assesses how well the generated summary aligns with the reference summary in terms of coherence and fluency, providing insights into the overall quality of the extraction process.
* **Matthews Correlation Coefficient (MCC)** takes into account true and false positives and negatives, thereby offering insights into the model's effectiveness in a binary classification context. Together, these metrics ensure a comprehensive assessment of a model's predictive capabilities in the challenging landscape of stock movement forecasting.
* **Sharpe Ratio (SR).** The Sharpe Ratio measures the model's risk-adjusted return, providing insight into how well the model's trading strategies perform relative to the level of risk taken. A higher Sharpe Ratio indicates a more favorable return per unit of risk, making it a critical indicator of the effectiveness and efficiency of the trading strategies generated by the model. This metric enables users to gauge the model’s overall profitability and robustness in various market conditions.
### Individual Tasks
We use 40 tasks on this leaderboard, across these categories:
- **Information Extraction(IE)**: NER, FiNER-ORD, FinRED, SC, CD, FNXL, FSRL
- **Textual Analysis(TA)**: FPB, FiQA-SA, TSA, Headlines, FOMC, FinArg-ACC, FinArg-ARC, MultiFin, MA, MLESG
- **Question Answering(QA)**: FinQA, TATQA, Regulations, ConvFinQA
- **Text Generation(TG)**: ECTSum, EDTSum
- **Risk Management(RM)**: German, Australian, LendingClub, ccf, ccfraud, polish, taiwan, ProtoSeguro, travelinsurance
- **Forecasting(FO)**: BigData22, ACL18, CIKM18
- **Decision-Making(DM)**: FinTrade
- **Spanish**: MultiFin-ES, EFP ,EFPA ,FinanceES, TSA-Spanish
<details><summary><b>Click here for a short explanation of each task</b></summary>
1. **[FPB (Financial PhraseBank Sentiment Classification)](https://huggingface.co/datasets/ChanceFocus/en-fpb) **
**Description:** Sentiment analysis of phrases in financial news and reports, classifying into positive, negative, or neutral categories.
**Metrics:** Accuracy, F1-Score
2. **[FiQA-SA (Sentiment Analysis in Financial Domain)](https://huggingface.co/datasets/ChanceFocus/flare-fiqasa)**
**Description:** Sentiment analysis in financial media (news, social media). Classifies sentiments into positive, negative, and neutral, aiding in market sentiment interpretation.
**Metrics:** F1-Score
3. **[TSA (Sentiment Analysis on Social Media)](https://huggingface.co/datasets/ChanceFocus/flare-fiqasa)**
**Description:** Sentiment classification for financial tweets, reflecting public opinion on market trends. Challenges include informal language and brevity. **Metrics:** F1-Score, RMSE
4. **[Headlines (News Headline Classification)](https://huggingface.co/datasets/ChanceFocus/flare-headlines)**
**Description:** Classification of financial news headlines into sentiment or event categories. Critical for understanding market-moving information.
**Metrics:** AvgF1
5. **[FOMC (Hawkish-Dovish Classification)](https://huggingface.co/datasets/ChanceFocus/flare-fomc)**
**Description:** Classification of FOMC statements as hawkish (favoring higher interest rates) or dovish (favoring lower rates), key for monetary policy predictions.
**Metrics:** F1-Score, Accuracy
6. **[FinArg-ACC (Argument Unit Classification)](https://huggingface.co/datasets/ChanceFocus/flare-finarg-ecc-auc)**
**Description:** Identifies key argument units (claims, evidence) in financial texts, crucial for automated document analysis and transparency.
**Metrics:** F1-Score, Accuracy
7. **[FinArg-ARC (Argument Relation Classification)](https://huggingface.co/datasets/ChanceFocus/flare-finarg-ecc-arc)**
**Description:** Classification of relationships between argument units (support, opposition) in financial documents, helping analysts construct coherent narratives.
**Metrics:** F1-Score, Accuracy
8. **[MultiFin (Multi-Class Sentiment Analysis)](https://huggingface.co/datasets/ChanceFocus/flare-es-multifin)**
**Description:** Classification of diverse financial texts into sentiment categories (bullish, bearish, neutral), valuable for sentiment-driven trading.
**Metrics:** F1-Score, Accuracy
9. **[MA (Deal Completeness Classification)](https://huggingface.co/datasets/ChanceFocus/flare-ma)**
**Description:** Classifies mergers and acquisitions reports as completed, pending, or terminated. Critical for investment and strategy decisions.
**Metrics:** F1-Score, Accuracy
10. **[MLESG (ESG Issue Identification)](https://huggingface.co/datasets/ChanceFocus/flare-mlesg)**
**Description:** Identifies Environmental, Social, and Governance (ESG) issues in financial documents, important for responsible investing.
**Metrics:** F1-Score, Accuracy
11. **[NER (Named Entity Recognition in Financial Texts)](https://huggingface.co/datasets/ChanceFocus/flare-ner)**
**Description:** Identifies and categorizes entities (companies, instruments) in financial documents, essential for information extraction.
**Metrics:** Entity F1-Score
12. **[FINER-ORD (Ordinal Classification in Financial NER)](https://huggingface.co/datasets/ChanceFocus/flare-finer-ord)**
**Description:** Extends NER by classifying entity relevance within financial documents, helping prioritize key information.
**Metrics:** Entity F1-Score
13. **[FinRED (Financial Relation Extraction)](https://huggingface.co/datasets/ChanceFocus/flare-finred)**
**Description:** Extracts relationships (ownership, acquisition) between entities in financial texts, supporting knowledge graph construction.
**Metrics:** F1-Score, Entity F1-Score
14. **[SC (Causal Classification)](https://huggingface.co/datasets/ChanceFocus/flare-causal20-sc)**
**Description:** Classifies causal relationships in financial texts (e.g., "X caused Y"), aiding in market risk assessments.
**Metrics:** F1-Score, Entity F1-Score
15. **[CD (Causal Detection)](https://huggingface.co/datasets/ChanceFocus/flare-cd)**
**Description:** Detects causal relationships in financial texts, helping in risk analysis and investment strategies.
**Metrics:** F1-Score, Entity F1-Score
16. **[FinQA (Numerical Question Answering in Finance)](https://huggingface.co/datasets/ChanceFocus/flare-finqa)**
**Description:** Answers numerical questions from financial documents (e.g., balance sheets), crucial for automated reporting and analysis.
**Metrics:** Exact Match Accuracy (EmAcc)
17. **[TATQA (Table-Based Question Answering)](https://huggingface.co/datasets/ChanceFocus/flare-tatqa)**
**Description:** Extracts information from financial tables (balance sheets, income statements) to answer queries requiring numerical reasoning.
**Metrics:** F1-Score, EmAcc
18. **[ConvFinQA (Multi-Turn QA in Finance)](https://huggingface.co/datasets/ChanceFocus/flare-convfinqa)**
**Description:** Handles multi-turn dialogues in financial question answering, maintaining context throughout the conversation.
**Metrics:** EmAcc
19. **[FNXL (Numeric Labeling)](https://huggingface.co/datasets/ChanceFocus/flare-fnxl)**
**Description:** Labels numeric values in financial documents (e.g., revenue, expenses), aiding in financial data extraction.
**Metrics:** F1-Score, EmAcc
20. **[FSRL (Financial Statement Relation Linking)](https://huggingface.co/datasets/ChanceFocus/flare-fsrl)**
**Description:** Links related information across financial statements (e.g., revenue in income statements and cash flow data).
**Metrics:** F1-Score, EmAcc
21. **[EDTSUM (Extractive Document Summarization)](https://huggingface.co/datasets/ChanceFocus/flare-edtsum)**
**Description:** Summarizes long financial documents, extracting key information for decision-making.
**Metrics:** ROUGE, BERTScore, BARTScore
22. **[ECTSUM (Extractive Content Summarization)](https://huggingface.co/datasets/ChanceFocus/flare-ectsum)**
**Description:** Summarizes financial content, extracting key sentences or phrases from large texts.
**Metrics:** ROUGE, BERTScore, BARTScore
23. **[BigData22 (Stock Movement Prediction)](https://huggingface.co/datasets/TheFinAI/en-forecasting-bigdata)**
**Description:** Predicts stock price movements based on financial news, using textual data to forecast market trends.
**Metrics:** Accuracy, MCC
24. **[ACL18 (Financial News-Based Stock Prediction)](https://huggingface.co/datasets/ChanceFocus/flare-sm-acl)**
**Description:** Predicts stock price movements from news articles, interpreting sentiment and events for short-term forecasts.
**Metrics:** Accuracy, MCC
25. **[CIKM18 (Financial Market Prediction Using News)](https://huggingface.co/datasets/ChanceFocus/flare-sm-cikm)**
**Description:** Predicts broader market movements (indices) from financial news, synthesizing information for market trend forecasts.
**Metrics:** Accuracy, MCC
26. **[German (Credit Scoring in Germany)](https://huggingface.co/datasets/ChanceFocus/flare-german)**
**Description:** Predicts creditworthiness of loan applicants in Germany, important for responsible lending and risk management.
**Metrics:** F1-Score, MCC
27. **[Australian (Credit Scoring in Australia)](https://huggingface.co/datasets/ChanceFocus/flare-australian)**
**Description:** Predicts creditworthiness in the Australian market, considering local economic conditions.
**Metrics:** F1-Score, MCC
28. **[LendingClub (Peer-to-Peer Lending Risk Prediction)](https://huggingface.co/datasets/ChanceFocus/cra-lendingclub)**
**Description:** Predicts loan default risk for peer-to-peer lending, helping lenders manage risk.
**Metrics:** F1-Score, MCC
29. **[ccf (Credit Card Fraud Detection)](https://huggingface.co/datasets/ChanceFocus/cra-ccf)**
**Description:** Identifies fraudulent credit card transactions, ensuring financial security and fraud prevention.
**Metrics:** F1-Score, MCC
30. **[ccfraud (Credit Card Transaction Fraud Detection)](https://huggingface.co/datasets/ChanceFocus/cra-ccfraud)**
**Description:** Detects anomalies in credit card transactions that indicate fraud, while handling imbalanced datasets.
**Metrics:** F1-Score, MCC
31. **[Polish (Credit Risk Prediction in Poland)](https://huggingface.co/datasets/ChanceFocus/cra-polish)**
**Description:** Predicts credit risk for loan applicants in Poland, assessing factors relevant to local economic conditions.
**Metrics:** F1-Score, MCC
32. **[Taiwan (Credit Risk Prediction in Taiwan)](https://huggingface.co/datasets/TheFinAI/cra-taiwan)**
**Description:** Predicts credit risk in the Taiwanese market, helping lenders manage risk in local contexts.
**Metrics:** F1-Score, MCC
33. **[Portoseguro (Claim Analysis in Brazil)](https://huggingface.co/datasets/TheFinAI/en-forecasting-portosegur**
**Description:** Predicts the outcome of insurance claims in Brazil, focusing on auto insurance claims.
**Metrics:** F1-Score, MCC
34. **[Travel Insurance (Claim Prediction)](https://huggingface.co/datasets/TheFinA**
**Description:** Predicts the likelihood of travel insurance claims, helping insurers manage pricing and risk.
**Metrics:** F1-Score, MCC
35. **[MultiFin-ES (Sentiment Analysis in Spanish)](https://huggingface.co/datasets/ChanceFocus/flare-es-multifin)**
**Description:** Classifies sentiment in Spanish-language financial texts (bullish, bearish, neutral).
**Metrics:** F1-Score
36. **[EFP (Financial Phrase Classification in Spanish)](https://huggingface.co/datasets/ChanceFocus/flare-es-efp)**
**Description:** Classifies sentiment or intent in Spanish financial phrases (positive, negative, neutral).
**Metrics:** F1-Score
37. **[EFPA (Argument Classification in Spanish)](https://huggingface.co/datasets/ChanceFocus/flare-es-efpa)**
**Description:** Identifies claims, evidence, and counterarguments in Spanish financial texts.
**Metrics:** F1-Score
38. **[FinanceES (Sentiment Classification in Spanish)](https://huggingface.co/datasets/ChanceFocus/flare-es-financees)**
**Description:** Classifies sentiment in Spanish financial documents, understanding linguistic nuances.
**Metrics:** F1-Score
39. **[TSA-Spanish (Sentiment Analysis in Spanish Tweets)](https://huggingface.co/datasets/TheFinAI/flare-es-tsa)**
**Description:** Sentiment analysis of Spanish tweets, interpreting informal language in real-time market discussions.
**Metrics:** F1-Score
40. **[FinTrade (Stock Trading Simulation)](https://huggingface.co/datasets/TheFinAI/FinTrade_train)**
**Description:** Evaluates models on stock trading simulations, analyzing historical stock prices and financial news to optimize trading outcomes.
**Metrics:** Sharpe Ratio (SR)
</details>
<details><summary><b>Click here for a detailed explanation of each task</b></summary>
This section will document each task within the categories in more detail, explaining the specific datasets, evaluation metrics, and financial relevance.
1. **FPB (Financial PhraseBank Sentiment Classification)**
* **Task Description.** In this task, we evaluate a language model's ability to perform sentiment analysis on financial texts. We employ the Financial PhraseBank dataset1, which consists of annotated phrases extracted from financial news articles and reports. Each phrase is labeled with one of three sentiment categories: positive, negative, or neutral. The dataset provides a nuanced understanding of sentiments expressed in financial contexts, making it essential for applications such as market sentiment analysis and automated trading strategies. The primary objective is to classify each financial phrase accurately according to its sentiment. Example inputs, outputs, and the prompt templates used in this task are detailed in Table 5 and Table 8 in the Appendix.
* **Metric.** Accuracy, F1-score.
2. **FiQA-SA (Sentiment Analysis on FiQA Financial Domain)**
* **Task Description.** The FiQA-SA task evaluates a language model's capability to perform sentiment analysis within the financial domain, particularly focusing on data derived from the FiQA dataset. This dataset includes a diverse collection of financial texts sourced from various media, including news articles, financial reports, and social media posts. The primary objective of the task is to classify sentiments expressed in these texts into distinct categories, such as positive, negative, and neutral. This classification is essential for understanding market sentiment, as it can directly influence investment decisions and strategies. The FiQA-SA task is particularly relevant in today's fast-paced financial environment, where the interpretation of sentiment can lead to timely and informed decision-making.
* **Metrics.** F1 Score.
3. **TSA (Sentiment Analysis on Social Media)**
* **Task Description.** The TSA task focuses on evaluating a model's ability to perform sentiment analysis on tweets related to financial markets. Utilizing a dataset comprised of social media posts, this task seeks to classify sentiments as positive, negative, or neutral. The dynamic nature of social media makes it a rich source of real-time sentiment data, reflecting public opinion on market trends, company news, and economic events. The TSA dataset includes a wide variety of tweets, featuring diverse expressions of sentiment related to financial topics, ranging from stock performance to macroeconomic indicators. Given the brevity and informal nature of tweets, this task presents unique challenges in accurately interpreting sentiment, as context and subtleties can significantly impact meaning. Therefore, effective models must demonstrate robust understanding and analysis of informal language, slang, and sentiment indicators commonly used on social media platforms.
* **Metrics.** F1 Score, RMSE. RMSE provides a measure of the average deviation between predicted and actual sentiment scores, offering a quantitative insight into the accuracy of the model's predictions.
4. **Headlines (News Headline Classification)**
* **Task Description.** The Headlines task involves classifying financial news headlines into various categories, reflecting distinct financial events or sentiment classes. This dataset consists of a rich collection of headlines sourced from reputable financial news outlets, capturing a wide array of topics ranging from corporate earnings reports to market forecasts. The primary objective of this task is to evaluate a model's ability to accurately interpret and categorize brief, context-rich text segments that often drive market movements. Given the succinct nature of headlines, the classification task requires models to quickly grasp the underlying sentiment and relevance of each headline, which can significantly influence investor behavior and market sentiment.
* **Metrics.** Average F1 Score (AvgF1). This metric provides a balanced measure of precision and recall, allowing for a nuanced understanding of the model’s performance in classifying headlines. A high AvgF1 indicates that the model is effectively identifying and categorizing the sentiment and events reflected in the headlines, making it a critical metric for assessing its applicability in real-world financial contexts.
5. **FOMC (Hawkish-Dovish Classification)**
* **Task Description.** The FOMC task evaluates a model's ability to classify statements derived from transcripts of Federal Open Market Committee (FOMC) meetings as either hawkish or dovish. Hawkish statements typically indicate a preference for higher interest rates to curb inflation, while dovish statements suggest a focus on lower rates to stimulate economic growth. This classification is crucial for understanding monetary policy signals that can impact financial markets and investment strategies. The dataset includes a range of statements from FOMC meetings, providing insights into the Federal Reserve's stance on economic conditions, inflation, and employment. Accurately categorizing these statements allows analysts and investors to anticipate market reactions and adjust their strategies accordingly, making this task highly relevant in the context of financial decision-making.
* **Metrics.** F1 Score and Accuracy.
6. **FinArg-ACC (Financial Argument Unit Classification)**
* **Task Description.** The FinArg-ACC task focuses on classifying argument units within financial documents, aiming to identify key components such as main claims, supporting evidence, and counterarguments. This dataset comprises a diverse collection of financial texts, including research reports, investment analyses, and regulatory filings. The primary objective is to assess a model's ability to dissect complex financial narratives into distinct argument units, which is crucial for automated financial document analysis. This task is particularly relevant in the context of increasing regulatory scrutiny and the need for transparency in financial communications, where understanding the structure of arguments can aid in compliance and risk management.
* **Metrics.** F1 Score, Accuracy.
7. **FinArg-ARC (Financial Argument Relation Classification)**
* **Task Description.** The FinArg-ARC task focuses on classifying relationships between different argument units within financial texts. This involves identifying how various claims, evidence, and counterarguments relate to each other, such as support, opposition, or neutrality. The dataset comprises annotated financial documents that highlight argument structures, enabling models to learn the nuances of financial discourse. Understanding these relationships is crucial for constructing coherent narratives and analyses from fragmented data, which can aid financial analysts, investors, and researchers in drawing meaningful insights from complex information. Given the intricate nature of financial arguments, effective models must demonstrate proficiency in discerning subtle distinctions in meaning and context, which are essential for accurate classification.
* **Metrics.** F1 Score, Accuracy
8. **MultiFin (Multi-Class Financial Sentiment Analysis)**
* **Task Description.** The MultiFin task focuses on the classification of sentiments expressed in a diverse array of financial texts into multiple categories, such as bullish, bearish, or neutral. This dataset includes various financial documents, ranging from reports and articles to social media posts, providing a comprehensive view of sentiment across different sources and contexts. The primary objective of this task is to assess a model's ability to accurately discern and categorize sentiments that influence market behavior and investor decisions. Models must demonstrate a robust understanding of contextual clues and varying tones inherent in financial discussions. The MultiFin task is particularly valuable for applications in sentiment-driven trading strategies and market analysis, where precise sentiment classification can lead to more informed investment choices.
* **Metrics.** F1 Score, Accuracy.
9. **MA (Deal Completeness Classification)**
* **Task Description:**
The MA task focuses on classifying mergers and acquisitions (M\&A) reports to determine whether a deal has been completed. This dataset comprises a variety of M\&A announcements sourced from financial news articles, press releases, and corporate filings. The primary objective is to accurately identify the status of each deal—categorized as completed, pending, or terminated—based on the information presented in the reports. This classification is crucial for investment analysts and financial institutions, as understanding the completion status of M\&A deals can significantly influence investment strategies and market reactions. Models must demonstrate a robust understanding of the M\&A landscape and the ability to accurately classify deal statuses based on often complex and evolving narratives.
* **Metrics:**
F1 Score, Accuracy.
10. **MLESG (ESG Issue Identification)**
* **Task Description:**
The MLESG task focuses on identifying Environmental, Social, and Governance (ESG) issues within financial texts. This dataset is specifically designed to capture a variety of texts, including corporate reports, news articles, and regulatory filings, that discuss ESG topics. The primary objective of the task is to evaluate a model's ability to accurately classify and categorize ESG-related content, which is becoming increasingly important in today's investment landscape. Models are tasked with detecting specific ESG issues, such as climate change impacts, social justice initiatives, or corporate governance practices. Models must demonstrate a deep understanding of the language used in these contexts, as well as the ability to discern subtle variations in meaning and intent.
* **Metrics:**
F1 Score, Accuracy.
11. **NER (Named Entity Recognition in Financial Texts)**
* **Task Description:**
The NER task focuses on identifying and classifying named entities within financial documents, such as companies, financial instruments, and individuals. This task utilizes a dataset that includes a diverse range of financial texts, encompassing regulatory filings, earnings reports, and news articles. The primary objective is to accurately recognize entities relevant to the financial domain and categorize them appropriately, which is crucial for information extraction and analysis. Effective named entity recognition enhances the automation of financial analysis processes, allowing stakeholders to quickly gather insights from large volumes of unstructured text.
* **Metrics:**
Entity F1 Score (EntityF1).
12. **FINER-ORD (Ordinal Classification in Financial NER)**
* **Task Description:**
The FINER-ORD task focuses on extending standard Named Entity Recognition (NER) by requiring models to classify entities not only by type but also by their ordinal relevance within financial texts. This dataset comprises a range of financial documents that include reports, articles, and regulatory filings, where entities such as companies, financial instruments, and events are annotated with an additional layer of classification reflecting their importance or priority. The primary objective is to evaluate a model’s ability to discern and categorize entities based on their significance in the context of the surrounding text. For instance, a model might identify a primary entity (e.g., a major corporation) as having a higher relevance compared to secondary entities (e.g., a minor competitor) mentioned in the same document. This capability is essential for prioritizing information and enhancing the efficiency of automated financial analyses, where distinguishing between varying levels of importance can significantly impact decision-making processes.
* **Metrics:**
Entity F1 Score (EntityF1).
13. **FinRED (Financial Relation Extraction from Text)**
* **Task Description:**
The FinRED task focuses on extracting relationships between financial entities mentioned in textual data. This task utilizes a dataset that includes diverse financial documents, such as news articles, reports, and regulatory filings. The primary objective is to identify and classify relationships such as ownership, acquisition, and partnership among various entities, such as companies, financial instruments, and stakeholders. Accurately extracting these relationships is crucial for building comprehensive knowledge graphs and facilitating in-depth financial analysis. The challenge lies in accurately interpreting context, as the relationships often involve nuanced language and implicit connections that require a sophisticated understanding of financial terminology.
* **Metrics:**
F1 Score, Entity F1 Score (EntityF1).
14. **SC (Causal Classification Task in the Financial Domain)**
* **Task Description:**
The SC task focuses on evaluating a language model's ability to classify causal relationships within financial texts. This involves identifying whether one event causes another, which is crucial for understanding dynamics in financial markets. The dataset used for this task encompasses a variety of financial documents, including reports, articles, and regulatory filings, where causal language is often embedded. By examining phrases that express causality—such as "due to," "resulting in," or "leads to"—models must accurately determine the causal links between financial events, trends, or phenomena. This task is particularly relevant for risk assessment, investment strategy formulation, and decision-making processes, as understanding causal relationships can significantly influence evaluations of market conditions and forecasts.
* **Metrics:**
F1 Score, Entity F1 Score (EntityF1).
15. **CD (Causal Detection)**
* **Task Description:**
The CD task focuses on detecting causal relationships within a diverse range of financial texts, including reports, news articles, and social media posts. This task evaluates a model's ability to identify instances where one event influences or causes another, which is crucial for understanding dynamics in financial markets. The dataset comprises annotated examples that explicitly highlight causal links, allowing models to learn from various contexts and expressions of causality. Detecting causality is essential for risk assessment, as it helps analysts understand potential impacts of events on market behavior, investment strategies, and decision-making processes. Models must navigate nuances and subtleties in text to accurately discern causal connections.
* **Metrics:**
F1 Score, Entity F1 Score (EntityF1).
16. **FinQA (Numerical Question Answering in Finance)**
* **Task Description:**
The FinQA task evaluates a model's ability to answer numerical questions based on financial documents, such as balance sheets, income statements, and financial reports. This dataset includes a diverse set of questions that require not only comprehension of the text but also the ability to extract and manipulate numerical data accurately. The primary goal is to assess how well a model can interpret complex financial information and perform necessary calculations to derive answers. The FinQA task is particularly relevant for applications in financial analysis, investment decision-making, and automated reporting, where precise numerical responses are essential for stakeholders.
* **Metrics:**
Exact Match Accuracy (EmAcc)
17. **TATQA (Table-Based Question Answering in Financial Documents)**
* **Task Description:**
The TATQA task focuses on evaluating a model's ability to answer questions that require interpreting and extracting information from tables in financial documents. This dataset is specifically designed to include a variety of financial tables, such as balance sheets, income statements, and cash flow statements, each containing structured data critical for financial analysis. The primary objective of this task is to assess how well models can navigate these tables to provide accurate and relevant answers to questions that often demand numerical reasoning or domain-specific knowledge. Models must demonstrate proficiency in not only locating the correct data but also understanding the relationships between different data points within the context of financial analysis.
* **Metrics:**
F1 Score, Exact Match Accuracy (EmAcc).
18. **ConvFinQA (Multi-Turn Question Answering in Finance)**
* **Task Description:**
The ConvFinQA task focuses on evaluating a model's ability to handle multi-turn question answering in the financial domain. This task simulates real-world scenarios where financial analysts engage in dialogues, asking a series of related questions that build upon previous answers. The dataset includes conversations that reflect common inquiries regarding financial data, market trends, and economic indicators, requiring the model to maintain context and coherence throughout the dialogue. The primary objective is to assess the model's capability to interpret and respond accurately to multi-turn queries, ensuring that it can provide relevant and precise information as the conversation progresses. This task is particularly relevant in financial advisory settings, where analysts must extract insights from complex datasets while engaging with clients or stakeholders.
* **Metrics:**
Exact Match Accuracy (EmAcc).
19. **FNXL (Numeric Labeling in Financial Texts)**
* **Task Description:**
The FNXL task focuses on the identification and categorization of numeric values within financial documents. This involves labeling numbers based on their type (e.g., revenue, profit, expense) and their relevance in the context of the text. The dataset used for this task includes a diverse range of financial reports, statements, and analyses, presenting various numeric expressions that are crucial for understanding financial performance. Accurate numeric labeling is essential for automating financial analysis and ensuring that critical data points are readily accessible for decision-making. Models must demonstrate a robust ability to parse context and semantics to accurately classify numeric information, thereby enhancing the efficiency of financial data processing.
* **Metrics:**
F1 Score, Exact Match Accuracy (EmAcc).
20. **FSRL (Financial Statement Relation Linking)**
* **Task Description:**
The FSRL task focuses on linking related information across different financial statements, such as matching revenue figures from income statements with corresponding cash flow data. This task is crucial for comprehensive financial analysis, enabling models to synthesize data from multiple sources to provide a coherent understanding of a company's financial health. The dataset used for this task includes a variety of financial statements from publicly traded companies, featuring intricate relationships between different financial metrics. Accurate linking of this information is essential for financial analysts and investors who rely on holistic views of financial performance. The task requires models to navigate the complexities of financial terminology and understand the relationships between various financial elements, ensuring they can effectively connect relevant data points.
* **Metrics:**
F1 Score, Exact Match Accuracy (EmAcc).
21. **EDTSUM (Extractive Document Summarization in Finance)**
* **Task Description:**
The EDTSUM task focuses on summarizing lengthy financial documents by extracting the most relevant sentences to create concise and coherent summaries. This task is essential in the financial sector, where professionals often deal with extensive reports, research papers, and regulatory filings. The ability to distill critical information from large volumes of text is crucial for efficient decision-making and information dissemination. The EDTSUM dataset consists of various financial documents, each paired with expert-generated summaries that highlight key insights and data points. Models are evaluated on their capability to identify and select sentences that accurately reflect the main themes and arguments presented in the original documents.
* **Metrics:**
ROUGE, BERTScore, and BARTScore.
22. **ECTSUM (Extractive Content Summarization)**
* **Task Description:**
The ECTSUM task focuses on extractive content summarization within the financial domain, where the objective is to generate concise summaries from extensive financial documents. This task leverages a dataset that includes a variety of financial texts, such as reports, articles, and regulatory filings, each containing critical information relevant to stakeholders. The goal is to evaluate a model’s ability to identify and extract the most salient sentences or phrases that encapsulate the key points of the original text. The ECTSUM task challenges models to demonstrate their understanding of context, relevance, and coherence, ensuring that the extracted summaries accurately represent the main ideas while maintaining readability and clarity.
* **Metrics:**
ROUGE, BERTScore, and BARTScore.
23. **BigData22 (Stock Movement Prediction)**
* **Task Description:**
The BigData22 task focuses on predicting stock price movements based on financial news and reports. This dataset is designed to capture the intricate relationship between market sentiment and stock performance, utilizing a comprehensive collection of news articles, social media posts, and market data. The primary goal of this task is to evaluate a model's ability to accurately forecast whether the price of a specific stock will increase or decrease within a defined time frame. Models must effectively analyze textual data and discern patterns that correlate with market movements.
* **Metrics:**
Accuracy, Matthews Correlation Coefficient (MCC).
24. **ACL18 (Financial News-Based Stock Prediction)**
* **Task Description:**
The ACL18 task focuses on predicting stock movements based on financial news articles and headlines. Utilizing a dataset that includes a variety of news pieces, this task aims to evaluate a model's ability to analyze textual content and forecast whether stock prices will rise or fall in the near term. The dataset encompasses a range of financial news topics, from company announcements to economic indicators, reflecting the complex relationship between news sentiment and market reactions. Models must effectively interpret nuances in language and sentiment that can influence stock performance, ensuring that predictions align with actual market movements.
* **Metrics:**
Accuracy, Matthews Correlation Coefficient (MCC).
25. **CIKM18 (Financial Market Prediction Using News)**
* **Task Description:**
The CIKM18 task focuses on predicting broader market movements, such as stock indices, based on financial news articles. Utilizing a dataset that encompasses a variety of news stories related to market events, this task evaluates a model's ability to synthesize information from multiple sources and make informed predictions about future market trends. The dataset includes articles covering significant financial events, economic indicators, and company news, reflecting the complex interplay between news sentiment and market behavior. The objective of this task is to assess how well a model can analyze the content of financial news and utilize that analysis to forecast market movements.
* **Metrics:**
Accuracy, Matthews Correlation Coefficient (MCC).
26. **German (Credit Scoring in the German Market)**
* **Task Description:**
The German task focuses on evaluating a model's ability to predict creditworthiness among loan applicants within the German market. Utilizing a dataset that encompasses various financial indicators, demographic information, and historical credit data, this task aims to classify applicants as either creditworthy or non-creditworthy. The dataset reflects the unique economic and regulatory conditions of Germany, providing a comprehensive view of the factors influencing credit decisions in this specific market. Given the importance of accurate credit scoring for financial institutions, this task is crucial for minimizing risk and ensuring responsible lending practices. Models must effectively analyze multiple variables to make informed predictions, thereby facilitating better decision-making in loan approvals and risk management.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
27. **Australian (Credit Scoring in the Australian Market)**
* **Task Description:**
The Australian task focuses on predicting creditworthiness among loan applicants within the Australian financial context. This dataset includes a comprehensive array of features derived from various sources, such as financial histories, income levels, and demographic information. The primary objective of this task is to classify applicants as either creditworthy or non-creditworthy, enabling financial institutions to make informed lending decisions. Given the unique economic conditions and regulatory environment in Australia, this task is particularly relevant for understanding the specific factors that influence credit scoring in this market.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
28. **LendingClub (Peer-to-Peer Lending Risk Prediction)**
* **Task Description:**
The LendingClub task focuses on predicting the risk of default for loans issued through the LendingClub platform, a major peer-to-peer lending service. This task utilizes a dataset that includes detailed information about loan applicants, such as credit scores, income levels, employment history, and other financial indicators. The primary objective is to assess the likelihood of loan default, enabling lenders to make informed decisions regarding loan approvals and risk management. The models evaluated in this task must effectively analyze a variety of features, capturing complex relationships within the data to provide reliable risk assessments.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
29. **ccf (Credit Card Fraud Detection)**
* **Task Description:**
The ccf task focuses on identifying fraudulent transactions within a large dataset of credit card operations. This dataset encompasses various transaction features, including transaction amount, time, location, and merchant information, providing a comprehensive view of spending behaviors. The primary objective of the task is to classify transactions as either legitimate or fraudulent, thereby enabling financial institutions to detect and prevent fraudulent activities effectively. Models must navigate the challenges posed by class imbalance, as fraudulent transactions typically represent a small fraction of the overall dataset.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
30. **ccfraud (Credit Card Transaction Fraud Detection)**
* **Task Description:**
The ccfraud task focuses on identifying fraudulent transactions within a dataset of credit card operations. This dataset comprises a large number of transaction records, each labeled as either legitimate or fraudulent. The primary objective is to evaluate a model's capability to accurately distinguish between normal transactions and those that exhibit suspicious behavior indicative of fraud. The ccfraud task presents unique challenges, including the need to handle imbalanced data, as fraudulent transactions typically represent a small fraction of the total dataset. Models must demonstrate proficiency in detecting subtle patterns and anomalies that signify fraudulent activity while minimizing false positives to avoid inconveniencing legitimate customers.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
31. **Polish (Credit Risk Prediction in the Polish Market)**
* **Task Description:**
The Polish task focuses on predicting credit risk for loan applicants within the Polish financial market. Utilizing a comprehensive dataset that includes demographic and financial information about applicants, the task aims to assess the likelihood of default on loans. This prediction is crucial for financial institutions in making informed lending decisions and managing risk effectively. Models must be tailored to account for local factors influencing creditworthiness, such as income levels, employment status, and credit history.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
32. **Taiwan (Credit Risk Prediction in the Taiwanese Market)**
* **Task Description:**
The Taiwan task focuses on predicting credit risk for loan applicants in the Taiwanese market. Utilizing a dataset that encompasses detailed financial and personal information about borrowers, this task aims to assess the likelihood of default based on various factors, including credit history, income, and demographic details. The model's ability to analyze complex patterns within the data and provide reliable predictions is essential in a rapidly evolving financial landscape. Given the unique economic conditions and regulatory environment in Taiwan, this task also emphasizes the importance of local context in risk assessment, requiring models to effectively adapt to specific market characteristics and trends.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
33. **Portoseguro (Claim Analysis in the Brazilian Market)**
* **Task Description:**
The Portoseguro task focuses on analyzing insurance claims within the Brazilian market, specifically for auto insurance. This task leverages a dataset that includes detailed information about various claims, such as the nature of the incident, policyholder details, and claim outcomes. The primary goal is to evaluate a model’s ability to predict the likelihood of a claim being approved or denied based on these factors. By accurately classifying claims, models can help insurance companies streamline their decision-making processes, enhance risk management strategies, and reduce fraudulent activities. Models must consider regional nuances and the specific criteria used in evaluating claims, ensuring that predictions align with local regulations and market practices.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
34. **Travel Insurance (Travel Insurance Claim Prediction)**
* **Task Description:**
The Travel Insurance task focuses on predicting the likelihood of a travel insurance claim being made based on various factors and data points. This dataset includes historical data related to travel insurance policies, claims made, and associated variables such as the type of travel, duration, destination, and demographic information of the insured individuals. The primary objective of this task is to evaluate a model's ability to accurately assess the risk of a claim being filed, which is crucial for insurance companies in determining policy pricing and risk management strategies. By analyzing patterns and trends in the data, models can provide insights into which factors contribute to a higher likelihood of claims, enabling insurers to make informed decisions about underwriting and premium setting.
