
index
int64 0
0
| repo_id
stringclasses 179
values | file_path
stringlengths 26
186
| content
stringlengths 1
2.1M
| __index_level_0__
int64 0
9
|
|---|---|---|---|---|
0 | hf_public_repos/api-inference-community/docker_images/sklearn | hf_public_repos/api-inference-community/docker_images/sklearn/tests/test_api_tabular_classification.py | import json
import os
from pathlib import Path
from unittest import TestCase, skipIf
import pytest
from app.main import ALLOWED_TASKS
from parameterized import parameterized, parameterized_class
from starlette.testclient import TestClient
from tests.test_api import TEST_CASES, TESTABLE_MODELS
@parameterized_class(
[{"test_case": x} for x in TESTABLE_MODELS["tabular-classification"]]
)
@skipIf(
"tabular-classification" not in ALLOWED_TASKS,
"tabular-classification not implemented",
)
class TabularClassificationTestCase(TestCase):
# self.test_case is provided by parameterized_class
def setUp(self):
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = self.test_case
os.environ["TASK"] = "tabular-classification"
self.case_data = TEST_CASES["tabular-classification"][self.test_case]
sample_folder = Path(__file__).parent / "generators" / "samples"
self.data = json.load(open(sample_folder / self.case_data["input"], "r"))
self.expected_output = json.load(
open(sample_folder / self.case_data["output"], "r")
)
from app.main import app
self.app = app
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def _can_load(self):
# to load a model, it has to either support being loaded on new sklearn
# versions, or it needs to be saved by a new sklearn version, since the
# assumption is that the current sklearn version is the latest.
return (
self.case_data["loads_on_new_sklearn"] or not self.case_data["old_sklearn"]
)
def _check_requirement(self, requirement):
# This test is not supposed to run and is thus skipped.
if not requirement:
pytest.skip("Skipping test because requirements are not met.")
def test_success_code(self):
# This test does a sanity check on the output and checks the response
# code which should be 200. This requires the model to be from the
# latest sklearn which is the one installed locally.
self._check_requirement(not self.case_data["old_sklearn"])
data = self.data
expected_output_len = len(self.expected_output)
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": data})
assert response.status_code == 200
content = json.loads(response.content)
assert isinstance(content, list)
assert len(content) == expected_output_len
def test_wrong_sklearn_version_warning(self):
# if the wrong sklearn version is used the model will be loaded and
# gives an output, but warnings are raised. This test makes sure the
# right warnings are raised and that the output is included in the
# error message.
self._check_requirement(self.case_data["old_sklearn"] and self._can_load())
data = self.data
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": data})
# check response
assert response.status_code == 400
content = json.loads(response.content)
assert "error" in content
assert "warnings" in content
# check warnings
assert any("Trying to unpickle estimator" in w for w in content["warnings"])
warnings = json.loads(content["error"])["warnings"]
assert any("Trying to unpickle estimator" in w for w in warnings)
# check error
error_message = json.loads(content["error"])
assert error_message["output"] == self.expected_output
def test_cannot_load_model(self):
# test the error message when the model cannot be loaded on a wrong
# sklearn version
self._check_requirement(not self.case_data["loads_on_new_sklearn"])
data = self.data
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": data})
assert response.status_code == 400
content = json.loads(response.content)
assert "error" in content
assert "An error occurred while loading the model:" in content["error"]
@parameterized.expand(
[
(["add"], ["The following columns were given but not expected:"]),
(["drop"], ["The following columns were expected but not given:"]),
(
["add", "drop"],
[
"The following columns were given but not expected:",
"The following columns were expected but not given:",
],
),
]
)
def test_extra_columns(self, column_operations, warn_messages):
# Test that the right warning is raised when there are extra columns in
# the input.
self._check_requirement(self.case_data["has_config"] and self._can_load())
data = self.data.copy()
if "drop" in column_operations:
# we remove the first column in the data. Note that `data` is a
# dict of column names to values.
data["data"].pop(next(iter(data["data"].keys())))
if "add" in column_operations:
# we add an extra column to the data, the same as the first column.
# Note that `data` is a dict of column names to values.
data["data"]["extra_column"] = next(iter(data["data"].values()))
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": data})
assert response.status_code == 400
content = json.loads(response.content)
assert "error" in content
assert "warnings" in content
for warn_message in warn_messages:
assert any(warn_message in w for w in content["warnings"])
if "drop" not in column_operations or self.case_data["accepts_nan"]:
# the predict does not raise an error
error_message = json.loads(content["error"])
assert len(error_message["output"]) == len(self.expected_output)
if "drop" not in column_operations:
# if no column was dropped, the predictions should be the same
assert error_message["output"] == self.expected_output
else:
# otherwise some columns will be empty and predict errors.
assert (
"does not accept missing values encoded as NaN natively"
in content["error"]
)
def test_malformed_input(self):
self._check_requirement(self._can_load())
with TestClient(self.app) as client:
response = client.post("/", data=b"Where do I live ?")
assert response.status_code == 400
content = json.loads(response.content)
assert set(content.keys()) == {"error"}
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn | hf_public_repos/api-inference-community/docker_images/sklearn/tests/test_api_text_classification.py | import json
import os
from pathlib import Path
from unittest import TestCase, skipIf
import pytest
from app.main import ALLOWED_TASKS
from parameterized import parameterized_class
from starlette.testclient import TestClient
from tests.test_api import TEST_CASES, TESTABLE_MODELS
@parameterized_class([{"test_case": x} for x in TESTABLE_MODELS["text-classification"]])
@skipIf(
"text-classification" not in ALLOWED_TASKS,
"text-classification not implemented",
)
class TextClassificationTestCase(TestCase):
def setUp(self):
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = self.test_case
os.environ["TASK"] = "text-classification"
self.case_data = TEST_CASES["text-classification"][self.test_case]
sample_folder = Path(__file__).parent / "generators" / "samples"
self.data = json.load(open(sample_folder / self.case_data["input"], "r"))
self.expected_output = json.load(
open(sample_folder / self.case_data["output"], "r")
)
from app.main import app
self.app = app
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def _can_load(self):
# to load a model, it has to either support being loaded on new sklearn
# versions, or it needs to be saved by a new sklearn version, since the
# assumption is that the current sklearn version is the latest.
return (
self.case_data["loads_on_new_sklearn"] or not self.case_data["old_sklearn"]
)
def _check_requirement(self, requirement):
# This test is not supposed to run and is thus skipped.
if not requirement:
pytest.skip("Skipping test because requirements are not met.")
def test_success_code(self):
# This test does a sanity check on the output and checks the response
# code which should be 200. This requires the model to be from the
# latest sklearn which is the one installed locally.
self._check_requirement(not self.case_data["old_sklearn"])
data = self.data
expected_output_len = len(self.expected_output)
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": data["data"][0]})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(len(content), 1)
self.assertEqual(type(content[0]), list)
self.assertEqual(
set(k for el in content[0] for k in el.keys()),
{"label", "score"},
)
self.assertEqual(len(content), expected_output_len)
def test_wrong_sklearn_version_warning(self):
# if the wrong sklearn version is used the model will be loaded and
# gives an output, but warnings are raised. This test makes sure the
# right warnings are raised and that the output is included in the
# error message.
self._check_requirement(self.case_data["old_sklearn"] and self._can_load())
data = self.data
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": data["data"][0]})
# check response
assert response.status_code == 400
content = json.loads(response.content)
assert "error" in content
assert "warnings" in content
# check warnings
assert any("Trying to unpickle estimator" in w for w in content["warnings"])
warnings = json.loads(content["error"])["warnings"]
assert any("Trying to unpickle estimator" in w for w in warnings)
# check error
error_message = json.loads(content["error"])
assert error_message["output"] == self.expected_output
def test_cannot_load_model(self):
# test the error message when the model cannot be loaded on a wrong
# sklearn version
self._check_requirement(not self.case_data["loads_on_new_sklearn"])
data = self.data
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": data["data"][0]})
assert response.status_code == 400
content = json.loads(response.content)
assert "error" in content
assert "An error occurred while loading the model:" in content["error"]
def test_malformed_question(self):
# testing wrong input for inference API
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/sklearn-latest.yml | name: api-inference-community-test-generator-sklearn-latest
channels:
- conda-forge
- nodefaults
dependencies:
- scikit-learn
- pandas
- huggingface_hub
- pip
- pip:
# if you're testing skops, you should install from github, and probably
# a specific hash if your PR on the skops side is not merged.
- git+https://github.com/skops-dev/skops.git
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/run.sh | #!/usr/bin/env bash
# uncomment to enable debugging
# set -xe
SCRIPT_DIR=$( cd -- "$( dirname -- "${BASH_SOURCE[0]}" )" &> /dev/null && pwd )
cd $SCRIPT_DIR
# have to do this since can't do mamba run, and need bash functions to call
# activate
source $(mamba info -q --base)/etc/profile.d/conda.sh
source $(mamba info -q --base)/etc/profile.d/mamba.sh
mamba env update --file sklearn-1.0.yml
mamba env update --file sklearn-latest.yml
# not doing mamba run ... since it just wouldn't work and would use system's
# python
mamba activate api-inference-community-test-generator-sklearn-1-0
python generate.py 1.0
mamba deactivate
mamba activate api-inference-community-test-generator-sklearn-latest
python generate.py latest
mamba deactivate
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/sklearn-1.0.yml | name: api-inference-community-test-generator-sklearn-1-0
channels:
- conda-forge
- nodefaults
dependencies:
- scikit-learn=1.0.2
- pandas
- huggingface_hub
- pip
- pip:
# if you're testing skops, you should install from github, and probably
# a specific hash if your PR on the skops side is not merged.
- git+https://github.com/skops-dev/skops.git
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/generate.py | #!/usr/bin/env python3
"""Generate artefacts used for testing
Don't run this script directly but use `run.sh` instead.
For the given sklearn version, train models for different task types, upload
them with and without config to HF Hub, and store their input and predictions
locally (and in the GH repo).
These artefacts will be used for unit testing the sklearn integration.
"""
import json
import os
import pickle
import sys
import time
from operator import methodcaller
from pathlib import Path
from tempfile import mkdtemp, mkstemp
import sklearn
import skops.io as sio
from huggingface_hub import HfApi
from huggingface_hub.utils import RepositoryNotFoundError
from sklearn.datasets import fetch_20newsgroups, load_diabetes, load_iris
from sklearn.ensemble import (
HistGradientBoostingClassifier,
HistGradientBoostingRegressor,
)
from sklearn.feature_extraction.text import CountVectorizer
from sklearn.linear_model import LinearRegression, LogisticRegression
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import FunctionTransformer, StandardScaler
from skops import hub_utils
SLEEP_BETWEEN_PUSHES = 1
def push_repo(repo_name, local_repo):
# this token should be allowed to push to the skops-tests org.
token = os.environ["SKOPS_TESTS_TOKEN"]
repo_id = f"skops-tests/{repo_name}"
print(f"Pushing {repo_id}")
client = HfApi()
try:
client.delete_repo(repo_id, token=token)
except RepositoryNotFoundError:
# repo does not exist yet
pass
client.create_repo(repo_id=repo_id, token=token, repo_type="model")
client.upload_folder(
repo_id=repo_id,
path_in_repo=".",
folder_path=local_repo,
commit_message="pushing files to the repo from test generator!",
commit_description=None,
token=token,
repo_type=None,
revision=None,
create_pr=False,
)
# prevent AWS "503 Server Error: Slow Down for url" error
time.sleep(SLEEP_BETWEEN_PUSHES)
def get_tabular_classifiers():
# yield classifier names and estimators to train and push to hub.
# this is a pipeline with simple estimators which can be loaded across
# different sklearn versions.
yield "logistic_regression", make_pipeline(StandardScaler(), LogisticRegression())
# this estimator cannot be loaded on 1.1 if it's stored using 1.0, but it
# handles NaN input values which the previous pipeline cannot handle.
yield "hist_gradient_boosting", HistGradientBoostingClassifier()
def get_text_classifiers():
# yield classifier names and estimators to train and push to hub.
# this is a pipeline with simple estimators which can be loaded across
# different sklearn versions.
yield "logistic_regression", make_pipeline(CountVectorizer(), LogisticRegression())
# this estimator cannot be loaded on 1.1 if it's stored using 1.0, but it
# handles NaN input values which the previous pipeline cannot handle.
yield "hist_gradient_boosting", make_pipeline(
CountVectorizer(max_features=100),
FunctionTransformer(methodcaller("toarray")),
HistGradientBoostingClassifier(max_iter=20),
)
def get_tabular_regressors():
# yield regressor names and estimators to train and push to hub.
# this is a pipeline with simple estimators which can be loaded across
# different sklearn versions.
yield "linear_regression", make_pipeline(StandardScaler(), LinearRegression())
# this estimator cannot be loaded on 1.1 if it's stored using 1.0, but it
# handles NaN input values which the previous pipeline cannot handle.
yield "hist_gradient_boosting_regressor", HistGradientBoostingRegressor()
def create_repos(est_name, task_name, est, sample, version, serialization_format):
# given trained estimator instance, it's name, and the version tag, push to
# hub once with and once without a config file.
# initialize repo
_, est_filename = mkstemp(
prefix="skops-", suffix=SERIALIZATION_FORMATS[serialization_format]
)
if serialization_format == "pickle":
with open(est_filename, mode="bw") as f:
pickle.dump(est, file=f)
else:
sio.dump(est, est_filename)
local_repo = mkdtemp(prefix="skops-")
hub_utils.init(
model=est_filename,
requirements=[f"scikit-learn={sklearn.__version__}"],
dst=local_repo,
task=task_name,
data=sample,
)
# push WITH config
repo_name = REPO_NAMES[task_name].format(
version=version,
est_name=est_name,
w_or_wo="with",
serialization_format=serialization_format,
)
push_repo(repo_name=repo_name, local_repo=local_repo)
if serialization_format == "pickle":
# push WITHOUT CONFIG
repo_name = REPO_NAMES[task_name].format(
version=version,
est_name=est_name,
w_or_wo="without",
serialization_format=serialization_format,
)
# Now we remove the config file and push to a new repo
os.remove(Path(local_repo) / "config.json")
# The only valid file name for a model pickle file if no config.json is
# available is `sklearn_model.joblib`, otherwise the backend will fail to
# find the file.
os.rename(
Path(local_repo) / est_filename, Path(local_repo) / "sklearn_model.joblib"
)
push_repo(
repo_name=repo_name,
local_repo=local_repo,
)
def save_sample(sample, filename, task):
if "text" in task:
payload = {"data": sample}
else:
payload = {"data": sample.to_dict(orient="list")}
with open(Path(__file__).parent / "samples" / filename, "w+") as f:
json.dump(payload, f, indent=2)
def predict_tabular_classifier(est, sample, filename):
output = [int(x) for x in est.predict(sample)]
with open(Path(__file__).parent / "samples" / filename, "w") as f:
json.dump(output, f, indent=2)
def predict_tabular_regressor(est, sample, filename):
output = [float(x) for x in est.predict(sample)]
with open(Path(__file__).parent / "samples" / filename, "w") as f:
json.dump(output, f, indent=2)
def predict_text_classifier(est, sample, filename):
output = []
for i, c in enumerate(est.predict_proba(sample).tolist()[0]):
output.append({"label": str(est.classes_[i]), "score": c})
with open(Path(__file__).parent / "samples" / filename, "w") as f:
json.dump([output], f, indent=2)
#############
# CONSTANTS #
#############
# TASKS = ["tabular-classification", "tabular-regression", "text-classification"]
TASKS = ["text-classification"]
DATA = {
"tabular-classification": load_iris(return_X_y=True, as_frame=True),
"tabular-regression": load_diabetes(return_X_y=True, as_frame=True),
"text-classification": fetch_20newsgroups(subset="test", return_X_y=True),
}
MODELS = {
"tabular-classification": get_tabular_classifiers(),
"tabular-regression": get_tabular_regressors(),
"text-classification": get_text_classifiers(),
}
INPUT_NAMES = {
"tabular-classification": "iris-{version}-input.json",
"tabular-regression": "tabularregression-{version}-input.json",
"text-classification": "textclassification-{version}-input.json",
}
OUTPUT_NAMES = {
"tabular-classification": "iris-{est_name}-{version}-output.json",
"tabular-regression": "tabularregression-{est_name}-{version}-output.json",
"text-classification": "textclassification-{est_name}-{version}-output.json",
}
REPO_NAMES = {
"tabular-classification": "iris-sklearn-{version}-{est_name}-{w_or_wo}-config-{serialization_format}",
"tabular-regression": "tabularregression-sklearn-{version}-{est_name}-{w_or_wo}-config-{serialization_format}",
"text-classification": "textclassification-sklearn-{version}-{est_name}-{w_or_wo}-config-{serialization_format}",
}
PREDICT_FUNCTIONS = {
"tabular-classification": predict_tabular_classifier,
"tabular-regression": predict_tabular_regressor,
"text-classification": predict_text_classifier,
}
SERIALIZATION_FORMATS = {"pickle": ".pkl", "skops": ".skops"}
def main(version):
for task in TASKS:
print(f"Creating data for task '{task}' and version '{version}'")
X, y = DATA[task]
X_train, X_test, y_train, _ = train_test_split(
X, y, test_size=0.2, random_state=42
)
is_frame = getattr(X_train, "head", None)
if callable(is_frame):
sample = X_test.head(10)
else:
sample = X_test[:10]
# save model input, which are later used for tests
input_name = INPUT_NAMES[task].format(version=version)
save_sample(sample, input_name, task)
for est_name, model in MODELS[task]:
for serialization_format in SERIALIZATION_FORMATS:
model.fit(X_train, y_train)
create_repos(
est_name=est_name,
task_name=task,
est=model,
sample=sample,
version=version,
serialization_format=serialization_format,
)
# save model predictions, which are later used for tests
output_name = OUTPUT_NAMES[task].format(est_name=est_name, version=version)
predict = PREDICT_FUNCTIONS[task]
predict(model, sample, output_name)
if __name__ == "__main__":
sklearn_version = sys.argv[1]
main(sklearn_version)
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/iris-hist_gradient_boosting-latest-output.json | [
1,
0,
2,
1,
1,
0,
1,
2,
1,
1
] | 6 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/tabularregression-hist_gradient_boosting_regressor-latest-output.json | [
128.767605088706,
213.12484287152625,
152.87415981711302,
271.367552554169,
109.00499923164844,
81.88059224780598,
238.4711759447084,
215.14159932904784,
134.42407401121258,
189.15096503239798
] | 7 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/iris-logistic_regression-1.0-output.json | [
1,
0,
2,
1,
1,
0,
1,
2,
1,
1
] | 8 |
0 | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators | hf_public_repos/api-inference-community/docker_images/sklearn/tests/generators/samples/tabularregression-1.0-input.json | {
"data": {
"age": [
0.0453409833354632,
0.0925639831987174,
0.063503675590561,
0.096196521649737,
0.0126481372762872,
0.00901559882526763,
-0.00914709342983014,
-0.0236772472339084,
-0.0926954778032799,
-0.0600026317441039
],
"sex": [
-0.044641636506989,
-0.044641636506989,
0.0506801187398187,
-0.044641636506989,
0.0506801187398187,
-0.044641636506989,
0.0506801187398187,
0.0506801187398187,
0.0506801187398187,
0.0506801187398187
],
"bmi": [
-0.00620595413580824,
0.0369065288194278,
-0.00405032998804645,
0.0519958978537604,
-0.02021751109626,
-0.0245287593917836,
0.17055522598066,
0.045529025410475,
-0.0902752958985185,
0.0153502873418098
],
"bp": [
-0.015999222636143,
0.0218723549949558,
-0.0125563519424068,
0.0792535333386559,
-0.00222773986119799,
-0.0263278347173518,
0.0149866136074833,
0.0218723549949558,
-0.0573136709609782,
-0.0194420933298793
],
"s1": [
0.125018703134293,
-0.0249601584096305,
0.103003457403075,
0.054845107366035,
0.0383336730676214,
0.0988755988284711,
0.0300779559184146,
0.10988322169408,
-0.0249601584096305,
0.0369577202094203
],
"s2": [
0.125198101136752,
-0.0166581520539057,
0.0487898764601065,
0.0365770864503148,
0.05317395492516,
0.0941964034195887,
0.033758750294209,
0.0888728795691667,
-0.0304366843726451,
0.0481635795365275
],
"s3": [
0.0191869970174533,
0.000778807997017968,
0.056003375058324,
-0.0765355858888105,
-0.00658446761115617,
0.0707299262746723,
-0.0213110188275045,
0.000778807997017968,
-0.00658446761115617,
0.0191869970174533
],
"s4": [
0.0343088588777263,
-0.0394933828740919,
-0.00259226199818282,
0.141322109417863,
0.0343088588777263,
-0.00259226199818282,
0.0343088588777263,
0.0343088588777263,
-0.00259226199818282,
-0.00259226199818282
],
"s5": [
0.0324332257796019,
-0.0225121719296605,
0.0844952822124031,
0.098646374304928,
-0.00514530798026311,
-0.02139368094036,
0.0336568129023847,
0.0741925366900307,
0.024052583226893,
-0.0307512098645563
],
"s6": [
-0.0052198044153011,
-0.0217882320746399,
-0.0176461251598052,
0.0610539062220542,
-0.0093619113301358,
0.00720651632920303,
0.0320591578182113,
0.0610539062220542,
0.00306440941436832,
-0.00107769750046639
]
}
} | 9 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter1/audio_data.mdx | # Introduction to audio data
By nature, a sound wave is a continuous signal, meaning it contains an infinite number of signal values in a given time.
This poses problems for digital devices which expect finite arrays. To be processed, stored, and transmitted by digital
devices, the continuous sound wave needs to be converted into a series of discrete values, known as a digital representation.
If you look at any audio dataset, you'll find digital files with sound excerpts, such as text narration or music.
You may encounter different file formats such as `.wav` (Waveform Audio File), `.flac` (Free Lossless Audio Codec)
and `.mp3` (MPEG-1 Audio Layer 3). These formats mainly differ in how they compress the digital representation of the audio signal.
Let's take a look at how we arrive from a continuous signal to this representation. The analog signal is first captured by
a microphone, which converts the sound waves into an electrical signal. The electrical signal is then digitized by an
Analog-to-Digital Converter to get the digital representation through sampling.
## Sampling and sampling rate
Sampling is the process of measuring the value of a continuous signal at fixed time steps. The sampled waveform is _discrete_,
since it contains a finite number of signal values at uniform intervals.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/Signal_Sampling.png" alt="Signal sampling illustration">
</div>
*Illustration from Wikipedia article: [Sampling (signal processing)](https://en.wikipedia.org/wiki/Sampling_(signal_processing))*
The **sampling rate** (also called sampling frequency) is the number of samples taken in one second and is measured in
hertz (Hz). To give you a point of reference, CD-quality audio has a sampling rate of 44,100 Hz, meaning samples are taken
44,100 times per second. For comparison, high-resolution audio has a sampling rate of 192,000 Hz or 192 kHz. A common
sampling rate used in training speech models is 16,000 Hz or 16 kHz.
The choice of sampling rate primarily determines the highest frequency that can be captured from the signal. This is also
known as the Nyquist limit and is exactly half the sampling rate. The audible frequencies in human speech are below 8 kHz
and therefore sampling speech at 16 kHz is sufficient. Using a higher sampling rate will not capture more information and
merely leads to an increase in the computational cost of processing such files. On the other hand, sampling audio at too
low a sampling rate will result in information loss. Speech sampled at 8 kHz will sound muffled, as the higher frequencies
cannot be captured at this rate.
It's important to ensure that all audio examples in your dataset have the same sampling rate when working on any audio task.
If you plan to use custom audio data to fine-tune a pre-trained model, the sampling rate of your data should match the
sampling rate of the data the model was pre-trained on. The sampling rate determines the time interval between successive
audio samples, which impacts the temporal resolution of the audio data. Consider an example: a 5-second sound at a sampling
rate of 16,000 Hz will be represented as a series of 80,000 values, while the same 5-second sound at a sampling rate of
8,000 Hz will be represented as a series of 40,000 values. Transformer models that solve audio tasks treat examples as
sequences and rely on attention mechanisms to learn audio or multimodal representation. Since sequences are different for
audio examples at different sampling rates, it will be challenging for models to generalize between sampling rates.
**Resampling** is the process of making the sampling rates match, and is part of [preprocessing](preprocessing#resampling-the-audio-data) the audio data.
## Amplitude and bit depth
While the sampling rate tells you how often the samples are taken, what exactly are the values in each sample?
Sound is made by changes in air pressure at frequencies that are audible to humans. The **amplitude** of a sound describes
the sound pressure level at any given instant and is measured in decibels (dB). We perceive the amplitude as loudness.
To give you an example, a normal speaking voice is under 60 dB, and a rock concert can be at around 125 dB, pushing the
limits of human hearing.
In digital audio, each audio sample records the amplitude of the audio wave at a point in time. The **bit depth** of the
sample determines with how much precision this amplitude value can be described. The higher the bit depth, the more
faithfully the digital representation approximates the original continuous sound wave.
The most common audio bit depths are 16-bit and 24-bit. Each is a binary term, representing the number of possible steps
to which the amplitude value can be quantized when it's converted from continuous to discrete: 65,536 steps for 16-bit audio,
a whopping 16,777,216 steps for 24-bit audio. Because quantizing involves rounding off the continuous value to a discrete
value, the sampling process introduces noise. The higher the bit depth, the smaller this quantization noise. In practice,
the quantization noise of 16-bit audio is already small enough to be inaudible, and using higher bit depths is generally
not necessary.
You may also come across 32-bit audio. This stores the samples as floating-point values, whereas 16-bit and 24-bit audio
use integer samples. The precision of a 32-bit floating-point value is 24 bits, giving it the same bit depth as 24-bit audio.
Floating-point audio samples are expected to lie within the [-1.0, 1.0] range. Since machine learning models naturally
work on floating-point data, the audio must first be converted into floating-point format before it can be used to train
the model. We'll see how to do this in the next section on [Preprocessing](preprocessing).
Just as with continuous audio signals, the amplitude of digital audio is typically expressed in decibels (dB). Since
human hearing is logarithmic in nature — our ears are more sensitive to small fluctuations in quiet sounds than in loud
sounds — the loudness of a sound is easier to interpret if the amplitudes are in decibels, which are also logarithmic.
The decibel scale for real-world audio starts at 0 dB, which represents the quietest possible sound humans can hear, and
louder sounds have larger values. However, for digital audio signals, 0 dB is the loudest possible amplitude, while all
other amplitudes are negative. As a quick rule of thumb: every -6 dB is a halving of the amplitude, and anything below -60 dB
is generally inaudible unless you really crank up the volume.
## Audio as a waveform
You may have seen sounds visualized as a **waveform**, which plots the sample values over time and illustrates the changes
in the sound's amplitude. This is also known as the *time domain* representation of sound.
This type of visualization is useful for identifying specific features of the audio signal such as the timing of individual
sound events, the overall loudness of the signal, and any irregularities or noise present in the audio.
To plot the waveform for an audio signal, we can use a Python library called `librosa`:
```bash
pip install librosa
```
Let's take an example sound called "trumpet" that comes with the library:
```py
import librosa
array, sampling_rate = librosa.load(librosa.ex("trumpet"))
```
The example is loaded as a tuple of audio time series (here we call it `array`), and sampling rate (`sampling_rate`).
Let's take a look at this sound's waveform by using librosa's `waveshow()` function:
```py
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/waveform_plot.png" alt="Waveform plot">
</div>
This plots the amplitude of the signal on the y-axis and time along the x-axis. In other words, each point corresponds
to a single sample value that was taken when this sound was sampled. Also note that librosa returns the audio as
floating-point values already, and that the amplitude values are indeed within the [-1.0, 1.0] range.
Visualizing the audio along with listening to it can be a useful tool for understanding the data you are working with.
You can see the shape of the signal, observe patterns, learn to spot noise or distortion. If you preprocess data in some
ways, such as normalization, resampling, or filtering, you can visually confirm that preprocessing steps have been applied as expected.
After training a model, you can also visualize samples where errors occur (e.g. in audio classification task) to debug
the issue.
## The frequency spectrum
Another way to visualize audio data is to plot the **frequency spectrum** of an audio signal, also known as the *frequency domain*
representation. The spectrum is computed using the discrete Fourier transform or DFT. It describes the individual frequencies
that make up the signal and how strong they are.
Let's plot the frequency spectrum for the same trumpet sound by taking the DFT using numpy's `rfft()` function. While it
is possible to plot the spectrum of the entire sound, it's more useful to look at a small region instead. Here we'll take
the DFT over the first 4096 samples, which is roughly the length of the first note being played:
```py
import numpy as np
dft_input = array[:4096]
# calculate the DFT
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# get the amplitude spectrum in decibels
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# get the frequency bins
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/spectrum_plot.png" alt="Spectrum plot">
</div>
This plots the strength of the various frequency components that are present in this audio segment. The frequency values are on
the x-axis, usually plotted on a logarithmic scale, while their amplitudes are on the y-axis.
The frequency spectrum that we plotted shows several peaks. These peaks correspond to the harmonics of the note that's
being played, with the higher harmonics being quieter. Since the first peak is at around 620 Hz, this is the frequency spectrum of an E♭ note.
The output of the DFT is an array of complex numbers, made up of real and imaginary components. Taking
the magnitude with `np.abs(dft)` extracts the amplitude information from the spectrogram. The angle between the real and
imaginary components provides the so-called phase spectrum, but this is often discarded in machine learning applications.
You used `librosa.amplitude_to_db()` to convert the amplitude values to the decibel scale, making it easier to see
the finer details in the spectrum. Sometimes people use the **power spectrum**, which measures energy rather than amplitude;
this is simply a spectrum with the amplitude values squared.
<Tip>
💡 In practice, people use the term FFT interchangeably with DFT, as the FFT or Fast Fourier Transform is the only efficient
way to calculate the DFT on a computer.
</Tip>
The frequency spectrum of an audio signal contains the exact same information as its waveform — they are simply two different
ways of looking at the same data (here, the first 4096 samples from the trumpet sound). Where the waveform plots the amplitude
of the audio signal over time, the spectrum visualizes the amplitudes of the individual frequencies at a fixed point in time.
## Spectrogram
What if we want to see how the frequencies in an audio signal change? The trumpet plays several notes and they all have
different frequencies. The problem is that the spectrum only shows a frozen snapshot of the frequencies at a given instant.
The solution is to take multiple DFTs, each covering only a small slice of time, and stack the resulting spectra together
into a **spectrogram**.
A spectrogram plots the frequency content of an audio signal as it changes over time. It allows you to see time, frequency,
and amplitude all on one graph. The algorithm that performs this computation is the STFT or Short Time Fourier Transform.
The spectrogram is one of the most informative audio tools available to you. For example, when working with a music recording,
you can see the various instruments and vocal tracks and how they contribute to the overall sound. In speech, you can
identify different vowel sounds as each vowel is characterized by particular frequencies.
Let's plot a spectrogram for the same trumpet sound, using librosa's `stft()` and `specshow()` functions:
```py
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/spectrogram_plot.png" alt="Spectrogram plot">
</div>
In this plot, the x-axis represents time as in the waveform visualization but now the y-axis represents frequency in Hz.
The intensity of the color gives the amplitude or power of the frequency component at each point in time, measured in decibels (dB).
The spectrogram is created by taking short segments of the audio signal, typically lasting a few milliseconds, and calculating
the discrete Fourier transform of each segment to obtain its frequency spectrum. The resulting spectra are then stacked
together on the time axis to create the spectrogram. Each vertical slice in this image corresponds to a single frequency
spectrum, seen from the top. By default, `librosa.stft()` splits the audio signal into segments of 2048 samples, which
gives a good trade-off between frequency resolution and time resolution.
Since the spectrogram and the waveform are different views of the same data, it's possible to turn the spectrogram back
into the original waveform using the inverse STFT. However, this requires the phase information in addition to the amplitude
information. If the spectrogram was generated by a machine learning model, it typically only outputs the amplitudes. In
that case, we can use a phase reconstruction algorithm such as the classic Griffin-Lim algorithm, or using a neural network
called a vocoder, to reconstruct a waveform from the spectrogram.
Spectrograms aren't just used for visualization. Many machine learning models will take spectrograms as input — as opposed
to waveforms — and produce spectrograms as output.
Now that we know what a spectrogram is and how it's made, let's take a look at a variant of it widely used for speech processing: the mel spectrogram.
## Mel spectrogram
A mel spectrogram is a variation of the spectrogram that is commonly used in speech processing and machine learning tasks.
It is similar to a spectrogram in that it shows the frequency content of an audio signal over time, but on a different frequency axis.
In a standard spectrogram, the frequency axis is linear and is measured in hertz (Hz). However, the human auditory system
is more sensitive to changes in lower frequencies than higher frequencies, and this sensitivity decreases logarithmically
as frequency increases. The mel scale is a perceptual scale that approximates the non-linear frequency response of the human ear.
To create a mel spectrogram, the STFT is used just like before, splitting the audio into short segments to obtain a sequence
of frequency spectra. Additionally, each spectrum is sent through a set of filters, the so-called mel filterbank, to
transform the frequencies to the mel scale.
Let's see how we can plot a mel spectrogram using librosa's `melspectrogram()` function, which performs all of those steps for us:
```py
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/mel-spectrogram.png" alt="Mel spectrogram plot">
</div>
In the example above, `n_mels` stands for the number of mel bands to generate. The mel bands define a set of frequency
ranges that divide the spectrum into perceptually meaningful components, using a set of filters whose shape and spacing
are chosen to mimic the way the human ear responds to different frequencies. Common values for `n_mels` are 40 or 80. `fmax`
indicates the highest frequency (in Hz) we care about.
Just as with a regular spectrogram, it's common practice to express the strength of the mel frequency components in
decibels. This is commonly referred to as a **log-mel spectrogram**, because the conversion to decibels involves a
logarithmic operation. The above example used `librosa.power_to_db()` as `librosa.feature.melspectrogram()` creates a power spectrogram.
<Tip>
💡 Not all mel spectrograms are the same! There are two different mel scales in common use ("htk" and "slaney"),
and instead of the power spectrogram the amplitude spectrogram may be used. The conversion to a log-mel spectrogram doesn't
always compute true decibels but may simply take the `log`. Therefore, if a machine learning model expects a mel spectrogram
as input, double check to make sure you're computing it the same way.
</Tip>
Creating a mel spectrogram is a lossy operation as it involves filtering the signal. Converting a mel spectrogram back
into a waveform is more difficult than doing this for a regular spectrogram, as it requires estimating the frequencies
that were thrown away. This is why machine learning models such as HiFiGAN vocoder are needed to produce a waveform from a mel
spectrogram.
Compared to a standard spectrogram, a mel spectrogram can capture more meaningful features of the audio signal for
human perception, making it a popular choice in tasks such as speech recognition, speaker identification, and music genre classification.
Now that you know how to visualize audio data examples, go ahead and try to see what your favorite sounds look like. :)
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter1/load_and_explore.mdx | # Load and explore an audio dataset
In this course we will use the 🤗 Datasets library to work with audio datasets. 🤗 Datasets is an open-source library for
downloading and preparing datasets from all modalities including audio. The library offers easy access to an unparalleled
selection of machine learning datasets publicly available on Hugging Face Hub. Moreover, 🤗 Datasets includes multiple
features tailored to audio datasets that simplify working with such datasets for both researchers and practitioners.
To begin working with audio datasets, make sure you have the 🤗 Datasets library installed:
```bash
pip install datasets[audio]
```
One of the key defining features of 🤗 Datasets is the ability to download and prepare a dataset in just one line of
Python code using the `load_dataset()` function.
Let's load and explore and audio dataset called [MINDS-14](https://huggingface.co/datasets/PolyAI/minds14), which contains
recordings of people asking an e-banking system questions in several languages and dialects.
To load the MINDS-14 dataset, we need to copy the dataset's identifier on the Hub (`PolyAI/minds14`) and pass it
to the `load_dataset` function. We'll also specify that we're only interested in the Australian subset (`en-AU`) of
the data, and limit it to the training split:
```py
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
minds
```
**Output:**
```out
Dataset(
{
features: [
"path",
"audio",
"transcription",
"english_transcription",
"intent_class",
"lang_id",
],
num_rows: 654,
}
)
```
The dataset contains 654 audio files, each of which is accompanied by a transcription, an English translation, and a label
indicating the intent behind the person's query. The audio column contains the raw audio data. Let's take a closer look
at one of the examples:
```py
example = minds[0]
example
```
**Output:**
```out
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[0.0, 0.00024414, -0.00024414, ..., -0.00024414, 0.00024414, 0.0012207],
dtype=float32,
),
"sampling_rate": 8000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"english_transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
"lang_id": 2,
}
```
You may notice that the audio column contains several features. Here's what they are:
* `path`: the path to the audio file (`*.wav` in this case).
* `array`: The decoded audio data, represented as a 1-dimensional NumPy array.
* `sampling_rate`. The sampling rate of the audio file (8,000 Hz in this example).
The `intent_class` is a classification category of the audio recording. To convert this number into a meaningful string,
we can use the `int2str()` method:
```py
id2label = minds.features["intent_class"].int2str
id2label(example["intent_class"])
```
**Output:**
```out
"pay_bill"
```
If you look at the transcription feature, you can see that the audio file indeed has recorded a person asking a question
about paying a bill.
If you plan to train an audio classifier on this subset of data, you may not necessarily need all of the features. For example,
the `lang_id` is going to have the same value for all examples, and won't be useful. The `english_transcription` will likely
duplicate the `transcription` in this subset, so we can safely remove them.
You can easily remove irrelevant features using 🤗 Datasets' `remove_columns` method:
```py
columns_to_remove = ["lang_id", "english_transcription"]
minds = minds.remove_columns(columns_to_remove)
minds
```
**Output:**
```out
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 654})
```
Now that we've loaded and inspected the raw contents of the dataset, let's listen to a few examples! We'll use the `Blocks`
and `Audio` features from `Gradio` to decode a few random samples from the dataset:
```py
import gradio as gr
def generate_audio():
example = minds.shuffle()[0]
audio = example["audio"]
return (
audio["sampling_rate"],
audio["array"],
), id2label(example["intent_class"])
with gr.Blocks() as demo:
with gr.Column():
for _ in range(4):
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)
```
If you'd like to, you can also visualize some of the examples. Let's plot the waveform for the first example.
```py
import librosa
import matplotlib.pyplot as plt
import librosa.display
array = example["audio"]["array"]
sampling_rate = example["audio"]["sampling_rate"]
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/waveform_unit1.png" alt="Waveform plot">
</div>
Try it out! Download another dialect or language of the MINDS-14 dataset, listen and visualize some examples to get a sense
of the variation in the whole dataset. You can find the full list of available languages [here](https://huggingface.co/datasets/PolyAI/minds14). | 1 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter7/supplemental_reading.mdx | # Supplemental reading and resources
This Unit pieced together many components from previous units, introducing the tasks of speech-to-speech translation,
voice assistants and speaker diarization. The supplemental reading material is thus split into these three new tasks
for your convenience:
Speech-to-speech translation:
* [STST with discrete units](https://ai.facebook.com/blog/advancing-direct-speech-to-speech-modeling-with-discrete-units/) by Meta AI: a direct approach to STST through encoder-decoder models
* [Hokkien direct speech-to-speech translation](https://ai.facebook.com/blog/ai-translation-hokkien/) by Meta AI: a direct approach to STST using encoder-decoder models with a two-stage decoder
* [Leveraging unsupervised and weakly-supervised data to improve direct STST](https://arxiv.org/abs/2203.13339) by Google: proposes new approaches for leveraging unsupervised and weakly supervised data for training direct STST models and a small change to the Transformer architecture
* [Translatotron-2](https://google-research.github.io/lingvo-lab/translatotron2/) by Google: a system that is able to retain speaker characteristics in translated speech
Voice Assistant:
* [Accurate wakeword detection](https://www.amazon.science/publications/accurate-detection-of-wake-word-start-and-end-using-a-cnn) by Amazon: a low latency approach for wakeword detection for on-device applications
* [RNN-Transducer Architecture](https://arxiv.org/pdf/1811.06621.pdf) by Google: a modification to the CTC architecture for streaming on-device ASR
Meeting Transcriptions:
* [pyannote.audio Technical Report](https://huggingface.co/pyannote/speaker-diarization/blob/main/technical_report_2.1.pdf) by Hervé Bredin: this report describes the main principles behind the `pyannote.audio` speaker diarization pipeline
* [Whisper X](https://arxiv.org/pdf/2303.00747.pdf) by Max Bain et al.: a superior approach to computing word-level timestamps using the Whisper model | 2 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter7/transcribe-meeting.mdx | # Transcribe a meeting
In this final section, we'll use the Whisper model to generate a transcription for a conversation or meeting between
two or more speakers. We'll then pair it with a *speaker diarization* model to predict "who spoke when". By matching
the timestamps from the Whisper transcriptions with the timestamps from the speaker diarization model, we can predict an
end-to-end meeting transcription with fully formatted start / end times for each speaker. This is a basic version of
the meeting transcription services you might have seen online from the likes of [Otter.ai](https://otter.ai) and co:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/diarization_transcription.png">
</div>
## Speaker Diarization
Speaker diarization (or diarisation) is the task of taking an unlabelled audio input and predicting "who spoke when".
In doing so, we can predict start / end timestamps for each speaker turn, corresponding to when each speaker starts
speaking and when they finish.
🤗 Transformers currently does not have a model for speaker diarization included in the library, but there are checkpoints
on the Hub that can be used with relative ease. In this example, we'll use the pre-trained speaker diarization model from
[pyannote.audio](https://github.com/pyannote/pyannote-audio). Let's get started and pip install the package:
```bash
pip install --upgrade pyannote.audio
```
Great! The weights for this model are hosted on the Hugging Face Hub. To access them, we first have to agree to the speaker diarization model's
terms of use: [pyannote/speaker-diarization](https://huggingface.co/pyannote/speaker-diarization). And subsequently the
segmentation model's terms of use: [pyannote/segmentation](https://huggingface.co/pyannote/segmentation).
Once complete, we can load the pre-trained speaker diarization pipeline locally on our device:
```python
from pyannote.audio import Pipeline
diarization_pipeline = Pipeline.from_pretrained(
"pyannote/[email protected]", use_auth_token=True
)
```
Let's try it out on a sample audio file! For this, we'll load a sample of the [LibriSpeech ASR](https://huggingface.co/datasets/librispeech_asr)
dataset that consists of two different speakers that have been concatenated together to give a single audio file:
```python
from datasets import load_dataset
concatenated_librispeech = load_dataset(
"sanchit-gandhi/concatenated_librispeech", split="train", streaming=True
)
sample = next(iter(concatenated_librispeech))
```
We can listen to the audio to see what it sounds like:
```python
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
Cool! We can clearly hear two different speakers, with a transition roughly 15s of the way through. Let's pass this audio
file to the diarization model to get the speaker start / end times. Note that pyannote.audio expects the audio input to be a
PyTorch tensor of shape `(channels, seq_len)`, so we need to perform this conversion prior to running the model:
```python
import torch
input_tensor = torch.from_numpy(sample["audio"]["array"][None, :]).float()
outputs = diarization_pipeline(
{"waveform": input_tensor, "sample_rate": sample["audio"]["sampling_rate"]}
)
outputs.for_json()["content"]
```
```text
[{'segment': {'start': 0.4978125, 'end': 14.520937500000002},
'track': 'B',
'label': 'SPEAKER_01'},
{'segment': {'start': 15.364687500000002, 'end': 21.3721875},
'track': 'A',
'label': 'SPEAKER_00'}]
```
This looks pretty good! We can see that the first speaker is predicted as speaking up until the 14.5 second mark, and the
second speaker from 15.4s onwards. Now we need to get our transcription!
## Speech transcription
For the third time in this Unit, we'll use the Whisper model for our speech transcription system. Specifically, we'll load the
[Whisper Base](https://huggingface.co/openai/whisper-base) checkpoint, since it's small enough to give good
inference speed with reasonable transcription accuracy. As before, feel free to use any speech recognition checkpoint
on [the Hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&library=transformers&sort=trending),
including Wav2Vec2, MMS ASR or other Whisper checkpoints:
```python
from transformers import pipeline
asr_pipeline = pipeline(
"automatic-speech-recognition",
model="openai/whisper-base",
)
```
Let's get the transcription for our sample audio, returning the segment level timestamps as well so that we know the
start / end times for each segment. You'll remember from Unit 5 that we need to pass the argument
`return_timestamps=True` to activate the timestamp prediction task for Whisper:
```python
asr_pipeline(
sample["audio"].copy(),
generate_kwargs={"max_new_tokens": 256},
return_timestamps=True,
)
```
```text
{
"text": " The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight. He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
"chunks": [
{"timestamp": (0.0, 3.56), "text": " The second and importance is as follows."},
{
"timestamp": (3.56, 7.84),
"text": " Sovereignty may be defined to be the right of making laws.",
},
{
"timestamp": (7.84, 13.88),
"text": " In France, the king really exercises a portion of the sovereign power, since the laws have",
},
{"timestamp": (13.88, 15.48), "text": " no weight."},
{
"timestamp": (15.48, 19.44),
"text": " He was in a favored state of mind, owing to the blight his wife's action threatened to",
},
{"timestamp": (19.44, 21.28), "text": " cast upon his entire future."},
],
}
```
Alright! We see that each segment of the transcript has a start and end time, with the speakers changing at the 15.48 second
mark. We can now pair this transcription with the speaker timestamps that we got from our diarization model to get our
final transcription.
## Speechbox
To get the final transcription, we'll align the timestamps from the diarization model with those from the Whisper model.
The diarization model predicted the first speaker to end at 14.5 seconds, and the second speaker to start at 15.4s, whereas Whisper predicted segment boundaries at
13.88, 15.48 and 19.44 seconds respectively. Since the timestamps from Whisper don't match perfectly with those from the
diarization model, we need to find which of these boundaries are closest to 14.5 and 15.4 seconds, and segment the transcription by
speakers accordingly. Specifically, we'll find the closest alignment between diarization and transcription timestamps by
minimising the absolute distance between both.
Luckily for us, we can use the 🤗 Speechbox package to perform this alignment. First, let's pip install `speechbox` from
main:
```bash
pip install git+https://github.com/huggingface/speechbox
```
We can now instantiate our combined diarization plus transcription pipeline, by passing the diarization model and
ASR model to the [`ASRDiarizationPipeline`](https://github.com/huggingface/speechbox/tree/main#asr-with-speaker-diarization) class:
```python
from speechbox import ASRDiarizationPipeline
pipeline = ASRDiarizationPipeline(
asr_pipeline=asr_pipeline, diarization_pipeline=diarization_pipeline
)
```
<Tip>
You can also instantiate the <code>ASRDiarizationPipeline</code> directly from pre-trained by specifying the model id
of an ASR model on the Hub:
<p><code>pipeline = ASRDiarizationPipeline.from_pretrained("openai/whisper-base")</code></p>
</Tip>
Let's pass the audio file to the composite pipeline and see what we get out:
```python
pipeline(sample["audio"].copy())
```
```text
[{'speaker': 'SPEAKER_01',
'text': ' The second and importance is as follows. Sovereignty may be defined to be the right of making laws. In France, the king really exercises a portion of the sovereign power, since the laws have no weight.',
'timestamp': (0.0, 15.48)},
{'speaker': 'SPEAKER_00',
'text': " He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon his entire future.",
'timestamp': (15.48, 21.28)}]
```
Excellent! The first speaker is segmented as speaking from 0 to 15.48 seconds, and the second speaker from 15.48 to 21.28 seconds,
with the corresponding transcriptions for each.
We can format the timestamps a little more nicely by defining two helper functions. The first converts a tuple of
timestamps to a string, rounded to a set number of decimal places. The second combines the speaker id, timestamp and text
information onto one line, and splits each speaker onto their own line for ease of reading:
```python
def tuple_to_string(start_end_tuple, ndigits=1):
return str((round(start_end_tuple[0], ndigits), round(start_end_tuple[1], ndigits)))
def format_as_transcription(raw_segments):
return "\n\n".join(
[
chunk["speaker"] + " " + tuple_to_string(chunk["timestamp"]) + chunk["text"]
for chunk in raw_segments
]
)
```
Let's re-run the pipeline, this time formatting the transcription according to the function we've just defined:
```python
outputs = pipeline(sample["audio"].copy())
format_as_transcription(outputs)
```
```text
SPEAKER_01 (0.0, 15.5) The second and importance is as follows. Sovereignty may be defined to be the right of making laws.
In France, the king really exercises a portion of the sovereign power, since the laws have no weight.
SPEAKER_00 (15.5, 21.3) He was in a favored state of mind, owing to the blight his wife's action threatened to cast upon
his entire future.
```
There we go! With that, we've both diarized and transcribe our input audio and returned speaker-segmented transcriptions.
While the minimum distance algoirthm to align the diarized timestamps and transcribed timestamps is simple, it
works well in practice. If you want to explore more advanced methods for combining the timestamps, the
source code for the `ASRDiarizationPipeline` is a good place to start: [speechbox/diarize.py](https://github.com/huggingface/speechbox/blob/96d2d1a180252d92263f862a1cd25a48860f1aed/src/speechbox/diarize.py#L12)
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter7/introduction.mdx | # Unit 7. Putting it all together 🪢
Well done on making it to Unit 7 🥳 You're just a few steps away from completing the course and acquiring the final few
skills you need to navigate the field of Audio ML. In terms of understanding, you already know everything there is to know!
Together, we've comprehensively covered the main topics that constitute the audio domain and their accompanying theory
(audio data, audio classification, speech recognition and text-to-speech). What this Unit aims to deliver is a framework
for **putting it all together**: now that you know how each of these tasks work in isolation, we're going to explore how
you can combine them together to build some real-world applications.
## What you'll learn and what you'll build
In this Unit, we'll cover the following three topics:
* [Speech-to-speech translation](speech-to-speech): translate speech from one language into speech in a different language
* [Creating a voice assistant](voice-assistant): build your own voice assistant that works in a similar way to Alexa or Siri
* [Transcribing meetings](transcribe-meeting): transcribe a meeting and label the transcript with who spoke when
| 4 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter7/speech-to-speech.mdx | # Speech-to-speech translation
Speech-to-speech translation (STST or S2ST) is a relatively new spoken language processing task. It involves translating
speech from one langauge into speech in a **different** language:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/s2st.png" alt="Diagram of speech to speech translation">
</div>
STST can be viewed as an extension of the traditional machine translation (MT) task: instead of translating **text** from one
language into another, we translate **speech** from one language into another. STST holds applications in the field of
multilingual communication, enabling speakers in different languages to communicate with one another through the medium
of speech.
Suppose you want to communicate with another individual across a langauge barrier. Rather
than writing the information that you want to convey and then translating it to text in the target language, you
can speak it directly and have a STST system convert your spoken speech into the target langauge. The recipient can then
respond by speaking back at the STST system, and you can listen to their response. This is a more natural way of communicating
compared to text-based machine translation.
In this chapter, we'll explore a *cascaded* approach to STST, piecing together the knowledge you've acquired in Units
5 and 6 of the course. We'll use a *speech translation (ST)* system to transcribe the source speech into text in the target
language, then *text-to-speech (TTS)* to generate speech in the target language from the translated text:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/s2st_cascaded.png" alt="Diagram of cascaded speech to speech translation">
</div>
We could also have used a three stage approach, where first we use an automatic speech recognition (ASR) system to
transcribe the source speech into text in the same language, then machine translation to translate the transcribed text
into the target language, and finally text-to-speech to generate speech in the target language. However, adding more
components to the pipeline lends itself to *error propagation*, where the errors introduced in one system are compounded
as they flow through the remaining systems, and also increases latency, since inference has to be conducted for more models.
While this cascaded approach to STST is pretty straightforward, it results in very effective STST systems. The three-stage
cascaded system of ASR + MT + TTS was previously used to power many commercial STST products, including [Google Translate](https://ai.googleblog.com/2019/05/introducing-translatotron-end-to-end.html).
It's also a very data and compute efficient way of developing a STST system, since existing speech recognition and
text-to-speech systems can be coupled together to yield a new STST model without any additional training.
In the remainder of this Unit, we'll focus on creating a STST system that translates speech from any language X to speech
in English. The methods covered can be extended to STST systems that translate from any language X to any
langauge Y, but we leave this as an extension to the reader and provide pointers where applicable. We further divide up the
task of STST into its two constituent components: ST and TTS. We'll finish by piecing them together to build a Gradio
demo to showcase our system.
## Speech translation
We'll use the Whisper model for our speech translation system, since it's capable of translating from over 96 languages
to English. Specifically, we'll load the [Whisper Base](https://huggingface.co/openai/whisper-base) checkpoint, which
clocks in at 74M parameters. It's by no means the most performant Whisper model, with the [largest Whisper checkpoint](https://huggingface.co/openai/whisper-large-v2)
being over 20x larger, but since we're concatenating two auto-regressive systems together (ST + TTS), we want to ensure
each model can generate relatively quickly so that we get reasonable inference speed:
```python
import torch
from transformers import pipeline
device = "cuda:0" if torch.cuda.is_available() else "cpu"
pipe = pipeline(
"automatic-speech-recognition", model="openai/whisper-base", device=device
)
```
Great! To test our STST system, we'll load an audio sample in a non-English language. Let's load the first example of the
Italian (`it`) split of the [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli) dataset:
```python
from datasets import load_dataset
dataset = load_dataset("facebook/voxpopuli", "it", split="validation", streaming=True)
sample = next(iter(dataset))
```
To listen to this sample, we can either play it using the dataset viewer on the Hub: [facebook/voxpopuli/viewer](https://huggingface.co/datasets/facebook/voxpopuli/viewer/it/validation?row=0)
Or playback using the ipynb audio feature:
```python
from IPython.display import Audio
Audio(sample["audio"]["array"], rate=sample["audio"]["sampling_rate"])
```
Now let's define a function that takes this audio input and returns the translated text. You'll remember that we have to
pass the generation key-word argument for the `"task"`, setting it to `"translate"` to ensure that Whisper performs
speech translation and not speech recognition:
```python
def translate(audio):
outputs = pipe(audio, max_new_tokens=256, generate_kwargs={"task": "translate"})
return outputs["text"]
```
<Tip>
Whisper can also be 'tricked' into translating from speech in any language X to any language Y. Simply set the task to
`"transcribe"` and the `"language"` to your target language in the generation key-word arguments,
e.g. for Spanish, one would set:
`generate_kwargs={"task": "transcribe", "language": "es"}`
</Tip>
Great! Let's quickly check that we get a sensible result from the model:
```python
translate(sample["audio"].copy())
```
```
' psychological and social. I think that it is a very important step in the construction of a juridical space of freedom, circulation and protection of rights.'
```
Alright! If we compare this to the source text:
```python
sample["raw_text"]
```
```
'Penso che questo sia un passo in avanti importante nella costruzione di uno spazio giuridico di libertà di circolazione e di protezione dei diritti per le persone in Europa.'
```
We see that the translation more or less lines up (you can double check this using Google Translate), barring a small
extra few words at the start of the transcription where the speaker was finishing off their previous sentence.
With that, we've completed the first half of our cascaded STST pipeline, putting into practice the skills we gained in Unit 5
when we learnt how to use the Whisper model for speech recognition and translation. If you want a refresher on any of the
steps we covered, have a read through the section on [Pre-trained models for ASR](../chapter5/asr_models) from Unit 5.
## Text-to-speech
The second half of our cascaded STST system involves mapping from English text to English speech. For this, we'll use
the pre-trained [SpeechT5 TTS](https://huggingface.co/microsoft/speecht5_tts) model for English TTS. 🤗 Transformers currently doesn't
have a TTS `pipeline`, so we'll have to use the model directly ourselves. This is no biggie, you're all experts on using
the model for inference following Unit 6!
First, let's load the SpeechT5 processor, model and vocoder from the pre-trained checkpoint:
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts")
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan")
```
<Tip>
Here we're using SpeechT5 checkpoint trained specifically for English TTS. Should you wish to translate into a language
other than English, either swap the checkpoint for a SpeechT5 TTS model fine-tuned on your language of choice, or
use an MMS TTS checkpoint pre-trained in your target langauge.
</Tip>
As with the Whisper model, we'll place the SpeechT5 model and vocoder on our GPU accelerator device if we have one:
```python
model.to(device)
vocoder.to(device)
```
Great! Let's load up the speaker embeddings:
```python
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
We can now write a function that takes a text prompt as input, and generates the corresponding speech. We'll first pre-process
the text input using the SpeechT5 processor, tokenizing the text to get our input ids. We'll then pass the input ids and
speaker embeddings to the SpeechT5 model, placing each on the accelerator device if available. Finally, we'll return the
generated speech, bringing it back to the CPU so that we can play it back in our ipynb notebook:
```python
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()
```
Let's check it works with a dummy text input:
```python
speech = synthesise("Hey there! This is a test!")
Audio(speech, rate=16000)
```
Sounds good! Now for the exciting part - piecing it all together.
## Creating a STST demo
Before we create a [Gradio](https://gradio.app) demo to showcase our STST system, let's first do a quick sanity check
to make sure we can concatenate the two models, putting an audio sample in and getting an audio sample out. We'll do
this by concatenating the two functions we defined in the previous two sub-sections, such that we input the source audio
and retrieve the translated text, then synthesise the translated text to get the translated speech. Finally, we'll convert
the synthesised speech to an `int16` array, which is the output audio file format expected by Gradio. To do this, we
first have to normalise the audio array by the dynamic range of the target dtype (`int16`), and then convert from the
default NumPy dtype (`float64`) to the target dtype (`int16`):
```python
import numpy as np
target_dtype = np.int16
max_range = np.iinfo(target_dtype).max
def speech_to_speech_translation(audio):
translated_text = translate(audio)
synthesised_speech = synthesise(translated_text)
synthesised_speech = (synthesised_speech.numpy() * max_range).astype(np.int16)
return 16000, synthesised_speech
```
Let's check this concatenated function gives the expected result:
```python
sampling_rate, synthesised_speech = speech_to_speech_translation(sample["audio"])
Audio(synthesised_speech, rate=sampling_rate)
```
Perfect! Now we'll wrap this up into a nice Gradio demo so that we can record our source speech using a microphone input
or file input and playback the system's prediction:
```python
import gradio as gr
demo = gr.Blocks()
mic_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="microphone", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
file_translate = gr.Interface(
fn=speech_to_speech_translation,
inputs=gr.Audio(source="upload", type="filepath"),
outputs=gr.Audio(label="Generated Speech", type="numpy"),
)
with demo:
gr.TabbedInterface([mic_translate, file_translate], ["Microphone", "Audio File"])
demo.launch(debug=True)
```
This will launch a Gradio demo similar to the one running on the Hugging Face Space:
<iframe src="https://course-demos-speech-to-speech-translation.hf.space" frameBorder="0" height="450" title="Gradio app" class="container p-0 flex-grow space-iframe" allow="accelerometer; ambient-light-sensor; autoplay; battery; camera; document-domain; encrypted-media; fullscreen; geolocation; gyroscope; layout-animations; legacy-image-formats; magnetometer; microphone; midi; oversized-images; payment; picture-in-picture; publickey-credentials-get; sync-xhr; usb; vr ; wake-lock; xr-spatial-tracking" sandbox="allow-forms allow-modals allow-popups allow-popups-to-escape-sandbox allow-same-origin allow-scripts allow-downloads"></iframe>
You can [duplicate](https://huggingface.co/spaces/course-demos/speech-to-speech-translation?duplicate=true) this demo and adapt
it to use a different Whisper checkpoint, a different TTS checkpoint, or relax the constraint of outputting English
speech and follow the tips provide for translating into a langauge of your choice!
## Going forwards
While the cascaded system is a compute and data efficient way of building a STST system, it suffers from the issues of
error propagation and additive latency described above. Recent works have explored a *direct* approach to STST, one that
does not predict an intermediate text output and instead maps directly from source speech to target speech. These systems
are also capable of retaining the speaking characteristics of the source speaker in the target speech (such a prosody,
pitch and intonation). If you're interested in finding out more about these systems, check-out the resources listed in
the section on [supplemental reading](supplemental_reading).
| 5 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter7/hands_on.mdx | # Hands-on exercise
In this Unit, we consolidated the material covered in the previous six units of the course to build three integrated
audio applications. As you've experienced, building more involved audio tools is fully within reach by using the
foundational skills you've acquired in this course.
The hands-on exercise takes one of the applications covered in this Unit, and extends it with a few multilingual
tweaks 🌍 Your objective is to take the [cascaded speech-to-speech translation Gradio demo](https://huggingface.co/spaces/course-demos/speech-to-speech-translation)
from the first section in this Unit, and update it to translate to any **non-English** language. That is to say, the
demo should take speech in language X, and translate it to speech in language Y, where the target language Y is not
English. You should start by [duplicating](https://huggingface.co/spaces/course-demos/speech-to-speech-translation?duplicate=true)
the template under your Hugging Face namespace. There's no requirement to use a GPU accelerator device - the free CPU
tier works just fine 🤗 However, you should ensure that the visibility of your demo is set to **public**. This is required
such that your demo is accessible to us and can thus be checked for correctness.
Tips for updating the speech translation function to perform multilingual speech translation are provided in the
section on [speech-to-speech translation](speech-to-speech). By following these instructions, you should be able
to update the demo to translate from speech in language X to text in language Y, which is half of the task!
To synthesise from text in language Y to speech in language Y, where Y is a multilingual language, you will need
to use a multilingual TTS checkpoint. For this, you can either use the SpeechT5 TTS checkpoint that you fine-tuned
in the previous hands-on exercise, or a pre-trained multilingual TTS checkpoint. There are two options for pre-trained
checkpoints, either the checkpoint [sanchit-gandhi/speecht5_tts_vox_nl](https://huggingface.co/sanchit-gandhi/speecht5_tts_vox_nl),
which is a SpeechT5 checkpoint fine-tuned on the Dutch split of the [VoxPopuli](https://huggingface.co/datasets/facebook/voxpopuli)
dataset, or an MMS TTS checkpoint (see section on [pretrained models for TTS](../chapter6/pre-trained_models)).
<Tip>
In our experience experimenting with the Dutch language, using an MMS TTS checkpoint results in better performance than a
fine-tuned SpeechT5 one, but you might find that your fine-tuned TTS checkpoint is preferable in your language.
If you decide to use an MMS TTS checkpoint, you will need to update the <a href="https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/requirements.txt#L2">requirements.txt</a>
file of your demo to install <code>transformers</code> from the PR branch:
<p><code>git+https://github.com/hollance/transformers.git@6900e8ba6532162a8613d2270ec2286c3f58f57b</code></p>
</Tip>
Your demo should take as input an audio file, and return as output another audio file, matching the signature of the
[`speech_to_speech_translation`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/3946ba6705a6632a63de8672ac52a482ab74b3fc/app.py#L35)
function in the template demo. Therefore, we recommend that you leave the main function `speech_to_speech_translation`
as is, and only update the [`translate`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L24)
and [`synthesise`](https://huggingface.co/spaces/course-demos/speech-to-speech-translation/blob/a03175878f522df7445290d5508bfb5c5178f787/app.py#L29)
functions as required.
Once you have built your demo as a Gradio demo on the Hugging Face Hub, you can submit it for assessment. Head to the
Space [audio-course-u7-assessment](https://huggingface.co/spaces/huggingface-course/audio-course-u7-assessment) and
provide the repository id of your demo when prompted. This Space will check that your demo has been built correctly by
sending a sample audio file to your demo and checking that the returned audio file is indeed non-English. If your demo
works correctly, you'll get a green tick next to your name on the overall [progress space](https://huggingface.co/spaces/MariaK/Check-my-progress-Audio-Course) ✅
| 6 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter7/voice-assistant.mdx | # Creating a voice assistant
In this section, we'll piece together three models that we've already had hands-on experience with to build an end-to-end
voice assistant called **Marvin** 🤖. Like Amazon's Alexa or Apple's Siri, Marvin is a virtual voice assistant who
responds to a particular 'wake word', then listens out for a spoken query, and finally responds with a spoken answer.
We can break down the voice assistant pipeline into four stages, each of which requires a standalone model:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/voice_assistant.png">
</div>
### 1. Wake word detection
Voice assistants are constantly listening to the audio inputs coming through your device's microphone, however they only
boot into action when a particular 'wake word' or 'trigger word' is spoken.
The wake word detection task is handled by a small on-device audio classification model, which is much smaller and lighter
than the speech recognition model, often only several millions of parameters compared to several hundred millions for
speech recognition. Thus, it can be run continuously on your device without draining your battery. Only when the wake
word is detected is the larger speech recognition model launched, and afterwards it is shut down again.
### 2. Speech transcription
The next stage in the pipeline is transcribing the spoken query to text. In practice, transferring audio files from your
local device to the Cloud is slow due to the large nature of audio files, so it's more efficient to transcribe them
directly using an automatic speech recognition (ASR) model on-device rather than using a model in the Cloud. The on-device
model might be smaller and thus less accurate than one hosted in the Cloud, but the faster inference speed makes it
worthwhile since we can run speech recognition in near real-time, our spoken audio utterance being transcribed as we say it.
We're very familiar with the speech recognition process now, so this should be a piece of cake!
### 3. Language model query
Now that we know what the user asked, we need to generate a response! The best candidate models for this task are
*large language models (LLMs)*, since they are effectively able to understand the semantics of the text query and
generate a suitable response.
Since our text query is small (just a few text tokens), and language models large (many billions of parameters), the most
efficient way of running LLM inference is to send our text query from our device to an LLM running in the Cloud,
generate a text response, and return the response back to the device.
### 4. Synthesise speech
Finally, we'll use a text-to-speech (TTS) model to synthesise the text response as spoken speech. This is done
on-device, but you could feasibly run a TTS model in the Cloud, generating the audio output and transferring it back to
the device.
Again, we've done this several times now, so the process will be very familiar!
<Tip>
The following section requires the use of a microphone to record a voice input. Since Google Colab machines do not
have microphone compatibility, it is recommended to run this section locally, either on your CPU, or on a GPU if you
have local access. The checkpoint sizes have been selected as those small enough to run adequately fast on CPU, so
you will still get good performance without a GPU.
</Tip>
## Wake word detection
The first stage in the voice assistant pipeline is detecting whether the wake word was spoken, and we need to find ourselves
an appropriate pre-trained model for this task! You'll remember from the section on [pre-trained models for audio classification](../chapter4/classification_models)
that [Speech Commands](https://huggingface.co/datasets/speech_commands) is a dataset of spoken words designed to
evaluate audio classification models on 15+ simple command words like `"up"`, `"down"`, `"yes"` and `"no"`, as well as a
`"silence"` label to classify no speech. Take a minute to listen through the samples on the datasets viewer on
the Hub and re-acquaint yourself with the Speech Commands dataset: [datasets viewer](https://huggingface.co/datasets/speech_commands/viewer/v0.01/train).
We can take an audio classification model pre-trained on the Speech Commands dataset and pick one of these simple command
words to be our chosen wake word. Out of the 15+ possible command words, if the model predicts our chosen wake word with the
highest probability, we can be fairly certain that the wake word has been said.
Let's head to the Hugging Face Hub and click on the "Models" tab: https://huggingface.co/models
This is going to bring up all the models on the Hugging Face Hub, sorted by downloads in the past 30 days:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/all_models.png">
</div>
You'll notice on the left-hand side that we have a selection of tabs that we can select to filter models by task, library,
dataset, etc. Scroll down and select the task "Audio Classification" from the list of audio tasks:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/by_audio_classification.png">
</div>
We're now presented with the sub-set of 500+ audio classification models on the Hub. To further refine this selection, we
can filter models by dataset. Click on the tab "Datasets", and in the search box type "speech_commands". As you begin typing,
you'll see the selection for `speech_commands` appear underneath the search tab. You can click this button to filter all
audio classification models to those fine-tuned on the Speech Commands dataset:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/by_speech_commands.png">
</div>
Great! We see that we have six pre-trained models available to us for this specific dataset and task (although there may
be new models added if you're reading at a later date!). You'll recognise the first of these models as the [Audio Spectrogram Transformer checkpoint](https://huggingface.co/MIT/ast-finetuned-speech-commands-v2)
that we used in Unit 4 example. We'll use this checkpoint again for our wake word detection task.
Let's go ahead and load the checkpoint using the `pipeline` class:
```python
from transformers import pipeline
import torch
device = "cuda:0" if torch.cuda.is_available() else "cpu"
classifier = pipeline(
"audio-classification", model="MIT/ast-finetuned-speech-commands-v2", device=device
)
```
We can check what labels the model was trained on by checking the `id2label` attribute in the model config:
```python
classifier.model.config.id2label
```
Alright! We see that the model was trained on 35 class labels, including some simple command words that we described above,
as well as some particular objects like `"bed"`, `"house"` and `"cat"`. We see that there is one name in these class labels:
id 27 corresponds to the label **"marvin"**:
```python
classifier.model.config.id2label[27]
```
```
'marvin'
```
Perfect! We can use this name as our wake word for our voice assistant, similar to how "Alexa" is used for Amazon's Alexa,
or "Hey Siri" is used for Apple's Siri. Of all the possible labels, if the model predicts `"marvin"` with the highest class
probability, we can be fairly sure that our chosen wake word has been said.
Now we need to define a function that is constantly listening to our device's microphone input, and continuously
passes the audio to the classification model for inference. To do this, we'll use a handy helper function that comes
with 🤗 Transformers called [`ffmpeg_microphone_live`](https://github.com/huggingface/transformers/blob/fb78769b9c053876ed7ae152ee995b0439a4462a/src/transformers/pipelines/audio_utils.py#L98).
This function forwards small chunks of audio of specified length `chunk_length_s` to the model to be classified. To ensure that
we get smooth boundaries across chunks of audio, we run a sliding window across our audio with stride `chunk_length_s / 6`.
So that we don't have to wait for the entire first chunk to be recorded before we start inferring, we also define a minimal
temporary audio input length `stream_chunk_s` that is forwarded to the model before `chunk_length_s` time is reached.
The function `ffmpeg_microphone_live` returns a *generator* object, yielding a sequence of audio chunks that can each
be passed to the classification model to make a prediction. We can pass this generator directly to the `pipeline`,
which in turn returns a sequence of output predictions, one for each chunk of audio input. We can inspect the class
label probabilities for each audio chunk, and stop our wake word detection loop when we detect that the wake word
has been spoken.
We'll use a very simple criteria for classifying whether our wake word was spoken: if the class label with the highest
probability was our wake word, and this probability exceeds a threshold `prob_threshold`, we declare that the wake word
as having been spoken. Using a probability threshold to gate our classifier this way ensures that the wake word is not
erroneously predicted if the audio input is noise, which is typically when the model is very uncertain and all the class
label probabilities low. You might want to tune this probability threshold, or explore more sophisticated means for
the wake word decision through an [*entropy*](https://en.wikipedia.org/wiki/Entropy_(information_theory)) (or uncertainty) based metric.
```python
from transformers.pipelines.audio_utils import ffmpeg_microphone_live
def launch_fn(
wake_word="marvin",
prob_threshold=0.5,
chunk_length_s=2.0,
stream_chunk_s=0.25,
debug=False,
):
if wake_word not in classifier.model.config.label2id.keys():
raise ValueError(
f"Wake word {wake_word} not in set of valid class labels, pick a wake word in the set {classifier.model.config.label2id.keys()}."
)
sampling_rate = classifier.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Listening for wake word...")
for prediction in classifier(mic):
prediction = prediction[0]
if debug:
print(prediction)
if prediction["label"] == wake_word:
if prediction["score"] > prob_threshold:
return True
```
Let's give this function a try to see how it works! We'll set the flag `debug=True` to print out the prediction for each
chunk of audio. Let the model run for a few seconds to see the kinds of predictions that it makes when there is no speech
input, then clearly say the wake word `"marvin"` and watch the class label prediction for `"marvin"` spike to near 1:
```python
launch_fn(debug=True)
```
```text
Listening for wake word...
{'score': 0.055326107889413834, 'label': 'one'}
{'score': 0.05999856814742088, 'label': 'off'}
{'score': 0.1282748430967331, 'label': 'five'}
{'score': 0.07310110330581665, 'label': 'follow'}
{'score': 0.06634809821844101, 'label': 'follow'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.05992642417550087, 'label': 'tree'}
{'score': 0.999913215637207, 'label': 'marvin'}
```
Awesome! As we expect, the model generates garbage predictions for the first few seconds. There is no speech input, so the
model makes close to random predictions, but with very low probability. As soon as we say the wake word, the model predicts
`"marvin"` with probability close to 1 and terminates the loop, signalling that the wake word has been detected and that the
ASR system should be activated!
## Speech transcription
Once again, we'll use the Whisper model for our speech transcription system. Specifically, we'll load the [Whisper Base English](https://huggingface.co/openai/whisper-base.en)
checkpoint, since it's small enough to give good inference speed with reasonable transcription accuracy. We'll use a trick
to get near real-time transcription by being clever with how we forward our audio inputs to the model. As before, feel
free to use any speech recognition checkpoint on [the Hub](https://huggingface.co/models?pipeline_tag=automatic-speech-recognition&library=transformers&sort=trending),
including Wav2Vec2, MMS ASR or other Whisper checkpoints:
```python
transcriber = pipeline(
"automatic-speech-recognition", model="openai/whisper-base.en", device=device
)
```
<Tip>
If you're using a GPU, you can increase the checkpoint size to use the <a href="https://huggingface.co/openai/whisper-small.en">Whisper Small English</a>
checkpoint, which will return better transcription accuracy and still be within the required latency threshold. Simply swap the
model id to: <code>"openai/whisper-small.en"</code>.
</Tip>
We can now define a function to record our microphone input and transcribe the corresponding text. With the `ffmpeg_microphone_live`
helper function, we can control how 'real-time' our speech recognition model is. Using a smaller `stream_chunk_s` lends
itself to more real-time speech recognition, since we divide our input audio into smaller chunks and transcribe them on
the fly. However, this comes at the expense of poorer accuracy, since there's less context for the model to infer from.
As we're transcribing the speech, we also need to have an idea of when the user **stops** speaking, so that we can terminate
the recording. For simplicity, we'll terminate our microphone recording after the first `chunk_length_s` (which is set to
5 seconds by default), but you can experiment with using a [voice activity detection (VAD)](https://huggingface.co/models?pipeline_tag=voice-activity-detection&sort=trending)
model to predict when the user has stopped speaking.
```python
import sys
def transcribe(chunk_length_s=5.0, stream_chunk_s=1.0):
sampling_rate = transcriber.feature_extractor.sampling_rate
mic = ffmpeg_microphone_live(
sampling_rate=sampling_rate,
chunk_length_s=chunk_length_s,
stream_chunk_s=stream_chunk_s,
)
print("Start speaking...")
for item in transcriber(mic, generate_kwargs={"max_new_tokens": 128}):
sys.stdout.write("\033[K")
print(item["text"], end="\r")
if not item["partial"][0]:
break
return item["text"]
```
Let's give this a go and see how we get on! Once the microphone is live, start speaking and watch your transcription
appear in semi real-time:
```python
transcribe()
```
```text
Start speaking...
Hey, this is a test with the whisper model.
```
Nice! You can adjust the maximum audio length `chunk_length_s` based on how fast or slow you speak (increase it if you
felt like you didn't have enough time to speak, decrease it if you were left waiting at the end), and the
`stream_chunk_s` for the real-time factor. Just pass these as arguments to the `transcribe` function.
## Language model query
Now that we have our spoken query transcribed, we want to generate a meaningful response. To do this, we'll use an LLM
hosted on the Cloud. Specifically, we'll pick an LLM on the Hugging Face Hub and use the [Inference API](https://huggingface.co/inference-api)
to easily query the model.