* **Metrics:**
F1 Score, Matthews Correlation Coefficient (MCC).
35. **MultiFin-ES (Multi-Class Financial Sentiment Analysis in Spanish)**
* **Task Description:**
The MultiFin-ES task focuses on analyzing
* sentiment in Spanish-language financial texts, categorizing sentiments into multiple classes such as bullish, bearish, and neutral. This dataset includes a diverse array of financial documents, including news articles, reports, and social media posts, reflecting various aspects of the financial landscape. The primary objective is to evaluate a model's ability to accurately classify sentiments based on contextual cues, linguistic nuances, and cultural references prevalent in Spanish financial discourse. Models must demonstrate proficiency in processing the subtleties of the Spanish language, including idiomatic expressions and regional variations, to achieve accurate classifications.
* **Metrics:**
F1 Score.
36. **EFP (Financial Phrase Classification in Spanish)**
* **Task Description:**
The EFP task focuses on the classification of financial phrases in Spanish, utilizing a dataset specifically designed for this purpose. This dataset consists of a collection of annotated phrases extracted from Spanish-language financial texts, including news articles, reports, and social media posts. The primary objective is to classify these phrases based on sentiment or intent, categorizing them into relevant classifications such as positive, negative, or neutral. Given the growing importance of the Spanish-speaking market in global finance, accurately interpreting and analyzing sentiment in Spanish financial communications is essential for investors and analysts.
* **Metrics:**
F1 Score.
37. **EFPA (Financial Argument Classification in Spanish)**
* **Task Description:**
The EFPA task focuses on classifying arguments within Spanish financial documents, aiming to identify key components such as claims, evidence, and counterarguments. This dataset encompasses a range of financial texts, including reports, analyses, and regulatory documents, providing a rich resource for understanding argumentative structures in the financial domain. The primary objective is to evaluate a model's ability to accurately categorize different argument units, which is essential for automating the analysis of complex financial narratives. By effectively classifying arguments, stakeholders can gain insights into the reasoning behind financial decisions and the interplay of various factors influencing the market. This task presents unique challenges that require models to demonstrate a deep understanding of both linguistic and domain-specific contexts.
* **Metrics:**
F1 Score.
38. **FinanceES (Financial Sentiment Classification in Spanish)**
* **Task Description:**
The FinanceES task focuses on classifying sentiment within a diverse range of financial documents written in Spanish. This dataset includes news articles, reports, and social media posts, reflecting various financial topics and events. The primary objective is to evaluate a model's ability to accurately identify sentiments as positive, negative, or neutral, thus providing insights into market perceptions in Spanish-speaking regions. Given the cultural and linguistic nuances inherent in the Spanish language, effective sentiment classification requires models to adeptly navigate idiomatic expressions, slang, and context-specific terminology. This task is particularly relevant as financial sentiment analysis expands globally, necessitating robust models that can perform effectively across different languages and cultural contexts.
* **Metrics:**
F1 Score.
39. **TSA-Spanish (Sentiment Analysis in Spanish)**
* **Task Description:**
The TSA-Spanish task focuses on evaluating a model's ability to perform sentiment analysis on tweets and short texts in Spanish related to financial markets. Utilizing a dataset comprised of diverse social media posts, this task aims to classify sentiments as positive, negative, or neutral. The dynamic nature of social media provides a rich source of real-time sentiment data, reflecting public opinion on various financial topics, including stock performance, company announcements, and economic developments. This task presents unique challenges in accurately interpreting sentiment, as context, slang, and regional expressions can significantly influence meaning. Models must demonstrate a robust understanding of the subtleties of the Spanish language, including colloquialisms and varying sentiment indicators commonly used across different Spanish-speaking communities.
* **Metrics:**
F1 Score.
40. **FinTrade (Stock Trading Dataset)**
* **Task Description:**
The FinTrade task evaluates models on their ability to perform stock trading simulations using a specially developed dataset that incorporates historical stock prices, financial news, and sentiment data over a period of one year. This dataset is designed to reflect real-world trading scenarios, providing a comprehensive view of how various factors influence stock performance. The primary objective of this task is to assess the model's capability to make informed trading decisions based on a combination of quantitative and qualitative data, such as market trends and sentiment analysis. By simulating trading activities, models are tasked with generating actionable insights and strategies that maximize profitability while managing risk. The diverse nature of the data, which includes price movements, news events, and sentiment fluctuations, requires models to effectively integrate and analyze multiple data streams to optimize trading outcomes.
* **Metrics:**
Sharpe Ratio (SR).
</details>
## How to Use the Open Financial LLM Leaderboard
When you first visit the OFLL platform, you are greeted by the **main page**, which provides an overview of the leaderboard, including an introduction to the platform's purpose and a link to submit your model for evaluation.
At the top of the main page, you'll see different tabs:
* **LLM Benchmark:** The core page where you evaluate models.
* **Submit here:** A place to submit your own model for automatic evaluation.
* **About:** More details about the benchmarks, evaluation process, and the datasets used.
### Selecting Tasks to Display
To tailor the leaderboard to your specific needs, you can select the financial tasks you want to focus on under the **"Select columns to show"** section. These tasks are divided into several categories, such as:
* **Information Extraction (IE)**
* **Textual Analysis (TA)**
* **Question Answering (QA)**
* **Text Generation (TG)**
* **Risk Management (RM)**
* **Forecasting (FO)**
* **Decision-Making (DM)**
Simply check the box next to the tasks you're interested in. The selected tasks will appear as columns in the evaluation table. If you wish to remove all selections, click the **"Uncheck All"** button to reset the task categories.
### Selecting Models to Display
To further refine the models displayed in the leaderboard, you can use the **"Model types"** and **"Precision"** filters on the right-hand side of the interface, and filter models based on their:
* **Type:** Pretrained, fine-tuned, instruction-tuned, or reinforcement-learning (RL)-tuned.
* **Precision:** float16, bfloat16, or float32.
* **Model Size:** Ranges from \~1.5 billion to 70+ billion parameters.
### Viewing Results in the Task Table
Once you've selected your tasks, the results will populate in the **task table** (see image). This table provides detailed metrics for each model across the tasks you’ve chosen. The performance of each model is displayed under columns labeled **Average IE**, **Average TA**, **Average QA**, and so on, corresponding to the tasks you selected.
### Submitting a Model for Evaluation
If you have a new model that you’d like to evaluate on the leaderboard, the **submission section** allows you to upload your model file. You’ll need to provide:
* **Model name**
* **Revision commit**
* **Model type**
* **Precision**
* **Weight type**
After uploading your model, the leaderboard will **automatically start evaluating** it across the selected tasks, providing real-time feedback on its performance.
## Current Best Models and Surprising Results
Throughout the evaluation process on the Open FinLLM Leaderboard, several models have demonstrated exceptional capabilities across various financial tasks.
As of the latest evaluation:
- **Best model**: GPT-4 and Llama 3.1 have consistently outperformed other models in many tasks, showing high accuracy and robustness in interpreting financial sentiment.
- **Surprising Results**: The **Forecasting(FO)** task, focused on stock movement predictions, showed that smaller models, such as **Llama-3.1-7b, internlm-7b**,often outperformed larger models, for example Llama-3.1-70b, in terms of accuracy and MCC. This suggests that model size does not necessarily correlate with better performance in financial forecasting, especially in tasks where real-time market data and nuanced sentiment analysis are critical. These results highlight the importance of evaluating models based on task-specific performance rather than relying solely on size or general-purpose benchmarks.
## Acknowledgments
We would like to thank our sponsors, including The Linux Foundation, for their generous support in making the Open FinLLM Leaderboard possible. Their contributions have helped us build a platform that serves the financial AI community and advances the evaluation of financial language models.
We also invite the community to participate in this ongoing project by submitting models, datasets, or evaluation tasks. Your involvement is essential in ensuring that the leaderboard remains a comprehensive and evolving tool for benchmarking financial LLMs. Together, we can drive innovation and help develop models better suited for real-world financial applications.
| 5 |
0 | hf_public_repos | hf_public_repos/blog/ethics-soc-1.md | ---
title: "Ethics and Society Newsletter #1"
thumbnail: /blog/assets/103_ethics-soc-1/thumbnail.png
authors:
- user: meg
---
# Ethics and Society Newsletter #1
Hello, world!
Originating as an open-source company, Hugging Face was founded on some key ethical values in tech: _collaboration_, _responsibility_, and _transparency_. To code in an open environment means having your code – and the choices within – viewable to the world, associated with your account and available for others to critique and add to. As the research community began using the Hugging Face Hub to host models and data, the community directly integrated _reproducibility_ as another fundamental value of the company. And as the number of datasets and models on Hugging Face grew, those working at Hugging Face implemented [documentation requirements](https://huggingface.co/docs/hub/models-cards) and [free instructive courses](https://huggingface.co/course/chapter1/1), meeting the newly emerging values defined by the research community with complementary values around _auditability_ and _understanding_ the math, code, processes and people that lead to current technology.
How to operationalize ethics in AI is an open research area. Although theory and scholarship on applied ethics and artificial intelligence have existed for decades, applied and tested practices for ethics within AI development have only begun to emerge within the past 10 years. This is partially a response to machine learning models – the building blocks of AI systems – outgrowing the benchmarks used to measure their progress, leading to wide-spread adoption of machine learning systems in a range of practical applications that affect everyday life. For those of us interested in advancing ethics-informed AI, joining a machine learning company founded in part on ethical principles, just as it begins to grow, and just as people across the world are beginning to grapple with ethical AI issues, is an opportunity to fundamentally shape what the AI of the future looks like. It’s a new kind of modern-day AI experiment: What does a technology company with ethics in mind _from the start_ look like? Focusing an ethics lens on machine learning, what does it mean to [democratize _good_ ML](https://huggingface.co/huggingface)?
To this end, we share some of our recent thinking and work in the new Hugging Face _Ethics and Society_ newsletter, to be published every season, at the equinox and solstice. Here it is! It is put together by us, the “Ethics and Society regulars”, an open group of people across the company who come together as equals to work through the broader context of machine learning in society and the role that Hugging Face plays. We believe it to be critical that we are **not** a dedicated team: in order for a company to make value-informed decisions throughout its work and processes, there needs to be a shared responsibility and commitment from all parties involved to acknowledge and learn about the ethical stakes of our work.
We are continuously researching practices and studies on the meaning of a “good” ML, trying to provide some criteria that could define it. Being an ongoing process, we embark on this by looking ahead to the different possible futures of AI, creating what we can in the present day to get us to a point that harmonizes different values held by us as individuals as well as the broader ML community. We ground this approach in the founding principles of Hugging Face:
- We seek to _collaborate_ with the open-source community. This includes providing modernized tools for [documentation](https://huggingface.co/docs/hub/models-cards) and [evaluation](https://huggingface.co/blog/eval-on-the-hub), alongside [community discussion](https://huggingface.co/blog/community-update), [Discord](http://discuss.huggingface.co/t/join-the-hugging-face-discord/), and individual support for contributors aiming to share their work in a way that’s informed by different values.
- We seek to be _transparent_ about our thinking and processes as we develop them. This includes sharing writing on specific project [values at the start of a project](https://huggingface.co/blog/ethical-charter-multimodal) and our thinking on [AI policy](https://huggingface.co/blog/us-national-ai-research-resource). We also gain from the community feedback on this work, as a resource for us to learn more about what to do.
- We ground the creation of these tools and artifacts in _responsibility_ for the impacts of what we do now and in the future. Prioritizing this has led to project designs that make machine learning systems more _auditable_ and _understandable_ – including for people with expertise outside of ML – such as [the education project](https://huggingface.co/blog/education) and our experimental [tools for ML data analysis that don't require coding](https://huggingface.co/spaces/huggingface/data-measurements-tool).
Building from these basics, we are taking an approach to operationalizing values that center the context-specific nature of our projects and the foreseeable effects they may have. As such, we offer no global list of values or principles here; instead, we continue to share [project-specific thinking](https://huggingface.co/blog/ethical-charter-multimodal), such as this newsletter, and will share more as we understand more. Since we believe that community discussion is key to identifying different values at play and who is impacted, we have recently opened up the opportunity for anyone who can connect to the Hugging Face Hub online to provide [direct feedback on models, data, and Spaces](https://huggingface.co/blog/community-update). Alongside tools for open discussion, we have created a [Code of Conduct](https://huggingface.co/code-of-conduct) and [content guidelines](https://huggingface.co/content-guidelines) to help guide discussions along dimensions we believe to be important for an inclusive community space. We have developed a [Private Hub](https://huggingface.co/blog/introducing-private-hub) for secure ML development, a [library for evaluation](https://huggingface.co/blog/eval-on-the-hub) to make it easier for developers to evaluate their models rigorously, [code for analyzing data for skews and biases](https://github.com/huggingface/data-measurements-tool), and [tools for tracking carbon emissions when training a model](https://huggingface.co/blog/carbon-emissions-on-the-hub). We are also developing [new open and responsible AI licensing](https://huggingface.co/blog/open_rail), a modern form of licensing that directly addresses the harms that AI systems can create. And this week, we made it possible to [“flag” model and Spaces repositories](https://twitter.com/GiadaPistilli/status/1571865167092396033) in order to report on ethical and legal issues.
In the coming months, we will be putting together several other pieces on values, tensions, and ethics operationalization. We welcome (and want!) feedback on any and all of our work, and hope to continue engaging with the AI community through technical and values-informed lenses.
Thanks for reading! 🤗
~ Meg, on behalf of the Ethics and Society regulars
| 6 |
0 | hf_public_repos | hf_public_repos/blog/cnil.md | ---
title: "Hugging Face Selected for the French Data Protection Agency Enhanced Support Program"
thumbnail: /blog/assets/146_cnil-accompaniment/logo.png
authors:
- user: yjernite
- user: julien-c
- user: annatrdj
- user: Ima1
---
# Hugging Face Selected for the French Data Protection Agency Enhanced Support Program
*This blog post was originally published on [LinkedIn on 05/15/2023](https://www.linkedin.com/pulse/accompagnement-renforc%25C3%25A9-de-la-cnil-et-protection-des-donn%25C3%25A9es/)*
We are happy to announce that Hugging Face has been selected by the [CNIL](https://www.cnil.fr/en/home) (French Data Protection Authority) to benefit from its [Enhanced Support program](https://www.cnil.fr/en/enhanced-support-cnil-selects-3-digital-companies-strong-potential)!
This new program picked three companies with “strong potential for economic development” out of over 40 candidates, who will receive support in understanding and implementing their duties with respect to data protection -
a daunting and necessary endeavor in the context of the rapidly evolving field of Artificial Intelligence.
When it comes to respecting people’s privacy rights, the recent developments in ML and AI pose new questions, and engender new challenges.
We have been particularly sensitive to these challenges in our own work at Hugging Face and in our collaborations.
The [BigScience Workshop](https://huggingface.co/bigscience) that we hosted in collaboration with hundreds of researchers from many different countries and institutions
was the first Large Language Model training effort to [visibly put privacy front and center](https://linc.cnil.fr/fr/bigscience-il-faut-promouvoir-linnovation-ouverte-et-bienveillante-pour-mettre-le-respect-de-la-vie),
through a multi-pronged approach covering [data selection and governance, data processing, and model sharing](https://montrealethics.ai/category/columns/social-context-in-llm-research/).
The more recent [BigCode project](https://huggingface.co/bigcode) co-hosted with [ServiceNow](https://huggingface.co/ServiceNow) also dedicated significant resources to [addressing privacy risks](https://huggingface.co/datasets/bigcode/governance-card#social-impact-dimensions-and-considerations),
creating [new tools to support pseudonymization](https://huggingface.co/bigcode/starpii) that will benefit other projects.
These efforts help us better understand what is technically necessary and feasible at various levels of the AI development process so we can better address legal requirements and risks tied to personal data.
The accompaniment program from the CNIL, benefiting from its expertise and role as France’s Data Protection Agency,
will play an instrumental role in supporting our broader efforts to push GDPR compliance forward and provide clarity for our community of users on questions of privacy and data protection.
We look forward to working together on addressing these questions with more foresight, and helping develop amazing new ML technology that does respect people’s data rights!
| 7 |
0 | hf_public_repos | hf_public_repos/blog/falcon2-11b.md | ---
title: "Falcon 2: An 11B parameter pretrained language model and VLM, trained on over 5000B tokens and 11 languages"
thumbnail: /blog/assets/179_falcon2-11b/thumbnail.jpg
authors:
- user: Quent-01
guest: true
org: tiiuae
- user: nilabhra
guest: true
org: tiiuae
- user: rcojocaru
guest: true
org: tiiuae
- user: Mughaira
guest: true
org: tiiuae
- user: gcamp
guest: true
org: tiiuae
- user: yasserTII
guest: true
org: tiiuae
- user: SanathNarayan
guest: true
org: tiiuae
- user: griffintaur
guest: true
org: tiiuae
- user: clefourrier
- user: SailorTwift
---
# Falcon 2: An 11B parameter pretrained language model and VLM, trained on over 5000B tokens and 11 languages
<a name="the-falcon-models"></a>
## The Falcon 2 Models
[TII](www.tii.ae) is launching a new generation of models, [Falcon 2](https://falconllm.tii.ae/), focused on providing the open-source community with a series of smaller models with enhanced performance and multi-modal support. Our goal is to enable cheaper inference and encourage the development of more downstream applications with improved usability.
The first generation of Falcon models, featuring [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) and [Falcon-180B](https://huggingface.co/tiiuae/falcon-180B), made a significant contribution to the open-source community, promoting the release of advanced LLMs with permissive licenses. More detailed information on the previous generation of Falcon models can be found in the [RefinedWeb, Penedo et al., 2023](https://proceedings.neurips.cc/paper_files/paper/2023/hash/fa3ed726cc5073b9c31e3e49a807789c-Abstract-Datasets_and_Benchmarks.html) and [The Falcon Series of Open Language Models, Almazrouei et al., 2023](https://arxiv.org/abs/2311.16867) papers, and the [Falcon](https://huggingface.co/blog/falcon) and [Falcon-180B](https://huggingface.co/blog/falcon-180b) blog posts.
The second generation of models is focused on increased usability and integrability, building a multi-modal ecosystem. We start this journey by releasing not only the base [11B LLM](https://huggingface.co/tiiuae/falcon-11B), but also the [11B VLM model](https://huggingface.co/tiiuae/Falcon-11B-vlm) that incorporates image understanding capabilities. The vision-language model, or VLM, will allow users to engage in chats about visual content using text.
As with our previous work, the models offer support mainly in English but have good capabilities in ten other languages, including Spanish, French, and German.
## Table of Contents
- [The Falcon 2 Models](#the-falcon-models)
- Falcon 2 11B LLM
- [11B LLM Training Details](#falcon2-11b-llm)
- [11B LLM Evaluation](#falcon2-11b-evaluation)
- [11B LLM Using the Model](#using-falcon2-11b)
- Falcon 2 11B VLM
- [11B VLM Training](#falcon2-11b-vlm)
- [11B VLM Evaluation](#falcon2-11b-vlm-evaluation)
- [11B VLM Using the Model](#using-falcon2-11b-falconvlm)
- [Licensing information](#license-information)
<a name="falcon2-11b-llm"></a>
## Falcon2-11B LLM
### Training Data
Falcon2-11B was trained on over 5,000 GT (billion tokens) of RefinedWeb, a high-quality filtered and deduplicated web dataset, enhanced with curated corpora. It followed a four-stage training strategy. The first three stages were focused on increasing the context length, from 2048 to 4096 and finally to 8192 tokens. The last stage aimed to further enhance performance using only high-quality data.
Overall, the data sources included RefinedWeb-English, RefinedWeb-Europe (*cs*, *de*, *es*, *fr*, *it*, *nl*, *pl*, *pt*, *ro*, *sv*), high-quality technical data, code data, and conversational data extracted from public sources.
The training stages were as follows:
| Stage | Context Length | GT |
|---------|------------------|------|
| Stage 1 | 2048 | 4500 |
| Stage 2 | 4096 | 250 |
| Stage 3 | 8192 | 250 |
| Stage 4 | 8192 | 500 |
The data was tokenized with [Falcon2-11B tokenizer](https://huggingface.co/tiiuae/falcon-11B/blob/main/tokenizer.json), the same tokenizer as for the previous Falcon models.
### Model Architecture
The following table summarizes some of the crucial details about the model architecture:
| Design choice | Value |
|------------------------------|-----|
| Number of Transformer Blocks | 60 |
| Number of Query Heads | 32 |
| Number of Key/Value Heads | 8 |
| Head Dimensions | 128 |
| Parallel Attention | yes |
| MLP Upscale Factor | 4 |
### Training Procedure
Falcon2-11B was trained on 1024 A100 40GB GPUs for the majority of the training, using a 3D parallelism strategy (TP=8, PP=1, DP=128) combined with ZeRO and Flash-Attention 2.
### Training Hyperparameters
| Hyperparameter | Value |
|----------------|-----------|
| Precision | bfloat16 |
| Optimizer | AdamW |
| Max LR | 3.7e-4 |
| Min LR | 1.89e-5 |
| LR schedule | Cos decay (stage 1) |
| Context length | 8192 (stages 3 and 4) |
| Weight decay | 1e-1 |
| Z-loss | 1e-4 |
| Batch size | Variable |
<a name="falcon2-11b-evaluation"></a>
## Falcon2-11B Evaluation
### English performance
Performance on Open LLM Leaderboard tasks:
| Checkpoint | GT | HellaSwag-10 | Winogrande-5 | ArcChallenge-25 | TruthfulQA-0 | MMLU-5 | GSMK8k-5 | Average |
|-------------|-------|--------------|--------------|-----------------|----------|--------|----------|-----------|
| Falcon2-11B | 5500 | 82.91 | 78.30 | 59.73 | 52.56 | 58.37 | 53.83 | 64.28 |
| Falcon-40B | 1000 | 85.28 | 81.29 | 61.86 | 41.65 | 56.89 | 21.46 | 58.07 |
| Falcon-7B | 1500 | 78.13 | 72.38 | 47.87 | 34.26 | 27.79 | 4.62 | 44.17 |
| Gemma-7B | 6000 | 82.47 | 78.45 | 61.09 | 44.91 | 66.03 | 52.77 | 64.29 |
| Llama3-8B | 15000 | 82.09 | 77.35 | 59.47 | 43.90 | 66.69 | 44.79 | 62.38 |
| Mistral-7B | N/A | 83.31 | 78.37 | 59.98 | 42.15 | 64.16 | 37.83 | 60.97 |
The Hugging Face Leaderboard team provided an official evaluation of our model on the [Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard) tasks. The model performs better than models such as Llama3-8B (trained on three times more data) and Mistral-7B, and on par with Gemma-7b.
Zero shot performance:
| Checkpoint | GT | HellaSwag | ArcEasy | Winogrande | ArcChallenge |
|-------------|------|-----------|----------|------------|--------------|
| Falcon2-11B | 5500 | 82.07 | 77.78 | 78.30 | 50.17 |
| Falcon-40B | 1000 | 82.82 | 81.86 | 76.4 | 54.69 |
| Falcon-7B | 1500 | 76.31 | 74.74 | 67.17 | 43.43 |
The evaluation results show that the Falcon2-11B shows similar performance to Falcon-40B, at a four times smaller model size!
### Multilingual capabilities
Using the [Multilingual LLM leaderboard](https://huggingface.co/spaces/uonlp/open_multilingual_llm_leaderboard), we compare the Falcon2-11B model to the Llama-7B and Bloom-7B. For reference, we also include Falcon-40B (that supports the same languages), Falcon-7B (that supports French) and Mistral-7B.
| Model | Language ID | ArcChallenge-25 | Hellaswag | MMLU 25 | TQA | Average |
|-------------|-------------|----------|----------|----------|-----------|----------|
| Falcon2-11B | *de* | 43.7 | 67.96 | 38.3 | 47.53 | **49.37** |
| | *es* | 46.2 | 73.63 | 37.9 | 46.43 | **51.06** |
| | *fr* | 45.8 | 72.41 | 39.53 | 47.30 | **51.27** |
| | *it* | 45.6 | 70.83 | 38.05 | 47.14 | **50.42** |
| | *nl* | 41.7 | 69.05 | 38.29 | 48.81 | **49.47** |
| | *ro* | 42.4 | 66.24 | 38.01 | 45.53 | **48.04** |
| Falcon-40B | *de* | 45.1 | 68.3 | 36.2 | 39.8 | 47.4 |
| | *es* | 48.5 | 73.9 | 37.2 | 39.0 | 49.6 |
| | *fr* | 47.6 | 72.9 | 37.3 | 38.5 | 49.1 |
| | *it* | 46.3 | 70.2 | 36.4 | 40.7 | 48.4 |
| | *nl* | 42.9 | 68.4 | 36.5 | 40.9 | 47.1 |
| | *ro* | 43.2 | 66.0 | 35.7 | 39.8 | 46.2 |
| Falcon-7B | *fr* | 37.3 | 64.1 | 28.4 | 34.0 | 40.9 |
| Mistral-7B | *de* | 41.2 | 58.7 | 40.5 | 44.9 | 46.3 |
| | *es* | 44.2 | 65.3 | 42.4 | 43.1 | 48.7 |
| | *fr* | 44.9 | 64.4 | 41.9 | 43.0 | 48.6 |
| | *it* | 43.2 | 60.9 | 39.7 | 43.1 | 46.7 |
| | *nl* | 40.0 | 57.9 | 41.4 | 43.3 | 45.7 |
| | *ro* | 40.7 | 53.6 | 39.3 | 43.6 | 44.3 |
| Llama-7B | *de* | 35.1 | 49.9 | 29.9 | 38.3 | 38.3 |
| | *es* | 36.8 | 56.4 | 30.3 | 37.0 | 40.1 |
| | *fr* | 37.3 | 55.7 | 30.5 | 39.9 | 40.9 |
| | *it* | 35.8 | 52.0 | 29.9 | 39.6 | 39.3 |
| | *nl* | 33.6 | 48.7 | 29.8 | 40.0 | 38.0 |
| | *ro* | 32.4 | 44.9 | 29.7 | 37.0 | 36.0 |
| Bloom-7B | *de* | 26.3 | 32.4 | 28.1 | 43.7 | 32.6 |
| | *es* | 38.1 | 56.7 | 28.9 | 40.4 | 41.0 |
| | *fr* | 36.7 | 56.6 | 29.9 | 40.9 | 41.0 |
| | *it* | 29.0 | 40.8 | 27.6 | 43.7 | 35.3 |
| | *nl* | 23.1 | 31.7 | 27.5 | 42.7 | 31.3 |
| | *ro* | 26.9 | 31.8 | 27.4 | 46.1 | 33.1 |
In the spirit of the original Falcon models, the Falcon2-11B was trained not only on English data but also on ten other languages. Our multilingual evaluation results show that the model presents good capabilities in the six languages (*de*, *es*, *fr*, *it*, *nl*, *ro*) featured on the Multilingual LLM Leaderboard and actually shows higher performance than the Falcon-40B and several other multilingual models on all the cited languages.
We will soon release more extensive evaluation results for multilingual capabilities in the [Falcon2-11B model card](https://huggingface.co/tiiuae/falcon-11B)!
### Code generation capabilities
We check the model's performance on code generation against the [BigCode Leaderboard](https://huggingface.co/spaces/bigcode/bigcode-models-leaderboard) on the HumanEval benchmark for the Python language, obtaining pass@1 of 29.59%.
<a name="using-falcon2-11b"></a>
## Using Falcon2-11B
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "tiiuae/falcon-11B"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.bfloat16,
device_map="auto",
)
```
And then, you'd run text generation using code like the following:
```python
sequences = pipeline(
"Can you explain the concept of Quantum Computing?",
max_length=200,
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
<a name="falcon2-11b-vlm"></a>
## Falcon2-11B VLM
[Falcon2-11B VLM](https://huggingface.co/tiiuae/Falcon-11B-vlm) is a vision-language model (VLM) built on top of the LLM, that additionally handles image inputs and is capable of answering queries about the images. To achieve this, we integrate the pretrained CLIP ViT-L/14 vision encoder with our Falcon2-11B chat-finetuned model, and train with image-text data.
To enhance the VLM's perception of fine-grained details w.r.t small objects in images, we employ a dynamic encoding mechanism at high-resolution for image inputs, similar to [LLaVA-Next](https://llava-vl.github.io/blog/2024-01-30-llava-next/).
### Training
The training is done in two stages: pretraining and finetuning. In both stages, the visual encoder weights are kept frozen. In the pretraining stage, the LLM is kept frozen, and only the multimodal projector is trained on 558K image-caption pairs.
This enables the multimodal projector to learn a mapping from visual to text embedding space. During finetuning, both the projector and LLM weights are trained on a corpus of 1.2M image-text instruction data from public datasets, which also includes multi-round conversations.
<a name="falcon2-11b-vlm-evaluation"></a>
## Falcon2-11B VLM Evaluation
| Model | MME | GQA | SQA | POPE | VQAv2 | TextVQA | MM-Bench | SEED-IMG | Average |
|----|----|----|----|----|----|----|----|----|----|
| Falcon2-11B VLM | **1589/343** | 64.5 | **74.9** | **88.4** | 82.1 | 66.7 | **72.0** | **72.3** |**74.4** |
| LLaVA-1.6 (Vicuna-7B) | 1519/332 | 64.2 | 70.1 | 86.5 | 81.8 | 64.9 | 67.4 | 70.2 | 72.1 |
| LLaVA-1.6 (Vicuna-13B) | 1575/326 | **65.4** | 73.6 | 86.2 | **82.8** | **67.1** | 70.0 | 71.9 |73.8 |
| LLaVA-1.6 (Mistral-7B) | 1498/321 |64.8 | 72.8 | 86.7 | 82.2 | 65.7 | 68.7 | 72.2 |73.3 |
<a name="using-falcon2-11b-falconvlm"></a>
## Using Falcon2-11B-FalconVLM
```python
from transformers import LlavaNextForConditionalGeneration, LlavaNextProcessor
from PIL import Image
import requests
import torch
processor = LlavaNextProcessor.from_pretrained("tiiuae/falcon-11B-vlm")
model = LlavaNextForConditionalGeneration.from_pretrained("tiiuae/falcon-11B-vlm", torch_dtype=torch.bfloat16)
url = "https://merzougabirding.com/wp-content/uploads/2023/09/falcon-size.jpg"
falcon_image = Image.open(requests.get(url, stream=True).raw)
prompt = "User: <image>\nWhat's special about this bird's vision?"
inputs = processor(prompt, images=falcon_image, return_tensors="pt", padding=True).to('cuda:0')
model.to('cuda:0')
output = model.generate(**inputs, max_new_tokens=256)
prompt_length = inputs['input_ids'].shape[1]
generated_captions = processor.decode(output[0], skip_special_tokens=True).strip()
print(generated_captions)
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/179_falcon2-11b/falcon_example_tiny.png" />
</p>
<a name="license-information"></a>
## License information
The Falcon 2 models are made available under the [TII Falcon 2 License](https://falconllm-staging.tii.ae/falcon-2-terms-and-conditions.html), a permissive Apache 2.0-based software license which includes an [acceptable use policy](https://falconllm-staging.tii.ae/falcon-2-acceptable-use-policy.html) that promotes the responsible use of AI. This license was crafted within the spirit of TII's commitment to the open source community.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/deep-rl-q-part2.md | ---
title: "An Introduction to Q-Learning Part 2/2"
thumbnail: /blog/assets/73_deep_rl_q_part2/thumbnail.gif
authors:
- user: ThomasSimonini
---
# An Introduction to Q-Learning Part 2/2
<h2>Unit 2, part 2 of the <a href="https://github.com/huggingface/deep-rl-class">Deep Reinforcement Learning Class with Hugging Face 🤗</a></h2>
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit2/q-learning)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
<img src="assets/73_deep_rl_q_part2/thumbnail.gif" alt="Thumbnail"/>
---
⚠️ A **new updated version of this article is available here** 👉 [https://huggingface.co/deep-rl-course/unit1/introduction](https://huggingface.co/deep-rl-course/unit2/q-learning)
*This article is part of the Deep Reinforcement Learning Class. A free course from beginner to expert. Check the syllabus [here.](https://huggingface.co/deep-rl-course/unit0/introduction)*
[In the first part of this unit](https://huggingface.co/blog/deep-rl-q-part1), **we learned about the value-based methods and the difference between Monte Carlo and Temporal Difference Learning**.
So, in the second part, we’ll **study Q-Learning**, **and implement our first RL agent from scratch**, a Q-Learning agent, and will train it in two environments:
1. Frozen Lake v1 ❄️: where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
2. An autonomous taxi 🚕: where the agent will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/envs.gif" alt="Environments"/>
</figure>
This unit is fundamental if you want to be able to work on Deep Q-Learning (Unit 3).
So let’s get started! 🚀
- [Introducing Q-Learning](#introducing-q-learning)
- [What is Q-Learning?](#what-is-q-learning)
- [The Q-Learning algorithm](#the-q-learning-algorithm)
- [Off-policy vs. On-policy](#off-policy-vs-on-policy)
- [A Q-Learning example](#a-q-learning-example)
## **Introducing Q-Learning**
### **What is Q-Learning?**
Q-Learning is an **off-policy value-based method that uses a TD approach to train its action-value function:**
- *Off-policy*: we'll talk about that at the end of this chapter.
- *Value-based method*: finds the optimal policy indirectly by training a value or action-value function that will tell us **the value of each state or each state-action pair.**
- *Uses a TD approach:* **updates its action-value function at each step instead of at the end of the episode.**
**Q-Learning is the algorithm we use to train our Q-Function**, an **action-value function** that determines the value of being at a particular state and taking a specific action at that state.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-function.jpg" alt="Q-function"/>
<figcaption>Given a state and action, our Q Function outputs a state-action value (also called Q-value)</figcaption>
</figure>
The **Q comes from "the Quality" of that action at that state.**
Internally, our Q-function has **a Q-table, a table where each cell corresponds to a state-action value pair value.** Think of this Q-table as **the memory or cheat sheet of our Q-function.**
If we take this maze example:
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Maze-1.jpg" alt="Maze example"/>
</figure>
The Q-Table is initialized. That's why all values are = 0. This table **contains, for each state, the four state-action values.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Maze-2.jpg" alt="Maze example"/>
</figure>
Here we see that the **state-action value of the initial state and going up is 0:**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Maze-3.jpg" alt="Maze example"/>
</figure>
Therefore, Q-function contains a Q-table **that has the value of each-state action pair.** And given a state and action, **our Q-Function will search inside its Q-table to output the value.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-function-2.jpg" alt="Q-function"/>
<figcaption>Given a state and action pair, our Q-function will search inside its Q-table to output the state-action pair value (the Q value).</figcaption>
</figure>
If we recap, *Q-Learning* **is the RL algorithm that:**
- Trains *Q-Function* (an **action-value function**) which internally is a *Q-table* **that contains all the state-action pair values.**
- Given a state and action, our Q-Function **will search into its Q-table the corresponding value.**
- When the training is done, **we have an optimal Q-function, which means we have optimal Q-Table.**
- And if we **have an optimal Q-function**, we **have an optimal policy** since we **know for each state what is the best action to take.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/link-value-policy.jpg" alt="Link value policy"/>
</figure>
But, in the beginning, **our Q-Table is useless since it gives arbitrary values for each state-action pair** (most of the time, we initialize the Q-Table to 0 values). But, as we'll **explore the environment and update our Q-Table, it will give us better and better approximations.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-1.jpg" alt="Q-learning"/>
<figcaption>We see here that with the training, our Q-Table is better since, thanks to it, we can know the value of each state-action pair.</figcaption>
</figure>
So now that we understand what Q-Learning, Q-Function, and Q-Table are, **let's dive deeper into the Q-Learning algorithm**.
### **The Q-Learning algorithm**
This is the Q-Learning pseudocode; let's study each part and **see how it works with a simple example before implementing it.** Don't be intimidated by it, it's simpler than it looks! We'll go over each step.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-2.jpg" alt="Q-learning"/>
</figure>
**Step 1: We initialize the Q-Table**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-3.jpg" alt="Q-learning"/>
</figure>
We need to initialize the Q-Table for each state-action pair. **Most of the time, we initialize with values of 0.**
**Step 2: Choose action using Epsilon Greedy Strategy**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-4.jpg" alt="Q-learning"/>
</figure>
Epsilon Greedy Strategy is a policy that handles the exploration/exploitation trade-off.
The idea is that we define epsilon ɛ = 1.0:
- *With probability 1 — ɛ* : we do **exploitation** (aka our agent selects the action with the highest state-action pair value).
- With probability ɛ: **we do exploration** (trying random action).
At the beginning of the training, **the probability of doing exploration will be huge since ɛ is very high, so most of the time, we'll explore.** But as the training goes on, and consequently our **Q-Table gets better and better in its estimations, we progressively reduce the epsilon value** since we will need less and less exploration and more exploitation.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-5.jpg" alt="Q-learning"/>
</figure>
**Step 3: Perform action At, gets reward Rt+1 and next state St+1**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-6.jpg" alt="Q-learning"/>
</figure>
**Step 4: Update Q(St, At)**
Remember that in TD Learning, we update our policy or value function (depending on the RL method we choose) **after one step of the interaction.**
To produce our TD target, **we used the immediate reward \\(R_{t+1}\\) plus the discounted value of the next state best state-action pair** (we call that bootstrap).
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-7.jpg" alt="Q-learning"/>
</figure>
Therefore, our \\(Q(S_t, A_t)\\) **update formula goes like this:**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Q-learning-8.jpg" alt="Q-learning"/>
</figure>
It means that to update our \\(Q(S_t, A_t)\\):
- We need \\(S_t, A_t, R_{t+1}, S_{t+1}\\).
- To update our Q-value at a given state-action pair, we use the TD target.
How do we form the TD target?
1. We obtain the reward after taking the action \\(R_{t+1}\\).
2. To get the **best next-state-action pair value**, we use a greedy policy to select the next best action. Note that this is not an epsilon greedy policy, this will always take the action with the highest state-action value.
Then when the update of this Q-value is done. We start in a new_state and select our action **using our epsilon-greedy policy again.**
**It's why we say that this is an off-policy algorithm.**
### **Off-policy vs On-policy**
The difference is subtle:
- *Off-policy*: using **a different policy for acting and updating.**
For instance, with Q-Learning, the Epsilon greedy policy (acting policy), is different from the greedy policy that is **used to select the best next-state action value to update our Q-value (updating policy).**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/off-on-1.jpg" alt="Off-on policy"/>
<figcaption>Acting Policy</figcaption>
</figure>
Is different from the policy we use during the training part:
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/off-on-2.jpg" alt="Off-on policy"/>
<figcaption>Updating policy</figcaption>
</figure>
- *On-policy:* using the **same policy for acting and updating.**
For instance, with Sarsa, another value-based algorithm, **the Epsilon-Greedy Policy selects the next_state-action pair, not a greedy policy.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/off-on-3.jpg" alt="Off-on policy"/>
<figcaption>Sarsa</figcaption>
</figure>
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/off-on-4.jpg" alt="Off-on policy"/>
</figure>
## **A Q-Learning example**
To better understand Q-Learning, let's take a simple example:
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Maze-Example-2.jpg" alt="Maze-Example"/>
</figure>
- You're a mouse in this tiny maze. You always **start at the same starting point.**
- The goal is **to eat the big pile of cheese at the bottom right-hand corner** and avoid the poison. After all, who doesn't like cheese?
- The episode ends if we eat the poison, **eat the big pile of cheese or if we spent more than five steps.**
- The learning rate is 0.1
- The gamma (discount rate) is 0.99
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-1.jpg" alt="Maze-Example"/>
</figure>
The reward function goes like this:
- **+0:** Going to a state with no cheese in it.
- **+1:** Going to a state with a small cheese in it.
- **+10:** Going to the state with the big pile of cheese.
- **-10:** Going to the state with the poison and thus die.
- **+0** If we spend more than five steps.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-2.jpg" alt="Maze-Example"/>
</figure>
To train our agent to have an optimal policy (so a policy that goes right, right, down), **we will use the Q-Learning algorithm**.
**Step 1: We initialize the Q-Table**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Example-1.jpg" alt="Maze-Example"/>
</figure>
So, for now, **our Q-Table is useless**; we need **to train our Q-function using the Q-Learning algorithm.**
Let's do it for 2 training timesteps:
Training timestep 1:
**Step 2: Choose action using Epsilon Greedy Strategy**
Because epsilon is big = 1.0, I take a random action, in this case, I go right.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-3.jpg" alt="Maze-Example"/>
</figure>
**Step 3: Perform action At, gets Rt+1 and St+1**
By going right, I've got a small cheese, so \\(R_{t+1} = 1\\), and I'm in a new state.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-4.jpg" alt="Maze-Example"/>
</figure>
**Step 4: Update \\(Q(S_t, A_t)\\)**
We can now update \\(Q(S_t, A_t)\\) using our formula.
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-5.jpg" alt="Maze-Example"/>
</figure>
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/Example-4.jpg" alt="Maze-Example"/>
</figure>
Training timestep 2:
**Step 2: Choose action using Epsilon Greedy Strategy**
**I take a random action again, since epsilon is big 0.99** (since we decay it a little bit because as the training progress, we want less and less exploration).
I took action down. **Not a good action since it leads me to the poison.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-6.jpg" alt="Maze-Example"/>
</figure>
**Step 3: Perform action At, gets \\(R_{t+1}\\) and St+1**
Because I go to the poison state, **I get \\(R_{t+1} = -10\\), and I die.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-7.jpg" alt="Maze-Example"/>
</figure>
**Step 4: Update \\(Q(S_t, A_t)\\)**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/q-ex-8.jpg" alt="Maze-Example"/>
</figure>
Because we're dead, we start a new episode. But what we see here is that **with two explorations steps, my agent became smarter.**
As we continue exploring and exploiting the environment and updating Q-values using TD target, **Q-Table will give us better and better approximations. And thus, at the end of the training, we'll get an estimate of the optimal Q-Function.**
---
Now that we **studied the theory of Q-Learning**, let's **implement it from scratch**. A Q-Learning agent that we will train in two environments:
1. *Frozen-Lake-v1* ❄️ (non-slippery version): where our agent will need to **go from the starting state (S) to the goal state (G)** by walking only on frozen tiles (F) and avoiding holes (H).
2. *An autonomous taxi* 🚕 will need **to learn to navigate** a city to **transport its passengers from point A to point B.**
<figure class="image table text-center m-0 w-full">
<img src="assets/73_deep_rl_q_part2/envs.gif" alt="Environments"/>
</figure>
Start the tutorial here 👉 https://colab.research.google.com/github/huggingface/deep-rl-class/blob/main/unit2/unit2.ipynb
The leaderboard 👉 https://huggingface.co/spaces/chrisjay/Deep-Reinforcement-Learning-Leaderboard
---
Congrats on finishing this chapter! There was a lot of information. And congrats on finishing the tutorials. You’ve just implemented your first RL agent from scratch and shared it on the Hub 🥳.
Implementing from scratch when you study a new architecture **is important to understand how it works.**
That’s **normal if you still feel confused** with all these elements. **This was the same for me and for all people who studied RL.**
Take time to really grasp the material before continuing.
And since the best way to learn and avoid the illusion of competence is **to test yourself**. We wrote a quiz to help you find where **you need to reinforce your study**.
Check your knowledge here 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit2/quiz2.md
It’s essential to master these elements and having a solid foundations before entering the **fun part.**
Don't hesitate to modify the implementation, try ways to improve it and change environments, **the best way to learn is to try things on your own!**
We published additional readings in the syllabus if you want to go deeper 👉 https://github.com/huggingface/deep-rl-class/blob/main/unit2/README.md
<a href="https://huggingface.co/blog/deep-rl-dqn">In the next unit, we’re going to learn about Deep-Q-Learning.</a>
And don't forget to share with your friends who want to learn 🤗 !
Finally, we want **to improve and update the course iteratively with your feedback**. If you have some, please fill this form 👉 https://forms.gle/3HgA7bEHwAmmLfwh9
### Keep learning, stay awesome,
| 9 |
0 | hf_public_repos | hf_public_repos/blog/lcm_lora.md | ---
title: "SDXL in 4 steps with Latent Consistency LoRAs"
thumbnail: /blog/assets/lcm_sdxl/lcm_thumbnail.png
authors:
- user: pcuenq
- user: valhalla
- user: SimianLuo
guest: true
- user: dg845
guest: true
- user: tyq1024
guest: true
- user: sayakpaul
- user: multimodalart
---
# SDXL in 4 steps with Latent Consistency LoRAs
[Latent Consistency Models (LCM)](https://huggingface.co/papers/2310.04378) are a way to decrease the number of steps required to generate an image with Stable Diffusion (or SDXL) by _distilling_ the original model into another version that requires fewer steps (4 to 8 instead of the original 25 to 50). Distillation is a type of training procedure that attempts to replicate the outputs from a source model using a new one. The distilled model may be designed to be smaller (that’s the case of [DistilBERT](https://huggingface.co/docs/transformers/model_doc/distilbert) or the recently-released [Distil-Whisper](https://github.com/huggingface/distil-whisper)) or, in this case, require fewer steps to run. It’s usually a lengthy and costly process that requires huge amounts of data, patience, and a few GPUs.
Well, that was the status quo before today!
We are delighted to announce a new method that can essentially make Stable Diffusion and SDXL faster, as if they had been distilled using the LCM process! How does it sound to run _any_ SDXL model in about 1 second instead of 7 on a 3090, or 10x faster on Mac? Read on for details!
## Contents
- [Method Overview](#method-overview)
- [Why does this matter](#why-does-this-matter)
- [Fast Inference with SDXL LCM LoRAs](#fast-inference-with-sdxl-lcm-loras)
- [Quality Comparison](#quality-comparison)
- [Guidance Scale and Negative Prompts](#guidance-scale-and-negative-prompts)
- [Quality vs base SDXL](#quality-vs-base-sdxl)
- [LCM LoRAs with other Models](#lcm-loras-with-other-models)
- [Full Diffusers Integration](#full-diffusers-integration)
- [Benchmarks](#benchmarks)
- [LCM LoRAs and Models Released Today](#lcm-loras-and-models-released-today)
- [Bonus: Combine LCM LoRAs with regular SDXL LoRAs](#bonus-combine-lcm-loras-with-regular-sdxl-loras)
- [How to train LCM LoRAs](#how-to-train-lcm-loras)
- [Resources](#resources)
- [Credits](#credits)
## Method Overview
So, what’s the trick?
For latent consistency distillation, each model needs to be distilled separately. The core idea with LCM LoRA is to train just a small number of adapters, [known as LoRA layers](https://huggingface.co/docs/peft/conceptual_guides/lora), instead of the full model. The resulting LoRAs can then be applied to any fine-tuned version of the model without having to distil them separately. If you are itching to see how this looks in practice, just jump to the [next section](#fast-inference-with-sdxl-lcm-loras) to play with the inference code. If you want to train your own LoRAs, this is the process you’d use:
1. Select an available teacher model from the Hub. For example, you can use [SDXL (base)](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), or any fine-tuned or dreamboothed version you like.
2. [Train a LCM LoRA](#how-to-train-lcm-models-and-loras) on the model. LoRA is a type of performance-efficient fine-tuning, or PEFT, that is much cheaper to accomplish than full model fine-tuning. For additional details on PEFT, please check [this blog post](https://huggingface.co/blog/peft) or [the diffusers LoRA documentation](https://huggingface.co/docs/diffusers/training/lora).
3. Use the LoRA with any SDXL diffusion model and the LCM scheduler; bingo! You get high-quality inference in just a few steps.
For more details on the process, please [download our paper](https://huggingface.co/latent-consistency/lcm-lora-sdxl/resolve/main/LCM-LoRA-Technical-Report.pdf).
## Why does this matter?
Fast inference of Stable Diffusion and SDXL enables new use-cases and workflows. To name a few:
- **Accessibility**: generative tools can be used effectively by more people, even if they don’t have access to the latest hardware.
- **Faster iteration**: get more images and multiple variants in a fraction of the time! This is great for artists and researchers; whether for personal or commercial use.
- Production workloads may be possible on different accelerators, including CPUs.
- Cheaper image generation services.
To gauge the speed difference we are talking about, generating a single 1024x1024 image on an M1 Mac with SDXL (base) takes about a minute. Using the LCM LoRA, we get great results in just ~6s (4 steps). This is an order of magnitude faster, and not having to wait for results is a game-changer. Using a 4090, we get almost instant response (less than 1s). This unlocks the use of SDXL in applications where real-time events are a requirement.
## Fast Inference with SDXL LCM LoRAs
The version of `diffusers` released today makes it very easy to use LCM LoRAs:
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
lcm_lora_id = "latent-consistency/lcm-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.load_lora_weights(lcm_lora_id)
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.to(device="cuda", dtype=torch.float16)
prompt = "close-up photography of old man standing in the rain at night, in a street lit by lamps, leica 35mm summilux"
images = pipe(
prompt=prompt,
num_inference_steps=4,
guidance_scale=1,
).images[0]
```
Note how the code:
- Instantiates a standard diffusion pipeline with the SDXL 1.0 base model.
- Applies the LCM LoRA.
- Changes the scheduler to the LCMScheduler, which is the one used in latent consistency models.
- That’s it!
This would result in the following full-resolution image:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-1.jpg?download=true" alt="SDXL in 4 steps with LCM LoRA"><br>
<em>Image generated with SDXL in 4 steps using an LCM LoRA.</em>
</p>
### Quality Comparison
Let’s see how the number of steps impacts generation quality. The following code will generate images with 1 to 8 total inference steps:
```py
images = []
for steps in range(8):
generator = torch.Generator(device=pipe.device).manual_seed(1337)
image = pipe(
prompt=prompt,
num_inference_steps=steps+1,
guidance_scale=1,
generator=generator,
).images[0]
images.append(image)
```
These are the 8 images displayed in a grid:
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-grid.jpg?download=true" alt="LCM LoRA generations with 1 to 8 steps"><br>
<em>LCM LoRA generations with 1 to 8 steps.</em>
</p>
As expected, using just **1** step produces an approximate shape without discernible features and lacking texture. However, results quickly improve, and they are usually very satisfactory in just 4 to 6 steps. Personally, I find the 8-step image in the previous test to be a bit too saturated and “cartoony” for my taste, so I’d probably choose between the ones with 5 and 6 steps in this example. Generation is so fast that you can create a bunch of different variants using just 4 steps, and then select the ones you like and iterate using a couple more steps and refined prompts as necessary.
### Guidance Scale and Negative Prompts
Note that in the previous examples we used a `guidance_scale` of `1`, which effectively disables it. This works well for most prompts, and it’s fastest, but ignores negative prompts. You can also explore using negative prompts by providing a guidance scale between `1` and `2` – we found that larger values don’t work.
### Quality vs base SDXL
How does this compare against the standard SDXL pipeline, in terms of quality? Let’s see an example!
We can quickly revert our pipeline to a standard SDXL pipeline by unloading the LoRA weights and switching to the default scheduler:
```py
from diffusers import EulerDiscreteScheduler
pipe.unload_lora_weights()
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
```
Then we can run inference as usual for SDXL. We’ll gather results using varying number of steps:
```py
images = []
for steps in (1, 4, 8, 15, 20, 25, 30, 50):
generator = torch.Generator(device=pipe.device).manual_seed(1337)
image = pipe(
prompt=prompt,
num_inference_steps=steps,
generator=generator,
).images[0]
images.append(image)
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-sdxl-grid.jpg?download=true" alt="SDXL results for various inference steps"><br>
<em>SDXL pipeline results (same prompt and random seed), using 1, 4, 8, 15, 20, 25, 30, and 50 steps.</em>
</p>
As you can see, images in this example are pretty much useless until ~20 steps (second row), and quality still increases noticeably with more steps. The details in the final image are amazing, but it took 50 steps to get there.
### LCM LoRAs with other models
This technique also works for any other fine-tuned SDXL or Stable Diffusion model. To demonstrate, let's see how to run inference on [`collage-diffusion`](https://huggingface.co/wavymulder/collage-diffusion), a model fine-tuned from [Stable Diffusion v1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5) using Dreambooth.
The code is similar to the one we saw in the previous examples. We load the fine-tuned model, and then the LCM LoRA suitable for Stable Diffusion v1.5.
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "wavymulder/collage-diffusion"
lcm_lora_id = "latent-consistency/lcm-lora-sdv1-5"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.load_lora_weights(lcm_lora_id)
pipe.to(device="cuda", dtype=torch.float16)
prompt = "collage style kid sits looking at the night sky, full of stars"
generator = torch.Generator(device=pipe.device).manual_seed(1337)
images = pipe(
prompt=prompt,
generator=generator,
negative_prompt=negative_prompt,
num_inference_steps=4,
guidance_scale=1,
).images[0]
images
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/collage.png?download=true" alt="LCM LoRA technique with a Dreambooth Stable Diffusion v1.5 model, allowing 4-step inference."><br>
<em>LCM LoRA technique with a Dreambooth Stable Diffusion v1.5 model, allowing 4-step inference.</em>
</p>
### Full Diffusers Integration
The integration of LCM in `diffusers` makes it possible to take advantage of many features and workflows that are part of the diffusers toolbox. For example:
- Out of the box `mps` support for Macs with Apple Silicon.
- Memory and performance optimizations like flash attention or `torch.compile()`.
- Additional memory saving strategies for low-RAM environments, including model offload.
- Workflows like ControlNet or image-to-image.
- Training and fine-tuning scripts.
## Benchmarks
This section is not meant to be exhaustive, but illustrative of the generation speed we achieve on various computers. Let us stress again how liberating it is to explore image generation so easily.
| Hardware | SDXL LoRA LCM (4 steps) | SDXL standard (25 steps) |
|----------------------------------------|-------------------------|--------------------------|
| Mac, M1 Max | 6.5s | 64s |
| 2080 Ti | 4.7s | 10.2s |
| 3090 | 1.4s | 7s |
| 4090 | 0.7s | 3.4s |
| T4 (Google Colab Free Tier) | 8.4s | 26.5s |
| A100 (80 GB) | 1.2s | 3.8s |
| Intel i9-10980XE CPU (1/36 cores used) | 29s | 219s |
These tests were run with a batch size of 1 in all cases, using [this script](https://huggingface.co/datasets/pcuenq/gists/blob/main/sayak_lcm_benchmark.py) by [Sayak Paul](https://huggingface.co/sayakpaul).
For cards with a lot of capacity, such as A100, performance increases significantly when generating multiple images at once, which is usually the case for production workloads.
## LCM LoRAs and Models Released Today
- [Latent Consistency Models LoRAs Collection](https://huggingface.co/collections/latent-consistency/latent-consistency-models-loras-654cdd24e111e16f0865fba6)
- [`latent-consistency/lcm-lora-sdxl`](https://huggingface.co/latent-consistency/lcm-lora-sdxl). LCM LoRA for [SDXL 1.0 base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0), as seen in the examples above.
- [`latent-consistency/lcm-lora-sdv1-5`](https://huggingface.co/latent-consistency/lcm-lora-sdv1-5). LCM LoRA for [Stable Diffusion 1.5](https://huggingface.co/runwayml/stable-diffusion-v1-5).
- [`latent-consistency/lcm-lora-ssd-1b`](https://huggingface.co/latent-consistency/lcm-lora-ssd-1b). LCM LoRA for [`segmind/SSD-1B`](https://huggingface.co/segmind/SSD-1B), a distilled SDXL model that's 50% smaller and 60% faster than the original SDXL.
- [`latent-consistency/lcm-sdxl`](https://huggingface.co/latent-consistency/lcm-sdxl). Full fine-tuned consistency model derived from [SDXL 1.0 base](https://huggingface.co/stabilityai/stable-diffusion-xl-base-1.0).
- [`latent-consistency/lcm-ssd-1b`](https://huggingface.co/latent-consistency/lcm-ssd-1b). Full fine-tuned consistency model derived from [`segmind/SSD-1B`](https://huggingface.co/segmind/SSD-1B).
## Bonus: Combine LCM LoRAs with regular SDXL LoRAs
Using the [diffusers + PEFT integration](https://huggingface.co/docs/diffusers/main/en/tutorials/using_peft_for_inference), you can combine LCM LoRAs with regular SDXL LoRAs, giving them the superpower to run LCM inference in only 4 steps.
Here we are going to combine `CiroN2022/toy_face` LoRA with the LCM LoRA:
```py
from diffusers import DiffusionPipeline, LCMScheduler
import torch
model_id = "stabilityai/stable-diffusion-xl-base-1.0"
lcm_lora_id = "latent-consistency/lcm-lora-sdxl"
pipe = DiffusionPipeline.from_pretrained(model_id, variant="fp16")
pipe.scheduler = LCMScheduler.from_config(pipe.scheduler.config)
pipe.load_lora_weights(lcm_lora_id)
pipe.load_lora_weights("CiroN2022/toy-face", weight_name="toy_face_sdxl.safetensors", adapter_name="toy")
pipe.set_adapters(["lora", "toy"], adapter_weights=[1.0, 0.8])
pipe.to(device="cuda", dtype=torch.float16)
prompt = "a toy_face man"
negative_prompt = "blurry, low quality, render, 3D, oversaturated"
images = pipe(
prompt=prompt,
negative_prompt=negative_prompt,
num_inference_steps=4,
guidance_scale=0.5,
).images[0]
images
```
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/lcm-lora/lcm-toy.png?download=true" alt="Combining LoRAs for fast inference"><br>
<em>Standard and LCM LoRAs combined for fast (4 step) inference.</em>
</p>
Need ideas to explore some LoRAs? Check out our experimental [LoRA the Explorer (LCM version)](https://huggingface.co/spaces/latent-consistency/lcm-LoraTheExplorer) Space to test amazing creations by the community and get inspired!
## How to Train LCM Models and LoRAs
As part of the `diffusers` release today, we are providing training and fine-tuning scripts developed in collaboration with the LCM team authors. They allow users to:
- Perform full-model distillation of Stable Diffusion or SDXL models on large datasets such as Laion.
- Train LCM LoRAs, which is a much easier process. As we've shown in this post, it also makes it possible to run fast inference with Stable Diffusion, without having to go through distillation training.
For more details, please check the instructions for [SDXL](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README_sdxl.md) or [Stable Diffusion](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README.md) in the repo.
We hope these scripts inspire the community to try their own fine-tunes. Please, do let us know if you use them for your projects!
## Resources
- Latent Consistency Models [project page](https://latent-consistency-models.github.io), [paper](https://huggingface.co/papers/2310.04378).
- [LCM LoRAs](https://huggingface.co/collections/latent-consistency/latent-consistency-models-loras-654cdd24e111e16f0865fba6)
- [For SDXL](https://huggingface.co/latent-consistency/lcm-lora-sdxl).
- [For Stable Diffusion v1.5](https://huggingface.co/latent-consistency/lcm-lora-sdv1-5).
- [For Segmind's SSD-1B](https://huggingface.co/latent-consistency/lcm-lora-ssd-1b).
- [Technical Report](https://huggingface.co/latent-consistency/lcm-lora-sdxl/resolve/main/LCM-LoRA-Technical-Report.pdf).
- Demos
- [SDXL in 4 steps with Latent Consistency LoRAs](https://huggingface.co/spaces/latent-consistency/lcm-lora-for-sdxl)
- [Near real-time video stream](https://huggingface.co/spaces/latent-consistency/Real-Time-LCM-ControlNet-Lora-SD1.5)
- [LoRA the Explorer (experimental LCM version)](https://huggingface.co/spaces/latent-consistency/lcm-LoraTheExplorer)
- PEFT: [intro](https://huggingface.co/blog/peft), [repo](https://github.com/huggingface/peft)
- Training scripts
- [For Stable Diffusion 1.5](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README.md)
- [For SDXL](https://github.com/huggingface/diffusers/blob/main/examples/consistency_distillation/README_sdxl.md)
## Credits
The amazing work on Latent Consistency Models was performed by the [LCM Team](https://latent-consistency-models.github.io), please make sure to check out their code, report and paper. This project is a collaboration between the [diffusers team](https://github.com/huggingface/diffusers), the LCM team, and community contributor [Daniel Gu](https://huggingface.co/dg845). We believe it's a testament to the enabling power of open source AI, the cornerstone that allows researchers, practitioners and tinkerers to explore new ideas and collaborate. We'd also like to thank [`@madebyollin`](https://huggingface.co/madebyollin) for their continued contributions to the community, including the `float16` autoencoder we use in our training scripts.
| 0 |
0 | hf_public_repos | hf_public_repos/blog/aya-expanse.md | ---
title: "A Deepdive into Aya Expanse: Advancing the Frontier of Multilinguality"
thumbnail: /blog/assets/aya-expanse/thumbnail.jpg
authors:
- user: johndang-cohere
guest: true
org: CohereForAI
- user: shivi
guest: true
org: CohereForAI
- user: dsouzadaniel
guest: true
org: CohereForAI
- user: ArashAhmadian
guest: true
org: CohereForAI
---
# A Deepdive into Aya Expanse: Advancing the Frontier of Multilinguality
> [!NOTE] This is a guest blog post by the Cohere For AI team. Cohere For AI is Cohere's research lab that seeks to solve complex machine learning problems.
With the release of the Aya Expanse family, featuring [8B](https://huggingface.co/CohereForAI/aya-expanse-8b) and [32B](https://huggingface.co/CohereForAI/aya-expanse-32b) parameter models, we are addressing one of the most urgent challenges in AI: the lack of highly performant multilingual models that can rival the capabilities of monolingual ones. While AI has made tremendous progress, there remains a stark gap in the performance of models across multiple languages. Aya Expanse is the result of several years of dedicated research at [C4AI](https://cohere.com/research) --- [data arbitrage](https://arxiv.org/abs/2408.14960), [multilingual preference training](https://arxiv.org/abs/2407.02552), [safety tuning](https://arxiv.org/abs/2406.18682), and [model merging](https://arxiv.org/abs/2410.10801).
These combined breakthroughs have resulted in new state-of-the-art performance on multilingual. We evaluate our models on a set of evaluations including the [Arena-Hard-Auto](https://huggingface.co/datasets/lmarena-ai/arena-hard-auto-v0.1) dataset ([paper](https://arxiv.org/abs/2406.11939)), translated to the 23 languages which we [release for others to use](https://huggingface.co/datasets/CohereForAI/m-ArenaHard). In pairwise comparison, [Aya Expanse 32B](https://huggingface.co/CohereForAI/aya-expanse-32b) outperforms Gemma 2 27B, Mistral 8x22B, and Llama 3.1 70B, a model more than 2x its size, setting a new state-of-the-art for multilingual performance. We also release [Aya Expanse 8B](https://huggingface.co/CohereForAI/aya-expanse-8b), which outperforms the leading open-weights models in its parameter class such as Gemma 2 9B, Llama 3.1 8B, and the recently released Ministral 8B with win rates ranging from 60.4% to 70.6%. We observe even larger gains across less challenging evals.


We release both models as open weights for the research community, and hope it will further accelerate multilingual progress. In this blog post, we share technical details behind each of the key algorithmic components used in the training pipeline.

## Avoiding Model Collapse in Synthetic Data
The use of synthetic data – data generated by an expert or “teacher” model to train another model – has become increasingly central to the development of LLMs, particularly as model training has exhausted current data sources. However, for multilingual data, especially with low-resource languages, there are few good examples of teacher models, creating an extra added challenge to leveraging synthetic data. Furthermore, [recent research](https://www.nature.com/articles/s41586-024-07566-y) has suggested that an over-reliance on synthetic data leads to model collapse.
In [our recent work](https://www.arxiv.org/pdf/2408.14960) we demonstrate that these limitations can be addressed through “data arbitrage” – strategically sampling from a pool of teacher models. This approach has important implications as it challenges the traditional reliance on a single-teacher model for generating synthetic data. Instead, *data arbitrage* leverages performance variations among a pool of models. Although this technique is applicable to any domain, it is particularly suited to the multilingual setting, where the absence of a universally effective teacher that excels across all languages presents significant challenges In the creation of high-quality synthetic multilingual datasets, *multilingual arbitrage* proves valuable by utilizing a diverse pool of models to strategically sample different parts of the data distribution for improved multilingual generations.
We first train a model pool for groups of languages and employ an ***Arbiter*** to evaluate and select the optimal generation. The Arbiter here is an internal reward model (RM) to score the model generations. In Reward-Based Routing, for each prompt in a given language, we generate completions from all models in the pool and score them using the reward model. The completion with the highest score is chosen as the final completion for that prompt. Our 8B model, even at the SFT stage trained with Multilingual Arbitrage, had over 9.1% improvement in win-rate measured against Gemma 2 9B compared to [the previous Aya 23 model](https://arxiv.org/abs/2405.15032), demonstrating the effectiveness of this approach in leveraging diverse model strengths across languages.