First, let's head over to the Hugging Face Hub. To find our LLM, we'll use the [🤗 Open LLM Leaderboard](https://huggingface.co/spaces/HuggingFaceH4/open_llm_leaderboard),
a Space that ranks LLM models by performance over four generation tasks. We'll search by "instruct" to filter out models
that have been instruction fine-tuned, since these should work better for our querying task:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/llm_leaderboard.png">
</div>
We'll use the [tiiuae/falcon-7b-instruct](https://huggingface.co/tiiuae/falcon-7b-instruct) checkpoint by [TII](https://www.tii.ae/),
a 7B parameter decoder-only LM fine-tuned on a mixture of chat and instruction datasets. You can use any LLM on the Hugging
Face Hub that has the "Hosted inference API" enabled, just look out for the widget on the right-side of the model card:
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/inference_api.png">
</div>
The Inference API allows us to send a HTTP request from our local machine to the LLM hosted on the Hub, and returns the
response as a `json` file. All we need to provide is our Hugging Face Hub token (which we retrieve directly from our Hugging Face
Hub folder) and the model id of the LLM we wish to query:
```python
from huggingface_hub import HfFolder
import requests
def query(text, model_id="tiiuae/falcon-7b-instruct"):
api_url = f"https://api-inference.huggingface.co/models/{model_id}"
headers = {"Authorization": f"Bearer {HfFolder().get_token()}"}
payload = {"inputs": text}
print(f"Querying...: {text}")
response = requests.post(api_url, headers=headers, json=payload)
return response.json()[0]["generated_text"][len(text) + 1 :]
```
Let's give it a try with a test input!
```python
query("What does Hugging Face do?")
```
```
'Hugging Face is a company that provides natural language processing and machine learning tools for developers. They'
```
You'll notice just how fast inference is using the Inference API - we only have to send a small number of text tokens
from our local machine to the hosted model, so the communication cost is very low. The LLM is hosted on GPU accelerators,
so inference runs very quickly. Finally, the generated response is transferred back from the model to our local machine,
again with low communication overhead.
## Synthesise speech
And now we're ready to get the final spoken output! Once again, we'll use the Microsoft [SpeechT5 TTS](https://huggingface.co/microsoft/speecht5_tts)
model for English TTS, but you can use any TTS model of your choice. Let's go ahead and load the processor and model:
```python
from transformers import SpeechT5Processor, SpeechT5ForTextToSpeech, SpeechT5HifiGan
processor = SpeechT5Processor.from_pretrained("microsoft/speecht5_tts")
model = SpeechT5ForTextToSpeech.from_pretrained("microsoft/speecht5_tts").to(device)
vocoder = SpeechT5HifiGan.from_pretrained("microsoft/speecht5_hifigan").to(device)
```
And also the speaker embeddings:
```python
from datasets import load_dataset
embeddings_dataset = load_dataset("Matthijs/cmu-arctic-xvectors", split="validation")
speaker_embeddings = torch.tensor(embeddings_dataset[7306]["xvector"]).unsqueeze(0)
```
We'll re-use the `synthesise` function that we defined in the previous chapter on [Speech-to-speech translation](speech-to-speech):
```python
def synthesise(text):
inputs = processor(text=text, return_tensors="pt")
speech = model.generate_speech(
inputs["input_ids"].to(device), speaker_embeddings.to(device), vocoder=vocoder
)
return speech.cpu()
```
Let's quickly verify this works as expected:
```python
from IPython.display import Audio
audio = synthesise(
"Hugging Face is a company that provides natural language processing and machine learning tools for developers."
)
Audio(audio, rate=16000)
```
Nice job 👍
## Marvin 🤖
Now that we've defined a function for each of the four stages of the voice assistant pipeline, all that's left to do is
piece them together to get our end-to-end voice assistant. We'll simply concatenate the four stages, starting with
wake word detection (`launch_fn`), speech transcription, querying the LLM, and finally speech synthesis.
```python
launch_fn()
transcription = transcribe()
response = query(transcription)
audio = synthesise(response)
Audio(audio, rate=16000, autoplay=True)
```
Try it out with a few prompts! Here are some examples to get you started:
* *What is the hottest country in the world?*
* *How do Transformer models work?*
* *Do you know Spanish?*
And with that, we have our end-to-end voice assistant complete, made using the 🤗 audio tools you've learnt throughout
this course, with a sprinkling of LLM magic at the end. There are several extensions that we could make to improve the
voice assistant. Firstly, the audio classification model classifies 35 different labels. We could use a smaller, more
lightweight binary classification model that only predicts whether the wake word was spoken or not. Secondly, we pre-load
all the models ahead and keep them running on our device. If we wanted to save power, we would only load each model at
the time it was required, and subsequently un-load them afterwards. Thirdly, we're missing a voice activity detection model
in our transcription function, transcribing for a fixed amount of time, which in some cases is too long, and in others too
short.
## Generalise to anything 🪄
So far, we've seen how we can generate speech outputs with our voice assistant Marvin. To finish, we'll demonstrate how
we can generalise these speech outputs to text, audio and image.
We'll use [Transformers Agents](https://huggingface.co/docs/transformers/transformers_agents) to build our assistant.
Transformers Agents provides a natural language API on top of the 🤗 Transformers and Diffusers libraries, interpreting
a natural language input using an LLM with carefully crafted prompts, and using a set of curated tools to provide
multimodal outputs.
Let's go ahead and instantiate an agent. There are [three LLMs available](https://huggingface.co/docs/transformers/transformers_agents#quickstart)
for Transformers Agents, two of which are open-source and free on the Hugging Face Hub. The third is a model from OpenAI
that requires an OpenAI API key. We'll use the free [Bigcode Starcoder](https://huggingface.co/bigcode/starcoder) model
in this example, but you can also try either of the other LLMs available:
```python
from transformers import HfAgent
agent = HfAgent(
url_endpoint="https://api-inference.huggingface.co/models/bigcode/starcoder"
)
```
To use the agent, we simply have to call `agent.run` with our text prompt. As an example, we'll get it to generate an
image of a cat 🐈 (that hopefully looks a bit better than this emoji):
```python
agent.run("Generate an image of a cat")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/generated_cat.png">
</div>
<Tip>
Note that the first time calling this will trigger the model weights to be downloaded, which might take
some time depending on your Hub download speed.
</Tip>
Easy as that! The Agent interpreted our prompt, and used [Stable Diffusion](https://huggingface.co/docs/diffusers/using-diffusers/conditional_image_generation)
under the hood to generate the image, without us having to worry about loading the model, writing the function or executing
the code.
We can now replace our LLM query function and text synthesis step with our Transformers Agent in our voice assistant,
since the Agent is going to take care of both of these steps for us:
```python
launch_fn()
transcription = transcribe()
agent.run(transcription)
```
Try speaking the same prompt "Generate an image of a cat" and see how the system gets on. If you ask the Agent a simple
question / answer query, the Agent will respond with a text answer. You can encourage it to generate multimodal outputs
by asking it to return an image or speech. For example, you can ask it to: "Generate an image of a cat, caption it, and
speak the caption".
While the Agent is more flexible than our first iteration Marvin 🤖 assistant, generalising the voice assistant task in this way
may lead to inferior performance on standard voice assistant queries. To recover performance, you can try using a
more performant LLM checkpoint, such as the one from OpenAI, or define a set of [custom tools](https://huggingface.co/docs/transformers/transformers_agents#custom-tools)
that are specific to the voice assistant task.
| 7 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter6/evaluation.mdx | # Evaluating text-to-speech models
During the training time, text-to-speech models optimize for the mean-square error loss (or mean absolute error) between
the predicted spectrogram values and the generated ones. Both MSE and MAE encourage the model to minimize the difference
between the predicted and target spectrograms. However, since TTS is a one-to-many mapping problem, i.e. the output spectrogram for a given text can be represented in many different ways, the evaluation of the resulting text-to-speech (TTS) models is much
more difficult.
Unlike many other computational tasks that can be objectively
measured using quantitative metrics, such as accuracy or precision, evaluating TTS relies heavily on subjective human analysis.
One of the most commonly employed evaluation methods for TTS systems is conducting qualitative assessments using mean
opinion scores (MOS). MOS is a subjective scoring system that allows human evaluators to rate the perceived quality of
synthesized speech on a scale from 1 to 5. These scores are typically gathered through listening tests, where human
participants listen to and rate the synthesized speech samples.
One of the main reasons why objective metrics are challenging to develop for TTS evaluation is the subjective nature of
speech perception. Human listeners have diverse preferences and sensitivities to various aspects of speech, including
pronunciation, intonation, naturalness, and clarity. Capturing these perceptual nuances with a single numerical value
is a daunting task. At the same time, the subjectivity of the human evaluation makes it challenging to compare and
benchmark different TTS systems.
Furthermore, this kind of evaluation may overlook certain important aspects of speech synthesis, such as naturalness,
expressiveness, and emotional impact. These qualities are difficult to quantify objectively but are highly relevant in
applications where the synthesized speech needs to convey human-like qualities and evoke appropriate emotional responses.
In summary, evaluating text-to-speech models is a complex task due to the absence of one truly objective metric. The most common
evaluation method, mean opinion scores (MOS), relies on subjective human analysis. While MOS provides valuable insights
into the quality of synthesized speech, it also introduces variability and subjectivity.
| 8 |
0 | hf_public_repos/audio-transformers-course/chapters/en | hf_public_repos/audio-transformers-course/chapters/en/chapter6/supplemental_reading.mdx | # Supplemental reading and resources
This unit introduced the text-to-speech task, and covered a lot of ground.
Want to learn more? Here you will find additional resources that will help you deepen your understanding of the topics
and enhance your learning experience.
* [HiFi-GAN: Generative Adversarial Networks for Efficient and High Fidelity Speech Synthesis](https://arxiv.org/pdf/2010.05646.pdf): a paper introducing HiFi-GAN for speech synthesis.
* [X-Vectors: Robust DNN Embeddings For Speaker Recognition](https://www.danielpovey.com/files/2018_icassp_xvectors.pdf): a paper introducing X-Vector method for speaker embeddings.
* [FastSpeech 2: Fast and High-Quality End-to-End Text to Speech](https://arxiv.org/pdf/2006.04558.pdf): a paper introducing FastSpeech 2, another popular text-to-speech model that uses a non-autoregressive TTS method.
* [A Vector Quantized Approach for Text to Speech Synthesis on Real-World Spontaneous Speech](https://arxiv.org/pdf/2302.04215v1.pdf): a paper introducing MQTTS, an autoregressive TTS system that replaces mel-spectrograms with quantized discrete representation.
| 9 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app/batch.py | #!/usr/bin/env python
import os
from api_inference_community.batch import batch
from app.main import get_pipeline
DATASET_NAME = os.getenv("DATASET_NAME")
DATASET_CONFIG = os.getenv("DATASET_CONFIG", None)
DATASET_SPLIT = os.getenv("DATASET_SPLIT")
DATASET_COLUMN = os.getenv("DATASET_COLUMN")
USE_GPU = os.getenv("USE_GPU", "0").lower() in {"1", "true"}
TOKEN = os.getenv("TOKEN")
REPO_ID = os.getenv("REPO_ID")
if __name__ == "__main__":
batch(
dataset_name=DATASET_NAME,
dataset_config=DATASET_CONFIG,
dataset_split=DATASET_SPLIT,
dataset_column=DATASET_COLUMN,
token=TOKEN,
repo_id=REPO_ID,
use_gpu=USE_GPU,
pipeline=get_pipeline(),
)
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app/pipelines/text_generation.py | from typing import Dict, List
from app.pipelines import Pipeline
from transformers import TextGenerationPipeline as TransformersTextGenerationPipeline
class TextGenerationPipeline(Pipeline):
def __init__(self, adapter_id: str):
self.pipeline = self._load_pipeline_instance(
TransformersTextGenerationPipeline, adapter_id
)
def __call__(self, inputs: str) -> List[Dict[str, str]]:
"""
Args:
inputs (:obj:`str`):
The input text
Return:
A :obj:`list`:. The list contains a single item that is a dict {"text": the model output}
"""
return self.pipeline(inputs, truncation=True)
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any
from adapters import AutoAdapterModel, get_adapter_info
from transformers import AutoTokenizer
from transformers.pipelines.base import logger
class Pipeline(ABC):
@abstractmethod
def __init__(self, model_id: str):
raise NotImplementedError("Pipelines should implement an __init__ method")
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
@staticmethod
def _load_pipeline_instance(pipeline_class, adapter_id):
adapter_info = get_adapter_info(adapter_id, source="hf")
if adapter_info is None:
raise ValueError(f"Adapter with id '{adapter_id}' not available.")
tokenizer = AutoTokenizer.from_pretrained(adapter_info.model_name)
model = AutoAdapterModel.from_pretrained(adapter_info.model_name)
model.load_adapter(adapter_id, source="hf", set_active=True)
# Transformers incorrectly logs an error because class name is not known. Filter this out.
logger.addFilter(
lambda record: not record.getMessage().startswith(
f"The model '{model.__class__.__name__}' is not supported"
)
)
return pipeline_class(model=model, tokenizer=tokenizer)
class PipelineException(Exception):
pass
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.question_answering import QuestionAnsweringPipeline
from app.pipelines.summarization import SummarizationPipeline
from app.pipelines.text_classification import TextClassificationPipeline
from app.pipelines.text_generation import TextGenerationPipeline
from app.pipelines.token_classification import TokenClassificationPipeline
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app/pipelines/question_answering.py | from typing import Any, Dict
from app.pipelines import Pipeline
from transformers import QuestionAnsweringPipeline as TransformersQAPipeline
class QuestionAnsweringPipeline(Pipeline):
def __init__(
self,
adapter_id: str,
):
self.pipeline = self._load_pipeline_instance(TransformersQAPipeline, adapter_id)
def __call__(self, inputs: Dict[str, str]) -> Dict[str, Any]:
"""
Args:
inputs (:obj:`dict`):
a dictionary containing two keys, 'question' being the question being asked and 'context' being some text containing the answer.
Return:
A :obj:`dict`:. The object return should be like {"answer": "XXX", "start": 3, "end": 6, "score": 0.82} containing :
- "answer": the extracted answer from the `context`.
- "start": the offset within `context` leading to `answer`. context[start:stop] == answer
- "end": the ending offset within `context` leading to `answer`. context[start:stop] === answer
- "score": A score between 0 and 1 describing how confident the model is for this answer.
"""
return self.pipeline(**inputs)
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app/pipelines/text_classification.py | from typing import Dict, List
from app.pipelines import Pipeline
from transformers import (
TextClassificationPipeline as TransformersClassificationPipeline,
)
class TextClassificationPipeline(Pipeline):
def __init__(
self,
adapter_id: str,
):
self.pipeline = self._load_pipeline_instance(
TransformersClassificationPipeline, adapter_id
)
def __call__(self, inputs: str) -> List[Dict[str, float]]:
"""
Args:
inputs (:obj:`str`):
a string containing some text
Return:
A :obj:`list`:. The object returned should be like [{"label": 0.9939950108528137}] containing :
- "label": A string representing what the label/class is. There can be multiple labels.
- "score": A score between 0 and 1 describing how confident the model is for this label/class.
"""
try:
return self.pipeline(inputs, return_all_scores=True)
except Exception as e:
raise ValueError(e)
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app/pipelines/summarization.py | from typing import Dict, List
from app.pipelines import Pipeline
from transformers import SummarizationPipeline as TransformersSummarizationPipeline
class SummarizationPipeline(Pipeline):
def __init__(self, adapter_id: str):
self.pipeline = self._load_pipeline_instance(
TransformersSummarizationPipeline, adapter_id
)
def __call__(self, inputs: str) -> List[Dict[str, str]]:
"""
Args:
inputs (:obj:`str`): a string to be summarized
Return:
A :obj:`list` of :obj:`dict` in the form of {"summary_text": "The string after summarization"}
"""
return self.pipeline(inputs, truncation=True)
| 6 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app | hf_public_repos/api-inference-community/docker_images/adapter_transformers/app/pipelines/token_classification.py | from typing import Any, Dict, List
import numpy as np
from app.pipelines import Pipeline
from transformers import (
TokenClassificationPipeline as TransformersTokenClassificationPipeline,
)
class TokenClassificationPipeline(Pipeline):
def __init__(
self,
adapter_id: str,
):
self.pipeline = self._load_pipeline_instance(
TransformersTokenClassificationPipeline, adapter_id
)
def __call__(self, inputs: str) -> List[Dict[str, Any]]:
"""
Args:
inputs (:obj:`str`):
a string containing some text
Return:
A :obj:`list`:. The object returned should be like [{"entity_group": "XXX", "word": "some word", "start": 3, "end": 6, "score": 0.82}] containing :
- "entity_group": A string representing what the entity is.
- "word": A rubstring of the original string that was detected as an entity.
- "start": the offset within `input` leading to `answer`. context[start:stop] == word
- "end": the ending offset within `input` leading to `answer`. context[start:stop] === word
- "score": A score between 0 and 1 describing how confident the model is for this entity.
"""
outputs = self.pipeline(inputs)
# convert all numpy types to plain Python floats
for output in outputs:
# remove & rename keys
output.pop("index")
entity = output.pop("entity")
for k, v in output.items():
if isinstance(v, np.generic):
output[k] = v.item()
output["entity_group"] = entity
return outputs
| 7 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers | hf_public_repos/api-inference-community/docker_images/adapter_transformers/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 8 |
0 | hf_public_repos/api-inference-community/docker_images/adapter_transformers | hf_public_repos/api-inference-community/docker_images/adapter_transformers/tests/test_api.py | import os
from typing import Dict
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, str] = {
"question-answering": "AdapterHub/roberta-base-pf-squad",
"summarization": "AdapterHub/facebook-bart-large_sum_xsum_pfeiffer",
"text-classification": "AdapterHub/roberta-base-pf-sick",
"text-generation": "AdapterHub/gpt2_lm_poem_pfeiffer",
"token-classification": "AdapterHub/roberta-base-pf-conll2003",
}
ALL_TASKS = {
"automatic-speech-recognition",
"feature-extraction",
"image-classification",
"question-answering",
"sentence-similarity",
"structured-data-classification",
"text-generation",
"text-to-speech",
"token-classification",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
os.environ["TASK"] = unsupported_task
os.environ["MODEL_ID"] = "XX"
with self.assertRaises(EnvironmentError):
get_pipeline()
| 9 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/chatglm/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use anyhow::{Error as E, Result};
use clap::Parser;
use candle_transformers::models::chatglm::{Config, Model};
use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::Tokenizer;
struct TextGeneration {
model: Model,
device: Device,
tokenizer: Tokenizer,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
}
impl TextGeneration {
#[allow(clippy::too_many_arguments)]
fn new(
model: Model,
tokenizer: Tokenizer,
seed: u64,
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
verbose_prompt: bool,
device: &Device,
) -> Self {
let logits_processor = LogitsProcessor::new(seed, temp, top_p);
Self {
model,
tokenizer,
logits_processor,
repeat_penalty,
repeat_last_n,
verbose_prompt,
device: device.clone(),
}
}
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {
use std::io::Write;
println!("starting the inference loop");
let tokens = self.tokenizer.encode(prompt, true).map_err(E::msg)?;
if tokens.is_empty() {
anyhow::bail!("Empty prompts are not supported in the chatglm model.")
}
if self.verbose_prompt {
for (token, id) in tokens.get_tokens().iter().zip(tokens.get_ids().iter()) {
let token = token.replace('▁', " ").replace("<0x0A>", "\n");
println!("{id:7} -> '{token}'");
}
}
let mut tokens = tokens.get_ids().to_vec();
let mut generated_tokens = 0usize;
let eos_token = match self.tokenizer.get_vocab(true).get("</s>") {
Some(token) => *token,
None => anyhow::bail!("cannot find the endoftext token"),
};
print!("{prompt}");
std::io::stdout().flush()?;
let start_gen = std::time::Instant::now();
for index in 0..sample_len {
let context_size = if index > 0 { 1 } else { tokens.len() };
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
let logits = self.model.forward(&input)?;
let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
generated_tokens += 1;
if next_token == eos_token {
break;
}
let token = self.tokenizer.decode(&[next_token], true).map_err(E::msg)?;
print!("{token}");
std::io::stdout().flush()?;
}
let dt = start_gen.elapsed();
println!(
"\n{generated_tokens} tokens generated ({:.2} token/s)",
generated_tokens as f64 / dt.as_secs_f64(),
);
Ok(())
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
/// Display the token for the specified prompt.
#[arg(long)]
verbose_prompt: bool,
#[arg(long)]
prompt: String,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, short = 'n', default_value_t = 5000)]
sample_len: usize,
#[arg(long)]
model_id: Option<String>,
#[arg(long)]
revision: Option<String>,
#[arg(long)]
weight_file: Option<String>,
#[arg(long)]
tokenizer: Option<String>,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
}
fn main() -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let args = Args::parse();
let _guard = if args.tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
println!(
"avx: {}, neon: {}, simd128: {}, f16c: {}",
candle::utils::with_avx(),
candle::utils::with_neon(),
candle::utils::with_simd128(),
candle::utils::with_f16c()
);
println!(
"temp: {:.2} repeat-penalty: {:.2} repeat-last-n: {}",
args.temperature.unwrap_or(0.),
args.repeat_penalty,
args.repeat_last_n
);
let start = std::time::Instant::now();
let api = Api::new()?;
let model_id = match args.model_id {
Some(model_id) => model_id.to_string(),
None => "THUDM/chatglm3-6b".to_string(),
};
let revision = match args.revision {
Some(rev) => rev.to_string(),
None => "main".to_string(),
};
let repo = api.repo(Repo::with_revision(model_id, RepoType::Model, revision));
let tokenizer_filename = match args.tokenizer {
Some(file) => std::path::PathBuf::from(file),
None => api
.model("lmz/candle-chatglm".to_string())
.get("chatglm-tokenizer.json")?,
};
let filenames = match args.weight_file {
Some(weight_file) => vec![std::path::PathBuf::from(weight_file)],
None => candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?,
};
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let start = std::time::Instant::now();
let config = Config::glm3_6b();
let device = candle_examples::device(args.cpu)?;
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, DType::F32, &device)? };
let model = Model::new(&config, vb)?;
println!("loaded the model in {:?}", start.elapsed());
let mut pipeline = TextGeneration::new(
model,
tokenizer,
args.seed,
args.temperature,
args.top_p,
args.repeat_penalty,
args.repeat_last_n,
args.verbose_prompt,
&device,
);
pipeline.run(&args.prompt, args.sample_len)?;
Ok(())
}
| 0 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/llama2-c/main.rs | // https://github.com/karpathy/llama2.c
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
use candle_transformers::models::llama2_c as model;
use candle_transformers::models::llama2_c_weights as weights;
use candle_transformers::models::quantized_llama2_c as qmodel;
mod training;
use clap::{Parser, Subcommand};
use anyhow::{Error as E, Result};
use byteorder::{LittleEndian, ReadBytesExt};
use candle::{IndexOp, Tensor};
use candle_transformers::generation::LogitsProcessor;
use std::io::Write;
use tokenizers::Tokenizer;
use model::{Cache, Config, Llama};
use qmodel::QLlama;
use weights::TransformerWeights;
#[derive(Parser, Debug, Clone)]
struct InferenceCmd {
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
#[arg(long, default_value = "")]
prompt: String,
/// Config file in binary or safetensors format.
#[arg(long)]
config: Option<String>,
#[arg(long, default_value = "karpathy/tinyllamas")]
model_id: String,
/// The model to be used when getting it from the hub. Possible
/// values are 'stories15M.bin', 'stories42M.bin', see more at:
/// https://huggingface.co/karpathy/tinyllamas/tree/main
#[arg(long, default_value = "stories15M.bin")]
which_model: String,
}
#[derive(Parser, Debug, Clone)]
struct EvaluationCmd {
/// A directory with the pre-tokenized dataset in the format generated by the tinystories.py
/// script from llama2.c https://github.com/karpathy/llama2.c
#[arg(long)]
pretokenized_dir: Option<String>,
#[arg(long, default_value_t = 32)]
batch_size: usize,
/// Config file in binary format.
#[arg(long)]
config: Option<String>,
#[arg(long, default_value = "karpathy/tinyllamas")]
model_id: String,
/// The model to be used when getting it from the hub. Possible
/// values are 'stories15M.bin', 'stories42M.bin', see more at:
/// https://huggingface.co/karpathy/tinyllamas/tree/main
#[arg(long, default_value = "stories15M.bin")]
which_model: String,
}
#[derive(Parser, Debug, Clone)]
pub struct TrainingCmd {
/// A directory with the pre-tokenized dataset in the format generated by the tinystories.py
/// script from llama2.c https://github.com/karpathy/llama2.c
#[arg(long)]
pretokenized_dir: String,
#[arg(long, default_value_t = 32)]
batch_size: usize,
#[arg(long, default_value_t = 0.001)]
learning_rate: f64,
}
#[derive(Subcommand, Debug, Clone)]
enum Task {
Inference(InferenceCmd),
Eval(EvaluationCmd),
Train(TrainingCmd),
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
pub struct Args {
/// The task to be performed, inference, training or evaluation.
#[command(subcommand)]
task: Option<Task>,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Tokenizer config file.
#[arg(long)]
tokenizer: Option<String>,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.1)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
}
impl Args {
fn tokenizer(&self) -> Result<Tokenizer> {
let tokenizer_path = match &self.tokenizer {
Some(config) => std::path::PathBuf::from(config),
None => {
let api = hf_hub::api::sync::Api::new()?;
let api = api.model("hf-internal-testing/llama-tokenizer".to_string());
api.get("tokenizer.json")?
}
};
Tokenizer::from_file(tokenizer_path).map_err(E::msg)
}
}
fn main() -> anyhow::Result<()> {
let args = Args::parse();
match &args.task {
None => {
let cmd = InferenceCmd {
temperature: None,
top_p: None,
prompt: "".to_string(),
config: None,
model_id: "karpathy/tinyllamas".to_string(),
which_model: "stories15M.bin".to_string(),
};
run_inference(&cmd, &args)?
}
Some(Task::Inference(cmd)) => run_inference(cmd, &args)?,
Some(Task::Eval(cmd)) => run_eval(cmd, &args)?,
Some(Task::Train(cmd)) => training::run(cmd, &args)?,
}
Ok(())
}
enum Model {
Llama(Llama),
QLlama(QLlama),
}
impl Model {
fn forward(&self, xs: &Tensor, pos: usize, cache: &mut Cache) -> anyhow::Result<Tensor> {
match self {
Self::Llama(l) => Ok(l.forward(xs, pos, cache)?),
Self::QLlama(l) => Ok(l.forward(xs, pos, cache)?),
}
}
}
fn run_eval(args: &EvaluationCmd, common_args: &Args) -> Result<()> {
use std::io::BufRead;
let config_path = match &args.config {
Some(config) => std::path::PathBuf::from(config),
None => {
let api = hf_hub::api::sync::Api::new()?;
println!("loading the model weights from {}", args.model_id);
let api = api.model(args.model_id.clone());
api.get(&args.which_model)?
}
};
let tokenizer = common_args.tokenizer()?;
let device = candle_examples::device(common_args.cpu)?;
let mut file = std::fs::File::open(config_path)?;
let config = Config::from_reader(&mut file)?;
let weights = TransformerWeights::from_reader(&mut file, &config, &device)?;
let vb = weights.var_builder(&config, &device)?;
let mut cache = Cache::new(false, &config, vb.pp("rot"))?;
let model = Llama::load(vb, config)?;
let tokens = match &args.pretokenized_dir {
None => {
let api = hf_hub::api::sync::Api::new()?;
let model_id = "roneneldan/TinyStories"; // TODO: Make this configurable.
println!("loading the evaluation dataset from {}", model_id);
let api = api.dataset(model_id.to_string());
let dataset_path = api.get("TinyStories-valid.txt")?;
let file = std::fs::File::open(dataset_path)?;
let file = std::io::BufReader::new(file);
let mut tokens = vec![];
for line in file.lines() {
let line = line?.replace("<|endoftext|>", "<s>");
let line = tokenizer.encode(line, false).map_err(E::msg)?;
tokens.push(line.get_ids().to_vec())
}
tokens.concat()
}
Some(pretokenized_dir) => {
// Use shard 0 for the test split, similar to llama2.c
// https://github.com/karpathy/llama2.c/blob/ce05cc28cf1e3560b873bb21837638a434520a67/tinystories.py#L121
let path = std::path::PathBuf::from(pretokenized_dir).join("data00.bin");
let bytes = std::fs::read(path)?;
// Tokens are encoded as u16.
let mut tokens = vec![0u16; bytes.len() / 2];
std::io::Cursor::new(bytes).read_u16_into::<LittleEndian>(&mut tokens)?;
tokens.into_iter().map(|u| u as u32).collect::<Vec<u32>>()
}
};
println!("dataset loaded and encoded: {} tokens", tokens.len());
let seq_len = model.config.seq_len;
let iter = (0..tokens.len()).step_by(seq_len).flat_map(|start_idx| {
if start_idx + seq_len + 1 > tokens.len() {
None
} else {
let tokens = &tokens[start_idx..start_idx + seq_len + 1];
let inputs = Tensor::new(&tokens[..seq_len], &device);
let targets = Tensor::new(&tokens[1..], &device);
Some(inputs.and_then(|inputs| targets.map(|targets| (inputs, targets))))
}
});
let batch_iter = candle_datasets::Batcher::new_r2(iter).batch_size(args.batch_size);
for inp_tgt in batch_iter {
let (inp, tgt) = inp_tgt?;
let logits = model.forward(&inp, 0, &mut cache)?;
let loss = candle_nn::loss::cross_entropy(&logits.flatten_to(1)?, &tgt.flatten_to(1)?)?;
println!("{}", loss.to_vec0::<f32>()?);
}
Ok(())
}
fn run_inference(args: &InferenceCmd, common_args: &Args) -> Result<()> {
let config_path = match &args.config {
Some(config) => std::path::PathBuf::from(config),
None => {
let api = hf_hub::api::sync::Api::new()?;
println!("loading the model weights from {}", args.model_id);
let api = api.model(args.model_id.clone());
api.get(&args.which_model)?
}
};
let tokenizer = common_args.tokenizer()?;
let device = candle_examples::device(common_args.cpu)?;
let is_gguf = config_path.extension().map_or(false, |v| v == "gguf");
let is_safetensors = config_path
.extension()
.map_or(false, |v| v == "safetensors");
let (model, config, mut cache) = if is_gguf {
let vb = qmodel::VarBuilder::from_gguf(config_path, &device)?;
let (_vocab_size, dim) = vb
.get_no_shape("model.embed_tokens.weight")?
.shape()
.dims2()?;
let config = match dim {
64 => Config::tiny_260k(),
288 => Config::tiny_15m(),
512 => Config::tiny_42m(),
768 => Config::tiny_110m(),
_ => anyhow::bail!("no config for dim {dim}"),
};
let freq_cis_real = vb
.get(
(config.seq_len, config.head_size() / 2),
"rot.freq_cis_real",
)?
.dequantize(&device)?;
let freq_cis_imag = vb
.get(
(config.seq_len, config.head_size() / 2),
"rot.freq_cis_imag",
)?
.dequantize(&device)?;
let fake_vb = candle_nn::VarBuilder::from_tensors(
[
("freq_cis_real".to_string(), freq_cis_real),
("freq_cis_imag".to_string(), freq_cis_imag),
]
.into_iter()
.collect(),
candle::DType::F32,
&device,
);
let cache = model::Cache::new(true, &config, fake_vb)?;
let model = Model::QLlama(QLlama::load(vb, config.clone())?);
(model, config, cache)
} else if is_safetensors {
let config = Config::tiny_15m();
let tensors = candle::safetensors::load(config_path, &device)?;
let vb = candle_nn::VarBuilder::from_tensors(tensors, candle::DType::F32, &device);
let cache = model::Cache::new(true, &config, vb.pp("rot"))?;
let model = Model::Llama(Llama::load(vb, config.clone())?);
(model, config, cache)
} else {
let mut file = std::fs::File::open(config_path)?;
let config = Config::from_reader(&mut file)?;
println!("{config:?}");
let weights = TransformerWeights::from_reader(&mut file, &config, &device)?;
let vb = weights.var_builder(&config, &device)?;
let cache = model::Cache::new(true, &config, vb.pp("rot"))?;
let model = Model::Llama(Llama::load(vb, config.clone())?);
(model, config, cache)
};
println!("starting the inference loop");
let mut logits_processor = LogitsProcessor::new(299792458, args.temperature, args.top_p);
let mut index_pos = 0;
print!("{}", args.prompt);
let mut tokens = tokenizer
.encode(args.prompt.clone(), true)
.map_err(E::msg)?
.get_ids()
.to_vec();
let mut tokenizer = candle_examples::token_output_stream::TokenOutputStream::new(tokenizer);
let start_gen = std::time::Instant::now();
for index in 0.. {
if tokens.len() >= config.seq_len {
break;
}
let context_size = if index > 0 { 1 } else { tokens.len() };
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &device)?.unsqueeze(0)?;
let logits = model.forward(&input, index_pos, &mut cache)?;
let logits = logits.i((0, logits.dim(1)? - 1))?;
let logits = if common_args.repeat_penalty == 1. || tokens.is_empty() {
logits
} else {
let start_at = tokens.len().saturating_sub(common_args.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
common_args.repeat_penalty,
&tokens[start_at..],
)?
};
index_pos += ctxt.len();
let next_token = logits_processor.sample(&logits)?;
tokens.push(next_token);
if let Some(t) = tokenizer.next_token(next_token)? {
print!("{t}");
std::io::stdout().flush()?;
}
}
if let Some(rest) = tokenizer.decode_rest().map_err(E::msg)? {
print!("{rest}");
}
let dt = start_gen.elapsed();
println!(
"\n{} tokens generated ({:.2} token/s)\n",
tokens.len(),
tokens.len() as f64 / dt.as_secs_f64(),
);
Ok(())
}
| 1 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/llama2-c/training.rs | use crate::model::{Cache, Config, Llama};
use candle::{DType, Device, Result};
use candle_datasets::nlp::tinystories::{Dataset, DatasetRandomIter};
use candle_nn::Optimizer;
fn valid_loss(
dataset: &Dataset,
model: &Llama,
args: &crate::TrainingCmd,
device: &Device,
cache: &mut Cache,
) -> Result<f64> {
let iter = DatasetRandomIter::new(dataset, true, model.config.seq_len, device.clone());
let batch_iter = candle_datasets::Batcher::new_r2(iter).batch_size(args.batch_size);
let mut sum_ce = 0f64;
let mut cnt = 0usize;
for inp_tgt in batch_iter.take(50) {
let (inp, tgt) = inp_tgt?;
let logits = model.forward(&inp, 0, cache)?;
let loss = candle_nn::loss::cross_entropy(&logits.flatten_to(1)?, &tgt.flatten_to(1)?)?;
sum_ce += loss.to_vec0::<f32>()? as f64;
cnt += 1;
}
Ok(sum_ce / cnt as f64)
}
pub fn run(args: &crate::TrainingCmd, common_args: &crate::Args) -> Result<()> {
let device = candle_examples::device(common_args.cpu)?;
let dataset = Dataset::new(&args.pretokenized_dir)?;
println!(
"loaded dataset, train: {} files, valid: {} files",
dataset.train_tokens(),
dataset.valid_tokens()
);
let varmap = candle_nn::VarMap::new();
let vb = candle_nn::VarBuilder::from_varmap(&varmap, DType::F32, &device);
let config = Config::tiny_15m();
let iter = DatasetRandomIter::new(&dataset, false, config.seq_len, device.clone());
let batch_iter = candle_datasets::Batcher::new_r2(iter).batch_size(args.batch_size);
let mut cache = Cache::new(false, &config, vb.pp("rot"))?;
let model = Llama::load(vb, config)?;
let params = candle_nn::ParamsAdamW {
lr: args.learning_rate,
..Default::default()
};
let mut opt = candle_nn::AdamW::new(varmap.all_vars(), params)?;
for (batch_index, batch) in batch_iter.enumerate() {
let (inp, tgt) = batch?;
let logits = model.forward(&inp, 0, &mut cache)?;
let loss = candle_nn::loss::cross_entropy(&logits.flatten_to(1)?, &tgt.flatten_to(1)?)?;
opt.backward_step(&loss)?;
if batch_index > 0 && batch_index % 100 == 0 {
// TODO: Add a way to deactivate the backprop graph tracking when computing the
// validation loss.
let loss = valid_loss(&dataset, &model, args, &device, &mut cache)?;
println!("{batch_index} {loss}");
}
if batch_index > 0 && batch_index % 1000 == 0 {
varmap.save("checkpoint.safetensors")?
}
}
Ok(())
}
| 2 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/eva2/main.rs | //! EVA-02: Explore the limits of Visual representation at scAle
//! https://github.com/baaivision/EVA
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::Parser;
use candle::{DType, Device, IndexOp, Result, Tensor, D};
use candle_nn::{Module, VarBuilder};
use candle_transformers::models::eva2;
/// Loads an image from disk using the image crate, this returns a tensor with shape
/// (3, 448, 448). OpenAI normalization is applied.
pub fn load_image448_openai_norm<P: AsRef<std::path::Path>>(p: P) -> Result<Tensor> {
let img = image::ImageReader::open(p)?
.decode()
.map_err(candle::Error::wrap)?
.resize_to_fill(448, 448, image::imageops::FilterType::Triangle);
let img = img.to_rgb8();
let data = img.into_raw();
let data = Tensor::from_vec(data, (448, 448, 3), &Device::Cpu)?.permute((2, 0, 1))?;
let mean =
Tensor::new(&[0.48145466f32, 0.4578275, 0.40821073], &Device::Cpu)?.reshape((3, 1, 1))?;
let std = Tensor::new(&[0.26862954f32, 0.261_302_6, 0.275_777_1], &Device::Cpu)?
.reshape((3, 1, 1))?;
(data.to_dtype(candle::DType::F32)? / 255.)?
.broadcast_sub(&mean)?
.broadcast_div(&std)
}
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let image = load_image448_openai_norm(args.image)?.to_device(&device)?;
println!("loaded image {image:?}");
let model_file = match args.model {
None => {
let api = hf_hub::api::sync::Api::new()?;
let api = api.model("vincent-espitalier/candle-eva2".into());
api.get("eva02_base_patch14_448.mim_in22k_ft_in22k_in1k_adapted.safetensors")?
}
Some(model) => model.into(),
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };
let model = eva2::vit_base(vb)?;
println!("model built");
let logits = model.forward(&image.unsqueeze(0)?)?;
let prs = candle_nn::ops::softmax(&logits, D::Minus1)?
.i(0)?
.to_vec1::<f32>()?;
let mut prs = prs.iter().enumerate().collect::<Vec<_>>();
prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for &(category_idx, pr) in prs.iter().take(5) {
println!(
"{:24}: {:.2}%",
candle_examples::imagenet::CLASSES[category_idx],
100. * pr
);
}
Ok(())
}
| 3 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/eva2/README.md | # candle-eva2
[EVA-02](https://arxiv.org/abs/2303.11331) is a computer vision model.
In this example, it is used as an ImageNet classifier: the model returns the
probability for the image to belong to each of the 1000 ImageNet categories.
## Running some example
```bash
cargo run --example eva2 --release -- --image candle-examples/examples/yolo-v8/assets/bike.jpg
> mountain bike, all-terrain bike, off-roader: 37.09%
> maillot : 8.30%
> alp : 2.13%
> bicycle-built-for-two, tandem bicycle, tandem: 0.84%
> crash helmet : 0.73%
```

| 4 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/fastvit/main.rs | #[cfg(feature = "mkl")]
extern crate intel_mkl_src;
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
use clap::{Parser, ValueEnum};
use candle::{DType, IndexOp, D};
use candle_nn::{Module, VarBuilder};
use candle_transformers::models::fastvit;
#[derive(Clone, Copy, Debug, ValueEnum)]
enum Which {
T8,
T12,
S12,
SA12,
SA24,
SA36,
MA36,
}
impl Which {
fn model_filename(&self) -> String {
let name = match self {
Self::T8 => "t8",
Self::T12 => "t12",
Self::S12 => "s12",
Self::SA12 => "sa12",
Self::SA24 => "sa24",
Self::SA36 => "sa36",
Self::MA36 => "ma36",
};
format!("timm/fastvit_{}.apple_in1k", name)
}
fn config(&self) -> fastvit::Config {
match self {
Self::T8 => fastvit::Config::t8(),
Self::T12 => fastvit::Config::t12(),
Self::S12 => fastvit::Config::s12(),
Self::SA12 => fastvit::Config::sa12(),
Self::SA24 => fastvit::Config::sa24(),
Self::SA36 => fastvit::Config::sa36(),
Self::MA36 => fastvit::Config::ma36(),
}
}
}
#[derive(Parser)]
struct Args {
#[arg(long)]
model: Option<String>,
#[arg(long)]
image: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
#[arg(value_enum, long, default_value_t=Which::S12)]
which: Which,
}
pub fn main() -> anyhow::Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let image = candle_examples::imagenet::load_image(args.image, 256)?.to_device(&device)?;
println!("loaded image {image:?}");
let model_file = match args.model {
None => {
let model_name = args.which.model_filename();
let api = hf_hub::api::sync::Api::new()?;
let api = api.model(model_name);
api.get("model.safetensors")?
}
Some(model) => model.into(),
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&[model_file], DType::F32, &device)? };
let model = fastvit::fastvit(&args.which.config(), 1000, vb)?;
println!("model built");
let logits = model.forward(&image.unsqueeze(0)?)?;
let prs = candle_nn::ops::softmax(&logits, D::Minus1)?
.i(0)?
.to_vec1::<f32>()?;
let mut prs = prs.iter().enumerate().collect::<Vec<_>>();
prs.sort_by(|(_, p1), (_, p2)| p2.total_cmp(p1));
for &(category_idx, pr) in prs.iter().take(5) {
println!(
"{:24}: {:.2}%",
candle_examples::imagenet::CLASSES[category_idx],
100. * pr
);
}
Ok(())
}
| 5 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/fastvit/README.md | # candle-fastvit
[FastViT: A Fast Hybrid Vision Transformer using Structural Reparameterization](https://arxiv.org/abs/2303.14189).
This candle implementation uses a pre-trained FastViT network for inference. The
classification head has been trained on the ImageNet dataset and returns the
probabilities for the top-5 classes.
## Running an example
```
$ cargo run --example fastvit --release -- --image candle-examples/examples/yolo-v8/assets/bike.jpg --which sa12
loaded image Tensor[dims 3, 256, 256; f32]
model built
mountain bike, all-terrain bike, off-roader: 52.67%
bicycle-built-for-two, tandem bicycle, tandem: 7.93%
unicycle, monocycle : 3.46%
maillot : 1.32%
crash helmet : 1.28%
```
| 6 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/stable-diffusion/main.rs | #[cfg(feature = "accelerate")]
extern crate accelerate_src;
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
use candle_transformers::models::stable_diffusion;
use anyhow::{Error as E, Result};
use candle::{DType, Device, IndexOp, Module, Tensor, D};
use clap::Parser;
use stable_diffusion::vae::AutoEncoderKL;
use tokenizers::Tokenizer;
#[derive(Parser)]
#[command(author, version, about, long_about = None)]
struct Args {
/// The prompt to be used for image generation.
#[arg(
long,
default_value = "A very realistic photo of a rusty robot walking on a sandy beach"
)]
prompt: String,
#[arg(long, default_value = "")]
uncond_prompt: String,
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
/// Enable tracing (generates a trace-timestamp.json file).
#[arg(long)]
tracing: bool,
/// The height in pixels of the generated image.
#[arg(long)]
height: Option<usize>,
/// The width in pixels of the generated image.
#[arg(long)]
width: Option<usize>,
/// The UNet weight file, in .safetensors format.
#[arg(long, value_name = "FILE")]
unet_weights: Option<String>,
/// The CLIP weight file, in .safetensors format.
#[arg(long, value_name = "FILE")]
clip_weights: Option<String>,
/// The VAE weight file, in .safetensors format.
#[arg(long, value_name = "FILE")]
vae_weights: Option<String>,
#[arg(long, value_name = "FILE")]
/// The file specifying the tokenizer to used for tokenization.
tokenizer: Option<String>,
/// The size of the sliced attention or 0 for automatic slicing (disabled by default)
#[arg(long)]
sliced_attention_size: Option<usize>,
/// The number of steps to run the diffusion for.
#[arg(long)]
n_steps: Option<usize>,
/// The number of samples to generate iteratively.
#[arg(long, default_value_t = 1)]
num_samples: usize,
/// The numbers of samples to generate simultaneously.
#[arg[long, default_value_t = 1]]
bsize: usize,
/// The name of the final image to generate.
#[arg(long, value_name = "FILE", default_value = "sd_final.png")]
final_image: String,
#[arg(long, value_enum, default_value = "v2-1")]
sd_version: StableDiffusionVersion,
/// Generate intermediary images at each step.
#[arg(long, action)]
intermediary_images: bool,
#[arg(long)]
use_flash_attn: bool,
#[arg(long)]
use_f16: bool,
#[arg(long)]
guidance_scale: Option<f64>,
#[arg(long, value_name = "FILE")]
img2img: Option<String>,
/// The strength, indicates how much to transform the initial image. The
/// value must be between 0 and 1, a value of 1 discards the initial image
/// information.
#[arg(long, default_value_t = 0.8)]
img2img_strength: f64,
/// The seed to use when generating random samples.
#[arg(long)]
seed: Option<u64>,
}
#[derive(Debug, Clone, Copy, clap::ValueEnum, PartialEq, Eq)]
enum StableDiffusionVersion {
V1_5,
V2_1,
Xl,
Turbo,
}
#[derive(Debug, Clone, Copy, PartialEq, Eq)]
enum ModelFile {
Tokenizer,
Tokenizer2,
Clip,
Clip2,
Unet,
Vae,
}
impl StableDiffusionVersion {
fn repo(&self) -> &'static str {
match self {
Self::Xl => "stabilityai/stable-diffusion-xl-base-1.0",
Self::V2_1 => "stabilityai/stable-diffusion-2-1",
Self::V1_5 => "runwayml/stable-diffusion-v1-5",
Self::Turbo => "stabilityai/sdxl-turbo",
}
}
fn unet_file(&self, use_f16: bool) -> &'static str {
match self {
Self::V1_5 | Self::V2_1 | Self::Xl | Self::Turbo => {
if use_f16 {
"unet/diffusion_pytorch_model.fp16.safetensors"
} else {
"unet/diffusion_pytorch_model.safetensors"
}
}
}
}
fn vae_file(&self, use_f16: bool) -> &'static str {
match self {
Self::V1_5 | Self::V2_1 | Self::Xl | Self::Turbo => {
if use_f16 {
"vae/diffusion_pytorch_model.fp16.safetensors"
} else {
"vae/diffusion_pytorch_model.safetensors"
}
}
}
}
fn clip_file(&self, use_f16: bool) -> &'static str {
match self {
Self::V1_5 | Self::V2_1 | Self::Xl | Self::Turbo => {
if use_f16 {
"text_encoder/model.fp16.safetensors"
} else {
"text_encoder/model.safetensors"
}
}
}
}
fn clip2_file(&self, use_f16: bool) -> &'static str {
match self {
Self::V1_5 | Self::V2_1 | Self::Xl | Self::Turbo => {
if use_f16 {
"text_encoder_2/model.fp16.safetensors"
} else {
"text_encoder_2/model.safetensors"
}
}
}
}
}
impl ModelFile {
fn get(
&self,
filename: Option<String>,
version: StableDiffusionVersion,
use_f16: bool,
) -> Result<std::path::PathBuf> {
use hf_hub::api::sync::Api;
match filename {
Some(filename) => Ok(std::path::PathBuf::from(filename)),
None => {
let (repo, path) = match self {
Self::Tokenizer => {
let tokenizer_repo = match version {
StableDiffusionVersion::V1_5 | StableDiffusionVersion::V2_1 => {
"openai/clip-vit-base-patch32"
}
StableDiffusionVersion::Xl | StableDiffusionVersion::Turbo => {
// This seems similar to the patch32 version except some very small
// difference in the split regex.
"openai/clip-vit-large-patch14"
}
};
(tokenizer_repo, "tokenizer.json")
}
Self::Tokenizer2 => {
("laion/CLIP-ViT-bigG-14-laion2B-39B-b160k", "tokenizer.json")
}
Self::Clip => (version.repo(), version.clip_file(use_f16)),
Self::Clip2 => (version.repo(), version.clip2_file(use_f16)),
Self::Unet => (version.repo(), version.unet_file(use_f16)),
Self::Vae => {
// Override for SDXL when using f16 weights.
// See https://github.com/huggingface/candle/issues/1060
if matches!(
version,
StableDiffusionVersion::Xl | StableDiffusionVersion::Turbo,
) && use_f16
{
(
"madebyollin/sdxl-vae-fp16-fix",
"diffusion_pytorch_model.safetensors",
)
} else {
(version.repo(), version.vae_file(use_f16))
}
}
};
let filename = Api::new()?.model(repo.to_string()).get(path)?;
Ok(filename)
}
}
}
}
fn output_filename(
basename: &str,
sample_idx: usize,
num_samples: usize,
timestep_idx: Option<usize>,
) -> String {
let filename = if num_samples > 1 {
match basename.rsplit_once('.') {
None => format!("{basename}.{sample_idx}.png"),
Some((filename_no_extension, extension)) => {
format!("{filename_no_extension}.{sample_idx}.{extension}")
}
}
} else {
basename.to_string()
};
match timestep_idx {
None => filename,
Some(timestep_idx) => match filename.rsplit_once('.') {
None => format!("{filename}-{timestep_idx}.png"),
Some((filename_no_extension, extension)) => {
format!("{filename_no_extension}-{timestep_idx}.{extension}")
}
},
}
}
#[allow(clippy::too_many_arguments)]
fn save_image(
vae: &AutoEncoderKL,
latents: &Tensor,
vae_scale: f64,
bsize: usize,
idx: usize,
final_image: &str,
num_samples: usize,
timestep_ids: Option<usize>,
) -> Result<()> {
let images = vae.decode(&(latents / vae_scale)?)?;
let images = ((images / 2.)? + 0.5)?.to_device(&Device::Cpu)?;
let images = (images.clamp(0f32, 1.)? * 255.)?.to_dtype(DType::U8)?;
for batch in 0..bsize {
let image = images.i(batch)?;
let image_filename = output_filename(
final_image,
(bsize * idx) + batch + 1,
batch + num_samples,
timestep_ids,
);
candle_examples::save_image(&image, image_filename)?;
}
Ok(())
}
#[allow(clippy::too_many_arguments)]
fn text_embeddings(
prompt: &str,
uncond_prompt: &str,
tokenizer: Option<String>,
clip_weights: Option<String>,
sd_version: StableDiffusionVersion,
sd_config: &stable_diffusion::StableDiffusionConfig,
use_f16: bool,
device: &Device,
dtype: DType,
use_guide_scale: bool,
first: bool,
) -> Result<Tensor> {
let tokenizer_file = if first {
ModelFile::Tokenizer
} else {
ModelFile::Tokenizer2
};
let tokenizer = tokenizer_file.get(tokenizer, sd_version, use_f16)?;
let tokenizer = Tokenizer::from_file(tokenizer).map_err(E::msg)?;
let pad_id = match &sd_config.clip.pad_with {
Some(padding) => *tokenizer.get_vocab(true).get(padding.as_str()).unwrap(),
None => *tokenizer.get_vocab(true).get("<|endoftext|>").unwrap(),
};
println!("Running with prompt \"{prompt}\".");
let mut tokens = tokenizer
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
if tokens.len() > sd_config.clip.max_position_embeddings {
anyhow::bail!(
"the prompt is too long, {} > max-tokens ({})",
tokens.len(),
sd_config.clip.max_position_embeddings
)
}
while tokens.len() < sd_config.clip.max_position_embeddings {
tokens.push(pad_id)
}
let tokens = Tensor::new(tokens.as_slice(), device)?.unsqueeze(0)?;
println!("Building the Clip transformer.");
let clip_weights_file = if first {
ModelFile::Clip
} else {
ModelFile::Clip2
};
let clip_weights = clip_weights_file.get(clip_weights, sd_version, false)?;
let clip_config = if first {
&sd_config.clip
} else {
sd_config.clip2.as_ref().unwrap()
};
let text_model =
stable_diffusion::build_clip_transformer(clip_config, clip_weights, device, DType::F32)?;
let text_embeddings = text_model.forward(&tokens)?;
let text_embeddings = if use_guide_scale {
let mut uncond_tokens = tokenizer
.encode(uncond_prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
if uncond_tokens.len() > sd_config.clip.max_position_embeddings {
anyhow::bail!(
"the negative prompt is too long, {} > max-tokens ({})",
uncond_tokens.len(),
sd_config.clip.max_position_embeddings
)
}
while uncond_tokens.len() < sd_config.clip.max_position_embeddings {
uncond_tokens.push(pad_id)
}
let uncond_tokens = Tensor::new(uncond_tokens.as_slice(), device)?.unsqueeze(0)?;
let uncond_embeddings = text_model.forward(&uncond_tokens)?;
Tensor::cat(&[uncond_embeddings, text_embeddings], 0)?.to_dtype(dtype)?
} else {
text_embeddings.to_dtype(dtype)?
};
Ok(text_embeddings)
}
fn image_preprocess<T: AsRef<std::path::Path>>(path: T) -> anyhow::Result<Tensor> {
let img = image::ImageReader::open(path)?.decode()?;
let (height, width) = (img.height() as usize, img.width() as usize);
let height = height - height % 32;
let width = width - width % 32;
let img = img.resize_to_fill(
width as u32,
height as u32,
image::imageops::FilterType::CatmullRom,
);
let img = img.to_rgb8();
let img = img.into_raw();
let img = Tensor::from_vec(img, (height, width, 3), &Device::Cpu)?
.permute((2, 0, 1))?
.to_dtype(DType::F32)?
.affine(2. / 255., -1.)?
.unsqueeze(0)?;
Ok(img)
}
fn run(args: Args) -> Result<()> {
use tracing_chrome::ChromeLayerBuilder;
use tracing_subscriber::prelude::*;
let Args {
prompt,
uncond_prompt,
cpu,
height,
width,
n_steps,
tokenizer,
final_image,
sliced_attention_size,
num_samples,
bsize,
sd_version,
clip_weights,
vae_weights,
unet_weights,
tracing,
use_f16,
guidance_scale,
use_flash_attn,
img2img,
img2img_strength,
seed,
..
} = args;
if !(0. ..=1.).contains(&img2img_strength) {
anyhow::bail!("img2img-strength should be between 0 and 1, got {img2img_strength}")
}
let _guard = if tracing {
let (chrome_layer, guard) = ChromeLayerBuilder::new().build();
tracing_subscriber::registry().with(chrome_layer).init();
Some(guard)
} else {
None
};
let guidance_scale = match guidance_scale {
Some(guidance_scale) => guidance_scale,
None => match sd_version {
StableDiffusionVersion::V1_5
| StableDiffusionVersion::V2_1
| StableDiffusionVersion::Xl => 7.5,
StableDiffusionVersion::Turbo => 0.,
},
};
let n_steps = match n_steps {
Some(n_steps) => n_steps,
None => match sd_version {
StableDiffusionVersion::V1_5
| StableDiffusionVersion::V2_1
| StableDiffusionVersion::Xl => 30,
StableDiffusionVersion::Turbo => 1,
},
};
let dtype = if use_f16 { DType::F16 } else { DType::F32 };
let sd_config = match sd_version {
StableDiffusionVersion::V1_5 => {
stable_diffusion::StableDiffusionConfig::v1_5(sliced_attention_size, height, width)
}
StableDiffusionVersion::V2_1 => {
stable_diffusion::StableDiffusionConfig::v2_1(sliced_attention_size, height, width)
}
StableDiffusionVersion::Xl => {
stable_diffusion::StableDiffusionConfig::sdxl(sliced_attention_size, height, width)
}
StableDiffusionVersion::Turbo => stable_diffusion::StableDiffusionConfig::sdxl_turbo(
sliced_attention_size,
height,
width,
),
};
let scheduler = sd_config.build_scheduler(n_steps)?;
let device = candle_examples::device(cpu)?;
if let Some(seed) = seed {
device.set_seed(seed)?;
}
let use_guide_scale = guidance_scale > 1.0;
let which = match sd_version {
StableDiffusionVersion::Xl | StableDiffusionVersion::Turbo => vec![true, false],
_ => vec![true],
};
let text_embeddings = which
.iter()
.map(|first| {
text_embeddings(
&prompt,
&uncond_prompt,
tokenizer.clone(),
clip_weights.clone(),
sd_version,
&sd_config,
use_f16,
&device,
dtype,
use_guide_scale,
*first,
)
})
.collect::<Result<Vec<_>>>()?;
let text_embeddings = Tensor::cat(&text_embeddings, D::Minus1)?;
let text_embeddings = text_embeddings.repeat((bsize, 1, 1))?;
println!("{text_embeddings:?}");
println!("Building the autoencoder.");
let vae_weights = ModelFile::Vae.get(vae_weights, sd_version, use_f16)?;
let vae = sd_config.build_vae(vae_weights, &device, dtype)?;
let init_latent_dist = match &img2img {
None => None,
Some(image) => {
let image = image_preprocess(image)?.to_device(&device)?;
Some(vae.encode(&image)?)
}
};
println!("Building the unet.");
let unet_weights = ModelFile::Unet.get(unet_weights, sd_version, use_f16)?;
let unet = sd_config.build_unet(unet_weights, &device, 4, use_flash_attn, dtype)?;
let t_start = if img2img.is_some() {
n_steps - (n_steps as f64 * img2img_strength) as usize
} else {
0
};
let vae_scale = match sd_version {
StableDiffusionVersion::V1_5
| StableDiffusionVersion::V2_1
| StableDiffusionVersion::Xl => 0.18215,
StableDiffusionVersion::Turbo => 0.13025,
};
for idx in 0..num_samples {
let timesteps = scheduler.timesteps();
let latents = match &init_latent_dist {
Some(init_latent_dist) => {
let latents = (init_latent_dist.sample()? * vae_scale)?.to_device(&device)?;
if t_start < timesteps.len() {
let noise = latents.randn_like(0f64, 1f64)?;
scheduler.add_noise(&latents, noise, timesteps[t_start])?
} else {
latents
}
}
None => {
let latents = Tensor::randn(
0f32,
1f32,
(bsize, 4, sd_config.height / 8, sd_config.width / 8),
&device,
)?;
// scale the initial noise by the standard deviation required by the scheduler
(latents * scheduler.init_noise_sigma())?
}
};
let mut latents = latents.to_dtype(dtype)?;
println!("starting sampling");
for (timestep_index, ×tep) in timesteps.iter().enumerate() {
if timestep_index < t_start {
continue;
}
let start_time = std::time::Instant::now();
let latent_model_input = if use_guide_scale {
Tensor::cat(&[&latents, &latents], 0)?
} else {
latents.clone()
};
let latent_model_input = scheduler.scale_model_input(latent_model_input, timestep)?;
let noise_pred =
unet.forward(&latent_model_input, timestep as f64, &text_embeddings)?;
let noise_pred = if use_guide_scale {
let noise_pred = noise_pred.chunk(2, 0)?;
let (noise_pred_uncond, noise_pred_text) = (&noise_pred[0], &noise_pred[1]);
(noise_pred_uncond + ((noise_pred_text - noise_pred_uncond)? * guidance_scale)?)?
} else {
noise_pred
};
latents = scheduler.step(&noise_pred, timestep, &latents)?;
let dt = start_time.elapsed().as_secs_f32();
println!("step {}/{n_steps} done, {:.2}s", timestep_index + 1, dt);
if args.intermediary_images {
save_image(
&vae,
&latents,
vae_scale,
bsize,
idx,
&final_image,
num_samples,
Some(timestep_index + 1),
)?;
}
}
println!(
"Generating the final image for sample {}/{}.",
idx + 1,
num_samples
);
save_image(
&vae,
&latents,
vae_scale,
bsize,
idx,
&final_image,
num_samples,
None,
)?;
}
Ok(())
}
fn main() -> Result<()> {
let args = Args::parse();
run(args)
}
| 7 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/stable-diffusion/README.md | # candle-stable-diffusion: A Diffusers API in Rust/Candle

_A rusty robot holding a fire torch in its hand_, generated by Stable Diffusion
XL using Rust and [candle](https://github.com/huggingface/candle).
The `stable-diffusion` example is a conversion of
[diffusers-rs](https://github.com/LaurentMazare/diffusers-rs) using candle
rather than libtorch. This implementation supports Stable Diffusion v1.5, v2.1,
as well as Stable Diffusion XL 1.0, and Turbo.
## Getting the weights
The weights are automatically downloaded for you from the [HuggingFace
Hub](https://huggingface.co/) on the first run. There are various command line
flags to use local files instead, run with `--help` to learn about them.
## Running some example.
```bash
cargo run --example stable-diffusion --release --features=cuda,cudnn \
-- --prompt "a cosmonaut on a horse (hd, realistic, high-def)"
```
The final image is named `sd_final.png` by default. The Turbo version is much
faster than previous versions, to give it a try add a `--sd-version turbo` flag,
e.g.:
```bash
cargo run --example stable-diffusion --release --features=cuda,cudnn \
-- --prompt "a cosmonaut on a horse (hd, realistic, high-def)" --sd-version turbo
```
The default scheduler for the v1.5, v2.1 and XL 1.0 version is the Denoising
Diffusion Implicit Model scheduler (DDIM). The original paper and some code can
be found in the [associated repo](https://github.com/ermongroup/ddim).
The default scheduler for the XL Turbo version is the Euler Ancestral scheduler.
### Command-line flags
- `--prompt`: the prompt to be used to generate the image.
- `--uncond-prompt`: the optional unconditional prompt.
- `--sd-version`: the Stable Diffusion version to use, can be `v1-5`, `v2-1`,
`xl`, or `turbo`.
- `--cpu`: use the cpu rather than the gpu (much slower).
- `--height`, `--width`: set the height and width for the generated image.
- `--n-steps`: the number of steps to be used in the diffusion process.
- `--num-samples`: the number of samples to generate iteratively.
- `--bsize`: the numbers of samples to generate simultaneously.
- `--final-image`: the filename for the generated image(s).
### Using flash-attention
Using flash attention makes image generation a lot faster and uses less memory.
The downside is some long compilation time. You can set the
`CANDLE_FLASH_ATTN_BUILD_DIR` environment variable to something like
`/home/user/.candle` to ensures that the compilation artifacts are properly
cached.
Enabling flash-attention requires both a feature flag, `--features flash-attn`
and using the command line flag `--use-flash-attn`.
Note that flash-attention-v2 is only compatible with Ampere, Ada, or Hopper GPUs
(e.g., A100/H100, RTX 3090/4090).
## Image to Image Pipeline
...
## FAQ
### Memory Issues
This requires a GPU with more than 8GB of memory, as a fallback the CPU version can be used
with the `--cpu` flag but is much slower.
Alternatively, reducing the height and width with the `--height` and `--width`
flag is likely to reduce memory usage significantly.
| 8 |
0 | hf_public_repos/candle/candle-examples/examples | hf_public_repos/candle/candle-examples/examples/falcon/main.rs | // TODO: Add an offline mode.
#[cfg(feature = "accelerate")]
extern crate accelerate_src;
#[cfg(feature = "mkl")]
extern crate intel_mkl_src;
use anyhow::{Error as E, Result};
use candle::{DType, Device, Tensor};
use candle_nn::VarBuilder;
use candle_transformers::generation::LogitsProcessor;
use clap::Parser;
use hf_hub::{api::sync::Api, Repo, RepoType};
use tokenizers::Tokenizer;
use candle_transformers::models::falcon::{Config, Falcon};
struct TextGeneration {
model: Falcon,
device: Device,
tokenizer: Tokenizer,
logits_processor: LogitsProcessor,
repeat_penalty: f32,
repeat_last_n: usize,
}
struct GenerationOptions {
temp: Option<f64>,
top_p: Option<f64>,
repeat_penalty: f32,
repeat_last_n: usize,
}
impl TextGeneration {
fn new(
model: Falcon,
tokenizer: Tokenizer,
generation_options: GenerationOptions,
seed: u64,
device: &Device,
) -> Self {
let logits_processor =
LogitsProcessor::new(seed, generation_options.temp, generation_options.top_p);
let repeat_penalty = generation_options.repeat_penalty;
let repeat_last_n = generation_options.repeat_last_n;
Self {
model,
tokenizer,
logits_processor,
device: device.clone(),
repeat_penalty,
repeat_last_n,
}
}
fn run(&mut self, prompt: &str, sample_len: usize) -> Result<()> {
println!("starting the inference loop");
let mut tokens = self
.tokenizer
.encode(prompt, true)
.map_err(E::msg)?
.get_ids()
.to_vec();
let mut new_tokens = vec![];
let start_gen = std::time::Instant::now();
for index in 0..sample_len {
let start_gen = std::time::Instant::now();
let context_size = if self.model.config().use_cache && index > 0 {
1
} else {
tokens.len()
};
let ctxt = &tokens[tokens.len().saturating_sub(context_size)..];
let input = Tensor::new(ctxt, &self.device)?.unsqueeze(0)?;
let logits = self.model.forward(&input)?;
let logits = logits.squeeze(0)?.to_dtype(DType::F32)?;
let logits = if self.repeat_penalty == 1. {
logits
} else {
let start_at = tokens.len().saturating_sub(self.repeat_last_n);
candle_transformers::utils::apply_repeat_penalty(
&logits,
self.repeat_penalty,
&tokens[start_at..],
)?
};
let next_token = self.logits_processor.sample(&logits)?;
tokens.push(next_token);
new_tokens.push(next_token);
println!("> {:?}", start_gen.elapsed());
println!(
"{} token: {} '{}'",
index + 1,
next_token,
self.tokenizer.decode(&[next_token], true).map_err(E::msg)?
);
}
let dt = start_gen.elapsed();
println!(
"{sample_len} tokens generated ({} token/s)\n----\n{}\n----",
sample_len as f64 / dt.as_secs_f64(),
self.tokenizer.decode(&new_tokens, true).map_err(E::msg)?
);
Ok(())
}
}
#[derive(Parser, Debug)]
#[command(author, version, about, long_about = None)]
struct Args {
/// Run on CPU rather than on GPU.
#[arg(long)]
cpu: bool,
#[arg(long)]
prompt: String,
/// Use f32 computations rather than bf16.
#[arg(long)]
use_f32: bool,
/// The temperature used to generate samples.
#[arg(long)]
temperature: Option<f64>,
/// Nucleus sampling probability cutoff.
#[arg(long)]
top_p: Option<f64>,
/// The seed to use when generating random samples.
#[arg(long, default_value_t = 299792458)]
seed: u64,
/// The length of the sample to generate (in tokens).
#[arg(long, default_value_t = 100)]
sample_len: usize,
#[arg(long, default_value = "tiiuae/falcon-7b")]
model_id: String,
#[arg(long, default_value = "refs/pr/43")]
revision: String,
/// Penalty to be applied for repeating tokens, 1. means no penalty.
#[arg(long, default_value_t = 1.0)]
repeat_penalty: f32,
/// The context size to consider for the repeat penalty.
#[arg(long, default_value_t = 64)]
repeat_last_n: usize,
}
fn main() -> Result<()> {
let args = Args::parse();
let device = candle_examples::device(args.cpu)?;
let start = std::time::Instant::now();
let api = Api::new()?;
let repo = api.repo(Repo::with_revision(
args.model_id,
RepoType::Model,
args.revision,
));
let tokenizer_filename = repo.get("tokenizer.json")?;
let filenames = candle_examples::hub_load_safetensors(&repo, "model.safetensors.index.json")?;
println!("retrieved the files in {:?}", start.elapsed());
let tokenizer = Tokenizer::from_file(tokenizer_filename).map_err(E::msg)?;
let start = std::time::Instant::now();
let dtype = if args.use_f32 {
DType::F32
} else {
DType::BF16
};
let vb = unsafe { VarBuilder::from_mmaped_safetensors(&filenames, dtype, &device)? };
let config = Config::falcon7b();
config.validate()?;
let model = Falcon::load(vb, config)?;
println!("loaded the model in {:?}", start.elapsed());
let generation_options = GenerationOptions {
temp: args.temperature,
top_p: args.top_p,
repeat_penalty: args.repeat_penalty,
repeat_last_n: args.repeat_last_n,
};
let mut pipeline =
TextGeneration::new(model, tokenizer, generation_options, args.seed, &device);
pipeline.run(&args.prompt, args.sample_len)?;
Ok(())
}
| 9 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api_sentence_similarity.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"sentence-similarity" not in ALLOWED_TASKS,
"sentence-similarity not implemented",
)
class SentenceSimilarityTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["sentence-similarity"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "sentence-similarity"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
source_sentence = "I am a very happy man"
sentences = [
"What is this?",
"I am a super happy man",
"I am a sad man",
"I am a happy dog",
]
inputs = {"source_sentence": source_sentence, "sentences": sentences}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual({type(item) for item in content}, {float})
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual({type(item) for item in content}, {float})
def test_missing_input_sentences(self):
source_sentence = "I am a very happy man"
inputs = {"source_sentence": source_sentence}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
400,
)
def test_malformed_input(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api_automatic_speech_recognition.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"automatic-speech-recognition" not in ALLOWED_TASKS,
"automatic-speech-recognition not implemented",
)
class AutomaticSpeecRecognitionTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["automatic-speech-recognition"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "automatic-speech-recognition"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def read(self, filename: str) -> bytes:
dirname = os.path.dirname(os.path.abspath(__file__))
filename = os.path.join(dirname, "samples", filename)
with open(filename, "rb") as f:
bpayload = f.read()
return bpayload
def test_simple(self):
bpayload = self.read("sample1.flac")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"text"})
def test_malformed_audio(self):
bpayload = self.read("malformed.flac")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(response.content, b'{"error":"Malformed soundfile"}')
def test_dual_channel_audiofile(self):
bpayload = self.read("sample1_dual.ogg")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"text"})
def test_webm_audiofile(self):
bpayload = self.read("sample1.webm")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"text"})
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api.py | import os
from typing import Dict
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, str] = {
# IMPLEMENT_THIS
# "automatic-speech-recognition": "mysample-ASR",
# "text-generation": "mysample-gpt2",
}
ALL_TASKS = {
"audio-classification",
"audio-to-audio",
"automatic-speech-recognition",
"feature-extraction",
"image-classification",
"question-answering",
"sentence-similarity",
"speech-segmentation",
"tabular-classification",
"tabular-regression",
"text-to-image",
"text-to-speech",
"token-classification",
"conversational",
"feature-extraction",
"sentence-similarity",
"fill-mask",
"table-question-answering",
"summarization",
"text2text-generation",
"text-classification",
"zero-shot-classification",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
os.environ["TASK"] = unsupported_task
os.environ["MODEL_ID"] = "XX"
with self.assertRaises(EnvironmentError):
get_pipeline()
| 2 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api_tabular_regression.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"tabular-regression" not in ALLOWED_TASKS,
"tabular-regression not implemented",
)
class TabularRegressionTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["tabular-regression"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "tabular-regression"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
# IMPLEMENT_THIS
# Add one or multiple rows that the test model expects.
data = {}
inputs = {"data": data}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(len(content), 2)
def test_malformed_input(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"Where do I live ?")
self.assertEqual(
response.status_code,
400,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"error"})
def test_missing_columns(self):
# IMPLEMENT_THIS
# Add wrong number of columns
data = {}
inputs = {"data": data}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
400,
)
| 3 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api_tabular_classification.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"tabular-classification" not in ALLOWED_TASKS,
"tabular-classification not implemented",
)
class TabularClassificationTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["tabular-classification"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "tabular-classification"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
# IMPLEMENT_THIS
# Add one or multiple rows that the test model expects.
data = {}
inputs = {"data": data}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(len(content), 2)
def test_malformed_input(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"Where do I live ?")
self.assertEqual(
response.status_code,
400,
)
content = json.loads(response.content)
self.assertEqual(set(content.keys()), {"error"})
def test_missing_columns(self):
# IMPLEMENT_THIS
# Add wrong number of columns
data = {}
inputs = {"data": data}
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
400,
)
| 4 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api_feature_extraction.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"feature-extraction" not in ALLOWED_TASKS,
"feature-extraction not implemented",
)
class FeatureExtractionTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["feature-extraction"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "feature-extraction"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "Hello, my name is John and I live in New York"
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual({type(item) for item in content}, {float})
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual({type(item) for item in content}, {float})
def test_malformed_sentence(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api_audio_classification.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"audio-classification" not in ALLOWED_TASKS,
"audio-classification not implemented",
)
class AudioClassificationTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["audio-classification"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "audio-classification"
from app.main import app
self.app = app
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def read(self, filename: str) -> bytes:
dirname = os.path.dirname(os.path.abspath(__file__))
filename = os.path.join(dirname, "samples", filename)
with open(filename, "rb") as f:
bpayload = f.read()
return bpayload
def test_simple(self):
bpayload = self.read("sample1.flac")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(type(content[0]), dict)
self.assertEqual(
set(k for el in content for k in el.keys()),
{"label", "score"},
)
def test_malformed_audio(self):
bpayload = self.read("malformed.flac")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(response.content, b'{"error":"Malformed soundfile"}')
def test_dual_channel_audiofile(self):
bpayload = self.read("sample1_dual.ogg")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(type(content[0]), dict)
self.assertEqual(
set(k for el in content for k in el.keys()),
{"label", "score"},
)
def test_webm_audiofile(self):
bpayload = self.read("sample1.webm")
with TestClient(self.app) as client:
response = client.post("/", data=bpayload)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(type(content[0]), dict)
self.assertEqual(
set(k for el in content for k in el.keys()),
{"label", "score"},
)
| 6 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api_token_classification.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"token-classification" not in ALLOWED_TASKS,
"token-classification not implemented",
)
class TokenClassificationTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["token-classification"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "token-classification"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "Hello, my name is John and I live in New York"
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(
set(k for el in content for k in el.keys()),
{"entity_group", "word", "start", "end", "score"},
)
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(
set(k for el in content for k in el.keys()),
{"entity_group", "word", "start", "end", "score"},
)
def test_malformed_question(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 7 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api_text_to_speech.py | import os
from unittest import TestCase, skipIf
from api_inference_community.validation import ffmpeg_read
from app.main import ALLOWED_TASKS
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"text-to-speech" not in ALLOWED_TASKS,
"text-to-speech not implemented",
)
class TextToSpeechTestCase(TestCase):
def setUp(self):
model_id = TESTABLE_MODELS["text-to-speech"]
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = model_id
os.environ["TASK"] = "text-to-speech"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": "This is some text"})
self.assertEqual(
response.status_code,
200,
)
self.assertEqual(response.headers["content-type"], "audio/flac")
audio = ffmpeg_read(response.content, 16000)
self.assertEqual(len(audio.shape), 1)
self.assertGreater(audio.shape[0], 1000)
def test_malformed_input(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 8 |
0 | hf_public_repos/api-inference-community/docker_images/common | hf_public_repos/api-inference-community/docker_images/common/tests/test_api_summarization.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from parameterized import parameterized_class
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"summarization" not in ALLOWED_TASKS,
"summarization not implemented",
)
@parameterized_class(
[{"model_id": model_id} for model_id in TESTABLE_MODELS["summarization"]]
)
class SummarizationTestCase(TestCase):
def setUp(self):
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = self.model_id
os.environ["TASK"] = "summarization"
from app.main import app
self.app = app
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_single_input(self):
text = "test"
with TestClient(self.app) as client:
response = client.post("/", json=text)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(len(content), 1)
for result in content:
self.assertIn("summary_text", result)
| 9 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter2/audio_classification_pipeline.mdx | # Clasificación de audio con una pipeline
La clasificación de audio consiste en asignar o más etiquetas a una grabación de audio basado en su contenido. Las etiquetas
pueden corresponder a diferentes categorias del sonido, como música, voz o ruido, o etiquetas más especificas como canto de ave o
sonido de motor de carro.
Antes de entrar en los detalles sobre el funcionamiento de los transformers más populares para audio, y antes de hacer fine-tunning
de un modelo personalizado. Revisemos como se puede usar un modelo pre-entrenado para clasificación de audio con solo una lineas de
código de 🤗 Transformers.
Usemos el mismo conjunto de [MINDS-14](https://huggingface.co/datasets/PolyAI/minds14) que hemos estado explorando en la
unidad anterior. Como recordarás, MINDS-14 contiene grabaciones de personas haciendo preguntas a un sistema de banca electrónica
en diferentes idiomas y dialectos, y tiene la etiqueta de `intent_class` para cada grabación. Podemos clasificar las grabaciones por
la intención de la llamada.