## Iteratively Improving with Global Preferences
Following supervised fine-tuning, alignment to human preferences is a key step for training today’s state-of-the-art LLMs. Although heavily adopted, it is known that [preference training is already challenging in a monolingual setting](https://arxiv.org/abs/2307.15217). Maximizing gains from preference training in a multilingual setting introduces even more challenges. The vast majority of existing preference datasets are exclusively English and the few existing multilingual preference datasets are often of low-quality. Moreover, modeling many diverse languages simultaneously is known to be a difficult optimization problem where naively optimizing for performance in some languages often leads to regressions in performance in other languages.
In [_LHF Can Speak Many Languages: Unlocking Multilingual Preference Optimization for LLMs_](https://arxiv.org/abs/2407.02552), we leverage a novel synthetic data generation technique to construct high-quality multilingual preference data pairs by contrasting in-language completions from a highly performant multilingual LLM with lower quality completions translated from English which were generated by a weaker model. This steers our model away from generating low-quality multilingual completions which often contain undesirable artifacts, such as those introduced by poor translation. We show that this method unlocks substantial gains in performance across all languages and often also results in gains for languages not included in the preference training data.
While this [work](https://arxiv.org/abs/2407.02552) also shows that preference training with online data outperforms its offline variant, during training of Aya Expanse, we found that the combination of first preference-training with offline data followed by preference-training with online data to be better than either online or offline training alone. In the first preference training stage, we train on data curated by taking the highest and lowest reward responses from the Arbitrage stage as the chosen and rejected completions, which makes the first stage of DPO training _offline_.
After offline preference training, we run _online_ iterative DPO, where we sample multiple online generations for each prompt from the model trained during the last iteration, rank these generations with a Reward Model, and then further train on these preference pairs. For both models, we repeat this process for 3 iterations as we found that going beyond 3 iterations led to minimal gains at the cost of additional re-tuning parameters like regularization coefficient (beta) and sometimes introduced reward hacking behavior. Overall, for Aya Expanse 8B, the combination of offline and online preference training on top of the model trained with arbitrage, led to 7.1% additional gains in win rate against Gemma 2 9B.
## Maximizing Performance through Model Merging
A reappearing problem throughout any post-training (and pre-training) pipeline, whether it consists of a single stage such as SFT, or a more complex multi-stage optimization pipeline, such as our pipeline above, is choosing the right data mixtures for training. The intricacies of this process demand considerable effort in fine-tuning hyperparameters and data combinations. Merging multiple models is an alternative approach for enabling complex multi-tasking at a reduced aggregate computational cost. In Aya Expanse, we directly build on the findings of our recent research paper [_Mix Data or Merge Models? Optimizing for Diverse Multi-Task Learning_](https://arxiv.org/abs/2410.10801) and apply merging in both the Arbitrage phase, and at each iteration of preference training.
When training multiple separate models with the goal of merging, it is important to maximize diversity between checkpoints. However, this should be balanced with ensuring that each individual model within the pool achieves high performance. To balance these objectives, we maximize diversity between checkpoints by training models for different language families. This takes advantage of [cross-lingual transfer](https://aclanthology.org/2024.acl-long.845.pdf) which often provides significant performance benefits while ensuring that linguistic differences provide sufficient differentiation between checkpoints.
Naively, one could split-train a model for each language and then merge, but this does not achieve the same benefits we observe from cross-lingual transfer. To improve robustness in merging, we include some shared languages across each cluster (here English, Spanish, and French). In the final recipe, we used multiple stages of merging runs trained on different clusters of data, and checkpoints within the same run.
In addition to weighted linear averaging, we experiment with multiple merging techniques, namely [SLERP](https://dl.acm.org/doi/10.1145/325165.325242), [TIES-merging](https://arxiv.org/pdf/2306.01708), and [DARE-TIES](https://arxiv.org/abs/2311.03099). However, we found weighted averaging to be the most consistent method. As a result, we use weighted averaging throughout the pipeline. Interestingly, we observed significantly larger gains from merging at the 35B scale compared to the 8B scale – up to 3x. This is inline with [recent work](https://arxiv.org/pdf/2410.03617) suggesting merging to be more effective at scale.
## Bringing it all Together

These diagrams show our end-to-end post-training pipeline, which resulted in the step-by-step gains discussed earlier. It is truly special to look back and see how far the Aya model series has come, since its inception with [Aya 101](https://huggingface.co/CohereForAI/aya-101) accompanied by the [Aya Collection](https://huggingface.co/datasets/CohereForAI/aya_collection), which stretched the limits of open-source collaboration, to now which combines steady progress in key open fundamental research questions to set a new standard for multilingual performance.

## Acknowledgements
This work wouldn’t have been possible without the core Aya Expanse team: Madeline Smith, Marzieh Fadaee, Ahmet Üstün, Beyza Ermis, Sara Hooker, John Dang, Shivalika Singh, Arash Ahmadian, Daniel D'souza, Alejandro Salamanca, Aidan Peppin, Arielle Bailey, Meor Amer, Sungjin Hong, Manoj Govindassamy, Sandra Kublik.
It also wouldn’t have been possible without the wider Cohere For AI and Cohere team. Special thanks to Acyr Locatelli, Adrien Morisot, Jon Ander Campos, Sara Elsharkawy, Eddie Kim, Julia Kreutzer, Nick Frosst, Aidan Gomez, Ivan Zhang.
A huge thanks also goes to our research community – the 220 language ambassadors from around the world who have been part of this release. Thank you to Sree Harsha Nelaturu, Bhavnick Minhas, Christopher Klamm, Isabella Bicalho Frazeto who contributed notebooks that are accessible on the model Hugging Face cards.
Special thank you to Hugging Face for helping make this come together: Omar Sanseviero, Pedro Cuenca, Vaibhav Srivastav, Lysandre Debut, Aritra Roy Gosthipaty.
## References
- [Multilingual Arbitrage: Optimizing Data Pools to Accelerate Multilingual Progress](https://www.arxiv.org/pdf/2408.14960)
- [RLHF Can Speak Many Languages: Unlocking Multilingual Preference Optimization for LLMs](https://arxiv.org/abs/2407.02552)
- [Back to Basics: Revisiting REINFORCE Style Optimization for Learning from Human Feedback in LLMs](https://arxiv.org/abs/2402.14740)
- [AI models collapse when trained on recursively generated data](https://www.nature.com/articles/s41586-024-07566-y)
- [Mix Data or Merge Models? Optimizing for Diverse Multi-Task Learning](https://arxiv.org/abs/2410.10801)
- [Aya 23: Open Weight Releases to Further Multilingual Progress](https://arxiv.org/abs/2405.15032)
- [Aya Model: An Instruction Finetuned Open-Access Multilingual Language Model](https://aclanthology.org/2024.acl-long.845/)
- [Aya Dataset: An Open-Access Collection for Multilingual Instruction Tuning](https://aclanthology.org/2024.acl-long.620/)
- [From Crowdsourced Data to High-Quality Benchmarks: Arena-Hard and BenchBuilder Pipeline](https://arxiv.org/abs/2406.11939)
- [Open Problems and Fundamental Limitations of Reinforcement Learning from Human Feedback](https://arxiv.org/abs/2307.15217)
- [Does the English Matter? Elicit Cross-lingual Abilities of Large Language Models](https://aclanthology.org/2023.mrl-1.14.pdf)
- [Animating rotation with quaternion curves](https://dl.acm.org/doi/10.1145/325165.325242)
- [Ties-merging: Resolving interference when merging models.](https://arxiv.org/pdf/2306.01708)
- [Language Models are Super Mario: Absorbing Abilities from Homologous Models as a Free Lunch](https://arxiv.org/abs/2311.03099)
- [What Matters for Model Merging at Scale?](https://arxiv.org/pdf/2410.03617)
| 1 |
0 | hf_public_repos | hf_public_repos/blog/databricks-case-study.md | ---
title: "Databricks ❤️ Hugging Face: up to 40% faster training and tuning of Large Language Models"
thumbnail: /blog/assets/78_ml_director_insights/databricks.png
authors:
- user: alighodsi
guest: true
- user: maddiedawson
guest: true
---
# Databricks ❤️ Hugging Face: up to 40% faster training and tuning of Large Language Models
Generative AI has been taking the world by storm. As the data and AI company, we have been on this journey with the release of the open source large language model [Dolly](https://huggingface.co/databricks/dolly-v2-12b), as well as the internally crowdsourced dataset licensed for research and commercial use that we used to fine-tune it, the [databricks-dolly-15k](https://huggingface.co/datasets/databricks/databricks-dolly-15k). Both the model and dataset are available on Hugging Face. We’ve learned a lot throughout this process, and today we’re excited to announce our first of many official commits to the Hugging Face codebase that allows users to easily create a Hugging Face Dataset from an Apache Spark™ dataframe.
#### “It's been great to see Databricks release models and datasets to the community, and now we see them extending that work with direct open source commitment to Hugging Face. Spark is one of the most efficient engines for working with data at scale, and it's great to see that users can now benefit from that technology to more effectively fine tune models from Hugging Face.”
— Clem Delange, Hugging Face CEO
## Hugging Face gets first-class Spark support
Over the past few weeks, we’ve gotten many requests from users asking for an easier way to load their Spark dataframe into a Hugging Face dataset that can be utilized for model training or tuning. Prior to today’s release, to get data from a Spark dataframe into a Hugging Face dataset, users had to write data into Parquet files and then point the Hugging Face dataset to these files to reload them. For example:
```swift
from datasets import load_dataset
train_df = train.write.parquet(train_dbfs_path, mode="overwrite")
train_test = load_dataset("parquet", data_files={"train":f"/dbfs{train_dbfs_path}/*.parquet", "test":f"/dbfs{test_dbfs_path}/*.parquet"})
#16GB == 22min
```
Not only was this cumbersome, but it also meant that data had to be written to disk and then read in again. On top of that, the data would get rematerialized once loaded back into the dataset, which eats up more resources and, therefore, more time and cost. Using this method, we saw that a relatively small (16GB) dataset took about 22 minutes to go from Spark dataframe to Parquet, and then back into the Hugging Face dataset.
With the latest Hugging Face release, we make it much simpler for users to accomplish the same task by simply calling the new “from_spark” function in Datasets:
```swift
from datasets import Dataset
df = [some Spark dataframe or Delta table loaded into df]
dataset = Dataset.from_spark(df)
#16GB == 12min
```
This allows users to use Spark to efficiently load and transform data for training or fine-tuning a model, then easily map their Spark dataframe into a Hugging Face dataset for super simple integration into their training pipelines. This combines cost savings and speed from Spark and optimizations like memory-mapping and smart caching from Hugging Face datasets. These improvements cut down the processing time for our example 16GB dataset by more than 40%, going from 22 minutes down to only 12 minutes.
## Why does this matter?
As we transition to this new AI paradigm, organizations will need to use their extremely valuable data to augment their AI models if they want to get the best performance within their specific domain. This will almost certainly require work in the form of data transformations, and doing this efficiently over large datasets is something Spark was designed to do. Integrating Spark with Hugging Face gives you the cost-effectiveness and performance of Spark while retaining the pipeline integration that Hugging Face provides.
## Continued Open-Source Support
We see this release as a new avenue to further contribute to the open source community, something that we believe Hugging Face does extremely well, as it has become the de facto repository for open source models and datasets. This is only the first of many contributions. We already have plans to add streaming support through Spark to make the dataset loading even faster.
In order to become the best platform for users to jump into the world of AI, we’re working hard to provide the best tools to successfully train, tune, and deploy models. Not only will we continue contributing to Hugging Face, but we’ve also started releasing improvements to our other open source projects. A recent [MLflow](https://www.databricks.com/blog/2023/04/18/introducing-mlflow-23-enhanced-native-llm-support-and-new-features.html) release added support for the transformers library, OpenAI integration, and Langchain support. We also announced [AI Functions](https://www.databricks.com/blog/2023/04/18/introducing-ai-functions-integrating-large-language-models-databricks-sql.html) within Databricks SQL that lets users easily integrate OpenAI (or their own deployed models in the future) into their queries. To top it all off, we also released a [PyTorch distributor](https://www.databricks.com/blog/2023/04/20/pytorch-databricks-introducing-spark-pytorch-distributor.html) for Spark to simplify distributed PyTorch training on Databricks.
_This article was originally published on April 26, 2023 in [Databricks's blog](https://www.databricks.com/blog/contributing-spark-loader-for-hugging-face-datasets)._
| 2 |
0 | hf_public_repos | hf_public_repos/blog/beating-gaia.md | ---
title: "Our Transformers Code Agent beats the GAIA benchmark 🏅"
thumbnail: /blog/assets/beating-gaia/thumbnail.jpeg
authors:
- user: m-ric
- user: sergeipetrov
---
## TL;DR
After some experiments, we were impressed by the performance of Transformers Agents to build agentic systems, so we wanted to see how good it was! We tested using a [Code Agent built with the library](https://github.com/aymeric-roucher/GAIA) on the GAIA benchmark, arguably the most difficult and comprehensive agent benchmark… and ended up on top!
## GAIA: a tough benchmark for Agents
**What are agents?**
In one sentence: an agent is any system based on an LLM that can call external tools or not, depending on the need for the current use case and iterate on further steps based on the LLM output. Tools can include anything from a Web search API to a Python interpreter.
> For a visual analogy: all programs could be described as graphs. Do A, then do B. If/else switches are forks in the graph, but they do not change its structure. We define **agents** as the systems where the LLM outputs will change the structure of the graph. An agent decides to call tool A or tool B or nothing, it decides to run one more step or not: these change the structure of the graph. You could integrate an LLM in a fixed workflow, as in [LLM judge](https://huggingface.co/papers/2310.17631), without it being an agent system, because the LLM output will not change the structure of the graph
Here is an illustration for two different system that perform [Retrieval Augmented Generation](https://huggingface.co/learn/cookbook/en/rag_zephyr_langchain): one is the classical, its graph is fixed. But the other is agentic, one loop in the graph can be repeated as needed.
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/beating_gaia/classical_vs_agentic_rag.png" alt="Classical vs Agentic RAG" width=90%>
</p>
Agent systems give LLMs superpowers. For more detail, read[ our earlier blog post on the release of Transformers Agents 2.0](https://huggingface.co/blog/agents).
[GAIA](https://huggingface.co/datasets/gaia-benchmark/GAIA) is the most comprehensive benchmark for agents. The questions in GAIA are very difficult and highlight certain difficulties of LLM-based systems.
Here is an example of a tricky question:
> Which of the fruits shown in the 2008 painting "Embroidery from Uzbekistan" were served as part of the October 1949 breakfast menu for the ocean liner that was later used as a floating prop for the film "The Last Voyage"? Give the items as a comma-separated list, ordering them in clockwise order based on their arrangement in the painting starting from the 12 o'clock position. Use the plural form of each fruit.
You can see this question involves several difficulties:
- Answering in a constrained format.
- Multimodal abilities to read the fruits from the image
- Several informations to gather, some depending on the others:
* The fruits on the picture
* The identity of the ocean liner used as a floating prop for “The Last Voyage”
* The October 1949 breakfast menu for the above ocean liner
- The above forces the correct solving trajectory to use several chained steps.
Solving this requires both high-level planning abilities and rigorous execution, which are precisely two areas where LLMs struggle.
Therefore, it’s an excellent test set for agent systems!
On GAIA’s[ public leaderboard](https://huggingface.co/spaces/gaia-benchmark/leaderboard), GPT-4-Turbo does not reach 7% on average. The top submission is (was) an Autogen-based solution with a complex multi-agent system that makes use of OpenAI’s tool calling functions, it reaches 40%.
**Let’s take them on. 🥊**
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/beating_gaia/prepare_for_battle.gif" alt="Let's fight" width=70%>
</p>
## Building the right tools 🛠️
We used three main tools to solve GAIA questions:
**a. Web browser**
For web browsing, we mostly reused the Markdown web browser from [Autogen team’s submission](https://github.com/microsoft/autogen/tree/gaia_multiagent_v01_march_1st/samples/tools/autogenbench/scenarios/GAIA/Templates/Orchestrator). It comprises a `Browser` class storing the current browser state, and several tools for web navigation, like `visit_page`, `page_down` or `find_in_page`. This tool returns markdown representations of the current viewport. Using markdown compresses web pages information a lot, which could lead to some misses, compared to other solutions like taking a screenshot and using a vision model. However, we found that the tool was overall performing well without being too complex to use or edit.
Note: we think that a good way to improve this tool in the future would be to to load pages using selenium package rather than requests. This would allow us to load javascript (many pages cannot load properly without javascript) and accepting cookies to access some pages.
**b. File inspector**
Many GAIA questions rely on attached files from a variety of type, such as `.xls`, `.mp3`, `.pdf`, etc. These files need to be properly parsed.. Once again, we use Autogen’s tool since it works really well.
Many thanks to the Autogen team for open-sourcing their work. It sped up our development process by weeks to use these tools! 🤗
**c. Code interpreter**
We will have no need for this since our agent naturally generates and executes Python code: see more below.
## Code Agent 🧑💻
### Why a Code Agent?
As shown by[ Wang et al. (2024)](https://huggingface.co/papers/2402.01030), letting the agent express its actions in code has several advantages compared to using dictionary-like outputs such as JSON. For us, the main advantage is that **code is a very optimized way to express complex sequences of actions**. Arguably if there had been a better way to rigorously express detailed actions than our current programming languages, it would have become a new programming language!
Consider this example given in their paper:
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/beating_gaia/code_vs_json.png" alt="Code agents are just more intuitive than JSON" width=100%>
It highlights several advantages of using code:
- Code actions are **much more concise** than JSON.
* Need to run 4 parallel streams of 5 consecutive actions ? In JSON, you would need to generate 20 JSON blobs, each in their separate step; in Code it’s only 1 step.
* On average, the paper shows that Code actions require 30% fewer steps than JSON, which amounts to an equivalent reduction in the tokens generated. Since LLM calls are often the dimensioning cost of agent systems, it means your agent system runs are ~30% cheaper.
- Code enables to re-use tools from common libraries
- Using code gets better performance in benchmarks, due to two reasons:
* It’s a more intuitive way to express actions
* LLMs have lots of code in their training data, which possibly makes them more fluent in code-writing than in JSON writing.
We confirmed these points during our experiments on[ agent_reasoning_benchmark](https://github.com/aymeric-roucher/agent_reasoning_benchmark).
From our latest experiments of building transformers agents, we also observed additional advantages:
- It is much easier to store an element as a named variable in code. For example, need to store this rock image generated by a tool for later use?
* No problem in code: using “rock_image = image_generation_tool(“A picture of a rock”)” will store the variable under the key “rock_image” in your dictionary of variables. Later the LLM can just use its value in any code blob by referring to it again as “rock_image”.
* In JSON you would have to do some complicated gymnastics to create a name under which to store this image, so that the LLM later knows how to access it again. For instance, save any output of the image generation tool under “image_{i}.png”, and trust that the LLM will later understand that image_4.png is the output of the tool call that precedes it in memory? Or let the LLM also output a “output_name” key to choose under which name to store the variable, thus complicating the structure of your action JSON?
- Agent logs are considerably more readable.
### Implementation of Transformers Agents’ CodeAgent
The thing with LLM generated code is that it can be really unsafe to execute as is. If you let an LLM write and execute code without guardrails, it could hallucinate anything: for instance that all your personal files need to be erased by copies of the Dune lore, or that this audio of you singing the Frozen theme needs to be shared on your blog!
So for our agents, we had to make code execution secure. The usual approach is top-down: “use a fully functional python interpreter, but forbid certain actions”.
To be more safe, we preferred to go the opposite way, and **build a LLM-safe Python interpreter from the ground-up**. Given a Python code blob provided by the LLM, our interpreter starts from the [Abstract Syntax Tree representation](https://en.wikipedia.org/wiki/Abstract_syntax_tree) of the code given by the [ast](https://docs.python.org/3/library/ast.html) python module. It executes the tree nodes one by one, following the tree structure, and stops at any operation that was not explicitly authorised
For example, an `import` statement will first check if the import is explicitly mentioned in the user-defined list of `authorized_imports`: if not, it does not execute. We include a default list of built-in standard Python functions, comprising for instance `print` and `range`. Anything outside of it will not be executed except explicitly authorized by the user. For instance, `open` (as in `with open("path.txt", "w") as file:`) is not authorized.
When encountering a function call (`ast.Call`), if the function name is one of the user-defined tools, the tool is called with the arguments to the call. If it’s another function defined and allowed earlier, it gets run normally.
We also do several tweaks to help with LLM usage of the interpreter:
- We cap the number of operations in execution to prevent infinite loops caused by issues in LLM-generated code: at each operation, a counter gets incremented, and if it reaches a certain threshold the execution is interrupted
- We cap the number of lines in print outputs to avoid flooding the context length of the LLM with junk. For instance if the LLM reads a 1M lines text files and decides to print every line, at some point this output will be truncated, so that the agent memory does not explode.
## Basic multi-agent orchestration
Web browsing is a very context-rich activity, but most of the retrieved context is actually useless. For instance, in the above GAIA question, the only important information to get is the image of the painting "Embroidery from Uzbekistan". Anything around it, like the content of the blog we found it on, is generally useless for the broader task solving.
To solve this, using a multi-agent step makes sense! For example, we can create a manager agent and a web search agent. The manager agent should solve the higher-level task, and assign specific web search task to the web search agent. The web search agent should return only the useful outputs of its search, so that the manager is not cluttered with useless information.
We created exactly this multi-agent orchestration in our workflow:
- The top level agent is a [ReactCodeAgent](https://huggingface.co/docs/transformers/main/en/main_classes/agent#transformers.ReactCodeAgent). It natively handles code since its actions are formulated and executed in Python. It has access to these tools:
- `file_inspector` to read text files, with an optional `question` argument to not return the whole content of the file but only return its answer to the specific question based on the content
- `visualizer` to specifically answer questions about images.
- `search_agent` to browse the web. More specifically, this Tool is just a wrapper around a Web Search agent, which is a JSON agent (JSON still works well for strictly sequential tasks, like web browsing where you scroll down, then navigate to a new page, and so on). This agent in turn has access to the web browsing tools:
- `informational_web_search`
- `page_down`
- `find_in_page`
- … (full list [at this line](https://github.com/aymeric-roucher/GAIA/blob/a66aefc857d484a051a5eb66b49575dfaadff266/gaia.py#L107))
This embedding of an agent as a tool is a naive way to do multi-agent orchestration, but we wanted to see how far we could push it - and it turns out that it goes quite far!
## Planning component 🗺️
There is now [an entire zoo](https://arxiv.org/pdf/2402.02716) of planning strategies, so we opted for a relatively simple plan-ahead workflow. Every N steps we generate two things:
- a summary of facts we know or we can derive from context and facts we need to discover
- a step-by-step plan of how to solve the task given fresh observations and the factual summary above
The parameter N can be tuned for better performance on the target use cas: we chose N=2 for the manager agent and N=5 for the web search agent.
An interesting discovery was that if we do not provide the previous version of the plan as input, the score goes up. An intuitive explanation is that it’s common for LLMs to be strongly biased towards any relevant information available in the context. If the previous version of the plan is present in the prompt, an LLM is likely to heavily reuse it instead of re-evaluating the approach and re-generating a plan when needed.
Both the summary of facts and the plan are then used as additional context to generate the next action. Planning encourages an LLM to choose a better trajectory by having all the steps to achieve the goal and the current state of affairs in front of it.
## Results 🏅
[Here is the final code used for our submission.](https://github.com/aymeric-roucher/GAIA)
We get 44.2% on the validation set: so that means Transformers Agent’s ReactCodeAgent is now #1 overall, with 4 points above the second! **On the test set, we get 33.3%, so we rank #2, in front of Microsoft Autogen’s submission, and we get the best average score on the hardcore Level 3 questions.**
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/beating_gaia/leaderboard.png" alt="We did it!" width=100%>
This is a data point to support that [Code actions work better](https://huggingface.co/papers/2402.01030). Given their efficiency, we think Code actions will soon replace JSON/OAI format as the standard for agents writing their actions.
LangChain and LlamaIndex do not support Code actions out of the box to our knowledge, Microsoft's Autogen has some support for Code actions (executing code in [docker containers](https://github.com/microsoft/autogen/blob/57ec13c2eb1fd227a7976c62d0fd4a88bf8a1975/autogen/code_utils.py#L350)) but it looks like an annex to JSON actions. So Transformers Agents is the only library to make this format central!
## Next steps
We hope you enjoyed reading this blog post! And the work is just getting started, as we’ll keep improving Transformers Agents, along several axes:
- **LLM engine:** Our submission was done with GPT-4o (alas), **without any fine-tuning**. Our hypothesis is that using a fine-tuned OS model would allow us to get rid of parsing errors, and score a bit higher!
- **Multi-agent orchestration:** our is a naive one, with more seamless orchestration we could probably go a long way!
- **Web browser tool:** using the `selenium` package, we could have a web browser that passes cookie banners and loads javascript, thus allowing us to read many pages that are for now not accessible.
- **Improve planning further:** We’re running some ablation tests with other options from the literature to see which method works best. We are planning to give a try to alternative implementations of existing components and also some new components. We will publish our updates when we have more insights!
Keep an eye on Transformers Agents in the next few months! 🚀
And don’t hesitate to reach out to us with your use cases, now that we have built internal expertise on Agents we’ll be happy to lend a hand! 🤝 | 3 |
0 | hf_public_repos | hf_public_repos/blog/synthid-text.md | ---
title: "Introducing SynthID Text"
thumbnail: /blog/assets/synthid-text/thumbnail.png
authors:
- user: sumedhghaisas
org: Google DeepMind
guest: true
- user: sdathath
org: Google DeepMind
guest: true
- user: RyanMullins
org: Google DeepMind
guest: true
- user: joaogante
- user: marcsun13
- user: RaushanTurganbay
---
# Introducing SynthID Text
Do you find it difficult to tell if text was written by a human or generated by
AI? Being able to identify AI-generated content is essential to promoting trust
in information, and helping to address problems such as misattribution and
misinformation. Today, [Google DeepMind](https://deepmind.google/) and Hugging
Face are excited to launch
[SynthID Text](https://deepmind.google/technologies/synthid/) in Transformers
v4.46.0, releasing later today. This technology allows you to apply watermarks
to AI-generated text using a
[logits processor](https://huggingface.co/docs/transformers/v4.46.0/en/internal/generation_utils#transformers.SynthIDTextWatermarkLogitsProcessor)
for generation tasks, and detect those watermarks with a
[classifier](https://huggingface.co/docs/transformers/v4.46.0/en/internal/generation_utils#transformers.SynthIDTextWatermarkDetector).
Check out the SynthID Text
[paper in _Nature_](https://www.nature.com/articles/s41586-024-08025-4) for the
complete technical details of this algorithm, and Google’s
[Responsible GenAI Toolkit](https://ai.google.dev/responsible/docs/safeguards/synthid)
for more on how to apply SynthID Text in your products.
## How it works
The primary goal of SynthID Text is to encode a watermark into AI-generated text
in a way that helps you determine if text was generated from your LLM without
affecting how the underlying LLM works or negatively impacting generation
quality. Google DeepMind has developed a watermarking technique that uses a
pseudo-random function, called a g-function, to augment the generation process
of any LLM such that the watermark is imperceptible to humans but is visible to
a trained model. This has been implemented as a
[generation utility](https://huggingface.co/docs/transformers/v4.46.0/en/internal/generation_utils#transformers.SynthIDTextWatermarkLogitsProcessor)
that is compatible with any LLM without modification using the
`model.generate()` API, along with an
[end-to-end example](https://github.com/huggingface/transformers/tree/v4.46.0/examples/research_projects/synthid_text/detector_training.py)
of how to train detectors to recognize watermarked text. Check out the
[research paper](https://www.nature.com/articles/s41586-024-08025-4) that has
more complete details about the SynthID Text algorithm.
## Configuring a watermark
Watermarks are
[configured using a dataclass](https://huggingface.co/docs/transformers/v4.46.0/en/internal/generation_utils#transformers.SynthIDTextWatermarkingConfig)
that parameterizes the _g_-function and how it is applied in the tournament
sampling process. Each model you use should have its own watermarking
configuration that **_should be stored securely and privately_**, otherwise your
watermark may be replicable by others.
You must define two parameters in every watermarking configuration:
- The `keys` parameter is a list integers that are used to compute _g_-function
scores across the model's vocabulary. Using 20 to 30 unique, randomly
generated numbers is recommended to balance detectability against generation
quality.
- The `ngram_len` parameter is used to balance robustness and detectability; the
larger the value the more detectable the watermark will be, at the cost of
being more brittle to changes. A good default value is 5, but it needs to be
at least 2.
You can further configure the watermark based on your performance needs. See the
[`SynthIDTextWatermarkingConfig` class](https://huggingface.co/docs/transformers/v4.46.0/en/internal/generation_utils#transformers.SynthIDTextWatermarkingConfig)
for more information.
The [research paper](https://www.nature.com/articles/s41586-024-08025-4)
includes additional analyses of how specific configuration values affect
watermark performance.
## Applying a watermark
Applying a watermark is a straightforward change to your existing generation
calls. Once you define your configuration, pass a
`SynthIDTextWatermarkingConfig` object as the `watermarking_config=` parameter
to `model.generate()` and all generated text will carry the watermark. Check out
the [SynthID Text Space](https://huggingface.co/spaces/google/synthid-text) for
an interactive example of watermark application, and see if you can tell.
```py
from transformers import (
AutoModelForCausalLM,
AutoTokenizer,
SynthIDTextWatermarkingConfig,
)
# Standard model and tokenizer initialization
tokenizer = AutoTokenizer.from_pretrained('repo/id')
model = AutoModelForCausalLM.from_pretrained('repo/id')
# SynthID Text configuration
watermarking_config = SynthIDTextWatermarkingConfig(
keys=[654, 400, 836, 123, 340, 443, 597, 160, 57, ...],
ngram_len=5,
)
# Generation with watermarking
tokenized_prompts = tokenizer(["your prompts here"])
output_sequences = model.generate(
**tokenized_prompts,
watermarking_config=watermarking_config,
do_sample=True,
)
watermarked_text = tokenizer.batch_decode(output_sequences)
```
## Detecting a watermark
Watermarks are designed to be detectable by a trained classifier but
imperceptible to humans. Every watermarking configuration you use with your
models needs to have a detector trained to recognize the mark.
The basic detector training process is:
- Decide on a watermarking configuration.
- Collect a detector training set split between watermarked or not, and training
or test, we recommend a minimum of 10k examples.
- Generate non-watermarked outputs with your model.
- Generate watermarked outputs with your model.
- Train your watermark detection classifier.
- Productionize your model with the watermarking configuration and associated detector.
A
[Bayesian detector class](https://huggingface.co/docs/transformers/v4.46.0/en/internal/generation_utils#transformers.BayesianDetectorModel)
is provided in Transformers, along with an
[end-to-end example](https://github.com/huggingface/transformers/tree/v4.46.0/examples/research_projects/synthid_text/detector_training.py)
of how to train a detector to recognize watermarked text using a specific
watermarking configuration. Models that use the same tokenizer can also share
watermarking configuration and detector, thus sharing a common watermark, so
long as the detector's training set includes examples from all models that share
a watermark.
This trained detector can be uploaded to a private HF Hub to make it accessible
across your organization. Google’s
[Responsible GenAI Toolkit](https://ai.google.dev/responsible/docs/safeguards/synthid)
has more on how to productionize SynthID Text in your products.
## Limitations
SynthID Text watermarks are robust to some transformations, such as cropping
pieces of text, modifying a few words, or mild paraphrasing, but this method
does have limitations.
- Watermark application is less effective on factual responses, as there is less
opportunity to augment generation without decreasing accuracy.
- Detector confidence scores can be greatly reduced when an AI-generated text is
thoroughly rewritten, or translated to another language.
SynthID Text is not built to directly stop motivated adversaries from causing
harm. However, it can make it harder to use AI-generated content for malicious
purposes, and it can be combined with other approaches to give better coverage
across content types and platforms.
## Acknowledgements
The authors would like to thank Robert Stanforth and Tatiana Matejovicova for
their contributions to this work.
| 4 |
0 | hf_public_repos | hf_public_repos/blog/sc2-instruct.md | ---
title: "StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation"
thumbnail: /blog/assets/sc2-instruct/sc2-instruct-banner.png
authors:
- user: yuxiang630
guest: true
- user: cassanof
guest: true
- user: ganler
guest: true
- user: YifengDing
guest: true
- user: StringChaos
guest: true
- user: harmdevries
guest: true
- user: lvwerra
- user: arjunguha
guest: true
- user: lingming
guest: true
---
# StarCoder2-Instruct: Fully Transparent and Permissive Self-Alignment for Code Generation
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/starcoder2-instruct-assets/resolve/main/banner.png" alt="StarCoder2-Instruct">
</div>
*Instruction tuning* is an approach of fine-tuning that gives large language models (LLMs) the capability to follow natural and human-written instructions. However, for programming tasks, most models are tuned on either human-written instructions (which are very expensive) or instructions generated by huge and proprietary LLMs (which may not be permitted). **We introduce [StarCoder2-15B-Instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1), the very first entirely self-aligned code LLM trained with a fully permissive and transparent pipeline**. Our open-source pipeline uses StarCoder2-15B to generate thousands of instruction-response pairs, which are then used to fine-tune StarCoder-15B itself without any human annotations or distilled data from huge and proprietary LLMs.
**StarCoder2-15B-Instruct achieves a 72.6 HumanEval score, even surpassing the 72.0 score of CodeLlama-70B-Instruct!** Further evaluation on LiveCodeBench shows that the self-aligned model is even better than the same model trained on data distilled from GPT-4, implying that an LLM could learn more effectively from data within its own distribution than a shifted distribution from a teacher LLM.
## Method
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/starcoder2-instruct-assets/resolve/main/method.png" alt="Method">
</div>
Our data generation pipeline mainly consists of three steps:
1. Extract high-quality and diverse seed functions from [The Stack v1](https://huggingface.co/datasets/bigcode/the-stack), a huge corpus of permissively licensed source code.
2. Create diverse and realistic code instructions that incorporate different code concepts present in the seed functions (e.g., data deserialization, list concatenation, and recursion).
3. For each instruction, generate a high-quality response through execution-guided self-validation.
In the following sections, we will explore each of these aspects in detail.
### Collecting seed code snippets
To fully unlock the instruction-following capabilities of a code model, it should be exposed to a diverse set of instructions encompassing a wide range of programming principles and practices. Motivated by [OSS-Instruct](https://github.com/ise-uiuc/magicoder), we further promote such diversity by mining code concepts from open-source code snippets that are, specifically, well-formed seed Python functions from The Stack V1.
For our seed dataset, we carefully extract all Python functions with docstrings in The Stack V1, infer dependencies required using [autoimport](https://lyz-code.github.io/autoimport/), and apply the following filtering rules on all functions:
1. **Type checking:** We apply the [Pyright](https://github.com/microsoft/pyright) heuristic type-checker to remove all functions that produce static errors, signaling a possibly incorrect item.
2. **Decontamination**: We detect and remove all benchmark items on which we evaluate. We use exact string match on both the solutions and prompts.
3. **Docstring Quality Filtering**: We utilize StarCoder2-15B as a judge to remove functions with poor documentation. We prompt the base model with 7 few-shot examples, requiring it to respond with either "Yes" or "No" for retaining the item.
4. **Near-Deduplication**: We utilize MinHash and locality-sensitive hashing with a Jaccard similarity threshold of 0.5 to filter duplicate seed functions in our dataset. This is the [same process](https://huggingface.co/blog/dedup) applied to StarCoder’s training data.
This filtering pipeline results in a dataset of 250k Python functions filtered from 5M functions with docstrings. This process is highly inspired by the data collection pipeline used in [MultiPL-T](https://huggingface.co/datasets/nuprl/MultiPL-T).
### Self-OSS-Instruct
After collecting the seed functions, we use Self-OSS-Instruct to generate diverse instructions. In detail, we employ in-context learning to let the base StarCoder2-15B self-generate instructions from the given seed code snippets. This process utilizes 16 carefully designed few-shot examples, each formatted as *(snippet, concepts, instruction)*. The instruction generation procedure is divided into two steps:
1. **Concepts extraction:** For each seed function, StarCoder2-15B is prompted to produce a list of code concepts present within the function. Code concepts refer to the foundational principles and techniques used in programming, such as *pattern matching* and *data type conversion*, which are crucial for developers to master.
2. **Instruction generation:** StarCoder2-15B is then prompted to self-generate a coding task that incorporates the identified code concepts.
Eventually, 238k instructions are generated from this process.
### Response self-validation
Given the instructions generated from Self-OSS-Instruct, our next step is to match each instruction with a high-quality response. Prior practices commonly rely on distilling responses from stronger teacher models, such as GPT-4, which hopefully exhibit higher quality. However, distilling proprietary models leads to non-permissive licensing and a stronger teacher model might not always be available. More importantly, teacher models can be wrong as well, and the distribution gap between teacher and student can be detrimental.
We propose to self-align StarCoder2-15B by explicitly instructing the model to generate tests for self-validation after it produces a response interleaved with natural language. This process is similar to how developers test their code implementations. Specifically, for each instruction, StarCoder2-15B generates 10 samples of the format *(NL Response, Test)* and we filter out those falsified by the test execution under a sandbox environment. We then randomly select one passing response per instruction to the final SFT dataset. In total, we generated 2.4M (10 x 238k) responses for the 238k instructions with temperature 0.7, where 500k passed the execution test. After deduplication, we are left with 50k instructions, each paired with a random passing response, which we finally use as our SFT dataset.
## Evaluation
On the popular and rigorous [EvalPlus](https://github.com/evalplus/evalplus) benchmark, StarCoder2-15B-Instruct stands out as the top-performing permissive LLM at its scale, outperforming the much larger Grok-1 Command-R+, DBRX, while closely matching Snowflake Arctic 480B and Mixtral-8x22B-Instruct. To our knowledge, StarCoder2-15B-Instruct is the first code LLM with a fully transparent and permissive pipeline reaching a 70+ HumanEval score. It drastically outperforms OctoCoder, which is the previous state-of-the-art permissive code LLM with a transparent pipeline.
Even compared to powerful LLMs with restrictive licenses, StarCoder2-15B-Instruct remains competitive, surpassing Gemini Pro and Mistral Large and comparable to CodeLlama-70B-Instruct. Additionally, StarCoder2-15B-Instruct, trained purely on self-generated data, closely rivals OpenCodeInterpreter-SC2-15B, which finetunes StarCoder2-15B on distilled data from GPT-3.5/4.
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/starcoder2-instruct-assets/resolve/main/evalplus.png" alt="EvalPlus evaluation">
</div>
Besides EvalPlus, we also evaluated state-of-the-art open-source models with similar or smaller sizes on [LiveCodeBench](https://livecodebench.github.io), which includes fresh coding problems created after 2023-09-01, as well as [DS-1000](https://ds1000-code-gen.github.io) that targets data science programs. On LiveCodeBench, StarCoder2-15B-Instruct achieves the best results among the models evaluated and consistently outperforms OpenCodeInterpreter-SC2-15B which distills GPT-4 data. On DS-1000, the StarCoder2-15B-Instruct is still competitive despite being trained on very limited data science problems.
<div class="flex items-center justify-center">
<img src="https://huggingface.co/datasets/bigcode/starcoder2-instruct-assets/resolve/main/lcb-ds1000.png" alt="LCB and DS1000 evaluation">
</div>
## Conclusion
StarCoder2-15B-Instruct-v0.1 showcases for the first time that we can create powerful instruction-tuned code models without relying on stronger teacher models like GPT-4. This model demonstrates that self-alignment, where a model uses its own generated content to learn, is also effective for code. It is fully transparent and allows for distillation, setting it apart from other larger permissive but non-transparent models such as Snowflake-Arctic, Grok-1, Mixtral-8x22B, DBRX, and CommandR+. We have made our datasets and the entire pipeline, including data curation and training, fully open-source. We hope this seminal work can inspire more future research and development in this field.
### Resources
- [StarCoder2-15B-Instruct-v0.1](https://huggingface.co/bigcode/starcoder2-15b-instruct-v0.1): the instruction-tuned model
- [starcoder2-self-align](https://github.com/bigcode-project/starcoder2-self-align): the self-alignment pipeline
- [StarCoder2-Self-OSS-Instruct](https://huggingface.co/datasets/bigcode/self-oss-instruct-sc2-exec-filter-50k/): the self-generated, instruction-tuning dataset
### Citation
```bibtex
@article{wei2024selfcodealign,
title={SelfCodeAlign: Self-Alignment for Code Generation},
author={Yuxiang Wei and Federico Cassano and Jiawei Liu and Yifeng Ding and Naman Jain and Zachary Mueller and Harm de Vries and Leandro von Werra and Arjun Guha and Lingming Zhang},
year={2024},
journal={arXiv preprint arXiv:2410.24198}
}
```
| 5 |
0 | hf_public_repos | hf_public_repos/blog/dreambooth.md | ---
title: Training Stable Diffusion with Dreambooth using Diffusers
thumbnail: /blog/assets/sd_dreambooth_training/thumbnail.jpg
authors:
- user: valhalla
- user: pcuenq
- user: 9of9
guest: true
---
# Training Stable Diffusion with Dreambooth using 🧨 Diffusers
[Dreambooth](https://dreambooth.github.io/) is a technique to teach new concepts to [Stable Diffusion](https://huggingface.co/blog/stable_diffusion) using a specialized form of fine-tuning. Some people have been using it with a few of their photos to place themselves in fantastic situations, while others are using it to incorporate new styles. [🧨 Diffusers](https://github.com/huggingface/diffusers) provides a Dreambooth [training script](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth). It doesn't take long to train, but it's hard to select the right set of hyperparameters and it's easy to overfit.
We conducted a lot of experiments to analyze the effect of different settings in Dreambooth. This post presents our findings and some tips to improve your results when fine-tuning Stable Diffusion with Dreambooth.
Before we start, please be aware that this method should never be used for malicious purposes, to generate harm in any way, or to impersonate people without their knowledge. Models trained with it are still bound by the [CreativeML Open RAIL-M license](https://huggingface.co/spaces/CompVis/stable-diffusion-license) that governs distribution of Stable Diffusion models.
_Note: a previous version of this post was published [as a W&B report](https://wandb.ai/psuraj/dreambooth/reports/Dreambooth-Training-Analysis--VmlldzoyNzk0NDc3)_.
## TL;DR: Recommended Settings
* Dreambooth tends to overfit quickly. To get good-quality images, we must find a 'sweet spot' between the number of training steps and the learning rate. We recommend using a low learning rate and progressively increasing the number of steps until the results are satisfactory.
* Dreambooth needs more training steps for faces. In our experiments, 800-1200 steps worked well when using a batch size of 2 and LR of 1e-6.
* Prior preservation is important to avoid overfitting when training on faces. For other subjects, it doesn't seem to make a huge difference.
* If you see that the generated images are noisy or the quality is degraded, it likely means overfitting. First, try the steps above to avoid it. If the generated images are still noisy, use the DDIM scheduler or run more inference steps (~100 worked well in our experiments).
* Training the text encoder in addition to the UNet has a big impact on quality. Our best results were obtained using a combination of text encoder fine-tuning, low LR, and a suitable number of steps. However, fine-tuning the text encoder requires more memory, so a GPU with at least 24 GB of RAM is ideal. Using techniques like 8-bit Adam, `fp16` training or gradient accumulation, it is possible to train on 16 GB GPUs like the ones provided by Google Colab or Kaggle.
* Fine-tuning with or without EMA produced similar results.
* There's no need to use the `sks` word to train Dreambooth. One of the first implementations used it because it was a rare token in the vocabulary, but it's actually a kind of rifle. Our experiments, and those by for example [@nitrosocke](https://huggingface.co/nitrosocke) show that it's ok to select terms that you'd naturally use to describe your target.
## Learning Rate Impact
Dreambooth overfits very quickly. To get good results, tune the learning rate and the number of training steps in a way that makes sense for your dataset. In our experiments (detailed below), we fine-tuned on four different datasets with high and low learning rates. In all cases, we got better results with a low learning rate.
## Experiments Settings
All our experiments were conducted using the [`train_dreambooth.py`](https://github.com/huggingface/diffusers/tree/main/examples/dreambooth) script with the `AdamW` optimizer on 2x 40GB A100s. We used the same seed and kept all hyperparameters equal across runs, except LR, number of training steps and the use of prior preservation.
For the first 3 examples (various objects), we fine-tuned the model with a batch size of 4 (2 per GPU) for 400 steps. We used a high learning rate of `5e-6` and a low learning rate of `2e-6`. No prior preservation was used.
The last experiment attempts to add a human subject to the model. We used prior preservation with a batch size of 2 (1 per GPU), 800 and 1200 steps in this case. We used a high learning rate of `5e-6` and a low learning rate of `2e-6`.
Note that you can use 8-bit Adam, `fp16` training or gradient accumulation to reduce memory requirements and run similar experiments on GPUs with 16 GB of memory.
### Cat Toy
High Learning Rate (`5e-6`)

Low Learning Rate (`2e-6`)

### Pighead
High Learning Rate (`5e-6`). Note that the color artifacts are noise remnants – running more inference steps could help resolve some of those details.

Low Learning Rate (`2e-6`)

### Mr. Potato Head
High Learning Rate (`5e-6`). Note that the color artifacts are noise remnants – running more inference steps could help resolve some of those details.

Low Learning Rate (`2e-6`)

### Human Face
We tried to incorporate the Kramer character from Seinfeld into Stable Diffusion. As previously mentioned, we trained for more steps with a smaller batch size. Even so, the results were not stellar. For the sake of brevity, we have omitted these sample images and defer the reader to the next sections, where face training became the focus of our efforts.
### Summary of Initial Results
To get good results training Stable Diffusion with Dreambooth, it's important to tune the learning rate and training steps for your dataset.
* High learning rates and too many training steps will lead to overfitting. The model will mostly generate images from your training data, no matter what prompt is used.
* Low learning rates and too few steps will lead to underfitting: the model will not be able to generate the concept we were trying to incorporate.
Faces are harder to train. In our experiments, a learning rate of `2e-6` with `400` training steps works well for objects but faces required `1e-6` (or `2e-6`) with ~1200 steps.
Image quality degrades a lot if the model overfits, and this happens if:
* The learning rate is too high.
* We run too many training steps.
* In the case of faces, when no prior preservation is used, as shown in the next section.
## Using Prior Preservation when training Faces
Prior preservation is a technique that uses additional images of the same class we are trying to train as part of the fine-tuning process. For example, if we try to incorporate a new person into the model, the _class_ we'd want to preserve could be _person_. Prior preservation tries to reduce overfitting by using photos of the new person combined with photos of other people. The nice thing is that we can generate those additional class images using the Stable Diffusion model itself! The training script takes care of that automatically if you want, but you can also provide a folder with your own prior preservation images.
Prior preservation, 1200 steps, lr=`2e-6`.

No prior preservation, 1200 steps, lr=`2e-6`.

As you can see, results are better when prior preservation is used, but there are still noisy blotches. It's time for some additional tricks!
## Effect of Schedulers
In the previous examples, we used the `PNDM` scheduler to sample images during the inference process. We observed that when the model overfits, `DDIM` usually works much better than `PNDM` and `LMSDiscrete`. In addition, quality can be improved by running inference for more steps: 100 seems to be a good choice. The additional steps help resolve some of the noise patches into image details.
`PNDM`, Kramer face

`LMSDiscrete`, Kramer face. Results are terrible!

`DDIM`, Kramer face. Much better

A similar behaviour can be observed for other subjects, although to a lesser extent.
`PNDM`, Potato Head

`LMSDiscrete`, Potato Head

`DDIM`, Potato Head

## Fine-tuning the Text Encoder
The original Dreambooth paper describes a method to fine-tune the UNet component of the model but keeps the text encoder frozen. However, we observed that fine-tuning the encoder produces better results. We experimented with this approach after seeing it used in other Dreambooth implementations, and the results are striking!
Frozen text encoder

Fine-tuned text encoder

Fine-tuning the text encoder produces the best results, especially with faces. It generates more realistic images, it's less prone to overfitting and it also achieves better prompt interpretability, being able to handle more complex prompts.
## Epilogue: Textual Inversion + Dreambooth
We also ran a final experiment where we combined [Textual Inversion](https://textual-inversion.github.io) with Dreambooth. Both techniques have a similar goal, but their approaches are different.
In this experiment we first ran textual inversion for 2000 steps. From that model, we then ran Dreambooth for an additional 500 steps using a learning rate of `1e-6`. These are the results:

We think the results are much better than doing plain Dreambooth but not as good as when we fine-tune the whole text encoder. It seems to copy the style of the training images a bit more, so it could be overfitting to them. We didn't explore this combination further, but it could be an interesting alternative to improve Dreambooth and still fit the process in a 16GB GPU. Feel free to explore and tell us about your results!
| 6 |
0 | hf_public_repos | hf_public_repos/blog/ethics-soc-4.md | ---
title: "Ethics and Society Newsletter #4: Bias in Text-to-Image Models"
thumbnail: /blog/assets/152_ethics_soc_4/ethics_4_thumbnail.png
authors:
- user: sasha
- user: giadap
- user: nazneen
- user: allendorf
- user: irenesolaiman
- user: natolambert
- user: meg
---
# Ethics and Society Newsletter #4: Bias in Text-to-Image Models
**TL;DR: We need better ways of evaluating bias in text-to-image models**
## Introduction
[Text-to-image (TTI) generation](https://huggingface.co/models?pipeline_tag=text-to-image&sort=downloads) is all the rage these days, and thousands of TTI models are being uploaded to the Hugging Face Hub. Each modality is potentially susceptible to separate sources of bias, which begs the question: how do we uncover biases in these models? In the current blog post, we share our thoughts on sources of bias in TTI systems as well as tools and potential solutions to address them, showcasing both our own projects and those from the broader community.
## Values and bias encoded in image generations
There is a very close relationship between [bias and values](https://www.sciencedirect.com/science/article/abs/pii/B9780080885797500119), particularly when these are embedded in the language or images used to train and query a given [text-to-image model](https://dl.acm.org/doi/abs/10.1145/3593013.3594095); this phenomenon heavily influences the outputs we see in the generated images. Although this relationship is known in the broader AI research field and considerable efforts are underway to address it, the complexity of trying to represent the evolving nature of a given population's values in a single model still persists. This presents an enduring ethical challenge to uncover and address adequately.
For example, if the training data are mainly in English they probably convey rather Western values. As a result we get stereotypical representations of different or distant cultures. This phenomenon appears noticeable when we compare the results of ERNIE ViLG (left) and Stable Diffusion v 2.1 (right) for the same prompt, "a house in Beijing":
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/ernie-sd.png" alt="results of ERNIE ViLG (left) and Stable Diffusion v 2.1 (right) for the same prompt, a house in Beijing" />
</p>
## Sources of Bias
Recent years have seen much important research on bias detection in AI systems with single modalities in both Natural Language Processing ([Abid et al., 2021](https://dl.acm.org/doi/abs/10.1145/3461702.3462624)) as well as Computer Vision ([Buolamwini and Gebru, 2018](http://proceedings.mlr.press/v81/buolamwini18a/buolamwini18a.pdf)). To the extent that ML models are constructed by people, biases are present in all ML models (and, indeed, technology in general). This can manifest itself by an over- and under-representation of certain visual characteristics in images (e.g., all images of office workers having ties), or the presence of cultural and geographical stereotypes (e.g., all images of brides wearing white dresses and veils, as opposed to more representative images of brides around the world, such as brides with red saris). Given that AI systems are deployed in sociotechnical contexts that are becoming widely deployed in different sectors and tools (e.g. [Firefly](https://www.adobe.com/sensei/generative-ai/firefly.html), [Shutterstock](https://www.shutterstock.com/ai-image-generator)), they are particularly likely to amplify existing societal biases and inequities. We aim to provide a non-exhaustive list of bias sources below:
**Biases in training data:** Popular multimodal datasets such as [LAION-5B](https://laion.ai/blog/laion-5b/) for text-to-image, [MS-COCO](https://cocodataset.org/) for image captioning, and [VQA v2.0](https://paperswithcode.com/dataset/visual-question-answering-v2-0) for visual question answering, have been found to contain numerous biases and harmful associations ([Zhao et al 2017](https://aclanthology.org/D17-1323/), [Prabhu and Birhane, 2021](https://arxiv.org/abs/2110.01963), [Hirota et al, 2022](https://facctconference.org/static/pdfs_2022/facct22-3533184.pdf)), which can percolate into the models trained on these datasets. For example, initial results from the [Hugging Face Stable Bias project](https://huggingface.co/spaces/society-ethics/StableBias) show a lack of diversity in image generations, as well as a perpetuation of common stereotypes of cultures and identity groups. Comparing Dall-E 2 generations of CEOs (right) and managers (left), we can see that both are lacking diversity:
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/CEO_manager.png" alt="Dall-E 2 generations of CEOs (right) and managers (left)" />
</p>
**Biases in pre-training data filtering:** There is often some form of filtering carried out on datasets before they are used for training models; this introduces different biases. For instance, in their [blog post](https://openai.com/research/dall-e-2-pre-training-mitigations), the creators of Dall-E 2 found that filtering training data can actually amplify biases – they hypothesize that this may be due to the existing dataset bias towards representing women in more sexualized contexts or due to inherent biases of the filtering approaches that they use.
**Biases in inference:** The [CLIP model](https://huggingface.co/openai/clip-vit-large-patch14) used for guiding the training and inference of text-to-image models like Stable Diffusion and Dall-E 2 has a number of [well-documented biases](https://arxiv.org/abs/2205.11378) surrounding age, gender, and race or ethnicity, for instance treating images that had been labeled as `white`, `middle-aged`, and `male` as the default. This can impact the generations of models that use it for prompt encoding, for instance by interpreting unspecified or underspecified gender and identity groups to signify white and male.
**Biases in the models' latent space:** [Initial work](https://arxiv.org/abs/2302.10893) has been done in terms of exploring the latent space of the model and guiding image generation along different axes such as gender to make generations more representative (see the images below). However, more work is necessary to better understand the structure of the latent space of different types of diffusion models and the factors that can influence the bias reflected in generated images.
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/fair-diffusion.png" alt="Fair Diffusion generations of firefighters." />
</p>
**Biases in post-hoc filtering:** Many image generation models come with built-in safety filters that aim to flag problematic content. However, the extent to which these filters work and how robust they are to different kinds of content is to be determined – for instance, efforts to [red-team the Stable Diffusion safety filter](https://arxiv.org/abs/2210.04610)have shown that it mostly identifies sexual content, and fails to flag other types violent, gory or disturbing content.
## Detecting Bias
Most of the issues that we describe above cannot be solved with a single solution – indeed, [bias is a complex topic](https://huggingface.co/blog/ethics-soc-2) that cannot be meaningfully addressed with technology alone. Bias is deeply intertwined with the broader social, cultural, and historical context in which it exists. Therefore, addressing bias in AI systems is not only a technological challenge but also a socio-technical one that demands multidisciplinary attention. However, a combination of approaches including tools, red-teaming and evaluations can help glean important insights that can inform both model creators and downstream users about the biases contained in TTI and other multimodal models.
We present some of these approaches below:
**Tools for exploring bias:** As part of the [Stable Bias project](https://huggingface.co/spaces/society-ethics/StableBias), we created a series of tools to explore and compare the visual manifestation of biases in different text-to-image models. For instance, the [Average Diffusion Faces](https://huggingface.co/spaces/society-ethics/Average_diffusion_faces) tool lets you compare the average representations for different professions and different models – like for 'janitor', shown below, for Stable Diffusion v1.4, v2, and Dall-E 2:
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/average.png" alt="Average faces for the 'janitor' profession, computed based on the outputs of different text to image models." />
</p>
Other tools, like the [Face Clustering tool](https://hf.co/spaces/society-ethics/DiffusionFaceClustering) and the [Colorfulness Profession Explorer](https://huggingface.co/spaces/tti-bias/identities-colorfulness-knn) tool, allow users to explore patterns in the data and identify similarities and stereotypes without ascribing labels or identity characteristics. In fact, it's important to remember that generated images of individuals aren't actual people, but artificial creations, so it's important not to treat them as if they were real humans. Depending on the context and the use case, tools like these can be used both for storytelling and for auditing.
**Red-teaming:** ['Red-teaming'](https://huggingface.co/blog/red-teaming) consists of stress testing AI models for potential vulnerabilities, biases, and weaknesses by prompting them and analyzing results. While it has been employed in practice for evaluating language models (including the upcoming [Generative AI Red Teaming event at DEFCON](https://aivillage.org/generative%20red%20team/generative-red-team/), which we are participating in), there are no established and systematic ways of red-teaming AI models and it remains relatively ad hoc. In fact, there are so many potential types of failure modes and biases in AI models, it is hard to anticipate them all, and the [stochastic nature](https://dl.acm.org/doi/10.1145/3442188.3445922) of generative models makes it hard to reproduce failure cases. Red-teaming gives actionable insights into model limitations and can be used to add guardrails and document model limitations. There are currently no red-teaming benchmarks or leaderboards highlighting the need for more work in open source red-teaming resources. [Anthropic's red-teaming dataset](https://github.com/anthropics/hh-rlhf/tree/master/red-team-attempts) is the only open source resource of red-teaming prompts, but is limited to only English natural language text.
**Evaluating and documenting bias:** At Hugging Face, we are big proponents of [model cards](https://huggingface.co/docs/hub/model-card-guidebook) and other forms of documentation (e.g., [datasheets](https://arxiv.org/abs/1803.09010), READMEs, etc). In the case of text-to-image (and other multimodal) models, the result of explorations made using explorer tools and red-teaming efforts such as the ones described above can be shared alongside model checkpoints and weights. One of the issues is that we currently don't have standard benchmarks or datasets for measuring the bias in multimodal models (and indeed, in text-to-image generation systems specifically), but as more [work](https://arxiv.org/abs/2306.05949) in this direction is carried out by the community, different bias metrics can be reported in parallel in model documentation.
## Values and Bias
All of the approaches listed above are part of detecting and understanding the biases embedded in image generation models. But how do we actively engage with them?
One approach is to develop new models that represent society as we wish it to be. This suggests creating AI systems that don't just mimic the patterns in our data, but actively promote more equitable and fair perspectives. However, this approach raises a crucial question: whose values are we programming into these models? Values differ across cultures, societies, and individuals, making it a complex task to define what an "ideal" society should look like within an AI model. The question is indeed complex and multifaceted. If we avoid reproducing existing societal biases in our AI models, we're faced with the challenge of defining an "ideal" representation of society. Society is not a static entity, but a dynamic and ever-changing construct. Should AI models, then, adapt to the changes in societal norms and values over time? If so, how do we ensure that these shifts genuinely represent all groups within society, especially those often underrepresented?
Also, as we have mentioned in a [previous newsletter](https://huggingface.co/blog/ethics-soc-2#addressing-bias-throughout-the-ml-development-cycle), there is no one single way to develop machine learning systems, and any of the steps in the development and deployment process can present opportunities to tackle bias, from who is included at the start, to defining the task, to curating the dataset, training the model, and more. This also applies to multimodal models and the ways in which they are ultimately deployed or productionized in society, since the consequences of bias in multimodal models will depend on their downstream use. For instance, if a model is used in a human-in-the-loop setting for graphic design (such as those created by [RunwayML](https://runwayml.com/ai-magic-tools/text-to-image/)), the user has numerous occasions to detect and correct bias, for instance by changing the prompt or the generation options. However, if a model is used as part of a [tool to help forensic artists create police sketches of potential suspects](https://www.vice.com/en/article/qjk745/ai-police-sketches) (see image below), then the stakes are much higher, since this can reinforce stereotypes and racial biases in a high-risk setting.
<p align="center">
<br>
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/152_ethics_soc_4/forensic.png" alt="Forensic AI Sketch artist tool developed using Dall-E 2." />
</p>
## Other updates
We are also continuing work on other fronts of ethics and society, including:
- **Content moderation:**
- We made a major update to our [Content Policy](https://huggingface.co/content-guidelines). It has been almost a year since our last update and the Hugging Face community has grown massively since then, so we felt it was time. In this update we emphasize *consent* as one of Hugging Face's core values. To read more about our thought process, check out the [announcement blog](https://huggingface.co/blog/content-guidelines-update) **.**
- **AI Accountability Policy:**
- We submitted a response to the NTIA request for comments on [AI accountability policy](https://ntia.gov/issues/artificial-intelligence/request-for-comments), where we stressed the importance of documentation and transparency mechanisms, as well as the necessity of leveraging open collaboration and promoting access to external stakeholders. You can find a summary of our response and a link to the full document [in our blog post](https://huggingface.co/blog/policy-ntia-rfc)!
## Closing Remarks
As you can tell from our discussion above, the issue of detecting and engaging with bias and values in multimodal models, such as text-to-image models, is very much an open question. Apart from the work cited above, we are also engaging with the community at large on the issues - we recently co-led a [CRAFT session at the FAccT conference](https://facctconference.org/2023/acceptedcraft.html) on the topic and are continuing to pursue data- and model-centric research on the topic. One particular direction we are excited to explore is a more in-depth probing of the [values](https://arxiv.org/abs/2203.07785) instilled in text-to-image models and what they represent (stay tuned!).
| 7 |
0 | hf_public_repos | hf_public_repos/blog/stable-diffusion-xl-coreml.md | ---
title: "Stable Diffusion XL on Mac with Advanced Core ML Quantization"
thumbnail: /blog/assets/stable-diffusion-xl-coreml/thumbnail.png
authors:
- user: pcuenq
- user: Atila
guest: true
---
# Stable Diffusion XL on Mac with Advanced Core ML Quantization
[Stable Diffusion XL](https://stability.ai/stablediffusion) was released yesterday and it’s awesome. It can generate large (1024x1024) high quality images; adherence to prompts has been improved with some new tricks; it can effortlessly produce very dark or very bright images thanks to the latest research on noise schedulers; and it’s open source!
The downside is that the model is much bigger, and therefore slower and more difficult to run on consumer hardware. Using the [latest release of the Hugging Face diffusers library](https://github.com/huggingface/diffusers/releases/tag/v0.19.0), you can run Stable Diffusion XL on CUDA hardware in 16 GB of GPU RAM, making it possible to use it on Colab’s free tier.
The past few months have shown that people are very clearly interested in running ML models locally for a variety of reasons, including privacy, convenience, easier experimentation, or unmetered use. We’ve been working hard at both Apple and Hugging Face to explore this space. We’ve shown [how to run Stable Diffusion on Apple Silicon](https://machinelearning.apple.com/research/stable-diffusion-coreml-apple-silicon), or how to leverage the [latest advancements in Core ML to improve size and performance with 6-bit palettization](https://huggingface.co/blog/fast-diffusers-coreml).
For Stable Diffusion XL we’ve done a few things:
* Ported the [base model to Core ML](https://huggingface.co/apple/coreml-stable-diffusion-xl-base) so you can use it in your native Swift apps.
* Updated [Apple’s conversion and inference repo](https://github.com/apple/ml-stable-diffusion) so you can convert the models yourself, including any fine-tunes you’re interested in.
* Updated [Hugging Face’s demo app](https://github.com/huggingface/swift-coreml-diffusers) to show how to use the new Core ML Stable Diffusion XL models downloaded from the Hub.
* Explored [mixed-bit palettization](https://github.com/apple/ml-stable-diffusion#-mbp-post-training-mixed-bit-palettization), an advanced compression technique that achieves important size reductions while minimizing and controlling the quality loss you incur. You can apply the same technique to your own models too!
Everything is open source and available today, let’s get on with it.
## Contents
- [Using SD XL Models from the Hugging Face Hub](#using-sd-xl-models-from-the-hugging-face-hub)
- [What is Mixed-Bit Palettization?](#what-is-mixed-bit-palettization)
- [How are Mixed-Bit Recipes Created?](#how-are-mixed-bit-recipes-created)
- [Converting Fine-Tuned Models](#converting-fine-tuned-models)
- [Published Resources](#published-resources)
## Using SD XL Models from the Hugging Face Hub
As part of this release, we published two different versions of Stable Diffusion XL in Core ML.
- [`apple/coreml-stable-diffusion-xl-base`](https://huggingface.co/apple/coreml-stable-diffusion-xl-base) is a complete pipeline, without any quantization.
- [`apple/coreml-stable-diffusion-mixed-bit-palettization`](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization) contains (among other artifacts) a complete pipeline where the UNet has been replaced with a mixed-bit palettization _recipe_ that achieves a compression equivalent to 4.5 bits per parameter. Size went down from 4.8 to 1.4 GB, a 71% reduction, and in our opinion quality is still great.
Either model can be tested using Apple’s [Swift command-line inference app](https://github.com/apple/ml-stable-diffusion#inference), or Hugging Face’s [demo app](https://github.com/huggingface/swift-coreml-diffusers). This is an example of the latter using the new Stable Diffusion XL pipeline:
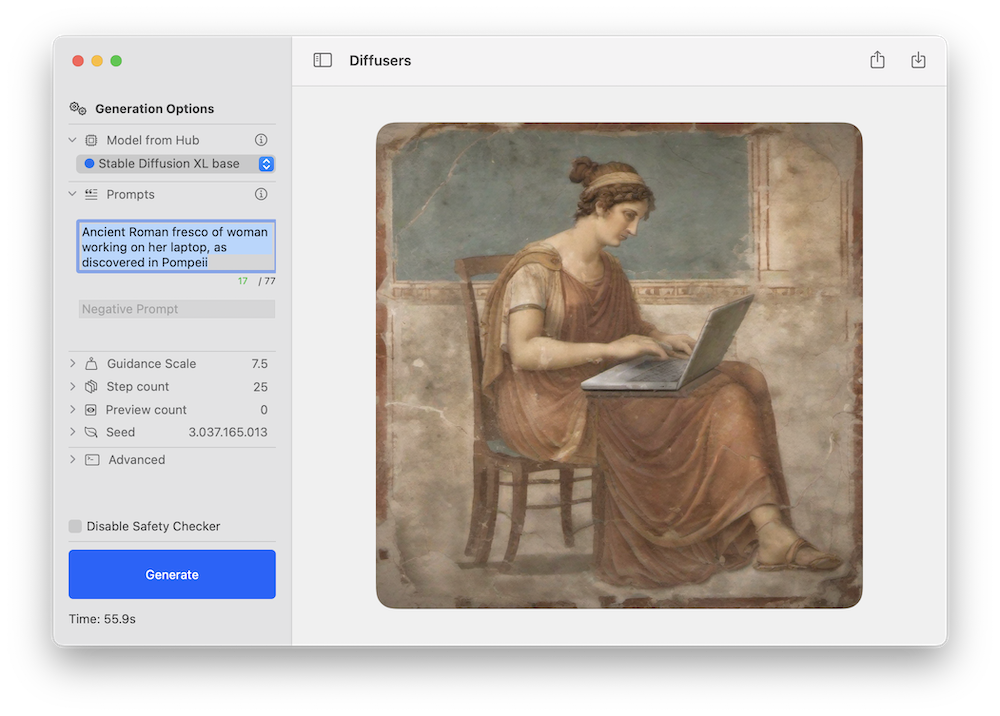
As with previous Stable Diffusion releases, we expect the community to come up with novel fine-tuned versions for different domains, and many of them will be converted to Core ML. You can keep an eye on [this filter in the Hub](https://huggingface.co/models?pipeline_tag=text-to-image&library=coreml&sort=trending) to explore!