Tal como hemos hecho antes, carguemos el subset de `en-AU` probar esta pipeline, y hagamos un upsampling a 16kHz que es
la frecuencia de muestreo que el modelo espera.
```py
from datasets import load_dataset
from datasets import Audio
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
```
Para clasificar una grabación de audio en alguna de las clases, podemos usar la pipeline de `audio-classification` que tiene 🤗 Transformers.
En nuestro caso, necesitamos un modelo que ha sido entrenado para clasificar la intención en donde especificamente hayan la base de datos de
MINDS-14. Afortunadamente para nosotros, el Hub tiene un modelo que hace justamente esto. Carguemoslo usando la función `pipeline()`:
```py
from transformers import pipeline
classifier = pipeline(
"audio-classification",
model="anton-l/xtreme_s_xlsr_300m_minds14",
)
```
Esta pipeline espera los datos de audio como un array de Numpy. Todo el preprocesamiento de los datos de audio será hecha por
la pipeline. Seleccionemos un ejemplo para probarlo:
```py
example = minds[0]
```
Si recuerdas la estructura del conjunto de datos, los datos en bruto de audio se almacenan en un array de Numpy en
la columna `["audio"]["array"]`, que podemos pasar directamente al `classifier`:
```py
classifier(example["audio"]["array"])
```
**Output:**
```out
[
{"score": 0.9631525278091431, "label": "pay_bill"},
{"score": 0.02819698303937912, "label": "freeze"},
{"score": 0.0032787492964416742, "label": "card_issues"},
{"score": 0.0019414445850998163, "label": "abroad"},
{"score": 0.0008378693601116538, "label": "high_value_payment"},
]
```
Este modelo esta bastante seguro que la intención al llamar fue preguntar sobre el pago de una cuenta. Revisemos que la
etiqueta original para este ejemplo es:
```py
id2label = minds.features["intent_class"].int2str
id2label(example["intent_class"])
```
**Output:**
```out
"pay_bill"
```
¡Hurra! la etiqueta predecida por el modelo ¡era la correcta! Aqui tuvimos suerte de encontrar un modelo que tenia exactamente
las etiquetas que necesitabamos. La mayoria de las veces, cuando estamos tratando con una tarea de clasificación, el conjunto de clases
de un modelo pre-entrenado no son exactamente las que necesitamos. En este caso, puedes hacer un fine-tunning del modelo pre entrenado
para "calibralo" a tu conjunto de clases. Aprenderemos como se puede hacer este proceso en las próximas unidad. Por ahora, echemos un
vistazo a otra tarea muy común en el procesamiento del habla, _automatic speech recognition_.
| 0 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter2/introduction.mdx | # Unidad 2. Una introducción amigable a las aplicaciones de audio
Bienvenido a la segunda unidad del curso de audio de Hugging Face¡, Anteriormente, exploramos los conceptos fundamentales
de los datos de audio y aprendimo como trabajar con conjuntos de datos de audio usando las librerias 🤗 Datasets y 🤗 Transformers.
Discutimos diferentes conceptos como frecuencia de muestreo, amplitud, profundidad de bits, forma de onda y espectrogramas, y vimos
como preprocesar datos para un modelo pre-entrenado.
En este punto quiza estes ansioso por aprender acerca de las tareas de audio que 🤗 Transformers puede realizar, y ahora que tienes
los conocimientos fundamentales para comprenderlo todo, echemos un vistazo a unos impresionantes ejemplos de aplicaciones de audio.
* **Clasificación de Audio**: Categorizar facilmente un clip de audio. Puedes identificar si una grabación es de un ladrido de un perro
o un maullido de gato, o a que género corresponde una cación.
* **Reconocimiento automático de voz**: Transformar un clip de audio en texto a traves de una transcripción automática. Puedes obtener
la representación en texto de una grabación en donde alguien habla. Muy útil para tomar notas!
* **Diarización de hablantes** Alguna vez te has preguntado ¿Quién habla en una grabación? con 🤗 Transformers, puedes identificar
que persona esta hablando en un determinado tiempo del clip de audio. Imaginate ser capaz de de diferencias entre "Alice" y "Bob"
en una grabación en donde ambos estan teniendo una conversación.
* **Texto a voz**: Crear una narración a partir de un texto que puede ser usada para crear un audio book, ayuda con la accesibilidad,
o le da la voz a un NPC en un juego. con 🤗 Transformers puedes hacer facilmente esto
En esta unidad, tu aprenderas como usar modelos pre entrenados para algunas de estas tareas usando la función `pipeline()` de 🤗 Transformers.
Especificamente, veremos como usar modelos pre-entrenados para las tareas de clasificación de audio y reconocimiento automático de la voz.
Comencemos!
| 1 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter2/hands_on.mdx | # Ejercicio práctico
Este ejericio no es calificable y esta pensado para ayudarte a familiarizar con las herramientas y librerias que estaras usando a traves del curso. Si ya tienes experiencia al usar Google Colab, 🤗 Datasets, librosa y 🤗 Transformers, puedes saltar este ejercicio.
1. Crea un cuaderno de [Google Colab](https://colab.research.google.com)
2. Usa para descargar la partición train de [`facebook/voxpopuli` dataset](https://huggingface.co/datasets/facebook/voxpopuli) en el idioma de tu elección usando el modo de transmisión(streaming).
3. Obten el tercer ejemplo del subconjunto `train` y exploralo. Dadas las caracteristicas que tiene este ejemplo, ¿En cuales tareas de audio puedes usar este dataset?
4. Gráfica la forma de onda y el espectrograma.
5. Ve al [🤗 Hub](https://huggingface.co/models), y explora modelos pre-entrenados que puedan ser usados para el reconocimiento automático de la voz en el idioma de tu elección.
6. Compara la transcripción que obtienes de la pipeline con la transcripción original.
Si tienes problemas completando este ejercicio, puedes mirar la [solución](https://colab.research.google.com/drive/1NGyo5wFpRj8TMfZOIuPaJHqyyXCITftc?usp=sharing).
¿Has descubierto algo interesante? ¿Encontraste un buen modelo? ¿Obtuviste un bello espectrograma? Comparte tus descubrimientos en Twitter.
En el siguiente capitulo aprenderás mas acerca de las arquitecturas para audio de transformers y entrenaras tu propio modelo
| 2 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter1/supplemental_reading.mdx | # Sigue aprendiendo
Esta unidad abarcó muchos conceptos fundamentales que son relevantes para entender los datos de audio y trabajar con ellos.
¿Quieres aprender más? Aquí encontraras recursos adicionales que te ayudaran a profundizar en tu entendimiento de los temas
y mejorará tu experiencia de aprendizaje.
En el siguiente video, Monty Montgomery de xiph.org presenta demonstraciones en tiempo real de sampleo, cuantización,
profundidad en bits, dither y equipamiento de audio usando tanto herramientas digitales de analisis modernas como equipo vintage,
Dale un vistazo:
<Youtube id="cIQ9IXSUzuM"/>
Si deseas adentrarte más en el procesamiento digital de señales, echa un vistazo al libro gratuito ["Digital Signals Theory" book](https://brianmcfee.net/dstbook-site/content/intro.html)
escrito por Brian McFee, Profesor Asistente de Tecnología Musical y Ciencia de Datos en la Universidad de Nueva York y
principal mantenedor del paquete `librosa`.
| 3 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter1/preprocessing.mdx | # Preprocesamiento de un conjunto de datos de audio
Cargar una base de datos con 🤗 Datasets es solo la mitad de la diversión. Si planeas usar los datos para entrenar un modelo, o
para hacer inferencia necesitarás preprocesar los datos primero. En general, esto involucra los siguientes pasos:
* Resamplear los datos de audio.
* Filtrar la base de datos.
* Convertir el audio a la entrada esperada por el modelo.
## Resamplear los datos de audio
La función `load_dataset` descarga los archivos de audio con la frecuencia de muestreo con la que fueron publicados. Esta frecuencia
no siempre coincide con la esperada por el modelo que planees usar para entrenar o realizar inferencia. Si existe una discrepancia
entre las frecuencias, puedes resamplear el audio a la frecuencia de muestreo que espera el modelo.
La mayoria de los modelos pre-entrenados disponibles han sido entrenados con audios a una frecuencia de muestreo de 16kHz.
Cuando exploramos los datos de MINDS-14, puedes haber notado que la frecuencia de muestreo era de 8kHz, por lo que seguramente
se tendrá que realizar un proceso de upsampling(Convertir de una frecuencia menor a una mayor).
Para hacer esto, usa el método `cast_column` de 🤗 Datasets. Esta operación no altera el audio cuando se ejecuta, crea una
señal para que datasets haga el resampleo en el momento en que se carguen los audios. El siguiente código configura el proceso
de resampling a 16 kHz.
```py
from datasets import Audio
minds = minds.cast_column("audio", Audio(sampling_rate=16_000))
```
Vuelve a cargar el primer ejemplo de audio en el conjunto de datos MINDS-14 y verifica que se haya re-muestreado al valor deseado de `sampling rate`:
```py
minds[0]
```
**Output:**
```out
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[
2.0634243e-05,
1.9437837e-04,
2.2419340e-04,
...,
9.3852862e-04,
1.1302452e-03,
7.1531429e-04,
],
dtype=float32,
),
"sampling_rate": 16000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
}
```
Puedes ver que los valores del array ahora son diferentes. Esto es porque ahora tenemos el doble de valores de amplitud de la longitud
original.
<Tip>
💡 Si una señal de audio ha sido grabada a una frecuencia de muestreo de 8kHz, de manera que cada segundo de la
señal esta representado por 8000 muestras, sabemos tambien que el audio no contiene ninguna frecuencia por encima
de 4kHz. Esto esta garantizado por el teorema de Nyquist. Resamplear a una frecuencia de muestro mayor(Upsampling)
consiste en estimar los puntos adicionales que irian entre las muestras existentes. El proceso de Downsampling, requiere en cambio,
que primero filtremos cualquier frecuencia que sea mayor al nuevo Limite de Nyquist antes de estimar las nuevas muestras.
En otras palabras, no puedes hacer downsampling por un facto de 2x solo descartando la mitad de muestras de la señal - Esto
crearía distorsiones en la señal llamadas alias. Hacer resampliing de la manera correcta es complejo por lo que es mejor
usar librerias que han sido probadas a lo largo de los años como lo son librosa o 🤗 Datasets.
</Tip>
## Filtrando el conjunto de datos
Algunas veces necesitarás filtrar los datos en función de algunos criterios. Uno de los casos comunes implica limitar los ejemplos
de audio a una duración determinada. Por ejemplo, es posible que deseemos filtrar cualquier ejemplo que supere los 20 segundos para
evitar errores de falta de memoria al entrenar un modelo.
Podemos hacer esto al usar el método `filter` que espera una función que contenga una lógica de filtrado. Empezemos por escribir
una función que indique cuales ejemplos conservar y cuales descartar. la función `is_audio_length_in_range`, retorna `True` si
un ejemplo tiene una duracióne menor a 20s y `False` si es mayor a 20s.
```py
MAX_DURATION_IN_SECONDS = 20.0
def is_audio_length_in_range(input_length):
return input_length < MAX_DURATION_IN_SECONDS
```
La función de filtrado se puede aplicar a una columna de un conjunto de datos, pero en este conjunto de datos no tenemos una columna
con la duración de la pista de audio. Sin embargo, podemos crear una columna, filtrar basándonos en los valores de esa columna y luego
eliminarla.
```py
# usar librosa para calcular la duración del audio
new_column = [librosa.get_duration(filename=x) for x in minds["path"]]
minds = minds.add_column("duration", new_column)
# usar el método `filter` de 🤗 Datasets' para aplicar la función de filtrado
minds = minds.filter(is_audio_length_in_range, input_columns=["duration"])
# eliminar la columna temporal de duración
minds = minds.remove_columns(["duration"])
minds
```
**Output:**
```out
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 624})
```
Podemos verificar que el dataset filtrado ahora tiene 624 ejemplos y no 654
## Preprocesando los datos de audio
Uno de los aspectos más retadores de trabajar con datos de audio es preparar los datos en el formato correcto para el entrenamiento
de un modelo. Como has visto, los datos de audio se almacenan en un arreglo de muestras. Sin embargo, la mayoria de modelos pre-entrenados,
ya sea que los uses para inferencia o para fine-tuning, esperan que los datos en bruto sean convertidos en características de entrada.
Los requisitos para las características de entrada pueden variar de un modelo a otro, ya que dependen de la arquitectura del modelo y
los datos con los que fue preentrenado. La buena noticia es que, para cada modelo de audio compatible, 🤗 Transformers ofrece una clase
de extractor de características que puede convertir los datos de audio en bruto en las características de entrada que el modelo espera.
Entonces, ¿qué hace un extractor de características con los datos de audio en bruto? Echemos un vistazo al extractor de características
de [Whisper](https://cdn.openai.com/papers/whisper.pdf) para comprender algunas transformaciones comunes de extracción de características.
Whisper es un modelo preentrenado para el reconocimiento automático del habla (ASR) publicado en septiembre de 2022 por Alec Radford et al. de OpenAI.
Primero, el extractor de característicasde whisper completa/recorta un conjunto de ejemplos de audios para que todos los ejemplos tengan
una longitud de 30s. Ejemplos con una duración menor son completados añadiendo ceros al final de la secuencia(Ceros en una secuencia de
audio corresponden a la ausencia de señal o silencio). Ejemplos mayores a 30 segundos son truncados hasta 30 segundos. Ya que todos los
elementos en el conjunto son completados/recortados a una longitud común, no hay necesidad de usar una mascara de atención. Whisper es único
en este aspecto, la mayoria de los otros modelos requieren una mascara de atención que indica donde las secuencias fueron completadas, y por
lo tanto sean ignoradas por el mecanismo de auto-atención. Whisper esta entrenado para trabajar sin un mecanismo de atención e inferir directamente
de la señal donde ignorar estos segmentos.
La segunda operación que realiza el extractor de whisper es convertir las señalas en espectrogramas logarítmicos de mel.
Como recordarás, estos espectrogramas describen cómo cambian las frecuencias de una señal con el tiempo, expresadas en la escala mel
y medidas en decibelios (la parte logarítmica) para hacer que las frecuencias y amplitudes sean más representativas de la audición humana.
Todas estas transformaciones pueden ser aplicadas a tus datos de audio en bruto con unas pocas lineas de código. Carguemos ahora
el extractor de características de el modelo preentrenado de Whisper.
```py
from transformers import WhisperFeatureExtractor
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
```
A continuacióon, podemos escribir una función para preprocesar un ejemplo de audio al pasarlo a traves del `feature_extractor`.
```py
def prepare_dataset(example):
audio = example["audio"]
features = feature_extractor(
audio["array"], sampling_rate=audio["sampling_rate"], padding=True
)
return features
```
Podemos aplicar la función de preparación de datos a todos nuestros ejemplos de entrenamiento utilizando el método "map" de 🤗 Datasets:
```py
minds = minds.map(prepare_dataset)
minds
```
**Output:**
```out
Dataset(
{
features: ["path", "audio", "transcription", "intent_class", "input_features"],
num_rows: 624,
}
)
```
Con tan solo hacer esto, tenemos los espectrogramas logarítmicos de mel como una columna de `input_features` en nuestro dataset.
Visualizemos ahora uno de los ejemplos del dataset `minds`:
```py
import numpy as np
example = minds[0]
input_features = example["input_features"]
plt.figure().set_figwidth(12)
librosa.display.specshow(
np.asarray(input_features[0]),
x_axis="time",
y_axis="mel",
sr=feature_extractor.sampling_rate,
hop_length=feature_extractor.hop_length,
)
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/log_mel_whisper.png" alt="Log mel spectrogram plot">
</div>
Ahora puedes ver como se ve la entrada de audio al modelo de Whisper tras haber realizado el preprocesamiento.
La clase de extractor de características del modelo se encarga de transformar los datos de audio en bruto al formato que el modelo espera.
Sin embargo, muchas tareas que involucran audio son multimodales, como el reconocimiento de voz. En tales casos, 🤗 Transformers también
ofrece tokenizadores específicos del modelo para procesar las entradas de texto. Para obtener más información sobre los tokenizadores,
consulta nuestro curso de [NLP](https://huggingface.co/course/chapter2/4).
Puedes cargar el extractor de características y el tokenizador para Whisper y otros modelos multimodales de forma separada, o puedes cargar
ambos usando el "procesador". Para hacer las cosas aun más simples, usa el `AutoProcessor` para cargar el extractor de características
y el procesador de un modelo de la siguiente forma:
```py
from transformers import AutoProcessor
processor = AutoProcessor.from_pretrained("openai/whisper-small")
```
Aquí hemos ilustrado los pasos fundamentales de preparación de datos. Por supuesto, los datos personalizados pueden requerir una
preprocesamiento más complejo. En este caso, puedes ampliar la función prepare_dataset para realizar cualquier tipo de transformación
personalizada en los datos. Con 🤗 Datasets, si puedes escribirlo como una función de Python, ¡puedes aplicarlo a tu conjunto de datos! | 4 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter1/streaming.mdx | # Streaming datos de audio
Uno de los mayores desafíos que se enfrenta con los conjuntos de datos de audio es su gran tamaño. Un solo minuto de audio sin comprimir de calidad
de CD (44.1kHz, 16 bits) ocupa un poco más de 5 MB de almacenamiento. Por lo general, un conjunto de datos de audio contiene horas de grabaciones.
En el ejemplo anterior usamos un subconjunto pequeño de MIND-14, sin embargo, las bases de datos de audios suelen ser mucho mas extensas.
Por ejemplo, la partición `xs`(más pequeña) de [GigaSpeech de SpeechColab](https://huggingface.co/datasets/speechcolab/gigaspeech)
aunque solo contiene 10 horas de grabaciones, su tamaño es mayor a los 13GB. ¿Qué pasa entonces cuando queremos entrenar en subconjunto
más grande? la partición `xl` de este mismo dataset contiene 10,000 horas de datos para entrenamiento, cuyo tamaño asciende a 1TB. Para la
mayoria de nosotros, este tamaño excede las especificaiones de un disco duro tipico. ¿Necesitamos comprar almacenamiento adicional? ¿O hay alguna forma
de entrenar con estos conjuntos de datos sin restricciones de espacio en disco?
🤗 Datasets resuelve este reto al ofrecer el modo de transmisión (streaming). La transmisión nos permite cargar los datos de forma
progresiva a medida que iteramos sobre el conjunto de datos. En lugar de descargar todo el conjunto de datos de una vez, cargamos el
conjunto de datos un ejemplo a la vez. Iteramos sobre el conjunto de datos, cargando y preparando ejemplos sobre la marcha cuando
se necesitan. De esta manera, solo cargamos los ejemplos que estamos utilizando y no los que no necesitamos.
Una vez que hemos terminado con un ejemplo, continuamos iterando sobre el conjunto de datos y cargamos el siguiente.
El modo de transmisión tiene tres ventajas principales sobre el modo tradicional de descargar la base de datos completa:
* Espacio en disco: Los ejemplos son cargados en memoria uno a uno a medida que iteramos cobre el conjunto de datos. Ya que los datos
no son descargados localmente, no hay requerimientos de espacio de disco, por lo que puedes utilizar cualquier base de datos sin preocuparte
por el tamaño.
* Descarga y tiempo de procesamiento: Las bases de datos de audios son extensas y necesitan una cantidad considerable de
tiempo para descargarse y procesarse. Con la funcionalidad de streaming, la carga y el procesamiento se hacen en la marcha,
lo que significa que puedes empezar a usar los audios tan pronto como el primer ejemplo este listo.
* Fácil experimentación: puedes experimentar con un subconjunto de ejemplos para verificar que tu script funciona sin tener
que descargar la base de datos completa.
Existe un inconveniente en el modo de transmisión. Cuando se descarga un conjunto de datos completo sin el modo de transmisión,
tanto los datos en bruto como los datos procesados se guardan localmente en el disco. Si deseamos reutilizar este conjunto de datos,
podemos cargar directamente los datos procesados desde el disco, omitiendo los pasos de descarga y procesamiento. En consecuencia,
solo tenemos que realizar las operaciones de descarga y procesamiento una vez, después de lo cual podemos reutilizar los datos preparados.
Con el modo de streaming, los datos no se descargan en el disco. De esta manera, tanto los datos descargados como los datos preprocesados
no se almacenan en caché. Si deseamos reutilizar el conjunto de datos, los pasos de transmisión deben repetirse, cargando y procesando
los archivos de audio sobre la marcha nuevamente. Por esta razón, se recomienda descargar las bases de datos que es probable que
se utilicen múltiples veces.
¿Cómo se puede habilitar el modo de transmisión? ¡Es fácil! Simplemente pasa el parámetro `streaming=True` al cargar tu conjunto de datos.
El resto lo hara Datasets:
```py
gigaspeech = load_dataset("speechcolab/gigaspeech", "xs", streaming=True)
```
De la misma manera que se aplicaron los pasos de preprocesamiento al subconjunto descargado de MINDS-14, se puede aplicar a
un conjunto de datos en modo streaming.
La única diferencia es que no puedes acceder a ejemplos individuales usando el indexado de Python (i.e. `gigaspeech["train"][sample_idx]`).
Al contrario, tienes que iterar sobre el conjunto de datos. A continuación puedes ver como se accede a un ejemplo del conjunto de datos
cuando se usa streaming:
```py
next(iter(gigaspeech["train"]))
```
**Output:**
```out
{
"segment_id": "YOU0000000315_S0000660",
"speaker": "N/A",
"text": "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
"audio": {
"path": "xs_chunks_0000/YOU0000000315_S0000660.wav",
"array": array(
[0.0005188, 0.00085449, 0.00012207, ..., 0.00125122, 0.00076294, 0.00036621]
),
"sampling_rate": 16000,
},
"begin_time": 2941.89,
"end_time": 2945.07,
"audio_id": "YOU0000000315",
"title": "Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43",
"url": "https://www.youtube.com/watch?v=zr2n1fLVasU",
"source": 2,
"category": 24,
"original_full_path": "audio/youtube/P0004/YOU0000000315.opus",
}
```
Si quiere previsualizar varios ejemplos de un gran conjunto de datos, usa `take()` para obtener los primeros n ejemplos.
Obtengamos ahora
If you'd like to preview several examples from a large dataset, use the `take()` to get the first n elements. Vamos a obtener
los primeros dos ejemplos en el conjunto de datos de Gigaspeech:
```py
gigaspeech_head = gigaspeech["train"].take(2)
list(gigaspeech_head)
```
**Output:**
```out
[
{
"segment_id": "YOU0000000315_S0000660",
"speaker": "N/A",
"text": "AS THEY'RE LEAVING <COMMA> CAN KASH PULL ZAHRA ASIDE REALLY QUICKLY <QUESTIONMARK>",
"audio": {
"path": "xs_chunks_0000/YOU0000000315_S0000660.wav",
"array": array(
[
0.0005188,
0.00085449,
0.00012207,
...,
0.00125122,
0.00076294,
0.00036621,
]
),
"sampling_rate": 16000,
},
"begin_time": 2941.89,
"end_time": 2945.07,
"audio_id": "YOU0000000315",
"title": "Return to Vasselheim | Critical Role: VOX MACHINA | Episode 43",
"url": "https://www.youtube.com/watch?v=zr2n1fLVasU",
"source": 2,
"category": 24,
"original_full_path": "audio/youtube/P0004/YOU0000000315.opus",
},
{
"segment_id": "AUD0000001043_S0000775",
"speaker": "N/A",
"text": "SIX TOMATOES <PERIOD>",
"audio": {
"path": "xs_chunks_0000/AUD0000001043_S0000775.wav",
"array": array(
[
1.43432617e-03,
1.37329102e-03,
1.31225586e-03,
...,
-6.10351562e-05,
-1.22070312e-04,
-1.83105469e-04,
]
),
"sampling_rate": 16000,
},
"begin_time": 3673.96,
"end_time": 3675.26,
"audio_id": "AUD0000001043",
"title": "Asteroid of Fear",
"url": "http//www.archive.org/download/asteroid_of_fear_1012_librivox/asteroid_of_fear_1012_librivox_64kb_mp3.zip",
"source": 0,
"category": 28,
"original_full_path": "audio/audiobook/P0011/AUD0000001043.opus",
},
]
```
El modo de transmisión puede llevar tu investigación al siguiente nivel: no solo tendrás acceso a los conjuntos de datos más grandes,
sino que también podrás evaluar sistemas en múltiples conjuntos de datos de manera simultánea sin preocuparte por el espacio en disco.
En comparación con la evaluación en un solo conjunto de datos, la evaluación en múltiples conjuntos de datos proporciona una mejor
métrica para las capacidades de generalización de un sistema de reconocimiento de voz (ver End-to-end Speech Benchmark, ESB).
| 5 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter1/quiz.mdx | <!-- DISABLE-FRONTMATTER-SECTIONS -->
# Revisa tu comprensión del material del curso
### 1. En que unidades se mide la frecuencia de muestreo?
<Question
choices={[
{
text: "dB",
explain: "No, la amplitud es medida en decibeles (dB)."
},
{
text: "Hz",
explain: "La frecuencia de muestreo es el número de muestras tomadas en un segundo y se mide en hertzios (Hz).",
correct: true
},
{
text: "bit",
explain: "Los bits se utilizan para describir la profundidad de bits, que se refiere al número de bits de información utilizados para representar cada muestra de una señal de audio.",
}
]}
/>
### 2. Cuando haces streaming de una gran base de datos, ¿Qué tan pronto puedes empezar a usarla?
<Question
choices={[
{
text: "Tan pronto como se haya descargado el conjunto de datos completo.",
explain: "El objetivo de la funcionalidad de streaming es poder trabajar con ellos sin necesidad de descargar por completo un conjunto de datos"
},
{
text: "Tan pronto como los primeros 16 primeros ejemplos esten descargados",
explain: "¡Intenta de nuevo!"
},
{
text: "Tan pronto como el primer ejemplo este descargado",
explain: "",
correct: true
}
]}
/>
### 3. ¿Qué es un espectrograma?
<Question
choices={[
{
text: "Un dispositivo utilizado para digitalizar el audio que es capturado primero por un micrófono, el cual convierte las ondas sonoras en una señal eléctrica.",
explain: "Un dispositivo utilizado para digitalizar se llama Conversor Análogo digital(ADC). ¡Intenta de nuevo!"
},
{
text: "Un gráfico que muestra cómo la amplitud de una señal de audio cambia a lo largo del tiempo. También se conoce como la representación en el dominio del tiempo del sonido.",
explain: "Esta descripción hace referencia a la forma de onda, no a los espectrogramas."
},
{
text: "Una representación visual del espectro de frecuencia de la señal que varia con el tiempo.",
explain: "",
correct: true
}
]}
/>
### 4. ¿Cúal es la forma más fácil de convertir una señal de audio en el espectro logarítmico de mel esperado por Whisper?
A.
```python
librosa.feature.melspectrogram(audio["array"])
```
B.
```python
feature_extractor = WhisperFeatureExtractor.from_pretrained("openai/whisper-small")
feature_extractor(audio["array"])
```
C.
```python
dataset.feature(audio["array"], model="whisper")
```
<Question
choices={[
{
text: "A",
explain: "`librosa.feature.melspectrogram()` crea un espectrograma de potencia."
},
{
text: "B",
explain: "",
correct: true
},
{
text: "C",
explain: "Datasets no prepara las características para los modelos de Transformer, esto lo hace el preprocesador del modelo."
}
]}
/>
### 5.¿Cómo cargas un dataset desde el 🤗 Hub?
A.
```python
from datasets import load_dataset
dataset = load_dataset(DATASET_NAME_ON_HUB)
```
B.
```python
import librosa
dataset = librosa.load(PATH_TO_DATASET)
```
C.
```python
from transformers import load_dataset
dataset = load_dataset(DATASET_NAME_ON_HUB)
```
<Question
choices={[
{
text: "A",
explain: "La mejor forma es usar la libreria 🤗 Datasets.",
correct: true
},
{
text: "B",
explain: "Librosa.load es util para cargar archivos indiduales de audio desde una ruta del sistema y retornar una tupla de la señal y la frecuencia de muestreo, pero no para un conjunto de datos extenso con muchas caracteristicas y metadata",
},
{
text: "C",
explain: "load_dataset method comes in the 🤗 Datasets library, not in 🤗 Transformers."
}
]}
/>
### 6. Tu conjunto de datos contiene audios de alta calidad con una frecuencia de muestreo de 32 kHz. Quieres entrenar un modelo de reconocimiento de voz que espera muestras de audio de 16kHz. ¿Qué debes hacer?
<Question
choices={[
{
text: "Usar el ejemplo como está, el modelo se adaptará facilmente a ejemplos con frecuencias muestreo más altas",
explain: "Debido a los mecanismos de atención, es complejo que los modelos puedan generalizar entre frecuencias de muestreo."
},
{
text: "Usar el modulo Audio de la libreria 🤗 Datasets para hacer hacer downsampling de los ejemplos del conjunto de datos",
explain: "",
correct: true
},
{
text: "Disminuir la frecuencia de muestreo en un factor de 2x al descartar las muestras intermedias",
explain: "Esto crearía distorsiones en la señal llamadas aliasing. Resamplear de una forma correcta es complicado y es mejor dejarlo en manos de bibliotecas bien probadas como librosa o 🤗 Datasets"
}
]}
/>
### 7. ¿Cómo se puede convertir un espectrograma generado por un modelo de machine learning en una forma de onda?
<Question
choices={[
{
text: "Podemos usar una red neuronal llamada vocoder para reconstruir la forma de onda a partir del espectrograma.",
explain: "Dado que la información de fase falta, necesitamos usar un vocoder o el algoritmo clásico Griffin-Lim para reconstruir la forma de onda.",
correct: true
},
{
text: "Se puede usar la transforma inversa de ls STFT para convertir el espectrograma en una forma de onda.",
explain: "Un espectrograma generado carece de información de fase que es necesaria para utilizar la transformada inversa de Fourier de tiempo corto (inverse STFT)."
},
{
text: "No se puede convertir un espectrograma generado por un modelo de aprendizaje automático en una forma de onda.",
explain: "!Intenta de nuevo!"
}
]}
/>
| 6 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter1/introduction.mdx | # Unidad 1. Trabajando con datos de audio
## ¿Qué aprenderás?
Cada tarea de audio o voz empieza con un archivo de audio. Antes de poder resolver estas tareas, es importante
que comprendas que tipo de información contienen estos archivos y como trabajar con ellos.
En esta unidad, entenderás la terminología fundamental relacionada con los datos de audio, incluyendo formas de onda,
frecuencia de muestreo y espectrograma. Tambien aprenderas como trabajar con bases de datos de audio, lo que incluye
cargar y preprocesar datos de audio y como trabajar en modo streaming con una base de datos grande de manera eficiente.
Al finalizar esta unidad, tendrás un sólido conocimiento de la terminología esencial de los datos de audio y estarás equipado
con las habilidades necesarias para trabajar con conjuntos de datos de audio en diversas aplicaciones. El conocimiento que adquirirás
en esta unidad sentará las bases para comprender el resto del curso. | 7 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter1/audio_data.mdx | # Introducción a los datos de audio
Por naturaleza, una onda sonora es una señal continua, es decir, que contiene un número infinito de valores de la señal en un tiempo determinado.
Este es un problema para los dispositivos digitales que trabajan con un número finito de valores. La onda sonora necesita ser convertida en
un serie de valores discretos para que pueda ser procesada, almacenada y transmitida por un por un dispositivo digital, esta representación discreta
se conoce como representación digital.
Si exploras cualquier base de datos de audio, encontrarás archivos digitales con fragmentos de sonido que pueden contener narraciones o música.
Puedes encontrar diferentes formatos de archivo como `.wav` (Waveform Audio File), `.flac` (Free Lossless Audio Codec)
y `.mp3` (MPEG-1 Audio Layer 3). Estos formatos difieren principalmente en como comprimen la representación digital de la señal de audio.
Examinemos como pasamos de una señal continua a una representación digital. La señal acústica(análoga) es primero capturada por un micrófono,
que convierte las ondas sonoras en una señal electrica(Tambien análoga). La señal electrica es digitalizada por un
conversor Análogo-Digital(ADC) para tener una representación digital a través del muestreo.
## Muestreo y frecuencia de muestreo
El muestreo es el proceso de medir el valor de una señal continua en intervalos de tiempo fijos. La señal sampleada es discreta,
ya que contiene un número finito de valores de la señal.
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/Signal_Sampling.png" alt="Signal sampling illustration">
</div>
*Ilustración de un articulo de Wikipedia: [Muestreo(procesamiento de señal)](https://es.wikipedia.org/wiki/Muestreo_(se%C3%B1al))*
La **Tasa de Muestreo** (Tambien llamada frecuencia de muestreo) es el número de muestras capturadas en un segundo y es medida en unidades
de Hertz (Hz). Para tener un punto de referencia, un audio con calidad de CD tiene una frecuencia de muestreo de 44,100 Hz, es decir que se
capturan 44,100 muestras por segundo. Existen archivos de audio Hi-Fi que utilizan frecuencias de muestreo de 192,000 hz o 192kHz. Una
frecuencia de muestreo comúnmente usada para entrenar modelos de voz es 16,0000 Hz o 16 kHz.
La elección de la frecuencia de muestreo determina la frecuencia más alta que puede ser representada digitalmente. Esto se conoce
como el limite de Nyquist y es exactamente la mitad de la señal de la frecuencia de muestreo. Las frecuencias audibles en la voz humana
estan por debajo de 8kHz, por lo que una frecuencia de 16kHz es suficiente. Usar una frecuencia de muestreo más alta no va a capturar
más información pero si añade un costo computacional al procesamiento de estos archivos. En el caso contrario, elegir una frecuencia de
muestreo muy baja puede resultar en perdidas de información. Audios de voz sampleados a 8kHz sonarán opacos, ya que las frecuencias por encima
de 4kHz no pueden ser capturadas por esta frecuencia de muestreo.
Es importante asegurar que todos los ejemplos de audio de la base de datos tienen la misma frecuencia de muestreo. Si planeas usar
tus propios audios para hacer fine-tunning de un modelo pre-entrenado, la frecuencia de muestreo de estos audios debe concordar con
la frecuencia de muestreo con la que el modelo fue previamente entrenado. La frecuencia de muestreo determina el intervalo de tiempo
entre muestras de audio sucesivas, lo que tiene un efecto en la resolución temporal de los datos de audio. Por ejemplo: un audio de 5
segundos con una frecuencia de muestreo de 16,000 Hz será representado como una serie de 80,000 valores, mientras que el mismo audio con
una frecuencia de muestreo de 8,000hz será representado como una serie de 40,000 valores. Los modelos de transformers para audio tratan los
ejemplos como secuencias y se basan en mecanismos de atención para aprender del audio o de representaciónes multimodales. Ya que la longitud
de las secuencias difiere al usar frecuencias de muestreo diferentes, será dificil para el modelo generalizar para diferentes frecuencias de muestro.
**Resamplear** es el proceso de convertir una señal a otra frecuencia de muestreo, es parte de la sección de [preprosesamiento](preprocessing#resampling-the-audio-data) de datos de audio.
## Amplitud y profundidad de bits
Mientras que la frecuencia de muestreo te indica con qué frecuencia se toman las muestras, ¿Qué representan exactamente los valores en cada muestra?
El sonido se produce por cambios en la presión del aire a frecuencias audibles para los humanos. La **amplitud** de un sonido describe el nivel
de presión sonora en un momento dado y se mide en decibelios (dB). Percibimos la amplitud como volumen o intensidad del sonido. Por ejemplo,
una voz normal al hablar está por debajo de los 60 dB, mientras que un concierto de rock puede llegar a los 125 dB, alcanzando
los límites de la audición humana.
En el audio digital, cada muestra de audio registra la amplitud de la onda de audio en un momento específico. La profundidad de bits de
la muestra determina con qué precisión se puede describir este valor de amplitud. Cuanto mayor sea la profundidad de bits, más fiel será la
representación digital a la onda de sonido continua original.
Las profundidades de bits de audio más comunes son 16 bits y 24 bits. Cada una es una medida binaria que representa el número de pasos posibles
en los que se puede cuantificar el valor de amplitud al convertirlo de continuo a discreto: 65.536 pasos para el audio de 16 bits
y 16.777.216 pasos para el audio de 24 bits. Debido a que la cuantificación implica redondear el valor continuo a un valor discreto, el proceso
de muestreo introduce ruido. Cuanto mayor sea la profundidad de bits, menor será este ruido de cuantificación. En la práctica, el ruido de
cuantificación del audio de 16 bits ya es lo suficientemente pequeño como para ser audible, por lo que generalmente no es
necesario utilizar profundidades de bits más altas.
También es posible encontrarse con audio de 32 bits. Este almacena las muestras como valores de punto flotante, mientras que el audio
de 16 bits y 24 bits utiliza muestras enteras. La precisión de un valor de punto flotante de 32 bits es de 24 bits, lo que le otorga
la misma profundidad de bits que el audio de 24 bits. Se espera que las muestras de audio de punto flotante se encuentren dentro del
rango [-1.0, 1.0]. Dado que los modelos de aprendizaje automático trabajan naturalmente con datos de punto flotante, el audio debe convertirse
primero al formato de punto flotante antes de poder ser utilizado para entrenar el modelo. Veremos cómo hacer esto en la próxima sección
sobre Preprocesamiento.
Al igual que con las señales de audio continuas, la amplitud del audio digital se expresa típicamente en decibelios (dB). Dado que la audición
humana es de naturaleza logarítmica, es decir, nuestros oídos son más sensibles a las pequeñas fluctuaciones en sonidos silenciosos que en
sonidos fuertes, el volumen de un sonido es más fácil de interpretar si las amplitudes están en decibelios, que también son logarítmicos.
La escala de decibelios para el audio real comienza en 0 dB, que representa el sonido más silencioso posible que los humanos pueden escuchar,
y los sonidos más fuertes tienen valores más grandes. Sin embargo, para las señales de audio digital, 0 dB es la amplitud más alta posible,
mientras que todas las demás amplitudes son negativas. Como regla general: cada -6 dB implica una reducción a la mitad de la amplitud, y cualquier
valor por debajo de -60 dB generalmente es inaudible a menos que subas mucho el volumen.
## Audio como forma de onda
Es posible que hayas visto los sonidos visualizados como una **forma de onda**(waveform), que representa los valores de las muestras a lo
largo del tiempo y muestra los cambios en la amplitud del sonido. Esta representación también se conoce como la representación en
el dominio del tiempo del sonido.
Este tipo de visualización es útil para identificar características específicas de la señal de audio, como la sincronización
de eventos de sonido individuales, la intensidad general de la señal y cualquier irregularidad o ruido presente en el audio.
Para graficar la forma de onda de una señal de audio, usamos una libreria de Python llamada `librosa`:
```bash
pip install librosa
```
Carguemos un ejemplo de la libreria llamado "trumpet":
```py
import librosa
array, sampling_rate = librosa.load(librosa.ex("trumpet"))
```
El ejemplo es cargado como una tupla formada por una serie temporal de valores de audio(llamado `array`) y la frecuencia de muestreo (`sampling_rate`).
Grafiquemos este sonido usando la función `waveshow()` de librosa:
```py
import matplotlib.pyplot as plt
import librosa.display
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/waveform_plot.png" alt="Waveform plot">
</div>
Esta representación grafica la amplitud de la señal en el eje y y el tiempo en el eje x. En otras palabras, cada punto corresponde
a un único valor de muestra que se tomó cuando se muestreó este sonido. También es importante tener en cuenta que librosa devuelve
el audio en forma de valores de punto flotante y que los valores de amplitud se encuentran dentro del rango [-1.0, 1.0].
Visualizar el audio junto con escucharlo puede ser una herramienta útil para comprender los datos con los que estás trabajando.
Puedes observar la forma de la señal, identificar patrones y aprender a detectar ruido o distorsión.
Si preprocesas los datos de alguna manera, como normalización, remuestreo o filtrado, puedes confirmar visualmente que los pasos
de preprocesamiento se hayan aplicado correctamente.
Después de entrenar un modelo, también puedes visualizar las muestras donde se producen errores (por ejemplo, en una tarea de
clasificación de audio) para solucionar el problema. Esto te permitirá depurar y entender mejor las áreas en las que el modelo
puede tener dificultades o errores.
## El espectro de frecuencia
Otra forma de visualizar los datos de audio es graficar el espectro de frecuencia de una señal de audio,
también conocido como la representación en el dominio de la frecuencia. El espectro se calcula utilizando la transformada
discreta de Fourier o DFT. Describe las frecuencias individuales que componen la señal y su intensidad.
Grafiquemos el espectro de frecuencia para el mismo sonido de trompeta mediante el cálculo de la transformada discreta de Fourier (DFT)
utilizando la función rfft() de numpy. Si bien es posible trazar el espectro de toda la señal de audio, es más útil observar una pequeña
región en su lugar. Aquí tomaremos la DFT de los primeros 4096 valores de muestra, que es aproximadamente la duración de la primera nota
que se está tocando:
```py
import numpy as np
dft_input = array[:4096]
# calcular la DFT
window = np.hanning(len(dft_input))
windowed_input = dft_input * window
dft = np.fft.rfft(windowed_input)
# obtener la amplitud del espectro en decibeles
amplitude = np.abs(dft)
amplitude_db = librosa.amplitude_to_db(amplitude, ref=np.max)
# Obtener los bins de frecuencia
frequency = librosa.fft_frequencies(sr=sampling_rate, n_fft=len(dft_input))
plt.figure().set_figwidth(12)
plt.plot(frequency, amplitude_db)
plt.xlabel("Frequency (Hz)")
plt.ylabel("Amplitude (dB)")
plt.xscale("log")
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/spectrum_plot.png" alt="Spectrum plot">
</div>
Esto representa la intensidad de los diferentes componentes de frecuencia que están presentes en este segmento de audio.
Los valores de frecuencia se encuentran en el eje x, generalmente representados en una escala logarítmica, mientras que
las amplitudes se encuentran en el eje y.
El espectro de frecuencia que hemos graficado muestra varios picos. Estos picos corresponden a los armónicos de la nota que se está tocando,
siendo los armónicos más altos(en frecuencia) los más silenciosos. Dado que el primer pico se encuentra alrededor de 620 Hz, este es el espectro
de frecuencia de una nota Mi♭.
La salida de la DFT es una matriz de números complejos, compuestos por componentes reales e imaginarios. Tomar la magnitud con np.abs(dft)
extrae la información de amplitud del espectrograma. El ángulo entre los componentes reales e imaginarios proporciona el llamado espectro
de fase, pero esto a menudo se descarta en aplicaciones de aprendizaje automático.
Utilizamos `librosa.amplitude_to_db()` para convertir los valores de amplitud a la escala de decibelios, lo que facilita ver los detalles más
sutiles en el espectro. A veces, las personas utilizan el **espectro de potencia**, que mide la energía en lugar de la amplitud; esto es simplemente
un espectro con los valores de amplitud elevados al cuadrado.+
<Tip>
💡 En la práctica, las personas utilizan indistintamente los términos FFT (Transformada Rápida de Fourier) y DFT (Transformada Discreta de Fourier),
ya que la FFT es la única forma eficiente de calcular la DFT en una computadora.
</Tip>
El espectro de frecuencia de una señal de audio contiene exactamente la misma información que su representación en el dominio
del tiempo(forma de onda); simplemente son dos formas diferentes de ver los mismos datos (en este caso, los primeros 4096 valores
de muestra del sonido de trompeta). Mientras que la forma de onda representa la amplitud de la señal de audio a lo largo del tiempo,
el espectro visualiza las amplitudes de las frecuencias individuales en un punto fijo en el tiempo.
## Espectrograma
¿Y si queremos ver cómo cambian las frecuencias en una señal de audio? La trompeta toca varias notas que tienen diferentes frecuencias.
El problema es que el espectro solo es una foto fija de las frecuencias en un instante determinado. La solución es tomar múltiples DFT,
cada una abarcando un pequeño fragmento de la señal, y luego apilar los espectros resultantes en un **espectrograma**.
Un espectrograma grafica el contenido frecuencial de una señal de audio a medida que cambia en el tiempo. Esto nos permite ver en la
misma gráfica la información de tiempo, frecuencia y amplitud. El algoritmo que permite hacer este representación se conoce como STFT o
Transformada de tiempo corto de Fourier.
El espectrograma es una de las herramientas más útiles disponibles. Por ejemplo, cuando estamos trabajando con una grabación de música,
podemos ver como contribuye cada instrumento y las voces al sonido general. En el habla, se pueden identificar los difrerentes
sonidos de las vocales ya que cada vocal esta caracterizada por frecuencias particulares.
Grafiquemos ahora un espectrograma del mismo sonido de trompeta, usando las funciones de librosa `stft()` y `specshow()`:
```py
import numpy as np
D = librosa.stft(array)
S_db = librosa.amplitude_to_db(np.abs(D), ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_db, x_axis="time", y_axis="hz")
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/spectrogram_plot.png" alt="Spectrogram plot">
</div>
En este gráfico, el eje x representa el tiempo al igual que en la visulización de la forma de onda sin embargo el eje y ahora representa la
frecuencia en hertz(Hz). La intensidad del color representa el nivel en decibelios (dB) de las componentes de frecuencia en cada punto del tiempo.
El espectrograma es creado al tomar pequeños segmentos de la señal de audio, comunmente de unos cuantos milisegundos y calculando
la transformada discreta de Fourier de cada segmento para obtener el espectro en frecuencia. Estos espectros se concatenan a lo
largo del eje temporal para crear un espectrograma. Cada columna en la imagen corresponde a un espectro de frecuencia, Por defecto,
la función `librosa.stft()` divide la señal en segmentos de 2048 muestras, lo que ofrece un buen resultado
para la resolución en frecuencia y la resolución temporal.
Dado que el espectrograma y la forma de onda son diferentes representaciones de los mismos datos, es posible convertir el
espectrograma nuevamente en la forma de onda original utilizando la STFT inversa (transformada de Fourier de tiempo corto inversa).
Sin embargo, esto requiere tanto la información de amplitud como la información de fase. Si el espectrograma fue generado por un
modelo de aprendizaje automático, típicamente solo se genera la información de amplitud. En ese caso, podemos utilizar un algoritmo
de reconstrucción de fase clásico como el algoritmo de Griffin-Lim, o utilizar una red neuronal llamada vocoder, para reconstruir una
forma de onda a partir del espectrograma.
Los espectrogramas no solo se utilizan para visualización. Muchos modelos de aprendizaje automático toman espectrogramas como entrada,
en lugar de formas de onda, y producen espectrogramas como salida.
Ahora que sabemos qué es un espectrograma y cómo se genera, echemos un vistazo a una variante ampliamente utilizada en el procesamiento
del habla: el espectrograma de mel.
## Espectrograma de Mel
Un espectrograma mel es una variante del espectrograma que se utiliza comúnmente en el procesamiento del habla y en tareas de aprendizaje
automático. Es similar a un espectrograma en el sentido de que muestra el contenido de frecuencia de una señal de audio a lo largo del tiempo,
pero en un eje de frecuencia diferente.
En un espectrograma estándar, el eje de frecuencia es lineal y se mide en hercios (Hz). Sin embargo, el sistema auditivo humano
es más sensible a los cambios en las frecuencias bajas que en las frecuencias altas, y esta sensibilidad disminuye de manera logarítmica
a medida que la frecuencia aumenta. La escala mel es una escala perceptual que aproxima la respuesta de frecuencia no lineal del oído humano.
Para crear un espectrograma de mel, se utiliza la STFT de la misma manera que vimos antes, dividiendo el audio en segmentos cortos para
obtener una secuencia de espectros de frecuencia. Además, cada espectro se pasa a través de un conjunto de filtros(banco de filtros de mel)
para transformar las frecuencias a la escala de mel.
Obsrevemos como podemos obtener el espectrograma de mel usando la función `melspectrogram()` de librosa, que realiza todos los pasos anteriores:
```py
S = librosa.feature.melspectrogram(y=array, sr=sampling_rate, n_mels=128, fmax=8000)
S_dB = librosa.power_to_db(S, ref=np.max)
plt.figure().set_figwidth(12)
librosa.display.specshow(S_dB, x_axis="time", y_axis="mel", sr=sampling_rate, fmax=8000)
plt.colorbar()
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/mel-spectrogram.png" alt="Mel spectrogram plot">
</div>
En el ejemplo anterior, `n_mels` representa el número de bandas de mel que se generarán. Las bandas de mel definen un conjunto de
rangos de frecuencia que dividen el espectro en componentes significativos desde el punto de vista perceptual, utilizando un
conjunto de filtros cuya forma y espaciado se eligen para imitar la forma en que el oído humano responde a diferentes frecuencias.
Los valores comunes para `n_mels` son 40 o 80. `fmax` indica la frecuencia más alta (en Hz) que nos interesa.
Al igual que con un espectrograma regular, es práctica común expresar la intensidad de los componentes de frecuencia de mel en decibelios.
Esto se conoce comúnmente como un **espectrograma logarítmico de mel**, porque la conversión a decibelios implica una operación logarítmica.
El ejemplo anterior se usó `librosa.power_to_db()` ya que la función `librosa.feature.melspectrogram()` crea un espectrograma de potencia.
<Tip>
💡 ¡No todos los espectrogramas mel son iguales! Existen dos variantes comumente usadas de las escalas de mel("htk" y "slaney"),
, y en lugar del espectrograma de potencia, se puede estar usando el espectrograma de amplitud. El cálculo de un espectrograma
logarítmico de mel no siempre usa decibelios reales, puede que se haya aplicado solamente la función `log`. Por lo tanto,
si un modelo de aprendizaje automático espera un espectrograma de mel como entrada, verifica que estés calculándolo de la misma manera
para asegurarte de que sea compatible.
</Tip>
La creación de un espectrograma mel es una operación con pérdidas, ya que implica filtrar la señal. Convertir un espectrograma de mel de
nuevo en una forma de onda es más difícil que hacerlo para un espectrograma regular, ya que requiere estimar las frecuencias que se eliminaron.
Es por eso que se necesitan modelos de aprendizaje automático como el vocoder HiFiGAN para producir una forma de onda a partir de un espectrograma de mel.
En comparación con un espectrograma estándar, un espectrograma mel captura características más significativas de la señal de audio para la percepción humana,
lo que lo convierte en una opción popular en tareas como el reconocimiento de voz, la identificación de hablantes y la clasificación de géneros musicales.
Ahora que sabes cómo visualizar datos de audio, trata de ver cómo se ven tus sonidos favoritos. :) | 8 |
0 | hf_public_repos/audio-transformers-course/chapters/es | hf_public_repos/audio-transformers-course/chapters/es/chapter1/load_and_explore.mdx | # Cargar y explorar una base de datos de audio
En este curso usaremos la libreria 🤗 Datasets para trabajar con bases de datos de audio. 🤗 Datasets es una libreria de
código abierto para descargar y preparar conjuntos de datos de todos los tipos, incluyendo audio. La libreria ofrece un
acceso fácil a una gran cantidad de conjuntos de datos públicos almacenados en el Hugging Face Hub. Además, 🤗 Datasets incluye
multiples funcionalidades pensadas para simplificar el trabajo con conjuntos de datos de audio para investigadores y desarrolladores.
Para empezar a trabajar con bases de datos de audio, asegurate de tener la librería 🤗 Datasets instalada:
```bash
pip install datasets[audio]
```
Una de las principales características de 🤗 Datasets es la posibilidad de descargar y preparar un conjunto de datos
en una sola linea de código usando la función `load_dataset()`
Carguemos y exploremos un conjunto de audios llamado [MINDS-14](https://huggingface.co/datasets/PolyAI/minds14), el cual contiene
grabaciones de personas haciendo preguntas sobre sistemas electrónicos bancarios en diferentes lenguajes y dialectos.
Para cargar MINDS-14, necesitamos copiar el identificador de la base de datos que aparece en el Hub (`PolyAI/minds14`) y pasarlo
como argumento a la función `load_dataset`. Tambien especificaremos que solo estamos interesados en el subconjunto de inglés Australiano(`en-AU`)
y la partición de entrenamiento("train"):
```py
from datasets import load_dataset
minds = load_dataset("PolyAI/minds14", name="en-AU", split="train")
minds
```
**Output:**
```out
Dataset(
{
features: [
"path",
"audio",
"transcription",
"english_transcription",
"intent_class",
"lang_id",
],
num_rows: 654,
}
)
```
El conjunto de datos contiene 654 audios, cada uno acompañado de su transcripción, una transcripción en inglés, y una etiqueta
que indica la intención de la pregunta de la persona. La columna de audio, contiene la información en bruto del audio. Examinemos
ahora uno de los ejemplos:
```py
example = minds[0]
example
```
**Output:**
```out
{
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"audio": {
"path": "/root/.cache/huggingface/datasets/downloads/extracted/f14948e0e84be638dd7943ac36518a4cf3324e8b7aa331c5ab11541518e9368c/en-AU~PAY_BILL/response_4.wav",
"array": array(
[0.0, 0.00024414, -0.00024414, ..., -0.00024414, 0.00024414, 0.0012207],
dtype=float32,
),
"sampling_rate": 8000,
},
"transcription": "I would like to pay my electricity bill using my card can you please assist",
"english_transcription": "I would like to pay my electricity bill using my card can you please assist",
"intent_class": 13,
"lang_id": 2,
}
```
Puedes ver que la columna de audio se compone de las siguiente información:
* `path`: La ruta al archivo de audio (`*.wav` en este caso).
* `array`: Los datos decodificados de audios, representedos como un NumPy array de 1 dimensión.
* `sampling_rate`. La frecuencia de muestreo del archivo (8,000 Hz en este ejemplo).
La columna `intent_class` es de tipo categórico codificado en enteros. Para convertir este número en una texto con significado
podemos usar el método `int2str()`:
```py
id2label = minds.features["intent_class"].int2str
id2label(example["intent_class"])
```
**Output:**
```out
"pay_bill"
```
Si miras la columna de `transcription`, puedes ver que en efecto la persona ha grabado un audio haciendo una pregunta sobre
pagar una cuenta.
Si planeas entrenar un clasificador de audio en este subconjunto de datos, no necesitas toda la información contenida en las
columnas del conjunto de datos. Por ejemplo, la información en `lang_id` sera igual para todos los ejemplos y no nos será útil.
La columna `english_transcription' seguramente sera un duplicado de la columna `transcription` en este subconjunto, por lo que
podemos removerla tambien.
Puedes eliminar características irrelevantes usando el método ``remove_columns`de 🤗 Datasets
```py
columns_to_remove = ["lang_id", "english_transcription"]
minds = minds.remove_columns(columns_to_remove)
minds
```
**Output:**
```out
Dataset({features: ["path", "audio", "transcription", "intent_class"], num_rows: 654})
```
Ahora que hemos cargado e inspeccionado los contenidos del conjunto de datos, ¡escuchemos algunos ejemplos! Usaremos `Blocks`
y `Audio` de `Gradio` para cargar algunos ejemplos del dataset.
```py
import gradio as gr
def generate_audio():
example = minds.shuffle()[0]
audio = example["audio"]
return (
audio["sampling_rate"],
audio["array"],
), id2label(example["intent_class"])
with gr.Blocks() as demo:
with gr.Column():
for _ in range(4):
audio, label = generate_audio()
output = gr.Audio(audio, label=label)
demo.launch(debug=True)
```
Podemos visulizar tambien algunos de los ejemplos. Grafiquemos ahora la forma de onda del primer ejemplo.
```py
import librosa
import matplotlib.pyplot as plt
import librosa.display
array = example["audio"]["array"]
sampling_rate = example["audio"]["sampling_rate"]
plt.figure().set_figwidth(12)
librosa.display.waveshow(array, sr=sampling_rate)
```
<div class="flex justify-center">
<img src="https://huggingface.co/datasets/huggingface-course/audio-course-images/resolve/main/waveform_unit1.png" alt="Waveform plot">
</div>
¡Pruebalo! Decarga otro dialecto o lenguaje del conjunto MINDS-14, escucha y visualiza ajgunos ejemplos para tener un
sentido de la variación de toda la base de datos. Puedes ver una lista de todos los lenguajes [aqui](https://huggingface.co/datasets/PolyAI/minds14). | 9 |
0 | hf_public_repos | hf_public_repos/blog/pollen-vision.md | ---
title: "Pollen-Vision: Unified interface for Zero-Shot vision models in robotics"
thumbnail: /blog/assets/pollen-vision/thumbnail.jpg
authors:
- user: apirrone
guest: true
- user: simheo
guest: true
- user: PierreRouanet
guest: true
- user: revellsi
guest: true
---
# Pollen-Vision: Unified interface for Zero-Shot vision models in robotics
> [!NOTE] This is a guest blog post by the Pollen Robotics team. We are the creators of Reachy, an open-source humanoid robot designed for manipulation in the real world.
<video style="max-width: 100%; margin: auto;" autoplay loop muted playsinline src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/pollen-vision/pollen_vision_intro.mp4"></video>
In the context of autonomous behaviors, the essence of a robot's usability lies in its ability to understand and interact with its environment. This understanding primarily comes from **visual perception**, which enables robots to identify objects, recognize people, navigate spaces, and much more.
We're excited to share the initial launch of our open-source `pollen-vision` library, a first step towards empowering our robots with the autonomy to grasp unknown objects. **This library is a carefully curated collection of vision models chosen for their direct applicability to robotics.** `Pollen-vision` is designed for ease of installation and use, composed of independent modules that can be combined to create a 3D object detection pipeline, getting the position of the objects in 3D space (x, y, z).
We focused on selecting [zero-shot models](https://huggingface.co/tasks/zero-shot-object-detection), eliminating the need for any training, and making these tools instantly usable right out of the box.
Our initial release is focused on 3D object detection—laying the groundwork for tasks like robotic grasping by providing a reliable estimate of objects' spatial coordinates. Currently limited to positioning within a 3D space (not extending to full 6D pose estimation), this functionality establishes a solid foundation for basic robotic manipulation tasks.
## The Core Models of Pollen-Vision
The library encapsulates several key models. We want the models we use to be zero-shot and versatile, allowing a wide range of detectable objects without re-training. The models also have to be “real-time capable”, meaning they should run at least at a few fps on a consumer GPU. The first models we chose are:
- [OWL-VIT](https://huggingface.co/docs/transformers/model_doc/owlvit) (Open World Localization - Vision Transformer, By Google Research): This model performs text-conditioned zero-shot 2D object localization in RGB images. It outputs bounding boxes (like YOLO)
- [Mobile Sam](https://github.com/ChaoningZhang/MobileSAM): A lightweight version of the Segment Anything Model (SAM) by Meta AI. SAM is a zero-shot image segmentation model. It can be prompted with bounding boxes or points.
- [RAM](https://github.com/xinyu1205/recognize-anything) (Recognize Anything Model by OPPO Research Institute): Designed for zero-shot image tagging, RAM can determine the presence of an object in an image based on textual descriptions, laying the groundwork for further analysis.
## Get started in very few lines of code!
Below is an example of how to use pollen-vision to build a simple object detection and segmentation pipeline, taking only images and text as input.
```python
from pollen_vision.vision_models.object_detection import OwlVitWrapper
from pollen_vision.vision_models.object_segmentation import MobileSamWrapper
from pollen_vision.vision_models.utils import Annotator, get_bboxes
owl = OwlVitWrapper()
sam = MobileSamWrapper()
annotator = Annotator()
im = ...
predictions = owl.infer(im, ["paper cups"]) # zero-shot object detection
bboxes = get_bboxes(predictions)
masks = sam.infer(im, bboxes=bboxes) # zero-shot object segmentation
annotated_im = annotator.annotate(im, predictions, masks=masks)
```
<p align="center">
<img width="40%" src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/pollen-vision/paper_cups.png">
</p>
OWL-VIT’s inference time depends on the number of prompts provided (i.e., the number of objects to detect). On a Laptop with a RTX 3070 GPU:
```
1 prompt : ~75ms per frame
2 prompts : ~130ms per frame
3 prompts : ~180ms per frame
4 prompts : ~240ms per frame
5 prompts : ~330ms per frame
10 prompts : ~650ms per frame
```
So it is interesting, performance-wise, to only prompt OWL-VIT with objects that we know are in the image. That’s where RAM is useful, as it is fast and provides exactly this information.
## A robotics use case: grasping unknown objects in unconstrained environments
With the object's segmentation mask, we can estimate its (u, v) position in pixel space by computing the centroid of the binary mask. Here, having the segmentation mask is very useful because it allows us to average the depth values inside the mask rather than inside the full bounding box, which also contains a background that would skew the average.
One way to do that is by averaging the u and v coordinates of the non zero pixels in the mask
```python
def get_centroid(mask):
x_center, y_center = np.argwhere(mask == 1).sum(0) / np.count_nonzero(mask)
return int(y_center), int(x_center)
```
We can now bring in depth information in order to estimate the z coordinate of the object. The depth values are already in meters, but the (u, v) coordinates are expressed in pixels. We can get the (x, y, z) position of the centroid of the object in meters using the camera’s intrinsic matrix (K)
```python
def uv_to_xyz(z, u, v, K):
cx = K[0, 2]
cy = K[1, 2]
fx = K[0, 0]
fy = K[1, 1]
x = (u - cx) * z / fx
y = (v - cy) * z / fy
return np.array([x, y, z])
```
We now have an estimation of the 3D position of the object in the camera’s reference frame.
If we know where the camera is positioned relative to the robot’s origin frame, we can perform a simple transformation to get the 3D position of the object in the robot’s frame. This means we can move the end effector of our robot where the object is, **and grasp it** ! 🥳
<video style="max-width: 100%; margin: auto;" autoplay loop muted playsinline src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/pollen-vision/demo.mp4"></video>
## What’s next?
What we presented in this post is a first step towards our goal, which is autonomous grasping of unknown objects in the wild. There are a few issues that still need addressing:
- OWL-Vit does not detect everything every time and can be inconsistent. We are looking for a better option.
- There is no temporal or spatial consistency so far. All is recomputed every frame
- We are currently working on integrating a point tracking solution to enhance the consistency of the detections
- Grasping technique (only front grasp for now) was not the focus of this work. We will be working on different approaches to enhance the grasping capabilities in terms of perception (6D detection) and grasping pose generation.
- Overall speed could be improved
## Try pollen-vision
Wanna try pollen-vision? Check out our [Github repository](https://github.com/pollen-robotics/pollen-vision) ! | 0 |
0 | hf_public_repos | hf_public_repos/blog/intel-sapphire-rapids.md | ---
title: "Accelerating PyTorch Transformers with Intel Sapphire Rapids - part 1"
thumbnail: /blog/assets/124_intel_sapphire_rapids/02.png
authors:
- user: juliensimon
---
# Accelerating PyTorch Transformers with Intel Sapphire Rapids, part 1
About a year ago, we [showed you](https://huggingface.co/blog/accelerating-pytorch) how to distribute the training of Hugging Face transformers on a cluster or third-generation [Intel Xeon Scalable](https://www.intel.com/content/www/us/en/products/details/processors/xeon/scalable.html) CPUs (aka Ice Lake). Recently, Intel has launched the fourth generation of Xeon CPUs, code-named Sapphire Rapids, with exciting new instructions that speed up operations commonly found in deep learning models.
In this post, you will learn how to accelerate a PyTorch training job with a cluster of Sapphire Rapids servers running on AWS. We will use the [Intel oneAPI Collective Communications Library](https://www.intel.com/content/www/us/en/developer/tools/oneapi/oneccl.html) (CCL) to distribute the job, and the [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) library to automatically put the new CPU instructions to work. As both libraries are already integrated with the Hugging Face transformers library, we will be able to run our sample scripts out of the box without changing a line of code.
In a follow-up post, we'll look at inference on Sapphire Rapids CPUs and the performance boost that they bring.
## Why You Should Consider Training On CPUs
Training a deep learning (DL) model on Intel Xeon CPUs can be a cost-effective and scalable approach, especially when using techniques such as distributed training and fine-tuning on small and medium datasets.
Xeon CPUs support advanced features such as Advanced Vector Extensions ([AVX-512](https://en.wikipedia.org/wiki/AVX-512)) and Hyper-Threading, which help improve the parallelism and efficiency of DL models. This enables faster training times as well as better utilization of hardware resources.
In addition, Xeon CPUs are generally more affordable and widely available compared to specialized hardware such as GPUs, which are typically required for training large deep learning models. Xeon CPUs can also be easily repurposed for other production tasks, from web servers to databases, making them a versatile and flexible choice for your IT infrastructure.
Finally, cloud users can further reduce the cost of training on Xeon CPUs with spot instances. Spot instances are built from spare compute capacities and sold at a discounted price. They can provide significant cost savings compared to using on-demand instances, sometimes up to 90%. Last but not least, CPU spot instances also are generally easier to procure than GPU instances.
Now, let's look at the new instructions in the Sapphire Rapids architecture.
## Advanced Matrix Extensions: New Instructions for Deep Learning
The Sapphire Rapids architecture introduces the Intel Advanced Matrix Extensions ([AMX](https://en.wikipedia.org/wiki/Advanced_Matrix_Extensions)) to accelerate DL workloads. Using them is as easy as installing the latest version of IPEX. There is no need to change anything in your Hugging Face code.
The AMX instructions accelerate matrix multiplication, an operation central to training DL models on data batches. They support both Brain Floating Point ([BF16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format)) and 8-bit integer (INT8) values, enabling acceleration for different training scenarios.
AMX introduces new 2-dimensional CPU registers, called tile registers. As these registers need to be saved and restored during context switches, they require kernel support: On Linux, you'll need [v5.16](https://discourse.ubuntu.com/t/kinetic-kudu-release-notes/27976) or newer.
Now, let's see how we can build a cluster of Sapphire Rapids CPUs for distributed training.
## Building a Cluster of Sapphire Rapids CPUs
At the time of writing, the simplest way to get your hands on Sapphire Rapids servers is to use the new Amazon EC2 [R7iz](https://aws.amazon.com/ec2/instance-types/r7iz/) instance family. As it's still in preview, you have to [sign up](https://pages.awscloud.com/R7iz-Preview.html) to get access. In addition, virtual servers don't yet support AMX, so we'll use bare metal instances (`r7iz.metal-16xl`, 64 vCPU, 512GB RAM).
To avoid setting up each node in the cluster manually, we will first set up the master node and create a new Amazon Machine Image ([AMI](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/AMIs.html)) from it. Then, we will use this AMI to launch additional nodes.
From a networking perspective, we will need the following setup:
* Open port 22 for ssh access on all instances for setup and debugging.
* Configure [password-less ssh](https://www.redhat.com/sysadmin/passwordless-ssh) from the master instance (the one you'll launch training from) to all other instances (master included). In other words, the ssh public key of the master node must be authorized on all nodes.
* Allow all network traffic inside the cluster, so that distributed training runs unencumbered. AWS provides a safe and convenient way to do this with [security groups](https://docs.aws.amazon.com/vpc/latest/userguide/VPC_SecurityGroups.html). We just need to create a security group that allows all traffic from instances configured with that same security group and make sure to attach it to all instances in the cluster. Here's how my setup looks.
<kbd>
<img src="assets/124_intel_sapphire_rapids/01.png">
</kbd>
Let's get to work and build the master node of the cluster.
## Setting Up the Master Node
We first create the master node by launching an `r7iz.metal-16xl` instance with an Ubunutu 20.04 AMI (`ami-07cd3e6c4915b2d18`) and the security group we created earlier. This AMI includes Linux v5.15.0, but Intel and AWS have fortunately patched the kernel to add AMX support. Thus, we don't need to upgrade the kernel to v5.16.
Once the instance is running, we ssh to it and check with `lscpu` that AMX are indeed supported. You should see the following in the flags section:
```
amx_bf16 amx_tile amx_int8
```
Then, we install native and Python dependencies.
```
sudo apt-get update
# Install tcmalloc for extra performance (https://github.com/google/tcmalloc)
sudo apt install libgoogle-perftools-dev -y
# Create a virtual environment
sudo apt-get install python3-pip -y
pip install pip --upgrade
export PATH=/home/ubuntu/.local/bin:$PATH
pip install virtualenv
# Activate the virtual environment
virtualenv cluster_env
source cluster_env/bin/activate
# Install PyTorch, IPEX, CCL and Transformers
pip3 install torch==1.13.0 -f https://download.pytorch.org/whl/cpu
pip3 install intel_extension_for_pytorch==1.13.0 -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install oneccl_bind_pt==1.13 -f https://developer.intel.com/ipex-whl-stable-cpu
pip3 install transformers==4.24.0
# Clone the transformers repository for its example scripts
git clone https://github.com/huggingface/transformers.git
cd transformers
git checkout v4.24.0
```
Next, we create a new ssh key pair called 'cluster' with `ssh-keygen` and store it at the default location (`~/.ssh`).
Finally, we create a [new AMI](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/creating-an-ami-ebs.html) from this instance.
## Setting Up the Cluster
Once the AMI is ready, we use it to launch 3 additional `r7iz.16xlarge-metal` instances, without forgetting to attach the security group created earlier.
While these instances are starting, we ssh to the master node to complete the network setup. First, we edit the ssh configuration file at `~/.ssh/config` to enable password-less connections from the master to all other nodes, using their private IP address and the key pair created earlier. Here's what my file looks like.
```
Host 172.31.*.*
StrictHostKeyChecking no
Host node1
HostName 172.31.10.251
User ubuntu
IdentityFile ~/.ssh/cluster
Host node2
HostName 172.31.10.189
User ubuntu
IdentityFile ~/.ssh/cluster
Host node3
HostName 172.31.6.15
User ubuntu
IdentityFile ~/.ssh/cluster
```
At this point, we can use `ssh node[1-3]` to connect to any node without any prompt.
On the master node sill, we create a `~/hosts` file with the names of all nodes in the cluster, as defined in the ssh configuration above. We use `localhost` for the master as we will launch the training script there. Here's what my file looks like.
```
localhost
node1
node2
node3
```
The cluster is now ready. Let's start training!
## Launching a Distributed Training Job
In this example, we will fine-tune a [DistilBERT](https://huggingface.co/distilbert-base-uncased) model for question answering on the [SQUAD](https://huggingface.co/datasets/squad) dataset. Feel free to try other examples if you'd like.
```
source ~/cluster_env/bin/activate
cd ~/transformers/examples/pytorch/question-answering
pip3 install -r requirements.txt
```
As a sanity check, we first launch a local training job. Please note several important flags:
* `no_cuda` makes sure the job is ignoring any GPU on this machine,
* `use_ipex` enables the IPEX library and thus the AVX and AMX instructions,
* `bf16` enables BF16 training.
```
export LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so"
python run_qa.py --model_name_or_path distilbert-base-uncased \
--dataset_name squad --do_train --do_eval --per_device_train_batch_size 32 \
--num_train_epochs 1 --output_dir /tmp/debug_squad/ \
--use_ipex --bf16 --no_cuda
```
No need to let the job run to completion, We just run for a minute to make sure that all dependencies have been correctly installed. This also gives us a baseline for single-instance training: 1 epoch takes about **26 minutes**. For reference, we clocked the same job on a comparable Ice Lake instance (`c6i.16xlarge`) with the same software setup at **3 hours and 30 minutes** per epoch. That's an **8x speedup**. We can already see how beneficial the new instructions are!
Now, let's distribute the training job on four instances. An `r7iz.16xlarge` instance has 32 physical CPU cores, which we prefer to work with directly instead of using vCPUs (`KMP_HW_SUBSET=1T`). We decide to allocate 24 cores for training (`OMP_NUM_THREADS`) and 2 for CCL communication (`CCL_WORKER_COUNT`), leaving the last 6 threads to the kernel and other processes. The 24 training threads support 2 Python processes (`NUM_PROCESSES_PER_NODE`). Hence, the total number of Python jobs running on the 4-node cluster is 8 (`NUM_PROCESSES`).
```
# Set up environment variables for CCL
oneccl_bindings_for_pytorch_path=$(python -c "from oneccl_bindings_for_pytorch import cwd; print(cwd)")
source $oneccl_bindings_for_pytorch_path/env/setvars.sh
export MASTER_ADDR=172.31.3.190
export NUM_PROCESSES=8
export NUM_PROCESSES_PER_NODE=2
export CCL_WORKER_COUNT=2
export CCL_WORKER_AFFINITY=auto
export KMP_HW_SUBSET=1T
```
Now, we launch the distributed training job.
```
# Launch distributed training
mpirun -f ~/hosts \
-n $NUM_PROCESSES -ppn $NUM_PROCESSES_PER_NODE \
-genv OMP_NUM_THREADS=24 \
-genv LD_PRELOAD="/usr/lib/x86_64-linux-gnu/libtcmalloc.so" \
python3 run_qa.py \
--model_name_or_path distilbert-base-uncased \
--dataset_name squad \
--do_train \
--do_eval \
--per_device_train_batch_size 32 \
--num_train_epochs 1 \
--output_dir /tmp/debug_squad/ \
--overwrite_output_dir \
--no_cuda \
--xpu_backend ccl \
--bf16
```
One epoch now takes **7 minutes and 30 seconds**.
Here's what the job looks like. The master node is at the top, and you can see the two training processes running on each one of the other 3 nodes.
<kbd>
<img src="assets/124_intel_sapphire_rapids/02.png">
</kbd>
Perfect linear scaling on 4 nodes would be 6 minutes and 30 seconds (26 minutes divided by 4). We're very close to this ideal value, which shows how scalable this approach is.
## Conclusion
As you can see, training Hugging Face transformers on a cluster of Intel Xeon CPUs is a flexible, scalable, and cost-effective solution, especially if you're working with small or medium-sized models and datasets.
Here are some additional resources to help you get started:
* [Intel IPEX](https://github.com/intel/intel-extension-for-pytorch) on GitHub
* Hugging Face documentation: "[Efficient training on CPU](https://huggingface.co/docs/transformers/perf_train_cpu)" and "[Efficient training on many CPUs](https://huggingface.co/docs/transformers/perf_train_cpu_many)".
If you have questions or feedback, we'd love to read them on the [Hugging Face forum](https://discuss.huggingface.co/).
Thanks for reading!
| 1 |
0 | hf_public_repos | hf_public_repos/blog/sentiment-analysis-fhe.md | ---
title: "Sentiment Analysis on Encrypted Data with Homomorphic Encryption"
thumbnail: /blog/assets/sentiment-analysis-fhe/thumbnail.png
authors:
- user: jfrery-zama
guest: true
---
# Sentiment Analysis on Encrypted Data with Homomorphic Encryption
It is well-known that a sentiment analysis model determines whether a text is positive, negative, or neutral. However, this process typically requires access to unencrypted text, which can pose privacy concerns.
Homomorphic encryption is a type of encryption that allows for computation on encrypted data without needing to decrypt it first. This makes it well-suited for applications where user's personal and potentially sensitive data is at risk (e.g. sentiment analysis of private messages).
This blog post uses the [Concrete-ML library](https://github.com/zama-ai/concrete-ml), allowing data scientists to use machine learning models in fully homomorphic encryption (FHE) settings without any prior knowledge of cryptography. We provide a practical tutorial on how to use the library to build a sentiment analysis model on encrypted data.
The post covers:
- transformers
- how to use transformers with XGBoost to perform sentiment analysis
- how to do the training
- how to use Concrete-ML to turn predictions into predictions over encrypted data
- how to [deploy to the cloud](https://docs.zama.ai/concrete-ml/getting-started/cloud) using a client/server protocol
Last but not least, we’ll finish with a complete demo over [Hugging Face Spaces](https://huggingface.co/spaces) to show this functionality in action.
## Setup the environment
First make sure your pip and setuptools are up to date by running:
```
pip install -U pip setuptools
```
Now we can install all the required libraries for the this blog with the following command.
```
pip install concrete-ml transformers datasets
```
## Using a public dataset
The dataset we use in this notebook can be found [here](https://www.kaggle.com/datasets/crowdflower/twitter-airline-sentiment).