Stable Diffusion XL works on Apple Silicon Macs running the public beta of macOS 14. It currently uses the `ORIGINAL` attention implementation, which is intended for CPU + GPU compute units. Note that the refiner stage has not been ported yet.
For reference, these are the performance figures we achieved on different devices:
| Device | `--compute-unit`| `--attention-implementation` | End-to-End Latency (s) | Diffusion Speed (iter/s) |
| --------------------- | --------------- | ---------------------------- | ---------------------- | ------------------------ |
| MacBook Pro (M1 Max) | `CPU_AND_GPU` | `ORIGINAL` | 46 | 0.46 |
| MacBook Pro (M2 Max) | `CPU_AND_GPU` | `ORIGINAL` | 37 | 0.57 |
| Mac Studio (M1 Ultra) | `CPU_AND_GPU` | `ORIGINAL` | 25 | 0.89 |
| Mac Studio (M2 Ultra) | `CPU_AND_GPU` | `ORIGINAL` | 20 | 1.11 |
## What is Mixed-Bit Palettization?
[Last month we discussed 6-bit palettization](https://huggingface.co/blog/fast-diffusers-coreml), a post-training quantization method that converts 16-bit weights to just 6-bit per parameter. This achieves an important reduction in model size, but going beyond that is tricky because model quality becomes more and more impacted as the number of bits is decreased.
One option to decrease model size further is to use _training time_ quantization, which consists of learning the quantization tables while we fine-tune the model. This works great, but you need to run a fine-tuning phase for every model you want to convert.
We explored a different alternative instead: **mixed-bit palettization**. Instead of using 6 bits per parameter, we examine the model and decide how many quantization bits to use _per layer_. We make the decision based on how much each layer contributes to the overall quality degradation, which we measure by comparing the PSNR between the quantized model and the original model in `float16` mode, for a set of a few inputs. We explore several bit depths, per layer: `1` (!), `2`, `4` and `8`. If a layer degrades significantly when using, say, 2 bits, we move to `4` and so on. Some layers might be kept in 16-bit mode if they are critical to preserving quality.
Using this method, we can achieve effective quantizations of, for example, 2.8 bits on average, and we measure the impact on degradation for every combination we try. This allows us to be better informed about the best quantization to use for our target quality and size budgets.
To illustrate the method, let’s consider the following quantization “recipes” that we got from one of our analysis runs (we’ll explain later how they were generated):
```json
{
"model_version": "stabilityai/stable-diffusion-xl-base-1.0",
"baselines": {
"original": 82.2,
"linear_8bit": 66.025,
"recipe_6.55_bit_mixedpalette": 79.9,
"recipe_4.50_bit_mixedpalette": 75.8,
"recipe_3.41_bit_mixedpalette": 71.7,
},
}
```
What this tells us is that the original model quality, as measured by PSNR in float16, is about 82 dB. Performing a naïve 8-bit linear quantization drops it to 66 dB. But then we have a recipe that compresses to 6.55 bits per parameter, on average, while keeping PSNR at 80 dB. The second and third recipes further reduce the model size, while still sustaining a PSNR larger than that of the 8-bit linear quantization.
For visual examples, these are the results on prompt `a high quality photo of a surfing dog` running each one of the three recipes with the same seed:
| 3.41-bit | 4.50-bit | 6.55-bit | 16-bit (original) |
| :-------:| :-------:| :-------:| :----------------:|
|  |  |  |  |
Some initial conclusions:
- In our opinion, all the images have good quality in terms of how realistic they look. The 6.55 and 4.50 versions are close to the 16-bit version in this aspect.
- The same seed produces an equivalent composition, but will not preserve the same details. Dog breeds may be different, for example.
- Adherence to the prompt may degrade as we increase compression. In this example, the aggressive 3.41 version loses the board. PSNR only compares how much pixels differ overall, but does not care about the subjects in the images. You need to examine results and assess them for your use case.
This technique is great for Stable Diffusion XL because we can keep about the same UNet size even though the number of parameters tripled with respect to the previous version. But it's not exclusive to it! You can apply the method to any Stable Diffusion Core ML model.
## How are Mixed-Bit Recipes Created?
The following plot shows the signal strength (PSNR in dB) versus model size reduction (% of float16 size) for `stabilityai/stable-diffusion-xl-base-1.0`. The `{1,2,4,6,8}`-bit curves are generated by progressively palettizing more layers using a palette with a fixed number of bits. The layers were ordered in ascending order of their isolated impact to end-to-end signal strength, so the cumulative compression's impact is delayed as much as possible. The mixed-bit curve is based on falling back to a higher number of bits as soon as a layer's isolated impact to end-to-end signal integrity drops below a threshold. Note that all curves based on palettization outperform linear 8-bit quantization at the same model size except for 1-bit.
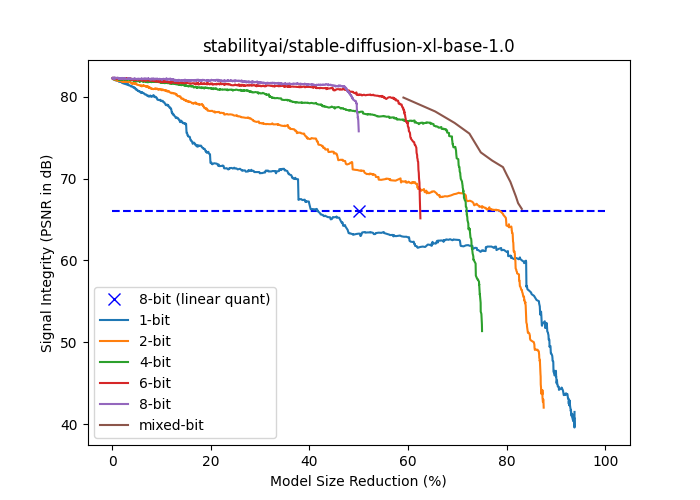
Mixed-bit palettization runs in two phases: _analysis_ and _application_.
The goal of the analysis phase is to find points in the mixed-bit curve (the brown one above all the others in the figure) so we can choose our desired quality-vs-size tradeoff. As mentioned in the previous section, we iterate through the layers and select the lowest bit depths that yield results above a given PSNR threshold. We repeat the process for various thresholds to get different quantization strategies. The result of the process is thus a set of quantization recipes, where each recipe is just a JSON dictionary detailing the number of bits to use for each layer in the model. Layers with few parameters are ignored and kept in float16 for simplicity.
The application phase simply goes over the recipe and applies palettization with the number of bits specified in the JSON structure.
Analysis is a lengthy process and requires a GPU (`mps` or `cuda`), as we have to run inference multiple times. Once it’s done, recipe application can be performed in a few minutes.
We provide scripts for each one of these phases:
* [`mixed_bit_compression_pre_analysis.py`](https://github.com/apple/ml-stable-diffusion/tree/main/python_coreml_stable_diffusion/mixed_bit_compression_pre_analysis.py)
* [`mixed_bit_compression_apply.py`](https://github.com/apple/ml-stable-diffusion/tree/main/python_coreml_stable_diffusion/mixed_bit_compression_apply.py)
## Converting Fine-Tuned Models
If you’ve previously converted Stable Diffusion models to Core ML, the process for XL using [the command line converter is very similar](https://github.com/apple/ml-stable-diffusion#-using-stable-diffusion-xl). There’s a new flag to indicate whether the model belongs to the XL family, and you have to use `--attention-implementation ORIGINAL` if that’s the case.
For an introduction to the process, check the [instructions in the repo](https://github.com/apple/ml-stable-diffusion#-converting-models-to-core-ml) or one of [our previous blog posts](https://huggingface.co/blog/diffusers-coreml), and make sure you use the flags above.
### Running Mixed-Bit Palettization
After converting Stable Diffusion or Stable Diffusion XL models to Core ML, you can optionally apply mixed-bit palettization using the scripts mentioned above.
Because the analysis process is slow, we have prepared recipes for the most popular models:
* [Recipes for Stable Diffusion 1.5](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/blob/main/recipes/runwayml-stable-diffusion-v1-5_palettization_recipe.json)
* [Recipes for Stable Diffusion 2.1](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/blob/main/recipes/stabilityai-stable-diffusion-2-1-base_palettization_recipe.json)
* [Recipes for Stable Diffusion XL 1.0 base](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/blob/main/recipes/stabilityai-stable-diffusion-xl-base-1.0_palettization_recipe.json)
You can download and apply them locally to experiment.
In addition, we also applied the three best recipes from the Stable Diffusion XL analysis to the Core ML version of the UNet, and published them [here](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/tree/main/unet-mbp-sdxl-1-base). Feel free to play with them and see how they work for you!
Finally, as mentioned in the introduction, we created a [complete Stable Diffusion XL Core ML pipeline](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization) that uses a `4.5-bit` recipe.
### Published Resources
* [`apple/ml-stable-diffusion`](https://github.com/apple/ml-stable-diffusion), by Apple. Conversion and inference library for Swift (and Python).
* [`huggingface/swift-coreml-diffusers`](https://github.com/huggingface/swift-coreml-diffusers). Hugging Face demo app, built on top of Apple's package.
* [Stable Diffusion XL 1.0 base (Core ML version)](https://huggingface.co/apple/coreml-stable-diffusion-xl-base). Model ready to run using the repos above and other third-party apps.
* [Stable Diffusion XL 1.0 base, with mixed-bit palettization (Core ML)](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/blob/main/coreml-stable-diffusion-mixed-bit-palettization_original_compiled.zip). Same model as above, with UNet quantized with an effective palettization of 4.5 bits (on average).
* [Additional UNets with mixed-bit palettizaton](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/tree/main/unet-mbp-sdxl-1-base).
* [Mixed-bit palettization recipes](https://huggingface.co/apple/coreml-stable-diffusion-mixed-bit-palettization/tree/main/recipes), pre-computed for popular models and ready to use.
* [`mixed_bit_compression_pre_analysis.py`](https://github.com/apple/ml-stable-diffusion/tree/main/python_coreml_stable_diffusion/mixed_bit_compression_pre_analysis.py). Script to run mixed-bit analysis and recipe generation.
* [`mixed_bit_compression_apply.py`](https://github.com/apple/ml-stable-diffusion/tree/main/python_coreml_stable_diffusion/mixed_bit_compression_apply.py). Script to apply recipes computed during the analysis phase.
| 8 |
0 | hf_public_repos | hf_public_repos/blog/llama2.md | ---
title: "Llama 2 is here - get it on Hugging Face"
thumbnail: /blog/assets/llama2/thumbnail.jpg
authors:
- user: philschmid
- user: osanseviero
- user: pcuenq
- user: lewtun
---
# Llama 2 is here - get it on Hugging Face
## Introduction
Llama 2 is a family of state-of-the-art open-access large language models released by Meta today, and we’re excited to fully support the launch with comprehensive integration in Hugging Face. Llama 2 is being released with a very permissive community license and is available for commercial use. The code, pretrained models, and fine-tuned models are all being released today 🔥
We’ve collaborated with Meta to ensure smooth integration into the Hugging Face ecosystem. You can find the 12 open-access models (3 base models & 3 fine-tuned ones with the original Meta checkpoints, plus their corresponding `transformers` models) on the Hub. Among the features and integrations being released, we have:
- [Models on the Hub](https://huggingface.co/meta-llama) with their model cards and license.
- [Transformers integration](https://github.com/huggingface/transformers/releases/tag/v4.31.0)
- Examples to fine-tune the small variants of the model with a single GPU
- Integration with [Text Generation Inference](https://github.com/huggingface/text-generation-inference) for fast and efficient production-ready inference
- Integration with Inference Endpoints
## Table of Contents
- [Why Llama 2?](#why-llama-2)
- [Demo](#demo)
- [Inference](#inference)
- [With Transformers](#using-transformers)
- [With Inference Endpoints](#using-text-generation-inference-and-inference-endpoints)
- [Fine-tuning with PEFT](#fine-tuning-with-peft)
- [How to Prompt Llama 2](#how-to-prompt-llama-2)
- [Additional Resources](#additional-resources)
- [Conclusion](#conclusion)
## Why Llama 2?
The Llama 2 release introduces a family of pretrained and fine-tuned LLMs, ranging in scale from 7B to 70B parameters (7B, 13B, 70B). The pretrained models come with significant improvements over the Llama 1 models, including being trained on 40% more tokens, having a much longer context length (4k tokens 🤯), and using grouped-query attention for fast inference of the 70B model🔥!
However, the most exciting part of this release is the fine-tuned models (Llama 2-Chat), which have been optimized for dialogue applications using [Reinforcement Learning from Human Feedback (RLHF)](https://huggingface.co/blog/rlhf). Across a wide range of helpfulness and safety benchmarks, the Llama 2-Chat models perform better than most open models and achieve comparable performance to ChatGPT according to human evaluations. You can read the paper [here](https://huggingface.co/papers/2307.09288).
_image from [Llama 2: Open Foundation and Fine-Tuned Chat Models](https://scontent-fra3-2.xx.fbcdn.net/v/t39.2365-6/10000000_6495670187160042_4742060979571156424_n.pdf?_nc_cat=104&ccb=1-7&_nc_sid=3c67a6&_nc_ohc=GK8Rh1tm_4IAX8b5yo4&_nc_ht=scontent-fra3-2.xx&oh=00_AfDtg_PRrV6tpy9UmiikeMRuQgk6Rej7bCPOkXZQVmUKAg&oe=64BBD830)_
If you’ve been waiting for an open alternative to closed-source chatbots, Llama 2-Chat is likely your best choice today!
| Model | License | Commercial use? | Pretraining length [tokens] | Leaderboard score |
| --- | --- | --- | --- | --- |
| [Falcon-7B](https://huggingface.co/tiiuae/falcon-7b) | Apache 2.0 | ✅ | 1,500B | 44.17 |
| [MPT-7B](https://huggingface.co/mosaicml/mpt-7b) | Apache 2.0 | ✅ | 1,000B | 47.24 |
| Llama-7B | Llama license | ❌ | 1,000B | 45.65 |
| [Llama-2-7B](https://huggingface.co/meta-llama/Llama-2-7b-hf) | Llama 2 license | ✅ | 2,000B | 50.97 |
| Llama-33B | Llama license | ❌ | 1,500B | - |
| [Llama-2-13B](https://huggingface.co/meta-llama/Llama-2-13b-hf) | Llama 2 license | ✅ | 2,000B | 55.69 |
| [mpt-30B](https://huggingface.co/mosaicml/mpt-30b) | Apache 2.0 | ✅ | 1,000B | 52.77 |
| [Falcon-40B](https://huggingface.co/tiiuae/falcon-40b) | Apache 2.0 | ✅ | 1,000B | 58.07 |
| Llama-65B | Llama license | ❌ | 1,500B | 61.19 |
| [Llama-2-70B](https://huggingface.co/meta-llama/Llama-2-70b-hf) | Llama 2 license | ✅ | 2,000B | 67.87 |
| [Llama-2-70B-chat](https://huggingface.co/meta-llama/Llama-2-70b-chat-hf) | Llama 2 license | ✅ | 2,000B | 62.4 |
*Note: the performance scores shown in the table below have been updated to account for the new methodology introduced in November 2023, which added new benchmarks. More details in [this post](https://huggingface.co/blog/open-llm-leaderboard-drop)*.
## Demo
You can easily try the 13B Llama 2 Model in [this Space](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat) or in the playground embedded below:
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.37.0/gradio.js"> </script>
<gradio-app theme_mode="light" space="huggingface-projects/llama-2-13b-chat"></gradio-app>
To learn more about how this demo works, read on below about how to run inference on Llama 2 models.
## Inference
In this section, we’ll go through different approaches to running inference of the Llama 2 models. Before using these models, make sure you have requested access to one of the models in the official [Meta Llama 2](https://huggingface.co/meta-llama) repositories.
**Note: Make sure to also fill the official Meta form. Users are provided access to the repository once both forms are filled after few hours.**
### Using transformers
With transformers [release 4.31](https://github.com/huggingface/transformers/releases/tag/v4.31.0), one can already use Llama 2 and leverage all the tools within the HF ecosystem, such as:
- training and inference scripts and examples
- safe file format (`safetensors`)
- integrations with tools such as bitsandbytes (4-bit quantization) and PEFT (parameter efficient fine-tuning)
- utilities and helpers to run generation with the model
- mechanisms to export the models to deploy
Make sure to be using the latest `transformers` release and be logged into your Hugging Face account.
```
pip install transformers
huggingface-cli login
```
In the following code snippet, we show how to run inference with transformers. It runs on the free tier of Colab, as long as you select a GPU runtime.
```python
from transformers import AutoTokenizer
import transformers
import torch
model = "meta-llama/Llama-2-7b-chat-hf"
tokenizer = AutoTokenizer.from_pretrained(model)
pipeline = transformers.pipeline(
"text-generation",
model=model,
torch_dtype=torch.float16,
device_map="auto",
)
sequences = pipeline(
'I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?\n',
do_sample=True,
top_k=10,
num_return_sequences=1,
eos_token_id=tokenizer.eos_token_id,
max_length=200,
)
for seq in sequences:
print(f"Result: {seq['generated_text']}")
```
```
Result: I liked "Breaking Bad" and "Band of Brothers". Do you have any recommendations of other shows I might like?
Answer:
Of course! If you enjoyed "Breaking Bad" and "Band of Brothers," here are some other TV shows you might enjoy:
1. "The Sopranos" - This HBO series is a crime drama that explores the life of a New Jersey mob boss, Tony Soprano, as he navigates the criminal underworld and deals with personal and family issues.
2. "The Wire" - This HBO series is a gritty and realistic portrayal of the drug trade in Baltimore, exploring the impact of drugs on individuals, communities, and the criminal justice system.
3. "Mad Men" - Set in the 1960s, this AMC series follows the lives of advertising executives on Madison Avenue, expl
```
And although the model has *only* 4k tokens of context, you can use techniques supported in `transformers` such as rotary position embedding scaling ([tweet](https://twitter.com/joao_gante/status/1679775399172251648)) to push it further!
### Using text-generation-inference and Inference Endpoints
**[Text Generation Inference](https://github.com/huggingface/text-generation-inference)** is a production-ready inference container developed by Hugging Face to enable easy deployment of large language models. It has features such as continuous batching, token streaming, tensor parallelism for fast inference on multiple GPUs, and production-ready logging and tracing.
You can try out Text Generation Inference on your own infrastructure, or you can use Hugging Face's **[Inference Endpoints](https://huggingface.co/inference-endpoints)**. To deploy a Llama 2 model, go to the **[model page](https://huggingface.co/meta-llama/Llama-2-7b-hf)** and click on the **[Deploy -> Inference Endpoints](https://ui.endpoints.huggingface.co/new?repository=meta-llama/Llama-2-7b-hf)** widget.
- For 7B models, we advise you to select "GPU [medium] - 1x Nvidia A10G".
- For 13B models, we advise you to select "GPU [xlarge] - 1x Nvidia A100".
- For 70B models, we advise you to select "GPU [2xlarge] - 2x Nvidia A100" with `bitsandbytes` quantization enabled or "GPU [4xlarge] - 4x Nvidia A100"
_Note: You might need to request a quota upgrade via email to **[[email protected]](mailto:[email protected])** to access A100s_
You can learn more on how to [Deploy LLMs with Hugging Face Inference Endpoints in our blog](https://huggingface.co/blog/inference-endpoints-llm). The [blog](https://huggingface.co/blog/inference-endpoints-llm) includes information about supported hyperparameters and how to stream your response using Python and Javascript.
## Fine-tuning with PEFT
Training LLMs can be technically and computationally challenging. In this section, we look at the tools available in the Hugging Face ecosystem to efficiently train Llama 2 on simple hardware and show how to fine-tune the 7B version of Llama 2 on a single NVIDIA T4 (16GB - Google Colab). You can learn more about it in the [Making LLMs even more accessible blog](https://huggingface.co/blog/4bit-transformers-bitsandbytes).
We created a [script](https://github.com/lvwerra/trl/blob/main/examples/scripts/sft_trainer.py) to instruction-tune Llama 2 using QLoRA and the [`SFTTrainer`](https://huggingface.co/docs/trl/v0.4.7/en/sft_trainer) from [`trl`](https://github.com/lvwerra/trl).
An example command for fine-tuning Llama 2 7B on the `timdettmers/openassistant-guanaco` can be found below. The script can merge the LoRA weights into the model weights and save them as `safetensor` weights by providing the `merge_and_push` argument. This allows us to deploy our fine-tuned model after training using text-generation-inference and inference endpoints.
First pip install `trl` and clone the script:
```bash
pip install trl
git clone https://github.com/lvwerra/trl
```
Then you can run the script:
```bash
python trl/examples/scripts/sft_trainer.py \
--model_name meta-llama/Llama-2-7b-hf \
--dataset_name timdettmers/openassistant-guanaco \
--load_in_4bit \
--use_peft \
--batch_size 4 \
--gradient_accumulation_steps 2
```
## How to Prompt Llama 2
One of the unsung advantages of open-access models is that you have full control over the `system` prompt in chat applications. This is essential to specify the behavior of your chat assistant –and even imbue it with some personality–, but it's unreachable in models served behind APIs.
We're adding this section just a few days after the initial release of Llama 2, as we've had many questions from the community about how to prompt the models and how to change the system prompt. We hope this helps!
The prompt template for the first turn looks like this:
```
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_message }} [/INST]
```
This template follows the model's training procedure, as described in [the Llama 2 paper](https://huggingface.co/papers/2307.09288). We can use any `system_prompt` we want, but it's crucial that the format matches the one used during training.
To spell it out in full clarity, this is what is actually sent to the language model when the user enters some text (`There's a llama in my garden 😱 What should I do?`) in [our 13B chat demo](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat) to initiate a chat:
```b
<s>[INST] <<SYS>>
You are a helpful, respectful and honest assistant. Always answer as helpfully as possible, while being safe. Your answers should not include any harmful, unethical, racist, sexist, toxic, dangerous, or illegal content. Please ensure that your responses are socially unbiased and positive in nature.
If a question does not make any sense, or is not factually coherent, explain why instead of answering something not correct. If you don't know the answer to a question, please don't share false information.
<</SYS>>
There's a llama in my garden 😱 What should I do? [/INST]
```
As you can see, the instructions between the special `<<SYS>>` tokens provide context for the model so it knows how we expect it to respond. This works because exactly the same format was used during training with a wide variety of system prompts intended for different tasks.
As the conversation progresses, _all_ the interactions between the human and the "bot" are appended to the previous prompt, enclosed between `[INST]` delimiters. The template used during multi-turn conversations follows this structure (🎩 h/t [Arthur Zucker](https://huggingface.co/ArthurZ) for some final clarifications):
```b
<s>[INST] <<SYS>>
{{ system_prompt }}
<</SYS>>
{{ user_msg_1 }} [/INST] {{ model_answer_1 }} </s><s>[INST] {{ user_msg_2 }} [/INST]
```
The model is stateless and does not "remember" previous fragments of the conversation, we must always supply it with all the context so the conversation can continue. This is the reason why **context length** is a very important parameter to maximize, as it allows for longer conversations and larger amounts of information to be used.
### Ignore previous instructions
In API-based models, people resort to tricks in an attempt to override the system prompt and change the default model behaviour. As imaginative as these solutions are, this is not necessary in open-access models: anyone can use a different prompt, as long as it follows the format described above. We believe that this will be an important tool for researchers to study the impact of prompts on both desired and unwanted characteristics. For example, when people [are surprised with absurdly cautious generations](https://twitter.com/lauraruis/status/1681612002718887936), you can explore whether maybe [a different prompt would work](https://twitter.com/overlordayn/status/1681631554672513025). (🎩 h/t [Clémentine Fourrier](https://huggingface.co/clefourrier) for the links to this example).
In our [`13B`](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat) and [`7B`](https://huggingface.co/spaces/huggingface-projects/llama-2-7b-chat) demos, you can easily explore this feature by disclosing the "Advanced Options" UI and simply writing your desired instructions. You can also duplicate those demos and use them privately for fun or research!
## Additional Resources
- [Paper Page](https://huggingface.co/papers/2307.09288)
- [Models on the Hub](https://huggingface.co/meta-llama)
- [Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard)
- [Meta Examples and recipes for Llama model](https://github.com/facebookresearch/llama-recipes/tree/main)
- [Chat demo (7B)](https://huggingface.co/spaces/huggingface-projects/llama-2-7b-chat)
- [Chat demo (13B)](https://huggingface.co/spaces/huggingface-projects/llama-2-13b-chat)
- [Chat demo (70B) on TGI](https://huggingface.co/spaces/ysharma/Explore_llamav2_with_TGI)
## Conclusion
We're very excited about Llama 2 being out! In the incoming days, be ready to learn more about ways to run your own fine-tuning, execute the smallest models on-device, and many other exciting updates we're prepating for you!
| 9 |
0 | hf_public_repos | hf_public_repos/candle-cublaslt/LICENSE-APACHE | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 0 |
0 | hf_public_repos | hf_public_repos/candle-cublaslt/README.md | # Candle CublasLt Matmul Layer
CublasLt Matmul operation for the Candle ML framework.
Allows for bias and Relu/Gelu fusing. | 1 |
0 | hf_public_repos/candle-cublaslt | hf_public_repos/candle-cublaslt/src/lib.rs | pub use cudarc::cublaslt::Activation;
use std::ffi::c_int;
use candle::backend::BackendStorage;
use candle::cuda_backend::WrapErr;
use candle::{CpuStorage, Device, Layout, Result, Shape, Storage, Tensor};
use half::{bf16, f16};
use std::sync::Arc;
use cudarc::cublaslt::{CudaBlasLT, Matmul, MatmulConfig};
#[derive(Debug, Clone)]
pub struct CublasLt(Arc<CudaBlasLT>);
impl CublasLt {
pub fn new(device: &Device) -> Result<Self> {
let dev = match &*device {
Device::Cuda(d) => d,
_ => candle::bail!("`device` must be a `cuda` device"),
};
let inner = CudaBlasLT::new(dev.cuda_device()).unwrap();
Ok(Self(Arc::new(inner)))
}
}
pub struct CublasLTMatmul {
pub cublaslt: Arc<CudaBlasLT>,
pub act: Option<Activation>,
pub c: Option<Tensor>,
pub alpha: Option<f32>,
pub beta: Option<f32>,
}
impl CublasLTMatmul {
pub fn fwd_f16(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
bias: Option<&candle::CudaStorage>,
bias_l: Option<&Layout>,
) -> Result<(candle::CudaStorage, Shape)> {
let dev = a.device();
// Assume TN
let (m, k) = a_l.shape().dims2()?;
let (n, b_1) = b_l.shape().dims2()?;
if b_1 != k {
candle::bail!("This layer only supports TN layout");
}
let lda = k;
let ldb = k;
let ldc = m;
let out_shape = Shape::from((n, m));
let a = a.as_cuda_slice::<f16>()?.slice(a_l.start_offset()..);
let b = b.as_cuda_slice::<f16>()?.slice(b_l.start_offset()..);
let bias = if let (Some(bias), Some(bias_l)) = (bias, bias_l) {
if bias_l.shape().dims1()? != m {
candle::bail!("Bias does not have the correct shape");
}
Some(bias.as_cuda_slice::<f16>()?.slice(bias_l.start_offset()..))
} else {
None
};
let mut out = if let Some(c) = &self.c {
let (c, c_l) = c.storage_and_layout();
let c = match &*c {
Storage::Cuda(storage) => storage.as_cuda_slice::<f16>()?,
_ => candle::bail!("`c` must be a cuda tensor"),
};
match c_l.contiguous_offsets() {
Some((o1, o2)) => {
if o1 != 0 {
candle::bail!("`c` start offset must be 0");
}
if o2 != out_shape.elem_count() {
candle::bail!("`c` end offset must be {}", out_shape.elem_count())
}
}
None => candle::bail!("`c` has to be contiguous"),
};
if c_l.shape().dims2()? != (n, m) {
candle::bail!("`c` does not have the correct shape");
}
c.clone()
} else {
// Allocate out tensor
unsafe { dev.alloc::<f16>(out_shape.elem_count()).w()? }
};
let config = MatmulConfig {
transa: true,
transb: false,
m: m as u64,
n: n as u64,
k: k as u64,
alpha: self.alpha.unwrap_or(1.0),
lda: lda as i64,
ldb: ldb as i64,
beta: self.beta.unwrap_or(0.0),
ldc: ldc as i64,
stride_a: None,
stride_b: None,
stride_c: None,
stride_bias: None,
batch_size: None,
};
unsafe {
self.cublaslt
.matmul(config, &a, &b, &mut out, bias.as_ref(), self.act.as_ref())
.map_err(|e| candle::Error::Cuda(Box::new(e)))?;
}
let out = candle::CudaStorage::wrap_cuda_slice(out, dev.clone());
Ok((out, out_shape))
}
pub fn fwd_bf16(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
bias: Option<&candle::CudaStorage>,
bias_l: Option<&Layout>,
) -> Result<(candle::CudaStorage, Shape)> {
let dev = a.device();
// Assume TN
let (m, k) = a_l.shape().dims2()?;
let (n, b_1) = b_l.shape().dims2()?;
if b_1 != k {
candle::bail!("This layer only supports TN layout");
}
let lda = k;
let ldb = k;
let ldc = m;
let out_shape = Shape::from((n, m));
let a = a.as_cuda_slice::<bf16>()?.slice(a_l.start_offset()..);
let b = b.as_cuda_slice::<bf16>()?.slice(b_l.start_offset()..);
let bias = if let (Some(bias), Some(bias_l)) = (bias, bias_l) {
if bias_l.shape().dims1()? != m {
candle::bail!("Bias does not have the correct shape");
}
Some(bias.as_cuda_slice::<bf16>()?.slice(bias_l.start_offset()..))
} else {
None
};
let mut out = if let Some(c) = &self.c {
let (c, c_l) = c.storage_and_layout();
let c = match &*c {
Storage::Cuda(storage) => storage.as_cuda_slice::<bf16>()?,
_ => candle::bail!("`c` must be a cuda tensor"),
};
match c_l.contiguous_offsets() {
Some((o1, o2)) => {
if o1 != 0 {
candle::bail!("`c` start offset must be 0");
}
if o2 != out_shape.elem_count() {
candle::bail!("`c` end offset must be {}", out_shape.elem_count())
}
}
None => candle::bail!("`c` has to be contiguous"),
};
if c_l.shape().dims2()? != (n, m) {
candle::bail!("`c` does not have the correct shape");
}
c.clone()
} else {
// Allocate out tensor
unsafe { dev.alloc::<bf16>(out_shape.elem_count()).w()? }
};
let config = MatmulConfig {
transa: true,
transb: false,
m: m as u64,
n: n as u64,
k: k as u64,
alpha: self.alpha.unwrap_or(1.0),
lda: lda as i64,
ldb: ldb as i64,
beta: self.beta.unwrap_or(0.0),
ldc: ldc as i64,
stride_a: None,
stride_b: None,
stride_c: None,
stride_bias: None,
batch_size: None,
};
unsafe {
self.cublaslt
.matmul(config, &a, &b, &mut out, bias.as_ref(), self.act.as_ref())
.map_err(|e| candle::Error::Cuda(Box::new(e)))?;
}
let out = candle::CudaStorage::wrap_cuda_slice(out, dev.clone());
Ok((out, out_shape))
}
pub fn fwd_f32(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
bias: Option<&candle::CudaStorage>,
bias_l: Option<&Layout>,
) -> Result<(candle::CudaStorage, Shape)> {
let dev = a.device();
// Assume TN
let (m, k) = a_l.shape().dims2()?;
let (n, b_1) = b_l.shape().dims2()?;
if b_1 != k {
candle::bail!("This layer only supports TN layout");
}
let lda = k;
let ldb = k;
let ldc = m;
let out_shape = Shape::from((n, m));
let a = a.as_cuda_slice::<f32>()?.slice(a_l.start_offset()..);
let b = b.as_cuda_slice::<f32>()?.slice(b_l.start_offset()..);
let bias = if let (Some(bias), Some(bias_l)) = (bias, bias_l) {
if bias_l.shape().dims1()? != m {
candle::bail!("Bias does not have the correct shape");
}
Some(bias.as_cuda_slice::<f32>()?.slice(bias_l.start_offset()..))