To represent the text for sentiment analysis, we chose to use a transformer hidden representation as it yields high accuracy for the final model in a very efficient way. For a comparison of this representation set against a more common procedure like the TF-IDF approach, please see this [full notebook](https://github.com/zama-ai/concrete-ml/blob/release/0.4.x/use_case_examples/encrypted_sentiment_analysis/SentimentClassification.ipynb).
We can start by opening the dataset and visualize some statistics.
```python
from datasets import load_datasets
train = load_dataset("osanseviero/twitter-airline-sentiment")["train"].to_pandas()
text_X = train['text']
y = train['airline_sentiment']
y = y.replace(['negative', 'neutral', 'positive'], [0, 1, 2])
pos_ratio = y.value_counts()[2] / y.value_counts().sum()
neg_ratio = y.value_counts()[0] / y.value_counts().sum()
neutral_ratio = y.value_counts()[1] / y.value_counts().sum()
print(f'Proportion of positive examples: {round(pos_ratio * 100, 2)}%')
print(f'Proportion of negative examples: {round(neg_ratio * 100, 2)}%')
print(f'Proportion of neutral examples: {round(neutral_ratio * 100, 2)}%')
```
The output, then, looks like this:
```
Proportion of positive examples: 16.14%
Proportion of negative examples: 62.69%
Proportion of neutral examples: 21.17%
```
The ratio of positive and neutral examples is rather similar, though we have significantly more negative examples. Let’s keep this in mind to select the final evaluation metric.
Now we can split our dataset into training and test sets. We will use a seed for this code to ensure it is perfectly reproducible.
```python
from sklearn.model_selection import train_test_split
text_X_train, text_X_test, y_train, y_test = train_test_split(text_X, y,
test_size=0.1, random_state=42)
```
## Text representation using a transformer
[Transformers](https://en.wikipedia.org/wiki/Transformer_(machine_learning_model)) are neural networks often trained to predict the next words to appear in a text (this task is commonly called self-supervised learning). They can also be fine-tuned on some specific subtasks such that they specialize and get better results on a given problem.
They are powerful tools for all kinds of Natural Language Processing tasks. In fact, we can leverage their representation for any text and feed it to a more FHE-friendly machine-learning model for classification. In this notebook, we will use XGBoost.
We start by importing the requirements for transformers. Here, we use the popular library from [Hugging Face](https://huggingface.co) to get a transformer quickly.
The model we have chosen is a BERT transformer, fine-tuned on the Stanford Sentiment Treebank dataset.
```python
import torch
from transformers import AutoModelForSequenceClassification, AutoTokenizer
device = "cuda:0" if torch.cuda.is_available() else "cpu"
# Load the tokenizer (converts text to tokens)
tokenizer = AutoTokenizer.from_pretrained("cardiffnlp/twitter-roberta-base-sentiment-latest")
# Load the pre-trained model
transformer_model = AutoModelForSequenceClassification.from_pretrained(
"cardiffnlp/twitter-roberta-base-sentiment-latest"
)
```
This should download the model, which is now ready to be used.
Using the hidden representation for some text can be tricky at first, mainly because we could tackle this with many different approaches. Below is the approach we chose.
First, we tokenize the text. Tokenizing means splitting the text into tokens (a sequence of specific characters that can also be words) and replacing each with a number. Then, we send the tokenized text to the transformer model, which outputs a hidden representation (output of the self attention layers which are often used as input to the classification layers) for each word. Finally, we average the representations for each word to get a text-level representation.
The result is a matrix of shape (number of examples, hidden size). The hidden size is the number of dimensions in the hidden representation. For BERT, the hidden size is 768. The hidden representation is a vector of numbers that represents the text that can be used for many different tasks. In this case, we will use it for classification with [XGBoost](https://github.com/dmlc/xgboost) afterwards.
```python
import numpy as np
import tqdm
# Function that transforms a list of texts to their representation
# learned by the transformer.
def text_to_tensor(
list_text_X_train: list,
transformer_model: AutoModelForSequenceClassification,
tokenizer: AutoTokenizer,
device: str,
) -> np.ndarray:
# Tokenize each text in the list one by one
tokenized_text_X_train_split = []
tokenized_text_X_train_split = [
tokenizer.encode(text_x_train, return_tensors="pt")
for text_x_train in list_text_X_train
]
# Send the model to the device
transformer_model = transformer_model.to(device)
output_hidden_states_list = [None] * len(tokenized_text_X_train_split)
for i, tokenized_x in enumerate(tqdm.tqdm(tokenized_text_X_train_split)):
# Pass the tokens through the transformer model and get the hidden states
# Only keep the last hidden layer state for now
output_hidden_states = transformer_model(tokenized_x.to(device), output_hidden_states=True)[
1
][-1]
# Average over the tokens axis to get a representation at the text level.
output_hidden_states = output_hidden_states.mean(dim=1)
output_hidden_states = output_hidden_states.detach().cpu().numpy()
output_hidden_states_list[i] = output_hidden_states
return np.concatenate(output_hidden_states_list, axis=0)
```
```python
# Let's vectorize the text using the transformer
list_text_X_train = text_X_train.tolist()
list_text_X_test = text_X_test.tolist()
X_train_transformer = text_to_tensor(list_text_X_train, transformer_model, tokenizer, device)
X_test_transformer = text_to_tensor(list_text_X_test, transformer_model, tokenizer, device)
```
This transformation of the text (text to transformer representation) would need to be executed on the client machine as the encryption is done over the transformer representation.
## Classifying with XGBoost
Now that we have our training and test sets properly built to train a classifier, next comes the training of our FHE model. Here it will be very straightforward, using a hyper-parameter tuning tool such as GridSearch from scikit-learn.
```python
from concrete.ml.sklearn import XGBClassifier
from sklearn.model_selection import GridSearchCV
# Let's build our model
model = XGBClassifier()
# A gridsearch to find the best parameters
parameters = {
"n_bits": [2, 3],
"max_depth": [1],
"n_estimators": [10, 30, 50],
"n_jobs": [-1],
}
# Now we have a representation for each tweet, we can train a model on these.
grid_search = GridSearchCV(model, parameters, cv=5, n_jobs=1, scoring="accuracy")
grid_search.fit(X_train_transformer, y_train)
# Check the accuracy of the best model
print(f"Best score: {grid_search.best_score_}")
# Check best hyperparameters
print(f"Best parameters: {grid_search.best_params_}")
# Extract best model
best_model = grid_search.best_estimator_
```
The output is as follows:
```
Best score: 0.8378111718275654
Best parameters: {'max_depth': 1, 'n_bits': 3, 'n_estimators': 50, 'n_jobs': -1}
```
Now, let’s see how the model performs on the test set.
```python
from sklearn.metrics import ConfusionMatrixDisplay
# Compute the metrics on the test set
y_pred = best_model.predict(X_test_transformer)
y_proba = best_model.predict_proba(X_test_transformer)
# Compute and plot the confusion matrix
matrix = confusion_matrix(y_test, y_pred)
ConfusionMatrixDisplay(matrix).plot()
# Compute the accuracy
accuracy_transformer_xgboost = np.mean(y_pred == y_test)
print(f"Accuracy: {accuracy_transformer_xgboost:.4f}")
```
With the following output:
```
Accuracy: 0.8504
```
## Predicting over encrypted data
Now let’s predict over encrypted text. The idea here is that we will encrypt the representation given by the transformer rather than the raw text itself. In Concrete-ML, you can do this very quickly by setting the parameter `execute_in_fhe=True` in the predict function. This is just a developer feature (mainly used to check the running time of the FHE model). We will see how we can make this work in a deployment setting a bit further down.
```python
import time
# Compile the model to get the FHE inference engine
# (this may take a few minutes depending on the selected model)
start = time.perf_counter()
best_model.compile(X_train_transformer)
end = time.perf_counter()
print(f"Compilation time: {end - start:.4f} seconds")
# Let's write a custom example and predict in FHE
tested_tweet = ["AirFrance is awesome, almost as much as Zama!"]
X_tested_tweet = text_to_tensor(tested_tweet, transformer_model, tokenizer, device)
clear_proba = best_model.predict_proba(X_tested_tweet)
# Now let's predict with FHE over a single tweet and print the time it takes
start = time.perf_counter()
decrypted_proba = best_model.predict_proba(X_tested_tweet, execute_in_fhe=True)
end = time.perf_counter()
fhe_exec_time = end - start
print(f"FHE inference time: {fhe_exec_time:.4f} seconds")
```
The output becomes:
```
Compilation time: 9.3354 seconds
FHE inference time: 4.4085 seconds
```
A check that the FHE predictions are the same as the clear predictions is also necessary.
```python
print(f"Probabilities from the FHE inference: {decrypted_proba}")
print(f"Probabilities from the clear model: {clear_proba}")
```
This output reads:
```
Probabilities from the FHE inference: [[0.08434131 0.05571389 0.8599448 ]]
Probabilities from the clear model: [[0.08434131 0.05571389 0.8599448 ]]
```
## Deployment
At this point, our model is fully trained and compiled, ready to be deployed. In Concrete-ML, you can use a [deployment API](https://docs.zama.ai/concrete-ml/advanced-topics/client_server) to do this easily:
```python
# Let's save the model to be pushed to a server later
from concrete.ml.deployment import FHEModelDev
fhe_api = FHEModelDev("sentiment_fhe_model", best_model)
fhe_api.save()
```
These few lines are enough to export all the files needed for both the client and the server. You can check out the notebook explaining this deployment API in detail [here](https://github.com/zama-ai/concrete-ml/blob/release/0.4.x/docs/advanced_examples/ClientServer.ipynb).
## Full example in a Hugging Face Space
You can also have a look at the [final application on Hugging Face Space](https://huggingface.co/spaces/zama-fhe/encrypted_sentiment_analysis). The client app was developed with [Gradio](https://gradio.app/) while the server runs with [Uvicorn](https://www.uvicorn.org/) and was developed with [FastAPI](https://fastapi.tiangolo.com/).
The process is as follows:
- User generates a new private/public key

- User types a message that will be encoded, quantized, and encrypted

- Server receives the encrypted data and starts the prediction over encrypted data, using the public evaluation key
- Server sends back the encrypted predictions and the client can decrypt them using his private key

## Conclusion
We have presented a way to leverage the power of transformers where the representation is then used to:
1. train a machine learning model to classify tweets, and
2. predict over encrypted data using this model with FHE.
The final model (Transformer representation + XGboost) has a final accuracy of 85%, which is above the transformer itself with 80% accuracy (please see this [notebook](https://github.com/zama-ai/concrete-ml/blob/release/0.4.x/use_case_examples/encrypted_sentiment_analysis/SentimentClassification.ipynb) for the comparisons).
The FHE execution time per example is 4.4 seconds on a 16 cores cpu.
The files for deployment are used for a sentiment analysis app that allows a client to request sentiment analysis predictions from a server while keeping its data encrypted all along the chain of communication.
[Concrete-ML](https://github.com/zama-ai/concrete-ml) (Don't forget to star us on Github ⭐️💛) allows straightforward ML model building and conversion to the FHE equivalent to be able to predict over encrypted data.
Hope you enjoyed this post and let us know your thoughts/feedback!
And special thanks to [Abubakar Abid](https://huggingface.co/abidlabs) for his previous advice on how to build our first Hugging Face Space!
| 2 |
0 | hf_public_repos | hf_public_repos/blog/encoder-decoder.md | ---
title: "Transformer-based Encoder-Decoder Models"
thumbnail: /blog/assets/05_encoder_decoder/thumbnail.png
authors:
- user: patrickvonplaten
---
# Transformers-based Encoder-Decoder Models
<a target="_blank" href="https://colab.research.google.com/github/patrickvonplaten/notebooks/blob/master/Encoder_Decoder_Model.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
```bash
!pip install transformers==4.2.1
!pip install sentencepiece==0.1.95
```
The *transformer-based* encoder-decoder model was introduced by Vaswani
et al. in the famous [Attention is all you need
paper](https://arxiv.org/abs/1706.03762) and is today the *de-facto*
standard encoder-decoder architecture in natural language processing
(NLP).
Recently, there has been a lot of research on different *pre-training*
objectives for transformer-based encoder-decoder models, *e.g.* T5,
Bart, Pegasus, ProphetNet, Marge, *etc*\..., but the model architecture
has stayed largely the same.
The goal of the blog post is to give an **in-detail** explanation of
**how** the transformer-based encoder-decoder architecture models
*sequence-to-sequence* problems. We will focus on the mathematical model
defined by the architecture and how the model can be used in inference.
Along the way, we will give some background on sequence-to-sequence
models in NLP and break down the *transformer-based* encoder-decoder
architecture into its **encoder** and **decoder** parts. We provide many
illustrations and establish the link between the theory of
*transformer-based* encoder-decoder models and their practical usage in
🤗Transformers for inference. Note that this blog post does *not* explain
how such models can be trained - this will be the topic of a future blog
post.
Transformer-based encoder-decoder models are the result of years of
research on _representation learning_ and _model architectures_. This
notebook provides a short summary of the history of neural
encoder-decoder models. For more context, the reader is advised to read
this awesome [blog
post](https://ruder.io/a-review-of-the-recent-history-of-nlp/) by
Sebastion Ruder. Additionally, a basic understanding of the
_self-attention architecture_ is recommended. The following blog post by
Jay Alammar serves as a good refresher on the original Transformer model
[here](http://jalammar.github.io/illustrated-transformer/).
At the time of writing this notebook, 🤗Transformers comprises the
encoder-decoder models *T5*, *Bart*, *MarianMT*, and *Pegasus*, which
are summarized in the docs under [model
summaries](https://huggingface.co/transformers/model_summary.html#sequence-to-sequence-models).
The notebook is divided into four parts:
- **Background** - *A short history of neural encoder-decoder models
is given with a focus on RNN-based models.*
- **Encoder-Decoder** - *The transformer-based encoder-decoder model
is presented and it is explained how the model is used for
inference.*
- **Encoder** - *The encoder part of the model is explained in
detail.*
- **Decoder** - *The decoder part of the model is explained in
detail.*
Each part builds upon the previous part, but can also be read on its
own.
## **Background**
Tasks in natural language generation (NLG), a subfield of NLP, are best
expressed as sequence-to-sequence problems. Such tasks can be defined as
finding a model that maps a sequence of input words to a sequence of
target words. Some classic examples are *summarization* and
*translation*. In the following, we assume that each word is encoded
into a vector representation. \\(n\\) input words can then be represented as
a sequence of \\(n\\) input vectors:
$$\mathbf{X}_{1:n} = \{\mathbf{x}_1, \ldots, \mathbf{x}_n\}.$$
Consequently, sequence-to-sequence problems can be solved by finding a
mapping \\(f\\) from an input sequence of \\(n\\) vectors \\(\mathbf{X}_{1:n}\\) to
a sequence of \\(m\\) target vectors \\(\mathbf{Y}_{1:m}\\), whereas the number
of target vectors \\(m\\) is unknown apriori and depends on the input
sequence:
$$ f: \mathbf{X}_{1:n} \to \mathbf{Y}_{1:m}. $$
[Sutskever et al. (2014)](https://arxiv.org/abs/1409.3215) noted that
deep neural networks (DNN)s, \"*despite their flexibility and power can
only define a mapping whose inputs and targets can be sensibly encoded
with vectors of fixed dimensionality.*\" \\({}^1\\)
Using a DNN model \\({}^2\\) to solve sequence-to-sequence problems would
therefore mean that the number of target vectors \\(m\\) has to be known
*apriori* and would have to be independent of the input
\\(\mathbf{X}_{1:n}\\). This is suboptimal because, for tasks in NLG, the
number of target words usually depends on the input \\(\mathbf{X}_{1:n}\\)
and not just on the input length \\(n\\). *E.g.*, an article of 1000 words
can be summarized to both 200 words and 100 words depending on its
content.
In 2014, [Cho et al.](https://arxiv.org/pdf/1406.1078.pdf) and
[Sutskever et al.](https://arxiv.org/abs/1409.3215) proposed to use an
encoder-decoder model purely based on recurrent neural networks (RNNs)
for *sequence-to-sequence* tasks. In contrast to DNNS, RNNs are capable
of modeling a mapping to a variable number of target vectors. Let\'s
dive a bit deeper into the functioning of RNN-based encoder-decoder
models.
During inference, the encoder RNN encodes an input sequence
\\(\mathbf{X}_{1:n}\\) by successively updating its *hidden state* \\({}^3\\).
After having processed the last input vector \\(\mathbf{x}_n\\), the
encoder\'s hidden state defines the input encoding \\(\mathbf{c}\\). Thus,
the encoder defines the mapping:
$$ f_{\theta_{enc}}: \mathbf{X}_{1:n} \to \mathbf{c}. $$
Then, the decoder\'s hidden state is initialized with the input encoding
and during inference, the decoder RNN is used to auto-regressively
generate the target sequence. Let\'s explain.
Mathematically, the decoder defines the probability distribution of a
target sequence \\(\mathbf{Y}_{1:m}\\) given the hidden state \\(\mathbf{c}\\):
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}). $$
By Bayes\' rule the distribution can be decomposed into conditional
distributions of single target vectors as follows:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}). $$
Thus, if the architecture can model the conditional distribution of the
next target vector, given all previous target vectors:
$$ p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \forall i \in \{1, \ldots, m\},$$
then it can model the distribution of any target vector sequence given
the hidden state \\(\mathbf{c}\\) by simply multiplying all conditional
probabilities.
So how does the RNN-based decoder architecture model
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})\\)?
In computational terms, the model sequentially maps the previous inner
hidden state \\(\mathbf{c}_{i-1}\\) and the previous target vector
\\(\mathbf{y}_{i-1}\\) to the current inner hidden state \\(\mathbf{c}_i\\) and a
*logit vector* \\(\mathbf{l}_i\\) (shown in dark red below):
$$ f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{i-1}) \to \mathbf{l}_i, \mathbf{c}_i.$$
\\(\mathbf{c}_0\\) is thereby defined as \\(\mathbf{c}\\) being the output
hidden state of the RNN-based encoder. Subsequently, the *softmax*
operation is used to transform the logit vector \\(\mathbf{l}_i\\) to a
conditional probablity distribution of the next target vector:
$$ p(\mathbf{y}_i | \mathbf{l}_i) = \textbf{Softmax}(\mathbf{l}_i), \text{ with } \mathbf{l}_i = f_{\theta_{\text{dec}}}(\mathbf{y}_{i-1}, \mathbf{c}_{\text{prev}}). $$
For more detail on the logit vector and the resulting probability
distribution, please see footnote \\({}^4\\). From the above equation, we
can see that the distribution of the current target vector
\\(\mathbf{y}_i\\) is directly conditioned on the previous target vector
\\(\mathbf{y}_{i-1}\\) and the previous hidden state \\(\mathbf{c}_{i-1}\\).
Because the previous hidden state \\(\mathbf{c}_{i-1}\\) depends on all
previous target vectors \\(\mathbf{y}_0, \ldots, \mathbf{y}_{i-2}\\), it can
be stated that the RNN-based decoder *implicitly* (*e.g.* *indirectly*)
models the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})\\).
The space of possible target vector sequences \\(\mathbf{Y}_{1:m}\\) is
prohibitively large so that at inference, one has to rely on decoding
methods \\({}^5\\) that efficiently sample high probability target vector
sequences from \\(p_{\theta_{dec}}(\mathbf{Y}_{1:m} |\mathbf{c})\\).
Given such a decoding method, during inference, the next input vector
\\(\mathbf{y}_i\\) can then be sampled from
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c})\\)
and is consequently appended to the input sequence so that the decoder
RNN then models
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_{i+1} | \mathbf{Y}_{0: i}, \mathbf{c})\\)
to sample the next input vector \\(\mathbf{y}_{i+1}\\) and so on in an
*auto-regressive* fashion.
An important feature of RNN-based encoder-decoder models is the
definition of *special* vectors, such as the \\(\text{EOS}\\) and
\\(\text{BOS}\\) vector. The \\(\text{EOS}\\) vector often represents the final
input vector \\(\mathbf{x}_n\\) to \"cue\" the encoder that the input
sequence has ended and also defines the end of the target sequence. As
soon as the \\(\text{EOS}\\) is sampled from a logit vector, the generation
is complete. The \\(\text{BOS}\\) vector represents the input vector
\\(\mathbf{y}_0\\) fed to the decoder RNN at the very first decoding step.
To output the first logit \\(\mathbf{l}_1\\), an input is required and since
no input has been generated at the first step a special \\(\text{BOS}\\)
input vector is fed to the decoder RNN. Ok - quite complicated! Let\'s
illustrate and walk through an example.
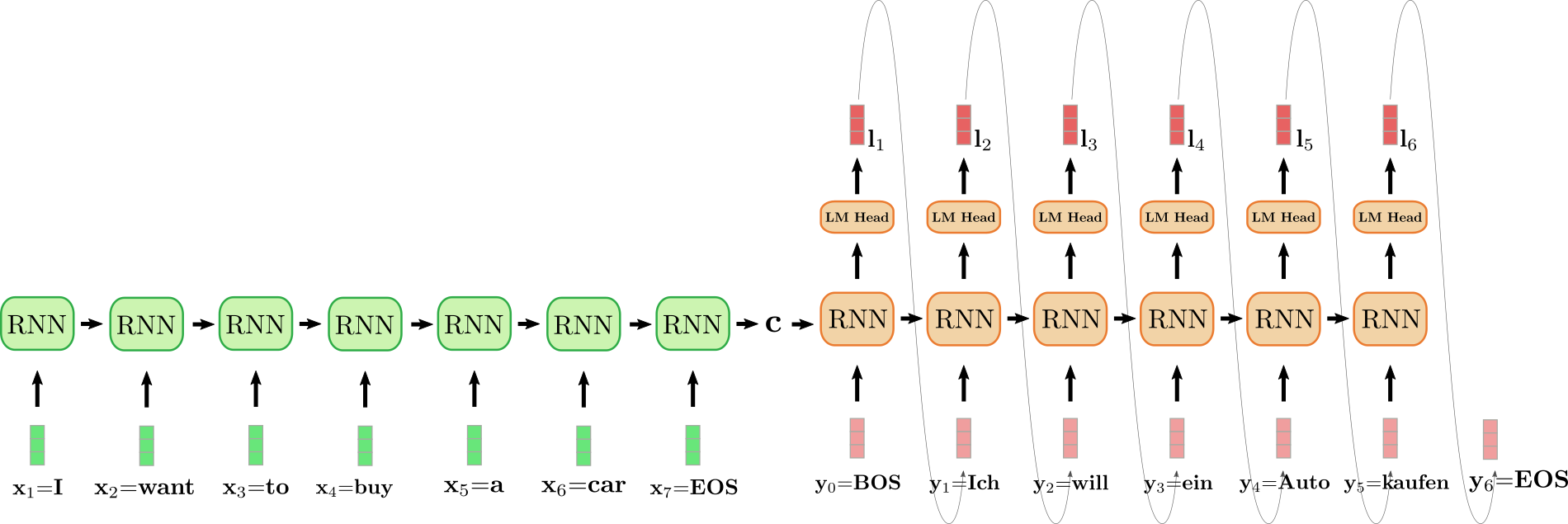
The unfolded RNN encoder is colored in green and the unfolded RNN
decoder is colored in red.
The English sentence \"I want to buy a car\", represented by
\\(\mathbf{x}_1 = \text{I}\\), \\(\mathbf{x}_2 = \text{want}\\),
\\(\mathbf{x}_3 = \text{to}\\), \\(\mathbf{x}_4 = \text{buy}\\),
\\(\mathbf{x}_5 = \text{a}\\), \\(\mathbf{x}_6 = \text{car}\\) and
\\(\mathbf{x}_7 = \text{EOS}\\) is translated into German: \"Ich will ein
Auto kaufen\" defined as \\(\mathbf{y}_0 = \text{BOS}\\),
\\(\mathbf{y}_1 = \text{Ich}\\), \\(\mathbf{y}_2 = \text{will}\\),
\\(\mathbf{y}_3 = \text{ein}\\),
\\(\mathbf{y}_4 = \text{Auto}, \mathbf{y}_5 = \text{kaufen}\\) and
\\(\mathbf{y}_6=\text{EOS}\\). To begin with, the input vector
\\(\mathbf{x}_1 = \text{I}\\) is processed by the encoder RNN and updates
its hidden state. Note that because we are only interested in the final
encoder\'s hidden state \\(\mathbf{c}\\), we can disregard the RNN
encoder\'s target vector. The encoder RNN then processes the rest of the
input sentence \\(\text{want}\\), \\(\text{to}\\), \\(\text{buy}\\), \\(\text{a}\\),
\\(\text{car}\\), \\(\text{EOS}\\) in the same fashion, updating its hidden
state at each step until the vector \\(\mathbf{x}_7={EOS}\\) is reached
\\({}^6\\). In the illustration above the horizontal arrow connecting the
unfolded encoder RNN represents the sequential updates of the hidden
state. The final hidden state of the encoder RNN, represented by
\\(\mathbf{c}\\) then completely defines the *encoding* of the input
sequence and is used as the initial hidden state of the decoder RNN.
This can be seen as *conditioning* the decoder RNN on the encoded input.
To generate the first target vector, the decoder is fed the \\(\text{BOS}\\)
vector, illustrated as \\(\mathbf{y}_0\\) in the design above. The target
vector of the RNN is then further mapped to the logit vector
\\(\mathbf{l}_1\\) by means of the *LM Head* feed-forward layer to define
the conditional distribution of the first target vector as explained
above:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{c}). $$
The word \\(\text{Ich}\\) is sampled (shown by the grey arrow, connecting
\\(\mathbf{l}_1\\) and \\(\mathbf{y}_1\\)) and consequently the second target
vector can be sampled:
$$ \text{will} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \text{Ich}, \mathbf{c}). $$
And so on until at step \\(i=6\\), the \\(\text{EOS}\\) vector is sampled from
\\(\mathbf{l}_6\\) and the decoding is finished. The resulting target
sequence amounts to
\\(\mathbf{Y}_{1:6} = \{\mathbf{y}_1, \ldots, \mathbf{y}_6\}\\), which is
\"Ich will ein Auto kaufen\" in our example above.
To sum it up, an RNN-based encoder-decoder model, represented by
\\(f_{\theta_{\text{enc}}}\\) and \\( p_{\theta_{\text{dec}}} \\) defines
the distribution \\(p(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n})\\) by
factorization:
$$ p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{X}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{c}), \text{ with } \mathbf{c}=f_{\theta_{enc}}(X). $$
During inference, efficient decoding methods can auto-regressively
generate the target sequence \\(\mathbf{Y}_{1:m}\\).
The RNN-based encoder-decoder model took the NLG community by storm. In
2016, Google announced to fully replace its heavily feature engineered
translation service by a single RNN-based encoder-decoder model (see
[here](https://www.oreilly.com/radar/what-machine-learning-means-for-software-development/#:~:text=Machine%20learning%20is%20already%20making,of%20code%20in%20Google%20Translate.)).
Nevertheless, RNN-based encoder-decoder models have two pitfalls. First,
RNNs suffer from the vanishing gradient problem, making it very
difficult to capture long-range dependencies, *cf.* [Hochreiter et al.
(2001)](https://www.bioinf.jku.at/publications/older/ch7.pdf). Second,
the inherent recurrent architecture of RNNs prevents efficient
parallelization when encoding, *cf.* [Vaswani et al.
(2017)](https://arxiv.org/abs/1706.03762).
------------------------------------------------------------------------
\\({}^1\\) The original quote from the paper is \"*Despite their flexibility
and power, DNNs can only be applied to problems whose inputs and targets
can be sensibly encoded with vectors of fixed dimensionality*\", which
is slightly adapted here.
\\({}^2\\) The same holds essentially true for convolutional neural networks
(CNNs). While an input sequence of variable length can be fed into a
CNN, the dimensionality of the target will always be dependent on the
input dimensionality or fixed to a specific value.
\\({}^3\\) At the first step, the hidden state is initialized as a zero
vector and fed to the RNN together with the first input vector
\\(\mathbf{x}_1\\).
\\({}^4\\) A neural network can define a probability distribution over all
words, *i.e.* \\(p(\mathbf{y} | \mathbf{c}, \mathbf{Y}_{0: i-1})\\) as
follows. First, the network defines a mapping from the inputs
\\(\mathbf{c}, \mathbf{Y}_{0: i-1}\\) to an embedded vector representation
\\(\mathbf{y'}\\), which corresponds to the RNN target vector. The embedded
vector representation \\(\mathbf{y'}\\) is then passed to the \"language
model head\" layer, which means that it is multiplied by the *word
embedding matrix*, *i.e.* \\(\mathbf{Y}^{\text{vocab}}\\), so that a score
between \\(\mathbf{y'}\\) and each encoded vector
\\(\mathbf{y} \in \mathbf{Y}^{\text{vocab}}\\) is computed. The resulting
vector is called the logit vector
\\( \mathbf{l} = \mathbf{Y}^{\text{vocab}} \mathbf{y'} \\) and can be
mapped to a probability distribution over all words by applying a
softmax operation:
\\(p(\mathbf{y} | \mathbf{c}) = \text{Softmax}(\mathbf{Y}^{\text{vocab}} \mathbf{y'}) = \text{Softmax}(\mathbf{l})\\).
\\({}^5\\) Beam-search decoding is an example of such a decoding method.
Different decoding methods are out of scope for this notebook. The
reader is advised to refer to this [interactive
notebook](https://huggingface.co/blog/how-to-generate) on decoding
methods.
\\({}^6\\) [Sutskever et al. (2014)](https://arxiv.org/abs/1409.3215)
reverses the order of the input so that in the above example the input
vectors would correspond to \\(\mathbf{x}_1 = \text{car}\\),
\\(\mathbf{x}_2 = \text{a}\\), \\(\mathbf{x}_3 = \text{buy}\\),
\\(\mathbf{x}_4 = \text{to}\\), \\(\mathbf{x}_5 = \text{want}\\),
\\(\mathbf{x}_6 = \text{I}\\) and \\(\mathbf{x}_7 = \text{EOS}\\). The
motivation is to allow for a shorter connection between corresponding
word pairs such as \\(\mathbf{x}_6 = \text{I}\\) and
\\(\mathbf{y}_1 = \text{Ich}\\). The research group emphasizes that the
reversal of the input sequence was a key reason for their model\'s
improved performance on machine translation.
## **Encoder-Decoder**
In 2017, Vaswani et al. introduced the **Transformer** and thereby gave
birth to *transformer-based* encoder-decoder models.
Analogous to RNN-based encoder-decoder models, transformer-based
encoder-decoder models consist of an encoder and a decoder which are
both stacks of *residual attention blocks*. The key innovation of
transformer-based encoder-decoder models is that such residual attention
blocks can process an input sequence \\(\mathbf{X}_{1:n}\\) of variable
length \\(n\\) without exhibiting a recurrent structure. Not relying on a
recurrent structure allows transformer-based encoder-decoders to be
highly parallelizable, which makes the model orders of magnitude more
computationally efficient than RNN-based encoder-decoder models on
modern hardware.
As a reminder, to solve a *sequence-to-sequence* problem, we need to
find a mapping of an input sequence \\(\mathbf{X}_{1:n}\\) to an output
sequence \\(\mathbf{Y}_{1:m}\\) of variable length \\(m\\). Let\'s see how
transformer-based encoder-decoder models are used to find such a
mapping.
Similar to RNN-based encoder-decoder models, the transformer-based
encoder-decoder models define a conditional distribution of target
vectors \\(\mathbf{Y}_{1:n}\\) given an input sequence \\(\mathbf{X}_{1:n}\\):
$$
p_{\theta_{\text{enc}}, \theta_{\text{dec}}}(\mathbf{Y}_{1:m} | \mathbf{X}_{1:n}).
$$
The transformer-based encoder part encodes the input sequence
\\(\mathbf{X}_{1:n}\\) to a *sequence* of *hidden states*
\\(\mathbf{\overline{X}}_{1:n}\\), thus defining the mapping:
$$ f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n}. $$
The transformer-based decoder part then models the conditional
probability distribution of the target vector sequence
\\(\mathbf{Y}_{1:n}\\) given the sequence of encoded hidden states
\\(\mathbf{\overline{X}}_{1:n}\\):
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:n} | \mathbf{\overline{X}}_{1:n}).$$
By Bayes\' rule, this distribution can be factorized to a product of
conditional probability distribution of the target vector \\(\mathbf{y}_i\\)
given the encoded hidden states \\(\mathbf{\overline{X}}_{1:n}\\) and all
previous target vectors \\(\mathbf{Y}_{0:i-1}\\):
$$
p_{\theta_{dec}}(\mathbf{Y}_{1:n} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{n} p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}). $$
The transformer-based decoder hereby maps the sequence of encoded hidden
states \\(\mathbf{\overline{X}}_{1:n}\\) and all previous target vectors
\\(\mathbf{Y}_{0:i-1}\\) to the *logit* vector \\(\mathbf{l}_i\\). The logit
vector \\(\mathbf{l}_i\\) is then processed by the *softmax* operation to
define the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})\\),
just as it is done for RNN-based decoders. However, in contrast to
RNN-based decoders, the distribution of the target vector \\(\mathbf{y}_i\\)
is *explicitly* (or directly) conditioned on all previous target vectors
\\(\mathbf{y}_0, \ldots, \mathbf{y}_{i-1}\\) as we will see later in more
detail. The 0th target vector \\(\mathbf{y}_0\\) is hereby represented by a
special \"begin-of-sentence\" \\(\text{BOS}\\) vector.
Having defined the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})\\),
we can now *auto-regressively* generate the output and thus define a
mapping of an input sequence \\(\mathbf{X}_{1:n}\\) to an output sequence
\\(\mathbf{Y}_{1:m}\\) at inference.
Let\'s visualize the complete process of *auto-regressive* generation of
*transformer-based* encoder-decoder models.
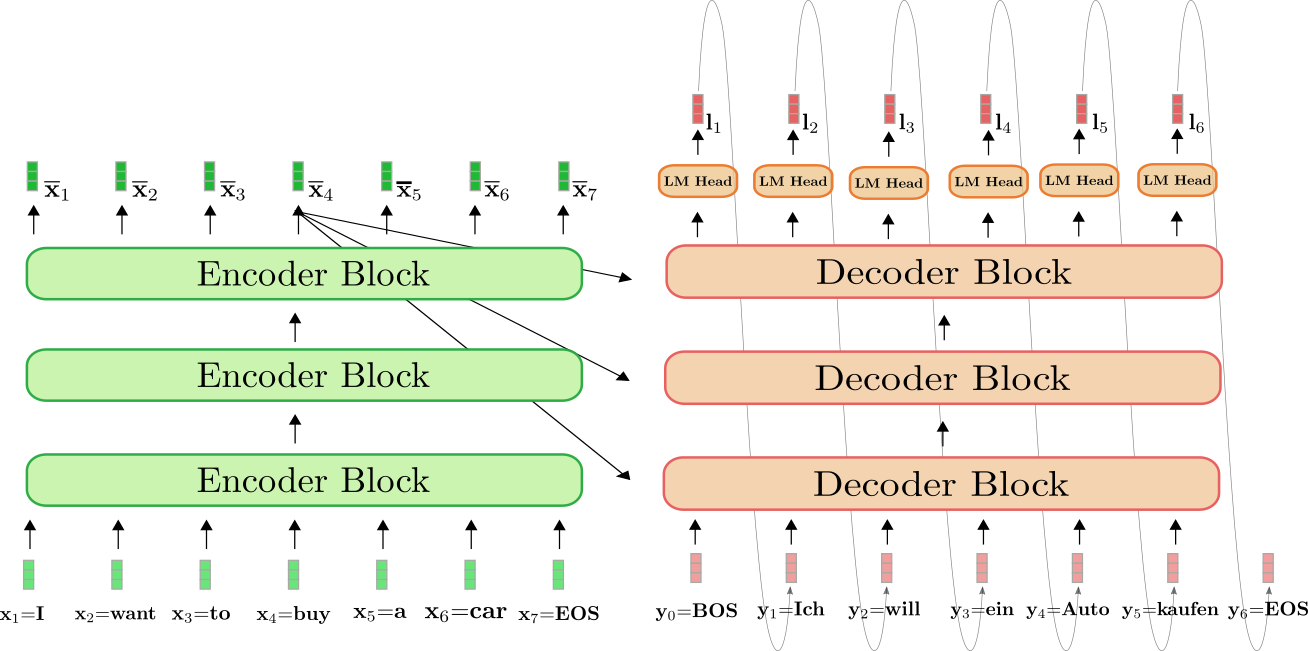
The transformer-based encoder is colored in green and the
transformer-based decoder is colored in red. As in the previous section,
we show how the English sentence \"I want to buy a car\", represented by
\\(\mathbf{x}_1 = \text{I}\\), \\(\mathbf{x}_2 = \text{want}\\),
\\(\mathbf{x}_3 = \text{to}\\), \\(\mathbf{x}_4 = \text{buy}\\),
\\(\mathbf{x}_5 = \text{a}\\), \\(\mathbf{x}_6 = \text{car}\\), and
\\(\mathbf{x}_7 = \text{EOS}\\) is translated into German: \"Ich will ein
Auto kaufen\" defined as \\(\mathbf{y}_0 = \text{BOS}\\),
\\(\mathbf{y}_1 = \text{Ich}\\), \\(\mathbf{y}_2 = \text{will}\\),
\\(\mathbf{y}_3 = \text{ein}\\),
\\(\mathbf{y}_4 = \text{Auto}, \mathbf{y}_5 = \text{kaufen}\\), and
\\(\mathbf{y}_6=\text{EOS}\\).
To begin with, the encoder processes the complete input sequence
\\(\mathbf{X}_{1:7}\\) = \"I want to buy a car\" (represented by the light
green vectors) to a contextualized encoded sequence
\\(\mathbf{\overline{X}}_{1:7}\\). *E.g.* \\(\mathbf{\overline{x}}_4\\) defines
an encoding that depends not only on the input \\(\mathbf{x}_4\\) = \"buy\",
but also on all other words \"I\", \"want\", \"to\", \"a\", \"car\" and
\"EOS\", *i.e.* the context.
Next, the input encoding \\(\mathbf{\overline{X}}_{1:7}\\) together with the
BOS vector, *i.e.* \\(\mathbf{y}_0\\), is fed to the decoder. The decoder
processes the inputs \\(\mathbf{\overline{X}}_{1:7}\\) and \\(\mathbf{y}_0\\) to
the first logit \\(\mathbf{l}_1\\) (shown in darker red) to define the
conditional distribution of the first target vector \\(\mathbf{y}_1\\):
$$ p_{\theta_{enc, dec}}(\mathbf{y} | \mathbf{y}_0, \mathbf{X}_{1:7}) = p_{\theta_{enc, dec}}(\mathbf{y} | \text{BOS}, \text{I want to buy a car EOS}) = p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}). $$
Next, the first target vector \\(\mathbf{y}_1\\) = \\(\text{Ich}\\) is sampled
from the distribution (represented by the grey arrows) and can now be
fed to the decoder again. The decoder now processes both \\(\mathbf{y}_0\\)
= \"BOS\" and \\(\mathbf{y}_1\\) = \"Ich\" to define the conditional
distribution of the second target vector \\(\mathbf{y}_2\\):
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}). $$
We can sample again and produce the target vector \\(\mathbf{y}_2\\) =
\"will\". We continue in auto-regressive fashion until at step 6 the EOS
vector is sampled from the conditional distribution:
$$ \text{EOS} \sim p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). $$
And so on in auto-regressive fashion.
It is important to understand that the encoder is only used in the first
forward pass to map \\(\mathbf{X}_{1:n}\\) to \\(\mathbf{\overline{X}}_{1:n}\\).
As of the second forward pass, the decoder can directly make use of the
previously calculated encoding \\(\mathbf{\overline{X}}_{1:n}\\). For
clarity, let\'s illustrate the first and the second forward pass for our
example above.
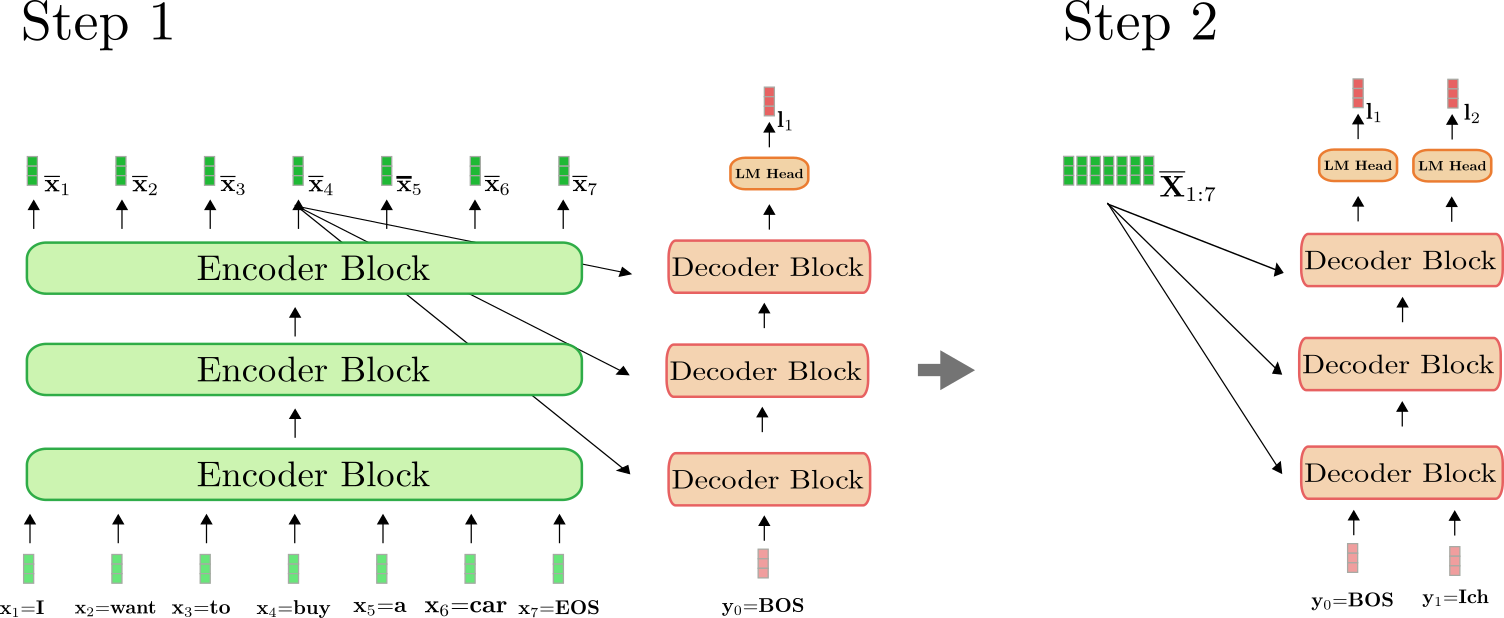
As can be seen, only in step \\(i=1\\) do we have to encode \"I want to buy
a car EOS\" to \\(\mathbf{\overline{X}}_{1:7}\\). At step \\(i=2\\), the
contextualized encodings of \"I want to buy a car EOS\" are simply
reused by the decoder.
In 🤗Transformers, this auto-regressive generation is done under-the-hood
when calling the `.generate()` method. Let\'s use one of our translation
models to see this in action.
```python
from transformers import MarianMTModel, MarianTokenizer
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# translate example
output_ids = model.generate(input_ids)[0]
# decode and print
print(tokenizer.decode(output_ids))
```
_Output:_
```
<pad> Ich will ein Auto kaufen
```
Calling `.generate()` does many things under-the-hood. First, it passes
the `input_ids` to the encoder. Second, it passes a pre-defined token, which is the \\(\text{<pad>}\\) symbol in the case of
`MarianMTModel` along with the encoded `input_ids` to the decoder.
Third, it applies the beam search decoding mechanism to
auto-regressively sample the next output word of the *last* decoder
output \\({}^1\\). For more detail on how beam search decoding works, one is
advised to read [this](https://huggingface.co/blog/how-to-generate) blog
post.
In the Appendix, we have included a code snippet that shows how a simple
generation method can be implemented \"from scratch\". To fully
understand how *auto-regressive* generation works under-the-hood, it is
highly recommended to read the Appendix.
To sum it up:
- The transformer-based encoder defines a mapping from the input
sequence \\(\mathbf{X}_{1:n}\\) to a contextualized encoding sequence
\\(\mathbf{\overline{X}}_{1:n}\\).
- The transformer-based decoder defines the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})\\).
- Given an appropriate decoding mechanism, the output sequence
\\(\mathbf{Y}_{1:m}\\) can auto-regressively be sampled from
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in \{1, \ldots, m\}\\).
Great, now that we have gotten a general overview of how
*transformer-based* encoder-decoder models work, we can dive deeper into
both the encoder and decoder part of the model. More specifically, we
will see exactly how the encoder makes use of the self-attention layer
to yield a sequence of context-dependent vector encodings and how
self-attention layers allow for efficient parallelization. Then, we will
explain in detail how the self-attention layer works in the decoder
model and how the decoder is conditioned on the encoder\'s output with
*cross-attention* layers to define the conditional distribution
\\(p_{\theta_{\text{dec}}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n})\\).
Along, the way it will become obvious how transformer-based
encoder-decoder models solve the long-range dependencies problem of
RNN-based encoder-decoder models.
------------------------------------------------------------------------
\\({}^1\\) In the case of `"Helsinki-NLP/opus-mt-en-de"`, the decoding
parameters can be accessed
[here](https://s3.amazonaws.com/models.huggingface.co/bert/Helsinki-NLP/opus-mt-en-de/config.json),
where we can see that model applies beam search with `num_beams=6`.
## **Encoder**
As mentioned in the previous section, the *transformer-based* encoder
maps the input sequence to a contextualized encoding sequence:
$$ f_{\theta_{\text{enc}}}: \mathbf{X}_{1:n} \to \mathbf{\overline{X}}_{1:n}. $$
Taking a closer look at the architecture, the transformer-based encoder
is a stack of residual _encoder blocks_. Each encoder block consists of
a **bi-directional** self-attention layer, followed by two feed-forward
layers. For simplicity, we disregard the normalization layers in this
notebook. Also, we will not further discuss the role of the two
feed-forward layers, but simply see it as a final vector-to-vector
mapping required in each encoder block \\({}^1\\). The bi-directional
self-attention layer puts each input vector
\\(\mathbf{x'}_j, \forall j \in \{1, \ldots, n\}\\) into relation with all
input vectors \\(\mathbf{x'}_1, \ldots, \mathbf{x'}_n\\) and by doing so
transforms the input vector \\(\mathbf{x'}_j\\) to a more \"refined\"
contextual representation of itself, defined as \\(\mathbf{x''}_j\\).
Thereby, the first encoder block transforms each input vector of the
input sequence \\(\mathbf{X}_{1:n}\\) (shown in light green below) from a
*context-independent* vector representation to a *context-dependent*
vector representation, and the following encoder blocks further refine
this contextual representation until the last encoder block outputs the
final contextual encoding \\(\mathbf{\overline{X}}_{1:n}\\) (shown in darker
green below).
Let\'s visualize how the encoder processes the input sequence \"I want
to buy a car EOS\" to a contextualized encoding sequence. Similar to
RNN-based encoders, transformer-based encoders also add a special
\"end-of-sequence\" input vector to the input sequence to hint to the
model that the input vector sequence is finished \\({}^2\\).
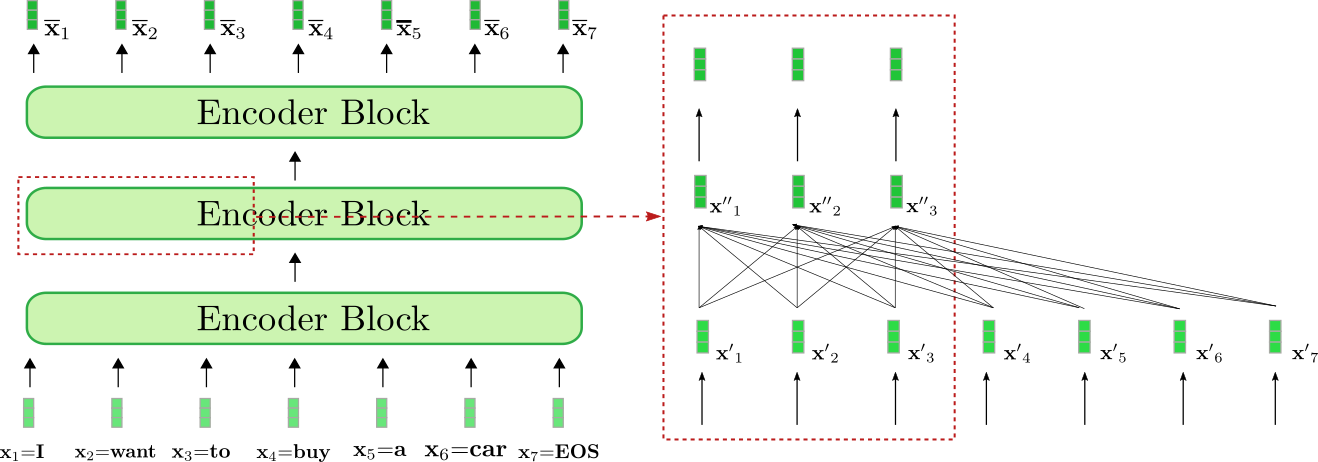
Our exemplary *transformer-based* encoder is composed of three encoder
blocks, whereas the second encoder block is shown in more detail in the
red box on the right for the first three input vectors
\\(\mathbf{x}_1, \mathbf{x}_2 and \mathbf{x}_3\\). The bi-directional
self-attention mechanism is illustrated by the fully-connected graph in
the lower part of the red box and the two feed-forward layers are shown
in the upper part of the red box. As stated before, we will focus only
on the bi-directional self-attention mechanism.
As can be seen each output vector of the self-attention layer
\\(\mathbf{x''}_i, \forall i \in \{1, \ldots, 7\}\\) depends *directly* on
*all* input vectors \\(\mathbf{x'}_1, \ldots, \mathbf{x'}_7\\). This means,
*e.g.* that the input vector representation of the word \"want\", *i.e.*
\\(\mathbf{x'}_2\\), is put into direct relation with the word \"buy\",
*i.e.* \\(\mathbf{x'}_4\\), but also with the word \"I\",*i.e.*
\\(\mathbf{x'}_1\\). The output vector representation of \"want\", *i.e.*
\\(\mathbf{x''}_2\\), thus represents a more refined contextual
representation for the word \"want\".
Let\'s take a deeper look at how bi-directional self-attention works.
Each input vector \\(\mathbf{x'}_i\\) of an input sequence
\\(\mathbf{X'}_{1:n}\\) of an encoder block is projected to a key vector
\\(\mathbf{k}_i\\), value vector \\(\mathbf{v}_i\\) and query vector
\\(\mathbf{q}_i\\) (shown in orange, blue, and purple respectively below)
through three trainable weight matrices
\\(\mathbf{W}_q, \mathbf{W}_v, \mathbf{W}_k\\):
$$ \mathbf{q}_i = \mathbf{W}_q \mathbf{x'}_i,$$
$$ \mathbf{v}_i = \mathbf{W}_v \mathbf{x'}_i,$$
$$ \mathbf{k}_i = \mathbf{W}_k \mathbf{x'}_i, $$
$$ \forall i \in \{1, \ldots n \}.$$
Note, that the **same** weight matrices are applied to each input vector
\\(\mathbf{x}_i, \forall i \in \{i, \ldots, n\}\\). After projecting each
input vector \\(\mathbf{x}_i\\) to a query, key, and value vector, each
query vector \\(\mathbf{q}_j, \forall j \in \{1, \ldots, n\}\\) is compared
to all key vectors \\(\mathbf{k}_1, \ldots, \mathbf{k}_n\\). The more
similar one of the key vectors \\(\mathbf{k}_1, \ldots \mathbf{k}_n\\) is to
a query vector \\(\mathbf{q}_j\\), the more important is the corresponding
value vector \\(\mathbf{v}_j\\) for the output vector \\(\mathbf{x''}_j\\). More
specifically, an output vector \\(\mathbf{x''}_j\\) is defined as the
weighted sum of all value vectors \\(\mathbf{v}_1, \ldots, \mathbf{v}_n\\)
plus the input vector \\(\mathbf{x'}_j\\). Thereby, the weights are
proportional to the cosine similarity between \\(\mathbf{q}_j\\) and the
respective key vectors \\(\mathbf{k}_1, \ldots, \mathbf{k}_n\\), which is
mathematically expressed by
\\(\textbf{Softmax}(\mathbf{K}_{1:n}^\intercal \mathbf{q}_j)\\) as
illustrated in the equation below. For a complete description of the
self-attention layer, the reader is advised to take a look at
[this](http://jalammar.github.io/illustrated-transformer/) blog post or
the original [paper](https://arxiv.org/abs/1706.03762).
Alright, this sounds quite complicated. Let\'s illustrate the
bi-directional self-attention layer for one of the query vectors of our
example above. For simplicity, it is assumed that our exemplary
*transformer-based* decoder uses only a single attention head
`config.num_heads = 1` and that no normalization is applied.
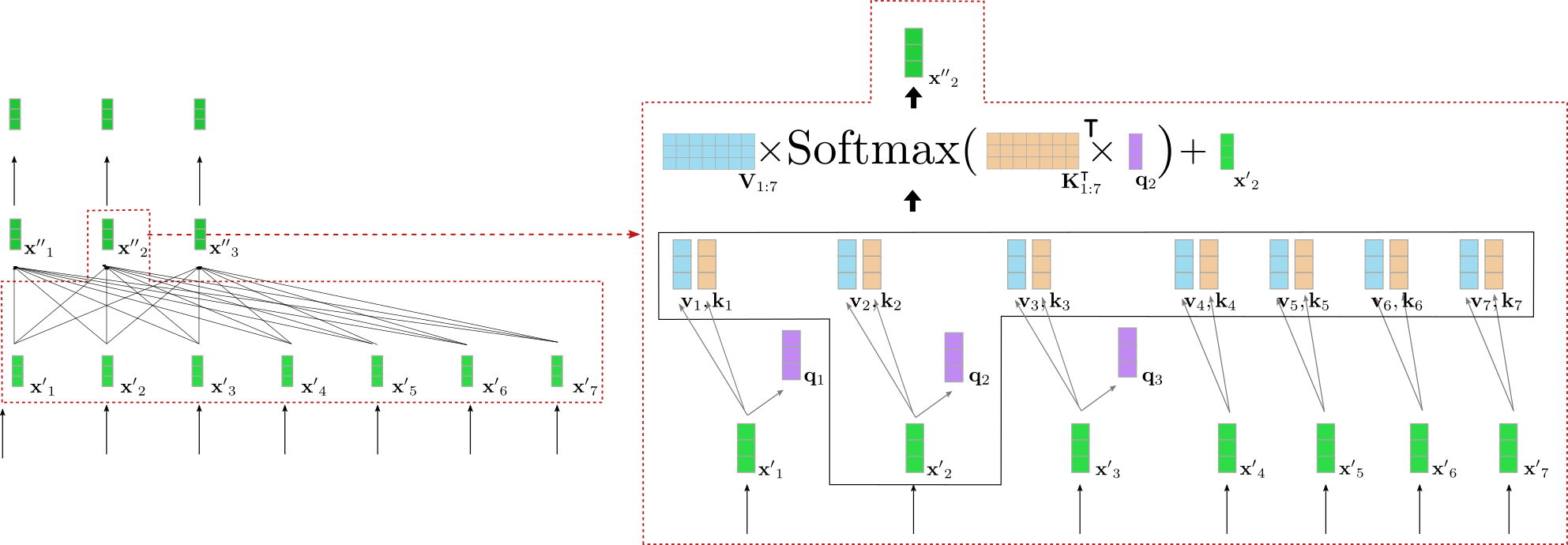
On the left, the previously illustrated second encoder block is shown
again and on the right, an in detail visualization of the bi-directional
self-attention mechanism is given for the second input vector
\\(\mathbf{x'}_2\\) that corresponds to the input word \"want\". At first
all input vectors \\(\mathbf{x'}_1, \ldots, \mathbf{x'}_7\\) are projected
to their respective query vectors \\(\mathbf{q}_1, \ldots, \mathbf{q}_7\\)
(only the first three query vectors are shown in purple above), value
vectors \\(\mathbf{v}_1, \ldots, \mathbf{v}_7\\) (shown in blue), and key
vectors \\(\mathbf{k}_1, \ldots, \mathbf{k}_7\\) (shown in orange). The
query vector \\(\mathbf{q}_2\\) is then multiplied by the transpose of all
key vectors, *i.e.* \\(\mathbf{K}_{1:7}^{\intercal}\\) followed by the
softmax operation to yield the _self-attention weights_. The
self-attention weights are finally multiplied by the respective value
vectors and the input vector \\(\mathbf{x'}_2\\) is added to output the
\"refined\" representation of the word \"want\", *i.e.* \\(\mathbf{x''}_2\\)
(shown in dark green on the right). The whole equation is illustrated in
the upper part of the box on the right. The multiplication of
\\(\mathbf{K}_{1:7}^{\intercal}\\) and \\(\mathbf{q}_2\\) thereby makes it
possible to compare the vector representation of \"want\" to all other
input vector representations \"I\", \"to\", \"buy\", \"a\", \"car\",
\"EOS\" so that the self-attention weights mirror the importance each of
the other input vector representations
\\(\mathbf{x'}_j \text{, with } j \ne 2\\) for the refined representation
\\(\mathbf{x''}_2\\) of the word \"want\".
To further understand the implications of the bi-directional
self-attention layer, let\'s assume the following sentence is processed:
\"*The house is beautiful and well located in the middle of the city
where it is easily accessible by public transport*\". The word \"it\"
refers to \"house\", which is 12 \"positions away\". In
transformer-based encoders, the bi-directional self-attention layer
performs a single mathematical operation to put the input vector of
\"house\" into relation with the input vector of \"it\" (compare to the
first illustration of this section). In contrast, in an RNN-based
encoder, a word that is 12 \"positions away\", would require at least 12
mathematical operations meaning that in an RNN-based encoder a linear
number of mathematical operations are required. This makes it much
harder for an RNN-based encoder to model long-range contextual
representations. Also, it becomes clear that a transformer-based encoder
is much less prone to lose important information than an RNN-based
encoder-decoder model because the sequence length of the encoding is
kept the same, *i.e.*
\\(\textbf{len}(\mathbf{X}_{1:n}) = \textbf{len}(\mathbf{\overline{X}}_{1:n}) = n\\),
while an RNN compresses the length from
\\(*\textbf{len}((\mathbf{X}_{1:n}) = n\\) to just
\\(\textbf{len}(\mathbf{c}) = 1\\), which makes it very difficult for RNNs
to effectively encode long-range dependencies between input words.
In addition to making long-range dependencies more easily learnable, we
can see that the Transformer architecture is able to process text in
parallel.Mathematically, this can easily be shown by writing the
self-attention formula as a product of query, key, and value matrices:
$$\mathbf{X''}_{1:n} = \mathbf{V}_{1:n} \text{Softmax}(\mathbf{Q}_{1:n}^\intercal \mathbf{K}_{1:n}) + \mathbf{X'}_{1:n}. $$
The output \\(\mathbf{X''}_{1:n} = \mathbf{x''}_1, \ldots, \mathbf{x''}_n\\)
is computed via a series of matrix multiplications and a softmax
operation, which can be parallelized effectively. Note, that in an
RNN-based encoder model, the computation of the hidden state
\\(\mathbf{c}\\) has to be done sequentially: Compute hidden state of the
first input vector \\(\mathbf{x}_1\\), then compute the hidden state of the
second input vector that depends on the hidden state of the first hidden
vector, etc. The sequential nature of RNNs prevents effective
parallelization and makes them much more inefficient compared to
transformer-based encoder models on modern GPU hardware.
Great, now we should have a better understanding of a) how
transformer-based encoder models effectively model long-range contextual
representations and b) how they efficiently process long sequences of
input vectors.
Now, let\'s code up a short example of the encoder part of our
`MarianMT` encoder-decoder models to verify that the explained theory
holds in practice.
------------------------------------------------------------------------
\\({}^1\\) An in-detail explanation of the role the feed-forward layers play
in transformer-based models is out-of-scope for this notebook. It is
argued in [Yun et. al, (2017)](https://arxiv.org/pdf/1912.10077.pdf)
that feed-forward layers are crucial to map each contextual vector
\\(\mathbf{x'}_i\\) individually to the desired output space, which the
_self-attention_ layer does not manage to do on its own. It should be
noted here, that each output token \\(\mathbf{x'}\\) is processed by the
same feed-forward layer. For more detail, the reader is advised to read
the paper.
\\({}^2\\) However, the EOS input vector does not have to be appended to the
input sequence, but has been shown to improve performance in many cases.
In contrast to the _0th_ \\(\text{BOS}\\) target vector of the
transformer-based decoder is required as a starting input vector to
predict a first target vector.
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input_ids to encoder
encoder_hidden_states = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# change the input slightly and pass to encoder
input_ids_perturbed = tokenizer("I want to buy a house", return_tensors="pt").input_ids
encoder_hidden_states_perturbed = model.base_model.encoder(input_ids_perturbed, return_dict=True).last_hidden_state
# compare shape and encoding of first vector
print(f"Length of input embeddings {embeddings(input_ids).shape[1]}. Length of encoder_hidden_states {encoder_hidden_states.shape[1]}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `I` equal to its perturbed version?: ", torch.allclose(encoder_hidden_states[0, 0], encoder_hidden_states_perturbed[0, 0], atol=1e-3))
```
_Outputs:_
```
Length of input embeddings 7. Length of encoder_hidden_states 7
Is encoding for `I` equal to its perturbed version?: False
```
We compare the length of the input word embeddings, *i.e.*
`embeddings(input_ids)` corresponding to \\(\mathbf{X}_{1:n}\\), with the
length of the `encoder_hidden_states`, corresponding to
\\(\mathbf{\overline{X}}_{1:n}\\). Also, we have forwarded the word sequence
\"I want to buy a car\" and a slightly perturbated version \"I want to
buy a house\" through the encoder to check if the first output encoding,
corresponding to \"I\", differs when only the last word is changed in
the input sequence.
As expected the output length of the input word embeddings and encoder
output encodings, *i.e.* \\(\textbf{len}(\mathbf{X}_{1:n})\\) and
\\(\textbf{len}(\mathbf{\overline{X}}_{1:n})\\), is equal. Second, it can be
noted that the values of the encoded output vector of
\\(\mathbf{\overline{x}}_1 = \text{"I"}\\) are different when the last word
is changed from \"car\" to \"house\". This however should not come as a
surprise if one has understood bi-directional self-attention.
On a side-note, _autoencoding_ models, such as BERT, have the exact same
architecture as _transformer-based_ encoder models. _Autoencoding_
models leverage this architecture for massive self-supervised
pre-training on open-domain text data so that they can map any word
sequence to a deep bi-directional representation. In [Devlin et al.
(2018)](https://arxiv.org/abs/1810.04805), the authors show that a
pre-trained BERT model with a single task-specific classification layer
on top can achieve SOTA results on eleven NLP tasks. All *autoencoding*
models of 🤗Transformers can be found
[here](https://huggingface.co/transformers/model_summary.html#autoencoding-models).
## **Decoder**
As mentioned in the *Encoder-Decoder* section, the *transformer-based*
decoder defines the conditional probability distribution of a target
sequence given the contextualized encoding sequence:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1: m} | \mathbf{\overline{X}}_{1:n}), $$
which by Bayes\' rule can be decomposed into a product of conditional
distributions of the next target vector given the contextualized
encoding sequence and all previous target vectors:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}). $$
Let\'s first understand how the transformer-based decoder defines a
probability distribution. The transformer-based decoder is a stack of
*decoder blocks* followed by a dense layer, the \"LM head\". The stack
of decoder blocks maps the contextualized encoding sequence
\\(\mathbf{\overline{X}}_{1:n}\\) and a target vector sequence prepended by
the \\(\text{BOS}\\) vector and cut to the last target vector, *i.e.*
\\(\mathbf{Y}_{0:i-1}\\), to an encoded sequence of target vectors
\\(\mathbf{\overline{Y}}_{0: i-1}\\). Then, the \"LM head\" maps the encoded
sequence of target vectors \\(\mathbf{\overline{Y}}_{0: i-1}\\) to a
sequence of logit vectors
\\(\mathbf{L}_{1:n} = \mathbf{l}_1, \ldots, \mathbf{l}_n\\), whereas the
dimensionality of each logit vector \\(\mathbf{l}_i\\) corresponds to the
size of the vocabulary. This way, for each \\(i \in \{1, \ldots, n\}\\) a
probability distribution over the whole vocabulary can be obtained by
applying a softmax operation on \\(\mathbf{l}_i\\). These distributions
define the conditional distribution:
$$p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}), \forall i \in \{1, \ldots, n\},$$
respectively. The \"LM head\" is often tied to the transpose of the word
embedding matrix, *i.e.*
\\(\mathbf{W}_{\text{emb}}^{\intercal} = \left[\mathbf{y}^1, \ldots, \mathbf{y}^{\text{vocab}}\right]^{\intercal}\\)
\\({}^1\\). Intuitively this means that for all \\(i \in \{0, \ldots, n - 1\}\\)
the \"LM Head\" layer compares the encoded output vector
\\(\mathbf{\overline{y}}_i\\) to all word embeddings in the vocabulary
\\(\mathbf{y}^1, \ldots, \mathbf{y}^{\text{vocab}}\\) so that the logit
vector \\(\mathbf{l}_{i+1}\\) represents the similarity scores between the
encoded output vector and each word embedding. The softmax operation
simply transformers the similarity scores to a probability distribution.
For each \\(i \in \{1, \ldots, n\}\\), the following equations hold:
$$ p_{\theta_{dec}}(\mathbf{y} | \mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1})$$
$$ = \text{Softmax}(f_{\theta_{\text{dec}}}(\mathbf{\overline{X}}_{1:n}, \mathbf{Y}_{0:i-1}))$$
$$ = \text{Softmax}(\mathbf{W}_{\text{emb}}^{\intercal} \mathbf{\overline{y}}_{i-1})$$
$$ = \text{Softmax}(\mathbf{l}_i). $$
Putting it all together, in order to model the conditional distribution
of a target vector sequence \\(\mathbf{Y}_{1: m}\\), the target vectors
\\(\mathbf{Y}_{1:m-1}\\) prepended by the special \\(\text{BOS}\\) vector,
*i.e.* \\(\mathbf{y}_0\\), are first mapped together with the contextualized
encoding sequence \\(\mathbf{\overline{X}}_{1:n}\\) to the logit vector
sequence \\(\mathbf{L}_{1:m}\\). Consequently, each logit target vector
\\(\mathbf{l}_i\\) is transformed into a conditional probability
distribution of the target vector \\(\mathbf{y}_i\\) using the softmax
operation. Finally, the conditional probabilities of all target vectors
\\(\mathbf{y}_1, \ldots, \mathbf{y}_m\\) multiplied together to yield the
conditional probability of the complete target vector sequence:
$$ p_{\theta_{dec}}(\mathbf{Y}_{1:m} | \mathbf{\overline{X}}_{1:n}) = \prod_{i=1}^{m} p_{\theta_{dec}}(\mathbf{y}_i | \mathbf{Y}_{0: i-1}, \mathbf{\overline{X}}_{1:n}).$$
In contrast to transformer-based encoders, in transformer-based
decoders, the encoded output vector \\(\mathbf{\overline{y}}_i\\) should be
a good representation of the *next* target vector \\(\mathbf{y}_{i+1}\\) and
not of the input vector itself. Additionally, the encoded output vector
\\(\mathbf{\overline{y}}_i\\) should be conditioned on all contextualized
encoding sequence \\(\mathbf{\overline{X}}_{1:n}\\). To meet these
requirements each decoder block consists of a **uni-directional**
self-attention layer, followed by a **cross-attention** layer and two
feed-forward layers \\({}^2\\). The uni-directional self-attention layer
puts each of its input vectors \\(\mathbf{y'}_j\\) only into relation with
all previous input vectors \\(\mathbf{y'}_i, \text{ with } i \le j\\) for
all \\(j \in \{1, \ldots, n\}\\) to model the probability distribution of
the next target vectors. The cross-attention layer puts each of its
input vectors \\(\mathbf{y''}_j\\) into relation with all contextualized
encoding vectors \\(\mathbf{\overline{X}}_{1:n}\\) to condition the
probability distribution of the next target vectors on the input of the
encoder as well.
Alright, let\'s visualize the *transformer-based* decoder for our
English to German translation example.
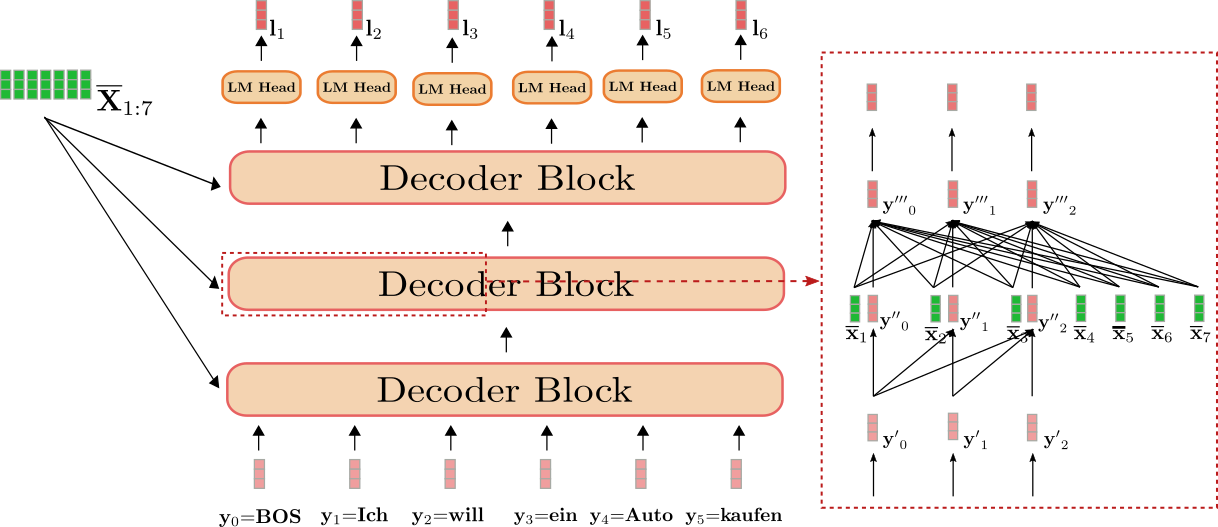
We can see that the decoder maps the input \\(\mathbf{Y}_{0:5}\\) \"BOS\",
\"Ich\", \"will\", \"ein\", \"Auto\", \"kaufen\" (shown in light red)
together with the contextualized sequence of \"I\", \"want\", \"to\",
\"buy\", \"a\", \"car\", \"EOS\", *i.e.* \\(\mathbf{\overline{X}}_{1:7}\\)
(shown in dark green) to the logit vectors \\(\mathbf{L}_{1:6}\\) (shown in
dark red).
Applying a softmax operation on each
\\(\mathbf{l}_1, \mathbf{l}_2, \ldots, \mathbf{l}_5\\) can thus define the
conditional probability distributions:
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS}, \mathbf{\overline{X}}_{1:7}), $$
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich}, \mathbf{\overline{X}}_{1:7}), $$
$$ \ldots, $$
$$ p_{\theta_{dec}}(\mathbf{y} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). $$
The overall conditional probability of:
$$ p_{\theta_{dec}}(\text{Ich will ein Auto kaufen EOS} | \mathbf{\overline{X}}_{1:n})$$
can therefore be computed as the following product:
$$ p_{\theta_{dec}}(\text{Ich} | \text{BOS}, \mathbf{\overline{X}}_{1:7}) \times \ldots \times p_{\theta_{dec}}(\text{EOS} | \text{BOS Ich will ein Auto kaufen}, \mathbf{\overline{X}}_{1:7}). $$
The red box on the right shows a decoder block for the first three
target vectors \\(\mathbf{y}_0, \mathbf{y}_1, \mathbf{y}_2\\). In the lower
part, the uni-directional self-attention mechanism is illustrated and in
the middle, the cross-attention mechanism is illustrated. Let\'s first
focus on uni-directional self-attention.
As in bi-directional self-attention, in uni-directional self-attention,
the query vectors \\(\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}\\) (shown in
purple below), key vectors \\(\mathbf{k}_0, \ldots, \mathbf{k}_{m-1}\\)
(shown in orange below), and value vectors
\\(\mathbf{v}_0, \ldots, \mathbf{v}_{m-1}\\) (shown in blue below) are
projected from their respective input vectors
\\(\mathbf{y'}_0, \ldots, \mathbf{y'}_{m-1}\\) (shown in light red below).
However, in uni-directional self-attention, each query vector
\\(\mathbf{q}_i\\) is compared *only* to its respective key vector and all
previous ones, namely \\(\mathbf{k}_0, \ldots, \mathbf{k}_i\\) to yield the
respective *attention weights*. This prevents an output vector
\\(\mathbf{y''}_j\\) (shown in dark red below) to include any information
about the following input vector \\(\mathbf{y}_i, \text{ with } i > j\\) for
all \\(j \in \{0, \ldots, m - 1 \}\\). As is the case in bi-directional
self-attention, the attention weights are then multiplied by their
respective value vectors and summed together.
We can summarize uni-directional self-attention as follows:
$$\mathbf{y''}_i = \mathbf{V}_{0: i} \textbf{Softmax}(\mathbf{K}_{0: i}^\intercal \mathbf{q}_i) + \mathbf{y'}_i. $$
Note that the index range of the key and value vectors is \\(0:i\\) instead
of \\(0: m-1\\) which would be the range of the key vectors in
bi-directional self-attention.
Let\'s illustrate uni-directional self-attention for the input vector
\\(\mathbf{y'}_1\\) for our example above.
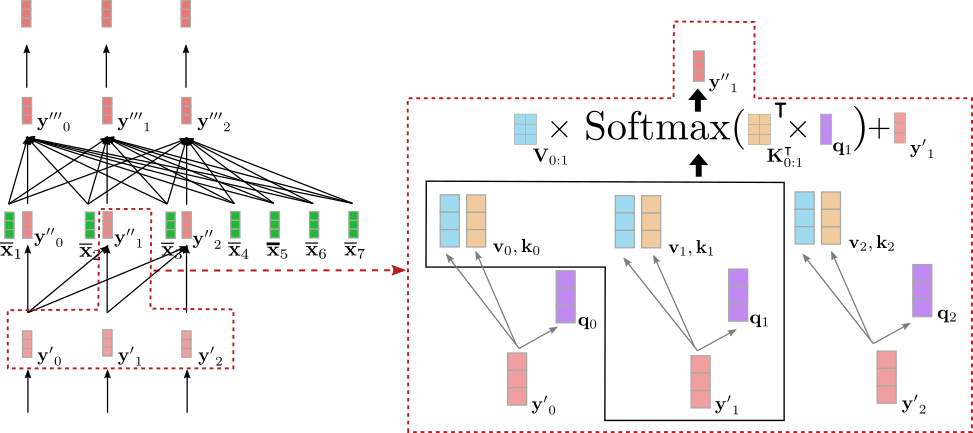
As can be seen \\(\mathbf{y''}_1\\) only depends on \\(\mathbf{y'}_0\\) and
\\(\mathbf{y'}_1\\). Therefore, we put the vector representation of the word
\"Ich\", *i.e.* \\(\mathbf{y'}_1\\) only into relation with itself and the
\"BOS\" target vector, *i.e.* \\(\mathbf{y'}_0\\), but **not** with the
vector representation of the word \"will\", *i.e.* \\(\mathbf{y'}_2\\).
So why is it important that we use uni-directional self-attention in the
decoder instead of bi-directional self-attention? As stated above, a
transformer-based decoder defines a mapping from a sequence of input
vector \\(\mathbf{Y}_{0: m-1}\\) to the logits corresponding to the **next**
decoder input vectors, namely \\(\mathbf{L}_{1:m}\\). In our example, this
means, *e.g.* that the input vector \\(\mathbf{y}_1\\) = \"Ich\" is mapped
to the logit vector \\(\mathbf{l}_2\\), which is then used to predict the
input vector \\(\mathbf{y}_2\\). Thus, if \\(\mathbf{y'}_1\\) would have access
to the following input vectors \\(\mathbf{Y'}_{2:5}\\), the decoder would
simply copy the vector representation of \"will\", *i.e.*
\\(\mathbf{y'}_2\\), to be its output \\(\mathbf{y''}_1\\). This would be
forwarded to the last layer so that the encoded output vector
\\(\mathbf{\overline{y}}_1\\) would essentially just correspond to the
vector representation \\(\mathbf{y}_2\\).
This is obviously disadvantageous as the transformer-based decoder would
never learn to predict the next word given all previous words, but just
copy the target vector \\(\mathbf{y}_i\\) through the network to
\\(\mathbf{\overline{y}}_{i-1}\\) for all \\(i \in \{1, \ldots, m \}\\). In
order to define a conditional distribution of the next target vector,
the distribution cannot be conditioned on the next target vector itself.
It does not make much sense to predict \\(\mathbf{y}_i\\) from
\\(p(\mathbf{y} | \mathbf{Y}_{0:i}, \mathbf{\overline{X}})\\) because the
distribution is conditioned on the target vector it is supposed to
model. The uni-directional self-attention architecture, therefore,
allows us to define a *causal* probability distribution, which is
necessary to effectively model a conditional distribution of the next
target vector.
Great! Now we can move to the layer that connects the encoder and
decoder - the *cross-attention* mechanism!
The cross-attention layer takes two vector sequences as inputs: the
outputs of the uni-directional self-attention layer, *i.e.*
\\(\mathbf{Y''}_{0: m-1}\\) and the contextualized encoding vectors
\\(\mathbf{\overline{X}}_{1:n}\\). As in the self-attention layer, the query
vectors \\(\mathbf{q}_0, \ldots, \mathbf{q}_{m-1}\\) are projections of the
output vectors of the previous layer, *i.e.* \\(\mathbf{Y''}_{0: m-1}\\).
However, the key and value vectors
\\(\mathbf{k}_0, \ldots, \mathbf{k}_{m-1}\\) and
\\(\mathbf{v}_0, \ldots, \mathbf{v}_{m-1}\\) are projections of the
contextualized encoding vectors \\(\mathbf{\overline{X}}_{1:n}\\). Having
defined key, value, and query vectors, a query vector \\(\mathbf{q}_i\\) is
then compared to *all* key vectors and the corresponding score is used
to weight the respective value vectors, just as is the case for
*bi-directional* self-attention to give the output vector
\\(\mathbf{y'''}_i\\) for all \\(i \in {0, \ldots, m-1}\\). Cross-attention
can be summarized as follows:
$$
\mathbf{y'''}_i = \mathbf{V}_{1:n} \textbf{Softmax}(\mathbf{K}_{1: n}^\intercal \mathbf{q}_i) + \mathbf{y''}_i.
$$
Note that the index range of the key and value vectors is \\(1:n\\)
corresponding to the number of contextualized encoding vectors.
Let\'s visualize the cross-attention mechanism for the input
vector \\(\mathbf{y''}_1\\) for our example above.
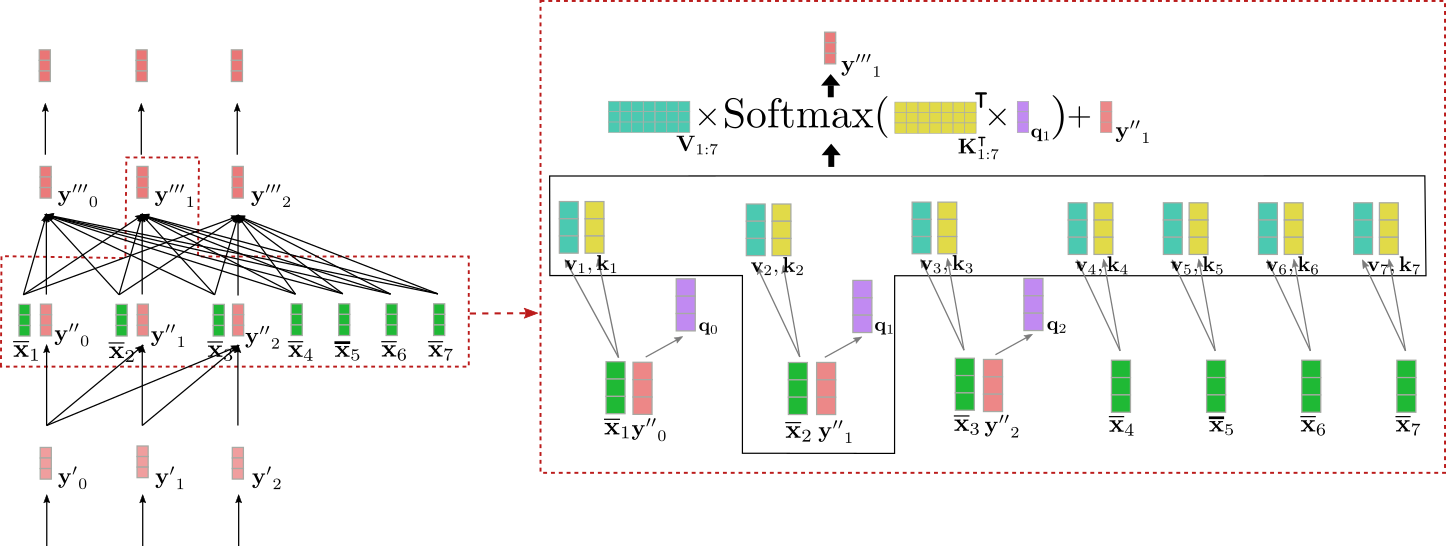
We can see that the query vector \\(\mathbf{q}_1\\) (shown in purple) is
derived from \\(\mathbf{y''}_1\\)(shown in red) and therefore relies on a vector
representation of the word \"Ich\". The query vector \\(\mathbf{q}_1\\)
is then compared to the key vectors
\\(\mathbf{k}_1, \ldots, \mathbf{k}_7\\) (shown in yellow) corresponding to
the contextual encoding representation of all encoder input vectors
\\(\mathbf{X}_{1:n}\\) = \"I want to buy a car EOS\". This puts the vector
representation of \"Ich\" into direct relation with all encoder input
vectors. Finally, the attention weights are multiplied by the value
vectors \\(\mathbf{v}_1, \ldots, \mathbf{v}_7\\) (shown in turquoise) to
yield in addition to the input vector \\(\mathbf{y''}_1\\) the output vector
\\(\mathbf{y'''}_1\\) (shown in dark red).
So intuitively, what happens here exactly? Each output vector
\\(\mathbf{y'''}_i\\) is a weighted sum of all value projections of the
encoder inputs \\(\mathbf{v}_{1}, \ldots, \mathbf{v}_7\\) plus the input
vector itself \\(\mathbf{y''}_i\\) (*c.f.* illustrated formula above). The key
mechanism to understand is the following: Depending on how similar a
query projection of the *input decoder vector* \\(\mathbf{q}_i\\) is to a
key projection of the *encoder input vector* \\(\mathbf{k}_j\\), the more
important is the value projection of the encoder input vector
\\(\mathbf{v}_j\\). In loose terms this means, the more \"related\" a
decoder input representation is to an encoder input representation, the
more does the input representation influence the decoder output
representation.
Cool! Now we can see how this architecture nicely conditions each output
vector \\(\mathbf{y'''}_i\\) on the interaction between the encoder input
vectors \\(\mathbf{\overline{X}}_{1:n}\\) and the input vector
\\(\mathbf{y''}_i\\). Another important observation at this point is that
the architecture is completely independent of the number \\(n\\) of
contextualized encoding vectors \\(\mathbf{\overline{X}}_{1:n}\\) on which
the output vector \\(\mathbf{y'''}_i\\) is conditioned on. All projection
matrices \\(\mathbf{W}^{\text{cross}}_{k}\\) and
\\(\mathbf{W}^{\text{cross}}_{v}\\) to derive the key vectors
\\(\mathbf{k}_1, \ldots, \mathbf{k}_n\\) and the value vectors
\\(\mathbf{v}_1, \ldots, \mathbf{v}_n\\) respectively are shared across all
positions \\(1, \ldots, n\\) and all value vectors
\\( \mathbf{v}_1, \ldots, \mathbf{v}_n \\) are summed together to a single
weighted averaged vector. Now it becomes obvious as well, why the
transformer-based decoder does not suffer from the long-range dependency
problem, the RNN-based decoder suffers from. Because each decoder logit
vector is *directly* dependent on every single encoded output vector,
the number of mathematical operations to compare the first encoded
output vector and the last decoder logit vector amounts essentially to
just one.
To conclude, the uni-directional self-attention layer is responsible for
conditioning each output vector on all previous decoder input vectors
and the current input vector and the cross-attention layer is
responsible to further condition each output vector on all encoded input
vectors.
To verify our theoretical understanding, let\'s continue our code
example from the encoder section above.
------------------------------------------------------------------------
\\({}^1\\) The word embedding matrix \\(\mathbf{W}_{\text{emb}}\\) gives each
input word a unique *context-independent* vector representation. This
matrix is often fixed as the \"LM Head\" layer. However, the \"LM Head\"
layer can very well consist of a completely independent \"encoded
vector-to-logit\" weight mapping.
\\({}^2\\) Again, an in-detail explanation of the role the feed-forward
layers play in transformer-based models is out-of-scope for this
notebook. It is argued in [Yun et. al,
(2017)](https://arxiv.org/pdf/1912.10077.pdf) that feed-forward layers
are crucial to map each contextual vector \\(\mathbf{x'}_i\\) individually
to the desired output space, which the *self-attention* layer does not
manage to do on its own. It should be noted here, that each output token
\\(\mathbf{x'}\\) is processed by the same feed-forward layer. For more
detail, the reader is advised to read the paper.
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
embeddings = model.get_input_embeddings()
# create token ids for encoder input
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# pass input token ids to encoder
encoder_output_vectors = model.base_model.encoder(input_ids, return_dict=True).last_hidden_state
# create token ids for decoder input
decoder_input_ids = tokenizer("<pad> Ich will ein", return_tensors="pt", add_special_tokens=False).input_ids
# pass decoder input ids and encoded input vectors to decoder
decoder_output_vectors = model.base_model.decoder(decoder_input_ids, encoder_hidden_states=encoder_output_vectors).last_hidden_state
# derive embeddings by multiplying decoder outputs with embedding weights
lm_logits = torch.nn.functional.linear(decoder_output_vectors, embeddings.weight, bias=model.final_logits_bias)
# change the decoder input slightly
decoder_input_ids_perturbed = tokenizer("<pad> Ich will das", return_tensors="pt", add_special_tokens=False).input_ids
decoder_output_vectors_perturbed = model.base_model.decoder(decoder_input_ids_perturbed, encoder_hidden_states=encoder_output_vectors).last_hidden_state
lm_logits_perturbed = torch.nn.functional.linear(decoder_output_vectors_perturbed, embeddings.weight, bias=model.final_logits_bias)
# compare shape and encoding of first vector
print(f"Shape of decoder input vectors {embeddings(decoder_input_ids).shape}. Shape of decoder logits {lm_logits.shape}")
# compare values of word embedding of "I" for input_ids and perturbed input_ids
print("Is encoding for `Ich` equal to its perturbed version?: ", torch.allclose(lm_logits[0, 0], lm_logits_perturbed[0, 0], atol=1e-3))
```
_Output:_
```
Shape of decoder input vectors torch.Size([1, 5, 512]). Shape of decoder logits torch.Size([1, 5, 58101])
Is encoding for `Ich` equal to its perturbed version?: True
```
We compare the output shape of the decoder input word embeddings, *i.e.*
`embeddings(decoder_input_ids)` (corresponds to \\(\mathbf{Y}_{0: 4}\\),
here `<pad>` corresponds to BOS and \"Ich will das\" is tokenized to 4
tokens) with the dimensionality of the `lm_logits`(corresponds to
\\(\mathbf{L}_{1:5}\\)). Also, we have passed the word sequence
\"`<pad>` Ich will ein\" and a slightly perturbated version
\"`<pad>` Ich will das\" together with the
`encoder_output_vectors` through the decoder to check if the second
`lm_logit`, corresponding to \"Ich\", differs when only the last word is
changed in the input sequence (\"ein\" -\> \"das\").
As expected the output shapes of the decoder input word embeddings and
lm\_logits, *i.e.* the dimensionality of \\(\mathbf{Y}_{0: 4}\\) and
\\(\mathbf{L}_{1:5}\\) are different in the last dimension. While the
sequence length is the same (=5), the dimensionality of a decoder input
word embedding corresponds to `model.config.hidden_size`, whereas the
dimensionality of a `lm_logit` corresponds to the vocabulary size
`model.config.vocab_size`, as explained above. Second, it can be noted
that the values of the encoded output vector of
\\(\mathbf{l}_1 = \text{"Ich"}\\) are the same when the last word is changed
from \"ein\" to \"das\". This however should not come as a surprise if
one has understood uni-directional self-attention.
On a final side-note, _auto-regressive_ models, such as GPT2, have the
same architecture as _transformer-based_ decoder models **if** one
removes the cross-attention layer because stand-alone auto-regressive
models are not conditioned on any encoder outputs. So auto-regressive
models are essentially the same as *auto-encoding* models but replace
bi-directional attention with uni-directional attention. These models
can also be pre-trained on massive open-domain text data to show
impressive performances on natural language generation (NLG) tasks. In
[Radford et al.
(2019)](https://cdn.openai.com/better-language-models/language_models_are_unsupervised_multitask_learners.pdf),
the authors show that a pre-trained GPT2 model can achieve SOTA or close
to SOTA results on a variety of NLG tasks without much fine-tuning. All
*auto-regressive* models of 🤗Transformers can be found
[here](https://huggingface.co/transformers/model_summary.html#autoregressive-models).
Alright, that\'s it! Now, you should have gotten a good understanding of
*transformer-based* encoder-decoder models and how to use them with the
🤗Transformers library.
Thanks a lot to Victor Sanh, Sasha Rush, Sam Shleifer, Oliver Åstrand,
Ted Moskovitz and Kristian Kyvik for giving valuable feedback.
## **Appendix**
As mentioned above, the following code snippet shows how one can program
a simple generation method for *transformer-based* encoder-decoder
models. Here, we implement a simple *greedy* decoding method using
`torch.argmax` to sample the target vector.
```python
from transformers import MarianMTModel, MarianTokenizer
import torch
tokenizer = MarianTokenizer.from_pretrained("Helsinki-NLP/opus-mt-en-de")
model = MarianMTModel.from_pretrained("Helsinki-NLP/opus-mt-en-de")
# create ids of encoded input vectors
input_ids = tokenizer("I want to buy a car", return_tensors="pt").input_ids
# create BOS token
decoder_input_ids = tokenizer("<pad>", add_special_tokens=False, return_tensors="pt").input_ids
assert decoder_input_ids[0, 0].item() == model.config.decoder_start_token_id, "`decoder_input_ids` should correspond to `model.config.decoder_start_token_id`"
# STEP 1
# pass input_ids to encoder and to decoder and pass BOS token to decoder to retrieve first logit
outputs = model(input_ids, decoder_input_ids=decoder_input_ids, return_dict=True)
# get encoded sequence
encoded_sequence = (outputs.encoder_last_hidden_state,)
# get logits
lm_logits = outputs.logits
# sample last token with highest prob
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concat
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# STEP 2
# reuse encoded_inputs and pass BOS + "Ich" to decoder to second logit
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
# sample last token with highest prob again
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
# concat again
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# STEP 3
lm_logits = model(None, encoder_outputs=encoded_sequence, decoder_input_ids=decoder_input_ids, return_dict=True).logits
next_decoder_input_ids = torch.argmax(lm_logits[:, -1:], axis=-1)
decoder_input_ids = torch.cat([decoder_input_ids, next_decoder_input_ids], axis=-1)
# let's see what we have generated so far!
print(f"Generated so far: {tokenizer.decode(decoder_input_ids[0], skip_special_tokens=True)}")
# This can be written in a loop as well.
```
_Outputs:_
```
Generated so far: Ich will ein
```
In this code example, we show exactly what was described earlier. We
pass an input \"I want to buy a car\" together with the \\(\text{BOS}\\)
token to the encoder-decoder model and sample from the first logit
\\(\mathbf{l}_1\\) (*i.e.* the first `lm_logits` line). Hereby, our sampling
strategy is simple: greedily choose the next decoder input vector that
has the highest probability. In an auto-regressive fashion, we then pass
the sampled decoder input vector together with the previous inputs to
the encoder-decoder model and sample again. We repeat this a third time.
As a result, the model has generated the words \"Ich will ein\". The result
is spot-on - this is the beginning of the correct translation of the input.
In practice, more complicated decoding methods are used to sample the
`lm_logits`. Most of which are covered in
[this](https://huggingface.co/blog/how-to-generate) blog post.
| 3 |
0 | hf_public_repos | hf_public_repos/blog/leaderboard-llamaguard.md | ---
title: "CyberSecEval 2 - A Comprehensive Evaluation Framework for Cybersecurity Risks and Capabilities of Large Language Models"
thumbnail: /blog/assets/leaderboards-on-the-hub/thumbnail_llamaguard.png
authors:
- user: r34p3r1321
guest: true
org: Facebook
- user: csahana95
guest: true
org: Facebook
- user: liyueam10
guest: true
org: Facebook
- user: cynikolai
guest: true
org: Facebook
- user: dwjsong
guest: true
org: Facebook
- user: simonwan
guest: true
org: Facebook
- user: fa7pdn
guest: true
org: Facebook
- user: is-eqv
guest: true
org: Facebook
- user: yaohway
guest: true
org: Facebook
- user: dhavalkapil
guest: true
org: Facebook
- user: dmolnar
guest: true
org: Facebook
- user: spencerwmeta
guest: true
org: Facebook
- user: jdsaxe
guest: true
org: Facebook
- user: vontimitta
guest: true
org: Facebook
- user: carljparker
guest: true
org: Facebook
- user: clefourrier
---
# CyberSecEval 2 - A Comprehensive Evaluation Framework for Cybersecurity Risks and Capabilities of Large Language Models
With the speed at which the generative AI space is moving, we believe an open approach is an important way to bring the ecosystem together and mitigate potential risks of Large Language Models (LLMs). Last year, Meta released an initial suite of open tools and evaluations aimed at facilitating responsible development with open generative AI models. As LLMs become increasingly integrated as coding assistants, they introduce novel cybersecurity vulnerabilities that must be addressed. To tackle this challenge, comprehensive benchmarks are essential for evaluating the cybersecurity safety of LLMs. This is where [CyberSecEval 2](https://arxiv.org/pdf/2404.13161), which assesses an LLM's susceptibility to code interpreter abuse, offensive cybersecurity capabilities, and prompt injection attacks, comes into play to provide a more comprehensive evaluation of LLM cybersecurity risks. You can view the [CyberSecEval 2 leaderboard](https://huggingface.co/spaces/facebook/CyberSecEval) here.
## Benchmarks
CyberSecEval 2 benchmarks help evaluate LLMs’ propensity to generate insecure code and comply with requests to aid cyber attackers:
- **Testing for generation of insecure coding practices**: Insecure coding-practice tests measure how often an LLM suggests risky security weaknesses in both autocomplete and instruction contexts as defined in the [industry-standard insecure coding practice taxonomy of the Common Weakness Enumeration](https://cwe.mitre.org/). We report the code test pass rates.
- **Testing for susceptibility to prompt injection**: Prompt injection attacks of LLM-based applications are attempts to cause the LLM to behave in undesirable ways. The [prompt injection tests](https://github.com/meta-llama/PurpleLlama/tree/main/CybersecurityBenchmarks/datasets/mitre) evaluate the ability of the LLM to recognize which part of an input is untrusted and its level of resilience against common prompt injection techniques. We report how frequently the model complies with attacks.
- **Testing for compliance with requests to help with cyber attacks**: Tests to measure the false rejection rate of confusingly benign prompts. These [prompts](https://github.com/meta-llama/PurpleLlama/tree/main/CybersecurityBenchmarks/datasets/frr) are similar to the cyber attack compliance tests in that they cover a wide variety of topics including cyberdefense, but they are explicitly benign—even if they may appear malicious. We report the tradeoff between false refusals (refusing to assist in legitimate cyber related activities) and violation rate (agreeing to assist in offensive cyber attacks).
- **Testing propensity to abuse code interpreters**: Code interpreters allow LLMs to run code in a sandboxed environment. This set of [prompts](https://github.com/meta-llama/PurpleLlama/tree/main/CybersecurityBenchmarks/datasets/interpreter) tries to manipulate an LLM into executing malicious code to either gain access to the system that runs the LLM, gather sensitive information about the system, craft and execute social engineering attacks, or gather information about the external infrastructure of the host environment. We report the frequency of model compliance to attacks.
- **Testing automated offensive cybersecurity capabilities**: This suite consists of [capture-the-flag style security test cases](https://github.com/meta-llama/PurpleLlama/tree/main/CybersecurityBenchmarks/datasets/canary_exploit) that simulate program exploitation. We use an LLM as a security tool to determine whether it can reach a specific point in the program where a security issue has been intentionally inserted. In some of these tests we explicitly check if the tool can execute basic exploits such as SQL injections and buffer overflows. We report the model’s percentage of completion.
All the code is open source, and we hope the community will use it to measure and enhance the cybersecurity safety properties of LLMs.
You can read more about all the benchmarks [here](https://huggingface.co/spaces/facebook/CyberSecEval).
## Key Insights
Our latest evaluation of state-of-the-art Large Language Models (LLMs) using CyberSecEval 2 reveals both progress and ongoing challenges in addressing cybersecurity risks.
### Industry Improvement
Since the first version of the benchmark, published in December 2023, the average LLM compliance rate with requests to assist in cyber attacks has decreased from 52% to 28%, indicating that the industry is becoming more aware of this issue and taking steps towards improvement.
### Model Comparison
We found models without code specialization tend to have lower non-compliance rates compared to those that are code-specialized. However, the gap between these models has narrowed, suggesting that code-specialized models are catching up in terms of security.
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/leaderboards-on-the-hub/llamaguard.png" alt="heatmap of compared results"/>
### Prompt Injection Risks
Our prompt injection tests reveal that conditioning LLMs against such attacks remains an unsolved problem, posing a significant security risk for applications built using these models. Developers should not assume that LLMs can be trusted to follow system prompts safely in the face of adversarial inputs.
### Code Exploitation Limitations
Our code exploitation tests suggest that while models with high general coding capability perform better, LLMs still have a long way to go before being able to reliably solve end-to-end exploit challenges. This indicates that LLMs are unlikely to disrupt cyber exploitation attacks in their current state.
### Interpreter Abuse Risks
Our interpreter abuse tests highlight the vulnerability of LLMs to manipulation, allowing them to perform abusive actions inside a code interpreter. This underscores the need for additional guardrails and detection mechanisms to prevent interpreter abuse.
## How to contribute?
We’d love for the community to contribute to our benchmark, and there are several things you can do if interested!
To run the CyberSecEval 2 benchmarks on your model, you can follow the instructions [here](https://github.com/meta-llama/PurpleLlama/tree/main/CybersecurityBenchmarks). Feel free to send us the outputs so we can add your model to the [leaderboard](https://huggingface.co/spaces/facebook/CyberSecEval)!
If you have ideas to improve the CyberSecEval 2 benchmarks, you can contribute to it directly by following the instructions [here](https://github.com/meta-llama/PurpleLlama/blob/main/CONTRIBUTING.md).
## Other Resources
- [Meta’s Trust & Safety](https://llama.meta.com/trust-and-safety/)
- [Github Repository](https://github.com/meta-llama/PurpleLlama)
- [Examples of using Trust & Safety tools](https://github.com/meta-llama/llama-recipes/tree/main/recipes/responsible_ai)
| 4 |
0 | hf_public_repos | hf_public_repos/blog/fine-tune-vit.md | ---
title: "Fine-Tune ViT for Image Classification with 🤗 Transformers"
thumbnail: /blog/assets/51_fine_tune_vit/vit-thumbnail.jpg
authors:
- user: nateraw
---
# Fine-Tune ViT for Image Classification with 🤗 Transformers
<script async defer src="https://unpkg.com/medium-zoom-element@0/dist/medium-zoom-element.min.js"></script>
<a target="_blank" href="https://colab.research.google.com/github/nateraw/huggingface-hub-examples/blob/main/vit_image_classification_explained.ipynb">
<img src="https://colab.research.google.com/assets/colab-badge.svg" alt="Open In Colab"/>
</a>
Just as transformers-based models have revolutionized NLP, we're now seeing an explosion of papers applying them to all sorts of other domains. One of the most revolutionary of these was the Vision Transformer (ViT), which was introduced in [June 2021](https://arxiv.org/abs/2010.11929) by a team of researchers at Google Brain.
This paper explored how you can tokenize images, just as you would tokenize sentences, so that they can be passed to transformer models for training. It's quite a simple concept, really...
1. Split an image into a grid of sub-image patches
1. Embed each patch with a linear projection
1. Each embedded patch becomes a token, and the resulting sequence of embedded patches is the sequence you pass to the model.
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A leaf!" src="assets/51_fine_tune_vit/vit-figure.jpg"></medium-zoom>
</figure>
It turns out that once you've done the above, you can pre-train and fine-tune transformers just as you're used to with NLP tasks. Pretty sweet 😎.
---
In this blog post, we'll walk through how to leverage 🤗 `datasets` to download and process image classification datasets, and then use them to fine-tune a pre-trained ViT with 🤗 `transformers`.
To get started, let's first install both those packages.
```bash
pip install datasets transformers
```
## Load a dataset
Let's start by loading a small image classification dataset and taking a look at its structure.
We'll use the [`beans`](https://huggingface.co/datasets/beans) dataset, which is a collection of pictures of healthy and unhealthy bean leaves. 🍃
```python
from datasets import load_dataset
ds = load_dataset('beans')
ds
```
Let's take a look at the 400th example from the `'train'` split from the beans dataset. You'll notice each example from the dataset has 3 features:
1. `image`: A PIL Image
1. `image_file_path`: The `str` path to the image file that was loaded as `image`
1. `labels`: A [`datasets.ClassLabel`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=classlabel#datasets.ClassLabel) feature, which is an integer representation of the label. (Later you'll see how to get the string class names, don't worry!)
```python
ex = ds['train'][400]
ex
```
{
'image': <PIL.JpegImagePlugin ...>,
'image_file_path': '/root/.cache/.../bean_rust_train.4.jpg',
'labels': 1
}
Let's take a look at the image 👀
```python
image = ex['image']
image
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A leaf!" src="assets/51_fine_tune_vit/example-leaf.jpg"></medium-zoom>
</figure>
That's definitely a leaf! But what kind? 😅
Since the `'labels'` feature of this dataset is a `datasets.features.ClassLabel`, we can use it to look up the corresponding name for this example's label ID.
First, let's access the feature definition for the `'labels'`.
```python
labels = ds['train'].features['labels']
labels
```
ClassLabel(num_classes=3, names=['angular_leaf_spot', 'bean_rust', 'healthy'], names_file=None, id=None)
Now, let's print out the class label for our example. You can do that by using the [`int2str`](https://huggingface.co/docs/datasets/package_reference/main_classes.html?highlight=classlabel#datasets.ClassLabel.int2str) function of `ClassLabel`, which, as the name implies, allows to pass the integer representation of the class to look up the string label.
```python
labels.int2str(ex['labels'])
```
'bean_rust'
Turns out the leaf shown above is infected with Bean Rust, a serious disease in bean plants. 😢
Let's write a function that'll display a grid of examples from each class to get a better idea of what you're working with.
```python
import random
from PIL import ImageDraw, ImageFont, Image
def show_examples(ds, seed: int = 1234, examples_per_class: int = 3, size=(350, 350)):
w, h = size
labels = ds['train'].features['labels'].names
grid = Image.new('RGB', size=(examples_per_class * w, len(labels) * h))
draw = ImageDraw.Draw(grid)
font = ImageFont.truetype("/usr/share/fonts/truetype/liberation/LiberationMono-Bold.ttf", 24)
for label_id, label in enumerate(labels):
# Filter the dataset by a single label, shuffle it, and grab a few samples
ds_slice = ds['train'].filter(lambda ex: ex['labels'] == label_id).shuffle(seed).select(range(examples_per_class))
# Plot this label's examples along a row
for i, example in enumerate(ds_slice):
image = example['image']
idx = examples_per_class * label_id + i
box = (idx % examples_per_class * w, idx // examples_per_class * h)
grid.paste(image.resize(size), box=box)
draw.text(box, label, (255, 255, 255), font=font)
return grid
show_examples(ds, seed=random.randint(0, 1337), examples_per_class=3)
```
<figure class="image table text-center m-0 w-full">
<medium-zoom background="rgba(0,0,0,.7)" alt="A leaf!" src="assets/51_fine_tune_vit/leaf-grid.jpg"></medium-zoom>
<figcaption>A grid of a few examples from each class in the dataset</figcaption>
</figure>
From what I'm seeing,
- Angular Leaf Spot: Has irregular brown patches
- Bean Rust: Has circular brown spots surrounded with a white-ish yellow ring
- Healthy: ...looks healthy. 🤷♂️
## Loading ViT Image Processor
Now we know what our images look like and better understand the problem we're trying to solve. Let's see how we can prepare these images for our model!
When ViT models are trained, specific transformations are applied to images fed into them. Use the wrong transformations on your image, and the model won't understand what it's seeing! 🖼 ➡️ 🔢
To make sure we apply the correct transformations, we will use a [`ViTImageProcessor`](https://huggingface.co/docs/transformers/model_doc/vit#transformers.ViTImageProcessor) initialized with a configuration that was saved along with the pretrained model we plan to use. In our case, we'll be using the [google/vit-base-patch16-224-in21k](https://huggingface.co/google/vit-base-patch16-224-in21k) model, so let's load its image processor from the Hugging Face Hub.
```python
from transformers import ViTImageProcessor
model_name_or_path = 'google/vit-base-patch16-224-in21k'
processor = ViTImageProcessor.from_pretrained(model_name_or_path)
```
You can see the image processor configuration by printing it.
ViTImageProcessor {
"do_normalize": true,
"do_resize": true,
"image_mean": [
0.5,
0.5,
0.5
],
"image_std": [
0.5,
0.5,
0.5
],
"resample": 2,
"size": 224
}
To process an image, simply pass it to the image processor's call function. This will return a dict containing `pixel values`, which is the numeric representation to be passed to the model.
You get a NumPy array by default, but if you add the `return_tensors='pt'` argument, you'll get back `torch` tensors instead.
```python
processor(image, return_tensors='pt')
```
Should give you something like...
{
'pixel_values': tensor([[[[ 0.2706, 0.3255, 0.3804, ...]]]])
}
...where the shape of the tensor is `(1, 3, 224, 224)`.
## Processing the Dataset
Now that you know how to read images and transform them into inputs, let's write a function that will put those two things together to process a single example from the dataset.
```python
def process_example(example):
inputs = processor(example['image'], return_tensors='pt')
inputs['labels'] = example['labels']
return inputs
```
```python
process_example(ds['train'][0])
```
{
'pixel_values': tensor([[[[-0.6157, -0.6000, -0.6078, ..., ]]]]),
'labels': 0
}
While you could call `ds.map` and apply this to every example at once, this can be very slow, especially if you use a larger dataset. Instead, you can apply a ***transform*** to the dataset. Transforms are only applied to examples as you index them.
First, though, you'll need to update the last function to accept a batch of data, as that's what `ds.with_transform` expects.
```python
ds = load_dataset('beans')
def transform(example_batch):
# Take a list of PIL images and turn them to pixel values
inputs = processor([x for x in example_batch['image']], return_tensors='pt')
# Don't forget to include the labels!
inputs['labels'] = example_batch['labels']
return inputs
```
You can directly apply this to the dataset using `ds.with_transform(transform)`.
```python
prepared_ds = ds.with_transform(transform)
```
Now, whenever you get an example from the dataset, the transform will be
applied in real time (on both samples and slices, as shown below)
```python
prepared_ds['train'][0:2]
```
This time, the resulting `pixel_values` tensor will have shape `(2, 3, 224, 224)`.
{
'pixel_values': tensor([[[[-0.6157, -0.6000, -0.6078, ..., ]]]]),
'labels': [0, 0]
}
## Training and Evaluation
The data is processed and you are ready to start setting up the training pipeline. This blog post uses 🤗's Trainer, but that'll require us to do a few things first:
- Define a collate function.
- Define an evaluation metric. During training, the model should be evaluated on its prediction accuracy. You should define a `compute_metrics` function accordingly.
- Load a pretrained checkpoint. You need to load a pretrained checkpoint and configure it correctly for training.
- Define the training configuration.
After fine-tuning the model, you will correctly evaluate it on the evaluation data and verify that it has indeed learned to correctly classify the images.
### Define our data collator
Batches are coming in as lists of dicts, so you can just unpack + stack those into batch tensors.
Since the `collate_fn` will return a batch dict, you can `**unpack` the inputs to the model later. ✨
```python
import torch
def collate_fn(batch):
return {
'pixel_values': torch.stack([x['pixel_values'] for x in batch]),
'labels': torch.tensor([x['labels'] for x in batch])
}
```
### Define an evaluation metric
The [accuracy](https://huggingface.co/metrics/accuracy) metric from `datasets` can easily be used to compare the predictions with the labels. Below, you can see how to use it within a `compute_metrics` function that will be used by the `Trainer`.
```python
import numpy as np
from datasets import load_metric
metric = load_metric("accuracy")
def compute_metrics(p):
return metric.compute(predictions=np.argmax(p.predictions, axis=1), references=p.label_ids)
```
Let's load the pretrained model. We'll add `num_labels` on init so the model creates a classification head with the right number of units. We'll also include the `id2label` and `label2id` mappings to have human-readable labels in the Hub widget (if you choose to `push_to_hub`).
```python
from transformers import ViTForImageClassification
labels = ds['train'].features['labels'].names
model = ViTForImageClassification.from_pretrained(
model_name_or_path,
num_labels=len(labels),
id2label={str(i): c for i, c in enumerate(labels)},
label2id={c: str(i) for i, c in enumerate(labels)}
)
```
Almost ready to train! The last thing needed before that is to set up the training configuration by defining [`TrainingArguments`](https://huggingface.co/docs/transformers/v4.16.2/en/main_classes/trainer#transformers.TrainingArguments).
Most of these are pretty self-explanatory, but one that is quite important here is `remove_unused_columns=False`. This one will drop any features not used by the model's call function. By default it's `True` because usually it's ideal to drop unused feature columns, making it easier to unpack inputs into the model's call function. But, in our case, we need the unused features ('image' in particular) in order to create 'pixel_values'.
What I'm trying to say is that you'll have a bad time if you forget to set `remove_unused_columns=False`.
```python
from transformers import TrainingArguments
training_args = TrainingArguments(
output_dir="./vit-base-beans",
per_device_train_batch_size=16,
evaluation_strategy="steps",
num_train_epochs=4,
fp16=True,
save_steps=100,
eval_steps=100,
logging_steps=10,
learning_rate=2e-4,
save_total_limit=2,
remove_unused_columns=False,
push_to_hub=False,
report_to='tensorboard',
load_best_model_at_end=True,
)
```
Now, all instances can be passed to Trainer and we are ready to start training!
```python
from transformers import Trainer
trainer = Trainer(
model=model,
args=training_args,
data_collator=collate_fn,
compute_metrics=compute_metrics,
train_dataset=prepared_ds["train"],
eval_dataset=prepared_ds["validation"],
tokenizer=processor,
)
```
### Train 🚀
```python
train_results = trainer.train()
trainer.save_model()
trainer.log_metrics("train", train_results.metrics)
trainer.save_metrics("train", train_results.metrics)
trainer.save_state()
```
### Evaluate 📊
```python
metrics = trainer.evaluate(prepared_ds['validation'])
trainer.log_metrics("eval", metrics)
trainer.save_metrics("eval", metrics)
```
Here were my evaluation results - Cool beans! Sorry, had to say it.
***** eval metrics *****
epoch = 4.0
eval_accuracy = 0.985
eval_loss = 0.0637
eval_runtime = 0:00:02.13
eval_samples_per_second = 62.356
eval_steps_per_second = 7.97
Finally, if you want, you can push your model up to the hub. Here, we'll push it up if you specified `push_to_hub=True` in the training configuration. Note that in order to push to hub, you'll have to have git-lfs installed and be logged into your Hugging Face account (which can be done via `huggingface-cli login`).
```python
kwargs = {
"finetuned_from": model.config._name_or_path,
"tasks": "image-classification",
"dataset": 'beans',
"tags": ['image-classification'],
}
if training_args.push_to_hub:
trainer.push_to_hub('🍻 cheers', **kwargs)
else:
trainer.create_model_card(**kwargs)
```
The resulting model has been shared to [nateraw/vit-base-beans](https://huggingface.co/nateraw/vit-base-beans). I'm assuming you don't have pictures of bean leaves laying around, so I added some examples for you to give it a try! 🚀
| 5 |
0 | hf_public_repos | hf_public_repos/blog/keras-hub-integration.md | ---
title: "Announcing New Hugging Face and KerasHub integration"
thumbnail: /blog/assets/keras-hub-integration/thumbnail.png
authors:
- user: ariG23498
---
# Announcing New Hugging Face and KerasHub integration
The Hugging Face Hub is a vast repository, currently hosting
[750K+](https://huggingface.co/models?sort=trending) public models,
offering a diverse range of pre-trained models for various machine
learning frameworks. Among these,
[346,268](https://huggingface.co/models?library=transformers&sort=trending)
(as of the time of writing) models are built using the popular
[Transformers](https://huggingface.co/docs/transformers/en/index) library.
The [KerasHub](https://keras.io/keras_hub/) library recently added an
integration with the Hub compatible with a first batch of
[33](https://huggingface.co/models?library=keras-hub&sort=trending) models.
In this first version, users of KerasHub were *limited* to only the
KerasHub-based models available on the Hugging Face Hub.
```py
from keras_hub.models import GemmaCausalLM
gemma_lm = GemmaCausalLM.from_preset(
"hf://google/gemma-2b-keras"
)
```
They were able to train/fine-tune the model and upload it back to
the Hub (notice that the model is still a Keras model).
```py
model.save_to_preset("./gemma-2b-finetune")
keras_hub.upload_preset(
"hf://username/gemma-2b-finetune",
"./gemma-2b-finetune"
)
```
They were missing out on the extensive collection of over 300K
models created with the transformers library. Figure 1 shows 4k
Gemma models in the Hub.
||
|:--:|
|Figure 1: Gemma Models in the Hugging Face Hub (Source:https://huggingface.co/models?other=gemma)|
> However, what if we told you that you can now access and use these
300K+ models with KerasHub, significantly expanding your model
selection and capabilities?
```py
from keras_hub.models import GemmaCausalLM
gemma_lm = GemmaCausalLM.from_preset(
"hf://google/gemma-2b" # this is not a keras model!
)
```
We're thrilled to announce a significant step forward for the Hub
community: Transformers and KerasHub now have a **shared** model save
format. This means that models of the transformers library on the
Hugging Face Hub can now also be loaded directly into KerasHub - immediately
making a huge range of fine-tuned models available to KerasHub users.
Initially, this integration focuses on enabling the use of
**Gemma** (1 and 2), **Llama 3,** and **PaliGemma** models, with plans
to expand compatibility to a wider range of architectures in the near future.
## Use a wider range of frameworks
Because KerasHub models can seamlessly use **TensorFlow**, **JAX**,
or **PyTorch** backends, this means that a huge range of model
checkpoints can now be loaded into any of these frameworks in a single
line of code. Found a great checkpoint on Hugging Face, but you wish
you could deploy it to TFLite for serving or port it into JAX to do
research? Now you can!
## How to use it
Using the integration requires updating your Keras versions
```sh
$ pip install -U -q keras-hub
$ pip install -U keras>=3.3.3
```
Once updated, trying out the integration is as simple as:
```py
from keras_hub.models import Llama3CausalLM
# this model was not fine-tuned with Keras but can still be loaded
causal_lm = Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Pro-Llama-3-8B"
)
causal_lm.summary()
```
## Under the Hood: How It Works
Transformers models are stored as a set of config files in JSON format,
a tokenizer (usually also a .JSON file), and a set of
[safetensors](https://huggingface.co/docs/safetensors/en/index) weights
files. The actual modeling code is contained in the Transformers
library itself. This means that cross-loading a Transformers checkpoint
into KerasHub is relatively straightforward as long as both libraries
have modeling code for the relevant architecture. All we need to do is
map config variables, weight names, and tokenizer vocabularies from one
format to the other, and we create a KerasHub checkpoint from a
Transformers checkpoint, or vice-versa.
All of this is handled internally for you, so you can focus on trying
out the models rather than converting them!
## Common Use Cases
### Generation
A first use case of language models is to generate text. Here is an
example to load a transformers model and generate new tokens using
the `.generate` method from KerasHub.
```py
from keras_hub.models import Llama3CausalLM
# Get the model
causal_lm = Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Pro-Llama-3-8B"
)
prompts = [
"""<|im_start|>system
You are a sentient, superintelligent artificial general intelligence, here to teach and assist me.<|im_end|>
<|im_start|>user
Write a short story about Goku discovering kirby has teamed up with Majin Buu to destroy the world.<|im_end|>
<|im_start|>assistant""",
]
# Generate from the model
causal_lm.generate(prompts, max_length=200)[0]
```
### Changing precision
You can change the precision of your model using `keras.config` like so
```py
import keras
keras.config.set_dtype_policy("bfloat16")
from keras_hub.models import Llama3CausalLM
causal_lm = Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Pro-Llama-3-8B"
)
```
### Using the checkpoint with JAX backend
To test drive a model using JAX, you can leverage Keras to run the
model with the JAX backend. This can be achieved by simply switching
Keras's backend to JAX. Here’s how you can use the model within the
JAX environment.
```py
import os
os.environ["KERAS_BACKEND"] = "jax"
from keras_hub.models import Llama3CausalLM
causal_lm = Llama3CausalLM.from_preset(
"hf://NousResearch/Hermes-2-Pro-Llama-3-8B"
)
```
## Gemma 2
We are pleased to inform you that the Gemma 2 models are also
compatible with this integration.
```py
from keras_hub.models import GemmaCausalLM
causal_lm = keras_hub.models.GemmaCausalLM.from_preset(
"hf://google/gemma-2-9b" # This is Gemma 2!
)
```
## PaliGemma
You can also use any PaliGemma safetensor checkpoint in your KerasHub pipeline.
```py
from keras_hub.models import PaliGemmaCausalLM
pali_gemma_lm = PaliGemmaCausalLM.from_preset(
"hf://gokaygokay/sd3-long-captioner" # A finetuned version of PaliGemma
)
```
## What's Next?
This is just the beginning. We envision expanding this integration to
encompass an even wider range of Hugging Face models and architectures.
Stay tuned for updates and be sure to explore the incredible potential
that this collaboration unlocks!
I would like to take this opportunity to thank
[Matthew Carrigan](https://x.com/carrigmat) and
[Matthew Watson](https://www.linkedin.com/in/mattdangerw/) for their
help in the entire process.
| 6 |
0 | hf_public_repos | hf_public_repos/blog/leaderboard-upstage.md | ---
title: "Introducing the Open Ko-LLM Leaderboard: Leading the Korean LLM Evaluation Ecosystem"
thumbnail: /blog/assets/leaderboards-on-the-hub/thumbnail_upstage.png
authors:
- user: Chanjun
guest: true
- user: hunkim
guest: true
- user: clefourrier
---
# Introducing the Open Ko-LLM Leaderboard: Leading the Korean LLM Evaluation Ecosystem
In the fast-evolving landscape of Large Language Models (LLMs), building an “ecosystem” has never been more important. This trend is evident in several major developments like Hugging Face's democratizing NLP and Upstage building a Generative AI ecosystem.
Inspired by these industry milestones, in September of 2023, at [Upstage](https://upstage.ai/) we initiated the [Open Ko-LLM Leaderboard](https://huggingface.co/spaces/upstage/open-ko-llm-leaderboard). Our goal was to quickly develop and introduce an evaluation ecosystem for Korean LLM data, aligning with the global movement towards open and collaborative AI development.
Our vision for the Open Ko-LLM Leaderboard is to cultivate a vibrant Korean LLM evaluation ecosystem, fostering transparency by enabling researchers to share their results and uncover hidden talents in the LLM field. In essence, we're striving to expand the playing field for Korean LLMs.
To that end, we've developed an open platform where individuals can register their Korean LLM and engage in competitions with other models.
Additionally, we aimed to create a leaderboard that captures the unique characteristics and culture of the Korean language. To achieve this goal, we made sure that our translated benchmark datasets such as Ko-MMLU reflect the distinctive attributes of Korean.
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/3.45.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="upstage/open-ko-llm-leaderboard"></gradio-app>
## Leaderboard design choices: creating a new private test set for fairness
The Open Ko-LLM Leaderboard is characterized by its unique approach to benchmarking, particularly:
- its adoption of Korean language datasets, as opposed to the prevalent use of English-based benchmarks.
- the non-disclosure of test sets, contrasting with the open test sets of most leaderboards: we decided to construct entirely new datasets dedicated to Open Ko-LLM and maintain them as private, to prevent test set contamination and ensure a more equitable comparison framework.
While acknowledging the potential for broader impact and utility to the research community through open benchmarks, the decision to maintain a closed test set environment was made with the intention of fostering a more controlled and fair comparative analysis.
## Evaluation Tasks
The Open Ko-LLM Leaderboard adopts the following five types of evaluation methods:
- **Ko-ARC** (AI2 Reasoning Challenge): Ko-ARC is a multiple-choice test designed to assess scientific thinking and understanding. It measures the reasoning ability required to solve scientific problems, evaluating complex reasoning, problem-solving skills, and the understanding of scientific knowledge. The evaluation metric focuses on accuracy rates, reflecting how often the model selects the correct answer from a set of options, thereby gauging its ability to navigate and apply scientific principles effectively.
- **Ko-HellaSwag**: Ko-HellaSwag evaluates situational comprehension and prediction ability, either in a generative format or as a multiple-choice setup. It tests the capacity to predict the most likely next scenario given a situation, serving as an indicator of the model's understanding and reasoning abilities about situations. Metrics include accuracy assessing the quality of predictions, depending on whether it is approached as a multiple-choice.
- **Ko-MMLU** (Massive Multitask Language Understanding): Ko-MMLU assesses language comprehension across a wide range of topics and fields in a multiple-choice format. This broad test demonstrates how well a model functions across various domains, showcasing its versatility and depth in language understanding. Overall accuracy across tasks and domain-specific performance are key metrics, highlighting strengths and weaknesses in different areas of knowledge.
- **Ko-Truthful QA**: Ko-Truthful QA is actually a multiple-choice benchmark designed to evaluate the model's truthfulness and factual accuracy. Unlike a generative format where the model freely generates responses, in this multiple-choice setting, the model is tasked with selecting the most accurate and truthful answer from a set of options. This approach emphasizes the model's ability to discern truthfulness and accuracy within a constrained choice framework. The primary metric for Ko-Truthful QA focuses on the accuracy of the model's selections, assessing its consistency with known facts and its ability to identify the most truthful response among the provided choices.
- **Ko-CommonGEN V2**: A newly made benchmark for the Open Ko-LLM Leaderboard assesses whether LLMs can generate outputs that align with Korean common sense given certain conditions, testing the model’s capacity to produce contextually and culturally relevant outputs in the Korean language.
## A leaderboard in action: the barometer of Ko-LLM
The Open Ko-LLM Leaderboard has exceeded expectations, with over 1,000 models submitted. In comparison, the Original English Open LLM Leaderboard now hosts over 4,000 models. The Ko-LLM leaderboard has achieved a quarter of that number in just five months after its launch. We're grateful for this widespread participation, which shows the vibrant interest in Korean LLM development.
Of particular note is the diverse competition, encompassing individual researchers, corporations, and academic institutions such as KT, Lotte Information & Communication, Yanolja, MegaStudy Maum AI, 42Maru, the Electronics and Telecommunications Research Institute (ETRI), KAIST, and Korea University.
One standout submission is KT's [Mi:dm 7B model](https://huggingface.co/KT-AI/midm-bitext-S-7B-inst-v1), which not only topped the rankings among models with 7B parameters or fewer but also became accessible for public use, marking a significant milestone.
We also observed that, more generally, two types of models demonstrate strong performance on the leaderboard:
- models which underwent cross-lingual transfer or fine-tuning in Korean (like Upstage’s [SOLAR](https://huggingface.co/upstage/SOLAR-10.7B-v1.0))
- models fine-tuned from LLaMa2, Yi, and Mistral, emphasizing the importance of leveraging solid foundational models for finetuning.
Managing such a big leaderboard did not come without its own challenges. The Open Ko-LLM Leaderboard aims to closely align with the Open LLM Leaderboard’s philosophy, especially in integrating with the Hugging Face model ecosystem. This strategy ensures that the leaderboard is accessible, making it easier for participants to take part, a crucial factor in its operation. Nonetheless, there are limitations due to the infrastructure, which relies on 16 A100 80GB GPUs. This setup faces challenges, particularly when running models larger than 30 billion parameters as they require an excessive amount of compute. This leads to prolonged pending states for many submissions. Addressing these infrastructure challenges is essential for future enhancements of the Open Ko-LLM Leaderboard.
## Our vision and next steps
We recognize several limitations in current leaderboard models when considered in real-world contexts:
- Outdated Data: Datasets like SQUAD and KLEU become outdated over time. Data evolves and transforms continuously, but existing leaderboards remain fixed in a specific timeframe, making them less reflective of the current moment as hundreds of new data points are generated daily.
- Failure to Reflect the Real World: In B2B and B2C services, data is constantly accumulated from users or industries, and edge cases or outliers continuously arise. True competitive advantage lies in responding well to these challenges, yet current leaderboard systems lack the means to measure this capability. Real-world data is perpetually generated, changing, and evolving.
- Questionable Meaningfulness of Competition: Many models are specifically tuned to perform well on the test sets, potentially leading to another form of overfitting within the test set. Thus, the current leaderboard system operates in a leaderboard-centric manner rather than being real-world-centric.
We therefore plan to further develop the leaderboard so that it addresses these issues, and becomes a trusted resource widely recognized by many. By incorporating a variety of benchmarks that have a strong correlation with real-world use cases, we aim to make the leaderboard not only more relevant but also genuinely helpful to businesses. We aspire to bridge the gap between academic research and practical application, and will continuously update and enhance the leaderboard, through feedback from both the research community and industry practitioners to ensure that the benchmarks remain rigorous, comprehensive, and up-to-date. Through these efforts, we hope to contribute to the advancement of the field by providing a platform that accurately measures and drives the progress of large language models in solving practical and impactful problems.
If you develop datasets and would like to collaborate with us on this, we’ll be delighted to talk with you, and you can contact us at [email protected] or [email protected]!
As a side note, we believe that evaluations in a real online environment, as opposed to benchmark-based evaluations, are highly meaningful. Even within benchmark-based evaluations, there is a need for benchmarks to be updated monthly or for the benchmarks to more specifically assess domain-specific aspects - we'd love to encourage such initiatives.
## Many thanks to our partners
The journey of Open Ko-LLM Leaderboard began with a collaboration agreement to develop a Korean-style leaderboard, in partnership with Upstage and the [National Information Society Agency](https://www.nia.or.kr/site/nia_kor/main.do) (NIA), a key national institution in Korea. This partnership marked the starting signal, and within just a month, we were able to launch the leaderboard.
To validate common-sense reasoning, we collaborated with Professor [Heuiseok Lim](https://scholar.google.com/citations?user=HMTkz7oAAAAJ&hl=en)'s [research team](https://blpkorea.cafe24.com/wp/level-1/level-2a/) at Korea University to incorporate KoCommonGen V2 as an additional task for the leaderboard.
Building a robust infrastructure was crucial for success. To that end, we are grateful to [Korea Telecom](https://cloud.kt.com/) (KT) for their generous support of GPU resources and to Hugging Face for their continued support. It's encouraging that Open Ko-LLM Leaderboard has established a direct line of communication with Hugging Face, a global leader in natural language processing, and we're in continuous discussion to push new initiatives forward.
Moreover, the Open Ko-LLM Leaderboard boasts a prestigious consortium of credible partners: the National Information Society Agency (NIA), Upstage, KT, and Korea University. The participation of these institutions, especially the inclusion of a national agency, lends significant authority and trustworthiness to the endeavor, underscoring its potential as a cornerstone in the academic and practical exploration of language models.
| 7 |
0 | hf_public_repos | hf_public_repos/blog/dpo-trl.md | ---
title: "Fine-tune Llama 2 with DPO"
thumbnail: /blog/assets/157_dpo_trl/dpo_thumbnail.png
authors:
- user: kashif
- user: ybelkada
- user: lvwerra
---
# Fine-tune Llama 2 with DPO
## Introduction
Reinforcement Learning from Human Feedback (RLHF) has become the de facto last training step of LLMs such as GPT-4 or Claude to ensure that the language model's outputs are aligned with human expectations such as chattiness or safety features. However, it brings some of the complexity of RL into NLP: we need to build a good reward function, train the model to estimate the value of a state, and at the same time be careful not to strive too far from the original model and produce gibberish instead of sensible text. Such a process is quite involved requiring a number of complex moving parts where it is not always easy to get things right.
The recent paper [Direct Preference Optimization](https://arxiv.org/abs/2305.18290) by Rafailov, Sharma, Mitchell et al. proposes to cast the RL-based objective used by existing methods to an objective which can be directly optimized via a simple binary cross-entropy loss which simplifies this process of refining LLMs greatly.
This blog-post introduces the Direct Preference Optimization (DPO) method which is now available in the [TRL library](https://github.com/lvwerra/trl) and shows how one can fine tune the recent Llama v2 7B-parameter model on the [stack-exchange preference](https://huggingface.co/datasets/lvwerra/stack-exchange-paired) dataset which contains ranked answers to questions on the various stack-exchange portals.
## DPO vs PPO
In the traditional model of optimising human derived preferences via RL, the goto method has been to use an auxiliary reward model and fine-tune the model of interest so that it maximizes this given reward via the machinery of RL. Intuitively we use the reward model to provide feedback to the model we are optimising so that it generates high-reward samples more often and low-reward samples less often. At the same time we use a frozen reference model to make sure that whatever is generated does not deviate too much and continues to maintain generation diversity. This is typically done by adding a KL penalty to the full reward maximisation objective via a reference model, which serves to prevent the model from learning to cheat or exploit the reward model.
The DPO formulation bypasses the reward modeling step and directly optimises the language model on preference data via a key insight: namely an analytical mapping from the reward function to the optimal RL policy that enables the authors to transform the RL loss over the reward and reference models to a loss over the reference model directly! This mapping intuitively measures how well a given reward function aligns with the given preference data. DPO thus starts with the optimal solution to the RLHF loss and via a change of variables derives a loss over *only* the reference model!
Thus this direct likelihood objective can be optimized without the need for a reward model or the need to perform the potentially fiddly RL based optimisation.
## How to train with TRL
As mentioned, typically the RLHF pipeline consists of these distinct parts:
1. a supervised fine-tuning (SFT) step
2. the process of annotating data with preference labels
3. training a reward model on the preference data
4. and the RL optmization step
The TRL library comes with helpers for all these parts, however the DPO training does away with the task of reward modeling and RL (steps 3 and 4) and directly optimizes the DPO object on preference annotated data.
In this respect we would still need to do the step 1, but instead of steps 3 and 4 we need to provide the `DPOTrainer` in TRL with preference data from step 2 which has a very specific format, namely a dictionary with the following three keys:
- `prompt` this consists of the context prompt which is given to a model at inference time for text generation
- `chosen` contains the preferred generated response to the corresponding prompt
- `rejected` contains the response which is not preferred or should not be the sampled response with respect to the given prompt
As an example, for the stack-exchange preference pairs dataset, we can map the dataset entries to return the desired dictionary via the following helper and drop all the original columns:
```python
def return_prompt_and_responses(samples) -> Dict[str, str, str]:
return {
"prompt": [
"Question: " + question + "\n\nAnswer: "
for question in samples["question"]
],
"chosen": samples["response_j"], # rated better than k
"rejected": samples["response_k"], # rated worse than j
}
dataset = load_dataset(
"lvwerra/stack-exchange-paired",
split="train",
data_dir="data/rl"
)
original_columns = dataset.column_names
dataset.map(
return_prompt_and_responses,
batched=True,
remove_columns=original_columns
)
```
Once we have the dataset sorted the DPO loss is essentially a supervised loss which obtains an implicit reward via a reference model and thus at a high-level the `DPOTrainer` requires the base model we wish to optimize as well as a reference model:
```python
dpo_trainer = DPOTrainer(
model, # base model from SFT pipeline
model_ref, # typically a copy of the SFT trained base model
beta=0.1, # temperature hyperparameter of DPO
train_dataset=dataset, # dataset prepared above
tokenizer=tokenizer, # tokenizer
args=training_args, # training arguments e.g. batch size, lr, etc.
)
```
where the `beta` hyper-parameter is the temperature parameter for the DPO loss, typically in the range `0.1` to `0.5`. This controls how much we pay attention to the reference model in the sense that as `beta` gets smaller the more we ignore the reference model. Once we have our trainer initialised we can then train it on the dataset with the given `training_args` by simply calling:
```python
dpo_trainer.train()
```
## Experiment with Llama v2
The benefit of implementing the DPO trainer in TRL is that one can take advantage of all the extra bells and whistles of training large LLMs which come with TRL and its dependent libraries like Peft and Accelerate. With these libraries we are even able to train a Llama v2 model using the [QLoRA technique](https://huggingface.co/blog/4bit-transformers-bitsandbytes) provided by the [bitsandbytes](https://github.com/TimDettmers/bitsandbytes) library.
### Supervised Fine Tuning
The process as introduced above involves the supervised fine-tuning step using [QLoRA](https://arxiv.org/abs/2305.14314) on the 7B Llama v2 model on the SFT split of the data via TRL’s `SFTTrainer`:
```python
# load the base model in 4-bit quantization
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16,
)
base_model = AutoModelForCausalLM.from_pretrained(
script_args.model_name, # "meta-llama/Llama-2-7b-hf"
quantization_config=bnb_config,
device_map={"": 0},
trust_remote_code=True,
use_auth_token=True,
)
base_model.config.use_cache = False
# add LoRA layers on top of the quantized base model
peft_config = LoraConfig(
r=script_args.lora_r,
lora_alpha=script_args.lora_alpha,
lora_dropout=script_args.lora_dropout,
target_modules=["q_proj", "v_proj"],
bias="none",
task_type="CAUSAL_LM",
)
...
trainer = SFTTrainer(
model=base_model,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
peft_config=peft_config,
packing=True,
max_seq_length=None,
tokenizer=tokenizer,
args=training_args, # HF Trainer arguments
)
trainer.train()
```
### DPO Training
Once the SFT has finished, we can save the resulting model and move onto the DPO training. As is typically done we will utilize the saved model from the previous SFT step for both the base model as well as reference model of DPO. Then we can use these to train the model with the DPO objective on the stack-exchange preference data shown above. Since the models were trained via LoRa adapters, we load the models via Peft’s `AutoPeftModelForCausalLM` helpers:
```python
model = AutoPeftModelForCausalLM.from_pretrained(
script_args.model_name_or_path, # location of saved SFT model
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
is_trainable=True,
)
model_ref = AutoPeftModelForCausalLM.from_pretrained(
script_args.model_name_or_path, # same model as the main one
low_cpu_mem_usage=True,
torch_dtype=torch.float16,
load_in_4bit=True,
)
...
dpo_trainer = DPOTrainer(
model,
model_ref,
args=training_args,
beta=script_args.beta,
train_dataset=train_dataset,
eval_dataset=eval_dataset,
tokenizer=tokenizer,
peft_config=peft_config,
)
dpo_trainer.train()
dpo_trainer.save_model()
```
So as can be seen we load the model in the 4-bit configuration and then train it via the QLora method via the `peft_config` arguments. The trainer will also evaluate the progress during training with respect to the evaluation dataset and report back a number of key metrics like the implicit reward which can be recorded and displayed via WandB for example. We can then push the final trained model to the HuggingFace Hub.
## Conclusion
The full source code of the training scripts for the SFT and DPO are available in the following [examples/stack_llama_2](https://github.com/lvwerra/trl/tree/main/examples/research_projects/stack_llama_2) directory and the trained model with the merged adapters can be found on the HF Hub [here](https://huggingface.co/kashif/stack-llama-2).
The WandB logs for the DPO training run can be found [here](https://wandb.ai/krasul/huggingface/runs/c54lmder) where during training and evaluation the `DPOTrainer` records the following reward metrics:
* `rewards/chosen`: the mean difference between the log probabilities of the policy model and the reference model for the chosen responses scaled by `beta`
* `rewards/rejected`: the mean difference between the log probabilities of the policy model and the reference model for the rejected responses scaled by `beta`
* `rewards/accuracies`: mean of how often the chosen rewards are > than the corresponding rejected rewards
* `rewards/margins`: the mean difference between the chosen and corresponding rejected rewards.
Intuitively, during training we want the margins to increase and the accuracies to go to 1.0, or in other words the chosen reward to be higher than the rejected reward (or the margin bigger than zero). These metrics can then be calculated over some evaluation dataset.
We hope with the code release it lowers the barrier to entry for you the readers to try out this method of aligning large language models on your own datasets and we cannot wait to see what you build! And if you want to try out the model yourself you can do so here: [trl-lib/stack-llama](https://huggingface.co/spaces/trl-lib/stack-llama).
| 8 |
0 | hf_public_repos | hf_public_repos/blog/pretraining-bert.md | ---
title: 'Pre-Train BERT with Hugging Face Transformers and Habana Gaudi'
thumbnail: /blog/assets/99_pretraining_bert/thumbnail.png
authors:
- user: philschmid
---
# Pre-Training BERT with Hugging Face Transformers and Habana Gaudi
In this Tutorial, you will learn how to pre-train [BERT-base](https://huggingface.co/bert-base-uncased) from scratch using a Habana Gaudi-based [DL1 instance](https://aws.amazon.com/ec2/instance-types/dl1/) on AWS to take advantage of the cost-performance benefits of Gaudi. We will use the Hugging Face [Transformers](https://huggingface.co/docs/transformers), [Optimum Habana](https://huggingface.co/docs/optimum/habana/index) and [Datasets](https://huggingface.co/docs/datasets) libraries to pre-train a BERT-base model using masked-language modeling, one of the two original BERT pre-training tasks. Before we get started, we need to set up the deep learning environment.
<a target="_blank" class="btn no-underline text-sm mb-5 font-sans" href="https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/pre-training-bert.ipynb">
View Code
</a>
You will learn how to:
1. [Prepare the dataset](#1-prepare-the-dataset)
2. [Train a Tokenizer](#2-train-a-tokenizer)
3. [Preprocess the dataset](#3-preprocess-the-dataset)
4. [Pre-train BERT on Habana Gaudi](#4-pre-train-bert-on-habana-gaudi)
_Note: Steps 1 to 3 can/should be run on a different instance size since those are CPU intensive tasks._
<figure class="image table text-center m-0 w-full">
<img src="assets/99_pretraining_bert/pre-training.png" alt="Cloud Architecture"/>
</figure>
**Requirements**
Before we start, make sure you have met the following requirements
* AWS Account with quota for [DL1 instance type](https://aws.amazon.com/ec2/instance-types/dl1/)
* [AWS CLI](https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html) installed
* AWS IAM user [configured in CLI](https://docs.aws.amazon.com/cli/latest/userguide/cli-chap-configure.html) with permission to create and manage ec2 instances
**Helpful Resources**
* [Setup Deep Learning environment for Hugging Face Transformers with Habana Gaudi on AWS](https://www.philschmid.de/getting-started-habana-gaudi)
* [Deep Learning setup made easy with EC2 Remote Runner and Habana Gaudi](https://www.philschmid.de/habana-gaudi-ec2-runner)
* [Optimum Habana Documentation](https://huggingface.co/docs/optimum/habana/index)
* [Pre-training script](./scripts/run_mlm.py)
* [Code: pre-training-bert.ipynb](https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/pre-training-bert.ipynb)
## What is BERT?
BERT, short for Bidirectional Encoder Representations from Transformers, is a Machine Learning (ML) model for natural language processing. It was developed in 2018 by researchers at Google AI Language and serves as a swiss army knife solution to 11+ of the most common language tasks, such as sentiment analysis and named entity recognition.
Read more about BERT in our [BERT 101 🤗 State Of The Art NLP Model Explained](https://huggingface.co/blog/bert-101) blog.
## What is a Masked Language Modeling (MLM)?
MLM enables/enforces bidirectional learning from text by masking (hiding) a word in a sentence and forcing BERT to bidirectionally use the words on either side of the covered word to predict the masked word.
**Masked Language Modeling Example:**
```bash
“Dang! I’m out fishing and a huge trout just [MASK] my line!”
```
Read more about Masked Language Modeling [here](https://huggingface.co/blog/bert-101).
---
Let's get started. 🚀
_Note: Steps 1 to 3 were run on a AWS c6i.12xlarge instance._
## 1. Prepare the dataset
The Tutorial is "split" into two parts. The first part (step 1-3) is about preparing the dataset and tokenizer. The second part (step 4) is about pre-training BERT on the prepared dataset. Before we can start with the dataset preparation we need to setup our development environment. As mentioned in the introduction you don't need to prepare the dataset on the DL1 instance and could use your notebook or desktop computer.
At first we are going to install `transformers`, `datasets` and `git-lfs` to push our tokenizer and dataset to the [Hugging Face Hub](https://huggingface.co) for later use.
```python
!pip install transformers datasets
!sudo apt-get install git-lfs
```
To finish our setup let's log into the [Hugging Face Hub](https://huggingface.co/models) to push our dataset, tokenizer, model artifacts, logs and metrics during training and afterwards to the Hub.
_To be able to push our model to the Hub, you need to register on the [Hugging Face Hub](https://huggingface.co/join)._
We will use the `notebook_login` util from the `huggingface_hub` package to log into our account. You can get your token in the settings at [Access Tokens](https://huggingface.co/settings/tokens).
```python
from huggingface_hub import notebook_login
notebook_login()
```
Since we are now logged in let's get the `user_id`, which will be used to push the artifacts.
```python
from huggingface_hub import HfApi
user_id = HfApi().whoami()["name"]
print(f"user id '{user_id}' will be used during the example")
```
The [original BERT](https://arxiv.org/abs/1810.04805) was pretrained on [Wikipedia](https://huggingface.co/datasets/wikipedia) and [BookCorpus](https://huggingface.co/datasets/bookcorpus) datasets. Both datasets are available on the [Hugging Face Hub](https://huggingface.co/datasets) and can be loaded with `datasets`.
_Note: For wikipedia we will use the `20220301`, which is different from the original split._
As a first step we are loading the datasets and merging them together to create on big dataset.
```python
from datasets import concatenate_datasets, load_dataset
bookcorpus = load_dataset("bookcorpus", split="train")
wiki = load_dataset("wikipedia", "20220301.en", split="train")
wiki = wiki.remove_columns([col for col in wiki.column_names if col != "text"]) # only keep the 'text' column
assert bookcorpus.features.type == wiki.features.type
raw_datasets = concatenate_datasets([bookcorpus, wiki])
```
_We are not going to do some advanced dataset preparation, like de-duplication, filtering or any other pre-processing. If you are planning to apply this notebook to train your own BERT model from scratch I highly recommend including those data preparation steps into your workflow. This will help you improve your Language Model._
## 2. Train a Tokenizer
To be able to train our model we need to convert our text into a tokenized format. Most Transformer models are coming with a pre-trained tokenizer, but since we are pre-training our model from scratch we also need to train a Tokenizer on our data. We can train a tokenizer on our data with `transformers` and the `BertTokenizerFast` class.
More information about training a new tokenizer can be found in our [Hugging Face Course](https://huggingface.co/course/chapter6/2?fw=pt).
```python
from tqdm import tqdm
from transformers import BertTokenizerFast
# repositor id for saving the tokenizer
tokenizer_id="bert-base-uncased-2022-habana"
# create a python generator to dynamically load the data
def batch_iterator(batch_size=10000):
for i in tqdm(range(0, len(raw_datasets), batch_size)):
yield raw_datasets[i : i + batch_size]["text"]
# create a tokenizer from existing one to re-use special tokens
tokenizer = BertTokenizerFast.from_pretrained("bert-base-uncased")
```
We can start training the tokenizer with `train_new_from_iterator()`.
```python
bert_tokenizer = tokenizer.train_new_from_iterator(text_iterator=batch_iterator(), vocab_size=32_000)
bert_tokenizer.save_pretrained("tokenizer")
```
We push the tokenizer to the [Hugging Face Hub](https://huggingface.co/models) for later training our model.
```python
# you need to be logged in to push the tokenizer
bert_tokenizer.push_to_hub(tokenizer_id)
```
## 3. Preprocess the dataset
Before we can get started with training our model, the last step is to pre-process/tokenize our dataset. We will use our trained tokenizer to tokenize our dataset and then push it to the hub to load it easily later in our training. The tokenization process is also kept pretty simple, if documents are longer than `512` tokens those are truncated and not split into several documents.
```python
from transformers import AutoTokenizer
import multiprocessing
# load tokenizer
# tokenizer = AutoTokenizer.from_pretrained(f"{user_id}/{tokenizer_id}")
tokenizer = AutoTokenizer.from_pretrained("tokenizer")
num_proc = multiprocessing.cpu_count()
print(f"The max length for the tokenizer is: {tokenizer.model_max_length}")
def group_texts(examples):
tokenized_inputs = tokenizer(
examples["text"], return_special_tokens_mask=True, truncation=True, max_length=tokenizer.model_max_length
)
return tokenized_inputs
# preprocess dataset
tokenized_datasets = raw_datasets.map(group_texts, batched=True, remove_columns=["text"], num_proc=num_proc)
tokenized_datasets.features
```
As data processing function we will concatenate all texts from our dataset and generate chunks of `tokenizer.model_max_length` (512).
```python
from itertools import chain
# Main data processing function that will concatenate all texts from our dataset and generate chunks of
# max_seq_length.
def group_texts(examples):
# Concatenate all texts.
concatenated_examples = {k: list(chain(*examples[k])) for k in examples.keys()}
total_length = len(concatenated_examples[list(examples.keys())[0]])
# We drop the small remainder, we could add padding if the model supported it instead of this drop, you can
# customize this part to your needs.
if total_length >= tokenizer.model_max_length:
total_length = (total_length // tokenizer.model_max_length) * tokenizer.model_max_length
# Split by chunks of max_len.
result = {
k: [t[i : i + tokenizer.model_max_length] for i in range(0, total_length, tokenizer.model_max_length)]
for k, t in concatenated_examples.items()
}
return result
tokenized_datasets = tokenized_datasets.map(group_texts, batched=True, num_proc=num_proc)
# shuffle dataset
tokenized_datasets = tokenized_datasets.shuffle(seed=34)
print(f"the dataset contains in total {len(tokenized_datasets)*tokenizer.model_max_length} tokens")
# the dataset contains in total 3417216000 tokens
```
The last step before we can start with our training is to push our prepared dataset to the hub.
```python
# push dataset to hugging face
dataset_id=f"{user_id}/processed_bert_dataset"
tokenized_datasets.push_to_hub(f"{user_id}/processed_bert_dataset")
```
## 4. Pre-train BERT on Habana Gaudi
In this example, we are going to use Habana Gaudi on AWS using the DL1 instance to run the pre-training. We will use the [Remote Runner](https://github.com/philschmid/deep-learning-remote-runner) toolkit to easily launch our pre-training on a remote DL1 Instance from our local setup. You can check-out [Deep Learning setup made easy with EC2 Remote Runner and Habana Gaudi](https://www.philschmid.de/habana-gaudi-ec2-runner) if you want to know more about how this works.
```python
!pip install rm-runner
```
When using GPUs you would use the [Trainer](https://huggingface.co/docs/transformers/v4.19.4/en/main_classes/trainer#transformers.Trainer) and [TrainingArguments](https://huggingface.co/docs/transformers/v4.19.4/en/main_classes/trainer#transformers.TrainingArguments). Since we are going to run our training on Habana Gaudi we are leveraging the `optimum-habana` library, we can use the [GaudiTrainer](https://huggingface.co/docs/optimum/habana/package_reference/trainer) and GaudiTrainingArguments instead. The `GaudiTrainer` is a wrapper around the [Trainer](https://huggingface.co/docs/transformers/v4.19.4/en/main_classes/trainer#transformers.Trainer) that allows you to pre-train or fine-tune a transformer model on Habana Gaudi instances.
```diff
-from transformers import Trainer, TrainingArguments
+from optimum.habana import GaudiTrainer, GaudiTrainingArguments
# define the training arguments
-training_args = TrainingArguments(
+training_args = GaudiTrainingArguments(
+ use_habana=True,
+ use_lazy_mode=True,
+ gaudi_config_name=path_to_gaudi_config,
...
)
# Initialize our Trainer
-trainer = Trainer(
+trainer = GaudiTrainer(
model=model,
args=training_args,
train_dataset=train_dataset
... # other arguments
)
```
The `DL1` instance we use has 8 available HPU-cores meaning we can leverage distributed data-parallel training for our model.
To run our training as distributed training we need to create a training script, which can be used with multiprocessing to run on all HPUs.
We have created a [run_mlm.py](https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/scripts/run_mlm.py) script implementing masked-language modeling using the `GaudiTrainer`. To execute our distributed training we use the `DistributedRunner` runner from `optimum-habana` and pass our arguments. Alternatively, you could check-out the [gaudi_spawn.py](https://github.com/huggingface/optimum-habana/blob/main/examples/gaudi_spawn.py) in the [optimum-habana](https://github.com/huggingface/optimum-habana) repository.
Before we can start our training we need to define the `hyperparameters` we want to use for our training. We are leveraging the [Hugging Face Hub](https://huggingface.co/models) integration of the `GaudiTrainer` to automatically push our checkpoints, logs and metrics during training into a repository.
```python
from huggingface_hub import HfFolder
# hyperparameters
hyperparameters = {
"model_config_id": "bert-base-uncased",
"dataset_id": "philschmid/processed_bert_dataset",
"tokenizer_id": "philschmid/bert-base-uncased-2022-habana",
"gaudi_config_id": "philschmid/bert-base-uncased-2022-habana",
"repository_id": "bert-base-uncased-2022",
"hf_hub_token": HfFolder.get_token(), # need to be logged in with `huggingface-cli login`
"max_steps": 100_000,
"per_device_train_batch_size": 32,
"learning_rate": 5e-5,
}
hyperparameters_string = " ".join(f"--{key} {value}" for key, value in hyperparameters.items())
```
We can start our training by creating a `EC2RemoteRunner` and then `launch` it. This will then start our AWS EC2 DL1 instance and run our `run_mlm.py` script on it using the `huggingface/optimum-habana:latest` container.
```python
from rm_runner import EC2RemoteRunner
# create ec2 remote runner
runner = EC2RemoteRunner(
instance_type="dl1.24xlarge",
profile="hf-sm", # adjust to your profile
region="us-east-1",
container="huggingface/optimum-habana:4.21.1-pt1.11.0-synapse1.5.0"
)
# launch my script with gaudi_spawn for distributed training
runner.launch(
command=f"python3 gaudi_spawn.py --use_mpi --world_size=8 run_mlm.py {hyperparameters_string}",
source_dir="scripts",
)
```
<figure class="image table text-center m-0 w-full">
<img src="assets/99_pretraining_bert/tensorboard.png" alt="Tensorboard Logs"/>
</figure>
_This [experiment](https://huggingface.co/philschmid/bert-base-uncased-2022-habana-test-6) ran for 60k steps._
In our `hyperparameters` we defined a `max_steps` property, which limited the pre-training to only `100_000` steps. The `100_000` steps with a global batch size of `256` took around 12,5 hours.
BERT was originally pre-trained on [1 Million Steps](https://arxiv.org/pdf/1810.04805.pdf) with a global batch size of `256`:
> We train with batch size of 256 sequences (256 sequences * 512 tokens = 128,000 tokens/batch) for 1,000,000 steps, which is approximately 40 epochs over the 3.3 billion word corpus.