} else {
None
};
let mut out = if let Some(c) = &self.c {
let (c, c_l) = c.storage_and_layout();
let c = match &*c {
Storage::Cuda(storage) => storage.as_cuda_slice::<f32>()?,
_ => candle::bail!("`c` must be a cuda tensor"),
};
match c_l.contiguous_offsets() {
Some((o1, o2)) => {
if o1 != 0 {
candle::bail!("`c` start offset must be 0");
}
if o2 != out_shape.elem_count() {
candle::bail!("`c` end offset must be {}", out_shape.elem_count())
}
}
None => candle::bail!("`c` has to be contiguous"),
};
if c_l.shape().dims2()? != (n, m) {
candle::bail!("`c` does not have the correct shape");
}
c.clone()
} else {
// Allocate out tensor
unsafe { dev.alloc::<f32>(out_shape.elem_count()).w()? }
};
let config = MatmulConfig {
transa: true,
transb: false,
m: m as u64,
n: n as u64,
k: k as u64,
alpha: self.alpha.unwrap_or(1.0),
lda: lda as i64,
ldb: ldb as i64,
beta: self.beta.unwrap_or(0.0),
ldc: ldc as i64,
stride_a: None,
stride_b: None,
stride_c: None,
stride_bias: None,
batch_size: None,
};
unsafe {
self.cublaslt
.matmul(config, &a, &b, &mut out, bias.as_ref(), self.act.as_ref())
.map_err(|e| candle::Error::Cuda(Box::new(e)))?;
}
let out = candle::CudaStorage::wrap_cuda_slice(out, dev.clone());
Ok((out, out_shape))
}
}
impl candle::CustomOp2 for CublasLTMatmul {
fn name(&self) -> &'static str {
"cublaslt-matmul"
}
fn cpu_fwd(
&self,
_: &CpuStorage,
_: &Layout,
_: &CpuStorage,
_: &Layout,
) -> Result<(CpuStorage, Shape)> {
candle::bail!("no cpu support for cublaslt-matmul")
}
fn cuda_fwd(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
) -> Result<(candle::CudaStorage, Shape)> {
match a.dtype() {
candle::DType::F16 => self.fwd_f16(a, a_l, b, b_l, None, None),
candle::DType::BF16 => self.fwd_bf16(a, a_l, b, b_l, None, None),
candle::DType::F32 => self.fwd_f32(a, a_l, b, b_l, None, None),
dt => candle::bail!("cublaslt-matmul is only supported for f16/bf16/f32 ({dt:?})"),
}
}
}
impl candle::CustomOp3 for CublasLTMatmul {
fn name(&self) -> &'static str {
"cublaslt-matmul-add"
}
fn cpu_fwd(
&self,
_: &CpuStorage,
_: &Layout,
_: &CpuStorage,
_: &Layout,
_: &CpuStorage,
_: &Layout,
) -> Result<(CpuStorage, Shape)> {
candle::bail!("no cpu support for cublaslt-matmul")
}
fn cuda_fwd(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
bias: &candle::CudaStorage,
bias_l: &Layout,
) -> Result<(candle::CudaStorage, Shape)> {
match a.dtype() {
candle::DType::F16 => self.fwd_f16(a, a_l, b, b_l, Some(bias), Some(bias_l)),
candle::DType::BF16 => self.fwd_bf16(a, a_l, b, b_l, Some(bias), Some(bias_l)),
candle::DType::F32 => self.fwd_f32(a, a_l, b, b_l, Some(bias), Some(bias_l)),
dt => candle::bail!("cublaslt-matmul is only supported for f16/bf16/f32 ({dt:?})"),
}
}
}
/// Fused matmul + add + Relu/Gelu activation using CublasLt
///
/// # Arguments
///
/// * `a` - Input tensor of size MxK
/// * `b` - Input tensor of size NxK
/// * `out` - Optional Output tensor of size NxK.
/// If set and beta != 0, will be added to the end result of A*B before `act`
/// * `alpha` - Optional scaling factor for A*B
/// * `beta` - Optional scaling factor for C
/// * `bias` - Optional bias tensor of size M
/// * `act` - Optional Gelu or Relu activation. If set, will be added to the end result
/// * `cublaslt` - CublasLt handle
///
/// The resulting tensor is of shape NxM
pub fn fused_matmul(
a: &Tensor,
b: &Tensor,
out: Option<&Tensor>,
alpha: Option<f32>,
beta: Option<f32>,
bias: Option<&Tensor>,
act: Option<Activation>,
cublaslt: CublasLt,
) -> Result<Tensor> {
let op = CublasLTMatmul {
act,
cublaslt: cublaslt.0,
c: out.cloned(),
alpha,
beta,
};
if let Some(bias) = bias {
a.apply_op3(&b, &bias, op)
} else {
a.apply_op2(&b, op)
}
}
pub struct CublasLTBatchMatmul {
pub cublaslt: Arc<CudaBlasLT>,
pub act: Option<Activation>,
pub c: Option<Tensor>,
pub alpha: Option<f32>,
pub beta: Option<f32>,
}
impl CublasLTBatchMatmul {
pub fn fwd_f16(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
bias: Option<&candle::CudaStorage>,
bias_l: Option<&Layout>,
) -> Result<(candle::CudaStorage, Shape)> {
let dev = a.device();
// Assume TN
let (batch_size, m, k) = a_l.shape().dims3()?;
let (b_0, n, b_2) = b_l.shape().dims3()?;
if b_2 != k {
candle::bail!("This layer only supports TN layout");
}
if b_0 != batch_size {
candle::bail!("`b` must have the same batch size as `a`")
}
let lda = k;
let ldb = k;
let ldc = m;
let out_shape = Shape::from((batch_size, n, m));
let a = a.as_cuda_slice::<f16>()?.slice(a_l.start_offset()..);
let b = b.as_cuda_slice::<f16>()?.slice(b_l.start_offset()..);
let bias = if let (Some(bias), Some(bias_l)) = (bias, bias_l) {
if bias_l.shape().dims1()? != m {
candle::bail!("Bias does not have the correct shape");
}
Some(bias.as_cuda_slice::<f16>()?.slice(bias_l.start_offset()..))
} else {
None
};
let (mut out, stride_c) = if let Some(c) = &self.c {
let (c, c_l) = c.storage_and_layout();
let c = match &*c {
Storage::Cuda(storage) => storage.as_cuda_slice::<f16>()?,
_ => candle::bail!("`c` must be a cuda tensor"),
};
match c_l.contiguous_offsets() {
Some((o1, o2)) => {
if o1 != 0 {
candle::bail!("`c` start offset must be 0");
}
if o2 != out_shape.elem_count() {
candle::bail!("`c` end offset must be {}", out_shape.elem_count())
}
}
None => candle::bail!("`c` has to be contiguous"),
};
if c_l.shape().dims3()? != (batch_size, n, m) {
candle::bail!("`c` does not have the correct shape");
}
// Set beta to 0.0 if it is not set
(c.clone(), c_l.stride()[0])
} else {
// Allocate out tensor
(
unsafe { dev.alloc::<f16>(out_shape.elem_count()).w()? },
(n * m),
)
};
let config = MatmulConfig {
transa: true,
transb: false,
m: m as u64,
n: n as u64,
k: k as u64,
alpha: self.alpha.unwrap_or(1.0),
lda: lda as i64,
ldb: ldb as i64,
beta: self.beta.unwrap_or(0.0),
ldc: ldc as i64,
stride_a: Some(a_l.stride()[0] as i64),
stride_b: Some(b_l.stride()[0] as i64),
stride_c: Some(stride_c as i64),
stride_bias: None,
batch_size: Some(batch_size as c_int),
};
unsafe {
self.cublaslt
.matmul(config, &a, &b, &mut out, bias.as_ref(), self.act.as_ref())
.map_err(|e| candle::Error::Cuda(Box::new(e)))?;
}
let out = candle::CudaStorage::wrap_cuda_slice(out, dev.clone());
Ok((out, out_shape))
}
pub fn fwd_bf16(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
bias: Option<&candle::CudaStorage>,
bias_l: Option<&Layout>,
) -> Result<(candle::CudaStorage, Shape)> {
let dev = a.device();
// Assume TN
let (batch_size, m, k) = a_l.shape().dims3()?;
let (b_0, n, b_2) = b_l.shape().dims3()?;
if b_2 != k {
candle::bail!("This layer only supports TN layout");
}
if b_0 != batch_size {
candle::bail!("`b` must have the same batch size as `a`")
}
let lda = k;
let ldb = k;
let ldc = m;
let out_shape = Shape::from((batch_size, n, m));
let a = a.as_cuda_slice::<bf16>()?.slice(a_l.start_offset()..);
let b = b.as_cuda_slice::<bf16>()?.slice(b_l.start_offset()..);
let bias = if let (Some(bias), Some(bias_l)) = (bias, bias_l) {
if bias_l.shape().dims1()? != m {
candle::bail!("Bias does not have the correct shape");
}
Some(bias.as_cuda_slice::<bf16>()?.slice(bias_l.start_offset()..))
} else {
None
};
let (mut out, stride_c) = if let Some(c) = &self.c {
let (c, c_l) = c.storage_and_layout();
let c = match &*c {
Storage::Cuda(storage) => storage.as_cuda_slice::<bf16>()?,
_ => candle::bail!("`c` must be a cuda tensor"),
};
match c_l.contiguous_offsets() {
Some((o1, o2)) => {
if o1 != 0 {
candle::bail!("`c` start offset must be 0");
}
if o2 != out_shape.elem_count() {
candle::bail!("`c` end offset must be {}", out_shape.elem_count())
}
}
None => candle::bail!("`c` has to be contiguous"),
};
if c_l.shape().dims3()? != (batch_size, n, m) {
candle::bail!("`c` does not have the correct shape");
}
// Set beta to 0.0 if it is not set
(c.clone(), c_l.stride()[0])
} else {
// Allocate out tensor
(
unsafe { dev.alloc::<bf16>(out_shape.elem_count()).w()? },
(n * m),
)
};
let config = MatmulConfig {
transa: true,
transb: false,
m: m as u64,
n: n as u64,
k: k as u64,
alpha: self.alpha.unwrap_or(1.0),
lda: lda as i64,
ldb: ldb as i64,
beta: self.beta.unwrap_or(0.0),
ldc: ldc as i64,
stride_a: Some(a_l.stride()[0] as i64),
stride_b: Some(b_l.stride()[0] as i64),
stride_c: Some(stride_c as i64),
stride_bias: None,
batch_size: Some(batch_size as c_int),
};
unsafe {
self.cublaslt
.matmul(config, &a, &b, &mut out, bias.as_ref(), self.act.as_ref())
.map_err(|e| candle::Error::Cuda(Box::new(e)))?;
}
let out = candle::CudaStorage::wrap_cuda_slice(out, dev.clone());
Ok((out, out_shape))
}
pub fn fwd_f32(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
bias: Option<&candle::CudaStorage>,
bias_l: Option<&Layout>,
) -> Result<(candle::CudaStorage, Shape)> {
let dev = a.device();
// Assume TN
let (batch_size, m, k) = a_l.shape().dims3()?;
let (b_0, n, b_2) = b_l.shape().dims3()?;
if b_2 != k {
candle::bail!("This layer only supports TN layout");
}
if b_0 != batch_size {
candle::bail!("`b` must have the same batch size as `a`")
}
let lda = k;
let ldb = k;
let ldc = m;
let out_shape = Shape::from((batch_size, n, m));
let a = a.as_cuda_slice::<f32>()?.slice(a_l.start_offset()..);
let b = b.as_cuda_slice::<f32>()?.slice(b_l.start_offset()..);
let bias = if let (Some(bias), Some(bias_l)) = (bias, bias_l) {
if bias_l.shape().dims1()? != m {
candle::bail!("Bias does not have the correct shape");
}
Some(bias.as_cuda_slice::<f32>()?.slice(bias_l.start_offset()..))
} else {
None
};
let (mut out, stride_c) = if let Some(c) = &self.c {
let (c, c_l) = c.storage_and_layout();
let c = match &*c {
Storage::Cuda(storage) => storage.as_cuda_slice::<f32>()?,
_ => candle::bail!("`c` must be a cuda tensor"),
};
match c_l.contiguous_offsets() {
Some((o1, o2)) => {
if o1 != 0 {
candle::bail!("`c` start offset must be 0");
}
if o2 != out_shape.elem_count() {
candle::bail!("`c` end offset must be {}", out_shape.elem_count())
}
}
None => candle::bail!("`c` has to be contiguous"),
};
if c_l.shape().dims3()? != (batch_size, n, m) {
candle::bail!("`c` does not have the correct shape");
}
// Set beta to 0.0 if it is not set
(c.clone(), c_l.stride()[0])
} else {
// Allocate out tensor
(
unsafe { dev.alloc::<f32>(out_shape.elem_count()).w()? },
(n * m),
)
};
let config = MatmulConfig {
transa: true,
transb: false,
m: m as u64,
n: n as u64,
k: k as u64,
alpha: self.alpha.unwrap_or(1.0),
lda: lda as i64,
ldb: ldb as i64,
beta: self.beta.unwrap_or(0.0),
ldc: ldc as i64,
stride_a: Some(a_l.stride()[0] as i64),
stride_b: Some(b_l.stride()[0] as i64),
stride_c: Some(stride_c as i64),
stride_bias: None,
batch_size: Some(batch_size as c_int),
};
unsafe {
self.cublaslt
.matmul(config, &a, &b, &mut out, bias.as_ref(), self.act.as_ref())
.map_err(|e| candle::Error::Cuda(Box::new(e)))?;
}
let out = candle::CudaStorage::wrap_cuda_slice(out, dev.clone());
Ok((out, out_shape))
}
}
impl candle::CustomOp2 for CublasLTBatchMatmul {
fn name(&self) -> &'static str {
"cublaslt-batch-matmul"
}
fn cpu_fwd(
&self,
_: &CpuStorage,
_: &Layout,
_: &CpuStorage,
_: &Layout,
) -> Result<(CpuStorage, Shape)> {
candle::bail!("no cpu support for cublaslt-batch-matmul")
}
fn cuda_fwd(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
) -> Result<(candle::CudaStorage, Shape)> {
match a.dtype() {
candle::DType::F16 => self.fwd_f16(a, a_l, b, b_l, None, None),
candle::DType::BF16 => self.fwd_bf16(a, a_l, b, b_l, None, None),
candle::DType::F32 => self.fwd_f32(a, a_l, b, b_l, None, None),
dt => {
candle::bail!("cublaslt-batch-matmul is only supported for f16/bf16/f32 ({dt:?})")
}
}
}
}
impl candle::CustomOp3 for CublasLTBatchMatmul {
fn name(&self) -> &'static str {
"cublaslt-batch-matmul-add"
}
fn cpu_fwd(
&self,
_: &CpuStorage,
_: &Layout,
_: &CpuStorage,
_: &Layout,
_: &CpuStorage,
_: &Layout,
) -> Result<(CpuStorage, Shape)> {
candle::bail!("no cpu support for cublaslt-batch-matmul-add")
}
fn cuda_fwd(
&self,
a: &candle::CudaStorage,
a_l: &Layout,
b: &candle::CudaStorage,
b_l: &Layout,
bias: &candle::CudaStorage,
bias_l: &Layout,
) -> Result<(candle::CudaStorage, Shape)> {
match a.dtype() {
candle::DType::F16 => self.fwd_f16(a, a_l, b, b_l, Some(bias), Some(bias_l)),
candle::DType::BF16 => self.fwd_bf16(a, a_l, b, b_l, Some(bias), Some(bias_l)),
candle::DType::F32 => self.fwd_f32(a, a_l, b, b_l, Some(bias), Some(bias_l)),
dt => candle::bail!(
"cublaslt-batch-matmul-add is only supported for f16/bf16/f32 ({dt:?})"
),
}
}
}
/// Fused batch matmul + add + Relu/Gelu activation using CublasLt
///
/// # Arguments
///
/// * `a` - Input tensor of size BxMxK
/// * `b` - Input tensor of size BxNxK
/// * `out` - Optional Output tensor of size BxNxK.
/// If set and beta != 0, will be added to the end result of A*B before `act`
/// * `alpha` - Optional scaling factor for A*B
/// * `beta` - Optional scaling factor for C
/// * `bias` - Optional bias tensor of size M
/// * `act` - Optional Gelu or Relu activation. If set, will be added to the end result
/// * `cublaslt` - CublasLt handle
///
/// The resulting tensor is of shape NxM
pub fn fused_batch_matmul(
a: &Tensor,
b: &Tensor,
out: Option<&Tensor>,
alpha: Option<f32>,
beta: Option<f32>,
bias: Option<&Tensor>,
act: Option<Activation>,
cublaslt: CublasLt,
) -> Result<Tensor> {
let op = CublasLTBatchMatmul {
act,
cublaslt: cublaslt.0,
c: out.cloned(),
alpha,
beta,
};
if let Some(bias) = bias {
a.apply_op3(&b, &bias, op)
} else {
a.apply_op2(&b, op)
}
}
#[cfg(test)]
mod tests {
use super::*;
use candle::{DType, Device};
fn to_vec2_round(t: Tensor, digits: i32) -> Result<Vec<Vec<f32>>> {
let b = 10f32.powi(digits);
let t = t.to_vec2::<f32>()?;
let t = t
.iter()
.map(|t| t.iter().map(|t| f32::round(t * b) / b).collect())
.collect();
Ok(t)
}
fn to_vec3_round(t: Tensor, digits: i32) -> Result<Vec<Vec<Vec<f32>>>> {
let b = 10f32.powi(digits);
let t = t.to_vec3::<f32>()?;
let t = t
.iter()
.map(|t| {
t.iter()
.map(|t| t.iter().map(|t| f32::round(t * b) / b).collect())
.collect()
})
.collect();
Ok(t)
}
#[test]
fn test_fused_matmul() -> Result<()> {
let device = Device::new_cuda(0)?;
let a = Tensor::randn(0., 1., (8, 4), &device)?.to_dtype(DType::F32)?;
let b = Tensor::randn(0., 1., (2, 4), &device)?.to_dtype(DType::F32)?;
let bias = Tensor::randn(0., 1., 8, &device)?.to_dtype(DType::F32)?;
let cublaslt = CublasLt::new(&device)?;
let res = fused_matmul(&a, &b, None, None, None, Some(&bias), None, cublaslt)?;
let expected = (b.matmul(&a.t()?)? + bias.broadcast_left(2)?)?;
assert_eq!(
to_vec2_round(res.to_dtype(DType::F32)?, 4)?,
to_vec2_round(expected.to_dtype(DType::F32)?, 4)?
);
Ok(())
}
#[test]
fn test_fused_batch_matmul() -> Result<()> {
let device = Device::new_cuda(0)?;
let a = Tensor::randn(0., 1., (3, 8, 4), &device)?.to_dtype(DType::F32)?;
let b = Tensor::randn(0., 1., (3, 2, 4), &device)?.to_dtype(DType::F32)?;
let c = Tensor::randn(0., 1., (3, 2, 8), &device)?.to_dtype(DType::F32)?;
let bias = Tensor::randn(0., 1., 8, &device)?.to_dtype(DType::F32)?;
let cublaslt = CublasLt::new(&device)?;
let res = fused_batch_matmul(
&a,
&b,
Some(&c),
None,
Some(1.0),
Some(&bias),
None,
cublaslt,
)?;
let expected = (b.matmul(&a.t()?)?.add(&c)? + bias.broadcast_left((3, 2))?)?;
assert_eq!(
to_vec3_round(res.to_dtype(DType::F32)?, 4)?,
to_vec3_round(expected.to_dtype(DType::F32)?, 4)?
);
Ok(())
}
}
| 2 |
0 | hf_public_repos | hf_public_repos/awesome-huggingface/awesome_collections.md | # Awesome Hugging Face Collections
<p align="center"><em>🎃 Note as part of <a href="https://hacktoberfest.com">Hacktoberfest 2023</a>, we're looking for contributions to this page! If you have a collection you'd like to add, please submit a PR! See this issue for more context! #TODO add issue link 🎃</em></p>
[Hugging Face Collections](https://huggingface.co/docs/hub/collections) provide a way of curating repositories from the Hub (models, datasets, Spaces and papers) on a dedicated page. This page collects some examples of awesome collections!
## Awesome Hand Curated Hugging Face Collections
- [Historic Multilingual Language Models](https://huggingface.co/collections/stefan-it/%F0%9F%93%9A-historic-multilingual-language-models-64f9c4f8383bbd73dddd2240) (_by [stefan-it](https://huggingface.co/stefan-it)_) - a collection of Historic Multilingual Language Models.
- [Protein Design & Protein Structure Prediction](https://huggingface.co/collections/simonduerr/protein-design---protein-structure-prediction-64f9c6fda9295717466dbe8f) (_by [simonduerr](https://huggingface.co/simonduerr)_) - Interactive Demos that can be used for protein structure prediction using AlphaFold2 or RoseTTAfold2, prediction of small metal ions.
- [👐🏻Accessible🧱Gradio🦹🏻🦸🏻♀️Themes](https://huggingface.co/collections/MultiTransformer/accessiblegradiothemes-65144019e31c0e2e3df7c411) (_by [MultiTransformer](https://huggingface.co/MultiTransformer)_) - Accessible Gradio Themes That Are Fun & Exciting , open organisation : join us today!
- [🛺🤖Autogen❤️Gradio🤗Huggingface](https://huggingface.co/collections/MultiTransformer/accessiblegradiothemes-65144019e31c0e2e3df7c411) (_by [MultiTransformer](https://huggingface.co/MultiTransformer)_) - Microsoft's Autogen Library Tutorials from the community to the community !
## Awesome Automatically Generated Hugging Face Collections
- [smol models](https://huggingface.co/collections/librarian-bots/smol-models-652032729004117947dc4f27) (_by [librarian-bots](https://huggingface.co/librarian-bots)_) - a collection of models on the Hub which are smaller than 50MB created via [this notebook](https://huggingface.co/spaces/librarian-bots/tutorials/blob/main/smol_models_collection.ipynb)
| 3 |
0 | hf_public_repos | hf_public_repos/awesome-huggingface/LICENSE | Apache License
Version 2.0, January 2004
http://www.apache.org/licenses/
TERMS AND CONDITIONS FOR USE, REPRODUCTION, AND DISTRIBUTION
1. Definitions.
"License" shall mean the terms and conditions for use, reproduction,
and distribution as defined by Sections 1 through 9 of this document.
"Licensor" shall mean the copyright owner or entity authorized by
the copyright owner that is granting the License.
"Legal Entity" shall mean the union of the acting entity and all
other entities that control, are controlled by, or are under common
control with that entity. For the purposes of this definition,
"control" means (i) the power, direct or indirect, to cause the
direction or management of such entity, whether by contract or
otherwise, or (ii) ownership of fifty percent (50%) or more of the
outstanding shares, or (iii) beneficial ownership of such entity.
"You" (or "Your") shall mean an individual or Legal Entity
exercising permissions granted by this License.
"Source" form shall mean the preferred form for making modifications,
including but not limited to software source code, documentation
source, and configuration files.
"Object" form shall mean any form resulting from mechanical
transformation or translation of a Source form, including but
not limited to compiled object code, generated documentation,
and conversions to other media types.
"Work" shall mean the work of authorship, whether in Source or
Object form, made available under the License, as indicated by a
copyright notice that is included in or attached to the work
(an example is provided in the Appendix below).
"Derivative Works" shall mean any work, whether in Source or Object
form, that is based on (or derived from) the Work and for which the
editorial revisions, annotations, elaborations, or other modifications
represent, as a whole, an original work of authorship. For the purposes
of this License, Derivative Works shall not include works that remain
separable from, or merely link (or bind by name) to the interfaces of,
the Work and Derivative Works thereof.
"Contribution" shall mean any work of authorship, including
the original version of the Work and any modifications or additions
to that Work or Derivative Works thereof, that is intentionally
submitted to Licensor for inclusion in the Work by the copyright owner
or by an individual or Legal Entity authorized to submit on behalf of
the copyright owner. For the purposes of this definition, "submitted"
means any form of electronic, verbal, or written communication sent
to the Licensor or its representatives, including but not limited to
communication on electronic mailing lists, source code control systems,
and issue tracking systems that are managed by, or on behalf of, the
Licensor for the purpose of discussing and improving the Work, but
excluding communication that is conspicuously marked or otherwise
designated in writing by the copyright owner as "Not a Contribution."
"Contributor" shall mean Licensor and any individual or Legal Entity
on behalf of whom a Contribution has been received by Licensor and
subsequently incorporated within the Work.
2. Grant of Copyright License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
copyright license to reproduce, prepare Derivative Works of,
publicly display, publicly perform, sublicense, and distribute the
Work and such Derivative Works in Source or Object form.
3. Grant of Patent License. Subject to the terms and conditions of
this License, each Contributor hereby grants to You a perpetual,
worldwide, non-exclusive, no-charge, royalty-free, irrevocable
(except as stated in this section) patent license to make, have made,
use, offer to sell, sell, import, and otherwise transfer the Work,
where such license applies only to those patent claims licensable
by such Contributor that are necessarily infringed by their
Contribution(s) alone or by combination of their Contribution(s)
with the Work to which such Contribution(s) was submitted. If You
institute patent litigation against any entity (including a
cross-claim or counterclaim in a lawsuit) alleging that the Work
or a Contribution incorporated within the Work constitutes direct
or contributory patent infringement, then any patent licenses
granted to You under this License for that Work shall terminate
as of the date such litigation is filed.
4. Redistribution. You may reproduce and distribute copies of the
Work or Derivative Works thereof in any medium, with or without
modifications, and in Source or Object form, provided that You
meet the following conditions:
(a) You must give any other recipients of the Work or
Derivative Works a copy of this License; and
(b) You must cause any modified files to carry prominent notices
stating that You changed the files; and
(c) You must retain, in the Source form of any Derivative Works
that You distribute, all copyright, patent, trademark, and
attribution notices from the Source form of the Work,
excluding those notices that do not pertain to any part of
the Derivative Works; and
(d) If the Work includes a "NOTICE" text file as part of its
distribution, then any Derivative Works that You distribute must
include a readable copy of the attribution notices contained
within such NOTICE file, excluding those notices that do not
pertain to any part of the Derivative Works, in at least one
of the following places: within a NOTICE text file distributed
as part of the Derivative Works; within the Source form or
documentation, if provided along with the Derivative Works; or,
within a display generated by the Derivative Works, if and
wherever such third-party notices normally appear. The contents
of the NOTICE file are for informational purposes only and
do not modify the License. You may add Your own attribution
notices within Derivative Works that You distribute, alongside
or as an addendum to the NOTICE text from the Work, provided
that such additional attribution notices cannot be construed
as modifying the License.
You may add Your own copyright statement to Your modifications and
may provide additional or different license terms and conditions
for use, reproduction, or distribution of Your modifications, or
for any such Derivative Works as a whole, provided Your use,
reproduction, and distribution of the Work otherwise complies with
the conditions stated in this License.
5. Submission of Contributions. Unless You explicitly state otherwise,
any Contribution intentionally submitted for inclusion in the Work
by You to the Licensor shall be under the terms and conditions of
this License, without any additional terms or conditions.
Notwithstanding the above, nothing herein shall supersede or modify
the terms of any separate license agreement you may have executed
with Licensor regarding such Contributions.
6. Trademarks. This License does not grant permission to use the trade
names, trademarks, service marks, or product names of the Licensor,
except as required for reasonable and customary use in describing the
origin of the Work and reproducing the content of the NOTICE file.
7. Disclaimer of Warranty. Unless required by applicable law or
agreed to in writing, Licensor provides the Work (and each
Contributor provides its Contributions) on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or
implied, including, without limitation, any warranties or conditions
of TITLE, NON-INFRINGEMENT, MERCHANTABILITY, or FITNESS FOR A
PARTICULAR PURPOSE. You are solely responsible for determining the
appropriateness of using or redistributing the Work and assume any
risks associated with Your exercise of permissions under this License.
8. Limitation of Liability. In no event and under no legal theory,
whether in tort (including negligence), contract, or otherwise,
unless required by applicable law (such as deliberate and grossly
negligent acts) or agreed to in writing, shall any Contributor be
liable to You for damages, including any direct, indirect, special,
incidental, or consequential damages of any character arising as a
result of this License or out of the use or inability to use the
Work (including but not limited to damages for loss of goodwill,
work stoppage, computer failure or malfunction, or any and all
other commercial damages or losses), even if such Contributor
has been advised of the possibility of such damages.
9. Accepting Warranty or Additional Liability. While redistributing
the Work or Derivative Works thereof, You may choose to offer,
and charge a fee for, acceptance of support, warranty, indemnity,
or other liability obligations and/or rights consistent with this
License. However, in accepting such obligations, You may act only
on Your own behalf and on Your sole responsibility, not on behalf
of any other Contributor, and only if You agree to indemnify,
defend, and hold each Contributor harmless for any liability
incurred by, or claims asserted against, such Contributor by reason
of your accepting any such warranty or additional liability.
END OF TERMS AND CONDITIONS
APPENDIX: How to apply the Apache License to your work.
To apply the Apache License to your work, attach the following
boilerplate notice, with the fields enclosed by brackets "[]"
replaced with your own identifying information. (Don't include
the brackets!) The text should be enclosed in the appropriate
comment syntax for the file format. We also recommend that a
file or class name and description of purpose be included on the
same "printed page" as the copyright notice for easier
identification within third-party archives.
Copyright [yyyy] [name of copyright owner]
Licensed under the Apache License, Version 2.0 (the "License");
you may not use this file except in compliance with the License.
You may obtain a copy of the License at
http://www.apache.org/licenses/LICENSE-2.0
Unless required by applicable law or agreed to in writing, software
distributed under the License is distributed on an "AS IS" BASIS,
WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied.
See the License for the specific language governing permissions and
limitations under the License.
| 4 |
0 | hf_public_repos | hf_public_repos/awesome-huggingface/CONTRIBUTING.md | <p align="center">
<img src="https://raw.githubusercontent.com/huggingface/awesome-huggingface/main/logo.svg?token=AFLYUK4HQBJT734TLKYP2R3A2CKW2" width="100px">
</p>
# Contributing
## Selection Criteria
To add a wonderful repo to this list of HF eco-system, please make sure the repo-to-add satisfies the following conditions:
- It should be built on, or an extension of 🤗 libraries (transformers, datasets, hub, etc.)
- It should have >100 stars, *or* have been published at a top-tier conference (ACL, EMNLP, NAACL, ICML, NeurIPS, ICLR, etc.) If you are very confident about the quality of the repo, there can be exceptions.
## How to Contribute
Thanks for your interest in contributing to `awesome-huggingface`! If you want to add any repo to the list, please follow the two-step guidance:
1. If there is already a category that fits the repo-to-add, you can simply make a **pull request**.
2. If there is no category that can fit the repo-to-add, please open an **issue** with the URL to the repo and several lines describing what the repo does.