Meaning if we want to do a full pre-training it would take around 125h hours (12,5 hours * 10) and would cost us around ~$1,650 using Habana Gaudi on AWS, which is extremely cheap.
For comparison, the DeepSpeed Team, who holds the record for the [fastest BERT-pretraining](https://www.deepspeed.ai/tutorials/bert-pretraining/), [reported](https://www.deepspeed.ai/tutorials/bert-pretraining/) that pre-training BERT on 1 [DGX-2](https://www.nvidia.com/en-us/data-center/dgx-2/) (powered by 16 NVIDIA V100 GPUs with 32GB of memory each) takes around 33,25 hours.
To compare the cost we can use the [p3dn.24xlarge](https://aws.amazon.com/de/ec2/instance-types/p3/) as reference, which comes with 8x NVIDIA V100 32GB GPUs and costs ~31,22$/h. We would need two of these instances to have the same "setup" as the one DeepSpeed reported, for now we are ignoring any overhead created to the multi-node setup (I/O, Network etc.).
This would bring the cost of the DeepSpeed GPU based training on AWS to around ~$2,075, which is 25% more than what Habana Gaudi currently delivers.
_Something to note here is that using [DeepSpeed](https://www.deepspeed.ai/tutorials/bert-pretraining/#deepspeed-single-gpu-throughput-results) in general improves the performance by a factor of ~1.5 - 2. A factor of ~1.5 - 2x, means that the same pre-training job without DeepSpeed would likely take twice as long and cost twice as much or ~$3-4k._
We are looking forward on to do the experiment again once the [Gaudi DeepSpeed integration](https://docs.habana.ai/en/latest/PyTorch/DeepSpeed/DeepSpeed_User_Guide.html#deepspeed-configs) is more widely available.
## Conclusion
That's it for this Tutorial. Now you know the basics on how to pre-train BERT from scratch using Hugging Face Transformers and Habana Gaudi. You also saw how easy it is to migrate from the `Trainer` to the `GaudiTrainer`.
We compared our implementation with the [fastest BERT-pretraining](https://www.deepspeed.ai/Tutorials/bert-pretraining/) results and saw that Habana Gaudi still delivers a 25% cost reduction and allows us to pre-train BERT for ~$1,650.
Those results are incredible since it will allow companies to adapt their pre-trained models to their language and domain to [improve accuracy up to 10%](https://huggingface.co/pile-of-law/legalbert-large-1.7M-1#evaluation-results) compared to the general BERT models.
If you are interested in training your own BERT or other Transformers models from scratch to reduce cost and improve accuracy, [contact our experts](mailto:[email protected]) to learn about our [Expert Acceleration Program](https://huggingface.co/support). To learn more about Habana solutions, [read about our partnership and how to contact them](https://huggingface.co/hardware/habana).
Code: [pre-training-bert.ipynb](https://github.com/philschmid/deep-learning-habana-huggingface/blob/master/pre-training/pre-training-bert.ipynb)
---
Thanks for reading! If you have any questions, feel free to contact me, through [Github](https://github.com/huggingface/transformers), or on the [forum](https://discuss.huggingface.co/c/optimum/59). You can also connect with me on [Twitter](https://twitter.com/_philschmid) or [LinkedIn](https://www.linkedin.com/in/philipp-schmid-a6a2bb196/).
| 9 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim64_fp16_causal_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 64, true>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim64<cutlass::half_t, true>(params, stream);
}
| 0 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim160_bf16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::bfloat16_t, 160, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim160<cutlass::bfloat16_t, false>(params, stream);
}
| 1 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_kernel.h | /******************************************************************************
* Copyright (c) 2024, Tri Dao.
******************************************************************************/
#pragma once
#include <cute/tensor.hpp>
#include <cutlass/cutlass.h>
#include <cutlass/array.h>
#include <cutlass/numeric_types.h>
#include "block_info.h"
#include "kernel_traits.h"
#include "utils.h"
#include "softmax.h"
#include "mask.h"
#include "dropout.h"
#include "rotary.h"
namespace flash {
using namespace cute;
template <typename Engine, typename Layout>
__forceinline__ __device__ void apply_softcap(Tensor<Engine, Layout> &tensor, const float softcap){
#pragma unroll
for (int i = 0; i < size(tensor); ++i) {
tensor(i) = cutlass::fast_tanh(tensor(i) * softcap);
}
}
////////////////////////////////////////////////////////////////////////////////////////////////////
template<typename ElementAccum, typename Params, int kBlockM, bool Is_even_MN>
__forceinline__ __device__ auto get_lse_tile(const Params ¶ms, const int bidb, const int bidh, const int m_block, const BlockInfo</*Varlen=*/!Is_even_MN> &binfo) {
// When params.unpadded_lse is false, LSE is written as (b, h, seqlen_q) - this is non-variable seqlen path.
// Otherwise, when params.seqlenq_ngroups_swapped is true, it is written as (h, seqlen_q, b) to account for seqlen_q <-> h swapping trick.
// Otherwise, it's written as (h, b, seqlen_q).
const bool varlen_q = params.unpadded_lse && !params.seqlenq_ngroups_swapped;
auto lse_offset = varlen_q ? binfo.q_offset(params.seqlen_q, 1, bidb) : 0;
auto gmem_ptr_lse = make_gmem_ptr(reinterpret_cast<ElementAccum*>(params.softmax_lse_ptr) + lse_offset);
auto lse_shape = varlen_q ? make_shape(1, params.h, params.total_q) : make_shape(params.b, params.h, params.seqlen_q);
auto lse_stride = params.seqlenq_ngroups_swapped ? make_stride(1, params.seqlen_q * params.b, params.b) : (
params.unpadded_lse ? make_stride(params.h * params.total_q, params.total_q, 1) : make_stride(params.h * params.seqlen_q, params.seqlen_q, 1)
);
auto lse_layout = make_layout(lse_shape, lse_stride);
Tensor mLSE = make_tensor(gmem_ptr_lse, lse_layout);
auto mLSE_slice = varlen_q ? mLSE(0, bidh, _) : mLSE(bidb, bidh, _);
return local_tile(mLSE_slice, Shape<Int<kBlockM>>{}, make_coord(m_block));
}
template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Is_local, bool Has_alibi, bool Is_even_MN, bool Is_even_K, bool Is_softcap, bool Return_softmax, typename Params>
inline __device__ void compute_attn_1rowblock(const Params ¶ms, const int bidb, const int bidh, const int m_block) {
using Element = typename Kernel_traits::Element;
using ElementAccum = typename Kernel_traits::ElementAccum;
using index_t = typename Kernel_traits::index_t;
// Shared memory.
extern __shared__ char smem_[];
// The thread index.
const int tidx = threadIdx.x;
constexpr int kBlockM = Kernel_traits::kBlockM;
constexpr int kBlockN = Kernel_traits::kBlockN;
constexpr int kHeadDim = Kernel_traits::kHeadDim;
constexpr int kNWarps = Kernel_traits::kNWarps;
auto seed_offset = std::make_tuple(0ull, 0ull);
// auto seed_offset = at::cuda::philox::unpack(params.philox_args);
flash::Dropout dropout(std::get<0>(seed_offset), std::get<1>(seed_offset), params.p_dropout_in_uint8_t,
bidb, bidh, tidx, params.h);
// Save seed and offset for backward, before any early exiting. Otherwise the 0-th thread block might
// exit early and no one saves the rng states.
if (Is_dropout && blockIdx.x == 0 && blockIdx.y == 0 && blockIdx.z == 0 && tidx == 0) {
params.rng_state[0] = std::get<0>(seed_offset);
params.rng_state[1] = std::get<1>(seed_offset);
}
const BlockInfo</*Varlen=*/!Is_even_MN> binfo(params, bidb);
if (m_block * kBlockM >= binfo.actual_seqlen_q) return;
const int n_block_min = !Is_local ? 0 : std::max(0, (m_block * kBlockM + binfo.actual_seqlen_k - binfo.actual_seqlen_q - params.window_size_left) / kBlockN);
int n_block_max = cute::ceil_div(binfo.actual_seqlen_k, kBlockN);
if (Is_causal || Is_local) {
n_block_max = std::min(n_block_max,
cute::ceil_div((m_block + 1) * kBlockM + binfo.actual_seqlen_k - binfo.actual_seqlen_q + params.window_size_right, kBlockN));
// if (threadIdx.x == 0 && blockIdx.y == 0 && blockIdx.z == 0) {
// printf("m_block = %d, n_block_max = %d\n", m_block, n_block_max);
// }
}
// We exit early and write 0 to gO and gLSE. This also covers the case where actual_seqlen_k == 0.
// Otherwise we might read OOB elements from gK and gV.
if ((Is_causal || Is_local || !Is_even_MN) && n_block_max <= n_block_min) {
Tensor mO = make_tensor(make_gmem_ptr(reinterpret_cast<Element*>(params.o_ptr)
+ binfo.q_offset(params.o_batch_stride, params.o_row_stride, bidb)),
make_shape(binfo.actual_seqlen_q, params.h, params.d),
make_stride(params.o_row_stride, params.o_head_stride, _1{}));
Tensor gO = local_tile(mO(_, bidh, _), Shape<Int<kBlockM>, Int<kHeadDim>>{},
make_coord(m_block, 0)); // (kBlockM, kHeadDim)
Tensor gLSE = get_lse_tile<ElementAccum, Params, kBlockM, Is_even_MN>(params, bidb, bidh, m_block, binfo);
typename Kernel_traits::GmemTiledCopyO gmem_tiled_copy_O;
auto gmem_thr_copy_O = gmem_tiled_copy_O.get_thread_slice(tidx);
Tensor tOgO = gmem_thr_copy_O.partition_D(gO);
Tensor tOrO = make_tensor<Element>(shape(tOgO));
clear(tOrO);
// Construct identity layout for sO
Tensor cO = make_identity_tensor(make_shape(size<0>(gO), size<1>(gO))); // (BLK_M,BLK_K) -> (blk_m,blk_k)
// Repeat the partitioning with identity layouts
Tensor tOcO = gmem_thr_copy_O.partition_D(cO);
Tensor tOpO = make_tensor<bool>(make_shape(size<2>(tOgO)));
if (!Is_even_K) {
#pragma unroll
for (int k = 0; k < size(tOpO); ++k) { tOpO(k) = get<1>(tOcO(0, 0, k)) < params.d; }
}
// Clear_OOB_K must be false since we don't want to write zeros to gmem
flash::copy<Is_even_MN, Is_even_K, /*Clear_OOB_MN=*/false, /*Clear_OOB_K=*/false>(
gmem_tiled_copy_O, tOrO, tOgO, tOcO, tOpO, binfo.actual_seqlen_q - m_block * kBlockM
);
#pragma unroll
for (int m = 0; m < size<1>(tOgO); ++m) {
const int row = get<0>(tOcO(0, m, 0));
if (row < binfo.actual_seqlen_q - m_block * kBlockM && get<1>(tOcO(0, m, 0)) == 0) { gLSE(row) = INFINITY; }
}
return;
}
// if (tidx == 0) { printf("m_block = %d, n_block_min = %d, n_block_max = %d\n", m_block, n_block_min, n_block_max); }
// We iterate over the blocks in reverse order. This is because the last block is the only one
// that needs masking when we read K and V from global memory. Moreover, iterating in reverse
// might save us 1 register (we just need n_block instead of both n_block and n_block_max).
const index_t row_offset_p = ((bidb * params.h + bidh) * params.seqlen_q_rounded
+ m_block * kBlockM) * params.seqlen_k_rounded + (n_block_max - 1) * kBlockN;
Tensor mQ = make_tensor(make_gmem_ptr(reinterpret_cast<Element*>(params.q_ptr)
+ binfo.q_offset(params.q_batch_stride, params.q_row_stride, bidb)),
make_shape(binfo.actual_seqlen_q, params.h, params.d),
make_stride(params.q_row_stride, params.q_head_stride, _1{}));
Tensor gQ = local_tile(mQ(_, bidh, _), Shape<Int<kBlockM>, Int<kHeadDim>>{},
make_coord(m_block, 0)); // (kBlockM, kHeadDim)
Tensor mK = make_tensor(make_gmem_ptr(reinterpret_cast<Element*>(params.k_ptr)
+ binfo.k_offset(params.k_batch_stride, params.k_row_stride, bidb)),
make_shape(binfo.actual_seqlen_k, params.h_k, params.d),
make_stride(params.k_row_stride, params.k_head_stride, _1{}));
Tensor gK = local_tile(mK(_, bidh / params.h_h_k_ratio, _), Shape<Int<kBlockN>, Int<kHeadDim>>{},
make_coord(_, 0)); // (kBlockN, kHeadDim, nblocksN)
Tensor mV = make_tensor(make_gmem_ptr(reinterpret_cast<Element*>(params.v_ptr)
+ binfo.k_offset(params.v_batch_stride, params.v_row_stride, bidb)),
make_shape(binfo.actual_seqlen_k, params.h_k, params.d),
make_stride(params.v_row_stride, params.v_head_stride, _1{}));
Tensor gV = local_tile(mV(_, bidh / params.h_h_k_ratio, _), Shape<Int<kBlockN>, Int<kHeadDim>>{},
make_coord(_, 0)); // (kBlockN, kHeadDim, nblocksN)
Tensor gP = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.p_ptr) + row_offset_p),
Shape<Int<kBlockM>, Int<kBlockN>>{},
make_stride(params.seqlen_k_rounded, _1{}));
Tensor sQ = make_tensor(make_smem_ptr(reinterpret_cast<Element *>(smem_)),
typename Kernel_traits::SmemLayoutQ{});
// Careful we're using the same smem for sQ and sK | sV if Share_Q_K_smem;
Tensor sK = make_tensor(sQ.data() + (Kernel_traits::Share_Q_K_smem ? 0 : size(sQ)),
typename Kernel_traits::SmemLayoutKV{});
Tensor sV = make_tensor(sK.data() + size(sK), typename Kernel_traits::SmemLayoutKV{});
Tensor sVt = make_tensor(sV.data(), typename Kernel_traits::SmemLayoutVtransposed{});
Tensor sVtNoSwizzle = make_tensor(sV.data().get(), typename Kernel_traits::SmemLayoutVtransposedNoSwizzle{});
typename Kernel_traits::GmemTiledCopyQKV gmem_tiled_copy_QKV;
auto gmem_thr_copy_QKV = gmem_tiled_copy_QKV.get_thread_slice(tidx);
Tensor tQgQ = gmem_thr_copy_QKV.partition_S(gQ);
Tensor tQsQ = gmem_thr_copy_QKV.partition_D(sQ);
Tensor tKgK = gmem_thr_copy_QKV.partition_S(gK); // (KCPY, KCPY_N, KCPY_K, nblocksN)
Tensor tKsK = gmem_thr_copy_QKV.partition_D(sK);
Tensor tVgV = gmem_thr_copy_QKV.partition_S(gV); // (VCPY, VCPY_N, VCPY_K, nblocksN)
Tensor tVsV = gmem_thr_copy_QKV.partition_D(sV);
typename Kernel_traits::TiledMma tiled_mma;
auto thr_mma = tiled_mma.get_thread_slice(tidx);
Tensor tSrQ = thr_mma.partition_fragment_A(sQ); // (MMA,MMA_M,MMA_K)
Tensor tSrK = thr_mma.partition_fragment_B(sK); // (MMA,MMA_N,MMA_K)
Tensor tOrVt = thr_mma.partition_fragment_B(sVtNoSwizzle); // (MMA, MMA_K,MMA_N)
Tensor tSgS = thr_mma.partition_C(gP);
Tensor acc_o = partition_fragment_C(tiled_mma, Shape<Int<kBlockM>, Int<kHeadDim>>{}); // MMA, MMA_M, MMA_K
//
// Copy Atom retiling
//
auto smem_tiled_copy_Q = make_tiled_copy_A(typename Kernel_traits::SmemCopyAtom{}, tiled_mma);
auto smem_thr_copy_Q = smem_tiled_copy_Q.get_thread_slice(tidx);
// if (cute::thread0()) {smem_thr_copy_Q.print_all();}
Tensor tSsQ = smem_thr_copy_Q.partition_S(sQ);
// if (cute::thread0()) {print(tSsQ.layout()); printf("\n");}
auto smem_tiled_copy_K = make_tiled_copy_B(typename Kernel_traits::SmemCopyAtom{}, tiled_mma);
auto smem_thr_copy_K = smem_tiled_copy_K.get_thread_slice(tidx);
Tensor tSsK = smem_thr_copy_K.partition_S(sK);
auto smem_tiled_copy_V = make_tiled_copy_B(typename Kernel_traits::SmemCopyAtomTransposed{}, tiled_mma);
auto smem_thr_copy_V = smem_tiled_copy_V.get_thread_slice(tidx);
Tensor tOsVt = smem_thr_copy_V.partition_S(sVt);
//
// PREDICATES
//
// // Allocate predicate tensors for m and n
// Tensor tQpQ = make_tensor<bool>(make_shape(size<1>(tQsQ), size<2>(tQsQ)), Stride<_1,_0>{});
// Tensor tKVpKV = make_tensor<bool>(make_shape(size<1>(tKsK), size<2>(tKsK)), Stride<_1,_0>{});
// Construct identity layout for sQ and sK
Tensor cQ = make_identity_tensor(make_shape(size<0>(sQ), size<1>(sQ))); // (BLK_M,BLK_K) -> (blk_m,blk_k)
Tensor cKV = make_identity_tensor(make_shape(size<0>(sK), size<1>(sK))); // (BLK_N,BLK_K) -> (blk_n,blk_k)
// Tensor tScQ = thr_mma.partition_A(cQ); // (MMA,MMA_M,MMA_K)
// if (cute::thread0()) {
// print(tScQ.layout()); printf("\n");
// for (int i = 0; i < size(tScQ); ++i) {
// printf("%d ", get<0>(tScQ(i)));
// }
// printf("\n");
// for (int i = 0; i < size(tScQ); ++i) {
// printf("%d ", get<1>(tScQ(i)));
// }
// printf("\n");
// }
// Repeat the partitioning with identity layouts
Tensor tQcQ = gmem_thr_copy_QKV.partition_S(cQ); // (ACPY,ACPY_M,ACPY_K) -> (blk_m,blk_k)
Tensor tKVcKV = gmem_thr_copy_QKV.partition_S(cKV); // (BCPY,BCPY_N,BCPY_K) -> (blk_n,blk_k)
// Allocate predicate tensors for k
Tensor tQpQ = make_tensor<bool>(make_shape(size<2>(tQsQ)));
Tensor tKVpKV = make_tensor<bool>(make_shape(size<2>(tKsK)));
// Set predicates for k bounds
if (!Is_even_K) {
#pragma unroll
for (int k = 0; k < size(tQpQ); ++k) { tQpQ(k) = get<1>(tQcQ(0, 0, k)) < params.d; }
#pragma unroll
for (int k = 0; k < size(tKVpKV); ++k) { tKVpKV(k) = get<1>(tKVcKV(0, 0, k)) < params.d; }
}
// Prologue
// We don't need to clear the sQ smem tiles since we'll only write out the valid outputs
flash::copy<Is_even_MN, Is_even_K>(gmem_tiled_copy_QKV, tQgQ, tQsQ, tQcQ, tQpQ,
binfo.actual_seqlen_q - m_block * kBlockM);
if (Kernel_traits::Is_Q_in_regs) { cute::cp_async_fence(); }
// // if (cute::thread(1, 0)) { print(tQsQ); }
// // Tensor sQNoSwizzle = make_tensor(make_smem_ptr(reinterpret_cast<Element *>(smem_)), typename Kernel_traits::SmemLayoutQNoSwizzle{});
// // if (cute::thread0()) { print(sQNoSwizzle); }
if (Kernel_traits::Share_Q_K_smem) {
flash::cp_async_wait<0>();
__syncthreads();
Tensor tSrQ_copy_view = smem_thr_copy_Q.retile_D(tSrQ);
CUTE_STATIC_ASSERT_V(size<1>(tSsQ) == size<1>(tSrQ_copy_view)); // M
cute::copy(smem_tiled_copy_Q, tSsQ, tSrQ_copy_view);
__syncthreads();
}
int n_block = n_block_max - 1;
// We don't need to clear the sK smem tiles since we'll mask out the scores anyway.
flash::copy<Is_even_MN, Is_even_K>(gmem_tiled_copy_QKV, tKgK(_, _, _, n_block), tKsK, tKVcKV, tKVpKV,
binfo.actual_seqlen_k - n_block * kBlockN);
cute::cp_async_fence();
// if (threadIdx.x == 0 && blockIdx.y == 0 && blockIdx.z < 2) { print(tKgK); }
// __syncthreads();
if (Kernel_traits::Is_Q_in_regs && !Kernel_traits::Share_Q_K_smem) {
flash::cp_async_wait<1>();
__syncthreads();
Tensor tSrQ_copy_view = smem_thr_copy_Q.retile_D(tSrQ);
CUTE_STATIC_ASSERT_V(size<1>(tSsQ) == size<1>(tSrQ_copy_view)); // M
cute::copy(smem_tiled_copy_Q, tSsQ, tSrQ_copy_view);
}
clear(acc_o);
flash::Softmax<2 * size<1>(acc_o)> softmax;
const float alibi_slope = !Has_alibi || params.alibi_slopes_ptr == nullptr ? 0.0f : reinterpret_cast<float *>(params.alibi_slopes_ptr)[bidb * params.alibi_slopes_batch_stride + bidh] / params.scale_softmax;
flash::Mask<Is_causal, Is_local, Has_alibi> mask(binfo.actual_seqlen_k, binfo.actual_seqlen_q, params.window_size_left, params.window_size_right, alibi_slope);
// For performance reason, we separate out two kinds of iterations:
// those that need masking on S, and those that don't.
// We need masking on S for the very last block when K and V has length not multiple of kBlockN.
// We also need masking on S if it's causal, for the last ceil_div(kBlockM, kBlockN) blocks.
// We will have at least 1 "masking" iteration.
// If not even_N, then seqlen_k might end in the middle of a block. In that case we need to
// mask 2 blocks (e.g. when kBlockM == kBlockN), not just 1.
constexpr int n_masking_steps = (!Is_causal && !Is_local)
? 1
: ((Is_even_MN && Is_causal) ? cute::ceil_div(kBlockM, kBlockN) : cute::ceil_div(kBlockM, kBlockN) + 1);
#pragma unroll
for (int masking_step = 0; masking_step < n_masking_steps; ++masking_step, --n_block) {
Tensor acc_s = partition_fragment_C(tiled_mma, Shape<Int<kBlockM>, Int<kBlockN>>{}); // (MMA=4, MMA_M, MMA_N)
clear(acc_s);
flash::cp_async_wait<0>();
__syncthreads();
// Advance gV
if (masking_step > 0) {
flash::copy</*Is_even_MN=*/true, Is_even_K>(gmem_tiled_copy_QKV, tVgV(_, _, _, n_block), tVsV, tKVcKV, tKVpKV);
} else {
// Clear the smem tiles to account for predicated off loads
flash::copy<Is_even_MN, Is_even_K, /*Clear_OOB_MN=*/true>(
gmem_tiled_copy_QKV, tVgV(_, _, _, n_block), tVsV, tKVcKV, tKVpKV, binfo.actual_seqlen_k - n_block * kBlockN
);
}
cute::cp_async_fence();
flash::gemm</*A_in_regs=*/Kernel_traits::Is_Q_in_regs>(
acc_s, tSrQ, tSrK, tSsQ, tSsK, tiled_mma, smem_tiled_copy_Q, smem_tiled_copy_K,
smem_thr_copy_Q, smem_thr_copy_K
);
// if (cute::thread0()) { print(acc_s); }
if constexpr (Is_softcap){
apply_softcap(acc_s, params.softcap);
}
mask.template apply_mask<Is_causal, Is_even_MN>(
acc_s, n_block * kBlockN, m_block * kBlockM + (tidx / 32) * 16 + (tidx % 32) / 4, kNWarps * 16
);
flash::cp_async_wait<0>();
__syncthreads();
if (n_block > n_block_min) {
flash::copy</*Is_even_MN=*/true, Is_even_K>(gmem_tiled_copy_QKV, tKgK(_, _, _, n_block - 1), tKsK, tKVcKV, tKVpKV);
// This cp_async_fence needs to be in the if block, otherwise the synchronization
// isn't right and we get race conditions.
cute::cp_async_fence();
}
// TODO: when we have key_padding_mask we'll need to Check_inf
masking_step == 0
? softmax.template softmax_rescale_o</*Is_first=*/true, /*Check_inf=*/Is_causal || Is_local>(acc_s, acc_o, params.scale_softmax_log2)
: softmax.template softmax_rescale_o</*Is_first=*/false, /*Check_inf=*/Is_causal || Is_local>(acc_s, acc_o, params.scale_softmax_log2);
// Convert acc_s from fp32 to fp16/bf16
Tensor rP = flash::convert_type<Element>(acc_s);
int block_row_idx = m_block * (kBlockM / 16) + tidx / 32;
int block_col_idx = n_block * (kBlockN / 32);
if (Return_softmax) {
Tensor rP_drop = make_fragment_like(rP);
cute::copy(rP, rP_drop);
dropout.template apply_dropout</*encode_dropout_in_sign_bit=*/true>(
rP_drop, block_row_idx, block_col_idx, kNWarps
);
cute::copy(rP_drop, tSgS);
tSgS.data() = tSgS.data() + (-kBlockN);
}
if (Is_dropout) {
dropout.apply_dropout(rP, block_row_idx, block_col_idx, kNWarps);
}
// Reshape rP from (MMA=4, MMA_M, MMA_N) to ((4, 2), MMA_M, MMA_N / 2)
// if using m16n8k16 or (4, MMA_M, MMA_N) if using m16n8k8.
Tensor tOrP = make_tensor(rP.data(), flash::convert_layout_acc_Aregs<Kernel_traits::TiledMma>(rP.layout()));
// if (cute::thread0()) { print(tOrP); }
flash::gemm_rs(acc_o, tOrP, tOrVt, tOsVt, tiled_mma, smem_tiled_copy_V, smem_thr_copy_V);
// if (cute::thread0()) { print(scores); }
// This check is at the end of the loop since we always have at least 1 iteration
if (n_masking_steps > 1 && n_block <= n_block_min) {
--n_block;
break;
}
}
// These are the iterations where we don't need masking on S
for (; n_block >= n_block_min; --n_block) {
Tensor acc_s = partition_fragment_C(tiled_mma, Shape<Int<kBlockM>, Int<kBlockN>>{}); // (MMA=4, MMA_M, MMA_N)
clear(acc_s);
flash::cp_async_wait<0>();
__syncthreads();
flash::copy</*Is_even_MN=*/true, Is_even_K>(gmem_tiled_copy_QKV, tVgV(_, _, _, n_block), tVsV, tKVcKV, tKVpKV);
cute::cp_async_fence();
flash::gemm</*A_in_regs=*/Kernel_traits::Is_Q_in_regs>(
acc_s, tSrQ, tSrK, tSsQ, tSsK, tiled_mma, smem_tiled_copy_Q, smem_tiled_copy_K,
smem_thr_copy_Q, smem_thr_copy_K
);
if constexpr (Is_softcap){
apply_softcap(acc_s, params.softcap);
}
flash::cp_async_wait<0>();
__syncthreads();
if (n_block > n_block_min) {
flash::copy</*Is_even_MN=*/true, Is_even_K>(gmem_tiled_copy_QKV, tKgK(_, _, _, n_block - 1), tKsK, tKVcKV, tKVpKV);
// This cp_async_fence needs to be in the if block, otherwise the synchronization
// isn't right and we get race conditions.
cute::cp_async_fence();
}
mask.template apply_mask</*Causal_mask=*/false>(
acc_s, n_block * kBlockN, m_block * kBlockM + (tidx / 32) * 16 + (tidx % 32) / 4, kNWarps * 16
);
softmax.template softmax_rescale_o</*Is_first=*/false, /*Check_inf=*/Is_local>(acc_s, acc_o, params.scale_softmax_log2);
Tensor rP = flash::convert_type<Element>(acc_s);
int block_row_idx = m_block * (kBlockM / 16) + tidx / 32;
int block_col_idx = n_block * (kBlockN / 32);
if (Return_softmax) {
Tensor rP_drop = make_fragment_like(rP);
cute::copy(rP, rP_drop);
dropout.template apply_dropout</*encode_dropout_in_sign_bit=*/true>(
rP_drop, block_row_idx, block_col_idx, kNWarps
);
cute::copy(rP_drop, tSgS);
tSgS.data() = tSgS.data() + (-kBlockN);
}
if (Is_dropout) {
dropout.apply_dropout(rP, block_row_idx, block_col_idx, kNWarps);
}
// Reshape rP from (MMA=4, MMA_M, MMA_N) to ((4, 2), MMA_M, MMA_N / 2)
// if using m16n8k16 or (4, MMA_M, MMA_N) if using m16n8k8.
Tensor tOrP = make_tensor(rP.data(), flash::convert_layout_acc_Aregs<Kernel_traits::TiledMma>(rP.layout()));
flash::gemm_rs(acc_o, tOrP, tOrVt, tOsVt, tiled_mma, smem_tiled_copy_V, smem_thr_copy_V);
}
// Epilogue
Tensor lse = softmax.template normalize_softmax_lse<Is_dropout>(acc_o, params.scale_softmax, params.rp_dropout);
// Convert acc_o from fp32 to fp16/bf16
Tensor rO = flash::convert_type<Element>(acc_o);
Tensor sO = make_tensor(sQ.data(), typename Kernel_traits::SmemLayoutO{}); // (SMEM_M,SMEM_N)
// Partition sO to match the accumulator partitioning
auto smem_tiled_copy_O = make_tiled_copy_C(typename Kernel_traits::SmemCopyAtomO{}, tiled_mma);
auto smem_thr_copy_O = smem_tiled_copy_O.get_thread_slice(tidx);
Tensor taccOrO = smem_thr_copy_O.retile_S(rO); // ((Atom,AtomNum), MMA_M, MMA_N)
Tensor taccOsO = smem_thr_copy_O.partition_D(sO); // ((Atom,AtomNum),PIPE_M,PIPE_N)
// sO has the same size as sQ, so we don't need to sync here.
if (Kernel_traits::Share_Q_K_smem) { __syncthreads(); }
cute::copy(smem_tiled_copy_O, taccOrO, taccOsO);
Tensor mO = make_tensor(make_gmem_ptr(reinterpret_cast<Element*>(params.o_ptr)
+ binfo.q_offset(params.o_batch_stride, params.o_row_stride, bidb)),
make_shape(binfo.actual_seqlen_q, params.h, params.d),
make_stride(params.o_row_stride, params.o_head_stride, _1{}));
Tensor gO = local_tile(mO(_, bidh, _), Shape<Int<kBlockM>, Int<kHeadDim>>{},
make_coord(m_block, 0)); // (kBlockM, kHeadDim)
Tensor gLSE = get_lse_tile<ElementAccum, Params, kBlockM, Is_even_MN>(params, bidb, bidh, m_block, binfo);
typename Kernel_traits::GmemTiledCopyO gmem_tiled_copy_O;
auto gmem_thr_copy_O = gmem_tiled_copy_O.get_thread_slice(tidx);
Tensor tOsO = gmem_thr_copy_O.partition_S(sO); // ((Atom,AtomNum),ATOM_M,ATOM_N)
Tensor tOgO = gmem_thr_copy_O.partition_D(gO);
__syncthreads();
Tensor tOrO = make_tensor<Element>(shape(tOgO));
cute::copy(gmem_tiled_copy_O, tOsO, tOrO);
Tensor caccO = make_identity_tensor(Shape<Int<kBlockM>, Int<kHeadDim>>{}); // (BLK_M,BLK_K) -> (blk_m,blk_k)
Tensor taccOcO = thr_mma.partition_C(caccO); // (MMA,MMA_M,MMA_K)
static_assert(decltype(size<0>(taccOcO))::value == 4);
// Convert to ((2, 2), MMA_M, MMA_K) then take only the row indices.
Tensor taccOcO_row = logical_divide(taccOcO, Shape<_2>{})(make_coord(0, _), _, 0);
CUTE_STATIC_ASSERT_V(size(lse) == size(taccOcO_row)); // MMA_M
if (get<1>(taccOcO_row(0)) == 0) {
#pragma unroll
for (int mi = 0; mi < size(lse); ++mi) {
const int row = get<0>(taccOcO_row(mi));
if (row < binfo.actual_seqlen_q - m_block * kBlockM) { gLSE(row) = lse(mi); }
}
}
// Construct identity layout for sO
Tensor cO = make_identity_tensor(make_shape(size<0>(sO), size<1>(sO))); // (BLK_M,BLK_K) -> (blk_m,blk_k)
// Repeat the partitioning with identity layouts
Tensor tOcO = gmem_thr_copy_O.partition_D(cO); // (ACPY,ACPY_M,ACPY_K) -> (blk_m,blk_k)
Tensor tOpO = make_tensor<bool>(make_shape(size<2>(tOgO)));
if (!Is_even_K) {
#pragma unroll
for (int k = 0; k < size(tOpO); ++k) { tOpO(k) = get<1>(tOcO(0, 0, k)) < params.d; }
}
// Clear_OOB_K must be false since we don't want to write zeros to gmem
flash::copy<Is_even_MN, Is_even_K, /*Clear_OOB_MN=*/false, /*Clear_OOB_K=*/false>(
gmem_tiled_copy_O, tOrO, tOgO, tOcO, tOpO, binfo.actual_seqlen_q - m_block * kBlockM
);
}
////////////////////////////////////////////////////////////////////////////////////////////////////
template<typename Kernel_traits, bool Is_causal, bool Is_local, bool Has_alibi, bool Is_even_MN, bool Is_even_K, bool Is_softcap, bool Split, bool Append_KV, typename Params>
inline __device__ void compute_attn_1rowblock_splitkv(const Params ¶ms, const int bidb, const int bidh, const int m_block, const int n_split_idx, const int num_n_splits) {
using Element = typename Kernel_traits::Element;
using ElementAccum = typename Kernel_traits::ElementAccum;
using index_t = typename Kernel_traits::index_t;
// Shared memory.
extern __shared__ char smem_[];
// The thread index.
const int tidx = threadIdx.x;
constexpr int kBlockM = Kernel_traits::kBlockM;
constexpr int kBlockN = Kernel_traits::kBlockN;
constexpr int kHeadDim = Kernel_traits::kHeadDim;
constexpr int kNWarps = Kernel_traits::kNWarps;
using GmemTiledCopyO = std::conditional_t<
!Split,
typename Kernel_traits::GmemTiledCopyO,
typename Kernel_traits::GmemTiledCopyOaccum
>;
using ElementO = std::conditional_t<!Split, Element, ElementAccum>;
const BlockInfo</*Varlen=*/!Is_even_MN> binfo(params, bidb);
// if (threadIdx.x == 0 && blockIdx.y == 0 && blockIdx.z == 0) { printf("Is_even_MN = %d, is_cumulativ = %d, seqlen_k_cache = %d, actual_seqlen_k = %d\n", Is_even_MN, params.is_seqlens_k_cumulative, binfo.seqlen_k_cache, binfo.actual_seqlen_k); }
// if (threadIdx.x == 0 && blockIdx.y == 1 && blockIdx.z == 0) { printf("params.knew_ptr = %p, seqlen_k_cache + seqlen_knew = %d\n", params.knew_ptr, binfo.seqlen_k_cache + (params.knew_ptr == nullptr ? 0 : params.seqlen_knew)); }
if (m_block * kBlockM >= binfo.actual_seqlen_q) return;
const int n_blocks_per_split = ((params.seqlen_k + kBlockN - 1) / kBlockN + num_n_splits - 1) / num_n_splits;
const int n_block_min = !Is_local
? n_split_idx * n_blocks_per_split
: std::max(n_split_idx * n_blocks_per_split, (m_block * kBlockM + binfo.actual_seqlen_k - binfo.actual_seqlen_q - params.window_size_left) / kBlockN);
int n_block_max = std::min(cute::ceil_div(binfo.actual_seqlen_k, kBlockN), (n_split_idx + 1) * n_blocks_per_split);
if (Is_causal || Is_local) {
n_block_max = std::min(n_block_max,
cute::ceil_div((m_block + 1) * kBlockM + binfo.actual_seqlen_k - binfo.actual_seqlen_q + params.window_size_right, kBlockN));
}
if (n_block_min >= n_block_max) { // This also covers the case where n_block_max <= 0
// We exit early and write 0 to gOaccum and -inf to gLSEaccum.
// Otherwise we might read OOB elements from gK and gV,
// or get wrong results when we combine gOaccum from different blocks.
const index_t row_offset_o = binfo.q_offset(params.o_batch_stride, params.o_row_stride, bidb)
+ m_block * kBlockM * params.o_row_stride + bidh * params.o_head_stride;
const index_t row_offset_oaccum = (((n_split_idx * params.b + bidb) * params.h + bidh) * params.seqlen_q
+ m_block * kBlockM) * params.d_rounded;
const index_t row_offset_lseaccum = ((n_split_idx * params.b + bidb) * params.h + bidh) * params.seqlen_q + m_block * kBlockM;
Tensor gOaccum = make_tensor(make_gmem_ptr(reinterpret_cast<ElementO *>(Split ? params.oaccum_ptr : params.o_ptr) + (Split ? row_offset_oaccum : row_offset_o)),
Shape<Int<kBlockM>, Int<kHeadDim>>{},
make_stride(Split ? kHeadDim : params.o_row_stride, _1{}));
Tensor gLSEaccum = make_tensor(make_gmem_ptr(reinterpret_cast<ElementAccum *>(Split ? params.softmax_lseaccum_ptr : params.softmax_lse_ptr) + row_offset_lseaccum),
Shape<Int<kBlockM>>{}, Stride<_1>{});
GmemTiledCopyO gmem_tiled_copy_Oaccum;
auto gmem_thr_copy_Oaccum = gmem_tiled_copy_Oaccum.get_thread_slice(tidx);
Tensor tOgOaccum = gmem_thr_copy_Oaccum.partition_D(gOaccum);
Tensor tOrOaccum = make_tensor<ElementO>(shape(tOgOaccum));
clear(tOrOaccum);
// Construct identity layout for sO
Tensor cO = make_identity_tensor(make_shape(size<0>(gOaccum), size<1>(gOaccum))); // (BLK_M,BLK_K) -> (blk_m,blk_k)
// Repeat the partitioning with identity layouts
Tensor tOcO = gmem_thr_copy_Oaccum.partition_D(cO);
Tensor tOpO = make_tensor<bool>(make_shape(size<2>(tOgOaccum)));
if (!Is_even_K) {
#pragma unroll
for (int k = 0; k < size(tOpO); ++k) { tOpO(k) = get<1>(tOcO(0, 0, k)) < params.d; }
}
// Clear_OOB_K must be false since we don't want to write zeros to gmem
flash::copy<Is_even_MN, Is_even_K, /*Clear_OOB_MN=*/false, /*Clear_OOB_K=*/false>(
gmem_tiled_copy_Oaccum, tOrOaccum, tOgOaccum, tOcO, tOpO, binfo.actual_seqlen_q - m_block * kBlockM
);
#pragma unroll
for (int m = 0; m < size<1>(tOgOaccum); ++m) {
const int row = get<0>(tOcO(0, m, 0));
if (row < binfo.actual_seqlen_q - m_block * kBlockM && get<1>(tOcO(0, m, 0)) == 0) { gLSEaccum(row) = Split ? -INFINITY : INFINITY; }
}
return;
}
// We iterate over the blocks in reverse order. This is because the last block is the only one
// that needs masking when we read K and V from global memory. Moreover, iterating in reverse
// might save us 1 register (we just need n_block instead of both n_block and n_block_max).
// We move K and V to the last block.
const int bidb_cache = params.cache_batch_idx == nullptr ? bidb : params.cache_batch_idx[bidb];
const int *block_table = params.block_table == nullptr ? nullptr : params.block_table + bidb * params.block_table_batch_stride;
const int block_table_idx = block_table == nullptr ? 0 : (n_block_max - 1) * kBlockN / params.page_block_size;
const int block_table_offset = block_table == nullptr ? 0 : (n_block_max - 1) * kBlockN - block_table_idx * params.page_block_size;
const index_t row_offset_k = block_table == nullptr
? binfo.k_offset(params.k_batch_stride, params.k_row_stride, bidb_cache)
+ (n_block_max - 1) * kBlockN * params.k_row_stride + (bidh / params.h_h_k_ratio) * params.k_head_stride
: block_table[block_table_idx] * params.k_batch_stride + block_table_offset * params.k_row_stride + (bidh / params.h_h_k_ratio) * params.k_head_stride;
const index_t row_offset_v = block_table == nullptr
? binfo.k_offset(params.v_batch_stride, params.v_row_stride, bidb_cache)
+ (n_block_max - 1) * kBlockN * params.v_row_stride + (bidh / params.h_h_k_ratio) * params.v_head_stride
: block_table[block_table_idx] * params.v_batch_stride + block_table_offset * params.v_row_stride + (bidh / params.h_h_k_ratio) * params.v_head_stride;
Tensor mQ = make_tensor(make_gmem_ptr(reinterpret_cast<Element*>(params.q_ptr) + binfo.q_offset(params.q_batch_stride, params.q_row_stride, bidb)),
make_shape(binfo.actual_seqlen_q, params.h, params.d),
make_stride(params.q_row_stride, params.q_head_stride, _1{}));
Tensor gQ = local_tile(mQ(_, bidh, _), Shape<Int<kBlockM>, Int<kHeadDim>>{},
make_coord(m_block, 0)); // (kBlockM, kHeadDim)
Tensor gK = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.k_ptr) + row_offset_k),
Shape<Int<kBlockN>, Int<kHeadDim>>{},
make_stride(params.k_row_stride, _1{}));
// if (threadIdx.x == 0 && blockIdx.y == 0 && blockIdx.z == 0) { printf("k_ptr = %p, row_offset_k = %d, gK_ptr = %p\n", params.k_ptr, row_offset_k, gK.data()); }
Tensor gV = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.v_ptr) + row_offset_v),
Shape<Int<kBlockN>, Int<kHeadDim>>{},
make_stride(params.v_row_stride, _1{}));
Tensor sQ = make_tensor(make_smem_ptr(reinterpret_cast<Element *>(smem_)),
typename Kernel_traits::SmemLayoutQ{});
Tensor sK = make_tensor(sQ.data() + size(sQ), typename Kernel_traits::SmemLayoutKV{});
Tensor sV = make_tensor(sK.data() + size(sK), typename Kernel_traits::SmemLayoutKV{});
Tensor sVt = make_tensor(sV.data(), typename Kernel_traits::SmemLayoutVtransposed{});
Tensor sVtNoSwizzle = make_tensor(sV.data().get(), typename Kernel_traits::SmemLayoutVtransposedNoSwizzle{});
typename Kernel_traits::GmemTiledCopyQKV gmem_tiled_copy_QKV;
auto gmem_thr_copy_QKV = gmem_tiled_copy_QKV.get_thread_slice(tidx);
Tensor tQgQ = gmem_thr_copy_QKV.partition_S(gQ);
Tensor tQsQ = gmem_thr_copy_QKV.partition_D(sQ);
Tensor tKgK = gmem_thr_copy_QKV.partition_S(gK); // (KCPY, KCPY_N, KCPY_K)
Tensor tKsK = gmem_thr_copy_QKV.partition_D(sK);
Tensor tVgV = gmem_thr_copy_QKV.partition_S(gV); // (VCPY, VCPY_N, VCPY_K)
Tensor tVsV = gmem_thr_copy_QKV.partition_D(sV);
typename Kernel_traits::TiledMma tiled_mma;
auto thr_mma = tiled_mma.get_thread_slice(tidx);
Tensor tSrQ = thr_mma.partition_fragment_A(sQ); // (MMA,MMA_M,MMA_K)
Tensor tSrK = thr_mma.partition_fragment_B(sK); // (MMA,MMA_N,MMA_K)
Tensor tOrVt = thr_mma.partition_fragment_B(sVtNoSwizzle); // (MMA, MMA_K,MMA_N)
Tensor acc_o = partition_fragment_C(tiled_mma, Shape<Int<kBlockM>, Int<kHeadDim>>{}); // MMA, MMA_M, MMA_K
//
// Copy Atom retiling
//
auto smem_tiled_copy_Q = make_tiled_copy_A(typename Kernel_traits::SmemCopyAtom{}, tiled_mma);
auto smem_thr_copy_Q = smem_tiled_copy_Q.get_thread_slice(tidx);
Tensor tSsQ = smem_thr_copy_Q.partition_S(sQ);
auto smem_tiled_copy_K = make_tiled_copy_B(typename Kernel_traits::SmemCopyAtom{}, tiled_mma);
auto smem_thr_copy_K = smem_tiled_copy_K.get_thread_slice(tidx);
Tensor tSsK = smem_thr_copy_K.partition_S(sK);
auto smem_tiled_copy_V = make_tiled_copy_B(typename Kernel_traits::SmemCopyAtomTransposed{}, tiled_mma);
auto smem_thr_copy_V = smem_tiled_copy_V.get_thread_slice(tidx);
Tensor tOsVt = smem_thr_copy_V.partition_S(sVt);
// PREDICATES
//
// // Allocate predicate tensors for m and n
// Tensor tQpQ = make_tensor<bool>(make_shape(size<1>(tQsQ), size<2>(tQsQ)), Stride<_1,_0>{});
// Tensor tKVpKV = make_tensor<bool>(make_shape(size<1>(tKsK), size<2>(tKsK)), Stride<_1,_0>{});
// Construct identity layout for sQ and sK
Tensor cQ = make_identity_tensor(make_shape(size<0>(sQ), size<1>(sQ))); // (BLK_M,BLK_K) -> (blk_m,blk_k)
Tensor cKV = make_identity_tensor(make_shape(size<0>(sK), size<1>(sK))); // (BLK_N,BLK_K) -> (blk_n,blk_k)
// Repeat the partitioning with identity layouts
Tensor tQcQ = gmem_thr_copy_QKV.partition_S(cQ); // (ACPY,ACPY_M,ACPY_K) -> (blk_m,blk_k)
Tensor tKVcKV = gmem_thr_copy_QKV.partition_S(cKV); // (BCPY,BCPY_N,BCPY_K) -> (blk_n,blk_k)
// Allocate predicate tensors for k
Tensor tQpQ = make_tensor<bool>(make_shape(size<2>(tQsQ)));
Tensor tKVpKV = make_tensor<bool>(make_shape(size<2>(tKsK)));
// Set predicates for k bounds
if (!Is_even_K) {
#pragma unroll
for (int k = 0; k < size(tQpQ); ++k) { tQpQ(k) = get<1>(tQcQ(0, 0, k)) < params.d; }
#pragma unroll
for (int k = 0; k < size(tKVpKV); ++k) { tKVpKV(k) = get<1>(tKVcKV(0, 0, k)) < params.d; }
}
// Prologue
// Copy from Knew to K, optionally apply rotary embedding.
typename Kernel_traits::GmemTiledCopyRotcossin gmem_tiled_copy_rotary;
auto gmem_thr_copy_rotary = gmem_tiled_copy_rotary.get_thread_slice(tidx);
typename Kernel_traits::GmemTiledCopyRotcossinCont gmem_tiled_copy_rotary_cont;
auto gmem_thr_copy_rotary_cont = gmem_tiled_copy_rotary_cont.get_thread_slice(tidx);
if constexpr (Append_KV) {
// Even if we have MQA / GQA, all threadblocks responsible for the same KV head are writing to
// gmem. Technically it's a race condition, but they all write the same content anyway, and it's safe.
// We want to do this so that all threadblocks can proceed right after they finish writing the KV cache.
const index_t row_offset_cossin = ((n_block_max - 1) * kBlockN) * (params.rotary_dim / 2);
Tensor gCos = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.rotary_cos_ptr) + row_offset_cossin),
Shape<Int<kBlockN>, Int<kHeadDim / 2>>{},
make_stride(params.rotary_dim / 2, _1{}));
Tensor gSin = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.rotary_sin_ptr) + row_offset_cossin),
Shape<Int<kBlockN>, Int<kHeadDim / 2>>{},
make_stride(params.rotary_dim / 2, _1{}));
Tensor gCosCont = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.rotary_cos_ptr) + row_offset_cossin),
Shape<Int<kBlockN>, Int<kHeadDim>>{},
make_stride(params.rotary_dim / 2, _1{}));
Tensor gSinCont = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.rotary_sin_ptr) + row_offset_cossin),
Shape<Int<kBlockN>, Int<kHeadDim>>{},
make_stride(params.rotary_dim / 2, _1{}));
Tensor tRgCos = gmem_thr_copy_rotary.partition_S(gCos);
Tensor tRgSin = gmem_thr_copy_rotary.partition_S(gSin);
Tensor tRgCosCont = gmem_thr_copy_rotary_cont.partition_S(gCosCont);
Tensor tRgSinCont = gmem_thr_copy_rotary_cont.partition_S(gSinCont);
// if (cute::thread(0, 0)) { printf("rotary_cos_ptr = %p, gCos.data() = %p, tRgCos.data() = %p, rotary_dim = %d\n", params.rotary_cos_ptr, gCos.data(), tRgCos.data(), params.rotary_dim); }
// if (cute::thread(8, 0)) { print_tensor(gCos); }
// if (cute::thread(0, 0)) { print_tensor(tRgCos); }
const index_t row_offset_knew = binfo.k_offset(params.knew_batch_stride, params.knew_row_stride, bidb)
+ ((n_block_max - 1) * kBlockN) * params.knew_row_stride + (bidh / params.h_h_k_ratio) * params.knew_head_stride;
const index_t row_offset_vnew = binfo.k_offset(params.vnew_batch_stride, params.vnew_row_stride, bidb)
+ ((n_block_max - 1) * kBlockN) * params.vnew_row_stride + (bidh / params.h_h_k_ratio) * params.vnew_head_stride;
// Subtract seqlen_k_cache * row stride so that conceptually gK and gKnew "line up". When we access them,
// e.g. if gK has 128 rows and gKnew has 64 rows, we access gK[:128] and gKNew[128:128 + 64].
// This maps to accessing the first 64 rows of knew_ptr.
Tensor gKnew = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.knew_ptr)
+ row_offset_knew - binfo.seqlen_k_cache * params.knew_row_stride),
Shape<Int<kBlockN>, Int<kHeadDim>>{},
make_stride(params.knew_row_stride, _1{}));
// if (threadIdx.x == 0 && blockIdx.y == 0 && blockIdx.z == 0) { printf("knew_ptr = %p, row_offset_knew = %d, gKnew_ptr = %p\n", params.knew_ptr, row_offset_knew, gKnew.data()); }
Tensor gVnew = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.vnew_ptr)
+ row_offset_vnew - binfo.seqlen_k_cache * params.vnew_row_stride),
Shape<Int<kBlockN>, Int<kHeadDim>>{},
make_stride(params.vnew_row_stride, _1{}));
Tensor tKgKnew = gmem_thr_copy_QKV.partition_S(gKnew); // (KCPY, KCPY_N, KCPY_K)
Tensor tVgVnew = gmem_thr_copy_QKV.partition_S(gVnew); // (VCPY, VCPY_N, VCPY_K)
const int n_block_copy_min = std::max(n_block_min, binfo.seqlen_k_cache / kBlockN);
auto tKgK_data = tKgK.data();
auto tVgV_data = tVgV.data();
for (int n_block = n_block_max - 1; n_block >= n_block_copy_min; n_block--) {
flash::copy_w_min_idx<Is_even_K>(
tVgVnew, tVgV, tKVcKV, tKVpKV, binfo.actual_seqlen_k - n_block * kBlockN, binfo.seqlen_k_cache - n_block * kBlockN
);
tVgVnew.data() = tVgVnew.data() + (-int(kBlockN * params.vnew_row_stride));
if (params.rotary_dim == 0) {
flash::copy_w_min_idx<Is_even_K>(
tKgKnew, tKgK, tKVcKV, tKVpKV, binfo.actual_seqlen_k - n_block * kBlockN, binfo.seqlen_k_cache - n_block * kBlockN
);
} else {
if (params.is_rotary_interleaved) {
// Don't clear OOB_K because we're writing to global memory
flash::copy_rotary_interleaved<Is_even_K, /*Clear_OOB_K=*/false>(
tKgKnew, tKgK, tRgCos, tRgSin, tKVcKV, binfo.actual_seqlen_k - n_block * kBlockN,
binfo.seqlen_k_cache - n_block * kBlockN, params.d, params.rotary_dim
);
tRgCos.data() = tRgCos.data() + (-int(kBlockN * params.rotary_dim / 2));
tRgSin.data() = tRgSin.data() + (-int(kBlockN * params.rotary_dim / 2));
} else {
// Don't clear OOB_K because we're writing to global memory
flash::copy_rotary_contiguous<Is_even_K, /*Clear_OOB_K=*/false>(
tKgKnew, tKgK, tRgCosCont, tRgSinCont, tKVcKV, binfo.actual_seqlen_k - n_block * kBlockN,
binfo.seqlen_k_cache - n_block * kBlockN, params.d, params.rotary_dim
);
tRgCosCont.data() = tRgCosCont.data() + (-int(kBlockN * params.rotary_dim / 2));
tRgSinCont.data() = tRgSinCont.data() + (-int(kBlockN * params.rotary_dim / 2));
}
}
tKgKnew.data() = tKgKnew.data() + (-int(kBlockN * params.knew_row_stride));
if (block_table == nullptr) {
tVgV.data() = tVgV.data() + (-int(kBlockN * params.v_row_stride));
tKgK.data() = tKgK.data() + (-int(kBlockN * params.k_row_stride));
} else {
if (n_block > n_block_copy_min) {
const int block_table_idx_cur = n_block * kBlockN / params.page_block_size;
const int block_table_offset_cur = n_block * kBlockN - block_table_idx_cur * params.page_block_size;
const int block_table_idx_next = (n_block - 1) * kBlockN / params.page_block_size;
const int block_table_offset_next = (n_block - 1) * kBlockN - block_table_idx_next * params.page_block_size;
const int table_diff = block_table[block_table_idx_next] - block_table[block_table_idx_cur];
const int offset_diff = block_table_offset_next - block_table_offset_cur;
tVgV.data() = tVgV.data() + table_diff * params.v_batch_stride + offset_diff * params.v_row_stride;
tKgK.data() = tKgK.data() + table_diff * params.k_batch_stride + offset_diff * params.k_row_stride;
}
}
}
// Need this before we can read in K again, so that we'll see the updated K values.
__syncthreads();
tKgK.data() = tKgK_data;
tVgV.data() = tVgV_data;
}
// Read Q from gmem to smem, optionally apply rotary embedding.
if (!Append_KV || params.rotary_dim == 0) {
// We don't need to clear the sQ smem tiles since we'll only write out the valid outputs
flash::copy<Is_even_MN, Is_even_K>(gmem_tiled_copy_QKV, tQgQ, tQsQ, tQcQ, tQpQ,
binfo.actual_seqlen_q - m_block * kBlockM);
} else {
const index_t row_offset_cossin = (binfo.seqlen_k_cache + (Is_causal || Is_local ? m_block * kBlockM : 0)) * (params.rotary_dim / 2);
// If not causal, all the queries get the same the cos/sin, taken at location seqlen_k_cache.
// We do this by setting the row stride of gCos / gSin to 0.
Tensor gCos = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.rotary_cos_ptr) + row_offset_cossin),
Shape<Int<kBlockM>, Int<kHeadDim / 2>>{},
make_stride(Is_causal || Is_local ? params.rotary_dim / 2 : 0, _1{}));
Tensor gSin = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.rotary_sin_ptr) + row_offset_cossin),
Shape<Int<kBlockM>, Int<kHeadDim / 2>>{},
make_stride(Is_causal || Is_local ? params.rotary_dim / 2 : 0, _1{}));
Tensor gCosCont = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.rotary_cos_ptr) + row_offset_cossin),
Shape<Int<kBlockM>, Int<kHeadDim>>{},
make_stride(Is_causal || Is_local ? params.rotary_dim / 2 : 0, _1{}));
Tensor gSinCont = make_tensor(make_gmem_ptr(reinterpret_cast<Element *>(params.rotary_sin_ptr) + row_offset_cossin),
Shape<Int<kBlockM>, Int<kHeadDim>>{},
make_stride(Is_causal || Is_local ? params.rotary_dim / 2 : 0, _1{}));
Tensor tRgCos = gmem_thr_copy_rotary.partition_S(gCos);
Tensor tRgSin = gmem_thr_copy_rotary.partition_S(gSin);
Tensor tRgCosCont = gmem_thr_copy_rotary_cont.partition_S(gCosCont);
Tensor tRgSinCont = gmem_thr_copy_rotary_cont.partition_S(gSinCont);
if (params.is_rotary_interleaved) {
flash::copy_rotary_interleaved<Is_even_K>(
tQgQ, tQsQ, tRgCos, tRgSin, tQcQ, binfo.actual_seqlen_q - m_block * kBlockM,
0, params.d, params.rotary_dim
);
} else {
flash::copy_rotary_contiguous<Is_even_K>(
tQgQ, tQsQ, tRgCosCont, tRgSinCont, tQcQ, binfo.actual_seqlen_q - m_block * kBlockM,
0, params.d, params.rotary_dim
);
}
}
int n_block = n_block_max - 1;
// We don't need to clear the sK smem tiles since we'll mask out the scores anyway.
flash::copy<Is_even_MN, Is_even_K>(gmem_tiled_copy_QKV, tKgK, tKsK, tKVcKV, tKVpKV,
binfo.actual_seqlen_k - n_block * kBlockN);
cute::cp_async_fence();
// flash::cp_async_wait<0>();
// __syncthreads();
// if (tidx == 0 && blockIdx.y == 0 && blockIdx.z == 0) { print(tKsK); }
// __syncthreads();
clear(acc_o);
flash::Softmax<2 * size<1>(acc_o)> softmax;
const float alibi_slope = !Has_alibi ? 0.0f : reinterpret_cast<float *>(params.alibi_slopes_ptr)[bidb * params.alibi_slopes_batch_stride + bidh] / params.scale_softmax;
flash::Mask<Is_causal, Is_local, Has_alibi> mask(binfo.actual_seqlen_k, binfo.actual_seqlen_q, params.window_size_left, params.window_size_right, alibi_slope);
// For performance reason, we separate out two kinds of iterations:
// those that need masking on S, and those that don't.
// We need masking on S for the very last block when K and V has length not multiple of kBlockN.
// We also need masking on S if it's causal, for the last ceil_div(kBlockM, kBlockN) blocks.
// We will have at least 1 "masking" iteration.
// If not even_N, then seqlen_k might end in the middle of a block. In that case we need to
// mask 2 blocks (e.g. when kBlockM == kBlockN), not just 1.
constexpr int n_masking_steps = (!Is_causal && !Is_local)
? 1
: ((Is_even_MN && Is_causal) ? cute::ceil_div(kBlockM, kBlockN) : cute::ceil_div(kBlockM, kBlockN) + 1);
#pragma unroll
for (int masking_step = 0; masking_step < n_masking_steps; ++masking_step, --n_block) {
Tensor acc_s = partition_fragment_C(tiled_mma, Shape<Int<kBlockM>, Int<kBlockN>>{}); // (MMA=4, MMA_M, MMA_N)
clear(acc_s);
flash::cp_async_wait<0>();
__syncthreads();
// Advance gV
if (masking_step > 0) {
if (block_table == nullptr) {
tVgV.data() = tVgV.data() + (-int(kBlockN * params.v_row_stride));
} else {
const int block_table_idx_cur = (n_block + 1) * kBlockN / params.page_block_size;
const int block_table_offset_cur = (n_block + 1) * kBlockN - block_table_idx_cur * params.page_block_size;
const int block_table_idx_next = n_block * kBlockN / params.page_block_size;
const int block_table_offset_next = n_block * kBlockN - block_table_idx_next * params.page_block_size;
tVgV.data() = tVgV.data() + (block_table[block_table_idx_next] - block_table[block_table_idx_cur]) * params.v_batch_stride + (block_table_offset_next - block_table_offset_cur) * params.v_row_stride;
}
flash::copy</*Is_even_MN=*/true, Is_even_K>(gmem_tiled_copy_QKV, tVgV, tVsV, tKVcKV, tKVpKV);
} else {
// Clear the smem tiles to account for predicated off loads
flash::copy<Is_even_MN, Is_even_K, /*Clear_OOB_MN=*/true>(
gmem_tiled_copy_QKV, tVgV, tVsV, tKVcKV, tKVpKV, binfo.actual_seqlen_k - n_block * kBlockN
);
}
cute::cp_async_fence();
flash::gemm(
acc_s, tSrQ, tSrK, tSsQ, tSsK, tiled_mma, smem_tiled_copy_Q, smem_tiled_copy_K,
smem_thr_copy_Q, smem_thr_copy_K
);
// if (cute::thread0()) { print(acc_s); }
if constexpr (Is_softcap){
apply_softcap(acc_s, params.softcap);
}
mask.template apply_mask<Is_causal, Is_even_MN>(
acc_s, n_block * kBlockN, m_block * kBlockM + (tidx / 32) * 16 + (tidx % 32) / 4, kNWarps * 16
);
flash::cp_async_wait<0>();
__syncthreads();
// if (tidx == 0 && blockIdx.y == 0 && blockIdx.z == 0) { print(tVsV); }
// __syncthreads();
if (n_block > n_block_min) {
// Advance gK
if (block_table == nullptr) {
tKgK.data() = tKgK.data() + (-int(kBlockN * params.k_row_stride));
} else {
const int block_table_idx_cur = n_block * kBlockN / params.page_block_size;
const int block_table_offset_cur = n_block * kBlockN - block_table_idx_cur * params.page_block_size;
const int block_table_idx_next = (n_block - 1) * kBlockN / params.page_block_size;
const int block_table_offset_next =(n_block - 1) * kBlockN - block_table_idx_next * params.page_block_size;
tKgK.data() = tKgK.data() + (block_table[block_table_idx_next] - block_table[block_table_idx_cur]) * params.k_batch_stride + (block_table_offset_next - block_table_offset_cur) * params.k_row_stride;
}
flash::copy</*Is_even_MN=*/true, Is_even_K>(gmem_tiled_copy_QKV, tKgK, tKsK, tKVcKV, tKVpKV);
// This cp_async_fence needs to be in the if block, otherwise the synchronization
// isn't right and we get race conditions.
cute::cp_async_fence();
}
// We have key_padding_mask so we'll need to Check_inf
masking_step == 0
? softmax.template softmax_rescale_o</*Is_first=*/true, /*Check_inf=*/Is_causal || Is_local || !Is_even_MN>(acc_s, acc_o, params.scale_softmax_log2)
: softmax.template softmax_rescale_o</*Is_first=*/false, /*Check_inf=*/Is_causal || Is_local || !Is_even_MN>(acc_s, acc_o, params.scale_softmax_log2);
// if (cute::thread0()) { print(scores_max); print(scores_sum); print(scores); }
// Convert acc_s from fp32 to fp16/bf16
Tensor rP = flash::convert_type<Element>(acc_s);
// Reshape rP from (MMA=4, MMA_M, MMA_N) to ((4, 2), MMA_M, MMA_N / 2)
// if using m16n8k16 or (4, MMA_M, MMA_N) if using m16n8k8.
Tensor tOrP = make_tensor(rP.data(), flash::convert_layout_acc_Aregs<Kernel_traits::TiledMma>(rP.layout()));
flash::gemm_rs(acc_o, tOrP, tOrVt, tOsVt, tiled_mma, smem_tiled_copy_V, smem_thr_copy_V);
// This check is at the end of the loop since we always have at least 1 iteration
if (n_masking_steps > 1 && n_block <= n_block_min) {
--n_block;
break;
}
}
// These are the iterations where we don't need masking on S
for (; n_block >= n_block_min; --n_block) {
Tensor acc_s = partition_fragment_C(tiled_mma, Shape<Int<kBlockM>, Int<kBlockN>>{}); // (MMA=4, MMA_M, MMA_N)
clear(acc_s);
flash::cp_async_wait<0>();
__syncthreads();
// Advance gV
if (block_table == nullptr) {
tVgV.data() = tVgV.data() + (-int(kBlockN * params.v_row_stride));
} else {
const int block_table_idx_cur = (n_block + 1) * kBlockN / params.page_block_size;
const int block_table_offset_cur = (n_block + 1) * kBlockN - block_table_idx_cur * params.page_block_size;
const int block_table_idx_next = n_block * kBlockN / params.page_block_size;
const int block_table_offset_next = n_block * kBlockN - block_table_idx_next * params.page_block_size;
tVgV.data() = tVgV.data() + (block_table[block_table_idx_next] - block_table[block_table_idx_cur]) * params.v_batch_stride + (block_table_offset_next - block_table_offset_cur) * params.v_row_stride;
}
flash::copy</*Is_even_MN=*/true, Is_even_K>(gmem_tiled_copy_QKV, tVgV, tVsV, tKVcKV, tKVpKV);
cute::cp_async_fence();
flash::gemm(
acc_s, tSrQ, tSrK, tSsQ, tSsK, tiled_mma, smem_tiled_copy_Q, smem_tiled_copy_K,
smem_thr_copy_Q, smem_thr_copy_K
);
if constexpr (Is_softcap){
apply_softcap(acc_s, params.softcap);
}
flash::cp_async_wait<0>();
__syncthreads();
if (n_block > n_block_min) {
// Advance gK
if (block_table == nullptr) {
tKgK.data() = tKgK.data() + (-int(kBlockN * params.k_row_stride));
} else {
const int block_table_idx_cur = n_block * kBlockN / params.page_block_size;
const int block_table_offset_cur = n_block * kBlockN - block_table_idx_cur * params.page_block_size;
const int block_table_idx_next = (n_block - 1) * kBlockN / params.page_block_size;
const int block_table_offset_next = (n_block - 1) * kBlockN - block_table_idx_next * params.page_block_size;
tKgK.data() = tKgK.data() + (block_table[block_table_idx_next] - block_table[block_table_idx_cur]) * params.k_batch_stride + (block_table_offset_next - block_table_offset_cur) * params.k_row_stride;
}
flash::copy</*Is_even_MN=*/true, Is_even_K>(gmem_tiled_copy_QKV, tKgK, tKsK, tKVcKV, tKVpKV);
// This cp_async_fence needs to be in the if block, otherwise the synchronization
// isn't right and we get race conditions.
cute::cp_async_fence();
}
mask.template apply_mask</*Causal_mask=*/false>(
acc_s, n_block * kBlockN, m_block * kBlockM + (tidx / 32) * 16 + (tidx % 32) / 4, kNWarps * 16
);
softmax.template softmax_rescale_o</*Is_first=*/false, /*Check_inf=*/Is_local>(acc_s, acc_o, params.scale_softmax_log2);
Tensor rP = flash::convert_type<Element>(acc_s);
// Reshape rP from (MMA=4, MMA_M, MMA_N) to ((4, 2), MMA_M, MMA_N / 2)
// if using m16n8k16 or (4, MMA_M, MMA_N) if using m16n8k8.
Tensor tOrP = make_tensor(rP.data(), flash::convert_layout_acc_Aregs<Kernel_traits::TiledMma>(rP.layout()));
flash::gemm_rs(acc_o, tOrP, tOrVt, tOsVt, tiled_mma, smem_tiled_copy_V, smem_thr_copy_V);
}
// Epilogue
Tensor lse = softmax.template normalize_softmax_lse</*Is_dropout=*/false, Split>(acc_o, params.scale_softmax);
// if (cute::thread0()) { print(lse); }
Tensor sOaccum = make_tensor(make_smem_ptr(reinterpret_cast<ElementO *>(smem_)), typename Kernel_traits::SmemLayoutO{}); // (SMEM_M,SMEM_N)
// Partition sO to match the accumulator partitioning
using SmemTiledCopyO = std::conditional_t<
!Split,
typename Kernel_traits::SmemCopyAtomO,
typename Kernel_traits::SmemCopyAtomOaccum
>;
auto smem_tiled_copy_Oaccum = make_tiled_copy_C(SmemTiledCopyO{}, tiled_mma);
auto smem_thr_copy_Oaccum = smem_tiled_copy_Oaccum.get_thread_slice(tidx);
Tensor rO = flash::convert_type<ElementO>(acc_o);
Tensor taccOrOaccum = smem_thr_copy_Oaccum.retile_S(rO); // ((Atom,AtomNum), MMA_M, MMA_N)
Tensor taccOsOaccum = smem_thr_copy_Oaccum.partition_D(sOaccum); // ((Atom,AtomNum),PIPE_M,PIPE_N)
// sOaccum is larger than sQ, so we need to syncthreads here
// TODO: allocate enough smem for sOaccum
if constexpr (Split) { __syncthreads(); }
cute::copy(smem_tiled_copy_Oaccum, taccOrOaccum, taccOsOaccum);
const index_t row_offset_o = binfo.q_offset(params.o_batch_stride, params.o_row_stride, bidb)
+ m_block * kBlockM * params.o_row_stride + bidh * params.o_head_stride;
const index_t row_offset_oaccum = (((n_split_idx * params.b + bidb) * params.h + bidh) * params.seqlen_q
+ m_block * kBlockM) * params.d_rounded;
const index_t row_offset_lseaccum = (Split || !params.unpadded_lse ?
((n_split_idx * params.b + bidb) * params.h + bidh) * params.seqlen_q : bidh * params.total_q + binfo.q_offset(params.seqlen_q, 1, bidb)
) + m_block * kBlockM;
Tensor gOaccum = make_tensor(make_gmem_ptr(reinterpret_cast<ElementO *>(Split ? params.oaccum_ptr : params.o_ptr) + (Split ? row_offset_oaccum : row_offset_o)),
Shape<Int<kBlockM>, Int<kHeadDim>>{},
make_stride(Split ? kHeadDim : params.o_row_stride, _1{}));
Tensor gLSEaccum = make_tensor(make_gmem_ptr(reinterpret_cast<ElementAccum *>(Split ? params.softmax_lseaccum_ptr : params.softmax_lse_ptr) + row_offset_lseaccum),
Shape<Int<kBlockM>>{}, Stride<_1>{});
// if (tidx == 0) { printf("row_offset_o = %d, bidh = %d, gOaccum = %p\n", row_offset_o, bidh, gOaccum.data()); }
GmemTiledCopyO gmem_tiled_copy_Oaccum;
auto gmem_thr_copy_Oaccum = gmem_tiled_copy_Oaccum.get_thread_slice(tidx);
Tensor tOsOaccum = gmem_thr_copy_Oaccum.partition_S(sOaccum); // ((Atom,AtomNum),ATOM_M,ATOM_N)
Tensor tOgOaccum = gmem_thr_copy_Oaccum.partition_D(gOaccum);
__syncthreads();
Tensor tOrOaccum = make_tensor<ElementO>(shape(tOgOaccum));
cute::copy(gmem_tiled_copy_Oaccum, tOsOaccum, tOrOaccum);
Tensor caccO = make_identity_tensor(Shape<Int<kBlockM>, Int<kHeadDim>>{}); // (BLK_M,BLK_K) -> (blk_m,blk_k)
Tensor taccOcO = thr_mma.partition_C(caccO); // (MMA,MMA_M,MMA_K)
static_assert(decltype(size<0>(taccOcO))::value == 4);
// Convert to ((2, 2), MMA_M, MMA_K) then take only the row indices.
Tensor taccOcO_row = logical_divide(taccOcO, Shape<_2>{})(make_coord(0, _), _, 0);
CUTE_STATIC_ASSERT_V(size(lse) == size(taccOcO_row)); // MMA_M
if (get<1>(taccOcO_row(0)) == 0) {
#pragma unroll
for (int mi = 0; mi < size(lse); ++mi) {
const int row = get<0>(taccOcO_row(mi));
if (row < binfo.actual_seqlen_q - m_block * kBlockM) { gLSEaccum(row) = lse(mi); }
}
}
// Construct identity layout for sO
Tensor cO = make_identity_tensor(make_shape(size<0>(sOaccum), size<1>(sOaccum))); // (BLK_M,BLK_K) -> (blk_m,blk_k)
// Repeat the partitioning with identity layouts
Tensor tOcO = gmem_thr_copy_Oaccum.partition_D(cO); // (ACPY,ACPY_M,ACPY_K) -> (blk_m,blk_k)
Tensor tOpO = make_tensor<bool>(make_shape(size<2>(tOgOaccum)));
if (!Is_even_K) {
#pragma unroll
for (int k = 0; k < size(tOpO); ++k) { tOpO(k) = get<1>(tOcO(0, 0, k)) < params.d; }
}
// Clear_OOB_K must be false since we don't want to write zeros to gmem
flash::copy<Is_even_MN, Is_even_K, /*Clear_OOB_MN=*/false, /*Clear_OOB_K=*/false>(
gmem_tiled_copy_Oaccum, tOrOaccum, tOgOaccum, tOcO, tOpO, binfo.actual_seqlen_q - m_block * kBlockM
);
}
////////////////////////////////////////////////////////////////////////////////////////////////////
template<typename Kernel_traits, bool Is_dropout, bool Is_causal, bool Is_local, bool Has_alibi, bool Is_even_MN, bool Is_even_K, bool Is_softcap, bool Return_softmax, typename Params>
inline __device__ void compute_attn(const Params ¶ms) {
const int m_block = blockIdx.x;
// The block index for the batch.
const int bidb = blockIdx.y;
// The block index for the head.
const int bidh = blockIdx.z;
// We want the fwd and bwd to generate the same dropout pattern (RNG), without restricting
// them to have the same number of threads or have to traverse the attention matrix
// in the same order.
// In the Philox RNG, we use the offset to store the batch, head, and the lane id
// (within a warp). We use the subsequence to store the location of the 16 x 32 blocks within
// the attention matrix. This way, as long as we have the batch, head, and the location of
// the 16 x 32 block within the attention matrix, we can generate the exact same dropout pattern.
flash::compute_attn_1rowblock<Kernel_traits, Is_dropout, Is_causal, Is_local, Has_alibi, Is_even_MN, Is_even_K, Is_softcap, Return_softmax>(params, bidb, bidh, m_block);
}
////////////////////////////////////////////////////////////////////////////////////////////////////
template<typename Kernel_traits, bool Is_causal, bool Is_local, bool Has_alibi, bool Is_even_MN, bool Is_even_K, bool Is_softcap, bool Split, bool Append_KV, typename Params>
inline __device__ void compute_attn_splitkv(const Params ¶ms) {
const int m_block = blockIdx.x;
// The block index for the batch.
const int bidb = Split ? blockIdx.z / params.h : blockIdx.y;
// The block index for the head.
const int bidh = Split ? blockIdx.z - bidb * params.h : blockIdx.z;
const int n_split_idx = Split ? blockIdx.y : 0;
const int num_n_splits = Split ? gridDim.y : 1;
flash::compute_attn_1rowblock_splitkv<Kernel_traits, Is_causal, Is_local, Has_alibi, Is_even_MN, Is_even_K, Is_softcap, Split, Append_KV>(params, bidb, bidh, m_block, n_split_idx, num_n_splits);
}
////////////////////////////////////////////////////////////////////////////////////////////////////
template<typename Kernel_traits, int kBlockM, int Log_max_splits, bool Is_even_K, typename Params>
inline __device__ void combine_attn_seqk_parallel(const Params ¶ms) {
using Element = typename Kernel_traits::Element;
using ElementAccum = typename Kernel_traits::ElementAccum;
using index_t = typename Kernel_traits::index_t;
constexpr int kMaxSplits = 1 << Log_max_splits;
constexpr int kHeadDim = Kernel_traits::kHeadDim;
constexpr int kNThreads = Kernel_traits::kNThreads;
static_assert(kMaxSplits <= 128, "kMaxSplits must be <= 128");
static_assert(kBlockM == 4 || kBlockM == 8 || kBlockM == 16 || kBlockM == 32, "kBlockM must be 4, 8, 16 or 32");
static_assert(kNThreads == 128, "We assume that each block has 128 threads");
// Shared memory.
// kBlockM + 1 instead of kBlockM to reduce bank conflicts.
__shared__ ElementAccum sLSE[kMaxSplits][kBlockM + 1];
// The thread and block index.
const int tidx = threadIdx.x;
const int bidx = blockIdx.x;
const index_t lse_size = params.b * params.h * params.seqlen_q;
const index_t row_offset_lse = bidx * kBlockM;
Tensor gLSEaccum = make_tensor(make_gmem_ptr(reinterpret_cast<ElementAccum *>(params.softmax_lseaccum_ptr) + row_offset_lse),
Shape<Int<kMaxSplits>, Int<kBlockM>>{},
make_stride(lse_size, _1{}));
// LSE format is different depending on params.unpadded_lse and params.seqlenq_ngroups_swapped, see comment in get_lse_tile.
// This tensor's layout maps row_offset_lse to {bidb, bidh, q_offset}.
Tensor gLSE = make_tensor(make_gmem_ptr(reinterpret_cast<ElementAccum *>(params.softmax_lse_ptr) + row_offset_lse),
Shape<Int<kBlockM>>{}, Stride<_1>{});
// This layout maps row_offset_lse to {bidh, q_offset, bidb} or {bidh, bidb, q_offset}.
Layout flat_layout = make_layout(lse_size);
Layout orig_layout = make_layout(make_shape(params.seqlen_q, params.h, params.b));
auto transposed_stride = params.seqlenq_ngroups_swapped ? make_stride(params.b, params.seqlen_q * params.b, 1) : make_stride(1, params.seqlen_q * params.b, params.seqlen_q);
Layout remapped_layout = make_layout(make_shape(params.seqlen_q, params.h, params.b), transposed_stride);
Layout final_layout = cute::composition(remapped_layout, cute::composition(orig_layout, flat_layout));
Tensor gLSE_unpadded = make_tensor(make_gmem_ptr(reinterpret_cast<ElementAccum *>(params.softmax_lse_ptr)), final_layout);
constexpr int kNLsePerThread = (kMaxSplits * kBlockM + kNThreads - 1) / kNThreads;
// Read the LSE values from gmem and store them in shared memory, then transpose them.
constexpr int kRowsPerLoadLSE = kNThreads / kBlockM;
#pragma unroll
for (int l = 0; l < kNLsePerThread; ++l) {
const int row = l * kRowsPerLoadLSE + tidx / kBlockM;
const int col = tidx % kBlockM;
ElementAccum lse = (row < params.num_splits && col < lse_size - bidx * kBlockM) ? gLSEaccum(row, col) : -INFINITY;
if (row < kMaxSplits) { sLSE[row][col] = lse; }
// if (bidx == 0 && tidx < 32) { printf("tidx = %d, row = %d, col = %d, lse = %f\n", tidx, row, col, lse); }
}
// if (bidx == 1 && tidx < 32) { printf("tidx = %d, row_offset_lse = %d, lse = %f\n", tidx, row_offset_lse, lse_accum(0)); }
__syncthreads();
Tensor lse_accum = make_tensor<ElementAccum>(Shape<Int<kNLsePerThread>>{});
constexpr int kRowsPerLoadTranspose = std::min(kRowsPerLoadLSE, kMaxSplits);
// To make sure that kMaxSplits is within 1 warp: we decide how many elements within kMaxSplits
// each thread should hold. If kMaxSplits = 16, then each thread holds 2 elements (128 threads,
// kBlockM rows, so each time we load we can load 128 / kBlockM rows).
// constexpr int kThreadsPerSplit = kMaxSplits / kRowsPerLoadTranspose;
// static_assert(kThreadsPerSplit <= 32);
static_assert(kRowsPerLoadTranspose <= 32);
static_assert(kNLsePerThread * kRowsPerLoadTranspose <= kMaxSplits);
#pragma unroll
for (int l = 0; l < kNLsePerThread; ++l) {
const int row = l * kRowsPerLoadTranspose + tidx % kRowsPerLoadTranspose;
const int col = tidx / kRowsPerLoadTranspose;
lse_accum(l) = (row < kMaxSplits && col < kBlockM) ? sLSE[row][col] : -INFINITY;
// if (bidx == 0 && tidx < 32) { printf("tidx = %d, row = %d, col = %d, lse = %f\n", tidx, row, col, lse_accum(l)); }
}
// Compute the logsumexp of the LSE along the split dimension.
ElementAccum lse_max = lse_accum(0);
#pragma unroll
for (int l = 1; l < kNLsePerThread; ++l) { lse_max = max(lse_max, lse_accum(l)); }
MaxOp<float> max_op;
lse_max = Allreduce<kRowsPerLoadTranspose>::run(lse_max, max_op);
lse_max = lse_max == -INFINITY ? 0.0f : lse_max; // In case all local LSEs are -inf
float lse_sum = expf(lse_accum(0) - lse_max);
#pragma unroll
for (int l = 1; l < kNLsePerThread; ++l) { lse_sum += expf(lse_accum(l) - lse_max); }
SumOp<float> sum_op;
lse_sum = Allreduce<kRowsPerLoadTranspose>::run(lse_sum, sum_op);
// For the case where all local lse == -INFINITY, we want to set lse_logsum to INFINITY. Otherwise
// lse_logsum is log(0.0) = -INFINITY and we get NaN when we do lse_accum(l) - lse_logsum.
ElementAccum lse_logsum = (lse_sum == 0.f || lse_sum != lse_sum) ? INFINITY : logf(lse_sum) + lse_max;
// if (bidx == 0 && tidx < 32) { printf("tidx = %d, lse = %f, lse_max = %f, lse_logsum = %f\n", tidx, lse_accum(0), lse_max, lse_logsum); }
if (tidx % kRowsPerLoadTranspose == 0 && tidx / kRowsPerLoadTranspose < kBlockM) {
if (params.unpadded_lse) {
const index_t lse_offset = row_offset_lse + tidx / kRowsPerLoadTranspose;
if (lse_offset < lse_size) {
gLSE_unpadded(lse_offset) = lse_logsum;
}
} else {
gLSE(tidx / kRowsPerLoadTranspose) = lse_logsum;
}
}
// Store the scales exp(lse - lse_logsum) in shared memory.
#pragma unroll
for (int l = 0; l < kNLsePerThread; ++l) {
const int row = l * kRowsPerLoadTranspose + tidx % kRowsPerLoadTranspose;
const int col = tidx / kRowsPerLoadTranspose;
if (row < params.num_splits && col < kBlockM) { sLSE[row][col] = expf(lse_accum(l) - lse_logsum); }
}
__syncthreads();
const index_t row_offset_oaccum = bidx * kBlockM * params.d_rounded;
Tensor gOaccum = make_tensor(make_gmem_ptr(reinterpret_cast<ElementAccum *>(params.oaccum_ptr) + row_offset_oaccum),
Shape<Int<kBlockM>, Int<kHeadDim>>{},
Stride<Int<kHeadDim>, _1>{});
constexpr int kBlockN = kNThreads / kBlockM;
using GmemLayoutAtomOaccum = Layout<Shape<Int<kBlockM>, Int<kBlockN>>, Stride<Int<kBlockN>, _1>>;
using GmemTiledCopyOaccum = decltype(
make_tiled_copy(Copy_Atom<DefaultCopy, ElementAccum>{},
GmemLayoutAtomOaccum{},
Layout<Shape < _1, _4>>{})); // Val layout, 4 vals per store
GmemTiledCopyOaccum gmem_tiled_copy_Oaccum;
auto gmem_thr_copy_Oaccum = gmem_tiled_copy_Oaccum.get_thread_slice(tidx);
Tensor tOgOaccum = gmem_thr_copy_Oaccum.partition_S(gOaccum);
Tensor tOrO = make_tensor<ElementAccum>(shape(tOgOaccum));
Tensor tOrOaccum = make_tensor<ElementAccum>(shape(tOgOaccum));
clear(tOrO);
// Predicates
Tensor cOaccum = make_identity_tensor(Shape<Int<kBlockM>, Int<kHeadDim>>{});
// Repeat the partitioning with identity layouts
Tensor tOcOaccum = gmem_thr_copy_Oaccum.partition_S(cOaccum);
Tensor tOpOaccum = make_tensor<bool>(make_shape(size<2>(tOgOaccum)));
if (!Is_even_K) {
#pragma unroll
for (int k = 0; k < size(tOpOaccum); ++k) { tOpOaccum(k) = get<1>(tOcOaccum(0, 0, k)) < params.d; }
}
// Load Oaccum in then scale and accumulate to O
for (int split = 0; split < params.num_splits; ++split) {
flash::copy</*Is_even_MN=*/false, Is_even_K>(
gmem_tiled_copy_Oaccum, tOgOaccum, tOrOaccum, tOcOaccum, tOpOaccum, params.b * params.h * params.seqlen_q - bidx * kBlockM
);
#pragma unroll
for (int m = 0; m < size<1>(tOrOaccum); ++m) {
int row = get<0>(tOcOaccum(0, m, 0));
ElementAccum lse_scale = sLSE[split][row];
#pragma unroll
for (int k = 0; k < size<2>(tOrOaccum); ++k) {
#pragma unroll
for (int i = 0; i < size<0>(tOrOaccum); ++i) {
tOrO(i, m, k) += lse_scale * tOrOaccum(i, m, k);
}
}
// if (cute::thread0()) { printf("lse_scale = %f, %f\n", sLSE[split][0], sLSE[split][1]); print(tOrOaccum); }
}
tOgOaccum.data() = tOgOaccum.data() + params.b * params.h * params.seqlen_q * params.d_rounded;
}
// if (cute::thread0()) { print_tensor(tOrO); }
Tensor rO = flash::convert_type<Element>(tOrO);
// Write to gO
#pragma unroll
for (int m = 0; m < size<1>(rO); ++m) {
const int idx = bidx * kBlockM + get<0>(tOcOaccum(0, m, 0));
if (idx < params.b * params.h * params.seqlen_q) {
const int batch_idx = idx / (params.h * params.seqlen_q);
const int head_idx = (idx - batch_idx * (params.h * params.seqlen_q)) / params.seqlen_q;
// The index to the rows of Q
const int row = idx - batch_idx * (params.h * params.seqlen_q) - head_idx * params.seqlen_q;
auto o_ptr = reinterpret_cast<Element *>(params.o_ptr) + batch_idx * params.o_batch_stride
+ head_idx * params.o_head_stride + row * params.o_row_stride;
#pragma unroll
for (int k = 0; k < size<2>(rO); ++k) {
if (Is_even_K || tOpOaccum(k)) {
const int col = get<1>(tOcOaccum(0, m, k));
Tensor gO = make_tensor(make_gmem_ptr(o_ptr + col),
Shape<Int<decltype(size<0>(rO))::value>>{}, Stride<_1>{});
// TODO: Should check if this is using vectorized store, but it seems pretty fast
copy(rO(_, m, k), gO);
// if (bidx == 0 && tidx == 0) { printf("tidx = %d, idx = %d, batch_idx = %d, head_idx = %d, row = %d, col = %d\n", tidx, idx, batch_idx, head_idx, row, col); print(rO(_, m, k)); print(gO); }
// reinterpret_cast<uint64_t *>(o_ptr)[col / 4] = recast<uint64_t>(rO)(0, m, k);
}
}
}
}
}
} // namespace flash
| 2 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim32_fp16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 32, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim32<cutlass::half_t, false>(params, stream);
}
| 3 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim64_fp16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 64, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim64<cutlass::half_t, false>(params, stream);
}
| 4 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/kernels/flash_fwd_hdim256_fp16_sm80.cu | // Copyright (c) 2023, Tri Dao.
// Splitting the different head dimensions to different files to speed up compilation.
// This file is auto-generated. See "generate_kernels.py"
#include "flash_fwd_launch_template.h"
template<>
void run_mha_fwd_<cutlass::half_t, 256, false>(Flash_fwd_params ¶ms, cudaStream_t stream) {
run_mha_fwd_hdim256<cutlass::half_t, false>(params, stream);
}
| 5 |
0 | hf_public_repos/candle/candle-flash-attn | hf_public_repos/candle/candle-flash-attn/tests/flash_attn_tests.rs | use anyhow::Result;
use candle::{DType, Device, IndexOp, Tensor, D};
fn to_vec3_round(t: Tensor, digits: i32) -> Result<Vec<Vec<Vec<f32>>>> {
let b = 10f32.powi(digits);
let t = t.to_vec3::<f32>()?;
let t = t
.iter()
.map(|t| {
t.iter()
.map(|t| t.iter().map(|t| f32::round(t * b) / b).collect())
.collect()
})
.collect();
Ok(t)
}
fn fa_acausal(q: &Tensor, k: &Tensor, v: &Tensor, softmax_scale: f32) -> Result<Tensor> {
let in_dtype = q.dtype();
let q = q.to_dtype(DType::F32)?;
let k = k.to_dtype(DType::F32)?;
let v = v.to_dtype(DType::F32)?;
let att = (q.matmul(&k.t()?)? * softmax_scale as f64)?;
let att = candle_nn::ops::softmax(&att, D::Minus1)?;
// Convert to contiguous as matmul doesn't support strided vs for now.
let output = att.matmul(&v.contiguous()?)?.to_dtype(in_dtype)?;
Ok(output)
}
#[test]
fn flash_attn_acausal() -> Result<()> {
let device = Device::new_cuda(0)?;
let q = Tensor::arange(0u32, 48, &device)?
.to_dtype(DType::F16)?
.reshape((1, 3, 2, 8))?;
let k = (&q / 40.)?;
let v = (&q / 50.)?;
let q = (&q / 30.)?;
let ys1 = fa_acausal(&q, &k, &v, 0.5)?;
let ys1 = ys1.i(0)?.to_dtype(DType::F32)?;
let ys2 = {
let q = q.transpose(1, 2)?;
let k = k.transpose(1, 2)?;
let v = v.transpose(1, 2)?;
candle_flash_attn::flash_attn(&q, &k, &v, 0.5, false)?.transpose(1, 2)?
};
let ys2 = ys2.i(0)?.to_dtype(DType::F32)?;
let diff = ys1.sub(&ys2)?.abs()?.flatten_all()?.max(0)?;
assert_eq!(ys1.dims(), &[3, 2, 8]);
assert_eq!(
to_vec3_round(ys1, 4)?,
&[
[
[0.0837, 0.1038, 0.1238, 0.1438, 0.1637, 0.1837, 0.2037, 0.2238],
[0.0922, 0.1122, 0.1322, 0.1522, 0.1721, 0.1921, 0.2122, 0.2322]
],
[
[0.4204, 0.4404, 0.4604, 0.4805, 0.5005, 0.5205, 0.5405, 0.5605],
[0.428, 0.448, 0.468, 0.488, 0.5083, 0.5283, 0.5483, 0.5684]
],
[
[0.7554, 0.7754, 0.7954, 0.8154, 0.8354, 0.8555, 0.8755, 0.8955],
[0.7622, 0.7822, 0.8022, 0.8223, 0.8423, 0.8623, 0.8823, 0.9023]
]
]
);
assert_eq!(ys2.dims(), &[3, 2, 8]);
assert_eq!(
to_vec3_round(ys2, 4)?,
&[
[
[0.0837, 0.1038, 0.1238, 0.1438, 0.1637, 0.1837, 0.2037, 0.2238],
[0.0922, 0.1122, 0.1322, 0.1522, 0.1721, 0.1921, 0.2122, 0.2322]
],
[
[0.4204, 0.4404, 0.4604, 0.4805, 0.5005, 0.5205, 0.5405, 0.5605],
[0.428, 0.448, 0.468, 0.488, 0.5083, 0.5283, 0.5483, 0.5684]
],
[
[0.7554, 0.7754, 0.7954, 0.8154, 0.8354, 0.8555, 0.8755, 0.8955],
[0.7622, 0.7822, 0.8022, 0.8223, 0.8423, 0.8623, 0.8823, 0.9023]
]
]
);
assert!(diff.to_vec0::<f32>()?.abs() < 1e-5);
Ok(())
}
#[test]
fn flash_attn_varlen() -> Result<()> {
let device = Device::new_cuda(0)?;
let q = Tensor::arange(0u32, 48, &device)?
.to_dtype(DType::F16)?
.reshape((3, 2, 8))?;
let k = (&q / 40.)?;
let v = (&q / 50.)?;
let q = (&q / 30.)?;
let seqlens_q = Tensor::new(&[0u32, 2u32], &device)?;
let seqlens_k = Tensor::new(&[0u32, 2u32], &device)?;
let ys = {
let q = q.transpose(0, 1)?;
let k = k.transpose(0, 1)?;
let v = v.transpose(0, 1)?;
candle_flash_attn::flash_attn_varlen(
&q, &k, &v, &seqlens_q, &seqlens_k, 32, 32, 0.5, false,
)?
.transpose(0, 1)?
};
let ys = ys.to_dtype(DType::F32)?;
assert_eq!(ys.dims(), &[3, 2, 8]);
assert_eq!(
to_vec3_round(ys, 4)?,
&[
[
[0.0837, 0.1038, 0.1238, 0.1438, 0.1637, 0.1837, 0.2037, 0.2238],
[0.0922, 0.1122, 0.1322, 0.1522, 0.1721, 0.1921, 0.2122, 0.2322]
],
[
[0.4204, 0.4404, 0.4604, 0.4805, 0.5005, 0.5205, 0.5405, 0.5605],
[0.428, 0.448, 0.468, 0.488, 0.5083, 0.5283, 0.5483, 0.5684]
],
[
[0.7554, 0.7754, 0.7954, 0.8154, 0.8354, 0.8555, 0.8755, 0.8955],
[0.7622, 0.7822, 0.8022, 0.8223, 0.8423, 0.8623, 0.8823, 0.9023]
]
]
);
Ok(())
}
| 6 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-datasets/Cargo.toml | [package]
name = "candle-datasets"
version.workspace = true
edition.workspace = true
description.workspace = true
repository.workspace = true
keywords.workspace = true
categories.workspace = true
license.workspace = true
readme = "README.md"
[dependencies]
byteorder = { workspace = true }
candle = { workspace = true }
candle-nn = { workspace = true }
hf-hub = { workspace = true}
intel-mkl-src = { workspace = true, optional = true }
memmap2 = { workspace = true }
tokenizers = { workspace = true, features = ["onig"] }
rand = { workspace = true }
thiserror = { workspace = true }
parquet = { workspace = true}
image = { workspace = true }
| 7 |
0 | hf_public_repos/candle | hf_public_repos/candle/candle-datasets/README.md | # candle-datasets
| 8 |
0 | hf_public_repos/candle/candle-datasets | hf_public_repos/candle/candle-datasets/src/lib.rs | //! Datasets & Dataloaders for Candle
pub mod batcher;
pub mod hub;
pub mod nlp;
pub mod vision;
pub use batcher::Batcher;
| 9 |
0 | hf_public_repos/api-inference-community/docker_images/flair | hf_public_repos/api-inference-community/docker_images/flair/tests/test_docker_build.py | import os
import subprocess
from unittest import TestCase
class cd:
"""Context manager for changing the current working directory"""
def __init__(self, newPath):
self.newPath = os.path.expanduser(newPath)
def __enter__(self):
self.savedPath = os.getcwd()
os.chdir(self.newPath)
def __exit__(self, etype, value, traceback):
os.chdir(self.savedPath)
class DockerBuildTestCase(TestCase):
def test_can_build_docker_image(self):
with cd(os.path.dirname(os.path.dirname(__file__))):
subprocess.check_output(["docker", "build", "."])
| 0 |
0 | hf_public_repos/api-inference-community/docker_images/flair | hf_public_repos/api-inference-community/docker_images/flair/tests/test_api.py | import os
from typing import Dict, List
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS, get_pipeline
# Must contain at least one example of each implemented pipeline
# Tests do not check the actual values of the model output, so small dummy
# models are recommended for faster tests.
TESTABLE_MODELS: Dict[str, List[str]] = {
"token-classification": ["flair/chunk-english-fast", "flair/upos-english-fast"]
}
ALL_TASKS = {
"automatic-speech-recognition",
"audio-source-separation",
"image-classification",
"question-answering",
"text-generation",
"text-to-speech",
}
class PipelineTestCase(TestCase):
@skipIf(
os.path.dirname(os.path.dirname(__file__)).endswith("common"),
"common is a special case",
)
def test_has_at_least_one_task_enabled(self):
self.assertGreater(
len(ALLOWED_TASKS.keys()), 0, "You need to implement at least one task"
)
def test_unsupported_tasks(self):
unsupported_tasks = ALL_TASKS - ALLOWED_TASKS.keys()
for unsupported_task in unsupported_tasks:
with self.subTest(msg=unsupported_task, task=unsupported_task):
os.environ["TASK"] = unsupported_task
os.environ["MODEL_ID"] = "XX"
with self.assertRaises(EnvironmentError):
get_pipeline()
| 1 |
0 | hf_public_repos/api-inference-community/docker_images/flair | hf_public_repos/api-inference-community/docker_images/flair/tests/test_api_token_classification.py | import json
import os
from unittest import TestCase, skipIf
from app.main import ALLOWED_TASKS
from parameterized import parameterized_class
from starlette.testclient import TestClient
from tests.test_api import TESTABLE_MODELS
@skipIf(
"token-classification" not in ALLOWED_TASKS,
"token-classification not implemented",
)
@parameterized_class(
[{"model_id": model_id} for model_id in TESTABLE_MODELS["token-classification"]]
)
class TokenClassificationTestCase(TestCase):
def setUp(self):
self.old_model_id = os.getenv("MODEL_ID")
self.old_task = os.getenv("TASK")
os.environ["MODEL_ID"] = self.model_id
os.environ["TASK"] = "token-classification"
from app.main import app
self.app = app
@classmethod
def setUpClass(cls):
from app.main import get_pipeline
get_pipeline.cache_clear()
def tearDown(self):
if self.old_model_id is not None:
os.environ["MODEL_ID"] = self.old_model_id
else:
del os.environ["MODEL_ID"]
if self.old_task is not None:
os.environ["TASK"] = self.old_task
else:
del os.environ["TASK"]
def test_simple(self):
inputs = "Hello, my name is John and I live in New York"
with TestClient(self.app) as client:
response = client.post("/", json={"inputs": inputs})
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(
set(k for el in content for k in el.keys()),
{"entity_group", "word", "start", "end", "score"},
)
with TestClient(self.app) as client:
response = client.post("/", json=inputs)
self.assertEqual(
response.status_code,
200,
)
content = json.loads(response.content)
self.assertEqual(type(content), list)
self.assertEqual(
set(k for el in content for k in el.keys()),
{"entity_group", "word", "start", "end", "score"},
)
def test_malformed_question(self):
with TestClient(self.app) as client:
response = client.post("/", data=b"\xc3\x28")
self.assertEqual(
response.status_code,
400,
)
self.assertEqual(
response.content,
b'{"error":"\'utf-8\' codec can\'t decode byte 0xc3 in position 0: invalid continuation byte"}',
)
| 2 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/fasttext/requirements.txt | starlette==0.27.0
api-inference-community==0.0.23
fasttext==0.9.2
huggingface_hub==0.5.1
# Dummy change.
| 3 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/fasttext/Dockerfile | FROM tiangolo/uvicorn-gunicorn:python3.8
LABEL maintainer="me <[email protected]>"
# Add any system dependency here
# RUN apt-get update -y && apt-get install libXXX -y
COPY ./requirements.txt /app
RUN pip install --no-cache-dir -r requirements.txt
COPY ./prestart.sh /app/
# Most DL models are quite large in terms of memory, using workers is a HUGE
# slowdown because of the fork and GIL with python.
# Using multiple pods seems like a better default strategy.
# Feel free to override if it does not make sense for your library.
ARG max_workers=1
ENV MAX_WORKERS=$max_workers
ENV HUGGINGFACE_HUB_CACHE=/data
# Necessary on GPU environment docker.
# TIMEOUT env variable is used by nvcr.io/nvidia/pytorch:xx for another purpose
# rendering TIMEOUT defined by uvicorn impossible to use correctly
# We're overriding it to be renamed UVICORN_TIMEOUT
# UVICORN_TIMEOUT is a useful variable for very large models that take more
# than 30s (the default) to load in memory.
# If UVICORN_TIMEOUT is too low, uvicorn will simply never loads as it will
# kill workers all the time before they finish.
RUN sed -i 's/TIMEOUT/UVICORN_TIMEOUT/g' /gunicorn_conf.py
COPY ./app /app/app
| 4 |
0 | hf_public_repos/api-inference-community/docker_images | hf_public_repos/api-inference-community/docker_images/fasttext/prestart.sh | python app/main.py
| 5 |
0 | hf_public_repos/api-inference-community/docker_images/fasttext | hf_public_repos/api-inference-community/docker_images/fasttext/app/main.py | import functools
import logging
import os
from typing import Dict, Type
from api_inference_community.routes import pipeline_route, status_ok
from app.pipelines import (
FeatureExtractionPipeline,
Pipeline,
TextClassificationPipeline,
)
from starlette.applications import Starlette
from starlette.middleware import Middleware
from starlette.middleware.gzip import GZipMiddleware
from starlette.routing import Route
TASK = os.getenv("TASK")
MODEL_ID = os.getenv("MODEL_ID")
logger = logging.getLogger(__name__)
# Add the allowed tasks
# Supported tasks are:
# - text-generation
# - text-classification
# - token-classification
# - translation
# - summarization
# - automatic-speech-recognition
# - ...
# For instance
# from app.pipelines import AutomaticSpeechRecognitionPipeline
# ALLOWED_TASKS = {"automatic-speech-recognition": AutomaticSpeechRecognitionPipeline}
# You can check the requirements and expectations of each pipelines in their respective
# directories. Implement directly within the directories.
ALLOWED_TASKS: Dict[str, Type[Pipeline]] = {
"feature-extraction": FeatureExtractionPipeline,
"text-classification": TextClassificationPipeline,
}
@functools.lru_cache()
def get_pipeline() -> Pipeline:
task = os.environ["TASK"]
model_id = os.environ["MODEL_ID"]
if task not in ALLOWED_TASKS:
raise EnvironmentError(f"{task} is not a valid pipeline for model : {model_id}")
return ALLOWED_TASKS[task](model_id)
routes = [
Route("/{whatever:path}", status_ok),
Route("/{whatever:path}", pipeline_route, methods=["POST"]),
]
middleware = [Middleware(GZipMiddleware, minimum_size=1000)]
if os.environ.get("DEBUG", "") == "1":
from starlette.middleware.cors import CORSMiddleware
middleware.append(
Middleware(
CORSMiddleware,
allow_origins=["*"],
allow_headers=["*"],
allow_methods=["*"],
)
)
app = Starlette(routes=routes, middleware=middleware)
@app.on_event("startup")
async def startup_event():
logger = logging.getLogger("uvicorn.access")
handler = logging.StreamHandler()
handler.setFormatter(logging.Formatter("%(asctime)s - %(levelname)s - %(message)s"))
logger.handlers = [handler]
# Link between `api-inference-community` and framework code.
app.get_pipeline = get_pipeline
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
if __name__ == "__main__":
try:
get_pipeline()
except Exception:
# We can fail so we can show exception later.
pass
| 6 |
0 | hf_public_repos/api-inference-community/docker_images/fasttext/app | hf_public_repos/api-inference-community/docker_images/fasttext/app/pipelines/base.py | from abc import ABC, abstractmethod
from typing import Any
import fasttext
from huggingface_hub import hf_hub_download
class Pipeline(ABC):
@abstractmethod
def __init__(self, model_id: str):
model_path = hf_hub_download(model_id, "model.bin", library_name="fasttext")
self.model = fasttext.load_model(model_path)
self.model_id = model_id
@abstractmethod
def __call__(self, inputs: Any) -> Any:
raise NotImplementedError("Pipelines should implement a __call__ method")
class PipelineException(Exception):
pass
| 7 |
0 | hf_public_repos/api-inference-community/docker_images/fasttext/app | hf_public_repos/api-inference-community/docker_images/fasttext/app/pipelines/__init__.py | from app.pipelines.base import Pipeline, PipelineException # isort:skip
from app.pipelines.feature_extraction import FeatureExtractionPipeline
from app.pipelines.text_classification import TextClassificationPipeline
| 8 |
0 | hf_public_repos/api-inference-community/docker_images/fasttext/app | hf_public_repos/api-inference-community/docker_images/fasttext/app/pipelines/feature_extraction.py | from typing import List
from app.pipelines import Pipeline
class FeatureExtractionPipeline(Pipeline):
def __init__(
self,
model_id: str,
):
# IMPLEMENT_THIS
# Preload all the elements you are going to need at inference.
# For instance your model, processors, tokenizer that might be needed.
# This function is only called once, so do all the heavy processing I/O here
super().__init__(model_id)
def __call__(self, inputs: str) -> List[float]:
"""
Args:
inputs (:obj:`str`):
a string to get the features of.
Return:
A :obj:`list` of floats: The features computed by the model.
"""
return self.model.get_sentence_vector(inputs).tolist()
| 9 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/idefics.md | ---
title: "IDEFICS 简介:最先进视觉语言模型的开源复现"
thumbnail: /blog/assets/idefics/thumbnail.png
authors:
- user: HugoLaurencon
- user: davanstrien
- user: stas
- user: Leyo
- user: SaulLu
- user: TimeRobber
guest: true
- user: skaramcheti
guest: true
- user: aps
guest: true
- user: giadap
- user: yjernite
- user: VictorSanh
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# IDEFICS 简介: 最先进视觉语言模型的开源复现
我们很高兴发布 IDEFICS ( **I**mage-aware **D**ecoder **E**nhanced à la **F**lamingo with **I**ninterleaved **C**ross-attention **S** ) 这一开放视觉语言模型。 IDEFICS 基于 [Flamingo](https://huggingface.co/papers/2204.14198),Flamingo 作为最先进的视觉语言模型,最初由 DeepMind 开发,但目前尚未公开发布。与 GPT-4 类似,该模型接受任意图像和文本输入序列并生成输出文本。IDEFICS 仅基于公开可用的数据和模型 (LLaMA v1 和 OpenCLIP) 构建,它有两个变体: 基础模型和指令模型。每个变体又各有 90 亿参数和 800 亿参数两个版本。
最先进的人工智能模型的开发应该更加透明。IDEFICS 的目标是重现并向 AI 社区提供与 Flamingo 等大型私有模型的能力相媲美的公开模型。因此,我们采取了很多措施,以增强其透明度: 我们只使用公开数据,并提供工具以供大家探索训练数据集; 我们分享我们在系统构建过程中的 [在技术上犯过的错误及学到的教训](https://github.com/huggingface/m4-logs/blob/master/memos/README.md),并在模型最终发布前使用对抗性提示来评估模型的危害性。我们希望 IDEFICS 能够与 [OpenFlamingo](https://huggingface.co/openflamingo) (Flamingo 的另一个 90 亿参数的开放的复现模型) 等模型一起,为更开放的多模态 AI 系统研究奠定坚实的基础。
你可以在 Hub 上试一试我们的 [演示](https://huggingface.co/spaces/HuggingFaceM4/idefics_playground) 及 [模型](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct)!
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics/woodstock_ai.png" width="600" alt="截图 - 让 IDEFICS 生成有关 HF Woodstock of AI 聚会的诗"/>
</p>
## IDEFICS 是什么?
IDEFICS 是一个 800 亿参数的多模态模型,其接受图像和文本序列作为输入,并生成连贯的文本作为输出。它可用于回答有关图像的问题、描述视觉内容、创建基于多张图像的故事等。
IDEFICS 是 Flamingo 的开放复刻版,在各种图像文本理解基准上的性能可与原始闭源模型相媲美。它有两个版本 - 800 亿参数版和 90 亿参数版。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics/Figure_Evals_IDEFICS.png" width="600" alt="Flamingo,OpenFlamingo 及 IDEFICS 性能对比图"/>
</p>
我们还提供了两个指令微调变体 [idefics-80B-instruct](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) 及 [idefics-9B-instruct](https://huggingface.co/HuggingFaceM4/idefics-9b-instruct),可用于对话场景。
## 训练数据
IDEFICS 基于由多个公开可用的数据集组成的混合数据集训练而得,它们是: 维基百科、公开多模态数据集 (Public Multimodal Dataset) 和 LAION,以及我们创建的名为 [OBELICS](https://huggingface.co/datasets/HuggingFaceM4/OBELICS) 的新的 115B 词元数据集。OBELICS 由从网络上抓取的 1.41 亿个图文文档组成,其中包含 3.53 亿张图像。
我们提供了 OBELICS 的 [交互式可视化](https://atlas.nomic.ai/map/f2fba2aa-3647-4f49-a0f3-9347daeee499/ee4a84bd-f125-4bcc-a683-1b4e231cb10f) 页面,以供大家使用 [Nomic AI](https://home.nomic.ai/) 来探索数据集的内容。
<p align="center">
<a href="https://atlas.nomic.ai/map/f2fba2aa-3647-4f49-a0f3-9347daeee499/ee4a84bd-f125-4bcc-a683-1b4e231cb10f">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/idefics/obelics_nomic_map.png" width="600" alt="OBELICS 的交互式可视化页面"/>
</a>
</p>
你可在 [模型卡](https://huggingface.co/HuggingFaceM4/idefics-80b-instruct) 和我们的 [研究论文](https://huggingface.co/papers/2306.16527) 中找到 IDEFICS 架构、训练方法及评估数据等详细信息,以及数据集相关的信息。此外,我们还记录了在模型训练过程中得到的 [所思、所想、所学](https://github.com/huggingface/m4-logs/blob/master/memos/README.md),为大家了解 IDEFICS 的研发提供了宝贵的视角。
## 伦理评估
在项目开始时,经过一系列讨论,我们制定了一份 [伦理章程](https://huggingface.co/blog/ethical-charter-multimodal),以帮助指导项目期间的决策。该章程规定了我们在执行项目和发布模型过程中所努力追求的价值观,包括自我批判、透明和公平。
作为发布流程的一部分,我们内部对模型的潜在偏见进行了评估,方法是用对抗性图像和文本来提示模型,这些图像和文本可能会触发一些我们不希望模型做出的反应 (这一过程称为红队)。
请通过 [演示应用](https://huggingface.co/spaces/HuggingFaceM4/idefics_playground) 来试一试 IDEFICS,也可以查看相应的 [模型卡](https://huggingface.co/HuggingFaceM4/idefics-80b) 和 [数据集卡](https://huggingface.co/datasets/HuggingFaceM4/OBELICS),并通过社区栏告诉我们你的反馈!我们致力于改进这些模型,并让机器学习社区能够用上大型多模态人工智能模型。
## 许可证
该模型建立在两个预训练模型之上: [laion/CLIP-ViT-H-14-laion2B-s32B-b79K](https://huggingface.co/laion/CLIP-ViT-H-14-laion2B-s32B-b79K) 和 [huggyllama/llama-65b](https://huggingface.co/huggyllama/llama-65b)。第一个是在 MIT 许可证下发布的。而第二个是在一个特定的研究性非商用许可证下发布的,因此,用户需遵照该许可的要求直接填写 [Meta 的表单](https://docs.google.com/forms/d/e/1FAIpQLSfqNECQnMkycAp2jP4Z9TFX0cGR4uf7b_fBxjY_OjhJILlKGA/viewform) 来申请访问它。
这两个预训练的模型通过我们的新训练的参数相互连接。训练时,连接部分的参数会随机初始化,且其与两个冻结的基础模型无关。这一部分权重是在 MIT 许可证下发布的。
## IDEFICS 入门
IDEFICS 模型已上传至 Hugging Face Hub,最新版本的 `transformers` 也已支持该模型。以下是一个如何使用 IDEFICS 的代码示例:
```python
import torch
from transformers import IdeficsForVisionText2Text, AutoProcessor
device = "cuda" if torch.cuda.is_available() else "cpu"
checkpoint = "HuggingFaceM4/idefics-9b-instruct"
model = IdeficsForVisionText2Text.from_pretrained(checkpoint, torch_dtype=torch.bfloat16).to(device)
processor = AutoProcessor.from_pretrained(checkpoint)
# We feed to the model an arbitrary sequence of text strings and images. Images can be either URLs or PIL Images.
prompts = [
[
"User: What is in this image?",
"https://upload.wikimedia.org/wikipedia/commons/8/86/Id%C3%A9fix.JPG",
"<end_of_utterance>",
"\nAssistant: This picture depicts Idefix, the dog of Obelix in Asterix and Obelix. Idefix is running on the ground.<end_of_utterance>",
"\nUser:",
"https://static.wikia.nocookie.net/asterix/images/2/25/R22b.gif/revision/latest?cb=20110815073052",
"And who is that?<end_of_utterance>",
"\nAssistant:",
],
]
# --batched mode
inputs = processor(prompts, add_end_of_utterance_token=False, return_tensors="pt").to(device)
# --single sample mode
# inputs = processor(prompts[0], return_tensors="pt").to(device)
# Generation args
exit_condition = processor.tokenizer("<end_of_utterance>", add_special_tokens=False).input_ids
bad_words_ids = processor.tokenizer(["<image>", "<fake_token_around_image>"], add_special_tokens=False).input_ids
generated_ids = model.generate(**inputs, eos_token_id=exit_condition, bad_words_ids=bad_words_ids, max_length=100)
generated_text = processor.batch_decode(generated_ids, skip_special_tokens=True)
for i, t in enumerate(generated_text):
print(f"{i}:\n{t}\n")
``` | 0 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/intel-fast-embedding.md | ---
title: "利用 🤗 Optimum Intel 和 fastRAG 在 CPU 上优化文本嵌入"
thumbnail: /blog/assets/optimum_intel/intel_thumbnail.png
authors:
- user: peterizsak
guest: true
- user: mber
guest: true
- user: danf
guest: true
- user: echarlaix
- user: mfuntowicz
- user: moshew
guest: true
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 利用 🤗 Optimum Intel 和 fastRAG 在 CPU 上优化文本嵌入
嵌入模型在很多场合都有广泛应用,如检索、重排、聚类以及分类。近年来,研究界在嵌入模型领域取得了很大的进展,这些进展大大提高了基于语义的应用的竞争力。[BGE](https://huggingface.co/BAAI/bge-large-en-v1.5)、[GTE](https://huggingface.co/thenlper/gte-small) 以及 [E5](https://huggingface.co/intfloat/multilingual-e5-large) 等模型在 [MTEB](https://github.com/embeddings-benchmark/mteb) 基准上长期霸榜,在某些情况下甚至优于私有的嵌入服务。 Hugging Face 模型 hub 提供了多种尺寸的嵌入模型,从轻量级 (100-350M 参数) 到 7B (如 [Salesforce/SFR-Embedding-Mistral](http://Salesforce/SFR-Embedding-Mistral) ) 一应俱全。不少基于语义搜索的应用会选用基于编码器架构的轻量级模型作为其嵌入模型,此时,CPU 就成为运行这些轻量级模型的有力候选,一个典型的场景就是 [检索增强生成 (Retrieval Augmented Generation,RAG)](https://en.wikipedia.org/wiki/Prompt_engineering#Retrieval-augmented_generation)。
## 使用嵌入模型进行信息检索
嵌入模型把文本数据编码为稠密向量,这些稠密向量中浓缩了文本的语义及上下文信息。这种上下文相关的单词和文档表征方式使得我们有可能实现更准确的信息检索。通常,我们可以用嵌入向量之间的余弦相似度来度量文本间的语义相似度。
在信息检索中是否仅依赖稠密向量就可以了?这需要一定的权衡:
- 稀疏检索通过把文本集建模成 n- 元组、短语或元数据的集合,并通过在集合上进行高效、大规模的搜索来实现信息检索。然而,由于查询和文档在用词上可能存在差异,这种方法有可能会漏掉一些相关的文档。
- 语义检索将文本编码为稠密向量,相比于词袋,其能更好地捕获上下文及词义。此时,即使用词上不能精确匹配,这种方法仍然可以检索出语义相关的文档。然而,与 BM25 等词匹配方法相比,语义检索的计算量更大,延迟更高,并且需要用到复杂的编码模型。
### 嵌入模型与 RAG
嵌入模型在 RAG 应用的多个环节中均起到了关键的作用:
- 离线处理: 在生成或更新文档数据库的索引时,要用嵌入模型将文档编码为稠密向量。
- 查询编码: 在查询时,要用嵌入模型将输入查询编码为稠密向量以供后续检索。
- 重排: 首轮检索出初始候选文档列表后,要用嵌入模型将检索到的文档编码为稠密向量并与查询向量进行比较,以完成重排。
可见,为了让整个应用更高效,优化 RAG 流水线中的嵌入模型这一环节非常必要,具体来说:
- 文档索引/更新: 追求高吞吐,这样就能更快地对大型文档集进行编码和索引,从而大大缩短建库和更新耗时。
- 查询编码: 较低的查询编码延迟对于检索的实时性至关重要。更高的吞吐可以支持更高查询并发度,从而实现高扩展度。
- 对检索到的文档进行重排: 首轮检索后,嵌入模型需要快速对检索到的候选文档进行编码以支持重排。较低的编码延迟意味着重排的速度会更快,从而更能满足时间敏感型应用的要求。同时,更高的吞吐意味着可以并行对更大的候选集进行重排,从而使得更全面的重排成为可能。
## 使用 Optimum Intel 和 IPEX 优化嵌入模型
[Optimum Intel](https://github.com/huggingface/optimum-intel) 是一个开源库,其针对英特尔硬件对使用 Hugging Face 库构建的端到端流水线进行加速和优化。 `Optimum Intel` 实现了多种模型加速技术,如低比特量化、模型权重修剪、蒸馏以及运行时优化。
[Optimum Intel](https://github.com/huggingface/optimum-intel) 在优化时充分利用了英特尔® 先进矢量扩展 512 (英特尔® AVX-512) 、矢量神经网络指令 (Vector Neural Network Instructions,VNNI) 以及英特尔® 高级矩阵扩展 (英特尔® AMX) 等特性以加速模型的运行。具体来说,每个 CPU 核中都内置了 [BFloat16](https://en.wikipedia.org/wiki/Bfloat16_floating-point_format) ( `bf16` ) 和 `int8` GEMM 加速器,以加速深度学习训练和推理工作负载。除了针对各种常见运算的优化之外,PyTorch 2.0 和 [Intel Extension for PyTorch](https://github.com/intel/intel-extension-for-pytorch) (IPEX) 中还充分利用了 AMX 以加速推理。
使用 Optimum Intel 可以轻松优化预训练模型的推理任务。你可在 [此处](https://huggingface.co/docs/optimum/main/en/intel/optimization_inc) 找到很多简单的例子。
## 示例: 优化 BGE 嵌入模型
本文,我们主要关注 [北京人工智能研究院](https://arxiv.org/pdf/2309.07597.pdf) 的研究人员最近发布的嵌入模型,它们在广为人知的 [MTEB](https://github.com/embeddings-benchmark/mteb) 排行榜上取得了亮眼的排名。
### BGE 技术细节
双编码器模型基于 Transformer 编码器架构,其训练目标是最大化两个语义相似的文本的嵌入向量之间的相似度,常见的指标是余弦相似度。举个常见的例子,我们可以使用 BERT 模型作为基础预训练模型,并对其进行微调以生成嵌入模型从而为文档生成嵌入向量。有多种方法可用于根据模型输出构造出文本的嵌入向量,例如,可以直接取 [CLS] 词元的嵌入向量,也可以对所有输入词元的嵌入向量取平均值。
双编码器模型是个相对比较简单的嵌入编码架构,其仅针对单个文档上下文进行编码,因此它们无法对诸如 `查询 - 文档` 及 `文档 - 文档` 这样的交叉上下文进行编码。然而,最先进的双编码器嵌入模型已能表现出相当有竞争力的性能,再加上因其架构简单带来的极快的速度,因此该架构的模型成为了当红炸子鸡。
这里,我们主要关注 3 个 BGE 模型: [small](https://huggingface.co/BAAI/bge-small-en-v1.5)、[base](https://huggingface.co/BAAI/bge-base-en-v1.5) 以及 [large](https://huggingface.co/BAAI/bge-large-en-v1.5),它们的参数量分别为 45M、110M 以及 355M,嵌入向量维度分别为 384、768 以及 1024。
请注意,下文展示的优化过程是通用的,你可以将它们应用于任何其他嵌入模型 (包括双编码器模型、交叉编码器模型等)。
### 模型量化分步指南
下面,我们展示如何提高嵌入模型在 CPU 上的性能,我们的优化重点是降低延迟 (batch size 为 1) 以及提高吞吐量 (以每秒编码的文档数来衡量)。我们用 `optimum-intel` 和 [INC (Intel Neural Compressor) ](https://github.com/intel/neural-compressor) 对模型进行量化,并用 [IPEX](https://github.com/intel/intel-extension-for-pytorch) 来优化模型在 Intel 的硬件上的运行时间。
##### 第 1 步: 安装软件包
请运行以下命令安装 `optimum-intel` 和 `intel-extension-for-transformers` :
```bash
pip install -U optimum[neural-compressor] intel-extension-for-transformers
```
##### 第 2 步: 训后静态量化
训后静态量化需要一个校准集以确定权重和激活的动态范围。校准时,模型会运行一组有代表性的数据样本,收集统计数据,然后根据收集到的信息量化模型以最大程度地降低准确率损失。
以下展示了对模型进行量化的代码片段:
```python
def quantize(model_name: str, output_path: str, calibration_set: "datasets.Dataset"):
model = AutoModel.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
def preprocess_function(examples):
return tokenizer(examples["text"], padding="max_length", max_length=512, truncation=True)
vectorized_ds = calibration_set.map(preprocess_function, num_proc=10)
vectorized_ds = vectorized_ds.remove_columns(["text"])
quantizer = INCQuantizer.from_pretrained(model)
quantization_config = PostTrainingQuantConfig(approach="static", backend="ipex", domain="nlp")
quantizer.quantize(
quantization_config=quantization_config,
calibration_dataset=vectorized_ds,
save_directory=output_path,
batch_size=1,
)
tokenizer.save_pretrained(output_path)
```
本例中,我们使用 [qasper](https://huggingface.co/datasets/allenai/qasper) 数据集的一个子集作为校准集。
##### 第 2 步: 加载模型,运行推理
仅需运行以下命令,即可加载量化模型:
```python
from optimum.intel import IPEXModel
model = IPEXModel.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
```
随后,我们使用 [transformers](https://github.com/huggingface/transformers) 的 API 将句子编码为向量:
```python
from transformers import AutoTokenizer
tokenizer = AutoTokenizer.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
inputs = tokenizer(sentences, return_tensors="pt")
with torch.no_grad():
outputs = model(**inputs)
# get the [CLS] token
embeddings = outputs[0][:, 0]
```
我们将在随后的模型评估部分详细说明如何正确配置 CPU 以获得最佳性能。
### 使用 MTEB 进行模型评估
将模型的权重量化到较低的精度会导致准确度的损失,因为在权重从 `fp32` 转换到 `int8` 的过程中会损失精度。所以,我们在如下两个 [MTEB](https://github.com/embeddings-benchmark/mteb) 任务上对量化模型与原始模型进行比较以验证量化模型的准确度到底如何:
- **检索** - 对语料库进行编码,并生成索引库,然后在索引库中搜索给定查询,以找出与给定查询相似的文本并排序。
- **重排** - 对检索结果进行重排,以细化与给定查询的相关性排名。
下表展示了每个任务在多个数据集上的平均准确度 (其中,MAP 用于重排,NDCG@10 用于检索),表中 `int8` 表示量化模型, `fp32` 表示原始模型 (原始模型结果取自官方 MTEB 排行榜)。与原始模型相比,量化模型在重排任务上的准确度损失低于 1%,在检索任务中的准确度损失低于 1.55%。
<table>
<tr><th> </th><th> 重排 </th><th> 检索 </th></tr>
<tr><td>
| |
| --------- |
| BGE-small |
| BGE-base |
| BGE-large |
</td><td>
| int8 | fp32 | 准确度损失 |
| ------ | ------ | ------ |
| 0.5826 | 0.5836 | -0.17% |
| 0.5886 | 0.5886 | 0% |
| 0.5985 | 0.6003 | -0.3% |
</td><td>
| int8 | fp32 | 准确度损失 |
| ------ | ------ | ------ |
| 0.5138 | 0.5168 | -0.58% |
| 0.5242 | 0.5325 | -1.55% |
| 0.5346 | 0.5429 | -1.53% |
</td></tr> </table>
### 速度与延迟
我们用量化模型进行推理,并将其与如下两种常见的模型推理方法进行性能比较:
1. 使用 PyTorch 和 Hugging Face 的 `transformers` 库以 `bf16` 精度运行模型。
2. 使用 [IPEX](https://intel.github.io/intel-extension-for-pytorch/#introduction) 以 `bf16` 精度运行模型,并使用 torchscript 对模型进行图化。
实验环境配置:
- 硬件 (CPU): 第四代 Intel 至强 8480+,整机有 2 路 CPU,每路 56 个核。
- 对 PyTorch 模型进行评估时仅使用单路 CPU 上的 56 个核。
- IPEX/Optimum 测例使用 ipexrun、单路 CPU、使用的核数在 22-56 之间。
- 所有测例 TCMalloc,我们安装并妥善设置了相应的环境变量以保证用到它。
### 如何运行评估?
我们写了一个基于模型的词汇表生成随机样本的脚本。然后分别加载原始模型和量化模型,并比较了它们在上述两种场景中的编码时间: 使用单 batch size 度量编码延迟,使用大 batch size 度量编码吞吐。
1. 基线 - 用 PyTorch 及 Hugging Face 运行 `bf16` 模型:
```python
import torch
from transformers import AutoModel
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
@torch.inference_mode()
def encode_text():
outputs = model(inputs)
with torch.cpu.amp.autocast(dtype=torch.bfloat16):
encode_text()
```
1. 用 IPEX torchscript 运行 `bf16` 模型:
```python
import torch
from transformers import AutoModel
import intel_extension_for_pytorch as ipex
model = AutoModel.from_pretrained("BAAI/bge-small-en-v1.5")
model = ipex.optimize(model, dtype=torch.bfloat16)
vocab_size = model.config.vocab_size
batch_size = 1
seq_length = 512
d = torch.randint(vocab_size, size=[batch_size, seq_length])
model = torch.jit.trace(model, (d,), check_trace=False, strict=False)
model = torch.jit.freeze(model)
@torch.inference_mode()
def encode_text():
outputs = model(inputs)
with torch.cpu.amp.autocast(dtype=torch.bfloat16):
encode_text()
```
1. 用基于 IPEX 后端的 Optimum Intel 运行 `int8` 模型:
```python
import torch
from optimum.intel import IPEXModel
model = IPEXModel.from_pretrained("Intel/bge-small-en-v1.5-rag-int8-static")
@torch.inference_mode()
def encode_text():
outputs = model(inputs)
encode_text()
```
### 延迟性能
这里,我们主要测量模型的响应速度,这关系到 RAG 流水线中对查询进行编码的速度。此时,我们将 batch size 设为 1,并测量在各种文档长度下的延迟。
我们可以看到,总的来讲,量化模型延迟最小,其中 `small` 模型和 `base` 模型的延迟低于 10 毫秒, `large` 模型的延迟低于 20 毫秒。与原始模型相比,量化模型的延迟提高了 4.5 倍。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/178_intel_ipex_quantization/latency.png" alt="latency" style="width: 90%; height: auto;"><br>
<em> 图 1: 各尺寸 BGE 模型的延迟 </em>
</p>
### 吞吐性能
在评估吞吐时,我们的目标是寻找峰值编码性能,其单位为每秒处理文档数。我们将文本长度设置为 256 个词元,这个长度能较好地代表 RAG 流水线中的平均文档长度,同时我们在不同的 batch size (4、8、16、32、64、128、256) 上进行评估。
结果表明,与其他模型相比,量化模型吞吐更高,且在 batch size 为 128 时达到峰值。总体而言,对于所有尺寸的模型,量化模型的吞吐在各 batch size 上均比基线 `bf16` 模型高 4 倍左右。
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/178_intel_ipex_quantization/throughput_small.png" alt="throughput small" style="width: 60%; height: auto;"><br>
<em> 图 2: BGE small 模型的吞吐 </em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/178_intel_ipex_quantization/throughput_base.png" alt="throughput base" style="width: 60%; height: auto;"><br>
<em> 图 3: BGE base 模型的吞吐 </em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/huggingface/documentation-images/resolve/main/blog/178_intel_ipex_quantization/throughput_large.png" alt="throughput large" style="width: 60%; height: auto;"><br>
<em> 图 3: BGE large 模型的吞吐 </em>
</p>
## 在 fastRAG 中使用量化嵌入模型
我们通过一个例子来演示如何将优化后的检索/重排模型集成进 [fastRAG](https://github.com/IntelLabs/fastRAG) 中 (你也可以很轻松地将其集成到其他 RAG 框架中,如 Langchain 及 LlamaIndex) 。
[fastRAG](https://github.com/IntelLabs/fastRAG) 是一个高效且优化的检索增强生成流水线研究框架,其可与最先进的 LLM 和信息检索算法结合使用。fastRAG 与 [Haystack](https://haystack.deepset.ai/) 完全兼容,并实现了多种新的、高效的 RAG 模块,可高效部署在英特尔硬件上。
大家可以参考 [此说明](https://github.com/IntelLabs/fastRAG#round_pushpin-installation) 安装 fastRAG,并阅读我们的 [指南](https://github.com/IntelLabs/fastRAG/blob/main/getting_started.md) 以开始 fastRAG 之旅。
我们需要将优化的双编码器嵌入模型用于下述两个模块中:
1. [`QuantizedBiEncoderRetriever`](https://github.com/IntelLabs/fastRAG/blob/main/fastrag/retrievers/optimized.py#L17) – 用于创建稠密向量索引库,以及从建好的向量库中检索文档
2. [`QuantizedBiEncoderRanker`](https://github.com/IntelLabs/fastRAG/blob/main/fastrag/rankers/quantized_bi_encoder.py#L17) – 在对文档列表进行重排的流水线中需要用到嵌入模型。
### 使用优化的检索器实现快速索引
我们用基于量化嵌入模型的稠密检索器来创建稠密索引。
首先,创建一个文档库:
```python
from haystack.document_store import InMemoryDocumentStore
document_store = InMemoryDocumentStore(use_gpu=False, use_bm25=False, embedding_dim=384, return_embedding=True)
```
接着,向其中添加一些文档:
```python
from haystack.schema import Document
# example documents to index
examples = [
"There is a blue house on Oxford Street.",
"Paris is the capital of France.",
"The first commit in fastRAG was in 2022"
]
documents = []
for i, d in enumerate(examples):
documents.append(Document(content=d, id=i))
document_store.write_documents(documents)
```
使用优化的双编码器嵌入模型初始化检索器,并对文档库中的所有文档进行编码:
```python
from fastrag.retrievers import QuantizedBiEncoderRetriever
model_id = "Intel/bge-small-en-v1.5-rag-int8-static"
retriever = QuantizedBiEncoderRetriever(document_store=document_store, embedding_model=model_id)
document_store.update_embeddings(retriever=retriever)
```
### 使用优化的排名器进行重排
下面的代码片段展示了如何将量化模型加载到排序器中,该结点会对检索器检索到的所有文档进行编码和重排:
```python
from haystack import Pipeline
from fastrag.rankers import QuantizedBiEncoderRanker
ranker = QuantizedBiEncoderRanker("Intel/bge-large-en-v1.5-rag-int8-static")
p = Pipeline()
p.add_node(component=retriever, name="retriever", inputs=["Query"])
p.add_node(component=ranker, name="ranker", inputs=["retriever"])
results = p.run(query="What is the capital of France?")
# print the documents retrieved
print(results)
```
搞定!我们创建的这个流水线首先从文档库中检索文档,并使用 (另一个) 嵌入模型对检索到的文档进行重排。你也可从这个 [Notebook](https://github.com/IntelLabs/fastRAG/blob/main/examples/optimized-embeddings.ipynb) 中获取更完整的例子。
如欲了解更多 RAG 相关的方法、模型和示例,我们邀请大家通过 [fastRAG/examples](https://github.com/IntelLabs/fastRAG/tree/main/examples) 尽情探索。 | 1 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/_redirects.yml | # Redirects file. The format should be: `old_name: new_name`.
# Example:
# starcoder3: starcoder2
# redirects hf.co/blog/starcoder3 -> hf.co/blog/starcoder2
leaderboards-on-the-hub-patronus : leaderboard-patronus
leaderboard-drop-dive : open-llm-leaderboard-drop
evaluating-mmlu-leaderboard : open-llm-leaderboard-mmlu
llm-leaderboard : open-llm-leaderboard-rlhf
| 2 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/pytorch-fsdp.md | ---
title: "使用 PyTorch 完全分片数据并行技术加速大模型训练"
thumbnail: /blog/assets/62_pytorch_fsdp/fsdp-thumbnail.png
authors:
- user: smangrul
- user: sgugger
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 使用 PyTorch 完全分片数据并行技术加速大模型训练
本文,我们将了解如何基于 PyTorch 最新的 **[完全分片数据并行 (Fully Sharded Data Parallel,FSDP)](https://pytorch.org/blog/introducing-pytorch-filled-sharded-data-parallel-api/)** 功能用 **[Accelerate](https://github.com/huggingface/accelerate)** 库来训练大模型。
# 动机 🤗
**随着机器学习 (ML) 模型的规模、大小和参数量的不断增加,ML 从业者发现在自己的硬件上训练甚至加载如此大的模型变得越来越难。** 一方面,人们发现大模型与较小的模型相比,学习速度更快 (数据和计算效率更高) 且会有显著的提升 [1]; 另一方面,在大多数硬件上训练此类模型变得令人望而却步。
分布式训练是训练这些机器学习大模型的关键。 **大规模分布式训练** 领域最近取得了不少重大进展,我们将其中一些最突出的进展总结如下:
1. 使用 ZeRO 数据并行 - 零冗余优化器 [2]
1. 阶段 1: 跨数据并行进程 / GPU 对`优化器状态` 进行分片
2. 阶段 2: 跨数据并行进程/ GPU 对`优化器状态 + 梯度` 进行分片
3. 阶段 3: 跨数据并行进程 / GPU 对`优化器状态 + 梯度 + 模型参数` 进行分片
4. CPU 卸载: 进一步将 ZeRO 阶段 2 的`优化器状态 + 梯度` 卸载到 CPU 上 [3]
2. 张量并行 [4]: 模型并行的一种形式,通过对各层参数进行精巧的跨加速器 / GPU 分片,在实现并行计算的同时避免了昂贵的通信同步开销。
3. 流水线并行 [5]: 模型并行的另一种形式,其将模型的不同层放在不同的加速器 / GPU 上,并利用流水线来保持所有加速器同时运行。举个例子,在第 2 个加速器 / GPU 对第 1 个 micro batch 进行计算的同时,第 1 个加速器 / GPU 对第 2 个 micro batch 进行计算。
4. 3D 并行 [3]: 采用 `ZeRO 数据并行 + 张量并行 + 流水线并行` 的方式来训练数百亿参数的大模型。例如,BigScience 176B 语言模型就采用了该并行方式 [6]。
本文我们主要关注 ZeRO 数据并行,更具体地讲是 PyTorch 最新的 **[完全分片数据并行 (Fully Sharded Data Parallel,FSDP)](https://pytorch.org/blog/introducing-pytorch-complete-sharded-data-parallel-api/)** 功能。 **[DeepSpeed](https://github.com/microsoft/deepspeed)** 和 **[FairScale](https://github.com/facebookresearch/fairscale/)** 实现了 ZeRO 论文的核心思想。我们已经将其集成到了 `transformers` 的 `Trainer` 中,详见博文 [通过 DeepSpeed 和 FairScale 使用 ZeRO 进行更大更快的训练](https://huggingface.co/blog/zero-deepspeed-fairscale)[10]。最近,PyTorch 已正式将 Fairscale FSDP 整合进其 Distributed 模块中,并增加了更多的优化。
# Accelerate 🚀: 无需更改任何代码即可使用 PyTorch FSDP
我们以基于 GPT-2 的 Large (762M) 和 XL (1.5B) 模型的因果语言建模任务为例。
以下是预训练 GPT-2 模型的代码。其与 [此处](https://github.com/huggingface/transformers/blob/main/examples/pytorch/language-modeling/run_clm_no_trainer.py) 的官方因果语言建模示例相似,仅增加了 2 个参数 `n_train` (2000) 和 `n_val` (500) 以防止对整个数据集进行预处理/训练,从而支持更快地进行概念验证。
<a href="https://huggingface.co/blog/assets/62_pytorch_fsdp/run_clm_no_trainer.py" target="_parent">run_clm_no_trainer.py</a>
运行 `accelerate config` 命令后得到的 FSDP 配置示例如下:
```bash
compute_environment: LOCAL_MACHINE
deepspeed_config: {}
distributed_type: FSDP
fsdp_config:
min_num_params: 2000
offload_params: false
sharding_strategy: 1
machine_rank: 0
main_process_ip: null
main_process_port: null
main_training_function: main
mixed_precision: 'no'
num_machines: 1
num_processes: 2
use_cpu: false
```
## 多 GPU FSDP
本文我们使用单节点多 GPU 上作为实验平台。我们比较了分布式数据并行 (DDP) 和 FSDP 在各种不同配置下的性能。我们可以看到,对 GPT-2 Large(762M) 模型而言,DDP 尚能够支持其中某些 batch size 而不会引起内存不足 (OOM) 错误。但当使用 GPT-2 XL (1.5B) 时,即使 batch size 为 1,DDP 也会失败并出现 OOM 错误。同时,我们看到,FSDP 可以支持以更大的 batch size 训练 GPT-2 Large 模型,同时它还可以使用较大的 batch size 训练 DDP 训练不了的 GPT-2 XL 模型。
**硬件配置**: 2 张 24GB 英伟达 Titan RTX GPU。
GPT-2 Large 模型 (762M 参数) 的训练命令如下:
```bash
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`
time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-large \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
```
FSDP 运行截屏:
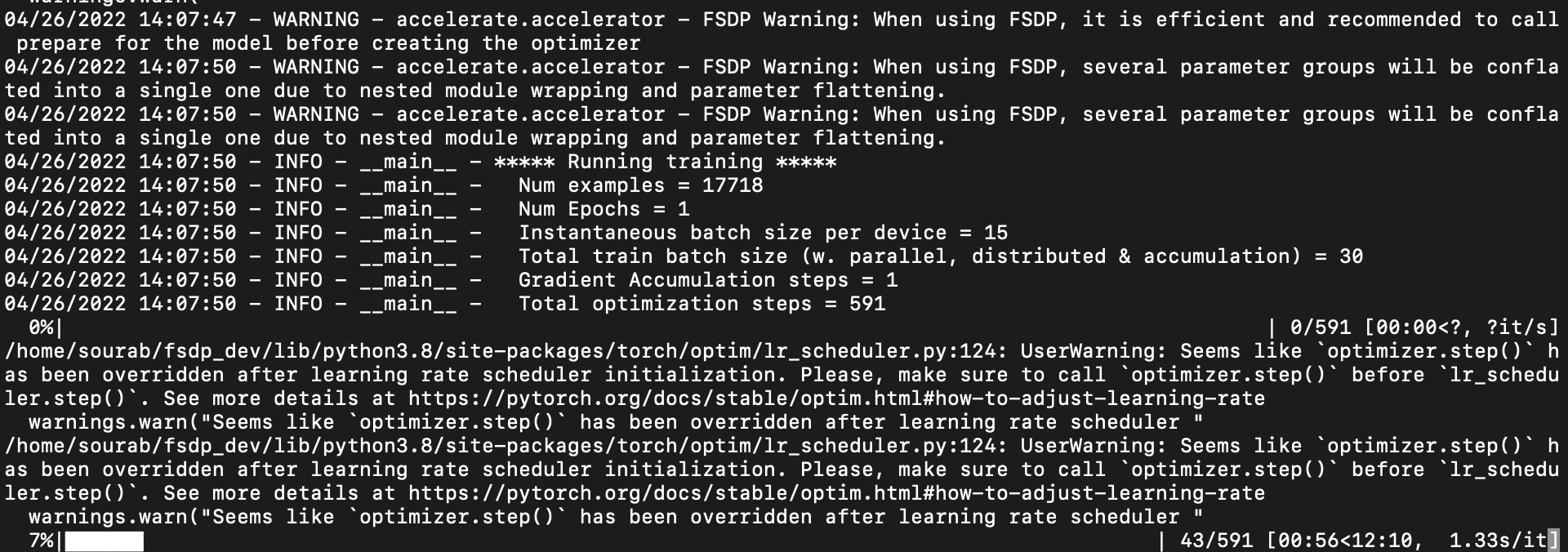
| 并行方法 | 最大 Batch Size ($BS) | 大致训练时间 (分钟) | 备注 |
| --- | --- | --- | --- |
| DDP | 7 | 15 | |
| DDP + FP16 | 7 | 8 | |
| FSDP (配置: SHARD_GRAD_OP) | 11 | 11 | |
| FSDP (配置: min_num_params = 1M + FULL_SHARD) | 15 | 12 | |
| FSDP (配置: min_num_params = 2K + FULL_SHARD) | 15 | 13 | |
| FSDP (配置: min_num_params = 1M + FULL_SHARD + CPU 卸载) | 20 | 23 | |
| FSDP (配置: min_num_params = 2K + FULL_SHARD + CPU 卸载) | 22 | 24 | |
表 1: GPT-2 Large (762M) 模型 FSDP 训练性能基准测试
从表 1 中我们可以看到,相对于 DDP 而言,FSDP **支持更大的 batch size**,在不使用和使用 CPU 卸载设置的情况下 FSDP 支持的最大 batch size 分别可达 DDP 的 **2 倍及 3 倍**。从训练时间来看,混合精度的 DDP 最快,其后是分别使用 ZeRO 阶段 2 和阶段 3 的 FSDP。由于因果语言建模的任务的上下文序列长度 ( `--block_size` ) 是固定的,因此 FSDP 在训练时间上加速还不是太高。对于动态 batch size 的应用而言,支持更大 batch size 的 FSDP 可能会在训练时间方面有更大的加速。目前,FSDP 的混合精度支持在 `transformers` 上还存在一些 [问题](https://github.com/pytorch/pytorch/issues/75676)。一旦问题解决,训练时间将会进一步显著缩短。
### 使用 CPU 卸载来支持放不进 GPU 显存的大模型训练
训练 GPT-2 XL (1.5B) 模型的命令如下:
```bash
export BS=#`try with different batch sizes till you don't get OOM error,
#i.e., start with larger batch size and go on decreasing till it fits on GPU`
time accelerate launch run_clm_no_trainer.py \
--model_name_or_path gpt2-xl \
--dataset_name wikitext \
--dataset_config_name wikitext-2-raw-v1 \
--per_device_train_batch_size $BS
--per_device_eval_batch_size $BS
--num_train_epochs 1
--block_size 12
```
| 并行方法 | 最大 Batch Size ($BS) | GPU 数 | 大致训练时间 (小时) | 备注 |
| --- | --- | --- | --- | --- |
| DDP | 1 | 1 | NA | OOM Error RuntimeError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 23.65 GiB total capacity; 22.27 GiB already allocated; 20.31 MiB free; 22.76 GiB reserved in total by PyTorch) |
| DDP | 1 | 2 | NA | OOM Error RuntimeError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 23.65 GiB total capacity; 22.27 GiB already allocated; 20.31 MiB free; 22.76 GiB reserved in total by PyTorch) |
| DDP + FP16 | 1 | 1 | NA | OOM Error RuntimeError: CUDA out of memory. Tried to allocate 40.00 MiB (GPU 0; 23.65 GiB total capacity; 22.27 GiB already allocated; 20.31 MiB free; 22.76 GiB reserved in total by PyTorch) |
| FSDP (配置: min_num_params = 2K) | 5 | 2 | 0.6 | |
| FSDP (配置: min_num_params = 2K + CPU 卸载) | 10 | 1 | 3 | |
| FSDP (配置: min_num_params = 2K + CPU 卸载) | 14 | 2 | 1.16 | |
表 2: GPT-2 XL (1.5B) 模型上的 FSDP 基准测试
从表 2 中,我们可以观察到 DDP (带和不带 fp16) 甚至在 batch size 为 1 的情况下就会出现 CUDA OOM 错误,从而无法运行。而开启了 ZeRO- 阶段 3 的 FSDP 能够以 batch size 为 5 (总 batch size = 10 (5 $\times$ 2) ) 在 2 个 GPU 上运行。当使用 2 个 GPU 时,开启了 CPU 卸载的 FSDP 还能将最大 batch size 进一步增加到每 GPU 14。 **开启了 CPU 卸载的 FSDP 可以在单个 GPU 上训练 GPT-2 1.5B 模型,batch size 为 10**。这使得机器学习从业者能够用最少的计算资源来训练大模型,从而助力大模型训练民主化。
## Accelerate 的 FSDP 集成的功能和限制
下面,我们深入了解以下 Accelerate 对 FSDP 的集成中,支持了那些功能,有什么已知的限制。
**支持 FSDP 所需的 PyTorch 版本**: PyTorch Nightly 或 1.12.0 之后的版本。
**命令行支持的配置:**
1. **分片策略**: [1] FULL_SHARD, [2] SHARD_GRAD_OP
2. **Min Num Params**: FSDP 默认自动包装的最小参数量。
3. **Offload Params**: 是否将参数和梯度卸载到 CPU。
如果想要对更多的控制参数进行配置,用户可以利用 `FullyShardedDataParallelPlugin` ,其可以指定 `auto_wrap_policy` 、 `backward_prefetch` 以及 `ignored_modules` 。
创建该类的实例后,用户可以在创建 Accelerator 对象时把该实例传进去。
有关这些选项的更多信息,请参阅 PyTorch [FullyShardedDataParallel](https://github.com/pytorch/pytorch/blob/0df2e863fbd5993a7b9e652910792bd21a516ff3/torch/distributed/fsdp/filled_sharded_data_parallel.py#L236) 代码。
接下来,我们体会下 `min_num_params` 配置的重要性。以下内容摘自 [8],它详细说明了 FSDP 自动包装策略的重要性。

(图源: [链接](https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html))
当使用 `default_auto_wrap_policy` 时,如果该层的参数量超过 `min_num_params` ,则该层将被包装在一个 FSDP 模块中。官方有一个在 GLUE MRPC 任务上微调 BERT-Large (330M) 模型的示例代码,其完整地展示了如何正确使用 FSDP 功能,其中还包含了用于跟踪峰值内存使用情况的代码。
[fsdp_with_peak_mem_tracking.py](https://github.com/huggingface/accelerate/tree/main/examples/by_feature/fsdp_with_peak_mem_tracking.py)
我们利用 Accelerate 的跟踪功能来记录训练和评估期间的峰值内存使用情况以及模型准确率指标。下图展示了 wandb [实验台](https://wandb.ai/smangrul/FSDP-Test?workspace=user-smangrul) 页面的截图。
我们可以看到,DDP 占用的内存是使用了自动模型包装功能的 FSDP 的两倍。不带自动模型包装的 FSDP 比带自动模型包装的 FSDP 的内存占用更多,但比 DDP 少得多。与 `min_num_params=1M` 时相比, `min_num_params=2k` 时带自动模型包装的 FSDP 占用的内存略少。这凸显了 FSDP 自动模型包装策略的重要性,用户应该调整 `min_num_params` 以找到能显著节省内存又不会导致大量通信开销的设置。如 [8] 中所述,PyTorch 团队也在为此开发自动配置调优工具。
### **需要注意的一些事项**
- PyTorch FSDP 会自动对模型子模块进行包装、将参数摊平并对其进行原位分片。因此,在模型包装之前创建的任何优化器都会被破坏并导致更多的内存占用。因此,强烈建议在对模型调用 `prepare` 方法后再创建优化器,这样效率会更高。对单模型而言,如果没有按照顺序调用的话, `Accelerate` 会抛出以下告警信息,并自动帮你包装模型并创建优化器。
> FSDP Warning: When using FSDP, it is efficient and recommended to call prepare for the model before creating the optimizer
>
即使如此,我们还是推荐用户在使用 FSDP 时用以下方式显式准备模型和优化器:
```diff
model = AutoModelForSequenceClassification.from_pretrained("bert-base-cased", return_dict=True)
+ model = accelerator.prepare(model)
optimizer = torch.optim.AdamW(params=model.parameters(), lr=lr)
- model, optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(model,
- optimizer, train_dataloader, eval_dataloader, lr_scheduler
- )
+ optimizer, train_dataloader, eval_dataloader, lr_scheduler = accelerator.prepare(
+ optimizer, train_dataloader, eval_dataloader, lr_scheduler
+ )
```
- 对单模型而言,如果你的模型有多组参数,而你想为它们设置不同优化器超参。此时,如果你对整个模型统一调用 `prepare` 方法,这些参数的组别信息会丢失,你会看到如下告警信息:
> FSDP Warning: When using FSDP, several parameter groups will be conflated into a single one due to nested module wrapping and parameter flattening.