We will process the PR and issues ASAP. Thanks again for your contribution!
| 5 |
0 | hf_public_repos | hf_public_repos/awesome-huggingface/logo.svg | <?xml version="1.0" encoding="UTF-8" standalone="no"?>
<!DOCTYPE svg PUBLIC "-//W3C//DTD SVG 1.1//EN" "http://www.w3.org/Graphics/SVG/1.1/DTD/svg11.dtd">
<svg xmlns:xl="http://www.w3.org/1999/xlink" xmlns="http://www.w3.org/2000/svg" xmlns:dc="http://purl.org/dc/elements/1.1/" version="1.1" viewBox="345 181 672.7646 615.5719" width="672.7646" height="615.5719">
<defs/>
<metadata> Produced by OmniGraffle 7.15
<dc:date>2021-06-14 13:22:10 +0000</dc:date>
</metadata>
<g id="Canvas___1" stroke="none" fill-opacity="1" stroke-dasharray="none" fill="none" stroke-opacity="1">
<title>版面 1</title>
<g id="Canvas___1: 图层 1">
<title>图层 1</title>
<g id="Group_52">
<g id="Graphic_43">
<path d="M 677.5599 584.6176 C 752.7013 584.6176 776.9438 518.2455 776.9438 484.16195 C 776.9438 466.44986 764.9257 472.0282 745.6774 481.46935 C 727.8854 490.19475 703.9239 502.22056 677.5599 502.22056 C 622.6703 502.22056 578.1761 450.0784 578.1761 484.16195 C 578.1761 518.2455 602.41855 584.6176 677.5599 584.6176 Z" fill="black"/>
</g>
<g id="Graphic_41">
<path d="M 867.3218 288.3897 C 971.0704 391.1752 971.0704 557.8233 867.3218 660.6088 C 763.5737 763.3949 595.3649 763.3949 491.61675 660.6088 C 387.8681 557.8233 387.8681 391.1752 491.61675 288.3897 C 595.3649 185.60365 763.5737 185.60365 867.3218 288.3897" fill="#ffd21e"/>
</g>
<g id="Group_34">
<g id="Graphic_35">
<path d="M 679.4693 661.9589 C 716.091 661.9589 745.7749 632.54476 745.7749 596.2685 C 745.7749 568.0075 727.765 543.9161 702.4962 534.6454 C 701.5673 534.30456 700.627 533.98645 699.6809 533.6854 C 693.31065 531.66876 686.5161 553.36295 679.4693 553.36295 C 672.8869 553.36295 666.5281 531.52675 660.5191 533.2991 C 633.1345 541.3769 613.1637 566.5135 613.1637 596.2685 C 613.1637 632.54476 642.8533 661.9589 679.4693 661.9589 Z" fill="#ef4e4e"/>
</g>
</g>
<g id="Graphic_33">
<ellipse cx="859.132" cy="413.90437" rx="24.8445688272564" ry="24.614054301874" fill="#ffd21e"/>
</g>
<g id="Graphic_32">
<ellipse cx="503.63675" cy="413.90437" rx="24.8445688272564" ry="24.614054301874" fill="#ffd21e"/>
</g>
<g id="Graphic_44">
<path d="M 676.1985 670.91135 C 737.8429 670.91135 757.7309 604.5393 757.7309 570.4557 C 757.7309 552.7436 747.87155 558.322 732.0806 567.7631 C 717.4845 576.4885 697.8269 588.5143 676.1985 588.5143 C 631.1682 588.5143 594.66606 536.37215 594.66606 570.4557 C 594.66606 604.5393 614.5541 670.91135 676.1985 670.91135 Z" fill="#ffd21e"/>
</g>
</g>
<g id="Graphic_69">
<path d="M 542.58056 318.09087 C 380.78566 311.58722 308.5167 371.05706 381.16873 450.8876 C 453.81357 530.7335 643.829 600.70525 805.6055 607.2003 C 811.1007 607.4207 816.2272 607.3754 821.5233 607.4467 L 756.1326 535.57396 C 630.3134 530.5286 489.0533 483.3012 440.65034 430.0769 C 392.2254 376.85173 454.9745 337.79727 580.7753 342.83404 L 580.2953 342.80695 L 580.7605 342.81776 C 724.5417 348.57555 895.1019 412.5855 961.677 485.76 C 993.8764 521.1512 995.6086 552.1067 972.8397 574.0917 C 1003.2718 550.0309 1003.8245 514.8477 966.9877 474.3711 C 894.3577 394.54143 704.34225 324.56968 542.58056 318.09087 Z" fill="#89b2fd"/>
</g>
<g id="Graphic_40">
<path d="M 945.1389 474.49926 C 945.1389 329.13286 826.1971 211.2946 679.4693 211.2946 C 532.7472 211.2946 413.8054 329.13286 413.8054 474.49926 C 413.8054 619.86 532.7472 737.6982 679.4693 737.6982 C 826.1971 737.6982 945.1389 619.86 945.1389 474.49926 Z M 383.22708 474.49926 C 383.22708 312.4035 515.8612 181 679.4693 181 C 843.0831 181 975.7172 312.4035 975.7172 474.49926 C 975.7172 636.58934 843.0831 767.99285 679.4693 767.99285 C 515.8612 767.99285 383.22708 636.58934 383.22708 474.49926 Z" fill="#ffac03"/>
</g>
<g id="Graphic_29">
<path d="M 910.2602 521.83566 C 922.6395 521.83566 933.7 526.87434 941.4119 536.00874 C 946.1824 541.6666 951.1708 550.78396 951.5722 564.4401 C 956.767 562.96316 961.7554 562.1395 966.4227 562.1395 C 978.2687 562.1395 988.9737 566.6385 996.5423 574.8072 C 1006.2669 585.29926 1010.5844 598.1885 1008.7037 611.08915 C 1007.8092 617.2299 1005.7394 622.74005 1002.6431 627.83555 C 1009.1739 633.0674 1013.9788 640.3556 1016.3067 649.1207 C 1018.1243 655.9886 1019.9878 670.298 1010.2518 685.03345 C 1010.8711 685.99915 1011.4502 686.9989 1011.9949 688.02144 C 1017.8491 699.0304 1018.2218 711.4766 1013.0557 723.065 C 1005.2176 740.6294 985.7456 754.46735 947.937 769.3221 C 924.4112 778.55875 902.8923 784.4666 902.6973 784.5234 C 871.5972 792.5103 843.473 796.5719 819.1216 796.5719 C 774.3693 796.5719 742.3289 782.9896 723.889 756.2113 C 694.21086 713.0842 698.4539 673.6382 736.8531 635.6123 C 758.1083 614.57136 772.2363 583.5496 775.1778 576.7386 C 781.1122 556.5782 796.7999 534.1682 822.8772 534.1682 L 822.8829 534.1682 C 825.079 534.1682 827.2979 534.33864 829.4825 534.6795 C 840.9042 536.4632 850.8868 542.97315 858.0196 552.77785 C 865.7201 543.29126 873.197 535.7474 879.9628 531.49267 C 890.1633 525.08496 900.3522 521.83566 910.2602 521.83566 M 910.2602 552.13027 C 906.3612 552.13027 901.5965 553.77764 896.3443 557.07806 C 880.0374 567.32586 848.5703 620.9109 837.0511 641.7587 C 833.1923 648.7401 826.5927 651.69404 820.6525 651.69404 C 808.8638 651.69404 799.6611 640.0829 819.5745 625.3304 C 849.5221 603.13064 839.0178 566.843 824.7177 564.60485 C 824.0928 564.5083 823.4735 564.46284 822.8772 564.46284 C 809.8787 564.46284 804.1449 586.6569 804.1449 586.6569 C 804.1449 586.6569 787.3449 628.4661 758.4752 657.0395 C 729.6056 685.6242 728.1148 708.56815 749.1578 739.1354 C 763.5038 759.9832 790.9744 766.2773 819.1216 766.2773 C 848.318 766.2773 878.2484 759.506 895.0255 755.1945 C 895.8512 754.9843 997.8554 726.4336 984.9371 702.1377 C 982.764 698.0534 979.1862 696.4174 974.6851 696.4174 C 956.4918 696.4174 923.3963 723.2468 909.1651 723.2468 C 905.9885 723.2468 903.7466 721.9062 902.8292 718.6342 C 896.7686 697.0877 995.0057 688.0271 986.7261 656.81226 C 985.264 651.2907 981.3077 649.0526 975.7401 649.05825 C 951.6983 649.05825 897.7548 690.9526 886.4478 690.9526 C 885.582 690.9526 884.9627 690.7027 884.6244 690.1687 C 878.9594 681.1138 882.0671 674.78566 921.9973 650.8476 C 961.9274 626.89825 989.9542 612.49226 974.0143 595.2971 C 972.1795 593.3146 969.5763 592.4341 966.4227 592.4341 C 942.1802 592.43976 884.8996 644.08204 884.8996 644.08204 C 884.8996 644.08204 869.4413 660.0104 860.0953 660.0104 C 857.9451 660.0104 856.116 659.1697 854.8775 657.0963 C 848.2492 646.0191 916.447 594.8199 920.2886 573.6938 C 922.8975 559.3787 918.4653 552.13027 910.2602 552.13027" fill="#ffac03"/>
</g>
<g id="Graphic_28">
<path d="M 749.1578 739.1354 C 728.1205 708.56815 729.6113 685.6242 758.4752 657.0395 C 787.3449 628.4661 804.1506 586.6569 804.1506 586.6569 C 804.1506 586.6569 810.4234 562.3724 824.7235 564.60485 C 839.0178 566.843 849.5164 603.13064 819.5688 625.3304 C 789.6212 647.5188 825.5319 662.6008 837.0511 641.7587 C 848.5761 620.9109 880.0317 567.32586 896.35 557.07806 C 912.6569 546.8303 924.136 552.57335 920.2944 573.6938 C 916.447 594.8199 848.2435 646.0191 854.8832 657.102 C 861.5172 668.17345 884.9054 644.08204 884.9054 644.08204 C 884.9054 644.08204 958.08 578.10194 974.0143 595.2971 C 989.9485 612.49226 961.9274 626.89825 921.9973 650.8476 C 882.0614 674.78566 878.9652 681.1138 884.6302 690.1687 C 890.3009 699.22925 978.4465 625.6031 986.7261 656.81226 C 995 688.0271 896.7686 697.0877 902.8292 718.6342 C 908.8956 740.192 972.0246 677.8475 984.9371 702.1377 C 997.8611 726.4336 895.8512 754.9843 895.0255 755.1945 C 862.0734 763.6642 778.3944 781.60355 749.1578 739.1354" fill="#ffd21e"/>
</g>
<g id="Graphic_31">
<path d="M 452.5028 521.83566 C 440.12925 521.83566 429.063 526.87434 421.35107 536.00874 C 416.58056 541.6666 411.5979 550.78396 411.1908 564.4401 C 406.0017 562.96316 401.00757 562.1395 396.346 562.1395 C 384.49424 562.1395 373.78925 566.6385 366.22064 574.8072 C 356.49613 585.29926 352.1786 598.1885 354.05927 611.08915 C 354.95374 617.2299 357.02364 622.74005 360.1199 627.83555 C 353.59483 633.0674 348.78418 640.3556 346.462 649.1207 C 344.63864 655.9886 342.77516 670.298 352.51688 685.03345 C 351.89763 685.99915 351.3128 686.9989 350.7738 688.02144 C 344.91387 699.0304 344.54117 711.4766 349.7073 723.065 C 357.5454 740.6294 377.0174 754.46735 414.83175 769.3221 C 438.35177 778.55875 459.87643 784.4666 460.06565 784.5234 C 491.16575 792.5103 519.29 796.5719 543.6414 796.5719 C 588.3937 796.5719 620.4341 782.9896 638.874 756.2113 C 668.5521 713.0842 664.3091 673.6382 625.9099 635.6123 C 604.6547 614.57136 590.52666 583.5496 587.5852 576.7386 C 581.65075 556.5782 565.9631 534.1682 539.8858 534.1682 L 539.88006 534.1682 C 537.684 534.1682 535.4708 534.33864 533.28046 534.6795 C 521.85875 536.4632 511.8762 542.97315 504.7434 552.77785 C 497.0429 543.29126 489.566 535.7474 482.80014 531.49267 C 472.60546 525.08496 462.41077 521.83566 452.5028 521.83566 M 452.5028 552.13027 C 456.40175 552.13027 461.16654 553.77764 466.4187 557.07806 C 482.7256 567.32586 514.19266 620.9109 525.71186 641.7587 C 529.57643 648.7401 536.1703 651.69404 542.1105 651.69404 C 553.8992 651.69404 563.10766 640.0829 543.18846 625.3304 C 513.2466 603.13064 523.7509 566.843 538.04525 564.60485 C 538.6702 564.5083 539.2895 564.46284 539.8858 564.46284 C 552.8843 564.46284 558.6181 586.6569 558.6181 586.6569 C 558.6181 586.6569 575.42385 628.4661 604.2878 657.0395 C 633.1574 685.6242 634.6482 708.56815 613.6109 739.1354 C 599.2592 759.9832 571.7886 766.2773 543.6414 766.2773 C 514.44495 766.2773 484.51455 759.506 467.7432 755.1945 C 466.91753 754.9843 364.9076 726.4336 377.82584 702.1377 C 379.99895 698.0534 383.57684 696.4174 388.07787 696.4174 C 406.27693 696.4174 439.3724 723.2468 453.59793 723.2468 C 456.7802 723.2468 459.01636 721.9062 459.93377 718.6342 C 466.0001 697.0877 367.7573 688.0271 376.0369 656.81226 C 377.499 651.2907 381.46107 649.0526 387.02285 649.05825 C 411.0704 649.05825 465.0139 690.9526 476.32095 690.9526 C 477.181 690.9526 477.8003 690.7027 478.13857 690.1687 C 483.80356 681.1138 480.7016 674.78566 440.77143 650.8476 C 400.8413 626.89825 372.8145 612.49226 388.75445 595.2971 C 390.58927 593.3146 393.18668 592.4341 396.346 592.4341 C 420.5885 592.43976 477.86335 644.08204 477.86335 644.08204 C 477.86335 644.08204 493.32165 660.0104 502.6735 660.0104 C 504.8179 660.0104 506.647 659.1697 507.8855 657.0963 C 514.51376 646.0191 446.32174 594.8199 442.47437 573.6938 C 439.8655 559.3787 444.30345 552.13027 452.5028 552.13027" fill="#ffac03"/>
</g>
<g id="Graphic_30">
<path d="M 613.6052 739.1354 C 634.6482 708.56815 633.1574 685.6242 604.2878 657.0395 C 575.4181 628.4661 558.6181 586.6569 558.6181 586.6569 C 558.6181 586.6569 552.3396 562.3724 538.04525 564.60485 C 523.74516 566.843 513.2523 603.13064 543.1942 625.3304 C 573.1418 647.5188 537.23105 662.6008 525.71186 641.7587 C 514.19266 620.9109 482.73134 567.32586 466.4187 557.07806 C 450.1118 546.8303 438.627 552.57335 442.47437 573.6938 C 446.316 594.8199 514.5195 646.0191 507.8855 657.102 C 501.24576 668.17345 477.86335 644.08204 477.86335 644.08204 C 477.86335 644.08204 404.68293 578.10194 388.7487 595.2971 C 372.82024 612.49226 400.83556 626.89825 440.7657 650.8476 C 480.7073 674.78566 483.80356 681.1138 478.13857 690.1687 C 472.4621 699.22925 384.3165 625.6031 376.0369 656.81226 C 367.76303 688.0271 465.9944 697.0877 459.93377 718.6342 C 453.87315 740.192 390.73835 677.8475 377.82584 702.1377 C 364.9076 726.4336 466.9118 754.9843 467.73747 755.1945 C 500.6896 763.6642 584.3743 781.60355 613.6052 739.1354" fill="#ffd21e"/>
</g>
<g id="Graphic_74">
<path d="M 861.8634 290.74465 C 965.8634 398.74465 973.8634 542.74465 877.8634 522.74465 C 781.8633 502.74514 657.8634 486.74465 557.86336 474.74465 C 457.8633 462.74516 376.7513 405.28557 480.5 302.5 C 584.2482 199.7139 757.8639 182.74412 861.8634 290.74465 Z" fill="#ffd21e"/>
</g>
<g id="Graphic_37">
<path d="M 677.5599 584.6176 C 752.7013 584.6176 776.9438 518.2455 776.9438 484.16195 C 776.9438 466.44986 764.9257 472.0282 745.6774 481.46935 C 727.8854 490.19475 703.9239 502.22056 677.5599 502.22056 C 622.6703 502.22056 578.1761 450.0784 578.1761 484.16195 C 578.1761 518.2455 602.41855 584.6176 677.5599 584.6176 Z" fill="#3a3b45"/>
</g>
<g id="Graphic_76">
<path d="M 383.92952 354.71663 C 383.92952 354.71663 313.44623 377.4205 386.09825 457.251 C 458.7431 537.0969 648.7585 607.0687 810.535 613.56375 C 816.0302 613.7841 821.1567 613.7388 826.4528 613.8101 L 761.0621 541.9374 C 635.2429 536.89204 493.98284 489.66464 445.57986 436.44034 C 397.1549 383.21515 422 329.5 422 329.5 Z" fill="#89b2fd"/>
</g>
<g id="Group_68">
<g id="Graphic_57">
<path d="M 756.9762 617.62004 L 789.2474 535.4207 L 804.7558 543.8668 L 772.4868 626.072 Z" fill="#99aab5"/>
</g>
<g id="Graphic_58">
<path d="M 778.1195 675.6945 C 775.744 681.7476 769.1903 684.133 763.47975 681.02295 L 727.28815 661.3173 C 721.5776 658.2072 718.8723 650.7746 721.2499 644.7274 L 736.30345 606.3567 C 738.6789 600.3036 745.2326 597.9182 750.9432 601.0283 L 787.1369 620.7398 C 792.8453 623.844 795.5506 631.2766 793.1751 637.3297 L 778.1195 675.6945 Z M 827.579 549.6506 C 825.2087 555.7018 818.6498 558.08904 812.94445 554.9771 L 776.7507 535.26555 C 771.04015 532.1555 768.337 524.7288 770.7125 518.67566 L 785.7733 480.30896 C 788.1488 474.25585 794.7025 471.8705 800.4131 474.98054 L 836.6016 494.694 C 842.3122 497.804 845.0153 505.23076 842.645 511.282 Z" fill="#55acee"/>
</g>
<g id="Graphic_59">
<path d="M 756.7335 554.2968 L 740.3542 532.0703 C 735.16965 525.04184 730.0079 526.4356 727.8575 531.9152 L 719.2582 553.83936 C 717.1026 559.3208 719.5452 564.856 727.4489 564.95554 L 752.4328 565.25596 Z" fill="#99aab5"/>
</g>
<g id="Graphic_60">
<path d="M 809.0995 612.7394 C 806.7189 618.7944 800.1652 621.1798 794.4568 618.0756 L 742.7546 589.91795 C 737.044 586.8079 734.3388 579.3753 736.7142 573.3222 L 749.6165 540.4447 C 751.9919 534.3916 758.5508 532.00435 764.2614 535.1144 L 815.9636 563.27206 C 821.669 566.384 824.3721 573.8107 821.9988 579.8697 Z" fill="#ccd6dd"/>
</g>
<g id="Graphic_61">
<path d="M 824.3153 601.2621 C 818.3803 616.3969 804.3014 623.62054 792.8824 617.4063 C 781.4613 611.1862 792.5277 602.32196 798.4678 587.1853 C 804.408 572.04864 802.9732 556.3808 814.3922 562.595 C 825.8082 568.817 830.2554 586.1255 824.3153 601.2621 Z" fill="#ccd6dd"/>
</g>
<g id="Graphic_62">
<path d="M 858.3983 583.0572 C 842.8929 574.60335 827.7382 581.2552 821.7938 596.38014 C 815.861 611.5208 821.3831 629.41465 836.8915 637.86075 Z M 849.799 604.9814 L 868.3265 621.7224 L 845.4982 615.94055 Z" fill="#99aab5"/>
</g>
<g id="Graphic_63">
<path d="M 872.4212 623.9524 C 871.2319 626.98286 867.9603 628.17366 865.1013 626.61664 C 862.2424 625.0596 860.893 621.3521 862.0822 618.3217 C 863.2714 615.29126 866.5431 614.1005 869.4021 615.6575 C 872.261 617.2145 873.6126 620.9279 872.4212 623.9524 Z" fill="#99aab5"/>
</g>
<g id="Graphic_64">
<path d="M 731.99144 617.3332 L 736.2983 606.3586 L 793.173 637.32385 L 788.8744 648.2889 Z M 770.7104 518.6698 L 775.0111 507.71063 L 831.8828 538.68366 L 827.582 549.6428 Z M 721.2417 644.737 L 725.5403 633.772 L 782.4181 664.7295 L 778.1173 675.68866 Z M 781.454 491.2815 L 785.74745 480.3184 L 842.6283 511.26816 L 838.3327 522.22543 Z" fill="#88c9f9"/>
</g>
<g id="Graphic_65">
<path d="M 729.7981 546.2828 C 728.6119 549.3055 725.335 550.4982 722.4782 548.94703 C 719.6193 547.39 718.2729 543.67477 719.457 540.6462 C 720.6483 537.62165 723.92 536.43086 726.7768 537.982 C 729.6358 539.539 730.9873 543.2524 729.7981 546.2828 Z" fill="#99aab5"/>
</g>
<g id="Graphic_66">
<path d="M 858.1356 651.2414 L 858.0371 650.9384 C 856.9982 647.64935 858.5238 644.2706 861.4412 643.3948 C 861.5261 643.3705 872.7367 639.7021 877.7391 626.9662 C 882.716 614.27284 877.8541 601.8653 877.8026 601.6914 C 876.4574 598.52715 877.6777 594.9539 880.4703 593.7515 C 883.2702 592.55304 886.6085 594.1548 887.9269 597.3421 C 888.2495 598.0352 895.0289 614.8735 888.0759 632.5911 C 881.1147 650.3183 865.837 655.1017 865.1874 655.2982 C 862.3602 656.1479 859.2651 654.34464 858.1356 651.2414 Z" fill="#f8a9e2"/>
</g>
<g id="Graphic_67">
<path d="M 868.6107 671.0661 C 868.378 670.42664 868.2321 669.7357 868.2012 669.0228 C 868.031 665.6235 870.3945 662.9363 873.4823 663.0282 C 874.1088 663.02605 890.2824 662.8461 899.6695 638.9145 C 909.1826 614.68466 899.0861 598.4292 898.6514 597.7503 C 896.8127 594.9052 897.3044 591.0856 899.7616 589.2678 C 902.2063 587.44794 905.6834 588.2551 907.5584 591.0871 C 908.1595 591.9977 922.112 613.7256 910.0137 644.54336 C 897.8092 675.6655 875.0624 675.3746 874.0999 675.3396 C 871.6545 675.273 869.4926 673.48885 868.6107 671.0661 Z" fill="#f8a9e2"/>
</g>
<g id="Graphic_39">
<path d="M 767.0461 410.2571 C 776.7935 413.66544 780.6696 433.50776 790.5088 428.32705 C 809.1493 418.5053 816.2248 395.57843 806.3168 377.1108 C 796.4031 358.6432 773.2615 351.63335 754.621 361.4494 C 735.9804 371.27117 728.9049 394.19804 738.8129 412.66566 C 743.4917 421.38537 758.3422 407.2123 767.0461 410.2571 Z" fill="#3a3b45"/>
</g>
<g id="Graphic_38">
<path d="M 595.1669 410.2571 C 585.42516 413.66544 581.5491 433.50776 571.7042 428.32705 C 553.0636 418.5053 545.9881 395.57843 555.90186 377.1108 C 565.80985 358.6432 588.9572 351.63335 607.59775 361.4494 C 626.2383 371.27117 633.3138 394.19804 623.4001 412.66566 C 618.72704 421.38537 603.8765 407.2123 595.1669 410.2571 Z" fill="#3a3b45"/>
</g>
</g>
</g>
</g>
</svg>
| 6 |
0 | hf_public_repos | hf_public_repos/awesome-huggingface/README.md | <p align="center">
<img src="https://raw.githubusercontent.com/huggingface/awesome-huggingface/main/logo.svg" width="100px">
</p>
# awesome-huggingface
This is a list of some wonderful open-source projects & applications integrated with Hugging Face libraries.
[How to contribute](https://github.com/huggingface/awesome-huggingface/blob/main/CONTRIBUTING.md)
## 🤗 Official Libraries
*First-party cool stuff made with ❤️ by 🤗 Hugging Face.*
* [transformers](https://github.com/huggingface/transformers) - State-of-the-art natural language processing for Jax, PyTorch and TensorFlow.
* [datasets](https://github.com/huggingface/datasets) - The largest hub of ready-to-use NLP datasets for ML models with fast, easy-to-use and efficient data manipulation tools.
* [tokenizers](https://github.com/huggingface/tokenizers) - Fast state-of-the-Art tokenizers optimized for research and production.
* [knockknock](https://github.com/huggingface/knockknock) - Get notified when your training ends with only two additional lines of code.
* [accelerate](https://github.com/huggingface/accelerate) - A simple way to train and use PyTorch models with multi-GPU, TPU, mixed-precision.
* [autonlp](https://github.com/huggingface/autonlp) - Train state-of-the-art natural language processing models and deploy them in a scalable environment automatically.
* [nn_pruning](https://github.com/huggingface/nn_pruning) - Prune a model while finetuning or training.
* [huggingface_hub](https://github.com/huggingface/huggingface_hub) - Client library to download and publish models and other files on the huggingface.co hub.
* [tune](https://github.com/huggingface/tune) - A benchmark for comparing Transformer-based models.
## 👩🏫 Tutorials
*Learn how to use Hugging Face toolkits, step-by-step.*
* [Official Course](https://huggingface.co/course) (from Hugging Face) - The official course series provided by 🤗 Hugging Face.
* [transformers-tutorials](https://github.com/nielsrogge/transformers-tutorials) (by @nielsrogge) - Tutorials for applying multiple models on real-world datasets.
## 🧰 NLP Toolkits
*NLP toolkits built upon Transformers. Swiss Army!*
* [AllenNLP](https://github.com/allenai/allennlp) (from AI2) - An open-source NLP research library.
* [Graph4NLP](https://github.com/graph4ai/graph4nlp) - Enabling easy use of Graph Neural Networks for NLP.
* [Lightning Transformers](https://github.com/PyTorchLightning/lightning-transformers) - Transformers with PyTorch Lightning interface.
* [Adapter Transformers](https://github.com/Adapter-Hub/adapter-transformers) - Extension to the Transformers library, integrating adapters into state-of-the-art language models.
* [Obsei](https://github.com/obsei/obsei) - A low-code AI workflow automation tool and performs various NLP tasks in the workflow pipeline.
* [Trapper](https://github.com/obss/trapper) (from OBSS) - State-of-the-art NLP through transformer models in a modular design and consistent APIs.
* [Flair](https://github.com/flairNLP/flair) - A very simple framework for state-of-the-art NLP.
## 🥡 Text Representation
*Converting a sentence to a vector.*
* [Sentence Transformers](https://github.com/UKPLab/sentence-transformers) (from UKPLab) - Widely used encoders computing dense vector representations for sentences, paragraphs, and images.
* [WhiteningBERT](https://github.com/Jun-jie-Huang/WhiteningBERT) (from Microsoft) - An easy unsupervised sentence embedding approach with whitening.
* [SimCSE](https://github.com/princeton-nlp/SimCSE) (from Princeton) - State-of-the-art sentence embedding with contrastive learning.
* [DensePhrases](https://github.com/princeton-nlp/DensePhrases) (from Princeton) - Learning dense representations of phrases at scale.
## ⚙️ Inference Engines
*Highly optimized inference engines implementing Transformers-compatible APIs.*
* [TurboTransformers](https://github.com/Tencent/TurboTransformers) (from Tencent) - An inference engine for transformers with fast C++ API.
* [FasterTransformer](https://github.com/NVIDIA/FasterTransformer) (from Nvidia) - A script and recipe to run the highly optimized transformer-based encoder and decoder component on NVIDIA GPUs.
* [lightseq](https://github.com/bytedance/lightseq) (from ByteDance) - A high performance inference library for sequence processing and generation implemented in CUDA.
* [FastSeq](https://github.com/microsoft/fastseq) (from Microsoft) - Efficient implementation of popular sequence models (e.g., Bart, ProphetNet) for text generation, summarization, translation tasks etc.
## 🌗 Model Scalability
*Parallelization models across multiple GPUs.*
* [Parallelformers](https://github.com/tunib-ai/parallelformers) (from TUNiB) - A library for model parallel deployment.
* [OSLO](https://github.com/tunib-ai/oslo) (from TUNiB) - A library that supports various features to help you train large-scale models.
* [Deepspeed](https://github.com/microsoft/DeepSpeed) (from Microsoft) - Deepspeed-ZeRO - scales any model size with zero to no changes to the model. [Integrated with HF Trainer](https://huggingface.co/docs/transformers/master/main_classes/deepspeed).
* [fairscale](https://github.com/facebookresearch/fairscale) (from Facebook) - Implements ZeRO protocol as well. [Integrated with HF Trainer](https://huggingface.co/docs/transformers/master/main_classes/trainer#fairscale).
* [ColossalAI](https://github.com/hpcaitech/colossalai) (from Hpcaitech) - A Unified Deep Learning System for Large-Scale Parallel Training (1D, 2D, 2.5D, 3D and sequence parallelism, and ZeRO protocol).
## 🏎️ Model Compression/Acceleration
*Compressing or accelerate models for improved inference speed.*
* [torchdistill](https://github.com/yoshitomo-matsubara/torchdistill) - PyTorch-based modular, configuration-driven framework for knowledge distillation.
* [TextBrewer](https://github.com/airaria/TextBrewer) (from HFL) - State-of-the-art distillation methods to compress language models.
* [BERT-of-Theseus](https://github.com/JetRunner/BERT-of-Theseus) (from Microsoft) - Compressing BERT by progressively replacing the components of the original BERT.
## 🏹️ Adversarial Attack
*Conducting adversarial attack to test model robustness.*
* [TextAttack](https://github.com/QData/TextAttack) (from UVa) - A Python framework for adversarial attacks, data augmentation, and model training in NLP.
* [TextFlint](https://github.com/textflint/textflint) (from Fudan) - A unified multilingual robustness evaluation toolkit for NLP.
* [OpenAttack](https://github.com/thunlp/OpenAttack) (from THU) - An open-source textual adversarial attack toolkit.
## 🔁 Style Transfer
*Transfer the style of text! Now you know why it's called transformer?*
* [Styleformer](https://github.com/PrithivirajDamodaran/Styleformer) - A neural language style transfer framework to transfer text smoothly between styles.
* [ConSERT](https://github.com/yym6472/ConSERT) - A contrastive framework for self-supervised sentence representation transfer.
## 💢 Sentiment Analysis
*Analyzing the sentiment and emotions of human beings.*
* [conv-emotion](https://github.com/declare-lab/conv-emotion) - Implementation of different architectures for emotion recognition in conversations.
## 🙅 Grammatical Error Correction
*You made a typo! Let me correct it.*
* [Gramformer](https://github.com/PrithivirajDamodaran/Gramformer) - A framework for detecting, highlighting and correcting grammatical errors on natural language text.
## 🗺 Translation
*Translating between different languages.*
* [dl-translate](https://github.com/xhlulu/dl-translate) - A deep learning-based translation library based on HF Transformers.
* [EasyNMT](https://github.com/UKPLab/EasyNMT) (from UKPLab) - Easy-to-use, state-of-the-art translation library and Docker images based on HF Transformers.
## 📖 Knowledge and Entity
*Learning knowledge, mining entities, connecting the world.*
* [PURE](https://github.com/princeton-nlp/PURE) (from Princeton) - Entity and relation extraction from text.
## 🎙 Speech
*Speech processing powered by HF libraries. Need for speech!*
* [s3prl](https://github.com/s3prl/s3prl) - A self-supervised speech pre-training and representation learning toolkit.
* [speechbrain](https://github.com/speechbrain/speechbrain) - A PyTorch-based speech toolkit.
## 🤯 Multi-modality
*Understanding the world from different modalities.*
* [ViLT](https://github.com/dandelin/ViLT) (from Kakao) - A vision-and-language transformer Without convolution or region supervision.
## 🤖 Reinforcement Learning
*Combining RL magic with NLP!*
* [trl](https://github.com/lvwerra/trl) - Fine-tune transformers using Proximal Policy Optimization (PPO) to align with human preferences.
## ❓ Question Answering
*Searching for answers? Transformers to the rescue!*
* [Haystack](https://haystack.deepset.ai/) (from deepset) - End-to-end framework for developing and deploying question-answering systems in the wild.
## 💁 Recommender Systems
*I think this is just right for you!*
* [Transformers4Rec](https://github.com/NVIDIA-Merlin/Transformers4Rec) (from Nvidia) - A flexible and efficient library powered by Transformers for sequential and session-based recommendations.
## ⚖️ Evaluation
*Evaluating model outputs and data quality powered by HF datasets!*
* [Jury](https://github.com/obss/jury) (from OBSS) - Easy to use tool for evaluating NLP model outputs, spesifically for NLG (Natural Language Generation), offering various automated text-to-text metrics.
* [Spotlight](https://github.com/Renumics/spotlight) - Interactively explore your HF dataset with one line of code. Use model results (e.g. embeddings, predictions) to understand critical data segments and model failure modes.
## 🔍 Neural Search
*Search, but with the power of neural networks!*
* [Jina Integration](https://github.com/jina-ai/jina-hub/tree/master/encoders/nlp/TransformerTorchEncoder) - Jina integration of Hugging Face Accelerated API.
* Weaviate Integration [(text2vec)](https://www.semi.technology/developers/weaviate/current/modules/text2vec-transformers.html) [(QA)](https://www.semi.technology/developers/weaviate/current/modules/qna-transformers.html) - Weaviate integration of Hugging Face Transformers.
* [ColBERT](https://github.com/stanford-futuredata/ColBERT) (from Stanford) - A fast and accurate retrieval model, enabling scalable BERT-based search over large text collections in tens of milliseconds.
## ☁ Cloud
*Cloud makes your life easy!*
* [Amazon SageMaker](https://huggingface.co/transformers/sagemaker.html) - Making it easier than ever to train Hugging Face Transformer models in Amazon SageMaker.
## 📱 Hardware
*The infrastructure enabling the magic to happen.*
* [Qualcomm](https://www.qualcomm.com/news/onq/2020/12/02/exploring-ai-capabilities-qualcomm-snapdragon-888-mobile-platform) - Collaboration on enabling Transformers in Snapdragon.
* [Intel](https://github.com/huggingface/tune) - Collaboration with Intel for configuration options.
| 7 |
0 | hf_public_repos | hf_public_repos/api-inference-community/setup.cfg | [isort]
default_section = FIRSTPARTY
ensure_newline_before_comments = True
force_grid_wrap = 0
line_length = 88
include_trailing_comma = True
known_first_party = main
lines_after_imports = 2
multi_line_output = 3
use_parentheses = True
[flake8]
ignore = E203, E501, E741, W503, W605
max-line-length = 88
per-file-ignores = __init__.py:F401
| 8 |
0 | hf_public_repos | hf_public_repos/api-inference-community/setup.py | from setuptools import setup
setup(
name="api_inference_community",
version="0.0.36",
description="A package with helper tools to build an API Inference docker app for Hugging Face API inference using huggingface_hub",
long_description=open("README.md", "r", encoding="utf-8").read(),
long_description_content_type="text/markdown",
url="http://github.com/huggingface/api-inference-community",
author="Nicolas Patry",
author_email="[email protected]",
license="MIT",
packages=["api_inference_community"],
python_requires=">=3.6.0",
zip_safe=False,
install_requires=list(line for line in open("requirements.txt", "r")),
extras_require={
"test": [
"httpx>=0.18",
"Pillow>=8.2",
"httpx>=0.18",
"torch>=1.9.0",
"pytest>=6.2",
],
"quality": ["black==22.3.0", "isort", "flake8", "mypy"],
},
)
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.