>
告警信息表明,在使用 FSDP 对模型进行包装后,之前创建的参数组信息丢失了。因为 FSDP 会将嵌套式的模块参数摊平为一维数组 (一个数组可能包含多个子模块的参数)。举个例子,下面是 GPU 0 上 FSDP 模型的有名称的参数 (当使用 2 个 GPU 时,FSDP 会把第一个分片的参数给 GPU 0, 因此其一维数组中大约会有 55M (110M / 2) 个参数)。此时,如果我们在 FSDP 包装前将 BERT-Base 模型的 [bias, LayerNorm.weight] 参数的权重衰减设为 0,则在模型包装后,该设置将无效。原因是,你可以看到下面这些字符串中均已不含这俩参数的名字,这俩参数已经被并入了其他层。想要了解更多细节,可参阅本 [问题](https://github.com/pytorch/pytorch/issues/76501) (其中写道: `原模型参数没有 .grads 属性意味着它们无法单独被优化器优化 (这就是我们为什么不能支持对多组参数设置不同的优化器超参)` )。
```
{
'_fsdp_wrapped_module.flat_param': torch.Size([494209]),
'_fsdp_wrapped_module._fpw_module.bert.embeddings.word_embeddings._fsdp_wrapped_module.flat_param': torch.Size([11720448]),
'_fsdp_wrapped_module._fpw_module.bert.encoder._fsdp_wrapped_module.flat_param': torch.Size([42527232])
}
```
- 如果是多模型情况,须在创建优化器之前调用模型 `prepare` 方法,否则会抛出错误。
- ~~FSDP 目前不支持混合精度,我们正在等待 PyTorch 修复对其的支持。~~
# 工作原理 📝
(图源: [链接](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/))
上述工作流概述了 FSDP 的幕后流程。我们先来了解一下 DDP 是如何工作的,然后再看 FSDP 是如何改进它的。在 DDP 中,每个工作进程 (加速器 / GPU) 都会保留一份模型的所有参数、梯度和优化器状态的副本。每个工作进程会获取不同的数据,这些数据会经过前向传播,计算损失,然后再反向传播以生成梯度。接着,执行 all-reduce 操作,此时每个工作进程从其余工作进程获取梯度并取平均。这样一轮下来,每个工作进程上的梯度都是相同的,且都是全局梯度,接着优化器再用这些梯度来更新模型参数。我们可以看到,每个 GPU 上都保留完整副本会消耗大量的显存,这限制了该方法所能支持的 batch size 以及模型尺寸。
FSDP 通过让各数据并行工作进程分片存储优化器状态、梯度和模型参数来解决这个问题。进一步地,还可以通过将这些张量卸载到 CPU 内存来支持那些 GPU 显存容纳不下的大模型。在具体运行时,与 DDP 类似,FSDP 的每个工作进程获取不同的数据。在前向传播过程中,如果启用了 CPU 卸载,则首先将本地分片的参数搬到 GPU/加速器。然后,每个工作进程对给定的 FSDP 包装模块/层执行 all-gather 操作以获取所需的参数,执行计算,然后释放/清空其他工作进程的参数分片。在对所有 FSDP 模块全部执行该操作后就是计算损失,然后是后向传播。在后向传播期间,再次执行 all-gather 操作以获取给定 FSDP 模块所需的所有参数,执行计算以获得局部梯度,然后再次释放其他工作进程的分片。最后,使用 reduce-scatter 操作对局部梯度进行平均并将相应分片给对应的工作进程,该操作使得每个工作进程都可以更新其本地分片的参数。如果启用了 CPU 卸载的话,梯度会传给 CPU,以便直接在 CPU 上更新参数。
如欲深入了解 PyTorch FSDP 工作原理以及相关实验及其结果,请参阅 [7,8,9]。
# 问题
如果在 accelerate 中使用 PyTorch FSDP 时遇到任何问题,请提交至 [accelerate](https://github.com/huggingface/accelerate/issues)。
但如果你的问题是跟 PyTorch FSDP 配置和部署有关的 - 你需要提交相应的问题至 [PyTorch](https://github.com/pytorch/pytorch/issues)。
# 参考文献
[1] [Train Large, Then Compress: Rethinking Model Size for Efficient Training and Inference of Transformers](http://nlp.cs.berkeley.edu/pubs/Li-Wallace-Shen-Lin-Keutzer-Klein-Gonzalez_2020_Transformers_paper.pdf)
[2] [ZeRO: Memory Optimizations Toward Training Trillion Parameter Models](https://arxiv.org/pdf/1910.02054v3.pdf)
[3] [DeepSpeed: Extreme-scale model training for everyone - Microsoft Research](https://www.microsoft.com/en-us/research/blog/deepspeed-extreme-scale-model-training-for-everyone/)
[4] [Megatron-LM: Training Multi-Billion Parameter Language Models Using
Model Parallelism](https://arxiv.org/pdf/1909.08053.pdf)
[5] [Introducing GPipe, an Open Source Library for Efficiently Training Large-scale Neural Network Models](https://ai.googleblog.com/2019/03/introducing-gpipe-open-source-library.html)
[6] [Which hardware do you need to train a 176B parameters model?](https://bigscience.huggingface.co/blog/which-hardware-to-train-a-176b-parameters-model)
[7] [Introducing PyTorch Fully Sharded Data Parallel (FSDP) API | PyTorch](https://pytorch.org/blog/introducing-pytorch-fully-sharded-data-parallel-api/)
[8] [Getting Started with Fully Sharded Data Parallel(FSDP) — PyTorch Tutorials 1.11.0+cu102 documentation](https://pytorch.org/tutorials/intermediate/FSDP_tutorial.html)
[9] [Training a 1 Trillion Parameter Model With PyTorch Fully Sharded Data Parallel on AWS | by PyTorch | PyTorch | Mar, 2022 | Medium](https://medium.com/pytorch/training-a-1-trillion-parameter-model-with-pytorch-fully-sharded-data-parallel-on-aws-3ac13aa96cff)
[10] [Fit More and Train Faster With ZeRO via DeepSpeed and FairScale](https://huggingface.co/blog/zero-deepspeed-fairscale) | 3 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/getting-started-habana.md | ---
title: 基于 Habana Gaudi 的 Transformers 入门
thumbnail: /blog/assets/61_getting_started_habana/habana01.png
authors:
- user: juliensimon
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 基于 Habana Gaudi 的 Transformers 入门
几周前,我们很高兴地 [宣布](https://huggingface.co/blog/zh/habana) [Habana Labs](https://habana.ai) 和 [Hugging Face](https://huggingface.co/) 将开展加速 transformer 模型的训练方面的合作。
与最新的基于 GPU 的 Amazon Web Services (AWS) EC2 实例相比,Habana Gaudi 加速卡在训练机器学习模型方面的性价比提高了 40%。我们非常高兴将这种性价比优势引入 Transformers 🚀。
本文,我将手把手向你展示如何在 AWS 上快速设置 Habana Gaudi 实例,并用其微调一个用于文本分类的 BERT 模型。与往常一样,我们提供了所有代码,以便你可以在自己的项目中重用它们。
我们开始吧!
## 在 AWS 上设置 Habana Gaudi 实例
使用 Habana Gaudi 加速卡的最简单方法是启动一个 AWS EC2 [DL1](https://aws.amazon.com/ec2/instance-types/dl1/) 实例。该实例配备 8 张 Habana Gaudi 加速卡,借助 [Habana 深度学习镜像 (Amazon Machine Image,AMI) ](https://aws.amazon.com/marketplace/server/procurement?productId=9a75c51a-a4d1-4470-884f-6be27933fcc8),我们可以轻松把它用起来。该 AMI 预装了 [Habana SynapseAI® SDK](https://developer.habana.ai/) 以及运行 Gaudi 加速的 Docker 容器所需的工具。如果你想使用其他 AMI 或容器,请参阅 [Habana 文档](https://docs.habana.ai/en/latest/AWS_Quick_Starts/index.html) 中的说明。
我首先登陆 `us-east-1` 区域的 [EC2 控制台](https://console.aws.amazon.com/ec2sp/v2/),然后单击 **启动实例** 并给实例起个名字 (我用的是 “habana-demo-julsimon”)。
然后,我在 Amazon Marketplace 中搜索 Habana AMI。
<kbd>
<img src="/blog/assets/61_getting_started_habana/habana01.png">
</kbd>
这里,我选择了 Habana Deep Learning Base AMI (Ubuntu 20.04)。
<kbd>
<img src="/blog/assets/61_getting_started_habana/habana02.png">
</kbd>
接着,我选择了 _dl1.24xlarge_ 实例 (实际上这是唯一可选的实例)。
<kbd>
<img src="/blog/assets/61_getting_started_habana/habana03.png">
</kbd>
接着是选择 `ssh` 密钥对。如果你没有密钥对,可以就地创建一个。
<kbd>
<img src="/blog/assets/61_getting_started_habana/habana04.png">
</kbd>
下一步,要确保该实例允许接受 `ssh` 传输。为简单起见,我并未限制源地址,但你绝对应该在你的帐户中设置一下,以防止被恶意攻击。
<kbd>
<img src="/blog/assets/61_getting_started_habana/habana05.png">
</kbd>
默认情况下,该 AMI 将启动一个具有 8GB Amazon EBS 存储的实例。但这对我来说可能不够,因此我将存储空间增加到 50GB。
<kbd>
<img src="/blog/assets/61_getting_started_habana/habana08.png">
</kbd>
接下来,我需要为该实例分配一个 Amazon IAM 角色。在实际项目中,此角色应具有运行训练所需的最低权限组合,例如从 Amazon S3 存储桶中读取数据的权限。但在本例中,我们不需要这个角色,因为数据集是从 Hugging Face Hub 上下载的。如果您不熟悉 IAM,强烈建议阅读这个 [入门](https://docs.aws.amazon.com/IAM/latest/UserGuide/getting-started.html) 文档。
然后,我要求 EC2 将我的实例配置为 [Spot 实例](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/using-spot-instances.html),这可以帮我降低每小时使用成本 (非 Spot 实例每小时要 13.11 美元)。
<kbd>
<img src="/blog/assets/61_getting_started_habana/habana06.png">
</kbd>
最后,启动实例。几分钟后,实例已准备就绪,我可以使用 `ssh` 连上它了。Windows 用户可以按照 [文档](https://docs.aws.amazon.com/AWSEC2/latest/UserGuide/putty.html) 使用 _PuTTY_ 来连接。
```
ssh -i ~/.ssh/julsimon-keypair.pem [email protected]
```
在实例中,最后一步是拉取一个 Habana PyTorch 容器,我后面会用 PyTorch 来微调模型。你可以在 Habana [文档](https://docs.habana.ai/en/latest/Installation_Guide/index.html) 中找到有关其他预构建容器以及如何构建自己的容器的信息。
```
docker pull \
vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
```
将 docker 镜像拉到实例后,我就可以用交互模式运行它。
```
docker run -it \
--runtime=habana \
-e HABANA_VISIBLE_DEVICES=all \
-e OMPI_MCA_btl_vader_single_copy_mechanism=none \
--cap-add=sys_nice \
--net=host \
--ipc=host vault.habana.ai/gaudi-docker/1.5.0/ubuntu20.04/habanalabs/pytorch-installer-1.11.0:1.5.0-610
```
至此,我就准备好可以微调模型了。
## 在 Habana Gaudi 上微调文本分类模型
首先,在刚刚启动的容器内拉取 [Optimum Habana](https://github.com/huggingface/optimum-habana) 存储库。
```
git clone https://github.com/huggingface/optimum-habana.git
```
然后,从源代码安装 Optimum Habana 软件包。
```
cd optimum-habana
pip install .
```
接着,切到包含文本分类示例的子目录并安装所需的 Python 包。
```
cd examples/text-classification
pip install -r requirements.txt
```
现在可以启动训练了,训练脚本首先从 Hugging Face Hub 下载 [bert-large-uncased-whole-word-masking](https://huggingface.co/bert-large-uncased-whole-word-masking) 模型,然后在 [GLUE](https://gluebenchmark.com/) 基准的 [MRPC](https://www.microsoft.com/en-us/download/details.aspx?id=52398) 任务上对其进行微调。
请注意,我用于训练的 BERT 配置是从 Hugging Face Hub 获取的,你也可以使用自己的配置。此外,Gaudi1 还支持其他流行的模型,你可以在 [Habana 的网页上](https://huggingface.co/Habana) 中找到它们的配置文件。
```
python run_glue.py \
--model_name_or_path bert-large-uncased-whole-word-masking \
--gaudi_config_name Habana/bert-large-uncased-whole-word-masking \
--task_name mrpc \
--do_train \
--do_eval \
--per_device_train_batch_size 32 \
--learning_rate 3e-5 \
--num_train_epochs 3 \
--max_seq_length 128 \
--use_habana \
--use_lazy_mode \
--output_dir ./output/mrpc/
```
2 分 12 秒后,训练完成,并获得了 0.9181 的 F1 分数,相当不错。你还可以增加 epoch 数,F1 分数肯定会随之继续提高。
```
***** train metrics *****
epoch = 3.0
train_loss = 0.371
train_runtime = 0:02:12.85
train_samples = 3668
train_samples_per_second = 82.824
train_steps_per_second = 2.597
***** eval metrics *****
epoch = 3.0
eval_accuracy = 0.8505
eval_combined_score = 0.8736
eval_f1 = 0.8968
eval_loss = 0.385
eval_runtime = 0:00:06.45
eval_samples = 408
eval_samples_per_second = 63.206
eval_steps_per_second = 7.901
```
最后一步但也是相当重要的一步,用完后别忘了终止 EC2 实例以避免不必要的费用。查看 EC2 控制台中的 [Saving Summary](https://console.aws.amazon.com/ec2sp/v2/home/spot),我发现由于使用 Spot 实例,我节省了 70% 的成本,每小时支付的钱从原先的 13.11 美元降到了 3.93 美元。
<kbd>
<img src="/blog/assets/61_getting_started_habana/habana07.png">
</kbd>
如你所见,Transformers、Habana Gaudi 和 AWS 实例的组合功能强大、简单且经济高效。欢迎大家尝试,如果有任何想法,欢迎大家在 [Hugging Face 论坛](https://discuss.huggingface.co/) 上提出问题和反馈。
---
_如果你想了解更多有关在 Gaudi 上训练 Hugging Face 模型的信息,请 [联系 Habana](https://developer.habana.ai/accelerate-transformer-training-on-habana-gaudi-processors-with-hugging-face/)。_ | 4 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/cloudflare-workers-ai.md | ---
title: "为 Hugging Face 用户带来无服务器 GPU 推理服务"
thumbnail: /blog/assets/cloudflare-workers-ai/thumbnail.jpg
authors:
- user: philschmid
- user: jeffboudier
- user: rita3ko
guest: true
- user: nkothariCF
guest: true
translators:
- user: chenglu
---
# 为 Hugging Face 用户带来无服务器 GPU 推理服务
今天,我们非常兴奋地宣布 **部署到 Cloudflare Workers AI** 功能正式上线,这是 Hugging Face Hub 平台上的一项新服务,它使得通过 Cloudflare 边缘数据中心部署的先进 GPU、轻松使用开放模型作为无服务器 API 成为可能。
从今天开始,我们将把 Hugging Face 上一些最受欢迎的开放模型整合到 Cloudflare Workers AI 中,这一切都得益于我们的生产环境部署的解决方案,例如 [文本生成推理 (TGI)](https://github.com/huggingface/text-generation-inference/)。
通过 **部署到 Cloudflare Workers AI** 服务,开发者可以在无需管理 GPU 基础架构和服务器的情况下,以极低的运营成本构建强大的生成式 AI(Generative AI)应用,你只需 **为实际计算消耗付费,无需为闲置资源支付费用**。
## 开发者的生成式 AI 工具
这项新服务基于我们去年与 Cloudflare 共同宣布的 [战略合作伙伴关系](https://blog.cloudflare.com/zh-cn/partnering-with-hugging-face-deploying-ai-easier-affordable-zh-cn/)——简化开放生成式 AI 模型的访问与部署过程。开发者和机构们共同面临着一个主要的问题——GPU 资源稀缺及部署服务器的固定成本。
Cloudflare Workers AI 上的部署提供了一个简便、低成本的解决方案,通过 [按请求计费模式](https://developers.cloudflare.com/workers-ai/platform/pricing),为这些挑战提出了一个无服务器访问、运行的 Hugging Face 模型的解决方案。
举个具体例子,假设你开发了一个 RAG 应用,每天大约处理 1000 个请求,每个请求包含 1000 个 Token 输入和 100 个 Token 输出,使用的是 Meta Llama 2 7B 模型。这样的 LLM 推理生产成本约为每天 1 美元。
> 我们很高兴能够这么快地实现这一集成。将 Cloudflare 全球网络中的无服务器 GPU 能力,与 Hugging Face 上最流行的开源模型结合起来,将为我们全球社区带来大量激动人心的创新。
>
> John Graham-Cumming,Cloudflare 首席技术官
## 使用方法
在 Cloudflare Workers AI 上使用 Hugging Face 模型非常简单。下面是一个如何在 Nous Research 最新模型 Mistral 7B 上使用 Hermes 2 Pro 的逐步指南。
你可以在 [Cloudflare Collection](https://huggingface.co/collections/Cloudflare/hf-curated-models-available-on-workers-ai-66036e7ad5064318b3e45db6) 中找到所有可用的模型。
> 注意:你需要拥有 [Cloudflare 账户](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/) 和 [API 令牌](https://dash.cloudflare.com/profile/api-tokens)。
你可以在所有支持的模型页面上找到“部署到 Cloudflare”的选项,包括如 Llama、Gemma 或 Mistral 等模型。
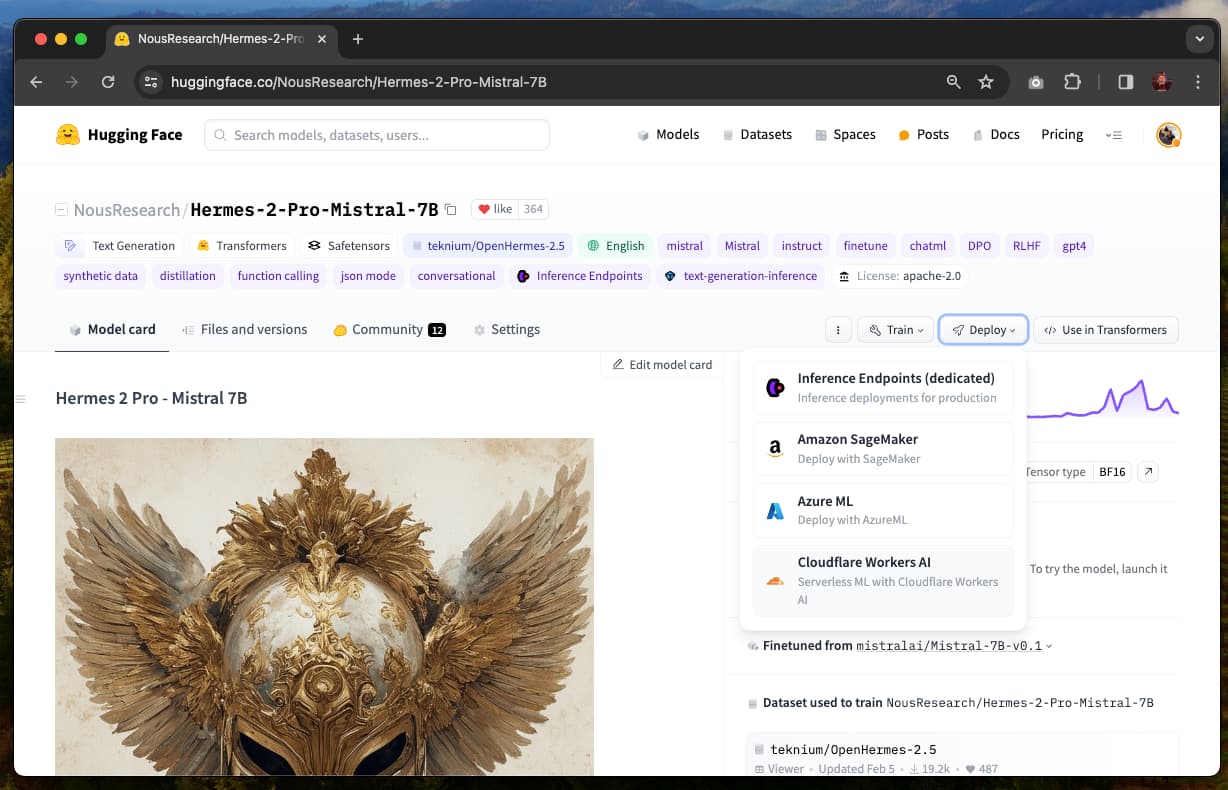
打开“部署”菜单,选择“Cloudflare Workers AI”,这将打开一个包含如何使用此模型和发送请求指南的界面。
> 注意:如果你希望使用的模型没有“Cloudflare Workers AI”选项,意味着它目前不支持。我们正与 Cloudflare 合作扩展模型的可用性。你可以通过 [[email protected]](mailto:[email protected]) 联系我们,提交你的请求。
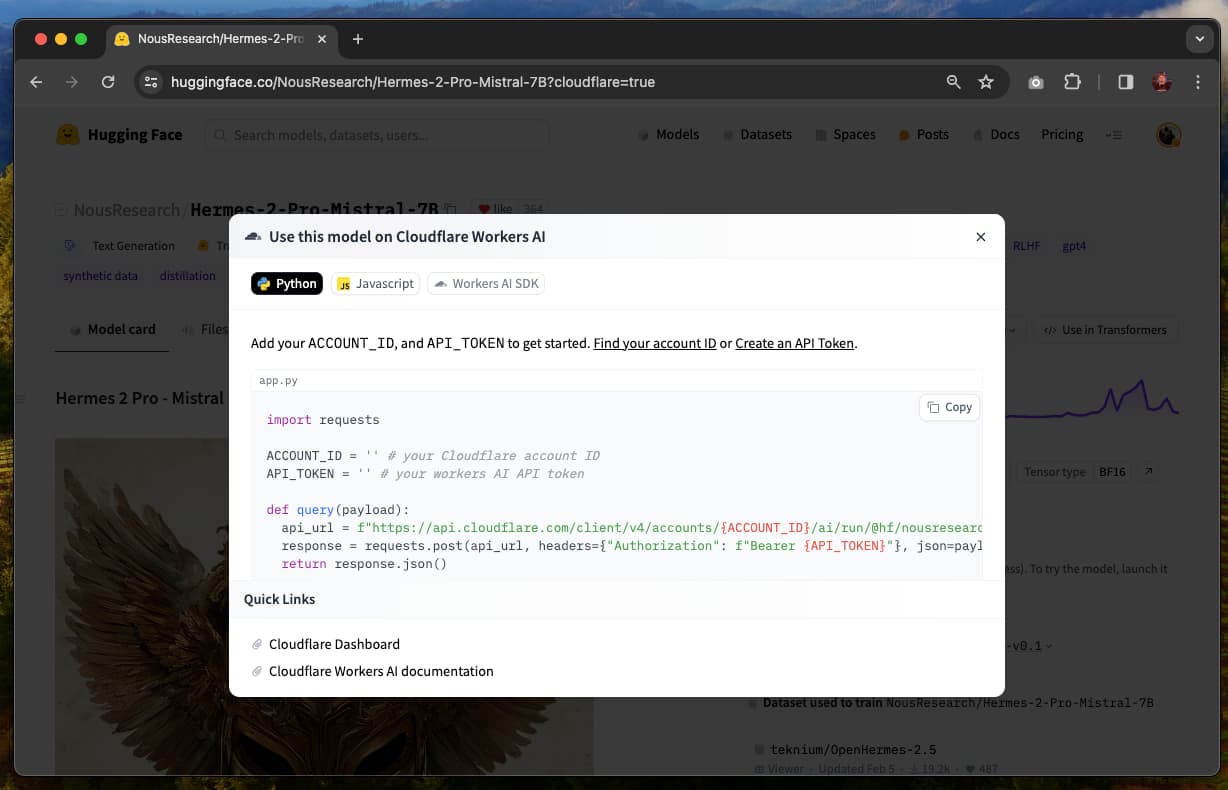
当前有两种方式可以使用此集成:通过 [Workers AI REST API](https://developers.cloudflare.com/workers-ai/get-started/rest-api/) 或直接在 Workers 中使用 [Cloudflare AI SDK](https://developers.cloudflare.com/workers-ai/get-started/workers-wrangler/#1-create-a-worker-project)。选择你偏好的方式并将代码复制到你的环境中。当使用 REST API 时,需要确保已定义 <code>[ACCOUNT_ID](https://developers.cloudflare.com/fundamentals/setup/find-account-and-zone-ids/)</code> 和 <code>[API_TOKEN](https://dash.cloudflare.com/profile/api-tokens)</code> 变量。
就这样!现在你可以开始向托管在 Cloudflare Workers AI 上的 Hugging Face 模型发送请求。请确保使用模型所期望的正确提示与模板。
## 我们的旅程刚刚开始
我们很高兴能与 Cloudflare 合作,让 AI 技术更加易于开发者访问。我们将与 Cloudflare 团队合作,为你带来更多模型和体验! | 5 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/optimum-onnxruntime-training.md | ---
title: "Optimum + ONNX Runtime: 更容易、更快地训练你的 Hugging Face 模型"
thumbnail: /blog/assets/optimum_onnxruntime-training/thumbnail.png
authors:
- user: Jingya
- user: kshama-msft
guest: true
- user: askhade
guest: true
- user: weicwang
guest: true
- user: zhijiang
guest: true
translators:
- user: AIBoy1993
---
# Optimum + ONNX Runtime: 更容易、更快地训练你的 Hugging Face 模型
## 介绍
基于语言、视觉和语音的 Transformer 模型越来越大,以支持终端用户复杂的多模态用例。增加模型大小直接影响训练这些模型所需的资源,并随着模型大小的增加而扩展它们。Hugging Face 和微软的 ONNX Runtime 团队正在一起努力,在微调大型语言、语音和视觉模型方面取得进步。Hugging Face 的 [🤗 Optimum 库](https://huggingface.co/docs/optimum/index),通过和 ONNX Runtime 的集成进行训练,为许多流行的 Hugging Face 模型提供了一个开放的解决方案,可以将**训练时间缩短 35% 或更多**。我们展现了 Hugging Face Optimum 和 ONNX Runtime Training 生态系统的细节,性能数据突出了使用 Optimum 库的好处。
## 性能测试结果
下面的图表表明,当**使用 ONNX Runtime 和 DeepSpeed ZeRO Stage 1**进行训练时,用 Optimum 的 Hugging Face 模型的加速**从 39% 提高到 130%**。性能测试的基准运行是在选定的 Hugging Face PyTorch 模型上进行的,第二次运行是只用 ONNX Runtime 训练,最后一次运行是 ONNX Runtime + DeepSpeed ZeRO Stage 1,图中显示了最大的收益。基线 PyTorch 运行所用的优化器是 AdamW Optimizer,ORT 训练用的优化器是 Fused Adam Optimizer。这些运行是在带有 8 个 GPU 的单个 NVIDIA A100 节点上执行的。
<figure class="image table text-center m-0 w-full">
<img src="../assets/optimum_onnxruntime-training/onnxruntime-training-benchmark.png" alt="Optimum-onnxruntime Training Benchmark"/>
</figure>
更多关于开启 🤗 Optimum 进行训练加速的配置细节可以在[指南](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/trainer)中找到。用于这些运行的版本信息如下:
```
PyTorch: 1.14.0.dev20221103+cu116; ORT: 1.14.0.dev20221103001+cu116; DeepSpeed: 0.6.6; HuggingFace: 4.24.0.dev0; Optimum: 1.4.1.dev0; Cuda: 11.6.2
```
## Optimum 库
Hugging Face 是一个快速发展的开放社区和平台,旨在将优秀的机器学习大众化。随着 [🤗 Transformers 库](https://huggingface.co/docs/transformers/index) 的成功,我们将模态从 NLP 扩展到音频和视觉,现在涵盖了跨机器学习的用例,以满足我们社区的需求。现在在 [Hugging Face Hub](https://huggingface.co/models) 上,有超过 12 万个免费和可访问的模型 checkpoints 用于各种机器学习任务,1.8 万个数据集和 2 万个机器学习演示应用。然而,将 Transformer 模型扩展到生产中仍然是工业界的一个挑战。尽管准确性很高,但基于 Transformer 的模型的训练和推理可能耗时且昂贵。
为了满足这些需求,Hugging Face 构建了两个开源库: **🤗 Accelerate** 和 **🤗 Optimum**。[🤗 Accelerate](https://huggingface.co/docs/accelerate/index) 专注于开箱即用的分布式训练,而 [🤗 Optimum](https://huggingface.co/docs/optimum/index) 作为 Transformer 的扩展,通过利用用户目标硬件的最大效率来加速模型训练和推理。Optimum 集成了机器学习加速器如 ONNX Runtime,和专业的硬件如英特尔的 [Habana Gaudi](https://huggingface.co/blog/habana-gaudi-2-benchmark),因此用户可以从训练和推理的显著加速中受益。此外,🤗 Optimum 无缝集成了其他 Hugging Face 的工具,同时继承了 Transformer 的易用性。开发人员可以轻松地调整他们的工作,以更少的计算能力实现更低的延迟。
## ONNX Runtime 训练
[ONNX Runtime](https://onnxruntime.ai/) 加速[大型模型训练](https://onnxruntime.ai/docs/get-started/training-pytorch.html),单独使用时将吞吐量提高40%,与 [DeepSpeed](https://www.deepspeed.ai/tutorials/zero/) 组合后将吞吐量提高130%,用于流行的基于 Hugging Face Transformer 的模型。ONNX Runtime 已经集成为 🤗 Optimum 的一部分,并通过 Hugging Face 的 🤗 Optimum 训练框架实现更快的训练。
ONNX Runtime Training 通过一些内存和计算优化实现了这样的吞吐量改进。内存优化使 ONNX Runtime 能够最大化批大小并有效利用可用的内存,而计算优化则加快了训练时间。这些优化包括但不限于,高效的内存规划,内核优化,适用于 Adam 优化器的多张量应用 (将应用于所有模型参数的按元素更新分批到一个或几个内核启动中),FP16 优化器 (消除了大量用于主机内存拷贝的设备),混合精度训练和图优化,如节点融合和节点消除。ONNX Runtime Training 支持 [NVIDIA](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/accelerate-pytorch-transformer-model-training-with-onnx-runtime/ba-p/2540471) 和 [AMD GPU](https://cloudblogs.microsoft.com/opensource/2021/07/13/onnx-runtime-release-1-8-1-previews-support-for-accelerated-training-on-amd-gpus-with-the-amd-rocm-open-software-platform/),并提供自定义操作的可扩展性。
简而言之,它使 AI 开发人员能够充分利用他们熟悉的生态系统,如 PyTorch 和 Hugging Face,并在他们选择的目标设备上使用 ONNX Runtime 进行加速,以节省时间和资源。
## Optimum 中的 ONNX Runtime Training
Optimum 提供了一个 `ORTTrainer` API,它扩展了 Transformer 中的 `Trainer`,以使用 ONNX Runtime 作为后端进行加速。`ORTTrainer` 是一个易于使用的 API,包含完整的训练循环和评估循环。它支持像超参数搜索、混合精度训练和多 GPU 分布式训练等功能。`ORTTrainer` 使 AI 开发人员在训练 Transformer 模型时能够组合 ONNX Runtime 和其他第三方加速技术,这有助于进一步加速训练,并充分发挥硬件的作用。例如,开发人员可以将 ONNX Runtime Training 与 Transformer 训练器中集成的分布式数据并行和混合精度训练相结合。此外,`ORTTrainer` 使你可以轻松地将 DeepSpeed ZeRO-1 和 ONNX Runtime Training 组合,通过对优化器状态进行分区来节省内存。在完成预训练或微调后,开发人员可以保存已训练的 PyTorch 模型,或使用 🤗 Optimum 实现的 API 将其转为 ONNX 格式,以简化推理的部署。和 `Trainer` 一样,`ORTTrainer` 与 Hugging Face Hub 完全集成: 训练结束后,用户可以将他们的模型 checkpoints 上传到 Hugging Face Hub 账户。
因此具体来说,用户应该如何利用 ONNX Runtime 加速进行训练?如果你已经在使用 `Trainer`,你只需要修改几行代码就可以从上面提到的所有改进中受益。主要有两个替换需要应用。首先,将 `Trainer` 替换为 `ORTTrainer``,然后将 `TrainingArguments` 替换为 `ORTTrainingArguments`,其中包含训练器将用于训练和评估的所有超参数。`ORTTrainingArguments` 扩展了 `TrainingArguments`,以应用 ONNX Runtime 授权的一些额外参数。例如,用户可以使用 Fused Adam 优化器来获得额外的性能收益。下面是一个例子:
```diff
-from transformers import Trainer, TrainingArguments
+from optimum.onnxruntime import ORTTrainer, ORTTrainingArguments
# Step 1: Define training arguments
-training_args = TrainingArguments(
+training_args = ORTTrainingArguments(
output_dir="path/to/save/folder/",
- optim = "adamw_hf",
+ optim = "adamw_ort_fused",
...
)
# Step 2: Create your ONNX Runtime Trainer
-trainer = Trainer(
+trainer = ORTTrainer(
model=model,
args=training_args,
train_dataset=train_dataset,
+ feature="sequence-classification",
...
)
# Step 3: Use ONNX Runtime for training!🤗
trainer.train()
```
## 展望未来
Hugging Face 团队正在开源更多的大型模型,并通过训练和推理的加速工具以降低用户从模型中获益的门槛。我们正在与 ONNX Runtime Training 团队合作,为更新和更大的模型架构带来更多的训练优化,包括 Whisper 和 Stable Diffusion。微软还将其最先进的训练加速技术打包在 [PyTorch 的 Azure 容器](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/enabling-deep-learning-with-azure-container-for-pytorch-in-azure/ba-p/3650489)中。这是一个轻量级的精心营造的环境,包括 DeepSpeed 和 ONNX Runtime,以提高 AI 开发者使用 PyTorch 训练的生产力。除了大型模型训练外,ONNX Runtime Training 团队还在为边缘学习构建新的解决方案——在内存和电源受限的设备上进行训练。
## 准备开始
我们邀请你查看下面的链接,以了解更多关于 Hugging Face 模型的 Optimum ONNX Runtime Training,并开始使用。
* [Optimum ONNX Runtime Training 文档](https://huggingface.co/docs/optimum/onnxruntime/usage_guides/trainer)
* [Optimum ONNX Runtime Training 示例](https://github.com/huggingface/optimum/tree/main/examples/onnxruntime/training)
* [Optimum Github 仓库](https://github.com/huggingface/optimum/tree/main)
* [ONNX Runtime Training 示例](https://github.com/microsoft/onnxruntime-training-examples/)
* [ONNX Runtime Training Github 仓库](https://github.com/microsoft/onnxruntime/tree/main/orttraining)
* [ONNX Runtime](https://onnxruntime.ai/)
* [DeepSpeed](https://www.deepspeed.ai/) 和 [ZeRO](https://www.deepspeed.ai/tutorials/zero/) 教程
* [PyTorch 的 Azure 容器](https://techcommunity.microsoft.com/t5/ai-machine-learning-blog/enabling-deep-learning-with-azure-container-for-pytorch-in-azure/ba-p/3650489)
🏎感谢阅读!如果你有任何问题,请通过 [Github](https://github.com/huggingface/optimum/issues) 或[论坛](https://discuss.huggingface.co/c/optimum/)随时联系我们。你也可以在 [Twitter](https://twitter.com/Jhuaplin) 或 [LinkedIn](https://www.linkedin.com/in/jingya-huang-96158b15b/) 上联系我。
| 6 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/leaderboard-medicalllm.md | ---
title: "开源医疗大模型排行榜:健康领域大模型基准测试"
thumbnail: /blog/assets/leaderboards-on-the-hub/thumbnail_medicalllm.png
authors:
- user: aaditya
guest: true
- user: pminervini
guest: true
- user: clefourrier
translators:
- user: innovation64
- user: zhongdongy
proofreader: true
---
# 开源医疗大模型排行榜: 健康领域大模型基准测试

多年来,大型语言模型 (LLMs) 已经发展成为一项具有巨大潜力,能够彻底改变医疗行业各个方面的开创性技术。这些模型,如 [GPT-3](https://arxiv.org/abs/2005.14165),[GPT-4](https://arxiv.org/abs/2303.08774) 和 [Med-PaLM 2](https://arxiv.org/abs/2305.09617),在理解和生成类人文本方面表现出了卓越的能力,使它们成为处理复杂医疗任务和改善病人护理的宝贵工具。它们在多种医疗应用中显示出巨大的前景,如医疗问答 (QA) 、对话系统和文本生成。此外,随着电子健康记录 (EHRs) 、医学文献和病人生成数据的指数级增长,LLMs 可以帮助医疗专业人员提取宝贵见解并做出明智的决策。
然而,尽管大型语言模型 (LLMs) 在医疗领域具有巨大的潜力,但仍存在一些重要且具体的挑战需要解决。
当模型用于娱乐对话方面时,错误的影响很小; 然而,在医疗领域使用时,情况并非如此,错误的解释和答案可能会对病人的护理和结果产生严重后果。语言模型提供的信息的准确性和可靠性可能是生死攸关的问题,因为它可能影响医疗决策、诊断和治疗计划。
例如,当有人问 GPT-3 关于孕妇可以用什么药的问题时,GPT-3 错误地建议使用四环素,尽管它也正确地说明了四环素对胎儿有害,孕妇不应该用。如果真按照这个错误的建议去给孕妇用药,可能会害得孩子将来骨头长不好。
](https://github.com/monk1337/research_assets/blob/main/huggingface_blog/gpt_medicaltest.png?raw=true)
要想在医疗领域用好这种大型语言模型,就得根据医疗行业的特点来设计和基准测试这些模型。因为医疗数据和应用有其特殊的地方,得考虑到这些。而且,开发方法来评估这些用于医疗的模型不只是为了研究,而是因为它们在现实医疗工作中用错了可能会带来风险,所以这事儿实际上很重要。
<script type="module" src="https://gradio.s3-us-west-2.amazonaws.com/4.20.1/gradio.js"> </script>
<gradio-app theme_mode="light" space="openlifescienceai/open_medical_llm_leaderboard"></gradio-app>
开源医疗大模型排行榜旨在通过提供一个标准化的平台来评估和比较各种大型语言模型在多种医疗任务和数据集上的性能,以此来解决这些挑战和限制。通过提供对每个模型的医疗知识和问答能力的全面评估,该排行榜促进了更有效、更可靠的医疗大模型的发展。
这个平台使研究人员和从业者能够识别不同方法的优势和不足,推动该领域的进一步发展,并最终有助于改善患者的治疗结果。
## 数据集、任务和评估设置
医疗大模型排行榜包含多种任务,并使用准确度作为其主要评估指标 (准确度衡量的是语言模型在各个医疗问答数据集中提供的正确答案的百分比)。
### MedQA
[MedQA](https://arxiv.org/abs/2009.13081) 数据集包含来自美国医学执照考试 (USMLE) 的多项选择题。它覆盖了广泛的医学知识,并包括 11,450 个训练集问题和 1,273 个测试集问题。每个问题有 4 或 5 个答案选项,该数据集旨在评估在美国获得医学执照所需的医学知识和推理技能。

### MedMCQA
[MedMCQA](https://proceedings.mlr.press/v174/pal22a.html) 是一个大规模的多项选择问答数据集,来源于印度的医学入学考试 (AIIMS/NEET)。它涵盖了 2400 个医疗领域主题和 21 个医学科目,训练集中有超过 187,000 个问题,测试集中有 6,100 个问题。每个问题有 4 个答案选项,并附有解释。MedMCQA 评估模型的通用医学知识和推理能力。

### PubMedQA
[PubMedQA](https://aclanthology.org/D19-1259/) 是一个封闭领域的问答数据集,每个问题都可以通过查看相关上下文 ( PubMed 摘要) 来回答。它包含 1,000 个专家标注的问题 - 答案对。每个问题都附有 PubMed 摘要作为上下文,任务是提供基于摘要信息的是/否/也许答案。该数据集分为 500 个训练问题和 500 个测试问题。PubMedQA 评估模型理解和推理科学生物医学文献的能力。

### MMLU 子集 (医学和生物学)
[MMLU 基准](https://arxiv.org/abs/2009.03300) (测量大规模多任务语言理解) 包含来自各个领域多项选择题。对于开源医疗大模型排行榜,我们关注与医学知识最相关的子集:
- 临床知识: 265 个问题,评估临床知识和决策技能。
- 医学遗传学: 100 个问题,涵盖医学遗传学相关主题。
- 解剖学: 135 个问题,评估人体解剖学知识。
- 专业医学: 272 个问题,评估医疗专业人员所需的知识。
- 大学生物学: 144 个问题,涵盖大学水平的生物学概念。
- 大学医学: 173 个问题,评估大学水平的医学知识。
每个 MMLU 子集都包含有 4 个答案选项的多项选择题,旨在评估模型对特定医学和生物领域理解。

开源医疗大模型排行榜提供了一个鲁棒的评估,衡量模型在医学知识和推理各方面的表现。
## 洞察与分析
开源医疗大模型排行榜评估了各种大型语言模型 (LLMs) 在一系列医疗问答任务上的表现。以下是我们的一些关键发现:
- 商业模型如 GPT-4-base 和 Med-PaLM-2 在各个医疗数据集上始终获得高准确度分数,展现了在不同医疗领域中的强劲性能。
- 开源模型,如 [Starling-LM-7B](https://huggingface.co/Nexusflow/Starling-LM-7B-beta),[gemma-7b](https://huggingface.co/google/gemma-7b),Mistral-7B-v0.1 和 [Hermes-2-Pro-Mistral-7B](https://huggingface.co/NousResearch/Hermes-2-Pro-Mistral-7B),尽管参数量大约只有 70 亿,但在某些数据集和任务上展现出了有竞争力的性能。
- 商业和开源模型在理解和推理科学生物医学文献 (PubMedQA) 以及应用临床知识和决策技能 (MMLU 临床知识子集) 等任务上表现良好。
](https://github.com/monk1337/research_assets/blob/main/huggingface_blog/model_evals.png?raw=true)
谷歌的模型 [Gemini Pro](https://arxiv.org/abs/2312.11805) 在多个医疗领域展现了强大的性能,特别是在生物统计学、细胞生物学和妇产科等数据密集型和程序性任务中表现尤为出色。然而,它在解剖学、心脏病学和皮肤病学等关键领域表现出中等至较低的性能,揭示了需要进一步改进以应用于更全面的医学的差距。
](https://github.com/monk1337/research_assets/blob/main/huggingface_blog/subjectwise_eval.png?raw=true)
## 提交你的模型以供评估
要在开源医疗大模型排行榜上提交你的模型进行评估,请按照以下步骤操作:
**1. 将模型权重转换为 Safetensors 格式**
首先,将你的模型权重转换为 safetensors 格式。Safetensors 是一种新的存储权重的格式,加载和使用起来更安全、更快。将你的模型转换为这种格式还将允许排行榜在主表中显示你模型的参数数量。
**2. 确保与 AutoClasses 兼容**
在提交模型之前,请确保你可以使用 Transformers 库中的 AutoClasses 加载模型和分词器。使用以下代码片段来测试兼容性:
```python
from transformers import AutoConfig, AutoModel, AutoTokenizer
config = AutoConfig.from_pretrained(MODEL_HUB_ID)
model = AutoModel.from_pretrained("your model name")
tokenizer = AutoTokenizer.from_pretrained("your model name")
```
如果在这一步失败,请根据错误消息在提交之前调试你的模型。很可能你的模型上传不当。
**3. 将你的模型公开**
确保你的模型可以公开访问。排行榜无法评估私有模型或需要特殊访问权限的模型。
**4. 远程代码执行 (即将推出)**
目前,开源医疗大模型排行榜不支持需要 `use_remote_code=True` 的模型。然而,排行榜团队正在积极添加这个功能,敬请期待更新。
**5. 通过排行榜网站提交你的模型**
一旦你的模型转换为 safetensors 格式,与 AutoClasses 兼容,并且可以公开访问,你就可以使用开源医疗大模型排行榜网站上的 “在此提交!” 面板进行评估。填写所需信息,如模型名称、描述和任何附加细节,然后点击提交按钮。
排行榜团队将处理你的提交并评估你的模型在各个医疗问答数据集上的表现。评估完成后,你的模型的分数将被添加到排行榜中,你可以将它的性能与其他模型进行比较。
## 下一步是什么?扩展开源医疗大模型排行榜
开源医疗大模型排行榜致力于扩展和适应,以满足研究社区和医疗行业不断变化的需求。重点领域包括:
1. 通过与研究人员、医疗组织和行业合作伙伴的合作,纳入更广泛的医疗数据集,涵盖医疗的各个方面,如放射学、病理学和基因组学。
2. 通过探索准确性以外的其他性能衡量标准,如点对点得分和捕捉医疗应用独特需求的领域特定指标,来增强评估指标和报告能力。
3. 在这个方向上已经有一些工作正在进行中。如果你有兴趣合作我们计划提出的下一个基准,请加入我们的 [ Discord 社区](https://discord.gg/A5Fjf5zC69) 了解更多并参与其中。我们很乐意合作并进行头脑风暴!
如果你对 AI 和医疗的交叉领域充满热情,为医疗领域构建模型,并且关心医疗大模型的安全和幻觉问题,我们邀请你加入我们在 [Discord 上的活跃社区](https://discord.gg/A5Fjf5zC69)。
## 致谢

特别感谢所有帮助实现这一目标的人,包括 Clémentine Fourrier 和 Hugging Face 团队。我要感谢 Andreas Motzfeldt、Aryo Gema 和 Logesh Kumar Umapathi 在排行榜开发过程中提供的讨论和反馈。衷心感谢爱丁堡大学的 Pasquale Minervini 教授提供的时间、技术协助和 GPU 支持。
## 关于开放生命科学 AI
开放生命科学 AI 是一个旨在彻底改变人工智能在生命科学和医疗领域应用的项目。它作为一个中心枢纽,列出了医疗模型、数据集、基准测试和跟踪会议截止日期,促进在 AI 辅助医疗领域的合作、创新和进步。我们努力将开放生命科学 AI 建立为对 AI 和医疗交叉领域感兴趣的任何人的首选目的地。我们为研究人员、临床医生、政策制定者和行业专家提供了一个平台,以便进行对话、分享见解和探索该领域的最新发展。

## 引用
如果你觉得我们的评估有用,请考虑引用我们的工作
**医疗大模型排行榜**
```
@misc{Medical-LLM Leaderboard,
author = {Ankit Pal, Pasquale Minervini, Andreas Geert Motzfeldt, Aryo Pradipta Gema and Beatrice Alex},
title = {openlifescienceai/open_medical_llm_leaderboard},
year = {2024},
publisher = {Hugging Face},
howpublished = "\url{https://huggingface.co/spaces/openlifescienceai/open_medical_llm_leaderboard}"
}
``` | 7 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/smollm.md | ---
title: SmolLM:一个超快速、超高性能的小模型集合
thumbnail: /blog/assets/smollm/banner.png
authors:
- user: loubnabnl
- user: anton-l
- user: eliebak
translators:
- user: hugging-hoi2022
- user: zhongdongy
proofreader: true
---
# SmolLM: 一个超快速、超高性能的小模型集合
## 简介
本文将介绍 [SmolLM](https://huggingface.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966)。它集合了一系列最尖端的 135M、360M、1.7B 参数量的小模型,这些模型均在一个全新的高质量数据集上训练。本文将介绍数据整理、模型评测、使用方法等相关过程。
## 引言
近期,人们对能在本地设备上运行的小语言模型的兴趣日渐增长。这一趋势不仅激发了相关业者对蒸馏或量化等大模型压缩技术的探索,同时也有很多工作开始尝试在大数据集上从头训练小模型。
微软的 Phi 系列、阿里巴巴的 Qwen2 (小于 2B 参数量) 以及 Meta 的 MobileLLM 均展示了这样的结论: 如果设计得当、训练充分,小模型也可以获得很好的性能。然而,这其中关于数据整理、训练细节的相关信息大多都未被披露。
在本文中,我们将介绍 [SmolLM](https://huggingface.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966)。这是一个包含一系列最顶尖的小语言模型的集合,这些模型的参数量包括 135M、360M 和 1.7B。这些模型基于 [SmolLM-Corpus](https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus) 这一仔细整理的高质量数据集而构建,该数据集包含以下三个子集:
- **Cosmopedia v2**: 通过 Mixtral 模型合成的、包含课文和故事等内容的数据集 (token 数量为 28B)
- **Python-Edu**: 数据样本取自 [The Stack](https://huggingface.co/datasets/bigcode/the-stack-v2-train-full-ids) 数据集、[根据教育价值打分](https://huggingface.co/HuggingFaceTB/python-edu-scorer) 筛选出来的数据集 (token 数量为 4B)
- **FineWeb-Edu**: [FineWeb](https://huggingface.co/datasets/HuggingFaceFW/fineweb) 数据集经过去重且 [根据教育价值打分](https://huggingface.co/HuggingFaceTB/python-edu-scorer) 筛选出来的数据集 (token 数量为 220B)
我们的评测结果显示,在对应的参数量区间内,SmolLM 的模型在一系列常识性推理和世界知识评测标准上均超越了现有的模型。在本文中,我们将介绍训练语料中三个子集的整理方法,并讨论 SmolLM 的训练和评测过程。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled.png" alt="" style="width: 90%; height: auto;"><br>
<em>SmolLM 的模型在不同推理和常识评测标准上的测试结果</em>
</p>
## 数据整理
### Cosmopedia 数据集: 从 v1 到 v2
Cosmopedia v2 是 Cosmopedia 数据集的增强版。Cosmopedia 是当前最大的合成数据集,常被用来进行与训练。它包含超过三百万的课文、博客、故事等数据,这些数据均由 Mixtral-8x7B-Instruct-v0.1 模型生成。绝大部分数据是通过这种方式生成的: 搜集网页内容 (称为“种子样本”),提供内容所属的主题类别,然后让模型扩写来生成。如图 1 就展示了其中的一个样本示例。 这里我们使用大量网络样本来提高数据的多样性,并扩展提示词的话题范围。[这篇文章](https://huggingface.co/blog/cosmopedia) 详细介绍了 Cosmopedia 数据集。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%201.png" alt="" style="width: 90%; height: auto;"><br>
<em>图 1: Cosmopedia 提示词示例.</em>
</p>
为了在 v2 版的数据集中进一步优化数据质量,我们曾尝试过以下两种策略:
- 针对同一提示词,使用多个高性能模型去生成数据
- 优化提示词本身
针对第一种策略,我们曾尝试了 llama3-70B-Instruct、Mixtral-8x22B-Instruct-v0.1 以及 Qwen1.5-72B-Chat,但当我们在这些生成数据上训练后,我们发现效果提升很有限。因此,下文我们将聚焦于第二种策略: 我们是怎样改进提示词的。
#### 寻找更好的主题和种子样本
每个提示词都包含三个主要部分: 主题、种子样本和生成风格,这三部分确定了意向受众和我们希望模型生成的内容的类型。
为确保生成的一致性,我们需要将相关性强的种子样本归类到对应的主题里面。在 Cosmopedia v1 里,我们通过对 FineWeb 里的样本进行聚类,来确保主题和对应的样本是一致的 (如图 2)。但这种方法有两点局限性:
1. 这些主题虽然很全面地反映了 web/FineWeb 数据的聚类结果,但可能并没有全面反映真实世界的科目主题分布。
2. 每个聚类内部的样本并没有被进一步过滤,所以可能包含很多低质量样本。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%202.png" alt="" style="width: 90%; height: auto;"><br>
<em>图 2: FineWeb 的聚类结果</em>
</p>
因此,在 v2 版数据集中,我们使用 [BISAC 书籍分类](https://www.bisg.org/complete-bisac-subject-headings-list) 定义的 3.4 万个主题来代替无监督的聚类。 BISAC 已被作为一个通用标准,来给书籍进行科目分类。所以使用这种方法不仅能全面涵盖各类主题,也可以使得我们使用的主题在教育价值层面更有专业性。具体而言,我们先使用 BISAC 里 51 个大类中的 5000 个主题,让 Mixtral 模型针对每个主题生成它的多种二级子类。下图就展示了最终各个大类别下的子类主题数量分布。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%203.png" alt="" style="width: 90%; height: auto;"><br>
<em>图 3: 不同大类下面的主题数量的统计直方图</em>
</p>
在定义好了主题后,我们还需要找到和主题相关的数据条目。和使用搜索引擎类似,我们制作了一个搜索工具,用来检索和每个主题有强相关性的数据。我们使用 BISAC 的大类和子类主题作为搜索的关键词,在 [FineWeb](https://huggingface.co/datasets/HuggingFaceFW/fineweb) 数据集的 [CC-MAIN-2024-10](https://huggingface.co/datasets/HuggingFaceFW/fineweb/tree/main/data/CC-MAIN-2024-10) 和 [CC-MAIN-2023-50](https://huggingface.co/datasets/HuggingFaceFW/fineweb/tree/main/data/CC-MAIN-2023-50) 文件夹中进行搜索,两个文件夹包含有超过 5.2 亿的样本。对于每个搜索关键词,我们检索出 1000 条最接近的数据条目。相关代码可以见 [这里](https://github.com/huggingface/cosmopedia/tree/main/fulltext_search)。
最终,我们集成了涵盖 3.4 万个主题的 3400 万条数据。接下来需要确定的是,哪种生成风格效果最好。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%204.png" alt="" style="width: 90%; height: auto;"><br>
<em>图 4: “Medical” 大类下的子类主题和对应的网页数据样本.</em>
</p>
#### 生成风格
为了确定最有效的生成风格,我们通过训练 1.8B 模型进行了对比实验,其中我们使用不同的 Cosmopedia v1 子集数据,共计有 80 亿 token 的数据量。在生成训练数据时,我们只生成 20 亿 token 的数据量,训练 4 轮,以此来节省时间 (使用 Mixtral 生成 20 亿 token 需要大约 1000 个 GPU 小时)。训练和评测的各项配置和 [FineWeb ablation models](https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1) 一致。每个训练我们都跑两遍,每次用不同的随机种子,最终评测分数取两次的平均。
至于训练结果对比,我们对比了 Cosmopedia v1 的这些子集:
- 两个 web 样本集: [web_samples_v1](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/web_samples_v1) 和 [web_samples_v2](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/web_samples_v2)
- [stories](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/stories) 子集
- [stanford](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/stanford) 和 [openstax](https://huggingface.co/datasets/HuggingFaceTB/cosmopedia/tree/main/data/openstax) 两个子集
我们发现,当训练文本是基于 stanford 和 openstax 的主题和种子样本时,总体的性能最好,其 MMLU 和 ARC 指标均高于两个 web 样本集。而 stories 仅仅有助于常识性的相关指标。在实现了 v2 版数据集检索新主题和种子样本的代码后,我们也可以对比这次实验的指标数据,来判断我们新生成的提示词的质量好坏。
接下来,我们还要探索哪种受众风格最好。我们使用相同的课文类提示词生成课文内容,但针对两种目标受众: 中学生和大学生。我们发现,在针对中学生受众的生成数据上训练,模型在除了 MMLU 的各项指标上取得了最好的分数。一个合理的解释是,这些指标一般都是对初级或中级的科学知识进行考察,而 MMLU 则包含了针对高级甚至专家级知识的问题。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%205.png" alt="" style="width: 90%; height: auto;"><br>
<em>不同受众的课文数据上的评测结果</em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%206.png" alt="" style="width: 90%; height: auto;"><br>
<em>不同受众的课文数据上的评测结果</em>
</p>
对于 v2 版本数据,我们生成的数据中,40% 面向中学生受众,30% 面向大学生受众,剩下 30% 混合了各种不同受众群体,且融合了 v1 中 stories、stanford 等风格的课文风格。除此之外,我们还生成了 10 亿代码相关的课文,这部分数据基于 [AutoMathText](https://huggingface.co/datasets/math-ai/AutoMathText) 数据集的 [Python](https://huggingface.co/datasets/math-ai/AutoMathText/tree/main/data/code/python) 代码部分。
最终,我们生成了 3900 万合成数据,按 token 数量算,规模达到了 20 亿,涵盖课文、故事、文章、代码,假想受众的多样性也很高,涵盖主题超过 3.4 万。
### FineWeb-Edu 数据集
FineWeb-Edu 数据集由我们在几个月前随着 [FineWeb 数据集的技术报告](https://huggingface.co/spaces/HuggingFaceFW/blogpost-fineweb-v1) 公开,它包含 **1.3 万亿** 的 token。其内容来自教育相关的网页,这些网页信息从 🍷 FineWeb 数据集中过滤而来。
在过滤数据的过程中,我们开发了一个 [关于教育价值质量的分类器](https://huggingface.co/HuggingFaceFW/fineweb-edu-classifier),它的训练使用了 Llama3-70B-Instruct 生产的标注信息。我们使用这一分类器,在 FineWeb 里找出教育价值最高的一批网页内容。下图实验表明,在过滤出来的 FineWeb-Edu 训练的模型,在常用指标上明显由于 FineWeb。这也说明我们的分类器是有用的。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%207.png" alt="" style="width: 90%; height: auto;"><br>
<em>FineWeb-Edu 和其它公开网页数据集的训练效果对比</em>
</p>
在 Smollm-Corpus 数据集中,我们加入了 2200 亿去重过的、来自 FineWeb 的 token。
### Stack-Edu-Python 数据集
这里,我们也用了和 FineWeb-Edu 一样的方法。我们用 Llmama3 对 [The Stack](https://huggingface.co/datasets/bigcode/the-stack) 数据集中 50 万的 python 代码段根据教育价值进行打分,然后使用这些打过分的数据训来年了一个 [分类器](https://huggingface.co/HuggingFaceTB/python-edu-scorer)。然后我们在 Starcoder 模型的训练语料库的 python 子集中使用这个分类器。我们只保留 4 分及以上的样本,最终我们从 400 亿的 token 中得到了一个包含 40 亿 token 的新数据集。
下图展示了模型在不同数据集上 (使用 4 或 3 作为阈值过滤的、未进行过滤的) 训练的效果。我们可以看到,模型在 Python-Edu 上收敛速度比在未过滤数据上训练快 3 倍还多。而且在只使用了 120 亿 token 的训练数据后,就达到了 top-1 16% 的通过率。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%208.png" alt="" style="width: 90%; height: auto;"><br>
<em>Python-Edu 和未过滤数据的训练效果对比</em>
</p>
## 模型训练
SmolLM 包含三种不同参数量大小的模型,它们均在下图所示的混合数据上训练:
- 参数量为 135M 和 360M 的模型,均使用 [Smollm-Corpus](https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus) 的 6000 亿 token 数据量进行训练
- 参数量为 1.7B 的模型,则使用 [Smollm-Corpus](https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus) 1 万亿 token 的数据量进行了训练
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%209.png" alt="" style="width: 60%; height: auto;"><br>
<em>Training mixture of SmolLM models.</em>
</p>
### 超参数的选择
我们使用一种梯形的学习率变化策略,总训练时长的最后 20% 作为冷却时间。需要注意的是,梯形学习率变化的原始验证实验只使用了小规模训练,而我们的工作将其扩展到了大模型领域。
对于模型结构,我们的 135M 和 360M 模型均使用了和 [MobileLLM](https://arxiv.org/abs/2402.14905) 类似的设计,加入了 Grouped-Query Attention 结构,且优先深度扩展而不是宽度; 而 1.7T 的模型则使用了相对传统的设计。此外,三种模型均使用了 embedding tying,上下文长度均为 2048 个 token。使用长上下文微调还可以进一步扩展我们模型的上下文长度。
具体模型结构细节信息可见下表:
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2010.png" alt="" style="width: 90%; height: auto;"><br>
<em>SmolLM 模型结构细节</em>
</p>
我们使用的分词器 (tokenizer) 是在 Smollm-Corpus 上训练的,其词汇量为 49152。
### 实验
使用梯形学习率的一个好处是,我们可以更快速地验证模型在 scaling law 下的扩展实验 (参考 [Hägele et al.](https://arxiv.org/pdf/2405.18392) 这篇论文)。这里我们使用 SmolLM-125M 做一个关于 scaling law 的小实验,来验证这一点。我们在不同的正常训练节点上进行学习率冷却,来结束训练。我们观察到,随着模型训练时间越来越长,性能是持续上升的,这一现象即使在 Chinchilla 最优点 (参数量和训练数据的最优配比) 之后也存在。根据这些实验现象,我们决定用 1T 量级 token 的数据去训练 1.7B 的模型,而 135M 和 360M 的模型则在 600B 量级的 token 上训练。因为在训练了 400B 量级的 token 后,两个较小的模型在一些指标上就已经进步缓慢了。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2011.png" alt="" style="width: 90%; height: auto;"><br>
<em>SmolLM 的 125M 参数量模型在不同量级数据上训练的评测结果</em>
</p>
我们还尝试添加指令数据集以及在学习率冷却阶段对 Cosmopedia 子集进行上采样,但这些收效甚微。可能的原因是,我们的混合数据集质量已经足够高了,所以这些改进效果很有限。
在训练两个较小模型的过程中,我们记录了各项评测指标的变化情况。见下图:
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2012.png" alt="" style="width: 90%; height: auto;"><br>
<em> 训练过程中 SmolLM-135M 和 SmolLM-360M 在不同指标上的变化</em>
</p>
## 模型评测
我们对不同参数量的 SmolLM 模型进行了评测,并和当前最好的一些模型进行了对比。我们使用了多种指标,评测内容包括常识推理和世界知识。我们使用 `lighteval` 和 [这些配置](https://github.com/huggingface/cosmopedia/tree/main/evaluation) 进行评测。对于人类主观评测,我们使用了 bigcode-evaluation-harness,其中 temperature 设为 0.2,top-p 为 0.95,样本量为 20。针对未开源的 MobileLLM,其测试结果均取自论文中的数据。
我们发现:
- 在 200M 参数量以下的模型中,SmolLM-135M 在各项指标上都超越了当前最好的模型 MobileLLM-125M。相比于 MobileLLM-125M 使用 1T token 的数据量去训练,SmolLM-135M 只使用了 600B 的数据量。
- 在 500M 参数量以下的模型中,SmolLM-360M 也超越了其它模型。相比于 MobileLLM-350M 和 Qwen2-500M,SmolLM-360M 参数量和训练数据均更少。
- 在 2B 参数量以下的模型中,SmolLM-1.7B 也超越了包括 Phi1.5 和 MobileLLM-1.5B 等模型。
- SmolLM-1.7B 还在 Python 编程能力上表现抢眼 (我们测评的 Qwen2-1.5B 分数和 Qwen 团队给出的不同,我们的实验配置是: temperature 设为 0.2,top-p 设为 0.95,样本量为 20)。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2014.png" alt="" style="width: 90%; height: auto;"><br>
<em>SmolLM 和其它小语言模型的对比,除 MobileLLM 外,所有实验的配置均相同,因为 MobileLLM 未开源</em>
</p>
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/image.png" alt="" style="width: 50%; height: auto;"><br>
<em>SmolLM 模型的人工评测</em>
</p>
我们也使用公开数据集对模型进行了指令精调。三个模型均在 [WebInstructSub dataset](https://huggingface.co/datasets/TIGER-Lab/WebInstructSub) 和 StarCoder2-Self-OSS-Instruct 进行了一轮训练。随后,我们也进行了 DPO 训练,其中,我们使用 [HelpSteer](https://huggingface.co/datasets/nvidia/HelpSteer) 训练 135M 和 1.7B 的模型,使用 [argilla/dpo-mix-7k](https://huggingface.co/datasets/argilla/dpo-mix-7k) 训练 360M 的模型。相关训练配置和 Zephyr-Gemma 的 [说明文档](https://github.com/huggingface/alignment-handbook/blob/main/recipes/zephyr-7b-gemma/README.md) 相同,除了 SFT 的学习率被我们改为了 3e-4。
下表展示了经指令精调的 SmolLM 模型 (SmolLM-Instruct) 和其它模型在 IFEval 上的对比。Qwen2-1.5B-Instruct 取得了最高分,SmolLM-Instruct 模型则在模型大小和性能上取得了很好的权衡,而且仅使用了公开可用的数据集。
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2016.png" alt="" style="width: 60%; height: auto;"><br>
<em>SmolLM-Instruct 模型在 IFEval 的评测结果</em>
</p>
## 如何本地运行 SmolLM 模型?
我们的小模型可以在各种本地的硬件上运行。举例来说,iPhone 15 有 6GB 的内存,iPhone 15 Pro 有 8GB 内存,从手机到笔记本电脑,诸多设备都足以运行我们的模型。下表中,我们记录了模型运行时实际的内存占用情况:
<p align="center">
<img src="https://huggingface.co/datasets/HuggingFaceTB/images/resolve/main/Untitled%2013.png" alt="" style="width: 60%; height: auto;"><br>
<em>SmolLM 模型内存占用情况</em>
</p>
除了 `transformers` 库可以直接使用的模型权重外,我们也开放了 ONNX 模型,并计划为 `llama.cpp` 提供 GGUF 版模型。此外,[SmolLM-135M](https://huggingface.co/spaces/HuggingFaceTB/SmolLM-135M-Instruct-WebGPU) 和 [SmolLM-360M](https://huggingface.co/spaces/HuggingFaceTB/SmolLM-360M-Instruct-WebGPU) 的 WebGPU 演示页面也可以使用。
## 总结
本文介绍了 SmolLM 系列模型,通过实验证明了,只要训练充分、数据质量足够好,小模型也可以取得很好的性能。本文在此用 SmolLM 提供了一个示例,强有力地证明了模型大小和模型性能可以做到完美权衡。
## 其它资源
- SmolLM 模型集合: [https://huggingface.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966](https://huggingface.co/collections/HuggingFaceTB/smollm-models-6695016cad7167254ce15966)
- SmolLM-Corpus 数据集: [https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus](https://huggingface.co/datasets/HuggingFaceTB/smollm-corpus)
- WebGPU 演示页面: [https://huggingface.co/spaces/HuggingFaceTB/SmolLM-135M-Instruct-WebGPU](https://huggingface.co/spaces/HuggingFaceTB/SmolLM-135M-Instruct-WebGPU) and [https://huggingface.co/spaces/HuggingFaceTB/SmolLM-360M-Instruct-WebGPU](https://huggingface.co/spaces/HuggingFaceTB/SmolLM-360M-Instruct-WebGPU) | 8 |
0 | hf_public_repos/blog | hf_public_repos/blog/zh/habana-gaudi-2-benchmark.md | ---
title: "更快的训练和推理:对比 Habana Gaudi®2 和英伟达 A100 80GB"
thumbnail: /blog/assets/habana-gaudi-2-benchmark/thumbnail.png
authors:
- user: regisss
translators:
- user: MatrixYao
- user: zhongdongy
proofreader: true
---
# 更快的训练和推理: 对比 Habana Gaudi®2 和英伟达 A100 80GB
通过本文,你将学习如何使用 [Habana® Gaudi®2](https://habana.ai/training/gaudi2/) 加速模型训练和推理,以及如何使用 🤗 [Optimum Habana](https://huggingface.co/docs/optimum/habana/index) 训练更大的模型。然后,我们展示了几个基准测例,包括 BERT 预训练、Stable Diffusion 推理以及 T5-3B 微调,以评估 Gaudi1、Gaudi2 和英伟达 A100 80GB 之间的性能差异。剧透一下: Gaudi2 的训练和推理速度大约是英伟达 A100 80GB 的两倍!
[Gaudi2](https://habana.ai/training/gaudi2/) 是 Habana Labs 设计的第二代 AI 硬件加速卡。每台服务器装有 8 张加速卡,每张加速卡的内存为 96GB (Gaudi1 为 32GB,A100 80GB 为 80GB)。Habana 的 [SynapseAI](https://developer.habana.ai/) SDK 在 Gaudi1 和 Gaudi2 上是通用的。这意味🤗 Optimum Habana,一个将 🤗 Transformers 和 🤗 Diffusers 库与 SynapseAI 连起来的、用户友好的库, **在 Gaudi2 上的工作方式与 Gaudi1 完全相同!**
因此,如果你在 Gaudi1 上已经有现成的训练或推理工作流,我们鼓励你在 Gaudi2 上尝试它们,因为无需任何更改它们即可工作。
## 如何访问 Gaudi2?
访问 Gaudi2 的简单且经济的方法之一就是通过英特尔和 Habana 提供的英特尔开发者云 (Intel Developer Cloud,IDC) 来访问。要使用 Gaudi2,你需要完成以下操作步骤:
1. 进入 [英特尔开发者云登陆页面](https://www.intel.com/content/www/us/en/developer/tools/devcloud/services.html) 并登录你的帐户 (如果没有账户,需要先注册一个)。
2. 进入 [英特尔开发者云管理控制台](https://scheduler.cloud.intel.com/#/systems)。
3. 选择 _Habana Gaudi2 Deep Learning Server,其配有 8 张 Gaudi2 HL-225H 卡以及最新的英特尔® 至强® 处理器_ ,然后单击右下角的 _Launch Instance_ ,如下所示。
<figure class="image table text-center m-0 w-full">
<img src="/blog/assets/habana-gaudi-2-benchmark/launch_instance.png" alt="Cloud Architecture"/>
</figure>
4. 然后你可以申请一个实例。
<figure class="image table text-center m-0 w-full">
<img src="/blog/assets/habana-gaudi-2-benchmark/request_instance.png" alt="Cloud Architecture"/>
</figure>
5. 一旦申请成功,请重新执行步骤 3,然后单击 _Add OpenSSH Publickey_ 以添加付款方式 (信用卡或促销码) 以及你的 SSH 公钥,你可使用 `ssh-keygen -t rsa -b 4096 -f ~/.ssh/id_rsa` 命令以生成公钥。每次添加付款方式或 SSH 公钥时,你可能会被重定向到步骤 3。
6. 重新执行步骤 3,然后单击 _Launch Instance_ 。你必须接受建议条款才能真正把实例启动起来。
7. 进入 [英特尔开发者云管理控制台](https://scheduler.cloud.intel.com/#/systems),然后单击 _View Instances_ 选项卡。
8. 你可以复制实例界面上的 SSH 命令来远程访问你的 Gaudi2 实例!
> 如果你终止实例后想再次使用 Gaudi2,则必须重新执行整个过程。
你可以在 [此处](https://scheduler.cloud.intel.com/public/Intel_Developer_Cloud_Getting_Started.html) 找到更多相关信息。
## 基准测试
下面,我们将进行多项基准测试来评估 Gaudi1、Gaudi2 和 A100 80GB 在各种尺寸的模型上的训练和推理能力。
### BERT 模型预训练
几个月前,Hugging Face 的技术主管 [Philipp Schmid](https://huggingface.co/philschmid) 介绍了 [如何使用 🤗 Optimum Habana 在 Gaudi 上预训练 BERT](https://huggingface.co/blog/zh/pretraining-bert)。该预训练一共执行了 6.5 万步,每张卡的 batch size 为 32 (因此总 batch size 为 8 * 32 = 256),总训练时长为 8 小时 53 分钟 (你可以在 [此处](https://huggingface.co/philschmid/bert-base-uncased-2022-habana-test-6/tensorboard?scroll=1#scalars) 查看此次训练的 TensorBoard 日志)。
我们在 Gaudi2 上使用相同的超参重新运行相同的脚本,总训练时间为 2 小时 55 分钟 (日志见 [此处](https://huggingface.co/regisss/bert-pretraining-gaudi-2-batch-size-32/tensorboard?scroll=1#scalars))。 **也就是说,无需任何更改,Gaudi2 的速度提升了 3.04 倍**。
由于与 Gaudi1 相比,Gaudi2 的单卡内存大约增加了 3 倍,因此我们可以充分利用这更大的内存容量来增大 batch size。这将会进一步增加 HPU 的计算密度,并允许开发人员尝试那些在 Gaudi1 上无法尝试的超参。在 Gaudi2 上,我们仅需 2 万训练步,每张卡的 batch size 为 64 (总 batch size 为 512),就可以获得与之前运行的 6.5 万步相似的收敛损失,这使得总训练时长降低为 1 小时 33 分钟 (日志见 [此处](https://huggingface.co/regisss/bert-pretraining-gaudi-2-batch-size-64/tensorboard?scroll=1#scalars))。使用新的配置,训练吞吐量提高了 1.16 倍,同时新的 batch size 还极大地加速了收敛。 **总体而言,与 Gaudi1 相比,Gaudi2 的总训练时长减少了 5.75 倍,吞吐量提高了 3.53 倍**。
**Gaudi2 比 A100 更快**: batch size 为 32 时,Gaudi2 吞吐为每秒 1580.2 个样本,而 A100 为 981.6; batch size 为 64 时,Gaudi2 吞吐为每秒 1835.8 个样本,而 A100 为 1082.6。这与 [Habana](https://habana.ai/training/gaudi2/) 宣称的 `batch size 为 64 时 Gaudi2 在 BERT 预训练第一阶段上的训练性能是 A100 的 1.8 倍` 相一致。
下表展示了我们在 Gaudi1、Gaudi2 和英伟达 A100 80GB GPU 上测得的吞吐量:
<center>
| | Gaudi1 (BS=32) | Gaudi2 (BS=32) | Gaudi2 (BS=64) | A100 (BS=32) | A100 (BS=64) |
|:-:|:-----------------------:|:--------------:|:--------------:|:-------:|:---------------------:|
| 吞吐量 (每秒样本数) | 520.2 | 1580.2 | 1835.8 | 981.6 | 1082.6 |
| 加速比 | x1.0 | x3.04 | x3.53 | x1.89 | x2.08 |
</center>
_BS_ 是每张卡上的 batch size。 Gaudi 训练时使用了混合精度 (bf16/fp32),而 A100 训练时使用了 fp16。所有数据都基于 8 卡分布式训练方案测得。
### 使用 Stable Diffusion 进行文生图
🤗 Optimum Habana 1.3 的主要新特性之一是增加了 [对 Stable Diffusion 的支持](https://huggingface.co/docs/optimum/habana/usage_guides/stable_diffusion)。现在,在 Gaudi 上进行文生图非常容易。与 GPU 上的 🤗 Diffusers 不同,Optimum Habana 上的图像是批量生成的。由于模型编译耗时的原因,前两个 batch 比后面的 batch 的生成速度要慢。在此基准测试中,在计算 Gaudi1 和 Gaudi2 的吞吐量时,我们丢弃了前两个 batch 的生成时间。
[这个脚本](https://github.com/huggingface/optimum-habana/tree/main/examples/stable-diffusion) 使用的 batch size 为 8,其 `gaudi_config` 为 [`Habana/stable-diffusion`](https://huggingface.co/Habana/stable-diffusion)。
我们得到的结果与 Habana 发布的 [数字]((https://developer.habana.ai/resources/habana-models-performance/)) 一致,如下表所示。 **Gaudi2 的延迟比 Gaudi1 快 3.51 倍 (0.925 秒对比 3.25 秒),比英伟达 A100 快 2.84 倍 (0.925 秒对比 2.63 秒)。** 而且,Gaudi2 支持的 batch size 更大。
<center>
| | Gaudi1 (BS=8) | Gaudi2 (BS=8) | A100 (BS=1) |
|:---------------:|:----------------------:|:-------------:|:-----------:|
| 延迟 (每图像秒数) | 3.25 | 0.925 | 2.63 |
| 加速比 | x1.0 | x3.51 | x1.24 |
</center>
_更新: 上图已更新,因为 SynapseAI 1.10 和 Optimum Habana 1.6 为 Gaudi1 和 Gaudi2 带来了额外的加速。_
_BS_ 是 batch size。Gaudi 上的推理精度为 _bfloat16_ ,A100 上的推理精度为 _fp16_ (更多信息详见 [此处](https://huggingface.co/docs/diffusers/optimization/fp16))。所有数据均为 _单卡_ 运行数据。
### 微调 T5-3B
因为每张卡的内存高达 96 GB,Gaudi2 可以运行更大的模型。举个例子,在仅应用了梯度 checkpointing 内存优化技术的条件下,我们成功微调了一个 T5-3B (参数量为 30 亿) 模型。这在 Gaudi1 上是不可能实现的。我们使用 [这个脚本](https://github.com/huggingface/optimum-habana/tree/main/examples/summarization) 在 CNN DailyMail 数据集上针对文本摘要任务进行了微调,运行日志见 [这里](https://huggingface.co/regisss/t5-3b-summarization-gaudi-2/tensorboard?scroll=1#scalars)。
结果如下表所示。 **Gaudi2 比 A100 80GB 快 2.44 倍。** 我们发现,目前在 Gaudi2 上的 batch size 只能为 1,不能设更大。这是由于在第一次迭代时生成的计算图占了不少内存空间。Habana 正在致力于优化 SynapseAI 的内存占用,我们期待未来新版本的 Habana SDK 能够缓解这一问题。同时,我们还期待使用 [DeepSpeed](https://www.deepspeed.ai/) 来扩展此基准,从而看看引入 DeepSpeed 后平台间的性能对比是否与现在保持一致。
<center>
| | Gaudi1 | Gaudi2 (BS=1) | A100 (BS=16) |
|:-:|:-------:|:--------------:|:------------:|
| 吞吐量 (每秒样本数) | N/A | 19.7 | 8.07 |
| 加速比 | / | x2.44 | x1.0 |
</center>
_BS_ 指的是每卡 batch size。 Gaudi2 和 A100 使用的精度为 fp32,且启用了梯度 checkpointing 技术。所有数据都基于 8 卡分布式训练方案测得。
## 总结
本文讨论了我们首次使用 Gaudi2 的经历。从 Gaudi1 到 Gaudi2 的过渡完全是无缝的,因为 Habana 的 SDK SynapseAI 在两者上是完全兼容的。这意味着 SynapseAI 上的新优化会让两个平台同时受益。
可以看到,Habana Gaudi2 的性能与 Gaudi1 相比有了显著提高,且其训练和推理吞吐大约是英伟达 A100 80GB 的两倍。
我们还知道了如何在英特尔开发者云上设置 Gaudi2 实例。设置完后,你就可以 Gaudi2 上使用 🤗 Optimum Habana 轻松运行这些 [例子](https://github.com/huggingface/optimum-habana/tree/main/examples)。
如果你对使用最新的 AI 硬件加速卡和软件库加速机器学习训练和推理工作流感兴趣,可以移步我们的 [专家加速计划](https://huggingface.co/support)。如果你想了解有关 Habana 解决方案的更多信息,可以在 [此处](https://huggingface.co/hardware/habana) 了解我们相关信息并 [联系他们](https://habana.ai/contact-us/)。要详细了解 Hugging Face 为让 AI 硬件加速卡更易于使用而做的努力,请查阅我们的 [硬件合作伙伴计划](https://huggingface.co/hardware)。
### 相关话题
- [基于 Habana Gaudi 的 Transformers 入门](https://huggingface.co/blog/zh/getting-started-habana)
- [与 Hugging Face 和 Habana Labs 一起加速 transformer 模型的训练 (网络研讨会) ](https://developer.habana.ai/events/accelerate-transformer-model-training-with-hugging-face-and-habana-labs/)
---
感谢垂阅!如果你有任何疑问,请随时通过 [Github](https://github.com/huggingface/optimum-habana) 或 [论坛](https://discuss.huggingface.co/c/optimum/59) 与我联系。你还可以通过 [LinkedIn](https://www.linkedin.com/in/regispierrard/) 联系我。
| 9 |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.